- 投稿日:2021-01-29T23:54:13+09:00
Pythonでconv
matlabで畳み込みを計算するconv。
ガウシアンフィルターなんかでおなじみのやつ。numpy.convolve
matlabのconvはnumpy.convolveとほぼ同じ。
matlabの
conv(u,v,shape)をpythonで書くと
numpy.convolve(u,v,shape)となる。
shapeが 'full' 'same' 'valid' のいずれか、というのも同じただし、u,vの長さが両方とも偶数で'same'のとき、返す範囲が1つだけ違うらしい。
まぁフィルタリングだとvはだいたい対称で長さは奇数なので、あまり問題にならないと思うけど。u,vの長さの少なくとも一方が奇数のとき
in Matlab
x=1:10; y=[0,1,0.5]; conv(x,y,'full') conv(x,y,'same') conv(x,y,'valid')Matlab 出力
ans = 0 1.0000 2.5000 4.0000 5.5000 7.0000 8.5000 10.0000 11.5000 13.0000 14.5000 5.0000 ans = 1.0000 2.5000 4.0000 5.5000 7.0000 8.5000 10.0000 11.5000 13.0000 14.5000 ans = 2.5000 4.0000 5.5000 7.0000 8.5000 10.0000 11.5000 13.0000in Python
import numpy as np x = range(1, 11) y = (0, 1, 0.5) print(np.convolve(x, y, 'full')) print(np.convolve(x, y, 'same')) print(np.convolve(x, y, 'valid'))Python 出力
[ 0. 1. 2.5 4. 5.5 7. 8.5 10. 11.5 13. 14.5 5. ] [ 1. 2.5 4. 5.5 7. 8.5 10. 11.5 13. 14.5] [ 2.5 4. 5.5 7. 8.5 10. 11.5 13. ]どちらも同じ。
u,vの長さが両方とも偶数のとき
in Matlab
x=1:9; y=[0,1,0.5,0.1]; conv(x,y,'full') conv(x,y,'same') conv(x,y,'valid')Matlab出力
ans = 0 1.0000 2.5000 4.1000 5.7000 7.3000 8.9000 10.5000 12.1000 13.7000 5.3000 0.9000 ans = 2.5000 4.1000 5.7000 7.3000 8.9000 10.5000 12.1000 13.7000 5.3000 ans = 4.1000 5.7000 7.3000 8.9000 10.5000 12.1000in Python
x = range(1, 10) y = (0, 1, 0.5,0.1) print(np.convolve(x, y, 'full')) print(np.convolve(x, y, 'same')) print(np.convolve(x, y, 'valid'))Python 出力
[ 0. 1. 2.5 4.1 5.7 7.3 8.9 10.5 12.1 13.7 5.3 0.9] [ 1. 2.5 4.1 5.7 7.3 8.9 10.5 12.1 13.7] [ 4.1 5.7 7.3 8.9 10.5 12.1]sameのとき、Matlabの方が出力が1つ長い
- 投稿日:2021-01-29T23:25:05+09:00
データ分析用Pythonメモ
備忘用にデータ分析におけるPythonメモです。
設定
#最大表示列数の指定(ここでは50列を指定) pd.set_option('display.max_rows', 50) #最大表示列数の指定(ここでは50列を指定) pd.set_option('display.max_columns', 50)汎用
リスト内包表記
[f"even{i:02}" for i in range(10) if i % 2 == 0] >['even00', 'even02', 'even04', 'even06', 'even08']読み込み
データの読み込み
# カンマ区切り 文字コード指定 先頭数行を飛ばす df = pd.read_csv(filename,encoding="cp932",skiprows=2) # タブ区切り 列名を指定して読み込み df = pd.read_table(filename,usecols=list_cols) # Excel df = read_excel(filename,sheet_name)モデルの読み込み
import pickle pickle.load(open(path_to_model, 'rb'))データ整形・加工
ベーシックな整形
# 行を抽出 df.query("col1 == xxx") # 列を抽出(列名指定) df[["col1", "col2"]] # 列を抽出(ある文字で始まる・終わる・含む) df.loc[:, df.columns.str.startswith('xxx')] df.loc[:, df.columns.str.endswith('xxx')] df.loc[:, df.columns.str.contains('xxx')] # 列を削除 df.drop(["col1"], axis=1) # NAを含む行を削除(列指定) df.dropna(subset = ["col1"]) # 列名を変更(完全一致) df.rename(columns = {"col_before" : "col_after"}) # 型を変換 df["numcol"].astype(str) # 文字列を日付型に変換 df["date"].to_datetime(format = '%y%m%d %H:%M') %Y 4桁の年数 (例 2018,1996…) %y 2桁の年数 (例 18, 96..) %m 2桁の月 [01,12] (例 01, 07, 12..) %d 2桁の日付 [01,31] (例 02, 28, 31..) %H 24時間表記の時間 [00,23] (例 00, 12, 21..) %I 12時間表記の時間 [01,12] (例 01, 07, 12..) %M 2桁の分 [00, 59] (例 00, 05, 38, 59..) %S 秒 [00, 61] (例 00, 15, 39, 60, 61..)60,61は00,01と同じ #値を置換(完全一致) df.["col1"].replace("before", "after") # 縦持ち⇒横持ちに変換 # 横持ち⇒縦持ちに変換 pd.melt(df,id_vars=["col_id1","col_id2"],var_name="col_var",value_name="col_val" ) # 横に結合 pd.merge(df1,df2,how="left",left_on=["col1"],right_on=["colone"]) # 縦に結合(ユニオン) pd.concat([df_1,df_2]) #複数の列を文字列として結合 df["col1"].str.cat(df["col2"], sep = "-")集計
# 集計 df.groupby(["col_id"]).mean()変換
# 上限・下限で変換 np.clip(a,min_value,max_value) # どちらかのときはNoneを使用 # Label Encoder from sklearn.preprocessing import LabelEncoder le = LabelEncoder() df["col1"] = le.fit_transform(df["col1"]) df2["col1"] = le.transform(df2["col1"]) le.inverse_transform(df["col1"]) #復元ちょっと特殊な整形
dataframeのあるカラムのある要素があるリストに含まれている場合にのみ抽出する。
df = pd.DataFrame({'Description': ['foo bar blah', 'new foo', 'newfoo', 'bar']}) keywords_list = ["foo", "bar"] df['Description'].str.split(expand = True).isin(keywords_list).any(1) >0 True >1 True >2 False >3 Trueモデリング
クロスバリデーション
from sklearn.model_selection import KFold folds = KFold(n_splits=nsplits, shuffle = True, random_state = rand) for tr_idx,va_idx in folds.split(X_train,y_train): X_tr = X_train.iloc[tr_idx] y_tr = y_train.iloc[tr_idx] X_va = X_train.iloc[va_idx] y_va = y_train.iloc[va_idx] model = make_model(X_tr,y_tr) y_pred = model.predict(X_va)可視化
表
# 列名・NaNでない列の数 df.info() # 各列の統計量 df.describe()seaborn
保存
CSV
# 文字コード指定で保存 インデックスは出力しない df.to_csv(filename,encoding="cp932",index=False) ## pickle ```Python import pickle pickle.dump(model, open(f'model{i}.pkl', 'wb'))
- 投稿日:2021-01-29T22:42:55+09:00
Metabaseのクエリ結果をPythonで取得する
はじめに
MetabaseのAPIをPythonで叩いてMetabaseで作成したクエリの結果を取得する方法のメモ。
環境
$sw_vers ProductName: Mac OS X ProductVersion: 10.13.6 BuildVersion: 17G14042$python --version Python 3.7.3事前準備
Metabase
インストール&起動
公式のドキュメント( https://www.metabase.com/start/oss/ )に記載されているように
docker run -d -p 3000:3000 --name metabase metabase/metabaseこれだけでMetabaseがローカルの環境で動きます。便利!
ただ、立ち上がるまでに時間がかかるので、docker logs -f metabaseで起動が終わるまでみていた方が良さそうでした。
Chromeなどのブラウザでhttp://localhost:3000でアクセスできます。ユーザ作成
ユーザ名:dy@sample.com
パスワード:P@ssw0rdとしてユーザを作っておきます。
DB
本来は既存のデータベース情報を登録して接続した上でクエリを投げますが、今回はサンプルとして用意されているものを使用するため、スキップします。
クエリ
「照会する」→「簡単な質問」からクエリを作成します。
下図にあるようにMetabaseに付属しているSample DatasetにあるORDERSテーブルからテキトーにSELECTしておきます。
このとき、クエリの番号がURLの
/question/の次の番号になります(今は1)。
このクエリ番号を使ってPythonから結果を取得します。MetabaseのPythonライブラリ
MetabaseはAPIが公開( https://www.metabase.com/docs/latest/api-documentation.html )されているので、ここにリクエストを投げればいいです。
ただPythonのライブラリがいくつかあるので、それを使います。
自分が調べた限り、現在3つライブラリがあります。
# ライブラリ名 URL 最終更新(2021年1月26日時点) 1 metabase-api https://pypi.org/project/metabase-api/
https://github.com/vvaezian/metabase_api_python2021/01/18 2 metabasepy https://github.com/mertsalik/metabasepy 2020/10/30 3 metabase-py https://github.com/STUnitas/metabase-py 2020/5/28 今回は最終更新が直近であった
metabase-apiを使用します。
他のライブラリは試していないので、もしかしたらそちらの方が便利かもしれません。
pip install metabase-apiでインストールしておきます。Pythonで取得する
run.pyを下の内容で作成します。run.pyfrom metabase_api import Metabase_API import pandas as pd mb = Metabase_API('http://localhost:3000', 'dy@sample.com', 'P@ssw0rd') out = mb.post('/api/card/1/query/json') df = pd.DataFrame.from_records(out) print(df.head())最初にMetabase_APIにドメイン、ユーザのメールアドレス、パスワードを渡して認証します。
そのあとのmb.postでクエリの結果を取得しています。
これはAPI一覧( https://www.metabase.com/docs/latest/api-documentation.html#post-apicardcard-idqueryexport-format )によると、クエリ結果を得るのにPOSTで/api/card/:card-id/query/:export-formatを叩けばいいという仕様だったためです。
:card-idがクエリ番号です。
結果をpandasのDataFrameにしたかったので、json形式でフォーマットを指定しています。
outの中身はjsonのListになっているので、pd.DataFrame.from_recordsでpandasのDataFrameに変換しています。$python run.py実行するとMetabaseで表示されているクエリ結果を確かに得られました。
ID USER_ID 0 1 1 1 2 1 2 3 1 3 4 1 4 5 1

- 投稿日:2021-01-29T22:23:11+09:00
方言を翻訳しようともがいた(失敗作)
結論
失敗しました。改善すべき点を記録して、改善に取り組んでいます。
苦しみの過程(github)
<unk>が「スガハッタ」に変換されている!錬金術かな?原因
- 方言訳はカタカナで書くことが殆ど
- 形態素解析器はカタカナを分割しない
- 1文=1単語になった(画像のplotを見ると分かると思います)
- 従って、
<unk>に対応できない翻訳機となった背景
- 日英翻訳機が大量にある。他の言語もある。エスペラント語もある。
- しかし、方言翻訳機はルールベースのものしかない(そもそも狙っている方言がマイナーなためか、翻訳機もない)
- 今時自作するなら機械翻訳だよね!
使ったもの
- ブラウザ(Chormeを使いました)
- Google Colab
- テキストエディタ
やったこと
- 方言アライメントを用意する(ネットサーフィンしまくりました)
- アライメントをtsvに変換する(リポジトリ内 Hiraki_Sudahi.ipynbで実行可能です)
- アライメントの方言訳がカタカナだったので、標準語をカタカナに開く(ココが間違いだった)
- 参考ソースコードを用いてアライメントをベクトル化する
- Tensorflowを用いて学習・予測する
参考にしたソースコード様
kawasaki-kento/Transformer
SudachiPyで分かち書きしたきのメモ補足
良質なコーパスを入手できる環境などがありましたらコメント頂けると嬉しいです。
TensorよりTorchの方が楽かも知れないと思ったりしました。けど、ひとまずこれで一通り試したい所存。

- 投稿日:2021-01-29T22:17:55+09:00
Python:正規表現によりボートレーサーのデータを整然データに変換する(LZH→CSV)
はじめに
・ボートレースHP「ダウンロード・他」レーサー期別成績ダウンロード(LZH形式)をPythonの正規表現によって整然データに変換しました。
リンク:https://www.boatrace.jp/owpc/pc/extra/data/download.html
対象とされる方
・ボートレーサーのデータが欲しい方
・ボートレースのデータ解析をやろうと思っている方
・Pythonを使って正規表現をやってみたいと思う方
・Pythonの基礎をだいたい理解されている方何をやったのか
具体的に何を起こったのかをスクリーンショットで説明しますと、以下のようなデータから、
↓
以下のようなデータ形式へと変換しました。
↓
実際の処理
1.整形前のデータを取得する
まず、前述しましたリンクであるボートレースHP「ダウンロード・他」に行き、データをダウンロードしてきてください。
データの構造や形式は全て同じだと思われますので、お好きな期を選びダウンロードしてください。この記事では2020年後期のものを使用しました。
ファイル名は独特で、2020年後期だとfan2004.lzh、2020年前期だとfan1910.lzh、2019年後期だとfan1904.lzh、2019年前期だとfan1810.lzh ... のような規則性を持ったファイル名のようです。ですので、「2020年のものをダウンロードしたのに...」と思われている方は安心してください。
2.LZH形式をTXT形式に変換する
LZH形式に馴染み深い方は多いのかわかりませんが、自分はこの形式には慣れていませんので他の形式に変換したいと思います。
Googleで「LZH 変換 解凍」と検索すれば何かしらの答えを見いだせると思いますが、ここではMac版を紹介したいと思います。(紹介するやり方以外で行う場合は変換後がTXT形式になるようにしてください。)
Mac版の解凍方法
App Storeに行ってもらい、「The Unarchiver」と検索していただければそのアプリが出ると思いますのでそれをダウンロードしてください。
ダウンロードできましたら、常時アプリが置かれているところにそのアプリを持ってきてください。
置けましたら、先ほどダウンロードしていただいたファイルをこのアプリのところまで持ってきてください。すると新しくファイルがfan〇〇.txtで生成されるはずです。
3.データの構造を理解する & 手法の検討
処理を行う前にデータの構造を理解していく必要があります。先ほどのサイトには「ダウンロードされるデータのレイアウト」というものがありまして、そこにはデータの内容が詰まっています。これを参考にしながら解読していけば良さそうです。
またそのアプローチの方法も非常に重要です。前述「何をやったのか」で紹介した通り数字がぎっしりと並んでおり"正規表現"と呼ばれるものを使えばうまくできそうです!(ご存知ない方はやっていく中で概念が掴めると思います)
4.正規表現でデータを得る
ここから実際の処理に入っていきます。
こういったデータではいきなりfor文などを使って一気にやりたい!と思うのは山々ですが人生そううまくいかないものです。細かいものを積み上げていく方式でアプローチしていきましょう。一番最初にある登番2014番の方を対象としてデータを得ていきたいと思います。まず必要なライブラリをimportしていき、データの読み込みも行なっていきます。
注意
・私のファイル名では、2020年後期のものになっていますが、ご自身がダウンロードされたファイル名に変えてください。
・相対パスを使っていますので、TXT形式に直したファイルをカレントディレクトリに置いてください。でないとエラーを吐かれてしまいます。
・以下のコードを実行する前はUnicode(UTF-8)に直してください。これも直さないとエラーを吐かれてしまいます。
・半年前に作成したコードですので、まだ注意点があるかもしれません(すみません)。適宜対応してみてください。
data_reader.pyimport re data_file=open('./fan2004.txt')#ファイル名注意行で分かれているようなので、分解して配列にしていきます。
data_reader.pydata_content=data_file.readlines() print(data_content)すごい見にくいです。笑
方針で決めたようにこのうち最初の成分のみ-つまり[0]-でまず構築していきます。
日本語データは「名前」と「出身地」があるようですが、データ解析する上でおそらく使用しないと思いますので省きます。(実際は日本語データの処理が面倒だった)data_reader.pydata_content=data_file.readlines()[0] print(data_content)
TXT形式で見たようなデータが返ってきました。日本語データを分岐点として2回に分けて正規表現でパターンマッチしていきます。
まず前半部分をやっていきます。data_reader.pydata_content_regex1=re.compile(r'''( (\d\d\d\d) )''',re.VERBOSE) number=data_content_regex1.search(data_content).group() print(number)2014登録番号のみが返ってきました。これは(\d\d\d\d)で数字4つを抜き出したからです。
後半の部分もやっていきましょう、と言いたいところですがこれはかなり骨の折れる作業です。前述したデータのレイアウトを見ながらバイト数に合わせて頑張って処理していきます。
やっていることは前半部分とはあまり変わりません。data_reader.pydata_content_regex2=re.compile(r'''( ([AB][12]) ([SH]\d\d\d\d\d\d) (\d) (\d\d) (\d\d\d) (\d\d) (.{1,2}) (\d\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (.{1,2}) (.{1,2}) (.{1,2}) (\d\d\d\d) (\d\d\d\d) (\d\d\d\d) (\d) (\d\d\d\d\d\d\d\d) (\d\d\d\d\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) )''',re.VERBOSE) mo=data_content_regex2.search(data_content).group() print(mo)B1S22030717316555O 045502530030160750000018013053801728001303080203900130231018440014021401731001100910142700110091022410B1B1B14800470020202201911012020043002000100600200100100101000000000000000000040030020010030000000000000000000003003003002002000000000000000000100200000600400100000000000000000000010030050000020000000000000000001000002000004004000000000000000000000000対象となるのはほぼ数字なので\dの組み合わせでなんとかなりますが、途中で文字も入ってきます。これは改行以外のすべての文字に対応できるピリオドで、その文字数には{a,b}で対応します。これはa字以上b字以下を表します。その他の詳しい説明は公式のドキュメント・関連する本・サイトを見てください。
うまく欲しい結果が返ってきたのであとはこれをグループで分けてエクセルに入力していけば良さそうです。
5.エクセルに得たデータを入力していく
OpenPyxlというモジュールを使います。PCにダウンロードされていない方は適宜ダウンロードしてください。Mac版のみ紹介します。Mac版のダウンロード方法
ターミナルを開き、以下のコードを入力し実行する。
ターミナルpip install openpyxlでは4で得たデータをエクセルにて入力していきます。
