- 投稿日:2020-06-19T23:38:32+09:00
QRadarにAWS CloudTrailを取り込んで見よう 〜ログソース設定
はじめに
これまではAWS環境にIBM QRadar Community Edition V7.3.3を構築した話を投稿してきました。
SIEM製品にログ情報が何も見えないのはつまらないため、ここから実際にログソースを登録することも試してみたいと思います。AWS CloudTrailとは何か?
AWSを触った方であれば、必須といっても良い監査ログ。AWS基盤においては最も重要となるAPI使用の監査情報になります。詳細は公式サイトをご参照下さい。
公式ドキュメントのCloudTrailサンプル例を見ると、実際に監査ログがどのように出力されているのか分かります。例)IAM ユーザーである Alice が AWS CLI を使用して、CreateUser アクションを呼び出し、Bob という名前の新しいユーザーを作成した際の監査ログ
{"Records": [{ "eventVersion": "1.0", "userIdentity": { "type": "IAMUser", "principalId": "EX_PRINCIPAL_ID", "arn": "arn:aws:iam::123456789012:user/Alice", "accountId": "123456789012", "accessKeyId": "EXAMPLE_KEY_ID", "userName": "Alice" }, "eventTime": "2014-03-24T21:11:59Z", "eventSource": "iam.amazonaws.com", "eventName": "CreateUser", "awsRegion": "us-east-2", "sourceIPAddress": "127.0.0.1", "userAgent": "aws-cli/1.3.2 Python/2.7.5 Windows/7", "requestParameters": {"userName": "Bob"}, "responseElements": {"user": { "createDate": "Mar 24, 2014 9:11:59 PM", "userName": "Bob", "arn": "arn:aws:iam::123456789012:user/Bob", "path": "/", "userId": "EXAMPLEUSERID" }} }]}AWSではCloudTrailのベストプラクティスを以下のように提言しています。
- 証跡の作成
- 証跡をすべての AWS リージョンに適用する
- CloudTrail ログファイルの整合性の実現
- Amazon CloudWatch Logs と統合する
- 専有および一元化された Amazon S3 バケットへのログ
- AWS KMS で管理されたキーを使用したサーバー側の暗号化
- ログファイルを保存する Amazon S3 バケットへの最低限のアクセス権限を実装する
- ログファイルを保存する Amazon S3 バケットで MFA Delete を有効にする
- ログファイルを保存する Amazon S3 バケットにオブジェクトライフサイクル管理を設定する
- AWSCloudTrailFullAccess ポリシーへのアクセスを制限するIBM QRadar SIEMにCloudTrailを取り込む場合、AWS側が推奨するCloudWatch Logsのアラート設定と若干被る部分も出てきますが、この辺りも実運用使い分けが出来ます。まず本編はQRadarにログソースとして追加し、CloudTrailを取り込むことを目的にご紹介します。
事前準備 - IBM QRadar
IBM QRadar側は以下の事前準備が必要です。
詳細はIBM QRadar DSMガイド AWS CloudTrailでご確認下さい。
- AWS CloudTrail DSMの導入(別投稿でご紹介しています。こちらをご参照下さい)
- AWS CloudTrailの証跡の有効化
- S3 BucketにCloudTrailが保管されていること
- CloudWatch LogsにCloudTrailが出力されていること
接続方式の比較 - メリット・デメリットを考える
ドキュメントを見ると幾つかの接続方法が掲載されていますが、AWSのテクノロジーとIBM QRadarに精通した方でないと中々分かり難い内容になっています。各方式について考えてみます。
- S3直接接続方式
- Amazon AWS CloudTrail log source that uses an S3 bucket with a directory prefix
- CloudTrailの出力先であるS3 Bucketに対して直接ポーリングを行う方法
- メリット
- 設定がシンプルで分かり易い。
- 切り分けなどが容易。
- デメリット
- マルチアカウントで束ねられている CloudTrail のS3 Bucketに未対応
- リージョンは特定リージョンのみ
- S3->SQSポーリング形式
- Amazon AWS CloudTrail log source that uses an S3 bucket with a directory prefix
- S3 Bucketに更新されたCloudTrailファイルをAmazon SQSキューに通知し、QRadarはSQSキューを読み込む方法
- メリット
- マルチアカウント/複数リージョンに対応する
- キューイングサービス経由で受け渡しを行うため、疎結合になっており耐障害性が高い。
- デメリット
- 設定がやや複雑(S3->SQS設定、IAM権限設定など)
- CloudTrail(CloudWatch Logs) -> Kinesis DataStream経由による方式
- Adding an Amazon AWS CloudTrail log source by using the Amazon Web Services protocol and Kinesis Data Streams
- CloudTrailの出力をCloudWatch Logsで行う
- CloudWatchLogsからQRadarへ受け渡しを行う際に、Kinesis Streamにキューイングさせ、QRadarはキュー経由での受け渡しを行う。(疎結合)
- メリット
- マルチアカウント/複数リージョンに対応する
- キューイングサービス経由で受け渡しを行うため、疎結合になっており耐障害性が高い。
- デメリット
- 設定が複雑(CloudWatch Logs->Kinesis設定、IAM権限設定など)
- CloudTrail(CloudWatch Logs) -> QRadar(Web Services Protocol収集)
- Configuring an Amazon AWS CloudTrail log source by using the Amazon Web Services protocol and CloudWatch Logs
- CloudWatch Logsに出力されているCloudTrailをQRadar側から読み込む
- メリット
- CloudWatch Logsを取り込む設定が容易。GuardDutyも同じ取り込み方法なので統一できる
- デメリット
- 疎結合ではない
昔はS3のRESTAPIだけだったのが選択が増えたため、どれを使うか迷われる方が多いのではと思います。
もし、本番環境のマルチアカウント環境に対して、CloudTrailの監視をIBM QRadarで行いたい、といった要望なのであれば 「2. S3->SQSポーリング形式」か、「3.CloudTrail(CloudWatch Logs)-> Kinesis DataStream」経由のどちらかかなと思います。
Splunkも取り込み方式が複数選べるのですが、パフォーマンスや受け渡し専用のキューイングを挟むことで障害切り分けもしやすくなる、といったメリットがあり、実践としてはSQS、Kinesisなどのサービスを経由させることが多いようです。DSM設定を行う 〜 AWS CloudTrail
それでは QRadar に AWS CloudTrailの設定を行ってみます。方法はもっともシンプルな1)のS3 RESTAPI直接続を試してみました。筆者の環境は QRadar Community Editionでライセンス制約があり、大量のイベントを取り込めないことや、まずはシンプルに接続した上でステップ毎に検討してみるのが重要です。
1. IAMロールの作成
今回、IBM QRadarはAWS環境のEC2にある想定で設定を行います。
EC2上にあるIBM QRadarから、CloudTrailのS3 Bucketにアクセスする場合、IAMロールの権限をEC2に設定することで、QRadar側にAPIのアクセスキー/パスワードを埋め込む必要が無くなります。
ドキュメントにあるIAMロールの例は以下です。Resource句のBucket名、AWSアカウントID、リージョン名などを収集する対象に変更しましょう。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "s3:GetObject", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::<bucket_name>", "arn:aws:s3:::<bucket_name>/AWSLogs/<AWS_account_number>/CloudTrail/ap-northeast-1/*" ] } ] }IBM QRadarのEC2にIAMロールを反映させます。
IBM QRadar DSM設定
DSMのログソース設定画面で設定した例です。
ログソースを設定後、デプロイを行なって反映させます。
ログアクテイビィティから確認
無事、ログソース接続が行われると、IBM QRadarのログアクティビティ画面より CloudTrail のログ情報が取り込まれているのが分かります。
まとめ
今回、AWS用のDSMを用いてCloudTrailのログを取り込んでみました。
次回からは、実際に取り込んだログを活用した IBM QRadar の相関分析ルールを実践してみたいと思います。




- 投稿日:2020-06-19T23:21:34+09:00
AWSのリソースを列挙して選択するコマンドを作った
↓のgifのように、awsのリソース(ec2のインスタンス、RDSのDBインスタンス等)を一覧で表示し、選択できるコマンドを作りました。
動機
AWS CLIの以下の2つのサブコマンドは非常に便利です。
- CloudWatch Logsのロググループに対してtail -fできるaws logs tail --follow
- ブラウザではなく、普段使ってる仮想端末でsshみたいなことができるaws ssm start-sessoin
ただ、これらのコマンドを利用する際、tailではロググループ名、start-sessionではec2のインスタンスIDを要求されます。ロググループ名は/aws/xxx/xxxxxxxみたいなやつで、インスタンス名はi-00000000000みたいなもので、自分はどちらも全く覚えることができません。
今年2月に一般利用可能になったAWS CLI v2ではパラメータ名に加え、値となるリソース値も補完してくれるようになったのですが、start-sessionの場合、補完対象のインスタンスIDがi-00000000000形式で列挙されるだけなので、この場面において、自分にとってはほぼ無力な機能です。
aws ssm start-session --targetを入力してからタブキーを押すとこのような状態になります。選ぶための手がかりがない……。
$ aws ssm start-session --target i-0 i-01dbc40d8766f2e2a i-04075abf1e235eca7 i-0a3e5b84784834154 i-0d3a413486b29ec6e i-01c08ae12cf4ec1dc i-02fade28796f8cbe8 i-0d71d42852cc2979f i-0e51e9f37b37d987eつくったもの
この事態に対処すべく、hrkkというコマンドを作りました。指定されたリソースをawsのAPIから取得し画面に表示、ファジーファインダー(skimを使ってます)を使って選択、選択されたもののIDを標準出力に返します。たとえば、hrkk ec2 instanceとして実行すると、ec2 instanceのNameタグの値、インスタンスIDなどを一覧で表示し、選択されたインスタンスのインスタンスIDを標準出力へ返します。
aws logs tailならロググループの名前が必要なので、
$ aws logs tail --follow $(hrkk -r 10 logs log-group)とすることで、アカウントに存在するロググループ名のリストを表示、あいまい検索して絞り込んでから選択し、そのロググループをtailすることができます。自分はbashを使ってるので$()ですが、他のシェルにも同じような機能があると思います(よく知りません)。あと、実際には↑のコマンドも覚えられないので、naviというチートシートツールに上のコマンドを登録して使っています。
*) -r オプションはリクエスト発行上限数です。aws APIのdescribe-XX系のコマンドは、一回の取得数に上限が設けられているため、繰り返しリクエストして取得する前提なのですが、あまりにも多数リクエストするとコストもかかるので、オプションで上限を指定してます。デフォルトは1なので、1リクエストで取得できる分しか取得しませんイメージが湧きづらいと思うので、用意したgifが一番↑のものです。
もともとは上記2つのコマンドのパラメーターを入力しやすくするために作り始めたのですが、コンソールからAWSの状態が確認できるとなんか面白いということがわかったので、現状、
- ssm : session, document, automation-execution
- rds : db-instance
- logs : log-stream, log-group
- ec2 :instance
- cloudwatch : alarm-history, alarm
などが追加してあります。
また、--exportオプションを使用すると、選択したリソースの情報をyamlで現在のディレクトリに出力できます。これはこの2つって設定おなじに見えるけど実際にはどこか違うの?というのをdiffで確認したりするのに使えます。
ちなみに複数選択する場合はタブキーを使用します。一覧の表示はskimをライブラリとして組み込んで使用しているので、キーバインド等はskimのreadmeを参照ください。
画面右のpreviewは自分がリソースを選択する際に見そうな項目を適当に抽出してあります。全部見たい場合は、~/.cache/hrkk 以下にcache用にレスポンスが保存されるので、そっちをご覧ください。
インストール
homebrew
homebrewが使えるlinuxかmacであれば、
brew install K2Da/tap/hrkkでインストールできると思います。自分の環境以外では試せてない(macも持ってない)ので動かなかったらすいません。
homebrewを利用してますが、homebrewのFormulaにはbin.installを指定してあり、実際にはreleaseページのバイナリをコピーするだけになっています。ビルドターゲットは、linuxがx86_64-unknown-linux-musl、macがx86_64-apple-darwinです。逆に言うと、homebrewがないばあいは、バイナリをコピーすれば動くと思います。
cargo
cargo環境がある方は、cargo install hrkkで良いと思います。
AWS cli設定
aws cliが動作するのに必要な設定(~/.aws/以下のファイル、もしくは環境変数)が必要です。hrkkを使うだけなら、aws cli自体は不要です。
Rusotoの認証を使っているので、基本的にaws cliと同じ順番でプロファイルを選択するようになっており、
- --profileオプションがあれば、指定されたプロファイル
- なければ環境変数
- 環境変数もなければdefaultプロファイル
を使います(はずです)。
describe-XX系の権限あるけどMFAしないと使えない、もしくはMFA + assume roleが必要、という方は、ngydvという別のコマンドも作ったので併用すると便利かも知れません。こちらは、create-sessionやassume-roleして取得したtokenをファイルに出力しておき、環境変数に設定することでprofileを切り替えるためのコマンドです。

- 投稿日:2020-06-19T23:08:50+09:00
AWS CloudFormationのYAMLファイルでCommaDelimitedListの空判定をしたい
TL; DR
!Joinがここで使えるんだ!はじめに
CloudFormationには、パラメーターの型に
List<Number>型とCommaDelimitedList型が存在します。
これらは、パラメーター値として,(カンマ)区切りの数値または文字列を入力すると、カンマで分割したリストに変換してくれるというものです。List<Number>
カンマで区切られた整数または浮動小数点値の配列。AWS CloudFormation は、このパラメータを数値として検証しますが、テンプレート内の他の場所で使用した場合には (Ref 組み込み関数を使用した場合など) 一連の文字列として扱います。
たとえば、"80,20" と指定し、Ref を使用した場合には ["80","20"] となります。
CommaDelimitedList
カンマで区切られたリテラル文字列の配列。文字列の合計数は、カンマの合計数よりも 1 つ多いはずです。また、各メンバー文字列の前後の空白は削除されます。
たとえば、"test,dev,prod" と指定し、Ref を使用した場合には ["test","dev","prod"] となります。これを使うことで、設定したい項目数を動的に変更したい場合1にも、表現の幅が広がります。
クロスアカウントアクセス
1例として、S3バケットのクロスアカウントアクセスに必要なAWSアカウントIDが挙げられます。
クロスアカウントアクセスとは、とあるAWSアカウントのS3バケットを、他AWSアカウントから見るようにできる設定のことを意味します。
設定方法は省略しますが、下記が参考になります。クロスアカウントアクセス時のCFn.yamlResources: Account1BucketPolicy: Type: AWS::S3::BucketPolicy Properties: Bucket: account1-bucket PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: AWS: - 000000000000 # クロスアカウントアクセス可能なAWSアカウント - 123456789012 # クロスアカウントアクセス可能なAWSアカウント Action: - s3:GetObject - s3:ListBucket Resource: - arn:aws:s3:::account1-bucket - arn:aws:s3:::account1-bucket/*
