- 投稿日:2020-12-23T23:55:03+09:00
Pythonでtwitterでいいねしたツイートにある画像を収集するプログラムを作ってみた
この記事はAkatsuki Advent Calender 2020の23日目になります
はじめに
運用して2~3年経っているのですが記事にしておらず今回いい機会なのですることにしました。
まず事の経緯として
twitterを覗いていると収集したい画像が回ってくることがあります。
そこでいちいち右クリック->ダウンロード->パス指定は非常に面倒だしそういうツイートが連続で来たら?となるとやってられません。そこで何かしらトリガーがあって自動でダウンロードしてくれないかなと。
それで閲覧する用のwebページがあれば完璧ではないかと。
そんな訳で収集欲と技術欲半々のなか作ることにしました。今回は収集のところだけ。
(それpixivとかで良くない?とか思うかもしれないですが
自分の欲しいやつだけ閲覧できるものが欲しいんです・・・)要件
・RTではなくいいねのツイートのみダウンロードすることに。
いいねだとクリック手順が1つ少ないので速攻次のツイートに移れる
・収集はレンタルサーバーか何かで行う
自宅に常時つけるPCはないので、収集タイミング時につけてないといけないのは利便性が悪い。
・実装当時はstreaming apiが生きていたのでそれでリアルタイムでいいねツイートを取得
-> なくなったのでrest apiで時間をおいて取得する方にしました。
・ツイート内容やURL、@ IDなどもwebページでの検索用として保存しておく開発環境
レンタルサーバー
・さくらサーバー言語
・python3.6使用ライブラリ
・requests_outhlib
・mysql.connectorTwitter Devへの登録
https://developer.twitter.com/
こちらで登録を行っておき、認証を通せるようにしときます。実装へ
ところどころ省略しています
1. セッションの生成
twitter developerにてappを作っておく。
そこでKey And Tokenのタブに認証に必要なKeyとTokenがあるのでコピーしておきます。
requests_outhlibにてセッションを作る際は
以下のコードで先程のKeyとTokenを指定します。twitter_session = OAuth1Session(consumerKey , consumerSecret , accessToken , accessSecret)2. APIの結果取得
https://developer.twitter.com/en/docs/twitter-api/v1/tweets/post-and-engage/api-reference/get-favorites-list
今回使ういいねAPIについてはこちらコードでは以下のように使用します
#APIのResources URLと渡すパラメータを指定 #パラメータは上のページに載っていますが今回は以下の2つをメインで使います #screen_name:@で表記するid 本来はuser_idを指定するのが確実ですが、収集アカウントは変える予定ないのでこれで #count:一度に取得するツイート数 (max:200) request = twitter_session.get("https://api.twitter.com/1.1/favorites/list.json", params = {"screen_name":ID, "count":200}) #古いのツイートを取得したい場合 パラメータに以下を追加します #tweet_idよりも前のツイートを取得するようになります。指定なしで最新のツイートからになります "max_id":tweet_id結果はjsonで返ってきます。
status_codeでエラーかどうか判別。request.textにjsonのデータが有るためjson.loadsでjsonに変換しておきます。if request.status_code == 200: print("rest connect") else: print("rest Error code%d", request.status_code) return "" tweets = json.loads(request.text)またこれを実行する際も以下の制限に気をつける必要があります
・75リクエスト/15分
・取得されるツイートの順番はいいねした順番ではなくいいね先のツイート日時が新しい順に取得されます
なので古いツイートを取得する場合は工夫する必要があります3. jsonデータを元に画像を取得
先程取得したtweets変数にはツイートが配列が入っているためfor文で1つずつ処理が可能です
for tweet in tweets: #ツイートから情報を取得 #ツイートのID 一番最後のtweet["id"]を上で説明したtwitter_session.getのmax_idに指定することで #次のリクエストで取得する結果がかぶることなく処理できます tweet["id"] #表示する名前 tweet["user"]["name"] #@id tweet["user"]["screen_name"] #画像一覧 (URL) tweet["extended_entities"]["media"] #ツイート文 tweet["text"] #ツイートURLは以下の組み合わせで "https://twitter.com/"+tweet["user"]["screen_name"]+"/status/"+tweet["id_str"]今回は画像一覧なので
#画像一覧 (URL) image_list = tweet["extended_entities"]["media"]これを使います。
これも配列としてやってくるのでfor文で処理します
色々と省略はしていますが基本的にこれでダウンロード後保存を繰り返しています。for image in image_list: url = image["media_url"] img = urllib.request.urlopen(url, timeout = 5).read() f = open(path, 'wb') f.write(img) f.close()流れとしては以下の通り
・セッション作成
・リミットまでgetリクエスト75回ループ
・取得ツイートの画像を取得
・取得ツイートの最後のツイートIDを保持してリクエスト時に渡すもし古いツイートを取得する場合は定期的に全いいねを見ていくのが良いかと
4.レンタルサーバーでCRON設定
今回はリクエストが15分ごとに制限があるのでそれに合わせてCRONを設定します
これでいいね自動収集化完了ですが
web上で閲覧・検索をするのであればDBにツイートの情報保存したりする必要があります。最後に
この後、DBやwebページは適宜設定して閲覧はできたのですが、
正直ほとんど見てません。収集とプログラムが動いたのでそこができただけで満足しちゃいました。
とはいえ学習するための題材としてはなかなか良かったと思います。スクリプト言語全然触っていなかったのと
自動化への興味が湧いた一番の作品?だったので。なお、現在収集できた枚数は
約 1 7 万 枚いいねの回数は
1 5 万 い い ね
自分でもこの人イカれてますねと思いました。自分だけど・・・もっと良いシステムを作るとするならば機械学習で収集する画像も自動化が一番いいのですが、一度やろうとしたところ
収集したい画像の判定がめちゃんこ難しくて諦めました。自分の好みを落とし込まないといけない難易度高い・・・
学習のための画像はあるんですけどね・・・・・




- 投稿日:2020-12-23T23:41:50+09:00
オブジェクトストレージ Cloudian/S3 にJSON形式のデータを書き込みしてみます
はじめに
AWS SDK for Python(boto3) を使って、プログラムをほぼ変更せずに Cloudian と S3 へのアクセスが可能となります。オブジェクトストレージをハイブリッド(オンプレミス:Cloudian、AWS:S3)で使いたい方への参考になればと、、、
概要
オブジェクトストレージ Cloudian/S3 上のバケット名「boto3-cloudian」に、JSON形式のデータを書込む Python プログラムです。
生成するJSON形式のデータ件数はパラメータで指定でき、ファイル「test-iot-dummy.json」に書き込まれます。プログラムをカスタマイズすることにより、なんちゃってIoTデータ生成として使えるかもと想定しております。生成されるデータ項目についてはプログラム内の「items」を参照ください。
- パラメータは以下の3種類となります。
- --count : 生成するデータ件数(デフォルト:10件)
- --proc : 生成するプロセス名(デフォルト:111)
- --mode : 生成データの出力先の指定 tm:ターミナルへの出力、 s3:Cloudian/S3への出力(デフォルト:tm)
プログラム実行時に、パラメータ「-h」を指定することにより表示されるヘルプも参照ください。
実行環境
macOS Big Sur 11.1
python 3.8.3クレデンシャル情報の定義
今回はクレデンシャル情報を .zshenv に定義してプログラムを実行しています。接続先に合わせて定義ください。
# AWS S3 export AWS_ACCESS_KEY_ID=xxxxxxxxxxxxx export AWS_SECRET_ACCESS_KEY=yyyyyyyyyyyyyyyyy export AWS_DEFAULT_REGION=ap-northeast-1 # Cloudian #export AWS_ACCESS_KEY_ID=aaaaaaaaaaaaaaaaaa #export AWS_SECRET_ACCESS_KEY=bbbbbbbbbbbbbbbbbbbb #export AWS_DEFAULT_REGION=pic実行プログラム
Cloudianへアクセスする場合は endpoint_url を記載ください(プログラム内を参照ください)。
IoTSample-write.pyimport random import json import time from datetime import date, datetime from collections import OrderedDict import argparse import string import boto3 import pprint from faker.factory import Factory BUCKET_NAME = 'boto3-cloudian' OBJECT_KEY = 'test-iot-dummy.json' # ダミーデータ作成のための Faker の使用 Faker = Factory.create fake = Faker() fake = Faker("ja_JP") # IoT機器のダミーセクション(小文字アルファベットを定義) section = string.ascii_uppercase # IoT機器で送信JSONデータの作成 def iot_json_data(count, proc): iot_items = json.dumps({ 'items': [{ 'id': i, # id 'time': generate_time(), # データ生成時間 'proc': proc, # データ生成プロセス名 'section': random.choice(section), # IoT機器セクション 'iot_num': fake.zipcode(), # IoT機器番号 'iot_state': fake.prefecture(), # IoT設置場所 'vol_1': random.uniform(100, 200), # IoT値−1 'vol_2': random.uniform(50, 90) # IoT値−2 } for i in range(count) ] }, ensure_ascii=False).encode('utf-8') return iot_items # IoT機器で計測されたダミーデータの生成時間 def generate_time(): dt_time = datetime.now() gtime = json_trans_date(dt_time) return gtime # date, datetimeの変換関数 def json_trans_date(obj): # 日付型を文字列に変換 if isinstance(obj, (datetime, date)): return obj.isoformat() # 上記以外は対象外. raise TypeError ("Type %s not serializable" % type(obj)) # メイン(ターミナル出力用) def tm_main(count, proc): print('ターミナル 出力') iotjsondata = iot_json_data(count, proc) pprint.pprint(iotjsondata) # メイン(Cloudian/S3 出力用) def s3_main(count, proc): print('Cloudian/S3 出力') iotjsondata = iot_json_data(count, proc) # pprint.pprint(iotjsondata) # client = boto3.client('s3', endpoint_url='http://s3-pic.networld.local') # Cloudianへのアクセス時 client = boto3.client('s3') # S3へのアクセス時 client.put_object( Bucket=BUCKET_NAME, Key=OBJECT_KEY, Body=iotjsondata ) if __name__ == '__main__': parser = argparse.ArgumentParser(description='IoT機器のなんちゃってダミーデータの生成') parser.add_argument('--count', type=int, default=10, help='データ作成件数') parser.add_argument('--proc', type=str, default='111', help='データ作成プロセス名') parser.add_argument('--mode', type=str, default='tm', help='tm(生成データをターミナル出力)/ s3(生成データをCloudian/S3出力)') args = parser.parse_args() start = time.time() if (args.mode == 's3'): s3_main(args.count, args.proc) else : tm_main(args.count, args.proc) making_time = time.time() - start print("") print(f"データ作成件数:{args.count}") print("データ作成時間(通常_API):{0}".format(making_time) + " [sec]") print("")プログラムの実行
最初にヘルプを表示してみます。
$ python IoTSample-write.py -h usage: IoTSample-write.py [-h] [--count COUNT] [--proc PROC] [--mode MODE] IoT機器のなんちゃってダミーデータの生成 optional arguments: -h, --help show this help message and exit --count COUNT データ作成件数 --proc PROC データ作成プロセス名 --mode MODE tm(生成データをターミナル出力)/ s3(生成データをCloudian/S3出力)次に、10万件のデータを生成し、それをターミナル出力してみます
$ python IoTSample-write.py --count 100000 : 出力内容は割愛 : データ作成件数:100000 データ作成時間(通常_API):4.5370988845825195 [sec]今度は実際に Cloudian/S3 に10万件のデータを生成してみます。
$ python IoTSample-write.py --count 100000 --mode s3 データ作成件数:100000 データ作成時間(通常_API):2.7221038341522217 [sec]まとめ
今回は、AWS SDK for Python(boto3) を使って、オブジェクトストレージ Cloudian / S3 へデータを生成することを確認できました(10万件のデータを数秒で作成完了(もちろん環境に依存します))。
Cloudianについては、ここ を確認ください。
- 投稿日:2020-12-23T23:34:20+09:00
[Python] 区間スケジューリング ABC103D
ABC103D
下図のようにすべて串刺しにするには、最小何本必要か、という問題である。
区間スケジューリング問題とは以下のような問題である:M 個の区間が与えられ、どの 2 つの区間も時間帯を共有しないように最大個数の区間を選べ
蟻本の Greedy の章の最初にも載っている有名問題で、区間の終端でソートして Greedy にとっていけばよい。
実は今回の問題の答えは、区間スケジューリング問題の最適解と同じになる:
- まず区間スケジューリング問題の答えが k 個だった場合、その k 個は時間帯を共有しないので、それらを全部刺すには最低でも k 本の串が必要である (弱双対性)
逆に k 本の串があれば十分であることは、区間スケジューリング問題に対する貪欲法の動きを注意深く追うと理解することができる。具体的には、
- 区間スケジューリング問題で選ぶ k 個の区間に対して、その右端から串を刺していけば、ちょうど k 本の串ですべての区間を串刺しにできる (強双対性)
サンプルコードfrom operator import itemgetter n, m = map(int, input().split()) # 区間の終端でソート ab = sorted([tuple(map(int, input().split())) for i in range(m)], key=itemgetter(1)) # 前回除いた橋 removed = -1 ans = 0 for a, b in ab: # a が removed より大きい = まだ取り除いてない if a > removed: removed = b - 1 ans += 1 print(ans)

- 投稿日:2020-12-23T22:58:06+09:00
statsmodelsでホールドアウト検証を実装する
はじめに
pythonでは,ロジスティック回帰モデルを利用できるライブラリとして主にsklearnとstatsmodelsが用いられます.statsmodelsには係数の有意差検定を自動でしてくれる等のsklearnにはない利点がある一方で,代表的なモデルの評価方法であるホールドアウト法や交差検証法に対応していません.そこで今回は,statsmodelsでホールドアウト法を実装するためのコードを作成してみます.
ライブラリのインストール
sample.ipynbimport numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.model_selection import StratifiedKFold import statsmodels.api as smデータのインストールと前処理
データには,私が卒業研究のために独自に集めたクラウドファンディングに関するデータを用います.
このデータは私のgithubページに置いているので必要なら自分の環境にダウンロードしてください.sample.ipynb#csvファイルの読み込み cultured = pd.read_csv("cultured.csvへのpath") #目的変数を作成 0:クラウドファンディング失敗 1:クラウドファンディング成功 cultured["achievement"] = cultured["支援総額"] // cultured["目標金額"] cultured["target"] = 0 cultured.loc[cultured['achievement']>=1,'target'] = 1 #目的変数(y)と説明変数(x)に分ける #add_constantで定数項を作成 y = cultured["target"] x_pre = cultured[["目標金額","支援者数","文字数","活動報告回数"]] x = sm.add_constant(x_pre)このデータは,説明変数である目標金額,支援者数,文字数,活動報告回数からクラウドファンディングプロジェクトが成功(y=1)か失敗(y=0)かを予測するためのものです.sklearnのロジスティック回帰では,定数項を勝手に生成してくれますが,statsmodelsにはその機能はないのでadd_constant()を用いて生成しています.
説明変数は(x)はこんな感じです.
実装(この記事のメイン)
sample.ipynb#ホールドアウト法 def hold_out(x,y): #データを訓練データとテストデータに分割 #test_sizeはデータ全体に対するテストデータの割合 X_train, X_test, y_train, y_test = train_test_split(x,y,test_size=0.2,random_state=42) #訓練データを用いて学習 model = sm.Logit(y_train, X_train) results = model.fit() #テストデータに対する予測をpredに格納 #ただし出力値は目的変数が1になる確率(今回だと成功確率)なので注意 pred = results.predict(X_test) #確率が0.5より大きいものを1に,それ以外を0に変換 #リスト内表記を利用 result = [1 if i>0.5 else 0 for i in pred] #train_test_splitでインデックスの順番がめちゃくちゃなので振り直す y_test_re = y_test.reset_index(drop=True) #カウントに初期値を格納 count=0 #y_testと予測値の値が一致するならばcountに1を足す for i in range(len(y_test)): if y_test_re[i] == result[i]: count+=1 #戻り値は予測の精度 return count/len(y_test)結果
sample.ipynbhold_out(x,y)関数を実行すると...
私の環境だと0.878でした!

- 投稿日:2020-12-23T22:49:27+09:00
Unix Domain SocketによるuWSGIとNginxの通信
本記事は東京学芸大学 櫨山研究室 Advent Calendar 2020の16日目の記事になります.
はじめに
本記事はPythonのWebフレームワークであるflaskで作成したアプリケーションをuWSGIサーバを使って動作させる内容を通してUnix Domain Socket通信について学ぶという内容になります.
Unix Domain Socketとは
Unix Domain SocketはPOSIX系のOSに搭載されている機能でTCP/UDPによるソケット通信とは異なり,カーネル内部で完結する高速なネットワークインタフェースを作成します.
カーネル内部で完結するため外部のコンピュータとは接続することはできません.flaskのアプリケーションの作成
エンドポイント
/でアクセスしてHello, Worldとだけ返す簡単なアプリケーションを作成します.app.pyfrom flask import Flask app = Flask(__name__) @app.route("/") def index(): return "Hello World" if __name__ == "__main__": app.run(host="0.0.0.0", debug=True)そして以下のコマンドを実行することでアプリケーションが起動します.
この時,起動には開発用の組み込みサーバが立ち上がります.python app.pyhttp://localhost:5000/
にアクセスしてHello, Worldと表示されれば成功です.uWSGIを使って動かす
先ほどの例では開発用の組み込みサーバを使用していました.
PythonにはアプリケーションサーバとしてuWSGIがあります.
uWSGIではUnix Domain Socketでの通信がサポートされています.まずは
uWSGIを使って先ほどのアプリケーションを動作させてみます.pip install uWSGIapp.pyfrom flask import Flask app = Flask(__name__) @app.route("/") def index(): return "Hello World" if __name__ == "__main__": app.run()
uWSGIで先ほどのアプリケーションを起動するには以下のコマンドを入力します.uwsgi --http=0.0.0.0:4000 --wsgi-file=app.py --callable=apphttp://localhost:4000/
にアクセスしてHello, Worldと表示されれば成功です.
uwsgi.iniという設定ファイルを作成することでより短いコマンドで起動することも可能です.uwsgi.ini[uwsgi] wsgi-file=app.py callable=app http=0.0.0.0:4000uwsgi uwsgi.iniNginxの導入
さてここからが本題のUnix Domina Socketでのアクセスです.これまでの起動方法ではHTTP通信(TCPソケット)でのアクセスでした.
実際に運用する場合は同一サーバで複数のアプリケーションを動作させることを考慮しNginxをリバースプロキシとする場合が多いでしょう.
この時,同一サーバ内の通信であればUnix Domain Socketを使ってHTTP通信よりも高速にアクセスすることができます.今回は便宜的にDockerを用いて動作させてみます.
uwsgi.iniの編集
uwsgi.iniを編集してUnix Domain Socketで通信するようにします.
Unix Domain Socketではファイルシステム上の指定した位置にソケットファイルができます.
クライアントはソケットファイルにアクセスを試みます.
つまりIPアドレスとポート番号ではなくファイルパスによって通信相手を決めます.今回は
/var/app/app.sockというソケットファイルを作成するようにします.uwsgi.ini[uwsgi] wsgi-file=app.py callable=app http=0.0.0.0:4000 # 追記 socket=/var/app/app.sockDocker環境の準備
まずは先ほどのflaskのアプリケーションを動作させる環境を用意する
Dockerfileを用意します.DockerfileFROM python:3.7 ENV LANG C.UTF-8 ENV TZ Asia/Tokyo WORKDIR /app ADD app.py ./ ADD uwsgi.ini ./ RUN pip install flask uWSGI CMD ["uwsgi", "uwsgi.ini"]
nginxも動かしたいのでdocker-compose.ymlを用意します.docker-compose.ymlversion: '3.7' services: app: container_name: uds_app build: context: . dockerfile: ./Dockerfile volumes: - ./tmp/:/var/app/ tty: true nginx: container_name: uds_nginx image: nginx volumes: - ./tmp:/var/app/ - ./nginx.conf:/etc/nginx/conf.d/default.conf ports: - 80:80 tty: trueここで重要なのはホストマシン上の
./tmpディレクトリをflaskアプリケーションコンテナとNginxコンテナの両方と共有していることです.
- ホストマシン上の
./tmpディレクトリ ←→ flaskアプリケーションコンテナの/var/appディレクトリ- ホストマシン上の
./tmpディレクトリ ←→ Nginxコンテナの/var/appディレクトリこれによりNginxコンテナからもソケットファイルを参照できます.
Nginxの設定ファイルを記述し
/へのアクセスをflaskのアプリケーションを呼び出すようにします.nginx.confserver { listen 80 default_server; listen [::]:80 default_server; server_name _; location / { include uwsgi_params; uwsgi_pass unix:/var/app/app.sock; } error_page 404 /404.html; location = /404.html { } error_page 500 502 503 504 /50x.html; location = /50x.html { } }
docker-compose upコマンドで起動してみましょう.docker-compose uphttp://localhost/
にアクセスして先ほどと同様にHello, Worldの文字列が確認できれば成功です.おわりに
本記事ではflaskで作成したアプリケーションにリバースプロキシのNginxからUnix Domain Socketで通信するということを扱いました.
TCP通信と異なりファイルパスによって通信相手を決めるという部分が伝わればと思います.
また余裕があれば性能も調査してきたいですね.
- 投稿日:2020-12-23T22:48:35+09:00
Google Colab で Dash する
python のデータ可視化のフレームワークに Dash(https://dash.plotly.com/) があります。
これが Google Colab でも利用可能に、、とすでに解説されている良記事を見つけてしまいました。
https://qiita.com/OgawaHideyuki/items/725f4ffd93ffb0d30b6cということで、この記事は参考にさせていただいて自分の手を動かしました、という記録です。
お題は安直にコロナ感染者数の可視化です。使用する環境など
Google Colaboratory を使用します。
その他は下記です。
- Dash(https://dash.plotly.com/) グラフライブラリである plotly を使用して、インンタラクティブなデータ可視化画面を簡単に作れる python フレームワークです。
- Johns Hopkins 大学の国・地域別感染者データを使わせていただきます。 https://github.com/CSSEGISandData/COVID-19
今回のノートブックは下記に置いています。
https://colab.research.google.com/drive/1fUP4818fSsFFFlUHlLGNoTxq8uoL2VAu?usp=sharing実行準備とデータ
まず Google Colab/Jupyter ノートブックから Dash を使用するためのパッケージをインストールします。
! pip install jupyter_dash ! pip install --upgrade plotlyDash と関連するパッケージを import します。
import dash from jupyter_dash import JupyterDash import dash_core_components as dcc import dash_html_components as html import plotly.express as px from dash.dependencies import Input, Outputコロナの感染者データを GitHub から取得します。
データに関しては下記のページを参考にさせていただいています。
https://dodotechno.com/covd-19-visualization/! wget https://github.com/CSSEGISandData/COVID-19/raw/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csvデータフレームにダウンロードした csv を読み込みます。
import pandas as pd df = pd.read_csv("time_series_covid19_confirmed_global.csv")region ごとの集計、緯度経度の削除、国ごとの列に転換し、date 列の追加を行います。
df = df.groupby(['Country/Region'], as_index=False).sum() df.drop(["Lat","Long"], axis=1,inplace=True) df = df.T df.columns = df.iloc[0] df = df[1:] df.reset_index(inplace=True) df.rename(columns={'index': 'date'},inplace=True) df結果、得られる表は以下のようになります。
画面に表示してみる
まずは日本の感染者数を表示してみます。
第一波(4月下旬)、第二波(8月上旬)、第三波(11月)らしき増加が見えます。px.line(df, x="date", y="Japan")
つづいて任意の国を選択可能にしてみます。
ノートブック上で選択できますので、試してみてください。
https://colab.research.google.com/drive/1fUP4818fSsFFFlUHlLGNoTxq8uoL2VAu#scrollTo=Kr-FsvLIpCoN&line=1&uniqifier=1app = JupyterDash(__name__) app.layout = html.Div([ dcc.Dropdown(id="my_dropdown", options=[{"value": country, "label": country} for country in df.columns.unique()], value=["Japan"], multi=True ), dcc.Graph(id="my_graph") ]) @app.callback(Output("my_graph", "figure"), Input("my_dropdown", "value")) def update_graph(selected_country): return px.line(df, x="date", y=selected_country) app.run_server(mode="inline")ドロップダウンから、日本とカナダを選択して表示します。カナダも増加傾向のようですね。
アメリカを追加して見ると、本当に日本の比ではないですね。。やはりグラフで見るとインパクトがあります。
ワクチンが有効打になって欲しいです(人ごとではありませんが)。
おわりに
ちょっとした可視化なら簡単に実装でき、Google Colab でインターネット公開も容易です。
csv の加工が一番手間かも。
地図上の可視化なども追加してみたいと思います。




