- 投稿日:2020-04-30T23:32:38+09:00
【Python】ROSのプログラムをPythonのclassを使ったらとても便利だった
はじめに
最近少しずつROSを触り始めていて、Pythonでノードを実装するときに1つのノード内でpublisherとsubscriberを実装するにあたって困ったポイントがあったので紹介します。Pythonのクラスを使うことできれいにすることができました。
自分でパッケージが作れる程度のROSの知識と少しのオブジェクト指向の知識がある前提です。実装例はこちら
やりたかったこと
このトピックのデータをsubscribeして、処理をして、あのトピックにpublishしたいな
ということがあると思います。調べ方が悪かったのか1つのノードで同時にsubscriberとpublisherを使うときはどうすればいいんだ、、、
と、かなりはまりました。Pythonで実装するROSのPublisherとSubscriber
ROS.orgやよく紹介されているPublisherとSubscriberのチュートリアルでは以下のようになっていることが多いと思います。
Publisher(talkerとも)
rospy.Publisherで トピック名とメッセージのタイプを指定して、pub.publish()でpublish。talker.py# rospyとメッセージのimport import rospy import std_msgs.msg import String def talker(): pub = rospy.Publisher('chatter', String, queue_size=10) rospy.init_node('talker', anonymous=True) # 処理が続く pub.publish(data) if __name__ == '__main__': try: talker() except rospy.ROSInterruptException: passSubscriber(listenerとも)
rospy.Subscriberでトピック名、データの型の指定、そしてcallback関数を指定してsubscribe後の処理をcallback関数で行う、という形になっています。listener.py# rospyとメッセージのimport import rospy from std_msgs.msg import String def callback(data): # subscribeのcallback関数 def listener(): rospy.init_node('listener', anonymous=True) rospy.Subscriber("chatter", String, callback) rospy.spin() if __name__ == '__main__': listener()Publish と Subscribeを同時に1つのノードで行う
チュートリアルが終わって、PublishとSubscribeの仕組みなどは一応理解しました。
じゃあ新しいノードを作ってPublishとSubscribe同時にやろうかなー。と思い、実装してみるとrospy.Subscriberのcallback関数内でPublishすればいいのか、、?とコードをきれいにできずに悩みました。その時にこの記事を見ていて、コードも拝見したところとてもきれいだったので参考にさせていただきました。
上記のチュートリアルではPythonのクラスを使っていませんでしたが、クラスを使うときれいに実装することができます。
__init__()でPublisher, Subscriberを作成し、callback関数、Publishする関数という流れで処理をしていきます。
実行する際にはmainの部分でクラスを作成すれば完了です!test.pyimport rospy from std_msgs.msg import String class testNode(): def __init__(self): # Subscriberの作成 self.sub = rospy.Subscriber('topic name', String, self.callback) # Publisherの作成 self.pub = rospy.Publisher('topic name', String, queue_size=1) def callback(self, data): # callback関数の処理をかく Publisher(data) def Publisher(self, data): self.pub.publish(data) def function(self, data): # そのほかの処理もあったら書く return data if __name__ == '__main__': rospy.init_node('test_node') time.sleep(3.0) node = testNode() while not rospy.is_shutdown(): rospy.sleep(0.1)おわりに
個人的にオブジェクト指向はとっかかりづらいと思っていましたが便利にきれいに書くことができました。
こんな感じでテンプレートを作ってくれている方もいますね!"ros python publish subscribe 同じノード" とかの検索に欲しい情報なかったです。。。ROS初心者すぎるから自分が見当違いなことしているのですかね。なにかおかしかったら教えてください。
参考
ROSの機械学習用に、OpenPoseから関節角度をTopicで流すパッケージ作った
ROS講座31 python基礎
ROS のプログラムテンプレート
シンプルな配信者(Publisher)と購読者(Subscriber)を書く(Python)
- 投稿日:2020-04-30T23:32:15+09:00
言語処理100本ノック 第4章: 形態素解析 31. 動詞
31. 動詞
問題
動詞の表層形をすべて抽出せよ.
https://nlp100.github.io/ja/ch04.html下記のInputデータからどうすりゃ良いのかイマイチよくわからんかったけど、既に解いた方の回答を参考にしたら、なるほどと。
リストの中のリストのデータを取るためにforループの中でもう一回forループすれば良いのか。
勉強になった。# inputデータ [[{'surface': '一', 'base': '一', 'pos': '名詞', 'pos1': '数詞'}], [{'surface': '吾輩', 'base': '吾輩', 'pos': '名詞', 'pos1': '普通名詞'}, {'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '副助詞'}, {'surface': '猫', 'base': '猫', 'pos': '名詞', 'pos1': '普通名詞'}, {'surface': 'である', 'base': 'だ', 'pos': '判定詞', 'pos1': '*'}, {'surface': '。', 'base': '。', 'pos': '特殊', 'pos1': '句点'}], [{'surface': '名前', 'base': '名前', 'pos': '名詞', 'pos1': '普通名詞'}, {'surface': 'は', 'base': 'は', 'pos': '助詞', 'pos1': '副助詞'}, {'surface': 'まだ', 'base': 'まだ', 'pos': '副詞', 'pos1': '*'}, {'surface': '無い', 'base': '無い', 'pos': '形容詞', 'pos1': '*'}, {'surface': '。', 'base': '。', 'pos': '特殊', 'pos1': '句点'}], ...回答
surface = [] for sentense in result_list: for morphene in sentense: if morphene['pos'] == '動詞': surface.append(morphene['surface']) surface # 結果 ['生れた', 'つか', 'した', '泣いて', 'して', '始めて', ...参考にしたサイト
- 投稿日:2020-04-30T23:27:24+09:00
「Scikit-learn」と「Chainer」で「回帰」分析の結果を比較する
Scikit-learnとChainerの勉強がてら、SIGNATEの「お弁当の需要予測」をやってみた。
・python3,pandas,numpy,scikit-learn,chainer
・JupyterNotebook
・Mac(1)環境構築
import pandas as pd import numpy as np from matplotlib import pyplot as plt %matplotlib inline #Scikit-learnのインストール from sklearn.linear_model import LinearRegression as LR #Chainerのインストール import chainer import chainer.functions as F import chainer.links as L(2)現状分析
①データ取得
SIGNATEからtrainデータとtestデータをダウンロードして取得する。
train = pd.read_csv("train.csv") test = pd.read_csv("test.csv") sample = pd.read_csv("sample.csv",header=None) #行や列を省略しない処理(以下は500文字をmaxとした) #解除する場合は、数値の箇所をNoneに変更 pd.set_option('display.max_columns', 500) pd.set_option('display.max_rows', 500) train.shape #(207,12) test.shape #(40,11) #データを確認する① train.head() #データを確認する② train.info() #<class 'pandas.core.frame.DataFrame'> #RangeIndex: 207 entries, 0 to 206 #Data columns (total 12 columns): # Column Non-Null Count Dtype #--- ------ -------------- ----- # 0 datetime 207 non-null object # 1 y 207 non-null int64 # 2 week 207 non-null object # 3 soldout 207 non-null int64 # 4 name 207 non-null object # 5 kcal 166 non-null float64 # 6 remarks 21 non-null object # 7 event 14 non-null object # 8 payday 10 non-null float64 # 9 weather 207 non-null object # 10 precipitation 207 non-null object # 11 temperature 207 non-null float64 #dtypes: float64(3), int64(2), object(7) #memory usage: 19.5+ KB②欠損値を埋める
train.isnull().sum() test.isnull().sum() train = train.fillna(0) test = test.fillna(0)③入力変数を加工(datetime)
datetimeを分解して、int型に変更する。
train["year"] = train["datetime"].apply(lambda x :x.split("-")[0]) train["month"] = train["datetime"].apply(lambda x :x.split("-")[1]) test["year"] = test["datetime"].apply(lambda x :x.split("-")[0]) test["month"] = test["datetime"].apply(lambda x :x.split("-")[1]) train["year"] = train["year"].astype(np.int) train["month"] = train["month"].astype(np.int) test["year"] = test["year"].astype(np.int) train["year"] = train["year"].astype(np.int)④入力変数を加工(remarks)
remarksの”お楽しみメニュー”を数値に変換する。
def henkan(x): if x == "お楽しみメニュー": return 1 else: return 0 train["remarks_henkan"] = train["remarks"].apply(lambda x:henkan(x)) test["remarks_henkan"] = train["remarks"].apply(lambda x:henkan(x))⑤入力変数を加工(event)
eventの中身を数値に変換する。
def henkan2(x): if x == 0: return 0 else: return 1 train["event_henkan"] = train["event"].apply(lambda x:henkan2(x)) test["event_henkan"] = test["event"].apply(lambda x:henkan2(x))⑥入力変数を加工(week)
#weekカラムのデータを抽出 train_week = train.iloc[:,2] type(train_week) #pandas.core.series.Series #pandasのSeries型を、pandasのDataframe型に変更 train_week = pd.DataFrame(train_week) #ダミー変数化する train_week = pd.get_dummies(train_week["week"]) #testも同様に対応する test_week = test.iloc[:,1] test_week = pd.DataFrame(test_week) test_week = pd.get_dummies(test_week["week"])⑦入力変数を加工(temperature)
temperatureをビニングする。
#最小値と最大値を確認する train["temperature"].describe() #count 207.000000 #mean 19.252174 #std 8.611365 #min 1.200000 #25% 11.550000 #50% 19.800000 #75% 26.100000 #max 34.600000 #Name: temperature, dtype: float64 temperature_bining_trainX = pd.cut(train["temperature"],[0,10,20,30,40]) type(temperature_bining_trainX) #pandas.core.series.Series #DataFrame型に変換 temperature_bining_trainX = pd.DataFrame(temperature_bining_trainX) trainX.info() #<class 'pandas.core.frame.DataFrame'> #RangeIndex: 207 entries, 0 to 206 #Data columns (total 11 columns): # Column Non-Null Count Dtype #--- ------ -------------- ----- # 0 event_henkan 207 non-null int64 # 1 remarks_henkan 207 non-null int64 # 2 year 207 non-null int64 # 3 month 207 non-null int64 # 4 payday 207 non-null float64 # 5 月 207 non-null uint8 # 6 火 207 non-null uint8 # 7 水 207 non-null uint8 # 8 木 207 non-null uint8 # 9 金 207 non-null uint8 # 10 temperature_bining 207 non-null category #dtypes: category(1), float64(1), int64(4), uint8(5) #memory usage: 9.6 KBtemperature_biningは、category型が確認できる。
数値でないと、scikit-learnやchainerで回帰分析できないためint型にする。
まず、いったん以下のようにstr型する。#temperature_biningをstr型に変換する。 trainX["temperature_bining"] = pd.DataFrame(trainX["temperature_bining"],dtype=np.str) trainX.info() #<class 'pandas.core.frame.DataFrame'> #RangeIndex: 207 entries, 0 to 206 #Data columns (total 11 columns): # Column Non-Null Count Dtype #--- ------ -------------- ----- # 0 event_henkan 207 non-null int64 # 1 remarks_henkan 207 non-null int64 # 2 year 207 non-null int64 # 3 month 207 non-null int64 # 4 payday 207 non-null float64 # 5 月 207 non-null uint8 # 6 火 207 non-null uint8 # 7 水 207 non-null uint8 # 8 木 207 non-null uint8 # 9 金 207 non-null uint8 # 10 temperature_bining 207 non-null object #dtypes: float64(1), int64(4), object(1), uint8(5) #memory usage: 10.8+ KBtestXも同様の対応する。
test["temperature"].describe() temperature_bining_testX = pd.cut(test["temperature"],[0,10,20,30,40]) temperature_bining_testX = pd.DataFrame(temperature_bining_testX) testX["temperature_bining"] = temperature_bining_testX["temperature"] testX["temperature_bining"] = pd.DataFrame(testX["temperature_bining"],dtype=np.str)⑧trainX,testXに加工したweekとtemperatureをドッキングする
temperatureについては、ドッキング時にint型にする。
