- 投稿日:2020-12-04T23:16:00+09:00
Golang による順列列挙のパフォーマンス研究 1. 再帰を用いたやり方
関連記事
本記事は Geek-Space Advent Calendar 2020 の 4 日目です。
- Golang による順列列挙のパフォーマンス研究 1. 再帰を用いたやり方 (本記事)
- Golang による順列列挙のパフォーマンス研究 2. スタックを用いたやり方 (執筆中)
- Golang による順列列挙のパフォーマンス研究 3. 繰り上がり法(仮名) (執筆中)
- Golang で順列・組み合わせ・重複順列・重複組み合わせの列挙 (執筆中)
はじめに
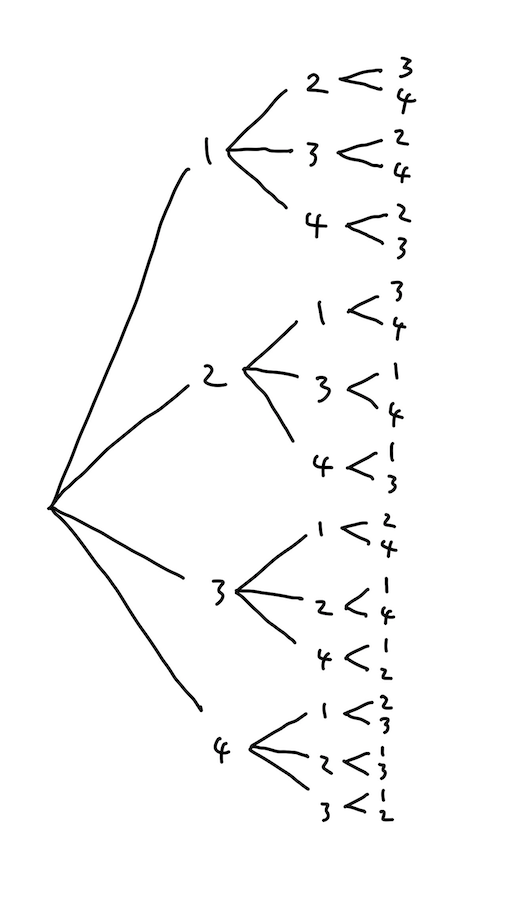
順列や組み合わせといえばこちら:
"樹形図"です。
自分は中学受験算数とかで習った覚えがあります。中学受験やってない人はどこで習うんでしょうね。
まあとにかく、人間はこれを描くことで、順列を機械的に列挙していくことができます。
「機械的に列挙できる」ということは、その手順を Golang で書き表せられれば、コンピューターにだって順列が列挙できるはずなわけです。そこで"樹形図"について考えてみると、これは見ての通り(かつ文字通り)木構造です。
つまり順列の列挙は、「"樹形図"という木構造を生成して探索する作業」と解釈することができます。木構造の探索には、"深さ優先探索"(Depth-First Search = DFS)と"幅優先探索"(Breadth-First Search = BFS)があります。
順列の列挙に上手く当てはまるのは DFS です。
DFS のやり方には、再帰を用いるやり方と、スタックを用いるやり方とがあります。
この記事では前者について考えていきます。なお、コードは全てこちらのリポジトリに上げてあります。
https://github.com/ikngtty/benchmark-go-combinatorics実装
下準備
以下のコードでパフォーマンスを計測していきます:
combinatorics/perm_test.gofunc BenchmarkPermutations(b *testing.B) { const n = 10 const k = 10 doSomethingForPattern := func(pattern []int) { total := 0 for i := 1; i < len(pattern); i++ { total += pattern[i] - pattern[i-1] } } targets := []struct { name string f func() }{ {"テスト対象関数の名前", func() { // テスト対象関数を用いて、[0, 1, ..., n-1]の数の中からk個選ぶ順列を生成し、 // 各順列に対して`doSomethingForPattern`を行う。 }}, // ... } for _, target := range targets { b.Run(target.name, func(b *testing.B) { for try := 0; try < b.N; try++ { target.f() } }) } }計測結果は少し編集して、実行時間(ns)、使用メモリ容量(B)、メモリ割り当て数(allocs)を載せます。
計測は以下のオンボロマシンで行いました:
macOS Big Sur バージョン 11.0.1 MacBook Air (11-inch, Early 2015) プロセッサ 1.6 GHz デュアルコアIntel Core i5 メモリ 4 GB 1600 MHz DDR3 go version go1.15.5 darwin/amd64まずは素直な再帰
combinatorics/perm.go// aの中からk個選ぶ順列の列挙 func PermutationsRecursive0(a []int, k int) [][]int { if k == 0 { pattern := []int{} return [][]int{pattern} } ans := [][]int{} for i := range a { // i番目の項目を抜いた配列を新しく作る aRest := make([]int, len(a)-1) for j := 0; j < i; j++ { aRest[j] = a[j] } for j := i + 1; j < len(a); j++ { aRest[j-1] = a[j] } // 再帰 childPatterns := PermutationsRecursive0(aRest, k-1) for _, childPattern := range childPatterns { // 各順列の左端にノードをくっつける感じ pattern := append([]int{a[i]}, childPattern...) ans = append(ans, pattern) } } return ans }
- 樹形図の左上のノードを用意する
- そのノードの右に続く樹形図を再帰で作る
- できた樹形図の左端にノードをくっつける
- 1 〜 3 を繰り返して左下のノード分まで縦に並べていく
みたいなイメージです。
木構造の再帰性に沿った、とても素直なコードですね。測定結果は以下:
PermutationsRecursive0 6376212126 ns 5168828952 B 89707744 allocs順列の数を先に計算して、配列のメモリ領域をまとめて確保する
上のコードはやりたいことに対してとても素直な実装でした。
パフォーマンスのことはあまり考えていません。
ここから非効率そうなところに目星をつけていき、色々改良を試みていきます。まず、結果の配列に対して繰り返し
appendしているのが気になります。
配列の場合、必要な要素数を最初にまとめて確保した方が効率が良いはず。
そのためには、順列についての"場合の数"を計算する必要があります。
数学で言うとnPkって書くやつ。combinatorics/perm.gofunc PermutationsRecursive1(a []int, k int) [][]int { if k == 0 { pattern := []int{} return [][]int{pattern} } // nPk分の空間を確保! ans := make([][]int, 0, PermutationCount(len(a), k)) for i := range a { aRest := make([]int, len(a)-1) for j := 0; j < i; j++ { aRest[j] = a[j] } for j := i + 1; j < len(a); j++ { aRest[j-1] = a[j] } childPatterns := PermutationsRecursive1(aRest, k-1) for _, childPattern := range childPatterns { pattern := append([]int{a[i]}, childPattern...) ans = append(ans, pattern) } } return ans } // nPk func PermutationCount(n, k int) int { ans := 1 for i := 0; i < k; i++ { ans *= n - i } return ans }PermutationsRecursive0 6376212126 ns 5168828952 B 89707744 allocs PermutationsRecursive1 4109722365 ns 3087847792 B 85046601 allocsわざわざ
nPkを計算している時間を差し引いても、だいぶ速くなりました。コールバック関数を使って、順列を遅延評価する
「順列をまず全部生成する」というやり方は、全ての順列をメモリに置いておく必要があります。
一方、遅延評価、つまり「順列を 1 つ生成して後続の処理を行わせる。終わったらその順列を破棄し、次の順列を生成する。」というやり方なら、順列 1 個分のメモリしか食わないはずです。今時の大体の言語には"ジェネレーター関数"という仕組みがあり、これによって要素を遅延評価で少しずつ返してくれるサムシングを作ることができます。
しかし悲しいかな、Golang にそんな仕組みはありません。
代わりに、「1 つの要素に対してやりたいことを記述した関数」を引数として渡してやる方法しかなさそうです。
いわゆる"コールバック関数"というやつ。combinatorics/perm.gofunc PermutationsRecursive2(a []int, k int, f func([]int)) { if k == 0 { pattern := []int{} // 順列を返すのではなく、コールバック関数に渡す f(pattern) return } for i := range a { aRest := make([]int, len(a)-1) for j := 0; j < i; j++ { aRest[j] = a[j] } for j := i + 1; j < len(a); j++ { aRest[j-1] = a[j] } // 再帰呼び出しの際にもコールバック関数を使うことになる PermutationsRecursive2(aRest, k-1, func(childPattern []int) { pattern := append([]int{a[i]}, childPattern...) f(pattern) }) } }PermutationsRecursive1 4109722365 ns 3087847792 B 85046601 allocs PermutationsRecursive2 3826715780 ns 2581433088 B 91281951 allocs(比較したい関数だけ並べています。)
ちょっとメモリ使用量が減り、ちょっと実行時間も減りました。
思ったより「ちょっと」でした。上では「順列 1 個分のメモリしか食わないはず」と書きましたが、考えてみれば、再帰呼び出しする度に新しい配列を作ったりはしているんですよね。
それと引数aの配列も再帰呼び出しする度に量産されています。
その辺でのメモリの食い方と比べると、焼け石に水だったのかもしれません。「使用可能な数字」をチェックリストで管理する
そんなわけで、今度は引数
a(=使用可能な数字群)を量産している点について、なんとかできないか考えてみます。
できればaをいちいちコピーするのではなく、各再帰呼び出しの間で使い回したいところ。
しかし配列において、「ある項目を除く(そして残りの項目を詰める)」「ある項目を挿入する」という操作は o(N) です。
これでは使い回そうにも効率が悪い。そこで、使用可能な数字群を
[]intではなく「チェックリスト形式」で表現することを考えます。
具体的には
- 使用した数字にチェックを入れる
- まだチェックが入っていない数字を使用可能とする
という感じ。
イメージとしてはbefore: after: [0,1,2,3] -> [o,o,o,o] [0,1,3] -> [o,o,X,o] [1,3] -> [X,o,X,o] [1] -> [X,o,X,X] [] -> [X,X,X,X]こんな感じです。
チェックリストの型は実際には[]boolになります。oと書いた部分がFalse、Xと書いた部分がTrueです。(普通、逆な気もしますが、「使った数字にチェックマークをつける」というイメージを伝えたかったのでこうなりました。)
この形式だと、値の書き換えだけで「使用可能な数字群」の変化を表現できます。除外や挿入と違い、値の書き換えの操作量は o(1) です。ただし、編集コストが減った分、参照コストは増えます。
例えばbefore: after: [0,1,2,3,4,5,6,7,8,9] -> [o,o,o,o,o,o,o,o,o,o] [5] -> [X,X,X,X,X,o,X,X,X,X]となることを考えると、以前ならたった 1 つの数字
5を参照するだけだった場面でも、チェックリスト式だと[X,X,X,X,X,o,X,X,X,X]という 10 個の項目を全て調べる羽目になるわけです。そんなわけで、最終的にどっちの方が速いのか予想がつかないところです。
まあ計算量をしっかり自分で計算すれば分かるのかもしれませんが、なんか難しそうなので、ここはちゃっちゃと実装して測っちゃうことにします。ここからは表面的な書き方の話。
引数aの代わりにチェックリストを引数にするのはあまり美しくないです。
チェックリストは実装の都合で生まれたもの。順列を列挙する関数への指示に使うパラメータとしては、あまり自然な形式ではありません。