- 投稿日:2020-12-23T22:40:19+09:00
DjangoでCORSカスタムミドルウェアをつくった
この記事は、 岩手大学 Advent Calendar 2020 の24日目の記事です。
はじめに
個人開発でDjangoを使ったAPIをつくるときがありました。
そのとき、APIの実装でCORS問題にぶち当たり、CORSの対応をする必要がありました。Djangoには django-cors-headers というものがあります。しかし、django-cors-headersを使って実装をしてみましたが、どうも
Access-Control-Allow-Originがうまく指定できず、他のサイトからでもリクエストを送れるようになってしまっていました。
そこで、Djangoのミドルウェアを作成しCORS対応をしましたのでご紹介します。Django初心者なので、間違いなどがありましたらご指摘していただけると勉強になります。
実装
実装は以下のようになりました。
custom_middlewares/custom_cors_middleware.pyfrom django.http import HttpResponse from django.utils.deprecation import MiddlewareMixin class CustomCorsMiddleware(MiddlewareMixin): def process_request(self, request): if request.method == 'OPTIONS': response = HttpResponse() response['Access-Control-Allow-Origin'] = 'http://localhost:3000' # クライアントのオリジン response['Access-Control-Allow-Headers'] = ', '.join([ # 許可するHeaderを追加 'Content-Type', ]) response['Access-Control-Allow-Methods'] = ', '.join([ # 許可するリクエストメソッドを追加 'DELETE', 'GET', 'OPTIONS', 'PATCH', 'POST', 'PUT', ]) return response else: return None def process_response(self, request, response): response['Access-Control-Allow-Origin'] = 'http://localhost:3000' # レスポンスを読み取ることができるオリジン response['Content-Type'] = 'application/json' # レスポンスタイプ return response
process_requestメソッドは、リクエストが来たときに実行され、Noneが返り値の場合はルーティングされているviewが実行されます。リクエスト ↓ process_request が実行 → 返り値がある場合はその返り値を返す ↓ 返り値が None の場合は、リクエストのルーティングに対応する`view`が実行される上記のコードでは、プリフライトリクエストに備えて、
OPTIONSメソッドの場合は、許可するオリジン・ヘッダー・リクエストメソッドをヘッダーに付与したレスポンスを返すようにしています。次に、
process_responseメソッドは、レスポンスをするときの最後に実行されます。view を実行 ↓ process_request が view から返されたレスポンスを受け取り、レスポンスに処理を行う ↓ レスポンス上記のコードでは、CORSでよく見る
Access to XMLHttpRequest at 'http://locahost:8000' from origin 'http://localhost:3000' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.のためにレスポンスを読み取ることができるオリジンを指定し、またレスポンスタイプに
application/jsonを指定しています。あとは、このカスタムミドルウェアを
settings.pyに追加してあげれば完了です。your_application_name/settings.pyMIDDLEWARE = [ 'custom_middlewares.custom_cors_middleware.CustomCorsMiddleware', # 追加 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ]おわりに
Djangoを触ってみて思ったのは、日本語のドキュメントが少ないことです。
英語のドキュメントでも日本語のように読めると苦労が減るのかもしれませんね。
- 投稿日:2020-12-23T22:34:11+09:00
木構造の復習ついでに BFS に挑戦
こんばんは(*´ω`)
最近、leatcode の問題が少しづつ解けるようになってきました。
皆様のおかげです、有難うございます。 m(_ _)mあくまで私見ですが、問題の傾向としてアルゴリズムの基本を
理解しているかを問われているような印象を持ちました。
まだ easy, チョット medium のレベルで恐縮ですが。。新しい問題にチャレンジする際に行き詰ったら
基本に戻って理解を底上げすることが前進するキッカケになると思います。
行き詰った方が居たら、ぜひ基本に戻ってみることをお勧めいたします。微力ながら次の leetcode の問題にチャレンジしたいので
基本の復習 + α(deque の勉強) として本誌を書くことにしました。はい、本題です。
まずは何も見ないで
どんなツリーを作りたいか想像して書いてみました。myTree.py### TreeImage ### # 0 # # / \ # # 1 2 # # / \ # # 3 4 # # / \ # # 5 6 # ################# class tree_node: def __init__(self,val,left=None,right=None): self.val = val self.left = left self.right = right class tree: def __init__(self): self.root = None def add_left(self,val): if not self.root: self.root = tree_node(val) else: if not self.root.left: self.root.left = tree_node(val) else: runner = self.root while runner.left: runner = runner.left runner.left = tree_node(val) def add_right(self,val): if not self.root: self.root = tree_node(val) else: if not self.root.right: self.root.right = tree_node(val) else: runner = self.root while runner.right: runner = runner.right runner.right = tree_node(val) T = tree() T.add_left(0) T.add_left(1) T.add_left(3) T.add_left(5) T.add_right(2) T.add_right(4) T.add_right(6)イメージ通りか確認してみましょう。
確認方法ですが、deque を使います。
今日触ったばかりなのでイメージが怪しいですが、
とりあえず TreeNode を丸々バッファすることができます。
この特徴を利用して BFS で読み込むにはどうしたら良いのか検討してみました。
こんな記述はどうでしょうか。myTree.pydef show(self): head = self.root q = deque([head]) ans = [] while q: nums = q.popleft() if not nums: continue ans.append(nums.val) if nums.left or nums.right: q.append(nums.left) q.append(nums.right) print(ans)今回作成したツリーはこちらでした。
tree_image.py### TreeImage ### # 0 # # / \ # # 1 2 # # / \ # # 3 4 # # / \ # # 5 6 # #################一応、イメージとしては、以下にあるように、
上から矢印の方向に、同一層の値を順番に読みだしてリストに順次格納していくつもりです(笑)tree_image.py### TreeImage ### # → 0 # # / \ # # → 1 2 # # / \ # # → 3 4 # # / \ # # →5 6 # #################そのため、配列に直して表示すると、[0,1,2,3,4,5,6] ってなるはずです。
それでは実行してみましょう。実行結果.py[0, 1, 2, 3, 4, 5, 6]うん、大丈夫そうです。
因みに、ジグザグっぽく読んでも一応 BFS ですよね?
イメージはこんな感じです。tree_image.py### TreeImage ### # → 0 # # / \ # # 1 2 ← # # / \ # # → 3 4 # # / \ # # 5 6 ← # #################ではでは行ってみましょう。
myTree.pydef show(self): head = self.root q = deque([head]) ans = [] i = 0 while q: if i%2 == 0: nums = q.popleft() else: nums = q.pop() if not nums: continue ans.append(nums.val) if nums.left or nums.right: q.append(nums.left) q.append(nums.right) i += 1 print(ans)実行結果.py### TreeImage ### # → 0 # # / \ # # 1 2 ← # # / \ # # → 3 4 # # / \ # # 5 6 ← # ################# [0, 2, 1, 3, 4, 6, 5]OK ですね、勉強になって良かった良かった( *´艸`)
木構造は冒頭に書いたやり方以外にもリストで作るやり方もあるようです。
やっておいた方がいいなー( ´ー`)y-~~
多分、触ってみた感想を本誌に追記しておくと思います。
ではでは( `ー´)ノ
- 投稿日:2020-12-23T22:29:41+09:00
機械学習エンジニア弁護士が解説するAIと権利の話
みなさん、こんにちは。
こちらは「ABEJAアドベントカレンダー2020」の23日目の記事です。はじめに
私は、弁護士として法律事務所に所属しつつ、ABEJAで法務のサポートなどをしています。
また、JDLAのE資格を取得したので、機械学習エンジニアを名乗って少しだけエンジニア的な活動をしたりもしています。
仕事柄、AIと法律の話をすることが多いのですが、その際に私がよく質問されるのが、
① 所有権とか著作権とか特許権とか、権利がいろいろあってAIとの関係で何が問題になるかよくわからない
② データの利用が法的にOK/NGってどういう観点から検討してるのかよくわからない
③ AI開発の委託・受託のときのモデルの権利問題がよくわからないといったものです。
そこで今日は、この3つの問題をできるだけわかりやすく、一気に解説してしまおう!という記事を書きました。
経産省の「AI・データの利用に関する契約ガイドライン(AI編)」にも少し触れながら解説します(この記事では「AI契約ガイドライン」といいます)。長文なので、気になるところだけでも読んで参考にしていただければ幸いです!
(ちなみに、ABEJA法務にはRDチームの立ち上げ経験があり自分で機械学習モデルの開発もやっちゃう弁護士もおりまして、その弁護士が書いた「AIと公平性」の記事も絶賛公開中です!)
ということで、早速本題に入っていきましょう!
よくある質問①:所有権とか著作権とか特許権とか、権利がいろいろあってAIとの関係で何が問題になるかよくわからない
AIの開発段階・利用段階は以下のように図示することができます(AI契約ガイドライン12頁より引用)。
また、AIの開発過程で様々なノウハウが共有されますし、新たに生まれてきます。
そうすると、開発の際の契約で問題になりそうなものとしては、生データ・学習用データセット・学習用プログラム・推論プログラム・学習済みパラメータ・ノウハウといったものが挙げられそうです。
権利と聞いてパッと思いつくのは、所有権・著作権・特許権あたりでしょうか(「知的財産権」が思いついたという方もいらっしゃるかもしれませんが、知的財産権は著作権・特許権・商標権…といった権利の総称として使われる言葉なので、今回は使いません)。
そうすると、次の表の空欄を埋めることができれば「何の権利が問題になるか」という疑問には答えられそうです。
空欄の中身がわかりますか?
それでは、空欄を埋めるべく、所有権・著作権・特許権を簡単に解説したいと思います。
(1) 所有権
答えから言うと、上記の表では所有権はいずれも発生しません!
なぜなら、所有権は「有体物」に生じる、とされているからです(民法206条→85条を読んでいただけるとわかります)。データやプログラムといったものは有体物ではないので、これらには所有権は生じない、ということです。データが記録媒体に保存されている場合、記録媒体を所有していても、中身のデータを所有している、とは言えません。
ということで、所有権の部分の答えは以下のようになります。
(2) 著作権
所有権とは異なり、著作権は、基本的に無体物に発生します。著作権は、「思想又は感情を創作的に表現したもの」に発生しえます。
著作権は、絵画や音楽などに加え、創作性のある文章や写真、プログラムにも発生しえます。
したがって、例えば学習につかう生データが、誰かが書いた文章や誰かが撮影した写真などであった場合、当該データには著作権が発生している可能性があります(他方、機械的に取得した数値データや機械的に撮影した写真などには、基本的に著作権は発生しません。また、パラメータにも発生しません)。
学習用プログラムや推論プログラムのソースコードにも、著作権が発生しえます。
ということで、著作権の部分の答えは以下のようになります。
(学習用データセットについては、△としていますが、「データベースの著作物」という解説しだすとややこしい問題があるので、ここでは省略します。)
ここで、「著作権が発生する」ということの意味を少しだけ解説します。
著作権は、よく「権利の束である」と言われます。どういうことかというと、著作権を持つと、著作物をコピーしたり(複製権)、Qiitaで公開したり(公衆送信権)、編集したり(翻案権)、といったことができるようになりますし、他人が無断でそういった行為をしていたらやめるように求めることができます。
著作権は、こういったいろいろな権利を束にしたものなのです。
所有権が、所有する「物」を支配する権利であるのに対し、著作権が無体物である創作に対する権利であることが何となくイメージできましたでしょうか?
例えば、絵画を例に挙げると、物体としての「絵」には所有権が生じ、無体物としての「絵」(これは見た感じでは物体としての絵と一体となっています)があります。物体としての絵が盗まれた場合には、所有権に基づいて返還請求をしますが、似たような絵を描いて販売しているのをやめさせたい場合には、基本的に所有権では対応できません(物体としての絵を奪われたわけではないため)。この場合には著作権を根拠に、似たような絵の作成をやめるよう請求することになります。(3) 特許権
特許権は、発明をした場合に、当該発明を出願し、登録されることで効力を生じる権利です。
著作権は著作物ができれば同時に発生しますが、特許権は出願し、登録されないと発生しないという点が一つの特徴です。
では、特許権はどういったものに生じるでしょうか。
特許権は発明である必要があるので、生データといった単純なデータには生じないのが通常です。
学習用プログラムについては、純粋にAIのモデルのみの開発を行う(周辺のシステムなどは含まない)場合を考えると、アルゴリズムについての発明に特許権が成立する可能性があります(有名な発明としては、Googleのバッチノーマライゼーションがありますね。バッチノーマライゼーションは米国等ではすでに特許として登録されており、日本でも特許出願されています。こういった、GAFA等による重要特許の取得についても語りたいことはたくさんあるのですが、ここでは書ききれないのでまたの機会にします)。ということで、特許権の部分の答えも埋まりましたね!
(4) 権利が発生しないものもある?
と、ここで気になる点が出てきたのではないでしょうか?
それは、全てが×(要は所有権・著作権・特許権のいずれも発生しえない)のものがあるということです。例えば、創作性のない生データや学習済みパラメータがそうですね。学習済みパラメータは、重要な情報ではありますが、創作性のない単純な行列の値なので著作権も特許権も基本的に生じないと考えられています。
こういった、「何も権利が生じていない情報」は何か保護がされるのでしょうか?
答えは「保護はされない」となります(ここでは割愛しますが、「営業秘密」「限定提供データ」などの例外はあります)。つまり、権利が発生しない情報をうっかり第三者に渡してしまった場合、第三者が情報をどう扱おうと、基本的になにも文句は言えないということになります。
それは困る!ということで出てくるのがNDAなどの秘密保持条項です。秘密保持条項では、通常、
・情報を●●という目的以外には使ってはならない(目的の限定)
・第三者に開示してはならない(対象者の限定)
・複製してはならない(利用態様の限定)
といった制約が置かれていますが、これは、権利が発生しない情報を守る、という効果もあるのです(情報授受の前にいちいちNDAを締結するのは面倒ですが、実はすごく重要だということがお分かりいただけるかと思います)。(5) まとめ
ということで、いったんここまでのポイントをまとめます。
まず、この図は重要ですね。
その他、以下の点が重要です。
- 所有権は有体物にしか生じないため、データやプログラムには生じない。
- 著作権・特許権は無体物に生じる。
- 著作権は創作と同時に発生するが、特許権は登録しないと発生しない。
- 著作権は権利の束。著作権を持っていると、複製、公表、編集など様々なことができる(著作権を持っていないとできない)。
- 所有権・著作権・特許権などの権利が発生しない情報もある。そのような情報を保護するには、開示する際に契約を締結して制限をかける必要がある。
よくある質問②:データの収集・利用が法的にOK/NGってどういう観点から検討してるのかよくわからない
(1) データの収集方法ごとの検討
機械学習では、まずデータを収集する必要があります。
データの確保には様々な方法がありますが、①自社で用意する、②特定の企業からデータを買う、③公開されているデータセットを使う、④不特定多数から収集する、といった方法が考えられますので、順にみていきましょう。① 自社で用意する場合
①自社で用意する場合の例はたくさんありますが、例えば、不良品検知のAIを作るために、自社製品の写真を大量に準備する、といったことが考えられます。この場合、準備した画像は(おそらく機械的に撮影するでしょうから)通常は創作性がなく、著作権は発生しなそうですね(生データに著作権が発生するかどうかは、データの創作性の有無によって異なってくることを先ほど説明しました。)。利用にあたっても、特に法的な障害はなさそうです。
② 特定の企業からデータを買ってくる場合
②特定の企業からデータを買ってくる場合には、売主の企業が権利を持っていることを確認して、権利ごと譲ってもらえば大丈夫そうです。また、権利は売主に残しつつ、学習に使うことを許可してもらう形でも良さそうです。
要は、締結する契約の内容次第ということですね。
実は、データの取引についても経産省からガイドラインが出ています(「AI・データの利用に関する契約ガイドライン(データ編)」)。興味がある人は見てみてください。③ 公開されているデータセットを使う場合
③公開されているデータセットを使う場合には、利用条件が設定されている場合が多いです。
例えば、有名な画像のデータセットであるCOCOでは、Creative Commons Attribution 4.0 LicenseのBYという要素が採用されており、原作者のクレジット(氏名、作品タイトルなど)を表示することが要求されています。このようなデータセットの利用条件は、データをダウンロードした時点で利用条件に同意した(=契約した)と解されるため、データ提供者と受領者との間での契約という形で当事者を規律します。契約上の義務として利用条件がかかってくるという構造はNDAとも同じですね(②特定の企業からデータを買ってくる場合も同様です)。
要は、設定している利用条件を検討する必要があるということになります。④ 不特定多数から収集する場合
④不特定多数から収集する場合には、どういった点が問題になるでしょうか?
例えば、クローリング・スクレイピングにより風景画像を収集して学習に使いたいと思った場合を考えてみましょう。収集した風景画像はいろんな人が撮影したものなので、著作権が発生しています。そして、学習に使おうとすると、画像をコピーして、リサイズ等の前処理やアノテーションをする必要がありますが、これは複製権や翻案権を侵害しそうです。また、著作権者に許諾を得ようにも誰が著作権者かがわかりません。
でも、実はこのような行為は著作権を侵害せずに行い得ます。
日本の著作権法が「機械学習パラダイス」と呼ばれていたりするのをご存じの方もいらっしゃるかもしれませんが、著作権法30条の4という条文で、機械学習のような情報解析の目的では、一定の場合に著作物を利用できるとされているからです。
この著作権法30条の4は、2019年1月1日施行の改正著作権法で改正されたもので、(改正前から機械学習パラダイスといわれていたのですが)より機械学習パラダイスな条文になっています。ちなみにABEJAでは、2019年2月にRPAテクノロジーズ様と提携し、改正法で初めて可能になったワンストップのデータセットクローリングサービスを展開しています。サービス開始時のプレスリリースでは、プレスリリースとしては珍しく、かなり詳細に改正法の解説をしました。
著作権法30条の4の内容が気になる方は是非プレスリリースを読んでみてください。不特定多数人からデータを収集するケースとして、もう一つ、街頭にカメラを設置して人の顔画像を収集する場合を考えてみましょう。カメラから機械的に取得される画像は基本的に著作物ではありませんが、この場合は、個人情報保護法やプライバシー・倫理という別の観点の制約に留意する必要があります。
このように、データの収集や利活用を行う場合には、個人情報保護法などの法令や、プライバシー・倫理といった観点からの検討が必要な場合があります。
(2) まとめ(データの収集・利活用の際のチェックポイント)
- 契約によってデータ利活用が制限されないか
- 個人情報保護法などの法令等によりデータ利活用が制限されないか
※ データの中に第三者の著作物が含まれていても、適法に利活用しうる
よくある質問③:AI開発の委託・受託のときのモデルの権利問題がよくわからない
(1) 学習用プログラム・推論プログラムと著作権
モデル開発の委託/受託では、学習用プログラム、推論プログラム、学習済みパラメータといったものについて、開発フェーズで納品されることが多いかと思います。
下図のとおり、学習用プログラム・推論プログラムには著作権が発生しますが、学習済みパラメータにはこういった権利は発生しません。
この記事では、特に重要な、著作権が生じる学習用プログラム・推論プログラムについて解説をしたいと思います。
納品予定の学習用プログラム・推論プログラムの著作権について契約で定める場合、①著作権をどちらに帰属させるか(権利帰属)、②双方がどういった条件で利用できるようにするか(利用条件)の二段階の検討が必要です。
(2) 著作権の権利帰属
まず、著作権がユーザ・ベンダのどちらに帰属するかを決める必要があります。
ユーザ帰属、ベンダ帰属、ユーザとベンダの共有、といった選択肢があります。
後述の利用条件のところでも述べるとおり、あまり「どちらに帰属させるべき」という定式はありませんが、
- ベンダがライセンスフィーで利益を得るようなビジネスモデルの場合には著作権の帰属にこだわることが多い
- ユーザが開発手法等についても主導権をもって開発を進め、ベンダの裁量が狭いような場合にはユーザに著作権を帰属させることも多い
- ユーザ・ベンダが協業して完成したモデルを売っていくような場合には共有にすることも多い
といった大まかな傾向はあるかもしれません。
ちなみに、権利帰属について契約で何も決めない場合は、基本的には、プログラムを生成したベンダに著作権が帰属します。
(3) 利用条件
所有権の対象(有体物)は、基本的に「一人しか対象物を利用できない」ことになりますが、著作権の対象(無体物)は多数の人が同時に利用可能です。
例えば、家は有体物で所有権の対象とりますが、
- 所有者が住む
- 所有者は使わずに賃借人に住まわせる
といった程度の選択肢しかありません。
他方、著作権の対象となるもの(たとえばプログラム)であれば、
- 著作権者だけが使う
- 著作権者も使うが、公開して世界中の人にも使わせてあげる。
- 著作権者は使わず、もっぱら知り合いに使わせてあげる。使うだけでなく、改良することも許可する。知り合いが改良版を公開したいといったので許可する。
といった、様々な使い方があります。
先ほど、著作権は「権利の束」だと説明しました。
この束のなかで、どの部分を許可するかを自由に決めることができるのです(a)。
例えば、
・複製は自由に許す
・貸与することも許すが、お金の支払いなどの条件を付ける
・翻案(編集)も許すが、編集できる範囲を制限する
・複製・貸与・翻案以外は禁止
といった具合です。
また、これも重要な視点ですが、著作権者の権利を契約によって制限することもできます(b)。
著作権者の権利を全部制限し、他方で第三者に広い範囲でライセンスを付与するような場合には、もはやライセンスを付与される第三者が著作権を持っているのとあまり変わらない状態にもなり得ます。
「権利をどちらに帰属するか」も重要ですが、「利用条件をどのように設定するか」が重要なことがお分かりいただけたでしょうか。
では、利用条件はどういった要素に着目して定めればよいでしょうか。
この点については、経産省のAI契約ガイドラインの次の表が参考になります(AI契約ガイドライン31頁)
例えば、
・著作権はベンダ帰属
・ユーザは自己の業務に必要な範囲で、無償・無期限の非独占的な利用の許諾を受ける
・ベンダは基本的に自由に使えるが、ユーザの競合企業である●●社には横展開してはならない
といった条件を定めることが考えられます。このような条件を決めたら、上記の表を「別紙」として契約書につけて、「別紙の条件で利用します」という趣旨の条項に落とし込めばOKです!(この表をいい感じに完成させて法務にもっていけばいい感じに契約に落とし込んでくれるはずです!)
以下はAI契約ガイドラインを参考にした規定例です(AI契約ガイドライン114~118頁参照)。第●●条(本件成果物の著作権)
1.本件成果物および本開発遂行に伴い生じた知的財産(以下「本件成果物等」という。)に関する著作権(著作権法第 27 条および第 28 条の権利を含む。)は、ユーザまたは第三者が従前から保有していた著作物の著作権を除き、ベンダに帰属する。
2.ユーザおよびベンダは、本契約に従った本件成果物等の利用について、他の当事者および正当に権利を取得または承継した第三者に対して、著作者人格権を行使しないものとする。第●●条(本件成果物の利用条件)
ユーザおよびベンダは、本件成果物等について、別紙「利用条件一覧表」記載のとおりの条件で利用できるものとする。同別紙の内容と本契約の内容との間に矛盾がある場合には同別紙の内容が優先するものとする。「著作者人格権」などの難しい表現は一旦さておき、何となくイメージを持っていただけたのではないでしょうか。
(4) 契約の落とし穴
最後に、契約締結の際に陥りがちな落とし穴を二つほど紹介します。
落とし穴①:「著作権共有」
著作権の帰属について、ユーザもベンダも譲らず決着がつかない…といった場合には、折衷案として著作権をユーザ・ベンダの一方に帰属させず、「共有」とすることもあるかと思います。また、共同開発のような場合にも共有とすることもあるでしょう。
この場合、「共有にしたからお互い自由に使える」と思っていませんか?
著作権法65条1項・2項を見てみましょう。
(共有著作権の行使)
第六十五条 共同著作物の著作権その他共有に係る著作権(以下この条において「共有著作権」という。)については、各共有者は、他の共有者の同意を得なければ、その持分を譲渡し、又は質権の目的とすることができない。
2 共有著作権は、その共有者全員の合意によらなければ、行使することができない。条文をみると、著作権の行使は「他の共有者の合意」が必要とされています。
つまり、「●●に使っていいよ」という合意を逐一得ないとなにもできない、ということですね。
ですので、共有にする場合には、同じ契約で「●●に使っていいよ」という合意を得ることが重要です。AI契約ガイドラインの契約書案でも、共有にする場合にはちゃんとこの「合意」についての規定があります(114頁)。
ちょっと長いですが、条文を貼っておきます。第●●条(本件成果物等の著作権)
1.本件成果物および本開発遂行に伴い生じた知的財産(以下「本件成果物等」という。)に関する著作権(著作権法第 27 条および第 28 条の権利を含む。)は、ユーザのベンダに対する委託料の支払いが完了した時点で、ユーザ、ベンダまたは第三者が従前から保有していた著作物の著作権を除き、ベンダおよびユーザの共有(持分均等)とする。なお、ベンダからユーザへの著作権移転の対価は、委託料に含まれるものとする。
2.前項の場合、ユーザおよびベンダは、共有にかかる著作権につき、本契約に別に定めるところに従い、前項の共有にかかる著作権の行使についての法律上必要とされる共有者の合意を、あらかじめこの契約により与えられるものとし、相手方の同意なしに、かつ、相手方に対する対価の支払いの義務を負うことなく、自ら利用することができるものとする。
3.ユーザ及びベンダは、相手方の同意を得なければ、第 1 項所定の著作権の共有持分を処分することはできないものとする。
4.ユーザおよびベンダは、本契約に従った本件成果物等の利用について、他の当事者および正当に権利を取得または承継した第三者に対して、著作者人格権を行使しないものとする。落とし穴②:「協議によって定める」
著作権の帰属について、ユーザもベンダも譲らず決着がつかない…という場合には、帰属について定めることをあきらめて「協議によって定める」といった規定がされることもあります。
しかし、これは当事者にとってリスクが残る契約といえます。著作権の帰属について何も定めなかった場合には、著作権は開発を行った側、すなわちベンダに帰属します。
そうすると、ユーザとしては、「協議によって定める」場合に協議がまとまらないと、権利を得られないことになります。また、利用許諾も得ていないと、せっかくできたモデルを何も使えない、ということになってしまいます。
ベンダとしても、例えばユーザに有償でライセンスして利益を得ようと思っていた場合、「協議」がまとまらないと結局このようなも目論見が外れてしまい、せっかく作ったのにお金にならない、、となりかねません。
したがって、権利帰属をペンディングにして「協議によって定める」ということは避けるべきです。
同様のことは、開発PJ開始時に権利帰属について定めていない場合にも妥当することがあります。
すなわち、アセスメント・PoCと個別に契約を締結して進めてきたものの、開発フェーズに入って初めてモデルの権利帰属を議論したところまとまらない、といった事態が生じうることがあります。
これはどうすれば防げたかというと、アセスメント開始時に、開発PJ全体に適用される「基本契約書」と締結し、そこでモデルの権利帰属について定めておけばよかった、ということになります。
ただ、開発PJ初期で開発対象が明確に決まっていないことも多く、そういった場合に無理して権利帰属の議論をすることは避けた方がよい場合もあり、どういった形の契約を締結するかは案件ごとに判断した方がよいです。(5) まとめ
- 学習用プログラム・推論プログラムには著作権が発生する。
- 権利帰属と利用条件の二つを決める必要がある。
- 利用条件を考える際には、AI契約ガイドライン31頁の表が参考になる。
- 著作権を共有にする場合には、行使についての合意をしておく。
- 「協議によって定める」といった条項は避けた方がよい場合が多い。
最後に
いかがでしたでしょうか?
今回、初めてQiitaに記事を投稿させていただいたのですが、これまでAIの開発契約を数多く見てきた中で、「技術者・ビジネスサイドと法務がもっと理解しあっていればもっとスムーズに契約交渉が進むのに…」と思ったことが数多くありました。また、技術者が法的なところで疑問を持っているが適切な相談相手がまわりにいない、という場面を見かけることもありました。
この記事が、少しでもそのような問題の解決の一助になれば、と思っております!
かなり長文になってしまったので、最後まで読んでくださった方はいるのだろうか。。。という気もしますが、
今後も記事を更新していくかもしれませんので、疑問点などあればお気軽にコメントなどしていただけますと幸いです!最後までお読みいただき、ありがとうございました。
※※※※※※※
・この記事のうち意見にわたる部分は私の個人的な見解でであり、私が所属する組織の見解ではないことにご留意ください。
・この記事は一般論を述べたものであり、具体的ケースのご判断の際には専門家にご相談ください。
・この記事はわかりやすさに重点を置いたため、厳密には不正確な表現となっている部分もあることにもご留意ください。
※※※※※※※













- 投稿日:2020-12-23T22:27:03+09:00
rpycモジュールを使ってMayaを外部のPythonインタプリタから操作する
この記事はTakumi Akashiro ひとり Advent Calendar 2020の23日目の記事です。
始めに
以前Houdiniを触った際、外部のPythonからHoudiniの
houオブジェクトを操作するhrpycモジュールが凄いなあ……1とおもったので、
hrpycを参考にして、Mayaで同じようなものが書けないかなあと思ったので作ってみました。使い方
pip install rpyc -t <mayaのScriptフォルダ>でrpycをインストールする。
バイナリは無いのでpython2系なら何でも大丈夫……なはず。- 以下のファイルをMayaのScriptフォルダを保存。
mrpyc.py#! python2 # encoding: utf-8 import threading from rpyc.utils import classic from rpyc.core import SlaveService from rpyc.utils.server import ThreadedServer PORT = 18812 def _start_server(port=PORT): t = ThreadedServer( SlaveService, hostname = '0.0.0.0', port = int(port), reuse_addr = True, authenticator = None, registrar = None, auto_register = False ) t.start() def start_server(port=PORT): thread = threading.Thread(target=lambda: _start_server(port)) thread.start() return thread def import_remote_maya_module(server="127.0.0.1", port=PORT): return classic.connect(server, port).modules['maya']3.MayaのScriptEditorなどで以下を実行してMayaのサーバーを立てる。
import mrpyc mrpyc.start_server()4.外部のインタプリタで以下を実行して、mayaモジュールを取得して、polyCubeを作ってみます。
import mrpyc maya = mrpyc.import_remote_maya_module() maya.cmds.polyCube()
締め
以外と簡単2にできましたね!
ただ実験した感じ、数分経つと接続が死んだり、Mayaがクラッシュしたりするので、
もうちょっとhrpycの_RemoteHouAttrWrapperを参考にして実装すると安全にできるのかもしれないです。


- 投稿日:2020-12-23T22:27:03+09:00
rpycモジュールを使って外部のPythonインタプリタからMayaを操作する
この記事はTakumi Akashiro ひとり Advent Calendar 2020の23日目の記事です。
始めに
以前Houdiniを触った際、外部のPythonからHoudiniの
houオブジェクトを操作するhrpycモジュールが凄いなあ……1とおもったので、
hrpycを参考にして、Mayaで同じようなものが書けないかなあと思ったので作ってみました。rpycモジュールとは
Remote Python Call、すなわち別のプロセスのPythonのオブジェクトを使うためのモジュールです。2
呼び出し元はサーバーを立て、呼び出し先にネットワーク経由でオブジェクトのプロキシを提供することで別セッションのPythonのオブジェクトを使えます。
詳細はrpyc · PyPIに任せますが、Houdiniで使うhrpycはrpycを非常に簡素にしたラッパーです。使い方
pip install rpyc -t <mayaのScriptフォルダ>でrpycをインストールする。
バイナリは無いのでpython2系なら何でも大丈夫……なはず。- 以下のファイルをMayaのScriptフォルダを保存。
mrpyc.py#! python2 # encoding: utf-8 import threading from rpyc.utils import classic from rpyc.core import SlaveService from rpyc.utils.server import ThreadedServer PORT = 18812 def _start_server(port=PORT): t = ThreadedServer( SlaveService, hostname = '0.0.0.0', port = int(port), reuse_addr = True, authenticator = None, registrar = None, auto_register = False ) t.start() def start_server(port=PORT): thread = threading.Thread(target=lambda: _start_server(port)) thread.start() return thread def import_remote_maya_module(server="127.0.0.1", port=PORT): return classic.connect(server, port).modules['maya']3.MayaのScriptEditorなどで以下を実行してMayaのサーバーを立てる。
import mrpyc mrpyc.start_server()4.外部のインタプリタで以下を実行して、mayaモジュールを取得して、polyCubeを作ってみます。
import mrpyc maya = mrpyc.import_remote_maya_module() maya.cmds.polyCube()
締め
以外と簡単3にできましたね!
ただ実験した感じ、数分経つと接続が死んだり、Mayaがクラッシュしたりするので、
もうちょっとhrpycの_RemoteHouAttrWrapperを参考にして実装すると安全にできるのかもしれないです。
- 投稿日:2020-12-23T22:23:26+09:00
性のクリスマスイブに彼女が居ないひとへ ◯ぎ声キーボード
みなさんこんにちは限界開発鯖のやばい人やFascodeNetworkの広報やブログでデブ活などなどをやっているくもことなおこです。
Qiitaで投稿したのが初めてなので若干至らない点があるかもしれませんがご了承ください作った経緯
早速自分が使いたいがために作った◯ぎ声キーボード、キーを押すたびに◯ぎ声がなるという恐ろしく世紀末的なPythonとVLCを使ったツール?です。
まずは自分が多少わかる言語でバックグラウンド上で動作するキー検知いわゆるキーロガーですね、、、を作らなくちゃいけません
その条件で色々探したところ
Pythonのpyxhookライブラリを使うのが一番楽そう
使い方に関してはここがわかりやすい
https://qiita.com/kaitaku/items/5c327ddd779260c63036コード
と言っても上の方のソースコードコピーしてちょいといじった感じですね。
キー入力検知したらサウンド鳴らすだけのコードです。GitHubのコード
https://gist.github.com/naoko1010hh/77d15c8658a4fadfc7e945da80446e22
実際に動かしてみた動画をTwitterに上げているのでもしよければ見てね。ボリューム小さくしてから見たほうがいいかも
https://twitter.com/naoko1010hh/status/1322766477649453057?s=19動画内で使用した音声はみじんこさんの音声有料素材を使用させていただきました。https://www.dlsite.com/maniax/work/=/product_id/RJ287819.html
最後に
後つけ感はありますが今後の目標はキーごとに音を割り振って支援が必要な方がキー配置を覚えられるようにしたいですね

