- 投稿日:2020-12-23T22:50:42+09:00
LaravelとVue.jsを使った見積作成アプリ その1
はじめに
この記事は私自身がLaravelとVue.jsを勉強する目的で学んだことをまとめたものです。
この記事で作成するアプリケーションについて
この記事は以下の環境で作成しました。
- Laravel 5.7.29
- PHP 7.3.11
- Vue.js 2.6.11
アプリケーションの全体像
今回作成する見積作成アプリは全部で6画面あり、認証機能まで備えたアプリケーションを作成していきます。
こちらが完成した見積作成アプリです。
- 見積一覧ページ
- このページでは作成した見積の一覧を表示します。
- 見積編集ページ
- このページで見積の内容を編集、保存します。
- PDF表示ページ
- このページでは作成した見積をPDFで表示し、保存と印刷を可能にします。
- ログインページ
- ログインページも作成します。最終的にはログイン中のユーザーの見積のみ表示するように実装します。
- 会員登録ページ
- 会員登録ではメールアドレス、ユーザー名、パスワードを入力します。
- プロフィール編集ページ
- このページで見積に表示される自分の情報を編集できるようにします。
テーブル定義
見積テーブルと商品テーブルを作成します。二つのテーブルの関係性は見積一つに対し商品が多数紐づく「一対多」にします。
見積テーブル ID id タイトル title 納入場所 location 取引方法 transaction 有効期限 effectiveness 宛先 customer 納入期限 deadline_at 見積日 estimated_at
商品テーブル ID id 見積ID estimate_id 商品名 name 単位 unit 数量 quantity 単価 unit_price 備考 other 見積一覧ページの作成
環境構築ができていてLaravelの初期画面が表示されている前提で進めます。
データベースの接続設定
まずは接続設定を.envで行います。estimateというデータベースを作成しています。環境構築にはHomesteadを使用しました。
DB_CONNECTION=pgsql DB_HOST=127.0.0.1 DB_PORT=5432 DB_DATABASE=estimate DB_USERNAME=homestead DB_PASSWORD=secretマイグレーションファイルとモデルクラスの作成
$ php artisan make:migration create_estimates_table --create=estimates作成されたファイルに記入していきます。
create_estimates_table.phpuse Illuminate\Support\Facades\Schema; use Illuminate\Database\Schema\Blueprint; use Illuminate\Database\Migrations\Migration; class CreateEstimatesTable extends Migration { /** * Run the migrations. * * @return void */ public function up() { Schema::create('estimates', function (Blueprint $table) { $table->increments('id'); $table->string('title', 100)->nullable(); $table->string('location', 100)->nullable(); $table->string('transaction', 100)->nullable(); $table->string('effectiveness', 100)->nullable(); $table->string('customer', 100)->nullable(); $table->string('deadline_at', 100)->nullable(); $table->date('estimated_at')->nullable(); $table->timestamps(); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('estimates'); } }テーブル名はestimatesとしました。格納したい物の名前の複数形にするのが一般的です。また、見積作成の途中で保存したい時や記入せずに作成したい場合に対応するため、nullable()でカラムにNULL値を許容しました。
マイグレーションを実行します。
$ php artisan migrate次にモデルクラスを作成します。
$ php artisan make:model EstimateappディレクトリにEstimateモデルが作成されます。
Estimate.php<?php namespace App; use Illuminate\Database\Eloquent\Model; class Estimate extends Model { // }Estimateモデルに記述はしていませんが、継承元であるModelクラスで様々な設定を読み取ってくれるらしいです。
これでデータを扱う準備ができたのですが、テストデータが入っていた方がコントローラーを書きやすいので、Seederを用いてデータを挿入します。
$ php artisan make:seeder EstimatesTableSeederrunメソッドの中にデータを挿入するコードを記述します。ここでは3つの見積を作りました。
EstimatesTableSeeder.php<?php use Carbon\Carbon; use Illuminate\Database\Seeder; use Illuminate\Support\Facades\DB; class EstimatesTableSeeder extends Seeder { /** * Run the database seeds. * * @return void */ public function run() { $user = DB::table('users')->first(); $titles = ['2021年おめでとうセール', '商品見積の件', 'サンプル見積の件']; $customers = ['株式会社XXX', '株式会社YYY', '株式会社ZZZ']; foreach (array_map(NULL, $titles, $customers) as [ $title, $customer ]) { DB::table('estimates')->insert([ 'title' => $title, 'user_id' => $user->id, 'customer' => $customer, 'created_at' => Carbon::now(), 'updated_at' => Carbon::now(), ]); } } }コマンドラインで実行します。
$ php artisan db:seed --class=EstimatesTableSeeder「Database seeding completed successfully.」と返ってきたら成功です。
ルーティングの設定
web.phpRoute::get('/estimates', 'EstimateController@index')->name('estimates.index');コントローラークラスの作成
コントローラークラスはコマンドラインから作成。
$ php artisan make:controller EstimateController作成されたEstimateController.phpにindexメソッドを追加します。
EstimateController.phpuse App\Estimate; // ★ 追加 public function index() { $estimates = Estimate::all(); return view('estimates/index', [ 'estimates' => $estimates, ]); }view関数でテンプレートにデータを渡し、その結果を返却しています。view関数の第一引数がテンプレートファイル名で第二引数がテンプレートに渡すデータです。
テンプレートの作成
テンプレートファイルを作成します。
$ mkdir resources/views/estimates $ touch resources/views/estimates/index.blade.php $ touch resources/views/layout.blade.phplayout.blade.phpとindex.blade.phpの中身は以下のように記述しました。
layout.blade.php<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="csrf-token" content="{{ csrf_token() }}"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>見積作成アプリ</title> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css" integrity="sha384-9aIt2nRpC12Uk9gS9baDl411NQApFmC26EwAOH8WgZl5MYYxFfc+NcPb1dKGj7Sk" crossorigin="anonymous"> <link rel="stylesheet" href="{{ asset('css/app.css') }}"> <link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/flatpickr/dist/flatpickr.min.css"> </head> <body> <header> <nav class="navbar navbar-expand-xs navbar-dark bg-dark p-1"> <a class="navbar-brand" href="{{ route('estimates.index') }}">見積作成アプリ</a> </nav> </header> @yield('content') <script src="https://code.jquery.com/jquery-3.5.1.slim.min.js" integrity="sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj" crossorigin="anonymous"></script> <script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/js/bootstrap.min.js" integrity="sha384-OgVRvuATP1z7JjHLkuOU7Xw704+h835Lr+6QL9UvYjZE3Ipu6Tp75j7Bh/kR0JKI" crossorigin="anonymous"></script> @yield('scripts') </body> </html>index.blade.php@extends('layout') @section('content') <main> <div class="container"> <div class="row"> <div class="col col-md-12"> <h2 class="text-center" style="padding-top:25px">見積一覧</h2> <table class="table table-bordered table-hover" style="table-layout:fixed;"> <thead class="thead-dark"> <tr> <th class="col">タイトル</th> <th class="col">見積もり期日</th> <th class="col">場所</th> <th class="col">宛先</th> </tr> </thead> <tbody> @foreach($estimates as $estimate) <tr> <td class="position-relative"> <a href="{{ route('estimates.edit', ['estimate' => $estimate->id]) }}" class="stretched-link"> {{ $estimate->title }} </a> </td> <td>{{ $estimate->estimated_at }}</td> <td>{{ $estimate->location }}</td> <td>{{ $estimate->customer }}</td> </tr> @endforeach </tbody> </table> </div> </div> </div> </main> <footer class="fixed-bottom bg-dark"> <nav class="my-navbar"> <div class="container"> <div class="row"> <div class="col-md-3"> <a href="#"> <button>新規作成</button> </a> </div> <div class="col-md-3 offset-md-6"> <a href="#"> <button>プロフィール設定</button> </a> </div> </div> </div> </nav> </footer> @endsectionテンプレートの中でも@を付ければPHPのようにforeachを使えます。この際、コントローラーから渡された$estimatesを参照しています。変数の値の展開は{{ }}のように波括弧二つで実現します。
CSSフレームワークにはBootstrapを使用しました。
見積編集ページの作成
商品テーブルの作成
まずは見積テーブルと同様にマイグレーションファイルを作成します。
$ php artisan make:migration create_items_table --create=itemsマイグレーションファイルを記述します。
create_items_table.php<?php use Illuminate\Support\Facades\Schema; use Illuminate\Database\Schema\Blueprint; use Illuminate\Database\Migrations\Migration; class CreateItemsTable extends Migration { /** * Run the migrations. * * @return void */ public function up() { Schema::create('items', function (Blueprint $table) { $table->increments('id'); $table->integer('estimate_id')->unsigned(); $table->string('name', 100)->nullable(); $table->string('unit', 10)->nullable(); $table->integer('quantity')->nullable(); $table->integer('unit_price')->nullable(); $table->string('other', 100)->nullable(); $table->timestamps(); $table->foreign('estimate_id')->references('id')->on('estimates')->onDelete('cascade'); }); } /** * Reverse the migrations. * * @return void */ public function down() { Schema::dropIfExists('items'); } }ここでは外部キー制約を設定しています。外部キー制約は他のテーブルとの結びつきを表現するためのカラムに設定します。外部キー制約が設定されたカラムには、好き勝手な値は入れられなくなります。今回の例で言うと、商品テーブルの見積ID列には実際に存在する見積IDの値しか入れることができなくなります。これによりデータの不整合を防ぎます。また、onDelete('cascade')により見積テーブルのデータを削除した場合、商品テーブル内の一致するデータを自動的に削除してくれます。
マイグレーションを実行します。
$ php artisan migrate続けて商品テーブルに対応するモデルクラスを作成します。
$ php artisan make:model ItemItem.php<?php namespace App; use Illuminate\Database\Eloquent\Model; class Item extends Model { // }テストデータを挿入するためにシーダーを作成します。
$ php artisan make:seeder ItemsTableSeederItemsTableSeder.php<?php use Carbon\Carbon; use Illuminate\Database\Seeder; use Illuminate\Support\Facades\DB; class ItemsTableSeeder extends Seeder { /** * Run the database seeds. * * @return void */ public function run() { $names = ['ガードレール', 'エムコール', '塩化カルシウム']; $units = ['式', '袋', '袋']; $quantities = [1, 10, 25]; $unit_prices = [150000, 5000, 1000]; foreach (array_map(NULL, $names, $units, $quantities, $unit_prices) as [ $name, $unit, $quantity, $unit_price ]) { DB::table('items')->insert([ 'estimate_id' => 1, 'name' => $name, 'unit' => $unit, 'quantity' => $quantity, 'unit_price' => $unit_price, ]); } } }今回はID=1の見積に対して3つの商品を登録しました。
$ php artisan db:seed --class=ItemsTableSeederルーティングの設定
web.phpRoute::get('/estimates/edit', 'EstimateController@showEditForm')->name('estimates.edit'); Route::post('/estimates/edit', 'EstimateController@edit'); Route::get('/estimates/create', 'EstimateController@create')->name('estimates.create'); Route::post('/estimates/create', 'EstimateController@create');コントローラーの作成
コントローラーを書いていきます。既存の見積もりを編集する場合はそのままshowEditFormへ、新規作成の場合はcreate->showEditFormと推移します。
EstimateController.phpuse App\Item; // ★ 追加 public function showEditForm(Request $request) { $estimate_id = $request->input('estimate'); $estimate = Estimate::find($estimate_id); return view('estimates/edit', [ 'estimate' => $estimate, ]); } public function create() { $estimate = new Estimate(); $estimate->save(); return redirect()->route('estimates.edit', [ 'estimate' => $estimate->id, ]); } public function edit(Request $request) { $estimate_id = $request->input('estimate'); $current_estimate = Estimate::find($estimate_id); $current_estimate->title = $request->title; $current_estimate->location = $request->location; $current_estimate->transaction = $request->transaction; $current_estimate->effectiveness = $request->effectiveness; $current_estimate->customer = $request->customer; $current_estimate->deadline_at = $request->deadline_at; $current_estimate->estimated_at = $request->estimated_at; $current_estimate->save(); return redirect()->route('estimates.edit', [ 'estimate' => $estimate_id ]); }コントローラーメソッドの引数にRequestクラスのインスタンスを受け入れる記述をすることでユーザーの入力値をRequestクラスのインスタンス$requestに詰めて引数として渡してくれます。Requestクラスのインスタンスにはリクエストヘッダや送信元IPなどいろいろな情報が含まれていますが、その中にフォームの入力値も入っています。
$request->title;リクエスト中の入力値は上記のようにプロパティとして取得することができます。
また、クエリパラメータの取得にはRequestクラスのinputメソッドを使用します。inputメソッドの第一引数へ、クエリパラメータのキーを指定します。今回指定するクエリパラメータのキーは'estimate'です。この為、inputメソッドの第一引数には'estimate'を指定します。
次のポイントはデータベースに書き込む処理です。データベースへの書き込みは以下の手順で実装します。
- モデルクラスのインスタンスを作成する。
- インスタンスのプロパティに値を代入する。
- saveメソッドを呼び出す。
これにより、モデルクラスが表すテーブルに対してINSERTが実行されます。
次回
ここまで、見積一覧ページと見積編集ページのコントローラーを作成しました。次回はVue.jsを利用した見積編集ページのテンプレートを作成します。
- 投稿日:2020-12-23T22:45:58+09:00
VScodeでPHPにコードユニペットを登録・追加する方法
開発に必須で何回も打つこいつ。
qiita.phpvar_dump($qiita);簡単に予測変換してくれないから登録した!
コードユニペットに登録する
PHP.jsonファイルを見つけ出す
Code > Preferences > User Snippets
検索窓に「PHP」と入力してPHP.json(PHP)を開く。
そしたらこんな内容のファイルが開かれる。
php.json{ // Place your snippets for php here. Each snippet is defined under a snippet name and has a prefix, body and // description. The prefix is what is used to trigger the snippet and the body will be expanded and inserted. Possible variables are: // $1, $2 for tab stops, $0 for the final cursor position, and ${1:label}, ${2:another} for placeholders. Placeholders with the // same ids are connected. // Example: // "Print to console": { // "prefix": "log", // "body": [ // "console.log('$1');", // "$2" // ], // "description": "Log output to console" // } }記述開始
php.json{ // Place your snippets for php here. Each snippet is defined under a snippet name and has a prefix, body and // description. The prefix is what is used to trigger the snippet and the body will be expanded and inserted. Possible variables are: // $1, $2 for tab stops, $0 for the final cursor position, and ${1:label}, ${2:another} for placeholders. Placeholders with the // same ids are connected. // Example: // "Print to console": { // "prefix": "log", // "body": [ // "console.log('$1');", // "$2" // ], // "description": "Log output to console" // } "var_dump": { "prefix": "vd", "body": [ "var_dump($1);" ], "description": "var_dump" } }これで、「vd」→「Enter」キーで、「var_dump( );」を入力できるようになった!
参照記事
- 投稿日:2020-12-23T22:14:51+09:00
【初心者】三項演算子を使用してみる
if文が良いのか三項演算子が良いのか…
if文を使う以外に条件式を使える三項演算子を使ってみた。
// 条件式 ? 条件式がtrueの式 : falseの式; $a = -7; $judge = $a > 5 ? "High" : "Low"; echo($judge) // 以下出力結果です Lowこのように、条件式の結果が true の時と false の時での結果を処理することができる。
この条件式をif文を使って記述すると…$a = -7; if ($a > 5) { echo "High"; }else { echo "Low"; } // 以下出力結果です Lowこれを比べると一見、if文より三項演算子の方が行数が少ないので良いのかなぁと思う。
ただし、if文を使うと以下のようなことができる。$a = -7; if ($a > 5) { echo "High"; }elseif ($a < 5) { echo "Low"; }elseif ($a == 5) { echo "equal"; } // 以下出力結果です Lowこのような、条件式が複数になったりするものに関しては、if文が良いのではないかと思う。
やはり色々はパターンを勉強することは非常に面白いと思う。
- 投稿日:2020-12-23T20:35:03+09:00
PHP foreach 参照渡し 罠
データの出力処理で、最後の行が出力されず、代わりに最後から2番目の行が2回出力されるというバグが起こりました。
調べてみると、foreachで陥りがちなバグであることがわかったので、対応して得たことをまとめました。事象
$arrayの要素を、すべて10倍したいとします。
配列の値をforeachの中で変更したいとき、
変数の前に「&」を付けることで、参照渡しで値を設定することができます。(1)
そのあとに、出力処理のために再度foreachしました。(2)bug.php<?php $array = array(10, 20, 30, 40); // (1) foreach ($array as &$value) { $value *= 10; } // (2) foreach ($array as $value) { var_dump($value); }出力されたものは、
int(100)
int(200)
int(300)
int(300)と、意図しない結果になっていました。
「!?」と思いましたが、ちゃんと原因がありました。原因はforeachの参照渡し
(1)のforeachを抜けたところの配列の中身を見てみると、
test.php<?php $array = array(10, 20, 30, 40); // (1) foreach ($array as &$value) { $value *= 10; } var_dump($array); // (2) // foreach ($array as $value) { // var_dump($value); // }こうなっています。
array(4) {
[0]=> int(100)
[1]=> int(200)
[2]=> int(300)
[3]=> &int(400)
}最後の要素にこっそり付いている「&」は、
「配列に含まれる要素の一部が参照(リファレンス)されている」ということを意味します。つまり、
「\$value に代入すると、\$array[3]を書き変られる状態が、foreaehを抜けた後も続いている」ということになります。
今回の場合、2回目のforeachでも \$value に代入しているので、$array[3]が書き変わってしまっていたのが原因でした。配列が壊れる過程
2回目のforeachで \$array[3]の身に何が起こったのか、順を追って整理しました。
ループの順番 foreach (\$array as \$value)で起こること \$array[3]の値 array[0] の番 \$value ( = array[3] = 400 ) に、array[0] ( = 100 ) を代入 400 から 100 に変わる array[1] の番 \$value ( = array[3] = 100 ) に、array[1] ( = 200 ) を代入 100 から 200 に変わる array[2] の番 \$value ( = array[3] = 200 ) に、array[2] ( = 300 ) を代入 200 から 300 に変わる array[3] の番 \$value ( = array[3] = 300 ) に、array[3] ( = 300 ) を代入 300のまま 400が入っていると思っていた$array[3]の値が次々に書き変わり、最終的に、直前の要素が入っていたということがよく理解できました。
対策①
対策を調べると、たくさんの人にunset($value)すればいいんだよと言われます。
unset.php<?php $array = array(10, 20, 30, 40); // (1) foreach ($array as &$value) { $value *= 10; } unset($value); // (2) foreach ($array as $value) { var_dump($value); }たしかにこれで解決できます。
しかし、unsetを書き忘れる危険性があります。
複数名でコードをメンテナンスするとなると、なおさらです。対策②
そもそもforeachで参照渡しをしなければ起こらないバグなので、
参照渡しにするのではなく、\$arrayを書き換えるという方法をとりました。key.php<?php $array = array(10, 20, 30, 40); // (1) foreach ($array as $key => $value) { $array[$key] *= 10; } // (2) foreach ($array as $value) { var_dump($value); }対策②のほうが安心できます。
foreachでの参照渡しは、必要でなければ使わないほうがよいと思いました。
参考:https://qiita.com/buntafujikawa/items/f192d724a3c714f39c45
- 投稿日:2020-12-23T18:12:24+09:00
EC2 (Amazon Linux 2 ) にPHP7.2 をインストールし、php.ini を設定するまでのまとめ
Amazon Linux は2020/12/31 でサポートが終了してしまうため、
後継のOS であるAmazon Linux 2 への移行が必要になりました。単純にOS アップデートできないようだったので、
新たにAmazon Linux 2 のインスタンスを作ってミドルウェアを入れ直しました。後々同じことをやる方のググる手間を省ければと思い、まとめました。
「とりあえずEC2でPHPを動かしたいぞ!!!」というあなたのお役に立てれば幸いです前提
■ 先にVPCやサブネットの用意を終わらせておくとスムーズです。
(ECインスタンス作成時に紐付けられるため)もしよろしければ、以下の記事を参考になさってみてください!
・VPC作成 〜 パブリック・プライベートサブネットを作るまでの手順①
・VPC作成 〜 パブリック・プライベートサブネットを作るまでの手順②■ CloudFormation を使った構築手順については今回触れません。
ざっくりの流れ
- EC2 インスタンスを作成
- タイムゾーンを日本に設定する
- 言語を日本語に設定する
- ホスト名を設定する ①
- ホスト名を設定する ②
- LAMP環境をインストールする
mbモジュールをインストールするphp-xmlモジュールをインストールするphp.iniを設定する1. EC2 インスタンスを作成
▼ 参考:
AWSコンソールからEC2インスタンスを作成する手順LAMP環境をインストールする際、EC2インスタンスにssh接続する必要があります。
EC2インスタンス作成時には既存のキーペアの選択or新しいキーペアの作成を選ぶようにしてください。▼ EC2インスタンスにssh接続するコマンド:
ssh -i [キーペアのパス] ec2-user@[パブリック IPv4 アドレス]2. タイムゾーンを日本に設定する
sudo cp /usr/share/zoneinfo/Japan /etc/localtimesudo vi /etc/sysconfig/clock/etc/sysconfig/clock#ZONE="UTC" ZONE="Asia/Tokyo" UTC=true3. 言語を日本語に設定する
sudo vi /etc/sysconfig/i18n/etc/sysconfig/i18nLANG=ja_JP.UTF-84. ホスト名を設定する ①
sudo hostnamectl set-hostname <ホスト名>▼ 参考:
Amazon Linux インスタンスのホスト名を変更する - Amazon Elastic Compute Cloudデフォルトのままだとわかりづらいため、わかりやすいホスト名に変更するのがおすすめです。
5. ホスト名を設定する ② ※ 不要な場合は飛ばしてOK
sudo vi /etc/cloud/cloud.cfg末尾に
preserve_hostname: trueを追記する▼ 参考:
Amazon Linux 2でカスタムAMIからの起動時にホスト名を固定する方法 | Developers.IOカスタムAMI を取得 → カスタムAMI から新しいインスタンスを起動してみたらホスト名の設定が無効になっていたので、有効にし続けるための設定です。
6. LAMP環境をインストールする
▼ 参考:
チュートリアル: Amazon Linux 2 に LAMP ウェブサーバーをインストールする - Amazon Elastic Compute Cloud7.
mbモジュールをインストールする▼ 参考:
Amazon Linuxでphpでmbstringを使う - QiitaPHPにはマルチバイト文字列を扱うための関数がいろいろあります。(例:
mb_substr)
mbモジュールをインストールしておかないと、PHPを実行した際にFatal errorが出てしまいます。8.
php-xmlモジュールをインストールするsudo yum install --enablerepo=remi,remi-php70 php-xmlsudo systemctl restart httpd問題なくインストールされていることの確認は以下のコマンドでできます。
[ec2-user@XXXXXX ~]$ yum list installed | grep php-xml php-xml.x86_64 7.2.34-1.amzn2 @amzn2extra-php7.2 [ec2-user@XXXXXX ~]$
php-xmlモジュールをインストールしていなかったために、PHPのエラーFatal error: Class 'DOMDocument' not foundが出てしまいました9.
php.iniを設定する▼ 参考:
【PHP】PHPをインストールしたらやっておきたい設定 - Qiita初期状態の
/etc/php.iniをコピーしてバックアップを取っておいてから設定を変更するようにすれば、何かあったときに戻せるので安心です。上記の記事で「セキュリティに関する設定」として記載されている
session.hash_functionなどはPHP 7.1.0から削除されているので設定不要です。参考

- 投稿日:2020-12-23T18:10:33+09:00
画像、PDFをPDF化
画像やPDFを1つのPDFにする
tcpdfとfpdiを使用。
jpgやpngなどの画像をPDF化するならtcpdfのみで可能ですが
PDFをPDFにマージするなどもしたい場合はfpdiも必要。fpdiはtcpdfまたはtfpdfの拡張機能としても使用できるので
fpdiをインストールして、tcpdfの機能を使いたかったらtcpdfもインストールする、
という認識です。インストール
composer require tecnickcom/tcpdf composer require setasign/fpdi処理
<?php namespace App\Services\Hoge; use setasign\Fpdi\Tcpdf; use File; use Utils; class HogeService { public function createPdf(string $id) { // ファイル取得 $files = Utils::getAllFiles('hoge', $id); $maxsize = 550; $tcpdf = new Tcpdf\Fpdi('p', 'px', 'A3'); $tcpdf->SetPrintHeader(false); $tcpdf->SetPrintFooter(false); foreach ($files as $file) { $extension = File::extension($file); $file_path = storage_path('app') . '/' . $file; if ($extension == 'pdf') { $pageCnt = $tcpdf->setSourceFile($file_path); for ($i = 1; $i <= $pageCnt; $i++) { $tcpdf->addPage(); $tcpdf->useTemplate($tcpdf->importPage($i)); } } else { $tcpdf->AddPage(); // @NOTE:フルパスでないとセットしてくれない // 第5引数大文字でないとセットしてくれない $img_size = getimagesize($file_path); $set_size = ($img_size[0] >= $maxsize) ? $maxsize : $img_size[0]; $tcpdf->Image( $file_path, // 画像ファイル名 5, // 領域左上のX座標 5, // 領域左上のY座標 $tcpdf->pixelsToUnits($set_size), // 領域の幅 [指定しない場合、自動計算される] 0, // 領域の高さ [指定しない場合、自動計算される] strtoupper($extension), // 画像フォーマット '', // AddLink()で作成したリンク識別子 '', // align ($img_size[0] >= $maxsize) ? true : false, // resize 300, // dpi '', // palign false, // ismask false, // imgmask 0, // border false, // fitbox false, // hidden false, // fitonpage false, // alt ); } } $pdf_path = storage_path('app') . "/data/hoge/$id/hoge_$id.pdf"; // 保存 $tcpdf->output($pdf_path, 'F'); } }
- 投稿日:2020-12-23T16:57:21+09:00
【PHP】連想配列の作成と要素の変更、追加方法まとめ。キーや値を変更・追加の実例。
PHPにおける連想配列の操作方法について。
PHPでは連想配列は、配列の各値にキー名が設定してあるものを指す。
目次
連想配列の作成方法
連想配列は配列の一種なので
array関数または[ ]を使う。KV(key-value)の指定は、キー名 => 値で行う。「=>」をダブルアロー演算子と呼ぶ。
※キー名が文字列の場合は、
'、"で囲む。整数の場合は不要。
※ダブルアロー「=>」を使う。アロー「->」は別の用途で使用される(インスタンスのプロパティやメソッドの指定)array関数$obj = array('a' => 1, 'b' => 2, 999 => 3); var_export($obj); array ( 'a' => 1, 'b' => 2, 999 => 3, )カッコを使う$obj2 = ['a' => 1, 'b' => 2, 999 => 3]; var_export($obj2); array ( 'a' => 1, 'b' => 2, 999 => 3, )カッコを使った方が簡単。
▼キー名に整数以外を使う場合は文字列にしないとエラーになる
$x = array(a => 1); #PHP Warning: Use of undefined constant a - assumed 'a' (this will throw an Error in a future version of PHP) in php shell code on line 1PHP Warning: Use of undefined constant a - assumed 'a' (this will throw an Error in a future version of PHP) in php shell code on line 1
aはダメ。'a'にしてとのメッセージ。
値の変更と追加まとめ
破壊を気にしなければ
$変数[キー名] = 値が最も使いやすい。非破壊で行いたい場合は
array_merge()が使いやすい。
項目 $変数[キー名] = 値 +演算子 array_merge関数 破壊/非破壊 破壊 非破壊 非破壊 KVの追加 可 可 可 値の変更 可 不可 可 整数のキーが通常の配列に変換 無し 無し 変換
値の変更
キー名を指定して新しい値を代入する。
$変数名[キー名] = 変更後の値$obj = array('a' => 1, 'b' => 2, 999 => 3); #値の変更 $obj['b'] = 1000; #変数の内容表示 var_export($obj); array ( 'a' => 1, 'b' => 1000, 999 => 3, )
値の追加
値を追加する方法はいくつかある。いずれの方法でも新たに追加した要素は一番後ろに入る。
1. キー名を指定する
先ほどの値を変更する方法で、存在しないキーを指定すると新たに
そのキーと値が追加される。
$変数名[追加するキー名] = 変更後の値$obj = array('a' => 1, 'b' => 2, 999 => 3); #キーと値の追加 $obj['c'] = 3; var_export($obj); array ( 'a' => 1, 'b' => 2, 999 => 3, 'c' => 3, )
2. +演算子を使う
連想配列に対して+演算子を使うことで、新たなKVのセットを追加することができる。
※+演算子の場合、既存の値変更はできない。
$obj = array('a' => 1, 'b' => 2, 999 => 3); #新たなキーと値を追加 $obj = $obj + array('c' => 3); var_export($obj); array ( 'a' => 1, 'b' => 2, 999 => 3, 'c' => 3, )
▼複数のKVを追加することも可能$obj = array('a' => 1, 'b' => 2, 999 => 3); #3つの要素を追加 $obj += array('c' => 3, 'str', 1000); var_export($obj); array ( 'a' => 1, 'b' => 2, 999 => 3, 'c' => 3, 0 => 'str', 1 => 1000, )キーを指定せずに値を追加した場合は、0から順に整数でキーが割り振られる。
これは、連想配列でない通常の配列要素になったことを示す。
(参考)通常の配列$arr = [1,2,3]; var_export($arr); array ( 0 => 1, 1 => 2, 2 => 3, )
▼既存のキーの値を変更はできない既存のキーの値を変更はできない$obj = array('a' => 1, 'b' => 2, 999 => 3); $obj = $obj + array('b' => 1); php > var_export($obj); array ( 'a' => 1, 'b' => 2, 999 => 3, )
3. array_merge関数を使う
array_merge(配列, 配列,,,,,)※数値や文字列は指定できない。(指定するとエラーになる)
※キーが数値の場合、0から順の数値に変換される。
※キーが重複する場合は後ろの配列の値が適用される(上書きされる)$obj = array('a' => 1, 'b' => 2, 999 => 3); $x = array('x' => 1); #配列を足し合わせる $obj = array_merge($obj, $x); var_export($obj); array ( 'a' => 1, 'b' => 2, 0 => 3, 'x' => 1, )
$objに$xが追加された。※キーが数値の場合、0から順の数値に変換される。
▼配列が複数の場合$obj = array('a' => 1, 'b' => 2, 999 => 3); $x = array('x' => 1); $arr = [1,2,3]; #配列を足し合わせる $obj = array_merge($obj, $x, array('c'=>4), $arr); var_export($obj); array ( 'a' => 1, 'b' => 2, 0 => 3, 'x' => 1, 'c' => 4, 1 => 1, 2 => 2, 3 => 3, )
▼キーが重複する場合$obj = array('a' => 1, 'b' => 2, 999 => 3); $obj2 = array('a' => 9, 'b' => 8, 999 => 7); $obj = array_merge($obj, $obj2); var_export($obj); array ( 'a' => 9, 'b' => 8, 0 => 3, 1 => 7, )キーが数値の場合は0からの連番に自動変更されるので、重複とみなされない。
キーの変更
値を変更したようにキーを指定して置き換える直接的な方法はない。
新しいキーをもつ配列を用意するか、元のキーを削除して新たにキーを作成し値を代入する方法が考えられる。
キー全体を変更する場合
foreachを使う
foreach文で値を一つづつ取り出し、新しいキーにセットしていく。
▼foreach文
変数の指定方法により、値のみ抜き出すか、キーと値の両方を抜き出すかが変わる。・
foreach( 配列 as 変数 ){処理}
配列が連想配列の場合、変数には各要素の値(value)が入る・
foreach( 配列 as 変数1 => 変数2 ){処理}
配列が連想配列の場合、変数1にはキー名(key)、変数2には値(value)が入る。$obj = array('a' => 1, 'b' => 2, 999 => 3); #新たなキー名を入れる連想配列 $newObj = []; #キー名の識別用 $i = 0; foreach ($obj as $v){ $newObj["key_$i"] = $v; $i += 1; } #中身確認 var_export($newObj); array ( 'key_0' => 1, 'key_1' => 2, 'key_2' => 3, )
新しい連想配列のキー名に古いキー名を活用する場合
foreach( 配列 as 変数1 => 変数2 ){処理}の変数1にキー名が入るため、これを新たなキー名として活用する。事例1(番号をふる)$obj = array('a' => 1, 'b' => 2, 999 => 3); #新たなキー名を入れる連想配列 $newObj = []; $i = 0; foreach ($obj as $k => $v){ $newObj[$k."_".$i] = $v; $i += 1; } #中身確認 var_export($newObj); array ( 'a_0' => 1, 'b_1' => 2, '999_2' => 3, )事例2(文字列をくっつける)$obj = array('a' => 1, 'b' => 2, 999 => 3); #新たなキー名を入れる連想配列 $newObj = []; foreach ($obj as $k => $v){ $newObj["new_$k"] = $v; } #中身確認 var_export($newObj); array ( 'new_a' => 1, 'new_b' => 2, 'new_999' => 3, )
元の変数をそのまま利用したい場合は、新たに作成した変数を代入すればいい。$obj = $newObj; php > var_export($obj); array ( 'new_a' => 1, 'new_b' => 2, 'new_999' => 3, )不要になった配列の削除unset($newObj); var_export($newObj); #PHP Notice: Undefined variable: newObj in php shell code on line 1 #NULL
unset(変数)は指定した変数を削除する関数。
array_combine関数を使う
・
array_combine ( array $keys , array $values )
第1引数の配列の要素をキーとして、第2引数の配列の要素を値として、連想配列を生成する関数。第2引数の配列は
array_values()で値のみを抜き出した配列を使用する。$obj = ['a' => 1, 'b' => 2, 999 => 3]; #keyとvalueの配列を作成 $keys = ['x', 'y', 'z']; $vals = array_values($obj); #結合 $res = array_combine($keys, $vals); #確認 var_export($res); array ( 'x' => 1, 'y' => 2, 'z' => 3, )
▼要素数が合わない場合はエラーになる
$obj = ['a' => 1, 'b' => 2, 999 => 3]; #keyは2つ $keys = ['x', 'y']; #valueは3つ $vals = array_values($obj); #結合 $res = array_combine($keys, $vals); PHP Warning: array_combine(): Both parameters should have an equal number of elements in php shell code on line 1PHP Warning: array_combine(): Both parameters should have an equal number of elements in php shell code on line 1
一部のキーだけを変更する方法
foreach文とif文を使う
if文で指定したキーのみ値を変更する。
$obj = ['a' => 1, 'b' => 2, 999 => 3]; #新たなキー名を入れる連想配列 $newObj = []; foreach ($obj as $k => $v){ #変更するキーを指定 if( $k == '999' ){ $newObj['c'] = $v; } #それ以外のキーと値はそのまま else { $newObj[$k] = $v; } } #中身確認 var_export($newObj); array ( 'a' => 1, 'b' => 2, 'c' => 3, )
array_combainとarray_keysを使う
・
array_combine ( array $keys , array $values )
第1引数の配列の要素をキーとして、第2引数の配列の要素を値として、連想配列を生成する関数。第1引数の配列は
array_keys()でキーのみを抜き出した配列を作成し、指定した要素の値を変更する。第2引数の配列は
array_values()で値のみを抜き出した配列を使用する。$obj = ['a' => 1, 'b' => 2, 999 => 3]; #キーの抽出 $keys = array_keys($obj); #指定した値の変更 $keys[2] = 'c'; #値の抽出 $vals = array_values($obj); #結合 $newObj = array_combine($keys, $vals); #中身確認 var_export($newObj); array ( 'a' => 1, 'b' => 2, 'c' => 3, )
- 投稿日:2020-12-23T15:46:45+09:00
WordPressのタクソノミーアーカイブのパーマリンクを変更する
ワードプレスのテーマtwentytwentyoneを基盤に、タクソノミーのアーカイブページのパーマリンクからタクソノミー名を削除する実装を行ったので、備忘録的にこの記事を残す。
環境情報
PHP:version 7.3.12
WordPress:version 5.5.3
WPテーマ:twentytwentyoneゴールの確認
カスタム投稿タイプでオリジナルのタクソノミーをカテゴリーのように使い、そのタクソノミーのアーカイブページをそれぞれ作成したい場合に起こる問題です。
※ポストタイプ名が topic 、タクソノミー名が topic_category 、ターム名が news で今回 news のアーカイブページを作りたい想定です。
今回のゴールはアーカイブページのリンクが /topic/news/ になることです。
カスタム投稿タイプ作成時の設定
register_post_type の args に入れる配列に以下の二つを指定します。
特に 'with_front' => false は忘れてはいけない!functions.php$args = array( 'has_archive' => true, 'rewrite' => array( 'with_front' => false ) );プラグイン Custom Post Type Permalinks の導入
Custom Post Type Permalinks というプラグインをインストールし、管理画面->設定->パーマリンク設定から topic のパーマリンク設定を /%topic_category%/%post_id%/ または /%topic_category%/%postname%/ などにします。
そして忘れてはいけないのが、「カスタマイズされたカスタムタクソノミーのパーマリンクを使用する。」にチェックを入れることです!
