- 投稿日:2021-01-03T23:45:03+09:00
【Python】Anacondaの環境構築(インストール、起動、仮想環境、パッケージ管理)Mac環境
こんにちは、かをるです。
今回は、Anacondaの環境構築の方法を紹介していきます。
PyCharm同様にGUIインストーラを使って進めていきますので、比較的簡単に進めることができます。
Anacondaはデータサイエンティスト向けのPythonパッケージになっておりますので、データサイエンティストを目指される方は使い慣れておくのがいいかと思います。
インストール自体は簡単に行えますが、色んな事を自動的に行なってくれるので、【中身がどの様に行われているのかわからない】というデメリットもありますのでご注意ください。
- 投稿日:2021-01-03T23:30:36+09:00
taichiの使い方⓪ 目次
- 投稿日:2021-01-03T23:24:45+09:00
Githubおもしろリポジトリ⓪ 目次
このシリーズについて
githubのトレンドリポジトリから情報を定期通知する機能を作ったのですが、それを通じて発見した面白そうなリポジトリを紹介するシリーズです。
目次
- 投稿日:2021-01-03T23:20:15+09:00
Web開発において最低限のテストを自動でする
はじめに
お正月、ダラダラしすぎると社会復帰できなくなるので、プログラミングをしてみた。昨年からPMしているWeb開発の案件で、どうやらクライアントも開発を依頼しているパートナーもテストがあまり得意ではないらしく、私さえ黙っていれば、全然動いてねーじゃん!みたいなものが納品できてしまいそうな雰囲気だ。が、そんなのありえないし、パートナーにもっとテストきちんとやってくださいと言って、言うけど、時間(お金)を取られるのも嫌なので、最低限クリアすべきテストを自動で行うプログラムを Python(BeautifulSoup/requests) で書いてみた。自動テストと偉そうに言うほどではないが、なレベル感。
出来上がったものはこちら
▶ kurab/simple_web_inspector気軽にテストしたり配ったあと説明したくないので、DB使ったり、class 作ってファイルに分けたりは、今回はしないことにした。
最低限テストしたい項目
今回は、最低限ということで、主にリンク切れ、仮置きリンクなどを調べることにした。
具体的には、
- http status
- TDK:
見えづらいのでバグが混入しやすい- 空リンク(href="" or 設定なし):
開発過程での仮置き放置- 仮置きリンクの疑い(href="#"):
同上- デッドリンク(404):
リンクが間違ってるか作るはずだったページが作られてないか- リダイレクトリンク(301, 302):
開発時点でリダイレクトするなら、リダイレクト先にリンクして欲しい- 読み込みファイルの数とステータス(css, js, font, favicon, img):
ブラウザでもエラー出るけど、そんなの見ないって人は割といるのでこれくらい当たり前に確認して欲しいけど、手動ではやってられない。普通自動でやると思うけど、どうやらそれは普通じゃないらしい。これが当たり前にクリアされ、最低限のレベルが上がることを期待。
最初に URL リストを作る
URL リストなんて、手動で作ってられないので、ザーッと取ってくることにする。LP などの、サイト内からは辿れないページは、手動で追加する方針。
やっていることは、ページ内の a タグの href をすべて取得し、
- 外部リンク
- アンカーリンク
- javascriptによる何らかの操作
などを除外してフルパスに整形して出力。その結果として出力された URL 群に対して同じことをやって、重複していないURLを追加していく。の繰り返し。
なお、プロトコルは、https で統一されているものとし、リダイレクトされているものは、その先のページまでは追わないこととした。
というだけ。サイトの階層分くらい繰り返せば良いかと思っていたけど、ページネーションなどがあると割とたくさん検出されてしまう。結果を見ながら適当に調整。
一時ファイルを2つ使うのが、いまいちで、もっとスマートな方法は暇があったら検討したい。
URLリストを元に検査する
前述の最低限テストしたいことを検査している。
今回は、結果の出力を Markdown にしている。やってみて、割といまいちというか、もうちょっと工夫が必要かなと思ったが、なぜ Markdown にしたかと言うと、常々、こういった網羅的なテストの結果はバージョン管理した方が良いと思っており、エクセルだのスプレッドシートだのではなく、csv でもなく、テキストファイルにしたかった。ただのテキストだと見づらいので、Markdown にした。用途のイメージとしては、git の develop ブランチが更新されたら、それをフックしてテスト実行。テスト他関連ドキュメントがソースコードの履歴に対応して保存されていくイメージ。そんなことを夢見ている。
Markdownって何?という相手には、PDF に出力して渡せばよい。
レポートサンプル
ページごとのレポートは、こんな感じになる。
Basic Information
item value url https://www.yourdomain.com/dir/ httpStatus 200 title Home Page description (not set) keywords test, automation, web Link Analysis
Invalid item count Empty Link('' or no href attr) 2 Temporary Link suspected(#) 10 Dead Link(404) 3 Redirected Link(301, 302) 0 Dead Link List (404 Not Found)
- https://www.yourdomain.com/dir/warranty
- https://www.yourdomain.com/dir/terms-conditions
- https://www.yourdomain.com/dir/privacy-policy-cookie-restriction-mode
Media Analysis
type total dead moved css 4 0 0 js 25 0 0 font 5 0 0 favicon 1 0 0 img 65 0 0 おわりに
こういうのがあると、クライアントに対しては、改善提案できるかも知れないし(上記サンプルならjs多すぎるからコンパイルしようとか)、そもそもがヤバいっすねと言えるかも知れないし、開発パートナーに対しては、こんなもの納品するつもりですか?とも言えるし、何よりバグの少ないプロダクトが出来るし、良いことだらけである。
2021年、この世から新型コロナウィルスとしょーもないバグがたくさん消えますように。あけましておめでとうございます。
- 投稿日:2021-01-03T23:11:56+09:00
クイズ形式で学ぶPythonの変数の値の交換や多重代入の注意点
クイズ
次のプログラムの出力結果を答えよ。
問1
1nums = [1, 2, 3] i = 0 nums[i], i = i, nums[i] print(nums)
答えを見る
[0, 2, 3]
問2
2nums = [1, 2, 3] i = 0 i, nums[i] = nums[i], i print(nums)
答えを見る
[1, 0, 3]
多重代入の実行順序
Pythonでは1行で複数の変数に値を代入することができます。
x, y = 0, 1 print(x) # 0 print(y) # 1また、これを利用して、変数の値を交換することができます。
x = 0 y = 1 x, y = y, x print(x) # 1 print(y) # 0以下のように多重代入を使用せずに値を交換する場合と比べ、新たな変数もいらず、行数も短く済むので便利です。
x = 0 y = 1 temp = x x = y y = temp print(x) # 1 print(y) # 0ただ、今回のクイズのように、単純な交換ではない場合は、実行順序に注意する必要があります。
代入文の右辺の変数の値は、代入文の実行前の値で確定しているのに対し、左辺の変数の値は、左から順に更新されていきます。
問1はこのようなコードでした。
1nums = [1, 2, 3] i = 0 nums[i], i = i, nums[i] print(nums) # [0, 2, 3]多重代入の右辺の
iの値は0であり、右辺のnums[i]、つまりnums[0]の値は1です。左辺の変数の値は左から順に更新されていくため、問1は以下のコードと同じことになります。
1'nums = [1, 2, 3] i = 0 # nums[i], i = i, nums[i] # => nums[i], i = 0, nums[0] # => nums[i], i = 0, 1 nums[i] = 0 # => nums[0] = 0 i = 1 print(nums) # [0, 2, 3]問2はこのようなコードでした。
2nums = [1, 2, 3] i = 0 i, nums[i] = nums[i], i print(nums) # [1, 0, 3]問2は以下のコードと同じことになります。
2'nums = [1, 2, 3] i = 0 # i, nums[i] = nums[i], i # => i, nums[i] = nums[0], 0 # => i, nums[i] = 1, 0 i = 1 nums[i] = 0 # => nums[1] = 0 print(nums) # [1, 0, 3]参考
- 投稿日:2021-01-03T23:10:16+09:00
Python数学シリーズ⓪ 目次
- 投稿日:2021-01-03T23:06:53+09:00
condaの更新が終わらない。
Anaconda prompt で condaの更新が一行に終わらない。
conda update -n base condaSolving Environment: |
のメッセージが出て | がグルグルずっと回っている。1時間以上ずっと回っている。
プロセス表示したら、どうやらPythonがCPU使ってるのでちゃんと何かをしているよう。不安になるのでdebugオプションつけたら
conda update -n base conda --debugこんな感じで依存性解決をずーっとやっているようだ。
は? 8千万の節があるの?
DEBUG conda.common._logic:_run_sat(607): Invoking SAT with clause count: 83289605メモリ見たら案の定。メモリが足りん。
これどうしいいの?


- 投稿日:2021-01-03T22:53:28+09:00
API GatewayとLambda(Python)でLINE BOT(Messaging API)開発 [前編]
API GatewayとLambda(Python)でLINE BOT(Messaging API)開発 [前編]
はじめに
先日、以前より興味のあったLINE BOT(Messaging API)を初めて作ってみました。
思っていたより簡単だったので、今後も気軽に作ってけたらなと思ってます。
せっかく作れるようになったので、このフレッシュな気持ちがなくなる前に記事を書いておきます。前編と後編と、2つに分けて書こうと思います。
前編では主に環境構築。何か話しかけると「こんにちは!」とだけ返すBOTを作成します。
後編ではline-bot-sdkというライブラリを利用して、もう少しリッチなやり取りする実装について書こうと思ってます。LINE Developpersでプロバイダーとチャンネルの作成
まずはLINE Developpersで作業します。
LINE Developpersにアカウントが必要ですが、登録手順については割愛。
LINE Developpers の コンソールにアクセスし、プロバイダーを作成します。
プロバイダー名を入力して作成します。
ここではプロバイダー名を「サンプルプロバイダー」としました。
チャンネル設定で「Messaging API」を選択します。
チャンネルアイコン、チャンネル名、チャネル説明、大業種、小業種、メールアドレス、プライバシーポリシーURL(任意)、サービス利用規約URL(任意)、などを設定・入力し、作成します。
ここではチャンネル名を「サンプルチャンネル」としました。
作成されたチャンネルの以下の情報は後ほど利用します。
・「チャンネル基本設定」にある チャネルシークレット
・「Messaging API設定」にある チャネルアクセストークン(長期) (※発行してください)「Messaging API設定」にある Webhook設定 > Webhook URL へは、これから作成するWebAPIのURLを設定します。
LINE Developpersでの作業はひとまずここまで。AWSでAPI GatewayとLambda(Python)の作成
続いてAWSで作業します。
AWSにアカウントが必要ですが、登録手順については割愛。Lambda(Python)の作成
AWSマネジメントコンソールのLambdaのページへアクセスし、関数を作成します。
関数名は「sample_function_from_line」、ランタイムは「Python 3.6」を選択しました。
関数コードの
lambda_function.pyはひとまず以下のコードとしておいてください。