- 投稿日:2020-12-23T22:05:12+09:00
SWIGでC/C++をラップしPythonの処理を高速化する。【概要編】
SWIGとは?
SWIGは、C/C++で書かれたプログラムをラップし、多言語で使えるようにするためのツールです。
サポートされている言語には、Javascript、Perl、PHP、Python、Tcl、Rubyなどのスクリプト言語や、C#、D、Go、Java、Lua、OCaml、Octave、Scilab、Rなどの非スクリプト言語があります。速度比較
C/C++で書かれたコードが早いのはよく知られていますが、実際にどれくらいの速度差があるのか、いくつかの条件で比較します。
<実行環境>
OS: Ubuntu18.04
CPU: Intel Corei7-7700k
メモリ: 24GB<コンパイル環境>
-O3オプションあり
並列化なしHello World
"hello world!"と1000回表示する関数の実行速度
python_time:2.356291e-03[sec] swig_time__:1.398325e-03[sec]2倍程度の差がありますが、一般的に言われているほどの差があるようには見えません。
厳密にはわかりませんが、文字列のコンソール表示速度のオーバーヘッドがあるからだと思われます。
コード
pythondef hello_world(): for i in range(1000): print("hello world!") def test1(): # python start = time.time() hello_world() python_time = time.time() - start # swig start = time.time() helloWorld() swig_time = time.time() - start print("python_time:{:e}".format(python_time) + "[sec]") print("swig_time__:{:e}".format(swig_time) + "[sec]")cvoid helloWorld() { for (int i = 0; i < 1000; i++) { printf("hello world!\n"); } }
数字のカウントアップ
1000までをカウントアップして返す関数の実行速度
python_time:6.842613e-05[sec] swig_time__:5.483627e-06[sec]今度は10倍以上の差が出ました。数字をカウントアップするだけでここまで差が出ると、pythonは遅いといわれる理由が垣間見えてきます。
コード
pythondef count_up(): res = 0 for i in range(1000): res += 1 return res def test2(): # python start = time.time() res = count_up() print(res) python_time = time.time() - start # swig start = time.time() res = countUp() print(res) swig_time = time.time() - start print("python_time:{:e}".format(python_time) + "[sec]") print("swig_time__:{:e}".format(swig_time) + "[sec]")cint countUp() { int res = 0; for (int i = 0; i < 1000; i++) { res += 1; } return res; }
画像の変換
グレースケール画像からRGB画像へ変換する関数の実行速度
※Python側ではOpenCVモジュールを使用python_time:1.032352e-04[sec] swig_time__:1.156330e-04[sec]こちらはほとんど変わらない結果になりました。OpenCVはそもそもC/C++で書かれているので、当然といえば当然の結果ですね。
しかし、このSWIGの実行速度には、np.zeros()で出力先のメモリを確保しておく処理が含まれています。OpenCVのpythonパッケージを利用している場合には不可能ですが、SWIGで書いている場合には出力先メモリを再利用することが可能です。
メモリ空間の確保を外だしした場合の速度は以下のようになります。python_time:1.101494e-04[sec] swig_time__:7.319450e-05[sec]この条件だとSWIGが30%以上高速化しています。複数回実行する場合はSWIGでのベタ書きにも優位性がありそうです。
コード
pythondef test3(): img_size = (256, 256) org_img = np.random.randint(0, 256, (img_size), dtype=np.uint8) # python start = time.time() res_py = cv2.cvtColor(org_img, cv2.COLOR_GRAY2RGB) python_time = time.time() - start # swig # res_swig = np.zeros((*img_size, 3), dtype=np.uint8) start = time.time() res_swig = np.zeros((*img_size, 3), dtype=np.uint8) imgGray2RGB(org_img, res_swig) swig_time = time.time() - start print("array_equal: {}".format(np.array_equal(res_py, res_swig))) print("python_time:{:e}".format(python_time) + "[sec]") print("swig_time__:{:e}".format(swig_time) + "[sec]")cvoid imgGray2RGB(unsigned char *inArr, int inDim1, int inDim2, unsigned char *inplaceArr, int inplaceDim1, int inplaceDim2, int inplaceDim3) { int height = inplaceDim1; int width = inplaceDim2; int channel = inplaceDim3; int h, w; int in_point, out_point; for (h = 0; h < height; h++) { for (w = 0; w < width; w++) { in_point = h * width + w; out_point = channel * (h * width + w); inplaceArr[out_point] = inArr[in_point]; inplaceArr[out_point + 1] = inArr[in_point]; inplaceArr[out_point + 2] = inArr[in_point]; } } }
(オプション) 画像の正規化
グレースケールからRGBへの変換に加え、画像の正規化を行った実行速度
※Python側ではOpenCVモジュールを使用python_time:1.460791e-03[sec] swig_time__:3.521442e-04[sec]OpenCVもC/C++で実装しているはずですが、SWIGがOpenCVより4倍の速度が出ています。
これは、一度のラスタ走査ですべての処理を終えており、処理の量が大きく削減されているためです。OpenCVのPythonパッケージは当然ながら関数単位でわかれているため、こういった処理の削減で高速化を狙う場合は、C/C++での処理が必須になります。
コード
pythondef test4(): img_size = (256, 256) mean = [0.485, 0.456, 0.406] std = [0.229, 0.224, 0.225] mean_np = np.array(mean, dtype=np.float32) std_np = np.array(std, dtype=np.float32) org_img = np.random.randint(0, 256, (img_size), dtype=np.uint8) # python start = time.time() res_py = cv2.cvtColor(org_img, cv2.COLOR_GRAY2RGB).astype(np.float32) res_py = ((res_py / 255) - mean_np) / std_np python_time = time.time() - start # swig start = time.time() res_swig = np.zeros((*img_size, 3), dtype=np.float32) imgNormalize(org_img, res_swig, *mean, *std) swig_time = time.time() - start print("array_equal: {}".format(np.array_equal(res_py, res_swig))) print("python_time:{:e}".format(python_time) + "[sec]") print("swig_time__:{:e}".format(swig_time) + "[sec]")cvoid imgNormalize(unsigned char *inArr, int inDim1, int inDim2, float *inplaceArr, int inplaceDim1, int inplaceDim2, int inplaceDim3, float meanR, float meanG, float meanB, float stdR, float stdG, float stdB) { int height = inplaceDim1; int width = inplaceDim2; int channel = inplaceDim3; int h, w; int val; int inPoint, outPoint; for (h = 0; h < height; h++) { for (w = 0; w < width; w++) { inPoint = h * width + w; outPoint = channel * (w + width * h); val = inArr[inPoint]; inplaceArr[outPoint] = ((float)val / 255 - meanR) / stdR; inplaceArr[outPoint + 1] = ((float)val / 255 - meanG) / stdG; inplaceArr[outPoint + 2] = ((float)val / 255 - meanB) / stdB; } } }
次回
次は実装編になります。実装編では基本的なSWIGの使い方から、Numpyを直接引数へ渡してC/C++側からポインタ参照する方法など、ちょっとした応用を紹介予定です。
- 投稿日:2020-12-23T20:41:34+09:00
TKinterを利用してパソコン設定変更アプリを作ってみるぞ?
pythonの勉強として簡単なソフトを作ってみよう!
なんて意気込みでtkinterで1つのソフトを作ってみます。
とりあえず、Windows上で設定変更をかけるソフト。名前は「お家に帰ろう」
「設定変更が便利になるといいな」的なコンセプトで作り始めました。
Windowsの設定変更ソフトを作りたい方に、少し参考になる程度の情報が提供できたらいいな!
tkinterとは?
python標準のGUIライブラリで、古い見た目のUIを実装できます。
調べていくと、どうやらtkinterとtkinter.ttkでUIデザインが異なる模様。
ttkの方がモダンなUIになります。さらに2018年からPySimpleGUIの開発が始まっており、コードも短く、よりモダンなデザインでGUIを組める模様。
今回はNETに情報が多いからtkinterでチャレンジしてみよう!ってわけで作成を開始しました。
作ったもの
こんな感じです。
うん。素人の作品っぽくていいですね 笑とりあえず下記を実装してみました。
・PC名変更
・IPv4変更
・自動ログオン作って気づいたこと
ごく当たり前のことで、薄々わかってたんですが、せめて設計書的なものは作りましょう 笑
はじめは「PC名変更」くらいしか考えてなかったのですが、後から実装したい機能がどんどん増えてきてしまいました。。
その都度UIに変更を加えていったので、ここがモーレツに面倒でした。
いや、ほんとアホですよね。うん。
思い付きはダメデスこんなノリで作り始めましたが、上の画像の機能自体はちゃんと動くようになりました。
Windowsは権限、UACの問題があるので、そのへんの動きをおさえて変更が完了するように作る必要があります。
そのほか、process.runやレジストリ書き込み、入力文字のチェックやログ出力の実装、pyarmor、exe化、モジュール分割などなど入れて、再起動後は自動的にstep2としてプログラムを起動するところまで作ってます。
デバッグやブラッシュアップができればフリーソフト公開なんてできればいいのですが、まだ先かなぁと思ってます。
でも、やっぱり1つのモノを作ることで1連の流れが見えてきますね!
勉強になりました。tkinterの実装
こんな感じのコードでGUIの実装を始めます。
class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() self.master.geometry("620x630") self.master.title("お家に帰ろう") nb = ttk.Notebook(width=200, height=200)メニューバーはこんな感じ。
# メニューバーの作成 self.menubar = tk.Menu(master) master.configure(menu = self.menubar) # ファイルメニュー filemenu = tk.Menu(self.menubar, tearoff = 0) self.menubar.add_cascade(label = "ファイル", menu = filemenu) # ~内容 filemenu.add_command(label = "ファイルから読み込む(開発中)") # ~内容 filemenu.add_command(label = "ファイルに保存する(開発中)") # セパレーター filemenu.add_separator() filemenu.add_command(label = "終了", command = lambda: master.destroy())タブの実装
#タブ tab1 = tk.Frame(nb) tab2 = tk.Frame(nb) tab3 = tk.Frame(nb) tab4 = tk.Frame(nb) self.textbox1 = tk.Text(tab4) self.textbox1.configure(font=("", 14, "")) self.textbox1.pack() self.textbox1.place(x=150, y=0,width = 460, height = 570) tab5 = tk.Frame(nb)ちなみにtab4はtextboxを実装します。
例えばエクセルからパラメータを張り付けて設定変更できると便利だよね?なんて発想。
実装自体は難しくないレベル。CSVファイルから読み込んでもいいですし、このあたりはどうやってデータを入れるか、運用に合わせて決めるといいですね!
設定変更コマンド
単純にコマンドプロンプトのコマンドをprocess.runで実装できます。ただ、errorlevelを受け取る方法がわかりませんでした。
なので判定を入れ込むならpowershellの方がいいかもしれませんね。
今回はpowershellでコンピュータ名を変更し、戻り値を判定して正常、異常を判定しています。
IP変更
今回はコマンドプロンプトで実装しました。
判定はレジストリからパラメータを取得し、変更後の値と比較すればOK。
単純にipconfigなんて打ってもオフライン時は出力しないので注意が必要。なお、レジストリを参照すれば「イーサネット」などのインタフェースもリストで出力できますヨ
チェック機能
値のチェックは入力なしや文字数などで判定させています。
ipaddressは以下のようなチェック方法があります。
import ipaddress as ipadd def chk_ipv4(self,ipaddress): try: ipadd.ip_address(ipaddress) return "ok" except ValueError: return "ng"難易度
pythonの初学者にとってちょうどいいくらいのレベルなのかな?と思います。
私自身、python勉強して2ヶ月くらいでつくりました。
ただしWindowsの動きがわかってないと作るのが難しいとは思います。
同じようなソフトを作る方へ
pyinstallerでexe化ができますが、process.runを利用する場合は下記の記事を読んだ方がいいです。とても参照になりました。(ありがとうございます。)
https://sapporo-president.com/archives/15581普通にexeにすると動作しませんでした。


- 投稿日:2020-12-23T20:41:34+09:00
TKinterを利用してパソコン設定変更ソフトを作ってみる(初心者)
pythonの勉強として簡単なソフトを作ってみよう!
なんて意気込みでtkinterで1つのソフトを作ってみます。
とりあえず、Windows上で設定変更をかけるソフト。名前は「お家に帰ろう」
「設定変更が便利になるといいな」的なコンセプトで作り始めました。
Windowsの設定変更ソフトを作りたい方に、少し参考になる程度の情報が提供できたらいいな!
tkinterとは?
python標準のGUIライブラリで、古い見た目のUIを実装できます。
調べていくと、どうやらtkinterとtkinter.ttkでUIデザインが異なる模様。
ttkの方がモダンなUIになります。さらに2018年からPySimpleGUIの開発が始まっており、コードも短く、よりモダンなデザインでGUIを組める模様。
今回はNETに情報が多いからtkinterでチャレンジしてみよう!ってわけで作成を開始しました。
作ったもの
こんな感じです。
うん。素人の作品っぽくていいですね 笑とりあえず下記を実装してみました。
・PC名変更
・IPv4変更
・自動ログオン作って気づいたこと
ごく当たり前のことで、薄々わかってたんですが、せめて設計書的なものは作りましょう 笑
はじめは「PC名変更」くらいしか考えてなかったのですが、後から実装したい機能がどんどん増えてきてしまいました。。
その都度UIに変更を加えていったので、ここがモーレツに面倒でした。
いや、ほんとアホですよね。うん。
思い付きはダメデスこんなノリで作り始めましたが、上の画像の機能自体はちゃんと動くようになりました。
Windowsは権限、UACの問題があるので、そのへんの動きをおさえて変更が完了するように作る必要があります。
そのほか、process.runやレジストリ書き込み、入力文字のチェックやログ出力の実装、pyarmor、exe化、モジュール分割などなど入れて、再起動後は自動的にstep2としてプログラムを起動するところまで作ってます。
デバッグやブラッシュアップができればフリーソフト公開なんてできればいいのですが、まだ先かなぁと思ってます。
でも、やっぱり1つのモノを作ることで1連の流れが見えてきますね!
勉強になりました。tkinterの実装
こんな感じのコードでGUIの実装を始めます。
class Application(tk.Frame): def __init__(self, master): super().__init__(master) self.pack() self.master.geometry("620x630") self.master.title("お家に帰ろう") nb = ttk.Notebook(width=200, height=200)メニューバーはこんな感じ。
# メニューバーの作成 self.menubar = tk.Menu(master) master.configure(menu = self.menubar) # ファイルメニュー filemenu = tk.Menu(self.menubar, tearoff = 0) self.menubar.add_cascade(label = "ファイル", menu = filemenu) # ~内容 filemenu.add_command(label = "ファイルから読み込む(開発中)") # ~内容 filemenu.add_command(label = "ファイルに保存する(開発中)") # セパレーター filemenu.add_separator() filemenu.add_command(label = "終了", command = lambda: master.destroy())タブの実装
#タブ tab1 = tk.Frame(nb) tab2 = tk.Frame(nb) tab3 = tk.Frame(nb) tab4 = tk.Frame(nb) self.textbox1 = tk.Text(tab4) self.textbox1.configure(font=("", 14, "")) self.textbox1.pack() self.textbox1.place(x=150, y=0,width = 460, height = 570) tab5 = tk.Frame(nb)ちなみにtab4はtextboxを実装します。
例えばエクセルからパラメータを張り付けて設定変更できると便利だよね?なんて発想。
実装自体は難しくないレベル。CSVファイルから読み込んでもいいですし、このあたりはどうやってデータを入れるか、運用に合わせて決めるといいですね!
設定変更コマンド
単純にコマンドプロンプトのコマンドをprocess.runで実装できます。ただ、errorlevelを受け取る方法がわかりませんでした。
なので判定を入れ込むならpowershellの方がいいかもしれませんね。
今回はpowershellでコンピュータ名を変更し、戻り値を判定して正常、異常を判定しています。
IP変更
今回はコマンドプロンプトで実装しました。
判定はレジストリからパラメータを取得し、変更後の値と比較すればOK。
単純にipconfigなんて打ってもオフライン時は出力しないので注意が必要。なお、レジストリを参照すれば「イーサネット」などのインタフェースもリストで出力できますヨ
チェック機能
値のチェックは入力なしや文字数などで判定させていますが、IPアドレス形式は下記で簡単にチェックできます。
import ipaddress as ipadd def chk_ipv4(self,ipaddress): try: ipadd.ip_address(ipaddress) return "ok" except ValueError: return "ng"難易度
pythonの初学者にとってちょうどいいくらいのレベルなのかな?と思います。
私自身、python勉強して2ヶ月くらいでつくりました。
ただしWindowsの動きがわかってないと作るのが難しいとは思います。
同じようなソフトを作る方へ
pyinstallerでexe化ができますが、process.runを利用する場合は下記の記事を読んだ方がいいです。とても参照になりました。(ありがとうございます。)
https://sapporo-president.com/archives/15581普通にexeにすると動作しませんでした。
- 投稿日:2020-12-23T19:37:31+09:00
【2021年度版】Pythonインストール Windows10(64bit)編
はじめに
Pythonをインストールする機会が多いのでマニュアル化しました。
本記事はWindows10(64bit)向けです。Python3.9 インストール
Python公式のダウンロードページ(https://www.python.org/downloads) にアクセスして「Download Python」をクリックします。
ダウンロードしたexeファイルをクリックします。
ダイアログ画面が起動しましたら「Add Python 3.9 to Path」にチェックを入れて「Install now」をクリックしてインストールを開始します。※チェックは入れることで、環境変数の設定が不要となるため楽です。
「Setup was successful」と表示されればインストール成功のため「Close」をクリックして閉じます。
Pythonコマンドのチェック
正常にインストールされたことをチェックするため、コマンドプロンプトを起動して以下コマンドを入力して実行します。
python -V今回私がダウンロードしたバージョンはPython3.9.1になるため「Python 3.9.1」と表示されれば成功です。
最後に
特に難しい手順はないですね!読んでいただきありがとうございます。




- 投稿日:2020-12-23T19:05:56+09:00
OpenCV で動画を加工する
OpenCVで簡単に動画に任意の処理ができます。
1、ビデオを読み込んで書き込む
import cv2 cap = cv2.VideoCapture('./video.mp4') #読み込む動画のパス fps = cap.get(cv2.CAP_PROP_FPS) fourcc = cv2.VideoWriter_fourcc('m','p','4', 'v') #mp4フォーマット video = cv2.VideoWriter('./edited_video.mp4', fourcc, fps, (1920,1080)) #書き込み先のパス、フォーマット、fps、サイズ avg = None while True: # 1フレームずつ取得する。 ret, frame = cap.read() if not ret: break #? 任意の処理をここに書く ? video.write(frame) key = cv2.waitKey(30) if key == 27: break cap.release() video.release()2、処理を書く
例えば、動画をスケッチ風にするには、
1、の任意の処理のところに以下を入れます。#? 任意の処理をここに書く ? # 白黒画像に grayImage = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 白黒反転 grayImageInv = 255 - grayImage # ぼかしをかける grayImageInv = cv2.GaussianBlur(grayImageInv, (21, 21), 0) #blend using color dodge output = cv2.divide(grayImage, 255-grayImageInv, scale=256.0) output = cv2.cvtColor(output, cv2.COLOR_GRAY2BGR) video.write(output)
?
フリーランスエンジニアです。
お仕事のご相談こちらまで
rockyshikoku@gmail.comCore MLを使ったアプリを作っています。
機械学習関連の情報を発信しています。


