- 投稿日:2020-12-18T23:14:56+09:00
登録した情報をなかったことするコマンド
- 投稿日:2020-12-18T22:14:05+09:00
値オブジェクトでRailsのFatModelを解消する
この記事はエイチーム引越し侍 / エイチームコネクトの社員による、Ateam Hikkoshi samurai Inc.× Ateam Connect Inc. Advent Calendar 2020 19日目の記事です。
はじめに
Railsでは、「Skinny Controller, Fat Model」という方針があります。
アプリケーションの主要なロジックをモデルに置き、
コントローラ(やビュー)はそのレイヤーでしかできないことに役割を限定するという方針です。この方針に則ることで、各レイヤー間の依存関係をわかりやすくし、
影響範囲を明確にすることでできます。しかし、ビジネスロジックをモデルに集中させるため、
適切にモデルを作成しないと、モデルが肥大化し過ぎてしまいます。そのモデルの肥大化の対策の1つとして、
値オブジェクトの導入があります。値オブジェクトとは
値オブジェクトとは、
ドメイン駆動設計ででてくる
ドメインモデルをコードで表現するためのパターンの1つです。
ドメインとは、アプリケーションが対象とする問題領域のことで、
そのドメインを分析して、構成概念を抽出することをモデリングといいます。
そして、モデリングの結果得られる概念のことをドメインモデルといいます。
ドメインモデルは、その概念に関する属性と振る舞いを持ちます。このドメインモデルをオブジェクトとして表現するものとして、
「エンティティ」と先程述べた「値オブジェクト」があります。エンティティと値オブジェクトの特徴
エンティティと値オブジェクトは、それぞれ下記のような特徴があります。
エンティティ 値オブジェクト 同一性 識別子が同じならば同一とみなす 属性の値が全て同じなら同一とみなす 可変性 生成後に属性を変化させることができる 生成後に属性が変化することがない エンティティの例
- 社員
- たとえ同じ名前の社員が2人いても、その2人は別人
- 誕生日を迎えて、年齢という属性が変化しても、別の人間にはならない
- 社員IDが同じなら、同じ社員として判定できる。
- 社員IDが識別子となっている
- 同一かどうかを識別子で判定しているので、エンティティとして考えられる
値オブジェクトの例
- 通貨
- 通貨を金銭的価値だけで比べる場合に、2枚の千円札は製造年が異なっていても同じとみなされる。
- 属性が一致していれば同じであると判定しているので、値オブジェクトとして考えられる
ちなみに、ActiveRecordを用いたモデルのインスタンスは、
「id」を識別子としており、エンティティの実装に用いられます。Railsでの値オブジェクトの活用例
「メールアドレス」という属性を持つUserモデルがあり、
そのUserが持つメールアドレスのドメイン名だけを返すロジックを追加したいとします。Modelが肥大化しやすい実装
Userモデルのインスタンスメソッドとして、ロジックを実装
class User < ApplicationRecord validates :email, format: { with: /^[a-zA-Z0-9.!#$%&'*+\/=?^_`{|}~-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)*$/ } def email_domain email.split("@").last end endこの実装の問題点
- 今後、メールアドレスに関するロジックが増えると、Userモデルが肥大化してしまう。
- User以外にもメールアドレスを持つモデルが現れた時に、そのモデルにも同じメソッドを実装する必要があるでは次に、これらの問題を解決するために、値オブジェクトを用いてロジックを実装してみます。
値オブジェクトを用いた実装
メールアドレスを値オブジェクトとして、Userモデルから切り分け
Emailという値オブジェクトを導入し、
そのオブジェクトにメールアドレス属性とメールアドレスに関するロジックを実装します。class Email attr_reader :value delegate :hash, to: :value def initialize(value) raise "Email is invalid" unless value.match?(/^[a-zA-Z0-9.!#$%&'*+\/=?^_`{|}~-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)*$/) # (*1) @value = value.frozen? ? value : value.dup.freeze # (*2) end def ==(other) self.class == other.class && value == other.value # (*3) end def domain email.split("@").last end end # (*1) # バリデートの処理も、Userモデルから切り分けることができました # (*2) # 値オブジェクトが満たすべき特徴として、不変性があります # そのため、オブジェクトが生成されてから、属性が変化しないようにしています。 # (*3) # 値オブジェクトが満たすべき特徴として、等価性があります # そのため、他のEmailオブジェクトと比較が行えるようにしています。class User < ApplicationRecord composed_of :email, mapping: %w[email value] # (*4) end # (*4) # composed_ofは、 Railsのモデルで、値オブジェクトを扱いやすくするためのメソッド # 詳しい説明はここではしないので、ぜひ調べてみてください。メールアドレスを値オブジェクトとして、切り分けることで得られるメリット
- メールアドレスのロジックが増えても、Userモデルが肥大化しない
- メールアドレスに関するロジックを実装する場所が明確になる
- User以外のモデルでも、メールアドレスのロジックを再利用できる
さいごに
Railsでモデリングを行なう際、ActiveRecordを使う関係で、無理やりエンティティで実装しがちです。ドメインモデルをすべてエンティティで表現しようとすると、FatModelになる可能性大なので、エンティティと値オブジェクト、どちらで実装すべきなのかをきちんと吟味することが大切です!!
参考文献
パーフェクト Ruby on Rails
ValueObjectという考え方
3分でわかる値オブジェクト
DDD基礎解説:Entity、ValueObjectってなんなんだ
composed_of を使って Rails で値オブジェクトを扱う
メールアドレスを表す現実的な正規表現明日
Ateam Hikkoshi samurai Inc.× Ateam Connect Inc. Advent Calendar 2020 19日目の記事は、いかがでしたでしょうか。
明日は @cheez921 さんの記事です!! ぜひ皆さん読んでください!!
- 投稿日:2020-12-18T20:59:50+09:00
フラッシュメッセージの実装
フラッシュメッセージとは
ユーザー側の入力に基づいて処理が行われた際に、その処理の結果をユーザー側にわかるように表示されるメッセージのことです。例えば、アカウント登録、アカウント情報の更新の処理などに使用されています。
実装はさほど難しいものではありませんので、仕組みをしっかり理解しておきましょう。
実装方法
本記事ではアクションコントローラーでユーザ登録機能を実装することにします。
登録フォームは下の画像のようなシンプルなフォームです。
登録ボタンを押すことで新規登録のアクションであるcreateアクションが実行されます。
(フラッシュメッセージ記述済み)app/controllers/users_controller.rbclass UsersController < ApplicationController def create @user = User.new(user_params) if @user.save flash[:success] = 'ユーザー登録が完了しました' redirect_to login_path else flash.now[:danger] = 'ユーザー登録に失敗しました' render :new end end private def user_params params.require(:user).permit(:last_name, :first_name, :email, :password, :password_confirmation) end endcreateアクションの最初の行でインスタンス変数
@userに入力した内容が渡されます。@user = User.new(user_params)補足で説明すると、
user_paramsはprivateメソッドとして下の行に定義されています。private def user_params params.require(:user).permit(:last_name, :first_name, :email, :password, :password_confirmation) endこれはストロングパラメーターというもので、簡単に説明すると、
permitの()内で括られた値以外は取得することを何人たりとも許可しないという意味になります。これは悪意のあるユーザーがユーザーが入力した以外の情報を取得することを防ぐセキュリティ対策で、Railsでは必須の知識です。インスタンス変数
@userは条件分岐でsaveメソッドにかけられます。if @user.saveこの
saveメソッドでユーザ登録に必要な情報が正しく入力されているかを判断し、情報に問題がなければtrueを返します。逆に、入力欄が空白であったり、確認用パスワードが入力したパスワードと違っていたりするとfalseを返します。いよいよ本記事のトピックであるflashメッセージとのご対面です。
情報が正しく入力されていれば登録完了の分岐となります。flash[:success] = 'ユーザー登録が完了しました' redirect_to login_path
flash[:success]に文字が格納され、リダイレクト先であるlogin_pathに「ユーザー登録が完了しました」、というメッセージが表示されます。本当にたったこれだけです!ちなみに上記の文章は一文で記述することもできます。
コードはプログラマーがコードを理解する速さが重視されるのでこちらの記述が好まれるでしょう。
(しかし、本記事の最後の節に記載するadd_flash_typesを実装しないとできませんのでご注意ください、、、。)redirect_to login_path, flash: 'ユーザー登録が完了しました'反対に、情報が正しく入力されていなかった場合、
else以降が実行されます。flash.now[:danger] = 'ユーザー登録に失敗しました' render :newこちらはレンダー先である新規登録ページでメッセージが表示されます。
flash.nowとflashの使い分け
結論から先に行ってしまうと、
成功時(リダイレクト)にはflash
失敗時(レンダー)にはflash.now詳しく説明すると、基本的に新規登録や編集機能などでは
if文を使って、trueの場合はredirect_to、falseの場合はrenderが使われます。
redirect_toとrenderには大きな違いがあります。redirect_to・・・アクションを経由して画面遷移
render・・・アクションを経由しないで画面遷移そして
flashとflash.nowにも違いがあります。flash・・・1回目のアクションの経由では消えず、次のアクションまで表示させる。
flash.now・・・次のアクションに移行した時点で消える。
renderはアクションを経由せずページだけを表示させるため、もしflashを使ってしまうと表示が消えるまでに2回のアクションが必要となります。
つまり、今回の例で言えば、正しい情報が入力されログインページにて、「ユーザー登録が完了しました」、というメッセージが次に遷移するログイン後のページにも元気よく、「ユーザー登録が完了しました」と表示されてしまうのです。逆に、
redireict_toは次のアクションを経由するのでFlash.nowでは表示すらされずに、結果そのメッセージを見ることは一生ないでしょう、、、。少しややこしかったかもしれませんが、まとめると
redirect_toにはflash、renderにはflash.nowを使用する!add_flash_typesでメッセージの色を変える
最後に補足で
add_flash_typesに触れておきます。
これはBootstrapに定義されているスタイルを読み込むことが可能になります。実装方法は簡単でrailsにデフォルトで用意されているapplication_contrller.rbに設定を追加するだけです。
app/controllers/application_controller.rbclass ApplicationController < ActionController::Base add_flash_types :success, :info, :warning, :danger endこれにより、メッセージの種類に合わせてメッセージの色を変えることができます。
(successは成功した感じの柔らかい色、dangerは失敗した時の感じの刺々しい色(笑))また、後述したように、成功時のフラッシュメッセージを表示するための
redirect_toが1行で記述できるようになります。redirect_to login_path, flash: 'ユーザー登録が完了しました'以上、フラッシュメッセージについてでした!

- 投稿日:2020-12-18T20:23:01+09:00
Rails アプリで、ページネーションに pagy を使う。
初めに
現場で使える Ruby on Rails 5速習実践ガイド では、ページネーション機能の実現のために、kaminari を紹介しています。
ここでは、kaminariより、40倍速いと評判の pagy を使って見たいと思います。
ページネーションとは
100件のtask(タスク、作業)があるときに、全てのデータを表示すると、ブラウザの表示も遅くなりますし、スクロールして見ていくのも大変です。
そのため、10件ずつ、あるいは20件ずつページ分けして表示するようにすると、快適に閲覧できるようになります。準備
pagyのために、Gemfileを編輯します。
# Gemfile gem 'pagy' # ページネーション% bundle install準備
pagy を使った、ページ分け機能が使えるよう、
ApplicationControllerと、ApplicationHelper に追記します。# app/controllers/application_controller.rb class ApplicationController < ActionController::Base include Pagy::Backend end# app/helpers/application_helper.rb module ApplicationHelper include Pagy::Frontend endページ分けを綺麗に表示できるよう、以下も記します。
# config/initializers/pagy.rb require 'pagy/extras/semantic' # 既定値は20件ですが、10件ごとにページ分けしたいときには、以下のように書きます。 # Pagy::VARS[:items] = 10他にもいろいろ設定できるよう提供されているので、以下から落としてきてもいいです。
https://raw.github.com/ddnexus/pagy/master/lib/config/pagy.rbページ番号に対応する範囲のデータを検索するようにする。
class TasksController < ApplicationController def index @pagy, @tasks = pagy(Task.all) end endビューにページ分けしたデータを表示する
== pagy_semantic_nav(@pagy) table thead tr th = Task.human_attribute_name(:name) tbody - @tasks.each do |task| tr td = task.nameあとがき
ざっくりと書きましたが、どなたかのお役に立てば幸いです。
参考

- 投稿日:2020-12-18T19:46:11+09:00
Active hashで作ったカテゴリーを用いてransackでカテゴリー検索
今回はアクティブハッシュを用いたカテゴリ検索をしたいと思います
自分は今コーヒーの感想を共有できるアプリを作ってます。
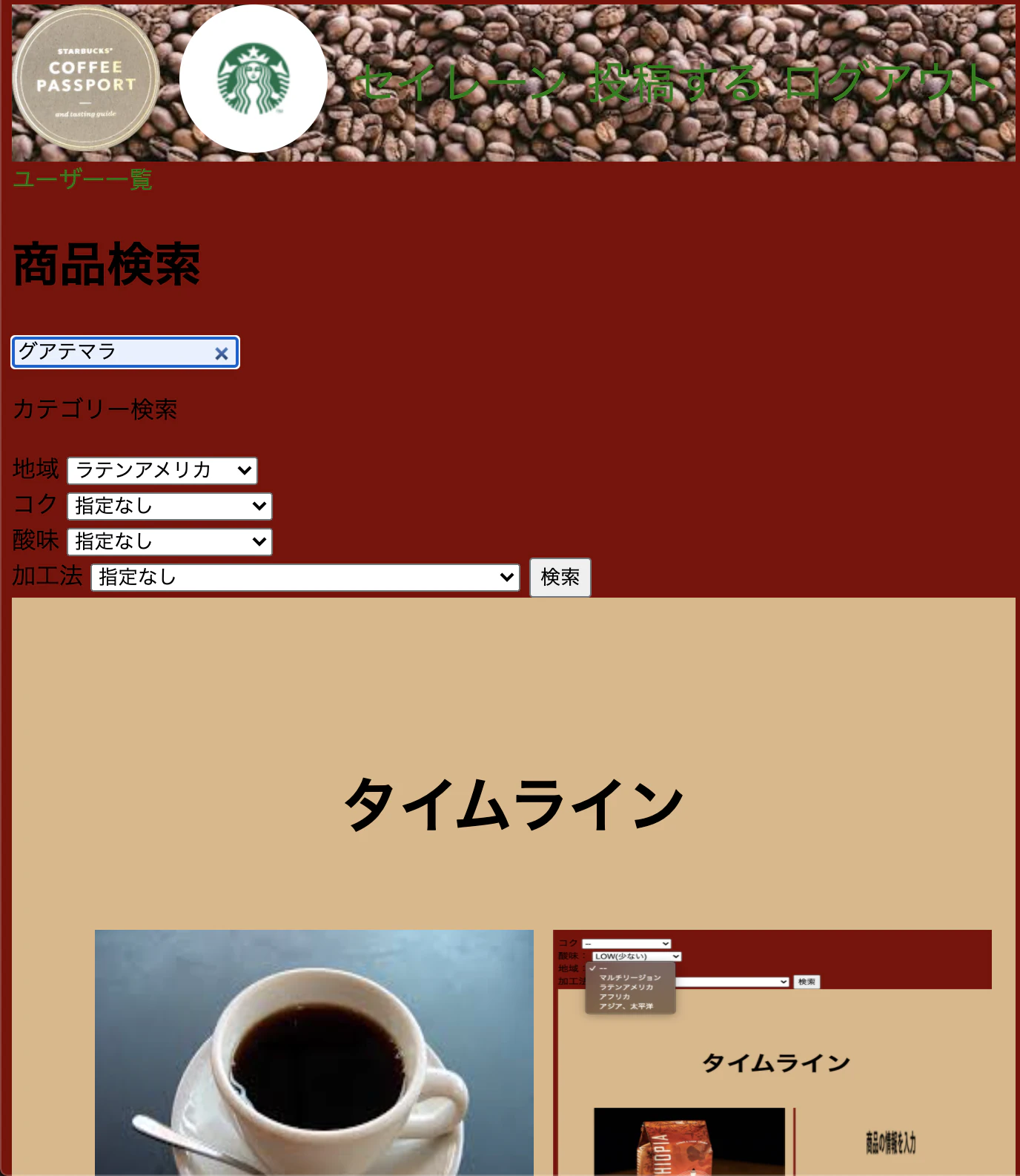
インスタのコーヒー版的な感じです。期待する動作!