「こんにちは!」と応答するだけのプログラムです。lambda_function.pyimport json import os import urllib.request import logging logger = logging.getLogger() logger.setLevel(logging.INFO) LINE_CHANNEL_ACCESS_TOKEN = os.environ['LINE_CHANNEL_ACCESS_TOKEN'] REQUEST_URL = 'https://api.line.me/v2/bot/message/reply' REQUEST_METHOD = 'POST' REQUEST_HEADERS = { 'Authorization': 'Bearer ' + LINE_CHANNEL_ACCESS_TOKEN, 'Content-Type': 'application/json' } REQUEST_MESSAGE = [ { 'type': 'text', 'text': 'こんにちは!' } ] def lambda_handler(event, context): logger.info(event) params = { 'replyToken': json.loads(event['body'])['events'][0]['replyToken'], 'messages': REQUEST_MESSAGE } request = urllib.request.Request( REQUEST_URL, json.dumps(params).encode('utf-8'), method=REQUEST_METHOD, headers=REQUEST_HEADERS ) response = urllib.request.urlopen(request, timeout=10) return 0環境変数に、LINE Developpersで作成したチャンネルの「Messaging API設定」で発行した チャネルアクセストークン(長期) を
LINE_CHANNEL_ACCESS_TOKENというキーの値として登録しておきます。
最後に、コードが保存されていることを確認のうえ、デプロイします。
API Gatewayの作成
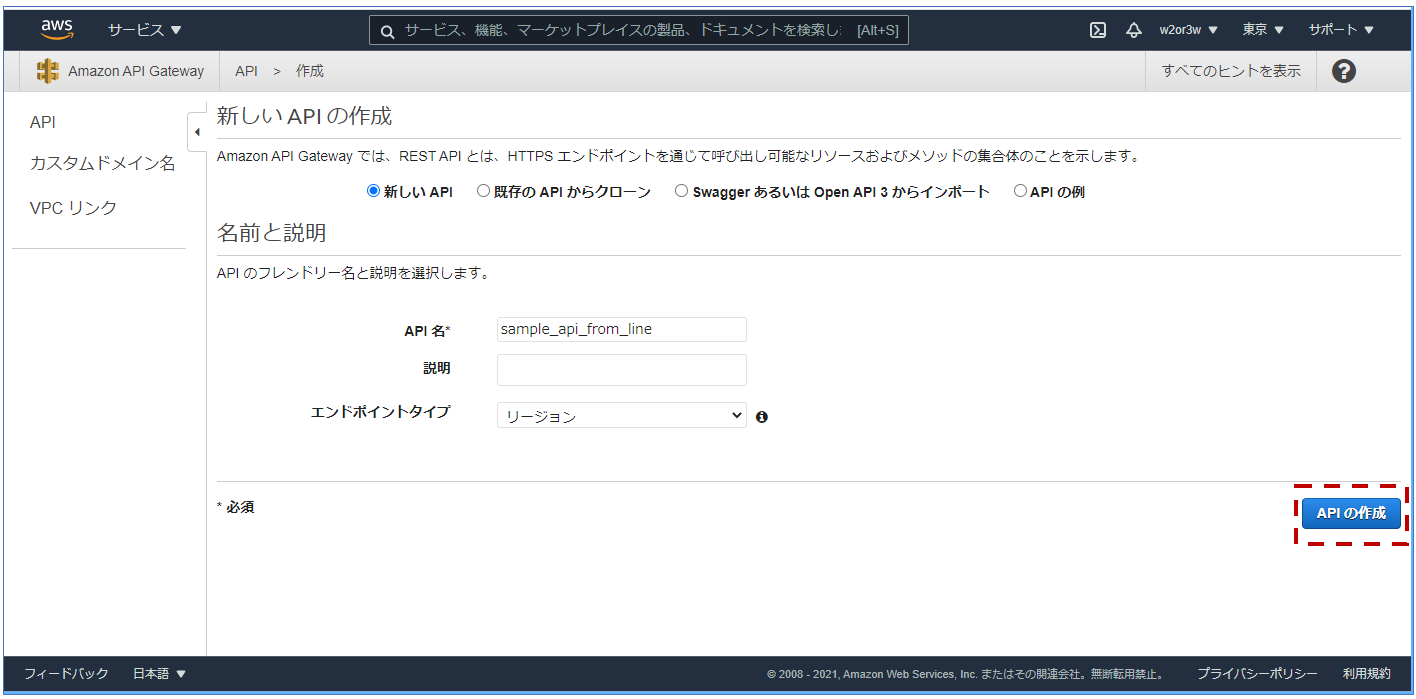
AWSマネジメントコンソールのAPI Gatewayのページへアクセスし、APIを作成します。
REST APIを構築します。
API名を入力、エンドポイントタイプはリージョンを選択し、作成します。
ここではAPI名は「sample_api_from_line」としました。
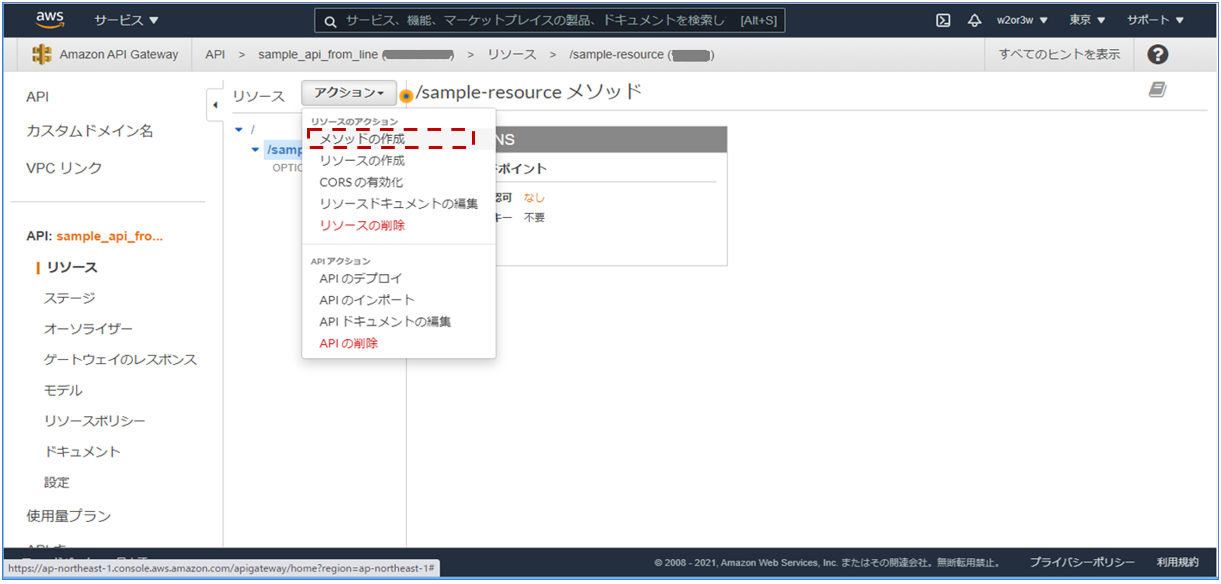
アクションから「リソースの作成」を選択し、
新しい子リソースの作成をします。
ここではリソース名を「sample-resource」としました。「API Gateway CORSを有効にする」のチェックはONとします。
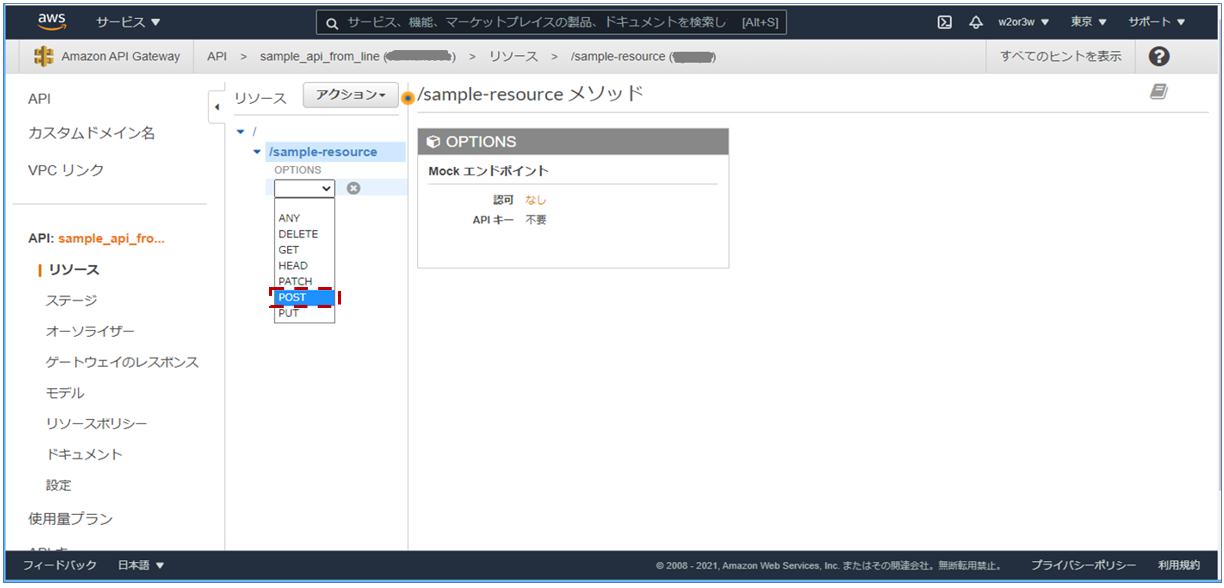
作成したリソースにPSOTメソッドを作成します。
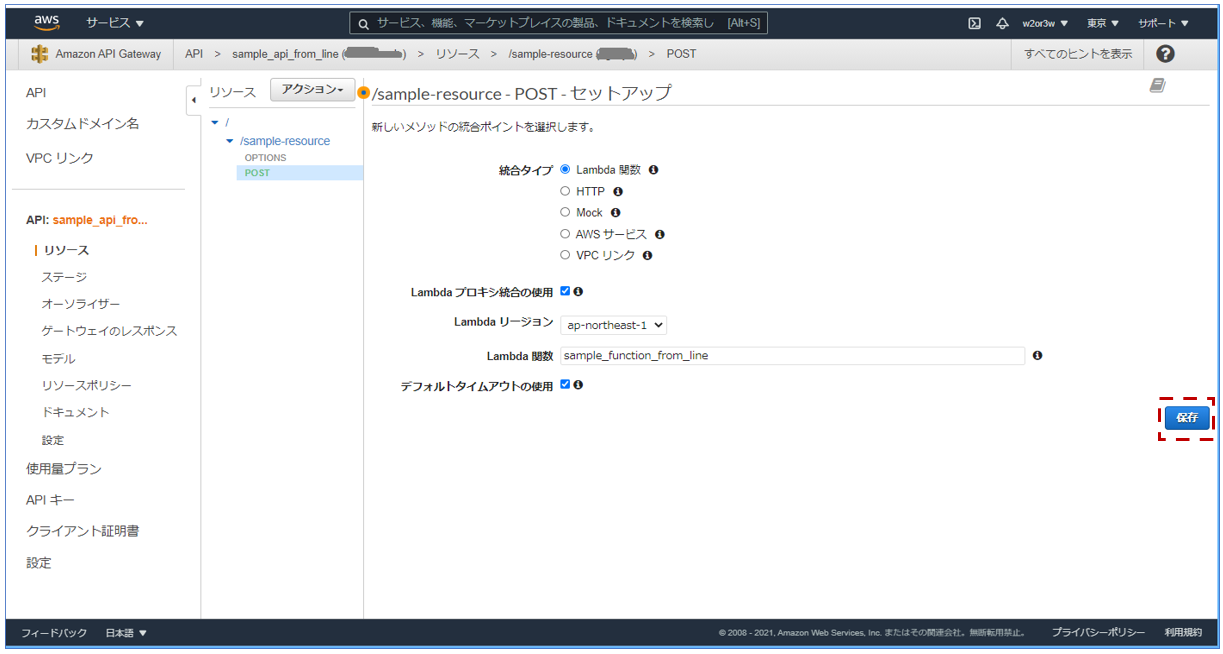
POSTメソッドのセットアップでは、先ほど作成したLambda関数(sample_function_from_line)を選択します。
「Lambdaプロキシ統合の使用」もONにしておきましょう。
「Lambda関数に情報を追加する
API Gatewayに、Lambda関数を呼び出す権限を与えようとしています:」
という確認メッセージが表示されますので、OKボタン押下で許可を与えます。
アクションから「APIのデプロイ」を選択します。
APIのデプロイ画面で新しいステージを作成し、デプロイします。
ステージ名は、ここでは「work」としておきました。
デプロイされたworkステージのPOSTメソッドを選択し、「URLの呼び出し」に表示されているURLを、
「Messaging API設定」にある Webhook設定 > Webhook URL へ設定します。LINEチャンネルのMessaging API設定
LINE Developpersのコンソールに戻りまして、作成しておいたサンプルチャンネルの「Messaging API設定」にある Webhook設定 > Webhook URL へ、デプロイしたPOSTメソッドのURLを設定します。
Webhookの利用ラジオボタンもONにします。
動作確認
これで一通りの設定は完了です。動作確認してみましょう。
「Messaging API設定」にあるQRコードから、作成したLINE BOTを友達追加することができます。
友達として追加して、何か話しかけてみましょう。
「メッセージありがとうございます!申し訳ありませんが、このアカウントでは個別のお問い合わせを受け付けておりません。次の配信までお待ちください。」という自動応答の後に続き、実装した「こんにちは!」を返してきてくれていますね。自動応答の設定
自動応答を無くすための設定は、チャンネル基本設定の基本設定にある「LINE Official Account Manager」へのリンクから飛んだ先で行う事ができます。
応答設定の応答メッセージを「オフ」にします。
なおここでは友達追加して最初に表示される「あいさつメッセージ」も非表示にしたり、内容を更新したりすることができます。それでは改めて動作確認してみましょう。
何か話しかけると「こんにちは!」とだけ返してくれるBOTが完成しました?
あとがき
後編へつづく!























- 投稿日:2021-01-03T22:45:16+09:00
データ可視化ライブラリDashを使ってマウスホバーで画像を表示するグラフを作成する
概要
データ可視化ライブラリのDashを使って、マウスホバーで対象データの画像を表示するグラフを作成する手順を記載しています。
Dashを使用するとpythonのみかつ非常に少ないコードでこのような動的なグラフの作成ができます。
作成したグラフは以下のような感じです。
背景
画像データから抽出した高次元の特徴量を、T-SNEやUMAPを使って次元削減して散布図としてグラフを作成してデータの分布を確認するということはよくあると思います。
その際に気になるデータの画像を確認できるような動的なグラフを簡単に作成したいと考えていました。環境
Google Colabで実施していますが、ローカルのJupyterでも実施可能です。
Jupyter内でグラフを表示していますが、数行変更すれば単独のアプリケーションとして起動することも可能です。この記事の下の補足にアプリケーションで起動する場合のコードを添付しました。手順
- ライブラリをインストール
- ライブラリをimport
- 補助関数を定義
- グラフを作成
- Dashで表示
1. ライブラリをインストール
dashとjupyter_dashをインストールします。
!pip install dash !pip install jupyter_dash2. ライブラリをimport
利用するライブラリーをimportします。
from jupyter_dash import JupyterDash import dash_core_components as dcc import dash_html_components as html import plotly.express as px from dash.dependencies import Input, Output from sklearn.datasets import load_digits from sklearn.manifold import TSNE import numpy as np from PIL import Image from io import BytesIO import base643. 補助関数を定義
numpyのarrayをbase64に変換する関数を定義します。
def numpy_to_b64(array): # Convert from 0-16 to 0-255 array = np.uint8(255 - 255/16 * array) im_pil = Image.fromarray(array) buff = BytesIO() im_pil.save(buff, format='png') im_b64 = base64.b64encode(buff.getvalue()).decode('utf-8') return im_b644. グラフを作成
mnistのデータをT-SNEで2次元に次元削減します。
その結果を散布図で表示するグラフを作成します。digits = load_digits() tsne = TSNE(n_components=2, random_state=0) projections = tsne.fit_transform(digits.data) fig = px.scatter( projections, x=0, y=1, color=digits.target )5. Dashで表示
マウスホバーで、画像が表示されるようにCallbackを定義します。
app = JupyterDash(__name__) app.layout = html.Div([ html.Div(id="output"), dcc.Graph(id="fig1", figure=fig) ]) @app.callback( Output('output', 'children'), [Input('fig1', 'hoverData')]) def display_image(hoverData): if hoverData: idx = hoverData['points'][0]['pointIndex'] im_b64 = numpy_to_b64(digits.images[idx]) value = 'data:image/png;base64,{}'.format(im_b64) return html.Img(src=value, height='100px') return None app.run_server(mode="inline")以上を実行するとグラフが表示されます。
補足
アプリケーションとして実行する場合は、app.pyのようなコードになります。
python app.pyのようにプログラムを実行して、http://127.0.0.1:8050/をブラウザーで開くとグラフが表示されます。app.pyimport dash import dash_core_components as dcc import dash_html_components as html import plotly.express as px from dash.dependencies import Input, Output from sklearn.datasets import load_digits from sklearn.manifold import TSNE import numpy as np from PIL import Image from io import BytesIO import base64 def numpy_to_b64(array): # Convert from 0-16 to 0-255 array = np.uint8(255. - 255./16. * array) im_pil = Image.fromarray(array) buff = BytesIO() im_pil.save(buff, format="png") im_b64 = base64.b64encode(buff.getvalue()).decode("utf-8") return im_b64 digits = load_digits() tsne = TSNE(n_components=2, random_state=0) projections = tsne.fit_transform(digits.data) fig = px.scatter( projections, x=0, y=1, color=digits.target ) app = dash.Dash(__name__) app.layout = html.Div([ html.Div(id="output"), dcc.Graph(id="fig1", figure=fig) ]) @app.callback( Output('output', 'children'), [Input('fig1', 'hoverData')]) def display_image(hoverData): if hoverData: idx = hoverData['points'][0]['pointIndex'] im_b64 = numpy_to_b64(digits.images[idx]) value = 'data:image/png;base64,{}'.format(im_b64) return html.Img(src=value, height='100px') return None app.run_server(debug=True)参考
Pythonの可視化ライブラリDashを使う 3 マウスホバーを活用する
https://qiita.com/OgawaHideyuki/items/b4e0c4f134c94037fd4fJupyter上でDashを使えるjupyter_dash
https://qiita.com/OgawaHideyuki/items/725f4ffd93ffb0d30b6c

- 投稿日:2021-01-03T21:57:11+09:00
Custom prefix を導入しよう!!
最初に
この記事書くとき、いろいろな作業が終わってからで、いろいろめんどくさがってるからいろいろと雑になってるよ!ごめんね!
