- 投稿日:2020-12-23T21:17:49+09:00
AWS の RDS(PostgreSQL)で Graviton2 インスタンスを試してみた
これは PostgreSQL Advent Calendar 2020 25 日目のエントリです。
昨日は Yugo Nagata (yugo-n) さんでした。
AWS のサービスをあまり追いかけていない間(10 月頃?)に RDS の Graviton2 プロセッサ対応が GA になっていました。
MySQL Advent Calendar 2020 のほうでは EC2 の Graviton2 インスタンスに MySQL を入れて試しましたが(「MySQL 8.0.22 で innodb_log_writer_threads の効果を見てみる」)、こちらでは RDS の PostgreSQL 12.4R1 で試してみます。
テスト内容
第 19 回 PostgreSQL アンカンファレンス @ オンラインのネタで(db.m5.xlarge インスタンスに対して)試した内容を db.m6g.xlarge インスタンスを使って再現し、db.m5.xlarge インスタンスの結果と比較しました。
- MySQL と PostgreSQL と主キー
- 中小規模の MySQL と PostgreSQL では、主キーにシーケンス値(
AUTO_INCREMENT/serial)を使うべきか UUIDv4 を使うべきか(実験してみた)、という話。先に記しておくと、中小規模・書き込みノード 1 つの PostgreSQL では、UUIDv4 よりもシーケンス値(
serial)を使ったほうが高速で、かつ安定していました。
今回は db.m6g.xlarge(Graviton2)と db.m5.xlarge(Intel x86_64)の間で性能差と特性の違いの有無を見てみました。テスト環境
- Amazon(AWS) RDS(PostgreSQL 12.4 R1)
- db.m6g.xlarge / db.m5.xlarge インスタンス(いずれも 4vCPU / メモリ 16GiB)を比較
- ストレージは SSD 700GiB
- Single AZ
- デフォルトパラメータグループ
テスト内容詳細
中小規模のシステム想定でひたすら行挿入をしたときの、主キーの種類別パフォーマンスを比較するものです。
今回は主キーの種類別に、Graviton2 と Intel x86_64 の速度を比較しつつ、それぞれの特性に違いがないか確認しました(MySQL との比較は外しました)。
- 120 万行のデータを 24 並列で挿入(合計 2,880 万行)
- 主キーとして以下の 3 種類を使い、挿入 100 万行あたりの所要時間の推移を確認
- (ⅰ)
serial- (ⅱ) UUIDv4(文字列)
- (ⅲ) UUIDv4(
uuid型)- テストに使うテーブルとして、以下の 2 種類を用意
- (1) 主キー列 +
integer列 +timestamp列- (2) 主キー列 +
integer列 +varchar(100)列(デフォルトで 100 文字入れる) +timestamp列テストに使用したテーブル
- (1) 主キー列 +
integer列 +timestamp列テーブル定義(1)-- (ⅰ) serial CREATE TABLE btree_test2 (id serial PRIMARY KEY NOT NULL, v1 integer, t1 timestamp(6) NOT NULL DEFAULT current_timestamp); -- (ⅱ) uuid_txt CREATE TABLE btree_test3 (id char(36) PRIMARY KEY NOT NULL, v1 integer, t1 timestamp(6) NOT NULL DEFAULT current_timestamp); -- (ⅲ) uuid CREATE TABLE btree_test4 (id uuid PRIMARY KEY NOT NULL, v1 integer, t1 timestamp(6) NOT NULL DEFAULT current_timestamp);
- (2) 主キー列 +
integer列 +varchar(100)列 +timestamp列テーブル定義(2)-- (ⅰ) serial CREATE TABLE btree_test2 (id serial PRIMARY KEY NOT NULL, v1 integer, t1 timestamp(6) NOT NULL DEFAULT current_timestamp, s1 varchar(100) DEFAULT '1234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890'); -- (ⅱ) uuid_txt CREATE TABLE btree_test3 (id char(36) PRIMARY KEY NOT NULL, v1 integer, t1 timestamp(6) NOT NULL DEFAULT current_timestamp, s1 varchar(100) DEFAULT '1234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890'); -- (ⅲ) uuid CREATE TABLE btree_test4 (id uuid PRIMARY KEY NOT NULL, v1 integer, t1 timestamp(6) NOT NULL DEFAULT current_timestamp, s1 varchar(100) DEFAULT '1234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890');テストに使用した SQL(文)の一部
SQL(文)-- (ⅰ) serial INSERT INTO btree_test2 (v1) VALUES (10), (11), (12), (13), (14), (15), (16), (17), (18), (19); -- これを 12 万行 1 ファイル × 24 種類用意 -- (ⅱ) uuid_txt INSERT INTO btree_test3 (id, v1) VALUES ('23ce3e9f-16de-4e5c-a293-6104ca45b47a', 10), ('ccf75ce2-49e9-4585-8561-9c55acf9e954', 11), ('493ec339-a21c-4ae9-be52-8c313758dd77', 12), ('aee11198-7767-42a6-9363-a16556d936b7', 13), ('7133eb96-fe19-4d45-b2f7-62ddc719234d', 14), ('cc1ae2ee-d99e-4102-9288-877eaae3bddc', 15), ('67fc7a86-b3c8-46fa-a237-d6479ee693b5', 16), ('c2e663e1-0168-4084-97fb-97b7d4575cf6', 17), ('602f2007-76f4-45d7-8a0f-e51430943afe', 18), ('f2b1ce06-db4a-48c4-b089-94198d3ddbe9', 19); -- これを(異なる UUID で)12 万行 1 ファイル × 24 種類用意 -- (ⅲ) uuid INSERT INTO btree_test4 (id, v1) VALUES ('23ce3e9f-16de-4e5c-a293-6104ca45b47a'::uuid, 10), ('ccf75ce2-49e9-4585-8561-9c55acf9e954'::uuid, 11), ('493ec339-a21c-4ae9-be52-8c313758dd77'::uuid, 12), ('aee11198-7767-42a6-9363-a16556d936b7'::uuid, 13), ('7133eb96-fe19-4d45-b2f7-62ddc719234d'::uuid, 14), ('cc1ae2ee-d99e-4102-9288-877eaae3bddc'::uuid, 15), ('67fc7a86-b3c8-46fa-a237-d6479ee693b5'::uuid, 16), ('c2e663e1-0168-4084-97fb-97b7d4575cf6'::uuid, 17), ('602f2007-76f4-45d7-8a0f-e51430943afe'::uuid, 18), ('f2b1ce06-db4a-48c4-b089-94198d3ddbe9'::uuid, 19); -- 同上テスト結果
(1) 主キー列 +
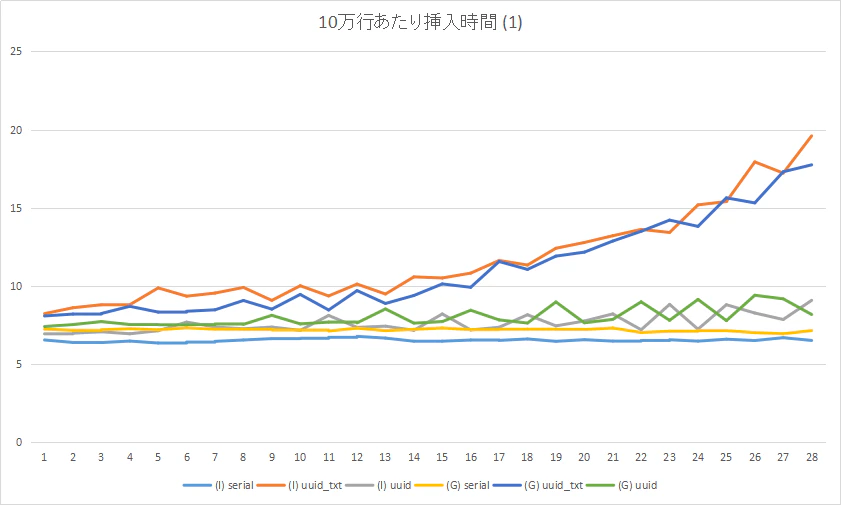
integer列 +timestamp列まずは「サイズの小さい行をひたすら挿入」のパターンです。
(I) が Intel x86_64、(G) が Graviton2 です。挿入 100 万行ごとに所要時間をプロットしています。縦軸は秒数です。
前述のとおり、主キーがserialのときに一番速く、かつ安定しています。Intel x86_64 と Graviton2 の比較では、主キーが
serialの場合は Intel x86_64 のほうが速くなりました。
逆に、主キーがchar(36)の UUIDv4 では、わずかに Graviton2 のほうが速くなりました。(2) 主キー列 +
integer列 +varchar(100)列 +timestamp列(1) よりも 1 行のサイズが大きいパターンです。
(1) と同じで主キーが
serialのときに一番速く、かつ安定しています。なお、こちらは Intel x86_64・Graviton2 の間での差がほとんどなくなりました。
例外として、主キーがchar(36)の UUIDv4 のみ Graviton2 のほうが速くなりました。【参考】テスト実行時のパフォーマンスインサイト
こんな感じになりました。
【おまけ 1 】(1) の (ⅲ) で、主キーの生成に
uuid-osspのuuid_generate_v4()を使用すると…「Graviton2 など Arm プロセッサでは乱数のエントロピー不足による性能問題が発生しやすい」という話がありましたので、念のため
uuid-osspを使って UUIDv4 を PostgreSQL 側で生成するパターンも試してみました。
- 【参考】Amazon EC2 を Arm に切り替えたら幸せなことしかありませんでした(CyberAgent Developers Blog)
別DBを用意してテーブル作成CREATE EXTENSION "uuid-ossp"; CREATE TABLE btree_test2 (id uuid PRIMARY KEY NOT NULL DEFAULT uuid_generate_v4(), v1 integer, t1 timestamp(6) NOT NULL DEFAULT current_timestamp);※SQL(文)は (ⅰ) serial と同じものを使用。
UUIDv4 の生成にわずかに時間が掛かるものの、明確な処理の滞留は見られませんでした。
※主キーが
uuid型の場合、挿入行数が増えてくるとuuid-osspを使わなくても処理が遅くなり単位行あたりの所要時間のばらつきも大きくなりましたが、uuid-osspを使ってもその傾向はほぼ変わりませんでした。【おまけ 2 】RDS でのインスタンスタイプ(インスタンスクラス)の変更
EC2 の場合とは異なり、Intel x86_64 と Graviton2 の間でも変更可能です。
まとめ
EC2 インスタンスに MySQL 8.0.22 を入れて試したときは、
- 2vCPU までなら Graviton2 が高速
- 8vCPU 以上なら概ね Intel x86_64 が高速
でしたが、今回の RDS PostgreSQL の 4vCPU 環境では「ほぼ同等の性能」という結果が出ました。
今回試したワークロードはある意味特殊ですのでこれだけで全てを判断することはできませんが、概ね MySQL on EC2 の結果と整合していますので、なんとなく傾向は掴める…かもしれません。
また、今後 Graviton2 への最適化が進むと結果は変わるかもしれません。
※実環境で使う場合は、使い方に合わせて性能調査を行いましょう。




- 投稿日:2020-12-23T20:47:41+09:00
CodeBuildのビルド環境にSessionManagerで入ってみた
CircleCIだとSSHを使用してビルド コンテナにアクセスできますが
CodeBuildも 2020年07月からSessionManagerを使って中に入れるようになっていたので使ってみました。
https://aws.amazon.com/jp/about-aws/whats-new/2020/07/aws-codebuild-now-supports-accessing-build-environments-with-aws-session-manager/やりかた
公式ドキュメント に書いてある通りですが。
1. BuildProjectのサービスロールに権限を追加
{ "Effect": "Allow", "Action": [ "ssmmessages:CreateControlChannel", "ssmmessages:CreateDataChannel", "ssmmessages:OpenControlChannel", "ssmmessages:OpenDataChannel" ], "Resource": "*" }2. ビルド一時停止するコマンド(codebuild-breakpoint)をbuildspecに追加しておく
phases: build: commands: - codebuild-breakpoint ←追加 - python -m unittest discover tests3. 「Enable session connection」にチェックを入れて実行
- [Advanced build overrides (高度なビルドの上書き)] で環境上書き設定を表示させる
- [Enable session connection(セッション接続を有効にする)] にチェックを入れる
4. codebuild-breakpointのところで止まるのでブラウザから入る
接続可能な状態になると Buils statusの右下に Session Manager へのリンクが出現するのでクリック
codebuild-breakpointで止めなくても現れますが、入ろうとしたらビルドが進んで終わっちゃったりしたので、止めて入るのがいいかなと思います。
5. おわったら「codebuild-resume」でビルドを再開して出る
CodeBuild側からみた実行状況
ローカルで成功していたはずのunittestが失敗していましたが、中に入って調べたおかげで原因解明できました。やったー!
備考
普段CodePipelineからCodeBuildを実行しているんですが、その場合「Enable session connection」にチェックを入れる相当の設定が見つけられなかったので、CodeBuild単独で動かして中に入っています。
普段から「codebuild-breakpoint」をbuildspecに仕込んでおいて、デバッグが必要なときだけCodeBuildから「Enable session connection」有効にして実行する。という運用がいいんですかね。
※「Enable session connection」してない場合はcodebuild-breakpointおよび codebuild-resume コマンドは無視される仕様。