この時点でデフォルトのパーマリンクが /topic/topic_category/news/ になっているはずです。
topic_category の部分を削除する
後は functions.php からリンク設定を行って、リライトで設定を書き換えれば完成です!
functions.php// topic_category のアーカイブページのパーマリンクを変更する function my_custom_post_type_permalinks_set($termlink, $term, $taxonomy){ return str_replace('/'.$taxonomy.'/', '/', $termlink); } add_filter('term_link', 'my_custom_post_type_permalinks_set',11,3); // ページネーションがある場合▽▽ add_rewrite_rule('topic/([^/]+)/?$', 'index.php?topic_category=$matches[1]', 'top'); add_rewrite_rule('topic/([^/]+)/page/([0-9]+)/?$', 'index.php?topic_category=$matches[1]&paged=$matches[2]', 'top'); // ページネーションがある場合△△
- 投稿日:2020-12-23T14:05:41+09:00
phpにおける削除ボタン
ソースコード
<?php require_once('function.php'); require_once('db_connect.php'); check_user_logged_in(); $id = $_GET['id']; if (empty($id)) { header("Location: main.php"); exit; } $pdo = db_connect(); try{ $sql = "DELETE FROM books WHERE id = :id"; $stmt = $pdo->prepare($sql); $stmt->bindParam(':id', $id); $stmt->execute(); header("Location: main.php"); }catch (PDOException $e) { // エラーメッセージの出力 echo 'Error: ' . $e->getMessage(); // 終了 die(); } ?>プロセス
①function.phpに入っているcheck_user_logged_in();を呼び出す。
function check_user_logged_in() { session_start(); if (empty($_SESSION["user_name"])) { header("Location: login.php"); exit; } }これでセッション確立。
②元のページから$id = $_GET['id'];でidを引っ張ってきて、代入。もし$idがempty(空)だったら、検索しても意味ないのでmain.phpにリダイレクトさせる。不正なアクセス対策。
$id = $_GET['id']; if (empty($id)) { header("Location: main.php"); exit; }以下はリンク元に記載してあるコード。a属性で囲むのはinput属性でボタンにしたほうが見た目的にはいいかも。
<a href="このページのリンク.php?id=<?php echo $row['id']; ?>">削除</a>
③db_connect.phpのdb_connect()を呼び出す。
define('DB_DATABASE', '****'); define('DB_USERNAME', 'root'); define('DB_PASSWORD', 'root'); define('PDO_DSN', 'mysql:host=localhost;charset=utf8;dbname='.DB_DATABASE); function db_connect() { try { // PDOインスタンスの作成 $pdo = new PDO(PDO_DSN, DB_USERNAME, DB_PASSWORD); // エラー処理方法の設定 $pdo->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION); return $pdo; } catch(PDOException $e) { echo 'Error: ' . $e->getMessage(); die(); } }データベースを呼び出す。
④その後はSQL文を用意して、プリペアしてビンドパラムして実行。そして、headerで元のリンクに戻る。echoで何か表示しているわけではないので、削除ボタンを押したらすぐに消えたように見える。
try{ $sql = "DELETE FROM books WHERE id = :id"; $stmt = $pdo->prepare($sql); $stmt->bindParam(':id', $id); $stmt->execute(); header("Location: main.php"); }catch (PDOException $e) { // エラーメッセージの出力 echo 'Error: ' . $e->getMessage(); // 終了 die(); }以上。
- 投稿日:2020-12-23T13:20:29+09:00
【PHP】コンソールで変数の中身を確認する方法。var_dump, var_export, print_rの違い
コンソールで変数の中身を確認する関数はいくつか存在する。
結論からいうとvar_exportが一番使い勝手がいい。目次
まとめ (var_dump, var_export, print_rの違い)
変数の中身を確認サクッと確認したいなら、
var_exportが便利。出力をそのままPHPコードとして使い回すことができる。値の型も確認したい場合は
var_dumpを使う。引数に変数を2つ同時に指定することも可能。
項目 var_export var_dump print_r 値の型表示 無し 有り 無し $str = "AAA"; AAA string(3) "AAA" AAA PHPコードとして利用 可 不可 不可 $x = array('x' => 1); array ('x' => 1) array(1) {["x"] => int(1)} Array([x] => 1) 戻り値を返す 有り 無し 有り 3行目と5行目は左カラムの変数を引数として渡した場合の出力結果を表示。
一番役に立たたなそうなのが
print_r。
php対話モードの使い方
コード実行のためここでは対話モードを使う。
php -a$ php -a Interactive shell php >
print_r
変数の値を表示する。
・
print_r ( $expression [, bool $return = false ] )
- $expressionには変数が入る。
- 第2引数は出力を戻り値とするか(任意)
- デフォルトはfalse。戻り値なし。
- 戻り値として出力する場合はtrueにする。
▼実際の使い方
・print_r( 変数 ):変数の中身を確認したい
・print_r( 変数, ture):変数を代入する場合など引き数1つの場合php > $obj = array("a" => 1, "b" => 2, "c" => 3); php > print_r($obj); Array ( [a] => 1 [b] => 2 [c] => 3 )引数2つ($return = true)
引数ありの場合は、戻り値が返るため変数に代入することができる。
第2引数にtureを指定した場合php > $obj2 = print_r($obj, true); php > print_r($obj2); Array ( [a] => 1 [b] => 2 [c] => 3 )上記処理の場合、いちいち
print_r(変数, true)としなくても直接代入できる。print_rを使わない処理php > $obj3 = $obj; php > print_r($obj3) php > ; Array ( [a] => 1 [b] => 2 [c] => 3 )
戻り値としない場合は代入できない戻り値にしない場合$obj2 = print_r($obj); Array ( [a] => 1 [b] => 2 [c] => 3 ) php > print_r($obj2); 1
var_export
変数のデータを構造化データとして返す。出力は有効なPHPコードになる。
var_export ( $expression [, bool $return = false ] )php > $obj = array("a" => 1, "b" => 2, "c" => 3); php > var_export($obj); array ( 'a' => 1, 'b' => 2, 'c' => 3, )出力結果が
array('a' => 1, 'b' => 2, 'c' => 3)となっており、連想配列の定義そのものになっている。第2引数ありの場合
php > $obj = array("a" => 1, "b" => 2, "c" => 3); php > $obj4 = var_export($obj, true); php > echo $obj4 php > ; array ( 'a' => 1, 'b' => 2, 'c' => 3, )
var_dump
var_dump ( $expression , ...$expressions )
型や値を構造化したデータを返す。
一度に2つの式(変数)を指定することができる。php > $obj = array("a" => 1, "b" => 2, "c" => 3); php > var_dump($obj); array(3) { ["a"]=> int(1) ["b"]=> int(2) ["c"]=> int(3) }var_exportとの大きな違いは2点
- 値の型を表示
- 式(変数)を2つ指定できる
引数で変数を2つ指定した場合
php > $obj = array("a" => 1, "b" => 2, "c" => 3); php > $x = array('x' => 1); php > var_dump($obj, $x); array(3) { ["a"]=> int(1) ["b"]=> int(2) ["c"]=> int(3) } array(1) { ["x"]=> int(1) }
- 投稿日:2020-12-23T13:12:43+09:00
5分で理解するオープン・クローズドの原則
この記事はエイチーム引越し侍 / エイチームコネクトの社員による、Ateam Hikkoshi samurai Inc.× Ateam Connect Inc. Advent Calendar 2020 13日目の記事です。2記事めの投稿!
オープン・クローズドの原則
この記事のゴール
- 10分で、オープン・クローズドの原則(OCP)の概要を理解する
前提:なぜ設計やアーキテクチャを考える必要があるのか
システムに求められるニーズを満たすために、必要な労力をできるだけ少なくしなければならない
オープン・クローズドの原則とは
「ソフトウェアの構成要素(クラス、モジュール、関数など)は拡張に対しては開いていて、修正に対して閉じていなければならない。」
(Bertrand Meyer. Object Oriented Software Construction, Printice Hallm 1988m p.23.)
オブジェクト指向設計(SOLID)について
Robert C. Martinによって作り出された、オブジェクト指向プログラミングにおける5つのガイドライン。
- SRP 単一責任の原則
- OCP オープン・クローズドの原則
- LSP リスコフの置換原則
- ISP インターフェイス分離の原則
- DIP 依存関係逆転の原則
それぞれの頭文字を一文字ずつとって、SOLID原則とも呼ばれます。
オープン・クローズドの原則とは
「ソフトウェアの構成要素(クラス、モジュール、関数など)は拡張に対しては開いていて、修正に対して閉じていなければならない。」
(Bertrand Meyer. Object Oriented Software Construction, Printice Hallm 1988m p.23.)
つまりどういうこと?
変更が発生した場合に、既存のコードには修正を加えずに、新しくコードを追加するだけで対応できるような設計にしましょう!
ということ。
どのような具体例があるの?
オープン・クローズドの原則に則らず設計すると...?
Badなクラス?
<?php /** * AreaCalcService * 面積を計算するクラス */ class AreaCalcService { private $length; public function __construct(int $length) { $this->length = $length; } /** * call * $lengthを二乗した値を返す * @return integer */ public function call(): int { return $this->length ** 2; } }
なぜBadなのか
円の面積など、新しいケースを計算できない。
- 「面積を計算するクラス」という役割に相応しくない
正方形以外の面積を計算できるようにするために、改修コストがかかる。
- 既存コードを読む、書き直す... という作業が発生する
Case: ?<円の面積を計算したいです!
<?php /** * AreaCalcService * 面積を計算するクラス */ class AreaCalcService { private $length; public function __construct(int $length, string $shape) { $this->length = $length; $this->shape = $shape; } /** * call * @return integer */ public function call(): int { if ($this->shape === 'square') { $this->length ** 2; } elseif ($this->shape === 'circle') { $this->length ** 2 * 3.14; } return $this->length; } }対応ケースが増えるごとに条件文が増えてしまい、AreaCalcServiceが肥大化してしまう?
オープン・クローズドの原則にのっとって設計してみる???
<?php // 正方形 class Square { public $length; public function area(): int { return $this->length ** 2; } } class AreaCalcService { private $shape; public function __construct(int $length, object $shape) { $this->shape = $shape; $this->shape->length = $length; } public function call(): mixed { return $this->shape->area(); } }
Case: ?<円の面積を計算したいです!
class Square { public $length; public function area(): int { return $this->length ** 2; } } // 円のクラスを新しく定義 class Circle { public $length; public function area(): float { return $this->length ** 2 * 3.14; } } // ↓のクラスは変更しなくてOK! class AreaCalcService { private $shape; public function __construct(int $length, object $shape) { $this->shape = $shape; $this->shape->length = $length; } public function call(): mixed { return $this->shape->area(); } }このように記述することで、Circleクラスを定義するだけで改修がOK!
(追記:このままだと長方形などのパターンに対応できないので、例としてよろしくない設計です..インターフェースを使うとかが良いかもです)
まとめ
システムに求められるニーズを満たすために、必要な労力をできるだけ少なくしなければならない。
オープン・クローズドの原則にのっとってクラス設計を行うことによって、リファクタ時に労力が少なくなる?
この原則をすぐに既存コードに応用!は難しいかもしれないが、新しくクラスを作る際や、メソッド作成時に頭の片隅においておくと?
次回予告
Ateam Hikkoshi samurai Inc.× Ateam Connect Inc. Advent Calendar 2020 13日目の記事でした!(めちゃめちゃ遅れての投稿になってしまいました
)
14日目のアドベントカレンダー記事は、尊敬する先輩エンジニア、@anneauさんです!

- 投稿日:2020-12-23T13:08:27+09:00
Paizaスキルチェックを始めてみた
お疲れ様です!TaYです!
もう今年も終わっちゃいますね。。。なんだかあっという間でした!(毎年言ってる)
ですが、コロナはまだまだ終わりそうにないので、しっかり予防を続けていきたいですさて、本題ですが先日からPaizaのスキルチェックを始めてみました!
感想としては
めちゃめちゃ楽しいやん、、、!
って感じです。
Paizaスキルチェックの簡単な概要
・問題にはD〜Sのランクがあって、ランクごとに難易度が変わる
・問題ごとに制限時間がある
・レーティングがあり、制限時間内に解けないとレーティングが下がる
・現在のランクより上のランクを解くとレーティングが上がる
・練習問題も用意されている(レーティングに影響しない)Dランクは文字列の出力や配列など、基礎的な要素が強めですがSランクになると特定のシチュエーションにあったプログラムを完成させなければなりません。
とても難しいですが、解けると楽しいし、自信もつきます
また、Paizaには無料プランと有料プラン(月額1000円くらい)がありますが、スキルチェックは無料プランでも挑戦できます。
自分のスキルを試すにもってこいなので是非挑戦してみてください!
では、今日はこの辺で
- 投稿日:2020-12-23T12:57:49+09:00
PHPで複数の文字で文字列を分割する
- 投稿日:2020-12-23T12:53:10+09:00
PHPによる繰り返し処理(FOREACH)の応用
はじめに
PHP学んで1ヶ月のクソ初心者。
日々の学びを投稿で残していきますわ。そもそもFOREACHとは
for文のように繰り返しループ処理を行う構文。
foreach が使えるのは配列とオブジェクトだけ。
構造には二種類の構文がある。①foreach (iterable_expression as $value) ②foreach (iterable_expression as $key => $value)★オブジェクト・・・現実世界に存在する「もの」や「概念」のこと。
①の実例
$x = [ "めろん" => "melon", "もも" => "peach", "いちご" => "strawberry" ]; foreach ($x as $fruit) { echo $fruit."<br>"; }①の表示結果
melon peach strawberry繰り返し処理を行わないで、単純に1つの値を連想配列の中から取り出すのであれば、
値を取り出すための「キー」を指定してあげる必要がある。
しかし!!!
FOREACHでは「キー」を指定することなく、値を順番に利用できる?②の実例
$x = [ "めろん" => "melon", "もも" => "peach", "いちご" => "strawberry" ]; foreach ($x as $kudamono => $fruit) { echo "キーは「".$kudamono."」<br>"; echo "値は「".$fruit."」<br>"; }②の表示結果
キーは「めろん」 値は「melon」 キーは「もも」 値は「peach」 キーは「いちご」 値は「strawberry」連想配列の値を取り出すときに使う時にキー自体を使うことも可能?♂️
実例(応用)
htmlにPHPを組み込んで使用したい場合を紹介します?
★一部コーディングは省略している。<?php $fruit = [ [ 'name' => 'めろん', 'price' => 1000, 'note' => '夕張メロンを推します' ], [ 'name' => 'もも', //省略 'note' => 'イチゴ狩り多し!' ], ] ?> <!-- 省略 --> <?php foreach ($fruit as $fruit){ ?> <div class="box"> <p class="name"><?php echo '果物名:'.'<br>'.$fruit['name'] ; ?></p> <p class="price"><?php echo'¥'.$fruit['price'] ; ?></p> <p class="note"><?php echo'メモ:'.'<br>'.$fruit['note'] ; ?></p> </div> <?php } ?>「fruit as」の後に同じ変数である「fruit」を使っているが、
FOREACHでは、左側の変数を一度別の変数(右側の変数)に入れて
表示というルールがあるため、このようなコーディングとなる。
★同じだからといって「as fruit」を省略してはダメ?♀️表示結果
おわりに
FOREACHって面白いね!(小並感)
てか、フルーツ食べたくなりました???参考サイト
公式はやっぱ神。はっきりわかんだね。
https://www.php.net/manual/ja/control-structures.foreach.phpスペシャルサンクス
会社のみなさん?♂️?♂️?♂️
ありがとうございまーす!

- 投稿日:2020-12-23T12:15:21+09:00
Laravel + livewire 年齢算出
laravelを使った開発が一旦暇になったのでlaravel8にあるlivewireを試しにいじってみました。
ある方の記事を参考に進めていった際2箇所ほどエラーにあったのでその際の記録。
(参考にした記事は誕生日から年齢を算出するものです。)livewireをインストール
composer require calebporzio/livewirelivewireに必要なファイルを作成
php artisan make:livewire birthday以下のファイルが作成される
app/Http/Livewire/Birthday.php
resources/views/livewire/birthday.blade.php年齢算出処理作成
app/Http/Livewire/Birthday.php
<?php namespace App\Http\Livewire; use Carbon\Carbon; use Livewire\Component; class Birthday extends Component { /** bladeとのデータ共有プロパティ */ public $year = 0; public $month = 0; public $day = 0; public $age = -1; public $last_day_of_month = 0; public function mount($year = 0, $month = 0, $day = 0) { $this->year = $year; $this->month = $month; $this->day = $day; $this->onChange(); } public function onChange() { $year = intval($this->year); $month = intval($this->month); $day = intval($this->day); // 該当月の日(28〜31日)を計算 if ($year > 0 && $month > 0) { $this->last_day_of_month = Carbon::create($this->year, $this->month)->endOfMonth()->day; } // 年齢を計算 if (checkdate($month, $day, $year)) { $this->age = Carbon::createFromDate($this->year, $this->month, $this->day)->age; } else { $this->age = -1; } } public function render() { return view('livewire.birthday'); } }ビュー作成
resources/views/livewire/birthday.blade.php
<div> {{-- 年 --}} {{ Form::select('birth-year', array_combine(range(1950, date("Y")), range(1950, date("Y"))), '', [ 'wire:model' => 'year', 'wire:change' => 'onChange', ])}} {{-- 月 --}} {{ Form::select('birth-month', array_combine(range(1, date("m")), range(1, date("m"))), '', [ 'wire:model' => 'month', 'wire:change' => 'onChange', ])}} {{-- 日 --}} {{ Form::select('birth-day', array_combine(range(1, $last_day_of_month), range(1, $last_day_of_month)), '', [ 'wire:model' => 'day', 'wire:change' => 'onChange', ])}} {{-- 年齢 --}} @if($age > -1) / {{ $age }}歳 @endif </div>呼び出したいblade箇所で以下のように呼び出します。
<html> <head> @livewireStyles </head> <body> <div> @livewire('birthday') </div> @livewireScripts </body> </html>1つ目のエラー
Call to undefined method CompilerEngine::startLivewireRendering()
参考記事主さんが質問していました。
https://github.com/livewire/livewire/issues/711bootstrap/cache/packages.php
の
facade/ignitionを
livewire/livewireの上に移動すれば解決とな。2つめのエラー
@livewire('birthday', 2000, 12, 31)呼び出し箇所を上記のようにしたら以下のエラー。
array_intersect_key(): Expected parameter 1 to be an array, int given (View: {ファイルパス}\index.blade.php)
エラー発生箇所は以下。
vendor\calebporzio\livewire\src\LifecycleManager.php
public function mount($params = []) { // Assign all public component properties that have matching parameters. collect(array_intersect_key($params, $this->instance->getPublicPropertiesDefinedBySubClass())) ->each(function ($value, $property) { $this->instance->{$property} = $value; });@livewire('birthday', 2000, 12, 31)で呼び出すと$paramsには'2000'がきていました。
$paramsには配列が来る想定だけど文字列がきているのが原因のようです。
以下のように呼び出せば解決しました。@livewire('birthday', ['year' => 2000, 'month' => 12, 'day' =>31])routeの第2引数の書き方と同じ要領。
参考記事
- 投稿日:2020-12-23T12:12:59+09:00
【PHP】対話モードに入る方法と注意点。サクッとコードを確認する方法。
PHPでコードを簡単に確認したいときに、phpの対話モードが使える。
コマンド
php -aを実行するだけ。$php -a Interactive shell php >
Dockerのコンテナ内でphp対話モードに入る場合
#PHPのサーバーが起動していることを確認 $docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1b52690b15e1 php_server_dev:latest "/docker/development…" 20 hours ago Up 18 hours 9000/tcp, 0.0.0.0:13001->80/tcp php_server_devコンテナ名は
php_server_dev#コンテナに入る $ docker exec -it php_server_dev bash #対話モード起動 root@1b52690b15e1:/app# php -a Interactive shell php >対話モード実行時の注意点
コードの終わりに
;必須。セミコロンがない場合改行してもコードが続いているとみなされる。php > echo "a"; a #;があるまで式が終わりとみなされない php > echo "a" php > php > php > php > ; a
- 投稿日:2020-12-23T10:21:38+09:00
PHP) Exceptionエラー設計原則とアプリケーション導入
Advent Calendarへの招待、ありがとうございます。
本記事が何方かの役に立つことができると幸いです。前書き
- すべての記事は、自分の勉強目的のため主観的な内容の整理を含まれています。あくまで参考レベルで活用してください。もし誤った情報などがあればご意見をいただけるととっても嬉しいです。
- 内容では省略するか曖昧な説明で、わかりづらいところもあると思います。そこは、連絡いただければ補足などを追加するので、ぜひ負担なくご連絡ください。
- 今回の記事は Java の Exception・Concept に起因した内容を一部含めています。Java と PHP のエラーの抽象化モデリングは少々違いがあるので、後述する内容は必ず PHP においての正解とは言えません。PHP の Exception に焦点をおくよりも、言語に関係なく Exception と Application においてのエラー設計観点の考察を主に記事にしたいという思いがあったので、この意図のところを踏まえてご覧いただけると幸いです。
概要
本記事は、PHP7 をベースにしています。
本記事は以下の内容で構成されています。● PART-0. 事前知識
Exception に関わる構文と特性を簡単に説明します。● PART-1. 例外(Exceptions)と「抽象化モデリング」の理解
Exception の仕組みに対して、設計思想・核心原則を、OOP の観点と原則に基づき解説します。● PART-2. 例外(Exceptions)の「責任」原則
Exception の「抽象レベル」「特性」「ユーザー定義例外」観点で、Exception の責任と、Exception に対しての我々の責任を元に、設計原則を解説します。● PART-3. Application 開発においての「Exceptions 設計・導入」
上記の原則を元に、アプリケーションではどういう風に導入できるのかの一例を、紹介します。● PART-4. 例外設計原則まとめ
PART-1 から PART-3 までの内容を踏まえて、「Exception 設計原則・目録」としてまとめます。記事の効率的な見方
当記事は、かなりのボリュームの内容になっておりますが、全ての方に対して全ての内容が必要な訳ではないと思います。
以下の「記事を見方」を参考し、読者の方が望む方向で、この記事を効率的にご活用いただければと思います。
もちろん、例外に興味が高い方、例外を深堀たい方、例外に関していろんな議論をしたい方は、是非初めから読んでいただくと、筆者としても嬉しいです。
PART-0. 事前知識
本記事を読んでいただく前い、事前知識として必要な内容を簡単に記述します。Exception に対して、すでに経験が豊富な方は軽くみて頂くか、次の PART から読んでいただいて構いません。
「PART-0」は PHP においての Exception の基本的な使い方を話します。現段階の内容が少し新しく感じる方は Exception に関わる事例コードとかをみて、書いて、その結果を身で直接感じた上で、次に進めることをお勧めします
※1。0-1. throw new Exception
throw は、投げるという意味の
「伝達・伝播」として、意味として、強く意識していただけると良いと思います。throw 構文を使うことで、新しい Exception のインスタンを throw することができます。
throw new Exception($message, $code, $previous)0-2. try catch finally
下位CALLSTACKから伝播された例外を明示的にハンドリングできる構文です。
※ finally は、php5.5.x 以降からサポートします
try { //throwが予想されるコードブロック } catch (MoreSpecificException $ex) { //先端は、より具体的なExceptionをcatch } catch (MoreAbstractiveException $ex) { //後端は、直前と同等か、より抽象度が高いExceptionをcatchしハンドリング } finally { //try blockの例外に関係なく実行されるコードブロック }0-3. Exception Class が提供するインタフェース
Exception クラスは、いろんなインタフェースを提供しており、エラーに関する有用な情報を取得できます。特に、
getMessage()とgetTrace()は、アプリケーション運用にとって、非常に有益な情報を提供してくれます。詳細は、php reference をご覧いただけます。
https://www.php.net/manual/ja/class.exception.php0-4. class CustomMyException extends RuntimeException
Exception の属性を継承し、プログラマーが新しい Exception を定義することもできます。
アプリケーション特有のエラーに対して、「OOP と Exception の特性を生かした抽象化・構造化」設計を可能とします。
class CustomMyException extends RuntimeException { //...can implements you need }PART-1. 例外(Exceptions)と「抽象化モデリング」の理解
PART-1 からは Exception を含む、言語が提供する例外モデルに対する考察と思想に基づいた「設計論」の話が主になります。
Exception とエラーに対する設計論は、様々な議論が存在し、システム要件と開発状況によって、正解というのが難しい分野だと思います。筆者自身にとっても苦難を重ねている分野でもある分、主観的な意見を多数含まれています。
そこを認識いただいた上で、参考までに読んでいただけると幸いです。筆者自身もいろんな意見をいただき、また知識の糧にしたいと存じます。
1-1. PHP の例外(Exception)の構成
1-1-1. 例外の構成図
PHP で基本提供している例外の構造は、上記の図になります。
- ここで話す「例外」は、throwable を継承する全てのクラスを意味します。
- Error クラスと、それを継承するクラスも「例外」です。
- ブロックは is-a 関係を表しています。特定クラスが特定の複数のブロックに含まれる場合、複数ブロックで示しているクラス名と is-a 関係が成立します。(インタフェース名も、便宜上クラス名と称します。)
- PDOException は、PDOException 自分自身であり、RuntimeException でもあり, Exception でもあり, Throwable でもあります。
- 色がついているクラスは、子クラスを持つ親クラスです。
- RuntimeException は、PDOException を子クラスで持ちます。
しかし、ここで全てのクラスの意味を説明したりはしません。
大事なのは構造です。上記の親とこの関係、ブロックと is-a 関係を主に意識していただいても大丈夫です。
なのでこれからは、以下のように図を簡略化して、説明していきます。一つ一つの例外を確認したい方は、言語レファレンスや、以下の記事をお勧めします。
https://www.php.net/manual/en/reserved.exceptions.php
https://www.php.net/manual/en/spl.exceptions.php
https://qiita.com/mpyw/items/c69da9589e72ceac470c1-1-2. 例外クラスの説明
上記に表している例外に関して、一部のみを簡略に説明します。しかし、今すぐその意味を全て理解する必要はありません。 各自の例外の継承するクラスと、その関係性を意識して頂くと良いです。
● Throwable
throw 特性を持つ全てのクラスの最上位インタフェース● Error
PHP 内部的に発生可能な全てのエラーのベースクラス● Exception
プルグラマー・ユーザーから起因可能な全ての例外エラーのベースクラス
Throwable を継承● RuntimeException
コンパイル段階で言語が探知できず、実行時に発生可能性がある例外。またはその特性を持つ子クラスの最上位クラス
Exception を継承● LogicException
未具現のメソッドの呼出や、誤った引数の指定など、実装の問題などで発生させることができる例外
Exception を継承● ClosedGeneratorException
PHP のジェネレーターを使う時、すでに closed のジェネレーターに対して実行を試みた時発生する例外
Exception を継承1-2. PHP の Exception の理解の核心は、OOP の「抽象化」
1-2-1. 例外は「抽象化」されたモデル
OOP 設計の核心は「抽象化モデリング」「抽象化されたモデル」と言えます。
もっと具体的に定義すると、「解決(具現)すべき課題を、クラスコンセプトに基づき抽象化モデリングし、解決手段を状態(member)と行動(method)をコードとして記述するプログラミング手法」と言えます。PHP の Exception の概念も、まさに OOP の抽象化モデリングの事例です。
まず、Exception を実際に扱う前に、ここを意識するのはすごく大事です。1-2-2. 簡略化した例外構成図と抽象レベル
上記の図は、PHP の例外構造を簡略化した上に、格例外の抽象レベルを表しています。
- Level の数字が低いほど、抽象レベルは高く、より抽象的で、幅広い意味を持ちます。
- Throwable は、「全ての例外」その物なのでとっても抽象的で、Throwable だという情報だけでは具体的に何なのかを特定できません。
- Level の数字が高いほど、中量レベルは低く、より具体的で、比較的に明確な意味を持ちます。
- PDOException は、より具体的で、PHP Data Object で発生した例外という特定ができるほど具体的です。
1-3. PHP のエラーは、プログラムで起き得る「事故を階層的に抽象化」したモデルである
では、例外というのは、何を課題を解決するためにあるのかを考えてみましょう。
まず、例外は、何らかの「事故」と理解しても問題はないと思います。
そして例外の概念は、「プログラムで起き得る事故を課題として扱い解決するため」に抽象化されたモデルと言えます。
この概念は、現実世界の事故の概念ともかなり似ています。
では、現実世界の「事故」を抽象化した物と、PHP の例外を、以下の観点で比較してみましょう。
- 現実世界と構成・構造が類似しているか?
