- 投稿日:2020-12-23T23:51:08+09:00
Windows上のファイルをLinuxコマンドで整理する - WSLを用いて -
当記事の目的
・「Linuxコマンドを試したいが、仮想環境の構築までは面倒だと考えている」方
・「勉強のために練習ディレクトリを作成するのではなく、実際に生きたファイルを使いたい」方
・「とりあえずWindows上のファイルを効率的に整理したい方」上記の方々にWSLを用いて、
Windows上のファイルをLinuxコマンドを用いて操作(整理)が出来るようになる事が目的です。※環境構築は簡単で、30分前後でWindows上でLinuxコマンドが実行出来るようになります!
WSLとは
・「Windows Subsystem for Linux」の略です。
・Windows OS上でLinuxの実行環境を実現するサブシステムです。WSLを用いたLinux環境の構築方法
今回は「Windows10」ユーザ向けに箇条書きで記載していきます。
1. WSLの有効化
WSLを利用するには、WSL機能を有効化する必要があります。
「スタート」→「設定」の順で移動し、「Windows の機能の有効化または無効化」タブを開く。
下記のように、「Linux 用 Windows サブシステム」をチェックし、PCを再起動をします。
2. Ubuntuのインストール
WSLを利用するには、Linuxディストリビューションが必要です。
下記のように、「Microsoft Store」でUbuntuと検索し、一番上に出てくる「Ubuntu」を
インストールします。
インストール完了したら、スタートメニューから「Ubuntu」を検索して起動をします。
3. WSLとWindows間のファイル連携方法
下記の方法で、WSLとWindowsのそれぞれのファイルを参照出来ます。WSLからWindowsファイルシステムへのアクセス(Ubuntuで入力)'cd /mnt/{ドライブ名}'WindowsからWSLファイルシステムへのアクセス(エクスプローラで入力)'\\wsl$'最後に
Linux環境の構築には、主に以下の2つの方法があり、それぞれにメリット・デメリットがあります。
それらを認識したうえで、Linuxコマンドの学習とファイルの整理を効率的に行っていきましょう!
WSL
メリット :ホストのファイルを直接参照するので、セキュリティ面に不安が残る。
デメリット:別のOSはインストールしないので、手軽にLinuxのCUI環境を利用できる。
仮想化
メリット :別のOSをインストールするので、ホストに影響を与えない分離した環境の構築。
デメリット:マシンのリソースを利用するので、パフォーマンスがスペック依存になる。


- 投稿日:2020-12-23T23:32:03+09:00
Proxy経由でゲームがしたいとき
この記事はProxyとの戦いに勝利したProxyを華麗にスルーしてWi-Fiを飛ばすには - Qiitaの後日談です。
環境などは上の記事に準じておりますので,是非ご一読の上こちらの記事をお読みください。Proxy経由だとなぜゲームができない?
ゲームではウェルノウンポート以外のポートを多用するためです。
つまり,ゲーム側がウェルノウンポート以外でTLS通信をしている場合は,Squid側で設定してあげることで正常に通信ができるようになります。具体的にどう設定したの(追加するポートを4432番とします)。
/etc/squid/squid.conf- acl SSL_ports port 443 + acl SSL_ports port 443 4432 + acl Safe_ports port 4432SSL_portsとSafe_portsに追加したいポートを加えるだけです。
参考文献
443以外のSSLポートを使用するプロキシサーバ(Squid)の設定 : https://minory.org/proxy-squid-403-error.html
- 投稿日:2020-12-23T14:09:48+09:00
LowMemoryKiller 〜AndroidのActivityが破棄される仕組み〜
この記事は、LIFULLその2 Advent Calendar 2020の23日目の記事です。
今回は、Androidの低レイヤーな話を取り上げてみようと思います。
具体的には、OOM Killerでプロセスがkillされるのを未然に防ぐLowMemoryKillerの仕組みについてです。ネイティブアプリの開発は、よりメモリの事を意識した開発が必要だなと日々感じていたので、もっと低いレイヤーで何が行われているかをちゃんと理解したいと思ったのがきっかけで、勉強してきた内容になります。
読んでいただけたらこの辺の内容を理解できる内容になっていると思います。
LowMemoryKillerの仕組みActivityが破棄される基準onSaveInstanceState()でBundleに保存するデータは実際どこに保存されているのかAndroidエンジニアじゃなくても、Androidの世界を少し覗いた気になれるような記事になればいいなと思います。
はじめに
Androidには、OOM Killerによってプロセスがkillされるのを未然に防ぐ
LowMemoryKillerという仕組みがあります。
AndroidでActivityが突如破棄されてしまうことがありますが、その仕組みに深く関係しているのがLowMemoryKillerです。LowMemoryKillerの必要性
LowMemoryKillerの仕組みに入る前に、LowMemoryKillerがどんなときに必要になるか話をします。まず前提知識になりますが、Androidアプリ開発でまず画面を用意するときは、
Activityというコンポーネントを使用します。1つのActivityが1つの画面というイメージでここでは大丈夫です。(Activity上で複数の画面をFragmentで管理する設計もありますが、今回はFragmentは話に必要ないので省きます)
一般的に、1つのアプリには複数のActivtityが含まれ、1アプリは1プロセスで実行されます。デフォルトでは、同じアプリのすべてのコンポーネントは同じプロセスで実行され、ほとんどのアプリでこの動作を変更する必要はありません。
アプリを閉じてもユーザーがアプリをkillしない限りバックグラウンドに残り続けます。Activityのインスタンスもプロセス内に残り続けます。
そのため、あるアプリがバックグラウンド時に他のアプリがメモリを要求した場合、アプリ側からみると以下のような段階を踏んで空きメモリを確保しようとします。
- メモリの開放
Activity#onLowMemory()、Activity#onTrimMemory(int)が呼び出される- (Fragmentの破棄などのタイミングがここにあたる)
- Activityの破棄
Activity#onDestroy()が呼び出される- ただし、
Activity#onSaveInstanceState(Bundle)が事前に呼び出され、必要な状態は保存される- プロセスの終了
- プロセスが終了される
- この場合、実行中のActivityは終了するが
Activity#onDestrory()は呼び出されない- アプリが
Activity#onStop()で停止している状態であれば、onSaveInstanceState(Bundle)は呼び出された後となるため、Activityの状態復元は可能このようにメモリが足りなくなると最終的にはアプリのプロセス終了に到ります。実際にプロセスの終了を行うカーネル側からみると、これがOOM Killerによってプロセスがkillされるタイミングですと、今ユーザーにとって重要なアプリでも問答無用でkillされることになってしまいます。
こんな事態にならないよう未然に防ぐのが
