- 投稿日:2021-01-29T23:52:31+09:00
【独学・未経験】Nuxt.js, Rails, Docker, AWS ECS(Fargate), TerraformなSPAポートフォリオを作成しました。
はじめに
プログラミング歴半年(独学)の実務未経験者がSPAなポートフォリオを制作しましたので紹介していきたいと思います!
今後もアップデートしていくのでフィードバックなど頂けますと嬉しいです。
記事の最後には、お世話になったWebサイトや教材をまとめておきましたので参考になれば幸いです。作者のスペック
年齢は27歳で今までにプログラミング経験は全くなし。
サーバーサイドエンジニアを目指してプログラミング学習中の初学者です。
本記事を執筆している時点でプログラミング学習期間は半年。(2021/1/29時点)
ポートフォリオに関わる技術のキャッチアップをしながら約4ヶ月程かけて完成させました。ポートフォリオ制作に着手した時点では、ProgateとRailsチュートリアルを終えた程度の実力。
至る所に詰みポイントがありひたすらググりまくって問題解決してました。(Google先生は神)アプリの概要
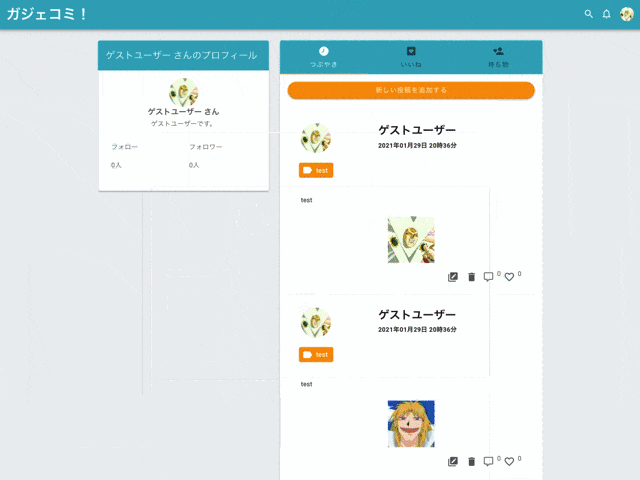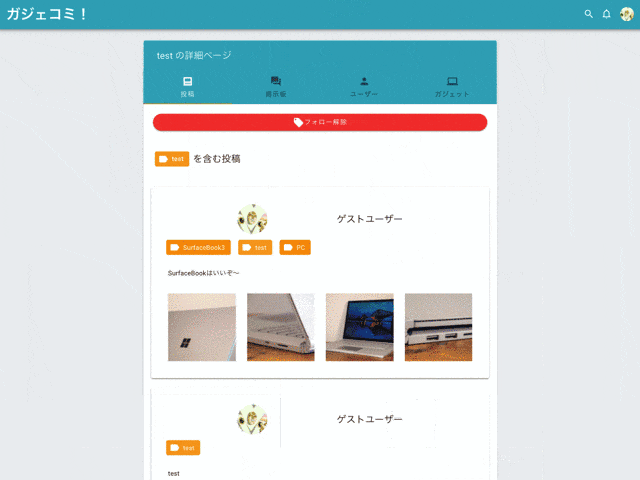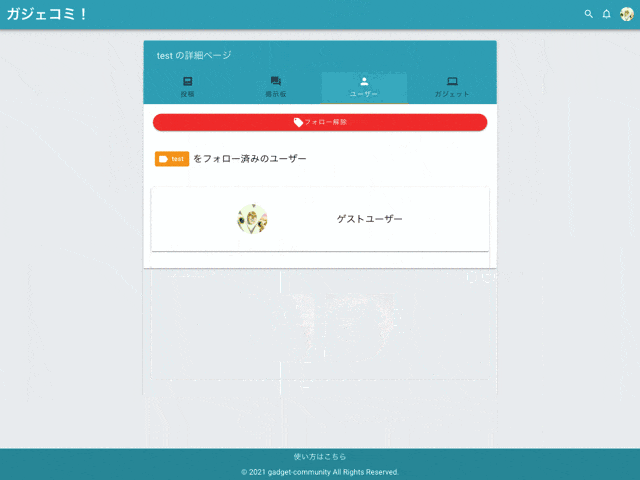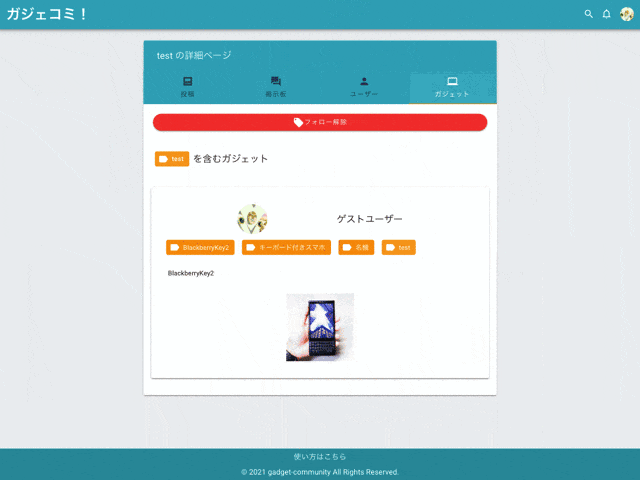
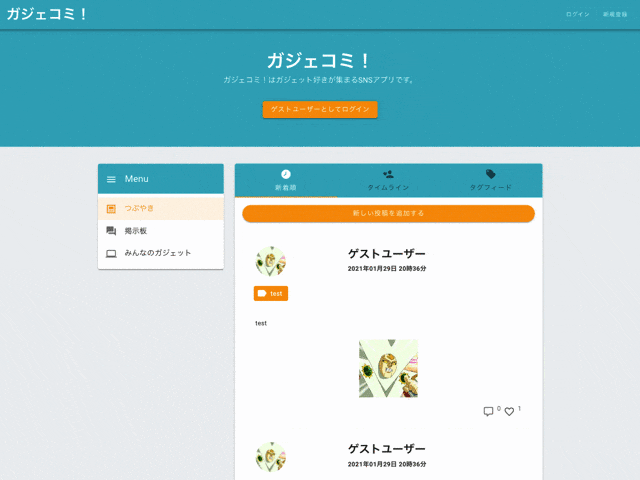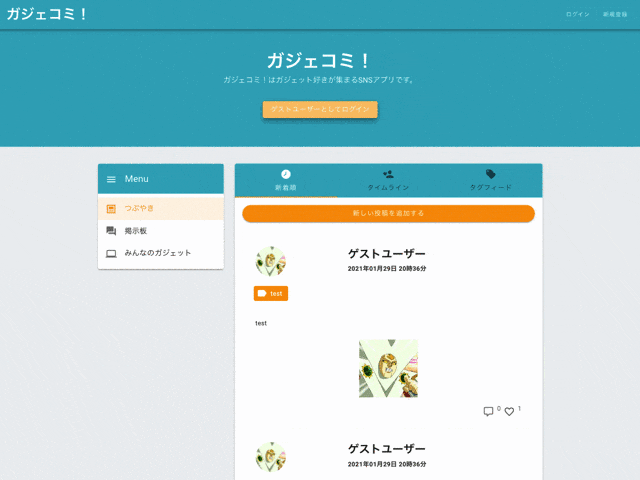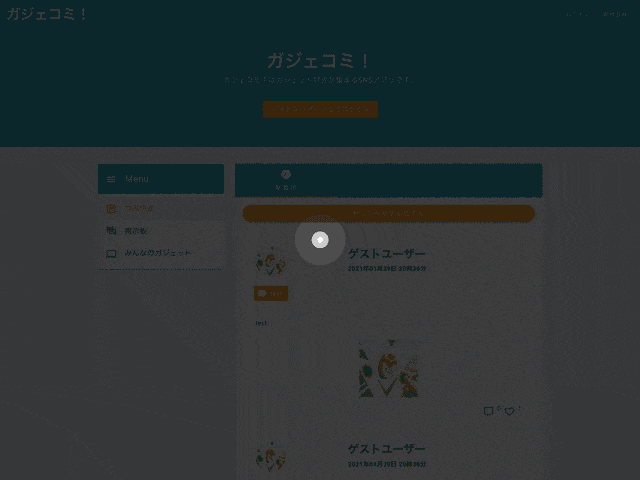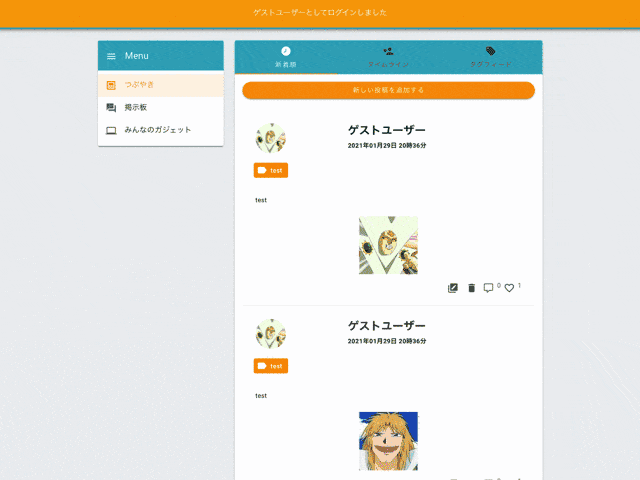
制作したアプリケーションがこちら。
『ガジェコミ!』はガジェット好きが集まれるSNS型のWebアプリケーションです。
簡単に言ってしまえば『Twitterクローン』に近いものなので、SNSに必要な機能を重点的に実装済み。
スマホ利用を想定しているのでモバイルからも気軽にお試し下さい!(ゲストログイン有ります)
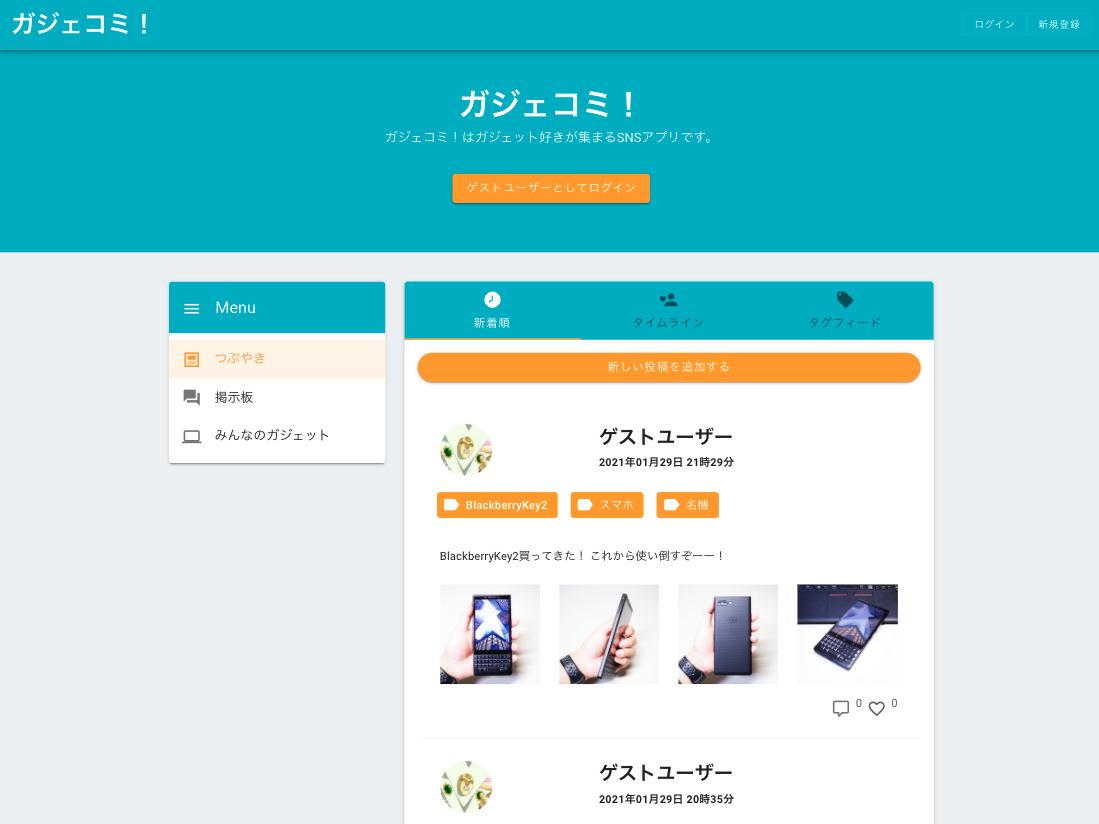
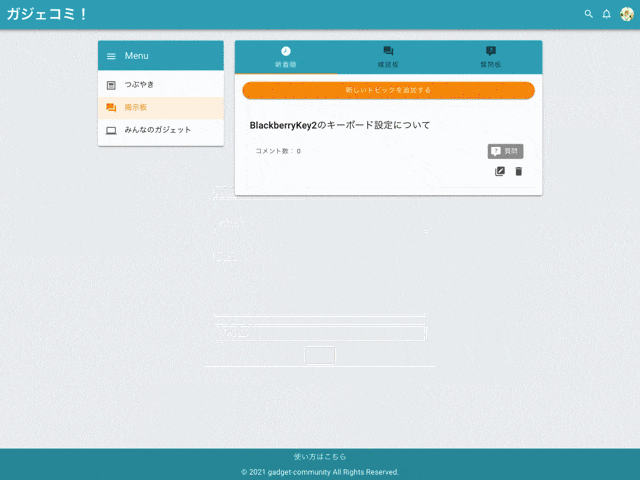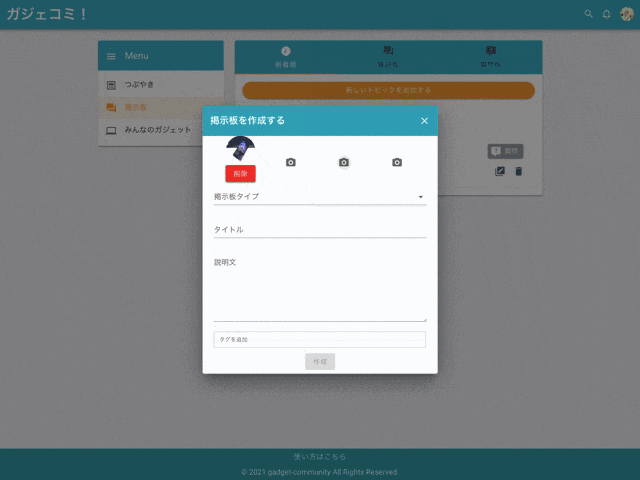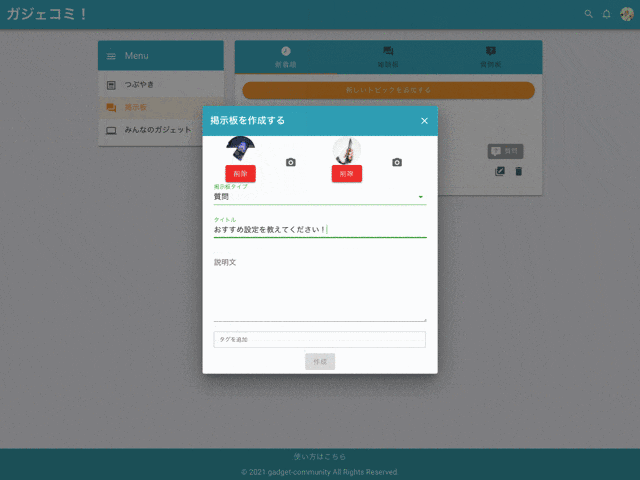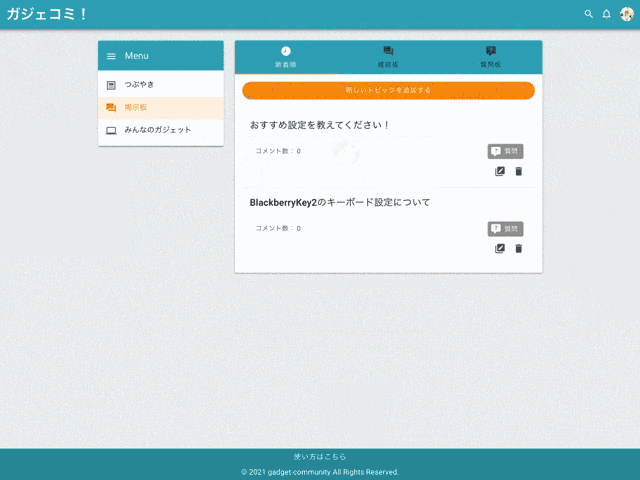
トップページ
レスポンシブ対応
スマホ利用も想定したUI設計。
Ajax処理
ネストした要素でもAjaxに動作します。
例) 『コメントアイコンをタップ → コメント欄を表示 → 既にあるコメントに返信』
例) 『コメントを削除』
ポートフォリオに使用した技術
各バージョン
- Ruby 2.7.1
- Rails 6.0.3.4
- nuxt 2.14.6
- @nuxtjs/vuetify 1.11.2
- Docker 19.03.13
- docker-compose 1.27.4
- Terraform 0.14.3
フロントエンド
名称 説明 Nuxt.js (SSR mode) フロントエンドフレームワーク Vuetify UIコンポーネント Firebase Authentication JWTを用いたログイン・ログアウト
Vuetifyコンポーネントを導入することで、スマホ利用を想定したレスポンシブデザインを実現。
Vuexストアでステート管理。
個人情報(メールアドレス・パスワード)は、外部API(Firebase Authentication)に保存する仕組みで、外部APIで発行されるJWTをSession Storageに保存してログイン・ログアウト機能を実装しました。
未ログイン状態でアクセスして欲しくないページ( /users/editなど )へのアクセス対策には、Nuxt.jsのmiddlewareを活用することで自動的にリダイレクトするようにしました。
ログイン状態でアクセスして欲しくないページ (ログインページ, 新規作成ページ) へのアクセスも同じくリダイレクトします。
バックエンド
名称 説明 Rails (API mode) APIサーバーとして利用 PostgreSQL データベース
RailsはAPIサーバーとして利用しており、フロントエンドコンテナからのリクエストに対してJSONデータを返しています。
画像データはActiveStorage経由でS3バケットに保存。
その他のデータはRDSに保存。
個人情報(メールアドレス・パスワード)は外部API(Firebase Authentication)に保存しているので、バックエンド側にセンシティブな情報を保存しない仕組みです。
テストコード
名称 説明 Jest フロントエンドテスト, Vuexストアの動作を少しだけ RSpec バックエンドテスト, バリデーションとアソシエーションのテストのみ
- CodePipelineのTestステージで実行するテストコードです。
インフラ
名称 説明 ECS Fargate サーバーレスな本番環境, オートスケール CodePipeline CI/CD環境 RDS 本番用DB(PostgreSQL) Docker, Docker-compose コンテナ環境 Github バージョン管理 Terraform 本番用インフラをコード管理
ローカル開発環境からデプロイまで一貫してDockerを使用。
ALBを通すことで常時SSL通信化。
CodePipelineは、 『Sourceステージ => Testステージ => Buildステージ => Deployステージ』の順で実行され、Testステージで問題が発生した場合は当該ソースでのDeployは実行されません。
本番環境の環境変数については SSM で管理。『システム環境変数 => Terraform => SSM => 各AWSサービス』というフローで環境変数を受け渡しています。
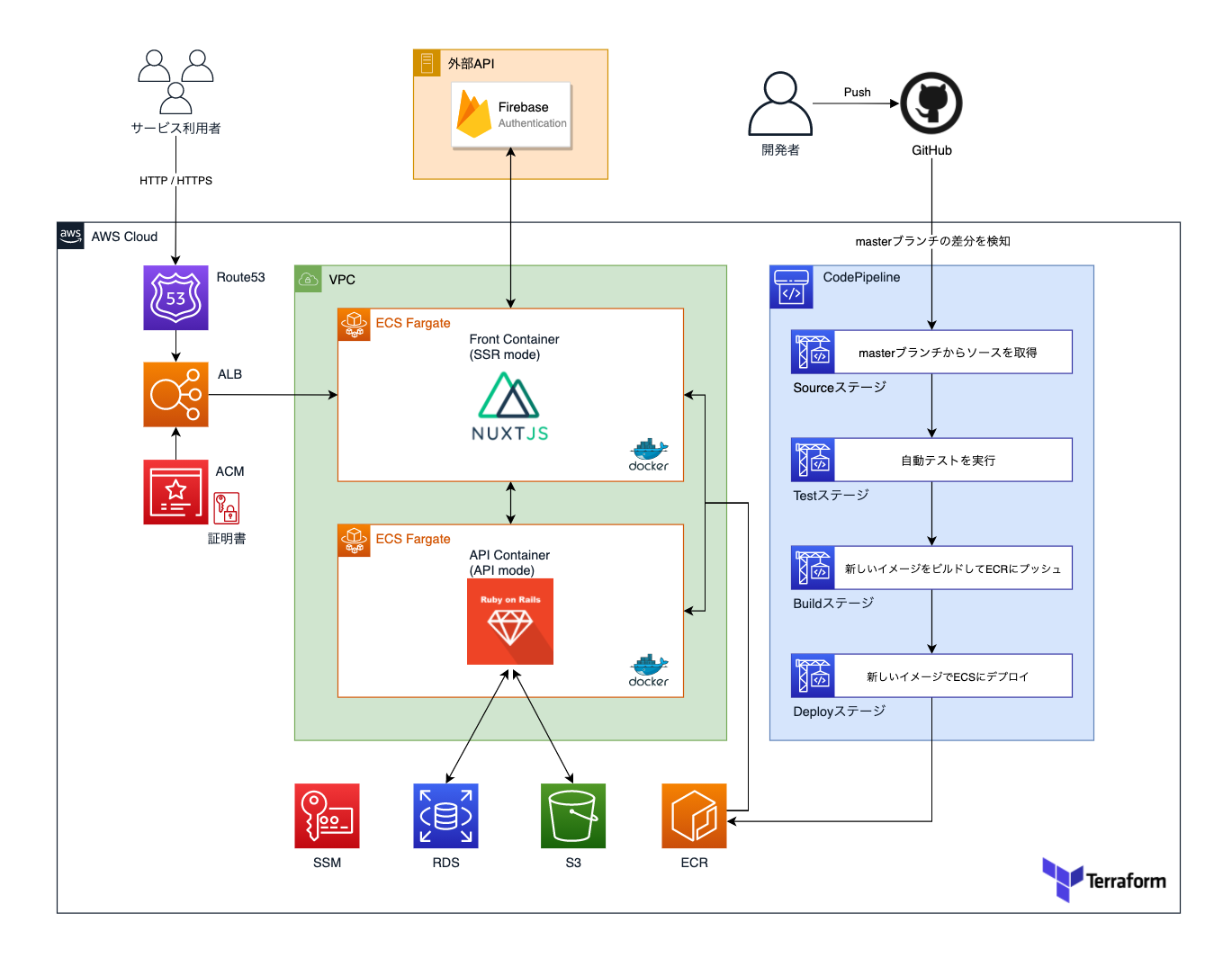
インフラ構成図
インフラの全体像をまとめたものがこちら。
RDSにはPostgreSQLを採用し、画像を除いたデータを保管。
画像データはS3に保管しています。
ER図
一貫性のあるテーブル名称を意識しました。
アプリの機能紹介
0. 機能一覧
機能名 説明 ユーザー機能 新規登録、登録内容変更、アバター登録、ログイン、ログアウト、フォロー つぶやき機能 投稿、編集、削除、画像複数枚登録 つぶやきコメント機能 つぶやきに対してコメント投稿、コメントへのリプライ投稿、削除、画像複数枚登録 つぶやきいいね機能 つぶやきをいいねできる、マイページのいいねタブにいいねしたつぶやきを一覧表示 掲示板機能 質問掲示板、雑談掲示板の作成、編集、削除、画像複数枚登録 掲示板コメント機能 掲示板に対してコメント投稿、コメントへのリプライ投稿、削除、画像複数枚登録 私物ガジェット機能 登録、編集、削除、画像複数枚登録 フィード機能 つぶやき新着表示、タイムライン表示、タグフィード表示 タグ管理機能 つぶやき・掲示板・私物ガジェットにはタグを登録可能、タグをタップしてタグ詳細ページを表示、タグ詳細ページではタグを含むコンテンツを表示 検索機能 各コンテンツを検索可能 通知機能 つぶやきにいいね・コメント、掲示板にコメント、他ユーザーからフォローされると通知を表示 管理者モード Godmode のトグルスイッチをONにすると、一時的に管理者権限が有効化、各コンテンツの削除メニューが表示される 1. ユーザー機能
登録・編集・削除
メールアドレスとパスワードを入力するだけでアカウント作成できます。
メールアドレス確認機能は未実装。VeeValidateを使用してフォームにバリデーションを設定しています。
詳細設定ページで登録情報を編集できます。
ユーザーにはアバターを設定できます。
アバター画像は各コンテンツで表示されます。
2. つぶやき機能
投稿・編集・削除
つぶやき作成は即時反映されます。
つぶやき編集は即時反映されます。
つぶやき削除は即時反映されます。
タグ付け
つぶやきにはタグを複数登録できます。
コメント
つぶやきにはコメントすることができます。
コメントに返信できます。
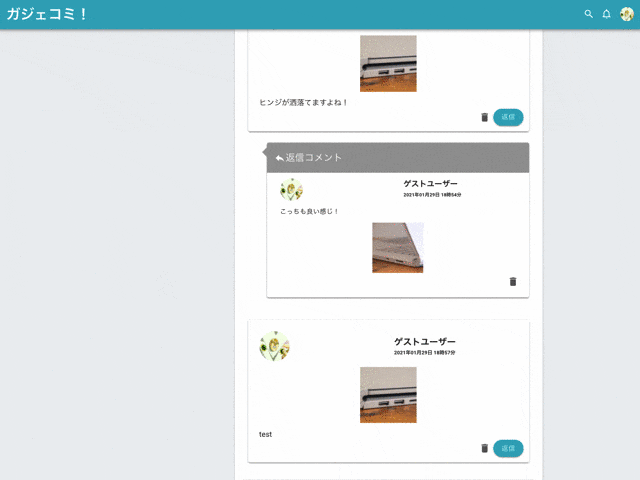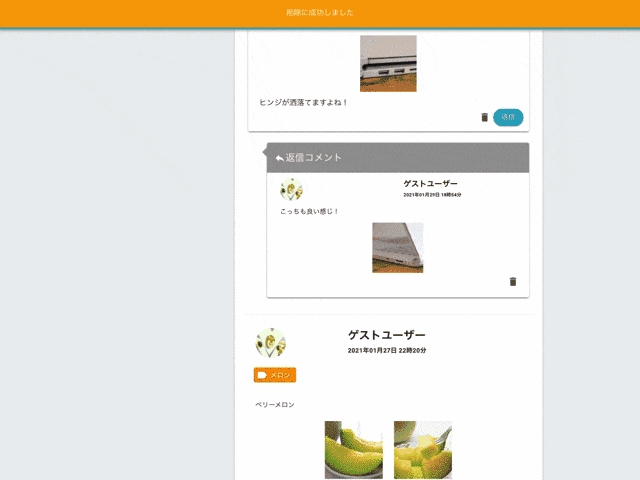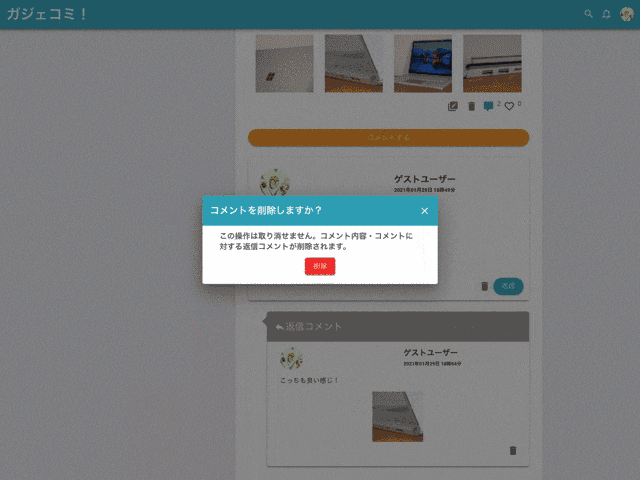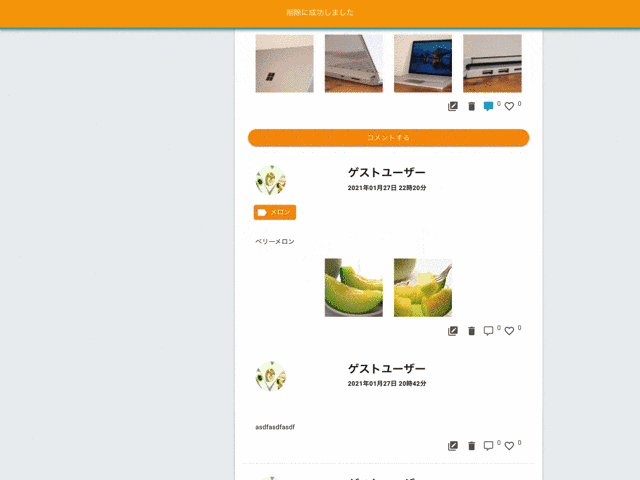
コメントは削除のみ可能です。編集機能はありません。
親コメントを削除すると子コメントも削除されます。
いいね
つぶやきにいいねできます。
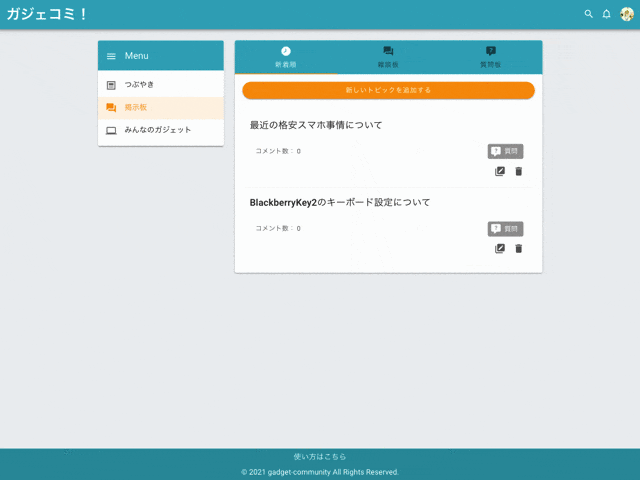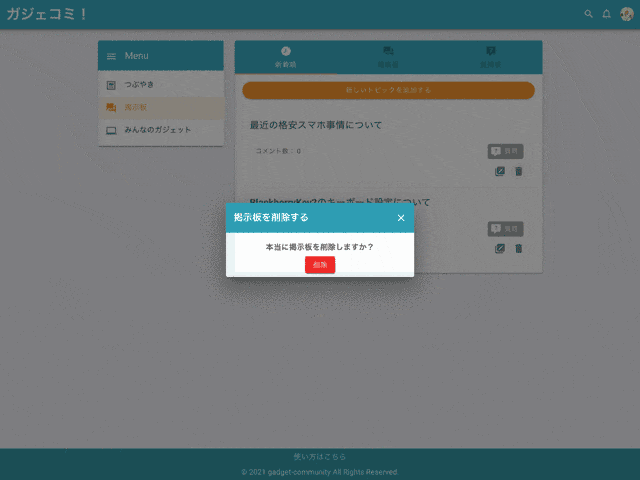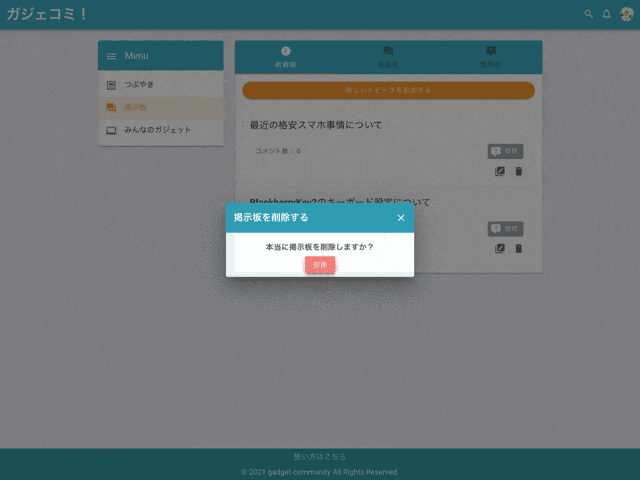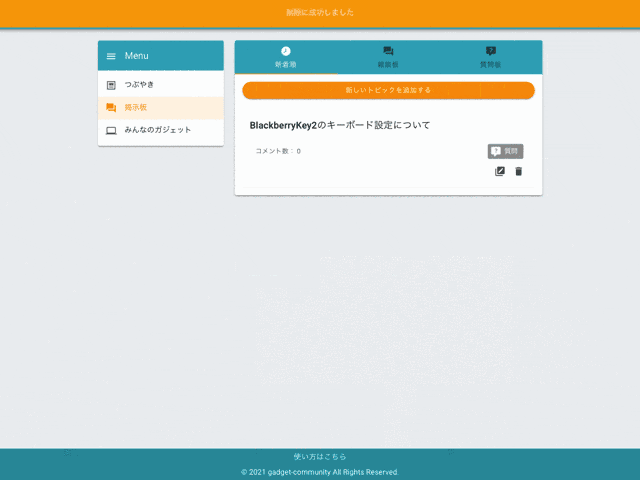
3. 掲示板機能
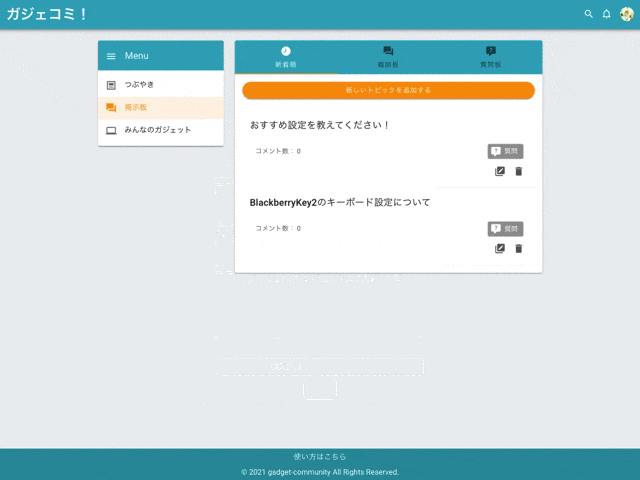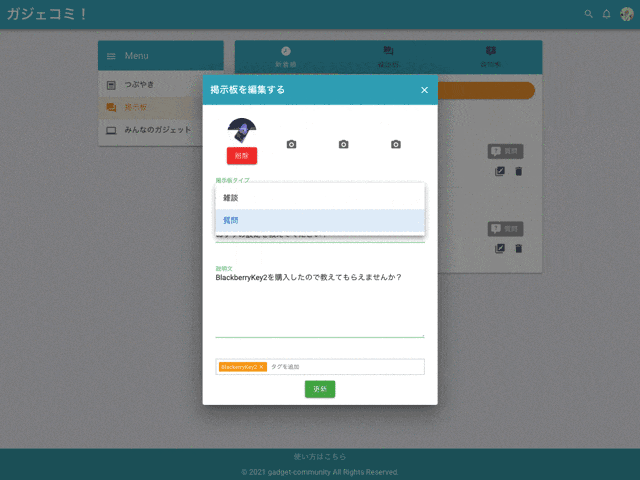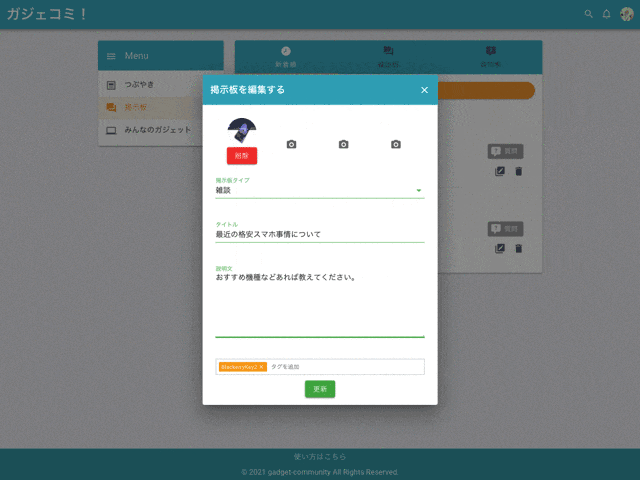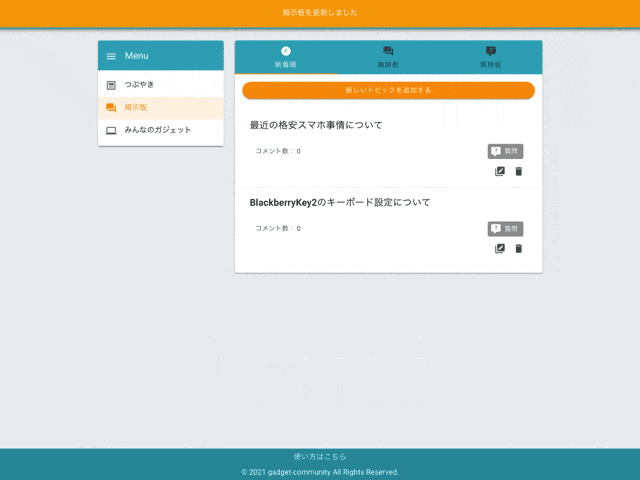
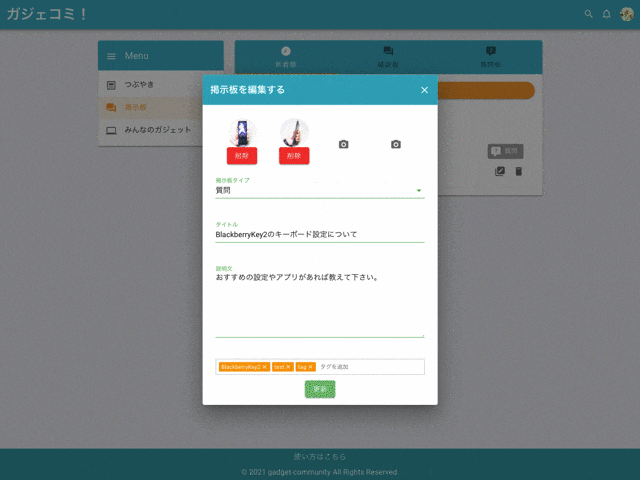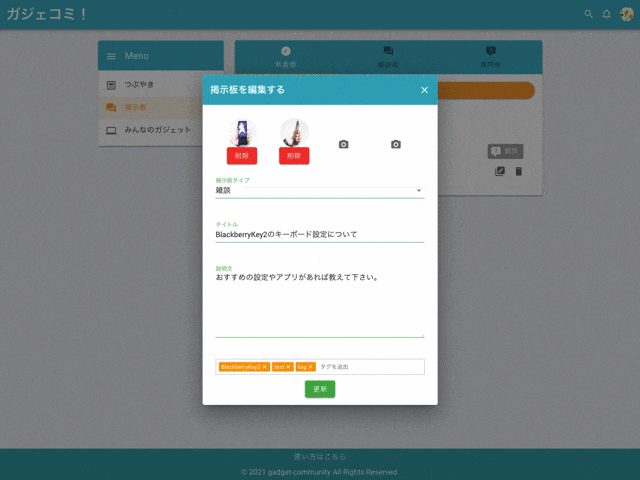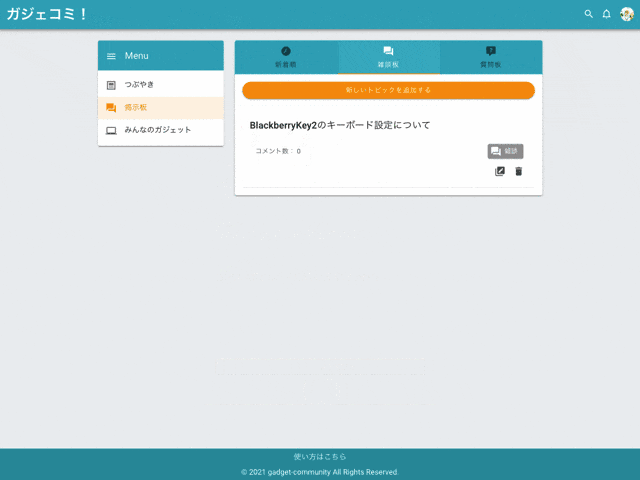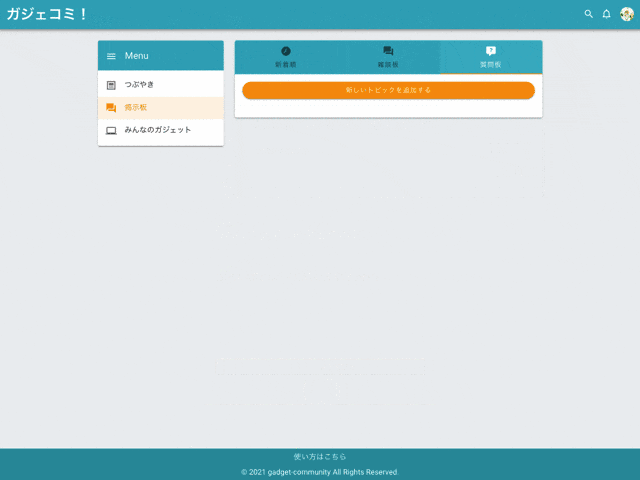
作成・編集・削除
掲示板作成は即時反映されます。
掲示板編集は即時反映されます。
掲示板削除は即時反映されます。
タグ付け
掲示板にはタグを複数登録できます。
掲示板タイプ
『雑談』『質問』を選択できます。
コメント
掲示板にはコメントすることができます。
コメントに返信できます。
コメントは削除のみ可能です。編集機能はありません。
親コメントを削除すると子コメントも削除されます。
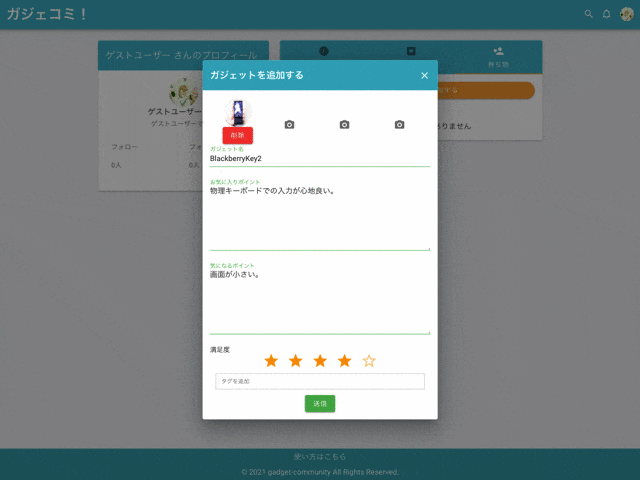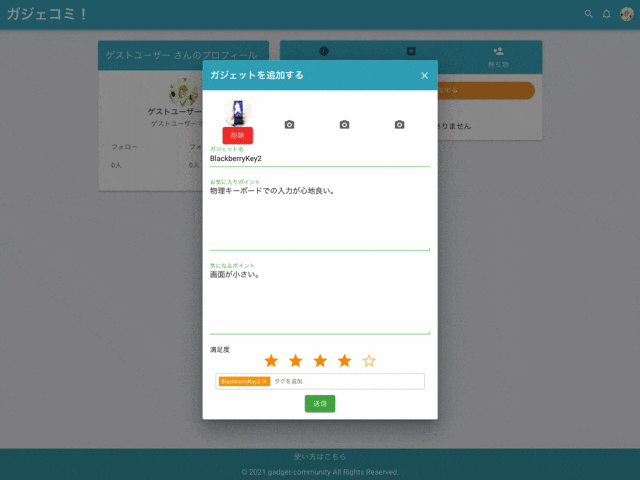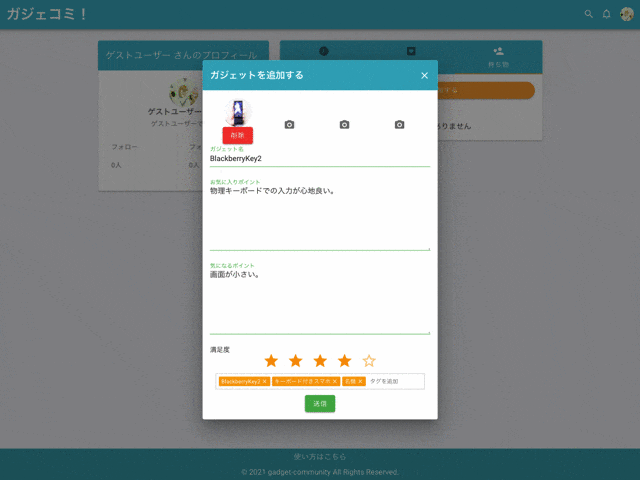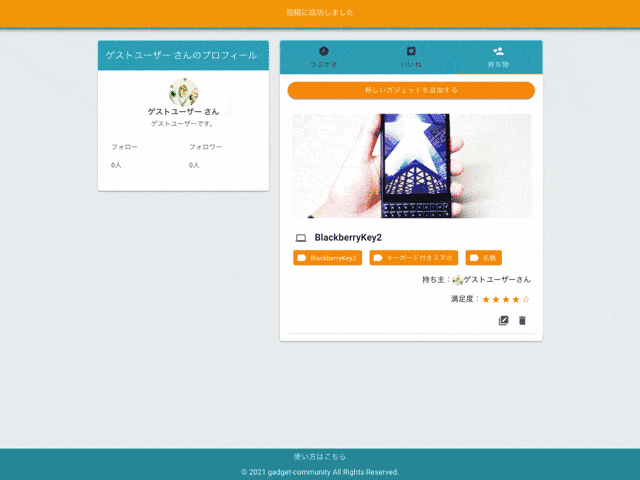
4. 私物ガジェット機能
登録・編集・削除
自分の私物ガジェットやお気に入りアイテムを登録できます。
登録したガジェットは一覧ページでは『みんなのガジェット』として新着表示されます。
ガジェット編集は即時反映されます。
ガジェット削除は即時反映されます。
タグ付け
私物ガジェットにはタグを複数登録できます。
5. フィード機能
つぶやきを一覧表示します。
無限スクロールで順次読み込みます。<タブによって表示する内容が異なります>
- 新着順 => 全てのつぶやきを新着順で表示
- タイムライン => フォロー済みユーザーのつぶやきのみ新着順で表示
- タグフィード => フォロー済みタグを含むつぶやきのみ新着順で表示
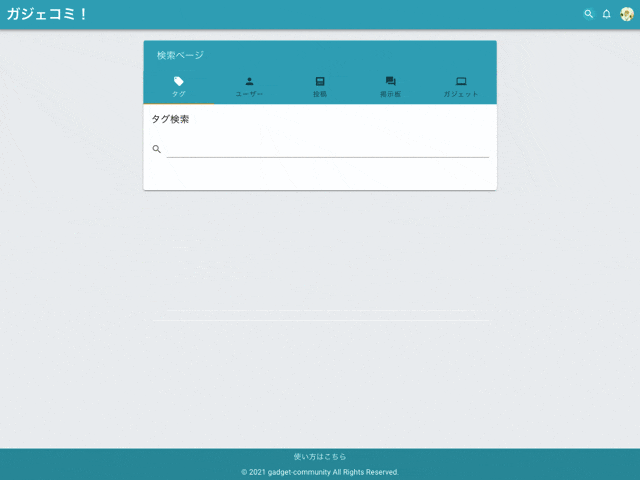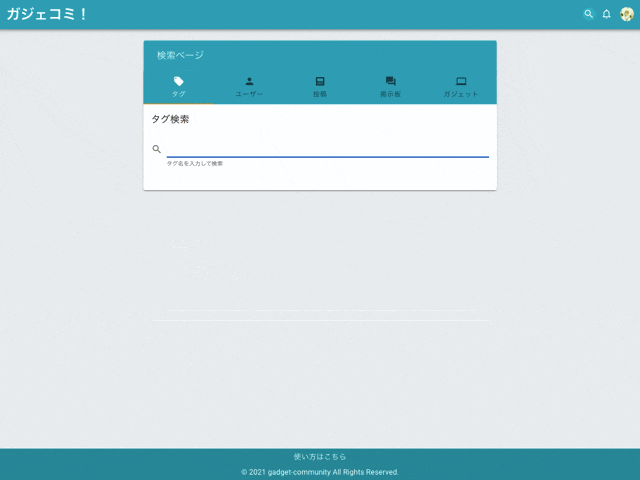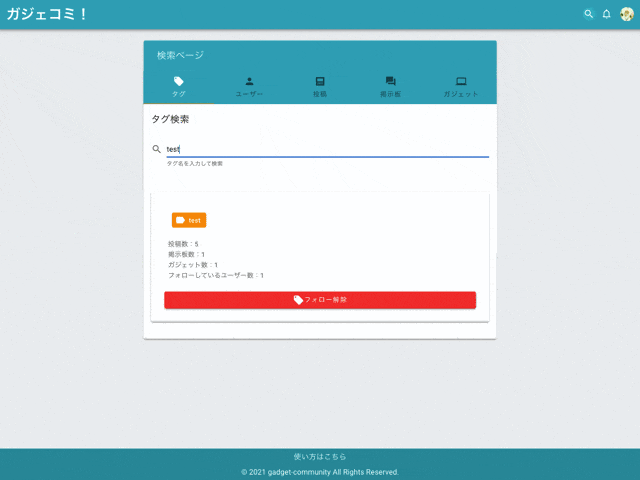
6. タグ管理機能
タグをフォローすることができます。
タグフィードに表示したいタグをフォローします。
つぶやき・掲示板・私物ガジェットはタグ付けすることができます。
タグをタップするとタグ詳細ページに遷移し、タグを含むつぶやき・掲示板・私物ガジェット・フォローしているユーザーの一覧を表示します。
7. 検索機能
検索ページでは、検索フォームに入力した内容に合わせて結果がリアルタイムに表示される機能を実装しております。
8. 通知機能
つぶやき・掲示板・ユーザーフォローにおいて、イベントが発生すると通知が表示されます。
新着通知
新しい通知が発生すると、ヘッダー内のベルアイコンにバッジが表示されます。
タップすると新しい通知がリスト表示され、通知をタップするとイベント発生元へ画面遷移します。
通知一覧
通知一覧をタップすると一覧ページへ画面遷移します。
通知一覧ページでは、今まで受け取った全ての通知を表示します。
9. ゲストユーザー機能
ユーザー専用機能を簡単に利用できるように、ゲストユーザーログイン機能を実装しています。
『ゲストユーザーとしてログイン』をタップするだけです。
未ログイン状態でユーザー専用機能にアクセスすると、ゲストユーザーログインを促すダイアログを表示するようにしております。
10. God mode
一時的に管理者権限を有効にするモードです。(管理者という概念が存在することを確認して頂くためのモードです。)
DB内 の Userモデルの adminカラム の true/false で 各ユーザーの管理者権限を管理しておりますが、God modeではVuexストアの値を一時的に変更して管理者権限を有効化しています。(DB上には保存されないのでブラウザ再読み込みでfalseに戻ります。)
つぶやき・掲示板・私物ガジェットにはそれぞれ『管理メニュー』が設定されており、作成者本人にのみ表示される仕組みです。
God mode を有効化にすると他のユーザーが作成したコンテンツでも『管理メニュー』を表示するようになり、『削除のみ』実行可能となります。
制作を終えてみて
ポートフォリオのアップデートは今後も行いますが、いったん区切りがついたのでホッとしています。
制作中に苦労したポイントをまとめてみると以下の内容で、主に初期学習のタイミングで壁が何度も現れました。
壁 内容 フロントエンドとバックエンドを分離した開発環境の構築 仮想コンテナの基礎知識やポートフォワーディングでつまりました。初めからdocker-composeを使うことをオススメします。 環境変数の受け渡し ローカル環境、本番環境のインフラ構成に合わせて環境変数の渡し方に工夫が必要でした。 Vuetifyモジュールの導入 Nuxt.jsの初期セットアップでVuetifyを選択するとエラー発生。VuetifyなしでNuxt.jsをセットアップ + 後からVuetifyを導入 + おまじないが必要で詰みました。 SSRモードで動作するNuxt.jsのライフサイクル SSRでSPA用コードを実行するとライフサイクルが一部違うので正常に動作しません。 AxiosモジュールのSSRモードでの挙動 SPAとSSRではAxiosのエンドポイントの設定に違いがあり詰みました。 Firebase Authenticationの導入 SSRモードでの解説記事が少なく、動作させるまでに苦労しました。 SSRモードでは動作しないプラグイン ポートフォリオで利用した『@johmun/vue-tags-input』がSSRモードでは動作しなかったので、特別なおまじないが必要でした。 親コンポーネントと子コンポーネントのデータ受け渡し props, emitの概念の理解に苦戦しました。 Vuexストアの扱い方 断片的な解説記事が多くて理解するのに時間が掛かりました。 終わらないN+1対策 アソシエーションの絡んだデータ取得をするたびに苦労しました。 ECS Fargateでのインフラ構築 FargateはSSHできないのでエラーログの取得やトラブルシュートに手間取りました。CloudWatchなどを利用して確実にログを取れる環境を作らないと、どこに問題があってコンテナが動いていないのか判断できなくて詰みます。 特に厳しかったのがECSデプロイでして、途中何度も諦めそうになりましたが何とかやり終えることができました...。(インフラ難しい)
何とか形になったものの、書いているコードは実務レベルから比べると『その場しのぎ』程度だと思いますし、
プログラミングにおける基礎知識が抜けていると思い知らされる場面も多々ありました。(特に学習初期の理解力)正直なところ、Nuxt.js や Rails という『ツール』を何となく使えている、というのが現時点での実力だと思います。
今後について
ポートフォリオが完成したので就活を始めるために準備を進めています!
就活以外では、課題である基礎力を伸ばすために基本情報技術者やJavaSliverなどの取得を目指して資格勉強も進めていくつもりです。(オススメ教材などあれば教えて欲しいです)
ただのポートフォリオ紹介記事ですが、最後までお付き合い頂きましてありがとうございました!
Twitterもやってますので是非フォローもよろしくお願いします!
関連リンク
お世話になった書籍や教材
ポートフォリオ制作中に何度もお世話になった資料一覧です。
これがなければ完成できていなかったので本当に感謝しています。ありがとうございました!
媒体 資料名 学習内容 Web Progate Ruby, Rails, HTML, CSS, JavaScript...などの基礎を学習 Web Railsチュートリアル いわずもがな、Railsの基礎、Herokuデプロイ、AWS S3、GitHubの扱いなどを学習 Web JavaScript Primer DOM操作以外のJavaScriptの基礎を学習 Web Rails + Nuxt.js + Docker なアプリを作ってみよう 神記事です。めちゃめちゃ参考になりました。ただしSPAモードなのでSSRモードで制作する場合は工夫が必要。 Web 独学プログラマ (Docker+Rails6+Nuxt.js+PostgreSQL)=>Heroku 環境構築~デプロイまでの手順書 神記事です。特に環境構築の手法がめちゃめちゃ参考になります。 Web Pikawaka Railsの基礎はここ見れば大体全部載ってます。マジでわかりやすくて助かりました。 Web SSRモードのNuxtでのFirebase認証 この記事とGitHubリポジトリがなければ実装するの諦めてました。本当にありがとうございます。 書籍 たのしいRuby Rubyの基礎を学習 書籍 Ruby on Rails速習実践ガイド Railsでよく使うコマンドやRailsの基礎を学習 書籍 プロを目指す人のためのRuby入門 実践的なRubyについて学習 書籍 Rubyによるクローラー開発技法 Rubyだけでスクレイピングアプリを作れます。学んだ基礎知識をアウトプットするために使用しました。 書籍 Nuxt.jsビギナーズガイド Nuxt.jsの基礎学習。Vue.jsの経験がないと難しいかも。 書籍 速習Vue.js3 Vue.jsの基礎学習。単一コンポーネント形式のサンプルが少ないので、これだけでは不十分かも。 書籍 実践Terraform AWSにおけるシステム設計とベストプラクティス 神本。これがなければECSデプロイできませんでした。感謝しています。 書籍 はじめての人のためのTerraform for AWS Terraformを全く触ったことない人向けの書籍。サンプルコードがちゃんと動作するので感じを掴むのに最適。 書籍 CircleCI実践入門 CI/CDってなに?って状態で感じを掴むために使用。結局CodePipelineで実装したけど自動テストの雰囲気が掴めて良かった。 書籍 Amazon Web Services 基礎からのネットワーク&サーバー構築 AWSの基礎学習にぴったり。EC2での解説なのでECSについては別途学習する必要あり。 書籍 Docker/Kubernetes実践コンテナ開発入門 Dockerの基礎学習。初心者向けの章節まで読めば十分でした。 書籍 達人に学ぶSQL徹底至難書 実践的なSQLを学習。 書籍 Webを支える技術 ネットワークの概念がイマイチ理解できてないときに使用。 書籍 GitHub実践入門 GitHubの基礎学習



























