- 投稿日:2020-06-19T23:54:40+09:00
yukicoder contest 253 参戦記
yukicoder contest 253 参戦記
A 1081 和の和
結論的に ∑Ni=1 N-1Ci-1Ai になる. N≤100 なのでパスカルの三角形でも解けるだろうけど、めんどくさいのでいつもの mcomb を貼った.
N = int(input()) A = list(map(int, input().split())) m = 1000000007 fac = [0] * N fac[0] = 1 for i in range(N - 1): fac[i + 1] = fac[i] * (i + 1) % m def mcomb(n, k): if n == 0 and k == 0: return 1 if n < k or k < 0: return 0 return fac[n] * pow(fac[n - k], m - 2, m) * pow(fac[k], m - 2, m) % m result = 0 for i in range(N): result += mcomb(N - 1, i) * A[i] result %= m print(result)B 1082 XORのXOR
並べ替えた Ai を元にすると、X = A1 xor A2 xor A2 xor A3 xor ... xor AN - 1 xor AN - 1 xor AN となる. A1 xor A1 = 1 なので、X = A1 xor AN となる. 結果として任意の i != j の i, j について Ai xor Aj の最大値が答えとなる.
N = int(input()) A = list(map(int, input().split())) result = 0 for i in range(N - 1): for j in range(i + 1, N): result = max(result, A[i] ^ A[j]) print(result)C 1083 余りの余り
K を i で割ったとして、j > i である j については K % i % j = K % i である. なので A を大きい順にソートして、AN で割るまでの総当りをすれば良い. 前進するだけなので計算量は O(2N-1) となり解ける.
N, K = map(int, input().split()) A = list(map(int, input().split())) A.sort(reverse=True) def f(k, i): if i == N: return k result = -1 for j in range(i, N): result = max(result, f(k % A[j], j + 1)) return result print(f(K, 0))D 1084 積の積
結構いいところまで行っていた(テストケースの3/4がAC)が、解けずに終了.
f(l,r) が 109 以上とならない l, r を求めるのは尺取り法を使うというのはすぐ分かる. f(l,r) が 109 未満のとき、l≤x≤r である x について f(x,r) も当然 109 未満だが、これをループで解に畳み込んでいくと、最大 N=105 の O(N2) になってしまうので TLE 必至. つまり、尺取り法のアキュムレータとは別にもう一つアキュムレータが必要となる.
例として、1,2,3 に4を追加することを考える. もう一つのアキュムレータを a とおくと4を追加する前は a=(1×2×3)×(2×3)×(3) となる. これを a=(1×2×3×4)×(2×3×4)×(3×4)×(4) に変えることになる. つまり変更操作は a = a×44 となる. 要するに「追加する数追加後の尺取りの長さ」を掛けることになる.
次に左端の1を削除することを考える. これは a=(1×2×3×4)×(2×3×4)×(3×4)×(4) を a=(2×3×4)×(3×4)×(4) に変更する操作で、1×2×3×4 を無くす操作となる. ちょうど尺取り法のアキュムレータが 1×2×3×4 で一致しているので、尺取り法のアキュムレータで割ればいい(といっても 1000000007 の mod なのでフェルマーの小定理を使うことになるが).
以上が分かっていれば、O(logN) の冪乗関数を使って、O(NlogN) で解が求めれる.
N = int(input()) A = list(map(int, input().split())) m = 1000000007 l = 0 a = 1 b = 1 result = 1 for r in range(N): a *= A[r] b *= pow(A[r], r - l + 1, m) b %= m while a >= 1000000000: b *= pow(a, m - 2, m) a //= A[l] l += 1 result *= b result %= m print(result)
- 投稿日:2020-06-19T23:45:26+09:00
【強化学習】OpenAI Gym を Google Corab上で描画する方法 (2020.6版)
0. はじめに
Google Colab上でOpenAI Gym を描画する方法を調べたのでメモ。
参考にしたサイト群
- ColaboratoryでOpenAI gym
- ChainerRL を Colaboratory で動かす
- OpenAI GymをJupyter notebookで動かすときの注意点一覧
- How to run OpenAI Gym .render() over a server
- Rendering OpenAI Gym Envs on Binder and Google Colab
1. 課題
gym.Envのrender()メソッドで環境を表示しようとする際にNoSuchDisplayExceptionエラーが出る。import gym env = gym.make('CartPole-v1') env.reset() env.render()NoSuchDisplayException Traceback (most recent call last) <ipython-input-3-74ea9519f385> in <module>() 2 env = gym.make('CartPole-v1') 3 env.reset() ----> 4 env.render()2. 対策
調べた限り、Colab上でGymの描画機能を利用する方法は3通りあることがわかった。
どの方法も長短あり、1つに絞ることができなかったので、3種類とも記載する。2.1 共通の準備
3種類いずれの方法でも、X11の仮想ディスプレイであるXvfbを利用するので、インストールする。
!apt update !apt install xvfb(Dockerイメージなどで独自にJupyter Notebookを起動させる際には、OpenGL関連も必要なため、
apt install python-openglとする。)さらに、Xvfbを Google Colab (Jupyter Notebook)上から利用するために、PyVirtualDisplayを利用する。
!pip install pyvirtualdisplay from pyvirtualdisplay import Display d = Display() d.start()
"DISPLAY"環境変数に{ディスプレイ番号}.{スクリーン番号}を設定するという記述があるサイトもあったが、不要だとPyVirtualDisplayの作者に教えてもらった。曰く、スクリーン番号は、複数ディスプレイがある状況で利用する値で、PyVirtualDisplayでは1つしか画面を生成しないので
0固定であり、かつスクリーン番号を書かないと自動的に0と解釈されるためだと。(StackOverflow参照)もっと言えば、
pyvirtualdisplay.Display.start()の中で環境変数を設定しているので、外部から変更することは必要ないとのことであった。
(少なくとも、2020年6月18日時点の最新版である1.3.2で確認済み)2.2 方法1
1つ目はシンプルにmatplotlibで画面データを描画しては消しを繰り返す方法である。
あまり速くない、かつ1回しか表示されないことがデメリットだが、描画データを保持せず上書きし続けるので、描画データが長くなっても対応できる方法である。
import gym from IPython import display from pyvirtualdisplay import Display import matplotlib.pyplot as plt d = Display() d.start() env = gym.make('CartPole-v1') o = env.reset() img = plt.imshow(env.render('rgb_array')) for _ in range(100): o, r, d, i = env.step(env.action_space.sample()) # 本当はDNNからアクションを入れる display.clear_output(wait=True) img.set_data(env.render('rgb_array')) plt.axis('off') display.display(plt.gcf()) if d: env.reset()2.3 方法2
2つ目は、
matplotlib.animation.FuncAnimationを使ってアニメーションを表示する方法である。描画画面を繰り返し表示することができ、フレームごとの表示速度を自由に設定できる一方、描画データを保持しておく必要があるためメモリーを多く必要とし、表示する画面サイズや表示枚数を調整しないとメモリーエラーを起こしうる。
(長ーい学習の途中で、エラーを出されると・・・。)import gym from IPython import display from pyvirtualdisplay import Display import matplotlib.pyplot as plt from matplotlib import animation d = Display() d.start() env = gym.make('CartPole-v1') o = env.reset() img = [] for _ in range(100): o, r, d, i = env.step(env.action_space.sample()) # 本当はDNNからアクションを入れる display.clear_output(wait=True) img.append(env.render('rgb_array')) if d: env.reset() dpi = 72 interval = 50 # ms plt.figure(figsize=(img[0].shape[1]/dpi,img[0].shape[0]/dpi),dpi=dpi) patch = plt.imshow(img[0]) plt.axis=('off') animate = lambda i: patch.set_data(img[i]) ani = animation.FuncAnimation(plt.gcf(),animate,frames=len(img),interval=interval) display.display(display.HTML(ani.to_jshtml()))2.4 方法3
最後は、
gym.wrappers.Monitorを利用して描画データを動画として保存する方法である。
render()メソッドは不要で、step(action)メソッドを呼び出す際に自動で保存される。import base64 import io import gym from gym.wrappers import Monitor from IPython import display from pyvirtualdisplay import Display d = Display() d.start() env = Monitor(gym.make('CartPole-v1'),'./') o = env.reset() for _ in range(100): o, r, d, i = env.step(env.action_space.sample()) # 本当はDNNからアクションを入れる if d: env.reset() for f in env.videos: video = io.open(f[0], 'r+b').read() encoded = base64.b64encode(video) display.display(display.HTML(data=""" <video alt="test" controls> <source src="data:video/mp4;base64,{0}" type="video/mp4" /> </video> """.format(encoded.decode('ascii'))))3. ライブラリ: Gym-Notebook-Wrapper
上記の方法を毎回書くのは面倒なため、ライブラリ化した。
- Gym-Notebook-Wrapper | GitLab.com
- Gym-Notebook-Wrapper | GitHub.com (ミラーレポジトリ)
- Gym-Notebook-Wrapper | PyPI
3.1 インストール
PyPIに公開しているので、
pip install gym-notebook-wrapperでインストールできる。!apt update && apt install xvfb !pip install gym-notebook-wrapperもちろん、Google Colab以外でも利用できるが、 Xvfb を利用するためLinuxが前提。
3.2 使い方
gym-notebook-wrapper だと、長いしハイフン(
-)が入っているので、 インポートできるモジュール名はgnwrapperにしてある。
- 方法1 →
gnwrapper.Animation- 方法2 →
gnwrapper.LoopAnimation- 方法3 →
gnwrapper.Monitor3.2.1
gnwrapper.Animation(= 2.2 方法1)import gnwrapper import gym env = gnwrapper.Animation(gym.make('CartPole-v1')) # Xvfbが起動される o = env.reset() for _ in range(100): o, r, d, i = env.step(env.action_space.sample()) # 本当はDNNからアクションを入れる env.render() # ここで、前の描画を消し、新しいステップの描画を行う。 if d: env.reset()3.2.2
gnwrapper.LoopAnimation(= 2.3 方法2)import gnwrapper import gym env = gnwrapper.LoopAnimation(gym.make('CartPole-v1')) # Xvfbが起動される o = env.reset() for _ in range(100): o, r, d, i = env.step(env.action_space.sample()) # 本当はDNNからアクションを入れる env.render() # ここで、描画データを保存する if d: env.reset() env.display() # ここで、保存した描画データをアニメーションとして表示する3.2.3
gnwrapper.Monitor(= 2.4 方法3)import gnwrapper import gym env = gnwrapper.Monitor(gym.make('CartPole-v1'),directory="./") # Xvfbが起動される o = env.reset() for _ in range(100): o, r, d, i = env.step(env.action_space.sample()) # 本当はDNNからアクションを入れる if d: env.reset() env.display() # ここで、ビデオとして保存した描画データを表示する4. 最後に
ネット上に色々記載されている情報を整理して、OpenAI GymをGoogle Colab上で描画する方法を3種類まとめた。
何度か実際に走らせて確認したコードのはずだけど、コピペミスとかしてたらすみません。Gym-Notebook-Wrapperはまだまだ荒削りでバグもあるかもしれないので、何かあれば気軽に issue を立ててもらえると嬉しい。
- 投稿日:2020-06-19T23:28:43+09:00
Tacotron2で始める日本語音声合成
はじめに
最も気になるのはやはりどの程度のものができるのかだと思うので、まずはこちらをお聞きください。
このモデルは
- pre-trained model を使用した転移学習
- 約一時間の前処理済みのデータ
- WaveGlow (published model)
で学習、推論しています。
これから始める方の参考になるように私のやり方を紹介します。Tacotron2についてはこちらが参考になります。
Tacotron2を用いた日本語TTS(Text-to-Speech)の研究・開発【まとめ】※デモを既に動かしていることを前提としています。
用意するもの
音声ファイル
- 22050Hz 16bit モノラル wav
- 音声区間毎に分割
ノイズが多いもの、笑い声等のテキストにしづらいものは除外します。
長過ぎるものは学習時にメモリエラーが出ることがあります。私は10秒以内のもののみにしています。テキスト
train.txt val.txt を作成
ljs_audio_text_val_filelist.txt を参考に
FILE PATH|TEXT
と表記していきます。
trainとvalのバランスは私は9:1にしています。音素バランスなどは考慮していません。音素表記
TEXTは下記を参考に音素で表記していきます。
wiki 日本語の音素
声優統計コーパス 音素バランス文使用できる文字はsymbols.pyの要素のみです。
このとき注意する点として
koNnichiwaと入力するとTacotron2の内部では['k','o','n','n','i','c','h','i','w','a']と変換されます。
もし['k','o','N','n','i','ch','i','w','a']としたいのであれば{}で囲う必要があります。
ただし使用できるのはcmudict.pyのvalid_symbols内の要素のみです。
ですのでko{N}ni{CH}iwaとする必要があります。また
k o {N} n i {CH} i w aというような表記でも良いかとおもいます。私はkonnnichiwaとしています。文末にEOSを追加
Model can not converge #254
学習時にattentionの収束が加速されるそうです。例
私はこのようにしています。
train.txt/wav/0126.wav|na&tanndesukedo-. /wav/0022.wav|biyo-inndake-yoyakuwasimasita. /wav/0149.wav|tasikani,ari!. /wav/0092.wav|sositara-. /wav/0063.wav|teyu-ne. /wav/0202.wav|donndonn,tama&tekunndesuyo.設定
hparams.pyを編集
- iters_per_checkpoint
好きな数値に変更- training_files
train.txtのpath- validation_files
val.txtのpath- text_cleaners
['basic_cleaners']に変更
transliteration_cleaners についてはこちらが参考になります。
Tacotron2系における日本語のunidecodeの不確かさ- batch_size
私は32にしています。issuesなどを見ると8~16くらいにしてる方が多いようです。GPUと相談して決めてください。train.pyにexponential learning rate decayを追加
学習
pre-trained model を使用して学習していきます。
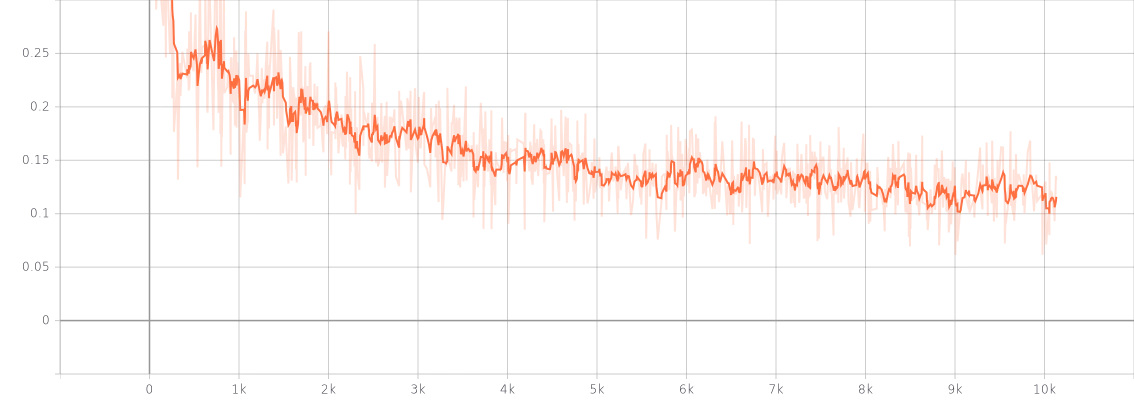
10k iterの結果です。Colab T4で約6時間半でした。
grad.norm
training.loss
推論
各checkpointの結果です。
sigma=1,denoiser未使用

- 投稿日:2020-06-19T23:24:52+09:00
Djangoのテンプレート内で定数を扱う
はじめに
Djangoのテンプレート内でドメイン名やサイト名などの基本的に固定となる定数値を扱いたいとき、Context Processorという機能を利用して、都度ビュー側から定数を渡さずにテンプレート内から定数のように扱うことができます。
環境
- Django 2.2
Context Processor とは
Context Processorはビューからテンプレートへコンテキストオブジェクトを渡す際に変数を追加する処理を記述できる関数です。
テンプレート内で利用するcsrf_token等がこの仕組みで実装されています。Context Processor の作成
Context Processorは
HTTP Requestオブジェクトを引数として、辞書型のオブジェクトを返す関数として定義します。関数の名前は任意の名前で作成し、ファイルはアプリケーションのディレクトリ配下等に作成します。
hogeapp/context_processors.pydef my_context_processor(req): return { 'domain_name': 'https://hogehoge.com', 'site_name': 'Hogehoge Site', }上記の例では単純に辞書オブジェクトを返却しているのみですが、通常の関数同様に処理を記述することもできます。これを利用して外部ファイルに別で定義した定数を参照したり、環境変数の値から環境によって値を変える等の使い方も可能です。
config.py設定
作成したContext Processorを利用するには、
config.pyへの設定が必要になります。
config.pyで定義されているTEMPLATESのOPTIONSにあるcontext_processorsへ前項で作成した関数を追加します。config.pyTEMPLATES = [ { 'OPTIONS': { 'context_processors': [ 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', 'hogeapp.context_processors.my_context_processor', # 追加 ], }, }, ]テンプレートからの呼び出し方法
Context Processorで追加される変数は、テンプレート内から通常のコンテキストの変数と同じように利用できます。
template.html<link rel="icon" href="{{ domain_name }}/favicon.ico"> <title>{{ site_name }}</title>参考
The Django template language: for Python programmers | Django ドキュメント | Django
https://docs.djangoproject.com/ja/2.2/ref/templates/api/#writing-your-own-context-processors
- 投稿日:2020-06-19T23:15:50+09:00
csvデータを取り出し、計算する
csvデータを取り扱う
データ分析をするとき、cvsデータの扱い方を毎回忘れてしまうので、メモとしてまとめておきたいと思います。
csvを読み込む
import pandas as pd pd.read_csv('data.csv')
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8e in position 0: invalid start byteとエラーが出てきてしまいました。pd.read_csv('data.csv' , encoding='cp932')
encoding='cp932'を後ろに付けたらちゃんと表示されました。csvデータから列・行を取り出す
csvから1行または1列だけデータを取得
df = pd.read_csv('data.csv' , encoding='cp932') df.iloc[0,:] #1行目すべてのデータを取り出す df.iloc[:,2] #3列目すべてのデータを取り出すpandas.DataFrameの行を取得
[行名・行番号のスライス]: 複数行を取り出す
df[1:4] #1行目から3行目まで取り出す列ごとに合計を計算する
1列のデータをすべて足して合計を出す
df.iloc[:,3].sum() #4列目のデータの合計を出すcsvデータをfor文で計算
csvデータの列データを一定の数で割りたいとき
#csvデータの3列目の数値をそれぞれ2で割る w = df.iloc[:,2] for i in w: d = i / 2 print(d)
- 投稿日:2020-06-19T22:58:03+09:00
ゼロから始めるLeetCode Day61「7. Reverse Integer」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
どうやら多くのエンジニアはその対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイトであり、海外のテックカンパニーでのキャリアを積みたい方にとっては避けては通れない道である。
と、仰々しく書いてみましたが、私は今のところそういった面接を受ける予定はありません。
ただ、ITエンジニアとして人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
Python3で解いています。
前回
ゼロから始めるLeetCode Day60「1481. Least Number of Unique Integers after K Removals」今はTop 100 Liked QuestionsのMediumを優先的に解いています。
Easyは全て解いたので気になる方は目次の方へどうぞ。Twitterやってます。
問題
難易度はEasy。
32ビット符号付き整数xが与えられたとき、整数の逆数を計算するアルゴリズムを設計してください、という問題です。Input: 123
Output: 321Input: -123
Output: -321Input: 120
Output: 21解法
Pythonの場合はスライスと
absを使えば要素の指定と絶対値の管理ができるので比較的解きやすいのではないかと思います。他の言語については知りませんが、スタックを使って解くのが一般的なのかもしれませんね。
今回は32bit整数という前提があるため、処理に入る前に別の桁を追加してもオーバーフローしないかを事前に確認しておく方が良いでしょう。
Pythonではint型に最大値がないのでメモリの有る限りいくらでも計算できます。
なので以下のように自分で設定しておく必要があります。max_32 = 2**31 - 1最初にこの値より
xが大きかった場合は無条件で0を返すときちんと場合分けできていると思います。そして、この後の分岐ですが、正の値ならば後ろから要素を取ってあげて、負の値ならば絶対値の逆から要素を取ってあげて代入する前に
-を付けてあげます。Pythonでは負の値ならば代入する要素の先頭に
-を付けてあげると反転し直した後にも-がついた状態になります。反転させたものを内包表記で書けば良くない?と思う方がいらっしゃるかもしれませんが、これだけで処理を終わらせてしまってはオーバーフローする可能性がまだ残っている可能性があります。
なので、最後の分岐に仮にオーバーフローしそうなら0を返し、それ以外の場合にのみ反転した値を返せば完成です。
これらの一連の流れをまとめたものが以下になります。
class Solution: def reverse(self, x: int) -> int: max_32 = 2**31 - 1 if abs(x) > max_32: return 0 if x < 0: reverse_int = -int(str(abs(x))[::-1]) else: reverse_int = int(str(x)[::-1]) if abs(reverse_int) > max_32: return 0 else: return reverse_int # Runtime: 28 ms, faster than 86.13% of Python3 online submissions for Reverse Integer. # Memory Usage: 14 MB, less than 9.77% of Python3 online submissions for Reverse Integer.そういえば新しくブログを始めました。
Qiitaでも発信は続けて行く予定ですが、まったりとした内容で書ける技術・ガジェットブログみたいな感じで書く予定なので興味ある方はプロフィールからどうぞ。今回はここまで。お疲れ様でした。
- 投稿日:2020-06-19T22:26:46+09:00
[光-Hikari-のPython]<補足>06章-05 関数(引数と戻り値4)
[Python]<補足>06章-05 引数と戻り値4
06章-04で関数における引数がリストだった場合について説明しました。
そのほかのデータ構造である、タプルやディクショナリを引数として受け取るもできます。今回はタプルとディクショナリを引数として受け取ることについて取り扱いたいと思います。
なお、この節は<補足>としていますので、時間のない方は読み飛ばしていただいても構いません。なお、基本情報技術者試験では今後タプルやディクショナリの引数の扱いをするといった問題も出題されることが予測されるため、目を通しておきましょう。
任意の数の引数~タプルで受け取る~
関数を呼び出す際に、実引数と仮引数の数は以下のプログラムのように一致させないといけません。chap06の中に、samp06-05-01.pyというファイル名でファイルを作成し、以下のコードを書いてください。
samp06-05-01.pydef called_func(x, y, z): print('関数内で実行しています。') print(x, y, z) #called_func(2) #←引数の数が一致していないので、関数を呼び出すとエラーとなります called_func(4, -1, 2)【実行結果】
関数内で実行しています。
4 -1 2最初の関数の呼び出しcalled_func(2)では実引数の数が1個ですが、仮引数の数は3つとなっており、一致していません。そのため、このコメントを外すとエラーとなります。
次に呼び出しているcalled_func(4, -1, 2)では、実引数と仮引数の数が一致しているため、呼び出すことができます。
しかし、Pythonの関数では、任意の数の引数を受け取ることができるのです。それが以下の方法です。先ほど書いたプログラムsamp06-05-01.pyを修正して、以下のコードを書いてください。
samp06-05-01.pydef called_func(*args): print('関数内で実行しています。') print(args) called_func(2) #←今度は呼び出せます called_func(4, -1, 2)【実行結果】
関数内で実行しています。
(2,)
関数内で実行しています。
(4, -1, 2)仮引数に*(アスタリスク)を付けると、タプルとして受け取っていることがわかります。
なお、関数内で*argsの中身を出力していますが、出力する際には*は不要です。また*argsという仮引数名を使用していますが、実際は何でも構いません。ただし、ほとんどの方が(慣習的に)argsを使用しています。
※argsはargumentの略では引数という意味です。任意の数のキーワード引数~ディクショナリの受け取り~
06章-03でキーワード引数について取り扱いました。実はこのキーワード引数を実引数で指定し、仮引数でまとめて任意の数を受け取ることができます。
chap06の中に、samp06-05-02.pyというファイル名でファイルを作成し、以下のコードを書いてください。samp06-05-02.pydef called_func(**kwargs): print('関数内で実行しています。') print(kwargs) called_func(x=1, y=2, z=3)【実行結果】
関数内で実行しています。
{'x': 1, 'y': 2, 'z': 3}実引数にキーワード引数を、仮引数に**(アスタリスク2つ)を付けると、ディクショナリとして受け取っていることがわかります。
なお、関数内で**kwargsの中身を出力していますが、出力する際には**は不要です。また**kwargsという仮引数名を使用していますが、実際は何でも構いません。ただし、ほとんどの方が(慣習的に)**kwargsを使用しています。最後に
引数の受け取り方は多種ありますので、押さえておきましょう。タプルやディクショナリとして受け取るといったケースは見かける機会はあまりないですが、こういったこともできるということは把握しておいてください。ただし、情報処理技術者試験では出題される可能性はありますので注意しましょう。
【目次リンク】へ戻る
- 投稿日:2020-06-19T21:31:12+09:00
コスパ最強IoT家電!TPLink製品をRaspberryPiから操作
TPLinkとは?
ルータを主力とする中国・深圳のネットワーク機器メーカーです。
近年はスマート電球、スマートプラグ等のIoT家電に力を入れており、コスパの良さからAmazonで独自の地位を築いています。今回は、APIを使用して、
・機器のON-OFF操作
・ON-OFF、電球の明るさ等の情報取得
を、PythonおよびNode.jsで実行してみましたIoT家電として思いつく用途の多くを上記でカバーできるので
応用の可能性を感じる結果となりました!必要なもの
・PC
・RaspberryPi
・TPLink製スマートプラグあるいは電球
今回は下記3製品を試しました
HS105:スマートプラグ
KL110:ホワイト電球
KL130:カラー電球①データ取得の確認
まずは、TPLinkからデータが取得できるかターミナル上でテストします。
※参考にさせて頂いた記事
https://lmjs7.net/blog/tag/tp-link/
https://qiita.com/tmisuoka0423/items/582ff0c303abe8570ee5IPを調べる
tplink-smarthome-api(参考)をインストール
sudo npm install -g tplink-smarthome-api下記コマンドで、接続しているTPLinkデバイス一覧を取得
tplink-smarthome-api searchHS105(JP) plug IOT.SMARTPLUGSWITCH 192.168.0.101 9999 B0BE76‥ スマートプラグ KL110(JP) bulb IOT.SMARTBULB 192.168.0.102 9999 98DAC4‥ ホワイト電球 KL130(JP) bulb IOT.SMARTBULB 192.168.0.103 9999 0C8063‥ カラー電球3つのデバイス全てが検出できていることが分かります
デバイス動作情報の取得確認
下記コマンドで、デバイスの設定やOnOffが取得できる
tplink-smarthome-api getSysInfo [デバイスのIPアドレス]:9999・KL130(カラー電球)の例
: ctrl_protocols: { name: 'Linkie', version: '1.0' }, ↓ここからがデバイスの設定 light_state: { on_off: 1, mode: 'normal', hue: 0, saturation: 0, color_temp: 2700, brightness: 100 }, ↑ここまでがデバイスの設定 is_dimmable: 1, is_color: 1, :on_off:0なら電源OFF、1なら電源ON
hue:色?(白色モードのとき0)
color_temp:色温度(白色モード以外のとき0)
brightness:明るさ(%単位)
と思われます・KL110(ホワイト電球)の例
: ctrl_protocols: { name: 'Linkie', version: '1.0' }, ↓ここからがデバイスの設定 light_state: { on_off: 1, mode: 'normal', hue: 0, saturation: 0, color_temp: 2700, brightness: 100 }, ↑ここまでがデバイスの設定 is_dimmable: 1, is_color: 0, :on_off:0なら電源OFF、1なら電源ON
hue:色相(白色モードのとき0)
saturation:彩度
color_temp:色温度(白色モード以外のとき0)
brightness:明るさ(%単位)
と思われます。
KL130とほぼ同じですが、カラーではないのでis_color: 0となっていると思われます。・KL105(スマートプラグ)の例
alias: '', ↓ここからがデバイスの設定 relay_state: 1, on_time: 288, active_mode: 'none', feature: 'TIM', updating: 0, icon_hash: '', rssi: -52, led_off: 0, longitude_i: 1356352, latitude_i: 348422, ↑ここまでがデバイスの設定 hwId: '047D‥',relay_state:0なら電源OFF、1なら電源ON
on_time:連続電源ON時間
rssi: WiFiの信号強度
と思われます。
経度(logitude)と緯度(latitude)も表示されていますが、実際の場所と5キロくらいずれていて謎が深まります。上記で、コマンドで欲しい情報が取得できることが確認できました!