LowMemoryKillerです。OOM Killerよりもっと前の段階で、そのActivityが重要か重要じゃないかを判断して、重要度の低いActivityを持つプロセスからkillしていき、メモリを空けるように動きます。
- OOM Killer
- どのプロセスがkillされるかは運任せに近く、重要なプロセスでも問答無用でkillする
- LowMemoryKiller
- 重要度が低いActivityを持つプロセス(ex. バックグラウンドにいるActivity)から段階的にkillすることを試みる
このように
LowMemoryKillerが裏で不要なプロセスをよしなにkillしてくれるおかげで私達は、普段快適にAndroidのスマートフォンを利用できているわけです。LowMemoryKillerの全体像
本題の
LowMemoryKillerの仕組みについてです。まずAndroidは、LinuxカーネルをベースとするOSであり、
LowMemoryKillerは、Linuxカーネルに既にある機能をうまく活用して実現されている仕組みになります。ざっくり書くと、OOM Killerによってプロセスがkillされる前に重要度が低いActivityを持つプロセスをkillしてメモリを空ける仕組みです。
LowMemoryKillerの登場人物は主に3つです。
ActivityManagerService
- 現在どのActivityが重要かを判断するActivityの管理人のような役割をする
- ActivityStackというスタックでActivityを管理
- Activityの重要度を示すスコアの更新依頼をカーネル側に行う
lmkdデーモン
- oom_score_adj というスコアを更新する
lowmemorykillerドライバ
- メモリの空きが少なくなってきたタイミングで表に出ていない重要度の低いアプリのプロセスのkillを試みる
- 実際にここでプロセスをkillする仕組みには、Linuxのディスクキャッシュの開放を行うshrink_slab()を活用している
例としてA画面 → B画面へのActivity遷移が起きたときの全体像をざっくり図に表すと以下のようになります。
- まず、
ActivityManagerServiceがActivity BをActivityStackに積むActivityManagerServiceは、各Activityの重要度を示すスコアをカーネル側に伝達するため、スコアの更新依頼を行うlmkdデーモンがスコア(oom_score_adj)を更新するlowmemorykillerドライバは、端末のメモリに空きが少なくなってきたときに、lmkdで更新されるスコアを参照して、スコアの高いActivityを持つプロセスからkillしていき、メモリを解放することを試みる※ただし、カーネル4.12の時点で、lowmemorykillerドライバはカーネルから削除されており、lmkdがメモリのモニタリングとプロセス強制終了タスクを実行するように変わっています。基本的に機能としてはlowmemorykillerドライバと同じ機能をサポートしていますが、Android10以降では、メモリプレッシャーの検出にカーネルプレッシャーストール情報(PSI)モニターを使用する、新しいlmkdモードがサポートされていたりします。詳しくは、ローメモリ キラー デーモン(Imkd)を参照ください。
Activityの重要度を示すスコア(oom_score_adj)
lmkdが更新するスコアに従って、メモリの空きが少なくなってきたときにActivityの破棄やプロセスのkillを段階的に行うので、このスコアをActivityが破棄される基準といえそうです。このスコアは、
oom_score_adjと呼ばれ、OOMKillerがプロセスをkillするときにも使用されます。
oom_score_adjは、プロセスとActivityのライフサイクルの状態によって決められるkillされる閾値(メモリ空き容量)を表します。実際に自分の端末でこのスコアを確認してみました。
(闘値は固定ではなく端末の状態で上下します。)$adb shell dumpsys activity oom OOM levels: -900: SYSTEM_ADJ ( 73,728K) -800: PERSISTENT_PROC_ADJ ( 73,728K) -700: PERSISTENT_SERVICE_ADJ ( 73,728K) 0: FOREGROUND_APP_ADJ ( 73,728K) 100: VISIBLE_APP_ADJ ( 92,160K) 200: PERCEPTIBLE_APP_ADJ ( 110,592K) 250: PERCEPTIBLE_LOW_APP_ADJ ( 129,024K) 300: BACKUP_APP_ADJ ( 221,184K) 400: HEAVY_WEIGHT_APP_ADJ ( 221,184K) 500: SERVICE_ADJ ( 221,184K) 600: HOME_APP_ADJ ( 221,184K) 700: PREVIOUS_APP_ADJ ( 221,184K) 800: SERVICE_B_ADJ ( 221,184K) 900: CACHED_APP_MIN_ADJ ( 221,184K) 999: CACHED_APP_MAX_ADJ ( 322,560K)
- 先頭についている3桁の数字:システム内で生かすべき優先順位
- [XXXX_XXX_ADJ]の語尾の()の中の数字:プロセスを終了する具体的なメモリの空き容量の闘値
システム内で生かすべき優先順位の数字がより小さいほどプロセスがkillされづらくなり、高いほどkillされやすくなります。システムや永続化サービスを除いた時、一番この中でkillされる可能性が低いのは、level:0のフォアグラウンドいるActivityということになります。
ちなみに、XXXX_XXX_ADJ の意味は、ProcessList.javaのソースコードを読めばわかります。
ActivityがフォアグラウンドにあればそのActivityのscoreはFOREGROUND_APP_ADJで0、1つ前に使っていたならPREVIOUS_APP_ADJで700、ホームのアプリのActivityならHOME_APP_ADJで600といった形で、Activityのライフサイクルの状態などによってスコアが変化します。
例えばActivityの画面遷移が起きた時のスコアの変遷は以下のようになります。
このようにActivityのライフサイクルが変わるたびに、
ActivityManagerServiceが各Activityの重要度を判断して、スコアを更新するということです。実際にスコアを更新するのはlmkdです。Androidを触っていると、”いつの間にかアプリがkillされている”ってことがありますが、内部的にはこのようにActivityのスコア更新を行って、メモリの空きが少なくなったときにはこのスコアの基準に従ってActivity破棄やプロセスのkillが行われているようです。
Bundleは実際どこに保存されているのか
アプリのプロセスが
LowMemoryKillerによってkillされる話をここまでしてきましたが、Androidでは、破棄されたActivityを復元させることもできます。LowMemoryKillerの必要性でも軽く触れましたが、その際は、
onSaveInstanceState()でデータをBundleに保存しておき、Activityを復元するときには保存しておいたBundleのデータを取り出すことで、Activityが突然破棄された場合に対処します。これに関してはAndroidエンジニアなら常識になっていると思いますが、このときBundleは実際どこに保存されているのでしょうか?