目的は整然データですので列名が必要です。列名は先ほどにも紹介したレイアウトのデータの名前を一つずつ打っていきます。きついです。data_reader.pyimport openpyxl wb=openpyxl.Workbook() sheet=wb.active #列名入力 #グループ1 sheet.cell(row=1,column=1).value='Number' sheet.cell(row=1,column=2).value='Rank' sheet.cell(row=1,column=3).value='birthday' sheet.cell(row=1,column=4).value='Sex' sheet.cell(row=1,column=5).value='Age' sheet.cell(row=1,column=6).value='Tall' sheet.cell(row=1,column=7).value='Weight' sheet.cell(row=1,column=8).value='BloodType' sheet.cell(row=1,column=9).value='Win_rate' sheet.cell(row=1,column=10).value='Wins_rate' sheet.cell(row=1,column=11).value='1st_num' sheet.cell(row=1,column=12).value='2nd_num' sheet.cell(row=1,column=13).value='Runs_num' sheet.cell(row=1,column=14).value='Yusyutu_num' sheet.cell(row=1,column=15).value='Champ_num' sheet.cell(row=1,column=16).value='ST_mean' #グループ2 sheet.cell(row=1,column=17).value='Course1_entry_num' sheet.cell(row=1,column=18).value='Course1_Wins_rate' sheet.cell(row=1,column=19).value='Course1_ST_mean' sheet.cell(row=1,column=20).value='Course1_Start_Rank' sheet.cell(row=1,column=21).value='Course2_entry_num' sheet.cell(row=1,column=22).value='Course2_Wins_rate' sheet.cell(row=1,column=23).value='Course2_ST_mean' sheet.cell(row=1,column=24).value='Course2_Start_Rank' sheet.cell(row=1,column=25).value='Course3_entry_num' sheet.cell(row=1,column=26).value='Course3_Wins_rate' sheet.cell(row=1,column=27).value='Course3_ST_mean' sheet.cell(row=1,column=28).value='Course3_Start_Rank' sheet.cell(row=1,column=29).value='Course4_entry_num' sheet.cell(row=1,column=30).value='Course4_Wins_rate' sheet.cell(row=1,column=31).value='Course4_ST_mean' sheet.cell(row=1,column=32).value='Course4_Start_Rank' sheet.cell(row=1,column=33).value='Course5_entry_num' sheet.cell(row=1,column=34).value='Course5_Wins_rate' sheet.cell(row=1,column=35).value='Course5_ST_mean' sheet.cell(row=1,column=36).value='Course5_Start_Rank' sheet.cell(row=1,column=37).value='Course6_entry_num' sheet.cell(row=1,column=38).value='Course6_Wins_rate' sheet.cell(row=1,column=39).value='Course6_ST_mean' sheet.cell(row=1,column=40).value='Course6_Start_Rank' #ぐる3 sheet.cell(row=1,column=41).value='bef_Rank' sheet.cell(row=1,column=42).value='bef_bef_Rank' sheet.cell(row=1,column=43).value='bef_bef_bef_Rank' sheet.cell(row=1,column=44).value='bef_Capavility_index' sheet.cell(row=1,column=45).value='Now_Capability_index' sheet.cell(row=1,column=46).value='Year' sheet.cell(row=1,column=47).value='Period' sheet.cell(row=1,column=48).value='CalcurationPeriod1' sheet.cell(row=1,column=49).value='CalcurationPeriod2' sheet.cell(row=1,column=50).value='GraduatePeriod' #グル4 sheet.cell(row=1,column=51).value='Course1_1st_num' sheet.cell(row=1,column=52).value='Course1_2nd_num' sheet.cell(row=1,column=53).value='Course1_3rd_num' sheet.cell(row=1,column=54).value='Course1_4th_num' sheet.cell(row=1,column=55).value='Course1_5th_num' sheet.cell(row=1,column=56).value='Course1_6th_num' sheet.cell(row=1,column=57).value='Course1_F_num' sheet.cell(row=1,column=58).value='Course1_L0_num' sheet.cell(row=1,column=59).value='Course1_L1_num' sheet.cell(row=1,column=60).value='Course1_K0_num' sheet.cell(row=1,column=61).value='Course1_K1_num' sheet.cell(row=1,column=62).value='Course1_S0_num' sheet.cell(row=1,column=63).value='Course1_S1_num' sheet.cell(row=1,column=64).value='Course1_S2_num' sheet.cell(row=1,column=65).value='Course2_1st_num' sheet.cell(row=1,column=66).value='Course2_2nd_num' sheet.cell(row=1,column=67).value='Course2_3rd_num' sheet.cell(row=1,column=68).value='Course2_4th_num' sheet.cell(row=1,column=69).value='Course2_5th_num' sheet.cell(row=1,column=70).value='Course2_6th_num' sheet.cell(row=1,column=71).value='Course2_F_num' sheet.cell(row=1,column=72).value='Course2_L0_num' sheet.cell(row=1,column=73).value='Course2_L1_num' sheet.cell(row=1,column=74).value='Course2_K0_num' sheet.cell(row=1,column=75).value='Course2_K1_num' sheet.cell(row=1,column=76).value='Course2_S0_num' sheet.cell(row=1,column=77).value='Course2_S1_num' sheet.cell(row=1,column=78).value='Course2_S2_num' sheet.cell(row=1,column=79).value='Course3_1st_num' sheet.cell(row=1,column=80).value='Course3_2nd_num' sheet.cell(row=1,column=81).value='Course3_3rd_num' sheet.cell(row=1,column=82).value='Course3_4th_num' sheet.cell(row=1,column=83).value='Course3_5th_num' sheet.cell(row=1,column=84).value='Course3_6th_num' sheet.cell(row=1,column=85).value='Course3_F_num' sheet.cell(row=1,column=86).value='Course3_L0_num' sheet.cell(row=1,column=87).value='Course3_L1_num' sheet.cell(row=1,column=88).value='Course3_K0_num' sheet.cell(row=1,column=89).value='Course3_K1_num' sheet.cell(row=1,column=90).value='Course3_S0_num' sheet.cell(row=1,column=91).value='Course3_S1_num' sheet.cell(row=1,column=92).value='Course3_S2_num' sheet.cell(row=1,column=93).value='Course4_1st_num' sheet.cell(row=1,column=94).value='Course4_2nd_num' sheet.cell(row=1,column=95).value='Course4_3rd_num' sheet.cell(row=1,column=96).value='Course4_4th_num' sheet.cell(row=1,column=97).value='Course4_5th_num' sheet.cell(row=1,column=98).value='Course4_6th_num' sheet.cell(row=1,column=99).value='Course4_F_num' sheet.cell(row=1,column=100).value='Course4_L0_num' sheet.cell(row=1,column=101).value='Course4_L1_num' sheet.cell(row=1,column=102).value='Course4_K0_num' sheet.cell(row=1,column=103).value='Course4_K1_num' sheet.cell(row=1,column=104).value='Course4_S0_num' sheet.cell(row=1,column=105).value='Course4_S1_num' sheet.cell(row=1,column=106).value='Course4_S2_num' sheet.cell(row=1,column=107).value='Course5_1st_num' sheet.cell(row=1,column=108).value='Course5_2nd_num' sheet.cell(row=1,column=109).value='Course5_3rd_num' sheet.cell(row=1,column=110).value='Course5_4th_num' sheet.cell(row=1,column=111).value='Course5_5th_num' sheet.cell(row=1,column=112).value='Course5_6th_num' sheet.cell(row=1,column=113).value='Course5_F_num' sheet.cell(row=1,column=114).value='Course5_L0_num' sheet.cell(row=1,column=115).value='Course5_L1_num' sheet.cell(row=1,column=116).value='Course5_K0_num' sheet.cell(row=1,column=117).value='Course5_K1_num' sheet.cell(row=1,column=118).value='Course5_S0_num' sheet.cell(row=1,column=119).value='Course5_S1_num' sheet.cell(row=1,column=120).value='Course5_S2_num' sheet.cell(row=1,column=121).value='Course6_1st_num' sheet.cell(row=1,column=122).value='Course6_2nd_num' sheet.cell(row=1,column=123).value='Course6_3rd_num' sheet.cell(row=1,column=124).value='Course6_4th_num' sheet.cell(row=1,column=125).value='Course6_5th_num' sheet.cell(row=1,column=126).value='Course6_6th_num' sheet.cell(row=1,column=127).value='Course6_F_num' sheet.cell(row=1,column=128).value='Course6_L0_num' sheet.cell(row=1,column=129).value='Course6_L1_num' sheet.cell(row=1,column=130).value='Course6_K0_num' sheet.cell(row=1,column=131).value='Course6_K1_num' sheet.cell(row=1,column=132).value='Course6_S0_num' sheet.cell(row=1,column=133).value='Course6_S1_num' sheet.cell(row=1,column=134).value='Course6_S2_num'わかりやすくするために一列一列丁寧に名前を打ちました。
ループするところは[名前]+[番号]~とすればかなり打つのが軽減されそうです!自分は脳筋でやりました。グループ別で2行目に打っていきましょう。
data_reader.py#エクセルに入力する for i in range(1): #ぐる1 sheet.cell(row=1+i,column=1).value=int(number) sheet.cell(row=1+i,column=2).value=mo.group(2) sheet.cell(row=1+i,column=3).value=mo.group(3) sheet.cell(row=1+i,column=4).value=int(mo.group(4)) sheet.cell(row=1+i,column=5).value=int(mo.group(5)) sheet.cell(row=1+i,column=6).value=int(mo.group(6)) sheet.cell(row=1+i,column=7).value=int(mo.group(7)) sheet.cell(row=1+i,column=8).value=mo.group(8) sheet.cell(row=1+i,column=9).value=int(mo.group(9))*0.01 sheet.cell(row=1+i,column=10).value=int(mo.group(10))*0.01 sheet.cell(row=1+i,column=11).value=int(mo.group(11)) sheet.cell(row=1+i,column=12).value=int(mo.group(12)) sheet.cell(row=1+i,column=13).value=int(mo.group(13)) sheet.cell(row=1+i,column=14).value=int(mo.group(14)) sheet.cell(row=1+i,column=15).value=int(mo.group(15)) sheet.cell(row=1+i,column=16).value=int(mo.group(16))*0.01 #ぐる2 sheet.cell(row=1+i,column=17).value=int(mo.group(17)) sheet.cell(row=1+i,column=18).value=int(mo.group(18))*0.01 sheet.cell(row=1+i,column=19).value=int(mo.group(19))*0.01 sheet.cell(row=1+i,column=20).value=int(mo.group(20))*0.01 sheet.cell(row=1+i,column=21).value=int(mo.group(21)) sheet.cell(row=1+i,column=23).value=int(mo.group(23))*0.01 sheet.cell(row=1+i,column=22).value=int(mo.group(22))*0.01 sheet.cell(row=1+i,column=24).value=int(mo.group(24))*0.01 sheet.cell(row=1+i,column=25).value=int(mo.group(25)) sheet.cell(row=1+i,column=26).value=int(mo.group(26))*0.01 sheet.cell(row=1+i,column=27).value=int(mo.group(27))*0.01 sheet.cell(row=1+i,column=28).value=int(mo.group(28))*0.01 sheet.cell(row=1+i,column=29).value=int(mo.group(29)) sheet.cell(row=1+i,column=30).value=int(mo.group(30))*0.01 sheet.cell(row=1+i,column=31).value=int(mo.group(31))*0.01 sheet.cell(row=1+i,column=32).value=int(mo.group(32))*0.01 sheet.cell(row=1+i,column=33).value=int(mo.group(33)) sheet.cell(row=1+i,column=34).value=int(mo.group(34))*0.01 sheet.cell(row=1+i,column=35).value=int(mo.group(35))*0.01 sheet.cell(row=1+i,column=36).value=int(mo.group(36))*0.01 sheet.cell(row=1+i,column=37).value=int(mo.group(37)) sheet.cell(row=1+i,column=38).value=int(mo.group(38))*0.01 sheet.cell(row=1+i,column=39).value=int(mo.group(39))*0.01 sheet.cell(row=1+i,column=40).value=int(mo.group(40))*0.01 #ぐる3 sheet.cell(row=1+i,column=41).value=mo.group(41) sheet.cell(row=1+i,column=42).value=mo.group(42) sheet.cell(row=1+i,column=43).value=mo.group(43) sheet.cell(row=1+i,column=44).value=int(mo.group(44))*0.01 sheet.cell(row=1+i,column=45).value=int(mo.group(45))*0.01 sheet.cell(row=1+i,column=46).value=int(mo.group(46)) sheet.cell(row=1+i,column=47).value=int(mo.group(47)) sheet.cell(row=1+i,column=48).value=int(mo.group(48)) sheet.cell(row=1+i,column=49).value=int(mo.group(49)) sheet.cell(row=1+i,column=50).value=int(mo.group(50)) #グル4 for j in range(51,134+1): sheet.cell(row=1+i,column=j).value=int(mo.group(j)) wb.save('boat_data.xlsx')「for?」と思われた方、正解です。完成品の手抜きです。
ですが、あらかじめforを使っておけば、完成品を作る際にインデントなどのめんどくさい作業がなくなります。最後に閉じて1人分はこれで完成です。
6.for文ですべてのデータを入力する
やっていることは4.5.と同じですので完成品を掲示します。少し変わっていたり、無駄な部分も散見されますが許してください。
data_reader.pyimport re import openpyxl data_file=open('./fan2004.txt') wb=openpyxl.Workbook() sheet=wb.active #列名入力 #グループ1 sheet.cell(row=1,column=1).value='Number' sheet.cell(row=1,column=2).value='Rank' sheet.cell(row=1,column=3).value='birthday' sheet.cell(row=1,column=4).value='Sex' sheet.cell(row=1,column=5).value='Age' sheet.cell(row=1,column=6).value='Tall' sheet.cell(row=1,column=7).value='Weight' sheet.cell(row=1,column=8).value='BloodType' sheet.cell(row=1,column=9).value='Win_rate' sheet.cell(row=1,column=10).value='Wins_rate' sheet.cell(row=1,column=11).value='1st_num' sheet.cell(row=1,column=12).value='2nd_num' sheet.cell(row=1,column=13).value='Runs_num' sheet.cell(row=1,column=14).value='Yusyutu_num' sheet.cell(row=1,column=15).value='Champ_num' sheet.cell(row=1,column=16).value='ST_mean' #グループ2 sheet.cell(row=1,column=17).value='Course1_entry_num' sheet.cell(row=1,column=18).value='Course1_Wins_rate' sheet.cell(row=1,column=19).value='Course1_ST_mean' sheet.cell(row=1,column=20).value='Course1_Start_Rank' sheet.cell(row=1,column=21).value='Course2_entry_num' sheet.cell(row=1,column=22).value='Course2_Wins_rate' sheet.cell(row=1,column=23).value='Course2_ST_mean' sheet.cell(row=1,column=24).value='Course2_Start_Rank' sheet.cell(row=1,column=25).value='Course3_entry_num' sheet.cell(row=1,column=26).value='Course3_Wins_rate' sheet.cell(row=1,column=27).value='Course3_ST_mean' sheet.cell(row=1,column=28).value='Course3_Start_Rank' sheet.cell(row=1,column=29).value='Course4_entry_num' sheet.cell(row=1,column=30).value='Course4_Wins_rate' sheet.cell(row=1,column=31).value='Course4_ST_mean' sheet.cell(row=1,column=32).value='Course4_Start_Rank' sheet.cell(row=1,column=33).value='Course5_entry_num' sheet.cell(row=1,column=34).value='Course5_Wins_rate' sheet.cell(row=1,column=35).value='Course5_ST_mean' sheet.cell(row=1,column=36).value='Course5_Start_Rank' sheet.cell(row=1,column=37).value='Course6_entry_num' sheet.cell(row=1,column=38).value='Course6_Wins_rate' sheet.cell(row=1,column=39).value='Course6_ST_mean' sheet.cell(row=1,column=40).value='Course6_Start_Rank' #ぐる3 