- 投稿日:2020-05-23T23:56:42+09:00
ディープラーニングを勉強、実装した備忘録
対象者
機械学習、ディープラーニングを一通り勉強したが、実装するときにどう関連するのかわからない人。
頭の中を整理したい人。
詳しい数学的な説明はしない。数学的な説明はchainerチュートリアルを参照すると良い。ディープラーニングのモデルになったもの
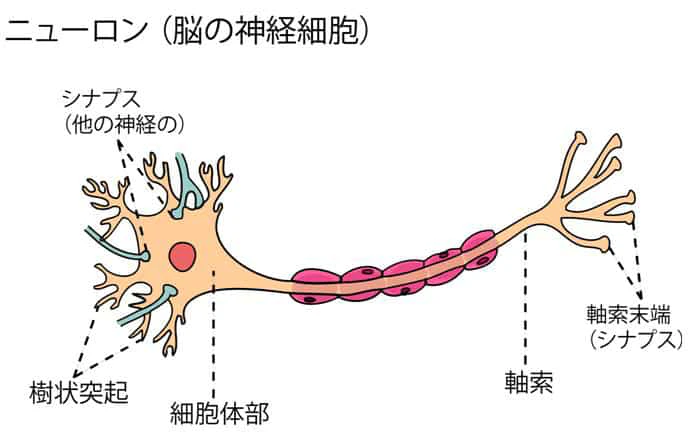
ディープラーニングは人の神経細胞における情報伝達の仕組みを真似て作られた。これにより、精度が飛躍的に向上した。
ニューラルネットワークの仕組み
ニューロンのモデル化
ニューラルネットワークでは、人間の神経細胞の動きをコンピュータで再現した数式モデルを作る。個々の神経細胞は簡単な演算能力しか持たないが、お互いに繋がり連動することで高度な認識、判断をすることができる。行列や特別な関数の計算をしながら情報伝達の仕組みを数式で再現していく。
ニューロンのモデル
ニューロンには多入力、1出力である。ニューラルネットワークの一つの層は複数のニューロンからなる。
重み:各入力に掛け合わせる係数。シナプスにおける伝達効率に相当し、値が大きいほど多くの情報が伝わる。学習中は自動更新されるので初期値しかいじらない。
バイアス:入力と重みをかけ合わせたものの総和に足す定数。ニューロンの興奮しやすさを調整するためのもの。学習中は自動更新されるので初期値しかいじらない。
活性化関数:ニューロンの興奮状態を表す関数。活性化関数がないとニューロンの演算は単なる積の総和になってしまい、ニューラルネットワークから複雑な表現をする力が失われてしまう。シグモイド関数やLeRUなど様々な関数があり、扱う問題によってある程度最適な関数が決まっている。各層毎に自分で選ぶ必要あり。関数の説明は活性化関数の種類参照。
ちなみに記号としてwは重み、bはバイアスとして表される。(蛇足) 画像認識ライブラリのyoloは、学習済み(重みやバイアスや層数などが自動調整済み)のwightファイルをインポートすると直ぐに認識ができるようになる。ただし、学習した環境を考慮しないと間違った認識をしたり、追加で学習させても上手く収束しなかったりする。例えばこの記事にあるように、アメリカで学んだ学習モデルだと「寿司」を「hotdog」と認識される。言い換えるなら育った環境(データセット)で性格(計算結果)が変わるとも言える。
ニューロンのネットワーク化(ニューラルネットワーク)
ニューロンを複数接続してネットワーク化することでニューラルネットワークが構築される。(x、v、yがニューロン) 図のような層状に並べる。
図 ニューラルネットワークのモデル (pythonで始める機械学習から引用)ニューラルネットワークにおける層は、入力層、中間層、出力層に分類される。入力層と出力層は1つしか無いが、中間層は増やすことができる。中間層を増やすことによって計算の振る舞いが変わるので調整する必要がある。
通常のニューラルネットワークは、1つのニューロンからの出力が、次の層の全てのニューロンの入力とつながっている。
入力から出力に向けて情報が伝わることを順伝播。
出力から入力に向けて情報が遡っていくことを逆伝播という。逆伝播は出力結果を遡って重みとバイアスを更新するときに行われるもの。通常は自動的に行われるので、調整パラメータと仕組を知っておけば十分使えるレベルになる。
出力された値はデータセットの正解ラベルと比較して誤差が計算され、正解ラベルに近づくように重みとバイアスが自動調整される。ニューラルネットワークで扱う2つの問題
ニューラルネットワークで扱う問題は、分類問題と回帰問題に分けられる。
ニューラルネットワークの種類
全結合型:「図 ニューラルネットワークのモデル」のように層間の全てのニューロンが接続されているもの。
畳み込み型:画像処理の分野でよく使われる。画像に対して畳み込みを行うことで、画像にある特徴を強めたり弱めたりすることができる。
再帰型:文脈を扱うことができるニューラルネットワークの一種。自然言語処理や系列データによく用いられる。回帰
回帰問題とは、データの傾向から連続的な数値を予測するもの。基本的な使い方として離散データを集めてそのデータから近似関数を作成させ、未知のデータの予測値を算出するもの。
主な例として
・身長から体重を予測する
・ユーザーの買い物傾向から次に購入するものを予測する
・これまでの株価の傾向から明日の株価を予測する
・物件の情報から家賃を予測する単回帰
一つの入力から1つの結果を予測するもの。身長から体重など2つの関係性を表す場合に使われる。
重回帰
物件の様々な情報から家賃を予測するなど多入力のものから1つの結果を予測するもの。こちらのほうがよく使われる。
分類
分類問題とは、データを決められた複数の枠に分類する問題のこと。回帰問題と違い出力が複数ある。出力がそのまま分類したものの確率を表している。
主な例として
・葉の画像から植物を分類する
・手書きの文字を分類する
・画像に映る乗り物が何かを判定する実際に学習させる場合の流れ
1 データセットの準備
データセットとは
学習データxと正解ラベルyが1セットになったデータ群である。データセットは更に訓練データとテストデータに分かれる。訓練データはネットワークの学習に用いるが、テストデータは訓練データから作成したモデルの性能を評価するのに用いる。通常、訓練データはテストデータよりも数を多くする。
学習データにより学習したネットワークがテストデータでも良い結果を出せば、ネットワークが未知のデータにも対応できていることになる。テストデータで良い結果が出なければ、ネットワーク自体や学習方法に何らかの問題があることになる。ネットワークが未知のデータにも対応できる能力を汎化性能と呼ぶ。データの集め方
学習データは手作業か、スクレイピングで自動で集める。集めるのは自動やることもできるが、ふさわしいデータかどうかは手作業で見極めるので一番大変な作業である。データの集め方はこちらの記事が参考になる。
データセットの作り方
データセットは手作業で作るか、ライブラリを使う。「データセット 作り方」とか検索すれば出てくる。画像の場合はアノテーションツールを使って作成する。ユーザーの多くの時間はこのデータセットの作成に費やされている。
適切な結果を得るためには、画像だったら通常何千枚単位の枚数が必要だが、集めることは困難なので水増しを行うのが普通。データセットの構造
データセットの学習データと正解ラベルはそれぞれベクトルになっている。
例えば身長の正解ラベルは、以下のような数値が並んだベクトルで表される。
[146.2 170.4 169.3 154.5 179.2]
この場合は、出力層に5個のニューロンがあり、それぞれの出力値が正解値に近づくようにバイアスと重みの勾配が調整される。
分類問題の場合は、正解ラベルは以下のように、正解が1で正解以外が全て0のベクトルになっている。
[0 0 1 0 0]
このように1が1つで残りが0の数値の並びを、one-hot表現という。データの整形
学習がしやすい形式に整形する。
2 パラメータの初期値の設定
学習に入る前に重みとバイアスの初期値の設定し、中間層と出力層それぞれの活性化関数を設定する。また、損失関数も設定する。
活性化関数の種類についてはやっぱりよくわからない活性化関数とはが参考になる。3 ハイパーパラメータの調整
以下の4つの値を設定する。これらはテストデータで評価した出力によってユーザーが何度も調整する。それぞれの説明はこちら
・エポック
・バッチサイズ
・学習係数
・最適化アルゴリズム4 学習
学習はニューロン同士の結びつきを調整していく過程だ。学習は以下の3つの過程を経る。
4.1 正解との誤差の導出
誤差を導出するために損失関数を用いる。
4.2 勾配の導出
勾配を求めるためには勾配降下法を用いる。出てきた損失関数$L$を$w$で偏微分して勾配$\frac{∂L}{∂w}$が得られる。
(引用:chaierチュートリアル)4.3 バックプロパゲーション(逆伝播)
順伝播により得られた出力と、予め用意した正解との誤差を1層ずづ逆向きに伝播させる。伝播した誤差をもとに各層で重みとバイアスの更新量を求める。更新後の重みは以下のように求められる。
w←w−η\frac{∂L}{∂w}ディープラーニングの多層化による問題
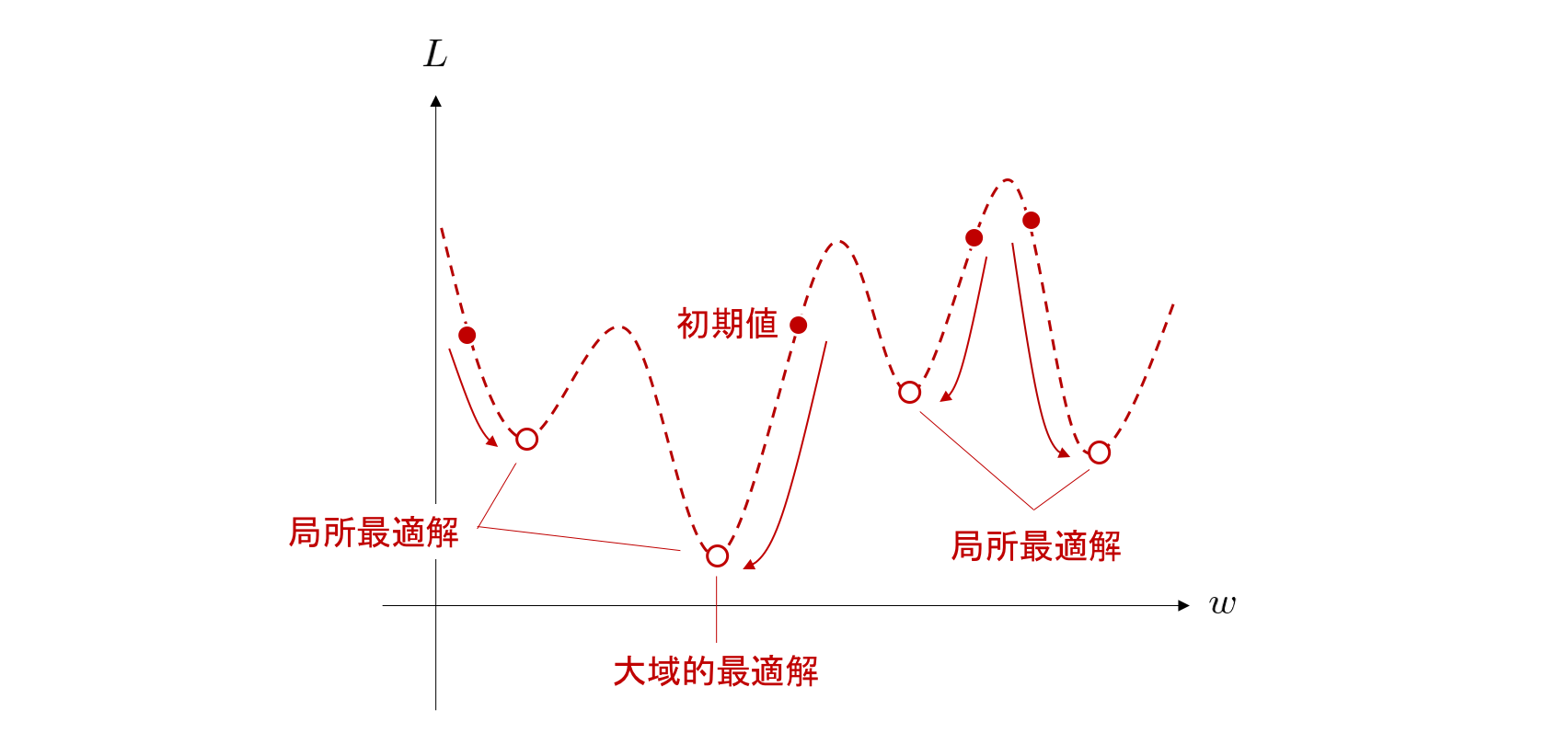
局所最適解へのトラップ
勾配を求める際に局所的な最適解に囚われてしまい、全体の最適解にたどり着けなくなる問題。場合によっては勾配が極端に減少してしまい、学習が進まなくなる問題もある。全体で最適な解を見つけるためには一度局所的にベストな状態を離れる必要がある。
(引用:chainerチュートリアル)過学習
ニューラルネットワークがある特定の範囲のデータのみに最適化されて学習し、未知のデータに対応できなくなってしまうこと。機械学習においては、訓練データに過剰に適合するあまり未知の入力データに対応して推定することができなくなってしまうことでもある。特定のパターンのみ最適化された局所最適解に陥っている状態ともいえる。いろいろなデータに対応できるように、生成されるネットワークは少しいい加減さがあるほうがよい。この過学習を抑制するために後述する様々なパラメータをユーザーが調整していく。
中間層やニューロンの数が多すぎると表現力の過剰により過学習が発生する。また、訓練データのサンプル数不足により発生することもある。勾配消失
主に活性化関数にシグモイド関数を使うことで起きる問題。シグモイド関数の勾配は最大値が0.25で0から離れるほど0に近づく。逆伝搬する際は、層を遡るごとに活性化関数の微分を各勾配にかけることになる。シグモイド関数の場合、層を遡る毎に各勾配が小さくなっていき勾配消失が発生する。そのため、ディープラーニングでは活性化関数にはReLUを使うことが多い。
学習に時間がかかる
多層のディープラーニングでは、重みとバイアスの数が膨大になる。そのため、学習には数日、数週間かかることもある。この問題に対処するためにはGPUを使う、スペックの高いマシンを使う、必要以上にネットワークを複雑にしないこと、パラメータを調整するなどがある。
ユーザーが調整するパラメータ
多層化に伴う問題は、機械が自動で調整することができないので、ユーザーが結果に合わせて調整する必要がある。そのため、より良い結果を得るために何度も調整と学習を繰り返さなくてはならない。調整する項目としては以下の7つがある。どれをどう調整するかはある程度の経験が必要になってくる。よく調整するのはハイパーパラメータ、データの拡張、データの前処理だ。
1 ハイパーパラメータ
エポック
全ての訓練データを1回学習することを1エポックと数える。
バッチサイズ
データセットをいくつかのサブセットに分けた際のそれぞれに含まれるデータ数のことを言う。学習時間やパフォーマンスに影響するパラメータ。詳しくはこちらの説明が参考になる。
学習係数
勾配降下法の勾配にかける係数。これで勾配の量を調整することができる。学習係数が大きすぎると繰り返しパラメータ更新を行っていく中で損失関数の値が振動したり、発散したりしてしまう。逆に小さすぎると、収束に時間がかかってしまう。この値は最適な値は決まっていないため、経験的に探す必要がある。
最適化アルゴリズム
勾配降下法では、勾配をもとに重みとバイアスを少しずつ調整し、誤差が最小になるようにネットワークを最適化する。この最適化の際に様々なアルゴリズムが存在する。各アルゴリズムの説明はこちら
2 重みとバイアスの初期値
学習の成否に関わる大事なハイパーパラメータ。ある程度小さな値でランダムにばらつきを持たせることが望ましい。
3 早期終了
学習を途中で打ち切る手法。学習を進めるとテストデータの誤差が途中から増加し、過学習になってしまうことがあるので、その前に学習を終了させる。誤差が停滞し学習が進まなくなった場合も、時間短縮のために終了させる。
4 データの拡張
訓練データのサンプル数が少ないと、過学習が起きやすくなる。その場合、サンプルの水増しを行って対処するのが一般的。様々なタイプのサンプルを学習させることでネットワークの汎化性能の向上に役立つ。この記事では実際に画像を学習させた際にサンプル不足で過学習に陥っている様子が書かれてるので参考に。
5 データの前処理
入力データに対して予め処理を施して扱いやすくしておくこと。前処理を行うことでネットワークの性能向上や学習の高速化が望める。機械学習の多くの時間がこれに費やされることになる。
pythonを使っている場合は「pandas」というライブラリを使うと簡単に前処理ができる。
前処理の種類には正規化や標準化など様々ある。やり方はこの記事が参考になる。6 ドロップアウト
過学習抑制テクニック。出力層以外のニューロンを一定の確率でランダムに消去するテクニック。規模の大きなネットワークほど過学習を起こしやすいので、ドロップアウトを用いることでネットワークの規模を下げることができる。
7 正則化
重みに制限を与えること。重みに制限を与えることで重みが極端な値をとり、局所最適解にトラップされることを防ぐ。
活性化関数の種類
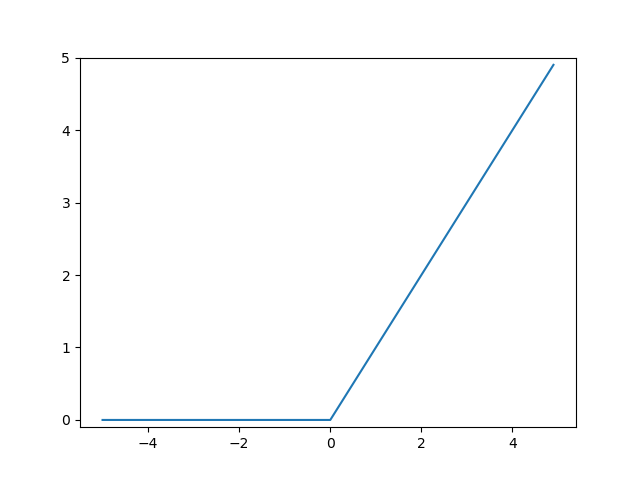
LeRU
0以下の入力で出力が0。0より上の入力で入力と同じ出力をする関数。分類問題によく使われる。分類問題では0以下の入力は取りえないため、ノイズ除去のために使われることが多い。プログラムで実装する場合は、if文で0以下を切り捨てる処理をすれば実装できる。
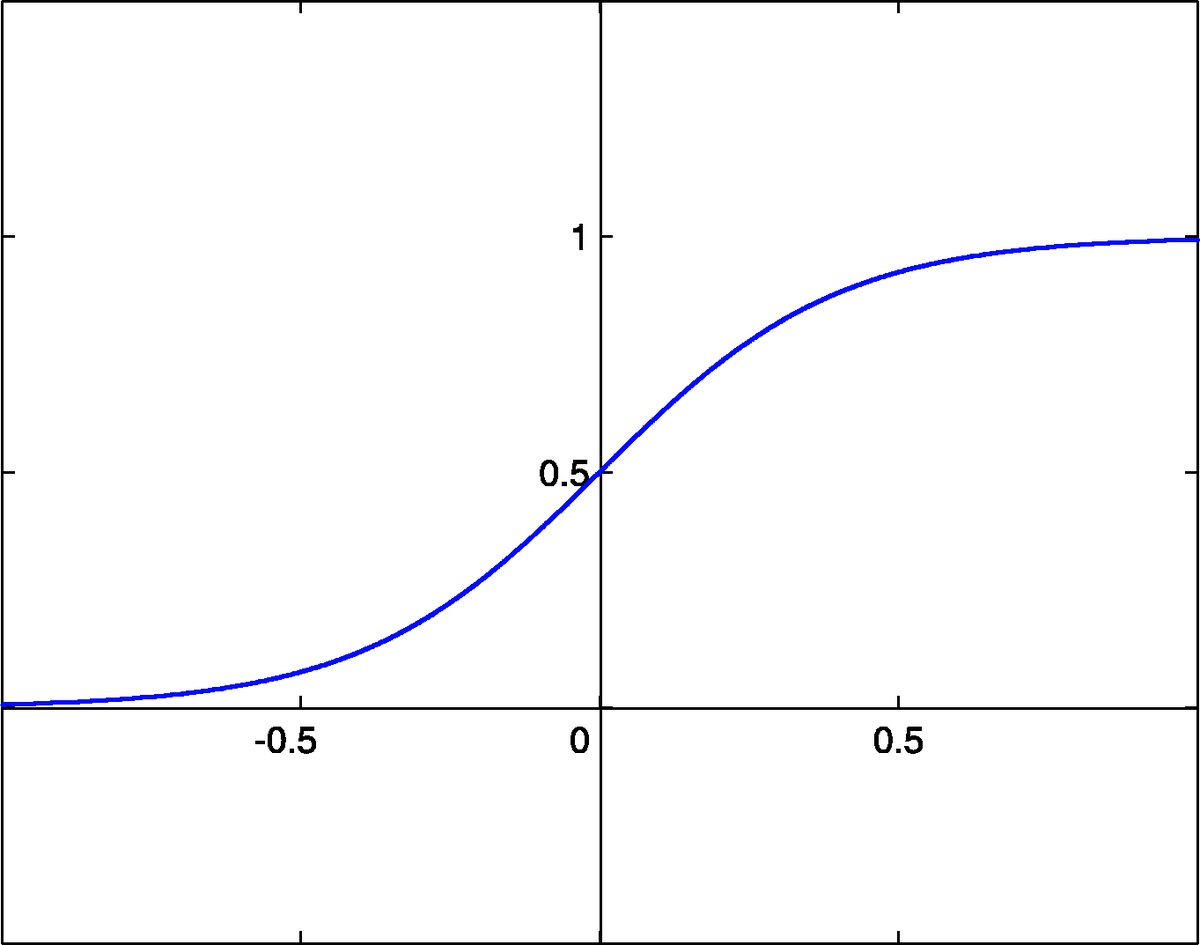
シグモイド関数
入力値が大きくなると一定の値に収束するため、入力が大きなものには使われない。
(wikipedia)ソフトマックス関数
分類問題を扱うのに適した関数。分類問題の出力層によく用いられる。この関数のK=1からnまでの全ての出力を足し合わせると1になる。そのため、ソフトマックス関数は複数の入力値からなるベクトルXがいかなる値を取ろうとも全出力の合計が1になるように正規化する性質を持つ。そのため、出力層のニューロンの出力値の合計を1として扱う分類問題と相性が良い。
y=\frac{e^{x}}{\sum_{k=1}^{N}e^{x_k}}恒等関数
入力をそのまま出力として返す関数。回帰問題の出力層の活性化関数としてよく用いられる。
損失関数一覧
平均二乗誤差
回帰問題をときたいときによく用いられる損失関数。
L= \frac{1}{N}\sum_{n=1}^{N}(t_n-y_n)^2交差エントロピー誤差
分類問題をときたい際によく用いられる損失関数。利点は出力と正解値との隔離が大きいときに学習速度が早い点。
L=\sum_{k=1}^{K}t_k(-\log(y_k))最適化アルゴリズム一覧
以下では代表的なものをメモしている。他の最適化アルゴリズムについてはこちらを参考に。
SGD(確率的勾配降下法)
更新毎にランダムにサンプルを呼び出すアルゴリズム。局所的最適解に囚われにくいという特徴を持つ。簡単なコードで実装できるが、学習の進行に応じて更新量の調整ができないため、学習に時間がかかることが多い。
AdaGard
更新量が自動的に調整される。学習が進むと次第に学習率が小さくなっていく。設定すべき定数が学習係数しかないため、調整に手間がかからない。
RMSProp
AdaGardの、更新量の低下により学習が停滞する弱点を克服したもの。
Adam
RMSpropを改良したもの。最もよく使われているらしい。
参考
チェイナーチュートリアル
pythonで始める機械学習入門
はじめてのディープラーニング Pythonで学ぶニューラルネットワークとバックプロパゲーション
キカガク ディープラーニングの基礎
https://www.sbbit.jp/article/cont1/33345
https://qiita.com/nishiy-k/items/1e795f92a99422d4ba7b
https://qiita.com/Lickey/items/b97c3450d7def207bfbf



- 投稿日:2020-05-23T23:56:02+09:00
ゼロから始めるLeetCode Day34「118. Pascal's Triangle」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day33「1. Two Sum」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
問題
偶然YouTubeでこの問題をJavaで解いてるのを見たので私も解いてみようと思いました。
難易度はEasyです!