- 投稿日:2021-01-29T23:52:31+09:00
【独学・未経験】Nuxt.js x Railsな完全SPAポートフォリオを制作しました!
概要
プログラミング歴半年(独学)の実務未経験者が完全SPAなポートフォリオを制作しましたので紹介していきたいと思います!
記事の最後には初学者が詰まるであろうポイントもまとめておきましたので、参考になれば幸いです。作者のスペック
年齢は27歳(今年で28歳)で今までにプログラミング経験はありませんでした。
今現在はエンジニアを目指して独学で学習中でして、本記事を執筆している時点でプログラミング学習期間は半年間です。
ポートフォリオに関わる技術のキャッチアップをしながら約4ヶ月程かけてポートフォリオを完成させました。ポートフォリオ制作に着手した時点では、ProgateとRailsチュートリアルを終えた程度の実力。
至る所に詰みポイントがありひたすらググりまくって問題解決してました。(Google先生は神)ポートフォリオ紹介
『ガジェコミ!』はガジェット好きが集まれるSNS型のWebアプリケーションです。
Nuxt.js x Rails という組み合わせて制作した完全SPAアプリケーションなので、同じような構成で制作される方の参考になれば幸いです!
ガジェコミ!
ポートフォリオに使用した技術
フロントエンド
- Nuxt.js(SSR mode) => フロントエンドフレームワーク
- Vuetify => UIコンポーネント
- Firebase Authentication => JWTを用いたログイン・ログアウト
バックエンド
- Rails(API mode) => APIサーバーとして実行
- PostgreSQL => データベース
テストコード
- フロントエンド => Jest(Vuexストアの動作を少しだけ)
- バックエンド => RSpec(バリデーションとアソシエーションのテストのみ)
インフラ
- AWS ECS Fargate => サーバーレスな本番環境、オートスケール
- AWS CodePipeline => CI/CD環境
- AWS RDS => 本番用DB(PostgreSQL)
- AWS S3 => 本番環境の画像データ保存用 x 1, CodePipelineのアーティファクト保存用 x 1
- AWS Route53 => ドメイン取得
- AWS ACM => SSL証明書の発行
- AWS ALB => ロードバランサー
- AWS ECR => 本番用Dockerイメージ管理
- AWS SSM => 本番用環境変数の一括管理
- Docker, Docker-compose => コンテナ環境
- Github => バージョン管理
- Terraform => 本番用インフラをコード管理
インフラ構成図
ER図
技術を選定した理由
- 採用担当者の目に留まるようなポートフォリオを制作するため
- 自分自身がプログラミングが好きかどうかを推し量るために、あえて高難度な技術を選定した
- 主流となりつつある『フロントエンドとバックエンドを切り離したWebアプリケーション』を制作してみたかったから
- 完全SPAアプリケーションの制作を経験してみたかったから
- 未経験な技術のキャッチアップを独学でどのように進めるか身を以て経験したおきたかったから
アプリの機能紹介
一般的なSNS型アプリケーションを意識して制作しているので、複雑なビジネスロジックが絡むような機能は残念ながら実装できておりません...。
とはいえレスポンシブ対応やAjax化に力を入れているので、実際に使ってみてください!
1. ユーザー機能
登録・編集・削除
メールアドレスとパスワードを入力するだけでアカウント作成できます。
メールアドレス確認機能は未実装。VeeValidateを使用してフォームにバリデーションを設定しています。
詳細設定ページで登録情報を編集できます。
ユーザーにはアバターを設定できます。
アバター画像は各コンテンツで表示されます。
2. つぶやき機能
投稿・編集・削除
つぶやき作成は即時反映されます。
つぶやき編集は即時反映されます。
つぶやき削除は即時反映されます。
タグ付け
つぶやきにはタグを複数登録できます。
コメント
つぶやきにはコメントすることができます。
コメントに返信できます。
コメントは削除のみ可能です。編集機能はありません。
親コメントを削除すると子コメントも削除されます。
いいね
つぶやきにいいねできます。
3. 掲示板機能
作成・編集・削除
掲示板作成は即時反映されます。
掲示板編集は即時反映されます。
掲示板削除は即時反映されます。
タグ付け
掲示板にはタグを複数登録できます。
掲示板タイプ
『雑談』『質問』を選択できます。
コメント
掲示板にはコメントすることができます。
コメントに返信できます。
コメントは削除のみ可能です。編集機能はありません。
親コメントを削除すると子コメントも削除されます。
4. 私物ガジェット機能
登録・編集・削除
自分の私物ガジェットやお気に入りアイテムを登録できます。
登録したガジェットは一覧ページでは『みんなのガジェット』として新着表示されます。
ガジェット編集は即時反映されます。
ガジェット削除は即時反映されます。
タグ付け
私物ガジェットにはタグを複数登録できます。
5. フィード機能
つぶやきを一覧表示します。
無限スクロールで順次読み込みます。<タブによって表示する内容が異なります>
- 新着順 => 全てのつぶやきを新着順で表示
- タイムライン => フォロー済みユーザーのつぶやきのみ新着順で表示
- タグフィード => フォロー済みタグを含むつぶやきのみ新着順で表示
6. タグ管理機能
タグをフォローすることができます。
タグフィードに表示したいタグをフォローします。
つぶやき・掲示板・私物ガジェットはタグ付けすることができます。
タグをタップするとタグ詳細ページに遷移し、タグを含むつぶやき・掲示板・私物ガジェット・フォローしているユーザーの一覧を表示します。
7. 検索機能
検索ページでは、検索フォームに入力した内容に合わせて結果がリアルタイムに表示される機能を実装しております。
8. 通知機能
つぶやき・掲示板・ユーザーフォローにおいて、イベントが発生すると通知が表示されます。
新着通知
新しい通知が発生すると、ヘッダー内のベルアイコンにバッジが表示されます。
タップすると新しい通知がリスト表示され、通知をタップするとイベント発生元へ画面遷移します。
通知一覧
通知一覧をタップすると一覧ページへ画面遷移します。
通知一覧ページでは、今まで受け取った全ての通知を表示します。
9. ゲストユーザー機能
ユーザー専用機能を簡単に利用できるように、ゲストユーザーログイン機能を実装しています。
『ゲストユーザーとしてログイン』をタップするだけです。
未ログイン状態でユーザー専用機能にアクセスすると、ゲストユーザーログインを促すダイアログを表示するようにしております。
10. God mode
一時的に管理者権限を有効にするモードです。(管理者という概念が存在することを確認して頂くためのモードです。)
DB内 の Userモデルの adminカラム の true/false で 各ユーザーの管理者権限を管理しておりますが、God modeではVuexストアの値を一時的に変更して管理者権限を有効化しています。(DB上には保存されないのでブラウザ再読み込みでfalseに戻ります。)
つぶやき・掲示板・私物ガジェットにはそれぞれ『管理メニュー』が設定されており、作成者本人にのみ表示される仕組みです。
God mode を有効化にすると他のユーザーが作成したコンテンツでも『管理メニュー』を表示するようになり、『削除のみ』実行可能となります。
11. レスポンシブデザイン
Vuetifyを活用したレスポンシブデザインで、スマホでも扱いやすいUI/UXを意識しました。
サブメニューとタブメニューを組み合わせることで、画面遷移ゼロで複数のコンテンツにアクセスできます。
技術面での詳解
フロントエンド
Nuxt.js を採用し、フロントエンドとバックエンドを分離した完全SPAアプリケーションを実現しております。
Nuxt.jsは、SEO面で有効とされるSSRモード(サーバーサイドレンダリング)で実行しております。
Vuetifyコンポーネントを導入することで、スマホ利用を想定したレスポンシブデザインを実現しています。
Vuexストアでステート管理をしており、ほぼ全ての動作をAjax化しました。(一部未完)
個人情報(メールアドレス・パスワード)の安全性については、外部API(Firebase Authentication)に任せることで確保しています。
Firebase Authentication で発行されるJWTをブラウザのSession Storageに保管することで、ログイン・ログアウトができる仕組みです。
未ログイン状態でアクセスして欲しくないページ( /users/editなど )へのアクセス対策には、Nuxt.jsのmiddlewareを活用することで自動的にリダイレクトするようにしました。
ログイン状態でアクセスして欲しくないページ (ログインページ, 新規作成ページ) へのアクセスも同じくリダイレクトします。
バックエンド
Rails(APIモード)で実行しており、フロントエンドコンテナからのリクエストに対してJSONデータを返しています。
個人情報(メールアドレス・パスワード)は外部API(Firebase Authentication)に保存しているので、バックエンド側にセンシティブな情報を保存しない仕組みです。
『N+1問題』への対策を施しているため、アソシエーションがネストしているコンテンツへアクセスしてもレスポンスが遅れません。
一貫性のあるテーブル名称を意識しました。
インフラ
ローカル開発環境から一貫してDockerを使用しており、ECSデプロイまでを想定した開発フローを実践しました。
AWS ECS(Fargate)で本番環境をサーバーレスで運用しております。
ALBを通すことで常時SSL通信を実現しました。
AWS CodePipelineを使用したCI/CDパイプラインを構築しております。
CodePipelineは、 『Sourceステージ => Testステージ => Buildステージ => Deployステージ』の順で実行され、Testステージで問題が発生した場合は当該ソースでのDeployは実行されません。
Terraformを用いて AWSの本番環境は全てコードで管理しています。
本番環境の環境変数については AWS SSM で管理しており、『システム環境変数 => Terraform => SSM => 各AWSサービス』というフローで環境変数を受け渡しています。
使用した教材
Progate
ドットインストール
Railsチュートリアル
書籍
Google先生
Githubのソースコード(チュートリアル用アプリケーションのソースを読んでました。)
バージョン
Ruby 2.7.1
Rails 6.0.3.4
nuxt 2.14.6
@nuxtjs/vuetify 1.11.2
Docker 19.03.13
docker-compose 1.27.4
Terraform 0.14.3
つまったポイント
フロントエンドとバックエンドを分離した開発環境の構築
=> 仮想コンテナの基礎知識やポートフォワーディングでつまりました。
=> 初めからdocker-composeを使うことをオススメします。環境変数の受け渡し
=> 渡せているはずなのに!という場面が何度もありました。各ソフトの仕様を把握していないと詰みます。SSRモードで動作するNuxt.jsのライフサイクル
=> SSRでSPA用コードを実行するとライフサイクルが一部違うので正常に動作しません。SSRモードでは動作しないプラグイン
=> ポートフォリオで利用した『@johmun/vue-tags-input』がSSRモードでは動作しなかったので、特別なおまじないが必要でした。Vuexストアの扱い方
=> 断片的な解説記事が多くて理解するのに時間が掛かりました。親コンポーネントと子コンポーネントのデータ受け渡し
=> Vue.jsの経験がある方であれば問題ないかと思います。Vuetifyモジュールの導入
=> Nuxt.jsの初期セットアップでVuetifyを選択するとエラー発生
=> VuetifyなしでNuxt.jsをセットアップ + 後からVuetifyを導入 + おまじないが必要で詰みました。AxiosモジュールのSSRモードでの挙動
=> SPAとSSRではAxiosのエンドポイントの設定に違いがあり詰みました。ECS Fargateでのインフラ構築
=> FargateはSSHできないのでエラーログの取得やトラブルシュートに手間取りました。
=> CloudWatchなどを利用して確実にログを取れる環境を作らないと、どこに問題があってコンテナが動いていないのか判断できなくて詰みます。制作を終えてみて
ポートフォリオのアップデートは今後も行いますが、いったん区切りがついたのでホッとしています。
特に厳しかったのがECSデプロイでして、途中何度も諦めそうになりましたが何とかやり終えることができました...。(インフラ難しい)
苦労した分だけ喜びも大きくなると言われますが、自作アプリにアクセスできた瞬間は嬉しかったですね!
ただし、書いているコードは実務レベルから比べると『その場しのぎ』程度だと思いますし、
プログラミングにおける基礎知識が抜けていると思い知らされる場面も多々ありました。(特に学習初期の理解力)正直なところ、Nuxt.js や Rails という『ツール』を何となく使えている、というのが現時点での実力だと思います。
今後について
ポートフォリオが完成したので就活を始めていきます。
課題である基礎力を伸ばすために、就活と同時に基本情報技術者やJavaSliverなどの取得を目指して資格勉強も進めていくつもりです。
コロナ渦で未経験からエンジニアになることが難しいと言われてますし、引き続き気合を入れて頑張っていきたいと思います。
ただのポートフォリオ紹介記事ですが、最後までお付き合い頂きましてありがとうございました!
Twitterもやってますので是非フォローもよろしくお願いします!
関連リンク


