- 投稿日:2020-08-18T23:44:57+09:00
変数命名でよく迷うやつ
個人的変数命名
今後、どんどん追加していきたい。
コメントも反映します⭐︎複数形
変数 解説 index インデックス (i, idx) indexes indexの配列 (ids) articles 記事の配列 article_id 記事のID article_ids 記事IDの配列, article_id + s articles_id いくつかの記事をまとめたID 関数 動詞 get_article 一つの記事を取得する get_articles 複数の記事を取得する よく使う単語
関数 解説 get_〇〇 〜を取得する calculate_〇〇 〜を計算する generate_〇〇 〜を生成する display_〇〇 〜を表示する format_〇〇 〜を整形する fetch_〇〇 〜を取得する import_〇〇 〜をインポートする convert_〇〇 〜を変換する complement_〇〇 〜を補完する save_〇〇 〜を保存する show_〇〇 〜を表示する Boolean
Boolean created_article 記事が作成されたか or not is_method〇〇_enabled 手法が有効か or not
- 投稿日:2020-08-18T23:41:30+09:00
blender, python, 球の動作
blender, python, 球の動作
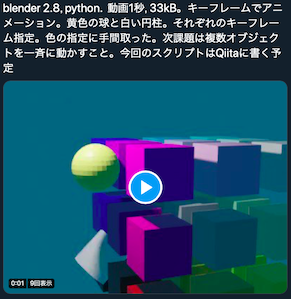
blender 2.8, python, の記事。続きです。今日やったのは立方体の配置、照明配置カメラ配置、着色。キーフレーム指定での球の動きと円柱の動き。球の着色に少し手間取りました。R,G,B,alphaと4つ数値を並べるのがわかるようでわからないまま。
twitterに1秒間の動画blender 2.8, python. 動画1秒, 33kB を投稿しています。画質は400px*300pxで荒いまま。
import bpy # nh06 ( キーフレーム応用で 円筒形と球形を動かす) # 既存 mesh, light, camera, みな削除 for item in bpy.data.objects: bpy.data.objects.remove(item) #立方体 original script は ---- http://tips.hecomi.com/entry/20120818/1345307205 START = 0 END = 100 N = 3 # Add color cubes for x in range(0, N): for y in range(0, N): for z in range(0, N): # Add a color cube bpy.ops.mesh.primitive_cube_add( location=(x*3, y*3, z*3) ) #obj = bpy.context.scene.objects.active #(old blender2.7script) obj = bpy.context.view_layer.objects.active #mat.diffuse_color = (x/N, y/N, z/N)#(old blender2.7script) mat = bpy.data.materials.new('Cube') mat.diffuse_color = (x/N, y/N, z/N, 0) #mat.use_transparency = True #(この行は2.8で試していない) #mat.alpha = 0.6 #(この行は2.8で試していない) obj.data.materials.append(mat) # new camera bpy.ops.object.add(radius=1.0, type='CAMERA', enter_editmode=False, align='WORLD', location=(20.0, -6.0, 8.0), rotation=(1.4, 0.0, 1.2)) # new lamps (出典 stack overflow Can you add a light source in blender using python) # create light datablock, set attributes light_data = bpy.data.lights.new(name="light_2.80", type='POINT') light_data.energy = 3000 # create new object with our light datablock light_object = bpy.data.objects.new(name="light_2.80", object_data=light_data) # link light object bpy.context.collection.objects.link(light_object) # make it active bpy.context.view_layer.objects.active = light_object #change location light_object.location = (5, -4, 10) # update scene, if needed dg = bpy.context.evaluated_depsgraph_get() dg.update() # 背景 world - surface - background bpy.data.worlds["World"].node_tree.nodes["Background"].inputs[0].default_value = (0.01, 0.15, 0.25, 1) bpy.data.worlds["World"].node_tree.nodes["Background"].inputs[1].default_value = 0.7 #===== # ================ # cylinder 動かす ( nh02 動きの応用) bpy.context.scene.frame_start = 1 bpy.context.scene.frame_end = 30 bpy.context.scene.frame_current = 10 # MOVE Cylinder mesh with KEY FRAME bpy.ops.mesh.primitive_cylinder_add(rotation=(-0.8, 0.0, 0.0)) bpy.context.scene.frame_current = 1 # set frame to 1 cdnow = bpy.context.object # get new object just created cdnow.location = (1,-1,1) # set the location bpy.ops.anim.keyframe_insert_menu(type='Location') # KEY FRAME bpy.context.scene.frame_current = 10 # set frame to 10 cdnow.location = (1,7,7) bpy.ops.anim.keyframe_insert_menu(type='Location') # KEY FRAME bpy.context.scene.frame_current = 20 # set frame to 20 cdnow.location = (8,6,3) bpy.ops.anim.keyframe_insert_menu(type='Location') # KEY FRAME bpy.context.scene.frame_current = 30 # set frame to 30 cdnow.location = (1,-1,1) bpy.ops.anim.keyframe_insert_menu(type='Location') # KEY FRAME # ================== # MOVE UV Sphere mesh with KEY FRAME (# Add UV Sphere) bpy.ops.mesh.primitive_uv_sphere_add (segments=32, ring_count=16, radius=1.0, calc_uvs=True, enter_editmode=False, align='WORLD', location=(4.0, -2.0, 6.0), rotation=(0.0, 0.0, 0.0)) mat = bpy.data.materials.new('Sphere') obj = bpy.context.view_layer.objects.active mat.diffuse_color = (0.8, 0.8, 0.1, 0.4) # sphere color (R,G,B,Alpha) obj.data.materials.append(mat) bpy.context.scene.frame_current = 1 # set frame to 1 cdnow = bpy.context.object # get new object just created cdnow.location = (4.0, -2.0, 6.0) # set the location bpy.ops.anim.keyframe_insert_menu(type='Location') # KEY FRAME bpy.context.scene.frame_current = 15 # set frame to 15 cdnow.location = (4.0, 1.0, 7.0) bpy.ops.anim.keyframe_insert_menu(type='Location') # KEY FRAME bpy.context.scene.frame_current = 22 # set frame to 22 cdnow.location = (4,3,4) bpy.ops.anim.keyframe_insert_menu(type='Location') # KEY FRAME bpy.context.scene.frame_current = 30 # set frame to 30 cdnow.location = (4.0, -2.0, 6.0) bpy.ops.anim.keyframe_insert_menu(type='Location') # KEY FRAME # ==================
- 投稿日:2020-08-18T22:45:24+09:00
プロ野球の実況ツイートからファンの民度を測ってみた
はじめに
プロ野球(NPB)がある程度わかる人向けの記事です。
ちなみにわたしは?ファンですが,特定のファンを悪く言う目的はない,ということを理解した上で見てください。以前,こんなニュースがありました。
プロ野球の応援マナーに関連したニュースが元となって,Twitterで議論が巻き起こるってたまにありますよね。ニュース自体に言及するというよりも,違うファン同士で「おまえらのほうがマナー悪いやんけ!」みたいな言い合い。よく見ます。
また,他球団への悪口やヤジ以外にも,自分の応援するチームの選手にも過激な言葉を吐く人もいたり。実際,こういう民度の低い言葉ってどのくらいあるんだろう?
民度の良し悪しは,球団によってどのくらい違うんだろう?という疑問を感じたので,今回はこれを簡単に分析していきます。
分析対象は,Twitterに投稿された実況ツイートです。
つまり,あくまでも「Twitter民」の民度ということをお忘れなく!民度の定義
今回は,分析を簡単にするために,ヤジ・悪口だと思われる単語(ここでは「ちくちく言葉」と呼びます)を定義し,その単語が含まれているツイートの割合を計算して,民度の低さを測ります。
ついでに,民度の高さ(ファンの優しさ)も同じように定義して,「ふわふわ言葉」の割合を計算してみます。これらを「ちくちく度」「ふわふわ度」として,下のように計算します。
$$チームAのファンのちくちく度=\frac{ちくちく言葉が入っているチームAのツイート数}{チームAのツイート数}$$
$$チームAのファンのふわふわ度=\frac{ふわふわ言葉が入っているチームAのツイート数}{チームAのツイート数}$$実験方法と結果
実験方法の概要はこのようになっています。
- ツイートの収集
- 実況ツイートの言語をモデル化
- ちくちく言葉・ふわふわ言葉の単語を定義
- ちくちく度・ふわふわ度の計算
次から具体的に説明していきます。
ツイートの収集
野球の試合時間内に投稿されたツイートを各球団のハッシュタグを元に収集
以前書いた記事「プロ野球の実況ツイートを全部取得する」の方法でツイートを収集しました。
今回の実験では,2019年度のデータを扱います。球団ごとの,ツイートを取得した試合数とツイートの総数は以下の通りです。
球団名 試合数 ツイート総数 巨人 127 590634 中日 125 250771 広島 119 442592 ヤクルト 122 400029 阪神 128 428525 DeNA 127 564144 日本ハム 120 415629 ソフトバンク 125 487349 楽天 122 256291 西武 123 528261 ロッテ 122 395208 オリックス 121 13710 ※ オリックスに関しては,取得できたツイートが少なかったので,今回は省きます。ごめんなさい...
実況ツイートの言語をモデル化
ツイートを前処理してWord2Vecのモデルを学習
前処理
テキストのクリーニング
以下の処理等を行います
- URL,ハッシュタグ,スペース等の除去
- @以下の文字の除去
- 数字とアルファベットを半角文字に統一
形態素解析による単語分割
▼ mecab-ipadic-neologdの辞書を使って,mecabによる形態素解析
def bow(mecab_dict,text): parts = ('名詞','形容詞','形容動詞','副詞','動詞','連体詞','感動詞','接続詞','記号') parsed = mecab_dict.parse(str(text)) lines = parsed.split('\n') # 解析結果を1行(1語)ごとに分けてリストにする lines = lines[0:-2] # 後ろ2行は不要なので削除 w_l = [] for word in lines: l = re.split('\t|,', word) d_ = {'Surface': l[0], 'POS1': l[1]} if d_['POS1'] in parts: w_l.append(d_['Surface']) return w_l mecab_dict = MeCab.Tagger('../data/mecab-ipadic-neologd/') # text_list = ['大山ツーベースでチャンス','いやいや、今の結構危なかったよ。', ...] words_list = [] for text in text_list: words = bow(mecab_dict,text) words_list.append(words) # words_list = [['大山','ツーベース','で','チャンス'],\ # ['いやいや','、','今','の','結構','危なかっ','た','よ','。']]Word2Vecのモデルを学習
▼ gensimのWord2Vecライブラリを使って,実況ツイートをコーパスとした言語モデルを学習
def train_word2vec(all_words_list,vecsize,window,min_count,iter_num): model = word2vec.Word2Vec(all_words_list,size=vecsize\ , window=window, min_count=min_count, iter=iter_num) model.save('モデルのファイル名.model') vecsize = 300 window = 10 min_count = 5 iter_num = 5 train_word2vec(words_list,vecsize,window,min_count,iter_num)▼ モデルがちゃんと学習できているか確認,
def word2vec_model_check(model,p_words,n_words): results = model.wv.most_similar(positive=p_words,negative=n_words,topn=10) print('model.wv.most_similar(positive=',p_words,',negative=',n_words,')') for result in results: print(result) return results model = word2vec.Word2Vec.load('モデルのファイル名.model') p_words, n_words = ['ラミレス'],[] word2vec_model_check(model,p_words,n_words) """ # 実行結果 model.wv.most_similar(positive= ['ラミレス'] ,negative= [] ) ('平石', 0.794029951095581) ('工藤', 0.7856395244598389) ('緒方', 0.7593538761138916) ('与田', 0.7247989177703857) ('辻', 0.7119660377502441) ('矢野', 0.7048444747924805) ('井口', 0.6532944440841675) ('名将', 0.6368062496185303) ('迷', 0.6259689331054688) ('采配', 0.6153334379196167) """ p_words, n_words = ['ホームラン'],[] word2vec_model_check(model,p_words,n_words) """ # 実行結果 model.wv.most_similar(positive= ['ホームラン'] ,negative= [] ) ('HR', 0.848455011844635) ('弾', 0.7043811082839966) ('アーチ', 0.6742182970046997) ('本塁打', 0.6652001142501831) ('ツーラン', 0.6070960760116577) ('ツーランホームラン', 0.5996525287628174) ('スリーランホームラン', 0.595179557800293) ('グラスラ', 0.5532823801040649) ('タイムリー', 0.4852123558521271) ('ヒット', 0.48372089862823486) """「ラミレス」と「ホームラン」に近い単語TOP10を表示してみました。
「ラミレス」さんは監督なので,他のチームの監督の名前が上位になっています。
「ホームラン」は,別の表記方法などが上位になっています。ちくちく言葉・ふわふわ言葉の単語を定義
初期設定となる,ちくちく言葉・ふわふわ言葉の単語を指定
どのような単語をツイート内検索するのかを定めるために,検索ワードを2種類用意します。
chikuchiku_wordsとfuwa fuwa_wordsを以下のように設定。
(テキストデータとして載せたくなかったので,スクショで失礼します)
Word2Vecを使って検索ワードを拡張
上記の単語だけだと,表記揺れや似たような表現があるはずなので,先ほど学習させたWord2Vecのモデルを用いて,検索ワードを拡張します。
初期の単語それぞれに対して,似た単語上位30件を抽出し,類似度が高い単語を検索ワードのリストに加えます。
def get_related_words(model,search_words,thres,remove_words): related_words = [] for sw in search_words: results = word2vec_model_check(model,sw,[]) for r in results: if r[1]>thres: related_words.append(r[0]) related_words = list(set(related_words+search_words)-set(remove_words)) return related_words # ちくちく言葉の単語リスト search_words = chikuchiku_words remove_words = [...省略] #抽出された単語でおかしいものを手動で削除 thres = 0.55 # 類似度の閾値 related_words = get_related_words(model,search_words,thres,remove_words) print(related_words) # ふわふわ言葉の単語リスト search_words = fuwafuwa_words remove_words = [...] #抽出された単語でおかしいものを手動で削除 thres = 0.55 # 類似度の閾値 related_words = get_related_words(model,search_words,thres,remove_words) print(related_words)結果,以下の言葉を「ちくちく言葉の単語リスト」「ふわふわ言葉の単語リスト」とします。
ちくちく度・ふわふわ度の計算
それぞれ,11球団のファンによる,ちくちく言葉(またはふわふわ言葉)が入っているツイート数とその割合を計算しました。
ちくちく度
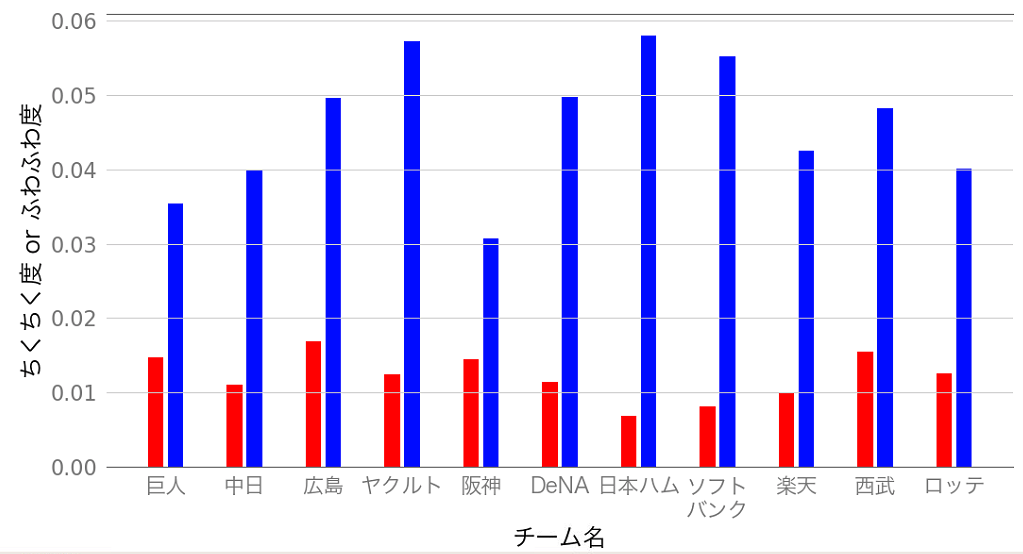
球団名 ちくちく言葉を含むツイート数 ツイート総数 ちくちく度 巨人 8663 590634 1.47 % 中日 2776 250771 1.11 % 広島 7469 442592 1.69 % ヤクルト 4992 400029 1.25 % 阪神 6217 428525 1.45 % DeNA 6468 564144 1.14 % 日本ハム 2846 415629 0.685 % ソフトバンク 3975 487349 0.816 % 楽天 2548 256291 0.994 % 西武 8163 528261 1.55 % ロッテ 4958 395208 1.25 % うん,だいたい思った通りの結果。
●:「ちくちく度」が一番高いのは広島,一番低いのは日ハムでした。ふわふわ度
球団名 ふわふわ言葉を含むツイート数 ツイート総数 ふわふわ度 巨人 20876 590634 3.53 % 中日 9989 250771 3.98 % 広島 21979 442592 4.97 % ヤクルト 22888 400029 5.72 % 阪神 13177 428525 3.07 % DeNA 28083 564144 4.98 % 日本ハム 24105 415629 5.80 % ソフトバンク 26886 487349 5.52 % 楽天 10877 256291 4.24 % 西武 25462 528261 4.82 % ロッテ 15831 395208 4.01 % ちくちく度のランキングとは少し違う様子。
●:「ふわふわ度」が一番高いのは日ハム,一番低いのは阪神でした。グラフにしてみた
◼︎ ちくちく度,◼︎ ふわふわ度
心の声(おい,阪神ファンの人たちもっと選手を褒めてやれよ!ツンデレか??)
考察
民度が低い投稿(ちくちく度)は,おおよそどの球団も1%前後ということがわかりました。
検索ワードの検討で,検索ワード(ちくちく言葉,ふわふわ言葉)を少し変えたりして実験してみはしましたが,大きく結果が変わることはありませんでした。
有意差の計算はしていないので,意味のある差かどうかはわかりませんでしたが,おおよそ予想どうりになったと思います。勝率との関係性
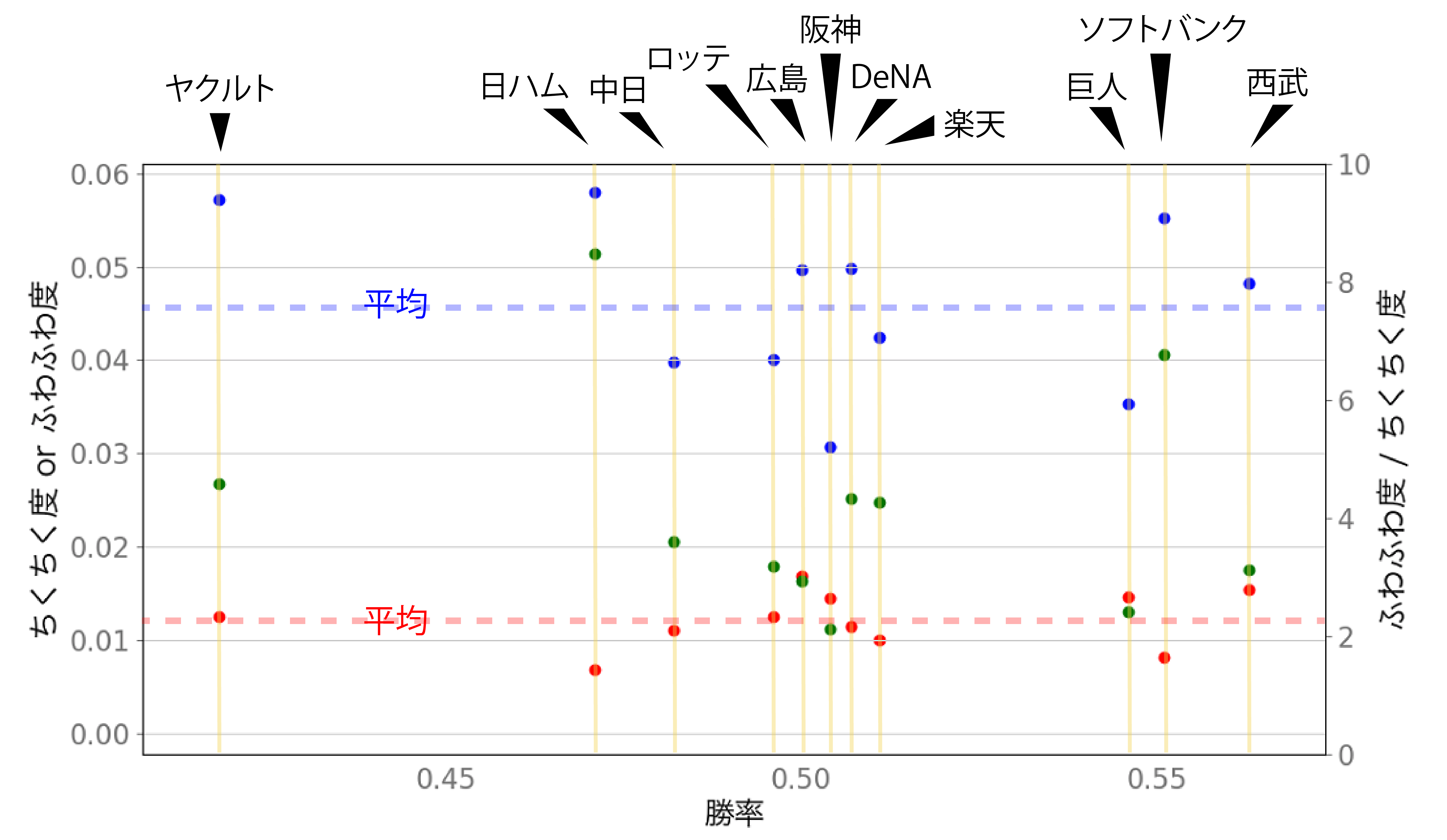
勝率をx軸として,「ちくちく度」「ふわふわ度」「ふわふわ度/ちくちく度」をプロットしてみた。(勝率は以下のデータから 2019年度 公式戦成績)
点線は値の平均です。「ふわふわ度/ちくちく度」は,この値が高いほど,ちくちく言葉が少なく,ふわふわ言葉が多いということになります。
(ふわふわ度のばらつきが大きいので,ふわふわ度にかなり左右される値かもしれませんが)●:「ちくちく度」,●:「ふわふわ度」
●:「ふわふわ度/ちくちく度」
見事に相関がない。
つまりファンの民度依存の結果ということなのでしょうか,やっぱり。
でも,時期で分けてチームごとの変動を計算すれば,もしかしたら相関が現れるかもしれません。(ホンマか?)「ちくちく度」「ふわふわ度」の関係
11球団の平均と比べたときに,球団の特徴が4つに分類できます。
ちくちく多・ふわふわ少 ➡︎ 巨人・阪神・ロッテ
ちくちく多・ふわふわ多 ➡︎ 広島・西武・ヤクルト
ちくちく少・ふわふわ少 ➡︎ 中日・楽天
ちくちく少・ふわふわ少 ➡︎ 日ハム・DeNA・ソフトバンク上の方が民度が低めってことでいいんだろうか???