問題としては、自然数である
numRowsが与えられるので、例のようなパスカルの三角形を作ってください、という問題です。Input: 5 Output: [ [1], [1,1], [1,2,1], [1,3,3,1], [1,4,6,4,1] ]解説
最初と最後に1を入れることは確定しているので、予め1を挿入した状態を用意してあげて、処理の最後に再び1をappendしてあげれば良さそうです。
問題はどういう風に上位の数字の和を計算し、挿入するかについてですが、forループを二重に回せば二つ分の要素を取得し、足すことが出来そうですね。
なお、今回はnumRowsが0と1の場合は例外として除外するような書き方をしました。
こうすることで、3段目からの処理のみを書けば良いのでより読みやすいと思います。class Solution: def generate(self, numRows: int) -> List[List[int]]: if numRows == 0: return [] elif numRows == 1: return [[1]] triangle = [[1]] for i in range(1,numRows): row = [1] for j in range(1,i): row.append(triangle[i-1][j-1] + triangle[i-1][j]) row.append(1) triangle.append(row) return triangle # Runtime: 28 ms, faster than 73.84% of Python3 online submissions for Pascal's Triangle. # Memory Usage: 13.8 MB, less than 7.14% of Python3 online submissions for Pascal's Triangle.はい、こんな感じになりました。
こっちの書き方の方が良いよ!とかこの言語で書いてみたよ!とかがあれば是非コメントしてみてください。
- 投稿日:2020-05-23T23:40:09+09:00
高知の「あしたの分も買うちょくきね。~飲食券先買い応援プロジェクト~「参加店舗」」を勝手にgoogle map上のマーカーでわかるようにした
高知に行きたくても行けないので勝手にやりました
https://script.google.com/macros/s/AKfycbzRJCvOuWC5uMFiqhl5soiLHnWbkGE5P-GAkxFmVT08u_3E2hRi/execあしたの分も買うちょくきね。~飲食券先買い応援プロジェクト~「参加店舗」
https://www.kochinews.co.jp/norikoeyo/asukau_eatery/
この店舗一覧をgoogle map上のマーカーでわかるようにしました構成
- フロントはgoogle app script
- フロントからAPI Gateway+LambdaのAPIを呼び店舗情報を取得
- 店舗データはDynamoDBに保存
という完全サーバレスです
まずは店舗一覧のデータ作成
https://www.kochinews.co.jp/norikoeyo/asukau_eatery/
このサイトをスクレイピングするlambdaを書きます(python)
座標取得するため、googleのAPIキーも事前に取得しておきましたimport requests import re import googlemaps import time import boto3 def lambda_handler(event, context): dynamo_db = boto3.resource('dynamodb') table = dynamo_db.Table('kouchi_shop') gmaps = googlemaps.Client(key=API_KEY) response = requests.get('https://www.kochinews.co.jp/norikoeyo/asukau_eatery/') response.encoding = response.apparent_encoding text = response.text.replace('\n', '') regex = r'<b>(\d+)(.*?)<\/b>\s*<br>(.*?)<br>' result = re.findall(regex, text) if result: for data in result: if not data[0]: continue number = data[0] shop_name = data[1].strip() href_result = re.findall(r'<a href=\"(.*?)\"', data[2]) shop_address = re.sub(r'<a.*<\/a>', '', data[2]).strip() url = href_result[0] if href_result else '' # 座標取得 geo_result = gmaps.geocode(shop_address) item = { 'id': int(number), 'name': shop_name, 'address': shop_address, 'url': url, 'lat': str(geo_result[0]["geometry"]["location"]["lat"]), 'lng': str(geo_result[0]["geometry"]["location"]["lng"]) } print(item) table.put_item(Item=item) # 念のため連続でリクエストしないようにsleepを入れておく time.sleep(0.5) return { 'statusCode': 200 }適当に一回実行してDynamoDBに店舗データを保存させます
beautifulsoupとかは使ってません(DOMの構造上あんまり意味なかったので)
ライブラリのインストールについてはこちらを参考にさせていただきました
https://tech.bita.jp/article/38店舗一覧を取得するAPIを作る
これもLambdaで書いて、トリガーをAPI Gatewayにします
import json import boto3 from decimal import Decimal def lambda_handler(event, context): dynamo_db = boto3.resource('dynamodb') table = dynamo_db.Table('kouchi_shop') return { 'statusCode': 200, 'body': json.dumps(table.scan(), default=decimal_default_proc) } def decimal_default_proc(obj): if isinstance(obj, Decimal): return str(obj) raise TypeError特に絞り込みとかしないので
scan()で全件取得してるだけです
bodyは連想配列のままだとAPIリクエストしたときに{"message":"Internal Server Error"}が出るので必ずjson.dumpsが必要でした(これでちょっと嵌った)あと、jsonに小数点があるとjsonエンコードでエラーになるので
decimal_default_procで文字列にキャストしてます(letとlngが小数点)
https://qiita.com/ekzemplaro/items/5fa8900212252ab554a3
こちらを参考にさせていただきましたフロント作成
google app scriptでhtmlを作成し、店舗一覧取得APIからマーカーを設置します
<script> var marker = []; var info_window = []; function init_map () { // 初期表示の中心 var map = new google.maps.Map(document.getElementById('map'), { center: { lat: 33.561067, lng: 133.531465 }, zoom: 15 }); get_shop(map) } function marker_event(i) { marker[i].addListener('click', function() { info_window[i].open(map, marker[i]); }); } function set_marker(items, map) { for (var i = 0; i < items.length; i++) { // マーカーの設置 marker[i] = new google.maps.Marker({ position: { lat: parseFloat(items[i]['lat']), lng: parseFloat(items[i]['lng']) }, map: map }); // マーカーをクリックした際のポップアップ var text = '[' + String(items[i]['id']) + '] ' + items[i]['name'] + '<br>' + items[i]['address']; if (items[i]['url']) { text += '<br><a href="' + items[i]['url'] + '" target="_blank">' + items[i]['url'] + '</a>'; } info_window[i] = new google.maps.InfoWindow({ content: text }); marker_event(i); } } function get_shop(map) { var req = new XMLHttpRequest(); req.onreadystatechange = function() { if (req.readyState == 4 && req.status === 200) { const obj = JSON.parse(req.responseText); set_marker(obj['Items'], map) } } req.open('GET', '店舗一覧取得API'); req.send(); } </script> <script src="https://maps.googleapis.com/maps/api/js?key=API_KEY&callback=init_map"></script>フロント作成については以下を参考にさせていただきました
https://tonari-it.com/gas-button-event-javascript/
https://www.tam-tam.co.jp/tipsnote/javascript/post7755.html
https://webdesignday.jp/inspiration/technique/css/4213/最後に
ここ最近毎年高知に行っていて、好きな土地の一つでもあります
早く高知に行けるようになって欲しいですまた、「あしたの分も買うちょくきね。~飲食券先買い応援プロジェクト~「参加店舗」」と私はまったくの無関係です
問題があるようでしたら即刻削除致します
- 投稿日:2020-05-23T23:40:09+09:00
高知の「あしたの分も買うちょくきね。~飲食券先買い応援プロジェクト~」の参加店舗を勝手にgoogle map上のマーカーでわかるようにした
高知に行きたくても行けないので勝手にやりました
https://script.google.com/macros/s/AKfycbzRJCvOuWC5uMFiqhl5soiLHnWbkGE5P-GAkxFmVT08u_3E2hRi/execあしたの分も買うちょくきね。~飲食券先買い応援プロジェクト~「参加店舗」
https://www.kochinews.co.jp/norikoeyo/asukau_eatery/
この店舗一覧をgoogle map上のマーカーでわかるようにしました構成
- フロントはgoogle app script
- フロントからAPI Gateway+LambdaのAPIを呼び店舗情報を取得
- 店舗データはDynamoDBに保存
という完全サーバレスです
まずは店舗一覧のデータ作成
https://www.kochinews.co.jp/norikoeyo/asukau_eatery/
このサイトをスクレイピングするlambdaを書きます(python)
座標取得するため、googleのAPIキーも事前に取得しておきましたimport requests import re import googlemaps import time import boto3 def lambda_handler(event, context): dynamo_db = boto3.resource('dynamodb') table = dynamo_db.Table('kouchi_shop') gmaps = googlemaps.Client(key=API_KEY) response = requests.get('https://www.kochinews.co.jp/norikoeyo/asukau_eatery/') response.encoding = response.apparent_encoding text = response.text.replace('\n', '') regex = r'<b>(\d+)(.*?)<\/b>\s*<br>(.*?)<br>' result = re.findall(regex, text) if result: for data in result: if not data[0]: continue number = data[0] shop_name = data[1].strip() href_result = re.findall(r'<a href=\"(.*?)\"', data[2]) shop_address = re.sub(r'<a.*<\/a>', '', data[2]).strip() url = href_result[0] if href_result else '' # 座標取得 geo_result = gmaps.geocode(shop_address) item = { 'id': int(number), 'name': shop_name, 'address': shop_address, 'url': url, 'lat': str(geo_result[0]["geometry"]["location"]["lat"]), 'lng': str(geo_result[0]["geometry"]["location"]["lng"]) } print(item) table.put_item(Item=item) # 念のため連続でリクエストしないようにsleepを入れておく time.sleep(0.5) return { 'statusCode': 200 }適当に一回実行してDynamoDBに店舗データを保存させます
beautifulsoupとかは使ってません(DOMの構造上あんまり意味なかったので)
ライブラリのインストールについてはこちらを参考にさせていただきました
https://tech.bita.jp/article/38店舗一覧を取得するAPIを作る
これもLambdaで書いて、トリガーをAPI Gatewayにします
import json import boto3 from decimal import Decimal def lambda_handler(event, context): dynamo_db = boto3.resource('dynamodb') table = dynamo_db.Table('kouchi_shop') return { 'statusCode': 200, 'body': json.dumps(table.scan(), default=decimal_default_proc) } def decimal_default_proc(obj): if isinstance(obj, Decimal): return str(obj) raise TypeError特に絞り込みとかしないので
scan()で全件取得してるだけです
bodyは連想配列のままだとAPIリクエストしたときに{"message":"Internal Server Error"}が出るので必ずjson.dumpsが必要でした(これでちょっと嵌った)あと、jsonに小数点があるとjsonエンコードでエラーになるので
decimal_default_procで文字列にキャストしてます(letとlngが小数点)
https://qiita.com/ekzemplaro/items/5fa8900212252ab554a3
こちらを参考にさせていただきましたフロント作成
google app scriptでhtmlを作成し、店舗一覧取得APIからマーカーを設置します
<script> var marker = []; var info_window = []; function init_map () { // 初期表示の中心 var map = new google.maps.Map(document.getElementById('map'), { center: { lat: 33.561067, lng: 133.531465 }, zoom: 15 }); get_shop(map) } function marker_event(i) { marker[i].addListener('click', function() { info_window[i].open(map, marker[i]); }); } function set_marker(items, map) { for (var i = 0; i < items.length; i++) { // マーカーの設置 marker[i] = new google.maps.Marker({ position: { lat: parseFloat(items[i]['lat']), lng: parseFloat(items[i]['lng']) }, map: map }); // マーカーをクリックした際のポップアップ var text = '[' + String(items[i]['id']) + '] ' + items[i]['name'] + '<br>' + items[i]['address']; if (items[i]['url']) { text += '<br><a href="' + items[i]['url'] + '" target="_blank">' + items[i]['url'] + '</a>'; } info_window[i] = new google.maps.InfoWindow({ content: text }); marker_event(i); } } function get_shop(map) { var req = new XMLHttpRequest(); req.onreadystatechange = function() { if (req.readyState == 4 && req.status === 200) { const obj = JSON.parse(req.responseText); set_marker(obj['Items'], map) } } req.open('GET', '店舗一覧取得API'); req.send(); } </script> <script src="https://maps.googleapis.com/maps/api/js?key=API_KEY&callback=init_map"></script>フロント作成については以下を参考にさせていただきました
https://tonari-it.com/gas-button-event-javascript/
https://www.tam-tam.co.jp/tipsnote/javascript/post7755.html
https://webdesignday.jp/inspiration/technique/css/4213/最後に
ここ最近毎年高知に行っていて、好きな土地の一つでもあります
早く高知に行けるようになって欲しいですまた、「あしたの分も買うちょくきね。~飲食券先買い応援プロジェクト~「参加店舗」」と私はまったくの無関係です
問題があるようでしたら即刻削除致します
- 投稿日:2020-05-23T22:52:51+09:00
GRUとAutoencoderを用いた,動画の再構成手法の検証と実装
概要
皆様,いかがお過ごしでしょうか.
コロナウイルス感染症の拡大に伴い,自宅でお仕事や研究をされている方も多いのではないでしょうか.
かくいう私も,ここ数か月はずっと自宅でPCとにらめっこの毎日です.さすがに疲れましたね笑さて,今回は,生成モデルを活用した再構成タスクに着目してみたいと思います.
特に,「動画」の再構成にトライします.
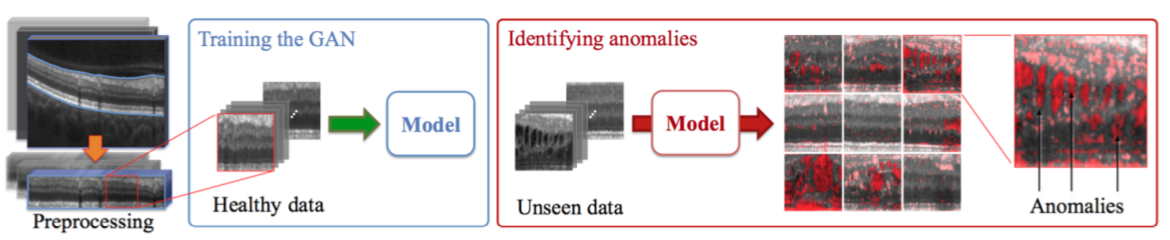
(当記事でご理解いただけるのは,動画の異常検知に拡張可能な,encoder-decoderベースの時系列モデルをかませた再構成手法の実験結果と考察であり,数式などの理論的背景までは追いません.)巷でよく,「異常検知」分野などに応用されているのは,「画像」の再構成ですね.
画像をencoder-decoderモデルに入力して再構成し,入出力間の差分をとることで異常度を計算する手法です.
画像の再構成に活用できる生成モデルとして,VAEは特に有名ですし,最近ではGANを活用した異常検知手法(AnoGAN,EfficientGANなど)なんかも登場しています.以下はAnoGANの例です.
上記画像はこちらから引用
しかしなぜか,「動画」の再構成となると,全然研究の事例が見つからないのです.
(動画「生成」の事例は,GANを活用した手法が散見されますが.)画像の異常検知技術は,産業応用などですさまじく世の中で普及しているかと思います.動画像もそれなりに需要があると思うのですが,あまり発展していないのですかね.
もちろん動画の異常検知,「再構成」にこだわらなければ昔からいろいろとありますね.
(昔ながらの,ST-Patch特徴量などからSVMを用いてクラス分類するなど)しかし,これだけDeepLearningが普及した世の中です.動画の再構成もできるでしょう!
今回は,時系列モデルであるGRUと,encoder-decoderモデルを組み合わせて,動画再構成モデルを実装します.なお,コードはすべてこちらで公開しております.動画再構成モデル
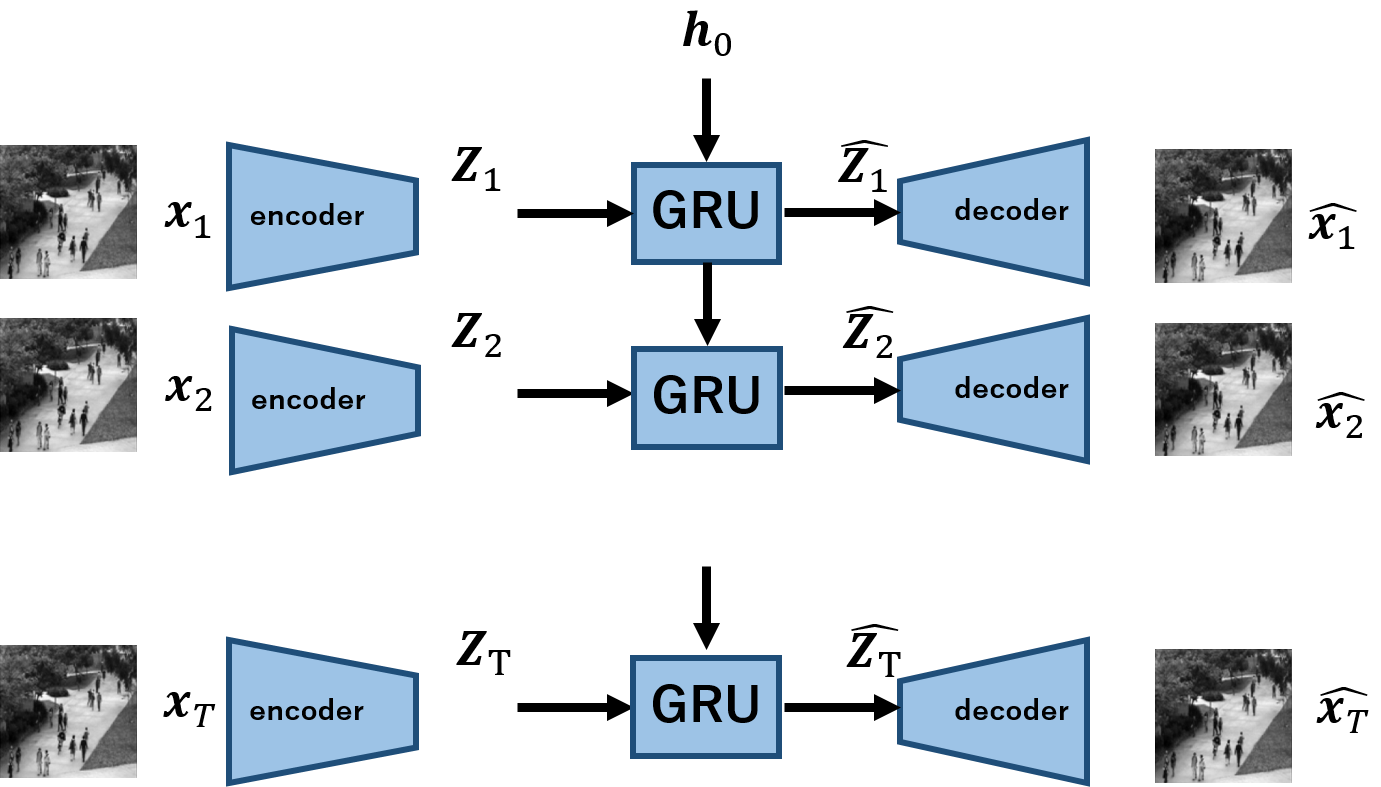
今回実装するモデルを以下に示します.
$\boldsymbol{x_1,x_2,...,x_T}$は,Tの長さを持つ動画を意味し,$\boldsymbol{x_t}$は各frameです.
encoderは各frameの画像を受け取り,$\boldsymbol{z}$へと写像します.これをT回繰り返すことで,入力の動画に対応する系列長の潜在変数,$\boldsymbol{Z_1,Z_2,...,Z_T}$を得ます.
この潜在変数を,GRUを用いてモデル化します.各tにおける出力が,$\boldsymbol{\hat{z_t}}$に対応します.あとはこれを用いて,decoderにより観測空間へ写像するという手順になります.動画像再構成タスクの鉄板がよくわからないので,上記のようなモデルが厳密な数学的正しさを保証できているかというと全く自信はありませんが,とりわけ優秀かどうかは置いといて,一応動画の再構成は可能です.
ここで一点補足ですが,なぜ動画像を潜在空間上の一点に符号化しないかという点についてです.
通常のencoder-decoderモデルでは,入力画像を潜在変数をただ一点に符号化しています.動画像に拡張する場合もこれに倣おうかと考えたのですが,ちょうど研究でGAN系の論文のサーベイを実施する中で,動画像を潜在空間上の一点に対応するのはやりすぎという議論があったのを発見しました.これには私も同意で,というのも過去の経験則的に言えます.以前,Kerasを用いて動画像の再構成にトライしたのですが,上記のやり方では思うような成果が挙げられませんでした.
そこで今回は,その反省を生かして,系列の潜在変数を扱うことを考え,上記のようなモデルを定義するに至りました.
モデルの学習・検証
再構成の流れとしては、以下の通りです。
- human action datasetを用意する
- GRU-AEで学習を行う
- 学習済みモデルを使って、動画の再構成を行う
1.human action dataset
こちらのデータは,MocoGANと呼ばれる動画の生成モデルで検証に用いられていたもので,(初出は知りませんが)その名の通り,人が歩いたり手を振ったりしている様子を収めたものとなっています.
こちらからダウンロードできます.(上記画像も,こちらのリンクにあるデータからの引用です.)
2. GRU-AEによる学習
続いて,上記のデータを用いてモデルを学習します.
損失関数はMSEで,当然ですが入出力間の誤差を最小化します.
モデルの詳細に関しては,こちらの実装コード(PyTorchで実装)をご覧ください.学習は10,000itr回し,lossは以下のように推移しました.後半ほぼ0となってしまい,あまり変化がわかりませんが,無事収束している印象です.
3.モデルによる動画の再構成
モデルを用いて推論を行います.上記の実装では,引数で指定したcheck point毎に再構成結果をlogsフォルダの中のgenerated_videosに保存していきます.
学習に連れて,以下のような挙動を示しました.各itr上段が入力,下段が出力です.
0 itr目
当然ながら全く再構成できません.
1,000 itr目
ぼやけてはいますが,人の形ができています.
5,000 itr目
5,000回ともなると,動きもよく再現されております.
9,000 itr目
サンプルが微妙ですが,ほぼ完全に近い形での再構成が可能となった印象です.
まとめ
今回は,GRU-AEを用いて動画像の再構成に挑戦しました.
シンプルなモデルですが,ポイントは潜在変数を時系列で扱っている点です.
本手法を用いて,異常検知などへの拡張も期待できそうですね.
しかし,正直なところ,最近はやっているのはGANと比較すると,新規性としてどうなの?というところです.
さらに,GANから再構成される画像なんかと比較すると,正直見劣りする(ぼやけているところがある)のは否めません.
(以前私の記事でも,VAEGANを紹介しました)
しかしシンプルな手法で手軽ではあるので,是非とも使用してみていただければ幸いです.