- 投稿日:2020-12-23T18:40:06+09:00
磁気流体の数値計算で遊ぶ
磁気流体とは
プラズマや液体金属のような電気伝導性の高い流体を扱う流体力学を磁気流体力学 (Magnetohydrodynamics) といいます。英語から略してよくMHDと呼ばれます。
この磁気流体の方程式系は保存形で書くと以下のようになります。\frac{\partial\mathbf{U}}{\partial t} + \frac{\partial\mathbf{F}}{\partial x} + \frac{\partial\mathbf{G}}{\partial y} + \frac{\partial\mathbf{H}}{\partial z}= \mathbf{0}\mathbf{U} = \begin{bmatrix} \rho \\ \rho u \\ \rho v \\ \rho w \\ B_x \\ B_y \\ B_z \\ e \end{bmatrix},\ \mathbf{F} = \begin{bmatrix} \rho u \\ \rho u^2+p_T-B_x^2 \\ \rho uv-B_xB_y \\ \rho uw-B_xB_z \\ 0 \\ B_yu-B_xv \\ B_zu-B_xw \\ \left(e+p_T\right)u-B_x\left(\mathbf{v}\cdot\mathbf{B}\right) \end{bmatrix},\ \mathbf{G} = \begin{bmatrix} \rho v \\ \rho vu-B_yB_x \\ \rho v^2+p_T-B_y^2 \\ \rho vw-B_yB_z \\ B_xv-B_yu \\ 0 \\ B_zv-B_yw \\ \left(e+p_T\right)v-B_y\left(\mathbf{v}\cdot\mathbf{B}\right) \end{bmatrix},\ \mathbf{H} = \begin{bmatrix} \rho w \\ \rho wu-B_zB_x \\ \rho wv-B_zB_y \\ \rho w^2+p_T-B_z^2 \\ B_xw-B_zu \\ B_yw-B_zv \\ 0 \\ \left(e+p_T\right)w-B_z\left(\mathbf{v}\cdot\mathbf{B}\right) \end{bmatrix}p = \left(\gamma-1\right)\left(e-\frac{1}{2}\rho|\mathbf{v}|^2-\frac{1}{2}|\mathbf{B}|^2\right),\ p_T = p+\frac{1}{2}|\mathbf{B}|^2ここで $\rho, p$ は密度・圧力で、$u, v, w$ はそれぞれ $x, y, z$ 方向の速度、$B_x, B_y, B_z$ はそれぞれ $x, y, z$ 方向の磁場、さらに $e$ はエネルギー密度を表しています。$\gamma$ は比熱比です。またここでは $\mu_0, 4\pi$ 等の磁場に関する係数が消える単位系を採用しています。
通常の流体と比べてみると、新たに磁場が変数として加わっていることがわかりますね。さて、この磁気流体の有名な問題にOrszag-Tang渦問題 (Orszag and Tang, 1979) というものがあります (Google画像検索) 。渦が衝撃波を形成しながら複雑に絡み合った模様が形成され、しかも数値的に発生する磁場発散を適切に除去できないと計算が破綻しやすいことが知られており、磁気流体計算の標準的なテスト問題としてよく用いられています。
具体的な設定は以下の通りです。\rho = \gamma^2,\ p = \gammau = -\sin y,\ v = \sin x,\ w = 0B_x = -\sin y,\ B_y = \sin 2x,\ B_z = 0\gamma = 5/3,\ 0\le x \le 2\pi,\ 0\le y \le 2\pi境界条件は $x, y$ 各方向に周期境界条件を課します。
今回はこれを解くのが目標です。最終的にはこんな図が出来上がります。
HLLD近似リーマン解法
ここで一旦簡単のために1次元とします。このとき方程式系は以下のように書けます。
\frac{\partial\mathbf{U}}{\partial t} + \frac{\partial\mathbf{F}}{\partial x} = \mathbf{0}\mathbf{U} = \begin{bmatrix} \rho \\ \rho u \\ \rho v \\ \rho w \\ B_y \\ B_z \\ e \end{bmatrix},\ \mathbf{F} = \begin{bmatrix} \rho u \\ \rho u^2+p_T-B_x^2 \\ \rho uv-B_xB_y \\ \rho uw-B_xB_z \\ B_yu-B_xv \\ B_zu-B_xw \\ \left(e+p_T\right)u-B_x\left(\mathbf{v}\cdot\mathbf{B}\right) \end{bmatrix}1次元の場合マクスウェル方程式の
\nabla\cdot\mathbf{B} = 0から $B_x$ は時間・空間的に常に一定となるので、$B_x$ は方程式の独立変数から外してあります。
さて、上の $\mathbf{F}$ のヤコビアンの固有値を求めることで、この磁気流体には7個の特性速度
\lambda_1 = u-c_{fx}, \lambda_2 = u-c_{ax}, \lambda_3 = u-c_{sx}, \lambda_4 = u, \lambda_5 = u+c_{sx}, \lambda_6 = u+c_{ax},\lambda_7 = u+c_{fx}があることがわかります (導出はめちゃくちゃ面倒なので省略します)。ここで
a = \sqrt{\frac{\gamma p}{\rho}},\ c_{a} = \frac{|\mathbf{B}|}{\sqrt{\rho}}c_{ax} = \frac{|B_x|}{\sqrt{\rho}},\ c_{fx,sx} = \left[\frac{a^2+c_a^2\pm\sqrt{\left(a^2+c_a^2\right)^2-4a^2c_{ax}^2}}{2}\right]^{1/2}で、 $\lambda_2, \lambda_6$ はAlfvén波、$\lambda_1, \lambda_7$ は速進磁気音波 (fast magnetosonic wave)、$\lambda_3, \lambda_5$ は遅進磁気音波 (slow magnetosonic wave)、そして $\lambda_4$ はエントロピー波を表しています。
通常の流体が前後の音波とエントロピー波の合計3種類だったことを考えると、随分波の種類が増えています。うーんこれは大変そう。
何しろ多くの場合無視される遅進磁気音波抜きにしても5個です。これら多種多様な波を的確に捉えて計算するのは、通常の流体と比べてもかなり難易度が高くなります。そんななか、HLLD近似リーマン解法 (Miyoshi and Kusano, 2005) は精度・計算効率・ロバスト性いずれも優れた解法として広く用いられており、今回はこれを採用したいと思います。
ここで以下のような原点を境に不連続に配置された初期値問題を考えます。
\mathbf{U} = \begin{cases} \mathbf{U}_L & (x > 0) \\ \mathbf{U}_R & (x < 0) \end{cases}これをリーマン問題といい、HLLD法をはじめとする近似リーマン解法系のスキームでは、各セル内では $\mathbf{U}$ が一様になっていると近似して、各セルの境界毎のリーマン問題に帰着させます (下図)。
そこでHLLD法の説明に入る前に、より単純なHLL法を説明します (後でこの結果を使います)。リーマン問題の解は中心からさまざまな波が広がってゆく、という形になりますが、HLL法では左向きの波 $S_L$ と右向きの波 $S_R$ の2種類のみを考えます。さらに2つの波に囲まれた領域 (リーマンファン) 内で $\mathbf{U}$ は一定と近似します。
この2つの波には左右に一番速い速進磁気音波を選び、その速さはS_L = \mathrm{min}\left(u_L-{c_{fx}}_L, u_R-{c_{fx}}_R\right), S_R = \mathrm{max}\left(u_L+{c_{fx}}_L, u_R+{c_{fx}}_R\right)または
S_L = \mathrm{min}\left(u_L, u_R\right)-\mathrm{max}\left({c_{fx}}_L, {c_{fx}}_R\right), S_R = \mathrm{max}\left(u_L, u_R\right)+\mathrm{max}\left({c_{fx}}_L, {c_{fx}}_R\right)などと求めます。
方程式を $x-t$ 平面内でグリーンの定理を使って積分すると\iint_S\left(\frac{\partial\mathbf{U}}{\partial t}+\frac{\partial\mathbf{F}}{\partial x}\right)dxdt = \oint_c\left(-\mathbf{U}dx+\mathbf{F}dt\right) = \mathbf{0}となるので、下図積分路①について、
-S_R\mathbf{U}_R+S_L\mathbf{U}_L+\mathbf{F}_R-\mathbf{F}_L+\left(S_R-S_L\right)\mathbf {U}^* = \mathbf{0}積分路②について、
-S_R\mathbf{U}_R+\mathbf{F}_R-\mathbf{F}_{HLL}+S_R\mathbf {U}^* = \mathbf{0}したがって、中間状態の $\mathbf{U}^*$ と $\mathbf{F}_{HLL}$ は、
\begin{aligned} \mathbf{U}^* &= \frac{S_R\mathbf{U}_R-S_L\mathbf{U}_L-\mathbf{F}_R+\mathbf{F}_L}{S_R-S_L} \\ \mathbf{F}_{HLL} &= \mathbf{F}_R+S_R\left(\mathbf{U}^*-\mathbf{U}_R\right) \\ &= \frac{S_R\mathbf{F}_L-S_L\mathbf{F}_R+S_R S_L\left(\mathbf{U}_R-\mathbf{U}_L\right)}{S_R-S_L} \end{aligned}と得られます。
ここでは一旦 $S_L < 0 < S_R$ の場合を考えていますが、もし $S_L > 0$ の場合には $\mathbf{F}_L$ を、$S_R < 0$ の場合には $\mathbf{F}_R$ をそれぞれセル境界でのフラックスとすればOKです。
次に以上の方法を拡張してHLLD法を導出してみましょう。HLLD法ではリーマンファン内で $u$ が一定と仮定します。これによって $p_T$ も一定となり、遅進磁気音波が除外されます。なのでこの場合リーマン問題の解は、下図のように
- 速進磁気音波より速い領域 × 2
- 速進磁気音波とAlfvén波の間の領域 × 2
- Alfvén波とエントロピー波の間の領域 × 2
の6領域に分かれます。
ここから領域内の $\mathbf{U}$ を次々求めてゆきましょう。
まず前提から以下が成り立ちます。u^*_L = u^{**}_L = u^{**}_R = u^*_R \equiv S_M{p_T}^*_L = {p_T}^{**}_L = {p_T}^{**}_R = {p_T}^*_R \equiv {p_T}^*$S_M$ はHLL法で得られた $\rho_{HLL}$ と $\left(\rho u\right)_{HLL}$ を使って以下のように求めます。
S_M = \frac{\left(\rho u\right)_{HLL}}{\rho_{HLL}} = \frac{\left(S_R-u_R\right)\rho_R u_R-\left(S_L-u_L\right)\rho_L u_L-{p_T}_R+{p_T}_L}{\left(S_R-u_R\right)\rho_R-\left(S_L-u_L\right)\rho_L}速進磁気音波に対するジャンプ条件
まず速進磁気音波の前後で値がどのように変わるか見てみましょう。
そのために積分路①を下図のように半分ずつ $\mathbf{U}_R$ の領域と $\mathbf{U}^*_R$ の領域が入るようにとります。
このとき
S_R\mathbf{U}_R-\mathbf{F}\left(\mathbf{U}_R\right) = S_R\mathbf{U}^*_R-\mathbf{F}\left(\mathbf{U}^*_R\right)で、これを具体的に成分で書くと以下のようになります。
S_R\begin{bmatrix} \rho_R \\ \rho_R u_R \\ \rho_R v_R \\ \rho_R w_R \\ {B_y}_R \\ {B_z}_R \\ e_R \end{bmatrix} - \begin{bmatrix} \rho_R u_R \\ \rho_R u_R^2+{p_T}_R-B_x^2 \\ \rho_R u_R v_R-B_x{B_y}_R \\ \rho_R u_R w_R-B_x{B_z}_R \\ {B_y}_R u_R-B_x v_R \\ {B_z}_R u_R-B_x w_R \\ \left(e_R+{p_T}_R\right)u_R-B_x \left(\mathbf{v}_R\cdot\mathbf{B}_R\right) \end{bmatrix} = S_R\begin{bmatrix} \rho^*_R \\ \rho^*_R S_M \\ \rho^*_R v^*_R \\ \rho^*_R w^*_R \\ {B_y}^*_R \\ {B_z}^*_R \\ e^*_R \end{bmatrix} - \begin{bmatrix} \rho^*_R S_M \\ \rho^*_R S_M^2+{p_T}^*-B_x^2 \\ \rho^*_R S_M v^*_R-B_x{B_y}^*_R \\ \rho^*_R S_M w^*_R-B_x{B_z}^*_R \\ {B_y}^*_R S_M-B_x v^*_R \\ {B_z}^*_R S_M-B_x w^*_R \\ \left(e^*_R+{p_T}^*\right)S_M-B_x \left(\mathbf{v}^*_R\cdot\mathbf{B}^*_R\right) \end{bmatrix}左側についても同様に考えることで、ここから $\mathbf{U}^*_\alpha$ が以下のように求められます。$\alpha$ はLまたはRという意味です。
\begin{aligned} \rho^*_\alpha &= \rho_\alpha\frac{S_\alpha-u_\alpha}{S_\alpha-S_M} \\ v^*_\alpha &= v_\alpha-B_x {B_y}_\alpha\frac{S_M-u_\alpha}{\rho_\alpha\left(S_\alpha-u_\alpha\right)\left(S_\alpha-S_M\right)-B_x^2} \\ w^*_\alpha &= w_\alpha-B_x {B_z}_\alpha\frac{S_M-u_\alpha}{\rho_\alpha\left(S_\alpha-u_\alpha\right)\left(S_\alpha-S_M\right)-B_x^2} \\ {B_y}^*_\alpha &= {B_y}_\alpha\frac{\rho_\alpha\left(S_\alpha-u_\alpha\right)^2-B_x^2}{\rho_\alpha\left(S_\alpha-u_\alpha\right)\left(S_\alpha-S_M\right)-B_x^2} \\ {B_z}^*_\alpha &= {B_z}_\alpha\frac{\rho_\alpha\left(S-u_\alpha\right)^2-B_x^2}{\rho_\alpha\left(S_\alpha-u_\alpha\right)\left(S_\alpha-S_M\right)-B_x^2} \end{aligned}\begin{aligned} p_T^* &= {p_T}_L+\rho_L\left(S_L-u_L\right)\left(S_M-u_L\right) \\ &= {p_T}_R+\rho_R\left(S_R-u_R\right)\left(S_M-u_R\right) \\ &= \frac{\left(S_R-u_R\right)\rho_R{p_T}_L-\left(S_L-u_L\right)\rho_L{p_T}_R+\rho_L\rho_R\left(S_R-u_R\right)\left(S_L-u_L\right)\left(u_R-u_L\right)}{\left(S_R-u_R\right)\rho_R-\left(S_L-u_L\right)\rho_L} \end{aligned}e^*_\alpha = \frac{\left(S_\alpha-u_\alpha\right)e_\alpha-{p_T}_\alpha u_\alpha+p_T^*S_M+B_x\left(\mathbf{v}_\alpha\cdot\mathbf{B}_\alpha-\mathbf{v}^*_\alpha\cdot\mathbf{B}^*_\alpha\right)}{S_\alpha-S_M}Alfvén波に対するジャンプ条件
次にAlfvén波の前後の変化を見るために、積分路②を下図のように半分ずつ $\mathbf{U}^*_R$ の領域と $\mathbf{U}^{**}_R$ の領域が入るようにとります。
ここで $S^{*}_L$ と $S^{*}_R$ は
S^*_L = S_M-\frac{|B_x|}{\sqrt{\rho^*_L}},\ S^*_R = S_M+\frac{|B_x|}{\sqrt{\rho^*_R}}ととります。積分路①の場合と同様にして、
S^*_R\mathbf{U}^*_R-\mathbf{F}\left(\mathbf{U}^*_R\right) = S^*_R\mathbf{U}^{**}_R-\mathbf{F}\left(\mathbf{U}^{**}_R\right)S^*_R\begin{bmatrix} \rho^*_R \\ \rho^*_R S_M \\ \rho^*_R v^*_R \\ \rho^*_R w^*_R \\ {B_y}^*_R \\ {B_z}^*_R \\ e^*_R \end{bmatrix} - \begin{bmatrix} \rho^*_R S_M \\ \rho^*_R S_M^2+{p_T}^*-B_x^2 \\ \rho^*_R S_M v^*_R-B_x{B_y}^*_R \\ \rho^*_R S_M w^*_R-B_x{B_z}^*_R \\ {B_y}^*_R S_M-B_x v^*_R \\ {B_z}^*_R S_M-B_x w^*_R \\ \left(e^*_R+{p_T}^*\right)S_M-B_x \left(\mathbf{v}^*_R\cdot\mathbf{B}^*_R\right) \end{bmatrix} = S^*_R\begin{bmatrix} \rho^{**}_R \\ \rho^{**}_R S_M \\ \rho^{**}_R v^{**}_R \\ \rho^{**}_R w^{**}_R \\ {B_y}^{**}_R \\ {B_z}^{**}_R \\ e^{**}_R \end{bmatrix} - \begin{bmatrix} \rho^{**}_R S_M \\ \rho^{**}_R S_M^2+{p_T}^*-B_x^2 \\ \rho^{**}_R S_M v^{**}_R-B_x{B_y}^{**}_R \\ \rho^{**}_R S_M w^{**}_R-B_x{B_z}^{**}_R \\ {B_y}^{**}_R S_M-B_x v^{**}_R \\ {B_z}^{**}_R S_M-B_x w^{**}_R \\ \left(e^{**}_R+{p_T}^*\right)S_M-B_x \left(\mathbf{v}^{**}_R\cdot\mathbf{B}^{**}_R\right) \end{bmatrix}となります。ここからわかるのは以下の $\rho^{**}_\alpha$ だけです。
\rho^{**}_\alpha = \rho^*_\alphaエントロピー波に対するジャンプ条件
さらに下図積分路③を考えます。
S_M\mathbf{U}^{**}_L-\mathbf{F}\left(\mathbf{U}^{**}_L\right) = S_R\mathbf{U}^{**}_R-\mathbf{F}\left(\mathbf{U}^{**}_R\right)S_M\begin{bmatrix} \rho^*_L \\ \rho^*_L S_M \\ \rho^*_L v^{**}_L \\ \rho^*_L w^{**}_L \\ {B_y}^{**}_L \\ {B_z}^{**}_L \\ e^{**}_L \end{bmatrix} - \begin{bmatrix} \rho^*_L S_M \\ \rho^*_L S_M^2+{p_T}^*-B_x^2 \\ \rho^*_L S_M v^{**}_L-B_x{B_y}^{**}_L \\ \rho^*_L S_M w^{**}_L-B_x{B_z}^{**}_L \\ {B_y}^{**}_L S_M-B_x v^{**}_L \\ {B_z}^{**}_L S_M-B_x w^{**}_L \\ \left(e^{**}_L+{p_T}^*\right)S_M-B_x \left(\mathbf{v}^{**}_L\cdot\mathbf{B}^{**}_L\right) \end{bmatrix} = S_M\begin{bmatrix} \rho^*_R \\ \rho^*_R S_M \\ \rho^*_R v^{**}_R \\ \rho^*_R w^{**}_R \\ {B_y}^{**}_R \\ {B_z}^{**}_R \\ e^{**}_R \end{bmatrix} - \begin{bmatrix} \rho^*_R S_M \\ \rho^*_R S_M^2+{p_T}^*-B_x^2 \\ \rho^*_R S_M v^{**}_R-B_x{B_y}^{**}_R \\ \rho^*_R S_M w^{**}_R-B_x{B_z}^{**}_R \\ {B_y}^{**}_R S_M-B_x v^{**}_R \\ {B_z}^{**}_R S_M-B_x w^{**}_R \\ \left(e^{**}_R+{p_T}^*\right)S_M-B_x \left(\mathbf{v}^{**}_R\cdot\mathbf{B}^{**}_R\right) \end{bmatrix}ここから以下のように $v^{**}$, $w^{**}$, ${B_y}^{**}$, ${B_z}^{**}$ が左右で等しいことが示されます。
\begin{aligned} v^{**}_L &= v^{**}_R \equiv v^{**} \\ w^{**}_L &= w^{**}_R \equiv w^{**} \\ {B_y}^{**}_L &= {B_y}^{**}_R \equiv {B_y}^{**} \\ {B_z}^{**}_L &= {B_z}^{**}_R \equiv {B_z}^{**} \end{aligned}これを踏まえ、今度は下図積分路④で積分します。
\begin{aligned} \mathbf{0} &= -S_R\mathbf{U}_R+S_L\mathbf{U}_L+\mathbf{F}_R-\mathbf{F}_L+\left(S_R-S^*_R\right)\mathbf{U}^*_R+\left(S^*_L-S_L\right)\mathbf{U}^*_L+\left(S^*_R-S_M\right)\mathbf{U}^{**}_R+\left(S_M-S^*_L\right)\mathbf{U}^{**}_L \\ &= -S^*_R\mathbf{U}^*_R+S^*_L\mathbf{U}^*_L+\mathbf{F}^*_R-\mathbf{F}^*_L+\left(S^*_R-S_M\right)\mathbf{U}^{**}_R+\left(S_M-S^*_L\right)\mathbf{U}^{**}_L \\ &= -\left(S_M+\frac{|B_x|}{\sqrt{\rho^*_R}}\right)\mathbf{U}^*_R+\left(S_M-\frac{|B_x|}{\sqrt{\rho^*_L}}\right)\mathbf{U}^*_L+\mathbf{F}^*_R-\mathbf{F}^*_L+\frac{|B_x|}{\sqrt{\rho^*_R}}\mathbf{U}^{**}_R+\frac{|B_x|}{\sqrt{\rho^*_L}}\mathbf{U}^{**}_L \end{aligned}ここから、
\begin{aligned} v^{**} &= \frac{\sqrt{\rho^*_L}v^*_L+\sqrt{\rho^*_R}v^*_R+\left({B_y}^*_R-{B_y}^*_L\right)\mathrm{sign}\left(B_x\right)}{\sqrt{\rho^*_L}+\sqrt{\rho^*_R}} \\ w^{**} &= \frac{\sqrt{\rho^*_L}w^*_L+\sqrt{\rho^*_R}w^*_R+\left({B_z}^*_R-{B_z}^*_L\right)\mathrm{sign}\left(B_x\right)}{\sqrt{\rho^*_L}+\sqrt{\rho^*_R}} \\ B_y^{**} &= \frac{\sqrt{\rho^*_L}{B_y}^*_R+\sqrt{\rho^*_R}{B_y}^*_L+\sqrt{\rho^*_L\rho^*_R}\left(v^*_R-v^*_L\right)\mathrm{sign}\left(B_x\right)}{\sqrt{\rho^*_L}+\sqrt{\rho^*_R}} \\ B_z^{**} &= \frac{\sqrt{\rho^*_L}{B_z}^*_R+\sqrt{\rho^*_R}{B_z}^*_L+\sqrt{\rho^*_L\rho^*_R}\left(w^*_R-w^*_L\right)\mathrm{sign}\left(B_x\right)}{\sqrt{\rho^*_L}+\sqrt{\rho^*_R}} \end{aligned}最後にAlfvén波に対するジャンプ条件をもう一度使うことで、以下が得られます。
e^{**}_\alpha = e^*_\alpha\mp\sqrt{\rho^*_\alpha}\left(\mathbf{v}^*_\alpha\cdot\mathbf{B}^*_\alpha-\mathbf{v}^{**}\cdot\mathbf{B}^{**}\right)\mathrm{sign}\left(B_x\right)複号はLのときマイナス、Rのときプラスをとります。
長くなりましたが、これで各領域の $\mathbf{U}$ がすべて求まりました。
以上をまとめますと最終的に以下の式になります。\mathbf{F}_{HLLD} = \begin{cases} \mathbf{F}_L & (0 < S_L) \\ \mathbf{F}_L^* & (S_L \le 0 < S_L^*) \\ \mathbf{F}_L^{**} & (S_L^* \le 0 < S_M) \\ \mathbf{F}_R^{**} & (S_M \le 0 < S_R^*) \\ \mathbf{F}_R^* & (S_R^* \le 0 < S_R) \\ \mathbf{F}_R & (S_R < 0) \end{cases}多次元化
多次元化を行うためには、単にHLLD法を $x,y,z$ 方向それぞれに適用すればよさそうな気がしますが、実際にはそう単純にはいかないところが磁気流体計算の難しさの一つです。
ここで問題になるのが磁場の発散です。本来ならマクスウェル方程式から磁場は常に非発散、つまり\nabla\cdot\mathbf{B} = 0でなければなりませんが、数値計算の場合誤差によってこれが破れることがあり、時には計算を破綻させてしまうほどの悪影響を及ぼします。これを回避する方法としては、大きく分けて
- 配置等を工夫することで磁場発散を初めから発生させない方法
- 方程式に変更を加えることで発生した磁場発散を抑制する方法
の2種類があります。前者はCT法が有名です。後者ではプロジェクション法や9 wave法が知られており、ここでは実装の比較的単純な9 wave法を紹介します。
9 wave法
Dedner et al. (2002) で提案された方法で、$\psi$ という新しい変数を導入して以下のように方程式を拡張します。
\frac{\partial\mathbf{U}}{\partial t} + \frac{\partial\mathbf{F}}{\partial x} + \frac{\partial\mathbf{G}}{\partial y} + \frac{\partial\mathbf{H}}{\partial z} = \mathbf{S}\mathbf{U} = \begin{bmatrix} \rho \\ \rho u \\ \rho v \\ \rho w \\ B_x \\ B_y \\ B_z \\ e \\ \psi \end{bmatrix},\ \mathbf{F} = \begin{bmatrix} \rho u \\ \rho u^2+p_T-B_x^2 \\ \rho uv-B_xB_y \\ \rho uw-B_xB_z \\ \psi \\ B_yu-B_xv \\ B_zu-B_xw \\ \left(e+p_T\right)u-B_x\left(\mathbf{v}\cdot\mathbf{B}\right) \\ c_h^2 B_x \end{bmatrix},\ \mathbf{G} = \begin{bmatrix} \rho v \\ \rho vu-B_yB_x \\ \rho v^2+p_T-B_y^2 \\ \rho vw-B_yB_z \\ B_xv-B_yu \\ \psi \\ B_zv-B_yw \\ \left(e+p_T\right)v-B_y\left(\mathbf{v}\cdot\mathbf{B}\right) \\ c_h^2 B_y \end{bmatrix},\ \mathbf{H} = \begin{bmatrix} \rho w \\ \rho wu-B_zB_x \\ \rho wv-B_zB_y \\ \rho w^2+p_T-B_z^2 \\ B_xw-B_zu \\ B_yw-B_zv \\ \psi \\ \left(e+p_T\right)w-B_z\left(\mathbf{v}\cdot\mathbf{B}\right) \\ c_h^2 B_z \end{bmatrix},\ \mathbf{S} = \begin{bmatrix} 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ 0 \\ -\frac{c_h^2}{c_p^2}\psi \end{bmatrix}この $\psi$ は磁場発散を抑制するために人工的に導入された変数なので、何か物理的な意味があるわけではありません。
セル境界での $B_x$ と $\psi$ は以下のようにして求めます。
\begin{aligned} {B_x}_M &= {B_x}_L+\frac{1}{2}\left({B_x}_R-{B_x}_L\right)-\frac{1}{2c_h}\left(\psi_R-\psi_L\right) \\ \psi_M &= \psi_L+\frac{1}{2}\left(\psi_R-\psi_L\right)-\frac{c_h}{2}\left({B_x}_R-{B_x}_L\right) \end{aligned}実際の計算においては $\psi$ のソース項をそのまま計算するのではなく、一旦ソース項を忘れて他変数と同様にフラックスの差から $\psi^*$ を求めた後、以下のようにして $\psi^{n+1}$ を求めるのが一般的です。
\psi^{n+1} = \psi^*\exp\left(-\Delta t_n\frac{c_h^2}{c_p^2}\right)なおここで出てくる $c_h$ と $c_p$ は、$\nabla\cdot\mathbf{B}$ および $\psi$ に対する人工的な伝播と減衰の速さを表すフリーパラメータになります。
$c_h$ としてはCFL条件によって許される最大速度、c_h = \mathrm{CFL}\cdot\mathrm{min}\left(\Delta x, \Delta y, \Delta z\right)/\Delta t_n$c_p$ としては $c_r = c_p^2/c_h$ が定数となるようにした上で、$c_r = 0.18$ を選ぶのが空間解像度によらず最適となるようです。
高精度化
$\mathbf{F}_{i+1/2}$ を求める際、$\mathbf{U}_L$ として $\mathbf{U}_i$ を、$\mathbf{U}_R$ として $\mathbf{U}_{i+1}$ を選ぶのはいわゆる風上差分に相当し、1次の空間精度になります。
後で図をお見せしますが、実はこれ、数値拡散が大きくかなりぼやけた解になります。そこでここでは空間精度を上げる方法を紹介します。
また時間精度についても、常微分方程式でRunge-Kutta法を用いることで精度が上げられたように、偏微分方程式でも同様のことを考えることができます。
(そろそろ長くなって疲れてきました。。。)空間の高精度化
${\mathbf{U}_{i+1/2}}_L$ として例えば
{\mathbf{U}_{i+1/2}}_L = \frac{-\mathbf{U}_{i-1}+4\mathbf{U}_i+\mathbf{U}_{i+1}}{4}を使うようにすれば空間2次精度が得られますが、このように $\mathbf{U}$ を単純に線形に組み合わせるだけだと数値振動が発生してしまいあまり好ましくありません。
そこでこれを回避するために様々な非線形スキームが考案されています。ここでは2次精度のMUSCLと5次精度のMP5を簡単に紹介します。MUSCL
van Leer (1979) で提案された手法で、以下のようにリミッターを導入することで基本は2次精度を保ちつつ、不連続面では数値振動が発生しないように1次精度に落とすことができます。
\begin{aligned} {\mathbf{U}_{i+1/2}}_L &= \mathbf{U}_i+\frac{1}{2}\Delta_i \\ {\mathbf{U}_{i-1/2}}_R &= \mathbf{U}_i-\frac{1}{2}\Delta_i \end{aligned}\Delta_i = \mathrm{limiter}\left(\mathbf{U}_{i+1}-\mathbf{U}_i, \mathbf{U}_i-\mathbf{U}_{i-1}\right)リミッターとしては以下のminmod (Roe, 1986) やMC (van Leer, 1977) がよく使われるようです。
\begin{aligned} \mathrm{minmod}\left(a, b\right) &= \frac{1}{2}\left[\mathrm{sign}\left(a\right)+\mathrm{sign}\left(b\right)\right]\mathrm{min}\left(|a|, |b|\right) \\ \mathrm{MC}\left(a, b\right) &= \frac{1}{2}\left[\mathrm{sign}\left(a\right)+\mathrm{sign}\left(b\right)\right]\mathrm{min}\left(2|a|, \frac{|a+b|}{2}, 2|b|\right) \end{aligned}MP5
Suresh and Huynh (1997) による方法です。まず ${\mathbf{U}_{i+1/2}}_L$ を5次精度の線形スキームで補間します。
{\mathbf{U}_{i+1/2}}^*_L = \frac{2\mathbf{U}_{i-2}-13\mathbf{U}_{i-1}+4\mathbf{U}_i+47\mathbf{U}_{i+1}-3\mathbf{U}_{i+2}}{60}もちろんこのままでは数値振動が発生してしまうため、ある下限値 $\mathbf{U}_{\mathrm{min}}$ と上限値 $\mathbf{U}_{\mathrm{max}}$ を定め、それらの中央値を使って ${\mathbf{U}_{i+1/2}}_L$ を求めます。
{\mathbf{U}_{i+1/2}}_L = \mathrm{median}\left({\mathbf{U}_{i+1/2}}^*_L, \mathbf{U}_{\mathrm{min}}, \mathbf{U}_{\mathrm{max}}\right)具体的な $\mathbf{U}_{\mathrm{min}}$ と $\mathbf{U}_{\mathrm{max}}$ の求め方は結構長いのでここでは省略します。
時間の高精度化
\frac{d\mathbf{U}}{dt} = L\left(\mathbf{U}\right)と書けるとき、以下のように解くのはいわゆるオイラー法に相当し、1次の時間精度になります。
\mathbf{U}^{n+1} = \mathbf{U}^n+\Delta tL\left(\mathbf{U}^n\right)しかしこれもRunge-Kutta法を使えば精度を上げることができます。
今回はRunge-Kutta法のうちでも、特に余分な数値振動を発生させないという意味で性質の良いSSPRK (strong stability preserving Runge-Kutta) シリーズ (Shu and Osher, 1988) を載せておきます。2次精度 SSPRK (2, 2)
\begin{aligned} \mathbf{U}^{\left(1\right)} &= \mathbf{U}^n+\Delta tL\left(\mathbf{U}^n\right) \\ \mathbf{U}^{n+1} &= \frac{1}{2}\mathbf{U}^n+\frac{1}{2}\mathbf{U}^{\left(1\right)}+\frac{1}{2}\Delta tL\left(\mathbf{U}^{\left(1\right)}\right) \end{aligned}3次精度 SSPRK (3, 3)
\begin{aligned} \mathbf{U}^{\left(1\right)} &= \mathbf{U}^n+\Delta tL\left(\mathbf{U}^n\right) \\ \mathbf{U}^{\left(2\right)} &= \frac{3}{4}\mathbf{U}^n+\frac{1}{4}\mathbf{U}^{\left(1\right)}+\frac{1}{4}\Delta tL\left(\mathbf{U}^{\left(1\right)}\right) \\ \mathbf{U}^{n+1} &= \frac{1}{3}\mathbf{U}^n+\frac{2}{3}\mathbf{U}^{\left(2\right)}+\frac{2}{3}\Delta tL\left(\mathbf{U}^{\left(2\right)}\right) \end{aligned}結果
以上を踏まえて、MP5およびSSPRK (3, 3)を用いて計算した結果が以下になります。以下はすべて分割数 $N_x\times N_y = 200\times 200$, $\mathrm{CFL} = 0.4$ で計算しています。
上は圧力のプロットです。折り畳んだところを開けばすべての変数が見られます。
動画
圧力
密度
$u$
$v$
$B_x$
$B_y$
$\psi$
画像
圧力
密度
$u$
$v$
$B_x$
$B_y$
$\psi$
良い感じ!
スキームによる違い
せっかくなのでスキームによる違いも見てみましょう。以下の3種類を比較してみます。
- 風上差分・オイラー法 (空間1次・時間1次)
- MUSCL-minmod・SSPRK (2, 2) (空間2次・時間2次)
- MP5・SSPRK (3, 3) (空間5次・時間3次)
こうしてみると歴然とした違いがありますね。特に風上差分・オイラー法は同じ空間解像度のはずなのに随分ぼやけてしまっています。
磁場発散処理の有無による違い
次に磁場発散処理を入れなかったらどうなるか見てみます。
両者の違いが一番見やすかったMUSCL-minmod・SSPRK (2, 2)で比較します。...
...
磁場発散処理を入れないと破綻してしまいました。。。
とりあえず計算が壊れる直前の図を見比べてみます。
左にはいかにもヤバそうな、怪しい縞模様が見えますね。
$|\nabla\cdot\mathbf{B}|$ をプロットしてみると、ちょうどそこで大きな磁場発散が生じてしまっていることがわかります。一方で右ではうまく抑えられていますね。
ソースコード
現時点でC++とPythonの2バージョンを作成しており、GutHubにて公開しています。
C++バージョンではOpenMPによる並列化を施しているので、$N_x\times N_y = 200\times 200$ のような大きなサイズの計算に適しています。なお、constexpr if文や構造化束縛を使っているのでコンパイルにはC++17以上が必要です。
一方Pythonバージョンではその場ですぐプロットするように作ったので、サクッと結果を見たい場合はこちらが良いかと思います。Pythonといってもfor文を排除してできるだけNumPyに計算を任せるようにしているので、そこそこのパフォーマンスになってくれる、はず。。。
長くなるのでここではPythonバージョンのみ載せておきます。
Pythonバージョンのソースコード
main.pyimport time import numpy as np import matplotlib.pyplot as plt import matplotlib.cm as cm # グリッド数 #XN = 200; YN = 200 XN = 100; YN = 100 # ファイル出力回数 PN = 100 # 保存変数の個数 VN = 9 # 計算領域のサイズ XL = 2.0*np.pi; YL = 2.0*np.pi TL = np.pi # グリッドサイズ dx = XL/XN; dy = YL/YN # CFL数 CFL = 0.4 # 比熱比 gam = 5.0/3.0 # 磁場発散抑制のためのパラメータ (Dedner et al., 2002) cr = 0.18 # MINMOD関数 def minmod(a, b): return 0.5*(np.sign(a)+np.sign(b))*np.minimum(np.abs(a), np.abs(b)) # 中央値 def median(a, b, c): return a+minmod(b-a, c-a) # x方向フラックス def mhdfx(rho, u, v, w, bx, by, bz, e, psi, pt, ch): fx = np.zeros((XN, YN, VN)) fx[:, :, 0] = rho*u fx[:, :, 1] = rho*u*u+pt-bx*bx fx[:, :, 2] = rho*v*u-bx*by fx[:, :, 3] = rho*w*u-bx*bz fx[:, :, 4] = psi fx[:, :, 5] = by*u-bx*v fx[:, :, 6] = bz*u-bx*w fx[:, :, 7] = (e+pt)*u-bx*(u*bx+v*by+w*bz) fx[:, :, 8] = ch*ch*bx return fx # y方向フラックス def mhdfy(rho, u, v, w, bx, by, bz, e, psi, pt, ch): fy = np.zeros((XN, YN, VN)) fy[:, :, 0] = rho*v fy[:, :, 1] = rho*u*v-by*bx fy[:, :, 2] = rho*v*v+pt-by*by fy[:, :, 3] = rho*w*v-by*bz fy[:, :, 4] = bx*v-by*u fy[:, :, 5] = psi fy[:, :, 6] = bz*v-by*w fy[:, :, 7] = (e+pt)*v-by*(u*bx+v*by+w*bz) fy[:, :, 8] = ch*ch*by return fy # HLLDリーマンソルバ (Miyoshi and Kusano, 2005) def hlldx(ql, qr, ch): # 密度 rhol = ql[:, :, 0] rhor = qr[:, :, 0] # 運動量 mxl = ql[:, :, 1] myl = ql[:, :, 2] mzl = ql[:, :, 3] mxr = qr[:, :, 1] myr = qr[:, :, 2] mzr = qr[:, :, 3] # 磁場 bxl = ql[:, :, 4] byl = ql[:, :, 5] bzl = ql[:, :, 6] bxr = qr[:, :, 4] byr = qr[:, :, 5] bzr = qr[:, :, 6] # エネルギー el = ql[:, :, 7] er = qr[:, :, 7] # 磁場発散抑制のための人工ポテンシャル (Dedner et al., 2002) psil = ql[:, :, 8] psir = qr[:, :, 8] # 速度 ul = mxl/rhol vl = myl/rhol wl = mzl/rhol ur = mxr/rhor vr = myr/rhor wr = mzr/rhor # (熱的) 圧力 pl = (gam-1.0)*(el-0.5*rhol*(ul*ul+vl*vl+wl*wl)-0.5*(bxl*bxl+byl*byl+bzl*bzl)) pr = (gam-1.0)*(er-0.5*rhor*(ur*ur+vr*vr+wr*wr)-0.5*(bxr*bxr+byr*byr+bzr*bzr)) ptl = pl+0.5*(bxl*bxl+byl*byl+bzl*bzl) # 総圧力 (熱的圧力 + 磁気圧) ptr = pr+0.5*(bxr*bxr+byr*byr+bzr*bzr) # 音速 al = np.sqrt(gam*pl/rhol) ar = np.sqrt(gam*pr/rhor) # Alfvén速度 cal = np.sqrt((bxl*bxl+byl*byl+bzl*bzl)/rhol) car = np.sqrt((bxr*bxr+byr*byr+bzr*bzr)/rhor) caxl = np.sqrt(bxl*bxl/rhol) caxr = np.sqrt(bxr*bxr/rhor) # 速進磁気音波速度 cfl = np.sqrt(0.5*(al*al+cal*cal+np.sqrt((al*al+cal*cal)**2-4.0*(al*caxl)**2))) cfr = np.sqrt(0.5*(ar*ar+car*car+np.sqrt((ar*ar+car*car)**2-4.0*(ar*caxr)**2))) sfl = np.minimum(ul-cfl, ur-cfr) sfr = np.maximum(ul+cfl, ur+cfr) sm = ((sfr-ur)*rhor*ur-(sfl-ul)*rhol*ul-ptr+ptl)/((sfr-ur)*rhor-(sfl-ul)*rhol) um = sm bxm = bxl+0.5*(bxr-bxl)-0.5/ch*(psir-psil) psim = psil+0.5*(psir-psil)-0.5*ch*(bxr-bxl) # リーマンファン外側 ptm = ((sfr-ur)*rhor*ptl-(sfl-ul)*rhol*ptr+rhol*rhor*(sfr-ur)*(sfl-ul)*(ur-ul))/((sfr-ur)*rhor-(sfl-ul)*rhol) rhoml = rhol*(sfl-ul)/(sfl-sm) rhomr = rhor*(sfr-ur)/(sfr-sm) vol = vl-bxm*byl*(sm-ul)/(rhol*(sfl-ul)*(sfl-sm)-bxm*bxm) vor = vr-bxm*byr*(sm-ur)/(rhor*(sfr-ur)*(sfr-sm)-bxm*bxm) wol = wl-bxm*bzl*(sm-ul)/(rhol*(sfl-ul)*(sfl-sm)-bxm*bxm) wor = wr-bxm*bzr*(sm-ur)/(rhor*(sfr-ur)*(sfr-sm)-bxm*bxm) byol = byl*(rhol*(sfl-ul)*(sfl-ul)-bxm*bxm)/(rhol*(sfl-ul)*(sfl-sm)-bxm*bxm) byor = byr*(rhor*(sfr-ur)*(sfr-ur)-bxm*bxm)/(rhor*(sfr-ur)*(sfr-sm)-bxm*bxm) bzol = bzl*(rhol*(sfl-ul)*(sfl-ul)-bxm*bxm)/(rhol*(sfl-ul)*(sfl-sm)-bxm*bxm) bzor = bzr*(rhor*(sfr-ur)*(sfr-ur)-bxm*bxm)/(rhor*(sfr-ur)*(sfr-sm)-bxm*bxm) eol = ((sfl-ul)*el-ptl*ul+ptm*sm+bxm*(ul*bxl+vl*byl+wl*bzl-um*bxm-vol*byol-wol*bzol))/(sfl-sm) eor = ((sfr-ur)*er-ptr*ur+ptm*sm+bxm*(ur*bxr+vr*byr+wr*bzr-um*bxm-vor*byor-wor*bzor))/(sfr-sm) srrhoml = np.sqrt(rhoml) srrhomr = np.sqrt(rhomr) sal = sm-np.sqrt(bxm*bxm/rhoml) sar = sm+np.sqrt(bxm*bxm/rhomr) # リーマンファン内側 vi = (srrhoml*vol+srrhomr*vor+(byor-byol)*np.sign(bxm))/(srrhoml+srrhomr) wi = (srrhoml*wol+srrhomr*wor+(bzor-bzol)*np.sign(bxm))/(srrhoml+srrhomr) byi = (srrhoml*byor+srrhomr*byol+srrhoml*srrhomr*(vor-vol)*np.sign(bxm))/(srrhoml+srrhomr) bzi = (srrhoml*bzor+srrhomr*bzol+srrhoml*srrhomr*(wor-wol)*np.sign(bxm))/(srrhoml+srrhomr) eil = eol-srrhoml*(vol*byol+wol*bzol-vi*byi-wi*bzi)*np.sign(bxm) eir = eor+srrhomr*(vor*byor+wor*bzor-vi*byi-wi*bzi)*np.sign(bxm) fxl = mhdfx(rhol, ul, vl, wl, bxm, byl, bzl, el, psim, ptl, ch) fxol = mhdfx(rhoml, um, vol, wol, bxm, byol, bzol, eol, psim, ptm, ch) fxil = mhdfx(rhoml, um, vi, wi, bxm, byi, bzi, eil, psim, ptm, ch) fxir = mhdfx(rhomr, um, vi, wi, bxm, byi, bzi, eir, psim, ptm, ch) fxor = mhdfx(rhomr, um, vor, wor, bxm, byor, bzor, eor, psim, ptm, ch) fxr = mhdfx(rhor, ur, vr, wr, bxm, byr, bzr, er, psim, ptr, ch) fx = np.zeros((XN, YN, VN)) slindex = sfl > 0.0 solindex = (0.0 >= sfl) & (sal > 0.0) silindex = (0.0 >= sal) & (sm > 0.0) sirindex = (0.0 >= sm) & (sar > 0.0) sorindex = (0.0 >= sar) & (sfr > 0.0) srindex = 0.0 >= sfr fx[slindex, :] = fxl[slindex, :] fx[solindex, :] = fxol[solindex, :] fx[silindex, :] = fxil[silindex, :] fx[sirindex, :] = fxir[sirindex, :] fx[sorindex, :] = fxor[sorindex, :] fx[srindex, :] = fxr[srindex, :] return fx def hlldy(ql, qr, ch): # 密度 rhol = ql[:, :, 0] rhor = qr[:, :, 0] # 運動量 mxl = ql[:, :, 1] myl = ql[:, :, 2] mzl = ql[:, :, 3] mxr = qr[:, :, 1] myr = qr[:, :, 2] mzr = qr[:, :, 3] # 磁場 bxl = ql[:, :, 4] byl = ql[:, :, 5] bzl = ql[:, :, 6] bxr = qr[:, :, 4] byr = qr[:, :, 5] bzr = qr[:, :, 6] # エネルギー el = ql[:, :, 7] er = qr[:, :, 7] # 磁場発散抑制のための人工ポテンシャル (Dedner et al., 2002) psil = ql[:, :, 8] psir = qr[:, :, 8] # 速度 ul = mxl/rhol vl = myl/rhol wl = mzl/rhol ur = mxr/rhor vr = myr/rhor wr = mzr/rhor # (熱的) 圧力 pl = (gam-1.0)*(el-0.5*rhol*(ul*ul+vl*vl+wl*wl)-0.5*(bxl*bxl+byl*byl+bzl*bzl)) pr = (gam-1.0)*(er-0.5*rhor*(ur*ur+vr*vr+wr*wr)-0.5*(bxr*bxr+byr*byr+bzr*bzr)) # 総圧力 (熱的圧力 + 磁気圧) ptl = pl+0.5*(bxl*bxl+byl*byl+bzl*bzl) ptr = pr+0.5*(bxr*bxr+byr*byr+bzr*bzr) # 音速 al = np.sqrt(gam*pl/rhol) ar = np.sqrt(gam*pr/rhor) # Alfvén速度 cal = np.sqrt((bxl*bxl+byl*byl+bzl*bzl)/rhol) car = np.sqrt((bxr*bxr+byr*byr+bzr*bzr)/rhor) cayl = np.sqrt(byl*byl/rhol) cayr = np.sqrt(byr*byr/rhor) # 速進磁気音波速度 cfl = np.sqrt(0.5*(al*al+cal*cal+np.sqrt((al*al+cal*cal)**2-4.0*(al*cayl)**2))) cfr = np.sqrt(0.5*(ar*ar+car*car+np.sqrt((ar*ar+car*car)**2-4.0*(ar*cayr)**2))) sfl = np.minimum(vl-cfl, vr-cfr) sfr = np.maximum(vl+cfl, vr+cfr) sm = ((sfr-vr)*rhor*vr-(sfl-vl)*rhol*vl-ptr+ptl)/((sfr-vr)*rhor-(sfl-vl)*rhol) vm = sm bym = byl+0.5*(byr-byl)-0.5/ch*(psir-psil) psim = psil+0.5*(psir-psil)-0.5*ch*(byr-byl) # リーマンファン外側 ptm = ((sfr-vr)*rhor*ptl-(sfl-vl)*rhol*ptr+rhol*rhor*(sfr-vr)*(sfl-vl)*(vr-vl))/((sfr-vr)*rhor-(sfl-vl)*rhol) rhoml = rhol*(sfl-vl)/(sfl-sm) rhomr = rhor*(sfr-vr)/(sfr-sm) wol = wl-bym*bzl*(sm-vl)/(rhol*(sfl-vl)*(sfl-sm)-bym*bym) wor = wr-bym*bzr*(sm-vr)/(rhor*(sfr-vr)*(sfr-sm)-bym*bym) uol = ul-bym*bxl*(sm-vl)/(rhol*(sfl-vl)*(sfl-sm)-bym*bym) uor = ur-bym*bxr*(sm-vr)/(rhor*(sfr-vr)*(sfr-sm)-bym*bym) bzol = bzl*(rhol*(sfl-vl)*(sfl-vl)-bym*bym)/(rhol*(sfl-vl)*(sfl-sm)-bym*bym) bzor = bzr*(rhor*(sfr-vr)*(sfr-vr)-bym*bym)/(rhor*(sfr-vr)*(sfr-sm)-bym*bym) bxol = bxl*(rhol*(sfl-vl)*(sfl-vl)-bym*bym)/(rhol*(sfl-vl)*(sfl-sm)-bym*bym) bxor = bxr*(rhor*(sfr-vr)*(sfr-vr)-bym*bym)/(rhor*(sfr-vr)*(sfr-sm)-bym*bym) eol = ((sfl-vl)*el-ptl*vl+ptm*sm+bym*(ul*bxl+vl*byl+wl*bzl-uol*bxol-vm*bym-wol*bzol))/(sfl-sm) eor = ((sfr-vr)*er-ptr*vr+ptm*sm+bym*(ur*bxr+vr*byr+wr*bzr-uor*bxor-vm*bym-wor*bzor))/(sfr-sm) srrhoml = np.sqrt(rhoml) srrhomr = np.sqrt(rhomr) sal = sm-np.sqrt(bym*bym/rhoml) sar = sm+np.sqrt(bym*bym/rhomr) # リーマンファン内側 wi = (srrhoml*wol+srrhomr*wor+(bzor-bzol)*np.sign(bym))/(srrhoml+srrhomr) ui = (srrhoml*uol+srrhomr*uor+(bxor-bxol)*np.sign(bym))/(srrhoml+srrhomr) bzi = (srrhoml*bzor+srrhomr*bzol+srrhoml*srrhomr*(wor-wol)*np.sign(bym))/(srrhoml+srrhomr) bxi = (srrhoml*bxor+srrhomr*bxol+srrhoml*srrhomr*(uor-uol)*np.sign(bym))/(srrhoml+srrhomr) eil = eol-srrhoml*(uol*bxol+wol*bzol-ui*bxi-wi*bzi)*np.sign(bym) eir = eor+srrhomr*(uor*bxor+wor*bzor-ui*bxi-wi*bzi)*np.sign(bym) fyl = mhdfy(rhol, ul, vl, wl, bxl, bym, bzl, el, psim, ptl, ch) fyol = mhdfy(rhoml, uol, vm, wol, bxol, bym, bzol, eol, psim, ptm, ch) fyil = mhdfy(rhoml, ui, vm, wi, bxi, bym, bzi, eil, psim, ptm, ch) fyir = mhdfy(rhomr, ui, vm, wi, bxi, bym, bzi, eir, psim, ptm, ch) fyor = mhdfy(rhomr, uor, vm, wor, bxor, bym, bzor, eor, psim, ptm, ch) fyr = mhdfy(rhor, ur, vr, wr, bxr, bym, bzr, er, psim, ptr, ch) fy = np.zeros((XN, YN, VN)) slindex = sfl > 0.0 solindex = (0.0 >= sfl) & (sal > 0.0) silindex = (0.0 >= sal) & (sm > 0.0) sirindex = (0.0 >= sm) & (sar > 0.0) sorindex = (0.0 >= sar) & (sfr > 0.0) srindex = 0.0 >= sfr fy[slindex, :] = fyl[slindex, :] fy[solindex, :] = fyol[solindex, :] fy[silindex, :] = fyil[silindex, :] fy[sirindex, :] = fyir[sirindex, :] fy[sorindex, :] = fyor[sorindex, :] fy[srindex, :] = fyr[srindex, :] return fy # 1次精度風上差分 def upwindx(q): qil = np.roll(q, 1, axis = 0) qi = q ql = qil qr = qi return ql, qr def upwindy(q): qjl = np.roll(q, 1, axis = 1) qj = q ql = qjl qr = qj return ql, qr # 2次精度MUSCL (minmod) (van Leer, 1979) def musclx(q): qill = np.roll(q, 2, axis = 0) qil = np.roll(q, 1, axis = 0) qi = q qir = np.roll(q, -1, axis = 0) ql = qil+0.5*minmod(qi-qil, qil-qill) qr = qi-0.5*minmod(qir-qi, qi-qil) return ql, qr def muscly(q): qjll = np.roll(q, 2, axis = 1) qjl = np.roll(q, 1, axis = 1) qj = q qjr = np.roll(q, -1, axis = 1) ql = qjl+0.5*minmod(qj-qjl, qjl-qjll) qr = qj-0.5*minmod(qjr-qj, qj-qjl) return ql, qr # 5次精度MP5 (Suresh and Huynh, 1997) def mp5x(q): qilll = np.roll(q, 3, axis = 0) qill = np.roll(q, 2, axis = 0) qil = np.roll(q, 1, axis = 0) qi = q qir = np.roll(q, -1, axis = 0) qirr = np.roll(q, -2, axis = 0) dll = qilll-2.0*qill+qil dl = qill-2.0*qil+qi d = qil-2.0*qi+qir dr = qi-2.0*qir+qirr dmml = minmod(dll, dl) dmm = minmod(dl, d) dmmr = minmod(d, dr) qull = qil+2.0*(qil-qill) qulr = qi+2.0*(qi-qir) #qull = qil+4.0*(qil-qill) #qulr = qi+4.0*(qi-qir) qav = 0.5*(qil+qi) qmd = qav-0.5*dmm qlcl = qil+0.5*(qil-qill)+4.0/3.0*dmml qlcr = qi+0.5*(qi-qir)+4.0/3.0*dmmr qminl = np.maximum(np.minimum(qil, qi, qmd), np.minimum(qil, qull, qlcl)) qmaxl = np.minimum(np.maximum(qil, qi, qmd), np.maximum(qil, qull, qlcl)) qminr = np.maximum(np.minimum(qi, qil, qmd), np.minimum(qi, qulr, qlcr)) qmaxr = np.minimum(np.maximum(qi, qil, qmd), np.maximum(qi, qulr, qlcr)) q5l = (2.0*qilll-13.0*qill+47.0*qil+27.0*qi-3.0*qir)/60.0 q5r = (2.0*qirr-13.0*qir+47.0*qi+27.0*qil-3.0*qill)/60.0 ql = median(q5l, qminl, qmaxl) qr = median(q5r, qminr, qmaxr) return ql, qr def mp5y(q): qjlll = np.roll(q, 3, axis = 1) qjll = np.roll(q, 2, axis = 1) qjl = np.roll(q, 1, axis = 1) qj = q qjr = np.roll(q, -1, axis = 1) qjrr = np.roll(q, -2, axis = 1) dll = qjlll-2.0*qjll+qjl dl = qjll-2.0*qjl+qj d = qjl-2.0*qj+qjr dr = qj-2.0*qjr+qjrr dmml = minmod(dll, dl) dmm = minmod(dl, d) dmmr = minmod(d, dr) qull = qjl+2.0*(qjl-qjll) qulr = qj+2.0*(qj-qjr) #qull = qjl+4.0*(qjl-qjll) #qulr = qj+4.0*(qj-qjr) qav = 0.5*(qjl+qj) qmd = qav-0.5*dmm qlcl = qjl+0.5*(qjl-qjll)+4.0/3.0*dmml qlcr = qj+0.5*(qj-qjr)+4.0/3.0*dmmr qminl = np.maximum(np.minimum(qjl, qj, qmd), np.minimum(qjl, qull, qlcl)) qmaxl = np.minimum(np.maximum(qjl, qj, qmd), np.maximum(qjl, qull, qlcl)) qminr = np.maximum(np.minimum(qj, qjl, qmd), np.minimum(qj, qulr, qlcr)) qmaxr = np.minimum(np.maximum(qj, qjl, qmd), np.maximum(qj, qulr, qlcr)) q5l = (2.0*qjlll-13.0*qjll+47.0*qjl+27.0*qj-3.0*qjr)/60.0 q5r = (2.0*qjrr-13.0*qjr+47.0*qj+27.0*qjl-3.0*qjll)/60.0 ql = median(q5l, qminl, qmaxl) qr = median(q5r, qminr, qmaxr) return ql, qr # dq/dtの計算 def dqdt(q, ch): # x方向 #ql, qr = upwindx(q) #ql, qr = musclx(q) ql, qr = mp5x(q) fx = hlldx(ql, qr, ch) # y方向 #ql, qr = upwindy(q) #ql, qr = muscly(q) ql, qr = mp5y(q) fy = hlldy(ql, qr, ch) # 保存則の計算 fxi = fx fyj = fy fxir = np.roll(fx, -1, axis = 0) fyjr = np.roll(fy, -1, axis = 1) dqdt = -(fxir-fxi)/dx-(fyjr-fyj)/dy return dqdt # 1次精度Euler法 def euler(q, dt): ch = CFL*np.minimum(dx, dy)/dt q1 = q+dqdt(q, ch)*dt return q1 # 2次精度Runge-Kutta def ssprk2(q, dt): ch = CFL*np.minimum(dx, dy)/dt q1 = q+dqdt(q, ch)*dt q2 = 0.5*q+0.5*(q1+dqdt(q1, ch)*dt) return q2 # 3次精度Runge-Kutta def ssprk3(q, dt): ch = CFL*np.minimum(dx, dy)/dt q1 = q+dqdt(q, ch)*dt q2 = 0.75*q+0.25*(q1+dqdt(q1, ch)*dt) q3 = 1.0/3.0*q+2.0/3.0*(q2+dqdt(q2, ch)*dt) return q3 def main(): # rho: 密度 # p: 圧力 # u: x方向速度 # v: y方向速度 # w: z方向速度 # mx: x方向運動量 # my: y方向運動量 # mz: z方向運動量 # bx: x方向磁場 # by: y方向磁場 # bz: z方向磁場 # e: エネルギー # psi: 磁場発散抑制のための人工ポテンシャル (Dedner et al., 2002) # q: 保存変数ベクトル # -- 0: rho # -- 1: mx # -- 2: my # -- 3: mz # -- 4: bx # -- 5: by # -- 6: bz # -- 7: e # -- 8: psi x = np.arange(0.0, XL, dx) y = np.arange(0.0, YL, dy) # 初期値 rho = np.ones((XN, YN))*gam**2 p = np.ones((XN, YN))*gam u = np.tile(-np.sin(y), (XN, 1)) v = np.tile(np.sin(x), (YN, 1)).T w = np.zeros((XN, YN)) bx = np.tile(-np.sin(y), (XN, 1)) by = np.tile(np.sin(2.0*x), (YN, 1)).T bz = np.zeros((XN, YN)) e = p/(gam-1.0)+0.5*rho*(u*u+v*v+w*w)+0.5*(bx*bx+by*by+bz*bz) psi = np.zeros((XN, YN)) q = np.zeros((XN, YN, VN)); q_n = np.zeros((XN, YN, VN)) q[:, :, 0] = rho q[:, :, 1] = rho*u q[:, :, 2] = rho*v q[:, :, 3] = rho*w q[:, :, 4] = bx q[:, :, 5] = by q[:, :, 6] = bz q[:, :, 7] = e q[:, :, 8] = psi # 計算開始 n = 0 t = 0.0 step = 0 start = time.time() while (t <= TL): # 密度 rho = q[:, :, 0] # 運動量 mx = q[:, :, 1] my = q[:, :, 2] mz = q[:, :, 3] # 磁場 bx = q[:, :, 4] by = q[:, :, 5] bz = q[:, :, 6] # エネルギー e = q[:, :, 7] # 磁場発散抑制のための人工ポテンシャル (Dedner et al., 2002) psi = q[:, :, 8] # 速度 u = mx/rho v = my/rho w = mz/rho # (熱的) 圧力 p = (gam-1.0)*(e-0.5*rho*(u*u+v*v+w*w)-0.5*(bx*bx+by*by+bz*bz)) # 音速 a = np.sqrt(gam*p/rho) # Alfvén速度 ca = np.sqrt((bx*bx+by*by+bz*bz)/rho) cax = np.sqrt(bx*bx/rho) cay = np.sqrt(by*by/rho) # 速進磁気音波速度 cfx = np.sqrt(0.5*(a*a+ca*ca+np.sqrt((a*a+ca*ca)**2-4.0*(a*cax)**2))) cfy = np.sqrt(0.5*(a*a+ca*ca+np.sqrt((a*a+ca*ca)**2-4.0*(a*cay)**2))) # CFL数をもとにdtを設定 dt = CFL*np.minimum(dx/np.max(np.abs(u)+cfx), dy/np.max(np.abs(v)+cfy)) # 磁場発散抑制のためのパラメータ (Dedner et al., 2002) ch = CFL*np.minimum(dx, dy)/dt cd = np.exp(-dt*ch/cr) # 時間発展 #q_n = euler(q, dt) #q_n = ssprk2(q, dt) q_n = ssprk3(q, dt) q_n[:, :, 8] = cd*q_n[:, :, 8] q = q_n # ファイル出力 if (np.floor(t*PN/TL) != np.floor((t-dt)*PN/TL)) : print("n: {0:3d}, t: {1:.2f}".format(n, t)) #varname = ["r", "p", "u", "v", "w", "bx", "by", "bz", "ps"] #vardata = [rho, p, u, v, w, bx, by, bz, psi] #for i in range(VN): # np.savetxt("../data/"+varname[i]+"_{0:0>3}.csv".format(n), vardata[i].T, delimiter = ",") n += 1 t += dt step += 1 elapsed_time = time.time()-start print("elapsed_time: {0} s".format(elapsed_time)) # 計算終了 # 計算失敗の検知 if (not np.isfinite(t)): print("Computaion failed: step = {0:3d}".format(step)) # y = πでの値 print(" x rho p u v w bx by bz psi") for i in range(0, XN, 5): j = YN//2 print("{0:4.2f} {1:5.2f} {2:5.2f} {3:5.2f} {4:5.2f} {5:5.2f} {6:5.2f} {7:5.2f} {8:5.2f} {9:5.2f}" .format(dx*i, rho[i, j], p[i, j], u[i, j], v[i, j], w[i, j], bx[i, j], by[i, j], bz[i, j], psi[i, j])) # 結果をプロット fig = plt.figure() plt.axes().set_aspect("equal") plt.title("p (t = {0:.2f})".format(t)) plt.xlabel("X") plt.ylabel("Y") im = plt.pcolor(x, y, p.T, cmap = cm.jet, shading = "auto") im.set_clim(0.0, 6.5) fig.colorbar(im) plt.show() if __name__ == "__main__": main()参考文献
- Orszag, S., & Tang, C. (1979). Small-scale structure of two-dimensional magnetohydrodynamic turbulence. Journal of Fluid Mechanics, 90(1), 129-143. doi:10.1017/S002211207900210X
- Takahiro Miyoshi, Kanya Kusano, A multi-state HLL approximate Riemann solver for ideal magnetohydrodynamics, Journal of Computational Physics, Volume 208, Issue 1, 2005, Pages 315-344, ISSN 0021-9991, https://doi.org/10.1016/j.jcp.2005.02.017.
- A. Dedner, F. Kemm, D. Kröner, C.-D. Munz, T. Schnitzer, M. Wesenberg, Hyperbolic Divergence Cleaning for the MHD Equations,Journal of Computational Physics, Volume 175, Issue 2, 2002, Pages 645-673, ISSN 0021-9991, https://doi.org/10.1006/jcph.2001.6961.
- Bram van Leer, Towards the ultimate conservative difference scheme. V. A second-order sequel to Godunov's method, Journal of Computational Physics, Volume 32, Issue 1, 1979, Pages 101-136, ISSN 0021-9991, https://doi.org/10.1016/0021-9991(79)90145-1.
- Roe, P L, Characteristic-Based Schemes for the Euler Equations, Annual Review of Fluid Mechanics, Volume 18, 337-365, 1986, https://doi.org/10.1146/annurev.fl.18.010186.002005
- Bram Van Leer, Towards the ultimate conservative difference scheme III. Upstream-centered finite-difference schemes for ideal compressible flow, Journal of Computational Physics, Volume 23, Issue 3, 1977, Pages 263-275, ISSN 0021-9991, https://doi.org/10.1016/0021-9991(77)90094-8.
- A. Suresh, H.T. Huynh, Accurate Monotonicity-Preserving Schemes with Runge–Kutta Time Stepping, Journal of Computational Physics, Volume 136, Issue 1, 1997, Pages 83-99, ISSN 0021-9991, https://doi.org/10.1006/jcph.1997.5745.
- Chi-Wang Shu, Stanley Osher, Efficient implementation of essentially non-oscillatory shock-capturing schemes, Journal of Computational Physics, Volume 77, Issue 2, 1988, Pages 439-471, ISSN 0021-9991, https://doi.org/10.1016/0021-9991(88)90177-5.
また、今回の記事執筆に際し、以下のページを全般に渡って参考にしています。

















