- 投稿日:2020-12-18T23:54:25+09:00
VS Code でデバッグ時の「Could not read source map for...」について
こやつに苦しめられた話。
Could not read source map for file:///d:/hoge/node_modules/fecha/lib/fecha.umd.js: ENOENT: no such file or directory, open 'd:\hoge\node_modules\fecha\lib\fecha.umd.js.map'
下記のように
.vscode/launch.json内の"type"を"node"から"pwa-node"へ変更したら出なくなりました。詳細分かる人いましたらぜひ共有いただきたいです!!!launch.json(変更前){ "version": "0.3.0", "configurations": [ { "type": "node", "request": "launch", "name": "MAIN", "program": "${workspaceFolder}\\index.js", "outputCapture": "std" } ] }launch.json(変更後){ "version": "0.3.0", "configurations": [ { "type": "pwa-node", "request": "launch", "name": "MAIN", "program": "${workspaceFolder}\\index.js", "outputCapture": "std" } ] }
- 投稿日:2020-12-18T22:15:21+09:00
[Node.js] Node.jsのフレームワーク「Express」とは……(これから勉強)
- 投稿日:2020-12-18T21:07:44+09:00
AWS LambdaとAPI GatewayでQiita検索botを作ってみた
完成物
■Qiita検索
検索したいタグを入れると、そのタグの新着記事が返ってくるLINE bot
今回使うもの
- LINE Messaging API
- Amazon API Gateway
- AWS Lambda(言語:node.js)
- Qiita API
LINE Messaging API, Amazon API Gateway, AWS Lambdaの準備は以下の記事に書きましたので、
こちらをご参照ください。
[過去記事]AWS(Lambda, API Gateway)でLINEの天気予報botを作ってみるこの記事では、実際のコードについてのみ書いています。
Lambda関数を書く
ローカルで、以下の通りにモジュールをインストールします。
$ npm install @line/bot-sdk $ npm install axiosindex.jsは以下の通り。
index.jsconst line = require('@line/bot-sdk'); const axios = require('axios'); axios.defaults.baseURL = 'https://qiita.com/api/v2'; const client = new line.Client({ channelAccessToken: process.env.ACCESSTOKEN }); let event; let callback; let userMessage = ''; let message = {}; exports.handler = (_event, _context, _callback) => { event = _event; callback = _callback; userMessage = JSON.parse(event.body).events[0].message.text; const url = '/tags/' + userMessage +'/items?page=1&per_page=5'; main(url); }; function main(url) { axios.get(url) .then(function (response) { if (response.data.length !== 0) { let columns = []; for (let i = 0; i < 5; i++) { let column = {}; let tags = ""; for (let j = 0; j < response.data[i].tags.length; j++) { tags += response.data[i].tags[j].name + ", "; } tags = tags.slice(0, -2); column = { "thumbnailImageUrl": response.data[i].user.profile_image_url, "title": response.data[i].title.length > 40 ? response.data[i].title.slice(0, 40) : response.data[i].title, //最大40文字 "text": tags.length > 55 ? "tag: " + tags.slice(0, 55) : "tag: " + tags, //最大60文字 "actions": [ { "type": "uri", "label": "記事を読む", "uri": response.data[i].url } ] } columns.push(column); } message = { "type": "template", "altText": "#" + userMessage + "の新着記事", "template": { "type": "carousel", "columns": columns } } } else { //検索結果が0件だった場合 message = { type: "text", text: "検索結果は0件でした。" }; } }) .catch(function (error) { //該当するタブが存在しない場合 console.log(error); message = { type: "text", text: "#" + userMessage + "は存在しません。" }; }) .finally(function () { //メッセージ返信 console.log(JSON.stringify(message)); client.replyMessage(JSON.parse(event.body).events[0].replyToken, message) .then(() => { callback(null, {}); }) .catch((err) => { callback(null, {}); }); }); };環境変数には、LINE botのチャネルアクセストークンを設定します。
