- 投稿日:2020-07-22T23:52:46+09:00
AWSとGCPの違い
AWSとは?
Amazonが提供するクラウドサーバーのサービス名。Amazon Web Servicesの略。
AWSのメリット
- サービスのメニューが豊富にある。
- ドキュメントが豊富で日本語情報も充実している。
AWSのデメリット
- サービスが多様である為、設定ノウハウが複雑で専門的な知識と経験が必要になる。
GCPとは?
Googleが提供するクラウドサーバーのサービス名。Google Cloud Platformの略。
GCPのメリット
- 検索エンジンで培ったビックデータ解析能力により高速でビッグデータを処理できる。
- コスト面でAWSより安い。
GCPのデメリット
- 日本語情報が少ない。
参考サイト:https://business.ntt-east.co.jp/content/cloudsolution/column-07.html
- 投稿日:2020-07-22T23:07:17+09:00
AWSインフラエンジニアでもスマホアプリを開発できるようになる Amazon Honeycode
図解で、ローコードなアプリ開発(プログラミング言語で記述しないアプリ開発)AWS プレビュー編。
Microsoft PowerApps でPCとiPhoneでデータを共有できるアプリ開発ができることは「もうさ、社内アプリはPowerApps使って内作でいいんじゃない?」の記事にある通り確認した。さすがマイクロソフト、とビジュアルなエディタでアプリ開発を楽しんでいたのも束の間、2020年6月24日にAWSから見た目も、出来ることも、ほぼ同じ Amazon Honeycode がベータ版としてアナウンスされた。またか。もうさ、世界をオレンジ色で一色に染めるのそろそろ減速していいんじゃないかな。
Hoenycode って何?
- Amazon Honeycode は、ビジネスアプリを簡単に作成できる。
- PowerPoint でプレゼンテーションを作るようなスキルで作成できる。
- 作成したアプリはクラウドに置き、PCやスマホで使える(iPhoneでも使える)。
- まだプレビュー中(お試し期間)。
何ができたの?
- CSVファイルからウィザード形式で「データ入出力アプリ」を1時間以内に作成できた。
- iPhoneとPCで、同じデータを操作できた。
- まだ本番運用には機能が少ない様に思うが、手軽にスマホアプリが動いた。
ログイン先が違う
いつものAWSマネージコンソールでは無く、<https://builder.honeycode.aws/auth/login
>からログインする。IDとパスワードもHoneycode用をサインアップする。完成したアプリもここからログインして利用できる。現時点のプレビュー版では。最初に試したこと(データ入出力アプリ)
Amazon Honeycode がどんなものだか知らなかったので、とりあえず試しにiPhoneでデータ入力して、PCで閲覧できるアプリを作ってみた。無料プランのBASICをサインアップ(米国西部オレゴンリージョンを選びます[東京リージョンは未だ無い])
(1) 新規にExcelファイルを開いていい加減な表データを作成してCSV形式でファイルを保存。
(2) 作成したCSVファイルをインポートします(Amazon Drive に保存)。
(3) うーぷす。文字コード間違えたかな、インポートエラーが出てしまった。
(4) 調べる余裕なかったので英語ASCIIだけでCSVファイルを再作成してトライ。今度はSuccess!
(5) AWS オンラインドライブでワークシートを編集できた。何だかAWSでワークシートというのが新鮮。
(6) ここで、データカラムの属性を設定する。例えばA列の日付はカレンダー形式にする。
(7) いよいよ、アプリを作成するウィザードを実行する。
(8) ウィザード1頁め:データ一覧となるリストビューを作成する。
(8)-1. アプリで使うデータカラムを選ぶ(不要なカラムを削除する)
(8)-2. 画面見出し[Table1]を[サービスリクエスト]に変えてみる。
(9) ウィザード2頁め:レコードを編集する画面を作る。
(10) ウィザード3頁め:新規レコードを追加する画面を作る。
(11) ウィザード4頁め:最後のステップ。アプリの名前を決めたら、作成したアプリを試す。
アプリの動作確認(PC画面編)
ウィザードで作成したアプリをパソコンで起動する。テキストしかないのでしんみりした画面だけど、ちゃんと[+Add]ボタンを押して新規データを入力できたよ。インプットボックスは、ちゃんとカレンダーコントロールで日付入力ができる。
入力したデータを削除できるかな。[本当に削除していいですか?]の確認メッセージも無く、即削除された。これはウィザードになかったのでコード追加しなきゃダメかな。
いよいよアプリの動作確認(スマホ編)
Honeycode編集画面の左側にメニューがあって、Mobile と Web を切り替えるだけ。スマホビューが表示される。
実はここがポイント。Microsoft PowerApps同様に、[AppStore]で iPhone に、アプリ実行環境である[Amazon Honeycode] アプリをインストールする。
iPhoneでアプリを実行! たらーん 先ほど作ったアプリ1個(サービスリクエスト)のメニューが表示されている。タップする。試しにスマホで新規レコードを登録する。
今回できたこと。
iPhoneで追加したレコードは、パソコンのアプリでも同じレコードを閲覧することができた。プログラミング言語でのコード記述はゼロ。ノーコードでスマホアプリを作ることができた。あ、WEBブラウザアプリも同時に出来てた。これ、そのまま Microsoft PowerApps じゃないですか。Honeycode のUIコンポーネントは未だ少ないので地味な画面、例えばデフォルトで選べるアイコンは4個だけとか。
あれ? Honeycode Automation って何だ?
他にも機能があった。Automation だ。指定した日時やデータ追加/削除/変更などのイベントでアクションを実行できる様だ。試しに午後20:00になったらデータ複製とメール送信をしてみよう。時刻設定はUTC(英国時間)なので注意。
(1) 自動実行する時刻を設定して
(2) レコード(row)をテーブルに追加して2カラム記入して
(3) メールを送る。メール件名、メール本文を書いて...。って、これも Micorsoft Automation そのままか。なんて分かりやすい。追加できる機能コンポーネントは未だ少ないのかな。
そして、時間になった
メールが届いた。「新しいデータが登録されたよ」
アプリで追加されたデータを確認したよ 設定間違えたかな。既存レコードが全て複製されたようだ、 }の部分。
まとめ
今回はプログラミング言語を1行も記述しないで、データ入力とデータ表示をする、WEBアプリとスマホアプリができた。つまり、プログラミング経験が無いインフラエンジニアでもスマホアプリを開発できるようになる時代がすぐに到来するような気がする。あ、違うな。サーバーOSを用意しないでアプリが動くんだからインフラエンジニアの仕事無くなっちゃうのかな...。
もう少し Amazon Honeycode で何ができるのか試してみたいけど、今、本当に使うアプリを作るなら機能が豊富な PowerAppsだよね。だけどAWSの機能拡張スピードすごいから今後も動向をウォッチしようと思う。
Microsoft AWS OracleCloud One Drive Amazon Drive Google Drive Excel Amazon Workbook Google SpreadSheet Microsoft PowerApps Amazon Honeycode Google App Maker Oracle Visual Builder Power Automate(旧Flow) Honeycode Automation Flow by TIE Kinetix




















- 投稿日:2020-07-22T22:55:08+09:00
pythonを利用したS3とEC2内一時ディレクトリのファイルやり取り
はじめに
オンプレ環境のGPUを持っていないので、私はAWSでGPUインスタンスを立ててディープラーニングを行っている。
学習データを利用する際、EC2内に一時ディレクトリを作成して、そこにS3から学習データをダウンロードして使うことで、以下のような利点が得られるんじゃないかと思ったので、紹介する。EC2インスタンス上にデータを入れっぱなしにしておくよりも、プログラムの実行が終わった際にEC2インスタンスからデータが消去される、かつS3に出力結果が上がるため、セキュリティの強化、出力結果紛失の危険性低減、EBS(ストレージ)の節約になる。
この記事では、EC2インスタンス内に一時ディレクトリを作成し、そこにS3からファイルをダウンロードする。
そして、一時ディレクトリからS3へのアップロードするまでを目指す。必要作業
- EC2にIAMロールの設定
- pythonモジュールのインストール(python3を利用)
- コードの記述
IAMロールの設定
ロールの作成
①AWSマネジメントコンソールからIAMのページに移動
②左のメニュー一覧からロールを選択
③ロールを作成を選択
④ユースケースはEC2を選択
⑤次のステップへ
⑥検索窓でS3と入力し検索
⑦AmazonS3FullAccessにチェックマークを入れる
⑧次のステップへ
⑨タグは設定してもしなくてもどちらでも良いが、複数人でAWSを利用している場合は、管理のしやすさのため、Userのみ設定しておくと良い
⑩次のステップへ
⑪任意のロール名をつける(ロール名から何ができるロールなのかわかるようにしておくと楽)
⑫ロールの作成
EC2インスタンスへのIAMロールの割当
EC2インスタンスを作成する際に先程作成したIAMロールを割り当てる
※インスタンス作成時にしかロールの割当できないかも?作成後にロールが割り当てられるかは要検証
pythonモジュールのインストール
必要モジュール
AWSモジュール
- boto3
一時ディレクトリモジュール
- tempfile(python標準モジュールのためインストール不要)インストールコマンド
pip install boto3コードの記述
以下のコードをノートブックファイルや.pyファイルにコピペすればダウンロード及びアップロードの完了
ダウンロード元やアップロード先の設定
import boto3 import tempfile #ダウンロード元バケット名 bucket_name = 'hogehoge' #アップロード先バケット名(今回はダウンロード先と同じ) out_bucket_name = bucket_name #バケットにある動画ファイル名 file_name = 'input.mp4' #アップロード先のフォルダ名 #下記の例だとS3にresultフォルダが作成され、そこに出力される out_folder_name = 'result'一時ディレクトリの作成及びS3からのダウンロード
#一時保存用ディレクトリの作成 tmpdir = tempfile.TemporaryDirectory() tmp = tmpdir.name + '/' #一時的な入力ファイル名(適当な名前で固定) #固定された名前で一時フォルダにダウンロードされる tmp_input = tmp + 'tmp.mp4' #S3からファイルをダウンロード s3_client = boto3.client('s3') s3 = boto3.resource('s3') bucket = s3.Bucket(bucket_name) bucket.download_file(file_name, tmp_input)ダウンロードされたファイルの使用例
以下の例はopencvで読み込みをし、何も処理せず一時ディレクトリに別名保存している
(一時ディレクトリにtmp.mp4とoutput.mp4がある状態)
import cv2 #一時ディレクトリに保存するビデオ名の設定 output_video =tmp + 'output.mp4' #動画ファイルを読み込む video = cv2.VideoCapture(tmp_input) # 幅と高さを取得 width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)) size = (width, height) #総フレーム数を取得 frame_count = int(video.get(cv2.CAP_PROP_FRAME_COUNT)) #フレームレート(1フレームの時間単位はミリ秒)の取得 frame_rate = int(video.get(cv2.CAP_PROP_FPS)) # 保存用 fmt = cv2.VideoWriter_fourcc('m', 'p', '4', 'v') writer = cv2.VideoWriter(output_video, fmt, frame_rate, size) for i in range(frame_count): ret, frame = video.read() ### ここに加工処理などを記述する ### writer.write(frame) writer.release() video.release() cv2.destroyAllWindows()#ビデオの読み込みS3へのアップロード
以下の例は先に設定したS3アップロード先にoutput_video.mp4という名前で上で作成したビデオがアップロードされている。
s3.Bucket(out_bucket_name).upload_file(output_video,out_folder_name+'/'+ 'output_video.mp4')一時ディレクトリの削除
tmpdir.cleanup()まとめ
それぞれの技術についてもっと細かく解説しているサイトはたくさんあると思うが、それをどうやってうまく組み合わせるのかが意外と難しいと思いこの記事を作成した。






- 投稿日:2020-07-22T22:39:37+09:00
circleci 自動デプロイ 初心者が死にかけてできた
circleciでやっと自動デプロイ設定ができたので、記録として投稿
参考URL
https://blog.adachin.me/archives/10997
この投稿でできること
GitHubでmasterにmergeされたらEC2にSSHログインしてデプロイができる。
事前確認
EC2へSSHでログインが成功していること!
- SSHについてはこちらを参考に。
circleciで該当のプロジェクトを「Add Projects」できていること。
まずは成功した設定ファイル
.circleci/config.ymlversion: 2.1 orbs: ruby: circleci/ruby@0.1.2 jobs: deploy: machine: enabled: true steps: - add_ssh_keys: fingerprints: - xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx - run: ssh -p $SSH_PORT $SSH_USER@$SSH_HOST "/home/ec2-user/my_app/deploy-me.sh" workflows: version: 2 deploy: jobs: - deploy: filters: branches: only: mastercircleciでの準備
SSHするサーバの秘密鍵をcircleciに登録する。
該当プロジェクトのproject settingのSSH Keysへ。
Add SSH Keyを選択
ここで注意なのがgithubのキーではなく、EC2へログインするためのキーを登録すること!!!!
秘密鍵を登録したら
ハッシュ化されているfingerprintsを.circleci/config.yml用にコピー
メモったfingerprintsを.circleci/config.ymlに記載
qiita.rb- add_ssh_keys: fingerprints: - xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx:xx #ここに貼り付け環境変数を設定
環境変数の設定はこちらから
設定する値は以下の通り。qiita.rb$SSH_PORT = 22 $SSH_USER = EC2にログインするときに使うユーザー名(ec2-userなど) $SSH_HOST = パブリックIPアドレスEC2上での準備
シェルスクリプトを書く
/home/ec2-user/my_app/以下にdeploy-me.shを作成
deploy-me.sh が実行されることによって、リモートからEC2にpullされる。注意2点
circleciでやる前に、EC2上で手動でできる確認しておく。
そして実行権限をちゃんと渡すこと!!!deploy-me.sh#!/bin/bash cd /home/ec2-user/my_app/ && git pull$ chmod +x deploy-me.sh #実行権限を渡す $ /home/ec2-user/my_app/deploy-me.sh #手動で実行ちなみにシェルスクリプトとは
シェルスクリプトは実行したいコマンドを記述したテキストファイルのこと。長〜いコマンドとかを毎回使うのはめんどいから、ファイルに書き込んで実行しちゃえ!!!って感じ。
ここまできたら
ローカルからGitHubにpushしてmasterへmerge!!!!
