- 投稿日:2020-12-18T23:30:28+09:00
2020年に使った技術
うなすけ氏が書いてるのを見て、自分もやってみようかなと思いました
(フロントエンド、サーバーサイドエンジニアとか関係無しに個人的なものとして)参考:https://blog.unasuke.com/2020/wrap-up-my-coding/
Application
- frontend
- Vue.js
- backend
- python, Flask
- java, Spring Boot
- other
- Docker
- Kubernetes
Vue.js, python, flaskは去年からずっと利用しているが、java, Spring Bootはつい最近触り始めた。
今のところ雰囲気でなんとかなっているが、ちゃんと勉強しとこうかなぁというところ。
Dockerも前から触っていたがkubernetesは今年になってちゃんとやった。Cloud (GCP)
- computing
- GAE (Google Application Engine)
- GKE (Google Kubernetes Engine)
- GCE (Google Compute Engine)
- Cloud Run
- firebase
- Container Registry
- DB / storage
- datastore
- BigQuery
- Cloud SQL
- realtime database
- Cloud Storage
- network
- Pub/Sub
- Cloud Endpoint
- Cloud Tasks
- Cloud Load Balancing
- Cloud DNS
- monitoring
- Stackdriver
- Cloud monitoring
- other
- Cloud workflow
- secret manager
GCPばかりいじっていた。やってるプロダクト、プロジェクトにも深く関わるのが大きな要因だが、couseraの学習コースとかでも触る機会が多かった。仕事だとGAEがメインだったが、cousera上ではGCEを作ったり消したりを繰り返していた。あとは新しく出たサービスが気になって動かしてみたものもある。
去年と比べるとネットワーク周りの設定を行ったり、GKEをガッツリさわった。
なお今年AWSは触らなかった模様。エディタの話は以下に書いたので割愛。
https://qiita.com/woody-kawagoe/items/2ab0226dd325bba5681b感想
GCPばかりやってて他に書く技術記事無えなぁと思いつつ過ごしていたけど振り返ってみると本当にGCP関連しかしてないことがわかってきた。仕事でかなり使うというのもそうだけど、新しいサービスが日々出るので気になるところであった。それとたまたま仕事でGKE触る機会ができたのも良かった。別にインフラエンジニアやってるわけではなくwebアプリ開発の方が主の業務なのだが、技術的な興味の向き先がどっちかというとインフラよりなのかもしれない。来年はkubernetes周りとかネットワークとかもっと汎用性のある記事かけたら良いなーと思う。
- 投稿日:2020-12-18T23:23:09+09:00
SQL入門(基本的なクエリの備忘録)
SQL クエリ
備忘録です。
カラムとテーブルの選択
SELECT カラム名 FROM テーブル名;
データの取得
WHERE
SELECT * FROM テーブル名 WHERE カラム名 = 要素 -- 「取得したい要素」と一致するものを検索 WHERE カラム名 LIKE %要素% -- 「取得したい要素」を含む要素を検索 WHERE NOT カラム名 = 要素 -- 「取得したい要素」と一致しないものを検索 WHERE カラム名 IS NULL -- 指定したカラムのなかでNULLのデータを検索 WHERE カラム名 IS NOT NULL -- 指定したカラムの中でNULLでないデータを検索比較演算子等
カラム名 = -- 一致 カラム名 >= -- 以上 カラム名 <= -- 以下 カラム名 < -- より大きい カラム名 > -- 未満 カラム名 LIKE -- 含む NOT カラム名 演算子 -- NOT文 カラム名 IS NULL -- NULL値である カラム名 IS NOT NULL -- NULL値でないAND / OR
WHERE 条件 AND 条件; -- AND文 WHERE 条件 OR 条件; -- OR文並び替え
ORDER BY 並び替えたいカラム 並び方; -- 並び替え文法 ASC -- 昇順 ascending order DESC -- 降順 descending order取得データ数の制限
LIMIT データの件数; -- 指定したデータの件数を取得する(numpyのheadとおなじ) /*クエリの最後に記述する*/
データベース・テーブルの作成
テーブルの作成
CREATE TABLE テーブル名( 行名1 データ型, 行名2 データ型 )データ型の種類
分類 データ型名 説明 数値型 int 整数型 ^ decimal(桁数) 固定長小数型 ^ money 通貨 ^ float 浮動小数点数値 文字列型 char(文字数), nchar(文字数) 固定長文字列型(~8000字) ^ varchar,nvarchar 可変長文字列型(~8000字) ^ text,ntext 可変長文字列型(~10億文字) 日付型 time hh ss
^ date YYYY-MM-DD ^ datetime YYYY-MM-DD hh
データの追加・更新・削除
データの追加
INSERT INTO テーブル名 -- 操作するテーブルを指定 (列名1,列名2,列名3) -- 操作する列を指定 VALUES (値1,値2,値3); -- 追加する値を入力データの更新(既に登録されているデータを新しいものに置き換える)
UPDATE テーブル名 SET 列名1 = 値1, 列名2 = 値2, 列名3 = 値3 --更新する値を入力 WHERE 条件 -- 更新する場所の条件を指定行の削除
DELETE FROM テーブル名 WHERE 条件 -- 指定した条件を満たす行を削除する列の追加・削除
ALTER TABLE テーブル名 ADD 列名 データ型 初期値 --列の追加 ALTER TABLE テーブル名 DROP COLUMN 列名 -- 列の削除 ALTER TABLE テーブル名 ALTER COLUMN 列名 データ型 -- 指定した列のデータ型の変更
データの加工
重複する要素を省く
/*指定したカラムから重複をのぞいて計算する*/ SELECT DISTINCT(カラム名) FROM テーブル名;計算を実行する
SELECT カラムⅠ,カラムⅡ*5 -- カラムⅠと、カラムⅡに5を掛けた値を取得
python(SQLiteの使い方)
モジュールのインポート
import sqlite3データベースとの接続
conn = sqlite3.connect("データベース.db") # データベースファイルと接続 c = conn.cursor() # カーソルオブジェクトの作成クエリの実行
c.execute(''' クエリ ''') # クエリの実行データベースとの切断
conn.close() # 切断を怠るとデータベースにロックがかかってしまう。
- 投稿日:2020-12-18T23:11:01+09:00
LeetCodeに毎日挑戦してみた 118. Pascal's Triangle(Python、Go)
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
28問目(問題118)
118. Pascal's Triangle
問題内容
Given a non-negative integer numRows, generate the first numRows of Pascal's triangle.
(日本語訳)
負でない整数numRowsが与えられた場合、 パスカルの三角形の最初のnumRowsを生成します。
In Pascal's triangle, each number is the sum of the two numbers directly above it.Example:
Input: 5 Output: [ [1], [1,1], [1,2,1], [1,3,3,1], [1,4,6,4,1] ]考え方
空の配列を作成し、数字の数だけfor分を回します
ループ内、appendでその数に応じた[1]の要素を追加します
左端、右端は1なのでそれを除いた範囲で上の階層を参考に値を代入していきます
最終的に作成したlistsを戻り値とします
解答コード
class Solution: def generate(self, numRows): lists = [] for i in range(numRows): lists.append([1]*(i+1)) if i>1 : for j in range(1,i): lists[i][j]=lists[i-1][j-1]+lists[i-1][j] return lists
- Goでも書いてみます!
func generate(numRows int) [][]int { answer := make([][]int, numRows) for i := 0; i < numRows; i += 1 { a := make([]int, i+1) // add ones a[0], a[i] = 1, 1 if i > 1 { for j := 1; j <= i/2; j += 1 { a[j] = answer[i-1][j-1] + answer[i-1][j] a[len(a)-1-j] = a[j] } } answer[i] = a } return answer }

- 投稿日:2020-12-18T23:05:24+09:00
ミツバサンコーワ製バイク用ドラレコEDR-21で撮影した動画ファイル(30秒毎、0.5秒の重複あり)をpythonを使ってうまく結合する
はじめに
この記事はここのアドベントカレンダーのやつです。
6月からバイクを始めました。免許も取ったばかりなので安全運転を心がけたいです。
このところあおり運転に関するニュースもよく聞きますので、自衛のためにもバイク用のドラレコを取り付けました。
ミツバサンコーワ MITSUBA バイク専用ドライブレコーダー EDR-21 前後2カメラ EDR-21
前後2カメラで、162°の超広角、暗いところも強く、256GBのSDカードも対応するいい感じのやつです。購入時点で23000円くらいだったと思います。バイクショップとかで購入&取付をすると、工賃含めて4〜5万円くらいになりそうなので、Amazonで購入して自分で取り付けました。
さて、このドラレコで撮影した動画はスマホ経由でも見ることができますし、SDカードをPCにつなげて直接見ることもできるのですが、30秒毎にファイルが細切れに保存される仕様となっており、結構扱いにくいです。
さらに、ファイル間の前後0.5秒程度が重複して保存されており、1本に結合しようとしたらこの重複した0.5秒をカットしないとキレイにつながらず、とてもめんどくさいことになります。こんなイメージです。
重複分を考慮してキレイにつなげようとすると、こんな感じにしないといけなく手動で30秒毎にこの編集するのは手間がかかります。
動画を1本に結合して何をするわけでもないですが、現時点でいい方法も見つからなかったので、お勉強も兼ねてpythonでやってみることにしました。
概要
ドラレコの映像には音声も乗っているので、映像と音声両方を0.5秒カットしてつなげるイメージになるでしょう。pythonでやるには、映像と音声同時に編集するのは難しそうなので、別々に編集する必要がありそうです。
使用するソフトウェア、ライブラリはこちらにしました。
- 映像と音声の分離・統合、動画エンコード:ffmpeg(Pythonからsubprocess.runで実行)
- 映像の0.5秒分カット&結合:opencv
- 音声の0.5秒分カット&結合:pydub
実装
準備
ドラレコ動画のファイルはどのように作成されているのかみてみましょう。
フロント/リアカメラ毎に、撮影開始日時、30秒動画の開始日時、をファイル名に保持しているようです。(N/Eは……とりあえず無視しておきます。まあ大丈夫でしょう)
実装イメージ
プログラム的には、カメラ毎×撮影開始日時単位にグルーピングして、動画開始日時順になるように塊を作って、塊毎に以下の処理をする感じで処理していくこととします。
- 30秒動画を映像と音声に分離
- 映像と音声のお尻0.5秒をカット
- つなげる
- 全部つながったら、映像と音声をくっつけて動画として再エンコード
実装
mitsuba.py# -*- coding: utf-8 -*- import os import shutil import cv2 import glob import subprocess from pydub import AudioSegment from collections import defaultdict from tqdm import tqdm, trange from multiprocessing import Pool,Process, Queue, TimeoutError from queue import Empty DUP_FRAME = 14 # multi processing WORKERS = 4 TIMEOUT = 10 def comb_movie(movie_files, out_path, num): # 作成済みならスキップ if os.path.exists(os.path.join("out",out_path)): return # 形式はmp4 fourcc = cv2.VideoWriter_fourcc('m', 'p', '4', 'v') #動画情報の取得 movie = cv2.VideoCapture(movie_files[0]) fps = movie.get(cv2.CAP_PROP_FPS) height = movie.get(cv2.CAP_PROP_FRAME_HEIGHT) width = movie.get(cv2.CAP_PROP_FRAME_WIDTH) # 出力先のファイルを開く out = cv2.VideoWriter(f"tmp/video_{num:02}.mp4", int(fourcc), fps, (int(width), int(height))) audio_merged = None for movies in movie_files: # 動画ファイルの読み込み,引数はビデオファイルのパス movie = cv2.VideoCapture(movies) count = movie.get(cv2.CAP_PROP_FRAME_COUNT) frames = [] if movie.isOpened() == False: # 正常に動画ファイルを読み込めたか確認 continue for _ in range(int(count)): ret, tmp_f = movie.read() # read():1コマ分のキャプチャ画像データを読み込む if ret: frames.append(tmp_f) # 読み込んだフレームを書き込み for frame in frames[:-DUP_FRAME]: out.write(frame) command = f"ffmpeg -y -i {movies} -vn -loglevel quiet tmp/audio_{num:02}.wav" subprocess.run(command, shell=True) audio_tmp = AudioSegment.from_file(f"tmp/audio_{num:02}.wav", format="wav") audio_tmp = audio_tmp[:int((count-DUP_FRAME)/fps*1000)] if audio_merged is None: audio_merged = audio_tmp else: audio_merged += audio_tmp # 結合した音声書き出し audio_merged.export(f"tmp/audio_merged_{num:02}.wav", format="wav") out.release() # 動画と音声結合 vf = "" #ビデオフィルタはお好みで 例)ややソフト・彩度アップ・ノイズ除去の場合 "-vf smartblur=lr=1:ls=1:lt=0:cr=-0.9:cs=-2:ct=-31,eq=brightness=-0.06:saturation=1.4,hqdn3d,pp=ac" # 高速なエンコーダに対応していればお好みで 例)h264_videotoolbox, libx264, h264_nvenc cv = f"-c:v libx264" # ビットレートは解像度に応じて固定にしています。 if height == 1080: # FHD bv = f"-b:v 11m" elif height == 720: # HD bv = f"-b:v 6m" else: # VGA bv = f"-b:v 3m" loglevel = "-loglevel quiet" command = f"ffmpeg -y -i tmp/video_{num:02}.mp4 -i tmp/audio_merged_{num:02}.wav {cv} {bv} {vf} -c:a aac {loglevel} out/{out_path}" subprocess.run(command, shell=True) def wrapper(args): comb_movie(*args) if __name__ == '__main__': os.makedirs("./tmp", exist_ok=True) os.makedirs("./out", exist_ok=True) # ディレクトリ内の動画を:フロント・リアカメラごと、撮影開始時間ごとにまとめる files_dict = defaultdict(list) for f in glob.glob("./in/*.MP4"): files_dict["_".join(f.split("/")[-1].split("_")[:2])].append(f) data = [] for i, (key_name, files_list) in enumerate(files_dict.items()): data.append((sorted(files_list), key_name+".mp4", i)) p = Pool(WORKERS) with tqdm(total=len(data)) as t: for _ in p.imap_unordered(wrapper, data): t.update(1) # tmp 削除 shutil.rmtree('./tmp/')補足
ソースコードはGithubでも公開しております。
※YouTube にサンプル動画上げました
- inフォルダにドラレコの生動画を入れておきます。
- 実行するとプログレスバーが表示されます。(本当はもう少し細かく表示したい)
- outフォルダに結合した動画ファイルが出来上がります。
DUP_FRAME = 14
重複しているフレーム数なので変更不要です。(動画が28fps:28フレーム/s × 0.5s = 14フレーム)WORKERS = 4
並列処理をして速くするオプションで、並列実行数を指定できます。環境に応じて変更してみてください。ビデオフィルタはお好みで
元動画は(ドラレコなので)シャープネスがややきつい感じなので、ソフトにしてみたり色々フィルタを設定できます。詳細はffmpegのフィルタで調べてみてください。高速なエンコーダに対応していればお好みで
- libx264:大体どの環境でも使えます
- h264_videotoolbox:mac用。libx264より数倍速いはず。
- h264_nvenc:linux用(windowsもいけるかな?)libx264より数倍速いはず。ビットレート
お好みですが、元の動画がそれほどキレイじゃないのでビットレート上げてもさほど効果はないかもおわりに
GoPro8を買っちゃったんですが、まあキレイです。ドラレコはドラレコとして使って、車載動画はGoProで取るほうが良さそうです。







- 投稿日:2020-12-18T22:59:41+09:00
PythonよりカッコいいElixirでラズパイ
本記事は「Raspberry Pi Advent Calendar 2020」の22日目です。
昨日は@shion21さんのiPhoneからラズパイにミラーリング!RPiPlayの使い方でした。
はじめに
2ヶ月前にラズパイを始めたとき、僕はプログラミング言語としては、Elixirを選びました。単にElixirの機能と文法が好きで、それをIoTにも使用したかったからです。一般的にはCやPythonが使用されることが多いようです。その点でElixirでラズパイをするのには不安な要素がありましたが、それが取り越し苦労だったという話です。
Elixir(えりくさ)言語とNerves(なあぶす)フレームワーク
Elixirは耐障害性、高い並列性能で長年実績のあるErlangの上に実装されたプログラミング言語で、最近ではWhatsAppなどの世界中のメッセージアプリ、チャットアプリ等でも使用されており、その性能に改めて注目が集まっていると聞きます。そのElixirをラズパイで使えるようにしてくれるNerves(なあぶす)というIoTフレームワークがあると聞き、勉強を始めたわけです。僕にとってPythonよりElixirのほうがモダンでカッコよく、Elixirを使わない理由はありません。
Nervesについて詳しくは@takasehidekiさんの「Slideshare:ElixirでIoT!?ナウでヤングでcoolなNervesフレームワーク」がわかりやすいです。また、「NervesJP」というコミュニティがあり勉強会等が実施されています。僕はNerves JPでNervesについて学んでます。
一瞬不安になったこと
世の中にあるほとんどのラズパイ情報がCかPythonを使用する前提で書かれているため、新しいことを学ぶ際には戸惑いました。例えば、先日LCDディスプレイに「Hello」と表示される練習をしようとしましたが、Elixirの資料がなかなか見つかりませんでした。ほとんどがCかPythonの既存ライブラリを使用してLCDを操作するというものでした。
大事なことは通信プロトコルと製品のデータシート
しばらく辛抱強く調査と勉強をしていると、あることに気づきました。上述のCかPythonライブラリの中身はLCDのデータシートに書かれたとおりの手順をコードにしただけで大した内容ではないと。言語がなにであろうと関係ないのですね。本当に重要なのは、パラレル通信vsシリアル通信、I2C、SPI等の通信プロトコルの基礎を学ぶことと製品のデータシートを自分の目でよく読み、分かる範囲で理解する努力をすることという結論になりました。
IoTでは最終的にハードウェアとやり取りをすることが多いと思います。その部分に関してはI2C、SPI等のシリアル通信さえできればプログラミング言語は関係がないのですね。素人の僕でも概要は理解できたので、しっかり読めば誰でもある程度の操作は(ライブラリに頼らなくても)自分でできると思います。
データシートを読まずに誰かの作ったライブラリをさがすことしか考えていなかったのが間違いでした。使える既存のライブラリがあるに越したことはないですが、いずれにしても通信プロトコルとデータシートについては理解が必要だと思います。
さいごに
いい経験になりました。別にPythonでなくても、もっとカッコいい言語で自由にラズパイを楽しめるのですね。データシートさえ読めば、特にライブラリがなくてもできる場合があることがわかり、スッキリしました。結果として自作のライブラリもできました。
僕がElixirでLCDを操作した成果は一般公開しているので、みなさんにもどんどんElixirとNervesを楽しんでもらえればと思います。
明日は@sho7650さんです。
- #NervesJP Advent Calendar 2020
- Elixir その1 Advent Calendar 2020
- Elixir その2 Advent Calendar 2020
- 【毎日自動更新】QiitaのElixir LGTMランキング! by @torifukukaiou


