- 投稿日:2020-10-21T22:38:42+09:00
AWSクラウドプラクティショナー 直前対策】
【AWSクラウドプラクティショナー 直前対策】
10/24に試験を受けます。
自分の直前対策用です。Amazon CloudWatch Logs⇔AWS CloudTrail
・Amazon CloudWatch Logs
AmazonEC2インタンス、AWS CloudTrail、Route 53、およびその他のソースのログファイルを監視、保存、アクセスできる。
・AWS CloudTrail
AWSアカウントのガバナンス、コンプライアンス、運用監査、リスク監査を行うためのサービス
AWSインフラストラクチャ全体でアカウントアクティビテイをログに記録し、継続的に監視し、保持できる。
→取得するログはユーザーアクティビティに関するものである。EC2インスタンスのログを取得することはできない。EBS⇔インスタンストア
・EBS
EC2インスタンスにアタッチ。
AZ内に自動レプリケート。
スナップショットは、S3に保存される。・インスタンストア
ホストのローカルストレージ。
インスタンス状態に依存するため、一時的。DynamoDB⇔RDS
・DynamoDB
水平スケーリング(スケールアウト、スケールイン)
リージョン選択、AZ気にしない。
RDSより管理範囲が狭い。・RDS
垂直スケーリング(スケールアップ、スケールダウン)
セキュリティグループ⇔ネットワークACL
・セキュリティグループ
ステートフル。
インスタンス単位。
EC2インスタンスとの通信を行う時のトラフィックを制御する仮想ファイアウォール・ネットワークACL
ステートレス。
サブネット単位。
サブネットに対しての仮想ファイアウォールSから始まるややこしい似てる4種
・Amazon SNS (Simple Notification Service)
マイクロサービス、分散型システム、およびサーバーレスアプリケーションの分離を可能にする、
高可用性で耐久性に優れたセキュアな完全マネージド型 pub/sub メッセージングサービスである。
プッシュ方式でコンポーネント間のメッセージングを処理することができる。・Amazon SES (Simple Email Service)
デジタルマーケティング担当者やアプリケーション開発者がマーケティング、通知、トランザクションに関するEメールを送信できるように設計されたクラウドベースのEメール送信サービス。
・Amazon SQS (Simple Queue Service)
完全マネージド型のメッセージキューイングサービス
マイクロサービス、分散システム、およびサーバーレスアプリケーションの切り離しとスケーリングが可能
プッシュ方式ではなくポーリング処理による通知を実施・AWS SMS (Server Migration Service)
オンプレミスの VMwarevSphere, Microsoft Hyper-V/SCVMMなどのAWSクラウドへの移行を自動化
AWSで提供されているデータベースサービス
RDS、Redshift、ElastiCache Redisには自動バックアップ(自動スナップショット)の機能がある。
基本的にはバックアップ運用をAWSに任せられる。
バックアップサイクル等の設定についてはサービス毎に差異がある。Amazon Auroraの DBインスタンスでは常に自動バックアップが有効。
バックアップはデータベースのパフォーマンスに影響を与えない。RDS
S3にDBインスタンスの自動バックアップは取得され、指定した期間保存される。
スナップショットも可。保存データやスナップショット、インスタンスを暗号化することができる。
オブジェクトは利用していない。
利用途中でインスタンスタイプを縮小することも可能。リードレプリカによって、データの冗長性を実現し、コスト最適に災害復旧対応を実現させる。(データ)
マルチAZ構成によって、プライマリデータベースが応答しない場合に自動フェールオーバーを実行する。(システム)AutoScalingによるキャパシティを自動向上させることはできない。
データ容量に限っては、スケーリングが可能。Route 53
アプリケーションとWebサーバーおよびその他のリソースのヘルスとパフォーマンスを監視するヘルスチェックを提供
ヘルスチェックに基づいて、Route 53は正常なエンドポイントのみにトラフィックをルーティングして、アプリケーションのフォールトトレランスのレベルを高める。EFS
EC2インスタンスからLAN上にあるNASとして利用できる共有ファイルストレージ
複数のEC2インスタンスから接続・共有可能なストレージとして機能する。
インターネットからアクセスができない。(S3は、インターネットからアクセス可能。直リージョン)
完全な内部サーバー向けのストレージとしてセキュリティを強化することができる。初めからマルチAZ構成のフォールトトレランス考慮
DynamoDB、S3
- 投稿日:2020-10-21T21:24:20+09:00
cloud9からlambdaを動かす際の注意点(No module named ~のエラーなど)
はじめに
AWS関連で、cloud9からlambdaを動かす際に少し躓いたことがあったのでその辺をまとめていきます。lambdaはサーバーレスでプログラムを実行してくれるので非常に便利で、私もスクレイピング等の定期実行のために使いはじめました。
この記事は主に初めてcloud9、lambdaを使う方向けになると思います。実践
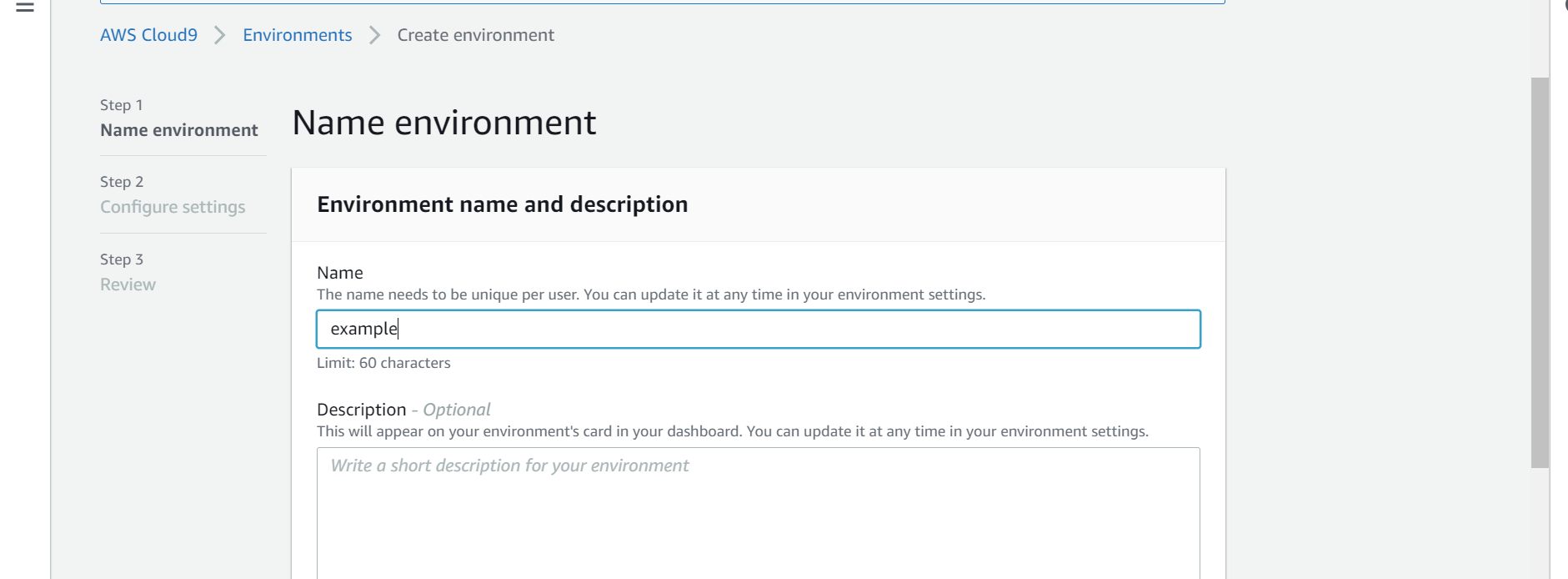
まず新しくcloud9の環境を作成。名前はexampleにしておきます。
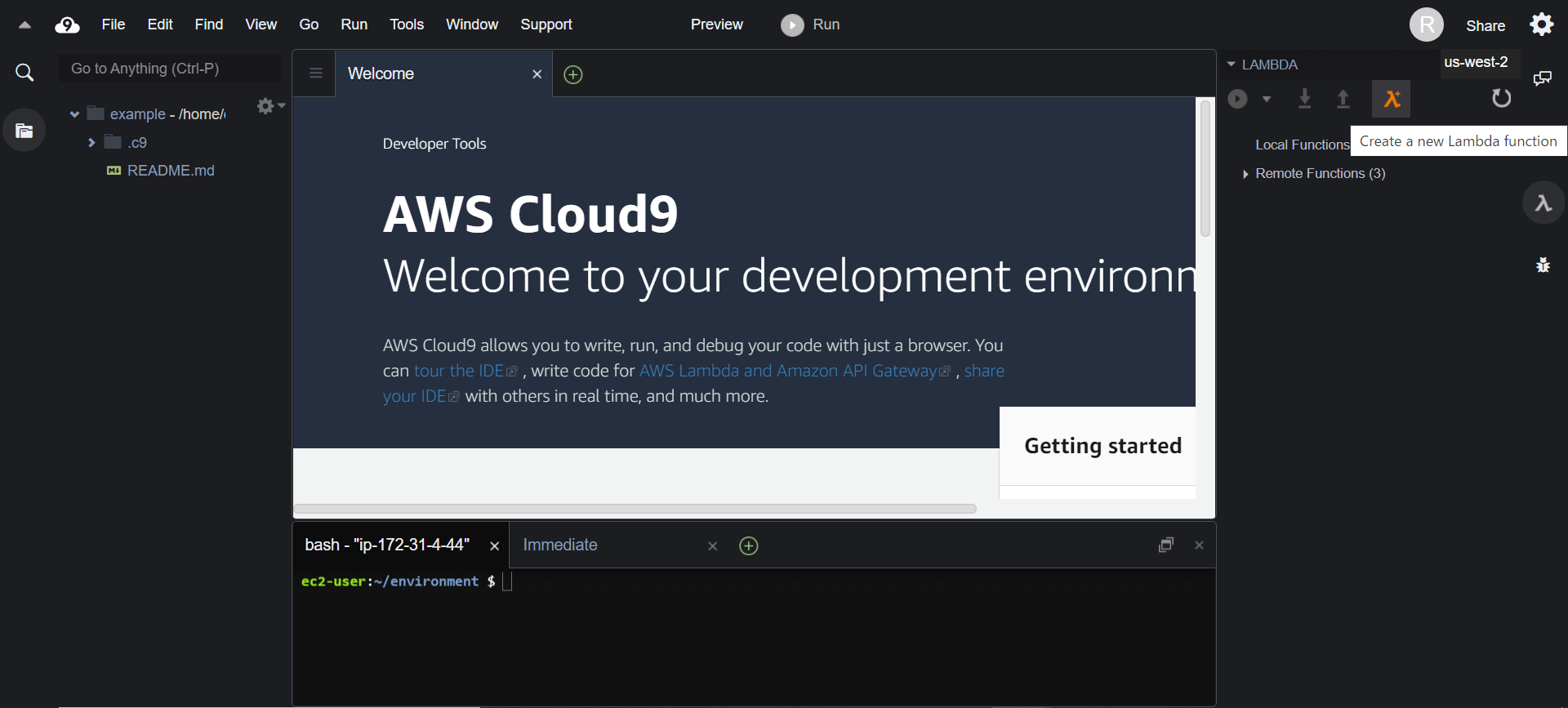
これが終わると下のような画面に移ります。画面右に表示されている漢字の「入」のようなボタンをクリック、さらにCreate a new Lambda function(画像のオレンジ色の部分)をクリックしてlambda-functionを作成できます。
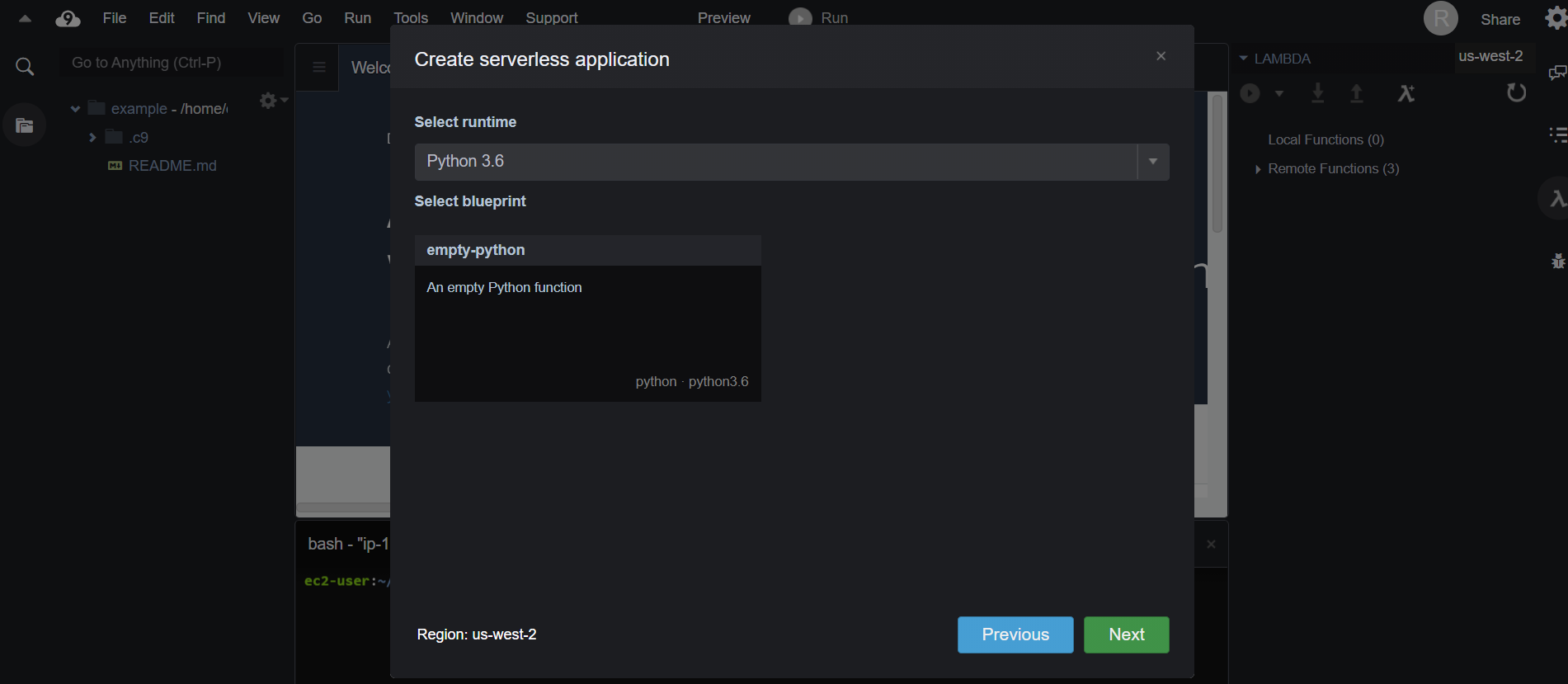
function名は適当に決めてあげて(ここではsample)、Select runtimeのところで使用する言語を選びます。(下の画像)今回はpythonを使ってスクレイピングに使用するBeautifulSoupライブラリのimportが成功するまでを書いていくので、「python3.6」を選びます。そのほかの設定は特にいじらなくて大丈夫だと思います。
home/ec2-user/environmentにsampleディレクトリが出来ていると思います。
次にhome/ec2-user/environment/sample/sampleにあるlambda_function.pyを開いてみてください。ここにプログラムを実行していくコードを書いていくことになります。lambda_function.pyfrom bs4 import BeautifulSoup def lambda_handler(event, context): return 'success'今回は練習なのでこれだけ書きます。bs4からBeautifulSoupをimportすることが出来ていたらsuccessが返ってきます。
ではbs4をinstallしていきます。
まずはsudo pip install --upgrade pipでpipを最新のバージョンにupgradeしましょう。
次に
pip install bs4を実行。(Permission deniedのエラーが出るときは末尾に --userを付け加えます)
無事インストールが成功しました。
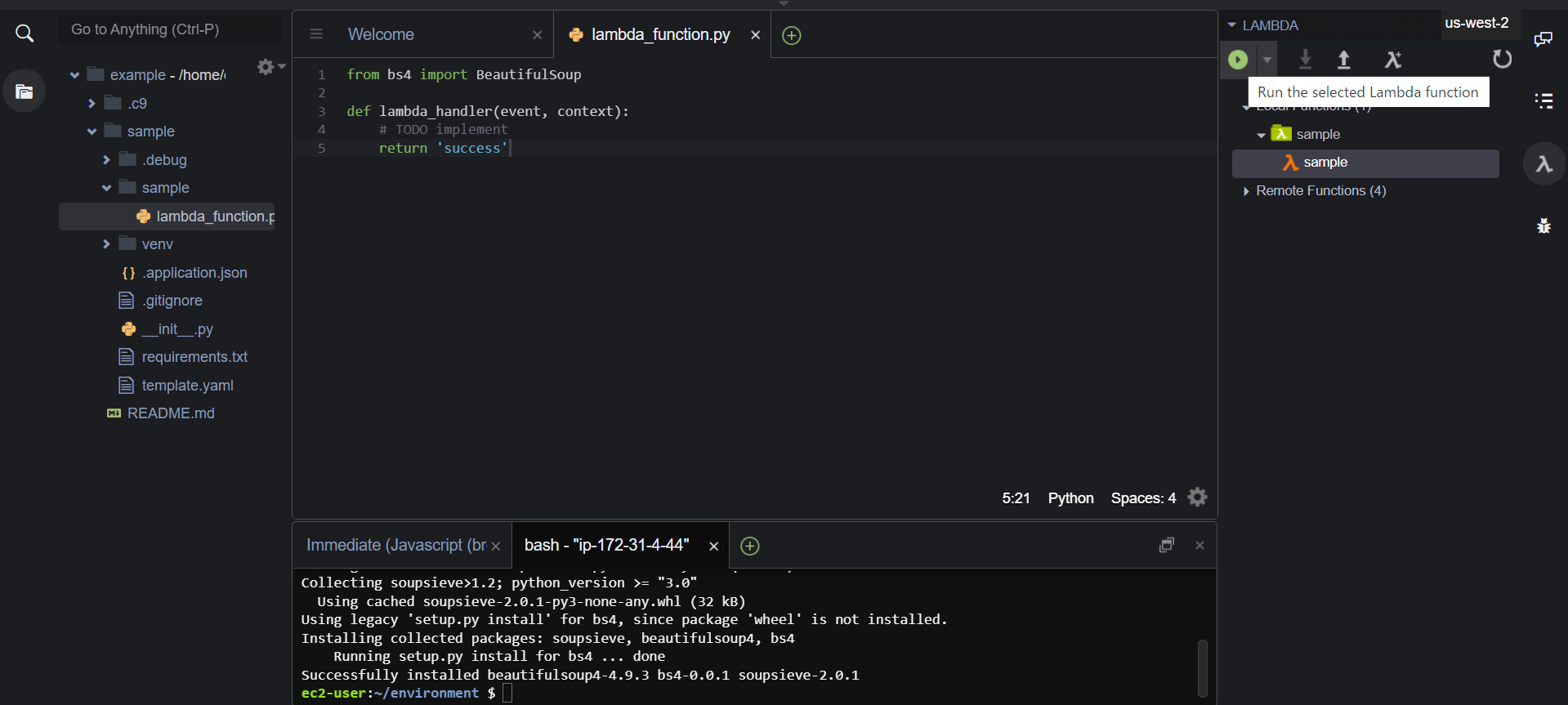
早速、lambda_functionを実行してみます。画面右のLocal Functions でsampleを選択し、Run the selected Lambda functionをクリックしましょう。
すると Unable to import module 'sample/lambda_function': No module named 'bs4'
とエラーが出てしまします。bs4のinstallは成功しているはずなのにbs4が見つからないと言われています。なぜでしょうか。答えとしては、lambdaはサーバーレスで動くので、lambdaの作業用ファイル(sample)内で完結している必要がある(使用するライブラリはファイル内に入れておかなければならない)からです。
解決策するためにcd sample pip install bs4 -t .を実行します(-tとディレクトリ名でinstall先を指定)
もう一度lambda_functionを動かしてみてください
successと返ってきたら成功です。最後にremoteにlambdaファイルをデプロイすれば終了です。(画面右上)
プログラムの定期実行を行いたいときはAmazon EventBridgeから設定することが出来ます。おわりに