まとめ
ツイッターに概要をかきました
プロ野球の実況ツイートからファンの民度を測ってみた https://t.co/kqUciEzsBD #Qiita
— のんのさん? (@p_lab_n) August 18, 2020
投稿しました! #npb #Qiita pic.twitter.com/SpNGQCExjV
今回の分析だけでは,一概にどの球団のファンの民度が低いということは言えないですけど,
だいたい,多くの人が思っているような結果になったんではないでしょうか。とにかく言えることは,
割合として「ちくちく度」<「ふわふわ度」になったのは本当に良かった?
あと,日ハムのファンの方たち素晴らしい???なんかもうちょっと考察が言える方がいらっしゃったら,コメントください。


- 投稿日:2020-08-18T22:35:00+09:00
OpenCVのスーパーピクセル
OpenCVのスーパーピクセルについて紹介がなかったので書こうかと思いました。
説明は使い方をサンプルで示す方法で記述していきます。
アルゴリズムの説明、関数インターフェイスについては、ググってお調べただけましたら
幸いです。
ただ、コンストラクタの引数については記載しないと、まるっきりとりつきが無い感じが
しましたので記載しました。スーパーピクセルについて
領域分割とかセグメンテーションアルゴリズムのことで、最初見たとき
その認識は無かったですが、資料を読んで分かった次第です。
OpenCVに実装されているスーパーピクセル機能は3種類あります。
- LSC (Linear Spectral Clustering)
- SEEDS(Superpixels Extracted via Energy-Driven Sampling)
- SLIC(Simple Linear Iterative Clustering)
さらに、3種類のアルゴリズムSLIC, SLICO, MSLICを引数に設定します。
この3種類にサンプルプログラムを作成し実行させ、セグメンテーションを
実施してみます。構成
サンプルプログラムの構造
サンプルプログラムの基本的な流れとして、下記のようにします。
- 画像読込む
- 入力画像の色空間をBGRからHSVに変換する。
- スーパーピクセル・インスタンスを生成。cv2.ximgproc.createSuperpixel***()
- 計算パラメータの設定。iterate(), enforceLabelConnectivity()
- セグメンテーションの境界を取得。getLabelContourMask()
- 境界線を読み込んだカラー画像に反映。
- 表示
入力画像について
入力画像は、上記のF-15の画像を使います。
写真出典は防衛省Webサイト 自衛隊写真館の画像で、それを400x533に縮小しています。スーパーピクセルLSC
サンプルプログラム
lsc.pyimport cv2 import numpy as np def main(): image = cv2.imread('F-15_400x533.jpg') # BGR-HSV変換 converted = cv2.cvtColor(image, cv2.COLOR_BGR2HSV_FULL) # パラメータ region_size = 20 ruler = 0.1 min_element_size = 10 num_iterations = 4 # LSCインスタンス生成 slc = cv2.ximgproc.createSuperpixelLSC(converted, region_size,float(ruler)) slc.iterate(num_iterations) slc.enforceLabelConnectivity(min_element_size) # スーパーピクセルセグメンテーションの境界を取得 contour_mask = slc.getLabelContourMask(False) image[0 < contour_mask] = (0, 255, 255) cv2.imshow('LSC result', image) cv2.waitKey(0) if __name__ == '__main__': main()cv2.ximgproc.createSuperpixelLSC()関数で、パラメータを設定し、LSCインスタンスを
生成、計算パラメータを設定します。
境界線情報を取得し、それを読み込んだ画像に反映して表示します。スーパーピクセルLSCのインスタンス生成
retval = cv.ximgproc.createSuperpixelLSC(image[, region_size[, ruler]]])
image - セグメント化するイメージ
region_size - スーパーピクセルの平均サイズ
ruler - スーパーピクセル平滑係数
retval - 返却値:LSCインスタンススーパーピクセルLSC 実行結果
スーパーピクセルSEEDS
サンプルプログラム
seeds.pyimport cv2 import numpy as np def main(): image = cv2.imread('F-15_400x533.jpg') # パラメータ height, width, channels= image.shape[:3] num_iterations = 5 prior = 2 double_step = True num_superpixels = 700 num_levels = 4 num_histogram_bins = 5 # スーパーピクセルSEEDSの生成 seeds = cv2.ximgproc.createSuperpixelSEEDS(width, height, channels, num_superpixels, num_levels, prior, num_histogram_bins, double_step) converted = cv2.cvtColor(image, cv2.COLOR_BGR2HSV_FULL) # 画像のスーパーピクセルSEEDSを計算 seeds.iterate(converted, num_iterations) # スーパーピクセルセグメンテーションの境界を取得 contour_mask = seeds.getLabelContourMask(False) result = image.copy() result[0 < contour_mask] = (0, 255, 255) # 画像表示 cv2.imshow('SEEDS result', result) cv2.waitKey(0) if __name__ == '__main__': main()cv2.ximgproc.createSuperpixelSEEDS()でインスタンスを生成しますが、この段階では
入力画像を設定しません。iterate()メソッドに入力画像を設定します。スーパーピクセルSEEDSのインスタンス生成
retval = cv.ximgproc.createSuperpixelSEEDS(image_width, image_height, image_channels,
num_superpixels, num_levels[, prior[, histogram_bins[, double_step]]] )
image_width - 画像幅
image_height - 画像高さ
image_channels - 画像チャンネル
num_superpixels - 必要なスーパーピクセルセグメンテーション数
num_levels - ブロックレベルの数
prior - 平滑オプション(0~5) 3x3平滑化を有効にします。
histogram_bins - ヒストグラムビンの数
double_step - Trueの場合、精度向上の為、各ブロックレベルをダブルで実施
retval - 返却値:スーパーピクセルSEEDSのインスタンススーパーピクセルSEEDS 実行結果
スーパーピクセルSLIC
サンプルプログラム
slic.pyimport cv2 import numpy as np def main(): image = cv2.imread('F-15_400x533.jpg') # パラメータ algorithms = [ ('SLIC', cv2.ximgproc.SLIC), ('SLICO', cv2.ximgproc.SLICO), ('MSLIC', cv2.ximgproc.MSLIC) ] region_size = 20 ruler = 30 min_element_size = 10 num_iterations = 4 # BGR-HSV変換 converted = cv2.cvtColor(image, cv2.COLOR_BGR2HSV_FULL) for alg in algorithms: slic = cv2.ximgproc.createSuperpixelSLIC(converted, alg[1], region_size,float(ruler)) slic.iterate(num_iterations) slic.enforceLabelConnectivity(min_element_size) result = image.copy() # スーパーピクセルセグメンテーションの境界を取得 contour_mask = slic.getLabelContourMask(False) result[0 < contour_mask] = (0, 255, 255) cv2.imshow('SLIC ('+ alg[0] + ') result', result) cv2.imwrite('images/SLIC_'+alg[0]+'_result.jpg', result) cv2.waitKey(0) if __name__ == '__main__': main()基本的身はスーパーピクセルLSCと同じです。
3種類のアルゴリズムを実行しているため、ループさせています。スーパーピクセルSLICのインスタンス生成
retval = cv.ximgproc.createSuperpixelSLIC(image[,algorithm[,region_size[,ruler]]])
image - セグメント化するイメージ
algorithm - アルゴリズム(SLIC, SLICO, MSLIC)
region_size - スーパーピクセルの平均サイズ
ruler - スーパーピクセル平滑係数
retval - 返却値:ーパーピクセルSLICインスタンススーパーピクセルSLIC SLICアルゴリズム 実行結果
スーパーピクセルSLIC SLICOアルゴリズム 実行結果
スーパーピクセルSLIC MSLICアルゴリズム 実行結果
終わりに
実行結果についてはコメントを書きませんでした。画像を見てご判断下さい。
用途、対象画像等々条件でアルゴリズムを選択することになるかともいます。
最初、規定値で行おうとも考えましたが、分割が細かくなってしまい、良く見えなかったので
見た目の分割サイズが同じようになるように、パラメータを調整してあります。
パラメータは、同じ名前であっても、アルゴリズムが異なるため動きが違ってきます。
さて、セグメンテーションについてはK-Meansなど他にも、いろいろあるかと思いますが、
そのうちの一つとして紹介しました。
ご覧いただきありがとうございました。実行環境
Windows10 Anaconda
Python 3.8.5
OpenCV 4.0.1参考
Emotion Explorer - OpenCVのスーパーピクセル(3) - SuperpixelLSCクラスを試す。
Emotion Explorer - OpenCVのスーパーピクセル(2) - SuperpixelSLICクラスを試す。
Emotion Explorer - OpenCVのスーパーピクセル(1) - SuperpixelSEEDSクラスを試す。
Emotion Explorer - Watershedアルゴリズムの領域分割
docs.opencv.org - Superpixels Extended Image Processing
docs.opencv.org - cv::ximgproc::SuperpixelSEEDS Class Reference
docs.opencv.org - cv::ximgproc::SuperpixelSLIC Class Reference
docs.opencv.org - cv::ximgproc::SuperpixelLSC Class Reference写真引用
防衛省Webサイト 自衛隊写真館を400x533に縮小して画像処理サンプルとして使用






- 投稿日:2020-08-18T21:58:02+09:00
自分の資産推移を自動でまとめるプログラムを書いた話
はじめに
半年ほど前から株を始めたけど,自分の資産額がどのように推移してるかを全く管理してなかったので,自動でまとめるプログラムを作ったので公開したいと思います.
証券会社HPから資産額をスクレイピングする
僕はSBI証券を使っているので,以下はSBI証券での資産額の取得法です.他の証券会社でもこの部分を変更すれば使えると思います(知らんけど).
ホーム画面から現金残高,ポートフォリオ画面から時価評価額(国内株と投資信託)を取得します.ホーム画面の現金残高
ココってところに金額が書かれているからセレニウムで取ってくる.このくらいサポートしてくれるAPIがあればいいんですが,ないので泥臭くHTMLをパースして取得します.
時価評価額の取得
ココってところをクリックするとcsvファイルがダウンロードされます.時価評価額をcsvファイルを解析して(csvファイルの最後の行に書いてある)取得します.このくらいサポートしてくれるAPIがあればいいんですが...
Googleシートへの自動書き込み
資産推移をGoogleSpreadSheetで管理することにしました.
Googleシートの構成
Cronでの自動実行
株を持っていると資産額は日々変化しますが,そう毎日記録するものでもないと思うので,日曜日にだけプログラムをcrontabで定時実行するようにしました.ちなみにRaspberryPi上で実行しています.
0 16 * * 0 cd /home/pi/asset-management && python3 run.py # 分 時 日 月 曜日 コマンド詰まったところ
- seleniumでファイルのダウンロード先の指定
- Google SheetでAPIから書き込むときはCredentialを作るときにSCOPEを追加する必要があること
できたもの
以下ができたコードです.
ディレクトリ構造
. ├── .credentials.json ├── .sbi.yaml ├── .token.pkl ├── data │ └── 2020-08-16.csv └── run.pySBI証券のユーザ情報
.sbi.yamlusername: SBI証券のユーザネーム password: SBI証券のログインパスワード(取引パスワードではない)メインのプログラム
run.pyimport os import pickle from datetime import datetime import yaml from selenium import webdriver from selenium.webdriver.chrome.options import Options from googleapiclient.discovery import build from google_auth_oauthlib.flow import InstalledAppFlow from google.auth.transport.requests import Request ### constants CHROME_DRIVER_PATH = "/usr/bin/chromedriver" SBI_URL = "https://www.sbisec.co.jp/ETGate" SBI_HOME_URL = # SBI証券のホーム画面のURL SBI_ASSET_URL = # 赤色のココってところのURL SBI_INFO = ".sbi.yaml" DOWNLOAD_PATH = os.path.abspath("data") # google api CRED_TOKEN = ".token.pkl" GSHEET_ID = # GoogleシートのID GSHEET_RANGE = "sbi-jp!A1" # webdriver driver = None def setup_webdriver(headless=True): global driver options = Options() options.headless = headless options.add_experimental_option("prefs", {"download.default_directory" : DOWNLOAD_PATH}) driver = webdriver.Chrome(CHROME_DRIVER_PATH, options=options) def quit_webdriver(): global driver driver.quit() def login_to_sbi(): with open(SBI_INFO, "r") as f: info = yaml.safe_load(f) driver.get(SBI_URL) username_form = driver.find_element_by_id("user_input")\ .find_element_by_name("user_id") username_form.send_keys(info["username"]) password_form = driver.find_element_by_id("password_input")\ .find_element_by_name("user_password") password_form.send_keys(info["password"]) login_button = driver.find_element_by_name("ACT_login") login_button.click() def get_cash_amount(): driver.get(SBI_HOME_URL) cash = driver.find_element_by_class_name("tp-table-01")\ .find_element_by_class_name("tp-td-01")\ .find_element_by_tag_name("span") return cash.text def get_market_value(timestamp): asset_file = f"{DOWNLOAD_PATH}/{timestamp}.csv" driver.get(SBI_ASSET_URL) os.rename(f"{DOWNLOAD_PATH}/New_file.csv", asset_file) with open(asset_file, "r", encoding="shift_jis") as f: content = f.read() ll = content.split("\n")[-2].split(",") return ll[0] def get_credential(): creds = None SCOPES = ['https://www.googleapis.com/auth/spreadsheets.readonly', "https://www.googleapis.com/auth/spreadsheets"] # The file token.pickle stores the user's access and refresh tokens, and is # created automatically when the authorization flow completes for the first # time. if os.path.exists(CRED_TOKEN): with open(CRED_TOKEN, 'rb') as token: creds = pickle.load(token) # If there are no (valid) credentials available, let the user log in. if not creds or not creds.valid: if creds and creds.expired and creds.refresh_token: creds.refresh(Request()) else: flow = InstalledAppFlow.from_client_secrets_file( '.credentials.json', SCOPES) creds = flow.run_local_server(port=0) # Save the credentials for the next run with open(CRED_TOKEN, 'wb') as token: pickle.dump(creds, token) return creds def update_gsheet(vals): creds = get_credential() service = build('sheets', 'v4', credentials=creds) body = {"values": [vals]} # Call the Sheets API resp = service.spreadsheets()\ .values()\ .append(spreadsheetId=GSHEET_ID, range=GSHEET_RANGE, valueInputOption="USER_ENTERED", insertDataOption="INSERT_ROWS", body=body)\ .execute() def main(): timestamp = datetime.now().strftime('%Y-%m-%d') setup_webdriver() login_to_sbi() cash = get_cash_amount() value = get_market_value(timestamp) quit_webdriver() update_gsheet([timestamp, cash, value]) if __name__ == '__main__': main()



- 投稿日:2020-08-18T21:40:01+09:00
グレースケールと輝度平滑化
実行環境
Google Colaboratoryで画像を読み込む為の準備
from google.colab import files from google.colab import drive drive.mount('/content/drive')必要なライブラリの読み込み
import cv2 #opencv import matplotlib.pyplot as plt %matplotlib inline img = plt.imread("/content/drive/My Drive/Colab Notebooks/img/Lenna.bmp") #↑この記事からplt.imreadで読み込むことにしました。いろんな変換
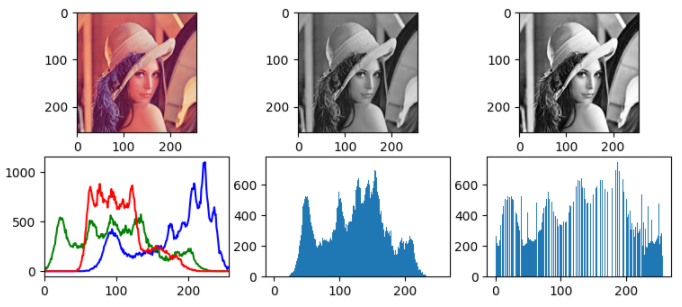
plt.figure(figsize=(9, 6), dpi=100, facecolor='w', linewidth=0, edgecolor='w') #オリジナル画像 plt.subplot(3,3,1) plt.imshow(img) plt.subplot(3,3,4) color = ('b','g','r') for i,col in enumerate(color): histr = cv2.calcHist([img],[i],None,[256],[0,256]) plt.plot(histr,color = col) plt.xlim([0,256]) #グレースケール plt.subplot(3,3,2) gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY) plt.imshow(gray) plt.subplot(3,3,5) plt.hist(gray.ravel(),256,[0,256]) #輝度平滑化 plt.subplot(3,3,3) dst = cv2.equalizeHist(gray) plt.imshow(dst) plt.subplot(3,3,6) plt.hist(dst.ravel(),256,[0,256]) plt.show()結果
左から、
オリジナル / グレースケール / 輝度平滑化文法
グレースケールcv2.cvtColor(src, cv2.COLOR_RGB2GRAY)輝度平滑化
cv2.equalizeHist(src)輝度平滑化することでヒストグラムが満遍なく広がり、
明暗がわかりやすくなりましたね。
特徴を検出するにはこの処理をしたほうが良さそう。
- 投稿日:2020-08-18T21:09:31+09:00
FastAPIをマルチプロセス&SSLで動かすためのステップバイステップ
Flask並みに簡単なのにモダンな開発スタイルも可能なフレームワークFastAPIを、本番を意識した構成で動かす方法を調べたので共有したいと思います。
構成に関する要件と討ち手
「本番を意識した構成」と大きく出てみたものの、やりたいことは以下2点です。
- マルチプロセス構成の管理をしたい ? gunicornでマルチプロセス管理
- SSLをオフロード&証明書を一元管理したい ? Nginxでリバースプロキシ
前者によりパフォーマンスや耐障害性を確保し、後者により運用しやすさやセキュリティを確保するようなイメージです。
Uvicornで起動(基本形)
ASGIサーバーとしてUvicornを使用してFastAPIをシングルプロセスで起動するまでの手順です。はじめにライブラリのインストール。
$ pip install fastapi uvicornインストールしたらファイル
run.pyを作成して以下の通りコードを記述してください。run.pyfrom fastapi import FastAPI app = FastAPI() @app.get('/') async def hello(): return {"text": "hello world!"}そしたらサーバーを起動してみましょう。
$ uvicorn run:app INFO: Started server process [13372] INFO: Waiting for application startup. INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)http://127.0.0.1:8000 でUvicornが起動したと出てきたのでブラウザでアクセスしてみると以下のようなJSONが返されるはずです。
{"text":"hello world!"}稼働確認はこれで完了です。
マルチプロセスにする
Uvicorn自体でマルチプロセスの仕組みは持っているのですが、プロセスを監視して落ちたら再起動するといったような仕組みが無いみたいです。
Uvicorn provides a lightweight way to run multiple worker processes, for example --workers 4, but does not provide any process monitoring.
https://www.uvicorn.org/deployment/#using-a-process-manager
そこで、最もシンプルな方法として示されているGunicornをプロセスマネージャーとして利用する方法を採用してみたいと思います。
Gunicornのインストール
以下の通り。簡単。
$ pip install Gunicornマルチプロセスで起動
早速Gunicornを使ったマルチプロセス管理のもとで(UvicornをASGIとした)FastAPIアプリを起動します。以下の例ではワーカープロセス4つ、ポート1234番で起動しています。
$ gunicorn -w 4 -k uvicorn.workers.UvicornWorker run:app --bind localhost:1234上記コマンドを実行すると、以下のようにワーカープロセスがずらずらと起動してきます。
[2020-08-18 19:52:58 +0900] [13404] [INFO] Starting gunicorn 20.0.4 [2020-08-18 19:52:58 +0900] [13404] [INFO] Listening at: http://127.0.0.1:1234 (13404) [2020-08-18 19:52:58 +0900] [13404] [INFO] Using worker: uvicorn.workers.UvicornWorker [2020-08-18 19:52:58 +0900] [13407] [INFO] Booting worker with pid: 13407 [2020-08-18 19:52:58 +0900] [13408] [INFO] Booting worker with pid: 13408 [2020-08-18 19:52:58 +0900] [13407] [INFO] Started server process [13407] [2020-08-18 19:52:58 +0900] [13407] [INFO] Waiting for application startup. :(略) [2020-08-18 19:52:58 +0900] [13410] [INFO] Waiting for application startup. [2020-08-18 19:52:58 +0900] [13410] [INFO] Application startup complete.ログが出てくるのが止まった後、http://127.0.0.1:1234 にアクセスしてHello worldが表示されたらGunicorn経由でのアクセスは成功です。
プロセス管理機能の確認
今回Gunicornを利用するねらいである、プロセス数監視&復活機能が働いていることを確認してみましょう。例ではワーカーとしてPID13407〜13410が起動したので、別のターミナルを起動してPID13407のプロセスを落としてみます。
$ kill 13407 -9すると以下のように13407が落ち、ただちに新たなワーカープロセスがPID13456として起動してくる様子が確認できると思います。
[2020-08-18 20:07:36 +0900] [13407] [INFO] Shutting down [2020-08-18 20:07:36 +0900] [13407] [INFO] Error while closing socket [Errno 9] Bad file descriptor [2020-08-18 20:07:36 +0900] [13407] [INFO] Waiting for application shutdown. [2020-08-18 20:07:36 +0900] [13407] [INFO] Application shutdown complete. [2020-08-18 20:07:36 +0900] [13407] [INFO] Finished server process [13407] [2020-08-18 20:07:36 +0900] [13407] [INFO] Worker exiting (pid: 13407) [2020-08-18 20:07:36 +0900] [13456] [INFO] Booting worker with pid: 13456 [2020-08-18 20:07:37 +0900] [13456] [INFO] Started server process [13456] [2020-08-18 20:07:37 +0900] [13456] [INFO] Waiting for application startup. [2020-08-18 20:07:37 +0900] [13456] [INFO] Application startup complete.Nginxのリバースプロキシ配下にする
Nginxをリバースプロキシとする方法について解説していきます。ここではMacを前提としていますので、Linuxなどを利用する場合はパスやコマンドを置き換えてください。
なおこの記事ではリバースプロキシもWebアプリも同じマシンで動かしますが、実際には異なるマシンになると思いますので、適宜アドレスなどを読み替えてください。Nginxのインストール
以下の通りです?