これで完成!
まとめ
今回は、簡単なカルーセルテンプレートを使用したので記事は5つのみの表示です。
ここに色々なメッセージタイプが載っているので、是非色々試してみてください。

- 投稿日:2020-12-18T18:34:30+09:00
【Node.js】TwitterAPIのRateLimitとcursorに気をつけろ
Node.jsアドベントカレンダー18日目の記事です。
APIの勉強で利用が楽、且つわかりやすいものが作れるのはTwitterか小説家になろうだと思っています。
参考:[JavaScript]なろうのランキングをAPIで一括取得する現在参画中のプロジェクトではAPIもフロントも両方開発していますが、サービスが本格運用前なことに加えてある程度仕様がゆるい状態での開発のため、APIリミットがキツいイメージがあったTwitterを触ってみることにしました。
Node.jsのTwitterAPIを使ってみよう系エントリーについてはAPI利用申請の部分に偏った物が多かった事と、
特徴となるcursorに触れている物が少なかったこともありコード側に寄せて実装時気になった箇所を纏めました。尚、Twitter API利用開始についてはTwitter APIを使ってみるを参考にしました。
3行で
・非同期処理時の残cursorの扱い(結果参照しPromiseを生成する)
・取得対象に応じて設定値が著しく異なるRateLimitに注意する
・entitiyの罠(screen_nameとUID)実装
app.js/* express関連の処理省略 API内部処理のみ記述 */ // 検索対象のIDを指定(実際はreqにて取得) const userId = "任意のID" // 初回カーソルの指定 let now_cursor = -1 // API取得情報の保持 const user = new Array() const getList = (nc) => { // 引数を受けてPromiseを返すfunctionを生成して返す return new Promise(() => { client.get("followers/list", { screen_name: userId, cursor: nc }) .then((res) => { user.push(res.users) now_cursor = res.next_cursor // cursorが0以外であれば次ページを取得、0ならファイル出力 if (now_cursor > 0) getList(now_cursor) else fileOutput(user, 'follow') }) .catch((e) => { // レートリミットの場合、15分経過したらリトライする if(e.code === 88) setTimeout(getList(now_cursor), 15 * 60* 1000) }) }) } // APIによるフォローリスト取得処理の実行 getList(now_cursor)今回はexpressのサーバーをFirebaseにてホスティングしてクライアントサイドから叩く想定のコードのうち、
取得処理のコアになる部分を抜粋しています。requestにてtwitterIdを受け取ったのち、そのidユーザーの
フォローしている人を全て取得する処理となります。非同期処理時の残cursorの扱い(結果参照しPromiseを生成する)
DM欄・フォロー欄・フォロワー欄・リプライ欄等の頻繁に更新が発生しないが一覧で表示したい項目については、新規ツイート取得と異なり全量取得しようとするとAPIによる取得が複数回発生する可能性があります。TwitterAPIのentityの使用上、連続するデータを取得するためにcursorを用いてページ遷移の如く次ページのデータへ移動し、データを取得していく必要があります。
リセットタイムとRateLimitを考慮してある程度先読みさせておくとAPIサーバーへの頻繁なアクセスを減らす事ができ、負荷分散ができることに加えてRateLimitを無駄にしないメリットがあります。
(5の倍数で処理を実行しデータをストック、cursorを保持して待機させ、細かいAPIアクセスを減らすなど)上記コードを伝えたい箇所のみを使用して簡略すると以下の内容になります。
const getList = (nc) => { return new Promise(() => { client.get() /* client.get()処理が終了するまで待機、成功でthen、失敗でcatchに入る*/ // 受け取った結果を使用して次のPromiseを生成する ※疑似ループ処理 .then((res) => if(res.nextcursor !== 0) getList(res.next_cursor) }) // 何かしらのエラーが発生したらエラー出力して処理を終了 .catch((e) => { console.log(e) return }) // RateLimit:コード88 の可能性が一番高くなる返却される結果の1要素を用いて次の処理を生成する必要があるため、引数を投げられるPromiseを生成する関数の内部で再帰的に処理させる事により
getList()を実行するだけでループの上全量取得を行います。(RateLimitは除く)※なにかしら制御しないとアクセスしまくってすごいことになるので、今回のようなエラーコードが
返却されるものでなく自作APIを叩く場合は必ず制御を入れるようにしましょう。(エラー返すとか、フラグ制御とか)少し本論とズレましたが、TwitterAPIのentityでcursorを使って次結果に移動するため保持する必要があることと、APIの制限に柔軟に対応できるよう一定回数の処理を纏めて実行できる処理を作りRateLimitを無駄にしないことを頭に入れておけばTwitterAPIによる開発がしやすくなると思います。
取得対象に応じて設定値が著しく異なるRateLimitに注意する
TwitterAPIのRate Limitの欄を見ると新ツイートの取得等と異なり、比較的短時間での変動が少ないList・follower等の取得については15分に15回とかなり強めな値に設定されています。List等であれば1回のリクエストですべて取りきれますが、特にフォロワー取得については今回のコードでフォロワー(1-200程度)を検証中に数回取得した所、リクエスト回数全てを消費してしまいました。
Twitter公式のフォロワーページでスクロールを行うと、一定距離スクロールをした所で追加取得の実行が確認できます。自己紹介文などbioの長さによりますが4-50userで1リクエスト=cursor1回分みたいな扱いになっている印象を受けました。15count*約50user≒750人以上取得する場合、1回(15分)のRateLimit内では取り切れない可能性があります。
とはいえ更新が少ない箇所のため見せ方とか作り次第でどうにかできるものではありますが、RateLimitが極端に少ない箇所もあるよという所は開発する機能によってはクリティカルな部分となるため認識しておく必要があると思います。