次章以降で、プログラム(Node.js&Python)から取得・操作する方法を記載します。②Node.jsで状態取得
※「Pythonを使うからNode.jsの説明はいらん!」という方は、この章を飛ばして③に移動してください
こちらを参考に、Node.jsを
npmにパスを通す(Windowの場合)
Windowsだとnpmのグローバルインストール先にパスが通っておらず、Node.jsでモジュールが読み込めないので、下記を参考にパスを通してください
https://qiita.com/shiftsphere/items/5610f692899796b03f99npmにパスを通す(RaspberryPiの場合)
下記コマンドで、グローバルでのnpmモジュールインストール先を調べます
(なぜかWindowsのときのコマンド"npm bin -g"で見つかるフォルダとは違うようです)npm ls -g下記コマンドで.profileを編集します。
※SSH環境では.profileの代わりに、.bash_profileを編集してくださいnano /home/[ユーザ名]/.profile.profileの最後に下記の1行を追加してrebootしてください
export NODE_PATH=[上で調べたパス]/node_modules下記コマンドで指定したパスが表示されれば成功です
printenv NODE_PATHnode.jsスクリプトの作成
下記スクリプトを作成します
tplink_test.jsconst { Client } = require('tplink-smarthome-api'); const client = new Client(); client.getDevice({ host: '192.168.0.102' }).then(device => { device.getSysInfo().then(console.log); });下記コマンドでスクリプトを実行すると、①と同様に各種情報が取得できます
node tplink_test.js※上記をcsvロギングするスクリプト(③のPythonスクリプトと同機能)も作成しましたが、私のJavaScriptスキルが低くうまく動作しないときがある(非同期部分の処理順が逆転する)ので、コードはここには貼らないこととします
下記GitHubにアップロードしたので、自己責任で改造して使用していただければと思います。
(願わくば無知な私に処理順が逆転する理由もコメント…頂けると嬉しいです笑)
https://github.com/c60evaporator/TPLink_Info_Nodejs③Pythonで状態取得
私のJavaScriptスキル不足でNode.jsでのロギングが上手くいかなかったので、
気を取り直してPythonで操作・ロギングするスクリプトを作りました。PythonはNode.jsほど丁寧なドキュメントが見当たらず苦戦しましたが、こちらやこちらのコードを解読して、スクリプトを作成しました。
TPLink操作クラスの作成
上記コードを参考に、下記の4つのクラスを作成しました
TPLink_Common():プラグ、電球共通機能のクラス
TPLink_Plug():プラグ専用機能のクラス(TPLink_Common()を継承)
TPLink_Bulb():電球専用機能のクラス(TPLink_Common()を継承)
GetTPLinkData():上記クラスを利用して、データを取得するクラスtplink.pyimport socket from struct import pack import json #TPLinkデータ取得用クラス class GetTPLinkData(): #プラグデータ取得用メソッド def get_plug_data(self, ip): #プラグ操作用クラス作成 plg = TPLink_Plug(ip) #データを取得し、dictに変換 rjson = plg.info() rdict = json.loads(rjson) return rdict #電球データ取得用メソッド def get_bulb_data(self, ip): #電球操作用クラス作成 blb = TPLink_Bulb(ip) #データを取得し、dictに変換 rjson = blb.info() rdict = json.loads(rjson) return rdict #TPLink電球&プラグ共通クラス class TPLink_Common(): def __init__(self, ip, port=9999): """Default constructor """ self.__ip = ip self.__port = port def info(self): cmd = '{"system":{"get_sysinfo":{}}}' receive = self.send_command(cmd) return receive def send_command(self, cmd, timeout=10): try: sock_tcp = socket.socket(socket.AF_INET, socket.SOCK_STREAM) sock_tcp.settimeout(timeout) sock_tcp.connect((self.__ip, self.__port)) sock_tcp.settimeout(None) sock_tcp.send(self.encrypt(cmd)) data = sock_tcp.recv(2048) sock_tcp.close() decrypted = self.decrypt(data[4:]) print("Sent: ", cmd) print("Received: ", decrypted) return decrypted except socket.error: quit("Could not connect to host " + self.__ip + ":" + str(self.__port)) return None def encrypt(self, string): key = 171 result = pack('>I', len(string)) for i in string: a = key ^ ord(i) key = a result += bytes([a]) return result def decrypt(self, string): key = 171 result = "" for i in string: a = key ^ i key = i result += chr(a) return result #TPLinkプラグ操作用クラス class TPLink_Plug(TPLink_Common): def on(self): cmd = '{"system":{"set_relay_state":{"state":1}}}' receive = self.send_command(cmd) def off(self): cmd = '{"system":{"set_relay_state":{"state":0}}}' receive = self.send_command(cmd) def ledon(self): cmd = '{"system":{"set_led_off":{"off":0}}}' receive = self.send_command(cmd) def ledoff(self): cmd = '{"system":{"set_led_off":{"off":1}}}' receive = self.send_command(cmd) def set_countdown_on(self, delay): cmd = '{"count_down":{"add_rule":{"enable":1,"delay":' + str(delay) +',"act":1,"name":"turn on"}}}' receive = self.send_command(cmd) def set_countdown_off(self, delay): cmd = '{"count_down":{"add_rule":{"enable":1,"delay":' + str(delay) +',"act":0,"name":"turn off"}}}' receive = self.send_command(cmd) def delete_countdown_table(self): cmd = '{"count_down":{"delete_all_rules":null}}' receive = self.send_command(cmd) def energy(self): cmd = '{"emeter":{"get_realtime":{}}}' receive = self.send_command(cmd) return receive #TPLink電球操作用クラス class TPLink_Bulb(TPLink_Common): def on(self): cmd = '{"smartlife.iot.smartbulb.lightingservice":{"transition_light_state":{"on_off":1}}}' receive = self.send_command(cmd) def off(self): cmd = '{"smartlife.iot.smartbulb.lightingservice":{"transition_light_state":{"on_off":0}}}' receive = self.send_command(cmd) def transition_light_state(self, hue: int = None, saturation: int = None, brightness: int = None, color_temp: int = None, on_off: bool = None, transition_period: int = None, mode: str = None, ignore_default: bool = None): # copy all given argument name-value pairs as a dict d = {k: v for k, v in locals().items() if k is not 'self' and v is not None} r = { 'smartlife.iot.smartbulb.lightingservice': { 'transition_light_state': d } } cmd = json.dumps(r) receive = self.send_command(cmd) print(receive) def brightness(self, brightness): self.transition_light_state(brightness=brightness) def purple(self, brightness = None, transition_period = None): self.transition_light_state(hue=277, saturation=86, color_temp=0, brightness=brightness, transition_period=transition_period) def blue(self, brightness = None, transition_period = None): self.transition_light_state(hue=240, saturation=100, color_temp=0, brightness=brightness, transition_period=transition_period) def cyan(self, brightness = None, transition_period = None): self.transition_light_state(hue=180, saturation=100, color_temp=0, brightness=brightness, transition_period=transition_period) def green(self, brightness = None, transition_period = None): self.transition_light_state(hue=120, saturation=100, color_temp=0, brightness=brightness, transition_period=transition_period) def yellow(self, brightness = None, transition_period = None): self.transition_light_state(hue=60, saturation=100, color_temp=0, brightness=brightness, transition_period=transition_period) def orange(self, brightness = None, transition_period = None): self.transition_light_state(hue=39, saturation=100, color_temp=0, brightness=brightness, transition_period=transition_period) def red(self, brightness = None, transition_period = None): self.transition_light_state(hue=0, saturation=100, color_temp=0, brightness=brightness, transition_period=transition_period) def lamp_color(self, brightness = None): self.transition_light_state(color_temp=2700, brightness=brightness)TPLink操作クラスの実行方法
上記クラスは、Pythonコード上で下記のように実行できます
・電球の電源をONにしたいとき
TPLink_Bulb(電球のIPアドレス).on()・プラグの電源をOFFにしたいとき
TPLink_Plug(プラグのIPアドレス).off()・10秒後にプラグをONにしたいとき
TPLink_Plug(プラグのIPアドレス).set_countdown_on(10)・電球の明るさを10%にしたいとき
TPLink_Bulb(電球のIPアドレス).brightness(10)・電球を赤色にしたいとき(カラー電球のみ)
TPLink_Bulb(電球のIPアドレス).red()・電球のOn-Off等の情報を取得
info = GetTPLinkData().get_plug_data(プラグのIPアドレス)※上記メソッドは、取得したjson情報をdict形式に変換して出力されます。
出力される電球情報は①を参照ください④ロギング用Pythonスクリプトの作成
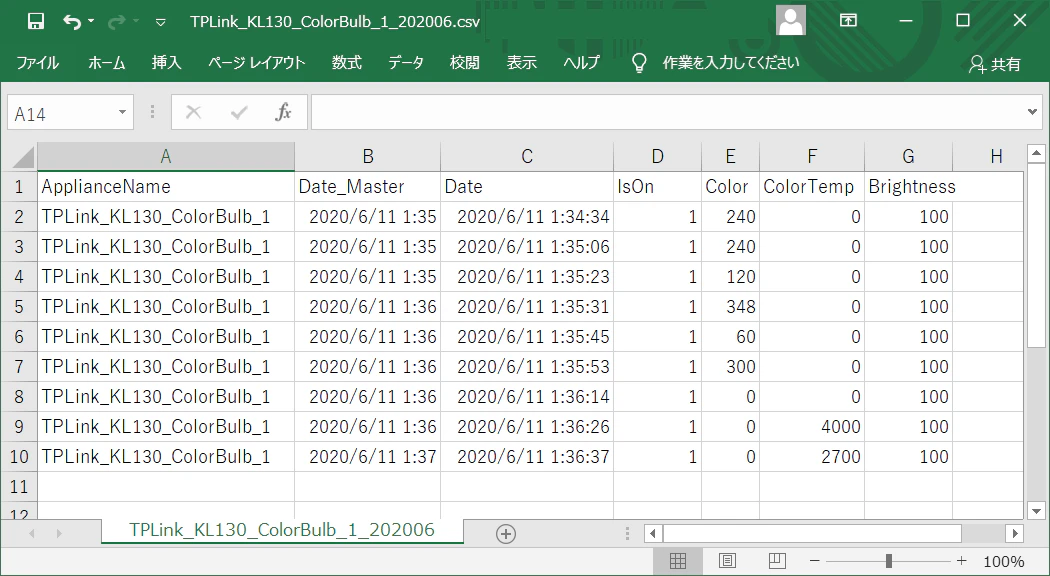
前章最後の方法を利用して、電球やプラグの情報をロギングするスクリプトを作成しました。
スクリプトの構造はこちらと同じなので、リンク先をご一読いただければと思います。設定ファイル
こちらの記事同様、管理をしやすくするため下記2種類の設定ファイルを作成しました
・DeviceList.csv:センサごとに必要情報を記載DeviceList.csv ApplianceName,ApplianceType,IP,Retry TPLink_KL130_ColorBulb_1,TPLink_ColorBulb,192.168.0.103,2 TPLink_KL110_WhiteBulb_1,TPLink_WhiteBulb,192.168.0.102,2 TPLink_HS105_Plug_1,TPLink_Plug,192.168.0.101,2カラムの意味は下記となります
ApplianceName:デバイス名を管理、同種類のデバイスが複数あるときの識別用
ApplianceType:デバイスの種類。
TPLink_ColorBulb:カラー電球(KL130等)
TPLink_WhiteBulb:白色電球(KL110等)
TPLink_Plug:スマートプラグ(HS105等)
IP:デバイスのIPアドレス
Retry:最大再実行回数詳細(取得失敗時の再実行回数、詳しくはこちら)・config.ini:CSVおよびログ出力ディレクトリを指定
config.ini
[Path]
CSVOutput = /share/Data/Appliance
LogOutput = /share/Log/Appliance
どちらもsambaで作成した共有フォルダ内に出力すると、RaspberryPi外からアクセスできて便利です。実際のスクリプト
appliance_data_logger.pyfrom tplink import GetTPLinkData import logging from datetime import datetime, timedelta import os import csv import configparser import pandas as pd #グローバル変数 global masterdate ######TPLinkのデータ取得###### def getdata_tplink(appliance): #データ値が得られないとき、最大appliance.Retry回スキャンを繰り返す for i in range(appliance.Retry): try: #プラグのとき if appliance.ApplianceType == 'TPLink_Plug': applianceValue = GetTPLinkData().get_plug_data(appliance.IP) #電球のとき elif appliance.ApplianceType == 'TPLink_ColorBulb' or appliance.ApplianceType == 'TPLink_WhiteBulb': applianceValue = GetTPLinkData().get_bulb_data(appliance.IP) else: applianceValue = None #エラー出たらログ出力 except: logging.warning(f'retry to get data [loop{str(i)}, date{str(masterdate)}, appliance{appliance.ApplianceName}]') applianceValue = None continue else: break #値取得できていたら、POSTするデータをdictに格納 if applianceValue is not None: #プラグのとき if appliance.ApplianceType == 'TPLink_Plug': data = { 'ApplianceName': appliance.ApplianceName, 'Date_Master': str(masterdate), 'Date': str(datetime.today()), 'IsOn': str(applianceValue['system']['get_sysinfo']['relay_state']), 'OnTime': str(applianceValue['system']['get_sysinfo']['on_time']) } #電球のとき else: data = { 'ApplianceName': appliance.ApplianceName, 'Date_Master': str(masterdate), 'Date': str(datetime.today()), 'IsOn': str(applianceValue['system']['get_sysinfo']['light_state']['on_off']), 'Color': str(applianceValue['system']['get_sysinfo']['light_state']['hue']), 'ColorTemp': str(applianceValue['system']['get_sysinfo']['light_state']['color_temp']), 'Brightness': str(applianceValue['system']['get_sysinfo']['light_state']['brightness']) } return data #取得できていなかったら、ログ出力 else: logging.error(f'cannot get data [loop{str(appliance.Retry)}, date{str(masterdate)}, appliance{appliance.ApplianceName}]') return None ######データのCSV出力###### def output_csv(data, csvpath): appliancename = data['ApplianceName'] monthstr = masterdate.strftime('%Y%m') #出力先フォルダ名 outdir = f'{csvpath}/{appliancename}/{masterdate.year}' #出力先フォルダが存在しないとき、新規作成 os.makedirs(outdir, exist_ok=True) #出力ファイルのパス outpath = f'{outdir}/{appliancename}_{monthstr}.csv' #出力ファイル存在しないとき、新たに作成 if not os.path.exists(outpath): with open(outpath, 'w', newline="") as f: writer = csv.DictWriter(f, data.keys()) writer.writeheader() writer.writerow(data) #出力ファイル存在するとき、1行追加 else: with open(outpath, 'a', newline="") as f: writer = csv.DictWriter(f, data.keys()) writer.writerow(data) ######メイン###### if __name__ == '__main__': #開始時刻を取得 startdate = datetime.today() #開始時刻を分単位で丸める masterdate = startdate.replace(second=0, microsecond=0) if startdate.second >= 30: masterdate += timedelta(minutes=1) #設定ファイルとデバイスリスト読込 cfg = configparser.ConfigParser() cfg.read('./config.ini', encoding='utf-8') df_appliancelist = pd.read_csv('./ApplianceList.csv') #全センサ数とデータ取得成功数 appliance_num = len(df_appliancelist) success_num = 0 #ログの初期化 logname = f"/appliancelog_{str(masterdate.strftime('%y%m%d'))}.log" logging.basicConfig(filename=cfg['Path']['LogOutput'] + logname, level=logging.INFO) #取得した全データ保持用dict all_values_dict = None ######デバイスごとにデータ取得###### for appliance in df_appliancelist.itertuples(): #ApplianceTypeがTPLinkeであることを確認 if appliance.ApplianceType in ['TPLink_Plug','TPLink_ColorBulb','TPLink_WhiteBulb']: data = getdata_tplink(appliance) #上記以外 else: data = None #データが存在するとき、全データ保持用Dictに追加し、CSV出力 if data is not None: #all_values_dictがNoneのとき、新たに辞書を作成 if all_values_dict is None: all_values_dict = {data['ApplianceName']: data} #all_values_dictがNoneでないとき、既存の辞書に追加 else: all_values_dict[data['ApplianceName']] = data #CSV出力 output_csv(data, cfg['Path']['CSVOutput']) #成功数プラス success_num+=1 #処理終了をログ出力 logging.info(f'[masterdate{str(masterdate)} startdate{str(startdate)} enddate{str(datetime.today())} success{str(success_num)}/{str(appliance_num)}]')上記を実行すれば、設定ファイル"CSVOutput"で指定したフォルダに、取得データがデバイス名と日時の名称でCSV出力されます
以上で、情報取得が完了です
おわりに
RaspberrypPiで24時間稼働、かつPythonはIFTTTよりも自由度が高いので、色々なアイデアを具現化可能です
・人感センサと組み合わせて、人が入ったら電気が点くようにする
・30分以上人がいなければ、電気を消す
・人によって電球の明るさを自動で切り替える
などなどです。いくつか作りたいものがあるので、製作が完了したらまた記事にしようと思います


- 投稿日:2020-06-19T21:26:58+09:00
Tkinter入門2:ボタン
※この記事は前回の続きです。
4. ボタンウィジェット
この章はボタンウィジェットについて紹介します。ボタンウィジェットは限られた選択肢に対して、ユーザーの意思決定を素早く直感的に入力することのできるウィジェットです。
以下はButtonウィジェットのオプションです。
- 4.0 Button Widgetの基本構造
- 4.1 activebackground
- 4.2 activeforeground
- 4.3 bd
- 4.4 bg
- 4.5 command
- 4.6 fg
- 4.7 font
- 4.8 heightとwidth
- 4.9 image
- 4.10 justify
- 4.11 padxとpady
- 4.12 relief
- 4.13 state
- 4.14 underline
- 4.15 wraplength
4.0 Button Widget の基本構造
このウィジェットはtkinter.Button()でインスタンス化することで使用出来ます。表示方法は前回と同様 .pack()で配置できます。
4.0_BasicButtonWidgetimport tkinter as tk pop = tk.Tk() # buttonという変数にボタンのインスタンス情報を格納する # tk.Button(対象のウィンドウ, text="ボタンに表示する文字列") button = tk.Button(pop, text="Hello") # ボタンを出力する button.pack() pop.mainloop()実行結果
今更ですが、ウィンドウのサイズがあまりにも小さいのでもう少し大きくすることにしましょう。
4.0_modify_x_yimport tkinter as tk pop = tk.Tk() # .geometry("縦x横")で大きさを指定できます ※xはエックスです pop.geometry("200x200") # 4.1からインスタンス化する際の追加オプションが含まれている行のみを載せます。 button = tk.Button(pop, text="Hello")##この行 button.pack() pop.mainloop()これでウィンドウのサイズを変更できたはずです。以降、追加オプションが含まれる行のみを載せます。全体的に大幅な変更がある場合はすべてのコードを載せます。
4.1 activebackground クリック中の背景色を指定する
ボタンが押されている間の背景色を指定します。
activebackground="色"で指定できます。
色の指定は、"red"や"blue"などの文字列を使った指定方法や、#を使った16進記法も使用できます。4.1_Button_activebackground# オプションの後に","を使用することで様々なオプションを付け足すことが出来ます。 # activebackgroundはボタンが押された時の背景色を出力します。 button = tk.Button(pop, text="Hello",activeforeground="red")実行結果(クリックしている間、背景色が変化します)
4.2 activeforeground クリック中の前景色を指定する
activebackground の前景色バージョンです。クリックしている間、前にある物の色を指定できます。今回の場合はHelloという文字列に対して色を指定できます。
4.2_Button_activeforeground# activeforegroundはボタンが押された時の前景色を出力します。 button = tk.Button(pop, text="Hello",activeforeground="red")実行結果(クリックしている間、前景色が変化します)
4.3 bd エッジのサイズを指定する
ボタンの淵のサイズ(単位はpixel)を指定します。このオプションを指定しない場合は生成する際に2pxで初期化されます。試しに、いくつかのボタンを表示してみましょう
4.3_Button_bd# ボタンのエッジのサイズを指定します button = tk.Button(pop, text="0px",bd="0") button1 = tk.Button(pop, text="2px",bd="2") button2 = tk.Button(pop, text="5px",bd="5") button3 = tk.Button(pop, text="10px",bd="10") button4 = tk.Button(pop, text="20px",bd="20") button.pack() button1.pack() button2.pack() button3.pack() button4.pack()実行結果
4.4 bg 背景色を指定する
ボタンの背景色を変更します。これはactiveforegroundやactivebackgroundとは違って、アクションに依存しないオプションとなります。
4.4_Button_bg# 通常状態の背景色を指定します。アクションに依存しません。 button = tk.Button(pop, text="Hello",bg="red")実行結果
4.5 command 指定したプログラムを実行する
command で指定したプログラムを実行します。commandには実行したい関数名を入れてあげます。下の例ではoutputという関数を使用したいので、
command=outputこれで設定完了です。4.5_Button_command# コンソールにhello tkinterと出力する def output(): print("hello tkinter!") # 指定したプログラムを実行出来ます。 # commandには関数名のみを入力します。 button = tk.Button(pop, text="Hello",command=output)実行結果
4.6 fg 前景色を指定する。
背景色ではbgというコマンドを使用しました。今回はfgです。fgは前面にあるコンテンツの色を指定します。なので今回の場合はhelloという文字列に色を指定できます。fgはbgと同様、アクションに依存しない指定方法です。
4.6_Button_fg# 前景色を指定します (※アクションには依存しない) button = tk.Button(pop, text="Hello",fg="red")
4.7 フォントを指定する
コンピュータにインストールされているフォントを参照し、任意の文字列に字体を付与します。実際にフォントが指定されているか複数のボタンを生成して試してみましょう。
4.7_Button_font# フォントを指定します button1 = tk.Button(pop, text="Hello") button2 = tk.Button(pop, text="Hello",font="gabriola") button3 = tk.Button(pop, text="Hello",font="consolas") button1.pack() button2.pack() button3.pack()実行結果
確かにフォントが指定できていることが確認できます。4.8 height,width ボタンの大きさを指定する
heightとwidthを使用することでボタンの大きさを調整できます。heightは高さ、widthは幅を表します。どちらか一つのみでも構いません。
4.8_Button_width_height# ボタンの大きさを指定します button = tk.Button(pop, text="Hello",width="20",height="10")実行結果
4.9 image ボタンに画像を配置する
後日記述します
4.10 justify 複数行文字列の時にどの位置に寄せるか指定する
複数行の文字列が存在するとき、文字列がどの位置に寄せるかを指定します。属性は"left","center","right"の3つがあります。
実際に幾つかボタンを作って試してみましょう。4.10_Button_justifybutton1 = tk.Button(pop, text="left\nleftleftleft",width="30",justify="left") button2 = tk.Button(pop, text="center\ncentercenter",width="30",justify="center") button3 = tk.Button(pop, text="right\nrightright",width="30",justify="right") button1.pack() button2.pack() button3.pack()実行結果
4.11 padx, pady 内側の空白を指定する
ボタンの内側の空白を指定します。padxは横軸に対して指定、padyは縦軸に対して指定できる。
4.11_Button_padding_x_y# ボタンの内側に空白を付与します。padxは横軸、padyは縦軸の空間を指定。 button = tk.Button(pop, text="Hello",padx='30',pady='50')実行結果
4.12 relief 淵のスタイルを指定する
ボタンの淵の種類を指定します。エッジの種類は5種類あり、必要に応じて指定することが出来ます。属性は以下の通りです。
- flat:平らなボタン
- sunken:押された状態
- raised:手前に飛び出た状態
- groove:淵が溝に埋まった状態
- ridge:淵が盛り上がる状態
- solid:太い溝
4.12_Button_relief# 淵のスタイルを指定します button1 = tk.Button(pop, text="Hello",relief='flat') button2 = tk.Button(pop, text="Hello",relief='sunken') button3 = tk.Button(pop, text="Hello",relief='raised') button4 = tk.Button(pop, text="Hello",relief='groove') button5 = tk.Button(pop, text="Hello",relief='ridge') button6 = tk.Button(pop, text="Hello",relief='solid') button1.pack() button2.pack() button3.pack() button4.pack() button5.pack() button6.pack()実行結果
4.13 state ボタンの属性を変える
stateはボタンをアクティブにしたり、非アクティブにすることが出来ます。属性は3種類ありますが、そのうちの一つは同じ意味を持つ属性なので省略します。
- normal:押すことが可能なボタン
- disable:ボタンを押せないようにします
実際に2個のボタンを試してみましょう。
4.13_Button_state# 淵のスタイルを指定します # ボタンの属性を変える button1 = tk.Button(pop, text="normal",state='normal') button2 = tk.Button(pop, text="active",state='active') button3 = tk.Button(pop, text="disable",state='disable') button1.pack() button2.pack() button3.pack()実行結果
4.14 underline 下線をつける
最初の文字を0番目として、何個目に下線を引くか指定します。デフォルトは-1でこの場合はどの文字にも下線が付きません。
4.14_Button_underline# 任意の文字に下線を引く button = tk.Button(pop, text="disable",underline='3')実行結果
4.15 wraplength 任意の大きさで文字を折り返す
好きな大きさで文字を折り返します。数字で指定しますが文字の桁数ではなく、pixel数であることに注意してください。
もし、20pxで折り返す場合は以下のように書きます。4.15_Button_state# 文字を任意の大きさで折り返します button = tk.Button(pop, text="wraplength",wraplength='20')実行結果
以上ボタンウィジェットでした。
次回はキャンバスについて学びたいと思います。















- 投稿日:2020-06-19T20:57:59+09:00
Python requestsで天気を取得する
梅雨になったので天気が知りたいなーと思って作った
1.requestsについて
2.天気の入手場所
3.ソース
4.ソース解説
5.実行結果
6.まとめrequestsについて
- HTTP通信用のPythonのライブラリ。
- WEBスクレイピングでHTMLやXMLファイルからデータを取得するのに使われる。
- コマンドプロンプトで
pip install requestsを入力すればインストールできる。- 使用例
import requests r = requests.get("https://news.yahoo.co.jp/") print(r.text)
- 実行結果(一部抜粋)
<!DOCTYPE html> <style data-styled="gpQmdr jhlPYu" data-styled-version="4.4.1" data-styled-streamed="true"> /* sc-component-id: sc-jAaTju */ .gpQmdr{display:-webkit-box;display:-webkit-flex;display:-ms- flexbox;display:flex;-webkit-align-items:center;-webkit-box-align:center;-ms-flex-align:center;align-items:center;-webkit-box-pack:center;-webkit-justify-content:center;-ms-flex-pack:center;justify-content:center;-webkit-flex-direction:column;-ms-flex-direction:column;flex-direction:column;overflow:hidden;position:relative;background-color:#efefef;height:80px;width:80px;} .gpQmdr::after{content:'';display:block;position:absolute;top:0;left:0;box-sizing:border-box;width:100%;height:100%;border:solid 1px rgba(0,0,0,0.06);}天気の入手場所
livedoor天気情報のお天気Webサービス
上記サイトの全国の地点定義表のリンク内のリクエストする地域の「1次細分区(cityタグ)」のidを探す。(例:京都府 京都市 = 260010)ソース
import requests class GetWeather: url = "http://weather.livedoor.com/forecast/webservice/json/v1?" def getWeather(self, citycode): query_params = {"city": citycode} self.data = requests.get(self.url, params = query_params).json() def showWeather(self): print(self.data["location"]["city"], "の天気は、") for weather in self.data['forecasts']: print(weather["date"]) print(weather["dateLabel"] + "の天気:" + weather["telop"]) print("") citycode = 260010 w = GetWeather() w.getWeather(citycode) w.showWeather()ソース解説
1行目
import requestsrequestsライブラリのインポート
3行目
class GetWeatherGetWeatherクラスの定義。
4行目
url = "http://weather.livedoor.com/forecast/webservice/json/v1?"JSONデータをリクエストする際のURL
6~8行目 getWeatherメソッド
def getWeather(self, citycode): query_params = {"city": citycode} self.data = requests.get(self.url, params = query_params).json()6行目:getWeatherメソッドの定義。引数に地域コードを指定。天気データの取得を行うメソッド。
7行目:地域コードをquery_paramsに代入。
8行目:requests.get()で天気データを取得。これで、urlに地域コードをセットした状態でquery_paramsで指定したコードの地域の天気が取得出来る。
10~15行目 showWeatherメソッド
def showWeather(self): print(self.data["location"]["city"], "の天気は、") for weather in self.data['forecasts']: print(weather["date"]) print(weather["dateLabel"] + "の天気:" + weather["telop"]) print("")10行目:showWeatherメソッドの定義。取得した天気の表示を行うメソッド。
11行目:お天気Webサービス仕様のレスポンスフィールドのプロパティ名を見ると、locationプロパティのcityプロパティに1次細分区名があることがわかるので、
self.data["location"]["city"]でcityプロパティの1次細分区名を表示できる。12行目:同じようにforecastsプロパティのdateプロパティに予報日(年月日)、dataLabelプロパティに予報日(今日、明日、明後日のいずれか)があることがわかるので、
for weather in self.data['forecasts']:でforecastsプロパティ内のプロパティを取り出す。13行目:
print(weather["date"])でdateプロパティの表示14行目:
print(weather["dateLabel"] + "の天気:" + weather["telop"])で
dateLabelプロパティ、telopプロパティの表示17~20行目
17行目:citycodeの定義。(ここでは京都府京都市)
18行目:GetWeatherクラスのインスタンスの生成。
19行目:getWeatherメソッドの呼び出し。
20行目:showWeatherメソッドの呼び出し。実行結果
京都 の天気は、 2020-06-19 今日の天気:雨のち曇 2020-06-20 明日の天気:曇のち晴 2020-06-21 明後日の天気:晴時々曇まとめ
- requestsでHTTP通信ができる
- ユーザー指定の都道府県、地域の天気が取得できたらおもしろいかも
- 普通に天気見たほうがはy( ' ^'c彡☆))Д´) パーン
- 投稿日:2020-06-19T20:25:19+09:00
【AWS入門】音声-テキスト変換して遊んでみた♪
同じように見えるがこちらは、資料がほとんど無い。
参考のものを見てどうにか出来た。
昨夜の音声を貼っておく。今夜はこれをテキスト変換した。
音声発生【参考】
①Getting Started (AWS SDK for Python (Boto))
②Amazon Transcribeで音声の文字起こしを行う。
③S3 → Lambda → Transcribe → S3 で文字起こしパイプラインを作成する参考①より、以下のようなコードが出来る。
ほぼ参考①と同じように見えるが、一か所参考③を見て、出力先をOutputBucketName='バケット名'として指定している。
これが無いと、ほぼどこに出力されたのかが分からなかった。
※特に指定して存在している場合もファイルは隠しファイルになっているようである
⇒最後にもう一度見たらファイルが見えましたfrom __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe') job_name = "test_tran3" job_uri = "https://バケット名.s3.amazonaws.com/speech.mp3" transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='mp3', #wav, mp4, mp3 LanguageCode='ja-JP', #'en-US' OutputBucketName='muauanmp3' ) while True: status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)上記コードで以下のような出力が得られる。Not ready yetは5秒に一回出力されるが、6回以上出力しているから30秒程度はかかっているようだ。
そして、一応結果のjsonを吐くがあまり意味は分からない。$ python3 boto_transcribe.py Not ready yet... ... Not ready yet... {'TranscriptionJob': {'TranscriptionJobName':..., 'content-length': '506', 'connection': 'keep-alive'}, 'RetryAttempts': 0}}そこで、参考②がやっているように、s3のバケットのファイルを確認する。
音声ファイルspeech.mp3と共に出力されたtest_tran3.jsonなどのファイルが見える。$ aws s3 ls s3://バケット名 2020-06-19 04:52:36 2 .write_access_check_file.temp ... 2020-06-18 23:44:17 35467 speech.mp3 ... 2020-06-19 04:45:47 1472 test_tran2.json 2020-06-19 04:54:09 1663 test_tran3.json次に、s3://バケット名/test_tran3.json をec2サーバーにコピーする。
$ aws s3 cp s3://バケット名/test_tran3.json ./ download: s3://バケット名/test_tran3.json to ./test_tran3.json最後に、jsonの中身を以下のコマンドで出力する。
ちゃんと言語があっていると、以下のように正しく出力されたが、同じ音声ファイルを英語の指定でtranscribeした結果は、下のようにアルファベットになっているが、どうも変!