- 投稿日:2021-01-29T23:52:31+09:00
【独学・未経験】Nuxt.js, Rails, Docker, AWS ECS(Fargate), Terraformな完全SPAポートフォリオを制作しました!
概要
プログラミング歴半年(独学)の実務未経験者が完全SPAなポートフォリオを制作しましたので紹介していきたいと思います!
記事の最後には初学者が詰まるであろうポイントもまとめておきましたので、参考になれば幸いです。作者のスペック
年齢は27歳(今年で28歳)で今までにプログラミング経験はありませんでした。
今現在はエンジニアを目指して独学で学習中でして、本記事を執筆している時点でプログラミング学習期間は半年間です。
ポートフォリオに関わる技術のキャッチアップをしながら約4ヶ月程かけてポートフォリオを完成させました。ポートフォリオ制作に着手した時点では、ProgateとRailsチュートリアルを終えた程度の実力。
至る所に詰みポイントがありひたすらググりまくって問題解決してました。(Google先生は神)ポートフォリオ紹介
『ガジェコミ!』はガジェット好きが集まれるSNS型のWebアプリケーションです。
Nuxt.js x Rails という組み合わせて制作した完全SPAアプリケーションなので、同じような構成で制作される方の参考になれば幸いです!
ガジェコミ!
ポートフォリオに使用した技術
フロントエンド
- Nuxt.js(SSR mode) => フロントエンドフレームワーク
- Vuetify => UIコンポーネント
- Firebase Authentication => JWTを用いたログイン・ログアウト
バックエンド
- Rails(API mode) => APIサーバーとして実行
- PostgreSQL => データベース
テストコード
- フロントエンド => Jest(Vuexストアの動作を少しだけ)
- バックエンド => RSpec(バリデーションとアソシエーションのテストのみ)
インフラ
- AWS ECS Fargate => サーバーレスな本番環境、オートスケール
- AWS CodePipeline => CI/CD環境
- AWS RDS => 本番用DB(PostgreSQL)
- AWS S3 => 本番環境の画像データ保存用 x 1, CodePipelineのアーティファクト保存用 x 1
- AWS Route53 => ドメイン取得
- AWS ACM => SSL証明書の発行
- AWS ALB => ロードバランサー
- AWS ECR => 本番用Dockerイメージ管理
- AWS SSM => 本番用環境変数の一括管理
- Docker, Docker-compose => コンテナ環境
- Github => バージョン管理
- Terraform => 本番用インフラをコード管理
インフラ構成図
ER図
技術を選定した理由
- 採用担当者の目に留まるようなポートフォリオを制作するため
- 自分自身がプログラミングが好きかどうかを推し量るために、あえて高難度な技術を選定した
- 主流となりつつある『フロントエンドとバックエンドを切り離したWebアプリケーション』を制作してみたかったから
- 完全SPAアプリケーションの制作を経験してみたかったから
- 未経験な技術のキャッチアップを独学でどのように進めるか身を以て経験したおきたかったから
技術面での詳解
フロントエンド
Nuxt.js を採用し、フロントエンドとバックエンドを分離した完全SPAアプリケーションを実現しております。
Nuxt.jsは、SEO面で有効とされるSSRモード(サーバーサイドレンダリング)で実行しております。
Vuetifyコンポーネントを導入することで、スマホ利用を想定したレスポンシブデザインを実現しています。
Vuexストアでステート管理をしており、ほぼ全ての動作をAjax化しました。(一部未完)
個人情報(メールアドレス・パスワード)の安全性については、外部API(Firebase Authentication)に任せることで確保しています。
Firebase Authentication で発行されるJWTをブラウザのSession Storageに保管することで、ログイン・ログアウトができる仕組みです。
未ログイン状態でアクセスして欲しくないページ( /users/editなど )へのアクセス対策には、Nuxt.jsのmiddlewareを活用することで自動的にリダイレクトするようにしました。
ログイン状態でアクセスして欲しくないページ (ログインページ, 新規作成ページ) へのアクセスも同じくリダイレクトします。
バックエンド
Rails(APIモード)で実行しており、フロントエンドコンテナからのリクエストに対してJSONデータを返しています。
個人情報(メールアドレス・パスワード)は外部API(Firebase Authentication)に保存しているので、バックエンド側にセンシティブな情報を保存しない仕組みです。
『N+1問題』への対策を施しているため、アソシエーションがネストしているコンテンツへアクセスしてもレスポンスが遅れません。
一貫性のあるテーブル名称を意識しました。
インフラ
ローカル開発環境から一貫してDockerを使用しており、ECSデプロイまでを想定した開発フローを実践しました。
AWS ECS(Fargate)で本番環境をサーバーレスで運用しております。
ALBを通すことで常時SSL通信を実現しました。
AWS CodePipelineを使用したCI/CDパイプラインを構築しております。
CodePipelineは、 『Sourceステージ => Testステージ => Buildステージ => Deployステージ』の順で実行され、Testステージで問題が発生した場合は当該ソースでのDeployは実行されません。
Terraformを用いて AWSの本番環境は全てコードで管理しています。
本番環境の環境変数については AWS SSM で管理しており、『システム環境変数 => Terraform => SSM => 各AWSサービス』というフローで環境変数を受け渡しています。
アプリの機能紹介
一般的なSNS型アプリケーションを意識して制作しているので、複雑なビジネスロジックが絡むような機能は残念ながら実装できておりません...。
とはいえレスポンシブ対応やAjax化に力を入れているので、実際に使ってみてください!
1. ユーザー機能
登録・編集・削除
メールアドレスとパスワードを入力するだけでアカウント作成できます。
メールアドレス確認機能は未実装。VeeValidateを使用してフォームにバリデーションを設定しています。
詳細設定ページで登録情報を編集できます。
ユーザーにはアバターを設定できます。
アバター画像は各コンテンツで表示されます。
2. つぶやき機能
投稿・編集・削除
つぶやき作成は即時反映されます。
つぶやき編集は即時反映されます。
つぶやき削除は即時反映されます。
タグ付け
つぶやきにはタグを複数登録できます。
コメント
つぶやきにはコメントすることができます。
コメントに返信できます。
コメントは削除のみ可能です。編集機能はありません。
親コメントを削除すると子コメントも削除されます。
いいね
つぶやきにいいねできます。
3. 掲示板機能
作成・編集・削除
掲示板作成は即時反映されます。
掲示板編集は即時反映されます。
掲示板削除は即時反映されます。
タグ付け
掲示板にはタグを複数登録できます。
掲示板タイプ
『雑談』『質問』を選択できます。
コメント
掲示板にはコメントすることができます。
コメントに返信できます。
コメントは削除のみ可能です。編集機能はありません。
親コメントを削除すると子コメントも削除されます。
4. 私物ガジェット機能
登録・編集・削除
自分の私物ガジェットやお気に入りアイテムを登録できます。
登録したガジェットは一覧ページでは『みんなのガジェット』として新着表示されます。
ガジェット編集は即時反映されます。
ガジェット削除は即時反映されます。
タグ付け
私物ガジェットにはタグを複数登録できます。
5. フィード機能
つぶやきを一覧表示します。
無限スクロールで順次読み込みます。<タブによって表示する内容が異なります>
- 新着順 => 全てのつぶやきを新着順で表示
- タイムライン => フォロー済みユーザーのつぶやきのみ新着順で表示
- タグフィード => フォロー済みタグを含むつぶやきのみ新着順で表示
6. タグ管理機能
タグをフォローすることができます。
タグフィードに表示したいタグをフォローします。
つぶやき・掲示板・私物ガジェットはタグ付けすることができます。
タグをタップするとタグ詳細ページに遷移し、タグを含むつぶやき・掲示板・私物ガジェット・フォローしているユーザーの一覧を表示します。
7. 検索機能
検索ページでは、検索フォームに入力した内容に合わせて結果がリアルタイムに表示される機能を実装しております。
8. 通知機能
つぶやき・掲示板・ユーザーフォローにおいて、イベントが発生すると通知が表示されます。
新着通知
新しい通知が発生すると、ヘッダー内のベルアイコンにバッジが表示されます。
タップすると新しい通知がリスト表示され、通知をタップするとイベント発生元へ画面遷移します。
通知一覧
通知一覧をタップすると一覧ページへ画面遷移します。
通知一覧ページでは、今まで受け取った全ての通知を表示します。
9. ゲストユーザー機能
ユーザー専用機能を簡単に利用できるように、ゲストユーザーログイン機能を実装しています。
『ゲストユーザーとしてログイン』をタップするだけです。
未ログイン状態でユーザー専用機能にアクセスすると、ゲストユーザーログインを促すダイアログを表示するようにしております。
10. God mode
一時的に管理者権限を有効にするモードです。(管理者という概念が存在することを確認して頂くためのモードです。)
DB内 の Userモデルの adminカラム の true/false で 各ユーザーの管理者権限を管理しておりますが、God modeではVuexストアの値を一時的に変更して管理者権限を有効化しています。(DB上には保存されないのでブラウザ再読み込みでfalseに戻ります。)
つぶやき・掲示板・私物ガジェットにはそれぞれ『管理メニュー』が設定されており、作成者本人にのみ表示される仕組みです。
God mode を有効化にすると他のユーザーが作成したコンテンツでも『管理メニュー』を表示するようになり、『削除のみ』実行可能となります。
11. レスポンシブデザイン
Vuetifyを活用したレスポンシブデザインで、スマホでも扱いやすいUI/UXを意識しました。
サブメニューとタブメニューを組み合わせることで、画面遷移ゼロで複数のコンテンツにアクセスできます。
つまったポイント
フロントエンドとバックエンドを分離した開発環境の構築
=> 仮想コンテナの基礎知識やポートフォワーディングでつまりました。
=> 初めからdocker-composeを使うことをオススメします。環境変数の受け渡し
=> 渡せているはずなのに!という場面が何度もありました。各ソフトの仕様を把握していないと詰みます。SSRモードで動作するNuxt.jsのライフサイクル
=> SSRでSPA用コードを実行するとライフサイクルが一部違うので正常に動作しません。SSRモードでは動作しないプラグイン
=> ポートフォリオで利用した『@johmun/vue-tags-input』がSSRモードでは動作しなかったので、特別なおまじないが必要でした。Vuexストアの扱い方
=> 断片的な解説記事が多くて理解するのに時間が掛かりました。親コンポーネントと子コンポーネントのデータ受け渡し
=> Vue.jsの経験がある方であれば問題ないかと思います。Vuetifyモジュールの導入
=> Nuxt.jsの初期セットアップでVuetifyを選択するとエラー発生
=> VuetifyなしでNuxt.jsをセットアップ + 後からVuetifyを導入 + おまじないが必要で詰みました。AxiosモジュールのSSRモードでの挙動
=> SPAとSSRではAxiosのエンドポイントの設定に違いがあり詰みました。ECS Fargateでのインフラ構築
=> FargateはSSHできないのでエラーログの取得やトラブルシュートに手間取りました。
=> CloudWatchなどを利用して確実にログを取れる環境を作らないと、どこに問題があってコンテナが動いていないのか判断できなくて詰みます。制作を終えてみて
ポートフォリオのアップデートは今後も行いますが、いったん区切りがついたのでホッとしています。
特に厳しかったのがECSデプロイでして、途中何度も諦めそうになりましたが何とかやり終えることができました...。(インフラ難しい)
苦労した分だけ喜びも大きくなると言われますが、自作アプリにアクセスできた瞬間は嬉しかったですね!
ただし、書いているコードは実務レベルから比べると『その場しのぎ』程度だと思いますし、
プログラミングにおける基礎知識が抜けていると思い知らされる場面も多々ありました。(特に学習初期の理解力)正直なところ、Nuxt.js や Rails という『ツール』を何となく使えている、というのが現時点での実力だと思います。
今後について
ポートフォリオが完成したので就活を始めていきます。
課題である基礎力を伸ばすために、就活と同時に基本情報技術者やJavaSliverなどの取得を目指して資格勉強も進めていくつもりです。
コロナ渦で未経験からエンジニアになることが難しいと言われてますし、引き続き気合を入れて頑張っていきたいと思います。
ただのポートフォリオ紹介記事ですが、最後までお付き合い頂きましてありがとうございました!
Twitterもやってますので是非フォローもよろしくお願いします!
関連リンク
使用した教材
Progate
ドットインストール
Railsチュートリアル
書籍
Google先生
Githubのソースコード(チュートリアル用アプリケーションのソースを読んでました。)
バージョン
Ruby 2.7.1
Rails 6.0.3.4
nuxt 2.14.6
@nuxtjs/vuetify 1.11.2
Docker 19.03.13
docker-compose 1.27.4
Terraform 0.14.3
- 投稿日:2021-01-29T23:05:48+09:00
【cloud9】no space left on deviceとなった時の対応方法
EBSのボリュームを増やす
https://qiita.com/ponsuke0531/items/edf2eee638202aa7f61f
ただボリューム増やしても即座に空きスペースが増えない。
ボリューム追加を反映させるためにはEC2インスタンスを再起動する必要があるEC2インスタンスを再起動させる
- 投稿日:2021-01-29T21:44:37+09:00
AWS ECRへのログイン方法
こちらを参考にDockerイメージをEC2にデプロイしようと、
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin アカウントID.dkr.ecr.ap-northeast-1.amazonaws.com
のコマンドをターミナルで実行
1. 以下のようなエラーがでた。
command not found aws
Cannot perform an interactive login from a non TTY device
まずAWSのコマンドが使えるようになっていないらしい。2. StackOverflowによると「AWS CLI version 2」というのをインストールしないといけないらしい。そのために、こちらのページの指示に従って、以下のコマンドをターミナルで実行する。
$ curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg"
$ sudo installer -pkg AWSCLIV2.pkg -target /
$ curl "https://awscli.amazonaws.com/AWSCLIV2.pkg" -o "AWSCLIV2.pkg"
$ sudo installer -pkg ./AWSCLIV2.pkg -target /3.AWSに認証情報を登録する
再度ターミナルで
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin アカウントID.dkr.ecr.ap-northeast-1.amazonaws.com
を実行したら、
Unable to locate credentials. You can configure credentials by running "aws configure".
というエラーがでた。こちらによると、認証情報が登録されていないため、それを登録する必要があるらしい。
このページの指示通り、aws configure listをターミナルで実行すると、以下のようにでて、確かに認証情報がない。
こちらに飛び、認証情報を登録する
この時点でAWSのIAMユーザのアカウントがなければこちらから作る。このページの「Creating an administrator IAM user and group (console)」の項目の最後までやればOK。
ここまでできたら、このページの「Access key ID and secret access key」項目の指示に従ってAccess key と Secret access key を作成する。作成したそれらはメモっておく。
次に、そのページにあるように、aws configureをターミナルで実行する
「Access Key Id」と「Secret Access Key」に先ほど作成したものを入れる。
「Default region name」には「ap-northeast-1」を入れる
「Default out put format」にはjsonを入れる
これで認証情報が登録完了4.再度
aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin アカウントID.dkr.ecr.ap-northeast-1.amazonaws.com
を実行
Login Succeeded
がターミナルに表示!


- 投稿日:2021-01-29T20:44:38+09:00
IAMとは?
勉強前イメージ
アカウントの管理のイメージ
触れるサービスを制御したりできる調査
IAM とは
Identity and Access Management の略で
AWSアカウントに対してユーザを作成したり、そのユーザに対してリソースへのアクセス制御を行うことができるサービス
グループ・ユーザ・ロールの作成ができ、またグループやユーザごとに制御を行うことが出来ます。そもそもAWSアカウントってどういう感じ?
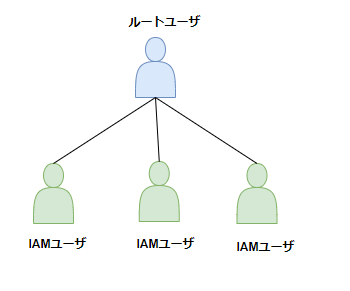
そもそもAWSのアカウントは2種類あります。
- ルートユーザ
- IAMユーザ
ルートユーザはlinuxでいうとrootユーザ(管理者)のイメージ
IAMユーザはlinuxでいうとuseraddコマンドで作成する、adminユーザなどのイメージです。図解すると以下のイメージです
※ルートアカウントは利用しない
アカウントを取得した際の最初のログインがルートユーザのログインですが、
このアカウントは上記でも記載したとおり、linuxのrootユーザ(管理者)のイメージです。
アカウントのすべてのリソースに対してフルアクセス権限がありますので、
リソースを使用する際は、基本的にはIAMユーザを作成して最小の権限で行います。IAMでのログイン方法
以下からログインすることが出来ます。
https://[アカウントID].signin.aws.amazon.com/console文言の確認
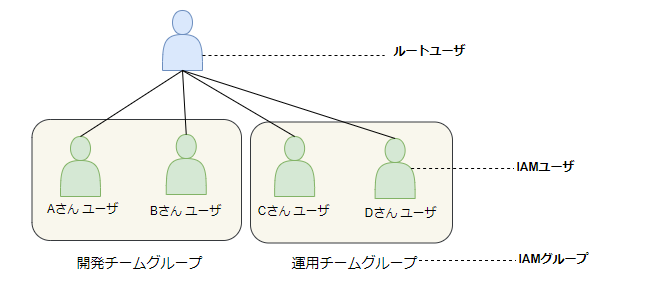
IAMユーザ
まずIAMユーザについて。
IAMユーザは個人で利用するアカウントに相当します。
IAMユーザのユーザ名は個人の名前で有ることが多く、下記のイメージで作成されます
IAMグループ
IAMグループはIAMユーザをまとめて管理するグループになります。
運用チームグループや、開発チームグループなどで作成することが出来ます。
IAMポリシー
IAMポリシーはAWSリソースにアクセスするための権限設定のことで、
s3やEC2、他のAWSリソースに対する権限などを設定します。以下のように、
開発チームのIAMグループにはs3,EC2,ACMの権限を許可するが、
運用チームのIAMグループにはs3の権限のみ許可する という設定ができます。
IAMロール
IAMロールはIAMポリシーをグループ化したものです。
例えば
以下のように開発用ポリシーをグループ化して、ロールにすることでセットで適応することが出来ます
勉強後イメージ
ふわっとわかってたけど、ちゃんと調べることで合ってたってことがわかった。
設定したこともあるし触り方とかもイメージ分かるけど、
正しく区切ってIAMは出来てないかもしれないから今度はコンソール上で確認したい参考



- 投稿日:2021-01-29T19:35:24+09:00
Dockerのローカル環境をAWSに載せてみる
はい!こんにちは!
1月中にこの記事を出そうと思ってましたが、なかなかうまくいかないものですね。
2/1に、第3者チェックを通してから2月頭に公開になりそうだ!!!! 現在 1/26 定時ちょい過ぎ今日はdockerについてAWSとの連携のイメージを簡単にご紹介しようと思います。
はじめに
今やもうコンテナって言葉を知らない人はいないと思います!
知らない人はちょこっと調べて、ローカルで実装してみて、動いたタイミングで
「AWSサーバに乗っけたい!」って思ったら参考程度に読んでみてください〜いつぞやのDockerfile(ちょっと復習)
Dockerfile# 基盤のimageファイル選択 FROM php:7.3-fpm # コンテナを立ち上げるときにライブラリ・パッケージのアップデートとインストール RUN apt-get update && apt-get install -y \ ... >>> 省略ローカルでDockerfileやdocker-compose.ymlで
コンテナの設計書書いて構築もできて開発してまーす!この状態でコンテナ化が完了したと思っているそこのあなた!
どうやってサービス展開するの?リリースするの?って疑問が出てくると思います。サービス展開するなら本番環境の構築なども必要ですよね?
以下AWSの複数サービスを使って、ローカルコンテナ環境をクラウドに移行する1手法をご紹介します!
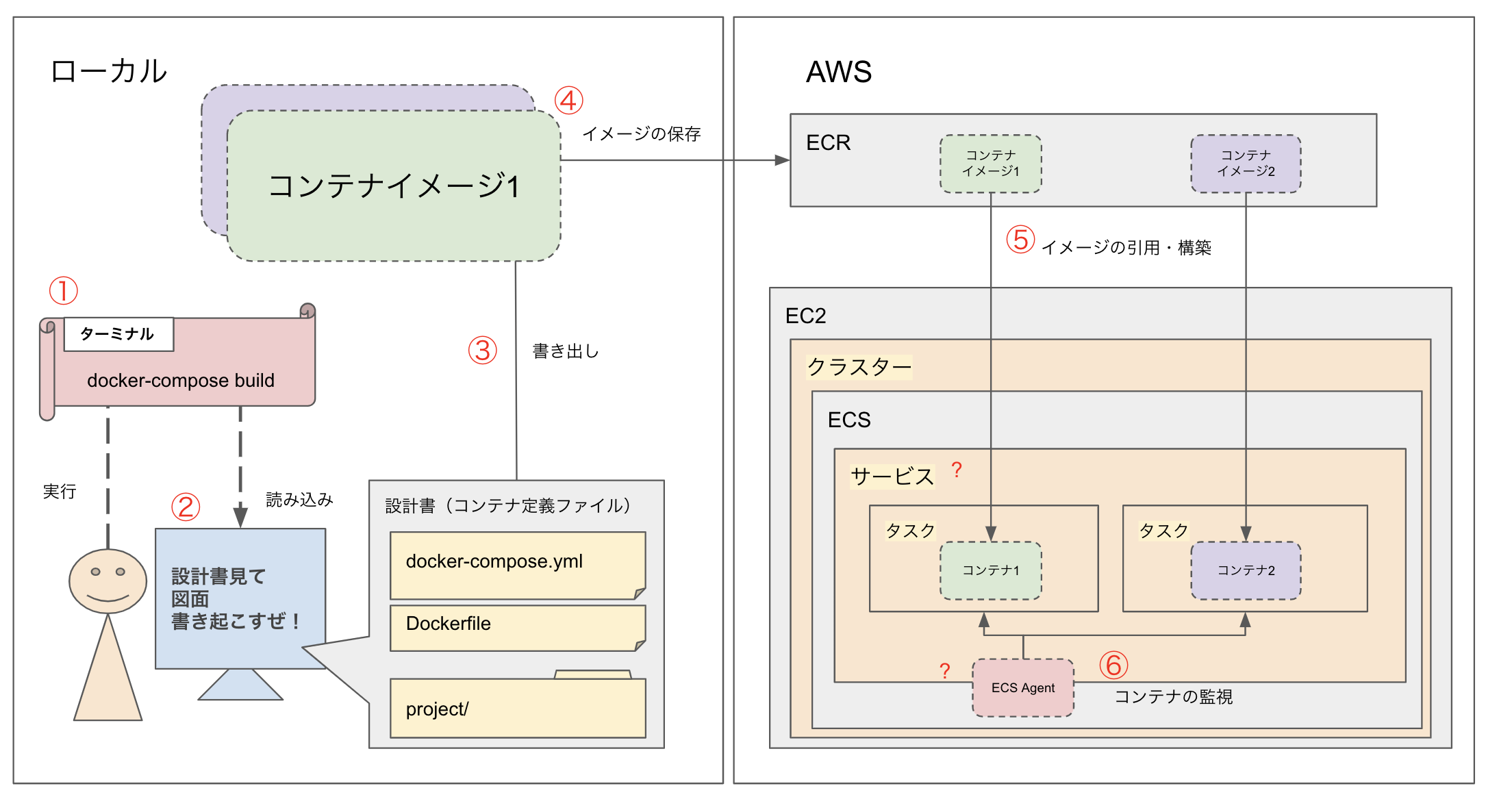
全体のイメージ(自己流)
ごちゃごちゃしていますが、これはどうしてもこうなる部分なんです、、あしからず、、、
使うAWSのサービス
- ECR(コンテナイメージの保存)
- EC2(ECSを乗っけるサーバー) ※本記事では触れませんがALBの設定なども必要です。
- ECS(クラスター 、サービス、タスク)
メインで関係してくるのはこの3つのサービスです!
- CodeCommit
- CodeBuild(CodeDeploy)
さらにCodeCommitとCodeDeployを使えば、CodeCommitへのPUSHを検知して、
コードのビルドができる仕組みも作ることができます。私は挫折しましたが、、、今は運用の中で、ソースコードについては一部コンテナに直接SSH接続して、pullする方法を取っていますが、
AWS側でもdocker-composeファイルを導入して複数コンテナの操作を1ファイルで行ったりすることができるそうですソースをコンテナに乗っける方法
私が今回行った方法は以下です。
- CodeCommitでソース管理をする
- CodeDeployのラインでCodeBuildの部分をいい感じに設定してmasterブランチにPUSHされたタイミングをトリガーとしてCodeBuildのビルドが走るようにする
- CodeBuildする時に、CodeCommitのソースをイメージの中に追加で配置した状態でBuildが走るように追加設定する
この方法だと、CodeBuildが通った時に出来上がっているコンテナには、
画像①で作成したコンテナ(インフラ部分)が構築されていて、頻繁に更新されているソースの部分は、
masterブランチにgit pushされた時に自動で乗っかるようになっています。
ただ、コンテナに配置したソースはコンテナ停止するとなくなるのが基本なので、データの永続化対応は別途必要です。DBもコンテナだったら、EC2側に、ボリュームを設定してあげるとかで対応できるはずです。
ただEC2関連の理解がまだまだ浅いので、間違ってたら指摘待ってます!そして、ソースをコンテナに乗っけるって部分も
おそらくもっとスマートな方法があると思うので、
その辺は次回構築時か、環境見直そうぜって時に調査実装したいなと思ってます!まとめ
今回AWSを初めてしっかり触って環境構築をしていきました。
時々先輩エンジニアの知恵をお借りしてセキュリティ部分を設定したり、
EC2のロードバランサーを設定したりしましたが、初学者にはサービスとサービスの連携が少し難しいと感じました。
(結果的に、かなり自己流の設定になってそうなので、工数が許されるのなら作り直したい、、w)
ある程度基本的なEC2の知識がある状態で、ECSに手を出すのがオススメです!そして本記事で紹介している方法とは別で
より良いコンテナクラウド化の方法がわかる方は、こっそり教えてくださいませー!本日も最後までお読みいただきありがとうございました!
また今度ネタができたら呟きます!
- 投稿日:2021-01-29T18:08:23+09:00
SageMakerのライフサイクル設定(Mecab+neologdなど)
メモです。
SageMakerのライフサイクルにMecab+neologdの設定を作成
#!/bin/bash sudo -u ec2-user -i <<'EOF' # python3の環境に適応 source activate python3 sudo yum install -y ca-certificates sudo yum install -y python-devel sudo yum install -y mysql-devel pip install mysqlclient pip install lightgbm pip install mecab-python3 ... git clone https://github.com/taku910/mecab.git git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git sudo mkdir -p /opt/mecab PATH=${PATH}:/usr/local/bin cd ~/mecab/mecab && ./configure --enable-utf8-only && make sudo make install cd ~/mecab/mecab-ipadic && ./configure --with-charset=utf8 && make sudo make install cd ~/mecab-ipadic-neologd && ./bin/install-mecab-ipadic-neologd -n -y -p /opt/mecab/lib/mecab/dic/neologd sudo ln -s /usr/libexec/gcc/x86_64-amazon-linux/4.8.5/cc1plus /usr/local/bin/ source deactivate EOFlogはCloudWatchで確認が可能
/aws/sagemaker/NotebookInstances → notebook名/LifecycleConfigOnStart
- 投稿日:2021-01-29T16:30:52+09:00
PostgreSQL のバージョンの違いを解消
RDS のバージョンと設定した PostgreSQL のバージョンが違っていたため、解消しました。
自分の設定ミスで起こったことなので、あまり皆さんに転用できないとは思いますが、解消まで苦労したので、よかったら見ていってください。参考資料
- 【PostgreSQL】psql version 8.4, server version 9.5
- Linuxの権限確認と変更(chmod)(超初心者向け) - Qiita
- 【CeontOS】「sudoers ファイル内にありません。この事象は記録・報告されます」というメッセージが出た時の対処
では、下記より内容に入ります。
RDS に接続した際にバージョンの違いに気づく
psql (9.2.24, サーバー 12.4) 注意: psql バージョン 9.2, サーバーバージョン 12.0. psql の機能の中で、動作しないものがあるかもしれません。 SSL 接続 (暗号化方式: ECDHE-RSA-AES256-GCM-SHA384, ビット長: 256) "help" でヘルプを表示します.手違いで違うバージョンをインストールしてしまっていたようなので、解消する。
【PostgreSQL】psql version 8.4, server version 9.5
[〇〇@ip-10-0-0-87 ~]$ su postgres パスワード: bash-4.2$ find / -name psql 2>/dev/null /usr/bin/psql /usr/pgsql-12/bin/psql bash-4.2$ mv /usr/bin/psql /usr/bin/psql.old mv: `/usr/bin/psql' から `/usr/bin/psql.old' へ移動できません: Permission deniedmv コマンド実行できないエラー
Permission dinied
Linuxの権限確認と変更(chmod)(超初心者向け) - Qiita
bash-4.2$ ls -al /usr/bin/psql -rwxr-xr-x 1 root root 445160 9月 7 2018 /usr/bin/psql権限ない?以下コマンド実施
bash-4.2$ chmod 777 /usr/bin/psql chmod: `/usr/bin/psql' のパーミッションを変更しています: Operation not permittedsudo コマンドで強制変更
-bash-4.2$ sudo chmod 777 /usr/bin/psql [sudo] password for postgres: postgres is not in the sudoers file. This incident will be reported.postgres is not in the sudoers file.
なんやねんコレ。。。。
sudoers ファイルについて
調べてみると sudo コマンドを使うためのユーザー設定が必要らしい。
【CeontOS】「sudoers ファイル内にありません。この事象は記録・報告されます」というメッセージが出た時の対処
[〇〇@ip-10-0-0-87 ~]$ sudo visudo## Allows people in group wheel to run all commands %wheel ALL=(ALL) ALL postgres ALL=(ALL) ALL ## ここ追加設定したら再度ログイン
[kouhei@ip-10-0-0-87 ~]$ su - postgres -bash-4.2$ sudo mv /usr/bin/psql /usr/bin/psql.old -bash-4.2$ sudo ln -s /usr/pgsql-12/bin/psql /usr/bin/psql上記コマンド打ってエラーが出なかったので、一旦ログアウト
RDS の方に入ってみる。
psql (12.5、サーバ 12.4) SSL 接続 (プロトコル: TLSv1.2、暗号化方式: ECDHE-RSA-AES256-GCM-SHA384、ビット長: 256、圧縮: オフ) "help"でヘルプを表示します。できた!
学んだこと
- 意味の分かっていないコマンドは打たない方が良い。
公式サイトや様々な記事を参考にしながら環境構築行っていましたが、途中から完全に迷子になってしまい、よくわからないままあれやこれやとコマンド打っていました。
こちらのエラーを解消していく中で、自分が何を設定したのか位置関係がなんとなく理解できました。
当たり前の話ですが、環境構築やってると自分が今どこにいて何をやってるのか把握しておくことが大事だと改めて思いました。
- 投稿日:2021-01-29T16:20:33+09:00
【RDS】簡単に機能をまとめてみた
はじめに
RDSについて、「AWSのデータベースのサービス」という認識しかなかったのですが、調べてみるとかなり色々な機能があることが分かりました。
本記事ではRDSについて僕が学んだことを書いていこうと思います。
もし誤った記載等があれば、コメントで優しく教えてください!RDSの概要
RDSは『マネージド型リレーショナルデータベース』です。
簡単に言うと、AWSがセキュリティ、バックアップ等を担ってくれるデータベースといったイメージです。データベースエンジンは以下の6種類から選択可能です。
【使用可能データベースエンジン】
- Amazon Aurora
- MySQL、MariaDB
- Oracle
- Microsoft SQL Server
- PostgreSQL
RDSの機能
それでは実際にRDSがどのように優れているのかを図示しながら記載していきます。
様々な機能はありますがまずは、以下の3つに絞って記載します。
マルチアベイラビリティゾーン
複数のアベイラビリティゾーン(以下AZと記載)にRDSを配置します。
このようにすることで、片方に障害が起きても、もう片方のRDSが稼働してくれるます。Master-Slave構成
異なるAZにSlaveのRDSを作成します。
SlaveでMasterのバックアップの役割をしています。
MasterとSlaveで異なるAZに配置しているため、障害にも強く、高い可用性が得られています。リードレプリカ
Master以外にReplicaを作成することができます。
Replicaは読み取り専用です。データベースの更新はMasterで行います。
このように役割を分けることで、片方のデータベースに負荷がかかることを防ぎます。
※異なるAZ中にもリードレプリカを作成することは可能です。
その他のRDSの機能については、簡単に表にまとめます。
【その他のRDSの機能】
機能・特徴 簡単な説明 エンドポイント通信 RDSは起動するとエンドポイントが発行されます。エンドポイント通信により、障害が起きた時に、RDSの切り替えが容易になります。 自動パッチ適用 常に最新のパッチが自動で適用されます。自分で条件等を指定することも可能です。 簡単なストレージのスケーリング サーバーを停止することんなくスケールアップさせることが可能です。また自動でスケーリングをする設定もあります。 自動スナップショット 自動でS3にスナップショットを記録してくれます。保存期間も指定できます。 保管中と転送中の暗号化 AWS Key Management Service (KMS) で管理するキーを使うと、データベースを暗号化することができます。 従量課金精度 使用した分のみ費用がかかります。ストレージの容量や種類等、設定によって金額は大きく変動します。 「もっと詳しく知りたい!」という方は公式のURLも参考にしてみてください。
https://aws.amazon.com/jp/rds/features/以上簡単では、ありますが、RDSについてまとめてみました。
これか実際に使用することで、より理解を深めていこうと思います。
もし、誤った記載等があればコメント等でご指摘いただけると幸いです。