$ brew install nginxインストールしたら起動してみましょう。
$ sudo nginxhttp://127.0.0.1:8080/ にアクセスしてNginxのウェルカムページが表示されたらインストールは成功です。
リバースプロキシの設定
/usr/local/etc/nginx/servers/fastapitestを作成して以下の通り定義します。ポート2345番に来たアクセスについて、ルート以下すべてをhttp://127.0.0.1:1234 のプロキシとして振る舞うような内容です。
proxy_set_headerはセットしてアプリに渡してあげないと、自身のドメインやプロトコルがわからない故に様々な問題が生じます。詳細はNginxのドキュメントなどを参照してください。なおこれはNginx固有の話ではなくリバースプロキシを利用する際の一般的な問題です。server { listen 2345; server_name fastapitest; proxy_set_header Host $host; proxy_set_header X-Forwarded-Host $host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Real-IP $remote_addr; location / { # 別マシンの場合は127.0.0.1ではなくそのマシンのアドレスにする proxy_pass http://127.0.0.1:1234/; } }定義が完了したら、以下のコマンドでNginxの設定をリロードします。
$ sudo nginx -s reloadhttp://127.0.0.1:2345 にアクセスしてHello worldが表示されたらNginx経由のアクセスは成功です。
SSLの設定
先ほどのリバースプロキシの定義に以下の通り追加します。証明書の取得手順は割愛します。監視するポート番号を443に変更し、
server_nameを実際のドメイン名に変更します。server { # 2345の監視をやめて443を監視 # listen 2345; listen 443 ssl; # ドメインを指定 # server_name fastapitest; server_name fastapitest.your.domain; # SSL関連の設定を追加 ssl_certificate_key /path/to/privkey.pem; # Key ssl_certificate /path/to/fullchain.pem; # Cert ssl_protocols TLSv1.1 TLSv1.2 TLSv1.3; # TLS1.1以上 ssl_ciphers HIGH:!aNULL:!MD5; # 暗号化方式。HIGH=128bit長以上とし、MD5は不許可 ssl_prefer_server_ciphers on; # サーバの設定を優先 # SSL関連の設定 ここまで proxy_set_header Host $host; proxy_set_header X-Forwarded-Host $host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Real-IP $remote_addr; location / { # 別マシンの場合は127.0.0.1ではなくそのマシンのアドレスにする proxy_pass http://127.0.0.1:1234/; } }なお
ssl_ciphersの値はNginxのデフォルト値なので指定しなくても同じですが、設定余地として明示したものです。定義を修正したら、
sudo nginx -s reloadでリロードしてhttps://fastapitest.your.domain/ にアクセスしてHello worldが表示されたらSSLオフロードも成功です。おまけ:Unixドメインソケットで接続
わざわざリバースプロキシをSSLオフロード用に構えたのに同一マシン内のGunicornに接続することもないと思いますが、いつか役に立つかもしれないのでメモしておきます。
まずはTCP通信ではなくUnixドメインソケットにバインドしてGunicornを起動しなおします。
$ gunicorn -w 4 -k uvicorn.workers.UvicornWorker run:app --bind unix:/tmp/myuvicorn.sock続いてNginxの設定変更です。WSGIであれば
locationディレクティブにuwsgi_passとしてUnixドメインソケットのパスを設定すればOKでしたが、ASGIの場合はソケットを含むupstreamディレクティブでサーバーグループを定義し、これをproxy_passディレクティブで指定する必要があるようです。:(略) location / { # proxy_pass http://127.0.0.1:1234/; proxy_pass http://uvicorntest; } } upstream uvicorntest { server unix:/tmp/myuvicorn.sock; }設定リロード後にアクセスしてHello worldが表示されたら成功です。
さいごに
私はFlask派でしたが、FastAPIを触ってみてのファーストインプレッションが良かったので徐々に軸足を移して行こうと思っています。
というわけで私もまだFastAPI素人・Uvicorn素人なので、「ここちがってるよー」みたいなのがあれば是非是非ご指摘いただけるとうれしいです?
- 投稿日:2020-08-18T21:06:32+09:00
Codeforces Round #654 (Div. 2) バチャ復習(8/18)
今回の成績
今回の感想
今回は感覚として非常に良い感じで解けていました。
しかし、途中に昼飯が入ったおかげで五完を逃しました。非常に悔しいです。
だんだん感覚が研ぎ澄まされてきている気がするので引き続き頑張りたいです。
夏休み中の目標のAtCoder青,Codeforces紫を目指して頑張ります。A問題
偶数本存在する時は$n+1$の長さのスティックを作るように、奇数本存在する時は$n$の長さのスティックを作るようにすればよく、この時、同じ長さになるスティックの本数は$[\frac{n}{2}]$本になります。
作りうる長さのスティックを小さい順に考えることで証明できますが、ここでは省略します。
A.pyfor _ in range(int(input())): n=int(input()) print(-(-n//2))B問題
色々罠を踏みそうな問題ですが、一つずつ注意して場合分けすることで正答にたどり着くことができます。
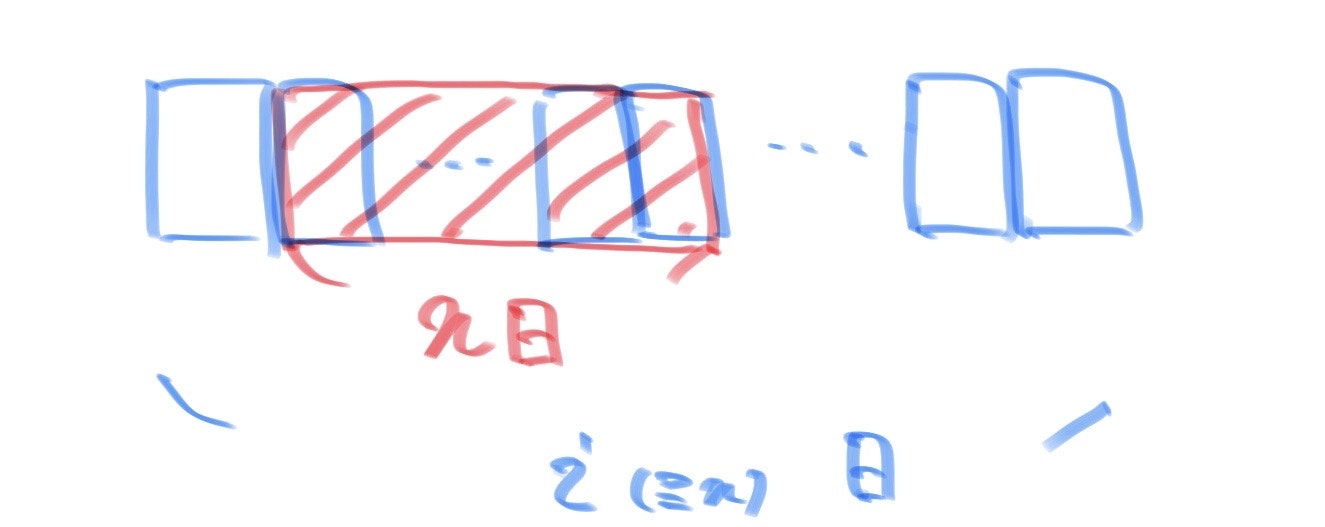
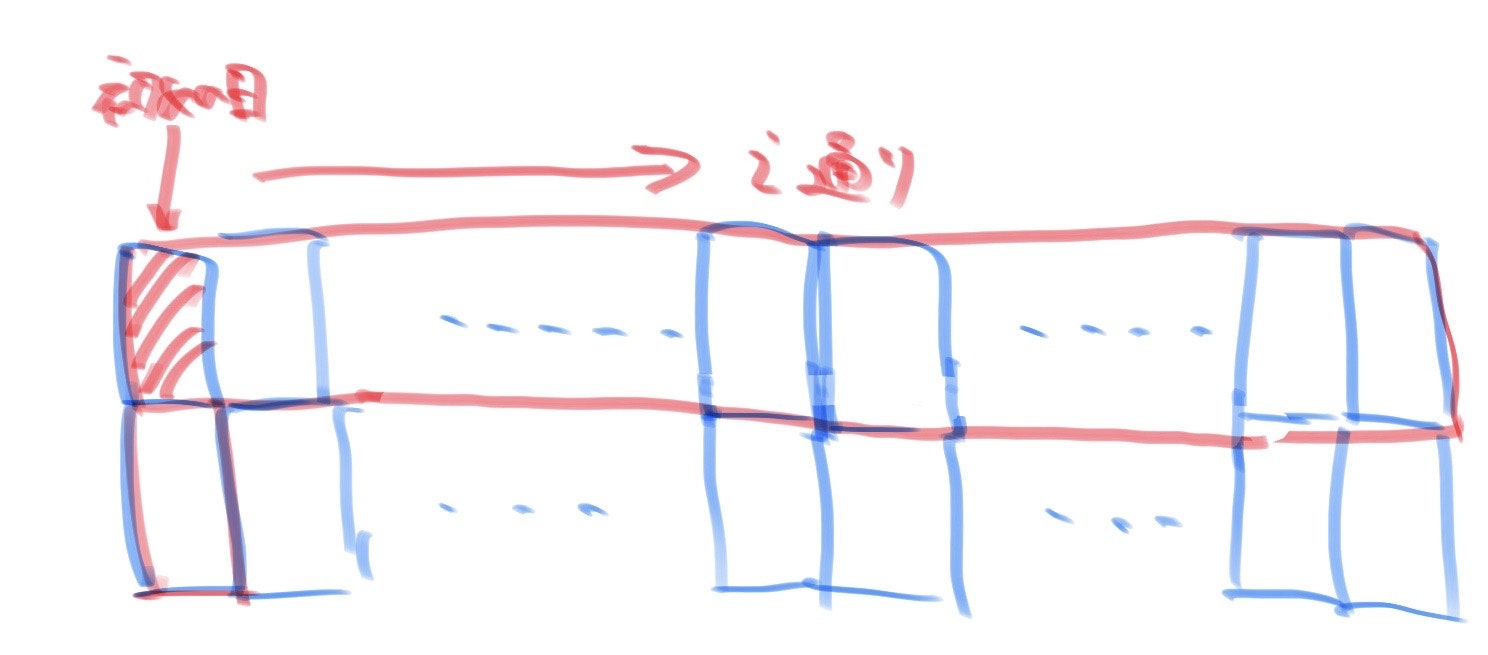
まず、繋がるように連続した$n$日を選ぶことを考えますが、一つの週に$n$日が含まれる場合は必ず繋がるのに対して、複数の週に跨がる場合は$n$日がつながらない可能性があります。したがって、一週が$i(1 \leqq i \leqq r)$日であるとした時、$i \geqq n$の場合と$i<n$の場合で場合分けを考えます。
(1)$i \geqq n$の場合
繋がるように連続した$n$日を選ぶ時は下図のようになり、任意の$i$についてその形状は平行移動すると一致して$1$通りとなるので、$r \geqq n$の時1通りで$r<n$の時は0通りです。
(2)$i<n$の場合
繋がるように連続した$n$日を選ぶ時、以下のように必ず複数の週に跨ります。したがって、平行移動しても同じにならない形状は、連続した$n$日の初めの一日で区別することができ、$i$通りになります。
また、$1 \leqq i \leqq min(n-1,r)$なので、$\sum_{i=1}^{min(n-1,r)}i=_{min(n,r+1)}C_2$が答えとなります。また、$i$の範囲を間違えて自分はサンプルが合いませんでした。
B.pyfor _ in range(int(input())): n,r=map(int,input().split()) if r<n: print(r*(r+1)//2) else: print(1+(n-1)*n//2)C問題
一種類目のゲストは多いクッキーから順に、二種類目のゲストは少ないクッキーから順に選んでいきます。この時、それぞれのゲストがクッキーを選ぶ時にクッキーが残っていない場合がないようにゲストの順番を決めることができるかを考えます。
まず、二種類目のゲストは少ない方のクッキーを選ぶことから選択肢が少なそうなので、少ない方のクッキーをできるだけ多く残しておきたいです。したがって、二種類目のゲストから先に選んでいく方が良いのではと考え、二種類目のゲストの選べるクッキーの枚数は高々$min(a,b)$であると考えました。また、二種類目のゲストがクッキーを選ぶ際に少ない方のクッキーの残りの枚数が同じ状態で二回選ぶことができないので、$min(a,b)$が最大の選べるクッキーの枚数になります。したがって、$m \leqq min(a,b)$であれば二種類目のゲストは少ない方のクッキーを常に選ぶことでクッキーを残したまま選ぶことができます。また、二種類目のゲストが選び終わった後に$(min(a,b)-m)+max(a,b)=a+b-m$枚のクッキーが残っていますが、残りのクッキーの全てを一種類目のゲストは選ぶことができるので、$a+b-m \leqq n$であれば一種類目のゲストも同様にクッキーを選ぶことができます。以上より、$m>min(a,b)$または$a+b<n+m$の時に"No",それ以外の時に"Yes"を出力すれば良いです。
C.pyfor _ in range(int(input())): a,b,n,m=map(int,input().split()) if m>min(a,b): print("No") elif n+m>a+b: print("No") else: print("Yes")D問題
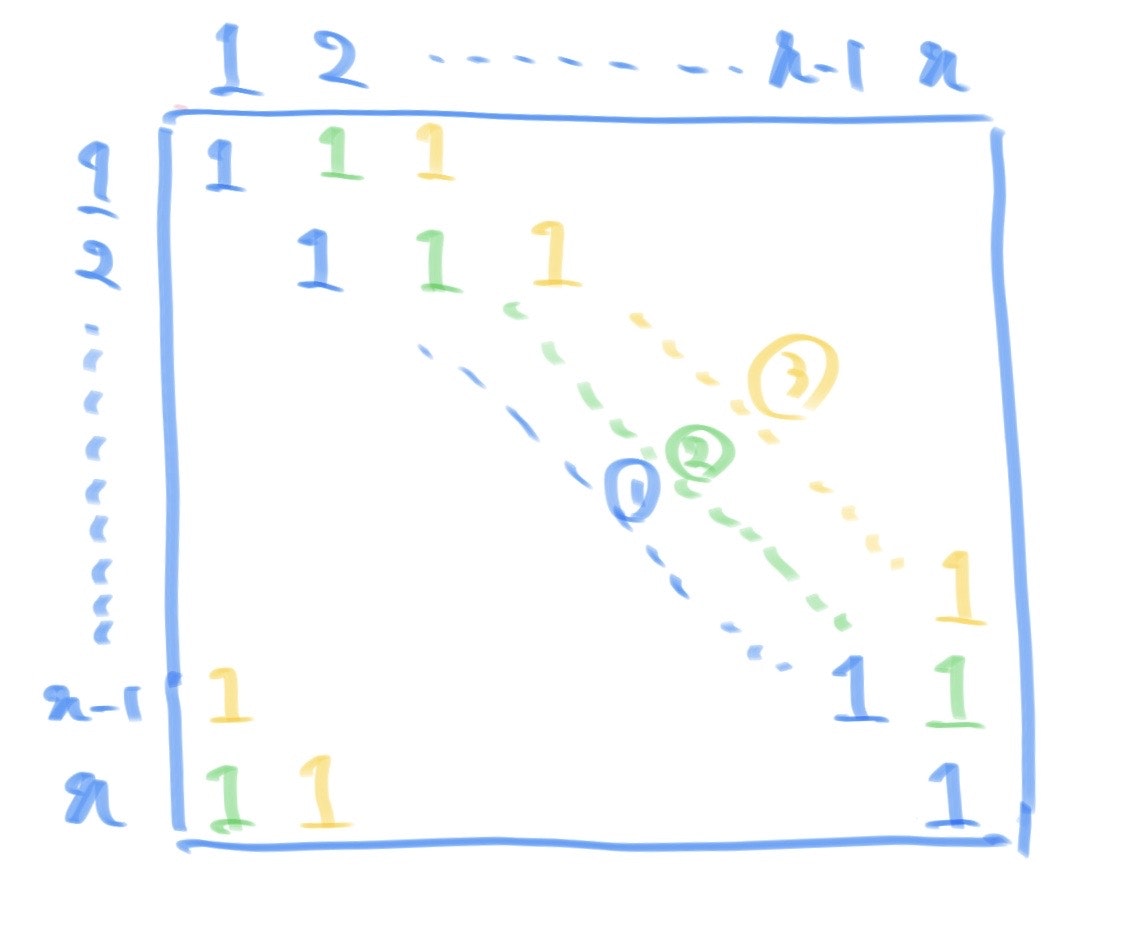
対称性を使うと見通しの良くなる問題で個人的には好きです(好みは別れそうですが)。
$f(A)=(max(R)-min(R))^2+(max(C)-min(C))^2$をできるだけ小さくする問題になります。まず、一次元の場合を考えればわかりやすいのですが、できるだけ均等に1の数を分けていくことで$f(A)$は小さくなります。
ここで、$k$個の1を順にできるだけ均等に1をそれぞれの行及び列に配置していくことを考えます。また、均等に配布していく際に、対称性を意識することと何らかのルールを決めることの二つを守りながら考えました。さらに、$max(R)-min(R)$及び$max(C)-min(C)$は$k\%n!=0$の時に0にならないので、それぞれ1にすることを目指した配置を考えます。すると、下図の①→②→③→…の順に配布することでこのルールにしたがって配置できることがわかります。
まず、①の場合は対角成分で対称性が高いことから思いつきました。また、次に隣の斜めの成分(緑の部分)に1を配置していけば良いのではと考えたのですが、この時も$max(R)-min(R)$及び$max(C)-min(C)$は常に0または1を保ったまま変化します。なぜなら、青や緑や黄の成分に含まれる行及び列は$n$個ずつで全て互いに異なるので、他の行及び列と比べてその和が2以上大きくなることがないからです。したがって、全て互いに異なるように配置すれば良いと一般化することができ、上図と同様に斜めの成分に順に配置していけば良いです。また、この成分は$0 \leqq i,j \leqq n-1$で$(i,(i+j)\%n)$として表すことができ、$i,j$を順に動かして$k$回1を配置したものを出力すれば良いです。
D.pyfor _ in range(int(input())): n,k=map(int,input().split()) ans=[[0]*n for i in range(n)] f=False for j in range(n): for i in range(n): if k==0: f=True break k-=1 ans[i][(i+j)%n]=1 if f: break r=[sum(ans[i]) for i in range(n)] mar,mir=max(r),min(r) c=[sum([ans[i][j] for i in range(n)]) for j in range(n)] mac,mic=max(c),min(c) print((mar-mir)**2+(mac-mic)**2) for i in range(n): print("".join(map(str,ans[i])))E1問題
昼飯を食べてて実装できませんでした、悔しいです!!
全ての敵に勝つ場合を想定しているので、初めに$x$個のキャンディーを持っているとすれば$i(0 \leqq i \leqq n-1)$番目の敵と戦う時に$x+i$個のキャンディーを持っています。また、敵以上の個数のキャンディーを持っていれば良いので、$i$番目の人は$x+i$個以下のキャンディーを持つ敵であれば勝利できます。また、このような敵の選び方は敵のキャンディーの数をソートしておけば(ソートせずに1WAを出しました…)、
bisect_rightにより求めることができます。また、$i$番目の人より前の人は$i$人の敵をすでに選んでいるので、実際に選べる敵の数は「($x+i$個以下のキャンディーを持つ敵の数)-$i$」人となります。また、この値が$0$以下になる人が存在する場合は敵の選び方は0通りで$p$で割り切れるので題意を満たしません。また、$x \geqq max(a)$の時は任意の敵の選び方ができるので$n!$通り、$x<min(a)$の時は選び方が存在しないので$0$通りより、いずれも$p$で割り切れるので、$min(a) \leqq x <max(a)$の範囲内で選び方の総数が$p$で割り切れないものを探せば良いです。E.pyn,p=map(int,input().split()) a=list(map(int,input().split())) a.sort() ans=[] from bisect import bisect_right for i in range(min(a),max(a)): for j in range(n): b=bisect_right(a,i+j)-j if b<=0: break elif b%p==0: break else: ans.append(i) print(len(ans)) print(" ".join(map(str,ans)))E2問題以降
今回は飛ばします

- 投稿日:2020-08-18T20:32:46+09:00
AtCoder 174 BCD
B問題
ポイント
- 累乗は**でした。^で計算しようとしてハマった
- 距離の計算でsqrt(x*2, y*2)とすると小数誤差が生じて等号の境界でぴたりと等号を満たせない可能性がある。代わりに以下が推奨
- 等号にせず、ごく小さいepsを大きく出るべき方に足すか小さく出るべき方で引く
- 両辺を二乗してsqrtを避け、整数で解く!!
