- 投稿日:2021-01-03T23:41:06+09:00
【ギリ初心者向け】Laravel Docker AWS(EC2) Webアプリ(PHP)を0から簡単にデプロイする方法(無料)①
できるようになること(MacOS前提です。同じことやればWinでも大丈夫)
Webアプリ(PHP)をDockerで作成し、AWSでデプロイする工程をわかりやすく書いていく!!
プログラミングはできるようになったけど作ったものを世の中に出したいけどわからん!となった人向けです①〜③の3部構成になります
①全体像と全体の流れ 目次みたいなもん
②Dockerを利用した理由とプロジェクト作成手順
③作成したプロジェクトをAWS(EC2インスタンス)にUPして世の中にだす!※知らない単語等も詳しく説明するつもりだが。都度ググってくださいな!ググる力もエンジニアの力の一つらしいですわ。(プロが言ってた)
まずは全体像から
全体のイメージはこんな感じ。
これを作成すれば作成したWebアプリを世の中に出せる!!0から世の中に出すまで順序(目次みたいなもんですわ)
1. DockerをPCにインストール
2. Project(ディレクトリを作成)
3. Projectの中でDockerを使って環境構築
- Webサーバー(nginx)をインストール
- アプリケーションサーバー(php:7.4-fpm)をインストール, PHPパッケージ管理ツール(Composer)インストール
- データベースサーバー(mysql)をインストール
- PHPを扱うフレームワーク(Laravel)をインストール4. ProjectをGithubにUP
5. ローカルの状態で自由自在にプログラミング!!
ここでLaravel(PHP)でプログラミングするよ!!6. できたものをGithubにUP
7. AWSに登録してEC2インスタンス(Ubuntu)を作成!!
8. EC2インスタンス(Ubuntu)の中に環境構築
- PHPをインストール
- Webサーバー(nginx)をインストール
- アプリケーションサーバー(php:7.4-fpm)をインストール, PHPパッケージ管理ツール(Composer)インストール
- データベースサーバー(mysql)をインストール
- PHPを扱うフレームワーク(Laravel)をインストール9. EC2インスタンス (Ubuntu)内のディレクトリにgit clone。Githubからプロジェクトを持ってくる!!
10. 該当URLにアクセスして表示!!デプロイ成功!
具体的にどうすればよいか??
疲れたので今回の記事ではこんな感じにします
次回はDockerを使った環境構築からGithubにアップするところまで
それでは②へGOQiita初投稿で読みづらい箇所や誤っている箇所などがあると思いますが、優しくコメントでご指摘いただけると幸いです。

- 投稿日:2021-01-03T23:28:39+09:00
Serverless Frameworkの使い方
Serverless Frameworkの使い方をまとめました。
今後何かいいTipsがあれば更新していこうかと思います。基本コマンド
インストール
事前にnodejsをインストールしておくこと
npm install -g serverlessバージョン確認
sls --versionログイン
sls loginAWSの認証情報の設定
sls config credentials --provider aws --key YOUR_KEY --secret YOUR_SECRET更新のときは -o オプションを加える
-o はオーバーライトの意味テンプレート作成
node.jsのテンプレートを使用
sls create --template aws-nodejs別フォルダにあるテンプレートを使用
sls create --template-path path/to/my/template/folder -p path/to/my/service -n my-new-serviceGithubとかにあるテンプレートを使用
serverless install -u https://github.com/foo-bar.....削除
sls removeデプロイ
sls deploy -v-v でプロセスを確認できる
作成も更新もこのコマンドで実行するCloudFormationのスタックを更新する場合
通常のコマンドでデプロイ可能sls deployLambda関数の更新には関数名を指定する場合
名前を指定するsls deploy function -f myFuncName【参考】
https://www.serverless.com/blog/quick-tips-for-faster-serverless-developmentdry run
sls deploy --noDeploy構文に誤りがないかチェック
応用
外部ファイルを参照する
serverless.ymlresources: - ${file(resources/s3.yml)}コードチェック
※事前にPythonをインストール
pip install cfn-lint以下のコマンドで確認
cfn-lint sample.ymlこれでCloudFormationの構文に誤りがないかチェックができる
詳細はこちら
https://github.com/aws-cloudformation/cfn-python-lintトラブルシューティング
バケットポリシーのバージョン表記
Version: 2012-10-17シングルクォーテーションなしの場合
slsが読み違えて時刻に変換してしまうので、
以下のように変更するVersion: '2012-10-17'resourcesフォルダ内のファイルを参照できない
ファイルパスが間違っている
変数を利用している場合、うまく参照できていない可能性がある外部ファイルを読み込めない
各CloudFormationのファイルは、
Resourcesではじまるように記述しないといけない、以下例Resources: S3Bucket: Type: AWS::S3::Bucket Properties:
Serverless Frameworkがわからなくてなったら
立ち寄りたい、、、そんな記事になれればと思います。
Thanks.
- 投稿日:2021-01-03T22:48:31+09:00
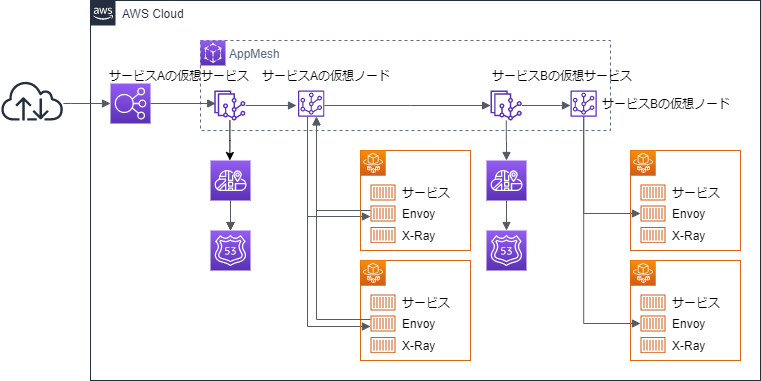
TerraformでAWS AppMeshを使ってECS Fargateのサービスを統合する(その3 仮想ルーター編)
はじめに
AWS AppMesh記事第3弾。
前回の記事の続き。今回は、これまでの記事のバックエンド側サービス(サービスB)に仮想ルータを導入し、Canary なデプロイを実現することを目指す(ELBを使わずサービスディスカバリを使った場合、こういったことをしないとクラウドネイティブなデプロイをするのは難しいと思われる)。
前回に引き続き、本記事を書いている 2021/1/3 時点で AWS AppMesh はまだまだ発展途上なサービスであり、情報が変わる可能性があることはご了承いただきたい。
仮想ルーター編で目指す構成
これまでの構成を以下のように変更する。
これまでの構成
今回の構成
Canary なデプロイをするということで、もう一つ ECS のサービスを Cloud Map を連動させておく。
これを以降では、サービスBv2として扱う。
サービスBv2は、サービスBと見分けがつきやすいように、返却するコンテンツなり応答なりをサービスBと変えるようにしておこう。今回は、サービスAについては特に変更することはない。
サービスBより先の部分が変わるため、サービスAとしては意識しなくても良い。AppMesh のサービスBに関連した項目の設定
AppMesh に関連したリソースを以下のように変更する。
ここで気を付けなければいけないのは、サービスBのaws_appmesh_virtual_serviceのnameは、名前解決可能な DNS なり Cloud Map の名前になっている必要があるということだ。また、サービスBの名前は、サービスAからの通信先として指定しているため、これを変更するにはサービスA側の設定変更も必要になる点について気を付けなければいけない。おいそれと「v1」みたいな名前をつけてしまうと、ずっとその名前を引きずることになるので気を付けよう。
resource "aws_appmesh_virtual_service" "service_b" { name = local.service_b_appmesh_service_name mesh_name = aws_appmesh_mesh.trial.id spec { provider { # 仮想ノード向けの通信を仮想ルーター向けに変更する # virtual_node { # virtual_node_name = aws_appmesh_virtual_node.service_b.name # } virtual_router { virtual_router_name = aws_appmesh_virtual_router.service_b.name } } } } resource "aws_appmesh_virtual_router" "service_b" { name = local.service_b_appmesh_virtualrouter_name mesh_name = aws_appmesh_mesh.trial.id spec { listener { port_mapping { port = 80 protocol = "http" } } } } resource "aws_appmesh_route" "service_b" { name = local.service_b_appmesh_route_name mesh_name = aws_appmesh_mesh.trial.id virtual_router_name = aws_appmesh_virtual_router.service_b.name spec { http_route { match { prefix = "/" } action { weighted_target { virtual_node = aws_appmesh_virtual_node.service_b.name weight = 4 } weighted_target { virtual_node = aws_appmesh_virtual_node.service_bv2.name weight = 1 } } } } }
aws_appmesh_virtual_routerについては、サービスアプリケーションの待ち受けポートを指定する以外は特に難しいことはない。これを、
aws_appmesh_routeに紐付けてやれば良い。
aws_appmesh_routeのactionブロックでは、上記の通り、weight属性を指定することでトラフィックの振り分けが可能だ。ここは 50, 50 とか書いても良いし、上記のように比率で書いても良い。
上記は、サービスBv2に 20% のトラフィックが流れるようにした例だ。動かしてみる
これで、NLB のパブリックドメインに対して curl で何度かトラフィックを入れてみると、サービスBとサービスBv2が混ざって返却されるようになる。
X-Ray のサービスマップでも、以下のようにサービスBとサービスBv2に振り分けられていることを確認できる。
なお、最終的にサービスBは廃止してサービスBv2をメインにしていく場合、サービスBの Cloud Map のレコードを削除してしまうとサービスAから通信できなくなってしまう。
なんとかして、元のサービスBのAレコードにサービスBv2を接続するようにして、切り替えていくことが必要になると考えられる。
この辺の使い勝手はイマイチなので、もう少し改善されることを信じたい……


- 投稿日:2021-01-03T21:32:37+09:00
EC2インスタンスを停止しても従量制課金が適用される
何が問題か
テスト用のEC2インスタンスをもう使わないと思い、停止したのだが後日料金が発生していることに気がついた。
12月の初め頃からEC2を停止していたはずなのだが、課金されている。。
解決方法
EC2インスタンスに紐づいていたElasticIPの関連付けを解除する。
問題解決までの流れ
EC2インスタンスは全て停止しているので、課金が発生するのはおかしいと思い調べたところAWSによる以下の説明が。
インスタンスを終了したが、アカウントに EC2 リソースがプロビジョニングされている
請求書の Elastic Compute Cloud の明細項目には、インスタンス以外のリソースが含まれています。EC2 インスタンスは、次のような他の EC2 リソースと共に使用されることがよくあります。
Elastic IP アドレス
Amazon Elastic Block Store (Amazon EBS) のボリュームhttps://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-billing-terminated/
どうやらEC2の請求明細にはElastic IP アドレスやAmazon Elastic Block Store (Amazon EBS) のボリューム(何のことかわからないです、初心者でスンマソ)が含まれているらしい。。
Amazon EBSを使った覚えはないので、Elastic IP アドレスが怪しいと睨んだ。
以下のAWSユーザーガイドを参考にElastic IPの解除を行う。手順は以下のとおり。
1.EC2コンソール( https://console.aws.amazon.com/ec2/ )を開く
2.リソースのElastic IPを選択
3.関連付けを解除するElasticIPアドレスを選択し、アクションから「ElasticIPアドレスの関連付けを解除」を選択
4.関連付けを解除するを選択
ElasticIPの料金体系
これで関連付けは解除できましたが、そもそもElasticIPって料金かかるんだっけ・・?という疑問が。
公式サイトで調べてみると、
次の条件がすべて満たされている限り、Elastic IP アドレスに料金は発生しません。
Elastic IP アドレスが EC2 インスタンスに関連付けられている。
Elastic IP アドレスに関連付けられているインスタンスが実行中である。
インスタンスには、1 つの Elastic IP アドレスしかアタッチされていない。
Elastic IP アドレスは、Network Load Balancer や NAT ゲートウェイなどのアタッチされたネットワークインターフェイスに関連付けられます。上記の条件を全て満たしている時のみ課金されないみたい。
私の場合、EC2を停止したことによって「Elastic IP アドレスに関連付けられているインスタンスが実行中である。」の条件を満たさなくなってしまったので、Elastic IPによる料金が発生するようになってしまったわけですね。。
料金について理解しておくの大事・・。
参考になったサイト
https://aws.amazon.com/jp/premiumsupport/knowledge-center/ec2-billing-terminated/
https://qiita.com/s_tatsuki/items/c808a916acf044d94afc何か気づいたことよ間違ったことあればご教授ください。