今回の設定ファイルはmasterにmergeしないと、動いてくれないので注意!!!!SUCCESSが出た時はお祭り騒ぎしても近所の人は目を瞑ってくれるので、おもっきり舞いましょう。
シェルスクリプトを強化
Gemfileの変更やCSS/JavaScript/画像の変更を反映させるためのコンパイルも実行する
これで本番環境に変更を反映できちゃう
deploy-me.sh#!/bin/bash cd /home/ec2-user/my_app/ && git pull && bundle install --path vendor/bundle --without test development && bundle exec rails assets:precompile RAILS_ENV=productioncircleciの嫌なところ
エラー文が不親切すぎて、初心者殺しすぎる。
circleciの設定やらするだけで2週間ぐらいかかってしもたし、あんま理解できてない。。。
勉強しよーっと。





- 投稿日:2020-07-22T21:33:58+09:00
自動で EC2 Autoscaling の起動設定をAttachするスクリプトを php で作った
背景
インスタンスの更新を行うたびに、手動で起動設定を作り直していた。
- 最新の EC2 から AMI を作る
- AMI から 起動設定を作る
- Autoscaling Group に Attach
- 不要になった起動設定を削除
- 不要になった AMI を削除
毎回この単純作業。
地味に時間がかかるのと、一つミスすると、スケールアウト時にちゃんと動かないとかトラブルになる。(開発環境でちょっとトラブルになりかけた)ミスになりそうな単純作業は自動化しちゃえと。
なぜ PHP で書いた?
10年ぐらい慣れ親しんだ言語なので! それだけ。
前提
- php 7.0 以上がローカルで動くこと
- aws-cli インストール済み
- jq コマンドインストール済み
- 東京リージョンで使う前提
そのソースコードを公開
gist に置いてます
$ git clone https://gist.github.com/208289a6de7f76ccf7c3709b5b83e760.git autoscaling-script $ cd $_ # list の中身を各自の環境に合わせる $ vim autoscaling-update.phpソースの中身
$listについて
$listは各ENV、各インスタンス、オートスケーリングの設定が記載された連想配列です。$list = [ 'stage' => [ 'web' => [ 'namelike' => 'stage-web', 'autoscaling_group' => 'stage-web-autoscaling', 'launch_namelike' => 'stage-web-launch', 'instance_type' => 't3.micro', 'key_name' => 'stage', 'security_groups' => 'sg-0dce82de47bea0926', 'iam_instance_profile' => 'stage-web-role', ], 'admin-web' => [ 'namelike' => 'stage-admin-web', 'autoscaling_group' => 'stage-admin-web-autoscaling', 'launch_namelike' => 'stage-admin-web-launch', 'instance_type' => 't3.micro', 'key_name' => 'stage', 'security_groups' => 'sg-0dce82de47bea0926', 'iam_instance_profile' => 'stage-admin-web-role', ], 'pointback' => [ ... snip ... ], ], 'prod' => [ 'web' => [ 'namelike' => 'prod-web', 'autoscaling_group' => 'prod-web-autoscaling', 'launch_namelike' => 'prod-web-launch', 'instance_type' => 'm5.large', 'key_name' => 'prod', 'security_groups' => 'sg-8faef0d139d0af', 'iam_instance_profile' => 'prod-web-role', ], 'admin-web' => [ ... snip ...ENV は stage (開発), prod (本番) 環境があり、
インスタンス種類は web(ユーザ画面), admin-web(管理画面), pointback(ポイントバック), batch(バッチ) が存在している想定です。この連想配列は使われる方に合わせて自由にカスタマイズしてもらえればOKです。
$list内の個々の記述について個々の記述では、どういう起動設定を作り、インスタンスタイプが何で、、、どの Autoscaling Group にAttachするのかが定義されています。
'namelike' => 'prod-web', 'autoscaling_group' => 'prod-web-autoscaling', 'launch_namelike' => 'prod-web-launch', 'instance_type' => 'm5.large', 'key_name' => 'prod', 'security_groups' => 'sg-8faef0d139d0af', 'iam_instance_profile' => 'prod-web-role',
- namelike: instance名を記載します (ami の名前の一部としても使うので namelike というキーにしました)
- autoscaling_group: Autoscaling Group 名
- launch_namelike: 起動設定名のプレフィックスです。実行した日時にあわせて重複でエラーとならないように prod-web-launch-20200721190000 のような起動設定名が適用されます
- instance_type: インスタンスタイプです。 t3.nano, t3.micro, ... m5.xlarge など 東京リージョンで定義されているインスタンスタイプを指定できます
- key_name: SSHキーに何を使うかを指定します
- security_groups: Security Group の ID を指定します。複数の場合は、半角スペースをあけて記載します
- iam_instance_profile: IAM インスタンス Profile です
実行について
以下のように動かします。
$ ./autoscaling-update.php prod web // stage admin-web 環境の場合 $ ./autoscaling-update.php prod web // prod web 環境の場合 $ ./autoscaling-update.php prod all // prod 全環境の場合実行すると以下のようなログが表示されます
$ ./autoscaling-update.php prod all ?[feature/add-attache-autoscaling- + scripts] [2020-07-21 20:22:22] 該当インスタンスいずれか一つ取得 [2020-07-21 20:22:22] execute command "aws ec2 describe-instances --region ap-northeast-1 \ | jq -r '.Reservations[].Instances[] | select(.Tags[].Key == "aws:autoscaling:groupName") | select(.Tags[].Value == "prod-web-autoscaling") | select(.State.Name == "running") |.InstanceId'|head -1" [2020-07-21 20:22:23] command result .. i-02e087ffcfdc9cb4f [2020-07-21 20:22:23] AMI 作成 [2020-07-21 20:22:23] execute command "aws ec2 create-image --region ap-northeast-1 --instance-id i-02e087ffcfdc9cb4f --no-reboot --name prod-web_20200721202223 | jq -r ".ImageId"" [2020-07-21 20:22:24] command result .. ami-04a9f007ba3509a30 [2020-07-21 20:22:24] AMI Tagging [2020-07-21 20:22:24] execute command "aws ec2 create-tags --region ap-northeast-1 --resources ami-04a9f007ba3509a30 \ --tags Key=Name,Value=prod-web_20200721202223 Key=Type,Value=autoscaling Key=Environment,Value=prod" [2020-07-21 20:22:25] command result .. ami-04a9f007ba3509a30 [2020-07-21 20:22:25] AMI 作成完了待ち [2020-07-21 20:22:25] execute command "aws ec2 wait image-available --region ap-northeast-1 --image-ids ami-04a9f007ba3509a30" [2020-07-21 20:24:42] 起動設定 作成 [2020-07-21 20:24:42] execute command "aws autoscaling create-launch-configuration \ --region ap-northeast-1 \ --launch-configuration-name prod-web-launch-20200721202223 \ --image-id ami-04a9f007ba3509a30 \ --instance-type m5.large \ --key-name hapi_lab \ --security-groups sg-0a09da7b2899abf20 \ --instance-monitoring Enabled=true \ --iam-instance-profile prod-web-role [2020-07-21 20:24:43] autoscaling group 更新 [2020-07-21 20:24:43] execute command "aws autoscaling update-auto-scaling-group --region ap-northeast-1 \ --auto-scaling-group-name prod-web-autoscaling \ --launch-configuration-name prod-web-launch-20200721202223" [2020-07-21 20:24:44] execute command "aws autoscaling describe-launch-configurations --region ap-northeast-1 --output json" [2020-07-21 20:24:46] prod-web-launch-202007091312 に関連する古い設定を削除します [2020-07-21 20:24:46] execute command "aws autoscaling delete-launch-configuration --region ap-northeast-1 --launch-configuration-name prod-web-launch-202007091312" [2020-07-21 20:24:47] prod-web-launch-202007091312 に関連する古い AMI の登録を解除します . amiId=ami-094d805c269cb018e [2020-07-21 20:24:47] execute command "aws ec2 deregister-image --image-id ami-094d805c269cb018e" [2020-07-21 20:24:48] 該当インスタンスいずれか一つ取得 [2020-07-21 20:24:48] execute command "aws ec2 describe-instances --region ap-northeast-1 \ | jq -r '.Reservations[].Instances[] | select(.Tags[].Key == "aws:autoscaling:groupName") | select(.Tags[].Value == "prod-admin-web-autoscaling") | select(.State.Name == "running") |.InstanceId'|head -1" [2020-07-21 20:24:50] command result .. i-003be640ea8229484 [2020-07-21 20:24:50] AMI 作成 [2020-07-21 20:24:50] execute command "aws ec2 create-image --region ap-northeast-1 --instance-id i-003be640ea8229484 --no-reboot --name prod-admin-web_20200721202450 | jq -r ".ImageId"" [2020-07-21 20:24:51] command result .. ami-02751dec1db361b4c [2020-07-21 20:24:51] AMI Tagging [2020-07-21 20:24:51] execute command "aws ec2 create-tags --region ap-northeast-1 --resources ami-02751dec1db361b4c \ --tags Key=Name,Value=prod-admin-web_20200721202450 Key=Type,Value=autoscaling Key=Environment,Value=prod" [2020-07-21 20:24:52] command result .. ami-02751dec1db361b4c [2020-07-21 20:24:52] AMI 作成完了待ち ... snip ...課題
- 設定ファイルとスクリプトを一緒にしている. yaml とかに分離させたい
- userdata どうするのとか、スポットインスタンス使いたいとか、起動テンプレート使いたいとか、東京リージョン固定が嫌だとか、汎用的にはしていない
- 投稿日:2020-07-22T21:27:42+09:00
IAM認証のAWS API GatewayにPythonからSigV4署名してアクセスするには
AWSのAPI GatewayのAPIのメソッドの設定で、IAM認証を使っている場合、APIリクエスト時に署名が必要です。
API Gatewayのメソッド設定画面はこんな感じです。英語のマネジメントコンソールだと「Authorization」、日本語だと「認可」という欄です。
デフォルトはNONEという設定になっていますが、これをAWS_IAMにするとAPI Gatewayは届いたリクエストの署名を確認するようになります。リクエストする側が署名をする必要があります。
API Gatewayが署名を確認するようになるとAPI GatewayのリソースポリシーにてIAMユーザやIAMロールで制限をかけられるようになります。
Pythonにて署名を付けてAPIリクエストするサンプルコードを書いておきます。
前提
IAMユーザのアクセスキーが
~/.aws/credentialsに設定されていて、そのIAMユーザからIAMロールにスイッチするIAM権限があり、そのIAMロールでAPI Gatewayにアクセスするものとします。(~/.aws/credentialsがあればよいので、以下のサンプルコードはGCPのCompute Engineインスタンスで動かしました)Pythonコード
import boto3 from botocore.awsrequest import AWSRequest from botocore.auth import SigV4Auth import urllib.request import sys endpoint_host = "xxxxxxxxxx.execute-api.ap-northeast-1.amazonaws.com" endpoint = "https://" + endpoint_host + "/stage" path = "/hello" url = endpoint + path # .aws/credentials または環境変数でアクセスキーが設定されているIAMユーザのセッションを生成。 session = boto3.session.Session() # .aws/credentials に複数のIAMユーザがある場合は profile_name を指定。 #session = boto3.session.Session(profile_name = "foo") sts_client = session.client("sts") # IAMロールのARNを指定して assume_role 。 # IAMロールが不要でIAMユーザのままでAPIリクエストする場合は、ここは不要。 assume_role_response = sts_client.assume_role( RoleArn = "arn:aws:iam::XXXXXXXXXXXX:role/ROLENAME", RoleSessionName = "test") # assume_role で得られたトークンなどからIAMロールでのセッションを生成。 # IAMロールが不要でIAMユーザのままでAPIリクエストする場合は、ここは不要。 session = boto3.session.Session( aws_access_key_id = assume_role_response['Credentials']['AccessKeyId'], aws_secret_access_key = assume_role_response['Credentials']['SecretAccessKey'], aws_session_token = assume_role_response['Credentials']['SessionToken']) # セッション情報からAPIリクエストに署名。 credentials = session.get_credentials() awsreq = AWSRequest(method = "GET", url = url) SigV4Auth(credentials, "execute-api", "ap-northeast-1").add_auth(awsreq) # urllib.request.Request 生成。 # この4つのリクエストヘッダーが必須。 # IAMロールが不要でIAMユーザのままでAPIリクエストする場合は、X-Amz-Security-Token は不要。 req = urllib.request.Request(url, headers = { "Authorization": awsreq.headers['Authorization'], "Host": endpoint_host, "X-Amz-Date": awsreq.context['timestamp'], "X-Amz-Security-Token": assume_role_response["Credentials"]["SessionToken"] }) # APIリクエスト実行 try: with urllib.request.urlopen(req) as response: # レスポンス出力 sys.stdout.buffer.write(response.read()) except urllib.error.HTTPError as err: # 403などの場合はここに到達 # エラーを出力 print(err) # レスポンスヘッダを出力 print(err.headers)エラーメッセージの例