trainX[["月","火","水","木","金"]] = train_week[["月","火","水","木","金"]] testX[["月","火","水","木","金"]] = test_week[["月","火","水","木","金"]] trainX["temperature_bining"] = temperature_bining_trainX["temperature"] testX["temperature_bining"] = temperature_bining_testX["temperature"] trainX["temperature_bining"] = pd.DataFrame(trainX["temperature_bining"],dtype=np.str) #str型をint型にする def henkan_u(x): if "(0, 10]" in x: return 0 elif "(10, 20]" in x: return 1 elif "(20, 30]" in x: return 2 else: return 3 trainX["temperature_bining"] = trainX["temperature_bining"].apply(lambda x:henkan_u(x)) testX["temperature_bining"] = pd.DataFrame(testX["temperature_bining"],dtype=np.str) testX["temperature_bining"] = testX["temperature_bining"].apply(lambda x:henkan_u(x))(2)入力変数を整理
trainX、testXの入力変数の確認、index数、columns数を確認する。
trainX.columns #Index(['event_henkan', 'remarks_henkan', 'year', 'month', 'payday', '月', '火','水', '木', '金', 'temperature_bining'],dtype='object')trainX.shape #(207, 11) testX.shape #(40, 11) y.shape #(207,)(3)Scikit-learnによる重回帰分析を行う
model = LR() model.fit(trainX,y) result = model.predict(testX) sample[1] = result sample.to_csv("submit.csv",header = None,index = None)ファイルをSIGNATEにアップデートしたところ、結果は、13.8053143となった。
```(4)Chainerによる重回帰分析を行う
①データ準備
pandasのDataFrame型からnumpyのndarray型に直す必要がある。
ndarray型にはvalues関数を使う。また、Chainerにおいて64bitではダメなので32ビットにする必要がある。float型64bitを32bitに変えるには、astype('f')とし、int型64bitを32bitに変えるにはastype('i')とする。(メモ:ただし、chainer回帰分析では入力変数、出力変数共に合わせないとtrainer.runでエラーになるので、x,t共にfloat型のastype('f')とする。)type(x) #pandas.core.frame.DataFrame x = x.values x.dtype #dtype('float32') x = trainX.values.astype('f') type(x) #numpy.ndarray x.shape #(207, 11)yも同様にarray, float型にする。
t = y.values y.dtype #dtype('int64') t = y.values.astype('f') t.dtyep #dtype('float32') t.shape #(207,)ここで、(207,)という結果値は「分類」の場合は問題ないが、「回帰」の場合は(207,1)
となっていないと、trainer.runのタイミングでエラーとなる(207と1列という明確な形が必要)ため、以下のようにする。t = t.reshape(len(t),1) t.shape #(207, 1)testXも対応
tx = testX.values.astype('f')②データセットの準備
Chainerで使用するデータセットの形式に変換。
x(入力変数)と、t(出力変数(教師データ))をChainerで使えるようにするには、まず、タプルで囲い(zip関数を使う)リスト化する必要がある。タプルで囲う際は(入力変数、出力変数(教師データ))の順で囲う。dataset = list(zip(x,t))③訓練データと検証データに分類
入力データを分類する。訓練データを7割、検証データを3割りとする。また、分割後はint型にして整数型にしておく。以下のように分割するがデータに偏りが出るためrandom関数でランダムとする。なおシードも設定する。
len(dataset) #207 n_train = int(len(dataset)*0.7) n_train #144 train,test = chainer.datasets.split_dataset_random(dataset,n_train,seed=0) len(train) #144 len(test) #63④モデルを定義する
以下のようにクラスを作成。
class NN(chainer.Chain): def __init__(self,n_mid_units1=5,n_mid_units2=3,n_out=1): super().__init__() with self.init_scope(): self.fc1 = L.Linear(None,n_mid_units1) self.fc2 = L.Linear(None,n_mid_units2) self.fc3 = L.Linear(None,n_out) self.bn = L.BatchNormalization(11) def __call__(self,x): h = self.bn(x) h = self.fc1(h) h = F.relu(h) h = self.fc2(h) h = F.relu(h) h = self.fc3(h) return h上記でクラスの定義(モデルの定義)が完了したのでインスタンス化する。
加えて、モデルを計算していく(学習)際に、評価関数など進捗のレポートの機能を標準装備するL.Classifierを使う。モデルを設定した際にランダムに初期化されるので、モデル定義の前にシードを設定する(数値はなんでもいい、この場合は1とした)。np.random.seed(0) nn = NN() model = L.Classifier(nn,lossfun = F.mean_squared_error) model.compute_accuracy = False⑤その他設定
#optimiezeの設定 optimizer = chainer.optimizers.Adam() optimizer.setup(model) #iteratorの設定 #大体10から100で設定、サンプルが207の設定なので10バッジで20回パラメータ更新して1epoch、どのくらいのepochを設定するかは後述で設定。 batchsize = 10 train_iter = chainer.iterators.SerialIterator(train,batchsize) test_iter = chainer.iterators.SerialIterator(train,batchsize,repeat=False,shuffle=False) #updaterの設定 from chainer import training updater = training.StandardUpdater(train_iter,optimizer,device=-1) #trainerとextensionsの設定 from chainer.training import extensions epoch = 1500 trainer = training.Trainer(updater,(epoch,'epoch'),out='result/obentou') trainer.extend(extensions.Evaluator(test_iter,model,device=-1)) trainer.extend(extensions.LogReport(trigger=(1,'epoch'))) trainer.extend(extensions.PrintReport(['epoch','main/loss','validation/main/loss','elapsed_time']),trigger=(1,'epoch'))#trainデータに対するloss(損失関数の値))、testデータに対するloss(損失関数の値)、経過時間を出力するという意味⑥学習の実行
trainer.run()⑦学習結果の可視化
import json with open("result/obentou/log")as f: logs = json.load(f) results = pd.DataFrame(logs) results[["main/loss","validation/main/loss"]].plot()二乗誤差なので、スケールを戻す。
import math math.sqrt(loss)⑧testデータを予測する
result=[] for i in range (40): x0 = tx[i].reshape(1,len(tx[i])) with chainer.using_config('train' , False),chainer.using_config('enable_backprop',False): y0_predict = model.predictor(x0) y1_predict = y0_predict.array result.append(y1_predict[0][0])ファイルをSIGNATEにアップデートしたところ、結果は、13.2649969となった。
(5)まとめ
Scikit-learnで回帰分析を行うと13.805、一方でChainerで回帰分析を行うと、13.264とわずかにChainerの方が良い結果となった。
結果として、成績は両方ともイマイチであった。恐らくもっと有効な手法があると思うが、これから掘り下げて学習していきたい。
- 投稿日:2020-04-30T23:20:01+09:00
非線形連立方程式ってPythonで簡単に解けるんですね
数値計算をやっていると、非線形連立方程式を解く機会ってまぁまぁありますよね。もう何年も前ですが大学院生で研究をやっていた頃は、Fortranでコトコト実装していました。最近Pythonでプログラムを書く機会が増えてきて、再び非線形連立方程式を解く場面に遭遇しました。非線形連立方程式の解法として有名なものと言えばNewton法ですが、ゼロから実装するの面倒なのでいいライブラリがないか探しました。
「Scipy.optimize.root」で解けちゃう
半端じゃなく簡単でした。今回は例題として以下のような非線形連立方程式を解きたいと思います。
$$
\begin{align}
x^{2}+y^{2}-1=0 \\
x=0
\end{align}
$$ソースコードは以下の通りです。あとで簡単な説明をします。
import numpy as np from scipy import optimize # 解きたい関数をリストで戻す def func(x): return [x[0]**2 + x[1]**2 -1.0, x[0]] result = optimize.root( func, [ 1.0, 0.0], method="broyden1") print(result)実行結果は以下の通りです。
fun: array([-1.98898568e-07, -5.14009858e-06]) message: 'A solution was found at the specified tolerance.' nit: 9 status: 1 success: True x: array([-5.14009858e-06, 9.99999901e-01])ソースコード/実行結果の説明
scipy.optimize.rootの利用方法の詳細はscipyドキュメントを参照してください。ここではざっくりの説明をします。optimize.rootの第一引数は、解きたい関数を定義したfunc関数です。第二引数は、問題を解き始めるときに使用する初期値です。第三引数は、解き方を指定する所となります。詳細は、scipyドキュメントを参照してもらいたいのですが、ここで1つ注意点。今回はmethodでbroyden1を指定してますが、引数によってはヤコビ行列が別に定義してやる必要があります。僕は面倒だったので、ヤコビ行列が不要なものを選びました。
また、実行結果について大事なところはx:array()の部分でこれが実際の解を表しており、$x=0,y=1$っぽいのであってそう。解の詳細については、scipy.optimize.OptimizeResultを参照。
最後に
Pythonって色々簡単に実装できて便利ですね。大学院生の時に出会いたかった。いや、出会っていたんだけど乗り換えが面倒だったので見て見ぬふりをしてました。ごめんなさい。
- 投稿日:2020-04-30T23:19:36+09:00
numpyメモリ使い回しチートシート
はじめに
大規模行列を扱う人にとっては行列の malloc/realloc は死活問題。メモリを使いまわしたい邪悪な人たちはこの短いチートシートに目を通しておこう。
配列のコピー
配列の中身を別の配列にコピーしたいときは
numpy.copytoを使う。numpy.copyは新しい配列を生成してしまうので注意。import numpy as np m, n = 2000, 1000 A = np.ones((m, n)) B = np.zeros(A.shape) # 新しい配列を生成しないコピー np.copyto(B, A)数学的操作
数学的操作も引数に
outを取れるものは格納先を指定できる。取れない場合も「実は配列自体はいじってない」みたいなことがある。四則演算/その他
Mathematical functionsで
outのパラメータが指定できる演算はメモリを使いまわせる。broadcasting で対応できる範囲内であれば配列のshapeが異なってもよい。代入先が元の行列に一致するならば+=などの代入演算子を使えばよい。import numpy as np A = np.array([[1, 2, 3], [4, 5, 6]]) B = np.array([[7, 8, 9], [8, 7, 6]]) C = np.zeros(A.shape) # 新しい配列を生成しない四則演算 np.add(A, B, out=C) np.multiply(A, B, out=C) np.subtract(A, B, out=C) np.divide(A, B, out=C) # 代入演算子を使うパターン A += B A -= B A *= B A /= B
A = A + Bは新しい行列が生成されてAに代入されるので注意。転置
転置はstridesというパラメータをいじってるだけらしく配列自体はいじっていないので高速である。
import numpy as np A = np.array([[1, 2, 3], [4, 5, 6]]) # 転置は新しい配列を生成することはない B = A.T B[0,1] = 9 print(A)outputarray([[1, 2, 3], [9, 5, 6]])本記事では紹介しないが同様に
reshapeも配列の並び順自体は変わっておらず高速である。スカラー倍
*=演算子を用いればよい。import numpy as np A = np.array([[1, 2, 3], [4, 5, 6]]) A *= 5行列積
numpy.dotもoutが指定できる。import numpy as np A = np.array([[1, 2, 3], [4, 5, 6]]) B = np.array([[7, 8, 9], [8, 7, 6]]) C = np.zeros((2, 2)) # 新しい配列を生成しない行列積 np.dot(A, B.T, out=C)完全に余談だが、複数の行列をかけるときは
numpy.linalg.multi_dotを使うともっとも効率的な順序で行列積を取ってくれる。ただしこちらはoutが指定できない。
- 投稿日:2020-04-30T23:04:08+09:00
「破壊的メソッド」はRuby用語なのか?
昨日、「データサイエンティストが知るべき破壊的メソッドのすべて」という記事を書いたのですが、友人から次のような意見を貰いました。
微妙に気になったけど、「破壊的メソッド」「非破壊的メソッド」ってプログラミング全般でなくRuby用語で、かつ、「レシーバを変更するメソッド」っていう意味じゃない?
もしあえて名前で呼ぶなら、inplace methodが正しそう。(日本語は見つからない)
https://discuss.pytorch.org/t/what-is-in-place-operation/16244
https://ja.wikipedia.org/wiki/In-placeアルゴリズム更に、例えばpandasでもinplaceという引数名が使われているので、データサイエンティスト向けならinplaceのほうが馴染みあるかもしれないとも言われました。
たしかに「破壊的」と調べて出てくる記事は、Rubyのものが多いように思います。少し気になったので、いろいろな言語のドキュメントで「破壊的(destructive)」「インプレース(in-place)」という単語で調べて比較してみました。
Pythonの場合: in-placeが優勢
ドキュメントを検索したところ、実際に「インプレース(in-place)」という単語がよく使われているようです。例えば「プログラミング FAQ」の中では次のようにあります。
文字列をインプレースに変更するにはどうしたらいいですか?¶
文字列はイミュータブルなので、それはできません。殆どの場合、組み立てたい個別の部品から単純に新しい文字列を構成するべきです。
一方で、「破壊的(destructive)」という単語も多少は使われています。例えばPython2.7のドキュメントには「破壊的に(destructively)」という単語があります。最新バージョンのドキュメントでは「消去して返します」とありますが、日本語の訳語が変わっただけでした。
集合のアルゴリズムで使われるのと同じように、
popitem()は辞書を破壊的にイテレートするのに便利です。辞書が空であれば、popitem()の呼び出しはKeyErrorを送出します。Python3.8でも「curses --- 文字セル表示を扱うための端末操作」の中に「非破壊的(non-destructive)」という単語が見つかりました。
ウィンドウを
destwinの上に重ね書き (overlay) します。ウィンドウは同じサイズである必要はなく、重なっている領域だけが複写されます。この複写は非破壊的です。少し離れた箇所に「破壊的(destructive)」もあります。
destwinの上にウィンドウの内容を上書き (overwrite) します。ウィンドウは同じサイズである必要はなく、重なっている領域だけが複写されます。この複写は破壊的です。Rubyの場合: destructive methodという用語が説明されている
Official Ruby FAQの中に「What is a destructive method?」という項目が用意されていました。日本語版の訳は見つかりませんでした。
The plain version creates a copy of the receiver, makes its change to it, and returns the copy. The “bang” version (with the !) modifies the receiver in place.
説明の中に「in place」という単語も使われています。
ドキュメントではあまりヒットしなかったので、るびまも見てみます。やはり「破壊的」という単語がよく使われています。例えば「Ruby コードの感想戦 【第 2 回】 WikiR」より。
force_encoding は ! がついていないので名前だけではわかりづらいですが、破壊的なメソッドです。 そのため、戻り値を text に代入する必要はありません。これで十分です。
「6 月 10 日 午前の部」でin-placeという単語が使われている箇所もありました。
