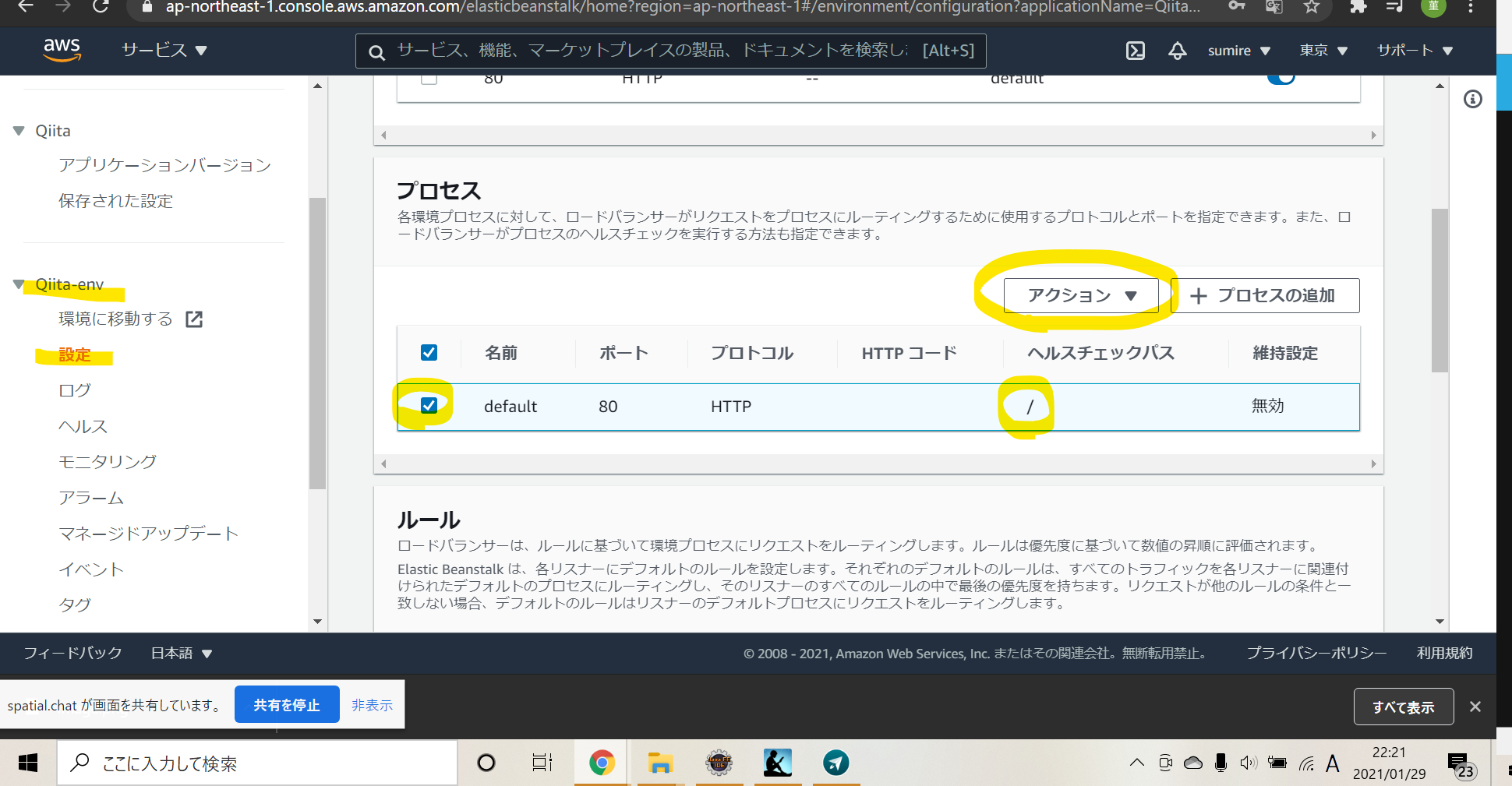
Description:
Failed to configure a DataSource: 'url' attribute is not specified and no embedded datasource could be configured.
Reason: Failed to determine a suitable driver class
Action:
Consider the following:
If you want an embedded database (H2, HSQL or Derby), please put it on the classpath.
If you have database settings to be loaded from a particular profile you may need to activate it (no profiles are currently active).
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.22.2:test (default-test) on project Qiita210129: There are test failures.
privatestaticConstructorresolveConstructor(ClasstargetClass,List<Type>types){for(Constructorconstructor:targetClass.getConstructors()){finalClass[]argumentTypes=constructor.getParameterTypes();if(argumentTypes.length!=types.size()){continue;}booleanallMatched=true;for(inti=0;i<argumentTypes.length;i++){if(!areAssignmentCompatible(argumentTypes[i],types.get(i).getReturnedClass())){allMatched=false;break;}}if(!allMatched){continue;}returnconstructor;}thrownewIllegalArgumentException("Could not locate appropriate constructor on class : "+targetClass.getName());}