その答えは、
SystemServerのプロセス上にあるActivityStackです。先ほどの
oom_score_adjの話を振り返ると、SystemServerのプロセスのoom_score_adjは-900になります。
アプリをバックグラウンドに移動すると、まず前回使っていたActivityとしてスコアは0から700になり、さらに時間が経つにつれてスコアが増えていくことを踏まえると、スコア-900のSystemServerのプロセスにデータを保存しておけばシステムから非常にkillされにくいということがいえます。ただし、もちろんですがSystemServerのプロセスのメモリを使用するので、Bundleにあまり大きなデータを保存してはいけません。SystemServerのメモリが大きくなりすぎると、メモリを空けようとして、裏のActivityをkillする頻度が上がるため、タスクの切り替えがすごく遅くなったように感じたり、メモリ不足によるアプリの異常終了などが多くなってしまうようです。
またBundleにあまり大きなデータを保存しようとすると、TransactionTooLargeExceptionという例外も発生します。
The Binder transaction buffer has a limited fixed size, currently 1Mb, which is shared by all transactions in progress for the process.
Activity間の画面遷移を行う際に、Intentに載せられるExtraのペイロードの上限が1MBであることはこのようにドキュメントに書かれていますが、手元で何度かこのエラーに遭遇したときは実際は1MBいってなくても発生していました。
個人的な解釈としては、
onSaveInstanceState()で保存するBundleにはidやBooleanなどだけで、大きなデータはViewModelか永続化領域に保存か、ネットワークから再取得するか、という使い方が適切なんだろうなと思います。
便利ですがBundleには、なんでもかんでもツッコまないようにしましょう。おわりに
Linuxカーネルのより詳細な話も書こうとしたのですが、長くなりすぎるので本記事では省略しました。でも今回説明した仕組みをより詳細に知るためにはLinuxの知識も必要となります。気になる方はぜひ参考文献に載せている書籍などをご覧ください。
普段何気なく書いてるコードもこうして裏では動いてくれているんだと思いをはせながら、来年は今年よりメモリに優しい開発をしていきたいなと思います。
メリークリスマス。よいお年を。
参考文献


- 投稿日:2020-12-23T13:18:27+09:00
OpenVPN 纏め + Amazon Linux2
概要
OpenVPNは、IP/TCPなどのL2、L3プロトコルを、SSL/TLSでカプセル化し、OpenVPNサーバーとOpenVPNクライアントとの間を安全に接続します。
OpenVPNは、PKI を利用します。
OpenVPNに必要なファイル
- CA(認証局):CA証明書、CA秘密鍵
- OpenVPNサーバー:CA証明書、サーバー証明書、サーバー秘密鍵、DHパラメーター
- OpenVPNクライアント:CA証明書、クライアント証明書、クライアント秘密鍵
接続形態
ルーティング接続 ブリッジ接続 仮想トンネルネットワーク経由で異なるネットワークに接続する方法です。
ルーティング処理を介して接続するので、 OpenVPNサーバーとOpenVPNクライアントは別々のネットワークが利用できます。
LAN同士を相互に接続する用途に向いており、大規模なアクセス制御に向いている。仮想インタフェースで接続する方法です。
接続ネットワークと同じネットワークセグメントのIPアドレスをOpenVPNクライアントの仮想インタフェースに割り当てることで、OpenVPNクライアントは、接続先ネットワークに参加できます。
ブロードキャストが届くので、SambaやWindowsサーバーなどが利用できます。小規模なネットワークや個人で利用するのに手軽である。OpenVPNサーバー側
easy-rsaパッケージを使って、認証局などを作成
# /usr/share/easy-rsa/3/easy-rsa init-pki # /usr/share/easy-rsa/3/easy-rsa build-caサーバー証明書を作成
# /usr/share/easy-rsa/3/easy-rsa build-ca build-server-full vpnsrv nopassクライアント証明書を作成
# /usr/share/easy-rsa/3/easy-rsa build-ca build-client-full vpncli nopassDHパラメータを作成。
# /usr/share/easy-rsa/3/easy-rsa gen-dh作成した証明書ファイルを、etc/openvpn/serverにコピーする。
# cp -r /usr/share/easy-rsa/3/pki etc/openvpn/serverTLS鍵を作成する。
# openvpn --genkey --secret /etc/openvpn/server/pki/ta.key/etc/openvpn/server/server.conf の設定。
/usr/share/doc/openvpn/2.4.9/sample/sample-config-files からサンプルをコピーして利用するといい。/etc/openvpn/server/server.conf#ポート番号 port 1194 #プロトコル proto udp #ブリッジ接続 dev tap #CA秘密鍵 ca ca.crt #サーバー証明書 cert issued/vpnsrv.crt #サーバー秘密鍵 key private/vpnsrv.key #DHパラメータ dh dh.pem #VPNで利用するネットワーク server 192.168.250.0 255.255.255.0 push "route 192.168.250.0 255.255.255.0" #TLS認証鍵 tls-auth ta.key #接続中のクライアントのリストを出力するファイル status /var/log/openvpn-status.log #ログを出力するファイル(指定しなければsyslogに出力) log /var/log/openvpn.logOpenVPNを起動する。
# systemctl start openvpn-server@server # systemctl -w net.ipv4.ip_forward=1OpenVPNクライアント側
OpenVPNクライアント側へ以下のファイルを転送します。
転送必要なファイル 説明 クライアント証明書 /etc/openvpn/server/pki/issued/vpncli1.crt クライアント秘密鍵 /etc/openvpn/server/pki/private/vpncli1.key CA秘密鍵 /etc/openvpn/server/pki/ca.crt TLS認証鍵 /etc/openvpn/server/pki/ta.key /etc/openvpn/client.conf#クライアントであることの指定。 client #ブリッジ接続 dev tap #プロトコル proto udp #接続先サーバー、ポート remoto server.naata.com 1194 #認証局証明書のファイル ca ca.crt #クライアント証明書のファイル cert issued/vpncli1.crt #クライアント秘密鍵のファイル key private/vpncli1.key #tls認証鍵 tls-auth ta.keyOpenVPNを起動します。
