- 投稿日:2020-12-04T23:59:00+09:00
【Windows・Ubuntu】Pythonの環境構築備忘録2020
最近のPython環境構築方法の動向
公式
最新のバージョンは、2020年12月現在、3.9.0です。
公式のインストール方法は、大きくは変わっていないです。Anaconda
以下の4種類があります。
大抵の人は、Individual Editionを使うと思います。
- Commercial Edition
- 7500を超える データサイエンス / Machine Learning のパッケージ
- セキュリティと互換性に優れたすべてのAnacondaのパッケージを利用できる
- $14.95/月
- Team Edition
- CVEレポート
- ユーザー・アクセス・コントロール
- $10,000~
- Enterprise Edition
- すべてそろってる
- サポートあり?
- 価格は相談
- Anaconda Individual Edition
- 個人用
- 無料
pyenv
大きな変化はなさそうです。
次のvirtualenvとの組み合わせがよさそうです。virtualenv
大きな変化はなさそうです。
上記pyenvとの組み合わせがよさそうです。公式の環境構築方法
ここでは、pythonの公式サイト(python.org)からダウンロードしてインストールする方法を説明します。
対象ユーザー
とにかく、シンプルにPythonをインストールしたい人向け。
メリット
- 一番簡単な構築方法なので、すぐに構築作業が終わる。
- 公式の構築方法なので、無償かつ、商用利用可能。
- exeのインストーラーを使って、グラフィカルに、ほとんど自動で構築が可能。
デメリット
- 簡単な分、あとで必要なライブラリが増えると、手動のセットアップ作業も増える。
- 複数の環境を同時に共存させられないので、環境ごとにPC(OS)を変えなければならない。
構築手順
Windows
Ubuntu
Anacondaの環境構築方法
対象ユーザー
メリット
デメリット
構築手順
Windows
Ubuntu
pyenv + virtualenv の環境構築方法
対象ユーザー
メリット
デメリット
構築手順
Windows
Ubuntu
まとめ
参考文献
- 投稿日:2020-12-04T23:50:30+09:00
【改訂版】日本語テキストから、SVO格を指定した検索単語を含む「係受け元単語 -> 係受け先単語」を全件出力するGUIツール
前回作成したGUIツールの画面を見やすく変えました。
・ 前回の記事
挙動確認
Terminal% python3 tkinter_ner_svo_list_filter_by_target_word_and_case_file_dialog2.py1. テキストファイルを選択
2. テキストファイルを選択
3. 選択可能な固有表現ラベルの中から、「地名」のラジオボタンを選択
( テキストファイル内に登場するすべての「地名」単語が、出現回数の多い順に表示される )
4. 出力された「地名」単語の中から、関心を寄せる単語の番号を入力
5. 「主語」を選択。選択した「地名」単語の文字列を含む単語が、「主語」の役割で登場する文脈箇所から、「係り受け元単語 -> 係り受け先単語」のペアを、全件出力する
( 他の「地名」も見てみる。4番目の地名「日本」を選択。さらに、「主語」を選択。)
( 単語「日本」を含む文字列が、「主語」の役割で登場する文脈箇所から、「係り受け元単語 -> 係り受け先単語」のペアを全件出力する )
( 単語「中国」を文字列に含む単語が、「主語」の役割で登場する文脈箇所からは、「係り受け元単語 -> 係り受け先単語」は、1件も見つからなかった。 )
選択可能な固有表現ラベルの中から、「組織名」のラジオボタンを選択
表示された1つ目の「組織名」(「ロシア軍」)という文字列を主語に持つ文脈から、「係り受け元単語 -> 係り受け先単語」のペアを全件、出力する。
改定後の実装コード
tkinter_ner_svo_list_filter_by_target_word_and_case_file_dialog2.py# Tkinterのライブラリを取り込む import tkinter, spacy, collections, CaboCha, os import tkinter.filedialog, tkinter.messagebox from typing import List, Dict, Tuple, TypeVar from tkinter import * from tkinter import ttk from tkinter import filedialog from tkinter import messagebox from spacy.matcher import Matcher # グローバル変数の宣言 exracted_entity_word_list = "" user_input_text = "" named_entity_label = "" T = TypeVar('T', str, None) Vector = List[T] # ターゲット単語の出現位置の格(主語(主格)、述語、目的語(目的格) case_num_dict = {1 : "主語", 2 : "述語", 3: "目的語"} # ファイルの参照処理 def click_refer_button(): fTyp = [("","*")] iDir = os.path.abspath(os.path.dirname(__file__)) filepath = filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir) file_path.set(filepath) # 固有表現抽出処理 def extract_words_by_entity_label(text, named_entity_label): nlp = spacy.load('ja_ginza') text = text.replace("\n", "") doc = nlp(text) words_list = [ent.text for ent in doc.ents if ent.label_ == named_entity_label] return words_list # 出力処理 def click_export_button(): # 選択された固有表現の種別名を取得 named_entity_label = flg.get() global user_input_text f = open(file_path, encoding="utf-8") user_input_text = f.read() label_word_list = extract_words_by_entity_label(user_input_text, named_entity_label) # 指定された固有表現に該当する単語を取得した結果(単語リスト)を、{単語文字列 : 出現回数}の辞書に変換する count_per_word = collections.Counter(label_word_list) # 出現回数の多い順番に並べる freq_per_word_dict = dict(count_per_word.most_common()) #output_list = ["{k} : {v}".format(k=key, v=value) for (key, value) in freq_per_word_dict.items()] # 単語数を取得する unique_word_num = len(freq_per_word_dict) if unique_word_num > 0: message = "{num}件の{label}が見つかりました。\n\n出現回数順に並べた結果は以下です。\n\n".format(num=unique_word_num, label=named_entity_label) word_list = list(freq_per_word_dict.keys()) word_freq_list = list(freq_per_word_dict.values()) for i in range(unique_word_num): tmp = "{rank}番目の単語 : {word}\n出現回数 : {count}\n\n===================\n".format(rank=i+1, word=word_list[i], count=word_freq_list[i]) message += tmp else: message = "{num}件の{label}が見つかりました。\n\n".format(num=unique_word_num, label=named_entity_label) textBox.insert(END, message) global exracted_entity_word_list exracted_entity_word_list = word_list return exracted_entity_word_list def get_svo_info_(sentence:str, target_word:str, case_num_of_target_word:int) -> Tuple[Dict, List]: c = CaboCha.Parser() tree = c.parse(sentence) size = tree.size() myid = 0 ku_list = [] ku = '' ku_id = 0 ku_link = 0 kakari_joshi = 0 kaku_joshi = 0 for i in range(0, size): token = tree.token(i) if token.chunk: if (ku!=''): ku_list.append((ku, ku_id, ku_link, kakari_joshi, kaku_joshi)) #前 の句をリストに追加 kakari_joshi = 0 kaku_joshi = 0 ku = token.normalized_surface ku_id = myid ku_link = token.chunk.link myid=myid+1 else: ku = ku + token.normalized_surface m = (token.feature).split(',') if (m[1] == u'係助詞'): kakari_joshi = 1 if (m[1] == u'格助詞'): kaku_joshi = 1 ku_list.append((ku, ku_id, ku_link, kakari_joshi, kaku_joshi)) # 最後にも前の句をリストに追加 for k in ku_list: if (k[2]==-1): # link==-1? # 述語である jutsugo_id = ku_id # この時のidを覚えておく #述語句 predicate_word = [k[0] for k in ku_list if (k[1]==jutsugo_id)] #for k in ku_list: # if (k[1]==jutsugo_id): # jutsugo_idと同じidを持つ句を探す # print(k[1], k[0], k[2], k[3], k[4]) #述語句に係る句 # jutsugo_idと同じidをリンク先に持つ句を探す word_to_predicate_list = [k[0] for k in ku_list if k[2]==jutsugo_id] # 述語句に係る句 -> 述語句 svo_arrow_text_list = [str(word_to_predicate) + "->" + str(predicate_word[0]) for word_to_predicate in word_to_predicate_list] #print(svo_arrow_text_list) desired_svo_arrow_text = [arrow_pair_str for arrow_pair_str in svo_arrow_text_list if target_word in arrow_pair_str] svo_dict = {} for num, k in enumerate(ku_list): if (k[2]==jutsugo_id): # jutsugo_idと同じidをリンク先に持つ句を探す if (k[3] == 1): subject_word = k[0] if target_word in subject_word: svo_dict["主語"] = subject_word #print(subject_word) if (k[4] == 1): object_word = k[0] if target_word in object_word: svo_dict["目的語"] = object_word #print(object_word) if (k[1] == jutsugo_id): predicate_word = k[0] if target_word in predicate_word: svo_dict["述語"] = predicate_word #print(predicate_word) case_type_of_search_word = case_num_dict[case_num_of_target_word] tmp_list_of_dict_list = [(svo_dict, desired_svo_arrow_text)] output_list_of_dict_list = [(dict_obj, list_obj) for (dict_obj, list_obj) in tmp_list_of_dict_list if list(dict_obj.keys())==[case_type_of_search_word]] # 空の要素を外す output = [elem for elem in output_list_of_dict_list if len(elem)>0] return output # 受け取ったstr型のテキストデータに複数の文が含まれる場合を、「。」の出現回数で判定して検出。 # 複数の文を、1つの文を要素に持つlistに格納する。その後、リスト内包表記のなかで、文を一つずつ、一つの文を受け取るget_svo_info_に渡す。 # 受け取ったstr型のテキストデータに、1つの文しか含まれない場合は、上記の処理を行わない。 def get_svo_info(text:str, target_word:str, case_num_of_target_word:int) -> List[Tuple[Dict, List]]: sentence_num = text.count("。") if sentence_num > 1: sentence_list = text.split("。") sentence_list = [sentence for sentence in sentence_list if not(sentence == "")] output_list = result_list = [get_svo_info_(sentence, target_word, case_num_of_target_word) for sentence in sentence_list] else: output = get_svo_info_(text, target_word, case_num_of_target_word) output_list = [output] return output_list def click_export_button2(): # 選択された格位置の種別番号を取得 case_label_int = flg2.get() case_name = case_num_dict[case_label_int] # 入力された単語を取得 order_num = int(subject_num.get())-1 #ユーザが1を入力したとき、配列の0番地を指定する。 target_word = exracted_entity_word_list[order_num] # 入力単語が、選択された格位置で出現する文脈箇所における「係受け単語関係」を抽出 output_list = get_svo_info(user_input_text, target_word, case_label_int) # 空の要素を配列からとる tmp_list = [elem for elem in output_list if any(elem)] tmp = tmp_list length = len(tmp) output_message = "" for i, elm in enumerate(tmp): if elm[0] is None: output_message = "\n該当するものは見当たりませんでした。\n" else: output_message += "\n\n【 以下の" + case_name + "が見つかりました。 】\n\n" + str(elm[0][0]) + "\n\n【 以下の係り受け関係の単語ペアが見つかりました。 】\n\n" + str(elm[0][1]) + "\n\n" if length > i+1: output_message += "------------------------" # subject_string = exracted_entity_word_list[order_num] # output_list = get_subject_predicate_pair_list(user_input_text, subject_string) message = """ 単語:「{search_word}」という文字列を{case}に含む「係り受け元単語 -> 係り受け先単語」のペアは、以下が見つかりました。 ========================================================================= {result} ========================================================================= 以上です。 """.format(search_word=target_word, case=case_name, result=output_message) textBox.insert(END, message) if __name__ == '__main__': # ウィンドウを作成 root = tkinter.Tk() root.title("文書内容_早見チェッカー") # アプリの名前 root.geometry("730x800") # アプリの画面サイズ # ファイル選択ウインドウを作成 # root.withdraw() fTyp = [("", "*.txt")] iDir = os.path.abspath(os.path.dirname(__file__)) tkinter.messagebox.showinfo('ファイル選択ダイアログ','処理ファイルを選択してください!') file_path = tkinter.filedialog.askopenfilename(filetypes = fTyp,initialdir = iDir) # 処理ファイル名の出力 tkinter.messagebox.showinfo('以下のファイルを選択しました。',file_path) # Frame1の作成 frame1 = ttk.Frame(root, padding=10) frame1.grid() # ラジオボタンの作成 #共有変数 flg= StringVar() #ラジオ1 rb1 = ttk.Radiobutton(frame1, text='人名',value="PERSON", variable=flg) rb1.grid(row=2,column=0) #ラジオ2 rb2 = ttk.Radiobutton(frame1, text='地名',value="LOC", variable=flg) rb2.grid(row=2,column=1) #ラジオ3 rb3 = ttk.Radiobutton(frame1, text='組織名', value="ORG", variable=flg) rb3.grid(row=2,column=2) #ラジオ4 rb4 = ttk.Radiobutton(frame1, text='日付',value="DATE", variable=flg) rb4.grid(row=3,column=0) #ラジオ5 rb5 = ttk.Radiobutton(frame1, text='イベント名',value="EVENT", variable=flg) rb5.grid(row=3,column=1) #ラジオ6 rb6 = ttk.Radiobutton(frame1, text='金額',value="MONEY", variable=flg) rb6.grid(row=3,column=2) # Frame2の作成 frame2= ttk.Frame(root, padding=10) frame2.grid() # 固有表現単語を抽出した結果を表示させるボタンの作成 export_button = ttk.Button(frame2, text='ファイルから指定した種類の単語を洗い出す', command=click_export_button, width=70) export_button.grid(row=0, column=0) # 「」ラベルの作成 t = StringVar() t.set('出力された「単語」の中から、注目する単語の番号を入力してください。:') label1 = ttk.Label(frame2, textvariable=t) label1.grid(row=2, column=0) #テキストボックス2(「主語述語ペア」の「主語」入力欄)の作成 subject_num = StringVar() subject_num_entry = ttk.Entry(frame2, textvariable=subject_num, width=50) subject_num_entry.grid(row=3, column=0) # Frame3の作成 frame3 = ttk.Frame(root, padding=20) frame3.grid() # ターゲット単語がどの格で出現している文脈箇所の係り受け関係を抽出するのかを指定する。 # 格を{1 : "主語", 2 : "述語", 3: "目的語"}でラジオボタンで選択可能にする。 # 「」ラベルの作成 u = StringVar() u.set('着目する「単語」が、どの格で登場する文中箇所を調べたいですか?') label2 = ttk.Label(frame3, textvariable=u) label2.grid(row=0, column=1) # Frame4の作成 frame4 =ttk.Frame(root, padding=10) frame4.grid() #共有変数 flg2= IntVar() #ラジオ1 rb_a = ttk.Radiobutton(frame4, text='主語',value=1, variable=flg2) rb_a.grid(row=3, column=1) #ラジオ2 rb_b = ttk.Radiobutton(frame4, text='述語',value=2, variable=flg2) rb_b.grid(row=3, column=5) #ラジオ3 rb_c = ttk.Radiobutton(frame4, text='目的語', value=3, variable=flg2) rb_c.grid(row=3, column=10) # Frame5の作成 frame5 =ttk.Frame(root, padding=10) frame5.grid() # 「係り受け関係にある単語ペア」を抽出した結果を表示させるボタンの作成 export_button2 = ttk.Button(frame5, text='指定単語が指定した格で登場するぬ文脈から、「係り受け元単語 -> 係り受け先単語」のペアを抜き出して表示する', command=click_export_button2, width=80) export_button2.grid(row=1, column=0) # テキスト出力ボックスの作成 textboxname = StringVar() textboxname.set('') label3 = ttk.Label(frame2, textvariable=textboxname) label3.grid(row=1, column=0) textBox = Text(frame2, width=100, height=35) textBox.grid(row=4, column=0) file_selected_message = """以下のファイルを選択しました。\n{filename}\n\n""".format(filename=file_path) textBox.insert(END, file_selected_message) # ウィンドウを動かす root.mainloop()








- 投稿日:2020-12-04T23:50:28+09:00
数理最適化モデリング言語 PySIMPLE の紹介
この記事は「数理最適化 Advent Calendar 2020」 5 日目の記事です.
4 日目は @kievdhia さんによる「確率計画法とその周辺の紹介」でした.0. はじめに
はじめまして,NTT データ数理システム の数理計画部でシニアリサーチャーをしている池田です.普段は,じゃがりこを並べたり,数理最適化モデリング言語の開発をしています.
要するに中の人なのですが,皆さまは数理最適化の仕事と言えば何を思い浮かべるでしょうか.おそらく,ソルバー開発や,ソルバーを用いた問題解決といったことが真っ先に出てくるはずです.実際は,上記に関わるさまざま仕事が存在し,私がしている数理最適化モデリング言語の開発なども存在します.今回は,こちらの紹介をしていきます.
1. 数理最適化モデリング言語
数理最適化などの数学的なアルゴリズムを実現するソフトウェアに,具体的な数理モデルを与えるには,ユーザが数理モデルをプログラムとして記述する必要があります.
ソルバーの API は,係数行列を与えるなど,しばしば数式で記述された定式化と乖離が発生します.そこで,定式化された数理モデルをより自然に記述するインターフェースとして,数理最適化問題を記述する専用のモデリング言語があると便利です.
数理最適化モデリング言語には,PuLP,Pyomo,AMPL など様々な種類がありますが,私は PySIMPLE というものを開発しています.
例えば,1 日目の @___monta___ さんによる「感動した! min-max max-min の最適化表現 手法」の定式化は PySIMPLE を用いると,次のように記述することができます.
from pysimple import * ###### 定数定義 # 格子の数 SIZE = 10 # ばらまくPointの数 N = 5 # 添字 i = Element(value=range(SIZE)) j = Element(value=range(SIZE)) k = Element(value=range(SIZE)) l = Element(value=range(SIZE)) # 2 点間の距離を算出する distvalue = {(x1, x2, y1, y2): sqrt((x1-x2)**2+(y1-y2)**2)/SIZE for x1, x2, y1, y2 in product(*[range(SIZE)]*4)} dist = Parameter(index=(i,k,j,l), value=distvalue) ###### 変数定義 # どこに Point を置くか x = BinaryVariable(index=(i,j)) # 今回のキモ 多目的のための変数(どんなに良くても対角の sqrt(2) 以下) z = Variable(lb=0, ub=1.5) # 問題定義 p = Problem(name='SpreadingPointsProblem', type=max) # z の最大化問題として定義 p += z p += Sum(x[i,j], (i,j)) == N, 'N 個の Point が配置される' # 確認した 2 点に同時に点が配置されているとしたばあい、その距離は z 以上 BIGM = z.ub ikjl = (i!=k) | (j!=l) p += z <= (1-x[ikjl(0,2)])*BIGM + (1-x[ikjl(1,3)])*BIGM + dist[ikjl], '2 点の距離は z 以上' p.solve(silent=True) assert p.status == NuoptStatus.OPTIMAL print(p.objective.val) # 結果出力 print(x[x[i,j].val==1].val) # 1 が立っている部分だけ Printf(','.join(['{:.0f}']*SIZE), *(x[i,j_].val for j_, in j.set)) # 表形式で2. 輸送問題
LP の例として次の輸送問題を考えてみましょう.
構成要素 名称 説明 添字 $d \in \{d0, d1, .. \}$ 倉庫 添字 $c \in \{c0, c1, .. \}$ 顧客 定数 $cost_{d, c}$ 輸送コスト 定数 $upper_d$ 倉庫上限 定数 $lower_c$ 顧客需要 変数 $z_{d,c}$ 輸送量 目的関数 $\sum_{d,c} cost_{d,c}\cdot z_{d,c}$ 輸送コスト 制約式 $\sum_c z_{d,c} \le upper_d$ 倉庫上限 制約式 $\sum_d z_{d,c} \ge lower_c$ 顧客需要 この定式化を PySIMPLE を使ってモデリングすると,次のようになります.
### データ用意 from random import seed, randint DSIZE, CSIZE = 2, 3 class value: seed(0) upper = {f'd{d}': randint(1, 100000) for d in range(DSIZE)} lower = {f'c{c}': randint(1, 10000) for c in range(CSIZE)} cost = {(f'd{d}',f'c{c}'): randint(1, 100) for d in range(DSIZE) for c in range(CSIZE)} ### 最適化 from pysimple import Element, Parameter, Variable, Sum, Problem, NuoptStatus, Printf d = Element(value=value.upper.keys()) # 倉庫 c = Element(value=value.lower.keys()) # 顧客 cost = Parameter(index=(d,c), value=value.cost) # 倉庫から顧客への輸送コスト upper = Parameter(index=d, value=value.upper) # 倉庫取扱量上限 lower = Parameter(index=c, value=value.lower) # 顧客需要量下限 z = Variable(index=(d,c), lb=0) # 倉庫から顧客への輸送量 problem = Problem(name='輸送問題') problem += Sum(cost[d,c]*z[d,c], (d,c)) problem += Sum(z[d,c], c) <= upper[d], '倉庫上限' problem += Sum(z[d,c], d) >= lower[c], '顧客需要' print(problem) problem.solve(silent=True) assert problem.status == NuoptStatus.OPTIMAL dc = z[d,c].val>0.1 # 値が入った部分 print(z[dc].val) Printf('倉庫{} -> 顧客{}: {:.0f}', dc, z[dc].val)添字を使うことで,定式化と同じように記述できています.
この出力は次のようになります.Problem(name='輸送問題', type=min): [constraints] 倉庫上限: -z[d0,c0]-z[d0,c1]-z[d0,c2]>=-50495 -z[d1,c0]-z[d1,c1]-z[d1,c2]>=-99347 顧客需要: z[d0,c0]+z[d1,c0]>=6891 z[d0,c1]+z[d1,c1]>=664 z[d0,c2]+z[d1,c2]>=4243 [objective] Sum((cost[d,c]*z[d,c])[d,c], (d,c)): 66*z[d0,c0]+63*z[d0,c1]+52*z[d0,c2]+39*z[d1,c0]+62*z[d1,c1]+46*z[d1,c2] z[d1,c0].val=6890.999999521996 z[d1,c1].val=663.9999587327063 z[d1,c2].val=4242.999993921036 倉庫d1 -> 顧客c0: 6891 倉庫d1 -> 顧客c1: 664 倉庫d1 -> 顧客c2: 42433. 輸送問題(スパース ver.)
今度は輸送経路のうち,一部の経路のみが定義されるように変更してみましょう.定式化は以下のようになります.
構成要素 名称 説明 添字 $dc \in DC=\{(d0,c1), (d1,c0), .. \}$ 倉庫から顧客への輸送経路(一部) 定数 $cost_{d,c}, (d,c) \in DC$ 輸送コスト 定数 $upper_d, d \in DC(0)$ 倉庫上限 定数 $lower_c, c \in DC(1)$ 顧客需要 変数 $z_{d,c}, (d,c) \in DC$ 輸送量 目的関数 $\sum_{d,c, (d,c) \in DC} cost_{d,c}\cdot z_{d,c}$ 輸送コスト 制約式 $\sum_{c, (d,c) \in DC} z_{d,c} \le upper_d$ 倉庫上限 制約式 $\sum_{d, (d,c) \in DC} z_{d,c} \ge lower_c$ 顧客需要 ここで $DC(0)$, $DC(1)$ は,集合 $DC$ の 1 次元目,2 次元目を射影した集合です.
この定式化のモデリングは,次のようになります.### データ用意 from random import seed, randint, random DSIZE, CSIZE, RATE = 2, 3, 0.5 class value: seed(0) upper = {f'd{d}': randint(1, 100000) for d in range(DSIZE)} lower = {f'c{c}': randint(1, 10000) for c in range(CSIZE)} cost = {(f'd{d}',f'c{c}'): randint(1, 100) for d in range(DSIZE) for c in range(CSIZE) if random() < RATE} ### 最適化 from pysimple import Element, Parameter, Variable, Sum, Problem, NuoptStatus, Printf dc = Element(value=value.cost.keys()) # 倉庫と顧客の疎な添字 cost = Parameter(index=dc, value=value.cost) # 倉庫から顧客への輸送コスト upper = Parameter(index=dc(0), value=value.upper) # 倉庫取扱量上限 lower = Parameter(index=dc(1), value=value.lower) # 顧客需要量下限 z = Variable(index=dc, lb=0) # 倉庫から顧客への輸送量 problem = Problem(name='輸送問題') problem += Sum(cost[dc]*z[dc]) problem += Sum(z[dc], dc(1)) <= upper[dc(0)], '倉庫上限' problem += Sum(z[dc], dc(0)) >= lower[dc(1)], '顧客需要' print(problem) problem.solve(silent=True) assert problem.status == NuoptStatus.OPTIMAL dc0 = z[dc].val>0.1 # 値が入った部分 print(z[dc0].val) Printf('倉庫{} -> 顧客{}: {:.0f}', dc0, z[dc0].val)この出力は次のようになります.
Problem(name='輸送問題', type=min): [constraints] 倉庫上限: -z[d0,c1]>=-50495 -z[d1,c0]-z[d1,c2]>=-99347 顧客需要: z[d0,c1]>=664 z[d1,c0]>=6891 z[d1,c2]>=4243 [objective] Sum((cost[dc]*z[dc])[dc], dc): 39*z[d0,c1]+28*z[d1,c0]+97*z[d1,c2] z[d0,c1].val=664.0000169446201 z[d1,c0].val=6891.000023601436 z[d1,c2].val=4243.0000068127865 倉庫d0 -> 顧客c1: 664 倉庫d1 -> 顧客c0: 6891 倉庫d1 -> 顧客c2: 4243先ほどのモデリングと比べて,一部の経路しか定義されていないことが分かりますね.
4. おわりに
現在の PySIMPLE は弊社の数理最適化パッケージ Numerical Optimizer に付属するモデリング言語となっています.来年 3 月リリースのバージョンでは MIP(混合整数計画問題) に加え,QP(二次計画問題),メタヒューリスティクスアルゴリズム も利用できるようになります.
明日は 梅谷先生(@umepon) による「本では紹介できなかった列生成法」です.