IAMユーザに assume_role する権限がないと assume_role を呼び出したところで
botocore.exceptions.ClientError: An error occurred (AccessDenied) when calling the AssumeRole operationという例外が発生します。
X-Amz-Security-Tokenが必要なのに足りてないと、403 Forbidden が返され、レスポンスヘッダに次のように書かれます。x-amzn-ErrorType: UnrecognizedClientExceptionAPI GatewayのリソースポリシーでこのIAMロールからのリクエストを拒否していると、403 Forbidden が返され、レスポンスヘッダに次のように書かれます。
x-amzn-ErrorType: AccessDeniedExceptionなお、IAMロールにAPI GatewayにアクセスするIAM権限がなくても、API Gatewayのリソースポリシーで許可していれば、AccessDeniedException にはならずに正常に処理できるようです。

- 投稿日:2020-07-22T19:37:37+09:00
Redshiftでのクラスター構築
はじめに
- ここではAWSのサービスの一つであるRedshiftにおけるクラスター作成について、備忘録も兼ねて簡単にまとめる。
- Redshiftについての基本的な知識や、AWSのネットワーク(VPCやセキュリティグループなど)に関してはここでは説明しない。
- 以下は、Windowsからの接続で検証を行った。
作成手順
- 以下の情報を入力後に「作成」を押す。
基本情報
- クラスタ名、ノードの種類、ノード数、マスターユーザー情報、DB名などを入力。
- ノード数は1つでも作成でき、リーダーノードがワーカーノードを兼任するようになる。
(その場合のノードロールはSharedとなるみたい)ネットワーク情報
VPCの選択
- Redshiftのクラスターを作成するVPCを選択する。
- VPCがグレーで選択できない場合は、立てる予定のリージョンにそもそもVPCが存在しないか、サブネットグループが存在しないかが原因。
- サブネットグループの作成方法はAWS公式のYouTubeを参照 → YouTube
セキュリティグループの設定
- セキュリティグループに関しては、どういったアーキテクチャーにするかによるので、次項で説明。
その他
- 外部公開設定もでき、公開にした場合は外部アドレスが付与されていた。
- 今回は外部公開する予定はなく、同一のVPC間の中で行う予定なので非公開とした。
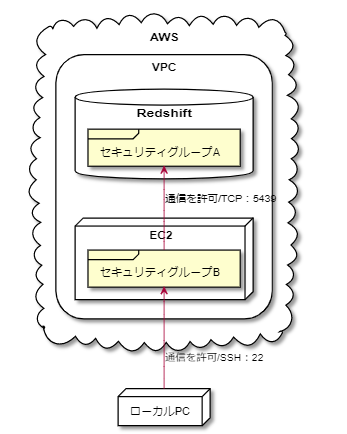
セキュリティグループについて
基本的には独立し、セキュリティの観点から直接アクセスできないようにし、踏み台経由のSSH接続とした。
そのためセキュリティグループによる通信の許可設定を行い、以下の構成とした。
接続方法
- ローカル環境よりつなぐ場合は、以下のコマンドでSSHポートフォワーディングを行い、psqleditなどのクライアントツールで接続する。
ssh -N -L {ローカルの任意のポート}:{Redshiftのエンドポイント}:{Redshiftのポート} -i {キーペアファイルのパス} -p 22 ec2-user@{踏み台サーバーの外部IPアドレス}
- 投稿日:2020-07-22T19:01:08+09:00
【AWS】WordPressを作った時の備忘録
はじめに
教材を使ってAWS上でWordPressを作ったので、備忘録として載せたい。
※WordPress作成後にスクリーンショットを撮ったので、一部実際の画面と異なる点がありますが、ご了承ください。手順
VPC・サブネット・ルーティングの作成
EC2の作成
SSH接続
ファイアウォールの設定
Elastic IPアドレスの割り当て
ドメインの購入
Route53でDNSを設定
プライベートサブネットの作成
RDSの設置
WEBサーバーからRDSを接続
WordPress用のデータベース作成
WordPressのインストール
WordPressの設定構成図は以下の通り。
方法
VPCの作成
VPCを開き、VPCの作成をクリックする。
画面を開けたら、以下の設定を行う。
名前タグを適当に設定する。
IPv4 CIDR ブロックでVPC全体のアドレスの範囲を指定。今回は「10.0.0.0/16」にする。
IPv6 CIDR ブロックとテナンシーはそのままで、「作成」を押す。
サブネットの作成
VPCサブネットを開く。
サブネットの作成を押す。まずはパブリックサブネットの作成。
名前タグは見返した時わかりやすい様に「public-subnet-1a」を入れると良い。
VPCでは先ほど作ったVPCを選択する。
アベイラビリティゾーンは「ap-northeast-1a」を選択する。
IPv4 CIDR ブロックで10.0.10.0/24を入力する。
確認できたら「作成」ボタンを押す。
次にプライベートサブネットの作成。
名前タグは見返した時わかりやすい様に「private-subnet-1a」を入れると良い。
VPCでは先ほど作ったVPCを選択する。
アベイラビリティゾーンは「ap-northeast-1a」を選択する。
IPv4 CIDR ブロックで10.0.20.0/24を入力する。
確認できたら「作成」ボタンを押す。
ルーティングの作成。
ルーティングをできる様にするため、インターネットゲートウェイを作る必要がある。
名前タグにインターネットゲートウェイとわかる様に「igw」を名前に含める。(タグ オプションはインターネットゲートウェイ の設定で自動で入力される。)
入力できたら、「インターネットゲートウェイ」の作成を押す。
VPCにインターネットゲートウェイをアタッチする。
該当のインターネットゲートウェイ選択し、「VPCにアタッチ」を選択する。
「使用可能なVPC」に先ほど作成した該当のVPCをアタッチする。
「インターネットゲートウェイのアタッチ」を押す。
ルートテーブルを設定する。
名前タグを入力し、VPCに先ほど作成した該当のVPCを選択する。
該当のルートテーブルを選択し、「サブネットの関連付け」>「サブネットの関連付けの編集」を押す。
サブネットでpublic-subnet-1aのものを選択する。
確認して、「保存」ボタンを押す。
該当のルートテーブルを選択し、「ルート」>「ルートの編集」をクリック。
「ルートの追加」をクリックし、送信先に0.0.0.0/0を入力。ターゲットで「Internet Gateway」を選択し、先ほど作ったものをクリックする。確認して「ルートの保存」を押す。
EC2の作成
EC2>インスタンスの作成を押す。
今回は「Amazon Linux 2 AMI (HVM), SSD Volume Type」を選択する。
t2.microを選択し、「次のステップ:インスタンスの詳細の設定」をクリックする。
「ネットワーク」で先ほど作ったVPCを選択。
「サブネット」で先ほど作ったpublic-1aを選択。
自動割り当てパブリックIPで有効を選択。
下にうつって、ネットワークインターフェイスのプライマリIPで10.0.10.10と設定する。
後はそのままにして「次のステップ:ストレージの追加」を押す
今回はそのままで「次のステップ:タグの追加」を押す。
タグの追加を行う。
「別のタグを追加」ボタンを押し、キーと値を適当に入力する。
「次のステップ:セキュリティグループの設定」を押す。
「新しいセキュリティグループを作成する」を選択し、「セキュリティグループ名」でwordpressを選択する。
「確認と作成」ボタンを押す。
内容を確認し、問題なければ「起動」ボタンを押す。
「新しいキーペアの作成」を選択し、キーペア名を適当に入力する。キーペアのダウンロードをクリックし、キーペアをローカルに保存する。
ダウンロードと保存をし終えたら、インスタンスの作成押す。
EC2>インスタンスに戻って、インスタンスが作成されていることを確認する。SSH接続
Macの場合ターミナルで、下記の通りに接続
$ chmod 600 ~/xxx.pem pemは秘密鍵のことで秘密鍵がある場所を入力 $ ssh -i ~/xxx.pem ec2-user@xx.xx.xx.xx xx.xx.xx.xxはIPv4パブリックIP(EC2の該当インスタンスで見ることができる) Are you sure you want to continue connecting (yes/no)? →yesと入力する $ sudo yum update -y $ sudo yum -y install httpd $ sudo systemctl start httpd.service $ sudo systemctl enable httpd.serviceファイアウォールの設定
EC2に戻り、該当のインスタンスを選択し、セキュリティグループをクリックする。
セキュリティグループを開いて、「インバウンドを編集」をクリック。(※私のルールはすでに設定済みのため画像ではHTTPもすでに許可されていますが、設定する前はSSHのみ許可されている状態です。)
「ルールを追加」ボタンを押し、タイプを「HTTP」リソースタイプを「任意の場所」に変更する。するとソースが0.0.0.0/0,::/0で自動入力される。入力できたら「ルールを保存」ボタンを押す。
IPv4パブリックIPをURL欄に入力し、Apacheのデフォルトページが出るか確認する。
Elastic IPアドレスの割り当て
このままだとEC2インスタンスの起動・停止時にIPアドレスが変わるため、固定アドレスにする。
EC2>Elastic IPをクリックし、「Elastic IPアドレスの割り当て」を押す。
その後「割り当て」ボタンを押したら、アドレスが作成されるので、成功したら閉じる。
アクションを押し、「Elastic IPアドレスの関連付け」ボタンを押す。
「インスタンス」を先ほど作成したものを選択し、プライベートIPアドレスを「10.0.10.10」と入力し、「関連付ける」を押す。
関連付けられたら、Elastic IPをURLに入力し、Apacheのデフォルトページが出るか確認する。
ドメインの購入
お名前.comなどでドメインを購入しましょう。
ドメインの購入方法は下記ページなどを参考にしてください。
https://tekito-style.me/columns/domain-onamaeRoute53でDNSを設定
Route53>ホストゾーンをクリック。「ホストゾーンの作成」を押す。
「ドメイン名」を先ほど購入したものを入力。
タイプを「パブリックホストゾーン」を選択する。
選択したら、「作成」をクリックする。
お名前.comでネームサーバーを変更する。(別のサイトでドメインを設定してたら、そこで変更してください。)変更手順は以下のサイトを参照。
https://www.onamae.com/guide/p/67「その他のネームサーバーを使う」で先ほど作成したドメインに行って、ネームサーバー名を確認する。
Route53>ホストゾーン>該当ドメインをクリック。
右にスクロールするとタイプが出てくるので「NS」の4つの値をお名前.comのネームサーバーに入力する。(最後の.は入れなくて良い。)そしたら「確認」ボタンと「設定」ボタンを押す。
ドメイン反映までしばらく待つ。(長いと1〜2日かかる場合もあるとのこと。)
Aレコードを作成するため、「値」にEC2の該当インスタンスのIPv4パブリックIPを入力。あとはそのままで「作成」を押す。
終わったらドメインの疎通確認を行う。(前述の通り、ネームサーバをお名前.comに変更直後だと反映に時間がかかります。)
dig xxx.com NS +short xxx.comには自分のドメインを入力Route53のネームサーバーが表示されている確認。
URLでも設定したドメインでApacheのデフォルトページが出るか確認。プライベートサブネットの作成
VPC>サブネットの作成をクリック。
名前タグに「private-subnet-1c」を含めて、VPCに先ほど作成したVPC、アベイラビリティーゾーンに「ap-northeast-1c」、IPv4CIDRブロックに10.0.21.0/24
RDSの設置
EC2>セキュリティグループ>セキュリティグループの作成をクリック。
セキュリティグループ名と説明を入力。今回は「wordpress-db」とする。VPCは先ほど作ったものにする。
インバウンドルールで「MYSQL/Aurora」、ソースはカスタム、虫眼鏡マークで先ほど作ったセキュリティグループのものを選ぶ。
RDS>サブネットグループを選択する。「DB サブネットグループを作成」ボタンをクリックする。
名前、説明を入力する。今回は「wordpress-subnet-group」とする。VPCは先ほど作ったものを選ぶ。
プライベートサブネットを選ぶため、アベイライビリティーゾーンを「ap-northeast-1a」、サブネットをCIDRブロック「10.0.20.0/24」、アベイラビリティゾーンを「ap-northeast-1c」サブネットをCIDRブロック「10.0.21.0/24」で選択する。こちらで「作成」ボタンを押す。
RDS>パラメータグループにいき、「パラメータグループの作成」をクリック。今回はパラメータグループファミリーに「mysql8.0」、グループ名に「wordpress-mysql80」、説明に「wordpress-mysql80」を入力する。入力できたら「作成」ボタンを押す。
RDS>オプショングループを選択。「オプショングループの作成」ボタンを押す。名前と説明をwordpress-mysql80で、エンジンをmysql、メジャーエンジンバージョンを8.0にし、「作成」ボタンを押す。
WEBサーバーからRDSを接続
RDSにいき、データベースの作成を押す。
テンプレートを費用を抑えるため今回は「開発/テスト」とする。(用途によって分ける。)
DBインスタンス識別子と認証情報の設定で入力する。(マスターユーザー名とマスターパスワードは忘れないようにメモしておく。)
DBインスタンスサイズを用途に応じて選択する。(db.t2.microだと安い。)
今回は負荷があまりかかることがないと想定し、「ストレージの自動スケーリングを有効にする」のチェックを外す。
接続ではVPCとサブネットグループを先ほど作ったものを選択する。
既存のVPCセキュリティグループを作成したものを今回作成したものを選択肢、アベイラビリティゾーンを「ap-northeast-1a」とする。
追加設定>データベースの選択肢でDBパラメータグループとオプショングループで今回作成したものを選択する。
モニタリングで拡張モニタリングの有効化のチェックを外し、メンテナンスをマイナーバージョン自動アップグレードの有効化を選択する。メンテナンスウインドウで時間を指定する。
概算月間コストを確認し、「データベースの作成」ボタンを押す。
ターミナルでの操作を行う。
$ ssh -i ~/xxx.pem ec2-user@xx.xx.xx.xx $sudo yum -y install mysql上記でMySQLをインストールする。
MySQLに入るためエンドポイントを確認する。
mysql -h エンドポイント -u マスターユーザー名 -pその後パスワードを入力する。
WordPress用のデータベースを作成
MySQLに入れたら下記を入力する。
$CREATE DATABASE データベース名 DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci $CREATE USER 'ユーザー名'@'%' IDENTIFIED BY 'password'; GRANT ALL ON データベース名.* TO 'ユーザー名'@'%'; FLUSH PRIVILEGES; $exit;WordPressのインストール
exit;でターミナルに戻る。
$sudo amazon-linux-extras install -y php7.2 $sudo yum install -y php php-mbstring $cd ~ $wget https://ja.wordpress.org/latest-ja.tar.gz $tar xzvf latest-ja.tar.gz $cd wordpress/ $sudo cp -r * /var/www/html/ $sudo chown apache:apache /var/www/html -R $sudo systemctl restart httpd.serviceWordPressの設定
URL欄にドメインを入力する。
WordPressの画面に進み、始めるボタンをクリックし、データベース名、ユーザー名、パスワード、データベースのホスト名(エンドポイント)を入力し、送信ボタンを押す。
接続完了したらインストール実行で、サイトのタイル、ユーザー名、パスワード、メールアドレス、検索エンジンでの表示を適宜入力する。できたら「WordPressをインストール」ボタンをクリックする。
これでログインをし、管理画面に入れるようになる。まとめ
レンタルサーバーだとボタンをポチポチしたらできたが、AWSだと結構手順を踏む必要があると思った。流れを意識しつつ実装しましょう、
教材
AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得























































- 投稿日:2020-07-22T18:55:38+09:00
AWS SageMaker Studioで"Auth token containing insufficient permissions"が出てアクセスできないときの対処
ポリシーをアタッチしたのにSageMaker Studioへの画面遷移がエラーになる!