# /sbin/openvpn /etc/openvpn/client.confOpenVPN を構築する(Amazon Linux2)
1.インストール
EPEL リポジトリを有効化
OpenVPN のインストール
sudo yum install openvpn -yeasy-rsa のインストール
sudo yum install easy-rsa --enablerepo=epel -y2.認証局と鍵の作成
認証局の初期化
sudo -s cd /usr/share/easy-rsa/3 ./easyrsa init-pki init-pki complete; you may now create a CA or requests. Your newly created PKI dir is: /usr/share/easy-rsa/3/pki認証局の作成
./easyrsa build-caDHパラメータの作成
./easyrsa gen-dhTLS認証鍵の作成
openvpn --genkey --secret /etc/openvpn/ta.keyサーバー証明書と秘密鍵の作成
./easyrsa build-server-full server nopassクライアント証明書と秘密鍵の作成
./easyrsa build-client-full client3./etc/openvpn/server.confの設定
/etc/openvpn/server.confの編集
cp /usr/share/doc/openvpn-2.4.9/sample/sample-config-files/server.conf /etc/openvpn//etc/openvpn/server.confport 1194 proto udp dev tun ca /usr/share/easy-rsa/3/pki/ca.crt cert /usr/share/easy-rsa/3/pki/issued/server.crt key /usr/share/easy-rsa/3/pki/private/server.key dh /usr/share/easy-rsa/3/pki/dh.pem server 10.8.0.0 255.255.255.0 ifconfig-pool-persist ipp.txt push "route 10.0.0.0 255.255.255.0" keepalive 10 120 #tls-auth ta.key 0 cipher AES-256-CBC comp-lzo persist-key persist-tun status openvpn-status.log verb 3 explicit-exit-notify 14.openVPNの開始と確認
フォワーディングの設定
/etc/sysctl.confnet.ipv4.ip_forward = 1network の再起動
systemctl restart networkopenvpnの再起動
systemctl start openvpn@server systemctl enable openvpn@serveropenvpnのステータス確認
systemctl list-unit-files -t service | grep openvpn5.AWS側の設定
OpenVPNをインストールしたインスタンスのセキュリティグループで 1194 番ポートを許可する
Privateネットワーク
- ルートテーブル:VPNクライアント側のセグメントから、OpenVPNをインストールしたサーバへのルーティングを設定する。
- セキュリティグループ:VPNクライアント側のセグメントからはいってくるパケットの許可
OpenVPNをインストールしたサーバで送信元/送信先の変更チェックを無効に設定する
※送信元/送信先の変更チェック無効化とは
EC2インスタンスはデフォルトで送信元/送信先チェックを有効化しています。つまり、対象のEC2インスタンス宛てでないパケットはデフォルトで弾く仕様ということです。今回はインターネット宛てのパケットをEC2で経由させる必要があるためこの機能を無効化し、パケットを弾かせないように変更する必要があります。参考:https://it.hirokun.net/entry/ec2-openvpn-easyrsa3#OpenVPN-6
6.Tunnelblick(MAC)で検証
Tunnelbrick で、接続する。
client dev tun proto udp remote OpenVPNサーバIPアドレス 1194 resolv-retry infinite nobind persist-key persist-tun ca ca.crt cert client.crt key client.key cipher AES-256-CBC keepalive 10 60 verb 3 mssfix 1280
- 投稿日:2020-12-23T10:40:24+09:00
Cで作るコンテナもどき #2
はじめに
この記事は、FUNアドベントカレンダー2020の22日目の記事になります。
昨日はともかさんの学内限定初心者に優しいハッカソンFunLocksを運営した話でした。
今年はpart1とpart2それぞれ記事を書いているのですが、2つともともかさんの次になります。なんででしょうね。不思議。環境
- debian buster
- kernel 4.19.0
さくらのクラウド上で実行しています。
今回で扱う範囲
namespace,chroot,cgroupを実装します。
今回、cgroupではcpuの制御しか行いません。namespaceの切り分け
コンテナを作成するために、namespaceの切り分けを行う必要があります。これに対応したシステムコールはunshareとなります。
似たような機能を持つシステムコールにcloneがあります。
せっかくですので、ここでunshareとcloneの違いを簡単にまとめてからどちらを使うか考えましょう。unshare
現在のプロセスに対して名前空間共有の制御を行う。
引数
- int flags
与えられたflagに対応した資源を共有しません。 つまり、何も指定しないとすべて共有されるってことかな。返り値 : int
成功時0, 失敗時-1
clone
子プロセスの作成と同時に名前空間共有制御を行う。
fork + unshareが混ざったイメージ引数
- unsigned long flags
与えられたflagに対応した資源を共有します。- void *child_stack
割愛- void *ptid
割愛- void *ctid
割愛- struct pt_regs *regs
割愛なんかいっぱいありますね。
unshareとは違い子プロセスも作成するので、子プロセスの使用するメモリやその他諸々が必要になります。(めんどくさくて調べていないので詳しくは各自で)返り値 : long
子プロセスのスレッドidが返されます。失敗時-1、子プロセスは作成されません。
結局どっち使うの?