- 投稿日:2021-01-29T16:15:30+09:00
AWS S3のパッケージインストール時に、composer require league/flysystem-aws-s3-v3を叩くと、Your requirements could not be resolved to an installable set of packages.とエラーが出るときの解決策。
前提条件
・macOS
・Laravel6
・初学者composer require league/flysystem-aws-s3-v3を叩いた結果
test@test laravel % composer require league/flysystem-aws-s3-v3 Using version ^2.0 for league/flysystem-aws-s3-v3 ./composer.json has been updated Running composer update league/flysystem-aws-s3-v3 Loading composer repositories with package information Updating dependencies Your requirements could not be resolved to an installable set of packages. Problem 1 - league/flysystem-aws-s3-v3[2.0.0, ..., 2.x-dev] require league/flysystem ^2.0.0 -> found league/flysystem[2.0.0-alpha.1, ..., 2.x-dev] but the package is fixed to 1.1.3 (lock file version) by a partial update and that version does not match. Make sure you list it as an argument for the update command. - league/flysystem-aws-s3-v3[2.0.0-alpha.1, ..., 2.0.0-alpha.2] require league/flysystem 2.0.0-alpha.1 -> found league/flysystem[2.0.0-alpha.1] but the package is fixed to 1.1.3 (lock file version) by a partial update and that version does not match. Make sure you list it as an argument for the update command. - league/flysystem-aws-s3-v3[2.0.0-alpha.4, ..., 2.0.0-beta.1] require league/flysystem 2.0.0-alpha.3 -> found league/flysystem[2.0.0-alpha.3] but the package is fixed to 1.1.3 (lock file version) by a partial update and that version does not match. Make sure you list it as an argument for the update command. - league/flysystem-aws-s3-v3[2.0.0-beta.2, ..., 2.0.0-beta.3] require league/flysystem ^2.0.0-beta.1 -> found league/flysystem[2.0.0-beta.1, ..., 2.x-dev] but the package is fixed to 1.1.3 (lock file version) by a partial update and that version does not match. Make sure you list it as an argument for the update command. - league/flysystem-aws-s3-v3 2.0.0-RC1 requires league/flysystem ^2.0.0-RC1 -> found league/flysystem[2.0.0-RC1, ..., 2.x-dev] but the package is fixed to 1.1.3 (lock file version) by a partial update and that version does not match. Make sure you list it as an argument for the update command. - Root composer.json requires league/flysystem-aws-s3-v3 ^2.0 -> satisfiable by league/flysystem-aws-s3-v3[2.0.0-alpha.1, ..., 2.x-dev]. Use the option --with-all-dependencies (-W) to allow upgrades, downgrades and removals for packages currently locked to specific versions. Installation failed, reverting ./composer.json and ./composer.lock to their original content.解決方法
バージョンがあってないよ〜。と言われている気がしたので、
test@test laravel % composer require league/flysystem-aws-s3-v3 ^1.0バージョン指定を入れることで解決できました。
参考記事
- 投稿日:2021-01-29T16:10:32+09:00
AWS Client VPN メモ ~固定グローバルIPでインターネット接続~
AWS Client VPNの環境構築してみました。
今回はビジネス用途で使うケース想定して、インターネットに出るグローバルIPを固定にする環境も併せて作りました。基本的には参考にさせていただいた記事、公式のドキュメントの通りですが、
実際に自分で手を動かしてみての、備忘録兼ねた自分用メモです。AWS Client VPN
『AWS Client VPN は、AWS リソースやオンプレミスネットワーク内のリソースに安全にアクセスできるようにする、クライアントベースのマネージド VPN サービスです。
クライアント VPN を使用すると、OpenVPN ベースの VPN クライアントを使用して、どこからでもリソースにアクセスできます。』ネットワーク機器の設定が不要で、クライアントソフトについてもAWSが提供しているものがあるため、簡単にVPN接続環境を構築できるのが良い所です。
Client VPNが登場するまでは、AWSにVPN接続をする場合はAWS Site-to-Site VPNを使用する必要がありました。
ただし、Site-to-Site VPNを使用する場合、ルーターを用意して接続設定をする必要があったり、実際に構築した後はルータの保守・運用をする必要があったりと、少しハードルが高めです。
それに比べるとClient VPN、は導入するまでの手順がだいぶ簡単になってます。仕組み(特徴)
ネットワーク的な仕組みについて、前述したAWS Site-to-Site VPNと比較すると、
大きな違いとしては以下になります。
- Site to Site VPNでは、接続先VPCを超えてVPC Peeringやインターネットへの通信はできない。
- ClientVPNでは、接続先VPCを超えた宛先への通信が可能。
上記それぞれの特徴の詳細な違いについては、以下の資料、
特に14ページからの「ClientVPNがVPCを超えた先への通信が可能」な理由が、とても分かりやすかったです。■[JAWS-UG Tokyo 32] AWS Client VPNの特徴
制限(クオータ)
AWS アカウントには、クライアント VPN エンドポイントに関連する次のクォータがあります。
特に明記されていない限り、これらのクォータの引き上げをリクエストできます。
クオータ数 アカウントあたりの クライアント VPN エンドポイント数 5 クライアント VPN エンドポイントあたりの承認ルールの数 50 クライアント VPN エンドポイントあたりのルート数 10 クライアント VPN エンドポイントあたりの同時クライアント接続数 2,000 クライアント証明書失効リストのエントリ数 20,000 料金(環境全体)
今回構築する環境全体で発生する費用としては、
大きく分けて、AWS Client VPNの費用とNATゲートウェイの費用の2つです。
(2021/01現在)東京リージョンで考えると、以下のようになります。①AWS Client VPNの料金
- ClientVPCエンドポイントに関連付けられているサブネットの数 × 利用時間:0.15USD/時間
- ClientVPCエンドポイントに接続されているアクティブなクライアントの数 × 利用時間:0.05USD/時間
②NAT ゲートウェイの料金
- NAT ゲートウェイがプロビジョニングされ利用可能であった 時間料金:0.062USD/時
- データ処理料金(NAT ゲートウェイで処理されたギガバイト単位) :0.062USD/GB
環境全体の料金(①+②)
(データ処理料金と VPN 接続料金は除いて)
環境を作って維持しておくだけで、以下の費用が発生します。結構いいお値段です。
- 1日あたり
(0.062 + 0.15) * 24時間 = 5.09USD/日- 1ヶ月あたり
5.09 * 30日 = 152.7USD/月※最新の情報、及び料金詳細については、以下公式ページをご参照ください。
AWS公式のVPN料金ページ
AWS公式のVPC料金ページ実際にやってみる(環境構築)
全体構成(アーキテクチャ)
認証
- VPN接続の認証は Active Directoryによるアカウント管理, サーバ証明書・クライアント証明書による相互認証、
その両方の3種から選択できますが、今回は証明書による相互認証で試します。(2021/01/29更新)SAML認証のサポートしてましたね。。
今度、AWS SSOサービスで試してみたいと思います。
AWS Client VPN で SAML 2.0 経由のフェデレーション認証のサポートを開始
- 認証に必要な証明書を作成について、今回はAWS上のCloud9(Linuxサーバ)で作成します。
環境構築手順
構築は以下の手順で進めます。
大きく分けて「AWSClientVPNの設定」と「NATゲートウェイの設定」の2つです。
AWS Client VPNの設定は公式ドキュメントの手順を参考にしています。1.AWS Client VPNの設定
- 証明書の作成
- 証明書をACMへインポート
- クライアントVPNエンドポイントの作成
- サブネットの関連付け
- クライアントのネットワークへのアクセスを承認する
- クライアントVPNエンドポイントの設定ファイルをダウンロードする
- クライアントアプリケーションの入手、設定
2.NATゲートウェイの設定
- パブリックサブネットにNAT Gatewayを作成
- プライベートサブネットのルートテーブルを設定
- Client VPN エンドポイントにプライベートサブネットを関連付け
- Client VPN エンドポイントのルートテーブル、認証ルールを設定
- 通信確認
1-1.証明書の作成
- OpenVPN easy-rsa を使用してサーバーとクライアントの証明書とキーを生成してから、
そのサーバーの証明書とキーを ACM にアップロードしますOpenVPN easy-rsa リポジトリのクローンをローカルコンピュータに作成して、easy-rsa/easyrsa3 フォルダに移動します。
$ git clone https://github.com/OpenVPN/easy-rsa.git $ cd easy-rsa/easyrsa3新しい PKI 環境を初期化します。
$ ./easyrsa init-pki新しい認証機関 (CA) を構築します。CommonNameは任意の名前を入力します。
$ ./easyrsa build-ca nopassサーバー証明書とキーを生成します。
$ ./easyrsa build-server-full server nopassクライアント証明書とキーを生成します。
$ ./easyrsa build-client-full client1.domain.tld nopassサーバー証明書とキー、およびクライアント証明書とキーをcert_folderフォルダにコピーして移動します。
$ mkdir ~/cert_folder/ $ cp pki/ca.crt ~/cert_folder/ $ cp pki/issued/server.crt ~/cert_folder/ $ cp pki/private/server.key ~/cert_folder/ $ cp pki/issued/client1.domain.tld.crt ~/cert_folder $ cp pki/private/client1.domain.tld.key ~/cert_folder/ $ cd ~/cert_folder/1-2.証明書をACMへインポート
- 作成した証明書をACM(AWS Certificate Manager)へインポートする必要があります。
AWS CLIでインポートする場合は以下のコマンドで実行できます。
今回はCloud9からそのままインポートを実行します。$ aws acm import-certificate --certificate fileb://server.crt --private-key fileb://server.key --certificate-chain fileb://ca.crt --region region $ aws acm import-certificate --certificate fileb://client1.domain.tld.crt --private-key fileb://client1.domain.tld.key --certificate-chain fileb://ca.crt --region regionマネジメントコンソールのACMの画面で見ると、インポートされているのが確認できます。
1-3.クライアント VPN エンドポイントの作成
- マネジメントコンソールのVPCの画面からクライアントVPNエンドポイントを作成していきます。
ナビゲーションペインで [クライアント VPN エンドポイント] を選択し、
[クライアント VPN エンドポイントの作成] を選択します。
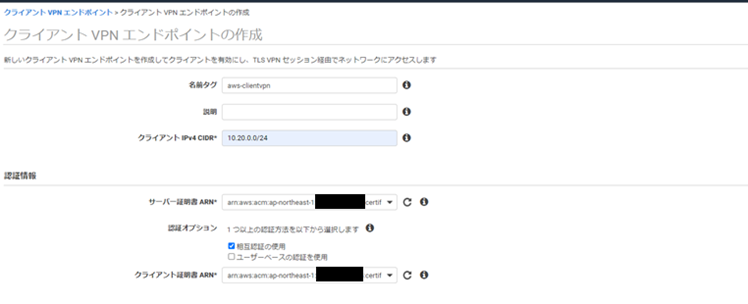
- 以下のように入力します。
- 名前タグ:任意の名前を入力します。記載しなくても問題ありません。
- クライアント IPv4 CIDR:PCが所属するネットワークのCIDRを指定します。VPCのCIDRとは別です。
- クライアント CIDR は、/12~/22 の範囲のブロックサイズが必要で、VPC CIDR またはルートテーブル内のその他のルートと重複できません。
- サーバー証明書 ARN: #1-2で、 ACMにインポートしたサーバ証明書を指定します。
- 認証オプション:[相互認証の使用]を選択します。
- クライアント証明書 ARN:#1-2で、ACMにインポートしたクライアント証明書を指定します。
- 以降の設定は、すべてデフォルトのままエンドポイントを作成します。
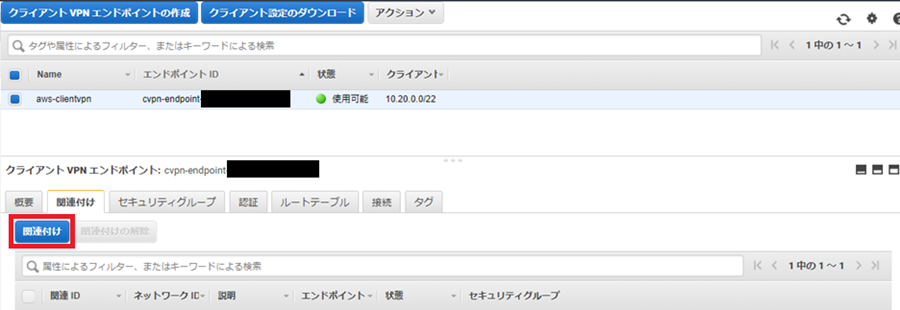
1-4.サブネットの関連付け
クライアントが VPN セッションを確立できるようにするため、ターゲットネットワークをクライアント VPN エンドポイントに関連付ける必要があります。ターゲットネットワークは、VPC のサブネットです.
関連付けするVPCとサブネットを選択します。
しばらくすると関連付けが完了して使用可能な状態になります。
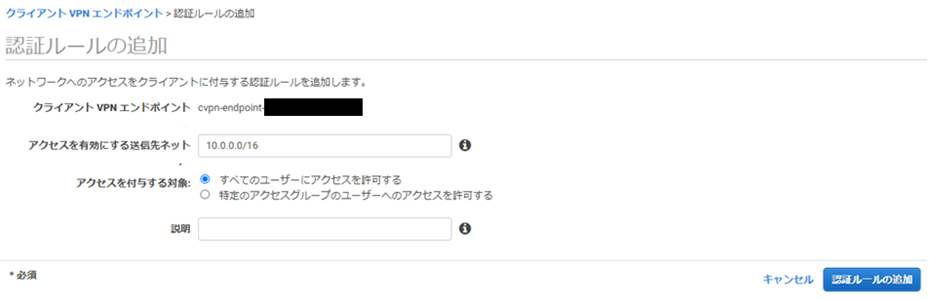
1-5.クライアントのネットワークへのアクセスを承認する
関連付けられているサブネットが存在する VPC へのアクセスをクライアントに承認するために、承認ルールを作成する必要があります。承認ルールには、どのクライアントが VPC にアクセスできるかを指定します。
アクセスを有効にする送信先ネットに接続するVPC全体のCIDR(今回でいうと10.0.0.0/16)を指定して「すべてのユーザーにアクセスを許可する」を選択します。
1-6.クライアント VPN エンドポイントの設定ファイルをダウンロードする
- 最後のステップでは、クライアント VPN エンドポイント設定ファイルをダウンロードして準備します。設定ファイルには、クライアント VPN エンドポイントと VPN 接続を確立するために必要な証明書情報が含まれています。
VPN 接続を確立するためにクライアント VPN エンドポイントに接続する必要があるクライアントにこのファイルを指定する必要があります。クライアントは、VPN クライアントアプリケーションにこのファイルをアップロードします。
エンドポイントの画面から設定ファイルをダウンロードします。
1-1で生成されたクライアント証明書とキーを確認しておきます。
クライアント証明書とキーは、クローンされた OpenVPN easy-rsa repo の次の場所にあります。
クライアント証明書 — easy-rsa/easyrsa3/pki/issued/client1.domain.tld.crt
クライアントキー — easy-rsa/easyrsa3/pki/private/client1.domain.tld.keyダウンロードした.ovpn拡張子のファイルを、任意のテキストエディタを使用してクライアント VPN エンドポイント設定ファイルを開き、
タグ間にクライアント証明書(client1.domain.tld.crt)の内容を追加し、
タグ間にプライベートキー(client1.domain.tld.key)の内容を追加します。<cert> -----BEGIN CERTIFICATE----- ※最初に作成したclient1.domain.tld.crt の中身 -----END CERTIFICATE----- </cert> <key> -----BEGIN PRIVATE KEY----- ※最初に作成したclient1.domain.tld.key -----END PRIVATE KEY----- </key>
- クライアント VPN エンドポイントの DNS 名の先頭にランダムな文字列を追加します。クライアント VPN エンドポイントの DNS 名を指定する行を見つけ、その前にランダム文字列を追加します
remote cvpn-endpoint-0102bc4c2eEXAMPLE.prod.clientvpn.us-west-2.amazonaws.com 443↓
remote asdfa.cvpn-endpoint-0102bc4c2eEXAMPLE.prod.clientvpn.us-west-2.amazonaws.com 4431-7. クライアントアプリケーションの入手、設定
- OpenVPN ベースのクライアントアプリケーションである、AWS公式のクライアントアプリケーションを今回は使用します。
以下からダウンロードして手順に沿って、インストールします。
https://aws.amazon.com/jp/vpn/client-vpn-download/
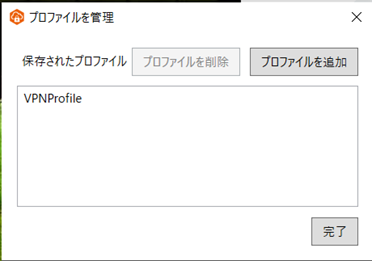
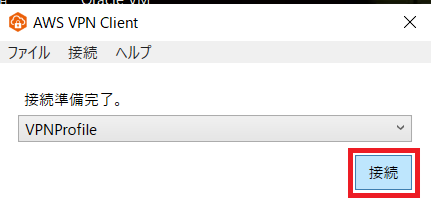
クライアントアプリケーションを起動して、先ほど修正した設定ファイルをプロファイルとして登録します。
接続準備完了となったら接続してみて、[接続済み]となればOKです。
PCのIPアドレスを確認すると、「クライアント IPv4 CIDR」に設定したネットワークのIPアドレス「10.20.0.130」が設定されていることがわかります。
2-1.パブリックサブネットにNAT Gatewayを作成
- パブリックサブネットにNAT Gatewayを作成します。ここで割り当てられたElastic IPが、インターネットにアクセスするSource IPになります。

2-2.プライベートサブネットのルートテーブルを設定
- 「#1.AWS Client VPNの設定」で既に作成しているプライベートサブネットに対して、専用のルートテーブルを作成し、宛先0.0.0.0/0へのターゲットを先ほど作成したNAT Gatewayに設定します。
- プライベートサブネットに設定するサブネットに、そのルートテーブルを割り当てます

2-3. Client VPN エンドポイントにプライベートサブネットを関連付け
- Client VPN エンドポイントのルートテーブルに、宛先0.0.0.0/0を設定し、ターゲットサブネットには同様にプライベートサブネットを選びます。

2-4. Client VPN エンドポイントのルートテーブル、認証ルールを設定
- 認証ルールの設定です。ルートテーブルと同様に、宛先0.0.0.0/0を追加して許可します。
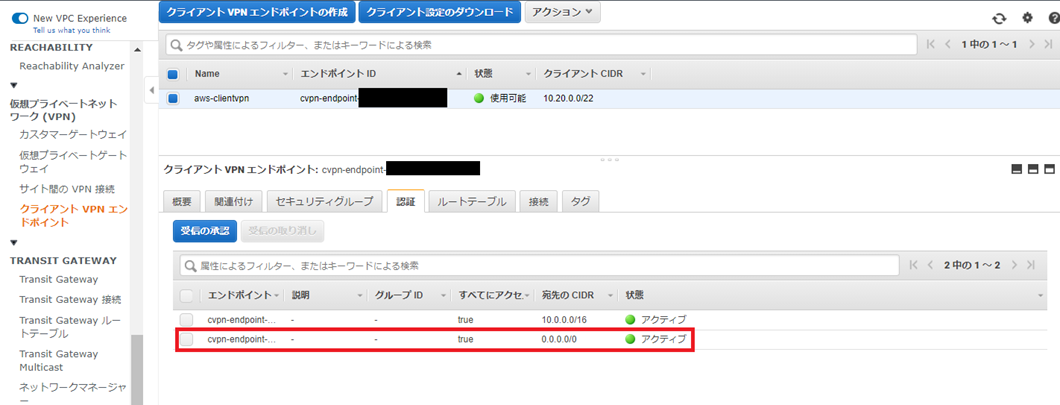
2-5.接続確認
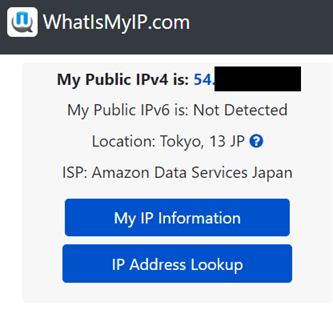
- 「1.AWS Client VPNの設定」で作成したVPNクライアントソフト、でVPN接続をおこないます。Whatismyip でアクセスしているIPアドレスを確認します。
- 「2-1.パブリックサブネットにNAT Gatewayを作成」で確認した、NAT Gateway割り当てのElastic IPと一致していることが確認できました。
参考にさせていただいた記事:















- 投稿日:2021-01-29T15:36:44+09:00
githubにあるrailsアプリをAWSにデプロイ
記事を書くにあたって
アルバイト先の塾内システムを構築している学生の記事です。
なおかつ初投稿ですので、至らない部分が多いと思いますが、よろしくお願い致します。今回は、年末年始に試行錯誤したのちに辿り着いたデプロイの流れを紹介します。
メインの参考文献1の中で、上手くいかなかったことを修正しながら進めていきます。
流れと同時にコードも紹介しますが、細かい説明は添付の記事を参照ください。0. 環境
Ruby 2.5.1
rails 5.2.4.4
mysql 8.0
Amazon Linux 2
nginx
unicorn1. VPCの作成からSSH通信によるEC2インスタンスへのログイン
参考文献1:https://hackmd.io/4_1NYUTBSaSsOC8cur7WhA?view#1-VPC%E3%81%AE%E4%BD%9C%E6%88%90
この文献の作成者様がYouTubeにて動画をアップしてくれています。上記の記事の
1. VPCの作成
2. サブネットの作成
3. インターネットゲートウェイの作成
4. ルートテーブルの作成
5. セキュリティグループの作成
6. EC2インスタンスの作成(ここではAmazon Linux 2を選択する)
7. Elastic IPの作成、紐付け
8. SSH通信によるインスタンスへのログイン
を実行する。
6.EC2 instance AMI Amazon Linux 2 AMI (HVM), SSD Volume Type - ami-01748a72bed07727c (64 ビット x86) / ami-0f53b51ee1388fd0b (64 ビット Arm)を選択。
2. mariadbを削除し、mysqlをインストール
参考文献2:https://qiita.com/miriwo/items/eb09c065ee9bb7e8fe06
Amazon Linux 2はcentOS7ベースで作られているため、デフォルトでmariadbが入っている。
参考文献2の通り実行する
3. EC2インスタンスの環境構築
1.と同じ記事を参考
参考文献1:https://hackmd.io/4_1NYUTBSaSsOC8cur7WhA?view#1-VPC%E3%81%AE%E4%BD%9C%E6%88%90参考文献の通り
・必要なパッケージのインストール
・rbenvのインストール
を済ませたのちにrubyのインストールではこちら(参考文献3)を元に以下のコードを実行する。$ rbenv install -v 2.5.1 $ rbenv global 2.5.1 $ rbenv rehashバージョンの確認
$ ruby -v参考文献1に戻り、
・node.jsのインストール
・railsのインストール
・bundlerのインストール
を行う。4. githubと連携
参考文献1:https://hackmd.io/4_1NYUTBSaSsOC8cur7WhA?view#1-VPC%E3%81%AE%E4%BD%9C%E6%88%90
参考文献の通り
・githubと連携
・アプリのclone
を行う。5. master.keyの登録
参考文献1:https://hackmd.io/4_1NYUTBSaSsOC8cur7WhA?view#1-VPC%E3%81%AE%E4%BD%9C%E6%88%90
master.keyは機密情報が入ったcredentials.ymlの暗号を解くための鍵ファイル。(ローカルのconfigディレクトリに両方入ってる。詳しくはこちら(参考文献4)
そのため、gitignoreされておりgit cloneを行っても、実行環境に降りてこない。アプリのディレクトリに移動し、
$ vi config/master.keyを実行し、新規にmaster.keyを実行環境に保存する。
中身はローカルのmaster.keyからコピペする。
その後、参考文献1の
・credentials.ymlの設定
を行う。6. mysqlのrootパスワードを変更し、設定を行う。
参考文献1:https://hackmd.io/4_1NYUTBSaSsOC8cur7WhA?view#1-VPC%E3%81%AE%E4%BD%9C%E6%88%90
mysqlをインストールした際に初期パスワードが設定されている。
それを変え、データベースの設定を行う。こちら(参考文献5)の通り、rootのパスワードを変更する。
その後、参考文献1の
・mysqlへ接続確認。先ほど設定したパスワードを入力してmysqlに接続できればOK。
・config/database.yml の編集
を行う。7. nginxの設定
参考文献1:https://hackmd.io/4_1NYUTBSaSsOC8cur7WhA?view#1-VPC%E3%81%AE%E4%BD%9C%E6%88%90
nginxは以下のコマンドよりインストールする
$ sudo amazon-linux-extras install nginx1その後、参考文献1の
・nginxの設定変更(以下のコマンドより)$ sudo vi /etc/nginx/conf.d/ec_site.conf・権限変更
を行う。8. Unicornの設定
参考文献1:https://hackmd.io/4_1NYUTBSaSsOC8cur7WhA?view#1-VPC%E3%81%AE%E4%BD%9C%E6%88%90
参考文献1の通り
・Gemfileに記述
・インストール実行
の後に、文献ではマイグレーションを行っているが、先にデータベースを作成する。$ rake db:create RAILS_ENV=productionその後は参考文献1に戻り
・マイグレーションの実行
・assets コンパイル実行
・EC2の再起動
・Nginxの起動
・Unicornの起動
・Unicornの起動の確認
を行う。1.で登録したelastic IPで検索をかける。
http://xxx.xxx.xxx.xxx/git cloneしたアプリが表示されれば、AWSへのデプロイ完了です!
お疲れ様でした!!!
最後に
参考文献1に頼りまくってデプロイを行いました。
デプロイ後には多くの人が独自ドメインの設定をすると思います。
以下の書籍を参考にするのがおすすめです。
ゼロからわかるAmazon Web Services超入門 はじめてのクラウド (かんたんIT基礎講座)非常に参考になりますが、今回の記事のように、そのままそっくり真似てもエラーが出る箇所があります。
今度はそれについて記事を書きたいと思います。(就活に余裕ができたら)ありがとうございました。
- 投稿日:2021-01-29T15:33:53+09:00
Lambdaがコンテナイメージをサーポートしたので試してみた
はじめに ローカルでLambdaを開発する際に、いざデプロイしようと思った時に困った方も少なくないと思います。 というのも、デフォルトでプリインストールされていないライブラリをimportしている場合はzipファイルにしてAWSコンソール上でアップロードする必要があります。 もしくはServerless FrameworkやSAMを導入されている方が多いのかと思います。 個人的にはちょっとした関数をLambdaで実装しようとした時にServerless FrameworkやSAMはゴツすぎるというかやりたいことに対して出来ることと、開発環境や設定が手間になると思い敬遠していました。 そこで今回Lambdaがコンテナイメージをサーポートしたので慣れ親しんだDockerfileでデプロイできるなら良いのではと考え試してみました。 使用環境とバージョン macOS Catalina aws-cli/2.0.28 Docker version 19.03.13 Lambdaの使用言語 Python3.8 記事の対象 ある程度AWSとDockerの知識がある方 ECSもしくはEKSを利用してアプリケーションを作成している方 事前準備 AWS CLIを利用できること IAMユーザもしくはスイッチロール先にecr:GetAuthorizationToken権限が付与されていること ※1 Amazon ECR の作成 dockerイメージをpushするリポジトリを事前に作成します。 AWS CLIで作成します。以下のコマンドをローカルで実行して下さい。 aws ecr create-repository \ --repository-name lambda-container 実行ファイルの作成 今回作成するLambdaには以下の要素を含めようと思います。 Lambda実行環境に標準で含まれないライブラリを使用する boto3により、AWSリソースにアクセスする 自分の経験則から、Lambdaを使用する際にpythonのライブラリを追加したいシーンがよくありました。 今まではpython -m venv {環境名}でローカルに仮想環境を構築し、追加ライブラリをinstallしてからzipにしてAWSコンソールからLambdaにアップロードしていました。 その辺りがdockerイメージを使用することで改善できることを期待しています。 また、LambdaではよくAWSリソースを参照することがあるのでboto3での権限周りを整理できればより実用的なものになると思います。 以下のpythonファイルを使用することとします。 lambda-container.py import os import logging import requests import json import boto3 rds = boto3.client('rds') logger = logging.getLogger() logger.setLevel(logging.INFO) # 返却用クラス class LambdaResponse: # コンストラクタ def __init__(self, db, zip): self.db = db self.zip = zip # json形式で返却 def json(self): db = {} instances = [] for instance in self.db['DBInstances']: res = {} res['Identifier'] = instance['DBInstanceIdentifier'] res['Status'] = instance['DBInstanceStatus'] instances.append(res) db['Instances'] = instances return { 'db': db, 'zip': self.zip } # メインハンドラー def lambda_handler(event, context): logger.info('event: {}'.format(event)) # お試し: RDSインスタンスをDescribe describe = rds.describe_db_instances(DBInstanceIdentifier='edu-demodb-rds01-postgres11') logger.info('describe db instances: {}'.format(describe)) # お試し: Defaultライブラリーに含まれない機能(郵便番号から住所を検索) response = requests.get('https://zipcloud.ibsnet.co.jp/api/search?zipcode={}'.format(event['zip'])) logger.info('Status: {}, Body: {}'.format(response.status_code, json.dumps(response.json(), ensure_ascii=False))) return LambdaResponse(describe, response.json()).json() requirements.txtの作成 こちらはpipでの一般的なインストール方法のため説明を省きます。 詳しく知りたい方は以下を参照して下さい。 pip install - pip documentation v20.3.3 ###### Requirements without Version Specifiers ###### requests # boto3 <- Lambdaのdockerイメージに含まれているため不要です。無くても動きます ###### Requirements with Version Specifiers ###### Dockerfileの作成 以下に使用するDockerfileになります。 pip install -r requirements.txtにて追加のライブラリをインストールします。 インストール先はDockerコンテナ内になるため、ローカル環境を汚すことはありませんでした。 CMDには実行対象となるハンドラーを指定して下さい。 Dockerfile FROM public.ecr.aws/lambda/python:3.8 COPY lambda-container.py requirements.txt ${LAMBDA_TASK_ROOT}/ RUN pip install --upgrade pip RUN pip install -r requirements.txt RUN pip list CMD [ "lambda-container.lambda_handler" ] dockerイメージは2種類ありDocker Hubにも用意されています。 基本的に同じものでリポジトリがAWSかDockerかの違いだと思うので基本的には手順通りのAWS側を使用すれば良いと思います。 amazon/aws-lambda-python - Docker Hub FROM amazon/aws-lambda-python:3.8 また、dockerイメージから以下の環境変数が提供されています。 ${LAMBDA_TASK_ROOT}に必要なファイルをCOPYして下さい。 The AWS base images provide the following environment variables: LAMBDA_TASK_ROOT=/var/task LAMBDA_RUNTIME_DIR=/var/runtime Creating Lambda container images - AWS Lambda ローカル環境でLambdaを実行 以下のディレクトリに成果物を配置することにします。事前に作成しておいて下さい。 $ mkdir lambda-container $ cd lambda-container $ ls Dockerfile lambda-container.py requirements.txt 以下の手順でローカル環境にてLambdaを実行することができます。 $ docker build -t lambda-container . $ docker run -p 9000:8080 lambda-container $ curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{"zip":"1310045"}' { "db": { "Instances": [ { "Identifier": "xxxxxxxxxx", "Status": "stopped" } ] }, "zip": { "message": null, "results": [ { "address1": "東京都", "address2": "墨田区", "address3": "押上", "kana1": "トウキョウト", "kana2": "スミダク", "kana3": "オシアゲ", "prefcode": "13", "zipcode": "1310045" } ], "status": 200 } } boto3の認証について 上記の通りにローカル実行すると、以下のようなエラーが発生します。 これはdockerコンテナ内にboto3用のCredentialsが存在しないためです。 { "errorMessage": "Unable to locate credentials", "errorType": "NoCredentialsError", "stackTrace": [ " File \"/var/task/lambda-container.py\", line 37, in lambda_handler\n describe = rds.describe_db_instances(DBInstanceIdentifier='xxxxxxxxx')\n", " File \"/var/runtime/botocore/client.py\", line 357, in _api_call\n return self._make_api_call(operation_name, kwargs)\n", " File \"/var/runtime/botocore/client.py\", line 662, in _make_api_call\n http, parsed_response = self._make_request(\n", " File \"/var/runtime/botocore/client.py\", line 682, in _make_request\n return self._endpoint.make_request(operation_model, request_dict)\n", " File \"/var/runtime/botocore/endpoint.py\", line 102, in make_request\n return self._send_request(request_dict, operation_model)\n", " File \"/var/runtime/botocore/endpoint.py\", line 132, in _send_request\n request = self.create_request(request_dict, operation_model)\n", " File \"/var/runtime/botocore/endpoint.py\", line 115, in create_request\n self._event_emitter.emit(event_name, request=request,\n", " File \"/var/runtime/botocore/hooks.py\", line 356, in emit\n return self._emitter.emit(aliased_event_name, **kwargs)\n", " File \"/var/runtime/botocore/hooks.py\", line 228, in emit\n return self._emit(event_name, kwargs)\n", " File \"/var/runtime/botocore/hooks.py\", line 211, in _emit\n response = handler(**kwargs)\n", " File \"/var/runtime/botocore/signers.py\", line 90, in handler\n return self.sign(operation_name, request)\n", " File \"/var/runtime/botocore/signers.py\", line 162, in sign\n auth.add_auth(request)\n", " File \"/var/runtime/botocore/auth.py\", line 357, in add_auth\n raise NoCredentialsError\n" ] } 幾つか解決方法があると思いますが、簡単な方法として以下のように、docker runする時に環境変数を設定します。 $ docker run \ -e AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} \ -e AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} \ -e AWS_DEFAULT_REGION=${AWS_DEFAULT_REGION} \ -p 9000:8080 lambda-container 以下のドキュメントにあるように、boto3はConfigオブジェクトを使用して明示的に上書しない限り、環境変数を使用して認証を行うようです。 Using environment variables Configurations can be set through the use of system-wide environment variables. If set, these configurations are global and will affect all clients created unless explicitly overwritten through the use of a Config object. Configuration — Boto3 Docs 1.16.49 documentation Amazon ECRにpush 無事ローカルでLambdaを実行することができたのでECRにpushします。 ECRへpushする方法については、以下の記事で解説していますので、手順のみ記載します。 Amazon ECRのDockerイメージをローカルにpull、pushする $ aws ecr get-login-password --region ap-northeast-1 \ | docker login --username AWS --password-stdin {aws_account_id}.dkr.ecr.{region}.amazonaws.com $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE lambda-container latest 9ec9f9c8cabf 5 months ago 402MB $ docker tag 9ec9f9c8cabf {aws_account_id}.dkr.ecr.{region}.amazonaws.com/lambda-container $ docker push {aws_account_id}.dkr.ecr.{region}.amazonaws.com/lambda-container Lmabdaをdockerイメージで作成 dockerイメージの準備が整ったので、Lambdaを作成していきます。 AWSコンソールにログインしてLambdaの作成でコンテナイメージを選択して下さい。 Lambdaの作成が完了しました。現状ではAWSコンソールではコードが表示されないようです。 テストも無事成功です。 まとめ ちょっとしたLambdaの場合は不要かと思いますが、何度も修正が想定される場合は良いと思いました。 また、CodeCommitで履歴管理し、CodePipelineで自動デプロイすればより使いやすいと思います。 参考記事 pip install - pip documentation v20.3.3 amazon/aws-lambda-python - Docker Hub Creating Lambda container images - AWS Lambda Configuration — Boto3 Docs 1.16.49 documentation Amazon ECRのDockerイメージをローカルにpull、pushする
- 投稿日:2021-01-29T15:28:56+09:00
AWS(Amazon Linux 2)にWebサーバ(nginx)を立ててWebサイトをデプロイする
HTML、CSS、JavaScriptで作成したWebサイトをWebサーバ(nginx)にデプロイする手順を残します。
作業環境
macOS BigSur 11.1
参考
- 【AWS】EC2にNginxをインストールして Hello, World! を表示させる | ハッシュテック
- 【scp】Linuxでリモート・ローカル間でファイルを転送するコマンド | UX MILK
手順
- AWSでWebサーバ用のインスタンス(Amazon Linux 2)の立ち上げ&各種設定
- nginxをインストール
- webアプリのコードをwebサイトに配置(scp転送を利用)
- nginxの設定変更
AWSでWebサーバ用のインスタンスの立ち上げ&各種設定
今回はWebサーバとしてAWSのインスタンスを使う。
インスタンスの立ち上げ手順は割愛します。デプロイ後にブラウザで確認するためにHTTPのインバウンド設定をしておく。
nginxをインストール
Amazon Linux 2 では Extras Library を使う(yumでnginxをインストールできない)
※Amazon Linux ではyumでインストールできるらしいExtras Library でインストールできるアプリケーションを確認してみる
# ライブラリの確認 $ amazon-linux-extras一覧で表示される。nginxは available(利用可能) になっている。
33 java-openjdk11 available [ =11 =stable ] 34 lynis available [ =stable ] 35 kernel-ng available [ =stable ] 36 BCC available [ =0.x =stable ] 37 mono available [ =5.x =stable ] 38 nginx1 available [ =stable ] 39 ruby2.6 available [ =2.6 =stable ] 40 mock available [ =stable ] 41 postgresql11 available [ =11 =stable ]nginxをインストールする
$ sudo amazon-linux-extras install nginx1ライブラリを確認すると、nginxが enabled(有効)になっている。
35 kernel-ng available [ =stable ] 36 BCC available [ =0.x =stable ] 37 mono available [ =5.x =stable ] 38 nginx1=latest enabled [ =stable ] 39 ruby2.6 available [ =2.6 =stable ] 40 mock available [ =stable ]nginxを起動する
# nginxの起動 $ sudo systemctl start nginx # nginxのステータスの確認(起動したことの確認) $ sudo systemctl status nginxwebアプリのコードをwebサイトに配置(scp転送を利用)
nginxのデフォルトでは、サーバにアクセスした際に
/usr/share/nginx/htmlに入っている index.htmlを表示する設定になっている。
/usr/share/nginx/配下にフォルダごとWebサイトの資材を置いて、nginxの参照先を変えることで自分のサイトを表示するようにできる。まずは格納するフォルダをサーバ側に作る。今回は
/usr/share/nginxの配下に mywebsite というフォルダを作成。# フォルダを作成 $ sudo mkdir /usr/share/nginx/mywebsite次にフォルダの権限設定を誰でも書き込みできるように変更。(サーバ側は
ec2-userでないと書き込めないので、そのままだと権限エラーになった)# フォルダのアクセス権限を変更 $ sudo chmod 777 mywebsiteまずはWebサイトの資材をscpで転送する。
# scpを使ったAWSへのファイル転送(-r オプションを付けてフォルダごと転送) $ scp -r -i [秘密鍵ファイル] [送信元のパス(PCローカル)] ec2-user@[インスタンスのグローバルIP]:/usr/share/nginx/mywebsiteなお、Git(GitHubやGitLab等)でソースを管理している場合はgitからcloneする方が楽です。
先に述べた通り、scpを使った転送では送信先のフォルダのアクセス権限が原因で何度か失敗しました。nginxの設定変更
nginxのconfigファイルを編集して、nginxが自分のWebサイトの資材を参照するようにする。
編集にはVimを使う。# Vimでconfigファイルを開く $ sudo vi etc/nginx/下記の
root部分が参照先のパスの設定。デフォルトを残しておきたかったので、デフォルトはコメントアウトにして設定を追加した。server { listen 80; listen [::]:80; server_name _; root /usr/share/nginx/mywebsite/omikuji; #root /usr/share/nginx/html; # Load configuration files for the default server block. include /etc/nginx/default.d/*.conf;設定を保存したら nginx を再起動する
# nginx の再起動 $ sudo systemctl restart nginxブラウザでWebサーバー(インスタンスのグローバルIP)にアクセスして確認する。
以上です。
- 投稿日:2021-01-29T13:03:45+09:00
sagemakerでEFSまたはAmazon FSx for Lustreを使用すると、どんなメリットがあるのか?
結論
トレーニングジョブを行う際、EFSまたはAmazon FSx for Lustreを使うと、高速な開始と短いトレーニング時間に短縮できる。
次の段落では、EFSまたはAmazon FSx for Lustre使用せず、S3に格納されている場合について説明する。SageMakerの全体像とs3にデータを格納した場合のフロー
sagemakerのデフォルトの設定では、以下のアーキテクチャが採用される。
データは、全てS3バケットに集約されている状態。
この状態だと、トレーニングジョブを開始する際、
S3バケット→トレーニングインスタンスにアタッチされた EBS ボリュームにダウンロードのフローになる。
一方、EFSまたはAmazon FSx for Lustreを使用した場合は、ダウンロードの手間が省かれる。
参照:https://www.accenture.com/jp-ja/blogs/cloud-diaries/amazon-sage-maker