- どれだけ抽象的かによって、抽象的、または具体的な事故が持つ意味が、事故と PHP 例外の間で類似しているか?
1-4. PHP の Exception は、「上位階層なほど抽象的、下位階層なほど具体的」である
うまくモデリングできたでしょうか。
正確に当てはまる訳ではないですが、現実世界の事故と、PHP の例外の階層を当てはめて比較してみましょう。
- Level の数字が低いほど、抽象レベルは高く、より抽象的で、幅広い意味を持ちます。
- 事故は、「全ての事故」その物なのでとっても抽象的で、事故だという情報だけでは具体的に何なのかを特定できません。
いまの情報では、筆者の生命封建や自動車保険で処理できる事案なのかわかりません。勝手に処理することもできません。- Level の数字が高いほど、中量レベルは低く、より具体的で、比較的に明確な意味を持ちます。
- 交通事故 → 物損事故は、より具体的で、自動車そのものの物損被害事故が発生したと特定できるほど具体的です。
幸い、筆者は自動車保険があるので、筆者が保険社を通してリカバリーできそうです。「事故」という単語は、現実世界の全ての種類の事故を意味しており、とっても抽象的です。PHP 例外の最上位の Throwable もまた、システム・プログラムないで起き得る全ての事故の意味を持つので、とっても抽象的だと言えます。
「自然災害事故」と、「人為災害事故」は、より具体的ですね。
「自然災害事故」は、普通は環境によって起きるので、PHP の Error Class と似てると思います。
「人為災害事故」は、人により起き得る物なので、PHP の Exception Class と似ていると言えるでしょう。しかし、まだ「人為災害事故」と言っても、具体的ではありません。どういう事故か、どういう風に対処すればいいか、現段階では予測できません。
「交通事故」までくると、かなり具体的になりました。RuntimeException に当たるレベルと似ている感じですね。
「物損事故」レベルまでくると、どういう原因・内容・対処法で良いのか予想がつくようになります。PDO Exception や、Custom Exceptions が、ここに当たる感じになります。
ここで、注目するべきは、「抽象レベルに基づいた階層構造」ということです。
現実世界の事故のモデリングもそうですが、PHP の Exception もまた、「どれだけ抽象的か?」を基準に、階層的に構造化されているという認識はすごく大事です。抽象レベルにより、例外自体が持つ責任と、我々が持つ責任が大きく変わるからです。
1-5. Specific Exception can be Abstractive
OOP の基本原則には、継承による「is-a relationship」という原則があります。
「交通事故」というクラスが「事故」というクラスを継承すると、交通事故は交通事故自身であり、事故でもある(交通事故 is a 事故)という原則です。ここで私たちが注目するところは、「a」という冠詞です。なぜいきなり英語?という考えるかもしませんが、「a」は「何かの、何らかの」の意味に近い不定冠詞と言えます。ざっくりいうと「指定されていない何らかの事故」という意味で、抽象的な概念を含むようになります。「あの、その」みたいに特定された一つの意味に近い「the」ではなく、「a」で表記しているところの理由はそこにあります。
つまり、「is-a relationship」は、同一性だけじゃなく、
「抽象性」も表している原則です。ここで、人に内容を伝えるときに、「交通事故 → 物損事故」と伝えるのと、「事故」と伝えるのでは、情報の抽象度が変わってきます。「事故」を聞くと、交通事故か、火事か、自然災害かわからないから、反応にも困るでしょう。そこでどういう事故?と聞いても、事故よ事故とだけ言われる、我々は具体的な情報を特定できないので、相当困るでしょう。
- 交通事故→物損事故 is a 交通事故→物損事故 (具体的) - 交通事故→物損事故 is a 交通事故 - 交通事故→物損事故 is a 人為災害事故 - 交通事故→物損事故 is a 事故 (抽象的)Exception と、その配下の Exception たちも、同じ関係です。
- PDO Exception is a PDOException (具体的) - PDO Exception is a RuntimeException - PDO Exception is a Exception - PDO Exception is a Throwable (抽象的)と言えます。
つまり、PDO Exception と言われると、「PHP Data Object 処理でエラーになったな」と予想できるものが、Throwable と言われると、どういう例外か予想しづらくなります。
そして、予想しづらい事故は、個人レベルで全て対応仕切れないし、無理に処理しようとしても状況が悪化する場合がおおいです。そして、情報を知るべき団体や国家は、その情報を把握できなくなります。
「Exception の世界もまた、それは同じだと言えます」
1-6. 抽象的な例外ほど予測と正確な対処が難しい
今までみてきたように、Throwable,または Exception クラスは、とっても多くのプログラムでの「事故」を意味している概念なので、正確な原因と対処が難しいのが一般的です。
public function createNewData() { ... try { $data = $clientDataServer->getTokenData($dataId); $saveToDatabaseUsingPDO->insertNew($data); ... } catch (Exception $ex) { Logger::critical("DB WORK FAILED!!", $ex->getMessage, $ex->getTrace()); //some recovery logic for DB WORK return; }上の例は、よくないと言えるエラーハンドリング例です。
プログラマーの意図としては、データの生成時に、DB 作業時で発生可能な何らかのエラーをハンドリング・リカバリーしたい意図があります。
しかし、
is-a原則を覚えていますでしょうか?Exception クラスは、DB 作業に関わる saveToDatabaseByPDO の例外だけでなく、clientDataServer や、その他で起き得る全てのエラーに対して、PDO エラーと同一視してしまいます。
ここは、具体的な PDO Exception を catch し、追加に clientDataServer で起き得る具体的な Exception を catch するか、予測できない例外は catch せず、上位に委任することが、一般的には望ましいです。
try { ... } catch (ClientDataServerException $ex) { ... } catch (PDOException $ex) {1-7. try-catch をするということは、一種の「保険」をかけること
プルグラムで、例外が予想されるポイントで、例外が起きた時の対応処理を事前に決めて実装したりします。
この概念もまた、現実世界の事故と類似しています。
筆者は自動車をもっていて、自動車保険に加入しています。
そこで、筆者がドライブをするとなると、「事故が会ったら保険証理しよう」という前提条件がすでに当たり前の認識なっていますね。ここをコードで表現すると、以下の模様になります。
class 筆者 { public function __construct( $自動車, //筆者は自動車をもっている $自動車保険社 //筆者は自動車保険者に加入している ){ ... } public function doDrive() { ... try { $this->自動車->運転中() } catch (交通事故\物損事故) { $this->自動車保険社->保険処理->請求() } } }
- 自動車保険会社のクラスは、保険会社のサービスに例えます。事前に登録しないと保険サービスを受けられないから、必ず登録しましょう
- try&catch 構文は、車両登録と保険会社の連絡先を前もって用意しておくとこに例えますね。自動車事故が起き得る状況にはちゃんと備えて起きましょう
- catch の中身の実装は、事故発生時の対応知識ですね。我々は、すでに学校や封建会社で学んでいるから当たり前にしっいることですが、システムはわからないので、ちゃんとコードで教えてあげましょう。
では次は、以下のシチュエーションを想像してみてください。
1-7-1. try - catch していない。(保険をかけていない)
いうまでもなく、お金的にも、民事訴訟的なところでも大変になるでしょう。
※ プログラム上でもも同じく大変になるかもしれません。
1-7-2. 「事故」として、catch していて処理している場合**
どういう事故なのかによって、できることの範囲は違ってきます。
- 自動車事項:自動車保険処理・連絡
- 盗難事故:警察に申告・連絡
- 事故:事態把握・連絡
そして、自動車事故を、自動車事故と認識せず、事故と認識すると、確実にしてもいものは、「自体把握・連絡」です。
この状態で、「自動車保険処理」をやっても、運が良ければ、いい対応になるかもすが、「実は盗難事故でした」だったり、「自動車事故なのに、間違って警察に申告てしまった」など、謝る処理をしてしまう可能性がおおきいでしょう。
※ プログラム上でも同じく、意図しない変な処理をしてしまうかもしれません。
1-7-3. 筆者がどうすることもできない「自然災害事故」が起きた場合
個人レベルでどうにかなる自然災害なら、事故として扱っても何とかなるかもしれせん。
しかし、個人レベルではどうしようもなく、国家レベルで対応するしかない自然災が起きたらどうでしょう。個人レベルで無理やり処理しようとすると、むしろ状況を悪化させる可能性が非常高くないでしょうか。
こういう時は、状況把握・事故に対する必須対応後、迅速に家に委任するのがいいでしょう。
※ プログラム上でも同じく、ログ記録・必須対応だけ行って、上位階層に委任するが最善な場合が多いです。
この論理は、プログラムでの例外と try-catch 関係と非常に類似しています。
つまり、 「例外を try-catch することは、一種の保険をかけること」 と言えると、筆者は思います。? PART-1 のまとめ「例外と抽象化モデルの理解」
PART-1 の内容をまとめると、以下になります。
- 例外(Exceptions)は、プログラム上で起き得る「事故を階層的に抽象化」モデリングした物である
- 「上位階層なほど抽象的、下位階層なほど具体的」である
- 「具体的」は「抽象的」にもなれる
- 抽象的な例外ほど予測と正確な対処が難しい
- try-catch をするということは、一種の「保険」をかけること
PART-2. 例外(Exceptions)の「責任」原則
「PART-1」では、例外はシステム、またはアプリケーション上での「事故」と表現しました。
現実世界でも、個人、または団体・国家が事故に対する事後処理をするように、アプリケーションを生み出した我々は、ここで起き得る「例外」という事故に対して、何らかの責任を果たす必要があります。
しかし、現実世界の事故も個人・団体レベルでは解決仕切れない物もあるように、我々が解決仕切れない例外も有ったりします。
そういう問題は、無理やり解決しようとするか、誤って解決をすると、もっと大変な事故による2次被害も起き得るのでしょう。そういう時は、もっと上位の団体や国家に委任するように、上位に委任し委ねるという考え方が一般的には好ましいです。では、我々は、様々な例外に対して、どういう風に責任をとり、解決、または委任するべきでしょう。
ここは、実はすごく難しいところですが、 「抽象レベル」「Exception 特性別」「Custom Exception」 の三つの観点でお話しします。
2-1. 「抽象レベル」観点での責任と原則
2-1-1. catch する時は、「具体的」な Exception を catch する
「具体的」な Exception というのは、以下のような特徴を持ちます。
- 比較的に明確な例外状況の意味をもっており、例外の特定・処理において明確な予想ができる
- 明確に予想できる例外は、必要有無によって、「後処理」後、「完結」するか「委任」するかを柔軟に選択できる
- 上位に委任するほど、抽象的になったしまう傾向が強い
※2まず、よくないコードの例をみましょう。
public function deepDepthMethod { ...code - should be thrown a MyValidationException which is HighSpecificException ...code - should be thrown a PDOException which is SomeSpecificException of Database Handling Driver } catch (Exception $ex) { ...some recovery logic & logging return $resultOfThisCase;上記のコードがよくない理由は、以下になります。
具体的な例外の予想がつくポイントで、抽象的例外として扱っている- 抽象的例外を扱うことで、予想しづらく、
何か正確にわからない何らかの問題が起きた時も、該当メソッドで処理し完結させてしまう。(正しい処理じゃないかもしれないのに)- 上位階層が知るべき情報も、このレベルで遮断され、適切な対応ができなくなる
※3。なので、こういう場合は、以下の原則を意識しながら実装するのが好ましいです。
1) 具体的に予想できる Exception を catch する
すでに、MyValidationException が例外として発生する可能性を我々はすでに知っています。その場合は、具体的な MyValidationException のみ処理し、それ以外の予測できない問題は、無理に catch せず、上位に委ねます。
public function deepDepthMethod { ...code should be thrown a MyValidationException which is HighSpecificException ...code should be thrown a PDOException which is SomeSpecificException of Database Handling Driver } catch (MyValidationException $ex) { ...some recovery logic & logging return $resultOfThisCase; //完結 } finally { //必要な場合 }2) 具体的な Exception を明示的に上位に委任する
具体的に予想される例外に対して、catch したとして、必ずしも完結させる必要はありません。必要に応じて、必要な処理だけをした後、上位に委ねることも可能です。
- 予測される例外に対して、このポイントでは必要な最小処理だけを行って、残りの処理は、上位の共通処理に委ねたい。
- 予測しづらい例外が発生した時でも、必ずこのポイントで遂行しなければいけない処理がある時、必要な処理だけを行って上位に委ねます。
public function deepDepthMethod { ...code should be thrown a MyValidationException which is HighSpecificException ...code should be thrown a PDOException which is SomeSpecificException of Database Handling Driver } catch (ValidationException $ex) { ...省略 } catch (PDOException $ex) { ...some recovery logic & logging throw $ex; //委任 }
2-1-2.「抽象的」な Exception は、なるべく上位に委任する
「抽象的」な Exception というのは、以下のような特徴を持ちます。
- 多くの例外状況の意味をもっており、具体的な例外の特定・処理が難しい。
- 無理やり catch し、処理しようとすると、例外を間違って特定・処理してしまう可能性が大きい。
例えば、「抽象レベルが高い Exception を処理している」というのは、以下のように Exception や Throwable という相対的最上位例外を catch している場合だと表現できます。
public function deepDepthMethod { ...code should be thrown a Throwable which is High-Abstractive } catch (Exception $ex) { ...some recovery logic & logging return false; } catch (Throwable $e) { ...some recovery logic & logging return false;上記の例は、deepDepthMethod という、比較的に「Call Stack の下位ポイント
※4」から呼ばれる設定のコードです。このコードがよくない理由は、以下になります。
- deepDepthMethod がカバーできる責任を超えて、後処理し完結させている。
- 新しい問題を生み出す可能性
- この「完結させ return する」構造だと、上位ポイントのメソッド各自が、return 結果に対しての責任者になり、全てのポイントで、return 結果による処理を実装しなきゃいけない
- エラーの制御処理実装の大変さ。
なので、こういう場合は、以下の原則を意識しながら、実装するのが好ましいです。
1) 抽象的な例外は、なるべく catch しない。
catch せず、上位に責任を委任することです。
この場合は、何が起きるのかわからない Exception に対しての対応なので、
phpdoc の throws 構文も書かない方が、筆者的にはお勧めです※5。/** * dont describe 「throws」 */ public function deepDepthMethod() { //no use try catch ...code should be thrown a Throwable2) 抽象的な Exception が予想されるが、必ず後処理をする必要がある場合は、「処理後委任」する
場合によっては、何らかの例外が起きた時、何らかの処理が必須な状況もあると思います。しかしそういうときには、処理後完結せず、「処理後委任」を意識しておくと良いです。
状況に応じて、以下の方法で対処できます。
① finally 構文を使った後処理
//finally構文で、例外に関係なく、後処理を行えます。 //例外が起きなくても実行されるところは注意しましょう。 //php 5.5.x versionからサポートします。 public function deepDepthMethod { ...code should be thrown a Throwable } finally { ...some finally logic && logging② そのまま再伝播(re-throw)
//そのままexceptionを再伝播できます。 public function deepDepthMethod { ...code should be thrown a Throwable } catch (Exception $ex) { ...some recovery logic & logging throw $ex③ Custom Exception でラッピング(Wrapping)
//Exception Wrappingは、アプリケーション全体におけるエラー設計が、かなり重要になってきます。 //必ずpreviousに原本のExceptionをアサインしてあげましょう。 //上位レベルのエラー処理で、previousの情報も処理&ログするようにしましょう。 public function deepDepthMethod { ...code should be thrown a Throwable } catch (Exception $ex) { ...some recovery logic & logging throw new CustomException('message', 'code', $ex); // ANTI PATTERN >> throw new Exception('message', 'code', $ex)
2-1-3. 抽象的な例外に対する後処理は、できるだけ上位階層のポイントで処理する
では、予測が難しい抽象的な例外に対しては、何もしなくていいのか?と聞かれると、そうではありません。
- 予測できない例外に対して、 「上位階層で意図的に検知」 すること
- 必要なら発生した「予測できなかった例外」に対して、 「原因と特定し具体的な例外として再定義」、潜在的な問題を解決すること
は、アプリケーション運用においてとっても大事なことです。
予測できなかった抽象的な例外も、実のところふかぼれば、我々ば単純に予測できなかっただけで、原因・現象・対象が明確な、具体的例外の場合は多いからです。
そして、ここで例える上位階層のポイントは、アプリケーションの実行ポイントを意味しており、例えるなら以下になります。
1) アプリケーションのエントリーポイント(進入ポイントの try catch)
アプリケーションの最上位進入ポイントで、最上位の例外を検知し、運用上気付けるような構造で Application を設計することもできます。
try { $application = new Application(); //applicationのビジネスロジックの進入 //ビジネスロジックでは、具体的な例外は処理しつつ、予想できない抽象的例外に対しては、最上位まで委任させる $application->run($request, $response); //applicationのビジネスロジックの完全終了 } catch (Exception $ex){ //Applicationレベルで責任を取れなかった、予測できない例外に対して、ログを残し、指定をレスポンスを返す $logger->critical($ex); $application->response(500)->toJson()->send(); throw $ex; }2) フレームワーク階層 (Error Hook, Error Handler、フレームワーク搭載の処理・ロギング)
例えば、Symfony には、Event Handler のインタフェースを提供しており、
onKernelExceptionのインタフェースを具現すると、Framework においての Global な例外に対して、処理ができます。詳細は、Symfony Framework の Event Listener をご参考できます。
https://symfony.com/doc/current/event_dispatcher.html// src/EventListener/ExceptionListener.php class ExceptionListener { public function onKernelException(ExceptionEvent $event) { // You get the exception object from the received event $ex = $event->getThrowable(); $logger->critical($ex); $response->setStatusCode(Response::HTTP_INTERNAL_SERVER_ERROR); $event->setResponse($response); } }このように、大体の framework は、例外に対して、制御インタフェースを提供する場合が多いので、予測できない例外の検知と対策として有用に活用できます。
3) PHP・コア階層 (PHP とウェブサーバーの基本エラー処理・ロギング)
例外をコードで特に Catch しないと、PHP の基本処理としてエラーページを表示し、ログに残します。(apache error log など)
これらの基本仕様にしたがって、ログ検知などをかければ、それなりに運用することはできます。
しかし、筆者としては、① や ② のようにアプリケーション要件に合わせて設計と実装するのをお勧めします。経験としては、PHP の基本エラー処理とロギングでは、情報が不足して、調査と特定が難しい場合が多かった記憶があったからですね。
もちろん、中途半端な ① や ② の方法を行うよりは、③ が良い場合もあるので、アプリケーションと要件と状況に合わせて導入を検討するのが良いでしょう。
2-2. 例外の特性観点での責任と原則
この題目は、PHP の例外の構造と特性上、分類がかなり難しいところではあります。
その理由はいろいろありますが、「①PHP では Exception を「the base class for all user exceptions」と定義している特性、② 実行要請ごとにコンパイルと実行を同時に行うという特性、③ コンパイルと実行の境界が曖昧という特性」、この 3 つの特性で、PHP での Exception 設計において、かなり複雑にするポイントだと思います。
それでも、この概念の理解は、Exception 設計の根元を理解するのにおいて、大事な概念だと思い、話すことにしました。あくまで参考までに見ていただき、実装時の観点の一つとして留めていただけると幸いです。Exception も実は、各種類の例外に対して、それぞれの特性をもっています。
その中で、Exception 全体に共通する属性と特性をもって、説明します。
- Runtime(Unchecked) Type
- Non-Runtime(Checked) Type
2-2-1. Runtime Exceptions vs Non-Runtime Exceptions
まず、Runtime Exceptions は、RuntimeException の特性を継承する Exception たちです。
PDOExceptionが代表的な例です。Runtime Exception を継承しない Exception は、全て Non-Runtime Exception と分類できます
※6。Runtime と Non-Runtime は、以下の意味と違いを持ちます。
① Runtime
Runtime は、アプリケーションの実行時に発生可能性がある例外を意味します。
ここで大事なのは、実行時に「発生するかもしれないし、しないかもしれない」という特性を理解するのが大事です。代表的に PDOException を例えられます。
※ Java の Exception Architecture Concept では、「unchecked type」と分類されます。
● PDOException の例え
PDOException: SQLSTATE[23000]: Integrity constraint violation: 1062 Duplicate...
を見た経験はあるのでしょうか?上記のエラーは、DB Insert 時に unique key field に対して重複データを入れようとした時に発生します。逆に重複しないデータを入れたときには、アプリケーションは正常に動くようになります。
そして、データというのは、直接データをもらい実行してみる前までは、発生するかしないかわかりません。ただ発生可能性もあるという予測ができるだけです。つまり Runtime 例外はプログラムの実行中、 「実行条件によって発生有無が変わる例外」 です。
② Non-Runtime
Non-Runtime 例外は、コンパイル時に発生する可能性がある例外です
※7。
場合によりますが、「コンパイル時に高い確実で発生可能」な例外を意味します。Throwable 配下の Error を継承する例外(CompileError)や、RuntimeException を継承しない Exception(LogicException, ClosedGeneratorException)が該当します。
※ Java の Exception Architecture Concept では、「checked type」と分類されます。
● LogicException の例え
LogicException は、プログラマーに提供される Exception インタフェースですが、未実装のメソッドの呼び出し(BadMethodCallException)など、コードレベルのミスに対する例外として定義できます。
● ClosedGeneratorException の例え
ClosedGeneratorException は、php の Generator 機能に関わる例外です。
PHP の Generator は、とある連続的なデータセットを、code looping を通して返却を保証するインタフェースであり、そのゆえに大量のデータの操作に関しても、最低のメモリーで処理を可能とします。
「code looping」を意識してください。つまり「実行前に連続的データを code に変換し実行」するという意味をもっています。
ClosedGeneratorException は、すでに Closed された Generator を呼び出そうとする時発生します。そしてこのエラーは、実行時のデータ条件により変わる例外というよりは、コンパイル時の Code Error として見なすこともできます。
の事例は、以下の stackoverflow で詳細に説明されているので、ご参考ください。
https://stackoverflow.com/questions/17483806/what-does-yield-mean-in-php2-2-2. (Java 引用) Concept -「Checked」or「Unchecked」Exception
Java では、Runtime 例外特性を「Unchecked」、Non-Runtime 例外特性を「Checked」に分類します。ここに関して、もっと詳しく見たい方は、Java の Exception Concept をご参考いただけると良いと思います。
この概念は 100%当てはまる訳ではないですが、相当部分が当てはまるので、その特性と責任を引用し説明します。
このように、PHP の Runtime Exception は「Unchecked Type」に、Non-Runtime Exception は「Checked Type」しても、かなり当てはまるところが多いと考えられます。
ここで注目するべきところは、 「確認時点」と、「後処理責任義務」 のところです。
ここに関しては混乱するかもしれませんが、次の Step で解説します。2-2-3. 「Runtime・Unchecked」。プログラマーが、プリケーション運用においてもっと注目するべき Exception Type
ここで、Runtime・Unchecked Type(以下 Runtime と表記)の「確認時点」と「後処理責任有無」をもう一度確認してみましょう。
- Runtime Type
- 確認時点:実行段階(発生しない可能性が常にある)
- 後処理責任有無:明示的に強制しない
ここで、疑問が浮かんできます。
- Q1) 同じ例外なので、なぜ処理を強制しないのでしょうか?
- Q2) なぜ、処理を強制しない Runtime Type を、プログラマーは、もっと注目しなきゃ行けないでしょうか?
- Q3) 具体的に、どういう部分を注目すればいいでしょうか?
この疑問に対して、回答しながら、その理由を解説します。
Q1) 同じ例外なのに、なぜ Runtime Type には「後処理」を強制しないのでしょうか?
ここでの 「後処理責任有無」というのは、人の観点ではありません。
言語とコンピューターシステムにおいての「処理責任有無」を表しています。わかりやすく解釈すると、観点に正確ではないかもですが、以下のような理解で良いと思います。
- 後処理責任有無-必ず処理必要
- 解説:処理してくれないと、プログラムを「コンパイルと実行ができない」から、処理してくれ!
- 後処理責任有無-明示的に強制しない
- 解説:一旦コンパイルは成功したし「実行もできた」から処理を強制はしないよ!ただ、何が起きるか「システムである私にはわからない」から、「君が責任をとって処理するかしないか決めてね!」
ここで、 「君が責任をとって処理するかしないか決めてね!」 が、大事な題目です。
Runtime Type の例外は、システムでは発生するか否かを判断できないので、処理を強制せず、まず実行を優先します。判断できない・発生しないかもしれない例外に対して、プログラムは実行を止めてまで、処理を強制することはできないからです。
つまり、Non-Runtime とは違って、 「システムには予想できない Runtime 特性の例外の責任は全的にプゴグラマーにある」 ということです。
Q2) なぜ、処理を強制しない Runtime Type を、プログラマーは、もっと注目しなきゃ行けないでしょうか?
サービス運用において、本当に難しく、深刻な状況を生み出すのは、どういう Type の例外でしょう。
筆者の経験では、Runtime 時に発生する予測しなかった問題が圧倒的ですね。
理由は、以下になります。● Non-Runtime の問題
主に、環境設定や、コーディングミスによる問題。
大体は実行の前段階で発生する。
故に、
- 発見・原因特定が簡単、修正対応が明確
- 実行されてもいないので、「システムの整合性の崩れ、永続性データの汚染」なども発生しづらい
● Runtime の問題
主に、予測していない入力値や、論理的欠陥による問題。
大体実行途中で、実行条件により、発生するかもしれないし、しないかもしれない。
故に、
- 発見・原因特定が難しい、修正対応も困難
- 実行途中で起きたので、「サービスの整合性の崩れ、永続性データの汚染」が発生しやすい。
「サービスの整合性の崩れ、永続性データの汚染」の捕捉するとこうです。
● サービスの整合性の崩れ
データの整形・数値の計算などで、意図していない論理的欠陥が発生することで、「サービスの論理的整合性」が崩れること● 永続性データの汚染
Database や File などで、処理途中で止まったか、意図していない結果のデータが、保存されることで、「永続性データの無欠性が崩れること」このように、Non-Runtime は、大体すぐ気づけて復旧する間にユーザーはその機能を使えないというレベルで止まる場合が多いですが、Runtime のエラーは、サービスの整合性と無欠性そのものを崩してしまう場合も有り得ます。
そしてここは、復旧が聞かないほどの「事業レベルでの損害」と繋がる場合も少なくはありません。
Q3) 具体的にどういう部分を注目すればいいでしょうか?