- 投稿日:2020-12-18T22:45:45+09:00
国会会議録検索システムAPIを使って国会発言をJSONで取得しCSV出力する
はじめに
政治の世界ってわかりにくいですよね。日々揚げ足取りみたいな議論が行われている様子や失言した議員さんなどがニュースに取り上げられがちですが、実際には様々な議論が交わされています(きっと)。
そんな議論の内容、議事録データを国立国会図書館がAPIで提供してくれていて、政治のオープン化やデータ解析の題材としてとても有用だと感じました。本記事では、そのデータをJSON形式で取得してCSV出力するPythonプログラムを作成したのでそちらを紹介します。
国会議事録APIの利用例と本記事の要点について
国会会議録検索システムAPIの公式説明を抜粋すると下記のように紹介されています。
「国会会議録検索システム」は、第1回国会(昭和22(1947)年5月開会)以降の国会会議録を検索・閲覧することができるデータベースです。国立国会図書館が、衆議院・参議院と共同で提供しています。
実はこの記事執筆のちょうど1年ほど前に、別の方がQiitaで同様の記事を書いてくださっています。この中で、国会会議録検索システムについての説明や、取得したデータの活用例を紹介されていますので是非そちらもご参照ください。
一方、その記事中で当該APIの課題として「APIのレスポンスがJSON形式はなくXML形式のみ」といった点が挙げられているのですが、おそらく2020年にAPIの仕様が改善されたのかJSONでのデータ取得ができるようになっていたので、二番煎じながらJSONデータで取得するケースを紹介させていただく次第です。
国会議事録APIからのデータ取得プログラム
私の実行環境 >> OS: macOS Big Sur / Python 3.6.6
KokkaiSpeech.pyimport requests import time import json import sys import csv import re #ベースとなるURL base_url = "https://kokkai.ndl.go.jp/api/speech" #URLパラメータ用の辞書を空の状態で用意し、後から順次格納する。01はヒット総数の確認用、02はデータ取得用。 params_01 = {} params_02 = {} #パラメータを対話的に入力する text_input = input('検索する文字列を入力(Enterキーでスキップ) >> ') if text_input != "": params_01['any'] = str(text_input) params_02['any'] = str(text_input) else: pass speaker_input = input('検索する発言者名を入力(Enterキーでスキップ) >> ') if speaker_input != "": params_01['speaker'] = str(speaker_input) params_02['speaker'] = str(speaker_input) else: pass from_input = input('開始日を入力 (e.g. 2020-09-01) >> ') if re.match(r'[0-9]{4}-[0-1][0-9]-[0-3][0-9]', from_input): #正規表現によるパターンマッチングにて入力値が有効か判定 params_01['from'] = str(from_input) params_02['from'] = str(from_input) else: params_01['from'] = "2020-09-01" params_02['from'] = "2020-09-01" print("'From' date is set to 2020-09-01 due to invalid input") until_input = input('終了日を入力 (e.g. 2020-11-30) >> ') if re.match(r'[0-9]{4}-[0-1][0-9]-[0-3][0-9]', until_input): #正規表現によるパターンマッチングにて入力値が有効か判定 params_01['until'] = str(until_input) params_02['until'] = str(until_input) else: params_01['until'] = "2020-09-30" params_02['until'] = "2020-09-30" print("'Until' date is set to 2020-09-30 due to invalid input") params_01['maximumRecords'] = 1 params_01['recordPacking'] = "json" response_01 = requests.get(base_url, params_01) #URLのパラメータをエンコードしてAPIへリクエスト jsonData_01 = response_01.json() #APIからのレスポンスをJSON形式で取得 #レスポンスに含まれているヒット件数を確認(レスポンスのJSONにレコード数の項目がない場合はクエリに問題ありと判断しエラー終了) try: total_num = jsonData_01["numberOfRecords"] except: print("クエリエラーにより取得できませんでした。") sys.exit() #件数を表示し、データ取得を続行するか確認をとる next_input = input("検索結果は " + str(total_num) + "件です。\nキャンセルする場合は 1 を、データを取得するにはEnterキーまたはその他を押してください。 >> ") if next_input == "1": print('プログラムをキャンセルしました') sys.exit() else: pass max_return = 100 #発言内容は一回のリクエストにつき100件まで取得可能なため、その上限値を取得件数として設定 pages = (int(total_num) // int(max_return)) + 1 #ヒットした全件を取得するために何回リクエストを繰り返すか算定 #全件取得用のパラメータを設定 params_02['maximumRecords'] = max_return params_02['recordPacking'] = "json" Records = [] #取得データを格納するための空リストを用意 #全件取得するためのループ処理 i = 0 while i < pages: i_startRecord = 1 + (i * int(max_return)) params_02['startRecord'] = i_startRecord response_02 = requests.get(base_url, params_02) jsonData_02 = response_02.json() #JSONデータ内の各発言データから必要項目を指定してリストに格納する for list in jsonData_02['speechRecord']: list_id = list['speechID'] list_kind = list['imageKind'] list_house = list['nameOfHouse'] list_topic = list['nameOfMeeting'] list_issue = list['issue'] list_date = list['date'] list_order = list['speechOrder'] list_speaker = list['speaker'] list_group = list['speakerGroup'] list_position = list['speakerPosition'] list_role = list['speakerRole'] list_speech = list['speech'].replace('\r\n', ' ').replace('\n', ' ') #発言内容の文中には改行コードが含まれるため、これを半角スペースに置換 list_url01 = list['speechURL'] list_url02 = list['meetingURL'] Records.append([list_id, list_kind, list_house, list_topic, list_issue, list_date, list_order, list_speaker, list_group, list_position, list_role, list_speech, list_url01, list_url02]) sys.stdout.write("\r%d/%d is done." % (i+1, pages)) #進捗状況を表示する i += 1 time.sleep(1) #リクエスト1回ごとに若干時間をあけてAPI側への負荷を軽減する #CSVへの書き出し with open("kokkai_speech_" + str(total_num) + ".csv", 'w', newline='') as f: csvwriter = csv.writer(f, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC) #CSVの書き出し方式を適宜指定 csvwriter.writerow(['発言ID', '種別', '院名', '会議名', '号数', '日付', '発言番号', '発言者名', '発言者所属会派', '発言者肩書き', '発言者役割', '発言内容', '発言URL', '会議録URL']) for record in Records: csvwriter.writerow(record)解説
上記のコード内コメントでほとんど解説を入れていますが、ポイントとしては下記となります。基本的には、API側に過剰な負荷をかけないような作法を心掛けて構成しています。
- コンソール上で対話的に検索クエリを入力していく形にしている。
- 検索クエリは発言内容の文字列や発言者名、期間を指定可能。必要なものを入力し不要なものはスキップできる。なお、期間のクエリをスキップした場合やそこに日付として不適な文字列が入った場合は、2020年9月の期間が設定されるようにプログラム上で条件分岐している。
- APIの仕様上、1回のリクエストで発言データは100件までしか取得できないので、まずは1件のみのリクエストを投げてそのレスポンスから検索クエリでのヒット総件数を確認し、その後に必要回数リクエストを繰り返してヒットした全件を取得する。
- 検索クエリでのヒット総件数を表示した時点でデータ取得をキャンセルできるようにした(検索結果が想定より多すぎる、少なすぎるといった際に無駄なデータ取得をしないように配慮)。
- プログラムの過程でAPIに繰り返しリクエストする際、API側への負荷軽減のため若干のインターバルを入れる。
コンソール上での動作例
例として、「宇宙」を含む今年の国会発言を取得してみましょう。
下記の要領でPythonコードを実行すると、コンソール上で検索文字列や検索開始日、終了日などの入力が順次求められます。必要なものは入力し、不要であればスキップします。
検索文字列は半角スペース区切りでOR検索が出来たりしますが、細かい仕様は当該APIの公式サイトをご覧ください。
その後は検索結果の件数が表示されるので、Enterキーなどを押して処理を進めます。
今回の例では268件が該当したので、3回に分けてプログラムが自動でリクエストを投げます。この進捗状況もコンソール上に表示されます。shellpython KokkaiSpeech.py 検索する文字列を入力(Enterキーでスキップ) >> 宇宙 検索する発言者名を入力(Enterキーでスキップ) >> 開始日を入力 (e.g. 2020-09-01) >> 2020-01-01 終了日を入力 (e.g. 2020-11-30) >> 2020-12-15 検索結果は 268件です。 キャンセルする場合は 1 を、データを取得するにはEnterキーまたはその他を押してください。 >> 3/3 is done.処理が終了したら、プログラムがあるフォルダに「kokkai_speech_268.csv」という名称のCSVファイルが出力されます。
おわりに
私も技術的にまだまだ勉強中の身ですが、APIを介したJSON形式でのデータ取得は一般的によく実施されるケースだと思いますので、そうした実務においても参考になれば幸いです。
また、本記事で紹介した私のプログラムは「発言内容」単位のものですが、当該APIでは「会議」単位での取得も可能になっていますので、そのあたりは適宜補正してお使いください。その際は、APIサーバ側に極端な負荷をかけないようご留意ください。
こうした議事録を文字起こしして配信いただいている国会図書館や関係者の方々に感謝しつつ、政治のオープン化、そしてより良い社会作りに役立てていきたいですね。
- 投稿日:2020-12-18T22:36:33+09:00
はじめての Intel Open VINO
はじめに
この記事は、シスコシステムズ合同会社の同士による Cisco Systems Japan Advent Calendar 2020 の 20 日目として投稿しています。
そもそも Intel OpenVINO™(以下OpenVINO)って何?Cisco とどんな関係があるの?という疑問もあると思いますのでそのあたりも含めてご紹介しようと思います。この記事でできるようになること
- 機械学習による画像認識の流れがわかる
- Intel OpenVINO™とは何かがわかる
- Intel OpenVINO™の利用方法がわかる
- Intel OpenVINO™を利用して基本的な物体認識ができる
- 物体認識に必要なモデルの利用方法がわかる
- モデルを組み合わせた複合的な物体認識ができる
最終的にこんなことができます
カメラからリアルタイムで顔認識
カメラからリアルタイムで感情認識
上記の二つを組み合わせてリアルタイムな顔と感情認識
Intel OpenVINO™ とは?
公式ページから
OpenVINO™ ツールキットは、インテル・アーキテクチャーの CPU、内蔵 GPU、インテル® FPGA、インテル® Movidius™ ビジョン・プロセッシング・ユニット (VPU) といった、インテルが 提供するさまざまなハードウェアでディープラーニング推論をより高速に実行するためのソフトウェア開発環境 / ライブラリー・スイートです。
開発者はツールキットに含まれるモデル・オプティマイザーを使用して、業界標準の DL フレームワークで作成した学習済みモデルデータを、さまざまなインテルのハードウェア上で動作するように最適化を行い、OpenVINO™ ツールキットの推論エンジンで使用する中間表現フォーマット (IR) に変換します。推論エンジンは CPU、内蔵 GPU、FPGA、VPU それぞれの性能を最大限に引き出すライブラリーで構成されています。
https://www.intel.co.jp/content/www/jp/ja/internet-of-things/solution-briefs/openvino-toolkit-essential-brief.html初めての方にはなんのことだろうという感じだと思いますので、詳しく解説していきます。
まず、そもそも機械学習による画像認識とはどういう流れで行われるのでしょうか。
主に機械学習は上記のようにモデルの作成とモデルの運用という部分に分割されます。
そして、実際にこのモデルを使用して推論処理を行うことにより様々なアプリケーションが実装されています。モデルを作成する際にもCPUやGPUなどのコンピューティングリソースは必要になりますが、学習するときほどではないにせよモデルを使用して推論する際にもコンピューティングリソースは必要になります。これまでは組み込み系のハードウェア、例えば監視カメラなどではコンピューティングリソースの制限などから推論処理をするためにはそれなりの場所と電力が必要でした。こういったことがハードルとなって、推論を利用したアプリケーションの活用が場所・価格・電力など様々な観点から遅れがちになっていました。
Intel OpenVINO™はこうした課題を解決するためのプラットフォームです。
後ほど詳しくご説明いたしますが、機械学習モデル精度をある程度保持したまま単純化することにより、推論精度への影響を最小限にしながら処理負荷を劇的に削減することでCPU, GPU, FPGA, VPUなどIntelの様々なプラットフォーム上で推論処理をさせることが可能となっております。以下のような特徴があります。特徴
- 非常に多くの機械学習モデルがすぐに利用可能(Open Model ZOO)
- CPU, GPU, FPGA, VPUなど様々なプラットフォームでの動作が可能
- クラウドでの開発環境も提供(Intel DevCloud for the Edge)
- 活用支援のためのトレーニングプログラムが充実
Ciscoとの関連性
Ciscoと画像認識のような機械学習分野はあまり結びつきを持たないイメージをお持ちの方もいらっしゃるかと思います。
あまり馴染みのない製品もあるかとは思いますが、ネットワーク機器だけではなくて以下のような製品群にて機械学習が利用されております。
2020年12月9日、10日で行われたWebexOneというイベントでもWebexの新製品発表が行われましたが、会議のその中にもリアルタイム自動翻訳やコールセンターの音声認識及び機械学習による自動音声応答など様々な分野の製品で機械学習が使用されております。
https://www.webexoneevent.com/IntelとCiscoとは古くから様々な分野でパートナーシップを結んでいます。最近では2020年11月12日に発表されました「5Gショーケース」のエコパートナー様としてご支援いただいております。
https://www.cisco.com/c/m/ja_jp/5g-showcase.html#~customer-partnerIntel OpenVINO™を利用してみよう
それでは実際にIntel OpenVINO™を使用してみましょう。
OpenVINOを使用した開発環境は主にローカルコンピュータ上で行うものと上述のIntel DevCloud for the Edgeというクラウド上で行うものとがあります。
クラウド上につきましては最後の方で軽く触れますが、Webアプリケーションへの組み込みなど柔軟性の観点から本稿ではローカルコンピュータ上での開発環境を使用致します。
なお、OpenVINOはCPPも利用できますが、本稿では開発言語としてPythonを使用致しますので、Python環境の構築についても触れていきます。OpenVINO利用の手順は以下の通りとなります。
1. Intel Basic Accountの作成
2. OpenVINOのダウンロード
3. OpenVINOのインストール
4. Python実行環境構築
5. 任意のエディタでCodeを記述
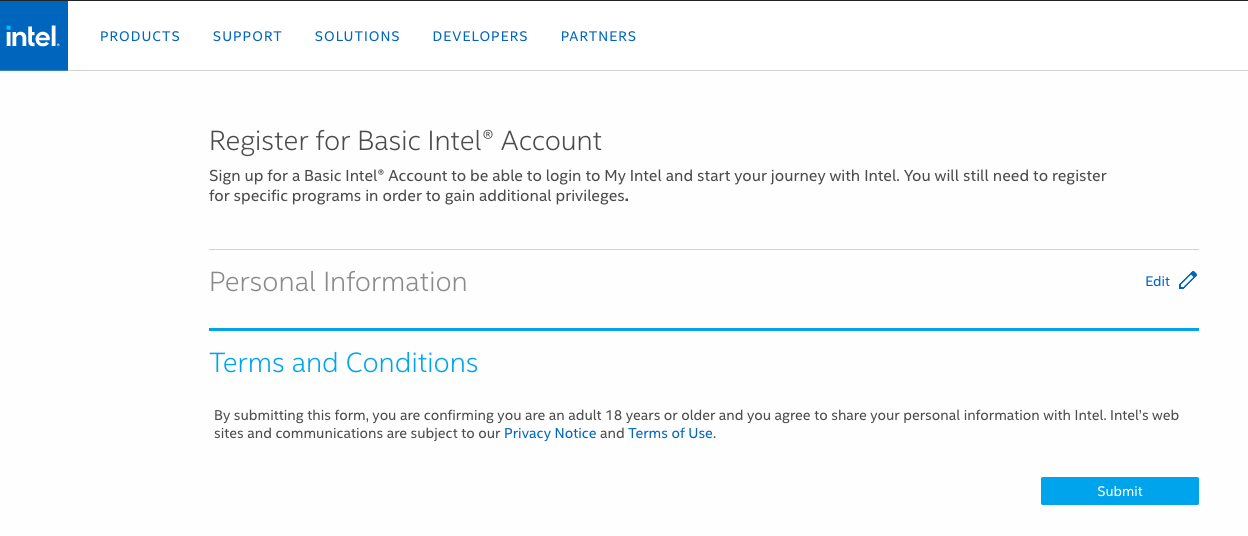
6. 実行及び結果の確認Intel Basic Accountを作成しよう
Register for Basic Intel® Accountにアクセスし、必要情報を入力します。入力する箇所が多いですが、めげないで入力しましょう。
入力したらNext Stepをクリックし、Privacy NoticeとTerms of Useに同意しSubmitをクリック。
OpenVINOのダウンロードをしてみよう
OpenVINO Downloadにアクセスし、ダウンロードする対象を選択します。以下のように選択します。
- Operating System: macOS
- Distribution: Web and Local Install
- Installer Type: Local
Register & Downloadを選択します。
Choose a Versionは2021.1を選択し、Full Packageを選択します。