このように,「地域 ラテンアメリカ、コク ほどよい」みたいにカテゴリーを選択して投稿
選択した、カテゴリがしっかり表示されてます。
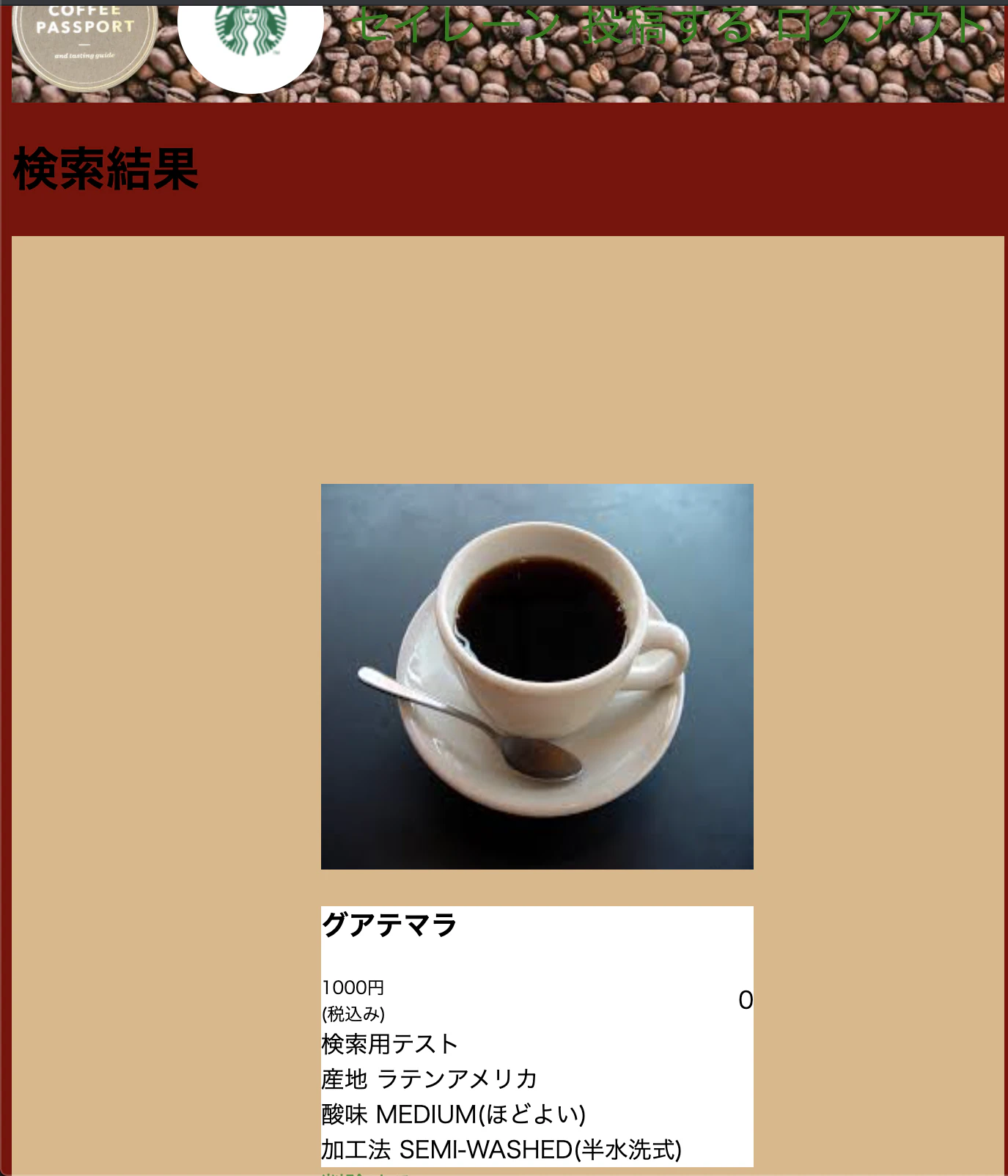
名前は、グアテマラ、地域はラテンアメリカにして、検索してみて
しっかり検索結果が表示されました!!
具体的な実装方法
今回はカテゴリ選択のactive hashと言うgemと検索機能を簡単に実装できるransackと言うgemを導入します。
active hashとは、都道府県名一覧やカテゴリーなど「基本的に変更されないデータ」があったとします。基本的に変更されないデータであるため、データベースに保存する必要性はありません。一方、ビューファイルなどにそれらのデータを直接書いてしまうと、可読性に欠けます。
そのようなケースでは、ActiveHashが有用です。
都道府県名などの変更がないデータをモデルに記述し、あたかもデータベースに保存されていたデータとして取り扱うことができるようにするGemです。すなわち、都道府県名などのデータに対して、ActiveRecordのメソッドを用いることができます。
テーブルの数を無駄に増やす必要もなくなります。ransackとはシンプルな検索フォームと高度な検索フォームの作成を可能にするgemです。
まずはこれらのgemを導入しましょう。
色々なカテゴリーを設けてますが、今回は酸味を表す、acidityカテゴリーだけに着目して解説していきます。
active hashでのカテゴリーの実装(わかってる方は飛ばしてください)
acidity.rb
class Acidity < ActiveHash::Base self.data = [ { id: 2, name: 'LOW(少ない)' }, { id: 3, name: 'MEDIUM(ほどよい)' }, { id: 4, name: 'HIGH(強い)' } ] endこれが、active hashで作った カテゴリーです。
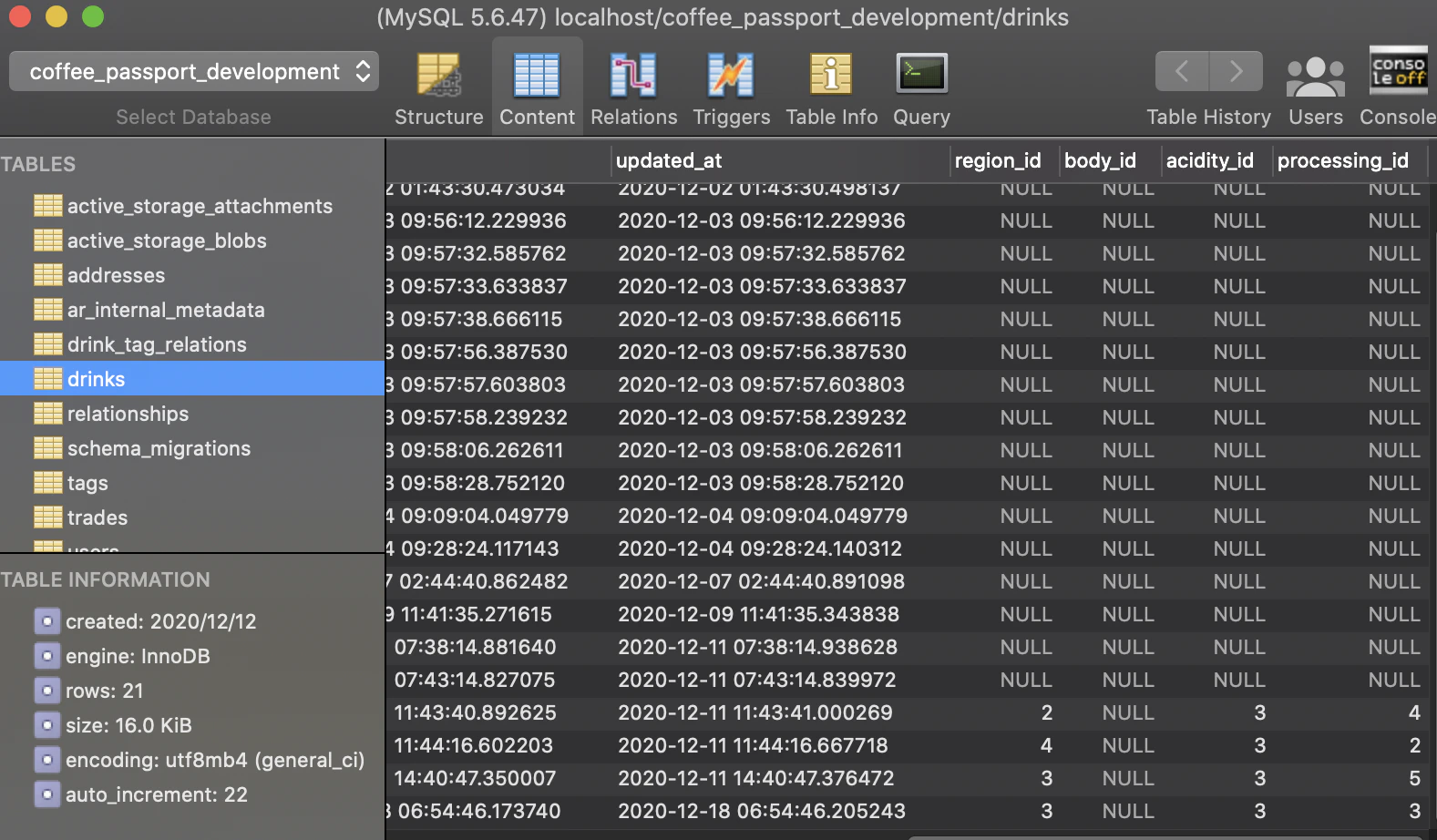
コーヒーの投稿を保存する、drinksテーブルにacidity_idを保存してます
drinks.rb
class Drink < ApplicationRecord extend ActiveHash::Associations::ActiveRecordExtensions belongs_to :user has_one :trade has_many :drink_tag_relations has_many :tags,through: :drink_tag_relations has_one_attached :image belongs_to_active_hash :region belongs_to_active_hash :body belongs_to_active_hash :acidity belongs_to_active_hash :processing with_options presence: true do validates :name validates :explain end endbelongs_to_active_hash :acidity
と記述することで、acidityとアソシエーションが組まれて、カテゴリ選択ができるようになります
```rubyextend ActiveHash::Associations::ActiveRecordExtensions
```
と記述して、moduleを取り込むことによって、 belongs_to_active_hashメソッド
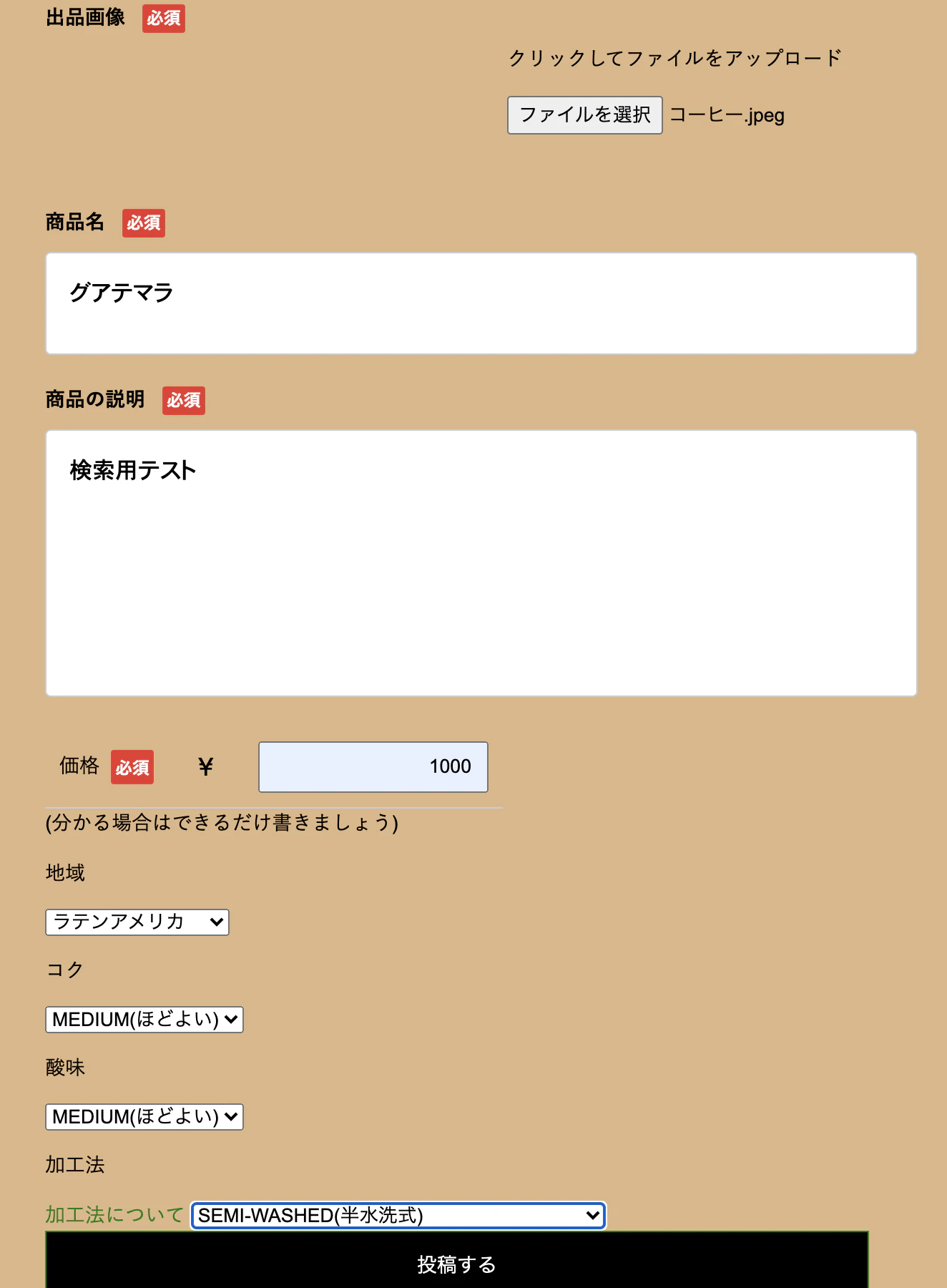
が使えますdrinks/new.html.erb
<%= f.collection_select(:acidity_id,Acidity.all,:id,:name,{},{class: "こんな感じでクラスを設定できます"})%>こんな感じでカテゴリが実装できます
第一引数に、保存先のカラム名,今回はacidity_id
第二引数に、表示したい配列データを指定する、Acidity.all
第三引数に、表示する際に参照するDBのカラム名
第四引数に、実際に表示されるカラム名
Acidity.rbのnameが厳密に言えばカラムではないが、
データベースのように扱えるので、nameを指定するこれで先ほどのようなプルダウン形式のカテゴリーの選択欄が作成できました。
検索機能の実装!
ルーティングの記述
routes.rb
Rails.application.routes.draw do root to: 'drinks#index' get '/drinks/searchdrink', to: 'drinks#search_drink' resources :drinks, only: [:index,:new,:show,:create,:destroy] do collection do get 'search' end endresourcesの上に、書かないと意図しない画面に遷移させられたりするので、それより上に書きましょう!
コントローラーの記述
drinks_controller.rb
class DrinksController < ApplicationController include SessionsHelper before_action :create_searching_object,only: [:index,:search_drink] def index @user = current_user @drinks = Drink.all.order("created_at DESC") end def new @drink = DrinkTag.new end def create @drink = DrinkTag.new(drink_params) if @drink.valid? @drink.save redirect_to drinks_path else render 'new' end end def search_drink @results = @p.result end private def drink_params params.require(:drink_tag).permit(:name,:price,:explain,:image,:tag_name,:region_id,:body_id,:acidity_id,:processing_id).merge(user_id: current_user.id) end def create_searching_object @p = Drink.ransack(params[:q]) endindexアクションでは、全投稿の情報を取得しています
create_searching_objectアクションでは、キー(:q)を使って、drinksテーブルから商品情報を探しています
@p と言う名前の検索オブジェクトを生成していますindex,search_drinkアクションのみで使用するので、before_actionで限定しています
search_drinkアクションでは@pに対して、.resultとすることで検索結果を取得して、@resultに代入しています
コントローラーの処理は以上です。
検索フォームの実装
ここでは、投稿の検索フォームを実装しましょう。その際、「search_form_for」と「collection_select」という2つのメソッドを使用します。
search_form_forはransack特有の検索フォームを生成するヘルパーメソッドです。
collection_selectメソッドはDBにある情報をプルダウン形式で表示できるヘルパーメソッドです。
drinks/index.html.erb
<%= search_form_for @p, url: drinks_searchdrink_path do |f| %> <%= f.search_field :name_cont%> <%# _contはidじゃなくて文字列のときに使う%> <p>カテゴリー検索</p> <%# ベースはドリンククラスで、第二引数で%> <%= f.label '酸味'%> <%= f.collection_select :acidity_id_eq,Acidity.all,:id,:name,include_blank: '指定なし' %> <%= f.submit '検索' %> <% end %>search_form_forの引数に「@p(検索オブジェクト)」を渡すことで検索フォームを生成しています。
urlはdrink#search_drinkに飛ばしたいので、rails routeで確認してこう言う感じになりました
<%= f.collection_select :acidity_id_eq,Acidity.all,:id,:name,include_blank: '指定なし' %>第一引数 検索したいカラム名
第二引数 実際に表示したい配列データを指定する
今回で言えば、Acidity.allです。
第三引数 表示する際に参照するDBのカラム名
第四引数 実際に表示されるカラム名
オプション include_black 何も選択してないときに表示される内容、今回は「指定無し」
検索結果を表示するビューを作成
search_drinkアクションの処理が終わったら、railsのデフォルトでsearch_drink.html.erbにリダイレクトされるので、
search_drink.html.erbを作成して<h1> 検索結果 </h1> <%# 検索結果の個数で条件分岐 %> <% if @results.length !=0 %> <% @results.each do |drink| %> <div class='main'> <%# 商品一覧 %> <div class='item-contents'> <h2 class='title'></h2> <ul class='item-lists'> <%# 商品のインスタンス変数になにか入っている場合、中身のすべてを展開できるようにしましょう %> <%if drink%> <li class='list'> <%= link_to drink_path(drink.id) do %> <div class='item-img-content'> <%= image_tag drink.image , class: "item-img" if drink.image.attached? %> <%# if drink.trade%> <%# end %> </div> <div class='item-info'> <h3 class='item-name'> <%= drink.name %> </h3> <div class='item-price'> <span><%= drink.price %>円<br>(税込み)</span> <div class='star-btn'> <%# image_tag "star.png", class:"star-icon" %> <span class='star-count'>0</span> </div> </div> <div class='item-explain'> <%= drink.explain%> </div> <div> <% if drink.region %> 産地 <%= drink.region.name%> <% end %> </div> <div> <% if drink.body%> コク <%= drink.body.name %> <% end %> </div> <div> <% if drink.acidity %> 酸味 <%= drink.acidity.name%> <% end %> </div> <div> <% if drink.processing%> 加工法 <%= drink.processing.name%> <% end %> </div> </div> <% if logged_in? && current_user.id == drink.user_id %> <div class="item-delete"> <%= link_to "削除する",drink_path(drink),method: :delete %> </div> <% if drink.trade%> <%= link_to "商品を購入する", drink_trades_path(drink) %> <% end %> <% end %> </li> <%end%> </ul> </div> <%end%> </div> <% end %> <% else %> 該当する商品はありません <% end %> <br> <%= link_to 'トップページへ戻る', root_path %>と、検索結果が、@resultに入っていて、
それをeach文で、ローカル変数をdrinkにして、検索結果があるだけ表示させています以上で、Active hashで作ったカテゴリーを用いてransackでカテゴリ検索をする実装が終わりました!