- 投稿日:2020-12-23T20:45:39+09:00
CloudFormationでACMを使用し, 外部で作成したSSL証明書をインポートすることはできない.
タイトルのままです。
CloudFormationはYAML形式で記述することが可能です。
※下記のコードは一例です。AWSTemplateFormatVersion: '2010-09-09' Description: ACM mycert: Type: AWS::CertificateManager::Certificate Properties: DomainName: example.com DomainValidationOptions: - DomainName: example.com ValidationDomain: example.comですが、筆者の執筆時点では、CloudFormationのACMをYAML形式で記述し、外部からSSL証明書をインポートすることはできませんでした。
ACMに外部で作成したSSL証明書をインポートする際には、AWS CLI を使用してインポートすることをおすすめします。
参考記事
・AWS::CertificateManager::Certificate
・ACMに外部で作成したSSL証明書をインポートする方法(CLI)
- 投稿日:2020-12-23T19:45:41+09:00
[AWS] re:Invent2020自分まとめ
re:Invent とは
- AWSの年末恒例イベント
- AWS のクラウドサービスに関わる技術的なセミナー・ハンズオンセッションなど、 2,500 を超えるセッション(2019 年実績)を提供しており、お客様が主体的に体験できる、学習機会が豊富なグローバルカンファレンス
- 今回は 11/30 (月) ~ 12/18 (金) 、1/12 (火) ~ 1/14 (木) にて完全オンライン、無料で開催
数多ある発表から個人的超抜粋
- 大量のアップデートがありました
- その中から「これは!」を厳選
コンピューティング
Amazon EC2 Mac Instance
- 今回の re:Invent の最初で最大の話題となったといっても過言ではない
- ほんまに Mac mini が裏で動いてるみたいですよ
Amazon ECS Anywhere
- ECS をオンプレミス環境で稼働できるようになる
- 今はオンプレほぼ関与してないんですけどね
- 複雑なコンテナオーケストレーションを自前実装しなくていい
- ECSは使い勝手非常に良いのでオンプレで使いたいですね
ECS にデプロイ時のサーキットブレーカー機能
- Deployment Circuit Breaker
- ECSはサービス正常稼働に至らない場合でも繰り返しデプロイする挙動になってる
- 今回の機能で正常でない場合に自動ロールバックできるようになった
- 繰り返されるタスクエラーを監視し閾値に到達したらロールバック
- 現在プレビュー
Amazon ECR Public Gallery
- コンテナをパブリック公開できる
- Docker Hubのイメージ
- 今後DockerHubじゃなくてこっちからイメージ取得すると良さげ
AWS Batch で Fargate が選択可能に
- EC2にプラスしてFargateが利用可能に
- インスタンス管理から開放される
AWS Lambda の課金単位が 100ms から 1ms に
- 以前は 1ms の利用でも 100ms として課金されていた
- 今後は 1ms は 1ms 分の課金になる
- 上記例だと 99ms 分のコスト削減となる
- 自社サービスでは実際にコスト減となっている
AWS Lambda でコンテナイメージのデプロイが可能に
- Lambdaにコンテナイメージが利用できるようになった
- ECS -> Lambda ができる
- イメージサイズ最大10GBまでいけるようなので今までデプロイできなかったライブラリもこれで解決できそう
AWS Lambda リソース上限緩和
- メモリ上限が 3008MB から 10240MB にUP
- よりLambdaの利用シーンが広がる
- (次は実行時間に期待!)
Amazon EC2 Spot Blueprints
- EC2 Spotインスタンスを簡単に利用できるようにするインフラコードジェネレーター
- CldouFormatio、Terraformに対応
- 出力されるコードはベストプラクティスが適用されている
- スポットインスタンス利用時には参考にするべきところか
ストレージ
Amazon EBS gp3 Volumes
- 汎用SSDに gp3 が新しく増えた
- gp2 とは違い ストレージサイズに関係なく 以下性能を常時提供
- 3,000 IOPS
- 125MB / s
- 上記性能を超えると追加課金される
- 追加課金が無ければ gp3 のが安い
S3 で読み取り一貫性の提供
- 今までは結果整合性
- これからは読み取り一貫性
- 裏側で自動で変わりアプリ側は何もしなくていい
- S3を簡易な Key-Value ストアとして利用しやすくなった?
AWS Compute Optimizer が EBS をサポート
- EC2にプラスしてEBSも解析対象に
- Anでは AWS Compute Optimizer を全アカウント有効にしてるので機会があれば見てください
- ※この機能は完全無料です
データベース
Amazon Aurora Serverless v2
- Auroraのサーバレスバージョン
- 今は v1 で プレビュー版で v2 がでた
- より高速にスケールするようになり
- v1 は初回アクセス返すのに数十秒かかってたとかなんとか、、、
- Aurora の機能を複数追加サポート
- マルチAZ, グローバルDB, リードレプリカ etc...
- 開発環境用途としても利用しやすくなる
- GAされたら開発環境のコスト削減に利用した
Amazon Aurora で R6g (AWS Graviton2) のサポート
- プレビューです
- より高性能なインスタンスタイプで利用可能に
- インスタンスは世代進めば確実に性能UPしてるので楽しみ
MySQL8.0互換の Amazon Aurora サポート予定
- ついに!という感じですが楽しみですね
- 公式でも 5.7 -> 8.0 で2倍高速!って言ってますしおすし
- Aurora だとどうなるのでしょうか
Amazon Aurora PostgreSQL の Lambda統合
- Auroraから直接Lambdaを呼び出せる機能
- ストアドプロシージャ or UDFを利用してLambdaを起動する
- 非同期、同期呼び出し両方に対応
- 例)あるテーブルの情報が変更されたらLambdaを呼び出し変更通知する とか
解析
AWS Glue Elastic Views のプレビュー
- 複数のデータソースにまたがるマテリアライズドビューを作成できる
- DynamoDB -> Elasticsearch なんてことが可能になる
- SQLでデータ指定可能でデータ反映は迅速
- 保存は良いけど検索がなぁ、、、という悩み解消に繋がるかに期待
EMR で Graviton2 インスタンス利用可能に
- M6g, C6g, R6g が利用可能に
- Spark 利用時に M5 と M6g で比較すると30%コスト削減と 15%性能UPが見込める
- 新しいインスタンスって素晴らしいですね
機械学習 & AI
Amazon DevOps Guru プレビュー
- 機械学習にてアプリケーションの運用上の問題や改善ポイントを指摘してくれる
- Amazon.comの経験をもとにしている
- 問題解決と可用性・信頼性の向上に必要なアドバイスをくれる
Amazon Lookout for Metrics
- プレビュー
- ビジネス上のメトリクスにおける異常値を検知するサービス
- Amazonと同じ機械学習テクノロジを使用
- 例えば配信遅延のようにビジネス的にユーザー影響あるような検知をできる、とか?
ネットワーク
VPC Reachability Analyzer
- VPC内のエンドポイント間または複数のVPC内でのネットワーク到達可能性を可視化
- 意図したネットワーク構成になっているか確認できる
- 今まで把握しづらかったネットワークが見える化された形
セキュリティ
AWS CloudTrail Advanced Event Selector
- CloudTrail で取得している各種ログに細かい制御を入れることが可能になった
- S3に対するGetObjectログは取得するが、DeleteObjectは取得しない、といった感じ
- 現状S3(GetObject, DeleteObject, PutObject)、Lambda(Invoke) の制御が可能
- 不要なログを抑えてコスト抑える
AWS Audit Manger
- AWS使用状況を継続監査し各種準拠しているか確認できる
AWS Fault Injection Simulator
- 2021年リリース予定
- カオスエンジニアリングのためのサービス
- EC2、ECS、RDSなどのサービスでは快適なイベントを発生させることが可能
- 実際の障害とほぼ同じ現象の発生が可能
- テストシナリオをテンプレート定義し複数障害を組み合わせることも可能
- DRテストがより実障害に近い状態でできる
管理/監視
CloudWatch Lambda InsightsがGA
- Lambdaのパフォ監視や最適化を可能にするツール
- 利用するにはLambda設定で有効化する必要がある
- サポートするランタイムも決まってる
- Service Lens と連携することで原因究明が用意になるそうな
AWS System Manager Fleet Manager
// TODO
その他
Amazon WorkSpaces で Streaming Protocol 対応
- WorkSpaces で Streaming Protocol 略してWSP
- WSPによりWorkSpaces上でZoomやTeamsを使うことが可能になった
- ビデオカメラも使用可能になった
- ただし現状動作が不安定とのこと
ApiGateway(HTTP API) が StepFunctionsの連携強化
- ApiGatewayのHTTP APIでStepFunctionsを同期的に呼びだせるようになった
- ApiGateway + StepFunctions で複雑な処理フローをまとめ管理する事をどんどn強化している
- 投稿日:2020-12-23T19:12:09+09:00
AWS Data PipelineのShellCommandActivityでDockerイメージを(暫定的に)動かす
背景・目的
我々のチームでは、以前からAWS Data Pipelineを利用して、次のような形でETLのプログラムを管理していました。
- RubyやPythonや必要なツールが入ったAMIを用意する
- ETLプログラムはチーム管理サーバーのGitlabで管理し、masterブランチへのpush時にJenkinsでzipで固めてS3にアップロードする
- Data PipelineのShellCommandActivityでEC2サーバーを立ち上げ、S3からソースコードをダウンロードして実行する
ただ、数年間の運用を経て、以下のような問題点が出てきています。
- AMIのバージョンアップが面倒で、できればコンテナ化してDockerfileで管理したいこと。Data Pipeline自体にはDockerイメージの実行機能が無いこと
- 全社的にGithubのOrganizationが標準になったが準拠できておらず、独自管理のGitlabやJenkinsが負担になっていること
- (これは我々の使い方が悪いのですが)Data Pipelineを単なるcron機能しか使っておらず、バッチの依存関係が定義できていないこと
ただ、システム全体を一気に移行するのは大変なので、次のような方針で実行しようとしています。
- まず(特に新規の)バッチ処理をコンテナ化してGithubに移行し、Github ActionsでECRにpushする
- ひとまずData Pipelineでそのコンテナイメージを実行するようにする
- その後、DataPipeline自体は後で適切なワークフローエンジンとコンテナ実行基盤を利用した形に移行する
一旦Data Pipelineを利用することにしたのは、バッチの再実行方法など運用が今までと大きく変わらないようにして、無理なくプロジェクトを進めるのが目的です。そのためあまりきれいな形ではなく、より適切なサービス(AWSではAWS BatchやMWAAなど)を利用すべきところかもしれませんが、一旦はData Pipeline上でコンテナイメージを実行する方法を調べて実装しました。
また、「DataPipelineを使ってdockerコンテナを定期実行してみる」という記事を見つけたのですが、とりあえずの運用のためにECSクラスターを導入するのも大変なので、Data Pipelineで起動したEC2インスタンス自体にDockerを実行させる方法にしています。
実装方法
次のような方針で実装しました。
- 前提としてGithub Actionsを利用して、Dockerイメージ自体はECRに既にpushされている状態
- AMIは素のAmazon Linux 2 (idは
ami-00f045aed21a5524064 ビット x86) を利用する- 認証情報などは、パラメータストアにkmsで暗号化した形で保存し、そこから取得して環境変数やファイル形式でイメージ内に渡す
- 詳しくは公式ドキュメントの「AWS Systems Manager Parameter Store で AWS KMS を使用する方法」を読んでください
- 余談ですが「余力があれば、環境変数よりコマンドラインのオプションとして渡したほうがいい。一般的にコマンドラインパーサーのほうがバリデーションがしっかりしているため」というアドバイスも貰っています
ShellCommandActivityの実装
次のようなシェルスクリプトで実装しました。以下が注意点です。
aws ssm get-parameterで、テキストのみ取得するためのオプションはこちらの記事を参考にした- ほとんどのバッチでBigQueryを利用しているため、GCPのcredentialsをファイルに吐き出してイメージ内に渡している
- Dockerイメージ内でawscliやAWS SDKを利用する場合、
AWS_ACCESS_KEY_IDとAWS_SECRET_ACCESS_KEYとしてコンテナ内に渡す必要がある。事前に適切な権限を持ったIAMユーザーを作る必要があるset -euを行うことで、エラーが出た行で処理を止めることができる。詳しくは「シェルスクリプトを書くときはset -euしておく」を参照。- awscli2のインストール方法がx86かARMかでも違うので、公式ドキュメントを参照してください
もう少しスッキリ書けそうな気もしますが、ひとまずこれで行ってます。
set -eu account="{AWSアカウントID}" region="{リージョン名}" repository="{ECRのリポジトリ名}" tag="latest" batch="{Dockerの引数}" sudo yum -y update # パラメータストアから環境変数や設定ファイルを読み込む IMAGE_AWS_ACCESS_KEY_ID=`aws ssm get-parameter --name "{パラメータストアのキー名}" \ --with-decryption --region "${region}" --output text --query Parameter.Value` IMAGE_AWS_SECRET_ACCESS_KEY=`aws ssm get-parameter --name "{パラメータストアのキー名}" \ --with-decryption --region "${region}" --output text --query Parameter.Value` aws ssm get-parameter --name "{パラメータストアのキー名}" --with-decryption \ --region "${region}" --output text --query Parameter.Value > /tmp/bigquery.json # `aws ecr get-login-password`を使う方式がAWS CLIのバージョン2からなのでインストールする # DataPipelineの再実行時はファイルが残っているので、削除コマンドが無いとエラーが起きる場合がある rm -rf ./aws curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip sudo ./aws/install --update # Dockerをインストールして起動 sudo amazon-linux-extras install -y docker sudo service docker start # ECRにログインしてイメージをpullする aws ecr get-login-password --region "${region}" | \ sudo docker login --username AWS --password-stdin "https://${account}.dkr.ecr.${region}.amazonaws.com" sudo docker pull "${account}.dkr.ecr.${region}.amazonaws.com/${repository}:${tag}" # 環境変数や設定ファイルを渡して実行する sudo docker run --env "AWS_ACCESS_KEY_ID=${IMAGE_AWS_ACCESS_KEY_ID}" \ --env "AWS_SECRET_ACCESS_KEY=${IMAGE_AWS_SECRET_ACCESS_KEY}" \ --env "GOOGLE_APPLICATION_CREDENTIALS=/credential/bigquery.json" -v "/tmp/bigquery.json:/credential/bigquery.json:ro" \ "${account}.dkr.ecr.${region}.amazonaws.com/${repository}" "${batch}"Resource Roleの設定方法
もう一つ設定で困るのが、EC2インスタンスに付与されるResource Roleです。基本的にはDockerイメージ内で処理は実行されるので、そこで利用するIAMユーザーに適切に権限を持たせればいいのですが、ECRやパラメータストアを参照できる権限を付与する必要があります。
- AmazonEC2RoleforDataPipelineRoleなどのDataPipeline自体のロギング等に必要なポリシー
- AmazonEC2ContainerRegistryReadOnlyなどのECSからpullするためのポリシー
- パラメータストアからデータを取得するためのロール(以下に記載)
- 復号のために、暗号化で利用したkmsも許可する必要があります
- 特に重要な情報なので、ここは厳しく権限を設定しています
パラメータストアからデータを取得するためのポリシー{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "ssm:DescribeParameters", "Resource": "*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "ssm:GetParameters", "Resource": "arn:aws:ssm:ap-northeast-1:{アカウントID}:parameter/{適切なパラメータストアの階層}/*" }, { "Sid": "VisualEditor2", "Effect": "Allow", "Action": "ssm:GetParameter", "Resource": "arn:aws:ssm:ap-northeast-1:{アカウントID}:parameter/{適切なパラメータストアの階層}/*" }, { "Sid": "VisualEditor3", "Effect": "Allow", "Action": [ "kms:Decrypt" ], "Resource": [ "arn:aws:kms:ap-northeast-1:{アカウントID}:key/{復号化キー}" ] } ] }まとめ
これらの設定で、今まで通りData Pipelineでのバッチ管理を止めずに、コンテナ移行を進めることができます。道のりは長いですががんばります。
- 投稿日:2020-12-23T19:08:14+09:00
Docker + DynamoDB local + C++ の環境構築と実践まで
環境構築
今回使うものはこちら
- Docker
- Dynamodb local
- AWS CLI バージョン 2
- vcpkg
- AWS SDK for C++
また、C++ のビルド環境には VC++ を使用します。
Docker の導入
Docker は、コンテナを用いてアプリケーションをすばやく構築、テスト、デプロイできるソフトウェアプラットフォームです。
ダウンロード
Docker のサイトからインストーラをダウンロードしましょう。
※この記事では、Docker Desktop for Windows を使用します。インストール
Docker Desktop requires Windows 10 Pro/Enterprise (16299+) or Windows 10 Home (18362.1040+).
インストール中に、上のようなエラーメッセージが出る場合は、Windows Update を確認してみてください。アップデート後に、もう一度インストールを試してみましょう。バージョン確認
コマンドラインからDocker のバージョンを確認してみましょう。インストールに成功していれば、以下のような出力が得られるはずです。
> docker --version Docker version 20.10.0, build 7287ab3DynamoDB local の導入
ダウンロード可能なバージョンの Amazon DynamoDB (DynamoDB local)では、DynamoDB ウェブサービスにアクセスせずに、アプリケーションを開発してテストすることができます。代わりに、データベースはコンピュータ上で自己完結型となります。
イメージを取得する
Docker を使って、DynamoDB local イメージを取得しましょう。
Amazon が公開している DynamoDB local のDocker イメージがありますので、
docker pullコマンドを使って取得します。> docker pull amazon/dynamodb-localコンテナを起動する
Docker を使って、DynamoDB local を起動しましょう。
docker runコマンドを使って起動します。> docker run -p 8000:8000 amazon/dynamodb-localこれで DynamoDB local のコンテナが起動しました。わかりやすくポート番号は8000を使用しました。
コンテナを確認する
docker psコマンドを使うと、現在起動しているコンテナのリストが出力されます。> docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 607c8a202aac amazon/dynamodb-local "java -jar DynamoDBL…" 2 seconds ago Up 7 seconds 0.0.0.0:8000->8000/tcp frosty_goldstineコンテナを終了する
docker killコマンドを使うと、起動しているコンテナを終了させることができます。このとき、コンテナIDを指定します。> docker kill 607c8a202aacAWS CLI バージョン 2 の導入
AWS CLI には、DynamoDB local を操作するためのコマンドラインツールが含まれています。
※今回はテーブル情報の読み出しのためだけに利用したいと思います。(C++ からのリクエストが正しく通っているかを確認するため。)事前にインストールしておきましょう。
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-cliv2-windows.html初回設定
1度だけこちらの4項目を設定しておきましょう。
それぞれ、設定内容はダミーでもよいですが、忘れないように覚えておく必要があります。もし忘れてしまったら設定しなおしましょう。
> aws configure AWS Access Key ID [****************XXXX]: (ローカルで使用するのでダミーのキーIDでよい) AWS Secret Access Key [****************XXXX]: (ローカルで使用するのでダミーのアクセスキーでよい) Default region name [us-west-2]:(ローカルで使用するのでダミーのリージョンでよい) Default output format [json]:動作確認(DynamoDB local のテーブルリストを取得する)
DynamoDB local にアクセスして、動作確認をしてみましょう。
まだテーブルを作っていないので、以下のような JSON が取得できるはずです。> aws dynamodb list-tables --endpoint-url http://localhost:8000 { "TableNames": [] }AWS SDK for C++ の導入
今回は、C++ からDynamoDB local にアクセスするので、AWS SDK for C++ というライブラリを使用します。
vcpkg をインストールする
vcpkg は、C++ のコマンド ライン パッケージ マネージャーです。 これにより、Windows、Linux、および macOS でのサードパーティ ライブラリの取得とインストール作業を大幅に簡素化できます。
https://github.com/Microsoft/vcpkg
github から取得し、ブートストラップを実行しましょう。
> git clone https://github.com/microsoft/vcpkg > ./vcpkg/bootstrap-vcpkg.batAWS SDK for C++ を取得する
vcpkg を使って、ライブラリを取得しましょう。
> ./vcpkg/vcpkg install aws-sdk-cpp:x64-windowsVC++ にインテグレートする
vcpkg を VC++ にインテグレートします。
これによって、先ほどダウンロードしたAWS SDK for C++ のためのインクルードパスの設定や、.lib のリンクを自動で行ってくれるようになります。> ./vcpkg/vcpkg integrate install※ただし、コーディング中のインテリセンスを働かせるためには、手動でインクルードパスを通す必要がありました。
また、インテグレートを解除したい場合は、以下のコマンドを使います。
> ./vcpkg/vcpkg integrate removeコーディング
主要なデータベース操作と、対応する AWS SDK for C++ の関数名を挙げておきます。
AWS のサイトにもサンプルコードがあるので、参考にしてみてください。
用途 関数名 テーブル追加 Aws::DynamoDB::DynamoDBClient::CreateTable テーブル削除 Aws::DynamoDB::DynamoDBClient::DeleteTable アイテム取得 Aws::DynamoDB::DynamoDBClient::GetItem アイテム追加 Aws::DynamoDB::DynamoDBClient::PutItem アイテム更新 Aws::DynamoDB::DynamoDBClient::UpdateItem アイテム削除 Aws::DynamoDB::DynamoDBClient::DeleteItem C++ Code Samples for Amazon DynamoDB
https://docs.aws.amazon.com/code-samples/latest/catalog/code-catalog-cpp-example_code-dynamodb.htmlテーブル作成(create-table)
#include <aws/core/Aws.h> #include <aws/core/utils/Outcome.h> #include <aws/dynamodb/DynamoDBClient.h> #include <aws/dynamodb/model/AttributeDefinition.h> #include <aws/dynamodb/model/CreateTableRequest.h> #include <aws/dynamodb/model/KeySchemaElement.h> #include <aws/dynamodb/model/ProvisionedThroughput.h> #include <aws/dynamodb/model/ScalarAttributeType.h> #include <iostream> // ここで、予め設定しておいたアクセスキーを使います const Aws::String AWS_ACCESS_KEY_ID = "XXXXXXXXXXXXXXXXXXXX"; const Aws::String AWS_SECRET_ACCESS_KEY = "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"; // 作成したいテーブルの名前を決める const Aws::String table("Game"); // ここで、予め設定しておいたリージョン名を使います const Aws::String region("us-west-2"); // エンドポイントを指定する Aws::Client::ClientConfiguration clientConfig; clientConfig.requestTimeoutMs = 1000; clientConfig.region = region; clientConfig.endpointOverride = "http://localhost:8000"; const Aws::DynamoDB::DynamoDBClient dynamoClient(Aws::Auth::AWSCredentials(AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY), clientConfig); // テーブル作成リクエスト Aws::DynamoDB::Model::CreateTableRequest req; Aws::DynamoDB::Model::AttributeDefinition haskKey; // "Name"という名前の属性を定義する、"Name"は文字列型である haskKey.SetAttributeName("Name"); haskKey.SetAttributeType(Aws::DynamoDB::Model::ScalarAttributeType::S); req.AddAttributeDefinitions(haskKey); // "Name" をハッシュキー(パーティションキー)として扱うようにスキーマを定義する Aws::DynamoDB::Model::KeySchemaElement keyscelt; keyscelt.WithAttributeName("Name").WithKeyType(Aws::DynamoDB::Model::KeyType::HASH); req.AddKeySchema(keyscelt); // 適当なキャパシティユニットを設定する Aws::DynamoDB::Model::ProvisionedThroughput thruput; thruput.WithReadCapacityUnits(5).WithWriteCapacityUnits(5); req.SetProvisionedThroughput(thruput); // テーブル名を指定する req.SetTableName(table); // テーブル作成リクエストをDynamoDB local に送信する(この関数はブロックするので注意!) const Aws::DynamoDB::Model::CreateTableOutcome& result = dynamoClient.CreateTable(req); if (result.IsSuccess()) { std::cout << "Table \"" << result.GetResult().GetTableDescription().GetTableName() << " created!" << std::endl; } else { std::cout << "Failed to create table: " << result.GetError().GetMessage(); }AWS CLI を使って、テーブルが作成できているかの確認をしてみましょう。
うまく作成できていれば、以下のような JSON が取得できるはずです。> aws dynamodb list-tables --endpoint-url http://localhost:8000 { "TableNames": [ "Game" ] }アイテム追加(put-item)
#include <aws/core/Aws.h> #include <aws/core/utils/Outcome.h> #include <aws/core/auth/AWSCredentialsProvider.h> #include <aws/dynamodb/DynamoDBClient.h> #include <aws/dynamodb/model/AttributeDefinition.h> //#include <aws/dynamodb/model/CreateTableRequest.h> #include <aws/dynamodb/model/PutItemRequest.h> #include <aws/dynamodb/model/PutItemResult.h> #include <iostream> //(途中省略...) Aws::DynamoDB::Model::PutItemRequest req; // 対象のテーブル名を指定する req.SetTableName(table); Aws::DynamoDB::Model::AttributeValue av; // "Name" が 文字列型"Switch" av.SetS("Switch"); req.AddItem("Name", av); // "State" が 文字列型"off" av.SetS("off"); req.AddItem("State",av); // アイテム追加リクエストをDynamoDB local に送信する(この関数はブロックするので注意!) const Aws::DynamoDB::Model::PutItemOutcome result = dynamoClient.PutItem(req); if (!result.IsSuccess()) { std::cout << result.GetError().GetMessage() << std::endl; return 1; } std::cout << "Done!" << std::endl;AWS CLI を使って、テーブルの内容を出力してみましょう。
aws dynamodb scanコマンドにテーブル名を渡すと、以下のようにテーブルの内容を JSON で取得できます。> aws dynamodb scan --table-name Game --endpoint-url http://localhost:8000 { "Items": [ { "State": { "S": "off" }, "Name": { "S": "Switch" } } ], "Count": 1, "ScannedCount": 1, "ConsumedCapacity": null }おわりに
非常に長い道のりでしたが、DynamoDB local を C++ から操作することができました。AWS SDK for C++ は扱いやすく、DynamoDB を操作するための一通りのAPI が揃っています。これを導入すれば、C++ プログラマにとっては DynamoDB の敷居が一気に下がるのではないでしょうか。
DynamoDB local は 簡単にレコードを追加したり、削除したりできるので、プロトタイピングにもおススメですね。
- 投稿日:2020-12-23T18:12:24+09:00
EC2 (Amazon Linux 2 ) にPHP7.2 をインストールし、php.ini を設定するまでのまとめ
Amazon Linux は2020/12/31 でサポートが終了してしまうため、
後継のOS であるAmazon Linux 2 への移行が必要になりました。単純にOS アップデートできないようだったので、
新たにAmazon Linux 2 のインスタンスを作ってミドルウェアを入れ直しました。後々同じことをやる方のググる手間を省ければと思い、まとめました。
「とりあえずEC2でPHPを動かしたいぞ!!!」というあなたのお役に立てれば幸いです前提
■ 先にVPCやサブネットの用意を終わらせておくとスムーズです。
(ECインスタンス作成時に紐付けられるため)もしよろしければ、以下の記事を参考になさってみてください!
・VPC作成 〜 パブリック・プライベートサブネットを作るまでの手順①
・VPC作成 〜 パブリック・プライベートサブネットを作るまでの手順②■ CloudFormation を使った構築手順については今回触れません。
ざっくりの流れ
- EC2 インスタンスを作成
- タイムゾーンを日本に設定する
- 言語を日本語に設定する
- ホスト名を設定する ①
- ホスト名を設定する ②
- LAMP環境をインストールする
mbモジュールをインストールするphp-xmlモジュールをインストールするphp.iniを設定する1. EC2 インスタンスを作成
▼ 参考:
AWSコンソールからEC2インスタンスを作成する手順LAMP環境をインストールする際、EC2インスタンスにssh接続する必要があります。
EC2インスタンス作成時には既存のキーペアの選択or新しいキーペアの作成を選ぶようにしてください。▼ EC2インスタンスにssh接続するコマンド:
ssh -i [キーペアのパス] ec2-user@[パブリック IPv4 アドレス]2. タイムゾーンを日本に設定する
sudo cp /usr/share/zoneinfo/Japan /etc/localtimesudo vi /etc/sysconfig/clock/etc/sysconfig/clock#ZONE="UTC" ZONE="Asia/Tokyo" UTC=true3. 言語を日本語に設定する
sudo vi /etc/sysconfig/i18n/etc/sysconfig/i18nLANG=ja_JP.UTF-84. ホスト名を設定する ①
sudo hostnamectl set-hostname <ホスト名>▼ 参考:
Amazon Linux インスタンスのホスト名を変更する - Amazon Elastic Compute Cloudデフォルトのままだとわかりづらいため、わかりやすいホスト名に変更するのがおすすめです。
5. ホスト名を設定する ② ※ 不要な場合は飛ばしてOK
sudo vi /etc/cloud/cloud.cfg末尾に
preserve_hostname: trueを追記する▼ 参考:
Amazon Linux 2でカスタムAMIからの起動時にホスト名を固定する方法 | Developers.IOカスタムAMI を取得 → カスタムAMI から新しいインスタンスを起動してみたらホスト名の設定が無効になっていたので、有効にし続けるための設定です。
6. LAMP環境をインストールする
▼ 参考:
チュートリアル: Amazon Linux 2 に LAMP ウェブサーバーをインストールする - Amazon Elastic Compute Cloud7.
mbモジュールをインストールする▼ 参考:
Amazon Linuxでphpでmbstringを使う - QiitaPHPにはマルチバイト文字列を扱うための関数がいろいろあります。(例:
mb_substr)
mbモジュールをインストールしておかないと、PHPを実行した際にFatal errorが出てしまいます。8.
php-xmlモジュールをインストールするsudo yum install --enablerepo=remi,remi-php70 php-xmlsudo systemctl restart httpd問題なくインストールされていることの確認は以下のコマンドでできます。
[ec2-user@XXXXXX ~]$ yum list installed | grep php-xml php-xml.x86_64 7.2.34-1.amzn2 @amzn2extra-php7.2 [ec2-user@XXXXXX ~]$
php-xmlモジュールをインストールしていなかったために、PHPのエラーFatal error: Class 'DOMDocument' not foundが出てしまいました9.
php.iniを設定する▼ 参考:
【PHP】PHPをインストールしたらやっておきたい設定 - Qiita初期状態の
/etc/php.iniをコピーしてバックアップを取っておいてから設定を変更するようにすれば、何かあったときに戻せるので安心です。上記の記事で「セキュリティに関する設定」として記載されている
session.hash_functionなどはPHP 7.1.0から削除されているので設定不要です。参考

- 投稿日:2020-12-23T17:32:46+09:00
「OpenSSH keys only supported if ED25519 is available」のエラーの解決方法
- 投稿日:2020-12-23T17:13:43+09:00
[Rails]本番環境のデータベースをリセットする方法(Capistrano版)
はじめに
前提
・Railsを使用してアプリケーションを開発
・Capistranoでの自動デプロイを実装している
・AWSのEC2にてサーバーを構築している
・RDSでMySQLを使用している背景
私は開発環境では、rails db:migrate:resetにていつもデータベースを作り直していましたが、本番環境ではどのようにすればいいのかという疑問から実装しました。
本番環境のデータベースをリセットする
まずはターミナルを用いてEC2で自分のアプリケーションフォルダの階層まで進む。
Capistranoでの実装をしているのでミスをしないように基本的にはcurrentディレクトリで作業するようにする。terminal[ec2-user@ip-222-22-2-222 アプリ名]cd currentcurrentRAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rails db:dropこれでデータベースが消去することができました。
データベース再度作成する
今回はRDSにMySQLを導入している前提でお話していきます。
まず引き続きターミナルは同じディレクトリでmysqlに接続します。
mysql -u (マスタユーザ名) -p -h (エンドポイント)
「-u」はユーザ名、「-p」はパスワードの入力、「-h」は接続先の情報を表すオプションです。
なお、「エンドポイント」は、RDSメニューで確認し、入力してください。
「パスワード」は、「マスターパスワード情報」で設定したパスワードを入力します。terminalmysql -u root -p -h rds-mysql-server.xxx.ap-northeast-1.rds.amazonaws.comこのコマンドを打つとpasswordの入力が求められるので入力すると無事mysqlに接続が完了しました。
削除したアプリケーション名と同じ名前をつけデータベースを再度作成します。
terminalmysql> create database アプリケーション名;再度本番環境でmigrateを実行します。
terminalbundle exec rails db:migrate RAILS_ENV=productionこれでデータベースのリセットは終了です。
あとは本番環境でcapistranoのコマンドを叩いて終了ですterminalbundle exec cap production deployお読みいただきありがとうございました
- 投稿日:2020-12-23T17:10:13+09:00
【AWS】Lambdaの実行ログから指定した文字列を検知してslackに通知
今回は自分が触れる機会の多いAWSのサービスを使用して運用の際などで利用できる通知方法の一つをご紹介します。
使用サービス
- Lambda
- CloudWatch
- Slack
実装フロー
1.Lambda関数からCloudWatch Logsへログを出力
2.CloudWatch Logsから指定した文字列を検知
3.検知された文字列をトリガーにSlack通知用のLambda関数を発火
4.通知用LambdaでSlackへ文字列を通知フロー詳細
実際に上記のフローで実装していきます。
手順1
今回は「test」という文字列でCloudWatch Logsへ出力します。
手順2
文字列検知にCloudWatch Logsのサブスクリプションフィルター(Lambda)を使用していきます。
手順3
通知用Lambda関数とログ形式およびフィルターパターンを設定します
手順4
環境変数「WebhookURL」には通知したいslackのWebhook URLを設定しています。
notifi.pyimport json import os import urllib.request import slackweb def lambda_handler(event, context): decoded_data = zlib.decompress( base64.b64decode(event['awslogs']['data']), 16+zlib.MAX_WBITS ) json_data = json.loads(decoded_data) print(json_data['logEvents']) for i in json_data['logEvents']: test = i['message'] # ログの内容 slack = slackweb.Slack(url=os.environ['WebhookURL']) slack.notify(text=test)先ほど設定した文字列を検知してslackに通知されることを確認しました。
まとめ
上記以外にも通知方法は複数ありますが、なるべく簡潔にまとめていった方が管理しやすいので簡略化できるところはどんどん楽にしていきたいですね。