筆者として注目するべきポイントは、以下だと思っています。
- 予測できる Runtime 特性の例外に関しては、必ずその影響を考え、必要な時は記録・通知・復旧対応をする
- 予測しづらいポイントに関しては、上位レベルで必ず catch し、詳細ログを記録する(stack trace まで)
- 予測しづらいポイントでの例外は、critical level とみなし、即時に気付けるようにして、その原因と影響の把握ができるように試みる
正直なところ、Runtime 時に発生できる例外を全て完璧に対象しておくのは、すごく難しいことです。
なので、大事なのは 「発生した時必ず気付けること、原因特定と復旧のために詳細に記録すること、一度発生した問題に対しては永久対応を試みること」 と言えます。
2-3. Custom Exception に対する責任と原則
我々は時々、言語で提供している Exception のインタフェースを継承し、Custom Exception を作る場合があります。特に Framework では、Framework 独自の Custom Exception を多数もっていたりもします。
では、この Custom Exception に対して、どういう責任を付与して、また我々は責任をはたすべきでしょうか。
2-3-1. 主に Runtime Exception 属性を持つ Custom Exception を設計すること
まず、Custom Exception を作る用途は様々ですが、主に推奨するのは、以下の目的での Exception です。
- Data Validation
- Broken Data & Status Integrity
- Access Control & Status Control
- API Communication Handling
- その他、ライブラリやフレームワークにおける、エラー処理
ここで、全体的に通用する特徴は「Runtime 特性で起き得る問題」ということです。
つまり、我々が Custom Exception を作る主なニーズは、「システムで責任を取れない Runtime 時に
の問題を人間が対処するために、対処すべき問題を例外としてモデリングする」ことと言えると思います。※ なぜ、Non-Runtime Exception の CustomException は主な関心事ではないのか?
未具現のメソットの呼び出しとかの例外をアプリケーション独自で処理したく、LogicException を継承して、コードレベルエラーに対して Non-Runtime Exception を定義することもできますが、必要性は低いです。
2-3-2.「明確・具体的」な Exception であること
Custom Exception は、プログラマーが定義する例外です。
つまりプログラマーが、何らかの意図を前もって定義するということです。
そしてその意図は明確で具体的でなければなりません。明確ではなく、抽象的な意図をもって CustomException を設計すると、システムの例外体型が崩壊します。
ここは、アプリケーションの要件により、様々な答えが正解になったり不正化になったりもする、難しいところではありますが、PART3 の「Application においての Exception 設計」を参考していただければと思います。
まずは、 CustomException は、「明確・具体的な例外であること」 を心に留めておいてください。
? PART-2 のまとめ「例外の責任と原則」
PART-2 の内容をまとめると、以下になります。
● 「抽象レベル」観点での責任と原則
- catch する時は、「具体的」な Exception を catch する
- 「抽象的」な Exception は、なるべく上位に委任する
- 「抽象的」な例外に対する後処理は、できるだけ上位階層のポイントで処理する
● 「例外特性」観点での責任と原則
- Runtime と Non-Runtime を意識して設計・ハンドリングする
- サービス・アプリケーション運用においては、Runtime 特性の例外を注目し対応・運用する
※ Runtime 特性の例外を軽視しては行けないという意味です。Non-Runtime 特性の例外を軽視してもいいという意味ではありません。
● 「Custom Exception」に対する責任と原則
- Custom Exception は、Runtime Exception を焦点に設計するのが好ましい
- Custom Exception は、「明確・具体的」であること
PART-3. Application 開発においての「Exceptions 設計・導入」
今回は、実際に Application の開発・運用において、どういう風に設計することができるのかを話します。
ここの話は、Application の要件と開発組織によって、正解だったり不正解だったりする、難しいところですが、筆者が考える、今までの原則を踏まえて解説しようと思います。
ここでお話しする Exception 設計と導入は、以下の意味を示しています。
- アプリケーション独自処理で、人が定義した、人が予想できる、処理するべきエラーという問題を Custom Exception として設計し定義
- プログラムで起き得る具体的な Exception の検知・処理
- プログラムで起き得る抽象的な Exception における検知・処理
- Exceptions 設計導入アプリケーションの運用
このパートは、Symfony Framework の内容を一部含めていますが、基本原則自体は変わらないので、どのアプリケーションにおいても参考にできれば幸いです。
そして、これまでみてきた内容の元に、話していくので、内容自体は重複する部分が多いとおもいます。今まで話した概念を、より活用に近い観点で再整理するという目線でご覧いただくと良いと思います。
3-1. Exception 設計の導入の長所
開発するアプリケーションにおいて、Exception 設計の導入は、以下の長所を持ちます。
3-1-1. Application における、OOP に基づいた Exception 導入の長所
1) 長所
Exception は「throw・上位伝播」特性をもっています。
そしてこの特性は、以下の長所を提供します。
- エラーに対して、Exception クラスの特性をもって定義し、詳細な情報を記述できる
- エラーの特定と対処がしやすくなる。
- エラーの制御処理が飛躍的に効率的になる。
- Exception を任意のポイントで発生させ、上位に伝播し、必要なポイントで検知・処理・委任できる。
- アプリケーション全体のエラーを、階層化・構造化できる
- エラーという問題は、抽象化モデリングし、綺麗な設計ができる
2) 長所解説 - Exception がいない場合と Exception がある場合のお話し
最近のプログラムは、昔に比べてより複雑になり、様々なライブラリやフレームワークが提供するクラスのメソッドを、階層的に呼ぶ傾向が多くなりました。
こういう環境で、例えば Exception 概念がない言語とみなし、特定のエラーを処理してみましょう。
① Exception 概念がない場合
class EntryPoint { public function execute() { (new DepthLevel1())->do(); } } class DepthLevel1 { public function do() { (new DepthLevel2())->do(); } } class DepthLevel2 { public function do() { ... if ($validationError) { return false or error情報を含む変数 or 強制終了 } if ($databaseWorkingError) { return false or error情報を含む変数 or 強制終了 } } } //実行 (new EntryPoint())->execute();上記は Exception を使わない場合、よくみられるエラー処理パターンです。
比較的に CallStackが深くなかった昔は、何とかやってこれましたが、プログラムが複雑になり、特に OOP の特性上 CallStack に深くなるしかない現代プログラムでは、以下の課題を抱えています。
- EntryPoint までエラー情報を伝達し、最終結果をユーザーに表示するためには、各自の CallPoint で、return を受け取り適切な処理をするロジックを実装するか、強制的に実行を終了して結果を返すしかできません。
- エラーに対して、特定の CallPoint で処理した後、完結させたり委任したりする場合、処理制御がとっても難しいです。
- return でのエラー伝達は、明確なエラーを伝えることと、エラー構造を守って開発し、プログラムを維持するのが難しいです。
- 上記の理由により、エラー処理自体がバグポイントになる可能性が高いです。
では、今の構造を Exception を導入したコードに変えてみましょう。
② Exception 概念がない場合
class EntryPoint { public function execute() { try { (new DepthLevel1())->do(); } catch (ValidationException $ex) { ...response 400. BadRequest } catch (Exception $ex) { ...logging specific information about Unknown Exception throw $ex; //もっと上位に委任 } } } class DepthLevel1 { public function do() { try { (new DepthLevel2())->do(); } catch (PDOException $ex) { ...data check & recovery if needed & logging throw $ex; } } } class DepthLevel2 { public function do() { ... if (validationError) { throw new ValidationException($message); } $stmt->execute(); //will be throw PDOException } } $result = (new EntryPoint())->execute();このように、
- 上位伝播の特性で、必要なポイントで、必要な処理を実装することで、簡単に制御処理を実現できます。
- Exception たちは、各自で具体的な意味と、詳細情報を含めているので、予測・原因特定・処理もシンプルになります。
- Exception たちは、すでにクラスとして構造化され定義されているので、コード観点での維持補修もシンプルになります。
- 制御の追加・修正もまた、柔軟に行える構造になっています。
OOP の言語では、今まで話した OOP 言語の特性・プログラムの複雑化・Exception 導入の長所をもっと、アプリケーションにおける Exception 設計の導入が勧められます。
3-1-2. Application における、Custom Exception 設計の長所
Custom Exception は、
「3-1-1」で語った長所を、サービス・アプリケーションにおいて、解決しなきゃいけない問題である「アプリケーション特有のエラー」に対しても引き継げることにあります。この長所は、これから説明する「設計パート」をご覧いただくと明確になると思います。
3-2. 導入における Application 構造説明
今回のアプリケーションは、「ユーザーを生成する」というシンプルな目的をはたすという、アプリケーションを想定します。
まず、アプリケーションのクラス構造と、階層を表すと、以下になります。
SymfonyFramework と DDD に起因する構造の説明は省略します。
DDD に関しては、以下の URL や、関連の書籍をご参考いただけると幸いです。http://uniknow.github.io/AgileDev/site/0.1.8-SNAPSHOT/parent/ddd/core/layered_architecture.html
格クラスの役目を簡単に説明します。
3-2-1. Application Layer
ユーザーの要請受信と、結果の応答、そして「サービスの呼出選定と制御」を果たします。ビジネスロジック処理の責任は持ちません。
● Controller/UserController
ユーザーを生成するための処理のエントリーポイントとなります。3-2-2. Domain / Service Layer
ドメインモデルの特定ドメインに対して、ビジネス要求に対する処理の責任を持ちます。
● Service/RequestValiator
ユーザーのリクエストに対して、リクエスト情報の整合性をチェックし、その結果を上位に返す機能を果たします。● Service/UserManagement
ユーザー情報を生成するための処理機能を担当します。
Entity/User のドメインに対して、永続性レポジトリー(DB)作業を遂行します。3-3-3. Domain / Entity Layer
ドメインモデルの特定ドメインに対して、ドメイン属性スキームの定義を持ちます。
● Entity/User
ユーザーというドメインに対する属性スキームの定義を記述したクラスです。
(簡単に例えると、DB の user テーブルの構造と属性がクラスに記述されています。)Repository 階層の ORM/EntityManager を通して、ドメイン属性情報を DB に永続的に保存したり、照会したり、修正したり、消したりします。
3-3-4. Repository Layer
インフラに当たる階層です。
Database や File など、永続性システムを利用するため提供されているパッケージや、基本提供コンポーネントなどが、この階層に属します。● ORM/EntityManage (Doctrine パッケージ・Framework 提供)
Database の永続性システムとのコミュニケーション・処理要請などを行うための DriverLibrary になります。
3-3. Application に Exception 設計導入
「3-2」で説明したアプリケーションの構成に、Exceptions 観点を追加して設計します。
CustomException と、説明のため、一部 PHP の Exception、Framework 提供 Exception を追加で表現します。
クラス構成図は以下になります。
では、今からは、設計観点に基づいて、クラス解説をしていきます。
3-3-1. 抽象階層 CustomException 定義と設計
Point
- カスタム例外の基盤になる上位階層の設計
- 抽象レベルが高い階層ということを意識
- 相対的。アプリケーション(CustomException)範囲に限って、抽象的という意味です。
- カスタム例外の拡張などで、階層的抽象化・構造の統一性を意識して設計
ここで、抽象階層
※8の CustomException は、以下と言えます。
抽象階層の Exception Class として、継承のみを許可し、インスタンス生成は許可しないようにするため、抽象クラスとして定義しています。① GenieAppException (Bundle/Exception)
- RuntimeException を継承し、RuntimeException が持つ特性と責任を継承します。
- 全ての Runtime 特性の CustomException の親になります。
- プログラマーのミスなどにより CustomException の誤った発生・処理漏れなどで、正しく処理されなかった CustomException に対して、上位レイヤで catch し、適切な情報記録と処理を果たします。
② ServiceException (Bundle/Exception/Service/)
- GenieAppException を継承します。
- 全ての Service 階層の Base Exception になります。
- ServiceException は、getUserMessage()メソッドを持ちます。
- ユーザーへの適切な応答メッセージの情報を提供する義務を持ちます。
3-3-2. 具体階層 CustomException の設計と設計
Point
- カスタム例外の具体的なエラーを設計
- 抽象レベルが低く、具体的な階層ということを意識
- カスタム例外のエラーは、一番具体的で明確であること
ここで、具体階層の CustomException は、以下と言えます。
① RequestValidatorException (Bundle/Exception/Service/)
- ServiceException を継承します。
- Service/RequestValidator から、発生します。
- Service と Exception を 1:1 でマッピングされるように定義し、各自のクラスの責任を単一責任になるように設計します。
- Service/RequestValidator から発生する時、明確なエラー情報をセットし、上位伝播します
- ServiceException は、この情報を元に、getUserMessage()の結果を返すことができます。
3-3-3. Service/UserManagement クラスに対する捕捉
UserManagement サービスに対しては、CustomException を定義する必要がないという設定です。
理由としては、
- UserEntity と EntityManager を通して、DB にデータを生成するという責任だけを持つサービス
- 予想される例外は、Entity 階層で発生する Entity&ORM Driver の例外(PDOException など)
の理由であり、UserManagement サービス独自で発生させる例外は不要です。
3-3. 例外のハンドリング
3-3-1. アプリケーション下位階層での、例外の発生とハンドリング
Point
- CustomException を、必要に応じで意図的に発生させる
- CustomException が保持する情報は、明確であること
- Exception を catch する時は、可能であれば具体的に catch する
- 可能であれば、catch するポイントでしかできない処理が必ず必要な時だけ catch し、必要な処理だけをした後、上位に委任する
- 処理必要がないか、予想できない、責任を取れない例外は上位に委任する。
① RequestValidator での CustomException の意図的発生
ビジネスロジックの処理で、検証に失敗したら、該当クラスとマッピングされる RequestValidatorException を throw するようにします。
これで、RequestValidator による Exception に対して、上位階層のどのポイントでも処理、またはスルーでき、必要に応じて処理制御を具現できるようになります。
namespace Bundle\Service; use Bundle\Exception\Service\RequestValidatorException; class RequestValidator { ... public function validate(...) { ... if ($validationFail) { throw new RequestValidatorException(...); } } }② Service/UserManagement 内の潜在的な例外のハンドリング
ここは前もってお話しした通り、CustomException の定義は不要という定義と、
Repository 階層の EntityManager は、プレイムワークや PHP が提供する特定 Exception を発生させる可能性があるので、具体的に予想がつく例外に対して対処します。※ ここは、各自の具体的例外に対して、処理が必要なプログラム要件だと定義します
例外発生が予想されても、このポイントで必ず処理すべき要件がないなら、catch を省略し上位に委任することも場合によっては可能です。// Service/UserManagement class UserManagement { ... public function create(EntityManager $em) { ... try{ $em->persist(...) $em->flush; } catch (DBALException $ex) { //some recovery logic & logging for Case of DBALException throw $ex; } catch (PDOException $ex) { //some recovery logic & logging for Case of PDOException throw $ex; } catch (ORMException $ex) { //some recovery logic & logging for Case of ORMException throw $ex; } } }3-3-2. アプリケーションでの上位段階での例外のハンドリング
Point
- アプリケーションにおいて、意図的に発生するエラーに対して共通の処理が必要な場合は、アプリケーションの上位ポイントで例外ハンドリングを行うことができる。
- アプリケーション要求事項としての共通エラー処理のみを処理する
- 可能であれば、予測できない、責任取れないエラーは、最上位に委任する。
- Controller の責任を意識する。(Controller の責任はロジックの流れの制御)
「アプリケーション」でおいての上位は、Contoller の ActionMethod を基準とします。
ここでは、「プルグラマーの意図によって発生可能なカスタム例外」に対しての処理責任を持ちます。
今回の場合は、RequestValidationException がその事例です。
そして、RequestValidationException が提供する情報をもって、意味のあるエラーメッセージ情報を応答としてレスポンスします。
class UserController { public function create( LoggerInterface $logger, RequestValidator $validator, UserManagement $userManagement ){ try { $validator->validate(...); $userManagement->create(...); } catch (RequestValidatorException $ex) { $logger->info(...); $response = new JsonResponse(...); $response->setStatusCode(Response::HTTP_BAD_REQUEST); $event->setResponse($response); } } }3-3-3. インフラ階層観点御最上位段階での例外のハンドリング
Point
- 想定していない例外に対して、探知の責任をはたす
- critical level として扱い、ログ記録と通知を前提とする
- 可能であれば、発生した例外に対して、恒久対応を試み、具体的な問題として再定義する。
- 正しいエラーハンドリングをアクリケーションに追加するという意味です
アプリケーションを含め、アプリケーション実行のための基盤階層(Framework, PHP)においての最上位段階での例外ハンドリングの一例になります。
今回は、Framework で提供する ExceptionListener という機能を使います。
この機能は、EventHook 概念で、Framework のロジック処理の段階の一部を横取りすることが可能です。
つまり、Framework に従い我々が実装したビジネスロジックのどこかで、catch していない得体不明の例外が投げられても、全てここで横取りできます。
ただし、ここは、サービス全体においての最上位と見なすべきなので、「想定されていない得体不明の例外の探知」を目的としたハンドリングを試みます。
// src/EventListener/ExceptionListener.php class ExceptionListener { public function onKernelException(ExceptionEvent $event) { // You get the exception object from the received event $ex = $event->getThrowable(); // Can handle for each Exceptions if you need if ($ex instanceOf ServiceException) { ...logic For Unexpected Custom Exception } else if ($ex instanceOf GenieAppException) { ...logic For Unexpected Custom Exception } else { ...logic For Unexpected UnknownException } $logger->critical($ex); //logging with stackTrace $response->setStatusCode(Response::HTTP_INTERNAL_SERVER_ERROR); $event->setResponse($response); } }3-4. Application への Exception 設計導入例におけるまとめ(長所と課題)
ユーザー情報を生成するという単純な機能に対して、Symfony(DDD)のアプリケーション構造に対する、Exceptions 設計導入方法の例を説明しました。
最後に、上記の設計において、筆者が思う長所と課題を記述します。実際のアプリケーションにおいての開発の時に、参考になると幸いです。
3-4-1. 長所
1) エラーの構造化
我々がサービスを開発する時、我々は様々な操作ケースに対して、常に正常結果のみを処理している訳ではありません。
「入力値検証・アクセス制御・操作プログレス制御・ステータス制御・外部 API 通信問題・システム状態によるトラブル」 など、様さざなイレギュラーケースに対して、我々は、アプリケーション要件として定義し、非正常結果として扱わなければなりません。
こういう、 「非正常」という課題に対して、Exceptions 設計導入は、課題に対する「階層的抽象化」モデルの確立を実現できる手法です。
これがもたらす、メリットに対しては、PART1 と PART3 の内容となります。
2) エラーに対する制御処理の柔軟性
例外は、「上位伝播」という特性をもっています。
そして catch には、「ポリモーフィズム」原理が適用されるので、エラー処理に対して、「どこで」「どういう」例外を、「処理」するか、「委任」するかを、柔軟に制御できます。特に、エラーの世界では、この柔軟さがシステムの「完結さ」と「底欠陥さ」をもたらしてくれます。
その理由に関しては、PART 2と PART3 の内容となります。
3) エラー処理の共通化
意図的に共通化したい例外、想定していない例外に対して、アプリケーション・インフラの上位階層で、共通処理を実現できることで、エラーに対する後処理の「統一性」「処理保証」「探知保証」をもたらしてくれます。
それで、エラー処理に対しる処理の漏れや、処理漏れ、認知漏れを防げます。
PART3 で紹介した、Entry Point での、Validation エラーに対する共通処理と、EventListener での onKernelException()の処理がその例です。
3-4-2. 課題
1) 維持補修開発において、設計構造の共通認識としてのハードル
しかし、この設計領域は、筆者自身としても、高難易度の設計領域です。
まず、設計のためには、「言語・フレームワーク観点でのプログラム設計」「基本提供の例外設計」「ビジネス・サービス要件に対しての要求定義と例外設計」のスキルがまず必要となってきます。
そして、作られた設計に対しても、チームで開発する時は「共通認識」として浸透させる必要があります。そうでない場合は、開発や維持補修段階で、統一性がくずれる可能性が高いです。
ここに関しては、難しいところですが、以下の対策を意識することで、補えると思います。
● ドキュメント化と、ドキュメントの運用
設計と、コードをドキュメント化し、運用することで、全体情報の熟知、最新情報に維持することができます。そして、プログラムの改修時の「監理」の役目も果たします。しかし、やはり時間が必要な対策です。
なので、「必要な文書だけシンプルに維持する」ことが大事です。2) 維持補修開発において、統一性を守というハードル
上記の内容でも少し話しましたが、アプリケーションの統一性を維持することがハードルになります。
- 変化し続けるビジネス要件
- 多数の人がプログラムを開発することによる、コードの差
- 現実的な時間確保の難しさ
などが、問題になってきます。
ここに関しても、やはり難しいところですが、以下の対策を意識することで、補えると思います。
● 実装前にインタフェース構造実装からする・レビュー後、具体的ロジックを実装
実装時にロジックをすぐ実装するのではなく、まずメソッドのインタフェースと、依存関係の先に「疑似コード」として、作成し、初期段階でコードレビューを行います。実際には詳細設計の下位工程のレビューと言えます。
これにより、プログラムの構造に対しての整合性に影響する可能性がある問題に関して事前に検知する可能性が高くなります。
● 周期的なリファクタリング
周期的リファクタリングを時間を持つと、プログラムはもちろん、アプリケーションの構造、ドキュメントの整理などもできます。
もちろん、上記に説明した問題は、Exceptions 設計に限る話ではないですが、Exceptions 設計は、場合によってはその課題の難易度を高め、さらに複雑なアプリケーションになってしまう可能性もまたあります。
そこを注意することは、とても大事です。
PART-4. 例外設計原則まとめ
4-1. Exceptions 設計原則まとめ(筆者主観含む)
今まで見てきた内容を、原則という文章でまとめます。
それ以外に、覚えておくと良いと思う原則も少し加えています。4-1-1. OOP 観点での原則
- 例外(Exceptions)は、プログラム上で起き得る「事故を階層的に抽象化」モデリングした物である
- 「上位階層なほど抽象的、下位階層なほど具体的」である
- 「具体的」は「抽象的」にもなれる
- 抽象的な例外ほど予測と正確な対処が難しい
- try-catch をするということは、一種の「保険」をかけること
4-1-2.「抽象レベル」観点での責任と原則
- catch する時は、「具体的」な Exception を catch する
- catch した時は、該当ポイントの制御フローまで責任をとる
※9- 例外発生前後は、クラスの状態が有効生を保つように意識する
- 「抽象的」な Exception は、なるべく上位に委任する
- できれば、Exception, RuntimeException のような General Exceptions を catch しない。
- 責任を取れそうにない例外は catch しない
- ほっとけば、最上位階層でまとめて処理される
- 「抽象的」な例外に対する後処理は、できるだけ上位階層のポイントで処理する
- 最上位のエラー処理は必ず「探知・ログ記録・通知」の責任をとる(特別なことがない限り)
4-1-3.「例外特性」観点での責任と原則
- Runtime と Non-Runtime を意識して設計・ハンドリングする
- サービス・アプリケーション運用においては、Runtime 特性の例外を注目し対応・運用する
4-1-4.「Custom Exception」に対する責任と原則
- Custom Exception は、Runtime Exception を焦点に設計するのが好ましい
- Custom Exception は、「明確・具体的」であること
4-2-5. その他、意識しておけば良い原則
- できれば、複数階層で重複で処理しない
- できれば、Error は処理しない
- できれば、Non-Runtime(Checked)属性の例外は、ビジネス的な意味がある要件の実現必要性がある時のみ導入する
- 例外の記録は、ログフレームワークを使い処理する。(監視・通知体勢も備える)
今回の後書き
最初、この記事を考えた理由は、最近、頭の中で考えていた「古いサービスの現状のエラー処理の課題間」と、追加開発においての「エラー設計」に関して、ふわっと思っていたところからです。
もちろん、今までの経験である程度の知識や経験はあったと思ってましたが、改めて「筆者自身は Exception に対してどれだけ理解していて、説明できるか?」を、自分自身に問うようになりました。
考えてみると、破片的な知識と経験が多くあるものの「まとまってない」ということが、自分自身の中で出した結論です。
そこで、この記事の作成を通して、以下の成そうとしました。
- ゴール
- 「まとまって明確な知識」として、自分自身の中で再構築
- 筆者地震の知識の情報検証
- 過程
- 破片的な知識と経験の可視化
- 上記の内容を、理論と照らし合わし検証
- 上記の内容を構造的に整理
- 上記の内容から核心を抽出
- 核心を強く認識し「まとまって明確な知識」として、自分自身の中で再構築
ゴールは、ある程度満たせたんじゃないかなと、思っています。
しかしやってみながら、まだ足りないところも多いなと思いながら、書いた感じです。
特に以下の部分などなどに関しては、まだまだ足りず、精進しないという反省もあります。
- もっと深い OOP の理解
- ビジネス課題を踏まえた DDD アーキテクチャ設計
- 基本提供エラー機能・クラスの理解
- FRAMEWORK 自体の理解
- Application においての、理想的なエラー設計・運用
そして、思ったより分量が多くなってしまったのは、筆者自身の課題かもしれません。
ともあれ、これからも、開発であれ、なんであれ、頑張って楽しくやって行きたいと存じます。
※注釈
※1)
Exception に関わる事例コードとかをみて、書いて、その結果を身で直接感じた上で、次に進めることをお勧めします本の分量だと 10page 内外だと思います。まずは全てを理解するより、書いたコードに対する結果を体感することの先行が大事だと思うので、軽い感じでお試しください。
※2
上位に委任するほど、抽象的になったしまう傾向が強い例外は、発生ポイントからだんだん上位に伝播されると、その上位ではだんだん抽象的例外として扱うことになるという意味です。
上位にいくほど、例外が発生するポイントとその種類もだんだん増えていくのがその理由です。
※3
上位階層が知るべき情報も、このレベルで遮断され、適切な対応ができなくなる。実は、特定の例外に対して、上位段階でも、ログを残したりとか通知をするとか、なんらかの対応の責任があるかもしれません。
しかし、発生ポイントで処理するまでは良いですが、上位階層でやるべき責務がある状態で、上位に伝播(報告)せず、例外を揉み消してしまうと、いろんな問題を起こしてしまう可能性もあります。
※4
Call Stack の下位ポイントCall Stackいうのは、プログラムのメソッドの呼出の深さを意味します。
以下の記事をご参考いただけます。
https://qiita.com/righteous/items/494340cf16c7a35f742e※5
何が起きるのかわからない Exception に対しての対応なので、phpdoc の throws 構文も書かない方が、筆者的にはお勧めですphpdocで、throwsを明示的に記載するのは、「ハンドリングをすることを強くアピールする」ことだと思います。なので、他の人がみると、不要にcatchする傾向が現れるかもしれません。
※6
Runtime Exception を継承しない Exception は、全て Non-Runtime Exception と分類できますしかし、前もって話したように、PHPの特性で境界が曖昧なところがあると思うのが、筆者としての考えです。
※7
Non-Runtime 例外は、コンパイル時に発生する可能性がある例外です。上記と同じく、PHPの特性で境界が曖昧なところがあると思うのが、筆者としての考えです。
※8
抽象階層プログラマーが具現するアプリケーション範囲に限定してでの、抽象階層という意味です。
FRAMEWORK, PHPなどインフラ階層まで含めると、インフラ階層よりは、Custom Exceptionが遥かに具体的階層に存在することになります。抽象的というのは、あくまで相対的ということを意識すると良いです。基準によって、基準より抽象的にもなるし、具体的にも慣れます。
※9
catch した時は、該当ポイントの制御フローまで責任をとるcatchをした場合は、処理として、該当ポイントの処理の最後やで責任をもって制御の責任をとることです。
方法としては、
- 上位に委任する (制御を途中で中断し、上位に責任を委ねる)
- 処理を完結する場合、該当ポイントの処理の結果の整合性に責任をとる。ということです。
例えば、
{変数宣言; try {変数に値をアサイン;} catch {エラー記録;} 変数操作・変更・リターン}が悪い例。catch 以降の処理が、制御責任を違反する動きだと言えます。
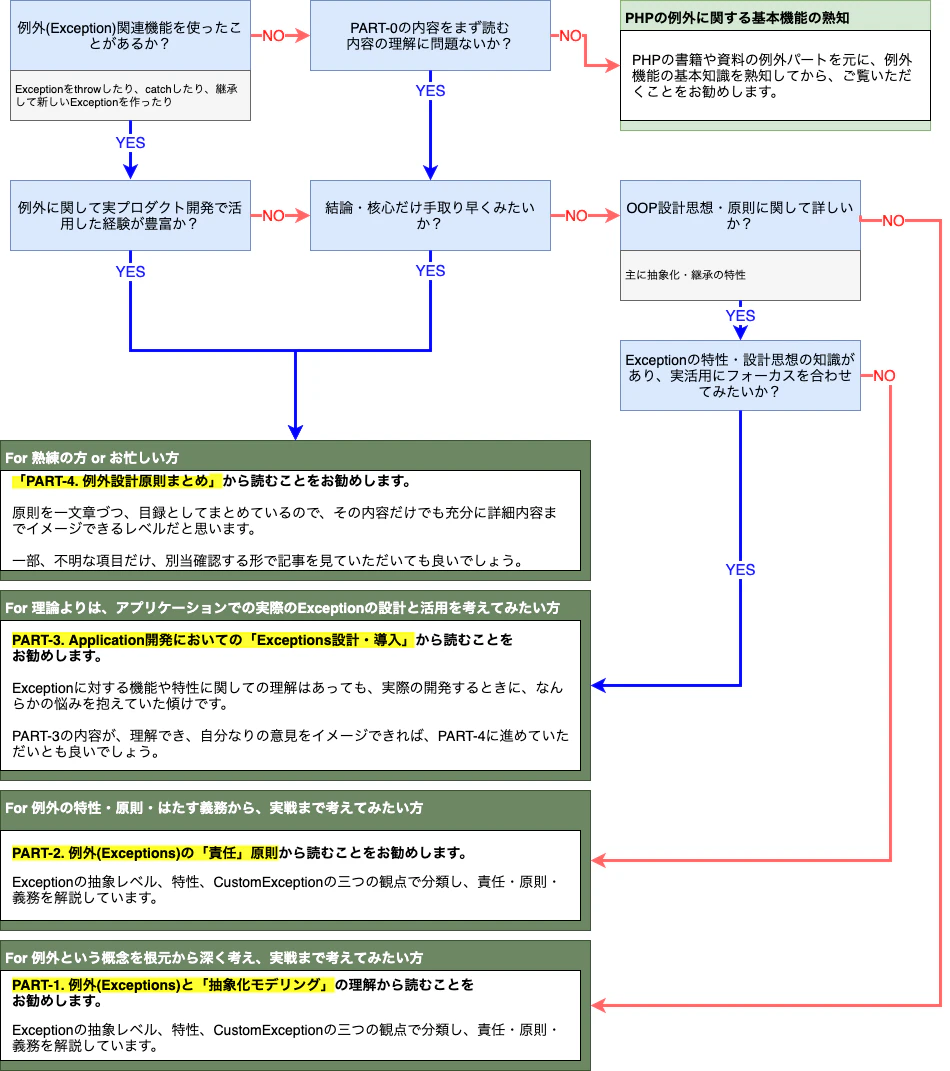

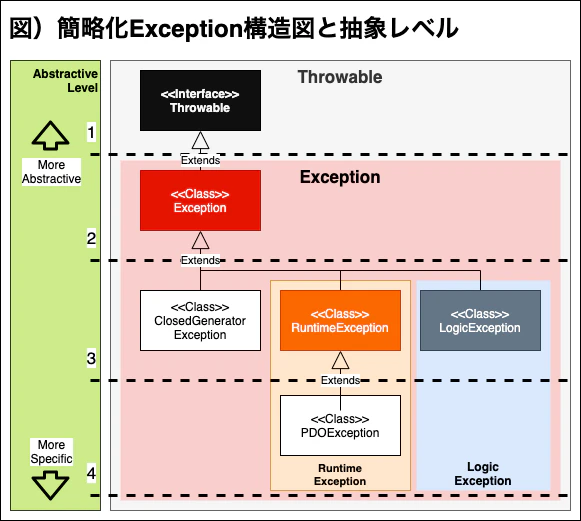
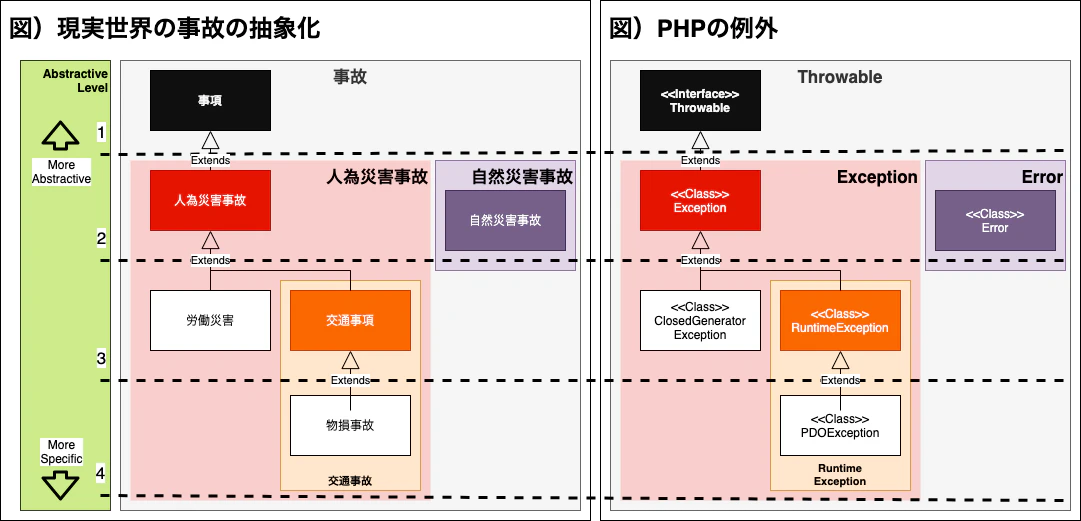
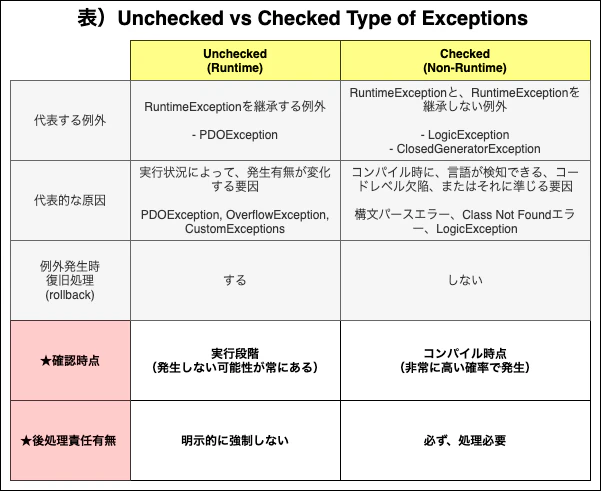