文法上、yield が先に入って、ブロックつき引数を後で導入したとき yield が邪魔になった。あと String で、in-place で mutate するしないがごっちゃになってよくない。Perl からもってきた組み込み変数の 98% は後悔してます。
PHPの場合: 両方とも併用されている
「in-place」と「destructive」という単語が両方とも使われているようです。これらの箇所の日本語への翻訳はまだ行われていない様子?
Sorts the sequence in-place, using an optional comparator function.
注意:
This method is not destructive.
その他の言語
Rubyに影響を与えたSmalltalkも調べてみたかったのですが、はっきりしたこととは分かりませんでした。ただ、Smalltalk-72のドキュメントを見ると、non-destructiveという単語が少なくとも一箇所使われていました。
Note that you can make non-destructive text by using xor ink which complements the background so that reshowing the text crases it while restoring what was
underneath.また、基本的に変数がイミュータブルなHaskellも調べてみたのですが、destructiveが「過去の互換性を切った言語仕様のアップデート」という意味で使われているものしか見つけられなかったのと、ドキュメント自体を読むのが今の私にとっては骨が折れそうだったので諦めました。
また、Rubyでは「destructive method」という固有名詞に近い使われ方をしているのに対して、他の言語のdestructiveは一般的な形容詞として使われているように見えます。もしかすると、「破壊的メソッド」というのはRubyのコミュニティで使われ始めた言葉が、日本語でプログラミング用語として認識されて広まったものなのかもしれません。機会があればまた調べてみます。
- 投稿日:2020-04-30T22:43:31+09:00
iOSウィジェットにCO2濃度を表示する 【Raspberry Pi × CO2-mini × co2meter】
WFH、捗ってますでしょうか。
我が家の場合、机やモニターなど家で仕事をするのに十分な設備は元々整っていたのですが、たったひとつだけオフィスにはあって自宅にないものがありました。
CO2モニターです。
成果物
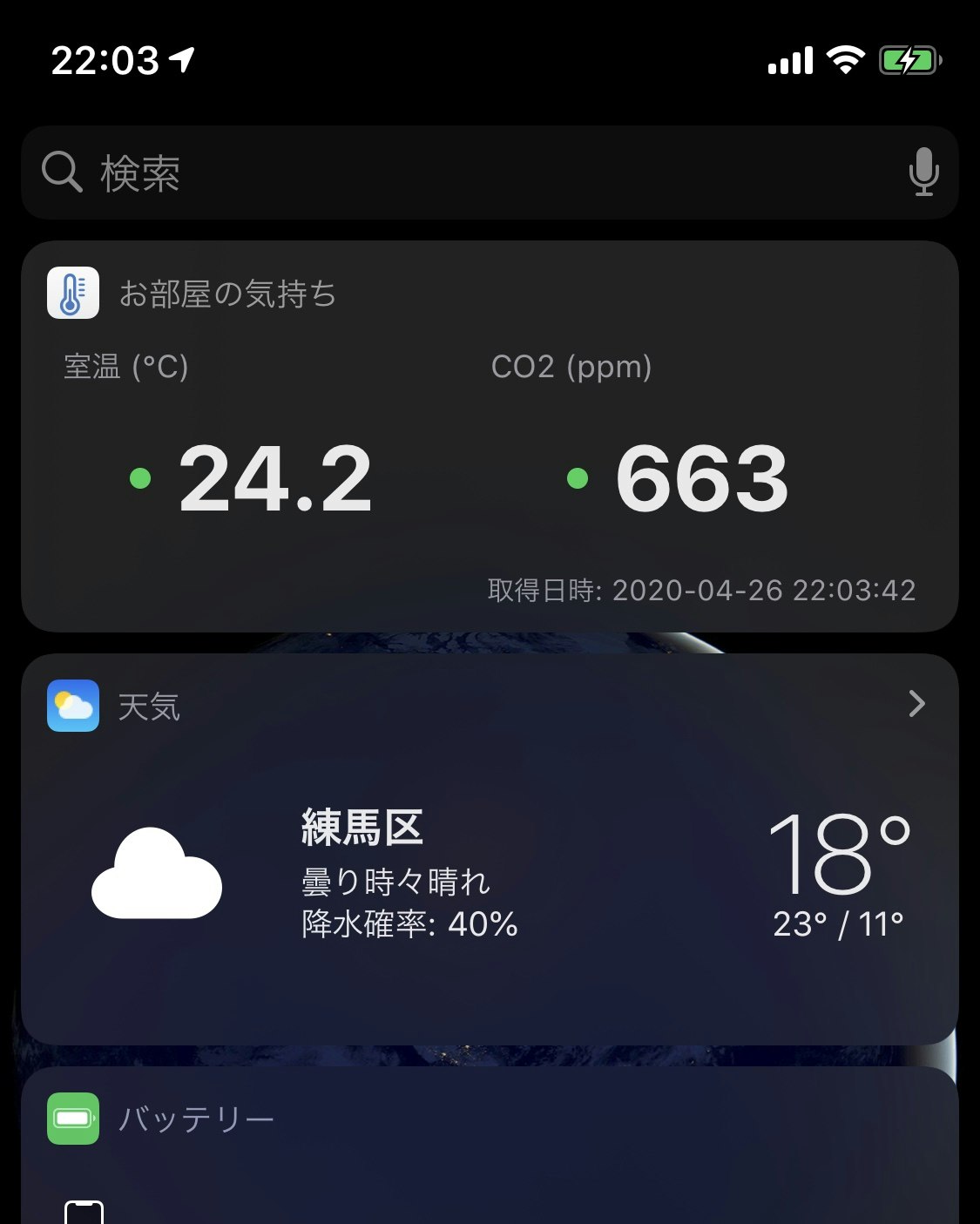
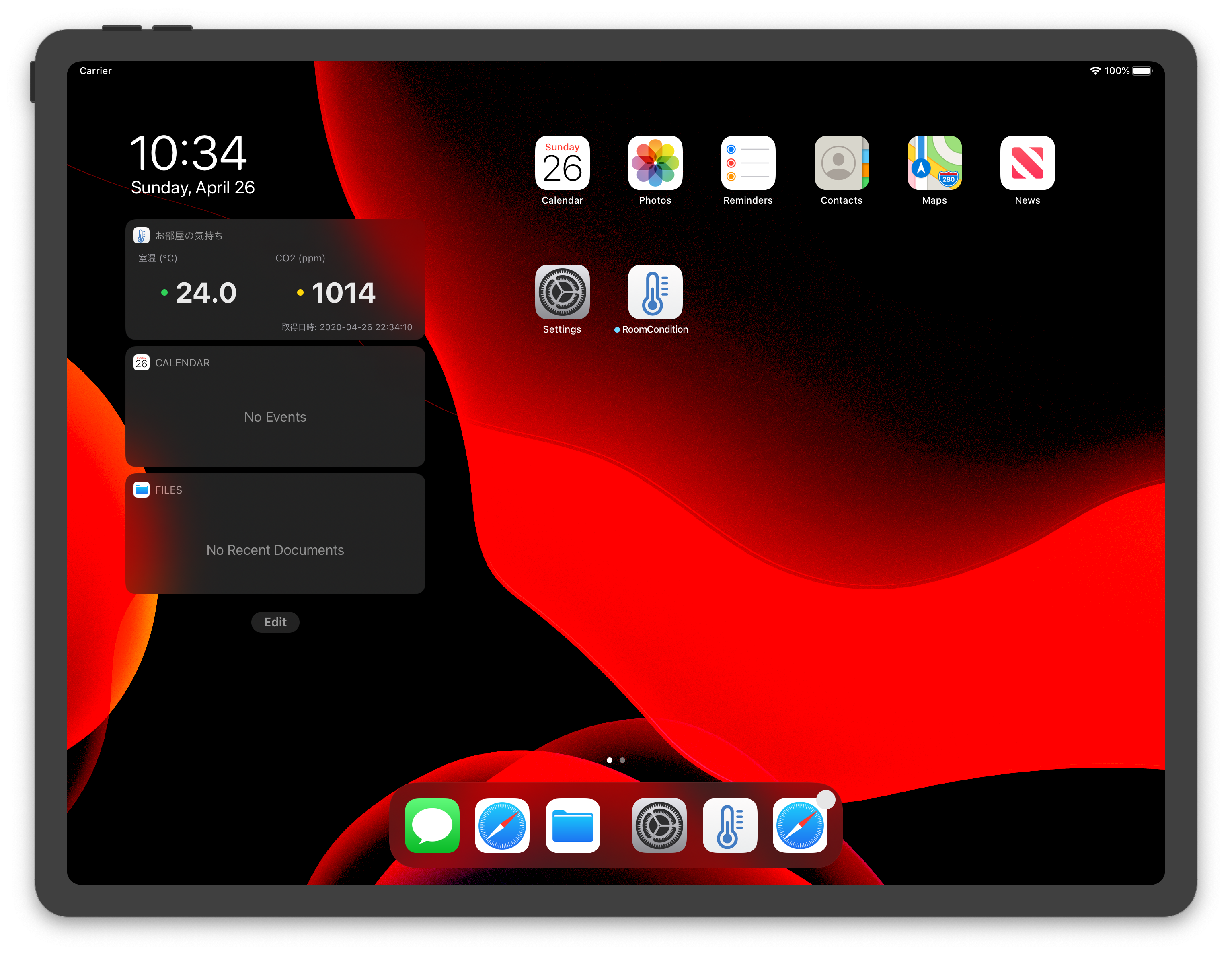
パッと目につくところに表示させたかったので、iOSのウィジェットに置くことにしました。
最終的にこんな感じでCO2濃度、ついでに室温が見えるようになりました。iPhone
iPad
構成と概要解説
構成はこんな感じです
ポイントは以下です。
- CO2-miniでCO2濃度、室温を計測する
- CO2-miniとRaspberry Piを接続して定期的な計測を行い、Webサーバーとしてアクセス可能にする
- iOSアプリからWebサーバーへアクセスし、ウィジェットとして表示する
- 換気したくなる
CO2-mini
CO2濃度の計測は既製品であるこちらを使います。
CO 2モニター CO2-mini | 自然環境測定器 - 製品情報 - 計測器のカスタムMH-Z19などのモジュールも検討したのですが、WFHによる需要の高まりのためか高価になってる or 配送に時間がかかるため、比較的手に入りやすいこちらを選択しました。
電源供給がmicro USB Type-Bなのでこれを利用してPaspberry Piと接続します。
公式でAPIが公開されているわけではありませんが、有志の解析によってOSSなどを経由してアクセスできるようになっています。なお、今回はCO2-miniに予め備わっている表示部を見て換気したくなる行為は反則負けとします。
サーバーサイド
主となるCO2濃度のロギング、Webサーバー化は
co2meterを使います。
https://github.com/vfilimonov/co2meterこのOSSを使うことで、Pythonを使ったCO2-miniへのアクセスが可能になります。さらに定期的な計測、JSON/CSVへの書き出し、FlaskによるWebサーバー化、折れ線グラフによる可視化まで担ってくれます。
クライアントサイド
iOSアプリ部分については自作して、簡単なものですが公開しました。
https://github.com/akeome/RoomConditionラズパイで構築したサーバーにアクセスして、レスポンスのJSONの最新値を表示するだけのものです。
CO2濃度を見える化する
この環境を構築するための手順を記します。
僕は今回初めてRaspberry Piをいじったので、備忘も兼ねてセットアップの記載から始めます。準備
必要なハード類です。
- Mac
- Raspberry Pi
- 今回はRaspberry Pi Zero WHを使いました。Wi-Fiに接続できればどのモデルでも大丈夫なはず
- CO2-mini
- microSDカード
- アダプタ、ケーブル等
- MacからmicroSDに書き込むためのハブなどが必要です
- Raspberry PiとCO2-miniの接続は、micro USB Type-Bとmicro USB Type-Bです
- Raspberry Pi Zero WHの場合、電源供給はmicro USB Type-Bです
Raspberry Pi のセットアップ
今回使用したRaspberry Pi Zero WHには有線LANポートがないので、Wi-Fi経由でMacから操作を行うための手順を書きます。
MacからmicroSDに書き込む
Paspberry PiにmicroSDを挿す前に、Macで諸々書き込んでいきます。
OSを書き込む
公式サイトからOSをダウンロードします。
https://www.raspberrypi.org/downloads/raspbian/
- GUIは使わないので軽量な
Raspbian Buster Liteにしました- めっちゃ時間かかります(1時間ぐらいかかりました)
diskutill listコマンドでMacに接続されているmicroSDのパスを取得します。$ diskutil list # (中略) /dev/disk4 (external, physical): #: TYPE NAME SIZE IDENTIFIER 0: FDisk_partition_scheme *32.0 GB disk4 1: Windows_FAT_32 NO NAME 32.0 GB disk4s1自分の環境の場合、32.0 GBの表示から
/dev/disk4が該当のmicroSDを指すとわかりました。
diskutil unmountDiskでアンマウントと、ddでOSの書き込みを行います。$ diskutil unmountDisk /dev/disk4 Unmount of all volumes on disk4 was successful $ sudo dd bs=1m if=/?パス/2020-02-13-raspbian-buster-lite.img of=/dev/rdisk4 conv=sync Password: 1764+0 records in 1764+0 records out 1849688064 bytes transferred in 55.800569 secs (33148194 bytes/sec)
/dev/disk4としている箇所は環境に合わせて変えてください?パスとしている箇所はOSをダウンロードしたパスです- .imgファイルのファイル名も時期によって変わるはずです
Macに
bootという名前でディスクが接続されていればOKです。$ ls /Volumes/ Macintosh HD bootssh接続を有効にする
MacからsshでRaspberry Piに(一時的に)接続するために空ファイルが必要です。持続的に接続する方法については後述します。
$ touch /Volumes/boot/sshWi-Fi接続を有効にする
Wi-Fi接続に必要なファイルを作成します。
$ nano /Volumes/boot/wpa_supplicant.conf以下の内容を書き込みます。
wpa_supplicant.confcountry=JP ctrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev update_config=1 network={ key_mgmt=WPA-PSK ssid="?SSID名" psk="?パスワード" }
- SSID、パスワード(場合によってはkey_mgmtも)は環境に合わせて変えてください
- パスワードを直接入力するとセキュリティ上のリスクがあります。ここでは触れませんが
wpa_passphraseコマンドで暗号化できますもちろん
nanoコマンドを使わなくても、.confを作成できればおっけーです。ここまででmicroSDへの書き込みは完了です。
Paspberry Piを起動する
諸々書き込みが終わったmicroSDカードをRaspberry Piに差し込みます。
電源に接続します。Raspberry Pi Zero WHの場合、電源供給はPWRと書かれた方の差込口を使います。
電源が入ると緑のLEDが点灯します。
sshコマンドでMacからラズパイに接続します。
接続先はpi@raspberrypi.local、パスワードはraspberryです。$ ssh pi@raspberrypi.local The authenticity of host 'raspberrypi.local (xxxx)' can't be established. ECDSA key fingerprint is SHA256:xxxx. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'raspberrypi.local,xxxx' (ECDSA) to the list of known hosts. pi@raspberrypi.local's password:pi@raspberrypi:~ $こんな感じでプロンプトがラズパイになっていれば成功です?
続いて諸々の設定をやっていきます。
タイムゾーンを設定する
ラズパイの設定画面に入るコマンドを使います。
pi@raspberrypi:~ $ sudo raspi-config
4 Localisation Options > I2 Change Timezone > Asia > Tokyo
でタイムゾーンを日本にしておきます。ssh接続を継続して利用可能にする
上記設定画面から、
5 Interfacing Options > P2 SSH > Yes
でssh接続が持続的に利用可能になります。IPアドレスを固定する
ifconfigで現在のIPアドレスを、route -nでデフォルトゲートウェイを確認します。pi@raspberrypi:~ $ ifconfig lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 inet6 ::1 prefixlen 128 scopeid 0x10<host> loop txqueuelen 1000 (Local Loopback) RX packets 4032 bytes 203013 (198.2 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 4032 bytes 203013 (198.2 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 wlan0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.100.50 netmask 255.255.255.0 broadcast 192.168.100.255 pi@raspberrypi:~ $ route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 192.168.100.254 0.0.0.0 UG 302 0 0 wlan0無線LANはwlan0なので、上記の場合
192.168.100.50が現在のIPです。
また、Gatewayに表示された192.168.100.254が現在のデフォルトゲートウェイです。確認できたら
sudo nano /etc/dhcpcd.confで以下の内容を追記します。dhcpcd.confinterface wlan0 static ip_address=192.168.100.50/24 static routers=192.168.100.254 static domain_name_servers=192.168.100.254
- ip_addressに固定するIPアドレスを入力します。今回は
ifconfigで確認した192.168.100.50を使っています。サブネットマスクは基本的にはそのまま/24でいいはずです- routersとdomain_name_serversには
route -nで確認したデフォルトゲートウェイを入力します再起動後、設定したIPアドレスになっていればおっけーです。
# 再起動 pi@raspberrypi:~ $ sudo reboot # 再接続 $ ssh pi@raspberrypi.local # IP確認 pi@raspberrypi:~ $ ifconfig wlan0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.100.50 netmask 255.255.255.0 broadcast 192.168.100.255各種ライブラリをアップデートする
ラズパイのセットアップでのお決まりのようです。
pi@raspberrypi:~ $ sudo apt update pi@raspberrypi:~ $ sudo apt upgradeデフォルトのPythonのバージョンを3系にする
これは必須ではありませんが、
pythonコマンドのデフォルトで Python2系が起動したので3系にしておきます。pi@raspberrypi:~ $ python --version Python 2.7.16 pi@raspberrypi:~ $ sudo unlink /user/bin/python pi@raspberrypi:~ $ sudo ln -s /user/bin/python3 python pi@raspberrypi:~ $ python --version Python 3.7.3Gitをインストールする
Gitをインストールします。ライブラリの使用に必要です。
pi@raspberrypi:~ $ sudo apt install git pi@raspberrypi:~ $ git --version git version 2.20.1Raspberry Pi と CO2-mini の接続
ラズパイとCO2-miniを接続します。
接続端子はお互いmicro USB Type-Bです。
接続できるとCO2-miniはしばらくの待機後、CO2濃度と室温を表示してくれます。
co2meterの事前準備Python製のライブラリ
co2meterを使って、ラズパイからCO2-miniへアクセスします。
vfilimonov/co2meter: A Python library for USB CO2 meterこのco2meterを動かすにあたって必要なライブラリをインストールしていきます。
依存ライブラリのインストール
USB接続機器にアクセスしたりするために必要になるみたいです。
pi@raspberrypi:~ $ sudo apt install libusb-1.0-0-dev libudev-devrulesファイルの作成
/etc/udev/rules.d/98-co2mon.rulesを作成します。root@raspberrypi:/home/pi# nano /etc/udev/rules.d/98-co2mon.rules以下を書き込みます。
98-co2mon.rulesKERNEL=="hidraw*", ATTRS{idVendor}=="04d9", ATTRS{idProduct}=="a052", GROUP="plugdev", MODE="0666" SUBSYSTEM=="usb", ATTRS{idVendor}=="04d9", ATTRS{idProduct}=="a052", GROUP="plugdev", MODE="0666"
udevadmコマンドで設定を反映させます。
が、この操作はrootユーザーとしての実行が必要らしく、まずはrootユーザーになるためにパスワードを設定します。pi@raspberrypi:~ $ sudo passwd root New password: Retype new password: passwd: password updated successfully
- パスワードを2度聞かれるので2度入力します
suコマンドでrootユーザーに変身します。pi@raspberrypi:~ $ su Password: root@raspberrypi:/home/pi#プロンプトが
root@raspberrypi:になっていればおっけーです。
この状態でudevadmコマンドを実行します。root@raspberrypi:/home/pi/# sudo udevadm control --reload-rules && udevadm triggerrootユーザーから一般ユーザーに戻るには
exitです。root@raspberrypi:/home/pi# exit exit pi@raspberrypi:~ $ここまでで事前準備は完了です。
ライブラリ
co2meterのインストールこれによっていよいよCO2-miniへのアクセスが可能になります。
pi@raspberrypi:~ $ pip3 install hidapi co2meterREADME記載の基本的な使い方を試してみます。
pi@raspberrypi:~ $ python>>> import co2meter as co2 >>> mon = co2.CO2monitor() >>> mon.read_data() (datetime.datetime(2020, 4, 25, 11, 10, 21), 1005, 24.100000000000023)取得できました??
内容は(タイムスタンプ, CO2濃度, 室温)のタプルです。Raspberry Pi をWebサーバーとして動かす
CO2濃度、室温が取得できることがわかったところで、続いてWebサーバーとして動かす方法を記載します。Webサーバーとして動かすことで、外部からブラウザ経由で計測結果を確認することができます。
co2meterには、予めサーバーとして動かす機能が実装されているので利用します。
- 定期的な計測
- JSON/CSVへのロギング
- 折れ線グラフによる可視化
- Webサーバー立ち上げ
といった機能が簡単に使えます。
関連パッケージのインストール
flask、pandasのインストール
co2meterのWebサーバー化はflaskで実装されています。pi@raspberrypi:~ $ pip3 install -U flask pandasWebサーバー起動
co2meterをサーバーとして実行するにはco2meter_serverコマンドだけでOKです。
これと組み合わせて、バックグラウンドでプロセスを継続させるためにnohupコマンドと&オプションをつけて実行します。pi@raspberrypi:~ $ nohup co2meter_server -H 0.0.0.0 -P 1201 &
-H 0.0.0.0オプションをつけることで外部のブラウザから(例えば同じLAN内のMacから)接続できます-P 1201オプションはポート番号です。デフォルトで使われていた1201に指定していますが数字に意味はないですこれで、ブラウザから
http://ラズパイのIPアドレス:ポート番号(この手順通りに進めていればhttp://192.168.100.50:1201/)へアクセスしてCO2濃度、室温が見れるようになりました???