m_openvino_toolkit_p_2021.1.110.dmgというファイルがダウンロードされます。
OpenVINO をインストールしてみよう
インストールの前提条件として以下の要件が必要になります。
一番下のApple Xcode IDEはOptionalです。
- CMake 3.10 or higher
- Python 3.6 - 3.7
- Apple Xcode* Command Line Tools (Optional) Apple Xcode* IDE (not required for OpenVINO, but useful for development)
インストール時にはCMakeが必要となりますので、homebrewでインストールしておきます。
$ brew install cmake$ brew install cmake Updating Homebrew... Warning: Treating cmake as a formula. For the cask, use homebrew/cask/cmake ==> Downloading https://homebrew.bintray.com/bottles/cmake-3.19.1.catalina.bottle.tar.gz Already downloaded: /Users/ktsutsum/Library/Caches/Homebrew/downloads/0908e631c8236f534e13e47da5070f8b651b7f59a5a97cd70899729d83baddd3--cmake-3.19.1.catalina.bottle.tar.gz ==> Pouring cmake-3.19.1.catalina.bottle.tar.gz ==> Caveats Emacs Lisp files have been installed to: /usr/local/share/emacs/site-lisp/cmake ==> Summary ? /usr/local/Cellar/cmake/3.19.1: 6,366 files, 63.9MB先ほどダウンロードしたm_openvino_toolkit_p_2021.1.110.dmgというファイルをダブルクリックして開きます。
以下のファイルをダブルクリックします。
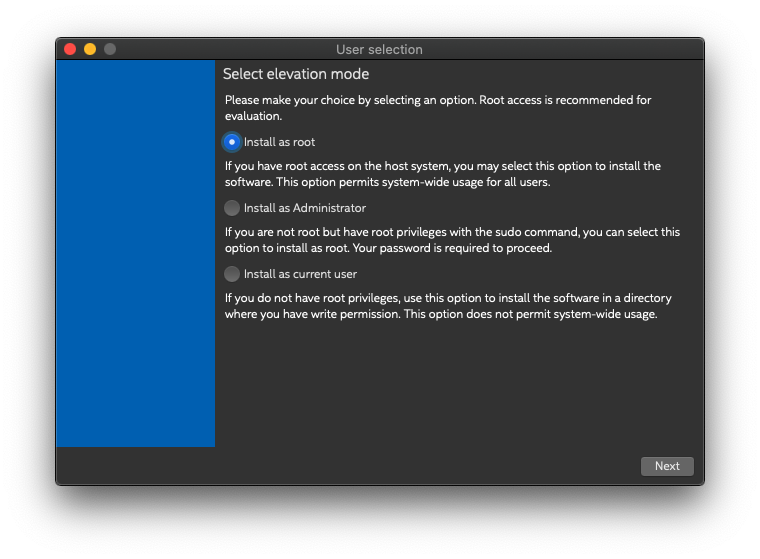
ここではRootとしてインストールしています。
なぜか再度ロゴが表示されます。
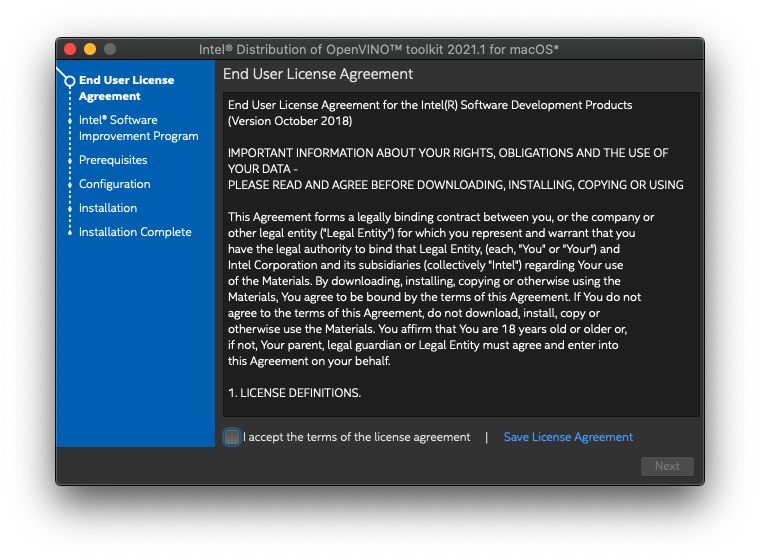
ライセンスに同意します。
情報提供を選択します。
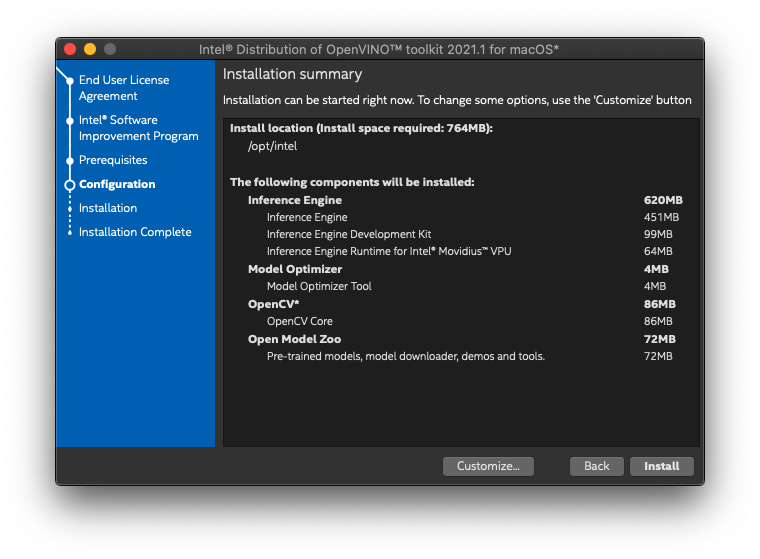
インストール内容を確認します。
インストールを待ちます。
最初のパートが終わったと表示されます。残りはFinishをクリックするとWebページに飛ばされます。
こちらのWebページに飛ばされます。
ここからは次のPython環境セットアップと一緒に進めていきます。Python実行環境を構築しよう
さて、次はPythonの実行環境を構築していきます。
1. pipenvのインストール
できるだけ環境を汚さないように仮想環境を作成します。仮想環境を作成する方法としてしてはAnacondaやpyenv,viratualenv等色々ありますが、今回は作成したCodeをWebアプリ化&コンテナ化するために必要パッケージをpackage-list.txtとして提示してくれるpipenvを利用します。
いつもどおりbrewでインストールしていきます。brew brewってなんやねん
macOS対応のパッケージ管理ソフトウェアです。Windowsでも使用できます。以下のリンクにある説明どおりにインストールすると今後も便利かと思います。
https://brew.sh/index_jaさて、気を取り直してpipenvをインストールしていきます。
$ brew install pipenv
出力結果は長いのでこんな感じです
$ brew install pipenv Updating Homebrew... ==> Downloading https://homebrew.bintray.com/bottles/openssl%401.1-1.1.1i.catalina.bottle.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/066b9f114617872e77fa3d4afee2337daabc2c181d7564fe60a5b26d89d69742?response-content-disposition=attachment%3Bfilename%3D%22o ######################################################################## 100.0% ==> Downloading https://homebrew.bintray.com/bottles/readline-8.1.catalina.bottle.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/fe4de019cf549376a7743dcb0c86db8a08ca2b6d0dd2f8cb796dd7cf973dc2e9?response-content-disposition=attachment%3Bfilename%3D%22r ######################################################################## 100.0% ==> Downloading https://homebrew.bintray.com/bottles/sqlite-3.34.0.catalina.bottle.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/7e04c1fcd0294ec7625e43eea05714d8bb4d15d24675c99484f1403fdcb438ec?response-content-disposition=attachment%3Bfilename%3D%22s ######################################################################## 100.0% ==> Downloading https://homebrew.bintray.com/bottles/python%403.9-3.9.1.catalina.bottle.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/2b9946108e230384c48fcb4fcc07febd31e3987a7b9e66ee952e2c4f153a5dee?response-content-disposition=attachment%3Bfilename%3D%22p ######################################################################## 100.0% ==> Downloading https://homebrew.bintray.com/bottles/pipenv-2020.11.15.catalina.bottle.tar.gz Already downloaded: /Users/ktsutsum/Library/Caches/Homebrew/downloads/eabcd8eb2a82ad7fbdd5f958a38256bd254a0d5fdf059e6217946c1a46fe950d--pipenv-2020.11.15.catalina.bottle.tar.gz ==> Installing dependencies for pipenv: openssl@1.1, readline, sqlite and python@3.9 ==> Installing pipenv dependency: openssl@1.1 ==> Pouring openssl@1.1-1.1.1i.catalina.bottle.tar.gz ==> Caveats A CA file has been bootstrapped using certificates from the system keychain. To add additional certificates, place .pem files in /usr/local/etc/openssl@1.1/certs and run /usr/local/opt/openssl@1.1/bin/c_rehash openssl@1.1 is keg-only, which means it was not symlinked into /usr/local, because macOS provides LibreSSL. If you need to have openssl@1.1 first in your PATH run: echo 'export PATH="/usr/local/opt/openssl@1.1/bin:$PATH"' >> /Users/ktsutsum/.bash_profile For compilers to find openssl@1.1 you may need to set: export LDFLAGS="-L/usr/local/opt/openssl@1.1/lib" export CPPFLAGS="-I/usr/local/opt/openssl@1.1/include" For pkg-config to find openssl@1.1 you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/openssl@1.1/lib/pkgconfig" ==> Summary ? /usr/local/Cellar/openssl@1.1/1.1.1i: 8,067 files, 18.5MB ==> Installing pipenv dependency: readline ==> Pouring readline-8.1.catalina.bottle.tar.gz ==> Caveats readline is keg-only, which means it was not symlinked into /usr/local, because macOS provides BSD libedit. For compilers to find readline you may need to set: export LDFLAGS="-L/usr/local/opt/readline/lib" export CPPFLAGS="-I/usr/local/opt/readline/include" For pkg-config to find readline you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/readline/lib/pkgconfig" ==> Summary ? /usr/local/Cellar/readline/8.1: 48 files, 1.6MB ==> Installing pipenv dependency: sqlite ==> Pouring sqlite-3.34.0.catalina.bottle.tar.gz ==> Caveats sqlite is keg-only, which means it was not symlinked into /usr/local, because macOS already provides this software and installing another version in parallel can cause all kinds of trouble. If you need to have sqlite first in your PATH run: echo 'export PATH="/usr/local/opt/sqlite/bin:$PATH"' >> /Users/ktsutsum/.bash_profile For compilers to find sqlite you may need to set: export LDFLAGS="-L/usr/local/opt/sqlite/lib" export CPPFLAGS="-I/usr/local/opt/sqlite/include" For pkg-config to find sqlite you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/sqlite/lib/pkgconfig" ==> Summary ? /usr/local/Cellar/sqlite/3.34.0: 11 files, 4.1MB ==> Installing pipenv dependency: python@3.9 ==> Pouring python@3.9-3.9.1.catalina.bottle.tar.gz ==> /usr/local/Cellar/python@3.9/3.9.1/bin/python3 -s setup.py --no-user-cfg install --force --verbose --install-scripts=/usr/local/Cellar/python@3.9/3.9.1/bin --install-lib=/usr/lo ==> /usr/local/Cellar/python@3.9/3.9.1/bin/python3 -s setup.py --no-user-cfg install --force --verbose --install-scripts=/usr/local/Cellar/python@3.9/3.9.1/bin --install-lib=/usr/lo ==> /usr/local/Cellar/python@3.9/3.9.1/bin/python3 -s setup.py --no-user-cfg install --force --verbose --install-scripts=/usr/local/Cellar/python@3.9/3.9.1/bin --install-lib=/usr/lo ==> Caveats Python has been installed as /usr/local/bin/python3 Unversioned symlinks `python`, `python-config`, `pip` etc. pointing to `python3`, `python3-config`, `pip3` etc., respectively, have been installed into /usr/local/opt/python@3.9/libexec/bin You can install Python packages with pip3 install <package> They will install into the site-package directory /usr/local/lib/python3.9/site-packages See: https://docs.brew.sh/Homebrew-and-Python ==> Summary ? /usr/local/Cellar/python@3.9/3.9.1: 4,452 files, 70.9MB ==> Installing pipenv ==> Pouring pipenv-2020.11.15.catalina.bottle.tar.gz ==> Caveats Bash completion has been installed to: /usr/local/etc/bash_completion.d ==> Summary ? /usr/local/Cellar/pipenv/2020.11.15: 1,868 files, 25.4MB ==> Upgrading 2 dependents: poppler 20.11.0 -> 20.12.0, diff-pdf 0.4.1_7 -> 0.4.1_8 ==> Upgrading poppler 20.11.0 -> 20.12.0 ==> Downloading https://homebrew.bintray.com/bottles/qt-5.15.2.catalina.bottle.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/51ab78a99ff3498a236d15d9bed92962ddd2499c4020356469f7ab1090cf6825?response-content-disposition=attachment%3Bfilename%3D%22q ######################################################################## 100.0% ==> Downloading https://homebrew.bintray.com/bottles/poppler-20.12.0.catalina.bottle.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/d89f6b867a6f012f44886b157f35f33179c583af93ace39329e7b62d2482eb31?response-content-disposition=attachment%3Bfilename%3D%22p ######################################################################## 100.0% ==> Installing dependencies for poppler: qt ==> Installing poppler dependency: qt ==> Pouring qt-5.15.2.catalina.bottle.tar.gz ==> Caveats We agreed to the Qt open source license for you. If this is unacceptable you should uninstall. qt is keg-only, which means it was not symlinked into /usr/local, because Qt 5 has CMake issues when linked. If you need to have qt first in your PATH run: echo 'export PATH="/usr/local/opt/qt/bin:$PATH"' >> /Users/ktsutsum/.bash_profile For compilers to find qt you may need to set: export LDFLAGS="-L/usr/local/opt/qt/lib" export CPPFLAGS="-I/usr/local/opt/qt/include" For pkg-config to find qt you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/qt/lib/pkgconfig" ==> Summary ? /usr/local/Cellar/qt/5.15.2: 10,688 files, 367.9MB ==> Installing poppler ==> Pouring poppler-20.12.0.catalina.bottle.tar.gz ? /usr/local/Cellar/poppler/20.12.0: 474 files, 26.8MB Removing: /usr/local/Cellar/poppler/20.11.0... (476 files, 26.7MB) Removing: /Users/ktsutsum/Library/Caches/Homebrew/poppler--20.11.0.catalina.bottle.tar.gz... (8.1MB) ==> Upgrading diff-pdf 0.4.1_7 -> 0.4.1_8 ==> Downloading https://homebrew.bintray.com/bottles/diff-pdf-0.4.1_8.catalina.bottle.tar.gz #=#=-# # curl: (22) The requested URL returned error: 404 Not Found Error: Failed to download resource "diff-pdf" Download failed: https://homebrew.bintray.com/bottles/diff-pdf-0.4.1_8.catalina.bottle.tar.gz Warning: Bottle installation failed: building from source. ==> Downloading https://homebrew.bintray.com/bottles/automake-1.16.3.catalina.bottle.tar.gz ==> Downloading from https://d29vzk4ow07wi7.cloudfront.net/25fe47e5fb1af734423e1e73f0dc53637e89d825ef8d8199add239352b5b974e?response-content-disposition=attachment%3Bfilename%3D%22a ######################################################################## 100.0% ==> Downloading https://github.com/vslavik/diff-pdf/releases/download/v0.4.1/diff-pdf-0.4.1.tar.gz ==> Downloading from https://github-production-release-asset-2e65be.s3.amazonaws.com/353360/b335c080-3951-11ea-98d4-aa100bba0fcf?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=AK ######################################################################## 100.0% Warning: A newer Command Line Tools release is available. Update them from Software Update in System Preferences or run: softwareupdate --all --install --force If that doesn't show you an update run: sudo rm -rf /Library/Developer/CommandLineTools sudo xcode-select --install Alternatively, manually download them from: https://developer.apple.com/download/more/. ==> Installing dependencies for diff-pdf: automake ==> Installing diff-pdf dependency: automake ==> Pouring automake-1.16.3.catalina.bottle.tar.gz ? /usr/local/Cellar/automake/1.16.3: 131 files, 3.4MB ==> Installing diff-pdf ==> ./configure --prefix=/usr/local/Cellar/diff-pdf/0.4.1_8 Last 15 lines from /Users/ktsutsum/Library/Logs/Homebrew/diff-pdf/01.configure: checking for style of include used by make... GNU checking dependency style of clang++... none checking for pkg-config... /usr/local/Homebrew/Library/Homebrew/shims/mac/super/pkg-config checking pkg-config is at least version 0.9.0... yes checking for POPPLER... no configure: error: Package requirements (poppler-cairo >= 0.10 poppler-glib >= 0.10 cairo-pdf) were not met: No package 'poppler-cairo' found Consider adjusting the PKG_CONFIG_PATH environment variable if you installed software in a non-standard prefix. Alternatively, you may set the environment variables POPPLER_CFLAGS and POPPLER_LIBS to avoid the need to call pkg-config. See the pkg-config man page for more details. READ THIS: https://docs.brew.sh/Troubleshooting These open issues may also help: diff-pdf failing to build on macOS 10.15.7 https://github.com/Homebrew/homebrew-core/issues/66385 Error: A newer Command Line Tools release is available. Update them from Software Update in System Preferences or run: softwareupdate --all --install --force If that doesn't show you an update run: sudo rm -rf /Library/Developer/CommandLineTools sudo xcode-select --install Alternatively, manually download them from: https://developer.apple.com/download/more/. ==> Checking for dependents of upgraded formulae... ==> No broken dependents to reinstall! ==> Caveats ==> openssl@1.1 A CA file has been bootstrapped using certificates from the system keychain. To add additional certificates, place .pem files in /usr/local/etc/openssl@1.1/certs and run /usr/local/opt/openssl@1.1/bin/c_rehash openssl@1.1 is keg-only, which means it was not symlinked into /usr/local, because macOS provides LibreSSL. If you need to have openssl@1.1 first in your PATH run: echo 'export PATH="/usr/local/opt/openssl@1.1/bin:$PATH"' >> /Users/ktsutsum/.bash_profile For compilers to find openssl@1.1 you may need to set: export LDFLAGS="-L/usr/local/opt/openssl@1.1/lib" export CPPFLAGS="-I/usr/local/opt/openssl@1.1/include" For pkg-config to find openssl@1.1 you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/openssl@1.1/lib/pkgconfig" ==> readline readline is keg-only, which means it was not symlinked into /usr/local, because macOS provides BSD libedit. For compilers to find readline you may need to set: export LDFLAGS="-L/usr/local/opt/readline/lib" export CPPFLAGS="-I/usr/local/opt/readline/include" For pkg-config to find readline you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/readline/lib/pkgconfig" ==> sqlite sqlite is keg-only, which means it was not symlinked into /usr/local, because macOS already provides this software and installing another version in parallel can cause all kinds of trouble. If you need to have sqlite first in your PATH run: echo 'export PATH="/usr/local/opt/sqlite/bin:$PATH"' >> /Users/ktsutsum/.bash_profile For compilers to find sqlite you may need to set: export LDFLAGS="-L/usr/local/opt/sqlite/lib" export CPPFLAGS="-I/usr/local/opt/sqlite/include" For pkg-config to find sqlite you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/sqlite/lib/pkgconfig" ==> python@3.9 Python has been installed as /usr/local/bin/python3 Unversioned symlinks `python`, `python-config`, `pip` etc. pointing to `python3`, `python3-config`, `pip3` etc., respectively, have been installed into /usr/local/opt/python@3.9/libexec/bin You can install Python packages with pip3 install <package> They will install into the site-package directory /usr/local/lib/python3.9/site-packages See: https://docs.brew.sh/Homebrew-and-Python ==> pipenv Bash completion has been installed to: /usr/local/etc/bash_completion.d ==> qt We agreed to the Qt open source license for you. If this is unacceptable you should uninstall. qt is keg-only, which means it was not symlinked into /usr/local, because Qt 5 has CMake issues when linked. If you need to have qt first in your PATH run: echo 'export PATH="/usr/local/opt/qt/bin:$PATH"' >> /Users/ktsutsum/.bash_profile For compilers to find qt you may need to set: export LDFLAGS="-L/usr/local/opt/qt/lib" export CPPFLAGS="-I/usr/local/opt/qt/include" For pkg-config to find qt you may need to set: export PKG_CONFIG_PATH="/usr/local/opt/qt/lib/pkgconfig"
2. 仮想環境の準備
作業フォルダに移動したら、pipenvでpythonの仮想環境を作成していきます。
以下のような書式でpythonのバージョンを指定します。OpenVINOはpython3.7までの対応のため今回はpython3.7にて環境を作成していきます。$ pipenv --python 3.7$ pipenv --python 3.7 Virtualenv already exists! Removing existing virtualenv... Warning: the environment variable LANG is not set! We recommend setting this in ~/.profile (or equivalent) for proper expected behavior. Creating a virtualenv for this project... Pipfile: /Users/ktsutsum/openvino/demos/Pipfile Using /usr/bin/python3 (3.7.3) to create virtualenv... ⠇ Creating virtual environment...created virtual environment CPython3.7.3.final.0-64 in 458ms creator CPython3macOsFramework(dest=/Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME, clear=False, global=False) seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/Users/ktsutsum/Library/Application Support/virtualenv) added seed packages: pip==20.2.4, setuptools==50.3.2, wheel==0.35.1 activators BashActivator,CShellActivator,FishActivator,PowerShellActivator,PythonActivator,XonshActivator ✔ Successfully created virtual environment! Virtualenv location: /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME3. 仮想環境を使用してOpenVINOインストールの続き
仮想環境利用してOpenVINOの残りのセットアップを進めていきましょう。
まず先ほど作成した仮想環境のShellに入ります。$ pipenv shellhttps://docs.openvinotoolkit.org/latest/openvino_docs_install_guides_installing_openvino_macos.html
OpenVINOインストール続きはこちらのページをご参照いただきながら進め行ければと思います。環境変数をSourceします。
(demos) bash-3.2$ source /opt/intel/openvino_2021/bin/setupvars.sh [setupvars.sh] OpenVINO environment initializedModel Optimizerのインストールに必要なパッケージを事前にインストールします。
(demos) bash-3.2$ cd /opt/intel/openvino_2021/deployment_tools/model_optimizer/install_prerequisites (demos) bash-3.2$ sudo ./install_prerequisites.sh WARNING: The directory '/Users/ktsutsum/Library/Caches/pip' or its parent directory is not owned or is not writable by the current user. The cache has been disabled. Check the permissions and owner of that directory. If executing pip with sudo, you may want sudo's -H flag. Ignoring tensorflow: markers 'python_version >= "3.8"' don't match your environment Requirement already satisfied: tensorflow<2.0,>=1.15.2 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from -r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.15.4) Requirement already satisfied: mxnet<=1.5.1,>=1.0.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from -r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 3)) (1.5.1) Requirement already satisfied: networkx>=1.11 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from -r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 4)) (2.5) Requirement already satisfied: numpy>=1.13.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from -r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 5)) (1.19.4) Requirement already satisfied: protobuf>=3.6.1 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from -r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 6)) (3.14.0) Requirement already satisfied: onnx>=1.1.2 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from -r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 7)) (1.8.0) Requirement already satisfied: test-generator==0.1.1 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from -r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 8)) (0.1.1) Requirement already satisfied: defusedxml>=0.5.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from -r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 9)) (0.6.0) Requirement already satisfied: six in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from test-generator==0.1.1->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 8)) (1.15.0) Requirement already satisfied: requests<3,>=2.20.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from mxnet<=1.5.1,>=1.0.0->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 3)) (2.25.0) Requirement already satisfied: graphviz<0.9.0,>=0.8.1 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from mxnet<=1.5.1,>=1.0.0->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 3)) (0.8.4) Requirement already satisfied: decorator>=4.3.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from networkx>=1.11->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 4)) (4.4.2) Requirement already satisfied: typing-extensions>=3.6.2.1 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from onnx>=1.1.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 7)) (3.7.4.3) Requirement already satisfied: astor>=0.6.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (0.8.1) Requirement already satisfied: wrapt>=1.11.1 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.12.1) Requirement already satisfied: tensorflow-estimator==1.15.1 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.15.1) Requirement already satisfied: termcolor>=1.1.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.1.0) Requirement already satisfied: google-pasta>=0.1.6 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (0.2.0) Requirement already satisfied: keras-preprocessing>=1.0.5 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.1.2) Requirement already satisfied: tensorboard<1.16.0,>=1.15.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.15.0) Requirement already satisfied: grpcio>=1.8.6 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.34.0) Requirement already satisfied: absl-py>=0.7.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (0.11.0) Requirement already satisfied: gast==0.2.2 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (0.2.2) Requirement already satisfied: opt-einsum>=2.3.2 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (3.3.0) Requirement already satisfied: wheel>=0.26 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (0.35.1) Requirement already satisfied: keras-applications>=1.0.8 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.0.8) Collecting numpy>=1.13.0 Downloading numpy-1.18.5-cp37-cp37m-macosx_10_9_x86_64.whl (15.1 MB) |████████████████████████████████| 15.1 MB 2.3 MB/s Requirement already satisfied: h5py in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from keras-applications>=1.0.8->tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (3.1.0) Requirement already satisfied: idna<3,>=2.5 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from requests<3,>=2.20.0->mxnet<=1.5.1,>=1.0.0->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 3)) (2.10) Requirement already satisfied: urllib3<1.27,>=1.21.1 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from requests<3,>=2.20.0->mxnet<=1.5.1,>=1.0.0->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 3)) (1.26.2) Requirement already satisfied: certifi>=2017.4.17 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from requests<3,>=2.20.0->mxnet<=1.5.1,>=1.0.0->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 3)) (2020.12.5) Requirement already satisfied: chardet<4,>=3.0.2 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from requests<3,>=2.20.0->mxnet<=1.5.1,>=1.0.0->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 3)) (3.0.4) Requirement already satisfied: markdown>=2.6.8 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorboard<1.16.0,>=1.15.0->tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (3.3.3) Requirement already satisfied: setuptools>=41.0.0 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorboard<1.16.0,>=1.15.0->tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (50.3.2) Requirement already satisfied: werkzeug>=0.11.15 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from tensorboard<1.16.0,>=1.15.0->tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.0.1) Requirement already satisfied: importlib-metadata in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from markdown>=2.6.8->tensorboard<1.16.0,>=1.15.0->tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (3.3.0) Requirement already satisfied: cached-property in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from h5py->keras-applications>=1.0.8->tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (1.5.2) Requirement already satisfied: zipp>=0.5 in /Users/ktsutsum/.local/share/virtualenvs/demos-UH30-bME/lib/python3.7/site-packages (from importlib-metadata->markdown>=2.6.8->tensorboard<1.16.0,>=1.15.0->tensorflow<2.0,>=1.15.2->-r /opt/intel/openvino_2021.1.110/deployment_tools/model_optimizer/install_prerequisites/../requirements.txt (line 1)) (3.4.0) Installing collected packages: numpy Attempting uninstall: numpy Found existing installation: numpy 1.19.4 Uninstalling numpy-1.19.4: Successfully uninstalled numpy-1.19.4 Successfully installed numpy-1.18.5 [WARNING] All Model Optimizer dependencies are installed globally. [WARNING] If you want to keep Model Optimizer in separate sandbox [WARNING] run install_prerequisites.sh venv {caffe|tf|tf2|mxnet|kaldi|onnx}こちらで仮想環境の構築とOpenVINOインストールは完了です。
実際に Code を書いてみよう
それでは実際にCodeを書いていきましょう。
今回使用するモジュールは以下のとおりです。はじめにこれらをImportします。
エディタはお好きなものを利用して良いと思います。私は普通にvimを使っています。
名称 概要 openvino OpenVINO本体 Numpy Pythonの数値計算を行うライブラリ Sys Python のインタプリタや実行環境に関連 # 必要なモジュール、ライブラリをインポート import cv2 import numpy as np import sys sys.path.append from openvino.inference_engine import IENetwork, IECoreなにやらIE NetworkとIE Coreというものが出てきましたね。
IEはInference Engineの略です。IENetworkというモジュールは今回の2021.1バージョンからIECoreに統合されましたので使用しないのですが、
2020バージョンを利用する場合の後方互換性としてCode上残してあります。
Inference Engineというのはモデルをモデルオプティマイザーによって最適化したものです。最適化とは何をしているかというと精度をほぼ失うことなくモデルの重みの最良歯科を行うことにより処理負荷を劇的に下げるような変換です。
ここで、今回使用するモデルのご紹介をいたします。
モデル名称 emotions_recognition_retail_0003 Input face orientation Frontal Rotation in-plane 2±15˚ Rotation out-of-plane Yaw: ±15˚ / Pitch: ±15˚ Min object width 64 pixels GFlops 0.126 MParams 2.483 Source framework Caffe
モデル名称 face-detection-retail-0004 AP (WIDER) 83.00% GFlops 1.067 MParams 0.588 Source framework Caffe 上記モデルを読み込みます。
# Face Detection Model net = ie.read_network(model='intel/face-detection-retail-0004/FP16/face-detection-retail-0004.xml', weights='intel/face-detection-retail-0004/FP16/face-detection-retail-0004.bin') exec_net = ie.load_network(network=net, device_name="CPU", num_requests=0) # Emotion Detection Model net_emotion = ie.read_network(model='intel/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.xml', weights='intel/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.bin') exec_net_emotion = ie.load_network(network=net_emotion, device_name="CPU", num_requests=0)ここで、モデルへのパス指定をしていますが、まだモデルは手元にないと思いますのでモデルをダウンローダーを使って手に入れましょう。
(face-detection) bash-3.2$ python3 /opt/intel/openvino_2021/deployment_tools/tools/model_downloader/downloader.py --name face-detection-retail-0004 Traceback (most recent call last): File "/opt/intel/openvino_2021/deployment_tools/tools/model_downloader/downloader.py", line 25, in <module> import requests ModuleNotFoundError: No module named 'requests'requests moduleをインストールします
(face-detection) bash-3.2$ pipenv install requests Installing requests... Adding requests to Pipfile's [packages]... ✔ Installation Succeeded Pipfile.lock (9be4f8) out of date, updating to (444a6d)... Locking [dev-packages] dependencies... Locking [packages] dependencies... Building requirements... Resolving dependencies... ✔ Success! Updated Pipfile.lock (444a6d)! Installing dependencies from Pipfile.lock (444a6d)... ? ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 0/0 — 00:00:00もう一度チャレンジ
(face-detection) bash-3.2$ python3 /opt/intel/openvino_2021/deployment_tools/tools/model_downloader/downloader.py --name face-detection-retail-0004 Traceback (most recent call last): File "/opt/intel/openvino_2021/deployment_tools/tools/model_downloader/downloader.py", line 37, in <module> import common File "/opt/intel/openvino_2021.1.110/deployment_tools/open_model_zoo/tools/downloader/common.py", line 33, in <module> import yaml ModuleNotFoundError: No module named 'yaml'pyyaml moduleをインストールします
(face-detection) bash-3.2$ pipenv install pyyaml Installing pyyaml... Adding pyyaml to Pipfile's [packages]... ✔ Installation Succeeded Pipfile.lock (444a6d) out of date, updating to (c30804)... Locking [dev-packages] dependencies... Locking [packages] dependencies... Building requirements... Resolving dependencies... ✔ Success! Updated Pipfile.lock (c30804)! Installing dependencies from Pipfile.lock (c30804)... ? ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 0/0 — 00:00:00今度こそ
(face-detection) bash-3.2$ python3 /opt/intel/openvino_2021/deployment_tools/tools/model_downloader/downloader.py --name face-detection-retail-0004 ################|| Downloading face-detection-retail-0004 ||################ ========== Downloading /Users/ktsutsum/openvino/demos/face-detection/intel/face-detection-retail-0004/FP32/face-detection-retail-0004.xml ... 100%, 98 KB, 166814 KB/s, 0 seconds passed ========== Downloading /Users/ktsutsum/openvino/demos/face-detection/intel/face-detection-retail-0004/FP32/face-detection-retail-0004.bin ... 100%, 2297 KB, 12116 KB/s, 0 seconds passed ========== Downloading /Users/ktsutsum/openvino/demos/face-detection/intel/face-detection-retail-0004/FP16/face-detection-retail-0004.xml ... 100%, 97 KB, 210379 KB/s, 0 seconds passed ========== Downloading /Users/ktsutsum/openvino/demos/face-detection/intel/face-detection-retail-0004/FP16/face-detection-retail-0004.bin ... 100%, 1148 KB, 20286 KB/s, 0 seconds passed ========== Downloading /Users/ktsutsum/openvino/demos/face-detection/intel/face-detection-retail-0004/FP16-INT8/face-detection-retail-0004.xml ... 100%, 240 KB, 257964 KB/s, 0 seconds passed ========== Downloading /Users/ktsutsum/openvino/demos/face-detection/intel/face-detection-retail-0004/FP16-INT8/face-detection-retail-0004.bin ... 100%, 586 KB, 13932 KB/s, 0 seconds passedこれでモデルをダウンローダーが完了です。
これと同じことをemotions-recognition-retail-0003についても実施します。
ここでは割愛しますが、上記のコマンドのモデル名だけを変更して実施してみてください。続いて解析本体部分となります。非常に短いCodeです。
本稿ではOpenVINOについて取り上げておりますので、その他の説明については簡易にとどめておきます。cap = cv2.VideoCapture(1) while True: ret, frame = cap.read() if ret == False: continue img = cv2.resize(frame, (300, 300)) img = img.transpose((2, 0, 1)) img = np.expand_dims(img, axis=0) out = exec_net.infer(inputs={'data': img}) out = out['detection_out'] out = np.squeeze(out) for detection in out: confidence = float(detection[2]) xmin = int(detection[3] * frame.shape[1]) ymin = int(detection[4] * frame.shape[0]) xmax = int(detection[5] * frame.shape[1]) ymax = int(detection[6] * frame.shape[0]) if confidence > 0.5: cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), color=(xmin, ymin, 0), thickness=3) frame_face = frame[ymin:ymax, xmin:xmax] img = cv2.resize(frame_face, (64, 64)) img = img.transpose((2, 0, 1)) img = np.expand_dims(img, axis=0) out = exec_net_emotion.infer(inputs={'data': img}) out = out['prob_emotion'] out = np.squeeze(out) index_max = np.argmax(out) list_emotion = ['neutral', 'happy', 'sad', 'surprise', 'anger'] cv2.putText(frame, list_emotion[index_max], (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (xmin, ymin, 0), 2) cv2.imshow('image', frame) key = cv2.waitKey(1) if key != -1: break cap.release() cv2.destoryAllWindows()まず以下の部分ですが、opencvを使用して内蔵カメラからの画像を取り込んでいます。
cv2.VideoCapture(1)の数字部分(1)はお手もと環境により異なります。通常は(0)の場合が多いです。
retにはtrue or false, frameには画像が配列で取り込まれます。画像がある場合ret = trueとなります。cap = cv2.VideoCapture(1) while True: ret, frame = cap.read() if ret == False: continue次にこちら。
img = cv2.resize(frame, (300, 300)) img = img.transpose((2, 0, 1)) img = np.expand_dims(img, axis=0)
- resizeにより入力に必要なサイズ(300, 300)へ変換しています。
- transposeにより(h, w, c)から(c, h, w)への変換をしています。
- h : height(高さ)
- w : width(幅)
- c : channel(チャネル:色情報)
OpenCVは(h, w, c)の順番で画像を取り込みますがこのモデルでは以下のように(c, w, h)の順番で渡してやる必要があリます。
- expand_dimsで次元の追加 上記のように入力が期待するものは[1x3x300x300]です。ただここまでの変換だと[3x300x300]と1次元足りません。 expand_dims(axis = 0)と指定することにより次元を追加し[1x3x300x300]とすることが可能です。
次のセクションに行きましょう。
out = exec_net.infer(inputs={'data': img})imgに対して事前に定義したexec_netのinferメソッドを利用し推論を実施します。
out = out['detection_out']ではoutのデータはどのようなものでしょうか?実際にprintしてみると以下のようなarrayで返されてきます。
detection_outという名前だということがわかりますので、out = out['detection_out']としています。{'detection_out': array([[[[0. , 1. , 1. , ..., 0.1926786 , 0.77813023, 0.92338395], [0. , 1. , 0.02098523, ..., 0.9338631 , 0.99440974, 1.0033596 ], [0. , 1. , 0.01355048, ..., 0.01246494, 0.70711267, 0.40890545], ..., [0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0. , 0. ], [0. , 0. , 0. , ..., 0. , 0. , 0. ]]]], dtype=float32)}ここで、outputのshapeを見てみましょう。[1, 1, N, 7]だということがわかりますが、はじめの[1, 1]は実際の処理には不要です。
そういった場合は、1次元の要素を削除できるsqueezeメソッドを利用します。
out = np.squeeze(out)さて、上記の[N, 7]という行列の"7"の中身を見てみましょう。以下のようになっています。
- image_id - ID of the image in the batch : 1個
- label - predicted class ID : 1個
- conf - confidence for the predicted class : 1個
- (x_min, y_min) - coordinates of the top left bounding box corner : 2個
- (x_max, y_max) - coordinates of the bottom right bounding box corner. : 2個
for detection in out: confidence = float(detection[2]) xmin = int(detection[3] * frame.shape[1]) ymin = int(detection[4] * frame.shape[0]) xmax = int(detection[5] * frame.shape[1]) ymax = int(detection[6] * frame.shape[0])Confidenceというここが顔だよという確信度をconfidenceに入れています。
下の部分では顔部分のx_min(x座標の最小値)、y_min(y座標の最小値)、x_max(x座標の最大値)、y_max(y座標の最大値)を求めています。
x_min, y_min, x_max, y_maxは0-1までの少数で与えられるため、実際のframeサイズを乗算して実際の一を割り出しています。ちなみに、NというのはBounding Boxの個数です。この1個めの座標、2個めの座標というような感じです。
if confidence > 0.5: cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), color=(xmin, ymin, 0), thickness=3) frame_face = frame[ymin:ymax, xmin:xmax]ここからは多少まとめて説明していきます。
Confidenceが0.5以上のものを選んで顔部分のBounding Boxの個数を減らしていきます。
cv2.rectangleメソッドを利用し四角形を書いていきます。frame_faceには顔部分の領域だけをndarrayとして切り出します。スライスを使います。
ここから先はemotions-recognition-retail-0003モデルを使用し、上記で切り出した顔領域に対して感情認識を行っていきます。img = cv2.resize(frame_face, (64, 64)) img = img.transpose((2, 0, 1)) img = np.expand_dims(img, axis=0)
顔領域認識モデルと同じ処理を行っていきます。
感情認識モデルは上記の通りinputの画像が64 x 64を期待するモデルです。
- resizeにより入力に必要なサイズ(64, 64)へ変換しています。
- transposeにより(h, w, c)から(c, h, w)への変換をしています。
out = exec_net_emotion.infer(inputs={'data': img}) out = out['prob_emotion'] out = np.squeeze(out)outにはexec_net_emotion.inferにより感情認識した結果が入ります。
どのような形式で結果が入るかというと上記にある通り、shape[1, 5, 1, 1]となり、2番めの要素として以下の5種類の感情に分類された結果が入ります。
- neutral
- happy
- sad
- surprise
- anger
ここでもoutがどういう結果になるか見てみましょう。
{'prob_emotion': array([[[[8.9757685e-03]], [[9.8825932e-01]], [[1.2316966e-03]], [[7.2518183e-04]], [[8.0798665e-04]]]], dtype=float32)}prob_emotionという名前の配列になっているということがわかります。
ということですので、outにはout['prob_emotion']を代入し、squeezeにより余分な要素を削除してきます。
上記の例ではhappyが確率が高いということがわかりますね。index_max = np.argmax(out) list_emotion = ['neutral', 'happy', 'sad', 'surprise', 'anger']人の目で判断してもよいのですが、argmaxを使うと最大値がわかります。一番確率の高いものがわかるわけですね。
list_emotionというリストを作り、モデルの出力と同じ順番で感情の分類をリストに入れていきます。
argmaxによりリストのどの要素が最大値となるかがわかりますので、この場合ですとhappyが選択されることになります。cv2.putText(frame, list_emotion[index_max], (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (xmin, ymin, 0), 2)フォントを指定し、putTextメソッドを利用しテキストを画面内に書いていきます。場所は顔領域の上側10pixelとします。1, (xmin, ymin, 0), 2はそれぞれフォントの大きさ、色、フォントの太さを表しています。ここでは複数の人物が画面内にいたときにすべて同じ色にならないように座標により色を変えています。実際にコードで試してみてください。
cv2.imshow('image', frame)imshowにより実際に画面に描画します。
key = cv2.waitKey(1) if key != -1: break cap.release() cv2.destoryAllWindows()waitKeyによりキー入力を待ち、何らかのキーが入力されたら画面を閉じます。
最後にコード全体を載せておきます。
import cv2 import numpy as np import sys sys.path.append from openvino.inference_engine import IENetwork, IECore ie = IECore() # Face Detection Model net = ie.read_network(model='intel/face-detection-retail-0004/FP16/face-detection-retail-0004.xml', weights='intel/face-detection-retail-0004/FP16/face-detection-retail-0004.bin') exec_net = ie.load_network(network=net, device_name="CPU", num_requests=0) # Emotion Detection Model net_emotion = ie.read_network(model='intel/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.xml', weights='intel/emotions-recognition-retail-0003/FP16/emotions-recognition-retail-0003.bin') exec_net_emotion = ie.load_network(network=net_emotion, device_name="CPU", num_requests=0) cap = cv2.VideoCapture(3) while True: ret, frame = cap.read() if ret == False: continue img = cv2.resize(frame, (300, 300)) img = img.transpose((2, 0, 1)) img = np.expand_dims(img, axis=0) out = exec_net.infer(inputs={'data': img}) out = out['detection_out'] out = np.squeeze(out) for detection in out: confidence = float(detection[2]) xmin = int(detection[3] * frame.shape[1]) ymin = int(detection[4] * frame.shape[0]) xmax = int(detection[5] * frame.shape[1]) ymax = int(detection[6] * frame.shape[0]) if confidence > 0.5: cv2.rectangle(frame, (xmin, ymin), (xmax, ymax), color=(xmin, ymin, 0), thickness=3) frame_face = frame[ymin:ymax, xmin:xmax] img = cv2.resize(frame_face, (64, 64)) img = img.transpose((2, 0, 1)) img = np.expand_dims(img, axis=0) out = exec_net_emotion.infer(inputs={'data': img}) out = out['prob_emotion'] out = np.squeeze(out) index_max = np.argmax(out) list_emotion = ['neutral', 'happy', 'sad', 'surprise', 'anger'] cv2.putText(frame, list_emotion[index_max], (xmin, ymin - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (xmin, ymin, 0), 2) cv2.imshow('image', frame) key = cv2.waitKey(1) if key != -1: break cap.release() cv2.destoryAllWindows()おまけ
本記事では主にローカルでの開発方法について記載していますが、クラウド上でOpenVINOのプロトタイプ開発も可能です。
Intel DevCloud for the EdgeというIntelが提供しているクラウド開発サービスがあります。
OpenVINOが予めインストールされたクラウド上の環境を利用でき、様々なIntelハードウェア(CPU/GPU/FPGA/VPU)上でアプリケーションを実行させることが可能です。
プロトタイプの実験を簡単に無料で実施することが可能です。
大きな特徴として、Jupyter-Notebookを利用した開発が可能ですが、簡単に①〜⑥について説明します。①②:コード作成
* Jupyter-NotebookによりOpenVINOを使ったコードを記述
* OpenModelZooやModel Optimizerを利用してモデルを準備
* もし必要であればStorageServerから動画やイメージを推論させることも可能③④:ジョブを実行
* CPU,FPGA,GPU,VPU等様々なハードウェアから実行環境を選択
* アプリケーションをジョブに登録し、単体もしくは並列処理でのEdge Inferenceを実施⑤⑥:結果の出力
* Jupyter-Notebookで推論結果を画像やデータで表示実際に使用するには灯籠が必要ですが、以下のReferenceから登録が可能ですので興味を持たれた方はぜひお試しください。
来年はWebアプリ開発とそのパフォーマンス分析でも書こうかな。。Reference
- OpenVINO Resource
- OpenVINOを使う上でもモデルの情報など各種情報が取り揃えてあります。
- OpenVINO Documentation
- OpenVINOのインストール方法やpython以外の使用方法なども記載されております。
- Intel DevCloud for the Edge
- クラウドでのプロトタイプ開発が可能。予めIntelのリソースを組み込んだものを利用可能。
免責事項
本サイトおよび対応するコメントにおいて表明される意見は、投稿者本人の個人的意見であり、シスコの意見ではありません。本サイトの内容は、情報の提供のみを目的として掲載されており、シスコや他の関係者による推奨や表明を目的としたものではありません。各利用者は、本 Web サイトへの掲載により、投稿、リンクその他の方法でアップロードした全ての情報の内容に対して全責任を負い、本 Web サイトの利用に関するあらゆる責任からシスコを免責することに同意したものとします。

















