- 投稿日:2020-12-04T23:03:11+09:00
既存の Amplify App をモノレポに対応させる
この記事はAWS Amplify Advent Calendar 2020 4 日目の記事となります。
はじめに
今年はじめより、Amplify Console がモノレポに対応しました。
モノレポ対応について公式のドキュメントはありませんが、こちらのブログ記事に作成方法について記述があります。ただ、このブログ記事には、既存の
Amplify Appをモノレポ化する方法について触れられていません。
(この記事では、Amplify Console 上で作成したアプリのことを、Amplify Appと呼ぶことにします)
(アプリを作り直せばいい話かもしれませんが、Ci/CD の関係上別アプリを作成するのは高コストでした)また、こちらのbuild-settingsで一部モノレポについて触れられてはいますが、内容が不十分だったり、間違っていたりしています。
(2020/12/04 時点。修正依頼は出したので、そのうち直るかもしれません)今回そのあたりを設定する機会があったので、備忘を兼ねて残しておきます。
前提
- 以下のようなリポジトリがあるものとする
repo ├── app1 └── app2
- 上記の App1 について、既に
Amplify Appが存在するものとする- 2.の
Amplify Appのbuild settingsのApp build specificationが以下のようになっているversion: 1 frontend: phases: preBuild: commands: - cd app1 - npm ci build: commands: - npm run build artifacts: baseDirectory: app1/build files: - "**/*" cache: paths: []対応方法
※amplify.yml を使用しているか否か、で対応が少し変わります。
amplify.yml を使用していない場合
applicationsでモノレポであることを明記appRootでビルドするディレクトリを指定具体的には、
App build specificationが以下のようになります。version: 1 applications: - frontend: phases: preBuild: commands: - npm ci build: commands: - npm run build artifacts: baseDirectory: / files: - "**/*" cache: paths: [] appRoot: app1amplify.yml を使用している場合
amplify.yml はルートディレクトリに設置する必要があります。
そのため、app1 と app2、2 つのプロジェクトのビルド手順を amplify.yml に記入する必要があります。version: 1 applications: - frontend: phases: preBuild: commands: - npm ci build: commands: - npm run build artifacts: baseDirectory: / files: - "**/*" cache: paths: [] appRoot: app1 - frontend: phases: preBuild: commands: - npm ci build: commands: - npm run build artifacts: baseDirectory: / files: - "**/*" cache: paths: [] appRoot: app2次に、各
Amplify AppのApp build specificationに以下を設定します。
これにより、それぞれのAmplify Appが app1, app2、どちらに対応しているか AWS が判断することができます。version: 0.1 applications: - appRoot: app1version: 0.1 applications: - appRoot: app2注意点
スラッシュは必要ない
こちらのドキュメントには
appRoot: /react-appのようにディレクトリ名の先頭にスラッシュをつけています。同じようにスラッシュをつけて実装しても満足に動作しなかったので AWS に問い合わせたところ、スラッシュをつけると正しく認識されない、とのことです。
よって、appRootに指定するディレクトリの先頭にはスラッシュをつけないのが正しいです。
(ドキュメントもそのうち修正されるとのこと)
App build specificationが常にamplify.ymlで上書きされるわけではない今まで、amplify.yml が存在する場合は
App build specificationに設定された値が上書きされるものとばかり思っていました。
モノレポではない場合それは正しいですが、モノレポの場合は上に示したように両者を適切に設定しないと思うように動作しません。
- 投稿日:2020-12-04T23:01:54+09:00
AWS認定ソリューションアーキテクト–アソシエイト(SAA-C02)に合格した体験記
本記事の概要
AWS認定ソリューションアーキテクト–アソシエイト(SAA-C02) を受験し取得したので勉強方法を備忘録として投稿します。
AWS-SAAを受けようと思っている方や、現在勉強している方がこの記事を参考の一つにしていただけたら幸いです。使用した教材
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
UdemyこれだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)
Udemy【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)
UdemyAWS Certified Solutions Architect Associate
WHIZLABSAWS Black Belt
AWSサービス別資料勉強の流れ その1
最初はAWSとはなんぞや?状態でしたので
「AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得」を実施。本当にゼロからでもハンズオンを通して一般的な
VPC+EC2+ELB+RDS+Route53+S3+CloudFront+CloudWatch+IAMを学ぶことができるので初学者にはとてもオススメ。(というか、今回使用した教材はすべてオススメします。)勉強の流れ その2
その1の教材を終えたらAWSの基本的なサービスはおさえている状態になったので、次は
これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(SAA-C02試験対応版)を実施。こちらの教材はより試験対策的な内容です。
といっても、以前の教材では扱われなかったサービスを学ぶことができます。
かぶる部分が多々ありますので、私は適宜飛ばしながら学習しました。こちらはかなりボリュームが多く、人によってはモチベーションを保つことが難しいかもしれません。
ちなみに私は着手してから終えるまで約1か月はかかりました。スケジューリングって大事。勉強の流れ その3
この後はひたすら問題演習です。
【SAA-C02版】AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(6回分390問)で問題に慣れましょう。こちらの教材は6回分の問題が含まれていますが、初回は3~5割程度の得点率でした。
3週ほど回し、8割くらいとれるようになったのでもういいかな?と思いましたが、
「AWS-SAAは問題演習で解いた問題はほとんど本番では出ない」という情報がネットに沢山転がっていたので不安になり、
AWS Certified Solutions Architect Associate (WHIZLABSのコース)を追加で実施。こちらはすべて英語の教材となります。
これを機に英語を克服するのもアリかも?Google翻訳にかけてしまうのも全然アリ。
ただ、私が試した限りはちょっと問題の意図を汲み取り辛いかなと思いました。WHIZLABSのコースではセクション毎にまとめられている問題があるので、最後の総復習のような形で利用しました。
ちなみに得点率は5割~7割ほどで、試験直前の1週間でやっていたのですが「これ本番大丈夫か...?」というメンタルになりました。試験結果
受験日:2020年11月29日
スコア:722
合格ライン:720
結果:passうーん、ギリギリ!w
正直言って、自信をもって解答できた問題よりも「たぶんこっちかな~」というノリでしか選べない問題のほうが多かったです。受験してみての感想
ネットの情報通り教材で出てくる問題と本番の問題はほとんど一致しませんでした。
この試験では、体系的にAWSのサービスを理解する必要があるということですね。
単純に問題演習を通した暗記では突破できないので私のようなタイプには難しい試験でした。でも、試験としては確実にその方針のほうが良いですよね。
今後もAWS認定SysOpsアドミニストレーター–アソシエイトとAWS認定デベロッパー–アソシエイトの三冠目指して頑張ります!この記事を開いていただき、また、
ここまで読んでいただきありがとうございました。
- 投稿日:2020-12-04T22:07:06+09:00
AWSのARMチップが激速だった^^;
早くも今日二個目の投稿となりました。
Hiro_Matsunoです。
AWSアドベンドカレンダー4日目の投稿です。
PHPer&HTML5が好きな自分がなぜC#に惚れたのかを書いてました。
こちらの方も読んでやってください。いま巷で大騒ぎのApple初のARMアーキテクチャチップM1が大騒ぎになってますが。
こっちも負けてはいません。
AWSで初めてARM64でWebサーバを組んだときの顛末記です。ARMアーキテクチャーを使ってるのはAppleだけじゃないぞ。
本当はこれを声を大にして言いたかったです。
3年前から実はAWSはARMアーキテクチャーのチップを使っているので有名です。
実は二の足を踏んでいて今回M1騒ぎに乗じて使ってみることにしたのが実の真相です。
本当はもっと前から使ってみたかったんですけどw。今回使ってみてどう思ったのか
今回本当に使ってみてわかったんですが。
正直M1なんて目じゃないです。
とにかく激速でじつはWebサーバ作るのにじつはIntelだと約2時間いるんですが。
なんと45分ぐらいでほぼ動く状態にまで持ってくことができました。
これは実際に先週の金曜日の出来事です。
そこまで移行の時間がなかったんです?。
本当に日々忙しく働いていましたので。
実はPHPerとして11月から復帰したので勉強に勤しんでました^^;。Intelと比べてどう思ったのか
Intel激遅っていうのが真相です。
ARMって実はカーエレクトロニクスでは当たり前で実は前職ではARM系Linuxの大御所とお仕事ができたこともありARMのLinuxってどうなのかなと思っていました。(ドイツの某B社の男性Linuxビルダーはみんな大御所だった。喧嘩ふっかけそうになったこともありました。拙い英語で異変を伝えるのに一苦労させられました^^;。翻訳ソフトは良いのを使いましょうねw。)
予測を遥かに超えた速さにびっくりしています。
処理の速さもさながらやはり色んな要素で使っていけるいいものだなと思いました。
特に一番時間のかかる作業ほどIntelより速さが際立ってました。
だけどもうハード系Linuxはこりましたがサーバ系だったら喜んで頑張ってビルドしますよ( ͡° ͜ʖ ͡°)。
こんなに速いんだったらもっと早く使っておくんだったと反省させられましたよ。
マジで。最近MacMiniをAWSは導入したんだけど
これ思いましたがすごいと思ってます。
MacMiniをサーバにできるなんて幸せな人っているんですかね。
どんな人かあってみたい。
実際のこと言うとMacMiniが使えるようになるってことはiOS開発が実は実機いらずになるんですね。
俺は好きで二台持ちしていますが(MacBookAir2013LateとMacBookAir2018Late)。
Windows機だけしか持ってない人にはすごい朗報だと思います。
諦めなくても良くなるってことはいいことです。
どうやらそのうちM1MacMiniの導入も検討されてるようです。
実際に先行してAWSで触ってみてから購入に走れるようになるのでいい方向になったと思います。さぁそんなところで言っておきたいのは二の足踏んでるんじゃなくARMアーキテクチャをEC2で使っちゃいましょう。
明日はclouddaisukiです。
どんな事書いてくれるんでしょう。
期待してますね。
- 投稿日:2020-12-04T21:21:27+09:00
fitbitとAlexaスキルを連携させてみる
はじめに
最近fitbit versa3を買いました。心拍数や睡眠状態など色々見れて面白いです。
このモデルにはAlexaが搭載されており、音声でスキル呼び出しが可能です。
fitbitの公式Alexaスキルはすでにありますが、自分でもスマートウォッチで集めた情報を利用したスキルを作れるのか、試してみようと思います。スキル開発
概要
スマートウォッチから直接情報を得るわけではなく、fitbitのサイトからAPI経由で取得します。だいたい以下のようなイメージですね。
Alexaのアカウントリンク機能を使って、Alexaとfitbit間でID連携する形になります。fitbit側
アプリケーション登録
fitbitのdeveloperサイトから、Regiter An Appでアプリケーションを新規登録します。
特に開発者アカウント登録などしなくても、通常のfitbitアカウントで利用できるようです。
以下のようにアプリケーション設定を登録します。
項目名 登録内容 Application Name 任意のアプリケーション名 Description アプリケーションの説明 Application Website アプリケーションのWebサイト。Alexaスキルが公開されたらamazon.co.jpの該当スキルの画面を入れるのがよさそうです Organization 自身の組織名 Organization Website 組織のWebサイト Terms Of Service Url 利用規約のURL Privacy Policy Url プライバシーポリシーのURL OAuth 2.0 Application Type Client Callback URL ※後述 Default Access Type Read-Only 試験的に動かすだけであれば、OAuth 2.0 Application Type、Callback URL、Default Access Type以外はダミー値で大丈夫です。ただし、利用者に提示される内容なので、実際に公開する場合はきちんとした値を入れる必要があります。
Callback URLだけは要注意です。
fitbit側で整合性チェックをしているようで、Alexa側から渡ってくるコールバックURLと一致した値を入れておかないと、後で利用者向けの同意画面を表示するときにエラーになります。
この時点ではとりあえず何かURLを入れておき、後続の作業でAlexa側のコールバックURLが判明したら書き換えます。登録できると、以下のように各種IDや連携に必要なURLが表示されます。
ここの値は次の工程で使います。
Alexaスキル側
アカウントリンク設定
Alexa Developer Consoleでアカウントリンク設定をしていきます。
設定内容は以下です。
項目名 登録内容 Authorization Grant種別 Auth Code Grant Web認証画面のURI fitbit側の「OAuth 2.0: Authorization URI」 アクセストークンのURI fitbit側の「OAuth 2.0: Access/Refresh Token Request URI」 ユーザーのクライアントID fitbit側の「OAuth 2.0 Client ID」 ユーザーのシークレット fitbit側の「Client Secret」 ユーザーの認可スキーム HTTP Basic認証 スコープ ※後述 ドメインリスト 空でOK デフォルトのアクセストークンの有効期限 空でOK スコープには、こちらを参照してアクセス許可を与える対象を指定します。
今回は心拍数の情報を使いたいので、「heartrate」を指定します。また、このタイミングでAlexaのリダイレクト先のURLがわかりますが、
このURLと同じ値を全て、fitbit側設定の「Callback URL」に反映させておきます。
実装
ここまでの設定で、利用者側でアカウントリンク設定が済んでいれば、fitbitのAPIを呼び出すためのアクセストークンが自動的にLambdaまで渡ってくるようになります。
{ "requestEnvelope": { "version": "1.0", "session": { "new": true, "sessionId": "amzn1.echo-api.session.xxx...", "application": { "applicationId": "amzn1.ask.skill.xxx..." }, "user": { "userId": "amzn1.ask.account.xxx...", "accessToken": "xxx..." // ←☆これ } },ソース内ではアクセストークンを取得し、API仕様を確認しながら必要なAPIを呼んであげればOKです。
index.jsconst LaunchRequestHandler = { canHandle(handlerInput) { return Alexa.getRequestType(handlerInput.requestEnvelope) === 'LaunchRequest'; }, async handle(handlerInput) { // アクセストークンを取得 const token = Alexa.getAccountLinkingAccessToken(handlerInput.requestEnvelope); // fitbitのAPIを呼び出す const url = `https://api.fitbit.com/1/user/-/activities/heart/date/today/1d.json`; const headers = { Authorization: `Bearer ${token}` }; let response; try { // リクエスト実行 response = await Axios.get(url, { headers: headers }); } catch (error) { throw new Error(`get fitbit data error , url:${url} , error:${error}`); } // API呼び出し結果を利用してAlexaの応答を組み立て const restingHeartRate = response.data['activities-heart'][0].value.restingHeartRate; const speakOutput = `今日の安静時の心拍数は${restingHeartRate}です。`; return handlerInput.responseBuilder .speak(speakOutput) .withSimpleCard('測定結果', speakOutput) .getResponse(); } };今回は、心拍数を取得するheart-rate APIを呼び出し、そこから安静時の心拍数(restingHeartRate)を取り出しています。
また、このソースでは省略していますが、実際にはトークンをとれなかったときに連携設定を促す処理などが別途必要になります。こちらなどを参考に実装するのがよいでしょう。利用者から見た動き
アカウントリンク
スキルを有効にした後、Alexaアプリからアカウントリンクを行います。
fitbitにログインしていなければログインを求められ、その後心拍数データ取得の同意を確認する画面フローになります。スキル呼び出し
fitbitに向かってスキル起動をを呼びかけてみます。
出た!やった!
画面表示だけでなく、きちんと読み上げてくれます。おわりに
アカウントリンク機能を使って、fitbitとAlexaスキルを連携させることができました。
利用者ごとのトークン管理やリフレッシュなどの面倒なところをAlexaが全部やってくれるので、思っていたより遥かに簡単でした。心拍数を表示するだけであれば標準機能でも普通にできますし、fitbitの上で動くカスタムアプリを作る方法もありそうなので、あえてAlexaスキルを使う強みがあるとしたら、音声が使える点や、他の据え置きのAmazon Echoなどからも同じように呼べる点になるかと思います。
どんなスキルを作れるかはアイデア次第ですね。







- 投稿日:2020-12-04T20:39:48+09:00
[AWS] -- Architecture Supporter[2] -- Setting Local Development Environment
At first.
This content is written by AWS Beginner.
So this content is a possibility that isn't Best Practice.
Please read this content as reference information.Work on this article.
- Install "Docker" on Windows.
- Install "Visual Studio Code".
- Setup Docker.
- Setup Visual Studio Code.
- Try connecting from Visual Studio Code to Docker.
1.Install "Docker" on Windows
(1) Open the page of 「"Download for Docker Installer"」.
(2) Click 「Docker Desktop for Windows」
◆Related arcticle
- 投稿日:2020-12-04T20:18:31+09:00
Serverless Framework で SNS + Lambda の Slack 通知を簡単に作る
任意のメッセージを Slack の特定のチャネルに通知する仕組みを AWS SNS + Lambda で作ります。
- アプリケーションから任意のメッセージを通知したい
- 複数の通知先がある(Slackとメーリングリストなど)
- しかし、通知先の設定などはなるべくアプリケーションで管理したくない
こういうときに役に立つと思います
Slack APP の登録とチャネルの Webhook URL の生成(手動)
https://api.slack.com/apps?new_app=1 にアクセスして、 Workspace に Slack APP を作成します
Incoming Webhooksを選択します
初期状態で Incoming Webhooks は有効になってないので、 ON にします
ON にすると Webhook を追加できるようになります
Add New Webhook to Workspaceを選択します
OAuth で権限をリクエストする画面に遷移します
Webhook でメッセージを投稿するさきのチャンネルを選択して許可します
Webhook URL が生成されました1
これは後ほど、 Serverless Framework で利用します
Sample curl request も生成されています
指定したチャネルへ Webhook でメッセージ送信できるか、事前にテストしておくこともできます
$ curl -X POST -H 'Content-type: application/json' --data '{"text":"Hello, World!"}' https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXXXX/XXXXXXXXXXXXXXXXXXXXXXXX ok%
Serverless Framework で SNS + Lambda を作成する
実際にこの手順どおりに実装したリポジトリを参考に置いておきます
https://github.com/ikasam/sls-sns-lambda-to-slack
Serverless Framework のインストールとプロジェクト作成
Get started や CLI reference を見てもらうのが一番良いですが、必要なステップだけ抜粋しておきます
環境は MacOS/Linux で、言語は python3 にします
他の環境へのインストール方法や他の言語のテンプレートはドキュメントを参照してください$ curl -o- -L https://slss.io/install | bash $ sls create --template aws-python3 Serverless: Generating boilerplate... _______ __ | _ .-----.----.--.--.-----.----| .-----.-----.-----. | |___| -__| _| | | -__| _| | -__|__ --|__ --| |____ |_____|__| \___/|_____|__| |__|_____|_____|_____| | | | The Serverless Application Framework | | serverless.com, v2.6.0 -------' Serverless: Successfully generated boilerplate for template: "aws-python3" Serverless: NOTE: Please update the "service" property in serverless.yml with your service name以下のファイルが生成されます
$ git status On branch master Your branch is up to date with 'origin/master'. Changes to be committed: (use "git restore --staged <file>..." to unstage) new file: .gitignore new file: handler.py new file: serverless.yml
handler.pyの中身を見てもらえればわかりますが、固定の文字列と Lambda event を返す関数が定義されていますhandler.pyimport json def hello(event, context): body = { "message": "Go Serverless v1.0! Your function executed successfully!", "input": event } response = { "statusCode": 200, "body": json.dumps(body) } return response # Use this code if you don't use the http event with the LAMBDA-PROXY # integration """ return { "message": "Go Serverless v1.0! Your function executed successfully!", "event": event } """このままデプロイしてみましょう
$ sls deploy -v Serverless: Packaging service... ...(snip)... Serverless: Stack update finished... Service Information service: sls-sns-lambda-to-slack stage: dev region: us-east-1 stack: sls-sns-lambda-to-slack-dev resources: 6 api keys: None endpoints: None functions: hello: sls-sns-lambda-to-slack-dev-hello layers: None Stack Outputs HelloLambdaFunctionQualifiedArn: arn:aws:lambda:us-east-1:000123456789:function:sls-sns-lambda-to-slack-dev-hello:1 ServerlessDeploymentBucketName: sls-sns-lambda-to-slack-serverlessdeploymentbuck-1drc5f5y43luq ************************************************************************************************************************************** Serverless: Announcing Metrics, CI/CD, Secrets and more built into Serverless Framework. Run "serverless login" to activate for free.. **************************************************************************************************************************************動作確認もしてみます
$ sls invoke -f hello -d "{\"message\": \"This is input message.\"}" { "statusCode": 200, "body": "{\"message\": \"Go Serverless v1.0! Your function executed successfully!\", \"input\": {\"message\": \"This is input message.\"}}" }Slack 通知する Lambda の実装
handler.pyの実装
- 受け取ったメッセージを Slack API の chat.postMessage payload に変換します
- payload を先程作成した Webhook に POST すれば良いです
handler.pyimport json import urllib3 import os http = urllib3.PoolManager() def invoke(event, context): message = event['message'] payload = json.dumps({'text': message}) url = os.environ["WEBHOOK_URL"] resp = http.request('POST', url, body=payload) print({ "url": url, "payload": payload, "status_code": resp.status, "response": resp.data }) return payload
serverless.ymlの修正も必要です
handler.pyのエントリポイントの関数名をhelloからinvokeに変更したので- ついでに Lambda の関数名もいい感じの名前 (
post-to-slack) に変えておきましょうserverless.yml- hello: - handler: handler.hello + post-to-slack: + handler: handler.invoke環境変数の設定
- Webhook を環境変数として渡しますが、リポジトリには commit したくありません 1
.gitignoreしたファイルで読ませることにしますserverless.yml- # environment: - # variable1: value1 + environment: + WEBHOOK_URL: ${file(./config.json):WEBHOOK_URL}config.json{ "WEBHOOK_URL": "https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXXXX/XXXXXXXXXXXXXXXXXXXXXXXX" }デプロイと動作確認
- ここまでの内容をデプロイして動作確認してみましょう
- Lambda へ渡す payload は
{"message": "Slack に投稿されるメッセージ"}という形式です
- Lambda が
event['message']で Slack に投稿するメッセージを受け取っています$ sls deploy -v $ sls invoke -f post-to-slack -d "{\"message\": \"Slack に投稿されるメッセージ\"}" "{\"text\": \"Slack \\u306b\\u6295\\u7a3f\\u3055\\u308c\\u308b\\u30e1\\u30c3\\u30bb\\u30fc\\u30b8\"}"
SNS Topic 作成と Lambda Subscription の設定
serverless.ymlを少し修正するだけで、 SNS Topic と Lambda Subscription を設定できますSNS Topic のリソースを定義
serverless.ymlresources: Resources: snsTopic: Type: AWS::SNS::Topic Outputs: snsTopicArn: Description: "ARN of SNS Topic" Value: !Ref snsTopicLambda Subscription の設定
関数にイベントとして SNS Topic を紐付けます
serverless.ymlfunctions: post-to-slack: handler: handler.invoke + events: + - sns: + arn: !Ref snsTopic + topicName: snsTopicたったこれだけです
デプロイして SNS Topic と Lambda Subscription が作成されたことを確認しましょう
SNS Topic からのメッセージを処理するよう、 Lambda 関数を修正
- SNS Topic はできましたが、まだ Lambda 関数が SNS Topic から送られてくる payload を解釈できていません
- AWS のコンソールなどから SNS Topic にメッセージを発行できますが、これまで使ってきた payload の形式で送ってもうまくいきません
[ERROR] KeyError: 'message' Traceback (most recent call last): File "/var/task/handler.py", line 9, in invoke message = event['message']
- SNS から送られてくる payload がどういう形で
eventに格納されているか、知る必要があります- とりあえず、関数の冒頭で
print(event)してログを見るとわかりやすいですhandler.pydef invoke(event, context): + print(event) message = event['message']
Records.0.Sns.Messageに SNS Topic 経由で送信されたメッセージの内容が格納されていることがわかりました
Lambda 関数のコードを修正してデプロイしましょう
handler.pydef invoke(event, context): - message = event['message'] + message = event['Records'][0]['Sns']['Message'] payload = json.dumps({'text': message}) url = os.environ["WEBHOOK_URL"] resp = http.request('POST', url, body=payload)
- AWS コンソールから SNS 経由でメッセージを送ってみます
- JSON payload にする必要がないので、メッセージ本文をそのまま submit します
届きましたね
アプリケーションから SNS Topic にメッセージを publish する
- あとは、アプリケーションから AWS SDK で SNS Topic にメッセージを publish するだけです
- 例として、 PHP/Laravel 2 で実装するサンプルはこんな感じです
$client = App::make('aws')->createClient('sns'); $client->publish([ 'Message' => 'アプリケーションから送信するメッセージ', // REQUIRED 'TopicArn' => 'arn:aws:sns:us-east-1:000123456789:sls-sns-lambda-to-slack-dev-snsTopic-1OUEKFS94QV16' ]);応用編: 通知の環境分離
- 環境ごとに通知先を分けたいニーズはよくあると思います
- Serverless Framework は環境の概念を持っていて、環境ごとに独立したリソースをデプロイできます
通知先チャネルごとの Webhook URL の作成
冒頭で実施した Webhook URL 生成と同じ手順で、Slack App に Webhook URL を追加しましょう
serverless.ymlとconfig.jsonの修正環境ごとに読み込む
config.jsonを分けることで、環境変数の Webhook URL を切り替えられるようにしますserverless.ymlenvironment: - WEBHOOK_URL: ${file(./config.json):WEBHOOK_URL} + WEBHOOK_URL: ${file(./config.${opt:stage, self:provider.stage, 'dev'}.json):WEBHOOK_URL}config.*.json$ ls -l config* -rw-r--r-- 1 m_kanno AD\Domain Users 103 Dec 4 19:58 config.dev.json -rw-r--r-- 1 m_kanno AD\Domain Users 103 Dec 4 19:58 config.stg.jsoncommit したくないファイルの名前が変わるので、
.gitignoreの修正も忘れずに.gitignore# config -config.json +config.*.json環境ごとにデプロイする
--stageオプションでデプロイ先の環境を指定できます--stageオプションを指定しなかった場合、デフォルトでdev環境にデプロイされます
- これまでは
dev環境にデプロイさていました- デフォルトの環境は
serverless.ymlで上書きすることも可能ですserverless.yml# you can overwrite defaults here # stage: dev # region: us-east-1$ sls deploy -v --stage stgstg 環境の SNS Topic などが作成されました
メッセージを送ってみます
別の Webhook URL で指定したチャネルにメッセージが届きました
リソースの削除
- 必要なくなったら、
sls removeでリソースを削除できます- これも
--stageオプションで環境ごとに削除できます$ sls remove $ sls remove --stage stgSlack App は手動で削除してください
まとめ
- Serverless Framework を使って、Slack 通知する SNS Topic + Lambda を簡単に作れます
- 慣れればリポジトリ作成から30分くらいでできるようになります
- Seerverless Framework は関連するリソースや IAM ポリシーもざっと作ってくれるのでアプリケーション開発に集中できます
参考
- Serverless Getting Started Guid
- Serverless - AWS Lambda - CLI Reference
- chat.postMessage method | Slack
Webhook URL を公開してしまわないように注意しましょう。 Webhook URL を知っていると、その Webhook に紐付いているチャンネルにメッセージを投稿し放題になってしまいます。 ↩
サンプルコードは
aws/aws-sdk-php-laravelを利用する前提です ↩




















- 投稿日:2020-12-04T19:09:39+09:00
AWS Amplify Admin UIは使いやすいのか
POLアドベントカレンダー4日目担当、ゲバラです。
先日発表されたAWS Amplify Admin UIを触ってみます。
そもそもAWS Amplifyって何?という方はこちらからどうぞAWS Amplify Admin UIとは
Amplifyのバックエンド環境をUI上で設定できる管理画面です。先日のre:Invent にて発表されました。AWSアカウントを作成しなくても管理画面専用のユーザアカウントを発行することができ、管理ハードルかなり下がりました。最初にアプリを作る場合でもデータモデリングとローカルでテストまでならAWSアカウントが必要ないそうです。AWS上にデプロイするときAWSアカウントが必要になります。
AWS Amplify Admin UIの始め方
最初からアプリを作成する場合
Amplifyが提供しているサンドボックスからアプリを作り始めることができます
https://sandbox.amplifyapp.com/getting-startedベースとなるデータモデルを選択したり
UI上でデータモデリングすることができます
ローカルでアプリを動かすことができます
AWS上にデプロイするためにAWSアカウントと紐付けます
すでにアプリを作成している場合
Amplifyコンソールのメニューに「Admin UI management」が追加されており、そこからAdminUIを使用するためにOnにします
しばらく待つとバックエンド環境ごとにAdminUIのURLが発行されます。この画面からAdminUIドメインを変更したり、管理ユーザを作成することができます
感動したのはAmplify CLIもAWSアカウントが必要になくなりました。amplify pullでAdminのログイン画面に遷移しログインすることでCLIが使用することができます。実際のUI
管理画面にログインするとこんな感じ。AWSにしては見やすい。
データモデリング
前まではスキーマのコードを書いて定義していましたが、UIで定義することができます。非常に直感的に操作することができてわかりやすいです。リレーションも貼りやすい。難点は@Authのようにモデルの権限周りはどうやら設定できなかったのでここはスキーマで定義する必要がありそうです。ここはアップデートに期待です。
ユーザ・グループ管理
ユーザ・グループ管理もすっきりしたUIで行うことができます
認証設定
こちらもわかりづらいCognaiteのUI比べ、必要な項目のみに絞られて設定しやすいUIに変わっています。OAuthやサインインのリダイレクトURLなどが設定できます。
コンテンツ管理
こちらは使ってみてませんがデータモデルのデータを編集できるコンテンツ管理が可能となりました、非エンジニアでもアプリのコンテンツをここで作成できるようになります。マークダウンで書けるとか最高。
参考:https://docs.amplify.aws/console/data/content-managementいかがだったでしょうか。バックエンド環境はCLIやコードベースで管理していたものが、UI上で管理できるようなることでますますAmplifyが使いやすくなりそうですね。広がれAmplifyの輪!!
明日はPOLのインフラ守護神@takahiro-yamadaさんです。