B.pyimport math N, D = list(map(int,input().split())) cnt = 0 for i in range(N): x, y = list(map(int, input().split())) if (x**2)+(y**2) <= D**2: cnt+=1 print(cnt)C問題
アルゴリズムも実装もわからずボロボロでした。
ポイント
- 7, 77, 777の数列はa_i = a_i*10 + 7 と規則的
- このとき、あまりも規則的(周期的)
- a_i をKでわったあまりをmod_iとすると、数列a_iは前項を10倍して7を足すので、当然前項に対して計算したあまりも10倍して7を足す。 => mod_i = (mod_i-1 * 10 + 7) % K
- Kで割った時のあまりはK以下。
- 上記より、あまりは0~Kの間で循環する。
- これは、K桁まで7を並べるケースを試せば、必ずどこかで一巡を終えるということ!!
- すなわちK桁の7を並べた数まで繰り返せばいい
- 循環すれば割り切れないと判断なので、あまりをリストで保持して循環を検知したい。
- しかし、要素数が非常に大きいときのappendはめちゃくちゃ遅い!!!
- なので貪欲にKまで繰り返せばいい
C.pyK=int(input()) amari=0 for i in range(K): amari = (amari * 10 + 7)% K if amari == 0: print(i+1) break if i == (K-1): print(-1)C_RE.pyK=int(input()) amari_list = [] amari = 7%K if amari == 0: print(1) amari_list.append(amari) for i in range(1,K): amari = (amari * 10 + 7)% K if amari == 0: print(i+1) break if amari in amari_list: print(-1) break if i == (K-1): print(-1) else: amari_list.append(amari)D問題
ポイント
- 最終状態をイメージする。
- 赤の左に白がだめ、というとき、ある白の右には(隣でなくとも)赤があってはいけない。
- そのような状態はいくつもある(WWWW, RWWW, RRWW...) ので、その起こりえる状態のなかでそれぞれ操作回数を比較すればよい
各状態の操作回数は現在の状態と目標の状態の差で決まる。
- 愚直に行えば、色が異なる数だけ色変えをする必要がある。しかし、都合のよい白と赤を交換すれば色変え2回分を一度の操作で達成できる。
- 状態毎にギャップを図り直すと2重ループ(O(n^2))になってしまうので、他の方法を考える。
- 状態を左からひとつずつ変えれば、その変えた部分だけ見ればよいのでループする必要がなくなる
未証明だが、より簡潔な解法でACした。
最終状態は左からRが連続し、右にはWが連続する状態になる。
これを達成したいとき、色変えよりも交換の方が常に効率的っぽい
- 入力例3で、「WRWWRWRR」が与えられたとき、色変えだけでは4回必要。交換を入れることで最小の3回になる。
交換だけでこれを最終状態を実現したいとき、必要な交換の回数は、最終状態のWの連続部分と現状のその部分を比較して、Rの数を数えればよい
D.py_ = input() s = input() R_num = s.count("R") print(s[:R_num].count("W"))
- 投稿日:2020-08-18T20:17:51+09:00
【言語処理100本ノック 2020】第8章: ニューラルネット
はじめに
自然言語処理の問題集として有名な言語処理100本ノックの2020年版が公開されました。
この記事では、以下の第1章から第10章のうち、「第8章: ニューラルネット」を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNN, CNN
- 第10章: 機械翻訳
事前準備
解答にはGoogle Colaboratoryを利用しています。
Google Colaboratoryのセットアップ方法や基本的な使い方は、こちらの記事が詳しいです。
本章ではGPUを利用するため、事前に「ランタイム」 -> 「ランタイムのタイプを変更」から、ハードウェアアクセラレータを「GPU」に変更し、保存しておいてください。
なお、以降の解答の実行結果を含むノートブックはgithubにて公開しています。第8章: ニューラルネット
第6章で取り組んだニュース記事のカテゴリ分類を題材として,ニューラルネットワークでカテゴリ分類モデルを実装する.なお,この章ではPyTorch, TensorFlow, Chainerなどの機械学習プラットフォームを活用せよ.
70. 単語ベクトルの和による特徴量
問題50で構築した学習データ,検証データ,評価データを行列・ベクトルに変換したい.例えば,学習データについて,すべての事例$x_i$の特徴ベクトル$\boldsymbol{x}_i$を並べた行列$X$と正解ラベルを並べた行列(ベクトル)$Y$を作成したい.
X = \begin{pmatrix} \boldsymbol{x}_1 \\ \boldsymbol{x}_2 \\ \dots \\ \boldsymbol{x}_n \\ \end{pmatrix} \in \mathbb{R}^{n \times d}, Y = \begin{pmatrix} y_1 \\ y_2 \\ \dots \\ y_n \\ \end{pmatrix} \in \mathbb{N}^{n}ここで,$n$は学習データの事例数であり,$\boldsymbol x_i \in \mathbb{R}^d$と$y_i \in \mathbb N$はそれぞれ,$i \in {1, \dots, n}$番目の事例の特徴量ベクトルと正解ラベルを表す.
なお,今回は「ビジネス」「科学技術」「エンターテイメント」「健康」の4カテゴリ分類である.$\mathbb N_{<4}$で$4$未満の自然数($0$を含む)を表すことにすれば,任意の事例の正解ラベル$y_i$は$y_i \in \mathbb N_{<4}$で表現できる.
以降では,ラベルの種類数を$L$で表す(今回の分類タスクでは$L=4$である).$i$番目の事例の特徴ベクトル$\boldsymbol x_i$は,次式で求める.
$$\boldsymbol x_i = \frac{1}{T_i} \sum_{t=1}^{T_i} \mathrm{emb}(w_{i,t})$$
ここで,$i$番目の事例は$T_i$個の(記事見出しの)単語列$(w_{i,1}, w_{i,2}, \dots, w_{i,T_i})$から構成され,$\mathrm{emb}(w) \in \mathbb{R}^d$は単語$w$に対応する単語ベクトル(次元数は$d$)である.すなわち,$i$番目の事例の記事見出しを,その見出しに含まれる単語のベクトルの平均で表現したものが$\boldsymbol x_i$である.今回は単語ベクトルとして,問題60でダウンロードしたものを用いればよい.$300$次元の単語ベクトルを用いたので,$d=300$である.
$i$番目の事例のラベル$y_i$は,次のように定義する.y_i = \begin{cases} 0 & (\mbox{記事}\boldsymbol x_i\mbox{が「ビジネス」カテゴリの場合}) \\ 1 & (\mbox{記事}\boldsymbol x_i\mbox{が「科学技術」カテゴリの場合}) \\ 2 & (\mbox{記事}\boldsymbol x_i\mbox{が「エンターテイメント」カテゴリの場合}) \\ 3 & (\mbox{記事}\boldsymbol x_i\mbox{が「健康」カテゴリの場合}) \\ \end{cases}なお,カテゴリ名とラベルの番号が一対一で対応付いていれば,上式の通りの対応付けでなくてもよい.
以上の仕様に基づき,以下の行列・ベクトルを作成し,ファイルに保存せよ.
- 学習データの特徴量行列: $X_{\rm train} \in \mathbb{R}^{N_t \times d}$
- 学習データのラベルベクトル: $Y_{\rm train} \in \mathbb{N}^{N_t}$
- 検証データの特徴量行列: $X_{\rm valid} \in \mathbb{R}^{N_v \times d}$
- 検証データのラベルベクトル: $Y_{\rm valid} \in \mathbb{N}^{N_v}$
- 評価データの特徴量行列: $X_{\rm test} \in \mathbb{R}^{N_e \times d}$
- 評価データのラベルベクトル: $Y_{\rm test} \in \mathbb{N}^{N_e}$
なお,$N_t, N_v, N_e$はそれぞれ,学習データの事例数,検証データの事例数,評価データの事例数である.
まずは、指定のデータをダウンロード後、データフレームとして読込みます。そして、学習データ、検証データ、評価データに分割し、保存します。
ここまでは、第6章の問題50とまったく同じ処理のため、そちらで作成したデータを読み込んでも問題ありません。# データのダウンロード !wget https://archive.ics.uci.edu/ml/machine-learning-databases/00359/NewsAggregatorDataset.zip !unzip NewsAggregatorDataset.zip# 読込時のエラー回避のためダブルクォーテーションをシングルクォーテーションに置換 !sed -e 's/"/'\''/g' ./newsCorpora.csv > ./newsCorpora_re.csvimport pandas as pd from sklearn.model_selection import train_test_split # データの読込 df = pd.read_csv('./newsCorpora_re.csv', header=None, sep='\t', names=['ID', 'TITLE', 'URL', 'PUBLISHER', 'CATEGORY', 'STORY', 'HOSTNAME', 'TIMESTAMP']) # データの抽出 df = df.loc[df['PUBLISHER'].isin(['Reuters', 'Huffington Post', 'Businessweek', 'Contactmusic.com', 'Daily Mail']), ['TITLE', 'CATEGORY']] # データの分割 train, valid_test = train_test_split(df, test_size=0.2, shuffle=True, random_state=123, stratify=df['CATEGORY']) valid, test = train_test_split(valid_test, test_size=0.5, shuffle=True, random_state=123, stratify=valid_test['CATEGORY']) # 事例数の確認 print('【学習データ】') print(train['CATEGORY'].value_counts()) print('【検証データ】') print(valid['CATEGORY'].value_counts()) print('【評価データ】') print(test['CATEGORY'].value_counts())出力【学習データ】 b 4501 e 4235 t 1220 m 728 Name: CATEGORY, dtype: int64 【検証データ】 b 563 e 529 t 153 m 91 Name: CATEGORY, dtype: int64 【評価データ】 b 563 e 530 t 152 m 91 Name: CATEGORY, dtype: int64続いて、第7章の問題60でも利用した学習済み単語ベクトルをダウンロードし、ロードします。
import gdown from gensim.models import KeyedVectors # 学習済み単語ベクトルのダウンロード url = "https://drive.google.com/uc?id=0B7XkCwpI5KDYNlNUTTlSS21pQmM" output = 'GoogleNews-vectors-negative300.bin.gz' gdown.download(url, output, quiet=True) # ダウンロードファイルのロード model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin.gz', binary=True)最後に、特徴ベクトルとラベルベクトルを作成し、保存します。
なお、このあとPyTorchによるニューラルネットのインプットとして利用するため、Tensor型に変換しています。import string import torch def transform_w2v(text): table = str.maketrans(string.punctuation, ' '*len(string.punctuation)) words = text.translate(table).split() # 記号をスペースに置換後、スペースで分割してリスト化 vec = [model[word] for word in words if word in model] # 1語ずつベクトル化 return torch.tensor(sum(vec) / len(vec)) # 平均ベクトルをTensor型に変換して出力# 特徴ベクトルの作成 X_train = torch.stack([transform_w2v(text) for text in train['TITLE']]) X_valid = torch.stack([transform_w2v(text) for text in valid['TITLE']]) X_test = torch.stack([transform_w2v(text) for text in test['TITLE']]) print(X_train.size()) print(X_train)出力torch.Size([10684, 300]) tensor([[ 0.0837, 0.0056, 0.0068, ..., 0.0751, 0.0433, -0.0868], [ 0.0272, 0.0266, -0.0947, ..., -0.1046, -0.0489, -0.0092], [ 0.0577, -0.0159, -0.0780, ..., -0.0421, 0.1229, 0.0876], ..., [ 0.0392, -0.0052, 0.0686, ..., -0.0175, 0.0061, -0.0224], [ 0.0798, 0.1017, 0.1066, ..., -0.0752, 0.0623, 0.1138], [ 0.1664, 0.0451, 0.0508, ..., -0.0531, -0.0183, -0.0039]])# ラベルベクトルの作成 category_dict = {'b': 0, 't': 1, 'e':2, 'm':3} y_train = torch.tensor(train['CATEGORY'].map(lambda x: category_dict[x]).values) y_valid = torch.tensor(valid['CATEGORY'].map(lambda x: category_dict[x]).values) y_test = torch.tensor(test['CATEGORY'].map(lambda x: category_dict[x]).values) print(y_train.size()) print(y_train)出力torch.Size([10684]) tensor([0, 1, 3, ..., 0, 3, 2])# 保存 torch.save(X_train, 'X_train.pt') torch.save(X_valid, 'X_valid.pt') torch.save(X_test, 'X_test.pt') torch.save(y_train, 'y_train.pt') torch.save(y_valid, 'y_valid.pt') torch.save(y_test, 'y_test.pt')71. 単層ニューラルネットワークによる予測
問題70で保存した行列を読み込み,学習データについて以下の計算を実行せよ.
\hat{y}_1=softmax(x_1W),\\\hat{Y}=softmax(X_{[1:4]}W)ただし,$softmax$はソフトマックス関数,$X_{[1:4]}∈\mathbb{R}^{4×d}$は特徴ベクトル$x_1$,$x_2$,$x_3$,$x_4$を縦に並べた行列である.
X_{[1:4]}=\begin{pmatrix}x_1\\x_2\\x_3\\x_4\end{pmatrix}行列$W \in \mathbb{R}^{d \times L}$は単層ニューラルネットワークの重み行列で,ここではランダムな値で初期化すればよい(問題73以降で学習して求める).なお,$\hat{\boldsymbol y_1} \in \mathbb{R}^L$は未学習の行列$W$で事例$x_1$を分類したときに,各カテゴリに属する確率を表すベクトルである.
同様に,$\hat{Y} \in \mathbb{R}^{n \times L}$は,学習データの事例$x_1, x_2, x_3, x_4$について,各カテゴリに属する確率を行列として表現している.はじめに、
SLPNetという単層ニューラルネットワークを定義します。__init__でネットワークを構成するレイヤーを定義し、forwardメソッドでインプットデータが順伝播時に通るレイヤーを順に配置していきます。from torch import nn class SLPNet(nn.Module): def __init__(self, input_size, output_size): super().__init__() self.fc = nn.Linear(input_size, output_size, bias=False) nn.init.normal_(self.fc.weight, 0.0, 1.0) # 正規乱数で重みを初期化 def forward(self, x): x = self.fc(x) return x続いて、定義したモデルを初期化し、指示された計算を実行します。
model = SLPNet(300, 4) # 単層ニューラルネットワークの初期化 y_hat_1 = torch.softmax(model(X_train[:1]), dim=-1) print(y_hat_1)出力tensor([[0.4273, 0.0958, 0.2492, 0.2277]], grad_fn=<SoftmaxBackward>)Y_hat = torch.softmax(model.forward(X_train[:4]), dim=-1) print(Y_hat)出力tensor([[0.4273, 0.0958, 0.2492, 0.2277], [0.2445, 0.2431, 0.0197, 0.4927], [0.7853, 0.1132, 0.0291, 0.0724], [0.5279, 0.2319, 0.0873, 0.1529]], grad_fn=<SoftmaxBackward>)72. 損失と勾配の計算
学習データの事例$x_1$と事例集合$x_1$,$x_2$,$x_3$,$x_4$に対して,クロスエントロピー損失と,行列$W$に対する勾配を計算せよ.なお,ある事例$x_i$に対して損失は次式で計算される.
$$l_i=−log[事例x_iがy_iに分類される確率]$$
ただし,事例集合に対するクロスエントロピー損失は,その集合に含まれる各事例の損失の平均とする.
ここでは、
nnパッケージのCrossEntropyLossを利用します。
モデルの出力ベクトルとラベルベクトルを入力することで、上式の平均損失を計算することができます。criterion = nn.CrossEntropyLoss()l_1 = criterion(model(X_train[:1]), y_train[:1]) # 入力ベクトルはsoftmax前の値 model.zero_grad() # 勾配をゼロで初期化 l_1.backward() # 勾配を計算 print(f'損失: {l_1:.4f}') print(f'勾配:\n{model.fc.weight.grad}')出力損失: 2.9706 勾配: tensor([[-0.0794, -0.0053, -0.0065, ..., -0.0713, -0.0411, 0.0823], [ 0.0022, 0.0001, 0.0002, ..., 0.0020, 0.0011, -0.0023], [ 0.0611, 0.0041, 0.0050, ..., 0.0549, 0.0316, -0.0634], [ 0.0161, 0.0011, 0.0013, ..., 0.0144, 0.0083, -0.0167]])l = criterion(model(X_train[:4]), y_train[:4]) model.zero_grad() l.backward() print(f'損失: {l:.4f}') print(f'勾配:\n{model.fc.weight.grad}')出力損失: 3.0799 勾配: tensor([[-0.0207, 0.0079, -0.0090, ..., -0.0350, -0.0003, 0.0232], [-0.0055, -0.0063, 0.0225, ..., 0.0252, 0.0166, 0.0039], [ 0.0325, -0.0089, -0.0215, ..., 0.0084, 0.0122, -0.0030], [-0.0063, 0.0072, 0.0081, ..., 0.0014, -0.0285, -0.0241]])73. 確率的勾配降下法による学習
確率的勾配降下法(SGD: Stochastic Gradient Descent)を用いて,行列$W$を学習せよ.なお,学習は適当な基準で終了させればよい(例えば「100エポックで終了」など).
学習に当たり、
DatasetとDataloaderを準備します。
Datasetは特徴ベクトルとラベルベクトルを合わせて保持することができる型で、以下のクラスを用いてもとのTensorを変換します。from torch.utils.data import Dataset class NewsDataset(Dataset): def __init__(self, X, y): # datasetの構成要素を指定 self.X = X self.y = y def __len__(self): # len(dataset)で返す値を指定 return len(self.y) def __getitem__(self, idx): # dataset[idx]で返す値を指定 return [self.X[idx], self.y[idx]]変換後、
DataLoaderを作成します。DataloaderはDatasetを入力とし、指定したサイズ(batch_size)にまとめたデータを順に取り出すことができます。ここではbatch_size=1としているので、1つずつデータを取り出すDataloaderを作成することを意味します。
なお、Dataloaderはfor文で順に取り出すか、またはnext(iter(Dataloader))で次のかたまりを呼び出すことが可能です。from torch.utils.data import DataLoader # Datasetの作成 Dataset_train = NewsDataset(X_train, y_train) dataset_valid = NewsDataset(X_valid, y_valid) dataset_test = NewsDataset(X_test, y_test) # Dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=1, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) dataloader_test = DataLoader(dataset_test, batch_size=len(dataset_test), shuffle=False)データの準備ができたので、行列$W$を学習します。
モデルの定義、損失関数の定義は前問と同様です。今回は計算した勾配から重みも更新するため、オプティマイザも定義します。ここでは指示に従いSGDをセットしています。
部品が揃ったところで、エポック数を10として学習を実行します。# モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # 学習 num_epochs = 10 for epoch in range(num_epochs): # 訓練モードに設定 model.train() loss_train = 0.0 for i, (inputs, labels) in enumerate(dataloader_train): # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失を記録 loss_train += loss.item() # バッチ単位の平均損失計算 loss_train = loss_train / i # 検証データの損失計算 model.eval() with torch.no_grad(): inputs, labels = next(iter(dataloader_valid)) outputs = model(inputs) loss_valid = criterion(outputs, labels) # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, loss_valid: {loss_valid:.4f}')出力epoch: 1, loss_train: 0.4745, loss_valid: 0.3637 epoch: 2, loss_train: 0.3173, loss_valid: 0.3306 epoch: 3, loss_train: 0.2884, loss_valid: 0.3208 epoch: 4, loss_train: 0.2716, loss_valid: 0.3150 epoch: 5, loss_train: 0.2615, loss_valid: 0.3141 epoch: 6, loss_train: 0.2519, loss_valid: 0.3092 epoch: 7, loss_train: 0.2474, loss_valid: 0.3114 epoch: 8, loss_train: 0.2431, loss_valid: 0.3072 epoch: 9, loss_train: 0.2393, loss_valid: 0.3096 epoch: 10, loss_train: 0.2359, loss_valid: 0.3219エポックが進むについて、徐々に学習データの損失が下がっていることが分かります。
74. 正解率の計測
問題73で求めた行列を用いて学習データおよび評価データの事例を分類したとき,その正解率をそれぞれ求めよ.
学習したモデルと
Dataloaderを入力として、正解率を算出する関数を定義します。def calculate_accuracy(model, loader): model.eval() total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: outputs = model(inputs) pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return correct / totalacc_train = calculate_accuracy(model, dataloader_train) acc_test = calculate_accuracy(model, dataloader_test) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')出力正解率(学習データ):0.920 正解率(評価データ):0.89175. 損失と正解率のプロット
問題73のコードを改変し,各エポックのパラメータ更新が完了するたびに,訓練データでの損失,正解率,検証データでの損失,正解率をグラフにプロットし,学習の進捗状況を確認できるようにせよ.