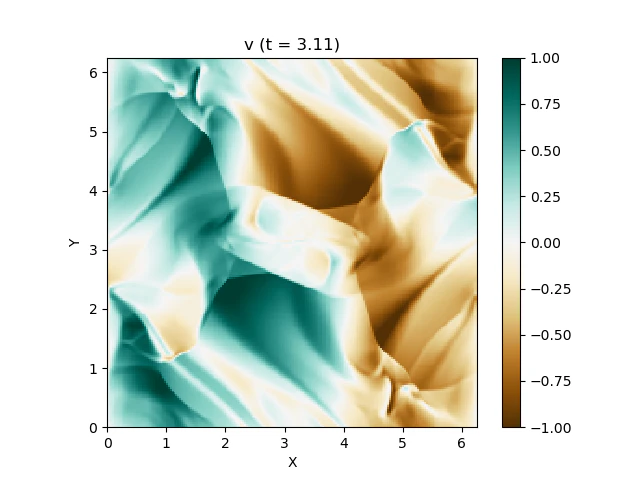






- 投稿日:2020-12-23T18:30:52+09:00
【mac】PythonでRealSense D415のサンプルを動かす
RealSense D415とは
Intel社の提供するRealsenseは奥行き知覚機能を有するカメラデバイス.公式ではmacのサポートをしていないが,librealsenseという非公式のライブラリで動かすことができる.
環境
- macBookPro(13-inch, 2017, Twoo Thunderbolt 3ports)
- macOS Catalina 10.15.7
- zsh
- Homebrewインストール済
- PyenvでPythonの環境構築済
環境構築手順
必要なライブラリをインストール
ターミナルを開きホームディレクトリで以下のコマンドを一行ずつ実行する
ターミナル$ brew install python $ brew install libusb pkg-config $ brew install homebrew/core/glfw3 $ brew install cmake $ brew install boost $ brew install flann $ brew install vtk5 –with-qt $ git clone https://github.com/PointCloudLibrary/pcl $ cd pcl $ mkdir build && cd build $ cmake .. $ make $ sudo make installlibrealsenseのソースコードをインストール&build
cdコマンドでホームディレクトリに戻り,librealsenseの本体をインストールする
3行目の使用しているPythonの絶対パスの部分はwhich pythonで出力されたパスに置き換えるターミナル$ git clone https://github.com/IntelRealSense/librealsense.git $ cd librealsense $ mkdir build && cd build $ cmake .. -DBUILD_EXAMPLES=true -DBUILD_WITH_OPENMP=false -DHWM_OVER_XU=false -DBUILD_PYTHON_BINDINGS=true -DPYTHON_EXECUTABLE:FILEPATH=使用しているPyhtonの絶対パス -G "Unix Makefiles" $ make -j2 $ sudo make install私の環境ではPythonのバージョンが3.8系では動かなかったため事前に3.6系へバージョンを変えておく(今回はpython3.6.7を使う)
/libresenseディレクトリに戻りターミナル$ pyenv install 3.6.7 $ pyenv local 3.6.7
pyenv versionsコマンドで/libresenseディレクトリ以下がpython3.6.7になっていることを確認する
また,このままだと動かないと思うので以下の手順でsoファイルがおいてある場所(以下A)を確認する
- VSCode等で
librealsense/build/CMakeCache.txtを開くcommand + Fで検索窓を開きPYTHON_INSTALL_DIR:PATHを検索するPYTHON_INSTALL_DIR:PATH:PATH=xxxとかいてある.xxxがsoファイルの置いてあるディレクトリ(A)シンボリックを置く場所(以下B)を確認する
ターミナル$ python3 >>>import site; site.getsitepackages()その後確認した場所(B)へ移動し,シンボリックを作成する
ターミナル$ cd Bへの絶対パス $ ln -s 確認したsoファイルのパス(A)/pyrealsense2.cpython-36m-darwin.so pyrealsense2.so $ ln -s 確認したsoファイルのパス(A)/pybackend2.cpython-36m-darwin.so pybackend2.so
pyrealsense2のインポートが通るか確認ターミナル$ python >>> import pyrealsense2 >>>このように
importが通ればOKサンプルを動かす
macとRealsenseをUSB接続し,サンプルファイルが置いてあるディレクトリに移動し実行する
ターミナル$ cd ~/librealsense/wrappers/python/examples $ python 動かしたいファイル名
参考
(参考Qiita1)[https://qiita.com/mizumasa/items/c6ca2c73fa86c9a5a39c](参考Qiita2)[https://qiita.com/comachi/items/14b358568365bc5ee474]
- 投稿日:2020-12-23T18:30:25+09:00
RhinocerosでモデリングしたネットワークをPythonで読み込む②
前回は、建築・都市におけるネットワーク分析の一例として歩行空間ネットワークを取り上げ、地図情報をもとにRhinocerosで実際に歩行空間ネットワークを描きました。
→RhinocerosでモデリングしたネットワークをPythonで読み込む①本記事では、描いたネットワークを分析ができる形にすることが目的です。
目標
- Rhinocerosでネットワークを描く
- Rhinocerosで描いたネットワークをPythonで読み込めるように書き出す
- 書き出したファイルをPythonで読み込んで隣接配列を作る
本記事では第2項に取り組みます。
隣接配列
ネットワークを表すデータ構造には隣接行列、距離行列、隣接配列などがあります。本記事では、ネットワークを隣接配列として表現する方法を紹介します。
その前に、それぞれのデータ構造について簡単な説明を以下に述べます。
・隣接行列
順序付けられたノードの隣接関係を0/1(隣接していない/隣接している)で表した正方行列を、隣接行列と言います。エッジの重みを考えず、ノードの隣接関係だけに着目したものを、厳密にはグラフと呼びます。例えば、
を隣接行列で表すと、\begin{pmatrix} 0&1&0&1\\ 1&0&1&0\\ 0&1&0&1\\ 1&0&1&0 \end{pmatrix}になります。
隣接行列を使えば、ノードからノードへの経路数を求めるなどが代数的にできます。上のグラフはエッジに向きがない(無向グラフ)ので隣接行列は対称ですが、対称性を崩して一方通行のエッジを表現することも可能です(有向グラフ)。
・距離行列
隣接行列の各成分は、ノード間の隣接関係を表していました。距離行列は、その要素にノード間を結ぶエッジの重みが与えられたものです。先ほどのグラフのエッジに重みを与えたネットワーク
の距離行列は、\begin{pmatrix} 0&1.5&0&8\\ 1.5&0&5&0\\ 0&5&0&2.3\\ 8&0&2.3&0 \end{pmatrix}になります。隣接していないノード間の要素に、便宜的に0を置いていますが、エッジの重みが0であることを意味しないことに注意してください。
・隣接配列
先のふたつのデータ構造は、どちらも行列を用いたものです。ここで、建築や都市の中にあるネットワークを考えてみると、あるノードと隣接するノードは高々4つか5つくらいであることが想像できます。そのとき、隣接行列、距離行列は0がたくさん並んだものになって、とても無駄が多いものになります。そこで、隣接しているノード間の関係だけを記憶しておこうというのが隣接配列です。先ほどのネットワークの隣接配列を実際に作ってみると、次のようになります。
\begin{align} &1: &[2, 4]\\ &2: &[1, 3]\\ &3: &[2, 4]\\ &4: &[1, 3] \end{align}コロンの左に注目するノード、右に隣接するノードの配列を記しています。同時に、エッジの重みも同様にして記憶しておきましょう。これを仮に距離配列と呼びます。
\begin{align} &1: &[1.5, 8]\\ &2: &[1.5, 5]\\ &3: &[5, 2.3]\\ &4: &[8, 2.3] \end{align}隣接配列と距離配列の順序が対応していることに注意してください。この対応によって、「隣接配列からノード3とノード2が隣接していることがわかる。そのエッジの重みは、ノード2がノード3の隣接配列の1番目にあるから、ノード3の距離配列の1番目を見て5だとわかる」というような検索が可能になります。
隣接配列を使えば、ネットワークが大きなものになっても要領よく記憶しておくことができます。やりたい分析や解析によっては隣接行列や距離行列が必要になることもありますが、当面は隣接配列で十分だと思われます。
モデリングしたネットワークを隣接配列にして書き出す
それではいよいよ、Rhinocerosでモデリングしたネットワークを隣接配列にしていきます。
環境はWindows10、Rhinoceros 5です。方法
以下のコードでは、ネットワークがすべて直線分でモデリングされていることを要求します。
まず、Rhinocerosのコマンドに、
EditPythonScriptと入力してPythonエディタを起動し、以下のコードを張り付けて、走らせます。check pointと書かれた部分については、後に説明を加えます。
rhino_network_write.py# coding utf-8 import rhinoscriptsyntax as rs import math import random import sys import os """ check point1 """ edges = rs.GetObjects("select objects") adjacentList = {} attributeList = {} """ check point2 """ coordinations = [] coordinations_rounded = [] # for checking if a point is searched already or not """ example adjacentList = {0: [1, 2, 3], 1: [0, 2],...} attributeList = {0: [2.0, 5.0, 8.6], 1: [2.0, 4.7], ...} coordinations = [[4.5, 8.2, 0.0], [5.2, 3.6, 0.0], ...] """ cnt = 0 # point id for i in range(len(edges)): edge = edges[i] try: end_points = rs.CurvePoints(edge) except: rs.ObjectColor(edge, (255, 0, 0)) print("Error", edge) break l = rs.CurveLength(edge) """ check point3 """ kind = rs.ObjectLayer(edge) for p in end_points: """ check point4 """ p_rounded = [round(p[0], 2), round(p[1], 2), round(p[2], 2)] # round to the second decimal place if p_rounded in coordinations_rounded: # this point is already searched pass else: # search a new point coordinations.append(p) coordinations_rounded.append(p_rounded) adjacentList[cnt] = [] attributeList[cnt] = [] cnt += 1 # two end points are connected point_ids = [coordinations_rounded.index([round(p[0], 2), round(p[1], 2), round(p[2], 2)]) for p in end_points] adjacentList[point_ids[0]].append(point_ids[1]) adjacentList[point_ids[1]].append(point_ids[0]) attributeList[point_ids[0]].append((l, kind)) # you can add another info in attributeList attributeList[point_ids[1]].append((l, kind)) for k in adjacentList.keys(): rs.AddTextDot(k, coordinations[k]) # set your path to the project folder f = open("C:\\Users\\Owner\\Desktop\\adjacentList.txt", "w") for k, v in adjacentList.items(): print(k, v) f.write(str(k)+"\n") for nei in v: f.write(str(nei)+",") f.write("\n") f.close() f = open("C:\\Users\\Owner\\Desktop\\attributeList.txt", "w") for k, v in attributeList.items(): print(k, v) f.write(str(k)+"\n") for ats in v: #ats = (length, layer_name) for at in ats: f.write(str(at)+"\n") f.write("_\n") f.close() f = open("C:\\Users\\Owner\\Desktop\\coordinations.txt", "w") for p in coordinations: for u in p: f.write(str(u)+"\n") f.close()コードが走り終わると、adjacentList.txt、attributeList.txt、coordinations.txtが得られます。
コードの注記
・check point1
コードを走らせると、まず、オブジェクトを選択するよう求められますが、それがこの箇所になります。選択するオブジェクトは、モデリングしたネットワークを構成する直線分すべてです。・check point2
分析結果の可視化など、追々ノードの座標が必要になるので、このコードの中で記憶しておきます。・check point3
このコードでは、エッジの重みとしてエッジの長さを想定しています。ただ、分析の目的によっては長さだけでなく、性質(平坦な道なのか階段なのか、一般道なのか高速道なのか)も紐づけておきたくなることがあります。それらの性質ごとにレイヤー分けしてモデリングしたならば、この行でそのレイヤー名をエッジに紐づけて記憶しておくことができます。レイヤー名は半角英数字としてください。・check point4
ネットワークをモデリングする際、スナップを効かせて線分の端点は一致させておくことが可能で、たいていの場合、座標が等しいかどうかでノードの同一性を確かめることが可能です。ただ、時折スナップを効かせられていないことに気づかなかった場合、同じノードが違うノードとしてデータ化されてしまうことがあります。それを防ぐために、あらかじめ許容誤差を設定しておいて、座標の差異がその誤差の範囲内なら同一ノードとみなすこととしています。ここでは、その誤差を小数第2位としていますが、ネットワークの広さやモデリングの際の単位に気を付けて設定してください。デモンストレーション
RhinocerosでPythonを動かすのが初めての人用に、画面遷移を示したいと思います。
まず、Rhinocerosを起動し、モデリングしたネットワークのファイルを開きます。次に、コマンドに
EditPythonScriptと打ち込み、エディタを起動します。
上図では、歩道(network\street)と横断歩道(network\crosswalk)をレイヤーで分けてモデリングしています。エディタ上部の緑の▶をクリックしてコードを走らせます。すると、Rhinocerosのコマンドに
select objects:と出てくるので、ネットワーク全体を選択してEnterを押します。
すると、adjacentList.txt、attributeList.txt、coordinations.txtが得られるとともに、ノードの位置にテキストドットで番号が振られます。出来上がったデータが正しいかどうか確かめる手段の一つとしてお使いください。
【次回】書き出したネットワークデータをPythonで読み込む
お気づきの方も多いかもしれませんが、実は、本記事で紹介したコードの中で、すでに、隣接配列そのものを一度作っており、それをまた.txtにして書き出すという回りくどいことをしました。Pythonにはネットワーク分析関連のモジュールが豊富に用意されているのですが、Rhinoceros上のPythonでは使えないことが多いためこのようなことをしています。
次回は、得られた.txtを隣接配列に再翻訳することで、Python上での分析を可能にします。
一連の記事に関連するコードは、以下にあります。
→関連するコードホームページのご案内
建築・都市計画数理に関する私の研究の内容や、研究にまつわるtips等は、個人ホームページにて公開しています。ゆくゆくは、気軽に使える分析ツールも作っていきたいと思っているので、ぜひ覗きに来てください。
→田端祥太の個人ホームページ