- 投稿日:2021-01-03T20:38:46+09:00
カオスエンジニアリングと聞いてカオスになった人必見(続)
はじめに
2年前に投稿した「カオスエンジニアリングと聞いてカオスになった人必見」なのですが、現在もなお、ジワジワとLGTM数が伸びています。また、AWS障害が発生する度、このページのアクセス数も増えるのですが、皆さんそれぞれ、障害対策にお困りなのだろうと推測しています。それを解消するために、まだ、このテクノロジーに注目があるようですので、カオスエンジニアリングの現状をUPDATEする形で続編を書いてみます。
カオスエンジニアリングの現在
カオスエンジニアリングは普及しているの?
定量的なトレンド評価をするため、Googleトレンドで、関連キーワードを比較してみました。
DockerやKubernetesの普及が進んできていることは伺えますが、Chaos Engineeringや連動するであろうキーワードのService MeshおよびIstioは、ほぼ横這いで、いまだ発展途上の印象です。実際に私の身の回りでも、検討はするも「実際に導入してみたよ」というプロジェクトは残念ながら、なかなか耳に入ってきませんし、まだ、高めのハードルを越えてまで、必要に迫られているケースは少ないのだと思っています。カオスエンジニアリングはもっと導入しやすくならないの?
去年の暮に行われた「AWS re:Invent 2020」で、AWSからカオスエンジニアリングサービス「AWS Fault Injection Simulator」が発表されました。
導入の敷居の高かったカオスエンジニアリングですが、これにより、AWS利用者は飛躍的にカオスエンジニアリングを導入しやすくなると思われます。クラスメソッドさんが「ついにAWSがマネージドなカオスエンジニアリングサービスを発表したぞ #reinvent」で上手に纏められていますので、良かったらご覧になってみてください。カオスエンジニアリングツールは今どれがいいの?
カオスエンジニアリングをSaaSとして提供している「
Gremlin」は、AWS、Azure、Google Cloud Platform(GCP)の各種IaaSクラウドに対応し、DockerやKubernetesのレイヤーからも、広範囲に疑似障害を発生させることができるため、他のカオスエンジニアリングツールよりも一線を画す存在になっており、現状だと、第一候補に挙がってくると思います。
また、「Gremlin」は、Windowsサポートを始めました。これまで、Linuxサーバを中心にカオスエンジニアリングのテクノロジーは発展していましたが、世界中のサーバの3分の1はWindows上で動いており、Windowsのサポートを求める声が多かったため、Windowsサポートを決断したとのことです。シェアも拡大し、好調な「Gremlin」に今後も注目です。カオスエンジニアリングは結局導入すべきなの?
マイクロサービスによるクラウドネイティブなシステムが急速に普及している状況の中、カオスエンジニアリングに対するニーズが高まっている一方、すべてのシステムに有効ではないのは現在も変わりません。また、この件に関して、国内で実績を持つクックパッドチームの記事「カオスエンジニアリングによる負荷試験を導入するクックパッドが学んだこと 耐障害性の仮説と検証」が、非常に参考になりました。実際に導入して得た所感(説得力のある生きた意見)が掲載されています。
以下に、ポイントを抜粋してみましたので、ご参考にしてみてください。[ポイント抜粋]
- カオスエンジニアリングの導入は、システム全体が巨大であり複雑になっていることが前提(複雑性が高くない段階でカオスエンジニアリングを取り入れても、効果が薄い)
- マイクロサービスや分散システムの推進によってサービス間通信が増え、障害が発生しうる箇所が増えた状況において、システム全体の信頼性を向上させたい場合や未知の脆弱性を発見したい場合に役に立つ
- システム全体がある程度成熟している状況でないと、カオスエンジニアリングは有効に働かない
- 普段は正常に動作しているけれど、何かのきっかけでシステムが不安定になってしまう、つまり障害や大量アクセスが起きたときでないと脆弱性が見つからないようなケースにおいて、カオスエンジニアリングという手法が効果的になる
まとめ
AWSからカオスエンジニアリングサービス「AWS Fault Injection Simulator」がリリース、そして、AWSにおける定量的なベストプラクティスも速やかに確立されるかと思われるので、カオスエンジニアリングの普及が、一気に加速すると予想しています。今すぐでないにしろ、まだまだ先の話と言う訳でもなくなってきた印象ですので、適用条件が合えば、ぜひカオスエンジニアリングの導入の検討(準備)をしてみてください。「攻め」も「守り」も、かっちりと。



- 投稿日:2021-01-03T20:08:36+09:00
AWS AmplifyでLambdaを使うwith Go
Amplifyはちょくちょく使う機会があるのですが、Amplifyを介したLambdaってほぼ使った事ないぞ、と思ったので使ってみようと思い立ちました。
そしてLambdaでGoが使えるけど、ちゃんと使った事なかった気がするので使ってみたいなとついでに。Functionが使えるらしい
FUNCTIONS - Overview
https://docs.amplify.aws/cli/function環境
- win10 Home(surface go) + WSL2 + ubuntu18.04
- node v14.1.0
- npm 6.14.5
- go version go1.10.4 linux/amd64
使ってみる
前置き
vueを使う設定にてamplifyをsetupしておきます。
詳しくはこのあたりから。
https://docs.amplify.aws/start/getting-started/installation/q/integration/vue$ vue create myamplifyproject $ cd myamplifyproject $ npm install $ amplify init $ npm install aws-amplify @aws-amplify/ui-vue $ vi src/main.js $ npm run serve
add function
$ amplify add function ? Select which capability you want to add: Lambda function (serverless function) ? Provide a friendly name for your resource to be used as a label for this category in the project: myamplifyproject3e7c 0b2b ? Provide the AWS Lambda function name: myamplifyproject3e7c0b2b ? Choose the runtime that you want to use: Go go executable was not found in PATH, make sure it's available. It can be installed from https://golang.org/doc/install Only one template found - using Hello World by default. ? Do you want to access other resources in this project from your Lambda function? No ? Do you want to invoke this function on a recurring schedule? No ? Do you want to configure Lambda layers for this function? No ? Do you want to edit the local lambda function now? Yes Please edit the file in your editor: /mnt/c/Users/user/myamplifyproject/amplify/backend/function/myamplifyproject3e7c0b2b/src/main.go ? Press enter to continue Successfully added resource myamplifyproject3e7c0b2b locally. Next steps: Check out sample function code generated in <project-dir>/amplify/backend/function/myamplifyproject3e7c0b2b/src "amplify function build" builds all of your functions currently in the project "amplify mock function <functionName>" runs your function locally "amplify push" builds all of your local backend resources and provisions them in the cloud "amplify publish" builds all of your local backend and front-end resources (if you added hosting category) and provisions them in the cloudそうすると
main.goってファイルができました。main.gopackage main import ( "fmt" "context" "github.com/aws/aws-lambda-go/lambda" ) type MyEvent struct { Name string `json:"name"` } func HandleRequest(ctx context.Context, name MyEvent) (string, error) { return fmt.Sprintf("Hello %s!", name.Name ), nil } func main() { lambda.Start(HandleRequest) }
github.com/aws/aws-lambda-go/lambdaをGETしておきましょう。$ go get github.com/aws/aws-lambda-go/lambda試しに実行
$ amplify function build ? Are you sure you want to continue building the resources? Yes ✔ All resources are built. $ amplify mock function myamplifyproject3e7c0b2b ? Provide the path to the event JSON object relative to /mnt/c/Users/masra/myamplifyproject/amplify/backend/function/mya mplifyproject3e7c0b2b src/event.json Starting execution... Local invoker binary was not found, building it... Launching Lambda process, port: 8000 Result: Hello Amplify! Finished execution.
amplify function buildでbuildした後、amplify mock function [functionname]でローカル実行できるみたいです。
なんかsamみたいな仕組み使ってそうだなー。deploy
おなじみの
amplify push&lify publishでdeployできます。cli使ってる人はgit経由ですかね
その前にhosting addもしておきますね。お試しなのでS3に直deployします。$ amplify hosting add ? Select the plugin module to execute Amazon CloudFront and S3 ? Select the environment setup: DEV (S3 only with HTTP) ? hosting bucket name myamplifyproject-20210102225615-hostingbucket ? index doc for the website index.html ? error doc for the website index.html You can now publish your app using the following command: Command: amplify publish$ amplify push | Category | Resource name | Operation | Provider plugin | | -------- | ------------------------ | --------- | ----------------- | | Function | myamplifyproject3e7c0b2b | Create | awscloudformation | | Hosting | S3AndCloudFront | Create | awscloudformation | ? Are you sure you want to continue? Yes $ amplify publish ✔ Successfully pulled backend environment test from the cloud. Current Environment: test | Category | Resource name | Operation | Provider plugin | | -------- | ------------------------ | --------- | ----------------- | | Function | myamplifyproject3e7c0b2b | Create | awscloudformation | | Hosting | S3AndCloudFront | Create | awscloudformation | ? Are you sure you want to continue? Yes ⠋ Updating resources in the cloud. This may take a few minutes... ... ✔ All resources are updated in the cloud Hosting endpoint: http://myamplifyproject-20210102233234-hostingbucket-test.s3-website-ap-northeast-1.amazonaws.com > myamplifyproject@0.1.0 build /mnt/c/Users/masra/myamplifyproject > vue-cli-service build ⠋ Building for production... ... frontend build command exited with code 0 Publish started for S3AndCloudFront ✔ Uploaded files successfully. Your app is published successfully. http://myamplifyproject-20210102233234-hostingbucket-test.s3-website-ap-northeast-1.amazonaws.com・・とまあdeployできました。
vueのdefault画面は表示できてます。functionはというと・・こんな感じで作成されてました。
はて?api gatewayも何もないけどどうやって実行するのだろう?
AppSyncの裏で使ったり、Scheduleから起動する方法しか書かれてないなー。
webapi的な使い方は想定されてないのだろうか。amplify add apiしてみる。
REST APIとして使えば使えるのでは?と思ったので試してみます。
$ amplify add api ? Please select from one of the below mentioned services: REST ? Provide a friendly name for your resource to be used as a label for this category in the project: api090983e4 ? Provide a path (e.g., /book/{isbn}): /items ? Choose a Lambda source Use a Lambda function already added in the current Amplify project ? Choose the Lambda function to invoke by this path myamplifyproject3e7c0b2b ? Restrict API access Yes ? Who should have access? Authenticated and Guest users ? What kind of access do you want for Authenticated users? create, read, update, delete ? What kind of access do you want for Guest users? create, read, update, delete Successfully added auth resource locally. ? Do you want to add another path? No Successfully added resource api090983e4 locally Some next steps: "amplify push" will build all your local backend resources and provision it in the cloud "amplify publish" will build all your local backend and frontend resources (if you have hosting category added) and provision it in the cloudそして
amplify pushします。$ amplify push ✔ Successfully pulled backend environment test from the cloud. Current Environment: test | Category | Resource name | Operation | Provider plugin | | -------- | ------------------------ | --------- | ----------------- | | Auth | cognito557e6fef | Create | awscloudformation | | Api | api090983e4 | Create | awscloudformation | | Function | myamplifyproject3e7c0b2b | No Change | awscloudformation | | Hosting | S3AndCloudFront | No Change | awscloudformation | ? Are you sure you want to continue? Yes ⠼ Updating resources in the cloud. This may take a few minutes... ... REST API endpoint: https://uyyhhs6ca8.execute-api.ap-northeast-1.amazonaws.com/test
お。でけた。
しかし、
{"message":"Missing Authentication Token"}と言われます。
なんかAuthのリソースも勝手につくられちゃってますしね。Cognitoの認証通ってないと実行できない感じなんでしょう。Amplifyから使うのであればそれでただしい。ただ、今回はその辺はすっとばしてとりあえず実行だけしたい。
Do you want to access other resources in this project from your Lambda function?って所でNoにしちゃったのが要因な気がするので今度はYesにしてみます。Add funtion
$ amplify function add ? Select which capability you want to add: Lambda function (serverless function) ? Provide a friendly name for your resource to be used as a label for this category in the project: myamplifyproject2451 e9a2 ? Provide the AWS Lambda function name: myamplifyproject2451e9a2 ? Choose the runtime that you want to use: Go Only one template found - using Hello World by default. ? Do you want to access other resources in this project from your Lambda function? Yes ? Select the category You can access the following resource attributes as environment variables from your Lambda function ? Do you want to invoke this function on a recurring schedule? No ? Do you want to configure Lambda layers for this function? No ? Do you want to edit the local lambda function now? Yes Please edit the file in your editor: /mnt/c/Users/user/myamplifyproject/amplify/backend/function/myamplifyproject2451e9a2/src/main.go ? Press enter to continue Successfully added resource myamplifyproject2451e9a2 locally. Next steps: Check out sample function code generated in <project-dir>/amplify/backend/function/myamplifyproject2451e9a2/src "amplify function build" builds all of your functions currently in the project "amplify mock function <functionName>" runs your function locally "amplify push" builds all of your local backend resources and provisions them in the cloud "amplify publish" builds all of your local backend and front-end resources (if you added hosting category) and provisions them in the cloud$ $ amplify add api ? Please select from one of the below mentioned services: REST ? Provide a friendly name for your resource to be used as a label for this category in the project: api62457bd3 ? Provide a path (e.g., /book/{isbn}): /hage ? Choose a Lambda source Use a Lambda function already added in the current Amplify project ? Choose the Lambda function to invoke by this path myamplifyproject2451e9a2 ? Restrict API access Yes ? Who should have access? Authenticated and Guest users ? What kind of access do you want for Authenticated users? create, read, update, delete ? What kind of access do you want for Guest users? create, read, update, delete ? Do you want to add another path? No Successfully added resource api62457bd3 locally Some next steps: "amplify push" will build all your local backend resources and provision it in the cloud "amplify publish" will build all your local backend and frontend resources (if you have hosting category added) and provision it in the cloud$ amplify push ✔ Successfully pulled backend environment test from the cloud. Current Environment: test | Category | Resource name | Operation | Provider plugin | | -------- | ------------------------ | --------- | ----------------- | | Api | api7dcd31c5 | Create | awscloudformation | | Auth | cognito557e6fef | Create | awscloudformation | | Api | api090983e4 | Create | awscloudformation | | Function | myamplifyproject3e7c0b2b | No Change | awscloudformation | | Function | myamplifyproject2451e9a2 | Create | awscloudformation | | Hosting | S3AndCloudFront | No Change | awscloudformation | ? Are you sure you want to continue? Yes ⠼ Updating resources in the cloud. This may take a few minutes... ... REST API endpoint: https://xdewrmoiva.execute-api.ap-northeast-1.amazonaws.com/testん~・・
でもダメっすねー。IAM認証がついてるのでToken必須か。
https://github.com/aws-amplify/amplify-cli/blob/fad6377bd384862ca4429cb1a83eee90efd62b58/packages/amplify-category-api/src/provider-utils/awscloudformation/service-walkthroughs/apigw-walkthrough.ts#L246
https://github.com/aws-amplify/amplify-cli/blob/master/packages/amplify-category-api/resources/awscloudformation/cloudformation-templates/apigw-cloudformation-template-default.json.ejs#L248このへんとかみてもIAM認証必須っぽいかな。authでもunauthでも。
まあ、本来はAmplifyの認証を介して使うものだからそれでいいんでしょうけどね。しかたないのでVueを介してAPIを叩いてみる。
なんで、ちゃんとAPI叩くようにしてみます。
authはadd apiの時に入っちゃったぽいので、vueを少し書き換えるだけ。
HelloWorld.vueを再利用してます。
なお、Amplifyの認証は行いません。Guestユーザーで叩いてる想定。それでもAmplifyのライブラリを使うとAPIリクエストの際にTokenが乗ってくるので叩ける・・はず。src/components/HelloWorld.vue<template> <div class="hello"> <h1>{{ msg }}</h1> <button @click="getHelloWorld">API.post</button> </div> </template> <script> import { API } from 'aws-amplify'; export default { name: 'HelloWorld', data: function() { return { msg: "" } }, methods: { getHelloWorld() { API.post('api5afc9d6e', '/hage', { response: true, body: { text: "Amplify" }, headers: {} }).then(result => { console.log(result.data) this.msg = result.data.text }).catch(err => { console.log(err) }) } } } </script>で、そのままAPI叩くとCORSでエラーになったのでResponse HeaderにAccess-Allow-Originしてやらないといけないかも。
GO+Lambdaのあたりはこちらを参考にさせていただきます。
https://qiita.com/coil_msp123/items/b1751dbe74ada7fdd5a1で、main.goはこういう感じに。
やっつけですみません。main.gopackage main import ( "fmt" "log" "encoding/json" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-lambda-go/events" ) func HandleRequest(request events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { reqBody := request.Body req := make(map[string]string) json.Unmarshal([]byte(reqBody), &req) req["text"] = fmt.Sprintf("Hello, %s!", req["text"]) bytes, _ := json.Marshal(req) log.Print(string(bytes)) return events.APIGatewayProxyResponse{ Body: string(bytes), StatusCode: 200, Headers: map[string]string{ "Content-Type": "application/json", "Access-Control-Allow-Origin": "*", "Access-Control-Allow-Headers": "withcredentials,origin,Accept,Authorization,Content-Type", }, }, nil } func main() { lambda.Start(HandleRequest) }
go get github.com/aws/aws-lambda-go/eventsも忘れずに。
で、amplify function buildとamplify function updateも実行しておきます。
さらにはamplify pushも。でもろもろ終わったら、
npm run serveしつつ、locahost:8080を開きまして、、
いけましたね。
最後に
$ amplify deleteはわすれません。エンドポイント名とかむき出しにしてましたし、ちゃんと消しておく。