とはいえ、これで一応の音声-テキスト変換が出来た。$ cat test_tran3.json |jq .results[][0].transcript "こんにちは 東京 横浜 も 少し 曇り です 声 は 水木 さん です" $ cat test_tran2.json |jq .results[][0].transcript "Tokyo, Yokohama, Moscow See Commodities, Cueva Mitic Sundays."しかし、実際に使う場合は、やはり手打ちではなくpythonコードでやりたい。
というわけで、いろいろ調査した結果、以下の参考のようなことが出来ることが分かった。【参考】
④boto3を使ってS3にファイルのアップ&ダウンロード
⑤pandasでJSON文字列・ファイルを読み込み(read_json)
⑥JSONで配列の入れ子構造や値の取得方法などをPythonを使って説明!
これらのやり方をコードに落とすと以下のようになる。
つまり、
① jsonファイルをダウンロード
② pandasで読み込む
③ 必要な部分を出力する
という方法である。import pandas as pd s3 = boto3.resource('s3') #S3オブジェクトを取得 bucket = s3.Bucket('バケット名') #bucket定義 bucket.download_file('test_tran3.json', 'test_tran3.json') #ec2へダウンロード;ダウンロードファイル、ダウンロード後ファイル df = pd.read_json('test_tran3.json') #jsonファイルをpandasで読込 print(df['results'][1][0]['transcript']) #jsonファイルから変換文字列を抽出こうして一連の作業の結果無事に以下のセンテンスが得られました。
※結果はよく見ると分かち書きされているのが分かりますこんにちは 東京 横浜 も 少し 曇り です 声 は 水木 さん です・バリエーション
アプリ応用
単品で、議事録や翻訳などは普通に使えそうです。
さらに、昨晩のテキスト-音声と合わせると、以下のようなシークエンスが構成出来ることが分かります。テキスト-音声-...-音声-テキストということで、...の部分の処理はいろいろ考えられます。
パーポや資料の読み上げと質問のシークエンスをテキストで記録する。
つまり、最初のテキストや音声と処理後の音声やテキストは異なると思われます。
また、他のシーケンスも考えられます。
会話アプリの場合だと、上記の配置は逆転して音声-テキスト-会話アプリ-テキスト-音声というのが考えられます。
これは、アレクサなんかのシークエンスですね。
この場合は、テキストベースの変換なので、普通に翻訳が出来そうです音声QA
アレクサみたいな音声-QAアプリも作れそうです。
質問をスマホなどの音声で受け付けて、その裏で上記のアプリを動かせばリアルタイムな音声QAも出来そうです。Twitter補助
Twitterに限らないけど、要は、入力は音声で出力も音声でやることもできそうです。
。。。ただし、これらのアプリにするにはもうひと頑張り必要ですね。まとめ
・音声―テキスト変換で遊んでみた
・pythonで一連の動作を作成できた・jsonファイルが存在すると二度できないので、毎回同じジョブでやるには一連のシーケンスで削除が必要
・何かアプリ作ろう...
・テキスト翻訳もやろう
- 投稿日:2020-06-19T20:10:08+09:00
DDPGでPendulum-v0を学習
概要
DQNなどの手法では方策によって各状態のQ(s,a)を計算し、Q値を最大化する行動を選択・行動をしていたが、これでは離散的な行動しか扱えなかった。それに対して、DDPGでは連続行動空間に対応するためQ値を最大化する行動を求めるのではなく、方策をパラメータ化し直接行動を出力することで対応した。そのため、決定的な方策となっている。
実装
リプレイバッファ
深層強化学習ではおなじみのリプレイバッファです。現在の状態、その時の行動、次状態、即時報酬、終端状態かどうかを一つのタプルとして保存しています。
from collections import deque, namedtuple import random Transition = namedtuple('Transition', ('state', 'action', 'next_state', 'reward', 'done')) class ReplayBuffer(object): def __init__(self, capacity=1e6): self.capacity = capacity self.memory = deque([], maxlen=int(capacity)) def append(self, *args): transition = Transition(*args) self.memory.append(transition) def sample(self, batch_size): return random.sample(self.memory, batch_size) def reset(self): self.memory.clear() def length(self): return len(self.memory) def __len__(self): return len(self.memory)モデル
DDPGでは現在の状態から行動を連続値で出力するActor$\mu(s)$と現在の状態と行動からQ値を出力するCritic$Q(s,a)$が存在します。各層の重みの初期化については元論文に沿っているので、詳しくはそちらを確認してください(下にリンクがあります)。特徴的なのはActorの最終層にtanhがあることと、Criticで行動を受け取る際に第二層で受け取ることですかね。もしPendulumで実験する場合には、行動範囲が[-2, 2]なので、出力に2を書けても良いかもしれません。
import torch import torch.nn as nn import torch.nn.functional as F import numpy as np def init_weight(size): f = size[0] v = 1. / np.sqrt(f) return torch.tensor(np.random.uniform(low=-v, high=v, size=size), dtype=torch.float) class ActorNetwork(nn.Module): def __init__(self, num_state, num_action, hidden1_size=400, hidden2_size=300, init_w=3e-3): super(ActorNetwork, self).__init__() self.fc1 = nn.Linear(num_state[0], hidden1_size) self.fc2 = nn.Linear(hidden1_size, hidden2_size) self.fc3 = nn.Linear(hidden2_size, num_action[0]) self.num_state = num_state self.num_action = num_action self.fc1.weight.data = init_weight(self.fc1.weight.data.size()) self.fc2.weight.data = init_weight(self.fc2.weight.data.size()) self.fc3.weight.data.uniform_(-init_w, init_w) def forward(self, x): h = F.relu(self.fc1(x)) h = F.relu(self.fc2(h)) y = torch.tanh(self.fc3(h)) # 2をかけてもよいかも? return y class CriticNetwork(nn.Module): def __init__(self, num_state, num_action, hidden1_size=400, hidden2_size=300, init_w=3e-4): super(CriticNetwork, self).__init__() self.fc1 = nn.Linear(num_state[0], hidden1_size) self.fc2 = nn.Linear(hidden1_size+num_action[0], hidden2_size) self.fc3 = nn.Linear(hidden2_size, 1) self.num_state = num_state self.num_action = num_action self.fc1.weight.data = init_weight(self.fc1.weight.data.size()) self.fc2.weight.data = init_weight(self.fc2.weight.data.size()) self.fc3.weight.data.uniform_(-init_w, init_w) def forward(self, x, action): h = F.relu(self.fc1(x)) h = F.relu(self.fc2(torch.cat([h, action], dim=1))) y = self.fc3(h) return yエージェント
エージェントでは行動を選択する際にそのままでは行動が決定的になってしまうため、ノイズ$\mathcal{N}$を加えます。このときのノイズはオルンシュタイン=ウーレンベック過程という確立過程に従います。詳しくはわからないです。時間経つに従って平均に近づいていくノイズだと思えばいいと思います。しらんけど。
a = \mu(s) + \mathcal{N}各モデルの学習についてはCriticはDQNなどと同様にTD誤差を最小化するように勾配を求めてモデルの更新を行います。損失関数については以下のとおりです。Nはバッチサイズです。
L = \frac{1}{N} \sum_{i=1}^N (r_i + \gamma Q^{\prime}(s_{i+1}, \mu^{\prime}(s_{i+1})) - Q(s_i, a_i))^2Actorの方はQ値を最大化するようにモデルの更新を行います。このとき最大化を行うので、Lossにマイナスがつくことに注意です。目的関数は以下の通りです。
J = \frac{1}{N}\sum_{i=1}^N Q(s_{i}, \mu{s_i})上記の目的関数ではダッシュがついてるものはtargetネットワークになります。これは学習を安定化させるためによく使われるものです。DQNなどではこのtargetネットワークの更新が数エポック毎に行われるのに対して、DDPGではハイパパラメータ$\tau(\ll 1)$を用いて
\theta \gets \tau \theta + (1 - \tau) \theta^{\prime}のように、緩やかに更新されます。これにより、学習が安定しますが学習時間が若干長くなってしまうらしいです。
import torch import torch.nn.functional as F import numpy as np import copy class OrnsteinUhlenbeckProcess: def __init__(self, theta=0.15, mu=0.0, sigma=0.2, dt=1e-2, x0=None, size=1, sigma_min=None, n_steps_annealing=1000): self.theta = theta self.mu = mu self.sigma = sigma self.dt = dt self.x0 = x0 self.size = size self.num_steps = 0 self.x_prev = self.x0 if self.x0 is not None else np.zeros(self.size) if sigma_min is not None: self.m = -float(sigma - sigma_min) / float(n_steps_annealing) self.c = sigma self.sigma_min = sigma_min else: self.m = 0 self.c = sigma self.sigma_min = sigma def current_sigma(self): sigma = max(self.sigma_min, self.m * float(self.num_steps) + self.c) return sigma def sample(self): x = self.x_prev + self.theta * (self.mu - self.x_prev) * self.dt + self.current_sigma() * np.sqrt(self.dt) * np.random.normal(size=self.size) self.x_prev = x self.num_steps += 1 return x class DDPG: def __init__(self, actor, critic, optimizer_actor, optimizer_critic, replay_buffer, device, gamma=0.99, tau=1e-3, epsilon=1.0, batch_size=64): self.actor = actor self.critic = critic self.actor_target = copy.deepcopy(self.actor) self.critic_target = copy.deepcopy(self.critic) self.optimizer_actor = optimizer_actor self.optimizer_critic = optimizer_critic self.replay_buffer = replay_buffer self.device = device self.gamma = gamma self.tau = tau self.epsilon = epsilon self.batch_size = batch_size self.random_process = OrnsteinUhlenbeckProcess(size=actor.num_action[0]) self.num_state = actor.num_state self.num_action = actor.num_action def add_memory(self, *args): self.replay_buffer.append(*args) def reset_memory(self): self.replay_buffer.reset() def get_action(self, state, greedy=False): state_tensor = torch.tensor(state, dtype=torch.float, device=self.device).view(-1, *self.num_state) action = self.actor(state_tensor) if not greedy: action += self.epsilon*torch.tensor(self.random_process.sample(), dtype=torch.float, device=self.device) return action.squeeze(0).detach().cpu().numpy() def train(self): if len(self.replay_buffer) < self.batch_size: return None transitions = self.replay_buffer.sample(self.batch_size) batch = Transition(*zip(*transitions)) state_batch = torch.tensor(batch.state, device=self.device, dtype=torch.float) action_batch = torch.tensor(batch.action, device=self.device, dtype=torch.float) next_state_batch = torch.tensor(batch.next_state, device=self.device, dtype=torch.float) reward_batch = torch.tensor(batch.reward, device=self.device, dtype=torch.float).unsqueeze(1) not_done = np.array([(not done) for done in batch.done]) not_done_batch = torch.tensor(not_done, device=self.device, dtype=torch.float).unsqueeze(1) # need to change qvalue = self.critic(state_batch, action_batch) next_qvalue = self.critic_target(next_state_batch, self.actor_target(next_state_batch)) target_qvalue = reward_batch + (self.gamma * next_qvalue * not_done_batch) critic_loss = F.mse_loss(qvalue, target_qvalue) self.optimizer_critic.zero_grad() critic_loss.backward() self.optimizer_critic.step() actor_loss = -self.critic(state_batch, self.actor(state_batch)).mean() self.optimizer_actor.zero_grad() actor_loss.backward() self.optimizer_actor.step() # soft parameter update for target_param, param in zip(self.actor_target.parameters(), self.actor.parameters()): target_param.data.copy_(target_param.data * (1.0 - self.tau) + param.data * self.tau) for target_param, param in zip(self.critic_target.parameters(), self.critic.parameters()): target_param.data.copy_(target_param.data * (1.0 - self.tau) + param.data * self.tau)学習
ここに関しては特に新しい点はありません。その他の強化学習のアルゴリズムと同様に環境からの状態を受け取って、行動、学習をしている感じになります。各ハイパーパラメータは元論文に沿っています。(多分)
import torch import torch.optim as optim import gym max_episodes = 300 memory_capacity = 1e6 # バッファの容量 gamma = 0.99 # 割引率 tau = 1e-3 # ターゲットの更新率 epsilon = 1.0 # ノイズの量をいじりたい場合、多分いらない batch_size = 64 lr_actor = 1e-4 lr_critic = 1e-3 logger_interval = 10 weight_decay = 1e-2 env = gym.make('Pendulum-v0') num_state = env.observation_space.shape num_action = env.action_space.shape max_steps = env.spec.max_episode_steps device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') actorNet = ActorNetwork(num_state, num_action).to(device) criticNet = CriticNetwork(num_state, num_action).to(device) optimizer_actor = optim.Adam(actorNet.parameters(), lr=lr_actor) optimizer_critic = optim.Adam(criticNet.parameters(), lr=lr_critic, weight_decay=weight_decay) replay_buffer = ReplayBuffer(capacity=memory_capacity) agent = DDPG(actorNet, criticNet, optimizer_actor, optimizer_critic, replay_buffer, device, gamma, tau, epsilon, batch_size) for episode in range(max_episodes): observation = env.reset() total_reward = 0 for step in range(max_steps): action = agent.get_action(observation) next_observation, reward, done, _ = env.step(action) total_reward += reward agent.add_memory(observation, action, next_observation, reward, done) agent.train() observation = next_observation if done: break if episode % logger_interval == 0: print("episode:{} total reward:{}".format(episode, total_reward)) for episode in range(3): observation = env.reset() env.render() for step in range(max_steps): action = agent.get_action(observation, greedy=True) next_observation, reward, done, _ = env.step(action) observation = next_observation env.render() if done: break env.close()gym.makeの環境を変えれば他の環境での学習もできるはず。
結果
累積報酬と学習エピソードのグラフです。いい感じに学習できているのではないでしょうか。
ちゃんとたてられていますね。えらい。(gifは作り方がわからないので、載せられてないです)おわりに
基本的に上のコードをそのまま一つファイルにまとめて実行してもらえれば、動作の確認ができると思います。実装で手一杯だったのでいくつか余分な変数などが残っています。Pendulum-v0であれば、GPUが利用可能な環境でなくてもcpuのみで学習はできます。ただ、少し学習が不安定になるときがあるのでそのときには再度実行してください。 機会があれば、他の手法の実装も行っていくつもりです。
参考文献

- 投稿日:2020-06-19T19:55:23+09:00
オープンデータを利用して有機フッ素化合物の環境中濃度を地図上にプロットしてみる
ChemTHEATREに収録されたデータを活用して有機フッ素化合物の濃度を可視化してみる
有機フッ素化合物とは
親水性と親油性の両方の性質を持ち,撥水剤や消化剤,油剤,エッチング剤など幅広い用途で使用されています。
有機フッ素化合物に関するわかりやすい解説は,NHKのクローズアップ現代のHPを参照。
https://www.nhk.or.jp/gendai/articles/4280/index.htmlその有害性から,有機フッ素化合物のうちペルフルオロオクタン酸(Perfluorooctanoic acid: PFOA)は2019年からその製造・使用・輸出入が国際的に禁止され,ペルフルオロオクタンスルホン酸(Perfluorooctanesulfonate: PFOS)は2009年から製造・使用・輸出入が制限されています。
有機フッ素化合物の基準値等
近年,両物質が井戸水から検出されたり,河川に流出するなど,問題となっています。
これを受け,厚生労働省は水質管理目標設定項目にPFOSとPFOAを追加しました(令和2年4月1日施行)。水道水質基準の目標値をPFOSとPFOAの合算値で50 ng/Lとしています。