サーバーとして動かすことでlogsディレクトリが作成され、CSVでログが蓄積されていきます。
計測間隔はデフォルトで約35秒のようです。pi@raspberrypi:~ $ cat logs/co2.csv timestamp,co2,temp 2020-04-26 15:01:59,772,23.9 2020-04-26 15:02:34,768,23.9 2020-04-26 15:03:09,766,23.9 2020-04-26 15:03:44,766,23.9 2020-04-26 15:04:20,760,24.0Webサーバーの停止
停止させるには、
psコマンドでPIDを確認してkillコマンドです。-9オプションは強制終了です。pi@raspberrypi:~ $ ps PID TTY TIME CMD 599 pts/0 00:00:00 bash 626 pts/0 00:23:44 co2meter_server 6201 pts/0 00:00:00 ps pi@raspberrypi:~ $ kill -9 626プロセスが表示されない場合は
xオプションをつけてps xで試してみてください。iOSウィジェットに表示する
ここまでの手順で念願のCO2濃度可視化は実現できました。
あとはどこにどんな感じで表示するかですが、今回はWebサーバーから返されるJSONを使ってiOSウィジェットに表示することにしました。できたソースはこちら
https://github.com/akeome/RoomConditionXcodeからこのプロジェクトをビルドすれば動くはずです。
- Targetはまず本体アプリ
RoomCondition、次にウィジェットRoomConditionTodayExtensionの順番でビルドします- 接続先のIPアドレス、ポート番号は
http://192.168.100.50:1201/にしています。環境に合わせて適宜変更してください。この記事通りに進めていればそのままで問題ないですちょっとコード解説
ウィジェット(Today Extension)は今回初めて実装してみたので知見を書いておきます。
API通信部分のコード共通化
本体アプリ、ウィジェットで共通して使う処理はFrameworkとして実装することで共通化できます。
Frameworkの作成はメニューの
File > New > Target > Frameworkです。
今回はAPIRequestという名前で作成しました。RoomCondition.swiftpublic struct RoomCondition: Codable { public let co2: String public let temp: String public let timestamp: String }APIRequest.swiftpublic struct API { public static func request(completion: @escaping (RoomCondition?) -> Void) { let url = "http://192.168.100.50:1201/log.json" let session = URLSession.shared let task = session.dataTask(with: URL(string: url)!) { data, urlResponse, error in let currentCondition = try! JSONDecoder().decode([RoomCondition].self, from: data!) completion(currentCondition.last) } task.resume() } }呼び出し側では
import APIRequestして使います。呼び出し側.swiftAPI.request(completion: { roomCondition in guard let roomCondition = roomCondition else { return } print(roomCondition) // RoomCondition(co2: "1015", temp: "21.4", timestamp: "2020-04-28 00:35:32") })今回は結局Today Extension側でしか使ってないのでFrameworkにしなくてもよかったかもしれません?
Today Extensionの更新契機について
ウィジェットが表示される度に
func widgetPerformUpdate(completionHandler: @escaping (NCUpdateResult) -> Void)が呼び出されるようです。
この中に通信処理を書いているのですがちゃんと都度最新の値を取ってきてくれます。
completionHandlerの引数にはNCUpdateResultを渡します。public enum NCUpdateResult : UInt { case newData case noData case failed }上から順に、新規データあり、新規データなし(更新不要)、失敗を表します。
これによっていい感じにウィジェットの再描画が行われるようです。色分けのロジック
CO2-miniの表示部に着想を得て、ppmによって色分けしました。
TodayViewController.swiftfunc co2Color(co2Value: String) -> UIColor { switch Int(co2Value) { case (..<1000)?: return .systemGreen case (..<1200)?: return .systemYellow default: return .systemRed } }快適
そろそろ換気しよ
あかん
1000とか1200の基準は環境にもよると思うので適宜変更してください。
また室温の色分けは季節によって変えるべきかもしれません。おまけ、本体アプリ
本体アプリを起動しても真っ白なのは寂しかったのでとりあえず
SFSafariViewControllerでダッシュボートを表示させておきました。ViewController.swiftoverride func viewDidAppear(_ animated: Bool) { super.viewDidAppear(animated) let url = URL(string: "http://192.168.100.50:1201/dashboard") if let url = url { let safari = SFSafariViewController(url: url) present(safari, animated: false) } }
おわりに 〜二酸化炭素濃度が人体に与える影響について〜
一般的に空気中の二酸化炭素濃度が概ね1000ppmを超えると眠気や倦怠感を誘発すると言われています。
厚生労働省が規定する建築物環境衛生管理基準においても、建築物の管理者は1000ppmになるように空調設備をちゃんとしてね〜との記載があります。
建築物環境衛生管理基準について|厚生労働省この基準値を検証する資料もありました。
1968年のWHO報告書を根拠としていると考えられる、との考察があったりなかなか興味深いです。
建築物環境衛生管理基準の設定根拠の検証について
(※pdfです)上記資料から一部抜粋
18ページ
二酸化炭素自体は、少量であれば人体に有害ではな
いが、1000ppmを超えると倦怠感、頭痛、耳鳴り、息苦しさ等の症
状を訴えるものが多くなり、フリッカー値(フリッカー値が小さいほ
ど疲労度が高い)の低下も著しい19ページ
1000ppmのCO2の吸入実験(Eliseeva 1964)で呼吸、循環器系、大
脳の電気活動に変化がみられたと報告している。街の噂で聞く1000ppmで眠くなる説はこのあたりがソースになっているのかもしれませんね。
ということで我が家のCO2濃度可視化の記録でした。
適度に換気して、快適なWFHを〜?参考記事
参考にさせていただきました。先人の皆様ありがとうございます。
- Raspberry Pi のセットアップ!モニター、キーボードなしでMacからSSH
- Raspberry Pi Zero W 環境構築ことはじめ MacOS編 - Qiita
- Raspberry Pi Zero(W, WH)のセットアップ - Qiita
- Raspberry Pi Zero WHの環境構築(Mac PC) - 日々の学びのアウトプットするブログ
- Raspberry Pi に固定IPアドレスを割り当てる方法(Raspbian Jessie) - Qiita
- RaspberryPiでPythonのデフォルトをPython2.7からPython3に変更する | そう備忘録
- 「apt-get」はもう古い?新しい「apt」コマンドを使ったUbuntuのパッケージ管理 | LFI
- How to Install Git on Raspberry Pi | Linuxize
- Python - Raspberry piでnumpyがimportできない。|teratail
- nohupを使ってsshログアウト後もシェルスクリプトを動かす - Qiita
- networking - Opening port not working - Unix & Linux Stack Exchange
- Today Extension Tutorial: Getting Started | raywenderlich.com










- 投稿日:2020-04-30T22:43:25+09:00
【Python】正規表現を利用したいつ・どこで・だれが・何をしたゲーム
目的
・正規表現を学んだのでとりあえず楽しく使ってみる
環境
- Visual Studio Code
- Python
手順
すべてひとつのファイル(practice.py)に書きました。
①正規表現のための標準ライブラリであるreモジュールをインポート
practice.pyimport re②質問を用意
practice.pyquestion = "いつ?どこで?だれが?何をした?"③関数four_ws_gameを定義
practice.pydef four_ws_game(sentence): words = re.findall(".*??", sentence) i = 0 while i < len(words): answer = input(f"{words[i]}:").strip() if answer == "": print("真面目にやってください") else: sentence = sentence.replace(words[i], answer) i += 1 print(sentence)わかりづらいので分解して見てみましょう。
3-1. reモジュールのfindall関数を利用
- findall関数は文章(sentence)の中で一致した部分をリストにして変数wordsに渡します
- 正規表現における. (ピリオド)は任意の一文字を意味する
- * (アスタリスク)は繰り返しを意味する
practice.pywords = re.findall(".*??", sentence)つまりこのプログラムは、文章(sentense)の中から末尾に?(全角クエスチョン)が付く任意の文字数の単語探し出し、リスト化します。
- ?(半角クエスチョン)は上記の単語を一つ一つ分けて取り出すために必要です
- ?(半角クエスチョン)の有無でリストの中身がどう変わるのか見てみましょう
有
practice.pywords = re.findall(".*??", sentence) print(words)実行結果['いつ?', 'どこで?', 'だれが?', '何をした?']無
practice.pywords = re.findall(".*?", sentence) print(words)実行結果['いつ?どこで?だれが?何をした?']3-2. 文章(sentence)の中身を入力値に書き換えてプリント
practice.pyi = 0 while i < len(words): answer = input(f"{words[i]}:").strip() if answer == "": print("真面目にやってください") else: sentence = sentence.replace(words[i], answer) i += 1 print(sentence)④sentenceを最初に用意した質問(question)にして実行
practice.pyfour_ws_game(question)コード全体
practice.pyimport re question = "いつ?どこで?だれが?何をした?" def four_ws_game(sentence): words = re.findall(".*??", sentence) i = 0 while i < len(words): answer = input(f"{words[i]}:").strip() if answer == "": print("真面目にやってください") else: sentence = sentence.replace(words[i], answer) i += 1 print("何があったの?:" + sentence) four_ws_game(question)
- 実行結果
いつ?:きのう どこで?:家で だれが?:ねこが 何をした?:ねころんだ 何があったの?:きのう家でねこがねころんだ
- 空欄にしようとすると怒られます
いつ?:きのう どこで?: 真面目にやってください どこで?:家で だれが?:ねこが 何をした?: 真面目にやってください 何をした?:犬になった 何があったの?:きのう家でねこが犬になった
- 投稿日:2020-04-30T22:43:25+09:00
【Python】正規表現を利用していつ・どこで・だれが・何をしたゲーム
目的
・正規表現を学んだのでとりあえず楽しく使ってみる
環境
- Visual Studio Code
- Python
手順
すべてひとつのファイル(practice.py)に書きました。
①正規表現のための標準ライブラリであるreモジュールをインポート
practice.pyimport re②質問を用意
practice.pyquestion = "いつ?どこで?だれが?何をした?"③関数four_ws_gameを定義
practice.pydef four_ws_game(sentence): words = re.findall(".*??", sentence) i = 0 while i < len(words): answer = input(f"{words[i]}:").strip() if answer == "": print("真面目にやってください") else: sentence = sentence.replace(words[i], answer) i += 1 print(sentence)わかりづらいので分解して見てみましょう。
3-1. reモジュールのfindall関数を利用
- findall関数は文章(sentence)の中で一致した部分をリストにして変数wordsに渡します
- 正規表現における. (ピリオド)は任意の一文字を意味する
- * (アスタリスク)は繰り返しを意味する
practice.pywords = re.findall(".*??", sentence)つまりこのプログラムは、文章(sentense)の中から末尾に?(全角クエスチョン)が付く任意の文字数の単語探し出し、リスト化します。
- ?(半角クエスチョン)は上記の単語を一つ一つ分けて取り出すために必要です
- ?(半角クエスチョン)の有無でリストの中身がどう変わるのか見てみましょう
有
practice.pywords = re.findall(".*??", sentence) print(words)実行結果['いつ?', 'どこで?', 'だれが?', '何をした?']無
practice.pywords = re.findall(".*?", sentence) print(words)実行結果['いつ?どこで?だれが?何をした?']3-2. 文章(sentence)の中身を入力値に書き換えてプリント
practice.pyi = 0 while i < len(words): answer = input(f"{words[i]}:").strip() if answer == "": print("真面目にやってください") else: sentence = sentence.replace(words[i], answer) i += 1 print(sentence)④sentenceを最初に用意した質問(question)にして実行
practice.pyfour_ws_game(question)コード全体
practice.pyimport re question = "いつ?どこで?だれが?何をした?" def four_ws_game(sentence): words = re.findall(".*??", sentence) i = 0 while i < len(words): answer = input(f"{words[i]}:").strip() if answer == "": print("真面目にやってください") else: sentence = sentence.replace(words[i], answer) i += 1 print("何があったの?:" + sentence) four_ws_game(question)
- 実行結果
いつ?:きのう どこで?:家で だれが?:ねこが 何をした?:ねころんだ 何があったの?:きのう家でねこがねころんだ
- 空欄にしようとすると怒られます
いつ?:きのう どこで?: 真面目にやってください どこで?:家で だれが?:ねこが 何をした?: 真面目にやってください 何をした?:犬になった 何があったの?:きのう家でねこが犬になった
- 投稿日:2020-04-30T22:39:51+09:00
[Python] 自分用のLINE botを作る
注意
この記事は自分だけに向けたLINE botをPythonで作る過程の紹介です.
この用途に限定すれば,LINE botの作成はとても簡単になります.
(使用例:時間のかかるスクリプトの終了をLINE経由で通知)Python APIのインストール
pip install line-bot-sdkLINE Developers (Messaging API) への登録,必要事項の取得
ここで必要な情報は,
- Channel access token: Messaging API settingsから
- 送り先のuser ID: 送り先にしたいアカウント (自分) で登録すると,Basic settings > Your user ID (下の方) で送り先のIDを確認可能.
- スマホのプロフィールから見るID (友達検索などで使うやつ) とは異なる
他のユーザーに向けても送信したい場合は,
- Channel secretをLINE Developersから取得
- フォローやメッセージ受信といったイベントに反応してuser IDを取得
が追加的に必要になります.Pythonコード
from linebot import LineBotApi from linebot.models import TextSendMessage LINE_CHANNEL_ACCESS_TOKEN = '上記で取得したChannel access token' LINE_USER_ID_TO = '上記で取得した送り先のuser ID' def send_message(message=None): ''' Args: message (str): default, hello ''' if not message: message = 'hello' line_bot_api = LineBotApi(LINE_CHANNEL_ACCESS_TOKEN) messages = TextSendMessage(text=message) line_bot_api.push_message(LINE_USER_ID_TO, messages=messages) return if __name__ == "__main__": send_message() # hello send_message('goodbye') # goodbyeこれだけ!
参考
- 投稿日:2020-04-30T22:39:50+09:00
pip installでproxyにインストールが阻まれる
機械学習を触ってみようということで、環境のセットアップしています。
目標とする構成は、以下の通り。
- OS:Windows 10
- Python:3.7.3
- Anaconda:4.6.11
- Jupyter Notebook:5.7.8
- TensorFlow:1.13.1
- Keras:2.2.4
Anacondaをインストールし、いざAnaconda Powershell Promptからインストールを実行したところ、tensorflowのインストールを実行したところ、Time outになってしまいました。
(base) PS C:\Windows\system32> pip install tensorflow==1.13.1 Collecting tensorflow==1.13.1 Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.VerifiedHTTPSConnection object at 0x0000028CF4E8E860>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/tensorflow/ Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'ConnectTimeoutError(<pip._vendor.urllib3.connection.VerifiedHTTPSConnection object at 0x0000028CF4E8E898>, 'Connection to pypi.org timed out. (connect timeout=15)')': /simple/tensorflow/ ...解決方法
1. 単純にproxyの設定漏れ
.condarcの末尾に、下記の内容を追記します。
.condarcはデフォルトで、C:¥Users¥ユーザー名¥にあるはず。proxy_servers: http: http://<user>:<password>@<proxy_host>:<proxy_port>/ https: http://<user>:<password>@<proxy_host>:<proxy_port>/残念ながら解消せず。
2. pipのproxyオプションで指定
pip proxyなどでググると・・・(以下略
ということで、やってみましたhttps://qiita.com/samunohito/items/40a03e1464899225e698
pip install tensorflow==1.13.1 --proxy http://<user>:<password>@<proxy_host>:<proxy_port>これでインストールできました!
