- 投稿日:2020-05-23T23:59:35+09:00
nodeでAbemaTVをダウンロードしてみる【スマホでもできる】
こんにちは。ひさしぶりです。
以前にはてなでAbemaTVが落とせなくなった〜!とかやり方見つけた!とか言うことを書いてたんですけど暇なんでqiitaにも書きます。
ざっと大まかに言うとminyamiっていうnodeライブラリを使います!以上!
Windowsとかのやり方ははてなを見てくれ。
https://ysok2135.hateblo.jp/entry/2020/01/04/022105※今はこの方法以外ではDLできない。(当方調べ)
minyamiをぶち込む
とりあえずいつものようにnpmでインスコします。
(グローバルのほうがおすすめ。)terminalnpm install -g minyamiChrome拡張機能を入れる
今回は拡張機能でhlsのリンクをゲットする寸法。
https://chrome.google.com/webstore/detail/minyami/cgejkofhdaffiifhcohjdbbheldkiaed
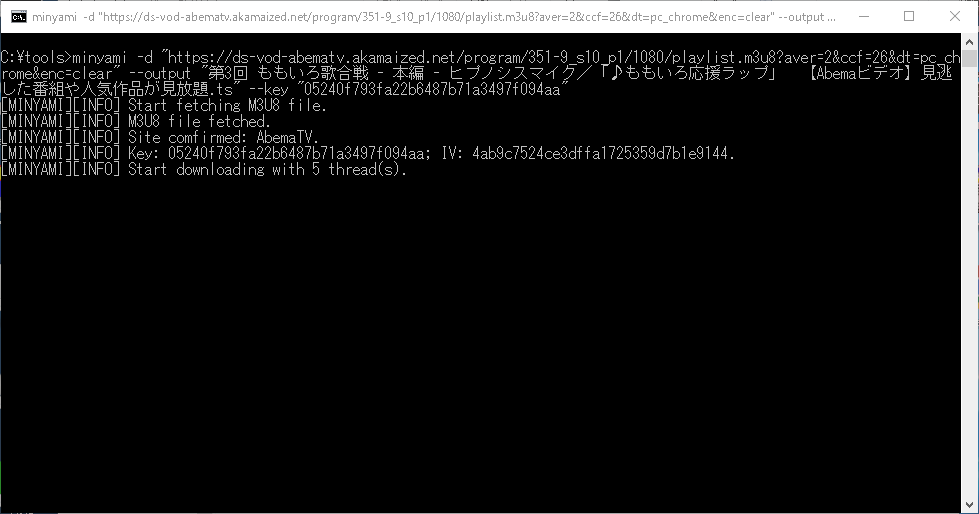
あとはDLするだけ。
Abemaのページを開いて、minyamiのマークをクリック。
適当な解像度を選びコピー。
あとはターミナルにそのまま貼り付ける。
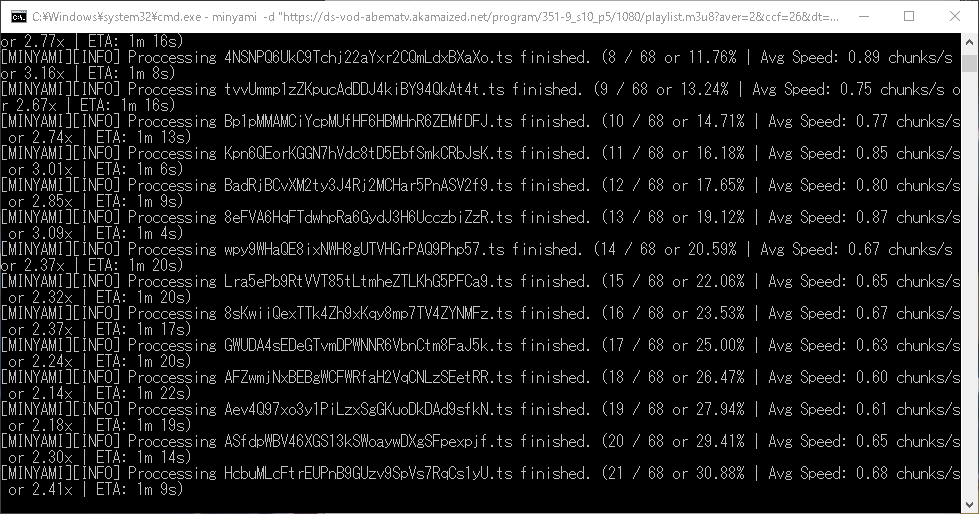
結構早く終わるよ。
スマホでできんのかコラァ!?
→できますよ。
◆必要なもの◆
・VPS(これチート。)
・JuiceSSH(Android用SSHターミナル。iOSはしらね。ggrks)
・KiwiBrowser(スマホ上で拡張機能が使える神ブラウザ。)
これさえあればできます。結構便利ですよね?ぜひお試しください!!
【注意】
ダウンロードしたファイルは必ず個人利用にとどめてください。またダウンロードしたファイルには著作権保有者様のコンテンツが含まれる場合があるため他人への譲渡賃貸などは著作権法に抵触する恐れがあります。また一切の責任を負いかねます。また、この方法は技術的保護手段の回避には当たりません。

- 投稿日:2020-05-23T18:50:08+09:00
Linux 環境構築(WSL環境上)
こんにちは。
Windows 10 の Windows Subsystem for Linux (WSL) を利用し、Linux 環境構築してみました(Linuxbrew もインストールしました)。その手順です1。1 Powershell を管理者権限で起動する
そして、ExecutionPolicyをRemoteSignedへ設定する。PS> Set-ExecutionPolicy RemoteSigned2 Windows Subsystem for Linux (WSL) の有効化
(同じく管理者権限の Powershell 上で)、下記のコマンドを実行し再起動する2。PS> Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Windows-Subsystem-Linux3 Linux ディストリビューションの入手インストール
Microsoft Store を起動し、検索欄に「WSL」などと入力し、Ubuntu 18.04 LTS (Linux)3 を見つけ、入手インストール起動する4。Microsoft アカウントのサインインはスキップ可能。インストールが始まり、sudo 用の username, password を決めて入力する。Enter new UNIX username: Enter new UNIX password: Retype new UNIX password:4 Linux ターミナル(ディストリビューションと同時にインストールされるデフォルトのもの)が起動できることを確認する
ターミナル環境を起動しコマンドが実行されることを確認する:$ uname -a Linux ... $ cat /etc/os-release : :5 Chocolatey をインストール
PowerShell を管理者権限で起動し、Chocolatey をインストールする。
そして下記のコマンド操作を行い、Windows Terminal (ターミナル環境) をインストールする(今回合わせて vscode も):PS> choco install -y microsoft-windows-terminal vscode6 ターミナル環境 を起動し(= Linux の起動)、各種設定を行う:
$ echo 'umask 002' >> ~/.bashrc $ echo 'export VISUAL="vim"\nexport EDITOR="vim"' >> ~/.bashrc $ echo 'export PATH="/home/linuxbrew/.linuxbrew/sbin:/home/linuxbrew/.linuxbrew/bin:$PATH"' >> ~/.bashrc7 Linux を再起動し下記の設定を行う:
今回、Linuxbrew をインストールしました。$ sudo apt update $ sudo apt upgrade -y $ sudo apt install git curl file build-essential $ sh -c "$(curl -fsSL https://raw.githubusercontent.com/Linuxbrew/install/master/install.sh)" $ brew doctor $ brew update $ brew install gcc zlib8 Linux 上のサービスを確認
試しに cron の状態を確認してみる$ sudo service cron status * cron is not running
多数の既存事例があり屋上屋を架すようで恐縮です。 ↩
もしくは、「コントロールパネル > プログラムと機能 > 「Windowsの機能の有効化または無効化」の中で有効化する」 ↩
Ubuntu 20.04 LTS (Linux) も良いかもしれません。 ↩
参考記事は、「Windows Subsystem for Linux (WSL)の設定手順」、「Windows 10でLinuxプログラムを利用可能にするWSLをインストールする(バージョン1803以降対応版)」、「【WSL入門】第1回 Windows 10標準Linux環境WSLを始めよう」 など ↩
- 投稿日:2020-05-23T18:05:13+09:00
WindowsでLinux -1-:debian導入
1.はじめに
WindowsでPowerShellを学ぶにつれ、Linuxのシェルが懐かしくなってきた。WindowsでLinuxのシェルコマンドを使った遊びがしたければCygwinという方法もあるが(今もあるよね?)、折角なのでWSLでWin上にLinux仮想環境を構築してみる。
2.環境
Windowsのバージョンは以下の通り。
C:\Users\hisabo>systeminfo ホスト名: HISABO-PC OS 名: Microsoft Windows 10 Home OS バージョン: 10.0.18363 N/A ビルド 18363 OS 製造元: Microsoft Corporation OS 構成: スタンドアロン ワークステーション OS ビルドの種類: Multiprocessor Free ・・・以下、略・・・3.目指すところ
- Windows上にWSLでdebian環境を構築する。
4.やってみよう
Microsoft StoreでLinuxを探す
ubuntuしかないのかと思ったら、debianがあったのでdebianにする。確かサイズが77MBとでていたからGUI環境は無しだろうな。その方が都合がいい。
インストールが終わってdebianを起動したら、なんかエラーが出た。以下のページを参考にWSLを有効にするようWindowsの設定を変える。
参考:パソコン工房さん(リンク)
再度、起動させるとうまくいった。とりあえずユーザ登録(ユーザ名、パスワード)を行い、シェルが立ち上がった。見事にCUIだ。とりあえず、packageのアップデートを行う。
hisabo@hisabo-PC:~$ sudo apt-get update We trust you have received the usual lecture from the local System Administrator. It usually boils down to these three things: #1) Respect the privacy of others. #2) Think before you type. #3) With great power comes great responsibility. [sudo] password for hisabo: Get:1 http://deb.debian.org/debian buster InRelease [121 kB] Get:2 http://security.debian.org/debian-security buster/updates InRelease [65.4 kB] Get:3 http://deb.debian.org/debian buster-updates InRelease [49.3 kB] (略) Get:12 http://deb.debian.org/debian buster-updates/main Translation-en [5,166 B] Fetched 15.0 MB in 40s (380 kB/s) Reading package lists... Done hisabo@hisabo-PC:~$ sudo apt-get upgrade Reading package lists... Done Building dependency tree Reading state information... Done Calculating upgrade... Done The following packages will be upgraded: apt apt-utils base-files cron e2fsprogs gpgv iputils-ping libapt-inst2.0 libapt-pkg5.0 libbz2-1.0 libcom-err2 libcryptsetup12 libdns-export1104 libext2fs2 libgnutls30 libidn2-0 libisc-export1100 libncurses6 libncursesw6 libss2 libssl1.1 libsystemd0 libtinfo6 libudev1 ncurses-base ncurses-bin sudo systemd systemd-sysv tzdata udev 31 upgraded, 0 newly installed, 0 to remove and 0 not upgraded. Need to get 17.2 MB of archives. After this operation, 10.2 kB of additional disk space will be used. Do you want to continue? [Y/n] Y Get:1 http://deb.debian.org/debian buster/main amd64 base-files amd64 10.3+deb10u4 [69.8 kB] (略) hisabo@hisabo-PC:~$シェルは何だ?