- 投稿日:2021-01-29T13:03:45+09:00
sagemakerでEFSまたはAmazon FSx for Lustreを使用する意義
結論
トレーニングジョブを行う際、EFSまたはAmazon FSx for Lustreを使うと、高速な開始と短いトレーニング時間に短縮できる。
次の段落では、EFSまたはAmazon FSx for Lustre使用せず、S3に格納されている場合について説明する。SageMakerの全体像
sagemakerのデフォルトの設定では、以下のアーキテクチャが採用される。
データは、全てS3バケットに集約されている状態。
この状態だと、トレーニングジョブを開始する際、
S3バケット→トレーニングインスタンスにアタッチされた EBS ボリュームにダウンロードのフローになる。
一方、EFSまたはAmazon FSx for Lustreを使用した場合は、ダウンロードの手間が省かれる。
参照:https://www.accenture.com/jp-ja/blogs/cloud-diaries/amazon-sage-maker
- 投稿日:2021-01-29T13:00:56+09:00
マネージドプレフィックスリストはどういうケースで使うのか?
マネージドプレフィックスリストとは?
複数のCIDRブロックをグループ化させ、管理できるサービス。
例えば、0.0.0.0/16と0.0.0.0/24というCIDRがあった場合、別名+グループ化させて管理する。
また、マネージドプレフィックスリストはルートテーブルとセキュリティグループに適用可能。
それでは、この機能がどういうケースで有効か?をセキュリティグループの設定を例に次の段落で説明する。具体的なユースケース
以下画像は、セキュリティグループの編集画面である。
3つのルールのうち、sshに関するルールが2つある。
sshの設定は重複しているが、ソースが異なるため設定項目が増えてしまう。
ソースをまとめて、設定を2つから1つに減らすことができないものか...?
そんな時に役立つのがマネージドプレフィックスリストである。
sshのの2つCIDRに「test」というマネージドプレフィックスリストを作成し、ルールを編集すると3つ設定していたルールを2つに減らすことができる。
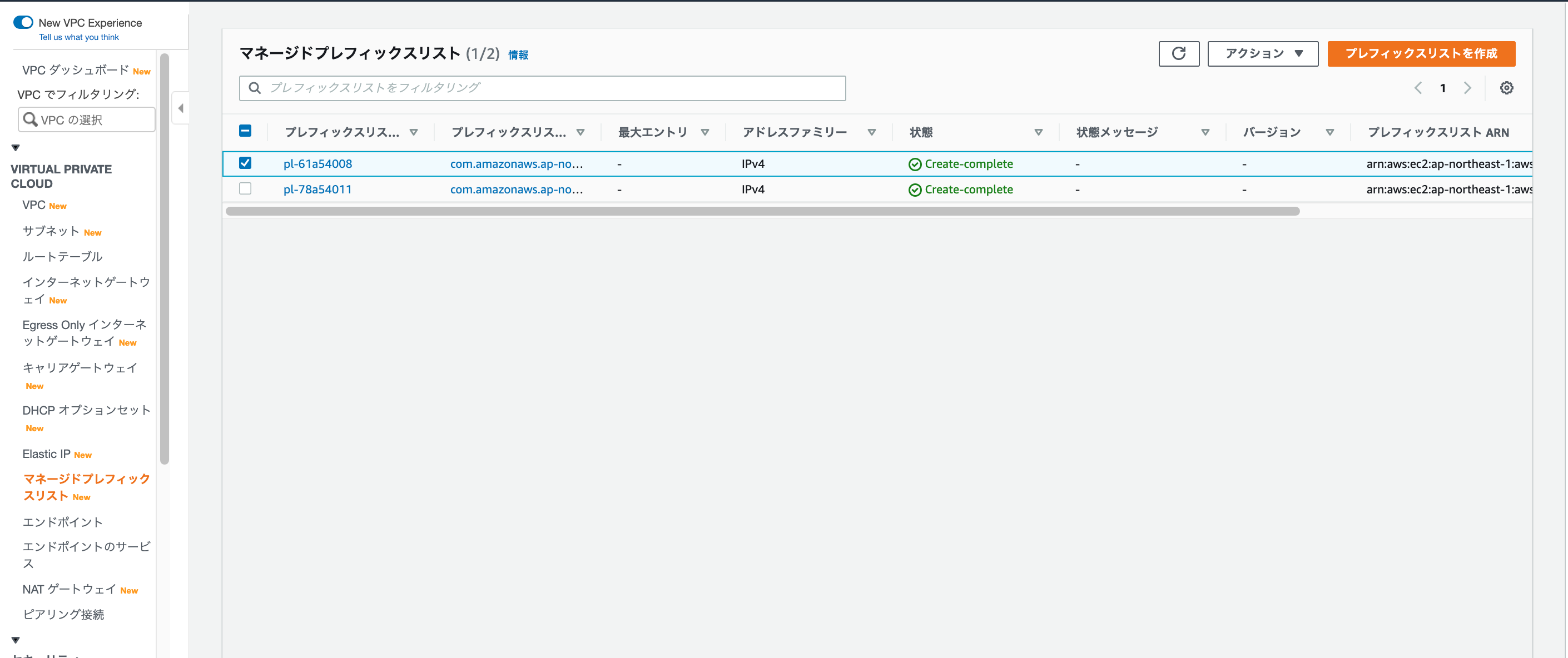
設定方法
コンソール上で、VPC→マネージドプレフィックスに遷移すると以下の画面にたどり着く。
デフォルトで2つのマネージドプレフィックスが設定してあり、それぞれS3とDynamoDBのCIDR範囲を管理するものである。
プレフィックスリストを作成をクリックすると、以下画面に遷移するので、実現したいリストを作成する。
下記画像より、作成が確認できる。




- 投稿日:2021-01-29T11:56:44+09:00
【Cloud9】Ruby on Railsでrails sしたときにBlocked hostが表示された時の対処法
環境
- Ruby on Rails6.×
- Cloud9
エラー概要
以下のコマンドを実行した際に、
Blocked hostと表示され、Railsのデフォルトページが表示されない場合があります。rails server
結論
config/environments/development.rbを以下のように修正してください。config/environments/development.rbRails.application.configure do config.hosts << "<許可したいホスト名>" #=====中略===== end
<許可したい表示名>には、「Blocked host:」のあとに表示されている「~.vfs.cloud9.us-east-2.amazonaws.com」で終わる文字列を入力してください。動作確認
再度アプリケーションを起動します。
rails server
上記のような画面が表示されたら、右上の「Pop Out New Windows」をクリックして下さい。
以下のようにRailsのデフォルトページが表示されます。
※本記事はTechpitの記事を一部修正したものです。


- 投稿日:2021-01-29T11:55:34+09:00
AWSのEC2でwebサイトを公開するまで
1. VPC構築
参考サイト
https://qiita.com/nago3/items/f5badeb4f7e5c32b05402. RDS構築
参考サイト
https://qiita.com/nago3/items/1cd6daa5ad6377e325ed
補足:データベースの設定のでDBの名前を指定していますが、設定項目がないので気にしないで3. 1・2が完了したらSSHでEC2のインスタンスに接続する
ターミナルでインスタンスに接続して下記の作業を実行
- OSのアップデート
- phpのインストール(参考サイト:https://qiita.com/miriwo/items/7d94303e7185e4118f52 )
- MySQLのインストール
- phpMyAdminのインストール(参考サイト:https://qiita.com/s_Pure/items/2bf5bafffdbb6f20422a )
- Apacheのインストール
ここまで行ったらパブリック IPv4 アドレス(もしくはElastic IP)をブラウザに入力してApacheのTestPageが表示されるか確認してみましょう
うまくいかなかったら下記をチェック
https://ti-tomo-knowledge.hatenablog.com/entry/2018/05/26/2024134. ドメインの設定
Elastic IPでグローバルIPを固定 ↓ ドメインの取得(今回はFreenomを利用) ↓ Route 53でDNSの設定 ↓ FreenomでNS(ネームサーバー)を設定 ↓ DNSの設定確認 ↓ 取得したドメインでブラウザに表示されるかを確認参考サイト
https://avinton.com/academy/route53-dns-vhost/5. https化
https://dev.classmethod.jp/articles/aws-web-server-https-for-beginner/
※「ロードバランサーのDNS名をDNSに追加する」の項目だけ説明した方法でできなかったので補足 Route53へアクセス ↓ ホストゾーン ↓ ドメイン名を選択 ↓ レコードを作成 ↓ レコード名は空白 ※ここに名前をつけるとhttps化できても安全性の警告が出ます。 例) ドメイン名:hoge.com レコード名:blog.hoge.com 証明書は「https://hoge.com」で照会されるので、レコード名を変更してしまうと、 「https://blog.hoge.com」からのアクセスと認識し、「なりすましかもしれない」という判断で警告画面を表示してしまいます。 ↓ エイリアスをON ↓ Application Load BalancerとClassic〜を選択 ↓ リージョンは設定したリージョンを選択(us-east-2など) ↓ 「ロードバランサーを選択」でロードバランサーの説明にあるDNSを選択できるはず ↓ レコードを作成 (レコードを作成する時に既に存在するという警告が出た場合は他のAレコードの「レコード名」を変更もしくは削除してください)