そこで、引数はただの整数n(使用可能な数字の個数)あたりにして、チェックリストは関数内部で作ることにします。
ここで問題となるのは、一度作ったチェックリストを再帰呼び出し先にどうやって渡すのか。
チェックリスト作成処理が関数の内部にある以上、普通に再帰呼び出しをすると、呼び出し先でまたチェックリスト作成処理が走るということになります。これではチェックリストを使い回すことができません。
解決策として、再帰呼び出し部分を絞って内部関数として書き、チェックリスト作成処理はその外側に書くことにします。combinatorics/perm.go// [0,1,...,n-1]の中からk個選ぶ順列の列挙 func PermutationsRecursive3(n, k int, f func([]int)) { checklist := make([]bool, n) // 再帰用の内部関数 var body func(k int, f func([]int)) body = func(k int, f func([]int)) { if k == 0 { f([]int{}) return } for num := range checklist { // チェックの入っている数字はスキップ if checklist[num] { continue } checklist[num] = true body(k-1, func(childPattern []int) { pattern := append([]int{num}, childPattern...) f(pattern) }) // きちんと元の状態に戻すのが使い回しのポイント checklist[num] = false } } body(k, f) }こうなりました。
PermutationsRecursive2 3826715780 ns 2581433088 B 91281951 allocs PermutationsRecursive3 3787541809 ns 2339606912 B 85046640 allocs結果は僅差でした。
1 つの順列を配列ではなくリストで表す
次は、再帰呼び出しをする度に順列を表現する配列を作り直している点について、改良を試みます。
現状は[] -> [2] -> [1, 2] -> [0, 1, 2]という形で配列が作り直されていっています。
要素数 N の配列に対し、左に要素を 1 つ足した新しい配列を作るのに o(N) 分のコストがかかっています。ここでは、配列ではなくリストを使うことで、左に要素 1 つ足すコストを o(1) にしてみることにします。
Golang はデフォルトではリストが存在しないので、自分で作ってみます。
こんな感じ:combinatorics/util.gotype IntList struct { first *intListNode last *intListNode len int } type intListNode struct { child *intListNode value int } func NewIntList() *IntList { return &IntList{nil, nil, 0} } func (list *IntList) Len() int { return list.len } func (list *IntList) Add(elem int) { node := intListNode{nil, elem} if list.first == nil { list.first = &node list.last = &node } else { list.last.child = &node list.last = &node } list.len++ } func (list *IntList) Concat(other *IntList) { if list.first == nil { *list = *other } else if other.first == nil { // Do nothing } else { list.last.child = other.first list.last = other.last list.len += other.len } } func (list *IntList) Each(f func(elem int)) { cur := list.first for cur != nil { f(cur.value) cur = cur.child } } func (list *IntList) ToA() []int { a := make([]int, list.Len()) { index := 0 list.Each(func(elem int) { a[index] = elem index++ }) } return a }この
IntList型を使って順列を表現します。
ただし、最終的には順列は配列である方が使い勝手が良いと思うので、
- 再帰呼び出し中だけリストで順列を表現する
- 左に要素を付け足し続けて完成したリストを、最後に配列に変換してコールバック関数に渡す
という手順で行こうと思います。
combinatorics/perm.gofunc PermutationsRecursive4(n, k int, f func([]int)) { checklist := make([]bool, n) var body func(k int, f func(*IntList)) body = func(k int, f func(*IntList)) { if k == 0 { f(NewIntList()) return } for num := range checklist { if checklist[num] { continue } checklist[num] = true body(k-1, func(childPattern *IntList) { pattern := NewIntList() pattern.Add(num) // o(1) pattern.Concat(childPattern) // o(1) f(pattern) }) checklist[num] = false } } body(k, func(list *IntList) { f(list.ToA()) // o(k) }) }PermutationsRecursive3 3787541809 ns 2339606912 B 85046640 allocs PermutationsRecursive4 5024220142 ns 2513788976 B 95933042 allocsむしろ前よりも遅くなってしまいました。
いちいち変換とかしてるからでしょうか。1 つの順列を表す配列について、はじめから必要な分のメモリ空間をまとめて確保する
というわけでリストではなく別の策。
最初から配列の要素数を必要な分だけ確保しておくことにより、配列の作り直しを防ぎます。
つまり以下のようなイメージです。before: after: [] [ , , ] -> [2] -> [ , , 2] -> [1, 2] -> [ , 1, 2] -> [0, 1, 2] -> [0, 1, 2](実際には空白で表した部分にも 0 が入ることになります。int には nil のような値は存在しないので。)
さて、今まで引数
kには「何桁の順列を作りたいか」を渡してきました。
再帰呼び出し先で 1 桁少ない順列を作る際も、このkに 1 減らした数を渡すことで実現しています。
しかし今回、「再帰呼び出し先で何桁の順列を作りたいか」とは別に「最初の呼び出し元は何桁の順列を作りたいのか(=配列の要素数はどれぐらい確保すれば良いのか)」のパラメータも必要になります。
両方を常に引数で渡すという書き方もできますが、実装のためだけに無駄に 2 つのパラメータを指定しなきゃいけないのは、例によって美しくない。
前者は内部関数専用の引数とします。combinatorics/perm.go// 引数`k`が「最初の呼び出し元は何桁の順列を作りたいのか」に相当 func PermutationsRecursive5(n, k int, f func([]int)) { checklist := make([]bool, n) // 引数`pos`は「今、順列の何桁目に値を入れようとしているか」。 // 説明文中では「再帰呼び出し先で何桁の順列を作りたいか」が必要と書きましたが、 // 実際にはこちらを引数に取る方が書きやすかったのでこちらにしました。 // 「再帰呼び出し先で何桁の順列を作りたいか」は`k-pos`で計算可能です。 var body func(pos int, f func([]int)) body = func(pos int, f func([]int)) { if pos == k { // 要素数を`k`個あらかじめ取りながら配列を生成! f(make([]int, k)) return } for num := range checklist { if checklist[num] { continue } checklist[num] = true body(pos+1, func(pattern []int) { // あらかじめ全桁分の領域が確保されているので、 // 配列へのappendではなく書き込みになりました。 pattern[pos] = num f(pattern) }) checklist[num] = false } } body(0, f) }PermutationsRecursive3 3787541809 ns 2339606912 B 85046640 allocs PermutationsRecursive5 1198652505 ns 655839184 B 19728209 allocs今度こそ改善できました。しかも劇的ですね。速度は 3 倍近いです。
1 つの配列(≒メモリ領域)の使い回しで全部の順列を表現してしまう
ここまで、順列を生成する時のメモリ領域をなるべく使い回すよう考えてきました。
その結果、再帰関数部分の仕事はだんだん「順列用の配列の生成」から「与えられた順列用の配列に値を入れる」という作業に移ってきています。
これを極端に最後まで推し進めてしまいましょう。
つまり、順列用の配列は再帰部分の外側で 1 つ作るのみ。
再帰関数はひたすらこの 1 つの配列相手に値を書き換え続けていきます。順列用の配列を 1 つしか作らないと、値の書き込み回数も劇的に減ります。
以下の例を見てください。[0, 1, 2, 3, 4]から3つ選ぶ順列群 before: after: [ [0, 1, 2], [0, 1, 2] [0, 1, 3], -> [_, _, 3] [0, 1, 4], -> [_, _, 4] [0, 2, 1], -> [_, 2, 1] [0, 2, 3], -> [_, _, 3] [0, 2, 4], -> [_, _, 4] [0, 3, 1], -> [_, 3, 1] [0, 3, 2], -> [_, _, 2] [0, 3, 4], -> [_, _, 4] [0, 4, 1], -> [_, 4, 1] [0, 4, 2], -> [_, _, 2] [0, 4, 3], -> [_, _, 3] [1, 0, 2], -> [1, 0, 2] [1, 0, 3], -> [_, _, 3] [1, 0, 4], -> [_, _, 4] ... ... [4, 3, 0], -> [_, 3, 0] [4, 3, 1], -> [_, _, 1] [4, 3, 2] ] -> [_, _, 2]左は
[ [順列], [順列], ..., [順列] ]という形で、配列を順列の数だけ作っていることを示しており、右は[順列] -> [順列] -> ... -> [順列]という形で、1 つの配列を徐々に書き換えていっていることを示しています。
そしてここがポイントなのですが、右で_と示している部分は、書き換え前の値と同じなので特に書き換える必要がない箇所です。