PrincipalハッシュにおけるAWSキーの値として、 複数のAWSアカウントを指定できます。
これにより、 Account1 の account1-bucket バケットを、 000000000000 アカウントと 123456789012 アカウントが GetObject および ListBucket できます。
AWSキーの値として、パラメーターCommaDelimitedList型の値を参照することで、下記のように1つ以上のAWSアカウントを設定できます。パラメーターによるクロスアカウントアクセス時のCFn.yamlParameters: AccountIdList: Type: CommaDelimitedList Resources: Account1BucketPolicy: Type: AWS::S3::BucketPolicy Properties: Bucket: account1-bucket PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: AWS: !Ref AccountIdList # クロスアカウントアクセス可能なAWSアカウントのリスト Action: - s3:GetObject - s3:ListBucket Resource: - arn:aws:s3:::account1-bucket - arn:aws:s3:::account1-bucket/*AWS::S3::BucketPolicy - AWS CloudFormation
これは嬉しいですよね。
問題点
しかし、1つだけ問題があります。
それは、0つ以上のAWSアカウントを設定できない点です。もし上記のCFn.yamlファイルを実行する際、パラメーターに空文字を入力する場合(または、Defaultを空文字にした上でパラメーターを与えない場合)、正しく動作しません。
これは、PrincipalハッシュにおけるAWSキーの値に空文字を入力できないためです。これを防ぐためには、 Condition によってリソース自体を除去するしか方法はありません。
しかし、下記の場合はエラーとなります。
every Fn::Equals object requires a list of 2 string parameters.と言われてしまうためです。Conditionを利用しようとしたクロスアカウントアクセス時のCFn.yamlParameters: AccountIdList: Type: CommaDelimitedList Default: '' Condition: IsEmpty: !Equals [ !Ref AccountIdList, [] ] # エラー! Resources: Account1BucketPolicy: Type: AWS::S3::BucketPolicy Condition: IsEmpty # false の場合に Account1BucketPolicy リソース自体を作成しないようにしたい Properties: Bucket: account1-bucket PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: AWS: !Ref AccountIdList # クロスアカウントアクセス可能なAWSアカウントIDのリスト Action: - s3:GetObject - s3:ListBucket Resource: - arn:aws:s3:::account1-bucket - arn:aws:s3:::account1-bucket/*解決策
!Equals組込み関数は、2つの値が両方とも String 型でなければならないリスト同士の比較はできないそうです。
ドキュメントにはそんなこと一言も書いてないどころか、任意の型で判定できるかのように書いてあるんですけどね。value
比較する任意の型の値です。
これを解決する手法の1つに、
!Join組込み関数によるリストの文字列への変換があります。
正直、!Joinが役立つ時が来ると思ってませんでした。次の例は、
"a:b:c"を返します。JSON
"Fn::Join" : [ ":", [ "a", "b", "c" ] ]YAML
!Join [ ":", [ a, b, c ] ]これで解決!と思いきや、実はもう一つ、隠れた理由があります。
それは、PrincipalハッシュにおけるAWSキーの値に空文字を設定したままである問題を解決できていないためです。この問題は、ポリシードキュメントの文法規則の穴を突くことで、解決できます。
すなわち、自身のAWSアカウントIDを代入するのです。
そもそもの原因は、ポリシードキュメントでは、事前にAWSアカウントIDが存在していることを確認するような挙動をしています。
自身のAWSアカウントIDを代入することで、ポリシードキュメントを騙し、 Condition により、ダミーポリシー自体を除去できます。まとめると、下記の通りです。
修正後のCFn.yamlParameters: AccountIdList: Type: CommaDelimitedList Default: '' Condition: IsEmpty: !Equals [ !Ref AccountIdList, '' ] # エラー! + !Equals [ !Join [ ',', !Ref AccountIdList ], '' ] Resources: Account1BucketPolicy: Type: AWS::S3::BucketPolicy Condition: IsEmpty # false の場合に Account1BucketPolicy リソース自体を作成しないようにしたい Properties: Bucket: account1-bucket PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Principal: - AWS: !Ref AccountIdList # クロスアカウントアクセス可能なAWSアカウントIDのリスト + AWS: + - !If + - IsEmpty + - !Ref AWS::AccountId # 自身のAWSアカウントID + - !Ref AccountIdList # クロスアカウントアクセス可能なAWSアカウントIDのリスト Action: - s3:GetObject - s3:ListBucket Resource: - arn:aws:s3:::account1-bucket - arn:aws:s3:::account1-bucket/*
IsEmptyの!Equals組込み関数内で、!Joinを利用するPrincipalハッシュにおけるAWSキーの値で!Ifを利用し、リストが空の場合は自身のAWSアカウントIDを設定するこれにより、 CommaDelimitedList の空判定ができました。
また、ついでに不要なポリシーの除去もできました。CloudFormation Condition on CommaDelimitedList : aws
ちなみに
別のステートメントがポリシードキュメント内に存在する場合は、 Condition によるリソース除去ではなく、
!If組込み関数による空ステートメントの挿入だけで良いです。
空ステートメントには、AWS::NoValue疑似変数を利用します。
AWS::NoValueは、ステートメントの定義ハッシュ自体を除去するため、自身のAWSアカウントIDを設定するという抜け道を利用しなくても、ポリシードキュメントの文法を問題なく通過できます。静的に定義するステートメントが別に存在する場合のCFn.yamlParameters: AccountIdList: Type: CommaDelimitedList Default: '' Condition: IsEmpty: !Equals [ !Join [ ',', !Ref AccountIdList ], '' ] Resources: Account1BucketPolicy: Type: AWS::S3::BucketPolicy Properties: Bucket: account1-bucket PolicyDocument: Version: 2012-10-17 Statement: # 静的に定義するステートメント - Effect: Allow Action: * Resource: * # 動的に定義したいステートメント - !If - IsEmpty - !Ref AWS::NoValue # リストが空の場合 - Effect: Allow # リストが空じゃない場合 Principal: AWS: !Ref AccountIdList # クロスアカウントアクセス可能なAWSアカウントIDのリスト Action: - s3:GetObject - s3:ListBucket Resource: - arn:aws:s3:::account1-bucket - arn:aws:s3:::account1-bucket/*AWS::NoValue
Fn::If組み込み関数の戻り値として指定すると、対応するリソースプロパティを削除します。おわりに
CFnを触り続けてひと月が経過しましたが、宣言型文法で動的処理をするのは骨が折れますね。
ただ、CFnはAWSの全てのサービスを大雑把でも理解していないと触れないと思うので、AWSに強くなったひと月だったと思います。皆さんも、CommaDelimitedListで
抜け道面白い使い方を見つけてみてください。
- 投稿日:2020-06-19T21:32:19+09:00
【AWS RDS】Unable to create a snapshot as the database instance is not in available stateの意味
エラー発生
RDSの作成中に「Unable to create a snapshot as the database instance is not in available state」のエラーが出た。
エラーの意味
調べてみると下記の英語のサイトに意味が載っていた。
https://docs.druva.com/Knowledge_Base/Druva_CloudRanger/Troubleshooting/Unable_to_create_a_snapshot_as_the_database_instance_is_not_in_available_state
サイトの内容は以下の通り。エラーの説明
エラーによりRDSのバックアップに失敗した。
"Unable to create a snapshot as the database instance is not in available state."
「DBインスタンスが利用可能状況ではないため、スナップショットを作ることができなかった。」ということだ。原因
AWSの制限
解決方法
RDSインスタンスを起動して、バックアップを起こしなさい。
今回の原因
RDSを作成したばかりで、まだ準備が整っておらずエラーが発生した。RDSの状態をチェックすると実行中になっていた。その後時間をおいて、もう一度スナップショットを作成したら無事作られた。
- 投稿日:2020-06-19T20:25:19+09:00
【AWS入門】音声-テキスト変換して遊んでみた♪
同じように見えるがこちらは、資料がほとんど無い。
参考のものを見てどうにか出来た。
昨夜の音声を貼っておく。今夜はこれをテキスト変換した。
音声発生【参考】
①Getting Started (AWS SDK for Python (Boto))
②Amazon Transcribeで音声の文字起こしを行う。
③S3 → Lambda → Transcribe → S3 で文字起こしパイプラインを作成する参考①より、以下のようなコードが出来る。
ほぼ参考①と同じように見えるが、一か所参考③を見て、出力先をOutputBucketName='バケット名'として指定している。
これが無いと、ほぼどこに出力されたのかが分からなかった。
※特に指定して存在している場合もファイルは隠しファイルになっているようである
⇒最後にもう一度見たらファイルが見えましたfrom __future__ import print_function import time import boto3 transcribe = boto3.client('transcribe') job_name = "test_tran3" job_uri = "https://バケット名.s3.amazonaws.com/speech.mp3" transcribe.start_transcription_job( TranscriptionJobName=job_name, Media={'MediaFileUri': job_uri}, MediaFormat='mp3', #wav, mp4, mp3 LanguageCode='ja-JP', #'en-US' OutputBucketName='muauanmp3' ) while True: status = transcribe.get_transcription_job(TranscriptionJobName=job_name) if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']: break print("Not ready yet...") time.sleep(5) print(status)上記コードで以下のような出力が得られる。Not ready yetは5秒に一回出力されるが、6回以上出力しているから30秒程度はかかっているようだ。
そして、一応結果のjsonを吐くがあまり意味は分からない。$ python3 boto_transcribe.py Not ready yet... ... Not ready yet... {'TranscriptionJob': {'TranscriptionJobName':..., 'content-length': '506', 'connection': 'keep-alive'}, 'RetryAttempts': 0}}そこで、参考②がやっているように、s3のバケットのファイルを確認する。
音声ファイルspeech.mp3と共に出力されたtest_tran3.jsonなどのファイルが見える。$ aws s3 ls s3://バケット名 2020-06-19 04:52:36 2 .write_access_check_file.temp ... 2020-06-18 23:44:17 35467 speech.mp3 ... 2020-06-19 04:45:47 1472 test_tran2.json 2020-06-19 04:54:09 1663 test_tran3.json次に、s3://バケット名/test_tran3.json をec2サーバーにコピーする。
$ aws s3 cp s3://バケット名/test_tran3.json ./ download: s3://バケット名/test_tran3.json to ./test_tran3.json最後に、jsonの中身を以下のコマンドで出力する。
ちゃんと言語があっていると、以下のように正しく出力されたが、同じ音声ファイルを英語の指定でtranscribeした結果は、下のようにアルファベットになっているが、どうも変!
とはいえ、これで一応の音声-テキスト変換が出来た。$ cat test_tran3.json |jq .results[][0].transcript "こんにちは 東京 横浜 も 少し 曇り です 声 は 水木 さん です" $ cat test_tran2.json |jq .results[][0].transcript "Tokyo, Yokohama, Moscow See Commodities, Cueva Mitic Sundays."しかし、実際に使う場合は、やはり手打ちではなくpythonコードでやりたい。
というわけで、いろいろ調査した結果、以下の参考のようなことが出来ることが分かった。【参考】
④boto3を使ってS3にファイルのアップ&ダウンロード
⑤pandasでJSON文字列・ファイルを読み込み(read_json)
⑥JSONで配列の入れ子構造や値の取得方法などをPythonを使って説明!
これらのやり方をコードに落とすと以下のようになる。
つまり、
① jsonファイルをダウンロード
② pandasで読み込む
③ 必要な部分を出力する
という方法である。import pandas as pd s3 = boto3.resource('s3') #S3オブジェクトを取得 bucket = s3.Bucket('バケット名') #bucket定義 bucket.download_file('test_tran3.json', 'test_tran3.json') #ec2へダウンロード;ダウンロードファイル、ダウンロード後ファイル df = pd.read_json('test_tran3.json') #jsonファイルをpandasで読込 print(df['results'][1][0]['transcript']) #jsonファイルから変換文字列を抽出こうして一連の作業の結果無事に以下のセンテンスが得られました。
※結果はよく見ると分かち書きされているのが分かりますこんにちは 東京 横浜 も 少し 曇り です 声 は 水木 さん です・バリエーション
アプリ応用
単品で、議事録や翻訳などは普通に使えそうです。
さらに、昨晩のテキスト-音声と合わせると、以下のようなシークエンスが構成出来ることが分かります。テキスト-音声-...-音声-テキストということで、...の部分の処理はいろいろ考えられます。
パーポや資料の読み上げと質問のシークエンスをテキストで記録する。
つまり、最初のテキストや音声と処理後の音声やテキストは異なると思われます。
また、他のシーケンスも考えられます。
会話アプリの場合だと、上記の配置は逆転して音声-テキスト-会話アプリ-テキスト-音声というのが考えられます。
これは、アレクサなんかのシークエンスですね。
この場合は、テキストベースの変換なので、普通に翻訳が出来そうです音声QA
アレクサみたいな音声-QAアプリも作れそうです。
質問をスマホなどの音声で受け付けて、その裏で上記のアプリを動かせばリアルタイムな音声QAも出来そうです。Twitter補助
Twitterに限らないけど、要は、入力は音声で出力も音声でやることもできそうです。
。。。ただし、これらのアプリにするにはもうひと頑張り必要ですね。まとめ
・音声―テキスト変換で遊んでみた
・pythonで一連の動作を作成できた・jsonファイルが存在すると二度できないので、毎回同じジョブでやるには一連のシーケンスで削除が必要
・何かアプリ作ろう...