※一応PEP8に準拠した書き方です。開発環境
・エディタ - Atom
・実行シェル - PlatformIO IDE Terminal(Atomの拡張機能)
|ただのコマンドプロンプトです。
・python - Python 3.9.1
・discord.py - discord.py 1.5.1本題
コード
# 必要なモジュールをインポート import json import discord from discord.ext import commands # 必須の変数の設定 default_prefix = 'ここにデフォルトとするprefixを入力' TOKEN = 'ここにTOKENを入力' # jsonファイルをロード prefix_json = None with open('prefix.json', encoding='UTF-8') as f: prefix_json = json.load(f) def custom_prefix(bot: commands.Bot, msg: discord.Message): # コマンドが実行されたサーバーでカスタムprefixが設定されていれば対応するprefixを返す if str(msg.guild.id) in prefix_json.keys(): return prefix_json[str(msg.guild.id)] # コマンドが実行されたサーバーでカスタムprefixが設定されていなければデフォルトprefixを返す else: return default_prefix # botという変数に情報を格納 bot = commands.Bot(command_prefix=custom_prefix) # intents は各自設定してください # botが起動したら実行 @bot.event async def on_ready(): print('ready') # testコマンド ※このコマンドは削除しても大丈夫です @bot.command() async def test(ctx): print('success') return # prefixを変更するコマンド ※エイリアスとして cp が設定されています。 @bot.command(aliases=['cp']) async def change_prefix(ctx, new_prefix: str): # コマンドが実行されたサーバーでカスタムprefixが設定されていれば実行 if str(ctx.message.guild.id) in prefix_json.keys(): # dictからコマンドを実行したサーバーのカスタムprefix情報を削除 prefix_json.pop(str(ctx.message.guild.id)) # dictにコマンドを実行したサーバーのカスタムprefix情報を追加 prefix_json[str(ctx.message.guild.id)] = new_prefix # jsonファイルにdict情報を記入 with open('prefix.json', 'w', encoding='UTF-8') as f: f.write(json.dumps(prefix_json)) # 完了メッセージ print(f'{ctx.message.guild.name} のprefixが{prefix_json[str(ctx.message.guild.id)]}に変更されました') return else: # dictにコマンドを実行したサーバーのカスタムprefix情報を追加 prefix_json[str(ctx.message.guild.id)] = new_prefix # jsonファイルにdict情報を記入 with open('prefix.json', 'w', encoding='UTF-8') as f: f.write(json.dumps(prefix_json)) # 完了メッセージ print(f'{ctx.message.guild.name} のprefixが{prefix_json[str(ctx.message.guild.id)]}に変更されました') return bot.run(TOKEN)解説
コードのほうでもコメントで軽く解説してあるので大丈夫だと思いますが、念のためもうちょい詳しく解説。
モジュールのインポート
import json import discord from discord.ext import commandsこちら、上から
・jsonファイルに手を加えるために必要なモジュール
・discord.pyをやるうえで必須なモジュール
・コマンドフレームワークをやるうえで必須なモジュール
です。jsonファイル関連
prefix_json = None with open('prefix.json', encoding='UTF-8') as f: prefix_json = json.load(f)・最初に
prefix_json = Noneと記入しているのはグローバル変数にしたいからです。もしかしたら必要ないかも。
・withを使ってfという変数にprefix.jsonというファイルの情報を格納しています。開発環境によってはencodingを指定しないとエラー吐きます。command_prefix
def custom_prefix(bot: commands.Bot, msg: discord.Message): if str(msg.guild.id) in prefix_json.keys(): return prefix_json[str(msg.guild.id)] else: return default_prefix
command_prefixって関数指定できるんですね。知らなかった。
・jsonファイルをロードしたときに取得したdict型変数(以下prefix_json)のkeysにコマンドを実行したサーバーのIDが入ってれば、それに対応したprefixを返します。入ってなければ上のほうで設定されたdefault_prefixを返します。
|jsonはkeyにint型の要素を指定できないのでstr型に変換してます。Botが起動したら
@bot.event async def on_ready(): print('ready')これはほとんどのD.pyプログラムに入ってますね。Botの準備が完了すると実行されるやつです。実行するプログラムは任意のものに変えてもらってOkです。
うまく動作できてるか確認
@bot.command() async def test(ctx): print('success') returnちゃんとうまいこといってるかどうかを確認するためにこのコマンドを実装しています。
本体
@bot.command(aliases=['cp']) async def change_prefix(ctx, new_prefix: str): if str(ctx.message.guild.id) in prefix_json.keys(): prefix_json.pop(str(ctx.message.guild.id)) prefix_json[str(ctx.message.guild.id)] = new_prefix with open('prefix.json', 'w', encoding='UTF-8') as f: f.write(json.dumps(prefix_json)) print(f'{ctx.message.guild.name} のprefixが{prefix_json[str(ctx.message.guild.id)]}に変更されました') return else: prefix_json[str(ctx.message.guild.id)] = new_prefix with open('prefix.json', 'w', encoding='UTF-8') as f: f.write(json.dumps(prefix_json)) print(f'{ctx.message.guild.name} のprefixが{prefix_json[str(ctx.message.guild.id)]}に変更されました') return_人人人人_
>急に長え<
 ̄^Y^Y^Y^Y ̄ powerd bydouble_alt_death上から順番に解説してくよー
if str(ctx.message.guild.id) in prefix_json.keys()は、コマンドを実行したサーバーでカスタムprefixが設定されたらTrue返すやつですね。判断方法として、prefix_jsonっていうdictのkeysに鯖のID(str型)があったら、カスタムprefixが設定されてるってことになるから、それで判断するってだけですね。Too easy.
prefix_json.pop(str(ctx.message.guild.id))は、prefix_jsonっていうdictからpop関数を使って要素を削除するっていうやつですね。更新しないといけないからね。うん。
prefix_json[str(ctx.message.guild.id)] = new_prefixは、prefix_jsonに要素を追加するってやつ。dictの使い方知ってる人なら何してるか理解できると思う。
with open('prefix.json', 'w', encoding='UTF-8') as f:は、更新されたprefix_jsonをバックアップのためにjsonファイルに書き込むだけです。これがないとBotを再起動したときに全部リセットされます。
f.write(json.dumps(prefix_json))
これの下のprintはprefixが変わったっていうのをお知らせするだけだからなんでもいいね。じゃあ次
else:以下のやつ。
prefix_json[str(ctx.message.guild.id)] = new_prefixは、prefix_jsonに要素を追加するだけ。上のやつと違ってまだprefix_jsonに要素がないから削除する必要ないね。
それよりしたのwith ~とかは上と全く同じなのでパス。はい!解説終わり!!!
注意事項
もしHerokuでBotを動かしている場合、確かHerokuはread onlyなので、読み込むことはできますが書き込むことができません。そのため、カスタムprefixを保存することができないので、ご注意ください。
もしかしたらなんかやる方法あるかもですが。後書き
前に一回くそみたいなカスタムprefixのコードかいてとあるサーバーの方たちに怒られたので下のほうにかいてある記事を参考にしていい感じにやってみたらある程度認めてもらえました。最初は書き方がPEP8に準拠してないって怒られましたが。これから普通にプログラミングしてくときに気を付けたい。
一応Githubにも同じようなの公開してるからよかったら見てね
Githubへはここから!参考にした記事
discord.pyでカスタムprefixを実装しよう!
【初心者必見!】PythonでJSONを扱う方法をわかりやすく解説!
- 投稿日:2021-01-03T21:55:02+09:00
【Python】Pandas(パンダス)ちょっとやってみた
環境メモ
⭐️Mac Book Pro(macOS Catalina)
⭐️Anaconda 4.9.2
⭐️Python 3.8.5
⭐️Jupyter Note book 6.1.6
⭐️Pandas 1.1.5?Python(Pandasパンダス)?
— non (@nonnonkapibara) January 3, 2021
?データ分析?が簡単にできるPythonのライブラリやってみた?
Oracle PL/SQLをやっていれば、直感的にCSVのデータ集計ができた?とっても便利☺️
【Python】Pandas(パンダス)ちょっとやってみたhttps://t.co/rphduxeNaT#Python #Pandas pic.twitter.com/lQIueLUpuTPython(Pandasパンダス)とは
データ分析が簡単にできるPythonのライブラリ。
環境作成
Anacondaでpandasをインストールしました。
詳細については下記を参考
【Python】AnacondaでJupyter Notebookを使ってpandasをインポートするとModuleNotFoundErrorが出るときの対処法
https://qiita.com/nonkapibara/items/b592b00eef112cb4df9dPandas(パンダス)の勉強した内容
・CSVの読み込み
・CSVの内容を表示する
・CSVの件数を表示する
・縦方向に結合(join)する
・Left innser joinとRight innser join4つのCSVを用意
チョコ菓子とキャンディの商品マスタのCSVを用意する
・sweet_chocolate_master.csv
・sweet_candy_master.csv
架空の店舗のお菓子の発注CSVを用意する
・store_name_seven.csv
・store_name_familymart.csv
Pandas(パンダス)の実装 In[1]
# パンダスライブラリを読み込む import pandas # お菓子(チョコ)マスターCSVを読み込む sweet_chocolate_master = pandas.read_csv('sweet_chocolate_master.csv') # お菓子(チョコ)マスターの内容を表示する sweet_chocolate_master
Pandas(パンダス)の実装 In[2]
# お菓子(キャンディ)マスターCSVを読み込む sweet_candy_master = pandas.read_csv('sweet_candy_master.csv') # お菓子(キャンディ)マスターの内容を表示する sweet_candy_master
Pandas(パンダス)の実装 In[3]
# チョコとキャンディのマスターを縦方向に結合(join)する sweet_master = pandas.concat([sweet_chocolate_master,sweet_candy_master],ignore_index=True) # 列の最大表示数を設定する pandas.set_option('display.max_columns', 20) # 行の最大表示数を設定する pandas.set_option('display.max_rows', 50) sweet_master
Pandas(パンダス)の実装 In[4]
# 件数 print('sweet_chocolate_master 件数:' + str(len(sweet_chocolate_master))) print('sweet_candy_master 件数:' + str(len(sweet_candy_master)))
Pandas(パンダス)の実装 In[5]
# seven店舗 store_name_seven = pandas.read_csv('store_name_seven.csv') store_name_seven
Pandas(パンダス)の実装 In[6]
# familymart店舗 store_name_familymart = pandas.read_csv('store_name_familymart.csv') store_name_familymart
Pandas(パンダス)の実装 In[7]
# Left innser join # 左側チョコレートマスタ、右側Seven店舗 chocolate_saven_left_join=pandas.merge(sweet_chocolate_master,store_name_seven[["sweet_id","store_id","store_name","order_count"]], on="sweet_id",how="left") chocolate_saven_left_join
Pandas(パンダス)の実装 In[8]
# Right innser join # 左側チョコレートマスタ、右側Seven店舗 chocolate_saven_right_join=pandas.merge(sweet_chocolate_master,store_name_seven[["sweet_id","store_id","store_name","order_count"]], on="sweet_id",how="right") chocolate_saven_right_join
Pandas(パンダス)の実装 In[9]
# Left innser join # 左側お菓子マスタ、右側family店舗 sweet_family_left_join=pandas.merge(sweet_master,store_name_familymart[["sweet_id","store_id","store_name","order_count"]], on="sweet_id",how="left") sweet_family_left_join
Pandas(パンダス)の実装 In[10]
# Right innser join # 左側お菓子(チョコとキャンディ結合)マスタ、右側familymart店舗 # チョコとキャンディのマスターを縦方向に結合(join)する sweet_familymart_right_join=pandas.merge(sweet_master,store_name_familymart[["sweet_id","store_id","store_name","order_count"]], on="sweet_id",how="right") sweet_familymart_right_join
Pandas(パンダス)の実装 In[11]
# Left joinn # 左側Seven店舗、右側がお菓子マスタ store_name_seven_left_join=pandas.merge(store_name_seven,sweet_master[["sweet_id","sweet_name"]], on="sweet_id",how="left") store_name_seven_left_join
Pandas(パンダス)の実装 In[12]
# Left joinn # 左側familymart店舗、右側がお菓子マスタ store_name_familymart_left_join=pandas.merge(store_name_familymart,sweet_master[["sweet_id","sweet_name"]], on="sweet_id",how="left") store_name_familymart_left_join
Pandas(パンダス)の実装 In[13]
# お菓子マスタにSeven店舗とFamilyMart店舗をJoinする # 左側がお菓子マスタで、右側がSeven店舗 sweet_saven_left_join=pandas.merge(sweet_master,store_name_seven[["sweet_id","store_id","store_name","order_count"]], on="sweet_id",how="left") # 左側上記結果で、右側がFamilyMart店舗 sweet_store_all=pandas.merge(sweet_saven_left_join,store_name_familymart[["sweet_id","store_id","store_name","order_count"]], on="sweet_id",how="left") sweet_store_all

















- 投稿日:2021-01-03T21:50:24+09:00
【Python】AnacondaでJupyter Notebookを使ってpandasをインポートするとModuleNotFoundErrorが出るときの対処法
環境メモ
⭐️Mac Book Pro(macOS Catalina)
⭐️Anaconda 4.9.2
⭐️Python 3.8.5
⭐️Jupyter Note book 6.1.6
⭐️Pandas 1.1.5AnacondaでJupyter Notebookを使用。
Pandas(パンダス)を実行するとModuleNotFoundError: No module named 'pandas'
のimportエラーが出て、実行できない場合の対処法を説明します。Anacondaでpandasをインストール
Anacondaを使っていれば、最初からpandasがインストールされているようです。
conda list | grep pandasインストールされていなければインストールする
conda install pandaspandasをアップデートする
conda update pandasAnaconda Navigatorでpandasのライブラリを追加する
Anaconda Navigatorでpandasのライブラリを追加します。
これでOK!!