- 投稿日:2020-12-18T19:38:43+09:00
Active Storage で複数画像を Cloudinary に上げて、Heroku に公開する。
初めに
現場で使える Ruby on Rails 5速習実践ガイド では、ファイルをアップロードしてモデルに添付する方法として、Active Storage が紹介されています。
ローカル環境で、一枚の画像を添付する方法について書かれておりました。
せっかくですので、
- 複数の画像の添付方法
- 画像や動画の管理が得意なクラウドサービス Cloudinary の利用方法
- Heroku への 公開方法
について、記していきます。
ついでに、SendGridを使ってメール送信できるようにします。
Active Storage とは
Rails 5.2 から、ActiveStorage が同梱されました。
クラウドストレージサービス(Amazon S3 や Cloudinaryなど)への画像・動画をアップロードして、データベース(ActiveRecord)に紐付けることが簡単にできるようになりました。Cloudinary とは
Cloudinaryとは、画像や動画の配信や編集ができるクラウドサービスです。
無料でも、一ヶ月当たり25クレジット(≒25GB)まで使うことができますので、小規模な開発には充分かと思います。準備
Active Storage は、Rails アプリを新規作成した際に導入されています。
そして、以下のGemも導入しておきます。# Gemfile gem 'image_processing' # (サイズ変更など)画像処理用 gem 'cloudinary', require: true # Cloudinary gem 'activestorage-cloudinary-service' # Cloudinary と Active Storage の連携をする gem 'active_storage_validations' # 画像ファイルのバリデーション用% bundle installActive Storage をインストールします。
% rails active_storage:installマイグレーションファイルが生成されますので、データベースに反映させるべく、migrate コマンドを実行します。
% rails db:migrate添付ファイルの実体を、どこに保存するのか、設定を行います。
開発環境ではローカルに、本番環境では cloudinary に、添付ファイルが保存されるように設定します。# config/development.rb Rails.application.configure do # Store uploaded files on the local file system (see config/storage.yml for options). # アップロードされたファイルをローカルファイルシステムに保存します # (オプションについては config/storage.yml を参照してください)。 config.active_storage.service = :local end# config/production.rb Rails.application.configure do config.active_storage.service = :cloudinary end:local, :cloudinary は、config/storage.yml に詳細を記述します。
# config/storage.yml local: service: Disk root: <%= Rails.root.join("storage") %> cloudinary: service: Cloudinary cloud_name: <%= Rails.application.credentials.dig(:cloudinary, :cloud_name) %> api_key: <%= Rails.application.credentials.dig(:cloudinary, :api_key) %> api_secret: <%= Rails.application.credentials.dig(:cloudinary, :api_secret) %>後々、ビューで画像を表示するのに便利なので、以下も記述しておきます。
enhance_image_tag: true と書くことで、
ビュー内で、= image_tag と書いた際に、cloudinary による便利な機能拡張が使えるようになります。# config/cloudinary.yml development: cloud_name: <%= Rails.application.credentials.dig(:cloudinary, :cloud_name) %> api_key: <%= Rails.application.credentials.dig(:cloudinary, :api_key) %> api_secret: <%= Rails.application.credentials.dig(:cloudinary, :api_secret) %> enhance_image_tag: true static_file_support: false production: cloud_name: <%= Rails.application.credentials.dig(:cloudinary, :cloud_name) %> api_key: <%= Rails.application.credentials.dig(:cloudinary, :api_key) %> api_secret: <%= Rails.application.credentials.dig(:cloudinary, :api_secret) %> enhance_image_tag: true static_file_support: false test: cloud_name: <%= Rails.application.credentials.dig(:cloudinary, :cloud_name) %> api_key: <%= Rails.application.credentials.dig(:cloudinary, :api_key) %> api_secret: <%= Rails.application.credentials.dig(:cloudinary, :api_secret) %> enhance_image_tag: true static_file_support: falseここで、書かれている Rails.application.credentials は、鍵の管理を行うために、Rails 5.2 から登場したcredentials(信任状)という機能です。
大切な鍵の情報は、config/credentials_yml.enc に暗号化されて保存されています。
次のコマンドで、暗号化された情報を見ることができます。% rails credentials:show編輯するためには、次のコマンドを実行します。
% rails credentials:editエディタが立ち上がりますので、適宜編輯します。
Command + S で保存して、Command + W でタブを閉じます。cloudinary: cloud_name: (cloudinaryに付けた任意の名前) api_key: (cloudinaryより指定された15桁の数字) api_secret: (cloudinaryより指定された27桁の英数記号) # Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies. secret_key_base: (128桁の16進数)タスクモデルに画像を添付できるようにする。
Taskモデルに画像ファイルを添付できるようにします。
ついでに、activestorage-validator による添付画像の検証も追加します。# app/models/task.rb class Task < ApplicationRecord # has_one_attached :image # 添付画像は一つ has_many_attached :images # 複数の添付画像 # activestorage-validator による添付画像の検証 validates :images, content_type: %i(gif png jpg jpeg), # 画像の種類 size: { less_than_or_equal_to: 5.megabytes }, # ファイルサイズ dimension: { width: { max: 2000 }, height: { max: 2000 } } # 画像の大きさ endビューも作成します。
# app/views/task/new.html.slim h1 タスクの新規登録 = link_to '一覧', tasks_path, class: 'ui right floated primary tertiary button' = render partial: 'form', locals: { task: @task }# app/views/task/_form.html.slim = form_with model: task, class: 'ui form', local: true do |f| .field = f.label :name = f.text_field :name, required: true .field = f.label :description = f.text_area :description .field = f.label :images - if task.images.attached? - task.images.each do |image| = image_tag image / = image_tag task.image.variant(resize_to_limit: [300, 300]) = f.check_box :image_ids, { multiple: true }, image.id, false = f.label "image_ids_#{image.id}" | 画像を削除する = f.file_field :images, accept: 'image/jpg, image/jpeg, image/png, image/gif', multiple: true = f.submit nil, class: 'ui primary button'画像の表示を担当しているのは、次の部分です。
画像の添付があった場合、eachメソッドで、全ての画像を表示させています。
ruby
- if task.images.attached?
- task.images.each do |image|
= image_tag image
また、不要な画像を削除できるよう、チェックボックスを設けています。
= f.check_box :image_ids, { multiple: true }, image.id, false = f.label "image_ids_#{image.id}" | 画像を削除する添付ファイルを複数選択できるようにするとともに、画像ファイルのみを選べるようにしています。
ruby
= f.file_field :images, accept: 'image/jpg, image/jpeg, image/png, image/gif', multiple: true
コントローラを作成します。
# app/controllers/tasks_controller.rb class TasksController < ApplicationController def update # 画像の削除処理 params[:task][:image_ids]&.each do |image_id| @task.images.find(image_id).purge end if @task.update(task_params) redirect_to tasks_url, notice: "タスク「#{@task.name}」を更新しました。" else render :edit end end private def task_params # 一つの画像を添付する場合 # params.require(:task).permit(:name, :description, :image) # 複数の画像を添付する場合 params.require(:task).permit(:name, :description, images:[]) end endupdate アクションで、チェックが入っている画像を削除できるようにしています。
また、フォームから添付ファイルを受け取れるよう、task_paramsに、imageを追加しています。以上で、Active Storage を使った複数画像の添付は完成です。
少し、ビューが味気ないので、
Fomantic-UI の card を使って画像を表示することとし、
css/javascript を使って、ファイルフォームを綺麗にすると、次のようになります。# app/views/task/_form.html.slim - if task.errors.present? ul#error_explanation - task.errors.full_messages.each do |message| li = message = form_with model: task, class: 'ui form', local: true do |f| .field = f.label :name = f.text_field :name, required: true .field = f.label :description = f.text_area :description .field = f.label :images - if task.images.attached? .ui.cards - task.images.each do |image| .card .image = image_tag image / / = image_tag task.image.variant(resize_to_limit: [300, 300]) .extra.content .ui.checkbox = f.check_box :image_ids, { multiple: true }, image.id, false = f.label "image_ids_#{image.id}" | 画像を削除する = f.file_field :images, accept: 'image/jpg, image/jpeg, image/png, image/gif', multiple: true, id: 'embed_file_input' .ui.fluid.action.input.mb-3 input#selected_filenames_display_area disabled="disabled" placeholder="画像ファイルはありません" type="text" label.ui.small.teal.left.floated.button for="embed_file_input" = semantic_icon('upload') | 画像選択 = f.submit nil, class: 'ui primary button' css: input[type="file"] { display: none; } #selected_filenames_display_area { opacity: 1; } javascript: // "embed_file_input" という ID属性の要素を取得する。(画像選択ボタン) const input_files = document.getElementById("embed_file_input"); // 選択ファイル名表示領域 const selected_filenames_display_area = document.getElementById("selected_filenames_display_area"); // 値が変化した時(ファイル選択時)に実行されるイベント input_files.onchange = function() { // FileList オブジェクトを取得する let file_lists = input_files.files; // 画像ファイル名格納用の配列 let file_names = [] for (let i = 0; i < file_lists.length; i++) { // File オブジェクトより、画像ファイル名を取得する file_names.push(file_lists[i].name) } // 選択ファイル名表示領域に、画像ファイル名を書き出す selected_filenames_display_area.value = file_names.join(', ') }本番環境でSendGridを使う
production.rb に SendGrid を使ってメール送信できるよう、追記します。
# config/environments/production.rb # Ignore bad email addresses and do not raise email delivery errors. # Set this to true and configure the email server for immediate delivery to raise delivery errors. config.action_mailer.raise_delivery_errors = false config.action_mailer.delivery_method = :smtp host = 'taskleaf.herokuapp.com' config.action_mailer.default_url_options = { host: host } ActionMailer::Base.smtp_settings = { address: 'smtp.sendgrid.net', port: '587', authentication: :plain, user_name: ENV['SENDGRID_USERNAME'], password: ENV['SENDGRID_PASSWORD'], domain: 'heroku.com', enable_starttls_auto: true }Heroku への公開
アカウントの作成
Heroku(へろく)は、Ruby on Rails で作成したウェブアプリを簡単に公開(デプロイ)できるサービスです。
https://heroku.com にアクセスし、Sign up から、自分のアカウントを作成します。CLI(Command Line Interface)のインストール
GUI(Graphical User Interface)を使って、ブラウザからウェブアプリの作成もできます。
そしてせっかくですから、Heroku Command Line Interface (CLI) もインストールしておきます。
ターミナルからコマンド一つで、いろいろできるようになるので、慣れると簡単です。% brew tap heroku/brew && brew install herokuウェブアプリの作成とGitを使っての公開(デプロイ)
% cd taskleaf % git init Initialized empty Git repository in .git/ % git add . % git commit -m "My first commit"Herokuにログインしてウェブアプリを作成します。
名前は、taskleaf にします。(すでに使われていたら別の名前にします。)% heroku login % heroku create taskleafHeroku では、いろいろなadd-on(追加機能)を使えるようになっています。
データベースには、Postgresql を、
ストレージサービスには、Cloudinary を、
メール送信サービスとして、SendGrid を使いたいので、
以下のコマンドで、機能追加します。
各アドオンとも、利用する容量等によって、さまざまな料金プランが用意されていますが、
ここでは、無料プランにしています。% heroku addons:create heroku-postgresql:hobby-dev % heroku addons:create cloudinary:starter % heroku addons:create sendgrid:starter % heroku config:get SENDGRID_USERNAME % heroku config:get SENDGRID_PASSWORD公開(デプロイ)します。
% git push heroku master公開できましたので、データベースを更新します。
% heroku run rails db:migrateブラウザで開いて確認します。
% heroku openローカル環境と同じようにファイルをアップロードできるはずです。
また、Cloudinaryのサイト(https://cloudinary.com/)にログインすると、
「Media Library」にアップロードした画像ファイルがあることが確認できるはずです。あとがき
ざっくりと書きましたが、どなたかのお役に立てば幸いです。
参考
【Rails 5.2】 Active Storageの使い方 - Qiita
【Rails on Docker on Heroku】ActiveStorage + Cloudinaryで画像を管理するメモ
- 投稿日:2020-12-18T18:46:56+09:00
railsでパラメータを付けてredirect_toする一つの方法
いろいろかっこいいやり方はあるみたい
https://blog.kozakana.net/2015/10/redirect_to-with-parameter/ですが、今回自分の状況的に(パラメータも一つだったので)
redirect_url = ENV["HOST"] + "/hoge?h=" + hash値 redirect_to redirect_urlって感じでstringで生成して事足りてしまった。
似たようなことで悩んでる人いればご参考までに。
- 投稿日:2020-12-18T16:27:26+09:00
MVCについて本気出してまとめてみた
はじめに
Railsを当たり前のように使っているのですが、
「ところでMVCって何?」と問われると、意外と説明が難しい…と感じたので
自分なりに言語化するために、今一度まとめてみました。※ここで扱うMVCは、Railsで使われる所謂「MVC2」と呼ばれるものです。
MVCとは
Model View Controllerの略称で、
プログラム全体を、データの表示部分とデータの処理、データベース管理の3つの要素に分けた、Webアプリケーションのデザインパターンです。Railsの場合、MVCの処理はざっと、下図(自作…
)の流れで行われます。
処理の流れに合わせて、MVCの各機能を順に説明します。
MVCに入る前の… ルーティングとは
クライアントからまずリクエストを受け取ります。
リクエスト内容から、対応する処理を持つコントローラーへ行先を指定する「対応表」のような役割を持ちます。C:Controller(コントローラー)
クライアントからのリクエストに対する処理を制御する部分です。
リクエストに該当するアクションを実行し、揃えた内容をレスポンスとしてクライアントへ返します。レスポンスに必要な情報を揃えるために
- モデルに伝えて、必要なデータを用意する
- 画面表示に必要なデータをビューに渡す
といった、他機能との「橋渡し」のような役割を持っています。
M:Model(モデル)
データベースとやり取りをする「窓口」のような機能を持ちます。
コントローラーからの指示を元にデータベースへアクセスし、
必要なデータを取得や、データの加工(挿入・更新・削除)を行う部分です。また、データの検証(バリデーション)やテーブル同士の関連付けなど、データベース内に保存されるデータについての細かい設定をする役割も担っています。
V:View(ビュー)
最終的なWebページの見た目を設定する部分です。
コントローラーから渡されたデータをHTMLなどで整形し、レスポンスとして返す画面表示を行います。また、入力フォームからデータを取得し、コントローラーへ渡すこともあります。
MVCのメリット
下記2点が大きなメリットです。
- 機能毎に分離しており、分業がしやすい
- 他の機能部分の変更による影響を受けにくく、保守性が高まる
終わりに/感想
個人開発でなんとなくMVCを分かっているつもりでしたが、
記事にまとめることで、改めて理解を深めることが出来たと感じています。初学者で拙い記事ですが、少しでもお役に立てると嬉しく思います。
最後まで読んでいただき、誠にありがとうございました。開発環境
Ruby 2.6.5
Rails 6.0.3.4
MySQL
Visual Studio Code
(GoogleChrome)参考記事・書籍
【書籍】Ruby on Rails6 超入門/掌田津耶乃
【公式】Railsドキュメント
【Qiita】MVCという概念をさくっと理解するためのまとめ。
【Qiita】MVCモデルについて
【Qiita】RailsのMVCをまとめてみる
【ピカワカ】MVCフレームワークを1から丁寧に解説!