- 投稿日:2020-12-18T21:27:52+09:00
Python 正規表現を利用して任意の文字列群を抽出する / 名前付きグループを利用する
この記事はTakumi Akashiro ひとり Advent Calendar 2020の18日目の記事です。
始めに
みなさまは正規表現使ってますかー?!!!
私は最後に使ったのが1ヶ月前ぐらいですね。
必要なときが来るとバリバリ使います。そんな正規表現ですが、しっかり使うと任意の文字列群を良い感じに抽出できます。
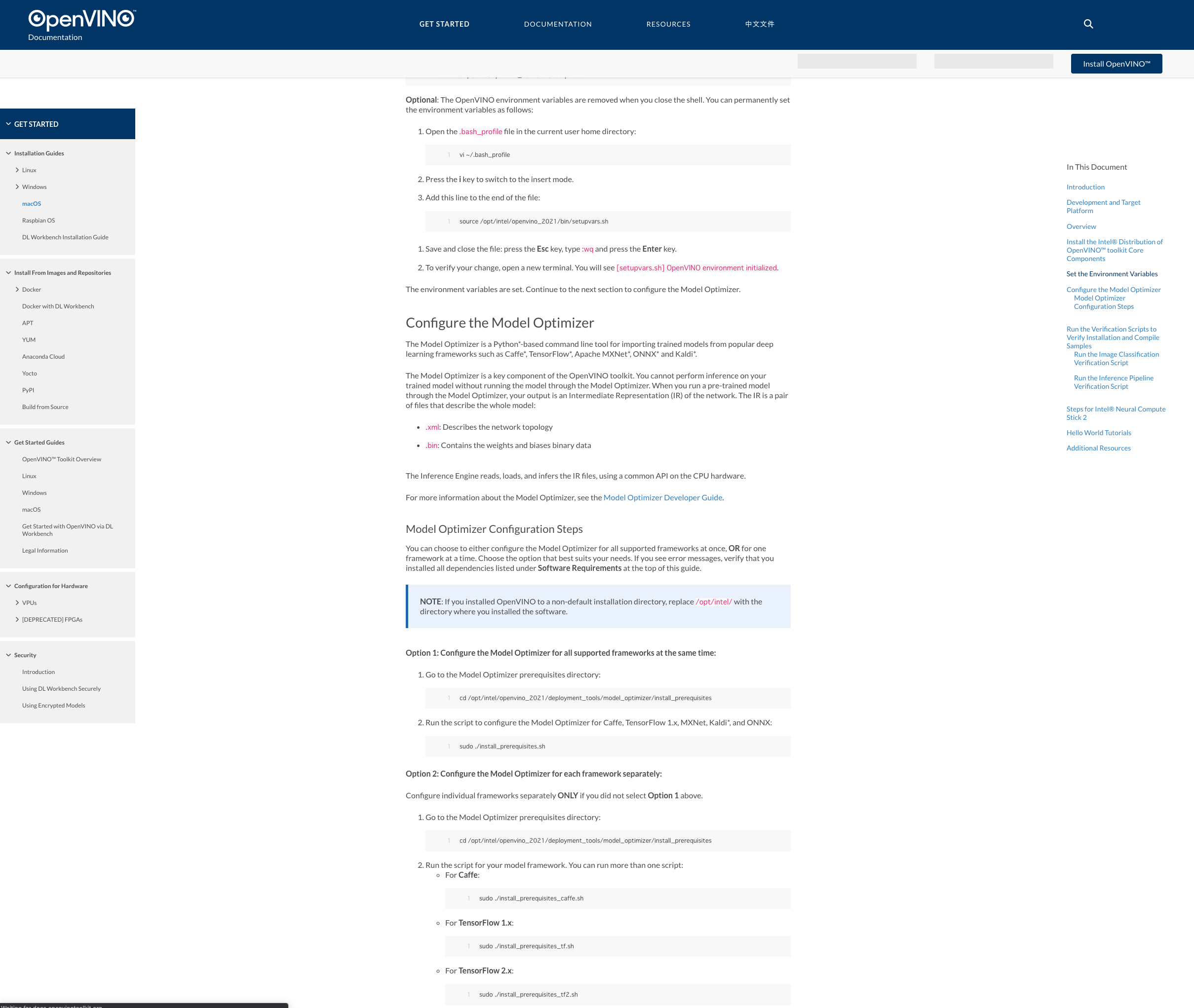
TLDL
文字列群を取り出すときは名前付きグループを使おう!
>> text = "environ/house-food/apple-pie02.fbx" >> import re >> reg_text = r'(?P<main>(chara|environ))/(?P<sub>[^-/]*)-?(?P<sub_sub>[^/]*)/(?P<filling>[^-]*)-pie' >> match = re.search(reg_text, text) >> print(match.groupdict()) {'main': 'environ', 'sub': 'house', 'sub_sub': 'food', 'filling': 'apple'}正規表現の基本
まず正規表現の基本、適当にマッチをしていきます。
#! python3 import re def main(): # NOTE: どうでもいいですけど、正規表現のサンプルでアップルパイってよく見かけますよね。 text = "environ/house-food/apple-pie02.fbx" match_obj= re.search(r'pie', text) if match_obj: print("ヒットしたよ!") else: print("ヒットしないよ!") if __name__ == '__main__': main()ま、こんなもんです。超簡単ですね。
速度が求められて[^先頭一致が可能な場合は
re.matchを使ったり、置換したいときはre.sub使うぐらいできれば、
とりあえず正規表現を使うのには困らないですね。1
ではここで、
pieの前にある文字列appleを抽出するにはどうしましょう。
色々文字列を削ったりして取り出すと思います。でも取得対象が複数あるときは?例えば
environ、house、foodとappleを一気に取りたい場合は?こんなときに利用できるのがグループです。
ちょっと公式ドキュメントを読んでみましょう。正規表現のシンタックス
(中略)
(...)
丸括弧で囲まれた正規表現にマッチするとともに、グループの開始と終了を表します。
グループの中身は以下で述べるように、マッチが実行された後で回収したり、その文字列中で以降 \number 特殊シーケンスでマッチしたりできます。
リテラル '(' や ')' にマッチするには、( や ) を使うか、文字クラス中に囲みます: [(]、 [)] 。……どう使うんだか分からん……
というわけでサンプルを出してみます。グループを使ってみる
#! python3 import re def main(): text = "environ/house-food/apple-pie02.fbx" match_obj= re.search(r'([^/-]*)-?pie)', text) print(match_obj.groups()) if __name__ == '__main__': main()
マッチオブジェクトに対して
match_obj.groups()することで、
グループ化した正規表現に引っかかった文字列のリストが取得できます。なので上記の
textからenviron、house、foodとappleを取り出したいと考えて,#! python3 import re def main(): text = "environ/house-food/apple-pie02.fbx" match = re.search(r'([^/-]*)/([^/-]*)-?([^/-]*)/([^/-]*)-?pie', text) if match: print(match.groups()) if __name__ == '__main__': main()とすれば……
無事、出来ましたね!まあまあ便利ですね!
listじゃなくてdictとしてほしいんだよなーとか、
正規表現じゃ()はよく使うから、必要な部分だけほしいんだよなーとかあると思います。そんなときにはコレ「名前付きグループ」です!
例のごとく、公式ドキュメントを読んでみます。
正規表現のシンタックス
(中略)
(?P<name>...)
通常の丸括弧に似ていますが、このグループがマッチした部分文字列はシンボリックグループ名 name でアクセスできます。
グループ名は有効な Python 識別子でなければならず、各グループ名は 1 個の正規表現内で一度だけ定義されていなければなりません。
シンボリックグループは、そのグループが名前付けされていなかったかのように番号付けされたグループでもあります。名前付きグループ を使ってみる
ま、とりあえず使えばわかるでしょうの精神で書きます。
#! python3 import re def main(): text = "environ/house-food/apple-pie02.fbx" match = re.search(r'(?P<main>[^/-]*)/(?P<sub>[^/-]*)-?(?P<sub_sub>[^/-]*)/(?P<filling>[^/-]*)-?pie', text) if match: print(match.groupdict()) if __name__ == '__main__': main()マッチオブジェクトに対して
match_obj.groupdict()することで、
名前がついたグループ化の辞書が取得できます。
いい感じに取り出せてますね!
締め
なんも思いつかねえ……便利ですね!
追記: 速度を気にするような話であれば、forループ内で同じ正規表現を使う場合、forの外で
re.compileして再利用するとが若干早くなりますね。 ↩