- 投稿日:2021-01-03T19:55:37+09:00
cloud9でLAMPならUbntuで作るべし
これまでAWSのcloud9を作るとき、Amazon Linuxを選択していました。
でも、PHPのバージョンが古いので、WordPressが思うように動かないことがありました。
そのため、PHPのバージョンを上げる手間があり、生産性が悪く思っていました。今回、ふとUbntuでcloud9を作ってみようと思い、試しました。
そうしたら、PHPもMySQLもApacheも、新しいバージョンのように見えました。そのためバージョンアップの手間が泣いため、最初からUbuntuを選択してcloud9を作ると良いと思いました。

- 投稿日:2021-01-03T19:40:35+09:00
【Terraform】ECS自動デプロイ - Terraform編 -
参考文献
- [Terraform][Backends][v0.9]tfstateファイルの管理方法
- グループ会社のインフラをECS/Fargateに移行して振り返る
- [AWS][Terraform][Fargate]ECSでコンテナをALB配下に置く
- circleci/aws-ecs@1.4.0
- AWS ECR/ECS へのデプロイ
ツリー図
. ├── acm.tf ├── alb.tf ├── backend.tf ├── ecs.tf ├── files │ └── task-definitions │ └── container.json ├── rds.tf ├── security_group.tf ├── terraform.tfvars ├── variables.tf ├── vpc.tf ├── vpc_gateway.tf ├── vpc_routetable.tf └── vpc_subnet.tfTerraform / AWS CLIコマンド
◆ AWS CLIコマンド
/// ECS $ aws ecs list-task-definitions --region ap-northeast-1 $ aws ecs list-clusters $ aws ecs register-task-definition --family sample-service --cli-input-json file://container.json /// RDS $ mysql -h sample-rds.XXXXXX.XXXXXX.rds.amazonaws.com -P 3306 -u XXXX -p◆ EC2インストール
$ sudo yum install git $ yum list installed | grep mariadb $ sudo yum remove mariadb-libs $ sudo yum-config-manager --disable mysql57-community $ sudo yum-config-manager --enable mysql80-community $ sudo yum install -y mysql-community-client $ mysql --version各tfファイル
◆ ecs.tf
ecs.tf# ==================== # Cluster # ==================== resource "aws_ecs_cluster" "sample-cluster" { name = "sample-cluster" } # ==================== # CloudWatch logs # ==================== resource "aws_cloudwatch_log_group" "sample-log-group" { name = "sample-log-group" tags = {} } # ==================== # task_definition # ==================== resource "aws_ecs_task_definition" "sample-task-definition" { //family:複数のタスク定義をまとめる際に使用 family = "sample-service" requires_compatibilities = ["FARGATE"] network_mode = "awsvpc" task_role_arn = "arn:aws:iam::${var.aws_account_id}:role/ecsTaskExecutionRole" execution_role_arn = "arn:aws:iam::${var.aws_account_id}:role/ecsTaskExecutionRole" cpu = 1024 memory = 2048 container_definitions = file("files/task-definitions/container.json") } # ==================== # Service # ==================== resource "aws_ecs_service" "sample-service" { cluster = aws_ecs_cluster.sample-cluster.id launch_type = "FARGATE" deployment_minimum_healthy_percent = 100 deployment_maximum_percent = 200 name = "sample-service" task_definition = aws_ecs_task_definition.sample-task-definition.arn //desired_count:タスク数 desired_count = 1 /// autoscalingで動的に変化する値を無視する /// lifecycle { ignore_changes = [desired_count, task_definition] } load_balancer { target_group_arn = aws_alb_target_group.sample-target-group.arn container_name = "sample-container" container_port = 80 } network_configuration { subnets = [aws_subnet.sample-subnet-1.id, aws_subnet.sample-subnet-2.id] security_groups = [aws_security_group.sample-security-group-app.id, aws_security_group.sample-security-group-rds.id] assign_public_ip = "true" } }◆ container.json
files/container.json[ { "image": "XXXXXX.dkr.ecr.XXXXXX.amazonaws.com/sample_dev:latest", "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "sample-log-group", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "cpu": 512, "memory": 1024, "mountPoints": [], "environment": [], "networkMode": "awsvpc", "name": "sample-container", "essential": true, "portMappings": [ { "hostPort": 80, "containerPort": 80, "protocol": "tcp" } ], "command": [ "/usr/bin/supervisord" ] } ]◆ alb.tf
alb.tf# ==================== # ALB # ==================== resource "aws_alb" "sample-alb" { name = "sample-alb" security_groups = [aws_security_group.sample-security-group-alb.id] subnets = [aws_subnet.sample-subnet-1.id, aws_subnet.sample-subnet-2.id] internal = false enable_deletion_protection = false } # ==================== # Target Group # ==================== resource "aws_alb_target_group" "sample-target-group" { name = "sample-target-group" depends_on = [aws_alb.sample-alb] port = 80 protocol = "HTTP" vpc_id = aws_vpc.sample-vpc.id target_type = "ip" health_check { protocol = "HTTP" path = "/ping" port = 80 unhealthy_threshold = 5 timeout = 5 interval = 10 matcher = 200 } } # ==================== # ALB Listener HTTP # ==================== resource "aws_alb_listener" "sample-alb-http" { load_balancer_arn = aws_alb.sample-alb.arn port = 80 protocol = "HTTP" default_action { target_group_arn = aws_alb_target_group.sample-target-group.arn type = "forward" } } # ==================== # ALB Listener HTTPS # ==================== resource "aws_alb_listener" "sample-alb-https" { load_balancer_arn = aws_alb.sample-alb.arn port = "443" protocol = "HTTPS" ssl_policy = "ELBSecurityPolicy-2015-05" certificate_arn = aws_acm_certificate.sample-acm.arn default_action { target_group_arn = aws_alb_target_group.sample-target-group.arn type = "forward" } } # ==================== # listener_rule # ==================== resource "aws_alb_listener_rule" "sample-listener-rule" { depends_on = [aws_alb_target_group.sample-target-group] listener_arn = aws_alb_listener.sample-alb-http.arn priority = 100 action { type = "forward" target_group_arn = aws_alb_target_group.sample-target-group.arn } condition { path_pattern { values = ["*"] } } }◆ acm.tf
acm.tf# ==================== # ACM # ==================== resource "aws_acm_certificate" "sample-acm" { domain_name = "sample.com" subject_alternative_names = ["*.sample.com"] validation_method = "DNS" lifecycle { create_before_destroy = true } }◆ rds.tf
rds.tf# ==================== # db_subnet_group # ==================== resource "aws_db_subnet_group" "sample-rds-subnet-group" { name = "sample-rds-subnet-group" description = "sample-rds-subnet-group" subnet_ids = [aws_subnet.sample-subnet-1.id, aws_subnet.sample-subnet-2.id] } # ==================== # db_instance # ==================== resource "aws_db_instance" "sample-rds" { identifier = "sample-rds" allocated_storage = 20 storage_type = "gp2" engine = "mysql" engine_version = "5.7" instance_class = "db.t2.micro" username = "test" password = "XXXXXX" parameter_group_name = "default.mysql5.7" port = "3306" vpc_security_group_ids = [aws_security_group.sample-security-group-rds.id] db_subnet_group_name = "${aws_db_subnet_group.sample-rds-subnet-group.name}" skip_final_snapshot = true }◆ security_group.tf
security_group.tf# ==================== # Security Group (app) # ==================== resource "aws_security_group" "sample-security-group-app" { vpc_id = aws_vpc.sample-vpc.id name = "sample-security-group-app" ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["X.X.X.X/16"] security_groups = [aws_security_group.sample-security-group-alb.id] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = "sample-security-group-app" } } # ==================== # Security Group(ALB) # ==================== resource "aws_security_group" "sample-security-group-alb" { name = "sample-security-group-alb" description = "sample-security-group-alb" vpc_id = aws_vpc.sample-vpc.id ingress { from_port = 80 to_port = 80 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } ingress { from_port = 443 to_port = 443 protocol = "tcp" cidr_blocks = ["0.0.0.0/0"] } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = "sample-security-group-alb" } } # ==================== # Security Group (RDS) # ==================== resource "aws_security_group" "sample-security-group-rds" { name = "sample-security-group-rds" description = "sample-security-group-rds" vpc_id = aws_vpc.sample-vpc.id ingress { from_port = 3306 to_port = 3306 protocol = "tcp" security_groups = [aws_security_group.sample-security-group-app.id] } ingress { from_port = 3306 to_port = 3306 protocol = "tcp" cidr_blocks = ["X.X.X.X/16"] description = "sample-security-group-rds" } ingress { from_port = 3306 to_port = 3306 protocol = "tcp" cidr_blocks = ["X.X.X.X/28"] description = "sample-security-group-rds" } egress { from_port = 0 to_port = 0 protocol = "-1" cidr_blocks = ["0.0.0.0/0"] } tags = { Name = "sample-security-group-rds" } }◆ vpc.tf