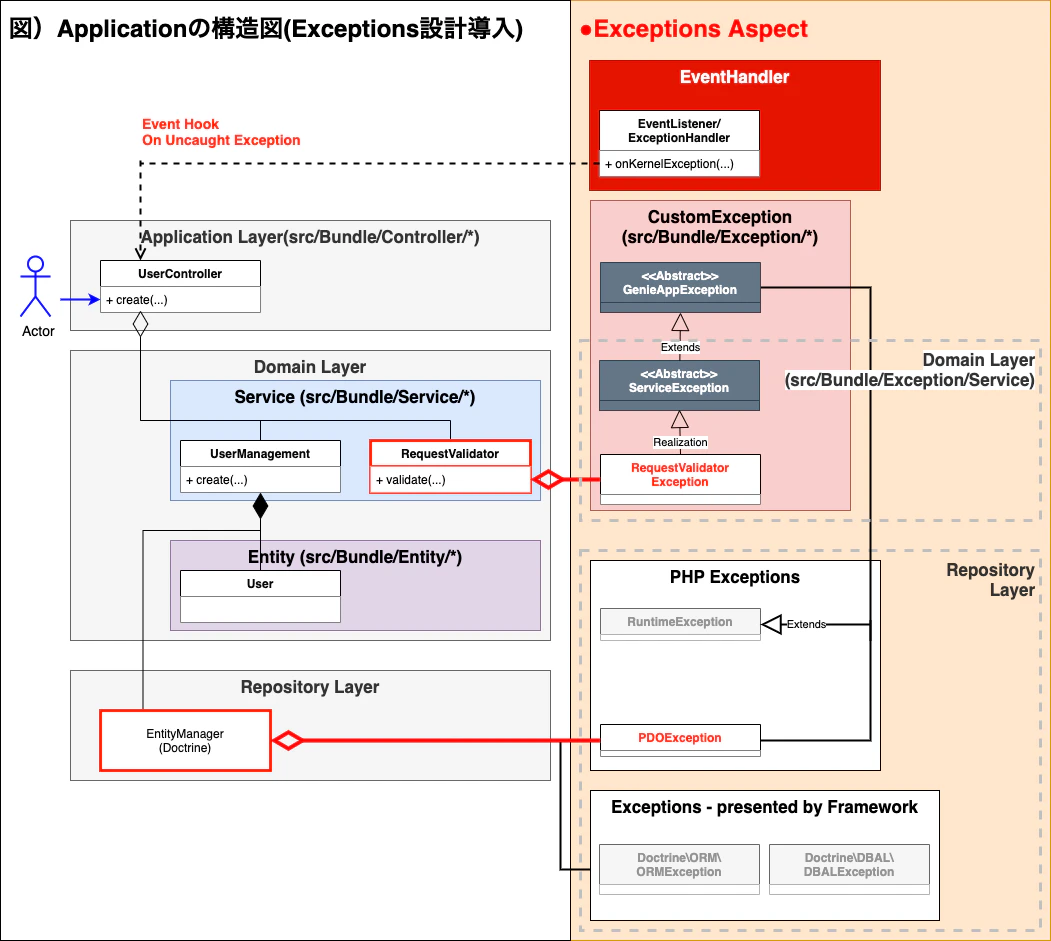
- 投稿日:2020-12-23T10:21:38+09:00
PHP) Exceptionエラー設計原則とアプリケーションへの導入
Advent Calendarへの招待、ありがとうございます。
本記事が何方かの役に立つことができると幸いです。前書き
- すべての記事は、自分の勉強目的のため主観的な内容の整理を含まれています。あくまで参考レベルで活用してください。もし誤った情報などがあればご意見をいただけるととっても嬉しいです。
- 内容では省略するか曖昧な説明で、わかりづらいところもあると思います。そこは、連絡いただければ補足などを追加するので、ぜひ負担なくご連絡ください。
- 今回の記事は Java の Exception・Concept に起因した内容を一部含めています。Java と PHP のエラーの抽象化モデリングは少々違いがあるので、後述する内容は必ず PHP においての正解とは言えません。PHP の Exception に焦点をおくよりも、言語に関係なく Exception と Application においてのエラー設計観点の考察を主に記事にしたいという思いがあったので、この意図のところを踏まえてご覧いただけると幸いです。
概要
本記事は、PHP7 をベースにしています。
本記事は以下の内容で構成されています。● PART-0. 事前知識
Exception に関わる構文と特性を簡単に説明します。● PART-1. 例外(Exceptions)と「抽象化モデリング」の理解
Exception の仕組みに対して、設計思想・核心原則を、OOP の観点と原則に基づき解説します。● PART-2. 例外(Exceptions)の「責任」原則
Exception の「抽象レベル」「特性」「ユーザー定義例外」観点で、Exception の責任と、Exception に対しての我々の責任を元に、設計原則を解説します。● PART-3. Application 開発においての「Exceptions 設計・導入」
上記の原則を元に、アプリケーションではどういう風に導入できるのかの一例を、紹介します。● PART-4. 例外設計原則まとめ
PART-1 から PART-3 までの内容を踏まえて、「Exception 設計原則・目録」としてまとめます。記事の効率的な見方
当記事は、かなりのボリュームの内容になっておりますが、全ての方に対して全ての内容が必要な訳ではないと思います。
以下の「記事を見方」を参考し、読者の方が望む方向で、この記事を効率的にご活用いただければと思います。
もちろん、例外に興味が高い方、例外を深堀たい方、例外に関していろんな議論をしたい方は、是非初めから読んでいただくと、筆者としても嬉しいです。
PART-0. 事前知識
本記事を読んでいただく前い、事前知識として必要な内容を簡単に記述します。Exception に対して、すでに経験が豊富な方は軽くみて頂くか、次の PART から読んでいただいて構いません。
「PART-0」は PHP においての Exception の基本的な使い方を話します。現段階の内容が少し新しく感じる方は Exception に関わる事例コードとかをみて、書いて、その結果を身で直接感じた上で、次に進めることをお勧めします
※1。0-1. throw new Exception
throw は、投げるという意味の
「伝達・伝播」として、意味として、強く意識していただけると良いと思います。throw 構文を使うことで、新しい Exception のインスタンを throw することができます。
throw new Exception($message, $code, $previous)0-2. try catch finally
下位CALLSTACKから伝播された例外を明示的にハンドリングできる構文です。
※ finally は、php5.5.x 以降からサポートします
try { //throwが予想されるコードブロック } catch (MoreSpecificException $ex) { //先端は、より具体的なExceptionをcatch } catch (MoreAbstractiveException $ex) { //後端は、直前と同等か、より抽象度が高いExceptionをcatchしハンドリング } finally { //try blockの例外に関係なく実行されるコードブロック }0-3. Exception Class が提供するインタフェース
Exception クラスは、いろんなインタフェースを提供しており、エラーに関する有用な情報を取得できます。特に、
getMessage()とgetTrace()は、アプリケーション運用にとって、非常に有益な情報を提供してくれます。詳細は、php reference をご覧いただけます。
https://www.php.net/manual/ja/class.exception.php0-4. class CustomMyException extends RuntimeException
Exception の属性を継承し、プログラマーが新しい Exception を定義することもできます。
アプリケーション特有のエラーに対して、「OOP と Exception の特性を生かした抽象化・構造化」設計を可能とします。
class CustomMyException extends RuntimeException { //...can implements you need }PART-1. 例外(Exceptions)と「抽象化モデリング」の理解
PART-1 からは Exception を含む、言語が提供する例外モデルに対する考察と思想に基づいた「設計論」の話が主になります。
Exception とエラーに対する設計論は、様々な議論が存在し、システム要件と開発状況によって、正解というのが難しい分野だと思います。筆者自身にとっても苦難を重ねている分野でもある分、主観的な意見を多数含まれています。
そこを認識いただいた上で、参考までに読んでいただけると幸いです。筆者自身もいろんな意見をいただき、また知識の糧にしたいと存じます。
1-1. PHP の例外(Exception)の構成
1-1-1. 例外の構成図
PHP で基本提供している例外の構造は、上記の図になります。
- ここで話す「例外」は、throwable を継承する全てのクラスを意味します。
- Error クラスと、それを継承するクラスも「例外」です。
- ブロックは is-a 関係を表しています。特定クラスが特定の複数のブロックに含まれる場合、複数ブロックで示しているクラス名と is-a 関係が成立します。(インタフェース名も、便宜上クラス名と称します。)
- PDOException は、PDOException 自分自身であり、RuntimeException でもあり, Exception でもあり, Throwable でもあります。
- 色がついているクラスは、子クラスを持つ親クラスです。
- RuntimeException は、PDOException を子クラスで持ちます。
しかし、ここで全てのクラスの意味を説明したりはしません。
大事なのは構造です。上記の親とこの関係、ブロックと is-a 関係を主に意識していただいても大丈夫です。なので、これからは図を簡略化して、説明していきます。
一つ一つの例外を確認したい方は、言語レファレンスや、以下の記事をお勧めします。
https://www.php.net/manual/en/reserved.exceptions.php
https://www.php.net/manual/en/spl.exceptions.php
https://qiita.com/mpyw/items/c69da9589e72ceac470c1-1-2. 例外クラスの説明
上記に表している例外に関して、一部のみを簡略に説明します。しかし、今すぐその意味を全て理解する必要はありません。 各自の例外の継承するクラスと、その関係性を意識して頂くと良いです。
● Throwable
throw 特性を持つ全てのクラスの最上位インタフェース● Error
PHP 内部的に発生可能な全てのエラーのベースクラス● Exception
プルグラマー・ユーザーから起因可能な全ての例外エラーのベースクラス
Throwable を継承● RuntimeException
コンパイル段階で言語が探知できず、実行時に発生可能性がある例外。またはその特性を持つ子クラスの最上位クラス
Exception を継承● LogicException
未具現のメソッドの呼出や、誤った引数の指定など、実装の問題などで発生させることができる例外
Exception を継承● ClosedGeneratorException
PHP のジェネレーターを使う時、すでに closed のジェネレーターに対して実行を試みた時発生する例外
Exception を継承1-2. PHP の Exception の理解の核心は、OOP の「抽象化」
1-2-1. 例外は「抽象化」されたモデル
OOP 設計の核心は「抽象化モデリング」「抽象化されたモデル」と言えます。
もっと具体的に定義すると、「解決(具現)すべき課題を、クラスコンセプトに基づき抽象化モデリングし、解決手段を状態(member)と行動(method)をコードとして記述するプログラミング手法」と言えます。PHP の Exception の概念も、まさに OOP の抽象化モデリングの事例です。
まず、Exception を実際に扱う前に、ここを意識するのはすごく大事です。1-2-2. 簡略化した例外構成図と抽象レベル
上記の図は、PHP の例外構造を簡略化した上に、格例外の抽象レベルを表しています。
- Level の数字が低いほど、抽象レベルは高く、より抽象的で、幅広い意味を持ちます。
- Throwable は、「全ての例外」その物なのでとっても抽象的で、Throwable だという情報だけでは具体的に何なのかを特定できません。
- Level の数字が高いほど、中量レベルは低く、より具体的で、比較的に明確な意味を持ちます。
- PDOException は、より具体的で、PHP Data Object で発生した例外という特定ができるほど具体的です。
1-3. PHP のエラーは、プログラムで起き得る「事故を階層的に抽象化」したモデルである
では、例外というのは、何を課題を解決するためにあるのかを考えてみましょう。
まず、例外は、何らかの「事故」と理解しても問題はないと思います。
そして例外の概念は、「プログラムで起き得る事故を課題として扱い解決するため」に抽象化されたモデルと言えます。
この概念は、現実世界の事故の概念ともかなり似ています。
では、現実世界の「事故」を抽象化した物と、PHP の例外を、以下の観点で比較してみましょう。
- 現実世界と構成・構造が類似しているか?
- どれだけ抽象的かによって、抽象的、または具体的な事故が持つ意味が、事故と PHP 例外の間で類似しているか?
1-4. PHP の Exception は、「上位階層なほど抽象的、下位階層なほど具体的」である
うまくモデリングできたでしょうか。
正確に当てはまる訳ではないですが、現実世界の事故と、PHP の例外の階層を当てはめて比較してみましょう。
- Level の数字が低いほど、抽象レベルは高く、より抽象的で、幅広い意味を持ちます。
- 事故は、「全ての事故」その物なのでとっても抽象的で、事故だという情報だけでは具体的に何なのかを特定できません。
いまの情報では、筆者の生命封建や自動車保険で処理できる事案なのかわかりません。勝手に処理することもできません。- Level の数字が高いほど、中量レベルは低く、より具体的で、比較的に明確な意味を持ちます。
- 交通事故 → 物損事故は、より具体的で、自動車そのものの物損被害事故が発生したと特定できるほど具体的です。
幸い、筆者は自動車保険があるので、筆者が保険社を通してリカバリーできそうです。「事故」という単語は、現実世界の全ての種類の事故を意味しており、とっても抽象的です。PHP 例外の最上位の Throwable もまた、システム・プログラムないで起き得る全ての事故の意味を持つので、とっても抽象的だと言えます。
「自然災害事故」と、「人為災害事故」は、より具体的ですね。
「自然災害事故」は、普通は環境によって起きるので、PHP の Error Class と似てると思います。
「人為災害事故」は、人により起き得る物なので、PHP の Exception Class と似ていると言えるでしょう。しかし、まだ「人為災害事故」と言っても、具体的ではありません。どういう事故か、どういう風に対処すればいいか、現段階では予測できません。
「交通事故」までくると、かなり具体的になりました。RuntimeException に当たるレベルと似ている感じですね。
「物損事故」レベルまでくると、どういう原因・内容・対処法で良いのか予想がつくようになります。PDO Exception や、Custom Exceptions が、ここに当たる感じになります。
ここで、注目するべきは、「抽象レベルに基づいた階層構造」ということです。
現実世界の事故のモデリングもそうですが、PHP の Exception もまた、「どれだけ抽象的か?」を基準に、階層的に構造化されているという認識はすごく大事です。抽象レベルにより、例外自体が持つ責任と、我々が持つ責任が大きく変わるからです。
1-5. Specific Exception can be Abstractive
OOP の基本原則には、継承による「is-a relationship」という原則があります。
「交通事故」というクラスが「事故」というクラスを継承すると、交通事故は交通事故自身であり、事故でもある(交通事故 is a 事故)という原則です。ここで私たちが注目するところは、「a」という冠詞です。なぜいきなり英語?という考えるかもしませんが、「a」は「何かの、何らかの」の意味に近い不定冠詞と言えます。ざっくりいうと「指定されていない何らかの事故」という意味で、抽象的な概念を含むようになります。「あの、その」みたいに特定された一つの意味に近い「the」ではなく、「a」で表記しているところの理由はそこにあります。
つまり、「is-a relationship」は、同一性だけじゃなく、
「抽象性」も表している原則です。ここで、人に内容を伝えるときに、「交通事故 → 物損事故」と伝えるのと、「事故」と伝えるのでは、情報の抽象度が変わってきます。「事故」を聞くと、交通事故か、火事か、自然災害かわからないから、反応にも困るでしょう。そこでどういう事故?と聞いても、事故よ事故とだけ言われる、我々は具体的な情報を特定できないので、相当困るでしょう。
- 交通事故→物損事故 is a 交通事故→物損事故 (具体的) - 交通事故→物損事故 is a 交通事故 - 交通事故→物損事故 is a 人為災害事故 - 交通事故→物損事故 is a 事故 (抽象的)Exception と、その配下の Exception たちも、同じ関係です。
- PDO Exception is a PDOException (具体的) - PDO Exception is a RuntimeException - PDO Exception is a Exception - PDO Exception is a Throwable (抽象的)と言えます。
つまり、PDO Exception と言われると、「PHP Data Object 処理でエラーになったな」と予想できるものが、Throwable と言われると、どういう例外か予想しづらくなります。
そして、予想しづらい事故は、個人レベルで全て対応仕切れないし、無理に処理しようとしても状況が悪化する場合がおおいです。そして、情報を知るべき団体や国家は、その情報を把握できなくなります。
「Exception の世界もまた、それは同じだと言えます」
1-6. 抽象的な例外ほど予測と正確な対処が難しい
今までみてきたように、Throwable,または Exception クラスは、とっても多くのプログラムでの「事故」を意味している概念なので、正確な原因と対処が難しいのが一般的です。
public function createNewData() { ... try { $data = $clientDataServer->getTokenData($dataId); $saveToDatabaseUsingPDO->insertNew($data); ... } catch (Exception $ex) { Logger::critical("DB WORK FAILED!!", $ex->getMessage, $ex->getTrace()); //some recovery logic for DB WORK return; }上の例は、よくないと言えるエラーハンドリング例です。
プログラマーの意図としては、データの生成時に、DB 作業時で発生可能な何らかのエラーをハンドリング・リカバリーしたい意図があります。
しかし、
is-a原則を覚えていますでしょうか?Exception クラスは、DB 作業に関わる saveToDatabaseByPDO の例外だけでなく、clientDataServer や、その他で起き得る全てのエラーに対して、PDO エラーと同一視してしまいます。
ここは、具体的な PDO Exception を catch し、追加に clientDataServer で起き得る具体的な Exception を catch するか、予測できない例外は catch せず、上位に委任することが、一般的には望ましいです。
try { ... } catch (ClientDataServerException $ex) { ... } catch (PDOException $ex) {1-7. try-catch をするということは、一種の「保険」をかけること
プルグラムで、例外が予想されるポイントで、例外が起きた時の対応処理を事前に決めて実装したりします。
この概念もまた、現実世界の事故と類似しています。
筆者は自動車をもっていて、自動車保険に加入しています。
そこで、筆者がドライブをするとなると、「事故が会ったら保険証理しよう」という前提条件がすでに当たり前の認識なっていますね。ここをコードで表現すると、以下の模様になります。
class 筆者 { public function __construct( $自動車, //筆者は自動車をもっている $自動車保険社 //筆者は自動車保険者に加入している ){ ... } public function doDrive() { ... try { $this->自動車->運転する() } catch (交通事故\物損事故) { $this->自動車保険社->保険処理->請求() } } }
- 自動車保険会社のクラスは、保険会社のサービスに例えます。事前に登録しないと保険サービスを受けられないから、必ず登録しましょう
- try&catch 構文は、車両登録と保険会社の連絡先を前もって用意しておくとこに例えますね。自動車事故が起き得る状況にはちゃんと備えて起きましょう
- catch の中身の実装は、事故発生時の対応知識ですね。我々は、すでに学校や封建会社で学んでいるから当たり前にしっいることですが、システムはわからないので、ちゃんとコードで教えてあげましょう。
では次は、以下のシチュエーションを想像してみてください。
1-7-1. try - catch していない。(保険をかけていない)
いうまでもなく、お金的にも、民事訴訟的なところでも大変になるでしょう。
※ プログラム上でもも同じく大変になるかもしれません。
1-7-2. 「事故」として、catch していて処理している場合**
どういう事故なのかによって、できることの範囲は違ってきます。
- 自動車事項:自動車保険処理・連絡
- 盗難事故:警察に申告・連絡
- 事故:事態把握・連絡
そして、自動車事故を、自動車事故と認識せず、事故と認識すると、確実にしてもいものは、「自体把握・連絡」です。
この状態で、「自動車保険処理」をやっても、運が良ければ、いい対応になるかもすが、「実は盗難事故でした」だったり、「自動車事故なのに、間違って警察に申告てしまった」など、謝る処理をしてしまう可能性がおおきいでしょう。
※ プログラム上でも同じく、意図しない変な処理をしてしまうかもしれません。
1-7-3. 筆者がどうすることもできない「自然災害事故」が起きた場合
個人レベルでどうにかなる自然災害なら、事故として扱っても何とかなるかもしれせん。
しかし、個人レベルではどうしようもなく、国家レベルで対応するしかない自然災が起きたらどうでしょう。個人レベルで無理やり処理しようとすると、むしろ状況を悪化させる可能性が非常高くないでしょうか。
こういう時は、状況把握・事故に対する必須対応後、迅速に家に委任するのがいいでしょう。
※ プログラム上でも同じく、ログ記録・必須対応だけ行って、上位階層に委任するが最善な場合が多いです。
この論理は、プログラムでの例外と try-catch 関係と非常に類似しています。
つまり、 「例外を try-catch することは、一種の保険をかけること」 と言えると、筆者は思います。? PART-1 のまとめ「例外と抽象化モデルの理解」
PART-1 の内容をまとめると、以下になります。
- 例外(Exceptions)は、プログラム上で起き得る「事故を階層的に抽象化」モデリングした物である
- 「上位階層なほど抽象的、下位階層なほど具体的」である
- 「具体的」は「抽象的」にもなれる
- 抽象的な例外ほど予測と正確な対処が難しい
- try-catch をするということは、一種の「保険」をかけること
PART-2. 例外(Exceptions)の「責任」原則
「PART-1」では、例外はシステム、またはアプリケーション上での「事故」と表現しました。
現実世界でも、個人、または団体・国家が事故に対する事後処理をするように、アプリケーションを生み出した我々は、ここで起き得る「例外」という事故に対して、何らかの責任を果たす必要があります。
しかし、現実世界の事故も個人・団体レベルでは解決仕切れない物もあるように、我々が解決仕切れない例外も有ったりします。
そういう問題は、無理やり解決しようとするか、誤って解決をすると、もっと大変な事故による2次被害も起き得るのでしょう。そういう時は、もっと上位の団体や国家に委任するように、上位に委任し委ねるという考え方が一般的には好ましいです。では、我々は、様々な例外に対して、どういう風に責任をとり、解決、または委任するべきでしょう。
ここは、実はすごく難しいところですが、 「抽象レベル」「Exception 特性別」「Custom Exception」 の三つの観点でお話しします。
2-1. 「抽象レベル」観点での責任と原則
2-1-1. catch する時は、「具体的」な Exception を catch する
「具体的」な Exception というのは、以下のような特徴を持ちます。
- 比較的に明確な例外状況の意味をもっており、例外の特定・処理において明確な予想ができる
- 明確に予想できる例外は、必要有無によって、「後処理」後、「完結」するか「委任」するかを柔軟に選択できる
- 上位に委任するほど、抽象的になったしまう傾向が強い
※2まず、よくないコードの例をみましょう。
public function deepDepthMethod { ...code - should be thrown a MyValidationException which is HighSpecificException ...code - should be thrown a PDOException which is SomeSpecificException of Database Handling Driver } catch (Exception $ex) { ...some recovery logic & logging return $resultOfThisCase;上記のコードがよくない理由は、以下になります。
具体的な例外の予想がつくポイントで、抽象的例外として扱っている- 抽象的例外を扱うことで、予想しづらく、
何か正確にわからない何らかの問題が起きた時も、該当メソッドで処理し完結させてしまう。(正しい処理じゃないかもしれないのに)- 上位階層が知るべき情報も、このレベルで遮断され、適切な対応ができなくなる
※3。なので、こういう場合は、以下の原則を意識しながら実装するのが好ましいです。
1) 具体的に予想できる Exception を catch する
すでに、MyValidationException が例外として発生する可能性を我々はすでに知っています。その場合は、具体的な MyValidationException のみ処理し、それ以外の予測できない問題は、無理に catch せず、上位に委ねます。
public function deepDepthMethod { ...code should be thrown a MyValidationException which is HighSpecificException ...code should be thrown a PDOException which is SomeSpecificException of Database Handling Driver } catch (MyValidationException $ex) { ...some recovery logic & logging return $resultOfThisCase; //完結 } finally { //必要な場合 }2) 具体的な Exception を明示的に上位に委任する
具体的に予想される例外に対して、catch したとして、必ずしも完結させる必要はありません。必要に応じて、必要な処理だけをした後、上位に委ねることも可能です。
- 予測される例外に対して、このポイントでは必要な最小処理だけを行って、残りの処理は、上位の共通処理に委ねたい。
- 予測しづらい例外が発生した時でも、必ずこのポイントで遂行しなければいけない処理がある時、必要な処理だけを行って上位に委ねます。
public function deepDepthMethod { ...code should be thrown a MyValidationException which is HighSpecificException ...code should be thrown a PDOException which is SomeSpecificException of Database Handling Driver } catch (ValidationException $ex) { ...省略 } catch (PDOException $ex) { ...some recovery logic & logging throw $ex; //委任 }
2-1-2.「抽象的」な Exception は、なるべく上位に委任する
「抽象的」な Exception というのは、以下のような特徴を持ちます。
- 多くの例外状況の意味をもっており、具体的な例外の特定・処理が難しい。
- 無理やり catch し、処理しようとすると、例外を間違って特定・処理してしまう可能性が大きい。
例えば、「抽象レベルが高い Exception を処理している」というのは、以下のように Exception や Throwable という相対的最上位例外を catch している場合だと表現できます。
public function deepDepthMethod { ...code should be thrown a Throwable which is High-Abstractive } catch (Exception $ex) { ...some recovery logic & logging return false; } catch (Throwable $e) { ...some recovery logic & logging return false;上記の例は、deepDepthMethod という、比較的に「Call Stack の下位ポイント
※4」から呼ばれる設定のコードです。このコードがよくない理由は、以下になります。
- deepDepthMethod がカバーできる責任を超えて、後処理し完結させている。
- 新しい問題を生み出す可能性
- この「完結させ return する」構造だと、上位ポイントのメソッド各自が、return 結果に対しての責任者になり、全てのポイントで、return 結果による処理を実装しなきゃいけない
- エラーの制御処理実装の大変さ。
なので、こういう場合は、以下の原則を意識しながら、実装するのが好ましいです。
1) 抽象的な例外は、なるべく catch しない。
catch せず、上位に責任を委任することです。
この場合は、何が起きるのかわからない Exception に対しての対応なので、
phpdoc の throws 構文も書かない方が、筆者的にはお勧めです※5。/** * dont describe 「throws」 */ public function deepDepthMethod() { //no use try catch ...code should be thrown a Throwable2) 抽象的な Exception が予想されるが、必ず後処理をする必要がある場合は、「処理後委任」する
場合によっては、何らかの例外が起きた時、何らかの処理が必須な状況もあると思います。しかしそういうときには、処理後完結せず、「処理後委任」を意識しておくと良いです。
状況に応じて、以下の方法で対処できます。
① finally 構文を使った後処理
//finally構文で、例外に関係なく、後処理を行えます。 //例外が起きなくても実行されるところは注意しましょう。 //php 5.5.x versionからサポートします。 public function deepDepthMethod { ...code should be thrown a Throwable } finally { ...some finally logic && logging② そのまま再伝播(re-throw)
//そのままexceptionを再伝播できます。 public function deepDepthMethod { ...code should be thrown a Throwable } catch (Exception $ex) { ...some recovery logic & logging throw $ex③ Custom Exception でラッピング(Wrapping)
//Exception Wrappingは、アプリケーション全体におけるエラー設計が、かなり重要になってきます。 //必ずpreviousに原本のExceptionをアサインしてあげましょう。 //上位レベルのエラー処理で、previousの情報も処理&ログするようにしましょう。 public function deepDepthMethod { ...code should be thrown a Throwable } catch (Exception $ex) { ...some recovery logic & logging throw new CustomException('message', 'code', $ex); // ANTI PATTERN >> throw new Exception('message', 'code', $ex)
2-1-3. 抽象的な例外に対する後処理は、できるだけ上位階層のポイントで処理する
では、予測が難しい抽象的な例外に対しては、何もしなくていいのか?と聞かれると、そうではありません。
- 予測できない例外に対して、 「上位階層で意図的に検知」 すること
- 必要なら発生した「予測できなかった例外」に対して、 「原因と特定し具体的な例外として再定義」、潜在的な問題を解決すること
は、アプリケーション運用においてとっても大事なことです。
予測できなかった抽象的な例外も、実のところふかぼれば、我々ば単純に予測できなかっただけで、原因・現象・対象が明確な、具体的例外の場合は多いからです。
そして、ここで例える上位階層のポイントは、アプリケーションの実行ポイントを意味しており、例えるなら以下になります。
1) アプリケーションのエントリーポイント(進入ポイントの try catch)
アプリケーションの最上位進入ポイントで、最上位の例外を検知し、運用上気付けるような構造で Application を設計することもできます。
try { $application = new Application(); //applicationのビジネスロジックの進入 //ビジネスロジックでは、具体的な例外は処理しつつ、予想できない抽象的例外に対しては、最上位まで委任させる $application->run($request, $response); //applicationのビジネスロジックの完全終了 } catch (Exception $ex){ //Applicationレベルで責任を取れなかった、予測できない例外に対して、ログを残し、指定をレスポンスを返す $logger->critical($ex); $application->response(500)->toJson()->send(); throw $ex; }2) フレームワーク階層 (Error Hook, Error Handler、フレームワーク搭載の処理・ロギング)
例えば、Symfony には、Event Handler のインタフェースを提供しており、
onKernelExceptionのインタフェースを具現すると、Framework においての Global な例外に対して、処理ができます。詳細は、Symfony Framework の Event Listener をご参考できます。
https://symfony.com/doc/current/event_dispatcher.html// src/EventListener/ExceptionListener.php class ExceptionListener { public function onKernelException(ExceptionEvent $event) { // You get the exception object from the received event $ex = $event->getThrowable(); $logger->critical($ex); $response->setStatusCode(Response::HTTP_INTERNAL_SERVER_ERROR); $event->setResponse($response); } }このように、大体の framework は、例外に対して、制御インタフェースを提供する場合が多いので、予測できない例外の検知と対策として有用に活用できます。
3) PHP・コア階層 (PHP とウェブサーバーの基本エラー処理・ロギング)
例外をコードで特に Catch しないと、PHP の基本処理としてエラーページを表示し、ログに残します。(apache error log など)
これらの基本仕様にしたがって、ログ検知などをかければ、それなりに運用することはできます。
しかし、筆者としては、① や ② のようにアプリケーション要件に合わせて設計と実装するのをお勧めします。経験としては、PHP の基本エラー処理とロギングでは、情報が不足して、調査と特定が難しい場合が多かった記憶があったからですね。
もちろん、中途半端な ① や ② の方法を行うよりは、③ が良い場合もあるので、アプリケーションと要件と状況に合わせて導入を検討するのが良いでしょう。
2-2. 例外の特性観点での責任と原則
この題目は、PHP の例外の構造と特性上、分類がかなり難しいところではあります。
その理由はいろいろありますが、「①PHP では Exception を「the base class for all user exceptions」と定義している特性、② 実行要請ごとにコンパイルと実行を同時に行うという特性、③ コンパイルと実行の境界が曖昧という特性」、この 3 つの特性で、PHP での Exception 設計において、かなり複雑にするポイントだと思います。
それでも、この概念の理解は、Exception 設計の根元を理解するのにおいて、大事な概念だと思い、話すことにしました。あくまで参考までに見ていただき、実装時の観点の一つとして留めていただけると幸いです。Exception も実は、各種類の例外に対して、それぞれの特性をもっています。
その中で、Exception 全体に共通する属性と特性をもって、説明します。
- Runtime(Unchecked) Type
- Non-Runtime(Checked) Type
2-2-1. Runtime Exceptions vs Non-Runtime Exceptions
まず、Runtime Exceptions は、RuntimeException の特性を継承する Exception たちです。
PDOExceptionが代表的な例です。Runtime Exception を継承しない Exception は、全て Non-Runtime Exception と分類できます
※6。Runtime と Non-Runtime は、以下の意味と違いを持ちます。
① Runtime
Runtime は、アプリケーションの実行時に発生可能性がある例外を意味します。
ここで大事なのは、実行時に「発生するかもしれないし、しないかもしれない」という特性を理解するのが大事です。代表的に PDOException を例えられます。
※ Java の Exception Architecture Concept では、「unchecked type」と分類されます。
● PDOException の例え
PDOException: SQLSTATE[23000]: Integrity constraint violation: 1062 Duplicate...