- 投稿日:2020-12-18T15:57:31+09:00
共同開発初心者によるコードレビューの仮説と検証
概要
現在所属しているオンラインサロンにてRailsアプリの共同開発を行うことになりました。(12月14日時点)
私自身、共同開発は初めての経験のため、人生で初めてコードレビューを行うことになります。
そこでこの貴重なコードレビューの機会をより有意義なものにしたいと思い、共同開発を開始する前に「どのようなプルリクエスト/コードレビューが好ましいか」について共同開発初心者なりに仮説を立てることにしました。
その仮説に基づきプルリクエストの作成およびコードレビューを行い、その後に仮説の検証結果と反省点もアウトプットしていきたいと思います。(1月上旬予定)
目次✅ プルリクエストの書き方とは ✅ コードレビューの書き方とは ✅ 仮説の検証結果と反省点プルリクエストの書き方とは
機能実装を完了し、コードレビューを受けたい人はプルリクエスト(PR)を作成することになります。実際に僕も個人開発をする際、ローカルのブランチをGitHubにpushしてPRを作成し、mergeしてローカルにpullするという流れを何度も行ってきました。
しかし、個人開発ということもあって変更の意図や変更点は自分自身で把握できているため、PRを作成する際にしっかりとコメントを残すことはありません。
一方、共同開発では自身が作成したPRを他のメンバーに見てもらう(コードレビューしてもらう)ため、自身が行った変更の意図や変更点をしっかり伝える必要があります。
そこで本章では、
ReviewerがレビューしやすいPRはどのようなPRか仮説を立てて、実際に共同開発で使用するPRのテンプレートを作成したいと思います。レビューしやすいPRとは
実際に僕自身、現時点ではコードレビューを経験したことがなくReviewerとしての経験から答えを導き出すことはできないので「自分がReviewerだったらこんな情報が欲しいな!」と思うことベースに考えていきます。
① 変更の目的
なぜこの変更を行うのか、変更の目的や変更の背景を記載することは必要不可欠であると考えます。
変更の目的を共有しておかなければ、Revieweeの意図に反したレビューを行うことになってしまうと考えるからです。例)「ユーザが掲示板を投稿できるようにするため」など
② 達成条件
上記の目的を達成するための条件の記載も必要不可欠であると考えます。Reviewerがコードを把握する上で、正しい挙動はどのようなものかを理解しておく必要があると思うからです。
例)「投稿内容が必須になっている」
「エラーメッセージが日本語で表示されるようになっている」
「投稿内容は140文字以内に制限されている」など③ 条件達成のために行った変更の内容
上記の条件達成のためにどのような変更を行なったのか、またどのファイルが関連しているのかを記載すべきであると考えます。
変更内容とその変更に伴って編集したファイルの情報を共有しておかないとコンフリクトが起こってしまう可能性があると考えるからです。例)modelのvalidationを設定
[update] app/models/post.rb投稿フォームを作成
[add] app/views/posts/new.html.haml
[remove] app/views/templates/new.html.haml④ 関連Issue
どのIssueの課題を解決する変更であるかを記載すべきだと考えます。
わからないことなどがあれば、Issueに飛んで容易に確認することができると考えるからです。
ちなみにCloses#<関連するIssue番号>と書くと、PRがmergeされたタイミングで、関連Issueも閉じてくれるそうです。例) 関連Issue ⇨ #1
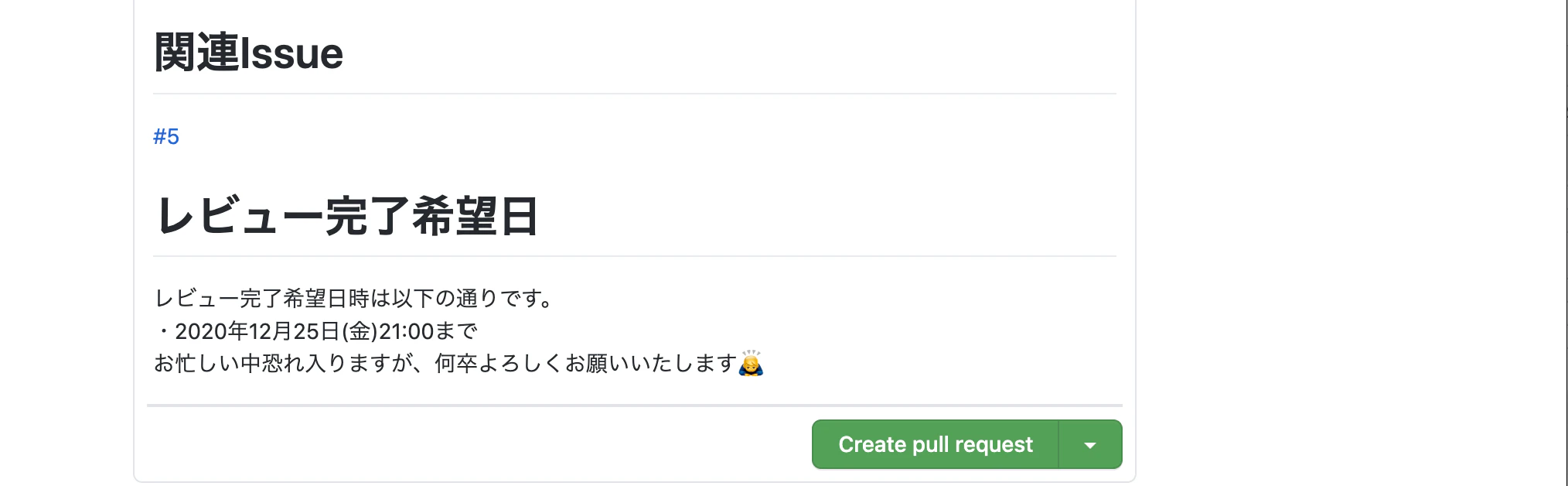
⑤ レビュー完了希望日
レビュー完了希望日も記載すべきだと考えます。今回の共同開発は、完成目標が2週間であり、またクリスマスや年末年始など多くのイベントを挟むため、しっかりとしたスケジュール管理が必要であると考えるからです。
実際の業務でも期限を設定しなければ仕事の優先順位を決めることはできないので、期限の設定は重要であると考えます。例)レビュー完了希望日時は以下の通りです。
・2020年12月25日(金)21:00まで
お忙しい中恐れ入りますが、何卒よろしくお願いいたします?♂️⑥ キャプチャ画像/動画
実際にRevieweeのローカル環境では動作確認ができていることを担保するために、キャプチャ画像や動画を掲載するのが親切であると考えます。
しっかりと動作することが前提のレビューの方がReviewerの負担が軽くなると考えるからです。⑦ 明確なコミットメッセージ
レビューを行う人によってはコミットメッセージまでしっかり見る人がいます(らしいです)。そのため、コミットメッセージもわかりやすく記述する必要があると考えます。
3ヶ月後の自分が見ても一眼でわかるようなコミットメッセージにしましょう。コミットメッセージについてはこちらの記事を参考に、以下のように記述したいと考えています。
コミットメッセージテンプレート[コミット種別選択]変更内容の概要 変更した理由を具体的に記述【コミット種別】
fix:バグ修正
add:新規(ファイル)機能追加
update:機能修正
remove:削除(ファイル)
clean:リファクタリングPRテンプレート
上記を踏まえて、今回の共同開発では以下のようなテンプレートを使用できればと考えます。
※PR作成の際には画像右上の
Reviewersにコードレビューしていただきたい人をアサインし、その下のAssigneesにPR作成者(自分)を忘れずにアサインしましょう。
PRテンプレート# 変更の目的 〇〇できるようにするため # 達成条件 - [ ] 条件① ※できればキャプチャ画像か動画を添付する - [ ] 条件② ※できればキャプチャ画像か動画を添付する - [ ] 条件③ ※できればキャプチャ画像か動画を添付する - [ ] 条件④ ※できればキャプチャ画像か動画を添付する # 条件達成のために行った変更の内容 - [ ] 変更内容 >[update][add][remove][fix]から選択 変更ファイル名を記載 - [ ] 変更内容 >[update][add][remove][fix]から選択 変更ファイル名を記載 # 関連Issue #○←関連Issue番号を記載 # レビュー完了希望日 レビュー完了希望日時は以下の通りです。 ・2020年○月○日(○曜日)〇〇:〇〇まで お忙しい中恐れ入りますが、何卒よろしくお願いいたします?♂️このテンプレートのよかった点や改善点などは共同開発が終了したらまとめていきたいと思っております。
コードレビューの書き方とは
次にコードレビューの書き方についてです。
PRの際にReviewerとしてアサインされた人はコードレビューを行うことになります。
コードレビューは個人開発では経験できない部分なので「どのようなコードレビューが有意義か」共同開発前にしっかりと仮説立てを行い、共同開発を通して検証していけたらいいなと思います。
コードレビューの流れ
まずざっくりとコードレビューの流れをまとめます。
① コードを確認する
Reviewerにアサインされた人はGitHubの[Pull Requestsタブ]の[Files Changed]でコードを確認します。
② レビューコメントを書く
コードの修正希望やコードの不明点があった場合は、対象の行を選択してコメントを残し[Start a review]を押します。
③ フィードバックを送信する
コードのレビューが終わり、コメントの記入が完了したら、画面右上にある[Finish your review]を押します。
この際、フィードバックの種類は以下3つから選択できるので状況に応じて使い分けます。Comment
コメントを残す際に使用します。
項目でいうと[NITS]や[IMO]や[Q]の場合に使用します。(後述)
また「コード読みやすいですね!」や「こんな書き方もあるんですね!勉強なりました!」など褒め合うことができたら最高です!Approve
コメントを残した上で、PRの承認まで行います。
基本的には、修正箇所がなくLGTMを出す際に利用すればいいと思います!Request changes
コードの修正依頼をする際に使用します。
項目でいうと[MUST]の時に使用します。(後述)
この際、修正して欲しい理由や自分なりの提案とその理由まで記述できればかなり素敵だなと思います。フィードバックの種類を選択し終えたら[Submit review]を押し、レビューを反映させます。
無事レビューが完了したら[Conversationタブ]にレビューの内容が反映されます。④ レビューの内容をもとにローカル環境で修正する
Revieweeはレビューしてもらった内容をもとにローカル環境で修正を行いましょう。
⑤ 修正が完了したら、対象ブランチをpushする
修正が完了したら、リモートにpushします。
この際に、[Conversation]のレビューに修正が完了した旨を伝えます。
⑥ Reviewerが修正内容を確認する
Reviewerは[Files Changed]でコードの修正内容を確認し、OKであれば[Conversation]にてLGTMを出します。
また[Resolve conversation]を押し、対象の修正内容がcloseしたことを明示しましょう。
⑦ masterにmergeする
Revieweeは全てのメンバーのLGTMをもらうことができたらリモートのmasterにmergeします。
mergeか完了したら共同開発メンバーは各自リモート環境のmasterブランチにpullを行います。
以上がコードレビューの大まかな流れです。
上記作業を繰り返して機能実装を行なっていきます。有意義なコードレビューとは
コードレビューの大まかな流れが確認できたので、コードレビューの内容に焦点を当てたいと思います。
今回は、自分自身含めてメンバーみな共同開発未経験者ということで、コードレビューの場を
「意見する場」ではなく、「知識を共有する場」、「コミュニケーションを学ぶ場」として活用するのが適切ではないかと考えています。そこで今回は「知識共有」「コミュニケーション」という観点でコードレビューのポイントを洗い出し、ポイントに沿ったコードレビューのテンプレートを作成していきたいと思います。
コードレビューのポイント
① 修正希望には理由と修正案も添える
修正希望を出す際には、修正希望だけではなく理由を添え流べきと考えます。ロジックを用いて相手が納得できるように伝えることで、双方納得して作業を進められ流と考えるからです。
また、修正案とその理由も伝えると知識を共有でき前向きなレビューになると考えます。② 修正希望には[MUST]など項目をつけて、その修正の重要度を明示する
修正を希望する場合は、その修正がどれくらい重要なものかを明示してあげることで良質なコミュニケーションになると考えます。
項目には以下のようなものが考えられます。項目[MUST] 絶対に修正して欲しいときにつけます。 [IMO] 「自分ならこうする!」や「自分はこう思うのだけどどう思いますか?」などの意見があるときにつけます。(In my opinionの略) [NITS] 細かい指摘や、軽い修正をして欲しいときにつけます。 (例)インデントを揃えて欲しいです![IMO]は知識の共有という観点でも積極的に使っていけたらいいなと思います。
それぞれ重要度によって使い分けてみましょう。③ わからない点があれば積極的に質問する
わからない点があれば、積極的に質問しましょう。
聞く側にとってはナレッジ共有の場として、教える側にとってはアウトプットの場として有意義であると考えます。また、質問がある際には以下のように項目づけを行うと良質なコミュニケーションになるでしょう。
項目[Q] 質問がある場合につけます。コードレビューのテンプレート
上記を踏まえて、今回の共同開発では以下のようなテンプレートを使用できればと考えます。
修正希望がある場合のレビューテンプレート
レビューテンプレート(修正希望)### 修正希望 [MUST][IMO][NITS]から適切なものを選択 [修正内容/気になる部分など] ### 理由 [上記修正を希望する理由] ### 提案 [自分が考える修正案]質問がある場合のレビューテンプレート
レビューテンプレート(質問)### 質問内容 [Q] [質問内容を記述] ### 理由 [質問理由を記述]仮説の検証結果と反省点
共同開発が終わり次第まとめます(1月上旬予定)
・コードレビューで見るべきポイントは?
・コミットメッセージをわかりやすくするためには?
・レビューしやすいプルリクエストとは? ...etc








- 投稿日:2020-12-18T15:27:33+09:00
railsとjsを用いてタグ付け機能を実装してみる
railsでタグ付け機能を実装して、後半ではJavaScriptで発展的なタグ付けをしましょう
今回は、このようにタグを入力できる機能と、タグを入力するたびに予測変換が下に表示される機能を実装していきたいと思います!
画像で言うと、tagの入力フォームに「酸」と打ったら、下に「酸味」って予測変換的な物が表示されています
ただ、ブラウザが賢いので、ブラウザも予測変換出しちゃってますが、、、笑下記コマンドを実行
ターミナル
% cd ~/projects % rails _6.0.0_ new tagtweet -d mysql % cd tagtweetデータベース作成
データベースを作成する前に、database.ymlに記載されているencodingの設定を変更しましょう。
config/database.yml
default: &default adapter: mysql2 # encoding: utf8mb4 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: socket: /tmp/mysql.sockんで、データベース作成
ターミナル
rails db:createで
Created database 'tagtweet_development'
Created database 'tagtweet_test'が作成される
データベース設計
tweet と tagは多対多の関係なので、
中間テーブルの
tweet_tag_relationsテーブルを作成するってのがポイントモデルを作成
ターミナル
% rails g model tweet% rails g model tag% rails g model tweet_tag_relationマイグレーションを編集
db/migrate/20XXXXXXXXXXXX_create_tweets.rb
class CreateTweets < ActiveRecord::Migration[6.0] def change create_table :tweets do |t| t.string :message, null:false # messegeカラムを追加 t.timestamps end end enddb/migrate/20XXXXXXXXXXXX_create_tags.rb
class CreateTags < ActiveRecord::Migration[6.0] def change create_table :tags do |t| t.string :name, null:false, uniqueness: true # nameカラムを追加 t.timestamps end end end今回は、タグの名前の重複を避けるために「uniqueness: true」という制約を設定します。
db/migrate/20XXXXXXXXXXXX_create_tweet_tag_relations.rb
class CreateTweetTagRelations < ActiveRecord::Migration[6.0] def change create_table :tweet_tag_relations do |t| t.references :tweet, foreign_key: true t.references :tag, foreign_key: true t.timestamps end end endtweet_tag_relationsテーブルでは、「tweetsテーブル」と「tagsテーブル」の情報を参照するので「foreign_key: true」としています。
ターミナル
rails db:migrate格モデルのアソシエーションを組む
tweet.rb
class Tweet < ApplicationRecord has_many :tweet_tag_relations has_many :tags, through: :tweet_tag_relations endtag.rb
class Tag < ApplicationRecord has_many :tweet_tag_relations has_many :tweets, through: :tweet_tag_relations endtweet_tag_relation.rb
class TweetTagRelation < ApplicationRecord belongs_to :tweet belongs_to :tag endルーティングを設定しましょう!
routes.rb
Rails.application.routes.draw do root to: 'tweets#index' resources :tweets, only: [:new, :create] end今回のアプリの仕様
何かつぶやくと,「つぶやき(tweet)」と「タグ(tag)」が同時に保存される仕様を目指します。
このような実装をする時に便利なのがFormオブジェクトというものです。Formオブジェクト
Formオブジェクトは、1つのフォーム送信で複数のモデルを更新するときに使用するツールです。自分で定義したクラスをモデルのように扱うことができます。
このFormオブジェクトは、「ActiveModel::Model」というモジュールを読み込むことで使うことができます。ActiveModel::Model
「ActiveModel::Model」とは、Active Recordの場合と同様に「form_for」や「render」などのヘルパーメソッドを使えるようになるツールです。
また、「モデル名の調査」や「バリデーション」の機能も使えるようになります。Fromオブジェクトを導入
まずはmodelsディレクトリにtweets_tag.rbを作成しましょう
app/models/tweets_tag.rbという配置です。
tweets_tag.rb
class TweetsTag include ActiveModel::Model # include ActiveModel::Modelを記述することでFromオブジェクトを作る attr_accessor :message, :name # ゲッターとセッターの役割両方できる仮想的な属性を作成 # :nameとかt保存したいカラムを書けば、保存できるって理解でまずはok with_options presence: true do validates :message validates :name end def save tweet = Tweet.create(message: message) tag = Tag.create(name: name) TweetTagRelation.create(tweet_id: tweet.id, tag_id: tag.id) end # saveメソッド内で、格テーブルに値を保存する処理を記述 end一意性の制約はモデル単位で設ける必要があるため、tagモデルに記述しましょう。
tag.rb
class Tag < ApplicationRecord has_many :tweet_tag_relations has_many :tweets, through: :tweet_tag_relations validates :name, uniqueness: true endコントローラーを作成して編集をしましょう
ターミナル
% rails g controller tweetstweets_controller.rb
class TweetsController < ApplicationController def index @tweets = Tweet.all.order(created_at: :desc) end def new @tweet = TweetsTag.new end def create @tweet = TweetsTag.new(tweet_params) if @tweet.valid? @tweet.save return redirect_to root_path else render "new" end end private def tweet_params params.require(:tweets_tag).permit(:message, :name) end end「Formオブジェクト」に対してnewメソッドを使用しています。
Fromオブジェクトで定義したsaveメソッドを使ってる
ビューの作成
tweets/index.html.erb
<div class="header"> <div class="inner-header"> <h1 class="title"> TagTweet </h1> <li class='new-post'> <%= link_to "New Post", new_tweet_path, class:"post-btn"%> </li> </div> </div> <div class="main"> <div class="message-wrap"> <% @tweets.each do |tweet|%> <div class="message"> <p class="text"> <%= tweet.message %> </p> <ul class="tag"> <li class="tag-list"> <%tweet.tags.each do |tag| %> #<%=tag.name%> <%end%> </li> </ul> </div> <%end%> </div> </div>tweets/new.html.erb
<%= form_with model: @tweet, url: tweets_path, class:'form-wrap', local: true do |f| %> <div class='message-form'> <div class="message-field"> <%= f.label :message, "つぶやき" %> <%= f.text_area :message, class:"input-message" %> </div> <div class="tag-field", id='tag-field'> <%= f.label :name, "タグ" %> <%= f.text_field :name, class:"input-tag" %> </div> <div id="search-result"> </div> </div> <div class="submit-post"> <%= f.submit "Send", class: "submit-btn" %> </div> <% end %>CSSは省略!!!