- 投稿日:2020-12-04T19:07:50+09:00
AWS Lambda LayerのTerraform化でハマったこと
この記事の目的
AWS Lambda LayerをTerraform化しました。
一部手間取ったので、自分と同僚用にメモを残します。まず結論
最終的に出来上がったTerraformはこちらです。
Terraform version
$ terraform version Terraform v0.12.24Layerを使用するLambda側
resource "aws_lambda_function" "main_lambda" { filename = "../../lambda_function/test_lambda/test_lambda.zip" function_name = "test_lambda" role = aws_iam_role.lambda_iam_role.arn handler = "lambda_function.lambda_handler" timeout = 30 runtime = "python3.8" layers = ["${aws_lambda_layer_version.lambda_layer.arn}"] }Layer側
resource "aws_lambda_layer_version" "lambda_layer" { layer_name = "test_layer" filename = "../../lambda_layer/test_layer/test_layer.zip" compatible_runtimes = ["python3.8"] # Lambda関数と互換性のあるruntimeを設定 source_code_hash = "${filebase64sha256("../../lambda_layer/test_layer/python.zip")}" }ハマったところ①
Layerのfilenameに設定しているzipファイルの圧縮単位にコツがいった。
初めは、
../../lambda_layer/test_layer/test_layer.pyのtest_layer.pyをzip化していた。
ところが、Terraforを実行してLambdaとLayerが作成されるも、LambdaからLayerが読み込めない。どうやら、LayerはLambda内の
/opt/pythonに展開しないといけないらしい。
そこで、Layerを../../lambda_layer/test_layer/python/test_layer.pyに置き、pythonごとzip化したら解決。ハマったところ②
Layerにはバージョンというものがあり、Layerのpyファイルを更新して再度アップロードすると、Layerのバージョンが上がるようになっている。
古いバージョンのLayerも残っており、使用することができる。
おそらく、Lambda Aではバージョン1のLayer、Lambda Bでは最新バージョンのLayerを使用したい、という使い分けのためだろうと思われる。
初め、以下のように
source_code_hashを設定していなかった。
すると、test_layer.pyを更新してtest_layer.zipを再作成しても、Terraform実行後のLayerのバージョンが上がらない。ずっと1のままだ。resource "aws_lambda_layer_version" "lambda_layer" { layer_name = "test_layer" filename = "../../lambda_layer/test_layer/test_layer.zip" compatible_runtimes = ["python3.8"] # Lambda関数と互換性のあるruntimeを設定 }
source_code_hashを設定すると、Layer自体のバージョン及びLambdaにひもづくLayerのバージョンも最新のものに上がるようになった。でもこれ、今はいいけどいずれTerraform上でLambda毎にLayerのバージョン指定したくなったらどうするのか……
aws_lambda_layer_version.lambda_layer.arnはバージョン付きのARNだけど、aws_lambda_layer_version.lambda_layer.layer_arnはバージョンなしのARNらしいので、その辺をうまく使うのかもしれない。
必要になったら検証します。報告するかは不明。以上

- 投稿日:2020-12-04T18:57:46+09:00
S3,SNS,SQS,Lambdaを利用したファンアウト構成
ファンアウト構成とは
一つの入力に対して複数の出力がある構成
Cloudformaionを使用したSNS,SQSの構築は、
検索しても少なかったので書きました。
(需要自体なさそう)Amazon SQS(Simple Queue Service)とは
メッセージキューイングサービスです。
送信側はキュー(データを先入れ先出しの構造で保持するもの)にメッセージを送り、
受信側はキューにポーリングしてメッセージを受け取ります。標準とFIFO
SQSではタイプとして、標準とFIFO配信を選択できます。
標準タイプでは、メッセージの順番を必ず保証はできません(ベストエフォート)。
FIFOタイプではメッセージの順番を守ります。
SNS、S3などのの連携をサポートしていません。
Amazon SNS(Simple Notification Service)とは
登録先にメッセージをプッシュ配信するサービスです。
特定のメールアドレスやSQSなどにメッセージを送ることができます。CloudWatchアラームでEC2のCPU使用率が閾値を超えた場合や、
S3にオブジェクトが置かれた場合の通知先で使用されるイメージ。注意点
複数メッセージ
SQSはAZ単位で冗長化してメッセージを保存しているため、AZ障害が発生した場合などに、複数メッセージをクライアントが受け取ってしまうことがあるみたいです。
FIFO配信でも同じことが起こります。つまり、SQSを使う場合は同じメッセージをクライアントが受信して、二回実行しても問題ないようにしなければなりません。
SNSを挟む理由
LambdaのトリガーとしてならばSQS Lambdaでも実装可能ですが、複数のサブスクライバー(送信先)にメッセージを受信させたい場合は、SNSが必要です。
複数のサブスクライバーにメッセージを送信する可能性がある場合は使用、そうでなければ使用しないで良いと思います。メリット
・複数の受信者へ同時にメッセージを送信することができる。
・送信コンポーネントと受信コンポーネントを分離することができる。
・SNSはサブスクライバーが常時メッセージを受け取れるようにしなければならないが、SQSでは受け取り準備ができてなくてもいい。
・複数のサブスクライバーに送りつつ、Eメールも送りたいとか追加の要望が来た場合でも対応可能。デメリット
・SNSの追加料金が発生する。
・SNSの通信時の処理が送信時に最大50msほどかかる。暗号化
暗号化する場合はデフォルトのキーでは不可。
新たにAWS KMSでキーを作成する必要があり、KMSのポリシーでSNSを許可してあげないと通信できない。今回作成したCloudformaionでは、以下のような処理になっている。
- S3 からイベント内容を SNSトピックへ通知
- SNS で通知データを CMK を使用して暗号化
- SNS で通知データを CMK を使用して平文に戻し、SQS キューに送付
- SQS でメッセージを CMK を使用して暗号化
- Lambda から SQS のメッセージを取得(取得時、SQS でメッセージを CMK を使用して平文に戻す)リソース
Cloudformaionで作成。
東京リージョンでしか試していません。AWSTemplateFormatVersion: "2010-09-09" Transform: "AWS::Serverless-2016-10-31" Resources: AWSTemplateFormatVersion: "2010-09-09" Resources: createCmk: Type: AWS::KMS::Key Properties: Description: "Encrypt sensitive data for Billboard site." KeyPolicy: Version: "2012-10-17" Id: key-consolepolicy-3 Statement: - Sid: "Allow administration of the key" Effect: Allow Principal: AWS: !Sub "arn:aws:iam::${AWS::AccountId}:root" Action: - "kms:*" Resource: "*" - Sid: "Allow Amazon SNS of the key" Effect: Allow Principal: Service: "sns.amazonaws.com" Action: - "kms:Decrypt" - "kms:GenerateDataKey*" Resource: "*" - Sid: "Allow Amazon S3 of the key" Effect: Allow Principal: Service: "s3.amazonaws.com" Action: - "kms:Decrypt" - "kms:GenerateDataKey*" Resource: "*" createKeyAlias: DependsOn: createCmk Type: 'AWS::KMS::Alias' Properties: AliasName: alias/testcmk TargetKeyId: !Ref createCmk sqsQueue: DependsOn: createKeyAlias Type: AWS::SQS::Queue Properties: QueueName: "snssqstestqueue" KmsMasterKeyId: alias/testcmk snsTopic: DependsOn: createKeyAlias Type: AWS::SNS::Topic Properties: TopicName: "snssqstesttopic" KmsMasterKeyId: alias/testcmk snsTopicPolicy: DependsOn: snsTopic Type: "AWS::SNS::TopicPolicy" Properties: PolicyDocument: Version: "2012-10-17" Statement: - Sid: "SID" Effect: Allow Principal: Service: "s3.amazonaws.com" Action: "SNS:Publish" Resource: !Ref snsTopic Condition: ArnLike: aws:SourceArn: !Join [ "", [ "arn:aws:s3:::", "snssqstestbuckets3" ]] Topics: - !Ref snsTopic s3Bucket: DependsOn: snsTopicPolicy Type: "AWS::S3::Bucket" Properties: BucketName: "snssqstestbuckets3" BucketEncryption: ServerSideEncryptionConfiguration: - ServerSideEncryptionByDefault: SSEAlgorithm: AES256 PublicAccessBlockConfiguration: BlockPublicAcls: True BlockPublicPolicy: True IgnorePublicAcls: True RestrictPublicBuckets: True NotificationConfiguration: TopicConfigurations: - Event: s3:ObjectCreated:* Filter: S3Key: Rules: - Name: suffix Value: txt Topic: !Ref snsTopic snsSubscription: DependsOn: snsTopic DependsOn: sqsQueue Type: AWS::SNS::Subscription Properties: Protocol: sqs Endpoint: !GetAtt sqsQueue.Arn TopicArn: !Ref snsTopic sqsQueuePolycy: DependsOn: snsTopic DependsOn: sqsQueue Type: AWS::SQS::QueuePolicy Properties: PolicyDocument: Version: "2012-10-17" Statement: - Sid: "SID" Effect: Allow Principal: "*" Action: "sqs:*" Resource: "*" Condition: ArnEquals: aws:SourceArn: !Ref snsTopic Queues: - !Ref sqsQueue lambdaRole: DependsOn: sqsQueue Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: Service: - "lambda.amazonaws.com" Action: - "sts:AssumeRole" ManagedPolicyArns: - "arn:aws:iam::aws:policy/AmazonRDSFullAccess" - "arn:aws:iam::aws:policy/AmazonS3FullAccess" - "arn:aws:iam::aws:policy/ReadOnlyAccess" - "arn:aws:iam::aws:policy/AmazonVPCFullAccess" - "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole" - "arn:aws:iam::aws:policy/AmazonSQSFullAccess" - arn:aws:iam::aws:policy/AWSKeyManagementServicePowerUser MaxSessionDuration: 3600 Path: "/" RoleName: "sqssnstestrole" lambdaFunction: DependsOn: lambdaRole Type: "AWS::Lambda::Function" Properties: FunctionName: "sqssnstestlambda" Handler: index.lambda_handler MemorySize: "128" Runtime: "python3.6" Code: ZipFile: > import json def lambda_handler(event, context): print(event) Role: !GetAtt lambdaRole.Arn Timeout: "10" sqsTrigger: Type: AWS::Lambda::EventSourceMapping DependsOn: lambdaFunction Properties: BatchSize: "10" Enabled: true EventSourceArn: !GetAtt sqsQueue.Arn FunctionName: Fn::GetAtt: - "lambdaFunction" - "Arn"

- 投稿日:2020-12-04T18:49:53+09:00
AWSの基礎知識
はじめに
本日はAWS(Amazon Web Services)の基礎中の基礎について投稿していきたいと思います。
これまで、herokuでのデプロイ経験しかありませんでしたが、皆様の記事と書籍を参考にしながら、AWSの知識を蓄えていきたいと思います。
そもそもAWSとは?
私たちが普段利用しているAmazon様が提供しているクラウドコンピューティングサービス。
(クラウドコンピューティングサービス:サーバーやネットワークなどをインターネット経由で貸してくれること)昔から、サーバーを貸してくれる会社はあったそうですが、AWSの特徴は、いろんな会社からそれぞれに借りなければいけなかった、ウェブサービスを提供するために必要なインフラたちを、まとめてAWSで調達できること!
AWSのサービスについて
実に160種類以上ものサービスを提供しているみたいですが、その中でも代表的?なものについて取り上げてみたいと思います。
Amazon EC2
サーバー、OS、ソフトウェアなどを一式用意できるものAmazon S3
インターネット上に画像などのデータを保存する箱を借りられるサービス(Herokuは再起動すると画像が消えてしまうので助かっています。。。)Amazon VPC
AWSアカウント専用の仮想ネットワーク。ルートテーブルやネットワークゲートウェイの設定などをして、仮想ネットワーキング環境を構成。Amazon RDS
リレーショナルデータベースの製品(MySQL,MariaDBなど)をクラウド上で利用できるサービス。(私の実装ではMariaDBを使用予定です)Amazon Route 53
DNS(ドメインネームサービス)。他にも数えきれないほどのサービスがあるみたいで、全部使いこなしてみたいなあと思っていますが、果てしないことのように思えてきました。。。この続きは徐々に更新していきます。。。
- 投稿日:2020-12-04T18:16:51+09:00
AWSを始めたい人向け
AWSを始めたい人向け
こんちわっす。ラクスのakiponです。自分がアドベントカレンダーを書くようになって3年目になります。
時間がたつのって早いですねぇ~
いつもは誕生日に書かされる書くのですが、今年はパイセンに奪われたため誕生日イブに投稿することになりました。
初めに
最近IaaS型のパブリッククラウドめっちゃ流行ってますね。
AWS,GCP,Azure,Alibabaなどなどいろいろありますね。
シェアでいうと↓のような感じになっているようです。
2019年 2018年 Amazon (AWS) 45.0% 47.9% Microsoft (Azure) 17.9% 15.6% Alibaba 9.1% 7.7% Google (GCP) 5.3% 4.1% Other 22.7% 24.8% 参考:IaaS型クラウドにおけるシェア
今のところ、AWSが圧倒的にシェアを獲得しているようですが、シェア数の伸びはAzureがすごい。
AWS勉強してみようかな?という人向けに書いてみようかと思います。
個人的にはGCP触ってみたい
そもそもAWSって?
- Amazon Web Service の略です。
- パブリッククラウドでいろんなサービスを提供している
何がいいの?
- 「やっぱやめた」がやりやすい。
- サーバを購入・設置・運用・保守する必要がない
- 故障したときにデータセンターダッシュをしなくていい
- 従量課金のため使った分のお金が請求される (ちゃんと考えれば安く使える?オンプレには勝てないか…)
- スケールアップ・スケールアウトがしやすい
怖いところは?
- セキュリティがぬるいとアカウントが乗っ取られるかも(オンプレも同じか…)
- 気が付かなくて使いすぎると請求額がとんでもないことに
- 突然メンテナンス予告が来る
AWS勉強しようと思っているけど、どう勉強していいかわからない人へ
結論から言うと実際触ってみるのが一番覚えます。
ただ、上記の怖いところでも記載しましたが、
「気が付かなくて使いすぎると請求額に震えた。」というような記事をちょくちょく見るので
ある程度の知識がないと触るの怖い。というな人もいるかも(ちなみに私はそうでした。)
AWS勉強したいけど何からしていいかわからん。
という方向けに私が勉強したことを書いていこうと思います。ということで!
AWS認定資格の「ソリューション・アーキテクト アソシエイト」を勉強しました。
というか、これを勉強したらだいたいの雰囲気は掴めると思います。
AWS ソリューションアーキテクト アソシエイト
レベル的にいうと「下の上」か「中の下」くらいのレベル感だと思います。
一番簡単なのが「プラクティショナー」その次が「アソシエイト」という感じ。
私が受けた時はプラクティショナーという資格がなかったためアソシエイトから勉強しました。
アソシエイトから3つの項目に分かれます。
資格 役割 ソリューションアーキテクト アーキテクチャ SysOpsアドミニストレーター 運用 デベロッパー 開発者 運用するにもアーキテクチャがわからんと話にならんのでまずはソリューションアーキテクトをお勧めします。
今だと、プラクティショナーを取得してからじゃないとアソシエイトの受験資格がないらしい。
ソリューションアーキテクトを勉強すると得るもの
AWSの基本知識が身につきます。
ぶっちゃけソリューションアーキテクトを勉強しても使い方や設定方法などはわかりませんが、
「このサービスを使えば、こういうことが実現できる。」
みたいなことはわかるようになります。
使い方とか運用周りは「SysOpsアドミニストレーター」のほうかな?
ソリューションアーキテクト アソシエイトの勉強の仕方
勉強法としては下記
- 本を読む 25%
- AWS サービス別資料 (BlackBelt)を読む 35%
- 実際に触る 40%
これにつきます。%はウェイトです。
1. 本を読む
私が勉強したときに読んだ本はこれ、AWSの雰囲気をつかむには良い本かと思います。
ただ、2016年に発売されたものなので情報は古くなっていると思います。
別の本を読んでもいいかも。おすすめあったら教えてください。合格対策 AWS認定 ソリューションアーキテクト アソシエイト
2. AWS サービス別資料 (BlackBelt)を読む
これはAWSサミットやウェビナーなどで実際に使われた過去資料のアーカイブみたいなもんです。
基本的な知識からユースケースまでが紹介されているため本を読んだ後こんな感じで使うのか~
という雰囲気をつかむにはもってこいかと思います。特に読むべきサービスとしては
- EC2
- ELB
- EBS
- ECS
- S3
- IAM
- Lambda
- RDS
- CloudWatch
- VPC
- Route53
などは把握しておいたほうがいい。(よく使うサービスだし。)
基本的に浅く広くサービスについて理解をしておけば試験には受かるし雰囲気は掴めるので何とかなる。
覚える内容としてはどういうサービスで、どんなことが実現できるのか
ベストプラクティス
課金システム
セキュリティだいたいこんな感じですかね。これを覚えておけばだいたい受かります。
3. 実際に触る
AWSアカウントを作るだけなら無料でEC2やS3、Lambdaは無料枠があるのでタダである程度は使えます。
百聞は一見に如かず
ビビらず実際に触ってみて使うのが一番手っ取り早いです。
私は業務で触らせてもらってたので何とかなりましたが、実際見ないとわからんないもんでしたね。
というか基本的に私は勉強苦手なので、体で覚えるタイプの人間は触るのが一番早いです。無料枠をまとめてくれているサイトがあるのでこちらを見て使ってみるのもありだと思いますm(__)m
AWS 無料枠一覧まとめ
まとめ
この3つを平日1~2時間ほどやった結果、1~2か月くらいで合格できました。
ただ、ソリューションアーキテクトだと本とAWS サービス別資料を読み込めば受かると思います。
実際に触るとイメージしやすくなって、覚えるのは早くなる苦労したこととしては、
- AWS特有の用語や概念 (AZってなんだっけ?とか)
- イメージしずらい
- 覚えることが多い
個人的には資格の勉強は「使わないことばっかり覚えてあんまり意味ない。」という感覚でしたが、
ソリューションアーキテクトで勉強したことはAWSを使う上で、実際に役に立つ情報が多かったという印象です。
ぜひこれからAWSを始めようと思う方は勉強してみてください。
- 投稿日:2020-12-04T18:01:28+09:00
セッションマネージャを導入する話
こんにちは。CAMPFIRE SREのsakakibaraです。
現在、セッションマネージャをプロダクトに導入中で、今回はそのセッションマネージャについてまとめてみたいと思います
セッションマネージャって何?
Session Manager はフルマネージド型 AWS Systems Manager 機能であり、インタラクティブなワンクリックブラウザベースのシェルや AWS Command Line Interface (AWS CLI) を介して Amazon Elastic Compute Cloud (Amazon EC2) インスタンス、オンプレミスインスタンス、および仮想マシン (VM) を管理できます。Session Manager を使用すると、インバウンドポートを開いたり、踏み台ホストを維持したり、SSH キーを管理したりすることなく、監査可能なインスタンスを安全に管理できます。また、Session Manager を使用すると、マネージドインスタンスへの簡単なワンクリックのクロスプラットフォームアクセスをエンドユーザーに提供しつつ、インスタンスへの制御されたアクセス、厳格なセキュリティプラクティス、完全に監査可能なログ (インスタンスアクセスの詳細を含む) が要求される企業ポリシーに簡単に準拠できます。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/session-manager.html
とありますが、
インスタンスに便利で安全に接続できるものです。セッションマネージャー入れると何がよいの?
- インスタンスへのアクセスの制御がしやすい
- 行動ログがとれる
- 鍵管理から解放される
- SSHポートを閉じれる
インスタンスへのアクセス制御がしやすい
セッションマネージャでインスタンスへのアクセスを管理すると、管理者はIAMポリシーのみ気にしていればよくなります。
セッションマネージャ経由でインスタンスにアクセスする場合は、awsコマンド or コンソール画面からアクセスすることになるので、IAMポリシーで権限がないユーザーはインスタンスにアクセスできなくなります。行動ログがとれる
何かあったときに、ユーザがなにをしたか知りたいですよね?
セッションマネージャなら、ユーザーの行動ログがs3バケットと連携するだけで簡単にとれます。鍵管理から解放される
IAMユーザーでインスタンスへのアクセスを制限するため、鍵管理から解放されます
SSHポートを閉じれる
SSHでのアクセスを許容しなくても良いため、SSHポートを閉じれます。
つまり、セキュリティグループの管理もなくなります。
→地味に嬉しいセッションマネージャ導入大変なの?
めっちゃ簡単です。
セッションマネージャを利用するためにはssm-agentが必要ですが、最新のAmazonLinuxにはデフォルトでインストールされています。
そのため、AmazonEC2RoleforSSMポリシーをもつIAMロールをEC2インスタンスに設定すればOK※古いAMIイメージの場合は、ユーザーデータにssm-agentのインストールするコマンドを追記しておくだけ
まとめ
規模が大きかったり、個人情報を扱うプロダクトの場合は、セキュリティは常に意識したいものです。
セッションマネージャなら、すべてのポートを塞ぐことができるので安全かつ、お手軽に導入できるので、ぜひ試してみてくださいー!