- 投稿日:2021-01-29T10:38:11+09:00
機械学習 PoC と本番運用のあいだ
はじめに
機械学習を使った PoC(Proof of Concept; 効果検証)は、近頃の AI ブームを受けて盛んに行われていることと思います。そしてその後、(とても幸運なことに、)PoC で良い結果を得られた場合、PoC の仕組みを本番運用したいという話が持ち上がります。しかしながら、探索的データ分析や予測モデルの作成などは多くの知見が共有されている一方、それらを運用していくための知見はまだあまり多くないように思います。
本記事では、PoC から本番運用へと移行するあいだに、技術的には何が必要なのかを検討していきます。機械学習 PoC が一過性のまま終わらず、本番運用によって価値を生み出していくための一助となれば幸いです。
↓本記事で検討した最終的なアーキテクチャ
本記事で書くこと
- PoC におけるデータ分析の進め方
- 機械学習 PoC のテスト運用の進め方(本記事のメイントピック)
- PoC、テスト運用の各フェーズでのアーキテクチャ(本記事のメイントピック)
- 本番運用に向けて追加で検討すべきこと
本記事では特にテスト運用にフォーカスして書いていきます。テスト運用では運用と分析を並列で行うことが多いですが、運用と分析を両立しながら、どのようにシステムのアーキテクチャをアップデートしていくかの一例を記載します。
本記事で書かないこと
- 機械学習モデルの予測精度向上に関する詳細
- 探索的データ分析の詳細
- 前処理や特徴量生成の詳細
- 予測モデルの詳細
- ミドルウェア(データベースや Web サーバ)よりも低レイヤーに関して
- 機械学習 PoC でのコンサルテーションに関するスキル
コンサルテーションに関するスキルは、不確実なことの多い機械学習プロジェクトにおいて大変重要な点ですが、本記事では技術にフォーカスするため記載しません。
本記事で想定するシステム
- 数 GB〜数十 GB の比較的小規模なデータを利用する
- 数億レコード級のデータではなく、メモリに載るサイズのデータを扱う
- バッチ学習、バッチ推論を行う
- オンライン(リアルタイム)での学習・推論は行わない
- システム構築はデータ分析と並行して進める
- 作るべきものは決まっておらず、走りながら必要に応じて作っていく
本記事で利用するデータ
本記事では、Kaggle で過去に開催されたコンペティションである「Home Credit Default Risk」のデータを利用します。このコンペティションは個人の与信情報をもとに、各個人が債務不履行になるかどうかを予測するものです。データにはローンの申込みごとにレコードがあり、1 つのレコードには申込者の与信に関する情報と、その人が返済できたか、あるいは債務不履行になったかを示すラベルが含まれています。
この記事では、自分がとあるローン貸付会社のデータ分析部門にいることを想定します。この与信情報をもとに、与信判定を機械学習を用いて自動化するとしたらどうするか、という仮定のもとで話を進めていきます。
説明の都合上、この仮定の上で、本コンペティションで利用できるデータのうち、「application_train.csv」を図のように分割して利用します。分割したデータはそれぞれ以下を仮定して使用します。
- 「initial.csv」:過去の与信情報。PoC で利用する
- 「20201001.csv」:2020 年 10 月分の与信情報。テスト運用ではこのデータは「initial.csv」と合わせて訓練データとして扱う
- 「20201101.csv」:2020 年 11 月分の与信情報。テスト運用ではこのデータは「initial.csv」と合わせて訓練データとして扱う
- 「20201201.csv」:2020 年 12 月分の与信情報。テスト運用ではこのデータは「initial.csv」と合わせて訓練データとして扱う
- 「20210101.csv」:2021 年 1 月分の与信情報。テスト運用ではこの月から予測を始める
データを分割した実際のコードは以下です。
split_data.ipynb
# データ読み込み train = pd.read_csv('../data/rawdata/application_train.csv') # initial.csv出力 train.iloc[:len(train)-40000,:].to_csv('../data/poc/initial.csv', index=False) # 各月データ出力 train.iloc[len(train)-40000:len(train)-30000,:].to_csv('../data/poc/20201001.csv', index=False) train.iloc[len(train)-30000:len(train)-20000,:].to_csv('../data/poc/20201101.csv', index=False) train.iloc[len(train)-20000:len(train)-10000,:].to_csv('../data/poc/20201201.csv', index=False) train.iloc[len(train)-10000:,:].to_csv('../data/poc/20210101.csv', index=False)検討に際して想定する状況
本記事では、説明をしやすくするため、以下のようなプロジェクトを想定して検討を進めていきます。以降のストーリーは、今回使用する「Home Credit Default Risk」のデータから筆者が妄想したものであるため、現実の会社や業務とは全く無関係です。また、筆者は与信業務に関して全くの素人であり、現実の業務と異なる可能性が大いにあります。
自分はデータサイエンティストとして、銀行の与信判定業務を自動化するプロジェクトに参画している。
与信判定業務は審査部門にて人手で行われているが、工数の低減や与信判定の精度向上のために機械学習が使えないか検討している。
サンプルデータはすでに提供されており、PoC を行う段階にある。サンプルデータは過去にローンを貸りた人が債務不履行になったかどうかが記録されている。このデータをもとに、もし新しくローンを借りたい人がいたときに、その人が債務不履行になるかどうかを予測することで、ローンを貸し付けるかどうかの判定ができるようにしたい。本記事の対象とするプロジェクトのスコープ
機械学習プロジェクトは通常、企画、PoC、テスト運用、本番運用と続いていきます。本記事では、技術的なポイントにフォーカスするため、PoC からテスト運用までをスコープとして記載します。特にテスト運用については、本番運用に移行するために多くの検証が必要になるため、3 つのフェーズに分けて説明します。なお本番運用については、筆者の経験が浅いため、検討すべき点を挙げるだけに留めています。
本記事で想定する体制
本記事では、プロジェクトをスモールスタートで進めていく方針で記載するため、ミニマムな体制を想定します。具体的には、ビジネス部門(本記事では与信審査部門)とやり取りをするコンサルタントが 1 名、データ分析からシステム構築までを行うデータサイエンティストが 1 名になります。実際には、監督としてマネージャーがいると思いますが、本記事では登場しません。またステークホルダーとしては、ビジネス部門が存在します。
PoC フェーズ
このフェーズでの目的
このフェーズの目的は、与信判定の自動化が可能なのかを検証することです。本フェーズでは主に 2 つのポイントについて検証していきます。1 つは、 1 つは利用するデータが本番運用時にも利用できるものであるか(予測時に利用可能なデータなのか、レコード同士に関連性がないか)というデータの妥当性の検証、もう 1 つは機械学習によって与信判定はどれくらいの精度で予測できるのかという予測精度の検証です。
このフェーズでのアーキテクチャ
このフェーズでは JupyterLab だけで作業を進めていきます。機械学習モデルの保存のために MLflow を記載していますが、(個人的には)最初期には必要ないと思っています。
データの妥当性検証
データサイエンティストとしてはすぐにでもデータを見始めたいところですが、まずはそのデータの妥当性を検証します。もしデータに欠陥があれば、そのデータを利用した予測は無駄になってしまう可能性が高いからです。妥当性の検証では、主に 2 つのポイントを確かめます。1 つは、各レコードにおいて、レコード内のそれぞれの列のデータはいつ入手できるのかを明らかにすることです。各列のデータは、こちらに提供された時点では揃っているように思えますが、それらが同時に入手できるとは限りません。最も簡単な例では、目的変数である「債務不履行に陥ったかどうか」が分かるのは、他の列より後になるでしょう。もう 1 つの確認ポイントは、レコード同士に関係がないかをチェックすることです。例えば、ある人物が 2 回ローンの申し込みをしたとして、学習データに 1 回目のレコードが、テストデータに 2 回目のレコードが存在してしまうと、予測に有利に働いてしまうことが予想できます。このような場合には、両方のレコードを、学習データまたはテストデータのどちらかに含めるようにするなどの処理をします。これらのポイント以外にも、そもそも各列のデータは何を意味しているのか、レコードの単位は何なのか(今回のデータでは人単位なのか、ローン申請単位なのか)などをビジネス部門からヒアリングして、データの定義を明確にしておくことも大切です。データの列ごとにこれらの確認ポイントをチェックする表を作成すると良いかもしれません。
探索的データ分析
データの妥当性が検証できたら、(あるいは妥当性の検証と並行して、)サンプルデータを可視化しながら、どのような列(特徴量)があるのかをJupyter Lab を使って見ていきます。この作業によってデータを理解し、特徴量エンジニアリングやモデル選択時の参考にします。また、データに問題がないかを探すきっかけとしても有用です。
まずは列ごとに、データ型、欠損値の割合などを確認します。
eda.ipynb
""" 各コードの実行結果は「>」以下に示します。 また、説明に不要と思われる一部の実行結果は、 「...」「省略」と記載して省略しています。 """ # ライブラリ読み込み import pandas as np # データ読み込み train = pd.read_csv('../../data/rawdata/application_train.csv') # 概要 train.head() > 省略 # 行数、列数 f"行:{len(train)} / 列:{len(train.columns)}" > '行:307511 / 列:122' # データ型 train.dtypes > SK_ID_CURR int64 TARGET int64 NAME_CONTRACT_TYPE object ... # 欠損値の数と割合 for c in train.columns: print(f'{c} 数:{train[c].isnull().sum()} / 割合:{train[c].isnull().sum() / len(train) * 100:0.4f}%') > SK_ID_CURR 数:0 / 割合:0.0% ... NAME_TYPE_SUITE 数:1292 / 割合:0.4201% ... COMMONAREA_AVG 数:214865 / 割合:69.8723% ...次に分布を見るために、可視化をしてみます。
データ型が数値型の場合はヒストグラムを、文字列型の場合はバーチャートを使います。eda.ipynb
# ライブラリ読み込み from bokeh.plotting import figure, output_file, show, output_notebook from bokeh.models import ColumnDataSource, Grid, LinearAxis, Plot, VBar, HoverTool # グラフをJupyterLab上で出力する設定 output_notebook() # ヒストグラム def plot_histogram(series, title, width=1000): p = figure(plot_width=width, plot_height=400, title=title, toolbar_location=None, tools="") hist, edges = np.histogram(series, density=True, bins=30) p.quad( top=hist, bottom=0, left=edges[:-1], right=edges[1:], fill_color="navy", alpha=0.2 ) p.y_range.start = 0 show(p) # バーチャート def plot_bar_chart(series, title, width=1000): items = dict(series.value_counts()) keys = list(items.keys()) values = list(items.values()) source = ColumnDataSource(data=dict( x=keys, y=values, )) TOOLTIPS = [ ("列名", "@x"), ("カウント", "@y"), ] p = figure(plot_width=width, plot_height=400, x_range=keys, title=title, toolbar_location=None, tooltips=TOOLTIPS, tools="") glyph = VBar(x="x", top="y", width=0.9) p.add_glyph(source, glyph) p.xgrid.grid_line_color = None p.y_range.start = 0 show(p) # 列ごとにグラフを出力する。欠損値は「-999」で補完する for c in train.columns: series = train[c].copy() if series.dtype == 'int64' or series.dtype == 'float64': series.fillna(-999, inplace=True) plot_histogram(series, c) else: series.fillna('-999', inplace=True) plot_bar_chart(series, c)出力されたグラフのうち 2 つを例として記載します。実際は 1 つずつ分布を見ていきますが、今回は割愛します。
AMT_CREDIT
NAME_INCOME_TYPE
予測精度の検証
ここからは実際にモデルを作成して予測精度を検証します。精度検証の際に重要なのが評価指標ですが、今回は「Home Credit Default Risk」の評価指標と同じく ROC の AUC を使います。実際はビジネス部門と協議して、どの指標を使うのかをあらかじめ合意しておきます。まずは、マニュアルで予測モデルを作る前に、PyCaret を使ってざっくりと予測してみます。これにより、どの特徴量・モデルが有効なのかを比較し、実際にモデルを作る際の参考にします。
eda.ipynb
# ライブラリ読み込み from pycaret.classification import * # セットアップ exp = setup(data=train, target='TARGET', session_id=123, ignore_features = ['SK_ID_CURR'], log_experiment = True, experiment_name = 'credit1', n_jobs=-1, silent=True)# モデルごとの予測精度比較 models = compare_models(include=['lr', 'dt', 'rf', 'svm','lightgbm'], sort='AUC')
今回は PyCaret がデフォルトで用意しているモデルのうち、以下をピックアップして比較しています。
- ロジスティック回帰
- 決定木
- ランダムフォレスト
- SVM
- LightGBM
評価指標を AUC とすると、LightGBM が優秀のようにみえます。一般に LightGBM は多くの場合精度と実行速度の両面で優秀であることが多いように思います。ところで、このデータでは正例が少ない不均衡データのため、Recall がどのモデルでも小さくなっています。ビジネス上のゴールにもよりますが、この後のモデル構築では、例えば Recall を上げて貸し倒れを防ぐモデルを作るなどします。本記事では、これ以上の詳細なモデリングは行わず、以降では LightGBM を使ってモデルを作成することとします。
次はどの特徴量が有効なのかを調べるため、PyCaret でモデルを LightGBM のモデルを作成し、評価します。
# LightGBMモデル作成 lgbm = create_model('lightgbm')
# モデルパラメータ詳細 evaluate_model(lgbm)
# SHAP重要度算出 interpret_model(lgbm)
# 重要度算出 importance = pd.DataFrame(models.feature_importances_, index=exp[0].columns, columns=['importance']) importance.sort_values('importance', ascending=False)
今回のデータのように特徴量が多い場合、予測で使用する特徴量を絞ることでモデルの安定性を保てる可能性が高まります。絞り方の簡単な方法としては、特徴量重要度を算出し、重要度が低いものを除外することです。今回は単純に、重要度上位の特徴量を使用します。なお、PyCaret が自動で前処理している列については、オリジナルの方の列を使うことにします。
それでは、マニュアルで予測モデルを作成していきます。
前処理
前処理としては、簡単のため、今回は欠損値の補完のみを行います。
forecast.ipynb
# 欠損値補完 train.fillna(-999, inplace=True)特徴量エンジニアリング
特徴量エンジニアリングとしては、特徴量の選択とカテゴリ変数のダミー変数化を行います。
forecast.ipynb
# 特徴量選択 features = [ 'EXT_SOURCE_1', 'EXT_SOURCE_3', 'EXT_SOURCE_2', 'DAYS_BIRTH', 'AMT_CREDIT', 'AMT_ANNUITY', 'DAYS_ID_PUBLISH', 'AMT_GOODS_PRICE', 'DAYS_REGISTRATION', 'DAYS_LAST_PHONE_CHANGE', 'AMT_INCOME_TOTAL', 'REGION_POPULATION_RELATIVE', 'OWN_CAR_AGE', 'AMT_REQ_CREDIT_BUREAU_YEAR', 'HOUR_APPR_PROCESS_START', 'TOTALAREA_MODE', 'CODE_GENDER', 'NAME_CONTRACT_TYPE', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS', 'TARGET' ] train = train.loc[:,features] # カテゴリ変数をダミー化 train = pd.get_dummies(train, drop_first=True, prefix=['CODE_GENDER', 'NAME_CONTRACT_TYPE', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS'], prefix_sep='_')予測
LightGBM を使ってモデルを作成します。また、Optunaを使ってハイパーパラメータのチューニングをします。
# ラベルと特徴量を分離 target = 'TARGET' X = train.drop(columns=target) y = train[target] # 訓練データとテストデータに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y) # 訓練データを一部バリデーション用に分割 X_train, X_eval, y_train, y_eval = train_test_split(X_train, y_train, test_size=0.2, random_state=1, stratify=y_train) # LightGBM用のデータセット作成 categorical_features = [] lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categorical_features, free_raw_data=False) lgb_eval = lgb.Dataset(X_eval, y_eval, reference=lgb_train, categorical_feature=categorical_features, free_raw_data=False) # パラメータチューニング def objective(trial): param = { 'objective': 'binary', 'metric': 'auc', 'verbosity': -1, 'n_jobs': -1, 'boosting_type': 'gbdt', 'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0), 'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0), 'num_leaves': trial.suggest_int('num_leaves', 2, 256), 'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0), 'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0), 'bagging_freq': trial.suggest_int('bagging_freq', 1, 7), 'min_child_samples': trial.suggest_int('min_child_samples', 5, 100), } evaluation_results = {} model = lgb.train( param, lgb_train, num_boost_round=1000, valid_names=['train', 'valid'], valid_sets=[lgb_train, lgb_eval], evals_result=evaluation_results, categorical_feature=categorical_features, early_stopping_rounds=50, verbose_eval=10) y_pred = model.predict(X_train, num_iteration=model.best_iteration) # metrics AUC fpr, tpr, thresholds = metrics.roc_curve(y_train, y_pred) score = metrics.auc(fpr, tpr) return score # Optunaでパラメータチューニング study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=10) print('Number of finished trials: {}'.format(len(study.trials))) print('Best trial:') trial = study.best_trial print(' Value: {}'.format(trial.value)) print(' Params: ') for key, value in trial.params.items(): print(' {}: {}'.format(key, value))# 二値分類 params = { 'boosting_type': 'gbdt', 'objective': 'binary', 'metric': 'auc', } # チューニングしたパラメータを合体 params = dict(params, **study.best_params) # 学習 evaluation_results = {} model = lgb.train( param, lgb_train, num_boost_round=1000, valid_names=['train', 'valid'], valid_sets=[lgb_train, lgb_eval], evals_result=evaluation_results, categorical_feature=categorical_features, early_stopping_rounds=50, verbose_eval=10) # best_iterationを保存 optimum_boost_rounds = model.best_iteration# 訓練データを予測 y_pred = model.predict(X_train, num_iteration=model.best_iteration) fpr, tpr, thresholds = metrics.roc_curve(y_train, y_pred) auc = metrics.auc(fpr, tpr) print(auc) plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc) plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True)
# テストデータを予測 y_pred = model.predict(X_test, num_iteration=model.best_iteration) fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred) auc = metrics.auc(fpr, tpr) print(auc) plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc) plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True)
この予測精度の検証では、PyCaret を使用したときとほぼ同じ精度での予測ができました。現実ではこの結果からさらに深堀りした分析を行っていきますが、本記事では PoC フェーズにおける検証はここまでとします。
ここから先は、PoC の結果をビジネス部門に報告し、 PoC のシステムを本番運用していく方針になったと仮定して話を進めていきます。ただ PoC からいきなり本番運用とはならず、実際は何回かのテスト運用を行い、徐々に本番運用に近づけていくはずです。そこで以降では、テスト運用を 3 つのフェーズに分けて検討します。各フェーズで少しずつ機能を追加していき、運用が徐々に自動化され本番運用に近づくようにします。
補足:機械学習モデルの管理
機械学習モデルの管理には、MLflow が便利です。本記事では詳細な説明は省きますが、Optuna で探索した各ハイパーパラメータでのモデルを管理できるなど、モデルの試行数が多くなるにつれて力を発揮します。
テスト運用
テスト運用の 3 つのフェーズ
PoC から本番運用に行くまでには、運用の自動化や推論単体での実行など、いくつかの機能を実装する必要があります。しかし、必要な機能すべてをすぐに実装することは工数的に難しいと思います。(さらに、この段階ではビジネス部門からの依頼でさらなる精度向上を求められていることでしょう。)そこで、必要な機能を 3 つのフェーズに分けて徐々に実装することで、運用しながら機能を拡充していくことにします。各フェーズではそれぞれ以下の機能を実装していきます。
- データパイプラインの構築と運用の半自動化
- 定型運用 API の実装
- クラウドへの移行と運用自動化
テスト運用フェーズ 1:データパイプラインの構築と運用の半自動化
このフェーズでの目的
フェーズ 1 では、PoC で作成したシステムを一部自動化して運用できるようにします。その前に、PoC のプログラムを特徴量エンジニアリングや予測などのブロックに分割・整理して、データパイプラインを構築します。これにより、学習や推論を単体で実行したり、途中から再実行できるようにします。さらに、それぞれのブロックに分けたプログラムを自動実行・スケジューリング実行できるように、ワークフローエンジンである Airflow を導入します。
このフェーズでのアーキテクチャ
PoC では 1 つの Jupyter Notebook で前処理や予測などをまとめて行っていましたが、このフェーズからは複数の Notebook に分割します。そしてそれらの Notebook を順番に実行できるように、新たに 2 つの OSS を導入します。1 つは「papermill」で、この OSS は Jupyter Notebook をコマンドラインから実行でき、かつ実行時にパラメータを渡すことができます。これにより、例えば実行する月をパラメータとして渡すことで、Notebook の中身を書き換えることなく異なる月の予測ができるようになります。さらに、各 Notebook を順番に実行するために「Airflow」を使用します。この OSS は自動実行だけでなく、スケジューリング実行や成功通知・失敗通知など、運用自動化に便利な機能を備えています。
データパイプライン
PoC で作成したプログラムを、「データ蓄積」「特徴量エンジニアリング」「学習」「推論」の4つのブロックに分割します。ブロックに分けるときは、各ブロック同士はデータをインターフェースとすることで、疎結合になるようにします。これによって、プログラムのロジックの変更に伴う影響範囲を限定させます。参考までに、本記事でのデータパイプラインのイメージを記載します。各ブロックでは、プログラムのはじめに papermill からパラメータとして実行月を渡せるように設定しておき、特定の月での実行ができるようにします。
以下には各ブロックのコードを記載します。基本的には PoC で使用したプログラムの再利用で、運用自動化のために多少の追加・修正をしています。
1. データ蓄積
accumulate.ipynb
# パラメータ設定 TARGET_DATE = '20210101' TARGET_DATE = str(TARGET_DATE) # ライブラリ読み込み import pandas as pd from datetime import datetime from dateutil.relativedelta import relativedelta # 初期データ読み込み train = pd.read_csv('../../data/poc/initial.csv') # 月次データ読み込み INITIAL_DATE = '20201001' date = datetime.strptime(INITIAL_DATE, '%Y%m%d') target_date = datetime.strptime(TARGET_DATE, '%Y%m%d') target_dates = [] while date < target_date: print(date) date_str = datetime.strftime(date, '%Y%m%d') target_dates.append(date_str) date += relativedelta(months=1) # データ結合 monthly_dataframes = [train] for d in target_dates: df = pd.read_csv(f'../../data/poc/{d}.csv') monthly_dataframes.append(df) train = pd.concat(monthly_dataframes, axis=0) # 前処理データ出力 train.to_pickle(f'../../data/trial/accumulate_{TARGET_DATE}.pkl')2. 特徴量エンジニアリング
feature_engineering.ipynb
# パラメータ設定 TARGET_DATE = '20210101' # DATA_TYPE = 'train' DATA_TYPE = 'test' TARGET_DATE = str(TARGET_DATE) # ライブラリ読み込み import pandas as pd # データ読み込み if DATA_TYPE == 'train': train = pd.read_pickle(f'../../data/trial/accumulate_{TARGET_DATE}.pkl') elif DATA_TYPE == 'test': train = pd.read_csv(f'../../data/trial/{TARGET_DATE}.csv') # 特徴量選択 features = [ 'EXT_SOURCE_1', 'EXT_SOURCE_3', 'EXT_SOURCE_2', 'DAYS_BIRTH', 'AMT_CREDIT', 'AMT_ANNUITY', 'DAYS_ID_PUBLISH', 'AMT_GOODS_PRICE', 'DAYS_REGISTRATION', 'DAYS_LAST_PHONE_CHANGE', 'AMT_INCOME_TOTAL', 'REGION_POPULATION_RELATIVE', 'OWN_CAR_AGE', 'AMT_REQ_CREDIT_BUREAU_YEAR', 'HOUR_APPR_PROCESS_START', 'TOTALAREA_MODE', 'CODE_GENDER', 'NAME_CONTRACT_TYPE', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS', 'TARGET' ] train = train.loc[:,features] # 欠損値補完 # object型の場合はNAN、それ以外(数値型)は-999で補完する for c in train.columns: if train[c].dtype == 'object': train[c].fillna('NAN', inplace=True) else: train[c].fillna(-999, inplace=True) # カテゴリ変数をダミー化 train = pd.get_dummies(train, drop_first=True, prefix=['CODE_GENDER', 'NAME_CONTRACT_TYPE', 'NAME_EDUCATION_TYPE', 'NAME_FAMILY_STATUS'], prefix_sep='_') # 列がない場合は作成 feature_order = [ 'EXT_SOURCE_1', 'EXT_SOURCE_3', 'EXT_SOURCE_2', 'DAYS_BIRTH', 'AMT_CREDIT', 'AMT_ANNUITY', 'DAYS_ID_PUBLISH', 'AMT_GOODS_PRICE', 'DAYS_REGISTRATION', 'DAYS_LAST_PHONE_CHANGE', 'AMT_INCOME_TOTAL', 'REGION_POPULATION_RELATIVE', 'OWN_CAR_AGE', 'AMT_REQ_CREDIT_BUREAU_YEAR', 'HOUR_APPR_PROCESS_START', 'TOTALAREA_MODE', 'CODE_GENDER_M', 'CODE_GENDER_XNA', 'NAME_CONTRACT_TYPE_Revolving loans', 'NAME_EDUCATION_TYPE_Higher education', 'NAME_EDUCATION_TYPE_Incomplete higher', 'NAME_EDUCATION_TYPE_Lower secondary', 'NAME_EDUCATION_TYPE_Secondary / secondary special', 'NAME_FAMILY_STATUS_Married', 'NAME_FAMILY_STATUS_Separated', 'NAME_FAMILY_STATUS_Single / not married', 'NAME_FAMILY_STATUS_Unknown', 'NAME_FAMILY_STATUS_Widow', 'TARGET', ] for c in feature_order: if c not in train.columns: train[c] = 0 # 列を並び替え train = train.loc[:, feature_order] # 特徴量データ出力 if DATA_TYPE == 'train': train.to_pickle(f'../../data/trial/feature_{TARGET_DATE}.pkl') elif DATA_TYPE == 'test': train.to_pickle(f'../../data/trial/predict_{TARGET_DATE}.pkl')3. 学習
learn.ipynb
# パラメータ設定 TARGET_DATE = '20210101' TARGET_DATE = str(TARGET_DATE) # ライブラリ読み込み import pandas as pd import numpy as np import argparse import shap import optuna import pickle import lightgbm as lgb from sklearn.metrics import accuracy_score, confusion_matrix, recall_score, f1_score, precision_score from sklearn.model_selection import train_test_split from sklearn import datasets from sklearn import metrics from sklearn.model_selection import StratifiedKFold import matplotlib.pyplot as plt # データ読み込み train = pd.read_pickle(f'../../data/trial/feature_{TARGET_DATE}.pkl') # ラベルと特徴量を分離 target = 'TARGET' X = train.drop(columns=target) y = train[target] # 訓練データとテストデータに分割 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y) # 訓練データを一部バリデーション用に分割 X_train, X_eval, y_train, y_eval = train_test_split(X_train, y_train, test_size=0.2, random_state=1, stratify=y_train) # LightGBM用のデータセット作成 categorical_features = [] lgb_train = lgb.Dataset(X_train, y_train, categorical_feature=categorical_features, free_raw_data=False) lgb_eval = lgb.Dataset(X_eval, y_eval, reference=lgb_train, categorical_feature=categorical_features, free_raw_data=False) # パラメータチューニング def objective(trial): param = { 'objective': 'binary', 'metric': 'auc', 'verbosity': -1, 'n_jobs': -1, 'boosting_type': 'gbdt', 'lambda_l1': trial.suggest_loguniform('lambda_l1', 1e-8, 10.0), 'lambda_l2': trial.suggest_loguniform('lambda_l2', 1e-8, 10.0), 'num_leaves': trial.suggest_int('num_leaves', 2, 256), 'feature_fraction': trial.suggest_uniform('feature_fraction', 0.4, 1.0), 'bagging_fraction': trial.suggest_uniform('bagging_fraction', 0.4, 1.0), 'bagging_freq': trial.suggest_int('bagging_freq', 1, 7), 'min_child_samples': trial.suggest_int('min_child_samples', 5, 100), } evaluation_results = {} model = lgb.train( param, lgb_train, num_boost_round=1000, valid_names=['train', 'valid'], valid_sets=[lgb_train, lgb_eval], evals_result=evaluation_results, categorical_feature=categorical_features, early_stopping_rounds=50, verbose_eval=10) y_pred = model.predict(X_train, num_iteration=model.best_iteration) # metrics AUC fpr, tpr, thresholds = metrics.roc_curve(y_train, y_pred) score = metrics.auc(fpr, tpr) return score # Optunaでパラメータチューニング study = optuna.create_study(direction='maximize') study.optimize(objective, n_trials=10) print('Number of finished trials: {}'.format(len(study.trials))) print('Best trial:') trial = study.best_trial print(' Value: {}'.format(trial.value)) print(' Params: ') for key, value in trial.params.items(): print(' {}: {}'.format(key, value)) # 二値分類 params = { 'boosting_type': 'gbdt', 'objective': 'binary', 'metric': 'auc', } # チューニングしたパラメータを合体 params = dict(params, **study.best_params) # 学習 evaluation_results = {} model = lgb.train( param, lgb_train, num_boost_round=1000, valid_names=['train', 'valid'], valid_sets=[lgb_train, lgb_eval], evals_result=evaluation_results, categorical_feature=categorical_features, early_stopping_rounds=50, verbose_eval=10) # best_iterationを保存 optimum_boost_rounds = model.best_iteration # 訓練データを予測 y_pred = model.predict(X_train, num_iteration=model.best_iteration) fpr, tpr, thresholds = metrics.roc_curve(y_train, y_pred) auc = metrics.auc(fpr, tpr) print(auc) plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc) plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) # テストデータを予測 y_pred = model.predict(X_test, num_iteration=model.best_iteration) fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred) auc = metrics.auc(fpr, tpr) print(auc) plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc) plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) # モデル出力 pickle.dump(model, open(f'../../data/trial/model_{TARGET_DATE}.pkl', 'wb'))4. 推論
inference.ipynb
# パラメータ設定 TARGET_DATE = '20210101' TARGET_DATE = str(TARGET_DATE) # ライブラリ読み込み import pandas as pd import numpy as np import pickle import lightgbm as lgb # 予測用データ読み込み test = pd.read_pickle(f'../../data/trial/predict_{TARGET_DATE}.pkl') # モデル読み込み model = pickle.load(open(f'../../data/trial/model_{TARGET_DATE}.pkl', 'rb')) # 予測 test.drop(columns=['TARGET'], inplace=True) y_pred = model.predict(test, num_iteration=model.best_iteration) y_pred_max = np.round(y_pred) # 予測データ作成 pred = pd.DataFrame() # ID読み込み rawdata = pd.read_csv(f'../../data/trial/{TARGET_DATE}.csv') pred['ID'] = rawdata['SK_ID_CURR'] pred['TARGET'] = y_pred_max # 予測データ出力 pred.to_csv(f'../../data/trial/pred_{TARGET_DATE}.csv', index=None)運用の半自動化
各処理が個別のプログラムに分割できたら、Airflow を利用して、それらを順序立てて実行できるようにします。実行時にパラメータとして予測月を渡すことで、その月の実行を行うことができます。またスケジュール実行したい場合は、「schedule_interval」に cron 式でスケジューリング実行の日時を定義できます。以下に、Airflow のコードを記載します。
trial_operation.py
from datetime import timedelta from airflow import DAG from airflow.operators.bash import BashOperator from airflow.utils.dates import days_ago args = { "owner": "admin", } dag = DAG( dag_id="trial_operation", default_args=args, schedule_interval=None, # スケジュール実行したい場合は"0 0 0 * *"のようにcron式で定義する start_date=days_ago(2), dagrun_timeout=timedelta(minutes=60), # tags=[], params={ "target_date": "20210101", "work_dir": "~/Code/between_poc_and_production/notebooks/trial/", }, ) accumulate = BashOperator( task_id="accumulate_train_data", bash_command="papermill --cwd {{ dag_run.conf['work_dir'] }} {{ dag_run.conf['work_dir'] }}accmulate.ipynb {{ dag_run.conf['work_dir'] }}logs/accmulate.ipynb -p TARGET_DATE {{ dag_run.conf['target_date'] }}", dag=dag, ) feat_eng_train = BashOperator( task_id="feature_engineering_train_data", bash_command="papermill --cwd {{ dag_run.conf['work_dir'] }} {{ dag_run.conf['work_dir'] }}feature_engineering.ipynb {{ dag_run.conf['work_dir'] }}logs/feature_engineering.ipynb -p TARGET_DATE {{ dag_run.conf['target_date'] }} -p DATA_TYPE train", dag=dag, ) feat_eng_test = BashOperator( task_id="feature_engineering_test_data", bash_command="papermill --cwd {{ dag_run.conf['work_dir'] }} {{ dag_run.conf['work_dir'] }}feature_engineering.ipynb {{ dag_run.conf['work_dir'] }}logs/feature_engineering.ipynb -p TARGET_DATE {{ dag_run.conf['target_date'] }} -p DATA_TYPE test", dag=dag, ) learn = BashOperator( task_id="learn", bash_command="papermill --cwd {{ dag_run.conf['work_dir'] }} {{ dag_run.conf['work_dir'] }}learn.ipynb {{ dag_run.conf['work_dir'] }}logs/learn.ipynb -p TARGET_DATE {{ dag_run.conf['target_date'] }}", dag=dag, ) inference = BashOperator( task_id="inference", bash_command="papermill --cwd {{ dag_run.conf['work_dir'] }} {{ dag_run.conf['work_dir'] }}inference.ipynb {{ dag_run.conf['work_dir'] }}logs/inference.ipynb -p TARGET_DATE {{ dag_run.conf['target_date'] }}", dag=dag, ) accumulate >> feat_eng_train >> learn [learn, feat_eng_test] >> inference if __name__ == "__main__": dag.cli()Airflow では定義したワークフローをフローチャートのように見ることができます。例えば上記のコードは以下のように可視化されます。この図は先に定義したデータパイプラインと同じ構成になっていることが分かります。(図では、一度予測を実行したため、各ボックスが緑色(実行完了)になっています。)
このフェーズ 1 での実装によって、毎月の運用は以下のように自動化できました。PoC で手作業で行っていた箇所が大幅に自動化できていることが分かります。
- PoC フェーズ
- 予測月のデータをアップロードする
- これまでの月の訓練データを結合する
- 訓練データを前処理・特徴量エンジニアリングする
- 訓練データからモデルを学習する
- テストデータを前処理・特徴量エンジニアリングする
- 学習したモデルを使ってテストデータを予測する
- 予測結果をダウンロードする
- テスト運用フェーズ 1
- 予測月のデータをアップロードする
- Airflow からワークフローを実行する
- 予測結果をダウンロードする
テスト運用フェーズ 2:定型運用 API の実装
このフェーズでの目的
フェーズ 1 では、前処理や推論などの機能を個別のプログラムに分割し、papermill と Airflow を組み合わせることで、毎月の運用を大幅に自動化できました。このフェーズ 2 では、更に自動化を進めていきます。具体的には、フェーズ 1 で手作業としていたデータのアップロード・ダウンロードの実行、定形運用の実行について、それぞれの API とそれを GUI から実行できる画面を用意します。これにより、ビジネス部門をはじめとする非エンジニアのユーザでも簡単に運用ができるようにします。こうすることで、定型的な運用をユーザに任せることができ、エンジニアは開発作業により集中することができます。
このフェーズでのアーキテクチャ
フェーズ 2 では、新たに Web サーバを立て、それを操作できる画面を作ります。
Web サーバの作成
Web サーバには以下の API を用意します。
- 入力ファイルのアップロード機能
- 定形運用の実行機能
- 予測ファイルのダウンロード機能
今回はFastAPI を利用して Web サーバを作成します。
server.py
from fastapi import FastAPI, File, UploadFile import os import shutil from fastapi.middleware.cors import CORSMiddleware from pydantic import BaseModel from fastapi.responses import FileResponse from airflow.api.client.local_client import Client ALLOWED_EXTENSIONS = set(["csv"]) UPLOAD_FOLDER = "./upload" DOWNLOAD_FOLDER = "./download/" app = FastAPI() origins = [ "http://localhost", "http://localhost:3000", ] app.add_middleware( CORSMiddleware, allow_origins=origins, allow_credentials=True, allow_methods=["*"], allow_headers=["*"], ) class PredictParam(BaseModel): target_date: str def allowed_file(filename): return "." in filename and filename.rsplit(".", 1)[1].lower() in ALLOWED_EXTENSIONS @app.post("/api/v1/upload-trial-input") async def upload(file: UploadFile = File(...)): if file and allowed_file(file.filename): filename = file.filename fileobj = file.file upload_dir = open(os.path.join(UPLOAD_FOLDER, filename), "wb+") shutil.copyfileobj(fileobj, upload_dir) upload_dir.close() return {"result": "Success", "message": f"successfully uploaded: {filename}"} if file and not allowed_file(file.filename): return { "result": "Failed", "message": "file is not uploaded or extension is not allowed", } @app.post("/api/v1/execute-trial-operation") async def execute(param: PredictParam): try: c = Client(None, None) c.trigger_dag( dag_id="trial_operation", conf={ "target_date": param.target_date, "work_dir": "~/Code/between_poc_and_production/notebooks/trial/", }, ) return {"result": "Success", "message": "successfully triggered"} except Exception as e: return {"result": "Failed", "message": f"error occured: {e}"} @app.get("/api/v1/download-trial-output") async def download(): return FileResponse( DOWNLOAD_FOLDER + "pred_20210101.csv", filename="pred_20210101.csv", media_type="text/csv", )GUI の作成
GUI では Web サーバの API を実行できるボタンと、データをアップロードできるフォームを用意します。今回はReact とTypescript を利用して自前で作成していますが、streamlit などの画面自体を作成するライブラリを用いたほうが素早く作成できるかもしれません。
App.tsx
import React from 'react'; import { useState } from 'react'; import './App.css'; import { makeStyles, createStyles, Theme } from '@material-ui/core/styles'; import { Toolbar, Button, AppBar, TextField, Divider, Input, Typography, } from '@material-ui/core'; const useStyles = makeStyles((theme: Theme) => createStyles({ root: { '& > *': { margin: theme.spacing(1), }, }, titleText: { paddingTop: '15px', paddingLeft: '15px', }, dateForm: { paddingTop: '10px', paddingLeft: '15px', }, fileForm: { paddingLeft: '15px', paddingBottom: '10px', }, button: { paddingLeft: '15px', }, }) ); const App: React.FC = () => { const classes = useStyles(); const [selectedFile, setSelectedFile] = useState<unknown | null>(); const [executeDate, setExecuteDate] = useState('20210101'); const changeHandler = (event: any) => { setSelectedFile(event.target.files[0]); }; const handelExecuteDate = (event: any) => { setExecuteDate(event.target.value); }; const handleSubmission = () => { const formData = new FormData(); formData.append('file', selectedFile as string); fetch('http://localhost:8000/api/v1/upload-trial-input', { method: 'POST', body: formData, }) .then((response) => response.json()) .then((result) => { console.log(result); }); }; async function postData(url = '', data = {}) { const response = await fetch(url, { method: 'POST', mode: 'cors', headers: { 'Content-Type': 'application/json', }, body: JSON.stringify(data), }); return response.json(); } return ( <> <div className='App'> <AppBar position='static'> <Toolbar variant='dense'> <Typography variant='h6' color='inherit'> Between PoC and Production </Typography> </Toolbar> </AppBar> </div> <Typography variant='h5' gutterBottom className={classes.titleText}> 定形運用 </Typography> <Divider variant='middle' /> <Typography variant='subtitle1' className={classes.titleText}> 実行日時の入力 </Typography> <div className={classes.dateForm}> <form noValidate autoComplete='off'> <TextField required id='standard-basic' value={executeDate} label='YYYYMMDD' InputLabelProps={{ shrink: true }} variant='outlined' onChange={handelExecuteDate} /> </form> </div> <Typography variant='subtitle1' className={classes.titleText}> 入力ファイルのアップロード </Typography> <div className={classes.fileForm}> <Input type='file' onChange={changeHandler} color='primary' /> </div> <div className={classes.button}> <Button onClick={handleSubmission} variant='contained' color='primary'> アップロード </Button> </div> <Typography variant='subtitle1' className={classes.titleText}> 定型運用の実行 </Typography> <div className={classes.button}> <Button onClick={() => postData('http://localhost:8000/api/v1/execute-trial-operation', { target_date: executeDate, }).then((result) => { console.log(result); }) } variant='contained' color='primary' > 予測実行 </Button> </div> <Typography variant='subtitle1' className={classes.titleText}> 予測結果のダウンロード </Typography> <div className={classes.button}> <Button variant='contained' color='primary' href='http://localhost:8000/api/v1/download' > ダウンロード </Button> </div> </> ); }; export default App;画面は以下のようなイメージになります。
テスト運用フェーズ 3:クラウドへの移行と運用自動化
このフェーズでの目的
フェーズ 3 では、さらなる運用の自動化に向けて、サーバをクラウドに移したり、一部の機能をマネージドサービスに移していきます。クラウドを使う目的は、インフラなどの運用をクラウドに任せることにより、システムの可用性を高めたり、アプリのエンハンスやメンテナンスに注力できるようにすることです。2021 年 1 月現在で機械学習システムの運用基盤として利用しやすいクラウドとしては、AWS、GCP、Azure があると思います。基本的な機能はどのクラウドにも共通してありますが、それぞれ特長・特色が異なるので、比較検討してみるのが良いと思います。
本記事では例として AWS への移行を簡単に検討してみます。移行例は 2 つあり、まずテスト運用フェーズ 2 までに作成したシステムをそのまま AWS に移行するパターン 1 と、そこから更に自動化を行ったパターン 2 を記載します。
AWS(Amazon Web Service) でのアーキテクチャパターン 1:EC2 のみのシンプルな構成
各サーバを EC2 上に構築し、データは EBS に格納します。使用感はローカルで動かす Linux とほぼ同じため、移行は難しくないと思います。しかしながら、入力データのアップロードや予測結果のダウンロードは依然手動で行う必要があります。また、システムの各機能はこれまで作ったものをそのまま EC2 で動かしているだけなので、エンハンス・メンテナンスのしやすさはあまり変わっていません。
AWS(Amazon Web Service) でのアーキテクチャパターン 2:更に自動化した構成
このパターン 2 では、パターン 1 で課題だった以下の点を改善しています。
- データ入出力の自動化
- 一部の機能を個別のプログラム・サービスに分割
まずデータ入出力の自動化ですが、共有フォルダとして S3 を使うことで、外部システムとのやり取りの窓口を作ります。CloudWatch・CloudTrail を使って S3 へのデータ入出力を監視し、Lambda を使って Airflow の定型運用 API をコールすることで、入力ファイルの格納をトリガーとして予測システムを実行できます。この仕組みがあれば、GUI や Web サーバを立てる必要がなくなります。クラウド上に Web サーバを立てると、認証機能や脆弱性対策が必要となるので、これらのリスクを抑えることにも繋がります。
また、一部の機能を個別のプログラム・サービスに分割することに関しては、以下のことを行いました
- 入出力ファイルの格納場所を S3 に変更
- システム実行のトリガープログラムを Lambda に移行
- 成功・失敗通知のプログラムを Lambda・SNS に移行
今回分割できた範囲はあまり広くありませんが、AWS の他のサービスを使うことで更にプログラムを分割し、エンハンス・メンテナンスがしやすくできると思います。ただし、あまり広げすぎるとベンダーロックインになりかねないので、移行容易性も合わせて検討する必要があります。
これでテスト運用フェーズ 3 までの検討はすべて完了しました。最初期に PoC で JupyterLab のみで分析を行っていた状況からは大きく変わったことが分かります。PoC のようなオンデマンドの分析業務を実際に運用していくには、技術的・ビジネス的にたくさんのハードルがありますが、今回検討したような手法が参考になれば幸いです。
本番運用に向けて追加で検討すべきこと
最後にこの章では、本番運用に向けて検討すべきことをリストアップしていきます。
クラウドの活用
テスト運用フェーズ 3 ではクラウドへの移行を行いましたが、クラウドには他にも様々な機能があるため、移植性を大きく損なわない範囲に活用すると良いです。例えば社内の認証機能とクラウドの認証機能を結びつけてデータガバナンスを導入したり、オートスケーリング機能を活用してより大きな規模のデータに対応するなどがあります。
また、自前のコードを極力排除して、マネージドサービスに移行することも大切です。長期に渡って運用していくことを考えると、自前のコードはメンテナンス性が低く、また属人的でもあるので、似た機能を持つサービスがあれば活用することも検討すべきです。例えば Airflow は GCP の「Cloud Composer」や AWS の「Amazon Managed Workflows for Apache Airflow」といったマネージドサービスがあるので、これらを使うことも一考の余地があります。
プログラムの再利用性
本記事では一貫して Jupyter Notebook での開発・運用を行ってきました。Jupyter Notebook は開発が簡単で便利な一方、Git での管理や実行、テストのし易さに難があります。開発スピードと品質の兼ね合いを見て、適宜 py ファイルに移行していくと良いかもしれません。また、このシステム自体を Docker や Kubernetes 上に構築できれば、システムの堅牢性を高められたり、処理のスケーリングが容易になるだけでなく、他の案件への展開が容易になるなどのビジネス上のメリットも大きいはずです。
データの保管方法
本記事ではデータは CSV または Pickle 形式で保管していましたが、どのデータをどの形式で保管するかは検討しておくと良いです。そのためにも、データパイプラインを策定した段階で、各データの定義書をスプレッドシートなどで管理すると後々役立ちます。筆者は、再作成が難しいデータ(入力データ)や外部との連携が必要なデータ(予測結果)は CSV、中間生成データは Pickle 形式で保管することが多いです。Pickle 形式は便利な反面、汎用性や安全性に乏しいため、データ型を別途定義して CSV で補完するか、知見がある人は「Parquet」と使うと良いかもしれません。
データのモニタリング
機械学習システムを継続的に運用していくためには、システムだけでなく、データにも気を配る必要があります。例えば入力データの傾向が変わってしまうと、システムに問題はなくとも予測精度に大きな影響を与える可能性があります。そこで、入力データをモニタリングする、例えば各列のデータの分布やラベルとの関係性は変わっていないかをチェックする必要があります。また、作成しているシステムによっては公平な予測ができているか、例えば男女によって予測結果が大きく変わることはないかといった予測の公平性という観点でも検証する必要があります。
データのガバナンス
PoC レベルであればデータへのアクセス権限は自然と絞られると思いますが、運用が長くなり、システムの関係者が多くなる場合は、データごとに適切なアクセス権限を設定する必要が出てきます。このような場合には、クラウドサービスの認証機能を活用すると良いです。例えば AWS の IAM で個別のアカウントを作成することで、個人個人の部署や役職に応じて S3 に格納したデータへのアクセス権限を柔軟に設定できます。また、クラウドサービスには社内の認証基盤と統合できる機能があるため、これらを活用するのも良いと思います。
本記事で利用したソフトウェアとそのバージョン
本記事で例として構築したシステムのソースは以下の GitHub のリポジトリに格納してあります。
https://github.com/koyaaarr/between_poc_and_production
使用した主なソフトウェアのバージョンは以下の通りです。
Software Version JupyterLab 2.1.5 Airflow 2.0.0 MLflow 1.13.1 papermill 2.2.2 FastAPI 0.63.0 React 17.0.1 Typescript 4.1.3 PyCaret 2.2.3 pandas 1.1.4 Bokeh 2.2.3 参考にした文献
機械学習プロジェクトの進め方に関して
- データ分析・AI のビジネス導入 (https://www.amazon.co.jp/dp/4627854110)
- 仕事ではじめる機械学習 (https://www.amazon.co.jp/dp/4873118255)
データ分析の技術に関して
- 前処理大全 (https://www.amazon.co.jp/dp/4774196479)
- Kaggle で勝つデータ分析の技術 (https://www.amazon.co.jp/dp/4297108437)
- 機械学習のための特徴量エンジニアリング (https://www.amazon.co.jp/dp/4873118689)
ユーザーインターフェースに関して
- Material UI (https://material-ui.com/)
機械学習 PoC システムの設計に関して
- Beyond Interactive: Notebook Innovation at Netflix (https://netflixtechblog.com/notebook-innovation-591ee3221233)
- Airflow を用いたデータフロー分散処理 (https://analytics.livesense.co.jp/entry/2018/02/06/132842)
- Jupyter だけで機械学習を実サービス展開できる基盤 (https://engineer.recruit-lifestyle.co.jp/techblog/2018-10-04-ml-platform/)
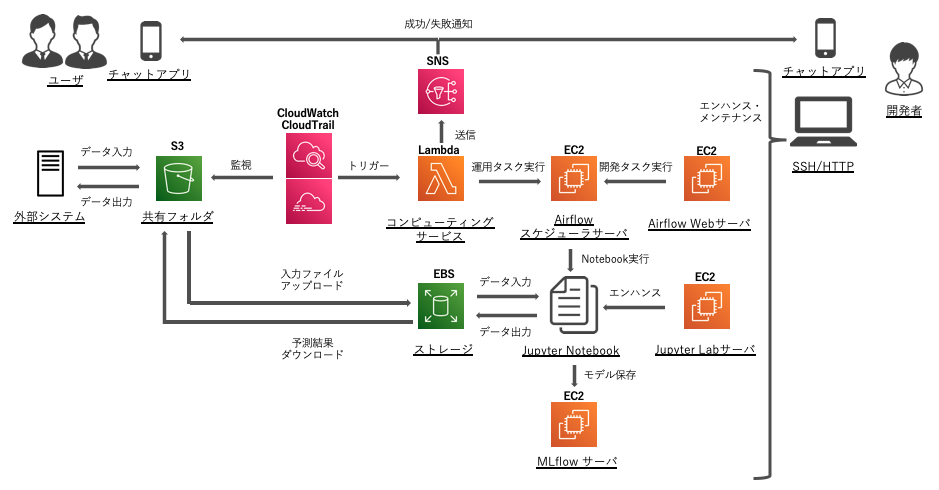
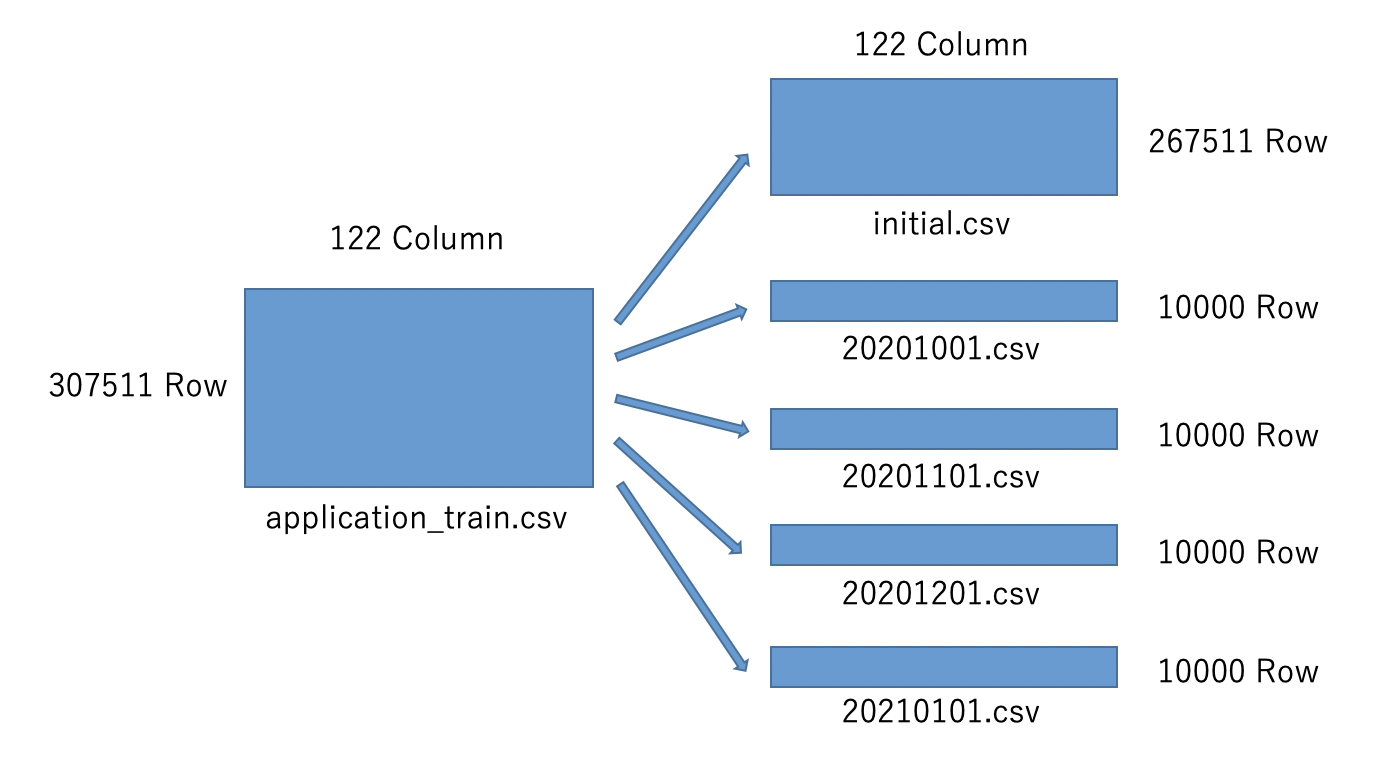