- 投稿日:2020-12-23T16:36:37+09:00
Application Load BalancerのTarget GroupにHealthy Hostが1台もなければ、独自設定のSorry Pageを出す
概要
Application Load Balancerのリスナールールに設定されたTarget Gropuにて、Healthy Hostが1台もなかった場合に、独自設定のSorry Pageを表示させる。
例えば、AutoScaling GroupをApplication Load BalancerのTarget Groupに設定した場合、Health Checkで失敗したInstanceはAuto Scalingグループから外れ、代わりに「起動設定」に従って新規にインスタンスが起動される。この時、仮にすべてのインスタンスが同時に外れた場合などを想定している。
また、Auto Scaling Groupを利用せず直接Target Groupにインスタンスを登録した時、全ホストがUnhealthyになった場合は、Application Load BalancerはUnhealthy Hostへルーティングを行うため、不適切なページが表示される可能性がある1。ここで、Healthy Hostが1台もなかった場合に、独自設定のSorry Pageを表示させる。問題発生時に、デフォルトで表示されるエラーページ「503 Service Temporarily Unavailable」以外のページを表示させたり、UnHealthy Hostからの返答の代わりに独自設定のSorry Pageを表示させる。
検証手順
1. 検証用のEC2インスタンスの構築
EC2インスタンスを起動し、ルートURL(/)に対してHello Worldページを表示するEC2インスタンスを構築する。
コマンド# httpdのインストール sudo yum update -y sudo yum install -y httpd # httpdの起動 sudo systemctl start httpd # hello worldページの設定 cd /var/www/html/ sudo vim index.html # -------- vim start -------- <!DOCTYPE html> <html> <head> <title>Hello World!</title> </head> <body> <h1>Hello World!</h1> </body> </html> # -------- vim end----------2. Target Groupおよび、Application Load Balancerのルールを作成する
2.1 Target Groupの作成
「1. 検証用のEC2インスタンスの構築」で作成したEC2をTargetsに登録したTarget Groupを作成する。Target GroupのPortはHTTP(80)に設定する。
2.2 Application Load Balancerのリスナールールの作成
Application Load Balancerにて、通常表示用のルールとSorry Page表示用のルールを作成する。通常表示用のルールにはTarget Group(alb-verification-ec2)を紐づける。Sorry Page表示用のルールでは固定レスポンスを設定する。
固定レスポンス設定例<!DOCTYPE html> <html> <head> <title>Sorry Page</title> </head> <body> <h1>Sorry.... This service is down</h1> </body> </html>2. Application Load Balancerのルールを切り替えるLambda関数を実装する
2.1 Lambda関数の実装
以下の方針でLambda関数を実装する。
- CloudWatchの対応するアラーム2を確認。すでにSorry Pageが表示されている場合などでは、処理を中断する。
- Application Load Balancerのルールのプライオリティを入れ替える。
Lambda関数import json import boto3 def lambda_handler(event, context): # [Variable] alb arn alb_arn = {Application Load BalancerのARN} # [Variable]listner arn alb_listner_arn = {Application Load BalancerのリスナーのARN} # this is the rule arns ## [Variable]target group target_group_rule_arn = {Application Load Balancerのリスナーの通常表示用のルールのARN} ## [Variable]ALB error page sorry_rule_arn = {Application Load BalancerのリスナーのARN} # 1. CloudWatchの対応するアラームを確認。すでにSorry Pageが表示されている場合などでは、処理を中断する。 cloudwatch = boto3.resource('cloudwatch') # [Variable]Cloud Watch Alarm alarm = cloudwatch.Alarm({Target GroupのHealthy Host Countを監視している、Cloud Watch Alarmの名称}) print(alarm) client = boto3.client('elbv2') current_rule_arn = client.describe_rules(ListenerArn=alb_listner_arn)['Rules'][0]['RuleArn'] print(current_rule_arn) # Check if it has already been set if alarm.state_value == "ALARM" and current_rule_arn == sorry_rule_arn: return { 'statusCode': 200, 'body': 'Sorry page is already displayed' } elif alarm.state_value == "OK" and current_rule_arn == target_group_rule_arn: return { 'statusCode': 200, 'body': 'Hello World page is already displayed' } # 2. Application Load Balancerのルールのプライオリティを入れ替える。 target_group_rule_priority = 1 sorry_rule_priority_rule_priority = 2 if current_rule_arn == target_group_rule_arn: target_group_rule_priority = 2 sorry_rule_priority_rule_priority = 1 response = client.set_rule_priorities( RulePriorities=[ { 'RuleArn': target_group_rule_arn, 'Priority': target_group_rule_priority }, { 'RuleArn': sorry_rule_arn, 'Priority': sorry_rule_priority_rule_priority }, ]) print(response) return { 'statusCode': 200, 'body': json.dumps(response) }2.2 Lambda関数に必要な権限を設定する
以下の権限をLambdaが使用するIAM Roleに設定する
+ cloudwatch:DescribeAlarms : Cloud Watch Alarmの状態(OK/Alarm)を取得する
+ elasticloadbalancing:DescribeRules : Application Load Balancerのリスナールールのプライオリティを取得する
+ elasticloadbalancing:SetRulePriorities : Application Load Balancerのリスナールールのプライオリティを更新するIAM_POLICY{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "cloudwatch:DescribeAlarms", "Resource": "*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "elasticloadbalancing:DescribeRules", "elasticloadbalancing:SetRulePriorities" ], "Resource": "*" } ] }3.Lamnbda関数とCloud Watchイベントを紐づける
3.1 Application Load BalancerのHealthy Host Countが0の時にアラートを出す、Cloud Watch Alarmを作成する。
以下の設定でCloud Wach Alarmを作成する。Target GroupにTargetsが1台も登録されていない場合、「HealthyHostCount」はデータ不足となるため、「欠落データを不正 (しきい値を超えている)として処理」する。
+ 対象メトリクス : ApplicationELB > AppELB別 > TG別メトリクス > {対象のTarget Group の「HealthyHostCount」メトリクス
+ 統計 : 最小
+ 期間 : 1分
+ 欠落データの扱い : 欠落データを不正 (しきい値を超えている)として処理3.2 Cloud Watch Event Ruleを作成する
作成したCloud Watch Alarmの状態が変更した際に、Lambd関数を実行するEvent Ruleを作成する。Cloud Watch Alarmの状態変更に対して2つのRule(Alarm→OK, OK→Alarm)を作成する。2つのルールどちらに対しても「2. Application Load Balancerのルールを切り替えるLambda関数を実装する」で作成したLambda関数を関連付ける。
Alarm→OK{ "source": [ "aws.cloudwatch" ], "detail-type": [ "CloudWatch Alarm State Change" ], "detail": { "alarmName": [ {3.1で作成したCloud Watch Alarm} ], "previousState": { "value": [ "ALARM" ] }, "state": { "value": [ "OK" ] } } }OK→Alarm{ "source": [ "aws.cloudwatch" ], "detail-type": [ "CloudWatch Alarm State Change" ], "detail": { "alarmName": [ {3.1で作成したCloud Watch Alarm} ], "previousState": { "value": [ "OK" ] }, "state": { "value": [ "ALARM" ] } } }4.動作検証
4.1 すべてのHostがUnhealthyになった場合
- Target GroupのHealth Check ruleをルート「/」から、対応していないパス「/check_unhealthy」に変更する。 → 独自Sorry Pageが表示される。
- Target GroupのHealth Check ruleを対応していないパス「/check_unhealthy」から、ルート「/」に変更する。 → Hello Worldページが表示される。
4.2 Target GroupのTargetsにHostがなくなった場合
- Target GroupのTargetsから今回作成したEC2を解除する。 → 独自Sorry Pageが表示される。
- Target GroupのTargetsから今回作成したEC2を再登録する。 → Hello Worldページが表示される。

- 投稿日:2020-12-23T16:25:10+09:00
【AWS】CodeGuru Profiler 触ってみた
本記事は Advent Calendar 2020 の2020/12/24分です。
※Advent Calendar 2020 へはHTCのチームメンバー5人で
毎日日替わりで投稿させていただいていますので、暇なときに覗いてください。
※HTCの紹介は本イベント1日目の投稿をご参照ください。
文系学部卒SIer新人のかいとです。
今回は、前回に投稿した記事の続きです。
前回ではCodeGuru Reviewerをハンズオンしてみましたので、
今回はCodeGuru Profilerをハンズオンしてみます!※以下、前回と同じ流れです(笑)
Amazon CodeGuru とは
Amazon CodeGuruは、機械学習を利用したデベロッパーツールで、コードの品質を向上し、アプリケーションの最もコストがかかっているコード行を特定するためのインテリジェントな推奨事項を提供します。(公式ドキュメントより引用)
簡単に言えば開発者がコーディング/管理者がソースの品質向上
を図ろうとする際にお助けしてくれるサービスという事です。また、CodeGuruにはProfilerと、Reviewerというサービスに分かれており(新機能としてSecurity Detectorが加わる)
Amazon CodeGuru Profiler
- デベロッパーがアプリケーションの最もコストがかかっているコード行を見つけるだけでなく、特定の視覚化と、コードを改善してコストを節約する方法に関する推奨事項を提供します。
Amazon CodeGuru Reviewer
- 機械学習を使用して、アプリケーション開発中に重大な問題や見つけにくいバグを特定し、コードの品質を向上します。
といった感じのサービスとなっております。
正直、テキストベースでは理解が進まないので、「Now Go Build(今すぐ手を動かして作ろう)」です!!
※「Now Go Build」はワーナーがKeynoteで毎年言う定番文句w用意するもの
- AWSアカウント
- すでにデプロイ済み(予定)のJava or Pythonモジュール
- リモートリポジトリ(ローカル開発環境と繋いでるもの)
- Bitbuket/GitHub/CodeCommit
Amazon CodeGuru Profiler 実践!
Step1:プロファイリンググループを作成
CodeGuru Profiler コンソール or CreateProfikingGroup API で作成できます!
※方法としては、①JVMエージェントを使用する(推奨らしい)②コードにPlofilerを取り込むの二択でした。
私は②で実施しました。
→詳しくはStep3でStep2:IAM権限付与
Plofiler Agent が使用する IAM User/Role に CodeGuru へプロファイルデータを送信するための権限を付与します。
プロファイリンググループを作成する際に、コンソール上の以下の部分で設定できます。
※私はWebサーバーに付与しているIAM Roleを指定しました。
でいいはずなんですが、
この設定ですすむと、プロファイルデータが送られてこない現象が起きました。。。
問題はこの設定部分で、確認したところGUIで選択したRoleにうまくポリシーが付与されておりませんでした!なんで?wという事で、IAMRoleに直接ポリシーをアタッチします!
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "codeguru-profiler:ConfigureAgent", "codeguru-profiler:PostAgentProfile" ], "Resource": "arn:aws:codeguru-profiler:<region>:<accountID>:profilingGroup/<profilingGroupName>" } ] }こんな感じ。これで安心。
Step3:アプリでプロファイラーを開始
Java アプリケーションを更新して、データを収集して CodeGuru プロファイラーに送信するには
- プロファイラーエージェント JAR に依存関係を追加します。
pom.xml<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> ... <repositories> <repository> <id>codeguru-profiler</id> <name>codeguru-profiler</name> <url>https://d1osg35nybn3tt.cloudfront.net</url> </repository> </repositories> ... <dependencies> <dependency> <groupId>com.amazonaws</groupId> <artifactId>codeguru-profiler-java-agent</artifactId> <version>1.1.0</version> </dependency> </dependencies> ... </project>
- アプリケーションの main 関数を含む Java ファイルに以下を追加
~.javaimport software.amazon.codeguruprofilerjavaagent.Profiler; //省略 //main関数に以下を追加 new Profiler.Builder() .profilingGroupName("2020bc-kokoda") .awsCredentialsProvider(myAwsCredentialsProvider) // optional .withHeapSummary(true) // optional - to start without heap profiling set to false or remove line .build().start();Step4:プロファイラーエージェントをスタート!
私の場合は、CodepipelineでCI/CD組んでいたので、リモートリポジトリ(Bitbucket)にpushするのみでした。
Step5:CodeGuru Profiler コンソールにて確認!
※稼働中のアプリケーションのスタットレースのサンプリングを集約したものだが、
スタート後のサンプリングには最大15分かかる。
こんな感じ。ビューの見方はいろいろあると思うので、個人に任せます!
(いろいろいじると面白い!)以上、CodeGuru Profiler でした!
まとめ
CodeGuru Profilerを触ってみて思う点は以下
・とにかくjava以外の言語(ようやくPythonだけできるようになったけど)を増やしてほしい。。。
・このサンプリングは継続的に収集でき、柔軟な可視化、対応ができそう!
てな感じです。このサービスをどのようにワークフローに落とし込んで、開発者・管理者の負担を手軽に減らすことができるのか
今後は考えてみたいと思います!以上です!