前問の関数を損失も計算できるように改変し、エポック毎に適用することで損失と正解率を記録します。
def calculate_loss_and_accuracy(model, criterion, loader): model.eval() loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: outputs = model(inputs) loss += criterion(outputs, labels).item() pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return loss / len(loader), correct / total# モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # 学習 num_epochs = 30 log_train = [] log_valid = [] for epoch in range(num_epochs): # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}')出力epoch: 1, loss_train: 0.3476, accuracy_train: 0.8796, loss_valid: 0.3656, accuracy_valid: 0.8840 epoch: 2, loss_train: 0.2912, accuracy_train: 0.8988, loss_valid: 0.3219, accuracy_valid: 0.8967 ・・・ epoch: 29, loss_train: 0.2102, accuracy_train: 0.9287, loss_valid: 0.3259, accuracy_valid: 0.8930 epoch: 30, loss_train: 0.2119, accuracy_train: 0.9289, loss_valid: 0.3262, accuracy_valid: 0.8945from matplotlib import pyplot as plt # 視覚化 fig, ax = plt.subplots(1, 2, figsize=(15, 5)) ax[0].plot(np.array(log_train).T[0], label='train') ax[0].plot(np.array(log_valid).T[0], label='valid') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[0].legend() ax[1].plot(np.array(log_train).T[1], label='train') ax[1].plot(np.array(log_valid).T[1], label='valid') ax[1].set_xlabel('epoch') ax[1].set_ylabel('accuracy') ax[1].legend() plt.show()
76. チェックポイント
問題75のコードを改変し,各エポックのパラメータ更新が完了するたびに,チェックポイント(学習途中のパラメータ(重み行列など)の値や最適化アルゴリズムの内部状態)をファイルに書き出せ.
学習途中のパラメータは
model.state_dict()、最適化アルゴリズムの内部状態はoptimizer.state_dict()でアクセス可能なので、各エポックでエポック数と合わせて保存する処理を追加します。
なお、出力は前問と同様のため省略します。# モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # 学習 num_epochs = 10 log_train = [] log_valid = [] for epoch in range(num_epochs): # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}')77. ミニバッチ化
問題76のコードを改変し,$B$事例ごとに損失・勾配を計算し,行列$W$の値を更新せよ(ミニバッチ化).$B$の値を$1,2,4,8,…$と変化させながら,1エポックの学習に要する時間を比較せよ.
バッチサイズを変えるごとにすべての処理を書くのは大変なので、
Dataloaderの作成以降の処理をtrain_modelとして関数化し、バッチサイズを含むいくつかのパラメータを引数として設定します。import time def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs): # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') return {'train': log_train, 'valid': log_valid}バッチサイズを変えながら、処理時間を計測します。
# datasetの作成 dataset_train = CreateDataset(X_train, y_train) dataset_valid = CreateDataset(X_valid, y_valid) # モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # モデルの学習 for batch_size in [2 ** i for i in range(11)]: print(f'バッチサイズ: {batch_size}') log = train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, 1)出力バッチサイズ: 1 epoch: 1, loss_train: 0.3237, accuracy_train: 0.8888, loss_valid: 0.3476, accuracy_valid: 0.8817, 5.4416sec バッチサイズ: 2 epoch: 1, loss_train: 0.2966, accuracy_train: 0.8999, loss_valid: 0.3258, accuracy_valid: 0.8847, 3.0029sec バッチサイズ: 4 epoch: 1, loss_train: 0.2883, accuracy_train: 0.8999, loss_valid: 0.3222, accuracy_valid: 0.8862, 1.5988sec バッチサイズ: 8 epoch: 1, loss_train: 0.2835, accuracy_train: 0.9023, loss_valid: 0.3179, accuracy_valid: 0.8907, 0.8732sec バッチサイズ: 16 epoch: 1, loss_train: 0.2817, accuracy_train: 0.9038, loss_valid: 0.3164, accuracy_valid: 0.8907, 0.5445sec バッチサイズ: 32 epoch: 1, loss_train: 0.2810, accuracy_train: 0.9038, loss_valid: 0.3159, accuracy_valid: 0.8900, 0.3482sec バッチサイズ: 64 epoch: 1, loss_train: 0.2806, accuracy_train: 0.9040, loss_valid: 0.3157, accuracy_valid: 0.8900, 0.2580sec バッチサイズ: 128 epoch: 1, loss_train: 0.2806, accuracy_train: 0.9041, loss_valid: 0.3156, accuracy_valid: 0.8900, 0.1984sec バッチサイズ: 256 epoch: 1, loss_train: 0.2801, accuracy_train: 0.9039, loss_valid: 0.3155, accuracy_valid: 0.8900, 0.1715sec バッチサイズ: 512 epoch: 1, loss_train: 0.2802, accuracy_train: 0.9038, loss_valid: 0.3155, accuracy_valid: 0.8900, 0.2177sec バッチサイズ: 1024 epoch: 1, loss_train: 0.2792, accuracy_train: 0.9038, loss_valid: 0.3155, accuracy_valid: 0.8900, 0.1603sec概ね、バッチサイズが大きいほど計算時間が短くなってることが分かります。
78. GPU上での学習
問題77のコードを改変し,GPU上で学習を実行せよ.
GPUを指定する引数
deviceをcalculate_loss_and_accuracy、train_modelに追加します。
それぞれの関数内で、モデルおよび入力TensorをGPUに送る処理を追加し、deviceにcudaを指定すればGPUを使用することができます。def calculate_loss_and_accuracy(model, criterion, loader, device): model.eval() loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) loss += criterion(outputs, labels).item() pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return loss / len(loader), correct / total def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs, device=None): # GPUに送る model.to(device) # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 inputs = inputs.to(device) labels = labels.to(device) outputs = model.forward(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train, device) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid, device) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') return {'train': log_train, 'valid': log_valid}# datasetの作成 dataset_train = CreateDataset(X_train, y_train) dataset_valid = CreateDataset(X_valid, y_valid) # モデルの定義 model = SLPNet(300, 4) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-1) # デバイスの指定 device = torch.device('cuda') # モデルの学習 for batch_size in [2 ** i for i in range(11)]: print(f'バッチサイズ: {batch_size}') log = train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, 1, device=device)出力バッチサイズ: 1 epoch: 1, loss_train: 0.3300, accuracy_train: 0.8874, loss_valid: 0.3584, accuracy_valid: 0.8772, 9.0342sec バッチサイズ: 2 epoch: 1, loss_train: 0.3025, accuracy_train: 0.8994, loss_valid: 0.3374, accuracy_valid: 0.8870, 4.6391sec バッチサイズ: 4 epoch: 1, loss_train: 0.2938, accuracy_train: 0.9005, loss_valid: 0.3321, accuracy_valid: 0.8855, 2.4228sec バッチサイズ: 8 epoch: 1, loss_train: 0.2894, accuracy_train: 0.9039, loss_valid: 0.3299, accuracy_valid: 0.8855, 1.2517sec バッチサイズ: 16 epoch: 1, loss_train: 0.2876, accuracy_train: 0.9038, loss_valid: 0.3285, accuracy_valid: 0.8855, 0.7149sec バッチサイズ: 32 epoch: 1, loss_train: 0.2867, accuracy_train: 0.9050, loss_valid: 0.3280, accuracy_valid: 0.8862, 0.4323sec バッチサイズ: 64 epoch: 1, loss_train: 0.2863, accuracy_train: 0.9050, loss_valid: 0.3277, accuracy_valid: 0.8862, 0.2834sec バッチサイズ: 128 epoch: 1, loss_train: 0.2869, accuracy_train: 0.9051, loss_valid: 0.3276, accuracy_valid: 0.8862, 0.2070sec バッチサイズ: 256 epoch: 1, loss_train: 0.2864, accuracy_train: 0.9054, loss_valid: 0.3275, accuracy_valid: 0.8862, 0.1587sec バッチサイズ: 512 epoch: 1, loss_train: 0.2859, accuracy_train: 0.9056, loss_valid: 0.3275, accuracy_valid: 0.8862, 0.2016sec バッチサイズ: 1024 epoch: 1, loss_train: 0.2858, accuracy_train: 0.9056, loss_valid: 0.3275, accuracy_valid: 0.8862, 0.1303sec79. 多層ニューラルネットワーク
問題78のコードを改変し,バイアス項の導入や多層化など,ニューラルネットワークの形状を変更しながら,高性能なカテゴリ分類器を構築せよ.
多層ニューラルネットワーク
MLPNetを新たに定義します。このネットワークは入力層 -> 中間層 -> 出力層の構成とし、中間層のあとにバッチノーマライゼーションを行うことにします。
また、train_modelでは新たに学習の打ち切り基準を導入します。今回はシンプルに、検証データの損失が3エポック連続で低下しなかった場合に打ち切るルールとします。
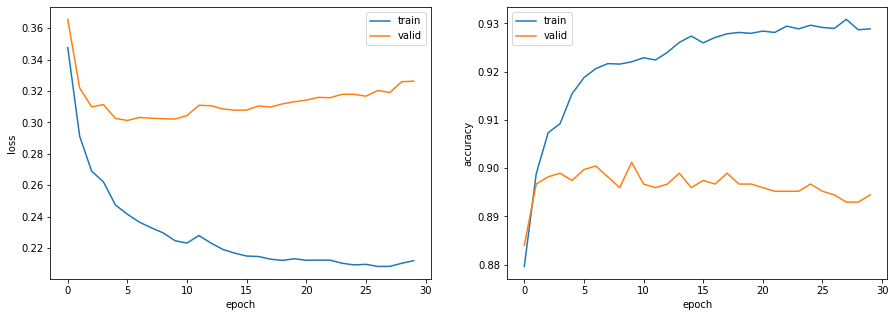
さらに、学習率を徐々に下げるスケジューラも追加し、汎化性能の向上を狙います。from torch.nn import functional as F class MLPNet(nn.Module): def __init__(self, input_size, mid_size, output_size, mid_layers): super().__init__() self.mid_layers = mid_layers self.fc = nn.Linear(input_size, mid_size) self.fc_mid = nn.Linear(mid_size, mid_size) self.fc_out = nn.Linear(mid_size, output_size) self.bn = nn.BatchNorm1d(mid_size) def forward(self, x): x = F.relu(self.fc(x)) for _ in range(self.mid_layers): x = F.relu(self.bn(self.fc_mid(x))) x = F.relu(self.fc_out(x)) return xfrom torch import optim def calculate_loss_and_accuracy(model, criterion, loader, device): model.eval() loss = 0.0 total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) loss += criterion(outputs, labels).item() pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return loss / len(loader), correct / total def train_model(dataset_train, dataset_valid, batch_size, model, criterion, optimizer, num_epochs, device=None): # GPUに送る model.to(device) # dataloaderの作成 dataloader_train = DataLoader(dataset_train, batch_size=batch_size, shuffle=True) dataloader_valid = DataLoader(dataset_valid, batch_size=len(dataset_valid), shuffle=False) # スケジューラの設定 scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, num_epochs, eta_min=1e-5, last_epoch=-1) # 学習 log_train = [] log_valid = [] for epoch in range(num_epochs): # 開始時刻の記録 s_time = time.time() # 訓練モードに設定 model.train() for inputs, labels in dataloader_train: # 勾配をゼロで初期化 optimizer.zero_grad() # 順伝播 + 誤差逆伝播 + 重み更新 inputs = inputs.to(device) labels = labels.to(device) outputs = model.forward(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 損失と正解率の算出 loss_train, acc_train = calculate_loss_and_accuracy(model, criterion, dataloader_train, device) loss_valid, acc_valid = calculate_loss_and_accuracy(model, criterion, dataloader_valid, device) log_train.append([loss_train, acc_train]) log_valid.append([loss_valid, acc_valid]) # チェックポイントの保存 torch.save({'epoch': epoch, 'model_state_dict': model.state_dict(), 'optimizer_state_dict': optimizer.state_dict()}, f'checkpoint{epoch + 1}.pt') # 終了時刻の記録 e_time = time.time() # ログを出力 print(f'epoch: {epoch + 1}, loss_train: {loss_train:.4f}, accuracy_train: {acc_train:.4f}, loss_valid: {loss_valid:.4f}, accuracy_valid: {acc_valid:.4f}, {(e_time - s_time):.4f}sec') # 検証データの損失が3エポック連続で低下しなかった場合は学習終了 if epoch > 2 and log_valid[epoch - 3][0] <= log_valid[epoch - 2][0] <= log_valid[epoch - 1][0] <= log_valid[epoch][0]: break # スケジューラを1ステップ進める scheduler.step() return {'train': log_train, 'valid': log_valid}# datasetの作成 dataset_train = CreateDataset(X_train, y_train) dataset_valid = CreateDataset(X_valid, y_valid) # モデルの定義 model = MLPNet(300, 200, 4, 1) # 損失関数の定義 criterion = nn.CrossEntropyLoss() # オプティマイザの定義 optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) # デバイスの指定 device = torch.device('cuda') # モデルの学習 log = train_model(dataset_train, dataset_valid, 64, model, criterion, optimizer, 1000, device)出力epoch: 1, loss_train: 1.1176, accuracy_train: 0.6679, loss_valid: 1.1150, accuracy_valid: 0.6572, 0.4695sec epoch: 2, loss_train: 0.8050, accuracy_train: 0.7620, loss_valid: 0.8005, accuracy_valid: 0.7687, 0.4521sec ・・・ epoch: 96, loss_train: 0.1708, accuracy_train: 0.9460, loss_valid: 0.2858, accuracy_valid: 0.9034, 0.4632sec epoch: 97, loss_train: 0.1702, accuracy_train: 0.9466, loss_valid: 0.2861, accuracy_valid: 0.9034, 0.5373sec97エポックで打ち切りとなりました。
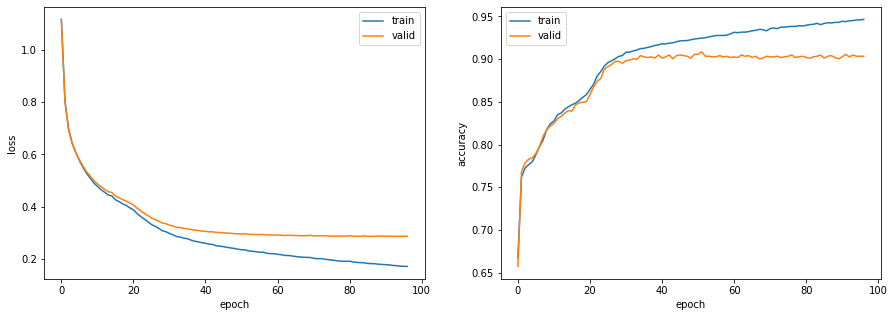
エポックごとの損失と正解率を可視化します。fig, ax = plt.subplots(1, 2, figsize=(15, 5)) ax[0].plot(np.array(log['train']).T[0], label='train') ax[0].plot(np.array(log['valid']).T[0], label='valid') ax[0].set_xlabel('epoch') ax[0].set_ylabel('loss') ax[0].legend() ax[1].plot(np.array(log['train']).T[1], label='train') ax[1].plot(np.array(log['valid']).T[1], label='valid') ax[1].set_xlabel('epoch') ax[1].set_ylabel('accuracy') ax[1].legend() plt.show()
評価データの正解率を確認します。
def calculate_accuracy(model, loader, device): model.eval() total = 0 correct = 0 with torch.no_grad(): for inputs, labels in loader: inputs = inputs.to(device) labels = labels.to(device) outputs = model(inputs) pred = torch.argmax(outputs, dim=-1) total += len(inputs) correct += (pred == labels).sum().item() return correct / total# 正解率の確認 acc_train = calculate_accuracy(model, dataloader_train, device) acc_test = calculate_accuracy(model, dataloader_test, device) print(f'正解率(学習データ):{acc_train:.3f}') print(f'正解率(評価データ):{acc_test:.3f}')出力正解率(学習データ):0.947 正解率(評価データ):0.921単層ニューラルネットワークでは評価データの正解率が0.891でしたが、多層にすることによって3ポイント向上しています。
おわりに
言語処理100本ノックは自然言語処理そのものだけでなく、基本的なデータ処理や汎用的な機械学習についてもしっかり学ぶことができるように作られています。
オンラインコースなどで機械学習を勉強中の方も、とても良いアウトプットの練習になると思いますので、ぜひ挑戦してみてください。
- 投稿日:2020-08-18T20:04:46+09:00
Pythonでハノンっぽい楽譜を作ったお話
はじめに
みなさん、ハノンピアノ教本をご存知ですか?
ピアノ経験者の方は嫌な思い出がある方も多いかもしれません。
ハノンピアノ教本は、ピアノを弾く上でとても基礎的なことが学べる教則本です。
百聞は一見に如かずなので、ぜひ演奏されている動画や楽譜を見てみてください。
今回は、ハノンピアノ教本のなかでも、1〜20番のような曲を自動でつくることを目指しました。使った言語やツール
使った言語は、Pythonです。
また、MITで開発されたPythonの音楽情報処理ライブラリであるmusic21を使用しました。
実は、music21自体が楽譜を作成するわけではなく、MuseScoreやLilypondで楽譜は作成されます。
(ただし、実際に自分がMuseScoreやLilypondを触るわけではないので、その辺の知識はなくて大丈夫です。)
music21については、このブログに大変お世話になりました。ハノンっぽさって?
ハノンっぽい楽譜を作るためには、ハノンっぽさについて考えなければなりません。
以下の条件をハノンっぽさと決めました。
音楽をやってない人にはわかりにくい内容かもしれないので、適当に自分で楽譜を見ながらルールを決めたんだな〜くらいに思ってもらえればいい感じです。
- 最初の音はド。
- 1小節目でやったことを2〜14小節目では繰り返す(上行)。繰り返す際に、前の小節より1音あげる。
- 右手と左手はオクターブ違いのユニゾン。
- 同じ音が連続しない。
- 1つの小節の音は、8度以内におさめる。
- 15〜28小節目は下行。
- 15小節目の最初の音はソから始まる。上行のときと動きが対照的になるようにする。
- 29小節目はドを伸ばして終わる。
これらの条件を守る楽譜をランダムで作成するように実装しました。
結果として、このツイートのような楽譜ができました!ソースコード
ソースコード
Hanon.py# -*- coding: utf-8 -*- from music21 import * import numpy import matplotlib import scipy import random #乱数生成 random_num = [-1 for _ in range(8)] random_num[0] = 0 for i in range(1,8): random_num[i] = random.randint(1, 7) if i >= 1: #前の音符と同じ音符がかぶらないようにする while True: if random_num[i] != random_num[i-1]: break else: random_num[i] = random.randint(1, 7) #楽譜をかくよ ##なんか最初のおまじない stream_right = stream.Part() stream_left = stream.Part() inst1 = instrument.Instrument() inst2 = instrument.Instrument() stream_right.append(inst1) stream_left.append(inst2) tc = clef.TrebleClef() #ト音記号 bc = clef.BassClef() #ヘ音記号 stream_right.append(tc) stream_left.append(bc) otos = ["C1", "D1", "E1", "F1", "G1", "A1", "B1", "C2", "D2", "E2", "F2", "G2", "A2", "B2", "C3", "D3", "E3", "F3", "G3", "A3", "B3", "C4", "D4", "E4", "F4", "G4", "A4", "B4", "C5", "D5", "E5", "F5", "G5", "A5", "B5", "C6"] ##右手 for i in range(14): #のぼり ###1小節目 meas = stream.Measure() n0 = note.Note(otos[random_num[0] + 14 + i], quarterLength = 0.25) meas.append(n0) n1 = note.Note(otos[random_num[1] + 14 + i], quarterLength = 0.25) meas.append(n1) n2 = note.Note(otos[random_num[2] + 14 + i], quarterLength = 0.25) meas.append(n2) n3 = note.Note(otos[random_num[3] + 14 + i], quarterLength = 0.25) meas.append(n3) n4 = note.Note(otos[random_num[4] + 14 + i], quarterLength = 0.25) meas.append(n4) n5 = note.Note(otos[random_num[5] + 14 + i], quarterLength = 0.25) meas.append(n5) n6 = note.Note(otos[random_num[6] + 14 + i], quarterLength = 0.25) meas.append(n6) n7 = note.Note(otos[random_num[7] + 14 + i], quarterLength = 0.25) meas.append(n7) stream_right.append(meas) for i in range(14): #くだり ###1小節目 meas = stream.Measure() x = 18 n0 = note.Note(otos[x + 14 - i], quarterLength = 0.25) meas.append(n0) n1 = note.Note(otos[x - random_num[1] + 14 - i], quarterLength = 0.25) meas.append(n1) n2 = note.Note(otos[x - random_num[2] + 14 - i], quarterLength = 0.25) meas.append(n2) n3 = note.Note(otos[x - random_num[3] + 14 - i], quarterLength = 0.25) meas.append(n3) n4 = note.Note(otos[x - random_num[4] + 14 - i], quarterLength = 0.25) meas.append(n4) n5 = note.Note(otos[x - random_num[5] + 14 - i], quarterLength = 0.25) meas.append(n5) n6 = note.Note(otos[x - random_num[6] + 14 - i], quarterLength = 0.25) meas.append(n6) n7 = note.Note(otos[x - random_num[7] + 14 - i], quarterLength = 0.25) meas.append(n7) stream_right.append(meas) ###最後の小節 meas = stream.Measure() n = note.Note("C3", quarterLength = 2) meas.append(n) stream_right.append(meas) ##左手 for i in range(14): #のぼり ###1小節目 meas = stream.Measure() n0 = note.Note(otos[random_num[0] + 7 + i], quarterLength = 0.25) meas.append(n0) n1 = note.Note(otos[random_num[1] + 7 + i], quarterLength = 0.25) meas.append(n1) n2 = note.Note(otos[random_num[2] + 7 + i], quarterLength = 0.25) meas.append(n2) n3 = note.Note(otos[random_num[3] + 7 + i], quarterLength = 0.25) meas.append(n3) n4 = note.Note(otos[random_num[4] + 7 + i], quarterLength = 0.25) meas.append(n4) n5 = note.Note(otos[random_num[5] + 7 + i], quarterLength = 0.25) meas.append(n5) n6 = note.Note(otos[random_num[6] + 7 + i], quarterLength = 0.25) meas.append(n6) n7 = note.Note(otos[random_num[7] + 7 + i], quarterLength = 0.25) meas.append(n7) stream_left.append(meas) for i in range(14): #くだり ###1小節目 meas = stream.Measure() x = 18 n0 = note.Note(otos[x + 7 - i], quarterLength = 0.25) meas.append(n0) n1 = note.Note(otos[x - random_num[1] + 7 - i], quarterLength = 0.25) meas.append(n1) n2 = note.Note(otos[x - random_num[2] + 7 - i], quarterLength = 0.25) meas.append(n2) n3 = note.Note(otos[x - random_num[3] + 7 - i], quarterLength = 0.25) meas.append(n3) n4 = note.Note(otos[x - random_num[4] + 7 - i], quarterLength = 0.25) meas.append(n4) n5 = note.Note(otos[x - random_num[5] + 7 - i], quarterLength = 0.25) meas.append(n5) n6 = note.Note(otos[x - random_num[6] + 7 - i], quarterLength = 0.25) meas.append(n6) n7 = note.Note(otos[x - random_num[7] + 7 - i], quarterLength = 0.25) meas.append(n7) stream_left.append(meas) ###最後の小節 meas = stream.Measure() n = note.Note("C2", quarterLength = 2) meas.append(n) stream_left.append(meas) ##最後のおまじない s = stream.Score() s.append(stream_right) s.append(stream_left) s.show('musicxml')GitHubでも見れます。
ここからは、ソースコードを区切って説明していきます。
ただ、わたしはmusic21を使い始めたばかりで、よくわからず他の方の真似をして書いている部分も多いので、間違っていたらご指摘お願いします。ライブラリたち
# -*- coding: utf-8 -*- from music21 import * import numpy import matplotlib import scipy import randomrandom以外は、music21を使うために必要らしいので、とりあえずインポートしときました。
乱数を作りたいので、randomをインポートしておきます。乱数を作る
#乱数生成 random_num = [-1 for _ in range(8)] random_num[0] = 0 for i in range(1,8): random_num[i] = random.randint(1, 7) if i >= 1: #前の音符と同じ音符がかぶらないようにする while True: if random_num[i] != random_num[i-1]: break else: random_num[i] = random.randint(1, 7)1小節目の2〜8音目のみをランダムにすれば、あとはそれを転調していくだけなので、乱数は7つ用意しました。
レ〜シと数字を対応させたかったので、乱数は1〜8の範囲で作りました。
同じ音が連続しないようにするために、while文を回しています。楽譜を書くための下準備
##なんか最初のおまじない stream_right = stream.Part() stream_left = stream.Part() inst1 = instrument.Instrument() inst2 = instrument.Instrument() stream_right.append(inst1) stream_left.append(inst2) tc = clef.TrebleClef() #ト音記号 bc = clef.BassClef() #ヘ音記号 stream_right.append(tc) stream_left.append(bc) otos = ["C1", "D1", "E1", "F1", "G1", "A1", "B1", "C2", "D2", "E2", "F2", "G2", "A2", "B2", "C3", "D3", "E3", "F3", "G3", "A3", "B3", "C4", "D4", "E4", "F4", "G4", "A4", "B4", "C5", "D5", "E5", "F5", "G5", "A5", "B5", "C6"]まず、右手と左手の2つのパートがあるので、パートを2つ用意しておきます。
そして、それぞれのパートにト音記号とヘ音記号をつけます。
最後に、これから使う音を配列で用意しておいてあげます。楽譜を書く!メインパート!!