https://www.mhlw.go.jp/stf/seisakunitsuite/bunya/topics/bukyoku/kenkou/suido/kijun/index.htmlまた,環境省は水環境におけるPFOSとPFOAの全国存在量調査を実施し,「水質汚濁に係る人の健康の保護に関する環境基準等の施行について(通知)」(令和2年5月28日付け)で,水環境に係る暫定的な目標値としてPFOSとPFOAの合算値で50 ng/Lを設定しました。
令和元年度PFOA及びPFOA全国存在量調査結果
https://www.env.go.jp/press/108091.htmlちなみに,令和2年6月に厚生労働省が公開した浄水場を対象とした調査結果では,水道水の暫定目標値であるPFOS+PFOA 50 ng/Lを超過したところはありませんでした。
https://www.mhlw.go.jp/content/10900000/000638290.pdfChemTHEATREから有機フッ素化合物の環境中濃度データを取得する
ChemTHEATREでは環境中の化学物質濃度のモニタリングデータを公開しており,有機フッ素化合物のデータも収録しています。実際に,PFOSやPFOAがどのくらいの濃度で検出されたのか,また,その合算値は基準値と比較してどの程度高い,あるいは低いのか,実際に見てみましょう。
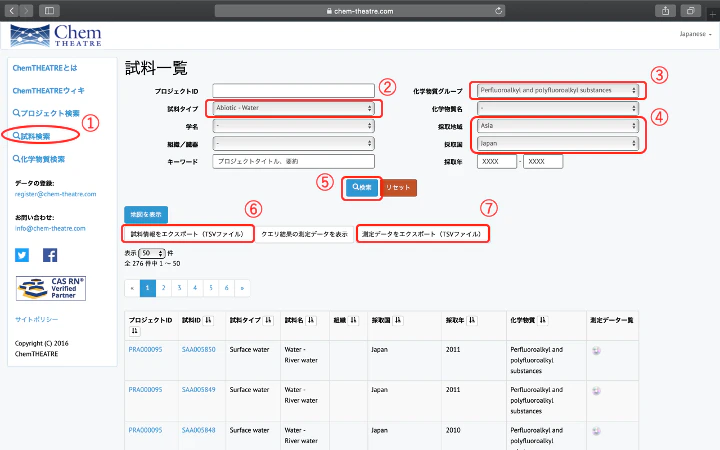
- ChemTHEATREのメニューバーから「試料検索」を選択する。
- 「試料タイプ」から「Abiotic - Water」(非生物 - 水)を選択する。
- 「化学物質グループ」から「Perfluoroalkyl and polyfluoroalkyl substances」を選択する。
- 「採取地域」から「Asia」を選択し,採取国を「Japan」にする。
- 「Search」ボタンをクリックすると,条件に合致する試料の一覧が出力される。
- 「Export samples」で試料の情報が,「Export measured data」で目的の化学物質の測定値が,タブ区切りのテキストファイルとして出力する。
エクスポートしたファイルを任意のディレクトリに保存して,解析に使用してください。
エクスポートしたデータを整形する
必要なライブラリとモジュールを読み込む。
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt from cartopy import crs as ccrs化学物質の測定値の情報を読み込む。
data_file = "measureddata_20200521044415.tsv" data = pd.read_csv(data_file, delimiter="\t") data
MeasuredID ProjectID SampleID ScientificName ChemicalID ChemicalName ExperimentID MeasuredValue AlternativeData Unit Remarks RegisterDate UpdateDate 0 81245 PRA000095 SAA005816 Water CH0000362 PFBS EXA000001 0.00100 <1.00E-3 μg/L NaN 2019/7/26 2019/7/26 1 81246 PRA000095 SAA005817 Water CH0000362 PFBS EXA000001 0.00100 <1.00E-3 μg/L NaN 2019/7/26 2019/7/26 2 81247 PRA000095 SAA005818 Water CH0000362 PFBS EXA000001 0.00100 NaN μg/L NaN 2019/7/26 2019/7/26 3 81248 PRA000095 SAA005819 Water CH0000362 PFBS EXA000001 0.00100 <1.00E-3 μg/L NaN 2019/7/26 2019/7/26 4 81249 PRA000095 SAA005820 Water CH0000362 PFBS EXA000001 0.00100 <1.00E-3 μg/L NaN 2019/7/26 2019/7/26 ... ... ... ... ... ... ... ... ... ... ... ... ... ... 3087 48619 PRA000060 SAA003645 Water CH0000793 THPFOS EXA000001 0.00030 NaN μg/L NaN 2018/2/9 2018/6/8 3088 48620 PRA000060 SAA003646 Water CH0000793 THPFOS EXA000001 0.00008 NaN μg/L NaN 2018/2/9 2018/6/8 3089 48621 PRA000060 SAA003647 Water CH0000793 THPFOS EXA000001 0.00159 NaN μg/L NaN 2018/2/9 2018/6/8 3090 48622 PRA000060 SAA003648 Water CH0000793 THPFOS EXA000001 0.00188 NaN μg/L NaN 2018/2/9 2018/6/8 3091 48623 PRA000060 SAA003649 Water CH0000793 THPFOS EXA000001 0.00070 NaN μg/L NaN 2018/2/9 2018/6/8 3092 rows × 13 columns
続いて,試料の情報を読み込む。
sample_file = "samples_20200521044410.tsv" sample = pd.read_csv(sample_file, delimiter="\t") sample
ProjectID SampleID SampleType TaxonomyID UniqCodeType UniqCode SampleName ScientificName CommonName CollectionYear ... FlowRate MeanPM10 MeanTotalSuspendedParticles HumidityStartEnd WindDirectionStartEnd WindSpeedMSStartEnd AmountOfCollectedAirStartEnd Remarks RegisterDate UpdateDate 0 PRA000048 SAA002867 ST014 NaN NaN NaN SW-St.1 Water Surface water 2004 ... NaN NaN NaN NaN NaN NaN NaN NaN 2017/10/25 2019/7/18 1 PRA000048 SAA002868 ST014 NaN NaN NaN SW-St.3 Water Surface water 2004 ... NaN NaN NaN NaN NaN NaN NaN NaN 2017/10/25 2019/7/18 2 PRA000048 SAA002869 ST014 NaN NaN NaN SW-St.4 Water Surface water 2004 ... NaN NaN NaN NaN NaN NaN NaN NaN 2017/10/25 2019/7/18 3 PRA000048 SAA002870 ST014 NaN NaN NaN SW-St.5 Water Surface water 2004 ... NaN NaN NaN NaN NaN NaN NaN NaN 2017/10/25 2019/7/18 4 PRA000048 SAA002871 ST014 NaN NaN NaN SW-St.7 Water Surface water 2004 ... NaN NaN NaN NaN NaN NaN NaN NaN 2017/10/25 2019/7/18 ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... ... 271 PRA000095 SAA005846 ST015 NaN NaN NaN W_1xyz24_20100821 Water River water 2010 ... NaN NaN NaN NaN NaN NaN NaN Around Kushiro Airport 2019/7/26 2019/7/26 272 PRA000095 SAA005847 ST015 NaN NaN NaN W_1xyz25_20100821 Water River water 2010 ... NaN NaN NaN NaN NaN NaN NaN Around Kushiro Airport 2019/7/26 2019/7/26 273 PRA000095 SAA005848 ST015 NaN NaN NaN W_1xyz26_20100821 Water River water 2010 ... NaN NaN NaN NaN NaN NaN NaN Downstream from the inflow of wastewater from ... 2019/7/26 2019/7/26 274 PRA000095 SAA005849 ST015 NaN ZETTAICODE_FY2011_W 113680.0 W_113680_20110702 Water River water 2011 ... NaN NaN NaN NaN NaN NaN NaN Upstream from the inflow of wastewater from Ch... 2019/7/26 2019/7/26 275 PRA000095 SAA005850 ST015 NaN ZETTAICODE_FY2011_W 118873.0 W_118873_20110702 Water River water 2011 ... NaN NaN NaN NaN NaN NaN NaN Downstream from the inflow of wastewater from ... 2019/7/26 2019/7/26 276 rows × 66 columns
pfos = data[data["ChemicalName"] == "PFOS"] #ChemicalNameがPFOSのデータだけを抽出 pfoa = data[data["ChemicalName"] == "PFOA"] #ChemicalNameがPFOAのデータだけを抽出それぞれの中身を確認すると,下記のように見える。
pfos
MeasuredID ProjectID SampleID ScientificName ChemicalID ChemicalName ExperimentID MeasuredValue AlternativeData Unit Remarks RegisterDate UpdateDate 269 35646 PRA000048 SAA002867 Water CH0000365 PFOS EXA000001 0.0073 NaN μg/L NaN 2017/10/25 2018/6/8 270 35647 PRA000048 SAA002868 Water CH0000365 PFOS EXA000001 0.0030 NaN μg/L NaN 2017/10/25 2018/6/8 271 35648 PRA000048 SAA002869 Water CH0000365 PFOS EXA000001 0.0034 NaN μg/L NaN 2017/10/25 2018/6/8 272 35649 PRA000048 SAA002870 Water CH0000365 PFOS EXA000001 0.0038 NaN μg/L NaN 2017/10/25 2018/6/8 273 35650 PRA000048 SAA002871 Water CH0000365 PFOS EXA000001 0.0020 NaN μg/L NaN 2017/10/25 2018/6/8 ... ... ... ... ... ... ... ... ... ... ... ... ... ... 540 81380 PRA000095 SAA005846 Water CH0000365 PFOS EXA000001 0.0010 <1.00E-3 μg/L NaN 2019/7/26 2019/7/26 541 81381 PRA000095 SAA005847 Water CH0000365 PFOS EXA000001 0.0010 <1.00E-3 μg/L NaN 2019/7/26 2019/7/26 542 81382 PRA000095 SAA005848 Water CH0000365 PFOS EXA000001 0.0076 NaN μg/L NaN 2019/7/26 2019/7/26 543 81383 PRA000095 SAA005849 Water CH0000365 PFOS EXA000001 0.0028 NaN μg/L NaN 2019/7/26 2019/7/26 544 81384 PRA000095 SAA005850 Water CH0000365 PFOS EXA000001 0.0120 NaN μg/L NaN 2019/7/26 2019/7/26 276 rows × 13 columns
pfoa
MeasuredID ProjectID SampleID ScientificName ChemicalID ChemicalName ExperimentID MeasuredValue AlternativeData Unit Remarks RegisterDate UpdateDate 896 46410 PRA000060 SAA003568 Water CH0000372 PFOA EXA000001 0.00436 NaN μg/L NaN 2018/2/9 2018/6/8 897 46411 PRA000060 SAA003569 Water CH0000372 PFOA EXA000001 0.01166 NaN μg/L NaN 2018/2/9 2018/6/8 898 46412 PRA000060 SAA003570 Water CH0000372 PFOA EXA000001 0.01180 NaN μg/L NaN 2018/2/9 2018/6/8 899 46413 PRA000060 SAA003571 Water CH0000372 PFOA EXA000001 0.00430 NaN μg/L NaN 2018/2/9 2018/6/8 900 46414 PRA000060 SAA003572 Water CH0000372 PFOA EXA000001 0.00439 NaN μg/L NaN 2018/2/9 2018/6/8 ... ... ... ... ... ... ... ... ... ... ... ... ... ... 1143 81135 PRA000095 SAA005846 Water CH0000372 PFOA EXA000001 0.00100 <1.00E-3 μg/L NaN 2019/7/26 2019/7/26 1144 81136 PRA000095 SAA005847 Water CH0000372 PFOA EXA000001 0.00200 NaN μg/L NaN 2019/7/26 2019/7/26 1145 81137 PRA000095 SAA005848 Water CH0000372 PFOA EXA000001 0.00140 tr(1.40E-3) μg/L NaN 2019/7/26 2019/7/26 1146 81138 PRA000095 SAA005849 Water CH0000372 PFOA EXA000001 0.03900 NaN μg/L NaN 2019/7/26 2019/7/26 1147 81139 PRA000095 SAA005850 Water CH0000372 PFOA EXA000001 0.02400 NaN μg/L NaN 2019/7/26 2019/7/26 252 rows × 13 columns
PFOSとPFOAのデータだけを抜き出したものから,SampleIDとMeausredValueの列だけを抜き出し,測定値のカラム名がどちらもMeasuredValueになっているので,これをそれぞれPFOS,PFOAに変更する。
pfos = pfos[["SampleID","MeasuredValue"]].rename(columns={'MeasuredValue': 'PFOS'}) pfoa = pfoa[["SampleID","MeasuredValue"]].rename(columns={'MeasuredValue': 'PFOA'})PFOSとPFOAのデータフレームをSampleIDでマージする。
df = pd.merge(pfos, pfoa, on="SampleID").astype({"PFOS": float}, {"PFOA": float}) df
SampleID PFOS PFOA 0 SAA003568 0.00551 0.00436 1 SAA003569 0.01877 0.01166 2 SAA003570 0.01546 0.01180 3 SAA003571 0.00356 0.00430 4 SAA003572 0.00682 0.00439 ... ... ... ... 247 SAA005846 0.00100 0.00100 248 SAA005847 0.00100 0.00200 249 SAA005848 0.00760 0.00140 250 SAA005849 0.00280 0.03900 251 SAA005850 0.01200 0.02400 252 rows × 3 columns
今回知りたいのはPFOSとPFOAの濃度の合計値なので,TOTALという列を作って,そこに合計値を入れる。
df['TOTAL'] = df.sum(axis=1, numeric_only=True) df
SampleID PFOS PFOA TOTAL 0 SAA003568 0.00551 0.00436 0.00987 1 SAA003569 0.01877 0.01166 0.03043 2 SAA003570 0.01546 0.01180 0.02726 3 SAA003571 0.00356 0.00430 0.00786 4 SAA003572 0.00682 0.00439 0.01121 ... ... ... ... ... 247 SAA005846 0.00100 0.00100 0.00200 248 SAA005847 0.00100 0.00200 0.00300 249 SAA005848 0.00760 0.00140 0.00900 250 SAA005849 0.00280 0.03900 0.04180 251 SAA005850 0.01200 0.02400 0.03600 252 rows × 4 columns
試料のテーブルから,SampleIDと緯度経度のデータだけを抜き出す。
sample = sample[["SampleID", "CollectionLongitudeFrom", "CollectionLatitudeFrom"]] sample
SampleID CollectionLongitudeFrom CollectionLatitudeFrom 0 SAA002867 139.850000 35.599333 1 SAA002868 140.000000 35.583000 2 SAA002869 139.834500 35.515833 3 SAA002870 139.900333 35.532500 4 SAA002871 139.833667 35.433000 ... ... ... ... 271 SAA005846 144.192783 43.062302 272 SAA005847 144.232365 43.041624 273 SAA005848 144.155650 42.997641 274 SAA005849 141.719167 42.765833 275 SAA005850 141.719167 42.782500 276 rows × 3 columns
これを,先に作成した濃度のテーブルとSampleIDでマージする。
df = pd.merge(df, sample, on="SampleID") df
SampleID PFOS PFOA TOTAL CollectionLongitudeFrom CollectionLatitudeFrom 0 SAA003568 0.00551 0.00436 0.00987 139.607158 35.453746 1 SAA003569 0.01877 0.01166 0.03043 139.677734 35.501549 2 SAA003570 0.01546 0.01180 0.02726 139.617230 35.528481 3 SAA003571 0.00356 0.00430 0.00786 139.498684 35.578287 4 SAA003572 0.00682 0.00439 0.01121 139.480358 35.536396 ... ... ... ... ... ... ... 247 SAA005846 0.00100 0.00100 0.00200 144.192783 43.062302 248 SAA005847 0.00100 0.00200 0.00300 144.232365 43.041624 249 SAA005848 0.00760 0.00140 0.00900 144.155650 42.997641 250 SAA005849 0.00280 0.03900 0.04180 141.719167 42.765833 251 SAA005850 0.01200 0.02400 0.03600 141.719167 42.782500 252 rows × 6 columns
出来上がったファイルをcsv形式で保存する。
df.to_csv("sum_pfcs.csv")これを,QGISに読み込ませます。
QGISを使って濃度データを地図上に表示させる
QGISは下記からダウンロードする。
https://www.qgis.org/ja/site/
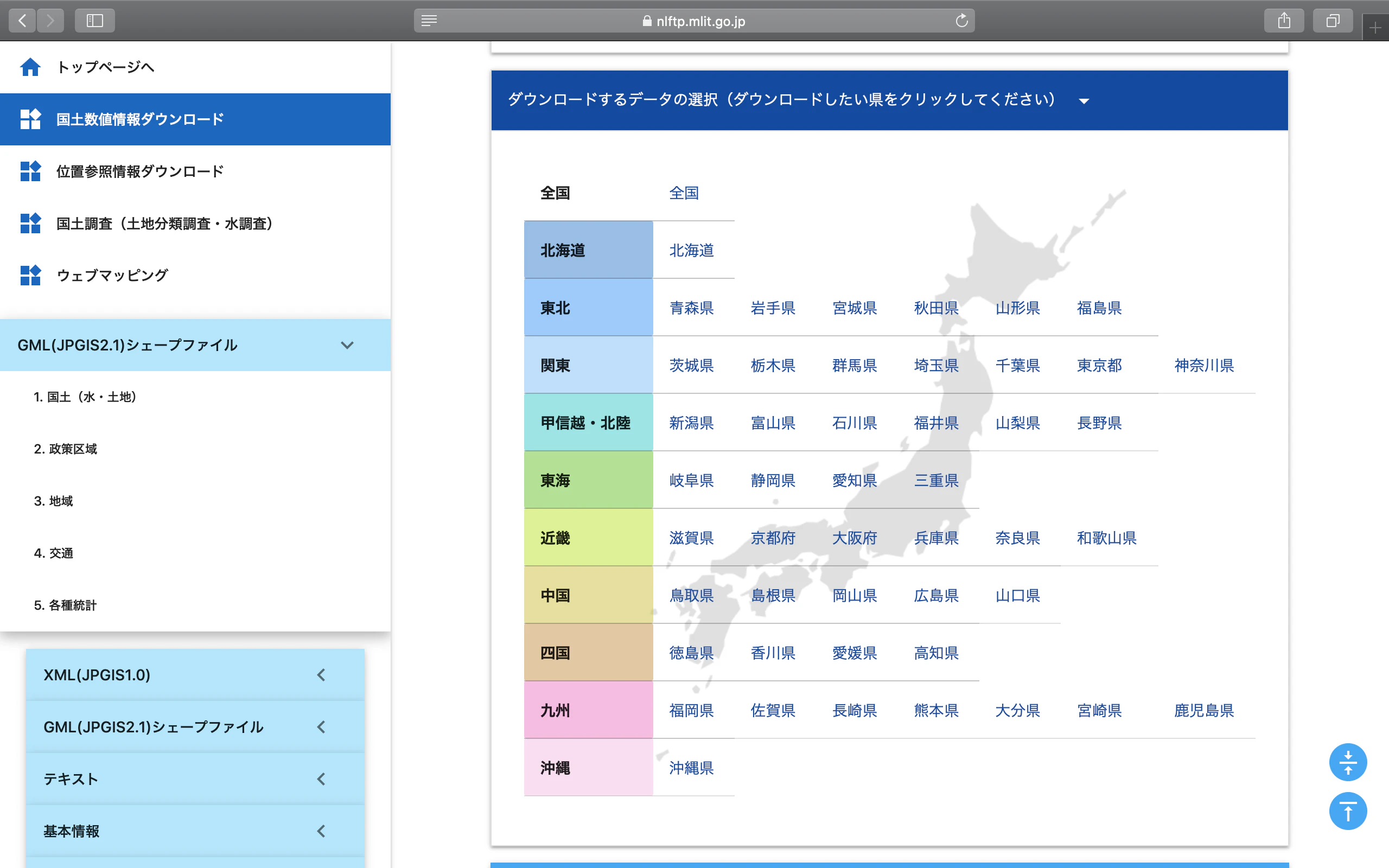
QGISの使用法はいろんなサイトで説明されているので,そちらを参照してください。地図情報(GMLシェープファイル)は,国土交通省のGISホームページからダウンロードする。
https://nlftp.mlit.go.jp/index.htmlとりあえず今回は,国土数値情報ダウンロードから,2. 政策区域のうち行政区域を利用する。
下記のページから「全国」のデータを選択してダウンロードする。年度は目的に応じて選んでください。
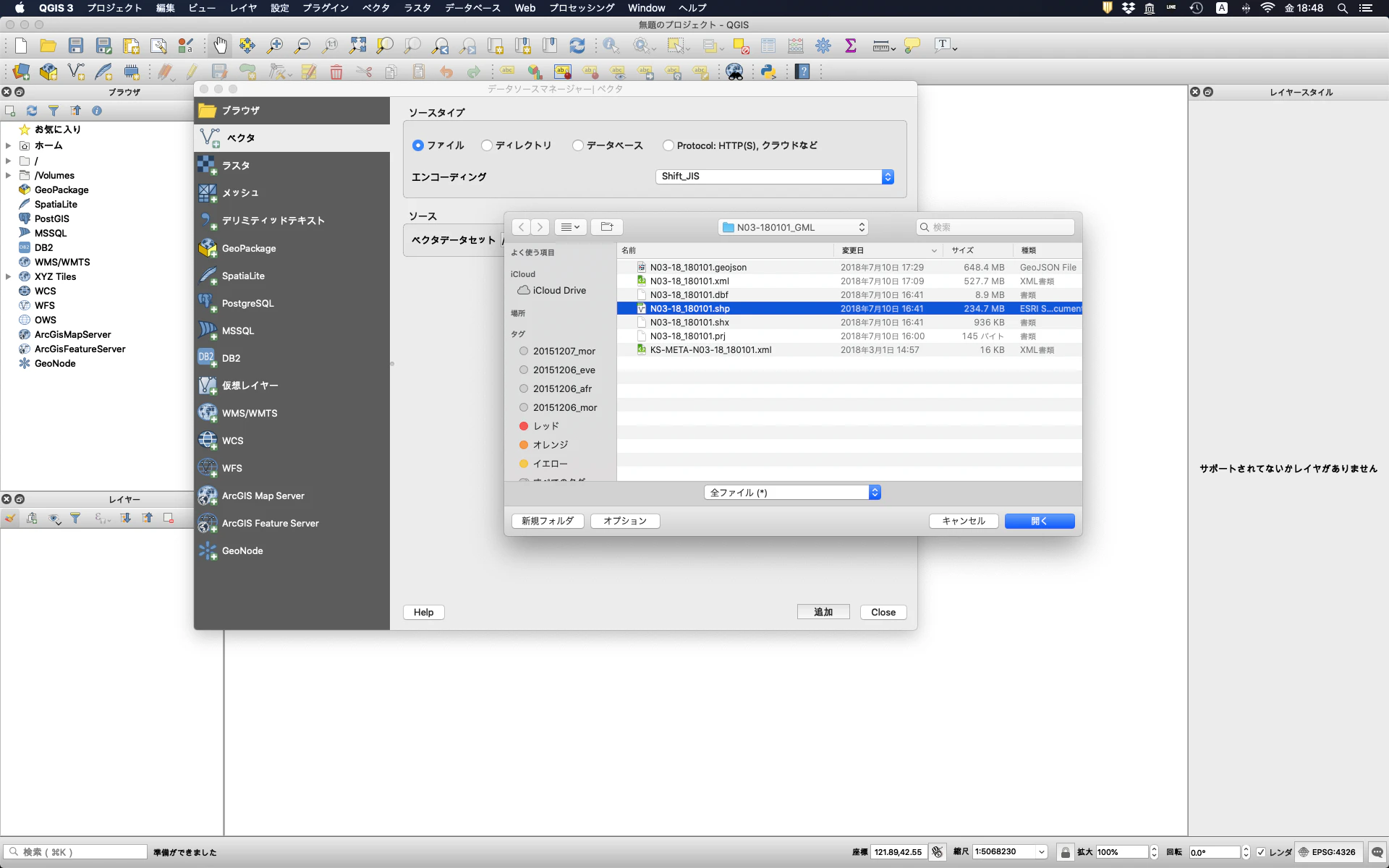
QGISを立ち上げ,データソースマネージャーからベクタのタブをクリックし,上でダウンロードした全国行政区域のシェープファイルを選択して「追加」をクリックする。
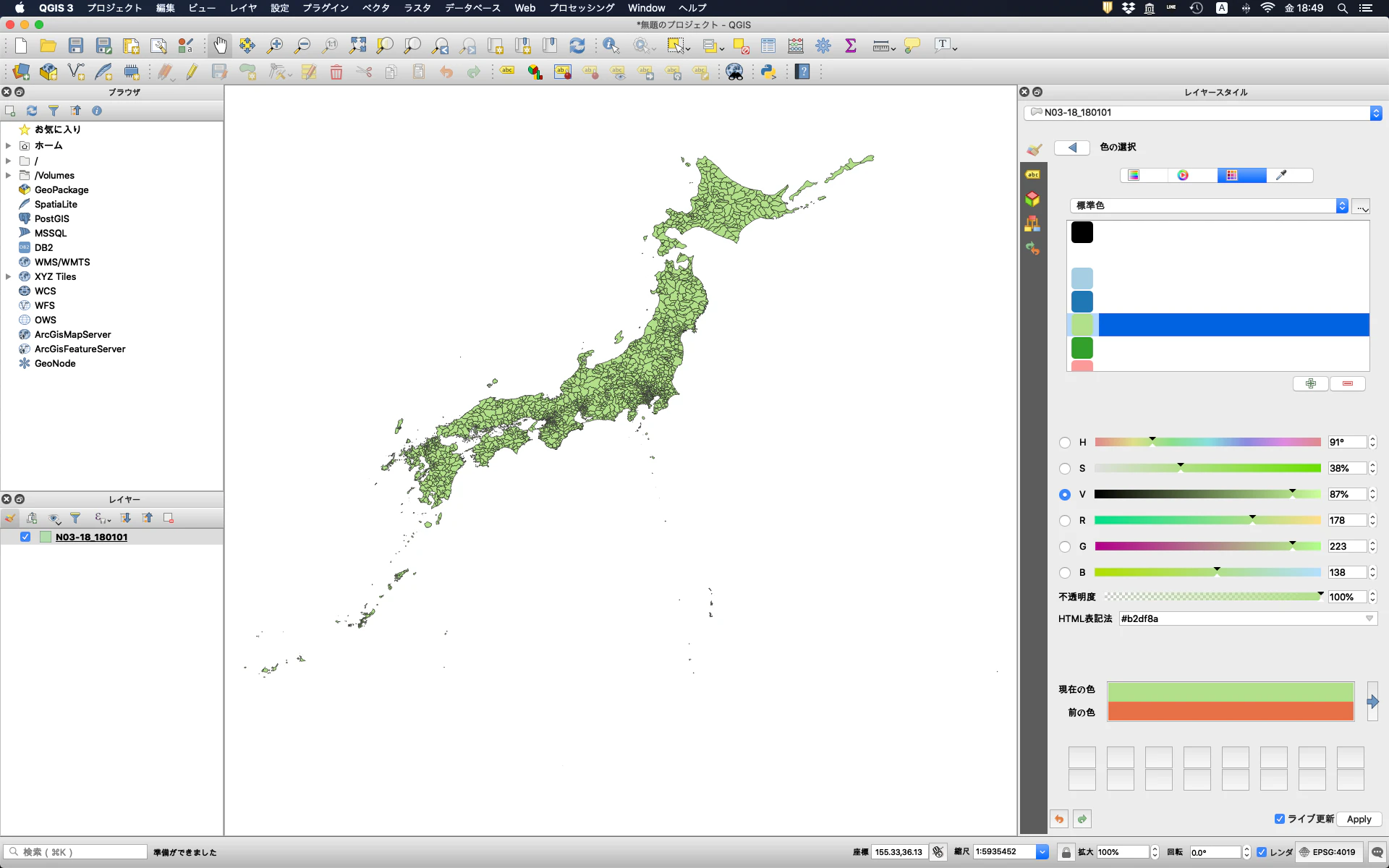
以下のように日本地図が読み込まれるので,好みの色に変更する。
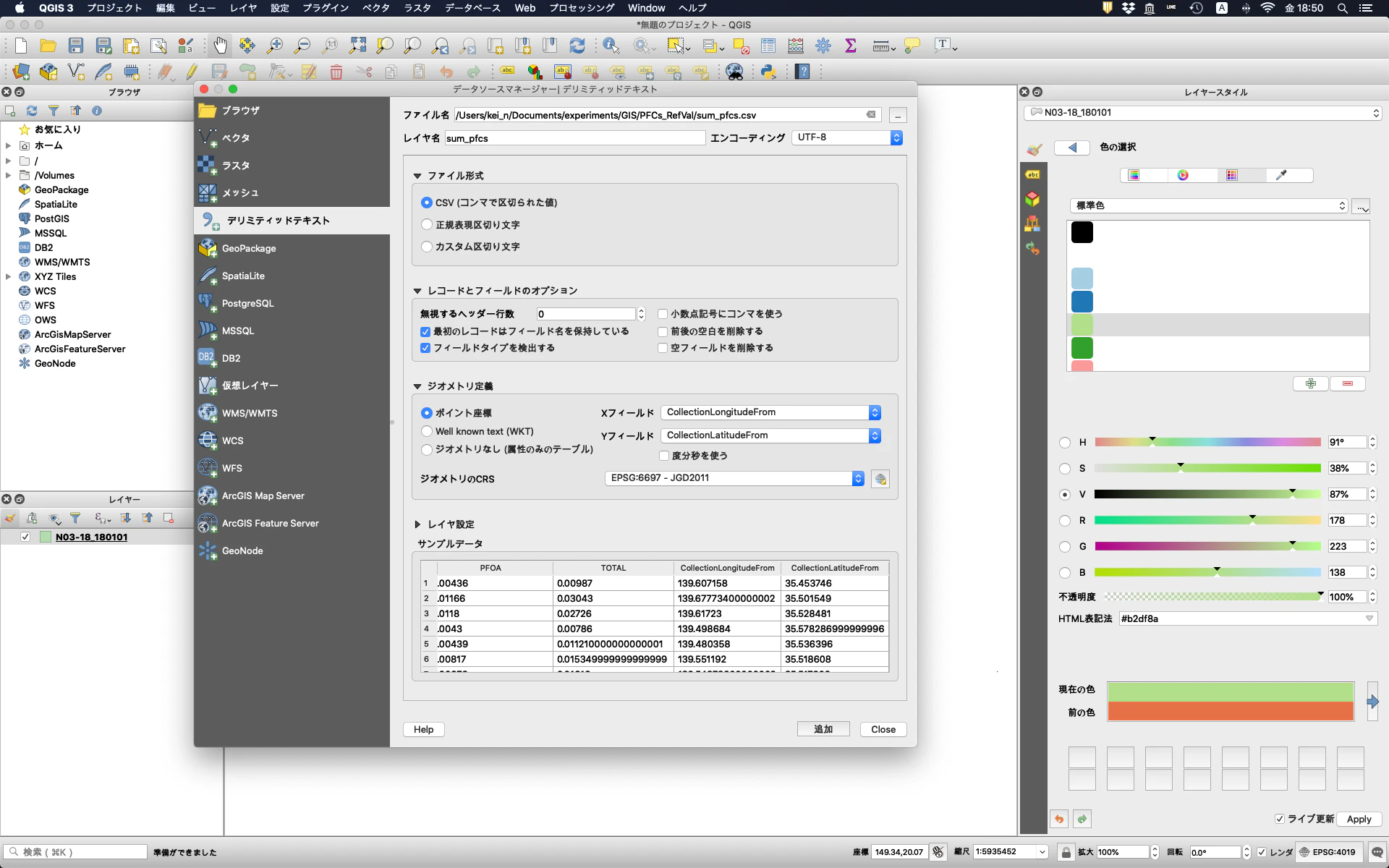
再び,データソースマネージャーからデリミティッドテキストのタブをクリックし,先のセクションで作成したCSVファイル(sum_pfcs.csv)を選択する。その後に,ジオメトリ定義のXフィールドに経度(CollectionLongitudeFrom)を,Yフィールドに緯度(CollectionLatitudeFrom)を選択し,「追加」をクリックする。
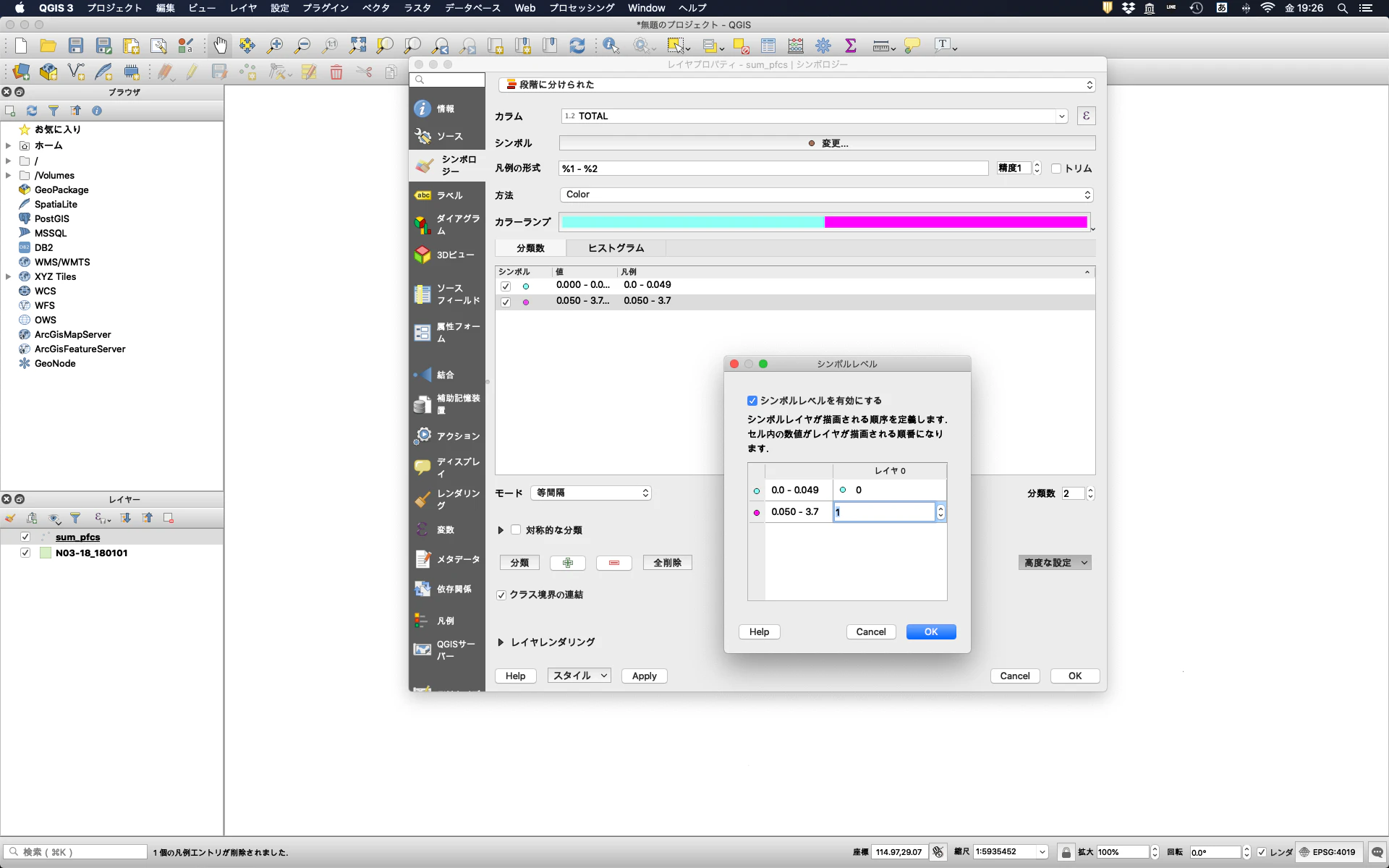
すると,サンプリング地点が地図上にプロットされる。次に,濃度で色分けをする。レイヤーから「sum_pfcs」をダブルクリックするとレイヤプロパティが開くので,シンボロジーのタブを選択する。シンボルは「段階に分けられた」を選び,PFOS+PFOAの濃度で色分けしたいので,カラムには「TOTAL」を選択する。シンボルはお好みで変更する。モードを等間隔のまま,分類数を変更すると,自動で等間隔の分類が出力される。ここでは,分類数を2にして,小さい数値のグループの値を0 - 0.05とする。(ChemTHEATREでは水中の化学物質濃度はµg/Lで統一されているので,50 ng/Lの基準値を超えるか超えないかで色分けしたい場合は,0.05とする必要がある。)デフォルトだと,高濃度のプロットが下層に表示されてしまうので,「高度な設定」から「シンボルレベル」を選択し,シンボルレベルを有効にするのチェックボックスにチェックを入れ,高濃度グループのレイヤを1に設定する。
その結果,PFOS+PFOAが50 ng/Lを超過する地点と超過しない地点が色分けされて表示される。この図を出力したい場合は,「プロジェクト」から「インポート/エクスポート」を選び,「地図を画像にエクスポート」あるいは「地図をPDFにエクスポート」を選択し,クリップボードにコピーするか,任意のディレクトリにファイルとして保存する。
いかがでしょう?出来ましたでしょうか?