- 投稿日:2020-12-23T16:17:12+09:00
IAM認証のAWS API GatewayにEC2インスタンスからSigV4署名してアクセスするには
IAM認証を使っているAWSのAPI Gatewayは、APIリクエスト時にSigV4署名が必要です。
以前に同様の記事を書きましたが、EC2のインスタンスプロファイルからIAMロールにスイッチしてからリクエスト署名する処理になっていました。
スイッチせずにインスタンスプロファイルで直接署名すればいいことがわかりましたので、そのコードをここに残しておきます。
前提
IAMロールのアタッチされているEC2インスタンスでC#のコードを実行します。
~/.aws/configは不要です。※前回の記事では、EC2にIAMロールがアタッチされているだけではなく、インスタンスプロファイルからIAMロールにスイッチする権限が必要でした。このような権限が必要なケースが前回の記事のコード以外の場面であるのかよくわからず、おそらく前回の記事はミスリードでした。
API GatewayのリソースポリシーにはこのIAMロールからのAPIアクセスを許可してあるものとします。
動作確認した環境はUbuntu 20.04です。
C#の環境は以下の通り。
$ dotnet --version 3.1.404本記事でのライブラリ等は2020/12/21時点のものです。
サンプルコードダウンロード
SigV4署名するC#のサンプルコードはAWS公式サイトにありますので、それをダウンロードし、必要なディレクトリのみ残します。
この手順の詳細は前々回の記事を参照。
$ mkdir sample $ cd sample $ mkdir tmp $ cd tmp $ wget https://docs.aws.amazon.com/AmazonS3/latest/API/samples/AmazonS3SigV4_Samples_CSharp.zip $ unzip AmazonS3SigV4_Samples_CSharp.zip $ cd .. $ mv tmp/AWSSignatureV4-S3-Sample/Signers ./ $ mv tmp/AWSSignatureV4-S3-Sample/Util ./ $ rm -r tmp $ grep -rl AWSSignatureV4_S3_Sample Signers | xargs sed -i 's/AWSSignatureV4_S3_Sample/Sample/g' $ grep -rl AWSSignatureV4_S3_Sample Util | xargs sed -i 's/AWSSignatureV4_S3_Sample/Sample/g'C#のプロジェクト作成
dotnetコマンドでプロジェクトを作成します。$ dotnet new console以下のようなディレクトリ構成になります。
$ tree . ├── obj │ ├── project.assets.json │ ├── project.nuget.cache │ ├── sample.csproj.nuget.dgspec.json │ ├── sample.csproj.nuget.g.props │ └── sample.csproj.nuget.g.targets ├── Program.cs ├── sample.csproj ├── Signers │ ├── AWS4SignerBase.cs │ ├── AWS4SignerForAuthorizationHeader.cs │ ├── AWS4SignerForChunkedUpload.cs │ ├── AWS4SignerForPOST.cs │ └── AWS4SignerForQueryParameterAuth.cs └── Util └── HttpHelpers.cs 3 directories, 13 files
sample.csprojに以下のようにRootNamespaceの項目を追加します。サンプルダウンロード後に全置換したnamespaceを指定します。<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> <RootNamespace>Sample</RootNamespace> </PropertyGroup> </Project>必要なパッケージをダウンロードします。
$ dotnet add package AWSSDK.SecurityTokenC#のソースコード
Program.csは以下です。using System; using System.Collections.Generic; using System.Threading.Tasks; using Amazon.Runtime; using Amazon.Runtime.CredentialManagement; using Amazon.SecurityToken; using Amazon.SecurityToken.Model; using Sample.Signers; using Sample.Util; namespace Sample { class Program { private static async Task Run() { InstanceProfileAWSCredentials instanceCredentials = new InstanceProfileAWSCredentials(); var credentials = await instanceCredentials.GetCredentialsAsync(); var uri = new Uri("https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello"); // 署名するためのソースとなるヘッダ情報 var headers = new Dictionary<string, string> { {AWS4SignerBase.X_Amz_Content_SHA256, AWS4SignerBase.EMPTY_BODY_SHA256}, {"content-type", "text/plain"}, {"x-amz-security-token", credentials.Token}, // IAMロールではこれが必要 }; // 署名を作成 var signer = new AWS4SignerForAuthorizationHeader { EndpointUri = uri, HttpMethod = "GET", Service = "execute-api", Region = "ap-northeast-1" }; var authorization = signer.ComputeSignature(headers, "", // no query parameters AWS4SignerBase.EMPTY_BODY_SHA256, credentials.AccessKey, credentials.SecretKey); // リクエストヘッダに署名を追加 headers.Add("Authorization", authorization); // リクエスト実行 // HttpHelpers はUtilで定義 HttpHelpers.InvokeHttpRequest(uri, "GET", headers, null); } static void Main(string[] args) { Run().Wait(); } } }
uriはAPI GatewayのAPIのURLを入れます。実行
以下のコマンドで実行できます。
$ dotnet runダウンロードしたサンプルコードの
SignersとUtilにデバッグ用出力があるので、いろいろ表示されますが、最後にAPI Gatewayからのレスポンスが表示されます。前回の記事との違い
前回は
InstanceProfileAWSCredentialsからassumeRoleしていたのが、今回はInstanceProfileAWSCredentialsをそのまま使っている点です。diffを見たほうが早いか。
@@ -16,21 +16,8 @@ { private static async Task Run() { - // ~/.aws/credentials からRoleArnを読み取る - SharedCredentialsFile sharedFile = new SharedCredentialsFile(); - sharedFile.TryGetProfile("default", out CredentialProfile credentialProfile); - string roleArn = credentialProfile.Options.RoleArn; - - // IAMロールにassumeする InstanceProfileAWSCredentials instanceCredentials = new InstanceProfileAWSCredentials(); - AmazonSecurityTokenServiceClient stsClient = new AmazonSecurityTokenServiceClient(instanceCredentials); - AssumeRoleRequest assumeRoleRequest = new AssumeRoleRequest - { - RoleArn = roleArn, - RoleSessionName = "test_session", - }; - var assumeRoleResponse = await stsClient.AssumeRoleAsync(assumeRoleRequest); - var credentials = assumeRoleResponse.Credentials; + var credentials = await instanceCredentials.GetCredentialsAsync(); var uri = new Uri("https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello"); @@ -39,7 +26,7 @@ { {AWS4SignerBase.X_Amz_Content_SHA256, AWS4SignerBase.EMPTY_BODY_SHA256}, {"content-type", "text/plain"}, - {"x-amz-security-token", credentials.SessionToken}, // IAMロールではこれが必要 + {"x-amz-security-token", credentials.Token}, // IAMロールではこれが必要 }; // 署名を作成 @@ -53,8 +40,8 @@ var authorization = signer.ComputeSignature(headers, "", // no query parameters AWS4SignerBase.EMPTY_BODY_SHA256, - credentials.AccessKeyId, - credentials.SecretAccessKey); + credentials.AccessKey, + credentials.SecretKey); // リクエストヘッダに署名を追加 headers.Add("Authorization", authorization);関連記事
SigV4署名に関する私の記事
- AWS RDSのログファイルを高速にダウンロードするスクリプト (11/06)
- IAM認証のAWS API GatewayにC#からIAMロールでSigV4署名してアクセスするには (2020/10/19)
- IAM認証のAWS API GatewayにC#からIAMユーザでSigV4署名してアクセスするには (2020/10/14)
- IAM認証のAWS API GatewayにPythonからSigV4署名してアクセスするには (2020/07/22)
最近API Gatewayの記事ばかり続いています。
- 投稿日:2020-12-23T16:02:25+09:00
CodeDeployのデバッグする際にとりあえず見てみるログファイル
経緯
CodeDeployでデプロイ失敗した際にAWSのコンソールに出てるエラーをググってみたがよく分からなかったのでEC2インスタンス内のログを調べてみた
その際デバッグするのに役立ったファイル紹介
環境
Amazon Linux 2
codedeploy-agent 1.2.1CodeDeployスクリプトのログファイル
/opt/codedeploy-agent/deployment-root/デプロイグループID/デプロイID/logs/scripts.logappspec.ymlのhooksセクションで実行されるスクリプトのログファイル
このファイルでエラーが見つかればhooksセクションで実行されるシェルスクリプトの見直しが必要リビジョンのファイル群保管ディレクトリ
/opt/codedeploy-agent/deployment-root/デプロイグループID/デプロイID/deployment-archiveここでのリビジョンとはGitHubやS3などに存在するこれからデプロイされるファイル群を指す
appspec.ymlのfilesセクションの記述に基づき指定のディレクトリにファイルを配置するCodeDeploy エージェントの動作ログファイル
/var/log/aws/codedeploy-agent/codedeploy-agent.logエラーログ
InstanceAgent::Plugins::CodeDeployPlugin::CommandPoller: Missing credentials - please check if this instance was started with an IAM instance profile
などが出ていたらEC2インスタンス適切なにIAMロールがアタッチされているか確認最後に
いちいちsshで入ってログファイルを確認するのも大変!
という方は自動でログを転送することもできるらしいですね。参考サイト↓
https://dev.classmethod.jp/articles/codedeploy-cloudwatchagent-cloudwatchlogs/
- 投稿日:2020-12-23T15:37:10+09:00
AWS IoT Greengrass 2.0 で Docker コンテナを動かしてみた
こちらは AWS Containers Advent Calendar 2020 の23日目の記事です。
re:Invent 2020 で AWS IoT Greengrass 2.0 が発表されました。
v1 がそうであったように、v2 でも Docker コンテナ の動作がサポートされています。さっそくやってみました。
やったこと
- EC2 インスタンス上に AWS IoT Greengrass 2.0 をインストールする
- Docker コンテナを動かす(ここでは nginx コンテナを動かしました)
AWS IoT Greengrass 2.0 のインストール on EC2
手元にラズパイはあるのですが、別の用途で使っているため、今回は EC2 インスタンスをたてて、そのうえで検証しました。
(t2.micro, x86, Amazon Linux2 の EC2 インスタンスを使っていますが、EC2インスタンスの作成手順は省略しています)EC2 へ必要なソフトウェアのインストール
Core Device の作成
AWS IoT の管理コンソールで、Core device の作成を行います(画像右側のオレンジボタンです)
Core Device名 と Things group名を入力します。
ここでは、それぞれgreengrass-v2-qiita-coreとgreengrass-v2-qiita-groupとしています。
ページをスクロールするとインストール手順が表示されるため、1つ1つやって行きましょう。
Step0: 追加手順
私はこれはやらずに次に進んだため、ハマってしまいました。
sudo visudoで以下のように root の設定を少しいじります。root ALL=(ALL) ALL ↓ root ALL=(ALL:ALL) ALLStep1: Install Java on the device
こちらを参考に Java 8(Corretto 8) を入れます。
sudo amazon-linux-extras enable corretto8 sudo yum install -y java-1.8.0-amazon-correttoStep2: Configure AWS credentials on the device
Greengrass のインストール(インストール後の AWS IoT への登録など)には、AWSの認証情報が必要になります。
必要な Policy だったり、環境変数を使った設定方法がドキュメントに記載されています。
- https://docs.aws.amazon.com/greengrass/v2/developerguide/install-greengrass-core-v2.html?icmpid=docs_gg_console
- https://docs.aws.amazon.com/greengrass/v2/developerguide/install-greengrass-core-v2.html#provision-minimal-iam-policyただ、この検証では、EC2 インスタンスを使っていますので、IAM Role を EC2 インスタンスにアタッチすることで、完了しています。手順は省略
検証なので、アタッチした IAM Role には Administratorの権限が紐付いています(本番だと絶対にやってはいけないですね)Step3: Run the installer
表示されたコマンドをコピペして、立ち上げた EC2 インスタンスにSSHで入って、コマンドを実行して、Greengrass をインストールします。
curl -s https://d2s8p88vqu9w66.cloudfront.net/releases/greengrass-nucleus-latest.zip > greengrass-nucleus-latest.zip && unzip greengrass-nucleus-latest.zip -d GreengrassCore Archive: greengrass-nucleus-latest.zip inflating: GreengrassCore/bin/greengrass.service.template inflating: GreengrassCore/bin/loader inflating: GreengrassCore/conf/nucleus-build.properties inflating: GreengrassCore/lib/Greengrass.jarsudo -E java -Droot="/greengrass/v2" -Dlog.store=FILE -jar ./GreengrassCore/lib/Greengrass.jar --aws-region us-east-1 --thing-name greengrass-v2-qiita-core --thing-group-name greengrass-v2-qiita-group --component-default-user ggc_user:ggc_group --provision true --setup-system-service true --deploy-dev-tools true Creating user ggc_user ggc_user created Creating group ggc_group ggc_group created Added ggc_user to ggc_group Provisioning AWS IoT resources for the device with IoT Thing Name: [greengrass-v2-qiita-core]... Creating new IoT policy "GreengrassV2IoTThingPolicy" Creating keys and certificate... Attaching policy to certificate... Creating IoT Thing "greengrass-v2-qiita-core"... Attaching certificate to IoT thing... Successfully provisioned AWS IoT resources for the device with IoT Thing Name: [greengrass-v2-qiita-core]! Adding IoT Thing [greengrass-v2-qiita-core] into Thing Group: [greengrass-v2-qiita-group]... Successfully added Thing into Thing Group: [greengrass-v2-qiita-group] Setting up resources for aws.greengrass.TokenExchangeService ... TES role alias "GreengrassV2TokenExchangeRoleAlias" does not exist, creating new alias... IoT role policy "GreengrassTESCertificatePolicyGreengrassV2TokenExchangeRoleAlias" for TES Role alias not exist, creating policy... Attaching TES role policy to IoT thing... IAM policy named "GreengrassV2TokenExchangeRoleAccess" already exists. Please attach it to the IAM role if not already Configuring Nucleus with provisioned resource details... Downloading Root CA from "https://www.amazontrust.com/repository/AmazonRootCA1.pem" Created device configuration Successfully configured Nucleus with provisioned resource details! Creating a deployment for Greengrass first party components to the thing group Configured Nucleus to deploy aws.greengrass.Cli component Successfully set up Nucleus as a system serviceAWS IoTの管理コンソールを見て、正常にインストールされていることを確認します
正常にインストールされていれば、図のように Core Device名 が表示されているはずです。
Docker コンテナを動かす
前提条件を満たすためにいろいろする
Docker のインストールと権限設定
Docker をインストールして、ggc_user に docker を実行できる権限を付加します。
(greengrass 経由で実行されるdocker コマンドはこの ggc_user で実行されるためです)sudo yum install -y docker sudo systemctl start docker sudo systemctl enable docker sudo usermod -a -G docker ggc_user sudo usermod -a -G docker ec2-user #このコマンドは必須ではないですが、いちいち sudo をつけるのがめんどくさいので実行していますusermod が有効になるように、一度 EC2インスタンスに入り直します。
ローカルでの動作確認
ここでは local 環境でデプロイを行って、動作することを確認します
docker image の用意
mkdir -p ~/GreengrassCore/artifacts/com.example.MyDockerComponent/1.0.0 docker pull public.ecr.aws/nginx/nginx docker save public.ecr.aws/nginx/nginx > ~/GreengrassCore/artifacts/com.example.MyDockerComponent/1.0.0/nginx.tar docker image rm public.ecr.aws/nginx/nginx #デプロイ時にローカルの image を使わないように削除しておくrecipe の用意
mkdir -p ~/GreengrassCore/recipes touch ~/GreengrassCore/recipes/com.example.MyDockerComponent-1.0.0.yamlcom.example.MyDockerComponent-1.0.0.yaml--- RecipeFormatVersion: '2020-01-25' ComponentName: com.example.MyDockerComponent ComponentVersion: '1.0.0' ComponentDescription: A component that runs a Docker container. ComponentPublisher: Amazon Manifests: - Platform: os: linux Lifecycle: Install: Script: docker load -i {artifacts:path}/nginx.tar Run: Script: docker run --rm -p 8080:80 public.ecr.aws/nginx/nginxローカルでのデプロイ
sudo /greengrass/v2/bin/greengrass-cli deployment create \ --recipeDir ~/GreengrassCore/recipes \ --artifactDir ~/GreengrassCore/artifacts \ --merge "com.example.MyDockerComponent=1.0.0" # output Dec 23, 2020 4:22:52 AM software.amazon.awssdk.eventstreamrpc.EventStreamRPCConnection$1 onConnectionSetup INFO: Socket connection /greengrass/v2/ipc.socket:8033 to server result [AWS_ERROR_SUCCESS] Dec 23, 2020 4:22:52 AM software.amazon.awssdk.eventstreamrpc.EventStreamRPCConnection$1 onProtocolMessage INFO: Connection established with event stream RPC server Local deployment submitted! Deployment Id: f86c969b-ce30-4f62-9cf4-fddb85987bc1ローカルデプロイの確認
ログを確認します(なんとかく docker run されていそうなのが分かります)
[ec2-user@ip-10-0-12-139 recipes]$ sudo tail -f /greengrass/v2/logs/com.example.MyDockerComponent.log ... 2020-12-23T05:43:26.313Z [INFO] (pool-2-thread-33) com.example.MyDockerComponent: shell-runner-start. {scriptName=services.com.example.MyDockerComponent.lifecycle.Install.Script, serviceName=com.example.MyDockerComponent, currentState=NEW, command=["docker load -i /greengrass/v2/packages/artifacts/com.example.MyDockerComponent..."]} 2020-12-23T05:43:32.796Z [INFO] (Copier) com.example.MyDockerComponent: stdout. Loaded image: public.ecr.aws/nginx/nginx:latest. {scriptName=services.com.example.MyDockerComponent.lifecycle.Install.Script, serviceName=com.example.MyDockerComponent, currentState=NEW} 2020-12-23T05:43:32.849Z [INFO] (pool-2-thread-33) com.example.MyDockerComponent: shell-runner-start. {scriptName=services.com.example.MyDockerComponent.lifecycle.Run.Script, serviceName=com.example.MyDockerComponent, currentState=STARTING, command=["docker run --rm -p 8080:80 public.ecr.aws/nginx/nginx"]} 2020-12-23T05:43:34.532Z [INFO] (Copier) com.example.MyDockerComponent: stdout. /docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration. {scriptName=services.com.example.MyDockerComponent.lifecycle.Run.Script, serviceName=com.example.MyDockerComponent, currentState=RUNNING} 2020-12-23T05:43:34.532Z [INFO] (Copier) com.example.MyDockerComponent: stdout. /docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/. {scriptName=services.com.example.MyDockerComponent.lifecycle.Run.Script, serviceName=com.example.MyDockerComponent, currentState=RUNNING} 2020-12-23T05:43:34.544Z [INFO] (Copier) com.example.MyDockerComponent: stdout. /docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh. {scriptName=services.com.example.MyDockerComponent.lifecycle.Run.Script, serviceName=com.example.MyDockerComponent, currentState=RUNNING} 2020-12-23T05:43:34.569Z [INFO] (Copier) com.example.MyDockerComponent: stdout. 10-listen-on-ipv6-by-default.sh: info: Getting the checksum of /etc/nginx/conf.d/default.conf. {scriptName=services.com.example.MyDockerComponent.lifecycle.Run.Script, serviceName=com.example.MyDockerComponent, currentState=RUNNING} 2020-12-23T05:43:34.605Z [INFO] (Copier) com.example.MyDockerComponent: stdout. 10-listen-on-ipv6-by-default.sh: info: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf. {scriptName=services.com.example.MyDockerComponent.lifecycle.Run.Script, serviceName=com.example.MyDockerComponent, currentState=RUNNING} 2020-12-23T05:43:34.605Z [INFO] (Copier) com.example.MyDockerComponent: stdout. /docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh. {scriptName=services.com.example.MyDockerComponent.lifecycle.Run.Script, serviceName=com.example.MyDockerComponent, currentState=RUNNING} 2020-12-23T05:43:34.615Z [INFO] (Copier) com.example.MyDockerComponent: stdout. /docker-entrypoint.sh: Configuration complete; ready for start up. {scriptName=services.com.example.MyDockerComponent.lifecycle.Run.Script, serviceName=com.example.MyDockerComponent, currentState=RUNNING}コンテナが動いていることも確認できますね!
docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 5f5281942e5b public.ecr.aws/nginx/nginx "/docker-entrypoint.…" 3 minutes ago Up 3 minutes 0.0.0.0:8080->80/tcp heuristic_sandersonnginx も動いていることが確認できますね!
curl localhost:8080 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>さて、これでローカルで動くことが確認できたので、実際にマネジメントコンソールからデプロイを行いましょう
デプロイ実施(準備編)
ローカルのデプロイメントを削除します
これで起動している docker コンテナが消えるはずです
sudo /greengrass/v2/bin/greengrass-cli deployment create --remove="com.example.MyDockerComponent"tar の Docker イメージ を S3 にアップロードします
S3の場所は各自でお好きな場所を指定してください
この場合は、s3://xxxxxx/greengrassv2/docker/nginx.tarに保存aws s3 cp ~/GreengrassCore/artifacts/com.example.MyDockerComponent/1.0.0/nginx.tar s3://xxxxxx/greengrassv2/docker/デプロイ実施(デプロイ編)
デプロイの方法は、AWS CLI, SDK などいろいろあるようですが、ここでは マネジメントコンソールからデプロイを行いました。
Component の作成
create component をクリック
Yamlを入力(ローカルデプロイのyamlと似ていますが、Artifacts という項目を追加しています)
--- RecipeFormatVersion: '2020-01-25' ComponentName: com.example.MyDockerComponent ComponentVersion: '1.0.0' ComponentDescription: A component that runs a Docker container. ComponentPublisher: Amazon Manifests: - Platform: os: linux Lifecycle: Install: Script: docker load -i {artifacts:path}/nginx.tar Run: Script: docker run --rm -p 8080:80 public.ecr.aws/nginx/nginx Artifacts: - Uri: s3://xxxxx/greengrassv2/docker/nginx.taryaml を保存したら、Deploy をクリックします。
初回インストールに作成されたデプロイメントを指定します
作成した Components を作成します
特にオプションは設定せずに、Deploy を選択します
これでデプロイされるはずので、動作確認をしてみましょう。
動作確認
docker コマンドで確認したり、localhostでアクセスしたりしてみます。
docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 4c3181250b11 public.ecr.aws/nginx/nginx "/docker-entrypoint.…" About a minute ago Up About a minute 0.0.0.0:8080->80/tcp recursing_montalcinicurl localhost:8080 <!DOCTYPE html> <html> <head> <title>Welcome to nginx!</title> <style> body { width: 35em; margin: 0 auto; font-family: Tahoma, Verdana, Arial, sans-serif; } </style> </head> <body> <h1>Welcome to nginx!</h1> <p>If you see this page, the nginx web server is successfully installed and working. Further configuration is required.</p> <p>For online documentation and support please refer to <a href="http://nginx.org/">nginx.org</a>.<br/> Commercial support is available at <a href="http://nginx.com/">nginx.com</a>.</p> <p><em>Thank you for using nginx.</em></p> </body> </html>docker コンテナも動いてて、nginx の動作も確認できました!
まとめ
発表された Greengrass 2.0 を使って、デバイス(今回はEC2インスタンス)に docker コンテナをデプロイしました。
今回は、EC2 インスタンスなので、有り難みはあまり感じないですが、これが IoT機器で、しかも、それが大量にあるという環境だとかなり便利に使えるのではないでしょうか?
現時点では、データの取得元(artifacts)は、S3 のみのため、docker image を tar にして S3 にアップロードするというのはやや残念ではありますが、まだリリースされたばかりなので今後のアップデートに期待ですね。










- 投稿日:2020-12-23T15:14:13+09:00
S3 で ホスティングしたウェブサイトをSSL化し、かつ特定の IP のみに開示する方法
はじめに
この記事は2020年の RevComm アドベントカレンダー25日目の記事です。クリスマス当日ですね!
前日は @qii-purine さんの「pythonでのアーキテクチャを考える」でした。
今回は最後となりますが、S3 で ホスティングしたウェブサイトをSSL化し、かつ特定の IP のみに開示する方法について紹介します。
やりたいこと
aws 使っている会社で、自分の作ったサイト(例えばデモサイト)を社内で共有するとき、みなさまどのように共有しますか。
典型的なやり方だと EC2 や Fargate でフロントエンドのサーバを立てるのではないかと思います。また、複数の静的ウェブページであれば、サーバーレスも検討するのではないかと思います。
そんな中、A) 頻繁にアクセスしない、B) 静的ファイルでも良い といった場合、 S3でのホスティング はコスト的に有効です。
しかし A) 社内のVPN のみで共有したい、B) サイトを転送時に暗号化したい と言う条件が加わると、SSL化 と 特定のIPのみに開示 する必要があります。そのためには SSL 証明書発行 と ファイヤーウォール を用意する必要があります。
今回 Route 53, WAF, CloudFront, Certificate Manager, S3 を使って, どのようにSSL化して S3 でホスティングするかを紹介します。
また、今回 CloudFront を使いますが、CloudFront の場合はデータがキャッシュされるため、TTL (Time to Live) を意図的に設定しない限り変更が即時反映されません。TTL を短くすればいい話ですが、今回 S3 にあるサイトを変更したときにどのようにサイトを更新し、変更を即反映させるかについて紹介します。
( 内容はこちらのリンクとほぼ被りますので、もし、本記事でわからないことがあればそちらを読んでいただけると幸いです)
全体構成
全体構成はこんな感じです。
作成手順
取り組む前の準備
- Route 53 でメインドメインをまだ作成していない場合は作成してください。
- Route 53 に追加するレコード名を予め、検討してください。( revcomm-christmas-demo.example.com とします。)
素材の準備
まず、画像を用意します。(頑張ってコピー等でダウンロードしてください。)
コードの準備
index.html<!DOCTYPE html> <html> <head> <meta charset='utf-8'> <title>Merry Christmas</title> <link rel='stylesheet' type='text/css' media='screen' href='main.css'> </head> <body> <div class="content"> <img class="tree" src="./christmas_tree.png"> </div> </body> </html>main.css.content{ text-align:center; position: relative; width: 100%; height: 100%; } .content .text{ position: absolute; text-align:center; top: 50%; left: 50%; transform: translate(-50%, -50%); font-family: 'Charm', cursive; font-size: 5em; } html { width: 100%; height: 100%; } body{ width: 100%; height: 100%; background: radial-gradient(#ffffff 50%, #91bee5 100%); } .ball{ position: absolute; padding: 0px; margin: 0px; width: 20px; height: 20px; border-radius: 10px; background-color: rgb(218, 233, 247); }S3 の設定
S3 にアクセスし、バケットを新規作成してください。(revcomm-christmas-demo にします)
次にコンテンツをアップロードしてください。(ドラッグアンドドロップで可能)
これで S3 にコンテンツが追加されました。
Certificate Manager の設定
SSL 証明書の作成です。
Certificate Manager にアクセスし、Region を N.Virginia にした状態で SSL 証明書の新規作成をクリックしてください。
予め検討した URL を入力してください。
DNS検証 にしてください。
レコード作成を選択してください。
レコードを追加すると、 Route 53 に SSL 証明書用のレコードが追加されます。
CloudFront の設定
CloudFront にアクセスし、CloudFront Distribution の新規作成をクリックしてください。
以下のようにパラメータを修正してください。(英語のままですが、ご容赦願います。)
- Enable Origin Shield: No
- Restrict Bucket Access: Yes
- Origin Access Identity: Create New Identity
- Generate Read Permissions on Bucket: Yes
- Viewer Protocol Policy: Redirect
- Price class: Use All Edge
- Default Root Object: index.html
- Alternate Domain Names: 予め検討した URL (revcomm-christmas-demo.example.com)
- SSL Certificate: Custom SSL Certificate
- Custom SSL: 予め検討した URL をタイプしてみてください。対応する SSL が出ます。(revcomm-christmas-demo と書けば出るはず)
しばらくすると、デプロイが完了します。(15分以上かかる可能性あり)
完了したら、 CloudFront のドメイン名をメモってください。
補足
- S3 のポリシーも自動的に更新します。
- OAI (Origin Access Identity) を使用することで、 S3 をpublic化をしない状態でホスティングすることができます。
Route 53 のレコード作成
Route 53 にアクセスし、ドメイン名 > レコードを追加 をクリックしてください。
レコードを作成してください。
Route ポリシーを Simple Route、 レコード名を予め検討した URL のサブドメイン名(revcomm-christmas-demo)、 レコードタイプをCNAME、 Value を先ほどメモった CloudFront を URL 入力してください。
WAF の設定
WAF にアクセスし、IP Sets で Region を Global (CloudFront) にした状態で新規 IP Set を作成してください。
IP を設定してください。
次にファイヤウィールの設定です。Web ACLs (Access Control List) で Region を Global (CloudFront) にした状態で 新規 ACL を作成してください。
任意の名前を設定して、関連リースの追加をクリックしてください。
WAF に関連するリソースを追加してください。(CloudFrontのID番号が表示する)
次へをクリックし、Add rules > Add my own rules ... をクリックしてください。
ルールタイプ IP Set を選択し、 ルール名(任意)を好きな名前にした状態で先ほど作成した IP set を入力し、作成してください。Default Action を Allow にしてください。
デフォルトを Block にしてください。
あとは ACL を作成して完成です。
結果
予め検討した URL (revcomm-christmas-demo.example.com) にアクセスすると、以下のようになります。
ちなみに IP アドレスを変えると、以下のようになります。
更新手順
次に更新方法です。
コードの修正
以下のようにコードを修正してください。
index.html<!DOCTYPE html> <html> <head> <meta charset='utf-8'> <title>Merry Christmas</title> <link rel='stylesheet' type='text/css' media='screen' href='main.css'> <link rel="preconnect" href="https://fonts.gstatic.com"> <link href="https://fonts.googleapis.com/css2?family=Charm:wght@700&family=Pacifico&display=swap" rel="stylesheet"> </head> <body> <div class="content"> <img class="tree" src="./christmas_tree.png"> <div class="text"> We wish you a Merry Christmas <br /> and a Happy New Year </div> </div> </body> <script> function drop_snow(){ var snow_ball = document.createElement("div") snow_ball.className = "ball" snow_ball.style.top = 0 + 'px' snow_ball.style.left = Math.random() * document.body.clientWidth + 'px' var content = document.getElementsByClassName('content')[0] content.appendChild(snow_ball); var pos = 0 var refreshIntervalId = setInterval(frame, 10); function frame() { if (pos > document.body.clientHeight) { content.removeChild(snow_ball); clearInterval(refreshIntervalId); } else { pos+= 1; snow_ball.style.top = pos + 'px'; snow_ball.style.opacity = (1 - pos/document.body.clientHeight) } } } for (let i=0; i < 10; i ++){ drop_snow() } setInterval(drop_snow, 500); </script> </html>main.css.content{ text-align:center; position: relative; width: 100%; height: 100%; } .content .text{ position: absolute; text-align:center; top: 50%; left: 50%; transform: translate(-50%, -50%); font-family: 'Charm', cursive; font-size: 5em; } html { width: 100%; height: 100%; } body{ width: 100%; height: 100%; background: radial-gradient(#ffffff 50%, #91bee5 100%); } .ball{ position: absolute; padding: 0px; margin: 0px; width: 20px; height: 20px; border-radius: 10px; background-color: rgb(218, 233, 247); }S3に再度アップロード
再度作成した S3 バケットにアップロードしてください。
CloudFront のキャッシュ無効化
CloudFront を通して一度サイトにアクセスすると、作成したウェブページがキャッシュされます。
そこで、キャッシュを無効化する必要があります。キャッシュを無効化するためにはまず CloudFront にアクセスし、作成した CloudFront Distribution をクリックしてください。
Invalidations で 無効化の作成 をクリックしてください。
あとは index.html 入力し、無効化を実行してください。
結果、こんな感じになります。(codepen です。画像だとつまらないので。)
See the Pen aws_s3_ssl_example1 by zomaphone1 (@zomaphone) on CodePen.
まとめ
以上で、S3 で ホスティングしたウェブサイトをSSL化し、かつ特定の IP のみに開示する方法について一つ紹介しました。
通常のホスティングであれば S3 で設定が済みますが、SSL化 と 特定の IP に対して公開したい場合、上記の手段は有効です。
もちろん他の手段として、S3 だけで解決する手段もあります。
こちらの記事のようにアクセスポイントを変えるだけ https で公開することもできます。IP と https のみを許容する場合は bucket policy を変えるだけで済みます。
Before: https://revcomm-christmas-demo.s3-website-ap-northeast-1.amazonaws.com/ After: https://s3-ap-northeast-1.amazonaws.com/revcomm-christmas-demo/index.htmlただし、このやり方で注意していただきたいのが、
httpsとindex.htmlを明示的に示さないといけないことです。そのため、共有するときに URL の扱いに注意しないといけなくなります。もし、リダイレクト等も含めたい、index.html まで記述させたくない場合、ぜひこちらの記事を参考に実施していただけると幸いです。
最後に
いかがでしたでしょうか。
今回の Qiita advent calendar は RevComm として初の試みではありましたが、有益な情報は得られましたでしょうか。
RevComm では「コミュニケーションを再発明し、人が人を想う社会を創る」というミッションを基に、電話営業をディープラーニングの技術で支援するプロダクト( Miitel ) をはじめ、コミュニケーションに関わる様々なプロダクト開発を行っており、日頃からコミュニケーションの在り方を再定義するという難しい課題に取り組んでいます。
弊社ではテックに関わらず成長に貪欲な人がたくさんいます。会社としてまだまだ若いところもありますが、新しい技術等に積極的に取り入れる会社ではあるので、エンジニアとしてテックスタックを広げたいという人にとってはいい会社です。
もし、弊社で一緒に働きたいという想いがあれば、あるいは少しでも興味があればぜひぜひ弊社の採用ページに応募してみてください。
ちなみに働き方について興味があれば、ぜひ CTO が書いたこちらの記事を読んでください。
では良いクリスマスを!!





