tweets_tag.rbを編集
tweets_tag.rb
class TweetsTag include ActiveModel::Model attr_accessor :message, :name with_options presence: true do validates :message validates :name end def save tweet = Tweet.create(message: message) tag = Tag.where(name: name).first_or_initialize tag.save TweetTagRelation.create(tweet_id: tweet.id, tag_id: tag.id) end endtag = Tag.where(name: name).first_or_initializeを解説していきます
first_or_initializeメソッドは、whereメソッドと一緒に使います。
whereメソッドは,
モデル.where(条件)のように、引数部分に条件を指定することで、テーブル内の「条件に一致したレコードのインスタンス」を配列の形で取得できます。
引数の条件には、「検索対象となるカラム」を必ず含めて、条件式を記述します。
whereで検索した条件のレコードがあれば、そのレコードのインスタンスを返し、なければ新しくインスタンスを
作るメソッドですとりあえずこれでタグ付けツイートの実装が完了しました
すでにデータベースへ保存されてるタグをタグ付けしたい場合、入力の途中で入力文字と一致するタグを候補として画面上に表示できる検索機能があれば、より便利なアプリケーションになりそうです逐次検索機能を実装
逐次検索機能とは、「rails」というタグがすでにデータベースに存在する場合、「r」の文字が入力されると、「r」の文字と一致する「rails」を候補としてリアルタイムで画面上に表示するっていうよくあるやつ
プログラミングで実装するときは** インクリメンタルサーチ**って言われるらしいそれでは実装していきましょう、と言いたいところですが、
application.js
require("@rails/ujs").start() // require("turbolinks").start() //この行をコメントアウトする require("@rails/activestorage").start() require("channels")上記の行をコメントアウトしないと、jsで設定したイベントが発火しないケースがあるので、コメントアウトしとくのが無難
インクリメンタルサーチ実装の準備
tweets_controller
class TweetsController < ApplicationController # 省略 def search return nil if params[:keyword] == "" tag = Tag.where(['name LIKE ?', "%#{params[:keyword]}%"] ) render json:{ keyword: tag } endとサーチアクションを定義
LIKE句は、曖昧な文字列の検索をするときに使用するものでwhereメソッドと一緒に使います
%は空白文字列含む任意の文字列を含む
要するに、params[:keyword]で受け取った値を条件に、nameカラムにその条件が一致するか、tagテーブルで検索した物をtagに代入
それをjson形式で、keywordをキーにして、tagを値にしてjsにその結果を返す。
ルーティングを設定
routes.rb
Rails.application.routes.draw do root to: 'tweets#index' resources :tweets, only: [:index, :new, :create] do collection do get 'search' end end endルーティングをネストする (入れ子にする) ことで、この親子関係をルーティングで表すことができるようになります。
collectionとmember
collectionとmemberは、ルーティングを設定する際に使用できます。
これを使用すると、生成されるルーティングのURLと実行されるコントローラーを任意にカスタムできます。collectionはルーティングに:idがつかない、memberは:idがつくという違いがあります。
今回の検索機能の場合、詳細ページのような:idを指定して特定のページに行く必要が無いため、collectionを使用してルーティングを設定しましょう
tag.jsを作成しましょう
app/javascript/packsはいかにtag.jsを作成しましょう
application.js
をtag.jsを読み込むために以下のように編集しましょう
require("@rails/ujs").start() // require("turbolinks").start() require("@rails/activestorage").start() require("channels") require("./tag")ここまではしっかりカリキュラムやった皆さんなら普通に理解できるはずです、こっからカリキュラムでは説明されてないとこをガッツリ解説します!
tag.js
if (location.pathname.match("tweets/new")){ document.addEventListener("DOMContentLoaded", () => { console.log("読み込み完了"); }); };location.pathnameは現在ページのURLを取得、
.matchは引数に渡された文字列のマッチング結果を返す
つまり現在tweets/newにいるときにイベント発火!documentはhtml要素全体
addEventListenerは様々なイベント処理を実行DOMContentLoadedはwebページ読み込み完了したときに
つまり、html要素全体が読み込みされたときに、イベントを実行
コンソールに「読み込み完了」と表示されたらok
タグの検索に必要な情報を取得
tag.js
if (location.pathname.match("tweets/new")){ document.addEventListener("DOMContentLoaded", () => { const inputElement = document.getElementById("tweets_tag_name"); inputElement.addEventListener("keyup", () => { const keyword = document.getElementById("tweets_tag_name").value; }); }); };tweets_tag_nameというidを持ったhtml要素を取得し、InputElementに代入
** ここで注意!!**
form_withによるidの付与
tweets_tag_nameっていったidを持った要素あったっけ??
tweets/new.html.erb
<%= form_with model: @tweet, url: tweets_path, class:'form-wrap', local: true do |f| %> <div class='message-form'> <div class="message-field"> <%= f.label :message, "つぶやき" %> <%= f.text_area :message, class:"input-message" %> </div> <div class="tag-field", id='tag-field'> <%= f.label :name, "タグ" %> <%= f.text_field :name, class:"input-tag" %> </div> <div id="search-result"> </div> </div> <div class="submit-post"> <%= f.submit "Send", class: "submit-btn" %> </div> <% end %>にも、index.html.erbにもそんなidはありません。。。。。
でもなぜ取得できるか?結論からいうと
form_withが勝手にidを付与してくれるから
詳しくいうと、例えば、
form_with model: @tweetは
tweets_controller
で
def new @tweet = TweetsTag.new endと定義されてあり、
まず、idがtweet_tagになる
そして、
drinks/new.html.erbの
<%= f.label :name, "タグ" %> <%= f.text_field :name, class:"input-tag" %>:nameが
tweet_tag にくっ付いて,tweet_tag_name
ってidが生成されます!!
「どこの誰がいったことか信じられねーよ!!」って意見ももっともなので
実際に検証ツールで form_withによってidが生成されてるかどうか調べます
つぶやきをツイートするmessageの場所には
tweets_tag_messagesというidが生成されて、それが、
<%= f.text_area :message, class:"input-message" %>に付与されます。
tag付けをする場所は
tweets_tag_nameというidが生成されて、それが
<%= f.text_field :name, class:"input-tag" %>に付与されます。
form_withによってidが付与される!!!
ってことを頭に入れておいてください
これで、入力フォームが取得できました
変数keywordの中身を確認
app/javascript/packs/tag.js
if (location.pathname.match("tweets/new")){ document.addEventListener("DOMContentLoaded", () => { const inputElement = document.getElementById("tweets_tag_name"); // form_withで生成されたidをもとに入力フォームそのものを取得 inputElement.addEventListener("keyup", () => { // 入力フォームからキーボードのキーが離されたときにイベント発火 const keyword = document.getElementById("tweets_tag_name").value; // .valueとすることで、入力フォームに入力された値を取り出すことができる // 実際に入力された値を取得して、keywordに入力 console.log(keyword); }); }); };ここまできたら、フォームに何か入力してみましょう。
入力した文字がコンソールに出力できていればokです。XMLHttpRequestオブジェクトを生成
packs/tag.js
if (location.pathname.match("tweets/new")){ document.addEventListener("DOMContentLoaded", () => { const inputElement = document.getElementById("tweets_tag_name"); inputElement.addEventListener("keyup", () => { const keyword = document.getElementById("tweets_tag_name").value; const XHR = new XMLHttpRequest(); }) }); };const XHR = new XMLHttpRequest();は
XMLHttpRequestオブジェクトを用いてインスタンスを生成し、変数XHRに代入しましょう
非同期通信に必要なXMLHttpRequestオブジェクトを生成しましょう。
XMLHttpRequestオブジェクトを用いることで、任意のHTTPリクエストを送信できます。openメソッドを用いてリクエストを定義
tag.js
if (location.pathname.match("tweets/new")){ document.addEventListener("DOMContentLoaded", () => { const inputElement = document.getElementById("tweets_tag_name"); inputElement.addEventListener("keyup", () => { const keyword = document.getElementById("tweets_tag_name").value; const XHR = new XMLHttpRequest(); XHR.open("GET", `search/?keyword=${keyword}`, true); XHR.responseType = "json"; XHR.send(); }) }); };XHR.open("GET", `search/?keyword=${keyword}`, true);openメソッドの第一引数にHTTPメソッド、第二引数にURL、第三引数には非同期通信であることを示すためにtrueを指定しましょう。
なぜこういうURLの指定になるかと言うと,
このURLはqueryパラメーターといって,http://sample.jp/?name=tanakaのように、
「?」以降に情報を綴るURLパラメーターです。
「?」以降の構造は、?<変数名>=<値>となっています。今回は:idとかでtweetsを識別する必要がないので、queryパラメーターを指定する
drinks#searchを動かしたいのに、searchがなぜURLで省略されてるのか
指定したパスの一個上のディレクトリを基準に,相対的にパスを指定できるから
例えば、今回指定したパスはsearch/keyword=hogehoge
で、一個上のディレクトリはtweetsなので、
一個上のディレクトリを勝手に補完してくれるらしい。。。。これで、Drinks#searchを動かせる
と、思ったが、
XHR.responseType = "json";を書いて、コントローラーから返却されるデータの形式にjson形式を指定しましょう
そして最後!
XHR.send();を書いて、リクエストを送信しましょう.
タグの入力フォームに何かしら入力されるたびに、railsのsearch アクションが動くといった形になってます!
サーバーサイドからのレスポンスを受け取りましょう
サーバーサイドの処理が成功したときにレスポンスとして返ってくるデータを受け取りましょう。データの受け取りには、responseプロパティを使用します。
tag.js
if (location.pathname.match("tweets/new")){ document.addEventListener("DOMContentLoaded", () => { # 省略 XHR.send(); XHR.onload = () => { const tagName = XHR.response.keyword; }; }); }); };const tagName = XHR.response.keyword;は、サーバーサイドの処理が成功したときに、レスポンスとして返ってくるデータを受け取って変数tagNameに代入してます
データの受け取りにはresponseプロパティを使用します。タグを表示させる処理を記述しましょう
このように、下に順に表示させていきましょう
タグを表示させる手順は以下の4つです。
1. タグを表示させる場所を取得する
search-resultと言うid名がついた要素を取得しています
- タグ名を格納させる場所を取得する。
createElementメソッドを用いてタグを表示させるための要素を生成しています。
生成した要素に検索結果のタグ名を指定しています。
- 2の要素にタグを挿入する
2で用意した要素を1の要素に挿入しています。
それぞれinnerHTMLプロパティとappendChildメソッドを用いています。
- 2と3の処理を検索結果があるだけ繰り返す
forEachを使って、繰り返し処理を行っています
tag.js
XHR.send(); XHR.onload = () => { const tagName = XHR.response.keyword; const searchResult = document.getElementById("search-result"); tagName.forEach((tag) => { // forEachを使う理由は、railsのsearchアクション // で、検索に引っかかったタグを、複数出していく // 場合もあるので const childElement = document.createElement("div"); // 2.タグを表示させるための要素を生成してる // 名前の通り,要素を作るメソッド childElement.setAttribute("class", "child"); childElement.setAttribute("id", tag.id); // 作ったdivタグにclass,idを付与する // forEachで作られたローカル変数のtagをここで使ってる childElement.innerHTML = tag.tag_name; // <div>tagname</div> って感じ // innerHTML を使用すると、 // 中身を入れ替えたり、書き換えたり、入れたりする // 3.サーバーサイドから返ってきたtagのtag_name // をchildElementの中に入れてくイメージ searchResult.appendChild(childElement); // htmlのsearch-resultの子要素に // childElementが並んでく // ここで初めて表示していく }); }; }); }); };new.html.erb
<%= form_with model: @tweet, url: tweets_path, class:'form-wrap', local: true do |f| %> <div class='message-form'> <div class="message-field"> <%= f.label :message, "つぶやき" %> <%= f.text_area :message, class:"input-message" %> </div> <div class="tag-field", id='tag-field'> <%= f.label :name, "タグ" %> <%= f.text_field :name, class:"input-tag" %> </div> <div id="search-result"> </div> </div> <div class="submit-post"> <%= f.submit "Send", class: "submit-btn" %> </div> <% end %>で
<div id="search-result"> </div>を、
tag.js
const searchResult = document.getElementById("search-result");で取得して、上記のような処理をおこなって、何か入力するたび候補を下に表示します
クリックしたタグ名がフォームに入力されるようにしましょう
タグを表示している要素にクリックイベントを指定します。
クリックされたら、フォームにタグ名を入力して、タグを表示してう要素を削除するようにしましょうtag.js
XHR.send(); XHR.onload = () => { const tagName = XHR.response.keyword; const searchResult = document.getElementById("search-result"); tagName.forEach((tag) => { const childElement = document.createElement("div"); childElement.setAttribute("class", "child"); childElement.setAttribute("id", tag.id); childElement.innerHTML = tag.name; searchResult.appendChild(childElement); const clickElement = document.getElementById(tag.id); clickElement.addEventListener("click", () => { document.getElementById("tweets_tag_name").value = clickElement.textContent; clickElement.remove(); }); }); }; }); }); };全体像こんな感じ
const clickElement = document.getElementById(tag.id); // さっき生成したタグ入力フォームの下に順に表示されていく、予測変換の欄の要素を取得 clickElement.addEventListener("click", () => { // 取得した要素をクリックすると、イベント発火 document.getElementById("tweets_tag_name").value = clickElement.textContent; // tweets_tag_nameはform_withで入力フォームに付与されるid // 入力フォームを取得 // さらに.valueとすることで、実際に入力された // 値を取得 // clickElementはタグの名前があるので // .textContentでタグの名前を取得できる // これでタグの部分をクリックしたら、タグの名前が // フォームに入ってく clickElement.remove(); // クリックしたタグのみ消えるしかし、このままだと同じタグが何度も表示されたままになってしまいます。
この原因は、インクリメンタルサーチが行われるたびに、前回の検索結果を残したまま最新の検索結果を追加してしまうからです。
インクリメンタルサーチが行われるたびに、直前の検索結果を消すようにしましょう。直前の結果検索を消すようにしましょう
検索結果を挿入している要素のinnerHTMLプロパティに対して、空の文字列を指定することで、表示されているタグを消します。
tag.js
if (location.pathname.match("tweets/new")){ document.addEventListener("DOMContentLoaded", () => { # 省略 XHR.send(); XHR.onload = () => { const tagName = XHR.response.keyword; const searchResult = document.getElementById("search-result"); searchResult.innerHTML = ""; // 検索結果を挿入してる要素のinnerHTMLプロパティに // 対して、空の文字列を指定することで、表示されてる // タグを消します // 最初にこの処理が呼び出される時は当然何もないので空文字でいいし // 2回目に呼び出された時はsearch-resultが空になる tagName.forEach((tag) => { const childElement = document.createElement("div"); childElement.setAttribute("class", "child"); childElement.setAttribute("id", tag.id); childElement.innerHTML = tag.name; searchResult.appendChild(childElement); const clickElement = document.getElementById(tag.id); clickElement.addEventListener("click", () => { document.getElementById("tweets_tag_name").value = clickElement.textContent; clickElement.remove(); }); }); }; }); }); };フォームに何も入力しなかった場合のエラーを解消する
本来、インクリメンタルサーチはフォームに何か入力された場合に動作する想定です。しかし、今回イベントに指定したkeyupは、バックスペースキーなどの「押しても文字入力されないキー」でも発火してしまいます。
その結果、検索に使用する文字列がないため、レスポンスにデータが存在せず、存在しないものをtagNameに定義しようとしているのでエラーが発生してしまいます。
レスポンスにデータが存在する場合のみ、タグを表示させる処理が行われるようにしましょう。レスポンスにデータが存在しない場合にもtagNameを定義しようとすると、XHR.responseがnullなのでエラーが発生してしまいます。レスポンスにデータが存在する場合のみ、タグを表示させる処理が行われるように修正しましょう。以下のようにif文を用いて解消します。
tag.js
if (location.pathname.match("tweets/new")){ document.addEventListener("DOMContentLoaded", () => { # 省略 XHR.send(); XHR.onload = () => { const searchResult = document.getElementById("search-result"); searchResult.innerHTML = ""; if (XHR.response) { // イベントに指定したkeyupは、バックスペースキー // などの押しても文字入力されないキーでも発火してしまう // 存在しないものをtagNameに定義するとエラーが起こる // レスポンスにデータがある場合のみタグを表示させる処理を行おう const tagName = XHR.response.keyword; tagName.forEach((tag) => { const childElement = document.createElement("div"); childElement.setAttribute("class", "child"); childElement.setAttribute("id", tag.id); childElement.innerHTML = tag.name; searchResult.appendChild(childElement); const clickElement = document.getElementById(tag.id); clickElement.addEventListener("click", () => { document.getElementById("tweets_tag_name").value = clickElement.textContent; clickElement.remove(); }); }); }; }; }); }); };これで実装完了です。お疲れ様でした。
tag.jsのコードのまとめ
if (location.pathname.match("drinks/new")){ // location.pathnameは // 現在ページのURLのパスを取得、変更 // .matchは引数に渡された文字列のマッチング結果を返す // 現在drinks/new にいる時にイベント発火 document.addEventListener("DOMContentLoaded",()=>{ // addEventListenerは様々なイベント処理を実行 // することができるメソッド // documentはhtml要素全体 // DOMContentLoaded"は // Webページ読み込みが完了した時に発動 // イベント発火する範囲広くね、、、? const inputElement = document.getElementById("tweet_tag_name") inputElement.addEventListener("keyup",()=>{ // フォームに入力して、キーボードが離されたタイミング // で順次イベント発火していく const keyword = document.getElementById("tweet_tag_name").value; // テキストボックスの入力した値を取得 const XHR = new XMLHttpRequest(); // XHLHttpRequest とはAjaxを可能にするためのオブジェクトでサーバーに // HTTPリクエストを非同期で行うことができます // インスタンスを生成して、変数に代入する XHR.open("GET",`search/?keyword=${keyword}`,true); // openはリクエストの種類を指定する // 第一引数 HTTPメソッドの指定 // 第二引数 パスの指定 // 第三引数 非同期通信のON/OFF // GETリクエストで、 // ?でパラメーターを渡せる // ?keywordはキーで、${keyword}が値 // queryパラメーターとは、http://sample.jp/?name=tanakaのように、 // 「?」以降に情報を綴るURLパラメーターです。 // 「?」以降の構造は、?<変数名>=<値>となっています。 // ?文字列とかの検索をかけたい時に使う // サーチアクションを動かしたい // drinksが省略されてる理由は // 指定したパスの一個上のディレクトリを基準に // 相対的にパスを指定できる // とりあえず、drinks#searchにリクエストを送って // 予測変換したい XHR.responseType = "json"; // コントローラーから返却されるデータの形式には // jsと相性がよく、データとして取り扱いやすい // json形式を指定してる XHR.send(); // tag.jsからサーバーサイドに送信したい // リクエストを定義できたので、 // 送信する処理を記述しましょう XHR.onload = () => { const searchResult = document.getElementById("search-result"); // 1.タグを表示させる場所である,search-resultを取得 searchResult.innerHTML = ""; // 同じタグが何度も表示されたままになってしまう // 直前の検索結果を消したい // 検索結果を挿入してる要素のinnerHTMLプロパティに // 対して、空の文字列を指定することで、表示されてる // タグを消します // 最初にこの処理が呼び出される時は当然何もないので空文字でいいし // 2回目に呼び出された時はsearch-resultが空になる if (XHR.response){ // イベントに指定したkeyupは、バックスペースキー // などの押しても文字入力されないキーでも発火してしまう // 存在しないものをtagNameに定義するとエラーが起こる // レスポンスにデータがある場合のみタグを表示させる処理を行おう const tagName = XHR.response.keyword; // サーバーサイドの処理が成功した時に // レスポンスとして返って来るデータを // 受け取って,変数に代入 // データの受け取りには // responseプロパティを使用する tagName.forEach((tag) => { // forEachを使う理由は、railsのsearchアクション // で、検索に引っかかったタグを、複数出していく // 場合もあるので const childElement = document.createElement("div"); // 2.タグを表示させるための要素を生成してる // 名前の通り,要素を作るメソッド childElement.setAttribute("class", "child"); childElement.setAttribute("id", tag.id); // 作ったdivタグにclass,idを付与する // forEachで作られたローカル変数のtagをここで使ってる childElement.innerHTML = tag.tag_name; // <div>tagname</div> って感じ // innerHTML を使用すると、 // 中身を入れ替えたり、書き換えたり、入れたりする // 3.サーバーサイドから返ってきたtagのtag_name // をchildElementの中に入れてくイメージ searchResult.appendChild(childElement); // htmlのsearch-resultの子要素に // childElementが並んでく // ここで初めて表示していく const clickElement = document.getElementById(tag.id); // クリックしたタグ名がフォームに入力されるようにしたい // 入力していったら,id = tag.idのdivのhtml要素 // ができているはずなので、それを取得 clickElement.addEventListener("click",()=>{ // clickElement要素をクリックした時にイベント発火 document.getElementById("tweet_tag_name").value = clickElement.textContent; // form_withで作られたidの要素を取得 // さらに.valueとすることで、実際に入力された // 値を取得 // clickElementはタグの名前があるので、 // .textContentでタグの名前を取得できる // これでタグの部分をクリックしたら、タグの名前が // フォームに入ってく clickElement.remove(); // クリックしたタグのみ消える }); }); }; }; }); }); };


- 投稿日:2020-12-18T14:33:03+09:00
RailsとVueでアプリを作るための環境構築
この記事はRailsとVueでHello Vue!をすることを目的としています。
プロジェクトの作成
何はともあれrails newですよね。ちなみにこの時点で--webpack=vueオプションでvueを始めからインストールできますが、今回はそれ以外の方法を紹介します。
と言ってもrails webpacker:install:vueをあとで叩くだけです。% rails -v Rails 6.0.3.4 % rails new memo-memo -d mysql --skip-test % cd memo-memo実はmysqlのインストールで躓いてそちらの記事も書いたので参考にしてください。
今回は失敗していない体(てい)で進みます。
rails newでmysqlのインストールに失敗するデータベースの作成
% rails db:create Created database 'memo_memo_development' Created database 'memo_memo_test'Hello World!