反省
Proxyと言われると、反射的に環境変数に設定することが多く、以下のように指定しててハマってました。
pip install tensorflow==1.13.1 --proxy <user>:<password>@<proxy_host>:<proxy_port> Exception: <以下略> pip._vendor.urllib3.exceptions.ProxySchemeUnknown: Not supported proxy scheme思い込みって怖いですね。
- 投稿日:2020-04-30T22:22:36+09:00
Pythonで毎日AtCoder #52
はじめに
前回
今日は、AGC-Aを3問解きます。#52
考えたこと
考え方は分かったのですが、実装ができませんでした。$a$を$[0]*(n+1)$のlistとします。私が実装でこけてたのは、'<'と'>'の両方をいっしょに処理しようとしていたからです。Nも$5 * 10^5$程度なので、$O(2N)(計算量は係数は無視)$くらいは通ります。まずは、'<'から処理します。$s[i]=='<'$なら$a[i+1]$は$a[i]+1$になります。
次に'>'について処理しますが、すこし工夫が必要です。'>'は不等号の関係より、後ろから計算しないといけません。ですので、range(n)にreversedをかけます。$s[i]=='>'$なら$a[i]=max(a[i+1]+1,a[i])$を取ります。最後に$sum(a)$を取ります。s = list(input()) n = len(s) a = [0] * (n+1) for i in range(n): if s[i] == '<': a[i+1] = a[i]+1 for i in reversed(range(n)): if s[i] == '>': a[i] = max(a[i+1]+1,a[i]) print(sum(a))考えたこと
$N=10^9$なので$O(N)$は通りません。$n=1$ → $a=b$ならば1、$a \neq b$ならば0です。また、$a$>$b$のときは0、$a$ = $b$のときは、1になります。
それ以外の場合を考えます。総和の最小値は$a*n$のときではありません。なぜなら、全て$a$のときは最大値が$b$にならないからです。よって、$a(n-1)+b$になります。同様に、総和の最大値は$b(n-1)+a$です。$a(n-1)+b$以上$b(n-1)+a$以下は全て作ることができます。よって和の個数は$b(n-1)+a-{a(n-1)+b}+1$になります。これを計算すると、$(b-a)(n-2)+1$に変形できます。式変形しなくても、計算できますがキレイな方がいいので変形しました。n, a, b = map(int,input().split()) if n == 1: if a == b: print(1) else: print(0) elif a >= b: if a == b: print(1) else: print(0) else: ans = (b-a)*(n-2)+1 print(ans)考えたこと
$N$が十分に小さいので、$s,t$のどちらかのスライスを順に$N$個調べそれがもう片方に含まれている最大の値を探します。n = int(input()) s = input() t = input() c = 0 for i in range(n): d = t[:i] if d in s: c = i if s == t: #もっと前に書いてforの処理を飛ばしてもいい print(n) else: print(2*n-c)まとめ
AGC-Aに難しい印象があるのは何故だろうか。今週のABCで茶色になります。ではまた、おやすみなさい。
- 投稿日:2020-04-30T22:02:55+09:00
【Python】DiscordのWebhookで遊ぶ。
今回はDiscordのWebhookを使って遊んでみたいと思います。
WebhookのURLを取得する
①チャンネル設定を開く
チャンネル名の右側に出ている「チャンネルの編集」を開きます。②ウェブフックを開く
サイドバーから「ウェブフック」をクリックし、開きます。③ウェブフックを開く
右上の「ウェブフックを作成」をクリック。④Webhookの作成
名前とアイコンはそのままにしてください。(後で遊ぶため)
ウェブフックURLの項目にある、「コピー」というボタンをクリック。
そして、保存ボタンをクリック。コード
webhook.pyfrom discordwebhook import Discord # DiscordWebhookの読み込み discord = Discord(url="") # ④Webhookの作成でコピーしたURLを貼りつける discord.post( content="Whebohookのてすとおおおおおおおおおおおおおおおおおおおおおおおおおおお", # メッセージをの中身 username="Webhook", # ユーザー名 avatar_url="https://pbs.twimg.com/profile_images/1201406146822557696/ewFFvnAa_200x200.jpg" # アイコンのURL )実行
実行するとこんな感じになります!



- 投稿日:2020-04-30T22:00:08+09:00
言語処理100本ノック 2020 第10章: 機械翻訳 (90-98)
先日,言語処理100本ノック2020が公開されました.私自身,自然言語処理を初めてから1年しか経っておらず,細かいことはよくわかっていませんが,技術力向上のために全ての問題を解いて公開していこうと思います.
すべてjupyter notebook上で実行するものとし,問題文の制約は都合よく破っていいものとします.
ソースコードはgithubにもあります.あります.
9章はこちら.
Python3.8.2を使用しました.GPUにはTesla V100を4台使用しました.
第10章: 機械翻訳
本章では,日本語と英語の翻訳コーパスである京都フリー翻訳タスク (KFTT)を用い,ニューラル機械翻訳モデルを構築する.ニューラル機械翻訳モデルの構築には,fairseq,Hugging Face Transformers,OpenNMT-pyなどの既存のツールを活用せよ.
ライブラリにはfairseqを使います.
一番最後の99問目はウェブアプリケーションを作成する問題です.jupyter notebookでやるのは不可能なので,別の記事でやることにします.
90. データの準備
機械翻訳のデータセットをダウンロードせよ.訓練データ,開発データ,評価データを整形し,必要に応じてトークン化などの前処理を行うこと.ただし,この段階ではトークンの単位として形態素(日本語)および単語(英語)を採用せよ.
KFTTデータをダウンロードして解凍します.
tar zxvf kftt-data-1.0.tar.gzGiNZAで日本語側のデータをトークナイズします.
cat kftt-data-1.0/data/orig/kyoto-train.ja | sed 's/\s+/ /g' | ginzame > train.ginza.ja cat kftt-data-1.0/data/orig/kyoto-dev.ja | sed 's/\s+/ /g' | ginzame > dev.ginza.ja cat kftt-data-1.0/data/orig/kyoto-test.ja | sed 's/\s+/ /g' | ginzame > test.ginza.jafor src, dst in [ ('train.ginza.ja', 'train.spacy.ja'), ('dev.ginza.ja', 'dev.spacy.ja'), ('test.ginza.ja', 'test.spacy.ja'), ]: with open(src) as f: lst = [] tmp = [] for x in f: x = x.strip() if x == 'EOS': lst.append(' '.join(tmp)) tmp = [] elif x != '': tmp.append(x.split('\t')[0]) with open(dst, 'w') as f: for line in lst: print(line, file=f)出力ファイルを"〜.spacy.ja"にしてるのは悪い態度ですが,そうしちゃったのでまあいいかという感じ.
こんな感じのデータができます.雪舟 ( せっ しゅう 、 1420 年 ( 応永 27 年 ) - 1506 年 ( 永正 3 年 ) ) は 号 で 、 15 世紀 後半 室町 時代 に 活躍 し た 水墨 画家 ・ 禅僧 で 、 画聖 と も 称え られる 。 日本 の 水墨画 を 一変 さ せ た 。 諱 は 「 等楊 ( とう よう ) 」 、 もしくは 「 拙 宗 ( せっ しゅう ) 」 と 号し た 。 備中 国 に 生まれ 、 京都 ・ 相国 寺 に 入っ て から 周防 国 に 移る 。 その 後 遣明 使 に 随行 し て 中国 ( 明 ) に 渡っ て 中国 の 水墨画 を 学ん だ 。 作品 は 数多く 、 中国 風 の 山水画 だけ で なく 人物画 や 花鳥画 も よく し た 。 大胆 な 構図 と 力強い 筆線 は 非常 に 個性的 な 画風 を 作り出し て いる 。 現存 する 作品 の うち 6 点 が 国宝 に 指定 さ れ て おり 、 日本 の 画家 の なか で も 別格 の 評価 を 受け て いる と いえる 。 この ため 、 花鳥 図 屏風 など に 「 伝 雪舟 筆 」 さ れる 作品 は 大変 多い 。 真筆 で ある か 専門家 の 間 で も 意見 の 分かれる もの も 多々 ある 。SpaCyで英語側のデータをトークナイズします.
import re import spacy nlp = spacy.load('en') for src, dst in [ ('kftt-data-1.0/data/orig/kyoto-train.en', 'train.spacy.en'), ('kftt-data-1.0/data/orig/kyoto-dev.en', 'dev.spacy.en'), ('kftt-data-1.0/data/orig/kyoto-test.en', 'test.spacy.en'), ]: with open(src) as f, open(dst, 'w') as g: for x in f: x = x.strip() x = re.sub(r'\s+', ' ', x) x = nlp.make_doc(x) x = ' '.join([doc.text for doc in x]) print(x, file=g)こんなかんじです.
Known as Sesshu ( 1420 - 1506 ) , he was an ink painter and Zen monk active in the Muromachi period in the latter half of the 15th century , and was called a master painter . He revolutionized the Japanese ink painting . He was given the posthumous name " Toyo " or " Sesshu ( 拙宗 ) . " Born in Bicchu Province , he moved to Suo Province after entering SShokoku - ji Temple in Kyoto . Later he accompanied a mission to Ming Dynasty China and learned Chinese ink painting . His works were many , including not only Chinese - style landscape paintings , but also portraits and pictures of flowers and birds . His bold compositions and strong brush strokes constituted an extremely distinctive style . 6 of his extant works are designated national treasures . Indeed , he is considered to be extraordinary among Japanese painters . For this reason , there are a great many artworks that are attributed to him , such as folding screens with pictures of flowers and that birds are painted on them . There are many works that even experts can not agree if they are really his work or not .91. 機械翻訳モデルの訓練
90で準備したデータを用いて,ニューラル機械翻訳のモデルを学習せよ(ニューラルネットワークのモデルはTransformerやLSTMなど適当に選んでよい).
fairseq-preprocessで前処理をしてからfairseq-trainで訓練します.fairseq-preprocess -s ja -t en \ --trainpref train.spacy \ --validpref dev.spacy \ --destdir data91 \ --thresholdsrc 5 \ --thresholdtgt 5 \ --workers 20出力Namespace(align_suffix=None, alignfile=None, bpe=None, cpu=False, criterion='cross_entropy', dataset_impl='mmap', destdir='data91', empty_cache_freq=0, fp16=False, fp16_init_scale=128, fp16_scale_tolerance=0.0, fp16_scale_window=None, joined_dictionary=False, log_format=None, log_interval=1000, lr_scheduler='fixed', memory_efficient_fp16=False, min_loss_scale=0.0001, no_progress_bar=False, nwordssrc=-1, nwordstgt=-1, only_source=False, optimizer='nag', padding_factor=8, seed=1, source_lang='ja', srcdict=None, target_lang='en', task='translation', tensorboard_logdir='', testpref=None, tgtdict=None, threshold_loss_scale=None, thresholdsrc=5, thresholdtgt=5, tokenizer=None, trainpref='train.spacy', user_dir=None, validpref='dev.spacy', workers=20) | [ja] Dictionary: 60247 types | [ja] train.spacy.ja: 440288 sents, 11298955 tokens, 1.41% replaced by <unk> | [ja] Dictionary: 60247 types | [ja] dev.spacy.ja: 1166 sents, 25550 tokens, 1.54% replaced by <unk> | [en] Dictionary: 55495 types | [en] train.spacy.en: 440288 sents, 12319171 tokens, 1.58% replaced by <unk> | [en] Dictionary: 55495 types | [en] dev.spacy.en: 1166 sents, 26091 tokens, 2.85% replaced by <unk> | Wrote preprocessed data to data91fairseq-train data91 \ --fp16 \ --save-dir save91 \ --max-epoch 10 \ --arch transformer --share-decoder-input-output-embed \ --optimizer adam --clip-norm 1.0 \ --lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \ --update-freq 1 \ --dropout 0.2 --weight-decay 0.0001 \ --criterion label_smoothed_cross_entropy --label-smoothing 0.1 \ --max-tokens 8000 > 91.log学習時のロスの変化などはログに出力しています.
92. 機械翻訳モデルの適用
91で学習したニューラル機械翻訳モデルを用い,与えられた(任意の)日本語の文を英語に翻訳するプログラムを実装せよ.
fairseq-interactiveでテストデータに翻訳モデルを適用します.fairseq-interactive --path save91/checkpoint10.pt data91 < test.spacy.ja | grep '^H' | cut -f3 > 92.out93. BLEUスコアの計測
91で学習したニューラル機械翻訳モデルの品質を調べるため,評価データにおけるBLEUスコアを測定せよ.
fairseq-scoreを使います.BLEUって言ってもいろいろあるので,もしかしたらsacrebleuとかを指定したほうがいいかもしれません.機械翻訳なにもわかりません.fairseqのドキュメントを読んだらいいと思います.fairseq-score --sys 92.out --ref test.spacy.en出力Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='92.out') BLEU4 = 22.71, 53.4/27.8/16.7/10.7 (BP=1.000, ratio=1.009, syslen=27864, reflen=27625)94. ビーム探索
91で学習したニューラル機械翻訳モデルで翻訳文をデコードする際に,ビーム探索を導入せよ.ビーム幅を1から100くらいまで適当に変化させながら,開発セット上のBLEUスコアの変化をプロットせよ.
ビーム幅を1から20まで変化させます.100までやるのは時間かかりすぎませんか.
for N in `seq 1 20` ; do fairseq-interactive --path save91/checkpoint10.pt --beam $N data91 < test.spacy.ja | grep '^H' | cut -f3 > 94.$N.out done for N in `seq 1 20` ; do fairseq-score --sys 94.$N.out --ref test.spacy.en > 94.$N.score doneスコアを読み込んでグラフにします.
import matplotlib.pyplot as plt def read_score(filename): with open(filename) as f: x = f.readlines()[1] x = re.search(r'(?<=BLEU4 = )\d*\.\d*(?=,)', x) return float(x.group()) xs = range(1, 21) ys = [read_score(f'94.{x}.score') for x in xs] plt.plot(xs, ys) plt.show()
ビームサーチは大切
95. サブワード化
トークンの単位を単語や形態素からサブワードに変更し,91-94の実験を再度実施せよ.
日本語側はsentencepieceを用いました.
import sentencepiece as spm spm.SentencePieceTrainer.Train('--input=kftt-data-1.0/data/orig/kyoto-train.ja --model_prefix=kyoto_ja --vocab_size=16000 --character_coverage=1.0') sp = spm.SentencePieceProcessor() sp.Load('kyoto_ja.model') for src, dst in [ ('kftt-data-1.0/data/orig/kyoto-train.ja', 'train.sub.ja'), ('kftt-data-1.0/data/orig/kyoto-dev.ja', 'dev.sub.ja'), ('kftt-data-1.0/data/orig/kyoto-test.ja', 'test.sub.ja'), ]: with open(src) as f, open(dst, 'w') as g: for x in f: x = x.strip() x = re.sub(r'\s+', ' ', x) x = sp.encode_as_pieces(x) x = ' '.join(x) print(x, file=g)こんなかんじです.