- 投稿日:2020-12-23T13:19:22+09:00
CloudWatchアラームのアクションを無効にする。
はじめに
CloudWatchアラームを設定したけれど、一時的に通知をOFFにしたいなどがあると思います。例えばメンテナンス作業などで不要なアラーム飛ばしたくない場合など。
ということで、アラームの状態確認方法・アクションの無効化/有効化についてまとめました。確認方法
ここでは 管理コンソール と aws-cli による確認方法を行います。
コンソール
「CloudWatchコンソール > アラーム」 から 歯車アイコン をクリックします。
アクションが有効になっています を有効にします。
すると以下の画像のように 有効 という文字が表示されます。
ちなみに、アラームアクションはデフォルト有効です。aws-cli
特定アラームの状態については以下のコマンドで確認ができます。
describe-alarms$ aws cloudwatch describe-alarms --alarm-names <アラーム名>出力例{ "MetricAlarms": [ { "EvaluationPeriods": 2, "AlarmArn": "arn:aws:cloudwatch:us-east-1:123456789012:alarm:myalarm", "StateUpdatedTimestamp": "2014-04-09T18:59:06.442Z", "AlarmConfigurationUpdatedTimestamp": "2012-12-27T00:49:54.032Z", "ComparisonOperator": "GreaterThanThreshold", "AlarmActions": [ "arn:aws:sns:us-east-1:123456789012:myHighCpuAlarm" ], "Namespace": "AWS/EC2", "AlarmDescription": "CPU usage exceeds 70 percent", "StateReasonData": "{\"version\":\"1.0\",\"queryDate\":\"2014-04-09T18:59:06.419+0000\",\"startDate\":\"2014-04-09T18:44:00.000+0000\",\"statistic\":\"Average\",\"period\":300,\"recentDatapoints\":[38.958,40.292],\"threshold\":70.0}", "Period": 300, "StateValue": "OK", "Threshold": 70.0, "AlarmName": "myalarm", "Dimensions": [ { "Name": "InstanceId", "Value": "i-0c986c72" } ], "Statistic": "Average", "StateReason": "Threshold Crossed: 2 datapoints were not greater than the threshold (70.0). The most recent datapoints: [38.958, 40.292].", "InsufficientDataActions": [], "OKActions": [], "ActionsEnabled": true, "MetricName": "CPUUtilization" } ] }
--alarm-namesなので複数のアラームを確認したいのであればスペースで続けて指定すれば確認できます。
また、全てのアラームについて確認したい場合はオプション無しでOKです。アクションステータス変更
まず、変更方法を調べたところドキュメントには以下の様に記載されていました。
ー 引用
アラームを無効または有効にするには、CloudWatch コンソール、DisableAlarmActions および EnableAlarmActions API アクション、または AWS CLI の disable-alarm-actions および enable-alarm-actions コマンドを使用します。CloudWatchコンソール とあるので管理コンソールからでも操作ができるのかと思ったのですが、、、見つかりません。仕方なくサポートに問い合わせて確認してみました。
すると、 「現時点において CloudWatch コンソールではアラームの無効化および有効化が行えません。」 との回答が。。。
ということで、アクションの無効化および有効化は aws-cli または sdk からのみ行えるそうです。(2020/12/14時点)アクション無効化
ここでは IAMPolicyChanges というアラーム名に対して無効化してみます。
無効化$ aws cloudwatch disable-alarm-actions --alarm-names IAMPolicyChangesアクションステータスの確認$ aws cloudwatch describe-alarms --alarm-names IAMPolicyChanges | grep ActionsEnabled "ActionsEnabled": false,ActionsEnabled が
falseとなれば無効になっている証拠です。
コンソールの場合は 無効 と表示されます。
アクション有効化
今度は先ほど無効にしたアラームを有効に戻します。
有効化$ aws cloudwatch enable-alarm-actions --alarm-names IAMPolicyChangesアクションステータスの確認$ aws cloudwatch describe-alarms --alarm-names IAMPolicyChanges | grep ActionsEnabled "ActionsEnabled": true,おわりに
アクションを無効化/有効化するのにaws-cliやsdkを使わないといけないのは運用的に少々(かなり)面倒ですよね。。。
サポートへも要望挙げておいたので、早くコンソールから操作できるようになって欲しいなと思います。参考
Amazon CloudWatch でのアラームの使用 - CloudWatch アラームでよく使用する機能
Amazon CloudWatch でのアラームの使用
AWS CLI Command Reference - cloudwatch




- 投稿日:2020-12-23T13:15:02+09:00
AWS EC2のGraviton2インスタンスにdocker-composeをインストールする
Graviton2のおかげでarm64アーキテクチャの環境が手軽に使えるようになりました。性能面もそうですがIntelやAMDより安価というメリットもあり積極的に使っていきたいと思っています。今のところスポットインスタンスで使えないのがちょっと痛いですが、使う人が増えてくればそのうち対応するでしょう。
とりあえずt4gインスタンスを立てて使おうとしたところdocker-composeのインストールでしばらく詰まったのでメモ。
環境
- t4g.microインスタンス
- Amazon Linux 2
何が問題か
Dockerは
yumでAWS公式提供のものをインストールできるので問題ないのですが、docker-composeは自分でインストールする必要があります。で、リリースされているものはというと、ここにあるようにx86_64のものしか用意されていません。なので、
pipでインストールを試みます。$ sudo yum install python3 python3-dev python3-pip gcc make openssl-devel libffi-devel $ sudo pip3 install -U docker-composeこれが通らない。Cryptographyというパッケージのビルドでこけます。
どうしたか
Amazon Linux 2で普通にインストールできるOpenSSLは1.0系のものですが、CryptographyはOpenSSL1.0のサポートを打ち切ったようでした。このため、OpenSSL1.1系を用意する必要がありました。
$ sudo yum remove openssl openssl-devel $ sudo yum install openssl11 openssl11-devel openssl11-libs $ sudo pip3 install wheel $ sudo pip3 install -U docker-composeworks for me.
- 投稿日:2020-12-23T13:13:00+09:00
Kinsta の WordPress に CloudFront を被せてみる
0.はじめに
Kinsta という WordPress のマネージドサービスがあリまして、
で、Kinsta のサービスにも Kinsta CDN という CDN の機能はあるんですが、
あまり細かい設定は出来ないみたいので、Kinsta CDN ではなく、AWS の CloudFront を利用出来ないか試してみました。
以前、WordPress @ EC2 への CloudFront の適用は、以下の記事にある様にやったことがありましたが、基本的にやり方は同じです。
1. Kinsta 上の WordPress サイト の IP アドレスを確認
Kinsta 側での対応は、基本的に無いんですが、
今回は、Kinsta 上の WordPress サイトに新しいドメインを割り当てておきたかったので、サイト の IP アドレスを確認しておきます。
2. CloudFront が参照するサイトドメインの DNS レコードの設定
- 以下の DNS レコードの設定を追加する。
- 新 :
???-kinsta.example.com:AXXX.XXX.XXX.XXX
XXX.XXX.XXX.XXXは Kinsta で確認したサイトの IP アドレス3. CloudFront に新しく Distribution を作成
作成した Distribution での設定項目は、以下。
General
- Alternate Domain Names (CNAMEs)
- [サイトドメイン]
- ※
???.example.com- AWS WAF Web ACL
- ※ 任意
- SSL Certificate
- [AWS Certificate Manager で登録した証明書]
- ※
*.example.com- Security Policy
- ※ 任意
- ※ 今回は、諸事情あって
TLSv1_2016を設定- Log Bucket
- ※ 任意
- Log Prefix
- ※ 任意
- ※
???.example.com- Cookie Logging
- ※ 任意
Origins and Origin Groups
- Origin Domain Name
- Origin ID
- ※ 自動
- Minimum Origin SSL Protocol
TLSv1.2- ※ Kinsta は TLS1.2 以上が必須。
- Origin Protocol Policy
- ※ 任意
- ※
HTTPS OnlyBehavior
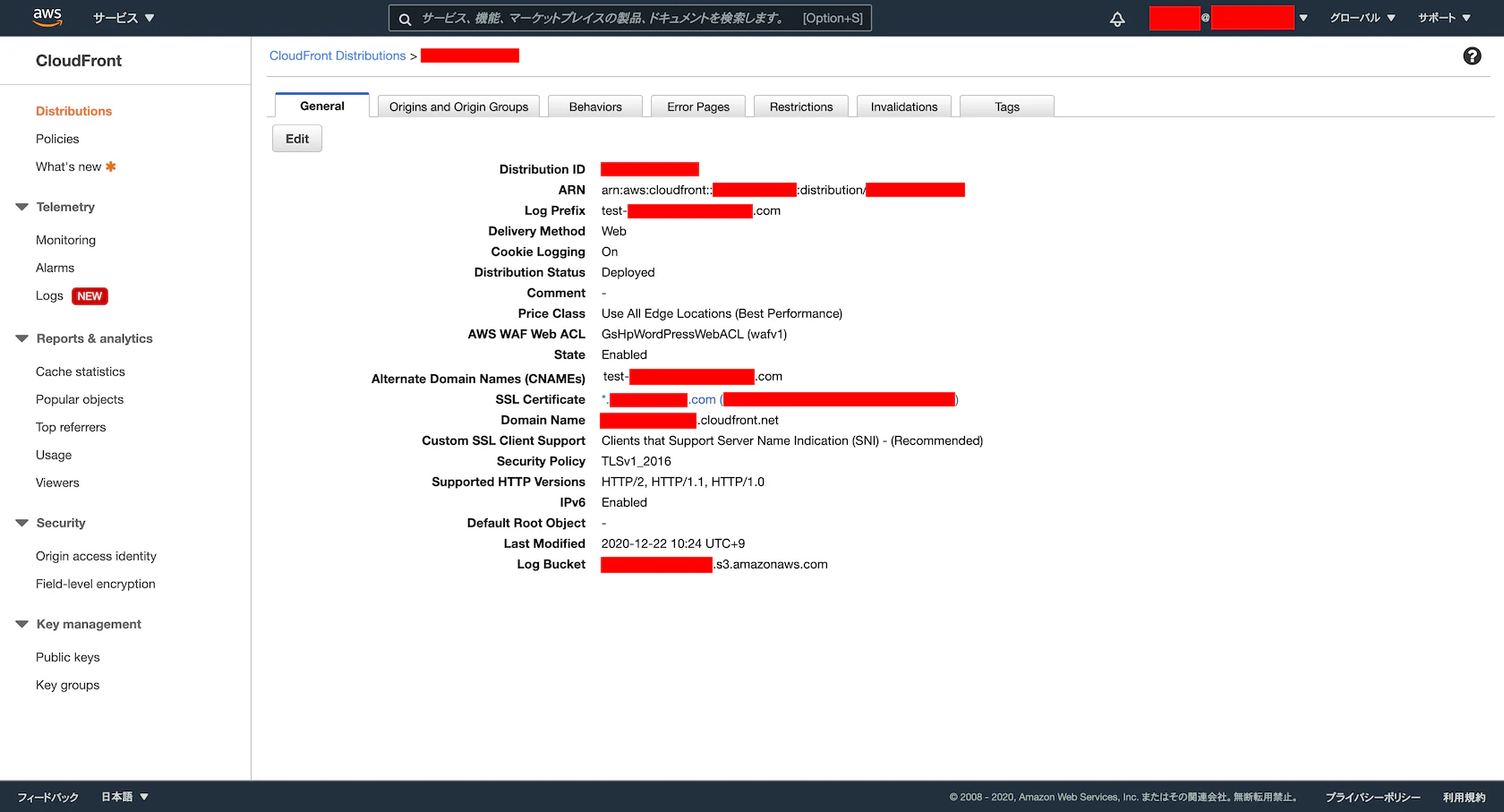
Default (*)※ キャッシュする場合の設定デフォルトでは、原則全てのコンテンツをキャッシュする設定が作成されますが、サイトに合わせて変更して下さい。
- Path Pattern
- Default (*)
- ※ デフォルト
- Origin or Origin Group
- ※ 作成した「Origins and Origin Groups」 を選択
- Viewer Protocol Policy
- ※ 任意
Redirect HTTP to HTTPS- Allowed HTTP Methods
GET, HEAD, OPTIONS, PUT, POST, PATCH, DELETE- Cache and origin request settings
Use legacy cache settings- Cache Based on Selected Request Headers
Whitelist- Whitelist Headers
CloudFront-Is-Desktop-ViewerCloudFront-Is-Mobile-ViewerCloudFront-Is-SmartTV-ViewerCloudFront-Is-Tablet-ViewerHostUser-agent- Forward Cookies
Whitelist- Whitelist Cookies
wordpress_logged_in*wp-settings*- Query String Forwarding and Caching
Forward all, cache based on all
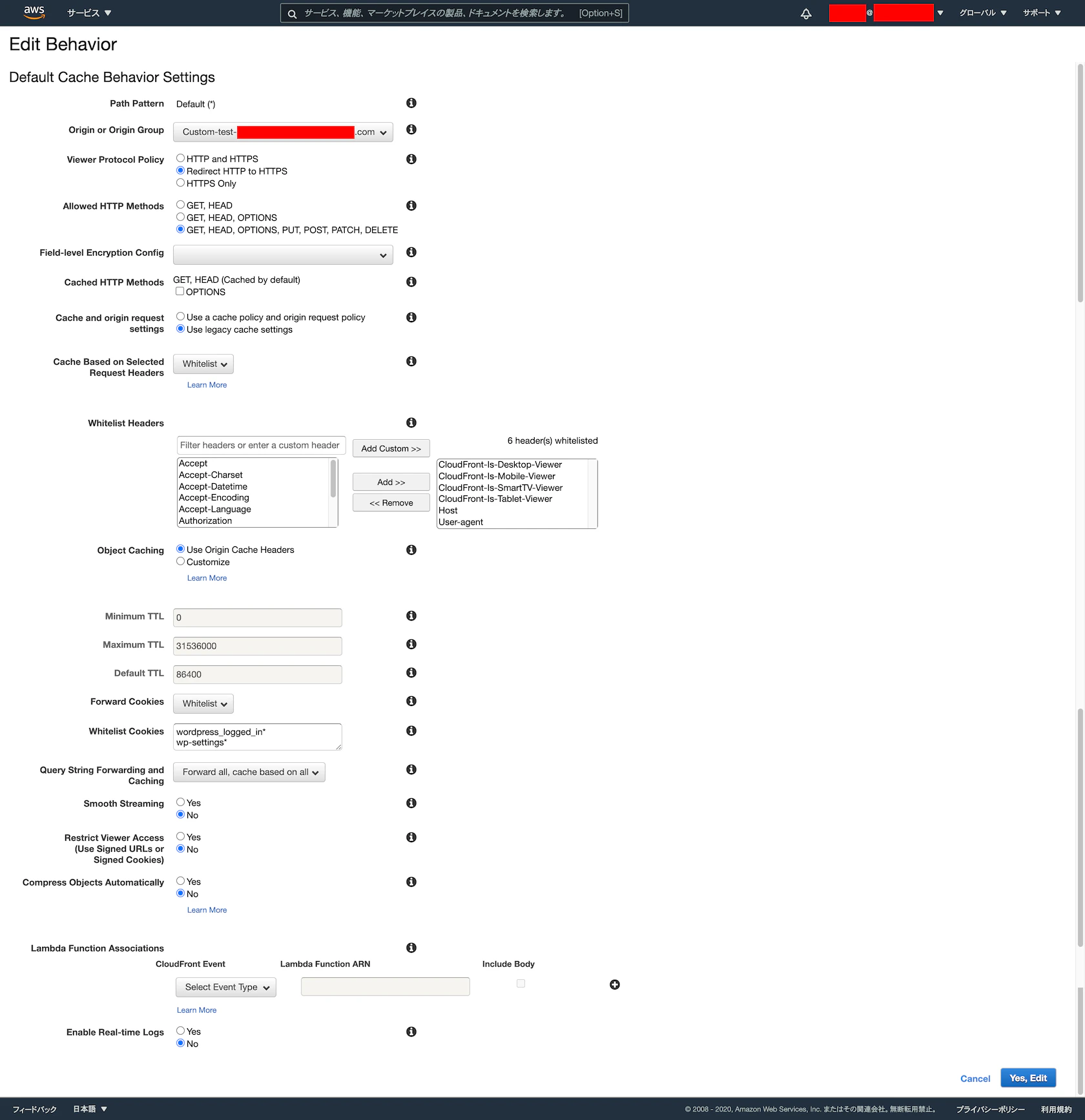
/wp-admin/*,*.php※ キャッシュしない場合の設定とりあえず、管理者画面などへのアクセス用に追加で設定しました。これも、サイトに合わせて変更して下さい。
※ キャッシュする場合との設定の違いは、以下のみ。
- Object Caching :
Customize- Minimum TTL :
0- Maximum TTL :
0- Default TTL :
04. 新しく作成した CloudFront ドメインの DNS レコードの設定
- 以下の DNS レコードの設定を変更する。
- 旧 :
- ???.example.com : A XXX.XXX.XXX.XXX
- 新 :
- ???.example.com : CNAME *************.cloudfront.net
- ※作成した CloudFront の Domain Name
99.ハマりポイント
- 今回は、一度ほぼ同じ対応をしたことがありましたので、特にハマることはありませんでした。
XX.まとめ
以前は、EC2 で動かしていましたが、今回は、 Kinsta で WordPress を動かす形で、CloudFront を適用してみました。
EC2 に比べて、Kinsta での運用となると、コストは掛かりますが、その分 Kinsta の便利な付加サービスを使えたり、Kinsta 側で補ってくれるメンテナンスやセキュリティ、パフォーマンス、サポートの対応などもありますので、それなりにメリットもあるかなと思います。
さらに、CloudFront を適用すると、Kinsta だけでは出来ないことや、その他の細やかな CDN での対応も出来る様になりますので、結構良いんじゃないかと。
因みに、Kinsta のチャットサポートは、だいたい 5 分以内に返事があるので、非常に使い勝手が良いですよ ♪♪♪
- レンタルサーバー&ホスティング サービスKinsta
- プラン一覧:KinstaマネージドWordPressホスティングソリューション
- Kinstaレビュー2020年―高パフォーマンスですが、1つだけ重大なデメリットが
ご参考になれば ♪♪♪
???