vpc.tf# ==================== # VPC # ==================== resource "aws_vpc" "sample-vpc" { cidr_block = "X.X.X.X/16" tags = { Name = "sample-vpc" } }◆ vpc_subnet.tf
vpc_subnet.tf# ==================== # Subnet # ==================== resource "aws_subnet" "sample-subnet-1" { cidr_block = "X.X.X.X/24" availability_zone = "ap-northeast-1a" vpc_id = aws_vpc.sample-vpc.id tags = { Name = "sample-subnet-1" } } resource "aws_subnet" "sample-subnet-2" { cidr_block = "X.X.X.X/24" availability_zone = "ap-northeast-1c" vpc_id = aws_vpc.sample-vpc.id tags = { Name = "sample-subnet-2" } }◆ vpc_routetable.tf
vpc_routetable.tf# ==================== # Subnet # ==================== resource "aws_subnet" "sample-subnet-1" { cidr_block = "X.X.X.X/24" availability_zone = "ap-northeast-1a" vpc_id = aws_vpc.sample-vpc.id tags = { Name = "sample-subnet-1" } } resource "aws_subnet" "sample-subnet-2" { cidr_block = "X.X.X.X/24" availability_zone = "ap-northeast-1c" vpc_id = aws_vpc.sample-vpc.id tags = { Name = "sample-subnet-2" } }◆ vpc_gateway.tf
vpc_gateway.tf# ==================== # Internet Gateway # ==================== resource "aws_internet_gateway" "sample-gateway" { vpc_id = aws_vpc.sample-vpc.id tags = { Name = "sample-gateway" } }◆ variables.tf
variables.tf/// tfファイルで使用する変数定義 /// /// 変数の中身はterraform.tfvarsに記載 /// variable "aws_access_key" {} variable "aws_secret_key" {} variable "region" {} variable "aws_account_id" {}◆ backend.tf
backend.tfprovider "aws" { access_key = "${var.aws_access_key}" secret_key = "${var.aws_secret_key}" region = "${var.region}" profile = "s3-profile" } terraform { backend "s3" { bucket = "sample-s3-file" key = "terraform.tfstate" region = "ap-northeast-1" shared_credentials_file = "~/.aws/credentials" profile = "s3-profile" } }
- 投稿日:2021-01-03T18:41:44+09:00
【CircleCI】ECS自動デプロイ - CircleCI編 -
参考文献
- [Terraform][Backends][v0.9]tfstateファイルの管理方法
- グループ会社のインフラをECS/Fargateに移行して振り返る
- [AWS][Terraform][Fargate]ECSでコンテナをALB配下に置く
- circleci/aws-ecs@1.4.0
- AWS ECR/ECS へのデプロイ
CircleCIコマンド
◆ config.ymlチェック
$ yamllint .circleci/config.yml◆ CircleCI jobチェック
$ circleci orb validate .circleci/config.yml $ circleci local execute -c .circleci/config.yml --job build $ circleci build --job rspec .circleci/config.yml.circleci/config.yml
.circleci/config.ymlversion: 2.1 orbs: aws-ecr: circleci/aws-ecr@6.12.2 aws-ecs: circleci/aws-ecs@1.3.0 /// executors: ジョブのステップ実行する環境を定義 /// executors: default: docker: - image: circleci/ruby:2.7.1-node-browsers-legacy environment: BUNDLE_JOBS: 3 BUNDLE_RETRY: 3 BUNDLE_PATH: vendor/bundle RAILS_ENV: test DATABASE_HOST: '127.0.0.1' DB_USERNAME: 'root' DB_PASSWORD: 'XXXXXX' - image: circleci/mysql:5.7 environment: MYSQL_DATABASE: sample_dev MYSQL_USER: 'root' MYSQL_ROOT_PASSWORD: 'XXXXXX' docker_build: machine: docker_layer_caching: true /// commands: ジョブ内で実行する一連のステップをマップとして定義 /// commands: bundle_install_rspec: steps: - run: name: Which bundler? command: bundle -v /// ジョブのキャッシュを復元することで、ジョブ高速化 /// - restore_cache: keys: - cache-gem-{{ checksum "Gemfile.lock" }} - cache-gem- - run: name: Bundle Install command: bundle check || bundle install - save_cache: key: cache-gem-{{ checksum "Gemfile.lock" }} paths: - vendor/bundle - run: name: Database create command: DISABLE_SPRING=true bin/rake db:create --trace - run: name: Database setup command: DISABLE_SPRING=true bin/rake db:schema:load --trace - run: name: Run rspec command: | TZ=Asia/Tokyo \ bundle exec rspec --profile 10 \ --out test_results/rspec.xml \ --format progress \ $(circleci tests glob "spec/**/*_spec.rb" | circleci tests split --split-by=timings) /// Vueインストール /// vue-installation: steps: - restore_cache: keys: - cache-yarn-{{ checksum "yarn.lock" }} - cache-yarn- - run: name: Yarn Install command: yarn install - save_cache: key: cache-yarn-{{ checksum "yarn.lock" }} paths: - node_modules /// jobs:実行処理 /// jobs: rspec: working_directory: ~/rspec executor: default steps: - checkout - bundle_install_rspec - vue-installation deploy_app: working_directory: ~/app executor: default steps: - setup_remote_docker - checkout /// workflows:全てのジョブのオーケストレーション /// workflows: version: 2 build-and-deploy: jobs: - rspec - deploy_app: requires: - rspec - aws-ecr/build-and-push-image: requires: - deploy_app account-url: AWS_ECR_ACCOUNT_URL aws-access-key-id: AWS_ACCESS_KEY_ID aws-secret-access-key: AWS_SECRET_ACCESS_KEY region: AWS_DEFAULT_REGION repo: "${AWS_RESOURCE_NAME_PREFIX}" dockerfile: docker/dev/app/Dockerfile tag: "${CIRCLE_SHA1}" - aws-ecs/deploy-service-update: requires: - aws-ecr/build-and-push-image aws-region: AWS_DEFAULT_REGION family: "${AWS_RESOURCE_NAME_PREFIX}-service" cluster-name: "${AWS_RESOURCE_NAME_PREFIX}-cluster" container-image-name-updates: "container=${AWS_RESOURCE_NAME_PREFIX}-container,image-and-tag=${AWS_ECR_ACCOUNT_URL}/${AWS_RESOURCE_NAME_PREFIX}:${CIRCLE_SHA1}" - aws-ecs/run-task: requires: - aws-ecs/deploy-service-update cluster: "${AWS_RESOURCE_NAME_PREFIX}-cluster" aws-region: AWS_DEFAULT_REGION task-definition: "${AWS_RESOURCE_NAME_PREFIX}-task-definition" count: 1 launch-type: FARGATE awsvpc: true subnet-ids: subnet-XXXXXX,subnet-XXXXXX security-group-ids: sg-XXXXXX,sg-XXXXXX overrides: "{\\\"containerOverrides\\\":[{\\\"name\\\": \\\"${AWS_RESOURCE_NAME_PREFIX}-container\\\",\\\"command\\\": [\\\"bundle\\\", \\\"exec\\\", \\\"rake\\\", \\\"db:migrate\\\", \\\"RAILS_ENV=test\\\"]}]}"
- 投稿日:2021-01-03T16:40:51+09:00
Serverless FrameworkとAWS Lambda with Rubyの環境にgemインストール
gemインストールが必要なAWS LambdaのRubyスクリプトをServerless Frameworkでデプロイする方法です。
手順概要
プラグインを入れれば簡単にできます。
serverless plugin install -n serverless-ruby-layerGemfile作成- あとは普通にデプロイすると勝手にいろいろやってくれる
手順詳細
Serverless Frameworkのサービス作成
$ serverless create --template aws-ruby Serverless: Generating boilerplate... _______ __ | _ .-----.----.--.--.-----.----| .-----.-----.-----. | |___| -__| _| | | -__| _| | -__|__ --|__ --| |____ |_____|__| \___/|_____|__| |__|_____|_____|_____| | | | The Serverless Application Framework | | serverless.com, v2.16.1 -------' Serverless: Successfully generated boilerplate for template: "aws-ruby" Serverless: NOTE: Please update the "service" property in serverless.yml with your service nameファイルが3つ生成されます。
.gitignore handler.rb serverless.ymlプラグインインストール
serverless-ruby-layerというプラグインをインストールします。$ serverless plugin install -n serverless-ruby-layer以下のファイルやディレクトリが増えます。
node_modules package.json package-lock.jsonServerless FrameworkがNode.jsで実装されているので、Rubyのプロジェクトなのに
node_modulesやpackage.jsonが存在することになるようです。ソースコード
serverless.yml
serverless.ymlは以下の内容にします。pluginsのところの記述はプラグインをインストールすると勝手に追記されています。service: sample frameworkVersion: '2' provider: name: aws runtime: ruby2.7 region: ap-northeast-1 functions: hello: handler: handler.hello plugins: - serverless-ruby-layerGemfile
Gemfileを作成し、以下の内容にします。gemのサンプルとして
holiday_japanを使ってみます。日本の祝日を判定するgemです。source "https://rubygems.org" gem 'holiday_japan'Rubyソースコード
handler.rbrequire 'json' require 'holiday_japan' def hello(event:, context:) holidayName = HolidayJapan.name(Date.new(2021, 8, 8)) puts(holidayName) # CloudWatch に "山の日" と書き出される endデプロイ
ここまで作成してから
serverlessコマンドでデプロイすると、Lambda本体だけでなく、serverlessコマンドが自動でgemインストールしたイメージを作成し、AWS LambdaのLayerとしてアップロードしてくれます。$ serverless deploy -v実行
デプロイ結果をAWSマネジメントコンソールで見ると次のように見えます。
Lambda
Layer
実行結果のCloudWatch Logs