sheet.cell(row=1,column=41).value='bef_Rank' sheet.cell(row=1,column=42).value='bef_bef_Rank' sheet.cell(row=1,column=43).value='bef_bef_bef_Rank' sheet.cell(row=1,column=44).value='bef_Capavility_index' sheet.cell(row=1,column=45).value='Now_Capability_index' sheet.cell(row=1,column=46).value='Year' sheet.cell(row=1,column=47).value='Period' sheet.cell(row=1,column=48).value='CalcurationPeriod1' sheet.cell(row=1,column=49).value='CalcurationPeriod2' sheet.cell(row=1,column=50).value='GraduatePeriod' #グル4 sheet.cell(row=1,column=51).value='Course1_1st_num' sheet.cell(row=1,column=52).value='Course1_2nd_num' sheet.cell(row=1,column=53).value='Course1_3rd_num' sheet.cell(row=1,column=54).value='Course1_4th_num' sheet.cell(row=1,column=55).value='Course1_5th_num' sheet.cell(row=1,column=56).value='Course1_6th_num' sheet.cell(row=1,column=57).value='Course1_F_num' sheet.cell(row=1,column=58).value='Course1_L0_num' sheet.cell(row=1,column=59).value='Course1_L1_num' sheet.cell(row=1,column=60).value='Course1_K0_num' sheet.cell(row=1,column=61).value='Course1_K1_num' sheet.cell(row=1,column=62).value='Course1_S0_num' sheet.cell(row=1,column=63).value='Course1_S1_num' sheet.cell(row=1,column=64).value='Course1_S2_num' sheet.cell(row=1,column=65).value='Course2_1st_num' sheet.cell(row=1,column=66).value='Course2_2nd_num' sheet.cell(row=1,column=67).value='Course2_3rd_num' sheet.cell(row=1,column=68).value='Course2_4th_num' sheet.cell(row=1,column=69).value='Course2_5th_num' sheet.cell(row=1,column=70).value='Course2_6th_num' sheet.cell(row=1,column=71).value='Course2_F_num' sheet.cell(row=1,column=72).value='Course2_L0_num' sheet.cell(row=1,column=73).value='Course2_L1_num' sheet.cell(row=1,column=74).value='Course2_K0_num' sheet.cell(row=1,column=75).value='Course2_K1_num' sheet.cell(row=1,column=76).value='Course2_S0_num' sheet.cell(row=1,column=77).value='Course2_S1_num' sheet.cell(row=1,column=78).value='Course2_S2_num' sheet.cell(row=1,column=79).value='Course3_1st_num' sheet.cell(row=1,column=80).value='Course3_2nd_num' sheet.cell(row=1,column=81).value='Course3_3rd_num' sheet.cell(row=1,column=82).value='Course3_4th_num' sheet.cell(row=1,column=83).value='Course3_5th_num' sheet.cell(row=1,column=84).value='Course3_6th_num' sheet.cell(row=1,column=85).value='Course3_F_num' sheet.cell(row=1,column=86).value='Course3_L0_num' sheet.cell(row=1,column=87).value='Course3_L1_num' sheet.cell(row=1,column=88).value='Course3_K0_num' sheet.cell(row=1,column=89).value='Course3_K1_num' sheet.cell(row=1,column=90).value='Course3_S0_num' sheet.cell(row=1,column=91).value='Course3_S1_num' sheet.cell(row=1,column=92).value='Course3_S2_num' sheet.cell(row=1,column=93).value='Course4_1st_num' sheet.cell(row=1,column=94).value='Course4_2nd_num' sheet.cell(row=1,column=95).value='Course4_3rd_num' sheet.cell(row=1,column=96).value='Course4_4th_num' sheet.cell(row=1,column=97).value='Course4_5th_num' sheet.cell(row=1,column=98).value='Course4_6th_num' sheet.cell(row=1,column=99).value='Course4_F_num' sheet.cell(row=1,column=100).value='Course4_L0_num' sheet.cell(row=1,column=101).value='Course4_L1_num' sheet.cell(row=1,column=102).value='Course4_K0_num' sheet.cell(row=1,column=103).value='Course4_K1_num' sheet.cell(row=1,column=104).value='Course4_S0_num' sheet.cell(row=1,column=105).value='Course4_S1_num' sheet.cell(row=1,column=106).value='Course4_S2_num' sheet.cell(row=1,column=107).value='Course5_1st_num' sheet.cell(row=1,column=108).value='Course5_2nd_num' sheet.cell(row=1,column=109).value='Course5_3rd_num' sheet.cell(row=1,column=110).value='Course5_4th_num' sheet.cell(row=1,column=111).value='Course5_5th_num' sheet.cell(row=1,column=112).value='Course5_6th_num' sheet.cell(row=1,column=113).value='Course5_F_num' sheet.cell(row=1,column=114).value='Course5_L0_num' sheet.cell(row=1,column=115).value='Course5_L1_num' sheet.cell(row=1,column=116).value='Course5_K0_num' sheet.cell(row=1,column=117).value='Course5_K1_num' sheet.cell(row=1,column=118).value='Course5_S0_num' sheet.cell(row=1,column=119).value='Course5_S1_num' sheet.cell(row=1,column=120).value='Course5_S2_num' sheet.cell(row=1,column=121).value='Course6_1st_num' sheet.cell(row=1,column=122).value='Course6_2nd_num' sheet.cell(row=1,column=123).value='Course6_3rd_num' sheet.cell(row=1,column=124).value='Course6_4th_num' sheet.cell(row=1,column=125).value='Course6_5th_num' sheet.cell(row=1,column=126).value='Course6_6th_num' sheet.cell(row=1,column=127).value='Course6_F_num' sheet.cell(row=1,column=128).value='Course6_L0_num' sheet.cell(row=1,column=129).value='Course6_L1_num' sheet.cell(row=1,column=130).value='Course6_K0_num' sheet.cell(row=1,column=131).value='Course6_K1_num' sheet.cell(row=1,column=132).value='Course6_S0_num' sheet.cell(row=1,column=133).value='Course6_S1_num' sheet.cell(row=1,column=134).value='Course6_S2_num' #行で処理 for i in range(1,1600+1): data_file=open('./fan2004.txt') k=i-1 print(k) data_content=data_file.readlines()[k] data_content_regex1=re.compile(r'''( (\d\d\d\d) )''',re.VERBOSE) number=data_content_regex1.search(data_content).group() data_content_regex2=re.compile(r'''( ([AB][12]) ([SH]\d\d\d\d\d\d) (\d) (\d\d) (\d\d\d) (\d\d) (.{1,2}) (\d\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d\d) (\d\d\d) (\d\d\d) (.{1,2}) (.{1,2}) (.{1,2}) (\d\d\d\d) (\d\d\d\d) (\d\d\d\d) (\d) (\d\d\d\d\d\d\d\d) (\d\d\d\d\d\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) (\d\d) )''',re.VERBOSE) mo=data_content_regex2.search(data_content) #エクセルに入力する #ぐる1 sheet.cell(row=1+i,column=1).value=int(number) sheet.cell(row=1+i,column=2).value=mo.group(2) sheet.cell(row=1+i,column=3).value=mo.group(3) sheet.cell(row=1+i,column=4).value=int(mo.group(4)) sheet.cell(row=1+i,column=5).value=int(mo.group(5)) sheet.cell(row=1+i,column=6).value=int(mo.group(6)) sheet.cell(row=1+i,column=7).value=int(mo.group(7)) sheet.cell(row=1+i,column=8).value=mo.group(8) sheet.cell(row=1+i,column=9).value=int(mo.group(9))*0.01 sheet.cell(row=1+i,column=10).value=int(mo.group(10))*0.01 sheet.cell(row=1+i,column=11).value=int(mo.group(11)) sheet.cell(row=1+i,column=12).value=int(mo.group(12)) sheet.cell(row=1+i,column=13).value=int(mo.group(13)) sheet.cell(row=1+i,column=14).value=int(mo.group(14)) sheet.cell(row=1+i,column=15).value=int(mo.group(15)) sheet.cell(row=1+i,column=16).value=int(mo.group(16))*0.01 #ぐる2 sheet.cell(row=1+i,column=17).value=int(mo.group(17)) sheet.cell(row=1+i,column=18).value=int(mo.group(18))*0.01 sheet.cell(row=1+i,column=19).value=int(mo.group(19))*0.01 sheet.cell(row=1+i,column=20).value=int(mo.group(20))*0.01 sheet.cell(row=1+i,column=21).value=int(mo.group(21)) sheet.cell(row=1+i,column=23).value=int(mo.group(23))*0.01 sheet.cell(row=1+i,column=22).value=int(mo.group(22))*0.01 sheet.cell(row=1+i,column=24).value=int(mo.group(24))*0.01 sheet.cell(row=1+i,column=25).value=int(mo.group(25)) sheet.cell(row=1+i,column=26).value=int(mo.group(26))*0.01 sheet.cell(row=1+i,column=27).value=int(mo.group(27))*0.01 sheet.cell(row=1+i,column=28).value=int(mo.group(28))*0.01 sheet.cell(row=1+i,column=29).value=int(mo.group(29)) sheet.cell(row=1+i,column=30).value=int(mo.group(30))*0.01 sheet.cell(row=1+i,column=31).value=int(mo.group(31))*0.01 sheet.cell(row=1+i,column=32).value=int(mo.group(32))*0.01 sheet.cell(row=1+i,column=33).value=int(mo.group(33)) sheet.cell(row=1+i,column=34).value=int(mo.group(34))*0.01 sheet.cell(row=1+i,column=35).value=int(mo.group(35))*0.01 sheet.cell(row=1+i,column=36).value=int(mo.group(36))*0.01 sheet.cell(row=1+i,column=37).value=int(mo.group(37)) sheet.cell(row=1+i,column=38).value=int(mo.group(38))*0.01 sheet.cell(row=1+i,column=39).value=int(mo.group(39))*0.01 sheet.cell(row=1+i,column=40).value=int(mo.group(40))*0.01 #ぐる3 sheet.cell(row=1+i,column=41).value=mo.group(41) sheet.cell(row=1+i,column=42).value=mo.group(42) sheet.cell(row=1+i,column=43).value=mo.group(43) sheet.cell(row=1+i,column=44).value=int(mo.group(44))*0.01 sheet.cell(row=1+i,column=45).value=int(mo.group(45))*0.01 sheet.cell(row=1+i,column=46).value=int(mo.group(46)) sheet.cell(row=1+i,column=47).value=int(mo.group(47)) sheet.cell(row=1+i,column=48).value=int(mo.group(48)) sheet.cell(row=1+i,column=49).value=int(mo.group(49)) sheet.cell(row=1+i,column=50).value=int(mo.group(50)) #グル4 for j in range(51,134+1): sheet.cell(row=1+i,column=j).value=int(mo.group(j)) wb.save('boat_data.xlsx')これですべてのレーサーの情報がたっぷり詰まったエクセルファイルがDesktopに表示されるはずです。
7.エクセルからCSV形式に直す
XLSX形式からCSV形式にするには、「名前をつけて保存」→「ファイル形式:CSV UTF-8 (コンマ区切り) (.csv)」にするだけです。
8.CSV形式を読み込む
ボートレーサーのCSV形式が完成しました。あとは、読み込んで機械学習したり統計的解析をしたりしてボートレースの順位予測ライフを楽しんでください。
racer_df=pd.read_csv('ボートレースのファイル名.csv')注意
CSVファイルで見てみるとデータがないところや、Pythonで読み込んでみてデータ解析してみると挙動が変だなと思う場面があると思います。
それはデータを整形する際に出たちょっとした弊害です。特に文字データ(A1,B2など)で不思議な挙動が確認されました。欠損値であるところが空白2文字分になっていたりします。
適宜対応していただくか、データ整形の段階でのコードをアレンジしてみてください。racer_df.loc[racer_df['bef_Rank'] == ' ','bef_Rank']='C' racer_df.loc[racer_df['bef_bef_Rank'] == ' ','bef_bef_Rank']='C' racer_df.loc[racer_df['bef_bef_bef_Rank'] == ' ','bef_bef_bef_Rank']='C'今後
今回紹介させていただいたものは半年ぐらい前に「バイトしたくないからボートレースで稼ぎたい」と思ったのが発端です。
統計学と機械学習を学んであったのでそこそこ自信はあったのですが結局その欲にまみれた計画はお陀仏となりました。ここに供養しますね。誰かこの意思を汲み取ってやってみてください。(泣)
今回はボート"レーサー"のデータの整形を紹介しましたが、次回あたりにボート"レース"の試合結果をWebスクレイピングでデータ収集する方法を紹介したいと思います。(これも供養)
他にも、Pythonを使って大学数学をプログラミングで解いたり、物理シミュレーションをしたり、kaggleもしているのでそういうのがまだネットに上がっていなければ書いていきたいと思います。(これもまた供養)
参考
[1]退屈なことはPythonにやらせよう OREILLY
[2]BOAT RACE (https://www.boatrace.jp/owpc/pc/extra/data/download.html)
[3]Mac OS XでLZH圧縮ファイルを解凍する方法 (https://fatherlog.com/apple/mac/200/)追記
初めてQiitaに記事を投稿しました。もし間違っている点やガイドラインに違反している等がありましたら私に連絡ください。







- 投稿日:2021-01-29T21:56:09+09:00
俺の書いたPythonのdiscordbotのコード!
中身
mine.pyimport discord import os import keep_alive import asyncio # 接続に必要なオブジェクトを生成 client = discord.Client() version = "1.0" noeconsole=input @client.event # 起動時に動作する処理 async def on_ready(): # 起動したらログイン通知が表示される print('ログインしました') print("erroがないか確認してください") await client.change_presence(activity=discord.Game (name="versionは"+(version)+"です。", )) await client.get_channel(782243365982175252).send("bot is online") # メッセージ受信時に動作する処理 @client.event async def on_message(message): if message.author.id == 302050872383242240: if 'https://disboard.org' in message.embeds[0].description: await message.channel.send('べ、別にbumpしてくれたってうれしくねーぞ///') else: await message.channel.send('あれれぇ?時間わからないのかなぁ?') # メッセージ送信者がBotだった場合は無視する if message.author.bot: return # ans のメッセージに対し ans と送信する if message.content == 'やっほー': await message.channel.send("あそぼ") if message.content == 'ねえねえ': await message.channel.send('どうした?') if message.content == 'おやすみ': await message.channel.send('おやすみー') #以下にコードを書いていく if message.content.startswith("p."): #ここは自由に変えてね query = message.content[2:].split(" ") #空白で区切る if query[0] == "timerh": #ここも自由にかえてね await message.channel.send("timer start")#ここも自由に変えてね if int(query[1]) > 60: await message.channel.send('1時間以上は設定できません!')#ここも(ry else: await asyncio.sleep(int(query[1])*60) #分を取得&60倍 await message.channel.send(f"{int(query[1])}分経ちました") #こ(ry #ここから下はおんなじ感じのコード if query[0] == "timer": #コマンドを判定 await message.channel.send("timer start") if int(query[1]) > 3600: await message.channel.send('1時間以上は設定できません!') else: await asyncio.sleep(int(query[1])) #分を取得&60倍 await message.channel.send(f"{int(query[1])}秒経ちました") #内容を変更 elif query[0] == "say": #コマンドその2 await message.channel.send(query[1]) else: await message.channel.send(">>> 不明なコマンドです。") keep_alive.keep_alive() client.run(os.getenv('TOKEN')別のファイル
keep_alive.pyfrom flask import Flask from threading import Thread app = Flask('') @app.route('/') def main(): return 'Bot is aLive!' def run(): app.run(host="0.0.0.0", port=8080) def keep_alive(): server = Thread(target=run) server.start()補足
トークンは新しく
.envってファイル作って
TOKEN=って入れた後ろに入れてね^^わかんなかったら
もしコードが動かないどういう意味?って思ったら「千尋#7566」にDM送ってね^^
宣伝
「プログラミングがしたい!」「わからないところがある!」って人は
https://discord.gg/c8vrrg6T8j
に参加してね!