・テキスト翻訳もやろう
- 投稿日:2020-06-19T17:22:17+09:00
[AWS][CLI][S3]s3コマンド実行したら Credential named assume-role-with-web-identity not found エラー
背景
EC2(Amazon Linux)でS3へのログバックアップが機能していなかったので確認したところ
aws s3 cpコマンドで実行エラーが発生していました。Credential named assume-role-with-web-identity not found環境
# 説明 OS Amazon Linux AMI 2018.03 AWS CLI $ aws --versionの結果aws-cli/1.18.83 Python/2.7.18 Linux/4.14.165-103.209.amzn1.x86_64 botocore/1.12.152 ちなみに他サーバの以下のバージョンでは動作しています。
- aws-cli/1.16.34 Python/2.7.5 Linux/3.10.0-1062.12.1.el7.x86_64 botocore/1.12.33
- aws-cli/1.16.179 Python/2.7.18 Linux/4.14.165-103.209.amzn1.x86_64 botocore/1.12.169
- aws-cli/2.0.24 Python/3.7.3 Linux/4.14.165-103.209.amzn1.x86_64 botocore/2.0.0dev28
おそらく
botocoreあたりの問題だと思われますが、アップグレードや再インストールしてみても解決できず。
- Strange "Credential named assume-role-with-web-identity not found." error · Issue #442 · 99designs/aws-vault · GitHub
- Deploy with cloudformation fails from awscli >= 1.16.210 · Issue #4384 · aws/aws-cli · GitHub
- amazon s3 - how to check awscli and compatible botocore package is installed - Stack Overflow
結局、AWS CLIのバージョン2が安定版としてリリースされて使用を推奨されているので素直に置き換えてみたところあっさり動作しました。
- 投稿日:2020-06-19T12:19:56+09:00
AWS☆☆☆ デプロイまでの道のり3(短いバージョン、全5回)
1)背景
第3回目です。自身のポートフォリオをデプロイするために、いよいよunicornを介してrailsを起動します。
AWS関連手順記事はすごく多いので、ここでは備忘録も含めて、非常に端的に手順を記載します。
全5話で進めます。2)環境
項目 内容 OS.Amazon Linux AMI release 2018.03 Ruby v2.5.1 Ruby On Rails v5.2.4.3 MySQL v5.6 Unicorn v5.4.1 3)内容
以下設定で75分程度かなと思います。(段取りが分かっていれば、30分)
※【ローカルマシン】指定以外は、全てAWSでの作業になります。(1)【ローカルマシン】Unicornの設定(20分)
- Gemfileにunicornを記述
- bundle installの実行(ユニコーン導入)
- 作成された設定ファイル(unicorn.rb)の編集
(2)Gitのクローニング(15分)
- 格納フォルダの配置と権限付与
- Gitからのクローニング(※)
- AWSのswap領域作成(別記事をご参照ください)
※クローニングする際には以下が必要です。
(1)先ほどのローカルunicorn設定がpushされていること
(2)最新master化
(3)本番環境(production)のDBユーザ設定(3)本番デプロイ設定(30分)
- bundlerのインストール
- bundle installの実行(時間がかかります。)
- 秘密鍵の取得
- 環境変数にdbユーザパスワード(productionと合わせる)と秘密鍵を設定する
- DB-CreateとDB-Migrateの実行
- assetsディレクトリのプレコンパイル
(4)本番Rails起動(10分)
- インスタンスの3000番ポート開放
- unicornを介してサービスの起動
ここまで完了したら、「http://ElasticIP:3000」にアクセスすると、アプリケーションのトップページに遷移するはずです。
以上、短く記載しました。
ここまで、全てストレートに行ったわけではなく、エラーも出力されました。この辺りは、環境や設定により様々ですので、別記事にてエラー対策を掲載したいと思います。
- 投稿日:2020-06-19T11:46:19+09:00
AWS MediaConvertとS3/CloudFrontで作るストリーミングサーバ~その1~
はじめに
AWSにはメディアサービスと呼ばれる、リアルタイムにライブ配信したり、動画をVOD方式で配信したりするための仕組みが充実してます。これらのシステムを使ってビジネス上のコンテンツデリバリーシステムを構築している方々もたくさんいます。私は"見る側"として、いろんな配信サービスを利用してますが、インフラエンジニアとして、そこにはどんなサーバやストレージがあって、どのように組み合わさって動いてるのか興味がありました。OSSのffmpegやnginxなどを利用して勉強し始めていたところだったんですが、並行して、AWSのサービスを使って配信プラットフォームの仕組みを勉強していきます。
というのもAWSは、公式の学習用コンテンツが豊富にそろっていますし、すでに基盤があるわけなので、サーバやストレージを組み上げなくても、配信技術そのものを把握するのに早いかなと思いました。多角的に理解を深めるためにもOSSを使った勉強もしていきたいですが。。。今後数回にわたって、AWSのサービスをセットアップする際に気になったことなどをメモしていきます。あくまでメモなので、いろいろとご指摘などありましたら、よろしくお願いします。
1.やりたいこと(VOD)
まずはVOD形式の配信サービスを構築してみたいと思っています。ざっくりイメージにするとこんな感じです。
このフローをAWSのサービスに当てはめるとこんな感じです。
Step 手順 AWSで使うサービス 1 元のファイルをストレージにアップロード S3 2 H.264やHEVCなどの符号化処理 MediaConvert 3 HLSやMPEG-DASHなどへのパッケージング MediaConvert 4 Webサーバにアップロード S3 5 エッジサーバでキャッシュ CloudFront 6 パソコンやスマホのブラウザで視聴 - できる限りAWSの解説も加えながら、スマホやパソコンで動画を視聴することをゴールに、環境を構築していきます。
2.ソースファイル配置用のS3バケットの作成
S3(Amazon Simple Storage Service)は、Amazonのクラウド型オブジェクトストレージサービスで、ファイルをオブジェクトとして格納します。NFSなどの共有ファイルサービスのようにディレクトリ構造での格納ではなく、バケットと呼ぶスペース(コンテナ)でオブジェクトを管理します。公式サイトによるとS3に書き込まれたデータは、複数のAZ(アベイラビリティゾーン)やデバイスに冗長的に書き込まれるので耐障害性が高いというのも特徴の一つです。オブジェクトストレージに関する投稿は、OpenStack swiftを題材にいつか書きたいなぁ。
またS3は単にファイルを保管・管理するだけでなく、静的なwebサイトとしても動作します。この辺りはコンテンツ公開用のWebサーバを立ち上げるところで説明します。
今回の環境を構築する上で、S3に2つのバケットを作る必要があります。
- MediaConvertへ元の動画ファイルを渡すためのソースとなるバケット
- MediaConvertでエンコード/パッケージ処理されて出来上がったファイルの格納先となるバケット
バケット自体は簡単に作れます。
AWSのコンソールで、サービスの中からS3を選択します。
+バケットを作成するボタンをクリックします。そうするとバケットの作成のウインドウが表示されます。名前とリージョン
元の動画ファイルを配置するバケットを
video-input-01という名前で作成しました。
設定項目 設定値 バケット名 video-input-01 リージョン アジアパシフィック(東京) 既存のバケットから設定をコピー 空欄 オプションの設定
こちらはすべてデフォルト値で進めました。
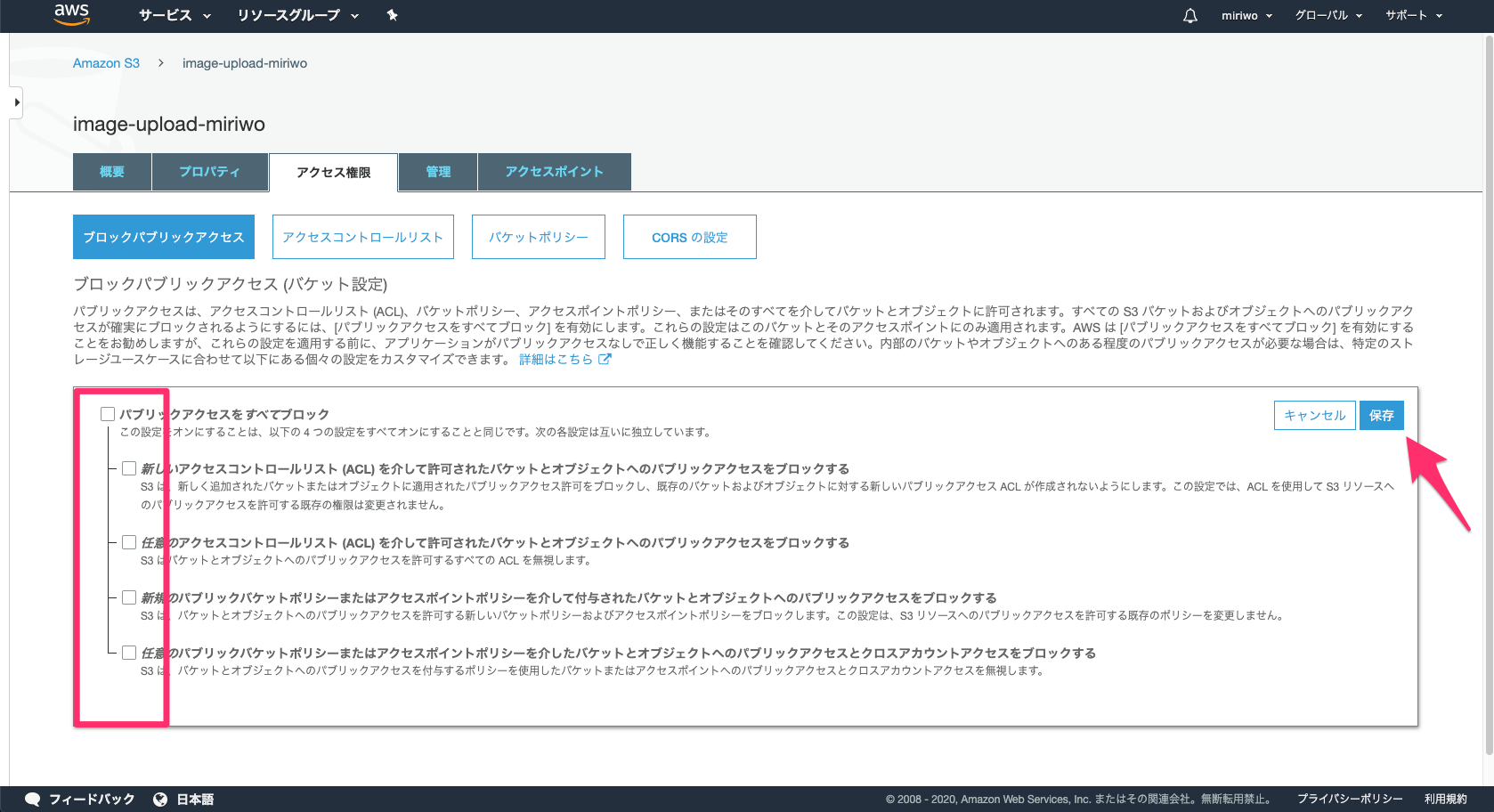
ブロックパブリックアクセス(バケット設定)
バケットに対するアクセス権に関する設定ですね。デフォルト値の☑パブリックアクセスをすべてブロックの状態のまま進めます。
バケットの作成
設定したことに間違いがないか確認してから、
バケットを作成をクリックします。これで、入力ソース用のビデオアップロード先ができました。3.ファイル書き出し用のS3バケットの作成
続いて同じ手順で、MediaConvertのアウトプットを格納するためのバケットを作ります。
こちらのバケット名はvideo-output-01にしました。今度はブロックパブリックアクセスは公開する設定にします。結果として以下の2つのバケットがコンソール上に現れます。
バケット名 アクセス権 リージョン video-input-01 パケットとオブジェクトは非公開 アジアパシフィック(東京) video-output-01 公開 アジアパシフィック(東京) この2つのバケットだけ用意しておけばよいのですが、出力先のvideo-output-01には、
dash01という名前で1つフォルダを作成しました。4.動画ファイルの準備
動画ファイルの入手
作成した
video-input-01にmovieファイルを置きます。今回は検証用ということで、Big Buck Bunnyの動画ファイルを使おうと思います。
- Big Buck Bunny, Sunflower version
Big Buck Bunny
Copyright (C) 2008 Blender Foundation | peach.blender.org
Some Rights Reserved. Creative Commons Attribution 3.0 license.