AnacondaやPythonのバージョンなど環境の確認する
AnacondaやPythonのバージョンなど環境の確認をする場合は、下記のコマンドで確認することができます。
conda infoAnacondaのpandasのバージョンを確認する
conda list | grep pandasJupyterのバージョン確認
下記コマンドでJupyterのバージョンを確認することができます。
jupyter --versionPythonのバージョン確認
下記コマンドでPythonのバージョンを確認することができます。
python --version

- 投稿日:2021-01-03T21:41:27+09:00
ABC 187 E - Through Path "オイラーツアー+区間和"のアプローチと 辺ではない任意の2点のクエリの考察
https://atcoder.jp/contests/abc187/tasks/abc187_e
は木DP解が適切ですが、オイラーツアーでたどる経路を使った区間和計算でも解けます。この考察過程を記録がてら記載します。ABC 187 Eでは、後述の通り隣接した2点のみに対してクエリされますが、一般的な2頂点が与えられた時の考察をします。その上で、これらに包含されるこの問題を解きます。オイラーツアー
木のオイラーツアーについては過去記事:オイラーツアーした木に対するクエリを参照してください。但し、以下、解説では、
- STEPを1-originで記載しています
- Discovery/Finishingをin/outと表現しています
以下のようにDFS順にパスを帰路pくします。
図では20step(20step目は終了)のツアーを行いました。これと同時に、costを同じ長さで定義します。これは、この瞬間のvisitのノードのコストではなくて、計算が終わったときのこのノードのコストを示します。(これは圧縮することも可能です)
一般的なクエリと、オイラーツアー上での考え方
ABC-Eでは、ある辺の二頂点が与えられるため、以下のAかBのパターンかつ、隣接2頂点が与えられた場合のみを扱いますが、ここでは、任意の2頂点$a,b$が与えられたとします。
ポイントは、木ではある2点が与えられた時、「1.どちらかのノードがもう一方のLCAのノード」か「2.そうではないか」のどちらかでしかありません。言い換えると、「1.片方のノードが一方のノードの部分木上のノードである」か「2.そうではない」のどちらかです。次に、それぞれのパターンを記載します。両ノードが同一である場合は考慮しません。
適当な頂点1を根としてオイラーツアーをしたパスとクエリであり得るバリエーションを以下に示します。"例:"はa,bのパラメータです。
この問題の操作は$a$側のノードから木を塗りつぶし、$b$はその塗りつぶしを防ぐ。塗りつぶされたノードはコストが$+x$される。という操作に見えます。
まず、$B,C,D$の操作は$b$の部分木以外のすべてのノード塗りつぶす操作で簡単に見えます。
ところが、$A$の操作が少し難しそうに見えます。この操作は良く見ると、(Aは$a=3$の方が深いので)$b=1$の子($2と7$)の部分木の中で$a$を含む部分木(つまり2の部分木)のすべてを塗りつぶす動作となるようです。これをオイラーツアーのパスと先ほど定義したcostすればよい区間を考えたのが図の下のテーブルです。青い両矢印直線はコストxを足せばいい区間です。"x"は$b$で止められている場所と考えると良いです。
$B,C,D$に関しては、非常にシンプルで、$b$の部分木以外のすべてのノードxを加算すればよいです。$b$の部分木は$b$のin, outの内部に含まれるノードなので、bの部分木でないとは$b$のinより小さいかoutより大きいすべてのcostにxを加算すればよいこととなります。
$A$の場合はアプローチが異なり、in, outだけでの加算範囲の判定が困難です。$a$が$b$の部分木であることは明らかのため、$a$のinより小さいSTEPで$b$は訪問されており、$a$のoutより大きなSTEPで$b$が訪問されることは明らかです。ただし、その左右に出現する$b$は1度とは限りません。例えば、図のpatAのように、3のoutの右側に1はSTEP 11と19の2度出現しています。これは、1の出現順順序を記録しておき、([1,11,19]のように)、$a$のinかout(必ずある区間に含まれるのでどちらでも良い)をキーに二分探索することで求まります。この2つのindexを+-1した区間にxを加算してやればよいです。ABC 187-Dの場合
さて、それでは出題された問題を考えます。この問題では、2点$a,b$が与えられるのではなく、木の辺が与えられます。木でこの2点を考えると必ず一方はLCAノードです。また、隣接した2点であるため、この深さの差は必ず1となります。
※図上少し混乱しやすいですが、patEでもpatFでも深いノードが主体になるため、in/outを注目すればいいのは3側のみです。この条件下では、上記のpatAとpatBを非常にシンプルに考えることができます。
- LCAは自明なのでの判定をする必要はない。尚、単にどちらかが部分木に含まれるかを確認するだけなら、一方のin/outがもう一方のin/outに包含されるかを確認すればよいだけなのでこれは面倒ではないです。
- inが若いノードがLCAノードである(オイラーツアーを考えると自明です)
- 深いノードの-+1のSTEPは必ず浅いノードを訪問している(patAの場合でも、加算すればよい区間の判定に訪問STEPの記録や二分探索などは不要でのin/out区間である)
つまり、以下のように考えます。あるノード$i$の深さを$dep(i)$とし、$add(l,r,x)$が$cost$の区間$[l,r)$にxを区間和する関数なら、ノード$a$のin,outを$ain,aout$で、ノード$b$のin,outを$bin,bout$するとき、
- $dep(a)$ > $dep(b)$の時、patEであり、$add(aout, ain+1, x)$すればよい(この場合は、$a$としてノード3のin/outが参照されます)
- $dep(a)$ < $dep(b)$の時、patFであり、$add(1, bin, x), $add(bout+1, 20, x)$ すればよい(つまり、$b$の部分木以外すべてにコスト追加/この場合は、$b$としてノード3のin/outが参照されます)
実装
Range Addする必要はありますが、QueryはSumのみであり、最後の1回だけ取ればよいため、imosで良いです。
また、eとqの数が多いので、pythonの場合、
input = sys.stdin.readlineは必須です。実行時間が400msくらい変わります。
n = int(input()) dat = [] G = [[] for _ in range(n)] for i in range(n - 1): a, b = map(int, input().split()) a -= 1 b -= 1 dat.append([a, b]) G[a].append(b) G[b].append(a) q = [] rootnode = 0 depth = [-1] * n nodein = [-1] * n nodeout = [-1] * n q.append([rootnode, 0, 0]) curtime = -1 parent = [None] * n while len(q) != 0: curtime += 1 curnode, curdepth, vcost = q.pop() if curnode >= 0: # 行き掛け if nodein[curnode] == -1: nodein[curnode] = curtime depth[curnode] = curdepth isLeaf = True if len(G[curnode]) == 0: # 子がいないときの処理 nodeout[curnode] = curtime + 1 for nextnode in G[curnode][::-1]: if depth[nextnode] != -1: continue isLeaf = False q.append([~curnode, curdepth, 0]) q.append([nextnode, curdepth + 1, 0]) parent[nextnode] = curnode if isLeaf is True: q.append([~curnode, curdepth, 0]) else: # もどりがけ curnode = ~curnode if nodein[curnode] == -1: nodein[curnode] = curtime nodeout[curnode] = curtime + 1 qq = int(input()) imos = [0] * (curtime + 10) for qqq in range(qq): t, e, x = map(int, input().split()) if t == 1: a, b = dat[e - 1] else: b, a = dat[e - 1] ain, aout = nodein[a], nodeout[a] bin, bout = nodein[b], nodeout[b] # a=スタートがbより深い場合 if ain > bin: # 部分木 PatEだけに加算 imos[ain] += x imos[aout + 1] += -x else: imos[0] += x imos[bin] += -x imos[bout + 1] += x imos[curtime + 2] += -x cur = 0 buf = [0] * (curtime + 10) for i in range(curtime + 5): cur += imos[i] buf[i] = cur for i in range(n): print(buf[nodein[i]])





- 投稿日:2021-01-03T21:41:27+09:00
AtCoder ABC 187 E - Through Path "オイラーツアー+区間和"のアプローチと 辺ではない任意の2点のクエリの考察
https://atcoder.jp/contests/abc187/tasks/abc187_e
は木DP解が適切ですが、オイラーツアーでたどる経路を使った区間和計算でも解けます。この考察過程を記録がてら記載します。ABC 187 Eでは、後述の通り隣接した2点のみに対してクエリされますが、一般的な2頂点が与えられた時の考察をします。その上で、これらに包含されるこの問題を解きます。オイラーツアー
木のオイラーツアーについては過去記事:オイラーツアーした木に対するクエリを参照してください。但し、以下、解説では、
- STEPを1-originで記載しています
- Discovery/Finishingをin/outと表現しています
以下のようにDFS順にパスを帰路pくします。
図では20step(20step目は終了)のツアーを行いました。これと同時に、costを同じ長さで定義します。これは、この瞬間のvisitのノードのコストではなくて、計算が終わったときのこのノードのコストを示します。(これは圧縮することも可能です)
一般的なクエリと、オイラーツアー上での考え方
ABC-Eでは、ある辺の二頂点が与えられるため、以下のAかBのパターンかつ、隣接2頂点が与えられた場合のみを扱いますが、ここでは、任意の2頂点$a,b$が与えられたとします。
ポイントは、木ではある2点が与えられた時、「1.どちらかのノードがもう一方のLCAのノード」か「2.そうではないか」のどちらかでしかありません。言い換えると、「1.片方のノードが一方のノードの部分木上のノードである」か「2.そうではない」のどちらかです。次に、それぞれのパターンを記載します。両ノードが同一である場合は考慮しません。
適当な頂点1を根としてオイラーツアーをしたパスとクエリであり得るバリエーションを以下に示します。"例:"はa,bのパラメータです。
この問題の操作は$a$側のノードから木を塗りつぶし、$b$はその塗りつぶしを防ぐ。塗りつぶされたノードはコストが$+x$される。という操作に見えます。
まず、$B,C,D$の操作は$b$の部分木以外のすべてのノード塗りつぶす操作で簡単に見えます。
ところが、$A$の操作が少し難しそうに見えます。この操作は良く見ると、(Aは$a=3$の方が深いので)$b=1$の子($2と7$)の部分木の中で$a$を含む部分木(つまり2の部分木)のすべてを塗りつぶす動作となるようです。これをオイラーツアーのパスと先ほど定義したcostすればよい区間を考えたのが図の下のテーブルです。青い両矢印直線はコストxを足せばいい区間です。"x"は$b$で止められている場所と考えると良いです。
$B,C,D$に関しては、非常にシンプルで、$b$の部分木以外のすべてのノードxを加算すればよいです。$b$の部分木は$b$のin, outの内部に含まれるノードなので、bの部分木でないとは$b$のinより小さいかoutより大きいすべてのcostにxを加算すればよいこととなります。
$A$の場合はアプローチが異なり、in, outだけでの加算範囲の判定が困難です。$a$が$b$の部分木であることは明らかのため、$a$のinより小さいSTEPで$b$は訪問されており、$a$のoutより大きなSTEPで$b$が訪問されることは明らかです。ただし、その左右に出現する$b$は1度とは限りません。例えば、図のpatAのように、3のoutの右側に1はSTEP 11と19の2度出現しています。これは、1の出現順順序を記録しておき、([1,11,19]のように)、$a$のinかout(必ずある区間に含まれるのでどちらでも良い)をキーに二分探索することで求まります。この2つのindexを+-1した区間にxを加算してやればよいです。ABC 187-Dの場合
さて、それでは出題された問題を考えます。この問題では、2点$a,b$が与えられるのではなく、木の辺が与えられます。木でこの2点を考えると必ず一方はLCAノードです。また、隣接した2点であるため、この深さの差は必ず1となります。
※図上少し混乱しやすいですが、patEでもpatFでも深いノードが主体になるため、in/outを注目すればいいのは3側のみです。この条件下では、上記のpatAとpatBを非常にシンプルに考えることができます。
- LCAは自明なのでの判定をする必要はない。尚、単にどちらかが部分木に含まれるかを確認するだけなら、一方のin/outがもう一方のin/outに包含されるかを確認すればよいだけなのでこれは面倒ではないです。
- inが若いノードがLCAノードである(オイラーツアーを考えると自明です)
- 深いノードの-+1のSTEPは必ず浅いノードを訪問している(patAの場合でも、加算すればよい区間の判定に訪問STEPの記録や二分探索などは不要でのin/out区間である)
つまり、以下のように考えます。あるノード$i$の深さを$dep(i)$とし、$add(l,r,x)$が$cost$の区間$[l,r)$にxを区間和する関数なら、ノード$a$のin,outを$ain,aout$で、ノード$b$のin,outを$bin,bout$するとき、
- $dep(a)$ > $dep(b)$の時、patEであり、$add(aout, ain+1, x)$すればよい(この場合は、$a$としてノード3のin/outが参照されます)
- $dep(a)$ < $dep(b)$の時、patFであり、$add(1, bin, x), $add(bout+1, 20, x)$ すればよい(つまり、$b$の部分木以外すべてにコスト追加/この場合は、$b$としてノード3のin/outが参照されます)
実装
Range Addする必要はありますが、QueryはSumのみであり、最後の1回だけ取ればよいため、imosで良いです。
また、eとqの数が多いので、pythonの場合、
input = sys.stdin.readlineは必須です。実行時間が400msくらい変わります。
n = int(input()) dat = [] G = [[] for _ in range(n)] for i in range(n - 1): a, b = map(int, input().split()) a -= 1 b -= 1 dat.append([a, b]) G[a].append(b) G[b].append(a) q = [] rootnode = 0 depth = [-1] * n nodein = [-1] * n nodeout = [-1] * n q.append([rootnode, 0, 0]) curtime = -1 parent = [None] * n while len(q) != 0: curtime += 1 curnode, curdepth, vcost = q.pop() if curnode >= 0: # 行き掛け if nodein[curnode] == -1: nodein[curnode] = curtime depth[curnode] = curdepth isLeaf = True if len(G[curnode]) == 0: # 子がいないときの処理 nodeout[curnode] = curtime + 1 for nextnode in G[curnode][::-1]: if depth[nextnode] != -1: continue isLeaf = False q.append([~curnode, curdepth, 0]) q.append([nextnode, curdepth + 1, 0]) parent[nextnode] = curnode if isLeaf is True: q.append([~curnode, curdepth, 0]) else: # もどりがけ curnode = ~curnode if nodein[curnode] == -1: nodein[curnode] = curtime nodeout[curnode] = curtime + 1 qq = int(input()) imos = [0] * (curtime + 10) for qqq in range(qq): t, e, x = map(int, input().split()) if t == 1: a, b = dat[e - 1] else: b, a = dat[e - 1] ain, aout = nodein[a], nodeout[a] bin, bout = nodein[b], nodeout[b] # a=スタートがbより深い場合 if ain > bin: # 部分木 PatEだけに加算 imos[ain] += x imos[aout + 1] += -x else: imos[0] += x imos[bin] += -x imos[bout + 1] += x imos[curtime + 2] += -x cur = 0 buf = [0] * (curtime + 10) for i in range(curtime + 5): cur += imos[i] buf[i] = cur for i in range(n): print(buf[nodein[i]])
- 投稿日:2021-01-03T21:39:17+09:00
SPAで作成されたWebサイトをスクレイピングする方法
Pythonでスクレイピングする方法としてこれまでrequestsモジュールを使っていたのですが、これはサーバ側で生成したHTMLを返すサイトでは使用できますが、JavaScriptを実行する前のレスポンスしか得られませんので、クライアント側でJavaScriptを実行してHTMLを手元で生成するようなSPAで作成されたサイトでは使えませんでした。
requests-htmlモジュール
SPAで作成されたサイトをスクレイピングするためにはrequests-htmlを使う必要があります。
インストール
pip install requests-html使い方
main.py# -*- coding: utf-8 -*- import requests from requests_html import HTMLSession def main_render_javascript_page(): url = 'https://hogehoge' session = HTMLSession() r = session.get(url) r.html.render() title = r.html.find('body', first=True).text print(title) def main_normal_page(): url = 'https://hogehoge' r = requests.get(url) print(r.text) if __name__ == '__main__': main_normal_page() main_render_javascript_page()公式
https://requests.readthedocs.io/projects/requests-html/en/latest/
参考サイト
https://dev.classmethod.jp/articles/python-asyncio/
https://blog.ikedaosushi.com/entry/2019/09/15/162445
- 投稿日:2021-01-03T21:31:36+09:00
Pythonの導入
PythonをMacにインストールしたので備忘録
pyenvのインストール
pyenvは、「複数のバージョンのPythonを管理できる」ツールです。
とりあえず、入れたほうがいい。homebrewでインストールbrew install pyenvインストールできたかは、以下にてバージョンが表示さればイントールできていることになる。
pyenv -vpyenvの設定
私は、zshを使用しているので以下を設定。
.zshrcの設定export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" export PATH="$HOME/.pyenv/shims:$PATH" eval "$(pyenv init -)"設定を反映させるsource .zshrcPythonのインストール
最初にも紹介した通り、pyenvでは複数のバージョンのPythonを使用することができます。
どのようなバージョンのPythonがインストールできるか以下のコマンドをターミナルで実行してみる。pyenv install --list上記リストにて私の場合は、3.9.0が最新のようでしたのでインストールしてみる。
pyenv install 3.9.0イントールできたかは以下で確認してみましょう。
pyenv versions[~/work] % pyenv versions * system 3.9.0 (set by /Users/XXXXX/.pyenv/version)上記では、systemのため、Macに標準でインストールされているバージョンのPythonを使用しています。
変更しましょう。pyevn global 3.9.0最後にちゃんと3.9.0に変更されていることを確認して完了です。
python --version
- 投稿日:2021-01-03T20:25:58+09:00