##右手 for i in range(14): #のぼり ###1小節目 meas = stream.Measure() n0 = note.Note(otos[random_num[0] + 14 + i], quarterLength = 0.25) meas.append(n0) n1 = note.Note(otos[random_num[1] + 14 + i], quarterLength = 0.25) meas.append(n1) n2 = note.Note(otos[random_num[2] + 14 + i], quarterLength = 0.25) meas.append(n2) n3 = note.Note(otos[random_num[3] + 14 + i], quarterLength = 0.25) meas.append(n3) n4 = note.Note(otos[random_num[4] + 14 + i], quarterLength = 0.25) meas.append(n4) n5 = note.Note(otos[random_num[5] + 14 + i], quarterLength = 0.25) meas.append(n5) n6 = note.Note(otos[random_num[6] + 14 + i], quarterLength = 0.25) meas.append(n6) n7 = note.Note(otos[random_num[7] + 14 + i], quarterLength = 0.25) meas.append(n7) stream_right.append(meas) for i in range(14): #くだり ###1小節目 meas = stream.Measure() x = 18 n0 = note.Note(otos[x + 14 - i], quarterLength = 0.25) meas.append(n0) n1 = note.Note(otos[x - random_num[1] + 14 - i], quarterLength = 0.25) meas.append(n1) n2 = note.Note(otos[x - random_num[2] + 14 - i], quarterLength = 0.25) meas.append(n2) n3 = note.Note(otos[x - random_num[3] + 14 - i], quarterLength = 0.25) meas.append(n3) n4 = note.Note(otos[x - random_num[4] + 14 - i], quarterLength = 0.25) meas.append(n4) n5 = note.Note(otos[x - random_num[5] + 14 - i], quarterLength = 0.25) meas.append(n5) n6 = note.Note(otos[x - random_num[6] + 14 - i], quarterLength = 0.25) meas.append(n6) n7 = note.Note(otos[x - random_num[7] + 14 - i], quarterLength = 0.25) meas.append(n7) stream_right.append(meas) ###最後の小節 meas = stream.Measure() n = note.Note("C3", quarterLength = 2) meas.append(n) stream_right.append(meas)まず、1小節目を作成します。
このとき、for文を使うと、なぜか1小節に音が1つしか入らなかったので、仕方なくべた書きしました。
note.Note(音の高さ、音の長さ)というふうに書きます。
音の長さは四分音符を1として、分数や小数で表します。
1小節目が完成したら、それを転調しながら14回繰り返すと上行の完成です!
下行も同じように書きます。
そして、最後の小節のドの伸ばしを忘れずに追加したら完成です!!
左手はオクターブ低いだけなので省略しました。MuseScoreで表示させる
##最後のおまじない s = stream.Score() s.append(stream_right) s.append(stream_left) s.show('musicxml')最後に、今まで書いたものをMuseScoreで表示させます。
最後の行を書き換えることで、Lilypondで表示させることもできます。最後に
もっとハノンっぽさを追求するために、機械学習とかをやってみるといいかも〜って言われたので、やってみたい気持ちがあります(なにも知らないので、0からお勉強しないと…)。
また、music21は楽曲分析とかにも使えるらしくて、何調かを調べてくれるなどできるらしい(すごい)ので、そういうのでも遊んでみたいな〜と思いました。
- 投稿日:2020-08-18T19:44:47+09:00
Python: 2次元データ分布状態の図化(カーネル密度推定)
はじめに
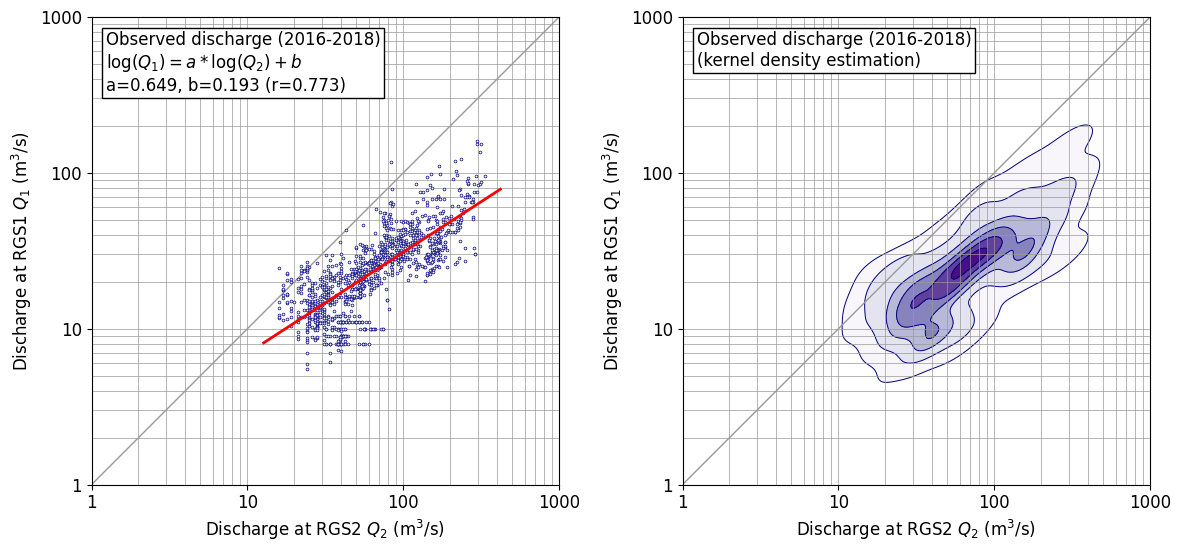
2次元分布するデータの分布状態を見たかったのでカーネル密度推定を
scipy.stats.gaussian_kdeでやってみた。成果図は以下の通り。(bw_method=‘scott’)
ちなみに、単回帰分析は、以下の通り
numpyでサラッとやっている。(色々やっていると、こういうコードがすぐに出てきて使えることは重要なので、あえて書き出しておく。)def sreq(x,y): # y=a*x+b res=np.polyfit(x, y, 1) a=res[0] b=res[1] coef = np.corrcoef(x, y) r=coef[0,1] return a,b,rやりかた
やりかたは、以下に従った。投稿者さん、ありがとうございます。
工夫したところは以下の通り。
- 表示は対数軸のほうが素直なので、対数軸としたが、軸の数値も読み取りたかったので、マニュアルで対数軸を描画した。データ処理は生データの常用対数をとって行っている。
- コンター線を引く間隔を自前で制御した。
gaussian_kdeでは確率密度が求まるため、この値のてっぺんを1として、[0.01, 0.1, 0.3, 0.5, 0.7, 0.9, 1.0]に線を引くようにしている。リストの最小値 0.01 はデータの範囲を概ねカバーできるよう、目視で定めた。最大値 1.0 は、これがないと 0.9 以上の範囲が着色されず白抜きになってしまうため加えてある。なお、この値は、確率値を示すものではないことに注意。あくまでも見た目の調整のためである。パラメータを変えてみると。。。
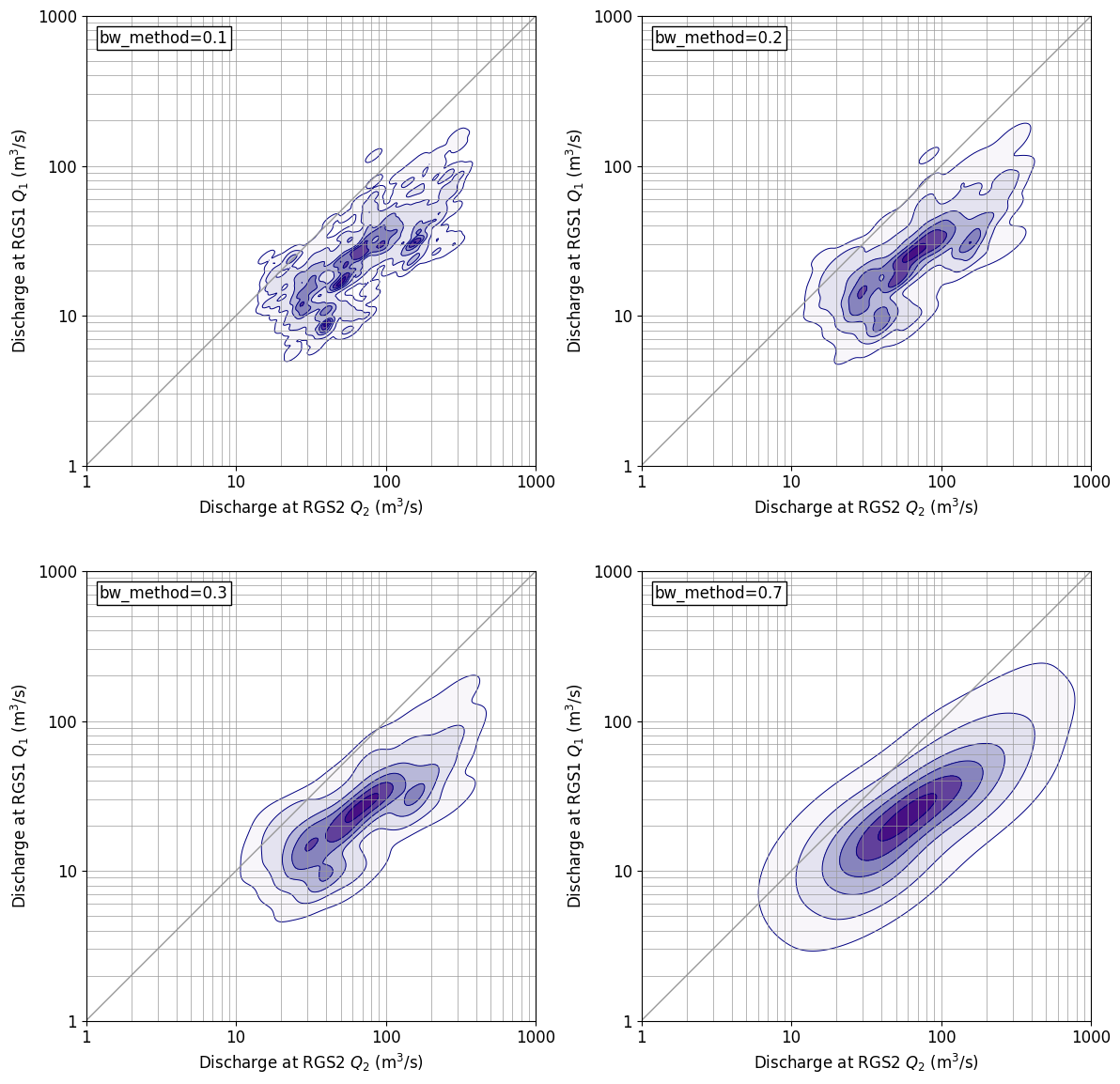
gaussin_kdeには、bw_methodというパラメータがあり、これを変えてやると分布形状を表示する細かさを変えることができる。上に示した成果図は、defaultである、bw_method=‘scott’の場合であるが、以下にbw_methodを変化させた場合の図を示す。bw_method=0.3だとdefaultに近い分布を示している。bw_methodの値が大きくなると、表示が粗っぽくなっていき、bw_method=0.7だと通常の2次元正規分布に近い表示となっている。
プログラム
「はじめに」に示した成果図を作成したプログラムを以下に示す。このプログラムを試してみたい場合は、データについては各人適宜作るなりしてやってみてください。
import numpy as np import pandas as pd import matplotlib.pyplot as plt import matplotlib.cm as cm from scipy.stats import gaussian_kde def sreq(x,y): # y=a*x+b res=np.polyfit(x, y, 1) a=res[0] b=res[1] coef = np.corrcoef(x, y) r=coef[0,1] return a,b,r def inp_obs(): fnameR='df_rgs1_tank_inp.csv' df1_obs=pd.read_csv(fnameR, header=0, index_col=0) # read excel data df1_obs.index = pd.to_datetime(df1_obs.index, format='%Y/%m/%d') df1_obs=df1_obs['2016/01/01':'2018/12/31'] # fnameR='df_rgs2_tank_inp.csv' df2_obs=pd.read_csv(fnameR, header=0, index_col=0) # read excel data df2_obs.index = pd.to_datetime(df2_obs.index, format='%Y/%m/%d') df2_obs=df2_obs['2016/01/01':'2018/12/31'] # return df1_obs,df2_obs def drawfig(x,y,sstr,fnameF): fsz=12 xmin=0; xmax=3 ymin=0; ymax=3 plt.figure(figsize=(12,6),facecolor='w') plt.rcParams['font.size']=fsz plt.rcParams['font.family']='sans-serif' # for iii in [1,2]: nplt=120+iii plt.subplot(nplt) plt.xlim([xmin,xmax]) plt.ylim([ymin,ymax]) plt.xlabel('Discharge at RGS2 $Q_2$ (m$^3$/s)') plt.ylabel('Discharge at RGS1 $Q_1$ (m$^3$/s)') plt.gca().set_aspect('equal',adjustable='box') plt.xticks([0,1,2,3], [1,10,100,1000]) plt.yticks([0,1,2,3], [1,10,100,1000]) bb=np.array([1,2,3,4,5,6,7,8,9,10,20,30,40,50,60,70,80,90,100,200,300,400,500,600,700,800,900,1000]) bl=np.log10(bb) for a0 in bl: plt.plot([xmin,xmax],[a0,a0],'-',color='#999999',lw=0.5) plt.plot([a0,a0],[ymin,ymax],'-',color='#999999',lw=0.5) plt.plot([xmin,xmax],[ymin,ymax],'-',color='#999999',lw=1) # if iii==1: plt.plot(x,y,'o',ms=2,color='#000080',markerfacecolor='#ffffff',markeredgewidth=0.5) a,b,r=sreq(x,y) x1=np.min(x)-0.1; y1=a*x1+b x2=np.max(x)+0.1; y2=a*x2+b plt.plot([x1,x2],[y1,y2],'-',color='#ff0000',lw=2) tstr=sstr+'\n$\log(Q_1)=a * \log(Q_2) + b$' tstr=tstr+'\na={0:.3f}, b={1:.3f} (r={2:.3f})'.format(a,b,r) # if iii==2: tstr=sstr+'\n(kernel density estimation)' xx,yy = np.mgrid[xmin:xmax:0.01,ymin:ymax:0.01] positions = np.vstack([xx.ravel(),yy.ravel()]) value = np.vstack([x,y]) kernel = gaussian_kde(value, bw_method='scott') #kernel = gaussian_kde(value, bw_method=0.1) f = np.reshape(kernel(positions).T, xx.shape) f=f/np.max(f) ll=[0.01, 0.1, 0.3, 0.5, 0.7, 0.9, 1.0] plt.contourf(xx,yy,f,cmap=cm.Purples,levels=ll) plt.contour(xx,yy,f,colors='#000080',linewidths=0.7,levels=ll) xs=xmin+0.03*(xmax-xmin) ys=ymin+0.97*(ymax-ymin) plt.text(xs, ys, tstr, ha='left', va='top', rotation=0, size=fsz, bbox=dict(boxstyle='square,pad=0.2', fc='#ffffff', ec='#000000', lw=1)) # plt.tight_layout() plt.savefig(fnameF, dpi=100, bbox_inches="tight", pad_inches=0.1) plt.show() def main(): df1_obs, df2_obs =inp_obs() fnameF='_fig_cor_test1.png' sstr='Observed discharge (2016-2018)' xx=df2_obs['Q'].values yy=df1_obs['Q'].values xx=np.log10(xx) yy=np.log10(yy) drawfig(xx,yy,sstr,fnameF) #============== # Execution #============== if __name__ == '__main__': main()以 上
- 投稿日:2020-08-18T18:04:29+09:00
Pandas 列名×行番号で要素を抽出する
はじめに
loc,ilocなど、行名/列名,行番号/列番号を基に要素抽出は出てくるものの、
列名×行番号による抽出方法が上手く探せなかったため、メモ投稿です。やりたかったこと
大元のデータフレーム(列名有り,行名無し)から、特定の要素を持つグループに分け、
各データフレームに対して1行ずつ参照して処理をしていく必要があった。その際、列の指定は出来るが行の指定が思うようにできないため、行番号で処理を試みた。
(reset_indexも考えたが、きっと列名×行番号での指定も出来るはず…)結論
atとindexを組み合わせ、df.at[df.index[行番号],'列名'] で抽出できる
(↓の記事をきちんと読めば良かった...)