- 投稿日:2020-12-04T23:47:13+09:00
Pythonの基礎を学ぶ②Aidemy
初めに
AidemiyのPython入門コースの勉強経過について書いてみる。
なぜAidemyか?
理由は無料だから(笑)
https://aidemy.net/mypage無料にした理由(無料vs有料)
・趣味としてプログラミングをやる目的なので挫折してもいい
・効率を重視するよりも、楽しみを重視したい。だから、強制力(負担)がないほうがいい、無料のメリット
・やめても損しない。経済的な損失がほぼゼロである。
・無料だからこそ勇気がいらず気軽に挑戦できる。
・サンクコストがゼロである。自分に合わなかったら簡単にやめることができる。有料のメリット(無料のデメリット)
・有料のほうが環境が充実している
・高額なスクールに通うと、ライザップのようにもったいない精神が働くから挫折しにくい。勉強の経過
Python入門の「Pythonの基礎」「Pythonの基礎文法」の勉強が完了し、
残りは、「関数の基礎」である。
感想など
・成長スピードがゆっくりなことは、反省したい。
‣習慣をつけるために、時間を決めて学習したい。
朝起きてすぐにプログラミング1時間など・初回、投稿でコメントもらえたのは嬉しかった。
‣アドバイスもらっているからこそ、より頑張ろうと思う。


- 投稿日:2020-12-04T23:43:20+09:00
OpenPyXLを使ったPythonでのExcel操作まとめ
OpenPyXLを利用したExcelをごにょごにょするツールを作成する機会があったので、実用ベースでの色々な操作方法(基礎的なものから幅広く)、注意点等をまとめておきます。
公式ドキュメント (http://openpyxl.readthedocs.io/en/default/)環境
Windows 10
Python 3.8.1
OpenPyXL 3.0.3
Excel 2019基本操作
ブック操作
import openpyxl # 新規作成 new_wb = openpyxl.Workbook() # 既存Excelファイル読込 filepath = r'C:\hoge\hogehoge.xlsx' wb = openpyxl.load_workbook(filename=filepath, read_only=False) # 保存 wb.save(file_path) # 閉じる wb.close()openpyxl.load_workbook()
引数 概要 read_only 読み取り専用(True)か書き込み可能(False)かを指定する。 keep_vba VBAを読み込む(True)か読み込まない(False)かを指定する。
※Falseで保存するとVBAが動かなくなるので注意!data_only 値のみ読み込む(True)か関数も読み込む(False)かを指定する。
※Trueで保存すると関数が消えます(値で張り付けを行った時と同様の状態)。
※Falseの場合にCell.valueで関数を設定しているセルの値を取得すると数式が文字列で取得されてしまいます。読み取り専用の場合等は
keep_vba=Falseにしておくと多少読込が早くなると思います。シート操作
# シートの取得 ws = wb.worksheets[0] #インデックス指定で取得(0が1シート目) ws = wb["シート名"] #シート名指定で取得 # シートのインデックス取得 index = wb.index(ws) # シート名の操作 ws_name = ws.title #シート名取得 ws_title = "シート名" #シート名変更 ws_name_list = wb.sheetnames #全シート名をリストで取得 ws_length = len(wb.sheetnames) #通常のリスト同様len()でシート数を取得可能 # シートの追加 ws_new = wb.create_sheet(title="新シート名", index=0) #1シート目に追加(index未指定の場合は末尾) # シートのコピー ws_copy = wb.copy_worksheet(ws) # シートの削除 wb.remove(ws) wb.remove(wb.worksheets[-1]) #末尾のシートを削除 wb.remove_sheet(ws) #非推奨ですがこっちでしか削除できない?ことがあったので一応 # タブの色を設定 ws.sheet_properties.tabColor = 'カラーコード'セル操作
# 数値座標でセルの値を取得 cell_data = ws.cell(1, 2).value #B1の値を取得 row_num = cell_data.row #横軸の座標:1 column_num = cell_data.col_idx #縦軸の座標:2 # Excel座標でセル値を取得 cell_data = ws['C1'].value #C1の値を取得 cell_address = cell_data.coordinate #Excel座標:B1 # セルに値を設定 ws.cell(1, 2).value = cell_data #C1の値をB1に設定基本的に数値座標の方が汎用性が高く、性能も良いです。
その他の実用的操作
範囲指定と各種ループ処理
# Excel座標で範囲指定 ws_range = sheet['A1':'C20'] #A1:C20のセル範囲を取得 for row in ws_range: #上から下に行でループ for cell in row: #左上から右下にセルでループ print(cell.value) #範囲のセル値を順に出力 # 数値座標で範囲指定 for row in ws.iter_rows(min_row=1, min_col=1, max_row=20, max_col=3): #A1:C20のセル範囲で上から下に行でループ for cell in row: #左上から右下にセルでループ print(cell.value) #A1:C20のセルの値を順に出力 # シートループ処理 for ws in wb: #1シート目から順にループ # 行ループ処理 for row in ws.iter_rows(min_row=1, max_row=20): #1~20行目まで行でループ if ws.cell(row[0].row, 3).value is None: continue #空白セルの場合スキップ print(ws.cell(row[0].row, 3).value) #C1〜C20(空白セルを除く)の値を順に出力 # row[0]で処理対象の行情報を取得できる # 列ループ処理 for col in ws.iter_cols(min_col=1, min_col=3): #1~20行目まで行でループ print(ws.cell(2, col[0].column).value) #A2,B2,C2の値を順に出力こちらも数値座標の方が汎用性が高く、性能も良いです。
横軸座標の最大値/最小値、縦軸座標の最大値/最小値を任意の値、任意の組み合わせで指定可能。
とりあえずセルでループさせているドキュメントも多いですが、基本的に行または列でループし、数値座標でcellにアクセスする方が性能が良いです。行・列操作
# 行追加 ws.insert_rows(5, 2) #5行目に2行追 # 列追加 ws.insert_cols(5, 2) #5列目に2列追加 # 行削除 ws.delete_rows(6, 3) #6行目を3行削除 # 列削除 ws.delete_cols(6, 3) #6列目を3列削除入力規則の設定
from openpyxl.worksheet.datavalidation import DataValidation # プルダウンを設定 dv = DataValidation(type="list", formula1="シート名!$A$1:$A$5") #formula1に選択値の範囲を指定(Excelと同様の記載でOK) dv.add(ws.cell(2, 2)) #B2にプルダウンを設定 ws.add_data_validation(dv) #シートに入力規則を登録
formula1='"A,B,C"'のように値で指定することも可能。
ただ、以下のような注意点があります。(回避方法があればご教授下さいm(_ _)m)
※ 重複したセル範囲のDataValidationを複数定義したワークブックをロードするとDataValidationが消える。
※ DataValidationを定義したシートをコピーしてもDataValidationはコピーされません。(コピーしたWorksheetオブジェクトに再度add_data_validation()することで定義されます)
一旦終わります。ご覧頂きありがとうございました。
誤りや非効率な書き方等があるかもしれませんがご容赦ください。
適宜追加していくと思います。
- 投稿日:2020-12-04T23:26:13+09:00
[Python] BFS (幅優先探索) ABC146D
ABC146D
当内容は、他サイトを参考に自分用に編集したものです。
はじめに
- 次数 (つながる辺の本数) が最大の頂点がボトルネックになる
- 次数の最大値を d とすると、d 色で塗り分けられそう
もし「具体的な塗り分け方を求めよ」と言われなければ、最大次数を出力してしまって良さそう。でも今回は、具体的な塗り方を求めることも要求されている。それは証明も込みで要求されているのに等しい。
木なので
今回は一般のグラフではないので割と考えやすい。ちなみに今回の問題、一般のグラフの場合は最大次数色では塗りきれないケースが存在する (最大次数色 + 1 で塗ることは可能)!!!!
それはさておき、木を扱うときに定番となる考え方は「根を一つテキトーに決めてしまう」というのがある。これをすると木の頂点にある種の順序付けができるのだ。下図の左側のグラフで青い矢印で示したように、頂点を 1 つ選んで根にすると、下のグラフのような根付き木になる。
そうすると、根頂点から順番に、その隣接辺の色を決めていけば良さそうに思えてくる (DFS でも BFS でもよい)。ここで注目したいのは新たな頂点について、その隣接辺たちに色を塗ろうとするとき
その隣接辺たちのうち、すでに色が塗られてしまっているのは一本だけ
ということだ。その一本というのは「親頂点」に他ならない。よって、その一色を避けるように色付けすればよいだけだ。DFS でも BFS でも
木の探索の仕方は、DFS でも BFS でもどちらでもいい。重要なことは、根付きにおいて、どの 2 つの頂点 u, v についても、
- u が v の先祖 (v が u の子孫) であるとき
- u が先に処理されていて、その後 v を処理する
という風にすることだ。計算量はいずれにしても O(N) となる。
サンプルコードは、BFSによるもの。
参考
BFS (幅優先探索) 超入門! 〜 キューを鮮やかに使いこなす 〜サンプルコードfrom collections import deque # 辺数 n=int(input()) # 辺 G=[[] for i in range(n+1)] G_order=[] for i in range(n-1): a,b=map(int,input().split()) # a,(<)bを紐付け G[a].append(b) G_order.append(b) # BFSのデータフレーム q=deque([1]) # 頂点1を始点とした訪問キュー color=[0]*(n+1) # 色のフラグ # BFS 開始 (キューが空になるまで探索を行う) while q: cur=q.popleft() # キューから先頭頂点(現在地)v取得 c=1 # 始めの色 # 現在点から伸びる辺に色を付ける for nx in G[cur]: if c==color[cur]: c+=1 color[nx]=c c+=1 q.append(nx) # 訪問先(頂点)を追加 print(max(color)) # 使用色数 for i in G_order: print(color[i])

- 投稿日:2020-12-04T23:11:08+09:00
バーナム暗号のアルゴリズム(Pythonで再現)
前書き
0011110000111100011100110100011011100010010100011010111110000101010010011010011011001110111100111101011111011001110011001000001000101100100101001111101111001101011000100001110101011011111000001111101111010110000000000101110101011011111101000100111100011101000011100010010011101000011011010111011110011101001010000010110100011000011101110100011110001010110100000100101010011010111110110000010110110101000111011001101101001011111111110000001111100101011111100110100000000110100011110010001111111111101111100010101
(key:1001010110011111001111000111111011011110111010111100011001000010111110101000101001010000100001101110001110111100010001110011000100000011111110000100000001110111000010101001010011011100001011001110010110001011001101001011111010000010011000100011000101110111011101011101110010000000101111101111000100110011110001010001000010101010100001011010000000101101011101111101001000100001110010011110100101110110100101101110011101010111011000101011000100001011100101110110011100001000010000111001100001001101110111111100111)はじめに
ご安心ください,お使いのコンピュータは正常です...
それはさておき,みなさん,暗号はお好きですか?
暗号の歴史は古く,紀元前3000年前頃のものが存在を確認されています.現存する最古の暗号は、紀元前 3000 年頃の石碑に描かれているヒエログリフ(古代エジプトで使われた 象形文字)であるとされています。
[引用元:https://www.digicert.co.jp/welcome/pdf/wp_encryption_history.pdf]現代社会においても,暗号は特に情報通信の分野において非常に大きな役割を果たしています.詳しくはこちらをご覧ください.
本記事では共通鍵暗号の一つ,「バーナム暗号」について取り扱います.
バーナム暗号の暗号化コード
暗号化の手順は以下の通りです.
- 平文をnビット二進数に変換
- KeyGenによって自動生成された,平文の二進数と同じサイズのnビット二進数を作成
- 1,2で作成された二進数のそれぞれ対応する各ビットごとに排他的論理和をとってnビット二進数を作成(これが暗号文のnビット二進数)
すなわち...
それではこれをコーディングしていきます.encryption.pyimport random def clear_to_ascii(ClearText): """ 1. 平文をnビット二進数に変換(今回はASCIIコードに変換する) """ clear_ASCII_list = [] for m in clearText: t = bin(ord(m)) clear_ASCII_list.append(str(t)[2:]) return "".join(clear_ASCII_list) def KeyGen(n): """ 2. keyとなる平文の二進数と同じサイズのnビット二進数をランダム生成 """ key = "" for i in range(0, n): k = int(random.random() * 2) key = f"{key}{str(k)}" return key def Enc(clear_ASCII, key, n): """ 3. 1,2で作成された二進数のそれぞれ対応する各ビットごとに排他的論理和をとってnビット二進数を作成 """ crypt_ASCII = "" for i in range(0, n): c = int(clear_ASCII[i]) ^ int(key[i]) crypt_ASCII = f"{crypt_ASCII}{c}" return crypt_ASCII if __name__ == "__main__": clearText = input('Clear text: ') n = len(clearText) * 7 # ASCIIコードはアルファベット一文字を7ビットの二進数で表すため key = KeyGen(n) print(f" 平:{clear_to_ascii(clearText)}") print(f" 鍵:{key}") print(f"暗号:{Enc(clear_to_ascii(clearText), key, n)}")[注意: 今回のメインは暗号化であるため,平文からASCIIへの変換部分は簡略化しました(大文字,小文字アルファベットのみ対応.数字,記号を入れるとエラーが起きることがある).]
実際に暗号化してみる
入力
Clear text: hogehoge出力
平:11010001101111110011111001011101000110111111001111100101 鍵:10010011111001001001000110101101100011101000001000110001 暗号:01000010010110111010111111110000100101010111000111010100上記の結果から,暗号の各ビットが,平文と鍵それぞれの各ビット同士の排他的論理和に対応していることがわかります.
実際に,この暗号のnビット二進数を無理やり文字列変換すると,"! u UcT "となり,"hogehoge"という文字列が暗号化されていることを確認できます.バーナム暗号の復号化コード
復号化は暗号化手順をほぼ逆から行えば良いだけです.
- nビットの暗号と,暗号化の際に用いたnビットの鍵のそれぞれ対応する各ビットごとに排他的論理和をとってnビット二進数を作成(これが平文のnビット二進数)
- 1で作成されたnビット二進数をアルファベットの文字列に変換する.
すなわち...
それではこれをコーディングしていきます.decryption.pydef Dec(crypt_ASCII, key, n): """ 1. nビットの暗号と,nビットの鍵のそれぞれ対応する各ビットごとに排他的論理和をとってnビット二進数を作成 """ clear_ASCII = "" for i in range(0, n): c = int(crypt_ASCII[i]) ^ int(key[i]) clear_ASCII = f"{clear_ASCII}{c}" return clear_ASCII def ascii_to_clear(clear_ASCII, n): """ 2. nビット二進数をアルファベットの文字列に変換する. """ v = [clear_ASCII[i: i+7] for i in range(0, n, 7)] clearText = "" for c in v: ch = chr(int(c, 2)) clearText = f"{clearText}{ch}" return clearText if __name__ == "__main__": crypt_ASCII = input("Cryptography(ASCII): ") key = input("key: ") n = len(key) print(f"平文: {ascii_to_clear(Dec(crypt_ASCII, key, n), n)}")実際に復号化してみる
先ほど暗号化によって出力した暗号文とkeyを用います.
入力
Cryptography(ASCII): 01000010010110111010111111110000100101010111000111010100 key: 10010011111001001001000110101101100011101000001000110001出力
平文: hogehoge先ほど暗号化の際に入力した平文"hogehoge"と一致していることが確認できます.
ついでに...
実は前書きにおけるnビット二進数列もバーナム暗号になっているのです.
この暗号文とkeyをdecryption.pyに入力してみます.入力
Cryptography(ASCII): 0011110000111100011100110100011011100010010100011010111110000101010010011010011011001110111100111101011111011001110011001000001000101100100101001111101111001101011000100001110101011011111000001111101111010110000000000101110101011011111101000100111100011101000011100010010011101000011011010111011110011101001010000010110100011000011101110100011110001010110100000100101010011010111110110000010110110101000111011001101101001011111111110000001111100101011111100110100000000110100011110010001111111111101111100010101 key: 1001010110011111001111000111111011011110111010111100011001000010111110101000101001010000100001101110001110111100010001110011000100000011111110000100000001110111000010101001010011011100001011001110010110001011001101001011111010000010011000100011000101110111011101011101110010000000101111101111000100110011110001010001000010101010100001011010000000101101011101111101001000100001110010011110100101110110100101101110011101010111011000101011000100001011100101110110011100001000010000111001100001001101110111111100111出力
平文: ThisArticleIsTheEleventhDayArticleOfSophiaUniversityElelaboAdventCalendar直訳すると
この記事は上智大学エレラボAdvent Calendar第11日目の記事です
となります.
上智大学エレラボAdvent Calendarには,サークルに属するメンバーの素晴らしい記事が多く掲載されているので,タイトルからいらっしゃった方も是非ご覧ください.まとめ
いかがでしたか?
排他的論理和の性質を利用した暗号...とても面白いと思います(個人の感想).バーナム暗号は1949年にShannonによって解読不可能であることが数学的に証明されている安全性の非常に高い暗号です.
しかし,平文のnビット二進数と同じサイズの鍵を用意しなければならないことから,効率が非常に悪い暗号と言えます.
このkeyのサイズをもう少し小さくできないか...ということで考案されたのがストリーム暗号と呼ばれる暗号です.この記事を読んで暗号に興味を持たれた方は是非,ストリーム暗号についても調べてみることをお勧めします.参考文献
IPUSIRON,暗号技術の全て,翔泳社,2017
↑暗号理論を一から学んでみたいという方にはお勧めの一冊です.
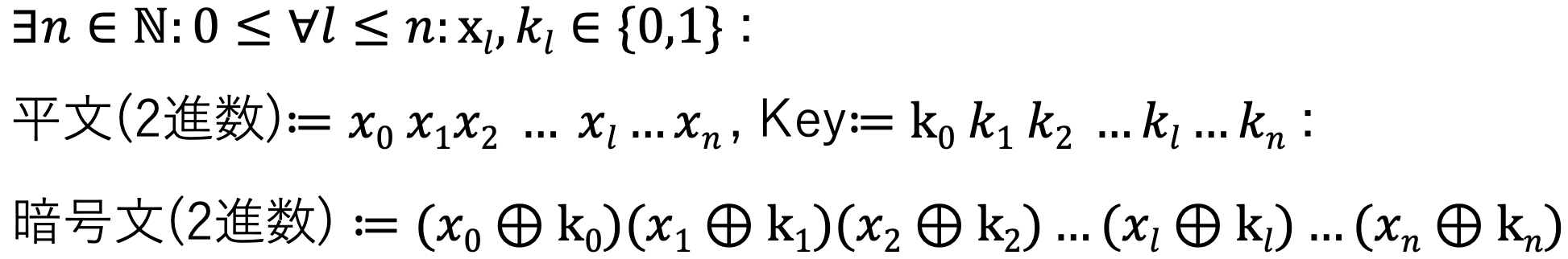
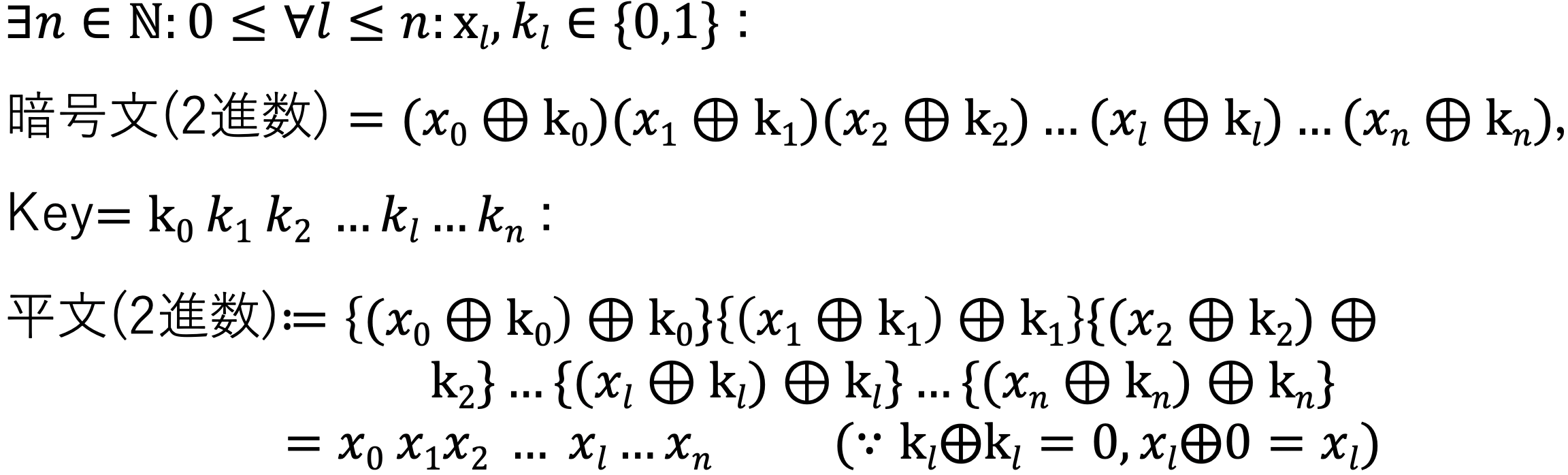
- 投稿日:2020-12-04T23:08:12+09:00
COVID-19の感染者数をProphetで予測 更新
概要
2週間前にProphetで予測した感染者数を最新のデータで再度予測した
差分だけを記載する
- 実施: 2020年12月04日
- パケージ:Prophet
Prophetで感染者数予測
2週間前のProphet予測では12月上旬は3000人を超えていたが、いまは幸い2500人くらいとなっている
この先30日の国内感染者数予測は下図となった
傾向は前回の予測同様、12月中旬に向けていったん減少するが、その後増加するらしい
試しに60日先まで予測すると下図となった
12月にいったん減少するが第一波、二波の後にあった小康状態が今回はなく、1月はずっと増加する予測
現実味を帯びた嫌な波形になったように感じる
今回は国内感染の陽性率も予測させてみた
データ更新以外のコードは前回の続きdf_ratio = pd.DataFrame() df_ratio['ds'] = pd.to_datetime(df_dom['DS']) df_ratio['y'] = df_dom['pos_def'] / df_dom['test_def'] * 100 # 国内陽性率 m = Prophet(yearly_seasonality=True, weekly_seasonality=True, daily_seasonality=True) m.fit(df_ratio[95:]) # 5月までの生データが暴れていたので前半をオミット future = m.make_future_dataframe(periods=30, freq='D', include_history=True) forecast = m.predict(future) forecast[['ds', 'yhat', 'yhat_lower', 'yhat_upper']].tail() fig = m.plot(forecast, figsize=(20, 10)) ax = add_changepoints_to_plot(fig.gca(), m, forecast) ax = fig.gca() ax.set_title("Positive / Tested", size=16) ax.set_xlabel("date", size=16) ax.set_ylabel("Ratio (%)", size=16) ax.tick_params(axis="x", labelsize=14) ax.tick_params(axis="y", labelsize=14)微増といったところか…
PCR検査は感染者数増加に追い付いていると考えられる
なお、空港検査でのPositive判定予測は下図となった