hisabo@hisabo-PC:/etc$ echo $SHELL /bin/bashbashですね。
念のため/etc/passwdでログインシェルを確認してみる。bashですね。日本語環境はどうなってる(簡易調査)
vi(vim)でinputメソッドの確認。日本語入力モードにどうやって変更するのか覚えている限りためしてみたが、どれもヒットせず。最後の最後に、半角/全角キーを押下したらすんなり日本語入力できた。保存して、cat、more、less、viewで閲覧確認したが、閲覧でも日本語が表示できている。パッと見は問題なさそうだ。
文字コード、ロケールを確認
hisabo@hisabo-PC:/etc$ echo $LANG en_US.UTF-8 hisabo@hisabo-PC:/etc$ locale LANG=en_US.UTF-8 LANGUAGE= LC_CTYPE="en_US.UTF-8" LC_NUMERIC="en_US.UTF-8" LC_TIME="en_US.UTF-8" LC_COLLATE="en_US.UTF-8" LC_MONETARY="en_US.UTF-8" LC_MESSAGES="en_US.UTF-8" LC_PAPER="en_US.UTF-8" LC_NAME="en_US.UTF-8" LC_ADDRESS="en_US.UTF-8" LC_TELEPHONE="en_US.UTF-8" LC_MEASUREMENT="en_US.UTF-8" LC_IDENTIFICATION="en_US.UTF-8" LC_ALL= hisabo@hisabo-PC:/etc$ locale -a C C.UTF-8 en_US.utf8 POSIX hisabo@hisabo-PC:/etc$やっぱりUTF-8なのね。さすがに今時eucはないか。
気が付いたがja_JP.UTF-8じゃないのね?まあいい、あとで調べよう。manがなかったのでmanをinstall
awkを使ってみようとコマンド打ったが、久しく使ってないので忘れてしまった。manで調べようとしたがmanがデフォルトではインストールされていないようだ。installする。
hisabo@hisabo-PC:/etc$ sudo apt-get install man Reading package lists... Done Building dependency tree Reading state information... Done Note, selecting 'man-db' instead of 'man' The following additional packages will be installed: groff-base libgdbm6 libpipeline1 libuchardet0 Suggested packages: groff apparmor www-browser The following NEW packages will be installed: groff-base libgdbm6 libpipeline1 libuchardet0 man-db 0 upgraded, 5 newly installed, 0 to remove and 0 not upgraded. Need to get 2,351 kB of archives. After this operation, 6,820 kB of additional disk space will be used. Do you want to continue? [Y/n] YGoogleがなかった時代はmanでコマンドの使い方を調べたものだ。今はいい時代だ。ネットの中にたいていの答えがある。
終.獲得した知識
- WSLでWindows10上にdebian環境を構築する方法





- 投稿日:2020-05-23T17:14:40+09:00
Linuxの認証にAzureADを使う
Sambaの認証をOffice365のユーザで認証させたいなぁと思ったのでその下準備としてLinuxの認証にAzureADを使えるようにする。
環境
Debian 10.2
Nodejs v10.19.0 (apt)
aad-login
Office365参考にしたサイト
設定
基本的には参考サイトの手順ですが+αやることありました。
AzureADでアプリケーションを作成
Azureのコンソールから"アプリの登録"を行います。
名前:わかりやすい名称
サポートされるアカウントの種類:"この組織ディレクトリのみに含まれるアカウント"アプリを登録すると、アプリケーション(クライアントID)が概要ページに表示されるのでコピーしておきます。
アプリケーションのマニフェスト修正
マニフェストページ表示するとJSONでマニフェストが表示されるので以下項目を設定します。
"allowPublicClient": true
私の場合は初期値がnullで設定されてました。この設定を忘れると認証させた時に
AADSTS7000218: The request body must contain the following parameter:
となって認証失敗します。APIのアクセス許可設定
APIのアクセス許可ページを開いて管理者がアクセス許可に対して同意する必要がありました。
"[名前]に管理者の同意を与えます"ボタンを押して同意を行います。
状態の項目に"[名前]に付与されました"と緑のチェックマーク付けばOKです。この設定を行わないと認証させた時に
AADSTS65001: The user or administrator has not consented to use the application with ID {クライアントID} named '[アプリ名]'.
となって認証失敗します。aad-loginのインストール
Linuxサーバー側の作業です。
bashsudo apt update sudo apt install -y nodejs npm git cd /tmp git clone https://github.com/bureado/aad-login cd aad-login/ mkdir -p /opt/aad-login cp aad-login.js package.json /opt/aad-login/ cp aad-login /usr/local/bin/ cd /opt/aad-login/ npm installaad-loginの設定
aad-login.jsvar directory = '[office365のドメイン名]'; var clientid = '[アプリケーションのID]';add-login.jsを見ると分かりますが、
username + '@' + directoryをuseridとして認証するのでoffice365で認証に使えるドメインをdirectoryに記載します。pam.dの設定
aad-loginのgitの説明にあるようにcommon-authの先頭に追記します。
/etc/pam.d/common-auth~省略~ # pam-auth-update to manage selection of other modules. See # pam-auth-update(8) for details. #↓ここ追加↓ auth sufficient pam_exec.so expose_authtok /usr/local/bin/aad-login #↑ここ追加↑ # here are the per-package modules (the "Primary" block) auth [success=1 default=ignore] pam_unix.so nullok_secure # here's the fallback if no module succeeds auth requisite pam_deny.so # prime the stack with a positive return value if there isn't one already; ~省略~ユーザの追加
認証させたいユーザを事前に追加しておく必要がありました。
追加するのは@より前のところになります。#hoge@directoryの場合 useradd hoge<<ユーザの追加しないで実行した場合>>
pam_exec.soが実行された時に"#010#012#015INCORRECT#010#012#015"がパスワードとして設定されてしまい認証できないようです。authをする前にユーザが居るか確認するようで、ユーザが居ない場合パスワードが上記のものに差し替わるようです。
個人用途ならまぁしょうがないかという感じ(゜゜)
と、ここまでやってSambaってユーザ管理別やんってことに気づいて当初の目的が果たせないことに気づく・・・
- 投稿日:2020-05-23T16:59:57+09:00
Explaining the dreaded “No init found.” boot hang message
https://www.kernel.org/doc/html/latest/admin-guide/init.html
Explaining the dreaded “No init found.” boot hang message
恐ろしい"No init found." boot hang messageを説明する。
OK, so you’ve got this pretty unintuitive message (currently located in init/main.c) and are wondering what the H*** went wrong. Some high-level reasons for failure (listed roughly in order of execution) to load the init binary are:
OK, あなたはこのかなり直感的ではないメッセージ(init/main.cに現在配置されています)を受け取り、H***が何がうまくいかなかった疑問に思っていることでしょう。init binaryをloadするのを失敗した、high-levelの理由がいくつかあります(このリストはざっくりと、実行順番に並べてあります):