を見た経験はあるのでしょうか?上記のエラーは、DB Insert 時に unique key field に対して重複データを入れようとした時に発生します。逆に重複しないデータを入れたときには、アプリケーションは正常に動くようになります。
そして、データというのは、直接データをもらい実行してみる前までは、発生するかしないかわかりません。ただ発生可能性もあるという予測ができるだけです。つまり Runtime 例外はプログラムの実行中、 「実行条件によって発生有無が変わる例外」 です。
② Non-Runtime
Non-Runtime 例外は、コンパイル時に発生する可能性がある例外です
※7。
場合によりますが、「コンパイル時に高い確実で発生可能」な例外を意味します。Throwable 配下の Error を継承する例外(CompileError)や、RuntimeException を継承しない Exception(LogicException, ClosedGeneratorException)が該当します。
※ Java の Exception Architecture Concept では、「checked type」と分類されます。
● LogicException の例え
LogicException は、プログラマーに提供される Exception インタフェースですが、未実装のメソッドの呼び出し(BadMethodCallException)など、コードレベルのミスに対する例外として定義できます。
● ClosedGeneratorException の例え
ClosedGeneratorException は、php の Generator 機能に関わる例外です。
PHP の Generator は、とある連続的なデータセットを、code looping を通して返却を保証するインタフェースであり、そのゆえに大量のデータの操作に関しても、最低のメモリーで処理を可能とします。
「code looping」を意識してください。つまり「実行前に連続的データを code に変換し実行」するという意味をもっています。
ClosedGeneratorException は、すでに Closed された Generator を呼び出そうとする時発生します。そしてこのエラーは、実行時のデータ条件により変わる例外というよりは、コンパイル時の Code Error として見なすこともできます。
の事例は、以下の stackoverflow で詳細に説明されているので、ご参考ください。
https://stackoverflow.com/questions/17483806/what-does-yield-mean-in-php
https://stackoverflow.com/questions/47183250/in-php-what-is-the-closedgeneratorexception
(※リンクのミスがあったので修正しました。)2-2-2. (Java 引用) Concept -「Checked」or「Unchecked」Exception
Java では、Runtime 例外特性を「Unchecked」、Non-Runtime 例外特性を「Checked」に分類します。ここに関して、もっと詳しく見たい方は、Java の Exception Concept をご参考いただけると良いと思います。
この概念は 100%当てはまる訳ではないですが、相当部分が当てはまるので、その特性と責任を引用し説明します。
このように、PHP の Runtime Exception は「Unchecked Type」に、Non-Runtime Exception は「Checked Type」しても、かなり当てはまるところが多いと考えられます。
ここで注目するべきところは、 「確認時点」と、「後処理責任義務」 のところです。
ここに関しては混乱するかもしれませんが、次の Step で解説します。2-2-3. 「Runtime・Unchecked」。プログラマーが、プリケーション運用においてもっと注目するべき Exception Type
ここで、Runtime・Unchecked Type(以下 Runtime と表記)の「確認時点」と「後処理責任有無」をもう一度確認してみましょう。
- Runtime Type
- 確認時点:実行段階(発生しない可能性が常にある)
- 後処理責任有無:明示的に強制しない
ここで、疑問が浮かんできます。
- Q1) 同じ例外なので、なぜ処理を強制しないのでしょうか?
- Q2) なぜ、処理を強制しない Runtime Type を、プログラマーは、もっと注目しなきゃ行けないでしょうか?
- Q3) 具体的に、どういう部分を注目すればいいでしょうか?
この疑問に対して、回答しながら、その理由を解説します。
Q1) 同じ例外なのに、なぜ Runtime Type には「後処理」を強制しないのでしょうか?
ここでの 「後処理責任有無」というのは、人の観点ではありません。
言語とコンピューターシステムにおいての「処理責任有無」を表しています。わかりやすく解釈すると、観点に正確ではないかもですが、以下のような理解で良いと思います。
- 後処理責任有無-必ず処理必要
- 解説:処理してくれないと、プログラムを「コンパイルと実行ができない」から、処理してくれ!
- 後処理責任有無-明示的に強制しない
- 解説:一旦コンパイルは成功したし「実行もできた」から処理を強制はしないよ!ただ、何が起きるか「システムである私にはわからない」から、「君が責任をとって処理するかしないか決めてね!」
ここで、 「君が責任をとって処理するかしないか決めてね!」 が、大事な題目です。
Runtime Type の例外は、システムでは発生するか否かを判断できないので、処理を強制せず、まず実行を優先します。判断できない・発生しないかもしれない例外に対して、プログラムは実行を止めてまで、処理を強制することはできないからです。
つまり、Non-Runtime とは違って、 「システムには予想できない Runtime 特性の例外の責任は全的にプゴグラマーにある」 ということです。
Q2) なぜ、処理を強制しない Runtime Type を、プログラマーは、もっと注目しなきゃ行けないでしょうか?
サービス運用において、本当に難しく、深刻な状況を生み出すのは、どういう Type の例外でしょう。
筆者の経験では、Runtime 時に発生する予測しなかった問題が圧倒的ですね。
理由は、以下になります。● Non-Runtime の問題
主に、環境設定や、コーディングミスによる問題。
大体は実行の前段階で発生する。
故に、
- 発見・原因特定が簡単、修正対応が明確
- 実行されてもいないので、「システムの整合性の崩れ、永続性データの汚染」なども発生しづらい
● Runtime の問題
主に、予測していない入力値や、論理的欠陥による問題。
大体実行途中で、実行条件により、発生するかもしれないし、しないかもしれない。
故に、
- 発見・原因特定が難しい、修正対応も困難
- 実行途中で起きたので、「サービスの整合性の崩れ、永続性データの汚染」が発生しやすい。
「サービスの整合性の崩れ、永続性データの汚染」の捕捉するとこうです。
● サービスの整合性の崩れ
データの整形・数値の計算などで、意図していない論理的欠陥が発生することで、「サービスの論理的整合性」が崩れること● 永続性データの汚染
Database や File などで、処理途中で止まったか、意図していない結果のデータが、保存されることで、「永続性データの無欠性が崩れること」このように、Non-Runtime は、大体すぐ気づけて復旧する間にユーザーはその機能を使えないというレベルで止まる場合が多いですが、Runtime のエラーは、サービスの整合性と無欠性そのものを崩してしまう場合も有り得ます。
そしてここは、復旧が聞かないほどの「事業レベルでの損害」と繋がる場合も少なくはありません。
Q3) 具体的にどういう部分を注目すればいいでしょうか?
筆者として注目するべきポイントは、以下だと思っています。
- 予測できる Runtime 特性の例外に関しては、必ずその影響を考え、必要な時は記録・通知・復旧対応をする
- 予測しづらいポイントに関しては、上位レベルで必ず catch し、詳細ログを記録する(stack trace まで)
- 予測しづらいポイントでの例外は、critical level とみなし、即時に気付けるようにして、その原因と影響の把握ができるように試みる
正直なところ、Runtime 時に発生できる例外を全て完璧に対象しておくのは、すごく難しいことです。
なので、大事なのは 「発生した時必ず気付けること、原因特定と復旧のために詳細に記録すること、一度発生した問題に対しては永久対応を試みること」 と言えます。
2-3. Custom Exception に対する責任と原則
我々は時々、言語で提供している Exception のインタフェースを継承し、Custom Exception を作る場合があります。特に Framework では、Framework 独自の Custom Exception を多数もっていたりもします。
では、この Custom Exception に対して、どういう責任を付与して、また我々は責任をはたすべきでしょうか。
2-3-1. 主に Runtime Exception 属性を持つ Custom Exception を設計すること
まず、Custom Exception を作る用途は様々ですが、主に推奨するのは、以下の目的での Exception です。
- Data Validation
- Broken Data & Status Integrity
- Access Control & Status Control
- API Communication Handling
- その他、ライブラリやフレームワークにおける、エラー処理
ここで、全体的に通用する特徴は「Runtime 特性で起き得る問題」ということです。
つまり、我々が Custom Exception を作る主なニーズは、「システムで責任を取れない Runtime 時に
の問題を人間が対処するために、対処すべき問題を例外としてモデリングする」ことと言えると思います。※ なぜ、Non-Runtime Exception の CustomException は主な関心事ではないのか?
未具現のメソットの呼び出しとかの例外をアプリケーション独自で処理したく、LogicException を継承して、コードレベルエラーに対して Non-Runtime Exception を定義することもできますが、必要性は低いです。
2-3-2.「明確・具体的」な Exception であること
Custom Exception は、プログラマーが定義する例外です。
つまりプログラマーが、何らかの意図を前もって定義するということです。
そしてその意図は明確で具体的でなければなりません。明確ではなく、抽象的な意図をもって CustomException を設計すると、システムの例外体型が崩壊します。
ここは、アプリケーションの要件により、様々な答えが正解になったり不正化になったりもする、難しいところではありますが、PART3 の「Application においての Exception 設計」を参考していただければと思います。
まずは、 CustomException は、「明確・具体的な例外であること」 を心に留めておいてください。
? PART-2 のまとめ「例外の責任と原則」
PART-2 の内容をまとめると、以下になります。
● 「抽象レベル」観点での責任と原則
- catch する時は、「具体的」な Exception を catch する
- 「抽象的」な Exception は、なるべく上位に委任する
- 「抽象的」な例外に対する後処理は、できるだけ上位階層のポイントで処理する
● 「例外特性」観点での責任と原則
- Runtime と Non-Runtime を意識して設計・ハンドリングする
- サービス・アプリケーション運用においては、Runtime 特性の例外を注目し対応・運用する
※ Runtime 特性の例外を軽視しては行けないという意味です。Non-Runtime 特性の例外を軽視してもいいという意味ではありません。
● 「Custom Exception」に対する責任と原則
- Custom Exception は、Runtime Exception を焦点に設計するのが好ましい
- Custom Exception は、「明確・具体的」であること
PART-3. Application 開発においての「Exceptions 設計・導入」
今回は、実際に Application の開発・運用において、どういう風に設計することができるのかを話します。
ここの話は、Application の要件と開発組織によって、正解だったり不正解だったりする、難しいところですが、筆者が考える、今までの原則を踏まえて解説しようと思います。
ここでお話しする Exception 設計と導入は、以下の意味を示しています。
- アプリケーション独自処理で、人が定義した、人が予想できる、処理するべきエラーという問題を Custom Exception として設計し定義
- プログラムで起き得る具体的な Exception の検知・処理
- プログラムで起き得る抽象的な Exception における検知・処理
- Exceptions 設計導入アプリケーションの運用
このパートは、Symfony Framework の内容を一部含めていますが、基本原則自体は変わらないので、どのアプリケーションにおいても参考にできれば幸いです。
そして、これまでみてきた内容の元に、話していくので、内容自体は重複する部分が多いとおもいます。今まで話した概念を、より活用に近い観点で再整理するという目線でご覧いただくと良いと思います。
3-1. Exception 設計の導入の長所
開発するアプリケーションにおいて、Exception 設計の導入は、以下の長所を持ちます。
3-1-1. Application における、OOP に基づいた Exception 導入の長所
1) 長所
Exception は「throw・上位伝播」特性をもっています。
そしてこの特性は、以下の長所を提供します。
- エラーに対して、Exception クラスの特性をもって定義し、詳細な情報を記述できる
- エラーの特定と対処がしやすくなる。
- エラーの制御処理が飛躍的に効率的になる。
- Exception を任意のポイントで発生させ、上位に伝播し、必要なポイントで検知・処理・委任できる。
- アプリケーション全体のエラーを、階層化・構造化できる
- エラーという問題は、抽象化モデリングし、綺麗な設計ができる
2) 長所解説 - Exception がいない場合と Exception がある場合のお話し
最近のプログラムは、昔に比べてより複雑になり、様々なライブラリやフレームワークが提供するクラスのメソッドを、階層的に呼ぶ傾向が多くなりました。
こういう環境で、例えば Exception 概念がない言語とみなし、特定のエラーを処理してみましょう。
① Exception 概念がない場合
class EntryPoint { public function execute() { (new DepthLevel1())->do(); } } class DepthLevel1 { public function do() { (new DepthLevel2())->do(); } } class DepthLevel2 { public function do() { ... if ($validationError) { return false or error情報を含む変数 or 強制終了 } if ($databaseWorkingError) { return false or error情報を含む変数 or 強制終了 } } } //実行 (new EntryPoint())->execute();上記は Exception を使わない場合、よくみられるエラー処理パターンです。
比較的に CallStackが深くなかった昔は、何とかやってこれましたが、プログラムが複雑になり、特に OOP の特性上 CallStack に深くなるしかない現代プログラムでは、以下の課題を抱えています。
- EntryPoint までエラー情報を伝達し、最終結果をユーザーに表示するためには、各自の CallPoint で、return を受け取り適切な処理をするロジックを実装するか、強制的に実行を終了して結果を返すしかできません。
- エラーに対して、特定の CallPoint で処理した後、完結させたり委任したりする場合、処理制御がとっても難しいです。
- return でのエラー伝達は、明確なエラーを伝えることと、エラー構造を守って開発し、プログラムを維持するのが難しいです。
- 上記の理由により、エラー処理自体がバグポイントになる可能性が高いです。
では、今の構造を Exception を導入したコードに変えてみましょう。
② Exception 概念がある場合
class EntryPoint { public function execute() { try { (new DepthLevel1())->do(); } catch (ValidationException $ex) { ...response 400. BadRequest } catch (Exception $ex) { ...logging specific information about Unknown Exception throw $ex; //もっと上位に委任 } } } class DepthLevel1 { public function do() { try { (new DepthLevel2())->do(); } catch (PDOException $ex) { ...data check & recovery if needed & logging throw $ex; } } } class DepthLevel2 { public function do() { ... if (validationError) { throw new ValidationException($message); } $stmt->execute(); //will be throw PDOException } } $result = (new EntryPoint())->execute();このように、
- 上位伝播の特性で、必要なポイントで、必要な処理を実装することで、簡単に制御処理を実現できます。
- Exception たちは、各自で具体的な意味と、詳細情報を含めているので、予測・原因特定・処理もシンプルになります。
- Exception たちは、すでにクラスとして構造化され定義されているので、コード観点での維持補修もシンプルになります。
- 制御の追加・修正もまた、柔軟に行える構造になっています。
OOP の言語では、今まで話した OOP 言語の特性・プログラムの複雑化・Exception 導入の長所をもっと、アプリケーションにおける Exception 設計の導入が勧められます。
3-1-2. Application における、Custom Exception 設計の長所
Custom Exception は、
「3-1-1」で語った長所を、サービス・アプリケーションにおいて、解決しなきゃいけない問題である「アプリケーション特有のエラー」に対しても引き継げることにあります。この長所は、これから説明する「設計パート」をご覧いただくと明確になると思います。
3-2. 導入における Application 構造説明
今回のアプリケーションは、「ユーザーを生成する」というシンプルな目的をはたすという、アプリケーションを想定します。
まず、アプリケーションのクラス構造と、階層を表すと、以下になります。
SymfonyFramework と DDD に起因する構造の説明は省略します。
DDD に関しては、以下の URL や、関連の書籍をご参考いただけると幸いです。http://uniknow.github.io/AgileDev/site/0.1.8-SNAPSHOT/parent/ddd/core/layered_architecture.html
格クラスの役目を簡単に説明します。
3-2-1. Application Layer
ユーザーの要請受信と、結果の応答、そして「サービスの呼出選定と制御」を果たします。ビジネスロジック処理の責任は持ちません。
● Controller/UserController
ユーザーを生成するための処理のエントリーポイントとなります。3-2-2. Domain / Service Layer
ドメインモデルの特定ドメインに対して、ビジネス要求に対する処理の責任を持ちます。
● Service/RequestValiator
ユーザーのリクエストに対して、リクエスト情報の整合性をチェックし、その結果を上位に返す機能を果たします。● Service/UserManagement
ユーザー情報を生成するための処理機能を担当します。
Entity/User のドメインに対して、永続性レポジトリー(DB)作業を遂行します。3-3-3. Domain / Entity Layer
ドメインモデルの特定ドメインに対して、ドメイン属性スキームの定義を持ちます。
● Entity/User
ユーザーというドメインに対する属性スキームの定義を記述したクラスです。
(簡単に例えると、DB の user テーブルの構造と属性がクラスに記述されています。)Repository 階層の ORM/EntityManager を通して、ドメイン属性情報を DB に永続的に保存したり、照会したり、修正したり、消したりします。
3-3-4. Repository Layer
インフラに当たる階層です。
Database や File など、永続性システムを利用するため提供されているパッケージや、基本提供コンポーネントなどが、この階層に属します。● ORM/EntityManage (Doctrine パッケージ・Framework 提供)
Database の永続性システムとのコミュニケーション・処理要請などを行うための DriverLibrary になります。
3-3. Application に Exception 設計導入
「3-2」で説明したアプリケーションの構成に、Exceptions 観点を追加して設計します。
CustomException と、説明のため、一部 PHP の Exception、Framework 提供 Exception を追加で表現します。
クラス構成図は以下になります。
では、今からは、設計観点に基づいて、クラス解説をしていきます。
3-3-1. 抽象階層 CustomException 定義と設計
Point
- カスタム例外の基盤になる上位階層の設計
- 抽象レベルが高い階層ということを意識
- 相対的。アプリケーション(CustomException)範囲に限って、抽象的という意味です。
- カスタム例外の拡張などで、階層的抽象化・構造の統一性を意識して設計
ここで、抽象階層
※8の CustomException は、以下と言えます。
抽象階層の Exception Class として、継承のみを許可し、インスタンス生成は許可しないようにするため、抽象クラスとして定義しています。① GenieAppException (Bundle/Exception)
- RuntimeException を継承し、RuntimeException が持つ特性と責任を継承します。
- 全ての Runtime 特性の CustomException の親になります。
- プログラマーのミスなどにより CustomException の誤った発生・処理漏れなどで、正しく処理されなかった CustomException に対して、上位レイヤで catch し、適切な情報記録と処理を果たします。
② ServiceException (Bundle/Exception/Service/)
- GenieAppException を継承します。
- 全ての Service 階層の Base Exception になります。
- ServiceException は、getUserMessage()メソッドを持ちます。
- ユーザーへの適切な応答メッセージの情報を提供する義務を持ちます。
3-3-2. 具体階層 CustomException の設計と設計
Point
- カスタム例外の具体的なエラーを設計
- 抽象レベルが低く、具体的な階層ということを意識
- カスタム例外のエラーは、一番具体的で明確であること
ここで、具体階層の CustomException は、以下と言えます。
① RequestValidatorException (Bundle/Exception/Service/)
- ServiceException を継承します。
- Service/RequestValidator から、発生します。
- Service と Exception を 1:1 でマッピングされるように定義し、各自のクラスの責任を単一責任になるように設計します。
- Service/RequestValidator から発生する時、明確なエラー情報をセットし、上位伝播します
- ServiceException は、この情報を元に、getUserMessage()の結果を返すことができます。
3-3-3. Service/UserManagement クラスに対する捕捉
UserManagement サービスに対しては、CustomException を定義する必要がないという設定です。
理由としては、
- UserEntity と EntityManager を通して、DB にデータを生成するという責任だけを持つサービス
- 予想される例外は、Entity 階層で発生する Entity&ORM Driver の例外(PDOException など)
の理由であり、UserManagement サービス独自で発生させる例外は不要です。
3-3. 例外のハンドリング
3-3-1. アプリケーション下位階層での、例外の発生とハンドリング
Point
- CustomException を、必要に応じで意図的に発生させる
- CustomException が保持する情報は、明確であること
- Exception を catch する時は、可能であれば具体的に catch する
- 可能であれば、catch するポイントでしかできない処理が必ず必要な時だけ catch し、必要な処理だけをした後、上位に委任する
- 処理必要がないか、予想できない、責任を取れない例外は上位に委任する。
① RequestValidator での CustomException の意図的発生
ビジネスロジックの処理で、検証に失敗したら、該当クラスとマッピングされる RequestValidatorException を throw するようにします。
これで、RequestValidator による Exception に対して、上位階層のどのポイントでも処理、またはスルーでき、必要に応じて処理制御を具現できるようになります。
namespace Bundle\Service; use Bundle\Exception\Service\RequestValidatorException; class RequestValidator { ... public function validate(...) { ... if ($validationFail) { throw new RequestValidatorException(...); } } }② Service/UserManagement 内の潜在的な例外のハンドリング
ここは前もってお話しした通り、CustomException の定義は不要という定義と、
Repository 階層の EntityManager は、プレイムワークや PHP が提供する特定 Exception を発生させる可能性があるので、具体的に予想がつく例外に対して対処します。※ ここは、各自の具体的例外に対して、処理が必要なプログラム要件だと定義します
例外発生が予想されても、このポイントで必ず処理すべき要件がないなら、catch を省略し上位に委任することも場合によっては可能です。// Service/UserManagement class UserManagement { ... public function create(EntityManager $em) { ... try{ $em->persist(...) $em->flush(); } catch (DBALException $ex) { //some recovery logic & logging for Case of DBALException throw $ex; } catch (PDOException $ex) { //some recovery logic & logging for Case of PDOException throw $ex; } catch (ORMException $ex) { //some recovery logic & logging for Case of ORMException throw $ex; } } }3-3-2. アプリケーションでの上位段階での例外のハンドリング
Point
- アプリケーションにおいて、意図的に発生するエラーに対して共通の処理が必要な場合は、アプリケーションの上位ポイントで例外ハンドリングを行うことができる。
- アプリケーション要求事項としての共通エラー処理のみを処理する
- 可能であれば、予測できない、責任取れないエラーは、最上位に委任する。
- Controller の責任を意識する。(Controller の責任はロジックの流れの制御)
「アプリケーション」でおいての上位は、Contoller の ActionMethod を基準とします。
ここでは、「プルグラマーの意図によって発生可能なカスタム例外」に対しての処理責任を持ちます。
今回の場合は、RequestValidationException がその事例です。
そして、RequestValidationException が提供する情報をもって、意味のあるエラーメッセージ情報を応答としてレスポンスします。
class UserController { public function create( LoggerInterface $logger, RequestValidator $validator, UserManagement $userManagement ){ try { $validator->validate(...); $userManagement->create(...); } catch (RequestValidatorException $ex) { $logger->info(...); $response = new JsonResponse(...); $response->setStatusCode(Response::HTTP_BAD_REQUEST); $event->setResponse($response); } } }3-3-3. インフラ階層観点御最上位段階での例外のハンドリング
Point
- 想定していない例外に対して、探知の責任をはたす
- critical level として扱い、ログ記録と通知を前提とする
- 可能であれば、発生した例外に対して、恒久対応を試み、具体的な問題として再定義する。
- 正しいエラーハンドリングをアクリケーションに追加するという意味です
アプリケーションを含め、アプリケーション実行のための基盤階層(Framework, PHP)においての最上位段階での例外ハンドリングの一例になります。
今回は、Framework で提供する ExceptionListener という機能を使います。
この機能は、EventHook 概念で、Framework のロジック処理の段階の一部を横取りすることが可能です。
つまり、Framework に従い我々が実装したビジネスロジックのどこかで、catch していない得体不明の例外が投げられても、全てここで横取りできます。
ただし、ここは、サービス全体においての最上位と見なすべきなので、「想定されていない得体不明の例外の探知」を目的としたハンドリングを試みます。
// src/EventListener/ExceptionListener.php class ExceptionListener { public function onKernelException(ExceptionEvent $event) { // You get the exception object from the received event $ex = $event->getThrowable(); // Can handle for each Exceptions if you need if ($ex instanceOf ServiceException) { ...logic For Unexpected Custom Exception } else if ($ex instanceOf GenieAppException) { ...logic For Unexpected Custom Exception } else { ...logic For Unexpected UnknownException } $logger->critical($ex); //logging with stackTrace $response->setStatusCode(Response::HTTP_INTERNAL_SERVER_ERROR); $event->setResponse($response); } }3-4. Application への Exception 設計導入例におけるまとめ(長所と課題)