SageMaker Studioを利用する際に
AmazonSageMakerFullAccessポリシーがアタッチされているのに画面遷移しようとすると"Auth token containing insufficient permissions"というエラーメッセージがでてHTTP403 Forbiddenになってしまうケースに遭遇しました。該当のエラーメッセージで検索してもAWSのフォーラムが1件しかヒットせず、しかも特に解決策が書いてなくて途方に暮れました。
原因は何だったのか
結論から言うとIAMのカスタムポリシーの不備でした。
{ "Statement": [ { "Sid": "SourceIPRestriction", "Effect": "Deny", "Action": "*", "Resource": "*", "Condition": { "NotIpAddress": { "aws:SourceIp": [ "オフィスのグローバルIPアドレスその1", "オフィスのグローバルIPアドレスその2" ] } } } ] }みたいなカスタムポリシーが前任者によって設定されていたのですが、これだと「オフィス内から以外のIPアドレスからのアクセスをすべて弾き」ます。
しかしSageMaker StudioはAWSによりリダイレクトされるため、アクセス元が(おそらく)AWS内のIPアドレスになっているため弾かれた、というのが事の真相のようでした。どうやって対処したのか
aws:ViaAWSService条件キーを設定しました。
aws:ViaAWSServiceはAWSが代わりにリクエストした場合(リダイレクトなど)を対象にするかどうかを条件に含めることが出来ます。{ "Statement": [ { "Sid": "SourceIPRestriction", "Effect": "Deny", "Action": "*", "Resource": "*", "Condition": { "Bool": { "aws:ViaAWSService": "false" }, "NotIpAddress": { "aws:SourceIp": [ "オフィスのグローバルIPアドレスその1", "オフィスのグローバルIPアドレスその2" ] } } } ] }こうすることで「AWSによるリクエストではない場合にオフィス以外からのアクセスを弾く」という設定になりました。
該当するケースが少ない現象だと思いますがどなたかの参考になれば。
- 投稿日:2020-07-22T18:45:45+09:00
AWS CLIをインストールせずにサクッと使用する方法
AWS CLIとは
AWS Command Line Interface (AWS CLI) は、コマンドラインシェルでコマンドを使用して AWS サービスとやり取りするためのオープンソースツールです。
詳しくはこちら↓
AWS Command Line Interface とはサクッと触ってみたいけどインストールが面倒
ローカルのLinuxマシンにインストールして触ってみようと思いましたが、インストールが中々面倒。
AWS CLIのインストール方法についてはこちら↓
Linux で AWS CLI バージョン 1 をインストールする
結構面倒くさいです。インストールせずにAWS CLIを使う方法
ここからが本題ですが、
AWS EC2でAmazon Linux(あるいはAmazon Linux2)を建てれば、
そのインスタンスでAWS CLIが使用できます。実はAWS CLIバージョン1は、Amazon LinuxおよびAmazon Linux2にプレインストールされています。
というお話でした。
勉強のためにAWS CLIを触りたいということであれば、
EC2無料枠のt2.microを建てちゃえば良さそうです。
- 投稿日:2020-07-22T17:32:23+09:00
Amazon Kinesis Video Streams WebRTC をiOSとAndroid動かしてみた
はじめに
Amazon Kinesis Video Streams に ビデオチャットサービスが加わりました。
ブラウザ(JavaScript)向けのSDKだけでなく、組み込み用途のC言語SDKや、iOS/Androidといったモバイルアプリ向けのSDKも用意されており、ビデオチャットサービスを実装することができます。
今回は iOS, Android のサンプルを動かし、iOS <-> Android アプリ間でビデオ通話をしてみようと思います。Getting Started
iOS SDK
Android SDKAWSでリソースを作成する
AndroidのSDKのREADMEの手順が分かりやすかったので、それに倣って進めていきます。
Amazon Kinesis Video Streams Android WebRTC SDK README.md
シグナリングチャンネルを作成する
Kinesis Video Streams でシグナリングチャンネルを作ります。
[シグナリングチャンネルを作成]を選択します。今回は東京リージョンに作りました。
シグナリングチャンネル名を入力します。今回は[demo-channnel]としました。
CognitoUserPool を作成する
CognitoUserPool を作成します。
[ユーザープールの管理]を選択し、次のページで[ユーザープールの作成]を選択します。
プール名を入力します。今回は[MyUserPool]としました。プール名を入力したら[デフォルトを確認する]を選択し、次のページでデフォルト値を変えずに[プールを作成]を選択します。
オレンジの矢印の先にある[プールId]をメモし、左のナビゲーションから [アプリクライアント]を選択します。
新しいアプリクライアントを作成します。まずアプリクライアント名を入力します。ここでは[MyAppClient]という名前で作成しました。
アプリクライアントの作成が完了したら[アプリクライアント ID]と[アプリクライアントのシークレット]をメモします。[詳細を表示]を選択すると表示されます。
CognitoIdentityPool を作成する
CognitoIdentityPool を作成します。
[IDプールの管理]を選択し、[新しいIDプールの作成]を選択します。
プール名を入力します。今回は[MyIdentityPool]としました。
[認証プロバイダー]の[Cognito]のタブを開き、[ユーザープールId]と[アプリクライアントId]に先ほどメモをした値を入力し、作成します。
Cognito_MyIdentityPoolAuth_RoleとCognito_MyIdentityPoolUnauth_Roleの2つロールが作成されます、一つはログイン済みユーザーに付与されるロールで、もう一つはログインされていないユーザーに付与されるロールです。つまりログイン済みのユーザーはkinesisvideoにアクセスできるように以下のポリシーをアタッチします。{ "Version":"2012-10-17", "Statement":[ { "Effect":"Allow", "Action":[ "cognito-identity:*", "kinesisvideo:*" ], "Resource":[ "*" ] } ] }
Android
AWSのリソースの作成ができたので、Android のサンプルアプリをビルドしていきます
- Androidのサンプルプロジェクトをダウンロードします。
$ git clone https://github.com/awslabs/amazon-kinesis-video-streams-webrtc-sdk-android.git
AndroidStudio を起動し、 Open an existing Android Studio project で先ほどダウンロードしたサンプルプロジェクトを開きます。
/res/raw/awsconfiguration.jsonにメモしたIdentityPoolId,UserPoolId,UserPoolAppClientSecret,UserPoolAppClientSecret,UserPoolAppClientIdを貼り付けます。IdentityPoolIdはリージョンも含めて入力する必要があるので気をつけてください。実機にインストールし、ユーザーを作成します。入力したメールアドレスに二要素認証のコードが送られてくるので間違えずに入力します。
ユーザーの作成とログインができたら [Start Viewer]でビデオチャットを始めます。
PCで Kinesis の demo-channel を開き、Master でビデオを流すと PC と Android アプリでビデオチャットができます。
カビゴンがPCのカメラで、エヴァ初号機がAndroidのカメラで撮ってます。
ブラウザ <-> Androidアプリ間でビデオ通信ができました。
iOS
基本的な設定はAndroidで既に終わっているので、設定を追加してビルドします。
$ git clone git@github.com:awslabs/amazon-kinesis-video-streams-webrtc-sdk-ios.git $ cd amazon-kinesis-video-streams-webrtc-sdk-ios $ cd Swift $ pod install # もし cocoapods が入っていなかったらインストールが必要
awsconfiguration.jsonを追加。awsconfiguration.json{ "Version": "1.0", "CredentialsProvider": { "CognitoIdentity": { "Default": { "PoolId": "YOUR_IDENTITY_POOL_ID", "Region": "ap-northeast-1" } } }, "IdentityManager": { "Default": {} }, "CognitoUserPool": { "Default": { "AppClientSecret": "YOUR_APP_CLIENT_SECRET", "AppClientId": "YOUR_APP_CLIENT_ID", "PoolId": "YOUR_USER_POOL_ID", "Region": "ap-northeast-1" } } }
Constants.swiftを開いて入力let CognitoIdentityUserPoolRegion: AWSRegionType = AWSRegionType.APNortheast1 let CognitoIdentityUserPoolId = "YOUR_USER_POOL_ID" let CognitoIdentityUserPoolAppClientId = "YOUR_APP_CLIENT_ID" let CognitoIdentityUserPoolAppClientSecret = "YOUR_APP_CLIENT_SECRET" let cognitoIdentityPoolId = "YOUR_IDENTITY_POOL_ID"ログインし、ビデオ通話を開始します。
先ほど作成したユーザーを使いまわしても大丈夫です。
TODO: Twilio との料金の比較
参考にさせて頂いた記事











- 投稿日:2020-07-22T16:06:59+09:00
[AWS]Slack + AWS Chatbot + Lambdaで朝会のファシリテーター指名してみた
現職場では、デイリースタンドアップとして、朝会を実施している。
そして、いつも開始日時になると、「え、今日・・・司会担当・・・だれ・・・?」
とTheWordになる。
※TheWord ・・・ リモート会議において、 無音が続き、最初に話した人がファシリテーターをしなければいけない空間のこと一応、SlackBotを使用して、それとなく機械的にファシリテーターを指名しているのだが、
「この人お休みだよ〜」 や 「昨日もやったんですけど〜」 とか
いちいち面倒臭い。
よし。朝会のファシリテーターをいい感じ(前回当たった人は当たらない、スムーズに再抽選ができる、
自分が選ばれない)に決めるToolを作ろう。はじめに
コミュニケーションToolはSlack
プラットフォームはAWSとする。構成
全体構成はこんな感じ。
朝会の担当者をランダムに選択し、Slackに通知するTool。
実行トリガーは2種類存在する。
1. CloudWathEventsから定期的(朝会の始まる5分前)に実行
2. Slack→AWS ChatBotから実行DynamoDBではファシリテーター担当履歴を管理。
(現時点では直近の担当者しか保存していない。)構築
AWS
ChatBot以外はCloudFormationで構築。
IAM等のユーザーは事前に発行しておくこと。
ソースコードLambda
ソース
Node.jsで実装。
コード全体とは以下の通り。index.js'use strict' const requestPromise = require('request-promise') const AWS = require('aws-sdk') const dynamodb = new AWS.DynamoDB.DocumentClient({ region: 'ap-northeast-1' }) let slackPostOption = { url: 'https://slack.com/api/chat.postMessage', method: 'POST', qs: { token: process.env.SLACK_TOKEN, channel: process.env.SLACK_CHANNEL, text: '', username: 'ぼくのいうことはぜったい' }, json: true } exports.handler = async () => { return new Promise((resolve, reject) => { Promise.resolve() .then(() => { // 直近のファシリテーターを取得 return getLatestFacilitator() }) .then((latestFacilitator) => { // ランダムに取得(直近を除く) return getFacilitator(latestFacilitator) }) .then((facilitator) => { // 直近のファシリテーターを登録 return putLatestFacilitator(facilitator) }) .then((facilitator) => { // Slackに通知 return postSlack(facilitator) }) .then(() => { resolve('Finish') }) .catch(reject) }) } const getLatestFacilitator = () => { const param = { TableName: 'FacilitatorHistory', Key: { status: 'latest' } } return new Promise((resolve, reject) => { dynamodb.get(param, (err, data) => { if (err) reject(err) resolve(data.Item ? data.Item.member : '') }) }) } const getFacilitator = (latestFacilitator) => { return new Promise((resolve, reject) => { const memberList = process.env.MEMBER.split(',') const get = () => { const facilitator = memberList[Math.floor(Math.random() * memberList.length)] if (latestFacilitator == facilitator) { get() return } resolve(facilitator) } get() }) } const putLatestFacilitator = (facilitator) => { return new Promise((resolve, reject) => { var param = { TableName: 'FacilitatorHistory', Item:{ status: 'latest', member: facilitator } } dynamodb.put(param, (err, data) => { if (err) reject(err) resolve(facilitator) }) }) } const postSlack = (facilitator) => { return new Promise((resolve, reject) => { slackPostOption.qs.text = `きょうのあさかいは <${facilitator}> だ。` requestPromise(slackPostOption) .then(resolve) .catch(reject) }) }内容
本来なら並列にできる部分もあるが、わかりやすく直列化している。
流れとしては
1. 直近のファシリテーターを取得
2. ファシリテーターをランダムに取得(直近のファシリテーターは除く)
3. Slackに担当者を通知
4. 2.で選ばれたファシリテーターを登録
といったシンプルなもの。
2.のファシリテーター取得ロジック部分で担当者ごとに重みをつけて、選ばれやすさを制御したり、自身だけ選ばれづらくするなどのイカサマはできそう。CloudFormation
yml
一部内容がベタが記されている部分があるので、使用する際には修正する必要がある。
template.ymlAWSTemplateFormatVersion: 2010-09-09 Resources: MorningFacilitatorFunction: Type: AWS::Lambda::Function Properties: Code: ./release/app.zip FunctionName: MorningFacilitatorFunction Handler: index.handler Runtime: nodejs12.x # Lambdaの実行ロール Role: {lambda arn} MemorySize: 128 Timeout: 30 Environment: Variables: TZ: Asia/Tokyo # カンマ区切りでファシリテーター候補のSlackユーザーIDを定義 MEMBER: '@yamada,@yamamoto,@yamashita,@yamagami,@yamsuda' # 各種Slackの情報 SLACK_TOKEN: {slack api token} SLACK_CHANNEL: {slack channel} FacilitatorHistory: Type: AWS::DynamoDB::Table Properties: TableName: FacilitatorHistory AttributeDefinitions: - AttributeName: status AttributeType: S KeySchema: - AttributeName: status KeyType: HASH ProvisionedThroughput: ReadCapacityUnits: 3 WriteCapacityUnits: 3 FacilitatorEventsRule: Type: AWS::Events::Rule Properties: Name: FacilitatorEventsRule # 朝会開始時間5分前(GMTなのでJST変換すると+9時間) ScheduleExpression: cron(55 0 * * ? *) State: ENABLED Targets: - Arn: !GetAtt MorningFacilitatorFunction.Arn Id: lambda MorningFacilitatorPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref MorningFacilitatorFunction Principal: events.amazonaws.com SourceArn: !GetAtt FacilitatorEventsRule.ArnCLI
デプロイする際は、AWS CLIを使用。
毎回入力するのは面倒なため、shを作成deploy.sh#!/bin/sh # ソースコードをアーカイブ rm -fr release && mkdir release zip -r app.zip index.js node_modules > /dev/null 2>&1 mv app.zip release/ # 必要な情報はベタがきするか、shの引数で対応 AWS_IAM_USER_NAME=$1 AWS_ACCESS_KEY_ID=$2 AWS_SECRET_ACCESS_KEY=$3 AWS_DEFAULT_REGION=$4 AWS_S3_BUCKET=$5 AWS_STACK=$6 aws configure set aws_access_key_id $AWS_ACCESS_KEY_ID --profile $AWS_IAM_USER_NAME aws configure set aws_secret_access_key $AWS_SECRET_ACCESS_KEY --profile $AWS_IAM_USER_NAME aws configure set region $AWS_DEFAULT_REGION --profile $AWS_IAM_USER_NAME aws cloudformation package --template-file template.yml --s3-bucket $AWS_S3_BUCKET --s3-prefix `date '+%Y%m%d%H%M%S'` --output-template-file output.yml --profile $AWS_IAM_USER_NAME aws cloudformation deploy --region $AWS_DEFAULT_REGION --template-file output.yml --stack-name $AWS_STACK --profile $AWS_IAM_USER_NAMEAWS Chatbot
クライアントの設定
AWS Chatbotのコンソールを開き、チャットクライアント「Slack」を選択し、クライアントを設定を押下。
権限を求められるので、許可する。
チャンネルの設定
新しいチャンネルを設定。
各種任意の値を入力し登録。
以上でAWS側の設定は完了。
Slack
SlackからLambda実行
メンバーが揃っているチャンネルで、@awsさんをインバイトする。
/invite @aws
このように表示されればOK。
SlackからLambdaの実行。
@aws lambda invoke --function-name MorningFacilitatorFunction --region ap-northeast-1
すると、ファシリテーターが指名される。
ただ、毎回このようなコマンドを入力するのは効率が悪いので、Slackワークフロー登録する。
Slackワークフロー
ワークフロービルダーを開く。
作成を押下して、適当な名前を入力。
※ 伸ばし棒が入らない・・・
ショートカットを選択、作成。
チャンネル名はメンバーが揃っているチャンネルを選択。
ステップを追加し、メッセージを送信を選択。
メッセージの送信先に「ワークフローを開始したチャンネル」
メッセージテキストに@aws lambda invoke --function-name MorningFacilitatorFunction --region ap-northeast-1を入力。
保存、そして公開。
これでワークフロー登録完了。
ショートカットから起動することが可能。
運用してみよう
カタカタカタ...