- 投稿日:2020-12-23T18:06:08+09:00
pythonでつくる数字判別アプリで6桁の数字を判別させてみた
はじめまして。
devと申します。Qiitaへの投稿は初めてです。
この投稿がどなたかの役に立てばと思い、記事を作成しています。今回はOCRを利用した数字判別アプリについてご紹介します。
アプリについて
ごく単純ですが、入力された画像をOCR(Google cloud vision api)で判別し、答えを返すWebアプリです。
作成理由
車のスピードメーターみたいなアナログなメーターを読み取れたら便利ですよね。
サービスとしては既に提供されているようだけど、「自分も少し近いことしてみたいなぁ」と思ったのが発端。でもメーターの読み取りって難易度高そう。初めてのアプリなので、「まずはアナログな走行距離数字を読み取ってみよう!」という訳で数字の識別にチャレンジです。
基本機能
6桁数字の画像を選んでポチれば、読み取った数字をWeb画面に返します。
例えばこんな画像を読み取れます。
作って感じたのは「Google cloud vision api」を使えばこんな簡単に高精度のアプリができるんだ!ってことですね。
簡単ながら、精度もGOOD(le)!
しかも、数字だけでなく文字も判定できちゃいます。
だからこんなのもOK
でも何に使えるの?
お遊びアプリなので、このままでは「何にも使えません」 笑
発展形としては「書類NOの通し番号読み取り」や「伝票読み取り」にも使えるかと思います。
別に「Google cloud vision api」を使わずとも「Tesseract」や、その他フリーソフトでもOCR機能は実現できますね。
実装環境
html
css
Flask選択肢
数字を読み取るために、以下の2つを検討しました。
・mnistの学習データ
・OCRmnistデータセットを使って学習させる
mnistの場合、学習させるのは比較的容易です。
ただし桁数を表現するために、1桁目、2桁目といった物体検出が必要。学習データは以下のような方法で保存できます。
■[参考]mnist学習のサンプルコードfrom keras.datasets import mnist from keras.models import Sequential, load_model from keras.layers.core import Dense, Activation, Flatten from keras.layers import Conv2D, MaxPooling2D, Dropout, Reshape from keras.utils import np_utils import numpy as np (X_train, y_train),(X_test, y_test) = mnist.load_data() X_train = np.array(X_train)/255 X_test = np.array(X_test)/255 y_train = np_utils.to_categorical(y_train) y_test = np_utils.to_categorical(y_test) model = Sequential() model.add(Reshape((28,28,1),input_shape=(28,28))) model.add(Conv2D(32,(3,3))) model.add(Activation("relu")) model.add(Conv2D(32,(3,3))) model.add(Activation("relu")) model.add(MaxPooling2D((2,2))) model.add(Dropout(0.5)) model.add(Conv2D(16,(3,3))) model.add(Activation("relu")) model.add(MaxPooling2D((2,2))) model.add(Dropout(0.5)) model.add(Flatten()) model.add(Dense(784)) model.add(Activation("relu")) model.add(Dropout(0.5)) model.add(Dense(10)) model.add(Activation("softmax")) model.compile(loss="categorical_crossentropy", optimizer="sgd", metrics=["accuracy"]) hist = model.fit(X_train, y_train, batch_size=200, verbose=1, epochs=1, validation_split=0.1) score = model.evaluate(X_test, y_test, verbose=1) print('Test loss:', score[0]) print("test accuracy:", score[1]) model.save("C:/test/mnist_main.h5")OCRを使って判別させる
何よりも手っ取り早いのがOCR。
GoogleのAPIを使うので精度も高く、作りこむ必要がありません。
桁数も気にせず読み取ってくれます。用途次第では十分利用できますね!
※「Google cloud vision api」実装はこちらを参考にさせていただきました。今後の発展
業務に合わせて、書類の通しNoを読み取る機能が実装できると役に立ちそうだなと思ってます。
空き時間をみて学習させてみるつもりです。




- 投稿日:2020-12-23T17:46:08+09:00
Pythonで学ぶ簿記 ~簿記一巡の流れ編~
はじめに
Python(主にPandas)で簿記一巡の流れをコーディングしながら理解することが、この記事の目的です。
おおまかな流れの理解を目的としているため、簿記の教科書に出てくる項目を一部省略して説明しています。
例えば、
- 商品在庫、仕入金額を元にした売上原価の算定
- 精算表の作成
- 翌期への繰越
といった事項は割愛しています。
0.簿記とは
企業で行われた取引を仕訳として記録し、貸借対照表(B/S)と損益計算書(P/L)を作成する手続きです。
仕訳のイメージは以下のとおりです。
仕訳の左側を借方、右側を貸方と呼びます。
残念ながら、これは覚えるしかない約束事です。貸借対照表(B/S)は企業の財政状態、平たく言うと
「企業が今どれだけの財産を持っているか」
をあらわす表です。
損益計算書(P/L)は企業の経営成績、平たく言うと
「企業が一定の期間にどれだけ儲かったか(損したか)」
をあらわす表です。
簿記の手続きは、ごく大まかに言うと以下1~3の流れで行います。
1. 仕訳の作成
取引を仕訳として仕訳帳に記録する。
2. 残高試算表(T/B)の作成
仕訳帳から勘定科目ごとの借方金額、貸方金額を集計し、残高試算表を作成する。
3. 貸借対照表(B/S)、損益計算書(P/L)の作成
残高試算表を貸借対照表(B/S)、損益計算書(P/L)に分割する。(注1)
なお1.仕訳の作成にあたっては以下4つのルールを守る必要があります。
- 仕訳ルール①:借方(左側)、貸方(右側)に勘定科目と金額を記載する
- 仕訳ルール②:借方、貸方それぞれの合計金額は必ず一致する
- 仕訳ルール③:資産の増加は借方、負債と純資産の増加は貸方に記載する
- 仕訳ルール④:費用は借方、収益は貸方に記載する
・・・ここまで、簿記特有の用語が次から次へと現れました。
特に簿記の初学者の方は、用語の多さに戸惑うことと思います。まずは、簿記の世界では
- 企業の取引を仕訳という形式であらわす
- 仕訳の左側を借方、右側を貸方と呼ぶ
という点だけ覚えてください。
その他用語については、仕訳を作成する中で①~④のルールを都度引用しながら説明していきます。
(注1)
簿記の教科書では、1→2の間に「決算整理仕訳」を作成し、2→3の間に「精算表」を作成する、とあります。
残高試算表 → 決算整理仕訳 → 貸借対照表、損益計算書
の数字を記録するのが精算表です。
しかし経理業務の現場では、決算整理仕訳は通常の仕訳と区別せず行うケースが多いものと思われます。
また2→3はシステム上自動で生成され、わざわざ精算表を作成しないケースが多いと思われるため、本稿では割愛します。
(簿記の試験のように手書きで財務諸表を作成する際には必要な表ですが。。)1.仕訳の作成
【やりたいこと】
取引を仕訳として仕訳帳に記録します。【コーディングの方針】
仕訳をPandasのDataFrame形式で、仕訳帳 df_siwake に入力します。
Siwakeクラスの関数 entry を呼び出すことで、df_siwakeに仕訳データの行を追加し、更新します。
仕訳ルール①:借方(左側)、貸方(右側)に勘定科目と金額を記載するに従い、仕訳を入力するための空のDataFrameとして仕訳帳 df_siwake を作成します。
import pandas as pd df_siwake = pd.DataFrame(index=[], columns=['仕訳番号', '日付', '借方科目', '借方金額', '貸方科目', '貸方金額'])例えば
(借方)現金 /(貸方)資本金
という仕訳を入力する場合、DataFrameの型に従って毎回df_siwake.append(pd.Series([1, 20200401, '現金', 1000, '資本金', 1000], index=df_kamoku.columns), ignore_index=True)というコードを書き、DataFrameの行を追加しても良いのですが、
- 複合仕訳(借方と貸方が1対1対応していない仕訳)を入力できない ・・・①
- 入力時に、仕訳のデータ型が正しいか(借方金額に文字列を入力するなど)確認できない ・・・②
- 入力時に、仕訳の貸借が一致しているか確認できない ・・・③
との問題があります。
※簿記の世界では③が守られていることが非常に重要です。
仕訳入力時に必ず貸借が一致していることにより、後ほど残高試算表を作るときにも、
貸借金額が一致することが保証されます。そこで仕訳入力用のクラス Siwake を定義し、まずは①複合仕訳の入力に対応する形で
関数 entry を定義します。※最終的には Siwake 内に②データ型チェック、③貸借一致チェックの関数を実装しますが、
コードが長くなるため、末尾に補足として追記します。class Siwake: def __init__(self): self.siwake_no = 0 def entry(self, df, date, kari, kashi): self.siwake_no += 1 # ...仕訳番号を更新 for i in range(len(kari)): # ...複合仕訳に対応するため[借方科目、借方金額]の数だけループを回す kari_entry = pd.Series([self.siwake_no] + [date] + kari[i] + ["", 0], index=df.columns) df = df.append(kari_entry, ignore_index=True) for i in range(len(kashi)): # ...複合仕訳に対応するため[貸方科目、貸方金額]の数だけループを回す kashi_entry = pd.Series([self.siwake_no] + [date] + ["", 0] + kashi[i], index=df.columns) df = df.append(kashi_entry, ignore_index=True) return dfクラス Siwake 内のコメントについて補足します。
仕訳帳には仕訳を日付順に記録していくため、クラス変数として仕訳番号siwake_noを定義しています。
仕訳が作成される(関数entryが呼び出される)ごとにself.siwake_no += 1 # ...仕訳番号を更新で仕訳番号を連番として更新しています。
また本稿では借方科目、貸方科目とも1行の仕訳のみを扱っていますが、実務上は複数行の仕訳を作成することが多いです。
複合仕訳に対応するため以下のようにループを回し、借方・貸方それぞれのpd.Seriesを生成した上で、
仕訳日記帳 df_siwake に行を追加しています。for i in range(len(kari)): # ...複合仕訳に対応するため[借方科目、借方金額]の数だけループを回す kari_entry = pd.Series([self.siwake_no] + [date] + kari[i] + ["", 0], index=df.columns) df = df.append(kari_entry, ignore_index=True) for i in range(len(kashi)): # ...複合仕訳に対応するため[貸方科目、貸方金額]の数だけループを回す kashi_entry = pd.Series([self.siwake_no] + [date] + ["", 0] + kashi[i], index=df.columns) df = df.append(kashi_entry, ignore_index=True)クラス Siwake の補足説明は以上です。
関数entryには以下の形式で入力します。
siwake.entry(df_siwake:仕訳帳, date:日付, kari :[[借方科目1, 借方金額1], [借方科目2, 借方金額2], ... ], kashi:[[貸方科目1, 貸方金額1], [貸方科目2, 貸方金額2], ... ])すると仕訳日記帳 df_siwake に以下の行が追加されます。
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 0 siwake_no
(数値)date
(数値)kari[0][0]
(文字列)kari[0][1]
(数値)""
(文字列)0
(数値)1 siwake_no
(数値)date
(数値)""
(文字列)0
(数値)kashi[0][0]
(文字列)kashi[0][1]
(数値)… … … … … … … それではクラスSiwakeのインスタンスを生成し、
siwake = Siwake()会社運営の最も基本的なサイクルである
- 会社を設立
- 商品の仕入
- 商品の販売
- 仕入代金の支払
- 販売代金の回収
の各取引について仕訳を作成していきます。
仕訳①:会社を設立
現金1000を元手に会社を設立しました。
この元手のことを資本金と呼び、仕訳は以下の通りです。
df_siwake = siwake.entry(df_siwake, 20200401, [['現金', 1000]], [['資本金', 1000]]) df_siwake[df_siwake['仕訳番号']==siwake.siwake_no]
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 0 1 20200401 現金 1000 0 1 1 20200401 0 資本金 1000 会社に払い込まれた現金は会社のもの、つまり資産ですから借方に記載します。
一方、資本金は現金1000を払込した(株式会社であれば)株主のものです。純資産といい、貸方に記載します。
借方金額1000と貸方金額1000が必ず一致していることが大事です。
少し話は先に進みますが、貸方の純資産はおおまかに言うと
会社設立時に払い込まれた資本金 + 会社設立後に稼いだ利益
からなります。
事業を行うことで利益を蓄積し、(株式会社であれば)株主に配当として還元する、
というのが会社の基本サイクルです。会社設立後に稼いだ利益が、貸方の純資産に来ることから、
- 収益の発生 → 貸方の利益を増やす → 貸方に記載
- 費用の発生 → 貸方の利益を減らす → 借方に記載
すなわち、
仕訳ルール④:費用は借方、収益は貸方に記載する
が導かれます。仕訳②:商品の仕入れ
商品500を外部業者より仕入れました。
仕訳は以下の通りです。df_siwake = siwake.entry(df_siwake, 20200402, [['商品', 500]], [['買掛金', 500]]) df_siwake[df_siwake['仕訳番号']==siwake.siwake_no]
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 2 2 20200402 商品 500 0 3 2 20200402 0 買掛金 500 仕入れた商品は会社のもの、つまり資産ですから借方に記載します。
(ルール③:資産の増加は借方、負債と純資産の増加は貸方に記載する)会社間の取引において、仕入代金は仕入先と〇〇日後支払、などの条件を取り決めて
後払いすることがほとんどです。
(もちろんその場で支払する場合もあります)この支払うまでの債務(代金を支払う義務)を買掛金といいます。
買掛金は将来、外部業者の現金となる、つまり負債ですから貸方に記載します。
(ルール③:資産の増加は借方、負債と純資産の増加は貸方に記載する)仕訳③:商品を売上
仕入れた商品のうち200について、価格300で販売しました。
売上についての仕訳は以下の通りです。df_siwake = siwake.entry(df_siwake, 20200403, [['売掛金', 300]], [['売上', 300]]) df_siwake[df_siwake['仕訳番号']==siwake.siwake_no]
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 4 3 20200403 売掛金 300 0 5 3 20200403 0 売上 300 会社間の取引において 、販売代金は販売先と〇〇日後回収、などの条件を取り決めて
後日回収することがほとんどです。
(もちらん、その場で回収する場合もあります)この回収するまでの債権(代金をもらう権利)を売掛金といいます。
売掛金は将来、会社の現金となる、つまり資産ですから借方に記載します。
(ルール③:資産の増加は借方、負債と純資産の増加は貸方に記載する)売上は収益であり、会社の純資産(貸方)を増やす効果がありますから、貸方に記載します。
(ルール④:費用は借方、収益は貸方に記載する)売上に対応する原価についての仕訳は以下の通りです。
df_siwake = siwake.entry(df_siwake, 20200403, [['売上原価', 200]], [['商品', 200]]) df_siwake[df_siwake['仕訳番号']==siwake.siwake_no]
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 6 4 20200403 売上原価 200 0 7 4 20200403 0 商品 200 商品を販売することで、会社のものである商品(借方)が減るので、その反対である貸方に記載します
(ルール③:資産の増加は借方、負債と純資産の増加は貸方に記載する
⇔ルール'③:資産の減少は貸方、負債と純資産の減少は借方に記載する)商品の減少と共に、商品の売上に対応する費用を売上原価として計上します。(注2)
費用は会社の純資産(貸方)を減らす効果がありますから、その反対である借方に記載します。
(ルール④:費用は借方、収益は貸方に記載する)
(注2)
本稿では簡略化のため、商品を売り上げたと同時に売上原価を計上しています。
実際には売上原価は、冒頭に少しだけ触れた「決算整理仕訳」により
売上原価 = 仕入金額の総額 + 期首の商品在庫金額 - 期末の商品在庫金額
という式で算定します。なお原価200の商品を、販売価額300で売り上げたため、その取引の利益は100になります。
しかし簿記の手続きでは、商品を販売するたびに利益を認識することはありません。
簿記の目的は一定の期間(会計期間)における利益を算定することであるためです。利益については、期末に当期分の収益および費用の合計金額を集計し、
その差額である利益について損益振替という仕訳を作成することで、
会計期間末に一度に認識します(後述)。仕訳④:仕入代金を支払
仕入代金500のうち300について、外部業者に支払いました。
(残りの200は翌月支払の契約と仮定します)
仕訳は以下の通りです。df_siwake = siwake.entry(df_siwake, 20200420, [['買掛金', 300]], [['現金', 300]]) df_siwake[df_siwake['仕訳番号']==siwake.siwake_no]
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 8 5 20200420 買掛金 300 0 9 5 20200420 0 現金 300 仕入代金を支払うことで、会社の資産である現金(借方)が減りますから、
その反対である貸方に記載します。
(ルール③:資産の増加は借方、負債と純資産の増加は貸方に記載する
⇔ルール'③:資産の減少は貸方、負債と純資産の減少は借方に記載する)一方、仕入先に代金を支払う債務である買掛金(貸方)も、支払完了と共になくなるため、
その反対である借方に記載します。
(ルール③:資産の増加は借方、負債と純資産の増加は貸方に記載する
⇔ルール'③:資産の減少は貸方、負債と純資産の減少は借方に記載する)仕訳⑤:販売代金を回収
販売代金200について、販売先から現金で回収しました。
(残りの100は翌月回収の契約と仮定します)
仕訳は以下の通りです。df_siwake = siwake.entry(df_siwake, 20200430, [['現金', 200]], [['売掛金', 200]]) df_siwake[df_siwake['仕訳番号']==siwake.siwake_no]
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 10 6 20200430 現金 200 0 11 6 20200430 0 売掛金 200 販売代金を回収することで、会社の資産である現金(借方)が増えますから、
借方に記載します。
(ルール③:資産の増加は借方、負債と純資産の増加は貸方に記載する)一方、販売先から代金をもらう債権である売掛金(借方)も、回収完了と共になくなるため、
その反対である貸方に記載します。
(ルール③:資産の増加は借方、負債と純資産の増加は貸方に記載する
⇔ルール'③:資産の減少は貸方、負債と純資産の減少は借方に記載する)ここまで
- 会社を設立
- 商品の仕入
- 商品の販売
- 仕入代金の支払
- 販売代金の回収
という一連の仕訳を作成しました。仕訳帳 df_siwake の中身を確認してみます。
df_siwake
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 0 1 20200401 現金 1000 0 1 1 20200401 0 資本金 1000 2 2 20200402 商品 500 0 3 2 20200402 0 買掛金 500 4 3 20200403 売掛金 300 0 5 3 20200403 0 売上 300 6 4 20200403 売上原価 200 0 7 4 20200403 0 商品 200 8 5 20200420 買掛金 300 0 9 5 20200420 0 現金 300 10 6 20200430 現金 200 0 11 6 20200430 0 売掛金 200 2.残高試算表の作成
【やりたいこと】
仕訳帳から勘定科目ごとの借方金額、貸方金額を集計し、残高試算表(T/B:Trial Balance)を作成します。【コーディングの方針】
仕訳帳 df_siwake から残高試算表 df_TB が生成されるよう、
クラス TrialBalance 内に、関数 create_tb および勘定科目のDataFrame df_kamokuを定義します。最終的に財務諸表を作成することを見据え、残高試算表の各勘定科目に以下の属性を与えるよう、
df_kamokuを定義します(注3)。
(注3)
実務上は仕訳帳や残高試算表などの他に、勘定科目マスタを用意し、科目コードや貸借区分などの属性を定義します。
仕訳の作成も科目コードで入力し、勘定科目名はマスタから引用するのが一般的です。
- 科目コード:科目の表示順
- 科目分類:資産、負債、純資産のいずれに属するか
- BS/PL:B/Sの科目か、P/Lの科目か
- 貸借区分:借方(資産)、貸方(負債、純資産)いずれに属するか
df_kamoku = pd.DataFrame({'貸借科目': ['現金', '売掛金', '商品', '買掛金', '資本金', '繰越利益剰余金', '売上', '売上原価', '当期利益'], '科目コード': ['100', '110', '120', '200', '300', '310', '400', '500', '600'], '科目分類': ['資産', '資産', '資産', '負債', '負債', '純資産', '収益', '費用', '利益'], 'BS/PL': ['BS', 'BS', 'BS', 'BS', 'BS', 'BS', 'PL', 'PL', 'PL'], '貸借区分': [1, 1, 1, -1, -1, -1, -1, 1, 1]})そして df_kamoku と、仕訳日記帳 df_siwake の金額を勘定科目ごとに集計したテーブル
df = df_siwake.groupby('貸借科目').sum()[['貸借金額']]を結合します。
なおPandasでの集計の都合上、借方をプラス、貸方をマイナスと考えたほうが扱いやすいため(注4)、
- 貸借金額:借方金額 - 貸方金額
とのカラムを作成します。
(注4)
「集計の都合上」と書きましたが、借方と貸方、プラスとマイナスとの概念は同値と言えます。
- プラスの反対がマイナス、マイナスの反対がプラス
- 借方の反対が貸方、貸方の反対が借方
- プラスの数とマイナスの数を足すとゼロになる
- 借方と貸方の金額は一致する
「借方」「貸方」という言葉の分かりにくさが、簿記を初めて学ぶ上での障害となりますが、
数学に親しい方は、プラスとマイナスの概念に置き換えれば理解しやすいかもしれません。class TrialBalance: df_kamoku = pd.DataFrame({'貸借科目': ['現金', '売掛金', '商品', '買掛金', '資本金', '繰越利益剰余金', '売上', '売上原価', '当期利益'], '科目コード': ['100', '110', '120', '200', '300', '310', '400', '500', '600'], '科目分類': ['資産', '資産', '資産', '負債', '負債', '純資産', '収益', '費用', '利益'], 'BS/PL': ['BS', 'BS', 'BS', 'BS', 'BS', 'BS', 'PL', 'PL', 'PL'], '貸借区分': [1, 1, 1, -1, -1, -1, -1, 1, 1]}) def create_tb(self, df_siwake): df = df_siwake.copy() df['貸借科目'] = df['借方科目'] + df['貸方科目'] df['貸借金額'] = df['借方金額'] - df['貸方金額'] df = df.groupby('貸借科目').sum()[['貸借金額']] df_merge = pd.merge(df, self.df_kamoku, on='貸借科目').sort_values('科目コード').reset_index(drop=True) return df_mergeTrialBalanceクラスのインスタンスを生成し、関数 create_tb に仕訳日記帳 df_siwake を渡して
残高試算表 df_TB を作成します。TB = TrialBalance() df_TB = TB.create_tb(df_siwake) df_TB
index 貸借科目 貸借金額 科目コード 科目分類 BS/PL 貸借区分 0 現金 900 100 資産 BS 1 1 売掛金 100 110 資産 BS 1 2 商品 300 120 資産 BS 1 3 買掛金 -200 200 負債 BS -1 4 資本金 -1000 300 負債 BS -1 5 売上 -300 400 収益 PL -1 6 売上原価 200 500 費用 PL 1 科目ごとの貸借金額(借方の場合+、貸方の場合-)が集計され、科目コードや科目分類などの属性が付与されています。
あとは残高試算表を、貸借対照表(B/S)、損益計算書(P/L)に分割するだけですが、
単純に分割しただけでは貸借対照表の借方金額、貸方金額が一致しないという問題が生じます。確認のため、残高試算表のうち科目分類が「BS」であるものだけを取り出します。
df_TB[df_TB['BS/PL']=='BS']
index 貸借科目 貸借金額 科目コード 科目分類 BS/PL 貸借区分 0 現金 900 100 資産 BS 1 1 売掛金 100 110 資産 BS 1 2 商品 300 120 資産 BS 1 3 買掛金 -200 200 負債 BS -1 4 資本金 -1000 300 負債 BS -1 一見問題ないように見えますが、この貸借対照表(B/S)は
ルール②:借方、貸方それぞれの合計金額は必ず一致する
を満たしていません。借方金額(貸借金額が+)、貸方金額(貸借金額が-)をそれぞれ集計してみます。
df_TB[(df_TB['BS/PL']=='BS') & (df_TB['貸借金額'] > 0)]
index 貸借科目 貸借金額 科目コード 科目分類 BS/PL 貸借区分 0 現金 900 100 資産 BS 1 1 売掛金 100 110 資産 BS 1 2 商品 300 120 資産 BS 1 df_TB[(df_TB['BS/PL']=='BS') & (df_TB['貸借金額'] < 0)]
index 貸借科目 貸借金額 科目コード 科目分類 BS/PL 貸借区分 3 買掛金 -200 200 負債 BS -1 4 資本金 -1000 300 負債 BS -1 print('借方金額合計:',df_TB[(df_TB['BS/PL']=='BS') & (df_TB['貸借金額'] > 0)].sum()['貸借金額']) print('貸方金額合計:',df_TB[(df_TB['BS/PL']=='BS') & (df_TB['貸借金額'] < 0)].sum()['貸借金額'])借方金額合計: 1300 貸方金額合計: -1200貸借対照表(B/S)における借方金額の合計と、貸方金額の合計が一致していないことがわかります。
この貸借対照表(B/S)における差額は、当期の損益計算書(P/L)における収益と費用の差額、つまり当期利益に一致します。
収益と費用の差額から当期利益を算出する手続きを損益振替といいます。
また損益計算書(P/L)における当期利益を、貸借対照表(B/S)の繰越利益剰余金という勘定に振り替える手続きを資本振替といいます。
資本振替の仕訳は以下のとおりです。
df_siwake = siwake.entry(df_siwake, 20200430, [['当期利益', 100]], [['繰越利益剰余金', 100]]) df_siwake[df_siwake['仕訳番号']==siwake.siwake_no]
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 12 7 20200430 当期利益 100 0 13 7 20200430 0 繰越利益剰余金 100 なお当期利益は売上300と売上原価200の差額100です。
損益振替および資本振替を行った後の仕訳帳 df_siwake および残高試算表 df_TB を見てみます。
df_siwake
index 仕訳番号 日付 借方科目 借方金額 貸方科目 貸方金額 0 1 20200401 現金 1000 0 1 1 20200401 0 資本金 1000 2 2 20200402 商品 500 0 3 2 20200402 0 買掛金 500 4 3 20200403 売掛金 300 0 5 3 20200403 0 売上 300 6 4 20200403 売上原価 200 0 7 4 20200403 0 商品 200 8 5 20200420 買掛金 300 0 9 5 20200420 0 現金 300 10 6 20200430 現金 200 0 11 6 20200430 0 売掛金 200 12 7 20200430 当期利益 100 0 13 7 20200430 0 繰越利益剰余金 100 df_TB = TB.create_tb(df_siwake) df_TB
index 貸借科目 貸借金額 科目コード 科目分類 BS/PL 貸借区分 0 現金 900 100 資産 BS 1 1 売掛金 200 110 資産 BS 1 2 商品 300 120 資産 BS 1 3 買掛金 -200 200 負債 BS -1 4 資本金 -1000 300 負債 BS -1 5 繰越利益剰余金 -1000 300 負債 BS -1 6 売上 -300 400 収益 PL -1 7 売上原価 200 500 費用 PL 1 8 当期利益 100 500 利益 PL 1 print('借方金額合計:',df_TB[(df_TB['BS/PL']=='BS') & (df_TB['貸借金額'] > 0)].sum()['貸借金額']) print('貸方金額合計:',df_TB[(df_TB['BS/PL']=='BS') & (df_TB['貸借金額'] < 0)].sum()['貸借金額'])借方金額合計: 1300 貸方金額合計: -1300損益振替および資本振替を行うことで、貸借対照表(B/S)の借方金額および貸方金額が一致するこどが確認できました。
3. 貸借対照表(B/S)、損益計算書(P/L)の作成
【やりたいこと】
残高試算表を貸借対照表(B/S)、損益計算書(P/L)に分割します。【コーディングの方針】
残高試算表 df_TBを「BS/PL」列が'BS'か、'PL'かにより分割します。なお「貸借金額」に「貸借区分」(+1、-1)を乗じることで、借方(+)貸方(-)それぞれの金額を絶対値に戻し、
「表示貸借」という列に格納します。BS = df_TB[df_TB['BS/PL']=='BS'].reset_index(drop=True) BS['表示貸借'] = BS['貸借金額'] * BS['貸借区分'] BS[['科目コード','科目分類', '貸借科目', '表示貸借']]
index 科目コード 科目分類 貸借科目 表示貸借 0 100 資産 現金 900 1 110 資産 売掛金 100 2 120 資産 商品 300 3 200 負債 買掛金 200 4 300 負債 資本金 1000 5 310 純資産 繰越利益剰余金 100 PL = df_TB[df_TB['BS/PL']=='PL'].reset_index(drop=True) PL['表示貸借'] = PL['貸借金額'] * PL['貸借区分'] PL[['科目コード','科目分類', '貸借科目', '表示貸借']]
index 科目コード 科目分類 貸借科目 表示貸借 0 400 収益 売上 300 1 500 費用 売上原価 200 2 600 利益 当期利益 100 貸借対照表(B/S)、損益計算書(P/L)が作成できました。
改めてイメージ図を表すと以下のとおりです。
もう一度振り返りますと、
1. 仕訳の作成
取引を仕訳として仕訳帳に記録する。
2. 残高試算表(T/B)の作成
仕訳帳から勘定科目ごとの借方金額、貸方金額を集計し、残高試算表を作成する。
3. 貸借対照表(B/S)、損益計算書(P/L)の作成
残高試算表を科目により貸借対照表(B/S)、損益計算書(P/L)に分割する。
との流れで、日々の取引を集計して財務諸表を作成することが、簿記一巡の手続きです。
補足:仕訳作成時のエラーチェック
仕訳入力用のクラス Siwake に②データ型チェック、③貸借一致チェックの関数を定義し、
- 仕訳のデータ型が正しいか、入力時に確認する …②
- 仕訳の貸借が一致しているか、入力時に確認する …③
ように実装します。
class Siwake: def __init__(self): self.siwake_no = 0 def entry(self, df, date, kari, kashi): # ...①複合仕訳に対応 if self.check_keishiki(date, kari, kashi): # ...②データ型チェック if self.check_taisyaku(kari, kashi): # ...③貸借一致チェック self.siwake_no += 1 # ...仕訳番号を更新 for i in range(len(kari)): #複合仕訳に対応するため[借方科目、借方金額]の数だけループを回す # 仕訳番号、日付、借方科目、借方金額、貸方科目、貸方金額をSereis化し、DataFrameに格納 # なお貸方科目は""、貸方金額は0とする kari_entry = pd.Series([self.siwake_no] + [date] + kari[i] + ["", 0], index=df.columns) df = df.append(kari_entry, ignore_index=True) for i in range(len(kashi)): #複合仕訳に対応するため[貸方科目、貸方金額]の数だけループを回す # 仕訳番号、日付、借方科目、借方金額、貸方科目、貸方金額をSereis化し、DataFrameに格納 # なお借方科目は""、借方金額は0とする kashi_entry = pd.Series([self.siwake_no] + [date] + ["", 0] + kashi[i], index=df.columns) df = df.append(kashi_entry, ignore_index=True) return df else: print("エラー:貸借金額を一致させてください") return df else: pass def check_keishiki(self, date, kari, kashi):# ...②データ型チェック for i , k in zip(range(len(kari)),range(len(kashi))): if type(date) != int or len(str(date)) != 8: print("エラー:日付は8桁の整数yyyymmddで入力してください") return False elif len(kari[i]) != 2: print("エラー:借方科目、借方金額のみ入力してください") return False elif type(kari[i][0]) != str or type(kari[i][1]) != int: print("エラー:データ型は 借方科目→文字列、借方金額→数値 としてください") return False elif len(kashi[k]) != 2: print("エラー:貸方科目、貸方金額のみ入力してください") return False elif type(kashi[k][0]) != str or type(kashi[k][1]) != int: print("エラー:データ型は 貸方科目→文字列、貸方金額→数値 としてください") return False else: return True def check_taisyaku(self, kari, kashi):# ...③貸借一致チェック kari_sum = 0 kashi_sum = 0 for i in range(len(kari)): kari_sum += kari[i][1] for i in range(len(kashi)): kashi_sum += kashi[i][1] if kari_sum != kashi_sum: return False else: return TrueSiwakeクラスのインスタンスを生成し、不正な仕訳を作成していきます。
siwake = Siwake()「日付」に不正な値を入れてみます。
df_siwake = siwake.entry(df_siwake, 1201, [['現金', 500]], [['資本金', 1000]])エラー:日付は8桁の整数yyyymmddで入力してください貸借金額が一致していない仕訳を入れてみます。
df_siwake = siwake.entry(df_siwake, 20200401, [['現金', 500]], [['資本金', 1000]])エラー:貸借金額を一致させてください余計な項目の入った仕訳を入れてみます。
df_siwake = siwake.entry(df_siwake, 20200401, [['現金', 500, '業者A']], [['資本金', 1000, '業者A']])エラー:借方科目、借方金額のみ入力してくださいデータ型が不正な仕訳を入れてみます。
df_siwake = siwake.entry(df_siwake, 20200401, [['現金', 500]], [['資本金', '1000']])エラー:データ型は 貸方科目→文字列、貸方金額→数値 としてください実務上は入力値が空でないかのチェック、勘定科目が科目マスタにあるかのチェックなど、
様々なチェック項目が考えられますが、本稿では最低限のチェックのみ実施しています。