pipコマンドの -t は忘れそうだったので記事にしてみました。少額ですが実行時間に応じてお金がかかるので、実行時間が長く頻繁に動かすなら注意した方がいいですね。

- 投稿日:2020-10-21T20:12:40+09:00
【AWS】Elasticsearch Service(Elasticsearch+Kibana)+LogstashでALBアクセスログを分析し、 送信元の地域をマップ上に可視化する
はじめに
先日、AWSのEC2でWebアプリを実行している環境で、国内のどの地域からのアプリ利用者が多いか知りたい、という要望に対応する機会がありました。
ElasticsearchのKibanaを使うと「Region Map」という地図を使ってデータを視覚化できます。
これを活用してALBのアクセスログに含まれる送信元IPアドレスの情報から送信元地域を特定し、Kibanaのマップ上に可視化することができましたので、今回の記事ではそのやり方を紹介したいと思います。
対象者
- Elasticsearchについて知りたい方
- AWSのElasticsearch Serviceについて知りたい方
- ALBのアクセスログを可視化してみたい方
- KibanaのVisualizeでRegion Mapを使ってみたい方 など
Elasticsearchとは
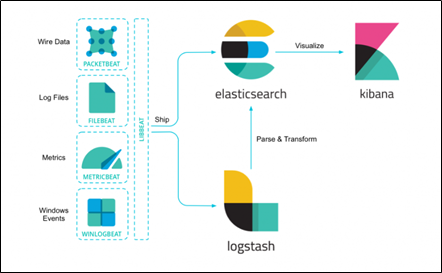
オープンソースのデータ検索エンジンです。
データ収集パイプラインのLogstash、視覚化ツールのKibanaと組み合わせることで、任意のデータの検索・分析・可視化を実現できます。Elasticsearchは、様々なユースケースを解決する分散型RESTful検索/分析エンジンです。
データを一元的に格納することで、超高速検索や、関連性の細かな調整、パワフルな分析が大規模に、手軽に実行可能になります。
(公式ページより抜粋)
Elasticsearch Serviceとは
Elasticsearchの実行環境を簡単にデプロイできるAWSのフルマネージド型のサービスです。
Kibanaがビルトインされており、デプロイ後すぐにデータ分析を開始できます。
フルマネージド型でインフラの管理が不要なのはもちろんですが、ESクラスターはVPCに作成されるため、外部との接続点を持たない内部ネットワークで完結する分析環境を簡単に作成できるというメリットがあります。実現すること
- AWSでElasticsearchの実行環境の作成する
- LogstashでALBのアクセスログを収集し、送信元IPから送信元の都道府県を特定する
- KibanaのVisualizeでRegion Mapの設定を行い、アクセスが多い地域・少ない地域が一目で分かるマップを作成する
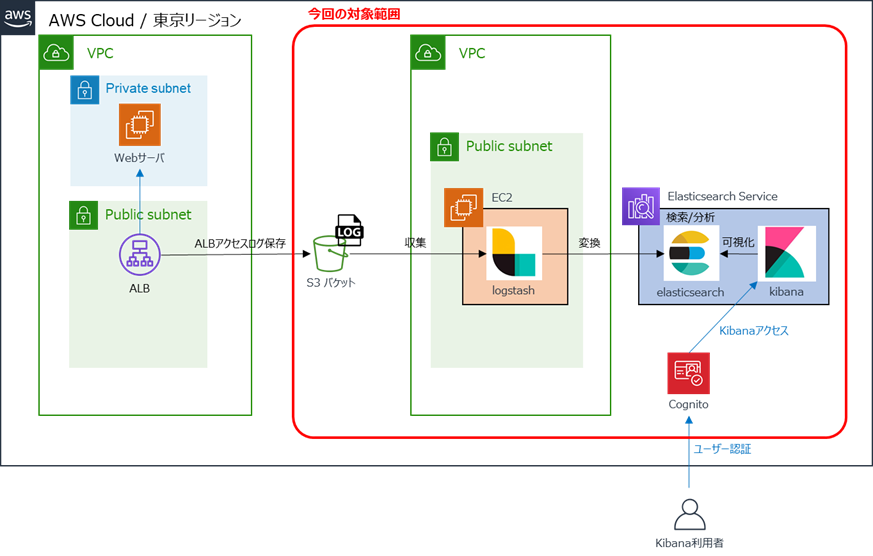
構成
Elasticsearchの導入にあたっては、管理の手間を削減するため、AWSのマネージドサービス「Amazon Elasticsearch Service(以下、Amazon ES)」を利用します。
Amazon ESで提供されるのはElasticsearch+Kibanaですが、地理情報のマッピングにLogstashが必要なため、別途EC2を作成してLogstashをインストールします。
構成イメージは以下のとおりです。
注意点
- 2020年10月時点の情報です。
- AWSマネジメントコンソールを使用します。ルートユーザもしくは権限を満たすIAMユーザを利用できる前提で進めます。
- AWS利用料にご注意ください。利用料については、AWSの公式ページをご参照ください。
環境構築
前提
・Elasticsearch Service
→バージョン:7.7
・Logstashサーバ
→AMI:Amazon Linux2
→インスタンスタイプ:t2.small
※microだとメモリ不足でlogstashがまともに動いてくれませんでした。small以上がおすすめです。
→Logstashバージョン:7.9.0構築手順
1.ELBログの有効化と、出力用のS3バケット作成
参考手順はこちら
2.ESクラスター作成
- 本番稼働用はマルチAZ構成となるため、シングル構成で問題ない場合は開発/テスト用を選択
- インターネットでVPCの外からKibanaにアクセスしたいため、ネットワーク構成はパブリックアクセスを選択
- Cognitoの設定を行い、Kibanaログインに認証を追加
Cognito設定については、こちらを参照
3.Logstash用EC2インスタンス作成、ログイン
4.Logstashインストール
OpenJDKインストール
yum install java-1.8.0-openjdk -yリポジトリ作成
vi /etc/yum.repos.d/logstash.repo/etc/yum.repos.d/logstash.repo[logstash-7.x] name=Elastic repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-mdLogstashインストール
yum install logstash -yamazon_esのプラグインを追加
/usr/share/logstash/bin/logstash-plugin install logstash-output-amazon_es5.logstash.conf設定
vi /etc/logstash/logstash.conf/etc/logstash/logstash.confinput { s3 { tags => "alb" bucket => "<バケット名>" region => "<リージョンコード>" interval => "60" sincedb_path => "/var/lib/logstash/sincedb_alb" } } filter { grok { match => [ "message", "%{ELB_ACCESS_LOG}" ] } date { match => [ "timestamp", "ISO8601" ] target => "@timestamp" } geoip { source => "clientip" } if [geoip][region_code] { mutate { add_field => { "[geoip][region_iso_code]" => "%{[geoip][country_code2]}-%{[geoip][region_code]}" } } } mutate { remove_field => ["timestamp", "message"] } } output { amazon_es { hosts => ["<Elasticsearch Serviceのエンドポイント>"] region => "<リージョンコード>" index => "<設定したいインデックス名>-%{+YYYY.MM.dd}" } }6.Logstash起動
cd /usr/share/logstash bin/logstash -f "/etc/logstash/logstash.conf"7.Kibanaログイン・設定
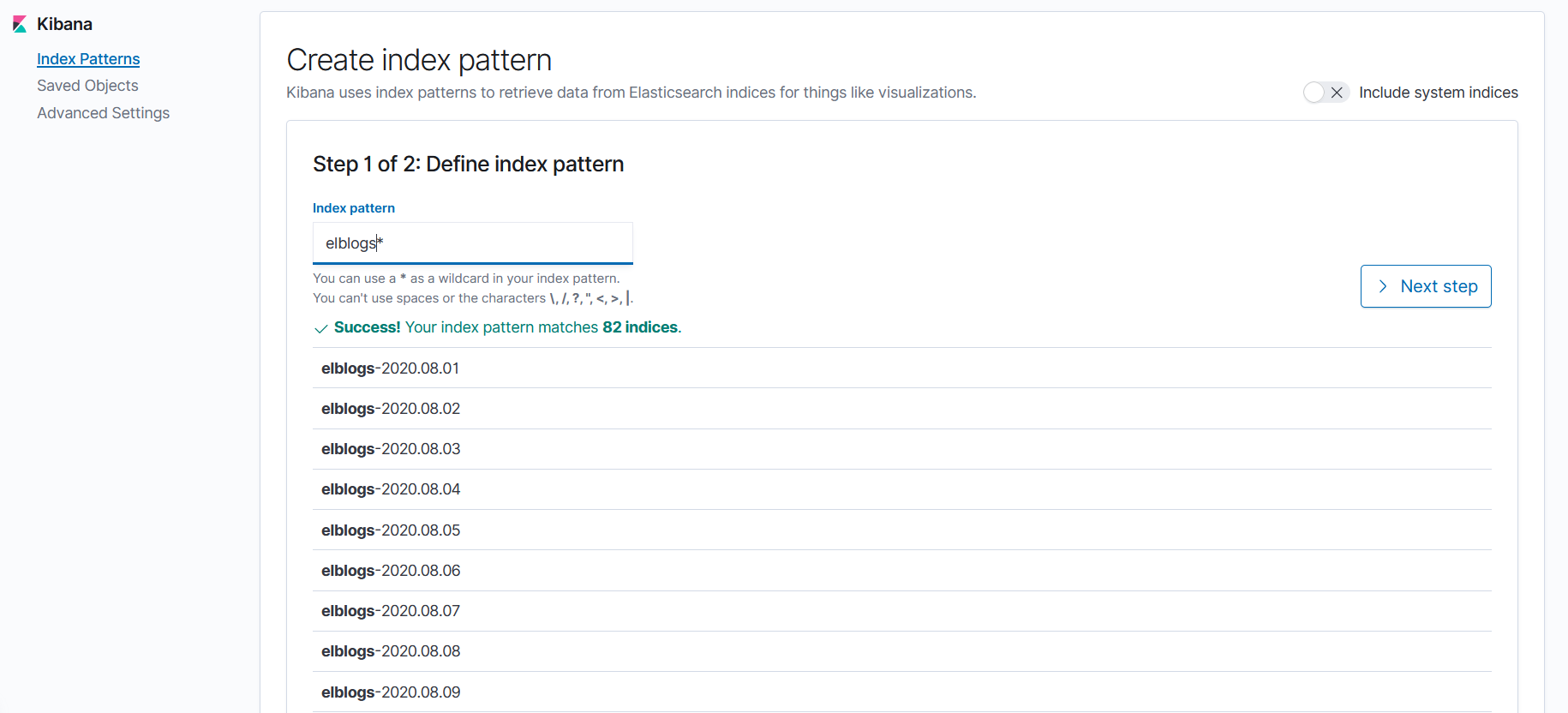
logstash.confに記載したindex名でindex patternを作成します。
以下の画面では、logstash.confのインデックス名に「elblogs」を設定したため、「elblogs-yyyymmdd」の形式でデータが作成されています。
この場合、index patternは「elblogs*」となります。
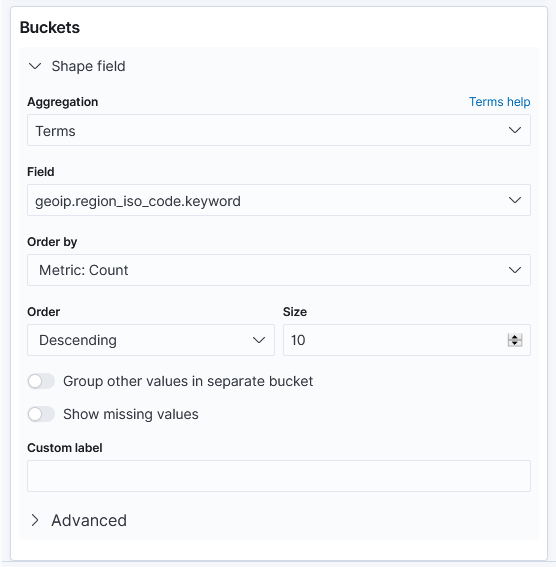
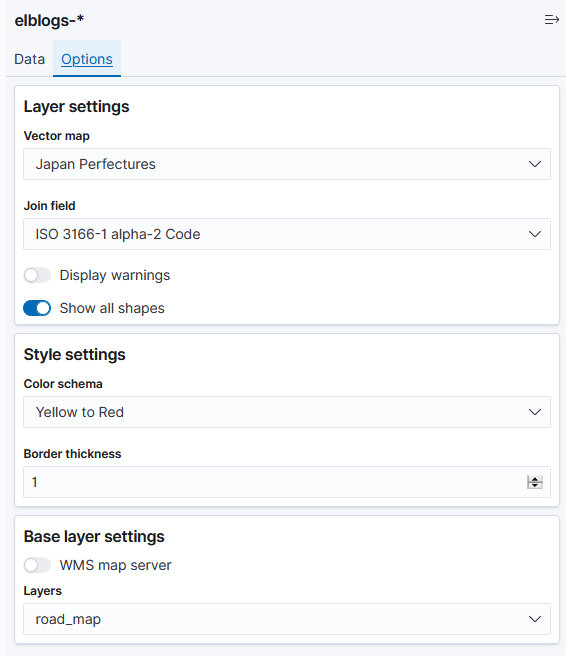
index patternを作成したら、VisualizeでRegion Mapを選択し、作成したindex patternを選んで設定を行います。
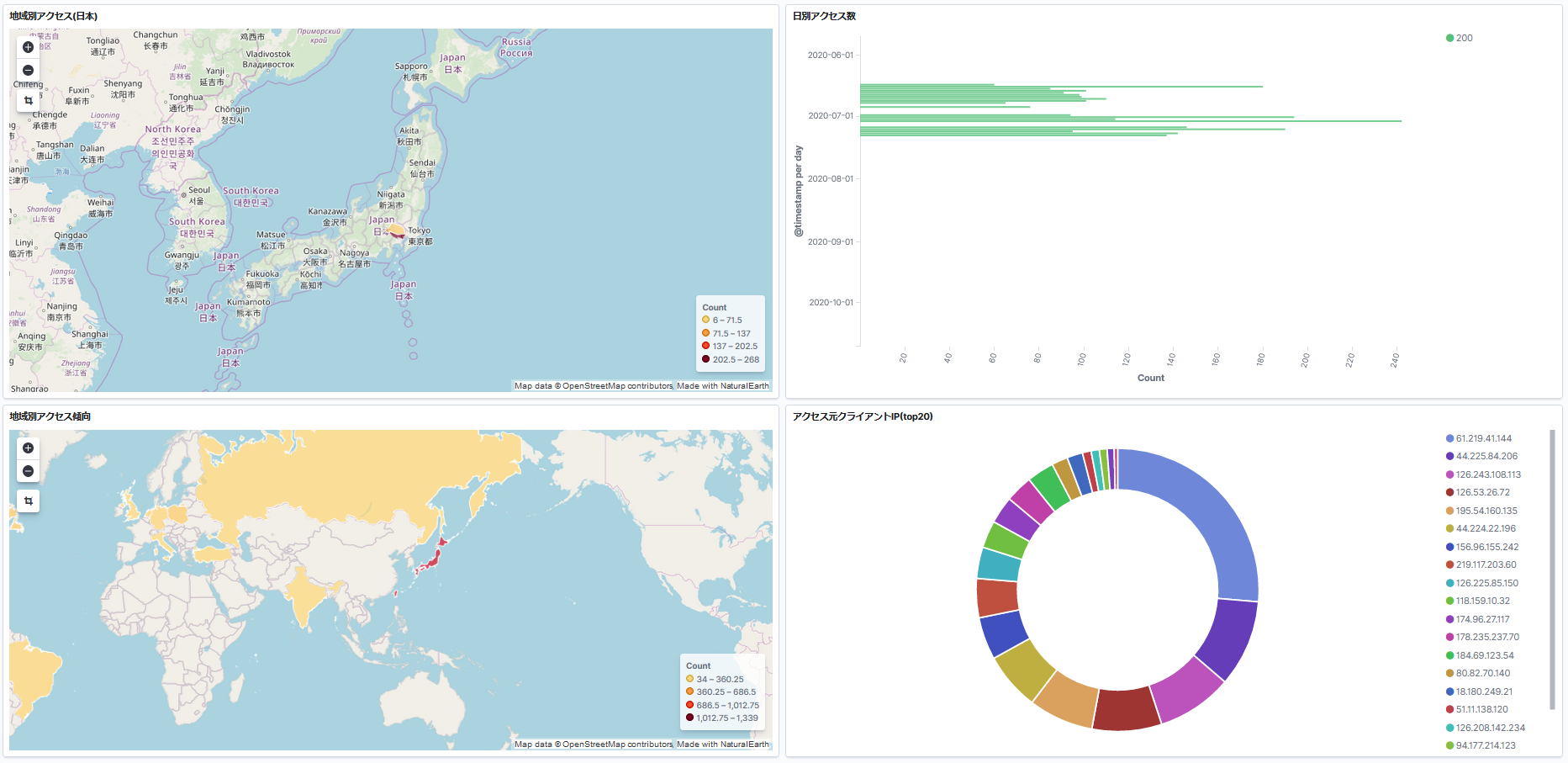
以下はRegion Mapで国内の送信元地域を確認する場合の参考画面です。
さらに上記に加えてFilterを設定すると、確認したい通信を絞って表示することができます。Visualize後のRegion Map
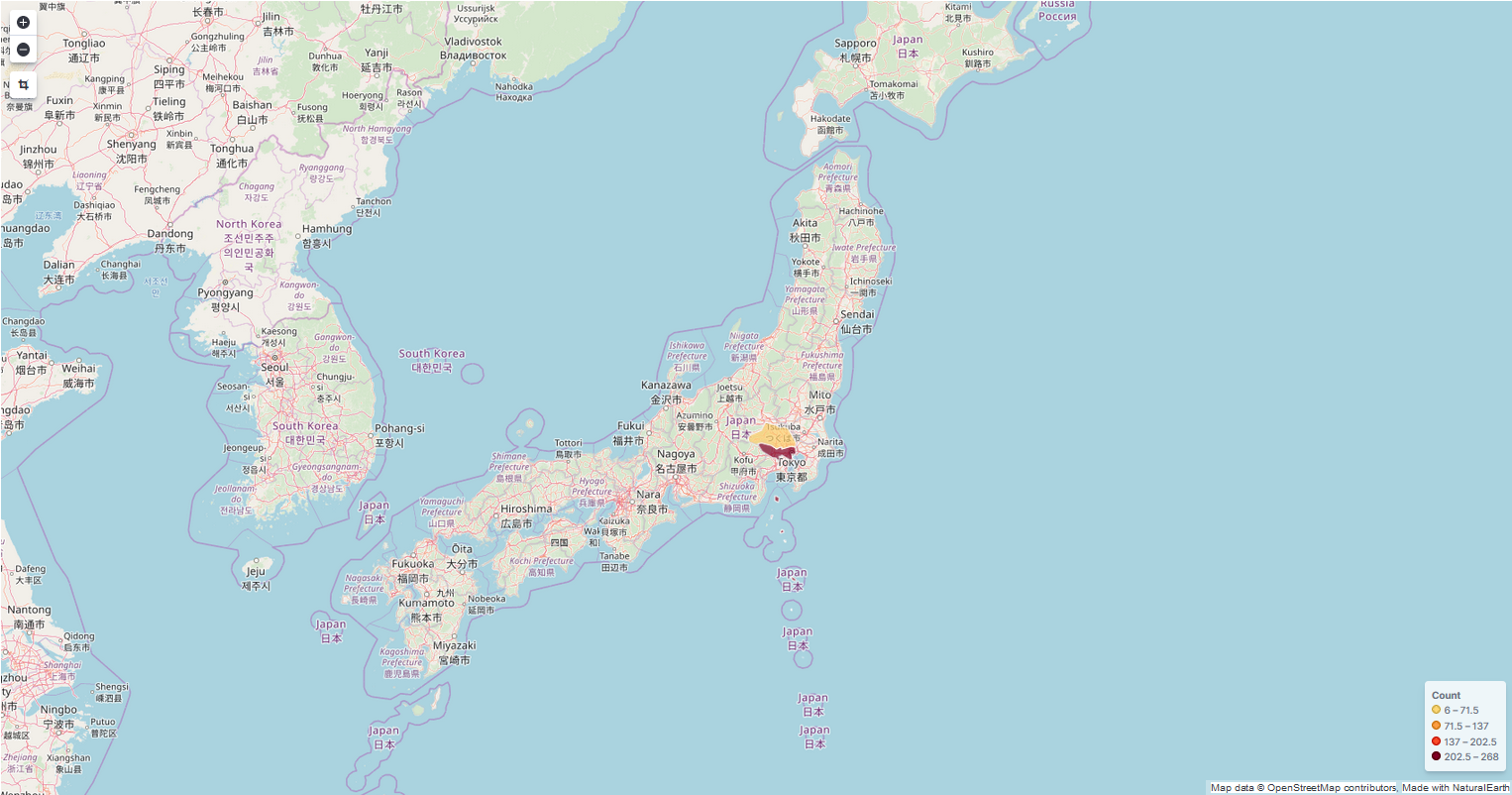
<イメージ①>国内のアクセス数確認
以下のマップでは、東京からのアクセスが多いことを確認できます。
(注)接続元のインターネットの回線によって、東京からアクセスしたものが埼玉にカウントされたり、千葉でアクセスしたものが東京にカウントされたりする場合があります。
都道府県というよりは、関東や関西といったおおまかな地域を判別するのに有効かと思います。
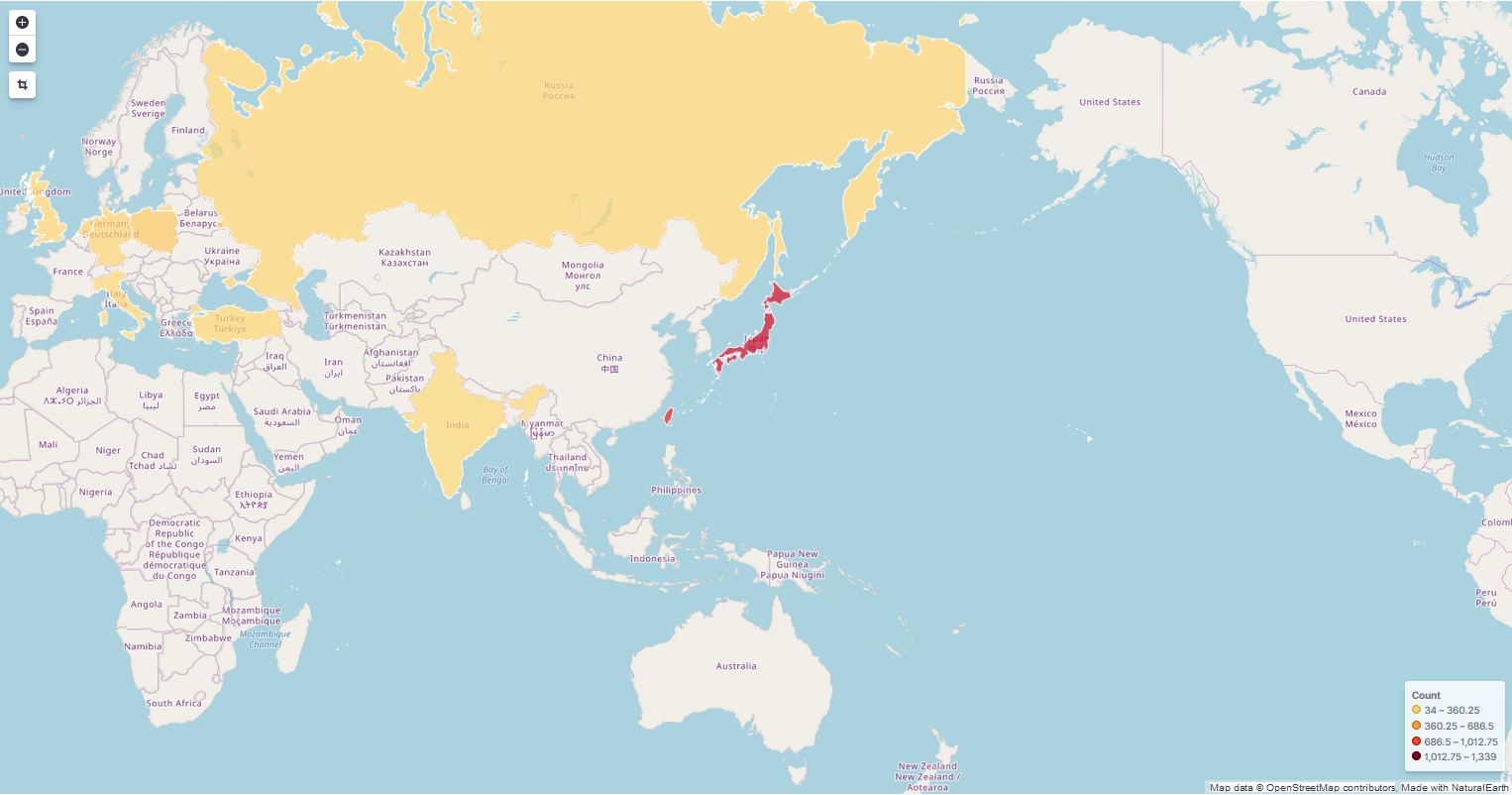
