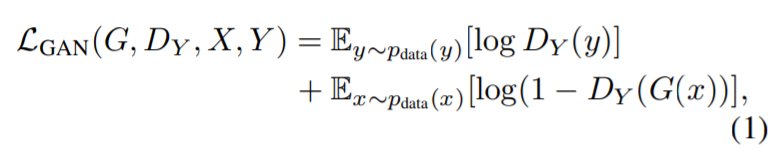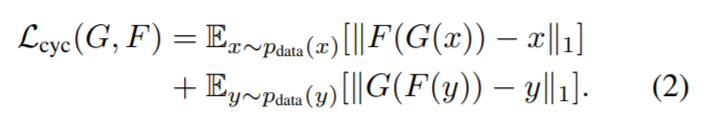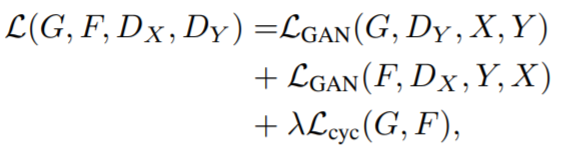- 投稿日:2020-05-23T20:57:26+09:00
FastAPIとTensorflowで簡単な画像認識APIを作ってみた
はじめに
普段Flaskをよく使いますが、「FastAPIはいいぞ!」と知人に進められたので簡単な画像認識APIを作って見ようと思いました。
しかし、あまりFastAPIとMLの日本語記事を見かけなかったので、メモ代わりに本記事を作成することにしました!本記事では、開発環境を整えた後、APIサーバとフロントエンドの簡単な説明を記載しております。
今回使用したコードはすべてGithubに公開しています。
(以下実装のフォルダ構成などはGithubを前提に記載しています。サンプルモデルのダウンロードについてもREADME.mdに記載しています。)FastAPIとは?
FlaskのようなPythonのフレームワークの1つです。
かんたんな概要と使い方のまとめは、以下の記事を参照していただけると良いと思います。(本記事でも大変お世話になりました、ありがとうございます!!)
もっと詳しく知りたい方は、FastAPIの公式チュートリアルが充実しておりオススメです!
画像認識について
今回は時間がなかったため、tensorflow.kerasのモデルを使って構築します!
具体的には、imagenetで学習されたResNet50をそのまま利用し、入力画像を1000クラスのどれに属するかを推論することとします。
(本当に使いたかったモデルは、只今絶賛学習中で間に合わなかった...)
https://www.tensorflow.org/versions/r1.15/api_docs/python/tf/keras?hl=ja
開発環境
Mac OS X Mojave
Python3.7.1(Anaconda)環境構築
必要なPythonライブラリをインストールします。
$pip install tensorflow==1.15 $pip install fastapi $pip install uvicorn以下のような条件があることから、それに必要なライブラリもインストールします。
- index.htmlをRenderする
- 画像ファイルをアップロードする
- 画像を読み込み、リサイズする$pip install Jinja $pip install aiofiles $pip install python-multipart $pip install opencv-pythonAPIサーバ
APIサーバの実装は以下のようになりました。
# -*- coding: utf-8 -*- import io from typing import List import cv2 import numpy as np import tensorflow as tf from tensorflow.keras.applications.resnet50 import decode_predictions from fastapi import FastAPI, Request, File, UploadFile from fastapi.staticfiles import StaticFiles from fastapi.templating import Jinja2Templates # 画像認識モデルの用意 global model, graph graph = tf.get_default_graph() model = tf.keras.models.load_model("./static/model/resnet_imagenet.h5") # FastAPIの用意 app = FastAPI() # static/js/post.jsをindex.htmlから呼び出すために必要 app.mount("/static", StaticFiles(directory="static"), name="static") # templates配下に格納したindex.htmlをrenderするために必要 templates = Jinja2Templates(directory="templates") def read_image(bin_data, size=(224, 224)): """画像を読み込む Arguments: bin_data {bytes} -- 画像のバイナリデータ Keyword Arguments: size {tuple} -- リサイズしたい画像サイズ (default: {(224, 224)}) Returns: numpy.array -- 画像 """ file_bytes = np.asarray(bytearray(bin_data.read()), dtype=np.uint8) img = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = cv2.resize(img, size) return img @app.post("/api/image_recognition") async def image_recognition(files: List[UploadFile] = File(...)): """画像認識API Keyword Arguments: files {List[UploadFile]} -- アップロードされたファイル情報 (default: {File(...)