- 投稿日:2020-05-23T22:52:26+09:00
Python: 株価予測その①
ツイートの取得
概要
株式投資において投資判断としてテクニカル分析とファンダメンタルズ分析の二つの方法があります。
今回扱うのはテクニカル分析の方です。Twitterを用いた日経平均株価の予測を行います。まず、大まかな流れを説明します。
1,TwitterAPIを用いてTwitterからあるアカウントの過去のツイートを取得します。
2,極性辞書を用いて日毎のツイートの感情分析をします。
3,日経平均株価の時系列データを取得します。
4,日毎のsentimentから次の日の株価の上下の予測を機械学習を用いて行います。アクセストークン
Twitteからツイートを取得する際にアクセストークンというものが必要となります。
これは、ユーザーアカウントにおけるIDとPASSのように「Access Token Key」「Access Token Secret」という2種類の文字列を指します。 ここではある単語を含むツイートを取得します。import time from requests_oauthlib import OAuth1Session import json import datetime, time, sys CK = 'AxH3XJGIeqsz8IcnROFYhMIxq' # Consumer Key CS = 'RdJRXRvVTncJ9K0I0aEUZr34NLi9E2lT3p3tHqQOqMUSLu8wwg' # Consumer Secret AT = '728488434826772481-158c2BioeYhEDOQoIuiYzq1xxgv2VtV' # Access Token AS = 'H5TrpQnd86JXCq9gPxnxk2CsTZYLYhzhEo4dtD3hajqh5' # Accesss Token Secert session = OAuth1Session(CK, CS, AT, AS) url = 'https://api.twitter.com/1.1/search/tweets.json' res = session.get(url, params = {'q':u'python', 'count':100}) res_text = json.loads(res.text) for tweet in res_text['statuses']: print ('-----') print (tweet['created_at']) print (tweet['text'])人工知能を含むツイートの取得がこちら
import time from requests_oauthlib import OAuth1Session import json import datetime, time, sys CK = 'AxH3XJGIeqsz8IcnROFYhMIxq' # Consumer Key CS = 'RdJRXRvVTncJ9K0I0aEUZr34NLi9E2lT3p3tHqQOqMUSLu8wwg' # Consumer Secret AT = '728488434826772481-158c2BioeYhEDOQoIuiYzq1xxgv2VtV' # Access Token AS = 'H5TrpQnd86JXCq9gPxnxk2CsTZYLYhzhEo4dtD3hajqh5' # Accesss Token Secert session = OAuth1Session(CK, CS, AT, AS) url = 'https://api.twitter.com/1.1/search/tweets.json' res = session.get(url, params = {'q':u'人工知能', 'count':100}) res_text = json.loads(res.text) for tweet in res_text['statuses']: print ('-----') print (tweet['created_at']) print (tweet['text'])アカウントのツイートを取得
日経産業新聞のツイートを取得してみます。
import tweepy import csv consumer_key = "AxH3XJGIeqsz8IcnROFYhMIxq" consumer_secret = "RdJRXRvVTncJ9K0I0aEUZr34NLi9E2lT3p3tHqQOqMUSLu8wwg" access_key = "728488434826772481-158c2BioeYhEDOQoIuiYzq1xxgv2VtV" access_secret = "H5TrpQnd86JXCq9gPxnxk2CsTZYLYhzhEo4dtD3hajqh5" auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_key, access_secret) api = tweepy.API(auth) #ツイート取得 tweet_data = [] tweets = tweepy.Cursor(api.user_timeline,screen_name = "@nikkei_bizdaily",exclude_replies = True) for tweet in tweets.items(): tweet_data.append([tweet.id,tweet.created_at,tweet.text.replace('\n',''),tweet.favorite_count,tweet.retweet_count]) tweet_datacsvデータとして保存
# tweets.csvという名前でdataフォルダ内に保存 with open('./6050_stock_price_prediction_data/tweets.csv', 'w', newline='', encoding='utf-8') as f: writer = csv.writer(f, lineterminator='\n') writer.writerow(["id", "text", "created_at", "fav", "RT"]) writer.writerows(tweet_data)感情分析
感情分析その1
感情分析とは自然言語処理を用いて、テキストがポジティブな意味合い
またはネガティブな意味合いを持つかを判断する技術のことです。商品のレビューを感情分析することで
マーケティングやカスタマーサポートなど幅広く利用されています。感情分析の主な仕組みは文中に出現する単語が
ポジティブ・ネガティブ・ニュートラルな意味合いを持つかどうかで判断します。判断の基準となるものに極性辞書があり
あらかじめ形態素にポジティブかネガティブが定義された辞書中に定義されています。文書中の各単語を極性辞書を参照することで、感情分析を行います。
それではまずMeCabを用いて形態素解析をします。import MeCab import re # MeCabインスタンスの作成.引数を無指定にするとIPA辞書になります. m = MeCab.Tagger('') # テキストを形態素解析し辞書のリストを返す関数 def get_diclist(text): parsed = m.parse(text) # 形態素解析結果(改行を含む文字列として得られる) lines = parsed.split('\n') # 解析結果を1行(1語)ごとに分けてリストにする lines = lines[0:-2] # 後ろ2行は不要なので削除 diclist = [] for word in lines: l = re.split('\t|,',word) # 各行はタブとカンマで区切られてるので d = {'Surface':l[0], 'POS1':l[1], 'POS2':l[2], 'BaseForm':l[7]} diclist.append(d) return(diclist)明日は晴れるでしょう。と引数に設定した場合がこちら
import MeCab import re # MeCabインスタンスの作成.引数を無指定にするとIPA辞書になります. m = MeCab.Tagger('') # テキストを形態素解析し辞書のリストを返す関数 def get_diclist(text): parsed = m.parse(text) # 形態素解析結果(改行を含む文字列として得られる) lines = parsed.split('\n') # 解析結果を1行(1語)ごとに分けてリストにする lines = lines[0:-2] # 後ろ2行は不要なので削除 diclist = [] for word in lines: l = re.split('\t|,',word) # 各行はタブとカンマで区切られてるので d = {'Surface':l[0], 'POS1':l[1], 'POS2':l[2], 'BaseForm':l[7]} diclist.append(d) return(diclist) get_diclist("明日は晴れるでしょう。")
感情分析その2
今回は極性辞書として単語感情極性対応表を用います。
これは「岩波国語辞書(岩波書店)」を参考に、-1から+1の実数値を割り当ています。
-1に近いほどnegative
+1に近いほどpositiveとなっています。それでは極性辞書を読み込み
リストと辞書を作成します。#word_list, pn_listにそれぞれリスト型でWordとPNを格納してください。 import pandas as pd pn_df = pd.read_csv('./6050_stock_price_prediction_data/pn_ja.csv', encoding='utf-8', names=('Word','Reading','POS', 'PN')) word_list=list(pn_df['Word']) pn_list=list(pn_df['PN']) #pn_dictとしてword_list, pn_listを格納した辞書を作成してください。 pn_dict = dict(zip(word_list,pn_list))感情分析その3
極性辞書を参照してPNの値を返すところの実装を行います。
また
get_diclist("明日は晴れるでしょう。")を関数add_pnvalueに渡して働きを調べて
またそれを関数get_meanに渡してPN値の平均を調べます。import numpy as np def add_pnvalue(diclist_old, pn_dict): diclist_new = [] for word in diclist_old: base = word['BaseForm'] # 個々の辞書から基本形を取得 if base in pn_dict: pn = float(pn_dict[base]) else: pn = 'notfound' # その語がPN Tableになかった場合 word['PN'] = pn diclist_new.append(word) return(diclist_new) # 各ツイートのPN平均値を求める def get_mean(dictlist): pn_list = [] for word in dictlist: pn = word['PN'] if pn!='notfound': pn_list.append(pn) if len(pn_list)>0: pnmean = np.mean(pn_list) else: pnmean=0 return pnmean dl_old = get_diclist("明日は晴れるでしょう。") # get_diclist("明日は晴れるでしょう。")を関数add_pnvalueに渡して働きを調べてください。 dl_new = add_pnvalue(dl_old, pn_dict) print(dl_new) # またそれを関数get_meanに渡してPN値の平均を調べてください。 pnmean = get_mean(dl_new) print(pnmean)
感情分析その4
PN値の変化をグラフで表示します。
import matplotlib.pyplot as plt %matplotlib inline df_tweets = pd.read_csv('./6050_stock_price_prediction_data/tweets.csv', names=['id', 'date', 'text', 'fav', 'RT'], index_col='date') df_tweets = df_tweets.drop('text', axis=0) df_tweets.index = pd.to_datetime(df_tweets.index) df_tweets = df_tweets[['text']].sort_index(ascending=True) # means_listという空のリストを作りそこにツイートごとの平均値を求めてください。 means_list = [] for tweet in df_tweets['text']: dl_old = get_diclist(tweet) dl_new = add_pnvalue(dl_old, pn_dict) pnmean = get_mean(dl_new) means_list.append(pnmean) df_tweets['pn'] = means_list df_tweets = df_tweets.resample('D', how='mean') # 日付をx軸PN値をy軸にしてプロットしてください。 x = df_tweets.index y = df_tweets.pn plt.plot(x,y) plt.grid(True) # df_tweets.csvという名前でdf_tweetsを再び出力してください。 df_tweets.to_csv('./6050_stock_price_prediction_data/df_tweets.csv')
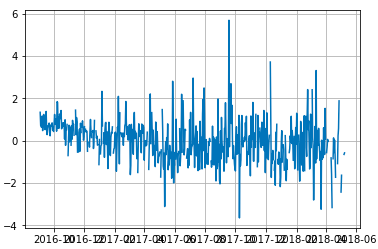
感情分析その5
グラフの結果を見ると全体的に負の値が多いように感じられます。
これは極性辞書にネガティブな意味合いの語彙が多く含まれているためです。
この結果を調整するために標準化を行います。PN値を標準化して
またPNを日付ごとの平均に変え、プロットします。# means_listに標準化を施し、x_stdとして出力 df_tweets['pn'] = (df_tweets['pn'] - df_tweets['pn'].mean()) / df_tweets['pn'].std() # またPNを日付ごとの平均に変え、プロットします。 df_tweets = df_tweets.resample('D', how='mean') x = df_tweets.index y = df_tweets.pn plt.plot(x,y) plt.grid(True)



- 投稿日:2020-05-23T22:30:24+09:00
MacでGPU ~PlaidMLの実装~(2020年5月現在)
実行環境
実行環境1
machine MacBook Air(Retina, 13-inch,2019) OS MacOS Catalina version 10.15.4 メモリ 8 GB 2133 MHz LPDDR3 グラフィック Intel UHD Graphics 617 1536 MB
module version Keras 2.2.4 plaidml 0.7.0 plaidml-keras 0.7.0 plaidbench 0.7.0
実行環境2
machine MacBook (Retina, 12-inch, 2017) OS MacOS Catalina version 10.15.4 メモリ 8 GB 1867 MHz LPDDR3 グラフィック Intel HD Graphics 615 1536 MB
module version Keras 2.2.4 plaidml 0.7.0 plaidml-keras 0.7.0 plaidbench 0.7.0
PlaidML実装の動機
GWに無料で機械学習を勉強することができるコンテンツが増えたことや元々やりたいと考えていた画像処理系の機械学習に手を出してみようと思ったため。
誇るほど高いスペックのマシーンを持っているわけでもなく、実行環境にも書いた通り、実行環境がMacBookということもあり、NVIDIA製のGPUを使うことができない環境は、PCにかける負担もですが、時間がとてもかかる。CPUだけでは学習に限界を感じたため、MacBookでもGPUを使って学習をすることができると噂のPlaidMLの実装をしてみました。参考文献
Plaid MLのGitHubをメインに参考にしました。
PlaidMLの実装について
何をするモジュールなのか
PlaidMLは、intelなどが開発している科学数理計算ライブラリのフレームワークです。
標準でKerasがサポートしてる科学数理計算ライブラリのフレームワークは、tensorflowやTheanoなどがあります。
これらのライブラリで、PCのGPU(グラフィック)を使おうとした時NVIDIA製のGPUでしかサポートされておりませんでした。
AMD製のGPUを搭載しているMacではGPUを使って計算することができませんでした。しかし、このPlaidMLはNVIDIA製という縛りがなく、GPUを使えるようにするためのモジュールとなっており、Kerasのバックエンドのフレームワークとして採用されているモジュールとなっています。
今回の実装では、このKerasのバックエンドにPlaidMLを設定するまでを行います。詰まるところ
Macで、GPUを使って、機械学習ができる
ということです。実装
PlaidML Github QuickStart Link
QuickStarでは、virtualenvを使った仮想環境を構築していますが、僕はしませんでした。
特に理由はないです。必要なモジュールのインストール
module_installpip3 install plaidml-keras plaidbench pip3 install kerasPlaidMLセットアップ
PlaidMLのセットアップを行います。
PlaidMLでCPUを使って計算をするのか、GPUを使って計算をするのかなどのセットアップを行います。plaidml-setupplaidml-setupQuick Start通りに進めましたが、ここでエラーが出ました。
エラー文は下記の通りとなっています。errorTraceback (most recent call last): File "/usr/local/bin/plaidml-setup", line 5, in <module> from plaidml.plaidml_setup import main File "/usr/local/lib/python3.7/site-packages/plaidml/__init__.py", line 50, in <module> import plaidml.settings File "/usr/local/lib/python3.7/site-packages/plaidml/settings.py", line 33, in <module> _setup_config('PLAIDML_EXPERIMENTAL_CONFIG', 'experimental.json') File "/usr/local/lib/python3.7/site-packages/plaidml/settings.py", line 30, in _setup_config 'Could not find PlaidML configuration file: "{}".'.format(filename)) plaidml.exceptions.PlaidMLError: Could not find PlaidML configuration file: "experimental.json".こちらのエラーに関して、GitHubの方で、すでに議論がありました。
興味がある方は覗いてみてください。
plaidml.exceptions.PlaidMLError: Could not find PlaidML configuration file: "experimental.json". #370結論として、
PATHが通っていないため、エラーが出ているという結論があったため、記載されていたPATHを設定します。
再度exportを実行し、設定したPATHが通っていることを確認したら...PATHexport PLAIDML_NATIVE_PATH=/usr/local/lib/libplaidml.dylib export RUNFILES_DIR=/usr/local/share/plaidml export再度セットアップを実行
plaidml-setupplaidml-setup~~ Enable experimental device support? (y,n)[n]:y #y を選択 Multiple devices detected (You can override by setting PLAIDML_DEVICE_IDS). Please choose a default device: 1 : llvm_cpu.0 2 : opencl_intel_uhd_graphics_617.0 3 : metal_intel(r)_uhd_graphics_617.0 Default device? (1,2,3)[1]:3 # 下二つが、GPU今回は、グラフィックの3を選択 ~~ # 今回の選択結果を保存するかどうか Save settings to /Users/linda/.plaidml? (y,n)[y]:y #yを選択
実行結果(全体)
PlaidML Setup (0.7.0) Thanks for using PlaidML! The feedback we have received from our users indicates an ever-increasing need for performance, programmability, and portability. During the past few months, we have been restructuring PlaidML to address those needs. To make all the changes we need to make while supporting our current user base, all development of PlaidML has moved to a branch — plaidml-v1. We will continue to maintain and support the master branch of PlaidML and the stable 0.7.0 release. Read more here: https://github.com/plaidml/plaidml Some Notes: * Bugs and other issues: https://github.com/plaidml/plaidml/issues * Questions: https://stackoverflow.com/questions/tagged/plaidml * Say hello: https://groups.google.com/forum/#!forum/plaidml-dev * PlaidML is licensed under the Apache License 2.0 Default Config Devices: llvm_cpu.0 : CPU (via LLVM) metal_intel(r)_uhd_graphics_617.0 : Intel(R) UHD Graphics 617 (Metal) Experimental Config Devices: llvm_cpu.0 : CPU (via LLVM) opencl_intel_uhd_graphics_617.0 : Intel Inc. Intel(R) UHD Graphics 617 (OpenCL) metal_intel(r)_uhd_graphics_617.0 : Intel(R) UHD Graphics 617 (Metal) Using experimental devices can cause poor performance, crashes, and other nastiness. Enable experimental device support? (y,n)[n]:y Multiple devices detected (You can override by setting PLAIDML_DEVICE_IDS). Please choose a default device: 1 : llvm_cpu.0 2 : opencl_intel_uhd_graphics_617.0 3 : metal_intel(r)_uhd_graphics_617.0 Default device? (1,2,3)[1]:3 Selected device: metal_intel(r)_uhd_graphics_617.0 Almost done. Multiplying some matrices... Tile code: function (B[X,Z], C[Z,Y]) -> (A) { A[x,y : X,Y] = +(B[x,z] * C[z,y]); } Whew. That worked. Save settings to /Users/linda/.plaidml? (y,n)[y]:y Success!
推論性能のベンチマーク
次に、MobileNetの推論性能をベンチマークしてみます。
plaidbench keras mobilenetRunning 1024 examples with mobilenet, batch size 1, on backend plaid INFO:plaidml:Opening device "metal_intel(r)_uhd_graphics_617.0" Compiling network...INFO:plaidml:Analyzing Ops: 266 of 413 operations complete Warming up... Running... Example finished, elapsed: 2.280s (compile), 32.101s (execution) ----------------------------------------------------------------------------------------- Network Name Inference Latency Time / FPS ----------------------------------------------------------------------------------------- mobilenet 31.35 ms 0.00 ms / 1000000000.00 fps Correctness: PASS, max_error: 6.440454399125883e-06, max_abs_error: 5.811452865600586e-07, fail_ratio: 0.0上から2行目
INFO:plaidml:Opening device "metal_intel(r)_uhd_graphics_617.0"
で、自分がセットアップしたアクセラレーターのベンチマークを取られていることが確認できます。実際にここまでで、設定自体は終わっていますが、本当にKerasのバックエンドが、PlaidMLに変わっているかを確認します。
このPATHなどを通してあるターミナル上で、
jupyterを起動させる。
要注意
ここで別のターミナルの窓でJupyterを起動させたり、今まで設定していたターミナルの窓を消すと設定がし直しになる。
PlaidMLの確認
jupyter上で
import plaidml.keras plaidml.keras.install_backend() #バックエンドに設定 import keras print(keras.backend.backend()) #Kerasのバックエンドの確認 >>> tensorflowkerasのバックエンドが、tensorflowのままです。
実際にはPlaidmlをkerasのバックエンドに設定するためには、
plaidml.keras.install_backend() #バックエンドに設定ではなく、バックエンドに設定するPATHを設定してあげる必要がある。
export KERAS_BACKEND=plaidml.keras.backendこのPATHを設定した後に確認すると...
```import keras print(keras.backend.backend()) >>>plaidml.keras.backend変更されていることが確認できる。
最後に
今後画像解析系の学習をさせていきたいと思います。
関連文献
- 投稿日:2020-05-23T22:18:21+09:00
【自然言語処理100本ノック 2020】第1章: 準備運動
はじめに
自然言語処理の問題集として有名な自然言語処理100本ノックの2020年版が4/6に公開されました。
この記事では、以下の第1章から第10章のうち、第1章: 準備運動を解いてみた結果をまとめています。
- 第1章: 準備運動
- 第2章: UNIXコマンド
- 第3章: 正規表現
- 第4章: 形態素解析
- 第5章: 係り受け解析
- 第6章: 機械学習
- 第7章: 単語ベクトル
- 第8章: ニューラルネット
- 第9章: RNN, CNN
- 第10章: 機械翻訳
事前準備
回答にはGoogle Colaboratoryを利用しています。
Google Colaboratoryのセットアップ方法や基本的な使い方は、こちらの記事が詳しいです。
なお、以降の回答の実行結果を含むノートブックはgithubにて公開しています。第1章: 準備運動
00. 文字列の逆順
文字列”stressed”の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.
str = 'stressed' ans = str[::-1] print(ans)01. 「パタトクカシーー」
「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.
str = 'パタトクカシーー' ans = str[::2] print(ans)02. 「パトカー」+「タクシー」=「パタトクカシーー」
「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ.
str1 = 'パトカー' str2 = 'タクシー' ans = ''.join([i + j for i, j in zip(str1, str2)]) print(ans)Python, zip関数の使い方: 複数のリストの要素をまとめて取得
Pythonリスト内包表記の使い方
Pythonで文字列を連結・結合03. 円周率
“Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.”という文を単語に分解し,各単語の(アルファベットの)文字数を先頭から出現順に並べたリストを作成せよ.
import re str = 'Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics.' str = re.sub("[,\.]", "", str) # ,と.を除去 splits = str.split() # スペースで区切って単語ごとのリストを作成 ans = [len(i) for i in splits] print(ans)04. 元素記号
“Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can.”という文を単語に分解し,1, 5, 6, 7, 8, 9, 15, 16, 19番目の単語は先頭の1文字,それ以外の単語は先頭に2文字を取り出し,取り出した文字列から単語の位置(先頭から何番目の単語か)への連想配列(辞書型もしくはマップ型)を作成せよ.
str = 'Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can.' splits = str.split() one_ch = [1, 5, 6, 7, 8, 9, 15, 16, 19] # 1文字を取り出す単語の番号リスト ans = {} for i in range(len(splits)): if i + 1 in one_ch: ans[splits[i][:1]] = i + 1 # リストにあれば1文字を取得 else: ans[splits[i][:2]] = i + 1 # なければ2文字を取得 print(ans)Pythonのfor文によるループ処理
Pythonで辞書を作成するdict()と波括弧、辞書内包表記05. n-gram
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,”I am an NLPer”という文から単語bi-gram,文字bi-gramを得よ.
def ngram(n, lst): return set(zip(*[lst[i:] for i in range(n)])) str = 'I am an NLPer' words_bi_gram = ngram(2, str.split()) chars_bi_gram = ngram(2, str) print('単語bi-gram:', words_bi_gram) print('文字bi-gram:', chars_bi_gram)Pythonで関数を定義・呼び出し
Python, set型で集合演算06. 集合
“paraparaparadise”と”paragraph”に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.さらに,’se’というbi-gramがXおよびYに含まれるかどうかを調べよ.
str1 = 'paraparaparadise' str2 = 'paragraph' X = ngram(2, str1) Y = ngram(2, str2) union = X | Y intersection = X & Y difference = X - Y print('X:', X) print('Y:', Y) print('和集合:', union) print('積集合:', intersection) print('差集合:', difference) print('Xにseが含まれるか:', {('s', 'e')} <= X) print('Yにseが含まれるか:', {('s', 'e')} <= Y)07. テンプレートによる文生成
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y=”気温”, z=22.4として,実行結果を確認せよ.
def generate_sentence(x, y, z): print('{}時のとき{}は{}'.format(x, y, z)) generate_sentence(12, '気温', 22.4)08. 暗号文
与えられた文字列の各文字を,以下の仕様で変換する関数cipherを実装せよ.