http://www.bigbuckbunny.org/ダウンロードサイトにはいろいろなバージョンのファイルがあるのですが、今回はStandard 2DのFull HD(1920x1080) 30fps H.264/AC-3のファイルにしました。
このファイルをBig Buck Bunnyの公式ダウンロードページからいったん手元の作業用PCにダウンロードします。
オーディオコーディングがAC-3というのが、1つ忘れてはならないポイントです。後で解説します。動画ファイルのアップロード
movieファイルのダウンロードが完了したら、そのファイルをS3のvideo-input-01に上げます。
- AWSコンソールでS3のコンソールを開きます。
- バケットの一覧が表示されているので、
video-input-01を選択します。アップロードボタンがあるのでクリックし、アップロードしたいファイルを選択し、アップロードボタンをクリックします。これでアップロードは完了です。
5.MediaConvertの符号化とパッケージングの設定
IAMロールの用意
MediaConvertを使った処理に入る前に、
IAMロールを設定します。IAMロールとはAWSの異なるサービス間を、セキュリティを担保しながら連携させるためのルール(ポリシー)の集まりのようなものです。
今回はS3とMediaConvertの2つのサービスを連動させるので、その間のアクセス権限を確保するためのIAMロールを用意します。
- AWSコンソールのサービスから
セキュリティ、ID、およびコンプライアンスにあるIAMをクリックします。- ダッシュボードから
アクセス管理>ロールをクリックします。ロールの作成をクリックします。信頼されたエンティティの種類を選択し、MediaConvertをクリックします。するとユースケースの選択にMediaConvert Allows MediaConvert service to call S3 APIs and API Gateway on your behalf.と表示されるので、次のステップ:アクセス権限をクリックします。- ロールに該当するポリシーが下記のように表示されますので、内容を確認して
次のステップ:タグをクリックします。
ポリシー名 次として使用 説明 AmazonAPIGatewayInvokeFullAccess Permissions policy(1) Provides full access to invoke APIs in Amazon API Gateway AmazonS3FullAccess Permissions policy(1) Provides full access to all backets via the AWS Management Console
- タグの追加については何も入力せず、
次のステップ:確認に進みます。- ここではロール名を指定します。私は
MediaConvert-01と名付けました。- 最後に
ロールの作成をクリックしてIAMロールの用意は完了です。MediaConvertでジョブをつくる
MediaConvertでエンコードしたりパッケージする処理はジョブという単位で行われます。
それでは先ほどアップロードしたビデオを処理するジョブを作ってみましょう。
- AWSコンソールのサービスから
メディアサービスにあるMediaConvertをクリックします。- 画面右上にある
ジョブの作成から今すぐ始めるをクリックします。入力の設定
ジョブの作成画面が表示されます。まずは入力1でソースのmovieファイルを指定します。
入力1にオブジェクトのパスを入力します。直接ではなくても参照ボタンを使えば、バケットとその中のファイルをプルダウン形式で選択できます。私の例では下記のように選択しました。
項目 設定 バケット video-input-01 ファイル bbb_sunflower_1080p_30fps_normal.mp4 結果として、パスは
s3://video-input-01/bbb_sunflower_1080p_30fps_normal.mp4となりました。この画面には、他にも
ビデオセレクタ、オーディオセレクタなど設定がたくさんあります。詳細は別途検証したいと思います。今回はこれらの設定はデフォルトのまま進めます。出力グループの設定(DASH-ISO)
出力グループを設定します。この設定は、いわゆる
パッケージャの設定になるところだと思います。
ここでは1つだけ出力グループを作ってみます。HLSやCMAFなどありますが、今回はDASH-ISOで作成します。
- 画面左にある
出力グループで追加ボタンをクリックします。- リストの中から
DASH-ISOを選択します。DASH ISOグループは、以下の通り設定しました。
設定項目 設定値 備考 カスタムグループ名 type-n-dash 送信先 s3://video-output-01/dash01/ S3上の出力先 サーバー側の暗号化 なし デフォルト値 アクセスコントロール パブリック読み取り 誰でも視聴できるように セグメント制御 セグメント化されたファイル セグメントファイルを分割して作成※1 フラグメントの長さ(秒) 2 デフォルト値※2 セグメントの長さ(秒) 30 デフォルト値※2 HbbTVのコンプライアンス なし デフォルト値 セグメントタイムラインを表現に書き込む チェックなし デフォルト値 MPDマニフェストプロファイル メイン セグメント化されたファイルの場合、メインのみ DRM暗号化は【Pro】用設定なのでoffのままです。
【設定していて理解できなかったこと】
※1:セグメントの制御の項目で
単一ファイルを選ぶと、1個のセグメントファイルだけが作成される。しかしこの単一ファイルで生成すると、どんな利点があるのかよく分からない。。。
※2:セグメントは分割された動画ファイル(.mp4)のことだと思ってて、その長さが30秒になるように生成されるという意味だと思うんだけど、その場合、ここで言うフラグメントの長さとはいったい何の長さなのかよく分からない。。。出力設定(Output1)
動画や音声に関するエンコードの設定をします。出力欄にある
Output 1をクリックします。
ここでも細かくいろいろなことが設定できます。いやいや細かすぎて私には理解しながら入力するのは今のままでは無理です...。
なので、今回は全体としてはデフォルト値を使って一部分だけ設定を変えてます。まず名前修飾子に、
bbb-dash_$Number$と入力しました。【動画】
ビデオコーデックはMPEG-4 AVC(H.264)を採用しました。というかそれ以外はすべて【Pro】用設定でした。
解像度を640x360、ビットレートを1.5mに設定して、あとはそのままです。【オーディオ1】
こちらは動画に比べわかりやすい設定値になってます。
オーディオコーデックをAdvanced Audio Codingにして、ビットレートは96.0、サンプルレートは48.0です。これらはすべてデフォルト値です。オーディオはAACでエンコードさせたかったです。ソースがAC-3なのでそのままパススルーされてしまうと、AC-3のコーデックが搭載されていないWindows環境では音が聞こえないからです。出力設定にはプリセットが用意されているのですが、そのプリセットを選択するとオーディオがエンコードされませんでした。選んだプリセットが悪かっただけなのだろうか...。一応全プリセットを確認したつもりなんですが。
IAMロールの設定
このジョブに、先の工程で作ったIAMロールを割り当てます
画面左にあるジョブの設定にある設定をクリックするとIAMロールを指定する箇所があるので、プルダウンメニューからMediaConvert-01を選びます。以上で、ジョブの作成は完了です。
4.ジョブの実行
画面下にある
作成ボタンをクリックすると、ジョブが生成されて同時に実行されます。ジョブのステータスがCOMPLETEに変わるまで待ちます。5.動画の視聴確認
送信先に設定したS3に、作成されたマニフェスト(.mpd)と、セグメントファイル(.mp4)が生成されているか確認します。S3サービスを開き、送信先のバケット/フォルダに移動します(私の場合、video-output-01/dash01)。1つのマニフェストとずらっとセグメントファイルが作られていることがわかります。
ブラウザからストリーミング再生して動画/音声が正しく視聴できるか確認してみましょう。とくにwebサーバを別途用意することなく、簡単にインターネットを介した視聴確認ができます。
ファイルのアクセス権の変更
まずはこれらのファイルのアクセス権を変更します。S3のコンソール上でvideo-output-01/dash01を開き、すべてのファイルを選択して
アクションから公開するを選びます。テスト視聴
ブラウザからマニフェストにアクセスできれば、順次セグメントファイルを読み込むので、このマニフェストのURLを知る必要があります。S3上でマニフェストを開くと、ここに
オブジェクトURLが表示されているので、このパスをコピーします。私はMicrosoft Edgeで視聴確認しました。URLバーに先ほどのオブジェクトURLをペーストして、S3にアクセスすると、問題なく視聴できました。
おわりに
今回は、MediaConvertの使い方の基本をなぞってみました。エンコーダのオプションなど、かなり手抜きになってすみません。素人なのでまずは基本フローを抑えることに重点を置きました。次回は S3 + CloudFrontを利用した公開用Web環境の設定をやってみたいと思います。
参考にしたページ
http://blog.serverworks.co.jp/tech/2020/01/16/mediaconvert/
https://qiita.com/montama/items/90bb8a3973d101be4690
https://docs.aws.amazon.com/ja_jp/AmazonS3/latest/gsg/GetStartedWithS3.html
https://docs.aws.amazon.com/ja_jp/mediaconvert/latest/ug/what-is.html

- 投稿日:2020-06-19T11:01:39+09:00
EC2の起動時にPython(Flask)を起動する方法
はじめに
EC2の起動時間が営業時間内に設定されている場合、毎朝コマンドを叩くのが面倒なので、
今回はpythonで作ったAPI(Flask)をshellを自動起動するようにしました。
参考サイトの方法を忘れないようにまとめたものです。apiのshell化
自分は権限が足りなかったのでsudo
# sudo vim /usr/local/start_api.sh ---------------------------------- #!/bin/bash nohup python3 /usr/local/api.py & exit 0自動起動の設定
ここでも権限が足りなかったので、sudoしました。
# sudo vim /etc/init.d/api_start ------------------------------- #!/bin/sh # chkconfig: 345 99 10 # description: start_api shell case "$1" in start) bash /usr/local/start_api.sh ;; stop) /usr/bin/kill python echo "stop!" ;; *) break ;; esac実行権限の付与
ここでもsudo
$ cd /etc/init.d $ sudo chmod 775 api_start自動起動への登録
$ chkconfig --add api_start ## 自動起動をonにする $ chkconfig app_start on ## 設定されているかを確認する $ chkconfig --list app_start api_start 0:off 1:off 2:on 3:on 4:on 5:on 6:offこうなれば終わり。
ちなみに、win10のコマンドプロンプロトの場合、ファイルの色が変わります。(白→緑)
最後に
インスタンスを再起動して、起動されているかを確認して、終わり。
参考サイト
https://hit.hateblo.jp/entry/aws/ec/initd
https://dev.classmethod.jp/articles/ec2shell/


- 投稿日:2020-06-19T10:54:40+09:00
AWS基礎
前提
AWS(プライベートサブネット)について学んだことを書いていきます。
本題
プライベートサブネット構築
いくら万全の対策をしていても、インターネットに接続している限りは、攻撃を受ける可能性が少なからずある。
そこでセキュリティを高める方法として検討したいのが、インターネットから隔離したプライベートサブネット。
データベースサーバーなどは、インターネットから隔離したプライベートサブネットに配置することで、安全性を高められる。プライベートサブネットの利点
パブリックサブネットは、インターネットゲートウェイを経由してインターネットに接続されている。
つまり、ここに配置したWebサーバーは、インターネットからSSHやWebブラウザでアクセスできる。
しかし、システムを構成するサーバー群の中には、インターネットから直接接続して欲しくないものもある。
例えば、データベースなどのバックエンドシステムは、その典型的な例。
隠したいサーバーは、インターネットから接続できないサブネットに配置するようにする。
このようなサブネットのことをプライベートサブネットと呼ぶ。
プライベートサブネットを構築することで、サーバーを隠すことができセキュリティを高められる。プライベートサブネットを作る
アベイラビリティーゾーンを確認
リージョンとは、データセンター群が配置されている地域のことであり、それらのデータセンターを論理的にグループ化したものをアベイラビリティーゾーンと呼ぶ。
AWSのサービスは、いずれかのアベイラビリティーゾーン上で実行される。
VPCも例外ではない。
VPCを使ってサブネットを構築するとそのサブネットはどこかのアベイラビリティーゾーン上に作られる。
サブネット内に配置したインスタンスは、そのサブネットと同じアベイラビリティーゾーンに属する。
プライベートサブネットにはデータベースサーバーを置き、パブリックサブネットに存在するWebサーバーと通信するように構成する。
サブネットは別々のアベイラビリティーゾーンにあっても問題なく通信できる。
しかし、距離による遅延が増加したり、アベイラビリティーゾーン間の通信費用が発生したりするので注意する必要がある。
※それぞれのリージョンにいくつかのアベイラビリティーゾーンがあるのは、耐障害性を高めるため。
アベイラビリティーゾーン同士は、物理的に相当離れた場所に構築されており、異なるネットワークや電源網を用いていて、地震や洪水などで同時に影響を受けることがないように設計されている。プライベートサブネットにサーバーを構築する
プライベートサブネットができたら、サーバーを構築していきます。
・pingコマンドで疎通確認できるようにする
DBサーバーか、Webサーバーからアクセスできるかどうか確認する。
サーバー間での疎通を確認するときによく用いるのがpingコマンド。
pingコマンドでは、ICMP(Internet Control Message Protocol)と言うプロトコルを用いる。
pingコマンドを実行すると、ネットワーク疎通を確認したいホストに対してICMPエコー要求と言うパケットを送信する。
それを受け取ったホストは、送信元に対してICMPエコー応答というパケットを返信する。
pingコマンドでは、このICMPエコー要求とICMPエコー応答のやりとりから、疎通を確認したり相手に届くまでの時間を計測したりする。・ICMPが通るように構成する
AWSのデフォルトのセキュリティグループの構成では、ICMPプロトコルは許可されていない。
※ファイアウォールには、インスタンスの外側から内側に流れる際に適用するインバウンドと、内側から外側に流れるアウトバウンドの2種類ある。
デフォルトでは、アウトバウンドには何ら通信制限がされていないため、何か通信を許可したいときには、インバウンドの方だけを調整すれば十分。踏み台サーバーを経由してSSHで接続
ここからSSHでログインし、MariaDBというデーターベースソフトをインストールする。
ここで一つ疑問がある。
DBサーバーはインターネットと接続されていないのにどうやってそこにSSHで接続すればいいか。