<イメージ②>国外のアクセス数確認
以下のマップでは、世界各地からのアクセス傾向を確認できます。
国内からのアクセスが多いのは当然ですが、想定していない海外からの通信(攻撃)がたくさん発生していることがわかりました(怖)
参考元リンク
logstash-output-amazon_esを使ってAmazon Elasticsearch Serviceにデータを投入する
Amazon Linux2でLogstash7.5を動かす [起動編]さいごに
今回は送信元のマップ表示に焦点を当ててきましたが、ALBアクセスログを対象データとする場合には、日別や時間帯別のアクセス傾向などをグラフで可視化することもできます。
また、Kibanaでは、複数のグラフや表をダッシュボードにまとめて表示することも可能です。↓ダッシュボードのイメージです
このように、アクセスログを分析するだけでも様々な情報を拾うことができます。
ALBを利用するシーンは多いですし、分析したデータはマーケティング等にも活用できると思いますので、試していない方は是非チャレンジしてみてください。
- 投稿日:2020-10-21T19:55:20+09:00
Amazon S3の結果整合性と読み取り一貫性
今日の目標
Amazon S3の読み取り一貫性と結果整合性を理解する。
読み取り一貫性
AmazonS3の特性を理解するために、読み取り一貫性について理解する必要があります。
読み取り一貫性はデータベースのトランザクション管理を行う際に、トランザクション分離レベルで出てくるキーワードです。
・あるトランザクションがデータを変更中の時、ほかのトランザクションからは変更される前のデータを参照します。
・ほかのトランザクションからは変更前の確定されたデータを参照します。
・あるユーザAが値をUPDATEしたとき、ユーザBがそのデータを参照すると、戻ってくる値はUPDATE前の値となります。
・あるトランザクションで変更した確定前のデータをほかのトランザクションから参照することはできません。結果整合性
AmazonS3の特性を理解するために、結果整合性も理解する必要があります。結果整合性は、クラウド環境でのストレージの考え方として最近語られるようになりました。
ひと言でいうならば、「更新はそのうち反映される」です。AmazonS3は分散されたインターネットストレージですので、一つのファイルをアップロードすると順次分散用のコピーが始まります。これにより障害時にファイルが消える確率を最小化することができます。
一方で、複数ユーザが同じファイルをアップロードや更新した場合はどうなるでしょうか。衝突(コンフリクト)しそうですよね。
結果整合性では、最後に更新した処理が終わると、時間経たば必ず全てのストレージに最新情報が反映されます。そのうち反映されるというのはかなり割り切った使い方ですが、常に最新を表示する必要がないデータを扱う用途にはピッタリです。例えば、Twitterのつぶやきはそのうち反映されればいいですよね。Amazon S3の動作例 1
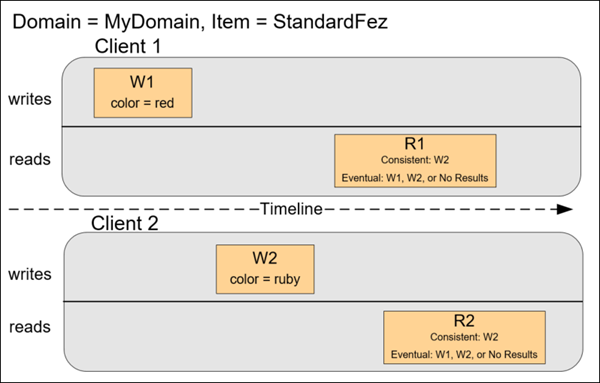
あるオブジェクトについて順次操作した場合の動作例です。
R1 (読み取り 1) と R2 (読み取り 2) の開始前に W1 (書き込み 1) と W2 (書き込み 2) が完了しています。整合性のある読み込みの場合、R1 と R2 の両方が color = ruby を返します。結果整合性のある読み込みの場合、経過時間により、R1 と R2 は color = red または color = ruby を返すことがあります。
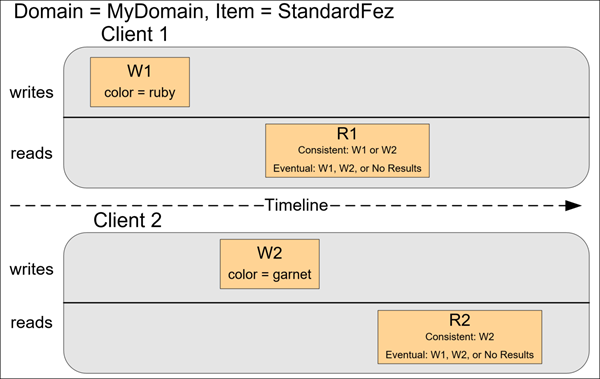
Amazon S3の動作例2
R1 の開始前に、W2 は完了していません。このため、整合性のある読み込みと結果的に整合性のある読み込みのどちらの場合にも、R1 は color = ruby または color = garnet を返す可能性があります。また、経過時間によっては、結果的に整合性のある読み込みが結果を返さないこともあります。
整合性のある読み込みの場合、R2 は color = garnet を返します。結果整合性のある読み込みの場合、経過時間により、R2 は color = ruby または color = garnet を返すことがあります。
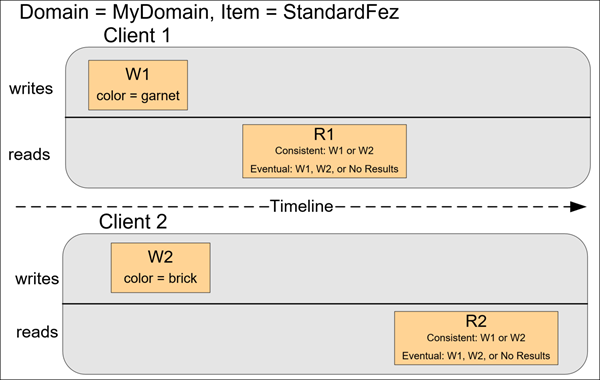
Amazon S3の動作例3
クライアント 2 は Amazon S3 が W1 の成功を返す前に W2 を実行するため、最終的な値の結果は不明です (color = garnet または color = brick)。それ以降の読み込み (整合性のある読み込みまたは結果的に整合性のある読み込み) ではどちらかの値を返す可能性があります。また、経過時間によっては、結果的に整合性のある読み込みが結果を返さないこともあります。
なお、どのような読み書きをしたとしても、アトミック性がありますので、部分的なデータが取れることはありません。
まとめ
Amazon S3は、パソコンのファイルシステムやデータベースと同じようにロックやトランザクション処理は行われないことをなんとなく感じて頂けたと思います。
AmazonS3は長期保存を目的としたインターネットストレージです。
ありがとうございました!
- 投稿日:2020-10-21T18:47:43+09:00
aws-cliを使って「キャパシタープロバイダー」にある「FARGATE」を見えなくする
FARGATE_SPOT 100%で動かしたいときによくあるコマンドでやると、使わないFARGATEが残ってて気持ち悪い、という人向け(要するに自分用メモ)
注意: ドキュメント曰くこれはaws-cli 1.xのやり方らしいです。現状2.0でのやり方が見当たらなかったので書いてますが、別のより良いやり方が存在する可能性があることを念頭において使用してください。
やり方
aws-cliで↓みたいな感じで
put-cluster-capacity-providersを叩く。aws ecs put-cluster-capacity-providers \ --cluster {{ ClusterName }} \ --capacity-providers FARGATE_SPOT \ # ここを残したいやつにする --default-capacity-provider-strategy capacityProvider=FARGATE,weight=1,base=1 # ここはお好みで
--capaity-providersのところに書いたやつがAWSコンソールに表示されるようになるので、そこに「FARGATE」を入れなければよい。その他FARGATE_SPOT以外に残したいやつがあればそこに書く。補足
タイトルがなぜ「見えなくする」なのか?
delete-capacity-providerのドキュメントを見るとこう書かれているため。たぶん内部的には存在しているけど、表示上見えなくなっていればいいやの気持ち。
Note
The FARGATE and FARGATE_SPOT capacity providers are reserved and cannot be deleted. You can disassociate them from a cluster using either the PutClusterCapacityProviders API or by deleting the cluster
https://docs.aws.amazon.com/cli/latest/reference/ecs/delete-capacity-provider.html参考
https://docs.aws.amazon.com/cli/latest/reference/ecs/put-cluster-capacity-providers.html
- 投稿日:2020-10-21T17:39:34+09:00
AWS CodeArtifactをTerraformで構築する(+Mavenから利用)
What's
- Terraform AWS Providerが3.9.0からAWS CodeArtifactに対応した
- https://github.com/terraform-providers/terraform-provider-aws/releases/tag/v3.9.0
- 3.9.0でドメイン、リポジトリ、ドメインパーミッション
- 3.10.0でリポジトリパーミッションポリシー、認証トークン
- 3.11.0でエンドポイント
- と対応の幅も広がり中
というわけで、TerraformでAWS CodeArtifactを構築してみたいと思います。
以前に書いたこちらの内容を、Terraformで行ってみようかな、と。
AWS CodeArtifactの基本的な説明はこちらの記事にそこそこ書いたので、今回はそのあたりは簡単にしておきます。
AWS CodeArtifactとは?