- 投稿日:2021-01-03T15:31:12+09:00
CIツールでecspressoを使いつつAWS CodePipelineの承認フローを通してECSへデプロイする
はじめに
ecspressoを使いつつAWS CodePipeline上での承認フローステージを通してECSへデプロイする方法を検証しました。
前提
- 既存ですでに以下のリソースが存在している前提になります。
- Docker Image on ECR
- ALB
- ECS Cluster
- ECS Task Definition
- ECS Service
- CodePipelineに付与するIAMサービスロール
- 上記を構成するためのVPC、サブネット、セキュリティグループなど諸々
- CIツールはGitLab CI
- ECSはFargateタイプであり、ECS ServiceのデプロイではCodeDeploy(Blue/Green)を利用している。
ローカル環境
$ sw_vers ProductName: Mac OS X ProductVersion: 10.15.6 BuildVersion: 19G2021 $ ecspresso version ecspresso v1.2.1Contents
概要
概要として今回は全体として以下のようなアプリケーションのデプロイフローを構築しました。
CIツールであるGitLab CIにてECRへDockerイメージをPushすることとS3へecspressoからtaskdef.jsonとappspec.yamlを出力。
CodePipelineでは承認フローを設定し承認されたらECS(Blue/Green)にてタスク定義が反映されCodeDeployからアプリケーションがデプロイされます。
ecspressoの初期設定
ecspressoの初期設定を行います。
既存でECSには以下のようなECS ClusterとECS Serviceがあり、このアプリケーションのデプロイフローを構築する場合、以下のようなに実行します。1
$ ecspresso init --config config.yaml --region ap-northeast-1 --cluster ecspressopoc --service rjpf-ecspressopoc-service上記を実行することで以下の3つのファイルが生成されます。
config.yaml-> ecspresso 設定ファイルecs-service-def.json-> ECSサービスの構成を定義するecspresso用ファイルecs-task-def.json-> aws cliで得られるのと同様なECSタスク定義ファイル
config.yamlとecs-service-def.jsonこちらの公式ドキュメントと同じ項目のファイルになっています。
config.yamlとecs-service-def.jsonに関しては修正する部分は特にありません。
ecs-task-def.json
ecs-task-def.jsonもこちらの公式ドキュメントと同様に出力されています。ここでCIツールを使って継続的にECS Task Definitionバージョンを更新できるように修正します。
ecspressoのテンプレート機能を利用します。2
ECR上のImageバージョンのimmutable性を保証するためにも
"Image"フィールドは以下のように修正します。ecs-task-def.jsonの一部"image": "{{ must_env `ECR_IMAGE_URL` }}",後述のCIツールのフロー内で
ECR_IMAGE_URL環境変数を設定しCIでのecspressoコマンドにてECRへPushしたURLに置換してECS Task Definitionへ更新します。また、アプリケーションの環境変数をデプロイ先の環境ごとに変えるためにECS Task Definitionの環境変数を設定する箇所も以下のようにしています。CIツールのフローは後述します。
ecs-task-def.jsonの一部"environment": [ { "name": "DB_HOST", "value": "{{ must_env `DB_HOST` }}" } ],CodePipelineのトリガーとなるS3バケットの作成
今回はCodePipelineのSource ActionとしてS3を利用するのでそのためのS3バケットを作成します。3
このS3は後述するCDKにて管理対象のリソースとして作成しています。
CIツール(GitLab CI) + ecspresso
以下が今回利用したGitLab CIでのYamlファイルになります。
ステップとして以下になります。
pushステージにて
docker buildで対象アプリケーションをビルドする。- AWS ECRへ対象イメージをタグ名(Gitコミットハッシュ)付きでDOCKER PUSHする。
deployステージにて
ecspresso renderでECS Task Definitionファイルのtaskdef.jsonをテンプレートから生成する。ecspresso appspecによりECS(Blue/Green)でのCodeDeployのためのappspec.yamlを生成する。- 上記2つのファイルをZIP化し上述のS3バケットへアップロードする。
.gitlab-ci.ymlvariables: IMAGE_TAG: ${CI_COMMIT_SHA} ECSPRESSO_VERSION: "v1.2.1" AWSCLI_VERSION: "1.18.134" ECR_NAME: "ecspressopoc" stages: - push - deploy .push_variables: &push_variables DOCKER_DRIVER: overlay2 .push_setup: &push_setup image: docker:stable services: - docker:18.09-dind before_script: - apk add git - apk -Uuv add groff less python3 py-pip - pip install awscli .push: &push stage: push script: - docker build -t ${ECR_NAME} . - aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin ${AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com - docker tag ${ECR_NAME}:latest ${AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com/${ECR_NAME}:${IMAGE_TAG} - docker push ${AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com/${ECR_NAME}:${IMAGE_TAG} .deploy_setup: &deploy_setup image: python:3.8 before_script: # install AWS CLI - pip install --upgrade pip - pip install --upgrade awscli==${AWSCLI_VERSION} # install commands - apt-get update -y && apt-get install -y curl unzip zip # install ecspresso - curl -sL -o ecspresso-${ECSPRESSO_VERSION}-linux-amd64.zip https://github.com/kayac/ecspresso/releases/download/${ECSPRESSO_VERSION}/ecspresso-${ECSPRESSO_VERSION}-linux-amd64.zip - unzip ecspresso-${ECSPRESSO_VERSION}-linux-amd64.zip - install ecspresso-${ECSPRESSO_VERSION}-linux-amd64 /usr/local/bin/ecspresso - ecspresso version .deploy: &deploy stage: deploy script: - export ECR_IMAGE_URL=${AWS_ACCOUNT_ID}.dkr.ecr.ap-northeast-1.amazonaws.com/${ECR_NAME}:${IMAGE_TAG} # For ecspresso - export DB_HOST=${DB_HOST} - ecspresso --config config.yaml render --task-definition > taskdef.json - ecspresso --config config.yaml appspec | sed -e '/TaskDefinition/ s/arn.*$/"<TASK_DEFINITION>"/' > appspec.yaml - zip ecspresso-deploy-poc.zip appspec.yaml taskdef.json - aws s3 cp ecspresso-deploy-poc.zip s3://dev-ecspresso-poc .dev_variables: &dev_variables AWS_ENV: "dev" AWS_ACCOUNT_ID: "123456789012" DB_HOST: ${DEV_DB_HOST} # variable is in GitLab CI setting .dev_config: &dev_config only: - develop tags: - my-platform_dev_docker allow_failure: false dev-push: variables: <<: *dev_variables <<: *push_variables <<: *dev_config <<: *push_setup <<: *push dependencies: - dev-migrate-task dev-deploy: variables: <<: *dev_variables <<: *dev_config <<: *deploy_setup <<: *deploy dependencies: - dev-push
ecspresso renderとecs appspecのそれぞれのサブコマンドについてはそれぞれ以下のページで詳細を確認できます。
- https://zenn.dev/fujiwara/articles/ecspresso-20201212
- https://zenn.dev/fujiwara/articles/ecspresso-20201218
CodePipeline with 承認フロー
CodePipelineをAWS CDKを利用して構築しました。
注意 ただし注意点として今回対象にしていたCodePipelineのECS Blue/Green Action ProviderがCDKでは2021年1月時点で未対応なのでその部分に関しては、私は現状ではそれ以前のステージまではCDKで対応し
cdk deploy後に手動で追加修正している状況です。GitHubでは https://github.com/aws/aws-cdk/issues/1559 のIssueが最新の動向になっています。この記事ではCDKのインストール方法と基本的な利用方法には言及しません。
今回はCDKではTypeScriptを利用しました。対象のコードとしては以下になります。
lib/ecspressopoc-cpipe-stack.tsimport { Role } from "@aws-cdk/aws-iam"; import { Bucket, BlockPublicAccess } from "@aws-cdk/aws-s3"; import { Stack, Construct, StackProps } from "@aws-cdk/core"; import { Pipeline, Artifact } from "@aws-cdk/aws-codepipeline"; import { S3SourceAction, ManualApprovalAction } from "@aws-cdk/aws-codepipeline-actions"; export class EcspressopocCpipeStack extends Stack { constructor(scope: Construct, id: string, props?: StackProps) { super(scope, id, props); // The code that defines your stack goes here // Source step // // S3 bucket as source const sourceBucket = new Bucket(this, 'ecspressopoc-bucket', { versioned: true, // a Bucket used as a source in CodePipeline must be versioned blockPublicAccess: BlockPublicAccess.BLOCK_ALL }); // Source Action const sourceOutput = new Artifact(); const sourceAction = new S3SourceAction({ actionName: 'S3Source', bucket: sourceBucket, bucketKey: 'ecspresso-deploy-poc.zip', output: sourceOutput, }); // Approval step // // Manual Approval Action const approvalAction = new ManualApprovalAction({ actionName: 'ManualApproval', }); // ECS Deploy step // TODO: Waiting for ECS Blue Green Deployment in CDK // Assemble pipeline new Pipeline(this, "Pipeline", { pipelineName: "ecspressopoc-cdk", role: Role.fromRoleArn(this, 'plRole', 'arn:aws:iam::12345678901:role/ecspresso-poc'); // role which can access to ECS Blue/Green Deployment, stages: [ { stageName: "S3-Source", actions: [sourceAction], }, { stageName: "Approval", actions: [approvalAction], } ], }); } }上記では前述のようにGitLab CIがアップロードする先のS3バケットを以下の設定で作成しています。
versioned: true← CodePipeline Source用のS3バケットは必ずVersioningをEnabledにしている必要がある。blockPublicAccess: BlockPublicAccess.BLOCK_ALL← 内部でしか利用しないのでPublicアクセスはすべてブロックにしておく。手動承認に関して今回は最小限の設定です。より詳しい仕様は公式ドキュメントで確認できます。
上記を
cdk deployによりデプロイした後に前述の理由から手動でECS(Blue/Green)でのデプロイ設定をします。以下スクショのようにしています。
CodePipelineでは以下のスクショのようになり、GitLab CIがS3へZIPファイルをアップロードすると処理が開始され、手動承認をするとアプリケーションがECSへデプロイされることを確認しました。
参考
詳細は https://zenn.dev/fujiwara/articles/f2314651691adcae5215.md 参照 ↩
テンプレート機能に関してはこちらの公式ドキュメントに詳細があります。 ↩
公式ドキュメント https://docs.aws.amazon.com/codepipeline/latest/userguide/action-reference-S3.html ↩