その解決方法の一つが踏み台サーバー。
WebサーバーにはSSHで接続できる。
そして、WebサーバーからDBサーバーには疎通確認がとれている。
そこで、❶WebサーバーにSSHでアクセス、❷WebサーバーからDBサーバーにSSHでアクセス、というようにWebサーバーを踏み台とすれば、ローカル環境からDBサーバーへとアクセスできる。秘密鍵のアップロード
インスタンスにSSHでアクセスするには、秘密鍵が必要。
つまり、WebサーバーからDBサーバーへとSSHで接続する場合、秘密鍵をWebサーバーに置いておく必要がある。
サーバーにファイルを転送するには、SCP(Secure Copy)というプロトコルを使う。Macの場合は、ターミナルからscpコマンドを使ってファイルを転送する。
カレントディレクトリに置かれたmy-key.pemファイルを自分のホームディレクトリ(「〜/」)にコピーするには、下記のようにする。$ scp -i my-key.pem my-key.pem ec2-user@ec2-18-177-32-60.ap-northeast-1.compute.amazonaws.com:~/WebサーバーからSSHで接続する
・鍵ファイルのパーミッションを変更
Webサーバーにログインしたら、まず秘密鍵ファイルのパーミッションを自分しか読めないように変更する。
そのためには、下記のコマンドを入力する。$ chmod 400 my-key.pem※この操作は、秘密鍵が見られると、誰もがサーバーにアクセスできてしまうので、それを防ぎ安全性を高めるのが狙い。
しかし、仮に安全性を気にしなくてもこの操作を省略できない。
自分だけが読み取れるというパーミッションになっていないと、sshコマンドを使って接続するときにエラーが表示されて接続できないから。・Webサーバーを踏み台にしDBサーバーにSSH接続する
Webサーバーにログインしたら、DBサーバーに割り当てたプライベートIPアドレスである10.0.2.10に対してログインする。$ ssh -i my-key.pem ec2-user@10.0.2.10プライベートサブネットに置かれたサーバーにアクセスするときに、このようにインターネットから接続可能なサーバーにログインしてから、それを踏み台にしてログインすることが一般的。
まとめ
インターネットから直接アクセスさせないプライベートサブネットの扱い方について書いていきました。
プライベートサブネットは、プライベートIPアドレスだけで構成したサブネットで、インターネットとの接続を持たない。
DBサーバーなど、インターネットから隠したいサーバー群を配置するときに用いる。
プライベートサブネットに設置したサーバーは、ローカル環境からアクセスできないためプライベートサブネットと通信可能な何らかのサーバーを踏み台にしてSSHでログインする。
この踏み台の方法を使えば、確かにローカル環境からサーバーへはアクセスできる。
- 投稿日:2020-06-19T10:27:37+09:00
AWS S3 Laravel 画像ファイルアップロード時にエラーが発生する
目的
- 画像ファイルのアップロード時にpublic指定してアップロードしたところ
実施環境
- ハードウェア環境
項目 情報 OS macOS Catalina(10.15.5) ハードウェア MacBook Pro (13-inch, 2020, Four Thunderbolt 3 ports) プロセッサ 2 GHz クアッドコアIntel Core i5 メモリ 32 GB 3733 MHz LPDDR4 グラフィックス Intel Iris Plus Graphics 1536 MB
- ソフトウェア環境(AWS EC2 AmazonLinux2内に下記の環境を構築、構築方法はこちら→AWS EC2 AmazonLinux2だけでLaravelのアプリをデプロイする)
項目 情報 備考 AWS EC2インスタンス AmazonLinux2 こちらの方法を用いてイメージからインスタンスを作成→AWS EC2 をMacで使ってみよう! PHP 7.4.5 こちらの方法でインストール→AWS EC2 AmazonLinux2 PHPをインストールする composer 1.10.7 こちらの方法でインストール→AWS EC2 AmazonLinux2 composerをインストールする MySQL 8.0.20 for Linux on x86_64 こちらの方法でインストール→AWS EC2 AmazonLinux2 MySQLを使えるようにする 問題までの経緯
- 下記の方法にてS3に対する画像アップロード処理を実装した。
画像アップロード時の処理を下記の様に修正してpublic状態でアップロードできる様にした。
修正前
アプリ名ディレクトリ/app/Http/Controllers/ImageController.phpStorage::disk('s3')->putFile('/test', $request->file('file'));修正後
アプリ名ディレクトリ/app/Http/Controllers/ImageController.phpStorage::disk('s3')->putFile('/test', $request->file('file'), 'public');処理の動作を確認するためブラウザから画像のアップロードを行った。
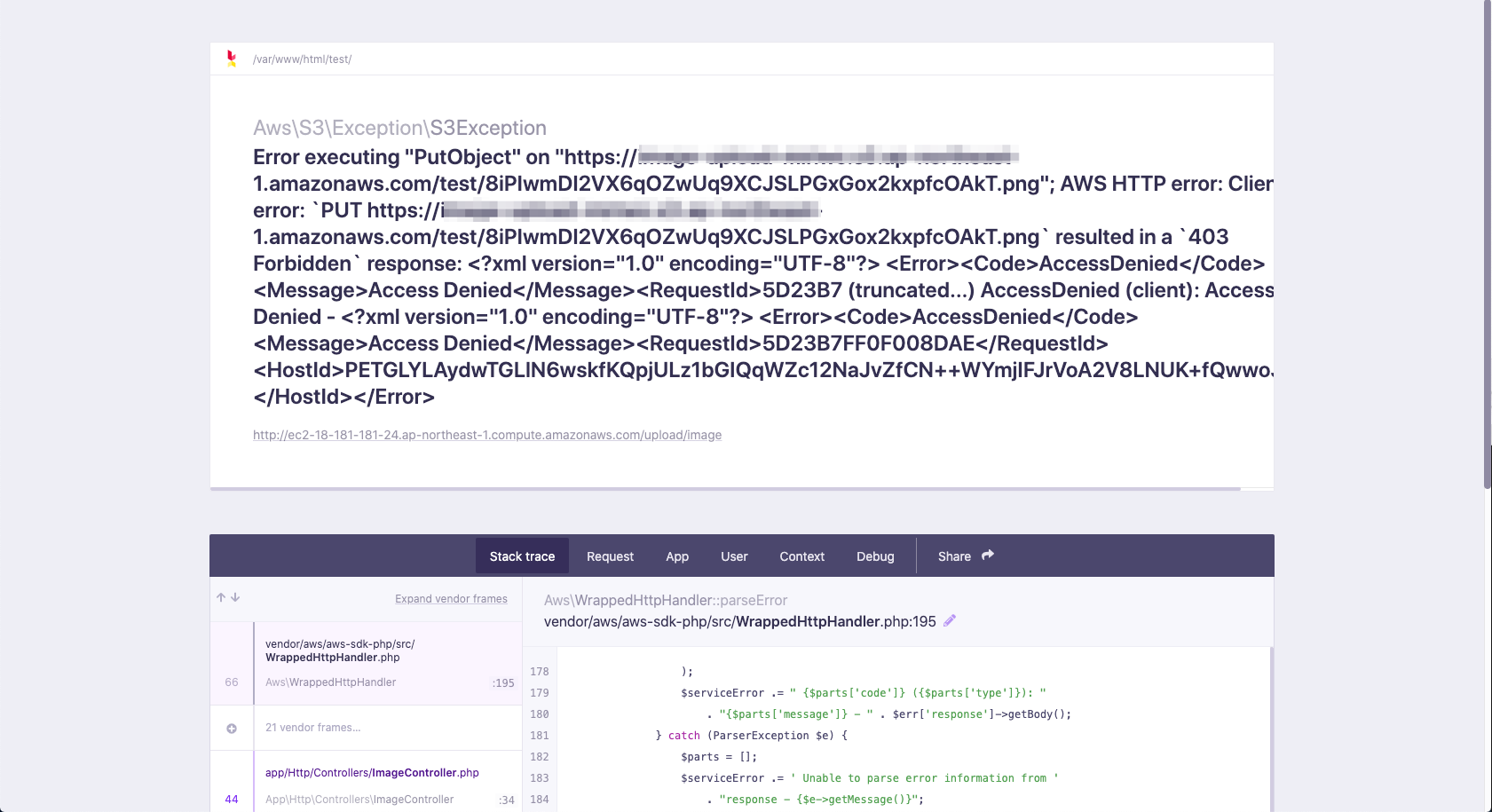
問題
下記エラーが発生する。
Error executing "PutObject" on "https://S3のバケットURL/test/8iPIwmDI2VX6qOZwUq9XCJSLPGxGox2kxpfcOAkT.png"; AWS HTTP error: Client error: `PUT https://S3のバケットURL/test/8iPIwmDI2VX6qOZwUq9XCJSLPGxGox2kxpfcOAkT.png` resulted in a `403 Forbidden` response: <?xml version="1.0" encoding="UTF-8"?> <Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>5D23B7 (truncated...) AccessDenied (client): Access Denied - <?xml version="1.0" encoding="UTF-8"?> <Error><Code>AccessDenied</Code><Message>Access Denied</Message><RequestId>5D23B7FF0F008DAE</RequestId><HostId>PETGLYLAydwTGLlN6wskfKQpjULz1bGIQqWZc12NaJvZfCN++WYmjIFJrVoA2V8LNUK+fQwwoJk=</HostId></Error>ブラウザでのエラー画面の表示を下記に記載する。
問題解決までの経緯
- AWSのコンソールにログインしてS3のコンソールを開く。
アップロードを行うバケット名をクリックする。
「アクセス権限」をクリックする。
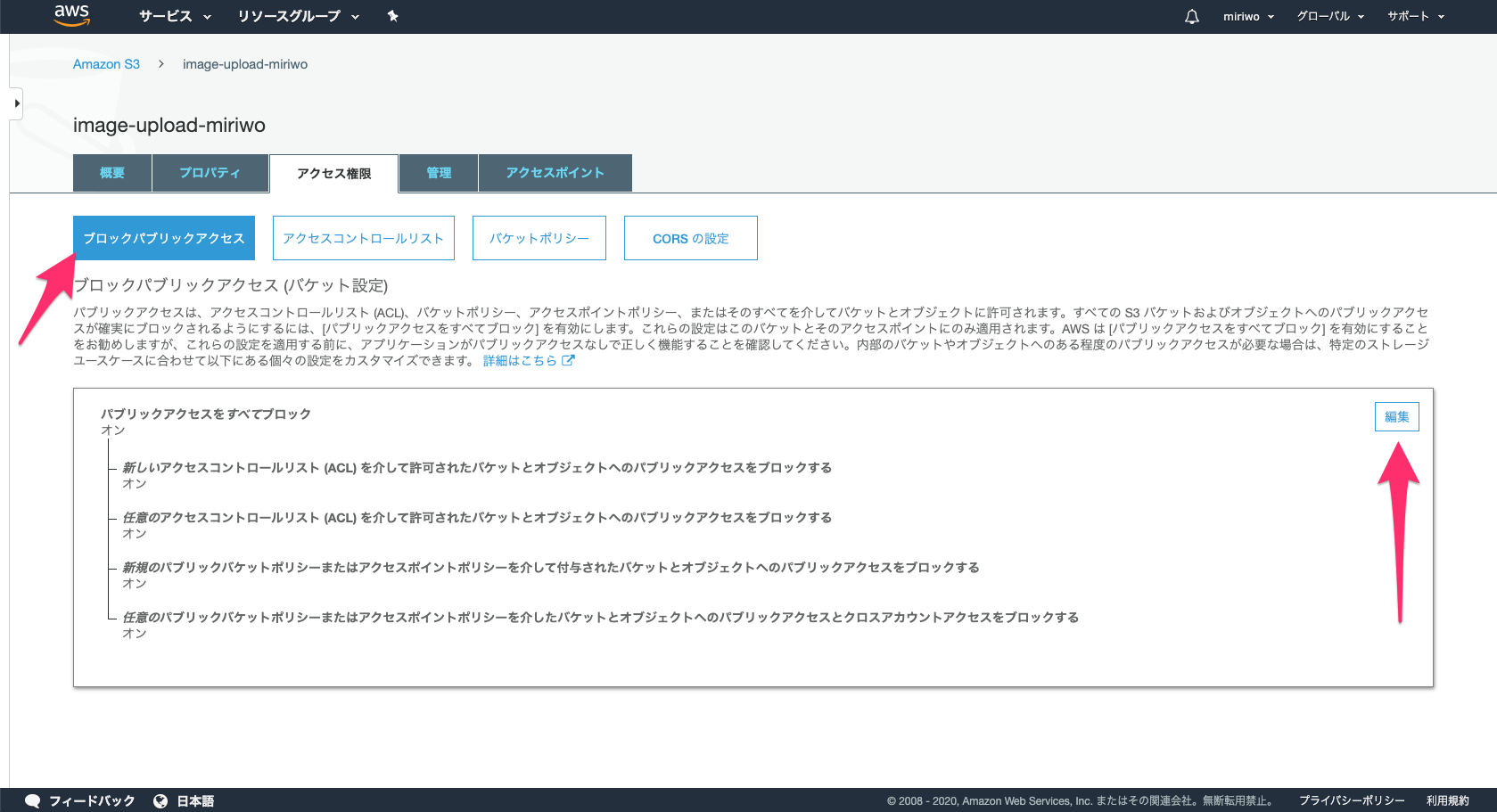
「パブリックアクセス」の「編集」をクリックする。
各チェックを外し「保存」をクリックする。
ブラウザから画像アップロードを実施したところエラーが解消され画像ファイルがアップロードされた。
- 投稿日:2020-06-19T10:07:56+09:00
AWS EC2のSSHがすぐ切れる時の対処方法
TerminalでAWS EC2に接続していると、すぐ接続が切れることがあります。
その時、EC2側の設定変更で接続がすぐ切れないようにする方法を紹介(メモ)します。
※ OSはAmazon Linux 2です。AWS EC2のSSHがすぐ切れる時の対処方法
1. EC2のsshd_configを修正
$ sudo vi /etc/ssh/sshd_configDefault値はこうなっています。
#ClientAliveInterval 0 #ClientAliveCountMax 32時間は接続を保ちたいので、以下のように変更します。
ClientAliveInterval 60 ClientAliveCountMax 1202. sshd 再起動
$ sudo service sshd restart Redirecting to /bin/systemctl restart sshd.service解説
- ClientAliveInterval 60 : クライアントが生きているかをチェックを60秒毎に行う
- ClientAliveCountMax 120 : クライアントが生きているかチェックを最大120回カウントする
つまり、1分毎にチェックして、120回までは接続を解除しないことになります。
これで2時間接続出来るようになりました。以上。
- 投稿日:2020-06-19T09:44:31+09:00
ワーカーノードのバージョン更新時にPodDisruptionBudgetの挙動でハマったこと
概要
EKSクラスタをv1.14からv1.15にバージョンアップする検証を開発環境で行なった際にハマったことを紹介します。
バージョンアップ手順は基本的にAWSから提供されている以下の公式ドキュメントにしたがって実施しました。
Amazon EKS クラスターの Kubernetes バージョンの更新
環境情報として、ワーカーノードタイプはマネージド型、コンピューティングタイプはEC2です。ノードグループ更新時にエラー発生
上記の手順の13を見ると、マネージド型ノードグループの更新へのリンクがあるため、これに従ってAWSのマネジメントコンソールからノードグループを更新したところ、以下のようなエラーが発生しました。
エラーコードに
PodEvictionFailureとあることから、既存ノードから新しいバージョンのノードにpodを移動する際の排出処理に失敗したのだろう、ということがわかります。PodDisruptionBudget設定時のpod排出時の挙動
podの排出処理に関わる設定なので、PodDisruptionBudgetにあたりをつけて検証しました。
関連していそうな設定値は以下の通りです。
オブジェクト種別 設定項目 設定値 HorizontalPodAutoscaler maxReplicas 2 HorizontalPodAutoscaler minReplicas 1 PodDisruptionBudget minAvailable 1 Deployment strategy rollingUpdate Deployment strategy.rollingUpdate.maxSurge 1 Deployment strategy.rollingUpdate.maxUnavailable 0 この設定値は開発環境のものであるため、コスト重視でpod数は控えめに設定しています。
この設定でpod排出時に以下のような挙動になることを期待しました。期待した挙動(実際にはならなかった)
1.更新後ノードが起動
2.更新前ノードのpodが起動したまま、更新後ノードに新規podが起動
3.更新前ノードのpodが停止
しかし実際には上記のような挙動にはならず、エラーが発生しました。
(エラーになるまで1時間半程度かかったので、すごく徒労感を感じました。)PodDisruptionBudgetのminAvailableはpodの最低数を保証するもので、保証できなければそのままエラーで排出処理を停止する、という挙動になるようです。改めて文章にしてみると当たり前のような気がしてきました。
事前にpod数を増やして再度実行
podの排出が可能な余白を作ってあげれば良さそうなので、minReplicasを1から2に増やして再度実行してみることにしました。
設定値としては以下のようになります。赤字箇所が変更点です。
オブジェクト種別 設定項目 設定値 HorizontalPodAutoscaler maxReplicas 2 HorizontalPodAutoscaler minReplicas 2 PodDisruptionBudget minAvailable 1 Deployment strategy rollingUpdate Deployment strategy.rollingUpdate.maxSurge 1 Deployment strategy.rollingUpdate.maxUnavailable 0 期待した挙動(実際にそうなった)
この設定をいれて再度ワーカーノードを更新しました。
期待した挙動としては以下のようになります。1.pod数を2にして再実行
2.PodDisruptionBudgetで指定した1podを残して排出
3.更新後ノードでpodが起動したら残りのpodを排出
上記の通り、正常にpodが排出され、ワーカーノードのバージョンを更新することができました。
最後に
PodDisruptionBudgetは普段の運用の中ではあまり意識することなかったのですが、今回の作業で詳しい挙動を知るいい機会になりました。







- 投稿日:2020-06-19T09:44:31+09:00
EKSのワーカーノードのバージョン更新時にPodDisruptionBudgetの挙動でハマったこと
概要
EKSクラスタをv1.14からv1.15にバージョンアップする検証を開発環境で行なった際にハマったことを紹介します。
バージョンアップ手順は基本的にAWSから提供されている以下の公式ドキュメントにしたがって実施しました。
Amazon EKS クラスターの Kubernetes バージョンの更新
環境情報として、ワーカーノードタイプはマネージド型、コンピューティングタイプはEC2です。ノードグループ更新時にエラー発生
上記の手順の13を見ると、マネージド型ノードグループの更新へのリンクがあるため、これに従ってAWSのマネジメントコンソールからノードグループを更新したところ、以下のようなエラーが発生しました。
エラーコードに
PodEvictionFailureとあることから、既存ノードから新しいバージョンのノードにpodを移動する際の排出処理に失敗したのだろう、ということがわかります。PodDisruptionBudget設定時のpod排出時の挙動
podの排出処理に関わる設定なので、PodDisruptionBudgetにあたりをつけて検証しました。
関連していそうな設定値は以下の通りです。
オブジェクト種別 設定項目 設定値 HorizontalPodAutoscaler maxReplicas 2 HorizontalPodAutoscaler minReplicas 1 PodDisruptionBudget minAvailable 1 Deployment strategy rollingUpdate Deployment strategy.rollingUpdate.maxSurge 1 Deployment strategy.rollingUpdate.maxUnavailable 0 この設定値は開発環境のものであるため、コスト重視でpod数は控えめに設定しています。
この設定でpod排出時に以下のような挙動になることを期待しました。期待した挙動(実際にはならなかった)
1.更新後ノードが起動
2.更新前ノードのpodが起動したまま、更新後ノードに新規podが起動
3.更新前ノードのpodが停止
しかし実際には上記のような挙動にはならず、エラーが発生しました。
(エラーになるまで1時間半程度かかったので、すごく徒労感を感じました。)PodDisruptionBudgetのminAvailableはpodの最低数を保証するもので、保証できなければそのままエラーで排出処理を停止する、という挙動になるようです。改めて文章にしてみると当たり前のような気がしてきました。
事前にpod数を増やして再度実行
podの排出が可能な余白を作ってあげれば良さそうなので、minReplicasを1から2に増やして再度実行してみることにしました。
設定値としては以下のようになります。赤字箇所が変更点です。
オブジェクト種別 設定項目 設定値 HorizontalPodAutoscaler maxReplicas 2 HorizontalPodAutoscaler minReplicas 2 PodDisruptionBudget minAvailable 1 Deployment strategy rollingUpdate Deployment strategy.rollingUpdate.maxSurge 1 Deployment strategy.rollingUpdate.maxUnavailable 0 期待した挙動(実際にそうなった)