- 投稿日:2020-12-18T20:42:52+09:00
たった1行から始めるPythonのAST(抽象構文木)入門
はじめに
この記事は2020年のRevCommアドベントカレンダー20日目の記事です。 19日目は@metal-presidentさんの「モバイルチームの成長とKMM導入に向けて」でした。
11月に株式会社RevCommに入社した@rhoboroです。
前職では主にGCP x Pythonで、現職では主にAWS x Pythonで日々業務を行なっています。
RevCommでは広島県の尾道からフルリモートワークで働いているので、そういった働き方にもし興味があればこちらの記事もご覧ください。それでは、本題に入ります。
PythonのAST(抽象構文木)とは?
この記事は、PythonのAST(抽象構文木、Astract Syntax Tree)に触れたことのない方を対象にしたASTの入門記事です。
そもそもASTとは何なのか、ASTを理解すると何ができるのかを中心に紹介していきます。さっそくですが、タイトルにもある通りまずは1行のコマンドを打ってみましょう。
次のモジュールschema.pyを用意してから、その下にあるpython3コマンドを実行してください。schema.py# このクラスは下記にありました # https://docs.python.org/ja/3/tutorial/classes.html class MyClass: """A simple example class""" i = 12345 def f(self): return 'hello world'$ python3 -c 'import ast; print(ast.dump(ast.parse(open("schema.py").read()), indent=4))'コマンドを実行すると、次のように出力されます。(この結果はPython3.9で実行したものです)
先ほどのschema.pyとよく見比べてみると、見た目は違いますがなんとなくソースコードと同じものを表現していることがわかると思います。また、ModuleやClassDef、ExprなどがPythonのクラス名だとすると、この結果はPythonのオブジェクトにも見えてきます。Module( body=[ ClassDef( name='MyClass', bases=[], keywords=[], body=[ Expr( value=Constant(value='A simple example class')), Assign( targets=[ Name(id='i', ctx=Store())], value=Constant(value=12345)), FunctionDef( name='f', args=arguments( posonlyargs=[], args=[ arg(arg='self')], kwonlyargs=[], kw_defaults=[], defaults=[]), body=[ Return( value=Constant(value='hello world'))], decorator_list=[])], decorator_list=[])], type_ignores=[])もうお気づきだと思いますが、これこそがPythonのASTオブジェクトです。このようにAST(抽象構文木)とは、文字列であるソースコードを解析し、それを木構造で表現したものです。
つまり、Pythonがプログラムを実行する際には、次のような処理が動いてます。
- ソースコードを解析してASTオブジェクトが生成される
- ASTオブジェクトからコードオブジェクトが生成される
- コードオブジェクトから実行可能なバイトコードが生成され、実行される
PythonのASTの見方
ここまででASTとはソースコードと実行可能なバイトコードの中間表現であることは何となく理解できたと思います。
それではもう少しASTオブジェクトの中を見ていきましょう。まずはそのために必要となる道具の紹介です。標準ライブラリのastモジュール
Pythonの標準ライブラリには、ASTオブジェクトを扱うのに便利なastモジュールがあります。
先ほど実行したコマンドでも、次の2つのヘルパー関数を利用していました。
ここではどちらも一言で説明していますので、詳細は公式ドキュメントのリンクを見てください。$ python3 -c 'import ast; print(ast.dump(ast.parse(open("schema.py").read()), indent=4))'
- ast.parse(): 渡されたソースを解析してASTオブジェクトを返します
- ast.dump(): 渡されたASTオブジェクトの木構造を見やすくダンプします
また、先ほどのコマンド出力結果にあった
ClassDefやExpr、Assignといったキーワードはすべてast.ASTクラスのサブクラスです。定義されているサブクラスの一覧は公式ドキュメントの抽象文法を見るとわかります。抽象文法の左辺のシンボルひとつずつにクラスがあり、右辺にあるコンストラクタはそれぞれ左辺のシンボルのサブクラスです。ASTオブジェクトを読み解く
これで必要なものが揃ったので実際にASTを見ていきましょう。
ただし、先ほどの出力結果だと大きすぎるので、ここではx=1というとてもシンプルなPythonのソースコードのASTオブジェクトを見ていきます。$ python3 -c 'import ast; print(ast.dump(ast.parse("x=1"), indent=4))' Module( body=[ Assign( targets=[ Name(id='x', ctx=Store())], value=Constant(value=1))], type_ignores=[])
Moduleは先ほどもあったのでここでは無視すると、x=1を表現しているのはAssignのところです。Assign( targets=[ Name(id="x", ctx=Store()) ], value=Constant(value=1) )Assignは名前からわかる通り代入(assignment)を表現するノードです。
代入の左辺にあたるものがtargetsに、右辺にあたるものがvalueにそれぞれ格納されています。1したがって、代入の左辺xを表現しているノードはName(id="x", ctx=Store())だとわかります。
Nameの引数ctxは、変数の格納、読み込み、削除と対応していて、それぞれStore()、Load()、Del()となっています。右辺1は定数なのでそのままConstant(value=1)ですね。これでこのASTオブジェクトが
x=1という式を表していることが理解できたと思います。この記事の最初のコマンド結果のASTオブジェクトも、同じようにastモジュールのドキュメントを片手にひとつずつ見ていくと読み解けるでしょう。ASTオブジェクトの活用
ASTオブジェクトは先ほども述べたようにソースコードと実行可能なバイトコードの中間表現です。
それでいてPythonオブジェクトでもあるため、ソースコードやコードオブジェクトよりもPythonのプログラムから処理しやすいです。そのため、ASTオブジェクトは様々な活用方法があります。例をあげるとmypyやflake8といった静的解析ツールなどで利用されていたり、pytestではassert文のASTオブジェクトを変更しassert文をより便利なものにしています。そのほかにも、通常のPythonのソースコードではないファイルからASTオブジェクトを生成してPythonのオブジェクトとして動かすこともできます。2
また、Python3.9で追加されたast.unparse()を使うと、ASTオブジェクトからソースコードを生成できます。これを利用してJSONファイルからASTオブジェクトを構築し、pydanticのモデルクラスを生成するライブラリpydantic-generatorを作成しました。もしよかったら触ってみてください。
最後に注意
ASTオブジェクトの変更はユーザーや他の開発者の思いもしない挙動となり、混乱を生じさせる可能性が高いです。
それ以外の方法がないというとき以外は使わないようにしましょう。3おわりに
わたし自身もそうでしたが、ASTは難しいという印象を持っている方も多いのではないでしょうか。
しかし、蓋を開けてみればドキュメントも1ページだけですし、ソースコードと1対1で対応しているためとてもシンプルなものです。
便利なこの1行でいろんなモジュールのASTオブジェクトを眺めてみてください。$ python3 -c 'import ast; print(ast.dump(ast.parse(open("YourFile.py").read()), indent=4))'明日はリサーチチームの@k_ishiさんです。
2020年のRevComm Advent Calendarは一日も途切れることなく続いてますので、明日もお楽しみに!
- 投稿日:2020-12-18T20:24:38+09:00
Raspberrry Pi4 でやってみた機械学習
Raspberrry Pi4 でやってみた機械学習
はじめに
今回、会社で学習用に存在した、Raspberrry Pi4を使ってインストールから解析するまでの説明をさせていただこうかなと思います。
やってみた流れは以下のようになります。
- インストールから起動まで
- SSHとRemote Desktop接続
- Coral AcceleratorとRaspberry Piカメラを使って画像解析とリアルタイム映像解析
インストールから起動まで
準備したもの
- Raspberry Pi 4 Model B(8GB基盤)
- SDカード(Sandisk Ultra 256GB)
- SD カードリーダー
- Type-C電源アダプターとスイッチ
- ケース
- MicroHDMI-to-HDMIケーブル
- Coral USB Accelerator
- Raspberry Piカメラ
- モニター、USBキーボード、USBマウス
- Macパソコン
- Wi-Fi(無線LAN)
ダウンロードとインストール
Mac(Pro)を使用してRaspberry Pi環境をmicroSDカードにインストールします。
OS は従来 Raspbian と呼ばれていた Raspberry Pi OS を利用します。
Raspberry Pi公式サイトに提供してるRaspberry Pi Imager を利用するため、イメージファイルを事前にダウンロードしておく必要はありません。以下の手順の通りに実行します。
Raspberry Pi Imager のインストール
MacOSだと
brew cask install raspberry-pi-imagerでインストール可能ですが、今回は公式サイトから「Raspberry Pi Imager for macOS」をダウンロードしてインストールします。Raspberry Pi OS をSDカードにインストール
SD カードリーダーに microSD カードをセットし、スタートメニューから Raspberry Pi Imager を起動します。
CHOOSE SD CARD で書き込む microSD カードを選択し、 CHOOSE OS をクリックします。
OS を選択すると、自動でイメージをダウンロードできます。
WRITE ボタンを押すと、書き込みが開始されます。
書き込みが完了すると、自動的にベリファイが走ります。
しばらく待って、ベリファイが完了するとSDカードにRaspbianのインストールが完了です。
※Raspberry Pi Imagerを使うと、他のツールを利用する必要が無いため、非常に便利です。SSHとRemote Desktop接続
初期設定として、自分のMacからSSHとRemote Desktopが実行できるように準備します。
理由はモニター、USBキーボード、USBマウスの切替が面倒なので、モニターに繋がず、自分のMac上でRaspberry Piを利用するためです。起動と接続
次に、以下の手順を実行していきます。
Raspbianを書き込んだmicroSDカードをRaspberry Pi4に挿入します。
初回のみ、HDMIケーブルをRaspberry Piに接続し、電源を入れて起動します。
起動シーケンスの後でログイン出来たら、以下の初期インストールを実行します。「Welcome to the Raspberry Pi Deskop!」が表示したら「Next」を押します。
「国、言語、キーボードタイプ、タイムゾーンなど」をセットし、「Next」を押します。
初期ユーザーとパスワードは pi と raspberry になっています、ここでは、新しいパスワードを設定し、「Next」を押します。
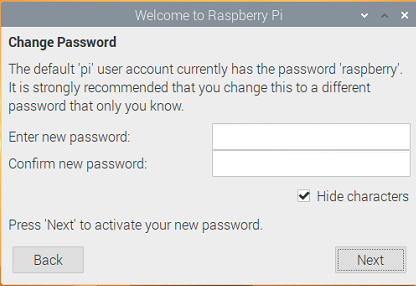
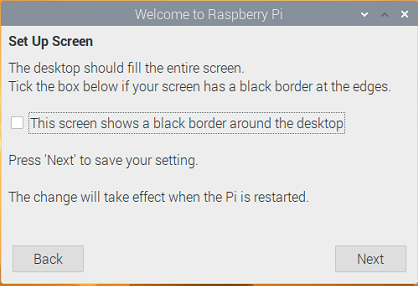
スクリーン設定画面で「This screen shows a black border around the desktop」をオンにして「Next」を押します(再起動してから反映されます)。
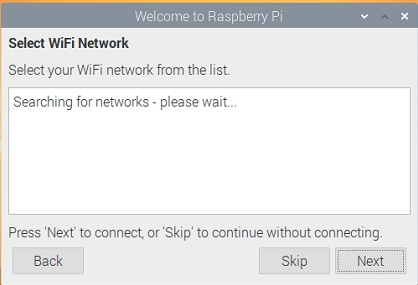
Wi-Fiネットワークを設定し、「Next」を押します。
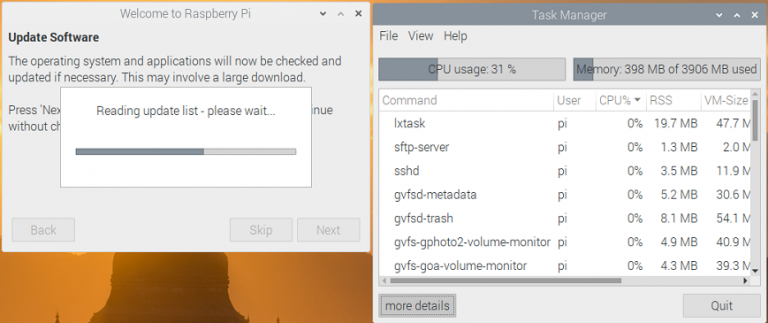
ソフトウェアの更新画面でスキップしてもいいですが、アップデートした良いので、「Next」を押します。
アップデート中にタスクマネージャーを開くと、プロセスを確認出来ます。
アップデートが完了したら、「Restart」を押して再起動を行います。
初期設定と接続設定
OS バージョン確認
pi@raspberrypi:~ $ uname -a Linux raspberrypi 5.4.79-v7l+ #1373 SMP Mon Nov 23 13:27:40 GMT 2020 armv7l GNU/Linuxパッケージ更新
pi@raspberrypi:~ $ sudo apt update pi@raspberrypi:~ $ sudo apt upgrade -yvim インストール
pi@raspberrypi:~ $ sudo apt install vim -yraspi-config による設定
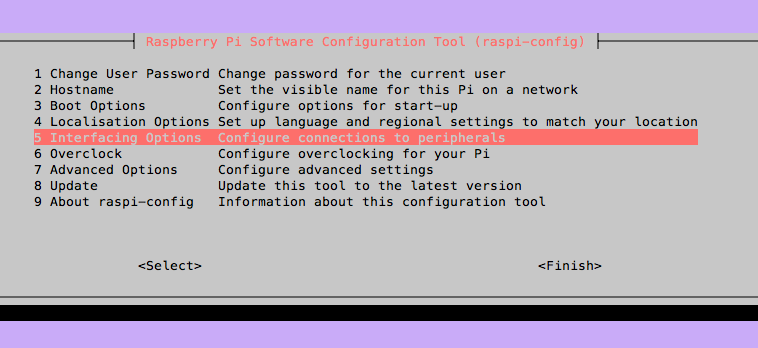
pi@raspberrypi:~ $ sudo raspi-config次のようなキャラクタベースのUIが起動します。
「5 Interfacing Options」を選択して、「P2 SSH」を選択しSSHを有効化と、「P3 VNC」を選択しVNCを有効化します。
※VNCが表示されない場合、以下のように手動でインストールしてください。pi@raspberrypi:~ $ sudo apt update pi@raspberrypi:~ $ sudo apt install realvnc-vnc-server realvnc-vnc-viewerその後、以下のコマンドで再起動させます。
pi@raspberrypi:~ $ sudo rebootVNC Viewerの設定
Raspberry Pi に割り振られた、private IPアドレスを調べます。pi@raspberrypi:~ $ ifconfig もしくは pi@raspberrypi:~ $ ping raspberrypi.localVNC Viewerを起動します。
VNC Viewerの検索ボックスに、Raspberry Piに割り振られたprivate IPアドレスを入力します。
「Connect to address」を押してRaspberry Piのユーザーとパスワードを入れます。
問題なく設定出来たらトップバーにアイコンが表示されます。
ついでに、画面解像度が良くなるように設定します。pi@raspberrypi:~ $ sudo vim /boot/config.txt ===== これを追加します。 hdmi_ignore_edid=0xa5000080 hdmi_group=2 hdmi_mode=85 =====次はRaspberry Piをsleepしないように設定します。
方法は2つあります。
方法1pi@raspberrypi:~ $ sudo vim /etc/lightdm/lightdm.conf ===== これを追加します。 xserver-command=X -s 0 -p 0 -dpms =====方法2
pi@raspberrypi:~ $ sudo apt-get install xscreensaverpreferenceからscreensaverに行って、Display ModesタグのModeをDisable Screen Saverを選択します。その後、再起動させます。
自分のMacからSSHで接続する
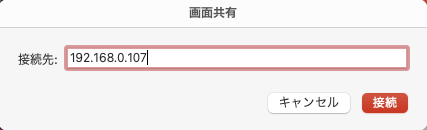
自分のMacの「ターミナル」に以下のコマンドを入力します。
IPのところにRaspberry Piに割り振られたprivate IPアドレスを入力します。[~]$ ssh pi@192.168.0.107この後、ログインパスワードを入力します。
自分のMacから画面共有アプリケーションで接続する
自分のMacの「Screen Sharing」画面共有アプリを開きます。
接続先の入力部に、Raspberry Piに割り振られたprivate IPアドレスを入力し、接続を押します。
パスワードの入力部に、ログインパスワードを入力しサインインを押します。(パスワードを保存するチェックボックスをオンにすると次回入力が楽になります。)
以下のように、raspberrypiの画面が表示されます。
CoralAcceleratorとRaspberry Piカメラを使って画像解析とリアルタイム映像解析
Raspberry Piにセットアップする
初めに、CoralAcceleratorの「Get started」を行います。
Coral USB AcceleratorをRaspberry Piに繋げます。
その後、以下の手順を実行します。pi@raspberrypi:~ $ echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list pi@raspberrypi:~ $ curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add - pi@raspberrypi:~ $ sudo apt-get update次に、Edge TPUランタイムをインストールします。
pi@raspberrypi:~ $ sudo apt-get install libedgetpu1-std次に、Raspberry PiカメラをRaspberry Piに繋げます。
その後、以下の手順を実行して、サンプル用に写真を撮ります。
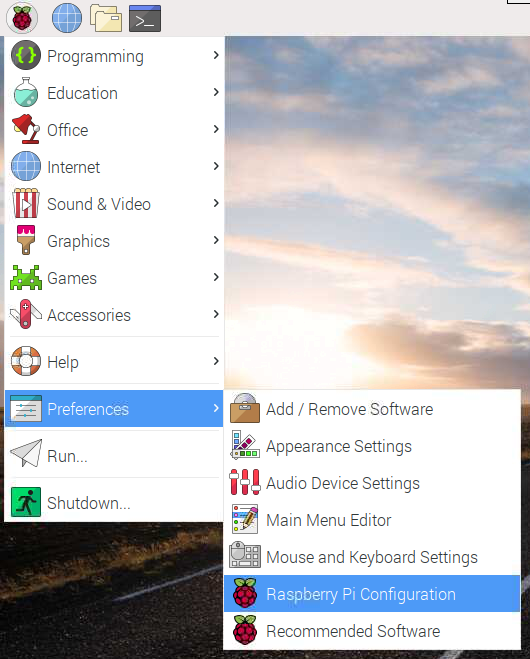
Raspberry Pi Configurationを開きます。
Interfacesタブからcameraをenabledにします。
次のコマンドで写真を撮ります。pi@raspberrypi:~ $ raspistill -o Desktop/image.jpg画像解析しましょう
これらの手順に従って、Coralが提供しているコンパイル済みのモデルとサンプルスクリプトを使用して、画像分類を実行します。
まずは、GitHubからダウンロードを行います。pi@raspberrypi:~ $ mkdir coral && cd coral pi@raspberrypi:~ $ git clone https://github.com/google-coral/tflite.git鳥の分類モデル、ラベルファイル、と鳥の写真をダウンロードします。
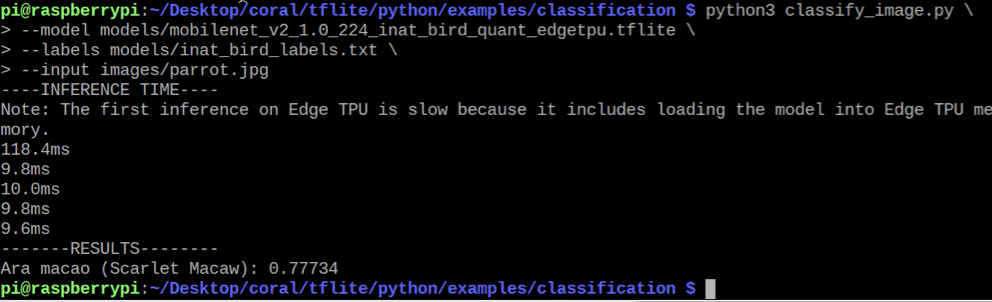
pi@raspberrypi:~ $ cd tflite/python/examples/classification pi@raspberrypi:~ $ bash install_requirements.sh以下の鳥の写真を使用して画像分類子を実行します。
pi@raspberrypi:~ $ python3 classify_image.py \ --model models/mobilenet_v2_1.0_224_inat_bird_quant_edgetpu.tflite \ --labels models/inat_bird_labels.txt \ --input images/parrot.jpg
以下のような結果になります。
リアルタイム映像解析
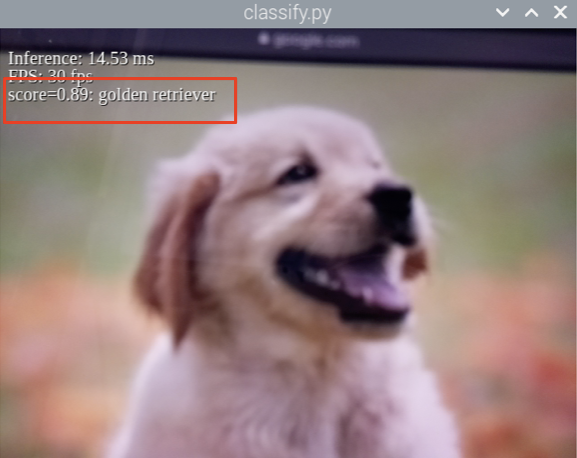
今回は、Coralが提供しているサンプルの中から「Image recognition with video」をRaspberry Piカメラを利用して、リアルタイム映像解析を行います。
まずは、GitHubからダウンロードします。pi@raspberrypi:~ $ mkdir google-coral && cd google-coral pi@raspberrypi:~ $ git clone https://github.com/google-coral/examples-camera --depth 1モデルをダウンロードします。
pi@raspberrypi:~ $ cd examples-camera pi@raspberrypi:~ $ sh download_models.shgstreamerライブラリをインストールします。
pi@raspberrypi:~ $ cd gstreamer pi@raspberrypi:~ $ bash install_requirements.shそして、デモを実行します。
pi@raspberrypi:~ $ python3 classify_capture.pyiPadで画像を表示して認識します。
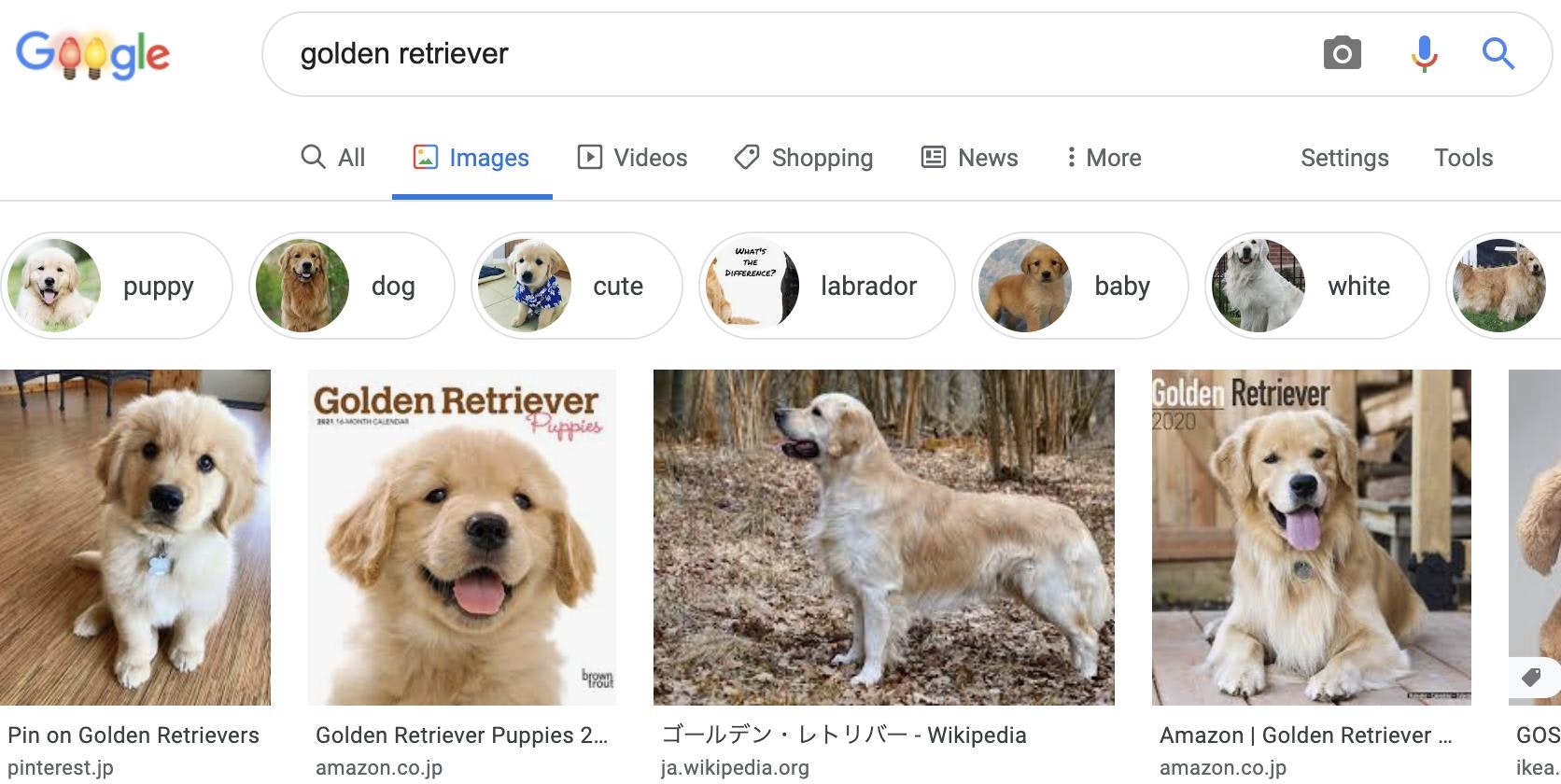
結果として、以下の画像が得られました。
得られた名前で検索を行い、結果が正しいことが確認できました。
以上で、学習結果の説明は終了となります。