ご覧の通り、半分以上(多分)の値を書き込まずに済ませることができています。combinatorics/perm.gofunc PermutationsRecursive6(n, k int, f func([]int)) { checklist := make([]bool, n) pattern := make([]int, k) var body func(pos int) body = func(pos int) { if pos == k { f(pattern) return } for num := range checklist { if checklist[num] { continue } // 以前は再帰呼び出しで生成された順列群の1つ1つに対して、 // 「左端にノードを加える」という作業が必要でした。 // 今回は「左端の値を書き換える」という作業を事前に1回行って、 // あとは再帰呼び出しに全部任せるだけでOKです。 // そのためコールバック関数を再帰部分に渡したりする手間がなくなりました。 pattern[pos] = num checklist[num] = true body(pos + 1) checklist[num] = false } } body(0) }PermutationsRecursive5 1198652505 ns 655839184 B 19728209 allocs PermutationsRecursive6 191816791 ns 96 B 2 allocsそんなわけで 6 倍近く速くなりました。メモリの改善に関しては比べ物にならないですね。
コードもなんか紆余曲折あった末、割とすっきりしたところに落ち着いた感じがします。さて、1 つの配列(≒メモリ領域)を使い回しているこの実装は、使い方に注意する必要があります。
以下のようにコールバック関数の中で受け取った順列を即時使い捨てるのであれば問題はないんですが:PermutationsRecursive6(3, 2, func(pattern []int) { fmt.Println(pattern) }) // Output: // [0 1] // [0 2] // [1 0] // [1 2] // [2 0] // [2 1]以下のように順列のスライスを溜めておいて後で使おうとすると大変なことになります:
perms := make([][]int, 0, 6) PermutationsRecursive6(3, 2, func(pattern []int) { perms = append(perms, pattern) }) fmt.Println(perms) // Output: // [[2 1] [2 1] [2 1] [2 1] [2 1] [2 1]]こうなってしまうのは、スライスが配列に対する参照でしかないからですね。
上記コードは同じ配列への参照を延々溜めているだけです。
その配列は繰り返し値を書き換えられた結果、最後の順列[2 1]の形に終着しています。
なので、出力結果は[2 1]が延々と並ぶ形になるわけです。順列を全部溜めておきたかったら、コールバック関数に渡された時点での配列の値を都度新しい配列にコピーして保存しておく必要があります:
perms := make([][]int, 0, 6) combinatorics.PermutationsRecursive6(3, 2, func(pattern []int) { // 新しい配列を用意 patternClone := make([]int, len(pattern)) // 現時点の順列の値を新しい配列に避難させる copy(patternClone, pattern) // 新しい配列への参照を溜めておく perms = append(perms, patternClone) }) fmt.Println(perms) // Output: // [[0 1] [0 2] [1 0] [1 2] [2 0] [2 1]]チェックリストを捨て、生成途中の順列配列から次に使用可能な数字を判断する
上の改良によって、樹形図を作る順番がしれっと変わりました。
以前は右のノードから順番に埋めていくイメージだったのが、左のノードから埋めるようになっています。
ということは、生成途中の順列配列を見れば、より左側のノードにはどの数字を使っていて、残りの使用可能な数字はどれなのか判断できることになります。
もうchecklistは要らないのでは?
ということで実装してみました:combinatorics/perm.gofunc PermutationsRecursive7(n, k int, f func([]int)) { pattern := make([]int, k) var body func(pos int) body = func(pos int) { if pos == k { f(pattern) return } for num := 0; num < n; num++ { // 数字が使われていたらスキップ willContinue := false // 大域脱出用 for i := 0; i < pos; i++ { if pattern[i] == num { // 大域脱出 willContinue = true break } } // 大域脱出 if willContinue { continue } // 数字が未使用だと分かり、安心してノードを埋める pattern[pos] = num body(pos + 1) } } body(0) }PermutationsRecursive6 191816791 ns 96 B 2 allocs PermutationsRecursive7 741371156 ns 80 B 1 allocs使用メモリのわずかな改善と引き換えに、めちゃくちゃ遅くなってしまいました。
チェックリストはやはり必要なようです。まとめ
結論実装は以下:
combinatorics/perm.gofunc PermutationsRecursive6(n, k int, f func([]int)) { checklist := make([]bool, n) pattern := make([]int, k) var body func(pos int) body = func(pos int) { if pos == k { f(pattern) return } for num := range checklist { if checklist[num] { continue } pattern[pos] = num checklist[num] = true body(pos + 1) checklist[num] = false } } body(0) }計測結果を全て並べておきます:
PermutationsRecursive0 6338217782 ns 5168828928 B 89707742 allocs PermutationsRecursive1 4109722365 ns 3087847792 B 85046601 allocs PermutationsRecursive2 3807560486 ns 2581434768 B 91281958 allocs PermutationsRecursive3 3787541809 ns 2339606912 B 85046640 allocs PermutationsRecursive4 5024220142 ns 2513788976 B 95933042 allocs PermutationsRecursive5 1198652505 ns 655839184 B 19728209 allocs PermutationsRecursive6 191816791 ns 96 B 2 allocs PermutationsRecursive7 741371156 ns 80 B 1 allocsNext: Golang による順列列挙のパフォーマンス研究 2. スタックを用いたやり方 (執筆中)
- 投稿日:2020-12-04T20:08:52+09:00
Goで書くDDDの仕様(Specification)パターン
この記事はドメイン駆動設計 Advent Calendar 2020 7日目の記事です。
DDDで紹介される戦術パターンの一つの仕様(Specification)パターンのGoでの実装を(自分へのメモ用と整理も兼ねて)2つ紹介します。
interfaceを利用
DDDはJavaで紹介されることが多いのですが、1つ目はこのJavaで紹介されるインターフェースを利用したものを素直に書いたパターンです。
例で見てみましょう。
// 仕様はRuleの集合で表現する type Specification struct { rules []rule } // 検証を表すインターフェース type rule interface { IsValid() bool } // 名前の長さのルール type nameLengthRule struct { name string } func (n nameLengthRule) IsValid() bool { return len(n.name) < 20 } // 有効な年齢のルール type ageRangeRule struct { age int } func (a ageRangeRule) IsValid() bool { return 0 <= a.age && a.age < 200 } func NewSpecification(name string, age int) Specification { return Specification{ rules: []rule{ nameLengthRule{name}, ageRangeRule{age}, }, } } func (s Specification) Satisfied() bool { for _, rule := range s.rules { if !rule.IsValid() { return false } } return true }検証内容をruleとしてinterfaceに切り出すことで、今後検証内容が増えても既存の影響はSpecificationの生成だけになります。
ビジネスルールは比較的頻繁に変わるので、変更に強いプログラムになると言われています。
(とはいえ、このくらいの検証でやるのは過剰ですが。。)typeを利用
もう一つはruleの関数自体を型にしてしまうものです。
これも例をみてみましょう。
type Specification struct { rules []rule } type rule func() bool func nameLengthRule(name string) rule { return func() bool { return len(name) < 20 } } func ageRangeRule(age int) rule { return func() bool { return 0 <= age && age < 200 } } func NewSpecification(name string, age int) Specification { return Specification{ rules: []rule{ nameLengthRule(name), ageRangeRule(age), }, } } func (s Specification) Satisfied() bool { for _, rule := range s.rules { if !rule() { return false } } return true }検証の内容は変わりませんが、structの宣言がなくなった分コードがスッキリします。
ポイントは関数のfunc() boolを型にしてしまうところです。
これによって関数宣言だけでルールが作れるので、シンプルな形になっています。Goでは関数も型にできるので、うまく利用するとインターフェースを使うよりもシンプルな形で実装できるので、参考になれば幸いです。
- 投稿日:2020-12-04T19:22:58+09:00
LeetCodeに毎日挑戦してみた 66. Add Binary(Python、Go)
はじめに
無料英単語サイトE-tanを運営中の@ishishowです。
プログラマとしての能力を上げるために毎日leetcodeに取り組み、自分なりの解き方を挙げていきたいと思います。
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
16問目(問題67)
67. Add Binary
問題内容
Given two binary strings
aandb, return their sum as a binary string.(日本語訳)
2つのバイナリ文字列
aとが与えられた場合b、それらの合計をバイナリ文字列として返します。Example 1:
Input: a = "11", b = "1" Output: "100"Example 2:
Input: a = "1010", b = "1011" Output: "10101"考え方
二進数の文字列を十進数に変換します
十進数のまま数字を足して、最後に二進数の文字列に変換します。
- 解答コード
class Solution: def addBinary(self, a, b): return bin(int(a, 2) + int(b, 2))[2:]
- Goでも書いてみます!