「...ふぅ。」
「おっとそろそろ朝会だなぁ。」
「今日の担当は・・・?」
「病弱太郎か。あれ?あいつ今日病気で休みだったよな・・」
「しょうがない。選ぶか。」
「ショートカットから...えい」
「ほうほう。朝会大好き子か。よしよし。今日の仕事を頑張ろう」
まとめ
正直、AWSでやるにはオーバースペック感が否めない。笑
とわ言え、
- 朝会前のTheWordが少なくなる(かも?)
- 興味のあったAWS Chatbotをさわれた
のでよかったかと。
AWS Chatbotは触ってみて、無限の可能性を感じた。
SlackトリガーでAWSのServiceを使用できるので、CI/CDを全てAWS上で構築することができれば、SlackOnlyで業務が回りそう。


















- 投稿日:2020-07-22T16:06:59+09:00
[AWS ChatBot]朝会のファシリテーターを決めて!
現職場では、デイリースタンドアップとして、朝会を実施している。
そして、いつも開始日時になると、「え、今日・・・司会担当・・・だれ・・・?」
とTheWordになる。
※TheWord ・・・ リモート会議において、 無音が続き、最初に話した人がファシリテーターをしなければいけない空間のこと一応、SlackBotを使用して、それとなく機械的にファシリテーターを指名しているのだが、
「この人お休みだよ〜」 や 「昨日もやったんですけど〜」 とか
いちいち面倒臭い。
よし。朝会のファシリテーターをいい感じ(前回当たった人は当たらない、スムーズに再抽選ができる、
自分が選ばれない)に決めるToolを作ろう。はじめに
コミュニケーションToolはSlack
プラットフォームはAWSとする。構成
全体構成はこんな感じ。
朝会の担当者をランダムに選択し、Slackに通知するTool。
実行トリガーは2種類存在する。
1. CloudWathEventsから定期的(朝会の始まる5分前)に実行
2. Slack→AWS ChatBotから実行DynamoDBではファシリテーター担当履歴を管理。
(現時点では直近の担当者しか保存していない。)構築
AWS
ChatBot以外はCloudFormationで構築。
IAM等のユーザーは事前に発行しておくこと。
ソースコードLambda
ソース
Node.jsで実装。
コード全体とは以下の通り。index.js'use strict' const requestPromise = require('request-promise') const AWS = require('aws-sdk') const dynamodb = new AWS.DynamoDB.DocumentClient({ region: 'ap-northeast-1' }) let slackPostOption = { url: 'https://slack.com/api/chat.postMessage', method: 'POST', qs: { token: process.env.SLACK_TOKEN, channel: process.env.SLACK_CHANNEL, text: '', username: 'ぼくのいうことはぜったい' }, json: true } exports.handler = async () => { return new Promise((resolve, reject) => { Promise.resolve() .then(() => { // 直近のファシリテーターを取得 return getLatestFacilitator() }) .then((latestFacilitator) => { // ランダムに取得(直近を除く) return getFacilitator(latestFacilitator) }) .then((facilitator) => { // 直近のファシリテーターを登録 return putLatestFacilitator(facilitator) }) .then((facilitator) => { // Slackに通知 return postSlack(facilitator) }) .then(() => { resolve('Finish') }) .catch(reject) }) } const getLatestFacilitator = () => { const param = { TableName: 'FacilitatorHistory', Key: { status: 'latest' } } return new Promise((resolve, reject) => { dynamodb.get(param, (err, data) => { if (err) reject(err) resolve(data.Item ? data.Item.member : '') }) }) } const getFacilitator = (latestFacilitator) => { return new Promise((resolve, reject) => { const memberList = process.env.MEMBER.split(',') const get = () => { const facilitator = memberList[Math.floor(Math.random() * memberList.length)] if (latestFacilitator == facilitator) { get() return } resolve(facilitator) } get() }) } const putLatestFacilitator = (facilitator) => { return new Promise((resolve, reject) => { var param = { TableName: 'FacilitatorHistory', Item:{ status: 'latest', member: facilitator } } dynamodb.put(param, (err, data) => { if (err) reject(err) resolve(facilitator) }) }) } const postSlack = (facilitator) => { return new Promise((resolve, reject) => { slackPostOption.qs.text = `きょうのあさかいは <${facilitator}> だ。` requestPromise(slackPostOption) .then(resolve) .catch(reject) }) }内容
本来なら並列にできる部分もあるが、わかりやすく直列化している。
流れとしては
1. 直近のファシリテーターを取得
2. ファシリテーターをランダムに取得(直近のファシリテーターは除く)
3. Slackに担当者を通知
4. 2.で選ばれたファシリテーターを登録
といったシンプルなもの。
2.のファシリテーター取得ロジック部分で担当者ごとに重みをつけて、選ばれやすさを制御したり、自身だけ選ばれづらくするなどのイカサマはできそう。CloudFormation
yml
一部内容がベタが記されている部分があるので、使用する際には修正する必要がある。
template.ymlAWSTemplateFormatVersion: 2010-09-09 Resources: MorningFacilitatorFunction: Type: AWS::Lambda::Function Properties: Code: ./release/app.zip FunctionName: MorningFacilitatorFunction Handler: index.handler Runtime: nodejs12.x # Lambdaの実行ロール Role: {lambda arn} MemorySize: 128 Timeout: 30 Environment: Variables: TZ: Asia/Tokyo # カンマ区切りでファシリテーター候補のSlackユーザーIDを定義 MEMBER: '@yamada,@yamamoto,@yamashita,@yamagami,@yamsuda' # 各種Slackの情報 SLACK_TOKEN: {slack api token} SLACK_CHANNEL: {slack channel} FacilitatorHistory: Type: AWS::DynamoDB::Table Properties: TableName: FacilitatorHistory AttributeDefinitions: - AttributeName: status AttributeType: S KeySchema: - AttributeName: status KeyType: HASH ProvisionedThroughput: ReadCapacityUnits: 3 WriteCapacityUnits: 3 FacilitatorEventsRule: Type: AWS::Events::Rule Properties: Name: FacilitatorEventsRule # 朝会開始時間5分前(GMTなのでJST変換すると+9時間) ScheduleExpression: cron(55 0 * * ? *) State: ENABLED Targets: - Arn: !GetAtt MorningFacilitatorFunction.Arn Id: lambda MorningFacilitatorPermission: Type: AWS::Lambda::Permission Properties: Action: lambda:InvokeFunction FunctionName: !Ref MorningFacilitatorFunction Principal: events.amazonaws.com SourceArn: !GetAtt FacilitatorEventsRule.ArnCLI
デプロイする際は、AWS CLIを使用。
毎回入力するのは面倒なため、shを作成deploy.sh#!/bin/sh # ソースコードをアーカイブ rm -fr release && mkdir release zip -r app.zip index.js node_modules > /dev/null 2>&1 mv app.zip release/ # 必要な情報はベタがきするか、shの引数で対応 AWS_IAM_USER_NAME=$1 AWS_ACCESS_KEY_ID=$2 AWS_SECRET_ACCESS_KEY=$3 AWS_DEFAULT_REGION=$4 AWS_S3_BUCKET=$5 AWS_STACK=$6 aws configure set aws_access_key_id $AWS_ACCESS_KEY_ID --profile $AWS_IAM_USER_NAME aws configure set aws_secret_access_key $AWS_SECRET_ACCESS_KEY --profile $AWS_IAM_USER_NAME aws configure set region $AWS_DEFAULT_REGION --profile $AWS_IAM_USER_NAME aws cloudformation package --template-file template.yml --s3-bucket $AWS_S3_BUCKET --s3-prefix `date '+%Y%m%d%H%M%S'` --output-template-file output.yml --profile $AWS_IAM_USER_NAME aws cloudformation deploy --region $AWS_DEFAULT_REGION --template-file output.yml --stack-name $AWS_STACK --profile $AWS_IAM_USER_NAMEAWS Chatbot
クライアントの設定
AWS Chatbotのコンソールを開き、チャットクライアント「Slack」を選択し、クライアントを設定を押下。
権限を求められるので、許可する。
チャンネルの設定
新しいチャンネルを設定。
各種任意の値を入力し登録。
以上でAWS側の設定は完了。
Slack
SlackからLambda実行
メンバーが揃っているチャンネルで、@awsさんをインバイトする。
/invite @aws
このように表示されればOK。
SlackからLambdaの実行。
@aws lambda invoke --function-name MorningFacilitatorFunction --region ap-northeast-1
すると、ファシリテーターが指名される。
ただ、毎回このようなコマンドを入力するのは効率が悪いので、Slackワークフロー登録する。
Slackワークフロー
ワークフロービルダーを開く。
作成を押下して、適当な名前を入力。
※ 伸ばし棒が入らない・・・
ショートカットを選択、作成。
チャンネル名はメンバーが揃っているチャンネルを選択。
ステップを追加し、メッセージを送信を選択。
メッセージの送信先に「ワークフローを開始したチャンネル」
メッセージテキストに@aws lambda invoke --function-name MorningFacilitatorFunction --region ap-northeast-1を入力。
保存、そして公開。
これでワークフロー登録完了。
ショートカットから起動することが可能。
運用してみよう
カタカタカタ...
「...ふぅ。」
「おっとそろそろ朝会だなぁ。」
「今日の担当は・・・?」
「病弱太郎か。あれ?あいつ今日病気で休みだったよな・・」
「しょうがない。選ぶか。」
「ショートカットから...えい」
「ほうほう。朝会大好き子か。よしよし。今日の仕事を頑張ろう」
まとめ
正直、AWSでやるにはオーバースペック感が否めない。笑
とわ言え、
- 朝会前のTheWordが少なくなる(かも?)
- 興味のあったAWS Chatbotをさわれた
のでよかったかと。
AWS Chatbotは触ってみて、無限の可能性を感じた。
SlackトリガーでAWSのServiceを使用できるので、CI/CDを全てAWS上で構築することができれば、SlackOnlyで業務が回りそう。
- 投稿日:2020-07-22T15:27:16+09:00
Athenaで気軽にS3のデータを集計する
S3のJSONを気軽にAthenaで集計したいと思い、安く済ます方法を調べた。
事前の印象では結構なお値段かかってしまうものだと思っていたが、小さいデータを最低コストで集計する分にはかなり安く済みそうだった。ということで、ここでやりたいのは、
- S3の小さいデータを
- 気軽に
- 安く
- SQLで集計する
ということで、RDSなど立てるのはもってのほかである。
前提知識
パーティション
データをパーティション分割することで、各クエリでスキャンするデータの量を制限し、パフォーマンスの向上とコストの削減を達成できます。Athena では、データのパーティション分割に Hive を使用します。すべてのキーでデータをパーティション化できます。一般的な方法では、時間に基づいてデータをパーティション分割します。これにより、通常、複数レベルのパーティション構成となります。たとえば、1 時間ごとに配信されるデータを年、月、日、時間でパーティション分割できます。別の例として、さまざまなソースから配信されるデータを 1 日 1 回ロードする場合、データソースと日付でパーティション分割できます。
データのパーティション分割 | Amazon AthenaこのようにS3のパスを年月日などで区切ると、それをパーティションとしてデータ分割することができる。
パーティションを分けることでクエリーの条件として利用できるようになり、条件を絞ることでスキャンするデータ量を削減できる。具体例はこんな感じ。どれも年月日でパーティションを分けている。
s3://datasource/year=2020/month=01/day=01/... s3://datasource/dt=2020-01-01/... s3://datasource/2020/01/01/...上2つの変な形式のことをHive形式と言うらしい。
Athenaはこの形式を認識して自動でパーティションを追加してくれる。
一番下の例はHive形式ではないので手動でパーティションを追加する必要がある。パーティションプロジェクション
Athena でパーティション射影を使用すると、高度にパーティション化されたテーブルのクエリ処理を高速化し、パーティション管理を自動化できます。
Amazon Athena を使用したパーティション射影 | Amazon Athena前述のパーティションデータはGlueデータカタログに保存されるデータだが、Athenaのパーティションプロジェクションを使うとテーブル設定から計算してパーティションを認識するようになる。
実際のパーティションデータを保持するわけではないので検索対象に存在しないパーティションがあり虫食い状態だと、クエリーに時間がかかってしまう場合がある。パーティションプロジェクションの制限事項/考慮事項は 公式ドキュメント を参照。今回はパーティションのデータ追加処理が不要になることで、Glueクローラーなどの処理コストが無料になるため利用している。
パーティションの追加/更新方法
パーティションはデータの追加に従って更新していかなければならない。
年月日でパーティションを切っている場合、翌月のデータが追加されたらパーティションも増えるから。
いくつか方法は考えられる。
手動でADD PARTITION/MSCK REPAIR TABLE
手動でDDLクエリーを実行する。
データが増えないのであれば、テーブル作成後に「パーティションのロード」を選択すれば同じ処理をしてくれるのでそれでいいと思う。LambdaでADD PARTITION/MSCK REPAIR TABLE
EventBridge+Lambdaで定期的に実行する。
でも無駄な管理リソースが1つ増えるので、こういうコードを書きたくない。Glueジョブのついでに
試してないがこちらの記事が参考になった。
Glueジョブを使っているならこの方法がよさそう。
[アップデート]AWS Glueがジョブ実行後のパーティション更新に対応しました! | Developers.IOGlueクローラー
パーティションの更新だけでなく、テーブル定義もデータを元に自動更新してくれたりする。有能だけど高い。Athenaパーティションプロジェクション
今回使った方法。
考慮事項と制約事項 | Amazon Athena最終的な構成
とにかくAWS Glueにコストがかかる。Athenaの料金体系の幅とはマッチしていない感じだった。
なのでGlueの利用は最低限にして、制限やバグを回避しつつAthena+S3で集計できるようにした。
S3 Selectも少し調べたが制限が多く、特殊な使い方しか出来なさそうだったので早々に諦めた。
S3
S3にNDJSON形式のファイルを置いてある前提(別のファイル形式でも問題ない)。
集計対象のパスが意味を持っているのでパスの設計に気をつけないといけなかった。Athena
S3というかGlueのデータカタログにSQLを投げられる便利なサービス。
パーティションプロジェクションの登場でお手軽に安く使えるようになった気がする。Glue
データに関する色々なことができるサービス。そのほとんどが今回不要。
ちゃんと使うとS3のデータレイクからGlueを介してAWSの豊富なデータベースサービスと連携できそう。
ただ今回は不要。もっと小物から大物まで利用できる柔軟な料金体系にして欲しい。
AWS Glue との統合 | Amazon Athena図にするほどでもないがこのような構成になった。
色々な用語がでてくるが、自動で設定される部分も多いので太字の部分だけ考えればいい感じ。
コスト
東京リージョンの場合。
ごらんの通りGlueクローラーが高いので、クローラーを使ったパーティションの自動更新をやめて、Athenaのパーティションプロジェクションを使うことでGlue分は無料になった。
これ以外にも通信量などもかかるが、今回の件に限った話ではないので割愛。S3
安い。
Athena
料金 | Amazon Athena
スキャンされたデータ1TB あたり 5ドル。
結果セットの大きさでなく、集計対象のデータの大きさに課金される。
気になる最低料金は10MB(0.000001TB)分の金額になる。
0.000001TB * 5ドル = 0.000005ドル/クエリー日次で1クエリー実行すると毎月0.0015ドル。ほんとか?