英小文字ならば(219 - 文字コード)の文字に置換
その他の文字はそのまま出力
この関数を用い,英語のメッセージを暗号化・復号化せよ.def cipher(str): rep = [chr(219 - ord(x)) if x.islower() else x for x in str] return ''.join(rep) message = 'the quick brown fox jumps over the lazy dog' message = cipher(message) print('暗号化:', message) message = cipher(message) print('復号化:', message)PythonでUnicodeコードポイントと文字を相互変換
Pythonで大文字・小文字を操作する文字列メソッド一覧09. Typoglycemia
スペースで区切られた単語列に対して,各単語の先頭と末尾の文字は残し,それ以外の文字の順序をランダムに並び替えるプログラムを作成せよ.ただし,長さが4以下の単語は並び替えないこととする.適当な英語の文(例えば”I couldn’t believe that I could actually understand what I was reading : the phenomenal power of the human mind .”)を与え,その実行結果を確認せよ.
import random def shuffle(words): splits = words.split() if len(splits) > 4: splits = splits[:1] + random.sample(splits[1:-1], len(splits) - 2) + splits[-1:] return ' '.join(splits) words = "I couldn't believe that I could actually understand what I was reading : the phenomenal power of the human mind." ans = shuffle(words) print(ans)おわりに
自然言語処理100本ノックは自然言語処理そのものだけでなく、基本的なデータ処理や汎用的な機械学習についてもしっかり学ぶことができるように作られています。
オンラインコースなどで機械学習を勉強中の方も、とても良いアウトプットの練習になると思いますので、ぜひ挑戦してみてください。
- 投稿日:2020-05-23T22:12:50+09:00
GitLab CIでPythonコードの静的コ解析
GitLab CIを使ってPythonコードの静的解析を行ったのでメモです。微妙に簡単な導入記事が見つからなかったので誰かのお役に立てれば。
目的
- GitLabはSaaS版、つまりWebブラウザ版をつかう
- しかも無課金
- Python
- とりあえずコードの静的解析さえできればいい
- 無料ではグループあたり2000分/月なのでマージリクエスト発行時だけをトリガーにする
ymlファイル作成
ルートディレクトリに
.gitlab-ci.ymlを作成します。.gitlab-ci.yml# Docker Imageを指定 image: python:latest # キャッシュの保存先 variables: PIP_CACHE_DIR: "$CI_PROJECT_DIR/.cache/pip" # pip installしたものをキャッシュするためにvirtualenvを導入 cache: paths: - .cache/pip - venv/ # 実行前スクリプト before_script: - python -V - pip install virtualenv - virtualenv venv - source venv/bin/activate # testというstageを使う # 長さが79文字以下はちょっといやだったので無視 test: script: # - python setup.py test - pip install flake8 - flake8 *.py --exclude venv/,.cache --ignore E501 only: refs: - merge_requests実行
このファイルが含まれたマージリクエストを作成してください。くるくるテストが回り始めます。テストに通るとマージできるようになります。
- 投稿日:2020-05-23T22:12:50+09:00
GitLab CIでPythonコードの静的解析
GitLab CIを使ってPythonコードの静的解析を行ったのでメモです。微妙に簡単な導入記事が見つからなかったので誰かのお役に立てれば。
目的
- GitLabはSaaS版、つまりWebブラウザ版をつかう
- しかも無課金
- Python
- とりあえずコードの静的解析さえできればいい
- 無料ではグループあたり2000分/月なのでマージリクエスト発行時だけをトリガーにする
ymlファイル作成
ルートディレクトリに
.gitlab-ci.ymlを作成します。.gitlab-ci.yml# Docker Imageを指定 image: python:latest # キャッシュの保存先 variables: PIP_CACHE_DIR: "$CI_PROJECT_DIR/.cache/pip" # pip installしたものをキャッシュするためにvirtualenvを導入 cache: paths: - .cache/pip - venv/ # 実行前スクリプト before_script: - python -V - pip install virtualenv - virtualenv venv - source venv/bin/activate # testというstageを使う # 長さが79文字以下はちょっといやだったので無視 test: script: # - python setup.py test - pip install flake8 - flake8 *.py --exclude venv/,.cache --ignore E501 only: refs: - merge_requests実行
このファイルが含まれたマージリクエストを作成してください。くるくるテストが回り始めます。テストに通るとマージできるようになります。
- 投稿日:2020-05-23T22:11:36+09:00
scikit-learnのAPIデザインの一貫性
はじめに
scikit-learnはPythonの便利な機械学習ライブラリで、Numpy・Scipy・Matplotlibと一緒に気軽に使うことができます。
scikit-learnは、APIのデザインパターンを知ると飛躍的に使いやすくなります。今回はscikit-learnの著者による論文をもとに、scikit-learnの魅力を解説します。
基本デザイン
scikit-learnのオブジェクトはAPIの一貫性を保つため、いくつかのパターンに従って設計されています。
このパターンを理解することでどのオブジェクトでも不自由なく使うことが出来ます。Estimator
scikit-learnではEstimatorというインターフェースが基本となっています。
Estimatorは、データに基づき何らかのモデル(のパラメータ)を学習させます。
必ずfitというメソッドを持っていて、fitの引数にデータを流すことで学習を行います。
また、学習に必要なハイパーパラメータを(コンストラクタまたはset_paramsメソッドで)設定することができます。ロジスティック回帰を行う
LogisticRegressionというクラスもEstimatorの一つです。from sklearn.linear_model import LogisticRegession clf = LogisticRegression(penalty="l1") # ハイパーパラメータの設定 clf.fit(X_train, y_train) # 訓練データに基づきモデルを学習Predictor
Estimatorの多くは同時にPredictorのインターフェスを導入しています。
Predictorはfitで学習したモデルをもとに予想(出力)を行います。
predictのメソッドにデータを引数として渡すと、予想が返されます。
また、scoreというメソッドを持っており、データセットとラベルを渡すことでモデルを評価できます。例えば、
LogisticRegressionはPredictorなので、predict、scoreのメソッドを問題なく使えます。clf.predict(X_test) # テストデータについて予測clf.score(X_test, y_test) # テストデータについての予想と実際の答えを比較Transformer
Predictorの他に、Transformerというインターフェスを導入するクラスもあります。
名前にある通り、Transformerはデータを変形することができます。
機械学習モデルよりはデータ処理のAPIにおいて多用されます。
transformというメソッドを使って変形されたデータを返します。
また、fit_transformというメソッドを使うと、学習と変形を同時に行うことが出来るような設計です。下の例では、データセットの標準化を行う
StandardScalerによる変形を実装します。
StandardScalerの場合、複雑なモデルではなく各特微量の平均と分散を学習します。from sklearn.preprocessing import StandardScaler scaler = StandScaler() X_train = scaler.fit_transform(X_train) # 訓練データを学習・変形 X_test = scaler.transform(X_test) # テストデータは学習せず変形(訓練データの平均・分散を用いる)また、PredictorとTransformerのインターフェスは同時に導入することができます。
パラメータ・ハイパーパラメータの取得
自分が設定したハイパーパラメータ、学習されたパラメータはオブジェクトの中に保存されています。(学習されたパラメータの名前はアンダーバーで終わります)
パラメータ・ハイパーパラメータのアクセス方法については、各オブジェクトのドキュメントで「Attributes」を参照してください。例:
StandardScalerが学習した平均、分散を取得する# 前から続く mean = scaler.mean_ variance = scaler.var_よって、どのEstimatorでも
1. インスタンスを作りハイパーパラメータを設定する
2.fitで学習する
3.predict、score、transformなどで目的を達成する、学習されたパラメータを確認する
という手順に従うことで、簡単にワークフローを構築することができます。
データ全処理からモデル学習・評価までの実装が全てEstimatorを使って行えます。応用デザイン
Estimatorの合成
全てのEstimatorが同じメソッドを持っているため、複数のEstimatorを簡単に合成することができます。
並列処理の場合Pipeline、並行処理の場合FeatureUnionを使って合成します。例えば、データを標準化しロジスティック回帰を行いたい場合、パイプラインを使うことできれいに処理を実装できます。
from sklearn.pipeline import Pipeline pipe = Pipeline([ {'std_scaler', StandardScaler()}, {'log_reg', LogisticRegression()} # transformerの変形したデータを受け取る ]) pipe.fit(X_train, y_train) pipe.score(X_test, y_test)Cross ValidationもEstimator
scikit-learnでは
GridSearchCVやRandomSearchCVなどといったクラスを使ってハイパーパラメータの検証を行うことができます。
これらも、Estimatorのインターフェスを導入しており、fitを使って学習を行います。例:ロジスティック回帰に最適なハイパーパラメータをGrid Searchを使って求める
from sklearn.model_selection import GridSearchCV clf = GridSearchCV( estimator=LogisticRegression(), param_grid={ 'C' = [1, 3, 10, 30, 100] } ) clf.fit(X_train, y_train) # param_gridにあるハイパーパラメータを一つずつ適用して複数のモデルを学習させる best_clf = clf.best_estimator_ # 最適なEstimatorをゲット!自前のEstimatorを作る
fitなど、インターフェースに定義されたメソッドを持つクラスを作ることで、簡単にパイプラインや検証に使うことができます。
Estimatorを作る場合、BaseEstimatorを継承し、さらにTransformerなどを作る場合は同時に適当なMixinを継承します。Transformerの例:
from sklearn.base import BaseEstimator, TransformerMixin class MyTransformer(BaseEstimator, TransformerMixin): def __init__(self, param_1, param_2): # ハイパーパラメータの処理 self.param_1 = param_1 # ... def fit(self, X, y=None): # 処理 return self def transform(self, X, y=None): # Numpy行列の処理 # X = ... return X # fit_transformは自動的にTransformerMixinが実装 transformer = MyTransformer() X_transformed = transformer.fit_transform(X_train)結論
scikit-learnには色々な機械学習手法を実装したオブジェクトが用意されていますが、内容が分からなくてもEstimator、Predictor、Transformerのデザインパターンを理解していれば一通り使えてしまいます。
scikit-learnのAPIは一貫性が高いところが魅力的で、簡単に機械学習を進めることができます。
- 投稿日:2020-05-23T22:00:05+09:00
Python マジのダミーデータ生成(住所編)
背景
faker-python の
fake.address()を使って住所生成したら,兵庫県中野区松石4丁目14番7号 クレスト千塚106こんな感じでフェイク住所が出て来ますが,実際マップを使用したアプリケーションでテストをする際など,これらの情報を検索にかけても実行結果が出ません.
なので
1. フェイクデータではなく実際の住所データを生成する.
2. またダミーデータとして一度の実行にの多くの住所を取得する.今回はこの2点を抑えてデータを生成したいと思います.
どうやって作るか
すぐに思いついたのが,住所情報を提供するAPI経由で,情報を整形して生成する方法.
とりあえずやってみます.HeartRails Geo API
今回お世話になるAPIは,HeartRails Geo API さんです.
ここの緯度経度による住所検索 APIを使ってダミー住所を生成していきます.
住所生成プログラム
import requests import random import json #xml_url = 'httpi://geoapi.heartrails.com/api/xml?method=searchByGeoLocation' json_url = 'http://geoapi.heartrails.com/api/json?method=searchByGeoLocation' # APIリクエスト関数 def get_data(lug,lat): payload = {'method': 'searchByGeoLocation', 'x': lug, 'y': lat} try: ret = requests.get(json_url, params=payload) json_ret = ret.json() except requests.exceptions.RequestException as e: print("ErrorContent: ",e) return json_ret # 住所データの整形関数 def data_serealize(data): try: enc = json.dumps(data, indent=2, ensure_ascii=False) dic = data['response']['location'][9] det = dic['prefecture'] + dic['city'] + dic['town'] return det except KeyError as e: print(e) # 軽度・緯度に使う乱数の生成 def gene_number(lug_fnum, lug_lnum, lat_fnum, lat_lnum): lug = round(random.uniform(lug_fnum,lug_lnum),6) lat = round(random.uniform(lat_fnum,lat_lnum),6) return lug,lat def main(): for i in range(10): lug,lat = gene_number(122,153,19,45) print("経度: " + str(lug) + "," + "緯度: " + str(lat) + "\n") ret = get_data(lug,lat) print(data_serealize(ret)) if __name__ == '__main__': main()データフォーマットは今回
json形式を選びました.理由は特にありません.・ get_data関数は,データを取ってくる関数.
・ data_number関数は,取ってきたデータを整形します.
・ gene_number関数は,日本国内の経度緯度を自動生成して,それをget_data関数に渡します.検証
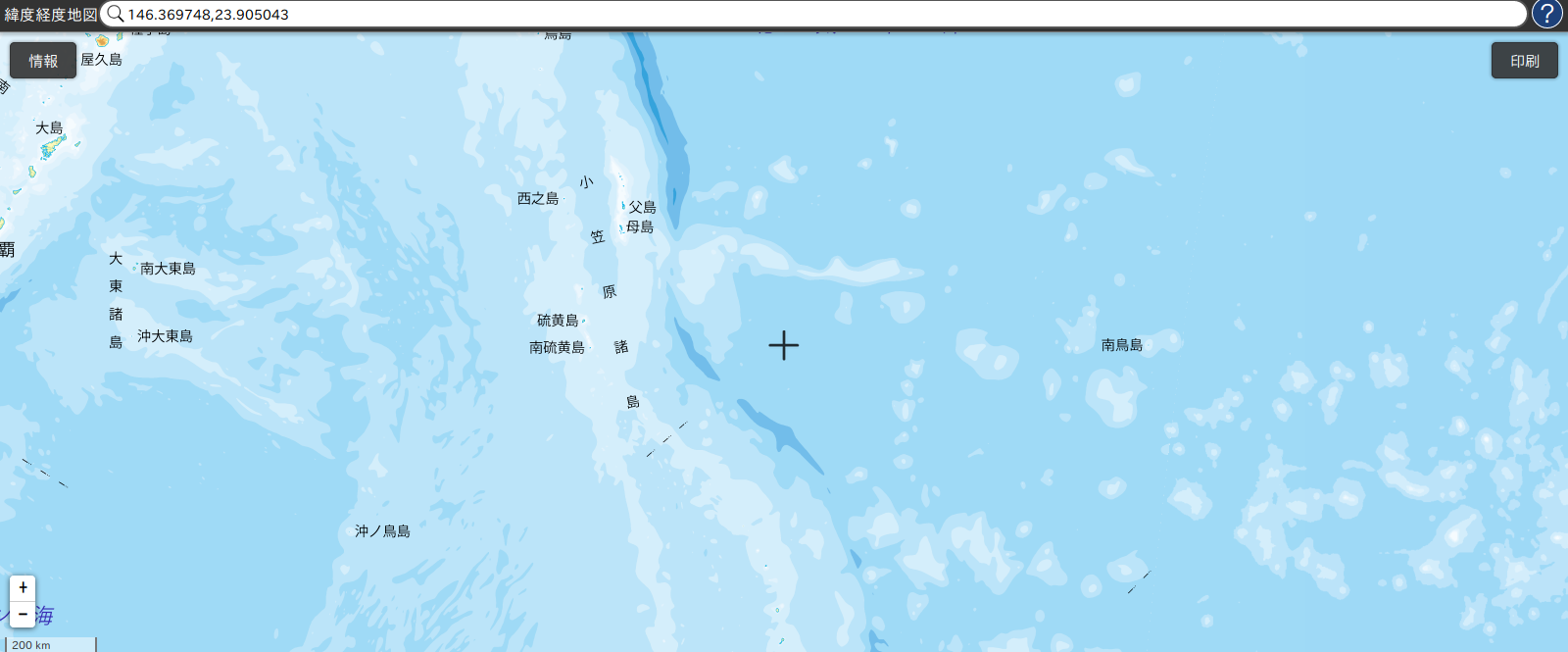
経度: 149.691295,緯度: 20.525873 'location' None 経度: 146.369748,緯度: 23.905043 'location' None 経度: 128.552226,緯度: 28.268003 'location' None 経度: 138.839354,緯度: 36.14651 群馬県甘楽郡甘楽町秋畑 経度: 128.442362,緯度: 24.173392 'location' None 経度: 149.328955,緯度: 35.501685 'location' None 経度: 143.701187,緯度: 31.806533 'location' None 経度: 152.518577,緯度: 38.932277 'location' None 経度: 131.0144,緯度: 38.670175 'location' None 経度: 149.70269,緯度: 36.445081 'location' None一度のプログラムの実行に10個のデータを生成するように指定しましたが,ほとんどのデータがNoneの表示されています.生成できたのは4番目の
群馬県甘楽郡甘楽町秋畑のデータのみです.どういうわけか...
あ..
試しに2番目の座標データを調べてみました.
海ですね.
経緯度の設定値を変える
経度: 139.286021,緯度: 34.639237 東京都大島町野増下平 経度: 138.097037,緯度: 34.790162 静岡県菊川市富田 経度: 138.110693,緯度: 34.654774 静岡県御前崎市門屋 経度: 138.752411,緯度: 34.708536 静岡県賀茂郡松崎町雲見 経度: 138.616241,緯度: 34.723031 'location' None 経度: 138.418079,緯度: 34.81724 静岡県焼津市田尻北 経度: 138.33815,緯度: 34.515467 'location' None 経度: 138.290422,緯度: 34.019396 'location' None 経度: 139.842906,緯度: 34.022007 'location' None 経度: 139.00311,緯度: 34.997854 静岡県伊豆市大野ちょっと増えた.
結論
どうやら,日本国土の経緯度レンジは大体(経度123-154),(緯度20-46)の範囲あるということで設定してみたら,海が含まれていることを忘れていた.
なので,設定する経緯度は,国土内の経度に的を絞ったほうが良さそうです.
後は,自作の関数や微調整なりでなんとかなりそう.

- 投稿日:2020-05-23T22:00:05+09:00
Python ダミーデータ生成(住所編)
背景
faker-python の
fake.address()を使って住所生成したら,兵庫県中野区松石4丁目14番7号 クレスト千塚106こんな感じで兵庫県の中に中野区がある、凄まじいフェイク住所が出て来てますが,実際マップを使用したアプリケーションでテストをする際など,これらの情報を検索にかけても実行結果が出ません.
なので
1. フェイクデータではなく実際の住所データを生成する.
2. またダミーデータとして一度の実行にの多くの住所を取得する.今回はこの2点を抑えてデータを生成したいと思います.
どうやって作るか
すぐに思いついたのが,住所情報を提供するAPI経由で,情報を整形して生成する方法.
とりあえずやってみます.HeartRails Geo API
今回お世話になるAPIは,HeartRails Geo API さんです.
ここの緯度経度による住所検索 APIを使ってダミー住所を生成していきます.
住所生成プログラム
import requests import random import json #xml_url = 'httpi://geoapi.heartrails.com/api/xml?method=searchByGeoLocation' json_url = 'http://geoapi.heartrails.com/api/json?method=searchByGeoLocation' # APIリクエスト関数 def get_data(lug,lat): payload = {'method': 'searchByGeoLocation', 'x': lug, 'y': lat} try: ret = requests.get(json_url, params=payload) json_ret = ret.json() except requests.exceptions.RequestException as e: print("ErrorContent: ",e) return json_ret # 住所データの整形関数 def data_serealize(data): try: dic = data['response']['location'][9] det = dic['prefecture'] + dic['city'] + dic['town'] return det except KeyError as e: print(e) # 軽度・緯度に使う乱数の生成 def gene_number(lug_fnum, lug_lnum, lat_fnum, lat_lnum): lug = round(random.uniform(lug_fnum,lug_lnum),6) lat = round(random.uniform(lat_fnum,lat_lnum),6) return lug,lat def main(): for i in range(10): lug,lat = gene_number(122,153,19,45) print("経度: " + str(lug) + "," + "緯度: " + str(lat) + "\n") ret = get_data(lug,lat) print(data_serealize(ret)) if __name__ == '__main__': main()データフォーマットは今回
json形式を選びました.理由は特にありません.・ get_data関数は,データを取ってくる関数.
・ data_number関数は,取ってきたデータを整形します.
・ gene_number関数は,日本国内の経度緯度を自動生成して,それをget_data関数に渡します.検証
経度: 149.691295,緯度: 20.525873 'location' None 経度: 146.369748,緯度: 23.905043 'location' None 経度: 128.552226,緯度: 28.268003 'location' None 経度: 138.839354,緯度: 36.14651 群馬県甘楽郡甘楽町秋畑 経度: 128.442362,緯度: 24.173392 'location' None 経度: 149.328955,緯度: 35.501685 'location' None 経度: 143.701187,緯度: 31.806533 'location' None 経度: 152.518577,緯度: 38.932277 'location' None 経度: 131.0144,緯度: 38.670175 'location' None 経度: 149.70269,緯度: 36.445081 'location' None一度のプログラムの実行に10個のデータを生成するように指定しましたが,ほとんどのデータがNoneの表示されています.生成できたのは4番目の
群馬県甘楽郡甘楽町秋畑のデータのみです.どういうわけか...
あ..
試しに2番目の座標データを調べてみました.
海ですね.
経緯度の設定値を変える
経度: 139.286021,緯度: 34.639237 東京都大島町野増下平 経度: 138.097037,緯度: 34.790162 静岡県菊川市富田 経度: 138.110693,緯度: 34.654774 静岡県御前崎市門屋 経度: 138.752411,緯度: 34.708536 静岡県賀茂郡松崎町雲見 経度: 138.616241,緯度: 34.723031 'location' None 経度: 138.418079,緯度: 34.81724 静岡県焼津市田尻北 経度: 138.33815,緯度: 34.515467 'location' None 経度: 138.290422,緯度: 34.019396 'location' None 経度: 139.842906,緯度: 34.022007 'location' None 経度: 139.00311,緯度: 34.997854 静岡県伊豆市大野ちょっと増えた.
結論
どうやら,日本国土の経緯度レンジは大体(経度123-154),(緯度20-46)の範囲あるということで設定してみたら,海が含まれていることを忘れていた.
なので,設定する経緯度は,国土内の経度に的を絞ったほうが良さそうです.
後は,自作の関数や微調整なりでなんとかなりそう.
- 投稿日:2020-05-23T21:10:01+09:00
Word に複数の自作スタイルを一括登録する
便利な反面、登録が面倒極まりない Microsoft Word のスタイルを python で一括登録します。
実行イメージ
- 文字単位のスタイルは背景色+下線の種類で区別
- 段落単位のスタイルは背景色+囲み線の色で区別
- 表は外周の罫線の色で区別
コード
別の記事 で書いたように、pywin32 を使って現在開いている文書を見ながら処理します(Word VBA の定数は こちらの記事 など参照)。
デフォルトだと「実行時点でカーソルがある段落の書式設定」を基準に新規スタイルが作成されます。冒頭にタイトルとして大きなフォントが指定されているような場合に困るので、「標準」スタイルの書式を基準にしました。
activeword_set-style.pyimport win32com.client class vb: wdLineStyleSingle = 1 wdLineWidth050pt = 4 wdLineWidth025pt = 2 wdLineWidth150pt = 12 wdStyleNormal = -1 wdStyleTypeCharacter = 2 wdStyleTypeParagraphOnly = 5 wdStyleTypeTable = 3 wdUnderlineThick = 6 wdUnderlineDouble = 3 wdUnderlineWavyHeavy = 27 wdUnderlineDotDotDashHeavy = 26 wdUnderlineDottedHeavy = 20 wdUnderlineDotDashHeavy = 25 wdUnderlineDashHeavy = 23 def colorhex_to_int(colorcode): hex = colorcode[1:7] r = int(hex[0:2], 16) g = int(hex[2:4], 16) b = int(hex[4:6], 16) return r + g*256 + b*256*256 def add_marker_style(doc, base_style): print('creating new marker style...') marker_color_table = ( [1, {"fill":"#f5ff3d", "border":"#1700c2"}], [2, {"fill":"#97ff57", "border":"#ff007b"}], [3, {"fill":"#5efffc", "border":"#ffaa00"}], [4, {"fill":"#ff91fa", "border":"#167335"}], [5, {"fill":"#ffca59", "border":"#2f5773"}], [6, {"fill":"#d6d6d6", "border":"#0f1c24"}], ) for mkr in marker_color_table: marker_style_name = f"myMaker{mkr[0]}" try: marker_style = doc.Styles.Add(marker_style_name, vb.wdStyleTypeParagraphOnly) marker_style.ParagraphFormat = base_style.ParagraphFormat for i in (-4,-3,-2,-1): marker_style.ParagraphFormat.Borders(i).LineStyle = vb.wdLineStyleSingle marker_style.ParagraphFormat.Borders(i).LineWidth = vb.wdLineWidth050pt marker_style.ParagraphFormat.Borders(i).Color = colorhex_to_int(mkr[1]["border"]) marker_style.Font = base_style.Font marker_style.NextParagraphStyle = base_style marker_style.ParagraphFormat.Shading.BackgroundPatternColor = colorhex_to_int(mkr[1]["fill"]) marker_style.ParagraphFormat.OutlineLevel = mkr[0] marker_style.QuickStyle = True print(f' + "{marker_style_name}"') except: print(f'failed to create style "{marker_style_name}" ...') def add_character_style(doc, base_style): print('creating new character style...') char_color_table = ( [1, "#ffda0a",vb.wdUnderlineThick], [2, "#66bdcc",vb.wdUnderlineDotDashHeavy], [3, "#a3ff52",vb.wdUnderlineDottedHeavy], [4, "#ff7d95",vb.wdUnderlineDouble], [5, "#bf3de3",vb.wdUnderlineDashHeavy], [6, "#ff9500",vb.wdUnderlineWavyHeavy], ) for char in char_color_table: char_style_name = f"myChar{char[0]}" try: char_style = doc.Styles.Add(char_style_name, vb.wdStyleTypeCharacter) char_style.Font = base_style.Font char_style.Font.Shading.BackgroundPatternColor = colorhex_to_int(char[1]) char_style.Font.Color = colorhex_to_int("#111111") char_style.Font.Underline = char[2] char_style.QuickStyle = True print(f' + "{char_style_name}"') except: print(f'failed to create style "{char_style_name}" ...') def add_table_style(doc, base_style): print(f'creating new table style...') border_color_table = ( [1,"#2b70ba"], [2,"#fc035a"], [3,"#0d942a"], [4,"#ff4f14"], [5,"#fffb00"], ) for tbl in border_color_table: table_style_name = f"myTable{tbl[0]}" try: table_style = doc.Styles.Add(table_style_name, vb.wdStyleTypeTable) table_style.Font = base_style.Font for i in (-4,-3,-2,-1): table_style.Table.Borders(i).LineStyle = vb.wdLineStyleSingle table_style.Table.Borders(i).LineWidth = vb.wdLineWidth150pt table_style.Table.Borders(i).Color = colorhex_to_int(tbl[1]) table_style.Table.Shading.BackgroundPatternColor = colorhex_to_int("#eeeeee") print(f' + "{table_style_name}"') except: print(f'failed to create style "{table_style_name}" ...') def main(): wdApp = win32com.client.Dispatch("Word.Application") if wdApp.Documents.Count < 1: if not wdApp.Visible: wdApp.Quit() return 0 doc = wdApp.ActiveDocument normalStyle = doc.Styles(vb.wdStyleNormal) add_marker_style(doc, normalStyle) add_character_style(doc, normalStyle) add_table_style(doc, normalStyle) if __name__ == '__main__': main()powershell から呼び出す
メイン使用の powershell から下記のコマンドレットを作って呼び出しています。もちろん
python activeword_set-style.pyで直接呼び出しても構いません。function Set-MyStyleToActiveWordDocumentWithPython { if ((Get-Process | Where-Object ProcessName -EQ "winword").Count -lt 1) { return } $pyCodePath = "{0}\python_code\activeword_set-style.py" -f $PSScriptRoot 'python -B "{0}"' -f $pyCodePath | Invoke-Expression }


- 投稿日:2020-05-23T20:59:06+09:00
製薬企業研究者がPythonにおけるファイル走査についてまとめてみた
はじめに
ここでは、Pythonを用いたファイル走査の方法として、osモジュールとpathlibモジュールの利用方法を紹介します。
osモジュール
osモジュールは、ファイルやディレクトリを扱う上でベーシックなモジュールです。
よく使うメソッドなどは以下になります。import os directory = 'ディレクトリー名' file = 'ファイル名' file_path = os.path.join(directory, file) print(file_path) # ディレクトリ名/ファイル名 print(os.path.isfile(file_path)) # True print(os.path.isdir(file_path)) # False print(os.path.isdir(directory)) # True print(os.path.exists(file_path)) # True entry_list = [] for entry in os.listdir(directory): entry_list.append(entry) print(directory_list) directory_list = [] file_list = [] path_list = [] for root, dirs, files in os.walk(directory): for drc in dirs: directory_list.append(drc) for file in files: file_list.append(file) file_path.append(os.path.join(root, file)) print(directory_list) print(file_list) print(path_list)pathlibモジュール
Python3.4以降はpathlibモジュールを利用することができます。
from pathlib import Path p_dir = Path('ディレクトリ名') p_file = Path('ファイル名') p_path = p_dir / p_file p_path.mkdir(parents=True, exist_ok=True) print(p_path) print(p_path.parts) print(p_path.parent) print(p_path.name) print(p_path.stem) print(p_path.suffix) print(p_path.is_file()) # True print(p_path.is_dir()) # False print(p_dir.is_dir()) # True print(p_path.exists()) # True p_path.rmdir() print(p_path.exists()) # Falseまとめ
ここでは、osモジュールとpathlibモジュールについて解説しました。
まだ説明不足なところもあるので、後日追記予定です。参考資料・リンク
- 投稿日:2020-05-23T20:57:26+09:00
FastAPIとTensorflowで簡単な画像認識APIを作ってみた
はじめに
普段Flaskをよく使いますが、「FastAPIはいいぞ!」と知人に進められたので簡単な画像認識APIを作って見ようと思いました。
しかし、あまりFastAPIとMLの日本語記事を見かけなかったので、メモ代わりに本記事を作成することにしました!本記事では、開発環境を整えた後、APIサーバとフロントエンドの簡単な説明を記載しております。
今回使用したコードはすべてGithubに公開しています。
(以下実装のフォルダ構成などはGithubを前提に記載しています。サンプルモデルのダウンロードについてもREADME.mdに記載しています。)FastAPIとは?