A. Unable to mount root FS
B. init binary doesn’t exist on rootfs
C. broken console device
D. binary exists but dependencies not available
E. binary cannot be loadedA. root FSをマウントできなかった。
B. rootfsにinit binaryが存在していなかった。
C. console deviceが壊れている
D. binary は存在するが、依存しているものが有効ではない
E. binary をloadできなかった。Detailed explanations:
詳細について述べていきます。
A. Set “debug” kernel parameter (in bootloader config file or CONFIG_CMDLINE) to get more detailed kernel messages.
更に詳細なkernel messageを取得するために、kernel parameterに"debug"をセットしてください(bootloaderの設定ファイルや、CONFIG_CMDLINEで行えます)
B. make sure you have the correct root FS type (and root= kernel parameter points to the correct partition), required drivers such as storage hardware (such as SCSI or USB!) and filesystem (ext3, jffs2 etc.) are builtin (alternatively as modules, to be pre-loaded by an initrd)
正しいroot FS typeであること(そして、root= kernel parameterが正しい位置を示していること)、storage hardware(SCSIやUSB等)や、filesystem(ext3, jffs2等)が組み込まれていること(あるいは、moduleとして、initrdで事前にloadされていること)を確認してください。
C. Possibly a conflict in console= setup –> initial console unavailable. E.g. some serial consoles are unreliable due to serial IRQ issues (e.g. missing interrupt-based configuration). Try using a different console= device or e.g. netconsole=.
おそらく、console= setup –> initial と競合しているconsoleは利用できません。例えばserial IRQの問題(例えば、割り込みベースの設定が存在していない)で、シリアルコンソールの中には信用がないものがあります。他のconsole= device、例えばnetconsole=を使ってください。
D. e.g. required library dependencies of the init binary such as /lib/ld-linux.so.2 missing or broken. Use readelf -d |grep NEEDED to find out which libraries are required.
例えば、init binaryが要求している、/lib/ld-linux.so.2のようなライブラリが存在していない、もしくは破損しているかもしれません。readelf -d |grep NEEDEDを利用し、それらのlibraryが要求しているものを確認してください。
E. make sure the binary’s architecture matches your hardware. E.g. i386 vs. x86_64 mismatch, or trying to load x86 on ARM hardware. In case you tried loading a non-binary file here (shell script?), you should make sure that the script specifies an interpreter in its shebang header line (#!/...) that is fully working (including its library dependencies). And before tackling scripts, better first test a simple non-script binary such as /bin/sh and confirm its successful execution. To find out more, add code to init/main.c to display kernel_execve()s return values.
E. binaryのアーキテクチャが、あなたのハードウェアと一致しているのかを確認してください。例えば、i386とx86_64での不整合、あるいは、ARM hardware上でx86をloadしようとしているのかもしれません。非binary file(shell script?)をloadしようとしている場合には、scriptがそのshebang header line (#!/...) で完全に機能している(ライブラリの依存関係を含む)インタープリターを指定していることを確認する必要があります。 また、scriptに取り組む前に、/bin/shのような単純な非スクリプトで最初にテストをして、実行できることを確認することをお勧めます。詳細を確認するためには、init/main.cのコードを追加し、kernel_execve()の戻り値を表示してください。
Please extend this explanation whenever you find new failure causes (after all loading the init binary is a CRITICAL and hard transition step which needs to be made as painless as possible), then submit patch to LKML. Further TODOs:
新しい失敗原因を見つけた場合には、この説明を拡張してください。(init binaryを全部loadすることは、重要でありhard transition stepdであるため、それは可能な限り単純化する必要があります)。そして、パッチをLKMLに送信してください。 そのほかのTODO:
・Implement the various run_init_process() invocations via a struct array which can then store the kernel_execve() result value and on failure log it all by iterating over all results (very important usability fix).
さまざまなrun_init_process()の呼び出しは、struct配列を介して実装します。これにより、kernel_execve()の戻り値を保存でき、失敗時にすべての結果で繰り返すことで、ログをすべて記録できます(非常に重要な使いやすくなります)。
・try to make the implementation itself more helpful in general, e.g. by providing additional error messages at affected places.
・一般的に、実装自体をより役立つものにするようにしてください。 例えば、影響を受ける場所に追加のエラーメッセージを提供する等。
Andreas Mohr <andi at lisas period de>
もともと、Linux Kernelのソースコードの一部なので、GPLv2扱いになる(はずの認識)。
https://www.kernel.org/doc/html/latest/index.html
Licensing documentation
The following describes the license of the Linux kernel source code (GPLv2), how to properly mark the license of individual files in the source tree, as well as links to the full license text.
https://www.kernel.org/doc/html/latest/process/license-rules.html#kernel-licensing
- 投稿日:2020-05-23T15:49:27+09:00
センスの悪いコード
コーディングセンス
コーディングにセンスはあるだろうか。
最適なアーキテクチャを選ぶことだろうか。
テスタビリティ、変更容易性の高いコードを書くことだろうか。
とにかく速くコードを書くことだろうか。人によって様々あると思うが、
リーナス・トーバルズにとってセンスのある人とは、
大きく見て直感で正しいコードがわかる人らしい。
たとえば、あるif文の特殊ケースを一般化できると見破ることができる人のことである。
次の例は上記動画で紹介されたコード片を動くコードに変えたものだ。#include "common.h" typedef struct linked_list { int value; struct linked_list* nextp; } linkedlist; linkedlist* firstlistp = NULL; void initList(int value); void addList(int value); linkedlist* findList(int value); void deleteList(linkedlist* entry); void printList(); int main() { initList(11); addList(12); addList(13); addList(14); addList(15); addList(16); addList(17); printList(); puts("TEST A"); linkedlist* lp = findList(14); deleteList(lp); printList(); puts("TEST B"); lp = findList(12); deleteList(lp); printList(); puts("TEST C"); lp = findList(16); deleteList(lp); printList(); puts("TEST D"); return 0; } void initList(int value) { linkedlist* newp; newp = malloc(sizeof(linkedlist)); newp->value = value; newp->nextp = NULL; firstlistp = newp; } void addList(int value) { linkedlist* newp; newp = malloc(sizeof(linkedlist)); newp->value = value; newp->nextp = firstlistp; firstlistp = newp; } linkedlist* findList(int value) { linkedlist* currentp; currentp = firstlistp; while((currentp != NULL) && (currentp->value != value)) { currentp = currentp->nextp; } return currentp; } #define BAD void deleteList(linkedlist* entryp) { #ifdef BAD linkedlist* prevp = NULL; linkedlist* walkp = firstlistp; while(walkp != entryp) { prevp = walkp; walkp = walkp->nextp; } if(!prevp) { firstlistp = entryp->nextp; } else { prevp->nextp = entryp->nextp; } #else linkedlist** indirectpp = &firstlistp; while((*indirectpp) != entryp) indirectpp = &(*indirectpp)->nextp; *indirectpp = entryp->nextp; #endif free(entryp); } void printList() { linkedlist* currentp = firstlistp; while(currentp != NULL) { printf("%d\n", currentp->value); currentp = currentp->nextp; } }紹介されたのはdeleteList関数。
BADルートとelseルートの違いはif文がないこと.