- 投稿日:2020-12-04T22:30:55+09:00
統計初心者が統計モデリング力を鍛えるための勉強法
以前、『結局、統計モデリングとは何なのか』という記事を書きました。
この記事は、その名の通り、「そもそも」何が統計モデリングで、何が統計モデリングではないのかということを扱った記事です。
今回は、「統計モデリングとは何か」を理解した方に向けて、実際に「統計モデリング力」を鍛えるためにはどうするかを書いていきたいと思います。
この記事の目的と対象者
上記でも述べたようにこの記事の目的は、どのように「統計モデリング力」を鍛えるかを書くことです。
統計学に入門するところから、高度な統計モデルを扱えるようになるまでの勉強法について書いています。
したがって、統計初心者からそれなりに理解している人までの幅広い層が想定読者となります。
ところどころで、プログラム言語で実際に手を動かしながら学ぶタイプの本を紹介することもありますので、そういった本を読むためにはPythonまたはRの知識が必要になります。統計モデリング力とはなにか
ここでいう「統計モデリング力」とは、
観測したデータをどのような統計モデルで扱うのが適切かを考えられる能力
のことです。
この世には、正規分布でモデリングするのがいいデータもあれば、二項分布で扱うのがいいデータもあります。ある変数(目的変数)をなにか別の変数(説明変数)で説明したいのであれば、
ただの線形モデルで太刀打ちできる場合もあれば、一般化線形モデルで分析する必要のある複雑なデータかもしれません。
もっと複雑になれば、一般化混合線形モデルを使う必要もあるかもしれません。時系列データを現代風に分析したければ、状態空間モデルを使いたくなるでしょう。
このように統計モデルは、場面場面で使い分けなければなりません。
適切なモデルを当てはめることができてはじめて、我々は現象をよりよく理解することができるからです。これは、機械学習モデルでも同じです。
どんな場面でも通用する機械学習モデルなんてものはあり得ません。
今や有名になったDeep Lerningでさえ、その得意分野は非常に限られています。
この広大なデータの世界では、Deep Lerningで扱うのが適切なのは、ほんの一握りのデータに過ぎません。様々な分析手法を自分の引き出しから出し、適材適所で使い分けることのできる人が優れたデータ分析者ということになるでしょう。
入門編〜知っている統計モデルの種類を増やそう〜
まずは、統計モデルの引き出しを増やしましょう。
知らなければ、使うことはできません。統計学に入門しよう
古典的(頻度主義的)統計学
まずは、頻度主義統計学に入門しましょう。
頻度主義的な統計学とは、大学などで(おそらく)一番最初に習う、みんなが思い浮かべる(?)統計学です。
私も大学一年生の必修で習ったような記憶があるような気がします(笑)後に紹介するベイズ統計学とは、立場・思想が大きく異なります。
同じキリスト教にも、カトリックとプロテスタントがあるようなものです。ですが、ベイズ統計学のほうが歴史的には新しい統計学であり、勉強するのであれば、頻度主義統計学の方を先に勉強する方がいいでしょう。
(新しいからといって、必ずしもベイズ統計学の方が優れていることにはなりません。宗教的思想の違いです。)頻度主義統計学の基礎としては、
『心理統計学の基礎―統合的理解のために』
を全力で推します。基礎はこの本で十分です。
『心理』統計学と書かれてはいますが、すべての分野に通用する統計学の基礎が非常にわかりやす、かつ、秩序立てて書かれています。
著者の南風原先生の圧倒的な智を感じます。この本では、1変数の単純な統計モデリングから、重回帰や分散分析といった説明変数で目的変数を説明しようとする統計モデリングまでの橋渡しが行われています。
ある意味では次節で述べている「説明・回帰型の統計モデリング」にも一部踏み込んでいると言えるでしょう。説明・回帰型の統計モデリング
古典的な頻度主義統計学を学んだ後は、より発展的な回帰型の統計モデリングを勉強しましょう。
身長で体重を回帰するように(おそらくある程度の相関はあるでしょう)、説明変数で目的変数を説明・回帰しようとする統計モデリングです。
もちろん、説明変数が複数あっても問題ありません。まずは、
言わずとしれた名著、通称・緑本『データ解析のための統計モデリング入門――一般化線形モデル・階層ベイズモデル・MCMC』
で、一般化線形モデルとその発展型の一般化混合線形モデルという考え方を学ぶのがよいでしょう。
この本が統計学における最大の名著の1つである(私の意見です 笑)理由は、
一般化線形モデルを通して、適切な統計モデリングとは何かという哲学的な問題に真っ向から立ち向かっている点です。
さらに素晴らしいのは、説明・回帰型の統計モデリングという題材を使いながら、なめらかに(ここがスゴい!!)ベイズ統計学にも入門させてくれる点です。ベイズ統計学
緑本を読んだ後は、ベイズ統計学の世界に本格的に入門しましょう。
ベイズ統計学はたくさんの入門書があります。
正直に言えば、評価の高いものを読めばそんなにハズレはないのですが、個人的には、
『基礎からのベイズ統計学』
を推します。
一冊でベイズ統計学の基礎から応用例までを理解することができます。時系列分析
時系列分析については、私が書いた別の記事『統計初心者が時系列分析を学ぶための勉強法・オススメ本』も参考にしてください。
時系列でモデリングといえば、近年流行りの状態空間モデルでしょう。
状態空間モデルでは、定番の入門書となった通称・隼本『時系列分析と状態空間モデルの基礎: RとStanで学ぶ理論と実装』をご一読ください。
難しいと言われる時系列分析ですが、隼本は非常に平易にかつイメージしやすいように書かれています。
時系列分析で挫折したことがある方も、一度騙されたと思って読んでいただけると、いつの間にか時系列分析の門をくぐっていることに気がつくでしょう。少し数学多めで難しいですが、
『基礎からわかる時系列分析 ―Rで実践するカルマンフィルタ・MCMC・粒子フィルタ』
階層ベイズ
緑本でもある程度扱われている階層ベイズですが、より詳細に理解するためには、
『ベイズモデリングの世界』
を読むといいでしょう。いわゆるオムニバス形式で、(お世辞ではなく)当代一流の先生方が、様々な場面でのベイズモデリングの適用について語ってくれます。
日本語で読める階層ベイズの本は多くない、かつ、実際の研究現場での実用例を我々一般人は垣間見る機会がないので、世界の碩学たる先生方の智に触れることのできる貴重な文献でしょう。実践編〜実際に統計モデリングしてみよう〜
ある程度理論を理解した後は、実践的な内容の本を読んで、より深く理解していきましょう!
統計的学習と呼ばれる、統計学の考え方に立って、機械学習的モデリングを扱う理論を題材にした本もオススメです。
ある程度ベイズ統計学を理解した後は、現実の場面にどう適用するのかを学ぶために、実践的問題を取り扱う本を読んでいきましょう。
入門編でも紹介した本を実践編で再度紹介するという革命的なスタイルでお送りしますが(笑)、
まずは、『基礎からのベイズ統計学』
の後半を読んで、どのように実践的な問題にベイズモデリングを当てはめていくのかを学びましょう。
また、実践的な頭の使い方ができるようになっても、実装できなければ意味がないので、
通称アヒル本『StanとRでベイズ統計モデリング』で、StanでMCMCする方法を学びましょう。
日本語でベイズ統計学の実装についてこれ以上詳しく、実践的に書かれた内容の本はありません。
また、実にキレイに整理されて書かれているので、非常に読みやすい本になっています。番外編〜統計モデリング以外のデータ分析手法を知ろう〜
統計以外では、近年流行りの機械学習について学んでみるといいでしょう。
ここでは詳しくは述べないので、
『機械学習・ディープラーニング初心者のためのおすすめ勉強順序』
も是非合わせて読んでみてください。統計学的アプローチと機械学習的アプローチの違いについて学ぶことで、データを分析するということがどういうことなのかをより深く理解することができるでしょう。
まとめ
本記事では、「統計モデリング力」を鍛えるための勉強法について書いてきました。
ここまで来て言うのもなんですが、勉強するだけでは、真の「統計モデリング力」は身につきません。(突然の悲しいお知らせ)
実際のデータを使って、何度も試行錯誤するプロセスは絶対に必要です。
その試行錯誤の苦しみの中でしか、本当に実践的な能力など身につかないのです。モデリングとは、データを人間にわかりやすいような型(それをモデルという)に当てはめる作業です。
複雑な現象を情報整理するための手法です。
ある意味では、データの複雑性をあえて捨てることで、人間の理解可能な形に落とし込む作業とも言えます。
適切なモデリングができなければ、重要な情報も捨ててしまうことにもなりかねませんし、誤った(歪んだ)見方をしてしまうかもしれません。適切に現象を理解するためには、過不足ない型にデータを当てはめる必要があります。
そしてそれを適切な「統計モデリング」といい、適切な統計モデリングができる力を「統計モデリング力」と呼ぶのです。本記事で紹介した本を読み、実践していく中で統計モデリング力を鍛え、現象をよりよく、そして、より深く理解できるようになりましょう!







- 投稿日:2020-12-04T22:20:36+09:00
【Python】 同じ名前のクラスがあってもエラーにならない
この記事の要約
- Python内で同じ名前のクラスがあってもエラーなく実行できる
- C++だと同じ名前のクラスがあればコンパイル時にエラーになる
- 特に大した情報を載せている記事ではない(重要)
- このエラー解決に丸1日費やした自分への戒め
Python内で同じ名前のクラスを作って実行してみる
class.pyimport os import sys class CLS: def __init__(self): self.value = 1 def print_value(self): print('value =', self.value) class CLS: def __init__(self): self.value = 2 def print_value(self): print('value =', self.value) def main(): cls = CLS() cls.print_value() if __name__ == "__main__": main()CLSという同じ名前のクラスを宣言しています.最初のCLSではvalueの値を1にし,次のCLSではvalueの値を2としています.これを実行すると
value = 22が表示されます.つまり,後から宣言されたCLSに置き換えられたことになります.
C++内で同じ名前のクラスを作ってコンパイルしてみる
同様のことをC++でも行ってみます.
class.cpp#include <iostream> class CLS { private: int value_; public: CLS(void): value_(1) {} void printValue(void) { printf("value = %d\n", value_); } }; class CLS { private: int value_; public: CLS(void): value_(2) {} void printValue(void) { printf("value = %d\n", value_); } }; int main(int argc, char **argv) { CLS cls; cls.printValue(); return 0; }コンパイルしてみます.
$ g++ -o class class.cpp error: redefinition of ‘class CLS’コンパイル時にエラーとなります.C/C++に慣れている人であれば当たり前の挙動ですね.当然ですが,それぞれのクラスを異なるnamespace内で宣言すれば,同じ名前のクラスを宣言することはできますし,使い分けることもできます.
なぜこの記事を書いたか
Keras(Tensorflowバックエンド)を使ってLSTMを実装しようとしました.LSTMを実装するクラスの名前を何にしようか迷った時に,安易に「class LSTM」と名付けてしまいました.当然,Kerasの中にもLSTMというクラスが宣言されています.その結果,Keras内で宣言されているLSTMが,自分が実装したLSTMで上書きされました.つまり,
LSTM.pyclass LSTM: def __init__(self): # do something x = LSTM(32, activation='relu')(x)みたいなコードを書いてしまい,これを実行して
TypeError: __init__() got an unexpected keyword argument 'activation'というエラーが出てきたわけです.「LSTMにactivationがないなんておかしい」と思うわけですが,KerasのLSTMは自分で実装したLSTMというクラスに上書きされているので当然です(しかし気づかない...).
そして,「エラーが出たらググる」が基本ですのでググると,KerasとTensorflowのバージョンの問題で「got an unexpected keyword argument」というエラーが出るという記事を見つけました(これもまた運が悪い...).そうなると,「これはバージョンの問題か!」と思って意気揚々とバージョン合わせを行うわけですが,一向にエラーが解決しません.
様々なバージョンを試し結局解決できず,今日は帰ろうかと思い最後にプログラムを眺めている時に,「LSTMって名前被ってるじゃん」と気づきました.そして名前を直したらあっけなく動きました.私はC++をメインに扱っているので,「同じ名前ならエラー出せよ!」と思いましたが,良くも悪くもこれがPythonなのですね.
今日(2020年12月4日)1日をこのエラー解決に全て費やした自分の愚かさを反省する意味も込めて,久しぶりの記事投稿です.同じエラーに苦しむ方の手助けになれば幸いです(そんなやついるか怪しいですが...).
- 投稿日:2020-12-04T22:04:55+09:00
電話番号トラッカーのアプリを作る - Python3 / PyQt5
追記: windowのresizeに対応したほうが良いでしょうか?
固定電話番号の大まかな住所を教えてくれるアプリを作ります。
固定電話番号は10桁ではじめの一桁は「国内プレフィックス」二桁目からの五桁が「市外市内局番」となります。今回使うのは二桁目から五桁目となります。
イメージ (電気通信番号指定状況 (総務省))見た目
イントロダクション
まず見た目の部分のを作って行きます。
ページは2ページで
mainページで電話番号を入力し、resultページで検索結果を表示します。それぞれわかりやすいようにまず階層構造を簡単にHTMLで表しましました。メインページ(
main_page)<div class="main_page"> <p class="main_page_title"></p> <p class="main_page_note"></p> <input class="main_page_phone_number"> <input class="main_page_track_btn"> </div>リザルトページ(
result_page)<div class="result_page"> <p class="result_page_title"></p> <p class="result_page_detail"></p> </div>こんな感じです。そしてこれらを、
StackedWidgetと呼ばれるものに追加します。それぞれsetCurrentIndex(int)でページを切り替えます。結果的に次のような形になります。最終的にメインウィンドウに
centralwidgetをセットします。<div class="centralwidget"> <div class="stackedwidget"> <div class="main_page"> ... </div> <div class="result_page"> ... </div> </div> </div>コーディング
自作メソッド
def setup_qlabel(self, label, text, size, color='#2e2e2e'): label.setText(text) label.setFont(self.setup_font(size)) label.setAlignment(QtCore.Qt.AlignHCenter) label.setStyleSheet('color: {}'.format(color)) def setup_font(self, size): font = QtGui.QFont() font.setPointSize(size) return font
setup_qlabelはQLabelを設定する共通のメソッド。デフォルトのテキストカラーは#2e2e2eとしている。
setup_fontはQLabel等のフォントサイズを設定する。main_window
main_window.setWindowTitle('Phone-number-tracker') size = { 'width': { 'default': 600, 'minimum': 100, 'maximum': 10000 }, 'height': { 'default': 400, 'minimum': 100, 'maximum': 10000 } } main_window.resize(size['width']['default'], size['height']['default']) main_window.setMinimumSize(size['width']['minimum'], size['height']['minimum']) main_window.setMaximumSize(size['width']['maximum'], size['height']['maximum'])メインウィンドウのサイズを設定する。
centralwidget
self.centralwidget = QtWidgets.QWidget(main_window)設定:
self.centralwidget.setStyleSheet('background-color: #eaeaea;')stackedwidget
self.stackedwidget = QtWidgets.QStackedWidget(self.centralwidget)設定:
self.stackedwidget.setGeometry(100, 100, size['width']['default'] - 200, size['height']['default'] - 200)main_page
self.main_page = QtWidgets.QWidget()設定:
self.main_page.setGeometry(100, 100, size['width']['default'] - 200, size['height']['default'] - 200) self.main_page_layout = QtWidgets.QVBoxLayout(self.main_page)main_page > title
self.main_page_title = QtWidgets.QLabel(self.main_page)設定:
self.setup_qlabel(self.main_page_title, 'The phone number tracker', 24, '#ea5506') self.main_page_title.setFixedHeight(100)
setFixedHeightで高さを設定している。setup_qlabelでは(何に, このテキストを, このサイズで, このカラーで)という順になっている。main_page > note
self.main_page_note = QtWidgets.QLabel(self.main_page)設定:
self.setup_qlabel(self.main_page_note, "Note: No '-' needed", 12, '#3e3e3e')電話番号にハイフンは必要で無いことを示している。
main_page > phone_number
elf.main_page_phone_number = QtWidgets.QLineEdit(self.main_page)設定:
self.main_page_phone_number.setFont(self.setup_font(14)) self.main_page_phone_number.setMaxLength(34) self.main_page_phone_number.setStyleSheet('color: #2e2e2e; border: 2px solid #7fbfff; border-radius: 4px; padding: 2px')main_page > track_btn
self.main_page_track_btn = QtWidgets.QPushButton(self.main_page)self.main_page_track_btn.setText('Track') self.main_page_track_btn.setFont(self.setup_font(14)) self.main_page_track_btn.setStyleSheet('color: #2e2e2e;')result_page
self.result_page = QtWidgets.QWidget()設定:
self.result_page.setGeometry(100, 100, size['width']['default'] - 200, size['height']['default'] - 200) self.result_page_layout = QtWidgets.QVBoxLayout(self.result_page) self.result_page_layout.setContentsMargins(0, 0, 0, 0)このページでは少しオブジェクトがキツキツなので
setContentsMarginesでマージンを0にしている。result_page > title
self.result_page_title = QtWidgets.QLabel(self.result_page)設定:
self.setup_qlabel(self.result_page_title, '', 16) self.result_page_title.setFixedHeight(26)result_page > detail
self.result_page_detail = QtWidgets.QPlainTextEdit(self.result_page)設定:
self.result_page_detail.setFont(self.setup_font(12)) self.result_page_detail.setStyleSheet('border: 2px solid #7fbfff; border-radius: 4px') self.result_page_detail.verticalScrollBar().setStyleSheet('border: none') self.result_page_detail.setReadOnly(True)三行目では垂直方向のスクロールバーのスタイルを指定している。
それぞれをレイアウトに組み込む
メインページ
self.main_page_layout.addWidget(self.main_page_title) self.main_page_layout.addWidget(self.main_page_note) self.main_page_layout.addWidget(self.main_page_phone_number) self.main_page_layout.addWidget(self.main_page_track_btn) self.stackedwidget.addWidget(self.main_page)1~4行目で
main_pageにそれぞれのオブジェクトを順に追加している。(詳しくは、main_pageのレイアウトであるmain_page_layoutに追加している)最後に、stackedwidgetにページを追加している。リザルトページ
self.result_page_layout.addWidget(self.result_page_title) self.result_page_layout.addWidget(self.result_page_detail) self.stackedwidget.addWidget(self.result_page)仕上げ
初期のページを設定する。
self.stackedwidget.setCurrentIndex(0)メインウィンドウに
centralwidgetをセットする。main_window.setCentralWidget(self.centralwidget)
中身
PhoneNumber class
まず
PhoneNumberクラスを作る。そして必要なのは2桁目から6桁目なのでその5桁を取り出す。class PhoneNumber: def __init__(self, number): self.number = number self.trimmed_number = number[1:6]次にホントに固定電話の番号かを軽くチェックするメソッドを作る。
def check_format(self): length = len(self.number) == 10 is_digit = self.number.isdigit return length and is_digit最後に住所を得るメソッドを作る。
def get_address(self): outer_list = [self.trimmed_number[:i] for i in range(1, 5)] data = pd.read_pickle('phone_numbers_data.pickle') result = data[data.outer.isin(outer_list)] result = result[result.inner.str.len() == result.inner.str.len().min()] address = result['address'] return list(address)5桁のうち、何桁までが市外局番かわからないので1桁の場合から4桁の場合までそれぞれ取り出す。次の例では
outer_listは電話番号:
0123456789=>outer_list:['1', '12', '123', 1234']のようになる。二行目でデータを読み込み、三行目で
outer列要素がouter_listに属している行をすべて取り出している。四行目でinner列要素の文字列の長さが一番短いつまりouter列要素が貪欲マッチする行を絞り込む。最後にinner,outerはもういらないので住所だけを取り出し、リストに変換しリターンする。SearchJob class
class SearchJob(): def __init__(self, value): self.phone_number = PhoneNumber(value) def search(self): if self.phone_number.check_format() is False: raise ValueError('Error: Invalid format') self.result = self.phone_number.get_address() if self.result is None: raise ValueError('Error: Not address found') def finish(self): return self.string_converter(self.result) def string_converter(self, result): return ''.join(f'{i+1}: {item}\n' for i, item in enumerate(result))クリックイベントの関数内でこのインスタンスを生成する。次に
searchメソッドを呼び出し、先程作ったcheck_formatメソッドがFalseを返すなら、例外を上げて、住所が取得できない場合も例外を上げる。string_converterメソッドでは、リストになった住所を次のような文字列に変換する。1: 住所 2: 住所 ...クリック時に実行する関数
def clicked_track(self): number = self.main_page_phone_number.text() job = SearchJob(number) try: job.search() result = job.finish() self.show_result(number, result) except ValueError as err: result = str(err) self.show_result(number, result) def show_result(self, number, result): self.result_page_title.setText(f'Result: {number}') self.result_page_detail.setPlainText(result) self.stackedwidget.setCurrentIndex(1)try節内で例外が発生した場合は例外を
show_resultに渡してresult_page > defailに表示する。それ以外の場合は住所を表示する。最後に
main_page > track_btnの設定にself.main_page_track_btn.clicked.connect(self.clicked_track)を追加してクリックされたらこれを実行するようにする。main.pyを作って動かす。
import sys from ui_class import UiMainWindow from search_job import SearchJob app = QtWidgets.QApplication(sys.argv) main_window = QtWidgets.QMainWindow() ui = UiMainWindow() ui.setup_ui(main_window) main_window.show() sys.exit(app.exec_())お疲れ様でこれで完成です。下の電話番号のデータも忘れないでください!
イメージ
登場する電話番号は実在の人物や団体などとは関係ありません。## 付録
(市外局番の一覧(総務省)(https://www.soumu.go.jp/main_content/000157336.doc) をCSVに変換して作成)
mk_pickle.py
import pandas as pd pd.read_csv('phone_numbers.csv', names=['address', 'outer', 'inner']).to_pickle('phone_numbers_data.pickle')



- 投稿日:2020-12-04T21:13:35+09:00
アバターを顔から探しやすくするWebサービス「kaogaii」を支える技術
VRChat Advent Calendar 2020の4日目の記事です。
kaogaiiというWebサービスをリリースしました。
BOOTHに登録されている中から選ばれた3,245種の商品(2020年11月末時点)アバター商品がメインだがそれ以外の物も含む。後述)からサムネイルを抽出し、ランダム選択 → 類似候補選択を繰り返すことによって、好みの商品にたどり着きやすくするサービスです。以下の章立てで話していきます。
- モチベーション
- スクレイピング
- 機械学習
- デプロイ
モチベーション
Boothには多数の3Dモデルが投稿されているため、数が多すぎるため、
- 一部のモデルに注目が集まる
- 自分好みのモデルを探そうと思っても探すのが大変
という問題があります。これを解決するために、それぞれのアバターの顔に注目して、
- とりあえずランダムに探す
- 好みの顔があったら似た顔も探す
ということを高速でできたら好みのアバターが見つけやすくなり、今まで目立たなかったアバターにも光が当たるのではないかという思いのもと、Webサービスを構築しました。
実は2年ぐらい前に、Googleスプレッドシートを利用して人力でデータベースを構築しようとしていたのですが、100体を超えたぐらいですぐに限界がきて破綻しました。それ以来、人力ではなく機械の力でそういったデータベースを作れないかと考えていたというのもあります。
スクレイピング
まずはBOOTHから商品URLとサムネイルを取得します。以下のようなPythonスクリプトを組みました。
import urllib.request as ur from bs4 import BeautifulSoup import requests import csv import cv2 def trim(img): #顔検出 img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) classifier = cv2.CascadeClassifier("lbpcascade_animeface.xml") faces = classifier.detectMultiScale(img_gray, minSize=(100, 100)) if len(faces) == 0: return False, img x = faces[0][0] y = faces[0][1] w = faces[0][2] h = faces[0][3] face_image = img[y:y+h, x:x+w] face_image = cv2.resize(face_image,(256,256)) return True, face_image def word_check(title): #NGワードを弾く words = ['専用','衣装','水着','シャツ','テクスチャ','着物','コスチューム','ドレス', 'ワンピース','ヘア','髪型','VRoid','Vroid','VROID',] for w in words: if w in title: return False return True def img_save(img_url,page_url,title): global count response = requests.get(img_url) image = response.content with open("tmp.png", "wb") as o: o.write(image) img = cv2.imread("tmp.png") faceimage = trim(img) if faceimage[0] and word_check(title): print(title,page_url) with open('imglist_exclude.csv',encoding='utf-8') as f: reader = csv.reader(f) nowcsv = [row for row in reader] exist = False for n in nowcsv: if n[1] == page_url: print("exist!") return count = len(nowcsv) file_name = "{}.png".format(count) cv2.imwrite("exclude_data/{}".format(file_name),faceimage[1]) with open("imglist_exclude.csv", "a", newline="", encoding='utf-8') as f: w = csv.writer(f, delimiter=",") w.writerow([count,page_url,title]) def img_search(url): html = ur.urlopen(url) soup = BeautifulSoup(html, "html.parser") title = str(soup.title.text) print("{}...".format(title[:15]),end="") char_list = '\/:*?"<>|~' for c in char_list: title = title.replace(c,"") for s in soup.find_all("img"): if str(s).find("market") > 0: img_url = s.get("src") if img_url is not None: img_save(img_url,url,title) break def page_access(page_number): url = page_number html = ur.urlopen(url) soup = BeautifulSoup(html, "html.parser") for s in soup.find_all("a"): if str(s).find("item-card__title-anchor") > 0: url = s.get("href") img_search(url) for i in range(430,515): print("{}ページ目を検索中...".format(i)) url = "dummyurl?page=" + str(i) #試したい方は実際のURLを入力してください page_access(url)「3Dモデル」タグを含む商品を探すと膨大になるため、まずOpenCVによる顔認識を行い、それにヒットしたものを候補としていきます。顔認識はアニメ顔専用のライブラリであるlbpcascade_animefaceが公開されており、かなり助かりました。このあたりは自分の過去記事で詳しく触れています。
また、これだけではアバター以外の商品であってサムネに顔を含むものも検出されてしまいます(衣装等のサムネイルはサンプル画像として他アバターの顔を含むものが多いです)。そのため、原始的ではすが、明らかに衣装やアクセサリーであろう単語をタイトルに含むアイテムは除外させてもらうことにしまいた。具体的なNGワードは以下の通りです。
words = ['専用','衣装','水着','シャツ','テクスチャ','着物','コスチューム','ドレス', 'ワンピース','ヘア','髪型','VRoid','Vroid','VROID',]このスクレイピングを回す時に、画像の番号とURLを紐付けたcsv(上のコードだと
exclude_data.csv)を生成しておきます。機械学習
無事に顔画像データが3,253枚取得できたので、今度はこれらの間の類似度を計算していきます。計算方法としては主成分分析を用いました。
import csv import cv2 import numpy as np from sklearn.decomposition import PCA with open('imglist_exclude.csv',encoding='utf-8') as f: reader = csv.reader(f) data = [row for row in reader] max_range = 3253 n_comp = 30 mat = np.zeros((max_range,196608)) for i in range(max_range): img = cv2.imread('exclude_data/{}.png'.format(i)) img = np.array(img)/256 img = np.reshape(img,(256*256*3)) mat[i] = img pca = PCA(n_components=n_comp,whiten=True) pca.fit(mat) pca_res = pca.transform(mat) for i in range(max_range): org = pca_res[i] dist_list = [] for j in range(max_range): dist = np.linalg.norm(org-pca_res[j]) dist_list.append([dist,j]) dist_list.sort() for j in range(9): data[i].append(dist_list[j][1]) with open('new_data.csv', 'w', encoding='utf-8', newline='') as f: writer = csv.writer(f) writer.writerows(data)さきほど生成されたcsvに、類似度が最も近い9個の画像へのリンクを追記して新たにcsv(上のコードだと
new_data.csv)として書き出します。画像の類似度を計算する一番プリミティブな手段は、画像データをベクトルとみなしてそれらの間のユークリッド距離を計算する方法ですが、これだと同じ画像が平行移動しているような場合でも大きな距離の違いと認識してしまい、人間の目から見て自然な類似候補の選択ができなくなってしまう恐れがあります。
そのため、主成分分析を用いて主成分(画像を構成するおおまかな成分)を比較することで、画像の「雰囲気」を比較できるようにしています。一応、オートエンコーダを利用したニューラルネットワークによる潜在空間での比較も試みたのですが、結果(類似度)にあまり違いが見られないというかむしろ推薦精度が下がるような印象を受けたので、主成分分析で済ませました。主成分分析を用いた画像の特徴量については、これもまた自分の過去記事で恐縮ですがこれなどが参考になるかもです。
デプロイ
類似度が計算できたので、今度はこれをWebアプリとして構築しデプロイしていきます。
今回はWebフレームワークとしてFlaskを、プラットフォームとしてHerokuを用いました。
フォルダ構成。(上の
new_data.csvをdatalist.csvとして入れております)kaogaii │ .gitignore │ app.py │ Procfile │ requirements.txt ├─models ├─static | (大量の画像) │ datalist.csv │ index.css └─templates faq.html index.htmlルーティング等を司る
app.py。app.pyfrom flask import Flask,render_template,request import numpy as np import csv app = Flask(__name__) @app.route('/') def index(): choice = request.args.get("choice") if choice is None: choice = "init" title = "title" url = "url" nums = [] for i in range(9): nums.append(np.random.randint(0,3253)) row1 = nums[0:3] row2 = nums[3:6] row3 = nums[6:9] else: with open('static/datalist.csv',encoding='utf-8') as f: reader = csv.reader(f) l = [row for row in reader] url = l[int(choice)][1] title = l[int(choice)][2] recos = [] for i in range(9): recos.append(l[int(choice)][3+i]) row1 = recos[0:3] row2 = recos[3:6] row3 = recos[6:9] return render_template("index.html", row1=row1, row2=row2, row3=row3, choice=choice, title=title, url=url, ) @app.route('/sample') def sample(): return render_template("index.html", row1=[0,1,2], row2=[3,4,5], row3=[6,7,8], choice="init", title=None, url=None, ) @app.route('/faq') def faq(): return render_template("faq.html") if __name__ == '__main__': app.run()メインページとなる
index.html。index.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link rel="icon" href="static/favicon.jpg" /> <link rel="stylesheet" href="static/index.css" /> <title>kaogaii</title> </head> <body> <div class="center"> <h1 class="center">BOOTHアイテム紹介サービス「kaogaii」</h1> <p>商品を購入の際には、<u>商品ページで利用規約等を確認した上で</u>購入お願いします。</p> <p>アバター商品を選ぶようにしていますが、技術的な仕様上、それ以外のモデルも交じっています。ご容赦ください?</p> {% if choice == "init" %} <h2>サムネイルをクリックしてください。</h2> {% else %} <h2>現在選ばれている商品(クリックすると商品ページに飛びます)</h2> <a href="{{url}}" target="_blank"> <img class="img-selected" src="static/{{choice}}.png" width="512" height="512"> </a> <h3>{{title}}</h3> {% endif %} <p><input type="button" value="Reset" onclick="location.href='./'"></p> {% if choice != "init"%} <h3>↓↓この顔に似ている候補↓↓</h3> {% endif %} <p> {% for row in row1 %} <img class="img-choise" src="static/{{row}}.png" onclick="location.href='./?choice={{row}}'" width="256" height="256"> {% endfor %} </p> <p> {% for row in row2 %} <img class="img-choise" src="static/{{row}}.png" onclick="location.href='./?choice={{row}}'" width="256" height="256"> {% endfor %} </p> <p> {% for row in row3 %} <img class="img-choise" src="static/{{row}}.png" onclick="location.href='./?choice={{row}}'" width="256" height="256"> {% endfor %} </p> <p>作者:<a href="https://twitter.com/hibit_at" target="_blank">@hibit_at</a></p> <p><a href="./faq">FAQと更新履歴</a></p> </div> </body> </html>上を見てわかる通り、画像データや類似度のデータについては、本当は他にストレージやDBサーバーを立てた方が良いのですが、面倒臭かったのですべてのデータ(3,000枚超の顔画像を含む)をstaticフォルダにぶちこむという男気あるソリューションを実行しました。さすがに容量が足りないかなと思いましたが、なんと360MBぐらいだったら(警告は出ましたが)デプロイできました。ありがとうHeroku。
Flaskは初めて使ってみたのですが、Djangoより手軽でいいですね。Pythonだけでミニマムサービスを作るなら最良の選択肢かなと思います。以下の記事に大いに助けられました。
今後に向けて
以下の点を改良したいです。
ノイズが多い
顔検出だけではアバター以外のモデルも大量に拾ってしまいます。NGワード方式で対処しているとはいえ、もう少しS/N比を上げたいです。手軽かつ確実なのは人力でNGリストを作ることですが、細かく対処していくとキリがないし、人力ではまだいつか限界を迎えそうなので、なるべく機械的に処理できるテクニックを考えたいです。
推薦の袋小路がある
上記のアルゴリズムだと、白っぽい画像や淡い画像が出やすいで、どのランダム候補から出発してもそのようなモデルに収束しやすいです。色々なモデルを紹介するという観点からは良くないので、うまく推薦先がばらけるようなアルゴリズムが必要になりそうです。
まとめ
今後ともkaogaiiをよろしくお願いします。また、色々なアバターを買ってモデラーさん達を応援しましょう!
提案や要望はGitHubリポジトリまでプルリクまたはイシューの形でお願いします。