https://note.nkmk.me/python-pandas-at-iat-loc-iloc/お試し
DataFrame# 列名のみのデータフレーム作成 df = pd.DataFrame({'person':['a','b','c','a','b','c'],\ 'name':['aa','bb','cc','aaa','bbb','ccc'],\ 'num':[100,200,300,1000,2000,3000]}) person name num 0 a aa 100 1 b bb 200 2 c cc 300 3 a aaa 1000 4 b bbb 2000 5 c ccc 3000単純に、大元のdfから"name"列 0行目 (=aa) を抽出するにはどちらでも可能
person_0df['name'][0] # 抽出した行に(大元の)index=0があるため抽出可能 # aa df.at[df.index[0],'name'] # aa今度は"person"列が同じ人に絞り、その上で0行目を取得してみる
※今回の話とはずれますが、行列を絞る際や要素抽出時に
"SettingWithCopyWarning"にハマらないよう注意(ハマりました。。)
https://linus-mk.hatenablog.com/entry/2019/02/02/200000
https://qiita.com/HEM_SP/items/56cd62a1c000d342bd70person_a_0# "person"列がaの行に絞る df_a = df[df['person']=="a"] df_a person name num 0 a aa 100 3 a aaa 1000 df_a['name'][0] # 抽出した行に(大元の)index=0があるため抽出可能 # aa df_a.at[df_a.index[0],'name'] # aaperson_b_0# "person"列がbの行に絞る df_b = df[df['person']=="b"] df_b person name num 1 b bb 200 4 b bbb 2000 df_b['name'][0] # 抽出した行にindex=0がないためエラー df_b.at[df_b.index[0],'name'] # bbatを使うことで、どのデータフレームに対しても行番号で要素を抽出出来た。
終わりに
少しでも、見つからずに困っている方の役に立てば嬉しいです。
- 投稿日:2020-08-18T17:44:53+09:00
datetime, time
datetime モジュールは、日付や時刻を操作するためのクラスを提供しています。
日付や時刻に対する算術がサポートされている一方、実装では出力のフォーマットや操作のための効率的な属性の抽出に重点を置いています。今の時間が知りたい場合
isoformatとすれば文字列に変換することができる
自分なりに表示形式を変える事もできるqiita.pyimport datetime now = datetime.datetime.now() print(now) print(now.isoformat()) print(now.strftime('%d/%m/%y-%H-%M-%S-%f'))実行結果
2020-08-18 16:57:51.138416 2020-08-18T16:57:51.138416 18/08/20-16-57-51-138416年月日のみを表示
qiita.pyimport datetime today = datetime.date.today() print(today) print(today.isoformat()) print(today.strftime('%d/%m/%y'))実行結果
2020-08-18 2020-08-18 18/08/20時間のみ表示
qiita.pyimport datetime t = datetime.time(hour=1,minute=10,second=5,microsecond=100) print(t) print(t.isoformat()) print(t.strftime('%H-%M-%S-%f'))実行結果
01:10:05.000100 01:10:05.000100 01-10-05-000100過去の時間を扱いたいとき
1週間前
qiita.pyimport datetime now = datetime.datetime.now() print(now) d = datetime.timedelta(weeks=-1) print(now+d)実行結果
2020-08-18 17:27:45.640006 2020-08-11 17:27:45.640006一年前
qiita.pyprint(now) d = datetime.timedelta(days=365) print(now-d)実行結果
2020-08-18 17:26:48.128885 2019-08-19 17:26:48.128885time
time.sleep(secs)
与えられた秒数の間、呼び出したスレッドの実行を停止します。qiita.pyimport time print("hei") time.sleep(5) print("#####")epochtime
協定世界時 (UTC) での1970年1月1日午前0時0分0秒から形式的な経過秒数(すなわち、実質的な経過秒数から、その間に挿入された閏秒を引き、削除された閏秒を加えたもの)として表される
qiita.pyimport time print(time.time())実行結果
1597739333.901404使い所
ファイルが存在しなければ作成
存在すれば、現在の時刻が記載されたファイルのコピーが生成されるqiita.pyimport os import shutil import datetime now = datetime.datetime.now() file_name = "test.txt" if os.path.exists(file_name): shutil.copy(file_name, '{}.{}'.format( file_name,now.strftime('%d_%m_%y_%H_%M_%S') )) with open(file_name,'w') as f: f.write('test')
- 投稿日:2020-08-18T17:36:35+09:00
RuntimeError: DataLoader worker (pid(s) ~) exited unexpectedlyの原因と解決法
実行環境
- Windows10 Home
- torch 1.1.0
PytorchでDataLoaderを使おうとしたところ以下のエラーが発生
実行したプログラムtorch.utils.data.DataLoader( dataset = dataset, batch_size = 100, shuffle = True, num_workers = 8)エラー文RuntimeError: DataLoader worker (pid(s) ~) exited unexpectedly原因
メモリ不足が原因
解決策
num_workersをエラーが出ない値まで小さくする
ex)num_workers = 0等
- 投稿日:2020-08-18T17:30:46+09:00
AttributeError: module ‘torch.utils’ has no attribute ‘data’の解決法
実行環境
- Windows10 Home
- torch 1.1.0
PytorchでDataLoaderを使おうとしたところ以下のエラーが発生
実行したプログラムimport torch torch.utils.data.DataLoader( dataset = dataset, batch_size = 100, shuffle = True, num_workers = 0)エラー文AttributeError: module ‘torch.utils’ has no attribute ‘data’解決策
import torchではなく、import torch.utils.dataとすると解決する。
- 投稿日:2020-08-18T17:24:31+09:00
Pythonのスクリプトを実行するための環境構築(for mac)
最近Instagramをやっていて思うこと、
「いいね、自動化できんかな〜」
を現実化するために調べたところ、この記事を見つけました。
しかしPythonワカラナイ私は環境構築がキツかったので、やったことを残しておきます。手順
(1) pipのアップグレード
$ python3 -m pip install --upgrade pip(2) seleniumのインストール
$ pip3 install Selenium(3) chromedriverのインストール
$ brew tap homebrew/cask $ brew cask install chromedriverこれで、
python3 <ファイル名.py>が実行できるようになりました〜
- 投稿日:2020-08-18T17:13:05+09:00
Pythonで配列から辞書に変換する方法【応用編】
概要
Pythonで配列から辞書に変換する方法を10サイトくらい閲覧しました。
「よくある入門解説ブログに掲載されていないパターン」を見つけましたので応用編と称して紹介します。よくある例
配列から辞書に変換する方法で検索すると、キーと値が1:1の例が多数ヒットします。
test002.pykey2=["name","age","kind"] data2=["siva",4,"dog"] print(dict(zip(key2,data2)))キーと値が別々の配列になっていましたが、きれいに辞書に変換できました。
output{'name': 'siva', 'age': 4, 'kind': 'dog'}実践
実際には以下のような複雑なデータを処理する場合があったりします。
よくある例を、そのまま当てはめても欲しい形式に変換することはできません。test001.pykey1=["name","age","kind"] data1=[["garm",4,"dog"],["chapalu",3,"cat"],["echidna",10,"snake"],["phoenix",6,"bird"]] print(dict(zip(key1,data1)))これでは、ぐちゃぐちゃです。役に立たないデータになってしまいました。
output{'name': ['garm', 4, 'dog'], 'age': ['chapalu', 3, 'cat'], 'kind': ['echidna', 10, 'snake']}結論
そこで、以下のように内包表記を利用してみます。
test001.pykey1=["name","age","kind"] data1=[["garm",4,"dog"],["chapalu",3,"cat"],["echidna",10,"snake"],["phoenix",6,"bird"]] print([dict(zip(key1,item)) for item in data1])上手くいきました。
output[{'name': 'garm', 'age': 4, 'kind': 'dog'}, {'name': 'chapalu', 'age': 3, 'kind': 'cat'}, {'name': 'echidna', 'age': 10, 'kind': 'snake'}, {'name': 'phoenix', 'age': 6, 'kind': 'bird'}]回帰
For文で書き直してみると、こうなります。
test001.pykey1=["name","age","kind"] data1=[["garm",4,"dog"],["chapalu",3,"cat"],["echidna",10,"snake"],["phoenix",6,"bird"]] mydata = [] for item in data1: mydata.append(dict(zip(key1,item))) print(mydata)結果は同じですね。
output[{'name': 'garm', 'age': 4, 'kind': 'dog'}, {'name': 'chapalu', 'age': 3, 'kind': 'cat'}, {'name': 'echidna', 'age': 10, 'kind': 'snake'}, {'name': 'phoenix', 'age': 6, 'kind': 'bird'}]参考
- キーと辞書が交互に並んだ特殊なパターン
Excelsior!!
- 投稿日:2020-08-18T16:41:22+09:00
subprocessでのコマンド実行
ターミナルでlsを行ったときと同様の結果が得られる
「LS」です。今、何がディレクトリの中にあるかを見ます。
これで、ファイルとディレクトリを表示することができますqiita.pyimport subprocess subprocess.run(['ls'])ls -alを行いたい場合
書き方が二通りある
2つ目の方法は shellに渡して行う方法
セキュリティ的に問題がある為、好まれない
例えばrmが組み込まれファイルが消されるなどqiita.pyimport subprocess #1つ目 subprocess.run(['ls','-al']) #2つ目 subprocess.run('ls -al', shell=True)exception
returncodeを用いた方法
returncode
子プロセスの終了コード。一般に、終了ステータス 0 はプロセスが正常に終了したことを示します。
負の値 -N は子プロセスがシグナル N により中止させられたことを示します (POSIX のみ)。存在しないコマンドを渡した場合
qiita.pyimport subprocess r = subprocess.run('lsa',shell=True) print(r.returncode)実行結果
lsaという存在しないコマンドを実行=127127 /bin/sh: lsa: command not foundcheckを用いることもできる
qiita.pyimport subprocess r = subprocess.run('lsa',shell=True, check=True)実行結果
エラー発生/bin/sh: lsa: command not found Traceback (most recent call last): File "/Users/kirinboy96/PycharmProjects/untitled1/lesson_package/NEW1.py", line 6, in <module> r = subprocess.run('lsa',shell=True, check=True) File "/opt/anaconda3/lib/python3.7/subprocess.py", line 512, in run output=stdout, stderr=stderr) subprocess.CalledProcessError: Command 'lsa' returned non-zero exit status 127.PIPE
stdout(出力)をsubprocess.PIPEにわたす
p2.communicate()[0]は出力
p2.communicate()[1]はエラーが返ってくるqiita.pyimport subprocess p1 = subprocess.Popen(['ls', '-al'], stdout=subprocess.PIPE) p2 = subprocess.Popen( ['grep', 'test'], stdin=p1.stdout,stdout=subprocess.PIPE ) p1.stdout.close() output = p2.communicate()[0] print(output)実行結果
b'-rw-r--r-- 1 kirinboy96 staff 22 Aug 18 00:44 test.csv\n-rw-r--r-- 1 kirinboy96 staff 216 Aug 18 14:20 test.tar.gz\n-rw-r--r-- 1 kirinboy96 staff 763 Aug 18 14:52 test.zip\ndrwxr-xr-x 4 kirinboy96 staff 128 Aug 18 02:52 test_dir\ndrwxr-xr-x 3 kirinboy96 staff 96 Aug 18 14:20 test_tar\n'
- 投稿日:2020-08-18T16:05:50+09:00
tempfile
tempfile.TemporaryFile(mode='w+b', buffering=None, encoding=None, newline=None, suffix=None, prefix=None, dir=None, *, errors=None)
一時的な記憶領域として使うことの出来る file-like object を返します。 ファイルは mkstemp() と同じルールにより安全に作成されます。 オブジェクトは閉じられる (オブジェクトのガベージコレクションによる暗黙的なものも含みます) とすぐに破壊されます。一時的なファイルの作成
tempfileは使い終わったら勝手に消してくれる
TemporaryFileは一時的なファイルという意味
このファイルはpythonにより消されるqiita.pyimport tempfile with tempfile.TemporaryFile(mode='w+') as t: t.write('hello') t.seek(0) print(t.read())実行結果
hello一時的でないファイルの作成
NamedTemporaryFileとしてdeleteをFalseにする
print(t.name)でpathを表示させているqiita.pyimport tempfile with tempfile.NamedTemporaryFile(delete=False) as t: print(t.name) with open(t.name, 'w+') as f: f.write('test\n') f.seek(0) print(f.read())実行結果
/var/folders/14/vk0vvxsn6jjbwjf0_nk2p7k40000gn/T/tmpxfqtokst test一時的なディレクトリの作成
qiita.pyimport tempfile with tempfile.TemporaryDirectory() as td: print(td)実行結果
/var/folders/14/vk0vvxsn6jjbwjf0_nk2p7k40000gn/T/tmpcmdgfsuu
- 投稿日:2020-08-18T14:39:20+09:00
ARC037バウムテストをPythonの再帰関数でとにかく丁寧に
初心者向けの記事です
本記事は競プロ初心者が勉強の理解度を深めるために書いたものであり、細かいところまで噛み砕いた記事となっています。同じ競プロ初心者の方の助けになればと思い、書きました。
また、本記事の解答コードは蟻本をPythonで (初級編)の記事を用いて行っています。ARC037バウムテスト
問題文はこちらで確認してください。
早速ですが、解答コードをまずは紹介します。python.pydef dfs(now, prev): global flag # 今いる頂点から行ける頂点を順に next に入れてループ for next in g[now]: if next != prev: if memo[next]: # 過去に訪れていれば閉路 flag = False else: memo[next] = True dfs(next, now) n, m = map(int, input().split()) g = [[] * n for i in range(n)] for i in range(m): u, v = map(int, input().split()) u -= 1 v -= 1 g[u].append(v) g[v].append(u) # 訪れたことがあるか memo = [False for i in range(n)] ans = 0 # 頂点をループ for i in range(n): if not memo[i]: flag = True dfs(i, -1) if flag: # 閉路がなければ木である ans += 1 print(ans)この解答コードを分割して説明していきます。
まず、各頂点から移動できる場所をリストとしてまとめる部分を説明します。list.pyn, m = map(int, input().split()) g = [[] * n for i in range(n)] for i in range(m): u, v = map(int, input().split()) u -= 1 #リストの番号と頂点の位置の番号を一致させるため v -= 1 g[u].append(v) g[v].append(u)個人的にまだこういう処理ができないため、躓いてしまいます…。
2つの数字の組(u,v)をm組渡された時、左側の数字を現在地、右側の数字を移動可能な場所として見ることで現在地がuである時の移動できる場所が、g[u]に格納されると考えられるわけですね。
次に再帰関数の部分に注目します。saiki.pydef dfs(now, prev): global flag #関数内でのflagの変化が関数外でも適用されるために。 # 今いる頂点から行ける頂点を順に next に入れてループ for next in g[now]: if next != prev: if memo[next]: # 過去に訪れていれば閉路 flag = False else: memo[next] = True dfs(next, now)この問題では再帰関数が呼ばれた位置を含むグラフが木になっているかどうかを判断する必要があります。そのためにまずflagを用いてTrueの場合は木、Falseの場合は閉路であると判定すると決めます。
次に再帰関数で行っていることを説明します。
再帰関数では、現在地をnowで指定してnowに含まれる次の移動の選択肢g[now]をnextに順番に代入して探索しています。nextがprevと異なり、訪れたことがない場所である時に次のnowにnextを代入してより深い場所での探索を行います。(ややこしい)
新しい場所を訪れた際には痕跡としてmemo[next]=Trueとしておきます。
また、もしnextで指定されるmemo[next]がすでにTrueとなっている場合は2回目の探索になるので閉路であると判定します。最後に再帰関数の呼び出し部分について説明します。
saikiyobidasi.pyans = 0 # 頂点をループ for i in range(n): if not memo[i]: flag = True dfs(i, -1) if flag: # 閉路がなければ木である ans += 1再帰関数呼び出しの部分はシンプルです。
木であると判定された回数をカウントするためにansを使っています。
for文では、n個の頂点に対して訪れたことがない場合に木判定をflag=Trueとしてスタートして再帰関数を呼び出します。
再帰関数での処理が終わった後にflag=Trueであればansを+1しています。以上でARC037の説明は終わりです。
個人的に蟻本の深さ優先ではこの問題がしんどかったので細かく説明することで自分の理解度を把握してみました。間違っているところがあればぜひご指摘ください。
- 投稿日:2020-08-18T14:04:34+09:00
AtCoderBeginnerContest175復習&まとめ(前半)
AtCoder ABC175
2020-08-15(土)に行われたAtCoderBeginnerContest175の問題をA問題から順に考察も踏まえてまとめたものとなります.
前半ではABCまでの問題を扱います.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFA問題 Rainy Season
問題文
AtCoder 町の、ある連続した$3$日間の天気の記録があります。天気の記録は長さ$3$の文字列$S$で表され、$i(1 \leqq i \leqq 3)$日目の天気は$i$文字目が"S"のとき晴れ、"R"のとき雨でした。
天気が雨である日が連続していた最大の日数を求めてください。解説にも書いてありますが,三日間であれば,8通りしかないので,場合分け書けば通せます.
条件の順番に注意すれば,以下のような場合分けで解けます.abc175a.pyn = input() if "RRR" in n: print(3) elif "RR" in n: print(2) elif "R" in n: print(1) else: print(0)B問題 Making Triangle
問題文
$1,⋯,N$の番号がついた$N$本の棒があります。棒$(i(1 \leqq i \leqq N)$の長さは$L_i$です。
このうち、三角形を作ることのできるような長さの異なる$3$本の棒を選ぶ方法は何通りあるでしょうか。
つまり、$3$つの整数$1 \leqq i < j < k \leqq N$の組であって次の$2$つの条件の両方を満たすものの個数を求めてください。
・$L_i,L_j,L_k$がすべて異なる
・$3$辺の長さが$L_i,L_j,L_k$であるような三角形が存在する全ての辺が異なる条件は簡単なので,三角形が成り立つ条件に関してですが,$3$辺の長さを$L_i < L_j < L_k$とすると,$L_i + L_j > L_k$のとき三角形が存在します.
最初に$N$本の棒をソートすることで,$N$本から$3$本選んだとき,選ばれた$3$本の中で一番右側が一番大きい値になります.
$N$は100以下なので,時間内に全組み合わせを調べることができます.abc175b.pyn = int(input()) l_list = list(map(int, input().split())) l_list.sort() count = 0 for i in range(0, n - 2): for j in range(i + 1, n - 1): for k in range(j + 1, n): a = l_list[i] b = l_list[j] c = l_list[k] if a == b or b == c or c == a: continue if a + b > c: count += 1 else: break print(count)C問題 Walking Takahashi
問題文
数直線上で暮らす高橋君は、今座標$X$にいます。これから高橋君はちょうど$K$回、座標の正または負の方向に$D$移動する行為を繰り返そうと考えています。
より正確には、$1$回の移動では座標$x$から$x+D$または$x−D$に移動できます。
高橋君は、ちょうど$K$回移動した後にいる座標の絶対値が最小となるように移動したいです。
$K$回の移動後の座標の絶対値としてあり得る値の最小値を求めてください。最初,座標$X$にいますが,求める最小値は座標の絶対値であることから,$X$と$-X$の答えは一致する.
$0 \leqq X$のときを考えると,移動回数$K$に制限がなければ,$X$を$D$で割った余り$T1$か,$T1$から$D$を引いた$T2$のどちらかが答えになる.(座標の絶対値を小さくしたいので,原点近くで行ったり来たりするのがベスト)
まず,$T1$に到達できるかどうかを判定し,到達できない場合は,$X$から移動回数×$D$を引いた値が答えとなる.
$T1$に到達できる場合,必ず$K$回移動しなければならないので,それまでに移動した回数から残りの移動回数を計算し,残りの移動回数が偶数か奇数かで,$T1$か$T2$が決まる.
$T2$は負となるため出力に注意.abc175c.pyx, k, d = map(int, input().split()) if x < 0: x *= -1 t1 = x % d t2 = t1 - d n = (x - t1) // d if k < n: print(x - k * d) else: n = k - n if n % 2 == 0: print(t1) else: print(-t2)前半はここまでとなります.
夏休み中ですが,論文が条件付き採録になって回答書作りで忙しいため,後半は時間ができたら書きたいと思います.
最後まで読んでいただきありがとうございました.
- 投稿日:2020-08-18T12:17:48+09:00
Pythonデータ解析お百度参り:復習を兼ねてアンケートその2
お疲れ様でした。これまであなたは、20個の課題をこなしました。
- 課題11:内積と外積
- 課題12:近似と絶対誤差
- 課題13:漸化式
- 課題14:数列の和
- 課題15:スタックとキュー
- 課題16:再帰呼び出し
- 課題17:階乗
- 課題18:フィボナッチ数列
- 課題19:ファイル読み込み
- 課題20:散布図
以上の課題を振り返って、難しかったとか、簡単だったとか、アンケートに答えてください(匿名です)。以下のリンクからお願いいたします。
https://docs.google.com/forms/d/e/1FAIpQLSfVqPrEIXW6ZmaCmaQM2TGsAOT-0FaNGg5l3qEE2z0yq93RyQ/viewform
* 次の課題に進む
* 前の課題に戻る
- 投稿日:2020-08-18T12:15:42+09:00
【簡単】webカメラでAI自動認識! for Google Colab
はじめに
「クラウドサービスの
Google Colab」と「ローカルPCのwebカメラ」を利用し、AIにより「モノの認識」が簡単にできたら楽しいと思いませんか?
公開されているモデルを利用することで簡単にそんなことができます。
では、早速やってみましょう!※Google Colabの使用方法は『0からはじめる「Python AIプログラミング」 for Google Colab』を参照して、簡単に理解しておいてください。
具体的にどんなことをやるか
webカメラからクラウドに映像を取り込み、そこに映ったものは何か、AIに
リアルタイム認識させ、画面にTOP3までを表示します。今回は、学習済みモデルを利用しますので、時間のかかるAI学習などはありませんので、サクッと遊べます。
※ローカルPC版の『【簡単】webカメラでAI自動認識! for PC』は、こちらです
開発環境準備
Google Colabが全部用意してくれるので、今回はインストールなどはありません。
「Google Colabサービス」を利用するのに「Googleアカウント」が必要なだけです。
No. 開発環境 説明 1 Googleアカウント Google Colab利用のためにGoogleアカウントを使用します。無料です。 2 Google Colabサービス Googleのクラウド仮想マシン上で動くPython実行環境。使用料は無料です。インストール等の作業などは不要です。GPUも無料で使用でき、AI学習も素早く計算が可能です。 3 クラアントPC with webカメラ クライアントPCのwebカメラを使用するため必要です。 DenseNet121
簡単って言うからやっているのに、
いきなりDenseNet121と言われて、ワケワカラン!
もうやめだ!大丈夫です。落ち着いてください。これは学習済みモデルのことで、今回は
DenseNet121という学習モデルを使用しますということです。細かいこと分からなくてもできます!
- なぜ
DenseNet121モデルに選定したのか?
kerasライブラリからVGG16、ResNet50など様々な画像分類モデルが簡単に使えるようになっていますが、その中から今回使用する画像分類モデルは、モデルサイズが33MBと比較的小さく認識率も良いためDenseNet121を選びました。「Keras Documentation」によると、DenseNet121でモノを認識させた場合、TOP5までの認識正解率が約92%となるそうです。(TOP1だけだと約75%です)
引用元:Keras Documentation
https://keras.io/ja/applications/#documentation-for-individual-modelsAIプログラム
今回Google Colab上でローカルPCのwebカメラを扱うプログラムとして、@a2kitiさんの記事(Colab上でwebカメラをリアルタイムに処理)を参考にさせて頂きました?