この設定をいれて再度ワーカーノードを更新しました。
期待した挙動としては以下のようになります。1.pod数を2にして再実行
2.PodDisruptionBudgetで指定した1podを残して排出
3.更新後ノードでpodが起動したら残りのpodを排出
上記の通り、正常にpodが排出され、ワーカーノードのバージョンを更新することができました。
最後に
PodDisruptionBudgetは普段の運用の中ではあまり意識することなかったのですが、今回の作業で詳しい挙動を知るいい機会になりました。
- 投稿日:2020-06-19T08:20:13+09:00
serverless deployでなにやってるのか確認をしてみました(Serverless Framework / AWS)
はじめに
Serverless FrameworkをAWS環境に対してサービスの作成・更新・削除で利用する場合に、実際にはどのAWSサービスのリソースが変更されているのか、というのがなんとなくわかっていたけど曖昧だったのと、実際に動かしてみたくなったため、各コマンドについて動かしつつ整理してみることにしました。
前提
- 作業環境
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G4032
- 執筆時点で最新(Latest release: 1.68.0)のバージョンでの動作を確認しています
- AWSで利用する場合 について記載しています
- AWS CLIの結果をターミナル上で整形するためにjqを利用しています
まとめ
やってみた結果は次の通りでした。
コマンド CloudFormationスタック それ以外(Lambda, API Gateway, S3, etc...) 1. deploy 更新する 更新する※ 2. deploy function 更新しない 更新する 3. remove 更新する 更新する※ ※注 スタックの更新に伴い間接的に更新
ちなみに、service名+stage名がスタック名として自動設定されるため、同じservice名で同じリージョンに対するserverless.ymlを作ると以前の設定が上書きされるので要注意です。
やってみたこと
やってみた結果わかったことは「まとめ」のセクションに書いたとおりですが、実際に確認したプロセスを記載します。
サービスの新規作成
1. テンプレートからサービスを作成
作業用ディレクトリを作成して、その中に新規サービスをテンプレートから作成します
$ mkdir app $ cd app $ serverless create --template aws-nodejs2. -v オプションを付けてデプロイ実行してログを追ってみる
deployコマンドに
-vを付けて実行します。
リソースの作成に関係しそうな部分としては以下の表示がありました。$ serverless deploy -vCloudFormation - CREATE_COMPLETE - AWS::S3::Bucket - ServerlessDeploymentBucket CloudFormation - CREATE_COMPLETE - AWS::S3::BucketPolicy - ServerlessDeploymentBucketPolicy CloudFormation - CREATE_COMPLETE - AWS::CloudFormation::Stack - app-dev Serverless: Uploading CloudFormation file to S3... Serverless: Uploading service app.zip file to S3 (389 B)... CloudFormation - CREATE_COMPLETE - AWS::Logs::LogGroup - HelloLogGroup CloudFormation - CREATE_COMPLETE - AWS::IAM::Role - IamRoleLambdaExecution CloudFormation - CREATE_COMPLETE - AWS::Lambda::Function - HelloLambdaFunction CloudFormation - CREATE_COMPLETE - AWS::Lambda::Version - HelloLambdaVersionWmPiX0uxnqMasoXkiuYJx9ARiVG14cpohy5OECjVrAここからやっぱりCloudFormationを使ってバケットとかビルド成果物のアップロード等を行っているんだな、ということは分かりました。
3. 生成されたリソースを整理してみる
2.で作成されたリソースに加え、ローカルにも中間ファイルが作成されています。
それらも含めて整理すると、deployコマンド実行後は次のようなリソースが出来上がっていました。
- 作業マシン側
- コードのzip
- 内部的に使うCloudFormationテンプレート
- 他
- AWS側
- CloudFormationスタック
- デプロイ中間ファイル配置用S3バケット
- LambdaのIAMロール
- Lambdaのロググループ
- Lambdaのfunction

サービスの更新
更新パターンについて
サービスの更新を行うパターンは次の2つがあります。
- serverless deploy
- serverless deploy function
serverless deployコマンドによる更新は「サービスの新規作成」のセクションで記述した挙動と同じでCloudFormationスタックの更新が行われますが、serverless deploy functionを実行する場合にはスタックの更新は行われません。Serverless Framework Commands - AWS Lambda - Deploy Function https://serverless.com/framework/docs/providers/aws/cli-reference/deploy-function/
The sls deploy function command deploys an individual function without AWS CloudFormation
serverless deploy functionによる更新をやってみた1. ソースを修正
handler.jsの出力メッセージ部分を編集します。
「Go Serverless〜」という文言を「Goo Serverless」に編集します。$ sed -n 8p handler.js message: 'Go Serverless v1.0! Your function executed successfully!!', $ sed -i '' '8s/Go/Goo/' handler.js $ sed -n 8p handler.js message: 'Goo Serverless v1.0! Your function executed successfully!!',2. デプロイ
serverless deploy functionによって指定した関数のみをデプロイします。
- デプロイ前にスタックの更新時刻を確認
デプロイ実行
デプロイ後にスタックの更新時刻を確認
serverless deploy function前後で確認したスタックの更新時刻から、スタックは更新されていないことが分かります。
serverless deployによる更新新規作成時と同じ挙動なので、確認したプロセスは割愛します。
サービスの削除
serverless removeによってリソースを削除してみました。
なるべく内部の挙動を確認したかったので-vを付けて実行しました。$ sls remove -v : CloudFormation - DELETE_COMPLETE - AWS::S3::BucketPolicy - ServerlessDeploymentBucketPolicy : CloudFormation - DELETE_COMPLETE - AWS::Lambda::Function - HelloLambdaFunction : Serverless: Stack removal finished...removeコマンドの実行結果からは、CloudFormationを通じてS3のデプロイメントバケットやLambda関数が削除されたことを確認できました。
$ aws cloudformation list-stack-resources --stack-name app-dev --region us-east-1 An error occurred (ValidationError) when calling the ListStackResources operation: Stack with id app-dev does not existスタックが削除されていることも確認できました。
サービス名が同じで、リソースの定義が違うセットを用意します。「サービスの新規作成」「サービスの更新」で用意したディレクトリをコピーして、関数名だけ変更したものを用意しました。
$ cp -r app app2$ vim app2/serverless.yml$ diff app app2 diff app/serverless.yml app2/serverless.yml 61c61 < hello: --- > hello2:まず1つ目のディレクトリで
serverless deployを行います$ cd app $ sls deploy次に、2つめのディレクトリでは
-vオプションを付けてserverless deployを行います$ cd app2 $ sls deploy -vすると、stack名が同じ(service名とstage名が同じ)であるため、「hello」関数の定義が差分として検出され、削除されました
CloudFormation - DELETE_IN_PROGRESS - AWS::Lambda::Function - HelloLambdaFunction CloudFormation - DELETE_COMPLETE - AWS::Lambda::Function - HelloLambdaFunctionこの状態で1つめのディレクトリへ移動して
serverless removeコマンドを実行してみます(-vオプションを付けて )$ cd app $ sls remove -vすると、2つめのディレクトリ内で定義していた関数もすべて削除されました。
CloudFormation - DELETE_COMPLETE - AWS::S3::BucketPolicy - ServerlessDeploymentBucketPolicy : CloudFormation - DELETE_COMPLETE - AWS::Lambda::Function - Hello2LambdaFunctionつまり、service名とstage名が同じ組み合わせのファイルを別々に作成すると、片方の設定が最新として処理されるため注意が必要です。
参考
- Serverless Framework Documentation https://www.serverless.com/framework/docs/
- 投稿日:2020-06-19T08:20:13+09:00
serverless deployでしくじって上書きしたので、なにやってるのかちゃんと確認をしてみました(Serverless Framework / AWS)
はじめに
Serverless FrameworkをAWS環境に対してサービスの作成・更新・削除で利用する場合に、実際にはどのAWSサービスのリソースが変更されているのか、というのがなんとなくわかっていたけど曖昧だったのと、実際に動かしてみたくなったため、各コマンドについて動かしつつ整理してみることにしました。やらかしたので。
前提
- 作業環境
$ sw_vers ProductName: Mac OS X ProductVersion: 10.14.6 BuildVersion: 18G4032
- 執筆時点で最新(Latest release: 1.68.0)のバージョンでの動作を確認しています
- AWSで利用する場合 について記載しています
- AWS CLIの結果をターミナル上で整形するためにjqを利用しています
まとめ
やってみた結果は次の通りでした。
コマンド CloudFormationスタック それ以外(Lambda, API Gateway, S3, etc...) 1. deploy 更新する 更新する※ 2. deploy function 更新しない 更新する 3. remove 更新する 更新する※ ※注 スタックの更新に伴い間接的に更新
ちなみに、service名+stage名がスタック名として自動設定されるため、同じservice名で同じリージョンに対するserverless.ymlを作ると以前の設定が上書きされるので要注意です。
やってみたこと
やってみた結果わかったことは「まとめ」のセクションに書いたとおりですが、実際に確認したプロセスを記載します。
サービスの新規作成
1. テンプレートからサービスを作成
作業用ディレクトリを作成して、その中に新規サービスをテンプレートから作成します
$ mkdir app $ cd app $ serverless create --template aws-nodejs2. -v オプションを付けてデプロイ実行してログを追ってみる
deployコマンドに
-vを付けて実行します。
リソースの作成に関係しそうな部分としては以下の表示がありました。$ serverless deploy -vCloudFormation - CREATE_COMPLETE - AWS::S3::Bucket - ServerlessDeploymentBucket CloudFormation - CREATE_COMPLETE - AWS::S3::BucketPolicy - ServerlessDeploymentBucketPolicy CloudFormation - CREATE_COMPLETE - AWS::CloudFormation::Stack - app-dev Serverless: Uploading CloudFormation file to S3... Serverless: Uploading service app.zip file to S3 (389 B)... CloudFormation - CREATE_COMPLETE - AWS::Logs::LogGroup - HelloLogGroup CloudFormation - CREATE_COMPLETE - AWS::IAM::Role - IamRoleLambdaExecution CloudFormation - CREATE_COMPLETE - AWS::Lambda::Function - HelloLambdaFunction CloudFormation - CREATE_COMPLETE - AWS::Lambda::Version - HelloLambdaVersionWmPiX0uxnqMasoXkiuYJx9ARiVG14cpohy5OECjVrAここからやっぱりCloudFormationを使ってバケットとかビルド成果物のアップロード等を行っているんだな、ということは分かりました。
3. 生成されたリソースを整理してみる
2.で作成されたリソースに加え、ローカルにも中間ファイルが作成されています。
それらも含めて整理すると、deployコマンド実行後は次のようなリソースが出来上がっていました。
- 作業マシン側
- コードのzip
- 内部的に使うCloudFormationテンプレート
- 他
- AWS側
- CloudFormationスタック
- デプロイ中間ファイル配置用S3バケット
- LambdaのIAMロール
- Lambdaのロググループ
- Lambdaのfunction
サービスの更新
更新パターンについて
サービスの更新を行うパターンは次の2つがあります。
- serverless deploy
- serverless deploy function