Githubおもしろリポジトリ② ~家中をどこからでもコントロール~
このシリーズについて
githubのトレンドリポジトリから情報を定期通知する機能を作ったのですが、それを通じて発見した面白そうなリポジトリを紹介するシリーズです。今回は、home-assistantというリポジトリを紹介します。
home-assistantとは
オープンソースのhome automationです。世界中のDIY好きたちがせっせと開発しているそうです。
アレクサやgoogleアシスタントなどのホームアシスタントと繋げて、webのUI上から電気やドアの開け閉め、テレビや冷房の操作などを行うことができます。対応しているホームアシスタントは以下の通りです。
ほんとは実際に試してみたいところですが、自分の家にホームアシスタントが無い&スマート家電が一つも無いということから、提供されているデモを操作してみた様子を紹介します。ホームアシスタント持っている方は、是非試してみて紹介してください。デモの様子
デモのページはこちらです。
まずは電気のON, OFFを制御しているデモです。右上の部屋の電気マークを押すか、左のスライドバーを動かすことにより家の電気の制御をできます。エアコンは、部屋の数字があることろで制御できるみたいですね。
カメラのマークを押すと、屋外のカメラと連動して、外の様子をチェックすることができます。
結構面白そうですね!まとめ
デモですが、試してみた様子を共有してみました。スマートアシスタントとスマート家電持ってる方は、実際にやってみる価値ありだと思います!家のどこからでも、というか家の外でも家中の設備を自由自在に動かせるのは楽しそうです。




- 投稿日:2021-01-03T18:35:16+09:00
はてなブックマーク3万件にみる技術トレンド2020年まとめ
tl;dr
2020年1年間のはてなブックマークの人気エントリー3万件をもとに技術トレンドを分析。
その結論とPythonでグラフ化した手順を書き記します。前置き
手元に2020年の1年間ではてなブックマークの技術カテゴリーで人気エントリーに一度でも乗ったことのある記事のタイトルデータが3万件ほどあったため、形態素解析を行い単語の出現頻度順に並べてみました。欠損の割合としては多くても1割程度、つまり少なくとも9割程度のデータは揃っているはずなので精度はかなり高いと思います。
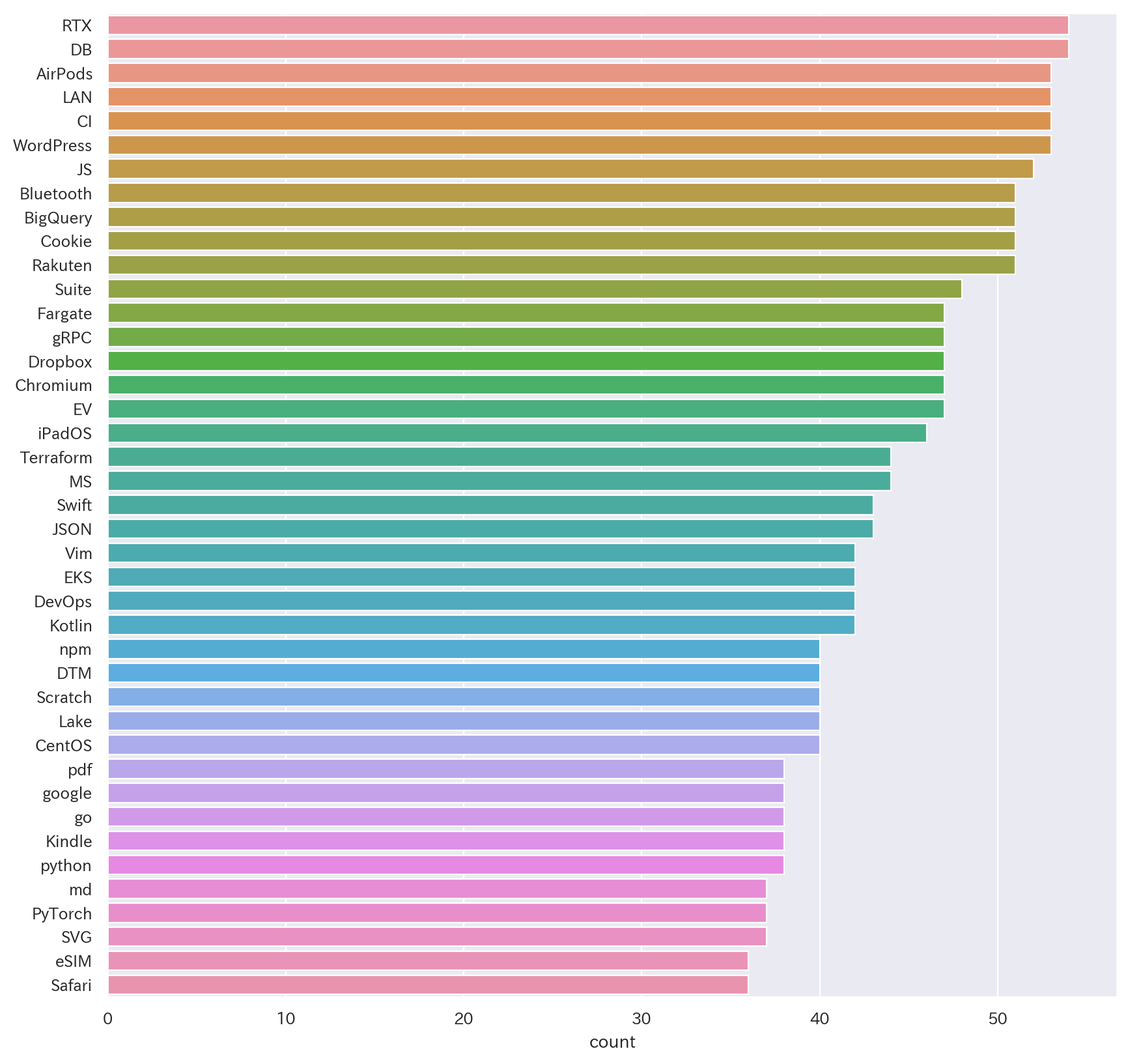
単純に上から並べると一般名詞やメディアの名前が上位を占めてしまうので、上位1000位のうち技術/技術系サービスに関係ありそうな単語だけをピックアップしました。結果としてピックアップした上位150位ほどで以下のようになっています。
結果
約150位まで全体像
1〜50位
51~100位
101位~
表記の揺れはある程度吸収できていそうですが、jsとJavaScriptなど一部吸収できていない部分もあります。TypeScriptも別で上位に入ってきていることを考えるとプログラミング言語系ではJavaScriptが頭抜けていてPythonが追従しているようなかたちが見て取れるかと。
また、KubernatesやRustなんかは200記事タイトル程度で言及されており自分の思ったより上位に入ってきていて驚きました(それだけ注目されているということだと思います)。枯れた技術で言うと、ネガティブな文脈で触れられることも多かったと感じますがRails(言語よりフレームワークが先に来るのがRubyらしいですね)がRustと同程度言及されていて、Javaが約150回言及で50位程度、PHPも100回弱言及で100以内には入ってきてるといったところで根強い人気がありそうです。
Kubernates/ECS/EKS/Fargateなどが入ってきていることを考えるとコンテナオーケストレーションの分野は体感通り注目をますます集めているなと感じます。
皆さんはギャップ・印象のほどいかがでしょうか。思っていたところと違ったところなどあればコメント等で意見交換できると面白いかもしれませんね。
(ちなみに、自分が普段業務で使っているScalaは頻度32回で150位圏外でした?)
手順
pythonは環境構築周りがかなりややこしいです。Macでやる場合はAnacondaかpyenvでpython3系を入れることになると思います。AnacondaはかなりリッチなのでpyenvでPython3を入れたあと、pip3で必要なライブラリだけをinstallするのが良さそうです。
condaとpip:混ぜるな危険 - onoz000’s blog
Anacondaとpipを併用すると干渉することがあるらしいので気をつけてください。Anacondaはpythonのディストリビューションの1つで機械学習系のライブラリがセットになったものだったと思います。今回はbrewでpyenvを入れていきます。
$ brew install pyenv $ pyenv install -l # ダウンロードできるバージョン一覧 $ pyenv install 3.7.9 # 自分の場合は3.7系依存のCLIツールを使っていたので3.7.9を入れる $ pyenv global 3.7.9 # pythonコマンドで使うバージョンを変更 $ python --version # => Python 3.7.9pip3が入るので必要なライブラリを導入していきます。
$ pip3 install collections matplotlib seaborn japanese_matplotlib pandas mecab-python3形態素解析にはMecabを使うので入れてなければbrewでいれます。
$ brew install mecab $ brew install mecab-ipadic # 辞書データpythonコードを書きます。固有名詞に絞ってしまうと、Lambdaなどの単語が一般名詞に分類されることもあったりで正確にカウントできないため、今回は泣く泣く一般名詞と固有名詞両方とも含めてカウントすることとしました。本来は固有名詞だけを正確にカウントできる方が楽かと思いますので、mecab-ipadic-NEologなど他の辞書データ検討で精度を上げていきたいところです。
count.pyimport MeCab import collections import seaborn as sns import matplotlib.pyplot as plt import japanize_matplotlib import pandas as pd # リストを平坦化するflatten関数 flatten = lambda x: [z for y in x for z in (flatten(y) if hasattr(y, '__iter__') and not isinstance(y, str) else (y,))] # csvデータの取り込み→リストへ data = pd.read_csv("trend-hatena-tech-2020.csv").values.tolist() flatten_data = flatten(data) m = MeCab.Tagger ('-Ochasen') # ここでmecab-ipadic-neologdなど別の辞書データを指定することも可能 m.parse('') # バグの迂回 words=[] for row in flatten_data: node = m.parseToNode(row) while node: # 名詞かつ一般名詞もしくは固有名詞の場合カウント対象のwordに含める hinshi=node.feature.split(",")[0] hinshi2=node.feature.split(",")[1] if hinshi == "名詞" and (hinshi2 == "一般" or hinshi2 == "固有名詞"): words.append(node.surface) node = node.next c = collections.Counter(words) del c['*'] common_words = c.most_common(1500) # 頻度上位1500位の単語をカウントしtuppleのリストで取得 sns.set(context="paper",font="IPAexGothic") # seabornの日本語対応 fig = plt.subplots(figsize=(100, 250), dpi=120) # 描画サイズとdpiの調整 sns.countplot(y=words,order=[i[0] for i in common_words]) plt.show() # プロット参考までにcsvの中身(記事の最初で示したスプレッドシートをcsvでエクスポートしたものです)。
$ cat trend-hatena-tech-2020.csv 「なんだこれは…」と絶句 HDD落札男性が見た中身:朝日新聞デジタル サカナクション、Chara、フジファブリック、女王蜂、米津玄師らを手がける土岐彩香の仕事術(前編) | エンジニアが明かすあのサウンドの正体 第9回 - 音楽ナタリー 社会人大学院で得たもの、失ったもの - 怠惰を求めて勤勉に行き着く GCP Projectを消しちゃった話 - 839の日記 Go でトランザクションをフルスクラッチで実装した - kawasin73のブログ 【山田祥平のRe:config.sys】在宅勤務時代のディスプレイ選び - PC Watch 「世界最悪級の流出」ブロードリンク社の2chスレを見ると事件は起こるべくして起こったことがわかる - アンテナ開発者ブログ 何度も使えるエコなカイロ 『ハクキンカイロ』がもうすぐ100年「使い捨ての13倍の暖かさ」「コスパ最強」 - Togetter LGの弱点も丸裸に、韓国メーカーを「駆逐」したダイキン 開発設計の3つの戦略と4つの戦術 | 日経 xTECH(クロステック) 2019年版 SEOのトレンドと注目すべきトピック - Speaker Deck ...実行します。
$ python count.py上記コードのようにフィルターせずに素直に全て表示した場合とても見にくいので
今回は気合でフィルターしました?
count.pyimport MeCab import collections import seaborn as sns import matplotlib.pyplot as plt import japanize_matplotlib import pandas as pd flatten = lambda x: [z for y in x for z in (flatten(y) if hasattr(y, '__iter__') and not isinstance(y, str) else (y,))] data = pd.read_csv("trend-hatena-tech-2020.csv").values.tolist() flatten_data = flatten(data) m = MeCab.Tagger ('-Ochasen') m.parse('') words=[] for index,row in enumerate(flatten_data): node = m.parseToNode(row) while node: hinshi=node.feature.split(",")[0] hinshi2=node.feature.split(",")[1] if hinshi == "名詞" and (hinshi2 == "一般" or hinshi2 == "固有名詞"): words.append(node.surface) node = node.next c = collections.Counter(words) del c['*'] common_words = c.most_common(1000) # filter条件(pythonワカラナイのでベタ書き?) filter_condition = lambda key: key == "iPhone" or key == "AWS" or key == "Apple" or key == "Windows" or key == "Mac" or key == "Twitter" or key == "Python" or key == "iOS" or key == "Linux" or key == "Chrome" or key == "js" or key == "Android" or key == "API" or key == "SEO" or key == "Kubernetes" or key == "CSS" or key == "Docker" or key == "LINE" or key == "amp" or key == "JavaScript" or key == "Go" or key == "TypeScript" or key == "React" or key == "Zoom" or key == "Excel" or key == "iPad" or key == "Rails" or key == "Rust" or key == "VR" or key == "OS" or key == "楽天" or key == "Raspberry" or key == "CPU" or key == "macOS" or key == "MacBook" or key == "Ruby" or key == "Facebook" or key == "Slack" or key == "Ryzen" or key == "Vue" or key == "Teams" or key == "UX" or key == "AMD" or key == "Edge" or key == "Azure" or key == "IoT" or key == "メルカリ" or key == "YouTube" or key == "Java" or key == "GPU" or key == "Lambda" or key == "Firefox" or key == "Ubuntu" or key == "Silicon" or key == "Pixel" or key == "Sim" or key == "Node" or key == "Adobe" or key == "VPN" or key == "NVIDIA" or key == "WSL" or key == "Actions" or key == "Oculus" or key == "Next" or key == "MySQL" or key == "SSD" or key == "PDF" or key == "ARM" or key == "Office" or key == "PHP" or key == "Firebase" or key == "Arm" or key == "Git" or key == "GCP" or key == "CLI" or key == "PhotoshopVIP" or key == "TikTok" or key == "IBM" or key == "GraphQL" or key == "HDD" or key == "Quest" or key == "SQL" or key == "Unity" or key == "ECS" or key == "ZOZO" or key == "Native" or key == "Mackerel" or key == "CTO" or key == "デー>タベース" or key == "Gmail" or key == "Netflix" or key == "SRE" or key == "Kyash" or key == "VSCode" or key == "KDDI" or key == "TensorFlow" or key == "AR" or key == "WebAssembly" or key == "Flutter" or key == "Chromebook" or key == "Surface" or key == "GeForce" or key == "ISUCON" or key == "RTX" or key == "DB" or key == "AirPods" or key == "LAN" or key == "CI" or key == "WordPress" or key == "JS" or key == "Bluetooth" or key == "BigQuery" or key == "Cookie" or key == "Rakuten" or key == "Suite" or key == "Fargate" or key == "gRPC" or key == "Dropbox" or key == "Chromium" or key == "EV" or key == "iPadOS" or key == "Terraform" or key == "MS" or key == "Swift" or key == "JSON" or key == "Vim" or key == "EKS" or key == "DevOps" or key == "Kotlin" or key == "npm" or key == "DTM" or key == "Scratch" or key == "Lake" or key == "CentOS" or key == "pdf" or key == "google" or key == "go" or key == "Kindle" or key == "python" or key == "md" or key == "PyTorch" or key == "SVG" or key == "eSIM" or key == "Safari" # dictへキャストし、フィルターしたあとでlistへ戻す filtered_common_words = list({key: value for key, value in dict(common_words).items() if filter_condition }.items()) sns.set(context="paper",font="IPAexGothic") fig = plt.subplots(figsize=(10, 25),dpi=100) # データ量が変わるのでサイズの調整 sns.countplot(y=words,order=[i[0] for i in filtered_common_words]) # フィルターしたリストを渡す plt.show()再び実行
$ python count.py最初の画像の出来上がり?
コメントアウトなど残ったままの走り書きのコードで良ければGithubにJupyterNotebookの実行結果と合わせて公開しておきます。ブックマーク数での重み付けなどしてみるとまた結果が変わって面白いかもしれませんね。以上。
参考
seabornで見てみる「ぼっちゃん」(お遊びpythonシリーズ)
pip install して import するだけで matplotlib を日本語表示対応させる
PythonでCSVファイルをリストに格納する方法




- 投稿日:2021-01-03T18:21:16+09:00
[Python / Pandas] DataFrameに対して`replace`で`None`に置き換えようとするとバグが発生する
何が起きたか
pandasのDataFrameにあるreplaceメソッドを使い、np.nanをNoneに置換しようとしたらバグが発生した(ように見えた)Environment
Google Colaboratory で実施
ソースコード
1. 置換前のDataFrame作成
動作確認用のDataFrameがこちら
import pandas as pd import numpy as np indexes = [ datetime.datetime(2020, 1, 1, 11, 50), datetime.datetime(2020, 1, 1, 12, 50), datetime.datetime(2020, 1, 1, 12, 52), datetime.datetime(2020, 1, 1, 18, 50), datetime.datetime(2020, 1, 1, 19, 50), datetime.datetime(2020, 1, 1, 21, 50), ] df = pd.DataFrame({ 'high': [1, np.nan, 3, np.nan, np.nan, 11], 'close': [4, 5, 6, 7, np.nan, 2], 'memo': ['sign', '', np.nan, 'sign2', np.nan, 'sign3'], 'bool': [True, None, True, False, None, False], 'stoploss': [True, None, True, False, None, False] }, index=indexes) df -> high close memo bool stoploss 2020-01-01 11:50:00 1.0 4.0 sign True True 2020-01-01 12:50:00 NaN 5.0 None None 2020-01-01 12:52:00 3.0 6.0 NaN True True 2020-01-01 18:50:00 NaN 7.0 sign2 False False 2020-01-01 19:50:00 NaN NaN NaN None None 2020-01-01 21:50:00 11.0 2.0 sign3 False False2. replace方法その1
バグが起こる方
df.replace(np.nan, None) -> high close memo bool stoploss 2020-01-01 11:50:00 1.0 4.0 sign True True 2020-01-01 12:50:00 1.0 5.0 True True 2020-01-01 12:52:00 3.0 6.0 True True 2020-01-01 18:50:00 3.0 7.0 sign2 False False 2020-01-01 19:50:00 3.0 7.0 sign2 False False 2020-01-01 21:50:00 11.0 2.0 sign3 False False...なんじゃこりゃ!!ヾノ。ÒдÓ)ノシ バンバン!!
np.nanだったところがNoneじゃなくて、直前の値で埋められてます
(fillnaされたみたいになってます)3. replace方法その2
大丈夫?な方
df.replace({np.nan: None}) -> high close memo bool stoploss 2020-01-01 11:50:00 1 4 sign True True 2020-01-01 12:50:00 None 5 None None 2020-01-01 12:52:00 3 6 None True True 2020-01-01 18:50:00 None 7 sign2 False False 2020-01-01 19:50:00 None None None None None 2020-01-01 21:50:00 11 2 sign3 False False期待通りではある(?