特殊ルートが消えて一般化された。可読性
コード品質の話をするとき、可読性の話題が上がる。
BADコードは読みやすいだろうか。
もしレビューでこのコードが出てきたら、BADコードを選ぶかもしれない。
すくなくても私の職場ではそうだと思う。センスの悪いコード
ある機能を実現するにあたって方法が多数あることがほとんどだと思う。
議論にでてくるのは実行速度、可読性、拡張容易性などだろう。
実行速度は計測できるので、より速いより遅いは客観的に判断できるが、
可読性は人によって見方が違うし、拡張容易性もどこが変更されるかわからない以上限界がある。
どこまで設定ファイルに依存するかも関わってくる。
センスの良い悪いは状況によるかもしれない。
だが、それぞれの状況に対してセンスの良いコードは存在している。
リーナスさんが言っているのはコードのコードの良し悪しがあり、それを直感でわかる人がいるということ。
難しい。余談
何を言いたいのか考えずに書き始めたらたら結局最後までわからず、結論のない記事になってしまった。
私にはコーディングのセンスも文章のセンスもないらしい。
C言語入門以来にリンクリストを書いた。今まで業務で自分で書くことはなかった。
で、久しぶりに書いたけど、リンクリスト結構難しいと思う。
処理的にこれより難しいものはあるけど、プログラム初心者が書くにはハードルが高いと思った。
追加するときに手前に追加するという概念、削除関数の処理この2個のハードルが高い。
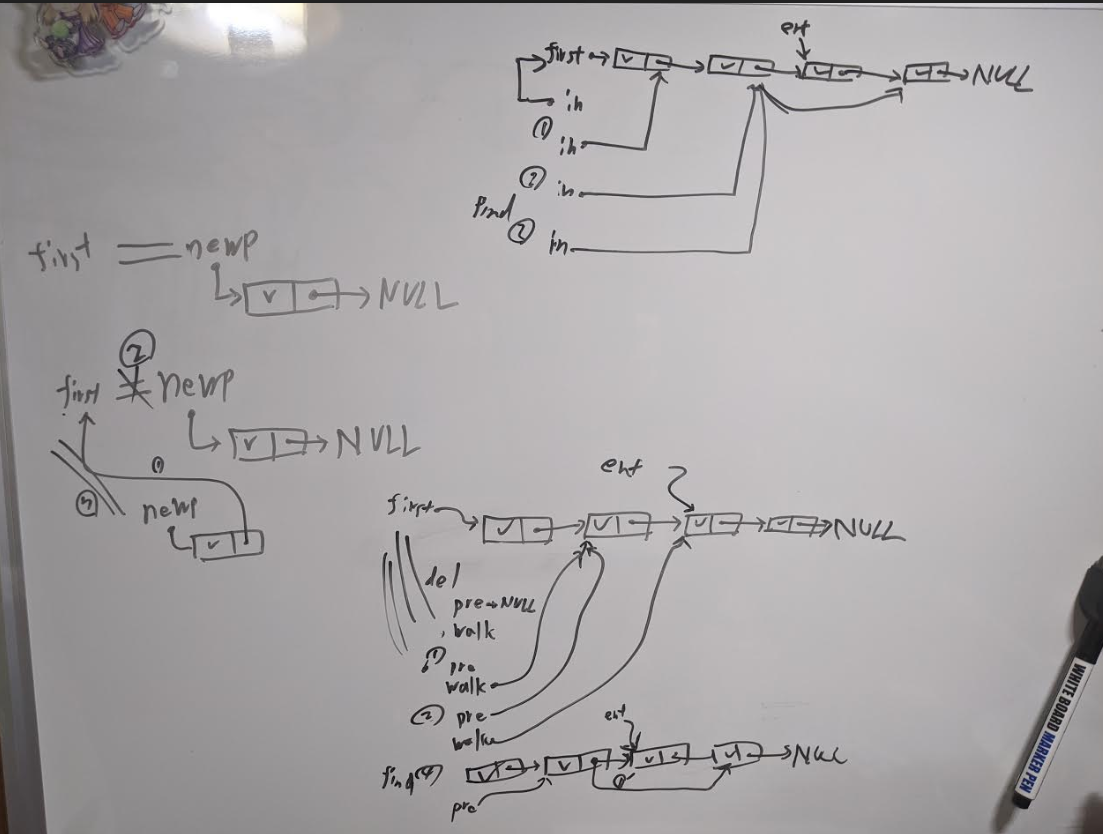
やればできるし、間違ったらすぐSEGVするからデバッグしやすいし、良い振るいとしては機能しているのかもしれない。初心に返って絵を書きながらコーディングしたら、誰もわからない絵になった。私には絵のセンスもないのか。。。

- 投稿日:2020-05-23T15:35:33+09:00
straceの実行結果をgrepしたい
以下のように標準エラー出力を標準出力にリダイレクトすることでgrepができるようになります。
strace <実行したいコマンド> 2>&1 | grep <キーワード>実行例:
$ strace -ff -s 15000 date 2>&1 | grep AT_FDCWD openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3 openat(AT_FDCWD, "/lib/x86_64-linux-gnu/libc.so.6", O_RDONLY|O_CLOEXEC) = 3 openat(AT_FDCWD, "/usr/lib/locale/locale-archive", O_RDONLY|O_CLOEXEC) = 3 openat(AT_FDCWD, "/etc/localtime", O_RDONLY|O_CLOEXEC) = 3
- 投稿日:2020-05-23T14:39:48+09:00
ReadyMedia + Reverse Proxy でDLNAを無理やり持ち出す
概要
自宅にある音声メディアを屋外で利用するにあたり、DLNAを持ち出すことを試した。
環境は限定されるが一応なんとか出来たのでその備忘録。※DLNAはロケーション フリーを加味しておらず。
応答速度が仕様含まれており、実質認められていない行為です。環境構成と設定値例
端末 場所 OS例 役割 host name Global IP VPN IP Private IP Server (1) 自宅 Cent OS 7
(Raspberry Pi 3)DLNA Server 192.168.5.2 192.168.1.2 Server (2) レンタル Cent OS 7
(レンタル)HTTP Gateway dlna.mydomain.org available 192.168.5.3 Client 屋外 android / iPhone Player 利用ツール
- ドメイン (Dynamic DNSでも普通に買うでも可)
- Server
- Linux (Cent OS)
- Apache Httpd
- mod_substitute
- ReadyMedia (miniDLNA)
- Tinc VPN
- Client
- foobar2000 (android / iOS)
手順
手順(1) ドメイン設定
Server(2)のグローバルIPとホスト名との紐付け設定をする。
(ドメイン レジストラとか、DDNSサービスのサイトとか)手順(2) [Server(1)] ReadyMediaの構築
ローカルのサーバーにReadyMediaをインストールし、DLNAサーバーを構築する。
(構築方法は2^10番煎じのため省略)手順(3) [Server(1), Server(2)] VPN構築
Reverse Proxyのため、サーバー間の相互通信を可能にしておくのが目的。
両サーバーが同一ネットワークにある場合は不要。
また、VPN構築もTinc VPN以外でも可能なため、割愛。
(と言うか、書くと長くなるので。。。)手順(4) [Server(2)] Reverse Proxyの設定
本稿のメイン。
Virtual HostでReverse Proxyの設定を行う。
DLNAはサーバーとのやり取りはXMLで行われるが、
コンテンツへのパスにIPアドレスを含んだフルパスで返されるため、
Reverse Proxy越しでは、メディアに到達することが出来ない。
そのため、XML内に記載されているIPをアドレスをホスト アドレスに置換する。
サーバー間はVPNでの通信になるため、置換元のIPはVPNでのIPになる。
項目 値 ホスト名 dlna.mydomain.org 転送先 192.168.5.2:8200 /etc/httpd/conf.d/httpd-vhosts.conf<VirtualHost *:80> ServerName dlna.mydomain.org AddOutputFilterByType SUBSTITUTE text/xml Substitute "s|192.168.5.2:8200|dlna.mydomain.org|i" ProxyRequests Off ProxyPass / http://192.168.5.2:8200/ ProxyPassReverse / http://192.168.5.2:8200/ </VirtualHost>terminalsystemctl restart httpd.service手順(5) [Client]
スマートフォン版 foobar2000を使用して聴く。
項目 値 Client foober2000
(Google Play, App Store)URL http://dlna.mydomain.org/rootDesc.xml 設定画面
画面サンプル
所感
- なかなかネットワーク越しにメディア ファイルを逐字再生する方法が無いので、ありがたい。
- ReadyMediaでプレイリスト ファイルが使えるので、PCでプレイリストを作成して垂れ流し出来るのは嬉しい。
- DLNAをURLで追加出来るクライアントはfoobar2000が唯一なので選択肢がない。
- しかし、foobar2000のGUIが悪すぎなので、そもそもDLNAクライアントとしても微妙。
- BTやヘッドホンの切断で再生が停止するのをOFFに出来ない。。
- 左右のスワイプは曲選(前の曲、後の曲)であってほしい、
- httpsやBASIC認証がかけられない、
- セキュリティを上げたきゃport forwardingでlocalhostに置換とか?
(そこまでする?)- BubleUPnPに比べたら、まだ使える方?
- 読み込み前に曲送りをすると、画面と実際の曲がズレる阿呆バグがあるので、、、
- UIもあまり変わらないし、、、
- もうPlexで良いじゃない?