下記3つのプログラムを全てGoogle Colabのコード行にコピペし終わったら、[
ランタイム]→[すべてのセルを実行]をクリックして、プログラムを実行してください。●Program1
Program1.pyimport IPython from google.colab import output from google.colab.patches import cv2_imshow # incompatible with Jupyter notebook import cv2 import numpy as np from PIL import Image, ImageDraw from io import BytesIO import base64 from keras.applications.densenet import DenseNet121 from keras.applications.densenet import preprocess_input, decode_predictions from keras.preprocessing import image model = DenseNet121(weights='imagenet') def run(img_str): #decode to image decimg = base64.b64decode(img_str.split(',')[1], validate=True) decimg = Image.open(BytesIO(decimg)) decimg = np.array(decimg, dtype=np.uint8); decimg = cv2.cvtColor(decimg, cv2.COLOR_BGR2RGB) #############your process############### # DenseNet121画像判定 resize_frame = cv2.resize(decimg, (300, 224)) # 640x480 -> 300x224(4:3)に画像リサイズ trim_x, trim_y = int((300-224)/2), 0 # 判定用に224x224へトリミング trim_h, trim_w = 224, 224 trim_frame = resize_frame[trim_y : (trim_y + trim_h), trim_x : (trim_x + trim_w)] x = image.img_to_array(trim_frame) x = np.expand_dims(x, axis=0) x = preprocess_input(x) preds = model.predict(x) # 画像AI判定 # 認識物体名, 認識率 表示用 TXT1 = "[DenseNet121 predict]" TXT2 = "TOP1 :" + decode_predictions(preds, top=3)[0][0][1] + " : " + str(int(decode_predictions(preds, top=3)[0][0][2] * 100)) + "%" TXT3 = "TOP2 :" + decode_predictions(preds, top=3)[0][1][1] + " : " + str(int(decode_predictions(preds, top=3)[0][1][2] * 100)) + "%" TXT4 = "TOP3 :" + decode_predictions(preds, top=3)[0][2][1] + " : " + str(int(decode_predictions(preds, top=3)[0][2][2] * 100)) + "%" img = Image.fromarray(trim_frame) draw = ImageDraw.Draw(img) draw.text((15, 10), TXT1, fill=(255, 255, 255, 0)) draw.text((15, 30), TXT2, fill=(255, 255, 255, 0)) draw.text((15, 50), TXT3, fill=(255, 255, 255, 0)) draw.text((15, 70), TXT4, fill=(255, 255, 255, 0)) img = np.array(img) # cv2_imshow(img) out_img = cv2.resize(img, (224*3, 224*3)) # 拡大表示 #############your process############### #encode to string _, encimg = cv2.imencode(".jpg", out_img, [int(cv2.IMWRITE_JPEG_QUALITY), 80]) img_str = encimg.tostring() img_str = "data:image/jpeg;base64," + base64.b64encode(img_str).decode('utf-8') return IPython.display.JSON({'img_str': img_str}) output.register_callback('notebook.run', run)●Program2
Program2.pyfrom IPython.display import display, Javascript from google.colab.output import eval_js def use_cam(quality=0.8): js = Javascript(''' async function useCam(quality) { const div = document.createElement('div'); document.body.appendChild(div); //video element const video = document.createElement('video'); video.style.display = 'None'; const stream = await navigator.mediaDevices.getUserMedia({video: true}); div.appendChild(video); video.srcObject = stream; await video.play(); //canvas for display. frame rate is depending on display size and jpeg quality. display_size = 640 const src_canvas = document.createElement('canvas'); src_canvas.width = display_size; src_canvas.height = display_size * video.videoHeight / video.videoWidth; const src_canvasCtx = src_canvas.getContext('2d'); src_canvasCtx.translate(src_canvas.width, 0); src_canvasCtx.scale(-1, 1); div.appendChild(src_canvas); const dst_canvas = document.createElement('canvas'); dst_canvas.width = src_canvas.width; dst_canvas.height = src_canvas.height; const dst_canvasCtx = dst_canvas.getContext('2d'); div.appendChild(dst_canvas); //exit button const btn_div = document.createElement('div'); document.body.appendChild(btn_div); const exit_btn = document.createElement('button'); exit_btn.textContent = 'Exit'; var exit_flg = true exit_btn.onclick = function() {exit_flg = false}; btn_div.appendChild(exit_btn); // Resize the output to fit the video element. google.colab.output.setIframeHeight(document.documentElement.scrollHeight, true); var send_num = 0 // loop _canvasUpdate(); async function _canvasUpdate() { src_canvasCtx.drawImage(video, 0, 0, video.videoWidth, video.videoHeight, 0, 0, src_canvas.width, src_canvas.height); if (send_num<1){ send_num += 1 const img = src_canvas.toDataURL('image/jpeg', quality); const result = google.colab.kernel.invokeFunction('notebook.run', [img], {}); result.then(function(value) { parse = JSON.parse(JSON.stringify(value))["data"] parse = JSON.parse(JSON.stringify(parse))["application/json"] parse = JSON.parse(JSON.stringify(parse))["img_str"] var image = new Image() image.src = parse; image.onload = function(){dst_canvasCtx.drawImage(image, 0, 0)} send_num -= 1 }) } if (exit_flg){ requestAnimationFrame(_canvasUpdate); }else{ stream.getVideoTracks()[0].stop(); } }; } ''') display(js) data = eval_js('useCam({})'.format(quality))●Program3
Program3.pyuse_cam()AIプログラム実行
こんな感じにGoogle Colab上でクライアントPCのwebカメラで映した映像が出力され、AIが認識したTOP3の情報が画面に表示されれば成功です。ちなみにうちのワンコ(トイプードル)を映した結果は、下記の様にAIが96%の確率でプードルでしょうと言っている(トイ・プードルでは49%?)ので、AIの認識はそれなりに正しいものになります?
【結果の一例】AIの認識率TOP3
1. toy_poodle : 49%
2. miniature_poodle : 45%
3. standard_poodle : 2%
※リアルタイムで認識率は変動します。識別可能クラス
「
imagenet_class_index.json」ファイルを参照すると、イメージデータが以下のNo.0~999の1000クラスに分類ができることが分かります。制限事項にもなりますが、ここに記載が無いものを認識させても、ここの中のどれかにクラス分類されてしまいます。ここに無いものを分類したい場合は、新たにモデルを作るか、転移学習、ファインチューニングなどを調べていただければと思います。imagenet_class_index.json{ "0": ["n01440764", "tench"], "1": ["n01443537", "goldfish"], "2": ["n01484850", "great_white_shark"], "3": ["n01491361", "tiger_shark"], "4": ["n01494475", "hammerhead"], "5": ["n01496331", "electric_ray"], "6": ["n01498041", "stingray"], "7": ["n01514668", "cock"], "8": ["n01514859", "hen"], "9": ["n01518878", "ostrich"], ~ 省略 ~ "990": ["n12768682", "buckeye"], "991": ["n12985857", "coral_fungus"], "992": ["n12998815", "agaric"], "993": ["n13037406", "gyromitra"], "994": ["n13040303", "stinkhorn"], "995": ["n13044778", "earthstar"], "996": ["n13052670", "hen-of-the-woods"], "997": ["n13054560", "bolete"], "998": ["n13133613", "ear"], "999": ["n15075141", "toilet_tissue"] }以上
Google Colabだと
cv2.imshow()など、cv2の特定メソッドを起動するとクラッシュしてしまうそうで、画像処理させるときには注意が必要です。cv2.imshow()については、Google Colabからパッチが出ている「from google.colab.patches import cv2_imshow」で代替できます。他のメソッドも実行してみてダメなら他の方法で代替するしかないみたいです。ちなみにcv2.resize()は大丈夫でしたが、cv2.putText()はダメでした?話は変わりますが、いまだとバウンディングボックスを表示してくれる
yolo Ver5なども公開されていますね。こちらも試してみましたがとても凄いです。AIは発展目覚ましいですね?お疲れ様でした!


- 投稿日:2020-08-18T11:13:03+09:00
Lake Counting(POJ NO.2386)をPython3で解く
蟻本の練習問題初級編
競プロの勉強中の者です。
探索問題で有名なLakeCountingをPythonを使って解いたので載せます。
再帰関数で解く方が多いのですが、僕はスタックを使って解きました(再帰がまだできない...)
以下が実装したコードです。
テストケースを2通りしか試していないので、処理できないパターンがあったら申し訳ありません。lakecounting.pyn,m=map(int,input().split()) field=[list(input()) for i in range(n)] visited = [[0 for i in range(m)] for j in range(n)] move = [[0,1],[1,0],[1,1],[0,-1],[-1,0],[-1,-1],[1,-1],[-1,1]] cnt=0 for i in range(n): for j in range(m): if field[i][j] == "W" and visited[i][j]==0: sx,sy=i,j stack=[[sx,sy]] visited[sx][sy]=1 while stack: x,y = stack.pop() for k in range(8): nx,ny = x+move[k][0],y+move[k][1] if 0<=nx<n and 0<=ny<m and visited[nx][ny]==0 and field[nx][ny]=="W": stack.append([nx,ny]) visited[nx][ny]=1 cnt += 1 print(cnt)標準入力を受け取る形で書いています。
もし何か間違いがあればご指摘ください。
- 投稿日:2020-08-18T10:19:56+09:00
Django-taggit
# タグ名称で取得 >>> blog_1.tags.names() <QuerySet ['Python', 'Django']> # slugで取得 >>> blog_1.tags.slugs() <QuerySet ['Python', 'Django']> # オブジェクトで取得 >>> blog_1.tags.all() <QuerySet [<Tag: Python>, <Tag: Django>]> #追加 >>> blog_1.tags.add('programming') <QuerySet ['Python', 'Django', 'programming']> #削除 >>> blog_1.tags.remove('programming') <QuerySet ['Python', 'Django']> #全部削除 >>> blog_1.tags.clear() <QuerySet []> # タグでfilter >>> Blog.objects.filter(tags__name__in=["Python", "Django"]) <QuerySet [<Blog: 1つ目の記事>, <Blog: 1つ目の記事>]> # タグでfilter(重複なし) >>> Blog.objects.filter(tags__name__in=["Python", "Django"]).distinct() <QuerySet [<Blog: 1つ目の記事>]> # 関連記事(共通のタグが多い順でオブジェクトを取得) >>> blog_1.tags.similar_objects() [<Blog: 3つ目の記事>, <Blog: 2つ目の記事>] # タグモデル取得 >>> Tag.objects.all() <QuerySet [<Tag: Python>, <Tag: Django>, <Tag: programming>]> # 「Pythonタグ」と紐づいたBlog一覧 >>> tag = Tag.objects.get(name="Python") >>> Blog.objects.filter(tags=tag) <QuerySet [<Blog: 1つ目の記事>, <Blog: 2つ目の記事>, <Blog: 3つ目の記事>]> 紐ずいたblgoの多い順 >>> Tag.objects.all().annotate(c=Count('taggit_taggeditem_items')).order_by('-c') <QuerySet [<Tag: programming>, <Tag: Python>, <Tag: Django>]>
- 投稿日:2020-08-18T06:54:01+09:00
StreamlitアプリケーションをGCP(GAE)にデプロイする方法
0. フォルダ構成
application_directory
└Dockerfile
└app.py
└app.yaml
└requirements.txt1. Dockerfileを作成する
以下のようなDockerfileを作成する
FROM python:3.7 EXPOSE 8080 WORKDIR /app COPY requirements.txt ./requirements.txt RUN pip3 install -r requirements.txt COPY . . CMD streamlit run app.py --server.port 8080※最後の行で
streamlit run app.pyとしているので、Pythonで書いたアプリケーションのファイルはapp.pyとなっていることを仮定しています。2. requirements.txtを作成する
以下のようなファイルを作成する。
streamlit※個人的には仮想環境下でアプリケーションの動作を確認した後に
$ pip freeze > requirements.txtでrequirements.txtを作成するのがおすすめです。3. app.yamlを作成する
app.yamlruntime: custom env: flex※ここでflex環境を使わなければいけないのかどうかは私はよく分かっていません。standardでもいけるのかも。
4. デプロイする
GCP上で任意のプロジェクトを作成する。
作成したプロジェクトのホームページのナビゲーションメニューから「App Engine」に行き、App Engineアプリケーションを作成する。Languageは「Python」を選択し、Environmentは「フレキシブル」を選択する。
Google Cloud SDKをインストールしていなければ、ダウンロードおよびインストールをする。これでgloudコマンドが使えるようになる。
application_directory内で以下の操作を行う。
まず、必要に応じてSDKを初期化する。
$gcloud init次に、App Engineにデプロイする。
$gcloud app deploy参考
https://stackoverflow.com/questions/59052104/how-do-you-deploy-a-streamlit-app-on-app-engine-gcp
- 投稿日:2020-08-18T02:54:55+09:00
SIFRankを日本語文書に適用してキーフレーズ抽出してみた
2020/08/18時点,SIFRankを日本語文書に適用できるようにしてみたという記事がまだなかったので,実際にキーフレーズ抽出を行うところまで書き残しておこうと思います.
荒削りな部分があるかと思いますので,ご指摘頂ければ幸いです.はじめに
SIFRankを提案した論文,オリジナルのリポジトリは,こちらになります.
• SIFRank: A New Baseline for Unsupervised Keyphrase Extraction Based on Pre-trained Language Model
• sunyilgdx/SIFRank今回使用するコードは,以下のリポジトリに置いておきます.
• tanajp/SIFRank_ja_model環境
• Google Colaboratory
• Python 3.6.9
• allennlp 0.8.4
• nltk 3.4.3
• torch 1.2.0
• stanza 1.0.0初期設定
まず,こちらのリポジトリを手元にcloneしてください.
そして,AllenNLPのサイトからELMoの日本語版モデルをダウンロードして,SIFRank_ja_modelフォルダ内のauxiliary_data配下に置きます.
(ここでは,weightsのみのダウンロードで結構です.)今回は,My Drive配下にフォルダを配置して進めていくこととします.
Googleドライブのマイドライブ配下に先ほどcloneしたフォルダを置いてください.
次に,Google Colabの設定は,左上の「ランタイム」より「ランタイムのタイプを変更」でGPUを選択し,保存してください.Google Driveにマウント
from google.colab import drive drive.mount('/content/drive')以下のように出力されれば成功です.
Enter your authorization code: ·········· Mounted at /content/driveインストール
必要となるライブラリのインストールを行います.
!pip install -r '/content/drive/My Drive/SIFRank_ja_model/requirements.txt'wordnetと,stanzaの日本語モデルをダウンロードしておきます.
import nltk import stanza nltk.download('wordnet') stanza.download('ja')SIFRankの実装
import sys sys.path.append('/content/drive/My Drive/SIFRank_ja_model') sys.path.append('/content/drive/My Drive/SIFRank_ja_model/embeddings') import stanza import sent_emb_sif, word_emb_elmo from model.method import SIFRank, SIFRank_plus #download from https://allennlp.org/elmo options_file = "https://exawizardsallenlp.blob.core.windows.net/data/options.json" weight_file = "/content/drive/My Drive/SIFRank_ja_model/auxiliary_data/weights.hdf5" ELMO = word_emb_elmo.WordEmbeddings(options_file, weight_file, cuda_device=0) SIF = sent_emb_sif.SentEmbeddings(ELMO, lamda=1.0) ja_model = stanza.Pipeline( lang="ja", processors={}, use_gpu=True ) elmo_layers_weight = [0.0, 1.0, 0.0] text = "ここにテキストを入力してください。" keyphrases = SIFRank(text, SIF, ja_model, N=5,elmo_layers_weight=elmo_layers_weight) keyphrases_ = SIFRank_plus(text, SIF, ja_model, N=5, elmo_layers_weight=elmo_layers_weight) print(keyphrases) print(keyphrases_)実行結果
例として,ANA、5000億円規模の資本調達協議 - ウィキニュースのテキストを入力として,キーフレーズ抽出を行ってみました.
2020-08-17 17:21:13 INFO: Loading these models for language: ja (Japanese): ======================= | Processor | Package | ----------------------- | tokenize | gsd | | pos | gsd | | lemma | gsd | | depparse | gsd | ======================= 2020-08-17 17:21:13 INFO: Use device: gpu 2020-08-17 17:21:13 INFO: Loading: tokenize 2020-08-17 17:21:13 INFO: Loading: pos 2020-08-17 17:21:14 INFO: Loading: lemma 2020-08-17 17:21:14 INFO: Loading: depparse 2020-08-17 17:21:15 INFO: Done loading processors! (['日本政策投資銀行', '資本調達', 'anaホールディングス', '融資', '民間金融機関'], [0.8466373488741734, 0.8303728302151282, 0.7858931046897192, 0.7837600983935882, 0.7821878670623081]) (['日本政策投資銀行', '日本経済新聞', '全日本空輸', '資本調達', 'anaホールディングス'], [0.8480482653338678, 0.8232344465718657, 0.8218706097094447, 0.8100789955114978, 0.8053839380458278])N=5として抽出してみた結果です.
最終出力は,キーフレーズとそれらに対するスコアになっています.上がSIFRank,下がSIFRank+での出力結果です.
ANAが日本政策投資銀行,民間金融機関と資金調達の協議を始めたという旨の記事ですので,キーフレーズの抽出が上手くいってそうです.ちなみに,tokenize,pos,lemma,depparseはそれぞれトークン化,POSタグの付与,見出し語化,依存構造解析を指しており,stanzaによるパイプライン処理の過程となっています.
おわりに
SIFRankを日本語文書に適用できるようにし,実際に使ってみました.
parserは日本語版モデルがあるものであれば何でも良いのですが,今回はstanzaを使用しました.
また,日本語のストップワード辞書はSlothlibを使用しています.SIFRank_ja_modelフォルダ内のauxiliary_data配下にあるjapanese_stopwords.txtを書き換えれば,ストップワードの編集は可能です.参考文献
• SIFRank: A New Baseline for Unsupervised Keyphrase Extraction Based on Pre-trained Language Model
• sunyilgdx/SIFRank
• AllenNLP
• 大規模日本語ビジネスニュースコーパスを学習したELMo(MeCab利用)モデルの紹介
• 大規模日本語ビジネスニュースコーパスを学習したELMo(MeCab利用)モデルの利用方法と精度比較検証
• 学習済みELMoをAllenNLPで読み込む -りたーんず!-
• Slothlib
- 投稿日:2020-08-18T02:46:27+09:00
ファイル操作
ファイルの存在を確認
qiita.pyimport os print(os.path.exists('test.text'))処理結果
Trueファイルの存在を確認
qiita.pyimport os print(os.path.isfile('test.text'))ディレクトリがどうか確認
qiita.pyimport os print(os.path.isdir('test.text'))ファイルの名前を変更
test.textからrenamed.txtに変更している
qiita.pyimport os os.rename('test.text','renamed.txt')symlinkを作る
symlin.txtが作成される
シンボリックリンク(英:symbolic link)とは
UNIX系のOS(MacとかLinuxとか)における、ファイルやフォルダの代理人ファイルのこと。qiita.pyimport os os.symlink('renamed.txt','symlink.txt')ディレクトリの作成,削除
rmdirはディレクトリが空のときのみ削除できる
qiita.pyimport os os.mkdir('test_dir') os.rmdir('test_dir')test_dirの中にtest_dir2を作成
その後、listdirでtest_dirの中を確認するqiita.pyimport os os.mkdir('test_dir') os.mkdir('test_dir/test_dir2') print(os.listdir('test_dir'))実行結果
['test_dir2']pathlib
pathlibを使いtest_dir2のなかにからのテキストファイルを作成
testdirの中をglobを用いて確認qiita.pyimport os import pathlib import glob import shutil pathlib.Path('test_dir/test_dir2/empty.txt').touch() print(glob.glob('test_dir/test_dir2/*'))実行結果
['test_dir/test_dir2/empty.txt']shutil
shutilを用いてディレクトリのコピー
qiita.pyimport os import pathlib import glob import shutil # pathlib.Path('test_dir/test_dir2/empty.txt').touch() shutil.copy('test_dir/test_dir2/empty.txt','test_dir/test_dir2/empty2.txt') print(glob.glob('test_dir/test_dir2/*'))中身があるディレクトリの削除
qiita.pyimport os import pathlib import glob import shutil shutil.rmtree('test_dir')現在の位置を確認
qiita.pyimport os import pathlib import glob import shutil print(os.getcwd())
- 投稿日:2020-08-18T00:49:46+09:00
CSVファイルの読み込みと書き込み
CSVファイルとは、「comma separated values」の略称を指し、その名の通り値や項目をカンマ(,)で区切って書いたテキストファイル・データのこと
書き込み
withステートメントでtest.csvというcsvファイルを作成
fieldnamesで各要素を定義qiita.pyimport csv with open("test.csv", 'w') as csv_file: fieldnames = ['Name', 'Count'] writer = csv.DictWriter(csv_file, fieldnames=fieldnames) writer.writeheader()実行結果
test.csvの中身Name,Countwriterowを用いて各データを追加していく
qiita.pyimport csv with open("test.csv", 'w') as csv_file: fieldnames = ['Name', 'Count'] writer = csv.DictWriter(csv_file, fieldnames=fieldnames) writer.writeheader() writer.writerow({'Name':'A', 'Count':1}) writer.writerow({'Name': 'B', 'Count': 2})実行結果
test.csvの中身Name,Count A,1 B,2読み込み
読むこむ際はDictreaderを使用し、forループを回す
qiita.pyimport csv with open('test.csv','r') as csv_file: reader = csv.DictReader(csv_file) for row in reader: print(row["Name"], row['Count'])