Glue
ストレージとリクエスト
ストレージは100万オブジェクトまで無料。
リクエストは毎月100万回まで無料。クローラー
高い。パーティションの自動更新などに利用するとびっくりする。
1DPUあたり0.44ドル/時かかる。DPUはData Processing Unitの略で、4vCPU/16GBメモリの計算リソース。
最低利用時間は10分だが、DPUは2つ利用されるという噂を見かけたので2DPUで計算しておく。
0.44ドル * 1/6時間 * 2DPU = 約0.146ドルこちらも日次で実行すると毎月4.38ドル。高い。
構築
データソースの用意
集計対象のファイルが置いてあるバケットを用意する。
元から/YYYY/MM/DD/形式で保存されているなら、その形式にするしかないと思う。もしくはGlueジョブなどで加工するか。これからパスを決められるならHive形式にするのが良さそう。今回は
/datehour=YYYY-MM-DD-HH/にした。パーティションプロジェクションのdate型、Firehose、Lambdaのタイムゾーン、などに合わせてUTCにしたかったのと、日本時間で集計するため−9時間できるように時間(HH)まで含めた。問題のあるHive形式のパス
当初
/year=2020/month=01/day=01/hour=00/にしたところ、パーティションプロジェクションでエラーになり認識できなかった。これはyearをdate型として認識させようとした場合yyyyではダメでjava.time.Year型が動作しないようだった。不具合と思われるのでAWSサポート経由でフィードバックした。
date型でなくinteger型で認識させた場合は問題なく動作するが、その場合NOW-3YEARSやNOW+1MONTHなどの相対日付文字列が使えなくなる。ここらへんのパーティションプロジェクションの設定については後述。Athenaのクエリー結果出力先
ワークグループ設定やクエリー実行時に出力先のS3バケットを指定する。
クエリーの実行結果だけでなく、クエリーを保存した場合もここに保存される。
なんなら保存してないクエリーもここに保存される(?)。
APIでも結果を取得できるので、直接ここを見ることは少ないかもしれない。データソースの追加
ドキュメント を参考にAthenaのデータソースを追加する。
データソースを追加することでデータベースとテーブルが登録され、Athenaで検索できるようになる。
以下、ドキュメントにある手動追加手順の補足。
8.テーブル名の入力
ここが一番の難関。データベース名やテーブル名に入力できる記号は_だけ。
-を入力してもここではエラーなど出ない。クエリー実行時になって意味不明なエラーがでるだけ。
本当に意味不明なので解決はできない。
テーブル、データベース、および列の名前 | Amazon Athena
予約キーワード | Amazon Athena11.データ形式
JSONを選択する。
JSON形式を選択すればNDJSONやJSON Linesのような改行区切りのJSONも認識する。14.パーティションの追加
ここでdatehour列を追加する。
型はstringにする。dateやtimestampにするとエラーになる。
これはデータソースの追加時に設定したS3パス(/datehour=YYYY-MM-DD-HH/)のdatehour部分に合わせる。16.テーブル作成クエリーの実行
生成されたクエリーに問題がなければ自動的に実行されたと思う。
問題があった場合エラーメッセージが表示される。されるが意味不明なので覚悟すること。パーティションプロジェクションの設定
ここまででクエリー自体は実行できるようになっている。
まだパーティションの設定をしていないのでクエリー結果は0件になるはず。続いてAthenaがパーティションを認識できるようパーティションプロジェクションの設定をする。
そのためにはGlueのテーブルにプロパティを追加する必要がある。
ドキュメントにはinteger型の例しか載っていないので、ここではdate型で設定してみる。
設定の流れはどちらも変わらないので、ドキュメントを参考のこと。
パーティション射影の設定 | Amazon Athenadate型のテーブルプロパティ
projection.enabledをtrueに設定するのは共通項目。
date型の設定として下記の項目を追加する(列名はdatehourの前提)。
日付型 | Amazon Athena
プロパティ名 値 備考 projection.enabled true 必須。固定値。 projection.datehour.type date 必須。固定値。 projection.datehour.range NOW-3YEARS,NOW 必須。カンマ区切りで下限,上限を指定する。
ここでは直近3年を指定している。projection.datehour.format yyyy-MM-dd-HH 必須。 projection.datehour.interval 1 単一日/単一月でなければ必須。
1時間単位を指定。projection.datehour.interval.unit HOURS 同上。1時間単位を指定。 パスがHive形式でない場合
データソースであるS3のパスが
/datehour=YYYY-MM-DD-HH/のようなHive形式でない場合、storage.location.templateテーブルプロパティを設定することでAthenaにパーティションとして自動認識させることができる。
例えばs3://bucket/prefix/yyyy/MM/dd/HH/...なら下記のように設定する。
プロパティ名 値 projection.enabled true projection.datehour.type date projection.datehour.range NOW-3YEARS,NOW projection.datehour.format yyyy/MM/dd/HH projection.datehour.interval 1 projection.datehour.interval.unit HOURS storage.location.template s3://bucket/prefix/${datehour} Amazon Kinesis Data Firehose 例 | Amazon Athena
余談だがFirehoseではHive形式も指定できるっぽい。
Amazon S3 オブジェクトのカスタムプレフィックス | Amazon Kinesis Data Firehose
Firehose でS3プリフィックスのカスタマイズが可能になりました | Developers.IOクエリーを実行する
パーティションプロジェクションの設定まで終わったので、これで検索できるようになっているはず。
パーティション列を条件に入れて検索してみる。これは日本時間で7月分のデータを検索するクエリー。SELECT * FROM database_name.table_name WHERE datehour >= '2020-06-30-15' AND datehour < '2020-07-31-15'パーティションを絞って検索しないと過去3年分の存在しないパーティションを検索しにいってしまいえらい処理時間がかかるので注意。
まとめ
- Athenaのパーティションプロジェクションありがとう
- Athena思ったより安い、というか料金体系に幅があってよい
- Glueデータカタログは無料枠が使える
- あまり気軽じゃないが1回やれば慣れる

- 投稿日:2020-07-22T12:57:09+09:00
【AWS】利用料金発生に怯えるあなたへ
はじめに
クラウドコンピューティングの勉強を始めたくて、AWSアカウントを作成。コンソールからぽちぽちと触ってみる。
あまりに簡単にサービスが立ち上がるので、楽しくなっていろいろ試していると……
「え、知らないうちに請求が来てるんだけどなんで!?」
なんて経験、誰しもあるのではないでしょうか。
あるいはクラウド破産という言葉を聞き、自分もそうなってしまうのではないかと怖くて手が出せない人もいるかもしれません。
世の中の良いサービスにお金が支払われるのは悪い事ではないのですが、予期せぬ課金はさすがに堪えるものです。予期せぬ課金を防止するためのポイントは、言ってしまえば課金されるパターンあるあるを知ることです。
つまりこの記事は、私のAWSアカウントに請求が来てしまった失敗談集でもあります。
請求に怯えながらコンソール画面を見ている・見る予定がある人のお役に立てれば、きっと私の予期せぬ利用料金たちも浮かばれるでしょう。この記事では説明しないこと
・初学者向けの範囲を逸脱した解説
→あくまで「ハンズオンとしてAWSアカウントを作成し、無料利用枠内で小さなサービスを作ってみる」場合を想定しています。
・セキュリティ対策
→AWS高額請求といえば、「重要なキーを誰でもアクセスできるところに置いてしまい、アカウントを乗っ取られた」などのセキュリティ周りでやらかしたパターンが有名ですが、当記事は「ユーザーの手で立ち上げたサービスにおける予期しない課金」を対象とします。予期せぬ課金パターンたち
EC2編
インスタンス
1年間無料対象枠に入っているインスタンスタイプは「t2.micro」のみです。また、無料利用枠には750時間制限(/月)があります。
個人用のハンズオンで無料利用枠を超えることはなかなかありませんし、コンソールからEC2を立ち上げる場合、他のインスタンスを誤って選択する可能性も低いでしょう。
注意すべきなのは、ハンズオンなどでCloudFormationテンプレートからスタックをデプロイする場合です。
CloudFormationのテンプレートを指定すると、次に「スタックの詳細を指定」の画面が出てきます。
つい読み飛ばしてしまいがちですが、よく目を通してみてください。
InstanceTypeがt2.largeになっていますね。当然このままデプロイすると料金が発生します。
どうしてもインスタンスサイズが大きくないとうまくいかない場合は選択するしかありませんが、もしt2.microでもハンズオンが行えそうであれば、サイズを変更してしまってください。Elastic IP
Elastic IPは、実行中のインスタンスに関連付けられている場合1つまで無料です。
「実行中」というのがポイントで、停止しているインスタンスに関連付けられているElastic IPや、インスタンスを削除したものの解放し忘れたElastic IPは料金が発生します。
インスタンスを停止する場合、もしくは削除する場合は必ずその前にElastic IPを解放するように癖をつけておくと安心です。
関連付けの解除方法については、公式ドキュメント内「Elastic IP アドレスの関連付け解除」をご確認ください。
私の初めての請求も、停止したインスタンスに関連付けていたElastic IPでした。VPC編
NATゲートウェイ
VPCにおいて料金発生ポイントは多くないのですが、NATゲートウェイは曲者です。
まず、NATゲートウェイは通信の方向に関わらず料金が発生します。AWSはデータインに関しては料金が発生しない場合が多く、NATゲートウェイが例外であることがまず注意点となります。
更に、AWS公式のVPC料金ページを見ていただくと分かるのですが、NATゲートウェイは結構高額です。一番安いバージニア北部リージョンでも、0.045USD/時の起動価格+データ転送料金として0.045USD/GBが生じます。
そして東京リージョンで利用すると更に高いです。
ここで考えるべきなのは、「本当にNATゲートウェイが必要な構成なのか?」ということです。
AWSリソースとの通信であれば、エンドポイントを利用した通信で事足ります。VPCエンドポイントを利用する場合、NATゲートウェイよりはるかに安価で済みます。
VPC間で通信するだけの構成であればそもそもNATゲートウェイを経由させる必要はありません。ほとんどのAWSサービスに於いて、同一リージョン内の通信は無料です。
私の経験談でもあるのですが、簡単なサービスをデプロイする程度のハンズオンであればNATゲートウェイは不要であることが多いです。
或いはNATゲートウェイをなるべく利用しないような構成を考えることも、ひとつの学習になることでしょう。RDS編
インスタンスタイプ
EC2同様、「db.t2.micro」以外のインスタンスタイプは無料利用枠の対象には入っていません。
(Oracle BYOL=独自ライセンス形式であれば「db.t3.micro」が無料利用枠に入りますが、なかなか個人のハンズオンで利用する機会はないと思います)
注意点はEC2の場合と同様、CloudFormationのスタックから起動させる場合です。インスタンスのサイズはきちんと確認しておきましょう。スナップショット
AWS公式のRDS料金ページの大見出しをざっと見る限りでは、「スナップショット」の料金は書かれていないように見えます。
よく見ると分かるのですが、スナップショットの料金については「バックアップストレージ」の項に記載されています。
かいつまんで読んでみると、「つまり、ほとんどのお客様にはバックアップストレージの料金が発生しません」の文字が目に入るかもしれません。
しかし、更にその後をじっくり読んでください。DB インスタンス終了後のバックアップストレージの料金は毎月 0.095USD USD/GiB です。
そう、RDSインスタンスを稼働させている間はバックアップストレージの料金はかからない(場合が多い)のに、インスタンスを終了させるとバックアップストレージの料金が発生するのです。
ハンズオンでDBを立ち上げ、終了時に削除。でもRDSの請求があるぞおかしいな、という場合はこれが原因かもしれません。
日割りなので、1日に積みあがっていく金額としてはそうでもないことだけが幸いなのですが、ふとCost Explorerを起動したときに
上記のようになっているとかなりゾッとします(見て分かる通り、この時は気付くまでに1週間ほどかかっています……)。スナップショットに課金されてしまうことを防ぐには、RDSを削除する前にスナップショットを削除してしまうのが一番です。
ただしスナップショットの作成タイミングによっては、削除した後にスナップショットが作成されてしまう場合もあるので、要注意です。
RDSスナップショットの削除方法に付いては、AWS公式ドキュメントをご参照ください。もしハンズオンに於いてスナップショットが不要であれば、最初から作成しないように設定するのが一番簡単です。
コンソール画面からデータベースサーバーを作成する際に、上記のチェックを外すだけです。
(※既存のCloudFormationテンプレートからRDSを作成する場合は、スナップショット不要の設定が行えないようです)S3編
S3の無料利用枠はAWS公式のS3料金ページによると、S3の無料利用枠は「S3標準ストレージクラスで5GBのAmazonS3ストレージ、20,000GETリクエスト、2,000PUT、COPY、POST、あるいはLISTリクエスト、データ送信15GB」です。
ハンズオンの範囲ではとても超えそうにない……と思いがちですが、実はとある設定をしていると簡単に超えてきます。CloudTrailの証跡作成です。
CloudTrailのログをS3に保存するようにすると、AWSにアクセスして何かする度に自ずとPUT数が増えるため簡単に無料利用枠をはみ出ます。
請求ダッシュボードの無料利用枠があっという間に100%を超える様は、初見だと度肝を抜かれるのではないでしょうか。
ただし他の場合と異なるのは、CloudTrailをきちんと設定し、アカウントに不審な動きがないか気を付けることが回り回ってコスト削減につながる場合があることです。