すこし長くなってしまいましたが、今回はunshareを使用したいと思います。
理由としては以下となります。
- 引数と返り値がわかりやすい。
- cloneの説明にスレッドに使うことが多いみたいなこと書いてある。
実装してみる
#define _GNU_SOURCE #include<sched.h> #include<unistd.h> #include<stdio.h> #include<errno.h> int main(){ const unsigned int UNSHARE_FLAGS = ( CLONE_FILES | CLONE_NEWIPC | CLONE_NEWUTS | CLONE_NEWPID); if (unshare(UNSHARE_FLAGS) < 0){ perror("unshare"); } printf("ok\n"); return 0; }で名前空間を分離することができるとおもいます。
unshareの実行しかしておらず、エラーが出なかったことだけしか確認していないので、この段階ではちゃんと動いたかわかりません。flagの説明は割愛します。UNSHAREに書いてあるので各自見てみてください。
rootの変更
namespaceを切り分けたあとはrootを変更してあげます。
システムコールのchrootを使います。chroot
ルートディレクトリの変更。
引数で指定したpathが以降で'/'として扱われます。引数
- const char* path
変更先のパス返り値
成功時0, エラーの場合-1
実装してみる
#include<unistd.h> #include<errno.h> #include<stdio.h> int main(){ char *argv[3]; argv[0] = "/"; argv[1] = NULL; if( chroot("./test") < 0 ){ perror("chroot"); return 1; } if ( chdir("./test") < 0 ){ perror("chdir"); return 1; } if ( execve("/bin/ls", argv, NULL) < 0){ perror("execve"); return 1; } printf("ok\n"); return 0; }testというディレクトリを作成し、そこにchrootを行います。
その後/bin/lsを実行するコードを書きました。
testは空のディレクトリなので、もちろん、/bin/lsなんてないのでうまくいきません。
これでchrootがうまく機能しているというのが確認できます。(賢い確認方法ではない)
ちなみに、ホストマシンのものではないdebianのrootディレクトリを用意して、chrootした場合は正常に動きました。リソースの制限
コンテナとして成り立たせるためにはリソースの制限を行う必要があります。例えば、メモリの使用量だとか、CPU利用の制限とか、いろいろです。
リソースの制限に関しては、システムコールがあるわけではなく、cgroupというLinuxの機能があります。
cgroupはv1とv2がありますが、今回はv2を使用します。
cgroup v2の細かい説明や仕様については長くなるのでここでは説明しません。
興味あるかたはぜひこちらをご覧になってください。cgroupを用いたリソースの制限
cgroupを使えるようにするには以下の手順を踏む必要があります。
1. cgroupfsのマウント
2. cgroupの作成(ディレクトリの作成)
3. cgroup.procsへ制御するプロセスIDの書き込み
4. サブシステムの登
5. サブシステムへの制限実装してみる
今回僕の環境では
/sys/fs/cgroupにすでにマウントされていたので行いません。#include<sys/mount.h> #include<fcntl.h> #include<unistd.h> #include<errno.h> #include<stdio.h> int main(){ //make cgroup if( access("/sys/fs/cgroup/container", F_OK) < 0){ if( mkdir("/sys/fs/cgroup/container", 0644) < 0){ perror("mkdir"); return -1; } } //set pid int fd; fd = open("/sys/fs/cgroup/container/cgroup.procs", O_WRONLY); if( fd < 0 ){ perror("cgroup open"); return -1; } int _pid = getpid(); char buff[6]; snprintf(buff, 6 , "%d", _pid); write(fd, buff, 6); close(fd); //set subsystem fd = open("/sys/fs/cgroup/container/cgroup.subtree_control", O_WRONLY); if( fd < 0 ){ perror("subsystem open"); return -1; } write(fd, "+cpu", 5); close(fd); //set cpu max fd = open("/sys/fs/cgroup/container/cpu.max", O_WRONLY); if( fd < 0 ){ perror("cpu open"); return -1; } write(fd, "10000", 6); close(fd); while(1){ fd = open("/dev/null", O_WRONLY); write(fd,"hello world\n", 12); close(fd); } }現在のプロセスに対して、CPU最大10%までの制限をかけて、"hello world"を/dev/nullに無限に出力するものです。
(yesコマンドみたいな?)
これを実行した状態でプロセスのCPU使用率を確認してみましょう。
おおよそ10%に固定されていることがわかります。
多分上手く動いてますね。補足
//set cpu max fd = open("/sys/fs/cgroup/container/cpu.max", O_WRONLY); if( fd < 0 ){ perror("cpu open"); return -1; } write(fd, "10000", 6); close(fd);cwriteで"10000"とありますが、これはCPU時間のことです。今回、CPU時間の最大が100000なので1/10の"10000"となっています。
これでCPU使用率の設定ができます。おわり
今回はnamespace,chroot,cgroupを実装しました。
コードの質問や、挙動が違う部分、間違ってる部分あればTwitterまでお願いします。
次回はいつになるかわかりませんが、capabilityを実装しようと思います。参考にしたところ
Cで作るコンテナもどき #1
LXCで学ぶコンテナ入門 -軽量仮想化環境を実現する技術
Man page of UNSHARE
Man page of CLONE
Man page of CHROOT

- 投稿日:2020-12-23T10:00:22+09:00
Homebrew + rbenv + ruby-build の関係性(後編)実際にrubyとRailsの導入もできます!