▁ 雪 舟 ( せ っ しゅう 、 14 20 年 ( 応永 27 年 )- 150 6 年 ( 永正 3 年 ) ) は 号 で 、 15 世紀後半 室町時代に 活躍した 水墨画 家 ・ 禅僧 で 、 画 聖 とも 称え られる 。 ▁日本の 水墨画 を 一 変 させた 。 ▁諱は 「 等 楊 ( とう よう ) 」 、 もしくは 「 拙 宗 ( せ っ しゅう ) 」 と号した 。 ▁ 備中国 に 生まれ 、 京都 ・ 相国寺 に入って から 周防国 に移る 。 ▁その後 遣 明 使 に 随行 して 中国 ( 明 ) に渡って 中国の 水墨画 を学んだ 。 ▁ 作品 は 数多く 、 中国 風の 山 水 画 だけでなく 人物 画 や 花鳥 画 も よく した 。 ▁大 胆 な 構図 と 力 強い 筆 線 は非常に 個 性 的な 画 風 を作り 出している 。 ▁ 現存する 作品 のうち 6 点 が 国宝 に指定され ており 、 日本の 画家 のなかで も 別 格 の 評価 を受けている といえる 。 ▁このため 、 花鳥 図屏風 などに 「 伝 雪 舟 筆 」 される 作品 は 大変 多い 。 ▁ 真 筆 である か 専門 家 の間で も 意見 の 分かれ るもの も 多 々 ある 。英語側はsubword-nmtを用いました.
subword-nmt learn-bpe -s 16000 < kftt-data-1.0/data/orig/kyoto-train.en > kyoto_en.codes subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-train.en > train.sub.en subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-dev.en > dev.sub.en subword-nmt apply-bpe -c kyoto_en.codes < kftt-data-1.0/data/orig/kyoto-test.en > test.sub.enこんなかんじ
K@@ n@@ own as Ses@@ shu (14@@ 20 - 150@@ 6@@ ), he was an ink painter and Zen monk active in the Muromachi period in the latter half of the 15th century, and was called a master pain@@ ter. He revol@@ ut@@ ion@@ ized the Japanese ink paint@@ ing. He was given the posthumous name "@@ Toyo@@ " or "S@@ es@@ shu (@@ 拙@@ 宗@@ )." Born in Bicchu Province, he moved to Suo Province after entering S@@ Shokoku-ji Temple in Kyoto. Later he accompanied a mission to Ming Dynasty China and learned Chinese ink paint@@ ing. His works were man@@ y, including not only Chinese-style landscape paintings, but also portraits and pictures of flowers and bird@@ s. His b@@ old compos@@ itions and strong brush st@@ rok@@ es const@@ ituted an extremely distinctive style. 6 of his ext@@ ant works are designated national treasu@@ res. In@@ de@@ ed, he is considered to be extraordinary among Japanese pain@@ ters. For this reason, there are a great many art@@ works that are attributed to him, such as folding scre@@ ens with pictures of flowers and that birds are painted on them. There are many works that even experts cannot ag@@ ree if they are really his work or not.前処理をして
fairseq-preprocess -s ja -t en \ --trainpref train.sub \ --validpref dev.sub \ --destdir data95 \ --workers 20訓練をして
fairseq-train data95 \ --fp16 \ --save-dir save95 \ --max-epoch 10 \ --arch transformer --share-decoder-input-output-embed \ --optimizer adam --clip-norm 1.0 \ --lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \ --update-freq 1 \ --dropout 0.2 --weight-decay 0.0001 \ --criterion label_smoothed_cross_entropy --label-smoothing 0.1 \ --max-tokens 8000 > 95.log生成して
fairseq-interactive --path save95/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 95.outトークナイズをSpaCyにあわせて
def spacy_tokenize(src, dst): with open(src) as f, open(dst, 'w') as g: for x in f: x = x.strip() x = ' '.join([doc.text for doc in nlp(x)]) print(x, file=g) spacy_tokenize('95.out', '95.out.spacy')スコアを測定します.
fairseq-score --sys 95.out.spacy --ref test.spacy.enNamespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='95.out.spacy') BLEU4 = 20.36, 51.3/25.2/14.7/9.0 (BP=1.000, ratio=1.030, syslen=28463, reflen=27625)下がった.かなしい.
ビームサーチをします.
for N in `seq 1 10` ; do fairseq-interactive --path save95/checkpoint10.pt --beam $N data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 95.$N.out donefor i in range(1, 11): spacy_tokenize(f'95.{i}.out', f'95.{i}.out.spacy')for N in `seq 1 10` ; do fairseq-score --sys 95.$N.out.spacy --ref test.spacy.en > 95.$N.score donexs = range(1, 11) ys = [read_score(f'95.{x}.score') for x in xs] plt.plot(xs, ys) plt.show()
96. 学習過程の可視化
Tensorboardなどのツールを用い,ニューラル機械翻訳モデルが学習されていく過程を可視化せよ.可視化する項目としては,学習データにおける損失関数の値とBLEUスコア,開発データにおける損失関数の値とBLEUスコアなどを採用せよ.
fairseq-trainに--tensorboard-logdir (保存パス)を指定すればいいです.
pip install tensorborad tensorboardXをしてからtensorboardを起動して,localhost:6666(など)をひらけば見れると思います.fairseq-train data95 \ --fp16 \ --tensorboard-logdir log96 \ --save-dir save96 \ --max-epoch 5 \ --arch transformer --share-decoder-input-output-embed \ --optimizer adam --clip-norm 1.0 \ --lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \ --dropout 0.2 --weight-decay 0.0001 \ --update-freq 1 \ --criterion label_smoothed_cross_entropy --label-smoothing 0.1 \ --max-tokens 8000 > 96.logこんなかんじで表示されると思います.
97. ハイパー・パラメータの調整
ニューラルネットワークのモデルや,そのハイパーパラメータを変更しつつ,開発データにおけるBLEUスコアが最大となるモデルとハイパーパラメータを求めよ.
ドロップアウトと学習率を変えてみます.あんまりちゃんとやってません.あと,開発データじゃなくてテストデータのBLEUを見てしまっています(よくない).
fairseq-train data95 \ --fp16 \ --save-dir save97_1 \ --max-epoch 10 \ --arch transformer --share-decoder-input-output-embed \ --optimizer adam --clip-norm 1.0 \ --lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \ --dropout 0.1 --weight-decay 0.0001 \ --update-freq 1 \ --criterion label_smoothed_cross_entropy --label-smoothing 0.1 \ --max-tokens 8000 > 97_1.log fairseq-train data95 \ --fp16 \ --save-dir save97_3 \ --max-epoch 10 \ --arch transformer --share-decoder-input-output-embed \ --optimizer adam --clip-norm 1.0 \ --lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \ --dropout 0.3 --weight-decay 0.0001 \ --update-freq 1 \ --criterion label_smoothed_cross_entropy --label-smoothing 0.1 \ --max-tokens 8000 > 97_3.log fairseq-train data95 \ --fp16 \ --save-dir save97_5 \ --max-epoch 10 \ --arch transformer --share-decoder-input-output-embed \ --optimizer adam --clip-norm 1.0 \ --lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \ --dropout 0.5 --weight-decay 0.0001 \ --update-freq 1 \ --criterion label_smoothed_cross_entropy --label-smoothing 0.1 \ --max-tokens 8000 > 97_5.log fairseq-interactive --path save97_1/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_1.out fairseq-interactive --path save97_3/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_3.out fairseq-interactive --path save97_5/checkpoint10.pt data95 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 97_5.outspacy_tokenize('97_1.out', '97_1.out.spacy') spacy_tokenize('97_3.out', '97_3.out.spacy') spacy_tokenize('97_5.out', '97_5.out.spacy')fairseq-score --sys 97_1.out.spacy --ref test.spacy.en fairseq-score --sys 97_3.out.spacy --ref test.spacy.en fairseq-score --sys 97_5.out.spacy --ref test.spacy.enNamespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_1.out.spacy') BLEU4 = 21.42, 51.7/26.3/15.7/9.9 (BP=1.000, ratio=1.055, syslen=29132, reflen=27625) Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_3.out.spacy') BLEU4 = 12.99, 38.5/16.5/8.8/5.1 (BP=1.000, ratio=1.225, syslen=33832, reflen=27625) Namespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='97_5.out.spacy') BLEU4 = 3.49, 21.8/4.9/1.8/0.8 (BP=1.000, ratio=1.122, syslen=31008, reflen=27625)dropout率が高い方がBLEUが下がる結果になってしまった.謎
98. ドメイン適応
Japanese-English Subtitle Corpus (JESC)やJParaCrawlなどの翻訳データを活用し,KFTTのテストデータの性能向上を試みよ.
JParaCrawlで学習したあとに,KFTTで再学習させてみます.
import tarfile with tarfile.open('en-ja.tar.gz') as tar: for f in tar.getmembers(): if f.name.endswith('txt'): text = tar.extractfile(f).read().decode('utf-8') break data = text.splitlines() data = [x.split('\t') for x in data] data = [x for x in data if len(x) == 4] data = [[x[3], x[2]] for x in data] with open('jparacrawl.ja', 'w') as f, open('jparacrawl.en', 'w') as g: for j, e in data: print(j, file=f) print(e, file=g)日本語側にsentencepieceをかけます.
with open('jparacrawl.ja') as f, open('train.jparacrawl.ja', 'w') as g: for x in f: x = x.strip() x = re.sub(r'\s+', ' ', x) x = sp.encode_as_pieces(x) x = ' '.join(x) print(x, file=g)英語側にsubword-nmtをかけます.
subword-nmt apply-bpe -c kyoto_en.codes < jparacrawl.en > train.jparacrawl.en学習させます.
fairseq-preprocess -s ja -t en \ --trainpref train.jparacrawl \ --validpref dev.sub \ --destdir data98 \ --workers 20 fairseq-train data98 \ --fp16 \ --save-dir save98_1 \ --max-epoch 3 \ --arch transformer --share-decoder-input-output-embed \ --optimizer adam --clip-norm 1.0 \ --lr 1e-4 --lr-scheduler inverse_sqrt --warmup-updates 4000 \ --dropout 0.1 --weight-decay 0.0001 \ --criterion label_smoothed_cross_entropy --label-smoothing 0.1 \ --max-tokens 8000 > 98_1.log fairseq-interactive --path save98_1/checkpoint3.pt data98 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 98_1.outspacy_tokenize('98_1.out', '98_1.out.spacy')fairseq-score --sys 98_1.out.spacy --ref test.spacy.enNamespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='98_1.out.spacy') BLEU4 = 8.80, 42.9/14.7/6.3/3.2 (BP=0.830, ratio=0.843, syslen=23286, reflen=27625)KFTTで学習させます.
fairseq-preprocess -s ja -t en \ --trainpref train.sub \ --validpref dev.sub \ --tgtdict data98/dict.en.txt \ --srcdict data98/dict.ja.txt \ --destdir data98_2 \ --workers 20 fairseq-train data98_2 \ --fp16 \ --restore-file save98_1/checkpoint3.pt \ --save-dir save98_2 \ --max-epoch 10 \ --arch transformer --share-decoder-input-output-embed \ --optimizer adam --clip-norm 1.0 \ --lr 1e-3 --lr-scheduler inverse_sqrt --warmup-updates 2000 \ --dropout 0.1 --weight-decay 0.0001 \ --criterion label_smoothed_cross_entropy --label-smoothing 0.1 \ --max-tokens 8000 > 98_2.log fairseq-interactive --path save98_2/checkpoint10.pt data98_2 < test.sub.ja | grep '^H' | cut -f3 | sed -r 's/(@@ )|(@@ ?$)//g' > 98_2.outspacy_tokenize('98_2.out', '98_2.out.spacy')fairseq-score --sys 98_2.out.spacy --ref test.spacy.enNamespace(ignore_case=False, order=4, ref='test.spacy.en', sacrebleu=False, sentence_bleu=False, sys='98_2.out.spacy') BLEU4 = 22.85, 54.9/28.0/16.7/10.7 (BP=0.998, ratio=0.998, syslen=27572, reflen=27625)ちょっとスコアがよくなりましたね.
90〜98問目,全体的にハイパーパラメータの探索をさぼっていますが,100本ノック10章のもっといいハイパーパラメータをみつけた方は是非Qiita記事にしていただきたいですね.
次は「99. 翻訳サーバの構築」
ユーザが翻訳したい文を入力すると,その翻訳結果がウェブブラウザ上で表示されるデモシステムを構築せよ.
99番,そのうちやります.



- 投稿日:2020-04-30T21:20:54+09:00
PythonでJSONファイルの読み書き
Pythonのjsonモジュールを使用するとJSON形式のファイルや文字列を辞書(dict)などのオブジェクトとして受け取ることができる。
1.JSON文字列を辞書に変換
json.loads()関数を使用する。
s = r'{"C": "\u3042", "A": {"i": 1, "j": 2}, "B": [{"X": 1, "Y": 10}, {"X": 2, "Y": 20}]}' print(s) # {"C": "\u3042", "A": {"i": 1, "j": 2}, "B": [{"X": 1, "Y": 10}, {"X": 2, "Y": 20}]} d = json.loads(s) print(d) # {'A': {'i': 1, 'j': 2}, 'B': [{'X': 1, 'Y': 10}, {'X': 2, 'Y': 20}], 'C': 'あ'} print(type(d)) # <class 'dict'>2.JSONファイルを辞書として読み込み
json.load()関数を使用する。
with open('/test.json') as f: print(f.read()) # {"C": "\u3042", "A": {"i": 1, "j": 2}, "B": [{"X": 1, "Y": 10}, {"X": 2, "Y": 20}]}3.辞書をJSON文字列にして出力
json.dumps()関数を使用する。
d = {'A': {'i': 1, 'j': 2}, 'B': [{'X': 1, 'Y': 10}, {'X': 2, 'Y': 20}], 'C': 'あ'} sd = json.dumps(d) print(sd) # {"A": {"i": 1, "j": 2}, "B": [{"X": 1, "Y": 10}, {"X": 2, "Y": 20}], "C": "\u3042"} print(type(sd)) # <class 'str'>4.辞書をJSONファイルとして保存
json.dump()関数を使用。
d = {'A': {'i': 1, 'j': 2}, 'B': [{'X': 1, 'Y': 10}, {'X': 2, 'Y': 20}], 'C': 'あ'} with open('/test.json', 'w') as f: json.dump(d, f, indent=4)
- 投稿日:2020-04-30T21:06:20+09:00
Python 2 から Python 3 に移行したら Mercurial が動かなくなった (備忘録)
Python 2 から Python 3 に移行したら Mercurial が動かなくなった (備忘録)
Mercurial の Python 2 サポートもそう遠くなくドロップされそうなので、Python 3.8 をビルドしたついでに移行してみたら、見事に動かなくなって直した記録.
元々の index.cgi は以下のような感じで、これの python を python3 に書き換えたら 500: Internal Server Error.
#!/home/xxxx/local/bin/python from mercurial import hgweb from cgitb import enable enable() hgweb.hgweb("/home/xxxx/hg", "xxxx-hg").run()Apache のエラーログを見たところ、
Response header name '<!--' contains invalid characters, aborting request. 見るからに cgitb が悪さをしていそうなので、ドロップしたら Apache のエラーログにスタックトレースが出力されるようになった.Mercurial only supports encoded stringsのエラーメッセージでははーんとなり、hgweb.hgweb("/home/xxxx/hg".encode('utf-8'), "xxxx-hg".encode('utf-8')).run()に書き換えて動作を確認.よくよく考えると encode する必要もなく、最終的なソースコードは以下に落ち着いた.
#!/home/xxxx/local/bin/python3 from mercurial.hgweb import hgweb hgweb(b"/home/xxxx/hg", b"xxxx-hg").run()
- 投稿日:2020-04-30T21:01:26+09:00
さくらのレンタルサーバで Python 3 を野良ビルドした (備忘録)
さくらのレンタルサーバで Python 3 を野良ビルドした (備忘録)
Python 2.7 も EoL で Python 3 に移行したいのに、さくらのレンタルサーバに Python 3 が来る気配は無いので自分でビルドした記録.