- ただ、少ないリソースで簡単に導入出来た感はある。
- とりあえず、先日フラッシュ セールで買った500曲あたりをひたすら消化するのには良さそう
参考
・mod_substitute - Apache HTTP Server Version 2.4
https://httpd.apache.org/docs/2.4/mod/mod_substitute.html
・まったく違うIP/ホスト名でアクセスするための、リバースプロキシ用VirtualHost - Qiita
https://qiita.com/tkykmw/items/d7f07f26b89f923d57d5
・Apacheによる本文書き換え mod_substitute + mod_filter - doodle-on-web
https://www.doodle-office.work/entry/mod_substitute_mod_filter
・mod rewrite - 逆プロキシされたホストへのHTTPリクエストでのApache mod_substitute - 初心者向けチュートリアル
https://tutorialmore.com/questions-757269.htm

- 投稿日:2020-05-23T13:32:06+09:00
Linux基礎6 -Vim-
Linuxシステム内には、アプリケーションやLinux自体の設定ファイルなど、たくさんの設定ファイルが含まれています。これらのテキストファイルを扱うために、テキストエディタには十分に慣れておく必要があります。
今回は、Vimというテキストエディタの使い方についてまとめます。テキストファイルとバイナリファイル
ファイルはその内容によって、テキストファイルとバイナリファイルの2種類に分けることができます。
ファイル 概要 テキストファイル 文字列が書かれたファイルのこと。
例:プログラムのソースコード、HTMLファイルバイナリファイル 文字列で書かれておらず、人が読むことを考慮していないもの。
例:画像ファイルや音声ファイル、Linuxコマンドの実態ファイルバイナリファイルの例
Linuxでは設定ファイルやアプリケーションのデータファイルなどの多くにはテキストファイルが使用されています。これはテキストファイルにはバイナリファイルにはない以下のような利点があるためです。
- 専用のアプリケーションを使用せずとも、内容が容易に理解できる
- 互換性が高く、1つのファイル形式を別のアプリケーションから利用しやすい
- Linuxにはテキストファイルを扱うためのコマンドが多く用意されており、それらの恩恵を受けられる
Vim
Linux向けのエディタには数多くの種類がありますが、ここではほとんどのLinuxディストリビューションに標準でインストールされているVimについてまとめます。
Vimのインストール
Vimのインストール$ vim --version #vimがインストールされているかの確認、バージョン情報が表示されればインストール済み インストールされていない場合は下記の手順 CentOS $ su #rootユーザへ変更 $ yum install vim #CentOSでのインストールコマンド Ubuntu $ sudo apt-get install vim #UbuntuでのインストールコマンドVimの起動と終了
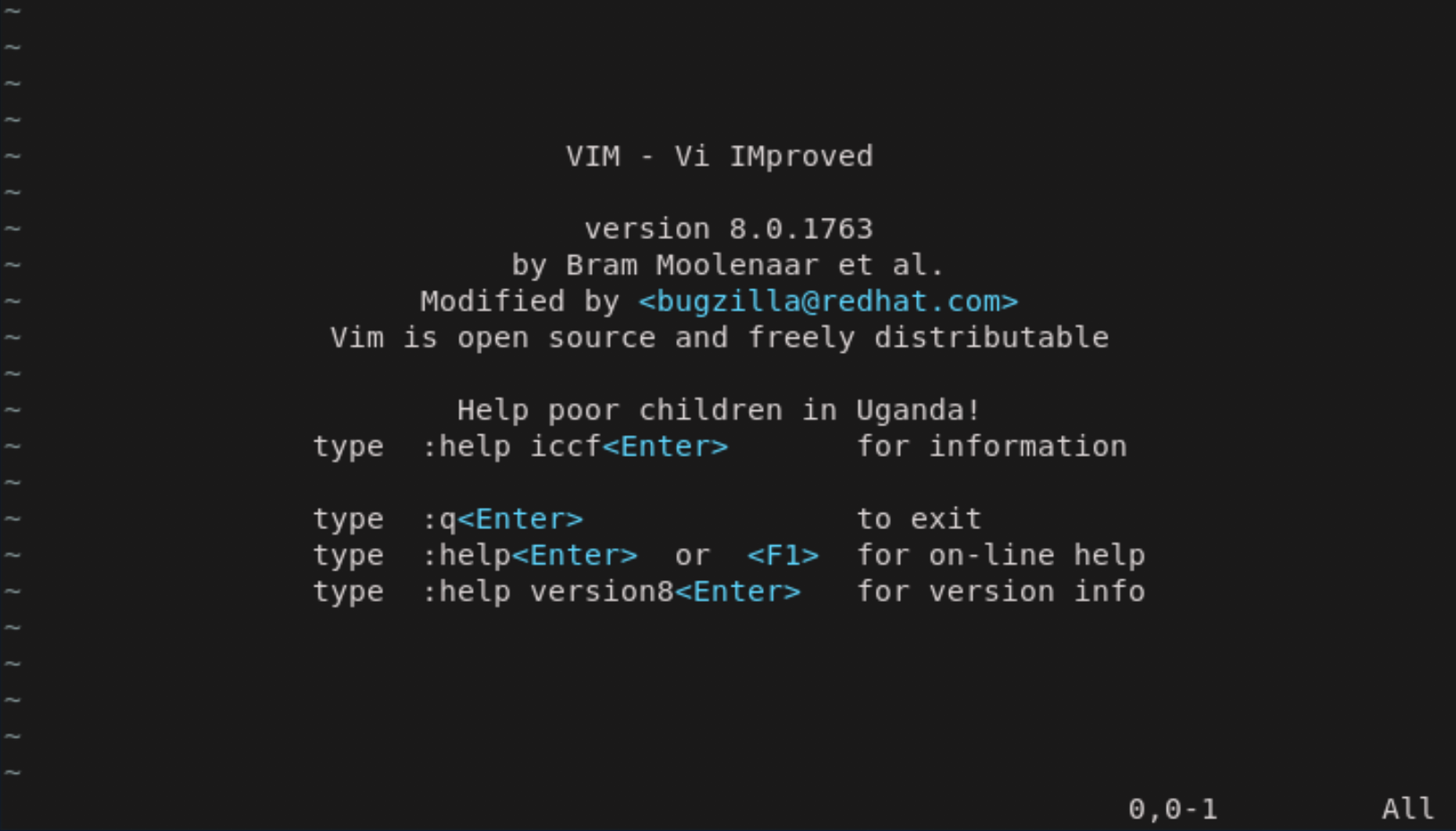
vimの起動と終了Vimの起動コマンド $ vim #$ viでも良い Vimの終了コマンド :q <Enter>Vimの起動画面
Vimでファイルを開く・保存する
ファイルを開く・保存するファイルを開く $ vim newfile1.txt #ファイル名を指定してvimを起動。存在しないファイルを指定すると新規作成。 ファイルの保存 :w <Enter> #既存のファイルの場合は上書き保存、新規の場合は新規作成される。 :w <ファイル名> <Enter> #:wの後にスペースを開けてファイル名を指定すると指定したファイル名で保存ファイルを開いて編集した後に:qコマンドで終了しようとすると、ファイルが保存されていませんとエラーメッセージがでます。
この場合は:wでファイルを保存してから終了するか、現在の編集内容を破棄したい場合は:q!で終了できます。vimの起動・終了に関するコマンドまとめ
コマンド 内容 :q Vimを終了する :w ファイルを上書き保存する :w <ファイル名> ファイルを名前をつけて保存する :q! ファイルを保存せずにVimを終了する Vimの編集操作
Vimを使ったテキストファイルの編集方法について解説していきます。
Vimのモード
Vimにはインサートモードとノーマルモードの2種類があります。
モード 概要 インサートモード テキスト入力ができる状態のこと ノーマルモード コマンド入力ができる状態のこと vimを起動した直後はノーマルモードです。iを押すとインサートモードに入ります。escを押すとノーマルモードに戻ります。
カーソルの移動
通常のカーソル移動
ノーマルモードでVimでカーソルを移動するにはh, k, j, lを使用します。もちろんカーソルキーでも移動できますが、カーソルキーを使うよりも手の移動が少ないため、コマンドを使用したカーソルの移動の方が疲れなくていいかもしれませんね。
インサートモードの場合は大人しくカーソルキーを使用しましょう。Ctrl+bなどの入力も^Bという文字列で解釈されます。単語単位のカーソル移動
単語単位でカーソルを移動することもできます(w or bコマンド)。ただしVimでは「,」(カンマ)や「(」(カッコ)も文字列の区切りとして認識されます。これを無視したい場合はスペース区切りで単語を移動するコマンド(shift+w or b)を使います。
行単位のカーソル移動
大きなテキストファイルを扱う際には行番号を指定して移動すると便利です。「<行番号>shift+g」と入力するとファイルの<行番号>行目に移動します。
また、ファイルの最初と最後へ移動する機会は多いため、行番号を指定せずに移動できるコマンドが用意されています。ファイルの最初の行へはgg、最後の行へはGです。
コマンド 内容 h 左に移動する j 下に移動する k 上に移動する l 右に移動する w 前方に単語1つ分移動する b 後方に単語1つ分移動する shift+w スペース区切りで前方に単語1つ分移動する shift+b スペース区切りで後方に単語1つ分移動する <行番号>shift+g <行番号>行目に移動 gg 最初の行へ移動 shift+g 最後の行へ移動 文字列の削除
ノーマルモードでカーソル一の文字列を削除する場合はxを押すことで削除が可能です。
コマンド 内容 x カーソル位置の文字を削除する カット、コピー、ペースト
Vimでも、他のテキストエディタと同様にカット、コピー、ペーストが可能です。ただしこれらの呼び方がVimでは異なります。
一般的なエディタでの名称 Vimでの名称 カット デリート(delete) コピー ヤンク(yank) ペースト プット(put) デリート
デリートを行うためには前出のxコマンドかdコマンドを使用します。ただしdコマンドはxコマンドとは使い方が異なります。dコマンドはdという文字の後ろにカーソル移動コマンドを合わせて指定する必要があります。
コマンド 内容 d$ 行末までをデリート d0 行頭までをデリート x, dl 1文字をデリート dw 単語1文字をデリート dgg 最初の行までをデリート dG 最後の行までをデリート dd 現在カーソルのある1行だけデリート ここで紹介したデリートコマンド以外にも、カーソル移動コマンドを組み合わせることで、dコマンドを使用することができます。
プット
dコマンドでデリートした文字列はプット(貼り付け)が可能です。貼り付けはpコマンドで実行できます。
コマンド 内容 p デリート(dコマンド)した内容をプット(貼り付け) ヤンク
デリートではなく単にコピー(ヤンク)したい場合は、dの代わりにyコマンドを使用します。yもdと同様にyの後ろにカーソル移動コマンドを指定して使用します。
なお、現在カーソルのある1行だけをヤンクしたい場合は、yyというコマンドが使えます。
コマンド 内容 yy 現在カーソルのある1行をヤンク その他の操作
下の行と連結する