前回の記事ではbrewでインストールしたプログラムが
/usr/local/Cellerディレクトリなどに入りシンボリンクを作成することでパスが通ること、各ディレクトリ構成について説明しました。今回は実際にrbenvとruby-buildをインストールして、それぞれのコマンドで何をしているのかを説明していきます。rbenv, ruby-buildのインストール
まずはbrewを最新の状態にしておきます。
% brew update次に
rbenvとruby-buildのインストールです。ruby-buildはrbenvのプラグインの1つです。rbenv installというRubyのバージョンをインストールするコマンドを提供しています。rbenvをインストールする際に、セットでインストールします。% brew install rbenv ruby-buildRBENV_ROOT とは
次のコマンドの説明に必要なのでこの用語の説明をします。RBENV_ROOT というのは rbenv の shims (後述) と versions (Ruby のインストール先) がある場所(パス)を指し示すための環境変数です。 デフォルトではホームディレクトリに直下になっており、以下のように確認できます。
% rbenv root /Users/shuntagami/.rbenvrbenv initの実体
話を戻します。rbenv のインストール手順によると以下のコマンドを実行するようにあります。
% echo 'eval "$(rbenv init -)"' >> ~/.zshrc #(`~/.zshrc`の部分は使っているシェルに応じて変えてください。)これは何を行うのでしょうか? 答えは書いてあるとおり、
shimsとautocompletionを有効化します。shimsには何が入っているのか確認してみましょう。% cd .rbenv % ls shims version versions % cd shims % ls bundle bundler erb gem irb rake rdoc ri ruby testrb,,,bundleやらrakeやらrailsを使ったことのある人ならおなじみのコマンドが入っています。つまり、
shimsを有効化することにより、$RBENV_ROOT/shimsをPATHに入れ,これらのコマンドがどこからでも使えるようになるということです。最後にシェルの設定ファイルの変更を以下のコマンドで読み込みましょう。source ~/.zshrc #(`~/.zshrc`の部分は使っているシェルに応じて変えてください。)rbenvでrubyをインストールする
ここまでで
rbenvのインストールが完了したのでrubyをインストールしていきます。インストール可能なバージョンは以下のように確認しましょう。% rbenv install --list特に理由がなければ最新のバージョンをインストールしましょう。
% rbenv install 2.7.2インストールしたバージョンを使うために以下のコマンドを実行します。
% rbenv global 2.7.2最後に
rbenvを読み込み、変更を反映させます。新しいバージョンの Ruby を入れたときや、実行ファイルを提供する gem を入れたあとには実行するようにしましょう。% rbenv rehashRailsを用意する
rubyの導入が終わり、せっかくなので
Railsの導入手順も説明していきます。bundlerのインストール
bundlerとは、gemのバージョンやgemの依存関係を管理してくれるgemです。bundlerを使うことで、複数人での開発やgemのバージョンが上がってもエラーを起こさずに開発できます。
% gem install bundlerbundler自体もgemなのでインストールが完了すると
1 gem installedと表示されるはずです。Railsのインストール
% gem install rails --version='6.0.0'バージョンを指定してインストールします。完了したら先ほど説明した
rbenv rehashコマンドを実行しましょう。参考
rbenv + ruby-build はどうやって動いているのか
https://takatoshiono.hatenablog.com/entry/2015/01/09/012040rbenv公式
https://github.com/rbenv/rbenv#basic-github-checkoutまとめ
rubyとRailsのインストール手順とそれぞれのコマンドの意味を見ていきました。あとはデータベース,yarn,Node.jsをインストールすればRailsを動かすことができるようになります
- 投稿日:2020-12-23T01:16:23+09:00
Linuxの先読みキャッシング read_ahead_kb
この記事面白すぎる!
先読み
必要なデータをユーザから要求があるたびに同期的に読み込んでいると、ディスクの I/O 待ちに時間がかかる。そのため、 I/O 要求がシーケンシャルリードだと判断した時点で要求されていない後続のブロックを先読みしておき、キャッシュを充実させる。先読みしたデータは使われるかもしれないし、無駄になるかもしれない。
先読みすることでどの程度効率化されているかを動作確認する。
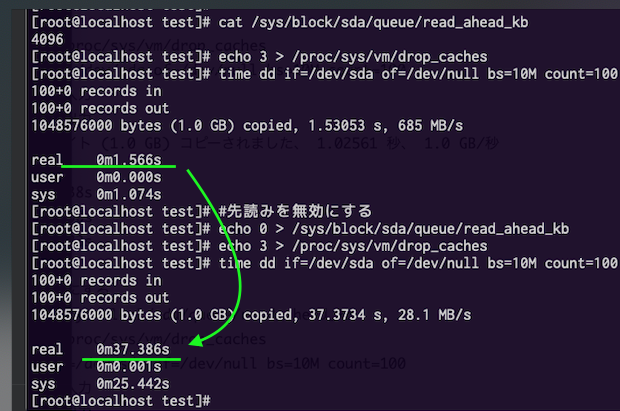
https://www.kimullaa.com/entry/2019/12/01/130347#// 先読みが有効であることを確認する cat /sys/block/sda/queue/read_ahead_kb # cache削除 echo 3 > /proc/sys/vm/drop_caches # (先読みあり) 読み込み速度計測 time dd if=/dev/sda of=/dev/null bs=10M count=100 #先読みを無効にする echo 0 > /sys/block/sda/queue/read_ahead_kb # cache削除 echo 3 > /proc/sys/vm/drop_caches # (先読みなし)読み込み速度計測 time dd if=/dev/sda of=/dev/null bs=10M count=100result
[root@localhost test]# cat /sys/block/sda/queue/read_ahead_kb 4096 [root@localhost test]# echo 3 > /proc/sys/vm/drop_caches [root@localhost test]# time dd if=/dev/sda of=/dev/null bs=10M count=100 100+0 records in 100+0 records out 1048576000 bytes (1.0 GB) copied, 1.53053 s, 685 MB/s real 0m1.566s user 0m0.000s sys 0m1.074s [root@localhost test]# #先読みを無効にする [root@localhost test]# echo 0 > /sys/block/sda/queue/read_ahead_kb [root@localhost test]# echo 3 > /proc/sys/vm/drop_caches [root@localhost test]# time dd if=/dev/sda of=/dev/null bs=10M count=100 100+0 records in 100+0 records out 1048576000 bytes (1.0 GB) copied, 37.3734 s, 28.1 MB/s real 0m37.386s user 0m0.001s sys 0m25.442s [root@localhost test]#