- 投稿日:2021-01-03T15:24:08+09:00
Fargate1.4.0以降でのVPC エンドポイント(PrivateLink)を設定する際の注意とterraformでの例
Fargate(ECS) + VPC + Natゲートウェイ + ECR の組み合わせにおいて、VPCエンドポイントを作成してPrivateLink経由にする事で、コスト削減が可能となります。
概要については偉大な先人達の記事をご参照ください。
Amazon ECR インターフェイス VPC エンドポイント (AWS PrivateLink) - Amazon ECR
[AWS] FargateをNatゲートウェイと組み合わせて完全に死亡した話 | 個人利用で始めるAWS学習記
PrivateLinkとALBを利用してECS Fargateをロードバランシングする | Enjoy IT Life
AWS ECRのPrivate Linkを作る
エンドポイントを使用してプライベートサブネットでECSを使用する | Developers.IOFargate1.4.0以降の場合の注意
AWSのDocumentには但し書きがたくさんありますが、Fargate1.4.0以降と未満では必要な設定が異なります。
解説/やってみた記事では、1.3.0以前(1.4.0未満)の内容になっている場合があるので注意が必要です。具体的には、
Fargate 起動タイプとプラットフォームバージョン 1.4.0 以降を使用する Amazon ECS タスクでこの機能を使用するには、com.amazonaws.region.ecr.dkr と com.amazonaws.region.ecr.api Amazon ECR VPC エンドポイントの両方、および Amazon S3 ゲートウェイエンドポイントが必要です。
が該当します。1.3.0未満との差分は、
com.amazonaws.region.ecr.apiが追加で必要になった事です。まとめると、
必要
- com.amazonaws.region.ecr.api
- com.amazonaws.region.ecr.dkr
- com.amazonaws.region.s3
log出力するなら必要
- com.amazonaws.region.logs
となります。
terraformで書く例
VPC、subnetは各自置き換えてください。
resource "aws_vpc_endpoint" "ecr_api" { service_name = "com.amazonaws.ap-northeast-1.ecr.api" vpc_endpoint_type = "Interface" vpc_id = aws_vpc.main.id subnet_ids = [aws_subnet.private_1a.id, aws_subnet.private_1c.id] security_group_ids = [ aws_security_group.https.id, ] private_dns_enabled = true tags = { "Name" = "ecr-api" } } resource "aws_vpc_endpoint" "ecr_dkr" { service_name = "com.amazonaws.ap-northeast-1.ecr.dkr" vpc_endpoint_type = "Interface" vpc_id = aws_vpc.main.id subnet_ids = [aws_subnet.private_1a.id, aws_subnet.private_1c.id] security_group_ids = [ aws_security_group.https.id, ] private_dns_enabled = true tags = { "Name" = "ecr-dkr" } } resource "aws_vpc_endpoint" "logs" { service_name = "com.amazonaws.ap-northeast-1.logs" vpc_endpoint_type = "Interface" vpc_id = aws_vpc.main.id subnet_ids = [aws_subnet.private_1a.id, aws_subnet.private_1c.id] security_group_ids = [ aws_security_group.https.id, ] private_dns_enabled = true tags = { "Name" = "logs" } } resource "aws_vpc_endpoint" "s3" { service_name = "com.amazonaws.ap-northeast-1.s3" vpc_endpoint_type = "Gateway" vpc_id = aws_vpc.main.id route_table_ids = [ aws_default_route_table.private.id ] tags = { "Name" = "-s3" } } resource "aws_security_group" "https" { name = "https" description = "https" vpc_id = aws_vpc.main.id egress { cidr_blocks = ["0.0.0.0/0"] from_port = 0 protocol = "-1" to_port = 0 } ingress { cidr_blocks = ["0.0.0.0/0"] from_port = 443 protocol = "tcp" to_port = 443 } timeouts {} tags = { Name = "https" } }
- 投稿日:2021-01-03T14:05:59+09:00
AWS コンピューティング
AWS コンピューティング
EC2
サイズ変更可能な仮想マシン(EC2インスタンス)をクラウド提供するサービス
Amazonマシンイメージ(AMI)
EC2を起動する際に必要なテンプレートがインストールされている
逆に、自分で設定したEC2レシピも保存しておくことが出来るインスタンスタイプ
EC2起動時に設定するもの、提供したいサービスの容量により変更可能
セキュリティグループ
ホワイトリスト形式(この通信はOK,NGと記述したリストで判断する形式)で制御される
そのためELB,RDS,ElasticCacheなんかも記述すれば設定できる(なんやそれ!!後述します)ELB(Elastic Load Balancing) 厳密にはELBのALB
※GW ← ELB(ALB) ← アプリ{パブリックサブネット(NATGW)←プライベートサブネット}
アクセス数に対して不可のバランスを複数のEC2に分散させる
もし1台のEC2だけでサイトを運営していた場合、サーバー障害が起きたら復旧まで何も出来ません。
ただし複数のEC2でサイトを運営していたら、1つに障害が起きても切り替えればOKということになります。
1つのEC2だけでなく、アクセスに応じてサイトアクセスのバランスをとってくるれる機能ですELBは3種類
・ALB(アプリケーション・ロードバランサー):HTTP/HTTPSに対応した不可分散
・NLB(ネットワーク・ロードバランサー) :TCP/UDPに対応した不可分散
・CLB(クラシック・ロードバランサー) :元ELBと呼ばれてましたが、ALBが出来たので名称変更EC2 AutoScailing機能
EC2のCPU使用率を監視し閾値を超えたら、自動的にELBの下にインスタンスを自動追加できる機能
ECS(Amazon Elastic Container Service)
例)1社がサービスを3つ持っている、そのサービスにつきEC2が複数あるような状態となっている
1個1個EC2を見て管理できますか?出来ませんよねと言う理由から生まれたECS
従来1つのサーバーに複数の機能を持たせていたが(メッセージ機能、コメント機能的な
Rilsでいうモデルを1つのファイルにまとめている状態)、があまりにも膨大になったことで、
クラウド技術で機能を分割(コンテナ化)して、ダメだったら捨てて、次にいきましょう(アジャイル化)
ということで使用されている。
そう言う観点から見ると、私のPFは旧来のサーバーを、AWSのEC2に置き換えてアプリが置いている状態
(このアプリの中に継ぎ足しをしている)と言える。
より実戦として考えたら、EC2インスタンスを機能ごとに増やさなければいけない。ECS
ECSクラスターをベースに、その上にECSインスタンス、その上にDockerコンテナを実行・停止が出来るサービスとなっている
ECSインスタンスは、{EC2を含む + Dockerコンテナ(アプリの概要)=タスク}を生み出せる
もう1個1個設定しなくてもECS様がやってくれる
ただし上記の動作を一発で解消してくれるためには、タスク定義をしなければいけない(初見殺し、ここで皆散っていきます)ECR(Elastic Container Registory(レシピ))
AWS版のDockerhub(Dockerレジストリ=コンテナの保管場所)
ローカルで作ったDockerイメージをpushすると保存、pullして保存した内容を引き出してくれる(DockerコマンドでOK)Fargate(どちらもECSを使う、EC2タイプ?Fargateタイプ?の違いだけ)
ECSを使用してEC2を使う=ECS(1つのECSインスタンスの中にEC2があり、設定が必要)
ECSを使用してEC2を使わない=Fargate(EC2部分の設定が不要で、コンテナあればOK)
※インフラ部分はAWSで補います!ということEKS(同じくコンテナオーケストレーションサービスのkubernetes用)
ECS同様にFargateタイプも選択することが出来る
- 投稿日:2021-01-03T12:36:10+09:00
AWS LambdaがコンテナイメージをサポートしたのでPuppeteerしてみた
あけましておめでとうございます。
AWS Lambdaがコンテナイメージをサポートしたので、Puppeteerでキャプチャを取るLambdaをつくてみました。
クラスメソッドさんの以下の記事の通りで、ローカルでの実行はうまくいきましたが、Lambdaへのデプロイするとうまく動作しませんでした。(Chromeの起動タイミングでエラー?)
Lambda コンテナイメージで Puppeteer を使ってみた | Developers.IO
https://dev.classmethod.jp/articles/try-using-puppeteer-with-a-lambda-container-image/試行錯誤の結果が、こちらとなります。
ソース
全体はこちらにアップロード済みです。
https://github.com/moritalous/m5core2-yweather/tree/master/lambdaDockerfile
クラスメソッドさんはGoogle Chromeとpuppeteer-coreの組み合わせでしたが、puppeteer単体で動かしたかったので、インストールするパッケージを変えました。
インストールするパッケージはこちらを参考にしました。
日本語フォントgoogle-noto-sans-japanese-fontsもインストールします。FROM amazon/aws-lambda-nodejs:12 RUN yum -y install libX11 libXcomposite libXcursor libXdamage libXext libXi libXtst cups-libs libXScrnSaver libXrandr alsa-lib pango atk at-spi2-atk gtk3 google-noto-sans-japanese-fonts COPY app.js package*.json ./ RUN npm install CMD [ "app.lambdaHandler" ]ソースコード
依存ライブラリーは
puppeteerとsharpです。
sharpは取得したスクリーンショットをリサイズするために追加しました。package.json"dependencies": { "puppeteer": "^5.5.0", "sharp": "^0.27.0" }
puppeteer.launchに指定するargsについて
ローカルでの実行の場合は--no-sandboxと--disable-setuid-sandboxの指定だけでうまくいきましたが、Lambda上ではエラーになりました。
/tmpディレクトリ以外が読み取り専用だからではないでしょうか?試行錯誤した結果、こんな感じです。
app.jsconst browser = await puppeteer.launch({ headless: true, args: [ '--no-sandbox', '--disable-setuid-sandbox', '-–disable-dev-shm-usage', '--disable-gpu', '--no-first-run', '--no-zygote', '--single-process', ] });キャプチャを撮って、リサイズして、PNGにしました。
API Gateway経由で返却したので、Base64エンコードしてレスポンスにセットします。app.jsbuff = await page.screenshot({ clip: rect }); buff = await sharp(buff).resize(320, 240).png().toBuffer(); base64 = buff.toString('base64'); await browser.close(); const response = { statusCode: 200, headers: { 'Content-Length': Buffer.byteLength(base64), 'Content-Type': 'image/png', 'Content-disposition': 'attachment;filename=weather.png' }, isBase64Encoded: true, body: base64 };ECRへプッシュ
Lambdaのコンテナイメージサポートですが、
- コンテナレジストリはECRでかつプライベート
ということのようです。
はじめはGitHub Container Registryで試してだめで、次にECRのパブリックで試してだめでした。。
$ aws ecr get-login-password --region ap-northeast-1 | docker login --username AWS --password-stdin [AWSアカウントID].dkr.ecr.ap-northeast-1.amazonaws.com $ docker build -t [AWSアカウントID].dkr.ecr.ap-northeast-1.amazonaws.com/[リポジトリ名]:latest . $ docker push [AWSアカウントID].dkr.ecr.ap-northeast-1.amazonaws.com/[リポジトリ名]:latestLambdaの作成
基本的にウィザードに従うだけです。
一点注意ですが、ECRに新しいイメージをプッシュするたびに、Lambdaで使用するイメージを指定し直す必要があります。
sha256ダイジェストの値を見ているようで、latestタグだとしても毎回指定する必要があります。API Gatewayの作成
Lambdaの画面でトリガーを追加します。かんたんです。
REST APIだと昔はバイナリサポートを有効化するとか色々手順があった気がしますが、何もしなくてもPNGイメージの返却ができました。
完成
ヤフーの天気をPNG画像にしてみました。



- 投稿日:2021-01-03T12:22:23+09:00
【Ruby on Rails】ActionMailbox + Sendgrid + AWS(Route53) を実装してみた
課題
Action Mailbox を実装してみたら意外と苦戦したので、未来の自分の為に纏め。
最低限の実装で取り敢えず動くところが目標です。前提
- 既に記録対象となるRailsサーバはAWS(EC2)で動作
- DNSはAWS(Route53)を使用
- メール配信サービスはSendgridを使用
やること
- ActionMailbox を導入して受け取ったPOSTをRailsでよろしく処理する準備
- メールをSendgridに送る為、Sendgrid宛のmxレコードをRoute53に作成
- Sendgridから受け取ったメールをRailsの特定URLにPOSTする設定を投入
ActionMailboxの導入
Rails6では初期状態から以下コマンドでActionMailboxをインストールできます。
ActionMailboxをインストール$ rails action_mailbox:installActiveStorageとActionMailboxのMigration Fileが作成されるのでmigrateして置きます。
この二つのテーブルの役割の説明は割愛します。migrate$ rails db:migrate以下作成されたばかりの app/mailboxes/application_mailbox.rb です。
ここに受け取ったメールの処理を加えて行きます。app/mailboxes/application_mailbox.rbclass ApplicationMailbox < ActionMailbox::Base # routing /something/i => :somewhere end細かい事は沢山できますが、まずは単純に受けとった全てのメールに対して処理する内容とします。
app/mailboxes/application_mailbox.rbclass ApplicationMailbox < ActionMailbox::Base routing all: :replies end class RepliesMailbox < ApplicationMailbox def process #Do something!! end endこの時点で、以下URLにアクセスするとローカルで挙動が確認できます。
http://localhost:3000/rails/conductor/action_mailbox/inbound_emails/new
外部からメールを受け取るようのパスワードを設定します。
credentialの設定$ EDITOR="vi" bin/rails credentials:edit -e productioncredentialaction_mailbox: ingress_password: 'greatpassword'最後に何処のメール配信サービスからリクエストが来るのか(今回はsendgrid)設定して完了です。
config/environments/production.rbclass ApplicationMailbox < ActionMailbox::Base ##省略## config.action_mailbox.ingress = :sendgrid endSendgridの登録と設定
- こちらからSendgridに登録します。
- settings -> Sender Authentication -> Domain Authenticationと選択します。
- CNAMEを3つ入力しろと言われるのでRoute53に記載して確認します。

----------ここから先はRoute53の設定が完了していることが前提です-----------
- settings -> Inbound Parse -> Add Host & URL と選択します。
- MXレコードとして記載したホスト名とURLを入力します。また、'POST the raw, full MIME message'のチェックも入れてください
[URL Example]
https://actionmailbox:greatpassword@host.example.com/rails/action_mailbox/sendgrid/inbound_emailsRoute53の設定
- MXレコードを設定します。Name: 'なんでもいい', Target: 'mx.sendgrid.net', Priority: '10'

- Sendgridで指定されたCNAMEの登録
以上で取り急ぎ動作すると思います。
参考情報
Action Mailbox Basics
https://guides.rubyonrails.org/action_mailbox_basics.htmlRails 6のAction Mailboxを使ってみよう(翻訳)
https://techracho.bpsinc.jp/hachi8833/2020_03_05/88539Rails6で導入されるAction Mailboxを試してみた
https://bagelee.com/programming/ruby-on-rails/rails6-action-mailbox/