- 投稿日:2020-12-18T20:13:51+09:00
YouTubeのPython解説を覚え書き。
Learn Python - Full Course for Beginners [Tutorial]
https://www.youtube.com/watch?v=rfscVS0vtbw
(英語字幕は ところどころ間違っているので 注意が必要。)
2:14 -
python download
https://www.python.org/downloads/
Python 3 or Python 2?
Python 3 は 今後も利用されていくバージョンで、サポートもされているため、このコースではこちらを利用します。
Python 3 は 初心者が学ぶのに適しています。
(2020-12-18 現在、Python 3.9.1 のみ ダウンロードリンクがあった。)次のインストール中のオプション 2つ:
Add Python 3.9 to PATH
Disable path length limit
これらは どちらも設定せずに インストールを完了するといいらしいです。(参考: https://gammasoft.jp/python/python-install-on-windows/)
4:53 -
Choose text editor
IDE - integrated development environment
PyCharm Community Edition を ダウンロードする。(現在 最新バージョンは 2020.3)
https://www.jetbrains.com/ja-jp/pycharm/download/#section=windowsinstallation Options
通常は何もチェックしなくて構いませんが、必要な場合は適宜チェックしてください。(参考: https://gammasoft.jp/python/pycharm-install-on-windows/)
6:42 -
Setup & Hello World7:07 -
動画内の旧バージョンのPyCharmでは 右下にConfigureのメニューがあるが、最新版の2020.3では 画面左 Customizeタブの "All settings..." から 設定ができるみたい。
また、動画ではAppearanceのThemeをDarculaに変更していたが、最新版ではデフォルトからDarculaだった。7:49 -
動画内では"Interpreter: "というオプションだけだが、最新版の初回起動時では New enviroment using: Virtualev と なっており、Base interpreterが"...Python39\python.exe"になっていれば良いようだ。
- 投稿日:2020-12-18T19:51:38+09:00
【Xonsh】Python製シェルが尖りまくってて神
Macのターミナル環境を色々改造しつつその一環としてshellも何個か見てきました。
bash, zsh, fish ...中でもここ半年くらいはPython製のXonshが超絶お気に入りなので自分なりに紹介します。
ちなみに元ネタと言うか見つけたきっかけは、機械学習界隈で有名なばんくしさんのブログです。
Python製シェルxonshを半年使った所感や環境設定のまとめ
この人すごすぎ
What's Xonsh
タイトルのまんまですが、Pythonで作られたShellです。
Pythonで作られ、Pythonで動き、Pythonが実行できます。他のシェルが何で動いてるかとかはわかりませんが、とにかくこいつが超尖っててイケてます。
Commnd and Python
Pythonで作られている事のメリットその1として、コマンドとPythonスクリプトの同居ができます。
[ ~/Desktop/tmp ] $ ls -al Permissions Size User Date Modified Name drwxr-xr-x - *** 18 12 19:20 . drwx------ - *** 18 12 19:18 .. [ ~/Desktop/tmp ] $ dirs = ['a', 'b', 'c'] [ ~/Desktop/tmp ] $ for dir in dirs: . mkdir @(dir) . [ ~/Desktop/tmp ] $ ls -al Permissions Size User Date Modified Name drwxr-xr-x - *** 18 12 19:21 . drwx------ - *** 18 12 19:18 .. drwxr-xr-x - *** 18 12 19:21 a drwxr-xr-x - *** 18 12 19:21 b drwxr-xr-x - *** 18 12 19:21 cこんな感じ。
わざわざ変数に入れてfor文回すよりmkdir × 3の方がはえーよ!!と思うかもしれませんが、
処理がえぐいくらい増えた時とかこれ使ったらめちゃくちゃイケてると思いませんか?当然のごとく関数だって定義できちゃいます。
[ ~/Desktop/tmp ] $ def hello_xonsh(): . print('hello xonsh !!!') . [ ~/Desktop/tmp ] $ hello_xonsh() hello xonsh !!!.xonshrc
他のシェル同様、xonshにもrcファイルがあります。(.xonshrc)
もう想像ついてるかもしれませんが、このrcファイルが全てPythonで記述できます。個人的にはこれが神すぎて使ってる
- Aliases
aliases['ls'] = 'exa -ahl --git' aliases['la'] = 'exa -ahl --git' aliases['ll'] = 'exa -ahl --git' aliases['l'] = 'exa -ahl --git' aliases['cat'] = 'bat' aliases['tf'] = 'terraform' aliases['do'] = 'docker' aliases['dc'] = 'docker-compose'aliasesという辞書型変数が内部で定義されていてそこに追加する。
かっこよすぎる。
- env
import os $DEV_ROOT = os.environ.get('HOME') + '/dev'環境変数は$ + 変数名で定義する。
importすればPythonの標準ライブラリも使い放題。
- Command
def _set_aws_profile(args): $AWS_PROFILE = args[0] $AWS_DEFAULT_PROFILE = args[0] print('aws profile is : ', p) aliases['awsp'] = _set_aws_profile複雑なコマンドは関数で定義してそのままaliasesに突っ込める。
args引数でコマンド引数を受け取れる。ちなみに、ここでは引数をargsしか定義してないけど、他にもstdinとかstdoutとかも取れるみたい。
(ここはうまく使いこなせてない)Install
ここまで読んでもし使いたくなってくれたらinstallは一瞬です。
$ brew install xonshもしくは
$ pip install xonshなどなど、他にも大体の環境でインストールできる。
起動はそのまんま
$ xonshUse Xonsh!
Xonshは尖りまくってるゆえにデメリットもあります。
例えばコマンドによっては引数をシングルクオートでうまく括らないと動かない時とかありました。でもそんなちっぽけなデメリットを遥かに上回るイケイケ具合なので使ってます。
Python好きはお試しを!!
- 投稿日:2020-12-18T19:08:30+09:00
【Python】YOLOv3を使ってみた
はじめに
前回記事投稿した『OpenCVを用いてネコ検出器を作る』においてうまくいった例とうまくいかなかった例がいくつか出てきました。どうにかもっと精度あげられないかと調べているときにYOLOv3という手法を見つけて試しに行なってみました(要するに思っていた以上に精度が悪く悔しかったので...)。前回の記事でも記載した私が経験したハッカソンでもYOLOという単語は出ていましたが別タスクを私は任されたためYOLOには触れずにハッカソンが終わってしまったのでいい勉強になったので記事に書かせていただきます。
YOLOv3とは
YOLOとはYou Only Look Once(一度見るだけで)の略らしいです。面白いですね!NN(ニューラルネット)を一からモデルを構築しなくても、YOLOなら大丈夫でYOLOをダウンロードすれば構築ができているので通すだけでできました。また画像だけでなく、Webカメラなどとも連動できるので、リアルタイムの検出も可能ですので画像において色々な場面で活躍ができそうだと感じました。YOLOの公式サイト
実際にYOLOを使うとこのようなことができます。
このように物体を検知して何かをラベリングすることが可能になっています。実際にネコ検出器でできなかった画像たちに試してみましょう!!YOLOv3を使う
YOLOの導入にはこちらの記事を参考に行いました。(Macで物体検知アルゴリズムYOLO V3を動かす)
ターミナルを使います。
前提としanacondaを導入されているという状態で説明します。anacondaが導入されていないのであればまずは先に導入してください。$ conda create -n yolo_v3 python=3.6 pip $ source activate yolo_v3これでPython仮想環境を作成できました。ここまで行うと
(yolo_v3) $となると思います。
次に必要なパッケージをそのままインストールしていきます。(yolo_v3) $ conda install pandas opencv (yolo_v3) $ conda install pytorch torchvision -c pytorch (yolo_v3) $ pip install matplotlib cython上記の参考記事ではエラーが
matplotlibをインストールするときにエラーが出ると書かれていましたがエラーは私の場合はmacですが特にエラーは出なかったと思います。ここまで終了したら'cd'で今回作業したいフォルダまで下がり
git cloneで次のファイルをインポートします。
新しいコマンドを立ち上げて下をコピペしてください。$ git clone https://github.com/ayooshkathuria/pytorch-yolo-v3.gitまた先ほどの
(yolo_v3)となっている端末に戻り(yolo_v3) $ cd ~~/pytorch-yolo-v3 (yolo_v3) $ wget https://pjreddie.com/media/files/yolov3.weights~~/pytorch-yolo-v3は個々人該当のディレクトリで行なってください。
wgetを行うとモデルの構築が自動で行われます。少し待つとYOLOv3が使える状態になりました。実際に試してみた
試す時も先ほどのコマンドプロンプトを用います。実行自体は下で示したコマンドでできますが、試したい画像をimagesというファイルに入れる必要があります。忘れずに入れてから実行してください。あたgithubをcloneしたときに何枚かサンプル画像はありましたのでそちらを試すでも良いと思います。
(yolo_v3) $ python detect.py --images imgs --det detエラーが出た・・
私の場合は下のようなエラーが出てしまったのでまたまた調べて対処を見つけました。pytorch-yolo-v3のRuntimeErrorを解消できたよ
Traceback (most recent call last): File "detect.py", line 234, in output = torch.cat((output,prediction)) RuntimeError: invalid argument 0: Sizes of tensors must match except in dimension 0. Got 8 and 86 in dimension 1 at d:\build\pytorch\pytorch-1.0.1\aten\src\th\generic\thtensormoremath.cpp:1307どうも
"pytorch-yolo-v3/util.py"というファイルを消去し新たに下のリンクのutil.pyに差し替えることで動きました。
こちらのリンクこのutil.pyをPCに保存する方法は
1. リンクを開く
2. Rawを右クリック
3.リンク先を別名を保存をクリック(名前は変えずにutil.pyにしました)
4."pytorch-yolo-v3/util.py"となるようにペーストする結果
デフォルトであった画像で結果をまずは試してみました。

画像に写っているhorseをラベル化できています!スゴイですね笑
続いて

信号機(traffic light)だったりcar,truckなど識別ができています。
実際にうまくいかなかった画像で試してみた

前回は斜めを向いていて反応してくれなかったのですが今回はcatとラベリングしてくれました!!

前回はネコ3匹のうち1匹のみ検出できていましたがネコ3匹全て検出ができしかもcarまで検出ができていてとても良い精度だなと感じました。
それでもうまくいかなかった例
※検出した最終の結果のみ載せます。
"dog"と誤認識していました。。まぁ見えるけど。。。という感じですね。(写真が悪いかもですが・・・)
"bird"と誤認識していました。。遠いからですね、なるほど。考察
写真が悪いものは誤認識されていますが、認識はとても精度がいいなと思いました。またYOLOはよく話で聞いていたのでやってみて精度がいいなと思いました。ネコ以外に渋谷ハロウィンのとても混み合っているニュースの写真で試してみてどれくらい遠い距離にいたり一部分のみしか写っていない写真でも精度は意外と良い印象を受けました。
考察ではないが、またハッカソンで吸収できなかったYOLOに関して結構調べて自分自身で結構吸収できたことがとてもよかったなぁと思った。
ハッカソンで扱った3つのモデルである顔認証・全身認証・歩容認証(骨格認証)のうち前回の記事で扱ったOpenCVでの顔認証・そして今回扱ったYOLOv3での全身認証がクリアしました。次は骨格認証で使ったOpenPose・HumanPoseなどについて調べて実装してみて記事を書きたいなと思います!また研究室の人だったりフォローしていただいている方から機械学習で使う基本的な数学について記事欲しいと要望があったのでいつか(多分年末までに?)数学について書こうと思います!何について書こうかな・・・?まだ決めてませんがw
ここまで読んでいただきありがとうございました。
もしよければフォロー・LGTMよろしくお願いいたします。参考
YOLOとかOpenCVとかで物体検知
Macで物体検知アルゴリズムYOLO V3を動かす
pytorch-yolo-v3のRuntimeErrorを解消できたよ
pytorch-yolo-v3







- 投稿日:2020-12-18T18:56:04+09:00
AssumeRoleをECS&Digdag環境で利用する
やりたいこと
AWS アカウント A
- S3 に日次でファイルが置かれる
AWS アカウント B
- アカウント A の S3 のファイルを取得したい
- 実行環境は ECS 上で動いている Digdag サーバー
AssumeRole は一時的なクレデンシャルを生成して、他の AWS アカウントからのアクセスを許可できるので、以下のようなセキュリティ的に避けたい設定を行わなくて済みます
- IAM ユーザーを作成し、AWS アクセスキー発行
- S3 の公開設定
AWS アカウント A - 参照先
ロールを作成
- AWS コンソールからロールを作成
- 信頼されたエンティティの種類を「別の AWS アカウント」にして、アカウント B のアカウント ID を設定
- この段階では、アカウント B の root に権限が付与される(ここは後で変えます)
- アカウント B 用のポリシーを作成して、ロールにアタッチ
以下は今回のやりたいことを実現する最低限のポリシーです{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "s3:GetObject", "Resource": ["arn:aws:s3:::[バケット名]/*"] } ] }AWS アカウント B - 参照元
AssumeRole のポリシーを作成
- AWS コンソールからポリシーを作成
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": "arn:aws:iam::[アカウントAのID]:role/[さっき作ったロール名]" } ] }
- ECS タスクのロールにこのポリシーをアタッチ
ECS タスクで使われているロールは、コンソールの ECS タスク定義から、「タスク実行ロール」で確認できますAWS アカウント A - 参照先
作成したロールの信頼関係タブから、以下のように編集
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::[アカウントBのID]:role/ECSタスクロール名" }, "Action": "sts:AssumeRole", "Condition": {} } ] }さきほどは、アカウント B の root に権限を与えていましたが、ECS タスクロールに権限を与えるように変更しました
動作確認
AWS CLI
Digdag のタスクが sh で、AWS CLI を使う場合
ECS タスクで使う Docker などで以下を用意する
~/.aws/configを作成[profile assume] role_arn = arn:aws:iam::[アカウントAのID]:role/[ロール名] credential_source = EcsContainer または echo "[profile assume]" > ~/.aws/config echo "role_arn = arn:aws:iam::[アカウントAのID]:role/[ロール名]" >> ~/.aws/config echo "credential_source = EcsContainer" >> ~/.aws/configaws s3 cp [コピー元] [コピー先] --recursive --profile assumePython
Digdag のタスクが Python の場合
from sts import STS # role_arn: arn:aws:iam::[アカウントAのID]:role/[ロール名] # bucket: 参照先のバケット名 # key: 参照先のオブジェクトキー # save_file_path: 保存先(Digdagコンテナー内) class S3(object): def get_by_sts(self, role_arn, bucket, key, save_file_path): resource = STS().get_resource(role_arn, "s3") resource.Bucket(bucket).download_file( key, save_file_path, )import boto3 class STS(object): sts_client = boto3.client("sts") def get_resource(self, role_arn, resource_name): role_obj = self.sts_client.assume_role( RoleArn=role_arn, RoleSessionName="AssumeRoleSession", ) resource = boto3.resource( resource_name, aws_access_key_id=role_obj["Credentials"]["AccessKeyId"], aws_secret_access_key=role_obj["Credentials"]["SecretAccessKey"], aws_session_token=role_obj["Credentials"]["SessionToken"], ) return resource
boto3.client("sts").assume_roleに RoleArn と任意のセッション名を渡して、一時的なクレデンシャルを発行しています
- 投稿日:2020-12-18T18:54:17+09:00
リスト・関数・for・while・with(open)・classと前回までの学習補足(Ruby学習後のPython初学)
リスト
test.pylist = ["0", "1", "2"] # Rubyの配列の扱いに近い list[0] # 0番目の"0"が取り出される。関数
test.pydef test(arg): return arg + 1 print(test(0)) #関数となるのがtest、引数となるのがargになる。 #関数の場合はreturnによる戻り値が必要である。上記の場合、test(0)の0を引数として関数testのargに入って、
戻り値として+1されてreturnされて出力されているfor文
test.pyfor index in range(100) print index #0回から99回まで数字を出力する for i in range(1,101) print index #1回から100回の範囲指定 #forとinの間はindexやiとされるのが通例。 #リストによるfor文 num = 0 list = ["0", "1", "2"] for item in list: print list[num] num += 1 #リストの中身に対して全て実行される。リストの場合はforとinの間はitemが通例。while文
test.pynum = 1 #カウンタ変数を初期化 while num <= 10: print(num) num += 1 #カウンタ変数を更新while前のnumの部分がカウンタ変数といい、while後の条件式で扱う。
なお、while文内でnumを更新し条件式に当てはまらないものを定めないとループするようになる。with(open)
test.py# with open('参照するfile', 'モードと呼ばれる実行処理') as file: # 実行する処理の記述例えばtest.pyの直上のディレクトリの中にtest.txtのfileがあった場合 ./test.txt と
書くことで参照先をパス指定できる。
なお、モードと呼ばれる実行処理の中にはread(読み取り)の頭文字に当たるrや
write(書き込み)の頭文字に当たるwなどがモードと飛ばれる実行処理になる。
(詳しい内容は次回以降の学習)class
test.py# class クラス名(頭文字は大文字): # def __init__(self, プロパティ1, プロパティ2, ...,): # self.プロパティ1 = プロパティ1 # def メソッド名(self): # return 実行する処理 #例 class Card: #Cardというクラス def __init__(self, date, user_name): self.date = date self.user_name = user_name def message(self): #クラス内の関数をメソッドという、今回はmessageというメソッド return self.user_name + self.date #メソッドの戻り値 date_a = '2020-01-01' user_name_a = 'Test' card_a = Card(date_a, user_name_a) #Cardクラスにcard_aというインスタンスを生成 print(card_a.message()) #card_aに対してmessageメソッドを実行してprint出力している前回までの補足
①VScodeでコードを書いてターミナルで実行できる環境を整えた所、実行するとエラーが出たので備忘録。#coding:utf-8の記述をしておかないと日本語を使用していることによるエラーが出る。
②予約語がPythonにもある
③print(type(調べたいもの))でstr型かint型かわかる。
④strでもintでもないブーリアン型がある。 例:T = True , N = False
⑤importできるモジュールに関してpypiで検索すると外部からのモジュールを探すことができる
有名なところでいうとNumPy、Pandas、Flask、Django等
- 投稿日:2020-12-18T18:39:36+09:00
__init__やselfに関する備忘録
今回は、プログラミングにおいて、
__init__やselfのことを深く理解してない状態だったので、備忘録として残しておきたいと思います。開発環境
MacOS
Python3.7(anaconda)
VSCodeクラスと self と init
【Python入門】クラスの基本を1から解説する―完全版
Python の super() 関数の使い方initとは
__init__とは、インスタンスを生成した際に、1番最初に呼び出される関数になります。class Human: name = 'Jack' def __init__(self): self.name = 'Bob' boku = Human() print(boku.name) -> Bobといった具合に、
インスタンス化が行われた後に、__init__が呼び出されるため、元々はnameにはJackが入っていましたが、実行した際はBobが出力されることになります。インスタンス化とは何か
インスタンス化とは、簡単に言えば、型作りのようなものですね。
人間という大雑把な形を作って、JackやBobという個人を作る部分に分かれてくるという具合です。class Human: def __init__(self) self.name1 = 'Jack' self.name2 = 'Bob' boku = Human() <- ここがインスタンス化 print(boku.name1) -> Jack print(boku.name2) -> Bobといった具合に、
boku = Human()によってインスタンス化が行われます。
インスタンス名 = クラス名()といった書き方になります。self.変数とは何か
まずは、
self.nameに実名を入れていくだけの処理を見ていきます。class Human: def __init__(self): self.name1 = 'Jack' self.name2 = 'Bob' boku = Human() print(boku.name1) print(boku.name2)これだと、nameを100人分作る場合は、
変数nameを100個用意しなければいけない状態になります。次に、
self.name=nameを使うバージョンclass Human: def __init__(self, name): self.name = name boku = Human('Jack')こちらは、
Human('Steve')やHuman('Bob')に変更することによって、名前を変更することができます。
こちらの処理の方が、よりシンプルに書けて無駄な処理をしなくて良い状態になっております。superとは何か
次に、
__init__の後によく見かけるsuperって何ですかいっていう説明をします。まず、複数のクラスで同じような処理をする場合は、毎度同じ処理を書くわけではありません。
1番最初に、メインのクラスを書いたら、そのクラスを
継承することで、同じ処理の記述を省くことにしています。class Human: def __init__(self, name, sex, weight): self.name = name self.sex = sex self.weight = weight boku = Human('Jack') print(boku.name) -> Jack class Bird(Human): def __init__(self, name, sex, height): super().__init__(name, sex) self.height = heightこのように、
クラス名の後に、継承したい親クラスの名前を書きます。そして、
super().__init__(親クラスと同じ処理をする変数)という記述をすることで、self.nameやself.sexを書く必要がなく、同じ処理を行うことができます。まとめ
理解しなくても処理を行うことはできるかと思いますが、個人的にモヤモヤした状態になってしまうので、今回記事にさせてもらいました。
わかりにくい部分が多いと思いますが、皆さんのお助けになればと思います。
- 投稿日:2020-12-18T18:16:38+09:00
Python で画像フィルタパラメータを blackbox 最適化で探索してみるメモ
背景
対象の関数(問題)がブラックボックス的なものですと, そのパラメータを求めるのは
blackbox 最適化や, 機械学習の分野では hyperparameter 最適化(探索)と呼ばれているようですね.
画像処理でも blackbox 最適化をしたい要求がよくあります.
たとえば, ターゲットとなるオシャンティな画像(インスタ映え画像)に見た目を合わせて, 自分のとったちょっとイマイチな写真でもオシャンティな画像にしたいとか. この場合, 明るさとか, セピア調/フィルム調フィルタとかのフィルタパラメータを探索します.
(手動で見つけるだと無限に時間が溶けてしまいつらい)今回はもう少し問題を単純化して, ImageMagick でブラーをかけた画像で, そのブラーのパラメータを推定してみます.
画像の誤差にはとりあえず RMSE を使ってみます
(一致するほど値が低くなる)Python で blackbox 関数の最適化をするメモ
https://qiita.com/syoyo/items/6c33acb0fd475e651f2fPython で外部プログラムを実行して結果の行をパースするメモ
https://qiita.com/syoyo/items/d13af423604192cee41cを参考にして, 外部コマンドで ImageMagick を動かし, benderopt で最適化してみます.
データとコード
ぼかし前
ぼかし後
(-blur 27x20)
from benderopt import minimize import numpy as np import logging import subprocess import parse logging.basicConfig(level=logging.DEBUG) # logging.INFO will print less information blurred_filename = "shimokita-blur.jpg" # convert -blur 27x20 ref_filename = "shimokita.jpeg" k_num_eval = 10000 def extract_result(lines): for line in lines: print(line.decode("utf-8")) ret = parse.parse("{:g} ({:g})", line.decode("utf-8")) if ret: return ret[0] raise RuntimeError("Failed to extract value from result.") count = 0 def f(radius, sigma): global count count += 1 print("run {} of {} ...".format(count, k_num_eval)) tmp_filename = "shimokita-tmp.jpg" cmd = "convert {} -blur {}x{} {}".format(ref_filename, radius, sigma, tmp_filename) ret = subprocess.run(cmd, shell=True) # Compare two images using RMSE cmp_cmd = "compare -metric rmse {} {} null:".format(tmp_filename, blurred_filename) ret = subprocess.run(cmp_cmd, shell=True, capture_output=True) # `compare`(ImageMagick) outputs result into stderr, not stdout lines = ret.stderr.splitlines() val = extract_result(lines) return val # We define the parameters we want to optimize: optimization_problem_parameters = [ { "name": "radius", "category": "uniform", "search_space": { "low": 0, "high": 100, } }, { "name": "sigma", "category": "uniform", "search_space": { "low": 0, "high": 100, } } ] # We launch the optimization best_sample = minimize(f, optimization_problem_parameters, number_of_evaluation=k_num_eval) print("radius", best_sample["radius"]) print("sigma", best_sample["sigma"]) print("err = ", f(best_sample["radius"], best_sample["sigma"]))結果
10,000 回まわしました.
radius 27.993241302558445 sigma 19.957452459359814 err = 49.5512Voila!
radius は 27(真値), 28(推定値)と 1 違いますが, それなりに真値に近しい結果が得られました.
idiff で差分を取ってみます.
https://openimageio.readthedocs.io/en/release-2.2.8.0/idiff.html
(差分を 20 倍. 差分等倍だと視覚的にはほぼ真っ黒(= 一致))
jpg 圧縮の影響が大きそうですね...
ちなみに 100 回では全然だめで, 1000 回でまあまあそこそこ近い, という結果でした.
TODO
- Bayesian Optimization など試したい.
- 画像の場合は非圧縮形式(PNG, BMP, TIFF)でやりましょう.
- ファイルに結果を書くタイプだと, ディスク I/O 消費が気になる(SSD だと寿命が縮まりそう?)ので memdisk を使えるか考えてみる
- benderopt は並列処理に対応していないので, 非マルチスレッドな外部プログラムを実行だと処理時間がかかってしまうので並列化できるライブラリの利用を検討します.
- 同様のやりかたで Photoshop あたりを操作してインスタ映え画像の生成を極める(コマンドライン制御できたような)