- 投稿日:2020-12-23T13:11:44+09:00
GreengrassでDockerアプリケーションをデプロイする
はじめに
会社の業務でAWS IoT Greengrassについて勉強したので、Ubuntu搭載デバイスとAWS IoTを利用したアプリケーションを紹介したいと思います。
今回はGreengrassでDockerアプリケーションをデプロイする方法12を紹介します。過去の記事:
UbuntuにAWS IoT Greengrassをインストールする
GreengrassのLambdaを作成してエッジデバイスにデプロイする※先日、Greengrass V23がリリースされましたが、この記事ではV1を使用します。
環境
動作確認済デバイス(OS)
e-RT3 Plus F3RP70-2L4(Ubuntu 18.04 32bit)
横河電機のエッジコントローラです。AWS IoT Greengrassの認定デバイス5に登録されています(e-RT3のページはこちら)。Raspberry Pi 4 Model B (Ubuntu Server 20.04 32bit)
これらのデバイスでは armhf アーキテクチャのパッケージが動作します。
また、Windows 10 搭載のPCでデバイスを操作しています。作業の流れ
Dockerアプリケーションの作成
開発用PCでDockerアプリケーションを開発します。Dockerイメージのプッシュ
Dockerイメージを作成してAmazon Elastic Container Registry (ECR)にプッシュします。docker-composeのアップロード
docker-composeを作成してAmazon Simple Storage Service (S3)にアップロードします。Dockerアプリケーションのデプロイ
必要なロールをGreengrass Groupに付与し、Dockerアプリケーションのデプロイメントコネクタ1を使用してDockerアプリケーションをデバイスにデプロイします。Dockerコンテナが起動し、アプリケーションが稼働します。準備
AWS CLIのインストール
PCにAWS CLIをインストールします。
インストール方法は以下のガイドを参照してください。
Windows での AWS CLI バージョン 2 のインストール、更新、アンインストール初回使用時には設定を行う必要があります。詳しくは以下のガイドを参照してください。
設定の基本 - AWS Command Line Interface※PCがproxy環境下にある場合はproxy設定が必要です。詳しくはコマンドのプロキシ設定をご覧ください。
Docker Desktop on Windowsのインストール
PCにDocker Desktop on Windowsをインストールします。
インストール方法はこちらのページを参照してください。※PCがproxy環境下にある場合はproxy設定が必要です。詳しくはこちらのページをご覧ください。
Python3.7のインストール
デバイスにGreengrassでDockerアプリケーションをデプロイするために必要なPython3.7をインストールします。
※デバイスがproxy環境下にある場合はproxy設定が必要です。詳しくはこちらをご覧ください。
e-RT3の場合
sudo apt update sudo apt install python3.7username@ubuntu:~$ python3.7 --version Python 3.7.5Raspberry Pi (Ubuntu Server 20.04 32bit)の場合
aptでインストールできないので、ソースからビルドしてインストールします。
ビルドに必要なパッケージをインストールします。sudo apt update sudo apt install build-essential libbz2-dev libdb-dev \ libreadline-dev libffi-dev libgdbm-dev liblzma-dev \ libncursesw5-dev libsqlite3-dev libssl-dev \ zlib1g-dev uuid-dev公式サイトからPython3.7のソースをダウンロードしてビルドします。
wget https://www.python.org/ftp/python/3.7.9/Python-3.7.9.tar.xz tar xvf Python-3.7.9.tar.xz cd Python-3.7.9 ./configure make sudo make altinstall cd ~インストールの成功を確認します。
username@ubuntu:~$ python3.7 --version Python 3.7.9dockerのインストール
デバイスにdockerとdocker-composeをインストールします。
docker
e-RT3の場合
最新版をインストールするために、公式ドキュメント6に従ってインストールします。
dockerのインストールに必要なパッケージをインストールします。sudo apt update sudo apt install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common資格情報7に必要なパッケージをインストールします。
sudo apt install passGPGキーを追加します。
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -フィンガープリントの下8桁で検索し、キーが追加されたことを確認します。
username@ubuntu:~$ sudo apt-key fingerprint 0EBFCD88 pub rsa4096 2017-02-22 [SCEA] 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 uid [ unknown] Docker Release (CE deb) <docker@docker.com> sub rsa4096 2017-02-22 [S]リポジトリを追加します。
sudo add-apt-repository \ "deb [arch=armhf] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable"dockerエンジンをインストールします。
sudo apt update sudo apt install docker-ce docker-ce-cli containerd.io #サービス起動 sudo systemctl start docker #サービス自動起動 sudo systemctl enable dockerusername@ubuntu:~$ docker --version Docker version 20.10.1, build 831ebeaRaspberry Pi(Ubuntu Server 20.04 32bit)の場合
Dockerの公式リポジトリにUbuntu20.04 armhf用のパッケージがないので、docker.ioでインストールします。
sudo apt install docker.io #サービス起動 sudo systemctl start docker #サービス自動起動 sudo systemctl enable dockerusername@ubuntu:~$ docker --version Docker version 19.03.8, build afacb8b7f0インストールの成功を確認します。
テスト用のイメージでコンテナを起動し、以下のようなメッセージが表示されたら成功です。username@ubuntu:~$ sudo docker run hello-world Hello from Docker! This message shows that your installation appears to be working correctly. ...※デバイスがproxy環境下にある場合はproxy設定が必要です。詳しくはdockerのプロキシ設定をご覧ください。
docker-compose
pipを利用してインストールします8。
必要なパッケージをインストールします。
sudo apt update sudo apt install libffi-dev libssl-dev python3-dev python3-venv仮想環境を作成してpipでインストールします。
python3 -m venv venv source venv/bin/activate (venv) username@ubuntu:~$ pip install wheel (venv) username@ubuntu:~$ pip install docker-compose (venv) username@ubuntu:~$ sudo cp venv/bin/docker-compose /usr/bin (venv) username@ubuntu:~$ deactivateインストールの成功を確認します。
username@ubuntu:~$ docker-compose --version docker-compose version 1.27.4, build unknownユーザー設定
GreengrassからデプロイされたDockerアプリケーションを実行するユーザーの設定を行います。
デフォルトではggc_userとなるので、今回はこのユーザーを使用します。S3バケットからダウンロードしたdocker-composeを保存するディレクトリを作成し、アクセス権を設定します。
sudo mkdir /home/ggc_user/myCompose sudo chown ggc_user:ggc_group /home/ggc_user/myCompose sudo chmod 700 /home/ggc_user/myComposeggc_userをdockerグループに追加します。
sudo usermod -aG docker ggc_user一度ログアウトして設定を反映させます。
1. Dockerアプリケーションの作成
PCでDockerアプリケーションを作成します。
今回は、アクセスすると「Hello World from Docker Container!」というメッセージを表示するPythonのwebアプリケーションを作成します。
以下の3つのファイルを同一のフォルダに保存してください。Flaskを利用したPythonのプログラムです。アクセスすると「Hello World from Docker Container!」というメッセージを表示します。
app.pyfrom flask import Flask app = Flask(__name__) @app.route("/") def hello(): return "Hello World from Docker Container!" if __name__ == "__main__": app.run()必要なPythonのパッケージを記したファイルです。今回はFlaskのみ利用します。
requirements.txtFlaskDockerのイメージを作成する際のコマンドを記したファイルです。
32bit arm用のイメージに必要なファイルやパッケージをインストールしています。DockerfileFROM arm32v7/python:3.7-alpine WORKDIR /usr/src/app ENV FLASK_APP app.py ENV FLASK_RUN_HOST 0.0.0.0 COPY requirements.txt . RUN pip install --no-cache-dir -r requirements.txt COPY . . CMD ["flask", "run"]2. Dockerイメージのプッシュ
Dockerイメージを作成してECRにプッシュします。
リポジトリの作成
左上のサービスからElastic Container Registryに進み、「Repositories」→「リポジトリを作成」をクリックします。
任意のリポジトリ名を入力し、「リポジトリを作成」をクリックします。
イメージの作成とプッシュ
PCのDocker Desktop on Windowsを起動しておきます。
リポジトリのページに移動し、「プッシュコマンドの表示」をクリックします。
Dockerアプリケーションの作成で作成したDockerfileのあるディレクトリでコマンドプロンプトを開き、表示されたコマンドを順番に実行します。
ECRにdockerイメージがプッシュされたことを確認します。
イメージのURIをこの後の手順で使用するので控えておきます。
3. docker-composeのアップロード
docker-composeの作成
PCでdocker-composeを作成します。
以下の内容をdocker-compose.ymlという名前で保存してください。
<image-uri>の部分はイメージの作成とプッシュで控えておいたURIで置き換えてください。docker-compose.ymlversion: '3' services: web: image: "<image-uri>" ports: - "5000:5000"S3バケットの作成
左上のメニューからS3へ進み、「バケット」→「バケットを作成」をクリックします。
任意のバケット名を入力し、「バケットを作成」をクリックします。
docker-composeのアップロード
作成したバケットをクリックし「アップロード」をクリックします。
「ファイルを追加」をクリックしdocker-composeの作成で作成したdocker-compose.ymlをアップロードします。
4. Dockerアプリケーションのデプロイ
ロールの作成とアタッチ
GreengrassがS3バケット、ECRにアクセスするために必要なロールを作成して、Greengrassグループにアタッチします。
ポリシーの作成
「IAM」→「ポリシー」と進み、「ポリシーの作成」をクリックします。
JSONタブをクリックして以下のJSONを入力し、S3バケットへのアクセスを許可します。
<bucket-name>の部分はS3バケットの作成で作成したS3バケット名に置き換えてください。
入力が完了したら「ポリシーの確認」をクリックします。{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowAccessToComposeFileS3Bucket", "Action": [ "s3:GetObject" ], "Effect": "Allow", "Resource": "arn:aws:s3:::<bucket-name>/*" } ] }
任意の名前と説明を入力して「ポリシーの作成」をクリックします。
同様の手順で、以下のJSONを使用してECRへのアクセスを許可するポリシーを作成します。
<region>、<account-id>の部分は使用しているリージョンとアカウントIDで、<repository-name>の部分はリポジトリの作成で作成したリポジトリ名で置き換えてください。{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowGetEcrRepositories", "Effect": "Allow", "Action": [ "ecr:GetDownloadUrlForLayer", "ecr:BatchGetImage" ], "Resource": [ "arn:aws:ecr:<region>:<account-id>:repository/<repository-name>" ] }, { "Sid": "AllowGetEcrAuthToken", "Effect": "Allow", "Action": "ecr:GetAuthorizationToken", "Resource": "*" } ] }ロールの作成
- 「IAM」→「ロール」と進み、「ロールの作成」をクリックします。
ユースケースの選択でGreengrassを選択し、次へ進みます。
ポリシーの作成で作成した2つのポリシーを選択します。
タグは設定せずに次へ進みます。
任意の名前と説明を入力してロールを作成します。
ロールのアタッチ
Greengrassのグループへ進み、「設定」→「ロールの追加」をクリックします。
ロールの作成で作成したロールを選択して「保存」をクリックします。
デプロイと動作確認
グループのページに進み、「コネクタ」→「コネクタの追加」をクリックします。
「Docker Application Deployment」を選択し、「次へ」をクリックします。
S3に保存したdocker-compose.ymlと、ユーザー設定で作成した、デバイス上でdocker-composeを保存するディレクトリを指定して、「追加」をクリックします。
グループのページに進み、デプロイをクリックします。
デプロイ完了後、しばらく待ってからPCで
http://<デバイスのIPアドレス>:5000にアクセスします。
※デバイスとPCが同一のネットワークに属している必要があります。以下の画面が表示されたら成功です。
※うまくいかない場合はデバイスの/greengrass/ggc/var/log/以下にあるログを確認してください。補足
環境により設定は異なりますが、参考までに今回私が行ったproxy設定を紹介します。
コマンドのプロキシ設定
Windowsのコマンドプロンプトで以下の内容を入力します。
set HTTP_PROXY=http://username:password@example.com:port/ set HTTPS_PROXY=http://username:password@example.com:port/dockerのプロキシ設定
Dockerのドキュメント9に従ってプロキシ設定を行います。
まずディレクトリを作成し、そのディレクトリ内にファイルを作成します。
sudo mkdir -p /etc/systemd/system/docker.service.d sudo vi /etc/systemd/system/docker.service.d/http-proxy.conf下記のフォーマットで
HTTP_PROXY、HTTPS_PROXYの環境変数をファイルに書き込み、保存します。
どちらか一方のみで良い場合やNO_PROXYの設定が必要な場合など、環境に合わせて適宜内容を変更してください。/etc/systemd/system/docker.service.d/http-proxy.conf[Service] Environment="HTTP_PROXY=http://username:password@example.com:port/" Environment="HTTPS_PROXY=http://username:password@example.com:port/"設定を反映するためにデーモンをリロードし、再起動します。
sudo systemctl daemon-reload sudo systemctl restart docker設定内容が反映されているか確認します。
# 一般ユーザusernameの場合 username@ubuntu:~$ sudo systemctl show --property=Environment docker Environment=HTTP_PROXY=http://username:password@example.com:port/ HTTPS_PROXY=http://username:password@example.com:port/参考
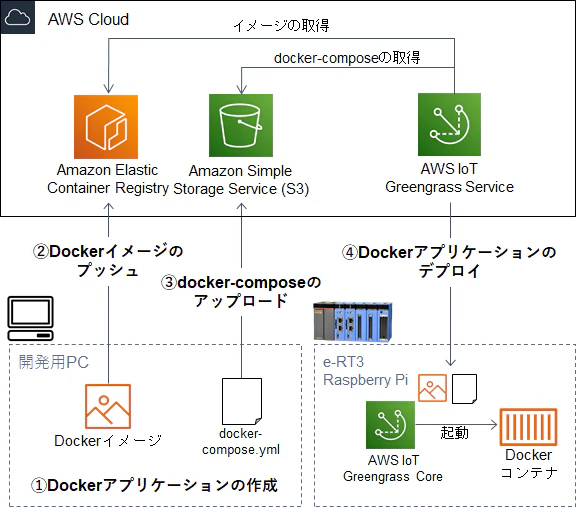










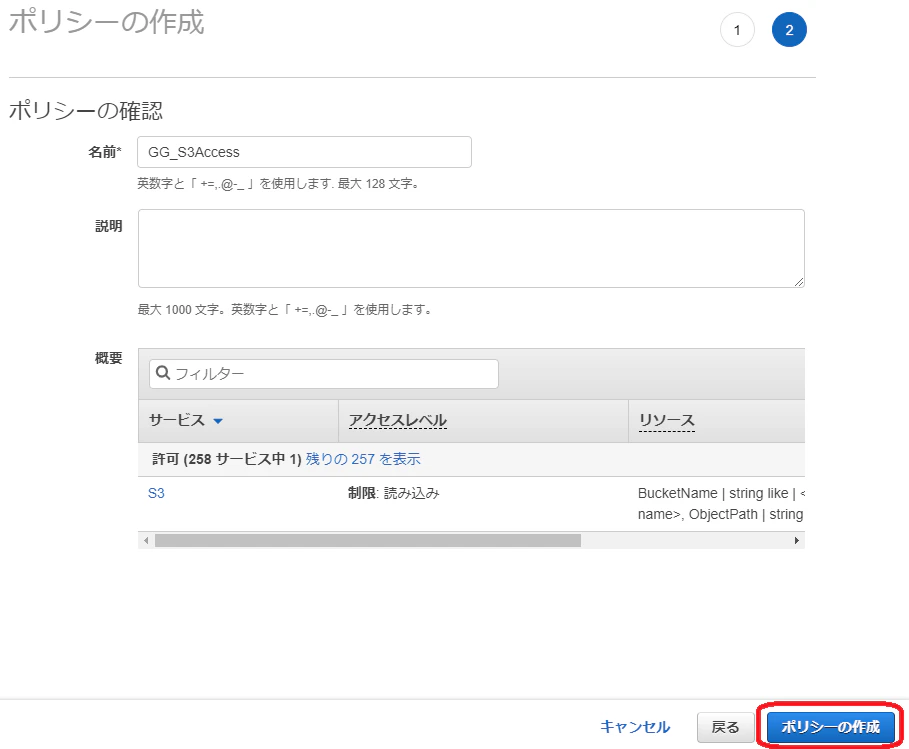
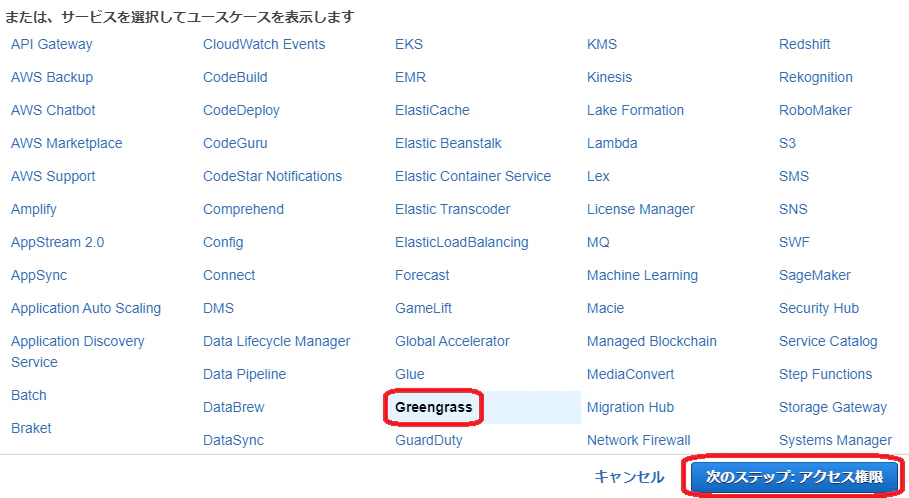

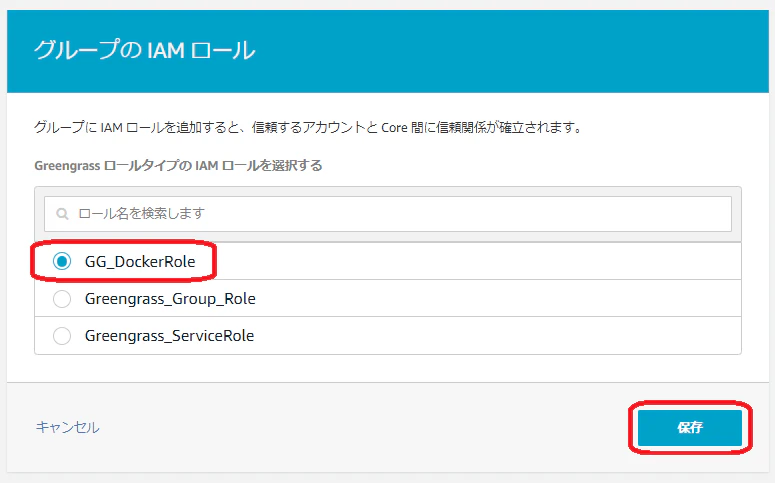



- 投稿日:2020-12-23T11:59:00+09:00
AWS EC2上でMySQLクライアント5.7をインストールし、RDSに接続する
AWSでのデプロイ作業についての学習中、別途AWSで作成したRDSの中身を見ようとしたものの標準では見る方法が見当たらない
そのため、EC2上にMySQLをインストールする必要があった。もともとAmazon Linux2には標準としてMariaDBというMySQL互換のデータベースサーバーがデフォルトでインストールされている。
しかし今回はそちらを使用しない。今回はRDSでMySQLを作成した際に、情報量の多さを理由として5.7を選択している。
環境
・MacOS Big Sur11.1
・Amazom Linux2
・RDS MySQL5.7(エンジンバージョン5.7.31)前提
ターミナルからEC2にSSH接続している
MySQLを追加する
コマンド
sudo yum install -y https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm入力後
読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd mysql80-community-release-el7-3.noarch.rpm | 25 kB 00:00:00 /var/tmp/yum-root-UE3j_l/mysql80-community-release-el7-3.noarch.rpm を調べています: mysql80-community-release-el7-3.noarch /var/tmp/yum-root-UE3j_l/mysql80-community-release-el7-3.noarch.rpm をインストール済みとして設定しています 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ mysql80-community-release.noarch 0:el7-3 を インストール --> 依存性解決を終了しました。 amzn2-core/2/x86_64 | 3.7 kB 00:00:00 amzn2extra-docker/2/x86_64 | 3.0 kB 00:00:00 依存性を解決しました ======================================================================================================================================================================= Package アーキテクチャー バージョン リポジトリー 容量 ======================================================================================================================================================================= インストール中: mysql80-community-release noarch el7-3 /mysql80-community-release-el7-3.noarch 31 k トランザクションの要約 ======================================================================================================================================================================= インストール 1 パッケージ 合計容量: 31 k インストール容量: 31 k Downloading packages: Running transaction check Running transaction test Transaction test succeeded Running transaction インストール中 : mysql80-community-release-el7-3.noarch 1/1 検証中 : mysql80-community-release-el7-3.noarch 1/1 インストール: mysql80-community-release.noarch 0:el7-3 完了しました!標準の状態だと8.0がインストールされるので、設定を5.7に変更する
disable = 無効にする
sudo yum-config-manager --disable mysql80-communityenable = 有効にする
sudo yum-config-manager --enable mysql57-communityMySQLクライアントのインストール
コマンド
sudo yum install -y mysql-community-client入力後
読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd mysql-connectors-community | 2.6 kB 00:00:00 mysql-tools-community | 2.6 kB 00:00:00 mysql57-community | 2.6 kB 00:00:00 mysql57-community/x86_64/primary_db | 247 kB 00:00:00 37 packages excluded due to repository priority protections 依存性の解決をしています --> トランザクションの確認を実行しています。 ---> パッケージ mysql-community-client.x86_64 0:5.7.32-1.el7 を インストール --> 依存性の処理をしています: mysql-community-libs(x86-64) >= 5.7.9 のパッケージ: mysql-community-client-5.7.32-1.el7.x86_64 --> 依存性の処理をしています: libncurses.so.5()(64bit) のパッケージ: mysql-community-client-5.7.32-1.el7.x86_64 --> 依存性の処理をしています: libtinfo.so.5()(64bit) のパッケージ: mysql-community-client-5.7.32-1.el7.x86_64 --> トランザクションの確認を実行しています。 ---> パッケージ mariadb-libs.x86_64 1:5.5.68-1.amzn2 を 不要 --> 依存性の処理をしています: libmysqlclient.so.18()(64bit) のパッケージ: 2:postfix-2.10.1-6.amzn2.0.3.x86_64 --> 依存性の処理をしています: libmysqlclient.so.18(libmysqlclient_18)(64bit) のパッケージ: 2:postfix-2.10.1-6.amzn2.0.3.x86_64 ---> パッケージ mysql-community-libs.x86_64 0:5.7.32-1.el7 を 非推奨 --> 依存性の処理をしています: mysql-community-common(x86-64) >= 5.7.9 のパッケージ: mysql-community-libs-5.7.32-1.el7.x86_64 ---> パッケージ ncurses-compat-libs.x86_64 0:6.0-8.20170212.amzn2.1.3 を インストール --> トランザクションの確認を実行しています。 ---> パッケージ mysql-community-common.x86_64 0:5.7.32-1.el7 を インストール ---> パッケージ mysql-community-libs-compat.x86_64 0:5.7.32-1.el7 を 非推奨 --> 依存性解決を終了しました。 依存性を解決しました ======================================================================================================================================================================= Package アーキテクチャー バージョン リポジトリー 容量 ======================================================================================================================================================================= インストール中: mysql-community-client x86_64 5.7.32-1.el7 mysql57-community 25 M mysql-community-libs x86_64 5.7.32-1.el7 mysql57-community 2.3 M mariadb-libs.x86_64 1:5.5.68-1.amzn2 を入れ替えます mysql-community-libs-compat x86_64 5.7.32-1.el7 mysql57-community 1.2 M mariadb-libs.x86_64 1:5.5.68-1.amzn2 を入れ替えます 依存性関連でのインストールをします: mysql-community-common x86_64 5.7.32-1.el7 mysql57-community 308 k ncurses-compat-libs x86_64 6.0-8.20170212.amzn2.1.3 amzn2-core 308 k トランザクションの要約 ======================================================================================================================================================================= インストール 3 パッケージ (+2 個の依存関係のパッケージ) 総ダウンロード容量: 29 M Downloading packages: 警告: /var/cache/yum/x86_64/2/mysql57-community/packages/mysql-community-common-5.7.32-1.el7.x86_64.rpm: ヘッダー V3 DSA/SHA1 Signature、鍵 ID 5072e1f5: NOKEY mysql-community-common-5.7.32-1.el7.x86_64.rpm の公開鍵がインストールされていません (1/5): mysql-community-common-5.7.32-1.el7.x86_64.rpm | 308 kB 00:00:00 (2/5): mysql-community-libs-5.7.32-1.el7.x86_64.rpm | 2.3 MB 00:00:00 (3/5): ncurses-compat-libs-6.0-8.20170212.amzn2.1.3.x86_64.rpm | 308 kB 00:00:00 (4/5): mysql-community-client-5.7.32-1.el7.x86_64.rpm | 25 MB 00:00:00 (5/5): mysql-community-libs-compat-5.7.32-1.el7.x86_64.rpm | 1.2 MB 00:00:00 ----------------------------------------------------------------------------------------------------------------------------------------------------------------------- 合計 68 MB/s | 29 MB 00:00:00 file:///etc/pki/rpm-gpg/RPM-GPG-KEY-mysql から鍵を取得中です。 Importing GPG key 0x5072E1F5: Userid : "MySQL Release Engineering <mysql-build@oss.oracle.com>" Fingerprint: a4a9 4068 76fc bd3c 4567 70c8 8c71 8d3b 5072 e1f5 Package : mysql80-community-release-el7-3.noarch (installed) From : /etc/pki/rpm-gpg/RPM-GPG-KEY-mysql Running transaction check Running transaction test Transaction test succeeded Running transaction インストール中 : mysql-community-common-5.7.32-1.el7.x86_64 1/6 インストール中 : mysql-community-libs-5.7.32-1.el7.x86_64 2/6 インストール中 : ncurses-compat-libs-6.0-8.20170212.amzn2.1.3.x86_64 3/6 インストール中 : mysql-community-client-5.7.32-1.el7.x86_64 4/6 インストール中 : mysql-community-libs-compat-5.7.32-1.el7.x86_64 5/6 削除中 : 1:mariadb-libs-5.5.68-1.amzn2.x86_64 6/6 検証中 : ncurses-compat-libs-6.0-8.20170212.amzn2.1.3.x86_64 1/6 検証中 : mysql-community-client-5.7.32-1.el7.x86_64 2/6 検証中 : mysql-community-libs-compat-5.7.32-1.el7.x86_64 3/6 検証中 : mysql-community-libs-5.7.32-1.el7.x86_64 4/6 検証中 : mysql-community-common-5.7.32-1.el7.x86_64 5/6 検証中 : 1:mariadb-libs-5.5.68-1.amzn2.x86_64 6/6 インストール: mysql-community-client.x86_64 0:5.7.32-1.el7 mysql-community-libs.x86_64 0:5.7.32-1.el7 mysql-community-libs-compat.x86_64 0:5.7.32-1.el7 依存性関連をインストールしました: mysql-community-common.x86_64 0:5.7.32-1.el7 ncurses-compat-libs.x86_64 0:6.0-8.20170212.amzn2.1.3 置換: mariadb-libs.x86_64 1:5.5.68-1.amzn2 完了しました!MySQLのバージョンを確認
コマンド
mysql --version入力後
mysql Ver 14.14 Distrib 5.7.32, for Linux (x86_64) using EditLine wrapperRDSに接続する
コマンド
mysql -h 'エンドポイント' -u 'ユーザー名' -pその後、パスワードを入力する
Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 2006 Server version: 5.7.31 Source distribution Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql> mysql> mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | newdatabase | | | innodb | | mysql | | performance_schema | | sys | +--------------------+ 6 rows in set (0.00 sec)無事ログインできれば完了。
ローカルで操作するように、MySQLコマンドによって操作できる。
- 投稿日:2020-12-23T10:57:14+09:00
serverless framework でローカルPCの環境変数を参照するやり方
公式の説明に書いてある様にローカルPCの環境変数を使うには
${env:SOME_VAR}を使うらしいです。自分の場合、cloudfrontに事前に取得したACMのARNを設定するために環境変数を使用したい。
CloudFrontDistribution: Type: AWS::CloudFront::Distribution Properties: DistributionConfig: Aliases: - ${self:custom.siteName} Origins: - DomainName: ${self:custom.siteName}.s3-website-${self:provider.region}.amazonaws.com Id: S3Origin CustomOriginConfig: HTTPPort: 80 HTTPSPort: 443 OriginProtocolPolicy: http-only Enabled: true DefaultRootObject: index.html DefaultCacheBehavior: AllowedMethods: - GET - HEAD TargetOriginId: S3Origin ForwardedValues: QueryString: true Cookies: Forward: none ViewerProtocolPolicy: redirect-to-https ViewerCertificate: AcmCertificateArn: ${env:ACM_ARN} # こんな感じで使いたい SslSupportMethod: sni-onlyどうやって設定するのか
macOSの場合
#設定方法 $ export ACM_ARN=arn:aws:acm:us-east-1:xxxxxxxxxx:certificate/xxxxxxxxxxxxxxx #確認 $ echo $ACM_ARN => arn:aws:acm:us-east-1:xxxxxxxxxx:certificate/xxxxxxxxxxxxxxx #全ての環境変数を確認する $ set #削除 $ unset ACM_ARN $ echo $ACM_ARN => 何も表示されない以上で設定ができます
- 投稿日:2020-12-23T08:57:11+09:00
JavaScript/TypeScriptでAWSのARNをパースする方法
JavaScript/TypeScriptでAWSのARNをパースして、サービス、リージョン、アカウントID、リソースIDなどを取得する方法をご紹介します。
ARNとは
ARNはAWS上のリソースを一意に識別するための識別子のことで、
arn:aws:s3:us-west-2:123456789012:accesspoint:myendpointのような文字列で表されます。
単純そうに見えてそのフォーマットにはいくつかのバリエーションがあり、自前でパースしようとするのはバグの温床となりえます。パッケージをインストール
ARNをパースするためのnpmパッケージはいくつかあるようですが、AWSが公式に提供している@aws-sdk/util-arn-parserを使うのがいいでしょう。
$ npm i @aws-sdk/util-arn-parserARNをパース
JavaScriptの場合:
const { parse } = require('@aws-sdk/util-arn-parser') const arn = 'arn:aws:s3:us-west-2:123456789012:accesspoint:myendpoint' const { partition, service, region, accountId, resource } = parse(arn) console.log(partition) // aws console.log(service) // s3 console.log(region) // us-west-2 console.log(accountId) // 123456789012 console.log(resource) // accesspoint:myendpointTypeScriptの場合:
import { parse } from '@aws-sdk/util-arn-parser' const arn = 'arn:aws:s3:us-west-2:123456789012:accesspoint:myendpoint' const { partition, service, region, accountId, resource } = parse(arn) console.log(partition) // aws console.log(service) // s3 console.log(region) // us-west-2 console.log(accountId) // 123456789012 console.log(resource) // accesspoint:myendpoint参考リンク
- 投稿日:2020-12-23T07:16:43+09:00
AWS Glueのパーティション毎のジョブ実行
概要
初めてデータパイプライン(データ分析基盤)を構築する際にAWS Glueを利用しました。
その際に学んだパーティション毎のDynamicFrame作成処理やDataFrameのrepartition関数などについて備忘録としてまとめていきます。