ユーザー情報を生成するという単純な機能に対して、Symfony(DDD)のアプリケーション構造に対する、Exceptions 設計導入方法の例を説明しました。
最後に、上記の設計において、筆者が思う長所と課題を記述します。実際のアプリケーションにおいての開発の時に、参考になると幸いです。
3-4-1. 長所
1) エラーの構造化
我々がサービスを開発する時、我々は様々な操作ケースに対して、常に正常結果のみを処理している訳ではありません。
「入力値検証・アクセス制御・操作プログレス制御・ステータス制御・外部 API 通信問題・システム状態によるトラブル」 など、様さざなイレギュラーケースに対して、我々は、アプリケーション要件として定義し、非正常結果として扱わなければなりません。
こういう、 「非正常」という課題に対して、Exceptions 設計導入は、課題に対する「階層的抽象化」モデルの確立を実現できる手法です。
これがもたらす、メリットに対しては、PART1 と PART3 の内容となります。
2) エラーに対する制御処理の柔軟性
例外は、「上位伝播」という特性をもっています。
そして catch には、「ポリモーフィズム」原理が適用されるので、エラー処理に対して、「どこで」「どういう」例外を、「処理」するか、「委任」するかを、柔軟に制御できます。特に、エラーの世界では、この柔軟さがシステムの「完結さ」と「底欠陥さ」をもたらしてくれます。
その理由に関しては、PART 2と PART3 の内容となります。
3) エラー処理の共通化
意図的に共通化したい例外、想定していない例外に対して、アプリケーション・インフラの上位階層で、共通処理を実現できることで、エラーに対する後処理の「統一性」「処理保証」「探知保証」をもたらしてくれます。
それで、エラー処理に対しる処理の漏れや、処理漏れ、認知漏れを防げます。
PART3 で紹介した、Entry Point での、Validation エラーに対する共通処理と、EventListener での onKernelException()の処理がその例です。
3-4-2. 課題
1) 維持補修開発において、設計構造の共通認識としてのハードル
しかし、この設計領域は、筆者自身としても、高難易度の設計領域です。
まず、設計のためには、「言語・フレームワーク観点でのプログラム設計」「基本提供の例外設計」「ビジネス・サービス要件に対しての要求定義と例外設計」のスキルがまず必要となってきます。
そして、作られた設計に対しても、チームで開発する時は「共通認識」として浸透させる必要があります。そうでない場合は、開発や維持補修段階で、統一性がくずれる可能性が高いです。
ここに関しては、難しいところですが、以下の対策を意識することで、補えると思います。
● ドキュメント化と、ドキュメントの運用
設計と、コードをドキュメント化し、運用することで、全体情報の熟知、最新情報に維持することができます。そして、プログラムの改修時の「監理」の役目も果たします。しかし、やはり時間が必要な対策です。
なので、「必要な文書だけシンプルに維持する」ことが大事です。2) 維持補修開発において、統一性を守というハードル
上記の内容でも少し話しましたが、アプリケーションの統一性を維持することがハードルになります。
- 変化し続けるビジネス要件
- 多数の人がプログラムを開発することによる、コードの差
- 現実的な時間確保の難しさ
などが、問題になってきます。
ここに関しても、やはり難しいところですが、以下の対策を意識することで、補えると思います。
● 実装前にインタフェース構造実装からする・レビュー後、具体的ロジックを実装
実装時にロジックをすぐ実装するのではなく、まずメソッドのインタフェースと、依存関係の先に「疑似コード」として、作成し、初期段階でコードレビューを行います。実際には詳細設計の下位工程のレビューと言えます。
これにより、プログラムの構造に対しての整合性に影響する可能性がある問題に関して事前に検知する可能性が高くなります。
● 周期的なリファクタリング
周期的リファクタリングを時間を持つと、プログラムはもちろん、アプリケーションの構造、ドキュメントの整理などもできます。
もちろん、上記に説明した問題は、Exceptions 設計に限る話ではないですが、Exceptions 設計は、場合によってはその課題の難易度を高め、さらに複雑なアプリケーションになってしまう可能性もまたあります。
そこを注意することは、とても大事です。
PART-4. 例外設計原則まとめ
4-1. Exceptions 設計原則まとめ(筆者主観含む)
今まで見てきた内容を、原則という文章でまとめます。
それ以外に、覚えておくと良いと思う原則も少し加えています。4-1-1. OOP 観点での原則
- 例外(Exceptions)は、プログラム上で起き得る「事故を階層的に抽象化」モデリングした物である
- 「上位階層なほど抽象的、下位階層なほど具体的」である
- 「具体的」は「抽象的」にもなれる
- 抽象的な例外ほど予測と正確な対処が難しい
- try-catch をするということは、一種の「保険」をかけること
4-1-2.「抽象レベル」観点での責任と原則
- catch する時は、「具体的」な Exception を catch する
- catch した時は、該当ポイントの制御フローまで責任をとる
※9- 例外発生前後は、クラスの状態が有効生を保つように意識する
- 「抽象的」な Exception は、なるべく上位に委任する
- できれば、Exception, RuntimeException のような General Exceptions を catch しない。
- 責任を取れそうにない例外は catch しない
- ほっとけば、最上位階層でまとめて処理される
- 「抽象的」な例外に対する後処理は、できるだけ上位階層のポイントで処理する
- 最上位のエラー処理は必ず「探知・ログ記録・通知」の責任をとる(特別なことがない限り)
4-1-3.「例外特性」観点での責任と原則
- Runtime と Non-Runtime を意識して設計・ハンドリングする
- サービス・アプリケーション運用においては、Runtime 特性の例外を注目し対応・運用する
4-1-4.「Custom Exception」に対する責任と原則
- Custom Exception は、Runtime Exception を焦点に設計するのが好ましい
- Custom Exception は、「明確・具体的」であること
4-2-5. その他、意識しておけば良い原則
- できれば、複数階層で重複で処理しない
- できれば、Error は処理しない
- できれば、Non-Runtime(Checked)属性の例外は、ビジネス的な意味がある要件の実現必要性がある時のみ導入する
- 例外の記録は、ログフレームワークを使い処理する。(監視・通知体勢も備える)
今回の後書き
最初、この記事を考えた理由は、最近、頭の中で考えていた「古いサービスの現状のエラー処理の課題間」と、追加開発においての「エラー設計」に関して、ふわっと思っていたところからです。
もちろん、今までの経験である程度の知識や経験はあったと思ってましたが、改めて「筆者自身は Exception に対してどれだけ理解していて、説明できるか?」を、自分自身に問うようになりました。
考えてみると、破片的な知識と経験が多くあるものの「まとまってない」ということが、自分自身の中で出した結論です。
そこで、この記事の作成を通して、以下の成そうとしました。
- ゴール
- 「まとまって明確な知識」として、自分自身の中で再構築
- 筆者自身の知識の情報検証
- 過程
- 破片的な知識と経験の可視化
- 上記の内容を、理論と照らし合わし検証
- 上記の内容を構造的に整理
- 上記の内容から核心を抽出
- 核心を強く認識し「まとまって明確な知識」として、自分自身の中で再構築
ゴールは、ある程度満たせたんじゃないかなと、思っています。
しかしやってみながら、まだ足りないところも多いなと思いながら、書いた感じです。
特に以下の部分などなどに関しては、まだまだ足りず、精進しないという反省もあります。
- もっと深い OOP の理解
- ビジネス課題を踏まえた DDD アーキテクチャ設計
- 基本提供エラー機能・クラスの理解
- FRAMEWORK 自体の理解
- Application においての、理想的なエラー設計・運用
そして、思ったより分量が多くなってしまったのは、筆者自身の課題かもしれません。
ともあれ、これからも、開発であれ、なんであれ、頑張って楽しくやって行きたいと存じます。
※注釈
※1)
Exception に関わる事例コードとかをみて、書いて、その結果を身で直接感じた上で、次に進めることをお勧めします本の分量だと 10page 内外だと思います。まずは全てを理解するより、書いたコードに対する結果を体感することの先行が大事だと思うので、軽い感じでお試しください。
※2
上位に委任するほど、抽象的になったしまう傾向が強い例外は、発生ポイントからだんだん上位に伝播されると、その上位ではだんだん抽象的例外として扱うことになるという意味です。
上位にいくほど、例外が発生するポイントとその種類もだんだん増えていくのがその理由です。
※3
上位階層が知るべき情報も、このレベルで遮断され、適切な対応ができなくなる。実は、特定の例外に対して、上位段階でも、ログを残したりとか通知をするとか、なんらかの対応の責任があるかもしれません。
しかし、発生ポイントで処理するまでは良いですが、上位階層でやるべき責務がある状態で、上位に伝播(報告)せず、例外を揉み消してしまうと、いろんな問題を起こしてしまう可能性もあります。
※4
Call Stack の下位ポイントCall Stackいうのは、プログラムのメソッドの呼出の深さを意味します。
以下の記事をご参考いただけます。
https://qiita.com/righteous/items/494340cf16c7a35f742e※5
何が起きるのかわからない Exception に対しての対応なので、phpdoc の throws 構文も書かない方が、筆者的にはお勧めですphpdocで、throwsを明示的に記載するのは、「ハンドリングをすることを強くアピールする」ことだと思います。なので、他の人がみると、不要にcatchする傾向が現れるかもしれません。
※6
Runtime Exception を継承しない Exception は、全て Non-Runtime Exception と分類できますしかし、前もって話したように、PHPの特性で境界が曖昧なところがあると思うのが、筆者としての考えです。
※7
Non-Runtime 例外は、コンパイル時に発生する可能性がある例外です。上記と同じく、PHPの特性で境界が曖昧なところがあると思うのが、筆者としての考えです。
※8
抽象階層プログラマーが具現するアプリケーション範囲に限定してでの、抽象階層という意味です。
FRAMEWORK, PHPなどインフラ階層まで含めると、インフラ階層よりは、Custom Exceptionが遥かに具体的階層に存在することになります。抽象的というのは、あくまで相対的ということを意識すると良いです。基準によって、基準より抽象的にもなるし、具体的にも慣れます。
※9
catch した時は、該当ポイントの制御フローまで責任をとるcatchをした場合は、処理として、該当ポイントの処理の最後やで責任をもって制御の責任をとることです。
方法としては、
- 上位に委任する (制御を途中で中断し、上位に責任を委ねる)
- 処理を完結する場合、該当ポイントの処理の結果の整合性に責任をとる。ということです。
例えば、
{変数宣言; try {変数に値をアサイン;} catch {エラー記録;} 変数操作・変更・リターン}が悪い例。catch 以降の処理が、制御責任を違反する動きだと言えます。
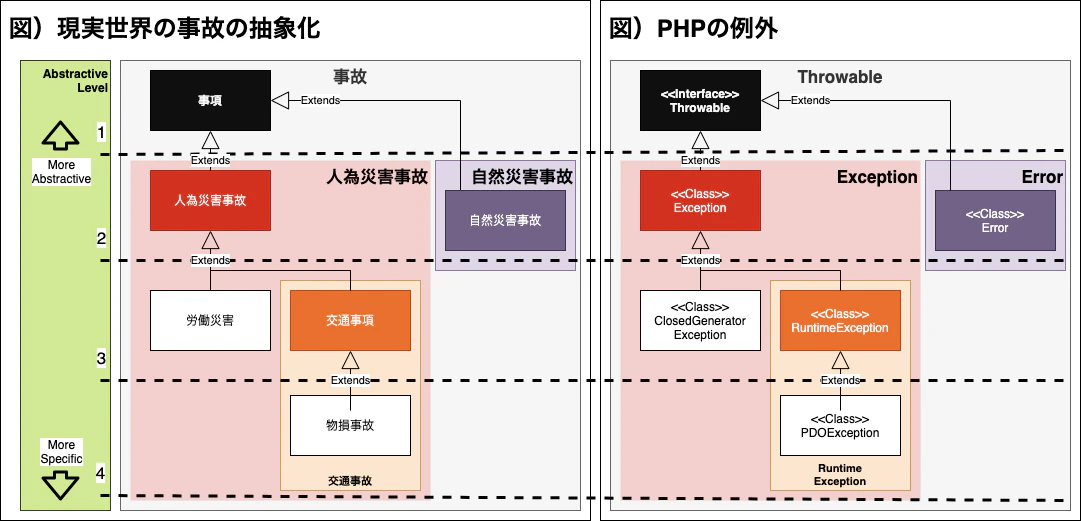
- 投稿日:2020-12-23T09:52:09+09:00
【サルが書く】特定文字列と特定文字列の間の特定文字列を取り除きたいときの操作
わきゃ!!
GIGアドベントカレンダー16日目になります!
GIGメンバーの投稿はこちら? から見てみてね!
https://qiita.com/organizations/gig-inc文字列から特定の文字列を取り出す操作は探せばあるけど、特定文字列と特定文字列の間の特定文字列を取り除きたいが見当たらなかったのでこれが役に立てば嬉しいです!
以下の例の場合は
<blockquote>と</blockquote>の間の<p>と</p>を取り除きたいという例です。
適宜入れ替えてご使用ください。$body = '<blockquote>hoge<p>fuga</p>piyo<\/blockquote>'; $htmlTags = ['<p>', '</p>']; $body = preg_replace_callback( '/<blockquote>(.*?)<\/blockquote>/', function ($matches) use ($htmlTags) { $quotation = str_replace($htmlTags, '', $matches[1]); return "<blockquote>{$quotation}</blockquote>"; }, $body );
- 投稿日:2020-12-23T08:52:14+09:00
laravel6 バッチを作って実行してみる
目的
- laravel6のアプリでバッチを作成し、実行する方法をまとめる。
実施環境
- ハードウェア環境
項目 情報 OS macOS Catalina(10.15.5) ハードウェア MacBook Pro (13-inch, 2020, Four Thunderbolt 3 ports) プロセッサ 2 GHz クアッドコアIntel Core i5 メモリ 32 GB 3733 MHz LPDDR4 グラフィックス Intel Iris Plus Graphics 1536 MB
- ソフトウェア環境
項目 情報 備考 PHP バージョン 7.4.8 Homebrewを用いてこちらの方法で導入→Mac HomebrewでPHPをインストールする Laravel バージョン 6.X commposerを用いてこちらの方法で導入→Mac Laravelの環境構築を行う MySQLバージョン 8.0.19 for osx10.13 on x86_64 Homwbrewを用いてこちらの方法で導入→Mac HomebrewでMySQLをインストールする 条件
- laravel6のアプリがありローカルサーバなどを起動しブラウザから確認する事ができること。
情報
- バッチの実行方法は手動でコマンドを叩いて実行するものとする。
- バッチの作成と手動実行の方法をまとめることが目的のためバッチの内部で実行する処理は最低限とし「Hello Japan!」をターミナルに表示するだけのものとする。
概要
- バッチの作成
- 実行と確認
詳細
バッチの作成
アプリ名ディレクトリで下記コマンドを実行してバッチクラスを作成する。
$ php artisan make:command EchoStrCommandアプリ名ディレクトリで下記コマンドを実行して作成したバッチクラスが記載されているファイルを開く。
$ vi app/Console/Commands/EchoStrCommand.php開いたファイルを下記のように修正する。
アプリ名ディレクトリ/app/Console/Commands/EchoStrCommand.php<?php namespace App\Console\Commands; use Illuminate\Console\Command; class EchoStrCommand extends Command { /** * The name and signature of the console command. * * @var string */ // 下記を修正 protected $signature = 'command:echo_str'; /** * The console command description. * * @var string */ // 下記を修正 protected $description = 'Echo Hello Japan!'; /** * Create a new command instance. * * @return void */ public function __construct() { parent::__construct(); } /** * Execute the console command. * * @return mixed */ public function handle() { //下記を追記 echo 'Hello Japan!'."\n"; } }実行と確認
アプリ名ディレクトリで下記コマンドを実行し出力結果の中に「command:echo_str」が存在していることを確認する。
$ php artisan listアプリ名ディレクトリで下記コマンドを実行する。
$ php artisan command:echo_str下記のようにターミナル上に「Hello Japan!」の文字が表示されることを確認する。

- 投稿日:2020-12-23T07:05:25+09:00
Laradockをちょっと便利にするコマンドラッパーを作った
この記事は個人開発 Advent Calendar 2020の23日目です。
TL;DR
Laradockをちょっと便利にするコマンドラッパーを作りました。
https://github.com/ngmy/laradockctl背景
WebサービスやOSSを開発するときはDockerを使うと開発マシンが汚れないので便利ですね。
私はもっぱらPHPで開発しており、また一からDockerで開発環境を構築する時間もないので、開発環境はLaradockのお世話になることが多いです。
LaradockはPHPの開発に必要なもの全部入りのDocker環境で、PHP界隈ではおなじみのツールです。そんなLaradockですが、使っていて個人的に不便に感じる点があります。
Laradockを使っていて個人的に不便に感じる点
1. どのコンテナを起動すればいいのか忘れる
「このWebサービスではnginxコンテナとmysqlコンテナを立ち上げて……」「このOSSではmailhogコンテナも立ち上げて……」といった具合に、プロジェクトに応じて起動するコンテナが異なるので、毎回どのコンテナを起動すればいいのか忘れます。
これはしばらく触っていなかったプロジェクトをひさしぶりにメンテナンスする必要が生じたときによく起こります。2. コマンドを打つのが面倒くさい
私はターミナルとVimで開発する古いタイプの人間なので、ターミナル上でカレントディレクトリをガンガン移動しながら開発します。
Laradockを操作するときはdocker-composeコマンドを実行することになるのですが、Laradockのインストールディレクトリ以外から実行するにはいちいち-fオプションや--env-fileオプションでdocker-compose.ymlファイルや.envファイルを指定しなければならず、コマンドを打つのが非常に面倒くさくなります。
かといって、いちいちLaradockのインストールディレクトリに移動するのも面倒です。作ったもの
というわけで、上記の不便に感じる点を解消するために、Laradockのコマンドラッパーを作りました。
https://github.com/ngmy/laradockctl下記のコマンドでプロジェクトルートにインストールして使います。
git submodule add https://github.com/ngmy/laradockctl.gitパスを通します。
export PATH=/PATH_TO_LARADOCKCTL/bin:$PATHdirenvを使ってパスを通すことをおすすめしています。
これでラッパーコマンド(
laradockctl)が使えるようになります。ラッパーコマンドの例です。
Composerを実行するlaradockctl workspace:composer # docker-compose -f /PATH_TO_LARADOCK/docker-compose.yml --env-file /PATH_TO_LARADOCK/.env workspace composer のラッパーArtisanを実行するlaradockctl laravel:artisan # docker-compose -f /PATH_TO_LARADOCK/docker-compose.yml --env-file /PATH_TO_LARADOCK/.env workspace php artisan のラッパーLaravelのアプリケーションログを表示するlaradockctl laravel:logs # docker-compose -f /PATH_TO_LARADOCK/docker-compose.yml --env-file /PATH_TO_LARADOCK/.env workspace tail storage/logs/laravel.log のラッパー素の
docker-composeコマンドを使う場合よりタイプ数がぐっと減ります。またカスタムコマンドを追加することもできます。
私はプロジェクトごとに開発環境の起動コマンドを書いて、プロジェクトのリポジトリに一緒にコミットしています。
下記の例では、開発環境用のLaradockの
.envファイルを使って必要なコンテナを起動して、開発環境用のLaravelの.envファイルをコピーして、Composerでパッケージをインストールして、Laravelの初期処理を行い、データベースマイグレーションを行い、フロントエンドのビルドを行うmy:upというコマンドを定義しています。開発環境を起動するカスタムコマンドの例#!/bin/bash set -Ceuo pipefail local NAME='my:up' local DESCRIPTION='Launch my development environment' handle() { cp -f ../.laradock/env-development .env docker-compose up -d nginx mysql mailhog workspace cp ../.env.development ../.env docker-compose exec workspace composer install docker-compose exec workspace php artisan key:generate docker-compose exec workspace php artisan migrate docker-compose exec workspace npm install docker-compose exec workspace npm run dev }このカスタムコマンドをプロジェクト内の適当な場所(
.laradock/commandsなど)に置いて、パスを通します。export LARADOCKCTL_COMMAND_PATH=/PATH_TO_YOUR_COMMAND:/PATH_TO_LARADOCKCTL/commandsこれもdirenvを使うことをおすすめします。
これでカスタムコマンドが使えるようになります。
laradockctl my:up上記のコマンドを実行するだけで開発環境が立ち上がるようになるので、ひさしぶりのメンテナンスでどのコンテナを起動すればいいのか忘れてしまっていても大丈夫です。
おわりに
Laradockをちょっと便利にするコマンドラッパーを作った話をしました。
Laradockを使っていて同じような点を不便に感じている人がいたらぜひ使ってみてください。
- 投稿日:2020-12-23T02:50:23+09:00
名前で呼べると色々と幸せになれるかもしれないphp関連の用語あれこれ
名前がわかんないものがあると困るよねって話
人と話すときに話題に出したいのに、名前がわからなくって伝えるのが難しい物ってありませんか?
プログラムとかでも、書けるし仕様も知ってるのに名前知らない物って意外とあるんじゃないかなと思います。
○○が××になってるアレ・・・・とか毎回言うのも結構まどろっこしいですよね。
そんな伝えられる時も伝える時も障害になってしまう名前のわからない「アレ」について、名前を調べたので紹介しようと思います。
自分でも名前のわからない物や、個人的に他の人と話すときにこの名前知ってて欲しいな〜って思うかつ、できるだけphpを中心に使われている物を基準に独断と偏見で選定しています。スコープ定義演算子
::参考
特定のスコープを指したり、staticのプロパティやメソッドにアクセスすることができるトークン。
これの名前って何なんだ・・・?そもそもあるのか?と思って調べたら名前が出てきたので、意外と名前知らないなと思ったのが今回の記事を書くことになったきっかけ。
ちなみにPaamayim Nekudotayimという別名がつけられているらしく、ダブルコロンを意味するヘブライ語なんだとか。class Sample { const NAME = 'name'; } var_dump(Sample::NAME);宇宙船演算子
<=>参考
左項と右項を比較した結果に応じて、対応するint値を返却してくれる演算子。
結果と対応する値は下記の通り。
1.小さい => 0より小さい
2.同じ => 0
3.大きい => 0より大きいvar_dump(10 <=> 50); var_dump(50 <=> 50); var_dump(100 <=> 50); // int(-1) // int(0) // int(1)あまり使うことは多くないですが、使うことが多くないからこそいざ使うときに困るというのがこの手の常。
null合体演算子
??参考
左項の値がnullの場合に右項の値として評価され、そうでない場合は左項の値として評価される演算子。
左項の値が存在しない場合でもwarningやnoticeが発生しないため、配列からキー指定で値を取り出す時とかに便利ですね。$nullValue = null; $notNullValue = 'this variable is not null'; var_dump($nullValue ?? 'this variable is null'); var_dump($notNullValue ?? 'this variable is null'); // string(21) "this variable is null" // string(25) "this variable is not null"ジェネレータ
function hogeGenerator() { // 何かしらの反復処理の中でその結果を都度返す yield $a; }参考
イテレータを簡易的に実装するための仕組みのこと。
ジェネレータ関数を作成、その中で何かしらの反復処理を行い、その値を都度yieldで返すことにより内部情報を記憶しておくiteratorオブジェクト分のメモリだけで大量のデータを扱うことができます。
例えば下記の例であれば、場合によっては4年分の日付文字列を配列に入れて扱う必要があるかもしれないところを、
iteratorオブジェクト分のメモリだけで扱うことができるようになります。// 指定した年と経過年数から存在する全ての日付文字列を返す function allDaysByYear(int $year, int $addYear): iterable { $dateTime = (new DateTime("{$year}-01-01")); $limitYear = $year + $addYear; $limitDateTime = (new DateTime("{$limitYear}-01-01")); while ($dateTime < $limitDateTime) { yield $dateTime->format('Y-m-d'); $dateTime->modify('+1 day'); } } foreach (allDaysByYear(2020, 4) as $dateTimeFormatString) { var_dump($dateTimeFormatString); } // string(10) "2020-01-01" // string(10) "2020-01-02" // string(10) "2020-01-03" // ..(中略) // string(10) "2023-12-29" // string(10) "2023-12-30" // string(10) "2023-12-31"正直この仕組みの存在を知っている人は名前も知ってる人がほとんどかも?
僕は実装済のプログラムから見たのがジェネレータとの馴れ初めだったので、しばらくの間yield(イールド)って呼んでました・・・。可変関数
$func = 'funcName'; $func();参考
変数名の後ろに括弧をつけることで、その変数の値と同名の関数を実行する仕組みのこと。
コールバックの実装とかで使ってる人もいるのではないでしょうか。function hello(): void { var_dump('hello'); } function goodBye(): void { var_dump('goodBye'); } $func = 'hello'; $func(); $func = 'goodBye'; $func(); // string(5) "hello" // string(7) "goodBye"この言語仕様自体は結構知ってる人多そうですが、可変関数って名前知ってる人もほぼ同数かと言われるとどうかというイメージ。
少なくとも僕は自信持って答えられるような状態ではなかったですはい。クロージャ
function ($arg) { // 何かしら処理 }参考
無名関数とも。
関数名の指定なしに関数を作成できるようになる仕組みのこと。
コールバック関数として使われていることを見るのが多いでしょうか。
個人的にこれを自由に扱えてると、初心者ではないなってイメージ。// 無名関数は変数に入れて使用も可能 $closureFunc = function (int $value) { // 渡された値を二倍にして返す return $value * 2; }; $array = [ 1, 2, 3, 4, ]; // コールバックとして使用 var_dump(array_map($closureFunc, $array)); // もちろんそのまま呼び出しもできる var_dump($closureFunc(10)); // array(4) { // [0]=> // int(2) // [1]=> // int(4) // [2]=> // int(6) // [3]=> // int(8) // } // int(20)アロー関数
参考
無名関数の簡潔な書き方。
java scriptでは割とメジャーな書き方なので、そっちやってる人は結構知ってる人多そうですね。fn ($arg) => $arg$arrowFunc = fn (int $value) => $value * 2; $array = [ 1, 2, 3, 4, ]; // 使い方は基本一緒 var_dump(array_map($arrowFunc, $array)); var_dump($arrowFunc(10)); // array(4) { // [0]=> // int(2) // [1]=> // int(4) // [2]=> // int(6) // [3]=> // int(8) // } // int(20)記事を書き終えて
結果的にphpのリファレンス眺めてその解説を載せた感じになっちゃった気がします・・・が、
普段そんなことそうそうないのでいい機会になったかなあと。
後思ったよりはちゃんと名前知ってるなと再確認もできたり。
色々見つかって面白いのでみなさんも気が向いたら見てみるのもまた一興かもしれません。
- 投稿日:2020-12-23T02:03:20+09:00
LaravelのCSRF対策の処理を実際のコードから見てみる
初めに
Laravelを使用している方でLaravelの扱い方に慣れていないころ、
419エラーに出会った方は割といるのではないかと思います。
今回はその419エラーを生み出しているLaravelのCSRF対策の仕組みついて実際のコードから見ていきます!環境
ツール バージョン PHP 7.4.8 Laravel 8.14.0 CSRF対策とは?