いや、気づいたけど、なんか、floatが、全部整数にされてる....
だいじょばないです(助けて)...なんて一瞬(30分以上)焦りましたが、よく見てみたら中身はfloatのままでした
tmp_df = df.replace({np.nan: None}) tmp_df.values -> array([[1.0, 4.0, 'sign', True, True], [None, 5.0, '', None, None], [3.0, 6.0, None, True, True], [None, 7.0, 'sign2', False, False], [None, None, None, None, None], [11.0, 2.0, 'sign3', False, False]], dtype=object)ε-(´∀`*)ホッ
この書き方覚えとかないとね...( ..)φ
df.replace({np.nan: None})参考資料
一応、pandasの公式ドキュメントでもこの件は言及されています。
ただ、見つけるのにかなり時間がかかったので、今回記録しておくことにしました。When value=None and to_replace is a scalar, list or tuple, replace uses the method parameter (default ‘pad’) to do the replacement. So this is why the ‘a’ values are being replaced by 10 in rows 1 and 2 and ‘b’ in row 4 in this case. The command s.replace('a', None) is actually equivalent to s.replace(to_replace='a', value=None, method='pad'):
日本語で書かれてたらもう少し早く気づけたかも...
その他関連資料
ちょっと関係あるのかわからないけれど、
Noneをnp.nanで埋めようとする場合も、別の問題が発生する模様
- 投稿日:2021-01-03T18:19:47+09:00
イベントカメラっぽい画像処理してみた
概要
イベントカメラっていうカメラがあります。
このイベントカメラ風に通常動画を変換してみたいと思います。
なんかに使えないかな〜。成果物
イベントカメラ風映像 pic.twitter.com/MFAUwzrdJt
— itdk (@itdk1996) January 3, 2021動画はなんでもよかったんですが、固定カメラだときれいにとれます。今回はGolfDBのデータからタイガーウッズのショットをやってみました
イベントカメラとは
イベントカメラは、一般的なカメラと根本的に仕組みが異なります。
一般的なカメラは、ある高さH、ある幅W、RGBのどれかCからH×W×Cの次元の数値を持ちます。
動画であれば、(T×H×W×C)になります。
一方で、イベントカメラは、あくまでイベントしか記録しません。ここで、イベントとは、「輝度値の変化」です。つまり時間方向で見て輝度値が閾値以上変化した「点」だけを記録していきます。記録するのはT×(X,Y,P)です。Pは輝度値が増えたら1、減ったら-1が入ります。変化がないところは記録されないのが特徴です。
イベントカメラの特徴
さて、イベントしか記録しないこのカメラですが、以下のような特徴があります。
・超高フレームレート
・低消費電力
・非同期的普通のカメラが60FPS程度なのに対し、イベントカメラは1000FPSを超えていきます。RGBカメラでは、FPSをあげるほど、カメラに入ってくる光の量が減って暗くなってしまうなどありますが、イベントカメラは入ってくる光の量が変わるか変わらないかなので高いFPSを保てます。
記録するデータが少ないので、低電力です。また、通常のカメラでは0.03秒目で1F、0.06秒目で2Fと一定のペースを開けてデータがありますが、イベントカメラの場合は
0.0012秒目で(100,200)で変化あり
0.0581秒目で(250,50)で変化あり
と変化があった時間でだけ記録されていきます。低電力で高い時間分解能をもつことから自動運転などにも応用が考えられます。
本題
簡単なコードですが、イベントカメラっぽいことをやってみます。
動画で変化があったフレームだけを残してみます。本当は「差分のあった点だけを取得する」のがイベントカメラの本質的なデータ構造です。
np.where使うと簡単にその形式に変換できます
イベントカメラは一般的に点群データ形式です。なので時間方向で点を集計して可視化することが多いので、画像からその可視化映像っぽいのだけ作ってみます。コード
今回は1画像前の各チャネルで差分をとって閾値以上の場合はイベントとして画素を残します
import numpy as np import cv2 def img2event_image(base_img, img, th = 10, plus = 128, minus = 255): img3 = base_img.astype(float) - img.astype(float) index1 = img3 > th img3[index1] = plus index2 = img3 < -1 * th img3[index2] = minus img3[~(index1) & ~(index2)] = 0 return img3.astype(np.uint8) def video2event_video(): stack = True path = "96.mp4" # output_name = "output.mp4" output_name = "output_stack.mp4" cap = cv2.VideoCapture(path) fourcc = cv2.VideoWriter_fourcc(*"mp4v") w = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH)) h = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) if stack: w *= 2 fps = cap.get(cv2.CAP_PROP_FPS) fps = 30 out = cv2.VideoWriter(output_name, fourcc, fps, (w, h)) success, image = cap.read() # image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) base_image = image[:] while success: b_img = img2event_image(base_image.copy(), image.copy()) if stack: b_img = cv2.hconcat([image, b_img]) out.write(b_img) base_image = image[:] success, image = cap.read() # image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) cap.release() cv2.destroyAllWindows()参考
イベントカメラ DAVIS346
https://nanoxeed.co.jp/product/eventcamera/イベントカメラの話
https://qiita.com/minomonter/items/6d71029f6c860da60740


- 投稿日:2021-01-03T18:13:42+09:00
自然言語処理ライブラリGiNZAの解析結果を解りやすく表示してみた
はじめに
この記事はspaCy/GiNZAを触ったことがない人を対象に、どのような解析結果が出力されるか把握し理解することを目的としています。
spaCy/GiNZAとは
GiNZAはUniversal Dependencies(UD)に基づいたオープンソースな日本語処理ライブラリです。
spaCyというMITライセンスで商用レベルな自然言語処理フレームワークをベースに構築されています。Pythonがインストールされていれば、簡単にインストールすることができます。
$ pip install -U ginzaまずはそのまま動かしてみる
ginzaコマンドが使えるようになっているためそのまま解析することができます。
$ ginza 銀座でランチをご一緒しましょう。今度の日曜日はどうですか。 # text = 銀座でランチをご一緒しましょう。 1 銀座 銀座 PROPN 名詞-固有名詞-地名-一般 _ 6 obl _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|NP_B|Reading=ギンザ|NE=B-GPE|ENE=B-City 2 で で ADP 助詞-格助詞 _ 1 case _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Reading=デ 3 ランチ ランチ NOUN 名詞-普通名詞-一般 _ 6 obj _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|NP_B|Reading=ランチ 4 を を ADP 助詞-格助詞 _ 3 case _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Reading=ヲ 5 ご ご NOUN 接頭辞 _ 6 compound _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=CONT|Reading=ゴ 6 一緒 一緒 VERB 名詞-普通名詞-サ変可能 _ 0 root _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=ROOT|Reading=イッショ 7 し する AUX 動詞-非自立可能 _ 6 advcl _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Inf=サ行変格,連用形-一般|Reading=シ 8 ましょう ます AUX 助動詞 _ 6 aux _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Inf=助動詞-マス,意志推量形|Reading=マショウ 9 。 。 PUNCT 補助記号-句点 _ 6 punct _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=CONT|Reading=。 # text = 今度の日曜日はどうですか。 1 今度 今度 NOUN 名詞-普通名詞-副詞可能 _ 3 nmod _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|NP_I|Reading=コンド 2 の の ADP 助詞-格助詞 _ 1 case _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Reading=ノ 3 日曜日 日曜日 NOUN 名詞-普通名詞-副詞可能 _ 5 nsubj _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=SEM_HEAD|NP_I|Reading=ニチヨウビ|NE=B-DATE|ENE=B-Day_Of_Week 4 は は ADP 助詞-係助詞 _ 3 case _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Reading=ハ 5 どう どう ADV 副詞 _ 0 root _ SpaceAfter=No|BunsetuBILabel=B|BunsetuPositionType=ROOT|Reading=ドウ 6 です です AUX 助動詞 _ 5 aux _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Inf=助動詞-デス,終止形-一般|Reading=デス 7 か か PART 助詞-終助詞 _ 5 mark _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=SYN_HEAD|Reading=カ 8 。 。 PUNCT 補助記号-句点 _ 5 punct _ SpaceAfter=No|BunsetuBILabel=I|BunsetuPositionType=CONT|Reading=。無事解析できましたが、コンソールだと見づらいですね。
今度はわかりやすく表示してみる
今回、構文従属関係や表を見やすくするためspaCyのVisualizerとStreamlitで可視化してみました。
構文従属関係の描画の際、PROPN・ADP・obl・advclといったUD用語を日本語に置き換えるためcreate_manual()を経由してsvgを生成し、streamlit.image()で描画しています。input_list = st.text_area("入力文字列").splitlines() nlp = spacy.load('ja_ginza') for input_str in input_list: doc = nlp(input_str) for sent in doc.sents: svg = spacy.displacy.render(create_manual(sent), style="dep", manual=True) streamlit.image(svg)また表を
streamlit.table()で固有表現(エンティティ)をstreamlit.components.v1.html()で描画しています。ソースコード全文はこちら動作結果はこんな感じになりました。
入力と解析結果は以下のような形になっています。
入力文字列
銀座でランチをご一緒しましょう。今度の日曜日はどうですか。
吾輩は猫である。 名前はまだ無い。1-1. 銀座でランチをご一緒しましょう。
構文従属関係
詳細
i(index) 0 1 2 3 4 5 6 7 8 orth(テキスト) 銀座 で ランチ を ご 一緒 し ましょう 。 lemma(基本形) 銀座 で ランチ を ご 一緒 する ます 。 reading_form(読みカナ) ギンザ デ ランチ ヲ ゴ イッショ シ マショウ 。 pos(PartOfSpeech) PROPN ADP NOUN ADP NOUN VERB AUX AUX PUNCT pos(品詞) 固有名詞 設置詞 名詞 設置詞 名詞 動詞 助動詞 助動詞 句読点 tag(品詞詳細) 名詞-固有名詞-地名-一般 助詞-格助詞 名詞-普通名詞-一般 助詞-格助詞 接頭辞 名詞-普通名詞-サ変可能 動詞-非自立可能 助動詞 補助記号-句点 inflection(活用情報) - - - - - - サ行変格連用形-一般 助動詞-マス意志推量形 - ent_type(エンティティ型) City - - - - - - - - ent_iob(エンティティIOB) B O O O O O O O O lang(言語) ja ja ja ja ja ja ja ja ja dep(dependency) obl case obj case compound ROOT advcl aux punct dep(構文従属関係) 斜格要素 格標識 目的語 格標識 複合語 ROOT 副詞的修飾節 助動詞 句読点 head.i(親index) 5 0 5 2 5 5 5 5 5 bunsetu_bi_label B I B I B I I I I bunsetu_position_type SEM_HEAD SYN_HEAD SEM_HEAD SYN_HEAD CONT ROOT SYN_HEAD SYN_HEAD CONT is_bunsetu_head TRUE FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSE ent_label_ontonotes B-GPE O O O O O O O O ent_label_ene B-City O O O O O O O O 文節区切り
銀座で/ランチを/ご一緒しましょう。
文節の主辞区間と句の区分
銀座(NP)/ランチ(NP)/ご一緒(VP)
固有表現(エンティティ)
1-2. 今度の日曜日はどうですか。
構文従属関係
詳細
i(index) 9 10 11 12 13 14 15 16 orth(テキスト) 今度 の 日曜日 は どう です か 。 lemma(基本形) 今度 の 日曜日 は どう です か 。 reading_form(読みカナ) コンド ノ ニチヨウビ ハ ドウ デス カ 。 pos(PartOfSpeech) NOUN ADP NOUN ADP ADV AUX PART PUNCT pos(品詞) 名詞 設置詞 名詞 設置詞 副詞 助動詞 助詞 句読点 tag(品詞詳細) 名詞-普通名詞-副詞可能 助詞-格助詞 名詞-普通名詞-副詞可能 助詞-係助詞 副詞 助動詞 助詞-終助詞 補助記号-句点 inflection(活用情報) - - - - - "助動詞-デス 終止形-一般" - ent_type(エンティティ型) - - Day_Of_Week - - - - - ent_iob(エンティティIOB) O O B O O O O O lang(言語) ja ja ja ja ja ja ja ja dep(dependency) nmod case nsubj case ROOT aux mark punct dep(構文従属関係) 名詞修飾語 格標識 名詞句主語 格標識 ROOT 助動詞 節標識 句読点 head.i(親index) 11 9 13 11 13 13 13 13 bunsetu_bi_label B I B I B I I I bunsetu_position_type SEM_HEAD SYN_HEAD SEM_HEAD SYN_HEAD ROOT SYN_HEAD SYN_HEAD CONT is_bunsetu_head TRUE FALSE TRUE FALSE TRUE FALSE FALSE FALSE ent_label_ontonotes O O B-DATE O O O O O ent_label_ene O O B-Day_Of_Week O O O O O 文節区切り
今度の/日曜日は/どうですか。
文節の主辞区間と句の区分
今度(NP)/日曜日(NP)/どう(ADVP)
固有表現(エンティティ)
構文従属関係などが解りやすくなったでしょうか?
GiNZAに少しでも興味持ってもらえたら幸いです。参考サイト
- GiNZA version 4.0: 多言語依存構造解析技術への文節APIの統合
- GiNZA入門 (1) - 事始め
- はじめての自然言語処理 第4回 spaCy/GiNZA を用いた自然言語処理
- 自然言語処理ライブラリのGiNZAを使って係り受け解析を試す
- 自然言語処理におけるPOSタグと係り受けタグ一覧
- Universal Dependencies 日本語コーパス
- 日本語の構文解析における3つの「係り受け」
- spaCy building blocks and visualizers for Streamlit apps
- 【簡単爆速第3弾】HTML要らずでWebアプリが作れるStreamlitで、HTMLが使えるようになったぞ





- 投稿日:2021-01-03T17:56:32+09:00
WSL2 + Docker + VSCode で C++ と Python の実行環境を作る
競プロで C++ と Python を使っていて,Windows での実行環境が欲しかったので作ってみました.
開発用ではないので必要最低限の設定になっています.対象
- C++ や Python の簡単な実行環境を作りたい方
- Windows ユーザ
- Docker 導入済み
- VSCode を使っている方
使用環境 / ツール
- GitHub
- Windows 10 + WSL2
- Docker Desktop for Windows (v3.0.0)
- VSCode (v1.52.1)
この記事で作れる実行環境のサンプルリポジトリ : https://github.com/e5pe0n/algo-training-sample
GitHub にリポジトリを作る
コードを管理しやすいように GitHub にリポジトリを作ります.