- 投稿日:2020-12-04T19:22:58+09:00
LeetCodeに毎日挑戦してみた 66. Add Binary(Python、Go)
はじめに
無料英単語サイトE-tanを運営中の@ishishowです。
プログラマとしての能力を上げるために毎日leetcodeに取り組み、自分なりの解き方を挙げていきたいと思います。
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
16問目(問題67)
67. Add Binary
問題内容
Given two binary strings
aandb, return their sum as a binary string.(日本語訳)
2つのバイナリ文字列
aとが与えられた場合b、それらの合計をバイナリ文字列として返します。Example 1:
Input: a = "11", b = "1" Output: "100"Example 2:
Input: a = "1010", b = "1011" Output: "10101"考え方
二進数の文字列を十進数に変換します
十進数のまま数字を足して、最後に二進数の文字列に変換します。
- 解答コード
class Solution: def addBinary(self, a, b): return bin(int(a, 2) + int(b, 2))[2:]
- Goでも書いてみます!
import ( "fmt" "math/big" ) func addBinary(a string, b string) string { var A, _ = new(big.Int).SetString(a, 2) var B, _ = new(big.Int).SetString(b, 2) return fmt.Sprintf("%b", new(big.Int).Add(A, B)) }
- 投稿日:2020-12-04T19:19:45+09:00
[誰でも出来る!]スタジオジブリ作品の場面写真を全て保存する方法
はじめに
今年の9月からスタジオジブリ全作品の場面写真が順次提供され始めました。
常識の範囲でご自由にお使いくださいとのことでダウンロードしたい人も多いはず。
現在提供されている作品は以下のようになっています。
- 「思い出のマーニー,かぐや姫の物語,風立ちぬ,コクリコ坂から,借りぐらしのアリエッティ,崖の上のポニョ,ゲド戦記,千と千尋の神隠し」
今月から、スタジオジブリ作品の場面写真の提供を開始します (2020.09.18)- 「ハウルの動く城,猫の恩返し,ギブリーズ episode2,ホーホケキョ となりの山田くん,もののけ姫,耳をすませば」
新しく、スタジオジブリ 6作品の場面写真を追加提供致します (2020.10.16)- 「平成狸合戦ぽんぽこ,海が聞こえる,紅の豚,魔女の宅急便,となりのトトロ」
新しく、スタジオジブリ5作品の場面写真を追加提供致します (2020.11.20)各作品50枚ずつなので,全部で950枚!!
好きな作品だけ、もしくは全部保存しようと思うと大変ですよね。
楽で簡単な方法があればいいなと思っている人もいるのではないでしょうか。そこで,提供されている場面写真全てを作品ごとにフォルダを分けて自動で保存できる方法を紹介します。
Google Colabを使ったダウンロード手順に記載している手順通りに作業して貰えれば大丈夫です。
動作確認済みの環境
Python 3.8.6 または Google Colab
コードについて
15行目で作品名を指定しているので,「好きな作品だけダウンロードしたい!」って人は好きな作品だけを指定して使ってください
name = ['marnie','kaguyahime','kazetachinu','kokurikozaka','karigurashi','ponyo','ged','chihiro','howl','baron','ghiblies','yamada','mononoke','mimi','tanuki','umi','porco','majo','totoro']例)
となりのトトロだけダウンロードしたいとき
name = ['totoro']ghibli_download.py
ghibli_download.pyimport os import urllib.error import urllib.request def download_file(url, path): try: with urllib.request.urlopen(url) as web_file, open(path, 'wb') as local_file: local_file.write(web_file.read()) except urllib.error.URLError as e: print(e) if not os.path.exists('ghibli_data'): os.mkdir('ghibli_data') names = ['marnie','kaguyahime','kazetachinu','kokurikozaka','karigurashi','ponyo','ged','chihiro','howl','baron','ghiblies','yamada','mononoke','mimi','tanuki','umi','porco','majo','totoro'] for name in names: if not os.path.exists('ghibli_data/'+name): os.mkdir('ghibli_data/'+name) for j in range(1,51): url = 'https://www.ghibli.jp/gallery/'+name+'{0:03d}'.format(j)+'.jpg' print(url) dir = 'ghibli_data/'+name+'/' download_file(url, os.path.join(dir, os.path.basename(url)))ダウンロード用作品名一覧
作品名 name 思い出のマーニー 'marnie' かぐや姫の物語 'kaguyahime' 風立ちぬ 'kazetachinu' コクリコ坂から 'kokurikozaka' 借りぐらしのアリエッティ 'karigurashi' 崖の上のポニョ 'ponyo' ゲド戦記 'ged' 千と千尋の神隠し 'chihiro' ハウルの動く城 'howl' 猫の恩返し 'baron' ギブリーズ episode2 'ghiblies' ホーホケキョ となりの山田くん 'yamada' もののけ姫 'mononoke' 耳をすませば 'mimi' 平成狸合戦ぽんぽこ 'tanuki' 海が聞こえる 'umi' 紅の豚 'porco' 魔女の宅急便 'majo' となりのトトロ 'totoro'
- 9月提供作品
['marnie','kaguyahime','kazetachinu','kokurikozaka','karigurashi','ponyo','ged','chihiro']- 10月提供作品
['howl','baron','ghiblies','yamada','mononoke','mimi']- 11月提供作品
['tanuki','umi','porco','majo','totoro']Google Colabを使ったダウンロード手順
- Google Colabに自分自身のGoogleアカウントを使ってアクセスする
- ノートブックを新規作成

- 左側の項目から図の赤丸で囲んだ部分をクリックしてドライブをマウント

- 右側のグレー部分に
cd drive/MyDrive/と入力し,隣の実行ボタンを押す
- 4.で入力した下のグレー部分にghibli_download.pyに記載しているコードをコピーして実行ボタンを押す

左側のdrive横の▼ → MyDrive横の▼を押して
ghibli_dataというフォルダができていることが確認できればダウンロード完了です!自分自身のGoogle Driveに
ghibli_dataというフォルダで保存されているのであとはご自由におわりに
このプログラムと方法が誰かの役に立つといいな
※作品が追加されたらこの記事も更新していくのでお楽しみに

- 投稿日:2020-12-04T19:10:04+09:00
TecoGAN 試してみた(私的備忘録・メモ帳) -(1)
はじめに
はじめまして
現在、深層学習・画像処理を趣味でやっている学生です。最近巷で流行っている(いた?)TecoGANを試してみました。※あくまで、私的な備忘録です。もし間違いなどありましたら、指摘して下さると幸いです。。
TecoGANとは?
深層学習を利用した動画(ビデオ)超解像手法の一つ。
元論文 https://arxiv.org/pdf/1811.09393.pdfGANを利用しているため、生成結果画像が人の知覚品質に近いものになるようです。
単眼(単一)超解像SRGANの動画版みたいです。超解像とは?
そもそも超解像とは何か?としばしば聞かれることがあるのでここにて記載しておきます。
超解像とはその名の通り画像を高解像度化させる処理です。
高解像度とは、画質がいい、鮮明に見えるなどいろいろありますが、ここでは、画素数が大きい+高周波成分を含んでいるという意味です。
低解像度画像 81×54 px 超解像処理後の画像 810×540 px この超解像ですが、いろいろな種類があります。
画像一枚を高解像度化する単一(単眼)超解像、動画を(各フレーム全て)高解像度化する動画(ビデオ)超解像など色々な種類・手法がありますが、今回のTecoGANは、深層学習を用いた後者のタイプになります。環境構築
PC環境
OS : Ubuntu 18.04
CPU: i7
GPU: Geforce GTX1080ti
python 3.6各種ライブラリの導入
https://github.com/thunil/TecoGAN
こちらがソースもとになります。
ソースもとの記載通りに、まず以下コマンドでtensorflownをインストールします。pip3 install --ignore-installed --upgrade tensorflow-gpu次に
requirements.txtに記載されている各ライブラリのインストールを行います。pip3 install -r requirements.txtよしこれで実装できるぞ!と思ったのですが、上手く実行できませんでした・・・(笑)
それもそのはずで、ソースが公開されたのが2年くらい前で、tensorflow-gpu,requirements.txtとともに当時に合わせて、ver〇.〇.〇以上をインストールと記載されているからです。しかし、現在(2020年/10月)において、それらをインストールすると、最新のものがインストールされ、結果として、ライブラリが最新バージョンだと仕様が変更されていたり、ライブラリ同士が噛み合わなかったりして、上手く実行できないようです。
なので参考までに以下にて自分が推論・評価・学習のすべてのモードにて実行可能であった
cuda,cudnn,tensorflow-gpu,requirements.txt各ライブラリのバージョンの組み合わせを載せておきます。
cuda
cuda : v10.0
cudnn
cudnn : 7.4.1
tensorflow-gpu
tensorflow-gpu==1.13.1
requirements.txt
numpy==1.16.2
scipy==1.0.1
scikit-image==0.14.0
matplotlib==3.0.3
pandas==0.23.1
Keras==2.1.2
torch==1.2.0
torchvision==0.4.0
opencv-python==3.1.0.5
ipython==7.4.0その他ライブラリ・まとめ
TecoGAN実行
学習済みモデル(とサンプル用画像)のダウンロード
以下コマンドで学習済みモデルとサンプル用連番画像(Vid4など)の低解像度(LR)、高解像度(HR)のセットをダウンロードします。
python3 runGan.py 0ダウンロード自体は、自分の環境においては数十分程かかった気がします。
推論モード
以下コマンドの実行でTecoGAN超解像の推論を実行できます。デフォルトでは、
LRフォルダ中のcalendarが入力となっています。python3 runGan.py 1結果
・calendar
LR(Input) 180×144 px TecoGAN(Output) 720×576 px 評価モード
以下コマンドの実行で画像の定量評価が行えます。
python3 runGan.py 2定量評価指標には、フレーム一枚を評価する空間評価指標とフレーム間のつながりを評価する時間評価指標の二種類、計5つあります。
空間評価指標 時間評価指標 (ⅰ)PSNR (ⅱ)SSIM (ⅲ)LPIPS (ⅳ)tOF (ⅴ)tLP LPIPSは、論文曰く、生成画像の多様性を評価する知覚的評価指標であり、値が低いほど知覚品質において良いとされているらしいです。
tOFは、これも論文曰く、正解フレーム間と生成フレーム間の各フレーム間の動き(optical flow)の類似度を評価するものらしいです。
tLPは、LPIPSにより、正解フレーム間と生成フレーム間の知覚的類似性を測定する?ものらしいです。(これだけいまいちピンときませんでした。)
終わり
TecoGANは自分が想像していた以上に出来栄えがよく素晴らしいものだと感じました!
ですが、他の方がすでにご指摘されている通り、4倍拡大にしか対応していなく、他の倍率に変えることはできないのかなと思いました。
また、デフォルトの入力動画だと、動きが緩やかなものしかないですが、動きが速い動画の場合は、オプティカルフローを求める処理など上手く対応できているのかな。。。なんてことも疑問に思いました。まあ何はともあれ、実装できてよかったです。
次回は、ネットワークの構造など理論的なことや学習モードについてまとめてみようと思います!