- 投稿日:2020-12-04T17:58:42+09:00
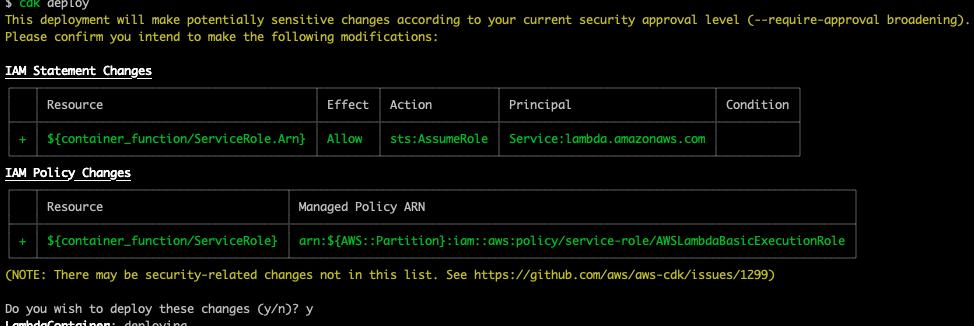
【re:Invent】AWS Lambda コンテナ試して見た
AWS Lambda Container Support が発表されました。最大 10GB のサイズのコンテナイメージがデポロイできます。現時点サポートされている、全てのランタイム(Python、Node.js、Java、.NET、Go、Ruby)のベースイメージを提供します。
全体像
従来は Lambda コンソールからソース編集かアップロードできますが、コンテナイメージ使う場合、一旦
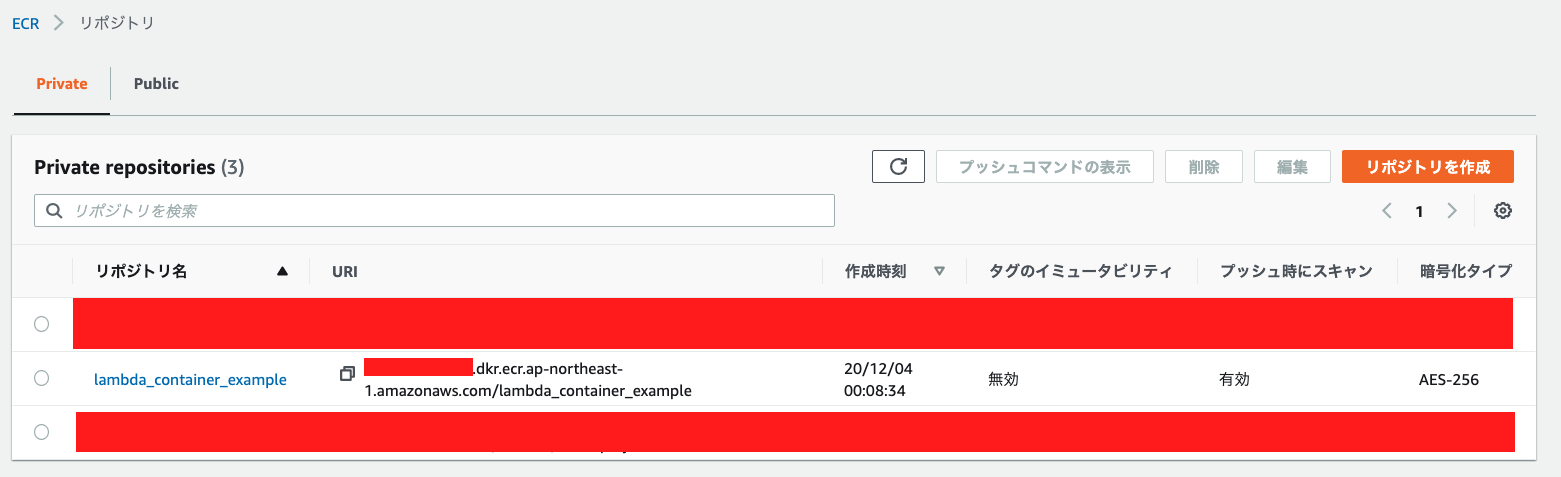
Amazon ECRに保存し、Lambda コンソールからデポロイを行います。
コンテナイメージ
Amazon ECR (Amazon Elastic Container Registry)
コンテナイメージを AWS に保管しますので、まず
ECR作ります。aws ecr create-repository \ --repository-name lambda-repo \ --region ap-northeast-1下記結果が返ってきます、
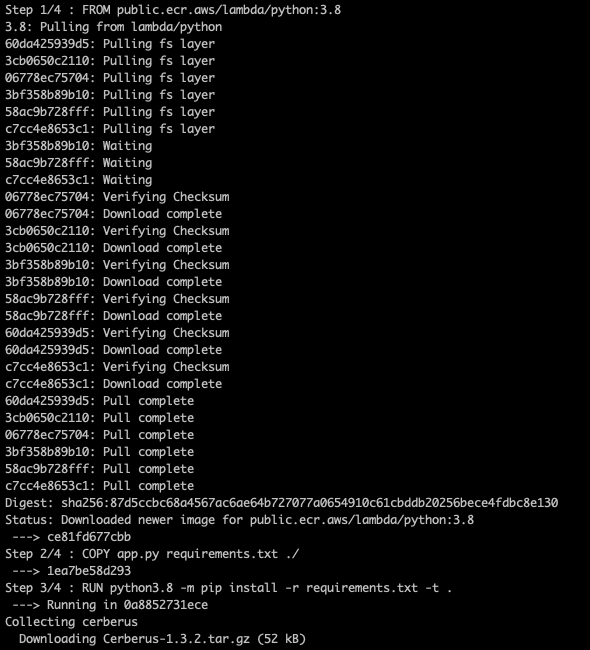
repositoryUriをメモしておきましょう。Output{ "repository": { "repositoryArn": "arn:aws:ecr:ap-northeast-1:[ACCOUNT_ID]:repository/lambda-repo", "registryId": "[ACCOUNT_ID]", "repositoryName": "lambda-repo1", "repositoryUri": "[ACCOUNT_ID].dkr.ecr.ap-northeast-1.amazonaws.com/lambda-repo", "createdAt": "2020-12-04T08:03:18+00:00", "imageTagMutability": "MUTABLE", "imageScanningConfiguration": { "scanOnPush": false }, "encryptionConfiguration": { "encryptionType": "AES256" } } }Dockerfile
イメージビルド用の
Dockerfileを準備します。テストコードも含めて作ります。
Base image は AWS が提供するamazon/aws-lambda-nodejs:12を使用します。Dockerfile# AWS Docker Image FROM amazon/aws-lambda-nodejs:12 WORKDIR /usr/local/app # Port EXPOSE 8000 # Application RUN echo $'\n\ exports.handler = async (event) => { \n\ const response = { \n\ statusCode: 200, \n\ body: JSON.stringify(\'Hello from Lambda!\'), \n\ }; \n\ return response; \n\ }; \n\ ' > index.js CMD [ "/usr/local/app/index.handler" ]最終的に ECR に保存して使うなので、
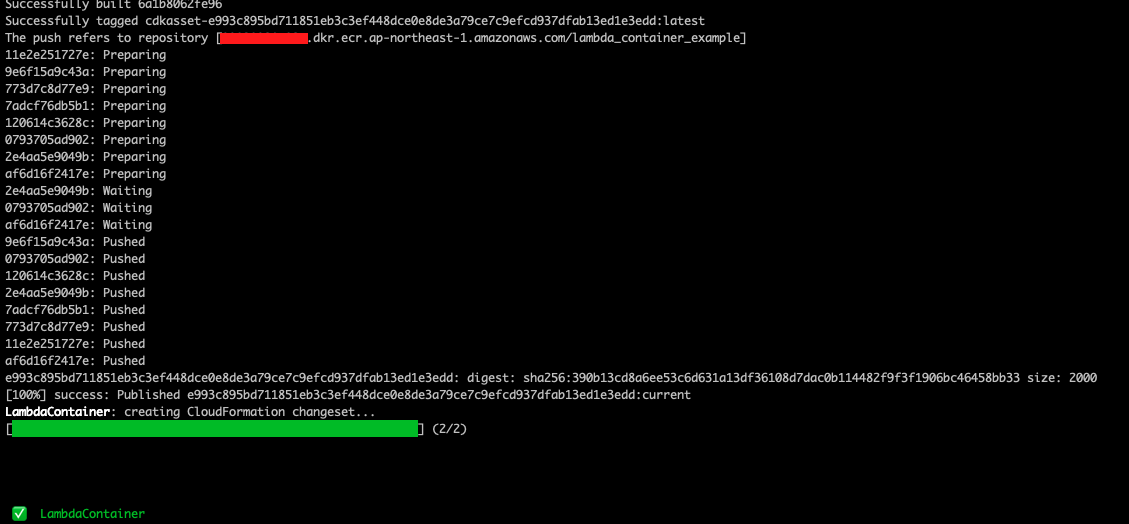
${repositoryUri}:${tag}のフォーマットでタグを付けます。ACCOUNT_IDは環境に合わせて修正する# docker build docker build -t [ACCOUNT_ID].dkr.ecr.ap-northeast-1.amazonaws.com/lambda-repo:latest . # ECR login (Linux) aws ecr get-login-password | docker login --username AWS --password-stdin [ACCOUNT_ID].dkr.ecr.ap-northeast-1.amazonaws.com # docker push docker push [ACCOUNT_ID].dkr.ecr.ap-northeast-1.amazonaws.com/lambda-repo:latestAWS Lambda デポロイ
AWS Lambda のコンソールで [Create Function] をクリックします。 [Container image] を選択し、[Browse images] をクリックします。
先ほど作った ECR Repository から、
latestタグ付けたコンテナイメージを選択し、[Select image] をクリックします。
最後は [Function name] を入れて、他の設定は全部デフォルトのままで、[Create function] をクリックします。
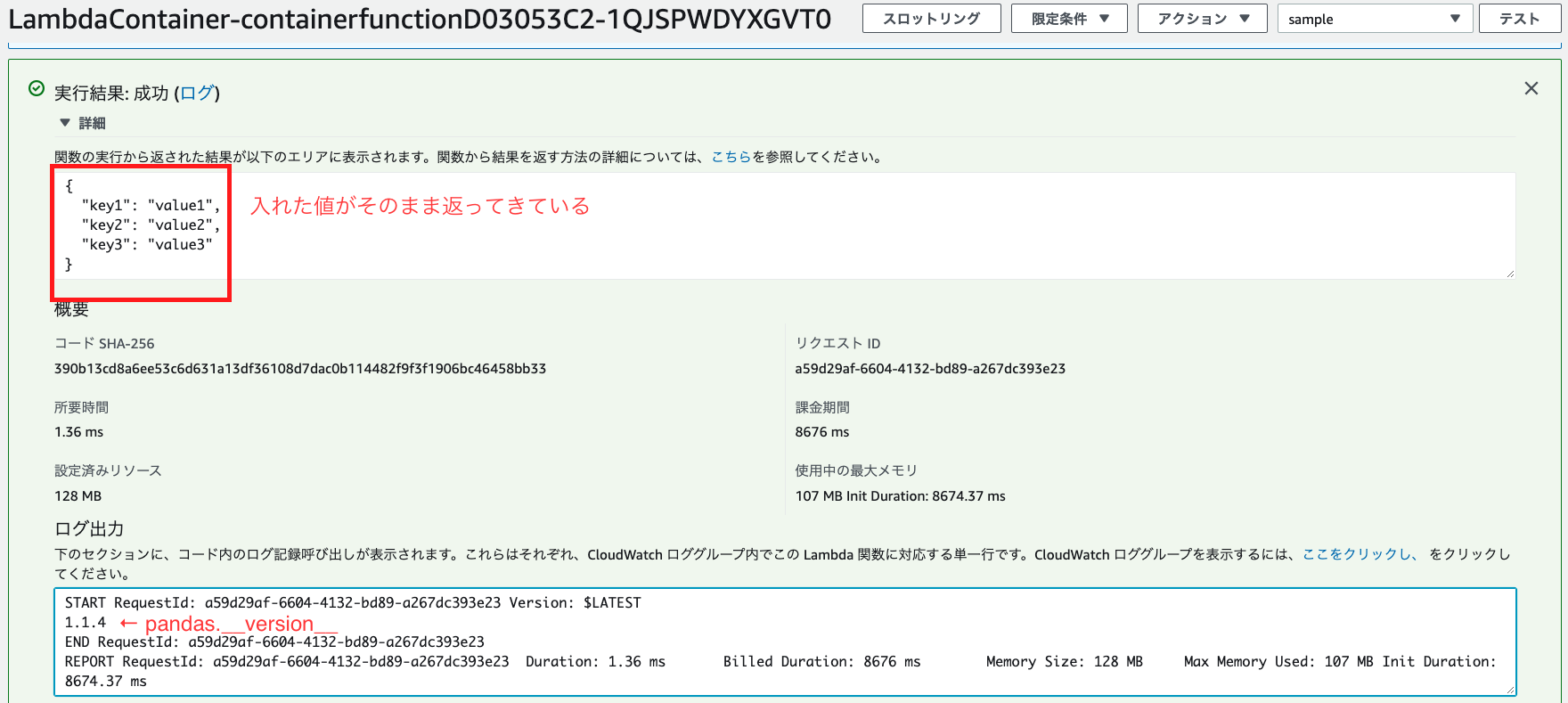
テスト
Lambda コンソールでテストしましょう。想定通りの結果が返ってきました。
パフォーマンス
コンテナイメージ大きいため、やはりコードスタート気になりますね。
イメージサイズ (MB) Lambdaメモリ (MB) コードスタート 正常コール (5回平均) 146.71 128 Duration (11.20 ms)
Billed duration (619 ms)Duration (7.6ms)
Billed duration (8 ms)146.71 640 Duration (2.28 ms)
Billed duration (584 ms)Duration (1.84ms)
Billed duration (2 ms)146.71 1280 Duration (1.98ms)
Billed duration (459 ms)Duration (0.95ms)
Billed duration (1 ms)結果から見ると、メモリを積めば、ある程度改善できます。
おまけに
Lambda コンテナベースイメージの自作方法は、公式ドキュメントに Python のみの記載があります。
日本語の翻訳またなので、英語のみとなります。
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/images-create.html





- 投稿日:2020-12-04T17:53:08+09:00
EC2上のCakephp4でRDSを使う
前提
EC2(Amazon Linux 2 AMI)にCakePHP4をインストールしてあることを前提としています。
今回、PHPのversionは7.4とします。
基本的に前回の投稿の続きです。RDSの立ち上げ
RDSの立ち上げは公式サイトにもありますのでここでは省略します。
初心者の方はこちらがおすすめです。MySQLとPHP拡張モジュールのインストール
MySQLとそれに繋ぐためのPHP拡張モジュールをインストールします。
$ sudo yum install -y mysql $ sudo yum install -y mysql57-server php74-mysqlnd以下のコマンドで先ほど立ち上げたRDSに接続できると思います。
$ mysql -h db-resume.crcdiqvbtctf.ap-northeast-1.rds.amazonaws.com -P 3306 -u admin -p Enter password: (パスワードを入力) Server version: 8.0.20 Source distribution Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. MySQL [(none)]>Cakephp接続設定
git管理下にあるconfig/app.phpにデータベースのパスワードやらをのせるのはまずいと思いますので、
接続情報は app.php ではなく、デフォルトでgitignoreされている app_local.php に書いておくのが無難だと思います。<?php return [ // 他の設定 'Datasources' => [ 'default' => [ 'className' => 'Cake\Database\Connection', 'driver' => 'Cake\Database\Driver\Mysql', 'persistent' => false, 'host' => 'testdb.abcdefghijkl.ap-northeast-1.rds.amazonaws.com', 'username' => 'cakephp', 'password' => 'secret', 'database' => 'testdb', 'encoding' => 'utf8mb4', 'timezone' => 'Asia/Tokyo', 'cacheMetadata' => true, ], ], // 他の設定 ];port番号を設定しなくても自動で探してくれるらしいです。
- 投稿日:2020-12-04T17:50:27+09:00
RDSコンソールからとAWS backupからのAuroraクラスターリストア時の挙動の違い
はじめに
DX 技術本部の yu-yama@sra です。
AWS 環境で DB(Aurora)のバックアップ・リストアを検証した際に、
AWS Backup で復旧ポイントからリストアする時の挙動が思っていたのと違ったのでここに記します。TL;DR
AWS Backup からリストアするとインスタンスが作成されないのでそのままではDBにアクセスできません。RDS コンソールからリストアしましょう
Aurora クラスターを AWS Backup の復元ジョブにて復旧ポイントからリストアする場合の挙動
AWS backup のコンソールから復元する場合
クラスターは作成されるのだが、0インスタンスとなってしまう。
DBクラスターのエンドポイント作成ステータスはずっと作成中のまま...
もちろんDBにはアクセスできない。
これはどういう状況かというと、DB クラスターのみが作成され、クラスターのプライマリインスタンスやレプリカインスタンスが作成されていない状態1になります2。
Amazon Aurora DB クラスター - Amazon Auroraリストアを行うと復旧ポイント時点での状態で新規にクラスターが立ち上がり、DBアクセスできる状態になっていることを期待していました。
この状態からDBアクセスするためにやること
- インスタンスがないのでインスタンスを作成する必要があります。
- マネジメントコンソールの現在の動作として、 RDSコンソールからプライマリインスタンスを追加する操作を実施できないため、AWS CLI の
create-db-instanceなどの API にてクラスターに対して DB インスタンスを追加します。参考:Amazon Aurora DB クラスターの作成 - Amazon Aurora
コンソールを使用して DB クラスターを作成する場合、Amazon RDS は自動的に使用する DB クラスターのプライマリインスタンス (ライター) を作成します。AWS CLI を使用して DB クラスターを作成する場合、使用する DB クラスターのプライマリインスタンスを明示的に作成する必要があります。プライマリ インスタンスは、DB クラスターで作成される最初の DB インスタンスです。
DB クラスターのプライマリインスタンスを作成するには、
create-db-instanceAWS CLI コマンドを呼び出します。--db-cluster-identifierオプション値として DB クラスターの名前を含めます。Linux、macOS、Unix の場合:
aws rds create-db-instance --db-instance-identifier sample-instance --db-cluster-identifier sample-cluster --engine aurora-postgresql --db-instance-class db.r4.large
Windows の場合:
aws rds create-db-instance --db-instance-identifier sample-instance --db-cluster-identifier sample-cluster --engine aurora-postgresql --db-instance-class db.r4.large
- インスタンスを作成することで、やっとDBにアクセスできる状態になります。
Aurora クラスターを RDS コンソールにて DB スナップショットから DB クラスターをリストアした場合の挙動
- AWS backupで取得したスナップショットはRDSコンソールからも参照できるので「RDS-スナップショット-バックアップサービス-対象のスナップショットを選択-スナップショットを復元」と復元する
インスタンスが作成された状態で新規にクラスターが立ち上がる3。
DBアクセスできる状態になっています。
まとめ
AWS backupでバックアップの一元管理できるようになったが、リストアの仕様が各サービスのコンソールと違う恐れがあるため、AWS backup でリストアする際は要確認。







- 投稿日:2020-12-04T17:26:39+09:00
マルチリージョン・マルチアカウントで発生するAWSイベントをChatBotでまるっと通知する
はじめまして。ZOZOテクノロジーズ CTO室 兼 SRE部 のkotatsu360です。
ウィスキーと葉巻とAWSが好きです∠( ゚д゚)/この記事は
ZOZOテクノロジーズ #4 Advent Calendar 2020 4日目です。
昨日はtajimaTheMemerさんのCloud Pub/Subから別のGCPプロジェクトのCloud Runをトークン認証付きで呼び出すでした。
マルチリージョン・マルチアカウントで発生するAWSイベントをChatBotでまるっと通知する
前説
先日、こんな発表をしました。
AWS Configを用いたマルチアカウント・マルチリージョンでのリソース把握とコンプライアンス維持への取り組みについて - Speaker Deck by kotatsu360AWS Configを使って、マルチアカウント・マルチリージョンの品質を維持しましょう!というお話でした。実はこの資料の内、動いたときに一番(っ'ヮ'c)ウゥッヒョオアアァアアアァとなったのは通知の部分だったりします。
この記事は、その通知部分を詳しく取り上げるものです。
登場するサービスについては登壇資料17ページあたりにまとめております。
もし、ナニコレというものがあればそちらを御覧ください。目指したところ
- 維持コストが無い(ほっといたら壊れてるがない)
- AWSアカウント増減に伴う手間がかからない
- 初期構築もできれば楽
1〜3の条件がそのまま優先度になっています。1は日常、2は時々、3は一回だけ。普段、手のかからないシステムは良いシステム。
これを目標にマネージドシステムを組み合わせました。最終的に、初期構築の手作業もChatbotを有効化する、それだけです!
作り方
見出しは
【リソース作成先アカウント】【対象リージョン】の構造です。
作業自体は全てMasterアカウントです。ステップ0のみ手動ですが、あとは
CloudFormationとCloudFormation Service Managed StackSetsで行います。
この記事を書いているときに、ステップ2に含まれるEventBusがDefaultじゃないことに気づいたので取り消し線を入れています。。すいません。 Defaultとそれ以外については、文中ででてきますのでそちらを御覧ください。0. 【Masterアカウント】【リージョンなし(グローバル)】準備
ChatbotとSlackをつなぐところは、OAuthによる認可が必要です。
Masterアカウントで一回だけ行います。Chatbotはグローバルなサービスなので、リージョンを気にする必要はありません。1. 【Masterアカウント】【シングルリージョン】Chatbotリソースの作成
ChatbotとSlackの認可が終わったら、実際にChatbotリソースを作成します。
Chatbotの設定をする際、Webコンソールからだと存在するSNSトピックしか設定できないのですが、CloudFormationからだと存在チェックを無視して指定できます。ここではリージョンの有効化状況に関係なく全リージョンを指定しておきます。
Resources: IAMRole: Type: 'AWS::IAM::Role' Properties: (略) ChatbotSlackChannelConfiguration: Type: 'AWS::Chatbot::SlackChannelConfiguration' Properties: ConfigurationName: !Ref AWS::StackName IamRoleArn: !GetAtt IAMRole.Arn SlackChannelId: #####通知したいSlackチャンネル##### SlackWorkspaceId: #####通知したいSlackワークスペース##### SnsTopicArns: # [NOTE] Chatbotが使うSNSTopicは、存在チェックされない。全リージョン列挙しておく。 - !Sub 'arn:aws:sns:us-east-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:us-east-2:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:us-west-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:us-west-2:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:af-south-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:ap-east-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:ap-south-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:ap-northeast-2:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:ap-southeast-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:ap-southeast-2:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:ap-northeast-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:ca-central-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:eu-central-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:eu-west-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:eu-west-2:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:eu-south-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:eu-west-3:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:eu-north-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:me-south-1:${AWS::AccountId}:my-events' - !Sub 'arn:aws:sns:sa-east-1:${AWS::AccountId}:my-events'2. 【Masterアカウント】【マルチリージョン】他アカウントからのイベントを受け取るEventBusを作成
次に、他アカウントからChatbotへイベントを仲介する、EventBusを作成します。作成せずとも
defaultというリソースが最初から用意されているのですが、ポリシーを設定して自分の好きにコントロールしたいので、myeventというリソースを新たに作成しています。なお、このEventBridgeはリージョナルなリソースなので、CloudFormation Stacksetsを用いて自分自身(Masterアカウント)の全リージョンへEventBusを作成します。
Resources: EventsEventBus: Type: 'AWS::Events::EventBus' Properties: Name: 'myevent' EventsEventBusPolicy: Type: 'AWS::Events::EventBusPolicy' Properties: Action: 'events:PutEvents' Condition: Type: 'StringEquals' Key: 'aws:PrincipalOrgID' Value: !Ref PrincipalOrgID # 組織内からの呼び出しであれば受け付ける EventBusName: !Ref EventsEventBus Principal: '*' StatementId: 'my-statement' SNSTopic: Type: 'AWS::SNS::Topic' Properties: TopicName: 'my-events' # ChatBotで指定するため固定 SNSTopicPolicy: Type: 'AWS::SNS::TopicPolicy' Properties: PolicyDocument: Version: '2008-10-17' Id: '__default_policy_ID' Statement: - Sid: '__default_statement_ID' # SNS Topicが持つ基本的な権限。適当なTopicからコピーしてくる。 (略) - Sid: 'events' # EventBusからのPutを許可 Effect: 'Allow' Principal: Service: 'events.amazonaws.com' Action: 'sns:Publish' Resource: !Ref SNSTopic Topics: - !Ref SNSTopic EventsRuleConfigComplianceChange: # EventBusが受け付けたイベントの内、PatternにマッチするものだけをSNSに流す Type: 'AWS::Events::Rule' Properties: EventBusName: 'myevent' EventPattern: source: - 'aws.config' detail-type: - 'Config Rules Compliance Change' detail: messageType: - 'ComplianceChangeNotification' newEvaluationResult: complianceType: - 'NON_COMPLIANT' - 'COMPLIANT' State: 'ENABLED' Targets: - Arn: !Ref SNSTopic Id: 'my-chatbot-sns'3. 【Memberアカウント】【マルチリージョン】Masterアカウントへイベントを送出するEventBusの作成
最後に、MemberアカウントへEventBusを作成します。
ここではMasterアカウントからCloudFormation Stacksetsを
SERVICE_MANAGEDモードで作成します。これにより、新規AWSアカウントに対する実行を自動化できます。なお、地味にハマった部分が、
EventBusName: 'default'の部分です。
AWSサービスが発するイベントを処理したい場合、defaultリソースに対してルールを設定する必要があります。最初は「全部自分で、EventBusの作成からやるぞ〜!!!」と作業した結果、待てど暮らせどイベントが来ない。。という状況になりました。
Resources: EventsRuleConfigComplianceChange: Type: 'AWS::Events::Rule' Properties: EventBusName: 'default' # [NOTE] AWSサービスのイベントはdefaultで受ける必要がある EventPattern: source: - 'aws.config' detail-type: - 'Config Rules Compliance Change' detail: messageType: - 'ComplianceChangeNotification' newEvaluationResult: complianceType: - 'NON_COMPLIANT' - 'COMPLIANT' State: 'ENABLED' Targets: - Arn: !Sub 'arn:aws:events:${AWS::Region}:${MasterAccount}:event-bus/myevent' Id: 'myevent' RoleArn: !GetAtt IAMRoleCloudWatchEvents.Arn IAMRoleCloudWatchEvents: Type: 'AWS::IAM::Role' Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: 'Allow' Principal: Service: 'events.amazonaws.com' Action: 'sts:AssumeRole' Policies: - PolicyDocument: Statement: - Action: - 'events:PutEvents' Effect: 'Allow' Resource: !Sub 'arn:aws:events:${AWS::Region}:${MasterAccount}:event-bus/myevent' PolicyName: 'post-to-parent-account'以上を実行することで、各Memberアカウント・各リージョンのAWS Configから発されたイベントを、回り回ってSlackへ届けることができます!
まとめ
EventBridgeが提供するEventBusを中心に、CloudFormationを駆使することで、マルチアカウント・マルチリージョンでも手作業を最大限減らした通知基盤ができました。ルールを追加することで、どんなイベントでも通知することが可能です。
なお、お気づきの方もおられるかと思いますが、、、実はリージョンが増えたときだけはCloudFormation StackSetsの設定を変更するなど、手作業が必要です。それでもアカウント作成ほど頻繁ではないのであまり問題にはなっていません。
紹介したテンプレートについて、リソース類は漏れなく記載いたしましたが一部重要でない部分は省略しています。
気になることがあればコメント等で質問ください!!明日はr-tezukaさんのBezier作図環境に関する記事です。お楽しみに!
謝辞
この構成を検討するにあたって以下の記事にはとてもお世話になりました。ありがとうございます。
【全リージョン対応】EventBridge + SNS + Chatbotで GuardDutyの結果を Slackチャンネルに通知する | Developers.IO



- 投稿日:2020-12-04T16:43:08+09:00
AWS CloudWatch Logs でWindowsサーバー上に出力されたログファイルを取得する。
作業の流れ
1.IAMロールを作成する。(「AmazonEC2RoleforSSM」と「CloudWatchAgentAdminPolicy」)
2.サーバーにCloudWatchエージェントをインストールする。
「Systems Manager」>「Run Command」>「コマンドの実行」から、「AWS-ConfigureAWSPackage」を実行する。
※コマンドのパラメータ の Name に AmazonCloudWatchAgent と入力します。3.CloudWatchエージェントの初期設定
Windowsサーバーにログインし、「C:\Program Files\Amazon\AmazonCloudWatchAgent¥amazon-cloudwatch-agent-config-wizard.exe」を実行する。
色々と設定値を指定する。
以下、設定ウィザードのサンプルです。============================================================= = Welcome to the AWS CloudWatch Agent Configuration Manager = ============================================================= On which OS are you planning to use the agent? 1. linux 2. windows default choice: [2]: 2 Trying to fetch the default region based on ec2 metadata... Are you using EC2 or On-Premises hosts? 1. EC2 2. On-Premises default choice: [1]: 1 Do you want to turn on StatsD daemon? 1. yes 2. no default choice: [1]: Which port do you want StatsD daemon to listen to? default choice: [8125] What is the collect interval for StatsD daemon? 1. 10s 2. 30s 3. 60s default choice: [1]: What is the aggregation interval for metrics collected by StatsD daemon? 1. Do not aggregate 2. 10s 3. 30s 4. 60s default choice: [4]: Do you have any existing CloudWatch Log Agent configuration file to import for migration? 1. yes 2. no default choice: [2]: Do you want to monitor any host metrics? e.g. CPU, memory, etc. 1. yes 2. no default choice: [1]: Do you want to monitor cpu metrics per core? Additional CloudWatch charges may apply. 1. yes 2. no default choice: [1]: Do you want to add ec2 dimensions (ImageId, InstanceId, InstanceType, AutoScalingGroupName) into all of your metrics if the info is available? 1. yes 2. no default choice: [1]: Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file. 1. 1s 2. 10s 3. 30s 4. 60s default choice: [4]: Which default metrics config do you want? 1. Basic 2. Standard 3. Advanced 4. None default choice: [1]: Current config as follows: { "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "LogicalDisk": { "measurement": [ "% Free Space" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "Memory": { "measurement": [ "% Committed Bytes In Use" ], "metrics_collection_interval": 60 }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" } } } } Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items. 1. yes 2. no default choice: [1]: Do you want to monitor any customized log files? 1. yes 2. no default choice: [1]: Log file path: C:\ProgramData\Amazon\AmazonCloudWatchAgent\Logs\test.log Log group name: default choice: [Logs¥test.log] Log stream name: default choice: [{instance_id}] Do you want to specify any additional log files to monitor? 1. yes 2. no default choice: [1]: 2 Do you want to monitor any Windows event log? 1. yes 2. no default choice: [1]: 2 Saved config file to config.json successfully. Current config as follows: { "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "C:\\ProgramData\\Amazon\\AmazonCloudWatchAgent\\Logs\\test.log", "log_group_name": "Logs¥test.log", "log_stream_name": "{instance_id}" } ] } } }, "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "LogicalDisk": { "measurement": [ "% Free Space" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "Memory": { "measurement": [ "% Committed Bytes In Use" ], "metrics_collection_interval": 60 }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" } } } } Please check the above content of the config. The config file is also located at config.json. Edit it manually if needed. Do you want to store the config in the SSM parameter store? 1. yes 2. no default choice: [1]: 2 Please press Enter to exit...※ここで指定した内容が、Systems Managerの「パラメータストア」に格納されます。
一つ注意点としては、「Log file path」を「C:\ProgramData\Amazon\AmazonCloudWatchAgent\Logs」配下のファイルにすることです。
(他のパスを指定するとおそらくログが出力されないです。)4.EC2のIAMロールを変更する。(「AmazonEC2RoleforSSM」と「CloudWatchAgentServerPolicy」に変更する。)
5.設定をインスタンスに適用する。
「Systems Manager」>「Run Command」>「コマンドの実行」から、「AmazonCloudWatch-ManageAgent」を実行する。コマンドのパラメータ の Optional Configuration Location にSSMパラメータストアに格納した設定値を入力する。
デフォルト値は「AmazonCloudWatch-windows」。以上になります。
ご参考までに、以下パラメータファイルのサンプルになります。
{ "logs": { "logs_collected": { "files": { "collect_list": [ { "file_path": "c:\\ProgramData\\Amazon\\AmazonCloudWatchAgent\\Logs\\test.log", "log_group_name": "test.log", "log_stream_name": "{instance_id}" } ] } } }, "metrics": { "append_dimensions": { "AutoScalingGroupName": "${aws:AutoScalingGroupName}", "ImageId": "${aws:ImageId}", "InstanceId": "${aws:InstanceId}", "InstanceType": "${aws:InstanceType}" }, "metrics_collected": { "LogicalDisk": { "measurement": [ "% Free Space" ], "metrics_collection_interval": 60, "resources": [ "*" ] }, "Memory": { "measurement": [ "% Committed Bytes In Use" ], "metrics_collection_interval": 60 }, "statsd": { "metrics_aggregation_interval": 60, "metrics_collection_interval": 10, "service_address": ":8125" } } } }参考にしたサイト:
https://dev.classmethod.jp/articles/monitoring-windows-eventlog-by-cloudwatch/
- 投稿日:2020-12-04T16:17:33+09:00
CloudMapper を daemon にする
CloudMapper とは
awsのネットワーク構成図を作成してくれるツールです。
python3で動きます。https://github.com/duo-labs/cloudmapper
インストール手順
daemon にする
/etc/systemd/system/cloudmapper.service[Unit] Description=cloudmapper After=network.target [Service] Type=simple WorkingDirectory=/var/www/github.com/duo-labs/cloudmapper/ ExecStart=/usr/local/pyenv/shims/python -u cloudmapper.py webserver Restart=always StandardOutput=journal StandardError=journal [Install] WantedBy=multi-user.targetcentos7sudo systemctl enable cloudmapper.service systemctl start cloudmapperハマり
daemon 化の経緯
ターミナルで
python ./cloudmapper.py webserverと叩くと、localhohst:8000 で cloudmapperが立ち上がり、ブラウザで見れるようになります。
ターミナルを終了すると見れなくなってしまうので、daemon にして永続的に見れるようにします。pythonで daemon
node の forever に相当するものはなくたぶん、service に入れることにしました。
(pythonピヨグラマーです)
- 1発目
ExecStart=/usr/bin/python -u {フルパス}/cloudmapper.py webserverpyenvでpythonをインストールしているので、/usr/bin/python はデフォルトで入っているバージョン(python2系)です。
cloudmapper はpython3でないと動かないので、which pythonで探しました。
- 2発目
ExecStart=/usr/local/pyenv/shims/python -u {フルパス}/cloudmapper.py webserverこれでも動きません。
ターミナルで叩くと、cloudmapper.py 内の show_help が呼び出され、usage: ~ が表示されます。
カレントフォルダが{フルパス}でなれば動かないと気づくのに時間を要しました。
cloudmapper.py の仕様と思いますたぶん
- 3発目
ExecStart=cd {フルパス};/usr/local/pyenv/shims/python -u cloudmapper.py webserverカレントフォルダを移動すればいいと分かったので、コマンドを繋げました
安直
コマンドエラーが出ていたので、すぐわかりました。
- 4発目(解決)
WorkingDirectory={フルパス}
ExecStart=/usr/local/pyenv/shims/python -u cloudmapper.py webserverWorkingDirectory でカレントフォルダを指定して解決です。
(所要時間: 3時間)
- 投稿日:2020-12-04T15:13:11+09:00
MYSQLWorkbenchからawsのRDSに作ったDBインスタンスに接続できなくなった問題と解決法
・事象
・解決法
別のwifiに接続を切り替える。おそらくパブリックIPアドレスが変わってしまうのでDBインスタンス作成の際のwifiに合わせないといけない?