- 投稿日:2020-12-23T01:05:44+09:00
vmstat コマンドの buff と cache の違い
buff と cache の違い
ページキャッシュとバッファキャッシュ
ほとんどのファイルシステムでは、ディスクから読み込んだデータをキャッシュする。データへのアクセス方式によって、ページキャッシュとバッファキャッシュに分けられる。
https://www.kimullaa.com/entry/2019/12/01/130347
x 「何のデータか」
o 「どうやって取得したか」cacheを増やす方法
ページキャッシュ
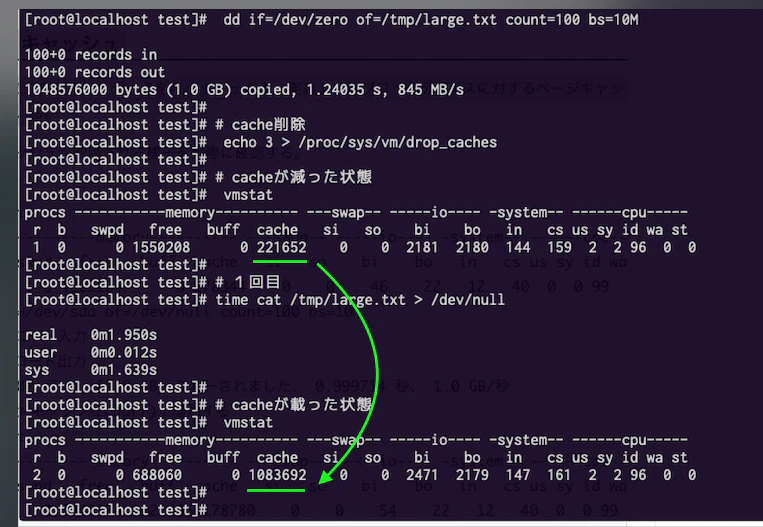
ファイルシステム経由でアクセスしたデータのキャッシュ。file system(HDD/SSD)からファイルを読む
# でかいファイルを作る dd if=/dev/zero of=/tmp/large.txt count=100 bs=10M # cache削除 echo 3 > /proc/sys/vm/drop_caches # cacheが減った状態 vmstat # 1回目 time cat /tmp/large.txt > /dev/null # cacheが載った状態 vmstatこの記事参照
https://qiita.com/uturned0/items/3eab2a8d03180677f768cache result
[root@localhost test]# # でかいファイルを作る [root@localhost test]# dd if=/dev/zero of=/tmp/large.txt count=100 bs=10M 100+0 records in 100+0 records out 1048576000 bytes (1.0 GB) copied, 1.24035 s, 845 MB/s [root@localhost test]# [root@localhost test]# # cache削除 [root@localhost test]# echo 3 > /proc/sys/vm/drop_caches [root@localhost test]# [root@localhost test]# # cacheが減った状態 [root@localhost test]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1550208 0 221652 0 0 2181 2180 144 159 2 2 96 0 0 [root@localhost test]# [root@localhost test]# # 1回目 [root@localhost test]# time cat /tmp/large.txt > /dev/null real 0m1.950s user 0m0.012s sys 0m1.639s [root@localhost test]# [root@localhost test]# # cacheが載った状態 [root@localhost test]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 688060 0 1083692 0 0 2471 2179 147 161 2 2 96 0 0 [root@localhost test]# [root@localhost test]#buffを増やす方法
バッファキャッシュ
raw I/O 経由でアクセスしたデータをキャッシュする。実装上は、ブロックデバイスに対するページキャッシュになっている。ファイルではなく、block device
/dev/sd*を直接読み込む。# buff削除 echo 3 > /proc/sys/vm/drop_caches # buffが減った状態 vmstat # buff を載せる time dd if=/dev/sda of=/dev/null count=100 bs=10M # buffが載った状態 vmstatbuff result
[root@localhost test]# # buff削除 [root@localhost test]# echo 3 > /proc/sys/vm/drop_caches [root@localhost test]# [root@localhost test]# # buffが減った状態 [root@localhost test]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1718432 0 53296 0 0 2430 2176 146 159 2 2 96 0 0 [root@localhost test]# [root@localhost test]# # buff を載せる [root@localhost test]# time dd if=/dev/sda of=/dev/null count=100 bs=10M 100+0 records in 100+0 records out 1048576000 bytes (1.0 GB) copied, 1.51047 s, 694 MB/s real 0m1.515s user 0m0.001s sys 0m1.122s [root@localhost test]# [root@localhost test]# # buffが載った状態 [root@localhost test]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 690092 1028096 53344 0 0 2771 2175 149 163 2 2 96 0 0 [root@localhost test]#


- 投稿日:2020-12-23T00:55:21+09:00
LinuxがPage cacheを使って高速化するのを体験してみる
こちらの超素敵な記事をまんま真似するだけです。
https://www.kimullaa.com/entry/2019/12/01/130347rootで実行します。
# でかいファイルを作る dd if=/dev/zero of=/tmp/large.txt count=100 bs=10M # 今のcache状態 vmstat # cache削除 echo 3 > /proc/sys/vm/drop_caches # cacheが減った状態 vmstat # 1回目 time cat /tmp/large.txt > /dev/null # cacheが載った状態 vmstat # 2回目は早くなるはず time cat /tmp/large.txt > /dev/null # お掃除 rm -rf /tmp/large.txtresult
10倍になりました。