- 投稿日:2020-12-04T19:03:46+09:00
Python小技:文字列から特定の文字コードに含まれない文字を削除する
文字列 string から、特定の文字コード(サンプルではCP932)に 含まれない 文字を削除するためには以下のようにするのがおそらく簡単です。
string = "Some string \u200b" string = string.encode('cp932`, errors='ignore').decode('cp932')要するに、以下の処理をしています。
- 最初に文字列を CP932 でエンコードします。この際エンコードできない文字を削除するために
encodeメソッドにerrors='ignore'をオプションとして渡します。- 出来上がったバイト列を再度デコードして文字列に直します。
補足: 実験した環境
> py --version --version Python 3.9.0 (tags/v3.9.0:9cf6752, Oct 5 2020, 15:34:40) [MSC v.1927 64 bit (AMD64)]
- 投稿日:2020-12-04T19:02:10+09:00
配列内に特定の部分配列が存在するか判定する
- 投稿日:2020-12-04T18:58:20+09:00
Multilingual T5で日本語の文章要約
Ateam Group Manager & Specialist Advent Calendar 2020の5日目は 株式会社エイチームライフスタイルの @yuko1658 が担当します。最近、文章生成を使って何かできないかと企んでおり、今回は日本語の文章要約をやってみました。
Multilingual T5とは
まずT5についてですが、Text-To-Text Transfer Transformerの略で、様々なタスクをText-to-Textで学習できるモデルです。
図の例では翻訳、分類、回帰、要約のタスクに一つのモデルで対応できていることがわかります。
T5にはColossal Clean Crawled Corpus(以下 C4)という大規模コーパスによる事前学習モデルが用意されています。
C4は英語のデータセットですが、日本語を含む101言語が含まれたmC4が公開されており、Multilingual T5(以下 mT5)はmC4で事前学習されています。
今回はこのmT5を利用して日本語の文章要約をやってみたいと思います。wikiHow要約データ
文章要約のデータセットはwikihow_japaneseを利用させていただきます。
wikiHowのデータは構造化されており、見出し部分が要約文として抽出されています。
詳しくは以下の記事で解説されています。
wikiHowから日本語要約データを作成してみたREDEMEの手順通りに記事をダウンロードした後、mT5でFine-Tuningする用に整形しておきます。
import pandas as pd df = pd.read_json('data/output/test.jsonl', orient='records', lines=True) df['inputs'] = df['src'].str.replace('\n', ' ').str.replace('\t', ' ') df['targets'] = df['tgt'].str.replace('\n', ' ').str.replace('\t', ' ') df[['inputs', 'targets']].to_csv('test.tsv', sep='\t', index=False)元データはsrcに本文、tgtに要約文が入っているので、それぞれ改行とタブを削除してinputs, targetsというカラムでtsvに出力しています。改行とタブを削除したのは、Fine-Tuningのさいに学習がうまく進まなかったためです。
上記はtest用ですが、train用(train.tsv), validation用(dev.tsv)も同様に作成しています。
データの内容は以下のようになっています。
Fine-Tuning
データが用意できたので、mT5でFine-Tuningしていきます。
以下の2つの記事を参考にさせていただきました。
はじめての自然言語処理 第7回 T5 によるテキスト生成の検証
Multilingual T5をカスタマーサポートの対話でfine-tuning
実行環境はGoogle ColaboratoryのGPU環境を利用しています。まず必要なライブラリをインストールします。
# T5ライブラリ !pip install t5[gcp] !pip install tensorflow-gpu !git clone https://github.com/google-research/multilingual-t5.git # 日本語を扱う上で必要なライブラリ !apt-get install mecab mecab-ipadic-utf8 !pip install mecab-python3==0.996.5 sumeval !apt-get install nkf !pip install janomeさきほど作成したデータ(train.tsv, dev.tsv, test.tsv)をColabにアップロードしておきます。
次にFine-Tuningするためのモジュールを作成します。%%bash cat <<EOF > multilingual-t5/t5_wikihow.py import t5.data from t5.data import sentencepiece_vocabulary from t5.evaluation import metrics from t5.data import preprocessors from t5.data import TaskRegistry from t5.data import TextLineTask import numpy as np import functools import tensorflow as tf from sumeval.metrics.rouge import RougeCalculator rouge_cal = RougeCalculator(stopwords=True, lang="ja") DEFAULT_SPM_PATH = "gs://t5-data/vocabs/mc4.250000.100extra/sentencepiece.model" DEFAULT_VOCAB = sentencepiece_vocabulary.SentencePieceVocabulary( DEFAULT_SPM_PATH) DEFAULT_OUTPUT_FEATURES = { "inputs": t5.data.Feature( vocabulary=DEFAULT_VOCAB, add_eos=True, required=False), "targets": t5.data.Feature( vocabulary=DEFAULT_VOCAB, add_eos=True) } # rouge-1, rouge-2, rouge-lを評価指標とします def rouge(targets, predictions): predictions = [tf.compat.as_text(x) for x in predictions] if isinstance(targets[0], list): targets = [[tf.compat.as_text(x) for x in target] for target in targets] else: targets = [tf.compat.as_text(x) for x in targets] targets = [targets] list_1, list_2, list_l = [], [], [] for i in range(len(predictions)): list_1.append(rouge_cal.rouge_n( summary=predictions[i], references=targets[0][i], n=1)) list_2.append(rouge_cal.rouge_n( summary=predictions[i], references=targets[0][i], n=2)) list_l.append(rouge_cal.rouge_l( summary=predictions[i], references=targets[0][i])) return {"rouge_1": np.array(list_1).mean(), "rouge_2": np.array(list_2).mean(), "rouge_l": np.array(list_l).mean()} task_name = "t5_wikihow" tsv_path = { "train": "/content/train.tsv", "validation": "/content/dev.tsv", "test": "/content/test.tsv", } TaskRegistry.add( task_name, TextLineTask, split_to_filepattern=tsv_path, text_preprocessor=[ functools.partial( preprocessors.parse_tsv, field_names=["inputs", "targets"]), ], output_features=DEFAULT_OUTPUT_FEATURES, metric_fns=[rouge]) EOF事前学習モデルをダウンロードします。
事前学習モデルはパラメータ数によって大小用意されているのですが、今回は色々試してColabのメモリサイズでぎりぎり動くlargeを選択しました。!gsutil cp gs://t5-data/pretrained_models/mt5/large/checkpoint /content/large !gsutil cp gs://t5-data/pretrained_models/mt5/large/model.ckpt-1000000* /content/large !gsutil cp gs://t5-data/pretrained_models/mt5/large/operative_config.gin /content/large作成したモジュールと事前学習モデルを使ってFine-Tuningを実行します。
!export PYTHONPATH=${PYTHONPATH}:. && cd multilingual-t5 && \ \ PRE_TRAINED_MODEL_DIR='/content/large' && \ OPERATIVE_CONFIG=$PRE_TRAINED_MODEL_DIR'/operative_config.gin' && \ FINE_TUNED_MODEL_DIR='/content/large' && \ FINE_TUNING_BATCH_SIZE=1024 && \ PRE_TRAINGING_STEPS=1000000 && \ FINE_TUNING_STEPS=`expr $PRE_TRAINGING_STEPS + 1000` && \ INPUT_SEQ_LEN=512 &&\ TARGET_SEQ_LEN=64 &&\ \ echo "OPERATIVE_CONFIG=$OPERATIVE_CONFIG" &&\ echo "FINE_TUNED_MODEL_DIR=$FINE_TUNED_MODEL_DIR" &&\ echo "FINE_TUNING_BATCH_SIZE=$FINE_TUNING_BATCH_SIZE" &&\ echo "PRE_TRAINGING_STEPS=$PRE_TRAINGING_STEPS" &&\ echo "FINE_TUNING_STEPS=$FINE_TUNING_STEPS" && \ echo "INPUT_SEQ_LEN=$INPUT_SEQ_LEN" && \ echo "TARGET_SEQ_LEN=$TARGET_SEQ_LEN" && \ \ t5_mesh_transformer \ --model_dir="$FINE_TUNED_MODEL_DIR" \ --module_import="t5_wikihow" \ --gin_file="dataset.gin" \ --gin_file="$OPERATIVE_CONFIG" \ --gin_param="run.layout_rules=''" \ --gin_param="run.mesh_shape=''" \ --gin_param="utils.get_variable_dtype.activation_dtype='float32'" \ --gin_param="MIXTURE_NAME = 't5_wikihow'" \ --gin_file="learning_rate_schedules/constant_0_001.gin" \ --gin_param="run.train_steps=$FINE_TUNING_STEPS" \ --gin_param="run.sequence_length = {'inputs': $INPUT_SEQ_LEN, 'targets': $TARGET_SEQ_LEN}" \ --gin_param="run.save_checkpoints_steps=200" \ --gin_param="run.batch_size=('tokens_per_batch', $FINE_TUNING_BATCH_SIZE)"入力のシーケンス長を512、出力を64とし、学習のステップ数は1,000に設定しています。
学習時間はColabで30分ほどで、GPUはTesla P100が割り当てられていました。結果
wikiHow要約データをFine-Tuningしたモデルが出来上がったので、どんな文章が生成されるのかと、評価指標を見ていきます。
モデルから要約文を生成
モデルを使って要約文を生成します。
!export PYTHONPATH=${PYTHONPATH}:. && cd multilingual-t5 && \ \ FINE_TUNED_MODEL_DIR='/content/large' && \ OPERATIVE_CONFIG=$FINE_TUNED_MODEL_DIR'/operative_config.gin' && \ \ echo "OPERATIVE_CONFIG=$OPERATIVE_CONFIG" &&\ echo "FINE_TUNED_MODEL_DIR=$FINE_TUNED_MODEL_DIR" &&\ \ t5_mesh_transformer \ --model_dir="$FINE_TUNED_MODEL_DIR" \ --module_import="t5_wikihow" \ --gin_file="$OPERATIVE_CONFIG" \ --gin_param="run.layout_rules=''" \ --gin_param="run.mesh_shape=''" \ --gin_file="infer.gin" \ --gin_file="beam_search.gin" \ --gin_param="utils.get_variable_dtype.slice_dtype='float32'" \ --gin_param="utils.get_variable_dtype.activation_dtype='float32'" \ --gin_param="MIXTURE_NAME='t5_wikihow'" \ --gin_param="run.batch_size=('tokens_per_batch', 512)" \ --gin_param="infer_checkpoint_step=1001000" \ --gin_param="input_filename='/content/inputs.txt'" \ --gin_param="output_filename='/content/outputs.txt'"inputs.txtというファイルを用意して、test.tsvからinputsをいくつかピックアップして入力としています。
outputs.txtにモデルから生成された要約文が出力されますが、byte形式で出力されるため、以下のようにしてデコードします。import pandas as pd pd.read_csv('outputs.txt-1001000', header=None)[0].apply(lambda s: eval(s).decode("utf-8"))いくつか生成された文章を見てみます。
例1
本文
脅威を感じた蛇は再び襲いかかります。したがって、噛まれた際は速やかに蛇の攻撃範囲から離れましょう。 少なくとも6mは間合いを取りましょう。できる限り速やかに医療処置を求めることが大切です。ほとんどの病院は、毒蛇用の抗毒素(血清)を用意しています。病院に到着する前の応急手当だけでは、あまり症状の改善にはつながりません。被害現場からすぐさま救急サービスに通報できれば不幸中の幸いです。救急車を呼べない場合は、何としても助けを求め、みなさんまたは被害者を最寄りの病院へ搬送しなければなりません。みなさんに噛みついた蛇がガラガラヘビかどうかが分からない場合でも、すぐに病院へ直行しましょう。実際に毒が体に回り、症状が出始めたとしても、病院にいれば安心できるでしょう。噛まれた箇所を心臓よりも上に置くと、毒を含んだ血液が猛スピードで心臓に流れ込みます。救助が来るまでの間、できれば被害者の体を静止させましょう。体を動かすと血流が増大し、あっという間に毒が回ります。したがって、毒蛇に噛まれた際は体の動きを最小限に抑えて安静にすることが大切です。もちろん、みなさんの周りに誰もいなければ、じっとしている場合ではありません。すぐに助けを求めましょう。
正解の要約文
ガラガラヘビから離れましょう。医療処置を受けましょう。決して患部を心臓よりも高い位置に置いてはいけません。体を動かさずにじっとしましょう。
生成された要約文
噛みついた蛇に噛まれた場合は、すぐに病院へ直行しましょう。
短めでちょっと文がおかしいですが、要点を抑えた文章にはなっていそうです。
例2
本文
NASAと言えば、一番最初に頭に浮かぶのは宇宙飛行士でしょう。宇宙に行くことに興味がなくても、NASAには他に魅力的な仕事があります。以下に挙げるのはNASAが雇用している専門的な職種のほんの一部です。医師、看護士、心理士やカウンセラー研究者、エンジニア、地質学者、微生物学者、物理学者ライター、人事管理者、通信技術者コンピュータープログラマー、IT技術者NASAで働くための計画の手始めに、なるべく早い段階で自分が何が得意なのか掘り下げてみるとよいでしょう。NASAのどのポジションが自分に合っているか考えをまとめる手助けとなるでしょう。以下の事を考えてみましょう。学校で秀でていた科目はなんですか?例えば、物理の実験クラスで、みんながあなたとペアになりたがったとしたら、NASAの物理分野が向いているかもしれません。例えば、数学や化学が得意だったとしても、NASAでの仕事では求められるものが大きく、応募条件を満たすための勉強もレベルが高く膨大なものになるでしょう。そのため、自分が秀でているものだけではなく、情熱をかけられる方向を選択することも考慮に入れましょう。目指したい職種が定まったのなら、高校や大学で選択すべき学科の大枠を注意深く立てましょう。定期的に履修学科アドバイザー(アカデミックアドバイザー)に会い、正しい学科を選択しているか、単位が足りているか確認しましょう。NASAの宇宙飛行士、エンジニア、科学者になりたいという目標がある場合は、STEM(科学、技術、工学、数学の教育分野の総称)に特化した教育を受けましょう。目指しているNASAでの職種に大学院を履修する必要がある場合は、早めに進むべき道を決断しましょう。その計画によって、どの学校に行くか、大学でどの科目を取るべきかに影響してくるでしょう。NASAに寄せられる、どうやったらNASAで働けますか?という質問に対する答えに「死ぬ気で勉強すること」という冗談がありますが、実際、一生懸命勉強することが夢を叶えるための鍵となります。真剣に勉強しましょう。ただ単位を取ればいいというのではなく、学んでいることをしっかりと自分のものにしましょう。この記事を読んでいるあなたがまだ高校生であるならば、今の内からNASAを目指す計画を立てて正解です。STEM教育に力を入れている大学や学校をじっくり探し、できるだけ条件に近い学校に入学できるようにしましょう。どのように道を切り開けば良いか探るには、先人の足跡を参考にするというのも一つの手です。NASAのウェブサイトに行って、NASAで成功している人の略歴やプロフィールを読んでみましょう。どこの大学と大学院を卒業しているか、インターンシップやフェローシップ(大学の特別研究員)などの経歴があるか注意深く読んでみましょう。経歴にあった大学に入学できそうですか?もうすでに大学に通っているが、履修しているプログラムが十分でない、または一流ではないという場合は、最後の1年~2年に他の大学に編入することも可能かもしれません。STEM教科に力を入れつつも、文系の教科も忘れないようにしましょう。例えば、哲学、歴史、倫理の教科は役に立つでしょう。文系の学科から複雑な文書の読解と分析、問題解決と批判的思考(クリティカル・シンキング)を磨き、道徳的な質問に深く考えを巡らすといった事柄を学ぶことができるでしょう。これらの事柄は将来NASAに就職した際に役に立つ時が来るでしょう。自己を磨き成長することも優先するようにしましょう。つまり、知識を増やすことだけに労力を費やすのではなく、自分自身をケアし、人を育て、リーダーシップを取ることも大切にしましょう。くつろぐ方法と楽しみを見つけることも大切です。バランス感覚を養うためにも課外活動やクラブ活動へ参加する時間を作るようにしましょう。例えば、化学クラブ、数学クラブ、討論クラブ、バレーボールクラブ、吹奏楽部などクラブ活動に参加したり、生徒会に立候補したりするなどしてみましょう。
正解の要約文
NASAの様々な職業について学びましょう。自分が得意な学問が何かを定めましょう。興味を持って情熱を注げる分野は何かを考えてみましょう。大学や教育機関でどの学科を選択するべきか計画を立てましょう。一生懸命勉強しましょう。正しい学校を選びましょう。現在NASAに所属している人たちの経歴を調べてみましょう。先人と同じような道筋を辿れるのかどうか自問しましょう。幅広く学習しましょう。物事へのバランス感覚を養いましょう。
生成された要約文
自分の何が得意なのか掘り下げましょう。自分の何が得意なのか掘り下げましょう。
要約しすぎている感じですかね。なぜか同じ文を繰り返してしまいました。
例3
本文
流水で数分洗ったらペーパータオルで余分な水分を吸い取り乾燥させます。小さなボウルにバターとレモン果汁を入れて完全に混ざり合うまでかき混ぜます。滑らかなバター液が出来上がりました。粉類を配合して、小麦粉の配合が滑らかに仕上がるまで同様にかき混ぜます。バターの効果で魚に粉類がつきます。魚を軽くふり、余分な粉類を落とします。風味付けに魚の上からパプリカをふります。パセリの小枝とレモンスライスで飾り付けをしたら、温かいうちにお召し上がりください。
正解の要約文
タラの切り身の下ごしらえ。バターとレモン果汁を混ぜます。小麦粉、塩、白胡椒を別のボウルで混ぜます。タラの切り身をバター液に付けた後、配合した粉類をまぶします。残っているバター液を魚の上からかけます。盛りつけをします。
生成された要約文
魚を洗う。バターとレモン果汁を混ぜる。バターとレモン果汁を混ぜる。バターとレモン果汁を混ぜる。
本文のはじめの方には「魚」という言葉は出てきていないのに、魚を洗っていると分かっているのはすごいと思いました。
ただ後半はまた繰り返しになってしまっています。他にもいくつか見てみましたが、同じ文を繰り返してしまう現象が多く見られました。
入出力のシーケンス長を変えたり、学習のステップ数を増やしたりしてみましたが、改善はされなかったです。評価指標の比較
生成された文はいまいちでしたが、一応評価指標も確認してみます。
要約の評価指標であるROUGE-1, 2, Lを用いました。ROUGEは正解の要約文と生成した要約文がどれだけ一致しているかという指標で、1に近いほどよいです。
以下で詳しく解説させています。
ROUGEを訪ねて三千里:より良い要約の評価を求めてtestデータの評価値を計算します。
!export PYTHONPATH=${PYTHONPATH}:. && cd multilingual-t5 && \ \ FINE_TUNED_MODEL_DIR='/content/large' && \ OPERATIVE_CONFIG=$FINE_TUNED_MODEL_DIR'/operative_config.gin' && \ \ echo "OPERATIVE_CONFIG=$OPERATIVE_CONFIG" &&\ echo "FINE_TUNED_MODEL_DIR=$FINE_TUNED_MODEL_DIR" &&\ \ t5_mesh_transformer \ --model_dir="$FINE_TUNED_MODEL_DIR" \ --module_import="t5_wikihow" \ --gin_file="$OPERATIVE_CONFIG" \ --gin_param="run.layout_rules=''" \ --gin_param="run.mesh_shape=''" \ --gin_file="eval.gin" \ --gin_file="beam_search.gin" \ --gin_param="utils.get_variable_dtype.slice_dtype='float32'" \ --gin_param="utils.get_variable_dtype.activation_dtype='float32'" \ --gin_param="MIXTURE_NAME = 't5_wikihow'" \ --gin_param="run.dataset_split='test'" \ --gin_param="run.batch_size=('tokens_per_batch', 512)" \ --gin_param="eval_checkpoint_step = 1001000" 2>&1 | tee test.log比較対象として、本文の始めの3文を要約とみなしたもの(Lead-3)を用いました。
手法 ROUGE-1 ROUGE-2 ROUGE-L Lead-3 0.300 0.084 0.212 mT5 0.255 0.081 0.234 ROUGE-Lでは勝っているものの、良い精度とは言い難い結果になりました。
生成された文が短かったり、同じ文が続けて生成されてしまう問題が原因かと考えています。まとめ
Multilingual T5でwikiHowの日本語要約データを用いて要約文の生成をやってみました。
うまく文が生成されず、悔しい結果となりましたが、要点をとらえた文章が生成されるのはすごいなと感じました。
引き続き原因を調べつつ、ちゃんとインスタンスを立ててより大きな事前学習モデルも試してみたいなと思います。さいごに
Ateam Group Manager & Specialist Advent Calendar 2020の6日目は @NMura3 がお送りします。お楽しみに!