- 投稿日:2020-12-04T12:51:46+09:00
IAMポリシーで特定のタグを持つEC2操作を制限する
特定のタグを持つEC2操作を制限する
はい皆さんこんにちは
この記事はIAMポリシーによってEC2のタグを参照して権限を付けた事例の紹介です。
詳細
要件としては以下の内容でした。
・EC2にEnvタグ(値:dev)が付いたものだけ操作したい。
・Envタグ(値:prod)は操作出来ないようにする。
・タグが一致しているならAMIやスナップショットも取りたい環境:
AWS EC2(AmazonLinux2)
コンソールにログインするユーザーのIAMポリシーを編集しながら検証最終的な設定
必要な権限を付与しつつ、EC2:*を許可しておく。
そのうえで、prodタグを持っているEC2の操作を拒否する。{ "Version": "2012-10-17", "Statement": [ { "Sid": "1", "Effect": "Allow", "Action": [ "trustedadvisor:*", "iam:*", "cloudwatch:*", "s3:*", "logs:*", "cloudtrail:*", "ec2:*", "support:*", "inspector:*", "directconnect:*" ], "Resource": "*" }, { "Sid": "2", "Effect": "Deny", "Action": [ "ec2:*" ], "Resource": "*", "Condition": { "StringEquals": { "ec2:ResourceTag/Env": "prod" } } } ] }色々やってみる
EC2のインスタンス一覧にはprodのサーバも表示される(これは仕方ない)
prodが入っているEC2のタグを操作しようとするとエラーになる
prodが入っているEC2の再起動でエラーになる
devが入っているEC2の再起動はOK
devが入っているEC2のAMIが取得できる
devが入っているEC2でスナップショットも可能です。
注意事項
タグが付いていないサーバも同様に操作が可能です。
何故こうしているかと言うと、
AMIやスナップショットが作成される時にタグが付いていないのでエラーになってしまいます。
なのでタグが無くてもAMIやスナップショットを許可する必要があります。なお、スナップショットにEnv:prodのタグを付けた後に削除しようとした場合、想定通りエラーになります。
運用で必ずタグをつけるようにしましょう。
感想
本当はもっと権限を絞れると思いますが、今回は細かい制限は入れませんでした。
(あまり時間が無かったのもあり。)
これ以外にもっと効率の良いものがあれば更新します。ありがとうございました。






- 投稿日:2020-12-04T11:39:09+09:00
AWS SAMをローカルDockerコンテナ上で動かす
目標
前回のAWS SAM CLIによるサーバレス環境構築に引き継ぎ、SAM環境構築で直接にローカルPCにインストールではなく、Docker内に入れます。Docker導入の良いところは、個人開発環境のパッケージのバージョンを統一できるメリットがもちろん、MysqlやElasticSearchなどの導入も迅速できます。
ちなみに、エキサイトの「開発現場でAWSサーバーレスを導入しました」記事も紹介しました。
前提
入門編に紹介している知識を把握していることが前提です。また、Dockerの基礎知識があり、ローカルPCにDockerインストールしておく必要。
構築
アプリケーションのひな形生成
初回だけ雛形生成が必要なので、前回みたい
sam init実行します。$ sam init \ --runtime python3.8 \ --name excite-serverless-project \ --app-template hello-worldexcite-serverless-projectプロジェクトが作成されました。
ディレクトリ構造を再編
最終的にこのようなフォルダー構成を作ります
├── README.md ├── __init__.py ├── bin │ ├── build.sh │ └── deploy.sh ├── docker │ └── Dockerfile ├── docker-compose.yml ├── src │ ├── hello_world │ │ ├── __init__.py │ │ ├── app.py │ │ └── requirements.txt │ └── template.yaml └── tests ├── __init__.py └── unit ├── __init__.py └── test_handler.pyとりあえず、Events不要なので削除します
$ rm -rf events/実際にAPIエンドポイントが複数あるので、もう1段を下げます
$ mkdir src $ mv hello_world template.yaml srcDocker環境構築
- AWSの認証設定 AWSへデプロイのため、アクセスキーIDとシークレットキー設定が必要です。
$ mkdir .aws保存フォルダーだけ先に作成しておきます。
- docker管理フォルダー作成
$ mkdir dockerDockerfileファイル作成、以下の内容を追加します
FROM python:3.8 # create local bin directory RUN mkdir -p /root/.local/bin ENV PATH $PATH:/root/.local/bin # Install awscli and aws-sam-cli RUN pip install -U pip setuptools wheel --no-cache-dir && \ pip install pipx --no-cache-dir && \ pipx install virtualenv && \ pipx install pipenv && \ pipx install awscli==1.* && \ pipx install aws-sam-cli==1.9.0 WORKDIR /usr/src最後にdocker-compose.yml作成します
version: "3" services: sam_instance: container_name: excite-sam-instance image: excite-sam-instance build: context: . dockerfile: ./docker/Dockerfile networks: - excite-sam-network volumes: - .:/usr/src networks: excite-sam-network: driver: bridgeコマンド省略化のために、bashファイルにまとめる
まず、スクリプト保存フォルダーを作成します
$ mkdir binbuild.shファイル作成、以下の内容を追加します。
#!/bin/bash set -o errexit # aws profile echo -n "AWS_ACCESS_KEY_ID:" read -r AWS_ACCESS_KEY_ID echo -n "AWS_SECRET_ACCESS_KEY:" read -r AWS_SECRET_ACCESS_KEY # aws credentials echo "[default]" > .aws/credentials echo "aws_access_key_id = $AWS_ACCESS_KEY_ID" >> .aws/credentials echo "aws_secret_access_key = $AWS_SECRET_ACCESS_KEY" >> .aws/credentials # aws config echo "[default]" > .aws/config echo "output = json" >> .aws/config echo "region = ap-northeast-1" >> .aws/config # build docker docker-compose build "${@}"次にdeploy.shファイル作成、以下の内容を追加します。
#!/bin/bash set -o errexit TEMPLATE_FILE=$1 DOCKER_IMAGE_NAME=excite-sam-instance STACK_NAME=excite-api-lambda-deploy-stack S3_BUCKET_NAME=excite-api-lambda-deploy-bucket # build SAM template docker run \ -v $(pwd):/usr/src \ -v $(pwd)/.aws:/root/.aws --rm $DOCKER_IMAGE_NAME \ sam build -t "$TEMPLATE_FILE" # SAM deploy docker run \ -v $(pwd):/usr/src \ -v $(pwd)/.aws:/root/.aws --rm $DOCKER_IMAGE_NAME \ sam deploy --template-file .aws-sam/build/template.yaml --stack-name "$STACK_NAME" \ --s3-bucket "$S3_BUCKET_NAME" --capabilities CAPABILITY_NAMED_IAM --no-fail-on-empty-changeset # remove unnecessary folder rm -rf .aws-samAWSへデプロイしてみる
まず、ビルド実施
$ ./bin/build.sh個別でテンプレートをAWSへデプロイ
$ ./bin/deploy.sh src/template.yamlAPI Gatewayのアクセスポイントでアクセスしてみる
$ curl https://xxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello {"message": "hello world"}と返ってくれば成功です。
最後に
実際の開発現場でdockerが非常に便利です。ローカルでAPIの開発・デバッグ・デプロイの一連作業ができます。次の単体テスト編は実際にコードを書いて、単体テストを実施してみます。
エキサイト株式会社では随時に仲間を募集しております。
- 投稿日:2020-12-04T10:22:25+09:00
AWS Chinaを使う場合に注意すること
この記事は DENSOアドベントカレンダー2020 の4日目の記事です。
今年は仕事でAWS上で構築したものをAWS Chinaでも動作するようにする機会があったのですが、まあそれ自体情報が少ないのと、AWS ChinaとAWSの違いで苦労したので、今後挑戦する方のためにまとめておきます。
はじめに
AWS Chinaとは?
中国版のAWS
https://www.amazonaws.cn/en/about-aws/china/
なんですがAWSと似ているようでちょっと違います。AWS ChinaとAWSの違いについて
少なくとも以下の違いはありました
1. グローバルで展開されているサービスがAWS Chinaで提供されていないことがある
2. ARNの書きかたが違う
3. コスト管理系のサービスのリージョンが違うグローバルで展開されているサービスがAWS Chinaで提供されていないことがある
https://pages.awscloud.com/rs/112-TZM-766/images/H1-07.pdf
にもまとまっていますがAWS Chinaで使用できないサービスがある場合もあります自分たちがすでに使用していたがAWS Chinaで使えなかったとサービスたち
他にもいろいろ違いがありますが
- AWS GuardDuty
- AWS Config のマネージドルールがない(guardduty-enabled-centralized,acm_certificate_expiration_check_enabled)ちなみにAWS Chinaで提供されているサービスはAWS Chinaのページから確認できます
ARNの書きかたが違う
ARNs for AWS services in Chinaに記載があるように
に
グローバル:aws
AWS China:aws-cn
となるARNの書き方が違うせいでTerraform ではこんなエラーが出た
Terraformを使用して構築を自動化していたのですがこのARNの違いによってAWS Chinaでは構築エラーになりました。
以下具体的に遭遇したエラーです。ロググループの定義でエラー
Error: Error putting IAM role policy lambda_cost-explorer: MalformedPolicyDocument: Partition "aws" is not valid for resource "arn:aws:logs:cn-north-1:*:log-group:/aws/lambda/cost_explorer_slack_notification:*". status code: 400, request id: 0413d587-ef1b-43e9-b1dd-1c98ada10e2d on modules/cost_explorer/iam.tf line 31, in resource "aws_iam_role_policy" "lambda_for_cost_explorer": 31: resource "aws_iam_role_policy" "lambda_for_cost_explorer" {もともとのコード
例えばTerraformのコードが以下のようになっていた部分があったのですがこれらが全部AWS Chinaではエラーになりました。{ "Version": "2012-10-17", "Statement": [ { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": ["arn:aws:logs:${var.region}:*:log-group:${aws_cloudwatch_log_group.cost_explorer_slack_notification.name}:*"],=>ここにawsと書いていた "Effect": "Allow" } ] }修正例
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": ["arn:*:logs:${var.region}:*:log-group:${aws_cloudwatch_log_group.cost_explorer_slack_notification.name}:*"], =>*にしちゃう "Effect": "Allow" } ] }大半のサービスは上記置き換えで動作するようになったのですが、S3の定義についてはこのような置き換えではエラーになったりします。
バケットポリシーでエラー
これはちょっとやっかいロググループみたいに*で置き換えたらエラーになる
Error: Error putting S3 policy: MalformedPolicy: Policy has invalid resource status code: 400, request id: 6774E20500A4AB30, host id: /6snJ2Mq7154TaCvqhOf5FAnOEFF6V92mgZKtRRRaS+PJo/59Aw3PMLhg7emCya6fHoWzk+6jtI= on modules/aws_config/main.tf line 15, in resource "aws_s3_bucket" "aws_config": 15: resource "aws_s3_bucket" "aws_config" {修正前(もともとのコード)
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AWSConfigBucketPermissionsCheck", "Effect": "Allow", "Principal": { "Service": "config.amazonaws.com" }, "Action": "s3:GetBucketAcl", "Resource": ["arn:aws:s3:::${local.config_bucket}"] }, { "Sid": "AWSConfigBucketDelivery", "Effect": "Allow", "Principal": { "Service": "config.amazonaws.com" }, "Action": "s3:PutObject", "Resource": ["arn:aws:s3:::${local.config_bucket}/AWSLogs/${var.account_id}/Config/*"], "Condition": { "StringEquals": { "s3:x-amz-acl": "bucket-owner-full-control" } } } ] }こうしないと中国では動かない(ただこれでは中国でしか動かなくなる)
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AWSConfigBucketPermissionsCheck", "Effect": "Allow", "Principal": { "Service": "config.amazonaws.com" }, "Action": "s3:GetBucketAcl", "Resource": ["arn:aws-cn:s3:::${local.config_bucket}"] }, { "Sid": "AWSConfigBucketDelivery", "Effect": "Allow", "Principal": { "Service": "config.amazonaws.com" }, "Action": "s3:PutObject", "Resource": ["arn:aws-cn:s3:::${local.config_bucket}/AWSLogs/${var.account_id}/Config/*"], "Condition": { "StringEquals": { "s3:x-amz-acl": "bucket-owner-full-control" } } } ] }修正例
バケットポリシーを後付にして作成したバケットからarnを取得するようにする。{ "Version": "2012-10-17", "Statement": [ { "Sid": "AWSConfigBucketPermissionsCheck", "Effect": "Allow", "Principal": { "Service": "config.amazonaws.com" }, "Action": "s3:GetBucketAcl", "Resource": ["${aws_s3_bucket.aws_config.arn}"] }, { "Sid": "AWSConfigBucketDelivery", "Effect": "Allow", "Principal": { "Service": "config.amazonaws.com" }, "Action": "s3:PutObject", "Resource": ["${aws_s3_bucket.aws_config.arn}/AWSLogs/${var.account_id}/Config/*"], "Condition": { "StringEquals": { "s3:x-amz-acl": "bucket-owner-full-control" } } } ] }コスト管理系のサービスのリージョンが違う
コスト管理系のサービス(AWS Cost Explorerとか)はAWSだとバージニア北部(us-east-1)ですがAWS ChinaだとNingxia(cn-northwest-1)になります。
詳細は
https://docs.aws.amazon.com/general/latest/gr/billing.html
に記載されている通り
コスト通知の仕組みを実装していてる場合はリージョンが変わるので注意まとめ
AWS Chinaを使用する場合に困ったこと、注意すべきことをまとめました。
AWS Chinaを使用することになったときに参考になれば幸いです。
- 投稿日:2020-12-04T10:07:28+09:00
バイク乗り向けハンズフリー音声ツイートシステムについて(iOS+AWS)
はじめに
いらっしゃいませ。わたしは@shnskfjwrです。
わたしは毎日すごい量のserverless.ymlを書いていますが、だれにも読ませるつもりはありません。ところで、わたしの趣味はおバイクとTwitterです。
基本はツーリングの休憩中にツイするのですが、運転中に面白いものを見つけたらその場でツイしたくなることもありますよね?
ですが、おバイクは車と違って基本的に両手が塞がってる上にグローブを装着してるので、その場ツイは難しいですね?
だからといって、わざわざ停車してツイする?そのネタ、そこまでするほど面白い?というわけで、それをどうにかしました。
何をするか
Siriの音声入力を利用したTwitter投稿
必要なもの
- iOS12以上がインストールされたiPhone
- ヘルメット内でsiriを起動できる環境(airpods2がおすすめ)
- AWSアカウント
- Twitterアカウント
TwitterAPI
Twitterへの投稿はTwitterAPIを利用します。
TwitterAPIをコールするにはキー&トークンが必要となるため、下記サイトを参考に開発者登録を行います。2020年度版 Twitter API利用申請の例文からAPIキーの取得まで詳しく解説
利用目的などは正直どう書いたか忘れてしまいましたが、正直に書いたら通った記憶があります。
なんやかんやで以下のキー情報を入手します。
- API key
- API key secret
- Access Token
- Access Token Secret
これらのキー&トークンを使って認証を行い、TwitterAPIをコールします。
AWS
Secrets Manager
Twitterキー情報はSecrets Managerに登録しておきます。今回は以下のように格納しました。
- twitter_api_keys
- api_key
- api_secret_key
- access_token
- access_token_secret
Lambdaのコード
認証情報をSecrets Managerから取得し、
リクエストに記載されたテキストをTwitterに投稿するシンプルな例です。import json import os import boto3 import base64 import requests from botocore.exceptions import ClientError from requests_oauthlib import OAuth1Session SECRET_NAME = os.environ.get('SECRET_NAME') STATUS_URL = "https://api.twitter.com/1.1/statuses/update.json" def get_secret(): session = boto3.session.Session() client = session.client( service_name='secretsmanager' ) try: get_secret_value_response = client.get_secret_value( SecretId=SECRET_NAME ) except ClientError as e: raise e else: if 'SecretString' in get_secret_value_response: secret = get_secret_value_response['SecretString'] else: secret = base64.b64decode(get_secret_value_response['SecretBinary']) return secret def handler(event, context): try: secret = json.loads(get_secret()) twitter = OAuth1Session( secret['api_key'], secret['api_secret_key'], secret['access_token'], secret['access_token_secret'] ) body = json.loads(event['body']) tweet = body['tweet'] params = { 'status': tweet[:140] } res = twitter.post(STATUS_URL, params = params) return { 'statusCode': res.status_code } except Exception as e: print (e) raise e公開されているコードを参考にさせていただきました。
API Gateway & Lambda
使い慣れてる Serverless Framework を使ってサクッとデプロイします。
service: tourin_tweeting frameworkVersion: '>=2.0.0 <3.0.0' plugins: - serverless-python-requirements custom: defaultStage: alpha pythonRequirements: layer: true provider: name: aws runtime: python3.7 region: ap-northeast-1 profile: ${opt:profile, ''} stage: ${opt:stage, self:custom.defaultStage} environment: TZ: Asia/Tokyo STAGE: ${self:provider.stage} SECRET_NAME: twitter_api_keys logRetentionInDays: 7 iamRoleStatements: - Effect: Allow Action: - 'secretsmanager:GetSecretValue' Resource: - '*' apiKeys: - defaultApiKey usagePlan: quota: limit: 1000 period: DAY throttle: burstLimit: 500 rateLimit: 250 functions: tweet: handler: src/tweet.handler layers: - !Ref PythonRequirementsLambdaLayer events: - http: path: /v1/tweet method: post cors: true integration: lambda-proxy private: trueデプロイ完了後、apiKeyがログに表示されますので控えておきます。
他の人に勝手にTwitterAPIを叩かれてしまうと面白い困るので、apiKeyを有効にして最低限のセキュリティは担保しています。ここまでの工程でTwitterAPIをwrapするAPIが完成しましたが、これだけではなんの意味もありません。
音声投稿を行うためには、iPhoneのパワーを借りる必要があります。ショートカット(ios)について
音声入力にはiOSに搭載されているSiriとショートカットを使います。
ショートカットは、iOS上で動作させられる簡易スクリプトのようなものです。
ショートカットはsiriから起動できるため、「HeySiri! {ショートカット名}!!」と話しかければ起動できます。つまり、Twitterに投稿するためのショートカットを用意し、それをSiri経由で起動することで
完全音声制御のツイが実現するというわけです。そしてネタばらしですが、今回の企画は以下の記事の内容を真似してみることから始まりました。
AirPodsだけでTwitter投稿も!SiriからTwitterにバックグラウンドで投稿するこちらの記事を読んでええやん!!と真似してみたところ、ちょっとした問題が発生しました。
それは、IFFFTからのTwitter投稿は24時間で25件までに制限されていること!!(2020/9時点)
そんなんじゃぜーんぜん足りないYO!!というわけで、わたし専用のTwitterAPI基盤を構築する必要があったのです。
ショートカットのインストール
ショートカットはicloudを経由して自由に公開・配布が可能になっています。
先述の記事で配布されていて、わたしがカスタムした「バックグラウンドでツイート」と「ツイート」をiPhoneにインストールします。
うまく行かない場合は先述記事を参考に、「信頼されていないショートカットを許可」してください。インストール後、「バックグラウンドでツイート」の最上部のテキスト(変数URL)をAPI Gatewayの実行URLに書き換えてください。
これで準備完了です。
動作確認
HeySiriに対応しているイヤホンをヘルメットに装着し、心の赴くままに叫びます。
「HeySiri! ツイート!!」
※iOS14以降、「StringAnswerは何にしますか?」と聞いてくるようになったので若干テンポが悪くなった。早く修正してほしい。
「テスト投稿!!」
「はい!!」
結果
実際におバイクで使ってみた感想
ゆっくり流してるときはきちんと聞き取ってくれます。
しかし、60km/h超えたあたりからは風切り音のせいでマイクの精度が低下してしまい微妙、
高速道路は絶望的という結果でした。それでも結構楽しい。実は、写真を音声シャッターで撮影しそれを添付してツイする機能も開発済なのですが、それはまたの機会に……。