import ( "fmt" "math/big" ) func addBinary(a string, b string) string { var A, _ = new(big.Int).SetString(a, 2) var B, _ = new(big.Int).SetString(b, 2) return fmt.Sprintf("%b", new(big.Int).Add(A, B)) }
- 投稿日:2020-12-04T19:22:58+09:00
LeetCodeに毎日挑戦してみた 67. Add Binary(Python、Go)
はじめに
無料英単語サイトE-tanを運営中の@ishishowです。
プログラマとしての能力を上げるために毎日leetcodeに取り組み、自分なりの解き方を挙げていきたいと思います。
Leetcodeとは
leetcode.com
ソフトウェア開発職のコーディング面接の練習といえばこれらしいです。
合計1500問以上のコーデイング問題が投稿されていて、実際の面接でも同じ問題が出されることは多いらしいとのことです。golang入門+アルゴリズム脳の強化のためにgoとPythonで解いていこうと思います。(Pythonは弱弱だが経験あり)
16問目(問題67)
67. Add Binary
問題内容
Given two binary strings
aandb, return their sum as a binary string.(日本語訳)
2つのバイナリ文字列
aとが与えられた場合b、それらの合計をバイナリ文字列として返します。Example 1:
Input: a = "11", b = "1" Output: "100"Example 2:
Input: a = "1010", b = "1011" Output: "10101"考え方
二進数の文字列を十進数に変換します
十進数のまま数字を足して、最後に二進数の文字列に変換します。
- 解答コード
class Solution: def addBinary(self, a, b): return bin(int(a, 2) + int(b, 2))[2:]
- Goでも書いてみます!
import ( "fmt" "math/big" ) func addBinary(a string, b string) string { var A, _ = new(big.Int).SetString(a, 2) var B, _ = new(big.Int).SetString(b, 2) return fmt.Sprintf("%b", new(big.Int).Add(A, B)) }
- 投稿日:2020-12-04T14:48:05+09:00
もうlintに怒られない!Goでより安全にzipを扱うために(Potential DoS vulnerability via decompression bombエラーへの対処法)
はじめに
フューチャー Advent Calendar 2020の5日目の記事です。昨日はAWSアソシエイト試験についての刺激的な記事でした!
バッチ処理などを実装していると、定期的に連携されるファイルを取り込む場面が出てきます。5日目の本記事では、そのうち、zip形式のファイル取り込みをGoで実装する際のTipsを書きます。今回はzipの実装を例に説明しますが、gzipファイル取り込みの際も同じ手法が使えます。環境・使用するライブラリ情報
()は実装時のバージョンです。
- Mac OS (Mojave 10.14)
- go (1.14.1 darwin/amd64)
- golangci-lint (1.31.0)
事象
zipファイル取り込みを実装してみると、lintで下記のような不穏なメッセージが。。
before.goimport ( "archive/zip" "io" "os" "path/filepath" "golang.org/x/xerrors" ) // src:対象zipファイルが格納されているパス // dest:対象zipファイルの格納先 func Decompress(src, dest string) error { r, err := zip.OpenReader(src) for _, f := range r.File { // zipファイルを開く rc, err := f.Open() // zipファイル格納先を定義する path := filepath.Join(dest, f.Name) // 新規ファイルを作成する f, err := os.OpenFile(path, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, 0666) // 作成したファイルにzipファイルをコピーする if _, err := io.Copy(f, rc); err != nil { return xerrors.Errorf("failed to io copy: %w", err) } } return nil }出力されるlintエラーbefore.go:21: G110: Potential DoS vulnerability via decompression bomb (gosec)取り込むファイルのファイルサイズ上限を設定していないことにより、DoS攻撃、この場合高圧縮ファイル爆弾1などの悪意ある攻撃が制御できないことの警告のようです。
対応策
外部システムからファイル連携される以上、どこかで怪しいファイルを検知しておかないと、いざという時にシステムがやられていまい大変なことになりますね。
それでは、上記の脅威とlintエラーを撲滅していきましょう。必要なことは3つです。
- 取り込むファイルサイズの上限値を設定する
io.CopyN()を使う- ファイルサイズ上限値抵触とそれ以外のエラーをそれぞれハンドリングする
以下、それぞれ解説します。
1. 取り込むファイルサイズの上限値を設定する
まず、取り込みを許容するファイルサイズの上限値を決めます。取り込もうとしているファイルが異常なものかどうかを判断する基準になります。
システムの要件にもよりますが、ここでは仮に1GBと置きます。const MaxFileSize = 1073741824 //1GB2. io.CopyN()を使う
io.Copy()は対象ファイルとコピーするファイルの2値を引数として動作しますが、これでは関数実行時にファイルが大きすぎることに気付くことができず、結局システムがクラッシュするまでコピーが実行されてしまいます。
そこで、io.CopyN()を使用します。2これにより、ファイルサイズ上限値を3つ目の引数として渡すことができます。
関数の中では、コピーしたファイルのバイト数が上限値に達するか、エラーが発生するまでコピーが実行されます。
before.go の実装を置き換えるとこのようになりますね。if _, err := io.CopyN(f, rc, MaxFileSize); err != nil { return xerrors.Errorf("failed to io copy: %w", err) }良さそうに見えますが、このままだと下記2点の課題が残ります。
- 上限値に満たないサイズのファイルが連携された時、EOFエラーを起こしてしまう
3つ目の引数で渡されたサイズ分コピーを行おうとするので、コピー元がそのファイルサイズより小さい場合、さらにアクセスしようとしてエラーとなってしまいます。
- 本当に悪意のあるファイルが来た時に警告することができない
仮に何十GBのファイルが来た場合、1GBでコピー処理は切り上げられるためシステムのクラッシュは避けることができますが、エラーが起こっているわけではないため異常なファイルが連携されたことを検知することはできないままです。
3. ファイルサイズ上限値抵触とそれ以外のエラーをそれぞれハンドリングする
そこで、以下のようにハンドリングするようにします。
上限値に満たないサイズのファイルが連携された時、EOFエラーを起こしてしまう
EOFエラーの制御を除外します。
エラーハンドリング時に、この関数がEOFエラーを返却する時は、すなわちコピー元のファイル分のコピーが完了していることとみなし、E0Fエラーでないことを条件に加えます。if err != nil && err.Error() != io.EOF.Error() { return xerrors.Errorf("failed to io copy: %w", err) }本当に悪意のあるファイルが来た時に警告することができない
io.CopyN()の1つ目の返り値である、コピー済みのファイルサイズ(byte単位)を利用します。
この値が、上限値を上回っているかどうか確認することで、異常な容量のファイルが連携された場合検知することができます!writeCount, err := io.CopyN(f, rc, MaxFileSize) // 先にEOF以外のエラーをハンドリングする if err != nil && err.Error() != io.EOF.Error() { return xerrors.Errorf("failed to io copy: %w", err) } // 正常にコピーできている状態かつ、コピーしたファイルサイズが上限値に抵触していないことを確認する if writeCount >= MaxFileSize { return xerrors.Errorf("this file might be a zip bomb!: %s", src) }まとめのコード
ここまでの処理をコードに表すとこのようになります。
これでlintからも警告が出力されなくなりました!after.goimport ( "archive/zip" "io" "os" "path/filepath" "golang.org/x/xerrors" ) // src:対象zipファイルが格納されているパス // dest:対象zipファイルの格納先 func Decompress(src, dest string) error { // 1. 取り込むファイルサイズの上限値を設定する const MaxFileSize = 1073741824 // 1GB r, err := zip.OpenReader(src) for _, f := range r.File { // zipファイルを開く rc, err := f.Open() // zipファイル格納先を定義する path := filepath.Join(dest, f.Name) // 新規ファイルを作成する f, err := os.OpenFile(path, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, 0666) // 作成したファイルにzipファイルをコピーする // 2. io.CopyN()を使う writeCount, err := io.CopyN(f, rc, MaxFileSize) // 3. ファイルサイズ上限値抵触とそれ以外のエラーをそれぞれハンドリングする // 先にEOF以外のエラーをハンドリングする if err != nil && err.Error() != io.EOF.Error() { return xerrors.Errorf("failed to io copy: %w", err) } // 正常にコピーできている状態かつ、コピーしたファイルサイズが上限値に抵触していないことを確認する if writeCount >= MaxFileSize { return xerrors.Errorf("this file might be a zip bomb!: %s", src) } } return nil }出力されるlintエラー(出力なし)終わりに
よくぶち当たりそうな課題だと感じましたが、どんぴしゃな記事がなくハマったので言語化にトライしました。
これでもうクラッシュもlintの警告も怖くありません!安心してzipを取り込みつつ、素敵なクリスマスをお過ごしください。
展開すると物凄い大きさのファイルサイズになり、読み込んだシステムの負荷を高めてクラッシュさせてしまうような、悪意のある圧縮ファイルのことです。英語ではZip Bombとも呼ばれます。参考:高圧縮ファイル爆弾(Wikipedia) ↩
- 投稿日:2020-12-04T12:57:03+09:00
golang でPDFの表紙サムネを高速作成!