entitiyの罠(screen_nameとUID)
ここに関してはentityの構造をちゃんと見ろという話ではありますがUserIdは各ユーザーに振られた固定の数値によるIDでありTwitterIdとして認識しているものはentityではscreen_nameである、だとか内部名称が自分が認識しているものと異なるので、先にある程度Twitter Developer Documentationのentityを見ておくとラグがなく作業ができるかなと思いました。(他の記事だとあまり触れられていなかったので念の為)
entity構造については参考サイトが日本語かつ公式より見やすかったため、必要そうな箇所を一通り読んでおけば比較的スムーズに実装できるかと思います。Twitter DeveloperのRate Limitと合わせて確認することをお勧めします。
補足
npmのTwitterモジュールは4年前から更新ストップしているため、Twitterの仕様変更によってはモジュールを使用したリクエストができなくなる可能性があります。(2020年12月現在で使えており生存ログの意味でもこの記事を書いています)
といってもWeeklyDL数は圧倒的だったりサクッと使いやすいため、使えなくなるタイミングについては注視しておく必要がありそうです。まとめ
・TwitterAPIはcursorのクセを理解して使う
・公式ドキュメント(特にentityとRateLimit)はよく読もう
・はじめからRateLimitを無駄にしない作りを意識しておくと後で困らないかも

- 投稿日:2020-12-18T18:30:22+09:00
【Node.js】TwitterAPIのRateLimitとcursorに気をつけろ
Node.jsアドベントカレンダー18日目の記事です。
APIの勉強で利用が楽、且つわかりやすいものが作れるのはTwitterか小説家になろうだと思っています。
参考:[JavaScript]なろうのランキングをAPIで一括取得する現在参画中のプロジェクトではAPIもフロントも両方開発していますが、サービスが本格運用前なことに加えてある程度仕様がゆるい状態での開発のため、APIリミットがキツいイメージがあったTwitterを触ってみることにしました。
Node.jsのTwitterAPIを使ってみよう系エントリーについてはAPI利用申請の部分に偏った物が多かった事と、
特徴となるcursorに触れている物が少なかったこともありコード側に寄せて実装時気になった箇所を纏めました。尚、Twitter API利用開始についてはTwitter APIを使ってみるを参考にしました。
3行で
・非同期処理時の残cursorの扱い(結果参照しPromiseを生成する)
・取得対象に応じて設定値が著しく異なるRateLimitに注意する
・entitiyの罠(screen_nameとUID)実装
app.js/* express関連の処理省略 API内部処理のみ記述 */ // 検索対象のIDを指定(実際はreqにて取得) const userId = "任意のID" // 初回カーソルの指定 let now_cursor = -1 // API取得情報の保持 const user = new Array() const getList = (nc) => { // 引数を受けてPromiseを返すfunctionを生成して返す return new Promise(() => { client.get("followers/list", { screen_name: userId, cursor: nc }) .then((res) => { user.push(res.users) now_cursor = res.next_cursor // cursorが0以外であれば次ページを取得、0ならファイル出力 if (now_cursor > 0) getList(now_cursor) else fileOutput(user, 'follow') }) .catch((e) => { // レートリミットの場合、15分経過したらリトライする if(e.code === 88) setTimeout(getList(now_cursor), 15 * 60* 1000) }) }) } // APIによるフォローリスト取得処理の実行 getList(now_cursor)今回はexpressのサーバーをFirebaseにてホスティングしてクライアントサイドから叩く想定のコードのうち、
取得処理のコアになる部分を抜粋しています。requestにてtwitterIdを受け取ったのち、そのidユーザーの
フォローしている人を全て取得する処理となります。非同期処理時の残cursorの扱い(結果参照しPromiseを生成する)
DM欄・フォロー欄・フォロワー欄・リプライ欄等の頻繁に更新が発生しないが一覧で表示したい項目については、新規ツイート取得と異なり全量取得しようとするとAPIによる取得が複数回発生する可能性があります。TwitterAPIのentityの使用上、連続するデータを取得するためにcursorを用いてページ遷移の如く次ページのデータへ移動し、データを取得していく必要があります。
リセットタイムとRateLimitを考慮してある程度先読みさせておくとAPIサーバーへの頻繁なアクセスを減らす事ができ、負荷分散ができることに加えてRateLimitを無駄にしないメリットがあります。
(5の倍数で処理を実行しデータをストック、cursorを保持して待機させ、細かいAPIアクセスを減らすなど)上記コードを伝えたい箇所のみを使用して簡略すると以下の内容になります。
const getList = (nc) => { return new Promise(() => { client.get() /* client.get()処理が終了するまで待機、成功でthen、失敗でcatchに入る*/ // 受け取った結果を使用して次のPromiseを生成する ※疑似ループ処理 .then((res) => if(res.nextcursor !== 0) getList(res.next_cursor) }) // 何かしらのエラーが発生したらエラー出力して処理を終了 .catch((e) => { console.log(e) return }) // RateLimit:コード88 の可能性が一番高くなる返却される結果の1要素を用いて次の処理を生成する必要があるため、引数を投げられるPromiseを生成する関数の内部で再帰的に処理させる事により
getList()を実行するだけでループの上全量取得を行います。(RateLimitは除く)※なにかしら制御しないとアクセスしまくってすごいことになるので、今回のようなエラーコードが
返却されるものでなく自作APIを叩く場合は必ず制御を入れるようにしましょう。(エラー返すとか、フラグ制御とか)少し本論とズレましたが、TwitterAPIのentityでcursorを使って次結果に移動するため保持する必要があることと、APIの制限に柔軟に対応できるよう一定回数の処理を纏めて実行できる処理を作りRateLimitを無駄にしないことを頭に入れておけばTwitterAPIによる開発がしやすくなると思います。