- 投稿日:2020-12-23T17:10:13+09:00
【AWS】Lambdaの実行ログから指定した文字列を検知してslackに通知
今回は自分が触れる機会の多いAWSのサービスを使用して運用の際などで利用できる通知方法の一つをご紹介します。
使用サービス
- Lambda
- CloudWatch
- Slack
実装フロー
1.Lambda関数からCloudWatch Logsへログを出力
2.CloudWatch Logsから指定した文字列を検知
3.検知された文字列をトリガーにSlack通知用のLambda関数を発火
4.通知用LambdaでSlackへ文字列を通知フロー詳細
実際に上記のフローで実装していきます。
手順1
今回は「test」という文字列でCloudWatch Logsへ出力します。
手順2
文字列検知にCloudWatch Logsのサブスクリプションフィルター(Lambda)を使用していきます。
手順3
通知用Lambda関数とログ形式およびフィルターパターンを設定します
手順4
環境変数「WebhookURL」には通知したいslackのWebhook URLを設定しています。
notifi.pyimport json import os import urllib.request import slackweb def lambda_handler(event, context): decoded_data = zlib.decompress( base64.b64decode(event['awslogs']['data']), 16+zlib.MAX_WBITS ) json_data = json.loads(decoded_data) print(json_data['logEvents']) for i in json_data['logEvents']: test = i['message'] # ログの内容 slack = slackweb.Slack(url=os.environ['WebhookURL']) slack.notify(text=test)先ほど設定した文字列を検知してslackに通知されることを確認しました。
まとめ
上記以外にも通知方法は複数ありますが、なるべく簡潔にまとめていった方が管理しやすいので簡略化できるところはどんどん楽にしていきたいですね。

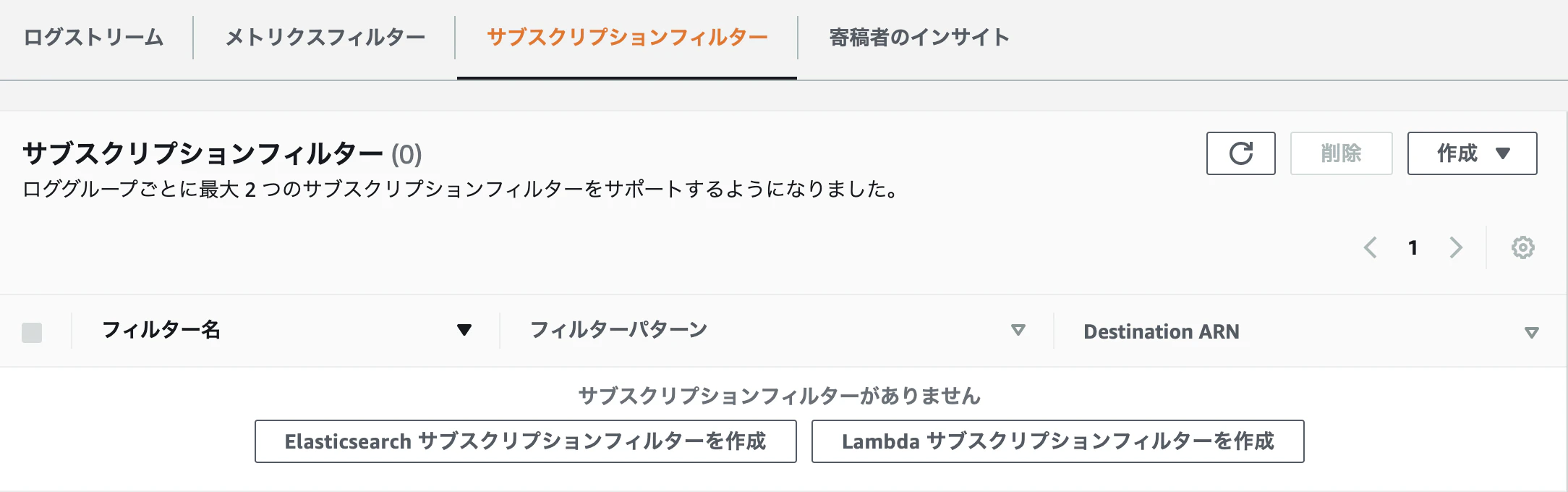


- 投稿日:2020-12-23T16:55:27+09:00
PythonでYouTube API を叩いてみる
この記事は福島高専 Advent Calendar 2020 25日目の記事です。
本記事はAPIについての記事です。内容の悪用は厳禁でお願いします。はじめに
昨今、APIの重要性について述べられている記事や動画などをちらほらと見かけるようになってきたので、自分もPythonの勉強がてら触ってみることにしました。まだまだ初学者なのでスマートなコードを書けませんが、よろしくお願いします。
概要
取り敢えず、比較的メジャーだと思われる
YouTube Data APIを叩いてYouTubeチャンネルや動画のデータを取得して、解析してみたいと思います。下記の事前準備は既に済んでいるという前提です。事前準備
- YouTube Data API v3のAPIキーを取得しておく
- Pythonをインストールし開発環境を整える
テスト実装
取り敢えず、APIの使い方を軽く理解するためにいくつかメソッドを利用してみます。因みにAPIのQuotas(1日の使用量)は10000が上限です。テストを繰り返していると案外あっさり到達する可能性があるので注意してください。
必要なパッケージのインストール
まず、PythonでYouTube Data APIを使用するためのパッケージをインストールします。
パッケージのインストール$ pip install google-api-python-client検索クエリを含むYouTubeチャンネルを取得する
手始めに検索ワードを含むYouTubeチャンネルを取得する処理を実装します。
getChannel.pyfrom apiclient.discovery import build API_KEY = '<API_KEY>' #取得したAPIキー YOUTUBE_API_SERVICE_NAME = 'youtube' YOUTUBE_API_VERSION = 'v3' youtube = build( YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey = API_KEY ) SEARCH_QUELY = input('Query >> ') response = youtube.search().list( q=SEARCH_QUELY, part='id,snippet', maxResults=10, type='channel').execute() for item in response.get('items', []): print(item['snippet']['title'])スクリプトを実行してキーワードを入力すると該当するチャンネル10個が一覧で出力されます。
<API_KEY>には各自取得したAPIキーを入れてください。response = youtube.search().list( q=SEARCH_QUELY, part='id,snippet', maxResults=10, type='channel').execute()肝となるのはここでしょうか。
search().list()メソッドの引数に各パラメータを与えることで取得したい情報を設定できます。パラメータの設定によって、チャンネルだけでなく動画や再生リストも取得できるようです。for item in response.get('items', []): print(item['snippet']['title'])データはjson形式で返ってくるため、
getで必要な情報を抜き出します。パラメータや返り値の詳細な形式はYouTube Data API Referenceで確認してください。指定したチャンネルの動画データを取得する
特定のチャンネルのIDを指定することでそのチャンネルの動画情報を取得できます。
getVideos.pyfrom apiclient.discovery import build API_KEY = '<API key>' YOUTUBE_API_SERVICE_NAME = 'youtube' YOUTUBE_API_VERSION = 'v3' CHANNEL_ID = '<Channel ID>' youtube = build( YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey=API_KEY ) response = youtube.search().list( part = "snippet", channelId = CHANNEL_ID, maxResults = 5, order = "date", type ='video' ).execute() for item in response.get("items", []): print(item['snippet']['title'])先ほどのコードを多少改変しただけです。
search().list()メソッドのパラメータが増えていますね。channelIdを指定すると該当するチャンネルの動画情報を最大値maxResultsまで取得することができます。orderでレスポンスのソート方法を指定できます。dateは日付順ですね。動画のコメントを取得する
特定の動画のコメントを取得する処理です。
getComments.pyimport json import requests from apiclient.discovery import build URL = 'https://www.googleapis.com/youtube/v3/' API_KEY = '<API_KEY>' YOUTUBE_API_SERVICE_NAME = 'youtube' YOUTUBE_API_VERSION = 'v3' VIDEO_ID = '<Video ID>' params = { 'key': API_KEY, 'part': 'snippet', 'videoId': VIDEO_ID, 'order': 'relevance', 'textFormat': 'plaintext', 'maxResults': 100, } response = requests.get(URL + 'commentThreads', params=params) resource = response.json() for item in resource['items']: name = item['snippet']['topLevelComment']['snippet']['authorDisplayName'] like_cnt = item['snippet']['topLevelComment']['snippet']['likeCount'] text = item['snippet']['topLevelComment']['snippet']['textDisplay'] print('ユーザ名: {}\n{}\nグッド数: {}\n'.format(name, text, like_cnt))チャンネルと同様にIDを指定すると特定の動画のコメントを取得できます。
response = requests.get(URL + 'commentThreads', params=params) resource = response.json()URLに指定したパラメータを繋いで
requestしています。for item in resource['items']: name = item['snippet']['topLevelComment']['snippet']['authorDisplayName'] like_cnt = item['snippet']['topLevelComment']['snippet']['likeCount'] text = item['snippet']['topLevelComment']['snippet']['textDisplay'] print('ユーザ名: {}\n{}\nグッド数: {}\n'.format(name, text, like_cnt))例の如く、レスポンスはjsonなので必要な情報を抜き出しています。今回はコメントしたユーザ名、本文、グッド数を取得していますが、他にも返信数や子コメントなども取得可能です。
データ解析
APIの使い方がなんとなく掴めたところで軽いデータ解析を行ってみます。データ解析といっても上記のコードを元に特定の動画のコメントを取得してCSV出力するだけの簡単なものです。具体的には
- 検索ワードを入力して関連するチャンネルを取得する
- チャンネルを指定して動画を取得する
- 動画を指定してコメントを取得する
- CSVに書き出す
といった処理を実装してみます。
youtube_api.pyで作成します。チャンネル取得
検索ワードを入力して関連するチャンネルタイトルをナンバリングしてを一覧で表示させます。
youtube_api.py#!/usr/bin/env python # -*- coding: utf-8 -*- import json import requests import pandas as pd from apiclient.discovery import build URL = 'https://www.googleapis.com/youtube/v3/' API_KEY = '<API_KEY>' YOUTUBE_API_SERVICE_NAME = 'youtube' YOUTUBE_API_VERSION = 'v3' SEARCH_QUELY ='' youtube = build( YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey = API_KEY ) def getChannel(): channel_list = [] num = 0 search_res = youtube.search().list( q=SEARCH_QUELY, part='id,snippet', maxResults=10, type='channel', order='rating' ).execute() for item in search_res.get('items', []): num += 1 channel_dict = {'num':str(num),'type':item['id']['kind'],'title':item['snippet']['title'],'channelId':item['snippet']['channelId']} channel_list.append(channel_dict) print('***Channel list***') for data in channel_list: print("Channel " + data["num"] + " : " + data["title"]) print('******************') return getId(input('Channel Number>> '),channel_list)軽く解説です。
search()のパラメータを関連チャンネル10個をリソースの評価が高い順に取得するように設定しています。
リソースのタイトルとChannelIDをdictionary型に格納しています。numは一覧から特定のチャンネルを指定するための番号です。dictionaryをさらにlistに格納します。選択したいチャンネルの番号を入力するとChannelIDを返します。動画取得
続いて指定したChannelIDから動画を取得して表示させるコードを追加します。
youtube_api.pydef getVideos(_channelId): video_list = [] num = 0 video_res = youtube.search().list( part = 'snippet', channelId = _channelId, maxResults = 100, type = 'video', order = 'date' ).execute() for item in video_res.get("items",[]): num += 1 video_dict = {'num':str(num),'type':item['id']['kind'],'title':item['snippet']['title'],'videoId':item['id']['videoId']} video_list.append(video_dict) print('***Video list***') for data in video_list: print("Video " + data["num"] + " : " + data["title"]) print('****************') return getId(input('Video Number>> '),video_list)同じようなことをやっているだけなので説明は省略。
コメント取得
さらに動画からコメントを取得するコードを追加します。
youtube_api.pydef getComments(_videoId): global API_KEY comment_list = [] params = { 'key': API_KEY, 'part': 'snippet', 'videoId': _videoId, 'order': 'relevance', 'textFormat': 'plaintext', 'maxResults': 100, } response = requests.get(URL + 'commentThreads', params=params) resource = response.json() for item in resource['items']: text = item['snippet']['topLevelComment']['snippet']['textDisplay'] comment_list.append([item['snippet']['topLevelComment']['snippet']['authorDisplayName'], item['snippet']['topLevelComment']['snippet']['likeCount'], item['snippet']['topLevelComment']['snippet']['textDisplay']]) return comment_listVideoIDで指定した動画からコメント100件のユーザ名、本文、グッド数をlistに格納しています。
CSV出力
DataFrameに格納して出力しているだけです。
youtube_api.pydef dataList(_comment_list): if(_comment_list != []): param=['User name', 'Like count', 'text'] df = pd.DataFrame(data = _comment_list,columns=param) df.to_csv("comments.csv") print('Output csv') else: print('None comment')全体コード
youtube_api.py#!/usr/bin/env python # -*- coding: utf-8 -*- import json import requests import pandas as pd from apiclient.discovery import build URL = 'https://www.googleapis.com/youtube/v3/' API_KEY = '<API_KEY>' YOUTUBE_API_SERVICE_NAME = 'youtube' YOUTUBE_API_VERSION = 'v3' SEARCH_QUELY ='' youtube = build( YOUTUBE_API_SERVICE_NAME, YOUTUBE_API_VERSION, developerKey = API_KEY ) def run(): global SEARCH_QUELY SEARCH_QUELY = input('検索ワード>> ') dataList(getComments(getVideos(getChannel()))) def getId(_num,_items): for data in _items: if data['num'] == _num: if data['type'] == 'youtube#channel': return data['channelId'] else: return data['videoId'] return '' def getChannel(): channel_list = [] num = 0 search_res = youtube.search().list( q=SEARCH_QUELY, part='id,snippet', maxResults=10, type='channel', order='rating' ).execute() for item in search_res.get('items', []): num += 1 channel_dict = {'num':str(num),'type':item['id']['kind'],'title':item['snippet']['title'],'channelId':item['snippet']['channelId']} channel_list.append(channel_dict) print('***Channel list***') for data in channel_list: print("Channel " + data["num"] + " : " + data["title"]) print('******************') return getId(input('Channel Number>> '),channel_list) def getVideos(_channelId): video_list = [] num = 0 video_res = youtube.search().list( part = 'snippet', channelId = _channelId, maxResults = 100, type = 'video', order = 'date' ).execute() for item in video_res.get("items",[]): num += 1 video_dict = {'num':str(num),'type':item['id']['kind'],'title':item['snippet']['title'],'videoId':item['id']['videoId']} video_list.append(video_dict) print('***Video list***') for data in video_list: print("Video " + data["num"] + " : " + data["title"]) print('****************') return getId(input('Video Number>> '),video_list) def getComments(_videoId): global API_KEY comment_list = [] params = { 'key': API_KEY, 'part': 'snippet', 'videoId': _videoId, 'order': 'relevance', 'textFormat': 'plaintext', 'maxResults': 100, } response = requests.get(URL + 'commentThreads', params=params) resource = response.json() for item in resource['items']: text = item['snippet']['topLevelComment']['snippet']['textDisplay'] comment_list.append([item['snippet']['topLevelComment']['snippet']['authorDisplayName'], item['snippet']['topLevelComment']['snippet']['likeCount'], item['snippet']['topLevelComment']['snippet']['textDisplay']]) return comment_list def dataList(_comment_list): if(_comment_list != []): param=['User name', 'Like count', 'text'] df = pd.DataFrame(data = _comment_list,columns=param) df.to_csv("comments.csv") print('Output csv') else: print('None comment') #実行 run()実行
では早速動かしてみましょう。
youtube_api.pyを実行してください。適当なワードを入力してみます。
チャンネル番号を指定。↓
動画番号を指定。↓
無事CSVに出力できたら成功です。お疲れ様でした。
今回はコメントを抜き出すだけの簡単な処理でしたが、チャンネルや動画のデータをグラフ化したりしてみても面白そうですね。また、別のAPIを使えばコメント文を感情分析してアンチコメントを割り出すみたいなこともできるようです。
今回使ったコードはGitHubにあるのでそちらを参照してください。編集後記
本当は別の内容を書きたかったのですが、時間の都合上でただAPIを叩いただけの薄い内容になってしまいました。ただAPIを利用するスキルは磨いておいて損はないのかなと思ったりしています。
本記事の内容に改善点やアドバイスなどがありましたら、よろしくお願いします。参考文献
- YouTube Data API Reference
- 【Python】YouTube Data API を使って、いろんな情報を取得してみた!
- Youtube のコメントを取得する in Python
GitHub



- 投稿日:2020-12-23T16:49:21+09:00
Opencvについて①
Opencv3系についてのメモ
基本的には公式ドキュメントを確認しながらの物。
環境
windows10 home 64bit
Python 3.7.9
opencv 3.4.2.17
Jupyter Notebook使用(Anaconda不使用)
使用画像について
画像については自分で撮影した肉を使用。
形式としては.pngを使用。
.jpgでも問題なしopencv_test.ipynbcap_dir = "使用画像を保存したフォルダを指定"以後はすべてこの変数を使用しています。
①画像読み込みについて
1)cv2.imread(第1引数、第2引数)
opencv_test.ipynbimg1 = cv2.imread(cap_dir,0) img2 = cv2.imread(cap_dir,1) img3 = cv2.imread(cap_dir,-1) img4 = cv2.imread(cap_dir,cv2.IMREAD_GRAYSCALE) img5 = cv2.imread(cap_dir,cv2.IMREAD_COLOR) img6 = cv2.imread(cap_dir,cv2.IMREAD_UNCHANGED)第1引数:読み込みたい画像
第2引数:画像に関するフラグ普通に使用するだけなら0 or 1で問題ないと思います。
読み込み後の処理でどうするかなのでカラーで使うかグレーで使うかでいいと思います。むしろアルファチャンネルなる物は初めて見ました。
画像みてもわかりません。
②画像表示について
1)cv2.imshow(第1引数、第2引数)
2)cv2.waitKey(第1引数)
3)cv2.destroyAllWindows(第1引数)
4)cv2.namedWindow(第1引数、第2引数)opencv_test.ipynbimg = cv2.imread(cap_dir,1) cv2.namedWindow('niku',cv2.WINDOW_NORMAL) cv2.imshow('niku',img) cv2.waitKey(0) cv2.destroyAllWindows()1)cv2.imshow(第1引数、第2引数)
第1引数:表示ウインドウ名(文字型で入力)
第2引数:表示したい画像2)cv2.waitKey(第1引数)
第1引数:キーボード入力待ち時間(ms単位)
ウエイトと思っていたが、公式曰く入力受付時間らしい
0にしておけば無制限入力待ちとなる。3)cv2.destroyAllWindows(第1引数)
第1引数:未入力なら開いているすべてのウインドウを閉じる。
複数開いているときに閉じたいウインドウ名を入力すると
入力した名前のウインドウを閉じる4)cv2.namedWindow(第1引数、第2引数)
第1引数:ウインドウ名(文字型)
第2引数:デフォルトでcv2.WINDOW_AUTOSIZEが設定されている。
通常開いた画像はウインドウの大きさは固定だが
第2引数にcv2.WINDOW_NORMALと入力すると
マウス操作で大きさを任意で変更出来る様になる。ただ注意として、第1引数をimshowの第1引数で設定した名前と違う名前にすると
画像のない別ウインドウが立ち上がって意味がなくなる。下記は名前が一致しない場合
ウインドウの大きさがいじれるのは左側
③画像保存について
1)cv2.imwrite(第1引数、第2引数)
opencv_test.ipynbcv2.imwrite('test.png',img)第1引数:保存画像名
第2引数:保存画像これで画像を保存するとスクリプトがある場所と同じ所に画像が保存される。
opencv_test.ipynbsave_dir = "画像を保存したいディレクトリ" save_name = "画像名" save_ext = ".png" cv2.imwrite((save_dir + save_name + save_ext),img)とすれば指定した場所に画像を保存する事が出来ます。
多分、上記の様な使い方がデフォになると思います。
④まとめ
他の物も順次まとめていく予定です。