serverless deployコマンドによる更新は「サービスの新規作成」のセクションで記述した挙動と同じでCloudFormationスタックの更新が行われますが、serverless deploy functionを実行する場合にはスタックの更新は行われません。Serverless Framework Commands - AWS Lambda - Deploy Function https://serverless.com/framework/docs/providers/aws/cli-reference/deploy-function/
The sls deploy function command deploys an individual function without AWS CloudFormation
serverless deploy functionによる更新をやってみた1. ソースを修正
handler.jsの出力メッセージ部分を編集します。
「Go Serverless〜」という文言を「Goo Serverless」に編集します。$ sed -n 8p handler.js message: 'Go Serverless v1.0! Your function executed successfully!!', $ sed -i '' '8s/Go/Goo/' handler.js $ sed -n 8p handler.js message: 'Goo Serverless v1.0! Your function executed successfully!!',2. デプロイ
serverless deploy functionによって指定した関数のみをデプロイします。
- デプロイ前にスタックの更新時刻を確認
デプロイ実行
デプロイ後にスタックの更新時刻を確認
serverless deploy function前後で確認したスタックの更新時刻から、スタックは更新されていないことが分かります。
serverless deployによる更新新規作成時と同じ挙動なので、確認したプロセスは割愛します。
サービスの削除
serverless removeによってリソースを削除してみました。
なるべく内部の挙動を確認したかったので-vを付けて実行しました。$ sls remove -v : CloudFormation - DELETE_COMPLETE - AWS::S3::BucketPolicy - ServerlessDeploymentBucketPolicy : CloudFormation - DELETE_COMPLETE - AWS::Lambda::Function - HelloLambdaFunction : Serverless: Stack removal finished...removeコマンドの実行結果からは、CloudFormationを通じてS3のデプロイメントバケットやLambda関数が削除されたことを確認できました。
$ aws cloudformation list-stack-resources --stack-name app-dev --region us-east-1 An error occurred (ValidationError) when calling the ListStackResources operation: Stack with id app-dev does not existスタックが削除されていることも確認できました。
サービス名が同じで、リソースの定義が違うセットを用意します。「サービスの新規作成」「サービスの更新」で用意したディレクトリをコピーして、関数名だけ変更したものを用意しました。
$ cp -r app app2$ vim app2/serverless.yml$ diff app app2 diff app/serverless.yml app2/serverless.yml 61c61 < hello: --- > hello2:まず1つ目のディレクトリで
serverless deployを行います$ cd app $ sls deploy次に、2つめのディレクトリでは
-vオプションを付けてserverless deployを行います$ cd app2 $ sls deploy -vすると、stack名が同じ(service名とstage名が同じ)であるため、「hello」関数の定義が差分として検出され、削除されました
CloudFormation - DELETE_IN_PROGRESS - AWS::Lambda::Function - HelloLambdaFunction CloudFormation - DELETE_COMPLETE - AWS::Lambda::Function - HelloLambdaFunctionこの状態で1つめのディレクトリへ移動して
serverless removeコマンドを実行してみます(-vオプションを付けて )$ cd app $ sls remove -vすると、2つめのディレクトリ内で定義していた関数もすべて削除されました。
CloudFormation - DELETE_COMPLETE - AWS::S3::BucketPolicy - ServerlessDeploymentBucketPolicy : CloudFormation - DELETE_COMPLETE - AWS::Lambda::Function - Hello2LambdaFunctionつまり、service名とstage名が同じ組み合わせのファイルを別々に作成すると、片方の設定が最新として処理されるため注意が必要です。
参考
- Serverless Framework Documentation https://www.serverless.com/framework/docs/
- 投稿日:2020-06-19T08:04:01+09:00
クラウドについて知っておきたい基本的な知識 AWS、Azure、GCP、Oracle Cloud
はじめに
本記事はクラウドインフラストラチャを導入する際に、各クラウドベンダーが提供するサービスの基本的な知識についてまとめています。
クラウドベンダーはAWS、Azure、GCP、Oracle Cloudを対象とし、サーバを中心とした内容になります。
クラウドインフラストラチャの選定で重要なのは利用したいサービスに対して、同じ軸で他のサービスを評価することです。
※本記事で記載している情報については過去に調べたときの情報を基に記載しているため、現在は変わっている場合があります。
サービス体系
各クラウドベンダーが提供するサービス体系の特徴について以下に記載します。
- AWS
- 従量制料金
- リザーブドインスタンス(前払いが大きいほど割引も大きくなる。)
- ボリュームディスカウント(使用量が増えるほど節約できる。)
- Azure
- 従量制料金
- Azure Reserved VM Instances(コミットメントを前払で、従量課金制の料金と比較して、最大 72% 割引)
- スポットの価格(従量課金制価格と比較して、最大 90% の大幅な割引)
- GCP
- 従量課金制
- 継続利用割引(請求月の特定の Compute Engine リソースの実行時間が一定の割合を超えた場合に自動的に適用される割引)
- 確約利用割引(1 年間または 3 年間の支払いを確約する代わりに、特定の量の vCPU、メモリ、GPU、ローカル SSD を割引価格で購入できる。)
- プリエンプティブル VM インスタンス割引(通常より低価格で作成、実行できるインスタンス。ただし、他のタスクのリソースへのアクセスが必要な場合に、Compute Engine によって終了(プリエンプト)される可能性がある。)
- Oracle Cloud
- Pay As You Go(前払いでの確約なしにリソースをオンデマンドでプロビジョニングし、使用した分についてのみ支払い)
- Monthly Flex(月単位の確約により、割引が適用され、支出が予測可能。また、リソースの完全な柔軟性を確保できる。)
AWS Azure GCP Oracle Cloud 料金 AWS 料金 Azure の価格 料金 Oracle Cloud Infrastructureの価格 料金計算ツール SIMPLE MONTHLY CALCULATOR 料金計算ツール Google Cloud Pricing Calculator Cost Estimator サポート AWS サポートのプラン比較 サポート プランの比較 Google Cloud のサポートプラン 標準搭載(無料) イメージ
各クラウドベンダーで利用可能なイメージについて以下に記載します。ポピュラーなイメージ以外にも様々なイメージが利用できます。
- AWS
- Amazon Linux
- CentOS
- Debian
- Kali
- Red Hat
- SUSE
- Ubuntu
- Windows Server 2003 R2、2008、2008R2、2012、2012 R2 および 2016
- Azure
- 独自の Linux イメージを Azure または BYOS に持ち込む
- Red Hat Enterprise Linux
- Oracle Linux
- Canonical Ubuntu Linux
- SUSE Linux Enterprise Server
- Rogue Wave Software (旧称 OpenLogic) による CentOS
- Debian
- CoreOS
- GCP
- [Shielded VM が追加されたイメージのサポート]
- CentOS
- Google のコンテナ用に最適化された OS
- Red Hat Enterprise Linux(RHEL)
- Ubuntu
- Windows Server
- Oracle Cloud
- Oracle Linux 6/7*
- CentOS 6.x/7.x
- Ubuntu 14.x/16.x
- Windows Server OS**
- Server 2016 Standard and Datacenter
- Server 2012 R2 Standard and Datacenter
- Server 2012 Standard and Datacenter
- Server 2008 R2 Standard, Enterprise and Datacenter
インスタンス
スペックが近いインスタンスの使用料金について比較したものが以下になります。リュージョンは日本リュージョンになりレートは本記事執筆時点で計算しています。
AWS Azure GCP Oracle Cloud シェイプ a1.medium(Linux) A1 v2(Linux) n1-standard-1 VM.Standard.E2.1(※1) vCPU 1 1 1 1(※2) メモリ 2 GiB 2 GiB 3.75GB 8GB 料金 Amazon EC2 料金表 Linux Virtual Machines の料金 VM インスタンスの料金 コンピュート - 仮想マシン・インスタンス 1時間 0.0321USD $0.054 $0.0610 $0.03 1ヶ月($) $23.88 $40.17 $45.38 $22.32 1ヶ月(¥) ¥2,556 ¥4,299 ¥4,857 ¥2,389 ※1 PIC_COMPUTE_STANDARD_E2
※2 Oracle Cloudの場合はOCPUと考え方で、1コアで2プロセッサとなる。ストレージ(ブロックストレージ)
各クラウドベンダーのブロックストレージについて以下に記載します。
AWS Azure GCP Oracle Cloud 概要 Amazon EBS ボリュームの種類 Azure で利用できるディスクの種類 ブロック ストレージのパフォーマンス ブロック・ボリューム・パフォーマンス IOPS インスタンスは最大8万IOPS ※3 ※4 インスタンスは最大40万IOPS 料金 Amazon EBS の価格 ブロック BLOB の価格 ディスクの料金体系 Oracle Storage Cloud Pricing ※3 ディスクの種類(Ultra Disk、Premium SSD、Standard SSD、Standard HDD)により異なる。
※4 永続ディスク IOPS およびスループットのパフォーマンスは、インスタンスの vCPU の数と I/O ブロックサイズによって異なる。ネットワーク
各クラウドベンダーのネットワークについて以下に記載します。
AWS Azure GCP Oracle Cloud インバウンド 無料 無料 無料 無料 アウトバウンド 1GBまで無料 5GBまで無料 ※5 10TBまで無料 料金 Amazon EC2 料金表 帯域幅の料金詳細 ネットワークの料金 Oracle Cloud Infrastructure ※5 世界各地、中国、オーストラリアで異なる料金。
データベース/サーバレス/マネージドサービス
各クラウドベンダーのデータベース/サーバレス/マネージドサービスについて、キーワードを以下に記載します。
AWS Azure GCP Oracle Cloud データベース RDS Azure SQL Database Cloud SQL Oracle Database サーバレス Lambda Azure Functions Google Cloud Functions Oracle Functions マネージドサービス Amazon EKS AKS GKE OKE その他
各クラウドベンダーを利用する際の留意事項について以下に記載します。
AWS Azure GCP Oracle Cloud リソース管理方法 アカウント リソースグループ リソースグループ コンパートメント スケールアップ/スケールダウン インスタンス停止必要。 インスタンス停止必要。 インスタンス停止必要。 インスタンス停止し、再作成が必要。なお、Elastic Instancesからダウンタイムなし。 DR 海外リージョンとの組み合わせが必要 国内においてディザスタリカバリ構成可能 国内においてディザスタリカバリ構成可能 国内においてディザスタリカバリ構成可能 準拠法/裁判地 アメリカ合衆国ワシントン州法/アメリカ合衆国ワシントン州キング郡に所在する州裁判所または連邦裁判所※6 日本法/東京地方裁判所 米国準拠法/カリフォルニア州サンタクララ郡の裁判所の対人管轄権および排他的裁判地 日本法/東京地方裁判所 ※6 日本法/東京地方裁判所に変更可能
ナレッジ
- クラウドベンダーによっては突然、契約形態が変わる場合があるため、契約更新のタイミング前には余裕を持って契約内容を確認しておいた方がよい。例としてクラウドベンダーの意向により突然、オプション形態が変わりしかも強制加入コースで決して安くない金額を請求される場合もある。
- サポートに問い合わせをなげる際に急ぎたい場合は、契約先の営業担当からサポートにプッシュしてもらうことで優先度を上げてもらうことができる。
- 外部連携するシステムがある場合は要件定義の段階で外部連携先に仕様を確認しておくこと。AWSなどの日本リュージョンにおけるインスタンスから出力されるパケットのルーティングは基本的に海外を経由している。そのため、外部連携先が海外からのアクセスを許可していなく、個別許可ができない場合は、国内からアクセスできる環境を用意しないといけない状況になる。
おわりに
以下、まとめです。これからはマネージドサービスが主流になるので、クラウドベンダーはマネージドサービスで比較することが重要になってくると思います。
- 従量課金で同程度のスペックでインスタンス単体を比較した場合は、OCP、AWS、Azure、GCPの順に安い
- AWSはクラウドの歴史が一番長いのでドキュメントやナレッジが多く、料金や使いやすで言うと一番バランスがいい。
- AzureはADなどWindows特有の機能を使用したい場合、勝手はあるが料金は高い。
- GCPはBigQueryあるのでデータ分析基盤を構築したい場合は最適である。
- Oracle Cloudはストレージの性能が良いのでデータベースとの相性がいい。また、従量課金のコストは一番安いと思われる。
- 投稿日:2020-06-19T07:57:20+09:00
Amazon AppStream 2.0 のお試し構築
Amazon AppStream 2.0 のお試し構築
テレワークのツールとして、Amazon Workspaces が注目されている昨今、WorkSpacesは各所で構築情報がありますがAppStream 2.0 は構築事例や作ってみた系の記事がないので、検証してみました。
AppStream2.0とは?