取得対象に応じて設定値が著しく異なるRateLimitに注意する
TwitterAPIのRate Limitの欄を見ると新ツイートの取得等と異なり、比較的短時間での変動が少ないList・follower等の取得については15分に15回とかなり強めな値に設定されています。List等であれば1回のリクエストですべて取りきれますが、特にフォロワー取得については今回のコードでフォロワー(1-200程度)を検証中に数回取得した所、リクエスト回数全てを消費してしまいました。
Twitter公式のフォロワーページでスクロールを行うと、一定距離スクロールをした所で追加取得の実行が確認できます。自己紹介文などbioの長さによりますが4-50userで1リクエスト=cursor1回分みたいな扱いになっている印象を受けました。15count*約50user≒750人以上取得する場合、1回(15分)のRateLimit内では取り切れない可能性があります。
とはいえ更新が少ない箇所のため見せ方とか作り次第でどうにかできるものではありますが、RateLimitが極端に少ない箇所もあるよという所は開発する機能によってはクリティカルな部分となるため認識しておく必要があると思います。
entitiyの罠(screen_nameとUID)
ここに関してはentityの構造をちゃんと見ろという話ではありますがUserIdは各ユーザーに振られた固定の数値によるIDでありTwitterIdとして認識しているものはentityではscreen_nameである、だとか内部名称が自分が認識しているものと異なるので、先にある程度Twitter Developer Documentationのentityを見ておくとラグがなく作業ができるかなと思いました。(他の記事だとあまり触れられていなかったので念の為)
entity構造については参考サイトが日本語かつ公式より見やすかったため、必要そうな箇所を一通り読んでおけば比較的スムーズに実装できるかと思います。Twitter DeveloperのRate Limitと合わせて確認することをお勧めします。
補足
npmのTwitterモジュールは4年前から更新ストップしているため、Twitterの仕様変更によってはモジュールを使用したリクエストができなくなる可能性があります。(2020年12月現在で使えており生存ログの意味でもこの記事を書いています)
といってもWeeklyDL数は圧倒的だったりサクッと使いやすいため、使えなくなるタイミングについては注視しておく必要がありそうです。まとめ
・TwitterAPIはcursorのクセを理解して使う
・公式ドキュメント(特にentityとRateLimit)はよく読もう
・はじめからRateLimitを無駄にしない作りを意識しておくと後で困らないかも
- 投稿日:2020-12-18T18:03:33+09:00
Node.js nmpをインストールする時の備忘録
知識が少ない自分のための記事
Cordovaを使おうとnmpをインストールした際
ほとんどはこの記事のまま実行
買いたてのMacにNode.jsとnpmをインストール実行パスを通すところの理解がたらず手間取ってしまった。
$ nodebrew setup Fetching nodebrew... Installed nodebrew in $HOME/.nodebrew ======================================== Export a path to nodebrew: export PATH=$HOME/.nodebrew/current/bin:$PATH ========================================この
PATH=$HOME/.nodebrew/current/bin:$PATHを使用して
$ echo 'export PATH=$HOME/.nodebrew/current/bin' >> ~/.bashrcと 書き込む
いずれ理解を深めていきたい
参考サイト
- 投稿日:2020-12-18T17:51:45+09:00
JavaScript開発にNoSQLデータベースを活用する(CEANスタック紹介) ~ Node.js + Couchbaseアプリ開発 ステップバイステップガイド 2
はじめに
本記事は、Node.js + NoSQL(Couchbase) を使ったアプリ開発をステップバイステップで解説していくシリーズの第二回目になります。
下記の第一回記事も適宜参照していただければ幸いですが、開発の実際に進む前に、まずは表題についての解説から始めます。
Node.js + NoSQL(Couchbase) アプリ開発 ステップバイステップガイド (1)
なぜ、JavaScriptとNoSQLの組み合わせなのか?
NoSQLは、非RDB(RDB以降の技術)であることのみを共通点として、様々な異なる特色を持った技術に対する総称となっていますが、ここで対象とするカテゴリーは、その中でもドキュメント指向データベース(ドキュメントストア)と呼ばれるものです。
ドキュメントストアは、JSONデータを格納することを特徴としており、自ずと、JavaScriptと親和性を持っています(JSON = Java Script Object Notation)。
その一方、RDBから移行するだけの利点があるのか、というのが実際的な関心なのではないかと思います。こちらについては後ほど触れていきます。
CEANスタック紹介
ここで、用いるCEANスタックとは、下記の技術要素からなります。
- C: Couchbase (NoSQLドキュメント指向データベース)
- E: Express (Webアプリケーション・フレームワーク)
- A: Angular (フロントエンド・フレームワーク)
- N: Node.js (サーバサイドJavaScript実行環境)
類似のものとして、MEANスタック、という言葉を聞いたことがある方もいるのではないかと思います(そうは言っても、LAMP程には、浸透していない気もしますが)。この場合のMは、MongoDBとなり、Couchbase同様、JSONデータを扱うことのできるNoSQLデータベースです。
以下では、NoSQL/ドキュメントストアとしてCouchbaseについてのみ記します(MongoDB/MEANスタックについては、様々存在する別の記事・情報に譲ります)。NoSQL/Couchbaseを選択する理由
慣れ親しんだRDBに替えて、あえてNoSQL/Couchbaseを選択する理由としては、様々な角度から語ることができますが、ここでは、以下の点にフォーカスしたいと思います。
それは、Couchbaseなら、JSONデータとクエリ言語の両方の利点を活用することができる、ということです。
一つずつ、見ていきたいと思います。
JSONデータの利点
これは、RDBの欠点と見ることもできます。つまり...