このようにして,ChemTHEATREに収録されたデータを地図上に表現するなどして活用していただければ幸いです。

- 投稿日:2020-06-19T19:48:17+09:00
DeepLabでSemantic Segmentationやーる(Windows10、Python3.6)
はじめに
DeepLabのセマンティックセグメンテーションをやっていきます
システム環境
- Windows10(RTX2080 Max-Q、i7-8750H、RAM16GB)
- Anaconda 2020.02
- Python 3.6
- CUDA Toolkit v10.0
導入
modelsをクローンします。
DeepLabはresearch/deeplabにあります。deeplab_demo.ipynbを実行してみましょう。まずは、deeplab環境を作成します。
CUDA Toolkit v10.0をインストールしてください。cudart64_100.dllが必要です。anaconda create -n deeplab python=3.6 conda activate deeplab pip install jupyter pip install matplotlib pip install pillow pip install tensorflow-gpu==1.15jupyter notebookを開きます。
cd models-master/research/deeplab jupyter notebookdeeplab_demo.ipynbを開きます。上から順番に実行していきましょう。
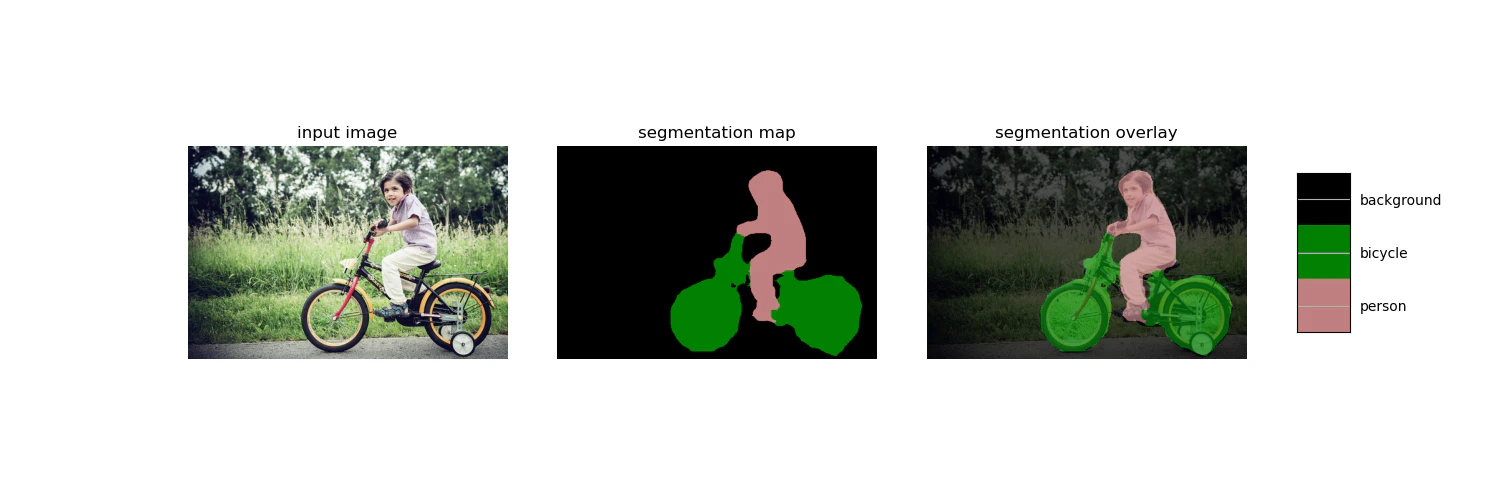
最初のセルの%tensorflow_version 1.x はエラーが出たので、コメントアウトしました。import os from io import BytesIO import tarfile import tempfile from six.moves import urllib from matplotlib import gridspec from matplotlib import pyplot as plt import numpy as np from PIL import Image # %tensorflow_version 1.x import tensorflow as tf実行結果はこちらです。
プログラムの部分をコピペして、deeplab_demo.pyを作成し、実行してみましょう。同じことができると思います。
ウェブカメラの映像を入力
ウェブカメラから読み込んで処理してみましょう。
描画にはOpenCVを用いるので、ライブラリをインストールします。pip install opencv-python次のプログラムを作成し、実行します。
import os from io import BytesIO import tarfile import tempfile from six.moves import urllib from matplotlib import gridspec from matplotlib import pyplot as plt import numpy as np from PIL import Image # %tensorflow_version 1.x import tensorflow as tf class DeepLabModel(object): """Class to load deeplab model and run inference.""" INPUT_TENSOR_NAME = 'ImageTensor:0' OUTPUT_TENSOR_NAME = 'SemanticPredictions:0' INPUT_SIZE = 513 FROZEN_GRAPH_NAME = 'frozen_inference_graph' def __init__(self, tarball_path): """Creates and loads pretrained deeplab model.""" self.graph = tf.Graph() graph_def = None # Extract frozen graph from tar archive. tar_file = tarfile.open(tarball_path) for tar_info in tar_file.getmembers(): if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name): file_handle = tar_file.extractfile(tar_info) graph_def = tf.GraphDef.FromString(file_handle.read()) break tar_file.close() if graph_def is None: raise RuntimeError('Cannot find inference graph in tar archive.') with self.graph.as_default(): tf.import_graph_def(graph_def, name='') self.sess = tf.Session(graph=self.graph) def run(self, image): """Runs inference on a single image. Args: image: A PIL.Image object, raw input image. Returns: resized_image: RGB image resized from original input image. seg_map: Segmentation map of `resized_image`. """ width, height = image.size resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height) target_size = (int(resize_ratio * width), int(resize_ratio * height)) resized_image = image.convert('RGB').resize(target_size, Image.ANTIALIAS) batch_seg_map = self.sess.run( self.OUTPUT_TENSOR_NAME, feed_dict={self.INPUT_TENSOR_NAME: [np.asarray(resized_image)]}) seg_map = batch_seg_map[0] return resized_image, seg_map def create_pascal_label_colormap(): """Creates a label colormap used in PASCAL VOC segmentation benchmark. Returns: A Colormap for visualizing segmentation results. """ colormap = np.zeros((256, 3), dtype=int) ind = np.arange(256, dtype=int) for shift in reversed(range(8)): for channel in range(3): colormap[:, channel] |= ((ind >> channel) & 1) << shift ind >>= 3 return colormap def label_to_color_image(label): """Adds color defined by the dataset colormap to the label. Args: label: A 2D array with integer type, storing the segmentation label. Returns: result: A 2D array with floating type. The element of the array is the color indexed by the corresponding element in the input label to the PASCAL color map. Raises: ValueError: If label is not of rank 2 or its value is larger than color map maximum entry. """ if label.ndim != 2: raise ValueError('Expect 2-D input label') colormap = create_pascal_label_colormap() if np.max(label) >= len(colormap): raise ValueError('label value too large.') return colormap[label] def vis_segmentation(image, seg_map): """Visualizes input image, segmentation map and overlay view.""" plt.figure(figsize=(15, 5)) grid_spec = gridspec.GridSpec(1, 4, width_ratios=[6, 6, 6, 1]) plt.subplot(grid_spec[0]) plt.imshow(image) plt.axis('off') plt.title('input image') plt.subplot(grid_spec[1]) seg_image = label_to_color_image(seg_map).astype(np.uint8) plt.imshow(seg_image) plt.axis('off') plt.title('segmentation map') plt.subplot(grid_spec[2]) plt.imshow(image) plt.imshow(seg_image, alpha=0.7) plt.axis('off') plt.title('segmentation overlay') unique_labels = np.unique(seg_map) ax = plt.subplot(grid_spec[3]) plt.imshow( FULL_COLOR_MAP[unique_labels].astype(np.uint8), interpolation='nearest') ax.yaxis.tick_right() plt.yticks(range(len(unique_labels)), LABEL_NAMES[unique_labels]) plt.xticks([], []) ax.tick_params(width=0.0) plt.grid('off') plt.show() LABEL_NAMES = np.asarray([ 'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv' ]) FULL_LABEL_MAP = np.arange(len(LABEL_NAMES)).reshape(len(LABEL_NAMES), 1) FULL_COLOR_MAP = label_to_color_image(FULL_LABEL_MAP) # @param ['mobilenetv2_coco_voctrainaug', 'mobilenetv2_coco_voctrainval', 'xception_coco_voctrainaug', 'xception_coco_voctrainval'] MODEL_NAME = 'mobilenetv2_coco_voctrainaug' _DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/' _MODEL_URLS = { 'mobilenetv2_coco_voctrainaug': 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz', 'mobilenetv2_coco_voctrainval': 'deeplabv3_mnv2_pascal_trainval_2018_01_29.tar.gz', 'xception_coco_voctrainaug': 'deeplabv3_pascal_train_aug_2018_01_04.tar.gz', 'xception_coco_voctrainval': 'deeplabv3_pascal_trainval_2018_01_04.tar.gz', } _TARBALL_NAME = 'deeplab_model.tar.gz' model_dir = tempfile.mkdtemp() tf.gfile.MakeDirs(model_dir) download_path = os.path.join(model_dir, _TARBALL_NAME) print('downloading model, this might take a while...') urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + _MODEL_URLS[MODEL_NAME], download_path) print('download completed! loading DeepLab model...') MODEL = DeepLabModel(download_path) print('model loaded successfully!') SAMPLE_IMAGE = 'image1' # @param ['image1', 'image2', 'image3'] IMAGE_URL = '' # @param {type:"string"} _SAMPLE_URL = ('https://github.com/tensorflow/models/blob/master/research/' 'deeplab/g3doc/img/%s.jpg?raw=true') def run_visualization(url): """Inferences DeepLab model and visualizes result.""" try: f = urllib.request.urlopen(url) jpeg_str = f.read() original_im = Image.open(BytesIO(jpeg_str)) except IOError: print('Cannot retrieve image. Please check url: ' + url) return print('running deeplab on image %s...' % url) resized_im, seg_map = MODEL.run(original_im) vis_segmentation(resized_im, seg_map) # image_url = IMAGE_URL or _SAMPLE_URL % SAMPLE_IMAGE # run_visualization(image_url) import cv2 def vis_segmentation_opencv(image, seg_map): seg_image = label_to_color_image(seg_map).astype(np.uint8) unique_labels = np.unique(seg_map) return seg_image, unique_labels cap = cv2.VideoCapture(0) while True: ret, frame = cap.read() if ret: resized_im, seg_map = MODEL.run( Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))) seg_image, unique_labels = vis_segmentation_opencv(resized_im, seg_map) seg_image_ = np.array(seg_image, dtype=np.uint8) h, w, ch = frame.shape resized_seg_im = cv2.resize(seg_image_, (w, h), interpolation=cv2.INTER_NEAREST) output = (0.4*resized_seg_im + 0.6*frame).astype("uint8") cv2.imshow('output', output) if cv2.waitKey(1) & 0xFF == ord('q'): break else: cap.set(cv2.CAP_PROP_POS_FRAMES, 0)結果はこちらになります。
DeepLabによるSemantic Segmentation #DeepLab #CV #Python #OpenCV pic.twitter.com/XBF0pdzB9E
— 藤本賢志(ガチ本)@pixivFANBOXはじめました (@sotongshi) June 19, 2020お疲れ様でした。
- 投稿日:2020-06-19T19:48:17+09:00
DeepLabのSemantic Segmentationやーる(Windows10、Python3.6)
はじめに
DeepLabのセマンティックセグメンテーションをやっていきます
システム環境
- Windows10(RTX2080 Max-Q、i7-8750H、RAM16GB)
- Anaconda 2020.02
- Python 3.6
- CUDA Toolkit v10.0
導入
modelsをクローンします。
DeepLabはresearch/deeplabにあります。deeplab_demo.ipynbを実行してみましょう。まずは、deeplab環境を作成します。
CUDA Toolkit v10.0をインストールしてください。cudart64_100.dllが必要です。$ anaconda create -n deeplab python=3.6 $ conda activate deeplab $ pip install jupyter $ pip install matplotlib $ pip install pillow $ pip install tensorflow-gpu==1.15jupyter notebookを開きます。
$ cd models-master/research/deeplab $ jupyter notebook出力されたURLにアクセスして、deeplab_demo.ipynbを開きます。上から順番に実行していきましょう。
最初のセルの%tensorflow_version 1.x はエラーが出たので、コメントアウトしました。import os from io import BytesIO import tarfile import tempfile from six.moves import urllib from matplotlib import gridspec from matplotlib import pyplot as plt import numpy as np from PIL import Image # %tensorflow_version 1.x import tensorflow as tf実行結果はこちらです。
プログラムの部分をコピペして、deeplab_demo.pyを作成し、実行してみましょう。同じことができると思います。
ウェブカメラの映像を入力
ウェブカメラから読み込んで処理してみましょう。
描画にはOpenCVを用いるので、ライブラリをインストールします。$ pip install opencv-python次のプログラムを作成し、実行します。
import os from io import BytesIO import tarfile import tempfile from six.moves import urllib from matplotlib import gridspec from matplotlib import pyplot as plt import numpy as np from PIL import Image # %tensorflow_version 1.x import tensorflow as tf class DeepLabModel(object): """Class to load deeplab model and run inference.""" INPUT_TENSOR_NAME = 'ImageTensor:0' OUTPUT_TENSOR_NAME = 'SemanticPredictions:0' INPUT_SIZE = 513 FROZEN_GRAPH_NAME = 'frozen_inference_graph' def __init__(self, tarball_path): """Creates and loads pretrained deeplab model.""" self.graph = tf.Graph() graph_def = None # Extract frozen graph from tar archive. tar_file = tarfile.open(tarball_path) for tar_info in tar_file.getmembers(): if self.FROZEN_GRAPH_NAME in os.path.basename(tar_info.name): file_handle = tar_file.extractfile(tar_info) graph_def = tf.GraphDef.FromString(file_handle.read()) break tar_file.close() if graph_def is None: raise RuntimeError('Cannot find inference graph in tar archive.') with self.graph.as_default(): tf.import_graph_def(graph_def, name='') self.sess = tf.Session(graph=self.graph) def run(self, image): """Runs inference on a single image. Args: image: A PIL.Image object, raw input image. Returns: resized_image: RGB image resized from original input image. seg_map: Segmentation map of `resized_image`. """ width, height = image.size resize_ratio = 1.0 * self.INPUT_SIZE / max(width, height) target_size = (int(resize_ratio * width), int(resize_ratio * height)) resized_image = image.convert('RGB').resize(target_size, Image.ANTIALIAS) batch_seg_map = self.sess.run( self.OUTPUT_TENSOR_NAME, feed_dict={self.INPUT_TENSOR_NAME: [np.asarray(resized_image)]}) seg_map = batch_seg_map[0] return resized_image, seg_map def create_pascal_label_colormap(): """Creates a label colormap used in PASCAL VOC segmentation benchmark. Returns: A Colormap for visualizing segmentation results. """ colormap = np.zeros((256, 3), dtype=int) ind = np.arange(256, dtype=int) for shift in reversed(range(8)): for channel in range(3): colormap[:, channel] |= ((ind >> channel) & 1) << shift ind >>= 3 return colormap def label_to_color_image(label): """Adds color defined by the dataset colormap to the label. Args: label: A 2D array with integer type, storing the segmentation label. Returns: result: A 2D array with floating type. The element of the array is the color indexed by the corresponding element in the input label to the PASCAL color map. Raises: ValueError: If label is not of rank 2 or its value is larger than color map maximum entry. """ if label.ndim != 2: raise ValueError('Expect 2-D input label') colormap = create_pascal_label_colormap() if np.max(label) >= len(colormap): raise ValueError('label value too large.') return colormap[label] def vis_segmentation(image, seg_map): """Visualizes input image, segmentation map and overlay view.""" plt.figure(figsize=(15, 5)) grid_spec = gridspec.GridSpec(1, 4, width_ratios=[6, 6, 6, 1]) plt.subplot(grid_spec[0]) plt.imshow(image) plt.axis('off') plt.title('input image') plt.subplot(grid_spec[1]) seg_image = label_to_color_image(seg_map).astype(np.uint8) plt.imshow(seg_image) plt.axis('off') plt.title('segmentation map') plt.subplot(grid_spec[2]) plt.imshow(image) plt.imshow(seg_image, alpha=0.7) plt.axis('off') plt.title('segmentation overlay') unique_labels = np.unique(seg_map) ax = plt.subplot(grid_spec[3]) plt.imshow( FULL_COLOR_MAP[unique_labels].astype(np.uint8), interpolation='nearest') ax.yaxis.tick_right() plt.yticks(range(len(unique_labels)), LABEL_NAMES[unique_labels]) plt.xticks([], []) ax.tick_params(width=0.0) plt.grid('off') plt.show() LABEL_NAMES = np.asarray([ 'background', 'aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tv' ]) FULL_LABEL_MAP = np.arange(len(LABEL_NAMES)).reshape(len(LABEL_NAMES), 1) FULL_COLOR_MAP = label_to_color_image(FULL_LABEL_MAP) # @param ['mobilenetv2_coco_voctrainaug', 'mobilenetv2_coco_voctrainval', 'xception_coco_voctrainaug', 'xception_coco_voctrainval'] MODEL_NAME = 'mobilenetv2_coco_voctrainaug' _DOWNLOAD_URL_PREFIX = 'http://download.tensorflow.org/models/' _MODEL_URLS = { 'mobilenetv2_coco_voctrainaug': 'deeplabv3_mnv2_pascal_train_aug_2018_01_29.tar.gz', 'mobilenetv2_coco_voctrainval': 'deeplabv3_mnv2_pascal_trainval_2018_01_29.tar.gz', 'xception_coco_voctrainaug': 'deeplabv3_pascal_train_aug_2018_01_04.tar.gz', 'xception_coco_voctrainval': 'deeplabv3_pascal_trainval_2018_01_04.tar.gz', } _TARBALL_NAME = 'deeplab_model.tar.gz' model_dir = tempfile.mkdtemp() tf.gfile.MakeDirs(model_dir) download_path = os.path.join(model_dir, _TARBALL_NAME) print('downloading model, this might take a while...') urllib.request.urlretrieve(_DOWNLOAD_URL_PREFIX + _MODEL_URLS[MODEL_NAME], download_path) print('download completed! loading DeepLab model...') MODEL = DeepLabModel(download_path) print('model loaded successfully!') SAMPLE_IMAGE = 'image1' # @param ['image1', 'image2', 'image3'] IMAGE_URL = '' # @param {type:"string"} _SAMPLE_URL = ('https://github.com/tensorflow/models/blob/master/research/' 'deeplab/g3doc/img/%s.jpg?raw=true') def run_visualization(url): """Inferences DeepLab model and visualizes result.""" try: f = urllib.request.urlopen(url) jpeg_str = f.read() original_im = Image.open(BytesIO(jpeg_str)) except IOError: print('Cannot retrieve image. Please check url: ' + url) return print('running deeplab on image %s...' % url) resized_im, seg_map = MODEL.run(original_im) vis_segmentation(resized_im, seg_map) # image_url = IMAGE_URL or _SAMPLE_URL % SAMPLE_IMAGE # run_visualization(image_url) import cv2 def vis_segmentation_opencv(image, seg_map): seg_image = label_to_color_image(seg_map).astype(np.uint8) unique_labels = np.unique(seg_map) return seg_image, unique_labels cap = cv2.VideoCapture(0) while True: ret, frame = cap.read() if ret: resized_im, seg_map = MODEL.run( Image.fromarray(cv2.cvtColor(frame, cv2.COLOR_BGR2RGB))) seg_image, unique_labels = vis_segmentation_opencv(resized_im, seg_map) seg_image_ = np.array(seg_image, dtype=np.uint8) h, w, ch = frame.shape resized_seg_im = cv2.resize(seg_image_, (w, h), interpolation=cv2.INTER_NEAREST) output = (0.4*resized_seg_im + 0.6*frame).astype("uint8") cv2.imshow('output', output) if cv2.waitKey(1) & 0xFF == ord('q'): break else: cap.set(cv2.CAP_PROP_POS_FRAMES, 0)結果はこちらになります。
DeepLabによるSemantic Segmentation #DeepLab #CV #Python #OpenCV pic.twitter.com/XBF0pdzB9E
— 藤本賢志(ガチ本)@pixivFANBOXはじめました (@sotongshi) June 19, 2020お疲れ様でした。
- 投稿日:2020-06-19T19:33:37+09:00
AtCoderで使えるnetworkx ケーススタディ
AtCoderで使えるnetworkx ケーススタディ
2020年のAtCoder言語アップデートにより、Python 3.8環境ではnetworkxが使えるようになりました。
networkxを使うことで自前実装に比べてコードを非常に簡潔に書くことができ、強力な武器になりえます。
PAST-O これで通るのか。 networkx ずるくない? pic.twitter.com/Dvvq8a6EwG
— きり (@kiri8128) June 6, 2020一方でnetworkxはメモリ使用量・実行速度ともにふんだんに使っていく傾向があり、自前実装に比べても比較的TLE/MLEしがちであることが分かっています。
この記事ではnetworkxの基本操作についてまとめた後、どのような問題なら現実的に利用可能か確認します。
- 本文にはAtCoder過去問の解説/実装が含まれますのでご理解ください。
基本的な操作
宣言
import networkx as nx G = nx.Graph() # 単純無向グラフ DG = nx.DiGraph() # 単純有向グラフ頂点の追加
G.add_node(1) # 頂点を一つ追加 G.add_nodes_from((2, 3, 4)) # 頂点を一括で追加 G.add_nodes_from(range(1, N + 1)) # 1からNまでの頂点を一括で追加辺の追加
G.add_edge(1, 2) # 辺を一つ追加。頂点が足りなければ自動で追加される G.add_edges_from([(1, 3), (2, 4)]) # 一括で追加有向グラフの場合、$from,to$の順に入れます。
add_edges_fromを使うと、例えば以下のような入力\begin{align} &N \\ &x_1 \ \ y_1 \\ &x_2 \ \ y_2 \\ &\vdots \\ &x_N\ \ y_N \end{align}に対して、
N = int(input()) G = nx.Graph() G.add_edges_from([tuple(map(int, input().split())) for _ in range(N)])のように書くことができます。
重み付き辺の追加
G.add_edge(1, 2, weight=3) # 一つ追加するだけだとキーワード引数で指定しないとダメ G.add_weighted_edges_from([(1, 3, 10),(2, 4, 15)] # 一括で追加
add_weighted_edges_fromでは、$from,to,weight$の順に入れます。AtCoderでの標準入力は多くの場合この順番なので、そのまま[tuple(map(int, input().split())) for _ in range(N)]で入れることができますね。で、実は
add_weighted_edges_fromに限ってはtupleを外して書ける([map(int, input().split()) for _ in range(N)]とできる)ようです。これが仕様なのかちょっとよく分かっていないので情報お待ちしています。辺・頂点の列挙
for n in G.nodes(): # 頂点n print(n) for x, y in G.edges(): # 辺(x,y) print(x, y) for x, y, d in G.edges(data=True): # 重み付き辺がいる場合。dは辞書なので注意 weight = d['weight'] print(x, y, weight)基本的な操作の速度検証
AtCoderコードテスト環境での検証です。
インポート
import networkx as nx標準入力:なし
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ 実行速度 $\mathrm{330\ ms}$ $\mathrm{312\ ms}$ $\mathrm{314\ ms}$ $\mathrm{321\ ms}$ $\mathrm{312\ ms}$ $\mathrm{318\ ms}$ $\mathrm{330\ ms}$ $\mathrm{318\ ms}$ $\mathrm{313\ ms}$ $\mathrm{309\ ms}$
import numpy as npも時間がかかることで有名ですが、それでも$0.1 \sec$とかなのでこれは大変に遅いです。インポート+宣言
import networkx as nx G = nx.Graph()標準入力:なし
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ 実行速度 $\mathrm{336\ ms}$ $\mathrm{315\ ms}$ $\mathrm{331\ ms}$ $\mathrm{315\ ms}$ $\mathrm{316\ ms}$ $\mathrm{318\ ms}$ $\mathrm{315\ ms}$ $\mathrm{315\ ms}$ $\mathrm{335\ ms}$ $\mathrm{314\ ms}$
Digraphでもやりましたがほとんど同じ感じでした。誤差といっていいと思います。インポート+宣言+頂点追加
頂点数$N=2 \times 10^5$で試します。ダイクストラ法などで一般的な制約だと思います。
import networkx as nx N = 2 * 10 ** 5 G = nx.DiGraph() G.add_nodes_from(range(1, N + 1))標準入力:なし
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ 実行速度 $\mathrm{606\ ms}$ $\mathrm{612\ ms}$ $\mathrm{604\ ms}$ $\mathrm{605\ ms}$ $\mathrm{612\ ms}$ $\mathrm{627\ ms}$ $\mathrm{625\ ms}$ $\mathrm{606\ ms}$ $\mathrm{610\ ms}$ $\mathrm{597\ ms}$ 頂点の追加は$10^5$個あたり$\mathrm{150\ ms}$程度とみてよさそうです。頂点数が$2 \times 10^5$になると頂点をつけるまでのだけで$\mathrm{500\ ms}$強ですから馬鹿にできません。
インポート+宣言+頂点追加+辺追加
頂点数$N=2 \times 10^5$、辺数$M=2 \times 10^5 - 1$の直線グラフで試します(もうちょい複雑なグラフの方がいいかもしれませんが生成が面倒なので)。
import networkx as nx N = 2 * 10 ** 5 E = [(i, i + 1) for i in range(1, N)] G = nx.Graph() G.add_nodes_from(range(1, N + 1)) G.add_edges_from(E)標準入力:なし
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ 実行速度 $\mathrm{904\ ms}$ $\mathrm{878\ ms}$ $\mathrm{913\ ms}$ $\mathrm{911\ ms}$ $\mathrm{907\ ms}$ $\mathrm{910\ ms}$ $\mathrm{880\ ms}$ $\mathrm{882\ ms}$ $\mathrm{885\ ms}$ $\mathrm{896\ ms}$ 辺の追加は$10^5$本あたり$\mathrm{150\ ms}$程度とみてよさそうです。実行時間 $2 \sec$の問題ならすでに半分を使い切ってしまいました。
ところで、networkxにはグラフに辺をつけるとき頂点がなければ自動で追加する機能があります。これを利用するとコード量は減りますが、実行時間はどうなるでしょうか。
import networkx as nx N = 2 * 10 ** 5 E = [(i, i + 1) for i in range(1, N)] G = nx.Graph() G.add_edges_from(E)標準入力:なし
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ 実行速度 $\mathrm{1018\ ms}$ $\mathrm{1014\ ms}$ $\mathrm{1025\ ms}$ $\mathrm{1029\ ms}$ $\mathrm{1056\ ms}$ $\mathrm{1005\ ms}$ $\mathrm{1002\ ms}$ $\mathrm{1025\ ms}$ $\mathrm{1022\ ms}$ $\mathrm{1046\ ms}$ 頂点はさぼらず最初に追加しておいた方がよいですね。
インポート+宣言+頂点追加+重み付き辺追加
頂点数$N=2 \times 10^5$、辺数$M=2 \times 10^5 - 1$、重みはすべて$2$の直線グラフで試します。
import networkx as nx N = 2 * 10 ** 5 E = [(i, i + 1, 2) for i in range(1, N)] G = nx.Graph() G.add_nodes_from(range(1, N + 1)) G.add_weighted_edges_from(E)標準入力:なし
① ② ③ ④ ⑤ ⑥ ⑦ ⑧ ⑨ ⑩ 実行速度 $\mathrm{932\ ms}$ $\mathrm{953\ ms}$ $\mathrm{937\ ms}$ $\mathrm{908\ ms}$ $\mathrm{905\ ms}$ $\mathrm{931\ ms}$ $\mathrm{898\ ms}$ $\mathrm{960\ ms}$ $\mathrm{923\ ms}$ $\mathrm{902\ ms}$ 重み付き辺の追加は$10^5$本あたり$\mathrm{170\ ms}$程度でした。
このように、networkxのグラフは生成が重いため、頂点数の巨大な問題はそれだけでかなり困難さが増しそうです。頂点数・辺数が小さい問題での利用が確実性が高いと思います。
単純グラフ
ダイクストラ法
ABC035 D - トレジャーハント
問題概要
$N$ 頂点 $M$ 辺の重み付き有向グラフが与えられます。ここでグラフの重みは、その辺を移動するのにかかる所要時間です。
頂点$i$に居ると毎分$A_i$円もらえます。時刻$0$に頂点$1$を出発し、時刻$T$には戻ってきている時所持金を最大化してください。
頂点数 $N$ 辺数 $M$ TL ML 提出例 提出解の時間計算量 実行結果 $10^5$ $\min(N(N-1)/2,10^5)$ $3 \sec$ $256\ \mathrm{MB}$ networkx① $O((N+M)\log N)$ MLE ($\mathrm{2729\ ms}$) networkx② 同上 $\mathrm{1474\ ms}$ scipy 同上 $\mathrm{603\ ms}$
解法概要
滞在する頂点は1つでよいので、各頂点$i$に対して$1 \to i \to 1$と移動したときの頂点$i$に居られる時間を求めることで、どの頂点を目指すのが最適か分かります。
頂点$i$に居られる時間は、$T-(往路1\to iの所要時間)-(復路i \to 1の所要時間)$です。往路の所要時間は頂点$1$始点のダイクストラ法で、復路の所要時間は有向辺の向きを逆にしたグラフにおける頂点$1$始点のダイクストラ法で求められるので、どちらも$O((N+M)\log N)$が実現できます。
実装
有向グラフなので
nx.DiGraph()を使います。有向辺の向きを逆にしたグラフの生成には、DiGraph.reverseというおあつらえ向きの関数があったのでそれを使います。次にダイクストラ法パートです。一口にダイクストラ法といっても色々な関数があるので是非公式リファレンスを見ていただきたいのですが、今回は「起点1つ、終点は全頂点、経路の構築不要」なので
single_source_dijkstra_path_lengthを使いました。import networkx as nx N, M, T = map(int, input().split()) A = tuple(map(int, input().split())) G = nx.DiGraph() G.add_nodes_from(range(1, N + 1)) G.add_weighted_edges_from([map(int, input().split()) for _ in range(M)]) G_inv = G.reverse() # 有向辺の向きを逆にしたグラフを生成 L = nx.single_source_dijkstra_path_length(G, 1) # {頂点名: 距離} の辞書型で返される L_inv = nx.single_source_dijkstra_path_length(G_inv, 1) ans = 0 for i in range(1, N + 1): # 頂点1と目標の頂点とが連結の場合のみkeyがある if i in L and i in L_inv: ans = max(ans, (T - L[i] - L_inv[i]) * A[i - 1]) print(ans)で、これを提出したのが提出例のnetworkx①ですが、MLEしました。
ここで工夫をします。先ほど
DiGraph.reverseという関数を使って有向辺の向きを逆転させたグラフをつくりましたが、この関数のキーワード引数をcopy=Falseとすることでグラフのビューを作るようになり再生成を避けられることが分かりました。これをやります。# 前略 G = nx.DiGraph() G.add_nodes_from(range(1, N + 1)) G.add_weighted_edges_from([map(int, input().split()) for _ in range(M)]) L = nx.single_source_dijkstra_path_length(G, 1) G_inv = G.reverse(copy=False) # ここを変更。ついでに往路のdijkstra法実行は前に持っていった L_inv = nx.single_source_dijkstra_path_length(G_inv, 1) # 後略これで、メモリ使用量だけでなくなんと実行時間も$1/2$近くなりました。
実行時間
頂点・辺が付与されたグラフをなるべく減らす・サイズを小さくすることがミソのようです。
しかしダイクストラ法に関してはscipyにもありますし、場合によっては自前実装したほうが高速で確実というケースもあるようです。一般的なグラフの問題でわざわざnetworkxのダイクストラ法メゾットを使う必要があるかは、微妙と言わざるを得ないと思います。
フロイドワーシャル法
ABC051 D - Candidates of No Shortest Paths
問題概要
$N$ 頂点 $M$ 辺の重み付き単純無向連結グラフが与えられます。どの異なる 2 頂点間の、どの最短経路にも含まれない辺の数を求めてください。
頂点数 $N$ 辺数 $M$ TL ML 提出例 提出解の時間計算量 実行結果 $100$ $\min(N(N-1)/2,1000)$ $2 \sec$ $256\ \mathrm{MB}$ networkx $O(N^3+MN^2)$ $\mathrm{1751\ ms}$
解法概要
まず全頂点間の最短経路長をフロイドワーシャル法で求めます。次に、各辺$(i,j)$に対して、
dist(s,i)+edge(i,j)+dist(j,t)=dist(s,j)を満たす$(s,t)$がないか全探索します(ただし$dist$は二点間の距離、$edge$は辺の長さを表す)。もし存在すれば、辺$(i,j)$はこの$(s,t)$間の最短経路に含まれます。
実装
無向グラフなので
nx.Graph()を使います。フロイドワーシャル法の関数もいくつかありますが(公式リファレンス)、ここは普通の
floyd_warshall関数を使います。次に辺と頂点を全探索するわけですが、列挙も下にある通りそれっぽい感じで上手くいきます。
(networkxとは関係ないですが、
itertools.combinationsはこの場合$N$頂点のうちから$2$頂点を順不同で選ぶ組み合わせを全列挙します)import networkx as nx import itertools N, M = map(int, input().split()) G = nx.Graph() G.add_nodes_from(range(1, N + 1)) G.add_weighted_edges_from([map(int, input().split()) for _ in range(M)]) S = nx.floyd_warshall(G) ans = M for i, j, d in G.edges(data=True): for s, t in itertools.combinations(G.nodes(), 2): if S[s][i] + d['weight'] + S[j][t] == S[s][t]: ans -= 1 break print(ans)実行時間
こちらも$10^6$くらいの計算回数があるわけですが、ギリギリ間に合っています。
あと本問に関しては、editorialによると全探索パートを高速化することができるらしいので、高速化するともう少しマシな実行時間になると思います。
その他
ABC075 C - Bridge
問題概要
$N$ 頂点 $M$ 辺の単純無向連結グラフが与えられます。与えられた $M$本のうち橋である辺の本数を求めてください。
頂点数 $N$ 辺数 $M$ TL ML 提出例 提出解の時間計算量 実行結果 $50$ $\min(N(N-1)/2,50)$ $2 \sec$ $256\ \mathrm{MB}$ networkx $O(N+M)$1 $\mathrm{337\ ms}$
実装
橋を列挙する関数があったので(!)、それを貼ります。
import networkx as nx N, M = map(int, input().split()) G = nx.Graph() G.add_nodes_from(range(1, N + 1)) G.add_edges_from([tuple(map(int, input().split())) for _ in range(M)]) print(len(tuple(nx.bridges(G))))# nx.bridges……橋となる辺をイテレータとして返す実行時間
想定解が$O(M(N+M))$だったようで、充分な時間で間に合っています(本当に
nx.bridgeの時間計算量が$O(N+M)$なのか怪しい気もしますが……)。さすがに今後こういう貼るだけが出ることはないでしょう。
グリッドグラフ
グリッドグラフを生成する関数として
nx.grid_graphが、特に二次元グリッドグラフを生成する関数としてnx.grid_2d_graphがあります。
nx.grid_2d_graphを使ってグラフを生成した場合、グラフの頂点名は自然に$(h,w)$のtupleになります。頂点名をこのようなtupleにできるのはとても扱いやすくて良さそうです。ABC020 C - 壁抜け
問題概要
$H \times W$のグリッド状に並んでいるマス上で、スタートからゴールまで行きたいです。マスには白マス(スタート・ゴールを含む)と黒マスがあり、白マスに入るには$1$秒、黒マスに入るには$x$秒かかります($x$はこちらが指定できます)。$T$秒以内にゴールにたどり着けるような$x$の最大値を求めてください。
頂点数 $N(=H \times W)$ 辺数 $M(=2H(W-1)+2(H-1)W)$ TL ML 提出例 提出解の時間計算量 実行時間 $100$ $180$ $2 \sec$ $256\ \mathrm{MB}$ networkx $O((N+M)\log N \log T)$ $\mathrm{374\ ms}$ scipy 同上 $\mathrm{193\ ms}$
解法概要
二分探索により$x$の最大値を探ります。$x$が固定されていれば、何秒でたどり着けるかはダイクストラ法により判定できます。
実装
nx.grid_graphで生成したグラフの辺には重みが登録されていません。重みが登録されていない辺は自動的に重み$1$としてダイクストラ法メゾットが実行されることを利用し、重み$x$の辺だけに重みを登録していきます。import networkx as nx H, W, T = map(int, input().split()) S = [input() for _ in range(H)] for h in range(H): for w in range(W): if S[h][w] == 'S': start = (h, w) elif S[h][w] == 'G': goal = (h, w) def canArrive(x): '''判定関数 ''' G = nx.DiGraph(nx.grid_2d_graph(H, W)) for h in range(H): for w in range(W): # 黒に入る辺の重みをxに変更 if S[h][w] == '#': for dh, dw in ((1, 0), (0, 1), (-1, 0), (0, -1)): if 0 <= h - dh < H and 0 <= w - dw < W: G[(h - dh, w - dw)][(h, w)]['weight'] = x return nx.dijkstra_path_length(G, start, goal) <= T # 二分探索 l, r = 1, 10 ** 9 while r - l > 1: m = (l + r) // 2 if canArrive(m): l = m else: r = m print(l)実行時間
こちらは$10^3$~$10^4$くらいの計算回数で、そもそもかなり実行時間がゆるいといえます。何回もグリッドグラフを生成するのでもしかしたら厳しいかな?とも思っていたのですが、頂点数が少ないのでなんとかなったという感じでしょうか。
ABC151 D - Maze Master
問題概要
$H \times W$のグリッド状に並んでいるマス上で、”道”のマスだけを通ってスタートからゴールまで最短経路で行きます。このような最短経路が最も長くなるようなスタートからゴールを探し、その道のりの長さを求めてください。
頂点数 $N(=H \times W)$ 辺数 $M(=2H(W-1)+2(H-1)W)$ TL ML 提出例 提出解の時間計算量 実行時間 $400$ $1520$ $2 \sec$ $1024\ \mathrm{MB}$ networkx① $O(N^2)$ $\mathrm{520\ ms}$ networkx② 同上 $\mathrm{520\ ms}$ 素Python 同上 $\mathrm{362\ ms}$
解法概要
各始点についてbfsをしてそれぞれ最も遠い点を探します。
実装
グリッドグラフから”壁”に入る辺を削除する実装にしてみました。
BFS用の関数
nx.bfs_edges()があったので使います。使いどころは限られるかもしれませんが、そこそこ便利です。import networkx as nx H, W = map(int, input().split()) maze = [input() for _ in range(H)] G = nx.grid_2d_graph(H, W) for h in range(H): for w in range(W): # 壁に入る辺を削除 if maze[h][w] == '#': for dh, dw in ((1, 0), (0, 1), (-1, 0), (0, -1)): if ((h - dh, w - dw), (h, w)) in G.edges(): G.remove_edge((h - dh, w - dw), (h, w)) def bfs(sy, sx): d = dict() d[(sy, sx)] = 0 for coordinate_from, coordinate_to in nx.bfs_edges(G, (sy, sx)): d[coordinate_to] = d[coordinate_from] + 1 return max(d.values()) ans = 0 for y in range(H): for x in range(W): if maze[y][x] == '.': ans = max(ans, bfs(y, x)) print(ans)実行時間
こちらは$10^5$くらいの計算回数です。グラフも小さいですし、十分通りますね。
上にコードを載せたのは提出例のnetworkx①です。
nx.grid_2d_graphを紹介したかったのでこういう実装になりましたが、普通に"道"どうしをつなぐ辺を加えていく実装でもよいです( networkx② )。②の方が実行速度は速くなるかな?と思っていましたがほぼ同じでした。木
ABC138 D - Ki
問題概要
$N$頂点の木が与えられます。根は頂点$1$とします。各頂点にカウンターがあり、はじめはカウンターの値は全ての頂点で$0$です。
以下の$Q$回のクエリを実行します。
- ある頂点$p_j$を根とする部分木に含まれるすべての頂点にあるカウンターに$x_j$を足す。
全てのクエリが終わった時、各頂点のカウンターの値を求めてください。
頂点数 $N$ TL ML 提出例 提出解の時間計算量 実行時間 $2 \times 10^5$ $2 \sec$ $1024\ \mathrm{MB}$ networkx $O(Q+N)$ TLE 素Python 同上 $\mathrm{1287\ ms}$
解法概要
累積和です。
実装
頂点をたどる順序は多分なんでもいいんですが、今回はDFS順にします。DFS用の関数
nx.dfs_edgesを使ってイテレートし、累積和をとっていきます。import networkx as nx int1 = lambda x: int(x) - 1 # 0-indexedに直す関数 N, Q = map(int, input().split()) G = nx.Graph() G.add_nodes_from(range(N)) G.add_edges_from([tuple(map(int1, input().split())) for _ in range(N - 1)]) lst = [0] * N for _ in range(Q): p, x = map(int, input().split()) lst[p - 1] += x # 累積和 for parent, child in nx.dfs_edges(G, 0): lst[child] += lst[parent] print(*lst)実行時間
頂点数が$2 \times 10^5$と巨大なので、やはり厳しかったようです。Pythonでも$1 \sec$かかっています。
ABC133 E - Virus Tree
問題概要
$N$頂点の木が与えられます。$K$色までの色を使って下記を満たすように木の頂点を塗り分けるとき、塗分け方を数え上げて$10^9+7$で割った余りを答えてください。
- 二つの異なる頂点 $x,y$間の距離が $2$ 以下ならば、頂点 $x$ の色と頂点 $y$ の色は異なる。
頂点数 $N$ TL ML 提出例 提出解の時間計算量 実行時間 $10^5$ $2 \sec$ $1024\ \mathrm{MB}$ networkx $O(N)$ $\mathrm{1588\ ms}$ 素Python 同上 $\mathrm{592\ ms}$
解法概要
適当に根を決めて根付き木とみなしたとき、各頂点$x$に対して以下が成り立ちます。
- 頂点$x$の子の数を$c_x$と置くと、子の塗分け方は${K-2}P{c_x}$通り。
あとは根に親がないことに注意して実装します。
実装
これもDFS順でたどってみます。
nx.degree()で各頂点の頂点名と次数とが対応した辞書が手に入ります。import networkx as nx int1 = lambda x: int(x) - 1 MOD = 10 ** 9 + 7 N, K = map(int, input().split()) G = nx.Graph() G.add_nodes_from(range(N)) G.add_edges_from([tuple(map(int1, input().split())) for _ in range(N - 1)]) deg = nx.degree(G) ans = K for i in range(deg[0]): ans = (ans * (K - i - 1)) % MOD for parent, child in nx.dfs_edges(G, 0): for i in range(deg[child] - 1): ans = (ans * (K - i - 2)) % MOD print(ans)実行速度
これもヤバいかなと思っていましたが、案外TLEしませんでした。
おわりに
結論としては、
- 自前実装より早くなることはまずない
- $O(N),O(N \log N)$は頂点数$10^5$、$O(N^3)$は頂点数$100$くらいが限界
といったところでしょうか。コンテストで使うとしたら、実行時間にゆとりがありそうだと見切った時に、実装を簡潔にするために使うくらいの付き合い方になるかなと感じました。高速化テクが発明されることを願っています。
- 投稿日:2020-06-19T18:16:25+09:00
結局pythonの可視化ツールはどれが人気なのか?