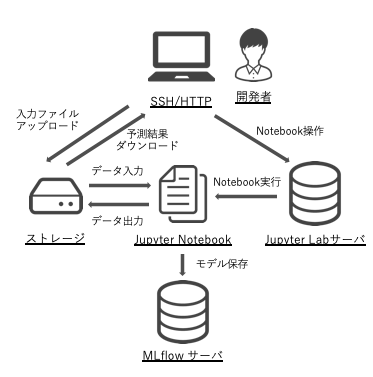


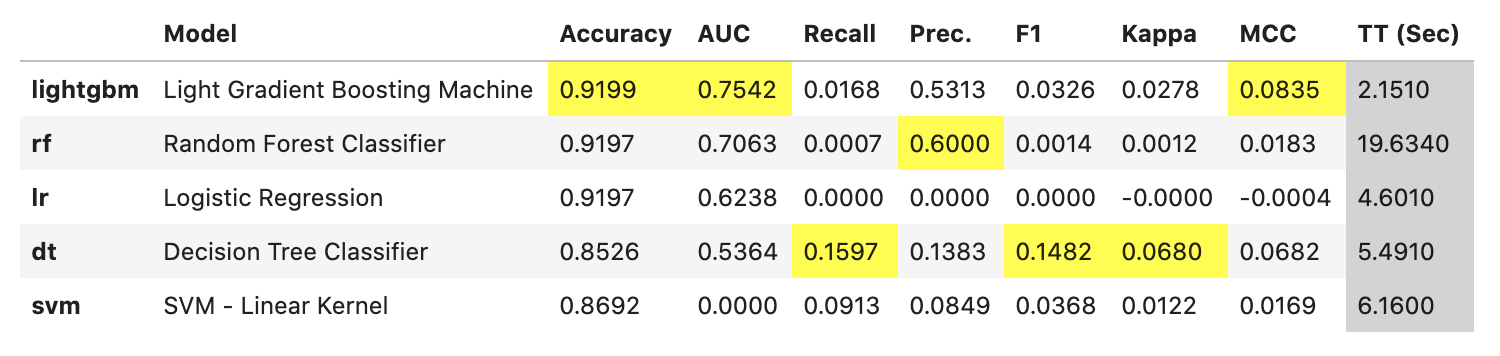




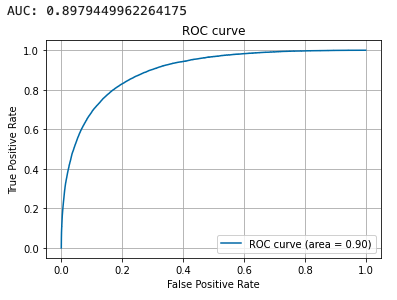






- 投稿日:2021-01-29T09:56:01+09:00
はじめてEC2の環境構築をしてみた。超ざっくりまとめてみた。
今回、AWSの基礎を学ぶ目的でEC2の環境構築と自分のPCから接続まで行いました!
細かい作業過程は割愛しますが、EC2環境構築で理解した基本構成の概要を自分の理解を深めるために、超ざっくりと基本要素をまとめます。
これを見れば、何の目的のために何を作るのか、一目で思い出せるはず!
また、この記事が、これからAWSの基礎学習を始める方の理解の助けとなり、AWSを触るハードルを下げる助けとなれば幸いです。みなさん頑張りましょう!
なお、AWSの学習は、AWS CloudTechを利用しています。
テンポの良い/わかりやすい動画説明をもとに、気軽に実践を積み、自分の血肉とできるオンラインスクールです。
コミュニティも存在し、Slackで会員通しの情報交換/質問も気楽にできます。
書籍を購入するような値段で学習ができ、とてもお得です。(個人的な感想です)
前置きは、これまでとして、そろそろ始めます。
- 説明を極力シンプルにするために、AWSのアカウント作成、IAMユーザの登録は完了している状態から始めます。
- 作図には AWS 公式アイコンセットを利用してます
- 全般的に概念的な説明のみとしています。
- 詳細なオペレーションを知りたい方は、この動画を参照して下さい。
最小限の構成要素での作り方
超ざっくりと説明すと、以下を行うだけです。
1. 自分用のネットワークを確保する
2. サーバを作成する
3. 外部からアクセスできるようにネットワークの設定を行うこれだけで、さくっと作れてしまいます。
1. 自分用のネットワークを確保する
AWSマネジメントコンソール(ブラウザ)から以下を作成します。
- 仮想ネットワーク:VPC(Virtual Private Cloud)
- VPC内にサブネット
上記のようなGUIで初心者でも簡単に作成できます。ここまでで以下構成が作成されています。
サブネットは、Availability Zoneを一つ決めてそこに作成します。
Availability Zoneは”データセンタのようなもの”と思ってください。
※最後に説明しますまた、今回の説明で記載するCIDERブロック(10.0.0.0/24)は、例の中で仮に設定しておりますので、他の値でも構いません。
※これ以降の記載でも他CIDERブロック(10.0.2.0/24)が出てきますが、それも同様です。2. サーバを作成する
これもAWSマネジメントコンソールで簡単に作成できます。(EC2インスタンスの作成と言います)
以下を順に指定していきます。
- OS
- CPU/メモリ
- サーバ配置先のサブネット
- ストレージ
- サーバ名 etc.
ここまでで以下構成が作成されています。
3. 外部からアクセスできるようにネットワークの設定を行う
外部からアクセスできるようにするためには以下を実施していきます。
- インターネットゲートウエイを作成し、VPCにアタッチ
- サブネットのルートテーブルへの設定
- EC2インスタンスに対するセキュリティグループの設定
インターネットゲートウエイは、インターネットとのやり取りをする口です。
これを作成し、VPCにアタッチすることで、VPCからインターネットに出入りすることが可能になります。また、どの宛先の通信の時に、VPC内部でのルーティングとし、どの場合にインターネットへルーティングするかの設定を行うため、サブネットのルートテーブル設定を行います。
最後に、セキュリティの観点からEC2アクセスに関するインバウンド/アウトバウンドルールの設定を行います。(F/W設定のようなものです)
これがセキュリティグループ設定です。ここまでで以下構成となりました。
以上で完成です。チュートリアルを見ながらやれば、時間もかからずサーバが作れてしまいます。
また一度触ってみると言葉/AWSのコンソールに慣れ、勉強のハードルがぐっと下がります。
壊しても作り直せばよいので、興味がある方は、どんどん触ることをお勧めします。なお、機密性が高いサーバがある場合は、インターネットに接続しないセグメント(Private subnet)を作成し、そこに置くことをお勧めします。
構成図としては以下のようになります。
これは、このサイトの講座1~4を実施することでハンズオンできます。
ぜひ自分の手を動かして、心のハードルを下げてください。
おまけ-Availability Zone-
- Availability Zone(以下AZと記載します)とは、物理的、ソフトウェア的に自律しているデータセンタの集合の単位です。
- AZというのは1つのデータセンタの事を指しているわけではなく、1つのAZは1つ以上のデータセンタから構成されています。
- ただし、同じAZに属するデータセンタ間の通信の遅延は0.25ms未満かつ帯域も十分に太いようです。概念的には1つの大きなデータセンタとみなしても差し支えなさそうですが、実際には複数のデータセンタから構成されていることがあります。
- AZ間の通信遅延は2ms未満になるように設計されていて、実際にはそれぞれのAZは100km以内に立地しているということです。

今回の記事では記載しませんでしたが、データセンタ障害などを考えると、AZをまたいでの冗長化を行う必要がります。
※複数のサブネットを異なるAZ上に作成し、その上にEC2インスタンスを配置しAZをまたいだ冗長化構成をとる










- 投稿日:2021-01-29T07:55:31+09:00
ECS+ロードバランサー的なことをEC2で実現して、コスト削減
dockerで開発している場合に、ECSとロードバランサーを遣うと、SSL環境でのサブドメインステージング環境とかあっという間に立てられますよね。
なれてないときはそんなのでポコポコサーバーを立てていたいのですが、ロードバランサー毎に費用がかかったりして立ち上げ期とかで開発予算が少ないときはなにげにボディーブローとなります。そこで、極小のリソースでワードプレスをAWS上に立ててみた方法をまとめます
要件
- 規模が大きくなってきたときにECSを遣うことを想定してそれに近い環境を構築する
- ほぼほぼ、それに近い形の開発環境でdocker-composeで実現する。というか、開発環境のdocker-composeをできる限りAWS上で実現する
- 取得済みのサブドメインでアクセスできる様にする
- 当然SSL接続を実現する
手順
ということで、wordpress のdocker環境をawsに立てる手順をまとめます
- amazon linux2 のEC2イメージを立てる
- 1のEC2イメージにdocker-compose可能な環境を構築する
- route53にドメインが登録されていることを前提に、1のEC2イメージにサブドメインでアクセスできる様にする
- 1のEC2イメージのapacheを設定しサブドメインでのアクセスに対応する
- 1のEC2イメージに無料のSSLをインストールする
- 1のEC2イメージにwordpressのdocker環境を作成して、81版ポートでアクセスできる様に設定する
- まずは sslなしのポート直接指定でアクセスする
- 1のEC2イメージのポートフォワード設定をし、ssl接続を可能にする
1. amazon linux2 のEC2イメージを立てる
AWSのアカウントはお持ちでしょうか?
AWSって、サインアップから12ヶ月間の無料枠が結構充実しているんですよね。
AWSのハンズオンイベントに参加すると、新規アカウントを作って初年度の無料クレジットを使ってハンズオンする手順が前提になっていたりします。
ということで、AWSのアカウントを作って12ヶ月以上経っている場合も異なるメールアドレスで新たにアカウント作成して無料枠で色々試してみるということが半ば公式になっていると考えていもいいかもですね。。
開発環境のdockerイメージのとして、centosやubuntuを選択していることが多いかと思いますし、最近だとalpineイメージをベースにして極限までdockerimageを減らす方法もおおい気もします。
で、docker imageを動かすことを前提にEC2環境を構築するとなると、EC2タイプのECSと同じ環境を構築すればいいのかなと。それが amazon-linux-2の様で、下を見ると別のECSに特化しているわけではなさそうです。中身は redhatとのことで、運用に当たって web上でも情報が検索出来る感じになっています
なにげに何か必要なものが出てきたら yum install でインストールして行きます今回必要なEC2イメージは 将来ECSに移行したときに再テストの懸念を極小にすることを念頭に置いているので、ECS向けのEC2構築と同じ手順で立ててみます。
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/getting-started-ecs-ec2.html
2021年1月現在、上の手順の真ん中辺にある「Amazon ECS-optimized AMI」がそれに当たります
AMIイメージにたどり着くのが結構大変なのですが
- https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/ecs-optimized_AMI.html
- Amazon ECS-optimized Amazon Linux 2 AMI バリアントという情報を知る
- AMI IDをAWS CLIで取得する(AWS CLIのインストールが必要・・)
- と書いてあるものの、こちらのページで最新情報がリストされていると見つける https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/ecs-ami-versions.html#ecs-ami-versions-linux
- Amazon ECS-optimized Amazon Linux 2 AMI の最新IDを見つけます
けど、image idが分からないんですよね。。とはいえ、ここでは、
20201209というキーワードが見つかるので、"ECS optimized 20201209"というキーワードで検索してみると・・
コミュニティAMIで一件見つかりました
正解は "amzn2-ami-ecs-hvm x86_64 20201209" とかで投げた結果が今の時点ではよさそうです。
もっと確実なのは、ちなみに AWS-CLIでコマンドを投げて返ってくる情報
この結果を基にすると
ami-021541b9f47c3c5ccにより、マシンイメージが特定されるわけです
違うのが返ってくるけど、まあ、amazon-ecs-optimizedとなっているのでどちらでも大丈夫そう・・
今回はAWS-CLIコマンドで返ってくるimage-idで作成します。
- EC2ダッシュボード → インスタンスを起動 →image-idで検索 → t2.microを選択 → "インスタンスの詳細設定", "ストレージの追加" それぞれデフォルトで進む(IAMロールとか特に設定しなくても目的は達せられます)
- セキュリティグループ設定:とりあえずは ssh, http, httpsを必要に応じて設定しましょう。ロードバランサーを遣わないので、このインスタンスに外部から直接つながる様に設定する必要があります
2. 1のEC2イメージにdocker-compose可能な環境を構築する
- userの作成(下の例では someuser) とsudo権限付与
- 'sudo adduser someuser'
- 'sudo visudo'
- %wheel ALL=(ALL) NOPASSWD: ALL のコメントを外す
- 'sudo usermod -aG wheel someuser'
- dockerのインストール→インストール済みだった。。
- 起動時にdockerが立ち上がっているようにする 'sudo systemctl enable docker'
- docker-composeの取得(最新版だとGLIBCのエラーになるのでその場合はバージョンを下げます)
- sudo curl -L "https://github.com/docker/compose/releases/download/1.28.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
- sudo chmod +x /usr/local/bin/docker-compose
3. route53にドメインが登録されていることを前提に、1のEC2イメージにサブドメインでアクセスできる様にする
4. 1のEC2イメージのapacheを設定しサブドメインでのアクセスに対応する
5. 1のEC2イメージに無料のSSLをインストールする
6. 1のEC2イメージにwordpressのdocker環境を作成して、81版ポートでアクセスできる様に設定する
7. まずは sslなしのポート直接指定でアクセスする
8. 1のEC2イメージのポートフォワード設定をし、ssl接続を可能にする




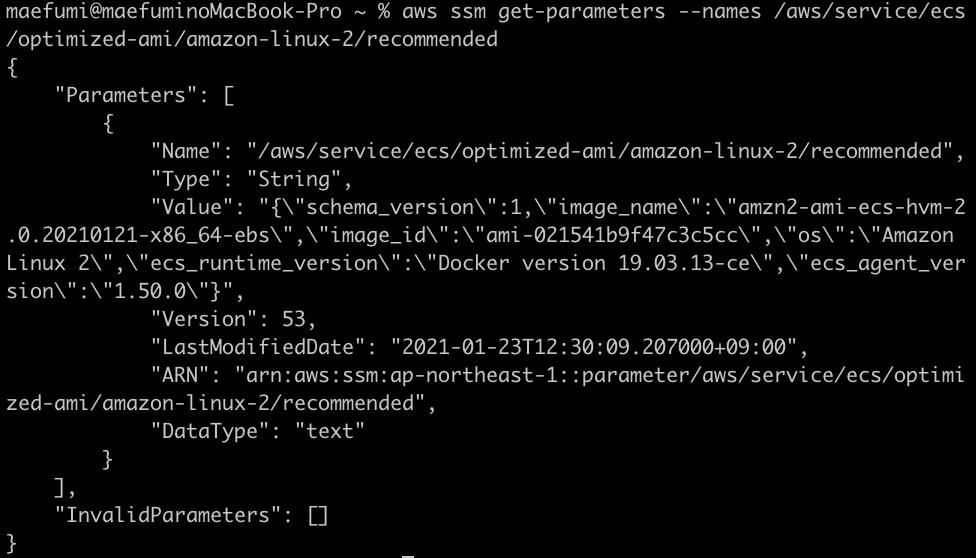
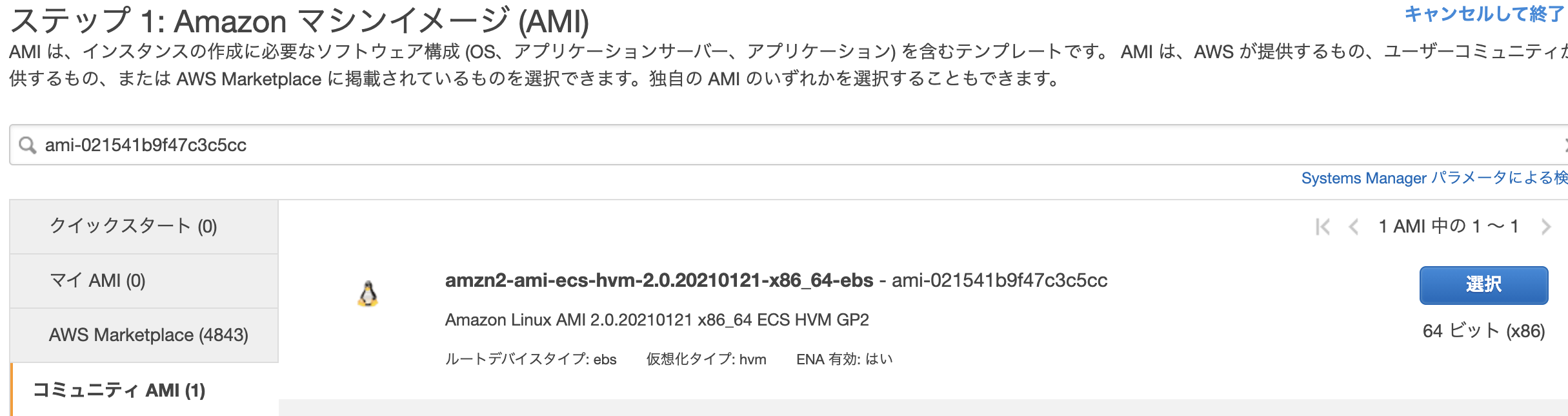


- 投稿日:2021-01-29T07:55:31+09:00
[書きかけ] ECS+ロードバランサー的なことをEC2で実現して、コスト削減
dockerで開発している場合に、ECSとロードバランサーを遣うと、SSL環境でのサブドメインステージング環境とかあっという間に立てられますよね。
なれてないときはそんなのでポコポコサーバーを立てていたいのですが、ロードバランサー毎に費用がかかったりして立ち上げ期とかで開発予算が少ないときはなにげにボディーブローとなります。そこで、極小のリソースでワードプレスをAWS上に立ててみた方法をまとめます
要件
- 規模が大きくなってきたときにECSを遣うことを想定してそれに近い環境を構築する
- ほぼほぼ、それに近い形の開発環境でdocker-composeで実現する。というか、開発環境のdocker-composeをできる限りAWS上で実現する
- 取得済みのサブドメインでアクセスできる様にする
- 当然SSL接続を実現する
手順
ということで、wordpress のdocker環境をawsに立てる手順をまとめます
- amazon linux2 のEC2イメージを立てる
- 1のEC2イメージにdocker-compose可能な環境を構築する
- route53にドメインが登録されていることを前提に、1のEC2イメージにサブドメインでアクセスできる様にする
- 1のEC2イメージに無料のSSLをインストールする
- 1のEC2イメージにwordpressのdocker環境を作成して、81版ポートでアクセスできる様に設定する
- まずは sslなしのポート直接指定でアクセスする
- 1のEC2イメージのポートフォワード設定をし、ssl接続を可能にする
1. amazon linux2 のEC2イメージを立てる
AWSのアカウントはお持ちでしょうか?
AWSって、サインアップから12ヶ月間の無料枠が結構充実しているんですよね。
AWSのハンズオンイベントに参加すると、新規アカウントを作って初年度の無料クレジットを使ってハンズオンする手順が前提になっていたりします。
ということで、AWSのアカウントを作って12ヶ月以上経っている場合も異なるメールアドレスで新たにアカウント作成して無料枠で色々試してみるということが半ば公式になっていると考えていもいいかもですね。。
開発環境のdockerイメージのとして、centosやubuntuを選択していることが多いかと思いますし、最近だとalpineイメージをベースにして極限までdockerimageを減らす方法もおおい気もします。
で、docker imageを動かすことを前提にEC2環境を構築するとなると、EC2タイプのECSと同じ環境を構築すればいいのかなと。それが amazon-linux-2の様で、下を見ると別のECSに特化しているわけではなさそうです。中身は redhatとのことで、運用に当たって web上でも情報が検索出来る感じになっています
なにげに何か必要なものが出てきたら yum install でインストールして行きます今回必要なEC2イメージは 将来ECSに移行したときに再テストの懸念を極小にすることを念頭に置いているので、ECS向けのEC2構築と同じ手順で立ててみます。
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/getting-started-ecs-ec2.html
2021年1月現在、上の手順の真ん中辺にある「Amazon ECS-optimized AMI」がそれに当たります
AMIイメージにたどり着くのが結構大変なのですが
- https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/ecs-optimized_AMI.html
- Amazon ECS-optimized Amazon Linux 2 AMI バリアントという情報を知る
- AMI IDをAWS CLIで取得する(AWS CLIのインストールが必要・・)
- と書いてあるものの、こちらのページで最新情報がリストされていると見つける https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/ecs-ami-versions.html#ecs-ami-versions-linux
- Amazon ECS-optimized Amazon Linux 2 AMI の最新IDを見つけます
けど、image idが分からないんですよね。。とはいえ、ここでは、
20201209というキーワードが見つかるので、"ECS optimized 20201209"というキーワードで検索してみると・・
コミュニティAMIで一件見つかりました
正解は "amzn2-ami-ecs-hvm x86_64 20201209" とかで投げた結果が今の時点ではよさそうです。
もっと確実なのは、ちなみに AWS-CLIでコマンドを投げて返ってくる情報
この結果を基にすると
ami-021541b9f47c3c5ccにより、マシンイメージが特定されるわけです
違うのが返ってくるけど、まあ、amazon-ecs-optimizedとなっているのでどちらでも大丈夫そう・・
今回はAWS-CLIコマンドで返ってくるimage-idで作成します。
- EC2ダッシュボード → インスタンスを起動 →image-idで検索 → t2.microを選択 → "インスタンスの詳細設定", "ストレージの追加" それぞれデフォルトで進む(IAMロールとか特に設定しなくても目的は達せられます)
- セキュリティグループ設定:とりあえずは ssh, http, httpsを必要に応じて設定しましょう。ロードバランサーを遣わないので、このインスタンスに外部から直接つながる様に設定する必要があります
2. 1のEC2イメージにdocker-compose可能な環境を構築する
- userの作成(下の例では someuser) とsudo権限付与
- 'sudo adduser someuser'
- 'sudo visudo'
- %wheel ALL=(ALL) NOPASSWD: ALL のコメントを外す
- 'sudo usermod -aG wheel someuser'
- dockerのインストール→インストール済みだった。。
- 起動時にdockerが立ち上がっているようにする 'sudo systemctl enable docker'
- docker-composeの取得(最新版だとGLIBCのエラーになるのでその場合はバージョンを下げます)
- sudo curl -L "https://github.com/docker/compose/releases/download/1.28.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
- sudo chmod +x /usr/local/bin/docker-compose
3. route53にドメインが登録されていることを前提に、1のEC2イメージにサブドメインでアクセスできる様にする
3-1. 固定ipをわりあてる。
起動しているEC2インスタンスに対してelastic ipを使う場合は料金が発生しないとのこと!
2. Elastic IPアドレスの割り当て 3. Elastic IPアドレスの関連付け 4. 上で起動したインスタンスを選択して「関連付ける」
3-2. DNS(Route53)でサブドメインを割り当てる
(既にホストゾーンが作成されていることを前提としています)
* 上で取得したIPアドレスをAレコードとして、サブドメン設定を追加する
* レコード名:サブドメイン ○○.sample.jp とか
* レコードタイプ:A
* 値:上で取得したipアドレス
* その他 デフォルト値で大丈夫かと (ex. TTL=300)4. 1のEC2イメージに無料のSSLをインストールする
ここからは1で作成したEC2イメージに ssh接続しての作業になります
インスタンス概要の「接続」の説明等が参考になります
色々とわかりやすい記事もたくさんあるので、こちらでは割愛します
4-1. apacheにバーチャルホストを設定する
大事なのは、次のプロセスで、certbot というツールを使って、証明書を取得するのですが、その際に証明書を取得したいアドレスでhttp接続出来ることが必要なのです。
ということで、まずはhttpサーバーを立てます。ここではapacheをインストールして、サービス登録します
(この先rootユーザーではなく、ステップ2で作ったユーザーでログインしている前提なので注意)sudo yum install -y httpd sudo systemctl start httpd sudo systemctl enable httpdこの環境だと、/etc/httpd/conf配下に httpd.confファイルがあるので、設定ファイル httpd.confを編集し、接続したいサブドメインをバーチャルホストとして設定します
設定の例はこちら
https://httpd.apache.org/docs/2.2/ja/vhosts/examples.htmlsudo vi /etc/httpd/conf/httpd.conf42行目あたりの
Listen 80を見つけて、その下あたりに次の様な設定を記載する
sub.sample.jp のあたりを書き換えてください。
ここでは、/var/www/html 配下のファイルを sub.sample.jpでアクセスできる様に設定しています
ちなみに、viコマンドで行番号を表示する場合 esc で:set numberで表示されます
DocumentRoot /var/www/html
ServerName sub.sample.jpOther directives here
書き換えたらsudo systemctl restart httpdで再起動します。
エラーがでたら、httpd.confの記載を見直してください4-2.certbotをインストールして証明書を導入
次の順番でcertbotがインストール出来ました
sudo yum install -y wget sudo yum install -y yum-config-manager sudo wget -r --no-parent -A 'epel-release-*.rpm' http://dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/ sudo rpm -Uvh dl.fedoraproject.org/pub/epel/7/x86_64/Packages/e/epel-release-*.rpm sudo amazon-linux-extras install epel -y sudo yum install -y certbot python2-certbot-apacheapacheに対して、SSL設定を導入します
sudo certbot
すると下のメッセージが得られるので、サブドメインを入力します
ここまで出来ていたら、certbotコマンドで証明書がインストール出来るはずなので、詳細は割愛します。
詳しくはcertbot apacheとかで検索してみて下さい
参考:https://avinton.com/academy/creating-ssl-certificate-by-certbot/
インストールすると、/etc/httpd/conf 下に httpd-le-ssl.confが生成され、
/etc/httpd/conf/httpd.confのバーチャルホスト設定に以下が追記されるようですRewriteEngine on RewriteCond %{SERVER_NAME} =wp.urcareer.jp RewriteRule ^ https://%{SERVER_NAME}%{REQUEST_URI} [END,NE,R=permanent]と最後の行に
Include /etc/httpd/conf/httpd-le-ssl.conf4-3. 証明書更新をスケジュールする
この状態だと3ヶ月で証明書が切れてしまうので、スケジューラー cronで自動更新するように設定します
crontab -e
でcron設定のエディタを起動し
00 04 01 * * root /bin/certbot renew --webroot-path /var/www/html/ --post-hook "systemctl reload httpd"と入力しますで、https://sub.sample.jpとかにアクセス出来るか確認してみましょう
5. 1のEC2イメージにwordpressのdocker環境を作成して、81版ポートでアクセスできる様に設定する
6. まずは sslなしのポート直接指定でアクセスする
7. 1のEC2イメージのポートフォワード設定をし、ssl接続を可能にする