- アプリケーションが必要とするデータ構造(ドメインオブジェクト)と、RDBが要請する形式(第一正規形テーブル構造)との間には、断絶がある。
- アプリケーションの設計、実装、改善、機能追加など、全ての工程において、データベースとの兼ね合いを図る必要がある(密結合)
これに対して、データ層が、JSONを許容した場合...
- データ層は、第一正規形を要請しないため、アプリケーションが必要とするデータ構造(ドメインオブジェクト)そのものを格納することができる。
- (JSONには、データ構造に関する情報がデータ自体に含まれているため)アプリケーション設計・開発工程において、特にデータ設計の変化に(データベース側の作業を伴うことなく)柔軟に対応できる
クエリ言語の利点
これは、RDBの持つ大きな利点であり、標準化されたクエリ言語(SQL)が様々な異なるデータベースで利用できることは、技術者層の拡大に繋がり、SQLの習得は、(特にオープンシステムのWEBアプリケーション全盛時代には)システム開発者にとって、必須知識といえるものとなっていました。
Couchbaseを選択することで、開発者は、SQLの知識を活用することができます。
サンプル・アプリケーション紹介
CEANスタックで開発したアプリケーションを下記に公開しています。
https://github.com/YoshiyukiKono/couchbase_step-by-step_node_jp
このアプリケーションは、下記の画面を見ていただければ分かるように、最小限の機能からなるシンプルなものとなっています。
アプリケーション実行方法
上記のリポジトリから、コードを取得します。
$ git clone https://github.com/YoshiyukiKono/couchbase_step-by-step_node_jp.git $ cd couchbase_step-by-step_node_jpその中に含まれる、
package.jsonには、下記の依存関係が定義されています。"dependencies": { "couchbase": "^3.1.0", "express": "^4.17.1" }第一回の内容も合わせて、参照していただきたいと思いますが、このアプリケーションでは、バケット名として
node_appを使っています。アプリケーション実行前に、下記のようにインデックスを作成しておく必要があります。
$ cbq -u Administrator Enter Password: Connected to : http://localhost:8091/. Type Ctrl-D or \QUIT to exit. ... cbq> CREATE PRIMARY INDEX node_app_primary ON node_app;このアプリケーションでは、下記のように、
server.jsを使います。$ node server.js Server up: http://localhost:80
http://localhost:80にアクセスします。プログラム解説
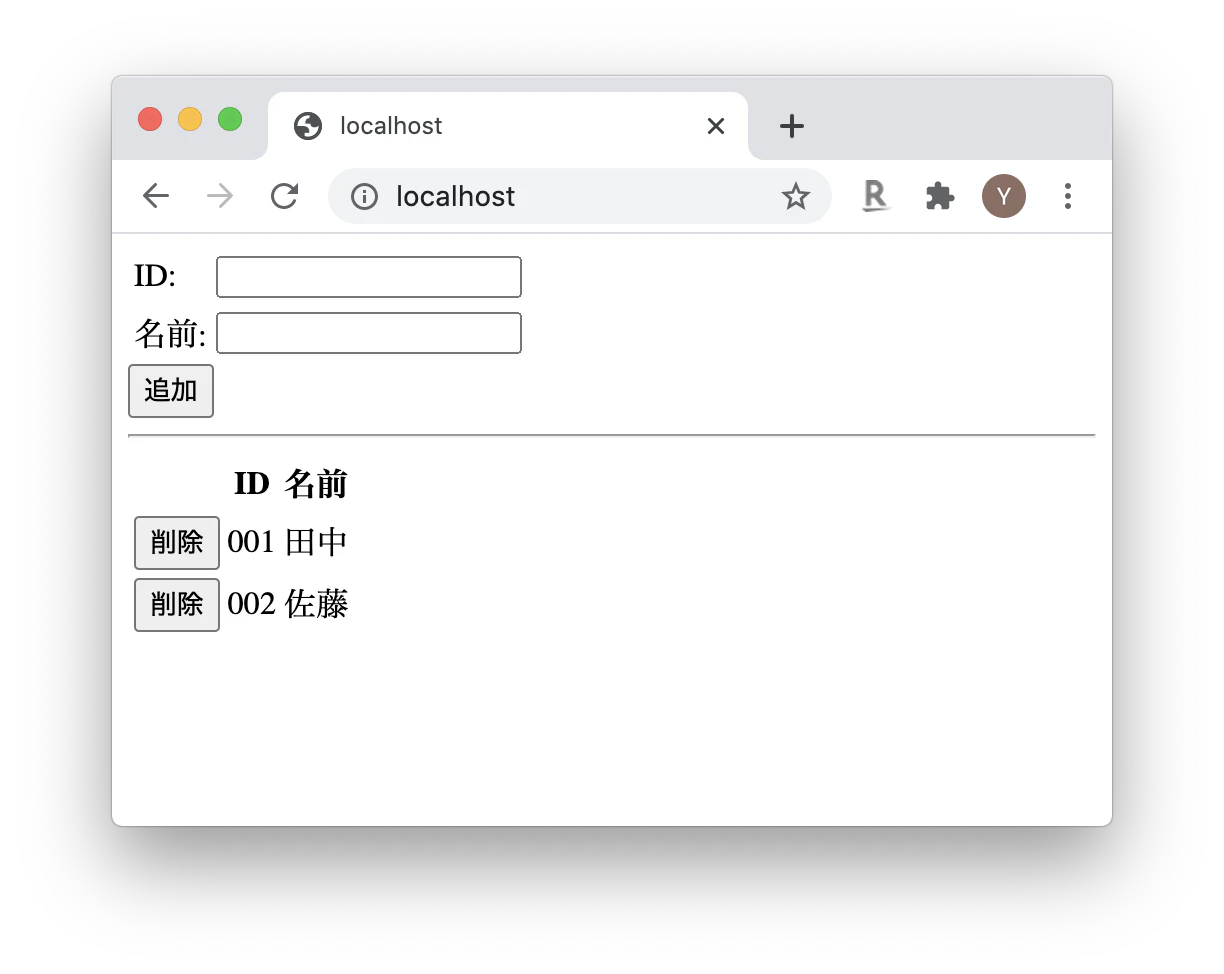
routes.jsを見ると、画面のリスト表示のために、下記のようなクエリが使われているのが分かります。const qs = `SELECT name, id from node_app WHERE type='user'`;一方、プログラム中のデータ(ドメインオブジェクト)の表現と、そのデータをデータベースへの保存する部分は、下記のようなものです。
const user = { type: "user", id: req.body.id, name: req.body.name, }; upsertDocument(user);const upsertDocument = async (doc) => { try { const key = `${doc.type}_${doc.id}`; const result = await collection.upsert(key, doc); } catch (error) { console.error(error); } };JavaScriptのディクショナリをそのまま格納しているのが分かります。
最後に
今回は以上です。コードができるだけ分かりやすいものとなるよう、処理やデータ構造は最小限のものとしています。
実は私自身、CEANスタックを用いるのは今回初めてだったのですが、いたずらに複雑でないぶん、コード自体を見ていただくことで、全体の関係が掴みやすいものになっているのではないかと思います。今後について
ディクショナリ/JSONデータをそのまま使うことで、ORマッピングなどを用いる必要がなく、シンプルに開発ができることがわかったかと思います。一方で、単なるマップ型のデータ構造ではなく、ドメインオブジェクトをクラスとして定義したいというニーズもあるかと思います。Couchbaseには、Ottoman.jsというオープンソースのODM(Object Document Mapping)フレームワークがあり、そうしたニーズにも対応することができます。
こちらについても、今後紹介していきたいと考えています。
- 投稿日:2020-12-18T01:35:27+09:00
【公式通りではダメ!?】Firestoreのデータを定期的にスケジューラーでバックアップ設定を行う方法
〜この記事の内容〜
Firestoreのバックアップを手動およびGCPのスケジューラーによる定期実行を行う手順を共有します。
公式の説明があるのだが、新しいNode.jsのバージョンだと手順通りに行っても動かないことがあるので、
一人でも多くの方が幸せになれるように、自分が苦戦して判明した問題箇所およびその解決策を共有します。■公式のExport手順ページ(こちらは問題なくできる)
- 公式_手動実行
- 公式_スケジュール実行(こちらに一部そのままだと動かない箇所がある)
ただし冒頭の通り、こちらはNode.jsのバージョンによってはそのままだと動かない問題がある。
■前提条件
1.Google Cloud Platform プロジェクトに対する課金を有効にします。エクスポートとインポートの機能を使用できるのは、課金が有効になっている GCP プロジェクトのみです。
ここは本記事では完了している前提です。
■GCPコンソールへ移動し、バケットを作成
ここからコンソールへ移動します
Cloud Storageバケットを作成
○-db-backup
というように設定した。Multi-Regionを選択し、実際のリージョンは自分のPJと同じリージョンを選択する必要がある
自分の場合はFirebaseプロジェクトをasiaで作成していたため、asiaを選択
Standardを選択
均一を選択
詳細設定はこのままで作成
■手動でExport
Cloud Shellにて、
gcloud config set project [PROJECT_ID]
->
Updated property [core/project].