AWSの提供する、マネージドなアーティファクトリポジトリサービスです。
現時点でサポートしているパッケージフォーマットは、npm、PyPI、Mavenです。
始め方
ざっくり言うと、
- AWS KMS CMKを作る(AWS管理のものでも可)
- ドメインを作る
- ドメイン内にリポジトリを作る
という感じです。
現時点(3.11.0)のTerraform AWS Providerでは、外部リポジトリへの接続はできません。
r/codeartifact_repository - support external connection #15569
前回の記事に加えて、Maven Centralへの接続も試そうかと思ったのですが、今回は諦めました…。
リポジトリを構築してみる
では、リポジトリを構築してみましょう。今回の環境は、こちらです。
$ terraform version Terraform v0.13.4 + provider registry.terraform.io/hashicorp/aws v3.11.0 $ aws --version aws-cli/2.0.58 Python/3.7.3 Linux/5.4.0-52-generic exe/x86_64.ubuntu.20AWSのクレデンシャルは、環境変数で設定しているものとします。
$ export AWS_ACCESS_KEY_ID=..... $ export AWS_SECRET_ACCESS_KEY=..... $ export AWS_DEFAULT_REGION=.....リソース定義。
main.tfterraform { required_version = "0.13.4" required_providers { aws = { version = "3.11.0" source = "hashicorp/aws" } } } provider "aws" {} resource "aws_kms_key" "codeartifact_key" { description = "CMK for My CodeArtifact Domain" deletion_window_in_days = 7 } resource "aws_kms_alias" "codeartifact_key" { name = "alias/my-codeartifact-key" target_key_id = aws_kms_key.codeartifact_key.key_id } resource "aws_codeartifact_domain" "domain" { domain = "my-domain" encryption_key = aws_kms_alias.codeartifact_key.arn } resource "aws_codeartifact_repository" "my_repository" { repository = "my-repo" domain = aws_codeartifact_domain.domain.domain }AWS KMS CMK。エイリアスも、なんとなく作っておきました。
resource "aws_kms_key" "codeartifact_key" { description = "CMK for My CodeArtifact Domain" deletion_window_in_days = 7 } resource "aws_kms_alias" "codeartifact_key" { name = "alias/my-codeartifact-key" target_key_id = aws_kms_key.codeartifact_key.key_id }AWS CodeArtifactのドメインとリポジトリ。ドメイン内に、リポジトリが含まれる形になります。
Resource: aws_codeartifact_domain
Resource: aws_codeartifact_repository
resource "aws_codeartifact_domain" "domain" { domain = "my-domain" encryption_key = aws_kms_alias.codeartifact_key.arn } resource "aws_codeartifact_repository" "my_repository" { repository = "my-repo" domain = aws_codeartifact_domain.domain.domain }CMKは、ドメインに対して設定します。
権限まわりの設定も可能なようですが、今回はいったんパス。
Resource: aws_codeartifact_domain_permissions_policy
Resource: aws_codeartifact_repository_permissions_policy
では、
applyしてみます。$ terraform init $ terraform apply確認してみましょう。
$ aws codeartifact describe-domain --domain my-domain { "domain": { "name": "my-domain", "owner": "[AWSアカウントID]", "arn": "arn:aws:codeartifact:ap-northeast-1:[AWSアカウントID]:domain/my-domain", "status": "Active", "createdTime": "2020-10-21T17:04:12.372000+09:00", "encryptionKey": "arn:aws:kms:ap-northeast-1:[AWSアカウントID]:key/fa1a0cf2-5534-467e-bd56-f034a3318d3c", "repositoryCount": 1, "assetSizeBytes": 0 } } $ aws codeartifact describe-repository --domain my-domain --repository my-repo { "repository": { "name": "my-repo", "administratorAccount": "[AWSアカウントID]", "domainName": "my-domain", "domainOwner": "[AWSアカウントID]", "arn": "arn:aws:codeartifact:ap-northeast-1:[AWSアカウントID]:repository/my-domain/my-repo", "upstreams": [], "externalConnections": [] } }OKですね。とても簡単にできました。
Mavenから使う
最後に、Apache Mavenから使ってみましょう。
内容は、前回の記事と同様に
- ライブラリを作って、AWS CodeArtifactリポジトリにアップロード
- ライブラリを使うアプリケーションを作って、依存ライブラリをAWS CodeArtifactリポジトリからダウンロード
という感じでやってみます。
環境については、こちら。
$ java --version openjdk 11.0.8 2020-07-14 OpenJDK Runtime Environment (build 11.0.8+10-post-Ubuntu-0ubuntu120.04) OpenJDK 64-Bit Server VM (build 11.0.8+10-post-Ubuntu-0ubuntu120.04, mixed mode, sharing) $ mvn --version Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f) Maven home: $HOME/.sdkman/candidates/maven/current Java version: 11.0.8, vendor: Ubuntu, runtime: /usr/lib/jvm/java-11-openjdk-amd64 Default locale: ja_JP, platform encoding: UTF-8 OS name: "linux", version: "5.4.0-52-generic", arch: "amd64", family: "unix"ライブラリ側
まずは、ライブラリを作ります。
AWS CodeArtifactリポジトリへのアップロードが必要になるので、ドキュメントに従い
settings.xmlを作成しましょう。
settings.xml<?xml version="1.0" encoding="UTF-8"?> <settings xmlns="http://maven.apache.org/SETTINGS/1.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 https://maven.apache.org/xsd/settings-1.0.0.xsd"> <servers> <server> <id>codeartifact</id> <username>aws</username> <password>${env.CODEARTIFACT_TOKEN}</password> </server> </servers> </settings>次に、認証トークンを取得します。
$ export CODEARTIFACT_TOKEN=`aws codeartifact get-authorization-token --domain my-domain --query authorizationToken --output text`認証トークンはTerraformでも取得可能なようですが、環境変数に設定しなくてはいけないので、ここはAWS CLIでよいでしょう。
参考までに、Terraformで扱う場合はこちらですね。
Data Source: aws_codeartifact_authorization_token
認証トークンの有効期限は、12時間です。
AWS CodeArtifact authentication and tokens
アーティファクトをリポジトリにアップロードする
ここまで揃ったら、ライブラリを作成してアーティファクトをAWS CodeArtifactリポジトリにアップロードします。
pom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.github.charon.r13b</groupId> <artifactId>library</artifactId> <version>0.0.1</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> </properties> <repositories> <repository> <id>codeartifact</id> <name>codeartifact</name> <url>https://my-domain-[AWSアカウントID].d.codeartifact.ap-northeast-1.amazonaws.com/maven/my-repo/</url> </repository> </repositories> <distributionManagement> <repository> <id>codeartifact</id> <name>codeartifact</name> <url>https://my-domain-[AWSアカウントID].d.codeartifact.ap-northeast-1.amazonaws.com/maven/my-repo</url> </repository> </distributionManagement> <dependencies> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.11</version> </dependency> </dependencies> </project>今回の使い方だと、少なくとも
distributionManagementにリポジトリ指定があればOKです。一応、Maven Centralから取得するライブラリも含めています。
ソースコード。
src/main/java/com/github/charon/r13b/library/MessageService.javapackage com.github.charon.r13b.library; import org.apache.commons.lang3.StringUtils; public class MessageService { String prefix; String suffix; public MessageService(String prefix, String suffix) { this.prefix = prefix; this.suffix = suffix; } public String decorate(String word) { return StringUtils.join(prefix, word, suffix); } }ビルドして、アップロードしてみます。
$ mvn deploy -s settings.xmlOKです。
[INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 9.789 s [INFO] Finished at: 2020-10-21T17:32:55+09:00 [INFO] ------------------------------------------------------------------------呼び出し側を作る
アップロードされたアーティファクトを使用する、アプリケーションを作成します。
pom.xml<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.github.charon.r13b</groupId> <artifactId>app</artifactId> <version>0.0.1</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding> <maven.compiler.source>11</maven.compiler.source> <maven.compiler.target>11</maven.compiler.target> </properties> <repositories> <repository> <id>codeartifact</id> <name>codeartifact</name> <url>https://my-domain-[AWSアカウントID].d.codeartifact.ap-northeast-1.amazonaws.com/maven/my-repo/</url> </repository> </repositories> <dependencies> <dependency> <groupId>com.github.charon.r13b</groupId> <artifactId>library</artifactId> <version>0.0.1</version> </dependency> </dependencies> </project>こちらは、