- 投稿日:2021-01-29T21:44:18+09:00
Pythonにおけるリストの高速処理
pythonにおいて、リストを利用する機会は多々ありますが、
リストの生成、検索においてどのように処理するのが一番速いのかを調べました。環境
Python 3.7.8
生成
まずはじめに、こんなプログラムを用意しました。
リストの生成にかかる平均秒数を計測する簡単なプログラムです。import random from time import time #### List Tests #### # テスト回数 num_tests = 25 # テスト回数分の測定値を保存するリスト timeList = [] for i in range(0, num_tests): # 10万まで要素を生成 end = 100_000 # 開始時刻 startTime = time() ##### リスト生成プログラム ######################### listComp = [i for i in range(0, end)] ################################################## # 終了時刻 endTime = time() # 測定値保存 timeList.append(endTime - startTime) # テストの平均値[s] avg = sum(timeList) / len(timeList) print(avg, '[s]')リスト生成プログラムの所を書き換えて計測していきましょう。
内包表記
まずは内包表記の場合です。
listComp = [i for i in range(0, end)]結果
0.006156406402587891 [s]appendメソッド
次はappendメソッドです。リスト生成プログラムを書き換えましょう。
append_list = [] for i in range(0,end): append_list.append(i)結果
0.01742997169494629 [s]初期化済みリスト
最後は、指定サイズ分要素を用意しておいて、
そこに値を代入しましょう。preAllocate = [0] * end for i in range(0, end): preAllocate[i] = i結果
0.014672718048095702 [s]生成のまとめ
リスト生成の計測値
方法 時間[ms] 内包表記 6.16 append 17.42 初期化済みリスト 14.67 内包表記 > 初期化済みリスト > append の順で速いのが分かると思います。
生成する要素数を変えてみても、内包表記が一番速いのは変わりませんでした。検索
次は検索の計測をしてみます。
先ほどのプログラムを少し書き換え、
1から30000の数値がランダムに入る、30000の要素を持つ配列を2つ用意して検索してみます。import random from time import time # Initialize Random random.seed(time()) #### List Tests #### # テスト回数 num_tests = 3 # テスト回数分の測定値を保存するリスト timeList = [] for i in range(0, num_tests): # 3万まで要素を生成 end = 30_000 # リストの生成 list_a = [random.randint(1, end) for i in range(0, end)] list_b = [random.randint(1, end) for i in range(0, end)] # 開始時刻 startTime = time() ##### リスト検索プログラム ######################### for i in list_a: for j in list_b: if i == j: break ############################################### # 終了時刻 endTime = time() # 測定値保存 timeList.append(endTime - startTime) # テストの平均値[s] avg = sum(timeList) / len(timeList) print(avg, '[s]')リスト検索プログラムの所を書き換えて計測していきましょう。
ダブルループ
まずはダブルループの場合です。
for i in list_a: for j in list_b: if i == j: break結果
34.66531833012899 [s]In検索
次はInを使って検索を行ってみましょう。
for i in list_a: if i in list_b: continue結果
7.02125096321106 [s]Set集合
次は検索する対象をSet集合にして、重複を無くしてみましょう。
Set集合の場合は、ハッシュ値を利用してアクセスするので、
1回の検索に必要な計算量はO(1)。n要素だったらO(n)。unique = set(list_b) for i in list_a: if i in unique: continue結果
0.0038799444834391275 [s]爆速
検索のまとめ
検索の計測値
方法 時間[s] 計算量[O] ダブルループ 34.6653 O(n^2) In検索 7.0213 ? Set集合 0.0039 O(n) やっぱりハッシュを使うSet集合は爆速です。ダブルループの比ではないですね。
in検索だけでもループに比べると1/4くらいになるのが分かります。リストから値を検索したい場合は、inを使いましょう。
そして、可能な場合はハッシュが使えるSet集合に変換しましょう。以上
- 投稿日:2021-01-29T21:30:59+09:00
ハッシュ探索について(個人用メモに近い)
1.はじめに
友人と応用情報の勉強会を始めたのでそれ用のまとめです.
各個人が気になったところ,もう少し知りたいなと思ったところを勝手にまとめて共有する方式の勉強会です.(毎回記事にするかは怪しい)
記事としては既出もいいところでしょうが,今回の僕のテーマは探索アルゴリズム(ハッシュ探索)です.(綺麗にまとまっていませんが後日時間があれば追記したり整理します...)
アルゴリズムについて
まず僕がこれをテーマに選んだのは,今までハッシュは全単射じゃないと意味がない(完全に全単射は無理でしょうが,それに近いもの)と思っていたのですが,このハッシュ探索では,全単射が理想ではあるものの,そうでなくとも探索対象の集合を分割できるだけでも意味があるんだ,というもので賢いなと感動したからです.
ハッシュはあくまでも道具であって,目的(解きたい問題)によっては使い方も変わるんだなと.
図にするとこんな感じで,冷静になると当たり前と言えば当たり前なのですが,アルゴリズムについてはこんな感じのイメージを持っておくのが良さそうだなと思いました.
2.ハッシュ探索について
ongoing
3.ハッシュ探索の実装(チェイン法)
class HashTable(object): def __init__(self, m: int): self.m = m hash_table = {} for key in self._hash_val_set: hash_table[key] = [] self.hash_table = hash_table def _hash_func(self, key): hash_val = key % self.m return hash_val @property def _hash_val_set(self): return set(range(self.m)) def insert(self, a: int): self.hash_table[self._hash_func(a)].append(a) def delete(self, a: int): self.hash_table[self._hash_func(a)].remove(a) def search(self, a: int) -> bool: for elem in self.hash_table[self._hash_func(a)]: if elem == a: return True return False def __str__(self): output_str = "" for key, val in self.hash_table.items(): output_str += f"{key}: {val}\n" return output_str4.計算量
計算したい$x_{i}$がハッシュテーブルの中に入っていないとき,リストの最後まで探索することになる.
このとき,各リストの長さはハッシュが単純一様ならば$n/m$の長さなので,ハッシュ関数の計算も含めて$1+n/m$.計算したい$x_{i}$がハッシュテーブルの中に入っているとき,以下のようになって,$1+n/m$.
(走り書きです...後日時間があれば綺麗にします)
つまりどちらの場合も$O(n/m)$となる.
5.時間を測ってみる
さてオーダーが$n/m$なので,実際に1つずつ変化させて時間を測ってみたらnを増やしたら線形に増える,mを増やしたら反比例して減るはずである.確かめてみる.
import timeit from random import randint import pandas as pd class Simulater(object): def __init__(self): self.max_int = 1000000 self.sim_iter_num = 100000 def _simulate(self, m, a_list): hashtable = HashTable(m=m) for a in a_list: hashtable.insert(a) result_time = timeit.timeit(lambda: hashtable.search(randint(0, self.max_int)), number=self.sim_iter_num) result_time_mean = result_time / self.sim_iter_num return result_time_mean def simulate_on_m(self, m_list: list, a_list: list) -> pd.DataFrame: result_time_mean_list = [] for m in m_list: result_time_mean = self._simulate(m, a_list) result_time_mean_list.append(result_time_mean) result_df = pd.DataFrame({"m": m_list, "time": result_time_mean_list}) return result_df def simulate_on_a_list_len(self, a_list_len_list: list, m: int) -> pd.DataFrame: result_time_mean_list = [] for a_list_len in a_list_len_list: a_list = [randint(0, self.max_int) for _ in range(0, a_list_len)] result_time_mean = self._simulate(m, a_list) result_time_mean_list.append(result_time_mean) result_df = pd.DataFrame({"a_list_len": a_list_len_list, "time": result_time_mean_list}) return result_df a_list = [randint(0, 1000000) for _ in range(0, 10000)] result_df_on_m = Simulater().simulate_on_m(range(1, 50, 3), a_list) result_df_on_a_list_len = Simulater().simulate_on_a_list_len(range(1, 10000, 1000), m=7)mを動かした時
nを動かした時
だいたいそうなってる.
6. 参考文献
- MIT教科書 アルゴリズムイントロダクション
- 平田富夫 アルゴリズムと設計とデータ構造





- 投稿日:2021-01-29T20:38:52+09:00
Pythonのsubprocessについて
はじめに
Twitterで一時期流行していた 100 Days Of Code なるものを先日知りました。本記事は、初学者である私が100日の学習を通してどの程度成長できるか記録を残すこと、アウトプットすることを目的とします。誤っている点、読みにくい点多々あると思います。ご指摘いただけると幸いです!
今回学習する教材
- 8章構成
- 本章216ページ
今日の進捗
- 第5章:並行性と並列性
- 本日学んだことの中で、よく忘れるところ、知らなかったところを書いていきます。
並行性と並列性
並行性は、見かけ上同時に実行しているように見えますが、実際は複数のプログラムを同時に実行するわけではなく、プログラムを素早く切り替えながら1つ1つ処理しています。
一方、並列性は、複数のプログラムを同時に実行することであり、並列の文字通り、並列にプログラムを実行しています。この章からPython での並行プログラムと並列プログラムの書き方を学んでいきます。
subprocess を使って子プロセスを管理する
Python ではサブプロセスを実行するのに、
- popen
- popen2
- os.exec*
- subprocess
などを含めて多数の方法が存在します。
現在のPythonで子プロセスを管理する最良の方法は、組み込みモジュールのsubprocessを使うことのようです。subprocessのPopenを使うことでサブプロセスを実行することができます。
Popen には多くの引数が存在するのですが、今回扱う引数は以下になります。
- args (第一引数)
- すべての呼び出しに必要で、文字列あるいはプログラム引数のシーケンスでなければいけない
- 0番目の要素に、'echo', 'sleep' (Unix系), 'timeout' (Windows環境) のようなコマンドを入れ、1番目の要素にそのコマンドにあった要素を入れる
- 1つの要素のみで使う場合はshell=Trueにしなければならない
- stdout
- 標準的な出力先
- 有効な値
- PIPE
- 新しいパイプが子プロセスに向けて作られる
- DEVNULL
- 特殊ファイルos.devnull が使用される
- None
- リダイレクトが起こらない
- shell
- 有効な値
- True
- 指定されたコマンドはシェルによって実行される
- False
続いて、Popenクラス内の本記事で扱うメソッドについて説明します。
- communicate()
- 子プロセスの出力を読み、終了するまで待つメソッド
- poll()
- 子プロセスが終了したかどうかを確認するメソッド
- 子プロセスが完了したらreturncode 属性を返す
- それ以外の場合は、Noneを 返す
- wait()
- 子プロセスが終了するまで待つメソッド
- terminate()
- 子プロセスを止めるメソッドです。
より詳しく知りたい場合は、こちらのドキュメントが参考になります。
https://docs.python.org/ja/3/library/subprocess.htmlimport subprocess import time proc = subprocess.Popen( ['echo', 'Hello from the child'], # args (第一引数) stdout=subprocess.PIPE, # 新しいパイプが子プロセスに向けて作られる shell=True) # Windows環境でこのコードを実行する場合に必要、それ以外の場合はshell=Trueは不要 out, err = proc.communicate() # 子プロセスの出力を読み終了まで待つ print(out.decode('utf-8')) # "Hello from the child"子プロセスは、親プロセスのPythonインタプリタとは独立に実行されます。その状態は、Pythongaが他の動作をしている間にもポーリング(イベントが発生していないか定期的にチェックすること)することができます。
import subprocess import time proc = subprocess.Popen( ['timeout', '1'], # ['sleep', '1'], # 本ではsleep だったが、Windows 環境だと動かず shell=True) while proc.poll() is None: print('\nWorking...') time.sleep(0.3)実行結果
Working... 0 秒待っています。続行するには何かキーを押してください ... Working...はじめから、すべての子プロセスを実行することもできます。
def run_sleep(period): proc = subprocess.Popen( ['timeout', str(period)], # ['sleep', str(period)], # 本ではsleep だったが、Windows 環境だと動かず shell=True) return proc start = time.time() procs = [] # 子プロセスを10個作る for _ in range(10): proc = run_sleep(1) procs.append(proc) # 子プロセスの出力を読む for proc in procs: proc.communicate() end = time.time() # 子プロセスの作成から終了までの時間を出力 print('Finished in %.3f seconds' %(end - start))実行結果
1 秒待っています。続行するには何かキーを押してください ... #... 10回表示される Finished in 1.166 secondssleep ではなく timeout を使ったため、余計なモノが出力されています。
これらのプロセスが順番に実行されていたら10秒ほどかかるはずですが、同時に実行されたため1秒ちょいで終わっています。communicateメソッドにtimeout引数を渡すことで、子プロセスが指定した時間内に応答しなければ、例外が引き起こされ、うまく動作しない子プロセスを停止することができます。
proc = run_sleep(10) try: proc.communicate(timeout=0.1) except subprocess.TimeoutExpired: proc.terminate() proc.wait() print('Exit status', proc.poll())ただし、timeout引数はPython3.3以降でないと使えないようです。
スレッドはブロッキングI/Oに使い、並列性に使うのは避ける
Pythonの標準実装は、CPythonです。
CPythonでは、次の2ステップでPythonプログラムを実行しています。
- ソーステキストをパースして、バイトコードにコンパイルする
- スタックベースのインタプリタでバイトコードを実行する
Pythonでは、プログラムが実行される間、プログラムに悪影響がでないように、実行中のスレッドに割りこんで制御を奪うような処理を相互排他ロックすることで防いでいます。この仕組みをグローバルインタプリタロック (global interpreter lock, GIL) と呼びます。
GILのお陰で、すべてのバイトコード命令が、CPython実装とC拡張モジュールで正しく動作することを保証しています。
しかし、相互排他ロックがかかっているために、マルチスレッドで実行しても1つ1つ実行されてしまうのです。
例として、素因数分解するプログラムを逐次実行とマルチスレッドで実行してみます。# 逐次実行 def factorize(number): for i in range(1, number + 1): if number % i == 0: pass numbers = [10003234, 3425932, 1835723, 2342812] start = time.time() for number in numbers: factorize(number) end = time.time() print('Sequential:%.3f seconds' % (end - start)) # マルチスレッドで実行 class FactorizeThread(Thread): def __init__(self, number): super().__init__() self.number = number def run(self): self.factors = factorize(self.number) start = time.time() threads = [] for number in numbers: thread =FactorizeThread(number) thread.start() threads.append(thread) for thread in threads: thread.join() end = time.time() print('Multi Thread:%.3f seconds' % (end - start))実行結果
Sequential:1.082 seconds Multi Thread:1.264 seconds早くなるどころか、マルチスレッドにした分の処理時間が伸びてしまいました。
マルチスレッドをブロッキングI/Oで扱う場合はどうでしょう。
実は、GILはPythonのコードを並列に実行していることを禁止していますが、システムコールについては並列化を禁止していません。
そのため、システムコールを含むコマンドの並列化は、高速になるのです。
単純な例として、sleep関数を逐次と並列で比較します。def sleep_func(): time.sleep(0.1) # 逐次処理 start = time.time() for _ in range(5): sleep_func() end = time.time() print(end - start) # マルチスレッド class SleepThread(Thread): def __init__(self): super().__init__() def run(self): sleep_func() start = time.time() threads = [] for _ in range(5): thread = SleepThread() thread.start() threads.append(thread) for thread in threads: thread.join() end = time.time() print('Multi Thread: %.3f' % (end - start))実行結果
Sequential:0.504 seconds Multi Thread:0.102 secondsマルチスレッドの方が5倍近く早く処理を完了することが確認できました。
- 投稿日:2021-01-29T19:44:45+09:00
勉強の息抜きに見たい、笑えるためになる動画 一選
最近、無料でもかなり質の高い情報が得られるようになったなーと思います。
基本的にはQiitaで調べることが多いですが、Youtubeでも本当にたくさんの方の動画が出ていて
ためになる&面白いものが多く有るのでメモがてらに記載したいと思います。タイトルの通り笑える内容だと思うので楽しんでみていただけたらと思います。
特に動画4分以降の畳み掛けがすごいです。
こいこいさんの動画は Excel、VBAやPython、AIの情報がメインです。
でも堅苦しい内容ではなくて
ポケモンとかコナンとかの話題が出てきたり、シュールなボケのツカミがあったりと
気難しい感じがしないのがとてもよかったりします。今後はそれ以外にもいろいろ追加していけたら、と思っています。
お粗末さまでした。。。
- 投稿日:2021-01-29T18:53:18+09:00
【Python】Excelシート見出しの色を変更する。
pythonを使用してExcelファイルの操作を勉強しています。
本日の気づき(復習)は、Excelシート見出しの色を変更です。見出しの色変更
同じフォルダー内にあるExcelファイル「テスト」の見出しの色を変更させます。
例from openpyxl import load_workbook wb = load_workbook('テスト.xlsx') for i, ws in enumerate(wb.worksheets): ws.sheet_properties.tabColor = 'ff8c00' wb.save('テスト_変更後.xlsx')色の指定方法
色を変更している記述ws.sheet_properties.tabColor = 'ff8c00'色の指定は正直迷いましたが、「cssの色指定と同じかも」と仮定してみたら
意外とすんなりいきました。
CSSとの違いは頭の「#」をどける事でしょうか。
色見本はこちらのサイトを参考にさせて頂きました。
https://www.colordic.org/
表示されている記述の#以外をコピーして貼り付けただけです。
ありがとうございます!条件付け
上記の記述はシートの見出し全てに同じ色を付けるものでしたので
条件を付けて合致するシートだけ色を変更するようにしてみます。5シートおきに色を変更させるfor i, ws in enumerate(wb.worksheets): if (i + 1) % 5 == 0: ws.sheet_properties.tabColor = 'ff8c00'ポイントは左から数えて何番目かということでしょうか。
if文を使えばいろんな指定が出来そうで楽しみです。
Rubyやcssと似た記述があってちょっとほっとしたのは内緒です。
- 投稿日:2021-01-29T18:33:31+09:00
「全て異なる」という条件をPythonで実験する
「a, b, cは全て異なる値かどうか」という条件に遭遇したので、Pythonでもしこう書いたらどうなるのか、という実験のメモです.
正しい条件式の書き方だけを知りたい方は一番下までスクロールしてください. ただ、論理演算を理解されている方にとっては特に目新しいことはないです.実験: a≠b≠cと書く
a, b, c全ての数値が異なる場合は「全て異なる数です」と出力し、a,b,cの中で2つ以上被っている場合は「同じ数が含まれています」と出力されるプログラムを考えます.
python.pya = 0 b = 0 c = 1 if a!=b!=c: print("全て異なる数です") else: print("同じ数が含まれています")全て異なる→a=b=cの逆→a≠b≠cじゃん!って考えた場合の書き方です.
ですが、これでは「全て異なる」を正しく判別できません.
上のように変数を定義した場合、同じ数が含まれていますと出力されるため、一見正しく書けているように思えます.
ですが、$a = 1, b = 0, c = 1$と定義した場合、全て異なる数ですと出力されてしまいます.
これはどうしてなのかというと、推測ではありますが、
$a=b かつ b=c → a=b=c$ と同様に、
$a≠b かつ b≠c → a≠b≠c$ であるとPythonが認識しているからだと考えられます.
つまり、a≠b≠cという条件のもとでは「a≠bかつb≠c」が成立しているかどうかを判別しているだけであって、a≠cまでは判別していないのです. 「a≠b≠cでは推移律が働かない」とでも言えばいいでしょうか(例に挙げたのは集合ではないですが).