gcloud firestore export gs://[BUCKET_NAME]※もし作成したバケットのリージョンがプロジェクトと異なると以下のようなエラーが出る
ERROR: (gcloud.firestore.export) INVALID_ARGUMENT: Bucket ○ is in location US-WEST4. This project can only operate on buckets spanning location asia-south1 or asia.
成功するとこのように先ほどのバケットへフォルダが作成される
■手動でImport
Cloud Shellにて、
gcloud firestore import gs://[BUCKET_NAME]/[EXPORT_PREFIX]/
[EXPORT_PREFIX]は上記のexportでストレージに保存されたフォルダ名ex)
gcloud firestore import gs://exports-bucket/2017-05-25T23:54:39_76544/試しに今あるFirestoreのドキュメントを適当に消して上記のImportコマンドを再度行ってみると、
しっかりデータが復元していた。これで手動でのバックアップに成功した。
■スケジューラーによる定期的なExport設定
- 公式_スケジュール実行(こちらに一部そのままだと動かない箇所がある)
firebase init functions --project PROJECT_ID
->
+ 言語には JavaScript を選択します。
+ 必要に応じて、ESLint を有効にします。
+ 「y」と入力して依存関係をインストールします。functions/index.js ファイル内のコードを次のコードで置き換えます
ここからが公式だと動かない可能性があることが分かった箇所。
*Node.jsのバージョンが8.0以下(公式はこちらの方法)
index.jsconst functions = require('firebase-functions'); const firestore = require('@google-cloud/firestore'); const client = new firestore.v1.FirestoreAdminClient(); // Replace BUCKET_NAME const bucket = 'gs://BUCKET_NAME'; exports.scheduledFirestoreExport = functions.pubsub .schedule('every 24 hours') .onRun((context) => { const databaseName = client.databasePath(process.env.GCP_PROJECT, '(default)'); return client.exportDocuments({ name: databaseName, outputUriPrefix: bucket, // Leave collectionIds empty to export all collections // or set to a list of collection IDs to export, // collectionIds: ['users', 'posts'] collectionIds: [] }) .then(responses => { const response = responses[0]; console.log(`Operation Name: ${response['name']}`); return response; }) .catch(err => { console.error(err); throw new Error('Export operation failed'); }); });スケジュール設定された関数をデプロイします
firebase deploy --only functions※BUCKET_NAMEだけ、自分のバケットの名前へ変更する。
これで動けば良かったが、自分のNode.jsのバージョンは12であり、このまま実行するとCloud Functionのログで以下のようにエラーが出た。
TypeError: Cannot read property 'toString' of undefined
at PathTemplate.render (/workspace/node_modules/google-gax/build/src/pathTemplate.js:110:37)
at FirestoreAdminClient.databasePath (/workspace/node_modules/@google-cloud/firestore/build/src/v1/firestore_admin_client.js:962:56)*Node.jsのバージョンが10.0以上(自分で変更した方法)
コードをこのように変えることで動作するようになる。
(Node.jsの環境の違いによって使い分けられるようにコメントをつけてどちらも残した)index.js//--- Node.jsのバージョンが10以上の時はこのように書き換える // const databaseName = client.databasePath(process.env.GCP_PROJECT, '(default)'); //--- Node.jsのバージョンが10以上の時はこのように書き換える const projectId = process.env.GCP_PROJECT || process.env.GCLOUD_PROJECT; const databaseName = client.databasePath( projectId, '(default)', )おまけで、時間もデフォルトの24hours以外にも定期実行のテスト用に3分おきや、
毎日0:00に行うバージョンも試したので、誰かが使えるようにコードを置いておく。index.js//============================================== // Periodical Automatic Backup (made by KASATA) //============================================== const functions = require('firebase-functions'); const firestore = require('@google-cloud/firestore'); const client = new firestore.v1.FirestoreAdminClient(); // Replace BUCKET_NAME const bucket = 'gs://BUCKET_NAME'; //======スケジュール設定値 // const timeSchedule = 'every 24 hours'; //24時間おき // const timeSchedule = 'every 3 minutes'; //3分おき(デバッグ用) const timeSchedule = 'every day 00:00';; //毎日0:00 //====== exports.scheduledFirestoreExport = functions.pubsub .schedule(timeSchedule) .onRun((context) => { //--- Node.jsのバージョンが10以上の時はこのように書き換える // const databaseName = client.databasePath(process.env.GCP_PROJECT, '(default)'); //--- Node.jsのバージョンが10以上の時はこのように書き換える const projectId = process.env.GCP_PROJECT || process.env.GCLOUD_PROJECT; const databaseName = client.databasePath( projectId, '(default)', ) return client.exportDocuments({ name: databaseName, outputUriPrefix: bucket, // Leave collectionIds empty to export all collections // or set to a list of collection IDs to export, // collectionIds: ['users', 'posts'] collectionIds: [] }) .then(responses => { const response = responses[0]; console.log(`Operation Name: ${response['name']}`); return response; }) .catch(err => { console.error(err); throw new Error('Export operation failed'); }); });あとは公式通り、スケジュール設定された関数をデプロイします