この記事のゴール
AWS Glue(PySpark)の具体的なユースケースを通じてAWS GlueやSparkのとっかかりになること。
想定読者
- AWS Glueの導入を検討している人
- AWS Glueを使い始めたばかりの人
- その他、データパイブライン構築などに興味のある人など
実行環境
Glue 2.0(Spark 2.4.3/Python 3.7)前提
- 作者は普段はバックエンドの開発(Go/AWSなど)をやっており、PythonやSpark、データ分析環境構築は初心者であること
- とりあえず素早く動くものを作ることが目的だった
上記理由のため、誤りや改善点等あるかもしれませんがご了承ください
AWS Glueについて
端的にいうと完全マネージド型ETLサービスです。
詳細は下記の公式ドキュメントを参照ください。https://docs.aws.amazon.com/ja_jp/glue/latest/dg/what-is-glue.html
機能特徴
- 他の様々なAWSサービスと楽に連携してETL環境を構築できる
- 半構造化データを操作するように設計されていて初期スキーマが必要ない
- 完全マネージド型で自分でサーバー構築が不要で素早く環境構築できる(CloudFormationも対応)
- 定期実行やイベント駆動による実行の設定もとても簡単で、リトライ処理も自動でやってくれる
まとめるとS3などのAWSサービス上にあるデータ用にETL環境構築をしたい場合にとても便利なETLのサービスです
本題
【AWSインフラ構成イメージ図】
やりたいこと
AWS S3上の下記のようなパスのcsvファイル一覧をtask_id毎に、user_id.csvファイルをまとめてgz形式で圧縮したファイルをデータターゲット先のS3に出力すること。
背景は省略しますが、Glueのジョブ自体は毎日一回深夜に前日分のデータに対して実行します。【データソース】
s3://バケットA/{YYYY-MM-DD}/{task_id}/{user_id}.csv↓
【データターゲット】
s3://バケットB/{YYYY-MM-DD}/{task_id}.gz具体例
S3://data_source_bucket_a/2020-12-23/task_01/user_id01.csv S3://data_source_bucket_a/2020-12-23/task_01/user_id02.csv S3://data_source_bucket_a/2020-12-23/task_02/user_id01.csv S3://data_source_bucket_a/2020-12-23/task_02/user_id04.csv↓
S3://data_target_bucket_b/2020-12-23/task_01.gz // user_id01.csv,user_id02.csvの圧縮ファイル S3://data_target_bucket_b/2020-12-23/task_02.gz // user_id01.csv,user_id04.csvの圧縮ファイル参考として、Glueのテーブルのスキーマとパーティションは下記のようなイメージです(カラムの構成とpartiton_1の値は伏せてあります)
【スキーマ】
【パーティショ】
ソースコード
実装の方をみていきます。
まず始めに全体のソースコードは下記になりますimport sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue.dynamicframe import DynamicFrame import datetime import boto3 # ジョブの実行時にスクリプトに渡される引数にアクセス args = getResolvedOptions(sys.argv, ['JOB_NAME','S3_BUCKET_NAME_BEFORE','S3_BUCKET_NAME_AFTER','GLUE_DB','GLUE_TABLE']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) today = datetime.datetime.today().astimezone(datetime.timezone(datetime.timedelta(hours=+9))) yesterday = (today.date() - datetime.timedelta(days=1)).strftime('%Y-%m-%d') prefix = yesterday + '/' # ジョブパラメータから各環境に応じた値を取得 # glueのデータソースのS3のバケット名 S3_BUCKET_NAME_BEFORE = args['S3_BUCKET_NAME_BEFORE'] # glueで加工した結果のCSVファイルの保存先S3のパス S3_BUCKET_NAME_AFTER = args['S3_BUCKET_NAME_AFTER'] # glueのデータベース名 GLUE_DB = args['GLUE_DB'] # glueのテーブル名 GLUE_TABLE = args['GLUE_TABLE'] s3 = boto3.resource('s3') bucket = s3.Bucket(S3_BUCKET_NAME_BEFORE) result = bucket.meta.client.list_objects( Bucket=bucket.name, Prefix=prefix, Delimiter='/' ) # 指定したprefixのS3のフォルダ一覧を走査 # ターゲットのS3のパス: s3://bucket_name/{YYYY-MM-DD}/{task_id}/user_id.csv # prefix(ex:2020-08-16/)で指定したフォルダの配下の一覧({task_id})を走査 if result.get('CommonPrefixes') != None: for o in result.get('CommonPrefixes'): # {task_id}のフォルダ名を抜き出し # o.get('Prefix') ex:2020-07-30/task_id01/ → partition1: task_id01 partition1 = o.get('Prefix').replace(prefix,"").replace('/','') # データカタログからDynamicFrameを取得 datasource0 = glueContext.create_dynamic_frame.from_catalog( database = GLUE_DB, table_name = GLUE_TABLE, transformation_ctx = "datasource0", push_down_predicate = '(partition_0 == "'+ yesterday + '" and partition_1 == "' + partition1+ '")' ) # DynamicFrameをSparkのDataFrameに変換し、repartitionメソッドによりファイルをパーティション毎に結合 dataframe1 = datasource0.toDF().repartition(1) # DataFrameをDynamicFrameに再変換 repartition1 = DynamicFrame.fromDF(dataframe1, glueContext, 'repartition1') # csvファイル保存先のS3のパスを指定 s3_path = S3_BUCKET_NAME_AFTER + yesterday # DynamicFrameをCSVファイル形式でS3に出力 datasink1 = glueContext.write_dynamic_frame.from_options( frame = repartition1, connection_type = "s3", connection_options = { "path": s3_path, "compression": "gzip" }, format = "csv", transformation_ctx = "datasink1" ) job.commit()解説
ポイント1
# データカタログからDynamicFrameを取得 datasource0 = glueContext.create_dynamic_frame.from_catalog( database = GLUE_DB, table_name = GLUE_TABLE, transformation_ctx = "datasource0", push_down_predicate = '(partition_0 == "'+ yesterday + '" and partition_1 == "' + partition1+ '")' )glueのcreate_dynamic_frame作成処理でプッシュダウン述語(上記の
push_down_predicateが該当)を利用します。
これにより、Glueのカタログで利用可能なパーティションのメタデータに直接フィルターを適用することで処理が必要なS3パーティションのみを残した状態でジョブを実行できるためコストを削減できます。https://aws.amazon.com/jp/premiumsupport/knowledge-center/glue-job-specific-s3-partition/
ポイント2
# DynamicFrameをSparkのDataFrameに変換し、repartitionメソッドによりファイルをパーティション毎に結合 dataframe1 = datasource0.toDF().repartition(1)SparkのDataFrameの
repartition関数により、パーティション毎にファイルを結合するようにしています。これにより本来は分割されて出力されるファイルを指定パーティションで結合することができます。
(パーティションが未指定の場合は1つ目のパーティションが使用されます。repartitionの代わりにcoalesce関数でも利用できます)
ここでは、DataFrameの関数であるrepartitionを利用するためにtoDF関数を利用してDynamicFrameをDataFrameに変換しています。なお、
repartitionを実行するとデータの再配置が実施されるためデータ量によってはパフォーマンスに影響が出る恐れがあるため事前に検証しておくと良さそうです。その他
- データソースなどのS3バケット名やGlueのDB名などは環境変数としてGlueのジョブパラメータで外から渡すように設定してます
- GlueではPythonとSparkに加えてGlue独自の
DynamicFrameの関数が利用できるため、上記例のtoDF()関数などを利用してSparkのDataFrameと相互に変換して柔軟なデータの加工処理が行うことができますまとめ
AWS Glueはとても便利で強力なETLのマネージドサービスであることが分かりました。
今後本格的にAWS上でデータ分析基盤を構築する際は、AWS GlueやSpark等を活用していければなと思いました。参考

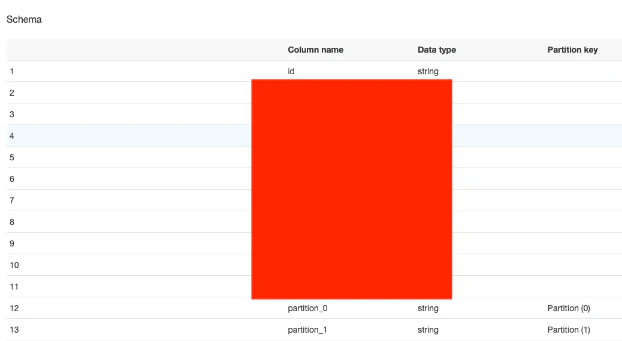
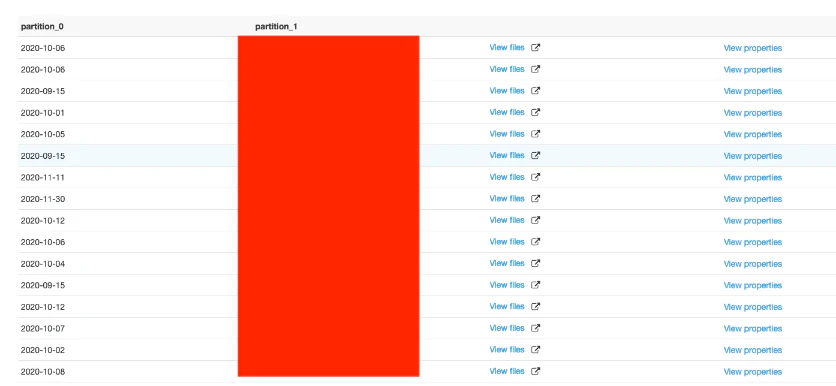
- 投稿日:2020-12-23T03:34:24+09:00
AWS Athenaで役立ちそうな機能をまとめてみた
この記事は、ニフティグループ Advent Calendar 2020 22日目の記事です。
昨日は@matsu-matsuさんで「PaizaIO API でコードジャッジシステムを作ってみた」でした。
私も競技プログラミングをしていたのですが、もし社内でコンテストを開きたいときに非常に役立ちそうですね。はじめに
以前にも増して社内でのデータ活用が活発になってきており、ETL処理の知識が重要になってきました。
社内で利用されている1.5年程前に開発されたシステムの一部でAthenaをつかってETL処理をしている箇所があるのですが、下記の問題が発生しています。
- 日次でデータが膨大に増える+クエリを複雑にしすぎてAthenaがTimeout
- View機能の使いすぎ
- 日次でパーティションが増えすぎて、Glueオブジェクトのコストが増加
- パーティション分割をしすぎ
- 読み込みデータ量削減のため、中間処理にもパーティションを作成している
- StepFunction内でLambda Function内からAthenaを読んでいるため、ステートマシンが複雑
- LambdaでAthenaクエリを実行して、Waitもしくはループでクエリの終了を判定
これらの問題はAthenaの既存機能や2020年内のアップデートで解決しやすくなったと思います。そこで本記事では、それらの機能を簡単にまとめてみました。
前提条件
本記事の例では下記のようなデータに対するクエリ記述しています。
Date,Categories,User,Cost 2018/11/01,Digital,Honda,0 2018/11/01,Book,Sasaki,669.54332 2018/11/01,Food,Sato,40.67488 2018/11/01,Digital,Sato,3644.17432また、クエリ対象となるS3のディレクトリ構造は下記のようにHive形式となっています。
- s3://sample_data/input/year={year}/month={month}/hoge.csv
CREATE TABLE AS SELECT (CTAS)によるETL
複雑過ぎてTimeoutしてしまうクエリは、中間処理にCREATE TABLE AS SELECT (CTAS)を使うことで解決する可能性があります。
CTASはSELECTクエリの結果から新たにテーブルを作成する機能です。
その他にパーティショニングや列データ化(Parquet等)も設定することができるので、簡単なETL処理にも使われています。似たような機能にViewがありますが、こちらは仮想的なテーブル記述のため実体を持たずクエリで仮想テーブルを用いた場合、その記述が展開されます。
そのため、Viewを多用し過ぎると非常に時間のかかるクエリになる可能性があります。
一方でCTASは実際にs3上にファイルを出力し、実テーブルを生成します。CREATE TABLE "sample_db"."sample_ctas" WITH ( format='PARQUET', external_location='s3://sample-data/ctas', partitioned_by=ARRAY['year','month'] ) AS SELECT "date", "categories", "user", "cost", element_at(split(date,'/'),1) AS year , element_at(split(date,'/'),2) AS month FROM "sample_db"."sample_data"上記の例では次のようなことを設定しています。
- 新たに
s3://sample-data/ctas/year=\${year}/${month}を出力する- 出力するファイルフォーマットは
parquet- yearとmonthについてパーティション分割
Partition Projectionによるパーティション数の抑制
日次でパーティション数が増大していき、Glueのオブジェクトに対するコストが高くなるケースには2020年6月に登場したPartition Projectionが役立つと思います。
Partition ProjectionはGlueデータカタログを用いず、設定からパーティションが計算されて用いられます。オブジェクトとして実体を持たないため、Glueオブジェクトのコストは発生しません。
また、date型のパーティションに対しては(NOW-3YEARS,NOW)のような現在からの範囲を設定することができます。
これにより、Glueクローラーやクエリにより行っていた定期的なパーティション管理が簡略化されます。Partition Projectionを使うに当たり、下記の点には注意が必要です。
- Partition Projectionによるパーティション設定はAthenaにしか適用されない
- Redsift等からはGlueデータカタログによるパーティション設定が必要
- 空のパーティションが多すぎるとクエリが遅くなる可能性がある
CREATE EXTERNAL TABLE "sample_db"."sample_projection" ( `date` string, `categories` string, `user` string, `cost` double) PARTITIONED BY ( `year` int, `month` int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 's3://sample_data/input' TBLPROPERTIES ( 'classification'='csv', 'delimiter'=',', 'projection.enabled'='true', 'projection.month.interval'='1', 'projection.month.range'='1,12', 'projection.month.type'='integer', 'projection.year.digits'='4', 'projection.year.interval'='1', 'projection.year.range'='2017,2021', 'projection.year.type'='integer', 'serialization.encoding'='utf8', 'skip.header.line.count'='1', 'storage.location.template'='s3://sample_data/input/year=${year}/month=${month}/', 'transient_lastDdlTime'='1608650935', 'typeOfData'='file')上記の例では次のようなことを設定しています。
設定名 値 説明 projection.enabled true Partition Projectionの有効化 storage.location.template s3://sample_data/input/year=\${year}/month=\${month}/ s3パスに対するパーティション箇所の記述 projection.{partition_name}.type integer パーティションのデータ型(整数型、日付型、列挙型など) projection.{partition_name}.range 1,12 パーティションの範囲 projection.{partition_name}.interval 1 パーティション値の間隔 projection.year.digits 4 (整数型の場合)パーティション値の桁数。先頭からゼロ埋め。 StepFunctionsのAthena統合によるステートマシンへの組み込み
2020年10月のアップデートでLambda Functionを介さずにStepFunctionsを使用してAthenaにクエリを実行できるようになりました。
現在、利用可能なAPIは以下の4つです。それぞれこのページの権限をStepFunctionsに設定されているIAMロールに付与する必要があります。
- StartQueryExecution
- StopQueryExecution
- GetQueryExecution
- GetQueryResults
Athenaは非同期実行のため、Lambda Functionから処理を開始する場合、今まで社内で利用しているシステムではポーリングや待機をしていました。
この機能の追加により、StepFunctions内ではStartQueryExecution.syncを利用することで簡単にクエリ完了まで待機することができるようになりました。{ "StartAt": "Athena クエリの実行を開始します。", "States": { "Athena クエリの実行を開始します。": { "Type": "Task", "Resource": "arn:aws:states:::athena:startQueryExecution.sync", "Parameters": { "QueryString": "SELECT\n\"user\",\n\"categories\",\nCAST(SUM(cost) AS decimal(12, 4)) cost\nFROM\n\"sample_db\".\"sample_projection\"\nWHERE\nuser = 'Tanaka'\nGROUP BY\n\"categories\",\n\"user\"\nORDER BY\ncost DESC", "WorkGroup": "sample_workgroup" }, "Next": "Athena クエリの実行結果を取得する" }, "Athena クエリの実行結果を取得する": { "Type": "Task", "Resource": "arn:aws:states:::athena:getQueryResults", "Parameters": { "QueryExecutionId.$": "$.QueryExecution.QueryExecutionId" }, "End": true } } }上記の例では単純にAthenaクエリを実行して、完了まで待機したあとで実行結果を取得しています。
以下が各ステップの出力です。
「Athena クエリの実行を開始します。」のステップ出力
{ "QueryExecution": { "Query": "SELECT\n\"user\",\n\"categories\",\nCAST(SUM(cost) AS decimal(12, 4)) cost\nFROM\n\"sample_db\".\"sample_projection\"\nWHERE\nuser = 'Tanaka'\nGROUP BY\n\"categories\",\n\"user\"\nORDER BY\ncost DESC", "QueryExecutionContext": {}, "QueryExecutionId": "********-****-****-****-************", "ResultConfiguration": { "OutputLocation": "s3://sample_data/output/********-****-****-****-************.csv" }, "StatementType": "DML", "Statistics": { "DataScannedInBytes": 7874805, "EngineExecutionTimeInMillis": 952, "QueryPlanningTimeInMillis": 279, "QueryQueueTimeInMillis": 213, "ServiceProcessingTimeInMillis": 30, "TotalExecutionTimeInMillis": 1195 }, "Status": { "CompletionDateTime": 1608659190086, "State": "SUCCEEDED", "SubmissionDateTime": 1608659188891 }, "WorkGroup": "sample_workgroup" } }
「Athena クエリの実行結果を取得する」のステップ出力
{ "ResultSet": { "ResultSetMetadata": { "ColumnInfo": [ { "CaseSensitive": true, "CatalogName": "hive", "Label": "user", "Name": "user", "Nullable": "UNKNOWN", "Precision": 2147483647, "Scale": 0, "SchemaName": "", "TableName": "", "Type": "varchar" }, { "CaseSensitive": true, "CatalogName": "hive", "Label": "categories", "Name": "categories", "Nullable": "UNKNOWN", "Precision": 2147483647, "Scale": 0, "SchemaName": "", "TableName": "", "Type": "varchar" }, { "CaseSensitive": false, "CatalogName": "hive", "Label": "cost", "Name": "cost", "Nullable": "UNKNOWN", "Precision": 12, "Scale": 4, "SchemaName": "", "TableName": "", "Type": "decimal" } ] }, "Rows": [ { "Data": [ { "VarCharValue": "user" }, { "VarCharValue": "categories" }, { "VarCharValue": "cost" } ] }, { "Data": [ { "VarCharValue": "Tanaka" }, { "VarCharValue": "Book" }, { "VarCharValue": "2669.8389" } ] }, ...(略)... ] }, "UpdateCount": 0 }今回は特に何もせずにステートマシンを終了していますが、本来はメール/Slack通知などの後続処理をつけると思います。
利用例としてはCloudtrailやCroudFrontログの定期レポートやアラートなどができそうです。おわりに
今回はお手軽にできるETLということでAthenaを利用しましたが、AWSでのETL手段はGlueやLambdaなど多彩にありますので要件にあったサービスを選択する必要があります。また、AWSのサービスはアップデートが多く、気がついたら課題解決が簡単になっている場合があるので情報を素早くキャッチしていきたいですね。
明日は@uyuqui1718さんです。お楽しみに!
- 投稿日:2020-12-23T02:53:48+09:00
オレのブログを安く運用したい。(aws から Oracle Cloud へ移行(その3))
はじめに
この記事は「Oracle Cloud Infrastructure(その3) Advent Calendar 2020」の12月23日の記事として投稿です。
さて、今日は3日目。今日から読む人たちのために、改めて、記載すると「今あるaws上のブログで使っているインスタンス2つをOCIへ移行させよう!そして、その先に待っているランニングコスト軽減を得るために!!」が目的になります
。
昨日は Oracle Cloud のアカウント(参考:オレのブログを安く運用したい。(aws から Oracle Cloud へ移行(その2)))を作りましたので、今日は AWS から OCI への移行手段を考えてみようと思います。
移行元(aws)と移行先(OCI)の整理
早速、移行方法を考えてみようと思います。今回、移行するために必要なことでザックリ思いつくところは、こんなところ
。
- ■移行元と移行先の接続
- データ移行するための経路
- ■移行元の何を移行させるのか。移行先のどこへ持って行くのか。
- AWSで用意されているサービスでOCIに存在しないものの取り扱い
今回は、最低でもAWSからOCIへ移行させるための通信経路(データ転送のため)とAWS独自サービスで稼働しているものの行き先を考える必要がありそうです。(放置されている私のブログではあるため、今回はサクッといけるかな?というくらいの検討です)
※実際のシステム移行を考えるのであれば、システムによって程度は異なるとは思いますが、移行元のシステムについての現状分析、それを踏まえての移行先のプラットフォーム選定について検討することをおすすめします。
移行元と移行先の接続
移行元と移行先でデータのやりとり(移行)するために、直接、AWSとOCIの接続。または、一旦、自PCを返して送り込む方法の2つの方法が考えられます。
今回はデータ量も少ないので、一旦、自PCへデータを吸い上げて送り込んでもいいかな?と思います。ただ用意したばかりのOCIには、お試し33,000円分のクレジットがもらえるので、コレを使っても良さそうですね。この2つの手段は、いずれの方法を採用してもOCI側の課金には響かなそうです移行元の何を移行させるのか。移行先のどこへ持って行くのか。
移行元で使っているサービスは、1日目で記載したとおり。
t2.micro x1 :ブログと各種バッチ実行
Lightsail x1 :ブログ
S3 :ブログ用の画像管理もう少し細かく整理するとこんな感じ
- t2.micro
- WordPressを構築
- WebServer : Apatch
- DB : MySQL
- Lightsail
- WordPress
- S3
- バケット2つ
これらをOCIのどのサービスに入れるか。というのを検討します。
今回の目的は如何にランニングコストを抑えられるか。という点なので、まずは無償範囲で対応できるものを選択したいと思います。こちらで考えると答えは単純で、AWS上で稼働している(t2.micro と Lightsail(*)) は、OCI(VM.Standard.E2.1.Micro)へ。
※OCI には Lightsail のようなものはないので、Compute 上に用意することにします。
DB は MySQL を使っているので、OCI だとフルマネージド・サービスの Oracle MySQL Database Service がありますが、今回は「オレのブログを安く運用したい」が目的なので見合わせます。(フルマネージドサービスの MySQL は興味ありますけど)ということで、今回は Compute にそのまま MySQL を立てます。
あとは S3 ですが、こちらは OCI だと Object Storage が同サービスで提供しているので、一択。まとめると移行元から移行先は、こちらを予定
・t2.micro → VM.Standard.E2.1.Micro(無料枠)
・Lightsail → VM.Standard.E2.1.Micro(無料枠)
・S3 → Object Storage(10GB以下(無料枠))素敵すぎる。すべて無料枠に乗せ換えられそう?「無料枠」が輝いて見えます
今回のAWSからOCIへ移行するまでの予定ステップ
- OCI上でAWS同様の構成を用意する
- AWS と OCI を接続する(データ移行の経路を確保する)
- AWS上で稼働しているインスタンスのデータ抽出
- AWS から OCI へデータを転送する
- OCI環境で再構築(データ移行)する
とりあえず、こんな感じで進めようかと思います。
おわりに(その3)
今日のお話は、ここまで。明日は、早速手順に従って作業してみようと思います。