先程のa = 1, b = 0, c = 1を例にすると、a≠bかつb≠cであることは確認しているけれども、a≠cであるかどうかまでは確認していないので、「a≠b≠cは満たされている」と判断されたわけです.ちなみに、if not a==b==c でもダメです(「全て同じ」の否定をベン図で可視化すると分かりやすいと思います).
解決策
python.pyif a!=b and b!=c and c!=a: print("全て異なる数です") else: print("同じ数が含まれています")素直に「全て異なる」という条件の中身を展開して、端折らずに書けば解決できます.
もしくは、比較するものが3つなら、python.pyif a!=b!=c and a!=c:$a≠b≠c → a≠b かつ b≠c$と認識している(と思われる)ことを利用して、推移律を補完する形で書いてもいいかもしれません.
そもそもa≠b≠cという書き方自体いい書き方だとは思わないので、他人に見せるコードに使うのは推奨しませんが...最後に
条件の否定は高校数学でも扱われるテーマですが、慣れるまではベン図などで可視化するのが良いかもしれません.
- 投稿日:2021-01-29T18:23:17+09:00
Python スクリプトを自動再起動するメモ
背景
numpy + C/C++ native module のある python コードでスクリプト自動リロードをやって開発効率を高めたい.
(native module の import はリロード対応していないため)yarr で Python で numpy データをさくっと RPC 通信するメモ
https://qiita.com/syoyo/items/c393d1a6d596c7f7f30fの続きです.
プロセスの自動起動は pm2 など使う手もありそうですが, いろいろセットアップがめんどいのでとりあえずは bash スクリプトで起動しなおしというふうにします.
方法
# server.py import sys import yarr import numpy import socketserver def proc_numpy(a): print(a) def quit(retcode: int): sys.exit(retcode) # server socketserver.TCPServer.allow_reuse_address = True yarr.yarr(('localhost', 8000), [proc_numpy, quit])yarr は内部で socketserver を使っています.
allow_reuse_addressを有効にしておかないと, カーネル側でソケットの情報がしばらく(5~10 秒くらい?)残るため, 再起動すると socket address already used エラーになります. これを解決します(もしくは quit するときに socket の close() を明示的に行うか)プロセス自動起動
プロセス自動起動ツールとかはぱぱっと使えるいいのが探してもありません
(悪用しやすいからですかね)とりあえず簡単な bash スクリプトで対応する場合.
#!/bin/bash while true; do echo "start server..." python server.py echo "retcode " $? sleep 1 echo "restart server..." done# client.py import yarr import numpy a = numpy.random.rand(256, 512, 512) yarr.call(('localhost', 8000), 'proc_numpy', a) # load() error in yarr will happen when exiting a server, so catch it as a work around. try: yarr.call(('localhost', 8000), 'quit', int(1)) except Exception as e: pass呼び出す側です.
yarr.callでは, RPC 発行のあといくつか後処理で相手と通信していますが, quit を呼ぶと相手はプロセス終了しておりエラーが発生してしまいます.
とりあえずは try/except で suppress します.これで自動でプロセスが再起動するようになりました!
python 自身で再起動
https://blog.petrzemek.net/2014/03/23/restarting-a-python-script-within-itself/
ありがとうございます.
os.execvで行けました.
自己実行形式にしていない場合は, `https://gist.github.com/plieningerweb/39e47584337a516f56da105365a2e4c6
にあるように
os.execv(sys.executable, ['python'] + sys.argv)にします.自己再実行の場合の server は以下のようになります.
import sys import yarr import numpy import os import socketserver def proc_numpy(a): print(a) def quit(retcode: int): print("restarting... ") # Restart python script itself os.execv(sys.executable, ['python'] + sys.argv) # server print("server start") socketserver.TCPServer.allow_reuse_address = True yarr.yarr(('localhost', 8000), [proc_numpy, quit])これで server 側の起動は普通に
$ python server.pyで起動するだけです! あとは quit コマンドを受け取ったら自分でよろしく再起動してくれます!
特に RPC で分けるほどではないスクリプトの場合(e.g. データロードなど前処理の量が多くない, jupyter-lab など使わずにコマンドラインで実行している)は,
os.execvであれば単体スクリプトのままで使えますね.C/C++ native module 含んだ python コードの開発がはかどりますね!
- 投稿日:2021-01-29T17:41:46+09:00
アカウント作成時のメール認証リンクをMailSlurp + Pythonで踏んでみた
はじめに
テストでアカウントを大量に作る必要があったので、操作の自動化しようと思ったのですがメール認証が!
むむむ...どうしよう...と思っていたところ、
MailSlurpなるものがあることを教えてもらいました。
よし!挑戦してみよう!利用環境
- macOS Big Sur 11.1
- Python 3.8.6
手順
準備
- MailSlurp公式サイト でアカウントを作成します
- アカウントを作成すると API Key が発行されるのでメモしておきます
MailSlurp公式サイト に再ログインする場合は、 ログイン画面 で登録したメールアドレスを入力します。
するとメールにアクセス用のリンクボタンが送られてくるので、そこからアクセスします。curl
まず試しにcurlで叩いてみます。
- メール Inbox の作成
% curl -X POST https://api.mailslurp.com/inboxes?apiKey=xxxxxxxxレスポンスで
InboxのIDとメールアドレスが取得できます。
- 受信メールの確認
% curl https://api.mailslurp.com/inboxes/ 『InboxのID』 /emails?apiKey=xxxxxxxxメールがあると以下のようなレスポンスが返ってきます。
[{ "id":" 『メールのID』 ", "subject":" 『メールの件名』 ", "to":[" 『MailSlurpで発行したメールアドレス』 "], "from":" 『メール差出人』 ", "bcc":[], "cc":[], "createdAt":"2021-01-29T07:20:43.295Z", "read":false, "attachments":[], "created":"2021-01-29T07:20:43.295Z" }]
- 全メール削除
% curl -X DELETE https://api.mailslurp.com/inboxes/ 『InboxのID』 /emails?apiKey=xxxxxxxx
- InBox の削除
% curl -X DELETE https://api.mailslurp.com/inboxes/ 『InboxのID』 ?apiKey=xxxxxxxxPython
curlで基本的な動きを確認できたのでPythonで実装していきます。
まず pip でインストールします。% pip install mailslurp-client実装
MailSlurpで受信したメールのメール本文を取得してみます。
import mailslurp_client from mailslurp_client.rest import ApiException configuration = mailslurp_client.Configuration() configuration.api_key['x-api-key'] = ### API Key ### with mailslurp_client.ApiClient(configuration) as api_client: api_instance = mailslurp_client.WaitForControllerApi(api_client) inbox_id = ### InboxのID ### timeout = 3000 unread_only = False try: email = api_instance.wait_for_latest_email(inbox_id = inbox_id, timeout = timeout, unread_only = unread_only) print(email.body) # 一旦ここでは出力まで except ApiException as e: print(e)上記でメール本文を取得します。
上では取得した本文を出力するだけになっていますが、実際には正規表現等で本文から欲しい箇所を抽出して、selenium 等に渡します。メールの本文から目的の要素を取得したらメールは不要になるので削除するようにします。
with mailslurp_client.ApiClient(configuration) as api_client: api_instance = mailslurp_client.EmailControllerApi(api_client) try: api_instance.delete_all_emails() except ApiException as e: print(e)合体
import mailslurp_client from mailslurp_client.rest import ApiException configuration = mailslurp_client.Configuration() configuration.api_key['x-api-key'] = ### API Key ### def main(): get_url() delete_all_email() def get_url(): with mailslurp_client.ApiClient(configuration) as api_client: api_instance = mailslurp_client.WaitForControllerApi(api_client) inbox_id = ### InboxのID ### timeout = 3000 unread_only = False try: email = api_instance.wait_for_latest_email(inbox_id = inbox_id, timeout = timeout, unread_only = unread_only) print(email.body) # 一旦ここでは出力まで except ApiException as e: print(e) def delete_all_emails(): with mailslurp_client.ApiClient(configuration) as api_client: api_instance = mailslurp_client.EmailControllerApi(api_client) try: api_instance.delete_all_emails() except ApiException as e: print(e) if __name__ == "__main__": main()今回はメール本文の取得までを目標としたので selenium 部分は省略します。
まとめ
MailSlurp 自体は良い感じだったのですが、無料アカウントだとメール受信数の月の制限が厳しく(100通)テストで使うには難しいかも
参考
GitHub(mailslurp / mailslurp-client-python)
We are recruiting !
株式会社GENZではソフトウェアのテストサービス業務を行っています。
キャリア採用も行っておりますので、ご興味がある方は以下をご確認ください!
株式会社GENZ - Webテスト自動化
株式会社GENZ - 採用情報
- 投稿日:2021-01-29T17:30:40+09:00
Pythonを使用してテンポ解析をおこなってみた
初めに
今回はPythonを使用してテンポ解析を行っていきました。
本記事は作成したプログラムの紹介と結果についてお伝えできればと思います。
今後何回か更新していこうと思います。
※精度がとてつもなく悪いです…
※プログラミングができる方は改善してコメントをお願いします<(_ _)>使用環境
Python 3.9.1
Windows 10 Home Edition
Anaconda Powershell Promptテンポ解析の詳細
解析順序
- wavファイルをN秒ごとに分割
- Librosaを使用して全体のテンポを解析
- 分割したwavファイルごとにテンポを解析
- テンポの推移をmatplotlibで表示
1. wavファイルをN秒ごとに分割
wavファイルを分割 → def cut_wav():
outputファイルを自動生成してそこに、
0.wav -> 1.wav ...と保存していきます。2.Librosaを使用して全体のテンポを解析
Librosaでテンポ解析をしていきます。
全体の曲を通すと、全体のテンポが出力されます。
※どのようにテンポを出しているかは、ウェブサイトをご覧ください。
Librosa3. 分割したwavファイルごとにテンポを解析
「2.Librosaを使用して全体のテンポを解析」と同じように、
分割したファイルごとテンポを推定していきます。
結構な外れ値が出てくるので注意が必要です。
※今後改善予定4. テンポの推移をmatplotlibで表示
推定したテンポをグラフで表示します。常に一定のテンポであれば直線が表示されるはずです。
実際のプログラム
import numpy as np import librosa import wave import struct import math import os from scipy import fromstring, int16 import matplotlib.pyplot as plt #---------------------------------------- # wavファイルの分割 #--------------------------------------- def cut_wav(filename, time): #ファイル読み出し wavf = filename + '.wav' wr = wave.open(wavf, 'r') #waveファイルが持つ性質を取得 ch = wr.getnchannels() width = wr.getsampwidth() fr = wr.getframerate() fn = wr.getnframes() total_time = 1.0 * fn / fr integer = math.floor(total_time) t = int(time) frames = int(ch * fr * t) num_cut = int(integer//t) # 確認用 print("total time(s) : ", total_time) print("total time(integer) : ", integer) print("time : ", t) print("number of cut : ", num_cut) # waveの実データを取得し数値化 data = wr.readframes(wr.getnframes()) wr.close() X = np.frombuffer(data, dtype=int16) print() for i in range(num_cut): print(str(i) + ".wav --> OK!") #出力データを生成 outf = 'output/' + str(i) + '.wav' start_cut = i*frames end_cut = i*frames + frames Y = X[start_cut:end_cut] outd = struct.pack("h" * len(Y), *Y) # 書き出し ww = wave.open(outf, 'w') ww.setnchannels(ch) ww.setsampwidth(width) ww.setframerate(fr) ww.writeframes(outd) ww.close() return num_cut #---------------------------------------- # 全体のテンポを求める #--------------------------------------- def totaltempo(filename): #検索するファイル名の作成 => output/ i .wav name = filename + ".wav" #wavファイルの読み込み y, sr = librosa.load(name) #テンポとビートの抽出 tempo , beat_frames = librosa.beat.beat_track(y=y, sr=sr) #全体のテンポを表示 print() print("total tempo : ", int(tempo)) print() #---------------------------------------- # 分割テンポを求める #--------------------------------------- def temposearch(num, time): #return用変数の宣言 l = [] t = [] t_time = 0 before_tempo = 0 print("division tempo") #音楽の読み込み for i in range(0,num,1): #検索するファイル名の作成 => output/ i .wav name = "output/" + str(i) + ".wav" #wavファイルの読み込み y, sr = librosa.load(name) #テンポとビートの抽出 tempo , beat_frames = librosa.beat.beat_track(y=y, sr=sr) int_tempo = int(tempo) #テンポの表示 print(str(i+1) + ":" + str(int_tempo)) #return用変数へ代入 l.append(int_tempo) t_time = t_time + int(time) t.append(t_time) return l, t #--------------------------------- # メイン関数 #--------------------------------- if __name__ == '__main__': # すでに同じ名前のディレクトリが無いか確認 file = os.path.exists("output") print(file) if file == False: #保存先ディレクトリの作成 os.mkdir("output") #ファイル名とカット時間を入力しwavファイルを分割 f_name = input('input filename -> ') cut_time = input('input cut time -> ') n = int(cut_wav(f_name,cut_time)) #テンポ解析 totaltempo(f_name) tempo, time = temposearch(n, cut_time) print() #タイトル用 name = "テンポ解析 " + cut_time + "秒で分割" #グラフ描写 plt.title(name, fontname="MS Gothic") plt.xlabel("時間(s)", fontname="MS Gothic") plt.ylabel("テンポ(bpm)", fontname="MS Gothic") plt.ylim(60, 180) plt.plot(time, tempo) plt.show()実行結果
今回は「威風堂々」という曲を解析していきます。
解析した曲はこちらから→フリーWave,MP3(base) PS C:\Users\Name\tempo> python tempo_main.py True input filename -> ifudoudou input cut time -> 10 total time(s) : 204.56489795918367 total time(integer) : 204 time : 10 number of cut : 20 0.wav --> OK! 1.wav --> OK! 2.wav --> OK! 3.wav --> OK! 4.wav --> OK! 5.wav --> OK! 6.wav --> OK! 7.wav --> OK! 8.wav --> OK! 9.wav --> OK! 10.wav --> OK! 11.wav --> OK! 12.wav --> OK! 13.wav --> OK! 14.wav --> OK! 15.wav --> OK! 16.wav --> OK! 17.wav --> OK! 18.wav --> OK! 19.wav --> OK! total tempo : 117 division tempo 1:123 2:117 3:117 4:117 5:123 6:123 7:123 8:123 9:99 10:99 11:99 12:99 13:117 14:117 15:123 16:117 17:99 18:99 19:99 20:117 (base) PS C:\Users\Name\tempo>表示するグラフ↓
結果について
結構、精度が悪いのがわかるでしょうか??
テンポが一定のところも数値にばらつきがみられますね。感想
単純に曲数が足りていないので、精度がよくわからないです。
たくさん解析をしてこのプログラムの特徴を見ていこうと思います。
改善点やこんな曲を分析してほしい!という意見があればどんどんコメントお願いします!

- 投稿日:2021-01-29T17:12:06+09:00
日立の社内ハッカソン参加者とPyCaretで競ってみた(後編)
はじめに
こんにちは。(株) 日立製作所の Lumada Data Science Lab. の清水目拓馬です。
前編の著者の小幡と、今回、PyCaretでのモデリングに取り組みました。日立のハッカソンデータを使ってPyCaretでモデリングしてみた(前編)の記事では、日立社内で実施したハッカソンで使用したデータを基にPyCaretで予測モデルを作成しました。後編となる今回は、複数の予測モデルを組み合わせたアンサンブル学習でどのぐらい分析精度が上がるかを検証します。
アンサンブル学習
◆バギング
前編で検討したモデルの比較で最も精度の良かったExtra Trees Regressorを用いて、バギングを実施しました。バギングとは、全体の学習データからデータ・説明変数を一部抽出して弱学習器を複数作成し、それらの予測値の平均を最終的な結果とする手法です。つまり、このバギングによって最終的に構築される予測モデルに多様性を持たせることが出来ます。
バギングの結果、
RMSE 217.61となり、前編のRMSE 223.43より精度が向上しました。Extra Trees Regressorは内部でバギング処理を⾏っており、二重にバギング処理を実施していることになりますので、元の予測モデルにチューニングの余地があったかもしれません。# Bagging bagged_dt = ensemble_model(et, method='Bagging') # テストデータで評価 pred_data = predict_model(bagged_dt, data=test_data) # 評価指標はRMSE print('RMSE', check_metric(pred_data['目的変数'], pred_data.Label, 'RMSE'))RMSE 217.6096◆ブースティング
ここでもExtra Trees Regressorを用いて、ブースティングを実施しました。ブースティングは、バギングと同様に弱学習器を用いますが、独立に作るのではなく、1つずつ順番に作成していき、直前の予測誤差を小さくするように(弱点を補うように)学習していきます。
ブースティングの結果、
RMSE 214.57となり、前編より精度が向上しました。バギングを⾏うExtra Trees Regressorにブースティングを重ねて実施しても精度が向上したのは面白い結果だと思います。# Boosting boosted_dt = ensemble_model(et, method='Boosting') # テストデータで評価 pred_data = predict_model(boosted_dt, data=test_data) # 評価指標はRMSE print('RMSE', check_metric(pred_data['目的変数'], pred_data.Label, 'RMSE'))RMSE 214.5677◆ブレンディング
ブレンディングは、複数の予測モデルの平均値を最終的な予測値とします。前編で検討したモデルの比較で精度の良かった上位3つのモデル Extra Trees Regressor, Random Forest, Gradient Boosting Regressorを組み合わせて予測値を決定します。
ブレンディングの結果、
RMSE 215.91となり、前編の結果よりも精度が向上しました。# 上位3つのモデルをブレンディング blender = blend_models(estimator_list=[et, rf, gbr]) # テストデータで評価 pred_data = predict_model(blender, data=test_data) # 評価指標はRMSE print('RMSE', check_metric(pred_data['目的変数'], pred_data.Label, 'RMSE'))RMSE 215.9084アンサンブル学習をした結果、分析精度が向上しました!