- 投稿日:2021-01-29T07:02:01+09:00
jqを使いながら、aws cliで取得した一時認証情報を環境変数に設定する
はじめに
AWS CLIを使用してIAMロールを引き受ける方法は、公式ドキュメントの通り1ですが、コマンド結果から都度コピペで
AWS_ACCESS_KEY_IDなどの環境変数を設定するのは手間です。本記事では、得られたjsonをjqでパースし、環境変数を設定する方法を説明します。
必要なもの
- awscli
- jq
AWS CloudShell には両方入っているので、とりあえず試すにはおすすめです。
おことわり
~/.aws/configを使うことでより簡単に設定できます2が、一時的な対応とかで必要になるケースがあり、本記事を作成しました。手順
以下のbashスクリプトのとおりです。
ROLE_ARNとSESSION_NAMEを設定し実行するだけです。# def var ROLE_ARN=arn:aws:iam::${ACCOUNT_ID}:role/${ROLE_NAME} SESSION_NAME=some-session # command eval $( aws sts assume-role --role-arn $ROLE_ARN --role-session-name $SESSION_NAME \ | jq -r '[ "export AWS_ACCESS_KEY_ID=" + (.Credentials.AccessKeyId|tostring), "export AWS_SECRET_ACCESS_KEY=" + (.Credentials.SecretAccessKey|tostring), "export AWS_SESSION_TOKEN=" + (.Credentials.SessionToken|tostring) ] | join(";") ' )正しく設定できているかは
aws sts get-caller-identityで確認してください。
- 投稿日:2021-01-29T04:50:10+09:00
Rails デプロイ後 iPhoneでの閲覧時のみページ遷移の挙動がおかしい
はじめに
Qiita初投稿です。
間違っている点、補足等あればご教授いただけますと幸いです。環境
Rails 5.2.4.4
起こったこと
デプロイ後、PCでは問題なく動くのに、iPhoneを使うと挙動がおかしくなりました。
原因発見にかなり時間がかかりましたので共有します。
まずは、具体的な事象を記載します。
- Deviceで実装したユーザー登録画面にiPhoneでアクセスすると画面が真っ白に
- 標準出力を見ると何度も同ページでリロードが行われている
- エラーメッセージは出力されず
- リンクからのアクセスではなく、URL直打ちの場合はアクセスできる ※ここが原因発見の鍵になりました。
原因
結論から申し上げますと、ターボリンクスが影響していました。
ページ遷移の高速化のため、Rails4から標準で搭載されています(application.jsに記載があります)。
JQueryの挙動に影響があるという記事も多いですが、
スマートフォンで、入力フォーム等のページへ遷移する際にエラーが起きる場合があるようです。解決策
_header.html.erb<%= link_to "新規登録", new_user_registration_path, data: {"turbolinks" => false} %>該当のリンクにターボリンクス無効化の記載をすれば問題なくアクセスできるようになりました。
念のためログインページ等フォームが絡むページにも記載。
原因が分かれば一瞬でした、、!
- 投稿日:2021-01-29T01:59:12+09:00
SpringBoot + JUnit + AWS Codebuild で レポート作成
前回 SpringBoot プロジェクトで JUnit のテストを行ってみました。
せっかくなので、テスト結果をAWSに保存するところまで試してみましょう。
流れとしては、
1. GitHub に push
2. その内容を CodeBuild でビルドとテストを実施
3. テストフェーズで作成されたテスト結果を AWS に保存して参照するといった方法で利用する想定です。
TL;DR
- buildspec.yml にテスト結果の xml をレポートとして保存する設定を追加
- CodeBuild のレポートグループから確認する
目次
1.CodeBuild でビルドプロジェクトを作成
2.buildspec.ymlの設定を追加
3.ビルド、テストを実行して結果の確認では早速始めましょう。
1. CodeBuild でビルドプロジェクトを作成
ビルドを行うためのビルドプロジェクトを作成しましょう。
- CodeBuild を検索
- 左メニューの
ビルド>ビルドプロジェクト>ビルドプロジェクトを作成する- 以下のパラメータを入力して
ビルドプロジェクトを作成する
key val プロジェクト名 任意の名前を入力 (例: testsample)説明 任意の説明を入力 ビルドバッジを有効にする false ソースプロバイダ GitHub リポジトリ パブリックリポジトリ GitHub リポジトリ GitHub repository の url を入力 環境イメージ マネージド型イメージ オペレーティングシステム Amazon Linux 2 ランタイム Standard イメージ aws/codebuild/amazonlinux2-x86_64-standard:3.0 イメージのバージョン 最新のバージョンを選択する 環境タイプ Linux サービスロール 新しいサービスロール ロール名 任意のロール名を入力 (例: testsample-role)ビルド仕様 buildspec ファイルを使用する Buildspec 名 バッチ設定を定義 false アーティファクト タイプ アーティファクトなし CloudWatch Logs true 2. buildspec.yml の設定を追加
buildspec.yml にレポート結果の設定を追加する。
SpringBootプロジェクトのルートに buildspec.yml を追加する。buildspec.ymlversion: 0.2 phases: build: commands: - echo start build at `date` - ./gradlew test - ls -la build/test-results/test reports: test-report: files: - '*' base-directory: build/test-results/test discard-paths: no定義した内容は、
phases.build.commands
ビルド時に実行するコマンドを定義する。./gradlew testでテストを実行する。reports
テストレポートの出力に関する設定test-report
任意のレポート名を設定する。テスト結果を保存するレポートグループの名前になる。
作られるレポートグループは<ビルドプロジェクト名>-<レポート名>になる。files, base-directory
レポート結果のファイルを指定する。base-directory からの相対パスを設定する。discard-paths
filesで指定したファイルの階層構造を保持する、しないを設定する。
noに設定すると
./build/test-results/test/TEST-com.sample.testsample.UserServiceTests.xml
が
./TEST-com.sample.testsample.UserServiceTests.xml
として保存される。3. ビルド、テストを実行して結果の確認
設定が追加できたら実際に実行してみましょう。
- CodeBuild を検索
- 左メニューの
ビルド>ビルドプロジェクト> 先ほど作成したプロジェクトを選択- ビルドを開始
- ビルドが終わるまでしばし待つ (テストに失敗するケースが含まれるとビルド結果が失敗になりますが、レポートはできてます。)
- ビルドが完了したら左メニューの
ビルド>レポートグループ- 作成されているレポートグループを選択
これでテスト結果が確認できます。
- 投稿日:2021-01-29T01:45:11+09:00
AWS基礎から学習②-CloudFormation-
はじめに
今回はCloudFormationでの環境構築について書いていきます。
CloudFormationはソースコードを記載することで自動でインフラの環境構築を行えるすばらしいサービスです。CloudFormationの特徴
①ソースコードの通りにインフラの環境構築を行う
②ソースコードを共有することで共有先でも同じ環境を用意できる
といった特徴があり、特に①は開発を行っていく上でヒューマンエラーがなくなる点で優れています。システムを構築する上では人間が行う操作はどうしてもエラー原因のもとを作ってしまうことが多く、これをできる限り少なくすることが、エラーの少ないシステムを作り上げる上では重要な要素となっています。
(例:システム作成時の手順操作が一つ抜けたor誤った等)しかし、ソースコードで環境構築を行うということで苦手意識を持つ方が多いと思います。
そこで今回は環境構築のイメージがしやすいように
①AWSコンソール操作画面時
②ソースコード
を並行してみながら環境構築するところを記事していきます。この形式であれば、テンプレートに苦手意識があった方でも作成時のイメージがしやすくなるかと思うのでぜひ一読いただければと思います。
CloudFormation始めて触ってみる方やテンプレートを見てもよくわからなかった方の参考になれば幸いです。
環境
・AWSサービス(2021/1/26時点)
※各種設定画面は都度アップデートされていますので画像と異なる場合があります。・エディタ…VisualStudioCode
※エディタは任意のもので作成してもいいですが、VisualStudioCodeにはCloudformationのソースを書く上で非常に便利な拡張機能があるのでそちらを使うと非常に効率よくコードを書けます。)
下記環境の構築の際に参考になる記事を用意しました。https://nopipi.hatenablog.com/entry/2019/04/27/155616
参照元:のぴぴのメモなお、今回はソースコードは画像で貼っていますので手元で確認しながら記事を見たい方はこちらの自分のGithubに置いていますのでこちらからダウンロードしてみてください。
目次
1.初期項目について
2.VPC作成
3.EC2作成
4.今回のソースコード
5.まとめ目標構成図
構成図は前回記事の構成図を再現していきます。
なお、CloudFormationのスタック(作成予定の目標環境)を区別するためVPC、EC2それぞれのサービスでテンプレートを用意します。
1.初期項目について
構成図の環境構築を行う前にまずCloudFormationで使われる初期項目について見ていきましょう。
項目 設定内容 必須/任意 AWSTemplateFormatVersion Cloudfromationのテンプレート形式バージョンを指定する。 [2010-09-09]はそのまま使用。 必須 Description 英訳の通り説明文になります。このテンプレートの説明を記載します。 任意 Metadata リソースに付与する情報を記載する。(例:認証情報やユーザー情報) 任意 Parameters Cloudformationの操作画面内で作成するAWSリソースのパラメータを任意に設定したい場合に記載する項目。(例:VPCの名前を都度任意に設定したい場合等) 任意 Mappings 取得したいリソースの参照先を表す際に記載する項目。主にリージョンを超えての参照を行う際に使われる。(例:作業場所が東京リージョンで使用したいAWSのリソースが北米リージョンにある場合など) 任意 Conditions テンプレートに記載のリソースを作成する条件を記載する項目。(例:スタックを追加するときに条件が合わなかった場合にそのリソースのみ環境構築を行わない場合等) 任意 Resources メインとなる作成するAWSリソースを記載する項目。 必須 Outputs 他スタックと連携する際に必要な指定した値を出力する項目。 任意 2.VPC作成
それではまずVPCサービスの構成を作成していきます。
・VPC
・インターネットゲートウェイ
・サブネット
・ElasticIP
・セキュリティグループ
・ルートテーブル
が対象です。ここから先はResources内に記載する内容です。
VPC
・左側:実際の操作画面
・右側:テンプレート
VPCの設定になります。
この後のリソース作成でも重要となってくるのが「myVPCID」の部分。
・myVPCID
→ここはVPCの論理IDとなります。
論理IDはそのテンプレート内で一意にしか持てないIDを指し、任意の名称を設定することが出来ます。
(自分は最初、論理IDは決まった値しかないと思い込んでしまい、複数のリソースを作成する際に迷ったことがありました。)
項目 設定内容 Type AWSのリソースの種類を指定します。VPCを指定するので「AWS::EC2::VPC」となります。 Properties 値を設定する項目一覧になります。properties以下に値入力が必要となる項目を設定します。 CidrBlock VPCのCIDRを設定します。 EnableDnsSupport VPC に対して DNS 解決がサポートされているかどうかを示します。作成時の画面では設定する場所はありませんがデフォルトで有効になっています。 Tags(Key,Value) →タグを設定
※KeyにNameと設定することでValueの値がVPCの名前になります。他のAWSリソースも同様に設定しています。インターネットゲートウェイ
インターネットゲートウェイの作成とアタッチまで行っています。ここで注目すべき点は黄枠と線で示した「!Ref [論理ID]」の部分です。
!Refを使うことでテンプレート内の指定した論理IDを参照することが出来ます。これでインターネットゲートウェイのVPCを設定する項目で関連付け(アタッチ)を行うことが出来ます。
(※以降の黄色枠、先は論理IDの参照を示します。)
項目 設定内容 IGWID インターネットゲートウェイの論理ID(任意) Type インターネットゲートウェイを指定するので「AWS::EC2::InternetGateway」 AttachGatewayID インターネットゲートウェイのアタッチ論理ID(任意) Type インターネットゲートウェイのアタッチを行うので「AWS::EC2::InternetGateway」 VpcId Vpcの論理IDを指定します。 InternetGatewayId インタネットゲートウェイの論理IDを指定します。 (この後に記載するテーブルの共通する項目は省略していきます。)
サブネット
■パブリックサブネット
■プライベートサブネット
サブネットの作成です。
基本的に項目の構成はあまり変わりませんね。
パブリック、プライベートサブネットはCIDRの範囲に気をつけながら設定してください。
項目 設定内容 PublicSubnetID PrivateSubnetID サブネットの論理ID(任意) Type サブネットの作成を指定するので「AWS::EC2::Subnet」 AvailabilityZone アベイラビリティゾーンを指定 ElasticIP
今回のElasticIPの設定は画面側と共通する項目はありませんが、割り当てるElasticIPをどのVPC内で利用するか指定します。
項目 設定内容 Domain ElasticIPを利用するVPCを指定 ここで作成したElasticIPは後ほどEC2に割り当てる際に利用します。
セキュリティグループ
■パブリックサブネットのセキュリティグループ
■プライベートサブネットのセキュリティグループ
セキュリティグループも基本的に操作画面に沿って設定していきます。
なお今回のアウトバウンドルールはコメントアウトしていますが、
コメントアウトした場合は現在の操作画面の設定が初期値として反映されます。またプライベートサブネットのセキュリティグループの設定を今回は0.0.0.0/0としていますが、セキュリティを高める場合には、コメントアウト部分に記載の通りEC2に設定するElasticIPを設定すると効果的です。
項目 設定内容 SecGroupNamePublicID
SecGroupNamePrivateIDセキュリティグループの論理ID(任意)
Type セキュリティグループの作成を指定するので「AWS::EC2::SecurityGroup」 GroupName セキュリティグループの名前 GroupDescription セキュリティグループの説明文 SecurityGroupIngress セキュリティグループのインバウンド IpProtocol ポート番号(今回SSH接続で22を指定) FromPort ポート番号(今回SSH接続で22を指定) CidrIp セキュリティグループのCIDRを設定 SecurityGroupEgress セキュリティグループのアウトバウンド ルートテーブル
■パブリックサブネットのルートテーブル
■プライベートサブネットのルートテーブル
参照が多くなってきて、複雑になってきました。ですが難しいことはありません。ルートテーブルを作成し、それぞれどのサブネットの論理IDに関連付けるか、またどこの画面操作をしているのか確認できればおのずと繋がって来ると思います。
■ルートテーブルの作成
項目 設定内容 RouteTableNamePublicID
RouteTableNamePrivateIDルートテーブルの論理ID(任意) Type ルートテーブルの作成を指定するので「AWS::EC2::RouteTable」 ■ルートテーブルの関連付け
項目 設定内容 SubnetId ルートテーブルの関連付けを指定するので「AWS::EC2::SubnetRouteTableAssociation」 SubnetId 関連付けるサブネット RouteTableId 関連付けるルートテーブル ■ルートテーブルのルートを指定
項目 設定内容 Type ルートテーブル内のルートを指定するので「AWS::EC2::Route」 RouteTableId ルートテーブルの論理ID(任意) DestinationCidrBlock 接続するCIDRブロックを指定
(ここでは0.0.0.0/0)GatewayId インターネットゲートウェイの論理ID(任意) Outputs
OutputsではResourcesで設定した値を出力することができ、その値を別のスタックで使用することが可能になります。今回の例ではVPCスタックで作成したものをEC2のスタックで利用できるようにします。
そして今回使用するVPCの値は①ElasticIP
→EC2に固定IPアドレスを付与します。②サブネット
→EC2を配置するサブネットの論理IDを出力します。②パブリック&プライベートサブネットのセキュリティグループ
→EC2に作成したセキュリティグループを設定します。
ここで注目したい点は「!GetAtt」の部分。
記載方法としては
!GetAtt [論理ID].[各種パラメータ]となっており、
対象の論理IDのAWSリソースから情報を取得します。
なお、[各種パラメータ]はそれぞれのAWSリソースで決まった値が入るので、ここはドキュメントで確認する作業が必要となります。
(例:セキュリティグループのドキュメント)ここまでの構成図
3.EC2作成
次にEC2のテンプレートです。
前準備
前準備としてキーペアはCloudformationで作成することが出来ないためキーペアは事前に作成します。
EC2メニューの「ネットワーク & セキュリティ>キーペア」でキーペアの作成を行います。
EC2作成
パブリックサブネット側とプライベートサブネット側で設定する内容は大きく変わらないので合わせて記載します。
ここでの注目点は「!ImportValue」です。
VPCのテンプレートでOutputで出力した値をここで使用しています。
Export>Nameで指定した値を入力して値を取得し、スタック間での連携が可能となります。
項目 設定内容 Type EC2を指定するので「AWS::EC2::Instance」 KeyName キーペアの名前 ImageId AMIを入力 InstanceType インスタンスタイプを入力 SecurityGroupIds セキュリティグループのIdを指定 SubnetId EC2を配置するサブネットIdを指定 UserData シェルスクリプトを記載する(今回は省略)
事前にEC2にインストールしたいソフトウェアをここで記載する。ElasticIPをEC2に割り当て
EC2にElasticIPアドレスを割り当て、外部からSSH接続でキーペアを使ってアクセス可能にします。
項目 設定内容 Type AWS::EC2::EIPAssociation AllocationId ElasticIPをEC2と関連付けるためのIdを指定
VPCで設定したElasticIPを関連付けるInstanceId EC2の論理IDを指定 割り当て後
Cloudformationでスタックを作成
※修正中です。※
cloudformationでの操作説明を記載予定です。最終的な構成図
構成図の作成はここまでとなります。
構成図完成後、接続確認をしますが、こちらは前回記事の接続方法を参考にしてみてください。4.今回のソースコード
今回作成したソースコードについては下記リンク先のgithubあげましたので、実際のソースコードを確認したい方はぜひ参考にしてみてください。
今回のソースコードはこちら5.まとめ
以上が今回のCloudformationでのEC2の環境構築でした。
実際の操作画面とソースコードを比較しながらやっていきましたが、
ソースコードでの環境構築のイメージがしやすかったのではないでしょうか?私としては実際の操作画面と比較しながら書いてみて
ソースコードを書く=操作手順説明書を書く
に近いイメージで書くことが出来ました。AWS Cloudformationのドキュメントを見て書いていくよりも断然理解が早く進んだのでこの学習方法も使えそうな気がします。
操作画面でポチポチ入力してインフラ環境を構築するだけでなく、ソースコード書いて自動で環境構築できるようになるとかっこいいですよね。
いつか実際の現場でCloudformation使いこなしてボタンひと押しで環境構築をサクッと終わらせてみたいですね。今回は以上です。
長くなりましたが、ここまで読んでいただきありがとうございました。
AWSを勉強する方の参考になれば幸いです。AWSの学習体験
当記事は動画学習サービスのAWSCloudTechの講座を参考に作成しました。
これからもっと普及するクラウドサービスの一角であるAWSを学びたい方におすすめです。現在、無料講座を開放しているようなので気になった方はぜひ体験してみてください。




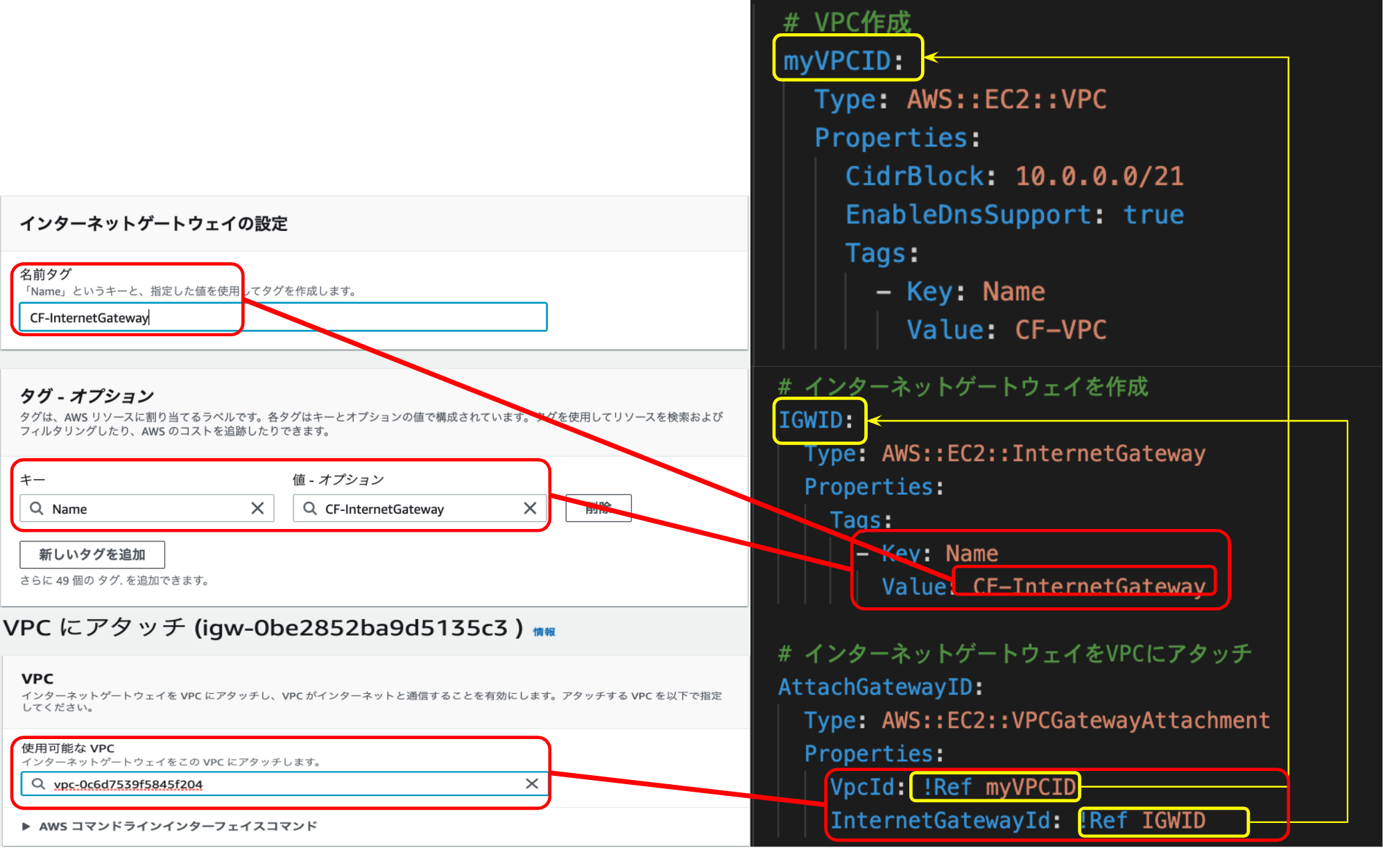

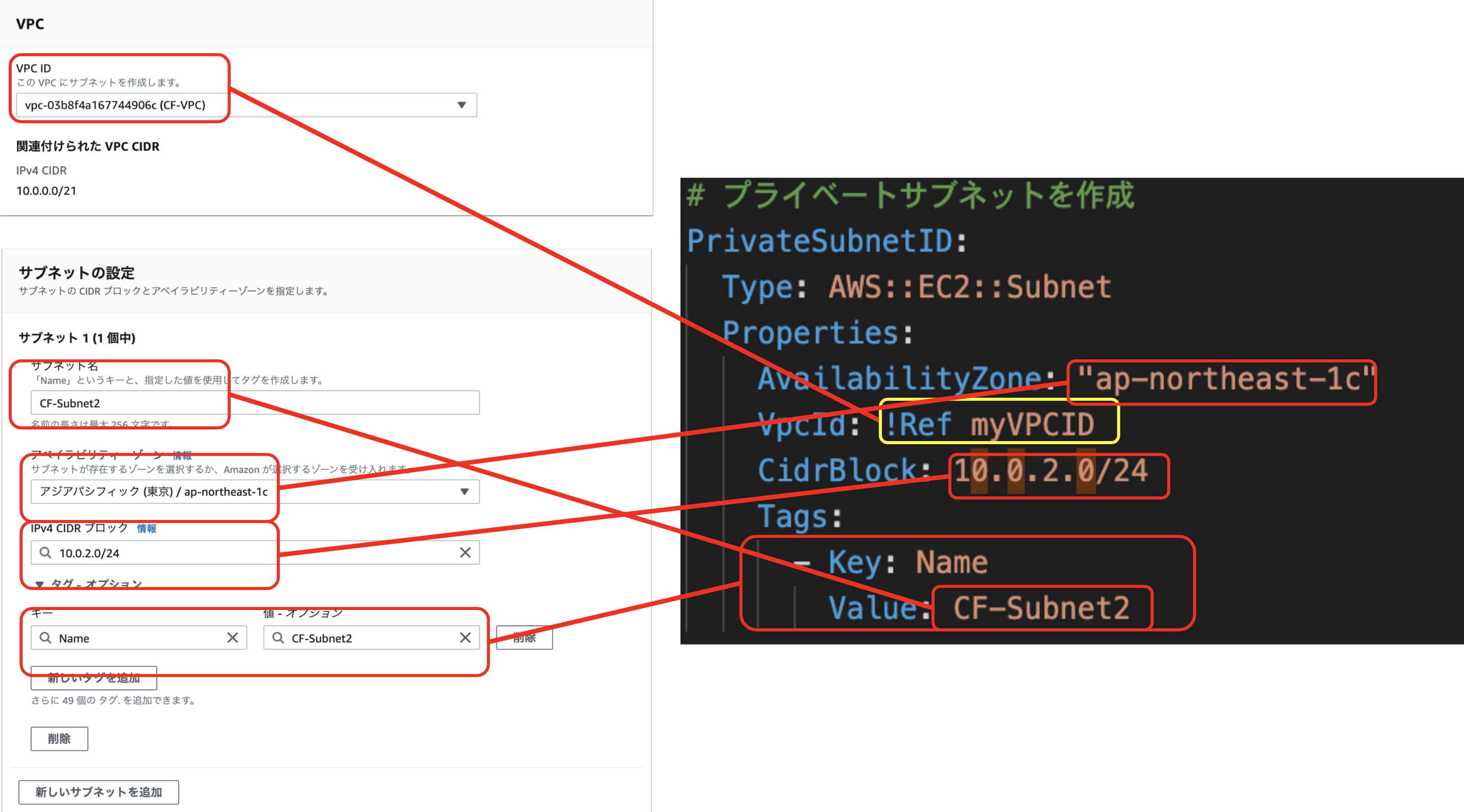
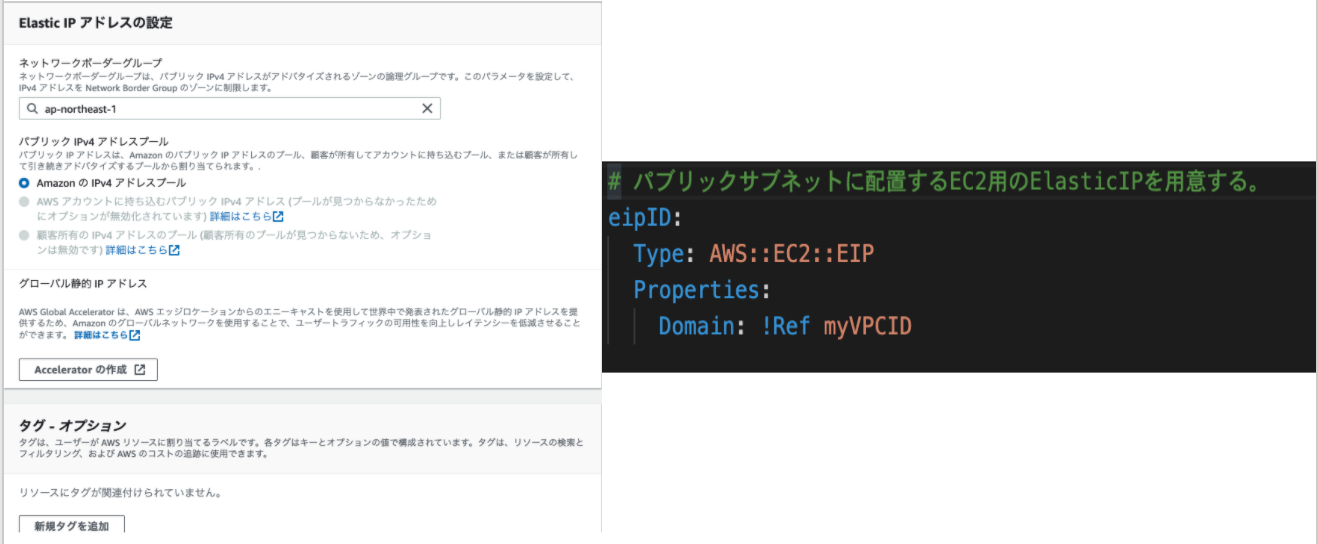







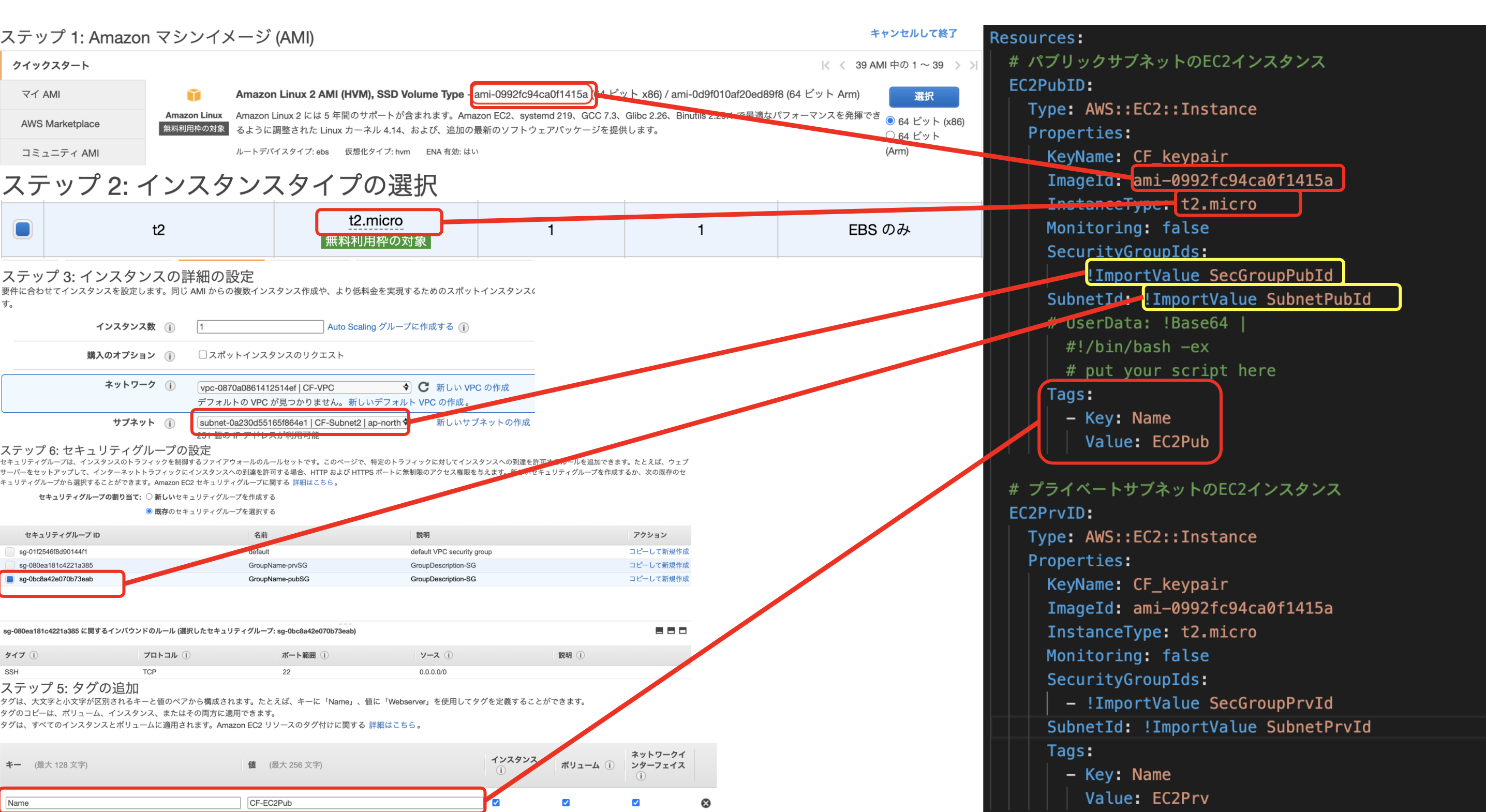



- 投稿日:2021-01-29T00:41:41+09:00
3週間で備えるAWS Certified Developer - Associateへの道
はじめに
某ベンダで、クラウドの人材育成企画と研修トレーニングのデリバリを担当してます。今度、自分で企画した「Developing on AWS」のトレーニング講師を務めることとなり、前提となる「AWS Certified Developer - Associate」(DOA)を受験することになりました。試験に備えてガッツリ勉強したので、勉強ノウハウを共有します。
勉強教材とスケジュール
DOA受験に際し、3週間の準備計画を立てました。ここ数年は企画畑を歩き回った分、開発現場から遠のいたので長めに設定しています。長期戦になるとモチベーション維持が難しので、僕的には3週間間が丁度良かったです。
以下、受験に利用した教材です。
・A CLOUD GURU
AWS Solution Architectは、Amazon.co.jpで探すと試験対策問題が沢山見つかるのですが、DOAはピンポイントの対策問題集がないのでCLOUD GURUを利用しました。全編英語版ですが、DOA以外の受験にも利用できること、AWSのイベントでよく見かけるベンダだったこと、ビデオ教材以外にオリジナルの模擬試験があったことが選定の決め手でした。
・「AWS 認定 デベロッパー アソシエイトサンプル問題を解説します」
AWSが公開しているサンプル情報に注釈を入れた解説記事です。執筆されたのはAWS Ambassadorの方ですかね、丁寧に解説が入ってます。シリーズものでDOA以外にも執筆されているようです、・Exam Readiness: AWS Certified Developer – Associate (Japanese)
AWSが提供している無償のデジタルトレーニングです。試験のトピックの分野を詳しく学習し、都度分野ごとの理解度を確認できます。
・AWS サービス別資料(通称ブラックベルト)
サービス毎の概要をプレゼン形式で綺麗に整理しています。個々の仕様書を読み込むのは骨が折れるので、毎回の試験時にお世話になるサイトです。今回は試験に関連する開発系の以下のサービスを読み込みました。・AWS Lambda
・Amazon API Gateway
・Amazon DynamoDB
・AWS Step Functions
・Amazon ElastiCache
・AWS CodeCommit
・AWS CodeBuild
・AWS CodeDeploy・「AWS 設計のベストプラクティスで最低限知っておくべき 10 のこと」の丸暗記
基本の 「基」、AWS設計のベストプラクティスを毎度のごとく丸暗記します。1. スケーラビリティを確保する 2. 環境を自動化する 3. 使い捨て可能なリソースを使用する 4. コンポーネントを疎結合にする 5. サーバではなくサービスで設計する 6. 適切なデータベースソリューションを選択する 7. 単一障害点を排除する 8. コストを最適化する 9. キャッシュを使用する 10. すべてのレイヤーでセキュリティを確保する 11. +1. 増加するデータの管理勉強の過程
張り切って3週間の計画を立てたものの、、、年末を挟んでしたまったことでスタートダッシュに乗れず。子供のクリスマスプレゼントにした「鬼滅の刃」に親が没頭する羽目になり朝晩漫画漬けの日々。。。。(いやー流行にはそれなりの根拠あり結局、2週間で試験対策することになりました。
まず最初に力試しに「AWS 認定 デベロッパー アソシエイトサンプル問題を解説します」に挑戦しましたが、半分くらいしかわからず。。。少し焦りを感じながら、CLOUD GURUの模擬試験を 2週間の間繰り返しました。
模擬試験は実際の問題に近い形式で非常に良くできています。全文英文なのですが、技術英語なので、そんなに難解な英単語は出てきません。最初は慣れないため時間がかかるものの、20回近く繰り返すと英単語から正解が見えてきました。(これが後述の試験本番で大きな助けになった。理解は浅い部分は、ブラックベルトでを見直しながら、正当率が9割近くになるまで”ガッツリ”模擬試験を繰り返しました。
試験1週間前には、Exam Readinessにトライしました。
さすがAWSの公式トレーニングだけあって、ポイントが綺麗に整理されていて非常に秀逸です。内容は日本語、サンプル問題よりも難易度は低めな印象です。「AWS 設計のベストプラクティスで最低限知っておくべき 10 のこと」は朝晩、マントラのごとく唱えました。AWSの試験全般に言えることですが、選択問題だと割と最後の2択で迷うこと多くなります。一見、どっちも技術的には正解ポイですのが、”AWSとして正解”が回答として設定されているため、AWSのベストプラクティスに沿った回答を導く必要があります。
試験当日
横浜のピアソン会場で受験しました。コロナの影響か、試験会場はあまり混んでおらず試験2日前に予約しました。
実際の試験問題はAWSサービスと同じく定期的にupdateされているのか、想定した問題とは違う問題が出てきて、最初の10問といた時点でかなり焦りました。(直前まで聞いてたMegadethのSkin o' My Teethが頭の中で何度もリピート)
頭の中はメタル、和訳はメタメタで、これまで受験したAWS試験の中で、一番日本語になっていない和訳問題でした。幸いCLOUD GURUで英語問題に慣れてたこと、基礎をしっかり学習できていたため、その場で対応することができました。
結果は800後半で、想定したよりも得点をとることができていました。(ふー)
所感
AWSのサービスと同じく、DOAの試験内容も日々更新されるためか、模擬試験とは少し設問が違いました。単にサービスの名前を覚える一問一答な問題ではなく、サービス内容を深く問われる内容が多かった印象です。”AWSのサービスが、開発時におけるどのような問題を解決するか?”を意識しながら基礎学習を繰り返すと突破できる試験だと思います。