- 投稿日:2020-12-23T02:05:09+09:00
[AWS] CloudWatch SyntheticsでVPC内外からのサービス監視を試す
CloudWatch Syntheticsはシンセティック監視(合成監視)を提供するサービスです。アプリケーションエンドポイント(REST API、URL、ウェブサイトコンテンツ等)の死活監視に利用することができますが、スクリプトを実装することで、Syntheticsの名の通り複雑なワークロード(UIアセットのロード、トランザクション、レイテンシー、ウィザードのフロー、途切れたリンク等)を継続的に検証できるようになります。
今回はそのCloudWatch Syntheticsを使用し、VPC内に構築したWebサイトをVPCの内側と外側から監視することを試してみました。
試した構成:
- 監視対象はQiita似のOSS Knowledge で試しました。
- CloudWatch Syntheticsで、KnowledgeのパブリックIP、プライベートをIPをそれぞれ指定して監視を行います。
- 図中のPublic IP(1)がKnowledgeのパブリックIP、Public IP(2)がNAT GatewayのIP(Knowledgeでアクセス許可するIP)を意味しています。
- 実際の監視設定は、CloudWatch SyntheticsでCanary(カナリア)と呼ばれるオブジェクトを作成して行います。
1.VPCの準備
- 構成図のように、パブリックサブネットとプライベートサブネットを持つVPCを作成します。
- 詳細の作成手順は省略しますが、試すだけならVPCウィザードの「パブリックとプライベートサブネットを持つVPC」そのままで大丈夫です。
- ポイントは、Canaryの実体がLambda Functionなので、VPC内での動作についてLambdaと同じ制約を受ける点です。具体的にはプライベートサブネットで動かす必要があるため、そのためにサブネット2つの構成になっています。
2.knowledge構築
今回は監視対象として(動きのあるWebサイトなら何でもいいのですが、)Qiita似OSSのKnowledgeを試す機会があったので利用しました。
ここは手をかけるところではないので、EC2上でDockerhubのパブリックイメージをそのまま動作させて試しました。# docker run -d -p 8080:8080 koda/docker-knowledge:latest起動後、テスト用の記事を登録しておきます。
3.CloudWatch Synthetics(Canary)作成
ここからが本題です。コンソールでCloudWatch Syntheticsから「Canaryを作成」を選択します。
作成方法を指定します。最初に「GUIワークフロービルダー」を試してみます。
画面の下に行きランタイムを選択します。現状nodejsとpythonが選択できますが、今回はpythonを選択します。
引き続き同じ画面の「ワークフロービルダー」でアクションを設定します。現状は以下のアクションが選択可能です。
例として、以下は検索ボックスに検索キーワードを入力する例です。GUIでセレクターとテキストを入力すると、
やはり同じ画面の「スクリプトエディタ」に下記のコードが自動生成されます。
# Execute customer steps def customer_actions_1(): browser.find_element_by_xpath("//input[@id='navSearch'][contains(text(),'test')]") await syn_webdriver.execute_step('verifyText', customer_actions_1)同様に、「検索」ボタンを押下する例で、アクション:クリックを選択してセレクターを入力します。
このKnowledgeの例ではid属性もname属性も無かったため、無理矢理classで検索しています。自動生成されるコードは以下です。
# Execute customer steps def customer_actions_1(): browser.find_element_by_xpath("//button[@class='btn-search']").click() await syn_webdriver.execute_step('click', customer_actions_1)今回は最終的に以下のコードを作成しました。内容としてはコメントにある通り、TopPageにアクセス → 検索ボックスに"test"を入力して検索 → 検索結果に"test"という記事があるか確認、という処理になっています。
import asyncio from aws_synthetics.selenium import synthetics_webdriver as syn_webdriver from aws_synthetics.common import synthetics_logger as logger, synthetics_configuration TIMEOUT = 60 async def main(): private_url = "http://10.0.0.13:8080/open.knowledge/list" public_url = "http://xx.xx.xx.xx:8080/open.knowledge/list" browser = syn_webdriver.Chrome() url = private_url # ここのみCanaryごとに編集 # synthetics設定(スクリーンショットの取得) synthetics_configuration.set_config({ "screenshot_on_step_start" : True, "screenshot_on_step_success": True, "screenshot_on_step_failure": True }); # TopPageにアクセス def navigate_to_toppage(): browser.implicitly_wait(TIMEOUT) browser.get(url) await syn_webdriver.execute_step("navigateToTopPage", navigate_to_toppage) # 検索ボックスにキーワード入力して検索 def input_search_word_and_search(): browser.find_element_by_xpath("//input[@id='navSearch']").send_keys("test") browser.find_element_by_xpath("//button[@class='btn btn-default']").click() await syn_webdriver.execute_step('inputSearchWordAndSearch', input_search_word_and_search) # 記事があるか確認 def check_search_result(): browser.find_element_by_xpath("//div[@class='list-title'][contains(.,'test')]") await syn_webdriver.execute_step('checkSearchResult', check_search_result) logger.info("Canary successfully executed") async def handler(event, context): # user defined log statements using synthetics_logger logger.info("Selenium Python workflow canary") return await main()後は
- S3バケット: 処理結果(スクリーンショット等)を保存するS3バケットを指定
- IAMロール: CloudWatchSyntheticsRole-canary-name-uuid という名前の新しいロールを作成するか、既存のロールを指定
- VPC: 事前に準備したVPC、プライベートサブネットを指定
- 定期実行かどうか
等設定して保存すると、Canaryが実行されます。なお、現状はGUIワークフロービルダーは新規作成時にしか使えず、一度作成した後はスクリプトエディタで直接スクリプトを編集していくようになります。
4.テストと結果の確認
テストの結果は、下記スクリーンショットのように表示されます。
プライベートIP指定でのテスト結果を見てみます。実行の詳細に行くと、各ステップでの結果と、スクリーンショットが保存されています。
S3に保存されているスクリーンショットを確認すると、検索処理がされていることが確認できます。(アドレスバーが無いので結果は全く同じですが)パブリックIP指定の実行結果も同様に確認できます。
パブリックアクセスのみブロックしてみる
テストとして、EC2セキュリティグループを変更して、パブリックIPでのアクセスを拒否してみると、以下のようにエラーが発生しました。保存されていたスクリーンショットは白一色の画像になっていました。
全体の確認結果を見ると、プライベートIP指定の方は成功していることが確認できます。両者はURLのみ変えて同じスクリプトを実行しているので、この状況ですとネットワーク経路に問題があるのではないかと推測できるかと思います。
今回の検証結果は以上になります。
参考資料





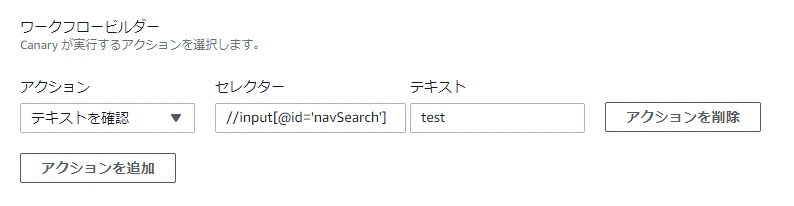




- 投稿日:2020-12-23T01:31:55+09:00
【初学者向け】最新版AWS認定ソリューションアーキテクト-アソシエイト(SAA-C02)合格までの道のり【2020年12月】
はじめに
エンジニア未経験の私がAWS SAAを取得した勉強法についてです。
これからAWS SAA取得を目指す方の参考になればと思います。
なお具体的なサービスの内容については記述致しません。
下記の教材で学べば十分合格できると思います。
合格時のスキルセット
・実務未経験
・プログラミング学習を本格的に初めて5ヶ月目
・AWS経験は少々(EC2、RDS、CloudWatch等を使用し、ポートフォリオサイトをデプロイしたことがあるレベル)勉強した期間
2020年11月7日から12月18日までの約40日間。
計160時間~200時間は学習にあてたと思います。使用した教材
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
Udemyで配信している講座です。AWSの主要サービスをハンズオン形式で学びながら試験対策もしっかり出来るので最もオススメです。
全くAWSを触ったことのない人にも親切な作りですし、試験の出題傾向を押さえつつ本試験とほぼ同難易度の模擬試験も3回分ついてくるのでセールの時に購入しておくとかなりお得だと思います。最初から最後までお世話になりました。
※全体的に音声が聞き取りづらいところだけマイナスです・・・【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
同じくUdemyで配信している問題集です。前述の口座と同時購入しましたが、1回分模擬試験が被っているので実質5回分でした。AWSSAAの試験において出題形式に慣れておくことはとても重要なので、なるべく数多くの問題を解いておく方が良いと思います。
ちなみに最初に解いた時はどの模擬試験でも正答率40~50%程度でした(試験直前での正答率は80~90%くらいです)。復習では正答を確認するだけでなくなぜその他の回答は誤答なのかという点を押さえる事が重要です。各種サービスの内容とユースケースをしっかりと学んでいきましょう。難易度は本番と同程度だと思います。徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
1回通しで読みました。AWS全体の内容をさくっと学ぶのにはいいかもしれませんが、AWSは常にサービスの内容が変化していくので、あえて1年近く前に発行された本で学習する必要はないと思います。模擬試験も現在の試験にはあまり即してないように思えました。※補足
AWS認定資格試験テキスト AWS認定ソリューションアーキテクト - アソシエイト 改訂第2版 Kindle版
どうしても書籍で学習したい方で、資格取得までの日数に余裕のある方は来年1/21に発売予定のこちらの本で学習する方が良いかもしれません。内容は把握していないので保証はできませんがSAA-C02に対応しているようですし、変化の速いサービスの学習はなるべく新しいテキストで勉強するに越したことはないと思います。AWS WEB問題集で学習しよう
WEB問題集です。有料会員になる必要がありますが2020年12月時点で#1~#140まで出題があり大体1000問近くの問題が掲載されています。#1~#140までを1周した後は#90~#140を2周しました。後半の問題になるにつれ現在の試験に近い内容になっているので。#90以降を重点的に学習するのがオススメです。順次問題も追加されるようなので、常に最新の試験に近い問題が解けるのではないでしょうか。試験前の最後の追い込みは大部分このサイトに頼っていました。
また、このサイトに掲載されている合格記は是非読んでみて下さい。直近で合格された方たちの率直な感想が読めるのでかなり参考になります。実際の試験に出た内容を踏まえて、確実に押さえておくべきサービスなどのアドバイスが載っておりかなり精度が高かったです。実際そのおかげでとれた問題が何問かありました。先人に感謝です。AWS Black Belt
Udemy講座のスライドで十分対応できる試験内容だとは思いますが、
試験直前にS3などの頻出サービスについてはBlackBeltのスライドを確認しました。本試験について
受験料16,000円
試験時間130分
問題数65問
1000点満点中720点以上で合格です。
大体80分くらいで解き終わって残りの時間は見直しにあてました。
わからない問題にはマークをつけれるのでつけておきましょう。
一週目は半分くらい回答に確信が持てなかったのでマークしてたと思います。
当たり前に聞こえるかも知れませんが一番重要なのは問題文をよく読むことです。
すぐに正解がわからなくても落ち着いて問題をよく読みましょう。
見直しは絶対したほうがいいです、集中力が切れても最後まで諦めないで下さい。
ちなみにピアソンVUEのテストセンターで受験しました。試験は毎日のようにやっていたので、前々日に予約しました。最後に
そもそものインフラの知識も乏しく実務未経験なので飲み込みが遅かったのかもしれませんが資格取得まで1ヶ月以上かかりました。聞き覚えのない言葉がたくさん出てくるので初めは苦労しましたが、毎日学習を継続してなんとか合格することが出来ました。この記事を読まれた方が無事試験に合格できるように祈っております。

- 投稿日:2020-12-23T00:33:43+09:00
リザーブドインスタンスはいいぞー。
最近の主流であるAWS。
これを活用していない会社はまずWEB系にはないだろ(いや、azureとかGCPで冗長化している会社は多くあると思いますが)そんな皆さん御用達のAWSのいいところなんてもうすでにネタが切れて、皆さんに細かい部分まで書かれているはず。
私はそれらを超えるものを書ける器量はないと断言できる。よって実環境のEC2インスタンス(もちろん私が担当しているサービスのみです)がリザーブインスタンス化するとどれぐらいコストを節約したか、皆さんにご報告いたします。
ぶっちゃけ、価格的に節約金額は2割か3割程度なはずだが、グラフを見ると「かなり減ってるやん、これ」と思ってしまう印象のため勢いあまりご紹介したいと思う次第で、殴り書きしております。
現状のインスタンス数(一部のサービス)とコスト
まず、私が担当しているサービスのEC2インスタンス環境を公開しよう!
インスタンスタイプ インスタンス数 c4.xlarge 6 c5.xlarge 1 c5n.large 1 m4.large 1 t2.large 4 t2.medium 2 t2.micro 4 t2.nano 5 t2.small 4 t3.medium 1 t3.nano 5 t3.small 7 合計 41 現状41のEC2インスタンスが稼働しております。(2020年11月現在)
そして、(5ヶ月間の平均ですが)現状1ヶ月あたりの金額として、2,712.85米ドル(日本円1ドル104円換算282,136円)ほどかかっております。
ちなみに、リザーブドインスタンスは一切購入していません。(リザーブドインスタンスは以前に買っていたが、今後のスケールアップなどもあって買ってなかったそうやで・・・。)ここから、幾つかのリザーブドインスタンスを購入します。
スプレッドシートなどを利用して最適解を探ろうと思ってましたが「AWS Cost Explorer」=>「予約」=>「推奨事項」にそってクリックしてもらうと、現状にあった推奨リザーブドインスタンス購入数を表示されます。(なんて便利)↓イメージ図
これを見る限り、すでに7,439米ドル(日本円773,656円)25%節約できるよと書いている。1年間、スタンダード前払なしで。では、AWS推奨するインスタンスタイプの構成は以下の通り
インスタンスタイプ インスタンス数 c4.large 12 t2.nano 133 t3.nano 37 c5.large 2 t3.nano 4 c5n.large 1 t2.nano 24 m4.large 1 合計 214 おやおや?現状の構成とは異なったインスタンス数とインスタンスタイプの構成です。
なぜかと言うと、推奨事項はある程度柔軟な構成になるようにできる限り下位のインスタンスを購入する仕組みのようです。
下位のインスタンスタイプ二つで、上位のインスタンスタイプ一つと同じ価値になるようで、
例としてnano2つで、micro1つ分と言うことになるようです。
詳しくは、AWSの1次情報を!(https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-resource-limits.html)そのため、まだスケールダウン時の再構成がしやすいかもしれないですね?
いやそれでも、現状からの再構成を考えるのは縛りプレイのようで難しいですが・・・。
余談ですが、リザーブドキャッシュノードでは、そういった柔軟な構成はできないようです。(AWSの人にききましたので、信憑性のある情報かと・・・)リザーブドインスタンス購入後のグラフ
ででで、実際どんな感じに下がるかと言いますと、これは言葉よりグラフで見せるほうが早いかなと思いますので、
グラフで表示します。デデン!
購入した日は12月16日と12月17日です。
二日に渡った理由は、購入できるリザーブドインスタンス数(月に1リージョン20ほどしか買えない・・・)が限られてたことを知ったため、日をまたいで購入する形となってしまいました。。。制限を解除する必要がありますが、詳しくは一次情報を!
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-reserved-instances.html16日と17日は、購入した日だからか費用が跳ね上がっています。
日 米ドル 16日 569米ドル 17日 354米ドル 合計 923米ドル ちなみにリザーブドインスタンスを買った当初、私は一つ勘違いをしておりました。
前払いなしと選択したはずなのに、「なんでこんなにグラフ跳ね上がってるんや」ということ。
私の中では、日単位に分散してまばらになるイメージだったのです。だって前払いなしって書いてたやん・・・
このことで上司には異常な数値報告をしまくった私、恥ずかしい・・・。
そんなこんなで、リザーブドインスタンスは月に一度大きく費用がかかる仕組みのようです。
ですので、いきなりコストが増加してもそれはリザーブドインスタンスですのでご安心ください。話は戻します。
リザーブドインスタンスを購入する前は、EC2コストは日平均90米ドルぐらいかかっております。
そのため、大体11日ほどでリザーブドインスタンスの購入費用は回収できて、それ以降はほぼほぼ4米ドル以下というイメージ。
あれ?このまま推移するとEC2の月額は、(イレギュラー除いて)4米ドル×31日+923米ドル=1,047米ドルぐらいになるんじゃないのか?
日平均90米ドルを月にしても2,710米ドル。
その金額とリザーブドインスタンスの金額を比べて、月額半額以上の節約になるのか?
あれ?3割ぐらいの節約金額はどこいったんや・・・。ただ、若干コスト計算に含まれていない数字も大いにあると予想されるので、おそらく月末のどこかで帳尻合わせをするのだろうかと思われるが、それを踏まえてもこの目に見える節約効果は大きいなと思うわけです。
もし、まだリザーブドインスタンスを購入していない人がいれば、ぜひとも推奨設定で購入してみてほしい。(もちろん自己責任でね?)
弊社自身、一部のみならず全体のサービスで購入すれば、もしかしたら毎月ハイスペックmacが買えるぐらいの節約になるのではないかと期待しております。
以上、リザーブドインスタンスの報告でしたー。

- 投稿日:2020-12-23T00:19:14+09:00
Amazon SNS ってどんなサービス?
勉強前イメージ
Amazon S*S っていくつかサービスあってややこしくて覚えれてない
SNSのメッセージ送る的なやつ?調査
Amazon SNSとは
Amazon Simple Notification Service の略で、
アプリケーション間のメッセージや、HTTP、Eメール、モバイルのプッシュ通知を行うことができます。Amazon SNSの特徴
- プッシュ型の配信
発信者のトリガーで配信されるため、ポーリング処理よりメッセージの配信に即時性があります
- 複数プロトコルに対応
- Amazon SQS(Simple Queue Service)
- AWS Lambda
- HTTP
- HTTPS
- Eメール
- SMS(Short Message Service)
上記のマルチプロトコルに対応しています
- 低コスト
前払い料金のない従量課金型で安価で提供されています
- シンプルなAPI
他のアプリケーションとも安易に統合させることができます
勉強後イメージ
lamdaとかにも入れれるし、
普通にSMS通知もできるし、通知系なら結構何でも行けるって感じなのかな・・・
他のやつ知らんけど
管理画面見てたら簡単そうだったらからやってみよう参考