- 投稿日:2021-01-03T12:22:23+09:00
【Ruby on Rails】ActionMailbox + Sendgrid + AWS(Route53) で送信メールを自動記録を実装してみた
課題
Action Mailbox を実装してみたら意外と苦戦したので、未来の自分の為に纏め。
最低限の実装で取り敢えず動くところが目標です。前提
- 既に記録対象となるRailsサーバはAWS(EC2)で動作
- DNSはAWS(Route53)を使用
- メール配信サービスはSendgridを使用
やること
- ActionMailbox を導入して受け取ったPOSTをRailsでよろしく処理する準備
- メールをSendgridに送る為、Sendgrid宛のmxレコードをRoute53に作成
- Sendgridから受け取ったメールをRailsの特定URLにPOSTする設定を投入
ActionMailboxの導入
Rails6では初期状態から以下コマンドでActionMailboxをインストールできます。
ActionMailboxをインストール$ rails action_mailbox:installActiveStorageとActionMailboxのMigration Fileが作成されるのでmigrateして置きます。
この二つのテーブルの役割の説明は割愛します。migrate$ rails db:migrate以下作成されたばかりの app/mailboxes/application_mailbox.rb です。
ここに受け取ったメールの処理を加えて行きます。app/mailboxes/application_mailbox.rbclass ApplicationMailbox < ActionMailbox::Base # routing /something/i => :somewhere end細かい事は沢山できますが、まずは単純に受けとった全てのメールに対して処理する内容とします。
app/mailboxes/application_mailbox.rbclass ApplicationMailbox < ActionMailbox::Base routing all: :replies end class RepliesMailbox < ApplicationMailbox def process #Do something!! end endこの時点で、以下URLにアクセスするとローカルで挙動が確認できます。
http://localhost:3000/rails/conductor/action_mailbox/inbound_emails/new
外部からメールを受け取るようのパスワードを設定します。
credentialの設定$ EDITOR="vi" bin/rails credentials:edit -e productioncredentialaction_mailbox: ingress_password: 'greatpassword'最後に何処のメール配信サービスからリクエストが来るのか(今回はsendgrid)設定して完了です。
config/environments/production.rbclass ApplicationMailbox < ActionMailbox::Base ##省略## config.action_mailbox.ingress = :sendgrid endSendgridの登録と設定
- こちらからSendgridに登録します。
- settings -> Sender Authentication -> Domain Authenticationと選択します。
- CNAMEを3つ入力しろと言われるのでRoute53に記載して確認します。
----------ここから先はRoute53の設定が完了していることが前提です-----------
- settings -> Inbound Parse -> Add Host & URL と選択します。
- MXレコードとして記載したホスト名とURLを入力します。また、'POST the raw, full MIME message'のチェックも入れてください
[URL Example]
https://actionmailbox:greatpassword@host.example.com/rails/action_mailbox/sendgrid/inbound_emailsRoute53の設定
- MXレコードを設定します。Name: 'なんでもいい', Target: 'mx.sendgrid.net', Priority: '10'
- Sendgridで指定されたCNAMEの登録
以上で取り急ぎ動作すると思います。
参考情報
Action Mailbox Basics
https://guides.rubyonrails.org/action_mailbox_basics.htmlRails 6のAction Mailboxを使ってみよう(翻訳)
https://techracho.bpsinc.jp/hachi8833/2020_03_05/88539Rails6で導入されるAction Mailboxを試してみた
https://bagelee.com/programming/ruby-on-rails/rails6-action-mailbox/
- 投稿日:2021-01-03T12:21:27+09:00
オンプレ環境におけるCloudWatch AgentとPrometheusの連携
概要
昨年、CloudWach Agent(以下CWA)にアップデートが入り、
PrometheusのExporterからメトリクスを収集し、CloudWatchにプッシュする機能が追加された。
参考: Amazon CloudWatch での Prometheus メトリクスの使用これにより、CWAの標準機能によるメトリクス収集だけでなく、既存のPrometheus Exporterからの収集も可能となり、さらにはそれをCloudWatchに集約することができるようになった。
上述の参考リンクに記載されている内容では、EKSにCWAをデプロイして、内部の様々なコンテナからメトリクス収集する方法が紹介されている 。
そうすると、何だかEKS専用にも感じてしまうかもしれないが、実はオンプレ環境などEKSが一切関係ない環境でも同じことが可能。
非常に簡単ではあるが、ひとまずEKS関係なく使える方法を紹介したい。
本記事のタイトルではオンプレ環境と書いているが、まぁつまりEKS以外の環境なら何でも可能。最近、既存オンプレ環境で展開しているPrometheusの資産を活かしつつ、どうにかAWSと組み合わせた良いやり方ないかなーと探していた過程で本方法を検証した。
なので、どちらかというと自分の備忘録的な意味合いが強い。ごめんなさい。環境
- CentOS Linux release 8.3.2011
- amazon-cloudwatch-agent 1.247346.1b249759
CWAはもっと低いバージョンでもいけるけど、ひとまず本記事で検証したバージョンはこれ
注意
詳細は後述するが、CWAによりexporterから収集されたメトリクスはログ化されCloudWatch Logsに集約される。
直接的なメトリクスとして保存されるわけではない。そのため、ログからメトリクス化する手間が必要となる。手順
CWAのインストール
以下から自環境に適したパッケージを落としてインストール
例えばCentOSならコレ。
https://s3.amazonaws.com/amazoncloudwatch-agent/centos/amd64/latest/amazon-cloudwatch-agent.rpm$ rpm -Uvh https://s3.amazonaws.com/amazoncloudwatch-agent/centos/amd64/latest/amazon-cloudwatch-agent.rpmちなみに最初に検証したときは、rpmなどのパッケージで公開されているバージョンでは実装されていなかった。
なのでGitHubに公開されているアップストリームのソースコードからコンパイルする必要があった。
本記事を書くにあたり改めて確かめたところ、公開されているrpmでも問題なかったので、その手順で紹介。検証用exporterを稼働
- node_exporterをコンテナとして起動しておく
- あとでCWAにこのexporterからメトリクス収集させてCloudWatchに集約させる
$ docker run -d \ --rm \ --net="host" \ --pid="host" \ -v "/:/host:ro,rslave" \ --name node_exporter \ quay.io/prometheus/node-exporter \ --path.rootfs=/host
- curlで動作確認
$ curl localhost:9100/metrics -s | head # HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles. # TYPE go_gc_duration_seconds summary go_gc_duration_seconds{quantile="0"} 0 go_gc_duration_seconds{quantile="0.25"} 0 go_gc_duration_seconds{quantile="0.5"} 0 go_gc_duration_seconds{quantile="0.75"} 0 go_gc_duration_seconds{quantile="1"} 0 go_gc_duration_seconds_sum 0 go_gc_duration_seconds_count 0 # HELP go_goroutines Number of goroutines that currently exist.AWSのConfigとCredentialの準備
自環境にあわせて適宜用意。
$ cat ~/.aws/config [default] region = ap-northeast-1 [profile AmazonCloudWatchAgent] region = ap-northeast-1$ cat ~/.aws/credentials [default] aws_access_key_id = hoge aws_secret_access_key = hogehoge [AmazonCloudWatchAgent] aws_access_key_id = foo aws_secret_access_key = foobarコンフィグの準備
必要なのは、CWAのコンフィグとCWAに読み込ませるPrometheusのコンフィグ。
今回は必要最低限な構成でコンフィグを用意する。CWAのコンフィグ
rpmインストールすると、
/etc/amazon/amazon-cloudwatch-agent/amazon-cloudwatch-agent.d/というディレクトリが出来ている。
その配下にfile_amazon-cloudwatch-agent.jsonというコンフィグにあたるjsonファイルを配置する。
*.jsonなら何でも読み込むと思うので、名前は好きに変えて良いと思う。
- /etc/amazon/amazon-cloudwatch-agent/amazon-cloudwatch-agent.d/file_amazon-cloudwatch-agent.json
- 最低限これだけ書いていれば動くと思う
log_group_nameに指定した名前でCloudWatch Logsにロググループを作成する (今回は検証用途なのでtest)prometheus_config_pathにはPrometheusのコンフィグパスを指定する (別にどこでも良い)/etc/amazon/amazon-cloudwatch-agent/amazon-cloudwatch-agent.d/file_amazon-cloudwatch-agent.json{ "agent": { "run_as_user": "root" }, "logs": { "metrics_collected": { "prometheus": { "log_group_name": "test", "prometheus_config_path": "/etc/prometheusconfig/prometheus.yaml" } }, "force_flush_interval": 5 } }Prometheusのコンフィグ
別にCWAと組み合わせるからといって特別な何かはない。通常のPrometheusのコンフィグそのまま。
ここは詳しく解説している人たちが他にいらっしゃると思うので詳細は割愛。
ちなみに、job_nameで指定した名前でCloudWatch上にログストリームが作成される。
今回は事前に準備したnode_exporterを狙い撃ちでコンフィグを用意。実環境では、ServiceDscoveryさせることになるだろう。本記事では、
/etc/prometheusconfig/prometheus.yamlというパスで用意しておく。/etc/prometheusconfig/prometheus.yamlglobal: evaluation_interval: 1m scrape_interval: 1m scrape_timeout: 10s scrape_configs: - job_name: 'node_exporter' sample_limit: 10000 metrics_path: /metrics static_configs: - targets: ['localhost:9100']CWAの起動
- rpmでインストールしたので、自動的にunitファイルが作成済み
$ systemctl list-unit-files | grep cloudwatch amazon-cloudwatch-agent.service disabled
- 起動。一応、自動起動も有効化しておきましょう。
$ systemctl start amazon-cloudwatch-agent $ systemctl enable amazon-cloudwatch-agentログ確認
journalctlでログも見れる。が、大した内容が出力されていない。
何かしらの問題があって起動できなかった場合、このログにまともな情報が出力されず、ほぼ役に立たない。$ journalctl -xu amazon-cloudwatch-agentCWAの実態は
/opt/aws/amazon-cloudwatch-agentに存在している。ここにはログファイルが出力されている。こっちを見たほうが便利。
例えばIAMの権限問題とかがあっても、こちらにはばっちり出力されているのでトラブルシュートが捗る。
ちなみにログ的にもオンプレ環境であることを検出している。
こちらメタデータがとれるかどうかで判断しているようで、EKSで動かせばEKS環境であることを正しく検出してくれる。
- /opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log
$ cat /opt/aws/amazon-cloudwatch-agent/logs/amazon-cloudwatch-agent.log 2021/01/03 02:29:34 I! 2021/01/03 02:29:34 E! ec2metadata is not available I! Detected the instance is OnPrem 2021/01/03 02:29:34 Reading json config file path: /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json ... /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json does not exist or cannot read. Skipping it. 2021/01/03 02:29:34 Reading json config file path: /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.d/file_amazon-cloudwatch-agent.json ... Valid Json input schema. I! Detecting runasuser... Got Home directory: /root I! Set home dir Linux: /root I! SDKRegionWithCredsMap region: ap-northeast-1 Got Home directory: /root No csm configuration found. Under path : /logs/ | Info : Got hostname localhost.localdomain as log_stream_name No metric configuration found. Configuration validation first phase succeeded 2021/01/03 02:29:34 I! Config has been translated into TOML /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.toml 2021/01/03 02:29:34 Reading json config file path: /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.json ... 2021/01/03 02:29:34 Reading json config file path: /opt/aws/amazon-cloudwatch-agent/etc/amazon-cloudwatch-agent.d/file_amazon-cloudwatch-agent.json ... 2021/01/03 02:29:34 I! Detected runAsUser: root 2021/01/03 02:29:34 I! Change ownership to root:root 2021-01-03T02:29:34Z I! Starting AmazonCloudWatchAgent 1.247346.1 2021-01-03T02:29:34Z I! Loaded inputs: prometheus_scraper 2021-01-03T02:29:34Z I! Loaded aggregators: 2021-01-03T02:29:34Z I! Loaded processors: 2021-01-03T02:29:34Z I! Loaded outputs: cloudwatchlogs 2021-01-03T02:29:34Z I! Tags enabled: host=localhost.localdomain 2021-01-03T02:29:34Z I! [agent] Config: Interval:1m0s, Quiet:false, Hostname:"localhost.localdomain", Flush Interval:1s 2021-01-03T02:29:34Z I! [logagent] starting 2021-01-03T02:29:34Z I! [logagent] found plugin cloudwatchlogs is a log backendCloudWatch側の確認
正しくコンフィグが作成され、exporterからメトリクス収集し、CloudWatchへプッシュできていれば、
下記のようにロググループやストリームが作成されているはず。
こんな感じでログが溜まっていく。CWAかexporterを停止させない限り、どんどん溜まっていく。
あとは、このログに対してメトリクスフィルターを作成する。
ここではCPU使用率のメトリクス化を行っているが、CloudWatchへのプッシュができているなら何でも可能。
あとがき
監視とかメトリクス収集とか難しいですよね。正解がわからない。
どんな仕組みが良いのか、どんなシステムが良いのか、どんなアーキテクチャが良いのか、どれもこれも帯に短し襷に長し。
元々この分野は詳しくないので尚更わからない。
まぁ環境やサービスの特性などによってコレといったものが言いづらいんだろうし、正解はないんだろうけど。
昨今、Prometheusを使っているユーザーは多いと思う。
exporterは引き続き使いつつ、Prometheus本体をなくしてCloudWatchに代替させる・・・という方法も一案としてはアリだと思う。先日のre:InventにてAWSフルマネージドなPrometheusが発表された。非常に興味深い。
まだ試していないので詳しいメリット/デメリットはわからないが、AWS-Prometheusの連携が捗りそうなので期待。
多分、こちらをうまく使えれば、こんなCWAに収集させる方法は使わなくて良い気がする。そのうち試してみたい。




- 投稿日:2021-01-03T12:03:39+09:00
API GatewayでIAM認証してみた
公式ナレッジのAPI Gateway API に IAM 認証を有効化するにはどうすればよいですか?を参考に実装してみました!
Lambda関数を作成
一から作成/ランタイムPython3.8/他はデフォルト
関数作成ユーザーが
iam:PassRoleの権限がないとエラーが発生します。
AWS のサービスにロールを渡すアクセス権限をユーザーに付与するテストなので超超シンプルな関数です。
API Gateway作成
- REST API > 構築 > 新しいAPIの作成
- アクションのプルダウンからメソッドの作成でGETを選択する。
- 先ほど作成したLambda関数と統合する。
保存が完了したらデプロイ

URLが発行されるのでPostmanから叩いてみます。
この時点ではパブリックAPIです。
API GatewayのIAM認証を有効化
API Gatewayでは、APIに対して以下のような認証方式が存在します。
- Cognitoを使った認証
- サードパーティの認証基盤とLambda Authorizerを使った認証
- IAM認証
今回はIAM認証での実装なので作成したメソッドリクエストの認可を
AWS_IAMに変更し再度デプロイします。
再度、APIをPostmanから叩いてみます。
すると
"Missing Authentication Token"とメッセージが返ってきます。
IAMの設定
- 作成したAPIのリクエストの権限ポリシーを作成
- IAMユーザー作成しポリシーをアタッチ
ポリシーの作成
作成したAPIの
arnをResourceに指定しインラインポリシーを作成します。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "execute-api:Invoke" ], "Resource": [ "arn:aws:execute-api:........../*/GET/" ] } ] }
IAMユーザーを作成し上記ポリシーをアタッチします。Postmanでテストする際に
Access key IDとSecret access keyを使うのでメモします。動作確認
- Postmanに作成したIAMの
Access key IDとSecret access keyをセットして叩いてみます。
出来ました!
ちなみに権限が足りないと下記のようなエラーが出ます。
ポリシーを確認してみてください。{ "Message": "User: arn:aws:iam::123456789:user/api-unvalid is not authorized to perform: execute-api:Invoke on resource: arn:aws:execute-api............../test/GET/" }










- 投稿日:2021-01-03T11:16:15+09:00
個人的に気になる最近のサーバーレス事情
思い
EC2の管理
なんてしたくない。
個人開発の金銭的ハードルが高い。
バーストアクセスでダウン...?まじかよ。。。サーバーレス って素敵なワード...