firebase deploy --only functions■権限の編集
自分のプロジェクトIDに応じて、ユーザーに
serviceAccount:PROJECT_ID@appspot.gserviceaccount.comができており、このユーザーの権限をそれぞれ然るべきものへ変更しておくCloud Shellにて、
gcloud projects add-iam-policy-binding PROJECT_ID \ --member serviceAccount:PROJECT_ID@appspot.gserviceaccount.com \ --role roles/datastore.importExportAdmingsutil iam ch serviceAccount:PROJECT_ID@appspot.gserviceaccount.com:admin \ gs://BUCKET_NAME■実行ログを見る方法
FirebaseのCloud FunctionsのログでエラーやOK statusなどを見ることができる。
以下は正常に定期バックアップできている状態
■終わりに
公式の通りにやっても動かないので、なかなかハマりポイントなので皆様ご注意を。








- 投稿日:2020-12-18T01:35:27+09:00
[公式通りではダメ!?] Firestoreのデータを定期的にスケジューラーでバックアップ設定を行う方法
〜この記事の内容〜
Firestoreのバックアップを手動およびGCPのスケジューラーによる定期実行を行う手順を共有します。
公式の説明があるのだが、新しいNode.jsのバージョンだと手順通りに行っても動かないことがあるので、
一人でも多くの方が幸せになれるように、自分が苦戦して判明した問題箇所およびその解決策を共有します。■公式のExport手順ページ(こちらは問題なくできる)
- 公式_手動実行
- 公式_スケジュール実行(こちらに一部そのままだと動かない箇所がある)
ただし冒頭の通り、こちらはNode.jsのバージョンによってはそのままだと動かない問題がある。
■前提条件
1.Google Cloud Platform プロジェクトに対する課金を有効にします。エクスポートとインポートの機能を使用できるのは、課金が有効になっている GCP プロジェクトのみです。
ここは本記事では完了している前提です。
■GCPコンソールへ移動し、バケットを作成
ここからコンソールへ移動します
Cloud Storageバケットを作成
○-db-backup
というように設定した。Multi-Regionを選択し、実際のリージョンは自分のPJと同じリージョンを選択する必要がある
自分の場合はFirebaseプロジェクトをasiaで作成していたため、asiaを選択
Standardを選択
均一を選択
詳細設定はこのままで作成
■手動でExport
Cloud Shellにて、
gcloud config set project [PROJECT_ID]
->
Updated property [core/project].
gcloud firestore export gs://[BUCKET_NAME]※もし作成したバケットのリージョンがプロジェクトと異なると以下のようなエラーが出る
ERROR: (gcloud.firestore.export) INVALID_ARGUMENT: Bucket ○ is in location US-WEST4. This project can only operate on buckets spanning location asia-south1 or asia.
成功するとこのように先ほどのバケットへフォルダが作成される
■手動でImport
Cloud Shellにて、
gcloud firestore import gs://[BUCKET_NAME]/[EXPORT_PREFIX]/
[EXPORT_PREFIX]は上記のexportでストレージに保存されたフォルダ名ex)
gcloud firestore import gs://exports-bucket/2017-05-25T23:54:39_76544/試しに今あるFirestoreのドキュメントを適当に消して上記のImportコマンドを再度行ってみると、
しっかりデータが復元していた。これで手動でのバックアップに成功した。
■スケジューラーによる定期的なExport設定
- 公式_スケジュール実行(こちらに一部そのままだと動かない箇所がある)
firebase init functions --project PROJECT_ID
->
+ 言語には JavaScript を選択します。
+ 必要に応じて、ESLint を有効にします。
+ 「y」と入力して依存関係をインストールします。functions/index.js ファイル内のコードを次のコードで置き換えます
ここからが公式だと動かない可能性があることが分かった箇所。
*Node.jsのバージョンが8.0以下(公式はこちらの方法)
index.jsconst functions = require('firebase-functions'); const firestore = require('@google-cloud/firestore'); const client = new firestore.v1.FirestoreAdminClient(); // Replace BUCKET_NAME const bucket = 'gs://BUCKET_NAME'; exports.scheduledFirestoreExport = functions.pubsub .schedule('every 24 hours') .onRun((context) => { const databaseName = client.databasePath(process.env.GCP_PROJECT, '(default)'); return client.exportDocuments({ name: databaseName, outputUriPrefix: bucket, // Leave collectionIds empty to export all collections // or set to a list of collection IDs to export, // collectionIds: ['users', 'posts'] collectionIds: [] }) .then(responses => { const response = responses[0]; console.log(`Operation Name: ${response['name']}`); return response; }) .catch(err => { console.error(err); throw new Error('Export operation failed'); }); });スケジュール設定された関数をデプロイします
firebase deploy --only functions※BUCKET_NAMEだけ、自分のバケットの名前へ変更する。
これで動けば良かったが、自分のNode.jsのバージョンは12であり、このまま実行するとCloud Functionのログで以下のようにエラーが出た。
TypeError: Cannot read property 'toString' of undefined
at PathTemplate.render (/workspace/node_modules/google-gax/build/src/pathTemplate.js:110:37)
at FirestoreAdminClient.databasePath (/workspace/node_modules/@google-cloud/firestore/build/src/v1/firestore_admin_client.js:962:56)*Node.jsのバージョンが10.0以上(自分で変更した方法)
コードをこのように変えることで動作するようになる。