「この記事では説明しないこと」の項で少しだけ触れましたが、AWS高額請求で多いのはアカウントが乗っ取られるパターンです。そうならないためにも、CloudTrailのログをきちんと保存し、S3のPUT数が無料枠を超えてしまうことには目を瞑る、というのが、AWSのベストプラクティスではあります。
どの程度サービスを利用するかにもよりますが、CloudTrailでログを保存する場合、個人のハンズオン目的での利用であれば月200円程度で済みます。それでも人は過つ
人間は間違える生き物です。気を付けていても避けられないことがあります。
とはいえ、サービスコンソール(GUI)画面に、個々のサービス利用料金が表示される機能はありません。
しかし、間違いに備えておくことで、課金による影響を最小限にすることは可能です。
つまり、利用料金が発生したらすぐに気付けるよう、通知を設定しておきます。「AWS Budgets」は、AWS利用料金についての予算を設定し、予算の一定割合を超過するとアラートという形で通知を送信することができます。
予算とアラート用のしきい値を非常に小さい額に設定しておけば、利用料金の発生がすぐに分かります。AWSに慣れてきたら、メールよりもLINEなどで通知が来た方が便利かも、と思うようになりかもしれません。
また、AWS Budgetsはアラートを一度オンにするとオフに戻すことはできません。
Amazon CloudWatchの「EstimatedCharges」メトリクスを利用すると、AWS内の他のサービスのトリガーとして利用でき、例えば一定金額を超えた時点でAWS Lambdaを動かしてLINEに通知する、という使い方が可能になります。
初心者向けの範囲を超えてしまうので、Amazon CloudWatchドキュメントをご参照ください。もし料金が発生していることが分かったら、すぐに詳細を確認しましょう。
請求が来たサービス一覧をただ眺めていても、理由が分からない場合が多いからです。
前日までの請求詳細は「Cost Explorer」で確認できます。
当日の請求確定は次の日に持ち越されてしまうため、その日の消し忘れは分からないところだけが難点です。
そのため、アラートに気付いたらすぐに確認、すぐに削除するようにしましょう。
(この辺りをカバーできるサービスとしてAWS Trusted Advisorが存在するのですが、月100ドルかかるビジネスプラン以上を利用する必要があり、個人利用には少し難しいでしょう)また、失敗から料金発生が起こってしまっても、次に繋がる勉強になったと割り切ることも大切です。
逆に言えば割り切れるほど小さな失敗で済むように、アラートは絶対設定しておきましょう。おわりに
以前、初めてクラウドサービスを触る人向けのハンズオンを作成するため、他のクラウドサービスとの比較検討を行う機会がありました。
そこで感じたのは、GCPやAzureといったバウチャーで無料利用枠を用意してくれるクラウドサービスに比べて、AWSは無料利用枠の概念が分かり辛く初学者のハードルが高いのではないか、ということです。
ただ、ハードルの高さに初学者が臆してしまうのはもったいないと感じるほどに、AWSは魅力的なサービスを取り扱っていることも確かです。
公式からのハンズオンや学習体系も充実している分、多くの人が臆しているポイントであろう「料金」の不安をわずかでも取り除けたらと思っています。
当記事がAWS初学者の支えになれば幸いです。弊社WebサイトではAWSを含むさまざまな技術記事を公開しています。ぜひご覧ください。






- 投稿日:2020-07-22T12:43:03+09:00
【メモ】 AWS EC2内、Railsアプリケーションの起動、停止コマンド &深堀
環境
言語:Rails 5.2.4.2
サーバー:AWS EC2
ターミナル:TeraTerm結論
サーバー起動
プロジェクトのルートディレクトリにて
rails s -e productionサーバー停止
プロジェクトのルートディレクトリにて
kill $(cat tmp/pids/puma.pid)解説
サーバー起動
rails s -e production・-e は -environmentの略
production環境でサーバーを起動しますよという意味になる。
・Gemfile内にて、group :production do内のGemを読み込んで実行する。
・-environmentを指定しない場合、デフォルトでdevelopmentになっている。
その為、Gemfile内group :development do中のGemが読み込まれ、本番環境ではエラーを起こす。サーバー停止
kill $(cat tmp/pids/puma.pid)・Railsアプリケーション起動中(サーバを立てている状態)、tmp/pids/下にpuma.pidというファイルが作成される。(Railsアプリケーション停止中は存在しない。)
・puma.pidには、起動中RailsアプリケーションのプロセスIDが記入されている。(ex. 1234)
・catコマンドを実行すると、指定したファイル内の内容(プロセスID)を出力する。
(実際にcat tmp/pids/puma.pidで確認できる。→「1234」が出力される)
・$kill プロセスID コマンドで、指定したプロセスIDのプロセスを終了する。
・つまり、上記コマンドを入力すると
$kill 1234
となり、プロセスID:1234(起動中Railsアプリケーション)を終了することができる。最後に
個人で調査した結果ですので、間違っておりましたら申し訳ございません。
- 投稿日:2020-07-22T12:04:09+09:00
Amazon LightsailでWebサイト構築(LAMP環境)
はじめに
自作Webサイトを某レンタルサーバからAmazon Lightsailに引越した際の手順として、Lightsailのインスタンス作成〜サイトの公開までの手順を紹介していきます。
前提
- 紹介する手順はLAMP環境となります(WordPressサイトではない)
- Webサイトの独自ドメインは取得済みとなります
- Lightsail自体の詳細説明はしていません
- AWSの類似サービス、レンタルサーバの比較はしていません
- ロードバランサーは使用していません
Amazon Lightsailとは(簡易版)
EC2同様仮想サーバを提供するサービスですが、Webサーバとして必要な機能がパッケージングされています。
詳細な説明はLightsailの紹介記事などを参考にしていただければと思います。
下記の特徴から、個人ブログやスモールサービスの運用に向いています。月額課金制
最低スペックで$3.5/月。アプリケーションの実行環境がプリセットされている
WordPress、LAMPなど選択可能。サーバの複製が簡単
サーバーのスナップショットから直接複製可能。他のAWSサービスの知識が不要
DBやストレージ機能も含んでいるので、EC2のように他サービスとの連携は不要。逆に言うとパッケージングされているためカスタマイズは難しい。※ EC2への移行は可能1.インスタンス作成
AWSの管理コンソールからLightsailサービスを選択します。
Lightsailのホーム画面が開いたら「インスタンス」タブから「インスタンスの作成」を押します。
※ 初めてLightsailを使う際には、ホーム画面でなくインスタンス作成画面が開きます。インスタンスロケーション
特に理由が無ければ変更不要。
インスタンスイメージの選択
プラットフォームの選択
「Linux/Unix」を選択します。設計図の選択
「アプリ + OS」を選択し、「LAMP」を選択します。
オプション
「起動スクリプトの追加」は設定なし。
「SSHキーペアの変更」を押してデフォルトのキーをダウンロードしておきます。
ダウンロードしたファイルは後ほどSSH接続などで利用します。
「自動スナップショットを有効化」を任意の時間に設定します。
(スナップショット不要であれば未設定にしてください)
インスタンスプランの選択
用途に合わせて選択します。ここでは最低料金のプランを選択します。
インスタンスを確認
リソースの名称やタグの設定が可能です。
複数の異なるリソースを管理する必要が無ければデフォルトのままで良いかと思います。
ここではデフォルトのリソース名のままタグも作成せず「インスタンスの作成」を押します。
インスタンスの作成
前画面で「インスタンスの作成」を押すとホーム画面に戻り、作成したインスタンスが表示されます。
しばらく待つと、インスタンスの状態が「保留中」から「実行中」になります。
インスタンスの作成はこれで完了です。
作成されたインスタンスを選択するとIPアドレスが表示され、ブラウザからアクセス可能となります。(bitnamiのメニュー画面が表示されます)
※ URLはIPアドレス2.独自ドメイン設定
静的IPの作成
作成したインスタンスのIPアドレスはインスタンスの再起動ごとに置き換わってしまうので、ドメインとIPアドレスを紐付けるために静的なIPアドレスを設定します。
ホーム画面の「ネットワーキング」タブから、「静的IPの作成」を押します。
「インスタンスへのアタッチ」で作成したインスタンスを選択し、「静的IPの指定」で任意の名前(ここではデフォルトの名前)を入力し、「作成」ボタンを押します。
DNSゾーンの作成
ホーム画面の「ネットワーキング」タブで「DNSゾーンの作成」を押します。
「登録済みドメインの入力」で、ドメイン名を入力します。
「DNSゾーンを確認」では、インスタンス作成時と同じようにタグの設定が可能ですが、ここでは未設定にします。
入力後、画面下部の「DNSゾーンの作成」ボタンを押します。
ドメインとIPの紐付け(Lightsail側の設定)
DNSゾーンの作成が完了すると、ホーム画面の「ネットワーキング」タブに作成したDNSゾーンが表示されます。
作成したDNSゾーンを選択し、以下の設定をします。
Aレコードを追加
「DNSレコード」の「レコードの追加」を押し、「Aのレコード」を選択。
サブドメインは、登録済みドメイン名のままで良い場合には「@」を入力。
解決先は、「静的IPの作成」で作成したIPを選択する。ネームサーバーの名前を控える
「ネームサーバー」に表示されるネームサーバーの名前を控える。
(スクリーンショットではマスクしていますが複数のネームサーバーが表示されます)
ドメインとIPの紐付け(ドメインプロバイダー側の設定)
Lightsail側の設定で表示されたネームサーバーを、ドメインプロバイダー(お名前.comなど)に設定します。
利用しているプロバイダーの設定方法に従ってください。独自ドメインの設定はこれで完了です。
登録済みドメインにブラウザアクセスすると、インスタンス作成後に表示されたbitnamiのメニュー画面が表示されます。
※ URLはドメイン名3.HTTPS化
ドメインとIPアドレスのマッピング確認
登録済みドメインが手順2で設定された静的IPアドレスにマッピングされていることを確認します。
$ host <登録済みドメイン名> <登録済みドメイン名> has address <静的IP>Bitnami HTTPS設定ツールの実行
このツールを使うことでLet's Encryptという無料SSL証明書が利用され、以下の設定を自動で行ってくれます。
- HTTPS証明書の設定
- 証明書の自動更新の作成
- HTTPからHTTPSへのリダイレクト
ツールの実行コマンド
sudo /opt/bitnami/becert-tool対話式のスクリプトが実行され、以下の内容を聞かれるので入力してください。
対象のドメイン名
Domain list []:
の後に登録済みドメイン名を入力。「www」付きのドメインでない場合、以下のように追加するか聞かれます。今回は「www」付きのドメイン名をプロバイダー側で設定していないため、追加なしにします。
The following domains were not included: www.<登録済みドメイン名>.
Do you want to add them? [Y/n]
→ 「n」を入力HTTPからHTTPSへのリダイレクトを有効にするか
Enable HTTP to HTTPS redirection [Y/n]:
→ 「Y」を入力ツールによる変更を許可するか
証明書追加や証明書自動更新などの変更を許可するか聞かれます。
自分が実行した時は6項目の変更点が表示された後、許可するか聞かれました。
Do you agree to these changes? [Y/n]:
→ 「Y」を入力Let's Encrypte関連設定
E-mail address []:
Let’s Encrypteに関連づけるメールアドレスの入力が求められます。
任意のアドレスを入力してください。Do you agree to the Let's Encrypt Subscriber Agreement? [Y/n]:
Let’s Encryptの利用に同意するか聞かれます。
→ 「Y」を入力ツールの実行に成功するとSuccessメッセージが表示されます。
The Bitnami HTTPS Configuration Tool succeeded in modifying your installation.
確認
ブラウザからHTTPSで登録済みドメインにアクセスして確認します。
HTTP接続した場合もHTTPSにリダイレクトされます。
※ URLはドメイン名4.Webサイト構成ファイルのアップロード
ここまでで構築したLightsailインスタンスにWebサイトのソースコードをアップロードします。
ここではFileZillaでの手順を記載します。サイトマネージャーを開きます。
新しいサイト
任意の名前でサイト設定を作成。
ここでは「lightsail」という名前で作成しています。プロトコル
SFTPを選択ホスト
Lightsailインスタンスに紐付けた静的IPアドレス、または登録済みドメイン名を入力ログオン タイプ
鍵ファイルを選択ユーザー
bitnamiを入力鍵ファイル
インスタンス作成時にダウンロードした鍵ファイルを参照入力、選択完了後「接続」を押して接続します。
接続後、apacheのhtdocsにソースファイルをアップロードします。
htdocsは以下の場所にあります。
/opt/bitnami/apache2/htdocsここでは、htdocs配下に「lightsailtest」というディレクトリを作成し、その下にhello worldを表示するindex.htmlをアップロードしています。
5.Webサイトの表示
ブラウザで以下のURLにアクセスし、表示されることを確認します。
https://<登録済みドメイン名>/lightsailtest/index.html
以上でWebサイト公開までの手順は終了です。
参考
https://blog.yuichisato.net/build-a-blog-with-onamae-amazon-lightsail-wordpress/#toc10
→ プロバイダーで取得済みのドメインとLightsailのインスタンス紐付けの手順などhttps://aws.amazon.com/jp/premiumsupport/knowledge-center/linux-lightsail-ssl-bitnami/
→ Bitnami HTTPS設定ツールの実行方法















- 投稿日:2020-07-22T08:30:29+09:00
AWS Copilotを触ってみた
きっかけ
最近Selenium WebDriverのテスト実行環境をDocker Composeで組んで、ECSに上げてみようかなーと思っていたところにAWS Copilotなるサービスが登場したので触ってみました。
今回はSeleniumを走らせるのではなく、チュートリアル的にシンプルなnginxのwebサーバを立てて動作を確認したいと思います。AWS Copilotって何が出来るの?