あらすじ
matplotlib使いの僕,他の可視化ツールに興味をもつ.
いろいろ調べてみると,インタラクティブに操作できるツールがたくさんあるっぽい.
例えば,
Pythonの可視化ツールはHoloViewsが標準になるかもしれない
Jupyter-notebook の作図ライブラリ比較
Pythonでボケ(Bokeh)よう ~ データ可視化ライブラリの紹介 ~など.では結局どれを使えばいいんだよ,という話ですが,現時点で多くの人が使っているもの,もしくは人気急上昇中のものを使っとけば問題ないでしょう,という考えを基に,それぞれの人気度を比較します.
人気ものを使うことには,エラーが起きてもググればたいていは問題解決できること,おそらく今後もアップデートされ続けるだろう,というメリットがあります.方法
googleトレンドを用いる.
調べるのは以下の5つ.説明には上記記事たちを参考にしました.
- matplotlib (王道中の王道のグラフ描画ライブラリ)
- Bokeh (ぼけ,と読むらしい.インタラクティブなデータ可視化ライブラリ)
- Plotly (こちらもインタラクティブに動かせる)
- HoloViews (matplotlibやBokehなどの可視化ツールを使いやすくしたラッパ,とのこと,シンプルさを売りにしている)
- Pygal (公式ドキュメントによると”Sexy python charting”ができる.某政治家を思い出すね.)
結果
見てください,圧倒的なmatplotlibの人気!
なんというか,予想どおりでしたね.
では,matplotlib以外だとどうでしょうか.
plotlyが人気ということでした.
bokehもなかなか人気が衰えていないですね.
HoloView,Pygalはそれらと比較してもまだまだ人気はない,という印象です.まとめ
1,matplotlibがやはり人気
2,インタラクティブなグラフを作りたいなら,plotlyが人気,次点でBokeh自分が好きなツール,目的にあったツールを使うのが一番良いと思いますが,どれが人気かという観点からは,以上のような結果になりました.
以下は自分のメモ用なのですが,plotlyの参考になるページをまとめてみました.公式ドキュメント
→ざっと見ただけでも,何ができるかがわかる,なんかいろいろ動いてて面白そう[Python] Plotlyでぐりぐり動かせるグラフを作る
→基本的な使い方をまとめてくれている印象.最終更新日から1年以上が経過している記事なので,今も参考になるかは不明[Python] Plotlyで標高データを球面に描画し、グルグル回せる地球儀を描いてみる
→はえ~~~,ってなる.さいごに
ないとは思いますが,googleトレンドの利用規約に反してる等ありましたらお知らせください
また,ざっと調べたことをまとめただけなので,きちんと裏はとっていません.間違いありましたらご指摘ください.
googleトレンドの画像は2020年6月時点のものです.
- 投稿日:2020-06-19T17:29:33+09:00
アンケート調査データを分析してみる【第3回:形態素解析】
今回は、テキストマイニングの基本的な手法のひとつである形態素解析(文章を意味のある最小単位に分解し、意味や品詞などを判別する)について、Pythonで試してみました。
データは、以下のアンケート調査より「電子版お薬手帳を使いたい理由」に関する自由回答を使用しました。
「電子版お薬手帳に関する意識調査」を行いました
https://www.nicho.co.jp/corporate/newsrelease/11633/①まずはライブラリをインポートします。今回はMeCabを使用しました。
import MeCab from MeCab import Tagger from matplotlib import pyplot as plt from wordcloud import WordCloud②テキストファイルを読み込み、形態素解析を行うことで文章を品詞別に分解してくれます。
df = "survey3.txt" with open(df, "r", encoding="utf-8") as f: opinion = f.read() tagger = MeCab.Tagger() parse = tagger.parse(opinion) print(parse)
③ワードクラウドにより、よく使われる単語を視覚的に表現できます。今回は名詞を選び、ワードクラウドを作成します。
with open('survey3.txt', mode='rt', encoding='utf-8') as fi: source_text = fi.read() tagger = MeCab.Tagger() tagger.parse('') node = tagger.parseToNode(source_text) word_list = [] while node: word_type = node.feature.split(',')[0] if word_type == '名詞': word_list.append(node.surface) node = node.next word_chain = ' '.join(word_list)matplotlibで可視化します。
W = WordCloud(width=1280, height=960, background_color='white', colormap='PuBu', font_path='C:\Windows\Fonts\yumin.ttf').generate(word_chain) plt.imshow(W) plt.axis('off') plt.show()出力されたワードクラウドを見ると「便利」や「管理」といった言葉が目立ちます。手帳を電子化することによる利便性の向上や、管理のしやすさがポイントであることが伺えます。
今回は基本的な手法として、形態素解析を実施し頻出単語を調べてみました。ここからさらに、共起分析などを行うことでより深い分析が可能になります。


- 投稿日:2020-06-19T17:14:12+09:00
[ev3dev×Python] タッチセンサ
この記事はPythonでev3を操作してみたい人のための記事です。
今回はタッチセンサを使っていろいろな操作をしていきたいと思います。目次
0 . 用意するもの
1 . タッチセンサのプログラム0.用意するもの
◯ ev3(タンク) と タッチセンサ
◯ パソコン(VSCode)
◯ bluetooth
◯ microSD
◯ 資料(これをみながら進めていくのがオススメです。)1.タッチセンサのプログラム(資料p.33)
1-0 . タッチセンサを押したら~するプログラム
touchsensor00.py#!/usr/bin/env python3 from ev3dev2.sensor.lego import TouchSensor from ev3dev2.sensor import INPUT_1,INPUT_2 from ev3dev2.sound import Sound from ev3dev2.led import Leds ts_1 = TouchSensor(INPUT_1) ts_2 = TouchSensor(INPUT_2) snd = Sound() led = Leds() while True: if ts_1.is_pressed: snd.beep() if ts_2.is_pressed: led.set_color("LEFT","YELLOW") led.set_color("RIGHT","YELLOW")Point :
タッチセンサ(ポート1)を押す度に音が鳴り,タッチセンサ(ポート2)を押す度にライトが黄色に光るプログラムPoint :
if 条件:
処理1
もし条件が真なら、処理1をするというプログラムPoint : is_pressed
A boolean indicating whether the current touch sensor is being pressed.Point : スクラッチで例えるとこんな仕組み↓
1-1 . "もし〜なら、でなければ" というプログラム
touchsensor01.py#!/usr/bin/env python3 from ev3dev2.motor import MediumMotor,OUTPUT_A from ev3dev2.sensor.lego import TouchSensor from ev3dev2.sensor import INPUT_1 M_A = MediumMotor(OUTPUT_A) ts_1 = TouchSensor(INPUT_1) while True: if ts_1.is_pressed: M_A.on(100) else: M_A.stop()Point :
タッチセンサ(ポート1)を押すとMモータが回転し、離すと止まるプログラムPoint :
if 条件:
処理1
else:
処理2もし条件が真なら、処理1をする,
偽なら処理2をする
というプログラムPoint : スクラッチで例えるとこんな仕組み↓
1-2 . ボタンを押していない間は~するプログラム
touchsensor02.py#!/usr/bin/env python3 from ev3dev2.motor import OUTPUT_A,OUTPUT_B,MoveSteering,SpeedPercent from ev3dev2.sensor.lego import TouchSensor from ev3dev2.sensor import INPUT_1 from ev3dev2.sound import Sound steering_drive = MoveSteering(OUTPUT_A,OUTPUT_B) ts_1 = TouchSensor(INPUT_1) snd = Sound() while True: while not ts_1.is_pressed: steering_drive.on(0,SpeedPercent(40)) snd.beep() steering_drive.on_for_seconds(0,SpeedPercent(-10),1) steering_drive.on_for_seconds(100,SpeedPercent(40),2)Point : 直進して、タッチセンサが押されたら音がなって、少し後ろに下がってから2秒間方向転換することを繰り返すプログラム。
Point :
while not ~:
処理1~でない間は、処理1を継続する
というプログラム1-3 . 往復運動と長押しに関するプログラム
touchsensor03.py#!/usr/bin/env python3 from ev3dev2.motor import OUTPUT_A,MediumMotor from ev3dev2.sensor.lego import TouchSensor from ev3dev2.sensor import INPUT_1 M_A = MediumMotor(OUTPUT_A) ts_1 = TouchSensor(INPUT_1) while True: ts_1.wait_for_bump() M_A.on(50) ts_1.wait_for_bump() M_A.on(-50) if not ts_1.wait_for_bump(2000): exit()Point : タッチセンサをバンプしたら回転方向が変わるプログラム。
2秒以上長押ししたらプログラムを終了する。wait_for_pressed(timeout_ms=None, sleep_ms=10)
→押されるまで待機する。
wait_for_released(timeout_ms=None, sleep_ms=10)
→離されるまで待機する。
wait_for_bump(timeout_ms=None, sleep_ms=10)
→ボタンがバンプ(押して離す)されるまで待機する。
押してから離すまでの時間制限を第1引数で設けることができるPoint : if not ts_1.wait_for_bump(2000): について。
if not タッチセンサを押してから2秒以内に離す:= if タッチセンサを押してから2秒以内に離さない
= if タッチセンサを2秒以上長押ししたら
1-4 . タッチセンサが同時に押されたら~するプログラム
touchsensor04.py#!/usr/bin/env python3 from ev3dev2.sensor.lego import TouchSensor from ev3dev2.sensor import INPUT_1,INPUT_2 from ev3dev2.sound import Sound ts_1 = TouchSensor(INPUT_1) ts_2 = TouchSensor(INPUT_2) snd = Sound() while True: if ts_1.is_pressed and ts_2.is_pressed: snd.beep()Point : タッチセンサが両方同時に押されたら音が鳴るプログラム。
Point : if文の条件式について
◯条件1が真 かつ 条件2が真のとき、処理を行う
if 条件1 and 条件2:
処理1◯条件1が真 または 条件2が真のとき、処理を行う
if 条件1 or 条件2:
処理1◯条件1が真 ではないとき、処理を行う
if not 条件1:
処理1Point : スクラッチで例えるとこんな仕組み↓
1-5 . タッチセンサ2つでラジコン操作するプログラム①
touchsensor05.py#!/usr/bin/env python3 from ev3dev2.motor import OUTPUT_A,OUTPUT_B,LargeMotor from ev3dev2.sensor.lego import TouchSensor from ev3dev2.sensor import INPUT_1,INPUT_2 L_A = LargeMotor(OUTPUT_A) L_B = LargeMotor(OUTPUT_B) ts_1 = TouchSensor(INPUT_1) ts_2 = TouchSensor(INPUT_2) while True: if ts_1.is_pressed: L_A.on(50) else: L_A.stop() if ts_2.is_pressed: L_B.on(50) else: L_B.stop()Point : タッチセンサ(1)でLモーター(A)を動かし、タッチセンサ(2)でLモーター(B)を動かすプログラム
Point : スクラッチで例えるとこんな仕組み↓
1-6 . タッチセンサ2つでラジコン操作するプログラム②
touchsensor06.py#!/usr/bin/env python3 from ev3dev2.motor import OUTPUT_A,OUTPUT_B,MoveTank from ev3dev2.sensor.lego import TouchSensor from ev3dev2.sensor import INPUT_1,INPUT_2 tank_drive = MoveTank(OUTPUT_A,OUTPUT_B) ts_1 = TouchSensor(INPUT_1) ts_2 = TouchSensor(INPUT_2) while True: if ts_1.is_pressed: tank_drive.on(50,50) else: if ts_2.is_pressed: tank_drive.on(-50,-50) else: tank_drive.stop()Point : タッチセンサ(1)で前進、タッチセンサ(2)で後進するプログラム。
Point : スクラッチで例えるとこんな仕組み↓
1-7 . タッチセンサ2つでラジコン操作するプログラム③
touchsensor07.py#!/usr/bin/env python3 from ev3dev2.motor import OUTPUT_A,OUTPUT_B,MoveTank from ev3dev2.sensor.lego import TouchSensor from ev3dev2.sensor import INPUT_1,INPUT_2 tank_drive = MoveTank(OUTPUT_A,OUTPUT_B) ts_1 = TouchSensor(INPUT_1) ts_2 = TouchSensor(INPUT_2) while True: if ts_1.is_pressed: if ts_2.is_pressed: tank_drive.on(100,100) else: tank_drive.on(40,100) else: if ts_2.is_pressed: tank_drive.on(100,40) else: tank_drive.stop()Point :
タッチセンサを両方押す:前進
タッチセンサ1のみ押す:左前方へ進む
タッチセンサ2のみ押す:右前方へ進む
タッチセンサを両方押さない:停止Point : 片方のタッチセンサのみ押したときのタンクの曲がる度合いを調整出来る。
Point : スクラッチで例えるとこんな仕組み↓
1-8 . 手動と自動の切り替えプログラム
touchsensor08.py#!/usr/bin/env python3 from ev3dev2.motor import OUTPUT_A,OUTPUT_B,MoveTank from ev3dev2.sensor.lego import TouchSensor,UltrasonicSensor from ev3dev2.sensor import INPUT_1,INPUT_2,INPUT_3 tank_drive = MoveTank(OUTPUT_A,OUTPUT_B) us = UltrasonicSensor(INPUT_3) ts_1 = TouchSensor(INPUT_1) ts_2 = TouchSensor(INPUT_2) while True: while us.distance_centimeters > 20: if ts_1.is_pressed: if ts_2.is_pressed: tank_drive.on(100,100) else: tank_drive.on(40,100) else: if ts_2.is_pressed: tank_drive.on(100,40) else: tank_drive.stop() while us.distance_centimeters < 30: tank_drive.on(-80,-80)Point :
障害物が20cmより近くにない時は、手動でラジコン操作が出来る。
だが、障害物が20cmより近くにある場合は、障害物との距離が30cmより遠くになるまで自動で後ろに逃げて緊急回避するプログラム。Point : スクラッチで例えるとこんな仕組み(内容は同じ)↓
Point : 〜まで繰り返す と 〜の間繰り返す
〜まで繰り返す : 条件が真でなくなるまで繰り返す
〜の間繰り返す : 条件が真の間は繰り返す最後に
読んで頂きありがとうございました!!
次回はカラーセンサについて書いていきたいと思います!より良い記事にしていきたいので
◯こうした方がわかりやすい
◯ここがわかりにくい
◯ここが間違っている
◯ここをもっと説明して欲しい
などの御意見、御指摘のほどよろしくお願い致します。




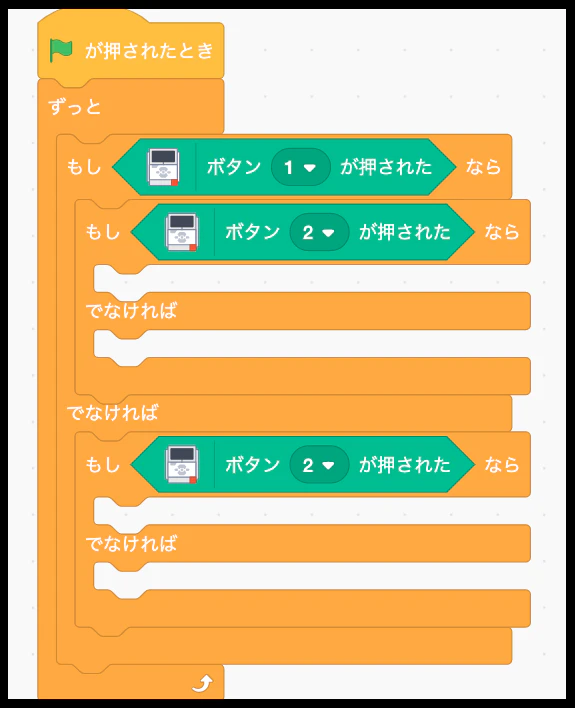

- 投稿日:2020-06-19T16:45:17+09:00
windowsでmusic 21のインストール方法
Install
基本的にはpipコマンドでインストールすれば良い。
pip install music21Musescoreで楽譜を表示してみる
Mususcoreをインストールする
Musescoreがインストールされたパスの設定をする
us = environment.UserSettings() us['musicxmlPath'] = 'C:/Program Files/MuseScore 3/bin/MuseScore3.exe' us['musescoreDirectPNGPath'] = 'C:/Program Files/MuseScore 3/bin/MuseScore3.exe'楽譜の表示
from music21 import note,stream,corpus,chord,environment,converter,midi note = note.Note("C4", quarterLength = 1) note.show()考えられるエラー
SubConverterFileIOException: png file of xml not found. Or file >999 pages?
対応策
subconverters.pyの891行目にある
os.system(musescoreRun)をsubprocess.run(musescoreRun). に変更し、import subprocessをsubconverters.pyに追記参考
https://stackoverflow.com/questions/53646669/unable-to-show-scores-in-music21
- 投稿日:2020-06-19T16:26:58+09:00
大量のexcelをマージして1つのexcelにするpython
30ファイルに及ぶ設定ファイルがexcelで、全て別ファイルとして丁寧に送られてきたので
一つ一つ開くのは基本的人権の侵害に当たると思い、pythonさんにやってもらった記録です。作戦
エクセルを1つのフォルダにすべてぶっこみ、同フォルダにpythonを一つ作って、
all.xlsx というファイルの1シート目に内容をすべて記載する。実践
ファイル配置
. ├── all.xlsx # 最終的に出来上がるエクセル ├── excel_merge.py # 今回作るpythonちゃん ├── site-packages # 利用するパッケージが入っている。今回使うのはnumpyだけ。 │ ├── bin │ ├── numpy │ └── numpy-1.18.5.dist-info ├── hogehoge1.xlsx # 丁寧に送られてきた大量のexcel様 ├── hogehoge2.xlsx ・・・ └── hogehoge30.xlsxnumpyをインストール
pip install numpy -t site-packages/-t でフォルダ名を指定すると、その場にファイルを展開してインストールしてくれます。
excel_merge.pyを作る
こんな感じのソースを書いて保存しましょう
import os, sys, glob sys.path.append(os.path.join(os.path.dirname(__file__), 'site-packages')) import openpyxl as px NEW_FILE = "all.xlsx" # エクセルのファイルを全て取得する files = glob.glob("./*.xls*") all_data = [] for f in files: # 開いているexcelがあったら無視。all.xlsxがあっても無視。 if f.startswith('./~') or f == NEW_FILE: continue # excelを開いて頂く wb=px.load_workbook(f, data_only=True) # シートを開いて頂く ws = wb.worksheets[0] # シートを読み込んで全行取得して頂く for row in ws.iter_rows(min_row=2): # 不要な行があったら飛ばす。 if row[0].value is None or \ not str(row[0].value).strip() or \ row[1].value is None or \ row[0].value == 'nanika zyogai sitai mozi': continue values = [] # 全セルを舐め回してデータを取得する for col in row: values.append(col.value) # 全セルデータを一つの配列に保存する all_data.append(values) # ここからall.xlsxを作る作業 # print(all_data) wb = px.Workbook() ws = wb.worksheets[0] start_row = 2 start_col = 3 # 全セルデータを順番に書き込み for y, row in enumerate(all_data): for x, cell in enumerate(row): ws.cell(row=start_row + y, column=start_col + x, value=all_data[y][x]) #名前を付けて保存 wb.save(NEW_FILE)
- 投稿日:2020-06-19T15:13:35+09:00
『Pythonで学ぶ強化学習 入門から実践まで』を読んでみた 第二章
前回のおさらい
強化学習が学習するもの
1、行動の評価方法→期待報酬(価値)$G_{t}$で行う、また価値を算出することを価値評価という。
2、(評価に基づく)行動の選び方=戦略 $\pi$簡潔にいうと、
強化学習が学習するもの
1、価値評価の学習
2、戦略の学習価値の定義と算出:Bellman Equation
第一章では以下のように「価値」を定義した。
行動選択の段階(時刻$t$)で「報酬の総和」を「見積もった」値で、将来の即時報酬については「割引率」を適用している。
$G_{t}:=r_{t+1}+\gamma r_{t+2}+\gamma ^{2}r_{t+3}+\ldots + \gamma ^{T-t-1}r_{T}$
$=\gamma^{k}r_{t+k+1}$$\sum ^{T-t-1}_{k=0}$※なぜかつなげるとバグってしまうため、$\gamma$ $r$を外に出しています、、、
だが、この「価値」には2つの問題があり、そのまま計算するのは困難である。
- 問題1:将来の即時報酬の値($r_{t+1},r_{t+2},\ldots$)が判明している必要がある点。
問題2:将来の即時報酬が必ず得られる点。
一方、実際行動しなければ即時報酬は分からない、また報酬の候補も複数あり、どれになるか確率的である。解決1:式を再帰的に定義することで解決する。第一章で再帰的な式に変化したわけはここにある。
$G_{t}:=r_{t+1}+\gamma G_{t+1}$
再帰的な式を定義することで、将来の即時報酬$G_{t+1}$の計算を持ち越すことができる。$G_{t+1}$にいったん適当な値を入れて、$G_{t}$を計算することが可能。つまり、計算時点将来の即時報酬が分からなくても大丈夫ということだ。
※また、後で詳しく説明するが、
動的計画法DPでは将来の即時報酬$G_{t+1}$について過去の計算値(キャッシュ)を使うことで計算する。これはメモ化という。
- 解決2:期待値を導入することで解決する。つまり、即時報酬に確率をかけること。
- 行動確率を定義できれば、行動の結果得られる報酬(即時報酬)に行動確率をかけることで期待値が計算できる。
- 戦略$\pi$に基づいて行動する場合、状態$s$で行動$a$をとる確率は$\pi(a|s)$となる。
- 発生しうる即時報酬の候補はいくつかあり、どれになるかは確率的になる。
- そのため、報酬の値は期待値(確率x値)で表すようにする(行動確率 x 即時報酬)。
この2つの問題を解決した式がBellman Equationです。
詳しくは戦略(Policy)ベース、価値(Value)ベースの部分で説明します。※ところで、行動確率って何?初めて出てきたよって思うよね?