repositories / repositoryに、構築したAWS CodeArtifactリポジトリを指定すればOKです。なお、リポジトリの利用にも認証トークンは必要となります。
アプリケーションのソースコード。
src/main/java/com/github/charon/r13b/app/App.javapackage com.github.charon.r13b.app; import com.github.charon.r13b.library.MessageService; public class App { public static void main(String... args) { MessageService messageService = new MessageService("★★★", "★★★"); System.out.println(messageService.decorate("Hello World!!")); } }実行。
-sで指定しているのは、アーティファクトをアップロードした時に使ったものと同じ、AWS CodeArtifactへの認証情報を書いたものです。mvn compile exec:java -s settings.xml -Dexec.mainClass=com.github.charon.r13b.app.App結果。
[INFO] --- exec-maven-plugin:1.6.0:java (default-cli) @ app --- ★★★Hello World!!★★★OKですね。
これで確認完了です。
最後に、リソースを破棄しておしましです。
$ terraform destroy
- 投稿日:2020-10-21T17:25:12+09:00
AWS S3向けのウイルススキャン機能をテストしてみた
はじめに
AWS S3にファイルをアップロードする際にウイルススキャンをしたいと考えている方、多いのではないでしょうか?特に外部の不特定多数のユーザから送ってくる情報の中に、マルウェアが潜んでいる可能性もあります。
前段でAmazon EC2にウイルス対策ソフトを入れて、一度EC2上でファイルをスキャンしてからS3にアップロードする運用もあるようですが、AWS EC2を常時起動しておかなければらないので余分なコストがかかってしまうかもしれません。
特にオブジェクトで管理されているS3に保存した個々のファイルがスキャンされたかどうかも知りたいのではないでしょうか。
このたび、S3向けのウイルススキャン機能を提供する製品Cloud One - File Storage Securityをテストしてみましたので感想を書かせていただきたいと思います。テスト手順
Cloud Oneアカウントの準備
アカウントは以下のURLから「Create an Account」でアカウントを申請します。
https://cloudone.trendmicro.com/
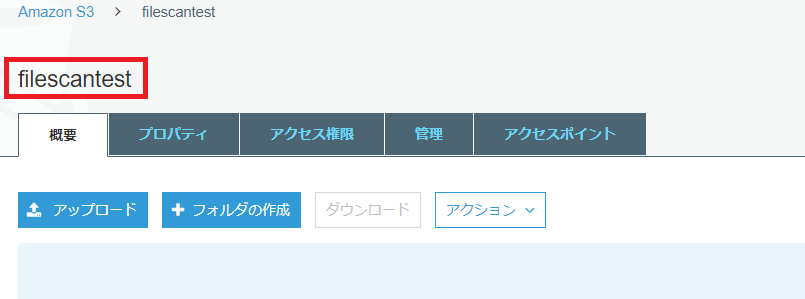
S3バケットの作成
テストでは[filescantest]という名前のバケットを作成します。
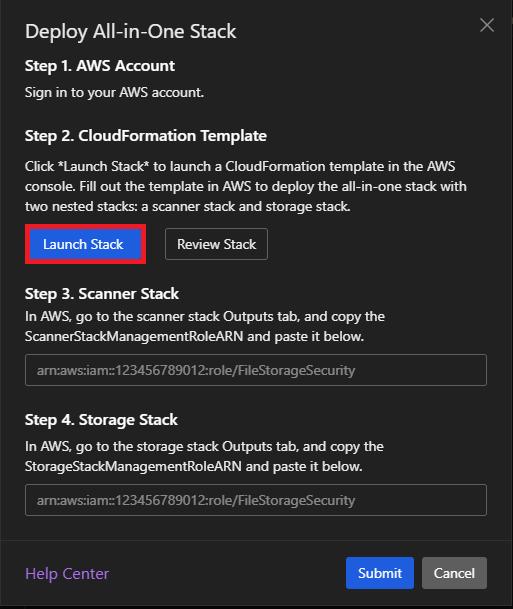
Cloud One - File Storage Securityの設定その1
Cloud Oneにログインし、File Storage Securityのコンソールに入り、「Deploy All-in-one Stack」- 「Launch Stack」を選択します。
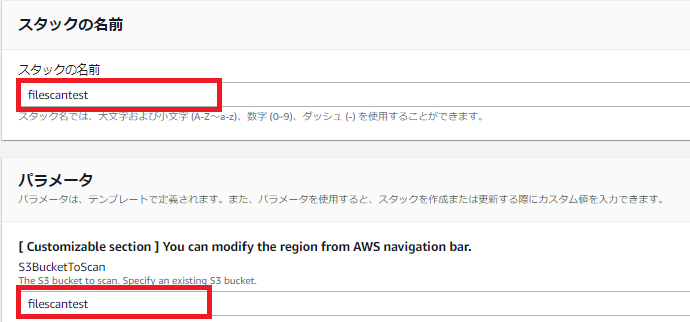
Cloud formationのテンプレート作成
テンプレートを作成するとはいっても、Stack名(任意)とバケット名(作成済みのバケット名)を入力するだけです。
テンプレートからスタックを展開
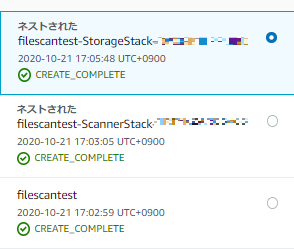
展開とはいっても作成済みのテンプレートから展開されるだけなので、待つのみです。
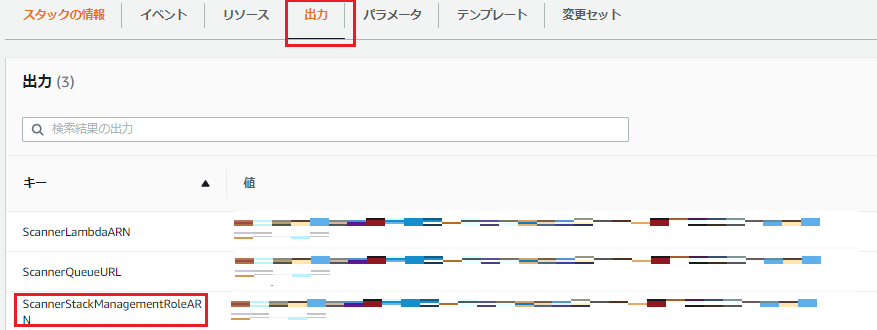
展開されれば、Scanner StackとStorage Stackの2つのStackが作れますので、それぞれのROLEARNをコピーします。
コピーするパラメータは各スタックの出力の中にあるStackManagementRoleARNの横にある値をコピーします。
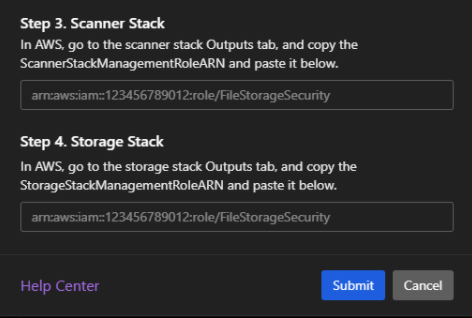
Cloud One - File Storage Securityの設定その2
コピーしたARNをそれぞれコピーし、Submitします。
以上で、File Storage Securityの導入が完了となります。
次にファイルをアップロードしてみましょう。ファイルのアップロード
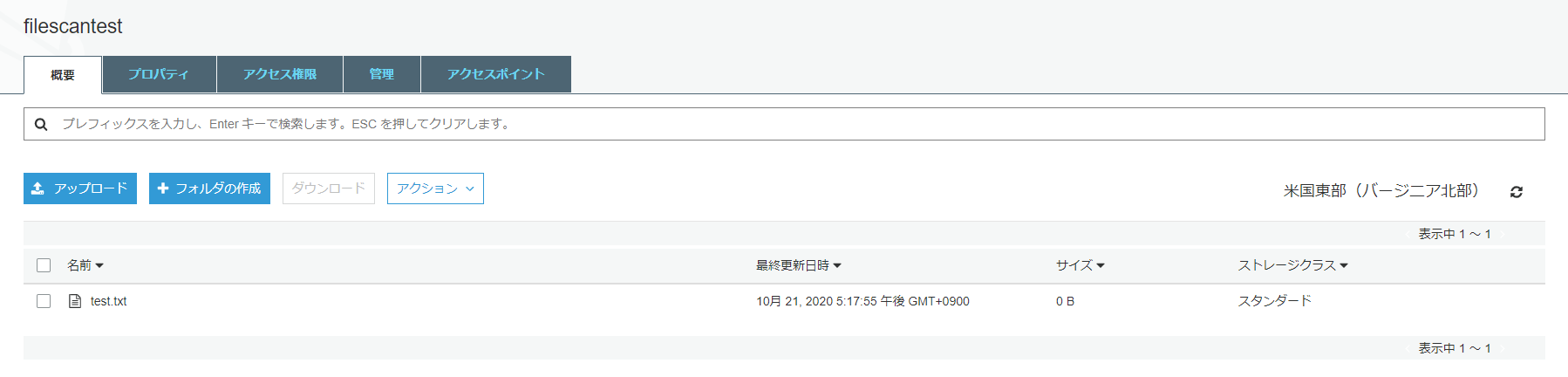
任意のファイルを作成し、アップロードします。
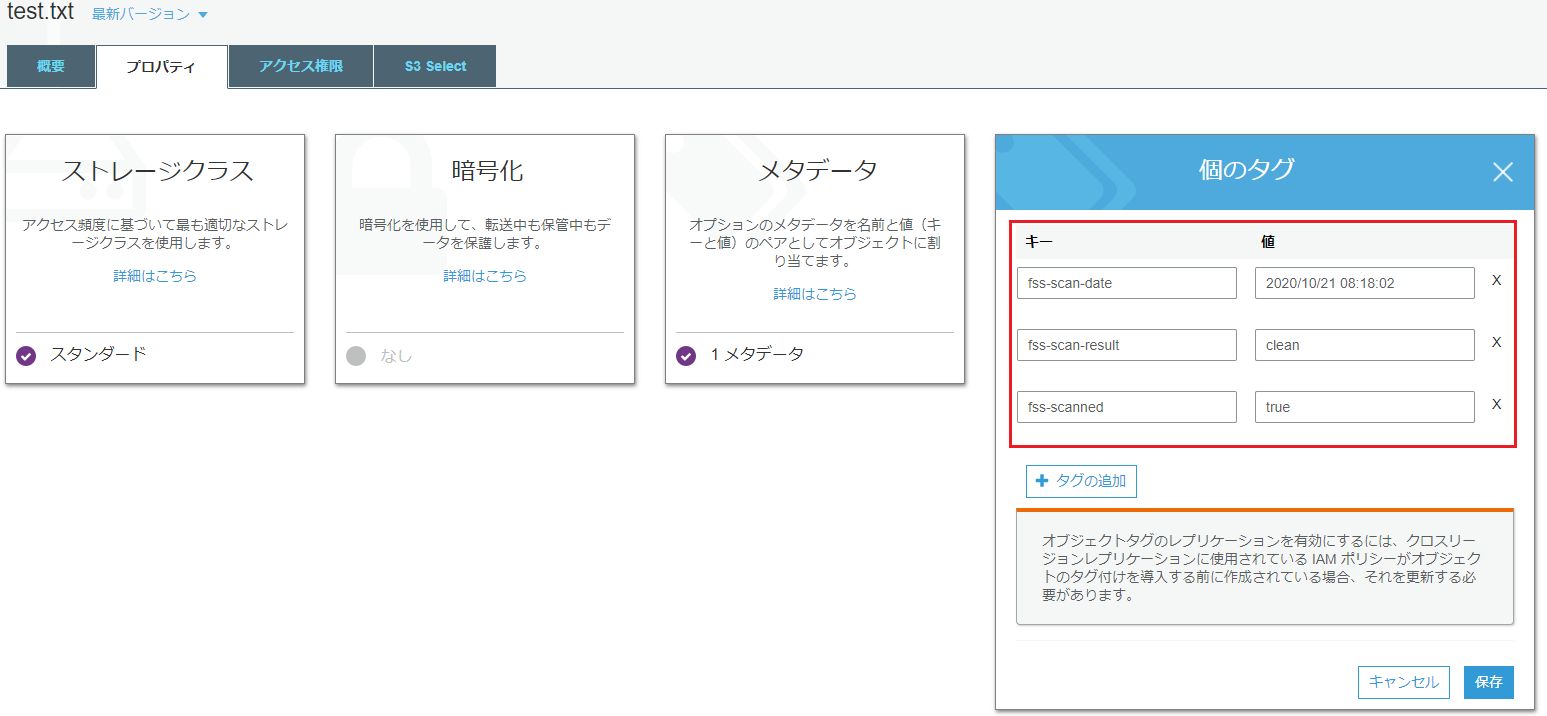
スキャン結果の確認
ファイルのプロパティを開き、スクリーンショットの通り、ファイルがクリーンかどうかや、スキャンした時間などの詳細を確認することができます。
感想
以上、どうでしょうか?導入まではたぶん10分もかからないですね。
テストしてみて思ったことですが、
1.導入がとにかく楽です。
2.個々のオブジェクトのスキャン結果とその日時が分かります。
3.AWSの知識がなくても簡単に導入できます。
4.サーバーレスで、管理サーバや、スキャンサーバの構築が不要です。こちらのプロダクトはPost-scan処理を柔軟に指定できるようですので、ワークフローをお客様のニーズに応じて設定できます。
例えばCleanのファイルをさらにクリーンファイルを格納するバケットに移したり、ウイルスが含まれるファイルであれば、隔離専用のバケットに移すことを実現できます。
次回はPost-scanについて触ってみたいと思います。
- 投稿日:2020-10-21T15:17:08+09:00
Glueデータカタログのテーブルにデータ型decimalを指定する際の注意点(Athena)
概要
AthenaやRedshift SpectrumからS3ファイルに対してクエリする際にテーブル定義をGlueデータカタログに登録するかと思いますが、その際のカラムのデータ型にdecimalを指定する際の注意点についてです。
事象
カラムのデータ型の指定で
decimal(10, 5)のようにprecisionとscaleの間に空白を入れると、Athenaからのクエリでは以下のようなエラーが出ます。HIVE_METASTORE_ERROR: com.facebook.presto.spi.PrestoException: Error: name expected at the position 11 of 'decimal(10, 5)' but ' ' is found.ちなみにRedshift Spectrumからのクエリではエラーは出ません。
解決策
上記のエラー文からもわかるように空白がエラー原因となっているため、空白を無くし
decimal(10,5)のようにすれば問題ありません。
Prestoの仕様なんでしょうね。。
- 投稿日:2020-10-21T14:41:40+09:00
webAPIを作ってみた! EC2でDjangoRestFramework 1から環境構築
はじめに
この記事ではDjangoでwebAPIを作成しよう!という記事です。
RDSのMySQLを使用しています。
前回の記事の続きですのでわからなくなったら参考にしてください
[AWS]EC2,RDS,Djangoを使ってみた。1から環境構築$ <- 自分のPCターミナルでのコマンド [ec2-user] $ <- EC2にログイン中でのコマンド MySQL > <- MySQLにログイン中でのコマンド # <- 私のコメント >>> <- 実行結果(出力値)前提条件
Djangoのプロジェクト作成
前回の記事でも書きましたが、もう一度書いておきます。
プロジェクトを作成しましょう
#testDjangoというプロジェクトを作成する [ec2-user] $ django-admin startproject testDjango [ec2-user] $ cd [ec2-user] $ cd testDjango #pollsと言う名前のアプリを作成する [ec2-user] $ python manage.py startapp pollsFileZillaを使ってsettings.pyを編集
testDjango/settings.py#IPアドレスをグーグルなどで検索した時エラー内容を返してくれる DEBUG = True #変更 ALLOWED_HOSTS = ['(EC2のオープンIPアドレス)','localhost'] #変更 INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'rest_framework', 'polls.apps.PollsConfig', ] #(アプリ名).apps.(先頭大文字アプリ名)Config ... (略) ... #デフォルトの設定をリマーク # DATABASES = { # 'default': { # 'ENGINE': 'django.db.backends.sqlite3', # 'NAME': BASE_DIR / 'db.sqlite3', # } # } #新しく記入 #[NAME]はRDS内のテーブル名、後に作成します。 #[USER,PASSWORD,HOST]はそれぞれ入力 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'dbtest', 'USER': '(DBマスターユーザー)', 'PASSWORD': '(DBマスターユーザーパスワード)', 'HOST': '(DBエンドポイント)', 'PORT': '3306', } } ... (略) ... #日本語に変更 #LANGUAGE_CODE = 'en-us' LANGUAGE_CODE = 'ja' #日本時間に変更 # TIME_ZONE = 'UTC' TIME_ZONE = 'Asia/Tokyo' USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/3.1/howto/static-files/ STATIC_URL = '/static/'RDSのMySQLにログイン
[ec2-user] $ mysql -h (DBエンドポイント) -u (DBマスターユーザー名) -p # パスワードを要求されるので入力(文字は表示されないが打ち込めています)(コピペ可) >>> Welcome to the MariaDB monitor. # が表示されればRDSのMySQLに接続ができた #データベース内一覧を表示(小文字でも可 show database;) MySQL > SHOW databases; #「dbtest」という名前のテーブルを作成 MySQL > CREATE DATABASE dbtest; #終了 MySQL > exitDjangoの設定
モデルの作成
polls/models.pyfrom django.db import models class User(models.Model): #作成時刻を記録 created = models.DateTimeField(auto_now_add=True) #Userの名前を記録 name = models.CharField(max_length=100, blank=True, default='') #Userのemail mail = models.TextField() class Meta: ordering = ('created',)データベースのマイグレーションを行う
[ec2-user] $ python manage.py makemigrations polls [ec2-user] $ python manage.py migrate確認してみます
MySQL > show databases; MySQL > use dbtest; MySQL > show tables; >>> +----------------------------+ | Tables_in_dbtest | +----------------------------+ | auth_group | | auth_group_permissions | | auth_permission | | auth_user | | auth_user_groups | | auth_user_user_permissions | | django_admin_log | | django_content_type | | django_migrations | | django_session | | example_table | | polls_user | <--生成されている +----------------------------+ (アプリ名)_user MySQL > exit以下の記事が参考になります
【学習メモ】MakemigrationsとMigrateについて
serializers.pyの作成
デフォルトでは生成されていないため、メモ帳か何かで作成しFileZillaで転送してください
- シリアライズとは、ソフトウェア内部で扱っているデータをそのまま、保存したり送受信することができるように変換することです。
polls/serializers.pyfrom rest_framework import serializers from polls.models import User class UserSerializer(serializers.ModelSerializer): class Meta: model = User fields = ('id', 'name', 'mail')views.pyを実装