適当な Repository Name を入力し,Add a README fileにチェックを入れて Create Repository をクリックします.
.gitignore はあとから作るのでここではチェックしません.
Dev Container の作成
いま作ったリポジトリを,実行環境となる Docker コンテナにクローンします.
VSCode に Remote Development を入れる
まずは VSCode からコンテナに接続できるように, VSCode を開いて拡張機能 Remote Development (ms-vscode-remote.vscode-remote-extensionpack) をインストールします.
VSCode と GitHub を紐づける
インストールが完了すると,エディタの一番左下に Remote Development の機能が使える緑色のボタンが表示されるので,それをクリックします.
出てきたメニューの中からRemote-Containers: Clone Repository in Container Volumeをクリックします.
リポジトリの URL を入力してエンターを押します.
初回では,VSCode で GitHub アカウントにサインインするかのダイアログが表示されたり,ブラウザに飛んで VSCode が GitHub にアクセスすることを許可するか聞かれたりするので,それぞれ Yes や Continue をクリックします.
クローンするブランチ
VSCode と GitHub が紐づけられると,クローンするブランチを聞かれるので
mainを選択します.
ボリュームの種類
ほかのリポジトリと併用しないので今回は
Create a unique volumeを選択します.
コンテナの種類
コンテナの種類は
Ubuntuにしましょう.
続いてバージョンを聞かれますがfocalにします.
これでひとまずリポジトリに紐づいたコンテナを作ることができました.
ここからは C++ や Python が実行できるようにコンテナの設定を整えていきます.コンテナの設定
初めてコンテナが作られたときは以下のようなディレクトリ構成になっていると思います.
ここから設定ファイルを編集したり,新しく設定ファイルを追加したりしていきます./workspaces/<repo-name> ├── .devcontainer │ ├── devcontainer.json │ └── Dockerfile ├── .git └── README.md最終的なディレクトリ構成はこんな感じです.
/workspaces/<repo-name> ├── .clang-format ├── .devcontainer │ ├── devcontainer.json │ └── Dockerfile ├── .git ├── .gitignore ├── README.md └── requirements.txt.gitignore の作成
リポジトリのディレクトリ直下で
touch .gitignoreを実行して空のファイルを作っておきます.
gitignore.io でvscode,C++,Pythonを入力して Create をクリックします.
表示された内容を全部先ほど作成した .gitignore にコピーして完成です.
必要があれば編集してください.Dockerfile の編集
Dockerfile の
# [Optional] Uncomment this ...以下の部分に,コンテナが作られるときに実行されるコマンドを追加していきます.
apt-getでインストールする build-essential は C++ のコンパイラ g++ が入っていて,clang-format は C++ ファイルのフォーマット用です.
また,デフォルトでは Python 3.8.2 が入っていますが,Python のパッケージインストーラ pip が入っていないので python3-pip をインストールします.# See here for image contents: https://github.com/microsoft/vscode-dev-containers/tree/v0.154.0/containers/ubuntu/.devcontainer/base.Dockerfile # [Choice] Ubuntu version: bionic, focal ARG VARIANT="focal" FROM mcr.microsoft.com/vscode/devcontainers/base:0-${VARIANT} # [Optional] Uncomment this section to install additional OS packages. RUN apt-get update && export DEBIAN_FRONTEND=noninteractive \ && apt-get -y install --no-install-recommends \ build-essential \ clang-format \ python3-pip.clang-format の作成
C++ ファイルのフォーマットの設定ファイルとして .clang-format を用意します.
VSCode のオートフォーマットを on にして C++ のフォーマッターを Clang-Format に設定することで,.clang-format の設定通り自動的にコードをフォーマットできます.
設定できる項目はめっちゃいっぱいある( https://clang.llvm.org/docs/ClangFormatStyleOptions.html )のでお好みで.
自分は正直よくわかってないのでとりあえず気になったものだけ設定しています.ColumnLimit: 110 AllowShortBlocksOnASingleLine: true AllowShortFunctionsOnASingleLine: Empty AllowShortIfStatementsOnASingleLine: true BinPackArguments: false BinPackParameters: false BreakBeforeBinaryOperators: NonAssignment ConstructorInitializerAllOnOneLineOrOnePerLine: true IndentWidth: 2requirements.txt の作成
requirements.txt は Python のパッケージ管理に使うファイルです.
ここにパッケージを列挙しておき,pip3 install -r requirements.txtを実行することで必要なパッケージを 1 コマンドでインストールすることができます.
導入するのは次のパッケージです.
パッケージ 説明 numpy 行列演算・数値計算とか用 flake8 リンター autopep8 フォーマッター これらを
pip3 installでインストールしたあと,インストールしたパッケージの一覧をpip3 freezeで requirements.txt に書き出します.$ pwd /workspaces/<repo-name> $ pip3 install numpy flake8 autopep8 $ pip3 freeze > requirements.txt依存しているパッケージも合わせると requirements.txt は次のようになっていると思います.
requirements.txtautopep8==1.5.4 flake8==3.8.4 mccabe==0.6.1 numpy==1.19.4 pycodestyle==2.6.0 pyflakes==2.2.0 toml==0.10.2devcontainer.json の編集
コンテナの設定ファイルです.
この中に VSCode の設定やコンテナが作られたあとのコマンドなどを書いておくことで,コンテナを作成したとき設定が自動的に反映されます.
オプション 説明 settings コンテナ独自の VSCode の設定 extensions コンテナで使う VSCode の拡張機能 postCreatedCommand コンテナが作られたあとに実行したいコマンド settings
VSCode の設定を書く部分です.
オプション 説明 editor.formatOnSave trueでファイル保存時に自動フォーマットpython.languageServer Python IntelliCode のサーバ python.pythonPath 使用する Python インタプリタのパス python.linting.flake8Args flake8 の引数 python.formatting.provider Python のフォーマッタを選択 [cpp]->editor.tabSize C++ ファイルでのインデントの文字数 [cpp]->editor.defaultFormatter C++ のフォーマッタを選択 extensions
インストールしたい VSCode の拡張機能を列挙するところです.
自分はとりあえず以下のものを書いています.
拡張機能 ID 説明 Visual Studio IntelliCode visualstudioexptteam.vscodeintellicode AI アシスタントがコード補完を提示してくれる C/C++ ms-vscode.cpptools C++ 用 Clang-Format xaver.clang-format C++ ファイル用フォーマッタ Git Extension Pack donjayamanne.git-extension-pack Git 用 Python ms-python.python Python 用 Pylance ms-python.vscode-pylance Python 用 Bracket Pair Colorizer 2 coenraads.bracket-pair-colorizer-2 対応する括弧をカラーリングしてくれる Trailing Spaces shardulm94.trailing-spaces 余分なスペースをハイライト・除去 Vim vscodevim.vim VSCode 用 Vim エミュレータ postCreateCommand
コンテナ作成後に実行されるコマンドを書くところです.
pip3 install -r requirements.txtをここに書いておくことで,先ほど書いた requirements.txt のパッケージを自動的にインストールしてくれます.remoteUser
root でコンテナに接続したいときは以下のようにコメントアウトします.
パーミッションまわりがいろいろ面倒なので自分は基本 root で使っています.// "remoteUser": "vscode"これらを設定すると devcontainer.json はこんな感じになります.
// For format details, see https://aka.ms/devcontainer.json. For config options, see the README at: // https://github.com/microsoft/vscode-dev-containers/tree/v0.154.0/containers/ubuntu { "name": "Ubuntu", "build": { "dockerfile": "Dockerfile", // Update 'VARIANT' to pick an Ubuntu version: focal, bionic "args": { "VARIANT": "focal" } }, // Set *default* container specific settings.json values on container create. "settings": { "terminal.integrated.shell.linux": "/bin/bash", "editor.formatOnSave": true, "python.languageServer": "Pylance", "python.pythonPath": "/usr/bin/python3", "python.linting.flake8Args": [ "--max-line-length", // 1 行あたりの文字数を 110 に設定 "110" ], "python.formatting.provider": "autopep8", "python.formatting.autopep8Args": [ "--max-line-length", // 1 行あたりの文字数を 110 に設定 "110" ], "[cpp]": { "editor.tabSize": 2, "editor.defaultFormatter": "xaver.clang-format" // 拡張機能 Clang-Format を選択 }, }, // Add the IDs of extensions you want installed when the container is created. "extensions": [ "visualstudioexptteam.vscodeintellicode", "ms-vscode.cpptools", "xaver.clang-format", "donjayamanne.git-extension-pack", "ms-python.python", "ms-python.vscode-pylance", "coenraads.bracket-pair-colorizer-2", "shardulm94.trailing-spaces", "vscodevim.vim" ], // Use 'forwardPorts' to make a list of ports inside the container available locally. // "forwardPorts": [], // Use 'postCreateCommand' to run commands after the container is created. "postCreateCommand": "pip3 install -r requirements.txt", // Comment out connect as root instead. More info: https://aka.ms/vscode-remote/containers/non-root. // "remoteUser": "vscode" }以上でコンテナの設定は完了です.
コンテナのリビルド
仕上げとして,設定に基づいてコンテナをリビルドします.
左下の緑色のDev Container: Ubuntuをクリックし,Remote-Containers: Rebuild Containerを選択します.
これで C++ と Python の実行環境ができました.
リビルドが完了したあと,例えば次の hello.cpp,hello.py をコンテナ内で実行できます.hello.cpp#include <bits/stdc++.h> using namespace std; int main() { cout << "I'm C++!" << endl; }# g++ -o hello hello.cpp # ./hello I'm C++!hello.pyprint("I'm Python!!")# python3 hello.py I'm Python!!あとはこれをリモートのリポジトリにプッシュしておけば,同じ環境をすぐに作ることができます.
おまけ
自分は新しくディレクトリを作るとき C++ と Python のディレクトリを分けたいので,テンプレートとして次のディレクトリをリポジトリに入れています.
template ├── cpp │ ├── build // C++ の実行ファイル置き場 │ │ └── .gitkeep │ ├── .gitkeep │ └── run.sh // C++ ファイル実行用スクリプト └── python └── .gitkeeprun.shf=`echo $1 | sed -e 's/\(.*\).cpp/\1/'` current_dir=$(eval pwd) g++ -std=c++17 -g -o ${current_dir}/build/${f}.out $1 eval ${current_dir}/build/${f}.outrun.sh は C++ ファイルをコンパイル + 実行するスクリプトで,
sh run.sh A.cppみたいに使います.
競プロをやっていく上でもっといい運用方法があればぜひ教えてほしいです!










![devcontainer.json - algo-training-sample [Dev Container_ Ubuntu] - Visual Studio Code 1_3_2021 5_20_06 PM_LI.jpg](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F319282%2F9cf99cc5-96d5-1e2e-0d21-758830db9f60.jpeg?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=18ea340c645095ef366c4e07f80b57db)
- 投稿日:2021-01-03T17:22:18+09:00
Python dict でキーがなかったらデフォルト値を返すメモ
- 投稿日:2021-01-03T17:17:13+09:00
緯度経緯をURLへ変換するサービス、マップクリエイター
マップクリエイターとは、どんなWebサービスですか?
Googleマップの任意の地点をWebページ化するサービスです。場所をWebページ化することで空間にテキストが紐付くので、検索サイトから検索した時スムーズにその場所がどこにあるのかが、日本国民全員に分かるようになります。マップクリエイターを作ろうと思ったきっかけは何だったのでしょうか?
旅行に行った時よくバスをよく利用するのですが、田舎のほうになるとバス停がどこにあるのか分からなかったり、バス停が分かってもどのバスがどこへ向かうのかが分からないことが多々あったので、それを上手い具合に解決したいと思って作りました。そこで、ITとかにあまり詳しくない人でも、特定の場所に対して簡単にテキストを埋め込めるサービスがあれば、Googleで検索した時にその場所の詳細がすぐ分かるだろうと思って作りました。
バス停だけにとどまらず、地元の名所やつっこんだ観光案内(雑学など)を書けば、地域復興にも繋がるかなと思います。
機能面でこだわった点などありますか?