CSRF(クロスサイト・リクエスト・フォージェリ)とは、ざっくり言うと罠サイト等から他の人のブラウザのCookieに書かれているセッションIDを取得し、そのIDを使用して特定のWebアプリケーションへアクセスすることで、元のセッションのデータの持ち主がリクエストをしたように偽装することです。詳しくはIPAの記事を見てみて下さい。
CSRF対策の一例
体型的に学ぶ安全なWebアプリケーションの作り方 第二版 4.5節 「重要な処理」の際に混入する脆弱性より入力画面 <?php session_start(); if (empty($_SESSION['token'])) { $token = bin2hex(openssl_random_pseudo_bytes(24)); $_SESSION['token'] = $token; } else { $token = $_SESSION['token']; } ?> <form action="45-003a.php" method="POST"> 新パスワード<input name="pwd" type="password"><br> <input type="hidden" name="token" value="<?php echo htmlspecialchars($token, ENT_COMPAT, 'UTF-8');?>"> <input type="submit" value="パスワード変更"> </form>結果を映す画面 <?php session_start(); $token = filter_input(INPUT_POST, 'token'); if (empty($_SESSION['token']) || $token !== $SESSION['token']) { die('正規の画面からご利用ください。'); //エラーメッセージ } //成功時の動作 ?>このプログラムが行っていることはこの3つです。
1. フォーム入力画面を作成時にPHPの暗号を生成する関数(openssl_random_pseudo_bytes)を実行し、その結果をセッションへセットする。
2. セッションへセットしたデータはhtmlの<form></form>内にtokenという名前でセットし、他の入力データと共にHTTPのPOSTリクエスト実行から結果を表示するプログラムへ送る。
3. 入力画面から送られてきたデータのうちtokenの名前に入っているデータを取り出し、それと入力画面作成時にセッションへセットしたデータを比べ、同じであれば成功時の処理を、違えばそこで処理を終了する。
図で表すとこのようになります。
次にLaravel内でのCSRF対策の処理を見ていきます。
LaraveのCSRF対策のコードを見てみる
コードを見る前に
LaravelのCSRF対策のコードは多数のクラスのメソッドによって成り立っているため、この章以降のコードを追うのみではCSRF対策の構造が分かりにくく、この記事自体を見る気が萎える方も出てしまう方も出てしまうかもしれません。なので、Laravelのコードを見る前にLaravelのデフォルトのCSRF対策のプログラムでやっていることとそのプログラムの進行の図をここでお見せします。もし、この章以降のコードを追う中でCSRF対策の構造の理解がしにくいな、と感じた場合はここを見返してみて下さい。
LaravelのCSRF対策でやっていることは、暗号作成時にその暗号の値を/storage/framework/sessions/暗号の値へファイルとして保存し、その暗号の照合時に、リクエスト内で@csrfなどでhtmlの<form></form>内に_tokenという名前セットされたその暗号の値と作成時に作られたファイルに記された暗号の値を比べる、ということです。つまり、LaravelのデフォルトのCSRF対策では$_SESSIONは用いていないということです。
図で表すとこんな感じです。
前振りはここまでにして、さっそくLaravelの実際のコードからCSRF対策の仕組みについて見ていきます。
セッションをチェックしているコードを見てみる
今回はセッションをチェックしているコードのうち、デフォルトでセットされている
VerifyCsrfTokenに焦点を当てました。VerifyCsrfToken
名前空間
Illuminate\Foundation\Http\Middlewarepublic function handle($request, Closure $next) { if ( $this->isReading($request) || // .....(1) $this->runningUnitTests() || // .....(2) $this->inExceptArray($request) || // .....(3) $this->tokensMatch($request) // .....(4) ) { return tap($next($request), function ($response) use ($request) { if ($this->shouldAddXsrfTokenCookie()) { $this->addCookieToResponse($request, $response); } }); // .....(5) } throw new TokenMismatchException('CSRF token mismatch.'); }セッションのチェックを実行する
handleメソッドをまずは見ていきます。
このメソッドで行われていることは、(1)~(4)の条件のどれかをクリアしたリクエストは(5)へ進み、それ以外は例外処理が行われ、エラーが表示されるということです。そして、(1)~(4)の条件は何なのかというと、
(1) リクエストのHTTPメソッドがHEAD、GET、OPTIONSであればtrue、それ以外はfalse
(2) リクエストがユニットテスト内の物であればtrue、それ以外はfalse
(3) セッションのチェックの対象外のリクエスト(App\Http\Middleware\VerifyCsrfTokenで設定できる)であればtrue、それ以外はfalse
(4) リクエストで送られてきたデータの中の_tokenの名前が与えられたデータとあらかじめ作成されたセッションデータが一致した場合true、そうではない場合はfalse(5)の内容は、リクエストで送られてきたセッションデータがある場合はそれを
XSRF-TOKENという名前を付けたCookieへ書き込み、ない場合は新たにセッションのデータを作成し、それを書き込む感じです。これは処理を渡されると必ず実行され、その結果が次の処理へ渡されます。(理由は$this->shouldAddXsrfTokenCookieメソッドはコードを書き換えない限り必ずtrueを返すから)先ほど見てきた(1)~(4)の条件の中で、セッションの確認を行っている④のメソッドについて次は見ていきます。
(4)を行っているメソッドはtokensMatchメソッドで、コードは以下のようになっています。protected function tokensMatch($request) { $token = $this->getTokenFromRequest($request); return is_string($request->session()->token()) && is_string($token) && hash_equals($request->session()->token(), $token); }内容は非常にシンプルで、リクエストから送られてきた
$tokenとリクエストにあらかじめセットされた$request->session()->token()が互いに文字列データであり一致している場合にtrueを返します。(hash_equalsを用いることでタイミング攻撃に対して安全に文字列データを比較できます。)セッションの値の確認方法は分かりましたが、
$request->session()->token()の値と比較する対象である$tokenがどのようにリクエストのデータから取得できるか謎なので、getTokenFromRequestメソッドについて調べていきます。protected function getTokenFromRequest($request) { $token = $request->input('_token') ?: $request->header('X-CSRF-TOKEN'); //..(1) if (! $token && $header = $request->header('X-XSRF-TOKEN')) { $token = CookieValuePrefix::remove($this->encrypter->decrypt($header, static::serialized())); } //...(2) return $token; }
getTokenFromRequestメソッドでは以下の二つのことが行われています。
(1) リクエストで送られてきた_tokenの名前の付いたデータの値かそれが空であれば、X-CSRF-TOKENという名前のリクエストのヘッダーの値が代わりに入る。
(2)$tokenの値がnullかつX-XSRF-TOKENという名前のリクエストのヘッダーの値が存在し、nullではない場合にX-XSRF-TOKENの値がうまく復号化できた場合にその値を$tokenに入れる。
X-CSRF-TOKENとX-XSRF-TOKENのデフォルトの値はnullなので、もしリクエストの_tokenのデータが設定されていない場合はgetTokenFromRequestメソッドはnullを返し、その場合tokensMatchメソッドの$request->session()->token()と$token一致しないため、tokensMatchメソッドはfalseを返します。こういうわけで@csrfなどを含めずにLaravelのPOSTメソッドを使ったリクエストを実行するとエラーが起こります。LaravelのCSRF対策のためのセッションの比較の仕方は分かりましたが、セッションの生成の方法がまだ分かりません。そこで今度はデフォルト時のLaravelのセッションの生成の仕方を見てみます。
セッションが作られる過程を見てみる
StartSession
名前空間
Illuminate\Session\Middleware
StartSessionはIlluminate\Foundation\Http\kernelの$middlewarePriority配列の要素の一つです。ちなみにこのkernelはpublic/index.phpを見てもらえれば分かると思うのですが、Laravelのシステム全体が動くときの起点となります。
では最初にhandleメソッドについて見ていきます。//初期設定 public function __construct(SessionManager $manager, callable $cacheFactoryResolver = null) { $this->manager = $manager; //SessionManagerはここでセットされている $this->cacheFactoryResolver = $cacheFactoryResolver; } public function handle($request, Closure $next) { if (! $this->sessionConfigured()) { return $next($request); } //...(1) $session = $this->getSession($request); //...(2) if ($this->manager->shouldBlock() || ($request->route() instanceof Route && $request->route()->locksFor())) { return $this->handleRequestWhileBlocking($request, $session, $next); } else { return $this->handleStatefulRequest($request, $session, $next); } //...(3) }このプログラムの内容はこの3つです。
(1) もしconfig\session.phpが存在しない、もしくは中身がない場合はfalseを返してクロージャの処理をするが、たいていのLaravelのアプリケーションの場合そんなことはないので、何もせずに次の処理へ
(2) セッションを取得する。詳しくは後で見ていく。
(3) もしconfig\session.php内の配列のblockキーの値がtrueまたはリクエストのURLの値からIlluminate\Routing\RouteインスタンスになるかつセッションごとにURLのリクエスト制限がない時に$this->handleRequestWhileBlocking($request, $session, $next)は行われるが、それ以外は$this->handleStatefulRequest($request, $session, $next);が実行される。
config\session.php内の配列のblockキーの値はたいてい設定のでfalseであり、セッションごとにURLのリクエスト制限はデフォルトではありません。よってhandleメソッドは大抵の場合$this->handleStatefulRequest($request, $session, $next);を最終的に実行します。全体の流れを見たところで、次はセッションの取得について見ていきます。
public function getSession(Request $request) { return tap($this->manager->driver(), function ($session) use ($request) { $session->setId($request->cookies->get($session->getName())); }); }
getSessionで行っていることは、セッションを扱うインスタンス(Illuminate\Session\Storeインスタンス、詳細は後で見ていく)をセットし、そのインスタンスへリクエストのCookieデータのうちconfig\session.php内の配列のcookieキーの値の名前が付けられたデータを代入します。次は
handleメソッドの処理の目玉であるhandleStatefulRequestについて見ていきます。protected function handleStatefulRequest (Request $request, $session, Closure $next) { $request->setLaravelSession($this->startSession($request, $session)); //...(1) $this->collectGarbage($session); //...(2) $response = $next($request); //...(3) $this->storeCurrentUrl($request, $session); //...(4) $this->addCookieToResponse($response, $session); //...(5) $this->saveSession($request); //...(6) return $response; }
handleStatefulRequestの内容はこの5つです。
(1) リクエストのCookieデータに従ってセッションを設定し、Illuminate\Session\StoreインスタンスをIlluminate\HttpRequestインスタンスへセットする。これを行うことで、$request->session()によりStoreインスタンスをいつでも呼び出せる。Storeインスタンスについては後で見ていく。
(2) 古くなったセッションデータ(config\session.php内の配列のlifetimeキーの値を超えているデータ)を削除する。
(3) セッションと関りが浅いと思い全く調べていないので、処理の詳細は分からない。おそらくIlluminate\HttpResponseインスタンスを返しているのかな?
(4)storeCurrentUrlの処理の説明は必要なときのために現在のURLを保存すると書いてあるが、これがどれほど重要かはいまいちわからない。GETリクエスト以外では効果なし。
(5) レスポンスのヘッダーに、config\session.php内の配列のcookieキーの値の名前がついたCookieのデータをセットする。
(6) セッションのデータを保存する。保存場所・方法については後で見ていく。(1)~(6)の処理が終わった後、レスポンスのインスタンスを返します。
ちなみにセッションをセットするstartSessionの処理はこんな感じです。protected function startSession(Request $request, $session) { return tap($session, function ($session) use ($request) { $session->setRequestOnHandler($request); //デフォルトの状態では無視してよし $session->start(); }); }
Illuminate\Session\Storeインスタンスのstartメソッドを実行しStoreインスタンスを返します。このstartメソッドについては後で見ていきます。これまではセッションの作成過程を大まかにみてきましたが、次はセッションの作成・管理を行うインスタンスがどのようにセットされているのかを見ていきます。
Manager(abstract class)
名前空間
Illuminate\Support
このManagerクラスは抽象クラスで、このクラス内にセッションを作成するなどの機能はなく、セッションや他のLaravelの機能を使用する際にそれぞれの機能を担うクラスたちをまとめる役割があります。public function driver($driver = null) { $driver = $driver ?: $this->getDefaultDriver(); //...(1) if (is_null($driver)) { throw new InvalidArgumentException(sprintf( 'Unable to resolve NULL driver for [%s].', static::class)); } //...(2) if (! isset($this->drivers[$driver])) { $this->drivers[$driver] = $this->createDriver($driver); } //...(3) return $this->drivers[$driver]; }このメソッドで行っていることは以下の三つです。
(1)このメソッドの引数にインスタンスが指定されていればそれを$driverへ入れ、引数が指定されていない場合は、継承先のクラスに存在するgetDefaultDriverメソッドの結果を入れる。デフォルトでは引数はnullなため、getDefaultDriverメソッドの結果が$driverへ入れられる。getDefaultDriverメソッドについては後で説明する。
(2)もし$driverの値がnull出会った時に例外処理が行われる。
(3)もし$this->drivers[$driver]に値が既にある場合は何もせず、ない場合は$driverの値をcreateDriverメソッドへ渡し、その結果を$this->drivers[$driver]へ入れる。(1)~(4)が終了した後、
$this->drivers[$driver]の値を返します。
次にこのメソッドの(3)に登場したcreateDriverメソッドについて見ていきます。protected function createDriver($driver) { if (isset($this->customCreators[$driver])) { return $this->callCustomCreator($driver); //...(1) } else { $method = 'create'.Str::studly($driver).'Driver'; //...(2) if (method_exists($this, $method)) { return $this->$method(); //...(3) } } throw new InvalidArgumentException("Driver [$driver] not supported."); }このメソッドで行っていることは以下の三つです。
(1)もし$this->customCreators[$driver]に値がセットされている場合はcallCustomCreatorメソッドの結果を返すが、あらかじめ$this->customCreators[$driver]に値がセットされていることはないのでここでは扱わない。
(2)あらかじめ設定されている文字列とLaravelのhelperメソッドの一つであるStr::studlyメソッドの引数へ$driverの値を入れるた結果の値を結合した値を$methodへ入れる。getDefaultDriverメソッドを紹介する時に説明するが、$driverの値は必ず文字列データになり、その値がStr::studlyメソッドによってそのデータの頭文字が大文字になる。
(3)method_existsのよってこのクラスまたは継承先のクラスに$methodの名前を持ったメソッドが存在する場合はその結果を返す。もし存在しない場合は例外処理が行われる。次は
Managerクラスの継承先の一つであり、getDefaultDriverメソッドと$methodの名前を持ったメソッドを有しているSessionManagerクラスについて見ていきます。SessionManager(Managerを継承)
名前空間
Illuminate\Sessionpublic function getDefaultDriver() { return $this->config->get('session.driver'); }このメソッドは継承元であるManagerクラスの
createDriverメソッドの引数である$driverの値を作成してます。
このメソッドは/config/session.phpの配列内のdriver要素の値を返します。この要素のデフォルトの値は'file'という文字データなので、createDriverメソッドの引数である$driverの値はデフォルトでは必ず文字列データになり、どうメソッド内の$methodの値はcreateFileDriverになります。先ほど見たように継承元であるManagerクラスの
createDriverメソッドは継承元かこのクラスの$methodの値のメソッドの結果を返します。さきほど$methodの値はcreateFileDriverということが分かったので、今度はこのクラス内のcreateFileDriverメソッドについて見ていきます。protected function createFileDriver() { return $this->createNativeDriver(); } protected function createNativeDriver() { $lifetime = $this->config->get('session.lifetime'); //...(1) return $this->buildSession(new FileSessionHandler( $this->container->make('files'), $this->config->get('session.files'), $lifetime)); //...(3) }
createFileDriverメソッドは同クラス内のcreateNativeDriverメソッドの結果を返します。ということでcreateNativeDriverメソッドについて見ていきます。
createNativeDriverメソッドの内容は以下の二つです。
(1)/config/session.phpの配列内のlifetime要素の値を$lifetimeへ入れる。(デフォルト値は120)
(2)$this->container->make('files')で得られる、ファイル書き込み機能を実装したIlluminate\Filesystem\Filesystemインスタンスと/config/session.phpの配列内のfiles要素の値である/storage/framework/sessions/までのパス名を引数として渡したセッションの値をファイルへ書きこむ機能を担うFileSessionHandlerインスタンスを同クラス内のbuildSessionメソッドへ渡し、その結果を返す。
buildSessionメソッドとはLaravelのセッションの様々な操作が書かれているクラスのインスタンスを返すメソッドなのですが、このメソッドについて掘り下げていきます。protected function buildSession($handler) { return $this->config->get('session.encrypt') ? $this->buildEncryptedSession($handler) : new Store($this->config->get('session.cookie'), $handler); }
buildSessionメソッドは、/config/session.phpの配列内のencrypt要素の値がfalseの場合はセッションの操作を行うプログラムが書かれたIlluminate\Session\Storeクラスの引数に先ほどのFileSessionHandlerインスタンスを入れたインスタンスが返され、falseの場合はStoreクラスに$this->container['encrypter']で得られるIlluminate\Encryption\Encrypterクラスの機能が合わさったIlluminate\Session\EncryptedStoreインスタンスが返されます。デフォルトの場合はencrypt要素の値はfalseなのでStoreインスタンスが返されます。いったんここまでの流れをまとめる(読み飛ばしても大丈夫)
ここまでCSRF対策を行う
VerifyCsrfTokenクラスやStartSessionクラスのコードを見ながら、Laravel内のCSRF対策やセッションの作成過程を見てきましたが、セッションの作成やセッションの内容のファイルへの書きこみ、取り出しの過程をPHPでどのように実現させているのかをまだ見ていません。なので、次はトークンの作成と管理の機能がPHPのコードにより実装されているクラスを見ていくのですが、そのクラスの理解を容易にするためにセッションの作成過程が書かれているStartSessionのhandleメソッドとhandleStatefulRequestメソッドで行われることの流れとその結果をおさらいします。
handleメソッドの流れとそれぞれの工程の結果はこんな感じでした。
- 送られてきたリクエストのCookieのからセッションのデータを取り出す。⇒
Illuminate\Session\StoreインスタンスのsetIdメソッドを実行したうえで、Storeインスタンスを呼び出す。Illuminate\Http\RequestインスタンスとStoreインスタンスをhandleStatefulRequestメソッドへ渡す。
handleStatefulRequestメソッドの流れとそれぞれの工程の結果はこんな感じでした。
- 同クラス内の
startSessionメソッドでセッションを作成する。⇒Storeインスタンスのstartメソッドを実行- 期限切れのセッションを削除する。⇒
StoreインスタンスのgetHandlerメソッドを実行- 作成したセッションを保存する。⇒
Storeインスタンスのsaveメソッドを実行上の二つのメソッドの結果を見てわかる通り、セッションの作成には
Illuminate\Session\Storeインスタンスが密接にかかわっています。ということで次はStoreインスタンスの元であるIlluminate\Session\Storeクラスについて見ていきます。Store
名前空間
Illuminate\Session//初期設定 public function __construct($name, SessionHandlerInterface $handler, $id = null) { $this->setId($id); $this->name = $name; $this->handler = $handler; }
Storeクラスのコンストラクトメソッドは、StartSessionクラスのgetSessionメソッド実行時、ひいてはManagerクラスのdriverメソッド実行時にStoreインスタンス作成した際に呼び出されます。その時の$nameの値は$this->config->get('session.cookie')、$handlerの値はIlluminate\Session\FileSessionHandlerインスタンスとなります。(ここら辺はSessionManagerクラスの説明の中で書かいています。)引数$idは指定されていないので、$this->idにはランダムな文字列データが入れられますが、getSessionメソッドの実行中に$this->idは書き換えられるので、気にしなくて良いです。public function setId($id) { $this->id = $this->isValidId($id) ? $id : $this->generateSessionId(); } public function isValidId($id) { return is_string($id) && ctype_alnum($id) && strlen($id) === 40; } protected function generateSessionId() { return Str::random(40); }
StartSessionクラスのgetSessionメソッドで呼び出されるこのクラス内のsetIdメソッドは、引数の値がセッションの形式に沿っているか確かめ、もし沿っているのであればその値を返し、ダメであれば新たにセッションIDを作成し、$this->idへその値を入れます。
セッションの形式の確認は同クラス内のisVaildIdメソッドで行っており、このメソッドでやっていることは、文字列データかつ英数字かつ文字数が40文字であればtrue、そうでなければfalseを返します。(詳しくはis_string、ctype_alnum、strlenを見て下さい。)
セッションIDの作成は同クラス内のgenerateSessionIdメソッドで行っています。このメソッドの内容はただ単にStr::random(40)で作成された40時のランダムな文字列データを返します。ちなみにStr::random()にはrandom_bytesが使われているようです。public function start() { $this->loadSession(); //...(1) if (! $this->has('_token')) { $this->regenerateToken(); } //...(2) return $this->started = true; //...(3) }
StartSessionクラスのstartSessionメソッドで実行されるstartメソッドで行われることは以下の三つです。
(1)セッション情報が書かれたファイルを取り出し、その値を$this->attributes配列へ入れる。詳しくは後で見ていく。
(2)もし$this->attributes配列に'_token'がキーとなる値が存在しない場合同クラス内のregenerateTokenメソッドを実行。regenerateTokenメソッドについては後で見ていく。
(3)最後に$this->startedにtrueを入れる。$this->startedはセッションの様々な操作に使われているようだが、どのように使われているかまでは調べきれなかったのでわからない。次は
startメソッドで一番初めに実行されるloadSessionについて見ていきます。protected function loadSession() { $this->attributes = array_merge($this->attributes, $this->readFromHandler()); } protected function readFromHandler() { if ($data = $this->handler->read($this->getId())) { //......(1) $data = @unserialize($this->prepareForUnserialize($data)); //......(2) if ($data !== false && ! is_null($data) && is_array($data)) { return $data; //......(3) } } return []; } public function getId() { return $this->id; }
loadSessionメソッドでは、同クラス内のreadFromHandlerメソッドの結果を$this->attributesへ加えています。そして、そのメソッド内で実行されているreadFromHandlerメソッドは以下の三つのことを行っています。
(1)同クラスのsetIdメソッドで$this->idへセットされた値をgetIdメソッドで呼び出し、その値を引数にとりFileSessionHandlerインスタンスのreadメソッドが実行される。raedメソッドによりもし$this->idの値と同じ名前のファイルが存在する場合、そのファイルの内容を$dataへ入れて(2)以降を実行し、存在しなければ文字列データの空の値('')を$dataへ入れ、何もせず空の配列を返す。
(2)ファイルから取得したセッションの情報は作成時に保存用の表現としてシリアル化されているので、unserializeメソッドでPHPで扱える値に復元する。(prepareForUnserializeメソッドはただ引数を返すだけ)
(3)もしデータがうまく復元されなかったり、nullであったり、文字列データ出ない場合は空の配列を返し、そうでなければ$dataの値をそのまま返す。今度は、
loadSessionメソッドが終了した後に行われるhasメソッドについて見ていきます。public function has($key) { return ! collect(is_array($key) ? $key : func_get_args()) ->contains(function ($key) { return is_null($this->get($key)); }); } public function get($key, $default = null) { return Arr::get($this->attributes, $key, $default); }
hasメソッドではcollectメソッドを使用してIlluminate\Support\Collectionインスタンスを呼び出し、そのインスタンスのメソッドであるcontainsメソッドにより引数の$keyがキーとなる値が$this->attributesにある場合はtrue、ない場合はfalseを返します。containsメソッドの引数内で実行されているgetメソッドArr::getによって$this->attributesに引数$keyの値をキーにとる値がある場合はその値を返し、ない場合はからの文字列データを返します。次にもし
hasメソッドの結果がtrueの場合(ブラウザのクッキーにセッションが存在しない状態でリクエストが来た場合)に行われるregenerateTokenメソッドとそのメソッド内で実行されるputメソッドを見ていきます。public function regenerateToken() { $this->put('_token', Str::random(40)); } public function put($key, $value = null) { if (! is_array($key)) { $key = [$key => $value]; } foreach ($key as $arrayKey => $arrayValue) { Arr::set($this->attributes, $arrayKey, $arrayValue); } }
regenerateTokenメソッドはgenerateSessionIdメソッドと同じようにランダムな文字列データを作成し、その値を同クラス内のputメソッドで_tokenをキーとして$this->attributesにセットします。putメソッドは引数の$keyをキーとし、$valueをその値としてArr::setにより$this->attributesへセットするか、$key自体が配列の場合はそれを$this->attributesへセットします。この次は
handleStatefulRequestメソッドの最後に実行されるsaveメソッドを見ていきます。public function save() { $this->ageFlashData(); $this->handler->write($this->getId(), $this->prepareForStorage( serialize($this->attributes))); $this->started = false; }このメソッドでは、
FileSessionHandlerインスタンスのwriteメソッドにより、リクエストのクッキーのセッションIDの値(なければ新たに作成)を名前にとるファイルを新たに作成し、それに$this->attributesを(serialize)[https://www.php.net/manual/ja/function.serialize]でシリアル化させた値を書き込みます。そして最後におそらくセッションの処理が終わったことを知らせるために`$this->started = false`を行います。そして、最後に後で説明するヘルパーメソッドである
csrf_tokenメソッドで実行されるtokenメソッドについて説明していきます。public function token() { return $this->get('_token'); }このメソッドの説明は簡潔で、
getメソッドにより_tokenをキーにとる値が$this->attributesに存在すればその値を返し、なければ空の文字列データを返します。$this->attributes[_token]が存在しないことはデフォルトではまずないので、何かしらの文字列データを返します。
Storeクラスの中でFileSessionHandlerインスタンスが何回か登場したので、今度はFileSessionHandlerクラスについて見ていきます。FileSessionHandler
名前空間:
Illuminate\Sessionpublic function __construct(Filesystem $files, $path, $minutes) { $this->path = $path; $this->files = $files; $this->minutes = $minutes; }このクラスのコンストラクトメソッドは
SessionManagerクラスのbuildSessionメソッドの中で実行されます。この時の引数$fileには$this->container->make('files')(Illuminate\Filesystem\Filesystemインスタンス), 引数$pathには$this->config->get('session.files')(/config/session.phpのfile要素の値)、引数$minutesには$this->config->get('session.lifetime')(/config/session.phpのlifetime要素の値)が入ります。
次はStoreクラスのreadFromHandlerメソッド内で実行されるreadメソッドについて見ていきます。public function read($sessionId) { if ($this->files->isFile($path = $this->path.'/'.$sessionId)) { //...(1) if ($this->files->lastModified($path) >= Carbon::now() ->subMinutes($this->minutes)->getTimestamp()) { //...(2) return $this->files->sharedGet($path); //...(3) } } return ''; }
readメソッドでは以下の三つのことを行っています。(1)
Illuminate\Filesystem\FilesystemクラスのisFileメソッドで$this->path.'/'.$sessionIdの値のパスとファイル名を持つファイルがないか検証し、ある場合は$pathへそのファイルのパスとファイル名を入れて次の処理へ進み、ない場合は空の文字列データを返す。
(2)FilesystemクラスのlastModifiedメソッドにより(1)で取得した情報からそのファイルが最後に書き込まれた時間を割り出し、もしその値がCarbon\CarbonクラスのsubMinutesメソッドなどを使用し、現在の時刻から/config/session.phpのlifetime要素の値を引いた数以上だった場合は次の処理へ進み、そうでない場合は空の文字列データを返す。lastModifiedメソッドとgetTimestampメソッド(こちらはおそらく)はint型のUnix タイムスタンプで時刻を返し、Unix タイムスタンプは時間が進むほど大きくなる。つまり、ここで行っていることを言い換えるとファイルの作成時刻とリクエストが発生した時刻の差分がlifetime要素の値より小さい(新しい)場合は次の処理、大きい(古い)場合は空の文字列データを返す、ということになる。
(3)ここでは$pathを引数にとりFilesystemクラスのsharedGetメソッドを実行する。sharedGetメソッドについては後で見ていく。最後に
Storeクラスのsaveメソッドで実行されるwriteメソッドを見ていきます。public function write($sessionId, $data) { $this->files->put($this->path.'/'.$sessionId, $data, true); return true; }といってもこのメソッドは単に、
$this->config->get('session.files')の値と引数$sessionIdの値を組み合わせたものと引数$dataをFilesystemクラスのputメソッドへ渡し、trueを返すということを行います。putメソッドについては後で見ていきます。次はこのクラスでたびたび出てきた
Filesystemクラスについて見ていきます。Filesystem
名前空間:
Illuminate\Filesystempublic function isFile($file) { return is_file($file); }このメソッドはis_fileの結果を返します。もし引数の
$fileが通常のファイルならtrueを返し、ディレクトリなどそれ以外ならfalseを返します。public function lastModified($path) { return filemtime($path); }このメソッドはfilemtimeメソッドの結果を返します。引数
$pathが最後に書き込まれた時刻をint型のUnix タイムスタンプで返します。失敗した時は警告が発生します。public function sharedGet($path) { $contents = ''; //...(1) $handle = fopen($path, 'rb'); //...(2) if ($handle) { //...(3) try { if (flock($handle, LOCK_SH)) { //...(4) clearstatcache(true, $path); //...(5) $contents = fread($handle, $this->size($path) ?: 1); //...(6) flock($handle, LOCK_UN); //...(7) } } finally { fclose($handle); //...(8) } } return $contents; //...(9) }このメソッドで行うことは以下の9つです。
(1)
$contentsの初期化
(2)fopenメソッドにより、$pathのファイルのポインタリソースを返す。つまり、対象のファイル中の動作をする場所を返している。もっと知りたい方はこちら(PHPのポインタについてはまだ勉強不足なので、ここについて詳しく書けない。)ちなみにfopenメソッドの第二引数は行う動作を決めるものであり、rbはバイナリモードでファイルを読み込むという動作を表している。バイナリモードについては勉強不足で説明できない。(教えて頂けるとありがたいです。)
(3)fopenメソッドは失敗した場合にfalseを返すので、失敗した時だけ(9)へ進み、それ以外は次の処理へ進む。
(4)flockメソッドとは、第一引数のポインタリソースを持つファイルの状態の変更を止めたり、他のプログラムからの参照を止めることで競合するプログラムが存在してもアプリケーション全体を問題なく動作させる機能を持つ。ちなみに第二引数のLOCK_SHによって、他のプログラムから同じファイルのデータを参照できるが、変更できなくさせている。もしぴんと来なければ、こちらの記事をどうぞ。
(5)clearstatcacheメソッドは第一引数をtrueにすることで第二引数のファイルのキャッシュ値を削除する機能を持つ。データが頻繁に変化するファイルを扱うときに便利。
(6)freadでfopenメソッドで参照するファイルのリソースポインタから同クラスのsizeメソッド内のfilesizeメソッドで入手したファイルのサイズ分(単位はバイト)の内容を読み込み、その結果を$contentsへ入れる。もしファイルサイズが読み取れなかった場合は1バイト分読み込む。
(7)ファイルの読み込みが終わった後、そのままでは他のプログラムが読み込んだファイルの変更ができないため第二引数をLOCK_UNにしたflockメソッドによって、ファイルを再び自由に変更可能にします。
(8)fopenメソッドで参照したファイルのリソースポインタを閉じる動作としてfcloseメソッドを行う。ちなみにこのメソッドを書かなくてもfopenメソッドで参照したファイルのリソースポインタは勝手に閉じられる。
(9)$contentsの値を返す。ここで、なぜfile-get-contentsメソッドを使用せず、
freadメソッドを使用しているのか疑問に思う方もいるかと思います。なぜfreadメソッドを使用するのかの解答は(調べてなくて)分かっていませんが、おそらくバイナリセーフなfreadメソッドを使用することでNullバイト攻撃を防ぐためだと思います。バイナリセーフ、Nullバイト攻撃についてはこちらの記事をどうぞ。最後に
Storeクラスのsaveメソッドで使用されたputメソッドを見ていきます。public function put($path, $contents, $lock = false) { return file_put_contents($path, $contents, $lock ? LOCK_EX : 0); }このメソッドで行われていることは、file_put_contentsメソッドで引数
$pathに書かれているファイルへ$contentsのデータを書き込みます。Storeクラスのsaveメソッドにより$lock=trueとなるため、file_put_contentsメソッドは他のプログラムによる書き込むファイルの読み込みと変更を禁止する状態(これを排他ロックというらしい)で実行されます。file_put_contentsメソッドが成功した場合はファイルへ書き込んだデータの量(バイト数)が返され、失敗した場合はfalseが返されます。一番最後に
$request->input('_token')の値を作成するヘルパーメソッドのcsrf_tokenメソッドを見ていきます。csrf_token(helper関数)
ファイル場所
laravel/framework/src/Illuminate/Foundation/if (! function_exists('csrf_token')) { /** * Get the CSRF token value. * @return string * @throws \RuntimeException * / function csrf_token() { $session = app('session'); if (isset($session)) { return $session->token(); } throw new RuntimeException('Application session store not set.'); } }このメソッドはもし
sessionの解決で何らかのインスタンス(おそらくStoreインスタンス)が得られた場合にそのインスタンスのtokenメソッドの結果を返します。もし何も得られなかった場合は例外処理に映ります。tokenメソッドについてはStoreクラスを見ていく中で取り上げているので、そちらを見て下さい。sessionの解決がStoreインスタンスを返す根拠は明確に見つかったわけではありませんが、同じヘルパーメソッドのsessionメソッドのコードのPHPDocの返り値の部分が@return mixed|\Illuminate\Session\Store|\Illuminate\Session\SessionManagerになっていたのに対し、実際に返している値がapp('session')だからです。ここについては今後もう少し調べていきます。終わりに
ここまで見てくれてありがとうございます、そしてお疲れ様です。
今回のコードリーディングで、Laravelと一般的なコードでCSRF対策のために行っていることの根本は変わらないということが知れて良かったです。
しかし、詳しく調べる気力が出なかったので、この記事の中には「きっとこんな感じだろう」という憶測で書いてしまっている部分もあります。今後もLaravelのコードを読むことで、このような部分を潰していきたいと思います。もし気になる、疑問に思うところがあれば指摘してくださるとありがたいです。
今後もLaravel内で気になることがあれば、こんな風にコードリーディングをできたらなーと思います。ちなみにこんな記事も書いてます。良かったらぜひ
Laravelのサービスコンテナのバインドと解決の仕組みが知りたい!
Laravelのsingletonメソッドの機能とその仕組みについて