行動確率$\pi(a|s)$だそう、だが詳しい説明はされていない、、、だが、この2つとはなんとなく違う
遷移確率$P_{a}\left( s,s'\right)$:右へ移動として実際に右へ移動できる確率
戦略$\pi$:状態を受け取り、行動を出力する関数個人的に理解したところ、
行動確率$\pi(a|s)$:
戦略に基づいて行動する→ 状態$s$を受け取り、行動$a$を出力する
状態$s$で行動$a$をとる確率→ ある状態(セル)から上下左右どの方向に行けるか確率が違う、それを行動確率$\pi(a|s)$と呼ぶ。だから4つあるかも、どうやって決まるか知らんけど。入力:状態$s$
戦略$\pi$
出力:行動$a$
状態と行動のペアの確率:行動確率$\pi(a|s)$
- 要は確率であるということで、その確率と報酬をかけて期待値を計算できることが分かればよいではないか?
※参考:DQN(Deep Q Network)を理解したので、Gopherくんの図を使って説明
とても分かりやすかったので、図も引用させて頂きました。
素晴らしい記事です、是非読んでみて!エージェントの行動を定義する2つの方法
エージェントの行動を定義する方法は2つある。
方法1:(エージェントは)保持している戦略に基づき行動する
方法2:(エージェントは)常に「価値」が最大になる行動を選択する戦略$\pi$に基づいて行動する場合、状態$s$で行動$a$をとる確率は$\pi(a|s)$となる。
そして、遷移先$s'$へは遷移関数から導かれる確率$T(s'|s,a)$で遷移する。($s'$は遷移先を意味する、つまり$s_{t}$の$s'$は$s_{t+1}$、$s_{t+1}$の$s'$は$s_{t+2}$)※あれ?遷移確率$P_{a}\left( s,s'\right)$とは違うのかな???
→遷移確率$T(s'|s,a)$という表し方もあるようだ方法1:戦略(Policy)ベース
状態$s$から戦略$\pi$に基づいて行動することで得られる価値$V_{\pi}(s)$
この$V_{\pi}(s)$は価値$G_{t}$と同様再帰的に定義できる$V_{\pi }\left( s_{t}\right) =E_{\pi }\left[ r_{t+1}+\gamma V\pi \left( s_{t+1}\right) \right]$
※$E$は期待値という意味
報酬を報酬関数$R(s,s')$で書き直す
価値$r_{t+1}+\gamma V\pi\left( s_{t+1}\right) $・行動価値${\pi}(a|s)$・遷移確率$T(s'|s,a)$を掛けると期待値$V_{\pi }(s_{t})$は以下のようになる$V _{\pi}(s) =\sum _{a}\pi \left( a|s\right) \sum _{s'}T\left( s'|s,a\right) \left( R(s,s')+\gamma V\pi \left( s'\right) \right)$
価値を再帰的かつ期待値で表現することで2つの問題点をクリアした、この式をBellman Equationと呼ぶ。
※解決1と解決2を適応したした式がBellman Equationだと考えてよい。
なおこの式にはPolicyベースとValueベースの2方法がある。この方法1のように、戦略に基づき行動する方法をPolicyベースと呼ぶ
特徴:行動の評価方法のみ学習し、評価単体行動を決定する。方法2:価値(Value)ベース
「価値が最大になる行動」を常に選択する場合は、この式を少し変換する。
→戦略$\pi$がmaxに置き換わる(価値=戦略)$V(s) =max_{a}\sum _{s'}T\left( s'|s,a\right) \left( R(s,s')+\gamma V\pi \left( s'\right) \right)$
特に報酬が状態のみで決まる場合、つまり$R(s)$のは以下のように書ける。
迷路にような環境、場所に応じて状態が決まる。
$V\left( s\right) =R\left( s\right) +\gamma \max _{a}\sum _{s'}T\left( s'|s,a\right) V\left( s'\right) $この方法2、価値が最大になるよう行動する方法をValueベースと呼ぶ。
特徴:戦略で行動を決定し、その評価/更新に行動評価が使われる。
→つまり、戦略と価値評価が相互的に影響し合う。補足
ValueベースのBellman Equationをでは価値を計算するのに、「価値が計算済み」である必要がある。
感覚的に行動は「価値が最大」なものを選ぶから、計算済みでない困ることは理解できるだろう。$V\left( s\right) =R\left( s\right) +\gamma \max _{a}\sum _{s'}T\left( s'|s,a\right) V\left( s'\right) $
※「価値」とは上の式の$V(s')$のこと
- 問題:すべての行動で$V$を計算し値が最大になる行動を選ぶ、だが状態数が多いと計算は難しい。
- 解決:動的計画法(Dynamic Programming:DP)では$V(s')$を適当な値に設定し、複数回計算を繰り返すことで値の精度が上がり、最適解に近づく。 再帰的に式を定義したおかげらしい。 証明可能であるという、証明は割愛するけど。
動的計画法(Dynamic Programming:DP)
学習方法の例として、動的計画法(Dynamic Programming:DP)がある
迷路環境のような遷移関数と報酬関数が明らかな場合は使える。遷移関数→出力:遷移先、遷移確率
報酬関数→出力:即時報酬
遷移先(次のセル)と遷移確率(右へ行こうとして右へ行ける確率)及び報酬(どのセルで何ポイント)が決まっている(というか決めているのが迷路?)
モデル
=環境
=環境の動作を決定する遷移関数・報酬関数遷移関数・報酬関数をベースに行動を学習する手法「モデルベース」の学習手法という。
強化学習限らず広く使われている。以下の解説は強化学習に限定した狭義の動的計画法である。
動的計画法による価値評価の学習:Value Iteration
基本的な考え:各状態の価値を算出し、値が最も高い状態に遷移するような行動をする。
価値反復法(Value Iteration):動的計画法によって各状態の価値を算出する(価値評価を学習する)方法。
$V_{i+1}\left( s\right)$$ :=\max _{a}$$\sum _{s}T\left( s'|s,a\right)$
$( R\left( s\right) +\gamma V_{i}\left( s'\right))$
※なぜかつなげるとバグってしまうため、上下に並べています、、、順番は合っています。
$V_{i+1}$は、前回($i$回目の計算結果($V_{i}$)を利用して算出される。
具体的には遷移先の価値を$V_{i}$から取得している($V_{i}(s')$)
正確な値に近づいたかは更新前後の差異$(|V_{i+1}(s)-V_{i}(s)|)$1が一定値(閾値)より低い=更新の必要ない
動的計画法による戦略の学習:Policy Iteration
基本的な考え:エージェントは保持している戦略に基づき行動する。
- 戦略は状態での行動確率$\pi(a|s)$を出力する。
- 行動確率$\pi(a|s)$から価値(期待値)の計算が可能になる。
- 戦略により価値を計算、価値を最大化するような戦略を更新する、というプロセスを繰り返して。価値の値(価値評価)、戦略双方の精度を高める。このプロセスをPolicy Iterationと呼ぶ。
- 計算された価値は戦略の評価に使用される、戦略による価値評価を戦略評価(Policy Evaluation)と呼ぶ。
- 価値の更新と戦略の更新が繰り返す相互更新がPolicy Iterationの中核である。これで価値評価と戦略両方が学習される。
$V_{\pi }\left( s\right) $
$=\sum _{a}\pi \left( a|s\right)$
$\sum _{s'}T\left( s'|s,a\right) $
$\left( R\left( s,s'\right) +\gamma V_{\pi} \left( s'\right) \right)$
※なぜかつなげるとバグってしまうため、上下に並べています、、、順番は合っています。
Value IterationとPolicy Iterationの比較
- Value Iterationは価値が最大の行動を必ず選ぶ
- Policy Iterationは戦略に基づき、各行動は確率的に選ばれる
Policy Iteration
メリット:全状態の価値を計算しない
デメリット:戦略が更新されるたび価値を計算し直さなければならない
どっちが良いかケースバイケースである。モデルベースとモデルフリー
モデル
=環境
=環境の動作を決定する遷移関数・報酬関数遷移関数・報酬関数をベースに行動を学習する手法「モデルベース」の学習手法という。
モデルベース特徴:
- エージェントを一歩も動かさず環境の情報のみから、シュミレートし最適な計画(戦略)を得る。
- 遷移関数と報酬関数が明らかかつ適切である必要がある。
- 例:エージェントを動かすコストが高い、ノイズが入りやすい(屋外でのドローン操作など)の環境に適している。
モデルフリー特徴:
- 遷移関数と報酬関数が不明な環境でも適用可能。
- 現実では遷移関数と報酬関数がが既知で、かつモデル化可能な場合は少ない。
- 現在では主流だけど、DNNでモデル可能になったものが増えているのでモデルベースも良き。
※モデルフリーは第三章で説明する。
※また、両方を組み合わせることでメリットを享受することも可能。まとめ
強化学習が学習するもの:
- 1、価値評価の学習
- 2、戦略の学習
価値の定義:行動選択の段階(時刻$t$)で「報酬の総和」を「見積もった」値で、将来の即時報酬については「割引率」を適用している。
- 問題1:将来の即時報酬の値($r_{t+1},r_{t+2},\ldots$)が判明している必要がある点。
- 問題2:将来の即時報酬が必ず得られる点。
解決法:価値を再帰的かつ期待値で表現することで2つの問題点をクリアした、この式をBellman Equationと呼ぶ。
エージェントの行動を定義する方法は2つある。
- 方法1:(エージェントは)保持している戦略に基づき行動する→Policyベース
- 方法2:(エージェントは)常に「価値」が最大になる行動を選択する→Valueベース
学習方法の例として、動的計画法(Dynamic Programming:DP)がある。
- 迷路環境のような遷移関数と報酬関数が明らかな場合は使える。
- 動的計画法DPでは将来の即時報酬$G_{t+1}$について過去の計算値(キャッシュ)を使うことで計算する。これはメモ化という。
動的計画法による価値評価の学習:Value Iteration
基本的な考え:各状態の価値を算出し、値が最も高い状態に遷移するような行動をする。動的計画法による戦略の学習:Policy Iteration
基本的な考え:エージェントは保持している戦略に基づき行動する。
価値の更新と戦略の更新が繰り返す相互更新がPolicy Iterationの中核である。これで価値評価と戦略両方が学習される。モデルベースとモデルフリーの特徴
参考資料
- 機械学習スタートアップシリーズ-Pythonで学ぶ強化学習-入門から実践まで
- Math Webmemo手書きの公式をLaTex変換してくれます!マジおすすめ!
- https://github.com/icoxfog417/baby-steps-of-rl-ja ※上記の本の公式アカウントです。コードや概要が見れます。
- DQN(Deep Q Network)を理解したので、Gopherくんの図を使って説明

- 投稿日:2020-06-19T14:10:01+09:00
「Apache Flink」新しい機械学習インターフェースとFlink-Pythonモジュール
このブログでは、新しい機械学習インターフェースやFlink-Pythonモジュールなど、Apache Flink 1.9.0について詳しく見ていきます。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
最も人気のあるプログラミング言語
下の画像はRedMonkプログラミング言語ランキングです。
上の画像のランキングトップ10は、GitHubやStack Overflowでの人気度に基づいています。
- JavaScript
- Java
- Python
- PHP
- C++
- C#
- CSS
- Ruby
- C
- TypeScript
3位にはPythonがランクインしています。他の人気プログラミング言語であるRとGoはそれぞれ15位と16位にランクインしています。この権威あるランキングは、Pythonのファン層の広さを十分に証明しています。プロジェクトにPythonのサポートを含めることは、そのプロジェクトのオーディエンスを拡大するための効果的な方法です。
インターネット業界のトレンド分野
ビッグデータコンピューティングは、現在のインターネット業界で最も注目されている分野の一つです。スタンドアロンコンピューティングの時代は終わった。スタンドアロンの処理能力は、データの成長に大きく後れを取っている。ビッグデータコンピューティングがインターネット業界で最も重要な分野の一つである理由を見てみましょう。
ビッグデータ時代の増え続けるデータ
クラウドコンピューティング、IoT、人工知能などの急速なITの発展により、データ量は大幅に増加しています。下の画像は、世界のデータ総量がわずか10年で16.1ZBから163ZBに増加すると予測されており、スタンドアロンのサーバーではもはやデータの保存と処理の要件を満たすことができないほどの大幅な増加となっています。
前の図のデータをZBとします。ここでは、データの統計的な単位を昇順に簡単に触れておきたいと思います。Bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DBです。これらの単位は以下のように変換されます。
- 1 Byte =8 bit
- 1 KB = 1,024 Bytes
- 1 MB = 1,024 KB
- 1 GB = 1,024 MB
- 1 TB = 1,024 GB
- 1 PB = 1,024 TB
- 1 EB = 1,024 PB
- 1 ZB = 1,024 EB
- 1 YB = 1,024 ZB
- 1 BB=1,024 YB
- 1NB = 1,024 BB
- 1 DB = 1,024 NB
世界的なデータの大きさに疑問を持ち、原因を掘り下げていくのは当たり前のことです。実際、私も統計を見て疑っていました。情報を集めて調べてみると、確かにグローバルデータは急激に増えていることがわかりました。例えば、Facebookには毎日何百万枚もの写真が投稿されていますし、ニューヨーク取引所では毎日TBもの取引データが作成されています。昨年のダブル11プロモイベントでは、取引額が2,135億元という記録的な規模となりましたが、この成功の裏には、アリババ社内の監視ログだけでも162GB/sのデータ処理能力があります。アリババのようなインターネット企業も、過去10年間のダブル11の取引額が示すように、データの急速な成長に貢献しています。
データ分析によるデータの価値
ビッグデータの価値を探るには間違いなく、ビッグデータの統計分析は、情報に基づいた意思決定を行うのに役立ちます。例えば、レコメンドシステムでは、購入者の長期的な購買習慣や購入履歴を分析して、その購入者の好みのアイテムを見つけ出し、さらに適切なレコメンドを提供することができます。前述したように、スタンドアロンのサーバーではこのような大量のデータを処理することはできません。では、限られた期間内に、どのようにしてすべてのデータを統計的に分析することができるのでしょうか?この点では、これら3つの有用な論文を提供してくれたGoogleに感謝する必要があります。
- GFS: 2003年にGoogleは、大規模な分散データ集約型アプリケーションのためのスケーラブルな分散fileシステムであるGoogle File Systemに関する論文を発表した。
- MapReduce:2004年、Googleはビッグデータのための分散コンピューティングについて述べたMapReduceの論文を発表した。MapReduceの主な考え方は、独立してあまり高いデータ処理能力を持たない複数のコンピューティングノード上で、タスクを分割し、分割されたタスクを同時に処理することです。MapReduceは、クラスタ上の並列分散アルゴリズムでビッグデータセットを処理し、生成するためのプログラミングモデルである。
- BigTable:2006年、GoogleはBigTableに関する論文を発表しました。 この3つのGoogleの論文のおかげで、オープンソースのApacheコミュニティは、HDFS、MapReduce(プログラミングモデル)、HBase(NoSQLデータベース)の3つのHadoopエコシステムを急速に構築しました。Hadoopエコシステムは、世界の学術界や産業界の注目を集め、瞬く間に人気を博し、世界中で応用されるようになりました。2008年、アリババはHadoopベースのYARNプロジェクトを立ち上げ、Hadoopをアリババの分散コンピューティングの中核技術システムとした。このプロジェクトでは、2010年には1000台のマシンのクラスターが稼働していました。下の写真は、アリババのHadoopクラスタの開発状況を示しています。
しかし、Hadoopを利用してMapReduceアプリケーションを開発するには、開発者はJava言語に習熟し、MapReduceの仕組みをよく理解している必要があります。これにより、MapReduce開発の敷居が高くなります。MapReduceの開発を容易にするために、代表的なHiveプロジェクトを含め、いくつかのオープンソースのフレームワークがオープンソースコミュニティで作成されています。HSQLを使用すると、SQLに似た方法でMapReduceの計算を定義して記述することができます。例えば、かつては数十行、数百行のコードが必要だったWord Countの演算が、今ではSQL文1つで実装できるようになり、開発にMapReduceを使う敷居が大幅に下がりました。Hadoopのエコシステムが成熟するにつれ、ビッグデータ向けのHadoopベースの分散コンピューティングは業界全体に普及していきます。
データの最大値と適時性
各データエントリには、特定の情報が含まれています。情報の適時性は、情報源から情報を送信してから、情報を受信し、処理し、転送し、利用するまでの時間間隔と情報効率で測定されます。時間間隔が短いほど、情報の適時性が高く、一般的にタイムリー性が高いほど価値が高くなります。例えば、嗜好推薦のシナリオでは、購入者が蒸し器を購入してから数秒後にオーブンの特価品が購入者に推薦された場合、購入者がオーブンも購入する可能性が高く、蒸し器の購入行動の分析に基づいて、1日後にオーブンのお勧めが表示された場合は、購入者がオーブンを購入する可能性は低いのです。これは、Hadoopのバッチ計算のデメリットの1つであるタイムリー性の低さを露呈しています。ビッグデータ時代の要件を満たすために、いくつかの代表的なリアルタイムコンピューティングプラットフォームが開発されました。2009年、カリフォルニア大学バークレー校のAMPラボでSparkが誕生。2010年には、NathanがStormのコアコンセプトであるBackTypeを提案し、また、2010年にはドイツのベルリンで調査プロジェクトとしてFlinkを立ち上げました。
AlphaGoとAI
2016年に行われた囲碁の対局では、GoogleのAlphaGoが九段目の棋士で世界囲碁選手権の優勝者でもあるイ・セドル(4:1)を破りました。これにより、より多くの人がディープラーニングを新たな視点から見るようになり、AIの流行を挑発しました。百度百科事典に与えられた定義によると、人工知能(AI)は、人間の知能を刺激し、拡張し、拡張する理論、方法、技術、応用、システムを研究開発するコンピュータ科学の新しい枝である。
機械学習は、人工知能を探求するための手法やツールです。SparkやFlinkに代表されるビッグデータプラットフォームでは、機械学習の優先度が高く、Sparkは近年、機械学習に莫大な投資を行っています。PySparkは多くの優れたMLクラスライブラリ(例えば代表的なPandas)を統合しており、Flinkよりもはるかに包括的なサポートを提供しています。そのため、Flink 1.9では、その欠点を補うために、新しいMLインターフェースやflink-pythonモジュールの開発が可能になります。
機械学習とPythonの関係は?また、機械学習で最もポピュラーな言語は何なのか、統計データを見てみましょう。
IBMのデータサイエンティストであるJean-Francois Puget氏は、かつて興味深い分析を行ったことがある。彼は有名な就活サイトから求人条件の変化に関する情報を集め、当時最も人気のあるプログラミング言語を探し出しました。機械学習を検索することで、彼も同様の結論に達しました。
そして、当時、機械学習のプログラミング言語として最も普及していたのはPythonであることがわかったそうです。この調査は2016年に行われたものですが、Pythonが機械学習において重要な役割を果たしていることを証明するには十分なものであり、前述のRedMonkの統計データからもそれをさらに示すことができます。
調査だけでなく、Pythonの特徴や既存のPythonエコシステムからも、Pythonが機械学習に最適な言語である理由が見えてきます。
Pythonは、1989年にオランダのプログラマーであるGuido van Rossumによって作成され、1991年に初めてリリースされたインタープリタ型・オブジェクト指向のプログラミング言語です。インタプリタ型言語は動作が非常に遅いですが、Pythonの設計思想は「唯一の方法」です。新しいPythonの構文を開発し、多くの選択肢がある場合、Pythonの開発者は通常、曖昧さがない、あるいはほとんどない明確な構文を選択します。そのシンプルさから、Pythonは多くのユーザーを抱えています。また、NumPy、SciPy、Pandas(構造化データを処理するための)など、多くの機械学習クラスライブラリがPythonで開発されています。Pythonの豊富なエコシステムが機械学習に大きな利便性を提供しているため、Pythonが機械学習用のプログラミング言語として最も人気のある言語になったのは当然のことです。
概要
今回の記事では、Apache FlinkがPython APIのサポートを追加した理由を理解することを試みました。具体的な統計を見ると、ビッグデータの時代に突入していることがわかります。データの価値を探るには、ビッグデータ分析が必要です。データの適時性は、有名なストリームコンピューティングプラットフォームであるApache Flinkを生み出しました。
ビッグデータコンピューティングの時代、AIは熱い開発トレンドであり、機械学習はAIの重要な側面の一つです。Python言語の特徴とエコシステムの利点から、Pythonは機械学習に最適な言語です。これが、Apache FlinkがPython APIのサポートを計画している重要な理由の一つです。Apache FlinkがPython APIをサポートすることは、ビッグデータ時代の要件を満たすためには避けて通れないトレンドです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ

- 投稿日:2020-06-19T13:30:38+09:00
UbuntuでDjangoの画像と静的資産を管理する
このチュートリアルでは、Django フレームワークを使ってウェブのユーザー体験を向上させるために django.contrib.staticfiles モジュールを効果的に使う方法を紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
目的
以下のチュートリアルの目標は以下の通りです。
- django フレームワークを使って画像や静的ファイルを提供する方法を示します。
- collectstatic コマンドを使用してイメージと静的ファイルを本番環境にデプロイする方法を示します。
前提条件
- ubuntu 18.04がインストールされたコンピュータまたは仮想マシンにアクセスしている
- IDEにアクセスできる
ステップ1: プロジェクトの初期化と設定
1.1. 環境の初期化
開発環境の設定については、ここで紹介した手順で行います。
1、 必要なライブラリのインストール
$ sudo apt install python3 # Install Python3 interpreter $ sudo apt install python3-pip # To manage python packages $ sudo apt install python3-virtualenv # To manage virtual python environments $ sudo apt install apache2 # To serve images and static assets2、 仮想環境を作成してアクティベートする
$ virtualenv --python=python3 venv # This create the virtual environment venv $ source venv/bin/activate # This is to activate the virtual environment3、 プロジェクトの依存関係のインストール
(venv)$ pip install Django==2.1 # Install Django v2.1 (venv)$ pip install Pillow # To manage images through Python code (venv)$ pip install easy_thumbnails # To easyly manage image thumbnails注:venv という名前の隔離された仮想環境の中で ruunning していることを示すために venv サフィックスが追加されています。
1.2. プロジェクトの設定
1、 djangoプロジェクトのフォトギャラリーを作成する
(venv)$ django-admin startptoject photogallery2、 djangoアプリケーションギャラリーを作成する
(venv)$ cd photogallery/ (venv)$ django-admin startapp gallery3、 プロジェクトのフォトギャラリーにギャラリーアプリを追加
そのためには、フォトギャラリープロジェクトのsettings.pyファイルにギャラリーアプリを追加する必要があります。
INSTALLED_APPS = [ ... 'photogallery.gallery' ... ]4、移行データをデータベースに保存する
(venv)$ pyhton manage.py migrate5、 ジャンゴ管理者ダッシュボードアプリケーションのスーパーユーザーを作成する
(venv)$ python manage.py createsuperuser --username admin (venv)$ Email address: yourmail@web.com (venv)$ Password: (venv)$ Password (again):6、 これを実行すると、プロジェクトフォルダの構造は以下のようになります。
. ├── db.sqlite3 ├── gallery │ ├── admin.py │ ├── apps.py │ ├── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── manage.py └── socialgallery ├── __init__.py ├── settings.py ├── urls.py └── wsgi.py7、 すべてがうまく機能していることを確認してください。
(venv)$ python manage.py runserver ... Starting development server at http://127.0.0.1:8000/ ...ステップ2: 静的ファイルサーバの設定
1、 プロジェクトの settings.py ファイル内の INSTALLED_APPS にアプリケーション django.contrib.staticfiles を追加します。
INSTALLED_APPS = [ ... 'django.contrib.staticfiles' ... ]2、 静的ファイル用のフォルダを作成し、正しいパーミッションを設定します。
# Create static folders on the webserver (venv)$ sudo mkdir /var/www/static (venv)$ sudo mkdir /var/www/media # Make static folders editable from the web browser (venv)$ sudo chown -R www-data:www-data /var/www/static (venv)$ sudo chown -R www-data:www-data /var/www/media # Allow the group to write to the directory with appropriate permissions (venv)$ sudo chmod -R 777 /var/www/static (venv)$ sudo chmod -R 777 /var/www/media # Add myself to the www-data group (venv)$ sudo usermod -a -G www-data $(whoami)3、 静的ファイルを提供するためにプロジェクトを構成します。
STATIC_URL = '/static/' # Used to include static resources in web pages STATIC_ROOT = '/var/www/static/' # Used to get static resources from web server MEDIA_URL = '/media/' # Used to include media items in web pages MEDIA_ROOT = '/var/www/media/' # Used to get media items from web server4、 画像および静的ファイルを STATIC_URL から STATIC_ROOT に、MEDIA_URL から MEDIA_ROOT に移行する。
# This command will copy everything from the STATIC_URL to the STATIC_ROOT (venv)$ python manage.py collectstatic注:このコマンドは、ユーザが追加した新しい静的ファイルを考慮してアプリケーションをデプロイするたびに実行する必要があります。
ステップ3: 画像と静的ファイルの使用
ウェブページで画像ファイルや静的ファイルを使用するには、該当するページで静的モジュールをプリロードする必要があります。そのためには、以下のコードをルートページのbase.htmlに追加します。
{% load static %}次に、このような方法でホームページにイマエを入れることができます。
<img src={% static 'gallery/images/background.jpg' alt='Background Image' %}>そして、これらのタグを含めることで、静的アセットをウェブページに追加することができます。
{% static 'gallery/css/bootstrap.css'%} {% static 'gallery/js/bootstrap.js'%} {% static 'gallery/js/jquery.js'%}ステップ4:データモデルの定義
本題から離れないように、ユーザーがアップロードした画像を管理するためのデータモデルを1つだけ作成します。
1、 以下は、gallery/models.pyファイルの内容です。
from django.db import models from django.contrib.auth.models import User class Image(models.Model): name = models.TextField(max_length='100') path = models.ImageField() number_views = models.IntegerField(default=0) def __str__(self): return self.name2、 モデルをデータベースに保存
(venv)$ python manage.py make migrations # This command will create migrations files (venv)$ python manage.py migrate # Here the migrations created are executedステップ5:ビューの書き方
ビューはユーザがアプリケーションとどのように対話するかを定義します。
ビューはファイル: socialgallery/gallery/views.pyで作成されます。
from django.shortcuts import render from django.urls import reverse_lazy from django.views.generic import ListView, CreateView, DetailView, \ UpdateView, DeleteView from .models import Image class ImageListView(ListView): model = Image template_name = 'gallery/image_list.html' class ImageDetailView(DetailView): model = Image template_name = 'gallery/image_detail.html' class ImageCreateView(CreateView): model = Image template_name = 'gallery/image_create.html' fields = '__all__' class ImageUpdateView(UpdateView): model = Image template_name = 'gallery/image_update.html' fields = '__all__' class ImageDeleteView(DeleteView): model = Image template_name = 'gallery/image_delete.html' success_url = reverse_lazy('image-list')ステップ6:URLの定義
ここで作成したビューにアクセスするためには、URLルートを設定しなければなりません。これらのルートはgallery/urls.pyファイルの中で設定しますので、もしこのフォルダがアプリのフォルダに存在しない場合は、続ける前に作成してください。
gallery/urls.pyファイルの内容は以下の通りです。
from django.urls import path from .views import ImageListView, ImageDetailView, ImageCreateView, \ ImageUpdateView, ImageDeleteView urlpatterns = [ path('', ImageListView.as_view(), name='image-list'), # Will serve as homepage path('<int:pk>', ImageDetailView.as_view(), name='image-detail'), path('create', ImageCreateView.as_view(), name='image-create'), path('update/<int:pk>', ImageUpdateView.as_view(), name='image-update'), path('delete/<int:pk>', ImageDeleteView.as_view(), name='image-delete'), ]そして、gallery/urls.py ファイルをプロジェクトの urls ファイル photogallery/urls.py に追加します。
以下はファイルsocialgallery/urls.pyの内容です。
from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('images/', include('gallery.urls')), ]ステップ7:HTMLテンプレートの作成
HTMLテンプレートの作成には、views.pyファイルで指定したHTMLテンプレートをDjangoが見つけるテンプレートフォルダを作成する必要があります。
(venv)$ mkdir gallery/templates templates/galleryギャラリーテンプレートファイルの中に、以下のhtmlファイルを作成します。
1、templates/gallery/image_list.html
{% block content %} <h2>Images</h2> <ul> {% for image in object_list %} <li>{{ image.name }} - {{ image.path }} </li> {% endfor %} </ul> {% endblock %}2、templates/gallery/image_detail.html
<p>Image</p> <p>name: {{ object.name }}</p> <p>Path: {{ object.path }}</p> <p>Views: {{ object.number_views }}</p>3、templates/gallery/image_create.html
<form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Save Image"> </form>4、templates/gallery/image_update.html
<form method="post"> {% csrf_token %} {{ form.as_p }} <input type="submit" value="Update User"> </form>5、templates/gallery/image_delete.html
<form method="post"> {% csrf_token %} <p>Are you sure you want to delete the image "{{ object.name }}"?</p> <input type="submit" value="Confirm"> </form>ステップ8:管理者ダッシュボードの設定
ギャラリーアプリの管理者ダッシュボードを設定するには、gallery/admin.pyファイルを修正して、内部にこのコードを追加しなければなりません。
from django.contrib import admin from .models import Image @admin.register(Image) class ImageAdmin(admin.ModelAdmin): model = Imageステップ9:すべてがうまく機能するかどうかのテスト
すべてが正常に動作することをテストするには、コマンドを使用して開発サーバーを起動する必要があります。
(venv)$ python manage.py runserver結論
このチュートリアルの最後まで来て、Django での静的リソースの使用例、統合、使用、サービスを見てきました。私たちは、画像を管理するアプリケーションを開発する際に考慮すべき設定と、これらすべてのファイルの安全なデプロイを確保する方法を見てきました。
以下はオンラインで公開されているアプリケーションのソースコードのリンクです。
https://github.com/binel01/photogallery.git
続きを読む
- 画像の管理に使われるパッケージ: django-easythumbnails, Django パッケージのサイトを参照しています。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ
- 投稿日:2020-06-19T12:53:14+09:00
[連載]ルービックキューブを解くプログラムを書いてみよう(中編)
はじめに
この記事はSpeedcubing Advent Calendar 2019の17日目の記事です。
[連載]ルービックキューブを解くプログラムを書いてみよう(前編) の続きをやっていきます。前編では、ルービックキューブの状態/操作を表現するクラスを作り、状態を操作するメソッドを書きました。
これで、キューブをプログラム的に自由に回せる状態になったので、探索を進めていきましょう。中編は、ルービックキューブ特化な話より、ベースになるアルゴリズム知識の補強が主になります。
環境
環境については、前編と同様Python3.6以上です。
前編に引き続き、以下で出てくるコードをColaboratoryノートブック化したもの