- 投稿日:2020-12-18T18:13:15+09:00
Pythonをはじめたばかりの人に送る過去15回分のABCのA問題分析
はじめに
この記事ではABCのA問題の分析をし、「if文と演算しか使えない」などの初心者のための記事です。複数のジャンルにまたがっている回もあります(例:AtCoder Beginner Contest 182)。「典型的な問題」と書かれている問題から解くと良いでしょう。
使う文の種類
演算(+,-,*,/,//,%)
AtCoder Beginner Contest 184 A.Determinant
AtCoder Beginner Contest 182 A.twiblr
AtCoder Beginner Contest 181 A.Heavy Rotation
AtCoder Beginner Contest 180 A.box
AtCoder Beginner Contest 178 A.Not
AtCoder Beginner Contest 177 A.Don't be late
AtCoder Beginner Contest 173 A.Payment
AtCoder Beginner Contest 172 A.Calc(典型的な問題)min,max
AtCoder Beginner Contest 185 A.ABC Preparation
if,else文
AtCoder Beginner Contest 183 A.ReLU
AtCoder Beginner Contest 182 A.twiblr
AtCoder Beginner Contest 179 A.Plural Form
AtCoder Beginner Contest 178 A.Not
AtCoder Beginner Contest 177 A.Don't be late
AtCoder Beginner Contest 174 A.Air Conditioner(典型的な問題)
AtCoder Beginner Contest 173 A.Payment切り上げ、切り下げ
math.ceilとint(//1でも可)を用いた切り上げ、切り下げの問題
AtCoder Beginner Contest 176 A.Takoyakicount
countを扱った問題はtryとwhile Trueの組み合わせやifとforの組み合わせでも解ける(A問題の制約ではTLEしない)。ここでは、countを使うと簡単に解ける問題はcountのところのみに書いてある。
AtCoder Beginner Contest 175 A.Rainy Seasonin
リストにある要素が入っているか確認する時などに使います。(ここではfor i in rangeのinは含めないこととする。
AtCoder Beginner Contest 171 A.αlphabetchr
アルファベットのリストなどを作ることができる組込み関数。
[python] いろいろな文字種のリストを作成を使うことができる。
AtCoder Beginner Contest 171 A.αlphabet感想
if,else文と演算の組み合わせが多い(例:AtCoder Beginner Contest 177 A.Don't be late)。また、多くのmin, max,countを使う問題はif文を使ってもACできる。意外とfor,whileを扱う問題が少なかった。また、言われた通りに実行すればACがもらえる問題が多い。AtCoder Beginner Contest 022 A.Best Bodyなど、昔のコンテストは難易度が300を超えているものがあるが、最近のコンテストは難易度が1桁のものが多い。(AtCoder Problemsを参考にした。)
参考文献
- 投稿日:2020-12-18T18:03:54+09:00
時間計測を with 構文でするようにしてコードを綺麗にする
普通に計算する
Python コード内で時間を計測する場合、開始時点と終了時点で
time.time()を呼び出し、その差分で秒数を計算します。import time start_time = time.time() # 処理 time.sleep(5) print("{:.2f} sec".format(time.time() - start_time))出力
5.01 sec課題点
上記のやり方で問題があるわけではありませんが、時間計測が沢山必要な場合、計算ロジックを描くことで行数が増えますし、一時的な変数も増えます。
with 内の時間を計算する
with の内部に入ったときに開始、出るときに終了を計測し、時間を表示するクラスです。
tm.pyimport time class Timer: def __init__(self): pass def __enter__(self): self.time = time.time() def __exit__(self, ex_type, ex_value, trace): print("{:.2f} sec".format(time.time() - self.time))使ってみた例
import time # 読み込み import tm with tm.Timer(): # 処理 time.sleep(3)出力結果
3.00 sec
- 投稿日:2020-12-18T17:30:44+09:00
はてなブログのstarを自動で押しまくる
はじめに
この記事は LOCAL students Advent Calendar 2020の19日の記事です。
よろしくおねがいします。まえおき
どうもこんにちは、今日から冬期休暇で毎週のレポートや辛い授業から開放されて喜びの舞を舞っているげんしです。
この時期は Advent Calendarが賑わっていて普段ブログを書かない人も書いたり書かなかったりする人が多くなると思います。この人の記事、、良い、、
先程言ったように、qiitaの記事やはてなブログの記事を見る機会がこの時期は増えると思います。そして人はブログを見ていく中で面白いブログやためになったブログにはLGTMや星をつけたりすると思います。
この星ですがなんと、はてなブログでは何度でも星をつけることができます!!!!
星を無限につけていけ
すごくいい記事に出会ったとき、人は無限に星をつけたくなります。
ですが、無限に星をつけるには無限に星をクリックしないといけません。
これは少し面倒です。作ったもの
はてなブログで星を任意の数自動でつけるものを作りました。
以下実行環境
ソフト バージョン python 3.9.0 pip 20.2.4 selenium 3.141.0 chromedriver-binary 87.0.4280.88.0 Seleniumのインストール
$ pip3 install seleniumGoogle Chromeをインストールしておいてください。
お願いします。
Chrome Driverのインストール
$ pip3 install chromedriver-binary==あなたのchromeのバージョンchromeの右上のメニュー/設定/chromeについて
から確認することができます。
僕の場合87.0.4280.88だったので
pip3 install chromedriver-binary==87.0.4280.88
でインストールしました。実際に無限に星をつけていく
スクレイピングする際にはてなブログにログインする必要があるので事前にユーザーネーム or メールアドレスとパスワードをkey.pyに入力しておきます。
key.pyEMAIL = "ご自身のはてなブログのメールアドレスかユーザー名を入れてください" PASSWORD = "ご自身のはてなブログのパスワードを入れてください"main.py# coding:utf-8 from key import EMAIL,PASSWORD from selenium import webdriver from selenium.webdriver.common.keys import Keys from time import sleep import chromedriver_binary url = input("starをつける記事のurlを入力 : ") starNum = int(input("starをつける個数を入力 : ")) username = EMAIL password = PASSWORD driver = webdriver.Chrome() #ログインページを開く loginUrl= "https://www.hatena.ne.jp/login" driver.get(loginUrl) #ログイン loginUserName = driver.find_element_by_xpath("//*[@id='login-name']") loginUserName.send_keys(username) loginPassword = driver.find_element_by_xpath("//*[@id='container']/div/form/div/div[2]/div/input") loginPassword.send_keys(password) submitButton = driver.find_element_by_class_name("submit-button") submitButton.click() sleep(5) #入力されたはてなブログのページにとぶ driver.get(url) starButton = driver.find_element_by_class_name("hatena-star-add-button") #入力された回数クリック for i in range(starNum): starButton.click() sleep(5) driver.close()DEMO
実際にこのLOCAL学生部のAdvent Calendarの1日目の記事の北海道の技術系学生コミュニティ LOCAL学生部のご紹介を30個starをつけたいと思います。
プログラムを実行し、記事のurlとstarの数を入力すると
ログイン画面が出たあと自動で入力、ログインをし、
このようにちゃんと30starをつけてくれました。
まとめ
星をたくさんつけたい記事があるときにぜひ使ってください。
自動でつけたような心のこもってない星をつけるのは心が痛むという人はクリックを頑張ってください。すごく単純で簡単なコードですが、Githubで公開しているのでurlを貼っておきます。
https://github.com/Genshi0916/auto-add-hatena-blog-star参考記事


- 投稿日:2020-12-18T17:13:39+09:00
【MicroPython】ESP32で入力フォームを作成
はじめに
ESP32 MicroPythonでWi-FiアクセスポイントとWebサーバーを立ち上げ入力フォームページを作成してみました.
↓こんな感じ
前提条件
- ESP32-WROOM-32
- MicroPython v1.13
プログラム
main.pyimport socket import network import ssl import re ESSID = "ESP32" PASSWORD = "ESPWROOM32" IP = "192.168.5.1" def wifi(essid, pwd, ip, mask, gw, dns): ap = network.WLAN(network.AP_IF) ap.config(essid = essid, authmode = 3, password = pwd) ap.ifconfig((ip,mask,gw,dns)) # print("(ip,netmask,gw,dns)=" + str(ap.ifconfig())) ap.active(True) return ap wifi(ESSID, PASSWORD, IP, '255.255.255.0', IP, '8.8.8.8') def web_page(): html = """ <html lang = "ja"> <head> <title>test</title> <meta charset="UTF-8" name="viewport" content="width=device-width, initial-scale=1"> <link rel="icon" href="data:,"> <style> </style> </head> <body> <h1>test page</h1> <h2>入力フォーム</h2> <form action = "" method = "GET"> <p><input type="text" name="test" size="40"></p> <p><input class="button" type="submit" value="送信"></p> </form> </body> </html> """ return html s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.bind(('', 80)) s.listen(5) while True: conn, addr = s.accept() response = web_page() conn.send('HTTP/1.1 200 OK\n') conn.send('Content-Type: text/html\n') conn.send('Connection: close\n\n') conn.sendall(response) request = str(conn.recv(1024)).lower() # print("request : "+ request) m = re.search(r'test=(\w+)', request) if m != None : word = m.group(0) print(word[5:]) conn.close()コード解説
def wifi(essid, pwd, ip, mask, gw, dns)
Wi-Fiアクセスポイントを立ち上げs.bind(('', 80))
HTTPポート80番で接続を待機m = re.search(r'test=(\w+)', request)
クライアントの入力データを取得word = m.group(0)
入力データを変数に入れる実行
スマホなどからESP32のアクセスポイントに接続しブラウザで
192.168.5.1にアクセスしてください.おわりに
おわりです.
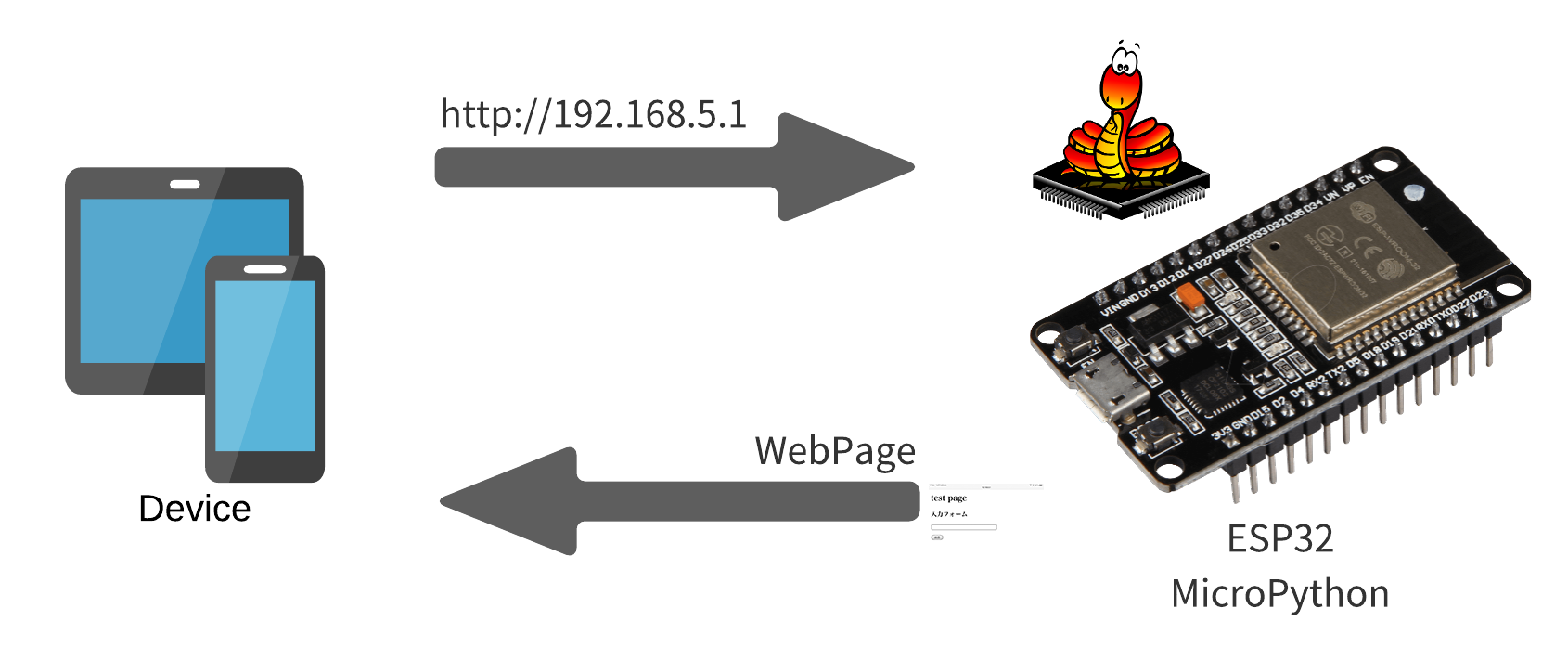
- 投稿日:2020-12-18T16:53:40+09:00
Pythonで学ぶアルゴリズム 第7弾:年号変換
#Pythonで学ぶアルゴリズム< 年号変換 >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第7弾として年号を扱う.西暦を年号へ
今回は明治~令和まで変換できるようにした.ただし,後でも記述するが,今回は汎用性のあるプログラムとしたため,年号の基準と年号名だけ追加することでいくらでも拡張することができる.ただし,同じ年の年号(例: 昭和64年と平成元年)は新たな元号とする.
明治~令和までの元年に対する西暦,つまり年号の境界を次に示す.
年号 西暦
明治元年 1868年
大正元年 1912年
昭和元年 1926年
平成元年 1989年
令和元年 2019年以上を踏まえて,pythonに実装する.
以下にコードと出力を示す.コード
era_name.py""" 2020/12/18 @Yuya Shimizu 年号変換 """ def trans2era_name(year): year_dict = {2019:"令和", 1989:"平成", 1926:"昭和", 1912:"大正", 1868:"明治"} #年号の境界 change = True #変換できたかどうかの判定用変数 #年号判定 for Y in year_dict: if year >= Y: year -= Y if year == 0: print(year_dict[Y] + "元年") else: print(year_dict[Y] + str(year + 1) + "年") change = False break # 年号変換対象外に対してのエラーメッセージ if change: print("明治~令和の範囲でのみ変換が可能です") trans2era_name(1868)出力1(2020年)
令和2年出力2(1868年)
明治元年出力3(1800年)
明治~令和の範囲でのみ変換が可能ですはじめにも述べたように,我ながら汎用性の高いものができたのではないかと思う.コードの説明を少し行う.year_dictの中に年号とその元年の西暦の組を格納している.定義した関数では,forでその辞書型配列を回しているため,year_dictの中身を追加するだけで,年号変換の対象を拡張することができる.ただし,年号変換できなかったときに出力されるエラーメッセージの内容は変える必要があるかもしれない.
※コメント欄の@shiracamusによる改良版ならば,その心配もなく,自動でエラーメッセージも変化してくれる.感想
今回取り扱った年号変換は参考文献の確認問題として出題されていたもので,自分で考えてプログラムを作成した.先ほども記述したように,我ながらうまくまとめれられたのではないかと思う.アルゴリズムは学び始めたばかりであるが,アルゴリズムや考え方は大切であると感じられ,いっそうアルゴリズムへの学習意欲が高まった.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社
- 投稿日:2020-12-18T16:47:20+09:00
pyrealsense2で距離カメラのデータを扱う
株式会社 日立情報通信エンジニアリング の追立です。
「IoT」が世間一般に浸透してしばらく経ちます。現場の情報収集に必要なセンサ類も、振動、電圧など色々なものが増えました。
距離カメラも様々な機種が安価に販売されるようになっており、距離+画像のデータが利活用されるようになってきました。本記事ではPythonから距離カメラを扱うことができるOSSという事でpyrealsense2でいろいろ試行した結果をご紹介します。
ノイズ処理や距離推定は結構使うかな?と思うのですがあまり情報を見つけられなかったのでこの記事が役立てば幸いです。
pyrealsense2とは?
pyrealsense2はIntel® RealSense™ SDK 2.0のPythonラッパーです。
Intel®社から市販されている距離カメラIntel® RealSense™シリーズを使用するためのOSSです。
License:Apache License, Version 2.0※本AdventCalendarの趣旨はOSSであるため、特に必要が無い限りカメラの製品仕様等については説明を省略しています。
製品情報については公式HPをご参照ください。導入
pipコマンドで導入することができます。
installpip3 install pyrealsense2インストールしたモジュールがimport可能なことを確認します。
import pyrealsense2今回インストールされたバージョンは2.39.0.2342でした。
距離データとRGB画像を保存する
早速PCにカメラを接続し、距離カメラとRGBカメラの情報を画像として保存します。
なお、今回検証で使用するカメラである「Intel® RealSense™ D435i」はステレオ方式のカメラであり、RGB映像用のカメラとは別に距離データ取得用のカメラが備わっています。よってそれぞれのカメラに対してconfigを設定していきます。import pyrealsense2 as rs import numpy as np # カメラの設定 conf = rs.config() # RGB conf.enable_stream(rs.stream.color, 1280, 720, rs.format.bgr8, 30) # 距離 conf.enable_stream(rs.stream.depth, 1280, 720, rs.format.z16, 30) # stream開始 pipe = rs.pipeline() profile = pipe.start(conf) cnt = 0 try: while True: frames = pipe.wait_for_frames() # frameデータを取得 color_frame = frames.get_color_frame() depth_frame = frames.get_depth_frame() # 画像データに変換 color_image = np.asanyarray(color_frame.get_data()) # 距離情報をカラースケール画像に変換する depth_color_frame = rs.colorizer().colorize(depth_frame) depth_image = np.asanyarray(depth_color_frame.get_data()) #お好みの画像保存処理ここで、変換したデータ(color_image,depth_image)を画像データとして保存することができます。
距離情報を取得する
取得したデータに対してピクセルを指定することで、当該ピクセルの距離情報(m)を取得することができます。
# 距離情報の取得 depth_data = depth_frame.get_distance(x,y)距離データとRGB映像を動画として保存する
カメラで撮影したデータを動画(.bag)として保存します。
enable_record_to_file()モジュールを先程の画像保存処理に下記のように追加することで保存することができます。# 省略 # カメラの設定 conf = rs.config() conf.enable_stream(rs.stream.color, 1280, 720, rs.format.bgr8, 30) conf.enable_stream(rs.stream.depth, 1280, 720, rs.format.z16, 30) conf.enable_record_to_file('export_filename.bag') #ADD # stream開始 pipe = rs.pipeline() profile = pipe.start(conf) # 省略後処理をする
カメラで撮影したデータや保存済の.bagデータに対して後処理をかけます。
後処理をすることによってノイズを減らすことができるようです。
Pythonラッパーにもいくつかのフィルタが用意されているようですが、今回は以下の三つを試してみました。
- Decimation Filter : 複雑さを軽減する効果
- Spatial Filter : 平滑化する効果
- Hole Filling Filter : 欠損データを補完する効果
後処理(Filter)# decimarion_filterのパラメータ decimate = rs.decimation_filter() decimate.set_option(rs.option.filter_magnitude, 1) # spatial_filterのパラメータ spatial = rs.spatial_filter() spatial.set_option(rs.option.filter_magnitude, 1) spatial.set_option(rs.option.filter_smooth_alpha, 0.25) spatial.set_option(rs.option.filter_smooth_delta, 50) # hole_filling_filterのパラメータ hole_filling = rs.hole_filling_filter() # disparity depth_to_disparity = rs.disparity_transform(True) disparity_to_depth = rs.disparity_transform(False) # 省略(フレーム取得処理) # filterをかける filter_frame = decimate.process(depth_frame) filter_frame = depth_to_disparity.process(filter_frame) filter_frame = spatial.process(filter_frame) filter_frame = disparity_to_depth.process(filter_frame) filter_frame = hole_filling.process(filter_frame) result_frame = filter_frame.as_depth_frame()フィルタをかける前後の結果を比較してみます。
フィルタをかける前:
フィルタをかけた後:
(応用編)撮った物体のサイズを推定をしてみる
pyrealsense2には画像上のピクセル座標と深度情報を与えるとカメラからの相対的な3次元座標情報を返してくれるモジュールが有ります。
これを使ってカメラに映っている物体のサイズを推定してみます。今回は↓の画像にある15cmの定規を対象にしてみます。
製品を見ると分かりますがRGB映像用のカメラと距離データ取得用の2つのIRカメラはついてる場所が異なります。
よって取得できるデータもRGBと距離データの間で微妙にずれています。まずはこれを補正します。補正# alignモジュールの定義 align_to = rs.stream.color align = rs.align(align_to) # (中間処理は省略) # frame処理で合わせる frames = pipe.wait_for_frames() aligned_frames = align.process(frames) depth_frame = aligned_frames.get_depth_frame() color_frame = aligned_frames.get_color_frame()次に距離データに後処理(フィルタ)をかけます。
今回はサイズを測ろうとする座標の深度データが必要なので、欠損は補間してやる必要が有ります。
処理自体は前章でご紹介したような内容でフィルタをかけていきます。処理前:
処理後:
いよいよ画像の座標から3次元座標を求めていきます。
rs2_deproject_pixel_to_point()を使いますが、これに必要なのが画像上の座標情報(x,y)と深度情報とカメラモジュールの内部パラメータです。
今回は画像をRGBカメラ側に補正していますのでRGBカメラモジュールの内部パラメータを取得します。内部パラメータ取得color_intr = rs.video_stream_profile(profile.get_stream(rs.stream.color)).get_intrinsics()次に取得する座標情報を決めます。
今回は15cm定規の端から端までの長さを推定してみます。開始点を「イ」、終了点を「ロ」として画像上の座標情報を取得します。
- イ : (685, 642)
- ロ : (685, 290)
これらの情報を元に長さを推定してみます。
長さの推定#イの3次元座標推定 I_d = result_frame.get_distance(685,642) point_I = rs.rs2_deproject_pixel_to_point(color_intr , [685,642], I_d) #ロの3次元座標推定 R_d = result_frame.get_distance(685,290) point_R = rs.rs2_deproject_pixel_to_point(color_intr , [685,290], R_d) #推定距離を算出 est_range = math.sqrt((Point_I[0]-Point_R[0])*(Point_I[0]-Point_R[0]) + (Point_I[1]-Point_R[1])*(Point_I[1]-Point_R[1]) +(Point_I[2]-Point_R[2])*(Point_I[2]-Point_R[2])) print(est_range) #------------- #結果(0.1471)[m]思ってたより実際の値に近い値が出ました。
あとがき
普段から業務で色々なデータをPythonで分析している関係上、Pythonラッパーとして提供されているので他の処理との連携がやりやすく感じました。
物体検出と組み合わせることで、カメラ1台から物体の位置などの情報を取得することもできますし、その他のセンサデータとの連携も敷居が低くなっているのではないかと思います。
データ利活用では単独のデータのみを扱うという場面は少ないと思いますので、こういったラッパーが提供されているとそれだけでとっつきやすく感じました。
参考文献
本記事の執筆にあたって以下を参考にさせて頂きました。
公式ドキュメント:https://dev.intelrealsense.com/docsその他
Intel®、Intel® RealSense™は、アメリカ合衆国および/またはその他の国における Intel Corporation の商標です。