% rails s Webpacker configuration file not found xxx/memo-memo/config/webpacker.yml. Please run rails webpacker:install Error: No such file or directory @ rb_sysopen - xxx/memo-memo/config/webpacker.yml (RuntimeError)webpackerがインストールされていないと怒られたので
% rails webpacker:install % rails s => Booting Puma => Rails 6.0.3.4 application starting in development => Run `rails server --help` for more startup options Puma starting in single mode... * Version 4.3.7 (ruby 2.6.3-p62), codename: Mysterious Traveller * Min threads: 5, max threads: 5 * Environment: development * Listening on tcp://127.0.0.1:3000 * Listening on tcp://[::1]:3000 Use Ctrl-C to stopWebpackerとは
世界に挨拶することができたので、Webpackerを用いてVueを使えるようにしていきます。
ここでWebpackerとは何かわからない方向けに説明すると、WebpackerとはRailsにWebpackを入れるためのライブラリーで、Webpackの設定をよしなにしてくれています。WebpackとはJSなどのファイルをひとつにまとめてくれるものになります。カッコよく言うと、モジュールバンドラーです。ファイルをひとつにまとめる理由はブラウザの読み込み速度を速くするためです。CPUで計算するのに比べて、ファイルを取りに行く方が圧倒的に時間がかかる処理で、ファイルを読み込む回数を減らすことがブラウザの読み込み速度に大きな効果があります。ちなみにコンパイルはWebpack本来の機能ではなく、あくまでwebpackerにloaderを入れることで実現しています。
また、実務ではWebpackerではエラーが起きた時に何が原因かわかりづらくなってしまうため、楽せずWebpackを使うらしいです。ただ、私と同じ初学者の方はWebpackerから入って問題ないと思います。
話が長くなりそうなので次に進みます。Vueのインストール
% rails webpacker:install:vueいくつかのファイルが追加されたと思いますが、重要なファイルはapp/javascript/packs/hello_vue.jsとapp/javascript/app.vueになります。これらのファイルでhello vue!ができるようになっています。
app/javascript/packs/hello_vue.jsimport Vue from 'vue' import App from '../app.vue' document.addEventListener('DOMContentLoaded', () => { const app = new Vue({ render: h => h(App) }).$mount() document.body.appendChild(app.$el) console.log(app) })app/javascript/app.vue<template> <div id="app"> <p>{{ message }}</p> </div> </template> <script> export default { data: function () { return { message: "Hello Vue!" } } } </script> <style scoped> p { font-size: 2em; text-align: center; } </style>何故、app.vueの他にhello_vue.jsが必要なのかと言うと、vueファイルを直接読み込まずにjsファイル介して読み込むためです。html.erbでhello_vue.jsを読み込めば、hello_vue.jsはapp.vueを読み込んでいるのでapp.vueを表示できます。app.vueファイルのscriptタグ内のmessageという変数にHello Vue!が定義されていて、templateタグ内のpタグの中に変数messageが書かれていることで、Hello Vue!が出力されることは何となくわかると思います。詳しい説明は割愛させていただきます。
Hello Vue!の表示
これからHello Vue!を表示するための簡単なページを作成したいと思います。
流れとしてはルーティング→コントローラー→ビューになります。
ここでは'localhost:3000/home'にアクセスするとHomeコントローラーのindexアクションにルーティングされて、indexアクションからapp/view/home/index.html.erbを表示させたいと思います。そのindex.html.erbでhello_vue.jsファイルを読み込むことでHello Vue!を表示します。それではルーティングの設定を行います。
routes.rbget 'home', to: 'home#index'この状態でlocalhost:3000/homeにアクセスするとどうなるかわかりますか?
'uninitialized constant HomeController'と出ていると思います。Homeコントローラが定義されていないので当たり前ですよね。Homeコントローラーを作っていきます。% rails g controller home create app/controllers/home_controller.rb invoke erb create app/views/home invoke helper create app/helpers/home_helper.rb invoke assets invoke scss create app/assets/stylesheets/home.scss作成されたapp/controllers/home_controller.rbファイルを開いて、indexアクションを追加します。
class HomeController < ApplicationController def index end endこれでindexアクションの定義は終わりです。何も定義しなくてもいいのは、暗黙的にrenderが呼ばれて、アクションと名前で対応付けられたテンプレートが実行されるからですよね。
ちなみにこの状態でlocalhost:3000/homeにアクセスするとどうなるかわかりますか?
missing a templateですよね。
次にapp/view/home/index.html.erbを作成します。作成したらhello_vue.jsを読み込んでください。
ビューでJavaScript packをインクルードするにはjavascript_pack_tag ''を使います。今回hello_vue.js を読み込みたいので、pack名の箇所にhello_vueを記載しています。<%= javascript_pack_tag 'hello_vue' %>それでは、http://localhost:3000/home にアクセスして「Hello Vue!」が表示されているか確認しましょう!
お疲れ様です。実際に開発していくとなると、rails sの他にbin/webpack-dev-serverのコマンドも実行していた方がいいです。このコマンドはJSファイルのホットリロードを行ってくれるものになります。rails sとbin/webpack-dev-serverをひとつのファイルに記述して、1つのコマンドで2つのコマンドを実行することも可能です。詳しくは説明しませんが、foremanというgemを必要とします。'foreman rails s bin/webpack-dev-server'で調べると出てくると思います。
また、bin/webpack-dev-serverについてはこちらの記事が参考になるかもです。
- 投稿日:2020-12-18T12:58:50+09:00
Rspec: subjectにメソッドを設定した場合に、実行後の状態をテストしたい
前提
context "ユーザを生成" do subject { User.create(name: "John") } it "ユーザが1つ生成される" do is_expected.to change(User.count).by(1) end endsubjectとして、ユーザ生成のためのメソッドを定義しました。
この状態で、生成されたユーザ名が"John"であることを、同じsubjectでテストしたいことがありました。うまくいかない場合
it "ユーザ名がJohnである" do subject expect(User.last.name).to eq("John") endこうしてもUser.lastがnilですよ、というエラーが出て、どうやらsubjectの中身が実行されていない様子。
原因究明
puts subject.classとしてクラスを調べると、
Procと返ってくる。
rubyではProcクラスという、実行コード自体を変数に格納するクラスが存在しています。
したがって
subjectとして書いても
"文字列"とか書いているのと同じようなもので、何も起こりません。
したがってProcクラスのオブジェクトとして実行してやる必要があります。解決方法
実行の方法は様々ですが、一例でいうと
subject.callがあります
したがって
it "ユーザ名がJohnである" do subject.call expect(User.last.name).to eq("John") endこれでパスしました。
別のコンテキストにしろよ、とか、subjectの設定がいまいち、とかもあるかもしれませんが、同じ状況に直面したらぜひご一考をば。
全体のコード
context "ユーザを生成" do subject { User.create(name: "John") } it "ユーザが1つ生成される" do is_expected.to change(User.count).by(1) end it "ユーザ名がJohnである" do subject.call expect(User.last.name).to eq("John") end end以上です。
- 投稿日:2020-12-18T12:04:17+09:00
countメソッドの落とし穴(クエリの大量発行に注意!)
はじめに
私は現在
railsを使って転職活動用のポートフォリオを作っています。その中でbulletというN+1問題を検知してくれるgemを使っていたのですが、それでは検知できずに無駄にクエリを発行していたことに気づいたので記事を残しておこうと思います。原因としては、「投稿一覧ページにおいて、いいねの合計数を取得するさいにcountメソッドを使っていたこと」です。N+1問題とその具体例
知っている人は読み飛ばしてください。
N+1問題とは、アソシエーションが組まれたテーブルのカラムを参照する際に必要以上にクエリを発行してしまう問題です。サーバー側に余計な負荷をかけ、ページの読み込みを遅くする原因になります。簡単な例としてUserモデルとPostモデルで次のようなテーブル設計が組まれている場合に、投稿一覧ページですべての記事と投稿者の名前を出力するといった状況を考えます。users テーブル
Column Type Options name string null: false Association
- has_many :posts
posts テーブル
Column Type Options user references null: false, foreign_key: true text string null: false Association
- belongs_to :user
N+1問題が発生する実装方法
app/controllers/posts_controller.rbclass PostsController < ApplicationController def index @posts = Post.all end endapp/views/index.html.erb<% @posts.each do |post|%> <%= post.user.name %> <%= post.text %> <% end%>この方法だと例えば3件の投稿があった場合、
@postsと呼び出したときにpostsテーブルの全レコードを取得(クエリ1回発行)し、post.user.nameで投稿の数だけ(クエリ3回発行usersテーブルにアクセスしなければなりません。これがN+1問題と言われる所以です。N+1問題の発生しているクエリPost Load (0.6ms) SELECT `posts`.* FROM `posts` WHERE `posts`.`created_at` BETWEEN '2019-12-17 00:00:00' AND '2020-12-17 23:59:59.999999' ORDER BY `posts`.`created_at` DESC LIMIT 6 OFFSET 0 ↳ app/views/posts/_index_posts.html.erb:2 User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 ↳ app/views/posts/_index_posts.html.erb:7 CACHE User Load (0.0ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 ↳ app/views/posts/_index_posts.html.erb:7 CACHE User Load (0.0ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1 LIMIT 1 ↳ app/views/posts/_index_posts.html.erb:7N+1問題を解決する実装方法
コントローラーで
preloadメソッドを使います。また、includesメソッドを使っても同じ動作をします。app/controllers/posts_controller.rbclass PostsController < ApplicationController def index @posts = Post.all.preload(:user) end endこれによって
@postsを宣言した際にアソシエーション先のuserをまとめて取得できます。これによりクエリを2つに分けることです。1つめのクエリは関連データを取得するクエリ、2つ目のクエリは最終的な結果を取得するクエリという具合です。仮にuserの数が増えたとしてもSELECTusers.* FROMusersWHEREusers.idIN (1, 2, 3,,,,)と一回で取得できます。N+1問題解消後のクエリPost Load (0.3ms) SELECT `posts`.* FROM `posts` WHERE `posts`.`created_at` BETWEEN '2019-12-18 00:00:00' AND '2020-12-18 23:59:59.999999' ORDER BY `posts`.`created_at` DESC LIMIT 6 OFFSET 0 ↳ app/views/posts/_index_posts.html.erb:2 User Load (0.3ms) SELECT `users`.* FROM `users` WHERE `users`.`id` = 1countメソッドでいいねの数を取得すると、、
本題に入っていきます。僕はpostに対するいいねの数を取得する際に
@posts each do |post|〜endのブロック内でpost.likes.countのようにしていました。すると以下のようにeach内で都度、合計値を取得する余分なクエリが発生します。また、BulletはN+1であると検出してくれません。countメソッドによりN+1問題の発生しているクエリ↳ app/views/posts/_index_posts.html.erb:2 (0.2ms) SELECT COUNT(*) FROM `likes` WHERE `likes`.`post_id` = 7 ↳ app/views/posts/_index_posts.html.erb:25 (0.2ms) SELECT COUNT(*) FROM `likes` WHERE `likes`.`post_id` = 6 ↳ app/views/posts/_index_posts.html.erb:25 (0.2ms) SELECT COUNT(*) FROM `likes` WHERE `likes`.`post_id` = 5 ↳ app/views/posts/_index_posts.html.erb:25 (0.2ms) SELECT COUNT(*) FROM `likes` WHERE `likes`.`post_id` = 4 ↳ app/views/posts/_index_posts.html.erb:25 (0.2ms) SELECT COUNT(*) FROM `likes` WHERE `likes`.`post_id` = 3 ↳ app/views/posts/_index_posts.html.erb:25 (0.2ms) SELECT COUNT(*) FROM `likes` WHERE `likes`.`post_id` = 2これは
countメソッドがEnumerableモジュールに定義されたメソッドであるからです。(このモジュールのメソッドは全てeachを用いて定義されています。Enumerableモジュールの詳細はこちら)そこで、この問題を解決する二通りの方法をみていきましょう。解決策①sizeメソッドを使う
先ほどの
countメソッドをsizeメソッドに変えれば解決します。しかしながら、ただ変えればいいというわけだはありません。これはsizeメソッドの定義を見ればわかります。sizeメソッドdef size loaded? ? @records.length : count(:all) endこれはすでに読み込まれた配列があれば、そのlength(要素数)を取得しますが、そうでない場合COUNTクエリが実行されることを意味します。これを解決するには先ほどのpreloadメソッドを使えばいいということです。これによりクエリは以下のようになります。
sizeメソッドによりN+1問題を解消したクエリLike Load (0.3ms) SELECT `likes`.* FROM `likes` WHERE `likes`.`post_id` IN (2, 3, 4, 5, 6, 7)解決策②カラム(likes_count)を追加する
railsでは関連づけられたモデルの数をカラムに持たせるオプションがサポートされています。それが
:counter_cacheオプションです。次のように使います。app/controllers/posts_controller.rbclass Like < ApplicationRecord belongs_to :post, counter_cache: :likes_count endこうすればPostsテーブルに
likes_countというカラムをinteger型で加えるだけで「いいねの数」を数をカラムとして持つことができます。したがって、post.likes_countのように値を取得して表示するだけならクエリは発行されません。(いいねの数が変わった時は発行されます)まとめ
countメソッドを使って生じたN+1問題を解決する方法を2通り紹介しました。最後に説明したカラムを追加する方法だとpreloadしない分ページの読み込みは早くなるけど、「ユーザーがたくさんいて一斉にいいねボタンを押す」みたいな状況だと逆に大量に負荷がかかってしまうのかあなというのが個人の見解です。また、
:counter_cacheオプションはデッドロックも発生しやすいみたいです。これを解決する方法としてcounter_cultureというgemを使う方法があるみたいなのでこれも使ってみてそのうち記事にしてみたいと思います。
- 投稿日:2020-12-18T10:56:13+09:00
PaperclipからActiveStorageに移行した話
こんにちは。@mshibuyaです。
現在副業として株式会社ZENKIGENさんのお手伝いをしておりまして、Web面接サービスharutakaのRailsまわりの改善を担当しています。今回はそちらで行ったPaperclipからActiveStorageへの移行におけるあれこれの話をしたいと思います。なおこの記事はRails Advent Calendar 2020の18日目のエントリーです。
動機
2018年4月リリースのRails 5.2でActiveStorageが登場し、ほどなくPaperclipのdeprecationが発表され早いもので2年以上が経ちました。Paperclipはこれ以上メンテされないわけなので、別の手段を検討していく必要があります。
harutakaにおいてもPaperclipを長く利用してきており、新たな手段への移行を模索し既に部分的にActiveStorageを利用する構成となっていました。とはいえPaperclipを利用する部分がそのまま残っておりActiveStorageと併存している状態もメンテナンス上好ましくないので、このたび全体を新方式へと刷新することとしました。
検討した移行先
ファイルアップロード機能を提供するライブラリとしていくつかの選択肢があるので、それぞれの特徴を整理し移行先候補を選定しました。
ActiveStorage
前述の通り、Railsの標準機能の一部として実装されたファイルアップロード機能です。
Pros
- Railsの一部であり、今後Rails界隈でデファクトスタンダードとなっていくことが期待される
- 同様にアクティブなメンテナンスが継続する期待がある
- harutakaで既に部分的に使われている実績がある
- Paperclipがofficialに移行先として指定しており、移行手順もある
Cons
- PaperclipやCarrierWaveと比較して機能が劣る
- Opinionatedな作りであり、思想にマッチしない使い方をすると苦労しそう
kt-paperclip
Kreeti社によりメンテされているPaperclipのforkです。
Pros
- 実績がある枯れたライブラリであるPaperclipを踏襲している
- harutakaでも主要部分に使われているため移行の手間が少ない
- それなりに多機能
Cons
- 本家によるメンテナンスではなくfork版であり、今後の先行きが不透明
CarrierWave
Paperclipに次いでメジャーなファイルアップロードライブラリですね。
Pros
- 多機能
- @mshibuyaがメンテナなのでなにかあっても安心?