今回、アンサンブル学習を実施した中で、最も精度が良かったのはブースティングでした。
Tips:前編では「初心者」レベルだったのが、「中級者」レベルまでランクアップしました。

ハッカソン上位者のノウハウ
今回のPyCaretの結果では中級者レベルにとどまりましたが、ハッカソンの上位者は下記のような点を考慮して精度向上につなげたようです。
- データクレンジングの実施
- 連続変数、離散変数またはカテゴリ変数のどちらで扱うかを見極める
- 異常値を確認、補間、または削除する
- 情報量を削減して、過学習を抑制する
- 新規変数の作成
- 交互作用変数を作成する(不快指数など)
- タイムスタンプを変数として扱う
- 時系列を意識した変数を作成する
結論
PyCaretだけでも、そこそこのデータ分析ができることがわかりました。
そこにデータサイエンティストのノウハウを加えることで、精度の向上が期待できると思います。おわりに
最後に、今回PyCaretを使用して、使いやすかった点と難しかった点をまとめます。
◆使いやすかった点
- 複数モデルの構築や精度検証ができ、工数を軽減できる
少ないコード量で多くのモデルを比較でき、データ分析作業の工数を軽減できると考えられます。- 分析結果を可視化しやすい
今回の記事では紹介しませんでしたが、説明変数の重要度、ROC曲線、学習曲線、混同行列など、様々なプロットが可能です。◆難しかった点
- 使用可能なAPIが多くて何を使ってよいのかわからない
様々な処理ができることはメリットですが、最初に使った感覚としては、使用可能なAPIの多さに戸惑いました。- 予期せぬエラーのデバッグがしづらい
PyCaretの内部がブラックボックスのため、自分で実装しない分、エラーが発生したときのデバッグがしづらい面があります。- 学習前にデータの確認が必要
数値変数の中に文字が含まれていた場合には数値変数がカテゴリ変数として扱われるため、何も考えずにデータをsetup関数に与えると、説明変数が膨大に増えてしまいます。その結果、計算時間がとんでもないことに!- 時系列分析は苦手?
時系列モデル(状態空間モデルなど)は現時点では実装されていません。
- 投稿日:2021-01-29T17:12:06+09:00
日立の社内ハッカソン参加者とPyCaretで競ってみた(後編)
はじめに
こんにちは。(株) 日立製作所の Lumada Data Science Lab. の清水目拓馬です。
前編の著者の小幡と、今回、PyCaretでのモデリングに取り組みました。日立のハッカソンデータを使ってPyCaretでモデリングしてみた(前編)の記事では、日立社内で実施したハッカソンで使用したデータを基にPyCaretで予測モデルを作成しました。後編となる今回は、複数の予測モデルを組み合わせたアンサンブル学習でどのぐらい分析精度が上がるかを検証します。
アンサンブル学習
◆バギング
前編で検討したモデルの比較で最も精度の良かったExtra Trees Regressorを用いて、バギングを実施しました。バギングとは、全体の学習データからデータ・説明変数を一部抽出して弱学習器を複数作成し、それらの予測値の平均を最終的な結果とする手法です。つまり、このバギングによって最終的に構築される予測モデルに多様性を持たせることが出来ます。
バギングの結果、
RMSE 217.61となり、前編のRMSE 223.43より精度が向上しました。Extra Trees Regressorは内部でバギング処理を⾏っており、二重にバギング処理を実施していることになりますので、元の予測モデルにチューニングの余地があったかもしれません。# Bagging bagged_dt = ensemble_model(et, method='Bagging') # テストデータで評価 pred_data = predict_model(bagged_dt, data=test_data) # 評価指標はRMSE print('RMSE', check_metric(pred_data['目的変数'], pred_data.Label, 'RMSE'))RMSE 217.6096◆ブースティング
ここでもExtra Trees Regressorを用いて、ブースティングを実施しました。ブースティングは、バギングと同様に弱学習器を用いますが、独立に作るのではなく、1つずつ順番に作成していき、直前の予測誤差を小さくするように(弱点を補うように)学習していきます。
ブースティングの結果、
RMSE 214.57となり、前編より精度が向上しました。バギングを⾏うExtra Trees Regressorにブースティングを重ねて実施しても精度が向上したのは面白い結果だと思います。# Boosting boosted_dt = ensemble_model(et, method='Boosting') # テストデータで評価 pred_data = predict_model(boosted_dt, data=test_data) # 評価指標はRMSE print('RMSE', check_metric(pred_data['目的変数'], pred_data.Label, 'RMSE'))RMSE 214.5677◆ブレンディング
ブレンディングは、複数の予測モデルの平均値を最終的な予測値とします。前編で検討したモデルの比較で精度の良かった上位3つのモデル Extra Trees Regressor, Random Forest, Gradient Boosting Regressorを組み合わせて予測値を決定します。
ブレンディングの結果、
RMSE 215.91となり、前編の結果よりも精度が向上しました。# 上位3つのモデルをブレンディング blender = blend_models(estimator_list=[et, rf, gbr]) # テストデータで評価 pred_data = predict_model(blender, data=test_data) # 評価指標はRMSE print('RMSE', check_metric(pred_data['目的変数'], pred_data.Label, 'RMSE'))RMSE 215.9084アンサンブル学習をした結果、分析精度が向上しました!
今回、アンサンブル学習を実施した中で、最も精度が良かったのはブースティングでした。
Tips:前編では「初心者」レベルだったのが、「中級者」レベルまでランクアップしました。
ハッカソン上位者のノウハウ
今回のPyCaretの結果では中級者レベルにとどまりましたが、ハッカソンの上位者は下記のような点を考慮して精度向上につなげたようです。
- データクレンジングの実施
- 連続変数、離散変数またはカテゴリ変数のどちらで扱うかを見極める
- 異常値を確認、補間、または削除する
- 情報量を削減して、過学習を抑制する
- 新規変数の作成
- 交互作用変数を作成する(不快指数など)
- タイムスタンプを変数として扱う
- 時系列を意識した変数を作成する
結論
PyCaretだけでも、そこそこのデータ分析ができることがわかりました。
そこにデータサイエンティストのノウハウを加えることで、精度の向上が期待できると思います。おわりに
最後に、今回PyCaretを使用して、使いやすかった点と難しかった点をまとめます。
◆使いやすかった点
- 複数モデルの構築や精度検証ができ、工数を軽減できる
少ないコード量で多くのモデルを比較でき、データ分析作業の工数を軽減できると考えられます。- 分析結果を可視化しやすい
今回の記事では紹介しませんでしたが、説明変数の重要度、ROC曲線、学習曲線、混同行列など、様々なプロットが可能です。◆難しかった点
- 使用可能なAPIが多くて何を使ってよいのかわからない
様々な処理ができることはメリットですが、最初に使った感覚としては、使用可能なAPIの多さに戸惑いました。- 予期せぬエラーのデバッグがしづらい
PyCaretの内部がブラックボックスのため、自分で実装しない分、エラーが発生したときのデバッグがしづらい面があります。- 学習前にデータの確認が必要
数値変数の中に文字が含まれていた場合には数値変数がカテゴリ変数として扱われるため、何も考えずにデータをsetup関数に与えると、説明変数が膨大に増えてしまいます。その結果、計算時間がとんでもないことに!- 時系列分析は苦手?
時系列モデル(状態空間モデルなど)は現時点では実装されていません。
- 投稿日:2021-01-29T16:42:30+09:00
日立の社内ハッカソン参加者とPyCaretで競ってみた(前編)
はじめに
こんにちは。(株) 日立製作所の Lumada Data Science Lab. の小幡拓也です。
AutoMLの自動化ライブラリとして、PyCaretが2020年4月にリリースされました。オープンソースでありながら高度な機能を持つということで、自動機械学習を気軽に実行できるツールとして注目を集めています。そんな「期待のルーキー」のPyCaret、人間が手動でデータ分析した場合と比べて優れている点はあるのでしょうか?
今回、日立社内で実施したハッカソンで使用したデータを基にPyCaretでモデルを作成し、人がデータ分析した場合と比べて精度にどのような違いが出るのかを比較していきます。なお、データはクレンジング前のものを使用します。PyCaretにそのまま読み込ませると、処理結果にどのような影響が出るのでしょうか。
前編となる今回は、PyCaret のモデリング例を中心に紹介します。後編では、分析結果の精度比較などを中心に紹介します。
PyCaretとは
PyCaret とは Python のオープンソース機械学習ライブラリで、機械学習モデル開発に必要なデータの前処理や結果の可視化が、たった数行のプログラミングでできてしまいます。
公式ホームページ:PyCaret
実施した社内ハッカソンとは?
日立グループ内の技術者が参加して1つのテーマに対して短期間でデータ分析を行い、その成果を競うイベントです。日立グループのデータサイエンティストの育成に向けた取り組みとして開催されています。2020年9月には、札幌駅前地下歩行空間(通称:チ・カ・ホ)の30分後の歩行者数を予測するというテーマで第2回目となるハッカソンが開催されました。
ハッカソンのテーマ企画、および使用するデータの準備につきましては株式会社Mewcket様のご協力をいただき、ハッカソンのプラットフォームとしてPeakersを使用させていただきました。
ハッカソンで使用したデータセット
ハッカソンで使用したデータセットは主に次の内容で構成されています。
人流データ
札幌駅前地下歩行通路内に設置されたセンサで検知した現時点および過去の歩行者数のデータです。センサーは5つあり、歩行通路内にほぼ等間隔で設置されています。今回のハッカソンでは、中央に配置されたセンサの値を他4つのセンサの値から予測します。
データは、札幌市オープンデータポータルから入手したものです。気象データ
札幌管区気象台で観測された気象データで、リアルタイムに取得できた場合を仮定しています。データは、気象庁から入手したものです。ハッカソンで使用したこれらのデータセットを基に、PyCaretを使ってモデル作成していきます。
ハッカソンの開催結果(人による分析)
社内ハッカソンの最終ランキングとスコアは次のとおりです。
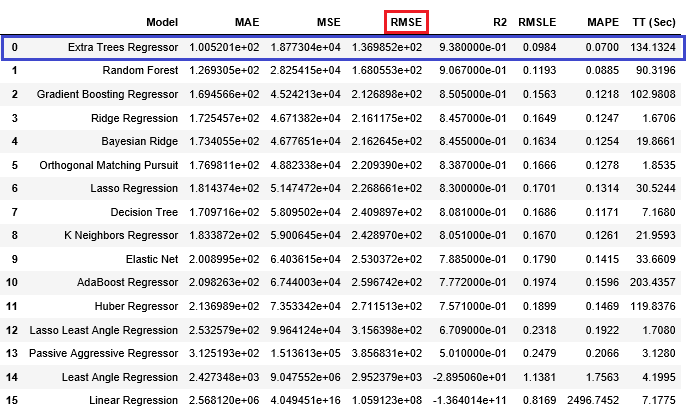
今回のハッカソンでは、RMSE (Root Mean Square Error) を評価指標としモデルの精度を競いました。RMSEとは回帰モデルの一般的な性能評価指標であり、以下の計算式で表されます。RMSEの値が小さい、つまり実際の値と予測値のズレが小さいほど、当てはまりの良いモデルだといえます。
$$RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}\left( y_i - \hat{y}_i \right)^2}$$
$$y_iはi番目の実測値 \hat{y}_iはi番目の予測値$$

モデリング(PyCaretによる分析)
データ読み込みからPyCaretの実行
下記のように実行すると PyCaret がデータを分析して、自動的に必要な前処理を実施してくれます。
Tips:下記のコードは汎用的なものを示しています。
import pandas as pd from pycaret.regression import * # csvファイル読み込み train_data = pd.read_csv('train.csv') test_data = pd.read_csv('test_Private.csv') # PyCaret用にデータを準備 setup(train_data, target='目的変数', ignore_features=None, numeric_features=col_list)今回のハッカソンのデータを使用して実施した結果が下記になります。
説明変数の次元が 45 から 666 に増えているのは、カテゴリ変数をダミー変数化した影響です。
モデルの比較
PyCaret はサポートする複数のモデルで学習し、複数の評価指標で評価した結果を出力します。説明変数の次元が 666 に増えていて非常に時間がかかるため、
catboost,tr,svm,ransacをblacklistに指定することで除外しています。Tips:ハッカソンと同様、RMSEを評価指標としています。
# Comparing All models top3 = compare_models(n_select=3, sort='RMSE', blacklist=['catboost', 'tr', 'svm', 'ransac'])
性能評価
今回は、最も精度の良いモデル「Extra Trees Regressor」を選択してテストデータを用いて性能評価しました。
et = create_model('et') # テストデータで評価 pred_data = predict_model(et, data=test_data) # 評価指標はRMSE print('RMSE', check_metric(pred_data['目的変数'], pred_data.Label, 'RMSE'))RMSE 223.43ハッカソン参加者 vs PyCaret
今回、PyCaret による分析結果はデータ分析初心者と同レベルとなりました。ただし、最も精度の高かった単一モデルを選択しただけのため、この結果となっています。
後編では、複数のモデルを組み合わせたアンサンブル学習でどのぐらい分析精度が上がるかを検証します。


- 投稿日:2021-01-29T16:15:46+09:00
manimの作法 その32
概要
manimの作法、調べてみた。
rate_func使ってみた。サンプルコード
from manimlib.imports import * class test(GraphScene): CONFIG = { "x_labeled_nums" : [], "y_labeled_nums" : [], "x_axis_label" : "Temperature", "y_axis_label" : "Pressure", "graph_origin" : 2.5 * DOWN + 2 * LEFT, "corner_square_width" : 4, "example_point_coords" : (2, 5), } def construct(self): self.setup_axes() path = VMobject().set_points_smoothly([ORIGIN, 2 * UP + RIGHT, 2 * DOWN + RIGHT, 5 * RIGHT, 4 * RIGHT + UP, 3 * RIGHT + 2 * DOWN, DOWN + LEFT, 2 * RIGHT]) point = self.coords_to_point(*self.example_point_coords) path.shift(point) path.set_color(GREEN) self.play(ShowCreation(path, run_time = 10, rate_func = linear)) self.wait() self.remove(path) self.play(ShowCreation(path, run_time = 10, rate_func = there_and_back)) self.wait() self.remove(path)生成した動画
https://www.youtube.com/watch?v=C6GRbNW-cyQ
以上。
- 投稿日:2021-01-29T16:11:19+09:00
manimの作法 その31
概要
manimの作法、調べてみた。
ValueTracker、 add_updater使ってみた。サンプルコード
from manimlib.imports import * class test(Scene): def construct(self): t = ValueTracker(0) dec = DecimalNumber(0) dec.add_updater(lambda a: a.set_value(t.get_value())) self.add(dec) self.play(t.set_value, 2, rate_func = linear, run_time = 4) self.wait()生成した動画
https://www.youtube.com/watch?v=dqtyqwGwqEU
以上。
- 投稿日:2021-01-29T16:06:48+09:00
初めてのRaspberry Pi Pico ② CircuitpythonでLチカ
CircuitPython 6.2.0-beta.1を使います。エディタはMu、開発環境はラズパイ4です。CircuitPythonは、2種類のファイルをダウンロードして利用します。Muのインストールは省略します。画面は、一部Windows10のchromeブラウザの画面が混じっています。
- CircuitPython 6.2.0-beta.1
- 6用のExamples/lib
CircuitPython 6.2.0-beta.1のダウンロード
downloads pageをクリックします。
https://github.com/adafruit/circuitpython/releases/tag/6.2.0-beta.1
検索欄にpicoと入れます。見つかったPicoをクリックします。
DOWNLOAD UF2 NOWをクリックします。左の言語がJAPANESEになっていますが、ベータ版なので、ENGLISHのほうがよいかもしれません。
ボード上のBOOTSELを押しながらUSBケーブルをつなぎます。画面にRPI-RP2ドライブがマウントされるので、adafruit-circuitpython.uf2ファイルをドラッグします。
コピーがすむと、画面にはCIRCUITPYドライブがマウントされます。準備は完了です。
バージョン6用のExamples/libのダウンロード
downloads pageのthis pageをクリックします。
中ほどのクリックしろという緑色のエリヤをクリックします。
最新のzipファイルをクリックしてダウンロードします。
ダウンロードしたzipファイルをダブルクリックすると、解凍ソフトが立ち上がっています。Extract filesをクリックします。
/tmpに解凍する画面が出ているので、そのままExtractをクリックします。
File Managerで、tmpを開きます。Examplesとlibのフォルダをpiフォルダにコピー(移動になる)します。
piのフォルダにコピーしたlibをデスクトップにあるCIRCUITPYドライブのlibにコピーして使いたいのですが、すべてコピーするには容量が足りません。
とりあえず、adafruit_bus_deviceフォルダとライブラリ・ファイル形式のadafruit_bmp280.mpyをコピーします。Lチカ
メニューのprogrammingのMuを起動します。Newで新規ファイルを開きます。
https://www.denshi.club/pc/python/circuitpython/circuitpython-10-2-l.html
からL地価のプログラムをコピーし、LEDのつながっているポートD13をGP25に変更します。import digitalio from board import * import time led = digitalio.DigitalInOut(GP25) led.direction = digitalio.Direction.OUTPUT while True: led.value = True time.sleep(0.1) led.value = False time.sleep(0.1)Saveをクリックし、code.pyに上書きします。Serialをクリックします。もう1回Saveをクリックすると、プログラムが実行されます。time.sleep(0.1)の時間を変更してSaveすると、変更した待ち時間になったでしょうか。
気圧センサBMP280をつなぐ
AdafruitのSTEMMA QTタイプのボードBMP280をつなぎます。SCLはGP9、SDAはGP8、Vccは3.3V、GNDはGNDへつなぎます。
examplesの中に入っているbmp280_simpletest.pyをMuに読み込みます。
i2c = busio.I2C(board.SCL, board.SDA)を、
i2c = busio.I2C(board.GP9, board.GP8)に変更してSaveします。ファイル名はcode.pyで上書きします。温度と気圧、高度を表示します。












- 投稿日:2021-01-29T16:05:47+09:00
manimの作法 その30
概要
manimの作法、調べてみた。
ValueTracker、 always_redraw使ってみた。サンプルコード
from manimlib.imports import * class test(Scene): def construct(self): angle_tracker = ValueTracker(90 * DEGREES) get_angle = angle_tracker.get_value formula = always_redraw(lambda: self.get_sine_formula(get_angle())) self.add(formula) self.play(angle_tracker.set_value, 0, run_time = 5, ) self.wait() self.play(angle_tracker.set_value, 90 * DEGREES, run_time = 5, ) self.wait() def get_sine_formula(self, angle): sin, lp, rp = TexMobject("\\sin", "(", ") = ") input_part = Integer(angle / DEGREES, unit = "^\\circ", ) input_part.set_color(YELLOW) output_part = DecimalNumber(np.sin(input_part.get_value() * DEGREES), num_decimal_places = 3, ) result = VGroup(sin, lp, input_part, rp, output_part) result.arrange(RIGHT, buff = SMALL_BUFF) sin.scale(1.1, about_edge = DOWN) lp.align_to(rp, UP) return result生成した動画