- 投稿日:2020-12-18T16:45:41+09:00
私の周りのPython 2020年ふりかえり
私の周りのPython 2020年ふりかえり
Python歴4年目に入った、いつもはメーカ系列でIoT屋やっている者です。
私の周りのPython 2020年と少し語ってみます。私の周りのPython 2020年まで
2017年~2018,9年頃までは、研究開発やそれに付随するPoC(実証実験)で、
IoT機器でのデータ収集やカメラ制御による画像関連、
AWSなどクラウド上での分析処理ぶん回し(笑)になどなどにpythonを利用していました。
それぞれの研究題材の特化したpythonプログラムがほとんどで、
いわゆるゴリゴリのコーディング(書いた本人しかわからんのでは?)。
正常動作して目的を達成すればよいって感じ。あくまでPythonは、研究者や技術者が目的達成の為に一時的に利用しているに過ぎない存在でした。
私の周りのPython 2020年
ところが今年(2020年)徐々に状況が変化してきたのです。
実用的な場面でPythonが利用され始めているのを実感した1年になりました。
例えば、
・情報提供系システムでの、バッチ処理や Diango,Flaskを利用したWebアプリケーション
Dashなど利用した、情報の見やすい可視化!
・IoT機器とのデータ連携の急増:非同期処理が使いやすくなってきている!(使いやすいハードの出現も要因)
・Apiサーバでの活用
などなど。それらは、
・Python経験者が増えてきた(特に若手)
・情報見える化のさらなる要求(現場でもデータ分析&結果からの次アクションのローテー)
のような事での利用拡大でありますが、
その他、Python的には、
・個人レベルでの開発でなく、ある程度の規模での開発&その為のルール付けや型ヒント等の開発支援のようなもの
が充実してきている。(もちろんエディタ等も)
・情報をみせるライブラリ・通信ライブラリの拡充
などなどが、後押ししているのでは
と、思っています。そして2021年
さて2021年のPython事情はどの様になっているでしょうか?
コロナ過でどこも予算厳しい時期でありますが、知恵絞りながらでも
上記2020年の動きのさらなる拡大は止まらんだろうなと。それでは!
- 投稿日:2020-12-18T16:21:58+09:00
Pythonで学ぶアルゴリズム 第6弾:うるう年
#Pythonで学ぶアルゴリズム< うるう年 >
はじめに
基本的なアルゴリズムをPythonで実装し,アルゴリズムの理解を深める.
その第6弾としてうるう年を扱う.うるう年
<条件>
4で割り切れる年をうるう年という.
※ただし,100で割り切れて,400で割り切れない年はうるう年ではない.
例)
2019年 : 4で割り切れない⇒うるう年でない
2020年 : 4で割り切れる⇒うるう年? → 100で割り切ない⇒うるう年である
1900年 : 4で割り切れる⇒うるう年? → 100で割り切れて,400で割り切れない⇒うるう年でない
2000年 : 4で割り切れる⇒うるう年? → 100で割り切れて400で割り切れる⇒うるう年であるこのように条件の注意(※)さえ,満たさなければ,単純に4で割り切れるものはうるう年ということである.これをpythonで実装してみた.
以下にコードと出力を示す.コード
leap_year.py""" 2020/12/18 @Yuya Shimizu うるう年 ・4で割り切れる年 ただし,100で割り切れて400で割り切れない年はうるう年でない """ def leap_year(year): if year%100 == 0 and year%400 != 0: print(str(year) + "年はうるう年でない.") else: if year%4 == 0: print(str(year) + "年はうるう年である.") else: print(str(year) + "年はうるう年でない.") year = int(input("うるう年判定\n>>")) leap_year(year)出力1
うるう年判定 >>2000 2000年はうるう年である.出力2
うるう年判定 >>1900 1900年はうるう年でない.ユーザ入力により判定するものとした.
コードはいたってシンプルで,注意したところは,より特殊な条件をはじめに持ってくることである.改編版
@shiracamusのコメントを参考に上記のプログラムを改編した.
具体的には,関数内のprintを省きTrue, Falseを返すようにした.
以下にそのコードと出力を示す.コード
leap_year_.py""" 2020/12/18 @Yuya Shimizu うるう年 ・4で割り切れる年 ただし,100で割り切れて400で割り切れない年はうるう年でない 改編版 @shiracamusの提案を参考に,True, Falseを返すプログラムにした """ def leap_year(year): if year%100 == 0 and year%400 != 0: return False else: if year%4 == 0: return True else: return False year = int(input("うるう年判定\n>>")) print(leap_year(year))出力
うるう年判定 >>2020 Trueよりよいものができた.
感想
今までに2,3回はうるう年のコードを書いたことはあったが,アルゴリズムを通して少し頭の中を整理できたおかげか,割とシンプルにかけたのではないかと思う.
参考文献
Pythonで始めるアルゴリズム入門 伝統的なアルゴリズムで学ぶ定石と計算量
増井 敏克 著 翔泳社
- 投稿日:2020-12-18T16:19:22+09:00
WebRTCで常時接続のペットカメラを作ってみた(Nuxt.js + Python + Firebase + SkyWay + ラズパイ)
はじめに
1泊2日の楽しい旅行!でも、留守番中の猫が気になってしょうがない。。
愛する猫のため「旅行中のペット見守りカメラ」を作ってみました
GitHubリポジトリはコチラ実はネタ元としてコチラの優良記事を参考にさせていただいています。
SkyWay WebRTC Gatewayハンズオンネタ元様はRubyです。
今回は大変恐縮ですが、Pythonにて機能やファイルをまとめたり、何度もカメラに再接続できるようにするなど改良を重ねさせていただきました。特徴
こんなことができます!
- WEBアプリを通して外出先から自宅のカメラ映像がいつでもどこでも見られる
- ログイン認証付きで安全
- LEDを点灯・消灯と操作(将来カメラの角度を動かしたい)
- WEBアプリからプログラムをシャットダウンできる(バルスと唱える!)
使用技術
- Nuxt.js(Vue.js): Webアプリの作成
- Python: 自宅カメラの制御
- SkyWay(WebRTC): カメラ映像・メッセージの送信
- Firebase: Webアプリのデプロイ、ログイン機能、SkyWay APIKeyの保存
RaspberryPi
自宅カメラ側として映像配信用に使用します。
USBカメラを接続し、SkyWayモジュールであるwebrtc-gateway、制御用Pythonプログラムを設定します。
大まかな仕組みとして、Pythonプログラムでカメラ映像を取得し、web-rtc-gatewayにアクセスして接続したWEBアプリ側にストリーム配信します。また、LEDを接続してWebアプリ側からのメッセージで点灯・消灯できるようにしました。
将来的には、GPIOを通してサーボモーターを制御してUSBカメラの向きや角度を操作したいと考えています。SkyWay
NTTコミュニケーションズのWebRTCを手軽に扱えるSDKです。
自宅カメラとWebアプリを接続し、映像、メッセージ送信のために使用しました。
詳しくはSkyWay公式サイト案内に沿って無料登録して、APIKEYを取得します。
Webアプリ側は、Node.jsのモジュールとして、SkyWayを操作します。
カメラ側のRaspberryPiは、Webブラウザを立ち上げるわけでなく、ヘッドレスなのでskyway-webrtc-gatewayモジュールを使用します。skyway-webrtc-gateway
IOT機器で、SkyWayを簡単に実行するためのコンパイルされたモジュール。
Webブラウザなしでも、WebRTCを実現して、映像や音声、メッセージを送受信することができます。
公式githubカメラ側のラズパイに、権限を付与して実行するだけでです。
Firebase
面倒な機能をサクッと実装したかったので、 今回はFirebaseを利用しました。
- Authentification: ログイン機能
- Firestore: SkyWayのAPI Keyを保存
- Hosting: WEBアプリのデプロイ先
Nuxt.js(WEBアプリ側)
Vue.jsのフロントエンドフレームワークであるNuxt.jsを用いて、WEBアプリ側を構築しました。
自宅映像という超プライベートなので、ログイン機能をFirebaseのAuthenticationを利用して実装。ついでにデプロイ先もFirebaseを利用しました。
SkyWayに接続するためのAPI Keyですが、フロントエンドに持たせたく無かったです。そこでFirestoreに保存して、ログイン済みユーザーでないとAPIKeyを取得できないようにしました。ディレクトリ構成
# 一部省略 frontend ├── components │ ├── Header.vue │ ├── Login.vue │ └── ProjectTitle.vue ├── layouts │ └── default.vue ├── middleware │ └── authenticated.js ├── pages │ ├── index.vue │ └── operate.vue ├── static │ └── favicon.ico ├── store │ └── index.js └── nuxt.config.js大まかな処理の流れ
- pages/index.vueにユーザーはアクセス
middleware/authenticated.jsにより、未ログインはindex以外の閲覧が不可- componets/login.vueを通してログイン
- ログインと同時に store/index.jsでfirestoreからSkyWay APIKeyを取得
- pages/operate.vueにユーザーはアクセス
- 取得したAPI Keyを利用してSkyWayに接続
- すでに接続済みの自宅カメラ側のラズパイとコネクションを確立
自宅のラズパイ側のWebRTC-gatewayからカメラ映像を視聴する一番のポイントは面倒な部分はFirebaseに任せたことです。
作りたいのはペットカメラシステムで、立派なWebサイトでは無いので、任せられる機能はFirebaseに丸投げしました。
特にAPIKeyをFirestoreに預けておくのは使い勝手がすごく良いです。Python(自宅カメラ・ラズパイ側)
メイン&一番楽しい部分です。
WebRTC-gatewayは実行させたら、RESTAPIを通してPythonで制御します。ディレクトリ構成
backend ├── __init__.py ├── config.py ├── data.py ├── media.py ├── peer.py ├── robot.py ├── util.py └── webrtc_control.py実行ファイルは
webrtc_control.pyです。
他のファイルは機能別のモジュールとなります。webrtc_control.py
WebRTC-gateway、USBカメラを制御するメインプログラムです。
gatewayの次にこちらのプログラムを実行することで、ペットカメラはリモートで使えるようにスタンバイされます。webrtc_control.py# ~省略~ def main(): queue = que.Queue() robot = Robot() peer_id = config.PEER_ID media_connection_id = '' data_connection_id = '' process_gst = None #Peerを確立します(SkyWayへの接続) peer_token = Peer.create_peer(config.API_KEY, peer_id) if peer_token is None: count_create = 1 retry_peer_id = '' # Peerが確立できなかったら、IDを変えて5秒おきにチャレンジ while peer_token is None: time.sleep(5) count_create += 1 retry_peer_id = peer_id + str(count_create) peer_token = Peer.create_peer(config.API_KEY, retry_peer_id) peer_id = retry_peer_id peer_id, peer_token = Peer.listen_open_event(peer_id, peer_token) # Peerへのeventを常時Listenするために、スレッド化します。 th_listen = threading.Thread(target=Peer.listen_event, args=(peer_id, peer_token, queue, robot)) th_listen.setDaemon(True) th_listen.start() # Webアプリからのメッセージを常時Listen、スレッド化します。 th_socket = threading.Thread(target=robot.socket_loop, args=(queue,)) th_socket.setDaemon(True) th_socket.start() try: while True: #スレッドからのキューを受け取る。 results = queue.get() #キューにList内のワード(「バルス」とか)が入っていれば、whileを抜ける if 'data' in results.keys(): if results['data'] in config.SHUTDOWN_LIST: break # 映像コネクションが確立したら、映像eventをListenする elif 'media_connection_id' in results.keys(): media_connection_id = results['media_connection_id'] th_media = threading.Thread(target=Media.listen_media_event, args=(queue, media_connection_id)) th_media.setDaemon(True) th_media.start() #Gstreamerによる映像ストリームを開始したら、そのプロセスを取得する。 elif 'process_gst' in results.keys(): process_gst = results['process_gst'] #データコネクション(メッセージのやり取り)が確立したら、そのIDを格納する。 elif 'data_connection_id' in results.keys(): data_connection_id = results['data_connection_id'] #映像eventで該当する内容(close、error)したら、新たに次に接続できるように #使用していた映像ストリーム、MediaConnection,DataConnectionを破棄する #この場合、接続していたWebアプリ側が閉じたり、エラーになった場合を指す elif 'media_event' in results.keys(): if results['media_event'] in ['CLOSE', 'ERROR']: process_gst.kill() Media.close_media_connections(media_connection_id) Data.close_data_connections(data_connection_id) except KeyboardInterrupt: pass robot.close() Peer.close_peer(peer_id, peer_token) process_gst.kill() print('all shutdown!') if __name__ == '__main__': main()マルチスレッド
Peerへのイベントコールを常時Listenするために、
th_listenでデーモン化してスレッド並列化しています。
th_socketもスレッドして並列してますが、こちらはDataConnection(webアプリからのmessage)のListenとなります。
while文で、各コネクションの状態が変わった時の処理分けをしています。
各スレッドはそれぞれ受け取ったeventによってqueueを飛ばすように仕込んでおり、このwhile文でそのqueue内容により処理を走らせています。
while内のth_mediaで、MediaConnectionからのイベントをListenします。各threadからの状態によりConnectionを開放・再準備することで、Webアプリ側が何度も途中で切っても、カメラ側のラズパイと再接続可能にしています。
本来ですと、media connectionを簡単に開放・すぐに確立できるはずなのですが、仕様なのでしょうか?それとも私が未熟なのか分かりませんが、
2回目以降新たにmedia connectionを作成しようとすると、WebRTC-gatewayが400エラーになってしまいますので、新たにmediaから作る強引な実装となっています。
本来ならもっとスマートな処理のハズだけど、公式通り動かないから多少冗長な書き方にナッテルヨ。です。util.py
WebRTC-gatewayとはRESTAPIて制御するので、頻繁にリクエストを送ることになります。
多用できるようにメソッドにまとめておきます。util.pyimport requests import config def request(method_name, _uri, *args): response = None uri = config.HOST + _uri if method_name == 'get': response = requests.get(uri, *args) elif method_name == 'post': response = requests.post(uri, *args) elif method_name == 'put': response = requests.put(uri, *args) elif method_name == 'delete': response = requests.delete(uri) else: print('There is no method called it') return responserobot.py
将来、ロボットアームでカメラ動かしたいと思って、こんな名前のクラスにしています。
このファイルは以下の機能となります。
- GPIOの制御(Lチカやモータ)
- socket通信の確立とデータ受け取り
Webアプリとデータコネクションを通して、GPIOへの指示を受けます。
(今はLEDのON/OFFしかできませんw)
以下は、webrtc_control.pyでスレッド化したメソッドです。robot.py# ~省略~ class Robot: # ~省略~ # スレッド化したメソッドです。 # Webアプリからのメッセージを待ち受けます。 def socket_loop(self, queue): """ソケット通信を待ち受ける """ # socket通信を作成 self.make_socket() while True: # データ(メッセージ)を受け取る data = self.recv_data() data = data.decode(encoding="utf8", errors='ignore') # メッセージ内容をキューに送信する queue.put({'data': data}) # メッセージ内容によりGPIOを操作(この場合、LEDの点灯・消灯) self.pin(data) # ~省略~peer.py
SkyWayとのPeer接続を確立して、SkyWayが使える状態にします。
以下は、webrtc_control.pyでスレッド化したメソッドです。peer.py# ~省略~ class Peer: """SkyWayと接続しセッション管理を行う """ # ~省略~ # スレッド化します。PeerへのeventをListenします。 @classmethod def listen_event(cls, peer_id, peer_token, queue, robot): """Peerオブジェクトのイベントを待ち受ける """ gst_cmd = "gst-launch-1.0 -e v4l2src ! video/x-raw,width=640,height=480,framerate=30/1 ! videoconvert ! vp8enc deadline=1 ! rtpvp8pay pt=96 ! udpsink port={} host={} sync=false" uri = "/peers/{}/events?token={}".format(peer_id, peer_token) while True: _res = request('get', uri) res = json.loads(_res.text) if 'event' not in res.keys(): # print('No peer event') pass # Webアプリから映像接続を要求されたら elif res['event'] == 'CALL': print('CALL!') media_connection_id = res["call_params"]["media_connection_id"] queue.put({'media_connection_id': media_connection_id}) # mediaを作成 (video_id, video_ip, video_port) = Media.create_media() # GstreamerによるUSBカメラから映像ストリームを作成 cmd = gst_cmd.format(video_port, video_ip) process_gst = subprocess.Popen(cmd.split()) queue.put({'process_gst': process_gst}) # WebアプリとmediaConnectionを接続する Media.answer(media_connection_id, video_id) # Webアプリからデータ接続(messageのやり取り)を要求されたら elif res['event'] == 'CONNECTION': print('CONNECT!') data_connection_id = res["data_params"]["data_connection_id"] queue.put({'data_connection_id': data_connection_id}) # Dataを作成 (data_id, data_ip, data_port) = Data.create_data() # データ(メッセージの飛ばし先をGPIOが処理しやすいportにリダイレクトする Data.set_data_redirect(data_connection_id, data_id, "127.0.0.1", robot.port) elif res['event'] == 'OPEN': print('OPEN!') time.sleep(1) # ~省略~media.py
PeerでSkyWayと接続が確立された後に、他のPeerユーザーとの映像・音声のやり取りを開始します。
以下は、webrtc_control.pyでスレッド化したメソッドです。media.py# ~省略~ class Media: """MediaStreamを利用する MediaConnectionオブジェクトと転送するメディアの送受信方法について指定 """ # ~省略~ # スレッド化したメソッド # mediaのイベントを待ち受ける # 端的に:接続したWebアプリが、クローズ、エラーしたら知らせる @classmethod def listen_media_event(cls, queue, media_connection_id): """MediaConnectionオブジェクトのイベントを待ち受ける """ uri = "/media/connections/{}/events".format(media_connection_id) while True: _res = request('get', uri) res = json.loads(_res.text) if 'event' in res.keys(): # イベントをキューに投げる queue.put({'media_event': res['event']}) # close,errorは別のスレッドでこのlitenの大元のmediaが開放されるので、このスレッドを終了する if res['event'] in ['CLOSE', 'ERROR']: break else: # print('No media_connection event') pass time.sleep(1) # ~省略~data.py
PeerでSkyWayと接続が確立された後に、他のPeerユーザーとのデータのやり取りを開始します。
今回は、文字のやり取りとなります。Mediaと似ており、特筆することもないのでスキップします。
config.py
設定ファイルです。
config.pyAPI_KEY = "skyway API Keyを入力" PEER_ID = "任意のpeer idを入力" HOST = "http://localhost:8000" SHUTDOWN_LIST = ['バルス', 'ばるす', 'balus', 'balusu', 'barusu', 'barus']
- API_KEY: SkyWayのAPIKeyです。
- PEER_ID: 自宅カメラ側のPEER_IDです。任意の名前に変更できます。
- HOST: gatewayを立ち上げたときのHOST先となります。
- SHUZTDOWN_LIST: Webアプリでこの単語を唱えると、プログラムがシャットダウンします。(バルス
)
リモートデバッグのススメ
GPIOを使ってLチカ、USBカメラから映像ストリーム取得、WebRTC-gatewayの実行と、ラズパイのハード依存が多かったので、リモートデバッグで開発しました。
今回の場合は、Mac上のIntellijでデバッグをしつつ、実際は同じネットワークのラズパイ上のコードで実行しています。
この方が、Mac上でのいつも通りのコーディング、デバッグしつつ、機種依存の機能もチェックできますのでとても開発しやすかったです。IntelliJのリモートデバッグ方法
Jetbrains社のIDE:IntelliJでの方法となります。PyCharmでも同じ方法でリモートデバッグ可能です。
実行/デバッグ構成からPython Debug Serverを選択
IDE ホスト名を入力。ローカルIPアドレスでも可。(この場合は、Mac)
続いて空いている任意のポートを入力(ここもMac)
パスパッピングは、Macとラズパイでディレクトリをマッピングしたい時に指定します。続いて説明欄の1.2を行います。
eggを追加するよりも、pipでインストールしてしまったほうが楽でした。#実行マシーンでインストールする(この場合はラズパイ) pip install pydevd-pycharm~=203.5981.155 #バージョンはIDEにより異なる。コードにコマンドを追加
今回の場合だと実行ファイルであるwebrtc_control.pyの冒頭に追加します。import pydevd_pycharm pydevd_pycharm.settrace(<IDEホスト名>, port=<ポート番号>, stdoutToServer=True, stderrToServer=True, suspend=False)ここまで準備完了です。
デバッグ実行は
- 先に、Mac側のIntelliJで
Python Debug Serverをデバッグ実行- ラズパイで、追加コードされたデバッグしたいコードを実行
これで、リモート環境のデバッグが可能になります。
通常のデバッグのようにブレイクポイントも、途中経過の変数の変遷も見ることができます、便利!!開発環境側のMacは固定IPにしておくのがおすすめです。
そうしないと毎回、追加コードのIP部分を書き直すハメになります、、おわりに
これでも十分にペットカメラとして使えますが、
機会があればロボットアームにカメラをつけて遠隔で動かしたいです。旅行中の自宅の猫を見るのにすごく便利&重宝しそうです
ここまで読んでいただいてありがとうございました!





- 投稿日:2020-12-18T16:18:20+09:00
Ubuntu18.04.05 LTS におけるpython仮想環境作成
Anacondaを使用しない仮想環境作成をUbuntuにて実施。
環境
Ubuntu18.04.05 LTS
python:3.6.9
仮想環境構築
①アップデート
$sudo apt-get update $sudo apt-get upgrade $sudo reboot
②venvのインストール
$sudo apt install python3-venvvenv: 仮想環境構築に必要なツール。Python3.3以降が必要らしい。
③仮想環境を作る
#まずは仮想環境を作るディレクトリを作成。 $mkdir test_env $cd test_envmkdir test_env
$cd test_envで作ったディレクトリ内に移動する。
$python -m venv tensorflow『tensorflow』名で仮想環境用のディレクトリを作成する。
中身は
これで仮想環境が完成。
3)仮想環境内に入る
$source test_env/tensorflow/bin/activateこれで仮想環境として機能します。
私はhomeに仮想環境用のtest_envディレクトリを作成して
さらにその下にtensorflowと作成しているので長いです。homeディレクトリに作っていれば
source tensorflow/bin/activateで環境に入れます。
仮想環境内で
(tensorflow)~@~$pip3 install numpy (tensorflow)~@~$pip3 install tensorflow-gpu==1.14 (tensorflow)~@~$pip3 install matplotlob等々をインストールすれば大丈夫です。
ただpip3 install opencv-pythonだけはエラーを吐いてうまくいかず。
エラーをコピーし忘れたのが痛いですが
結果としてpipが古くて必要なモジュールがないって吐いていました。pip3 install -U pipこれを打ち込んでアップグレードしてOKとなりました。
その後に
pip3 install opencv-python==3.4.11.45と入力してインストール出来ました。
バージョン指定したのはopencv4系の不具合が怖かったからです。
とりあえずはこれで何とか行けました。
④仮想環境をJupyter等で使用出来る様にする
仮想環境下で
(tensorflow)~@~$pip install ipykernel #installが終わったら (tensorflow)~@~$ipython kernel install --user --name=tensorflow
これでjupyternotebookでカーネルの選択が可能になります。
まぁ色々と試してる最中です。





- 投稿日:2020-12-18T16:05:35+09:00
pythonで外部コマンドを実行する(結果を受け取る/受け取らない場合の両方)
python3, MacOSとLinuxで動作確認済み。
import os import subprocess def exec_os_system(cmd: str): ''' コマンドを同期実行し、 標準出力と標準エラー出力は、実行したプロンプトに随時表示する 戻り値はコマンドのリターンコード ''' # os.systemはwaitで子プロセスの終了を待つため、リターンコードの上位8bitにリターンコードが格納される # それを取るため8bit右にシフトする # see http://d.hatena.ne.jp/perlcodesample/20090415/1240762619 rt = os.system(cmd) >> 8 return rt def exec_subprocess(cmd: str, raise_error=True): ''' コマンドを同期実行し、 標準出力と標準エラー出力は最後にまとめて返却する raise_errorがTrueかつリターンコードが0以外の場合は例外を出す 戻り値は3値のタプルで (標準出力(bytes型), 標準エラー出力(bytes型), リターンコード(int)) ''' child = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE) stdout, stderr = child.communicate() rt = child.returncode if rt != 0 and raise_error: raise Exception(f"command return code is not 0. got {rt}. stderr = {stderr}") return stdout, stderr, rt if __name__ == "__main__": exec_os_system("date") stdout, stderr, rt = exec_subprocess("date") print(stdout) print(stderr) print(rt)実行結果
Fri Dec 18 16:04:49 JST 2020 b'Fri Dec 18 16:04:49 JST 2020\n' b'' 0
- 投稿日:2020-12-18T16:00:16+09:00
pythonで緯度経度2地点間の距離計算(球面三角法利用)
import math def get_distance_m(lat1, lon1, lat2, lon2): """ 2点間の距離(m) 球面三角法を利用した簡易的な距離計算 GoogleMapAPIのgeometory.computeDistanceBetweenのロジック https://www.suzu6.net/posts/167-php-spherical-trigonometry/ """ R = 6378137.0 # 赤道半径 lat1 = math.radians(lat1) lon1 = math.radians(lon1) lat2 = math.radians(lat2) lon2 = math.radians(lon2) diff_lon = lon1 - lon2 dist = math.sin(lat1) * math.sin(lat2) + math.cos(lat1) * math.cos(lat2) * math.cos(diff_lon) return R * math.acos(min(max(dist, -1.0), 1.0)) if __name__ == "__main__": # 緯度と経度方向に1秒角移動したときの距離を計算する distance = get_distance_m(lon1=139.0, lat1=35.0, lon2=139.0 + 1.0 / 3600.0, lat2=35.0 + 1.0 / 3600.0) print(distance)実行結果
39.972442531744505
- 投稿日:2020-12-18T15:53:44+09:00
pythonリトライするデコレータ
from functools import wraps import time def retry_decorator(retry_num: int, sleep_sec: int): """ リトライするデコレータを返す :param retry_num: リトライ回数 :param sleep_sec: リトライするまでにsleepする秒数 :return: デコレータ """ def _retry(func): @wraps(func) def wrapper(*args, **kwargs): for retry_count in range(1, retry_num + 1): try: ret = func(*args, **kwargs) return ret except Exception as exp: # pylint: disable=broad-except if retry_count == retry_num: print(f"Retry_count over ({retry_count}/{retry_num})") raise Exception from exp else: print(f"Retry after {sleep_sec} sec ({retry_count}/{retry_num}). Error = {exp}") time.sleep(sleep_sec) return wrapper return _retry @retry_decorator(retry_num=3, sleep_sec=1) def hoge(): raise Exception("fail") if __name__ == "__main__": hoge()実行結果
Retry after 1 sec (1/3). Error = fail Retry after 1 sec (2/3). Error = fail Retry_count over (3/3) Traceback (most recent call last): File "retry.py", line 18, in wrapper ret = func(*args, **kwargs) File "retry.py", line 35, in hoge raise Exception("fail") Exception: fail The above exception was the direct cause of the following exception: Traceback (most recent call last): File "retry.py", line 39, in <module> hoge() File "retry.py", line 23, in wrapper raise Exception from exp Exception