FlaskのようなPythonのフレームワークの1つです。
かんたんな概要と使い方のまとめは、以下の記事を参照していただけると良いと思います。(本記事でも大変お世話になりました、ありがとうございます!!)
もっと詳しく知りたい方は、FastAPIの公式チュートリアルが充実しておりオススメです!
画像認識について
今回は時間がなかったため、tensorflow.kerasのモデルを使って構築します!
具体的には、imagenetで学習されたResNet50をそのまま利用し、入力画像を1000クラスのどれに属するかを推論することとします。
(本当に使いたかったモデルは、只今絶賛学習中で間に合わなかった...)
https://www.tensorflow.org/versions/r1.15/api_docs/python/tf/keras?hl=ja
開発環境
Mac OS X Mojave
Python3.7.1(Anaconda)環境構築
必要なPythonライブラリをインストールします。
$pip install tensorflow==1.15 $pip install fastapi $pip install uvicorn以下のような条件があることから、それに必要なライブラリもインストールします。
- index.htmlをRenderする
- 画像ファイルをアップロードする
- 画像を読み込み、リサイズする$pip install Jinja $pip install aiofiles $pip install python-multipart $pip install opencv-pythonAPIサーバ
APIサーバの実装は以下のようになりました。
# -*- coding: utf-8 -*- import io from typing import List import cv2 import numpy as np import tensorflow as tf from tensorflow.keras.applications.resnet50 import decode_predictions from fastapi import FastAPI, Request, File, UploadFile from fastapi.staticfiles import StaticFiles from fastapi.templating import Jinja2Templates # 画像認識モデルの用意 global model, graph graph = tf.get_default_graph() model = tf.keras.models.load_model("./static/model/resnet_imagenet.h5") # FastAPIの用意 app = FastAPI() # static/js/post.jsをindex.htmlから呼び出すために必要 app.mount("/static", StaticFiles(directory="static"), name="static") # templates配下に格納したindex.htmlをrenderするために必要 templates = Jinja2Templates(directory="templates") def read_image(bin_data, size=(224, 224)): """画像を読み込む Arguments: bin_data {bytes} -- 画像のバイナリデータ Keyword Arguments: size {tuple} -- リサイズしたい画像サイズ (default: {(224, 224)}) Returns: numpy.array -- 画像 """ file_bytes = np.asarray(bytearray(bin_data.read()), dtype=np.uint8) img = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = cv2.resize(img, size) return img @app.post("/api/image_recognition") async def image_recognition(files: List[UploadFile] = File(...)): """画像認識API Keyword Arguments: files {List[UploadFile]} -- アップロードされたファイル情報 (default: {File(...)}) Returns: dict -- 推論結果 """ bin_data = io.BytesIO(files[0].file.read()) img = read_image(bin_data) with graph.as_default(): pred = model.predict(np.expand_dims(img, axis=0)) result_label = decode_predictions(pred, top=1)[0][0][1] return {"response": result_label} @app.get("/") async def index(request: Request): return templates.TemplateResponse("index.html", {"request": request})フロントからデータを受け取る
@app.post("/api/image_recognition") async def image_recognition(files: List[UploadFile] = File(...)): """画像認識API Keyword Arguments: files {List[UploadFile]} -- アップロードされたファイル情報 (default: {File(...)}) Returns: dict -- 推論結果 """ bin_data = io.BytesIO(files[0].file.read()) img = read_image(bin_data) with graph.as_default(): pred = model.predict(np.expand_dims(img, axis=0)) result_label = decode_predictions(pred, top=1)[0][0][1] return {"response": result_label}今回は、FastAPIのUploadFileを使用してPOSTされる画像を取得しております。
bin_data = io.BytesIO(files[0].file.read())ファイルは一つしかPOSTされないのでfiles[0]としており、フロント側からBASE64形式で渡されるのでAPI側でBytes配列に変換しました。
データを画像に変換する
def read_image(bin_data, size=(224, 224)): """画像を読み込む Arguments: bin_data {bytes} -- 画像のバイナリデータ Keyword Arguments: size {tuple} -- リサイズしたい画像サイズ (default: {(224, 224)}) Returns: numpy.array -- 画像 """ file_bytes = np.asarray(bytearray(bin_data.read()), dtype=np.uint8) img = cv2.imdecode(file_bytes, cv2.IMREAD_COLOR) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) img = cv2.resize(img, size) return imgopencvの力を借りて、Byte配列からuint8の画像に変換します。
このとき、opencvのデフォルトフォーマットがBGRなため、RGBに変換してリサイズしました。推論する
global model, graph graph = tf.get_default_graph() model = tf.keras.models.load_model("./static/model/resnet_imagenet.h5") ... with graph.as_default(): pred = model.predict(np.expand_dims(img, axis=0)) result_label = decode_predictions(pred, top=1)[0][0][1]事前にresnet_imagenet.h5を作成しておき、それをファイル上部で読み込んでいます。
推論処理自体は、with graph.as_default() でグローバルで設定したTensorFlowのグラフにこのスレッドでのコンテキストを固定して、predict関数で推論しています。今回はtf.kerasのResNet50を使っていることから、predictの結果をラベルに変換するdecode_predictionsを使って推論結果を取得しています。
他のモデルや自作モデルも、プロジェクトディレクトリのどこかに.h5ファイルを保存しておき、それをload_modelすることで、この実装のように使うことができるかと思います。
フロント実装
こちらを参考にさせていただきました。(ありがとうございます!)
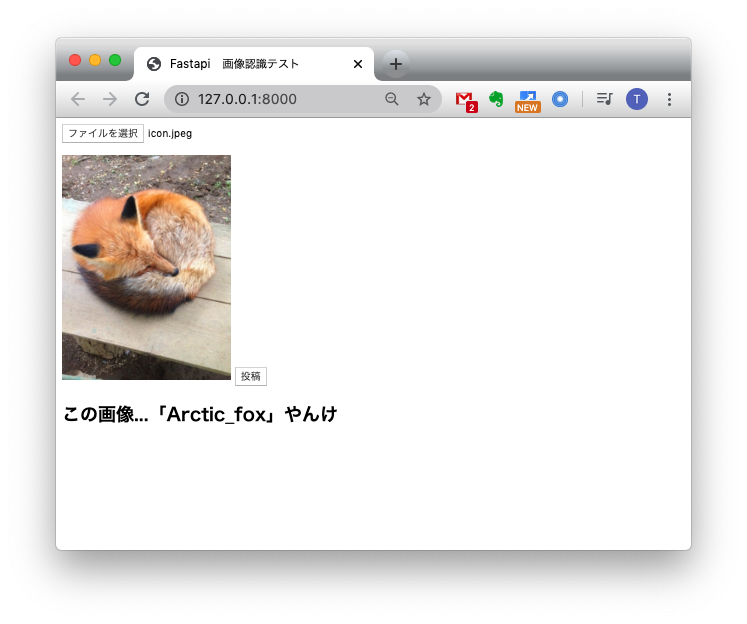
<html> <head> <meta http-qeuiv="Content-Type" content="text/html; charset=utf-8"> <title>Fastapi 画像認識テスト</title> <script src="//code.jquery.com/jquery-2.2.3.min.js"></script> <script src="/static/js/post.js"></script> </head> <body> <!-- ファイル選択ボタン --> <div style="width: 500px"> <form enctype="multipart/form-data" method="post"> <input type="file" name="userfile" accept="image/*"> </form> </div> <!-- 画像表示領域 --> <canvas id="canvas" width="0" height="0"></canvas> <!-- アップロード開始ボタン --> <button class="btn btn-primary" id="post">投稿</button> <br> <h2 id="result"></h2> </body> </html>// 画像をリサイズして、HTMLで表示する $(function () { var file = null; var blob = null; const RESIZED_WIDTH = 300; const RESIZED_HEIGHT = 300; $("input[type=file]").change(function () { file = $(this).prop("files")[0]; // ファイルチェック if (file.type != "image/jpeg" && file.type != "image/png") { file = null; blob = null; return; } var result = document.getElementById("result"); result.innerHTML = ""; // 画像をリサイズする var image = new Image(); var reader = new FileReader(); reader.onload = function (e) { image.onload = function () { var width, height; // 縦or横の長い方に合わせてリサイズする if (image.width > image.height) { var ratio = image.height / image.width; width = RESIZED_WIDTH; height = RESIZED_WIDTH * ratio; } else { var ratio = image.width / image.height; width = RESIZED_HEIGHT * ratio; height = RESIZED_HEIGHT; } var canvas = $("#canvas").attr("width", width).attr("height", height); var ctx = canvas[0].getContext("2d"); ctx.clearRect(0, 0, width, height); ctx.drawImage( image, 0, 0, image.width, image.height, 0, 0, width, height ); // canvasからbase64画像データを取得し、POST用のBlobを作成する var base64 = canvas.get(0).toDataURL("image/jpeg"); var barr, bin, i, len; bin = atob(base64.split("base64,")[1]); len = bin.length; barr = new Uint8Array(len); i = 0; while (i < len) { barr[i] = bin.charCodeAt(i); i++; } blob = new Blob([barr], { type: "image/jpeg" }); console.log(blob); }; image.src = e.target.result; }; reader.readAsDataURL(file); }); // アップロード開始ボタンがクリックされたら $("#post").click(function () { if (!file || !blob) { return; } var name, fd = new FormData(); fd.append("files", blob); // API宛にPOSTする $.ajax({ url: "/api/image_recognition", type: "POST", dataType: "json", data: fd, processData: false, contentType: false, }) .done(function (data, textStatus, jqXHR) { // 通信が成功した場合、結果を出力する var response = JSON.stringify(data); var response = JSON.parse(response); console.log(response); var result = document.getElementById("result"); result.innerHTML = "この画像...「" + response["response"] + "」やんけ"; }) .fail(function (jqXHR, textStatus, errorThrown) { // 通信が失敗した場合、エラーメッセージを出力する var result = document.getElementById("result"); result.innerHTML = "サーバーとの通信が失敗した..."; }); }); });ajaxを使って画像認識APIへPOSTを行い、結果を表示しています。
動作確認
結果こんな感じに動くようになりました!
(フロントをもうちょっとオサレにしたかったのですが...)
おわりに
FastAPIのお勉強に画像認識APIを作ってみました。
今回作った実装がベストプラクティスではないと思いますが、動くものをつくることができてよかったかと思います。今後どのフレームワークを使って仕事をするかわかりませんが、FastAPIは割と使いやすくてFlaskから乗り換えようかなぁと思いました。
最後となりますが、参考にさせていただいた皆様に感謝いたします!
- 投稿日:2020-05-23T20:52:06+09:00
【初心者用】O'reillyのサンプルコードをGoogleColabで実装する方法
サンプルコードをGoogleColabで実装
オライリー「ゼロから作るDeep Learning ~Pythonで学ぶディープラーニングの理論と実装~」では、サンプルコードがGitHubに載っていますが、GoogleColabで実装する際に少しだけ困ったので残しておきます。
もっとうまい方法があるとは思いますが、今はこれでパッと使えているので一方法としてご覧ください。
また、用語の使い方の間違いがあるかもしれませんが、ご了承ください。
ちなみにwindows10での方法です。GitHubのコードをローカルにクローンする
この記事を書いている私も超初心者なので丁寧に書いていきます。
また、ローカルにクローンとかいう言い回しが苦手だったのでできるだけ噛み砕いて説明したいと思います。(意味合いが微妙に違うのはご了承を。)
では、いきます。まずローカルにクローンするとは、自分のPCのフォルダにサンプルコードをコピーして持ってくることです。
今回コピーしたいサンプルコードは以下のURLから確認できます。
https://github.com/oreilly-japan/deep-learning-from-scratchGitHubのコードをクローンするためには、Gitというソフトが必要です。
インストールの方法は、他のめちゃ分かりやすいサイトがあるのでご覧ください。
僕はこのサイトを参考にしました。
https://eng-entrance.com/git-install#i-3その後、インストールと初期設定を終えたらGitHubのクローンをします。
今回は先ほど載せたページでクローンしたいので、先ほどのURLにいきます。
こんな感じですね。
そして画面の中央右手の緑のタブを押すと上のようなポップアップ的なものがでるので、コピーします。
コピーをしたら、Git Bashを開きます。Git Bashは画面左下のwindowsマークのところを開いてGitの中に入っていると思います。Git Bashを開いたら以下のコードを打ち込みます。
GitBashcd projects git clone https://github.com/oreilly-japan/deep-learning-from-scratch.gitこれでローカルにクローンできたはずです。
自分のフォルダ漁ってみてください。GoogleColabでサンプルコードを実装する
まず、さきほど自分のPCのフォルダにクローンしたフォルダを丸ごとGoogle DriveのMy Driveに入れます。
それからGoogleColabを開きます。
GoogleColabの左側に3つほどタブがあると思いますが、その一番下のフォルダマークを押します。
そこを開くと、「ドライブをマウントする」というボタンがあるので押してください。
許可しますか?みたいなポップアップがでるので許可します。
するど、そこにドライブの階層構造が出てきます。
こんな感じですね。(画面が散らかっててすみません。。。)
このMy Driveの中に先ほど入れた「deep-learning-from-scratch」というフォルダがあります。名前を変えていなければこの名前のはずです。My Driveを開くとそのファイルがあるはずなのでポインターを当てると左端に黒点が3つ並ぶのでそれを押します。
すると、パスをコピーとでるので押します。
それから、右のセルに以下のコードを打ち込んでください。セルcd(さきほどコピーしたもの)実際に書く際は()は省略してください。
このコードは自分はこれからこのファイルがあるところで作業しますよ!ということです。
これをしないと、コードをコピペして実行したときに知らないモジュールがあります、というエラーが出てしまいます。
これでコードをコピペして使ったりできるはずです。つっこみどころ満載の記事だと思いますが、最後まで読んで頂きありがとうございました。


- 投稿日:2020-05-23T20:22:25+09:00
今日のAtCoder ~茶色コーダーまでの道~
AtCoderの日記として、今日解いた問題を記述してきます。
基本は、ここ*1に書かれている問題を解いていく形にしています。
競技プログラミングをやるときは、ローカルの環境よりも、楽に実行出来るPaiza.ioを使っています。ほぼ日記なので、口癖などは、気にしないでください。
本日解いた問題
- A - RGB Cards
- A - Infinite Coins
- A - Round Up the Mean
- A - Something on It
- A - Already 2018
- B - i18n
- B - Two Anagrams
- B - Break Number
- B - Maximum Difference
それぞれのコード
一問目
r,g,b=map(str,input().split()) res=int(r+g+b) if res%4==0: print("YES") else: print("NO")四の倍数ならばという条件だったので、あまりが0なら成立するんじゃね?と考えてかいた。
二問目
正解
N=int(input()) A=int(input()) s=N%500 if s<=A: print("Yes") exit() print("No")不正解
N=int(input()) A=int(input()) s=N//500 for i in range(A): if i+s*500==N: print("Yes") exit() print("No")最初は、合計金額を出して、求めれば良いのでは?と考えて実装した。
最後のテストの時にWAが出たので、組み直した。
二回目は、500のあまりが、1円の合計で作れたら良いんじゃね?というイメージで作成した。三問目
a,b=map(int,input().split()) s=a+b ss=s//2 s2=s%2 if s2==1: print(ss+1) exit() print(ss)
import mathを使って、関数を使うやり方が、シンプルになるんだろうけど、アルゴリズムを書く力を鍛えたいなと思って、切り捨ててから、+1をするという書き方で書いてみた。
(全然スマートじゃない書き方)四問目
最初
S=input() cou=int(S.count("o"))*100 print(700+cou)二回目
S=input() res=700 for i in S: if i=="o": res+=100 print(res)三回目
res=700 for i in input(): if i=="o": res+=100 print(res)countを使って調べて計算すれば、簡単に求まるなと思ったので、countを使った。
countを使えない時用に、ifとforを使って書いてみたのが二回目
若干、コードを短く出来ると思って、三回目を書きました。五問目
S=input() S="2018"+S[4:] print(S)print("2018"+input()[4:])最初を2018に変更すれば良いだけだったので、最初の数文字を2018に変更して、出力した。短くしようと思ったら、1行で出力できた。
六問目
s=input() fir=s[0] las=s[-1] s=s[1:] s=s[:-1] print(fir+str(len(s))+las)間の文字をカウントして、最初と最後の文字を結合して出力すれば、良いという問題だった。
最初の文字と最後の文字を代入
最初と最後の文字を消す
中の文字をカウントする
文字列にして出力するという書き方で書いた。七問目
s=input() t=input() s=sorted(s) s="".join(s) t=sorted(t,reverse=True) t="".join(t) # print(s,t) if s<t: print("Yes") else: print("No")sortedの使い方をわかることが出来た問題
結構無駄があるコードになった。八問目
N=int(input()) n=1 while True: if n>N: print(int(n/2)) break n=n*22で割れる数字は、2のn乗が一番大きいので、2倍していく形にした。
九問目
N=int(input()) lis=list(map(int,input().split())) lis.sort(reverse=True) print(lis[0]-lis[-1])ソートして、最初と最後の文字を引けば良いなと思って、ソートして出力した。
元記事だと、for文でかけるぜ!的な事が書かれていたけど、どうやったら良いんだろ。参考文献
- 投稿日:2020-05-23T20:10:17+09:00
自分なりのAMLを作ってみた
誰にでもAIを気軽に作れる世界
1995年、Windows95 OSが発売され、一般大衆にもハード製品が普及したことによってインターネットは誰でも気軽に使えるツールとなりました。これは「インターネットのインフラ整備」と表現されると思います。
これと同じようなことが機械学習技術にも起きようとしています。DataRobotやAzure Machine Learningのようなサービスはその典型的な例です。従来、機械学習によるデータ分析は、エンジニアやデータサイエンティストなどの専門的な職業のみの専売特許であったと思います。しかし、このようなAuto MLの出現により「機械学習の民主化」の波が始まっています。
今回は、それを作ってしまおうぜ(シンプルなもの)ということが目的です。
MLとは
AMLのお話の前に機械学習(Machine Learning 以下ML)とは?からお話しします。
英語版wikipediaには以下の記載がありました。
Machine learning (ML) is the study of computer algorithms that improve automatically through experience. It is seen as a subset of artificial intelligence. Machine learning algorithms build a mathematical model based on sample data, known as "training data", in order to make predictions or decisions without being explicitly programmed to do so.