(Node.jsの環境の違いによって使い分けられるようにコメントをつけてどちらも残した)index.js//--- Node.jsのバージョンが10以上の時はこのように書き換える // const databaseName = client.databasePath(process.env.GCP_PROJECT, '(default)'); //--- Node.jsのバージョンが10以上の時はこのように書き換える const projectId = process.env.GCP_PROJECT || process.env.GCLOUD_PROJECT; const databaseName = client.databasePath( projectId, '(default)', )おまけで、時間もデフォルトの24hours以外にも定期実行のテスト用に3分おきや、
毎日0:00に行うバージョンも試したので、誰かが使えるようにコードを置いておく。index.js//============================================== // Periodical Automatic Backup (made by KASATA) //============================================== const functions = require('firebase-functions'); const firestore = require('@google-cloud/firestore'); const client = new firestore.v1.FirestoreAdminClient(); // Replace BUCKET_NAME const bucket = 'gs://BUCKET_NAME'; //======スケジュール設定値 // const timeSchedule = 'every 24 hours'; //24時間おき // const timeSchedule = 'every 3 minutes'; //3分おき(デバッグ用) const timeSchedule = 'every day 00:00';; //毎日0:00 //====== exports.scheduledFirestoreExport = functions.pubsub .schedule(timeSchedule) .onRun((context) => { //--- Node.jsのバージョンが10以上の時はこのように書き換える // const databaseName = client.databasePath(process.env.GCP_PROJECT, '(default)'); //--- Node.jsのバージョンが10以上の時はこのように書き換える const projectId = process.env.GCP_PROJECT || process.env.GCLOUD_PROJECT; const databaseName = client.databasePath( projectId, '(default)', ) return client.exportDocuments({ name: databaseName, outputUriPrefix: bucket, // Leave collectionIds empty to export all collections // or set to a list of collection IDs to export, // collectionIds: ['users', 'posts'] collectionIds: [] }) .then(responses => { const response = responses[0]; console.log(`Operation Name: ${response['name']}`); return response; }) .catch(err => { console.error(err); throw new Error('Export operation failed'); }); });あとは公式通り、スケジュール設定された関数をデプロイします
firebase deploy --only functions■権限の編集
自分のプロジェクトIDに応じて、ユーザーに
serviceAccount:PROJECT_ID@appspot.gserviceaccount.comができており、このユーザーの権限をそれぞれ然るべきものへ変更しておくCloud Shellにて、
gcloud projects add-iam-policy-binding PROJECT_ID \ --member serviceAccount:PROJECT_ID@appspot.gserviceaccount.com \ --role roles/datastore.importExportAdmingsutil iam ch serviceAccount:PROJECT_ID@appspot.gserviceaccount.com:admin \ gs://BUCKET_NAME■実行ログを見る方法
FirebaseのCloud FunctionsのログでエラーやOK statusなどを見ることができる。
以下は正常に定期バックアップできている状態
■終わりに
公式の通りにやっても動かないので、なかなかハマりポイントなので皆様ご注意を。
- 投稿日:2020-12-18T00:18:29+09:00
開発する初期段階で見て欲しい、Expressでつかむべき全体像
新しい言語やフレームワークを勉強した時、一番に気になるところは自分の慣れ親しんだ言語とかといかに違うのか、そしてそれらを含めたアプリ全体の構造ではないでしょうか。
ということで、javascriptのフレームワークであるexpressを使った開発を経験した際、最初にこういった記事あるといいな〜という視点で記事を書きました。
ご指摘ありましたら、コメントお願いいたします。
1.controllerファイルやディレクトリがない
最初これに驚きました。自分はRailsから入ったのでcontrollerに関数とか処理を記述しようとしていたのですが、
「ナイジャン!!」
代わりにroutingの部分に処理をかけます。
router.get('/new', authenticationEnsurer, (req, res, next) => { res.render('new', { user: req.user }); }); router.post('/', authenticationEnsurer, (req, res, next) => { //DB処理など記述 });2.requireだけではだめ。exportが必要
requireだけで他のファイルの情報とかを取得することができると勘違いしていました。
実際には、module.exports = router;やappConfig.jsmodule.exports = { //パスワードなど };といった風に他のファイルに渡したいものはexportしてあげないといけません。
3.一連の流れ
MVCアーキテクチャのwebアプリにおいて流れはしっかり知っておくべきことだと思います。どのファイルやどういったコードを通って最終的にviewにたどり着いているか。それを知ることは開発の効率を上げるでしょう。
app.js
まず最初はapp.jsから気にするべきでしょう。
最初に読み込まれるファイルです。したがって、ここにアプリの挙動が集中しています。routing
app.jsの中でroutingの設定をします。
var indexRouter = require('./routes/index');app.use('/', indexRouter);indexRouterを呼び込んで、appに使わせる指示をします。
action
routes/index.js'use strict'; const express = require('express'); const router = express.Router(); const Pages = require('../models/pages'); router.get('/', (req, res, next) => { if (req.user) { Pages.findAll({ where: { createdBy: req.user.id }, order: [['updatedAt', 'DESC']] }).then(pages => { res.render('index', { user: req.user, pages: pages }); }); } else { res.render('index', { user: req.user }); } }); module.exports = router;このようにget/postの中にルーティングの際の処理を入れていきます。
今回は投稿(pages)の一覧を取得してます。
4.最後に
expressわかりやすいです。正直Railsよりもわかりやすく書きやすいなと感じました。
express初心者の方の参考になれば幸いです。