行末の改行を削除して2行を1行としてまとめる場合にjコマンドが使用できます。
コマンド 内容 j 現在の行とそのすぐ下の行を連結されて1つの行にする アンドゥ(元に戻す)とリドゥ(やり直し)
Vimではデリートなどの直後に、編集操作をやり直すことができます。直前の編集操作を取り消して前の状態に戻るには、uコマンドを使用します。この機能をアンドゥ(undo)といいます。
間違ってアンドゥしてしまった場合は、Ctrl+rを押すとアンドゥを取り消すことができます。これをリドゥと呼びます。
コマンド 内容 u 編集操作をやり直す(アンドゥ) Ctrl+r アンドゥを取り消す(リドゥ) 検索と置換
検索
Vimではファイル内の文字列検索ができます。
文字列の検索はLinuxでlessコマンドを実行したときと同様の操作で行うことができます。
コマンド 内容 /<文字列> 下方向に向かって<文字列>を検索する ?<文字列> 上方向に向かって<文字列>を検索する n 次の検索結果に移動する shift+n 前の検索結果に移動する 置換
テキストファイルの中である文字列を別の文字列に置き換えたい場合には、次のコマンドを利用します。
これまでと同様に:を押すと再家業にコマンド入力欄が表示されますので、そこに入力します。vimによる置換:%s/<置換元文字列>/<置換後文字列>/gヘルプとドキュメント
これまで紹介してきた意外にもたくさんの機能がVimにはあります。ここでは必要に応じてvimの機能を調べられるようにドキュメントを紹介します。
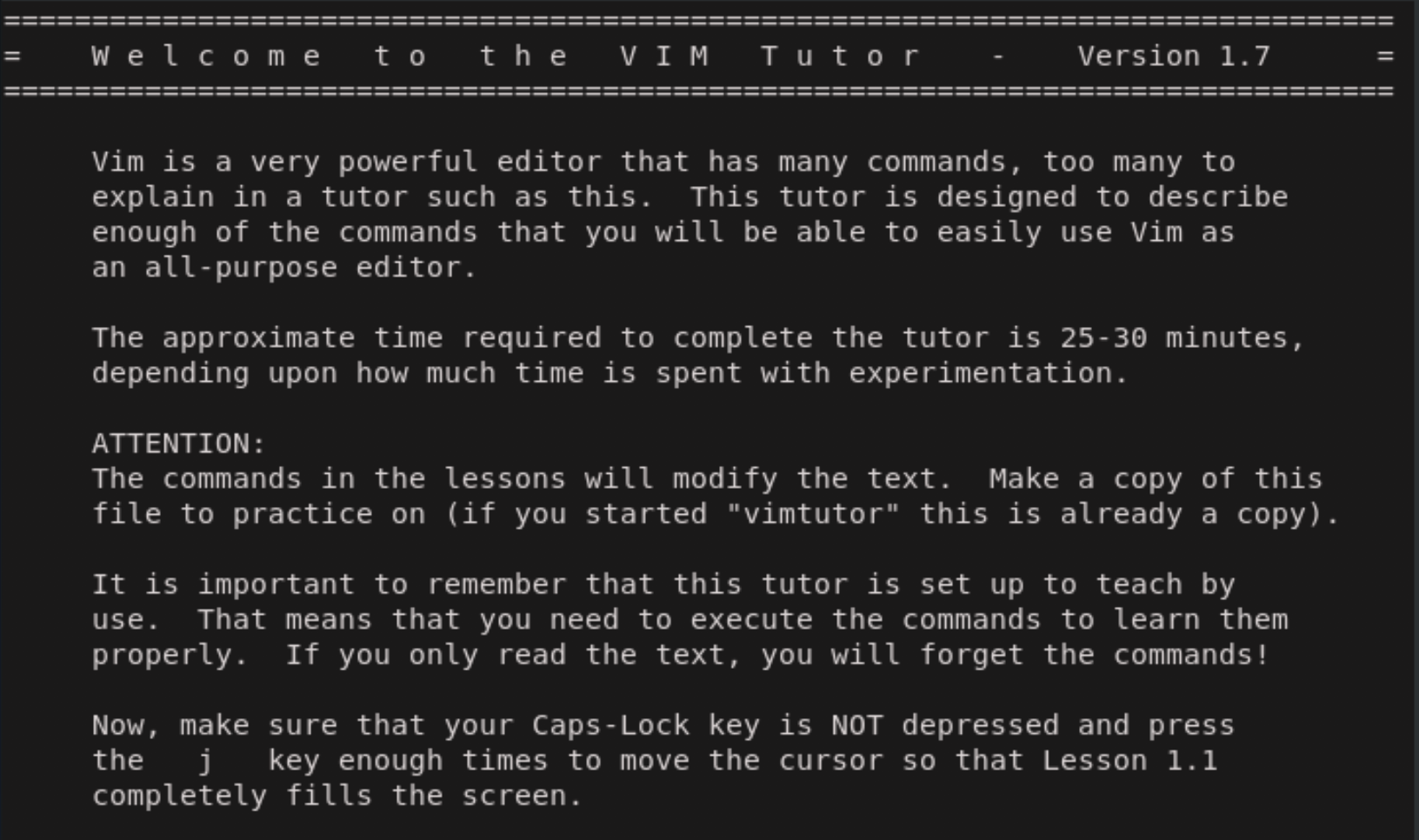
vimのドキュメント$ vimtutor #vimのチュートリアルを開始するコマンド :help #Vimを実行中にヘルプを起動 :qで終了 :help d :help :w #:helpの後ろに特定のコマンド名や単語を指定すると関連するヘルプを表示することができる Ctrl+] #helpのリンクへ Ctrl+t #リンク先から元の場所へ戻るVimのチュートリアル画面
ここまでのVimコマンドのまとめ
コマンド 内容 :q Vimを終了する :w ファイルを上書き保存する :w <ファイル名> ファイルを名前をつけて保存する :q! ファイルを保存せずにVimを終了する h 左に移動する j 下に移動する k 上に移動する l 右に移動する w 前方に単語1つ分移動する b 後方に単語1つ分移動する shift+w スペース区切りで前方に単語1つ分移動する shift+b スペース区切りで後方に単語1つ分移動する <行番号>shift+g <行番号>行目に移動 gg 最初の行へ移動 shift+g 最後の行へ移動 d$ 行末までをデリート d0 行頭までをデリート x, dl 1文字をデリート dw 単語1文字をデリート dgg 最初の行までをデリート dG 最後の行までをデリート dd 現在カーソルのある1行だけデリート p デリート(dコマンド)した内容をプット(貼り付け) yy 現在カーソルのある1行をヤンク j 現在の行とそのすぐ下の行を連結されて1つの行にする u 編集操作をやり直す(アンドゥ) Ctrl+r アンドゥを取り消す(リドゥ) /<文字列> 下方向に向かって<文字列>を検索する ?<文字列> 上方向に向かって<文字列>を検索する n 次の検索結果に移動する shift+n 前の検索結果に移動する vimの起動$ vim #$ viでも良いファイルを開く$ vim newfile1.txt #ファイル名を指定してvimを起動。存在しないファイルを指定すると新規作成。vimによる置換:%s/<置換元文字列>/<置換後文字列>/gvimのドキュメント$ vimtutor #vimのチュートリアルを開始するコマンド :help #Vimを実行中にヘルプを起動 :qで終了 :help d :help :w #:helpの後ろに特定のコマンド名や単語を指定すると関連するヘルプを表示することができる Ctrl+] #helpのリンクへ Ctrl+t #リンク先から元の場所へ戻る参考資料


- 投稿日:2020-05-23T10:30:38+09:00
Linuxのパケットフィルタリングツール
はじめに
本記事ではLinuxで使用可能なパケットフィルタリングツールについて記載しています。
環境はCentOS7を例に解説しています。ebtables
ebtablesはEthernetフレームのルールを設定するためのツールです。
ebtablesではiptablesと同様に「テーブル」、「チェイン」、「ターゲット」を用いてルールを設定します。
テーブル 概要 使用可能なチェイン filter Ethernetフレームのフィルタリング INPUT、OUTPUT、FORWARD nat MACアドレスの変更 PREROUTING、OUTPUT、POSTROUTING broute ブリッジとルータ機能 BROUTING
- ルールの追加
# ebtables -t broute -A BROUTING -p IPv6 -j ACCEPT- brouteテーブルのチェインを表示
# ebtables -t broute -LBridge table: broute Bridge chain: BROUTING, entries: 2, policy: ACCEPT -j BROUTING_direct -p IPv6 -j ACCEPT Bridge chain: BROUTING_direct, entries: 1, policy: ACCEPT -j RETURN
- brouteテーブルのチェインを表示(パケットバイトカウントも表示)
# ebtables -t broute -L --LcBridge table: broute Bridge chain: BROUTING, entries: 2, policy: ACCEPT -j BROUTING_direct, pcnt = 0 -- bcnt = 0 -p IPv6 -j ACCEPT , pcnt = 0 -- bcnt = 0 Bridge chain: BROUTING_direct, entries: 1, policy: ACCEPT -j RETURN , pcnt = 0 -- bcnt = 0iptables
Linuxのパケットフィルタリングは、Linuxカーネル内のNetfilterにより行われています。
Centos7以降ではFirewalldが使用されていますが、Firewalldの中でiptablesを呼び出し、Netfilterを動作させるための設定を行っています。本記事ではiptablesについて記載しています。
iptablesはLinuxカーネルのパケットフィルタルールを設定するためのツールです。
IPv6の場合はip6tablesを使用します。iptablesは「テーブル」、「チェイン」、「ターゲット」を用いてルールを設定します。
テーブル 概要 使用可能なチェイン filter パケットのフィルタリング INPUT、OUTPUT、FORWARD nat パケット変換 PREROUTING、OUTPUT、POSTROUTING mangle(※) IPヘッダ書き換え PREROUTING、INPUT、OUTPUT、FORWARD、POSTROUTING (※)カーネル 2.4.18 からは、INPUT、 FORWARD、 POSTROUTINGの3つの組み込みチェインをサポートしています。
CentOS7ではfirewalldがデフォルトになっているため、iptablesをサービスとして使用したい場合は、iptables-servicesをインストールする必要があります。なお、firewalldとiptablesの共存はできません。
- iptables-servicesのインストール