はじめに
golang からPDFの表紙サムネを高速に作成する方法を紹介します。
よくある選択肢としてはImageMagickがあると思いますが、今回はより軽量なlibvipsを利用します。やってみよう
必用なもの
- golang
- libvips (
apt insall libvipson Utuntu 20.04)やりかた?
libvips を golang から使えるようにしてくれるありがたいパッケージ bimg (https://github.com/h2non/bimg) を使います。
main.gopackage main import ( "log" "github.com/h2non/bimg" ) func main() { buffer, err := bimg.Read("input.pdf") if err != nil { log.Fatal(err) } jpg, err := bimg.NewImage(buffer).Convert(bimg.PNG) if err != nil { log.Fatal(err) } thumb, err := bimg.NewImage(jpg).Resize(256, 256) if err != nil { log.Fatal(err) } bimg.Write("thumb.png", thumb) }input.pdf を用意して上記のコードを実行すると、PDFの1ページ目のサムネが thumb.png に保存されます。
非常に高速で大きなサイズのPDFでも高速でした。
ファイラーやDrive系サービス用のサムネ生成などにはいいかもしれません。
- 投稿日:2020-12-04T10:54:27+09:00
Eventarcを使用した非同期でジョブを実行するSlackAppづくり
はじめに
本記事はGoogle Cloud + Gaming Advent Calendar 2020 7日目の記事です。
Cloud Runを使ったSlackAppにおいて普通のVMにおける開発とは違う注意点があったのでそのあたりを書いていきたいと思います。
なぜCloud Runを使うかについては「開発環境をGKE運用からサーバーレス運用に変更してみた」にて書かせていただきました。こちらも合わせて読んでいただけると嬉しいです。とはいえSlackAppづくりだけであれば同じサーバーレスサービスのCloud Functionsの方が向いているとは思います(笑)。
また本記事でのEventarcについては一部まだpreview版の機能を使用しているため今後の変更により動かなくなることもあるかもしれませんのでご了承ください。Eventarcについて
先月発表されましたGCPの新しい機能です。下手な説明するよりもこちらの記事が分かりやすいです。
- Trigger Cloud Run with events from more than 60 Google Cloud sources
- 60 を超える Google Cloud ソースのイベントで Cloud Run をトリガーする
簡潔に説明するのなら、、上記タイトルの通りです(笑)。
以前からCloud BuildやCloud Storage等のイベントは特定のCloud Pub/Subトピックにpushされる仕組みがあって(cloudbuild-notifications, storage-notifications)それを使ってCloud Functions等を動かしていたので、特別使用感が変わることはなさそうですが、Eventarcによってそれらイベントが一元管理されるのかな、ぐらいの認識です。
今後のビジョンとしてはCloud Run意外のたくさんのトリガー(Event Sinkというみたいです)を作れるようになるみたいです。
Long Term Vision
まだ発表されたばかりなので今後の動きに注目です!とはいえ現在はCloud RunのみSinkを作れるのでCloud Functionsではまだ使えません。
したがって(?)、本記事のタイトルはEventarcですが基本的にはCloud Runの話です。 Eventarcのユースケースを考えていたらSlackAppづくりで使えそうと思ったので、、手段が目的になっています。Cloud RunにおけるSlackAppづくりの注意点
環境変数に機密情報を入れてはいけない
多くの場合SlackApp開発のサンプルコードでは、SlackのAccessTokenやSigningSecretは環境変数から取得するものが多いと思います。普通ならそれでも特に問題ないのですがGCPのサーバーレスサービスにおいては大問題です。これはCloud RunだけでなくCloud Functionsも同様です。
GCPのマネージドサーバーレスサービスはログをCloud Loggingに出力してくれます。とても便利です。しかし、使用しているライブラリによっては環境変数をすべてログに出力するようなものもあるみたいなので、環境変数に機密情報を入れていると思わぬところで流出しかねません(外部に、というよりログ閲覧権限しかIAMで振ってない人やサービスに対しても、という意味。)。したがって環境変数に機密情報を格納すべきではないです。Cloud Run
Cloud Functions
ただ、そもそもCloud RunやCloud Functionsに限らず環境変数に機密情報は置かないほうが良いと思います。これは個人の意見です。
機密情報管理のベストプラクティス
ずばりSecret Managerを使うことです。とても簡単に使えて便利です。
あまりに簡単なのでドキュメント通りに作るだけです。普段はgcloudコマンドで作成・更新しています。Makefileにまとめているのでgcloudコマンドを意識してはいませんが(笑)。Secret Managerへアクセスするための設定(Terraform)
普段GCPの設定はTerraformを使っているのでTerraformにて説明していきます。ただし、Secret自体の作成・更新は性質上terraformのコードとはリポジトリを切り分けたかったのでterraformではなくgcloudコマンドを使っています。
▼ サービスアカウントの作成
resource "google_service_account" "this" { account_id = "サービスアカウントのID(なんか適当に)" display_name = "CloudRun用のサービスアカウント" }▼ 作成したサービスアカウントにSecretManagerへのアクセス権を付与
resource "google_secret_manager_secret_iam_member" "this" { secret_id = "作成したシークレット名" role = "roles/secretmanager.secretAccessor" member = "serviceAccount:${google_service_account.this.email}" }▼ そのサービスアカウントをCloudRunサービスに使わせる
Cloud Run自体のTerraformはいろいろ省略してますがサービスアカウントの部分だけを見ていただければと思います。
これをしないとデフォルトではCompute Engine のデフォルトのサービス アカウントが使用されます。それはEditor権限を持ったサービスアカウントなので強すぎます。ドキュメントでは専用のサービスアカウントにすることをおすすめする程度ですがCloud Runのサービスごとサービスアカウントは分けたほうが良いと思います。これは個人の意見です。
あとEditor権限だけだとSecretManagerへのアクセス権はないので共同開発者にはEditor権限とは別にSecret Manager Admin権限等も必要かもしれません。resource "google_cloud_run_service" "this" { name = "CloudRunサービス名" location = "asia-northeast1" template { spec { containers { // 省略... } service_account_name = google_service_account.this.email } } }Secret Managerへアクセスする(Golang)
普段Golangで開発することが多いのでGolangでの説明になります。また、実際に動いているコードではなく抜粋して編集しているため、もしかするとそのままだと動かないかもしれません。
また、SecretManagerで保存したテキストは下記のようなyaml形式を想定したものです。SlackAccessToken: xoxb-xxxxxxxxxxx-xxxxxxxxxx SlackSigningSecret: xxxxxxxxxxxxxxxxxxxxxxpackage main import ( "context" "fmt" "os" "cloud.google.com/go/secretmanager/apiv1" secretmanagerpb "google.golang.org/genproto/googleapis/cloud/secretmanager/v1" "gopkg.in/yaml.v2" ) func main() { // Cloud RunではPROJECT_IDとPORTが自動でついてきます。 // httpサーバーをリッスンするときにこのPORTを使います。 port := os.Getenv("PORT") projectID := os.Getenv("PROJECT_ID") // SecretManagerのSecretNameはコード埋め込みでも環境変数でもどちらでもいいと思います。 secretName := "demo-secret" // SecretManagerのSecretVersionは環境変数で渡してます。 // これに関してはコード埋め込みだとCloudRun上では使い勝手悪いと思います。 secretVersion := os.Getenv("SECRET_VERSION") ctx := context.Background() // Secret Manager Client作成 client, err := secretmanager.NewClient(ctx) if err != nil { panic(err) } defer client.Close() // Secret Managerへアクセスする req := &secretmanagerpb.AccessSecretVersionRequest{ Name: fmt.Sprintf("projects/%s/secrets/%s/versions/%s", projectID, secretName, secretVersion), } result, err := client.AccessSecretVersion(ctx, req) if err != nil { panic(err) } // yamlのunmarshal cfg := &config{} if err := yaml.Unmarshal(result.Payload.Data, cfg); err != nil { panic(err) } } type config struct { SlackAccessToken string `yaml:"SlackAccessToken"` SlackSigningSecret string `yaml:"SlackSigningSecret"` }slackの制約上3秒以内にレスポンスしたいが非同期でジョブを動かせない
本記事の本題です。
まずslackのslash commandやinteractive eventは3000ms以内にレスポンスを返さないとタイムアウトしてしまいます。
したがってslash command等で重いジョブを動す場合、通常であれば一度slackにレスポンスを返して裏で非同期でジョブを動かす手法が多いと思います。シーケンス図で表すとこのようなイメージだと思います。User -> Slack : スラッシュコマンド実行 Slack -> 自作SlackApp : webhook発行 自作SlackApp -> 自作SlackApp : Slackからの通信か検証 自作SlackApp -> Slack : 一旦200OKで返す Slack -> User : スラッシュコマンドが完了する 自作SlackApp -> 自作SlackApp : 任意のジョブ動かす 自作SlackApp -> Slack : chat.postMessage APIを使ってジョブ結果を伝える Slack -> User : 追加の情報が表示される
Cloud Runはリクエストがなくなればコンテナがなくなる?