- 投稿日:2020-12-04T18:54:45+09:00
プログラミング素人がAutoware.AIを使ったコンテストに参加した話(その1:Autoware.AIの環境構築)
まずはじめに
仕事ではプログラミングとは全く縁がありませんが数年前からAIに興味を持って独学で勉強を始めました。
コマンドや参考リンク等は最新の状況では当てはまらないかもしれません。
これは素人が環境構築するだけでもとても大変で非常に勉強になったことをまとめて記事にしたものです。
項番 ページ内リンク 0 コンテストに参加したきっかけ 1 Ubuntuが起動しない 2 CUDA、docker、nvidia-docker2とそれぞれインストール 3 Autoware.AIのビルド 4 参考リンク 0. コンテストに参加したきっかけ
ソフトウェアファーストやコネクティッドの考え方とともにモノづくりが変わろうとしています。私は普段の業務ではソフトウェアにはほとんど関わらないのですがそれではいけないと思い、2年ほど前から社内の有志とともにAIをはじめとしたプログラミング勉強を仕事とは別にやってきました。そのなかで自動運転とAIという非常にホットなワードがある自動運転AIチャレンジに参加しました。(ものすごく大変だった。。。)
1. Ubuntuのインストール
Ubuntuが起動しない。(PCが起動しない)
当時はUbuntuって何?という知識レベルでした。とりあえずUbuntu18.04のインストーラーを使って起動したのですが何故か起動しません。NVIDIA GPUと標準のUbuntuのグラフィックドライバーの相性が悪いためうまく起動しないようです。
こちらの記事を参考にして解決。
nouveauの無効化
1. BIOSのメニューに入り、Secure Boot を Disabled にしておく
(BIOSへの入り方はPCによって異なるので型番とかと合わせてググってください。)
2.Install Ubuntu にカーソルを合わせて eを押し起動オプションの設定3.
quiet splash ---となっているところをquiet splash nomodeset ---
と書き換えるとnouveauを無効化できます。2. 必要なものインストール
おそらくGPUを使用しない場合はCUDAとnvidia-dockerは必要ありませんが、沼にハマりやすく抜け出すのはかなり難しいので最初にやっておくことをおすすめします。
CUDA Toolkit 10.0 をインストール
まずCUDAをインストールします。今回はAutowareの推奨がCUDA10なのでそちらをインストールします。
CUDA_Toolkit_10.0wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-ubuntu1804.pin sudo mv cuda-ubuntu1804.pin /etc/apt/preferences.d/cuda-repository-pin-600 sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub sudo add-apt-repository "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/ /" sudo apt-get update sudo apt-get -y install cuda-10.0 # パスをbashrcに追加 echo -e "\n## CUDA and cuDNN paths" >> ~/.bashrc echo 'export PATH=/usr/local/cuda-10.0/bin:${PATH}' >> ~/.bashrc echo 'export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64:${LD_LIBRARY_PATH}' >> ~/.bashrc source ~/.bashrc # PCを再起動 sudo rebootdockerのインストール
dockerのサイト:Install Docker Engine on Ubuntuにそっていけばインストールできます。
Install_Docker_Engine_on_Ubuntusudo apt-get update sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-common curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable" sudo apt-get update sudo apt-get install docker-ce docker-ce-cli containerd.io # 一般ユーザがdockerコマンドを使えるようにする sudo usermod -aG docker $USER rebootnvidia-docker nvidia-docker2のインストール
こちら
NVIDIA Docker って今どうなってるの? (19.11版)→ こちらが最新のようですNVIDIA Docker って今どうなってるの? (20.09 版)と
こちらNVIDIA-DOCKER2の始め方を参考にしてインストールします。
確認コマンドが動作してイメージをpullしてこない場合はうまく行っていないので注意してください。nvidia-docker確認コマンドdocker run --runtime nvidia nvidia/cuda:10.0-base nvidia-smi docker run --gpus all nvidia/cuda:10.0-base nvidia-smiROSのインストール
ROSはOSのバージョンによって対応するバージョンが異なり、Ubuntu18.04にはmelodicをインストールします。
こちらにそってインストールしましょう。ROS_melodic_installsudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list' sudo apt-key adv --keyserver 'hkp://keyserver.ubuntu.com:80' --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654 sudo apt update sudo apt install ros-melodic-desktop-full # 次回起動時もROSの環境ファイルが読み込まれるようにbashrcに追加 echo "source /opt/ros/melodic/setup.bash" >> ~/.bashrc source ~/.bashrc # 依存関係のインストール sudo apt install python-rosdep python-rosinstall python-rosinstall-generator python-wstool build-essential sudo apt install python-rosdep sudo rosdep init rosdep update3. Autowareのビルド
Autoware.AIにはdockerで起動するAutoware-dockerとローカルPCに直接ビルドする方法の2種類あります。
環境的な制約もあるかもしれませんがAutoware-dockerをおすすめします。
もしROS環境やAutowareがこわれて動かなくなってもdockerならすぐにもとに戻すことができますので。。。Autoware-dockerの場合
まずユーザーIDを調べます。
ユーザID確認idあとはAutoware-docker buildにしたがってビルドしていきます。今回はv1.13.0をビルドしていくためバージョン指定します。
ユーザID確認git clone https://github.com/Autoware-AI/docker.git cd docker/generic # uid=1000のとき ./run.sh -t 1.13.0 # uid!=1000のとき ./run.sh -s -t 1.13.0【補足】dockerからexitしてもimageが残るようにする。
このままではdockerからexitするとimageが残らないためまたパッケージのビルドからはじめないといけません。
それを避けるためにAutoware-docker/run.shの最後の部分を変えると簡単です。その代わり./run.shするたびにイメージが作成されるようになることになりますが。。。run.sh# 最後のdockerコマンド ***** docker run \ -it\ #<=--rm コマンドを消すだけ $VOLUMES \ --env="XAUTHORITY=${XAUTH}" \ --env="DISPLAY=${DISPLAY}" \ --env="USER_ID=$USER_ID" \ --privileged \ --net=host \ $RUNTIME \ $IMAGEソースビルドする場合
こちらAutoware-docker Source Buildにそってすすめていきます。私の環境の場合はEigenをビルドするところがちょっとうまく行かなかったので変えています。
Autoware_AI_Source_Build# 依存ライブラリのインストール sudo apt update sudo apt install -y python-catkin-pkg python-rosdep ros-$ROS_DISTRO-catkin sudo apt install -y python3-pip python3-colcon-common-extensions python3-setuptools python3-vcstool pip3 install -U setuptools # Eigenのインストール cd && wget http://bitbucket.org/eigen/eigen/get/3.3.7.tar.gz mkdir eigen && tar --strip-components=1 -xzvf 3.3.7.tar.gz -C eigen cd eigen && mkdir build && cd build && cmake .. && make sudo make install #<=ここにsudoをいれるあとはこちらUbuntu18.04にAutoware.AIをインストールにそってやればビルドが完了します。
Autoware_AI_Source_Buildmkdir -p autoware.ai/src cd autoware.ai # v1.13.0をビルドしていくためバージョン指定 wget -O autoware.ai.repos "https://gitlab.com/autowarefoundation/autoware.ai/autoware/raw/1.13.0/autoware.ai.repos?inline=false" vcs import src < autoware.ai.repos sudo rosdep init rosdep update rosdep install -y --from-paths src --ignore-src --rosdistro melodic source /opt/ros/melodic/setup.bash # CUDA support ありでビルド AUTOWARE_COMPILE_WITH_CUDA=1 colcon build --cmake-args -DCMAKE_BUILD_TYPE=Release # CUDA Support なしでビルド colcon build --cmake-args -DCMAKE_BUILD_TYPE=ReleaseAutowareのRuntime Managerが起動できればビルド成功です。
Autoware_runtime_managerの起動# Autowareの環境ファイルの読み込み source ~/Autoware/install/local_setup.bash # runtime_managerの起動 roslaunch runtime_manager runtime_manager.launchお疲れ様でした。どんなに順調に行ってもここまでやるのに丸一日はかかると思います。(初めてやったときは試行錯誤で4日くらいかかった。)
ここまででようやくAutoware.AIを動かす環境設定が終わりました。
かなり長くなってしまったのであらためてROSの勉強方法とAutoware.AIの使い方など書きたいと思います。4. 参考リンク
・自動運転AIチャレンジ
・Deep Learning 環境の構築
・Autoware.AI Source Build
・Ubuntu 18.04へのCUDAインストール方法
・NVIDIA CUDA Installation Guide for Linux
・Install Docker Engine on Ubuntu
・NVIDIA Docker って今どうなってるの? (19.11版)
・NVIDIA Docker って今どうなってるの? (20.09 版)
・NVIDIA-DOCKER2の始め方
・Ubuntu install of ROS Melodic
・id - ユーザIDやグループIDを表示する
・Autoware-docker build
・Autoware-docker Source Build
・Ubuntu18.04にAutoware.AIをインストール
- 投稿日:2020-12-04T18:54:19+09:00
プログラミング素人がAutoware.AIを使ったコンテストに参加した話(その2:ROSの情報まとめ)
まずはじめに
Autoware.AIはROSをベースに構成されています。Autoware.AIを使う前にROSについてある程度知識を持っている必要があります。
今回はROSの情報をまとめます。ROSについては私もほとんどわかってないので細かい説明はしてません(できないです。)
Autowareとラズパイマウスをちょっと触った程度の知識レベルなのでまちがってたらすみません。
ご指摘、ご指導ご鞭撻をお願いいたします。・その1:Autoware.AIの環境設定
・その2:ROSの情報まとめ←いまここ
・その3:Autoware.AIとLGSVLシミュレータを使ってみる
項番 ページ内リンク 1 1. ROSの教材 2 2. よく使うrosコマンド 3 参考リンク ROSをはじめるとき
身近にいるROSユーザーを見つけてコンタクトをとりましょう。
その人にくっついていろいろ教えてもらうのが一番早いと思います。ROSユーザーが身近にいないとき(←自分の場合)
ROSのバージョン違い(kineticとかmelodicとかいろいろ)に注意しながらROSの教材で勉強しよう。
独学はかなりしんどいですががんばりましょう。ラズパイマウスやTurtlebotシミュレータなどを動かしながら覚えています。1. ROSの教材
ROS Japan UGの勉強会に参加しよう。
ROS Japan UGの勉強会に参加して実際に何ができるのか何をやっているのか触れてみよう。
最初は何言ってるかわからなかったけどだんだんわかってくると聞いているだけで勉強になります。
有識者のみなさまのtwitterを勝手にフォローして日々追いかけて勉強させていただいております。
この場をお借りして厚く御礼申し上げますROS Japan UGのSlackに登録してみよう。最新情報が入手できます。
お手軽に試せるもの
まずROS講座 ←かなり詳しく書いてあってわかりやすい。
ROSTutorialsを読む。ROSのturtlebot3(Gazeboのシミュレータ) を動かしてみましょう。 ←これならタダ!
ROBOTIS e-Manual ←Navigationまでやりたい方はこちらが参考になります。
もうすこしやってみたいならラズパイマウス←給付金でかえます(ROSやるならLidar付)
Raspberry Pi Mouse V3 ただしセットアップがちょっと大変。
Welcome to Mashykom WebSite Raspberry Pi Mouseの使い方やコードをざっくり知ることができます。
・raspimouse_ros_examples ROSのサンプルコードはこちらROSチートシートの紹介
チートシートはお守り代わりに持っておくとよいかも。ここらに載っているコマンドは頻出なので知らないコマンドは調べて使ってみて覚えるといいです。知らないコマンドあったら調べて使ってみましょう。Linuxコマンドも載っているのもあります。
ROS CHEAT SHEET MELODIC
ROS platform Cheat SheetROSコマンド紹介
・よく使用するROSコマンド
・ROS(Robot Operating System)を使うROS参考情報
ROSにはメッセージ型(基本形はこちら)というものがありセンサなどの情報をROSメッセージに基づいた型で通信(Publishしたり、Subscribeしたり)しています。
オリジナルのメッセージを作ることも可能です。ROSにはTF(tf)というものがあります。センサ情報や関節、自分の座標値などの相対関係をまとめるときに使います。
例えばAutowareではマップと自車の位置関係とか、Velodyneセンサは自車のこの辺についているとか、カメラはこの辺についているとか相対位置情報がないとVelodyneの点群情報なんかつかえないよね。という程度の理解です。すみません。2. よく使うROSコマンド
・よく使用するROSコマンド
・ROS(Robot Operating System)を使うパッケージコマンド
catkin_create_pkg [パッケージ名]- 実行したワークスペース内にパッケージディレクトリ/src、及び関連したファイルpackage.xml, CMakeList.txtを作成する。
rosdep install --from-paths src --ignore-src --rosdistro melodic -y- 実行したワークスペース内のROS の依存関係を確認・解釈・解決・更新してくれるツール。
ディレクトリーコマンド
roscd [パッケージ名]- 指定したROSパッケージのディレクトリに移動できます。
実行コマンド
roscore- rosマスタを起動します。
killall -9 roscore- rosマスタを強制的に停止します。(ctl+cでrosマスタが停止できないときに使用しています。)
rosrun [パッケージ名] [ノード名]- 指定したパッケージのノードを実行します。一つのターミナルで一つのノードを走らせます。
roslaunch [パッケージ名] [launchファイル]- ローンチファイルを起動します。roscoreが起動していなければroscoreが自動で起動されます。
roslaunch [launchファイル]と直接launchファイルを指定することもできます。rosclean [オプション]- ROSログファイル削除に使うコマンド。
ROSマスタを起動したときにlogが残ることがあり、logの容量が1GBを超えると警告が出るのでそんなときに使ってる。(←多分間違ってるけど)ノードコマンド
rosnode list- rosマスタで実行中のノードのリストを表示します。
rosnode info [ノード名]- 指定したノードの情報を表示します。トピックのSubscriberとPublisherの情報も確認できるので非常に便利。
ROSのnodeは必要なトピックがないと動作しないのでこれでシラミツブシに調べました。トピックコマンド
rostopic list- rosマスタで登録されている全てのトピックのリストを表示します。
rostopic echo[トピック名]- 指定したトピックのメッセージの内容をリアルタイムで表示します。
rostopic type [トピック名]- 指定したトピックのメッセージ型を表示します。
自分でパッケージ作ってSubscriberとかPublisherとか作るときにメッセージの型を確認するために使います。rostopic info [トピック名]- 指定したトピックの情報を表示します。
パラメーターコマンド
rosparam list- roscoreに登録されている全てのパラメータを表示します。
rosparam set [パラメータ名]- 指定したパラメータの値を設定します。
ツールコマンド
rosbag record [オプション] [トピック名]- 指定したトピックのメッセージをbagファイルに記録します。
rosbag play [ファイル名]- 指定したbagファイルを再生します。
roswtf [launchファイル名]- launchファイルの不具合を見つける。Autowareはバージョンによってパラメータが異なるので確認するのにすごく便利。
rosrun rviz rviz- rvizを起動する
rosrun rqt_graph rqt_graph- システム進行状況・挙動を示す,動的なグラフを生成します。
いま起動しているノードやPubSubされているメッセージを確認するのにすごく便利。rosrun tf view_frames- view_framesは現在のtfの構成を可視化してPDFグラフを作るデバッグツールです。
参考図書
ROS-melodicの本なかなかないです。(あったら教えてください)
そして全部目を通せてないので積み本になりかけ。
・ROSロボットプログラミングバイブル -Amazonリンク
・実用ロボット開発のためのROSプログラミング (日本語) -Amazonリンク
・プログラミングROS ―Pythonによるロボットアプリケーション開発 (オライリー・ジャパン) -Amazonリンク ←分厚い
・トランジスタ技術 2020年 9月号 ロボット1日開発 初めてのROS&位置推定 -CQ出版社リンク ←トランジスタ技術でもROSでロボット作ってる特集があるので参考になります。
・ロベールのC++入門講座 -Amazonリンク ←分厚くてびびった(最近ようやく読み始めた)
・OpenCVによるコンピュータビジョン・機械学習入門 -Amazonリンク←C++とpython両方のコードが載っています。
(ROSはOpenCV3系までしか対応してない)まとめ
結局ROSはむずかしいことがわかりました。Autowareなんてさらに複雑。
ということでこれからもよろしくお願いいたします。
かなり長くなってしまったのでAutowareの使い方は別にまとめます。
(LGSVLを使ったAutowareの使い方についてご紹介。)3. 参考リンク
・ROSTutorials
・ROS Japan UG
・ROS講座
・Raspberry Pi Mouse V3
・Welcome to Mashykom WebSite
・ROS MelodicでTurtlebot3をGazeboで動かしてついでにSLAMする
・ROS CHEAT SHEET MELODIC
・MRS lab ROS platform Cheat Sheet
・ROBOTIS e-Manual
・raspimouse_ros_examples
・よく使用するROSコマンド
・ROS(Robot Operating System)を使う
・ROS tf
・ROS common_msgs
・ROS Japan UGのSlack
・ROS Japan UGのSlack登録フォーム
・OpenCVによるコンピュータビジョン・機械学習入門
- 投稿日:2020-12-04T17:35:11+09:00
Google ColabからDriveに大規模データをアップロードするときの注意
はじめに
高専5年で画像処理系の卒業研究をしている弱い学生です。
GPUが手軽に使えて、時勢的に家からでも研究を進められるようにColabを実行環境にしています。便利な時代になったなあ...所謂機械学習云々をしているのでデータセットとしてCOCO Datasetを用いているのですが、色々問題が発生したので書いておきます。少しでも参考になれば...
起こった問題
いくつか問題が発生したので列挙していきます。
その1:大規模ZIPが解凍できない
画像系に限らず、Web上で収集できる学習用のデータセットは大抵圧縮された状態でダウンロードするかと思います。
Colab上でデータセットのダウンロード・解凍をするのであれば、#ドライブのマウント from google.colab import drive drive.mount('/content/drive') #URLから対象のファイルをドライブにダウンロード !wget -P "/content/drive/My Drive/ダウンロード先のディレクトリ名" https://Dataset.No.URL #指定ZIPの解凍 !unzip "/content/drive/My Drive/ダウンロード先のディレクトリ名/filename.zip" -d "/content/drive/My Drive/解凍先のディレクトリ名"という記述をすると思うのですが、ここで詰まったことが。
train2017(18GB,約12万ファイル)を解凍中、途中でzipfile read errorを吐きました。(タイムアウトとは違うっぽい...?)
詳しいボーダーはわかりませんが、フォーラムをいくつか覗く限り、一度に扱えるファイル数は制限がある模様。自分も含め、約15,000くらいっぽいです。
かといってDriveにて対象ZIPを直接ZIP Extractorで解凍しようと試みてもエラーを吐きます。うーん。解決策
Colabにてファイルを扱うにはいくつか方法がありますが、セッションストレージ上にアップロードすることはランタイムリセット時に消滅してしまうため、あまり好ましくありません。
どうにかして最終的にはドライブにデータセットを揃えたいところです。とりあえず無理やり感が強いですが、以下の流れでどうにかすべてドライブにアップロードできました。
1. ローカルにてファイルを複数ディレクトリに分割
おそらく一度に処理できるファイル数は15,000程であるので、12万枚の画像ファイルを10個のディレクトリに分割して配置し、それぞれ圧縮してDriveにアップロードしました。
億劫だったので手動で行いましたが、githubでソースを上げている方がいたので、リンクを貼っておきます。※当方未検証のため要検証
⇒Unable to read file from a large folder (Input/output error)2. アップロードしたZIPをそれぞれ解凍
先に挙げたZIP解凍のソース通りです。出力先はデータセットを置いておきたいディレクトリの下とかでいいと思います。
3. 解凍されたディレクトリ内部のファイルを統合
流石に /My Drive/Dataset とかの下にディレクトリが乱立しているのは面倒なので、中身だけまとめたいところ。Colabにて、
import os %cd "/content/drive/My Drive/dataset/001" #分割したデータセットファイルがまとまっているディレクトリ !mv *.jpg "/content/drive/My Drive/dataset" #移動先でまとめて上位の階層に中身を移動できます。なんとなく*.jpgで拡張子を指定して拾っていますが、ここはディレクトリの中身と相談するところです。
その2:一気にファイルのやり取りを行うとDriveが死ぬ
Driveは仕様上、例えば1万枚の画像をColabでスクリプトを用いたりしてアップロードしたときに反映のラグが結構あります。ランタイム上ではアップロード処理は完了しているのに、Driveをのぞくとファイルが見当たらない...というのは結構ザラです。
そんなDriveへの反映がスタックしている中、さらに処理を続けたり、失敗したと思って再度アップロードのスクリプトを走らせる(本当はもうアップロードは済んでいるのに)と、やばいことが起きます。
指定したパスを無視して最上位ディレクトリにアップロードされるのです。
そしてさらに、
最上位ディレクトリにファイルがあふれた結果、Colabからのマウントを受け付けなくなるのです。
詳しく説明していきます。1. Driveへの反映・処理遅延について
一気にデータを動かそうとするとどうしてもDriveへの反映は遅くなります。処理が進んでいるのに失敗したと思って再度走らせたりした場合、パスの指定が無視されてDrive最上位の /content/drive/My Drive に中身がすべて展開されることがありました。
自分は2回ほど経験していて、2万超の画像ファイルがMy Drive直下に展開されました。泣きたかった。
2. Driveへのマウント制限について
別にColabからコマンド使って一括で削除してしまえればそんなに苦しい話ではないのですが、Driveの仕様に阻まれました。
Driveのファイルをあれこれする場合、前述したスクリプトを用いてColabとDriveをマウントさせる必要があるのですが、以下の時、アクセスできないことがあるようです。
- フォルダ内のファイル数やサブフォルダ数が増えすぎたとき
- 「マイドライブ」直下に多量のファイルがあるとき
- 既定のユーザー単位およびファイル単位のオペレーション数を超過したとき など
⇒詳細:https://research.google.com/colaboratory/faq.html#drive-timeout
この中でも自分がぶつかったのが"「マイドライブ」直下に多量のファイルがあるとき"です。
前述の事象により、マイドライブは大量のファイルで埋め尽くされています。これにより、ドライブへのマウントが行えず、手作業で消去するにも量が多すぎるため、途方にくれました。サポセンにチャットで問い合わせをし、ドライブ内の一括削除(初期化)をお願いしましたが行っていないとのことで、ひたすら手作業での消去がはじまりました。
(ドライブはShift+Aでファイルの全選択ができますが、表示件数と処理の都合により頑張っても1000枚くらいしか一気に消せない、しかもめっちゃ時間がかかる、そしてごみ箱の削除も時間がかかる、苦行)解決策
まずはこうならないように気をつけることが大事だと思いますが、起きてしまった場合の対応策を書いておきます。無理だったら手作業で消去です。つらい。
1. ランタイム接続を解除せず、My Driveのファイル数の監視をする
Driveへの反映が遅いなと感じたら、反映が終わるまで待ってみるのが吉です。ただ、膨大な処理を実行していた場合、My Drive直下にファイルが生成されることがあるかもしれません。
そこで、実行後から反映までの間、事故ると再マウントできなくなるのでランタイムをリセットせず、%cd "/content/drive/My Drive" import os !echo | xargs ls | wcというような感じでMy Driveのファイル数の推移を監視しておくことをおすすめします。
出力は↓のような感じ。
/content/drive/My Drive 5 6 732. My Drive下にある特定ファイルを一括消去する
仮にMy Drive下にめっちゃファイルを広げてしまったとしても、マウントが維持されていればrmを用いて一括での削除が可能です。
%cd "/content/drive/My Drive" import os !rm ./*jpg #ワイルドカードで拡張子を指定さいごに
自分の備忘録的な側面もありますが、お役に立てれば幸いです。
初学者なので気になる点等あればお手柔らかに...
- 投稿日:2020-12-04T17:10:32+09:00
pymongo.errors.CursorNotFoundの対処法
PyMongoでこのエラーが出た時の対処法が1つにまとめられていなかったので、ここに記述します。
こちらの記事によると、2つの原因が考えられるという。
https://qiita.com/koshilife/items/bece28d331cda5469c33
- タイムアウトの設定時間超過
- バッチ取得サイズ16MBを超えた時
タイムアウトの設定時間超過
タイムアウトの設定時間超過が原因の場合、
no_cursor_timeout=Trueのオプションを追加する事によって解決ができる。そして、cursorは使用後に自分で閉じる必要があるので、cursor.close()を記述する。cursor = collection.find(query, no_cursor_timeout=True) cursor.close()バッチ取得サイズの超過
バッチ取得サイズの超過が原因の場合、
batch_size=10のオプションを追加する事によって解決ができる。ただしbatch_sizeは自分の環境に合わせて適切な値に設定してください。cursor = collection.find(query, batch_size=10)
- 投稿日:2020-12-04T17:00:14+09:00
Pythonで指定ディレクトリのHEICファイルをJPEGへ変換する
1.はじめに
iphoneの写真データをPCにインポートしたら見慣れない拡張子を発見しました。
なんというか不便なのでJPEGへの変換方法を調べたので、自分用のメモ兼ねて残します2.準備とか参考にした記事とか
コード書くにあたってこちらの記事を参考にさせていただきました。
HEICとか何なのかは知りません。でも、とりあえずはPNGにしよう!
ありがとうございます!!pythonの標準ライブラリ以外でPillowとpyheifを使います。
pyheifについてはこちらを参照ください。
pyheifpyheifのインストール
$ pip install pyheif3.コードとか
難しいことはやってないです。
カレントディレクトリと下にHEICファイル突っ込んで、同じフォルダにJPEGファイルを生成するだけ!from PIL import Image import pyheif import pathlib import glob def heic_png(image_path, save_path): # HEICファイルpyheifで読み込み heif_file = pyheif.read(image_path) # 読み込んだファイルの中身をdata変数へ data = Image.frombytes( heif_file.mode, heif_file.size, heif_file.data, "raw", heif_file.mode, heif_file.stride, ) # JPEGで保存 data.save(str(save_path), "JPEG") # 変換対象のファイルがあるディレクトリ # カレントの下のtempディレクトリを指定 image_dir = pathlib.Path('./temp') # globでディレクトリ内のHEICファイルをリストで取得 heic_path = list(image_dir.glob('**/*.HEIC')) # リストのHEICファイルを1個づつJPEGへ変換 for i in heic_path: m = "./" + str(i) n = './temp/' + str(i.stem) + '.jpg' heic_png(m, n)間違いなどありましたら、ご指摘お願いします!
- 投稿日:2020-12-04T16:42:42+09:00
PyCaretの初心者向けまとめ(回帰編)
はじめに
Pythonの機械学習ライブラリ「PyCaret」は、非常に簡単に動くライブラリですのでモデルの分析結果を出すまでは、初めての方でもサクサク出来るはずです。
ですが、モデルの種類や評価指標、解析結果の図の意味や見方がわからない場合「結局、どうしたらいいの?」という状況に陥ると思います。(私がそうでした・・・公式サイトは英語で、読むだけでも一苦労。)
このような中、共同でPyCaretを勉強してる方々の支えもあり色々と情報を仕入れることができましたので、私個人の備忘含め、PyCaretの全体像が理解できるようにこの記事に纏めてみました。※細かい内容では無いことを予めお伝えしておきます。
※この記事は「回帰編」です。
「分類編」は「PyCaretの初心者向けまとめ(分類編)」を参照ください。1.PyCaretとは
1-1.PyCaretとは
「PyCaret」とは、様々な種類の機械学習を少しのコードで実現してくれる便利なライブラリです。
公式サイトでは次のように紹介されています。PyCaretは、Pythonのオープンソースのローコード機械学習ライブラリであり、仮説から考察までのサイクルタイムを短縮することを目的としています。
PyCaretを使用すると、選択したノートブック環境を使用して、データの準備からモデルのデプロイまで数秒で行うことができます。
https://pycaret.org/guide/ より引用
1-2.PyCaretのメリット
- コード実装が非常に簡単(数行で実装可能)
- データの前処理も自動で実施
- ハイパーパラメータの自動最適化が可能
- 色々な解析結果を図で確認が可能
1-3.PyCaretの実装手順
- PyCaretのインストール
- データの読み込み
- データの前処理
- 各種モデルの評価と精度の比較
- ハイパーパラメータの最適化
- モデルの精度の可視化
- モデルの確定
- 予測の実行
- 予測結果をCSVでダウンロード
2.環境・バージョン
- OS:windows10
- Jupyter Notebook:6.0.3
- PyCaret:2.2.1
3.PyCaretのインストール
まずは、pycaret のパッケージをインストールします。
※インストールに結構時間が掛かると思います。pip install pycaret4.データの読み込み
4-1.パッケージの読み込み
次に、必要なパッケージを読み込みます。
# パッケージの読み込み import pandas as pd from pycaret.regression import *今回は「回帰」を行うので
pycaret.regressionとしました。
尚、モジュール一覧は次の通りです。
モジュール インポート方法 分類 pycaret.classification 回帰 pycaret.regression クラスタリング pycaret.clustering 異常検出 pycaret.anomaly 自然言語処理 pycaret.nlp アソシエーション分析 pycaret.arules 4-2.データの読み込み
次に、データを読み込みます。
手持ちデータか否かでやり方を分けて記載しています。
【今回の記事は手持ちではない場合で話を進めていきます。】手持ちデータではない場合(とりあえずPyCaretを動かしたい場合)
PyCaretに用意されているデータ【PyCaret’s Data Repository】より回帰では定番といわれる
「ボストン地価データ」を使用します。
詳しくはコチラを参照してください。 https://pycaret.org/get-data/# 使用するデータの読み込み from pycaret.datasets import get_data boston_data = get_data('boston')
それぞれの項目の説明は以下です。
項目名 説明 データ型 crim 犯罪発生率(町ごとの一人当たり犯罪率) float64 zn 25,000 平方フィート以上の住宅区画の割合 float64 indus 小売業以外の商業が占める土地面積の割合 float64 chas チャールズ川沿いかどうかのダミー変数 (1: 川沿い、 0: それ以外) int64 nox 窒素酸化物の濃度(pphm単位) float64 rm 1戸あたりの平均部屋数 float64 age 1940年よりも前に建てられた物件の割合 float64 dis ボストンにある5つの雇用施設までの重み付きの距離 float64 rad 環状高速道路へのアクセス指数 int64 tax 10,000ドルあたりの固定資産税の割合 int64 ptratio 町ごとの生徒と教師の比率 float64 black 1000(Bk – 0.63)^2 の値。BKは町ごとの黒人の割合。 float64 lstat 低所得者の割合 (%) float64 medv 住宅価格の中央値(単位 1000ドル) float64 手持ちデータの場合(実務でPyCaretを動かす場合)
実務ではCSVファイルを読み込むケースが多いと思います。
その場合はPandasのpd.read_csvで次のように読み込んでください。# CSVデータの読み込み data = pd.read_csv('c:/path_to_data/file.csv')[補足1]
上記のように引数を何も指定しないと、CSVファイルはUTF-8で読み込みます。
CSVファイルをShift-JISで読み書きしたいときには、引数で指定する必要があります。(以下、例)
data = pd.read_csv('c:/path_to_data/file.csv', encoding = "shift-jis")[補足2]
WindowsでPythonを使う時の注意として、ファイルのパスを指定をする場合、
ファイルのパスを「¥」区切りで指定するとエラーになります。主な対処方法は次の2つです。パスの区切りを¥¥にする
data = pd.read_csv('c:\\path_to_data\\file.csv', encoding = "shift-jis")パスの区切りを/にする
data = pd.read_csv('c:/path_to_data/file.csv', encoding = "shift-jis")5.データの前処理
次に、PyCaretを起動します。
# PyCaretを起動 exp1 = setup(boston_data, target = 'medv', ignore_features = None)目的変数は住宅価格を意味する「medv」としています。
※setupコマンドの説明は下表の通りです。
項目 説明 備考 第一引数 解析に用いる読み込んだデータ 必須 第二引数 予測に用いる目的変数の列名 必須 第三引数 分析から外す説明変数の列名 任意 実行すると次のように自動的にデータ型を設定してくれます。
データ型を変更せず、このまま続ける場合は"Enter"を押下します。データ型の変更が必要な場合は、"quit"と入力し"Enter"を押下します。
例えば、chas 列はCategoricalとして認識されていますが、Numericとして扱いたい場合は
setupコマンドを次のようにオプションを記述します。
※オプション一覧はこちらが非常に参考になります。# PyCaretを起動(データ型を変更する場合) exp1 = setup(boston_data, target = 'medv', ignore_features = None, numeric_features = ['chas'])※
numeric_featuresオプションを使用し、, numeric_features = ['chas']を追加しています。これを実行すると、次のようにchas 列がNumericとして変更されていることがわかります。
setupコマンドが完了すると次のようにセットアップ結果が表示されます。
データによっては算出できない項目もあるため、その場合は「False」や「None」と表示されます。
6.各種モデルの評価と精度の比較
6-1.モデルの比較
次に、モデルを比較します。
# モデルの比較 compare_models()これを実行すると次のように各種モデルを評価・比較し誤差の少ない順番に並べた一覧が表示されます。
(回帰の場合、デフォルトではR2で並べ替えられます。)
この例の場合、「CatBoost Regressor」というモデルの評価が高いことがわかります。
※各評価指標のトップが黄色で網掛けされます。
ただし、この分析ではハイパーパラメータの最適化までは行われていません。(この後に最適化を進めます。)
尚、処理の概要は次のようになっています。
- 偏りなく、満遍なく教師データと検証データを入れ替えることを指す「交差検証(クロスバリデーション)」を実施
- デフォルトでは、教師データと検証データを7:3で分割し、Fold=10(データを10分割して、教師データと検証データを入れ替えている)として各種モデルの平均のスコアを表示している
6-2.評価指標について
回帰で使用される評価指標の概要と見方は次の通りです。(ここ重要です。)
MAE
MAE(Mean Absolute Error)では、予測値の誤差の大きさを評価します。
数式は下記の通りです。\begin{eqnarray} MAE = \frac{1}{N} \sum|y_i - \hat{y_i}| \end{eqnarray}$y_i$ : $i$番目サンプルの実測値
$\hat{y_i}$ : $i$番目サンプルの予測値
$N$ : サンプル数
項目 概要 判断基準 ・0に近いほど良い値 解釈 ・予測値と実測値の平均的なズレ(誤差)の大きさ 特徴 ・大きく予測を外したケースをあまり重要視していない
・MAEを基準として良いモデルを選ぶと最大誤差が大きくなる傾向にある
・RMSEに比べて外れ値の影響を受けにくいMSE
MSE(Mean Squared Error)では、大きな誤差を重要視して評価します。
数式は下記の通りです。\begin{eqnarray} MSE = \frac{1}{N} \sum(y_i - \hat{y_i})^2 \end{eqnarray}$y_i$ : $i$番目サンプルの実測値
$\hat{y_i}$ : $i$番目サンプルの予測値
$N$ : サンプル数
項目 概要 判断基準 ・0に近いほど良い値 解釈 ・予測値と実測値のズレの大きさと解釈できる
・MAEと類似しているが、MAEのように実際の平均的な誤差とは異なる特徴 ・大きく予測を外したケースを重要視している
・予測を大きく外すと大幅にMSEが大きくなる傾向にあるRMSE
RMSE(Root Mean Squared Error)では、大きな誤差を重要視して評価します。
数式は下記の通りです。\begin{eqnarray} RMSE = \sqrt{\frac{1}{N} \sum(y_i - \hat{y_i})^2} \end{eqnarray}$y_i$ : $i$番目サンプルの実測値
$\hat{y_i}$ : $i$番目サンプルの予測値
$N$ : サンプル数
項目 概要 判断基準 ・0に近いほど良い値 解釈 ・予測値と実測値のズレの大きさと解釈できる
・MAEと類似しているが、MAEのように実際の平均的な誤差とは異なる特徴 ・大きく予測を外したケースを重要視している
・予測を大きく外すと大幅にRMSEが大きくなる傾向にある
・回帰モデルの最も一般的な性能評価指標として用いられるR2(決定係数)
決定係数$R^2$では、推定された回帰モデルの当てはまりの良さを評価します。
数式は下記の通りです。\begin{eqnarray} R^2 = 1 - \sum \frac{(y_i - \hat{y_i})^2}{(y_i - \bar{y})^2} \end{eqnarray}$y_i$ : $i$番目サンプルの実測値
$\hat{y_i}$ : $i$番目サンプルの予測値
$\bar{y}$ : 実測値の平均
項目 概要 判断基準 0.6以下:全然予測できてない
0.8以上:良いモデル
0.9以上:過学習の可能性あり解釈 ・回帰モデルの当てはまりの良さを評価 特徴 ・説明変数が多くなると1に近づいていく
・非線形モデルを評価することはできないRMSLE
RMSLE(Root Mean Square Logarithmic Error)では、予測値の誤差の大きさを比率や割合で評価します。
数式は下記の通りです。\textrm{RMSLE} = \sqrt{\frac{1}{N}\sum_{i=1}^{N}(\log (1+y_{i})-\log (1+\hat{y}_{i}))^{2}}$y_i$ : $i$番目サンプルの実測値
$\hat{y_i}$ : $i$番目サンプルの予測値
$N$ : サンプル数
項目 概要 判断基準 ・0に近いほど良い値 解釈 ・予測値と実測値のズレの大きさをを比率や割合で解釈できる 特徴 ・目的変数のとりうる値の範囲が広いデータに利用 MAPE
MAPE(Mean Absolute Percentage Error)では、実測値の大きさあたりの予測誤差の大きさを評価します。
数式は下記の通りです。\begin{eqnarray} MAPE = \frac{1}{N} \sum|\frac{y_i - \hat{y_i}}{y_i}| \end{eqnarray}$y_i$ : $i$番目サンプルの実測値
$\hat{y_i}$ : $i$番目サンプルの予測値
$N$ : サンプル数
項目 概要 判断基準 ・0に近いほど良い値 解釈 ・実測値の大きさに対する予測値の平均的なズレ(誤差)の割合 特徴 ・実測値に対する予測誤差の割合の大きさを重要視している
・実測値が0を取るケースでは使用できない6-3.モデルの種類
回帰では、次のモデルが搭載されています。
ID(引数) モデル名 概要 catboost CatBoost Regressor ・キャットブースト
・決定木ベースの勾配ブースティングに基づくモデル
・カテゴリカル変数(質的変数)の扱い方が上手い
・決定木のツリー構造を最適にして過学習を防ぐ
・XgboostやLightGBMよりも精度が高くなる可能性があるgbr Gradient Boosting Regressor ・勾配ブースティング
・弱い予測モデル(決定木)のアンサンブル形式で生成したものet Extra Trees Regressor ・エクストラツリー
・Random Forestと同じようにランダムな木を複数用意してバギングする
・ブートストラップサンプリングはせずに訓練データ全てを用いる
・シンプルで高速に動き、分類精度もRandom Forestに匹敵するrf Random Forest ・ランダムフォレスト
・決定木の王道といわれている
・決定木をたくさん集めて並列に扱う手法(バギング)xgboost Extreme Gradient Boosting ・エックスジーブースト
・ブースティングという手法で決定木を直列に扱う
・精度が比較的高いが、学習に時間が掛かるlightgbm Light Gradient Boosting ・ライトジービーエム
・xgboostの軽量版的なモデル
・精度の上げるためには特徴量の調整が必要ada AdaBoost Regressor ・アダブースト
・勾配ブースティング系アルゴリズムの走り
・直前の弱識別器で誤ったサンプルに対する重みを大きくして学習を行うlr Linear Regression ・線形回帰
・線形モデルによる回帰分析を行う
ridge Ridge Regression ・リッジ回帰
・過学習を抑える手法の一つ
・線形回帰に正則化項(ペナルティ項)としてL2ノルムを導入したモデルlar Least Angle Regression ・最小角回帰(LARS)
・Lassoの推定アルゴリズムbr Bayesian Ridge ・ベイズ線形回帰
・最適解を含めて分布として捉えようとするモデルdt Decision Tree ・決定木
・条件による分岐を「根」からたどることで、最も条件に合致する「葉」を検索するアルゴリズム
・決定木単体では弱い予測モデルen Elastic Net ・エラスティックネット
・リッジ回帰とラッソ回帰の折衷案のモデル
・Lasso回帰のモデルに取り込める説明変数の数に制限がある」という問題点をカバーlasso Lasso Regression ・ラッソ回帰
・不要なパラメータ(次元や特徴量)を削ることができる手法の一つ
・線形回帰に正則化項(ペナルティ項)としてL2ノルムを導入したモデルhuber Huber Regressor ・フーバー回帰
・ロバスト回帰で使われる損失勘定の1つ
・外れ値が大きくても引きづられにくいモデルomp Orthogonal Matching Pursuit ・直交マッチング追跡(OMP)
・貪欲法の1つknn K Neighbors Regressor ・K近傍法
・次元の呪いのため、高次元データには向かない
・トレーニングデータ数・特徴量が増えると予測が遅くなるllar Lasso Least Angle Regression ・ラッソ最小角回帰
・LARSを使ったラッソ回帰par Passive Aggressive Regressor ・PA
・オンライン機械学習のアルゴリズムの一つ
・訓練事例を正しく分類できなかった場合重みを更新ard Automatic Relevance Determination ・関連度自動決定(ARD)
・目的変数に対する個々の説明変数の寄与の大きさを見積もる手法ransac Random Sample Consensus ・RANSAC
・外れ値をうまく無視して法則性(パラメータ)を推定をする手法tr TheilSen Regressor ・テイルセン回帰
・外れ値の影響を受けないモデルkr Kernel Ridge ・カーネルリッジ回帰
・カーネル法を回帰問題に適用したものsvm Support Vector Machine ・サポートベクターマシン(SVM)
・認識性能が優れた学習モデルの一つ
・未学習データに対して高い識別性能を得るための工夫があるmlp Multi Level Perceptron ・多層パーセプトロン(MLP)
・複数の形式ニューロンが多層に接続されたネットワーク
・現在の機械学習の基盤となっている※上表のIDは次項で記載の
create_modelの引数として使用します。7.ハイパーパラメータの最適化
7-1.モデルの作成
次に、モデルを作成します。
今回は、決定木系の王道といわれる「Random Forest(ランダムフォレスト)」のモデルを作成します。# Random Forestのモデルを作成 rf = create_model('rf')尚、
create_modelの引数は、windowsの場合は引数を記入する箇所で「Shift+Tab」のショートカットキーを使うとツールチップが表示されますので、コチラの内容を指定します。(上記、6-3.モデルの種類のID(引数)のことです。)
これを実行すると次のように初期設定である交差検証「10回」にて、検証が行われています。
Mean(平均値)、SD(標準偏差)も同時に表示されています。
7-2.ハイパーパラメータの最適化
次に、ハイパーパラメータの最適化を行います。
# Random Forestのモデルを最適化 tuned_rf = tune_model(rf, n_iter = 500, optimize = 'r2')※tune_modelコマンドの説明は下表の通りです。
項目 説明 備考 第一引数 モデルの名称 必須 第二引数 ランダムグリッドサーチの回数 任意 第三引数 最適化の対象 ※デフォルトは「R2」 任意 これを実行した結果(最適化後)と実行前を比較すると、R2が「0.8331」から「0.8574」と増加し最適化が行われたことが確認できます。※PyCaretの最適化はランダムグリッドサーチが採用されています。
8.モデルの精度の可視化
次に解析した結果を可視化します。
# 解析結果の確認 evaluate_model(tuned_rf)これを実行すると、解析結果を選択できるタブが表示されます。
回帰でプロットされるモデルの概要と見方はそれぞれ次の通りです。(ここ重要です。)
Hyperparameters(ハイパーパラメータ)
こちらは、ハイパーパラメータを確認できるプロットです。
Residuals(残差プロット)
こちらは、残差プロットです。
横軸に予測値、縦軸に残差をプロットします。良い予測モデルであれば、残差と予測値は相関しないので、残差0のところに横に並ぶようなプロットになります。残差はランダムな誤差になるはずなので、ヒストグラムは正規分布になります。
外れ値が生じるケースは、以下の通りです。
- 回帰式が適切ではない
- データが不適切
- 学習不足
Prediction Error(予測誤差プロット)
こちらは予測誤差プロットです。
横軸に実際の値を、縦軸に予測値をプロットしたものです。予測が完全であれば、傾き1の直線上に点が乗ります。点が傾き1の直線周辺に集まるモデルが良いモデルになります。
Cooks Distance(クックの距離のプロット)
こちらはクックの距離のプロットです。
クックの距離とは、「i番目の観測値を使用して計算された係数と、観測値を使用しないで計算された係数との間の距離に対する測度」です。図中の破線が、推奨される閾値です。これ以上は「外れ値の可能性あり」と判断できます。
Feature Selection(特徴量選択)
こちらは特徴量選択です。
特徴量(説明変数)の選択数に応じて予測スコアを折れ線グラフとして表示するものになっています。グラフの横軸が特徴量の数で、縦軸が予測精度を表し、予測精度が最大の特徴量数のところに縦に点線が引かれます。
今回の場合、特徴量の個数が12個のときに最大スコア「0.864」になったことがわかります。
特徴量選択の特徴量の選択優先順位は後述するFeature Importance(特徴量の重要度)の順位が高いもの(モデルの予測精度に大きく寄与している説明変数)から選択されています。
Learning Curve(学習曲線)
こちらは学習曲線です。
データ数に応じた予測精度を表示するグラフで、横軸にデータサイズ、縦軸に予測精度をプロットしています。
良いモデルの指標としてはデータが増えるごとにtraining scoreが減少し、cross validation scoreが増加することが望ましいといわれています。もし、cross validation scoreとtraining scoreの差が大きかった場合は、学習数が足りてない恐れがあるため、データ数を増やすことでモデルの精度の向上が図れるかもしれません。
Manifold Learning(多様体学習)
こちらは多様体学習です。
高次元データ(説明変数が複数あるもの)を2次元に落としてプロットしたグラフです。この多様体学習では、t-SNE(ティースニ) (t-Distributed Stochastic Neighbor Embedding)(t分布型確率的近傍埋め込み法)が使用されています。t-SNEの主な目的は、高次元データの視覚化です。したがって、データが2次元または3次元に埋め込まれる場合に最適に機能します。
新しい特徴量を加える場合や高次元のデータセットを扱う場合には、最も有用な特徴量だけを残して残りを捨てて特徴量の数を減らす(次元削減)のは良い考えだと言われています。なぜなら次元削減をすることでモデルが単純になって解釈しやすくなるだけでなく、汎化性能が向上するからです。
Validation Curve(検証曲線)
こちらは検証曲線です。先述の学習曲線に似ています。
ハイパーパラメーターの値を変えた時の予測精度を表示するグラフで、横軸にハイパーパラメータ、縦軸に予測精度をプロットしています。一つのハイパーパラメータがどれくらい寄与するか見たいときに使用します。適切なハイパーパラメータ(例:max_depth:木の深さ)の値はどこかを確認でき、訓練精度と検証制度の差が小さく、精度が高いものを選ぶようにします。(学習不足や過学習を確認することができます。)
尚、薄く塗りつぶされた範囲は、クロスバリデーション(交差検証)により求められた精度の最大値と最小値の範囲を表しています。
また、横軸のハイパーパラメータは使用する学習モデル(アルゴリズム)によって異なります。詳細は次の通りです。
学習モデル 横軸 Decision Tree
Random Forest
Gradient Boosting Regressor
Extra Trees Regressor
Extreme Gradient Boosting
Light Gradient Boosting
CatBoost Regressormax_depth Support Vector Machine C Multi Level Perceptron
Ridge Regressionalpha AdaBoost Regressor n_estimators K Neighbors Regressor n_neighbors Feature Importance(特徴量の重要度)
こちらは特徴量の重要度です。
目的変数に及ぼす影響が大きい順に上から特徴量が表示されています。(上位10位まで)
Feature Importance(ALL)(特徴量の重要度(全ての特徴量))
こちらは特徴量の重要度(全ての特徴量)です。
Feature Importance(特徴量の重要度)では、上位10位の特徴量が表示されていますが、ここでは解析に用いたデータの全ての特徴量を表示します。
Decision Tree(決定木)
※「Random Forest(ランダムフォレスト)」では表示されないため、「Decision Tree(決定木)」の結果で解説
こちらは決定木です。
木構造を用いて分類や回帰を行う機械学習の手法の一つで、比較的単純なモデルですが、モデルをツリーで表現できるので、どの説明変数が目的変数にどのように効いているのかが視覚的に分かりやすいというメリットがあります。▼全体
▼拡大図
9.モデルの確定
次に、モデルを確定します。(当然ながら解析結果などを考慮したうえで)
#モデルの確定 final_rf = finalize_model(tuned_rf) print(final_rf)実行すると次のような最適化されたハイパーパラメータを確認することができます。
これで、学習済みのモデルができあがりました。
10.予測の実行
学習済みモデルが出来上がったら、未知なるデータを投入してみます。
(今回は、ボストン地価データを用いていましたので、未知なるデータは適当なものを準備しました。)
data_unseenという名前のデータフレームに入れます。#未知なるデータを読み込む data_unseen = pd.read_csv('c:/path_to_data/unseen_boston.csv') print(data_unseen)これを実行すると次のように未知なるデータが読み込まれます。
この”unseen_data” を、今回作成した予測モデルに投入し、価格の予測を行わせてみます。
#予測の実行 unseen_predictions = predict_model(final_rf, data = data_unseen) print(unseen_predictions)これを実行すると次のように予測値が
Labelとして追加されているのが分かります。
本来は未知のデータについて、目的変数であるmedvは分からないのですが、今回は適当に未知なるデータを準備したのでmedvがデータに入っています。
適当な未知なるデータなので、何とも言えませんが、未知なるデータの価格medvと予測モデルが予測した予測値であるLabelを比べると、まずまずな感じの値が出ていることがわかります。
11.予測結果をCSVでダウンロード
次に、予測した結果をCSVファイルでダウンロードしてみます。
実務では予測した結果を何らかに利用することになるかと思います。#CSVファイルでダウンロードする unseen_predictions.to_csv('unseen_data_predicted_Label.csv')これを実行すると、次のようにCSVファイルがダウンロードされます。
12.まとめ
実際に私がPyCaretを使ってみてPyCaretを扱う上で大切になるだろうと思ったことは次の4点でした。
- 大前提として取扱うデータをよく理解すること
- モデルの種類とそれぞれのモデルの特徴を理解すること
- 評価指標の種類と見方を理解すること
- 解析結果(図)の種類と見方を理解すること
※使いこなしてきたらデータ型やハイパーパラメータの調整ができることが大切になるのだろうと思いました。
13.参考文献
- PyCaret公式サイト
- scikitlearn公式サイト(データセット)
- RIGHTCODEブログ 機械学習の自動化を可能にする「PyCaret」の実力を把握してみる
- Tableauから始めるデータサイエンス PyCaret を使って東京の中古マンション価格を予測してみよう!
- PyCaretのsetup関数の引数について
14.最後に
いかがでしたでしょうか?
とりあえずPyCaretを使えて、全体像を理解いただけていれば幸いです。
細かい内容は無いので、隔靴掻痒(痒い所に手が届かない)な点はご容赦ください。PyCaretリリース前の時代を知らない私からすると便利なPyCaretにこれから頼ってしまいそうな予感です。(これで本当にいいのか?とも思いますが。)
この界隈の玄人の方からするとPyCaretは自動車でいうところのAT車のような感じで見られているのかな?とも思います。「MT車のシフトチェンジこそが、最大燃費を叩き出す!」みたいなイメージでしょうか?とにもかくにも、初心者の私にとっては、データサイエンスの取っ掛かりとしてPyCaretは最高のライブラリだと感じました。最後までお付き合いいただきましてありがとうございました。

