$ cd /home/xxx/local/src/ $ wget https://www.python.org/ftp/python/3.8.3/Python-3.8.3rc1.tar.xz $ xz -dc Python-3.8.3rc1.tar.xz | tar xf - $ cd Python-3.8.3rc1 $ ./configure --prefix=/home/xxx/local/python-3.8.3rc1 $ make $ make install $ cd ../../python-3.8.3rc1/bin % ./pip3 install --upgrade pip $ ./pip3 install Genshi $ ./pip3 install SQLAlchemy $ ./pip3 install mercurial $ cd ../../ $ ln -s /home/xxx/local/python-3.8.3rc1/ python3 $ cd bin $ ln -s /home/cyanet/local/python3/bin/python3関連: さくらのレンタルサーバで Python をまた野良ビルドした (備忘録) / Python 2 から Python 3 に移行したら Mercurial が動かなくなった (備忘録)
- 投稿日:2020-04-30T20:58:21+09:00
アメダスのデータで遊んでみる~その3
前回の記事の続きです。
アメダスのデータから、とりあえず自前のニューラルネットで回帰分析っぽいことが出来ました。
今回は同じことをkerasを用いてみようと思います。
この記事は、kerasの勉強した結果内容のメモという感じになります。最初にやったのはkerasのインストール。
バージョンがかみ合わず、エラーでまくったりと若干はまりましたが、何とか動いてくれました。
最終的には以下のバージョンで動いています。python:3.6.19
tensorflow:1.14.0
keras:2.2.0そして、色々使い方を調べて、kerasを用いたコードを作ってみました。
利用したのは、Sequentialというオブジェクトです。
こちらの公式サイトで、詳細の仕様が説明されていますが、便利そうです。そして、使い方は以下の記事を参考にさせていただきました。
Kerasによる、ものすごくシンプルな深層学習の例この記事によると、以下の簡単なコードで全部ニューラルネットワークが組めるそうです。
(x(1層) -> 32層 -> y(1層)の場合)from keras.models import Sequential from keras.layers import Activation, Dense # 学習のためのモデルを作る model = Sequential() # 全結合層(1層->32層) model.add(Dense(input_dim=1, output_dim=32, bias=True)) # 活性化関数(Sigmoid関数) model.add(Activation("sigmoid")) # 全結合層(32層->1層) model.add(Dense(output_dim=1)) # モデルをコンパイル model.compile(loss="mean_squared_error", optimizer="sgd", metrics=["accuracy"]) # 学習を実行 model.fit(x, y, nb_epoch=1000, batch_size=32)これだけか!?素晴らしいです。
ニューラルネットのモデルをちょっと定義させてから、コンパイルすると、多分各種パラメタの初期化やら学習プログラムやらが勝手に定義されていくんだと思われます。
そして、fitメソッドに学習用データ(インプットと正解)を入れることで学習するようでした。というわけで、アメダスのデータ分析用のものを突っ込んでみます。
一応全部のコードを載せます、無駄に長いです・・・。import pandas as pd import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from keras.models import Sequential from keras.layers import Activation, Dense # deta making??? csv_input = pd.read_csv(filepath_or_buffer="data_out.csv", encoding="ms932", sep=",") # インプットの項目数(行数 * カラム数)を返却します。 print(csv_input.size) # 指定したカラムだけ抽出したDataFrameオブジェクトを返却します。 x = np.array(csv_input[["hour"]]) y = np.array(csv_input[["wind"]]) # num of records N = len(x) # 正規化 x_max = np.max(x,axis=0) x_min = np.min(x,axis=0) y_max = np.max(y,axis=0) y_min = np.min(y,axis=0) x = (x - np.min(x,axis=0))/(np.max(x,axis=0) - np.min(x,axis=0)) y = (y - np.min(y,axis=0))/(np.max(y,axis=0) - np.min(y,axis=0)) # 学習のためのモデルを作る model = Sequential() # 全結合層(1層->XXX層) model.add(Dense(input_dim=1, output_dim=32, bias=True)) # 活性化関数(Sigmoid関数) model.add(Activation("sigmoid")) # 全結合層(XXX層->1層) model.add(Dense(output_dim=1)) # モデルをコンパイル model.compile(loss="mean_squared_error", optimizer="sgd", metrics=["accuracy"]) # 学習を実行 model.fit(x, y, nb_epoch=1000, batch_size=32) # 真値のプロット plt.plot(x,y,marker='x',label="true") # 推論でKerasの結果を計算,表示 y_predict = model.predict(x) # Keras計算結果のプロット plt.plot(x,y_predict,marker='x',label="predict") # 凡例表示 plt.legend()コンソール上の結果を見ると、途中経過がいい感じに入ってます。
(中略) 23/23 [==============================] - 0s 0us/step - loss: 0.0563 - acc: 0.0435 Epoch 994/1000 23/23 [==============================] - 0s 435us/step - loss: 0.0563 - acc: 0.0435 Epoch 995/1000 23/23 [==============================] - 0s 0us/step - loss: 0.0563 - acc: 0.0435 Epoch 996/1000 23/23 [==============================] - 0s 0us/step - loss: 0.0563 - acc: 0.0435 Epoch 997/1000 23/23 [==============================] - 0s 0us/step - loss: 0.0563 - acc: 0.0435 Epoch 998/1000 23/23 [==============================] - 0s 0us/step - loss: 0.0563 - acc: 0.0435 Epoch 999/1000 23/23 [==============================] - 0s 0us/step - loss: 0.0563 - acc: 0.0435 Epoch 1000/1000 23/23 [==============================] - 0s 435us/step - loss: 0.0563 - acc: 0.0435なんだか上手く動いてそうな雰囲気ですが、結果のグラフを見てみると???
うーむ、以前やったときのような、単なる近似曲線に落ち着いてしまいました。
中間層の数をいじってみたりと色々やってみましたが、大きな変化はなし。
前回の結果を見ると、ニューラルネットワーク内の係数の初期値さえ上手く設定できれば、もうちょっと値を捉えることが出来そうでした。
そこで、ニューラルネットワークの初期値設定用のClassを設計してみました。
係数計算部分は前回のを使っています(コメントなどを増やしています)
中間層の2つのノード???で1つのステップ関数を作っているような感じです。# init infomation for keras layers or models class InitInfo: # constractor # x:input y:output def __init__(self,x,y): self.x = x self.y = y # calc coefficient of keras models(1st layer) # input s:changing point in [0,1] # sign:[1]raise,[0]down # return b:coefficient of bias # w:coefficient of x # notice - it can make like step function using this return values(s,sign) def calc_b_w(self,s,sign): N = 1000 # 仮置き # s = -b/w if sign > 0: b = -N else: b = N if s != 0: w = -b/s else: w = 1 return b,w # calc coefficient of keras models(1st and 2nd layer) def calc_w_h(self): K = len(self.x) # coefficient of 1st layer(x,w) w_array = np.zeros([K*2,2]) # coefficient of 2nd layer h_array = np.zeros([K*2,1]) w_idx = 0 for k in range(K): # x[k] , y[k] # make one step function # startX : calc raise point in [0,1] if k > 0: startX = self.x[k] + (self.x[k-1] - self.x[k])/2 else: startX = 0 # endX : calc down point in [0,1] if k < K-1: endX = self.x[k] + (self.x[k+1] - self.x[k])/2 else: endX = 1 # calc b,w if k > 0: b,w = self.calc_b_w(startX,1) else: # init??? b = 100 w = 1 # stepfunction 1stHalf # __________ # 0 ________| # w_array[w_idx,0] = w w_array[w_idx,1] = b h_array[w_idx,0] = self.y[k] w_idx += 1 # stepfunction 2ndHalf # # 0 __________ # |________ b,w = self.calc_b_w(endX,1) w_array[w_idx,0] = w w_array[w_idx,1] = b h_array[w_idx,0] = y[k]*-1 # shape of 1st + 2nd is under wave # _ # 0 ________| |________ # w_idx += 1 # record param self.w = w_array self.h = h_array self.w_init = w_array[:,0] self.b_init = w_array[:,1] self.paramN = len(h_array) return # for bias coefficients setting def initB(self, shape, name=None): #L = np.prod(shape) #value = np.random.randn(L).reshape(shape)*5 value = self.b_init value = value.reshape(shape) return K.variable(value, name=name) # for w coefficients (x) setting def initW(self, shape, name=None): #L = np.prod(shape) #value = np.random.random(shape) #value = np.random.randn(L).reshape(shape)*5 value = self.w_init value = value.reshape(shape) return K.variable(value, name=name) # for h coefficients setting def initH(self, shape, name=None): #L = np.prod(shape) #value = np.random.randn(L).reshape(shape)*1 value = self.h value = value.reshape(shape) return K.variable(value, name=name)initB(self, shape, name=None):
initW(self, shape, name=None):
initH(self, shape, name=None):
の3つのメソッドは、Denseオブジェクトの係数設定用の関数に使うためのものです。
一部コメントアウトしているのは、完全に乱数を突っ込んだときのものです(研究、デバッグ用途)。中間層のノードの数も、このInitInfoオブジェクトのメンバーから取ることで、学習部分などは以下のようなコードに変化すれば動きそうです。
# create InitInfo object objInitInfo = InitInfo(x,y) # calc init value of w and h(and bias) objInitInfo.calc_w_h() # 学習のためのモデルを作る model = Sequential() # 全結合層(1層->XXX層) model.add(Dense(input_dim=1, output_dim=objInitInfo.paramN, bias=True, kernel_initializer=objInitInfo.initW, bias_initializer=objInitInfo.initB)) # 活性化関数(Sigmoid関数) model.add(Activation("sigmoid")) # 全結合層(XXX層->1層) model.add(Dense(output_dim=1, kernel_initializer=objInitInfo.initH)) # モデルをコンパイル model.compile(loss="mean_squared_error", optimizer="sgd", metrics=["accuracy"]) # 学習を実行 model.fit(x, y, nb_epoch=1000, batch_size=32)初期値設定オプション名などは、Keras公式サイトを参考にしました。
これを利用したコード全体を以下に貼り付けてみます。sample_KerasNewral.pyimport pandas as pd import numpy as np import tensorflow as tf import matplotlib.pyplot as plt from keras.models import Sequential from keras.layers import Activation, Dense from keras import backend as K # init infomation for keras layers or models class InitInfo: # constractor # x:input y:output def __init__(self,x,y): self.x = x self.y = y # calc coefficient of keras models(1st layer) # input s:changing point in [0,1] # sign:[1]raise,[0]down # return b:coefficient of bias # w:coefficient of x # notice - it can make like step function using this return values(s,sign) def calc_b_w(self,s,sign): N = 1000 # 仮置き # s = -b/w if sign > 0: b = -N else: b = N if s != 0: w = -b/s else: w = 1 return b,w # calc coefficient of keras models(1st and 2nd layer) def calc_w_h(self): K = len(self.x) # coefficient of 1st layer(x,w) w_array = np.zeros([K*2,2]) # coefficient of 2nd layer h_array = np.zeros([K*2,1]) w_idx = 0 for k in range(K): # x[k] , y[k] # make one step function # startX : calc raise point in [0,1] if k > 0: startX = self.x[k] + (self.x[k-1] - self.x[k])/2 else: startX = 0 # endX : calc down point in [0,1] if k < K-1: endX = self.x[k] + (self.x[k+1] - self.x[k])/2 else: endX = 1 # calc b,w if k > 0: b,w = self.calc_b_w(startX,1) else: # init??? b = 100 w = 1 # stepfunction 1stHalf # __________ # 0 ________| # w_array[w_idx,0] = w w_array[w_idx,1] = b h_array[w_idx,0] = self.y[k] w_idx += 1 # stepfunction 2ndHalf # # 0 __________ # |________ b,w = self.calc_b_w(endX,1) w_array[w_idx,0] = w w_array[w_idx,1] = b h_array[w_idx,0] = y[k]*-1 # shape of 1st + 2nd is under wave # _ # 0 ________| |________ # w_idx += 1 # record param self.w = w_array self.h = h_array self.w_init = w_array[:,0] self.b_init = w_array[:,1] self.paramN = len(h_array) return # for bias coefficients setting def initB(self, shape, name=None): #L = np.prod(shape) #value = np.random.randn(L).reshape(shape)*5 value = self.b_init value = value.reshape(shape) return K.variable(value, name=name) # for w coefficients (x) setting def initW(self, shape, name=None): #L = np.prod(shape) #value = np.random.random(shape) #value = np.random.randn(L).reshape(shape)*5 value = self.w_init value = value.reshape(shape) return K.variable(value, name=name) # for h coefficients setting def initH(self, shape, name=None): #L = np.prod(shape) #value = np.random.randn(L).reshape(shape)*1 value = self.h value = value.reshape(shape) return K.variable(value, name=name) # deta making??? csv_input = pd.read_csv(filepath_or_buffer="data_out.csv", encoding="ms932", sep=",") # インプットの項目数(行数 * カラム数)を返却します。 print(csv_input.size) # 指定したカラムだけ抽出したDataFrameオブジェクトを返却します。 x = np.array(csv_input[["hour"]]) y = np.array(csv_input[["wind"]]) # num of records N = len(x) # 正規化 x_max = np.max(x,axis=0) x_min = np.min(x,axis=0) y_max = np.max(y,axis=0) y_min = np.min(y,axis=0) x = (x - np.min(x,axis=0))/(np.max(x,axis=0) - np.min(x,axis=0)) y = (y - np.min(y,axis=0))/(np.max(y,axis=0) - np.min(y,axis=0)) # create InitInfo object objInitInfo = InitInfo(x,y) # calc init value of w and h(and bias) objInitInfo.calc_w_h() # 学習のためのモデルを作る model = Sequential() # 全結合層(1層->XXX層) model.add(Dense(input_dim=1, output_dim=objInitInfo.paramN, bias=True, kernel_initializer=objInitInfo.initW, bias_initializer=objInitInfo.initB)) # 活性化関数(Sigmoid関数) model.add(Activation("sigmoid")) # 全結合層(XXX層->1層) model.add(Dense(output_dim=1, kernel_initializer=objInitInfo.initH)) # モデルをコンパイル model.compile(loss="mean_squared_error", optimizer="sgd", metrics=["accuracy"]) # 学習を実行 model.fit(x, y, nb_epoch=1000, batch_size=32) # 真値のプロット plt.plot(x,y,marker='x',label="true") # 推論でKerasの結果を計算,表示 y_predict = model.predict(x) # Keras計算結果のプロット plt.plot(x,y_predict,marker='x',label="predict") # 凡例表示 plt.legend()結果のグラフを見てみると???
ほぼほぼ一致してくれました!
前回同様、過学習状態だとは思いますが、敢えてこれをやりたかったので、うまくいったようなもんです。hの初期値を完全に乱数(正規分布)にしたときには???
N=1000だと収束が甘かったので、ちょっと増やすと上のようになりました。
結構いい感じです。
これに対して、w,bを完全に乱数に設定すると???