}) Returns: dict -- 推論結果 """ bin_data = io.BytesIO(files[0].file.read()) img = read_image(bin_data) with graph.as_default(): pred = model.predict(np.expand_dims(img, axis=0)) result_label = decode_predictions(pred, top=1)[0][0][1] return {"response": result_label} @app.get("/") async def index(request: Request): return templates.TemplateResponse("index.html", {"request": request})フロントからデータを受け取る
@app.post("/api/image_recognition") async def image_recognition(files: List[UploadFile] = File(...)): """画像認識API Keyword Arguments: files {List[UploadFile]} -- アップロードされたファイル情報 (default: {File(...)}) Returns: dict -- 推論結果 """ bin_data = io.BytesIO(files[0].file.read()) img = read_image(bin_data) with graph.as_default(): pred = model.predict(np.expand_dims(img, axis=0)) result_label = decode_predictions(pred, top=1)[0][0][1] return {"response": result_label}今回は、FastAPIのUploadFileを使用してPOSTされる画像を取得しております。
bin_data = io.BytesIO(files[0].file.read())ファイルは一つしかPOSTされないのでfiles[0]としており、フロント側からBASE64形式で渡されるのでAPI側でBytes配列に変換しました。
データを画像に変換する
def read_image(bin_data, size=(224, 224)): """画像を読み込む Arguments: bin_data {bytes} -- 画像のバイナリデータ Keyword Arguments: size {tuple} -- リサイズしたい画像サイズ (default: {(224, 224)}) Returns: numpy.array -- 画像 """ file_bytes = np.asarray(bytearray(bin_data.read()), dtype=np.uint8) img = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = cv2.resize(img, size) return imgopencvの力を借りて、Byte配列からuint8の画像に変換します。
このとき、opencvのデフォルトフォーマットがBGRなため、RGBに変換してリサイズしました。推論する
global model, graph graph = tf.get_default_graph() model = tf.keras.models.load_model("./static/model/resnet_imagenet.h5") ... with graph.as_default(): pred = model.predict(np.expand_dims(img, axis=0)) result_label = decode_predictions(pred, top=1)[0][0][1]事前にresnet_imagenet.h5を作成しておき、それをファイル上部で読み込んでいます。
推論処理自体は、with graph.as_default() でグローバルで設定したTensorFlowのグラフにこのスレッドでのコンテキストを固定して、predict関数で推論しています。今回はtf.kerasのResNet50を使っていることから、predictの結果をラベルに変換するdecode_predictionsを使って推論結果を取得しています。
他のモデルや自作モデルも、プロジェクトディレクトリのどこかに.h5ファイルを保存しておき、それをload_modelすることで、この実装のように使うことができるかと思います。
フロント実装
こちらを参考にさせていただきました。(ありがとうございます!)