つまり「過去の経験(データ)から、人の介在なしで未来を 予測 するもの」と言えます。
下の図をご覧ください。生データ(row data)を準備し、それを「前処理」→「特徴量エンジニアリング」→「学習」→「モデル選択・スコアリング」といったフロー全体に通して「ターゲット」を予測することを機械学習と言います。たとえば、明日の天気を予測したいときには、昨日や今日の天気、気温、湿度、風向きなどの情報から予測できそうですね。このとき「明日の天気」を「ターゲット」、「昨日や今日の情報」などの過去の情報を「生データ」と表現しています。(なお、この場合、時系列データなので他にも考慮しなければいけないことはたくさんありますが)
機械学習によって解くタスクには「分類問題」と「回帰問題」の2つがあります。今回は、「分類問題」に絞ったお話になります。
Auto ML
では、Auto MLとはどういうものでしょうか。上記の説明においての「前処理」→「特徴量エンジニアリング」を自動化してくれる機械学習のことをさします。
一口にAuto MLと言ってもその方法は多岐に渡りますが、今回目指すのは以下の機能を兼ね備えて、かつそれぞれのモデルの精度を比較するAuto MLを開発することです。なお、本来であればパラメータチューニングなどの作業も自動化する必要もありますが、今回は許してください ><
- データパスからデータをロード
- onehotエンコーディング
- 欠損値を「平均値」「中央値」「最頻値」のいずれかで補完
- 特徴量選択
- グリッドリサーチ
- ランダムリサーチ
- 混合行列
- ROC曲線
- スコアリング
コード全体
今回のコードはgithub上においてあります
データ用意
今回は、みなさんお馴染みのtitanic datasetを使用します。
ディレクトリ構成
aml |----data | |---train.csv | |---test.csv | |----model | |---こちらにモデルが保存される | |----myaml.inpynb前処理と特徴量エンジニアリングと学習
お先に使い方のコードをお示しします。APIのexampleに対応するものです。
model_data = 'data/train.csv' scoring_data = 'data/test.csv' aml = MyAML(model_data, scoring_data, onehot_columns=None) aml.drop_cols(['Name', 'Ticket', 'Cabin']) # NameとTicketとCabinの情報は使わない # 前処理と特徴量エンジニアリング(特徴量選択) aml.preprocessing(target_col='Survived', index_col='PassengerId', feature_selection=False) # 学習とモデル比較結果表示(ホールドアウト法を採用) aml.holdout_method(pipelines=pipelines_pca, scoring='auc')
test train gb 0.754200 0.930761 knn 0.751615 0.851893 logistic 0.780693 0.779796 rf 0.710520 0.981014 rsvc 0.766994 0.837220 tree 0.688162 1.000000 前処理
ここでの前処理は次の2つをさします。なお、以降のコードは大切なところのみ掻い摘んで説明できたらと思います
- onehotエンコーディング
- 欠損値を「平均値」「中央値」「最頻値」のいずれかで補完
onehotエンコーディング
def _one_hot_encoding(self, X: pd.DataFrame) -> pd.DataFrame: ... # one_hot_encoding if self.ohe_columns is None: # obejct型またはcategory型の列のみone_hot_encoding X_ohe = pd.get_dummies(X, dummy_na=True, # NULLもダミー変数化 drop_first=True) # 最初のカテゴリーを除外 else: # self.ohe_columnsで指定された列のみone_hot_encoding X_ohe = pd.get_dummies(X, dummy_na=True, # NULLもダミー変数化 drop_first=True, # 最初のカテゴリーを除外 columns=self.ohe_columns) ...MyAMLクラスの初期化で、インスタンス変数に格納された
onehot_columnsは、「onehotエンコーディングさせたいカラム名」をリストで受け取ります。何も指定しなければ、受け取ったデータフレームのカラムのうちobejct型またはcategory型であるものをonehotエンコーディングします。欠損値補完
def _impute_null(self, impute_null_strategy): """ 欠損値をimpute_null_strategyで補完する impute_null_strategyの種類 mean...平均値で補完 median...中央値で補完 most_frequent...最頻値で補完 """ self.imp = SimpleImputer(strategy=impute_null_strategy) self.X_model_columns = self.X_model.columns.values self.X_model = pd.DataFrame(self.imp.fit_transform(self.X_model), columns=self.X_model_columns)
scikit-learnのSimpleImputerクラスを用いて欠損値補完を行います。
impute_null_strategyは「何」で補完するのかを表す引数です。対応する補完方法は次の通りです。
mean...平均値で補完median...中央値で補完most_frequent...最頻値で補完特徴量エンジニアリング
特徴量エンジニアリングも奥が深いですが、今回は単純化して「ランダムフォレストによる特徴量選択」を考えます。
def _feature_selection(self, estimator=RandomForestClassifier(n_estimators=100, random_state=0), cv=5): """ 特徴量選択 @param estimator: 特徴量選択を実施するための学習器 """ self.selector = RFECV(estimator=estimator, step=.05, cv=cv) self.X_model = pd.DataFrame(self.selector.fit_transform(self.X_model, self.y_model), columns=self.X_model_columns[self.selector.support_]) self.selected_columns = self.X_model_columns[self.selector.support_]最初の行で、
RFECVクラスを初期化します。この際の推定器はRandomForestClassifierをデフォルトとして指定しています。
次の行で、特徴量として重要性が高いものを選び出します。
最後に、選ばれしものたちをインスタンス変数selected_columnsに格納します。学習
ホールドアウト法により、モデルとデータの相性を比較します。
ホールドアウト法とは、訓練データ(モデルの学習に使われるデータ)とテストデータ(学習には使われない検証のためのデータ)に分ける方法です。この方法では、訓練データはずっと訓練データであり、テストデータはずっとテストデータであります。モデルとデータの相性を比較する別の方法として、クロスバリデーションも実装していますが説明は割愛します。
def holdout_method(self, pipelines=pipelines_pca, scoring='acc'): """ ホールドアウト法によりモデルの精度を確認する @param piplines: パイプライン(試すモデルの辞書) @param scoring: 評価指標 acc: 正解率 auc: ROC曲線の面積 """ X_train, X_test, y_train, y_test = train_test_split(self.X_model, self.y_model, test_size=.2, random_state=1) y_train=np.reshape(y_train,(-1)) y_test=np.reshape(y_test,(-1)) scores={} for pipe_name, pipeline in pipelines.items(): pipeline.fit(X_train, y_train) joblib.dump(pipeline, './model/'+ pipe_name + '.pkl') if scoring == 'acc': scoring_method = accuracy_score elif scoring == 'auc': scoring_method = roc_auc_score scores[(pipe_name, 'train')] = scoring_method(y_train, pipeline.predict(X_train)) scores[(pipe_name, 'test')] = scoring_method(y_test, pipeline.predict(X_test)) display(pd.Series(scores).unstack())ここで変数
piplinesは以下のような形式をしています。# make pipelines for PCA pipelines_pca={ """ 'モデル名': Pipeline([('scl', 標準化を行うクラス) , ('pca', 主成分分析を行うクラス) , ('est', モデル)]) """ 'knn': Pipeline([('scl', StandardScaler()) , ('pca', PCA(random_state=1)) , ('est', KNeighborsClassifier())]), 'logistic': Pipeline([('scl', StandardScaler()) , ('pca', PCA(random_state=1)) , ('est', LogisticRegression(random_state=1))]), ... }
Pipelineクラスに閉じ込められた3つのクラスはそれぞれ次のような機能を果たします。
- 'scl': 標準化を行う
- 'pca': 主成分分析を行う
- 'est': モデル
ゆえに、
pipeline.fit(X_train, y_train)の際に「標準化」→「主成分分析による特徴量解析」→「学習」の一連の流れをします。My Dream
自分には夢があります。
「インターネットが誰にでも使えるように、機械学習や深層学習のモデルが誰にでも簡単に作れる社会の実現です」
そのAIインフラの整備の第一歩として、今回は「パスを通すだけで機械学習の一連のプロセスが動くシステム」を実装いたしました。まだまだ、至らないところだらけですがこれからも頑張っていきます。

- 投稿日:2020-05-23T19:53:06+09:00
深層学習/ゼロから作るディープラーニング2 第6章メモ
1.はじめに
名著、「ゼロから作るディープラーニング2」を読んでいます。今回は6章のメモ。
コードの実行はGithubからコード全体をダウンロードし、ch06の中で jupyter notebook にて行っています。2.LSTMモデル
PTBデータセットの語順を学習する、ch06/train_rnnlm.py のコードです。5章のシンプルなRNNモデルでは、学習データセットの先頭1000語のみを学習しましたが、今回は学習データセット全体約90万語を学習します。
time_size = 35, batch_size = 20, word_size = hidden_size = 100, max_eopch = 4 で実行します。
import sys sys.path.append('..') from common.optimizer import SGD from common.trainer import RnnlmTrainer from common.util import eval_perplexity from dataset import ptb from rnnlm import Rnnlm # ハイパーパラメータの設定 batch_size = 20 wordvec_size = 100 hidden_size = 100 # RNNの隠れ状態ベクトルの要素数 time_size = 35 # RNNを展開するサイズ lr = 20.0 max_epoch = 4 max_grad = 0.25 # 学習データの読み込み corpus, word_to_id, id_to_word = ptb.load_data('train') corpus_test, _, _ = ptb.load_data('test') vocab_size = len(word_to_id) xs = corpus[:-1] ts = corpus[1:] # モデルの生成 model = Rnnlm(vocab_size, wordvec_size, hidden_size) optimizer = SGD(lr) trainer = RnnlmTrainer(model, optimizer) # 勾配クリッピングを適用して学習 trainer.fit(xs, ts, max_epoch, batch_size, time_size, max_grad, eval_interval=20) trainer.plot(ylim=(0, 500)) # テストデータで評価 model.reset_state() ppl_test = eval_perplexity(model, corpus_test) print('test perplexity: ', ppl_test) # パラメータの保存 model.save_params()
私のMacbookAirでは終了するまでに33分掛かりました。4epoch後の perplexityは111.47, テストデータによる perplexityは136.3 でした。次の単語を予測した場合の選択肢が136語ということですね。5章でやったのとは全然条件が違うので比較はできませんが、思ったより大きいです。
5章の単純RNNモデルでは、勾配爆発が起こりやすいため、LSTMモデルではそれを抑制するためにtrainerクラスに、勾配クリッピング( -threshold < ||$\hat{g}$|| < threshold とする) 機能が含まれています。
3.Rnnlm
import sys sys.path.append('..') from common.time_layers import * from common.base_model import BaseModel class Rnnlm(BaseModel): def __init__(self, vocab_size=10000, wordvec_size=100, hidden_size=100): V, D, H = vocab_size, wordvec_size, hidden_size rn = np.random.randn # 重みの初期化 embed_W = (rn(V, D) / 100).astype('f') lstm_Wx = (rn(D, 4 * H) / np.sqrt(D)).astype('f') lstm_Wh = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b = np.zeros(4 * H).astype('f') affine_W = (rn(H, V) / np.sqrt(H)).astype('f') affine_b = np.zeros(V).astype('f') # レイヤの生成 self.layers = [ TimeEmbedding(embed_W), TimeLSTM(lstm_Wx, lstm_Wh, lstm_b, stateful=True), TimeAffine(affine_W, affine_b) ] self.loss_layer = TimeSoftmaxWithLoss() self.lstm_layer = self.layers[1] # すべての重みと勾配をリストにまとめる self.params, self.grads = [], [] for layer in self.layers: self.params += layer.params self.grads += layer.grads def predict(self, xs): for layer in self.layers: xs = layer.forward(xs) return xs def forward(self, xs, ts): score = self.predict(xs) loss = self.loss_layer.forward(score, ts) return loss def backward(self, dout=1): dout = self.loss_layer.backward(dout) for layer in reversed(self.layers): dout = layer.backward(dout) return dout def reset_state(self): self.lstm_layer.reset_state()
Rnnlmのレイヤ構成は、5章のモデルの Time RNNレイヤ を Time LSTMレイヤに置き換えただけです。Time LSTMを見る前に、そこで使われているLSTMレイヤをまず見てみましょう。4.LSTMレイヤ
class LSTM: def __init__(self, Wx, Wh, b): self.params = [Wx, Wh, b] self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] self.cache = None def forward(self, x, h_prev, c_prev): Wx, Wh, b = self.params N, H = h_prev.shape A = np.dot(x, Wx) + np.dot(h_prev, Wh) + b f = A[:, :H] g = A[:, H:2*H] i = A[:, 2*H:3*H] o = A[:, 3*H:] f = sigmoid(f) g = np.tanh(g) i = sigmoid(i) o = sigmoid(o) c_next = f * c_prev + g * i h_next = o * np.tanh(c_next) self.cache = (x, h_prev, c_prev, i, f, g, o, c_next) return h_next, c_next
LSTMレイヤの順伝播の部分です。セルへの記憶と3つのゲートの順伝播の式は、いずれも同じ形をしているので、重み$W_x,W_h,b$はそれぞれまとめてAを計算し、その後Aをスライシングして活性化関数を通すのが効率的です。
def backward(self, dh_next, dc_next): Wx, Wh, b = self.params x, h_prev, c_prev, i, f, g, o, c_next = self.cache tanh_c_next = np.tanh(c_next) ds = dc_next + (dh_next * o) * (1 - tanh_c_next ** 2) dc_prev = ds * f di = ds * g df = ds * c_prev do = dh_next * tanh_c_next dg = ds * i di *= i * (1 - i) df *= f * (1 - f) do *= o * (1 - o) dg *= (1 - g ** 2) dA = np.hstack((df, dg, di, do)) dWh = np.dot(h_prev.T, dA) dWx = np.dot(x.T, dA) db = dA.sum(axis=0) self.grads[0][...] = dWx self.grads[1][...] = dWh self.grads[2][...] = db dx = np.dot(dA, Wx.T) dh_prev = np.dot(dA, Wh.T) return dx, dh_prev, dc_prev
逆伝播は、df, dg, di, doをそれぞれ求め hstach で連結すれば dA が求まります。後は、MatMulの逆伝播なので、dWx, dWh, db, dx, dh_prev が求まります。5.TimeLSTM
class TimeLSTM: def __init__(self, Wx, Wh, b, stateful=False): self.params = [Wx, Wh, b] self.grads = [np.zeros_like(Wx), np.zeros_like(Wh), np.zeros_like(b)] self.layers = None self.h, self.c = None, None self.dh = None self.stateful = stateful def forward(self, xs): Wx, Wh, b = self.params N, T, D = xs.shape H = Wh.shape[0] self.layers = [] hs = np.empty((N, T, H), dtype='f') if not self.stateful or self.h is None: self.h = np.zeros((N, H), dtype='f') if not self.stateful or self.c is None: self.c = np.zeros((N, H), dtype='f') for t in range(T): layer = LSTM(*self.params) self.h, self.c = layer.forward(xs[:, t, :], self.h, self.c) hs[:, t, :] = self.h self.layers.append(layer) return hs
基本的には、TimeRNNの場合と同様です。TimeLSTMレイヤは、T個のLSTMレイヤを連結したネットワークです。ブロック間の状態hを引き継ぐかどうかをstatefulという引数で調整できるようにします。また、記憶を保存するセルCがあります。
順伝播では、まず出力用の容器 hs(N, T, H) を用意します。そして、forループを回しながら、xs[:, t, :]によってt番目のデータを切り出して、通常のLSTMに入力し、出力はhs[:, t, :]で用意した容器の指定位置に格納して行くと共に、layersにレイヤーを登録して行きます。
def backward(self, dhs): Wx, Wh, b = self.params N, T, H = dhs.shape D = Wx.shape[0] dxs = np.empty((N, T, D), dtype='f') dh, dc = 0, 0 grads = [0, 0, 0] for t in reversed(range(T)): layer = self.layers[t] dx, dh, dc = layer.backward(dhs[:, t, :] + dh, dc) dxs[:, t, :] = dx for i, grad in enumerate(layer.grads): grads[i] += grad for i, grad in enumerate(grads): self.grads[i][...] = grad self.dh = dh return dxs def set_state(self, h, c=None): self.h, self.c = h, c def reset_state(self): self.h, self.c = None, NoneTimeLSTMの順伝播は出力が3つあるので、逆伝播のときはその3つが合算された$dh_t+dh_{next}+dc_{next}$が入力されます。
まず、下流に流す容器dxsを作り、順伝播とは逆順でLSTMレイヤのbackward()で各時刻の勾配dxを求め、dxsの該当するインデッックスに代入します。重みパラメータは、各レイヤの重み勾配を加算し最終結果をself.gradsに上書きします。
6.改良版LSTMモデル
さて、先程の改良モデル train_better_rnnlm.py を動かしてみましょう。さすがに、これはCPUだけではつらいので、windowsマシンにcupyをインストールしました。
time_size = 35, batch_size = 20, word_size = hidden_size = 650, max_epoch = 40 で実行します。
import sys sys.path.append('..') from common import config # GPUで実行する場合は下記のコメントアウトを消去(要cupy) # ============================================== config.GPU = True # ============================================== from common.optimizer import SGD from common.trainer import RnnlmTrainer from common.util import eval_perplexity, to_gpu from dataset import ptb from better_rnnlm import BetterRnnlm # ハイパーパラメータの設定 batch_size = 20 wordvec_size = 650 hidden_size = 650 time_size = 35 lr = 20.0 max_epoch = 40 max_grad = 0.25 dropout = 0.5 # 学習データの読み込み corpus, word_to_id, id_to_word = ptb.load_data('train') corpus_val, _, _ = ptb.load_data('val') corpus_test, _, _ = ptb.load_data('test') if config.GPU: corpus = to_gpu(corpus) corpus_val = to_gpu(corpus_val) corpus_test = to_gpu(corpus_test) vocab_size = len(word_to_id) xs = corpus[:-1] ts = corpus[1:] model = BetterRnnlm(vocab_size, wordvec_size, hidden_size, dropout) optimizer = SGD(lr) trainer = RnnlmTrainer(model, optimizer) best_ppl = float('inf') for epoch in range(max_epoch): trainer.fit(xs, ts, max_epoch=1, batch_size=batch_size, time_size=time_size, max_grad=max_grad) model.reset_state() ppl = eval_perplexity(model, corpus_val) print('valid perplexity: ', ppl) if best_ppl > ppl: best_ppl = ppl model.save_params() else: lr /= 4.0 optimizer.lr = lr model.reset_state() print('-' * 50) # テストデータでの評価 model.reset_state() ppl_test = eval_perplexity(model, corpus_test) print('test perplexity: ', ppl_test)
windowsマシン(GTX1060)で3時間弱で完了しました。40eopch後のテストデータによる評価はperplexity=76〜79まで改善しています。このコードでは、1epch毎にテストデータのperplexityを計算し、その値が悪化した場合のみ学習係数 lrを下げるという工夫がされています。それでは、BetterRnnlmを見てみましょう。
7.BetterRnnlm
import sys sys.path.append('..') from common.time_layers import * from common.np import * # import numpy as np from common.base_model import BaseModel class BetterRnnlm(BaseModel): def __init__(self, vocab_size=10000, wordvec_size=650, hidden_size=650, dropout_ratio=0.5): V, D, H = vocab_size, wordvec_size, hidden_size rn = np.random.randn embed_W = (rn(V, D) / 100).astype('f') lstm_Wx1 = (rn(D, 4 * H) / np.sqrt(D)).astype('f') lstm_Wh1 = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b1 = np.zeros(4 * H).astype('f') lstm_Wx2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_Wh2 = (rn(H, 4 * H) / np.sqrt(H)).astype('f') lstm_b2 = np.zeros(4 * H).astype('f') affine_b = np.zeros(V).astype('f') self.layers = [ TimeEmbedding(embed_W), TimeDropout(dropout_ratio), TimeLSTM(lstm_Wx1, lstm_Wh1, lstm_b1, stateful=True), TimeDropout(dropout_ratio), TimeLSTM(lstm_Wx2, lstm_Wh2, lstm_b2, stateful=True), TimeDropout(dropout_ratio), TimeAffine(embed_W.T, affine_b) # weight tying!! ] self.loss_layer = TimeSoftmaxWithLoss() self.lstm_layers = [self.layers[2], self.layers[4]] self.drop_layers = [self.layers[1], self.layers[3], self.layers[5]] self.params, self.grads = [], [] for layer in self.layers: self.params += layer.params self.grads += layer.grads def predict(self, xs, train_flg=False): for layer in self.drop_layers: layer.train_flg = train_flg for layer in self.layers: xs = layer.forward(xs) return xs def forward(self, xs, ts, train_flg=True): score = self.predict(xs, train_flg) loss = self.loss_layer.forward(score, ts) return loss def backward(self, dout=1): dout = self.loss_layer.backward(dout) for layer in reversed(self.layers): dout = layer.backward(dout) return dout def reset_state(self): for layer in self.lstm_layers: layer.reset_state()
BetterRnnlmのレイヤ構成です。特徴は、LSTMレイヤの多層化(2個)、Dropoutの使用(2個)、Time Embedding とTime Affine の重み共有、の3つです。LSTMの多層化で表現力を上げる一方で、過学習抑制のためにTimeDropout(中身は基本的にDropoutと同一です)を入れています。重みの共有化は、Time Embeddinhレイヤの重みは(V, H)、Affineレイヤの重みは(H, v)なので、Time Embeddingレイヤの重みの転置をAffineレイヤの重みとすることで学習パラメータを減らし、過学習を抑制すると共に学習を容易にしています。
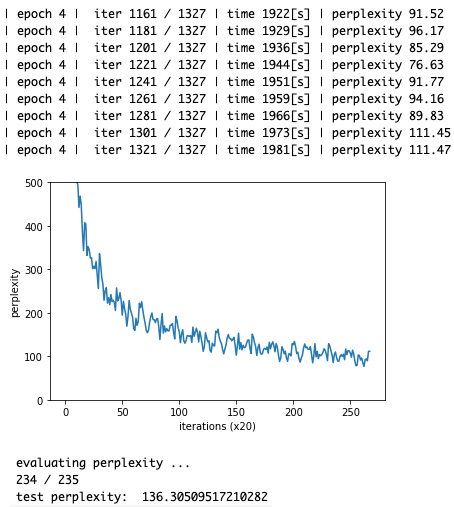
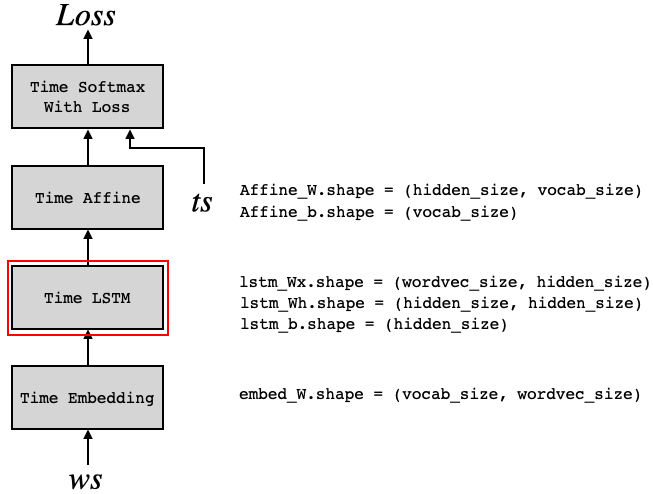

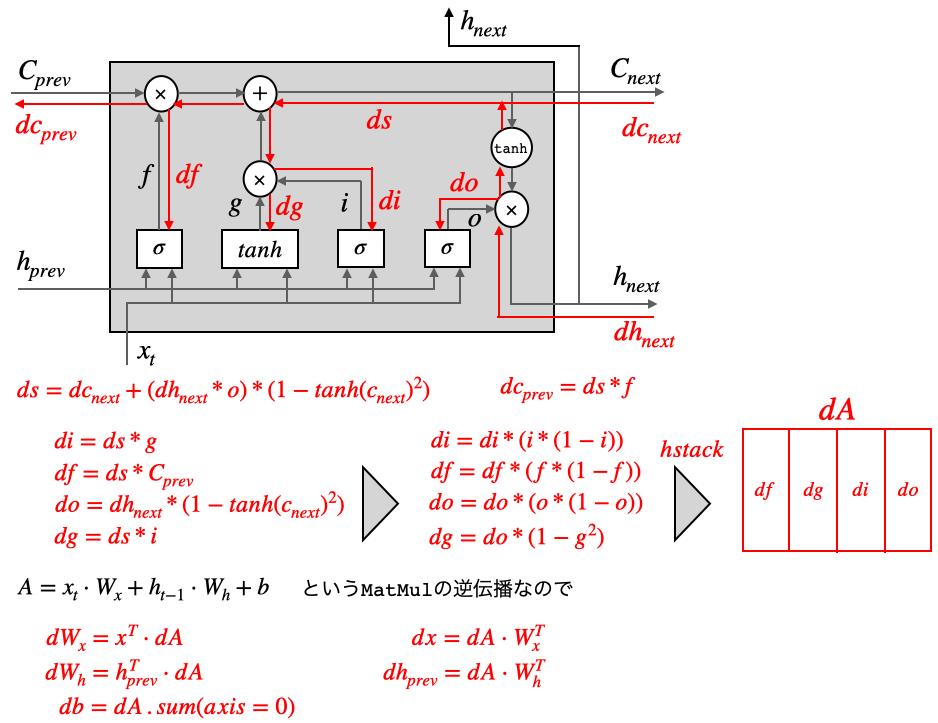
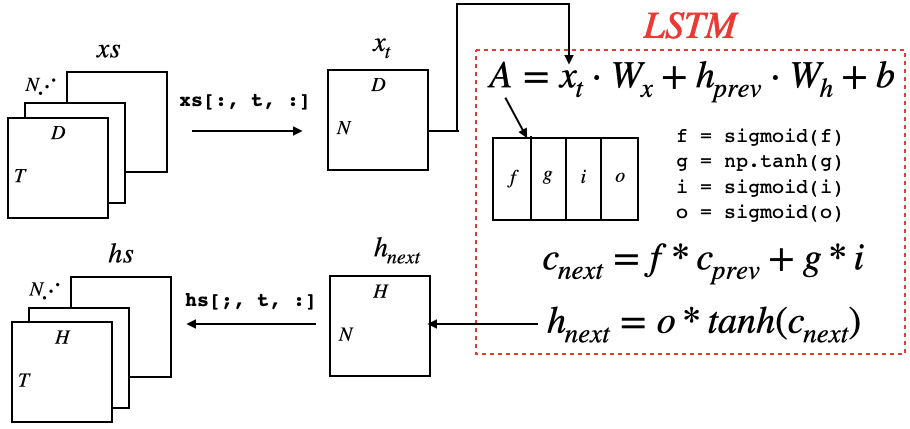

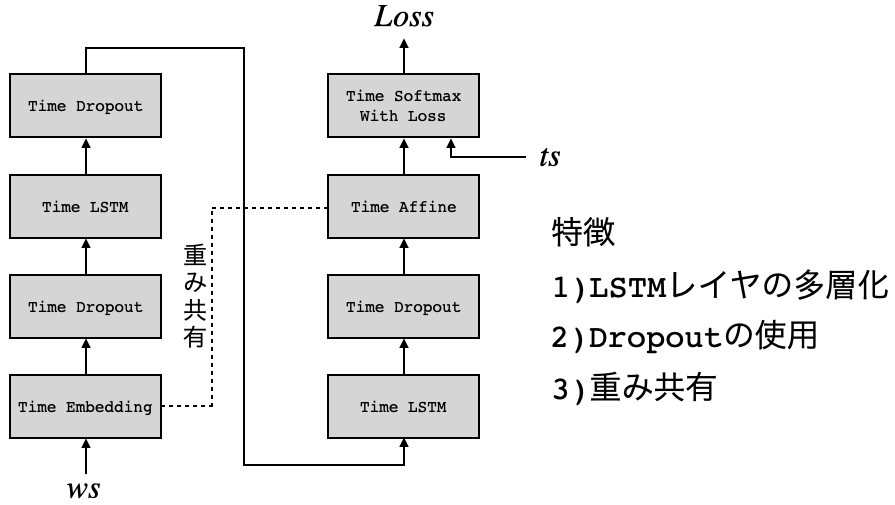
- 投稿日:2020-05-23T18:59:39+09:00
100日後にエンジニアになるキミ - 64日目 - プログラミング - 確率について2
昨日までのはこちら
100日後にエンジニアになるキミ - 63日目 - プログラミング - 確率について1
100日後にエンジニアになるキミ - 59日目 - プログラミング - アルゴリズムについて
100日後にエンジニアになるキミ - 53日目 - Git - Gitについて
100日後にエンジニアになるキミ - 42日目 - クラウド - クラウドサービスについて
100日後にエンジニアになるキミ - 36日目 - データベース - データベースについて
100日後にエンジニアになるキミ - 24日目 - Python - Python言語の基礎1
100日後にエンジニアになるキミ - 18日目 - Javascript - JavaScriptの基礎1
100日後にエンジニアになるキミ - 14日目 - CSS - CSSの基礎1
100日後にエンジニアになるキミ - 6日目 - HTML - HTMLの基礎1
期待値について
期待値とは1回の試行で得られる平均値のことです。得られる全ての値とそれが起こる確率の積を足し上げたものです。
サイコロの例で考えてみましょう。
サイコロの目が出る確率は以下の通りです。
出る目(x) 1 2 3 4 5 6 確率(p) 1/6 1/6 1/6 1/6 1/6 1/6 出る目の期待値は
出る目 * 確率を足し上げたものです。$ 1 * \frac{1}{6} + 2 * \frac{1}{6} +3 * \frac{1}{6} +4 * \frac{1}{6} +5 * \frac{1}{6} +6 * \frac{1}{6} = 3.5$
サイコロを1回振る際の平均は3.5になると期待できます。
還元率
ギャンブルにも期待値があります。その際掛け金に対して、払い戻される金額の割合を
還元率と言っていたりします。例えば1000万円払って50%の確率で1500万円、40%で500万円、10%の確率で0円になるギャンブルがあったとします。
期待値は(50%×1500万円)+(40%×500万円)+(20%×0円)=950万円
還元率は950万円/1000万円で95%となります。こんなギャンブルがあったらやりますか?