https://www.youtube.com/watch?v=yq0aPkkQCAQ
以上。
- 投稿日:2021-01-29T16:03:43+09:00
Pythonで処理結果をファイルに保存
Matlabではsave/loadコマンドでmatファイルを作るみたいなことをpythonでもやりたい。
pickle or joblib
Matlabのsaveでやるようなシリアライズをするのには、よくpickleというモジュールが使われるようだ。
(ちなみに複数形はpickles,つまりピクルスだ。酢漬けにして保存しとくイメージなのか)pickleはかなりメジャーなモジュールのようだが、最近ではjoblibというのも使われているらしい。
joblibはそもそもは並列処理用のモジュールらしく、なぜそれがシリアライズにも使えるのかは知らないが
オプションを指定するだけでいい感じに圧縮できて、そこそこ速いっぽいので、joblibを使ってみる。書き込み joblib.dump()
まずは処理をしてファイルに書き込む
例は何でも良かったのだけれど、巷で噂(?)のUMAP。import os import joblib import umap from sklearn.datasets import load_digits digits = load_digits() reducer3d = umap.UMAP() reducer3d.n_components = 3 reducer2d.fit(digits.data) reducer3d.fit(digits.data) joblib.dump((reducer2d, reducer3d), os.path.expanduser('~/Desktop/umap.joblib'), compress=True)複数のインスタンスもタプルにして渡せばOKっぽい。
compressに1~9またはTrueを渡すと圧縮してくれる。(Trueはcompress=3と同じらしい)
数字は大きいほど高圧縮。読み込み joblib.load()
import os import numpy as np import joblib red = joblib.load(os.path.expanduser('~/Desktop/uMap.joblib')) (reducer2d, reducer3d) = red読み込むときは(当然ながら)タプルに入っているので、読み出してから切り出す。
どの変数を何番目に入れたか覚えているなら、最初からアンパックして読み出してもOK(reducer2d, reducer3d) = joblib.load(os.path.expanduser('~/Desktop/uMap.joblib'))いたってシンプル。
おまけ
せっかくなので可視化しとく
from sklearn.datasets import load_digits import matplotlib.pyplot as plt digits = load_digits() embedding2d = reducer2d.transform(digits.data) embedding3d = reducer3d.transform(digits.data) fig = plt.figure(figsize=(12, 5), dpi=72) ax = fig.add_subplot(1, 2, 1, title='n_components = 2') ax.spines['top'].set_visible(False) ax.spines['right'].set_visible(False) sc = ax.scatter(embedding2d[:, 0], embedding2d[:, 1], c=digits.target, cmap='Spectral', s=5) cb = fig.colorbar(sc, boundaries=np.arange(11) - 0.5, shrink=0.6) cb.set_ticks(np.arange(10)) ax = fig.add_subplot(1, 2, 2, projection='3d', title='n_components = 3') sc = ax.scatter(embedding3d[:, 0], embedding3d[:, 1], embedding3d[:, 2], c=digits.target, cmap='Spectral', s=5) cb = fig.colorbar(sc, boundaries=np.arange(11) - 0.5, shrink=0.6) cb.set_ticks(np.arange(10)) plt.show()結果

- 投稿日:2021-01-29T14:57:26+09:00
Pycharm キーボードショートカット
Matlabからpythonに移住するにあたって、Pycharm(professional版)を使うことにしたので、キーボードショートカットをメモ。
まずはセルの区切り方
キーボードショートカットのメモといいつつ、まずはセクショニング。
matlab
hoge %% fugapycharm
hoge #%% fugaこれでhogeとfugaの間でセルが区切れる。
pycharmの細かい設定とか
・表示メニューからscientific modeをオンへ
・pycharm > preference > tool > python scientificと進み、ツールウィンドウにプロットを表示 をオフにこれで大体matlabチックな感じになる。
あと、macのデフォルトだと^Spaceが日本語英語切り替えとかぶるので、環境設定>キーボード>ショートカット>入力ソースから設定を変えておくと良いキーボードショートカット
(ちなみに、macを使っているのでMatlabのショートカットはmac版のもの)
⇧ shift ⌘ command ⌥ option ^ control ⏎ return
操作内容 Matlab PyCharm 選択範囲を実行 ⇧F7 ⌥⇧E セルを実行 ⌘⏎ セルを実行して次へ ⌘⇧⏎ ^⏎ ファイルを実行 ⌥⌘R ^R 設定 ⌘, ⌘, コメント ⌘/ ⌘/ アンコメント ⌘T ⌘/ コード補完 Tab(?) ^Space コードの整形 ⌘I ⌘⌥L クリップボードの履歴から貼り付け ⌘⇧V 保存 ⌘S ⌘S 思い出したら足すかも。
- 投稿日:2021-01-29T14:13:00+09:00
f-stringsで衛星画像ファイルに名前を付けながら保存(Python)
概要
こんにちは。
衛星画像ファイルを処理して作成したファイルを保存する際に、逐一ファイル名を手動で付けていくのは面倒です。Linuxなりのコマンドラインでやってしまうのも一手ですが、pythonでNumpy Arrayの形で保持しているものをそのまま画像として保存できれば手間が少なくて済みそうです。f-stringsを使うことで「Numpy array→いい感じのファイル名で保存」手順が自動で進むので、簡単にご紹介できればと思います。f-stringsについての詳しい説明はこちらなどを参考にしてみてください⇒Pythonのf-stringsについてしっかり調べてみた前提条件
- Google Colabで実行 (記事執筆時点でのバージョンはpython 3.6.9)
- 辞書型配列の形で年月日とNumpy Arrayが紐づけられていること
コード
SaveImages.pyfrom PIL import Image #database_arrayは辞書型配列で、keysには対象年、valuesには画像として保存したいarrayが入っています for y in database_arary.keys(): img=Image.fromarray(database_array[f"{y}"].astype(np.uint8)) img.save(f'/content/drive/My Drive/Colab Notebooks/outputs/output_{y}.png')コードとしてはこれだけですが、沢山ある処理結果に名前を付けるのがとても楽になったので、よろしければお試しください!
- 投稿日:2021-01-29T13:56:39+09:00
PIL.UnidentifiedImageError: cannot identify image fileの解決に時間を費やし過ぎた
- 投稿日:2021-01-29T13:28:54+09:00
【Django REST Framework チュートリアル】#4 ReactとAPIサーバー繋ぐ【入門】
DjangoでAPIサーバー作成⇨React(axios)で取得して表示
Django REST Frameworkの初心者入門として、前回記事までで、ReactでJSON PlaceholderでAPIをデータを取得しましたので、JSON Placeholderで取得できるのと同じデータをAPIサーバーを作って表示Reactで表示させようと思います。
/posts: 記事全部取得
/posts/:id: 個別記事取得これと同じデータ取得できるようなAPIサーバーをDjango REST Frameworkで作ります。
シリーズ記事
- 【初心者】#1 Reactの基礎とMaterial-UI使って綺麗に作ってみる
- 【初心者】#2 React axiosでAPI データ取得
- 【React初心者】 #3 ルーティング・ページ遷移を作る! react-router-dom
Django導入
環境の準備が難しい場合は、anaconda入れるといいと思います。
私は今回、pipenvで作ろうと思います。
好きなところにディレクトリ作って開始します。
$ pip install pipenv $ pipenv --python 3.8.7Pythonのバージョンを指定してます。
2020年の年末Djnagoを少しいじってたら、3.9だと動かないライブラリあったので3.8系を使ってます。※ 以下
pipenvを使用しますが、anacondaやDockerなど他の環境でやるときはpip installしてください。$ pipenv install django $ pipenv install djangorestframework仮想環境pipenvで作業
pipfileが置いてあるところで、仮想環境の中に入ります。
普段、作業を開始するときはここから開始。$ pipenv shell一応確認。
$ python -V Python 3.8.7djangoのプロジェクトとアプリを作成
backendというプロジェクトを作成。
最後の.はカレントディレクトリにプロジェクト作成すると言う意味。
アプリの名前はapiという名前にします。プロジェクト名も、アプリ名も好きに決めてください。
$ django-admin startproject backend . $ django-admin startapp apiサーバー起動
manage.pyがあるところで、以下のコマンド実行
$ python manage.py runserverデフォルトでは以下でサーバーが起動します。
ポート変更したかったら、
python manage.py runserver 7000ブラウザでURLにアクセスして、ロケットが飛んだらOK
設定変更
日本語表示と、タイムゾーンを変更します。
settings.pyLANGUAGE_CODE = 'ja' TIME_ZONE = 'Asia/Tokyo'settings.pyINSTALLED_APPS = [ ... 'rest_framework', 'api.apps.ApiConfig', ]あとは、シークレットキーなど隠す必要ある方は、一番最後の
補足: python-dotenvで環境変数を設定を見て設定してみてください。ルーティング urls.py
アプリごとにurls.pyを作って管理した方が良いのでurls.pyを作ります。
$ touch api/urls.py↓まだ記述が足りないです。後で付け足します。
api/urls.pyfrom django.urls import path, include from rest_framework import routers router = routers.DefaultRouter() urlpatterns = [ path('', include(router.urls)), ]includeを足してアプリ(api)側に作ったurls.pyのルーティングを反映させる。
backend/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('api/', include('api.urls')), ]model作成
今回とりあえず必要なのは、
id, title, bodyです。
idはデフォルトで作られるので、title,bodyを作ります。api/models.pyfrom django.db import models class Post(models.Model): title = models.CharField(max_length=50, blank=False) body = models.CharField(max_length=4000, blank=False) def __str__(self): return self.titlemax_lengthは最大何文字にするかです。テキトウに決めました。
def __str__(self)にself.titleと書くことで、
あとで、どんなデータか、タイトルのデータ表示で見やすくなるので設定しておいた方がいいと思います。
必須ではないです。モデルにDBの構造を書いたので、
makemigrationsでマイグレーションファイルを作成して、
マイグレーションファイルの記述通りにDBを作るため、migrateします。$ python manage.py makemigrations $ python manage.py migrateこれで、DBにテーブルが作成されました。
シリアライザーを作る
データの加工とか、形式正しいかとかの処理をするのがシリアライザーです。
とりあえず、やってみないとピンとこないと思うので作ってみましょう。$ touch api/serializers.pydjango-react-material/api/serializers.pyfrom rest_framework import serializers from .models import Post class PostSerializer(serializers.ModelSerializer): class Meta: model = Post fields = ['id', 'title', 'body']使用するモデルがPostなので
model = Post
id, title, bodyをReactに渡すので、
fields = ['id', 'title', 'body']例えば、Reactで
id, titleだけでいいなら
fields = ['id', 'title']になります。
必要なデータだけ選択するようにします。views.py設定
DjangoはMVC(Model View Controller)モデルでなくMVT(Model View Template)です。
DB関係を扱う「Model」、
HTMLっぽい記述をする「Template」
「Views」は、その二つの間でデータを処理・加工など両者の受け渡しというか、、、
そんな感じです。ViewsがMVCのControllerに当たるもので、なんか紛らわしいですね。
とりあえず、ModelViewsetというのを使うと、CRUD(Create Read Update Delete)を少ない記述で簡単に作れますので使ってみます。
(記述量増えるけど、細かく処理させたいこと決めたいならAPIviewとか使う)とりあえず、Postテーブルに登録されているデータを全部JSONとして返すコードを書きます。
↓django-react-material/api/views.pyfrom django.shortcuts import render from rest_framework import viewsets from django.http import HttpResponse from .serializers import PostSerializer from .models import Post class PostViewSet(viewsets.ModelViewSet): queryset = Post.objects.all() serializer_class = PostSerializeradmin管理画面に入る
情報を取得しようとしても、今は、DBに何もデータがありません。
これでは、データが取得できたかわからないですね。ということで、管理画面を設定します。
Djangoの管理画面を作る
Djangoの管理画面は最初から付属しています。
簡単にデータを追加・修正したり、ユーザーを追加したりすることができます。django-react-material/api/admin.pyfrom django.contrib import admin from .models import Post admin.site.register(Post)作成したmodelをインポートして登録しましょう。
これで管理画面で確認、追加、編集、。削除などできます。管理画面に入る
ユーザーを作っていないと入れないですね。
コマンドでスーパーユーザーを作成します。$ python manage.py createsuperuserユーザー名、メール、パスワードを設定してユーザーを作成します。
テストですので、簡単なパスワードでもいいと思います。
Bypass password validation and create user anyway? [y/N]:
みたいにパスワード単純すぎるよ!みたいなこと言われるけど、無視してy入れていいです。
※ デプロイするときは、単純なパスワードは避ける作成したユーザーでログインしてください。
モデルの名前である、
「POST」をクリック ⇨ 右上の「Postを追加」押して、データを追加します。
そうしたら、以下のような登録フォーム出るのでデータを追加します。
データを何個か追加してみてください。
DBにデータが追加されます。ルーターに追加
最後に、ルートを追加します。
djnago-react-material/django-react-material/api/urls.pyfrom django.urls import path, include from rest_framework import routers from api.views import PostViewSet router = routers.DefaultRouter() router.register('posts', PostViewSet) urlpatterns = [ path('', include(router.urls)), ]
router.register('posts', PostViewSet)postsというURLに割り当てるのは、
views.pyに書いた、PostViewSetの処理という意味です。紛らわしいですが、元からあったurls.pyには
path('api/', include('api.urls')),と書いたので、
api/というURL以降にapiフォルダの方にある、urls.pyの記述を足します。ということで、
api/+postsなのでにアクセスするとAPIサーバーからデータを取れることになります。
処理の流れ
- APIを叩かれる。URLが
http://127.0.0.1:8000/api/posts/- views.pyに書いてある
PostViewSetの処理が実行queryset = Post.objects.all()でPostテーブルからデータを全て取得
- SQLなら
SELECT * FROM POSTみたいな感じ。正確にはDBのテーブル名違うけど- シリアライザーでデータを整える。
- 今回は、単純な処理なので、処理はほぼしていない。
- いらないカラムデータを削除(fieldsで指定したりする)、データを加工してJSONにするとかできる
- 例えば、2021-01-17 12:00:00が見にくいから、2021年1月17日にしてJSONデータ作るとか
- JSON形式でDjangoのAPIサーバーがデータを送信
少し長くなりましたが、これでできました。
URLにアクセスすると、以下のように先ほど管理画面で登録したデータを取得できているのがわかります。
Postmanで取得してみる
インストールしてない人はここから
APIを叩く(APIサーバーからデータもらう)ときによく使われるツールです。
先ほど確認できたので、大丈夫ですが、一応体験しましょう。今回はGetで取得しますね。
手順
create request ⇨ URL入れる ⇨ Send
認証のトークンをつけてAPIを叩いたり、
POSTデータを送信することもできるなどなど便利ツールです。
(今回はあまり使う意味なかったけど、WEBアプリ開発するなら入れておきましょう。使います。)これだけだと、Reactで読み込めない
一見良さそうなんですけど、セキュリティとかの関係で今のままだと、
ReactではAPIを叩いてもデータを取得できません。
必要なものをインストールして、設定をします。$ pipenv install django-cors-headers設定が必要なので、以下を追加します。
settings.pyINSTALLED_APPS = [ 'corsheaders', # 追加 ] MIDDLEWARE = [ 'corsheaders.middleware.CorsMiddleware', # 追加 ] CORS_ALLOWED_ORIGINS = [ 'http://127.0.0.1:3000', 'http://localhost:3000', ]
CORS_ALLOWED_ORIGINSは通信を許可するIPとポートを指定する設定です。
Reactのデフォルトで起動するのはhttp://localhost:3000ですのでこのように書いてます。localhostのIPの設定は意図的に変更しない限り、
127.0.0.1なので一応書いてます。※
CORS_ORIGIN_WHITELISTで指定するという情報がありました。
最近のバージョンではCORS_ALLOWED_ORIGINSですので注意。一応ちゃんと確認したい方は、リポジトリを見てください
Djangoはこれで完成です!?