- 投稿日:2020-12-04T09:39:34+09:00
Amazon SageMaker Data Wrangler を実際に使ってみた[re:Invent 2020]
はじめに
この記事は株式会社ナレッジコミュニケーションが運営する Amazon AI by ナレコム Advent Calendar 2020 の 4日目にあたる記事になります。
AWS が開催する re:Invent 2020 で発表された Amazon SageMaker の新機能である Amazon SageMaker Data Wrangler を実際に触ってみました。
Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler
SageMaker Data Wrangler とは AWS の各種サービスからデータをインポートし、データの可視化(リアルタイムで!)や変換の処理を GUI 上で行えるサービスのようです。
実際に行った処理をノートブックとしてエクスポートすることもできるので手元で処理して可視化して、処理して可視化して、、、という縦長ノートブックとのにらめっこからオサラバできそうですね。
名前が似ている AWS Data Wrangler というオープンソースの Python ライブラリがありますが、こちらとは別物のようです。
今回紹介されている Amazon SageMaker Data Wrangler はあくまでも SageMaker Studio の追加機能、という位置づけのようです。SageMaker Data Wrangler の機能や使用方法について簡単にまとめると
SageMaker Data Wrangler は SageMaker Studio の追加機能であり、
- ETL 処理をグラフィカルに記述する flow ファイルの作成
- インポートするデータの選択
- データの変換および分析の記述
- 記述した処理をエクスポート
という流れで ETL 処理をサポートする機能であるといえると思います。
実際に触ってみる。
今回は kaggle の COVID-19 Dataset を用いて実際に Data Wrangler を使ってみました。
まずは Amazon SageMaker Studio に入ります。
データのインポート
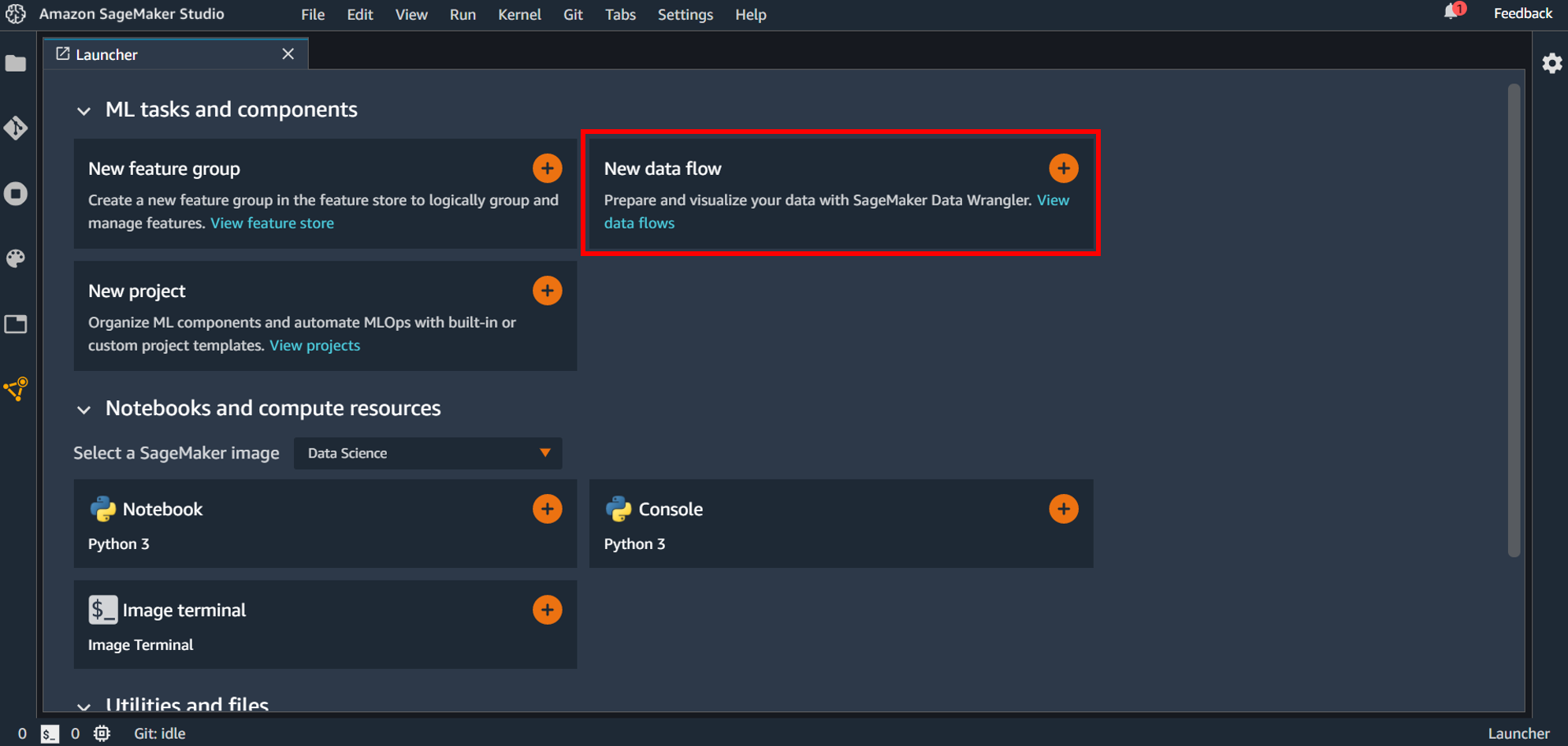
Data Wrangler を使うには最初に flow ファイルを作成します。最初のランチャー画面にある「New data flow」の+ボタンをクリックするか、
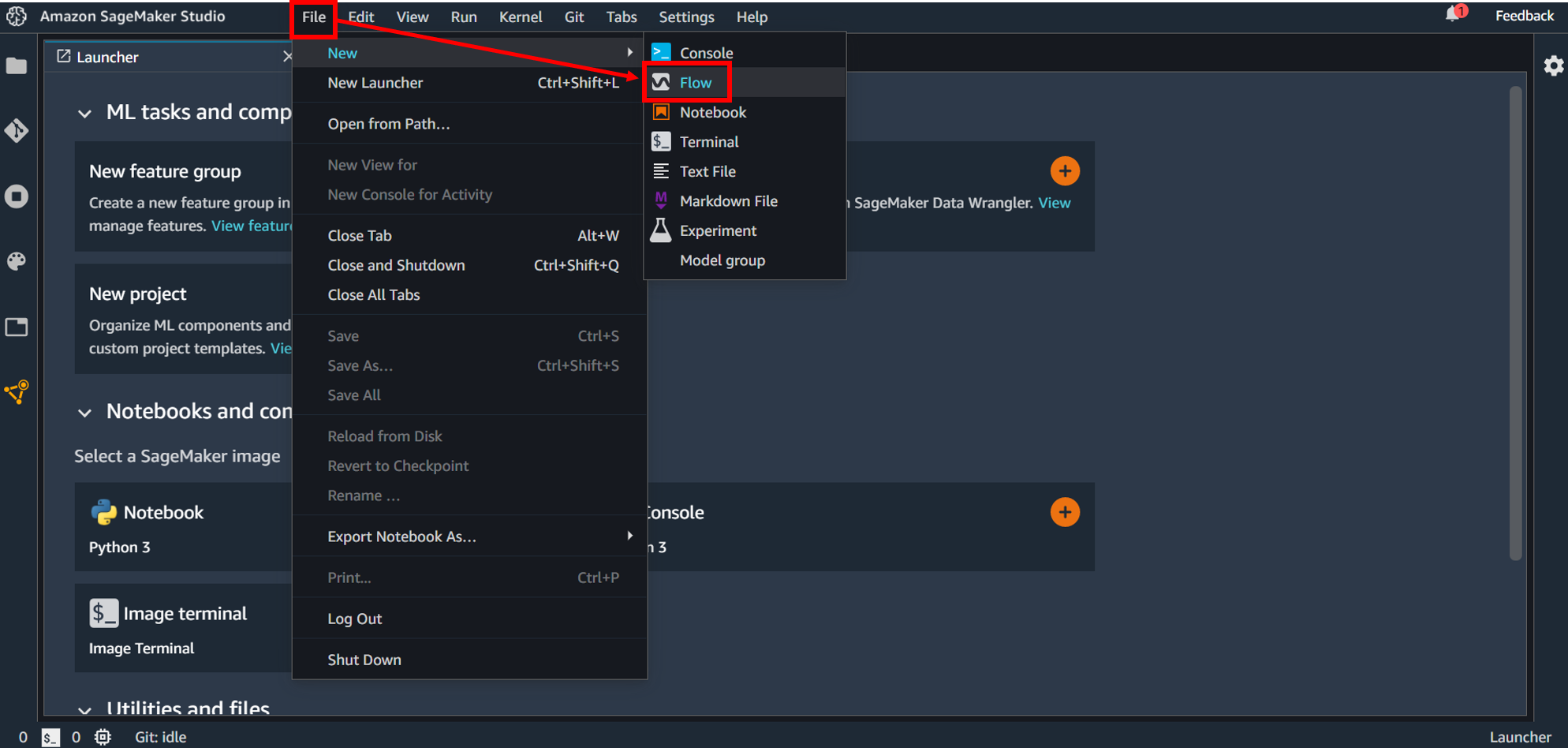
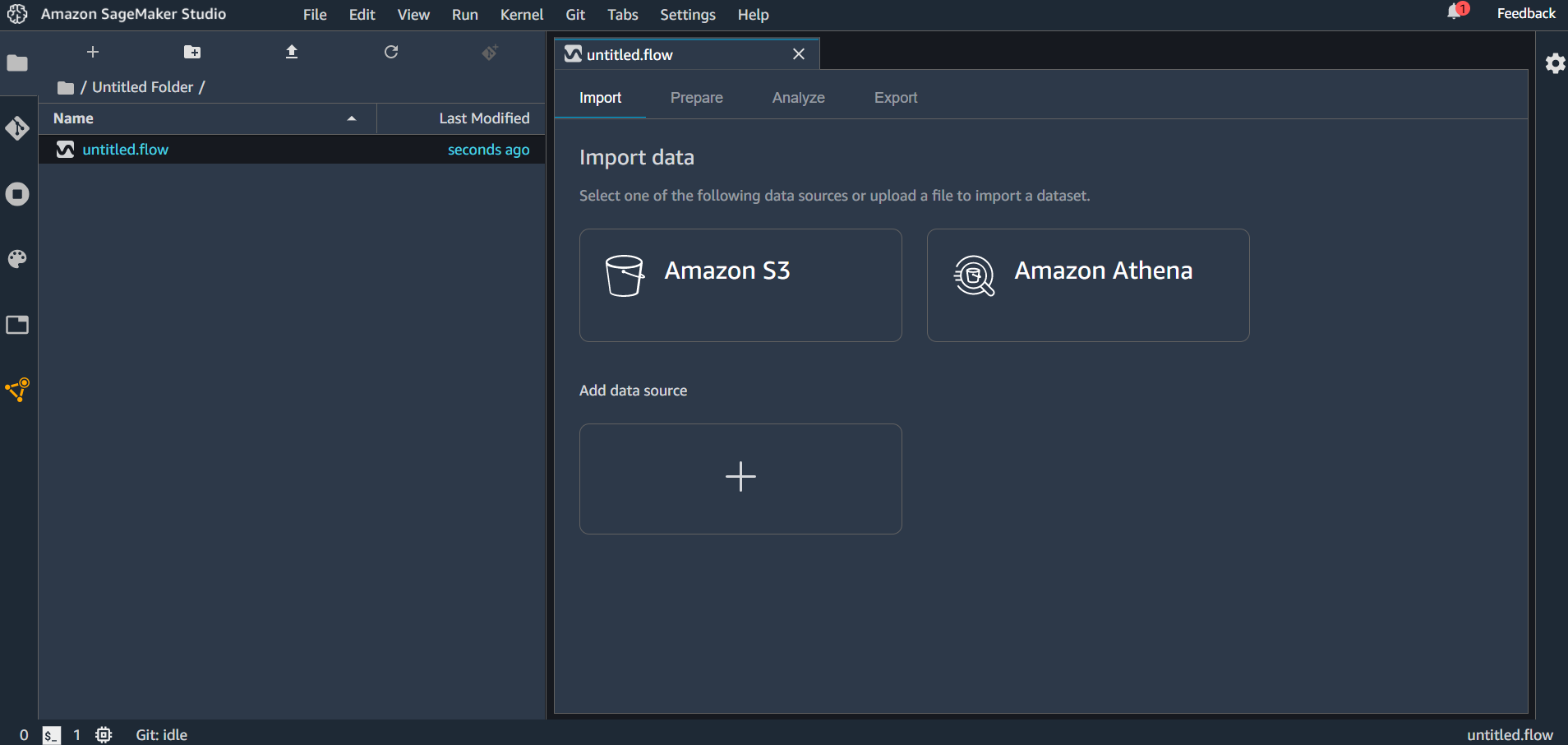
画面上部の「File」→「New」→「Flow」としてファイルを作成します。
flow ファイルを作成すると「untitled.flow」というデータが生成されます。(名前の変更もできます。)インポートできるデータソースとしては Amazon S3 と Amazon Athena が選択できます。「Add data source」をクリックしてみると Redshift が選択できるようになっていました。
flow ファイルには4種類のタブがあり、それぞれ
- Import → データのインポート設定を行う
- Prepare → グラフィカルにデータ変換・分析のフローを記述する
- Analyze → 分析結果の表示
- Export → エクスポートするコンポーネントを選択し、エクスポートする
ということが行えます。
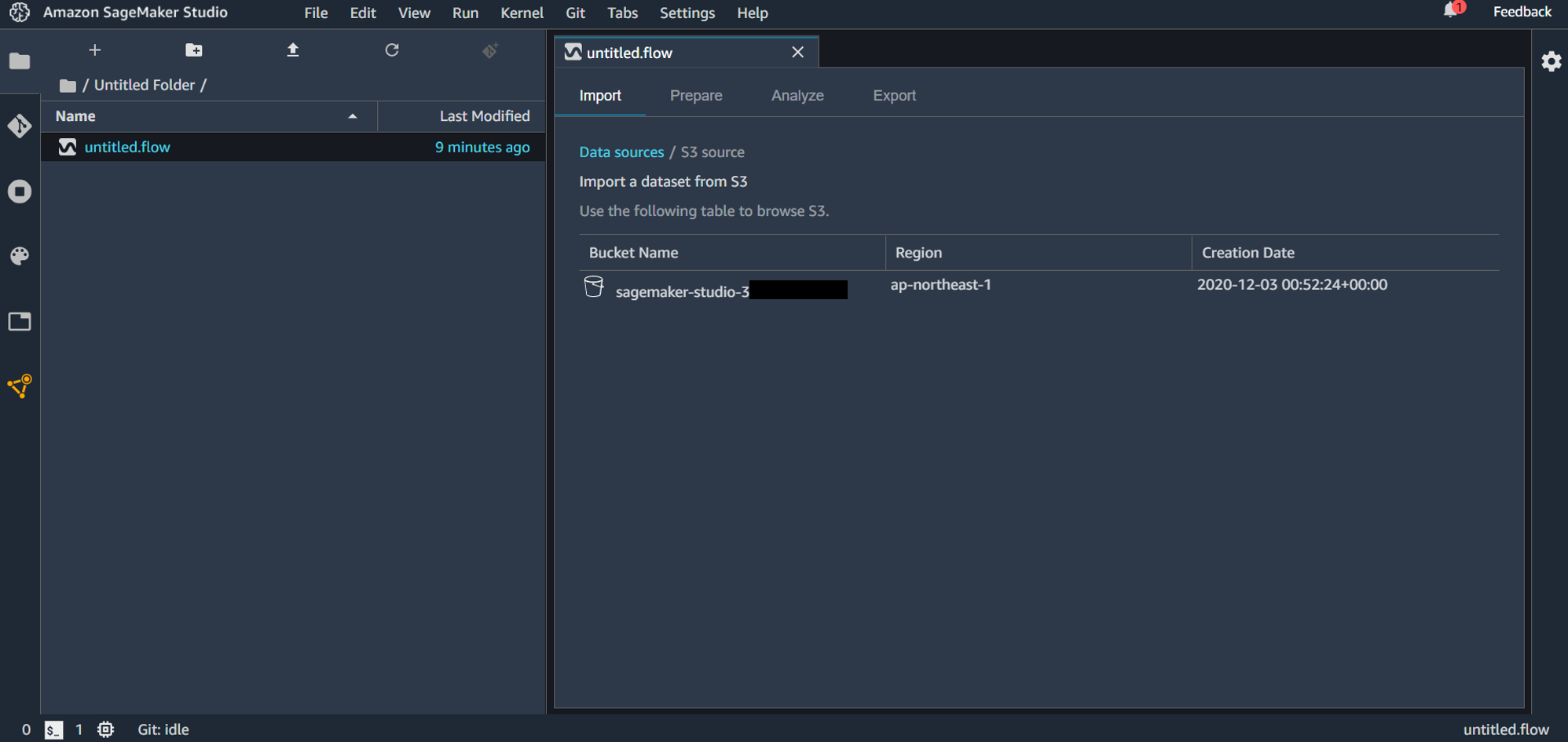
S3 に事前にアップロードしておいたファイルをインポートしていきます。「Amazon S3」を選択すると、バケット選択画面になります。
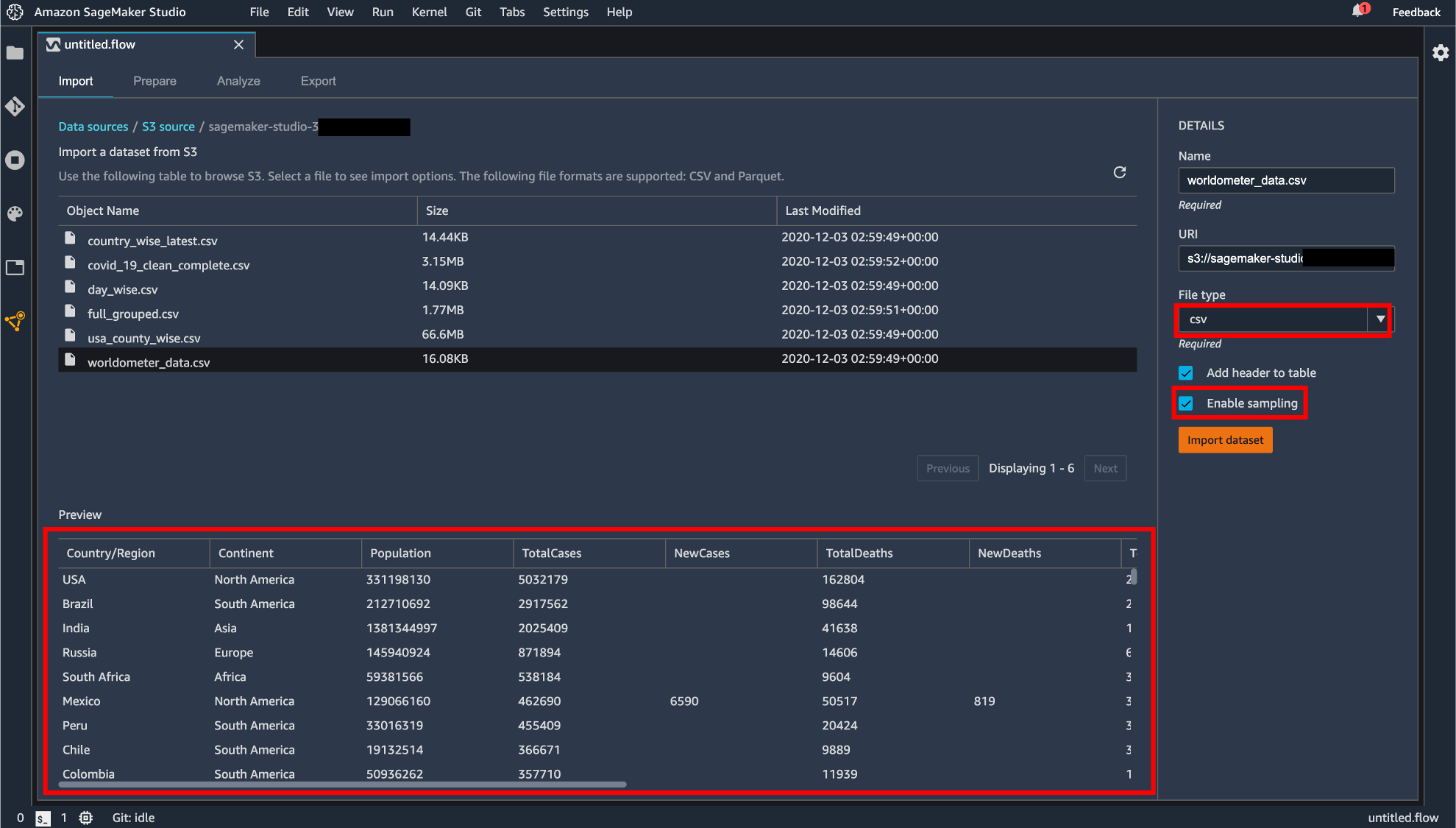
バケットを選択して、アップロードするファイルを選択します。S3 からのアップロードは CSV または Parquet が対応しています。
ファイルを選択すると画面下部にプレビュー画面が表示されます。拡張子がついていないファイルは画面右の「File Type」から CSV か Parquet を選択する必要があります。「Enable sampling」が有効になっている場合、インポートされるファイルが最大100MBに制限されます。設定が終わったら「Import dataset」をクリックします。
データフローの作成
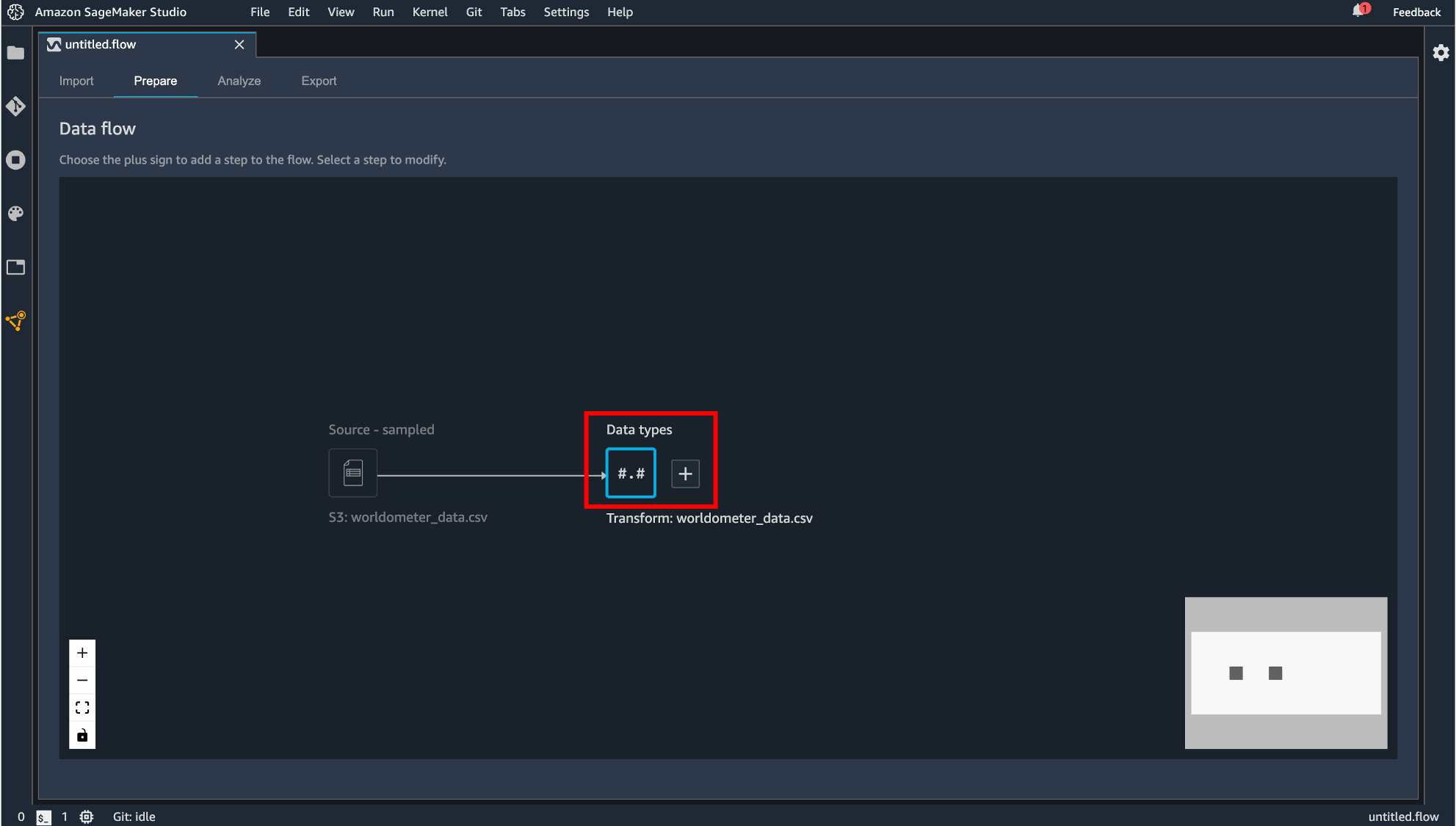
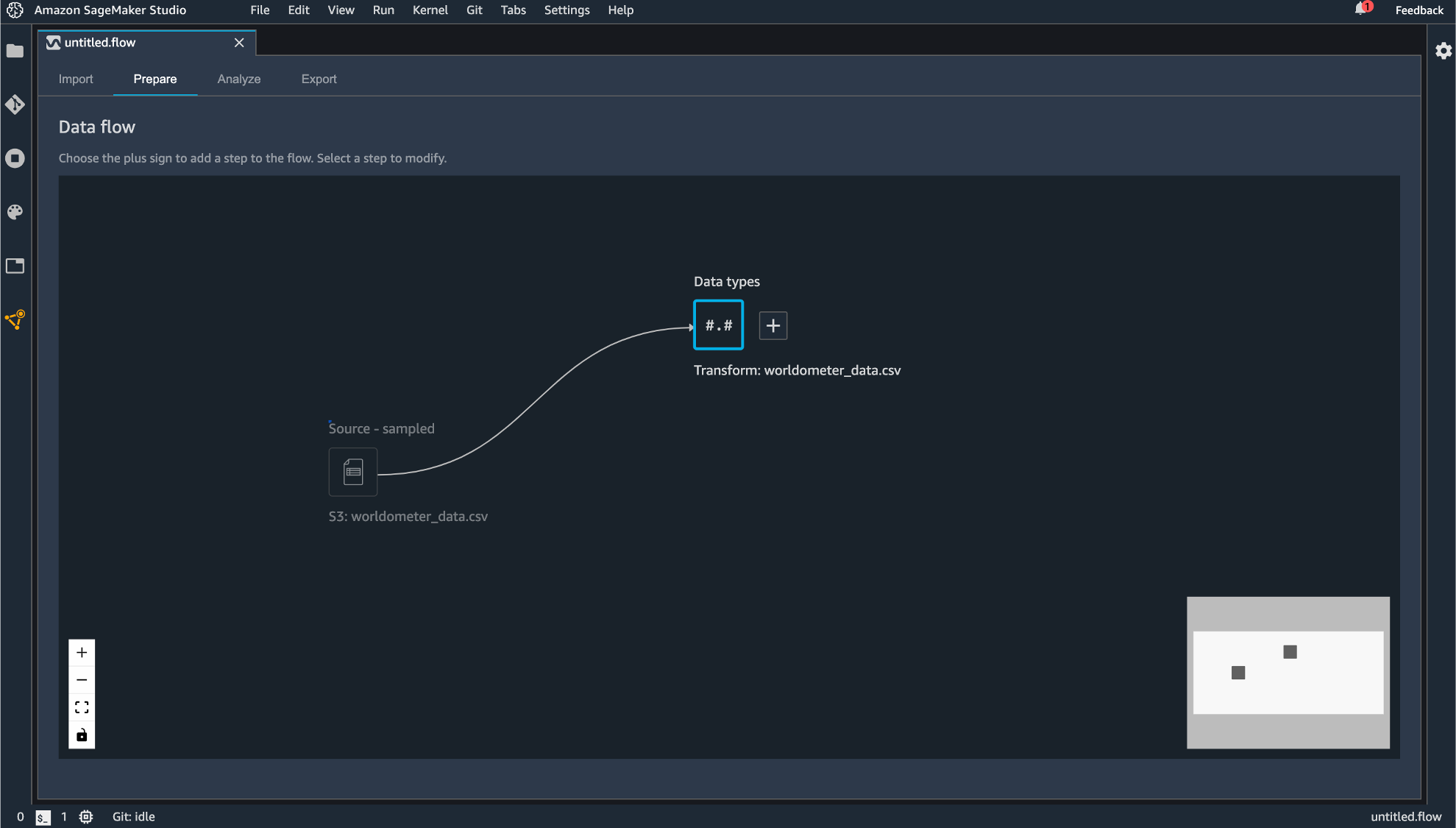
インポートが完了すると、Prepare タブに遷移し、今回作成するデータフローがグラフィカルに表示されます。
Data Wrangler はインポートされたデータのデータ型を自動で推測し、データフレームを作成します。表示されている「Data types」というコンポーネントが自動生成されるデータフレームになります。
生成されるコンポーネントはドラッグすることで動かすこともできます。
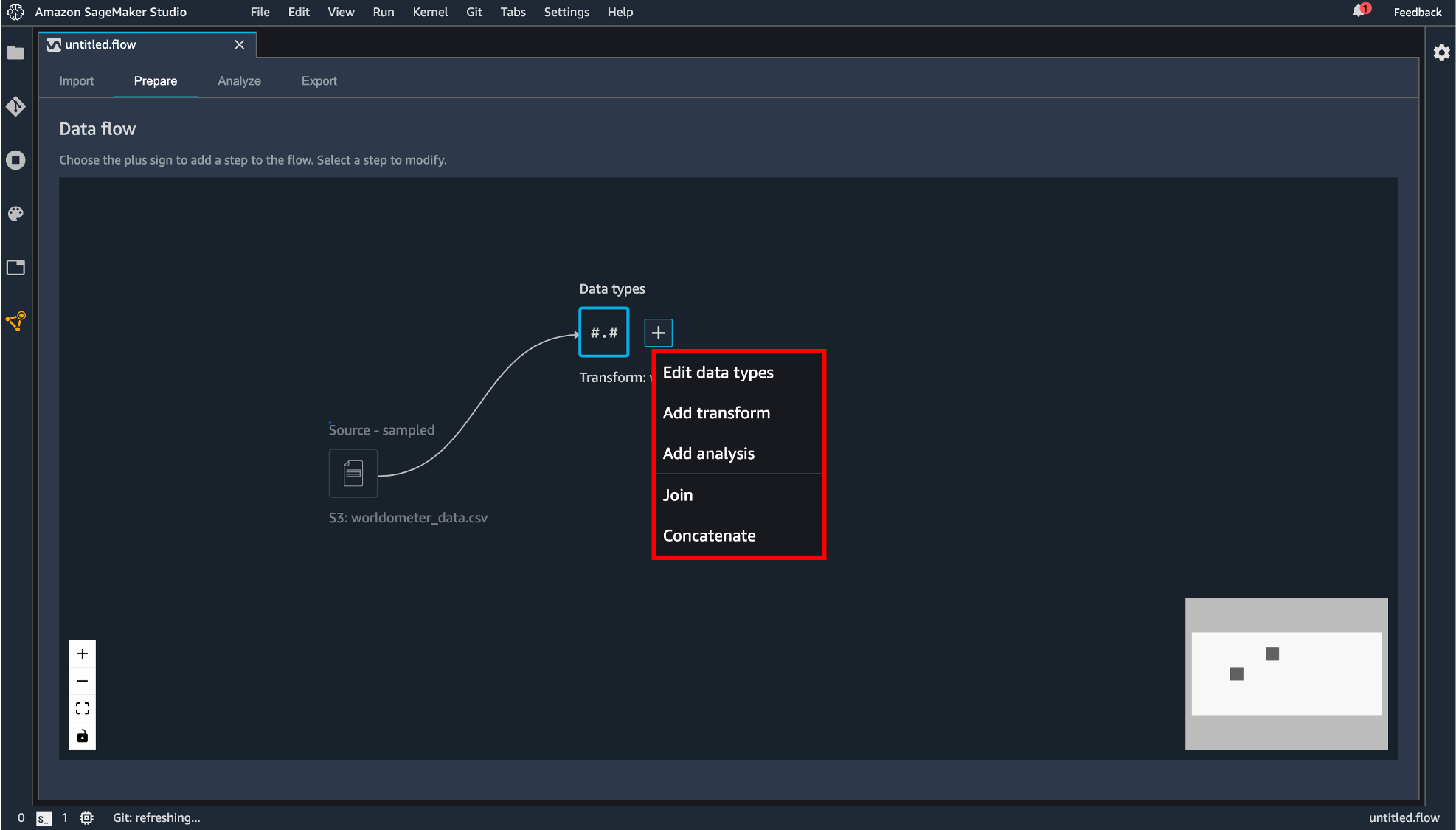
「Data types」の横にある+ボタンをクリックすると後続の処理を追加できます。
後続処理として追加できるコンポーネントには次のものがあります。
Edit data types
データインポート時に自動生成されたデータフレームの各カラムのデータ型の変更が行えます。「Type」のプルダウンから選択できます。
変更する型を指定したら「Preview」で変更後のデータフレームが表示され、よければ「Apply」します。
Add transform
読み込み時にデータフレームの変換処理を記述します。
変換できる処理は次のようになっています。
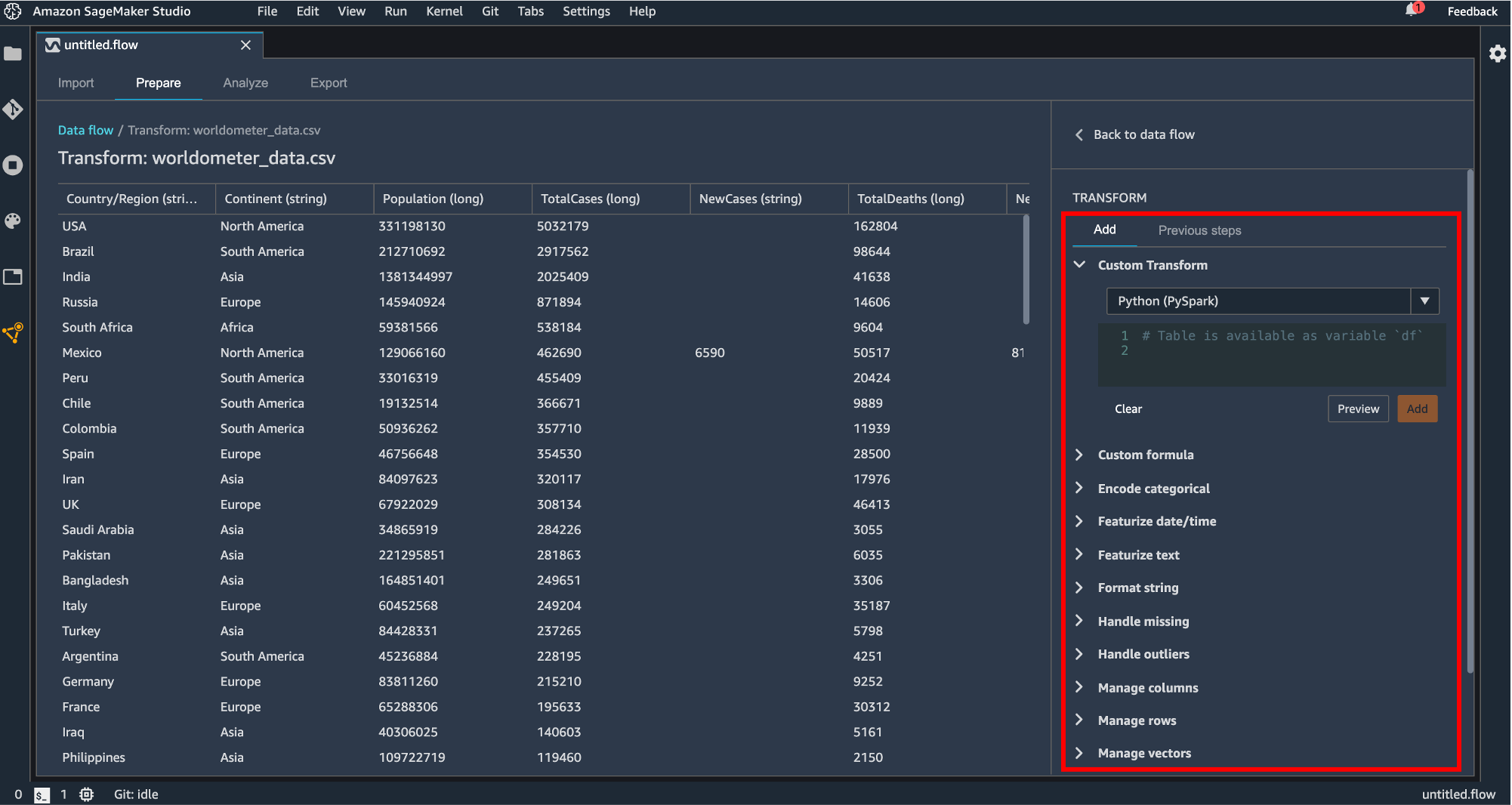
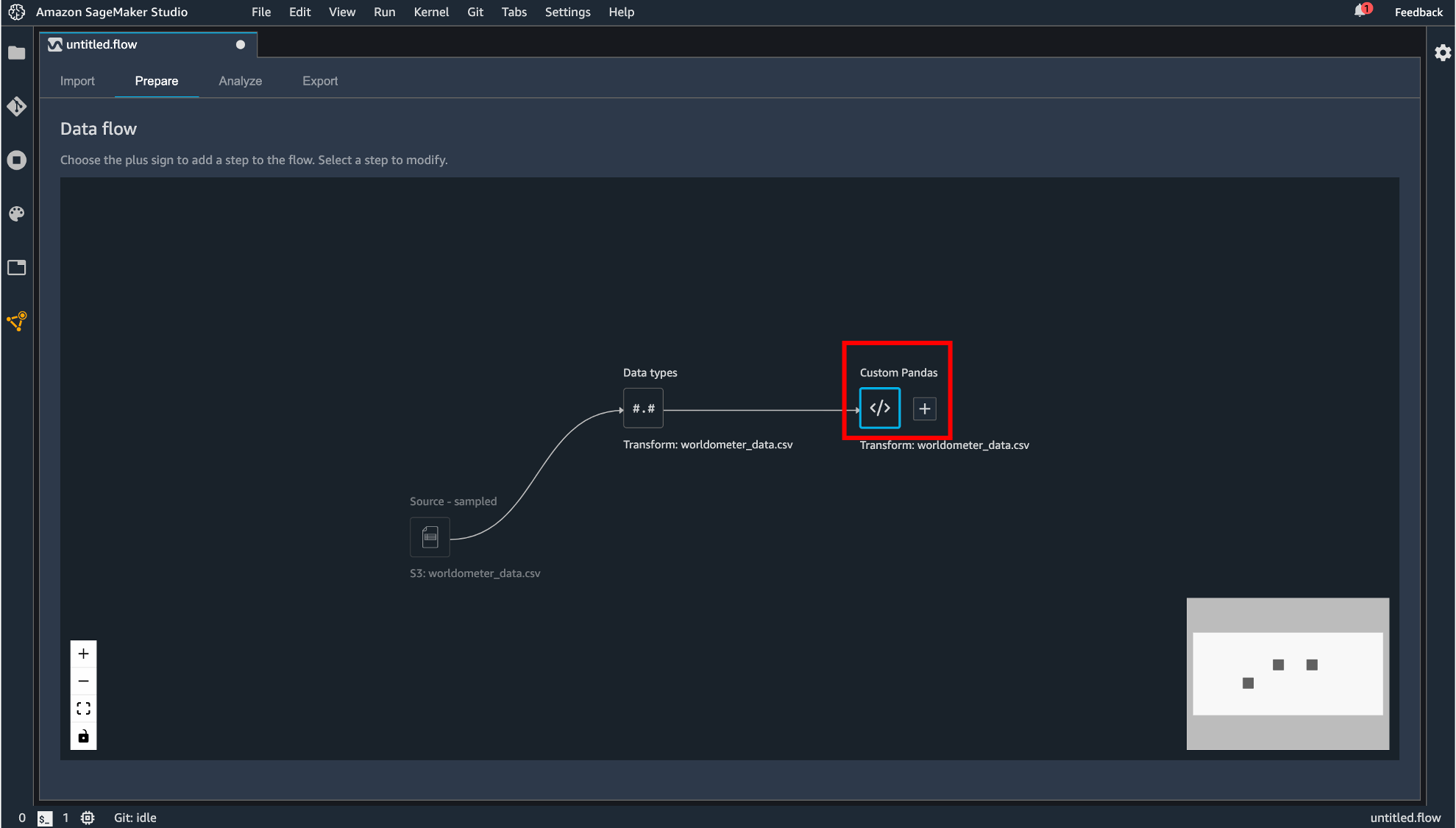
Custom Transform
Python(Pandas, Pyspark)または SQL(Spark SQL) で変換処理を記述します。Custom formula
新しいカラムを Spark SQL でクエリ書いて追加します。Encode categorical
カテゴリのカラムをプルダウンで指定して One-hot encode または Ordinal encode します。欠損値の処理も Skip, Error, Keep, Replace with NaN から選択することができます。Featurize date/time
date/time の型のデータを数値やベクトル表現に変換できます。Featurize text
自然言語のカラムを Character statistics, vector に変換できます。Character statistics には単語数や文字数などがあり、新しい出力カラムが生成されます。Format string
文字列のフォーマット(大文字、小文字、右寄せ、左寄せなど)を指定して変換してくれます。Handle missing
欠損値の処理を指定します。変換の方法を impute, drop missing などから指定してそれぞれの方法に対して詳細な設定ができます。(impute ならカラムの型がなんであり、中央値か平均を代入する、など)Handle outliers
外れ値の処理をかけます。標準偏差や quantile などを指定してどのように処理するか設定します。Manage columns
カラムの移動、削除、複製、リネームなどを行います。Manage rows
ソートやシャッフルをすることができます。Manage vectors
数値データ列とベクトル列を Assemble や Flatten で処理できます。Parse column as type
データ型を指定してキャストします。Process numeric
標準化を行ったりロバストスケーラーや最大値最小値の範囲でスケーリングします。処理には Spark が使われているようです。Search and edit
データの検索と、検索した値の編集ができます。置換や区切り文字で分割もできます。Validate string
カラムに対して条件を指定して True または False で表現されるカラムを生成します。追加した変換処理を Apply するとコンポーネントが追加されます。
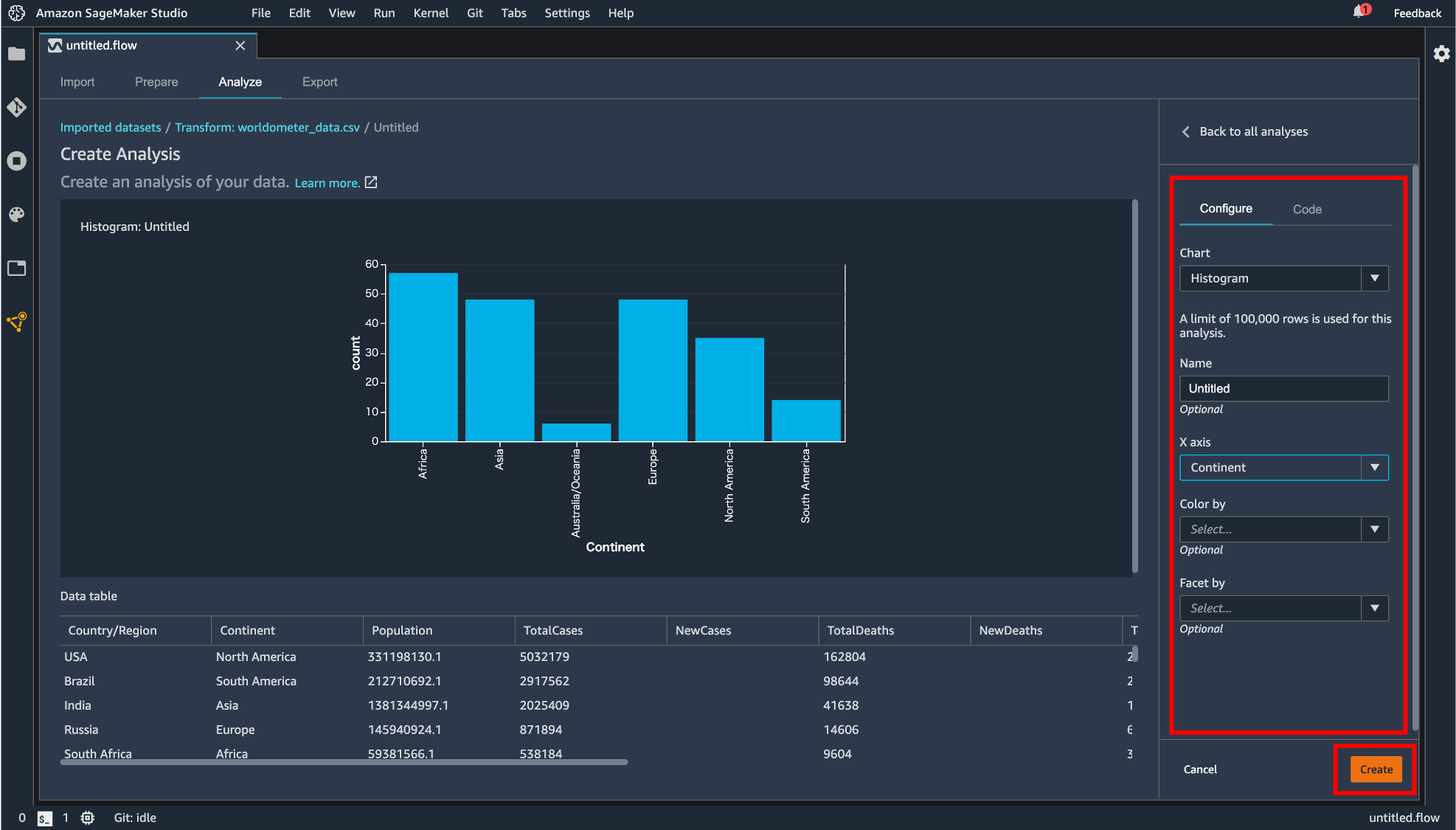
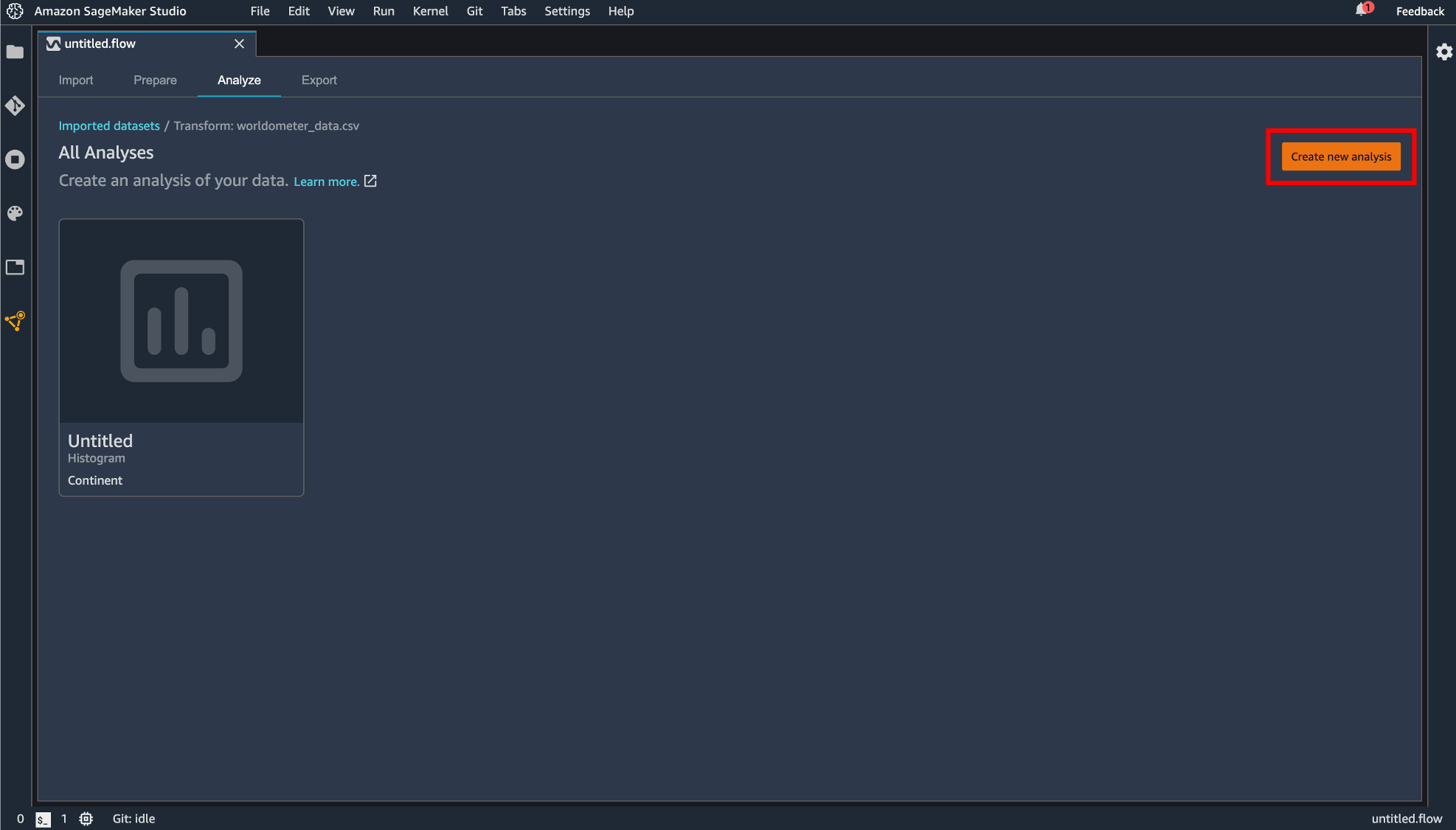
Add analysis
変換処理などを行ったデータを可視化できます。「Configure」タブではヒストグラムや散布図などを指定して表示させることができます。「Code」タブでは Pandas で記述できます。「Create」ボタンで描画した図を保存することができます。
保存された図は flow ファイルの「Analyze」タブに保存されています。この画面からも「Create new analysis」から新しい図を描画できます。
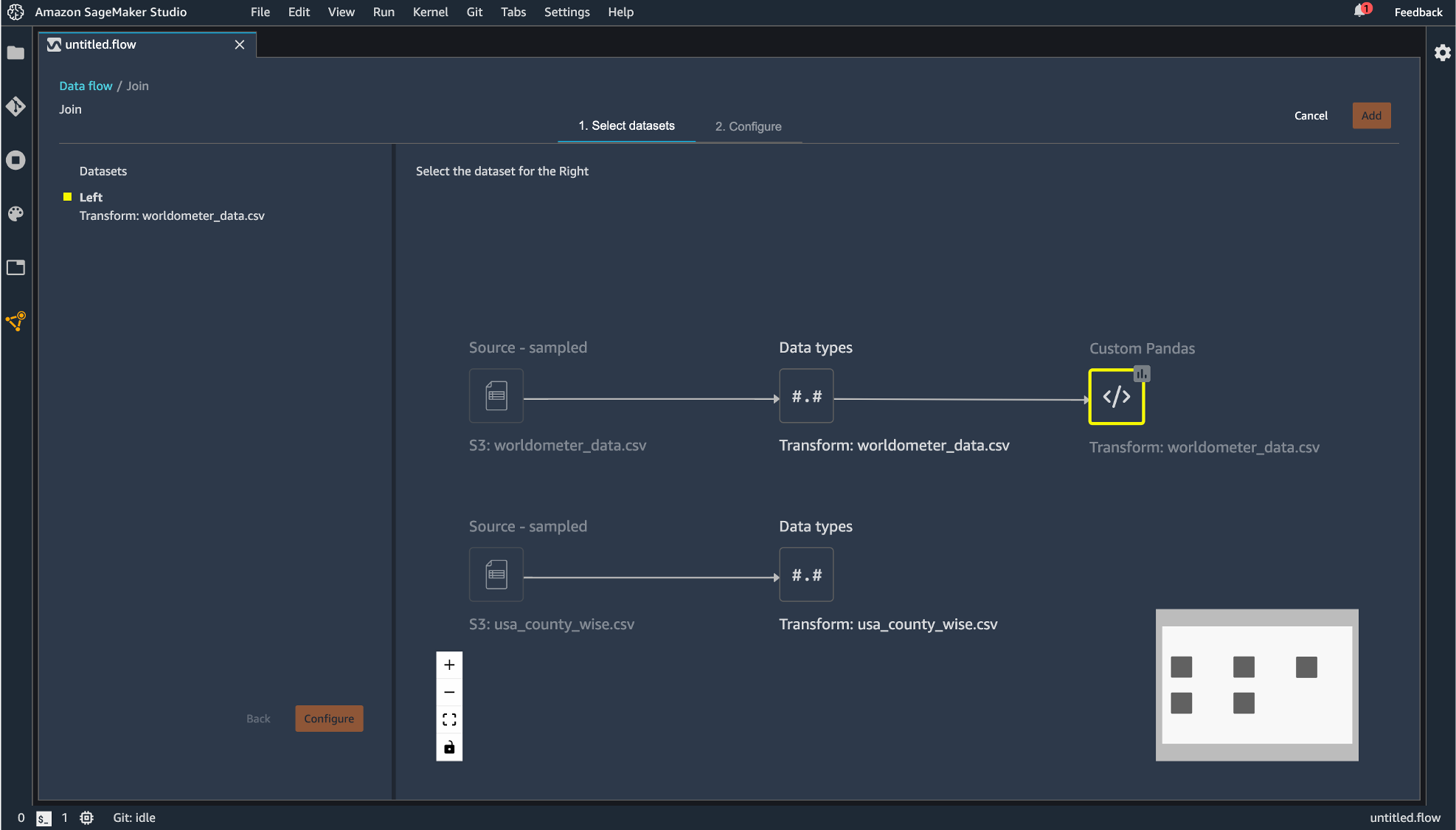
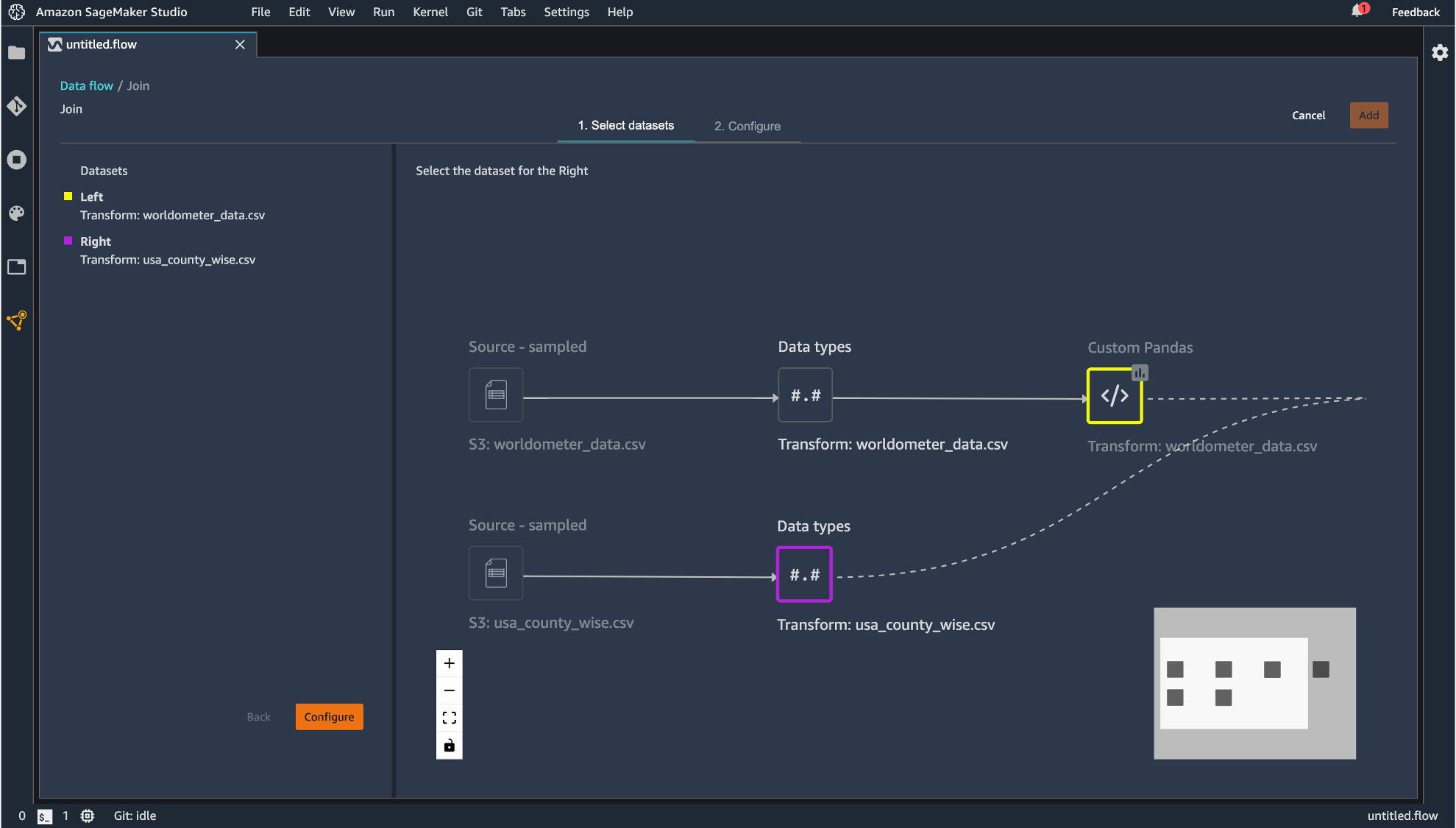
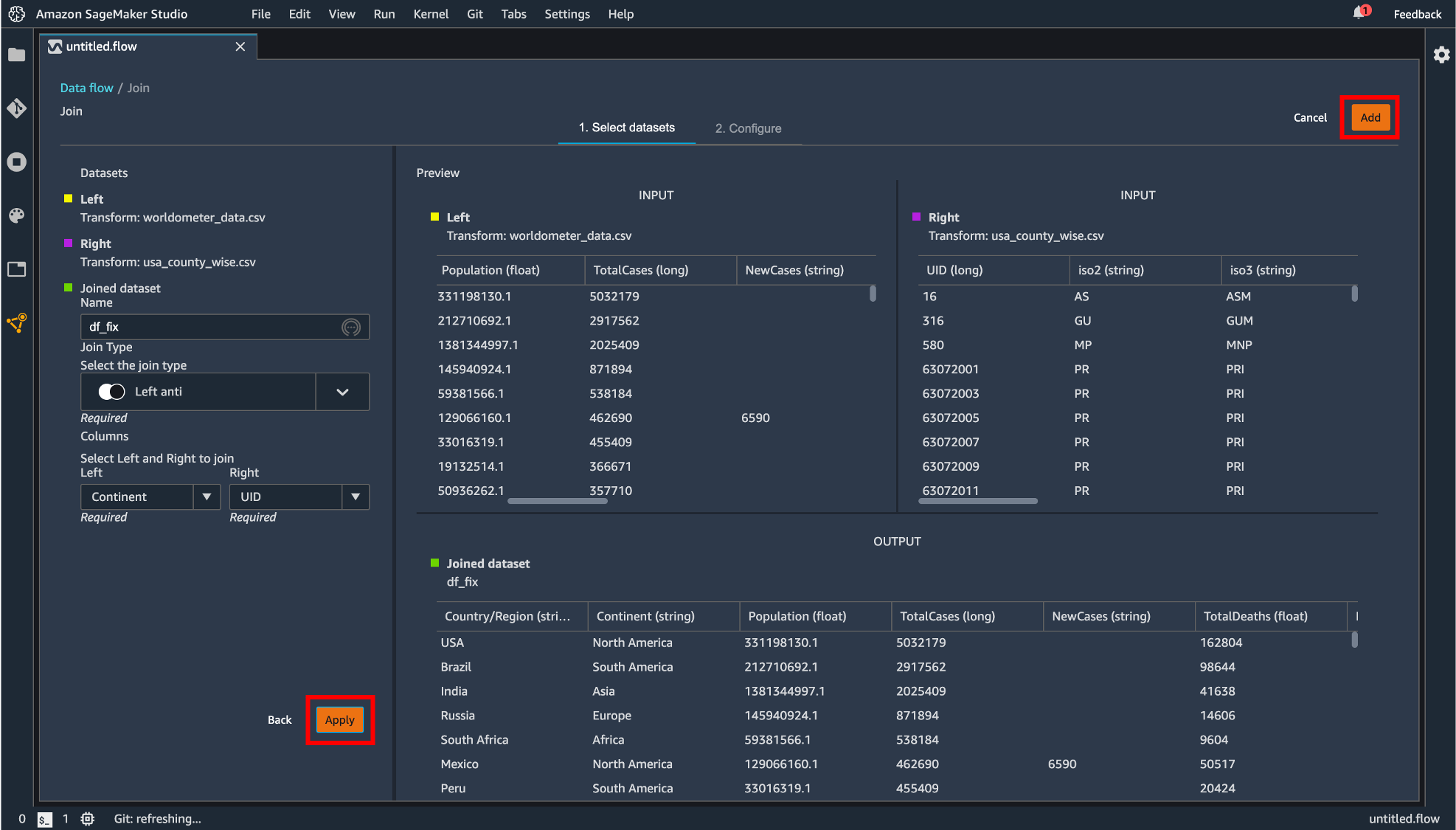
Join
2つのデータセットの結合が行えます。データセットが複数必要になるには「Import」タブから最初にデータをインポートした時と同じ手順で実施します。
「Join」をクリックしたデータフレームが左側として指定されます。
右側にのデータフレームを指定すると結合後のフローが現れるので「Configure」すると、
プレビュー画面が表示され、どのように結合を行うのかを指定します。設定したら「Apply」して「Add」します。
生成したデータフレームがコンポーネントとして追加されました。
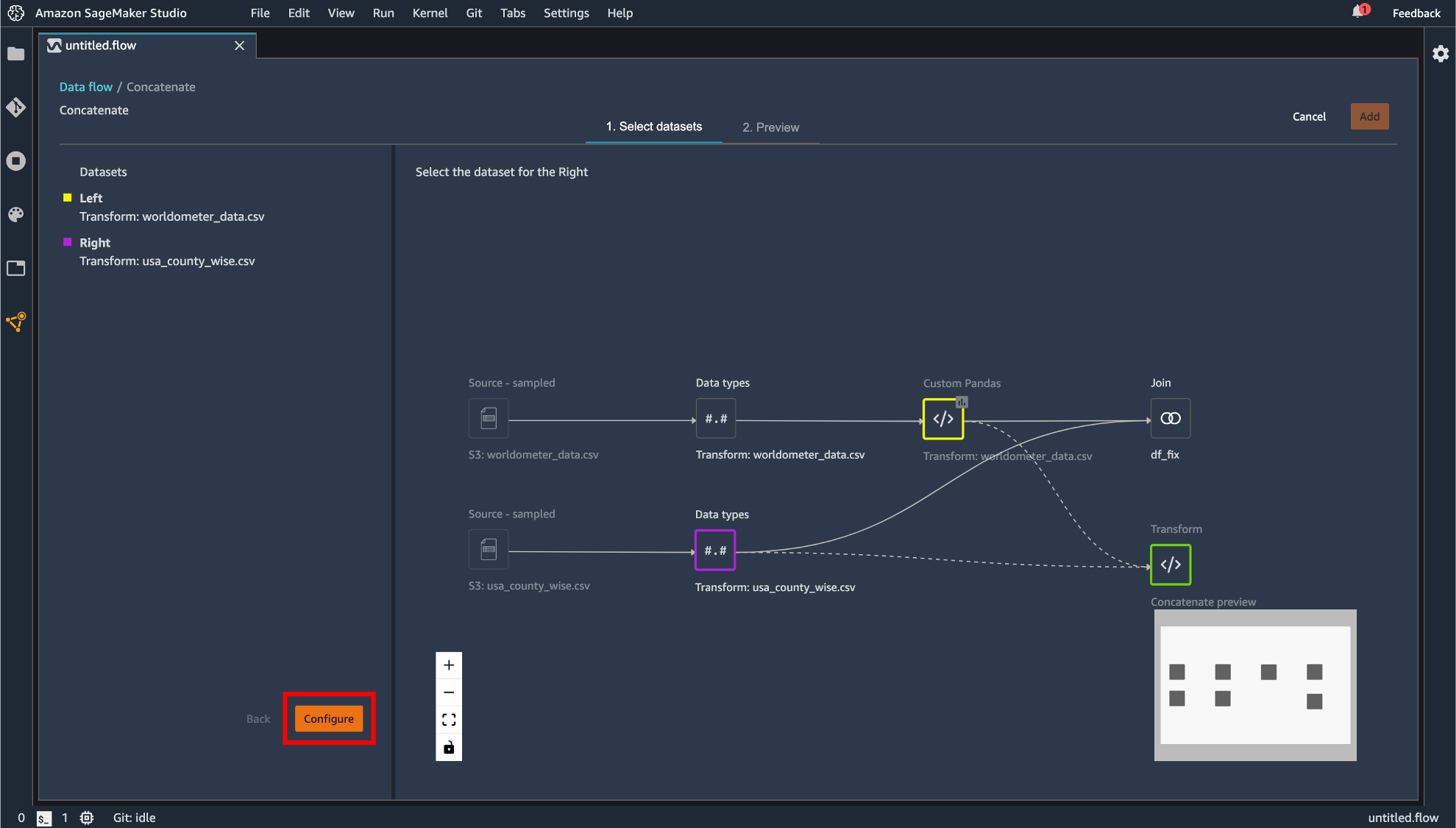
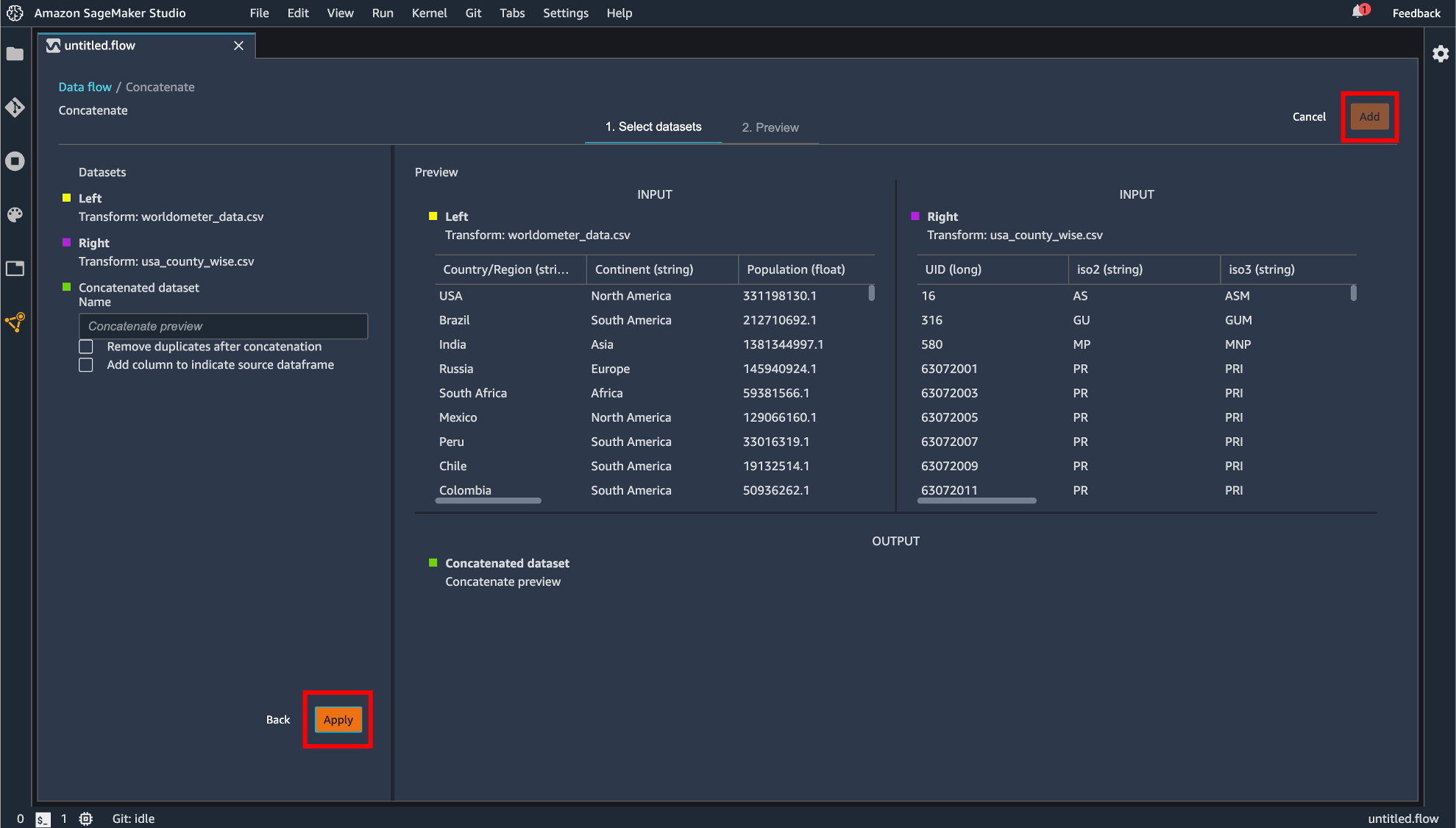
Concatenate
データの連結を行えます。手順としては Join の操作に準じています。
指定したら「Apply」して「Add」します。
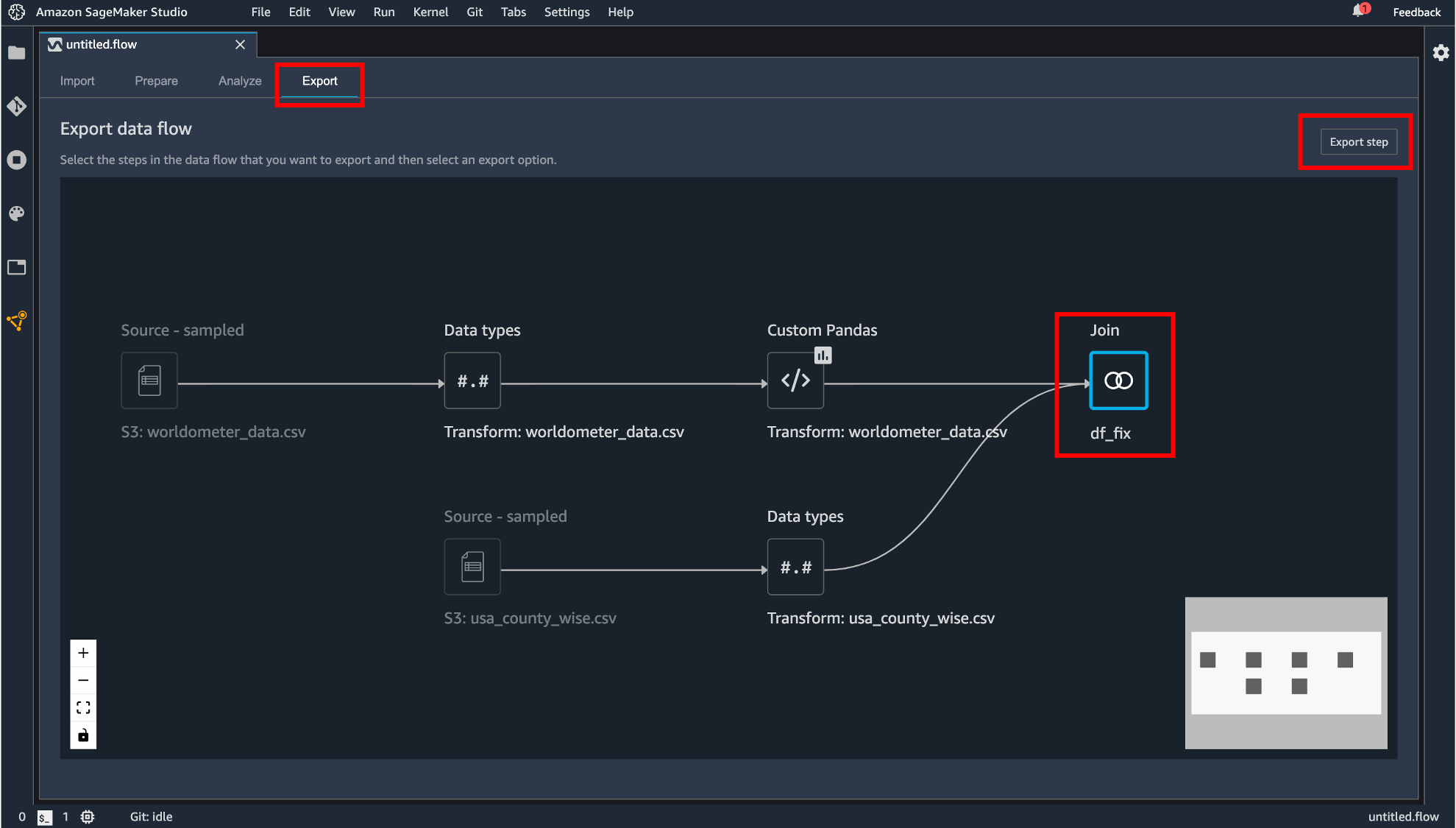
データフローのエクスポート
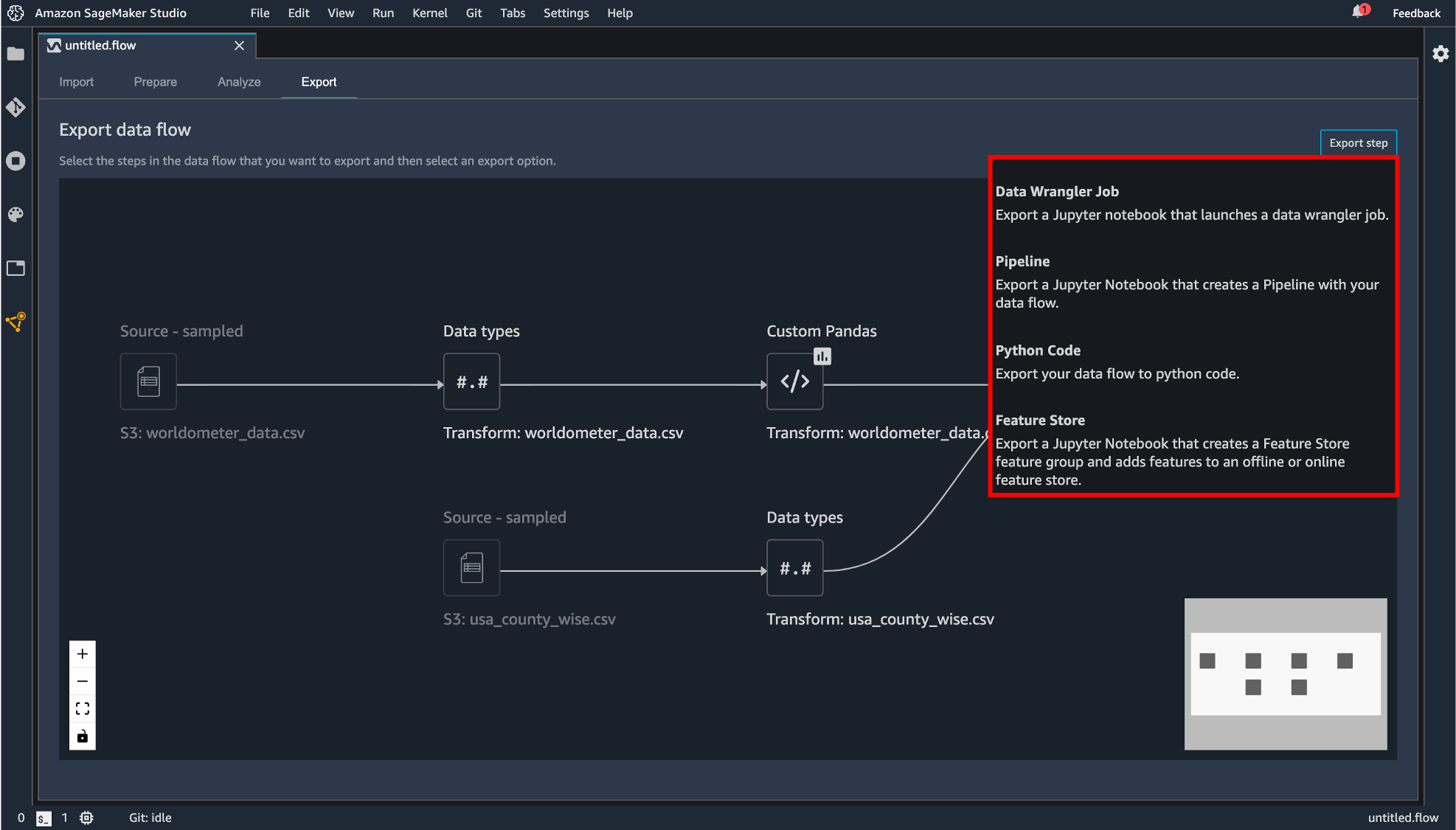
作成したデータフローをエクスポートします。まず「Export」タブに移動します。エクスポートしたいコンポーネントをクリックして「Export step」をクリックします。
エクスポートの方法は現在4種類用意されています。
- Data Wrangler Job
- Pipeline
- Python Code
- Feature Store
Python Code では.py の拡張子を持つファイルとして生成されます。他の3つは SageMaker に統合されたノーブック形式でエクスポートします。
違いとしてはData Wrangler Job
作成したデータフローを丸ごとコード化Pipeline
作成したデータフローのコード + Pipeline という機能への統合するためのコードが追記Feature Store
作成したデータフローのコード + Feature Store という機能への統合するためのコードが追記という感じのようです。 とりあえず Data Wrangler Job としてエクスポートしてみます。
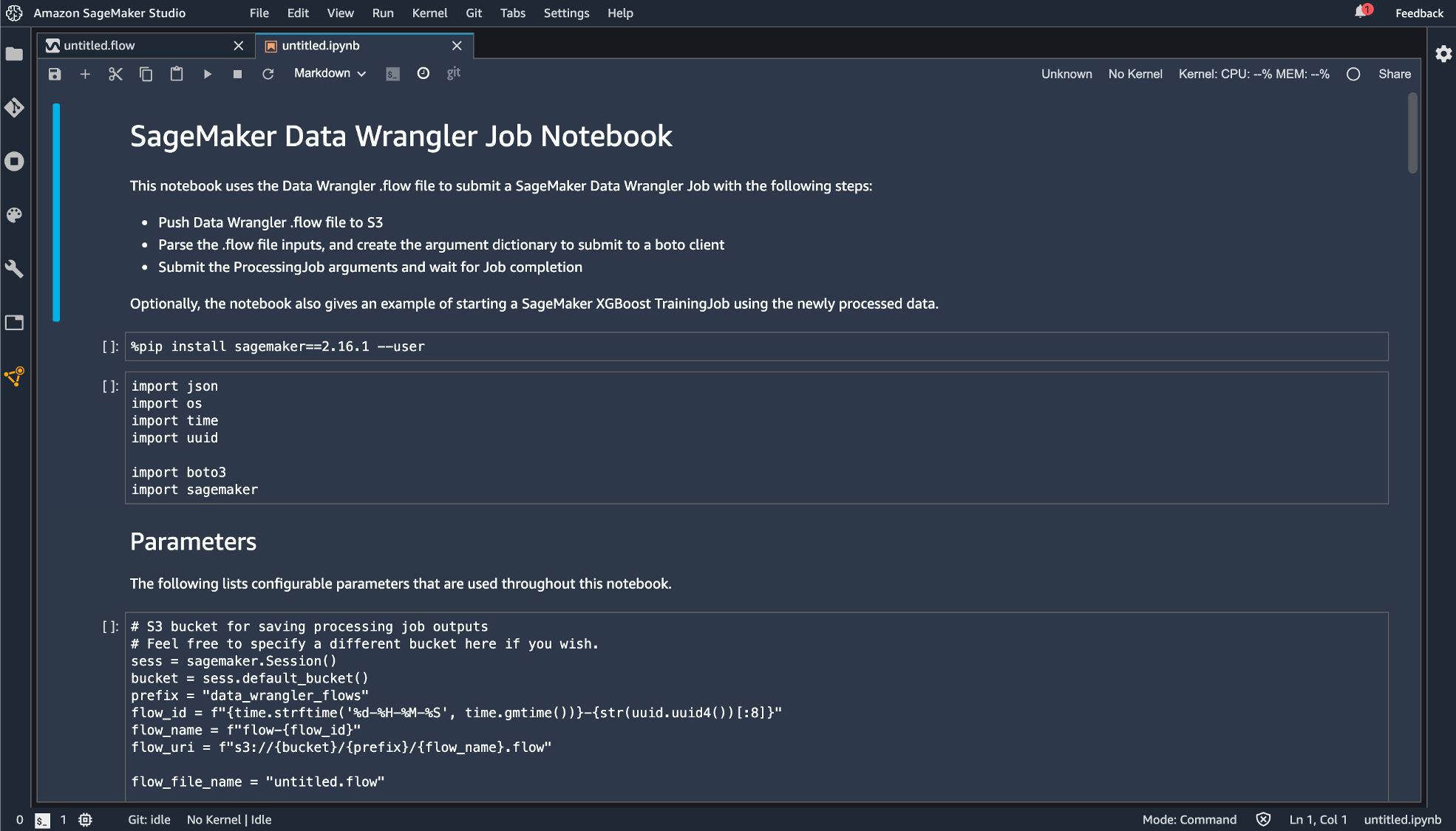
無事エクスポートできました!
おわりに
データの様々な前処理が GUI 上でできるのは本当に便利だと思います。今後はこの機能を使い倒していきたいと思います。
また、Pipeline や Feature Store も今回のre:Invent 2020で紹介されていた機能なので検証してみたいと思っています。