やり続ければやり続けるほど、お金が減っていくと思います。よく言われている国内のギャンブルの還元率は
種類 還元率 競馬 約75% 競輪 約75% 競艇 約75% オートレース 約75% 宝くじ 約46% サッカーくじ 約50% パチンコ 約80~90% やればやるほどお金が減っていくわけですね。
宣伝費をかけて集客をしても
人が集まれば集まるだけ親が儲かるのですから
たまらない商売ですね。基本的に還元率が100%を超えるギャンブルは存在し得ないハズです。
もし還元率が100%を超えるギャンブルが有ったとしたら
掛けている側のお金がどんどん増えていきます。ギャンブルの確率
様々なギャンブルの確率を考えてみましょう。
競馬
競馬は16,18頭だてで着順を当てにいくものです。
当てる着順によって買い方が変わります。単勝
1着を当てに行きます。
この場合当たる確率は
16頭だて$\frac{1}{16} = 6.25$%
18頭だて$\frac{1}{18} = 5.556$%複勝
1-3着に入る馬を当てます。
予想した馬が1位でも3位でも良いので
単純に単勝の3倍になります。この場合当たる確率は
16頭だて$\frac{3}{16} = 18.75$%
18頭だて$\frac{3}{18} = 16.667$%複勝であれば
6回に1回は当たるという確率ですね。ただし払い戻しは平均2倍程度なので
あまり美味しくはありません。枠連
18頭の馬は9の枠に入れられます。
それぞれ1-2頭ほどで構成され
その枠での順位を当てるというものです。9枠の中から2枠を選ぶというものです。
36通り有るので
$\frac{1}{36} = 2.7778$%馬連
選んだ2頭が1-2着になる組み合わせで1-2,2-1どちらでも良いという買い方です。
16頭だて$\frac{1}{120} = 0.83333$%
18頭だて$\frac{1}{153} = 0.65359$%馬単
選んだ2頭が1-2着になる組み合わせで1-2着をそのまま当てる買い方です。
16頭だて$\frac{1}{240} = 0.41667$%
18頭だて$\frac{1}{306} = 0.3268$%ワイド
3着以内に入る組み合わせのうち2つを
それらの着順に依らず順不同で予想するものです。1-2 , 1-3 , 2-3着になれば良いので
単純に馬連の3倍の確率になります。16頭だて$\frac{3}{120} = 2.5$%
18頭だて$\frac{3}{153} = 1.9608$%3連複
1着・2着・3着になる組み合わせを順不同で予想する
組み合わせ16C3,18C316頭だて$\frac{1}{560} = 0.17857$%
18頭だて$\frac{1}{816} = 0.12255$%3連単
1着・2着・3着になる組み合わせを着順通りに予想する
順列16P3,18P316頭だて$\frac{1}{3360} = 0.029762 $%
18頭だて$\frac{1}{4896} = 0.020425 $%WIN5
JRAが指定する5つのレース
それぞれの1着を予想するものです。
単勝の5乗ですね18頭だて$\frac{1}{1889568} = 0.0000529221$%
約190万分の1の確率です。
宝くじなどの確率が
1000万分の1の確率で同じくらいの金額なので
WIN5の方が期待値は上かと思います。競馬の確率の高さは
複勝>単勝>枠連>ワイド>馬連>馬単>3連複>3連単>WIN5
になります。
ロトシックス
ロト6は1-43まで数字のうち
本数字6個と1個のボーナス数字
計7個の数字を選択して当てるもので1-5等まであります。1等
本数字6個すべて一致
43C6$\frac{1}{6096454} = 0.0000164030$%
1等は約600万分の1の確率となります。
2等
本数字5個と一致,ボーナス数字1個と一致
$\frac{6}{6096454} = 0.0000984179$%
2等は約100万分の1の確率となります。
3等
6個のうち5個が本数字に一致
$\frac{216}{6096454} = 0.0035430432$%
大雑把に3万分の1くらいの確率です。
4等
6個のうち4個が本数字に一致
$\frac{9990}{6096454} = 0.1638657488 $%
600回に一回くらいは当たる確率ですかね。
5等
6個のうち3個が本数字に一致
$\frac{155400}{6096454} = 2.5490227598 $%
40回に1回くらいの確率ですね。
5等は
1000円なので2.5%の確率でしか当たらないので
40回買っても1000円しか戻ってこないのです。1位がでなければキャリーオーバーで持ち越しになり、金額が増えますが
そもそも600万分の1の確率では人生において当たることはほぼないでしょうね。ポーカー
ポーカーはトランプ52枚を使ったゲームで役が決まっています。
その役がどれだけ有るのかを求めます。役は
役 内容 ロイヤルストレートフラッシュ A-K-Q-J-10 ストレートフラッシュ 連続した数字で(絵柄)
同じスートの5枚のカードフォーカード 同じランクのカード4枚と他1枚カー フルハウス 同じランクのカード 3 枚と別の同じランクのカード 2 枚。 フラッシュ 同じスートの 5 枚のカード。 ストレート 連続した数字の 5 枚のカード。 スリーカード 同じランクのカード 3 枚と、ランクの異なる 2 枚のサイドカード。 ツーペア 同じランクのカード 2 枚 1 組が 2 組と、1 枚のサイドカード。 ワンペア 同じランクのカード 2 枚と、ランクの異なる 3 枚のサイドカード。 ハイカード 上記のどれにも当てはまらない手札。ブタ 今回は役を判定するプログラムを作って
全カードの組み合わせからその役がなんなのかを判定して
役の組み合わせ数を求めます。デッキはカード52枚としてそれを判定する関数を作成し
全52枚の中から5枚を選んだ際の組み合わせから
役が何かを求めて役の個数をカウントします。# デッキの生成 deck=[b+':'+str(a) for a in range(1,14) for b in ['C','S','D','H']] # 役の判定 def jadge_role(card): s = {} for c in card: k = int(c.split(':')[1]) if k in s: s[k]+=1 else: s[k] =1 t = {c.split(':')[0] for c in card} n = sorted([c for c in s.keys()]) if len(t)==1 and all([1 in n,10 in n ,11 in n,12 in n,13 in n]): return 'RSF' if len(t)==1 and (all([1 in n,10 in n ,11 in n,12 in n,13 in n]) or (max(n)-min(n)==4) and len(s)==5): return 'SF' if 4 in s.values(): return '4C' if 3 in s.values() and 2 in s.values(): return 'FH' if len(t)==1: return 'FL' if (all([1 in n,10 in n ,11 in n,12 in n,13 in n]) or (max(n)-min(n)==4) and len(s)==5): return 'ST' if 3 in s.values(): return '3C' if list(s.values()).count(2)==2: return '2P' if list(s.values()).count(2)==1: return '1P' return 'BT' # 組み合わせを計算 cards = itertools.combinations(deck,5) calc_dict = {} for card in cards: role = jadge_role(card) if role in calc_dict: calc_dict[role] += 1 else: calc_dict[role] = 1 # 結果 poker_base = math.factorial(52) // (math.factorial(52 - 5) * math.factorial(5)) print(poker_base) for k,v in sorted(calc_dict.items(),reverse=True,key=lambda x:x[1]): print(k,'\t',v,'\t','{0:.10f}%'.format(v/poker_base*100))2598960
役 回数 割合 BT 1302540 50.12% 1P 1098240 42.26% 2P 123552 4.75% 3C 54912 2.1128% ST 10200 0.39246% FL 5108 0.19654% FH 3744 0.144057% 4C 624 0.024009% SF 36 0.001385% RSF 4 0.0001539% このような結果になります。
ロイヤルストレートフラッシュは
約64万回に1回ほどは出る計算ですね
フラッシュとストレートではストレートの方が2倍も出る確率が高いのです。
なのでどちらかを迷う場合は確率の高いストレートを狙うというのが
戦略になるのかもしれませんね。まとめ
確率、期待値が求められれば、還元率についても計算することができます。
ガチャなどはルーレットゲームなどと一緒なので
確率を求めれば、どれくらいの金額を突っ込めばキャラが当たるのか
シミュレーションできます。ゲームやガチャなどでは確率、期待値を求めることも多いので
様々な確率の計算方法などを押さえておくといいかもしれません。君がエンジニアになるまであと36日
作者の情報
乙pyのHP:
http://www.otupy.net/Youtube:
https://www.youtube.com/channel/UCaT7xpeq8n1G_HcJKKSOXMwTwitter:
https://twitter.com/otupython
- 投稿日:2020-05-23T18:55:06+09:00
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (3)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (1)
筑波大学の機械学習講座:課題のPythonスクリプト部分を作りながらsklearnを勉強する (2)
https://github.com/legacyworld/sklearn-basic課題 3.2 多項式単回帰の訓練誤差とテスト誤差
Youtubeの解説は第4回(1) 40分あたり
$y = \cos(1.5\pi x)$に$N(0,1)\times0.1$の誤差を載せた30個の訓練データを作り、多項式回帰を行う。
ここから交差検証が入る。
1次から20次まで順に回帰していく。
訓練データはこれ。
ソースコード
Homework_3.2.pyimport pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.preprocessing import PolynomialFeatures as PF from sklearn import linear_model from sklearn.pipeline import Pipeline from sklearn.metrics import mean_squared_error from sklearn.model_selection import cross_val_score DEGREE = 20 def true_f(x): return np.cos(1.5 * x * np.pi) np.random.seed(0) n_samples = 30 # 描画用のx軸データ x_plot = np.linspace(0,1,100) # 訓練データ x_tr = np.sort(np.random.rand(n_samples)) y_tr = true_f(x_tr) + np.random.randn(n_samples) * 0.1 # Matrixへ変換 X_tr = x_tr.reshape(-1,1) X_plot = x_plot.reshape(-1,1) for degree in range(1,DEGREE+1): plt.scatter(x_tr,y_tr,label="Training Samples") plt.plot(x_plot,true_f(x_plot),label="True") plt.xlim(0,1) plt.ylim(-2,2) filename = f"{degree}.png" pf = PF(degree=degree) linear_reg = linear_model.LinearRegression() steps = [("Polynomial_Features",pf),("Linear_Regression",linear_reg)] pipeline = Pipeline(steps=steps) pipeline.fit(X_tr,y_tr) plt.plot(x_plot,pipeline.predict(X_plot),label="Model") y_predict = pipeline.predict(X_tr) mse = mean_squared_error(y_tr,y_predict) scores = cross_val_score(pipeline,X_tr,y_tr,scoring="neg_mean_squared_error",cv=10) plt.title(f"Degree: {degree} TrainErr: {mse:.2e} TestErr: {-scores.mean():.2e}(+/- {scores.std():.2e})") plt.legend() plt.savefig(filename) plt.clf()前回の課題3.1ではPolynomialFeaturesで$x,x^2,x^3$等を用意してから、LinearRegressionを行っていたが、pipelineというのを使うと一発で出来ることを学んだ。
実際に課題3.1の解説動画の中のソースコードを見るとpipelineを使っていた。
何も難しいことは無く、stepsで処理内容を列挙するだけである。steps = [("Polynomial_Features",pf),("Linear_Regression",linear_reg)] pipeline = Pipeline(steps=steps) pipeline.fit(X_tr,y_tr)この部分以外で課題3.1と異なるのは交差検証が入っていることである。
プログラムでいうとこの部分。scores = cross_val_score(pipeline,X_tr,y_tr,scoring="neg_mean_squared_error",cv=10)
cv=10でデータを10分割してから1部分をテストデータにしてテスト誤差を評価している。
基本的にはこのテスト誤差が小さいものが優れていることになる。
プログラムを実行すると1.png - 20.pngまで20個のグラフファイルが作成される。
- 訓練誤差が最も小さいもの = 次数が20
- テスト誤差が最も小さいもの = 次数が3
ここから如何に過学習がだめかということがわかる。
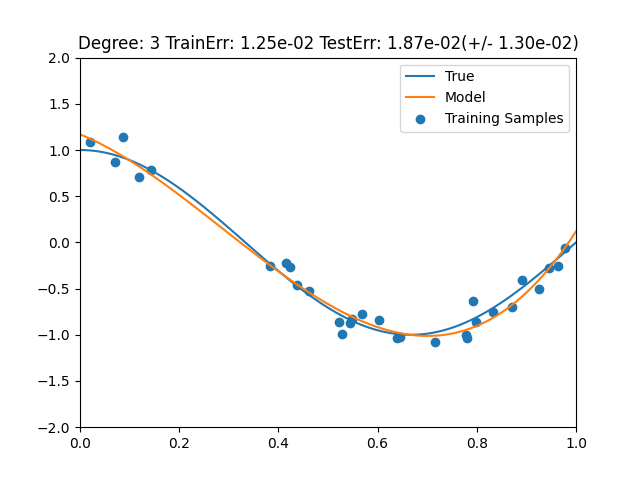
- 投稿日:2020-05-23T18:31:40+09:00
フォルダ内にある全てのCSVを一つのCSVにまとめる方法
inputフォルダ内に複数のCSVファイルがあり、それを一つのCSVにまとめて出力させている
import glob import pandas as pd files = glob.glob('input/*.csv') files.sort() df_list = [] for file in files: df_next = pd.read_csv(file) df_list.append(df_next) df = pd.concat(df_list, ignore_index=True) df.to_csv('output.csv')
- 投稿日:2020-05-23T18:29:42+09:00
DataFrameを分割して保存する方法
以下のkの値を指定することで、1DataFrameあたりの行数を指定することが可能
k = 10000 # 1DataFrameあたりの行数 dfs = [df.loc[i:i+k-1, :] for i in range(0, len(df), k)] for i, df_i in enumerate(dfs): fname = str(i) + ".csv" df_i.to_csv(fname)
- 投稿日:2020-05-23T18:22:00+09:00
Markdownで、DataFrameを表として表示させる方法
こういうコードを書くと
print('|', end="") for col in df.columns: print(col,'|', end="", sep='') print() for row in range(len(df)): print('|', end="") for col in range(df.shape[1]): print(df.iat[row,col],'|', end="", sep='') print()このように出力がされる
| sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | | ---- | ---- | ---- | ---- | ---- | | 5.1 | 3.5 | 1.4 | 0.2 | setosa | | 4.9 | 3.0 | 1.4 | 0.2 | setosa | | 4.7 | 3.2 | 1.3 | 0.2 | setosa | | 4.6 | 3.1 | 1.5 | 0.2 | setosa | | 5.0 | 3.6 | 1.4 | 0.2 | setosa |それをコピペしてMarkdownファイルに出力すると、
以下のように表として表示することができる。
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target 5.1 3.5 1.4 0.2 setosa 4.9 3.0 1.4 0.2 setosa 4.7 3.2 1.3 0.2 setosa 4.6 3.1 1.5 0.2 setosa 5.0 3.6 1.4 0.2 setosa
- 投稿日:2020-05-23T18:19:14+09:00
素人基盤エンジニアがDockerでDjangoを触るシリーズ⑤:View, Template, CSS
TL;DR
素人基盤エンジニアがDockerでDjangoを触るシリーズ④:urls.pyの続き。
1から読みたい場合は↓こちら。
素人基盤エンジニアがDockerでDjangoを触るシリーズ①:DockerでDjangoを作る
今回もDjango Girlsのサンプルを作りながらdjangoと戯れる。
viewでは、modelを介して受け取ったデータをTemplateに渡したり、その他処理を行うことができる。
Templateは見た目を整える部分。htmlやCSSなどはこのTemplateにあたる。
まずは、シンプルなViewを作ることでその構造を見ていく。view
①views.pyを編集する
views.py
views.pyfrom django.shortcuts import render from django.utils import timezone from .models import Post def post_list(request): posts = Post.objects.filter(published_date__lte=timezone.now()).order_by('published_date') return render(request, 'blog/post_list.html', {'posts': posts})よくわかる解説
from django.shortcuts import rendershortcuts関数は、DjangoにおけるMTVの各レベルを橋渡しするのに必要な関数やクラスを定義している。今回は、引数として指定したtemplateをレンダしてHttpResponseを返すrenderという関数をインポートしている。
from django.utils import timezone from .models import Postユーティリティ関数に含まれている時間に関する機能を提供するtimezoneと、モデルの作成の時に作成したPostのモデルをインポートしている。Viewの立ち位置については第二回の時にも触れたが、モデル関数を利用して実際にデータを取得し、Templateに渡す役割もあるので、利用したいモデルはViewの中でインポートし、Templateのオプションとして引き渡す必要がある。
def post_list(request): posts = Post.objects.filter(published_date__lte=timezone.now()).order_by('published_date') return render(request, 'blog/post_list.html', {'posts': posts})post_list関数の定義部分。前回のurls.pyを記述した際に、
views.post_listを指定したのは覚えているだろうか。urls.pyへリクエストが来た際に、パスに応じて指定したviews.pyの中の関数が呼び出されリクエストが転送される。そして、必要な処理を行った後にTemplateをレンダリングしてレスポンスを返すということである。二行目では、Postモデルを使ってpublished_dateが現在の時間よりも前の投稿を取得し、新しい順に並び変えた上でblog/post_list.htmlに渡している。Template
①html用のディレクトリを作成する
cd ~/blog/template mkdir blogアプリケーションのディレクトリであるblogディレクトリの下に、templateというディレクトリがあるので、その下にさらにblogというディレクトリを作成する。
なぜこんなややこしい構造にするのかと思うかもしれないが、大規模なアプリケーションを管理しようとするとhtmlに関しても機能ごとにディレクトリを分けておいたほうがよいらしい。②post_list.htmlを編集する
post_list.html
blog/template/blog/post_list.html{% load static %} <html> <head> <title>Django Girls blog</title> <link rel="stylesheet" href="//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/css/bootstrap.min.css"> <link rel="stylesheet" href="//maxcdn.bootstrapcdn.com/bootstrap/3.2.0/css/bootstrap-theme.min.css"> <link rel="stylesheet" href="{% static 'css/blog.css' %}"> </head> <body> <div class="page-header"> <h1><a href="/">Django Girls Blog</a></h1> </div> <div class="content container"> <div class="row"> <div class="col-md-8"> {% for post in posts %} <div class="post"> <div class="date"> <p>published: {{ post.published_date }}</p> </div> <h2><a href="">{{ post.title }}</a></h2> <p>{{ post.text|linebreaksbr }}</p> </div> {% endfor %} </div> </div> </div> </body> </html>HTMLの基本的な部分を解説するのは主旨とずれるので、ここでは重要な部分のみを解説する。
よくわかる解説
{% load static %}{% load static %}は後述するCSSファイルのような、静的コンテンツを読み込むための記述。
<link rel="stylesheet" href="{% static 'css/blog.css' %}">ここで読み込むCSSを指定している。
{% for post in posts %} <div class="post"> <div class="date"> <p>published: {{ post.published_date }}</p> </div> <h2><a href="">{{ post.title }}</a></h2> <p>{{ post.text|linebreaksbr }}</p> </div> {% endfor %}この部分で注目したいのは、{{ post.OBJECT }}でPostモデルの項目を指定している部分。Postモデルを利用して取得した投稿に関しては、前述したviews.pyの中でこのTemplateに渡されているため、このように簡単に呼び出せるということだ。Postモデルで取得した投稿はリストの形になっているため、for文を利用して複数の表示を実現することもできる。
③CSS用のディレクトリを作成する
cd ~/blog/static mkdir css④blog.cssを編集する
blog/static/css/blog.css.page-header { background-color: #C25100; margin-top: 0; padding: 20px 20px 20px 40px; } .page-header h1, .page-header h1 a, .page-header h1 a:visited, .page-header h1 a:active { color: #ffffff; font-size: 36pt; text-decoration: none; } .content { margin-left: 40px; } h1, h2, h3, h4 { font-family: 'Lobster', cursive; } .date { color: #828282; } .save { float: right; } .post-form textarea, .post-form input { width: 100%; } .top-menu, .top-menu:hover, .top-menu:visited { color: #ffffff; float: right; font-size: 26pt; margin-right: 20px; } .post { margin-bottom: 70px; } .post h2 a, .post h2 a:visited { color: #000000; }CSSの解説についてはさらに本筋ではないので、形を整えるためにはこんなものを書くんだというくらいの認識でコピペいただければと思う。HTML, CSSに関してはそれ専用の本などで勉強されることをお勧めする。
ブログ表示用サイトの起動
docker-compose up
ここまでで、(表示をするのみだが)webサイトが完成しているはずである。
dockercompose.yamlが配置されているディレクトリまで移動して、docker-compose upを使って実際に起動してみよう。docker-compose uphttp://[IPADDRESS]:8000/にアクセスしてみる。
表示された!