完全マネージド型のアプリケーションストリーミングサービスです。
デスクトップアプリケーションを AppStream 2.0 で集中管理し、任意のコンピュータのブラウザへ安全に配信できます。ようするにアプリケーションの配信(Workspacesを特定アプリにだけアクセスできるよう制限したような形で利用)できるサービスです。
Workspacesはユーザがアプリ以外のデスクトップアイコンやOSの各種設定画面にまでアクセス出来てしまいますがAppStreamだとアプリへのアクセスだけに限定できます。利用イメージ
ユーザがアクセスすると特定のアプリを選択して利用する(図だとsofficeの1つですが...)
構築手順
- 1 Imagesの作成
- 2 Fleetの作成
- 3 Stackの作成
- 4 ユーザの作成、登録
Stackとは・・・ユーザが利用する全体環境の設定
Storageはどのサービスを使うか、クリップボード機能のON/OFF
どのFleetに関連付けるか、ユーザがアクセスしたときの画面の設定Fleetとは・・・インスタンスの実行環境の設定
どのVPCにデプロイするか、セキュリティグループはどれを利用するか
どのインスタンスタイプを利用するかImagesとは・・・配信するアプリケーションのスナップショット
普通ならStack → Fleet →Images と作成するかと思いきや逆の流れで作成していきます。
※詳細は後述実際にやってみた
まずImagesを作っていきます。
今回はユーザ独自のImageを作りますのでImageBuilderを選択します。
次に利用するインスタンスのタイプを選択します。今回は特に処理能力の高いインスタンスは必要ないので一般的なWindows Server OSを選択します。
Imageの名前とTag(必要に応じて)、CPU/メモリタイプを選択
デプロイするVPC、セキュリティグループ、サブネットを選択
Default Internet Accessにチェックを入れてください。チェックを入れてないと、後の工程でインターネット越しにアプリのインストールが出来なくなります。Imagesが出来上がりました。
Status がPendingからRunningに変わるまで15分程度かかります。続いて、作成したImageにアクセスして、アプリの配信設定をしていきます。
StatusがRunningになった後にImageを選択して、[Connect]を選択すると、ブラウザーでアクセスできます。ログインする際にはユーザはAdministrator でログインしてください
ログインすると以下画面になります。
デスクトップ上のImage Assistant とアイコンをクリック
「+Add App」をクリックして、配信するアプリを登録していきます
今回はインターネット経由でインストールしたLibre Office を配信する設定を行います。
Name にアプリ名を入力し、アプリ(exeファイル)の場所をLaunch Path に入力します。
その他の項目は空欄もしくはデフォルトのままでOKです。ユーザからアクセスした際に表示されるアプリのアイコンですが、デフォルトだとAppstreamno
のアイコンになるので、必要に応じて、Icon Pathを変更してください。設定したアプリが登録されていることが確認できます。
「Next」をクリックすると以下のような画面になります。
ユーザを切替えて、アプリのセッティングをしなさいという旨の指示がありますので必要に応じで設定をしてください。
今回は特にないですが念のためSwitch user でTest user にスイッチして確認します。
ImageBuilderTest というユーザでログインしており、デスクトップ上にLibre Office があることが確認できました。
再度Switch User でAdministrator にログインし直してください。
次の「TEST」フェーズも特に今回は設定はないので、割愛します。次の「Optimize」で「Lanch」をクリックします。
次の「Configure Images」と「Review」も特に設定することはないため、必要情報を入力してImagesの設定完了まで進めてください。
完了するとImagesのStatusがSnapshottingになりますので、Runningになるまで待ちます。続いてFleetの設定をしていきます。
Fleetの画面で「Create Fleet」を選択します。
Images を選択する画面が表示されますので、先ほど作成したImagesを選択します。
続いてFleetの環境設定をしていきますが基本的にはデフォルトの設定のままで進めます。
Fleet Type ですが「On-Demand」と「Always-On」があります。
ちがいは以下です。
使うときだけ起動させて利用する=「On-Demand」=利用開始までの時間がかかる
常時起動させておく=「Always-On」=すぐに利用開始できる当然どちらのタイプかで料金が変わってきますので、試験環境ではあまり料金のかからない「On-Demand」を選択しています。
次にVPCやサブネット、適用するセキュリティグループを選択します。
これでFleetの設定も完了です。
最後のStackを設定していきます。
Name、Display Nameは任意の名称を設定して、Fleetは先ほど設定したFleetを選択します。
Redirect URLやFeedback URLは空欄のままでもOKです。続いて、アプリ内のデータを格納するストレージをどうするかを設定していきます。
デフォルトはAmazon S3なので、問題なければこのままでOKです。
S3バケットも自動的に作成されます。
一応OneDriveやGoogleDriveも設定することができます。
次のユーザ環境の設定をしていきます。
まずクリップボードを使えるようにするか、どうかを設定します。
今回はコピーも張り付けも利用できるように設定しました。
次にユーザがデータをアップロード、ダウンロードできるようにするかを設定します。
これでStackも設定完了です。
残りはユーザの登録だけです。User Poolで「Create User」でAppStream を利用させたいユーザを登録していきます。
登録できたらAssign Stack でユーザとStackを紐づけしていきます。
ユーザを紐づけする画面で、ユーザに対して通知メールを送信することができます。
ユーザに通知されるメールは以下のような文面です。
ユーザログイン画面にアクセスして、メールアドレスとPWを入力すると
配信設定したLibreOffice(表示名:soffice)が選択できます。
これでアプリ配信ができることが確認できました!
今回はユーザをStackにアサインして、ユーザメールアドレスとPWで認証する方式でしたが
Stackのところで「Creat Streaming URL」で誰でもアクセスできるURLを発行しておくことも可能です。
URLには有効期間を設定して、期間限定で公開するということもできます。
最後に
WorkSpacesと比べてマイナー感がありますが、特定の業務アプリだけ利用したいという場合は
非常に便利だと思います。
今回はWebブラウザー経由でアクセスして、検証していましたがWorkSpaces同様に専用クライアントアプリもあるので、アプリ配信限定のWorkSpacesという位置づけでの利用もできそうな気がします。
































- 投稿日:2020-06-19T00:54:04+09:00
ecs-cliでCloud Map
AWS Cloud Mapを調べる機会があったので、ついでにecs-cliで実際に構成してみた際のメモ。
やりたいこと
- AWS Cloud Mapを理解する
- ECS Fargateクラスターで実際にCloud Mapを使ってみる
AWS Cloud Mapって何
コンテナでサービスディスカバリーをするためのサービス、ぐらいのフワッとした概念しかなかったので、公式で調べてみる。
結果、わかったこと。
- バージョン変化等に伴うマイクロサービスのエンドポイント変化に追従しつつ、サービスの「場所」を返すことができるサービス。
- DNSっぽいなと思ったら、Route 53 Auto Namingの上位互換だった。
- DNSクエリーに対してIPを返す、またはHTTP APIコールに対してURLやARNを返す。
- Route 53のように、ヘルスチェックを行って異常系を検出結果から除外できる。
- ECSとインテグレーションされている。
- ecs-cliとecs-params.ymlで簡単に有効化できそう。
ということで、以前試した方法を拡張して、ecs-cliでハンズオンしてみることにする。
Step by Step
1. ecs-params.ymlの修正
これやこれを見ると、コマンドラインでも比較的簡単に設定出来そうだが、面倒なのでecsparams.ymlに記載できないか試してみる。
前回作成したecsparams.yamlはこちら。
ecsparams.yml(旧)version: 1 task_definition: task_execution_role: ecsTaskExecutionRole ecs_network_mode: awsvpc task_size: mem_limit: 0.5GB cpu_limit: 256 run_params: network_configuration: awsvpc_configuration: subnets: - "subnet-XXXXXXXX" - "subnet-YYYYYYYY" security_groups: - "sg-ZZZZZZZZ" assign_public_ip: ENABLEDそして、パラメータ一覧を眺めつつ、
service_discoveryセクションを追加したecsparams.ymlがこちら。ecsparams.yml(新)version: 1 task_definition: task_execution_role: ecsTaskExecutionRole ecs_network_mode: awsvpc task_size: mem_limit: 0.5GB cpu_limit: 256 run_params: network_configuration: awsvpc_configuration: subnets: - "subnet-XXXXXXXX" - "subnet-YYYYYYYY" security_groups: - "sg-ZZZZZZZZ" assign_public_ip: ENABLED service_discovery: private_dns_namespace: vpc: "vpc-AAAABBBB" name: "myDiscovery"VPC IDとCloud Mapの名前空間名だけ追加すればよい模様。
2. ECSクラスターの生存確認
ecs-cli composeでサービスを追加する際に有効化するようなので、大元となるFargateクラスターをまずは生存確認。
無事生きてた。
3. Cloud Map(サービスディスカバリー)を有効化したFargateサービスの作成
先程作成したecsparams.ymlを使って、Fargateサービスを作成する。
この際に、service_discoveryセクションの記載を用いてCloud Mapを有効化することになる。% ecs-cli compose --project-name SvcDiscoveryTest service up --enable-service-discovery INFO[0000] Using ECS task definition TaskDefinition="SvcDiscoveryTest:1" INFO[0006] Waiting for the private DNS namespace to be created... INFO[0006] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS WARN[0066] Defaulting DNS Type to A because network mode was awsvpc INFO[0071] Waiting for the Service Discovery Service to be created... INFO[0072] Cloudformation stack status stackStatus=CREATE_IN_PROGRESS INFO[0102] Auto-enabling ECS Managed Tags INFO[0108] (service SvcDiscoveryTest) has started 1 tasks: (task 9bac8a5967b24ca0891fc94eac0424b1). timestamp="2020-06-18 15:21:52 +0000 UTC" INFO[0153] Service status desiredCount=1 runningCount=1 serviceName=SvcDiscoveryTest INFO[0153] ECS Service has reached a stable state desiredCount=1 runningCount=1 serviceName=SvcDiscoveryTest INFO[0153] Created an ECS service service=SvcDiscoveryTest taskDefinition="SvcDiscoveryTest:1"できた。
Cloud Map側から見るとこのような感じ。
同じものをFargate側から見ると、以下のようになっている。
SvcDiscoveryTest.myDiscovery4. 名前解決テスト
今回は特定のVPCからのみアクセスできるプライベート名前空間として作成したので、同じサブネット上のEC2から
SvcDiscoveryTest.myDiscoveryを解決してみる。まずDNS。
$ nslookup SvcDiscoveryTest.myDiscovery Server: 10.100.0.2 Address: 10.100.0.2#53 Non-authoritative answer: Name: SvcDiscoveryTest.myDiscovery Address: 10.100.10.33プライベートIPが返ってきた。
次いでAPI。% aws servicediscovery discover-instances --namespace-name myDiscovery --service-name SvcDiscoveryTest { "Instances": [ { "InstanceId": "9ba(中略)4b1", "NamespaceName": "myDiscovery", "ServiceName": "SvcDiscoveryTest", "HealthStatus": "HEALTHY", "Attributes": { "AVAILABILITY_ZONE": "ap-northeast-1a", "AWS_INIT_HEALTH_STATUS": "HEALTHY", "AWS_INSTANCE_IPV4": "10.100.10.33", "ECS_CLUSTER_NAME": "myFargate", "ECS_SERVICE_NAME": "SvcDiscoveryTest", "ECS_TASK_DEFINITION_FAMILY": "SvcDiscoveryTest", "REGION": "ap-northeast-1" } } ] }最後にcurlも試してみる。
$ curl SvcDiscoveryTest.myDiscovery <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"> <title>Simple PHP App</title> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <link href="assets/css/bootstrap.min.css" rel="stylesheet"> <style>body {margin-top: 40px; background-color: #333;}</style> <link href="assets/css/bootstrap-responsive.min.css" rel="stylesheet"> <!--[if lt IE 9]><script src="http://html5shim.googlecode.com/svn/trunk/html5.js"></script><![endif]--> </head> <body> <div class="container"> <div class="hero-unit"> <h1>Simple PHP App</h1> <h2>Congratulations</h2> <p>Your PHP application is now running on a container in Amazon ECS.</p> <p>The container is running PHP version 5.4.16.</p>以上、ecs-cliから試してみたCloud Mapでした。