<html> <head> <meta http-qeuiv="Content-Type" content="text/html; charset=utf-8"> <title>Fastapi 画像認識テスト</title> <script src="//code.jquery.com/jquery-2.2.3.min.js"></script> <script src="/static/js/post.js"></script> </head> <body> <!-- ファイル選択ボタン --> <div style="width: 500px"> <form enctype="multipart/form-data" method="post"> <input type="file" name="userfile" accept="image/*"> </form> </div> <!-- 画像表示領域 --> <canvas id="canvas" width="0" height="0"></canvas> <!-- アップロード開始ボタン --> <button class="btn btn-primary" id="post">投稿</button> <br> <h2 id="result"></h2> </body> </html>// 画像をリサイズして、HTMLで表示する $(function () { var file = null; var blob = null; const RESIZED_WIDTH = 300; const RESIZED_HEIGHT = 300; $("input[type=file]").change(function () { file = $(this).prop("files")[0]; // ファイルチェック if (file.type != "image/jpeg" && file.type != "image/png") { file = null; blob = null; return; } var result = document.getElementById("result"); result.innerHTML = ""; // 画像をリサイズする var image = new Image(); var reader = new FileReader(); reader.onload = function (e) { image.onload = function () { var width, height; // 縦or横の長い方に合わせてリサイズする if (image.width > image.height) { var ratio = image.height / image.width; width = RESIZED_WIDTH; height = RESIZED_WIDTH * ratio; } else { var ratio = image.width / image.height; width = RESIZED_HEIGHT * ratio; height = RESIZED_HEIGHT; } var canvas = $("#canvas").attr("width", width).attr("height", height); var ctx = canvas[0].getContext("2d"); ctx.clearRect(0, 0, width, height); ctx.drawImage( image, 0, 0, image.width, image.height, 0, 0, width, height ); // canvasからbase64画像データを取得し、POST用のBlobを作成する var base64 = canvas.get(0).toDataURL("image/jpeg"); var barr, bin, i, len; bin = atob(base64.split("base64,")[1]); len = bin.length; barr = new Uint8Array(len); i = 0; while (i < len) { barr[i] = bin.charCodeAt(i); i++; } blob = new Blob([barr], { type: "image/jpeg" }); console.log(blob); }; image.src = e.target.result; }; reader.readAsDataURL(file); }); // アップロード開始ボタンがクリックされたら $("#post").click(function () { if (!file || !blob) { return; } var name, fd = new FormData(); fd.append("files", blob); // API宛にPOSTする $.ajax({ url: "/api/image_recognition", type: "POST", dataType: "json", data: fd, processData: false, contentType: false, }) .done(function (data, textStatus, jqXHR) { // 通信が成功した場合、結果を出力する var response = JSON.stringify(data); var response = JSON.parse(response); console.log(response); var result = document.getElementById("result"); result.innerHTML = "この画像...「" + response["response"] + "」やんけ"; }) .fail(function (jqXHR, textStatus, errorThrown) { // 通信が失敗した場合、エラーメッセージを出力する var result = document.getElementById("result"); result.innerHTML = "サーバーとの通信が失敗した..."; }); }); });ajaxを使って画像認識APIへPOSTを行い、結果を表示しています。