- 投稿日:2020-12-04T09:24:05+09:00
[AWS] AWSにユーザー登録しました
AWSにユーザー登録しました
本日(2020/12/04)AWSにユーザー登録してみました! というだけの投稿です。
「今後 12 か月は、無料利用枠の制限内で主要な AWS コンピューティング、ストレージ、データベース、およびアプリケーションサービスに無料でアクセスしていただけます.」とのことです。
以下の設定をしました。
- AWS マネジメントコンソール → マイ請求ダッシュボード
- Billing の設定
- E メールで PDF 版請求書を受け取る をON
- 無料利用枠の使用アラートを受信する をON
- 請求アラートを受け取る をON
- 請求アラートを管理する をクリック
- CloudWatchの画面が開くので、請求額が5ドルを越えたら通知がくるよう設定
- 投稿日:2020-12-04T04:15:01+09:00
AWS SSOのユーザx権限一覧をつくる
はじめまして。ZOZOテクノロジーズ CTO室 兼 SRE部 のkotatsu360です。
ウィスキーと葉巻とAWSが好きです∠( ゚д゚)/この記事は
ZOZOテクノロジーズ #2 Advent Calendar 2020 #2 4日目です。
昨日はtippyさんのCSVから一括でファイル名を変更するMacアプリを作ったでした。
AWS SSOのユーザx権限一覧をつくる
AWS SSO
AWS SSO使ってますか?
複数アカウントへのログインを一つのID/Passで管理できるとても便利な存在です。各AWSアカウントに対してIAMユーザを作る必要もありません。AWS SSO単体でのユーザ管理もできますが、弊社は外部IdPとしてAzure ADを利用しています。
AWS SSOの詳細は過去このような記事も書いているのでよろしければ御覧ください!
AWS Single Sign-Onを用いた、セキュアでより良いログイン体験への取り組み - Speaker Deck by kotatsu360今日の本題
AWS SSOは長らくWebAPIが存在せず、Webコンソールが唯一のインターフェースでした。しかし、今年の9月にとうとうWebAPIが公開され、機械的な連携が可能になりました!1
個人的に9月の発表というのが渡りに船でした。ちょうど10月、下期の始まりということでAWS SSOに登録されているユーザとそのユーザが持つ権限の棚卸しをする予定だったためです。
棚卸し、大事です。
(参考)ちなみに、APIが無いかったらどうなるの・・・?
このようにアカウントごとに「ユーザ」と「権限」が表示されるので、気合でコピペします。
API使ってみる
スクリプト
これでバッチリ( ゚д゚ )クワッ!!
#!/bin/bash set -e export AWS_PAGER='' export STORE_ID=#####AWS SSO設定画面に表示されているIDストアID##### export INSTANCE_ARN=#####AWS SSO設定画面に表示されているARN##### echo "user,account,role" > sso.list.csv # # パーミッションセット取得 for permission in $(aws --region us-east-1 sso-admin list-permission-sets --instance-arn ${INSTANCE_ARN} --output text --query PermissionSets); do echo $permission permission_name=$(aws --region us-east-1 sso-admin describe-permission-set --instance-arn ${INSTANCE_ARN} --permission-set-arn ${permission} --output text --query PermissionSet.Name) # パーミッションセットからプロビジョンされているアカウント一覧を取得 for account in $(aws --region us-east-1 sso-admin list-accounts-for-provisioned-permission-set --instance-arn ${INSTANCE_ARN} --permission-set-arn ${permission} --output text --query AccountIds); do echo $account # あるアカウントでそのパーミッションセットに所属しているユーザ一覧を取得 for user in $(aws --region us-east-1 sso-admin list-account-assignments --instance-arn ${INSTANCE_ARN} --account-id ${account} --permission-set-arn ${permission} --output text --query AccountAssignments[].PrincipalId); do echo "${user},${account},${permission_name}" >> sso.list.csv done done done for userid in $(cut -f1 -d, sso.list.csv | sort | uniq | grep -E ^[0-9].*$ ) ; do username=$(aws --region us-east-1 identitystore describe-user --identity-store-id ${STORE_ID} --user-id ${userid} --output text --query UserName) sed -i -e "s/${userid}/${username}/g" sso.list.csv done for accountid in $(cut -f2 -d, sso.list.csv | sort | uniq | grep -E ^[0-9]+$) ; do accountname=$(aws --region us-east-1 organizations describe-account --account-id ${accountid} --output text --query Account.Name) sed -i -e "s/${accountid}/${accountname}/g" sso.list.csv doneエラー処理・・・?スリープ・・・?loop深くない・・・?
(∩゚д゚)アーアーきこえなーいかなりマッチョな実装になっていますが、ここでは参照だけと割り切って実装しています。
工夫次第でいくらかはスッキリかけるかと思います。リージョンがus-east-1なのは、AWS SSOのリソースがus-east-1にあるためです。
実行
$ aws --version aws-cli/2.1.1 Python/3.9.0 Darwin/19.6.0 source/x86_64 $ bash path/to/script.sh $ cat sso.list.csv user,account,role taro.yamada@example.com, acccount-hoge, ReadOnlyAccess # taroさんはaccount-hogeにReadOnly権限を持っている hanako.tanaka@example.com, account-hoge, ReadOnlyAccess # hanakoさんはaccount-hogeにReadOnly権限を持っている ...取れましたね!
かんたんな解説
SSOの階層構造
Q. あるSSOインスタンスで設定されるユーザx権限のリストを作ろうとしたら?
- SSOインスタンスに存在するパーミッションセット一覧(A, B)を取得
- パーミッションセットAがプロビジョンされているアカウント一覧(HOGE, FUGA)を取得
- アカウントHOGEのパーミッションセットAに所属しているユーザ一覧(ユーザ2)を取得
(以下、延々と繰り返し)
簡単ですね(?)若干、遠回りな気はしますが、上の順番でAPIを実行する必要がありました。ここまで実施すると次の結果が得られます。
user,account,role <user id>,<12桁のAWSアカウントID>,<パーミッションセット名>アカウント棚卸しのためには、
<user id>と<account id>では都合が悪かったので、
スクリプトでは、最後にもう一度APIを叩いてユーザ名とアカウント名で置換しています。user,account,role taro.yamada@example.com, acccount-hoge, ReadOnlyAccess注意点
スクリプトに登場するAWS CLIのサブコマンドの内、
sso-adminとorganizationsはReadOnly権限があれば実行可能ですが、identitystoreはより強い権限が必要です。このときはPowerUser権限で実行しています。まとめ
若干強引でしたが、APIをつかってAWS SSOからユーザx権限一覧をつくることができました。
一覧さえ取得できれば、あとはどうとでも棚卸しが可能です。なお、実はスクリプトだけでは考慮できていない状況があります。どのパーミッションセットにも所属していないユーザは結果に含まれません。
これについては、現状のAPIでもうまく取得できなかったため、Webコンソールからユーザリストをコピペしています。最後に。本記事では出番がありませんでしたが、9月の時点で更新系のAPIも公開されています。
現在は、権限を設定する作業をWebAPI経由でできないか検証をしているところです。みなさまもWebAPIで良きAWS SSOライフをお楽しみください!!明日は、YasuhiroKimesawaさんの「リモートワークにおける健康について考える」です。お楽しみに!