ReactからDjangoのAPIサーバーにアクセス
※ こちらは前回作ったReactの続きです。
こちらはそれほどやることはなくて、URLを変更すれば良いだけです。
material-react/src/components/Content.jsfunction Content() { const [post, setPosts] = useState([]) useEffect(() => { // axios.get('https://jsonplaceholder.typicode.com/posts') axios.get('http://127.0.0.1:8000/api/posts/') .then(res => { setPosts(res.data) }) }, []) const getCardContent = getObj => { const bodyCardContent = {...getObj, ...cardContent}; return ( <Grid item xs={12} sm={4} key={getObj.id}> <BodyCard {...bodyCardContent} /> </Grid> ); }; return ( <Grid container spacing={2}> {post.map(contentObj => getCardContent(contentObj))} </Grid> ) }
BodyCard.jsでconst { userId, id, title, body, avatarUrl, imageUrl } = props;と書いてあって、ここにデータが渡ります。userIdは今回作っていませんが、もともと使っていなかったので表示には問題ないです。
(※ 消してもよかったですね…)Reactサーバー起動
Reactを開発したディレクトリにて、サーバーを起動して、
$ npm startURLにアクセスすると、
うまくいけば、表示されます。
Djangoの管理画面でデータを登録したら増えますので試してください。
APIで個別記事のデータ取得
次は、「詳細をみる」ボタンで表示される個別の詳細記事です。
実は、ModelViewSetを使うと一通りの機能を作ってくれているので、すでに完成しています。とブラウザのURLのところに入れれば、データが表示されます。
ついでに、コード書いてないですが、削除、変更もすでに実装されています。
DELETE、PUTのボタンありますよね。この画面のボタンを押しても、編集できますし、Postmanで、HTTPの通信を使って、
消したり、変更したりを、所定の形式に従って送ってやれば実行されるAPIが完成してるんですね。まあ、今のうちは、
ModelViewSet使うと簡単にCRUD作れるんだねー
くらいで良いと思います。Reactからこの個別記事詳細データを取得
前回の
[【初心者】React #3 ルーティング・ページ遷移 react-router-dom]
ですでにボタンから個別の記事に飛べるようにもなっていますので
API叩くためのURLを変えるだけでOKmaterial-react/src/components/PostContent.jsimport React, {useState, useEffect} from 'react'; import axios from 'axios'; import { useParams } from 'react-router-dom' import { Grid } from '@material-ui/core' import BodyCard from './BodyCard' const cardContent = { avatarUrl: "https://joeschmoe.io/api/v1/random", imageUrl: "https://picsum.photos/150" } function PostContent() { const { id } = useParams(); const [post, setPosts] = useState([]) useEffect(() => { // axios.get(`https://jsonplaceholder.typicode.com/posts/${id}`) axios.get(`http://127.0.0.1:8000/api/posts/${id}`) .then(res => { setPosts(res.data) }) }, []) return ( <Grid container spacing={2}> <Grid item xs={12} key={post.id}> <BodyCard {...{...post, ...cardContent}} /> </Grid> </Grid> ) } export default PostContentURLを変えるだけで詳細ページはOKです。
一覧表示の
BodyCardコンポーネントをそのまま使ったので
「詳細をみる」ボタンはここには必要ないし、画面の引き伸ばし感がひどいですが、
個別記事のルーティングもできていますねまとめ
- Django Rest Frameworkを使ってAPIサーバーを作成
- Reactから作成したAPIサーバーにアクセスできるようにDjangoで設定
- Reactで作成したAPIサーバーからデータが取得できることを確認
補足: python-dotenvで環境変数を設定
必須ではないです。必要な人はやってみましょう。
githubなどにpublicで公開するとき、APIキーなど公開すると危険な情報はを.envに書き、
.gitignoreで除外しましょうやり方よく忘れるので、メモしときます。
デプロイするものなどは、githubのpublicにしないか、
公開したらやばいものは公開しないようにしてください。環境変数を
.envから読めるようにします。$ pipenv install python-dotenvプロジェクト直下、manage.pyとかと同じところに.envファイル作って、ここにみられたえらやばい情報を追加します。
$ vim .envSECRET_KEYと、DEBUGも一応追加しておきます。
setting.pyに書いてある、SECRET_KEYと、
ついでにDEBUGの値を以下のように貼り付け。.envSECRET_KEY=1234567890asdfghjklwertyzx DEBUG=True.envから読み込む記述と、
SECRET_KEY,DEBUGをos.getenv('ここに.envに書いた名前書く')にする。backend/settings.pyimport os from dotenv import load_dotenv load_dotenv(verbose=True) dotenv_path = os.path.join(BASE_DIR, ".env") load_dotenv(dotenv_path) SECRET_KEY = os.getenv('SECRET_KEY') DEBUG = os.getenv('DEBUG').gitignore作ってなかったら、.envと同じプロジェクト直下に作成して以下の記述を足してください。
ついでに.githubのリポジトリ作るときに、.gitignoreを追加⇨python選べば、
こんな感じの記述はすでに書かれていると思うのでその場合は不要です。.gitignore.env .venv env/ venv/ ENV/ env.bak/ venv.bak/.gitignoreに追加すれば、変更を追跡しなくなるので、
うっかり、やばい情報をgithubに公開してしまった!
ということはなくなります。今回はDjangoのSECRET_KEYでしたが、APIキー、
特にAWS関係の情報を晒したら、悪用されて多額の請求来ます!
githubに公開しないといけないときには使いましょう。






- 投稿日:2021-01-29T12:03:17+09:00
Djangoで更新可能な一覧画面を作成する
自治会の運営を楽にしたいと思って自治会ネットというWEBサービスを立ち上げました。
環境はAWS + Python(Django)です。
構築にあたって、偉大なる先人方の記事に助けられたので微力ながら自分も誰かの助けになれたらと思い、記事を書いてみることにしました。やりたいこと
ユーザーの一覧を表示しつつ一部の情報だけを変更できるような画面を作りたい。
djangoはデフォルトで用意されている管理画面でもそうですが、一覧画面→詳細画面に遷移して更新するのが基本です。
でもたくさんのデータを1つ1つ開いて更新していくのは面倒なので、権限とかの更新は一覧画面で一度に行えるようにしたい。
ニーズはありそうなのですが、意外と情報が少なかったので書いてみました。実現方法
django-extra-viewsというライブラリを使います。
今回使ったのはこの中のModelFormSetView手順
djangoの基本的な使い方については他の方が記事を書いてくださってますので省略します。
ライブラリのインストール
pip install django-extra-viewsAPPの追加
INSTALLED_APPS = [ ... 'extra_views', ... ]models.py
from django.db import models class Group(models.Model): code = models.CharField(max_length=15, primary_key=True) name = models.CharField('グループ名', max_length=30) def __str__(self): return self.code class Member(models.Model): full_name = models.CharField('名前', max_length=150) group = models.ForeignKey(to=Group, on_delete=models.CASCADE) auth = models.BooleanField( '権限A', default=False, )forms.py
from django import forms from django.db import models from django.forms import ModelForm from .models import Member, Group class MemberUpdateForm(ModelForm): class Meta: model = Member fields = ( 'full_name', 'group', 'auth')urls.py
from sample import views as sample urlpatterns = [ path('update_sample', sample.ListUpdateView.as_view(), name='update_sample'), ]view.py
from extra_views import ModelFormSetView from .models import Member from .forms import MemberUpdateForm class ListUpdateView(ModelFormSetView): model = Member template_name = 'update_sample.html' form_class = MemberUpdateFormupdate_sample.html
<form method="post"> {{ formset }} <div> <button class="btn btn-warning" type="submit">変更</button> </div> </form>ここまでの結果
とりあえず更新可能な一覧が表示されました。
最後の一行は新規行を追加するためのものです。
しかし、このままでは見た目も悪いし名前も編集できてしまうので修正していきます。
まずは{{ formset }}を展開します。update_sample.html
<form id="members_form" method="post"> {% csrf_token %} {{ formset.management_form }} <table class="table"> <thead> <tr> <th scope="col">ID</th> <th scope="col">名前</th> <th scope="col">グループ</th> <th scope="col">権限A</th> </tr> </thead> <tbody> {% for form in formset %} <tr> <td>{{ form.id }}</td> <td>{{ form.full_name }}</td> <td>{{ form.group }}</td> <td>{{ form.auth }}</td> </tr> {% endfor %} </tbody> </table> <div> <button class="btn btn-warning" type="submit">変更</button> </div> </form>formsetには「management_form」という、formのトータル行数や元の行数を持ってる要素が含まれているので、formsetを展開する場合には{{ formset.management_form }}を記述する必要があります。
management_form の中身
<input type="hidden" name="form-TOTAL_FORMS" value="3" id="id_form-TOTAL_FORMS"> <input type="hidden" name="form-INITIAL_FORMS" value="2" id="id_form-INITIAL_FORMS"><input type="hidden" name="form-MIN_NUM_FORMS" value="0" id="id_form-MIN_NUM_FORMS"> <input type="hidden" name="form-MAX_NUM_FORMS" value="1000" id="id_form-MAX_NUM_FORMS">また、formset = 複数formをまとめたものなので{% for form in formset %}で
formを一行ずつ取り出して表示してあげます。
bootstrapのtableにセットしてあげると簡単に見やすくできます。ID(PK)はhidden項目ですが、書かないとformのvalidationでエラーになるので更新できません。
該当の列をdisplay: noneにするなどして見えなくしておきましょう。ここまでの結果
だいぶ見た目がマシになりました。
次に名前を編集不可にするため、readonlydisabled(disabledだと更新できないです)属性をつけてcssでテキストボックスの見た目を消します。
(注)disableにしても開発者ツールとか使えば編集できてしまうので完全に禁止できるわけではないです。
何か良い方法ご存知の方がいれば教えてください。属性の追加はこちらの記事参照
update_sample.html
{% load widget_tweaks %} #追加 <form id="members_form" method="post"> {% csrf_token %} {{ formset.management_form }} <table class="table"> <thead> <tr> <th class="hidden" scope="col">ID</th> #変更 <th scope="col">名前</th> <th scope="col">グループ</th> <th scope="col">権限A</th> </tr> </thead> <tbody> {% for form in formset %} {% if not forloop.last %} #追加 <tr> <td class="hidden">{{ form.id }}</td> #変更 <td>{{ form.full_name }}</td> <td>{{ form.group }}</td> <td>{{ form.auth }}</td> </tr> {% endif %} #追加 {% endfor %} </tbody> </table> <div> <button class="btn btn-warning" type="submit">変更</button> </div> </form>css
input { border: 0; color: #000000; background-color: rgba(255,255,255,255); } .hidden { display: none; }最後に、グループの選択肢をコードではなく名前にします。
forms.py
from django import forms from django.db import models from django.forms import ModelForm from .models import Member, Group # nameをlabelにするModelChoiceField class ModelNameChoiceField(forms.ModelChoiceField): def label_from_instance(self, obj): return "%s" % obj.name class MemberUpdateForm(ModelForm): class Meta: model = Member fields = ( 'full_name', 'group', 'auth') group = ModelNameChoiceField(Group.objects)完成!
所感
初めて記事を書きましたが、間違ってないか実際に動かしながら確認するので時間もかかるし大変ですね。
先人の方々に改めて感謝です。
今後はAWSでの環境構築などの記事を書いていけたらと思います。参考




- 投稿日:2021-01-29T11:51:31+09:00
Pythonで大量の画像をPowerPointに綺麗に貼り付ける
はじめに
弊社で使用している業務アプリにて、機器の計測値や分析結果をダッシュボード形式で表示する機能があるのですが、ある測定範囲での結果をまとめてほしいとの要望が来ました。
しかし貼り付ける画像の量が膨大で(数百枚ある)、手作業でひとつひとつ位置やサイズを揃えようにもめっちゃ大変だったので自動化することにしました。完成予想図
こんな感じ。python-pptxライブラリ
pythonでPowerPointファイルを操作できるライブラリで
pptxというものがあるらしく、さっそくインストールpip install python-pptx
pip install pptxではありませんのでご注意を。基本的な使い方
公式リファレンスの
Getting Startedのページを見ながら、サンプルコードを改造する形でコーディングしていきます。記載のあるサンプルは以下の通り。
Hello World! example
- 最もシンプルで基本的なpptxの使い方
Bullet slide example
- 箇条書きの入れ子になっているサンプル。テキストのみ
add_textbox() example
- テキストボックスを追加したい時のサンプル
add_picture() example
- 画像を追加したい時のサンプル
- 今回は主にこのサンプルを参考にしました
add_shape() example
- 基本図形を追加したい時のサンプル
add_table() example
- 表を追加したい時のサンプル
Extract all text from slides in presentation
- スライド内のテキストを全て抽出する
使ってみる
公式のサンプルコードを参考に、以下のようなコードを記述
makeSlide.pyfrom pptx import Presentation from pptx.util import Inches prs = Presentation() # スライドサイズをA4に指定 prs.slide_height = Inches(11.69) prs.slide_width = Inches(8.27) # 白紙スライドを追加 blank_slide_layout = prs.slide_layouts[6] slide = prs.slides.add_slide(blank_slide_layout) # 見出し text_width = Inches(4) text_height = Inches(0.5) txBox = slide.shapes.add_textbox( left=Inches(0.5), top=Inches(0.3), width=text_width, height=text_height ) txFrame = txBox.text_frame txFrame.text = "見出し" # ヘッダ画像 header_path = "./images/header.png" slide.shapes.add_picture( header_path, left=Inches(3.5), top=Inches(1), width=Inches(3.5), height=Inches(2.5) ) # 画像1-6 image_width = Inches(3.3) image_height = Inches(2.3) images_top = Inches(4) # 画像群,上部の座標 for index in range(6): image_path = f"images/image_{str(index+1).zfill(2)}.png" # 中央寄せで描画 slide.shapes.add_picture( image_path, left=(prs.slide_width/2)-image_width+(index%2)*image_width, top=images_top+int(index/2)*image_height, width=image_width, height=image_height ) prs.save('output.pptx')ディレクトリ構成はこんな感じ
│ makeSlide.py └─images header.png image_01.png image_02.png image_03.png image_04.png image_05.png image_06.png実行結果
ちゃんとPowerPointスライドが生成されました。
1枚できれば、残りの作業はほぼ同じなので簡単に実装できそうです。また、このPowerPointファイルを開いた状態で書き込み(プログラム実行)しようとすると、
Permission Errorとなるのでご注意ください。参考・リンク

- 投稿日:2021-01-29T11:02:08+09:00
%matplotlib inline に関するエラー
はじめに
今回初めてPythonを触った初心者。Visual Studio Codeを使用。
以下の記事「pythonで一から画像処理 (5)フーリエ変換」を実践しようとする。
https://qiita.com/fugunoko/items/41c33ca163c7bb52d283エラーでつまづいたが、最終的には実行できた。
その過程の記録。出現したエラー
諸々インストールしていないエラー
OpenCV
script.pyimport cv2を実行するためにOpenCVをインストール
pip install opencv-pythonNumPy
script.pyimport numpy as npを実行するためにNumPyをインストール
pip install opencv-python問題の「%matplotlib inline」
SyntaxError: invalid syntaxが出る
最終的な解決法→この一文を消す
この「%matplotlib inline」というのは開発環境である「Jupyter Notebook」というものを使っていない場合には必要ない様子。
これを消したらうまく行きました!
過程での対処
途中でいろいろエラーが出て、それに対する打ち手ももしかしたら影響しているかもしれない…?
最初はModuleNotFoundError: No module named 'matplotlib'というエラーだったのでまずはこれをインストールするところから。
pip install matplotlibそれでもエラーが出たりしたので一旦「%matplotlib inline」を
from IPython import get_ipython get_ipython().run_line_magic('matplotlib', 'inline')というコードに書き換えました(どこかのネットの記事を参照したのにその参照元を忘れてしまいました…)
するとこういうエラーが出るのでまたインストールModuleNotFoundError: No module named 'IPython'pip install ipythonしかしまだまだこんなエラーが出てきて…
get_ipython().run_line_magic('matplotlib', 'inline') AttributeError: 'NoneType' object has no attribute 'run_line_magic'このエラーが解決できずに結局どうしようもないとなってしまい、元々のプログラムに戻して再度エラーを確認し、調べ直すことに。
そしたら答えが見つかりました!
(英語だったけど)
https://stackoverflow.com/questions/39449549/python-syntaxerror-invalid-syntax-matplotlib-inline/39449990使用する環境によって書いたり書かなかったりするコードがあるんですね。メモメモ。
これにて最初に書いた通り、%matplotlib inlineを消すことで一見落着です。終わりに
Python難しいなと思ってたけど、意外にどうにかなるものでした。
まだまだ勉強を続けていきますー