も用意したので、[Play Groundで開く]をクリックし、順に実行しながら進めれば、環境構築など不要で楽だと思います。総当りでルービックキューブを解く
ルービックキューブは 約 4.3*10^19 通りの状態数があり、最短手数は平均18手くらいです。
最悪の場合でも20手で完成することが証明されています (c.f. https://www.cube20.org/) 。総当りでは現実的な時間では太刀打ちできない規模ですが、まずは、総当りでルービックキューブを解くプログラムを書いてみて、それをベースに改善していきましょう。
ルービックキューブは状態数が膨大のため、幅優先探索はメモリの使用量が大きすぎます。
ルービックキューブを総当りで解くには、反復深化深さ優先探索が使えます。
探索の深さ (解の長さ) に制限を加えた深さ優先探索 (深さ制約探索) を制限深さを徐々に増やして繰り返していくやり方です。完成状態を判定する関数
まず、探索の過程で現れる状態が完成状態かどうかを判定しなければいけないので判定する関数を書いておきます。
EO, CO, EP, CPが全部揃っていれば完成状態ということなのでそのように判定する関数を書きました。def is_solved(state): return (state.eo == [0] * 12 # EOが全部揃っている and state.co == [0] * 8 # COが全部揃っている and state.ep == list(range(12)) # EPが全部揃っている and state.cp == list(range(8)) # CPが全部揃っている )前の1手から次の1手として使えるかを返す関数
前の1手を参照し、操作が次の1手として使えるかを返す関数を書いておきます。
単純なケースとして、同じ面を連続して回すのは不可です。 (
R' R2など)
他にも、U D UはU2 Dと同じなので、まずいです。
これを避けるため、対面を続けて回すときは面の名前の辞書順で順序を固定しておきます(D Uの順は良いが、U Dの順は不可のように)。inv_face = { "U": "D", "D": "U", "L": "R", "R": "L", "F": "B", "B": "F" } def is_move_available(prev_move, move): """ 前の1手を考慮して次の1手として使える操作であるかを判定する - 同じ面は連続して回さない (e.g. R' R2 は不可) - 対面を回すときは順序を固定する (e.g. D Uは良いが、U Dは不可) """ if prev_move is None: return True # 最初の1手はどの操作も可 prev_face = prev_move[0] # 1手前で回した面 if prev_face == move[0]: return False # 同一面は不可 if inv_face[prev_face] == move[0]: return prev_face < move[0] # 対面のときは、辞書順なら可 return True反復深化深さ優先探索の実装
こんな感じで書きました。
start_searchでは、0手からスタートして、次第に手数を増やしながら深さ制限探索の実装を呼び、解を見つけたらそれを返します。
depth_limited_searchの引数depthは使える残りの深さを意味し、これを減らしながら探索を進め、depth=0のときに今探索している手数になるようにしています。class Search: def __init__(self): self.current_solution = [] # 今探索している手順を入れておくstack def depth_limited_search(self, state, depth): if depth == 0 and is_solved(state): # is_solvedがTrueなら完成しているので解が見つかったということでTrueを返す # depth==0はなくてもいいが、depth > 0には解がないことがすでにわかっているのでいちいち判定関数を呼ぶ必要はない return True if depth == 0: # depth 0 までたどり着いたのに解が見つからなかったらFalseを返す return False # depth=0まで探索を続ける prev_move = self.current_solution[-1] if self.current_solution else None # 1手前の操作 for move_name in move_names: if not is_move_available(prev_move, move_name): continue self.current_solution.append(move_name) if self.depth_limited_search(state.apply_move(moves[move_name]), depth - 1): return True self.current_solution.pop() def start_search(self, state, max_length=20): for depth in range(0, max_length): # 0から次第にに手数を増やしながら深さ制限探索を繰り返す print(f"# Start searching length {depth}") if self.depth_limited_search(state, depth): # 解が見つかったらその時点でそれを返却 return " ".join(self.current_solution) return None反復深化深さ優先探索を実行してみる
この実装では、普通のランダムスクランブルでは、現実的な時間では解は見つからないので、適当な6手のスクランブルを与えてみます。
34秒で解が見つかりました。当然ですが、スクランブルを逆から回したものが解となります。import time scramble = "R U R' F2 D2 L" scrambled_state = scamble2state(scramble) search = Search() start = time.time() solution = search.start_search(scrambled_state) print(f"Finished! ({time.time() - start:.2f} sec.)") if solution: print(f"Solution: {solution}.") else: print("Solution not found.")Finished! (34.11 sec.) Solution: L' D2 F2 R U' R'.枝刈りによる高速化 (IDA*探索)
探索を高速化するテクニックとして枝刈りがあります。
ルービックキューブに関する事前知識を使って、もうこれ以上探索しても意味がないと分かる探索はどんどん切り上げていくことができます。
このように反復深化深さ優先探索を知識ありにしたものを IDA*探索 といいます (c.f. https://en.wikipedia.org/wiki/Iterative_deepening_A* )。例えば、
depth=1(残り1手) の時点で、揃っているパーツが1つも揃っていなかったらどうでしょうか。
ルービックキューブを完成状態から1手動かしてみてください。残り1手の状態では、少なくともコーナー4個とエッジ8個が揃っていなければ、次の1手で揃うことはありません。
ですので、そこから次の1手depth=0の探索を進めても無意味です。同じように、
depth=2(残り2手) のとき、コーナーはすべて崩れている可能性がありますが (L Rなど)、エッジは必ず4つは揃っていないと残り2手で完成する可能性はありません。
depth=3(残り3手) では、その時点でエッジが少なくとも2個揃っていなければ残り3手で完成することはありません。この知識を使った枝刈りを実装してみます。
def count_solved_corners(state): """ 揃っているコーナーの個数をカウント """ return sum([state.cp[i] == i and state.co[i] == 0 for i in range(8)]) def count_solved_edges(state): """ 揃っているエッジの個数をカウント """ return sum([state.ep[i] == i and state.eo[i] == 0 for i in range(12)]) def prune(depth, state): """ それ以上探索を進めても無意味ならTrueを返す """ if depth == 1 and (count_solved_corners(state) < 4 or count_solved_edges(state) < 8): # 残り1手で揃っているコーナーが4個未満、もしくは、揃っているエッジが8個未満ならもう揃わない return True if depth == 2 and count_solved_edges(state) < 4: # 残り2手で揃っているエッジが4個未満ならもう揃わない return True if depth == 3 and count_solved_edges(state) < 2: # 残り3手で揃っているエッジが2個未満ならもう揃わない return True return Falseclass Search: def __init__(self): self.current_solution = [] def depth_limited_search(self, state, depth): if depth == 0 and is_solved(state): return True if depth == 0: return False # 枝刈り (変えたのはこの2行の追加のみ) if prune(depth, state): return False prev_move = self.current_solution[-1] if self.current_solution else None # 1手前の操作 for move_name in move_names: if not is_move_available(prev_move, move_name): continue self.current_solution.append(move_name) if self.depth_limited_search(state.apply_move(moves[move_name]), depth - 1): return True self.current_solution.pop() def start_search(self, state, max_length=20): for depth in range(0, max_length): print(f"# Start searching length {depth}") if self.depth_limited_search(state, depth): return " ".join(self.current_solution) return None枝刈りした場合の探索時間
34秒かかった探索が1秒未満になりました。
このように、枝刈りはとても強力です。scramble = "R U R' F2 D2 L" scrambled_state = scamble2state(scramble) search = Search() start = time.time() solution = search.start_search(scrambled_state) print(f"Finished! ({time.time() - start:.2f} sec.)") if solution: print(f"Solution: {solution}.") else: print("Solution not found.")Finished! (0.21 sec.) Solution: L' D2 F2 R U' R'.これだけでも、3x3x3の一部分 (2x2x3ブロックを揃える手順の探索など) や、ピラミンクスや2x2x2キューブなど、小さめのパズルなら現実的な時間で解くことができます。
Two-Phase-Algorithm
総当りでルービックキューブを解くプログラムを書き、枝刈りで多少高速化できましたが、任意の状態から短時間で解を見つけるには程遠いです。
現実的な時間でルービックキューブの準最適解を見つけるアルゴリズムとして、Two-Phase-Algorithmが広く使われています。
ルービックキューブの解法をを2つのフェーズに分解し、それぞれを総当りで解くというやり方です。Phase1では、ルービックキューブを自由に動かして、
<U,D,R2,L2,F2,B2>の動きだけで完成できる状態に持っていきます。
Phase2では、そこから<U,D,R2,L2,F2,B2>の動きだけを使って完成まで持っていきます。Phase1は最悪で12手、だいたい10手くらい、
Phase2は最悪で18手、だいたい13〜14手くらいで完成できます (c.f. http://kociemba.org/math/symmetric.htm)。フェーズを分けずに総当りするとだいたい18手掛かるのに対し、探索深さ (手順長) が深くなればなればなるほど指数関数的に探索範囲も増えていくので、10手の探索と13手の探索に分ければ速くなります。
しかも、Phase2は操作の種類数も減っているので更に速いです。Two-Phase-Algorithmは、程よく2フェーズに分解して手数の短い2ステップに分けたということも重要なのですが、加えて重要なのは、フェーズを2つに分けたことにより各フェーズの状態数が減り、状態をインデックス化し予め状態遷移表を作っておくことができる点と、枝刈り用の表も事前計算しておけるということです。
探索に時間をかければ最適解にどんどん近づけて行くことができるのも特徴です。
Two-Phase-Algorithmの実装は後編に回します。参考文献
- 投稿日:2020-06-19T12:53:14+09:00
ルービックキューブを解くプログラムを書いてみよう(中編) (IDA*探索)
はじめに
この記事はSpeedcubing Advent Calendar 2019の17日目の記事です。
[連載]ルービックキューブを解くプログラムを書いてみよう(前編) の続きをやっていきます。前編では、ルービックキューブの状態/操作を表現するクラスを作り、状態を操作するメソッドを書きました。
これで、キューブをプログラム的に自由に回せる状態になったので、探索を進めていきましょう。中編では総当りで探索するので、まだ任意の状態のルービックキューブの解を見つけられるようにはなりませんが、ピラミンクスや2x2x2キューブなどの小さいパズルならこの方法でも解くことができます。
環境
環境については、前編と同様Python3.6以上です。
前編に引き続き、以下で出てくるコードをColaboratoryノートブック化したもの
も用意したので、[Play Groundで開く]をクリックし、順に実行しながら進めれば、環境構築など不要で楽だと思います。総当りでルービックキューブを解く
ルービックキューブは 約 4.3*10^19 通りの状態数があり、最短手数は平均18手くらいです。
最悪の場合でも20手で完成することが知られています (c.f. https://www.cube20.org/) 。総当りでは現実的な時間では太刀打ちできない規模ですが、まずは、総当りでルービックキューブを解くプログラムを書いてみて、それをベースに改善していきましょう。
ルービックキューブは状態数が膨大のため、幅優先探索はメモリの使用量が大きすぎます。
ルービックキューブを総当りで解くには、反復深化深さ優先探索が使えます。
探索の深さ (解の長さ) に制限を加えた深さ優先探索 (深さ制約探索) を制限深さを徐々に増やして繰り返していくやり方です。完成状態を判定する関数
まず、探索の過程で現れる状態が完成状態かどうかを判定しなければいけないので判定する関数を書いておきます。
EO, CO, EP, CPが全部揃っていれば完成状態ということなのでそのように判定する関数を書きました。def is_solved(state): return (state.eo == [0] * 12 # EOが全部揃っている and state.co == [0] * 8 # COが全部揃っている and state.ep == list(range(12)) # EPが全部揃っている and state.cp == list(range(8)) # CPが全部揃っている )前の1手から次の1手として使えるかを返す関数
前の1手を参照し、操作が次の1手として使えるかを返す関数を書いておきます。
単純なケースとして、同じ面を連続して回すのは不可です。 (
R' R2など)
他にも、U D UはU2 Dと同じなので、まずいです。
これを避けるため、対面を続けて回すときは面の名前の辞書順で順序を固定しておきます(D Uの順は良いが、U Dの順は不可のように)。inv_face = { "U": "D", "D": "U", "L": "R", "R": "L", "F": "B", "B": "F" } def is_move_available(prev_move, move): """ 前の1手を考慮して次の1手として使える操作であるかを判定する - 同じ面は連続して回さない (e.g. R' R2 は不可) - 対面を回すときは順序を固定する (e.g. D Uは良いが、U Dは不可) """ if prev_move is None: return True # 最初の1手はどの操作も可 prev_face = prev_move[0] # 1手前で回した面 if prev_face == move[0]: return False # 同一面は不可 if inv_face[prev_face] == move[0]: return prev_face < move[0] # 対面のときは、辞書順なら可 return True反復深化深さ優先探索の実装
こんな感じで書きました。
start_searchでは、0手からスタートして、次第に手数を増やしながら深さ制限探索の実装を呼び、解を見つけたらそれを返します。
depth_limited_searchの引数depthは残りの深さを表し、これを減らしながら再帰的に探索を進め、depth=0のときに今探索している手数になるようにしています。今考えている解 (手順) を管理するスタックを一つ用意します。
探索の過程で次のノードに入るときに操作をpush、出るときにpopすれば、今探索中の解が常にこのスタックに入った状態になり、状態ごとに解を持つ必要はありません。class Search: def __init__(self): self.current_solution = [] # 今探索している手順を入れておくスタック def depth_limited_search(self, state, depth): if depth == 0 and is_solved(state): # is_solvedがTrueなら完成しているので解が見つかったということでTrueを返す # depth==0はなくてもいいが、depth > 0には解がないことがすでにわかっているのでいちいち判定関数を呼ぶ必要はない return True if depth == 0: # depth 0 までたどり着いたのに解が見つからなかったらFalseを返す return False # depth=0まで探索を続ける prev_move = self.current_solution[-1] if self.current_solution else None # 1手前の操作 for move_name in move_names: if not is_move_available(prev_move, move_name): continue self.current_solution.append(move_name) if self.depth_limited_search(state.apply_move(moves[move_name]), depth - 1): return True self.current_solution.pop() def start_search(self, state, max_length=20): for depth in range(0, max_length): # 0から次第にに手数を増やしながら深さ制限探索を繰り返す print(f"# Start searching length {depth}") if self.depth_limited_search(state, depth): # 解が見つかったらその時点でそれを返却 return " ".join(self.current_solution) return None反復深化深さ優先探索を実行してみる
この実装では、普通のランダムスクランブルに対しては現実的な時間では解は見つからないので、適当な6手のスクランブルを与えてみます。
34秒で解が見つかりました。当然ですが、スクランブルを逆から回したものが解となります。import time scramble = "R U R' F2 D2 L" scrambled_state = scamble2state(scramble) search = Search() start = time.time() solution = search.start_search(scrambled_state) print(f"Finished! ({time.time() - start:.2f} sec.)") if solution: print(f"Solution: {solution}.") else: print("Solution not found.")Finished! (34.11 sec.) Solution: L' D2 F2 R U' R'.枝刈りによる高速化 (IDA*探索)
探索を高速化するテクニックとして枝刈りがあります。
ルービックキューブに関する事前知識を使って、もうこれ以上探索しても意味がないと分かった場合はどんどん切り上げていくことができます。
このように反復深化深さ優先探索を知識ありにしたものを IDA*探索 といいます (c.f. https://en.wikipedia.org/wiki/Iterative_deepening_A* )。例えば、
depth=1(残り1手) の時点で、揃っているパーツが1つも揃っていなかったらどうでしょうか。
ルービックキューブを完成状態から1手動かしてみてください。残り1手の状態では、少なくともコーナー4個とエッジ8個が揃っていなければ、次の1手で揃うことはありません。
ですので、そこから次の1手depth=0の探索を進めても無意味です。同じように、
depth=2(残り2手) のとき、コーナーはすべて崩れている可能性がありますが (L Rなど)、エッジは必ず4つは揃っていないと残り2手で完成する可能性はありません。
depth=3(残り3手) では、その時点でエッジが少なくとも2個揃っていなければ残り3手で完成することはありません。この知識を使った枝刈りを実装してみます。
def count_solved_corners(state): """ 揃っているコーナーの個数をカウント """ return sum([state.cp[i] == i and state.co[i] == 0 for i in range(8)]) def count_solved_edges(state): """ 揃っているエッジの個数をカウント """ return sum([state.ep[i] == i and state.eo[i] == 0 for i in range(12)]) def prune(depth, state): """ それ以上探索を進めても無意味ならTrueを返す """ if depth == 1 and (count_solved_corners(state) < 4 or count_solved_edges(state) < 8): # 残り1手で揃っているコーナーが4個未満、もしくは、揃っているエッジが8個未満ならもう揃わない return True if depth == 2 and count_solved_edges(state) < 4: # 残り2手で揃っているエッジが4個未満ならもう揃わない return True if depth == 3 and count_solved_edges(state) < 2: # 残り3手で揃っているエッジが2個未満ならもう揃わない return True return Falseclass Search: def __init__(self): self.current_solution = [] def depth_limited_search(self, state, depth): if depth == 0 and is_solved(state): return True if depth == 0: return False # 枝刈り (変えたのはこの2行の追加のみ) if prune(depth, state): return False prev_move = self.current_solution[-1] if self.current_solution else None # 1手前の操作 for move_name in move_names: if not is_move_available(prev_move, move_name): continue self.current_solution.append(move_name) if self.depth_limited_search(state.apply_move(moves[move_name]), depth - 1): return True self.current_solution.pop() def start_search(self, state, max_length=20): for depth in range(0, max_length): print(f"# Start searching length {depth}") if self.depth_limited_search(state, depth): return " ".join(self.current_solution) return None枝刈りした場合の探索時間
34秒かかった探索が1秒未満になりました。
このように、枝刈りはとても強力です。scramble = "R U R' F2 D2 L" scrambled_state = scamble2state(scramble) search = Search() start = time.time() solution = search.start_search(scrambled_state) print(f"Finished! ({time.time() - start:.2f} sec.)") if solution: print(f"Solution: {solution}.") else: print("Solution not found.")Finished! (0.21 sec.) Solution: L' D2 F2 R U' R'.これだけでも、ピラミンクスや2x2x2キューブなど小さめのパズルなら現実的な時間で解くことができます。
一部のマニアには、ルービックキューブの一部分 (2x2x3ブロックを揃える手順など) を探索したいなどの人もいるかと思いますが、短いものであればここまでの方法で対応できます。
最初の解を見つけてもすぐにreturnせずに、探索を続けるように改変すれば、複数種類の解を探すこともできます。次回予告: 状態のインデックス化 + Two-Phase-Algorithm
総当りでルービックキューブを解くプログラムを書き、枝刈りで多少高速化できましたが、任意の状態から短時間で解を見つけるには程遠いです。
現実的な時間でルービックキューブの準最適解を見つけるアルゴリズムとして、Two-Phase-Algorithmが広く使われています。
ルービックキューブの解法をを2つのフェーズに分解し、それぞれを総当りで解くというやり方です。Phase1では、ルービックキューブを自由に動かして、
<U,D,R2,L2,F2,B2>の動きだけで完成できる状態に持っていきます。
Phase2では、そこから<U,D,R2,L2,F2,B2>の動きだけを使って完成まで持っていきます。Phase1は最悪で12手、だいたい10手くらい、
Phase2は最悪で18手、だいたい13〜14手くらいで完成できます (c.f. http://kociemba.org/math/symmetric.htm)。探索深さ (手順長) が深くなればなればなるほど指数関数的に探索範囲も増えていくので、フェーズを分けずに総当りするとだいたい18手掛かるのに対し、10手の探索と13手の探索に分ければ速くなります。
Two-Phase-Algorithmは、程よく2フェーズに分解して手数の短い2ステップに分けたということも重要なのですが、加えて重要なのは、フェーズを2つに分けたことにより各フェーズの状態数が減り、状態をインデックス化し予め状態遷移表を作っておくことができる点と、枝刈り用の表も事前計算しておけるということです。
中編の実装は、探索のたびにStateクラスのインスタンスが生成されていて、その部分も実は遅いです。状態のインデックス化によってそこも改善していくことができます。探索に時間をかければ最適解にどんどん近づけて行くことができるのも特徴です。
Two-Phase-Algorithmの実装は後編に回します。参考文献
- 投稿日:2020-06-19T12:36:36+09:00
Format表記
t = (1, 2, 3) print('{0[0]} {0[2]}'.format(t)) #1 3 print('{t[0]} {t[2]}'.format(t=t)) #1 3 print('{} {}'.format(t[0], t[2])) #1 3 こちらは数が多くなると面倒 print('{0} {2}'.format(*t)) #1 3 展開 print('{0} {2}'.format(1, 2, 3)) #1 3 上と同じ d = {'name': 'jun', 'family': 'sakai'} print('{0[name]} {0[family]}'.format(d)) #jun sakai print('{name} {family}'.format(**d)) #jun sakai 展開 print('{name} {family}'.format(name='jun', family='sakai')) #jun sakai 上と同じ print('{:<30}'.format('left')) #全体が30文字で左寄りに表示 print('{:>30}'.format('right')) #全体が30文字で右寄りに表示 print('{0:^30}'.format('center')) #全体が30文字で中央寄りに表示 print('{0:*^30}'.format('center')) #全体が30文字で中央寄りに表示、*で隙間を埋める print('{name:*^30}'.format(name='center')) #上と同じ print('{name:{fill}{align}{width}}'.format(name='center', fill='*', align='^', width=30)) #上と同じ print('{:,}'.format(123456789)) #123,456,789 print('{:+f} {:+f}'.format(3.14, -3.14)) #+3.140000 -3.140000 print('{:f} {:f}'.format(3.14, -3.14)) #3.140000 -3.140000 print('{:-f} {:-f}'.format(3.14, -3.14)) #3.140000 -3.140000 print('{:.2%}'.format(19/22)) #86.36% print('{}'.format(19/22)) #0.8636363636363636 print(int(100), hex(100), oct(100), bin(100)) #100 0x64 0o144 0b1100100 print('{0:d} {0:#x} {0:#o} {0:#b}'.format(100)) #100 0x64 0o144 0b1100100 print('{0:d} {0:x} {0:o} {0:b}'.format(100)) #100 64 144 1100100 0x,0o,0bなどの表示が消える for i in range(20): for base in 'bdX': print('{:5{base}}'.format(i, base=base), end=' ') print()実行結果:
1 3 1 3 1 3 1 3 1 3 jun sakai jun sakai jun sakai left right center ************center************ ************center************ ************center************ 123,456,789 +3.140000 -3.140000 3.140000 -3.140000 3.140000 -3.140000 86.36% 0.8636363636363636 100 0x64 0o144 0b1100100 100 0x64 100 0b1100100 100 64 100 1100100 0 0 0 1 1 1 10 2 2 11 3 3 100 4 4 101 5 5 110 6 6 111 7 7 1000 8 8 1001 9 9 1010 10 A 1011 11 B 1100 12 C 1101 13 D 1110 14 E 1111 15 F 10000 16 10 10001 17 11 10010 18 12 10011 19 13
- 投稿日:2020-06-19T11:01:39+09:00
EC2の起動時にPython(Flask)を起動する方法
はじめに
EC2の起動時間が営業時間内に設定されている場合、毎朝コマンドを叩くのが面倒なので、
今回はpythonで作ったAPI(Flask)をshellを自動起動するようにしました。
参考サイトの方法を忘れないようにまとめたものです。apiのshell化
自分は権限が足りなかったのでsudo
# sudo vim /usr/local/start_api.sh ---------------------------------- #!/bin/bash nohup python3 /usr/local/api.py & exit 0自動起動の設定
ここでも権限が足りなかったので、sudoしました。
# sudo vim /etc/init.d/api_start ------------------------------- #!/bin/sh # chkconfig: 345 99 10 # description: start_api shell case "$1" in start) bash /usr/local/start_api.sh ;; stop) /usr/bin/kill python echo "stop!" ;; *) break ;; esac実行権限の付与
ここでもsudo
$ cd /etc/init.d $ sudo chmod 775 api_start自動起動への登録
$ chkconfig --add api_start ## 自動起動をonにする $ chkconfig app_start on ## 設定されているかを確認する $ chkconfig --list app_start api_start 0:off 1:off 2:on 3:on 4:on 5:on 6:offこうなれば終わり。
ちなみに、win10のコマンドプロンプロトの場合、ファイルの色が変わります。(白→緑)
最後に
インスタンスを再起動して、起動されているかを確認して、終わり。
参考サイト
https://hit.hateblo.jp/entry/aws/ec/initd
https://dev.classmethod.jp/articles/ec2shell/


- 投稿日:2020-06-19T10:59:46+09:00
Python超初心者の超初心者のためのPython #辞書型1
環境
windows7 (Mac Book Pro 16inch欲しい)
Visual Studio Code
chrome
python ver3.8.3この記事はプログラミング初心者かつPython初心者に向けて記述します。
辞書型
辞書型の作成は難しくはないのですが、超初心者の私はいくつかミスをしてしまいます。
まずは辞書型の作り方です。
{ }波括弧の中にキーと値を記述します。
キーは{ }の中にキーの名前と:(コロン)で記述し、値は:(コロン)の後に記述します。
このときに私がミスしやすいのが、キーと値に文字列を記述するときに" "で囲うのを
忘れてしまいます・・・。お気をつけください。
キー1:値1と記述し、続いて,(カンマ)で区切ります。dict.py{ "キー1":"値1","キー2":"値2","キー3":"値3,・・・・・・ }辞書型を作成出来た所でこの辞書型の使い方です。
キーに対応する値は下記のように取り出します。dict.pyacademy_awards = {"グリーンブック": 2019, "シカゴ": 2003, "タイタニック": 1998} print(academy_awards["グリーンブック"]) #2019作成した辞書型で設定していない(存在していない)キーを指定するとErrorがでます。
しかし、.getメソッドを使うと設定していない(存在していない)キーを指定するとNone
が返ってきます。dict.pyacademy_awards = {"グリーンブック": 2019, "シカゴ": 2003, "タイタニック": 1998} print(academy_awards["ジョーカー"]) #KeyError: 'ジョーカー' print(academy_awards.get("ジョーカー")) #None
.getメソッドは引数の2つ目に文字列を記述すると、キーが存在しなかった場合に2つ目の
引数を返します。dict.pyacademy_awards = {"グリーンブック": 2019, "シカゴ": 2003, "タイタニック": 1998} print(academy_awards.get("ジョーカー", "その映画は作品賞には存在しません")) #その映画は作品賞には存在しませんその他にも、キーを全て取り出す、値を全て取り出す、キーと値全て取り出すことも出来ます。
それぞれ、.keys()、.values()、.items()で行います。python.dict.pyacademy_awards = {"グリーンブック": 2019, "シカゴ": 2003, "タイタニック": 1998} print(academy_awards.keys()) #キーを取り出す #dict_keys(['グリーンブック', 'シカゴ', 'タイタニック']) print(academy_awards.values()) #値を取り出す #dict_values([2019, 2003, 1998]) print(academy_awards.items()) #全てを取り出す #dict_items([('グリーンブック', 2019), ('シカゴ', 2003), ('タイタニック', 1998)])fin
目次
Python超初心者の超初心者のためのPython #Hello World
Python超初心者の超初心者のためのPython #こんがらがりやすいとこ
Python超初心者の超初心者のためのPython #型(type)と型(type)の確かめ方
Python超初心者の超初心者のためのPython #型(type)を変換する方法:str編
Python超初心者の超初心者のためのPython #型(type)を変換する方法:int、float編
Python超初心者の超初心者のためのPython #.txtファイルを作業中の.pyで読み込む
Python超初心者の超初心者のためのPython #関数1
Python超初心者の超初心者のためのPython #関数2
Python超初心者の超初心者のためのPython #len関数
- 投稿日:2020-06-19T10:51:32+09:00
Flake8でチェック対象外を指定する方法
需要があるか分からないが、日本語の技術情報を増やすためにも書いてみる。
PythonのコードチェックにFlake8を使う際、ファイルやディレクトリをチェック対象から外したい場合があると思う。そんな時のやり方。
flake8 --exclude=./env/lib/python3.8/site-packages/ .上記のように、「--exclude」オプションでチェック対象外のファイルやディレクトリを指定できる。ちなみに、上記は
- 「./env/lib/python3.8/site-packages/」ディレクトリを除いて
- カレントディレクトリ(最後の「.」で指定)をチェック対象とする
という意味になる。
参考
https://flake8.pycqa.org/en/latest/user/options.html#cmdoption-flake8-exclude