- 投稿日:2020-12-04T03:30:31+09:00
AWS SAM CLI で Lambda Container Support をお試し
この記事は セゾン情報システムズ Advent Calendar 2020 4日目の記事です。
はじめに
AWS re:Invent 2020 で AWS Lambda の Container イメージサポートが発表されました。
AWS Lambda now supports container images as a packaging format
https://aws.amazon.com/about-aws/whats-new/2020/12/aws-lambda-now-supports-container-images-as-a-packaging-format/ついに AWS にも Cloud Run のようなものがきたか!と思ったそこのあなた
残念ながらあらゆるコンテナイメージを簡単に Lambda で動かすことができるという機能ではありません。
Lambda 関数をコンテナイメージとしてパッケージ化してデプロイできる機能であるため、
作成するコンテナイメージは Lambda Runtime APIを実装し、Lambda関数と互換性を持たせる必要があります。AWS SAM CLI も v1.13.1 で コンテナイメージをサポートしています。
https://github.com/aws/aws-sam-cli/releases/tag/v1.13.1やってみる
前述のとおり、AWS SAM CLI は v1.13.1 以上である必要があります。
$ sam --version SAM CLI, version 1.13.1プロジェクト作成
sam initで利用できるプロジェクトテンプレートでパッケージタイプImageが
選択できるようになっています。
ここでは nodejs12.x のベースイメージを使用してサンプルプロジェクトを作成します。$ sam init Which template source would you like to use? 1 - AWS Quick Start Templates 2 - Custom Template Location Choice: 1 What package type would you like to use? 1 - Zip (artifact is a zip uploaded to S3) 2 - Image (artifact is an image uploaded to an ECR image repository) Package type: 2 Which base image would you like to use? 1 - amazon/nodejs12.x-base 2 - amazon/nodejs10.x-base 3 - amazon/python3.8-base 4 - amazon/python3.7-base 5 - amazon/python3.6-base 6 - amazon/python2.7-base 7 - amazon/ruby2.7-base 8 - amazon/ruby2.5-base 9 - amazon/go1.x-base 10 - amazon/java11-base 11 - amazon/java8.al2-base 12 - amazon/java8-base 13 - amazon/dotnetcore3.1-base 14 - amazon/dotnetcore2.1-base Base image: 1 Project name [sam-app]: Cloning app templates from https://github.com/aws/aws-sam-cli-app-templates ----------------------- Generating application: ----------------------- Name: sam-app Base Image: amazon/nodejs12.x-base Dependency Manager: npm Output Directory: . Next steps can be found in the README file at ./sam-app/README.md作成されるファイルは以下のとおりです。
Dockerfile が作成されていることがわかります。$ cd sam-app $ tree . ├── events │ └── event.json ├── hello-world │ ├── app.js │ ├── Dockerfile │ ├── package.json │ └── tests │ └── unit │ └── test-handler.js ├── README.md └── template.yamlDockerfile では AWS が提供しているベースイメージが指定されています。
AWS 提供のベースイメージであれば Lambda 関数を実行するために必要なランタイムと
その他のコンポーネントがプリロードされているため、Lambda 関数のコードとその依存関係を
追加するだけで問題ありません。FROM public.ecr.aws/lambda/nodejs:12 COPY app.js package.json ./ RUN npm install # Command can be overwritten by providing a different command in the template directly. CMD ["app.lambdaHandler"]独自コンテナイメージを Lambda 互換にするには Lambda Runtime APIを実装する一連の
ソフトウェアパッケージである Runtime Interface Clients (RIC) を
ベースイメージに追加する必要があります。
template.yamlの内容は以下のとおりです。template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > sam-app Sample SAM Template for sam-app # More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst Globals: Function: Timeout: 3 Resources: HelloWorldFunction: Type: AWS::Serverless::Function Properties: PackageType: Image # ImageConfig: # Uncomment this to override command here from the Dockerfile # Command: ["app.lambdaHandler"] Events: HelloWorld: Type: Api Properties: Path: /hello Method: get Metadata: DockerTag: nodejs12.x-v1 DockerContext: ./hello-world Dockerfile: Dockerfile Outputs: # ServerlessRestApi is an implicit API created out of Events key under Serverless::Function # Find out more about other implicit resources you can reference within SAM # https://github.com/awslabs/serverless-application-model/blob/master/docs/internals/generated_resources.rst#api HelloWorldApi: Description: "API Gateway endpoint URL for Prod stage for Hello World function" Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/hello/" HelloWorldFunction: Description: "Hello World Lambda Function ARN" Value: !GetAtt HelloWorldFunction.Arn HelloWorldFunctionIamRole: Description: "Implicit IAM Role created for Hello World function" Value: !GetAtt HelloWorldFunctionRole.Arnコンテナイメージでパッケージ化を行うには、
PackageType: Imageを指定する必要があります。
指定は省略可能で、指定可能な値はZiporImageです。
https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/sam-resource-function.html#sam-function-packagetypeProperties: PackageType: ImageSAM CLI でコンテナイメージをビルドするには Metadata リソース属性で、
Dockerfile, Context, Tag などの情報を宣言します。
DockerBuildArgs エントリでビルド時の引数を指定することも可能です。
https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-using-build.html#build-container-imageMetadata: DockerTag: nodejs12.x-v1 DockerContext: ./hello-world Dockerfile: Dockerfileイメージのビルド
sam build コマンドでコンテナイメージをビルドします。
$ sam build Building codeuri: . runtime: None metadata: {'DockerTag': 'nodejs12.x-v1', 'DockerContext': './hello-world', 'Dockerfile': 'Dockerfile'} functions: ['HelloWorldFunction'] Building image for HelloWorldFunction function Setting DockerBuildArgs: {} for HelloWorldFunction function Step 1/4 : FROM public.ecr.aws/lambda/nodejs:12 ---> ccbddaf00c51 Step 2/4 : COPY app.js package.json ./ ---> fb16c5342f63 Step 3/4 : RUN npm install ---> Running in faa9eb4d503c npm WARN deprecated debug@3.2.6: Debug versions >=3.2.0 <3.2.7 || >=4 <4.3.1 have a low-severity ReDos regression when used in a Node.js environment. It is recommended you upgrade to 3.2.7 or 4.3.1. (https://github.com/visionmedia/debug/issues/797) npm WARN deprecated mkdirp@0.5.4: Legacy versions of mkdirp are no longer supported. Please update to mkdirp 1.x. (Note that the API surface has changed to use Promises in 1.x.) npm notice created a lockfile as package-lock.json. You should commit this file. added 107 packages from 544 contributors and audited 107 packages in 5.755s 16 packages are looking for funding run `npm fund` for details found 0 vulnerabilities ---> 8db6f5505058 Step 4/4 : CMD ["app.lambdaHandler"] ---> Running in 08e14cc877aa ---> 271c7f34a0c7 Successfully built 271c7f34a0c7 Successfully tagged helloworldfunction:nodejs12.x-v1 Build Succeeded Built Artifacts : .aws-sam/build Built Template : .aws-sam/build/template.yaml Commands you can use next ========================= [*] Invoke Function: sam local invoke [*] Deploy: sam deploy --guidedパッケージ化されたコンテナイメージが作成されました
$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE helloworldfunction nodejs12.x-v1 271c7f34a0c7 3 minutes ago 471MBローカルテスト
コンテナイメージとしてパッケージ化された Lambda関数をローカルでテストするために
軽量のウェブサーバーである Lambda Runtime Interface Emulator(RIE)を使用することができます。
AWS 提供のベースイメージには RIE が組み込まれているため、ビルドしたイメージから
コンテナを作成するだけですぐにテストを実行できます。$ docker run -d -p 9000:8080 helloworldfunction:nodejs12.x-v1 a510b1f8bf0fd5c0d7c6a3716ddaf96462452abcdff26285d1e8471c6e829cc8 $ curl -XPOST "http://localhost:9000/2015-03-31/functions/function/invocations" -d '{}' {"statusCode":200,"body":"{\"message\":\"hello world\"}"}RIE は HTTP リクエストを JSON イベントに変換し、プロキシする役割であるため、
X-Ray や その他の Lambda 統合機能についてはサポートしていません。独自のベースイメージを使用する場合、RIE をイメージに組み込んだり、
bind マウントした RIE を Entrypoint としてコンテナを起動することでテストを実行できます。
https://docs.aws.amazon.com/lambda/latest/dg/images-test.html#images-test-alternativeもちろん今回は SAM CLI を使用しているので、
sam local invokeによるテストも実行可能です。$ sam local invoke Invoking Container created from helloworldfunction:nodejs12.x-v1 Image was not found. Building image................. Skip pulling image and use local one: helloworldfunction:rapid-1.13.1. START RequestId: 05284faf-5a20-46fc-a695-111eb3d0f085 Version: $LATEST END RequestId: 05284faf-5a20-46fc-a695-111eb3d0f085 REPORT RequestId: 05284faf-5a20-46fc-a695-111eb3d0f085 Init Duration: 1.86 ms Duration: 96.09 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 128 MBデプロイ
コンテナイメージを push するための リポジトリはあらかじめ作成しておく必要がありますが
イメージの push 自体は SAM CLI に任せることができます!$ aws ecr create-repository --repository-name lambda-container-test { "repository": { "repositoryUri": "123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-container-test", "imageScanningConfiguration": { "scanOnPush": false }, "registryId": "123456789012", "imageTagMutability": "MUTABLE", "repositoryArn": "arn:aws:ecr:ap-northeast-1:123456789012:repository/lambda-container-test", "repositoryName": "lambda-container-test", "createdAt": 1606926983.0 } }
sam deploy --guidedを実行します。Image Repositoryに先ほど作成したリポジトリを指定することで
デプロイ時にイメージの push が自動で行われます。$ sam deploy --guided Configuring SAM deploy ====================== Looking for config file [samconfig.toml] : Not found Setting default arguments for 'sam deploy' ========================================= Stack Name [sam-app]: AWS Region [us-east-1]: ap-northeast-1 Image Repository []: 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-container-test Images that will be pushed: helloworldfunction:nodejs12.x-v1 to 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-container-test:helloworldfunction-271c7f34a0c7-nodejs12.x-v1 #Shows you resources changes to be deployed and require a 'Y' to initiate deploy Confirm changes before deploy [y/N]: n #SAM needs permission to be able to create roles to connect to the resources in your template Allow SAM CLI IAM role creation [Y/n]: y HelloWorldFunction may not have authorization defined, Is this okay? [y/N]: y Save arguments to configuration file [Y/n]: y SAM configuration file [samconfig.toml]: SAM configuration environment [default]: Looking for resources needed for deployment: Found! Managed S3 bucket: aws-sam-cli-managed-default-samclisourcebucket-xxxxxxxxxxxxx A different default S3 bucket can be set in samconfig.toml Saved arguments to config file Running 'sam deploy' for future deployments will use the parameters saved above. The above parameters can be changed by modifying samconfig.toml Learn more about samconfig.toml syntax at https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-config.html The push refers to repository [123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-container-test] 6d7acece320f: Pushed 105893862807: Pushed 3642f26c4fcb: Pushed 1807102b87b6: Pushed 120614c3628c: Pushed 0d8c48ae73f7: Pushed e4f26f8be15f: Pushed af6d16f2417e: Pushed helloworldfunction-271c7f34a0c7-nodejs12.x-v1: digest: sha256:7a83998f07e54249948db91846abd9dbfecbe175181fe0876b5980a635b9e70f size: 1998 Deploying with following values =============================== Stack name : sam-app Region : ap-northeast-1 Confirm changeset : False Deployment image repository : 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-container-test Deployment s3 bucket : aws-sam-cli-managed-default-samclisourcebucket-xxxxxxxxxxxxx Capabilities : ["CAPABILITY_IAM"] Parameter overrides : {} Signing Profiles : {} ~~以降省略~~作成された API Gateway にリクエストして、動作を確認します。
$ curl https://xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com/Prod/hello/ {"message":"hello world"}成功しました。
Lambda のコンソール側でも関数コードがコンテナイメージとしてデプロイされていることを確認できます。
注意点など
- CloudFormation のスタックを削除しても、ECR 側のイメージは削除されません。
気になったところ
- コールドスタード時の実行時間
厳密な比較が行えていないので一概には言えないと思いますが、 zip のデプロイパッケージと比較すると
若干 Init Duration に時間を要しているように伺えました。
- コンテナイメージのサイズ
なぜか ECR にアップロードするとイメージサイズが小さくなるように見える。
ローカルで 470 MB ほどあるが、、、$ docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE 123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/lambda-container-test helloworldfunction-271c7f34a0c7-nodejs12.x-v1 271c7f34a0c7 About an hour ago 471MBECR 上は 約 151 MB