Google マップでは場所によっては緯度経緯が表示されず、プラスコードというアルファベットだけの表示になることもあるので、プラスコードにも対応させました。また悪用防止のため、作成したページを削除する機能も付けました。(マップクリエイターは2018年に作ったwebサービスです)
- 投稿日:2021-01-03T17:08:14+09:00
Pydocstringのスニペットを動的に展開する [vim/neovim]
tl;dr
vim/neovimでultisnipsを使用して動的なpydocstringを展開する機能を開発した
背景
PythonでDocstringを自動で挿入する方法は無数に考えられますが、個人的には
"""(triple quotes) でトリガーされるスニペットのように機能してかつ、
記述が必要なプレースホルダーに次々ジャンプできるようなものがほしいと思っていました。イメージ
def sugoi_kansuu(hoge: int, fuga: str) -> None: """カーソルがここにある展開すると
def sugoi_kansuu(hoge: int, fuga: str) -> None: """ {関数の説明を書く場所} Args: hoge (int): {引数の説明を書く場所} fuga (str): {引数の説明を書く場所} """このようになってタブかなにかしらのキーで説明を書く場所にカーソルが次々にジャンプしていくようなものです
完成
感想
少し便利
補足
使用するには以下のようなultisnipsの設定を用意するだけ
global !p from nayvy_vim_if.ultisnips import ( generate_pydocstring, ) endglobal post_jump "generate_pydocstring(snip)" snippet """ "Pydocstring" w endsnippet

- 投稿日:2021-01-03T17:02:12+09:00
日本のコロナ患者数データを解析する
日本のコロナ患者数データを解析して予測モデルを作っていきます。
ここではFacebookが提供しているProphetというライブラリを使用します。環境
Windows10にAnacondaをインストールしたときに一緒にインストールされるJupyter Notebookを使用
使用するデータ
- nhk_news_covid19_domestic_daily_data.csv: NHKが発表しているコロナ患者数データ
データ提供元:
https://www3.nhk.or.jp/news/special/coronavirus/data-all/ライブラリのインポート
fbprophet、plotly、およびxgboostをそれぞれAnacona Promptで
conda install -c conda-forge fbprophet
pip install plotly
pip install xgboost
でインストールした上で、JupyterNotebook上で以下によりライブラリのインポートを行った。import pandas as pd import seaborn as sns import numpy as np from scipy.stats import norm from sklearn.preprocessing import MinMaxScaler from sklearn.preprocessing import StandardScaler pd.pandas.set_option('display.max_columns', None) from scipy import stats import warnings warnings.filterwarnings('ignore') %matplotlib inline from sklearn.linear_model import Lasso from sklearn.feature_selection import SelectFromModel pd.pandas.set_option('display.max_columns', None) import matplotlib.pyplot as plt from fbprophet import Prophet import plotly.express as px from sklearn.ensemble import RandomForestRegressor from xgboost import XGBRegressor from sklearn.metrics import accuracy_score from sklearn import metrics from sklearn.model_selection import ParameterGrid from tqdm import tqdm from sklearn.pipeline import Pipeline from sklearn.decomposition import PCAProphet
ProphetはFacebookが開発した時系列予測のライブラリで詳細は以下に書かれてます。
https://facebook.github.io/prophet/docs/quick_start.html特徴:
- Prophetの入力は列がdsとyのデータフレームである必要がある
- dsはデートスタンプ(日付)、yは予測を行いたい数値測定データデータ解析
データフレームの表示:
path = "../input/covid19data_from_NHK/nhk_news_covid19_domestic_daily_data.csv" df_Jap = pd.read_csv(path,encoding = 'utf-8') df_Jap
グラフの表示:
fig = px.area(df_Jap, x="日付", y="国内の感染者数_1日ごとの発表数", height=600, width=700, color_discrete_sequence = ["blue"]) fig.update_layout(xaxis_rangeslider_visible=True) fig.show()
2020年の4月ごろ第一波、8月ごろ第二波、12月ごろ第三波が来ているのがわかります。(第三波は現在進行形です)
Prophetによる感染者数予測
トレーニングデータとテストデータ
データをトレーニングデータとテストデータに分けるのですが、ここでは
トレーニングデータ:2020/7/14~2020/11/30
テストデータ:2020/12/1~2020/12/31
とします。
2020/7/14~としたのはそれ以前は患者数が0に近く、データの特徴が変わると考えたからです。Train_Jap=df_Jap[df_Jap.loc[df_Jap['日付']=='2020/7/14'].index.values[0]:df_Jap.loc[df_Jap['日付']=='2020/12/1'].index.values[0]-1] Test_Jap=df_Jap[df_Jap.loc[df_Jap['日付']=='2020/12/1'].index.values[0]:-1]Prophetの設定
Prophetのモデルをトレーニングデータ(Train_Jap)に対し学習させ、テストデータ(Test_Jap)に対し予測させますが、以下の設定ができます。
- growth
growth='linear'(線型)とgrowth='logistic'(ロジスティック関数)を選択できます。
growth='logistic'ではデータの上限('cap'(環境収容力))と下限を設定でき、ここではこちらを使います。
'cap'はグラフの見易さを理由にここでは10000とします。(1日の感染者数が10000人を超えない限りこれでいいです)Train_Jap['cap']=10000 Test_Jap['cap']=10000
- changepoints
トレンドの変化点として
'2020/8/7', '2020/9/7', '2020/10/24', '2020/11/20'
を設定します。(グラフから目で読み取りました)
- seasonality_mode
seasonality_mode='additive'(加法的季節性)
seasonality_mode='multiplicative'(乗法的季節性)
の二つが選べますが、上のグラフを見ると週周期性が感染者数に比例して大きくなっているため、乗法的季節性の方を採用します。
- seasonality_prior_scale
モデルの周期性をデータにフィットさせる度合いを調整するパラメータ。
まず暫定的に1としますが、後にグリッドサーチで複数の値を入れてみます。
- changepoint_prior_scale
トレンド項の事前分布であるラプラス分布の分散を表しており、大きければ大きいほど変化点が検出されやすくなる。この項を大きくし過ぎると、かなり多くのポイントが変化点として検知される。
まず暫定的に1としますが、後にグリッドサーチで複数の値を入れてみます。情報元:
https://www.atmarkit.co.jp/ait/articles/1906/07/news004_2.html
- interval_width
不確定性区間の幅を表し、デフォルトでは0.8である。
こちらも後にグリッドサーチで複数の値を入れてみます。model=Prophet(growth='logistic', seasonality_mode='multiplicative', seasonality_prior_scale=1, changepoint_prior_scale=1, changepoints=['2020/8/7', '2020/9/7', '2020/10/24', '2020/11/20']) model.fit(Train_Jap) forecast = model.predict(Test_Jap) fig = model.plot_components(forecast)トレンドと週周期の学習結果が出ました↓
(日曜の検査数が少ないので)月曜は感染者数が少なくなるのは知っていましたが、逆に木金土は多くなるといった傾向があるようです:
トレーニングデータと予測結果を表示します。
設定したトレンドの変化点を赤い破線、予測のトレンドの線を赤線、予測結果を青線で表示します。from fbprophet.plot import add_changepoints_to_plot plot = model.plot(forecast) a = add_changepoints_to_plot(plot.gca(), model, forecast) plt.ylim([-0, 5000])
学習によって得られた予測値yhatをTest_Japに列として追加します:
Test_Jap['yhat']=forecast['yhat'].values12月の実際の感染者数と予測結果を比較します:
plt.figure(figsize=(20, 8)) plt.plot(Test_Jap['ds'], Test_Jap['y'], 'b-', label = 'Actual') plt.plot(Test_Jap['ds'], Test_Jap['yhat'], 'r--', label = 'Prediction') plt.xlabel('Date',rotation=90); plt.ylabel('Sales'); plt.title('Actual vs Prediction') plt.xticks(rotation=90) plt.legend();
accuracyを計算してみます:
Test_Jap['diff']=(Test_Jap.y-Test_Jap.yhat).abs() acc_ts2=(1-(Test_Jap['diff'].sum()/Test_Jap['y'].sum()))*100 acc_ts2 #85.55183564855452今回のaccuracyは約86%となりました。
さらに指標として
MAE(Mean Absolute Error:平均絶対誤差)
MSE(Mean Squared Error:平均二乗誤差)
RMSE(Root Mean Square Error:平均平方二乗誤差)
を計算してみます。MAE_ts=metrics.mean_absolute_error(Test_Jap['y'], Test_Jap['yhat']) MSE_ts=metrics.mean_squared_error(Test_Jap['y'], Test_Jap['yhat']) RMSE_ts=np.sqrt(metrics.mean_squared_error(Test_Jap['y'], Test_Jap['yhat'])) print('MAE:', MAE_ts) print('MSE:', MSE_ts) print('RMSE:', RMSE_ts) MAE: 404.44140578238205 MSE: 305342.084316079 RMSE: 552.5776726543328すでに悪くないと思いますが、以下でグリッドサーチによりパラメータチューニングを行います。
グリッドサーチ
'changepoint_prior_scale'、'seasonality_prior_scale'、および'interval_width'について以下の値を設定しました。
params_grid = {'changepoint_prior_scale':[0.1, 0.5, 1, 2, 10], 'seasonality_prior_scale':[0.1, 0.5, 1, 2, 10], 'interval_width':[0.8, 0.85, 0.9, 0.95] } grid = ParameterGrid(params_grid)model_parameters = pd.DataFrame(columns = ['Acc','Parameters']) for p in tqdm(grid): Train=Train_Jap.copy() Valid=Test_Jap[['ds','y','cap']].reset_index() m=Prophet(growth='logistic', seasonality_mode='multiplicative', seasonality_prior_scale=p['seasonality_prior_scale'], changepoint_prior_scale=p['changepoint_prior_scale'], changepoints=['2020/8/7', '2020/9/7', '2020/10/24', '2020/11/20'], interval_width = p['interval_width'] ) m.fit(Train_Jap) forecast = m.predict(Valid[['ds','cap']]) forecast = forecast.astype({"ds": object,"cap": object}) Valid=pd.concat([Valid.reset_index()[['ds','y']],forecast['yhat']], axis=1) #performance metric Valid['diff']=(Valid.y-Valid.yhat).abs() acc=(1-((Valid['diff'].sum()/Valid['y'].sum())))*100 model_parameters = model_parameters.append({'Acc':acc,'Parameters':p},ignore_index=True) parameters = model_parameters.sort_values(by=['Acc'],ascending=False) parameters = parameters.reset_index(drop=True) best_parameters=parameters['Parameters'][0]ベストパラメータは
'changepoint_prior_scale': 0.5,
'interval_width': 0.8,
'seasonality_prior_scale': 2
となりました。これらのパラメータで改めてグラフ描画やaccuracy計算をしてみます。m = Prophet(growth='logistic', seasonality_mode='multiplicative', seasonality_prior_scale=best_parameters['seasonality_prior_scale'], changepoint_prior_scale=best_parameters['changepoint_prior_scale'], changepoints=['2020/8/7', '2020/9/7', '2020/10/24', '2020/11/20'], interval_width =best_parameters['interval_width'] ) m.fit(Train_Jap) forecast=m.predict(Test_Jap)from fbprophet.plot import add_changepoints_to_plot plot = model.plot(forecast) a = add_changepoints_to_plot(plot.gca(), model, forecast) plt.ylim([-0, 5000])
Test_Jap['yhat']=forecast['yhat'].values plt.figure(figsize=(20, 8)) plt.plot(Test_Jap['ds'], Test_Jap['y'], 'b-', label = 'Actual') plt.plot(Test_Jap['ds'], Test_Jap['yhat'], 'r--', label = 'Prediction') plt.xlabel('Date',rotation=90); plt.ylabel('Sales'); plt.title('Actual vs Prediction') plt.xticks(rotation=90) plt.legend();
Test_Jap_best['diff']=(Test_Jap_best.y-Test_Jap_best.yhat).abs() acc_ts2=(1-(Test_Jap_best['diff'].sum()/Test_Jap_best['y'].sum()))*100 acc_ts2 #90.92890097106074accuracyは約91%で、MAE、MSE、およびRMSEは以下のようになりました。
MAE_ts=metrics.mean_absolute_error(Test_Jap['y'], Test_Jap['yhat']) MSE_ts=metrics.mean_squared_error(Test_Jap['y'], Test_Jap['yhat']) RMSE_ts=np.sqrt(metrics.mean_squared_error(Test_Jap['y'], Test_Jap['yhat'])) print('MAE:', MAE_ts) print('MSE:', MSE_ts) print('RMSE:', RMSE_ts) #MAE: 253.92347110782634 #MSE: 111763.48089497152 #RMSE: 334.31045585648604







- 投稿日:2021-01-03T15:52:02+09:00
pythonでのスライスエラー(´;ω;`)
エラー発生!!!
pythonにて、無効なメールアドレスをはじくメソッドを書いていました。
def isValidEmail(email): if email[0] == '@': return False elif ' ' in email: return False elif email.count('@') > 1: return False elif email['@':].count('.') < 1: return False else: return True条件の4個目の「@」以降に「.」が無いメールアドレスをはじく条件を付けたかったのですが、エラーになりました。
エラー内容は「slice indices must be integers or None or have an __ index __ method」
となっておりました。
どうやらスライスの中身は整数である必要があるとのこと。解決策
事前に@以降のドメイン名を切り出した変数を用意し、その中で「.」を検索することとしました。成功!
def isValidEmail(email): domain = email.find('@') if email[0] == '@': return False elif ' ' in email: return False elif email.count('@') > 1: return False elif email[domain:].count('.') < 1: return False else: return True根本的な解決ではないかもしれませんが、とりあえず解決!
- 投稿日:2021-01-03T15:32:51+09:00
Django検索
Djangoでの検索
find.py変数 = モデル名.objects.filter(フィルター内容)フィルター内容
文字検索
samle.py変数 = モデル名.objects.filter(フィルター内容) # 完全一致 変数 = モデル名.objects.filter(項目名=値) # 値で始まる 変数 = モデル名.objects.filter(項目名__startswith=値) # 値で終わるものを検索 変数 = モデル名.objects.filter(項目名__endswith=値) # あいまい検索 変数 = モデル名.objects.filter(項目名__contains=値) # 大小区別しない検索 変数 = モデル名.objects.filter(項目名__iexact=値) # 大小区別しないあいまい検索 変数 = モデル名.objects.filter(項目名__icontains=値) 変数 = モデル名.objects.filter(項目名__istartswith=値) 変数 = モデル名.objects.filter(項目名__iendswith=値)数値比較
sample.py変数 = モデル名.objects.filter(フィルター内容) # 値と等しい 変数 = モデル名.objects.filter(項目名=int(値)) # より大きい 変数 = モデル名.objects.filter(項目名__gt=int(値)) # 以上 変数 = モデル名.objects.filter(項目名__gte=int(値)) #より小さい 変数 = モデル名.objects.filter(項目名__lt=int(値)) # 以下 変数 = モデル名.objects.filter(項目名__lte=int(値))AND検索
sample.py変数 = モデル名.objects.filter(1つ目の条件,2つ目の条件,...) 変数 = モデル名.objects \ .filter(1つ目の条件) \ .filter(2つ目の条件) \OR検索
sample.py変数 = モデル名.objects.filter(Q(1つ目の条件)|Q(2つ目の条件),...)リスト検索
sample.py変数 = モデル名.objects.filter(項目名__in=リスト)SQLでの検索
sample.py変数 = モデル名.objects.raw(sql文) # sql文 sql = 'SELECT * FROM テーブル名' ##テーブル名 アプリケーション名_モデル名
- 投稿日:2021-01-03T14:52:18+09:00
pandas DataFrameの整形表示
サンプルデータ:楽天レシピカテゴリー
from tabulate import tabulate import pandas as pd from pprint import pprint df = pd.read_csv('small_category.csv', encoding='utf-8-sig') br = '\n' print(br + 'print'.center(20, '=') + br) print(df.head()) print(br + 'pprint'.center(20, '=') + br) pprint(df.head()) print(br + 'tabulate psql'.center(20, '=') + br) print(tabulate(df.head(), headers='keys', tablefmt='psql', numalign='right', stralign='left', showindex=False)) print(br + 'tabulate simple'.center(20, '=') + br) print(tabulate(df.head(), headers='keys', tablefmt='simple', numalign='right', stralign='left', showindex=False)) ----------出力---------- =======print======== Id Type mediumId largeId Name 0 50 small 66 10 ソーセージ・ウインナー 1 1491 small 67 10 生ハム 2 1492 small 67 10 鶏ハム 3 321 small 67 10 その他のハム 4 49 small 68 10 ベーコン =======pprint======= Id Type mediumId largeId Name 0 50 small 66 10 ソーセージ・ウインナー 1 1491 small 67 10 生ハム 2 1492 small 67 10 鶏ハム 3 321 small 67 10 その他のハム 4 49 small 68 10 ベーコン ===tabulate psql==== +------+--------+------------+-----------+-------------+ | Id | Type | mediumId | largeId | Name | |------+--------+------------+-----------+-------------| | 50 | small | 66 | 10 | ソーセージ・ウインナー | | 1491 | small | 67 | 10 | 生ハム | | 1492 | small | 67 | 10 | 鶏ハム | | 321 | small | 67 | 10 | その他のハム | | 49 | small | 68 | 10 | ベーコン | +------+--------+------------+-----------+-------------+ ==tabulate simple=== Id Type mediumId largeId Name ---- ------ ---------- --------- ----------- 50 small 66 10 ソーセージ・ウインナー 1491 small 67 10 生ハム 1492 small 67 10 鶏ハム 321 small 67 10 その他のハム 49 small 68 10 ベーコン
- 投稿日:2021-01-03T14:28:31+09:00
ebayのAPI触ってみた
はじめに
eBay Developers Programへの登録を済ませておいてください
こちらにガイドがあるので参考にしてくださいFinding APIを使用してみる
Finding APIは
eBayプラットフォームの商品検索機能です
eBayに出品された商品に対する検索結果をAPIで取得することができますpythonで実行してみます
ebay_api.pyimport requests import csv appkey = 取得したAPP KEY keywords = 検索したいキーワード URL = "http://svcs.ebay.com/services/search/FindingService/v1?OPERATION-NAME=findItemsByKeywords"\ "&SERVICE-VERSION=1.0.0"\ f"&SECURITY-APPNAME={appkey}"\ "&RESPONSE-DATA-FORMAT=JSON"\ "&REST-PAYLOAD"\ f"&keywords={keywords}" def get_page(): request = requests.get(URL) products = request.json() # print(products) for item in (products["findItemsByKeywordsResponse"][0]["searchResult"][0]["item"]): itemId = item["itemId"][0] title = item["title"][0] currency = item["sellingStatus"][0]["currentPrice"][0]["@currencyId"] price = item["sellingStatus"][0]["currentPrice"][0]["__value__"] try: condition = item["condition"][0]["conditionDisplayName"][0] except: condition = "--" try: watchCount = item["listingInfo"][0]["watchCount"][0] except: watchCount = "0" data = { "itemId": itemId, "title": title, "condition": condition, "watchCount": watchCount, "currency": currency, "price": price } with open("eBayAPI.csv", "a") as csvfile: row = [ data["itemId"], data["title"], data["condition"], data["watchCount"], data["currency"], data["price"] ] writer = csv.writer(csvfile) writer.writerow(row) if __name__ == "__main__": get_page()このコードを実行すると検索結果がcsvで出力されるはずです
他にもフィルター検索や特定のストアで検索かけることもできるみたいなので
上手く活用していけば市場調査が楽になるかと思います次はebaysdkの記事について書こうと思います