動作確認
結果こんな感じに動くようになりました!
(フロントをもうちょっとオサレにしたかったのですが...)
おわりに
FastAPIのお勉強に画像認識APIを作ってみました。
今回作った実装がベストプラクティスではないと思いますが、動くものをつくることができてよかったかと思います。今後どのフレームワークを使って仕事をするかわかりませんが、FastAPIは割と使いやすくてFlaskから乗り換えようかなぁと思いました。
最後となりますが、参考にさせていただいた皆様に感謝いたします!
- 投稿日:2020-05-23T16:49:52+09:00
CycleGANを実装してみた(1)
Linux上でCycleGANの実装をしてみた
今回は、CycleGANの実装をしてみました。
基本的に、githubで公開されているコードをもとに実装を行っていきます。
本ページでは、軽い論文の説明と実装をしていきます。
自分のデータセットを用いて適用する回は、次回やっていきたいと思います。
- CycleGANについて
- Linux上での実装
簡単ではありますが、上の2項目に従って説明します。
CycleGANについて
論文:https://arxiv.org/pdf/1703.10593.pdf
こちらの論文に沿って説明をしていきます。導入
CycleGANは、画風変換を可能とするGenerative Adversarial Network (GAN)です。
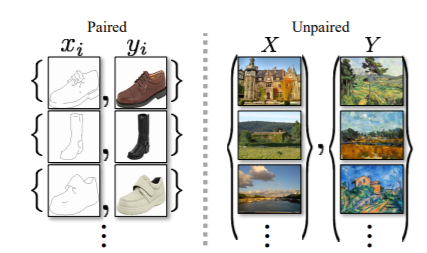
上の図は、論文内記載のものですが、左のような画風変換(色塗り)をしたい場合は、pix2pixに代表されるような、入力と出力の画像のペアで用いる学習方法が採用されていました。
つまり、図のPairedに示されるような1対1の対応が必要となります。
一方で、右に表されるような、Unpairedの画風変換を可能とする手法も提案されています。
Unpairedの手法では、画風変換のタスクごとに、クラスラベル空間、画像特徴空間、ピクセル空間など、様々な距離空間を定義し、それらを用いて入力と出力の距離を近づける必要がありました。そこで、CycleGANは、1対1のペア画像を必要とせず、さらにタスクに合わせて学習方法を変える必要がない、そんな手法として提案されました。
これが、CycleGANによって変換された画像たちです。
風景などの写真が、世界的画家であるMonetやGoghの画風へと変換されています。
これは、pix2pixのようなペアを必要とする学習ではなし得ません。
なぜなら、Goghらが描いた風景の写真を撮るためには、タイムスリップしなければいけないからです。
そして、ZebraとHorseの変換、SummerとWinterの変換も可能としています。
タスクに沿って学習方法を変えることなく、CycleGANでは画風変換を学習可能となります。
目的関数
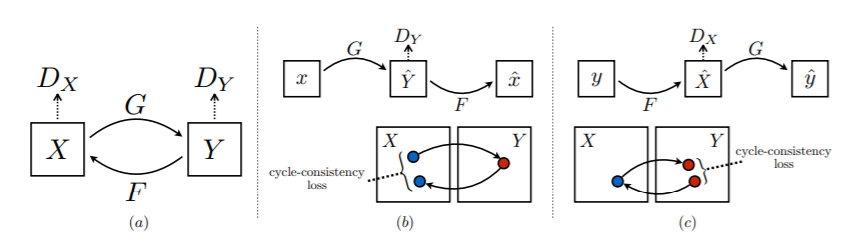
それを可能とするのが、Cycle-consustency lossの導入です。
これが本手法の肝となりますので、後ほどこちらについて説明します。
上の画像は、Cycle-GANで用いられるlossを表したものになります。
まず、(a)は、GANの一般的なlossである、Adversarial lossになります。
上式で定式化されますが、第1項では、Discriminatorは、本物のデータyを本物と識別することを意味します。
第2項では、Generatorによって生成されたデータを偽物と識別することを意味します。
このAdversarial lossをDiscriminatorに対して最大化(正しく識別する)かつGeneratorに対して最小化(誤識別させる)ように学習を行います。
Discriminatorに関して、第1項の最大化の意味は、本物のデータyの確率値が1(本物)と識別されることです。
また、第2項の最大化の意味は、zに対してG( )を用いて生成した偽物G(z)の確率値を0(偽物)と識別することです。
Generatorに関しては、その逆、ということになります。
Discriminatorが識別できないようなG()を作ることを目的としています。
これらの最大化・最小化を行う際は、片方は固定します。
この最大化・最小化を交互に行うことで、学習を進めていきます。
これを、両方のドメインに対して、行います。
つまり、と
に対して、最適化を行っていくということです。
続いて、(b)と(c)についてです。
こちらが、Cycle-consustency lossと呼ばれ、下式で表されます。
こちらの第1項では、xをG( )を用いて生成したデータG(x)をF( )を用いて元のドメインに戻したデータF(G(x))が、ちゃんとxになっているか、というものをL1ノルムを使って表しています。