- 投稿日:2020-12-04T16:30:16+09:00
TensorFlow 2.4.0-rc3のビルド手順(Windows10, CUDA11.1.1, cuDNN 8.0.5, Python 3.9.0)
2020/11/30時点でのTensorFlow 2.4.0-rc3のビルド方法の概要を残しておきます。
毎回同じような手順でビルドできるようになってきていますが、その時々で注意すべきポイントや手順があったりします。今回の組み合わせでは、Numpyのバージョンにだけ気をつければ正常にビルドできました。ビルド時点でNumpyの最新バージョンは1.19.4でしたが、このバージョンはWindows環境だとNumpyをimportするだけでエラーになるので、1つ前の
1.19.3を使用します。環境情報
ビルドに利用した環境です。CUDAやcuDNNのフォルダなど、事前にパスを通した状態になっています。
- Windows 10 Pro 20H2 (64bit)
- Visual Studio Community 2019 Ver 16.8.2
- Python 3.9.0
- MSYS2(
pacman -S git patch unzipで必要なパッケージを導入済み)- Bazel 3.7.1 (3.1.0以上のバージョンを使う必要あり)
- CUDA 11.1.1
- cuDNN 8.0.5.39
ビルド用のフォルダ構成など
今回は
S:\build\build_tf240rc3フォルダ配下にTensorFlowのソースコードをダウンロードしてビルドしています。Pythonの仮想環境も、TensorFlowビルド用に用意します。S:/build/build_tf240rc3 # 作業フォルダRoot + tensorflow # gitで取得してくるソースコード + venv # Python仮想環境 + wheelhouse # 作成したwhlファイルを格納するフォルダビルド手順
x64 Native Tools Command Prompt for VS 2019を起動して以下の手順でビルドを行います。# 仮想環境を作成して有効化する python -m venv s:\build\build_tf240rc3\venv cd /d s:\build\build_tf240rc3 .\venv\Scripts\activate.bat # 必要なパッケージのインストール # 注意:Numpyは最新の1.19.4を使うとエラーになるので1.19.3を使用 python -m pip install --upgrade pip pip install numpy==1.19.3 pip install six wheel pip install keras_applications==1.0.8 --no-deps pip install keras_preprocessing==1.1.2 --no-deps # ソースコード取得(v2.4.0-rc3のタグ指定) git clone -b v2.4.0-rc3 https://github.com/tensorflow/tensorflow.git cd tensorflow # 環境によってはコマンドのパラメーターが長くなりすぎてエラーになるので不要な環境変数を削除 set _OLD_VIRTUAL_PATH= # ビルド構成の設定 # CUDA support: Y # CUDA compute capabilities: 7.5 (利用環境に合わせて変更) # Optimization: /arch:AVX2 (利用環境に合わせて変更) # それ以外はデフォルト設定(Enter) python ./configure.py # ビルド # TensorFlow 2.3.0+CUDA11の場合は「DTHRUST_IGNORE_CUB_VERSION_CHECK」のおまじない(CUB互換チェックのスキップ)が必要だったが今回は不要 bazel build --config=opt --config=avx2_win --config=short_logs --config=cuda --define=no_tensorflow_py_deps=true --copt=-nvcc_options=disable-warnings //tensorflow/tools/pip_package:build_pip_package # パッケージの作成(wheelhouseフォルダにパッケージを作成) # 数分間画面が更新されないので心配になりますが、きちんと処理されているのでしばらく待ちましょう bazel-bin\tensorflow\tools\pip_package\build_pip_package ..\wheelhouseこれで完了です。
なおビルドに使用したbazelの中間ファイル等は%UserProfile%\_bazel_%UserName%フォルダに作成され、容量も20GB近くになるので、不要であれば削除しても問題ありません。Bazelが起動していると削除できないので、その場合はコマンドプロンプトでbazel shutdownとして、Bazelを終了してから削除してください。
- 投稿日:2020-12-04T16:15:09+09:00
Pythonで、あの文豪たちが作品に最も使用した単語を調べる
はじめに
夏目漱石、芥川龍之介、川端康成、太宰治、三島由紀夫・・・
日本を代表する文学者たちが、小説に最も使用した単語は一体何なのでしょうか?
今回は名詞・動詞・形容詞それぞれについて、Pythonを使って分析してみました。この記事で学べること
- テキスト分析の進め方、考え方
- Pythonによるスクレイピング
- MeCabによる形態素解析
- Seabornによるグラフの描画
etc...
環境
- Python 3.7.4
- Anaconda 4.8.3
- Jupyter notebook
分析
それでは、早速分析していきましょう。
データ集め
今回使用する文章データは「青空文庫」様より拝借します。
まずは一例として夏目漱石のデータを取得してみます。
夏目漱石の作品一覧は以下のURLに収められています。https://www.aozora.gr.jp/index_pages/person148.html
このURLの「148」が夏目漱石の作家IDとなります。
つまり、このIDの部分を変えれば、任意の作家のデータを収集する事ができます。そして、このページに夏目漱石の作品一覧と、それらの作品IDが掲載されているようです。
例えば「草枕」であれば作品IDは「776」です。
この作品番号が分かると、青空文庫APIを用いて以下のURLにアクセスすれば、本文をhtmlで取得できます。http://pubserver2.herokuapp.com/api/v0.1/books/776/content?format=html
つまりは、夏目漱石のページから持って来た「作品ID」一覧を、このURLの「776」の部分にどんどん入れていけば、青空文庫に収められている夏目漱石の作品データを全て取得できることになります。
では、やっていきます。
from bs4 import BeautifulSoup import requests res = requests.get("https://www.aozora.gr.jp/index_pages/person148.html") soup = BeautifulSoup(res.content,"html.parser") ol_data = soup.find("ol").textまずは夏目漱石のページにアクセスして、作品ID一覧をリスト形式で取得しています。
ソースを確認した所、作品名はolタグで箇条書きされていたので、上記URLのolタグ内の記述を全て引っ張って来ました。ol_dataの中身はこんな感じです。
'\nイズムの功過\u3000(新字新仮名、作品ID:2314)\u3000\n一夜\u3000(新字新仮名、作品ID:1086)\u3000\n永日小品\u3000(新字新仮名、作品ID:758)......ここで、改めて作品一覧を見ると、同じ作品の旧仮名遣いバージョンなども収録されている事が分かりました。
"新字新仮名"と"新字旧仮名"と"旧字旧仮名"が別に収録されている場合があるんですね。これを全て含めてしまうと、同じ作品の単語がダブルカウントされてしまうので、今回は"新字新仮名"である作品のみに絞ります。
import re id_list = re.findall("新字新仮名、作品ID:[0-9]+",ol_data) id_list = [i.split(":")[1] for i in id_list]ということで正規表現を用いて、ol_dataの中から「新字新仮名、作品ID:<数字>」という部分をlist形式で抽出します。
そしてsplitメソッドにて「:」で分割した後の文字列を、リスト内包表記を用いてlist化しています。すると、id_listは
['2314', '1086', '758', '2669', '59017', '792',......となりました。
無事に作品ID一覧が取得できたようです。
さて、それでは青空文庫APIのURLにこのIDを突っ込んでいき、各ページをスクレイピングしていきます。import pandas as pd import time def get_text(id_num): time.sleep(1) res = requests.get("http://pubserver2.herokuapp.com/api/v0.1/books/"+ str(id_num) +"/content?format=html") soup = BeautifulSoup(res.content,"html.parser") title = soup.find("title").text doc = soup.find("div",{"class":"main_text"}).text return title,docget_textは、作品IDを与えると、その作品のタイトル名と本文テキストを返してくれる関数です。
html中のtitleタグに作品名、divタグのmain_textクラス内に本文が入っていたので、その通りにデータを引っ張ります。
そして、取得してきたデータを扱いやすくするため、最後にデータフレームに格納しました。ちなみに、夏目漱石の作品数分だけスクレイピングしている訳ですが、これはつまり青空文庫のホームページに何度も自動アクセスしていることになります。
なので、一気に何百回、何千回とアクセスしてしまうと、もはやDoS攻撃と変わらず、非常に迷惑です。
よって、1回データを取得する事にsleep(1)で1秒ずつ処理を休ませています。(大切)それでは、この関数を用いて、id_listの番号それぞれについてデータを取得して、データフレームに格納しましょう。
doc_list = [] for i in id_list: title,doc = get_text(i) doc_list.append([title,doc]) df_doc = pd.DataFrame(doc_list,columns=["作品名","本文"])df_docを見てみると...
無事に夏目漱石の作品一覧がデータフレーム形式で取得できたようです。
形態素解析
さて、データも手に入った事ですので、いよいよ分析していきます。
まずは、テキストデータを入力したら形態素解析して、そこから名詞・動詞・形容詞をそれぞれ抽出するメソッドを定義します。
import MeCab m = MeCab.Tagger("-Ochasen") def word_analysis(doc): node = m.parseToNode(doc) meishi_list = [] doshi_list = [] keiyoshi_list = [] while node: hinshi = node.feature.split(",")[0] if hinshi == "名詞": meishi_list.append(node.surface) elif hinshi == "動詞": doshi_list.append(node.feature.split(",")[6]) elif hinshi == "形容詞": keiyoshi_list.append(node.feature.split(",")[6]) node = node.next return pd.Series([list(set(meishi_list)), list(set(doshi_list)), list(set(keiyoshi_list))])今回、形態素解析器にはMeCabを使用しました。
新語や固有名詞を多数収録したmecab-ipadic-NEologdもありますが、今回扱うのは古い文章なので、あえて使用していません。
※試してはみましたが、「あなたに」で一語になってしまったりしたので...(おそらく同名の楽曲あるため)また、動詞と形容詞に関しては、単語の活用形があります。
これを別々に取得すると、「行く」「行った」「行こう」・・・という言葉が別の単語となってしまうのであまり宜しくありません。そこで、node.featureを「,」で分割した6番目に用語の原型が入っているので、そこを取得するようにしています。
returnはSeries型で名詞リスト・動詞リスト・形容詞リストを返却しています。
今回、1つの小説で複数回出てくる単語はすべて「1回」と数えることにしました。
そのためにset関数を噛ませて、1つの文章内で重複する単語を排除しています。
逆に、1つの小説で複数回出てくる単語もそのまま集計したければset関数を除いてください。では、この関数を用いて、作品ごとの名詞リスト・動詞リスト・形容詞リストを先のデータフレームの左側にくっつけます。
df_doc[["名詞","動詞","形容詞"]] = df_doc["本文"].apply(word_analysis)さて、では再びdf_docを確認してみます。
なかなか良い感じですね。
結果の集計、グラフ化
では、集計に移ります。
list内の要素数をカウントして、ランキング化するのはcollectionsメソッドを使うのが便利です。...が、現在、データフレームの中にlistが入っているという形になっています。
つまり、2次元リスト"風"になっているため、collectionsメソッドを使うにはまずこれを1次元にする必要があります。
そこで、itertools.chain.from_iterableメソッドを用いると、2次元リストが1次元になります。では、試しに「動詞」の列を用いて出現頻度ランキングを作ってみましょう。
import itertools import collections words = list(itertools.chain.from_iterable(df_doc["動詞"])) c = collections.Counter(words) c.most_common()collectionsのCounterで用語ごとの出現頻度が計算でき、most_common()で降順に並び替えられます。
では、結果を確認してみましょう。[('する', 84), ('れる', 83), ('いる', 83), ('思う', 83), ('ある', 83), ('なる', 82), ('見る', 81), ('来る', 78), ('出る', 77),...どうやら、これで夏目漱石が小説に多用した動詞ランキングが完成したようです。
折角なので(?)、グラフ化して視覚的に分かりやすくしてみます。
import seaborn as sns import matplotlib.pyplot as plt fig = plt.subplots(figsize=(8, 10)) sns.set(font="Hiragino Maru Gothic Pro",context="talk",style="white") sns.countplot(y=words,order=[i[0] for i in c.most_common(20)],palette="Blues_r")グラフ作成には、matplotlibとseabornを使います。
回数を棒グラフにするのはseabornのcountplotです。
フォントやサイズ、色合いなどはお好みで。countplotで、上位〜件のみを表示する方法はリスト内包表記を用いた、ちょっとしたテクニックです。
今回は上位20位までを出力します。すると・・・
無事にグラフ化できました。
分析の目的によって適宜変わって来ますが、「する」「いる」などは大概の文章で頻出するので除いてしまってもいいかもしれません。
また、形態素解析も完璧ではないので、例えば「く」という言葉が絶対に動詞として用いられているのか、などは不確実なのでご留意ください。このように、作者IDや、取得する品詞などを色々と変えれば、様々な結果が得られます。
では、試しに夏目漱石が使った形容詞のTOP20のグラフを書いてみます。
続いては、太宰治が使った形容詞のTOP20のグラフを書いてみると、
・・・となりました。
夏目漱石よりも、太宰治はネガティブな単語が上位に来るように見受けられます。
作者自身のイメージと一致するような気がしますね。おわりに
以上、Pythonで、文学作品のテキストマイニングをやっていきました。
この分析の様子は以下のYouTubeにもアップロードしています。
(本記事のソースコードは、この動画中に作成したものを新たに最適化したものです。)
もし宜しければ、こちらでリアルなデータ分析の感覚も味わっていただければと思います。是非、この記事を通してテキスト分析の方針や具体的な手法など、ご参考になれば幸いです。