[root@localhost test]# # でかいファイルを作る [root@localhost test]# dd if=/dev/zero of=/tmp/large.txt count=100 bs=10M 100+0 records in 100+0 records out 1048576000 bytes (1.0 GB) copied, 1.29639 s, 809 MB/s [root@localhost test]# [root@localhost test]# # 今のcache状態 [root@localhost test]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 79216 0 1692164 0 0 1084 2053 166 195 3 2 95 0 0 [root@localhost test]# [root@localhost test]# # cache削除 [root@localhost test]# echo 3 > /proc/sys/vm/drop_caches [root@localhost test]# [root@localhost test]# # cacheが減った状態 [root@localhost test]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 0 1592220 0 179268 0 0 1086 2053 166 195 3 2 95 0 0 [root@localhost test]# [root@localhost test]# # 1回目 [root@localhost test]# time cat /tmp/large.txt > /dev/null real 0m1.455s user 0m0.008s sys 0m1.075s [root@localhost test]# [root@localhost test]# # cacheが載った状態 [root@localhost test]# vmstat procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 2 0 0 567092 0 1204456 0 0 1565 2053 170 200 3 2 95 0 0 [root@localhost test]# [root@localhost test]# # 2回目は早くなるはず [root@localhost test]# time cat /tmp/large.txt > /dev/null real 0m0.139s user 0m0.003s sys 0m0.135s [root@localhost test]#

- 投稿日:2020-12-23T00:16:05+09:00
Homebrew + rbenv + ruby-build の関係性(前編)
はじめに
最近rubyの管理を
rbenvからanyenv経由でrbenvをインストールする形式に変えようと思っていました。というのも、.zshrc(bashを使う人は.bash_profile)にanyenvのパスを通すだけで済むのでファイルをきれいに保てるというのが1番の理由です。その移行方法について調べている際に「rbenvをよくわかってなかったなあ」と感じたので記事を書くことにしました。また、今回の記事は「homebrewでインストールしたとき」を想定しています。brewでインストールしたものはどこにある?
まず私はこんな基本的なこともわたしは理解していませんでした。homebrewでインストールしたものは
/usr/local/Cellerに入るようになっています。「/usr/local/Cellerにパスを通したことなんてない!」と思ったのですが、homebrew の仕組みにしたがって、適切なバージョンの実行可能ファイルに/usr/local/binからのシンボリックリンク(ショートカット)が作成されるみたいです。つまり、/usr/local/binへのパスが通っていればhomebrewでインストールしたコマンドは使えるようになります。以下のような感じです。$ ll /usr/local/bin/{rbenv,ruby-build} lrwxr-xr-x 1 shuntagami admin 31B 8 3 15:26 /usr/local/bin/rbenv -> ../Cellar/rbenv/1.1.2/bin/rbenv lrwxr-xr-x 1 shuntagami admin 44B 12 20 08:13 /usr/local/bin/ruby-build -> ../Cellar/ruby-build/20201210/bin/ruby-buildちなみに、
PATHは環境変数$PATHに設定されており、echo $PATHで確認できます。以下は私の例です。$ echo $PATH /Users/shuntagami/.anyenv/envs/nodenv/shims:/Users/shuntagami/.anyenv/envs/nodenv/bin:/Users/shuntagami/bin:/usr/local/bin:/usr/bin:/bin:/usr/sbin:/sbinパスは
:で区切られるので見やすくしてあげます。$ echo $PATH /Users/shuntagami/.anyenv/envs/nodenv/shims /Users/shuntagami/.anyenv/envs/nodenv/bin /Users/shuntagami/bin /usr/local/bin /usr/bin /bin /usr/sbin /sbin
/usr/local/binへのパスが通っていますね!補足で、$PATHに同じパスが通っていたらtypeset -U path PATHで解消できます。binがいっぱいあるけどどういう意味?
先ほどの環境変数
$PATHには/usr/,/binなどがありましたがそれらの違いについて説明します。そもそもbinとはBinary codeのことで実行可能プログラム置き場ということです。 コマンドも実態はプログラムなので権限や用途に合わせてわけて保存されます。/bin
シングルユーザモードでも利用できるコマンドを置きます。逆の言い方をすると、「/usr/bin」や「/usr/local/bin」に置かれているコマンドなどはシングルユーザモードで利用できないということになります。シングルユーザモードは、基本的にOSが壊れて正常に起動できないなど非常時に利用するものですので、「/bin」にはごく基本的かつ非常時に利用するコマンドが置かれることになります。
/sbin
ここにはシステム管理用のコマンドが保存されます。多くのシステム管理用のコマンドはrootユーザーで(管理者になってから)実行されます。
/usr/bin
/usr/binには「シングルユーザモードで利用しない」かつ「RPMやdebなどのパッケージ管理システムによって、システムに管理されるコマンドやプログラム」が置かれます。非常時に利用するものではないが、システムを構成する重要なコマンドやプログラムはここに置かれることになります。また、ここには1000以上のコマンドがあるので
ls -l /usr/bin | lessコマンドを使うと確認しやすいです。/usr/sbin
/binと/usr/binの違いと同様。
/usr/local/bin
/usr/local/binは自分でインストールしたコマンドや自作のコマンドを置くのに使います。
まとめ
brewでインストールしたプログラムが/usr/local/Cellerディレクトリなどに入りシンボリンクを作成することでパスが通ること、各ディレクトリ構成について説明しました。後編では実際にrbenvとruby-buildをインストールして詳細を解説していきます!
参考
「/bin」「/usr/bin」「/usr/local/bin」ディレクトリの使い分け
https://linuc.org/study/knowledge/544/Linux標準教科書
https://linuc.org/textbooks/linux/