第2項では、その逆をやっていますね。
考え方としては簡単です。
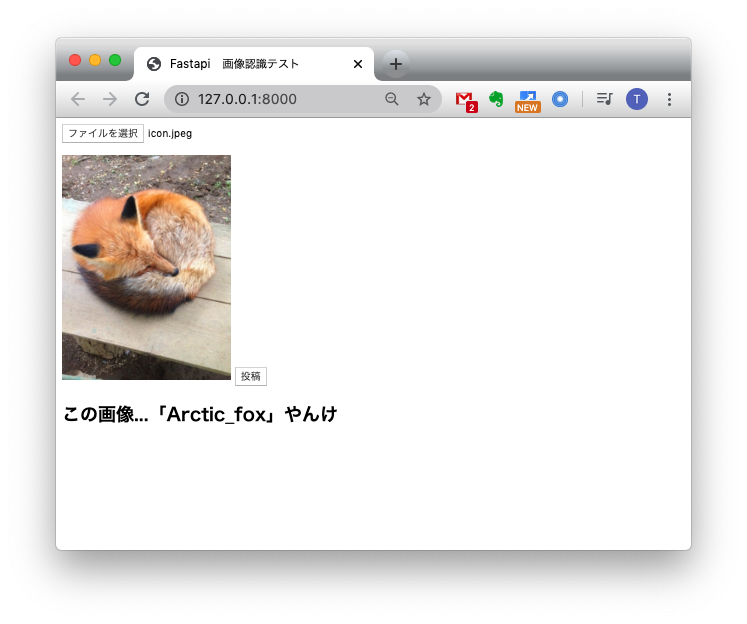
最終的に、(a)~(c)を合わせて、
こちらのように目的関数を設定します。
この最適化問題を解くことで、目的のGとFが学習できます。
実験結果
実験結果の一例です。
「うま」と「しまうま」の変換、風景写真における「夏」と「冬」の変換、「りんご」と「みかん」の変換など、様々なタスクにおいて、高精度な画風変換が実現していることが分かります。
これは、失敗例です。
プーチン大統領がしまうまになっちゃっていますね。
この様に、テクスチャの変換はうまくいくものの、形状を捉えた変換は難しい場合もあるようです。
物体検出手法の導入なんかで解決されていくのではと思います。もっと結果を見たいという方は、論文をのぞいてみてください。
Linux上での実装
公開コード
https://github.com/xhujoy/CycleGAN-tensorflow実装環境
- Ubuntu 18.04 LTS
- Python 3.6
- PyTorch 0.4.0
- Tensorflow 1.4.0
- numpy 1.11.0
- scipy 0.17.0
- pillow 3.3.0公開データセットで実装
まずは、任意のディレクトリにgitをクローンします。
続いて、CycleGAN-tensorflow/のディレクトリに移動します。
今回は、論文でも使用されていたhorse2zebraのデータセットをダウンロードしていきます。$ git clone https://github.com/xhujoy/CycleGAN-tensorflow $ cd CycleGAN-tensorflow/ $ bash ./download_dataset.sh horse2zebra学習
続いて、ダウンロードしたhorse2zebraのデータセットで学習を行っていきます。
$ CUDA_VISIBLE_DEVICES=0 python main.py --dataset_dir=horse2zebraGPU指定の場合は、
CUDA_VISIBLE_DEVICES=で指定してください。
学習が始まります。Epoch: [ 0] [ 0/1067] time: 14.2652 Epoch: [ 0] [ 1/1067] time: 16.9671 Epoch: [ 0] [ 2/1067] time: 17.6442 Epoch: [ 0] [ 3/1067] time: 18.3194 Epoch: [ 0] [ 4/1067] time: 19.0001 Epoch: [ 0] [ 5/1067] time: 19.6724 Epoch: [ 0] [ 6/1067] time: 20.3511 Epoch: [ 0] [ 7/1067] time: 21.0326 Epoch: [ 0] [ 8/1067] time: 21.7106 Epoch: [ 0] [ 9/1067] time: 22.3866 Epoch: [ 0] [ 10/1067] time: 23.0501 Epoch: [ 0] [ 11/1067] time: 23.7298 . . .初期設定では、Epochは200回になっています。
こちらは自身が適用するデータセットに合わせて、変更しても良いと思います。
そこまで大きな差異を含む変換の学習ではないのならば、Epochを減らしてみてもいいかもしれません。
ここで注意なのですが、ダウンロードしたdatasets/horse2zebra/ディレクトリの中にtestA/、testB/、trainA/、trainB/が存在し、それぞれのディレクトリ内には画像が入っています。
学習時であっても、testA/またはtestB/のいずれにもデータが入っていないと、以下のエラーを吐かれてしまいます。ValueError: Cannot feed value of shape (1, 256, 256, 6) for Tensor 'real_A_and_B_images:0', which has shape '(?, 512, 512, 6)'自分自身でデータセットを構築し、実装する際は注意が必要です。
テスト
テストは以下のコマンドで行います。
$ CUDA_VISIBLE_DEVICES=0 python main.py --dataset_dir=horse2zebra --phase=test --which_direction=AtoB
--which_direction=のオプションで、AtoBかBtoAを指定します。
datasets/horse2zebra/testAもしくはdatasets/horse2zebra/testB内の画像が変換され、test/に保存されていきます。
それぞれの画像にはわかりやすく、AtoB_もしくはBtoA_が記されます。以下はテスト結果の一例です。
horse2zebra (AtoB)
zebra2horse (BtoA)
しっかりと変換ができています。すごいです。
以上がLinux上での実装となります。
次回は、自身のデータセットに適用してみたいと思います。
参考資料
論文:https://arxiv.org/pdf/1703.10593.pdf
Github:https://github.com/xhujoy/CycleGAN-tensorflow