ちなみにThis is test postという投稿は、第三回で説明したadminページを利用して投稿したもの。ユーザがポストを行うには、投稿フォームを備えたページを作成する必要がある。フォームを作成するにあたって、Djangoはformsという便利な機能を提供している。その話はまた次回。まずは一区切りといった感じだろうか。。
つづく
- 投稿日:2020-05-23T18:13:37+09:00
AtCoderProblemsのRecommendationをpythonで解く(20200517-0523)
この記事に記載した問題の一覧
- AGC057 A Shik and Stone
- ABC070 C Multiple Clocks
- ABC123 C Five Transportations
- AGC008 A Simple Calculator
- ARC059 C いっしょ
- ABC047 C 一次元リバーシ
- ABC143 D Triangles
- ABC035 B ドローン
- AGC011 A Airport Bus
- AGC002 B Box and Ball
- ABC078 C HSI
- ARC054 A 動く歩道
- ABC065 C Reconciled?
- パナソニックプログラミングコンテスト2020 C Sqrt Inequality
上記問題を解く上で学んだこと
reduceについて
- reduceとは畳み込みのこと
- 高階関数の一種
- 高階関数とは、関数を引数にとる関数のこと(下は高階関数の例)
map(各イテレータに関数を実行してイテレータで返す)filter(各イテレータに関数を実行した結果がTrueのもののみをイテレータで返す))reduce(function, iterater, initializer(option))の形で使用functionをイテレータに順に実行していって結果を返す桁の丸めについて
- 競プロではたまに桁の丸めによって、コードとしては正しく見えるが、WAになるケースがある(上の5.や14.)
- 四捨五入
round()を使うとダメなケースがあるので、(<num>*2+1)//2を使う。- ルート
math.sqrt()を使うとダメなケースがあるので、<num>**(decimal("0.5"))を使う。
※1:from Decimal import decimalが必要。
※2:decimalの引数は文字列で与える(数値で与えるとその時点で丸め誤差が生じる)。二分探索について
- ソート済みリストから値をサーチするときは、線形探索より二分探索をした方がいい(ことが多い)
<idx> = bisect.bisect_left(<list>, <value>)のような形で使うことができる。
※import bisectが必要二分探索を用いることで線形探索と比較して、計算量を$O(n)$から$O(\log n)$に減らすことができる。
各問題の解法
AGC057 A Shik and Stone
- 所要時間:10分弱
- ポイント:初めは
collections.counterを使おうと思ったが、#の数を数えるだけであれば、<list>のcount()で十分な気がしたのでそちらに変更して実装# AGC057 A Shik and Stone h,w = map(int, input().split()) _list = [] for i in range(h): _list += list(input()) if _list.count("#") == (h+w-1): print("Possible") else: print("Impossible")ABC070 C Multiple Clocks
- 所要時間:11分
- ポイント:LCMを求める問題であることはぱっと見わかったので、LCMの実装方法をググった。
reduceについて勉強する時間は所要時間には含めない。# ABC070 C Multiple Clocks from functools import reduce from fractions import gcd #python3.5より前 # from math import gcd #python3,5以降 def lcm_base(x,y): return (x*y)//gcd(x,y) def multi_lcm(numbers): return reduce(lcm_base, numbers) n = int(input()) t_list = [int(input()) for i in range(n)] print(multi_lcm(t_list))ABC123 C Five Transportations
- 所要時間:-分
- ポイント:紙に例を書いてみるとわかる
# ABC123 C Five Transportations import math n = int(input()) a = int(input()) b = int(input()) c = int(input()) d = int(input()) e = int(input()) _min = min([a,b,c,d,e]) _ans = math.ceil(n/_min) print(_ans+4)AGC008 A Simple Calculator
感想
- パッと見簡単だが、パターン分けが意外と多い(もっときれいにできるかもしれない)
- どちらかが0のときのパターン分けを雑にやったために2回WAになった。# AGC008 A Simple Calculator x, y = map(int, input().split()) _x = abs(x) _y = abs(y) if x > 0 and y > 0: if x <= y: print(y-x) else: print(x-y+2) elif x * y < 0: print(abs(_y-_x)+1) elif x == 0: if y >= 0: print(y) else: print(_y+1) elif y == 0: if x > 0: print(x+1) else: print(_x) else: if _x < _y: print(_y-_x+2) else: print(_x-_y)ARC059 C いっしょ
感想
- 問題自体は簡単。計算量も全要素一つずつ計算しても問題なさそうだったのでそこも問題ない。
-round()では四捨五入が正しくできないケースがあるので、(<num>*2+1//2)で四捨五入をした。(なぜround()が正しく四捨五入されないかはここでは割愛)# ARC059 C いっしょ n = int(input()) a_list = [int(x) for x in input().split()] ave = ((sum(a_list) / len(a_list)) * 2 + 1) // 2 ans = sum([(x-ave)**2 for x in a_list]) print(int(ans))ABC047 C 一次元リバーシ
感想
-itertools.groupby()が思いつけば一瞬。
- ただし、イテレータの要素数を取得する方法はないらしいので、↓のプログラムみたいにイテレータを使い切る必要がある# ABC047 C 一次元リバーシ import itertools s = itertools.groupby(list(input())) ans = 0 for _ in s: ans += 1 print(ans - 1)ABC143 D Triangles
- その1
- 安直に全探索で解いてみたが、案の定TLEになった。
- その2
- 二分探索(
bisect)を用いる。その2を用いることで、計算量を$O(n^{3})$から$O(n^{2}\log n)$に減らすことができる。
その1
# ABC143 D Triangles TLE n = int(input()) l_list = [int(x) for x in input().split()] l_list.sort() ans = 0 # (i < j < k) -> (_a < _b < _c) for i in range(n-2): _a = l_list[i] for j in range(i+1,n-1): _b = l_list[j] _tmp = _a + _b for k in range(j+1,n): _c = l_list[k] if _c < _tmp: ans += 1 else: break print(ans)その2
# ABC143 D Triangles import bisect n = int(input()) l_list = [int(x) for x in input().split()] l_list.sort() ans = 0 for i in range(n-2): _a = l_list[i] for j in range(i+1,n-1): _b = l_list[j] _tmp = bisect.bisect_left(l_list, _a+_b) if j < _tmp: ans += _tmp - j - 1 print(ans)ABC035 B ドローン
Counter()を使えばすぐに解ける。# ABC035 B ドローン from collections import Counter s = Counter(input()) t = int(input()) l = s["L"] r = s["R"] u = s["U"] d = s["D"] q = s["?"] x = r-l y = u-d if t == 1: print(abs(x) + abs(y) + q) else: _tmp = abs(x) + abs(y) if _tmp >= q: print(_tmp - q) elif (_tmp - q) % 2 == 0: print("0") else: print("1")AGC011 A Airport Bus
- その1
- はじめは
bisect()(二分探索)さえ使えば間に合うと思ったが、TLEになった。- その2
- リストの頭からデータを取得する処理が多いので、
dequeにしてみたところ通った。リストの頭からデータを取得する場合、キューにすべきということを再確認した。
その1
# AGC011 A Airport Bus TLE import bisect n, c, k = map(int, input().split()) t_list = [int(input()) for _ in range(n)] t_list.sort() ans = 0 while len(t_list) > 0: _tmp = t_list[0] + k _idx = bisect.bisect_right(t_list, _tmp) if c <= _idx + 1: t_list = t_list[c:] else: t_list = t_list[_idx:] ans += 1 print(ans)その2
# AGC011 A Airport Bus import bisect from collections import deque n, c, k = map(int, input().split()) t_list = [int(input()) for _ in range(n)] t_list.sort() t_list = deque(t_list) ans = 0 while len(t_list) > 0: _tmp = t_list.popleft() + k _idx = bisect.bisect_right(t_list, _tmp) if c-1 <= _idx: for _ in range(c-1): t_list.popleft() else: for _ in range(_idx-1): t_list.popleft() ans += 1 print(ans)AGC002 B Box and Ball
# AGC002 B Box and Ball n, m = map(int, input().split()) b_list = [0] * (n+1) b_list[1] = 1 c_list = [1] * (n+1) for i in range(m): _x, _y = map(int, input().split()) c_list[_x] -= 1 c_list[_y] += 1 if b_list[_x] == 1: b_list[_y] = 1 if c_list[_x] == 0: b_list[_x] = 0 print(sum(b_list))ABC078 C HSI
# ABC078 C HSI n, m = map(int, input().split()) i = (1/2)**m x = (100*(n-m) + 1900*m) / i print(int(x))ARC054 A 動く歩道
# ARC054 A 動く歩道 l, x, y, s, d = map(int, input().split()) ans = float("Inf") j = (d-s)%l r = (s-d)%l ans = min(ans,j/(y+x)) if y > x: ans = min(ans,r/(y-x)) print(ans)ABC065 C Reconciled?
# ABC065 C Reconciled? import math n, m = map(int, input().split()) A = 10**9 + 7 if abs(n-m) > 1: print("0") elif n == m: print(((math.factorial(m)**2)*2)%A) else: print((math.factorial(m)*math.factorial(n))%A)パナソニックプログラミングコンテスト2020 C Sqrt Inequality
- その1
math.sqrt()を使うと桁が丸められてNGになるケースがある。- その2
decimal.Decimal()を使うことで正しく計算ができる。その1
# パナソニックプログラミングコンテスト2020 C Sqrt Inequality WA import math from decimal import Decimal a, b, c = map(Decimal, input().split()) _a, _b, _c = map(math.sqrt, [a,b,c]) if _a + _b < _c: print("Yes") else: print("No")その2
# パナソニックプログラミングコンテスト2020 C Sqrt Inequality from decimal import Decimal a, b, c = map(int,input().split()) a, b, c = Decimal(a),Decimal(b),Decimal(c) if a**Decimal("0.5") + b**Decimal("0.5") < c**Decimal("0.5"): print('Yes') else: print('No')
- 投稿日:2020-05-23T16:49:52+09:00
CycleGANを実装してみた(1)
Linux上でCycleGANの実装をしてみた
今回は、CycleGANの実装をしてみました。
基本的に、githubで公開されているコードをもとに実装を行っていきます。
本ページでは、軽い論文の説明と実装をしていきます。
自分のデータセットを用いて適用する回は、次回やっていきたいと思います。
- CycleGANについて
- Linux上での実装
簡単ではありますが、上の2項目に従って説明します。
CycleGANについて
論文:https://arxiv.org/pdf/1703.10593.pdf
こちらの論文に沿って説明をしていきます。導入
CycleGANは、画風変換を可能とするGenerative Adversarial Network (GAN)です。
上の図は、論文内記載のものですが、左のような画風変換(色塗り)をしたい場合は、pix2pixに代表されるような、入力と出力の画像のペアで用いる学習方法が採用されていました。
つまり、図のPairedに示されるような1対1の対応が必要となります。
一方で、右に表されるような、Unpairedの画風変換を可能とする手法も提案されています。
Unpairedの手法では、画風変換のタスクごとに、クラスラベル空間、画像特徴空間、ピクセル空間など、様々な距離空間を定義し、それらを用いて入力と出力の距離を近づける必要がありました。そこで、CycleGANは、1対1のペア画像を必要とせず、さらにタスクに合わせて学習方法を変える必要がない、そんな手法として提案されました。
これが、CycleGANによって変換された画像たちです。
風景などの写真が、世界的画家であるMonetやGoghの画風へと変換されています。
これは、pix2pixのようなペアを必要とする学習ではなし得ません。
なぜなら、Goghらが描いた風景の写真を撮るためには、タイムスリップしなければいけないからです。
そして、ZebraとHorseの変換、SummerとWinterの変換も可能としています。
タスクに沿って学習方法を変えることなく、CycleGANでは画風変換を学習可能となります。
目的関数
それを可能とするのが、Cycle-consustency lossの導入です。
これが本手法の肝となりますので、後ほどこちらについて説明します。
上の画像は、Cycle-GANで用いられるlossを表したものになります。
まず、(a)は、GANの一般的なlossである、Adversarial lossになります。
上式で定式化されますが、第1項では、Discriminatorは、本物のデータyを本物と識別することを意味します。
第2項では、Generatorによって生成されたデータを偽物と識別することを意味します。
このAdversarial lossをDiscriminatorに対して最大化(正しく識別する)かつGeneratorに対して最小化(誤識別させる)ように学習を行います。
Discriminatorに関して、第1項の最大化の意味は、本物のデータyの確率値が1(本物)と識別されることです。
また、第2項の最大化の意味は、zに対してG( )を用いて生成した偽物G(z)の確率値を0(偽物)と識別することです。
Generatorに関しては、その逆、ということになります。
Discriminatorが識別できないようなG()を作ることを目的としています。
これらの最大化・最小化を行う際は、片方は固定します。
この最大化・最小化を交互に行うことで、学習を進めていきます。
これを、両方のドメインに対して、行います。
つまり、と
に対して、最適化を行っていくということです。
続いて、(b)と(c)についてです。
こちらが、Cycle-consustency lossと呼ばれ、下式で表されます。
こちらの第1項では、xをG( )を用いて生成したデータG(x)をF( )を用いて元のドメインに戻したデータF(G(x))が、ちゃんとxになっているか、というものをL1ノルムを使って表しています。
第2項では、その逆をやっていますね。
考え方としては簡単です。
最終的に、(a)~(c)を合わせて、
こちらのように目的関数を設定します。
この最適化問題を解くことで、目的のGとFが学習できます。
実験結果
実験結果の一例です。
「うま」と「しまうま」の変換、風景写真における「夏」と「冬」の変換、「りんご」と「みかん」の変換など、様々なタスクにおいて、高精度な画風変換が実現していることが分かります。
これは、失敗例です。
プーチン大統領がしまうまになっちゃっていますね。
この様に、テクスチャの変換はうまくいくものの、形状を捉えた変換は難しい場合もあるようです。
物体検出手法の導入なんかで解決されていくのではと思います。もっと結果を見たいという方は、論文をのぞいてみてください。
Linux上での実装
公開コード
https://github.com/xhujoy/CycleGAN-tensorflow実装環境
- Ubuntu 18.04 LTS
- Python 3.6
- PyTorch 0.4.0
- Tensorflow 1.4.0
- numpy 1.11.0
- scipy 0.17.0
- pillow 3.3.0公開データセットで実装
まずは、任意のディレクトリにgitをクローンします。
続いて、CycleGAN-tensorflow/のディレクトリに移動します。
今回は、論文でも使用されていたhorse2zebraのデータセットをダウンロードしていきます。$ git clone https://github.com/xhujoy/CycleGAN-tensorflow $ cd CycleGAN-tensorflow/ $ bash ./download_dataset.sh horse2zebra学習
続いて、ダウンロードしたhorse2zebraのデータセットで学習を行っていきます。
$ CUDA_VISIBLE_DEVICES=0 python main.py --dataset_dir=horse2zebraGPU指定の場合は、
CUDA_VISIBLE_DEVICES=で指定してください。
学習が始まります。Epoch: [ 0] [ 0/1067] time: 14.2652 Epoch: [ 0] [ 1/1067] time: 16.9671 Epoch: [ 0] [ 2/1067] time: 17.6442 Epoch: [ 0] [ 3/1067] time: 18.3194 Epoch: [ 0] [ 4/1067] time: 19.0001 Epoch: [ 0] [ 5/1067] time: 19.6724 Epoch: [ 0] [ 6/1067] time: 20.3511 Epoch: [ 0] [ 7/1067] time: 21.0326 Epoch: [ 0] [ 8/1067] time: 21.7106 Epoch: [ 0] [ 9/1067] time: 22.3866 Epoch: [ 0] [ 10/1067] time: 23.0501 Epoch: [ 0] [ 11/1067] time: 23.7298 . . .初期設定では、Epochは200回になっています。
こちらは自身が適用するデータセットに合わせて、変更しても良いと思います。
そこまで大きな差異を含む変換の学習ではないのならば、Epochを減らしてみてもいいかもしれません。
ここで注意なのですが、ダウンロードしたdatasets/horse2zebra/ディレクトリの中にtestA/、testB/、trainA/、trainB/が存在し、それぞれのディレクトリ内には画像が入っています。
学習時であっても、testA/またはtestB/のいずれかにデータが入っていないと、以下のエラーを吐かれてしまいます。ValueError: Cannot feed value of shape (1, 256, 256, 6) for Tensor 'real_A_and_B_images:0', which has shape '(?, 512, 512, 6)'自分自身でデータセットを構築し、実装する際は注意が必要です。
テスト
テストは以下のコマンドで行います。
$ CUDA_VISIBLE_DEVICES=0 python main.py --dataset_dir=horse2zebra --phase=test --which_direction=AtoB
--which_direction=のオプションで、AtoBかBtoAを指定します。
datasets/horse2zebra/testAもしくはdatasets/horse2zebra/testB内の画像が変換され、test/に保存されていきます。
それぞれの画像にはわかりやすく、AtoB_もしくはBtoA_が記されます。以下はテスト結果の一例です。
horse2zebra (AtoB)
zebra2horse (BtoA)
しっかりと変換ができています。すごいです。
以上がLinux上での実装となります。
次回は、自身のデータセットに適用してみたいと思います。
参考資料
論文:https://arxiv.org/pdf/1703.10593.pdf
Github:https://github.com/xhujoy/CycleGAN-tensorflow

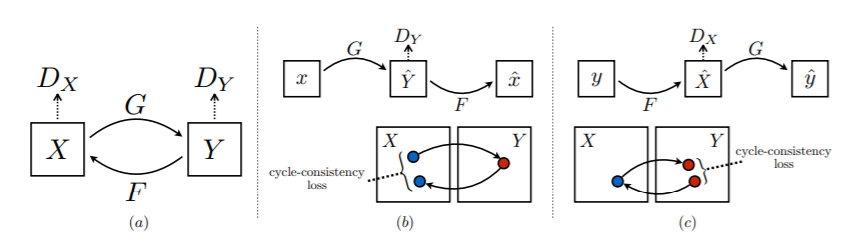
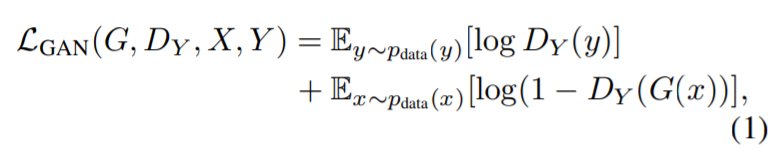
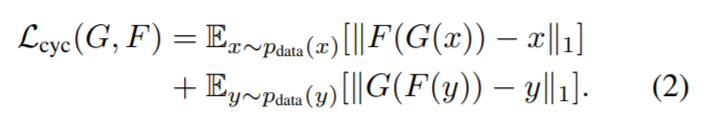





- 投稿日:2020-05-23T16:17:57+09:00
[Python]クラス、インスタンス
クラス定義
class クラス名:
class MenuItem: passインスタンスの生成
変数名 = クラス()
menu_item1 = MenuItem()インスタンス変数
menu_item1.name = "ヒレカツ"インスタンス変数の値の取得
インスタンス.インスタンス変数名
print(menu_item1.name)出力結果
ヒレカツ
メソッド(クラス内で定義された関数)
メソッドの呼び出し
インスタンス.メソッド名()第1引数はselfにする
class MenuItem: def hello(self): print("こんにちは") menu_item1 = MenuItem() menu_item1.hello()__init__メソッド
インスタンスの生成直後に処理を実行できる
__init__メソッドを使った場合class MenuItem: def __init__(self , name) self.name = name menu_item1 = MenuItem("ヒレカツ") print(menu_item1.name)
- 投稿日:2020-05-23T16:02:45+09:00
【Python3】BeautifulSoupの基礎を理解する
はじめに
Pythonの学習を始めました。
Webスクレイピングについて理解を深めたいため、自分なりにまとめてみます。Webの仕組み
本記事では割愛しますが、分散系の開発を行うならば、ある程度理解しておく必要があると思います。
個人的に、学習にはこちらの書籍がおすすめです。
Webを支える技術 -HTTP、URI、HTML、そしてREST (WEB+DB PRESS plus)BeautifulSoupとは
本題です。
書籍などでは、HTMLの解析を行うライブラリと説明されています。
公式サイトも確認しましょう。特徴は以下3点。
- ツリー構造をナビゲート、検索、変更するためのメソッドを提供している。
- 自動的にエンコードしてくれる(BeautifulSoupがドキュメントのencodeを特定できない場合を除く)。
- 受信ドキュメントはUnicode
- 送信ドキュメントはUTF-8
- 利用するParserを選択できる。
- html.parser:標準ライブラリ。処理速度は早くもなく遅くもなく。
- lxml:サードパーティ製ライブラリ。処理速度の速さが特徴的。
- html5lib:サードパーティ製ライブラリ。HTML5の文法をサポートしWebブラウザと同様の方法の解釈を行うなど高性能。処理速度は他より劣る。
BeautifulSoupのインストール
BeautifulSoupライブラリをインストールします。
- 私はMacOSを使っているため、「pip3」コマンドを利用します。
- BeautifulSoupの最新バージョンは4.9.1です(2020/05/23現在)。
インタラクティブシェルで以下のコマンドを実行します。
> pip3 install BeautifulSoup4importできればインストールに成功しています。
bs4はライブラリです。>>> from bs4 import BeautifulSoup4BeautifulSoupを使ってWebサイトから情報抽出してみる
今回は、YAHOO!JAPANのニュース一覧のタイトルとURLを抽出します。
実装すること
- requestsを利用し、サイト情報を取得する。
- BeautifulSoupを利用し、要素を解析する。
- reを利用し、正規表現で項目を取得する。
- ブラウザの開発者ツールから取得対象のタグ構造を特定する。
- 今回は、href属性"news.yahoo.co.jp/pickup"にマッチさせれば取得できる。
- 正規表現を利用するため、標準ライブラリであるreモジュールをimportする。
- 公式ドキュメントを後で確認。
- 取得した項目から、テキスト属性とhref属性を抽出する。
コード
ScrapingSample.pyimport requests from bs4 import BeautifulSoup import re url = "https://www.yahoo.co.jp/" # requetsを使ってサイト情報を取得 result = requests.get(url) # 要素を解析 bs = BeautifulSoup(result.text, "html.parser") # リンクが"news.yahoo.co.jp/pickup"にマッチする項目を取得 news_list = bs.find_all(href=re.compile("news.yahoo.co.jp/pickup")) # 取得した項目からテキスト属性とhref属性を抽出 for news in news_list: print("{0} , {1}".format(news.getText(), news.get('href')))実行結果
3府県解除 マスクの買い物客 , https://news.yahoo.co.jp/pickup/6360522 米が核実験再開を議論 米紙 , https://news.yahoo.co.jp/pickup/6360527 スバルと三菱 コロナで明暗NEW , https://news.yahoo.co.jp/pickup/6360528 抗マラリア薬 死亡リスク増かNEW , https://news.yahoo.co.jp/pickup/6360523 未明に震度4、80代女性が骨折 , https://news.yahoo.co.jp/pickup/6360529 岩手でマスク配達 今更との声NEW , https://news.yahoo.co.jp/pickup/6360521 馬術部ピンチ 殺処分避けたい , https://news.yahoo.co.jp/pickup/6360510 秋山莉奈 第2子男児を出産NEW , https://news.yahoo.co.jp/pickup/6360531「NEW」も抽出されてしまっていますが、不要であればreplaceしてあげれば良いのかなと思っています(今回の実装には含めていません)。
おわりに
簡単な内容でしたが、公式ドキュメントなども読んで、理解の幅を深めて行きたいと思います。