- 投稿日:2020-12-04T16:15:09+09:00
Pythonで、文学者ごとの頻出単語ランキングを作る
はじめに
夏目漱石、芥川龍之介、川端康成、太宰治、三島由紀夫・・・
日本を代表する文学者たちが、小説に最も使用した単語は一体何なのでしょうか?
今回は名詞・動詞・形容詞それぞれについて、Pythonを使って分析してみました。この記事で学べること
- テキスト分析の進め方、考え方
- Pythonによるスクレイピング
- MeCabによる形態素解析
- Seabornによるグラフの描画
etc...
環境
- Python 3.7.4
- Anaconda 4.8.3
- Jupyter notebook
分析
それでは、早速分析していきましょう。
データ集め
今回使用する文章データは「青空文庫」様より拝借します。
まずは一例として夏目漱石のデータを取得してみます。
夏目漱石の作品一覧は以下のURLに収められています。https://www.aozora.gr.jp/index_pages/person148.html
このURLの「148」が夏目漱石の作家IDとなります。
つまり、このIDの部分を変えれば、任意の作家のデータを収集する事ができます。そして、このページに夏目漱石の作品一覧と、それらの作品IDが掲載されているようです。
例えば「草枕」であれば作品IDは「776」です。
この作品番号が分かると、青空文庫APIを用いて以下のURLにアクセスすれば、本文をhtmlで取得できます。http://pubserver2.herokuapp.com/api/v0.1/books/776/content?format=html
つまりは、夏目漱石のページから持って来た「作品ID」一覧を、このURLの「776」の部分にどんどん入れていけば、青空文庫に収められている夏目漱石の作品データを全て取得できることになります。
では、やっていきます。
from bs4 import BeautifulSoup import requests res = requests.get("https://www.aozora.gr.jp/index_pages/person148.html") soup = BeautifulSoup(res.content,"html.parser") ol_data = soup.find("ol").textまずは夏目漱石のページにアクセスして、作品ID一覧をリスト形式で取得しています。
ソースを確認した所、作品名はolタグで箇条書きされていたので、上記URLのolタグ内の記述を全て引っ張って来ました。ol_dataの中身はこんな感じです。
'\nイズムの功過\u3000(新字新仮名、作品ID:2314)\u3000\n一夜\u3000(新字新仮名、作品ID:1086)\u3000\n永日小品\u3000(新字新仮名、作品ID:758)......ここで、改めて作品一覧を見ると、同じ作品の旧仮名遣いバージョンなども収録されている事が分かりました。
"新字新仮名"と"新字旧仮名"と"旧字旧仮名"が別に収録されている場合があるんですね。これを全て含めてしまうと、同じ作品の単語がダブルカウントされてしまうので、今回は"新字新仮名"である作品のみに絞ります。
import re id_list = re.findall("新字新仮名、作品ID:[0-9]+",ol_data) id_list = [i.split(":")[1] for i in id_list]ということで正規表現を用いて、ol_dataの中から「新字新仮名、作品ID:<数字>」という部分をlist形式で抽出します。
そしてsplitメソッドにて「:」で分割した後の文字列を、リスト内包表記を用いてlist化しています。すると、id_listは
['2314', '1086', '758', '2669', '59017', '792',......となりました。
無事に作品ID一覧が取得できたようです。
さて、それでは青空文庫APIのURLにこのIDを突っ込んでいき、各ページをスクレイピングしていきます。import pandas as pd import time def get_text(id_num): time.sleep(1) res = requests.get("http://pubserver2.herokuapp.com/api/v0.1/books/"+ str(id_num) +"/content?format=html") soup = BeautifulSoup(res.content,"html.parser") title = soup.find("title").text doc = soup.find("div",{"class":"main_text"}).text return title,docget_textは、作品IDを与えると、その作品のタイトル名と本文テキストを返してくれる関数です。
html中のtitleタグに作品名、divタグのmain_textクラス内に本文が入っていたので、その通りにデータを引っ張ります。
そして、取得してきたデータを扱いやすくするため、最後にデータフレームに格納しました。ちなみに、夏目漱石の作品数分だけスクレイピングしている訳ですが、これはつまり青空文庫のホームページに何度も自動アクセスしていることになります。
なので、一気に何百回、何千回とアクセスしてしまうと、もはやDoS攻撃と変わらず、非常に迷惑です。
よって、1回データを取得する事にsleep(1)で1秒ずつ処理を休ませています。(大切)それでは、この関数を用いて、id_listの番号それぞれについてデータを取得して、データフレームに格納しましょう。
doc_list = [] for i in id_list: title,doc = get_text(i) doc_list.append([title,doc]) df_doc = pd.DataFrame(doc_list,columns=["作品名","本文"])df_docを見てみると...
無事に夏目漱石の作品一覧がデータフレーム形式で取得できたようです。
形態素解析
さて、データも手に入った事ですので、いよいよ分析していきます。
まずは、テキストデータを入力したら形態素解析して、そこから名詞・動詞・形容詞をそれぞれ抽出するメソッドを定義します。
import MeCab m = MeCab.Tagger("-Ochasen") def word_analysis(doc): node = m.parseToNode(doc) meishi_list = [] doshi_list = [] keiyoshi_list = [] while node: hinshi = node.feature.split(",")[0] if hinshi == "名詞": meishi_list.append(node.surface) elif hinshi == "動詞": doshi_list.append(node.feature.split(",")[6]) elif hinshi == "形容詞": keiyoshi_list.append(node.feature.split(",")[6]) node = node.next return pd.Series([list(set(meishi_list)), list(set(doshi_list)), list(set(keiyoshi_list))])今回、形態素解析器にはMeCabを使用しました。
新語や固有名詞を多数収録したmecab-ipadic-NEologdもありますが、今回扱うのは古い文章なので、あえて使用していません。
※試してはみましたが、「あなたに」で一語になってしまったりしたので...(おそらく同名の楽曲あるため)また、動詞と形容詞に関しては、単語の活用形があります。
これを別々に取得すると、「行く」「行った」「行こう」・・・という言葉が別の単語となってしまうのであまり宜しくありません。そこで、node.featureを「,」で分割した6番目に用語の原型が入っているので、そこを取得するようにしています。
returnはSeries型で名詞リスト・動詞リスト・形容詞リストを返却しています。
今回、1つの小説で複数回出てくる単語はすべて「1回」と数えることにしました。
そのためにset関数を噛ませて、1つの文章内で重複する単語を排除しています。
逆に、1つの小説で複数回出てくる単語もそのまま集計したければset関数を除いてください。では、この関数を用いて、作品ごとの名詞リスト・動詞リスト・形容詞リストを先のデータフレームの左側にくっつけます。
df_doc[["名詞","動詞","形容詞"]] = df_doc["本文"].apply(word_analysis)さて、では再びdf_docを確認してみます。
なかなか良い感じですね。
結果の集計、グラフ化
では、集計に移ります。
list内の要素数をカウントして、ランキング化するのはcollectionsメソッドを使うのが便利です。...が、現在、データフレームの中にlistが入っているという形になっています。
つまり、2次元リスト"風"になっているため、collectionsメソッドを使うにはまずこれを1次元にする必要があります。
そこで、itertools.chain.from_iterableメソッドを用いると、2次元リストが1次元になります。では、試しに「動詞」の列を用いて出現頻度ランキングを作ってみましょう。
import itertools import collections words = list(itertools.chain.from_iterable(df_doc["動詞"])) c = collections.Counter(words) c.most_common()collectionsのCounterで用語ごとの出現頻度が計算でき、most_common()で降順に並び替えられます。
では、結果を確認してみましょう。[('する', 84), ('れる', 83), ('いる', 83), ('思う', 83), ('ある', 83), ('なる', 82), ('見る', 81), ('来る', 78), ('出る', 77),...どうやら、これで夏目漱石が小説に多用した動詞ランキングが完成したようです。
折角なので(?)、グラフ化して視覚的に分かりやすくしてみます。
import seaborn as sns import matplotlib.pyplot as plt fig = plt.subplots(figsize=(8, 10)) sns.set(font="Hiragino Maru Gothic Pro",context="talk",style="white") sns.countplot(y=words,order=[i[0] for i in c.most_common(20)],palette="Blues_r")グラフ作成には、matplotlibとseabornを使います。
回数を棒グラフにするのはseabornのcountplotです。
フォントやサイズ、色合いなどはお好みで。countplotで、上位〜件のみを表示する方法はリスト内包表記を用いた、ちょっとしたテクニックです。
今回は上位20位までを出力します。すると・・・
無事にグラフ化できました。
分析の目的によって適宜変わって来ますが、「する」「いる」などは大概の文章で頻出するので除いてしまってもいいかもしれません。
また、形態素解析も完璧ではないので、例えば「く」という言葉が絶対に動詞として用いられているのか、などは不確実なのでご留意ください。このように、作者IDや、取得する品詞などを色々と変えれば、様々な結果が得られます。
では、試しに夏目漱石が使った形容詞のTOP20のグラフを書いてみます。
続いては、太宰治が使った形容詞のTOP20のグラフを書いてみると、
・・・となりました。
夏目漱石よりも、太宰治はネガティブな単語が上位に来るように見受けられます。
作者自身のイメージと一致するような気がしますね。おわりに
以上、Pythonで、文学作品のテキストマイニングをやっていきました。
この分析の様子は以下のYouTubeにもアップロードしています。
(本記事のソースコードは、この動画中に作成したものを新たに最適化したものです。)
もし宜しければ、こちらでリアルなデータ分析の感覚も味わっていただければと思います。是非、この記事を通してテキスト分析の方針や具体的な手法など、ご参考になれば幸いです。
- 投稿日:2020-12-04T16:15:09+09:00
Pythonで、好きな文学者の頻出単語ランキングを作る
はじめに
夏目漱石、芥川龍之介、川端康成、太宰治、三島由紀夫・・・
日本を代表する文学者たちが、小説に最も使用した単語は一体何なのでしょうか?
今回は名詞・動詞・形容詞それぞれについて、Pythonを使って分析してみました。この記事で学べること
- テキスト分析の進め方、考え方
- Pythonによるスクレイピング
- MeCabによる形態素解析
- Seabornによるグラフの描画
etc...
環境
- Python 3.7.4
- Anaconda 4.8.3
- Jupyter notebook
分析
それでは、早速分析していきましょう。
データ集め
今回使用する文章データは「青空文庫」様より拝借します。
まずは一例として夏目漱石のデータを取得してみます。
夏目漱石の作品一覧は以下のURLに収められています。https://www.aozora.gr.jp/index_pages/person148.html
このURLの「148」が夏目漱石の作家IDとなります。
つまり、このIDの部分を変えれば、任意の作家のデータを収集する事ができます。そして、このページに夏目漱石の作品一覧と、それらの作品IDが掲載されているようです。
例えば「草枕」であれば作品IDは「776」です。
この作品番号が分かると、青空文庫APIを用いて以下のURLにアクセスすれば、本文をhtmlで取得できます。http://pubserver2.herokuapp.com/api/v0.1/books/776/content?format=html
つまりは、夏目漱石のページから持って来た「作品ID」一覧を、このURLの「776」の部分にどんどん入れていけば、青空文庫に収められている夏目漱石の作品データを全て取得できることになります。
では、やっていきます。
from bs4 import BeautifulSoup import requests res = requests.get("https://www.aozora.gr.jp/index_pages/person148.html") soup = BeautifulSoup(res.content,"html.parser") ol_data = soup.find("ol").textまずは夏目漱石のページにアクセスして、作品ID一覧をリスト形式で取得しています。
ソースを確認した所、作品名はolタグで箇条書きされていたので、上記URLのolタグ内の記述を全て引っ張って来ました。ol_dataの中身はこんな感じです。
'\nイズムの功過\u3000(新字新仮名、作品ID:2314)\u3000\n一夜\u3000(新字新仮名、作品ID:1086)\u3000\n永日小品\u3000(新字新仮名、作品ID:758)......ここで、改めて作品一覧を見ると、同じ作品の旧仮名遣いバージョンなども収録されている事が分かりました。
"新字新仮名"と"新字旧仮名"と"旧字旧仮名"が別に収録されている場合があるんですね。これを全て含めてしまうと、同じ作品の単語がダブルカウントされてしまうので、今回は"新字新仮名"である作品のみに絞ります。
import re id_list = re.findall("新字新仮名、作品ID:[0-9]+",ol_data) id_list = [i.split(":")[1] for i in id_list]ということで正規表現を用いて、ol_dataの中から「新字新仮名、作品ID:<数字>」という部分をlist形式で抽出します。
そしてsplitメソッドにて「:」で分割した後の文字列を、リスト内包表記を用いてlist化しています。すると、id_listは
['2314', '1086', '758', '2669', '59017', '792',......となりました。
無事に作品ID一覧が取得できたようです。
さて、それでは青空文庫APIのURLにこのIDを突っ込んでいき、各ページをスクレイピングしていきます。import pandas as pd import time def get_text(id_num): time.sleep(1) res = requests.get("http://pubserver2.herokuapp.com/api/v0.1/books/"+ str(id_num) +"/content?format=html") soup = BeautifulSoup(res.content,"html.parser") title = soup.find("title").text doc = soup.find("div",{"class":"main_text"}).text return title,docget_textは、作品IDを与えると、その作品のタイトル名と本文テキストを返してくれる関数です。
html中のtitleタグに作品名、divタグのmain_textクラス内に本文が入っていたので、その通りにデータを引っ張ります。
そして、取得してきたデータを扱いやすくするため、最後にデータフレームに格納しました。ちなみに、夏目漱石の作品数分だけスクレイピングしている訳ですが、これはつまり青空文庫のホームページに何度も自動アクセスしていることになります。
なので、一気に何百回、何千回とアクセスしてしまうと、もはやDoS攻撃と変わらず、非常に迷惑です。
よって、1回データを取得する事にsleep(1)で1秒ずつ処理を休ませています。(大切)それでは、この関数を用いて、id_listの番号それぞれについてデータを取得して、データフレームに格納しましょう。
doc_list = [] for i in id_list: title,doc = get_text(i) doc_list.append([title,doc]) df_doc = pd.DataFrame(doc_list,columns=["作品名","本文"])df_docを見てみると...
無事に夏目漱石の作品一覧がデータフレーム形式で取得できたようです。
形態素解析
さて、データも手に入った事ですので、いよいよ分析していきます。
まずは、テキストデータを入力したら形態素解析して、そこから名詞・動詞・形容詞をそれぞれ抽出するメソッドを定義します。
import MeCab m = MeCab.Tagger("-Ochasen") def word_analysis(doc): node = m.parseToNode(doc) meishi_list = [] doshi_list = [] keiyoshi_list = [] while node: hinshi = node.feature.split(",")[0] if hinshi == "名詞": meishi_list.append(node.surface) elif hinshi == "動詞": doshi_list.append(node.feature.split(",")[6]) elif hinshi == "形容詞": keiyoshi_list.append(node.feature.split(",")[6]) node = node.next return pd.Series([list(set(meishi_list)), list(set(doshi_list)), list(set(keiyoshi_list))])今回、形態素解析器にはMeCabを使用しました。
新語や固有名詞を多数収録したmecab-ipadic-NEologdもありますが、今回扱うのは古い文章なので、あえて使用していません。
※試してはみましたが、「あなたに」で一語になってしまったりしたので...(おそらく同名の楽曲あるため)また、動詞と形容詞に関しては、単語の活用形があります。
これを別々に取得すると、「行く」「行った」「行こう」・・・という言葉が別の単語となってしまうのであまり宜しくありません。そこで、node.featureを「,」で分割した6番目に用語の原型が入っているので、そこを取得するようにしています。
returnはSeries型で名詞リスト・動詞リスト・形容詞リストを返却しています。
今回、1つの小説で複数回出てくる単語はすべて「1回」と数えることにしました。
そのためにset関数を噛ませて、1つの文章内で重複する単語を排除しています。
逆に、1つの小説で複数回出てくる単語もそのまま集計したければset関数を除いてください。では、この関数を用いて、作品ごとの名詞リスト・動詞リスト・形容詞リストを先のデータフレームの左側にくっつけます。
df_doc[["名詞","動詞","形容詞"]] = df_doc["本文"].apply(word_analysis)さて、では再びdf_docを確認してみます。
なかなか良い感じですね。
結果の集計、グラフ化
では、集計に移ります。
list内の要素数をカウントして、ランキング化するのはcollectionsメソッドを使うのが便利です。...が、現在、データフレームの中にlistが入っているという形になっています。
つまり、2次元リスト"風"になっているため、collectionsメソッドを使うにはまずこれを1次元にする必要があります。
そこで、itertools.chain.from_iterableメソッドを用いると、2次元リストが1次元になります。では、試しに「動詞」の列を用いて出現頻度ランキングを作ってみましょう。
import itertools import collections words = list(itertools.chain.from_iterable(df_doc["動詞"])) c = collections.Counter(words) c.most_common()collectionsのCounterで用語ごとの出現頻度が計算でき、most_common()で降順に並び替えられます。
では、結果を確認してみましょう。[('する', 84), ('れる', 83), ('いる', 83), ('思う', 83), ('ある', 83), ('なる', 82), ('見る', 81), ('来る', 78), ('出る', 77),...どうやら、これで夏目漱石が小説に多用した動詞ランキングが完成したようです。
折角なので(?)、グラフ化して視覚的に分かりやすくしてみます。
import seaborn as sns import matplotlib.pyplot as plt fig = plt.subplots(figsize=(8, 10)) sns.set(font="Hiragino Maru Gothic Pro",context="talk",style="white") sns.countplot(y=words,order=[i[0] for i in c.most_common(20)],palette="Blues_r")グラフ作成には、matplotlibとseabornを使います。
回数を棒グラフにするのはseabornのcountplotです。
フォントやサイズ、色合いなどはお好みで。countplotで、上位〜件のみを表示する方法はリスト内包表記を用いた、ちょっとしたテクニックです。
今回は上位20位までを出力します。すると・・・
無事にグラフ化できました。
分析の目的によって適宜変わって来ますが、「する」「いる」などは大概の文章で頻出するので除いてしまってもいいかもしれません。
また、形態素解析も完璧ではないので、例えば「く」という言葉が絶対に動詞として用いられているのか、などは不確実なのでご留意ください。このように、作者IDや、取得する品詞などを色々と変えれば、様々な結果が得られます。
では、試しに夏目漱石が使った形容詞のTOP20のグラフを書いてみます。
続いては、太宰治が使った形容詞のTOP20のグラフを書いてみると、
・・・となりました。
夏目漱石よりも、太宰治はネガティブな単語が上位に来るように見受けられます。
作者自身のイメージと一致するような気がしますね。おわりに
以上、Pythonで、文学作品のテキストマイニングをやっていきました。
この分析の様子は以下のYouTubeにもアップロードしています。
(本記事のソースコードは、この動画中に作成したものを新たに最適化したものです。)
もし宜しければ、こちらでリアルなデータ分析の感覚も味わっていただければと思います。是非、この記事を通してテキスト分析の方針や具体的な手法など、ご参考になれば幸いです。
- 投稿日:2020-12-04T16:12:54+09:00
django-filterで同じ誕生日の人を検索したい!
はじめに
この記事はDjango Advent Calendar 2020 9日目の記事です。
2年連続2回目の参加です。django-filterを使って同じ誕生日の人(月日が同じ)を取得したかった。
サンプルを作りました。
django-filterで同じ誕生日の人を検索するサンプル生年月日をDateFieldで持っているので、そのままdjango-filterを使うとこんな感じ↓
生年月日全部同じ人ではなく、誕生日の年月が同じ人を取得したいのですが、これだと「日付を正しく入力してください」となります。
YYYY-MM-DDの形式で入力してないからですね。DateFieldの月日だけを検索するためには、
(api)/views.pyにフィルタセットを作成します。(api)/views.pyfrom django_filters import rest_framework as filters from rest_framework import viewsets from sample.models import Samplepeople from sampleapi.serializers import SamplepeopleSerializers # フィルタセット class SampleFilter(filters.FilterSet): # Date型の月、日をそれぞれ検索できるようにする birthday_month = filters.NumberFilter(field_name='date_of_birth', lookup_expr='month') birthday_day = filters.NumberFilter(field_name='date_of_birth', lookup_expr='day') class Meta: model = Samplepeople fields = ['id', 'name', 'kana', 'date_of_birth',] # 通常のViewSet class SampleViewSet(viewsets.ReadOnlyModelViewSet): queryset = Samplepeople.objects.all() serializer_class = SamplepeopleSerializers filter_backends = [filters.DjangoFilterBackend] # 上記のFilterを追加する filter_class = SampleFilterフィルタセットで設定した項目が追加されます。
早速、同じ誕生日の人を検索します。
生まれた年は異なりますが、月日が同じ人が検索されました。
あとはAPI叩く際に
?birthday_month=&birthday_day=に月と日をいれてあげればOKです。
これなら同じ誕生月の人を検索するのも楽々ですね。また、lookup_expr='year'を追加すれば同じ年に生まれた人を検索することもできます。DateTimeFilterではない
DateFieldの検索だからDateTimeFilterを使うのかな?と思いましたが、最初のやつと同様に「日付を正しく入力してください」になります。
DateTimeFilterもYYYY-MM-DD(YYYY-MM-DD HH24-mm-SS)の形式で入力しないといけないからですね(1敗)おわりに
もっといいやり方があれば教えてください。
参考





- 投稿日:2020-12-04T16:08:45+09:00
Pythonで多次元尺度法 (MDS) 〜距離行列から位置関係を再現する〜
n個体間の非類似度または距離が与えられているとき、それらn個体の位置関係を(低次元の)座標で表現する手法として、多次元尺度法 (MDS : Multi-Dimensional Dcaling) があります。
MDSの数理的な解説は別の機会に譲るとして、今回はscikit-learnのパッケージを使ってMDSを試してみます。MDSには大きく分けて計量MDSと非計量MDSに分けられますが、今回扱うのは計量MDSになります。
ライブラリのインポート
scikit-learnでは
sklearn.manifold.MDSをインポートすることでMDSパッケージを利用できます。Inimport numpy as np import pandas as pd import matplotlib.pyplot as plt from tqdm import tqdm # forループの進捗バーを表示するライブラリ from sklearn.manifold import MDSデータの読込み、前処理
駅データ.jpより、
station20200619free.csvをダウンロードし、pandas DataFrameとして読み込みます。Indata = pd.read_csv('station20200619free.csv') print(data.head())Outstation_cd station_g_cd station_name station_name_k station_name_r line_cd pref_cd post address lon lat open_ymd close_ymd e_status e_sort 0 1110101 1110101 函館 NaN NaN 11101 1 040-0063 北海道函館市若松町12-13 140.726413 41.773709 1902-12-10 0000-00-00 0 1110101 1 1110102 1110102 五稜郭 NaN NaN 11101 1 041-0813 函館市亀田本町 140.733539 41.803557 0000-00-00 0000-00-00 0 1110102 2 1110103 1110103 桔梗 NaN NaN 11101 1 041-0801 北海道函館市桔梗3丁目41-36 140.722952 41.846457 1902-12-10 0000-00-00 0 1110103 3 1110104 1110104 大中山 NaN NaN 11101 1 041-1121 亀田郡七飯町大字大中山 140.713580 41.864641 0000-00-00 0000-00-00 0 1110104 4 1110105 1110105 七飯 NaN NaN 11101 1 041-1111 亀田郡七飯町字本町 140.688556 41.886971 0000-00-00 0000-00-00 0 1110105緯度(lat)・経度(lon)の情報をもとにmatplotlibで描画してみます。
Infig, ax = plt.subplots() data.plot('lon', 'lat', kind='scatter', ax=ax, marker='.') plt.show()
日本ですね!ただこのままだとデータ数が多いので、九州部分だけを切り出してみます。
Indata = data[(data['lon']>128)&(data['lon']<132)] data = data[data['lat']<34] len(data) # 1207Infig, ax = plt.subplots() data.plot('lon', 'lat', kind='scatter', ax=ax, marker='.') plt.show()
距離行列の計算
抽出したデータをもとに各駅間の距離行列$\boldsymbol{D}$を計算します。ユークリッド距離行列の場合、駅間距離の二乗の値になります。
InN = len(data) D = np.zeros((N, N), dtype=float) for i in tqdm(range(N)): for j in range(N): lon_diff = (data['lon'].iloc[i] - data['lon'].iloc[j]) lat_diff = (data['lat'].iloc[i] - data['lat'].iloc[j]) D[i][j] = lon_diff**2 + lat_diff**2 print(D)Outarray([[0.00000000e+00, 1.26355528e-03, 6.53891820e-03, ..., 1.06203018e+00, 1.06368290e+00, 1.05709741e+00], [1.26355528e-03, 0.00000000e+00, 2.39660029e-03, ..., 9.92989742e-01, 9.94425737e-01, 9.87970532e-01], [6.53891820e-03, 2.39660029e-03, 0.00000000e+00, ..., 9.02220608e-01, 9.03831353e-01, 8.97815038e-01], ..., [1.06203018e+00, 9.92989742e-01, 9.02220608e-01, ..., 0.00000000e+00, 6.80062050e-05, 1.68960250e-04], [1.06368290e+00, 9.94425737e-01, 9.03831353e-01, ..., 6.80062050e-05, 0.00000000e+00, 3.12263650e-05], [1.05709741e+00, 9.87970532e-01, 8.97815038e-01, ..., 1.68960250e-04, 3.12263650e-05, 0.00000000e+00]])低次元空間へのマッピング
距離行列$\boldsymbol{D}$のみを用いて、もとの二次元空間の位置関係を再現していきます。
sklearn.manifold.MDSクラスに次の引数を与えてモデルを生成し、fit_transform()メソッドで適合・変換します。
n_components... マッピング先の次元数。今回は二次元空間なので2。dissimilarity...
euclideanまたはprecomputed(デフォルト :euclidean)- 距離行列を既に計算している場合は
precomputedを指定。random_state... 再現性を持たせるために乱数シードを設定。Inmds = MDS(n_components=2, dissimilarity="precomputed", random_state=0) pos = mds.fit_transform(D)結果の確認
Inres = pd.DataFrame(pos, columns=['x', 'y']) plt.scatter(res['x'], res['y'], marker='.')
九州のようなものが見えます。軸が回転しているので戻してみしょう。
Indef inverse(x): return x*(-1) plt.scatter(res2['y'].map(inverse), res2['x'], marker='.')
ちょっと歪ですが九州ですね!ということで無事、距離行列のみから平面上の位置関係を再現することが出来ました。
参考