polls/views.pyfrom django.http import HttpResponse, JsonResponse from django.views.decorators.csrf import csrf_exempt from rest_framework.parsers import JSONParser from polls.models import User from polls.serializers import UserSerializer @csrf_exempt def user_list(request): if request.method == 'GET': #UserをMySQLから全件取得 polls = User.objects.all() serializer = UserSerializer(polls, many=True) #Jsonで返してくる return JsonResponse(serializer.data, safe=False) elif request.method == 'POST': data = JSONParser().parse(request) serializer = UserSerializer(data=data) if serializer.is_valid(): serializer.save() #登録成功するとJsonデータが帰ってくる ##status 200番台は処理が成功した return JsonResponse(serializer.data, status=201) return JsonResponse(serializer.errors, status=400)polls/urls.pyを作成する
これも新規作成してください
polls/urls.pyfrom django.urls import path from polls import views urlpatterns = [ path('user/', views.user_list), ]大元のurls.pyに接続します
testDjango/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('polls.urls')), ]これで設定は終了です。
テストする
ローカルのサーバーを立てます
ローカルとはなんぞ?と言う方は以下の記事がわかりやすかったです
djangoは誰が動かしているのか?(デプロイのための俯瞰)[ec2-user] $ cd [ec2-user] $ cd testDjango [ec2-user] $ python manage.py runserverこのあとGoogleChromeなどで
http://(EC2のオープンIPアドレス)/user/と検索すると
[]と空の括弧が返ってきたと思います。
データを入れる
このままだと不便なので
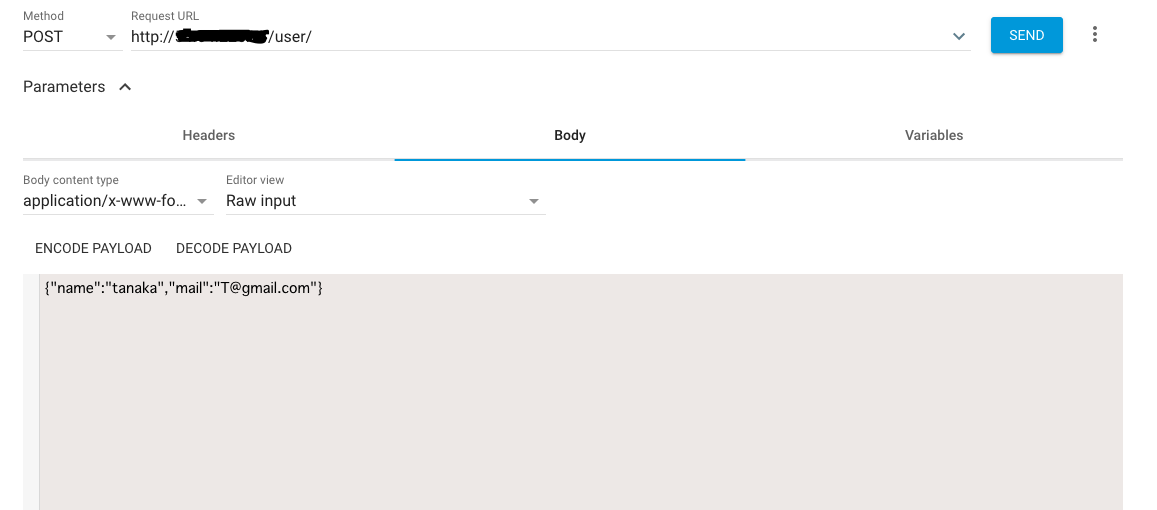
GoogleChromeの拡張機能のARCをダウンロードしましょうGETで通信してみると空の括弧が返ってきます
POSTで通信してみます。その際に
{"name":"tanaka","mail":"T@gmail.com"}この情報を追加します。
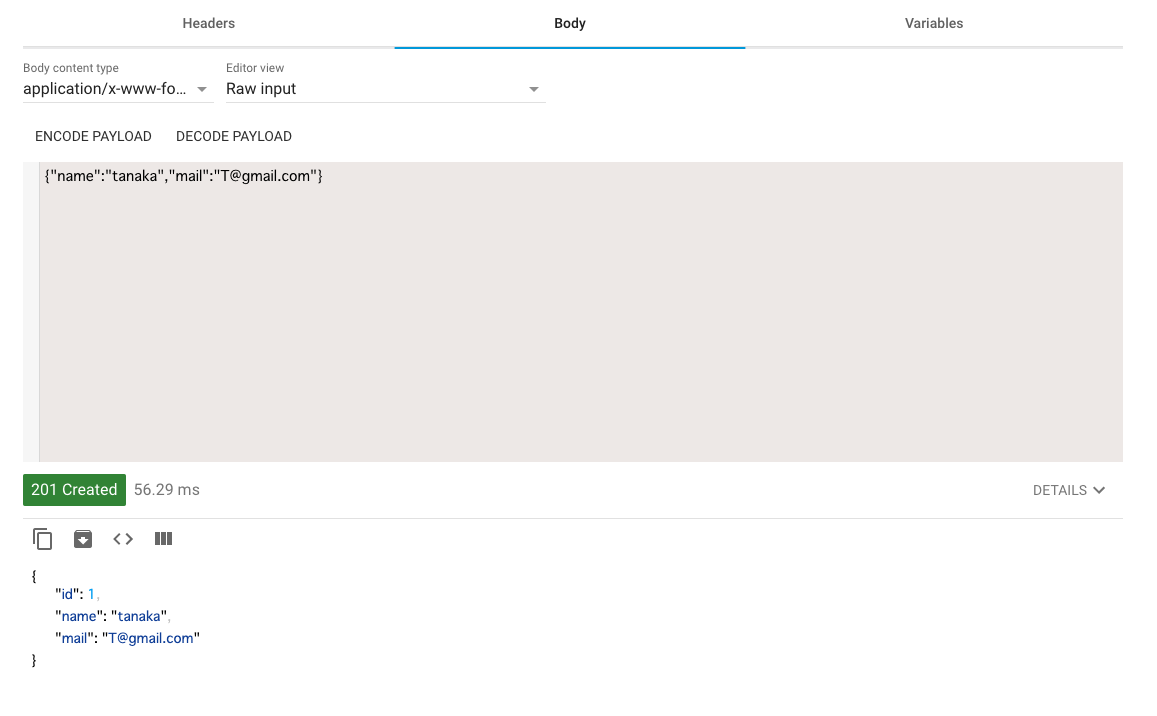
SENDを押すとレスポンスが返ってきます
またGETできちんと登録できたか確認してみるといいでしょう。
またデータベースは
MySQL > use dbtest; MySQL > SELECT * FROM polls_user; >>> +----+----------------------------+--------+-------------+ | id | created | name | mail | +----+----------------------------+--------+-------------+ | 1 | 2020-10-21 05:10:23.730602 | tanaka | T@gmail.com | +----+----------------------------+--------+-------------+これで登録に成功しました。
おわりに
この記事で誰かの役に立っていただければ幸いです。
次回は NginX,Gunicorn を使って本番環境(初心者の私が作る)を作ってみようかと思います。
それではでは
参考サイト
以下と本記事の途中に非常に参考にさせていただいたサイトを紹介しています。
ありがとうございました。[1].Django REST frameworkチュートリアル その1
[2].djangoは誰が動かしているのか?(デプロイのための俯瞰)
[3].【学習メモ】MakemigrationsとMigrateについて
[4].よく使うMySQLコマンド集

- 投稿日:2020-10-21T14:27:16+09:00
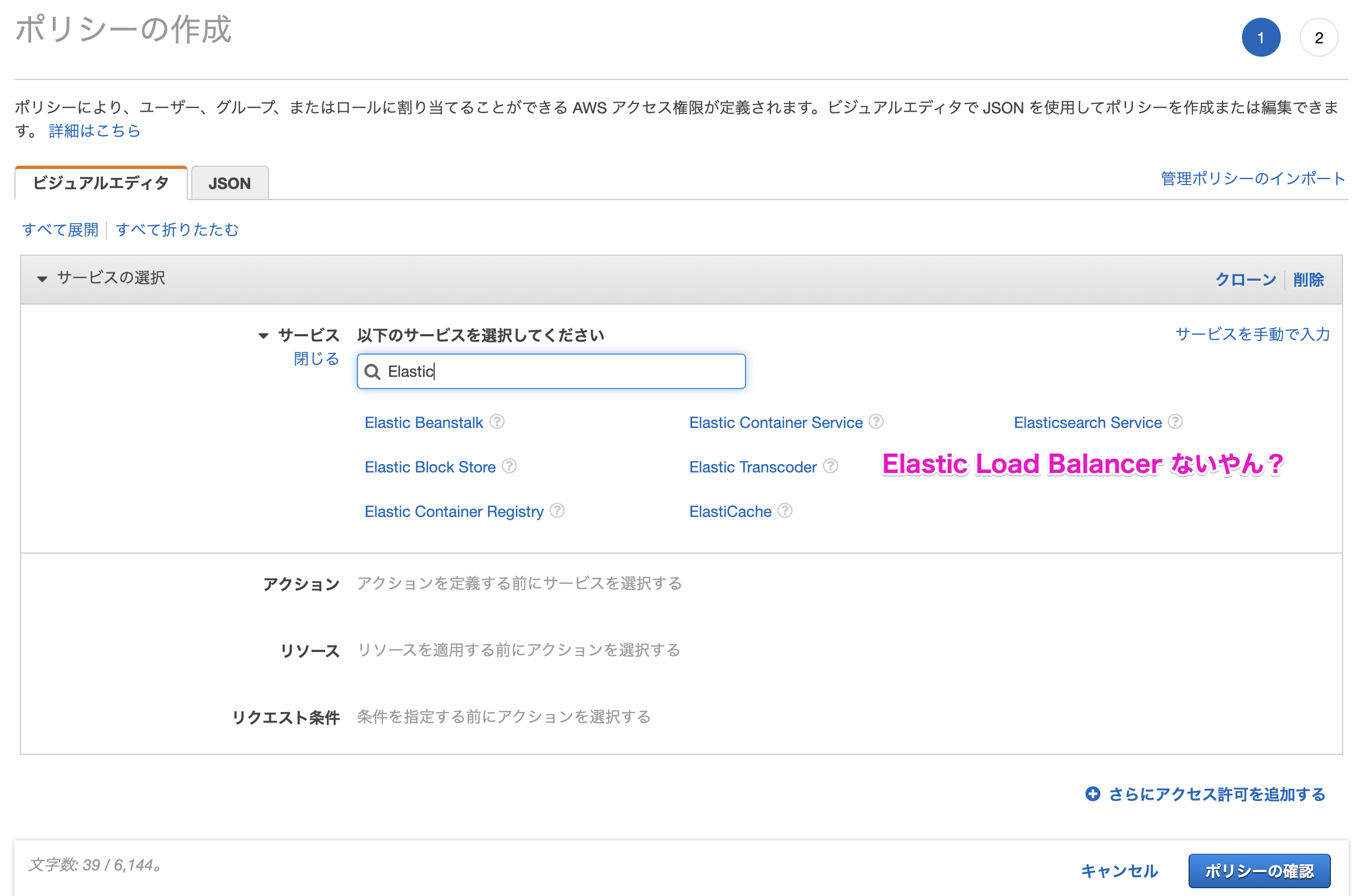
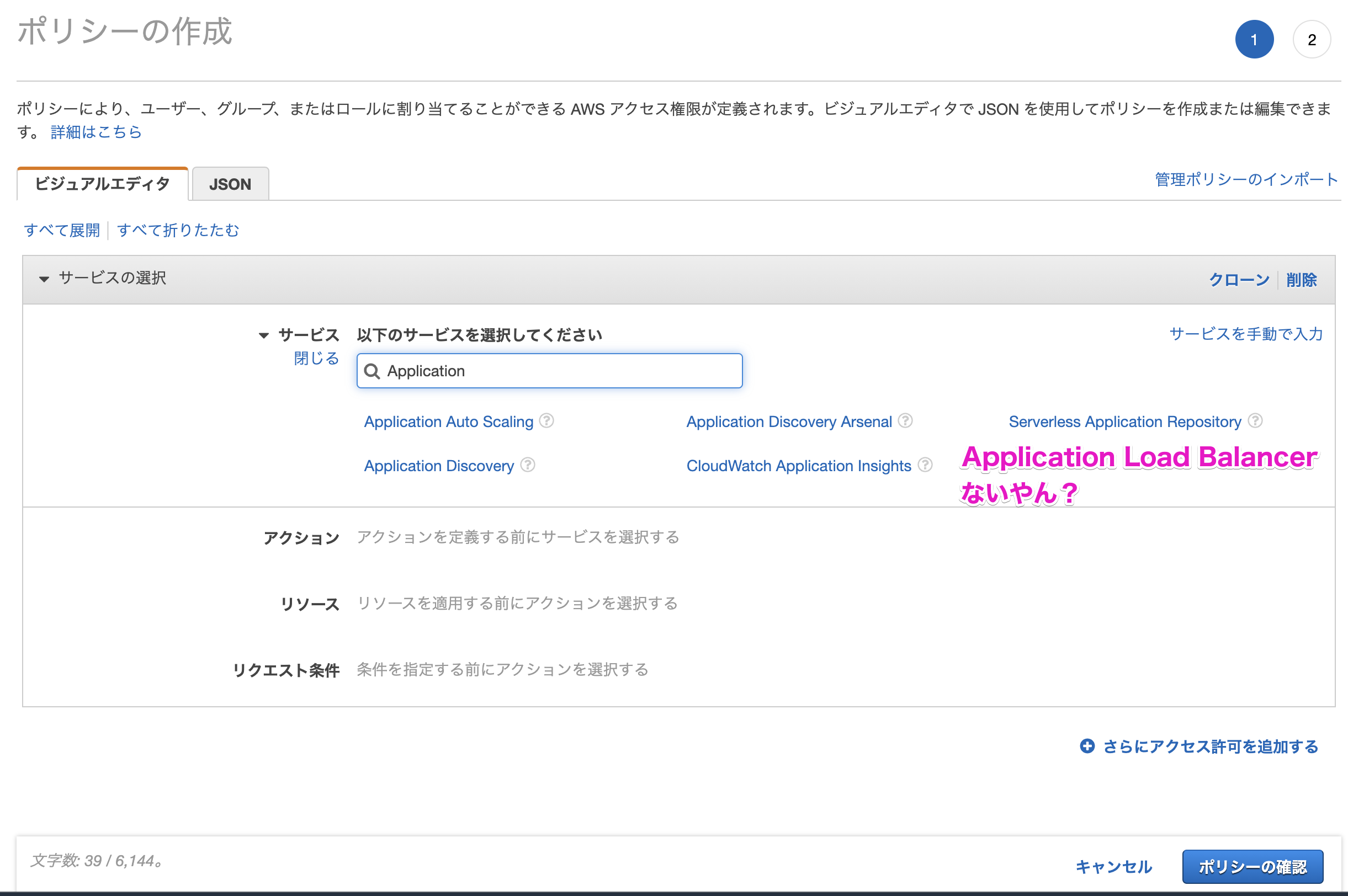
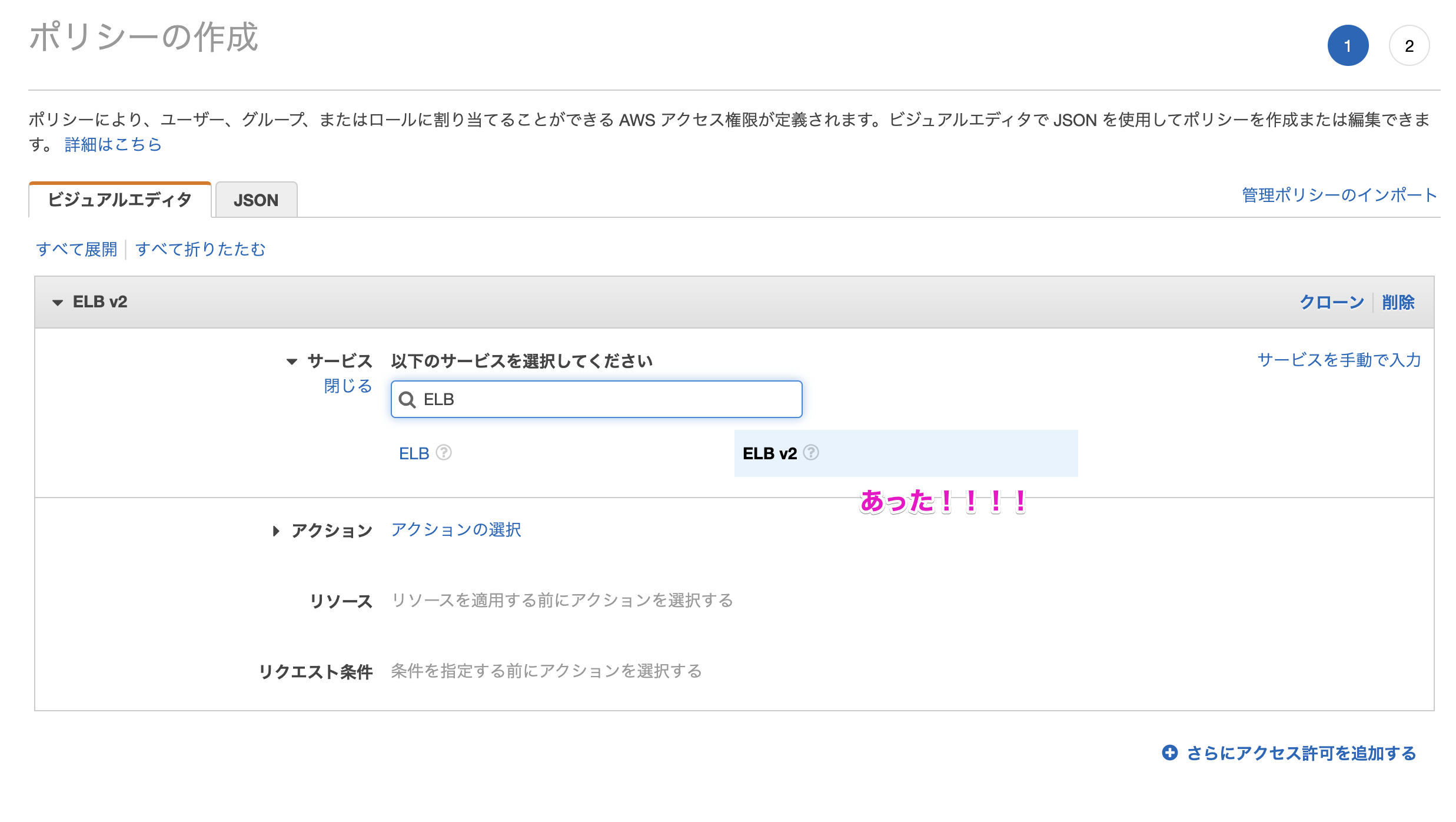
ALBのIAM設定しようとしたけどビジュアルエディタで見つからない場合
- 投稿日:2020-10-21T13:48:19+09:00
StepFunctionsのStateMachineをCDKを使って生成しよう
仕事で開発しているプロダクトのアーキテクチャをわかりやすく制御するため、StepFunctionsを導入しようとして調査しました。
Lambdaを主体としたマイクロサービスという形で作成しているのですが、Lambdaを細分化する方針なので、細分化された機能群をStepFunctionsで統合して機能として動かそうかと。
この記事ははオフィシャルで出ているチュートリアルを実行して概要を理解し、StepFunctionsをCDKで作成してデプロイできるところまで進みます。StepFunctionsの概要
ドキュメントを見ると複雑な用語が並んでいますが、今回は目的に鑑みてStateMachineに特化して解説していこうと思います。
かなりざっくり説明すると、複数のtipsとして作成した機能体を統合して処理とデータの流れを規定、管理するマネジメントツールです。それゆえスケーラビリティの調整も容易であり、より調整しやすく運用しやすいアーキテクチャを実現できます。単一責任原則に従ってコードを細分化して管理する手法という感じで、Lambdaのような関数でなくてもちょっとした調整を行うPassとかChoiceなどの機能体、またそれらの機能体をMap処理に乗せるようなことも簡単なコードでさっくりと実現できます。
このようなツールなので、使い方次第で山ほど価値を生んでくれます。ドキュメントを見ながらご自身の用途を探してみてください。
個人的には結果として仕上がるフロー図と、その処理の進行状況をその図の中で示してくれるUIが気に入っています。
ローカルテストのためのSAMというシステム上でも稼働させられるので、ローカル検証も非常に簡単です。
触って理解を深めよう
では早速公式のチュートリアルを触ってみましょう!いっぱいあるので、興味あるやつを触ってみてください。
ここでは基本的にAmazon States Languageを使って処理の流れを規定しています。ここでAmazon States Languageに慣れておけば、CDKデプロイで作成したStateMachineをリモート上で詳細に検証できるので、やり込んでみてください!CDKでループのチュートリアルを再現しよう
Githubにアクセスしてmainブランチをクローンして開いてみてください。
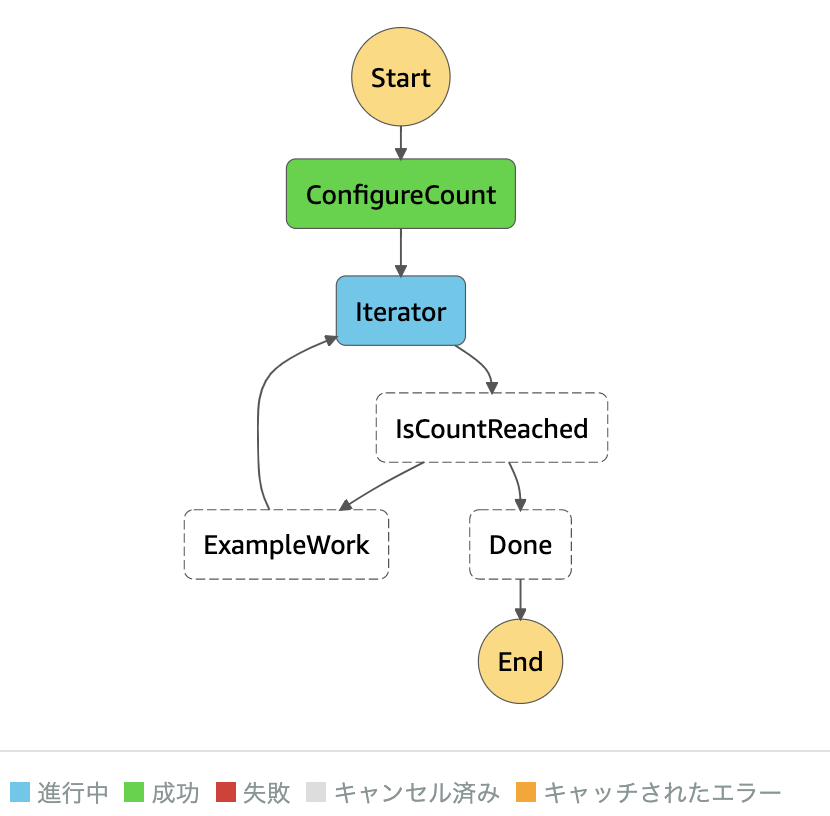
このコードが実現するのは、このチュートリアルで作成するものと全く同様のものです。制作物をAmazon States Languageに変換したjsonコードは下記になります。{ "StartAt": "ConfigureCount", "States": { "ConfigureCount": { "Type": "Pass", "Result": { "count": 10, "index": 0, "step": 1 }, "ResultPath": "$.iterator", "Next": "Iterator" }, "Iterator": { "Next": "IsCountReached", "Type": "Task", "ResultPath": "$.iterator", "Resource": "arn:aws:lambda:ap-northeast-1:333005747499:function:IteratorLambda" }, "ExampleWork": { "Type": "Pass", "Result": { "success": true }, "ResultPath": "$.result", "Next": "Iterator" }, "IsCountReached": { "Type": "Choice", "Choices": [ { "Variable": "$.iterator.continue", "BooleanEquals": true, "Next": "ExampleWork" } ], "Default": "Done" }, "Done": { "Type": "Pass", "End": true } } }さて、ではリポジトリの内容を見ていきましょう。
Lambdaのスクリプトコードはsrcの中を見ていただければわかるはずですので飛ばし、今回はCDKに特化して説明します。下準備としてルートディレクトリのターミナルで下記を実行しておいてください。これにより、
.distディレクトリにデプロイするLambdaのコードが準備され、CDK周りのモジュールもインストールされます。terminalnpm install npm run dist cd aws-cdk npm installCDKにおいて、エントリポイントは
aws-cdk/cdk.jsonにて宣言します。ここではaws-cdk/bin/index.tsを指定しています。
ここでもしJSファイルを指定する感じにすると、tscでコンパイルしてからでなければデプロイできなくなります。
従って、まずはaws_cdk/bin/index.tsの内容から見ていきます。aws-cdk/bin/index.tsimport 'source-map-support/register'; import * as cdk from '@aws-cdk/core'; import { AwsStack } from '../lib'; // デプロイするパッケージの中身は../lib/aws-stackにて定義されている const account = 'AWS_ID'; const app = new cdk.App(); new AwsStack(app, 'CdkLoopDev', {tags: {stage: 'dev'}, env: {region: 'ap-northeast-1', account}}); // stg環境をデプロイする際のCloudFormationパッケージこのファイルにはあまりごちゃごちゃ書かずに何をデプロイするのかだけ大づかみに記述するのが通例です。ここでは
'AWS_ID'となっているaccount定数にAWSのIDとして持っているアカウントID(数字の文字列)を代入してください。ここで大事なのは、デプロイするまとまりのことを僕がCdkLoopDevと呼ぶと定義づけている点のみです。ここから本番です。コードは下記になります。
aws-cdk/lib/index.tsimport * as sfn from '@aws-cdk/aws-stepfunctions'; import * as tasks from '@aws-cdk/aws-stepfunctions-tasks'; import * as lambda from '@aws-cdk/aws-lambda'; import * as iam from '@aws-cdk/aws-iam'; import * as cdk from '@aws-cdk/core'; export class AwsStack extends cdk.Stack { constructor(scope: cdk.Construct, id: string, props?: cdk.StackProps) { super(scope, id, props); const configCount = new sfn.Pass(this, 'ConfigureCount', { result: sfn.Result.fromObject({ count: 10, index: 0, step: 1, }), resultPath: '$.iterator' }); const role = new iam.Role(this, `LambdaExecuteRole`, { assumedBy: new iam.ServicePrincipal('lambda.amazonaws.com'), }); role.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole')); let iterlambda = new lambda.Function(this, 'IteratorLambda', { functionName: 'IteratorLambda', code: lambda.Code.fromAsset('../.dist/iterator'), handler: 'index.handler', runtime: lambda.Runtime.NODEJS_12_X, tracing: lambda.Tracing.ACTIVE, role }); const iterator = new tasks.LambdaInvoke(this, 'Iterator', { lambdaFunction: iterlambda, resultPath: '$.iterator', payloadResponseOnly: true, }); const isCountReaced = new sfn.Choice(this, 'IsCountReached'); const exampleWork = new sfn.Pass(this, 'ExampleWork', { result: sfn.Result.fromObject({ success: true }), resultPath: '$.result' }); const done = new sfn.Pass(this, 'Done', {}); const definition = configCount .next(iterator) .next(isCountReaced .when(sfn.Condition.booleanEquals('$.iterator.continue', true), exampleWork.next(iterator)) .otherwise(done) ); const stateMachine = new sfn.StateMachine(this, 'CdkLoop', { definition, }); } }私がまず最初に思ったのが、Amazon States Languageじゃないんだ。。ということでした。
せっかく覚えたのに…というところですが、ご安心ください。どのみちCDKが結果としてどのようなJSONになるかを確認することになるので、努力は無駄になりません。
さて、ざっくりとコードを解説していきます。
● インストールするモジュールは@aws-cdk/aws-stepfunctions@aws-cdk/aws-stepfunctions-tasks@aws-cdk/aws-lambda@aws-cdk/aws-iam@aws-cdk/coreになります。