AWS Copilotを使うことで、対話形式のセットアップで簡単にDockerfileからAmazon ECSでコンテナ起動ができます。
テスト環境や本番環境など環境毎のコンテナデプロイも簡単に行えます。インストール
Homebrewか直接バイナリダウンロードでインストールを行います。
# Homebrew $ brew install aws/tap/copilot-cli # 直接ダウンロード $ curl -Lo /usr/local/bin/copilot https://github.com/aws/copilot-cli/releases/download/v0.1.0/copilot-darwin-v0.1.0 && chmod +x /usr/local/bin/copilot && copilot --help # インストール確認 $ copilot --version copilot version: v0.1.0必要なファイルの準備
Dockerfileと今回はnginxを動かすのでWebサーバ用のindex.htmlファイルを用意しておきます。
# ファイル置き場 . ├── Dockerfile └── index.htmlDockerfileの中身はシンプルに以下の内容です。
FROM nginx EXPOSE 80 COPY index.html /usr/share/nginx/htmlアプリケーションのセットアップおよびテスト環境へのデプロイ
インストールが終わったら以下のコマンドで対話形式のセットアップを行います。
今回はnginxを立ち上げるのでservice typeはLoad Balanced Web Serviceを選択します。# 任意のフォルダで $ copilot init What would you like to name your application? [? for help] # アプリケーション名を指定 Which service type best represents your service's architecture? [Use arrows to move, type to filter, ? for more help] > Load Balanced Web Service # インターネットフェイシングなパブリックサービス Backend Service # プライベートなバックエンドサービス What do you want to name this Load Balanced Web Service? [? for help] # サービス名を指定 Which Dockerfile would you like to use for nginx-test? [Use arrows to move, type to filter, ? for more help] # 自動検出されるDockerfileを選択します。copilot init実行配下のフォルダの中のDockerfileも見つけてくれます。これだけで必要なものは自動的にセットアップされます。(処理が終わるまで少し時間がかかります)
しばらく待ってセットアップが完了すると
All right, you're all set for local development.
と表示され、テスト環境にデプロイをするかどうか聞かれます。(テスト環境だけ自動で作成され、他の環境は後述のコマンドで作ります。)
ここではテスト環境にデプロイをします。Would you like to deploy a test environment? [? for help] (y/N)するとデプロイが開始され、またしばらく待ちます。(10分くらい?)
デプロイが完了するとAmazon ECRのイメージタグの指定を聞かれます。Input an image tag value:すべてが完了すると最後にデプロイしたテスト環境へのアクセスURLが表示されます。
ブラウザでアクセス出来るか確認してみましょう。
もしアクセス先のURLが分からなくなった場合は、以下のコマンド結果のRoutesに載っています。$ copilot svc showデプロイ先環境の作成
テスト環境は自動で作られていましたが、それ以外にSTG環境や本番環境など任意の環境を作りたい場合は以下のコマンドで作成します。
$ copilot env init What is your environment's name? [? for help] # 作成する環境名 Which named profile should we use to create 『指定した環境名』? [Use arrows to move, type to filter, ? for more help] # AWS CLIで複数profileを設定している場合に選択する作成まで少し時間がかかります。
作成した環境一覧は以下のコマンドで確認できます。
$ copilot env ls作成したデプロイ先環境にデプロイ
環境を作成したらデプロイを行います。
テスト環境のデプロイと同じようにAmazon ECRのイメージタグの指定を聞かれます。$ copilot svc deploy --env 『作成したデプロイ環境』 Input an image tag value:デプロイが完了したらURLが表示されます。
複数の環境を作成した場合、
./copilot/『サービス名』/manifest.ymlに以下の記述を追記することで環境毎にスペックを変更することも可能です。
詳しくはAWS Copilot のご紹介 | Amazon Web Services ブログを確認してください。environments: 『デプロイ環境名』: count: 2 # アプリケーションを複製して動かす数 cpu: 1024 # CPUの割当量 memory: 2048 # メモリの割当量その他のCopilotのコマンド
アプリケーションの一覧を表示
$ copilot app lsアプリケーションに含まれるサービスや環境の一覧を表示
$ copilot app showアプリケーションの削除
ここまでで作成したアプリを丸ごと削除します。
$ copilot app deleteサービスの一覧を表示
$ copilot svc lsサービスのログを表示
デプロイした環境が複数ある場合はログ出力する環境を聞かれます。
色々フラグがあるので詳しくはsvc logs command · aws/copilot-cli Wikiを確認してください。$ copilot svc logsサービスのステータスの表示
デプロイした環境が複数ある場合はログ出力する環境を聞かれます。
$ copilot svc statusまとめ
copilot pipeline initまで手が出せなかった(というかやったけど上手くいかなかった)ので、pipelineも理解したら続きを書いたいと思います。We're hiring!
AIチャットボットを開発しています。
ご興味ある方は Wantedlyページ からお気軽にご連絡ください!参考
ECSのオペレーションを劇的に簡略化するAWS Copilotが発表されました! | Developers.IO
AWS Copilot のご紹介 | Amazon Web Services ブログ
Home · aws/copilot-cli Wiki
- 投稿日:2020-07-22T02:19:53+09:00
AWS DMS Binary Readerを試してみる :下準備
ASM + Binary Readerが試したかった
Source DBの準備
OCIのDBCSでサクッと行きたかった。
DBの作成
「DBシステムの作成」から、
- シェイプ・タイプの選択: 仮想マシン
- シェイプの選択: VM.Standard2.1
- 合計ノード数:1
- Oracle Databaseソフトウェア・エディション: Enterprise Edition
- ストレージ管理ソフトウェアの選択: Oracle Grid Infrastructure
- 使用可能なストレージ(GB):256GB
- SSHキー:適当に追加
- データベースのバージョン:11.2
CPUを絞ったせいか、あまりサクッとは行かなかった。後続のインスタンス作成を進めたほうが良い。
起動済: 2020年7月21日(火) 11:12:03 UTC 終了済: 2020年7月21日(火) 12:02:43 UTCDMS用ユーザ作成(DB)
[opc@testdb0721 ~]$ sudo -i [root@testdb0721 ~]# su - oracle 最終ログイン: 2020/07/21 (火) 12:37:14 UTC [oracle@testdb0721 ~]$ sqlplus / as sysdbaSQL> CREATE USER dms_user IDENTIFIED BY dmsTESTuser0721 DEFAULT TABLESPACE USERS; User created. SQL> ALTER USER dms_user ACCOUNT UNLOCK; User altered. SQL>権限付与
AWS DMS のソースとしての Oracle データベースの使用
GRANT CONNECT TO dms_user; GRANT SELECT ANY TRANSACTION TO dms_user; GRANT SELECT on V_$ARCHIVED_LOG TO dms_user; GRANT SELECT on V_$LOG TO dms_user; GRANT SELECT on V_$LOGFILE TO dms_user; GRANT SELECT on V_$DATABASE TO dms_user; GRANT SELECT on V_$THREAD TO dms_user; GRANT SELECT on V_$PARAMETER TO dms_user; GRANT SELECT on V_$NLS_PARAMETERS TO dms_user; GRANT SELECT on V_$TIMEZONE_NAMES TO dms_user; GRANT SELECT on V_$TRANSACTION TO dms_user; GRANT SELECT on ALL_INDEXES TO dms_user; GRANT SELECT on ALL_OBJECTS TO dms_user;GRANT SELECT on v_$transportable_platform TO dms_user; GRANT EXECUTE on DBMS_FILE_GROUP TO dms_user;上のマニュアルにはないが、下記の権限も必要っぽい。
Oracle をソースエンドポイントとして使用する場合に、AWS DMS が必要とするアクセス許可について教えてください。GRANT SELECT on SYS.DBA_REGISTRY to dms_user; GRANT SELECT on SYS.OBJ$ to dms_user;テストデータ作成用
GRANT CREATE TABLE TO dms_user; GRANT UNLIMITED TABLESPACE TO dms_user;ASMユーザの作成
rootに戻ってgridからASMインスタンスにログイン。(DBCSのGIは19cみたい)
[root@testdb0721 ~]# su - grid 最終ログイン: 2020/07/21 (火) 13:14:18 UTC [grid@testdb0721 ~]$ sqlplus / as sysasm SQL*Plus: Release 19.0.0.0.0 - Production on Tue Jul 21 13:19:56 2020 Version 19.7.0.0.0 Copyright (c) 1982, 2020, Oracle. All rights reserved. Connected to: Oracle Database 19c Enterprise Edition Release 19.0.0.0.0 - Production Version 19.7.0.0.0 SQL>CREATE USER dms_asm_user IDENTIFIED BY dmsTESTasm0721; GRANT SYSASM to dms_asm_user;DBの設定
DBレベルでのサプリメンタルロギングを有効化する。
SELECT supplemental_log_data_min FROM v$database; ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; SELECT supplemental_log_data_min FROM v$database;DMSの準備
レプリケーションインスタンス
DBCSのインスタンス作成と並行して、
- インスタンスクラス: dms.t2.micro
- エンジンバージョン: 3.3.3
- パブリックアクセス可能にチェック
- 今回はインターネット越しにやるので。
Target DBの準備
Aurora
DBCSのデプロイを待つ間に進めます。
RDSから、
- 標準作成
- エンジンのオプション: Amazon Aurora
- エディション: PostgreSQL との互換性を持つ Amazon Aurora
- バージョン: Compatible with PostgreSQL 11.6
- テンプレート: 開発/テスト
- DB インスタンスクラス: バースト可能クラス (t クラスを含む) > db.t3.medium
- マルチ AZ 配置: Aurora レプリカを作成しない
- パブリックアクセス可能:あり
追加設定 > 最初のデータベース名: DB名を入れておく
セキュリティグループは待ち受けポートへのアクセス許可がついたものをつけておく。
DMSの設定
Target エンドポイント
エンドポイントの作成から、ターゲットエンドポイントを選び、
「RDS DBインスタンスの選択」を選ぶと適宜補完してくれる。
- パスワードとDB名だけ入れる
- 接続テストで問題なければok
Source エンドポイント
- ソースエンジン: oracle
- サーバー名: IPアドレス
- ポート: 設定したポート(デフォルト1521)
追加の接続パラメータ
useLogMinerReader=N;useBfile=Y;asm_user=dms_asm_user;asm_server=RAC_server_ip_address:port_number/+ASM;入れずに接続テストをすると、LogMiner用の権限も必要になる。
Aurora(postgreSQL)のクライアント
DBCSのインスタンスに入れてしまう。
# yum install postgresql # psql -h <host名> -u <user名>動作テスト
ソーステーブル
Oracle DB
CREATE TABLE TEST1 ( COL_A NUMBER(4) PRIMARY KEY ,COL_B DATE ); insert into TEST1 values(0000,SYSDATE); commit;テーブルレベルのサプリメンタルロギングを有効化しておく。
alter table TEST1 add supplemental log data (PRIMARY KEY) columns;SQL> select COL_A, to_char(COL_B,'YYYY/MM/DD hh24:Mi:ss') from TEST1; COL_A TO_CHAR(COL_B,'YYYY ---------- ------------------- 0 2020/07/21 15:26:15ターゲットDB
とりあえず同名のスキーマを作成しておく。
CREATE SCHEMA DMS_USER; postgres=> \dn スキーマ一覧 名前 | 所有者 ----------+---------- dms_user | postgres public | postgres (2 行)DMS
データベース移行タスクからタスク作成。
テーブルマッピングで対象のテーブルを追加する。確認
Auroradms_test=> select * from "DMS_USER"."TEST1"; COL_A | COL_B -------+--------------------- 0 | 2020-07-21 15:26:15 (1 行)oracleinsert into TEST1 values((select max(COL_A) + 1 from TEST1),SYSDATE); commit; select * from TEST1 where COL_A = (select max(COL_A) from TEST1);CDCがうまく動かなかった
フルロードは完了するものの、ソースを更新しても反映されず。
とりあえずここまで。
- 投稿日:2020-07-22T00:36:33+09:00
http→httpsにしてjQueryが動かなくなった時の対処法
前提
RailsでEC2にデプロイをしたアプリケーションをSSL化したいと思い、AWSの
ALBを使ってhttps化しました。
https://www.アプリ名.com/でアクセスしてみると、アプリケーション自体はエラーを吐かずにトップ画面が表示されたのですが、トップ画面の画像が表示されない。
というのも、jQueryで動きをつけていたからでした。EC2にデプロイ時にも、同じ現象が起きました。
解決法
app/views/layouts/_default.html.erb<%= csrf_meta_tags %> <%= csp_meta_tag %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_pack_tag 'application', 'data-turbolinks-track': 'reload' %> <%= stylesheet_pack_tag 'application', 'data-turbolinks-track': 'reload' %> #ここが引っかかってた <script src="http://ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script>app/views/layouts/_default.html.erb<%= csrf_meta_tags %> <%= csp_meta_tag %> <%= stylesheet_link_tag 'application', media: 'all', 'data-turbolinks-track': 'reload' %> <%= javascript_pack_tag 'application', 'data-turbolinks-track': 'reload' %> <%= stylesheet_pack_tag 'application', 'data-turbolinks-track': 'reload' %> #httpを削除 <script src="//ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script>
https://www.アプリ名.com/で再度ブラウザで確認してみると、無事にjQueryが動きました。
デプロイ時点で、<script src="//ajax.googleapis.com/ajax/libs/jquery/1.9.1/jquery.min.js"></script>と記述できていたら、今回の事象が起きなかったですが次回にいかします。
それでは。