気になったお話
それぞれわかりやすそうな記事を貼り付けていますが公式のものは各記事からリンクで飛んでください

- Lambdaの実行時間の課金単位が1ミリ秒に短縮されました
- RDS ProxyがGAされました!!
- Lambda 関数が VPC 環境で改善されます
- Lambdaのメモリ割り当てを自動で最適化!!AWS Lambda Power Tuning
- Amazon Aurora Serverless v2(プレビュー)Lambdaの実行時間の課金単位が1ミリ秒に短縮されました
https://dev.classmethod.jp/articles/lambda-billed-duration-1ms/
課金単位が短くなったので単純にコストがより最適化されるようになりました
個人開発としては嬉しいですねRDS ProxyがGAされました!!
https://dev.classmethod.jp/articles/rds-proxy-ga/
lambdaとRDSの組み合わせは今までタブーでした。
lambdaは実行毎でDBにコネクションを取りに行くのでRDSのmax connectionに引っかかってDBに接続ができなくなります。
従来のアプリケーションではアプリケーションでコネクションを保持して使い回すようにしており、これをコネクションプールといいます。
RDS ProxyはこのコネクションプールをAWSマネージドで行ってくれます。
=> 結果lambdaでもコネクションを食い潰すことがなくなりました。アプリケーションからAWSマネージドに持っていくことで以下のメリットがあります(特に上はサーバーレス関係なくでかい!)
- アプリケーションを冗長構成にしていく時にmax connectionを気にして冗長上限を気にしなくて良くなる
- 複数の接続先(複数のアプリやBIやローカル...etc)でコネクションを使いまわせる(やった方がいいかはおいておいて)
Lambda 関数が VPC 環境で改善されます
https://aws.amazon.com/jp/blogs/news/announcing-improved-vpc-networking-for-aws-lambda-functions/
今までは接続毎でENIを作成してVPC内にアタッチしていたことにより「初期起動に時間がかかる」「ENIの上限に引っかかる」という問題があったようです。(その時代に明るくなく...)
それをVPC to VPC Natを用意することによって解消されたようですLambdaのメモリ割り当てを自動で最適化!!AWS Lambda Power Tuning
https://dev.classmethod.jp/articles/aws-lambda-power-tuning/
lambdaではメモリーを自分で指定する必要があります。
これは大概よくわからずちょっと多めに構えて徐々に調整するという感じだったと思います。(私は個人開発だったのでデフォルトで放置してました...)
最近のアップデートで最低なメモリーサイズをAWSの方で提案してくれるようになったようです。Amazon Aurora Serverless v2(プレビュー)
https://aws.amazon.com/jp/rds/aurora/serverless/
※ 2021/01段階でプレビューです!
RDSがついにサーバーレスで使いやすくなってきそうですね!
今まではRDSはスケールアップするにしても数秒のダウンタイムが発生したりとなかなか変更が難しいので普段から大きいサイズのインスタンスで構えることが多かったです。(しかしこいつまじで高いんですよね。。。。)
Aurora Serverlessでは自動でスケールアップをしてくれて、アクセスが低い時には自動でスケールダウンしてくれる。アプリケーションが消費する容量に対してのみ料金を支払い、ピーク負荷の容量をプロビジョニングするコストと比較して、データベースコストを最大 90% 節約できます。
ほんの一瞬で数百から数十万のトランザクションに瞬時にスケールします。
夢のような言葉が綴られており見た瞬間お祈りポーズでした
v1にはいくつか問題点もあるようで特に一定時間アイドルすると停止されて再開に1分程度かかるという部分はだいぶ致命的かなと思います。
こちらv2でどうなっているのか見れていないので情報あったら教えて欲しいです
そのほかv1の問題点まとめられているのでぜひこちらも参考にしていただけるとです。
参考: https://dev.classmethod.jp/articles/lessons-learned-from-up-and-running-aurora-serverless/
- 投稿日:2021-01-03T11:16:15+09:00
個人的に気になる最近のサーバーレス事情(2021/01)
思い
EC2の管理
なんてしたくない。
個人開発の金銭的ハードルが高い。
バーストアクセスでダウン...?まじかよ。。。サーバーレス って素敵なワード...
気になったお話
それぞれわかりやすそうな記事を貼り付けていますが公式のものは各記事からリンクで飛んでください
- Lambdaの実行時間の課金単位が1ミリ秒に短縮されました
- RDS ProxyがGAされました!!
- Lambda 関数が VPC 環境で改善されます
- Lambdaのメモリ割り当てを自動で最適化!!AWS Lambda Power Tuning
- Amazon Aurora Serverless v2(プレビュー)Lambdaの実行時間の課金単位が1ミリ秒に短縮されました
https://dev.classmethod.jp/articles/lambda-billed-duration-1ms/
課金単位が短くなったので単純にコストがより最適化されるようになりました
個人開発としては嬉しいですねRDS ProxyがGAされました!!
https://dev.classmethod.jp/articles/rds-proxy-ga/
lambdaとRDSの組み合わせは今までタブーでした。
lambdaは実行毎でDBにコネクションを取りに行くのでRDSのmax connectionに引っかかってDBに接続ができなくなります。
従来のアプリケーションではアプリケーションでコネクションを保持して使い回すようにしており、これをコネクションプールといいます。
RDS ProxyはこのコネクションプールをAWSマネージドで行ってくれます。
=> 結果lambdaでもコネクションを食い潰すことがなくなりました。アプリケーションからAWSマネージドに持っていくことで以下のメリットがあります(特に上はサーバーレス関係なくでかい!)
- アプリケーションを冗長構成にしていく時にmax connectionを気にして冗長上限を気にしなくて良くなる
- 複数の接続先(複数のアプリやBIやローカル...etc)でコネクションを使いまわせる(やった方がいいかはおいておいて)
Lambda 関数が VPC 環境で改善されます
https://aws.amazon.com/jp/blogs/news/announcing-improved-vpc-networking-for-aws-lambda-functions/
今までは接続毎でENIを作成してVPC内にアタッチしていたことにより「初期起動に時間がかかる」「ENIの上限に引っかかる」という問題があったようです。(その時代に明るくなく...)
それをVPC to VPC Natを用意することによって解消されたようですLambdaのメモリ割り当てを自動で最適化!!AWS Lambda Power Tuning
https://dev.classmethod.jp/articles/aws-lambda-power-tuning/
lambdaではメモリーを自分で指定する必要があります。
これは大概よくわからずちょっと多めに構えて徐々に調整するという感じだったと思います。(私は個人開発だったのでデフォルトで放置してました...)
最近のアップデートで最低なメモリーサイズをAWSの方で提案してくれるようになったようです。Amazon Aurora Serverless v2(プレビュー)
https://aws.amazon.com/jp/rds/aurora/serverless/
※ 2021/01段階でプレビューです!
RDSがついにサーバーレスで使いやすくなってきそうですね!
今まではRDSはスケールアップするにしても数秒のダウンタイムが発生したりとなかなか変更が難しいので普段から大きいサイズのインスタンスで構えることが多かったです。(しかしこいつまじで高いんですよね。。。。)
Aurora Serverlessでは自動でスケールアップをしてくれて、アクセスが低い時には自動でスケールダウンしてくれる。アプリケーションが消費する容量に対してのみ料金を支払い、ピーク負荷の容量をプロビジョニングするコストと比較して、データベースコストを最大 90% 節約できます。
ほんの一瞬で数百から数十万のトランザクションに瞬時にスケールします。
夢のような言葉が綴られており見た瞬間お祈りポーズでした
v1にはいくつか問題点もあるようで特に一定時間アイドルすると停止されて再開に1分程度かかるという部分はだいぶ致命的かなと思います。
こちらv2でどうなっているのか見れていないので情報あったら教えて欲しいです
そのほかv1の問題点まとめられているのでぜひこちらも参考にしていただけるとです。
参考: https://dev.classmethod.jp/articles/lessons-learned-from-up-and-running-aurora-serverless/
- 投稿日:2021-01-03T10:18:41+09:00
【AWS S3】「バケットを削除する十分なアクセス許可がありません」のエラーが出た




- 投稿日:2021-01-03T03:07:41+09:00
Floating IP とは
勉強前イメージ
EC2インスタンスのIPがどうとかってイメージだけど
なにするかはわからん。調査
Floating IP とは
AWSのEC2を使ったデザインパターンの一種で、
何らかの理由でEC2インスタンスを停止させたい場合でも停止時間を短くサーバの切り替えができるパターン構成
サーバを落としたいとき、ElasticIPを付け替えることによってEC2インスタンスへのアクセスをなくす。
似たようなやり方でDNSの向き先を変更する方法があるが、TTL値を気にしないといけないしアクセスが0になることはあまりない(TTL値の関係)
ElasticIPを付け替えることでTTL値を気にせずとも別のEC2インスタンスに任せることができる
また、ElasticIPはAZ(アベイラビリティゾーン)を超えて設定することができるので、AZの障害があっても対処することができる
特徴
上でも書いたことがかぶるが・・・
- ElasticIPを付け替えるだけなので、DNSのTTL値に影響されない
- ElasticIPはAZを超えて設定ができる
勉強後イメージ
これを機に、デザインパターンというのがあるのを知った。(言葉は知ってたけど)
ちゃんと見てみたらFloating IPだけじゃなくて他にも、こういうときはこういう構成の仕方があるよーって書いてあってすごい勉強になったので他のデザインパターンも見てみます。参考

- 投稿日:2021-01-03T00:04:53+09:00
AWSCodebuildでビルドする
構成
- ほぼそのまま使える
- Githubと連携するときは、AWSアカウントをGithubで許可する必要あり
- これはAWSからGit連携のボタンを押したときに画面遷移するので1アカウントに付き1回やれば良い模様
- https://registry.terraform.io/providers/hashicorp/aws/latest/docs/resources/codebuild_project
locals { TENANT_ID = "xxxxxxxx" } resource "aws_s3_bucket" "manual" { bucket = "manual" acl = "private" } resource "aws_codebuild_project" "manual" { name = "manual" description = "" build_timeout = "60" queued_timeout = "480" source_version = "master" badge_enabled = false service_role = aws_iam_role.codebuild.arn artifacts { encryption_disabled = false location = aws_s3_bucket.manual_front.bucket name = "manual" namespace_type = "BUILD_ID" override_artifact_name = false packaging = "NONE" type = "S3" } cache { modes = [] type = "NO_CACHE" } environment { compute_type = "BUILD_GENERAL1_SMALL" image = "aws/codebuild/standard:4.0-20.09.14" image_pull_credentials_type = "CODEBUILD" privileged_mode = false type = "LINUX_CONTAINER" environment_variable { name = "NODE_HOST" type = "PLAINTEXT" value = "vamdemic" } environment_variable { name = "API_HTTPS" type = "PLAINTEXT" value = "true" } } logs_config { cloudwatch_logs { status = "ENABLED" } s3_logs { encryption_disabled = false status = "DISABLED" } } source { git_clone_depth = 1 insecure_ssl = false location = "https://github.com/vamdemic/manual.git" report_build_status = false type = "GITHUB" git_submodules_config { fetch_submodules = false } } tags = { Environment = "AutoDeployment" } }buildspecファイル
- CodeBuildで指定したブランチのルートディレクトリにファイルを配置しておく
- または、awscli実行時に上書き指定することで読み込ませることもできる
- CodeBuildから呼び出されるビルド用コンテナの中で実行したいコマンドを列挙していく
- install
- yarn installやnpm installなどのセットアップ系を処理を書くところ
- build
- buildコマンドなどを書くところ
- pre_なんとか
- buildの前の処理を書くところ
- sedしたりファイルを配置したりなど
- artifacts
- ビルドされたものの管理
- この例では、カレントディレクトリの
distというディレクトリをまとめてアーティファクトとして保存するという意味- アーティファクト用に指定したs3に保存されているので見てみる
buildspec.yamlversion: 0.2 phases: install: runtime-versions: nodejs: 10 commands: - echo Installing source NPM dependencies... - yarn install build: commands: - NODE_HOST=template yarn build - pwd - ls artifacts: files: - '**/*' base-directory: 'dist'実行
- ビルドが
SUCCESSになるまで待機するシェル--environment-variables-overrideは環境変数を上書きしているcode-build-manual.sh#!/bin/bash # Build実行 BUILD_RESULT=$(aws codebuild start-build \ --project-name manual \ --environment-variables-override '[ { "name": "API_HOST", "value": "'${1}'.vamdemic.jp", "type": "PLAINTEXT" }, { "name": "ADMIN_ROOT_PATH", "value": "https://'${1}'.vamdemic.jp/", "type": "PLAINTEXT" } ]' ) # IDを取得 EXECUTE_ID=$(echo ${BUILD_RESULT} | jq -r ".build.id") BUILD_STATUS=$(aws codebuild batch-get-builds \ --ids ${EXECUTE_ID} \ | jq -r ".builds[].buildStatus" ) #echo ${BUILD_STATUS} while [ "${BUILD_STATUS}" != "SUCCEEDED" ] do sleep 10 BUILD_STATUS=$(aws codebuild batch-get-builds \ --ids ${EXECUTE_ID} \ | jq -r ".builds[].buildStatus" ) done echo "$(echo ${EXECUTE_ID} | awk -F ':' '{print $2}')"