● 次に下記のコードです。aws-cdk/lib/index.ts/12-19行目const configCount = new sfn.Pass(this, 'ConfigureCount', { result: sfn.Result.fromObject({ count: 10, index: 0, step: 1, }), resultPath: '$.iterator' });sfn.Passという構造体は、AWS States Languageでいうところの
"Type": "Pass"に対応しています。今回のコードでは上のJSONでいう"ConfigureCount"というPassに対応しています。ループ処理で徐々にカウントアップさせていく$.iterator内のオブジェクトの初期宣言になります。
● そして次のコードです。aws-cdk/lib/index.ts/21-39行目const role = new iam.Role(this, `LambdaExecuteRole`, { assumedBy: new iam.ServicePrincipal('lambda.amazonaws.com'), }); role.addManagedPolicy(iam.ManagedPolicy.fromAwsManagedPolicyName('service-role/AWSLambdaBasicExecutionRole')); let iterlambda = new lambda.Function(this, 'IteratorLambda', { functionName: 'IteratorLambda', code: lambda.Code.fromAsset('../.dist/iterator'), handler: 'index.handler', runtime: lambda.Runtime.NODEJS_12_X, tracing: lambda.Tracing.ACTIVE, role }); const iterator = new tasks.LambdaInvoke(this, 'Iterator', { lambdaFunction: iterlambda, resultPath: '$.iterator', payloadResponseOnly: true, });これはJSON内の
"Iterator"に対応するコードになります。まずrole及びiterlambdaに関して。これはlambdaを生成するためのコードになります。必要な権限を付与したIAMロールを定義し、lambdaの宣言と同時にそのロールをアタッチしています。
ここで重要なのはiteratorです。Taskステートに関しては、cdk上ではモジュールごと切り分けられています。このタスクはiterlambdaをinvokeし、返却されるデータを'$.iterator'というresultPathで受け取ります。ここでpayloadResponseOnly: true,が必要な理由ですが、これがないとresultPathを'$.iterator'としていても、そのパスの中にPayloadなどのプロパティが複数生成されてしまうので、このStateMachineで変数的に利用する'$.iterator'をシンプルに保つためにこのプロパティを指定するわけです。このおかげで、lambdaの返り値がそのまま'$.iterator'に保存されます。● そして次。
aws-cdk/lib/index.ts/41-56行目const isCountReached = new sfn.Choice(this, 'IsCountReached'); const exampleWork = new sfn.Pass(this, 'ExampleWork', { result: sfn.Result.fromObject({ success: true }), resultPath: '$.result' }); const done = new sfn.Pass(this, 'Done', {}); const definition = configCount .next(iterator) .next(isCountReached .when(sfn.Condition.booleanEquals('$.iterator.continue', true), exampleWork.next(iterator)) .otherwise(done) );まずChoiceステート
isCountReachedですが、これは条件に従って分岐させるためのステートになります。'$.iterator.continue'のboolean値がtrueならexampleWorkPass、falseならdonePassに続きますが、宣言の時点では分岐を記述せず、後続のPassを宣言した後で記述します。(ここではdefinition定数内で記述しています)
exampleWorkは'$.result'に{success: true}を格納してiteratorに接続するためのPassであり、doneはEndに続くためだけのPassです。また、ここまではJSONでいうところの
"Next":"〇〇"みたいな定義文を書いていませんでしたが、これをdefinitionで定義しています。これは後続のStateMachineの宣言にて使用するdefinitionプロパティとして使用するものです。● 最後の宣言文はご覧の通り。
さて解説は以上になりますが、もっと試したいことがある場合にはぜひCDKのリファレンスを覗いてみて試してください。
CDKデプロイ
では早速デプロイしてみましょう!まずはpackage.jsonを編集します。
8行目の、スクリプト定義の"bootstrap"をご覧ください。文字列の中にAWS_IDとあると思いますので、ご自身のAWSアカウントIDと書き換えてください。で、下記のコマンドを実行します。
terminalnpm run build npm run bootstrap npm run deployこれでデプロイは完了です。
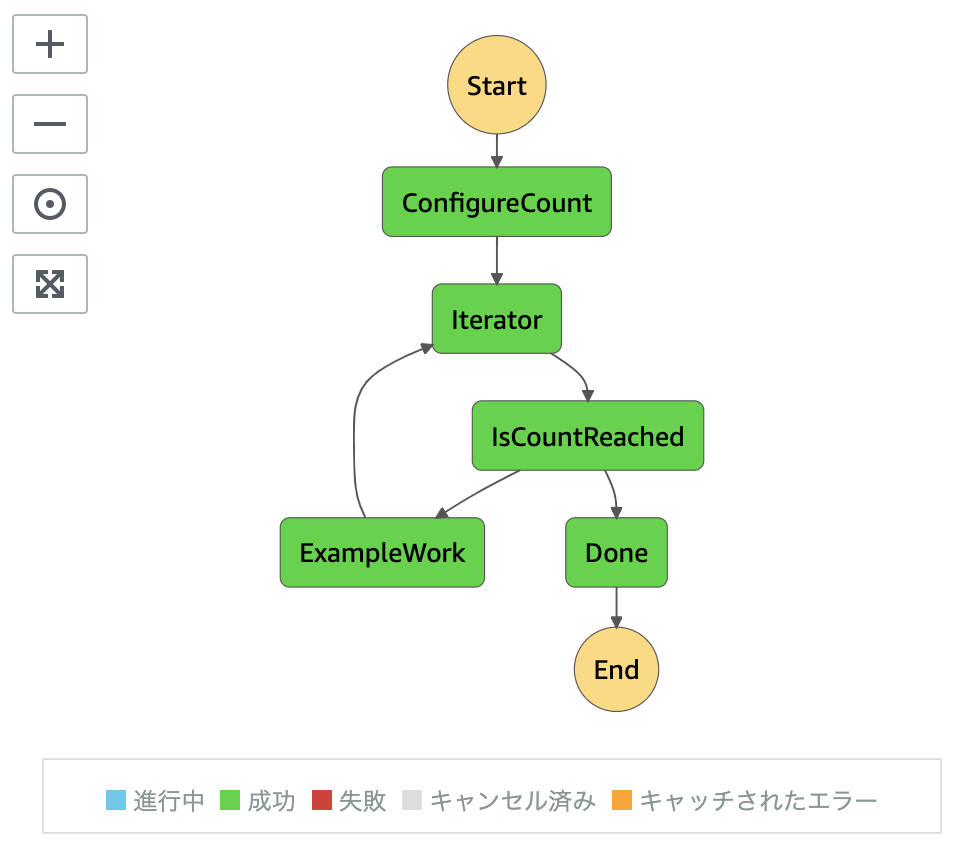
awsのマネジメントコンソールにログインし、AWS StepFunctionsのコンソールにアクセスしてください。
ステートマシンの中にCdkLoopで始まる名称のものがあると思いますので、それを開いて実行してみます。
成功すると思いますが、もし失敗したら定義のタブからJSONをチェックし、エラー文が出ていればトラブルシュートしてみてください。最後に
とまあ手元でのテストの一部を公開してみましたが、StepFunctionsの雰囲気を把握できてきたんじゃないかと思います。StepFunctionsにはアクティビティなどの便利機能がたくさんあるので、やりたいことに従って色々と拡張してみてください。トリガーやMap、Choiceなどを状況に合わせてうまく使えば相当強力な武器になると思います。

- 投稿日:2020-10-21T13:19:17+09:00
EC2インスタンスのNameタグをhostnameに(ローカルから)
目的
EC2インスタンス自体にawscliをインストールせず、インスタンスのhostnameをNameタグの値にする
経緯
仕事上複数のインスタンスを扱うことがあるのですが、その際に今どのインスタンスにログインしているかがわからなくなります。
ネットにはインスタンスにログインしてNameタグを取得するためにawscliをインストールして...といった記事はありましたが、一つ一つにそのような作業をするのはめんどくさいですし無駄にパッケージを追加したくありません。
そこでローカルでNameタグを取得して、それをリモートのhostnameに適用する、というようなシェルスクリプトを書きました。前提
awscli がローカルにインストール、設定されていること
スクリプト
set-hostname.shtag_name=`aws ec2 describe-instances \ --query 'Reservations[].Instances[].{Name:Tags[?Key==\`Name\`].Value}' \ --filter "Name=ip-address,Values=$1" \ --profile プロファイル \ | jq -r '.[0].Name[0]'` echo $tag_name ssh -i <秘密鍵へのパス> ec2-user@$1 "sh " <<-EOS sudo hostnamectl set-hostname $tag_name EOS実行set-hostname.sh <設定したいインスタンスのPublic IP>説明
ほぼ見たままなので詳細は省きますが、ローカルの変数をリモートで使用するというところで少し詰まりました。参考欄のteratailで同じような質問をされている方がいたので興味があれば。
プロファイルや秘密鍵へのパス、ユーザー名などは引数にする。スクリプトの最後にsshコマンドを書いてそのままログインできるようにする。などして各々利便性を向上していただければと思います。
(自分は複数のAWS環境にアクセスする必要があるのでプロファイルを引数に取れるようにしています)参考
- AWS EC2のNameタグをインスタンスのホスト名として設定する方法
https://qiita.com/tabimoba/items/4fc4a38d93499c72a99f- AWS公式ドキュメント
https://docs.aws.amazon.com/cli/latest/reference/ec2/describe-instances.html- ローカルのシェル変数をリモートで適用
https://teratail.com/questions/53734
- 投稿日:2020-10-21T12:41:30+09:00
Djangoチュートリアル(ブログアプリ作成)⑥ - 記事詳細・編集・削除機能編
前回、Djangoチュートリアル(ブログアプリ作成)⑤ - 記事作成機能編では
アプリ内で記事を作成する機能を追加しました。今回は CRUD でいうところの C(Create) が出来るようになったので、残りの機能 (詳細、編集、削除) 機能を追加していきます。
記事の詳細表示、編集、削除機能もクラスベース汎用ビューで実装していきます。
urls.py の修正
これから盛り込む機能では、各記事の固有となるキーをもとにアクセスをして編集することになります。
そのキーとなる値が各記事のプライマリキーです。Django のクラスベース汎用ビューの機能を使うと、urls.py 内でのルーティング設定において
各記事のプライマリキーint:pk という文字列で URL パターンを指定することができます。例えば詳細表示機能でいうと 'blog/post_detail/int:pk' というURLパターンを設定するだけで
作られた記事をプライマリキーで判別し、詳細・編集・削除を司る View へのルーティングが可能になります。view クラスの名前はそれぞれ下記の名前で設定していきます。
- 詳細:PostDetailView
- 編集:PostUpdateView
- 削除:PostDeleteView
この時、urls.py は次のようになります。
urls.pyfrom django.urls import path from . import views app_name = 'blog' urlpatterns = [ path('', views.IndexView.as_view(), name='index'), path('post_list', views.PostListView.as_view(), name='post_list'), path('post_create', views.PostCreateView.as_view(), name='post_create'), path('post_detail/<int:pk>/', views.PostDetailView.as_view(), name='post_detail'), # 追加 (例) /blog/detail/1 ※特定のレコードに対して処理を行うので pk で識別 path('post_update/<int:pk>/', views.PostUpdateView.as_view(), name='post_update'), # 追加 (例) /blog/update/1 ※同上 path('post_delete/<int:pk>/', views.PostDeleteView.as_view(), name='post_delete'), # 追加 (例) /blog/delete/1 ※同上 ]各記事の detail, update, delete についてはスラッシュ区切りのプライマリキーで指定していることが分かるかと思います。
これで、例えば一番最初の記事の詳細であれば /blog/post_detail/1/ でアクセスできるようになります。
(ローカルホストであれば 127.0.0.1:8000/blog/post_detail/1 という URL でブラウザからアクセスできます)views.py の修正
続けて、各ビューを作成していきます。
先に完成形をお見せします。views.py... class PostDetailView(generic.DetailView): # 追加 model = Post # pk(primary key)はurls.pyで指定しているのでここではmodelを呼び出すだけで済む class PostUpdateView(generic.UpdateView): # 追加 model = Post form_class = PostCreateForm # PostCreateFormをほぼそのまま活用できる success_url = reverse_lazy('blog:post_detail') class PostDeleteView(generic.DeleteView): # 追加 model = Post success_url = reverse_lazy('blog:post_list')PostDetailView の解説
コード量の少なさに驚いたのではないでしょうか?
特にプライマリキーのことなどは記述する必要がなく、汎用ビューの力のおかげでたったこれだけで詳細ページを作成できるようになります。
また、template を post_detail.html というファイル名にしてあげることで自動的に識別してくれるようになります。PostUpdateView
実は UpdateView は、新規作成時と同じフォームをそのまま使えるという特徴もあり CreateView と酷似しています。
python:views.py の解説
...
class PostCreateView(generic.CreateView):
model = Post
form_class = PostCreateForm
success_url = reverse_lazy('blog:post_list')
...