リクエスト終了からどのくらい経つとコンテナが終了するのかはわかりませんが、さきほどのシーケンス図でいうところの「一旦200OKで返す」をして任意のジョブを動かしている最中にコンテナが強制終了してしまうかもしれません。これに関しては申し訳ありませんが未確認です。
Webhookプロバイダにタイムアウト制約がある場合の非同期処理
前述の方法でジョブが中断されるかは未確認ではありますが、ドキュメントにはこういったケースの注意事項が記載されています。
まさにこれはslackのことを言っているのではないでしょうか!
ということで従来であればPub/Subへpushして別のCloud Runがそのpushをトリガーに起動する、といった方法を取るところですが、今回はEventarcを使っていきたいと思います。Eventarc設定方法
EventarcについてはまだTerraformもありませんしGCPコンソール上にもありませんのでgcloudコマンドで設定していきます。
ドキュメントはこちらです。
...書いていこうかと思ったのですが、ほぼドキュメントと同じ記述になってしまうのでやめました。
golang側のコードに関してもこちらがそのまま使えると思います。
簡単な流れは
- Eventarcをトリガーに起動する用(Event Sink)のCloud Runを作成する。
- 今回でいうとこれはジョブを実行する用のCloud Runです。
- そのCloud Run(Event Sink)に紐付いたEventarcのpub/subトリガーを作成
- するとpub/subトピックが作成されている
- slackからのレシーバー用Cloud Runからそのトピックへpushする
User -> Slack : スラッシュコマンド実行 Slack -> 自作SlackApp1 : webhook発行 自作SlackApp1 -> 自作SlackApp1 : Slackからの通信か検証 自作SlackApp1 -> CloudPubSub : Eventarc用のトピックへ情報をpush 自作SlackApp1 -> Slack : 200OKで返す Slack -> User : スラッシュコマンドが完了する CloudPubSub -> 自作SlackApp2 : Eventarcによって起動する 自作SlackApp2 -> 自作SlackApp2 : 任意のジョブ動かす 自作SlackApp2 -> Slack : chat.postMessage APIを使ってジョブ結果を伝える Slack -> User : 追加の情報が表示される
まとめ
今回Eventarcのユースケースについて考えてみました。Eventarcを使わずに普通のPub/Subを使ってしまうと実装者によってバラバラなフォーマットがトピックに流れてしまうかもしれません。Eventarcを使うことで統一され、より整合性のあるコードになるのではないかと思います。また、今回カスタムソースについてしか触れませんでしたが、他にも60を超えるGoogleCloudソースが扱えるわけですから、別の利用方法も模索していきたいと思います。



- 投稿日:2020-12-04T08:06:04+09:00
Golang on さくらVPS
株式会社アクシスのアドベントカレンダー5日目担当のヤマウチです!
さくらVPSを契約して遊んでみたので、それを記事にしました!ということでさっそく本題。
先日作成した記事「【Go】標準入力から受け取ったポケモンの種族値を返すツールを作成」のAPI部分をさくらVPSに乗せました。
いつでもどこからでもAPIを叩きたい衝動に駆られて、VPS契約しました。
固定IP最高\(^o^)/
まあ、一番安いプランですが。ということで、今回はさくらVPSにOSをインストールした直後から、GoのAPIを叩ける状態にする、という部分の記事です。
前提条件
- centos8
- rootユーザーにSSH接続ができる
- xxx.xxx.xxx.xxx はIPアドレスを意味する
- wsl2
さて、始めます。
ユーザー作成
VPSにSSH接続を行い、
keisukeという一般ユーザーを作成する。# ユーザー作成 $ adduser keisuke # パスワード設定 $ passwd keisukesudo権限を付与
作成したユーザーにsudo権限を付与する。
$ visudo以下の2行のコメントアウトを外す。
- %wheel ALL=(ALL) ALL
- %wheel ALL=(ALL) NOPASSWD: ALL
ユーザーをwheelグループに追加する。
$ usermod -aG wheel keisukewheelに追加されたか確認する。
# 作成したユーザーにログイン $ su keisuke # 所属しているグループを確認 $ groups # wheelと表示されればOKもしwheelと表示されない場合は、ターミナルを再起動して、再度
groupsを実行。ユーザーでSSH接続
続いて作成したユーザーでSSH接続できるようにする。
(必要あるかわかんないけど)一般ユーザーに切り替える。$ su keisuke.sshを作成
ユーザーを作成したばかりで.sshディレクトリが存在しないので、作成する。
# ホームディレクトリに移動 $ cd ~ # .sshを作成 $ mkdir .ssh # パーミッションを700に変更 $ chmod 700 .sshSSHするためには.sshディレクトリのパーミッションを700にする必要がある。
公開鍵を登録する
一旦
exitでSSH接続から抜け、scpを使って公開鍵をVPSにコピーする。
※事前に各自、公開鍵を置いているディレクトリに移動$ scp id_rsa.pub xxx.xxx.xxx.xxx:~/.ssh
scpで公開鍵をコピーしたらSSH接続をする。# 作成したkeisukeでSSH接続 $ ssh keisuke@xxx.xxx.xxx.xxx # .sshに移動 $ cd .ssh # id_rsa.pubがあるか確認 $ ls # 公開鍵を登録 $ cat id_rsa.pub >> authorized_keys # パーミッションを変更 $ chmod 600 authorized_keys公開鍵の登録が完了したら、一度exitでSSHから抜け、再度SSH接続をする。
その際にパスワードを求められなければ、公開鍵でのSSH接続が成功している。SSH接続の設定を変更する
設定ファイルをいじるので、rootユーザーでログインする。
$ su -SSH接続のパスワード認証を禁止
/etc/ssh/sshd_configを編集する。#PasswordAuthentication yes ↓ PasswordAuthentication norootユーザーでのSSH接続を禁止
引き続き
/etc/ssh/sshd_configを編集する。PermitRootLogin yes ↓ PermitRootLogin nosshdを再起動
設定ファイルを反映させるため、sshdを再起動する。
$ systemctl restart sshdGoのバイナリファイルをSCP
ここまでで基本的な設定は完了したので、次にGoのバイナリファイルをさくらVPSに置く。
まずはローカルのプロジェクト配下に移動する。$ cd projectバイナリファイルを作成
まずは
go buildを行い、バイナリファイルを作成する。
普通にgo buildをすると自分の開発環境にあったバイナリファイルが作成されるため、実行環境に合わせたバイナリファイルを生成する必要がある。
今回の僕のパターンだと、windows端末で開発をして、実行する環境はさくらVPSのCentOSなので、CentOSで動くバイナリファイルを生成する。
とはいえ、WSL2を使用しているので今回は気にしなくて良さげ。一応現状を確認
$ go env GOOS # linux $ go env GOARCH # amd64うむ、そのままbuildする。
$ go build main.go # mainというファイルが生成されていることを確認する $ lsscpでファイルをサーバーにコピー
どこに置くのが正解かわかってないので、とりあえず今回はユーザーのディレクトリにコピーする。
# vpsはssh_configで設定している $ scp main vps:~ # これも必要なのでscp $ scp pokedex.json vps:~バイナリファイルを実行する
ファイルのコピーが完了したので、実行する。
まずはSSH接続。$ ssh vps
mainがコピーされていることを確認する。$ ls確認ができたら
mainを実行する。$ ./main&実行状態をlsofコマンドで確認する。
今回のアプリがLISTENしているのは18888なので、そのポートを確認する。
※lsofのインストール手順等は省略# ポート18888をLISTENしていることを確認する $ lsof -i:18888 # こんな表示が出る COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME main 22373 keisuke 3u IPv6 135702 0t0 TCP *:apc-necmp (LISTEN)問題なさそう。
ということでxxx.xxx.xxx.xxx:18888にアクセスしてみる。このサイトにアクセスできません
ここがハマりポイント。
今回書いてはいないがfirewallの設定もしており、そこに原因があると思って一生懸命調べていたが、
原因はさくらVPSのパケットフィルタの設定だった。。。ということでさくらVPSのコンソールへGO!