# yum -y install iptables-services- 外部から80へのアクセスを許可する設定
# iptables -A INPUT -p tcp --dport 80 -j ACCEPT- 特定のネットワークからのアクセスを破棄する設定
# iptables -A INPUT -s 10.0.0.0/8 -j DROP- 特定のIPアドレスから22に対するアクセスを許可する設定
# iptables -A INPUT -s 192.168.0.2 -p tcp --dport 22 -j ACCEPT- 内部のトラフィックを外部にマスカレードする設定
# iptables -t nat -A POSTROUTING -s 192.168.0.0/24 -o enp0s8 -j MASQUERADE- 外部からネットワネットワークに対するアクセスを特定のアドレスにマスカレードする設定
iptables -t nat -A PREROUTING -d 192.168.0/24 -i enp0s8 -j DNAT --to 192.168.10.2iptablesで設定したルールはOS再起動を行うと、消失してしまいます。
iptablesの設定をファイルへ保存するには、iptables-saveコマンドで保存します。
- iptablesのバックアップ
# iptables-save > iptables.backup- iptablesのリストア
# iptables-restore < iptables.backupサーバ起動時にiptablesのサービスと、iptablesのルールを記載したスクリプトを起動することでフィルタリングの自動起動ができます。
ipset
ipsetはIPアドレスをグループでまとめて管理するためのツールです。
セットの作成
# ipset create mynetwork hash:netネットワークの登録
# ipset add mynetwork 10.0.0.0/24登録内容の確認
# ipset list mynetworkName: mynetwork Type: hash:net Revision: 6 Header: family inet hashsize 1024 maxelem 65536 Size in memory: 440 References: 0 Number of entries: 1 Members: 10.0.0.0/24
- iptablesへの追加
# iptables -I INPUT -m set --match-set mynetwork src -j ACCEPT- iptablesの確認
# iptables -t filter -LChain INPUT (policy ACCEPT) target prot opt source destination ACCEPT all -- anywhere anywhere match-set mynetwork srcipsetで設定したルールはOS再起動を行うと、消失してしまいます。
そのため、永続的な設定を行う場合は以下のコマンドを実行し、ルールを出力してサービス化する必要があります。
- ルールの保存
# ipset save > /etc/ipset.confipsetのルールを削除する場合は、一度firewallのサービスを停止して以下のコマンドを実行すると削除できます。
- firewallの停止
# systemctl stop firewalld- ルールの削除
# ipset destroy- ルールの確認
# ipset listリストは以下のコマンドで実行できます。
- ipsetのリストア
# ipset restore < /etc/ipset.conf(※)入力で読み込むファイルは
ipset saveコマンドで出力したファイルを指定nft
nftはカーネル3.13以降に追加されたiptablesに変わるパケットフィルタリング機能です。
CentOSの場合は以下のコマンドでインストールできます。
- nftのインストール
# yum install -y nftablesiptablesに比べるとパフォーマンスが向上しています。なお、iptablesと変わってテーブルやチェインをデフォルトで持たないため、自分で作成する必要があります。
nftを利用する場合は以下の手順で設定します。
- テーブルの作成
- チェインの作成
- ルールの作成
テーブルの作成
# nft add table ip mynetworkチェインの作成
# nft add chain ip mynetwork localchain { type filter hook input priority 0 \; }ルールの作成
# nft add rule ip mynetwork localchain tcp dport 22 acceptルールの確認
# nft list rulesettable ip TESTTABLE { chain testchain { type filter hook input priority 0; policy accept; tcp dport ssh accept } } table ip mynetwork { chain localchain { type filter hook input priority 0; policy accept; tcp dport ssh accept } }おわりに
クラウドが浸透した今、Linuxのパケットフィルタリングを使う機会は減っていますが、システム管理者には必要な知識です。
- 投稿日:2020-05-23T07:43:58+09:00
ipアドレスを公開せずに自分のサーバーを公開する
概要
自分のサーバーを公開するってかなりロマンがあると思います。私も長い間webサーバーを作りたいなー と思ってきました。そんな感じのことをtwitterで呟いていたらある人が ngrok というものを教えてくれました。ngrokとは簡単に言うと自分のローカルホスト(ブラウザでhttp://localhost/ と入れると出てくるページ)などを外部に公開できるサービスです。
ここに書かれている方法はdebian系Linuxディストリビューションすべてに使えると思います。(ラズパイも含め)
作り方
Apache2をインストール
Apache2とはwebサーバーソフトです(気になる人はググってください)。
sudo apt install apache2
を実行するだけでインストールできます。ここでもう一度 http://localhost/ を覗いてみましょう。「apache2 ubuntu default page」的なのが表示されていれば成功です。webサイトを作る
/var/www/html直下にwebサイトを作ります。index.htmlがサイトを読み込んだときに表示される最初のページですngrokをインストール
https://ngrok.com/ にアクセスしてユーザー登録を行ってください。Googleアカウントかgit hubアカウントも使用できます。完了したら自分に適したアーキテクチャ用にngrokをダウンロードします。
完了したら、ダウンロードしたファイルを展開して好きなパスに持ってき、そのパスへ移動します。続いて以下のコマンドを実行します。
./ngrok authtoken XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
xxxxにはあなたのauthtokenを入力します。authtokenは https://dashboard.ngrok.com/auth/your-authtoken で確認できます。そして公開
このコマンド一発で公開できます
./ngrok http http://localhost/Session Status online Account nexryai (Plan: Free) Version 2.2.8 Region United States (us) Web Interface http://127.0.0.1:4040 Forwarding http://xxxxxxxx.ngrok.io -> localhost:8006 Forwarding https://xxxxxxxx.ngrok.io -> localhost:8006の
https://xxxxxxxx.ngrok.ioの部分があなたの公開urlです。(ただしngrokを終了する度に変わります)お疲れ様でした!
- 投稿日:2020-05-23T05:06:21+09:00
Linuxコマンド備忘録【初心者向け】
よく使うLinuxコマンド集
Linuxでは基本的にCUI(Character User Interface)を用いて色々な作業をする.