違うのは、編集成功時の success_url を UpdateView では記事詳細画面としているぐらいですが、
これも記事一覧 (post_list) と同じでよければ全く中身は同じコートでいけてしまいます。また、実は PostCreate で使っている post_form.html をそのまま流用することができるため、
template を新たに用意する必要はありません。PostDetailView の解説
削除では、入力フォームを用いるわけではないのでフォームの呼び出しは必要ありません。
ただし、Update とは違う点で2つ注意が必要になります。ひとつは、template 名は post_confirm_delete.html とすることです。
これまでの流れから post_delete.html としてしまいそうになりますが、
アクセスしてもいきなり削除するわけではないことから少し名前の定義が異なります。もう一つは、削除成功時のリダイレクト先です。
UpdateView では一覧画面か詳細画面、どちらでもよかったのですが
削除をしてしまうとアクセス対象の記事がなくなってしまうので、詳細画面 (post_detail) にはリダイレクトさせないように注意してください。template の準備
では views.py でも少し触れた通り、template/blog/ 配下に詳細、削除用の template (html) を作ります。
└── templates └── blog ├── index.html ├── post_confirm_delete.html # 追加 ├── post_detail.html # 追加 ├── post_form.html └── post_list.htmlでは、まずは post_detail.html を編集していきます。
post_detail.html<table> <tr> <th>タイトル</th> <td>{{ post.title }}</td> </tr> <tr> <th>本文</th> <!-- linebreaksbk を入れると改行タグでちゃんと改行して表示されるようになる --> <td>{{ post.text | linebreaksbr}}</td> </tr> <tr> <th>日付</th> <td>{{ post.date }}</td> </tr> </table>post という変数を template 側で受け取って {{ post.title }} & {{ post.text }} & {{ post.date }} で表示させています。
なお post.text 後にある 「| linebreaksbr」 を入れると、記事本文のように長いものでも自動で改行してくれるようになります。次に post_confirm_delete.html を編集します。
post_confirm_delete.html<form action="" method="POST"> <table> <tr> <th>タイトル</th> <td>{{ post.title }}</td> </tr> <tr> <th>本文</th> <td>{{ post.text }}</td> </tr> <tr> <th>日付</th> <td>{{ post.date }}</td> </tr> </table> <p>こちらのデータを削除します。</p> <button type="submit">送信</button> {% csrf_token %} </form>最初の行では、記事の削除という POST メソッドを使うため、form では POST メソッドを指定しています。
POST 送信先など、処理は view 側で調整をしてくれるので template 側では記述する必要はありません。
最後に CSRF 対策で {% csrf_token %} を記述することにも注意しましょう。これで template の編集は終了です。
ユニットテストの作成
先に追加
test_views.py... class PostDetailTests(TestCase): # 追加 """PostDetailView のテストクラス""" def test_not_fount_pk_get(self): """記事を登録せず、空の状態で存在しない記事のプライマリキーでアクセスした時に 404 が返されることを確認""" response = self.client.get( reverse('blog:post_detail', kwargs={'pk': 1}), ) self.assertEqual(response.status_code, 404) def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" post = Post.objects.create(title='test_title', text='test_text') response = self.client.get( reverse('blog:post_detail', kwargs={'pk': post.pk}), ) self.assertEqual(response.status_code, 200) self.assertContains(response, post.title) self.assertContains(response, post.text) class PostUpdateTests(TestCase): # 追加 """PostUpdateView のテストクラス""" def test_not_fount_pk_get(self): """記事を登録せず、空の状態で存在しない記事のプライマリキーでアクセスした時に 404 が返されることを確認""" response = self.client.get( reverse('blog:post_update', kwargs={'pk': 1}), ) self.assertEqual(response.status_code, 404) def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" post = Post.objects.create(title='test_title', text='test_text') response = self.client.get( reverse('blog:post_update', kwargs={'pk': post.pk}), ) self.assertEqual(response.status_code, 200) self.assertContains(response, post.title) self.assertContains(response, post.text) class PostDeleteTests(TestCase): # 追加 """PostDeleteView のテストクラス""" def test_not_fount_pk_get(self): """記事を登録せず、空の状態で存在しない記事のプライマリキーでアクセスした時に 404 が返されることを確認""" response = self.client.get( reverse('blog:post_delete', kwargs={'pk': 1}), ) self.assertEqual(response.status_code, 404) def test_get(self): """GET メソッドでアクセスしてステータスコード200を返されることを確認""" post = Post.objects.create(title='test_title', text='test_text') response = self.client.get( reverse('blog:post_delete', kwargs={'pk': post.pk}), ) self.assertEqual(response.status_code, 200) self.assertContains(response, post.title) self.assertContains(response, post.text)GET メソッドで 200 が返ってくることを確認するあたりはこれまでのユニットテストと大きく変わりはありませんが、
存在はずの記事に reponse を得るあたりの処理が大きく違っています。... def test_not_fount_pk_get(self): """記事を登録せず、空の状態で存在しない記事のプライマリキーでアクセスした時に 404 が返されることを確認""" response = self.client.get( reverse('blog:post_delete', kwargs={'pk': 1}), ) self.assertEqual(response.status_code, 404) ...ユニットテストの中でデータベースにデータを登録(ここでいえば記事を作成)できることは既にお伝えしました。
しかし、記事が存在していない状態でプライマリキーが 1 の記事=最初の記事の詳細・編集・削除画面へアクセスしようとすると
当然ページは存在していないので、ページが存在していないことを示す HTTPステータスコードの 404 を返してきます。上記のテストメソッドでは、あえて存在しない記事の個別ページへアクセスして操作をしようとしても
エラーが返ってくることを確認しています。これでユニットテストを実行すると、エラーもなく通るはずです。
(blog) bash-3.2$ python3 manage.py test Creating test database for alias 'default'... System check identified no issues (0 silenced). ................. ---------------------------------------------------------------------- Ran 17 tests in 0.460s OK Destroying test database for alias 'default'...これで CRUD 機能を無事に追加することができたため、大きな機能としてはおしまいです。
次は template を修正し、全画面に共通のナビゲーションバーをつけることで全ページで表示させていきましょう。
- 投稿日:2020-10-21T12:26:22+09:00
Argo Rollouts と ALB Ingress Controller による Canary デプロイメント
概要
Kubernetes で GitOps を実現するツールである Argo CDと、Kubernetes で blue/grenn デプロイや canary リリースを実現するためのデプロイメントコントローラーであるArgo Rolloutsを使用して、canaryリリースの動作検証をしてみます。
前回 Argo Rollouts(以下 Rollouts とします。) と Nginx Ingress Controller(以下 Nginx とします。) の連携の記事を書きました。今回は ALB Ingress Controller(以下 ALB とします。)版となります。
説明が Nginx とかぶる部分があるので、ここでは ALB 特有の設定について説明します。
前回の記事(Argo Rollouts と Nginx Ingress Controller による Canary デプロイメント)
https://qiita.com/tomozo6/items/1bfc65a86a528f63d205各マニフェスト
Ingress
ALB用の Ingress です。
Nginx と Rollouts を連携させたときは、 ingress についてはあまり特殊な設定をすることは無かったのですが、 ALB の場合は ingress の設定がキモになります。ing.yamlapiVersion: extensions/v1beta1 kind: Ingress metadata: name: tomozo namespace: tomozo annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/security-groups: tomozo-securitygroup-arn alb.ingress.kubernetes.io/certificate-arn: tomozo-certificate-arn alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS":443}]' alb.ingress.kubernetes.io/actions.ssl-redirect: '{"Type": "redirect", "RedirectConfig": { "Protocol": "HTTPS", "Port": "443", "StatusCode": "HTTP_302"}}' alb.ingress.kubernetes.io/conditions.x-canary-header: '[{"Field":"http-header","HttpHeaderConfig":{"HttpHeaderName": "X-Canary", "Values":["true"]}}]' alb.ingress.kubernetes.io/actions.x-canary-header: '{"Type":"forward","ForwardConfig":{"TargetGroups":[{"ServiceName":"tomozo-canary","ServicePort":"8080"}]}}' spec: rules: - host: tomozo.tokyo http: paths: - path: /* backend: serviceName: ssl-redirect servicePort: use-annotation - path: /* backend: serviceName: x-canary-header servicePort: use-annotation - path: /* backend: serviceName: tomozo-stable servicePort: use-annotation細かく解説していきます。
ALB の基本的な設定(Rollouts関係無し)
annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing alb.ingress.kubernetes.io/security-groups: tomozo-securitygroup-arn alb.ingress.kubernetes.io/certificate-arn: tomozo-certificate-arnこれは Rollouts 連携が無くても必要な、ALB自体の設定となります。そのため特にここでは解説しません。
http -> https リダイレクト設定(Rollouts関係無し)
annotations: alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}, {"HTTPS":443}]' alb.ingress.kubernetes.io/actions.ssl-redirect: '{"Type": "redirect", "RedirectConfig": { "Protocol": "HTTPS", "Port": "443", "StatusCode": "HTTP_302"}}' ~ spec: rules: - host: tomozo.tokyo http: paths: - path: /* backend: serviceName: ssl-redirect servicePort: use-annotationこれも Rollouts 連携とは関係ありません。 http -> https への強制リダイレクト設定となります。詳しくは ALB のドキュメントを参考にしてください。
特定のリクエストヘッダーを付与してアクセスすると必ず Canary サービスにルーティングされるようにする
annotations: alb.ingress.kubernetes.io/conditions.x-canary-header: '[{"Field":"http-header","HttpHeaderConfig":{"HttpHeaderName": "X-Canary", "Values":["true"]}}]' alb.ingress.kubernetes.io/actions.x-canary-header: '{"Type":"forward","ForwardConfig":{"TargetGroups":[{"ServiceName":"tomozo-canary","ServicePort":"8080"}]}}' ~ spec: rules: - host: tomozo.tokyo http: paths: - path: /* backend: serviceName: x-canary-header servicePort: use-annotationCanaryリリースは本来
stableとcanaryに決めた割合でルーティングされますが、この仕組みを入れることで開発者側からは必ずcanary側にルーティングされるようにできます。canary側へ振られる割合を 0% にすれば、ヘッダールーティングによる Blue/Green デプロイにもなります。Nginx のときは、Rollouts の
strategy.canary.trafficRouting.nginx.additionalIngressAnnotationsにて、ヘッダールーティング(canary-by-header)の設定できたのですが、ALB用の strategy ではそのような設定が無かったのでだいぶ悩みました。まあおそらく Rollouts の開発者も「ALBのingressでできるからそっちでよしなにやってよ」ということなんだと思います。ここでの設定は、リクエストヘッダー
X-Canaryの値がtrueの場合は、tomozo-canaryにルーティングさるという設定になっています。Rollouts との連携箇所
spec: rules: - host: tomozo.tokyo http: paths: - path: /* backend: serviceName: tomozo-stable servicePort: use-annotationここが今回理解が難しかったです。ここに記載している
tomozo-stableは、Kubernetesのsvcを指しているのではなく、 annotation名(alb.ingress.kubernetes.io/actions.tomozo-stable)を指しているのです。なので servicePortがuser-annotationになっているのです。
alb.ingress.kubernetes.io/actions.tomozo-stable は Rollouts が Kubernetes上 で追記するので、現時点では存在しないのです。だから結構混乱しました…Service
通常(安定版)用の Service として tomozo-stable。Canary用の Service として tomozo-canaryを定義します。名前以外は全て同じ設定値で問題ありません。
--- kind: Service apiVersion: v1 metadata: name: tomozo-stable spec: type: NodePort selector: app: tomozo ports: - port: 8080 --- kind: Service apiVersion: v1 metadata: name: tomozo-canary spec: type: NodePort selector: app: tomozo ports: - port: 8080rollout
strategy:より上は deployment と書き方変わりません。大事なのは trafficRouting で alb を指定しているところです。
apiVersion: argoproj.io/v1alpha1 kind: Rollout metadata: name: tomozo labels: app: tomozo spec: selector: matchLabels: app: tomozo template: metadata: labels: app: tomozo spec: serviceAccountName: tomozo containers: - name: tomozo image: tomozo-repo/tomozo:0.0.1 # -----この行から上は元のDeploymentと一緒------ # -----この行から下はRolloutの拡張部分------ strategy: canary: stableService: tomozo-stable # ingressに actions.tomozo-stable が作成される canaryService: tomozo-canary trafficRouting: alb: ingress: tomozo # ingress名を指定する servicePort: 8080 steps: - setWeight: 10 - pause: {}このように tomozo-stable を設定することで、 ingress に以下のアノテーションが追加されます。
alb.ingress.kubernetes.io/actions.tomozo-stable: | { "Type":"forward", "ForwardConfig":{ "TargetGroups":[ { "Weight":0, "ServiceName":"tomozo-canary", "ServicePort":"8080" }, { "Weight":100, "ServiceName":"tomozo-stable", "ServicePort":"8080" } ] } }新しいコンテナイメージをリリースすると、
tomozo-stable.steps.setWeightに合わせて、 上記アノテーションの Weight を調整することで Canaryデプロイメントを実現しています。
- 投稿日:2020-10-21T11:49:53+09:00
CapistranoでEC2への自動デプロイ時、SSHキー認証エラーが出たときの対処法
共有すること
Railsで開発を行っていて、Capistranoを使用しAWSへの自動デプロイを実装しました。
あるとき突然、SSHキー認証エラーが起きてデプロイできなくなってしまったので、
その解決策を簡単に共有します。エラー内容
$ bundle exec cap production deployでデプロイ実行時、以下のようなエラーが出ました。
SSHKit::Runner::ExecuteError: Exception while executing as ec2-user@ElasticIP: Authentication failed for user ec2-user@ElasticIP解決策
ターミナルを再起動するとsshキーが消えてしまうようなので以下のようにすることで、登録し直しが必要でした。
ターミナルのローカルで
$ eval \`ssh-agent ` $ ssh-add -K ~/.ssh/<キーの名前>.pemこのようにすることで、sshキーを保存しておくことができまして、無事にデプロイできました!
会社の紹介
私は現在、株式会社ダイアログという物流×ITの会社に勤務しております。
2020年10月現在、エンジニアの募集はしていませんが、他にも様々な職種を募集しているので、Wantedlyのページをご覧ください。
- 投稿日:2020-10-21T10:03:00+09:00
【AWS】EC2でssh接続する際のユーザー名の備忘録
ssh接続できない...
EC2でのssh接続をしようとした所、以下のメッセージが出てログインができなかった。
$ ssh -i ~/hoge/hoge.pem ec2-user@xx.xxx.xxx.xxx The authenticity of host 'xx.xxx.xxx.xxx (xx.xxx.xxx.xxx)' can't be established. ECDSA key fingerprint is hoge Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'xx.xxx.xxx.xxx' (ECDSA) to the list of known hosts. ec2-user@xx.xxx.xxx.xxx: Permission denied (publickey).鍵はあっているし、いつもと違うAMIを使用しているからユーザー名が違うのかと思い調べると、ユーザー名はAMI毎に違うようだ。本稿では備忘録としてAMI毎のユーザー名を簡単にまとめたいと思う。
ユーザー名一覧
AMI ユーザー名 Amazon Linux2 または Amazon Linux AMI ec2-user CentOS AMI centos Debian AMI admin Fedora AMI ec2-user または fedora RHEL AMI ec2-user または root SUSE AMI ec2-user または root Ubuntu AMI ubuntu いつもはAmazon Linuxを使用していたのでユーザー名を
ec2-userだったが、今回はUbuntu AMIだったのでubuntuに変更したら無事ssh接続できた。https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/managing-users.html
- 投稿日:2020-10-21T00:39:35+09:00
[AWS][AmazonLinux]docker-composeでディスク容量不足のエラー分析
背景
コンテナを起動しようとしたところ怒られた
# docker-compose up ERROR: failed to register layer: Error processing tar file(exit status 1): write /usr/sbin/mysqld: no space left on deviceどうやらデバイスに容量がないらしい
原因分析
全ファイルシステムの空き容量を見る
dfコマンド・・・パーティションサイズ、空き容量をパーティションごとに表示する# df -h Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 485220 0 485220 0% /dev tmpfs 503468 0 503468 0% /dev/shm tmpfs 503468 704 502764 1% /run tmpfs 503468 0 503468 0% /sys/fs/cgroup /dev/xvda1 8376300 7869788 506512 94% / tmpfs 100696 0 100696 0% /run/user/1000おそらく/dev/xvda1が94%を使用していて、dockerイメージをDLできないらしい。
では何に容量を食っているのか。調べたところ、もともと入っているライブラリが容量を食っているらしい。
Amazon無料枠に余裕はない模様
duコマンド・・・ディスクの使用量を表示するコマンド# du -sh /usr/* 817M /usr/bin 0 /usr/etc 0 /usr/games 28M /usr/include 344M /usr/lib 613M /usr/lib64 90M /usr/libexec 12M /usr/local 1.9G /usr/sbin 355M /usr/share 0 /usr/src 0 /usr/tmp解決
最低限使えればいいのでディスク容量を8GB→12GB拡張する。(AWSを利用している方はおそらく課金対象になるため注意)
Amazon Linxのディスク容量拡張方法については下記参照
https://qiita.com/Ponkotwo/items/fd87d356fd3a735fde99
- 投稿日:2020-10-21T00:26:47+09:00
AWSのAmazon linuxでディスク容量を拡張する方法
大きな流れ
①AWSのEC2 コンソールからボリュームサイズを拡張
②Amazon Linux内のディスク容量(パーティション)を拡張①AWSのEC2 コンソールからボリュームサイズを拡張
EC2のインスタンス→ボリューム→アクション→ボリュームの変更
私の場合指定のボリュームサイズを8GB→12Gbにした。参考
EBS ボリュームの変更をリクエストする
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/requesting-ebs-volume-modifications.html②Amazon Linux内のディスク容量(パーティション)を拡張
lsblkコマンドで①の設定が反映されていることを確認
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 12G 0 disk ┗xvda1 202:1 0 8G 0 part※
xvda・・・デバイス名
xvda1・・・xvdaのパーティション番号1を表すボリュームサイズが12Gに対しパーティションサイズが8Gなので拡張してあげる必要がある。
パーティションサイズを変更
gworpartというパーティションサイズ拡張パッケージが必要なのでインストール# yum install cloud-utils-growpartパッケージリストにgrowpartがあるか確認
# rpm -qa | grep cloud cloud-utils-growpart-0.31-2.amzn2.noarchgrowpartコマンドでパーティションサイズを拡張し、再起動
# growpart /dev/xvda 1 # rebootxvdaの1番パーティションが12Gに拡張されていることを確認
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 12G 0 disk ┗xvda1 202:1 0 12G 0 part /
- 投稿日:2020-10-21T00:26:47+09:00
[AWS]Amazon linuxでディスク容量を拡張する方法
大きな流れ
①AWSのEC2 コンソールからボリュームサイズを拡張
②Amazon Linux内のディスク容量(パーティション)を拡張①AWSのEC2 コンソールからボリュームサイズを拡張
EC2のインスタンス→ボリューム→アクション→ボリュームの変更
私の場合指定のボリュームサイズを8GB→12Gbにした。参考
EBS ボリュームの変更をリクエストする
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/requesting-ebs-volume-modifications.html②Amazon Linux内のディスク容量(パーティション)を拡張
lsblkコマンドで①の設定が反映されていることを確認
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 12G 0 disk ┗xvda1 202:1 0 8G 0 part※
xvda・・・デバイス名
xvda1・・・xvdaのパーティション番号1を表すボリュームサイズが12Gに対しパーティションサイズが8Gなので拡張してあげる必要がある。
パーティションサイズを変更
gworpartというパーティションサイズ拡張パッケージが必要なのでインストール# yum install cloud-utils-growpartパッケージリストにgrowpartがあるか確認
# rpm -qa | grep cloud cloud-utils-growpart-0.31-2.amzn2.noarchgrowpartコマンドでパーティションサイズを拡張し、再起動
# growpart /dev/xvda 1 # rebootxvdaの1番パーティションが12Gに拡張されていることを確認
# lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT xvda 202:0 0 12G 0 disk ┗xvda1 202:1 0 12G 0 part /