パケットフィルタの設定を追加する。
これ↑をこう↓
これで再度APIを叩いてみる。
xxx.xxx.xxx.xxx:18888にアクセス。
よし、返ってきてる。
まとめ
ということで無事さくらVPSにGoのバイナリファイルを置いて、APIを叩くことができました。
バイナリファイルを置くだけでAPIを叩けるってのがすごい。
nginxとか、webサーバーがなくてもいいってのが、その辺の知識が弱いせいで「マジかよ」ってなってます。firewallの設定を間違ったせいでSSH接続が一切できなくなるというのも経験しました。。。w
それを自分のVPSで経験できただけでも、良かったかなぁって感じです。
github actionsを使用して、自動デプロイもできるようにしたので、気が向けば記事にしますwおしまい。




- 投稿日:2020-12-04T07:00:18+09:00
分散トレーシングシステムのJaegerをKubernetes環境に導入する
背景
約1年前に分散トレーシングシステムの DatadogAPM (Application Performance Monitoring)を導入したのですが、高級な機能なため、先月この機能の利用をやめることにしました。
そこで代わりとなるツールの内、Jaegerを検証も兼ねて環境構築したので、手順などをまとめることにしました。今回はgRPC ServerをGoで実装し、Kubernetesにデプロイします。
また、ORMのgormを使って、sqlごとにspanを記録するための実装も紹介します。分散トレーシングとは
分散トレーシングは、マイクロサービスなどのアプリケーションの監視やトラブルシューティングなどに使用される方法です。障害が発生した場所とパフォーマンスの低下の原因を特定するのに役立ちます。
分散トレーシングには、主に
TraceとSpanという概念があります。
Spanは、1回のsqlの実行や、1回の外部へのリクエストなど、各操作の開始から終了を表します。
Traceは、全体の開始から終了までのSpanの集合です。
以下の図を見ると、イメージしやすいと思います。
Architecture — Jaeger documentationJaegerとは
CNCF(Cloud Native Computing Foundation)のGraduatedプロジェクト。
公式には以下のように書かれています。
Jaeger, inspired by Dapper and OpenZipkin, is a distributed tracing system released as open source by Uber Technologies. It is used for monitoring and troubleshooting microservices-based distributed systems, including:
・Distributed context propagation
・Distributed transaction monitoring
・Root cause analysis
・Service dependency analysis
・Performance / latency optimizationマイクロサービスベースの分散システムの監視、トラブルシューティング、パフォーマンス/レイテンシーの最適化などに利用されているようです。Uberが開発したみたいですね。
環境
Docker for Macを用いて、以下のKubernetes環境で構築していきます。
$ kubectl version --short Client Version: v1.17.4 Server Version: v1.18.8インストール
公式には jaeger-kubernetes と jaeger-operator の2種類がありますが、前者はアーカイブされていて開発が止まっているので、後者を使います。
前提として、ingress-controllerがデプロイされている必要があります。
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.41.2/deploy/static/provider/cloud/deploy.yaml次に、Jaeger Operatorをインストールしていきます。
$ kubectl create namespace observability $ kubectl create -n observability -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/crds/jaegertracing.io_jaegers_crd.yaml $ kubectl create -n observability -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/service_account.yaml $ kubectl create -n observability -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/role.yaml $ kubectl create -n observability -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/role_binding.yaml $ kubectl create -n observability -f https://raw.githubusercontent.com/jaegertracing/jaeger-operator/master/deploy/operator.yaml次に、Jaegerインスタンスを作成します。
$ kubectl apply -n observability -f - <<EOF apiVersion: jaegertracing.io/v1 kind: Jaeger metadata: name: simplest EOFしばらく待ってから以下のコマンドを実行し、JaegerUIのアクセス情報を取得します。
$ kubectl get -n observability ingress NAME CLASS HOSTS ADDRESS PORTS AGE simplest-query <none> * localhost 80 74mこれにより、http://localhost でJaegerUIにアクセスできます。
この画面が表示できたら、JaegerUIの構築は完了です。
実装
公式の サンプルコード を参考にして、Tracerを実装します。
ライブラリのインストール
$ go get -u github.com/uber/jaeger-client-go $ go get -u github.com/grpc-ecosystem/grpc-opentracingTracerの初期化
package main import ( "io" "github.com/grpc-ecosystem/grpc-opentracing/go/otgrpc" "github.com/opentracing/opentracing-go" jaegercfg "github.com/uber/jaeger-client-go/config" jaegerlog "github.com/uber/jaeger-client-go/log" "github.com/uber/jaeger-lib/metrics" "google.golang.org/grpc" ) func main() { closer, err := startJaegerTracer() if err != nil { panic(err) } defer closer.Close() s := grpc.NewServer( grpc.UnaryInterceptor( otgrpc.OpenTracingServerInterceptor(opentracing.GlobalTracer()), ), ) // continue main() } func startJaegerTracer() (io.Closer, error) { cfg, err := jaegercfg.FromEnv() if err != nil { return nil, err } tracer, closer, err := cfg.NewTracer(jaegercfg.Logger(jaegerlog.StdLogger), jaegercfg.Metrics(metrics.NullFactory)) if err != nil { return nil, err } opentracing.SetGlobalTracer(tracer) return closer, nil }環境変数から必要な値を取得し、Tracerを初期化します。
opentracing.SetGlobalTracerに渡すことで、シングルトンとして保持できます。
また、grpc.UnaryInterceptorに、Spanを開始するための関数を渡します。gormの実装
各sqlの開始と終了でSpanが記録されるようにする必要があるので、gormのコールバックを実装します。
package database import ( "strings" "github.com/jinzhu/gorm" "github.com/opentracing/opentracing-go" "github.com/opentracing/opentracing-go/ext" ) const ( parentSpanGormKey = "opentracingParentSpan" spanGormKey = "opentracingSpan" ) func WithCallbacks(db *gorm.DB) { afterFunc := func(operation string) func(*gorm.Scope) { return func(scope *gorm.Scope) { after(scope, operation) } } db.Callback().Create().Before("gorm:create").Register("tracing:create_before", before) db.Callback().Create().After("gorm:create").Register("tracing:create_after", afterFunc("gorm.create")) db.Callback().Update().Before("gorm:update").Register("tracing:update_before", before) db.Callback().Update().After("gorm:update").Register("tracing:update_after", afterFunc("gorm.update")) db.Callback().Delete().Before("gorm:delete").Register("tracing:delete_before", before) db.Callback().Delete().After("gorm:delete").Register("tracing:delete_after", afterFunc("gorm.delete")) db.Callback().Query().Before("gorm:query").Register("tracing:query_before", before) db.Callback().Query().After("gorm:query").Register("tracing:query_after", afterFunc("gorm.query")) db.Callback().RowQuery().Before("gorm:row_query").Register("tracing:row_query_before", before) db.Callback().RowQuery().After("gorm:row_query").Register("tracing:row_query_after", afterFunc("gorm.row_query")) } func before(scope *gorm.Scope) { v, ok := scope.Get(parentSpanGormKey) if !ok { return } parentSpan := v.(opentracing.Span) tr := parentSpan.Tracer() sp := tr.StartSpan("sql", opentracing.ChildOf(parentSpan.Context())) ext.DBType.Set(sp, "sql") scope.Set(spanGormKey, sp) } func after(scope *gorm.Scope, operation string) { v, ok := scope.Get(spanGormKey) if !ok { return } sp := v.(opentracing.Span) if operation == "" { operation = strings.ToUpper(strings.Split(scope.SQL, " ")[0]) } ext.Error.Set(sp, scope.HasError()) ext.DBStatement.Set(sp, scope.SQL) sp.SetTag("db.table", scope.TableName()) sp.SetTag("db.method", operation) sp.SetTag("db.err", scope.HasError()) sp.SetTag("db.count", scope.DB().RowsAffected) sp.Finish() }この
WithCallbacksをDB接続時に実行します。// ConnectDB connects to mysql. func ConnectDB() *gorm.DB { db, err := gorm.Open("mysql", "root:password@tcp(db)/innovators?charset=utf8mb4&parseTime=True&loc=UTC") if err != nil { panic(err.Error()) } database.WithCallbacks(db) return db }最後に、各APIでgormのDBインスタンスに親のSpanをセットします。
親のSpanは、先ほどのgRPCのInterceptorで、コンテキストから取得できるようになっています。
これによって、クエリ1つ1つが子のSpanとして記録されるようになります。package database func SetSpan(ctx context.Context, db *gorm.DB) *gorm.DB { if ctx == nil { return db } parentSpan := opentracing.SpanFromContext(ctx) if parentSpan == nil { return db } return db.Set(parentSpanGormKey, parentSpan) }環境変数