- 投稿日:2020-12-23T16:42:29+09:00
pandasのdataframeの要素を通常のstring型へ変換
res = df.loc[ <インデックス名>, <カラム名> ]とすればいいです。
df.loc[ <インデックス名>, [ <カラム名> ] ]とするとできないので注意。
- 投稿日:2020-12-23T16:41:24+09:00
PythonでGoogleDriveAPIを使ってGoogle Driveにファイルを定期的にアップロードする
背景
pythonでgoogle driveにファイルを定期的にアップロードするジョブのスクリプトが欲しい。
検索すると、PyDriveを使った記事が多いが、PyDriveはメンテナンスがあまりされていないし、Google Drive APIのv2を使っていて今使うのは得策ではなさそう。
今回は GoogleDriveAPIを使って実装してみる。参考リンク集
Python Quickstart
- GoogleDriveAPIの雰囲気が掴める掴む
- この例では一度コンソールでログインする必要がある
- 今回の仕様としては、コンソールログインなどのユーザーアクションなしで定期アップロードを行うようにしたいので別の認証を考える必要がある
Upload file data
- ファイルアップロードのサンプル
- Pythonのサンプルが少なくてしっくりこない
Lambda(Python)でGoogle Driveへファイルアップロード
- GCPのサービスアカウントを使用したサンプルが紹介されている
- このqiita記事が一番参考になった
実装サンプル
sample.pyfrom googleapiclient.discovery import build from googleapiclient.http import MediaFileUpload from oauth2client.service_account import ServiceAccountCredentials import os def uploadFileToGoogleDrive(fileName, localFilePath): service = getGoogleService() # "parents": ["****"]この部分はGoogle Driveに作成したフォルダのURLの後ろ側の文字列に置き換えてください。 file_metadata = {"name": fileName, "mimeType": "text/csv", "parents": ["****"] } media = MediaFileUpload(localFilePath, mimetype="text/csv", resumable=True) file = service.files().create(body=file_metadata, media_body=media, fields='id').execute() def getGoogleService(): scope = ['https://www.googleapis.com/auth/drive.file'] keyFile = 'credentials.json' credentials = ServiceAccountCredentials.from_json_keyfile_name(keyFile, scopes=scope) return build("drive", "v3", credentials=credentials, cache_discovery=False) getGoogleService() uploadFileToGoogleDrive("hoge", "hige.csv")
- 投稿日:2020-12-23T16:16:50+09:00
GitHub Actionsでprivate repositoryのPythonライブラリを含むDockerイメージをビルドする
背景・目的
Github ActionsでPythonのイメージをビルドするとき、別のprivate repositoryにある社内用ライブラリを持ってくる方法についてまとめました。
既に同僚の @elyunim26 の「GitHub Actionsでビルドするコンテナ内でGitHubのprivate repositoryをセキュアに参照する」という記事があったのですが、私はマシンユーザーではなくデプロイキーを利用していたため、安全にssh認証をする方法が必要でした。Build-time secretsを使うことでsshキーも安全にイメージのビルドに利用できます。
実装方法
簡単に説明すると、以下のような手順で実現できます。
- Github Actionsでsecretsからデプロイキー(秘密鍵)を読み込む
- DockerのBuildkitの機能を使ってセキュアに受け渡す
- 通常通り
pip installを行うデプロイキーの設定
まず、ライブラリ側のリポジトリにデプロイキーを設定する必要があります。デプロイキーの設定方法はGithubの公式ドキュメントを参照してください。
Github Actionsの設定
次のような要素に気をつける必要があります。トラブルシューティングには(Pythonとnode.jsという違いはありますが)GitHub Actions で private repository の node module をインストールするが役に立ちました。
GITHUBで始まるsecretsは禁止されている- secretsでは改行が使えないため、事前に改行を
\nなどに置換した形で登録して、sedで置換するなどの回避方法が必要以下は設定例です。我々のチームではAWSを利用しているため、後半にECRにpushするコードも含まれています。
github_actions_ecr.yml- name: Build, tag, and push image to Amazon ECR id: build-image env: ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }} ECR_REPOSITORY: ${{ steps.extract_repository.outputs.repository }} IMAGE_TAG: ${{ github.sha }} DEPLOY_KEY_GITHUB: ${{ secrets.DEPLOY_KEY_GITHUB }} run: | echo ${DEPLOY_KEY_GITHUB} > .deploy_key sed -i -e "s#\\\\n#\n#g" .deploy_key chmod 600 .deploy_key DOCKER_BUILDKIT=1 docker build --secret id=ssh,src=.deploy_key \ -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG \ -t $ECR_REGISTRY/$ECR_REPOSITORY:latest \ . rm .deploy_key docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG docker push $ECR_REGISTRY/$ECR_REPOSITORY:latestDockerfileの設定
我々のチームではpoetryを使うことが多いので
pyproject.tomlを利用していますが、requirements.txtを使う場合でも同様の設定でいけるはずです。Dockerfile# syntax=docker/dockerfile:experimental FROM python:3.7 # ssh-keyscanの実行のため、元にするイメージによってはopenssh-clientのインストールが必要 RUN apt-get install -y openssh-client git COPY ./pyproject.toml /app/pyproject.toml COPY ./src /app/src WORKDIR /app RUN mkdir -m 700 $HOME/.ssh RUN ssh-keyscan -H github.com > $HOME/.ssh/known_hosts RUN --mount=type=secret,id=ssh,dst=$HOME/.ssh/id_rsa \ pip install --upgrade pip && \ pip install . && rm pyproject.toml
pyproject.tomlでは次のように記述されています。これはpoetryの公式ドキュメントにもある通り、poetry addコマンドでリポジトリを指定することで作成されるものです。pyproject.toml[tool.poetry.dependencies] {ライブラリ名} = {git = "ssh://git@github.com/{ユーザー名}/{ライブラリ名}.git", rev = "main"}参考にした記事
- 投稿日:2020-12-23T15:32:26+09:00
ロングポーリングからの解放!DjangoのChannelsをしばく
挨拶
書いてある内容は公式チュートリアルと同じです。公式ドキュメント以外にDjangoのChannelsを1から10まで分かりやすく説明している親切な記事がなく、どう学習したらいいのか困ったので後の走者のために書き記しておきます。
「公式ドキュメント読んでるよね?」みたいな記事しかないのもきついですし。
公式ドキュメントが前提ならそっち読むわ!みたいなねあと記事が古くてうまく動かない、っていうのもあると思うので。
一番いい勉強法はChannel公式ドキュメントのチュートリアルから始めることですが、まぁこの記事を見つけたなら始めなくて良いです。
想定読者は「Djangoちょっと使えるけどChannelsに手が出せない」みたいな方です。
あと、先に言っておくと僕自身Djangoに詳しくないです。
とりあえず動くWebsocketアプリが作れるまでを紹介します。Channelsの概念
Channelsは今までのDjangoにWebsocket通信を追加します。
HTTP通信はそのままに、websocket通信が来たときのみにviewsではなくconsumerを呼び出します。次にchannelとgroup、layerという概念があります(ドキュメントとの整合性のため英語表記します)。
channel: クライアントのメールボックスみたいなもの。これに対してメッセージを送れば結果的にクライアントに届くことになる。
group: channelの集まり。チャットの部屋みたいなもの。channelsはgroupで変化があったらgroup全体に通知する、みたいな仕組みを基本として想定しているんだと思う。
layer: groupのさらなる上位概念。何のためにあるかいまいちわからない。基本的に1個で足りるらしい。これらを前提知識として実装していきます。別に覚えなくてもニュアンスで分かりますし、分からなくても問題ないです。
準備
chanellsをインストールしましょう
python -m pip install -U channels
つぎにプロジェクトを作ります。プロジェクト名を変えた場合は読み替えてください
django-admin startproject mysiteつぎにプロジェクト内に移動して
python3 manage.py startapp chat
これもアプリ名を変えた場合は読み替えてくださいまぁここまではおまじないです。最初に形だけ作っとく、みたいなもんだと思ってください。
次にchatの中身をふっとばします。以下の形になるようにファイルを消したり作ったりしてください。chat/ __init__.py consumers.py routing.py urls.py views.pyファイルを作るのはマジでいつもの感じで新しいファイルを作れば大丈夫です。
結果的にプロジェクト全体はこんな感じになると思います。
chat/ migrations __init__.py consumers.py routing.py urls.py views.py mysite/ __init__.py asgi.py settings.py urls.py wsgi.py db.sqlite3 manage.pyこれで形だけは完成です。
asgi.pyがない場合はdjangoのバージョンが間違っている場合があります。Channelsが使えるバージョンを用意してください。次に各ファイルをいじっていきます。
mystite/settings.py
mysite/settings.pyINSTALLED_APPS = [ 'channels',#追加 'chat',#追加 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ] #一番下に追加 ASGI_APPLICATION = 'mysite.asgi.application' CHANNEL_LAYERS = { "default": { "BACKEND": "channels.layers.InMemoryChannelLayer"#インメモリを使う場合 }, }INSTALLED_APPS内に'channels'と'アプリ名'を追加します。まぁこれはDjangoの仕様です。
一番下に追加したのは変更の分かりやすさのためです。
レイヤーとはグループが集団のことで、公式ドキュメントによると1アプリ1レイヤーが普通らしいです。
"default"はレイヤーの名前です。現在はインメモリを使うことにしていますがこれだと同じプロセス内でしか動作しないらしいです。
なのでRedisというキャッシュサーバーを使うことで解消できます。Redisとは共用メモリみたいなもんだと思います。#推奨 redisというキャッシュサーバーを用いた方が良い, CHANNEL_LAYERS = { 'default': { 'BACKEND':'channels_redis.core.RedisChannelLayer', 'CONFIG': { "hosts": [('127.0.0.1', 6379)], }, }, }この場合はポート番号6379にあるRedisサーバーをキャッシュサーバーとして使っています。
mysite/urls.py
以下のようにします。
mysite/urls.pyfrom django.conf.urls import include from django.urls import path from django.contrib import admin urlpatterns = [ path('chat/', include('chat.urls')), path('admin/', admin.site.urls), ]includeは別のURL書いてあるファイルを使うよ~ってことです。
chat/urls.py
chat/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), path('<str:room_name>/', views.room, name='room'), ]これに関してはDjangoと全く一緒です。
urlになんもない場合はviews.pyのindexを、なんかある場合はview.pyのroomを呼び出しています。その際にroom_nameとして取り出していて、views.py内ではそれを使っています。chat/routing.py
chat/routing.pyfrom django.urls import re_path from . import consumers websocket_urlpatterns = [ re_path(r'ws/chat/(?P<room_name>\w+)/$', consumers.ChatConsumer.as_asgi()), ]次にrouting.pyの内容です。routing.pyはwebsocketの接続について書きます。
re_pathはURLRouterの制限のためと書いてありましたがよくわかりません。まぁこう書けばいいんでしょう。
as_asgi()は後に用意するcomsumerクラスを使うための呼び出し方です。comsumerクラスを用意してこの呼び出し方をすれば後は勝手にやってくれるっぽいです。comsumerクラスの書き方は後で紹介します。mysite/asgi.py
mysite/asgi.pyimport os from channels.auth import AuthMiddlewareStack from channels.routing import ProtocolTypeRouter, URLRouter from django.core.asgi import get_asgi_application import chat.routing os.environ.setdefault("DJANGO_SETTINGS_MODULE", "mysite.settings") application = ProtocolTypeRouter({ "http": get_asgi_application(),#http://ならこっち "websocket": AuthMiddlewareStack(#ws:// wss://ならこっち URLRouter( chat.routing.websocket_urlpatterns#chat/routing.py ) ), })これはHTTP接続かWebsocket通信かを判断して振り分けます。HTTPならchat/urlsに飛んでそこではviewsなどを使ってHTTPで返します。
Websocketならばrouting.pyに飛んで処理をします。chat/consumers.py
これがwebsocketの処理になります。とりあえずまずはコピーして、下の解説を見ながら読んでください。
chat/consumers.pyimport json from channels.generic.websocket import AsyncWebsocketConsumer #asyncをつけることでパフォーマンスが上がる #websocketConsumerからAsyncWebsocketConsumerになる class ChatConsumer(AsyncWebsocketConsumer): async def connect(self): self.room_name = self.scope['url_route']['kwargs']['room_name']#scopeは接続の情報を持つ、 self.room_group_name = 'chat_%s' % self.room_name#roomのstrを作ってる # Join room group await self.channel_layer.group_add( #グループ参加処理、まぁこういう書き方するんだよ、ぐらい #ChatComsumerは同期だがchannel_layerは非同期 self.room_group_name, self.channel_name ) await self.accept()#websocketをacceptする,acceptしない場合rejectされる async def disconnect(self, close_code): # Leave room group await self.channel_layer.group_discard(#退出処理 self.room_group_name, self.channel_name ) # Receive message from WebSocket async def receive(self, text_data): text_data_json = json.loads(text_data) message = text_data_json['message'] # Send message to room group await self.channel_layer.group_send(#グループにメッセージを送る self.room_group_name, { 'type': 'chat_message', 'message': message } ) # Receive message from room group async def chat_message(self, event): message = event['message'] # Send message to WebSocket await self.send(text_data=json.dumps({ 'message': message }))まぁちょっと長いです。
もともとasyncではないのですが、asyncで実装することでスレッド呼び出しがなくなってパフォーマンスがあがる(?)らしいです。従ってawaitやasyncがついています。
connect、disconnect、receiveはchat/routing.pyにてas_asgi()として呼び出すための関数です。このように書いておけば後は勝手にやってくれるっぽいですね。connectはurlを入力して接続したとき、disconnectはcloseしたとき、receiveはsendしたときに実行されるっぽいです。
sendのtypeに特定の関数を設定しておくことで誰かがsendした際にその関数が実行され、それが結果的にサーバーからクライアントにメッセージを送ることになります。今回はchat_messageがそれに該当して結果的にグループに所属する全クライアントにsendを行っていますね。
動かす
動かす際にはここにあるindex.htmlやここにあるroom.htmlを参考にchat/Templates/chat/内にHTMLを書いておいてください。
py manage.py runserverをしてサーバーを動かしたのちにhttp://127.0.0.1:8000/chat/lobby/ に2つのブラウザ(ウィンドウ)でアクセスします。
するとなんということでしょう!相手側にも反映されています!!!!
すごい!!!!!!!
はい。
まぁ使う場合は「JavaScript websocket」や「python websocket」、「Unity websocket」で調べてください。多分サーバーからsendされた場合はonReceiveみたいなイベント関数が用意されていると思います。以上。
参考
公式ドキュメント・チュートリアル
https://channels.readthedocs.io/en/stable/tutorial/part_2.htmlstack overflow「channels without channel layer or any other free hosting」
https://stackoverflow.com/questions/53271407/channels-without-channel-layer-or-any-other-free-hosting
- 投稿日:2020-12-23T15:20:28+09:00
Python でJSONオブジェクトマッパーを作る
この記事は、Pythonその2 Advent Calendar 2020 23日目の記事です。
自己紹介
バックエンドのエンジニアとしてそろそろ8年が経ちます、星光輝と申します。
守備範囲はサーバーサイドですが、アプリ・インフラ・テスト・開発環境改善あたりの経験もある、広く浅い系エンジニアです。
最近は chalice というフレームワークを使い、およそ1年近く python に関わっています。今回書くこと
API を作る時に、入力として受け取った JSON を意図したクラスにマッピングして欲しいなぁ...と思うことがあり、
python にそれっぽいライブラリがなかったので、自作したお話です。
python のバージョンは 3.8 です (from typing import get_origin get_args /できるのが3.8以降)。なぜ作るのか?
汎用ライブラリの json の json.loads でも簡易的にはできるようなんですが、
そのために設定を頑張って書かないといけなさそうだし、汎用的に書くのは難しそうな感じがしました。Java でも 古くから Jackson という有名なライブラリがあるのだから、探せばあるだろうと思いましたが、それらしい記載は出てきません。
そこで、いっそのこと作ってしまおうということで作りました。作っていく
全体的な設計方針
クラスのインスタンスを何らかのデータ形式に落とすことをシリアライズと言い、
逆に何らかのデータ形式をクラスのインスタンスに変換することをデシリアライズと言います。ここでは、下記のような使い方をするとしましょう。
@dataclass class Hello: hello: str objectMapper = ObjectMapper() instance = objectMapper.deserialize('{"hello": "mapper"}', Hello) print(instance.hello) ## 出力: mapper今回は、下記のクラス構造で作ります。
まずはインタフェースを書く
import json from typing import Type, TypeVar, List from abc import ABCMeta, abstractmethod class NotImplementedError(Exception): def __init__(self, message): super().__init__(message) class JsonDeserializer(metaclass=ABCMeta): @abstractmethod def canDeserialize(self, json: object, mappingClass: type) -> bool: pass @abstractmethod def deserialize(self, json: object, mappingClass: type) -> object: pass T = TypeVar('T') class ObjectMapper: deserializers: List[JsonDeserializer] = [] def deserialize(self, jsonText: str, mappingClass: Type[T]) -> T: jsonData = json.loads(jsonText) for deserializer in ObjectMapper.deserializers: if deserializer.canDeserialize(jsonData, mappingClass): return deserializer.deserialize(jsonData, mappingClass) raise NotImplementedError(f'Cannot deserialize json({jsonData}) to class({mappingClass}).')このようにして、ObjectMapper 内に JsonDeserializer のオブジェクトをリスト形式で持ち、
対応できる JsonDeserializer が見つかったら(canDeserialize(json, mappingClass) == true)、
それを使って様々なクラスに対して利用できるようにします。単純ケースの攻略
まずは、リテラルに対する単体テストを書きます。
from main.json_deserializer import ObjectMapper class TestObjectMapper: def test_deserializeInt(self): actual = ObjectMapper().deserialize('1', int) assert actual == 1 def test_deserializeStr(self): actual = ObjectMapper().deserialize('"1"', str) assert actual == '1' def test_deserializeFloat(self): actual = ObjectMapper().deserialize('1.5', float) assert actual == 1.5 def test_deserializeNull(self): actual = ObjectMapper().deserialize('null', str) assert actual is None$ python -m pytest ================================================================ short test summary info ================================================================= FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeInt - main.json_deserializer.NotImplementedError: Cannot deserialize json(1) to c... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeStr - main.json_deserializer.NotImplementedError: Cannot deserialize json(1) to c... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeFloat - main.json_deserializer.NotImplementedError: Cannot deserialize json(1.5) ... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeNull - main.json_deserializer.NotImplementedError: Cannot deserialize json(Null) ... =================================================================== 5 failed in 0.21s ====================================================================```まだ実装していないので当然こけますね。リテラル用の JsonDeserializer を実装します。
class ObjectMapper: deserializers: List[JsonDeserializer] = [ LiteralDeserializer() ## 追加 ] class LiteralDeserializer(JsonDeserializer): def canDeserialize(self, json: object, mappingClass: type) -> bool: return type(json) in [int, float, str, type(None)] def deserialize(self, json: object, mappingClass: type) -> object: return jsoncollected 4 items tests/test_object_mapper.py .... =================================================================== 4 passed in 0.03s ====================================================================リテラルなんだけど、日時・Enum などの型にしたい場合
今度は下記のようなテストを加えます。
from datetime import datetime, date from enum import Enum class Member(Enum): JOHN = 'john' BOB = 'bob' ----(省略)---- def test_deserializeDate(self): actual = ObjectMapper().deserialize('"2020-12-23"', date) assert actual == date(2020, 12, 23) def test_deserializeNaiveDateTime(self): actual = ObjectMapper().deserialize('"2020-12-23T03:00:00"', datetime) assert actual == datetime(2020, 12, 23, 3, 0, 0) def test_deserializeAwareDateTime(self): actual = ObjectMapper().deserialize('"2020-12-23T03:00:00+0900"', datetime) assert actual == datetime(2020, 12, 23, 3, 0, 0, tzinfo=timezone(timedelta(hours=+9), 'JST')) def test_deserializeEnum(self): actual = ObjectMapper().deserialize('"john"', Member) assert actual is Member.JOHN日時には、Naive(タイムゾーンなし), Aware(タイムゾーンあり)があります。
異なる日時同士では計算できなかったりして、紛らわしいことがあるので全てを Aware にする方がいいこともありますが、
今回はどっちでも対応するデータを作成できるようにします。試しにテスト実行
================================================================ short test summary info ================================================================= FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeDate - AssertionError: assert '2020-12-23' == datetime.date(2020, 12, 23) FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeNativeDateTime - AssertionError: assert '2020-12-23T03:00:00' == datetime.datetim... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeAwareDateTime - AssertionError: assert '2020-12-23T03:00:00+0900' == datetime.dat... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeEnum - AssertionError: assert 'john' is <Member.JOHN: 'john'> ============================================================== 4 failed, 4 passed in 0.12s ===============================================================...ってことで、実装。
class DateDeserializer(JsonDeserializer): def canDeserialize(self, json: object, mappingClass: type) -> bool: return mappingClass == date def deserialize(self, json: object, mappingClass: type) -> object: dt = datetime.strptime(json, '%Y-%m-%d') return date(dt.year, dt.month, dt.day) class DatetimeDeserializer(JsonDeserializer): def canDeserialize(self, json: object, mappingClass: type) -> bool: return mappingClass == datetime def deserialize(self, json: object, mappingClass: type) -> object: try: return datetime.strptime(json, '%Y-%m-%dT%H:%M:%S%z') # かなり雑.. except ValueError: return datetime.strptime(json, '%Y-%m-%dT%H:%M:%S') class EnumDeserializer(JsonDeserializer): def canDeserialize(self, json: object, mappingClass: type) -> bool: return issubclass(mappingClass, Enum) def deserialize(self, json: object, mappingClass: type) -> object: for enum in mappingClass: if enum.value == json: return enum class ObjectMapper: deserializers: List[JsonDeserializer] = [ DatetimeDeserializer(), ## 追加 EnumDeserializer(), ## 追加 DateDeserializer(), ## 追加 LiteralDeserializer() ]collected 8 items tests/test_object_mapper.py ........ =================================================================== 8 passed in 0.07s ====================================================================コンテナクラスを扱う
さて次からはコンテナクラスを扱います。今回は、下記のコンテナクラスを作ります。
- List
- Map
- Object
まずは、コンテナ共通クラスを作ります。このようなことをするのは、
コンテナクラスは内部の別構造に対して、再度デシリアライズ依頼をしなければならないからです。
(少しトリッキーですが、内部構造に対して再度 ObjectMapper._deserialize を呼んでいます)class ContainerDeserializer(JsonDeserializer): def deserializeChild(self, json: object, mappingClass: type) -> object: return ObjectMapper._deserialize(json, mappingClass) class ObjectMapper: deserializers: List[JsonDeserializer] = [ ...JsonDeserializer ] def deserialize(self, jsonText: str, mappingClass: Type[T]) -> T: return self._deserialize(json.loads(jsonText), mappingClass) @staticmethod def _deserialize(jsonData: object, mappingClass: Type[T]) -> T: for deserializer in ObjectMapper.deserializers: if deserializer.canDeserialize(jsonData, mappingClass): return deserializer.deserialize(jsonData, mappingClass) raise NotImplementedError(f'Cannot deserialize json({jsonData}) to class({mappingClass}).')そして、まずは構造を変えたので既存構造が壊れていないことを確認します。
collected 8 items tests/test_object_mapper.py ........ [100%] =================================================================== 8 passed in 0.07s ====================================================================大丈夫なようですので、再度テストを追加します。
@dataclass class Person: name: str age: int @dataclass class Group: name: str leader: Person ## ---テスト追加---- def test_deserializeRawList(self): actual = ObjectMapper().deserialize('[{"age": 35, "name": "鈴木"}, {"age": 21, "name": "山田"}]', list) assert len(actual) == 2 assert actual[0].age == 35 assert actual[0].name == '鈴木' assert actual[1].age == 21 assert actual[1].name == '山田' def test_deserializeTypedList(self): actual = ObjectMapper().deserialize('[{"age": 35, "name": "鈴木"}, {"age": 21, "name": "山田"}]', List[Person]) assert len(actual) == 2 assert type(actual[0]) == Person assert actual[0].age == 35 assert actual[0].name == '鈴木' assert type(actual[1]) == Person assert actual[1].age == 21 assert actual[1].name == '山田' def test_deserializeRawDict(self): actual = ObjectMapper().deserialize('{"ID1":{"age": 35, "name": "鈴木"}, "ID3": {"age": 21, "name": "山田"}}', dict) assert len(actual) == 2 assert actual['ID1'].age == 35 assert actual['ID1'].name == '鈴木' assert actual['ID3'].age == 21 assert actual['ID3'].name == '山田' def test_deserializeTypedDict(self): actual = ObjectMapper().deserialize( '{"ID1":{"age": 35, "name": "鈴木"}, "ID3": {"age": 21, "name": "山田"}}', Dict[str, Person] ) assert len(actual) == 2 assert type(actual['ID1']) == Person assert actual['ID1'].age == 35 assert actual['ID1'].name == '鈴木' assert type(actual['ID3']) == Person assert actual['ID3'].age == 21 assert actual['ID3'].name == '山田' def test_deserializeRawObject(self): actual = ObjectMapper().deserialize('{"name": "グループ", "leader": {"age": 35, "name": "鈴木"}}', object) assert actual.name == 'グループ' assert actual.leader.age == 35 assert actual.leader.name == '鈴木' def test_deserializeTypedObject(self): actual = ObjectMapper().deserialize('{"name": "グループ", "leader": {"age": 35, "name": "鈴木"}}', Group) assert type(actual) == Group assert actual.name == 'グループ' assert type(actual.leader) == Person assert actual.leader.age == 35 assert actual.leader.name == '鈴木'試しにテスト実行...当然実装していn(ry
================================================================ short test summary info ================================================================= FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeRawList - main.json_deserializer.NotImplementedError: Cannot deserialize json([{'... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeTypedList - main.json_deserializer.NotImplementedError: Cannot deserialize json([... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeRawDict - main.json_deserializer.NotImplementedError: Cannot deserialize json({'I... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeTypedDict - main.json_deserializer.NotImplementedError: Cannot deserialize json({... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeTypedObject - main.json_deserializer.NotImplementedError: Cannot deserialize json... FAILED tests/test_object_mapper.py::TestObjectMapper::test_deserializeRawObject - main.json_deserializer.NotImplementedError: Cannot deserialize json({... ============================================================== 6 failed, 8 passed in 0.36s ===============================================================実装。
from inspect import signature, _ParameterKind from typing import Type, TypeVar, List, Dict, Set, get_origin, get_args class ListDeserializer(ContainerDeserializer): def canDeserialize(self, json: object, mappingClass: type) -> bool: return get_origin(mappingClass) == list or mappingClass == list def deserialize(self, json: object, mappingClass: type) -> object: genericParams = get_args(mappingClass) hasGenericParams = genericParams is not None and len(genericParams) > 0 param = genericParams[0] if hasGenericParams else object return [self.deserializeChild(el, param) for el in json] class DictDeserializer(ContainerDeserializer): def canDeserialize(self, json: object, mappingClass: type) -> bool: return get_origin(mappingClass) == dict or mappingClass == dict def deserialize(self, json: object, mappingClass: type) -> object: genericParams = get_args(mappingClass) hasKeyParam = genericParams is not None and len(genericParams) > 0 hasValueParam = genericParams is not None and len(genericParams) > 1 return { self.deserializeChild(k, genericParams[0] if hasKeyParam else object) : self.deserializeChild(v, genericParams[1] if hasValueParam else object) for k, v in json.items() } class ObjectDeserializer(ContainerDeserializer): def canDeserialize(self, json: object, mappingClass: type) -> bool: return type(json) == dict def deserialize(self, json: object, mappingClass: type) -> object: if mappingClass == object: return self.createRawObject(json) else: return self.createObject(json, mappingClass) def createRawObject(self, args: Dict[str, object]) -> object: className = ''.join(key.title() for key in args.keys()) + 'Obejct' newInstance = type(className, (object,), {})() for k, v in args.items(): setattr(newInstance, k, self.deserializeChild(v, object)) return newInstance def createObject(self, args: Dict[str, object], mappingClass: type) -> object: annotations = self.findAnnotations(mappingClass) requireArgs = self.findInitRequireArgs(mappingClass) result = object.__new__(mappingClass) initArgs = {} for k, v in args.items(): val = self.deserializeChild(v, annotations.get(k, object)) if k in requireArgs: initArgs[k] = val else: setattr(result, k, val) for req in requireArgs: if req not in initArgs: initArgs[req] = None result.__init__(**initArgs) return result @staticmethod def findAnnotations(mappingClass: type) -> Dict[str, type]: if hasattr(mappingClass, '__annotations__'): return mappingClass.__annotations__ for k, v in signature(mappingClass.__init__).parameters.items(): return {k:v.annotation for k,v in signature(mappingClass.__init__).parameters.items()} @staticmethod def findInitRequireArgs(mappingClass: type) -> Set[str]: return { k for k, v in signature(mappingClass.__init__).parameters.items() if v.name != 'self' and v.kind == _ParameterKind.POSITIONAL_OR_KEYWORD } class ObjectMapper: deserializers: List[JsonDeserializer] = [ DateDeserializer(), DatetimeDeserializer(), EnumDeserializer(), LiteralDeserializer(), ListDeserializer(), ## 追加 DictDeserializer(), ## 追加 ObjectDeserializer() ## 追加 ]テスト実行
collected 14 items tests/test_object_mapper.py .............. [100%] =================================================================== 14 passed in 0.18s ===================================================================Object デシリアライザの挙動説明
Objectをマッピングするものになると、急に難易度が高くなりましたね。..なので、軽く説明します。
また、オブジェクトに内包されているデータをデシリアライズするには、
データのクラスを取得しなければいけませんが、それが格納されている可能性があるのは下記の二箇所です。
- classに型定義がある場合 (下記コードの Group, GroupWithoutDataclass)
- init の引数で型を定義している場合 (下記コードの GroupInitDef)
@dataclass class Person: name: str age: int # パターン1 @dataclass class Group: name: str leader: Person # パターン2 class GroupWithoutDataclass: name: str leader: Person # パターン3 class GroupInitDef: def __init__(self, name: str, leader: Person): self.name = name self.leader = leaderまた、python では
Person('AA', 23)と実行するとPersonクラスの__init__メソッドが実行されます。
このメソッドでは、可変長引数(*args, **kwargs等)で定義されている変数以外は指定しないとエラーになります。
そのため、def findInitRequireArgs(mappingClass: type) -> Set[str]で定義すべき変数名を取得しています。そして、今回はJSONデータとマッピングデータが下記のような関係だった場合に、下記の実装にしています。
- JSONデータ が マッピングに必要なデータを持っていない → None で埋める
- JSONデータ が マッピングに不必要なデータを持っている → setattr で属性追加している
今回は、このようにしていますが、場合によってはエラーにしたほうがいいケースもあるかもしれません。
念の為テストを追加。(Group は先ほどテストしているので省略)
def test_deserializeTypedObjectWithoutDataclass(self): actual = ObjectMapper().deserialize('{"name": "グループ", "leader": {"age": 35, "name": "鈴木"}}', GroupWithoutDataclass) assert type(actual) == GroupWithoutDataclass assert actual.name == 'グループ' assert type(actual.leader) == Person assert actual.leader.age == 35 assert actual.leader.name == '鈴木' def test_deserializeTypedObjectInitDef(self): actual = ObjectMapper().deserialize('{"name": "グループ", "leader": {"age": 35, "name": "鈴木"}}', GroupInitDef) assert type(actual) == GroupInitDef assert actual.name == 'グループ' assert type(actual.leader) == Person assert actual.leader.age == 35 assert actual.leader.name == '鈴木' def test_deserializeTypedObjectEmptyJson(self): actual = ObjectMapper().deserialize('{}', Group) assert type(actual) == Group assert actual.name == None assert actual.leader == None def test_deserializeTypedObjectRedundantData(self): actual = ObjectMapper().deserialize('{"name": "グループ", "id": 2, "leader": {"age": 35, "name": "鈴木", "role": "課長"}}', Group) assert actual.name == 'グループ' assert actual.id == 2 assert type(actual.leader) == Person assert actual.leader.age == 35 assert actual.leader.name == '鈴木' assert actual.leader.role == '課長'collected 18 items tests/test_object_mapper.py .................. [100%] =================================================================== 18 passed in 0.17s ===================================================================もっと工夫をするなら...
実際はもうちょっと面倒な仕様があったりするので、プロジェクトに合わせて仕様を調整する必要があるかもしれません。
__init__メソッド に*args: T,**kwargs: Tのような可変長引数- デフォルト値への対応
- オブジェクト初期化時には init 実行しないようにして欲しいんだけど?
OrderedDict等の順序があるものにも対応できるのか?ただ、今回はAPI等で受け取った JSON をクラスにマッピングすることが目的です。
JSONモデルに通常はそんなに複雑な要件は必要ないでしょう。最後に
今回は、JSON からクラスのインスタンスを生成するオブジェクトマッパーを作成しました。
それほど大変な実装ではないですし、都度都度デシリアライズのロジックを追加していけばどんなものでも対応できるので、
メンテナンスはそれほど大変ではないと思います。python は型定義がどんどん便利になっていますので、このような仕組みを押さえておくと今後何かいいことがあるかもしれません。