Cons
- 若干使い方が複雑
- harutakaでの利用実績がなく、まったく新規での導入になる
以上を総合的に踏まえ、既存のPaperclipによる実装をActiveStorage化することでActiveStorageへの一本化を行うこととしました。
移行にあたっての方針
使い勝手をなるべく既存のものに近づけたい
フルタイムで開発に関わっているわけでない立場上、他の開発者の方々に過度に負担かけたくないという意図がありました。
何か問題があったときに切り戻し可能にしたい
画像や動画を保存・閲覧できる機能はharutakaの中でも重要度の高い部分であるので、今回の移行において不具合等が本番リリース後にあったようなときはすぐにPaperclip実装に切り戻して普通に利用を続けられることを目指しました。
S3に既に保存されているデータの移行はせずに済ませたい
保存されたデータの移行をするのは時間がかかり、その間のシステム利用を止めるか移行中のデータ更新を反映できる仕組みを用意する必要があるので考えることが増えるため、少なくとも移行初期のタイミングでは行いたくないと考えました。
そのため、不足する機能についてはActiveStorageにパッチを当てることでなんとかすることを目指すわけですが…
ActiveStorageに足りなかった機能
まぁここでActiveStorageのシンプルかつopinionatedな作りにより色々と足りない機能が出てきます。どんな機能が足りなかったか、それをどうしたかをご紹介していくことにします。
なおここで例示しているコードはActiveStorage 5.2を想定しています。他のバージョンではそのまま動かないかもしれないのでよしなに読み替えていただければと思います。
CloudFrontの署名付きURLを利用してのファイル配信
まず、ActiveStorageはS3をバックエンドにしてのデータ保存および配信にはもちろん対応しているのですが、意外にもCloudFrontを利用した配信については標準ではサポートしていません。
とはいえこれの解決策は比較的簡単です。ActiveStorageにはserviceとしてローカルディスク・S3といった様々なストレージバックエンドを差し替えられるような作りとなっているので、
require 'active_storage/service/s3_service' module ActiveStorage class Service::CloudFrontService < ActiveStorage::Service::S3Service def url(key, expires_in:, filename:, disposition:, content_type:) instrument :url, key: key do |payload| generated_url = Aws::CF::Signer.sign_url "https://#{CLOUD_FRONT_HOST}/#{key}" payload[:url] = generated_url generated_url end end end endのようにS3Serviceを継承する形でCloudFrontServiceを作り、storage.ymlで
production: service: CloudFront access_key_id: xxx secret_access_key: xxx ...とすると「S3にファイルを保存し、CloudFrontの署名つきURLで配信」という状態が作れます。
(※ここではcloudfront-signer gemを使っていて、その設定は別途必要です)URLを受け取りデータを保存する機能
Paperclipは、ファイルそのものではなくURLを受け取るとそのURLからデータをダウンロードし保存するという機能があります。これはPaperclipのIOAdapterのひとつ、UriAdapterとして実装されているのですが、同様の仕組みはActiveStorageにはないためパッチとして実装する必要があります。
イメージこんな感じですね。ActiveStorage::Attachedをモンキーパッチします。
ActiveStorage::Attached.prepend Module.new { def create_blob_from(attachable) case attachable when String uri = URI.parse(attachable) rescue nil if uri.is_a?(URI::HTTP) file = DownloadedFile.new uri ActiveStorage::Blob.create_after_upload! \ io: file.io, filename: file.filename, content_type: file.content_type elsif attachable.present? super end else super end end } class DownloadedFile attr_reader :io def initialize(uri) @uri = uri @io = uri.open end def content_type @io.meta["content-type"].presence end def filename CGI.unescape(@uri.path.split("/").last || '') end endS3への保存先pathのカスタマイズ
PaperclipはURL Interpolationによりファイル保存先のpathを非常に柔軟性高く指定することを可能としています。一方、ActiveStorageはそういったカスタマイズの余地はなく、ファイルの保存先pathは常に
generate_unique_secure_tokenにより生成されたランダム生成された文字列となります。
ActiveStorageはかなり強い意志をもってこの対応を入れないことを選択しているようで、過去に寄せられているPRも却下しており将来的にも入る見込みはなさそうです…。なのでパッチしてなんとかします。モデル側でこのようにkeyを生成するprocを渡せるようにした上で、
has_one_attached :image, key: -> (filename) { "files/image/#{record.class.generate_unique_secure_token}/#{filename}" }このprocをActiveStorage::Blobまで引き回し
ActiveSupport.on_load(:active_storage_blob) do prepend Module.new { def key self[:key] ||= if attachment key_proc = options[:key] # 引き回してきたやつ (key_proc && attachment.instance_exec(filename, &key_proc)) || super else super end end } endと値がなければprocをinstance_execするようにして望み通りのkeyを生成します。
名前つきのstyle
Paperclipはサムネイル画像の生成についてstyleという概念を持っており、生成する画像サイズに名前をつけることができます。
has_attached_file :photo, styles: {thumb: "100x100#"}ActiveStorageももちろんサムネイル生成に対応しているのですが、こちらは画像保存時ではなく利用時に動的にサイズを渡し生成する方式です。
<%= image_tag user.avatar.variant(resize: "100x100").service_url %>でも、名前がついている方が用途がわかりやすいですし変に似たようなサイズの画像が乱立してしまうのを防げるので、こうできるようにしたいですよね?
<%= image_tag user.avatar.variant(:thumb).service_url %>そこでパッチします。モデル側から
has_one_attached :image, variants: {thumb: "100x100#"}こんな風に指定できるようにした上でまたこのoptionsをActiveStorage::Blobまで引き回して
ActiveSupport.on_load(:active_storage_blob) do prepend Module.new { def variants options[:variants] || {} # 引き回したやつ end def variant(style_or_transformations) if style_or_transformations.try(:to_sym) == :original self elsif variable? && variants[style_or_transformations] Variant.new(self, variants[style_or_transformations]) else super end end } endとすることで実現できます。
Paperclipのカラムに値を保存する
ActiveStorage実装をリリースしてしばらく使った後になにか問題が発覚して切り戻しを行う場面を想定します。ストレージバックエンドであるS3はPaperclip/ActiveStorageで共通して使うので問題ないとして、ActiveStorage移行後なので新規にアップロードされたファイルについてはActiveStorage側のテーブル(モデルでいうとActiveStorage::AttachmentおよびActiveStorage::Blob)には値が入っているものの、Paperclip側で使われていた各モデルのカラム(
*_file_name,*_file_size…など)には値が入らない状態になります。これでは切り戻しの際にはActiveStorage側からPaperclip側へ逆データ移行する作業が必要になってしまいます。それを防ぐため、ActiveStorage側にファイルをアップロードしたらPaperclip側で使われていたカラムにも値を書き込む処理を入れてみます。
モデルで
has_one_attached :image after_save { image.replicate_for_paperclip! }としておいて、ActiveStorage::Attached::Oneをパッチし
ActiveStorage::Attached::One.prepend Module.new { def replicate_for_paperclip! return unless attached? attributes = {} attributes["#{name}_file_name"] = filename.to_s if record.attributes.has_key?("#{name}_file_name") attributes["#{name}_content_type"] = content_type if record.attributes.has_key?("#{name}_content_type") attributes["#{name}_file_size"] = byte_size if record.attributes.has_key?("#{name}_file_size") attributes["#{name}_updated_at"] = blob.created_at if record.attributes.has_key?("#{name}_updated_at") record.assign_attributes(attributes) record.save! if record.changed? end }これでActiveStorageアップロード時にPaperclip側カラムにも値を埋めておけるようになります。
まとめ
PaperclipからActiveStorageへの移行を行ったこと、そこでActiveStorageに不足している機能をどのように補ったかをご紹介しました。上記方針により、アプリケーションの土台に関わる大きな変更ながらもなるべく低リスクで実施可能なよう作り上げることができたのではないかと考えています。
(とはいえ本番リリースはまだこれからなのですが。何も問題起こらないといいな…)Paperclipを使い続けてきており、今後どうするか決まっていないRailsアプリケーションをお持ちの方も少なからずおられると思うので、この記事が参考になれば幸いです。
皆様のファイルアップロードライフがよいものでありますように!
- 投稿日:2020-12-18T10:55:26+09:00
rails newでmysqlのインストールが失敗する
初めてのQiita投稿になります!当初はRailsとVueのタスク管理アプリを作りながら記事を書くつもりでしたが、rails newの時点でmyqlのインストールが上手くいかずに躓いたので、こちらの記事を書くことにしました。
ただ、解決方法は最後に書いており、それまでは解決方法にたどり着くまでのストーリーになっているので飛ばしてもらった方がいいです。筆者自身の備忘録も読みたい方は上から読んで頂ければと思います。
環境は見れば分かる人もいるかもしれませんが、Macです。(zshでbrewを使っていればMacですよね?)
最近知ったのですが、zshはジーシェルって読むらしいです。プロジェクト開始のはずが
何はともあれ、rails newですね。
% rails -v Rails 6.0.3.4 % rails new memo-memo -d mysql --skip-test早速エラーが発生しましたw
An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'` succeeds before bundling.言われた通りにやります。
% gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'Pemission errorが発生したのでここも思考停止でsudoをつけます。
% sudo gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'今度は良くわからないですね。
Don't know how to set rpath on your system, if MySQL libraries are not in path mysql2 may not load ----- ----- Setting libpath to /usr/local/Cellar/mysql/8.0.22_1/libそもそもMacに正しくmysqlが入っていることを確認してみます。
するとBrewさんは私に不満があるらしく色々とヒントをくれました。% brew info mysql mysql: stable 8.0.22 (bottled) Open source relational database management system https://dev.mysql.com/doc/refman/8.0/en/ Conflicts with: mariadb (because mysql, mariadb, and percona install the same binaries) percona-server (because mysql, mariadb, and percona install the same binaries) /usr/local/Cellar/mysql/8.0.22_1 (294 files, 296.5MB) * Poured from bottle on 2020-12-13 at 08:50:29 From: https://github.com/Homebrew/homebrew-core/blob/HEAD/Formula/mysql.rb License: GPL-2.0 ==> Dependencies Build: cmake ✘ Required: openssl@1.1 ✔, protobuf ✔ ==> Caveats We've installed your MySQL database without a root password. To secure it run: mysql_secure_installation MySQL is configured to only allow connections from localhost by default To connect run: mysql -uroot To have launchd start mysql now and restart at login: brew services start mysql Or, if you don't want/need a background service you can just run: mysql.server start ==> Analytics install: 85,291 (30 days), 236,256 (90 days), 823,613 (365 days) install-on-request: 83,799 (30 days), 231,594 (90 days), 798,215 (365 days) build-error: 0 (30 days)どうやらmariadbとpercona-serverがconflictを起こしていることとcmakeがインストールされていないことが悪いのかなと考えました。そこでまず、簡単な方のcmakeをインストールを試してみました。その後再度brew info mysqlを叩いてみました。
% brew install cmake % brew info mysqlとりあえず、cmakeの✖️からレ点に変わったので進歩しました。一応、mysqlがinstallできるか確認してみました。
% sudo gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'相変わらずインストールができないことが確認できました。今度はしっかりとエラーを確認してみます。
Building native extensions. This could take a while... ERROR: Error installing mysql2: ERROR: Failed to build gem native extension. current directory: /Library/Ruby/Gems/2.6.0/gems/mysql2-0.5.3/ext/mysql2 /System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/bin/ruby -I /System/Library/Frameworks/Ruby.framework/Versions/2.6/usr/lib/ruby/2.6.0 -r ./siteconf20201218-6446-1qkv5ft.rb extconf.rb checking for rb_absint_size()... yes checking for rb_absint_singlebit_p()... yes checking for rb_wait_for_single_fd()... yes ----- Using mysql_config at /usr/local/bin/mysql_config ----- checking for mysql.h... yes checking for errmsg.h... yes checking for SSL_MODE_DISABLED in mysql.h... yes checking for SSL_MODE_PREFERRED in mysql.h... yes checking for SSL_MODE_REQUIRED in mysql.h... yes checking for SSL_MODE_VERIFY_CA in mysql.h... yes checking for SSL_MODE_VERIFY_IDENTITY in mysql.h... yes checking for MYSQL.net.vio in mysql.h... yes checking for MYSQL.net.pvio in mysql.h... no checking for MYSQL_ENABLE_CLEARTEXT_PLUGIN in mysql.h... yes checking for SERVER_QUERY_NO_GOOD_INDEX_USED in mysql.h... yes checking for SERVER_QUERY_NO_INDEX_USED in mysql.h... yes checking for SERVER_QUERY_WAS_SLOW in mysql.h... yes checking for MYSQL_OPTION_MULTI_STATEMENTS_ON in mysql.h... yes checking for MYSQL_OPTION_MULTI_STATEMENTS_OFF in mysql.h... yes checking for my_bool in mysql.h... no ----- Don't know how to set rpath on your system, if MySQL libraries are not in path mysql2 may not load ----- ----- Setting libpath to /usr/local/Cellar/mysql/8.0.22_1/lib ----- creating Makefile current directory: /Library/Ruby/Gems/2.6.0/gems/mysql2-0.5.3/ext/mysql2 make "DESTDIR=" clean current directory: /Library/Ruby/Gems/2.6.0/gems/mysql2-0.5.3/ext/mysql2 make "DESTDIR=" compiling client.c compiling infile.c compiling mysql2_ext.c compiling result.c compiling statement.c linking shared-object mysql2/mysql2.bundle ld: warning: directory not found for option '-L/Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.15.Internal.sdk/usr/local/lib' ld: library not found for -lssl clang: error: linker command failed with exit code 1 (use -v to see invocation) make: *** [mysql2.bundle] Error 1 make failed, exit code 2 Gem files will remain installed in /Library/Ruby/Gems/2.6.0/gems/mysql2-0.5.3 for inspection. Results logged to /Library/Ruby/Gems/2.6.0/extensions/universal-darwin-19/2.6.0/mysql2-0.5.3/gem_make.outlibpathを通した方がいいのかな?と思い通してみます。(この解釈は間違っていることにあとで気付きます)
% export LIBRARY_PATH=/usr/local/Cellar/mysql/8.0.22_1/lib % sudo gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'しかし、エラー内容が変わらず。ここでCreating Makefileの後にゴニョゴニョ書いていることからgem installするときに何かしらのMakefileを実行していて、その途中でld: liblary not found for -lsslで失敗してインストールが失敗しているのではないかと考えました。(間違っていたらすみません。)
ここで白旗を上げて、同じ問題に当たっている人を探すことにしました。すると以下の優良な記事がヒットしました!
mysql2 gemインストール時のトラブルシュートここをみてもらえば最初から解決できる話でしたww
ここまで読んでくれた人は申し訳ございませんでした。Qiitaを書きながらなのリアルなエラー解決のストーリーとなっているのでご了承ください。意訳すると、LIBRARY_PATH=/usr/local/Cellar/mysql/8.0.22_1/libにパスを設定したけど、お目当てのライブラリーが見つからないためにlibrary not foundになっていて、--with-cppflagsと--with-ldflagsを指定することでちゃんとライブラリーが見つけれるようになって、インストールできるよになるという話です。正確には元記事を参考にしてください。
解決方法
% brew info openssl For compilers to find openssl you may need to set: export LDFLAGS="-L/usr/local/opt/openssl/lib" export CPPFLAGS="-I/usr/local/opt/openssl/include" % sudo gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/' -- --with-cppflags=-I/usr/local/opt/openssl/include --with-ldflags=-L/usr/local/opt/openssl/lib % bundle installお疲れ様でした。もしrails newしたけど、mysqlのインストールでつまづいた人がいれば参考にしていただければ幸いです。
- 投稿日:2020-12-18T09:48:03+09:00
【Rails】多対多の作成
本投稿の目的
・Railsについての議事録です。
学習に使った教材
Udemyの以下2つの教材を参考にまとめました。
・"はじめてのRuby on Rails入門-RubyとRailsを基礎から学びWebアプリケーションをネットに公開しよう"
・"フルスタックエンジニアが教える 即戦力Railsエンジニア養成講座"
○多対多の関係とは?