参考
New for AWS Lambda – Container Image Support
https://aws.amazon.com/jp/blogs/aws/new-for-aws-lambda-container-image-support/
AWS Lambda - Developer Guide
https://docs.aws.amazon.com/lambda/latest/dg/lambda-images.html
AWS Serverless Application Model - Developer Guide
https://docs.aws.amazon.com/serverless-application-model/latest/developerguide/serverless-sam-cli-using-build.html以上です。
参考になれば幸いです。


- 投稿日:2020-12-04T02:18:04+09:00
AWS Fargateで AutoScaling を有効にして Amazon SQS からメッセージを取り出す
こちらは AWS Containers Advent Calendar 2020 の4日目の記事です。
メッセージキューイングサービス「Amazon SQS」をご存知でしょうか。
複数のサービス間連携を疎結合にするために利用されている方も多いのではないでしょうか。その中で、SQS にキューイングされたメッセージ数に応じて、メッセージを取り出す Worker の数を AutoScaling させたいことってありませんか?
EC2 インスタンスを worker として利用する場合の手順は、ドキュメント に記載があります。
実際のユースケースでは、worker として、AWS Lambda が使われていたり、AWS Fargate が使われていたり、色々なパターンがあるかと思います。
そこで、本記事では、このドキュメントを参考にしながら、Amazon ECS on AWS Fargate を worker として利用した際の、AutoScaling の実装方法について紹介したいと思います。さっそく構成図
何をしているか?
- ECS 上に 2つのサービスを作成します。
- 1つ目は、Monitoring用(monitoring-service)です。具体的には、SQSのメッセージ数とWorker数から 1workerあたりのメッセージ(backlog)数を計算して、CloudWatchカスタムメトリクスとして登録します。
- 2つ目は、Worker用(worker-serivce)です。SQSからメッセージの取り出しを行います。カスタムメトリクスを指標にした、ターゲットトラッキングポリシーを設定することで、backlog数に応じてtask数のAutoScalingが行われます。
Monitoring Service(monitoring-service) について
こちらはドキュメントでいう「ステップ 1: CloudWatchカスタムメトリクスを作成する」の部分の実装例になります。
- SQS のメッセージ数(ApproximateNumberOfMessages)を取得
- ECS 上の Worker Service(worker-service)で動いているタスク数を取得
- 1タスクあたりのメッセージ(backlog)数を算出し、CloudWatch カスタムメトリクスへ登録
- 上記の動きを1分に一度に行う
(Dockerfile、タスク定義、サービスなどの詳細は割愛しています)
monitorig.pyimport boto3 import time session = boto3.Session(region_name="us-east-1") sqs = session.resource('sqs') ecs = session.client('ecs') cloudwatch = session.client('cloudwatch') while True: # メッセージ(backlog)数を取得 queue = sqs.get_queue_by_name(QueueName="qiita-sqs") msgs = queue.attributes.get('ApproximateNumberOfMessages') # workerとして動いているtask数を取得 response = ecs.describe_services( cluster='QiitaCluster', services=[ 'worker-service' ] ) tasks = response['services'][0]['runningCount'] # 1taskあたりのblacklog数の算出 if int(tasks) == 0: # taskが動いていない場合 backlog = int(msgs) else: backlog = int(msgs) / int(tasks) # 1taskあたりのblacklog数をカスタムメトリクスとして送信 cloudwatch.put_metric_data( MetricData=[ { 'MetricName': 'backlogpertask', 'Dimensions': [ { 'Name': 'SQSName', 'Value': "qiita-sqs" }, ], 'Unit': 'Count', 'Value': backlog }, ], Namespace='SQS/BACKLOG' ) time.sleep(60)これで、1タスクあたりのbacklog数が、CloudWatch カスタムメトリクスとして取得できるようになります。
Worker Service(worker-service)について
取り出したメッセージは、実際のワークロードの場合は、何らかの処理をするかと思いますが、この記事では簡素化のため、取り出したメッセージは「何もせず、すぐに削除する」実装になっています。
(Dockerfile、タスク定義、サービスなどの詳細は割愛しています)
worker.pyimport boto3 import time session = boto3.Session(region_name="us-east-1") sqs = session.resource('sqs') while True: # メッセージを取得 queue = sqs.get_queue_by_name(QueueName="qiita-sqs") msgs = queue.receive_messages(MaxNumberOfMessages=10) if msgs: for msg in msgs: # 取得次第、消す msg.delete() # なんとなく少しsleepしてみる time.sleep(0.2)Worker Service(worker-serivce)のターゲットトラッキングポリシー設定
ECS Service の AutoScaling 設定方法自体は、こちら に記載されています。
しかし、現時点では、マネジメントコンソールでは、カスタムメトリクスを使用したターゲットトラッキングポリシーは設定できないため、本記事では AWS CLI で設定を行います。TargetValue(1 taskあたりのbacklog目標値)は、実際のワークロードの場合は慎重に決める必要がありますが、ここではドキュメントの設定例と同じ 100 に設定しています。
config.json{ "TargetValue": 100.0, "CustomizedMetricSpecification": { "MetricName": "backlogpertask", "Namespace": "SQS/BACKLOG", "Dimensions": [ { "Name": "SQSName", "Value": "qiita-sqs" } ], "Statistic": "Average", "Unit": "Count" }, "ScaleOutCooldown": 60, "ScaleInCooldown": 60 }aws application-autoscaling put-scaling-policy --service-namespace ecs --scalable-dimension ecs:service:DesiredCount --resource-id service/QiitaCluster/worker-service --policy-name backlog100-target-tracking-scaling-policy --policy-type TargetTrackingScaling --target-tracking-scaling-policy-configuration file://config.jsonこちらで、カスタムメトリクスを使用したターゲットトラッキングポリシーが設定できました。
動作確認
SQSにメッセージ投入
- SQS のスタンダードキューとして「qiita-sqs」を作成
- なんらかの方法でSQSへ大量のメッセージを投入(私は単純なシェルスクリプトを書いて、ローカル環境で多重起動しました)
ApproximateNumberOfMessages の確認
この時点では、まだ worker は作成していないため、SQSにメッセージが貯まり続けています。
* ApproximateNumberOfMessagesの値は CloudWatch メトリクスでは確認できないため、ここでは ApproximateNumberOfMessagesVisible のメトリクスを表示しています
monitoring-serviceの作成とカスタムメトリクスの確認
1 taskあたりのbacklog数を算出し、カスタムメトリクスとして登録するための service を作成しました。
この時点では、まだ worker は作成していないため、1 taskあたりのbacklog数 = SQS内のメッセージ数 となり、値が増え続けていることがわかります。
worker-serviceの作成
実際に SQSからメッセージを取り出す、worker service を作成しました。
作成後に、カスタムメトリクスを使用したターゲットトラッキングポリシーを設定しています。(サービス作成時は 1 task のみ起動, Max 10 taskまでスケーリング)
前述のカスタムメトリクス(1taskあたりのbacklog数)は 100 を遥かに超えているので、AutoScalingが発動して、
task数が増え、その結果、カスタムメトリクス(1taskあたりのbacklog数)の値が減少していくはずです。task数の推移
CloudWatch Container Insights のメトリクスで 起動しているタスク数を確認することができます。 task数は想定通り、初期値の1 から徐々に増えて、最大値に設定した 10 task まで増えていることが分かります。
カスタムメトリクスの推移
いまは、workerの数が増え、どんどん SQS からメッセージを取り出している状態なので、カスタムメトリクス(1taskあたりのbacklog数)も減っていることが分かります。
task数のスケールイン
カスタムメトリクスの値がターゲットである100以下になっているため、暫くするとtask数のスケールインが発生します。
(まだスケールインの途中でのスクショですが、task数が 10 -> 7 に減っています)
まとめ
本記事では、AWSのドキュメントを参考にしながら、Amazon ECS on AWS Fargate を SQS の worker として利用した際の、AutoScaling の実装パターンの1例について紹介しました。
AutoScalingの実装方法に悩まれている方、もしくは、これから設定しようとされている方のお役にたてば幸いです。







- 投稿日:2020-12-04T01:43:44+09:00
【超ミニマム】AWS AppSync + AmplifyでiOSチャットアプリを作る
はじめに
この記事はand factory Advent Calendar 2020 の4日目の記事です。
昨日は@ykkdさんのSwiftlint autocorrectでコードを自動修正するでした!?AWS AppSync / Amplify
チャットアプリをはじめとしたモバイルのバックエンドとしてFirebaseが利用されることが多いと思いますが、
AWSのマネージドサービスには、他のAWSサービスとの連携が容易という大きなメリットがあります。
私自身iOSエンジニアではあるもののAWSの提供しているサービスや構成には興味があったので、
今回はAppSyncとAmplifyを使ってみることにしました。AppSyncとはAWSが提供しているGraphQLでのサービス開発をサポートするマネージドサービスで、
GraphQLで用意されているサブスクリプション機能を使うことでチャット機能を比較的用意に作ることができます。
また、AmplifyはクライアントがAppSyncにアクセスするために提供されているツールで、
iOSではAmplify SDKを利用することで、AppSyncとのデータの受け渡しをSDK側が請け負ってくれます。こんなイメージだと思っています↓
今回はAWS AppSync + Amplifyで爆速で(?)超ミニマムなチャットアプリを作ってみます。
Amplifyのセットアップ
前提条件
- AWSアカウントを持っている
- Amplifyのセットアップが完了している
- Amplifyを実行するコマンドラインツールのセットアップ、Podのインストールを行います。
- 詳細はこちらを参照ください。
Amplifyのコマンドラインツールで以下を実行します。
Amplifyの初期化
amplify initその後プロジェクト名などの初設定を尋ねられるので回答します。今回は以下のように答えました。
? Enter a name for the project -> SampleChatApp ? Enter a name for the environment -> dev ? Choose your default editor: -> Visual Studio Code ? Choose the type of app that you're building -> ios ? Do you want to use an AWS profile? -> Yes ? Please choose the profile you want to use -> default✅ Amplify setup completed successfully.
と出たら完了です。APIのセットアップ
amplifyのセットアップが終わったら、コマンドラインツールを使ってAPIをセットアップしていきます。
プロジェクトルートで下記のコマンドを実行し、確認内容に沿って回答していきます。
amplify add api再び質問されます。次はAPIについての初設定です。今回のケースの回答は以下です。
? Please select from one of the below mentioned services: -> GraphQL ? Provide API name: -> samplechatapp ? Choose the default authorization type for the API -> API key ? Enter a description for the API key: -> SampleChatApp's API key. ? After how many days from now the API key should expire (1-365): -> 7 ? Do you want to configure advanced settings for the GraphQL API -> No, I am done. ? Do you have an annotated GraphQL schema? -> No ? Choose a schema template: -> Single object with fields (e.g., “Todo” with ID, name, description) GraphQL schema compiled successfully. ? Do you want to edit the schema now? -> Yes // Yesとするとエディタが開き、スキーマを編集できるモデル定義
APIの作成の最後の質問にYesで答えるとエディタが開きスキーマを編集できるようになります。
GraphQLではgraphqlファイルで定義されたスキーマをもとにAPIを作成します。
ここでは簡単にメッセージのモデルを以下のように定義しました。
テキスト、作成日(エポックマイクロ秒を想定)、UserIDの最小限のプロパティです。schema.graphqltype Message @model { id: ID! text: String! createdAt: String! user: String! }スキーマを定義したら、
これまでに作成したスキーマやらAPIの定義ファイルやらのローカルのリソースをリモートにpushします。amplify pushpushに成功すると、例によって質問がなされます。
この回答に基づいて作成したAPIにアクセスするためのラップ処理の種類や命名などが決まります。? Do you want to generate code for your newly created GraphQL API -> Yes ? Enter the file name pattern of graphql queries, mutations and subscriptions -> graphql/**/*.graphql ? Do you want to generate/update all possible GraphQL operations - queries, mutations and subscripti ons -> Yes ? Enter maximum statement depth [increase from default if your schema is deeply nested] -> 2 ? Enter the file name for the generated code -> API.swiftここまで行うとAmplifyのコマンドラインツールにてAPIが作成され、
AWSのコンソール->サービス→AppSyncから確認することができます。
クライアント実装
セットアップ
amplify initの際に作成された、
amplifyconfiguration.jsonとawsconfiguration.jsonのふたつのjsonファイルを
Xcodeのプロジェクト内に移し替えます。また、アプリ起動時のAmplifyのセットアップ処理としてAppDelegateで以下を実行します。
AppDelegate.swiftimport UIKit import Amplify import AmplifyPlugins @UIApplicationMain class AppDelegate: UIResponder, UIApplicationDelegate { var window: UIWindow? func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool { // Setup Amplify do { try Amplify.add(plugin: AWSAPIPlugin(modelRegistration: AmplifyModels())) try Amplify.configure() } catch { print("An error occurred setting up Amplify: \(error)") } // 略 return true } }チャット機能実装
チャット機能の実装です。
viewDidLoadでデータソースに保存されたメッセージを取得する
REST APIでのGetはGraphQLではqueryが請け負います。
Amplify SDKではAmplify.API.query(request:)を実行すして、Messageの配列を取得します。
また、件数を指定するlimitや次の値の参照を持つnextTokenを組み合わせることでページネーションを行うこともできます。ChatViewController.swift@IBOutlet private weak var tableView: UITableView! var messages: [Message] = [] override func viewDidLoad() { super.viewDidLoad() self.fetchMessage() } func fetchMessage() { // Amplify SDK経由でqueryオペレーションを実行しMessageの配列を取得 Amplify.API.query(request: .list(Message.self, where: nil)) { event in switch event { case .success(let result): // GraphQLの場合、Query失敗時のerrorもレスポンスに含まれる switch result { case .success(let messages): self.messages = messages DispatchQueue.main.async { // tableViewを更新 self.tableView.reloadData() } case .failure(let error): // サーバーから返されるエラーはこっち } case .failure(let error): // 通信エラー等の場合はこっち } } }送信ボタンでデータを投稿する
GraphQLにおいてデータの作成、変更などの書き込み操作はmutateが行います。
ChatViewController.swift@IBAction func tappedSendButton() { // キーボード閉じる self.textField.resignFirstResponder() // メッセージ内容 guard let text = self.textField.text, !text.isEmpty else { return } // 送信時間を取得 let createdAt = String(Date().timeIntervalSince1970) // 別管理しているUserID let user = UserIdRepositoryProvider.provide().getUserId() let message = Message(text: text, ts: ts, user: user!) // mutateで新規メッセージを作成 Amplify.API.mutate(request: .create(message)) { event in switch event { case .success(let result): switch result { case .success(let message): print("Successfully created the message: \(message)") case .failure(let graphQLError): // サーバーからのエラーの場合はこっち print("Failed to create graphql \(graphQLError)") } case .failure(let apiError): // 通信まわりなどのErrorになった場合はこっち print("Failed to create a message", apiError) } } // 初期化しておく self.textField.text = "" }データソースの購読
最後にリアルタイムな結果の反映について実装します。
GraphQLではサブスクリプション機能を使うことによって、双方向のソケット通信を実現します。
Amplifyでは、Amplify.API.subscribe()を実行することで、データソースの変更をレスポンシブに反映できるようになります。ChatViewController.swiftoverride func viewDidLoad() { super.viewDidLoad() self.fetchMessage() self.subscribeMessage() } func subscribeMessage() { // 新たなメッセージの作成を購読する subscription = Amplify.API.subscribe(request: .subscription(of: Message.self, type: .onCreate), valueListener: { (subscriptionEvent) in // 購読したイベント内容をチェック switch subscriptionEvent { // サブスクリプションの接続状態の変更を検知 case .connection(let subscriptionConnectionState): print("Subscription connect state is \(subscriptionConnectionState)") // データの更新を検知 case .data(let result): switch result { case .success(let createdMessage): self.messages.append(createdMessage) DispatchQueue.main.async { // テーブル更新 self.tableView.reloadData() // 最新のメッセージまでスクロール let indexPath = IndexPath(row: self.messages.count - 1, section: 0) self.tableView.scrollToRow(at: indexPath, at: .bottom, animated: true) } case .failure(let error): print("Got failed result with \(error.errorDescription)") } } }) { result in switch result { case .success: print("Subscription has been closed successfully") case .failure(let apiError): print("Subscription has terminated with \(apiError)") } } }ひとまず完成
できてるっぽい〜〜〜
やりきれなかったこと
できてるっぽい雰囲気が若干しますが、実は今回ソートができませんでした。
(サブスクリプションで購読したものは時系列順で取得できるのでごまかせるのですが、queryで取得したものはKeyのMessageのIDでソートされてしまい順序性が狂ってしまいます)
時系列順 ID順(再度queryで取得した場合) チャットであれば当然時系列順に並んでほしいところですが、超ミニマムということでお許しください。
(schema.graphqlをいじってソートキーにcreatedAtを指定することはできるのですが、
Amplify SDKで経由でどのように呼び出せばいいのかわからず。。知見がある人がいたら教えていただきたいです。)おわりに
本記事では全く触れられませんでしたが、チャット機能に関しては
- 認証情報との紐付け
- 送信開始時点で送信中というステータスがユーザーに伝わるようにする
- 送信に失敗したときにユーザーに通知して再送信を促す
- 送信中にアプリを落としても送信が行われるようにする
- 画像や動画などコンテンツの拡充
- データの永続化をしてユーザービリティを高める
など考え出すとどんどん検討項目が出てくるので、
SDKにどこまでおまかせするべきなのか難しいところだなと思いました。
とはいえAmplify iOS SDKに関してはまだまだ調査段階なので、
また色々触って理解度深めていきたいところです。最後まで見ていただきありがとうございました?♂️




- 投稿日:2020-12-04T00:26:26+09:00
reInvent2020で発表されたLambdaContainerをCDKで実装してみる
1. はじめに
日本時間の2020年12月2日午前1時ごろから始まった1つ目のKeyNoteで、
突如LambdaContainerが発表されました(参考)。私も、この発表はリアルタイムでみていて「うぉぉぉぉ!」と心の中で雄叫びを上げました。
コンソールなどではすでに利用できるみたいです。また、驚いたのが、AWS CDKでも、LambdaContainerの発表から数時間後には
versionが1.76.0に上がり、その際にLambdaContainerがサポートされたみたいですねw2. 実装
CDKでの実装に関するドキュメントは公式にて提供されており、これまでのデプロイと大差なく利用できそうです。
また、DockerFileはDevelopers.IOさんのこの記事を参考にしました。
2.1 ファイル構成
CDKをデプロイするファイル構成は以下の通りです。
lambda-container/ ├── app.py ├── cdk.json └── docker/ ├── Dockerfile ├── app.py └── requirements.txt2.2 Lambdaのメイン関数
特に意味のないLambdaの関数です。
requirements.txtにてinstallしたpackageが正しく利用できるか、
pandasのバージョンを表示させてみます。docker/app.pyimport pandas as pd def lambda_handler(event, _): print(pd.__version__) return event2.3 Dockerfile
Lambdaに載せるDockerfileの例は以下の通りです。
(こちらのDockerfileは参考の記事をそのまま利用させてもらいました。)FROM public.ecr.aws/lambda/python:3.8 COPY app.py requirements.txt ./ RUN python3.8 -m pip install -r requirements.txt -t . # ここのコマンドは # app.pyのスクリプトにある、lambda_handlerという関数をエントリポイントにする、 # という意味です。 CMD ["app.lambda_handler"]他のPythonのバージョンはここを参考にしていただくと良いかと思います!
(2.7とかも一応利用できるみたいですね。)2.4 CDK上での実装
公式ドキュメントを参考に実装していきます。
app.pyfrom aws_cdk import ( aws_lambda as lambda_, core, ) class LambdaContainer(core.Stack): def __init__(self, app: core.App, _id: str): super().__init__(scope=app, id=_id) _ = lambda_.DockerImageFunction( scope=self, id="container_function", code=lambda_.DockerImageCode.from_image_asset( directory="docker", repository_name="lambda_container_example" ) ) def main(): app = core.App() LambdaContainer(app, "LambdaContainer") app.synth() if __name__ == "__main__": main()2.5 デプロイ
ここまでできたら、CDKのapp.pyがあるディレクトリにて、以下のコマンドを実行すればデプロイ可能です。
# pythonコードが正しいか確認 # 構文エラーがなければ、デプロイ可能なStackが表示されます。 $ cdk ls LambdaContainer # 実際にdeploy $ cdk deploydeployを開始すると、いつものようにリソースを作成するか聞かれます。
yを押して進むと、dockerのbuildが始まり、
ECRにPUSHされて、CDKとしてのdeployが完了しました。
2.6 確認
実際にLambdaの画面にて確認してみましょう。
入力したeventの値がそのまま返ってきていたり、pandas.__version__が表示されており、
docker/app.pyで設定した通りに動作していることがわかりますね。
また、実行してみたところ、初回こそ起動にちょっと時間(3秒程度)がかかりましたが、
2回目以降は即時に結果が返ってきました。ECRの画面を確認すると
repository_nameで記述した名前で登録されていました。
2.7 リソースの削除
最後に、作成したリソースは以下のコマンドで削除するようにしましょう。
$ cdk destroyただし、
ECRのリポジトリまでは削除されないので、不要な場合は手動で削除するようにしてください。3. おわりに
LambdaはLambdaなので実行時間などの観点から利用どころを見極める必要はありますが、
Lambdaでもコンテナを利用できるようになったことで、他のコンテナのサービスに柔軟に移行できるようになるのは非常に嬉しいことですね!どちらかというと、今まではLambda用に独自のデプロイ環境などを用意する必要がありましたが、
それがなくなったことでより多くの人が触りやすくなったと思います。これから、reInventでは4つのKeyNoteもありますし、2020年もまだまだ楽しめますね!!