勿論デスクトップ環境を提供しているディストリビューションも数多く存在するが,
サーバー構築や各種Config設定, DockerやGCP,AWSといった仮想環境ではCUIでの作業がほとんど.そこで,基本的なコマンドを紹介していきます.また各コマンドでよく使うオプションも紹介します.
逆にパイプなどを用いた複雑な使い方などは紹介しません.
同時に元の英語も紹介していくので,文字の羅列で覚えるのだけでなく,意味も覚えてみてください.ファイル,ディレクトリ操作関連
cd [PATH][Change Directory] の意味. linuxにおけるファイル=ディレクトリ.
cdの後ろに任意のディレクトリを指定して移動する.
絶対パス,相対パスともに使用可.
一つ前のディレクトリに移動する場合は,
cd ..
とすることで戻ることができる.
またcdのみで入力すると,ホームディレクトリに移動する.
pwd[Print Working Directory] の意味. Print=表示/出力.
今現在作業しているディレクトリの絶対パスを表示する.
ls [PATH][List Segments] の意味.
指定したディレクトリ内のファイルやフォルダ一覧を表示する.
後半のパスは省略可,その場合はカレントディレクトリ内の一覧を表示する.
- options
-a (--all) : ピリオドから始まるディレクトリやファイルを含め,すべて表示
-l : 権限や日付データなど,詳細な情報を含めて表示
ファイル内容表示,移動関連
cat [File name] ...[Catenate] の意味. Catenate=連結.
指定したファイルの内容をコマンドライン上に表示.
また複数のファイルを指定すると,各ファイルの中身を連結してコマンドライン上に表示する.
less [File name]指定したファイル内容をコマンドライン上に表示.
catと酷似しているが,長いファイルなどを見る場合はlessの方をお勧めする.
閲覧を終了する場合はqキーで終了する. (quit : 終了)
mv [Source] [Destination][Move] の意味.
主な使い方は2つあり,
1. ファイル/ディレクトリ名変更
2. ファイル/ディレクトリを指定先に移動
ファイル名変更はmv hoge hoge2のように,元ファイル 変更したい名前の順で記述. ディレクトリも可.
指定先に移動はmv hoge workspace/のように,元ファイル 移動先ディレクトリの順で記述.
cp [Source] [Destination][Copy] の意味.
記述方法はmvと同じ.
cp hoge hoge2とすると, hogeの内容が複製されたhoge2が作成される. hogeは削除されない.
cp hoge workspace/とすると,ファイル名はそのままで,指定したディレクトリ内にコピーする.
またcp hoge hoge2の際にhoge2というファイルが存在していた場合,上書きされるので注意.
- options
-r : ディレクトリをコピーする.
-i : 上書きされるファイルがある場合,警告を表示する. (y/n)で選択.
ファイル/ディレクトリ作成,削除関連
touch [File name]空のファイルを作成する. その他タイムスタンプを変更する機能がある.
mkdir [Directory name][Make Directory] の意味.
任意のディレクトリを作成. パスを指定しての作成も可.
rmdir [Directory name][Remove Directory] の意味. Remove=削除.
指定したディレクトリを削除. ただし指定したディレクトリ内が空でない場合,削除することができない.
rm [File name][Remove] の意味.
指定したファイルを削除. ディレクトリは削除することが出来ないが,以下のオプションで可能.
- options
-r : ディレクトリ削除可能. 空でないディレクトリも削除できる.
-i : 削除前に警告文表示. (y/n)を入力で削除するかどうか選択.
管理者権限,インストール関連
sudo apt-get install [Package name] ...パッケージのインストールコマンド.
- options
-y : パッケージインストール時に問い合わせがあった場合,すべてを[y]で答える.(y入力省略)
sudo[Substitute(Super or Switch) User Do] の意味. 所説ある.
他の管理者権限でコマンドを実行する場合に,先頭にこのコマンドを入力してから使う.
上記sudo apt-get installもその一例.
ちなみに管理者権限がほぼ必要になるconfigファイルの設定などを多くする場合には,
あらかじめroot権限に入っておくほうがいい場合もある. その際は
sudo su
とすることでroot権限に移行する. 終了する際はexitその他コマンド,入力関連
上記までのコマンドは基本的な操作のものだが,ここからCUIでの作業で便利なコマンドや
入力の手助けになる操作方法を紹介していきます.
clearコマンドラインの表示をクリアする.
作業が続いた際や別の作業を始める際に,コマンドラインをリセットすることで作業しやすくなる.
また標準設定の場合,Ctrl + Lでも同様の効果が得られる. Lは小文字で可.
man [command][Manual] の意味.
使い方やオプションの種類などを調べることができる. 公式のリファレンス.
標準ではlessコマンドを用いて表示されるため, 終了する際はq
コマンドだけでなく,システムディレクトリやシステムコール関連のマニュアルも見ることができる.
TAB キーコマンドではないが,CUIにおいて
TABキーは非常に重要なキーになっている.
TABキーを使いこなせるようになるとCUIでの作業効率が格段に上がるので,常に使用する事をお勧めします.TABキーの主な効果は次のようなものがある.
1. コマンドの候補を表示
2. ディレクトリの候補を表示1. コマンドの候補を表示 とは,コマンドを忘れてしまった場合や入力の手間を省くのに有効である.
たとえばapt-get installのような長いコマンドの場合,すべて入力せずに
apt-g+ TABキー +i+ TABキー
のように途中まで入力してTABキーを押すことで,該当するコマンドを全部入力してくれる.
なお,aptにはapt-get以外にもapt-config,apt-add-repositoryなど多くの種類がある.
その場合,
apt+ TABキー x 2回
のようにTABキーを二回連続で押すことで,aptに該当するコマンド候補一覧を表示してくれる.
もちろんaptのみならず全コマンドで可能.2. ディレクトリの候補を表示 とは,上記の例で言う該当コマンド候補一覧と非常に似ている.
例えばcdコマンドを入力した際に,
cd+ TABキー x 2回
のようにすることで,カレントディレクトリ内のディレクトリを全て表示してくれる.
またcd hoge/の段階でTABキーを2回押すことで, hogeディレクトリ内のディレクトリを表示することも可能.主な機能としてはこれらが上げられる. TABキーは非常に便利なので,ぜひ使いこなしてみて下さい.
最後に
初心者向け備忘録のため,コマンドによっては一部しか解説していないですが,
何事も基本から.まずはこれらを使いこなせるようにしましょう.
- 投稿日:2020-05-23T02:12:32+09:00
日本語キーボードのバックスラッシュは「ろ」
概要
Mac 上の Virtual Box に日本語化した Kali Linux(2020.2) を入れて遊んでいたところ、バックスラッシュ
\が入力できなくて困った。
結果、ろに割り当てられているのを発見した。
便利そうなので Mac でも同じ方法で入力できるように設定した。
Windows 10 は¥とろが両方¥(にみえる\)に割りあたっていた。これはもしかして常識…?
on (Kali) Linux
以下の方法で日本語化した。キーボードレイアウトは 日本語 (OADG 109A) とした。
Kali Linux 2020.1 導入と日本語化 | セキュリティ | DoRubyターミナルで作業していたところ
\を含むコマンドが必要になった。
Mac の作法に倣ってAlt + ¥と押すと謎の文字�が入力された。これはさすがに違う。
Windows のノリで¥キーを押したら、¥が出てきた。気にせずコマンド実行したらエラー。あかんか。
で、いろいろ触っていたらろ(右 Shift の左隣)で\が入力できることを発見した。on Mac OSX
アンダーバー・アンダースコア
_はShift + ろと指が覚えてしまっているが、 Mac ではShiftなしのろだけで_を入力できる。
ならば Linux に合わせてしまおう。Karabiner-Elements を使ったキーバインドの変更方法は、以下を参照。
Macでバックスラッシュを入力しやすくする設定 by Karabiner-Elements - モノラルログ追記:そのまま適用すると VirtualBox でも入力が置換されてしまい本末転倒だった。
frontmost_application_unlessで VirtualBox を除外すると良い。
設定例
{ "title": "backslash", "rules": [ { "description": "underscore to backslash", "manipulators": [ { "from": { "key_code": "international1" }, "to": [ { "key_code": "international3", "modifiers": [ "option" ] } ], "type": "basic", "conditions": [ { "type": "frontmost_application_unless", "bundle_identifiers": [ "^org\\.virtualbox\\.app\\.VirtualBoxVM" ] } ] } ] } ] }
参考)Karabiner-Elementsの設定項目をまとめました - Qiitaon Windows 10
ところで Windows はどうだったか、と確認したところ、
¥とろは同じ入力、つまり¥にみえる\に割りあたっていた。どちらに見えるかはアプリケーションに依存する。いったい、なぜ今まで気づかなかったのか…