・複数のcolumnが相互に紐づいたmodel同士の関係
・例):掲示板アプリのboard とtagのような関係 (投稿内容は異なるがtagが同じような投稿は多対多の関係)○紐付けのポイント
・中間テーブルを用意する (本投稿での説明では,model(中)と定義)
・中間テーブルは [:id,多1_id,多2_id] のみのシンプルな構造○紐付け設定方法
①model多1とmodel多2を普通にgenerateする
rails g <model(多)1> <column情報> rails g <model(多)2> <column情報>②中間テーブルをgenerateする
rails g model <model(中)> <model(多)1>:references <model(多)2>:references・中間テーブルは通常は "model(多)1_model(多)2_relations" という名前が一般的
③migrationを実行
rails db:migrate・①②で設定したmodelがdbのtableに反映される
④中間テーブルのmodelへの記述
model(中).rbclass model(中) < ApplicationRecord belongs_to :model(多)1 belongs_to :model(多)2 end・この記述はgenerate時に自動記述
・belongs_toが2つ設定済みのためノータッチでOK⑤moel(多)1のmodelへの処理
model(多)1.rbclass model(多)1 < ApplicationRecord has_many :<model(中)s> has_many :<model(多)2>, through: :<model(中)s> end・
through: :<model(中)s>は,2つのmodel間にmodel(中)を経由するという意味
・(model(多)1 → model(中) → model(多)2 という意味)
・中間テーブルを経由することをここで記述して置く必要がある⑥model(多)2のmodelへの処理
model(多)2.rbclass model(多)2 < ApplicationRecord has_many :<model(中)s> has_many :<model(多)1>, through: :<model(中)s> end・model(多)1と同様に2つのhas_manyを設定
- 投稿日:2020-12-18T09:29:20+09:00
【Rails】dependentの設定
本投稿の目的
・Railsについての議事録です。
学習に使った教材
Udemyの以下2つの教材を参考にまとめました。
・"はじめてのRuby on Rails入門-RubyとRailsを基礎から学びWebアプリケーションをネットに公開しよう"
・"フルスタックエンジニアが教える 即戦力Railsエンジニア養成講座"
○dependent の設定
・1対多のmodelの関係において,model(1)のcolumnが消去されると,そのcolumnに紐づくmodel(多)のcolumnは必要なくなる
・これを自動的に消去してくれる設定であるdependentには以下2つがある
・どちらもmodel(1)ファイルに対して記述を追加する○dependent: :delete_all
model(1).rbclass model(1) < ApplicationRecord has_many :model(多), dependent: :delete_all end・model1の削除=紐付けデータも同時削除 になる
・親が削除されると子たちは自動で消される
・例):親であるquestionのcolumn情報が削除されると,それに紐づいたanswer のcolumn情報も一緒に削除される○dependent: :destroy
model(1).rbclass model(1) < ApplicationRecord has_many :model(多), dependent: :destroy end・
delete_allと同じ処理がされるが,オブジェクトを1つずつ消していく
・パフォーマンスはdelete_allに比べて低い
・紐付けが2階層以上ある場合は,こちらを使用しないとできないことがある
*(基本的に1階層の時は,delete_allを使用する)○dependentの有効範囲
・紐づけ自動削除機能は,destroyアクション時のみ有効
・controllerのdeleteメソッドをdestroyメソッドに変更しておく必要がある
- 投稿日:2020-12-18T09:08:47+09:00
【Rails6】ランキング機能
はじめに
補助金に関する記事の閲覧・検索ができるアプリケーションの作成をしています。今回いいね機能が実装できたため、いいねの数が多い順番に記事を並べる、ランキング機能を実装しました。備忘録及び復讐のため記述します。
環境
Ruby on Rails '6.0.0'
Ruby '2.6.5'前提
・ユーザー管理機能実装済み(Userテーブル)
・記事の投稿・閲覧機能実装済み(Articleテーブル)
・いいね機能実装済み(Likeテーブル)実装方法
複数の記事の中からいいね数が多い順番に取得することができれば良いため、Articleテーブルからの記事の取得方法を記述します。
コントローラーの編集
先に実装方法を記述し、中身について解説していきます。
app/controllers/articles_controller.rbdef index @ranks = Article.find(Like.group(:article_id).order('count(article_id) DESC').limit(4).pluck(:article_id)) endArticle.find(~)
- findメソッドを使用して()の中で指定する記事を探して取得します。
Like.group(:article_id)
- Likeテーブルの中にある、article_idが重複するレコードをまとめて並べ替えています。
order('count(article_id) DESC')
- count(article_id)したデータをDESC(降順)で並べ替えています。
count(article_id)
- article_idが同じものを数えるメソッドです。Likeテーブルに保存されているレコードを数えることで、いいねの数を取得しています。
limit(4)
- 上から4つ取得するメソッドです。今回は4位まで表示させたいと思ったので、この表現にしました。
pluck(:article_id)
- 引数としてカラム名のリストを与えると、指定したカラムの値の配列を、対応するデータ型で返します。
おわりに
https://qiita.com/mitsumitsu1128/items/18fa5e49a27e727f00b4
こちらの記事を参考にさせていただきました!!!ありがとうございました。
- 投稿日:2020-12-18T08:36:57+09:00
【AWS】“Aws::S3::Errors::AccessDenied in 〇〇sController#create”エラー(AWSのS3に保存できない)
エラー内容
AWSのS3を使い、画像データを保存できるように実装していたが、
1. ローカル環境においてエラー
2. 本番環境においてエラー
3. AWSのS3上のバケットにはデータなし(保存されていない)
という事象が発生。ローカル環境↓
本番環境↓
エラーが起こったときのターミナルのログ↓
エラーが起こったときの設定の状況
- macOS Catalina バージョン10.15.7
- Rails Rails 6.0.3.4
- Herokuを使ってデプロイ
- AWSのアカウント・IAMユーザー・S3のバケットの3つを新規作成したばかり
解決した方法(結論)
「AWSのアカウント削除→作成し直し」を行ったところ、エラー解決。
(保存できるようになった)解決方法の補足
- AWSアカウント作成時、Googleのシステム障害が発生していた。
- メンターさんにも見てもらいタイポや記述もれが無いのにも関わらず、保存ができなかった。
- アカウントの新規作成から1日以上、保存できない状況が続いた。(時間をおいても反映されない)
- AWSアカウントを削除して、新規登録し直す際、前回登録していたメールアドレスが90日間以内であれば再開できる対象になるからか、使えない状況になる。(前回のメールアドレス以外を選択しないといけない)
の方法を試すも、今回は上手くいかなかった。
AWSアカウント作成し直す前の確認作業
(1)AWS上のバケットポリシーは適切か?
結果:①②あたる部分は、ともに適切だった。
{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "①今回のIAMユーザーのARNをここに記述" }, "Action": "s3:*", "Resource": "arn:aws:s3:::②今回のバケット名をここに記述" } ] }(2)ブロックパブリックアクセスのバケット設定は適切か?
結果:適切だった。
(3)VSコード上の、保存先は適切か?
結果:適切だった。
:amazonになっているのでOK。(開発環境)config/environments/development.rb# Store uploaded files on the amazon file system (see config/storage.yml for options). config.active_storage.service = :amazon
:amazonになっているのでOK。(本番環境)config/environments/production.rb# Store uploaded files on the amazon file system (see config/storage.yml for options). config.active_storage.service = :amazon”今回のバケット名”にあたる部分について、合っていたためOK。
config/storage.ymlamazon: service: S3 region: ap-northeast-1 bucket: 今回のバケット名 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %>(4)環境変数は適切か?
結果:適切だった。
環境変数の確認方法(MacOSがCatalina以降の場合)
terminalvim ~/.zshrc
:wqで閉じる。- もし誤っていた場合には
iを押して編集し、escを押してから、:wqで閉じる。コンソール確認
rails cで立ち上げ。storage.ymlに記載の変数名を入力。
確認した内容は以上。
AWSアカウント(ルートユーザー)を作り直し
上記の通り、確認したが誤りはない様子。
思い当たる仮説としては、「Googleの調子が悪い頃、ちょうどアカウント登録していた」だったため、アカウントを作り直すことにした。
AWSを作り直したあとは、
- 環境変数の設定し直し
- バケットポリシーの設定し直し
が必要となる。感想
- 今回のケースは、因果関係が定かではないが、「システム障害が起きている前後は、アカウントの作成をしないほうがよい」ことを学んだ。
- 今回はアカウントを新規作成したばかりで、作り直しても手間はかかるが他に消えると困る設定をしていなかった他の登録がなかったためラッキーだった。
- 2回作成したので、AWS作成の復習になった。
以上です。
同じように困った人の解決になれば幸いです。
(間違いあった時は、教えてください!)


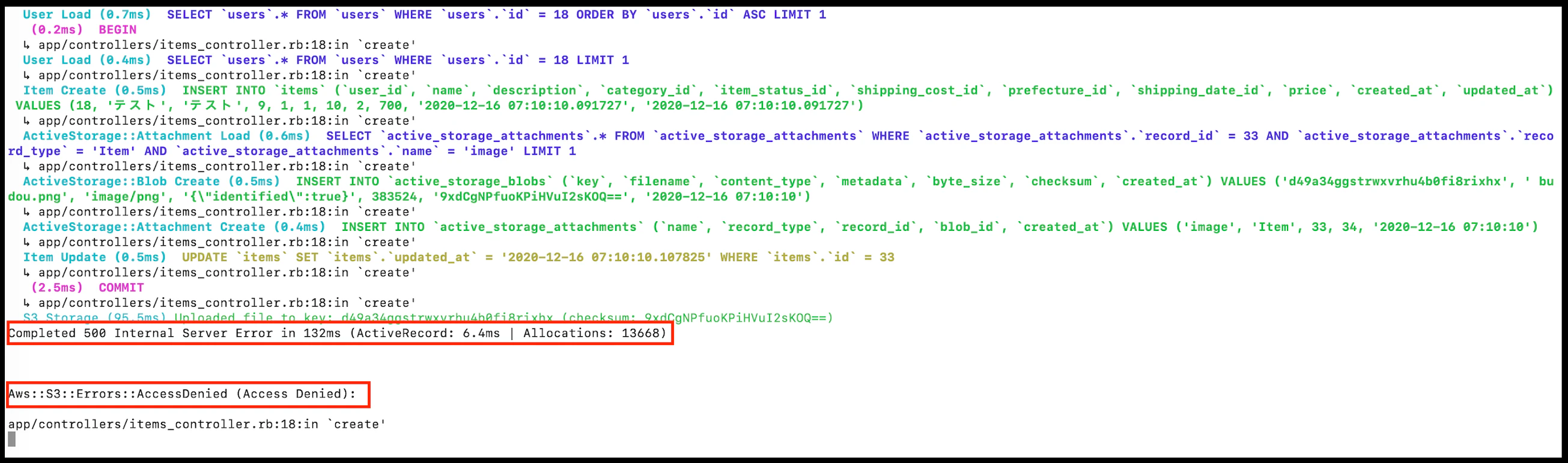




- 投稿日:2020-12-18T08:36:57+09:00
【AWS】“Aws::S3::Errors::AccessDenied in 〇〇sController#create”エラー(AWSのS3に保存されない)
エラー内容
AWSのS3を使い、画像データを保存できるように実装していたが、
1. ローカル環境においてエラー
2. 本番環境においてエラー
3. AWSのS3上のバケットにはデータなし(保存されていない)
という事象が発生。ローカル環境↓
本番環境↓
エラーが起こったときのターミナルのログ↓
エラーが起こったときの設定の状況
- macOS Catalina バージョン10.15.7
- Rails Rails 6.0.3.4
- Herokuを使ってデプロイ
- AWSのアカウント・IAMユーザー・S3のバケットの3つを新規作成したばかり
解決した方法(結論)
「AWSのアカウント削除→作成し直し」を行ったところ、エラー解決。
(保存できるようになった)解決方法の補足
- AWSアカウント作成時、Googleのシステム障害が発生していた。
- メンターさんにも見てもらいタイポや記述もれが無いのにも関わらず、保存ができなかった。
- アカウントの新規作成から1日以上、保存できない状況が続いた。(時間をおいても反映されない)
- AWSアカウントを削除して、新規登録し直す際、前回登録していたメールアドレスが90日間以内であれば再開できる対象になるからか、使えない状況になる。(前回のメールアドレス以外を選択しないといけない)
- こちらの方法を試すも、今回は上手くいかなかった。
AWSアカウント作成し直す前の確認作業
(1)AWS上のバケットポリシーは適切か?
結果:①②あたる部分は、ともに適切だった。
{ "Version": "2012-10-17", "Id": "Policy1544152951996", "Statement": [ { "Sid": "Stmt1544152948221", "Effect": "Allow", "Principal": { "AWS": "①今回のIAMユーザーのARNをここに記述" }, "Action": "s3:*", "Resource": "arn:aws:s3:::②今回のバケット名をここに記述" } ] }(2)ブロックパブリックアクセスのバケット設定は適切か?
結果:適切だった。
(3)VSコード上の、保存先は適切か?
結果:適切だった。
:amazonになっているのでOK。(開発環境)config/environments/development.rb# Store uploaded files on the amazon file system (see config/storage.yml for options). config.active_storage.service = :amazon
:amazonになっているのでOK。(本番環境)config/environments/production.rb# Store uploaded files on the amazon file system (see config/storage.yml for options). config.active_storage.service = :amazon”今回のバケット名”にあたる部分について、合っていたためOK。
config/storage.ymlamazon: service: S3 region: ap-northeast-1 bucket: 今回のバケット名 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %>(4)環境変数は適切か?
結果:適切だった。
環境変数の確認方法(MacOSがCatalina以降の場合)
terminalvim ~/.zshrc
:wqで閉じる。- もし誤っていた場合には
iを押して編集し、escを押してから、:wqで閉じる。コンソール確認
rails cで立ち上げ。storage.ymlに記載の変数名を入力。確認した内容は以上。
AWSアカウント(ルートユーザー)を作り直し
上記の通り、確認したが誤りはない様子。
思い当たる仮説としては、「Googleの調子が悪い頃、ちょうどアカウント登録していた」だったため、アカウントを作り直すことにした。
- 請求がゼロか確認
- バケットの削除
- IAMユーザーの削除(今回はルートユーザーに紐づけて作成したため、無し)
- AWSアカウント(ルートユーザー)の削除 (補足)リンク先は、1と同じ。
AWSを作り直したあとは、
- 環境変数の設定し直し
- バケットポリシーの設定し直し が必要となる。
感想
- 今回のケースは、因果関係が定かではないが、「システム障害が起きている前後は、アカウントの作成をしないほうがよい」ことを学んだ。
- 今回はアカウントを新規作成したばかりで、作り直しの手間はかかるが、他に消えると困る設定をしていなかったのでラッキーだった。
- 2回作成したので、AWS作成の復習になった。
以上です。
同じように困った人の解決になれば幸いです。
(間違いあった時は、教えてください!)
- 投稿日:2020-12-18T00:37:27+09:00
【Rails carrierwave】画像アップロード 未選択状態でもエラー画面に遷移しない方法
解決方法
requireではなく、fetchメソッドを使用することで、paramsがnilの場合を許容する。
private def food_record_params params.fetch(:food_record, {}).permit(:image) end使用技術
carrierwaveを使用して、画像アップロード機能を実装。
gem 'carrierwave'carrierwaveの使用方法
https://qiita.com/uchida0331/items/f99aba46fd1a6df9e753問題点
画像アップロード画面で、画像未選択の状態で登録ボタンを押下すると、エラー画面に遷移する事象が発生。
原因
エラーログの通り、requireメソッドではparameterに値が入っていないと、エラーになってしまう。
requireは、paramsに値が入っていない場合に、例外を出すためのメソッドだからである。参考資料
ruby2.7リファレンス
https://docs.ruby-lang.org/ja/latest/method/Hash/i/fetch.html