Jaeger Client Go Initializationによると、以下の3つの環境変数を使用するようです。
変数名 説明 JAEGER_SERVICE_NAME サービス名 JAEGER_AGENT_HOST JaegerAgentのホスト名。デフォルトlocalhost JAEGER_AGENT_PORT JaegerAgentのポート。デフォルト6831 また、
jaegercfg.FromEnv()の実装を見ると、これらの環境変数を読み込むようになっています。const ( // environment variable names envServiceName = "JAEGER_SERVICE_NAME" envAgentHost = "JAEGER_AGENT_HOST" envAgentPort = "JAEGER_AGENT_PORT" ) // FromEnv uses environment variables and overrides existing tracer's Configuration func (c *Configuration) FromEnv() (*Configuration, error) { if e := os.Getenv(envServiceName); e != "" { c.ServiceName = e } // 省略 if r, err := c.Reporter.reporterConfigFromEnv(); err == nil { c.Reporter = r } else { return nil, errors.Wrap(err, "cannot obtain reporter config from env") } // 省略 } // reporterConfigFromEnv creates a new ReporterConfig based on the environment variables func (rc *ReporterConfig) reporterConfigFromEnv() (*ReporterConfig, error) { // 省略 useEnv := false host := jaeger.DefaultUDPSpanServerHost if e := os.Getenv(envAgentHost); e != "" { host = e useEnv = true } port := jaeger.DefaultUDPSpanServerPort if e := os.Getenv(envAgentPort); e != "" { if value, err := strconv.ParseInt(e, 10, 0); err == nil { port = int(value) useEnv = true } else { return nil, errors.Wrapf(err, "cannot parse env var %s=%s", envAgentPort, e) } } if useEnv || rc.LocalAgentHostPort == "" { rc.LocalAgentHostPort = fmt.Sprintf("%s:%d", host, port) } // 省略 }というわけで、環境変数を設定していきます。
JAEGER_SERVICE_NAMEは何でも構いません。私が所属しているプロジェクトはVISITS innovatorsという名前なので、これを設定します。
JAEGER_AGENT_HOSTとJAEGER_AGENT_PORTは適切な値を設定する必要があります。
何を設定すべきか、調べてみましょう。$ kubectl get svc -n observability NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE jaeger-operator-metrics ClusterIP 10.106.87.188 <none> 8383/TCP,8686/TCP 115m simplest-agent ClusterIP None <none> 5775/UDP,5778/TCP,6831/UDP,6832/UDP 115m simplest-collector ClusterIP 10.107.219.132 <none> 9411/TCP,14250/TCP,14267/TCP,14268/TCP 115m simplest-collector-headless ClusterIP None <none> 9411/TCP,14250/TCP,14267/TCP,14268/TCP 115m simplest-query ClusterIP 10.105.33.225 <none> 16686/TCP 115m
simplest-agentがJaeger Agent用のServiceです。
ただし、アプリケーションのPodとは別のNamespaceなので、JAEGER_AGENT_HOSTはsimplest-agent.observabilityになります。
ポートはデフォルトのまま(6831)で問題ありません。アプリケーションの都合上、Secretを作成することにします。
$ kubectl create secret generic env-secret \ --from-literal=JAEGER_SERVICE_NAME='VISITS innovators' \ --from-literal=JAEGER_AGENT_HOST='simplest-agent.observability' \ --from-literal=JAEGER_AGENT_PORT=6831動作確認
アプリケーションを起動し、適当にAPIを叩いてみました。
すると、JaegerUIでは以下のように、TraceやSpanが表示されました。
まとめ
あるAPIのレイテンシが長いとき、どこに原因があるのか特定するために、分散トレーシングシステムは有効と言えるでしょう。実際、私のプロジェクトでも、パフォーマンスの悪いクエリが実行され、異様に長いSpanが記録されたことで、原因の特定および修正を迅速に行えた実績があります。
Jaegerは公式ドキュメントも充実していますし、導入コストも割と低い気がします。
いきなり有料のツールを使うのではなく、まずはJaegerのようなOSSの分散トレーシングシステムを使ってみてはいかがでしょうか。




- 投稿日:2020-12-04T06:29:33+09:00
Goのnilに関するヤヤコシイ話
問題
以下のコードを実行するとどうなるか?
package main import "fmt" type unit struct{} func (u *unit) String() string { return "UNIT" } func null() *unit { return nil } func main() { var s fmt.Stringer = null() if s != nil { fmt.Println(s.String()) } }
- コンパイルエラー
- 実行時panic
UNITが出力される- 何も起こらない
解答
解答
3.UNITが出力される
解説
本問題のテーマは「Goのヤヤコシイnilの挙動」です。要点は次の2つです。
- ポインタのnil値は「参照ができない」だけ
- インタフェースのnil値とポインタのnil値は違う
ポインタのnil値
ポインタのnil値は「参照先が存在しない」ことを示すものであるため、参照先取得(dereference)はできない(panicが発生する)のは当然です。注意すべきなのは「参照先取得が起こらない限りはnil値の操作は問題がない」ということです。
本問題では、ポインタのnil値をもつ変数
xについてのセレクタ式x.fの解釈が問題になっています。これについて言語規格では以下のように定めています。If
xis of pointer type and has the valuenilandx.fdenotes a struct field, assigning to or evaluatingx.fcauses a run-time panic.
(Selectors)もし「
xが構造体のポインタでありfがその構造体のフィールドを指す」のであれば、x.fは実質的に(*x).fと等価であり、そのフィールドへのアクセスは「xの参照先取得」を要するためpanicとなります。しかし、
fがメソッドを指す場合は、x.fという式そのものはxの参照先取得を伴いません。またx.f(…)のようにメソッドを呼び出す場合についても、(ポインタレシーバである場合は)レシーバのxは単に引数として関数に渡されるだけなのでやはりxの参照先取得は起こりません。つまり、x.f(…)は無問題です。※もしメソッド
x.fが値レシーバである場合は、関数に渡されるのは参照先取得した*xとなるため、x.f(…)はpanicになります。インタフェースのnil値
明確な記述がなくてアレなんですが、言語規格において、「インタフェースのnil値1」は「ポインタのnil値」とは(また「その他の種類」の型のnil値」とも)区別されています。
Variables of interface type also have a distinct dynamic type, which is the concrete type of the value assigned to the variable at run time (unless the value is the predeclared identifier nil, which has no type). The dynamic type may vary during execution but values stored in interface variables are always assignable to the static type of the variable.
(Variables)ここでは、インタフェースのnil値は動的型を持たないと述べられていて、この点でポインタのnil値とは性質が異なることがわかります。また、この文には以下の例示コードが続いています。
var x interface{} // x is nil and has static type interface{} var v *T // v has value nil, static type *T x = 42 // x has value 42 and dynamic type int x = v // x has value (*T)(nil) and dynamic type *T1行目は「
xがインタフェースのnil値」をもつ場合で、これについては「xはnilである」と書かれています。これに対して「xが*T型のポインタのnil値」をもつ4行目では「xは値(*T)(nil)をもち動的型*Tをもつ」と書かれています。先の引用文にある規定より「xがnilであるならば動的型をもたない」はずなので、結局この場合は「xはnilではない」と解釈するしかありません。つまり、言語規格では、「インタフェース型の変数xがポインタのnil値(*T)(nil)をもつ」場合は「xはnil値をもたない」(あるいは「xはnilではない」)と扱われるのです。要するに「インタフェース型の話をするときにはポインタのnil値はnilではない」のです。詳細
以上の要点を踏まえて
main()の実行を追ってみます。1行目var s fmt.Stringer = null()
null()は*unit型のnil値を返します。上の文は以下のものと同値です。var s fmt.Stringer = (*unit)(nil)つまり
sには*unit型の「ポインタのnil値」が入ります。2行目if s != nil {インタフェース型の等価比較は次のように決められています。
Interface values are comparable. Two interface values are equal if they have identical dynamic types and equal dynamic values or if both have value
nil.
(Comparison operators)つまり「①両者が同一の動的型と等価な動的値をもつ」または「②両者がnil値をもつ」場合です。従って、
s == nilの比較では両方ともnilであるため②に該当する……のではありません! 先ほど述べた通り、「インタフェース型の話をするときにはポインタのnil値はnilではない」ので左辺のsは「nilではない」ことになります。(右辺のnilは「インタフェースのnil値」なので「nilである」ことになります。)従って②は成立しません。①については、右辺のnil(インタフェースのnil値)は動的型をもたないので成立しません。結果、s == nilの等価比較は偽になります。従って、
if s != nil {…}の条件は成立することになるためブロックの中が実行されます。3行目fmt.Println(s.String())
s.String()というインタフェースのメソッド呼出について考えてみます。インタフェースに対するセレクタ式について次の規定があります。If
xis of interface type and has the valuenil, calling or evaluating the methodx.fcauses a run-time panic.
(Selectors)しかしこれまで散々述べた通り、「
sはnilではない」のでこれは適用されません。For a value
xof typeIwhereIis an interface type,x.fdenotes the actual method with namefof the dynamic value ofx. If there is no method with namefin the method set ofI, the selector expression is illegal.
(Selectors)
sの動的型は*unitなので、この規定に従い、s.String()は結局(*unit)(s).String()、つまりは(*unit)(nil).String()に帰着されます。unitには実際にポインタレシーバのStringメソッドが存在します。func (u *unit) String() string { return "UNIT" }レシーバの値はポインタのnil値ですが、先に述べた通り何も問題はなく、この
Stringメソッドがuをnilとして呼ばれます。関数定義の中でもuは一度も参照されていないため、何の問題も起こらず、"UNIT"が返ってきます。すなわち、
s.String()の値は"UNIT"であるため、UNITが出力されてプログラムは終了します。まとめ
- ポインタのnil値は「参照ができない」だけ
- インタフェースのnil値とポインタのnil値は違う
Goのnilはヤヤコシイ
「nilインタフェース値(nil interface value)」という語は規格書の中で1度だけ登場します。 ↩