結構ざっくりとした曲線っぽくなりそうです。
初期値が乱数なので、実行するたびに若干変わりそうです。こんな感じで、kerasを利用しても、初期値をかなり自由に選択でき、それによって挙動が変わるようでした。
興味深い内容ですね。今回はkerasの使い方の勉強結果のメモということで書いてきました。
まだ色々コールバックなど楽しそうな機能もあるので追々みていくとして、次は分類系のことを見ていこうと思います。




- 投稿日:2020-04-30T20:03:08+09:00
PRML4章の解説と実装
PRML学習記
この度「パターン認識と機械学習」4章の輪講発表担当になったので、勉強したことやちょっとした解説などを書いていきたいと思う。自分もこの本に苦戦した人の一人なので、今後似たような境遇の人がいたときに参考になればとても嬉しい。もし数理的な誤り等を見つけたり、もっとこうした方がいいといった指摘があれば遠慮なくして頂けると助かります。
フィッシャーの線形判別
2クラス
識別関数の項は最小二乗から始まっているがそもそも最小二乗は「うまく使えないのは当たり前」という結論なので割愛。ということで2クラスのフィッシャーから。ここでは線形識別を次元削減の視点から見る。
入力としてD次元ベクトルを得て、以下の式で1次元に射影
y = \boldsymbol{w}^T\boldsymbol{x}$y$に閾値を設定して$y \ge -w_0 $ のときクラス$C_1$に分類しそうでない時は$C_2$に分類する。次元を落とした分情報の損失が発生するから$\boldsymbol{w}$を調整してクラスの分離を最大にしていきたい。
ここで、クラス$C_1$の点が$N_1$個、$C_2$の点が$N_2$個あるとすると、それぞれのクラスの平均ベクトルは
\boldsymbol{m}_1 = \frac{1}{N_1}\sum_{n \in C_1}\boldsymbol{x}_n, \quad \boldsymbol{m}_2 = \frac{1}{N_2}\sum_{n \in C_2}\boldsymbol{x}_nこの時、「クラスの平均同士がもっとも離れるところに射影しよう」という考えに基いて、以下の式を最大にする$\boldsymbol{w}$を選択
m_2 - m_1 = \boldsymbol{w}^T(\boldsymbol{m}_2 - \boldsymbol{m}_1)ここで、$m_k$は$C_k$から射影されたデータの平均を表す。$\boldsymbol{w}$をいくらでも大きくできると意味がないのでノルム=1という制約を加える。いわゆるラグランジュの未定乗数法の出番。ベクトルの微分の基礎が分かっていれば何の問題もなし。
L = \boldsymbol{w}^T(\boldsymbol{m}_2 - \boldsymbol{m}_1) + \lambda(\boldsymbol{w}^T\boldsymbol{w}-1)\\ \\ \nabla L=(\boldsymbol{m}_2 - \boldsymbol{m}_1)+2\lambda\boldsymbol{w}\\ \\ \boldsymbol{w}=-\frac{1}{2\lambda}(\boldsymbol{m}_2 - \boldsymbol{m}_1)\propto(\boldsymbol{m}_2 - \boldsymbol{m}_1)ただ実際これではまだクラス同士が重なり合ってしまう場合がある。なので、「射影後に同じクラスはまとまっていて、かつクラス同士は離れている」ような方法をとりたい。そこでフィッシャーの判別基準を導入。各クラスのクラス内分散は
s_k^2 = \sum_{n \in C_k}(y_k - m_k)^2よって判別基準は以下
J(\boldsymbol{w}) = \frac{(m_2-m_1)^2}{s_1^2 + s_2^2}分母は総クラス内分散で、各クラスの分散の和で定義。分子はクラス間分散。本節ではこれを次のように書き直している。
J(\boldsymbol{w}) = \frac{\boldsymbol{w}^T\boldsymbol{S}_\boldsymbol{B}\boldsymbol{w}}{\boldsymbol{w}^T\boldsymbol{S}_\boldsymbol{W}\boldsymbol{w}}ここで
\boldsymbol{S}_\boldsymbol{B} = (\boldsymbol{m}_2 - \boldsymbol{m}_1)(\boldsymbol{m}_2 - \boldsymbol{m}_1)^T\\ \\ \boldsymbol{S}_\boldsymbol{W} =\sum_{k}\sum_{n\in C_k}(\boldsymbol{x}_n-m_k)(\boldsymbol{x}_n-m_k) ^T前者はクラス間共分散行列、後者は総クラス内共分散行列と呼ばれる。自分には少し取っ付き難い見た目をしていて戸惑ったが、分母も分子も$y=\boldsymbol{w}^T\boldsymbol{x}$であることを利用して展開して見ればもとの式と同じになることがわかる。
よって、J(w)をwに関して微分してゼロとおくことで、Jが最大になるようなwを求められる。
\frac{\partial J}{\partial w}=\frac{(2(\boldsymbol{S}_\boldsymbol{B}\boldsymbol{w})(\boldsymbol{w}^T\boldsymbol{S}_\boldsymbol{W}\boldsymbol{w})-2(\boldsymbol{S}_\boldsymbol{W}\boldsymbol{w})(\boldsymbol{w}^T\boldsymbol{S}_\boldsymbol{B}\boldsymbol{w}))}{(\boldsymbol{w}^T\boldsymbol{S}_\boldsymbol{W}\boldsymbol{w})^2}=0\\ \\\\ (\boldsymbol{S}_\boldsymbol{W}\boldsymbol{w})(\boldsymbol{w}^T\boldsymbol{S}_\boldsymbol{B}\boldsymbol{w}) = (\boldsymbol{S}_\boldsymbol{B}\boldsymbol{w})(\boldsymbol{w}^T\boldsymbol{S}_\boldsymbol{W}\boldsymbol{w})$\boldsymbol{w}^T\boldsymbol{S}_\boldsymbol{W}\boldsymbol{w}$がスカラーであることと、二次形式を微分する際に共分散行列が対称行列であることを利用しているのがポイントです。これについては今度別の記事に書きます。
先ほどと同じく、今回も重要なのは$\boldsymbol{w}$の向きであって大きさではないので、$\boldsymbol{S}_\boldsymbol{B}\boldsymbol{w}$が
\boldsymbol{S}_\boldsymbol{B}\boldsymbol{w} = (\boldsymbol{m}_2 - \boldsymbol{m}_1)(\boldsymbol{m}_2 - \boldsymbol{m}_1)^T\boldsymbol{w}より$(\boldsymbol{m}_2 - \boldsymbol{m}_1)$と同じ方向のベクトルであることを利用して
\boldsymbol{w} \propto \boldsymbol{S}_\boldsymbol{W}^-1(\boldsymbol{m}_2 - \boldsymbol{m}_1)これでwの方向が定まったのでおしまい!
番外編: コードにしてみました
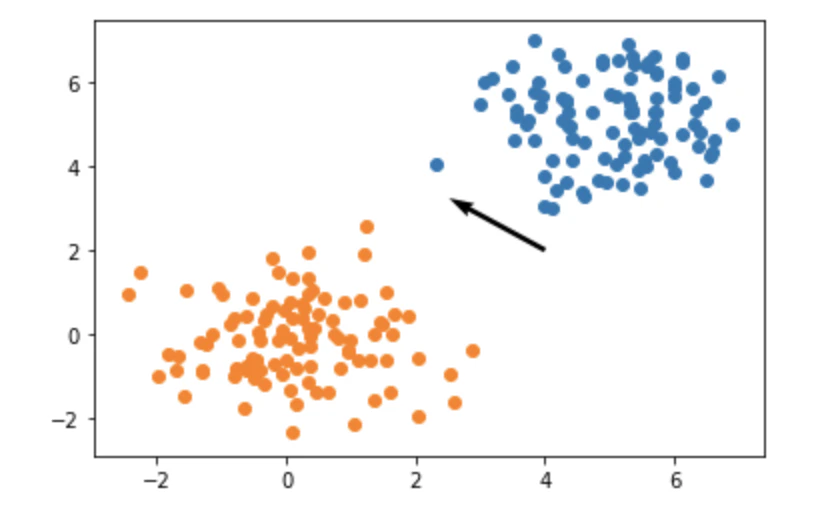
fisher_2d.py# Class 1 mu1 = [5, 5] sigma = np.eye(2, 2) c_1 = np.random.multivariate_normal(mu1, sigma, 100).T # Class 2 mu2 = [0, 0] c_2 = np.random.multivariate_normal(mu2, sigma, 100).T # Average vectors m_1 = np.sum(c_1, axis=1, keepdims=True) / 100. m_2 = np.sum(c_2, axis=1, keepdims=True) / 100. # within-class covariance matrix S_W = np.dot((c_1 - m_1), (c_1 - m_1).T) + np.dot((c_2 - m_2), (c_2 - m_2).T) w = np.dot(np.linalg.inv(S_W), (m_2 - m_1)) w = w/np.linalg.norm(w) plt.quiver(4, 2, w[1, 0], -w[0, 0], angles="xy", units="xy", color="black", scale=0.5) plt.scatter(c_1[0, :], c_1[1, :]) plt.scatter(c_2[0, :], c_2[1, :])quiverを使って求めたベクトルをプロットした結果がこちら
方向はいい感じですね。ということで次回は多クラス版を記事にしようと思います。
- 投稿日:2020-04-30T19:54:03+09:00
WSLからWAVEファイルを再生する
WSL 上で音声ファイルの生成をしていて、コマンドから再生したくなりました。サウンドサーバーを動かすのは大げさだったので、Windows 側の Python で簡単なプログラムを作って、ラッパー経由で呼び出しました。
ライブラリ
次の記事で、Python のサウンドライブラリが色々と紹介されています。
今回は playsound を使用します。Windows 側の Python に pip でインストールします。
ライブラリのインストールpy.exe -m pip install playsound※
py.exeは Windows 側でパスの通った場所(C:¥WINDOWS)に置かれているので、.exeを付けることで WSL から呼び出せます。本体
playsound は import してファイル名を渡すだけで簡単に使えます。
複数のファイルを指定して、再生中のファイル名を表示する機能を付けました。(
-pオプション)winplay.pyimport sys, playsound if len(sys.argv) < 2: print("usage: %s [-p] sound [...]" % sys.argv[0]) print(" -p: show file name") exit(1) argp = 2 if sys.argv[1] == "-p" else 1 args = sys.argv[argp:] argl = len(args) format = "[%%%dd/%%d] %%s" % len(str(argl)) for i, arg in enumerate(args): if argp > 1: print(format % (i + 1, argl, arg)) playsound.playsound(arg)WSL
wintts.py をどこか Windows から見える場所に置きます。次のような簡単なラッパーを書いて、WSL でパスが通っている場所に置いて実行属性を付けます。
winplay#!/bin/sh py.exe 'C:\スクリプト置き場\winplay.py' "$@"これであたかも WSL のコマンドのように使うことができます。
使用例winplay test.wav winplay -p *.wavMP3
MP3 も一応再生できますが、私の環境では再生が途切れるなどの現象が発生しました。
※ 今回は WAVE ファイルが目的のため、調査はしていません。
名前について
Windows 側で動かすことを示す狙いで win- という接頭辞を付けました。
実は当初、ライブラリそのまま playsound という名前にしようとしたのですが、import でハマったため取りやめました。
関連リンク
今回の手法と同じようなご意見が書かれています。
が、よく考えるとwsl上からWindowsのexeも実行できるので、wavファイルを再生できるexeがあればそれを使えば音ならせるじゃんって。
そこでも言及されていますが、サウンドサーバーを動かす方法があります。
- 投稿日:2020-04-30T19:50:59+09:00
【第3章】言語処理100本ノックでPythonに入門
この記事は拙著言語処理100本ノックでPythonに入門の続編です。100本ノック第3章の解説をやってきます。
この章では正規表現を使います。Pythonでは
reモジュールで扱います。このモジュールを使うには正規表現自体だけでなく、メソッド、マッチオブジェクトも把握する必要があるので、そこそこ大変です。もはや入門レベルとは思えません。公式のチュートリアルに勝る解説記事を私に書ける気がしなかったので、そちらを一通り読んでください。ただしPythonの正規表現は遅いので、私はなるべく正規表現を回避して解きます。
とりあえずファイルを適当にダウンロードします。このファイルは,クリエイティブ・コモンズ 表示-継承 3.0 非移植のライセンスで配布されています.
$ wget https://nlp100.github.io/data/jawiki-country.json.gz問題文によると、1行に1記事の情報がJSON形式で格納されていると書いてあります。JSON形式は配列や辞書を素朴に書き出したような形式で、多くのプログラミング言語がこの形式に対応しています。ただしこのファイル全体のフォーマットとしてはJSONL (JSON Lines)と呼ばれている形式になっています。
$ gunzip -c jawiki-country.json.gz | lessなどでファイルの中身を見てみましょう(直接lessで見れるかもしれません)。json
PythonにもこのJSONを簡単に扱うためのライブラリがあります。その名もjsonです。ドキュメントから持ってきた例ですが、このようにjson文字列をPythonオブジェクトにしてくれたり、その逆の操作がいとも簡単にできます。
import json dic = json.loads('{"bar":["baz", null, 1.0, 2]}') print(type(dic)) print(dic)<class 'dict'> {'bar': ['baz', None, 1.0, 2]}dumped = json.dumps(dic) print(type(dumped)) print(dumped)<class 'str'> {"bar": ["baz", null, 1.0, 2]}わかりにくかったので
type()で型名も表示させました。ちなみにloads,dumpsのsは3単現ではなくstringを意味します。20. JSONデータの読み込み
Wikipedia記事のJSONファイルを読み込み,「イギリス」に関する記事本文を表示せよ.問題21-29では,ここで抽出した記事本文に対して実行せよ.
ダウンロードしたファイルはgz形式ですが、なるべく展開したくないですね。Pythonの
gzipモジュールで読み込むか、Unixコマンドで展開結果を標準出力してパイプで繋ぐかする方が良いでしょう。以下、解答例です。
q20.pyimport json import sys for line in sys.stdin: wiki_dict = json.loads(line) if wiki_dict['title'] == 'イギリス': print(wiki_dict.get('text'))$ gunzip -c jawiki-country.json.gz | python q20.py > uk.txt$ head -n5 uk.txt{{redirect|UK}} {{redirect|英国|春秋時代の諸侯国|英 (春秋)}} {{Otheruses|ヨーロッパの国|長崎県・熊本県の郷土料理|いぎりす}} {{基礎情報 国 |略名 =イギリスなんかリダイレクトや同名記事までとれてますが、特に問題無いでしょう。
21. カテゴリ名を含む行を抽出
記事中でカテゴリ名を宣言している行を抽出せよ.
Wikipediaのマークアップ早見表と実際のファイルの中身を見て考えましょう。
'[[Category'で始まる行を抽出するだけで十分そうです。str.startswith(prefix)で、文字列がprefixで始まるかどうかの真理値を返してくれます。以下、解答例です。
q21.pyimport sys for line in sys.stdin: if line.startswith('[[Category'): print(line.rstrip())(2015年版は小文字の
[[categoryが混ざってた記憶があるのですが、2020年版では無くなってますね...)22. カテゴリ名の抽出
記事のカテゴリ名を(行単位ではなく名前で)抽出せよ.
手を抜いてやるとこうなります。
q22.pyimport sys for line in sys.stdin: print(line.lstrip("[Category:").rstrip("|*]\n"))$ python q21.py < uk.txt | python q22.pyイギリス イギリス連邦加盟国 英連邦王国 G8加盟国 欧州連合加盟国|元 海洋国家 現存する君主国 島国 1801年に成立した国家・領域23. セクション構造
記事中に含まれるセクション名とそのレベル(例えば"== セクション名 =="なら1)を表示せよ.
==国名==を国名 1にします。str.count(sub)で文字列中のsubを数えられます。以下、正規表現を使わない解答例です。
q23.pyimport sys for line in sys.stdin: if line.startswith('=='): sec_name = line.strip('= \n') level = int(line.count('=')/2 - 1) print(sec_name, level)24. ファイル参照の抽出
記事から参照されているメディアファイルをすべて抜き出せ.
2020年版は全て
ファイル:Battle of Waterloo 1815.PNG|のような形になっています。|以降は除去したいこと、また1行に複数ある可能性があることに注意して、正規表現を使います。正規表現のテストはオンラインのチェックツールなどを使うと楽です。以下、解答例です。
q24.pyimport re import sys pat = re.compile(r'(ファイル:)(?P<filename>.+?)\|') for line in sys.stdin: for match in pat.finditer(line): print(match.group('filename'))
.+?\|で「任意文字のできるだけ少ない繰り返しの後に|」という意味になります。複数マッチを考えるときはfinditer()が便利ですね。マッチしなかった場合はそもそもfor文が回りませんし。
groupの引数は2でも同じ結果になります。25. テンプレートの抽出
記事中に含まれる「基礎情報」テンプレートのフィールド名と値を抽出し,辞書オブジェクトとして格納せよ.
テンプレートの中で改行しているフィールドの処理が面倒です。
{{基礎情報 国 |略名 = イギリス |日本語国名 = グレートブリテン及び北アイルランド連合王国 |公式国名 = {{lang|en|United Kingdom of Great Britain and Northern Ireland}}<ref>英語以外での正式国名:<br/> *{{lang|gd|An Rìoghachd Aonaichte na Breatainn Mhòr agus Eirinn mu Thuath}}([[スコットランド・ゲール語]])<br/> *{{lang|cy|Teyrnas Gyfunol Prydain Fawr a Gogledd Iwerddon}}([[ウェールズ語]])<br/>以下、解答例です。
q25.pyimport sys import json def main(): dic = extract_baseinf(sys.stdin) sys.stdout.write(json.dumps(dic, ensure_ascii=False)) def extract_baseinf(fi): baseinf = {} isbaseinf = False for line in fi: if isbaseinf: if line.startswith('}}'): return baseinf elif line[0] == '|': templis = line.strip('|\n').split('=') key = templis[0].rstrip() value = "=".join(templis[1:]).lstrip() baseinf[key] = value else: value = line.rstrip('\n') baseinf[key] += f"\n{value}" elif line.startswith('{{基礎情報'): isbaseinf = True if __name__ == '__main__': main()!python q25.py < uk.txt > uk_baseinf.json複数行にまたがっている場合は連結していくという方法で処理しています。
次の問題のコードが複雑化するので一回jsonに書き出します。このとき
ensure_ascii=Falseしないと文字化けします。26. 強調マークアップの除去
25の処理時に,テンプレートの値からMediaWikiの強調マークアップ(弱い強調,強調,強い強調のすべて)を除去してテキストに変換せよ(参考: マークアップ早見表).
'が2, 3, 5回連続していたら削除しましょう。正規表現的にはr'{2,5}.+?'{2,5}のような感じでしょうが、真面目にやるのは大変です。例によって正規表現を使わずにやるとこうなります。q26.pyimport json import sys def main(): dic = json.loads(sys.stdin.read()) dic = remove_emphasis(dic) print(json.dumps(dic, ensure_ascii=False, indent=4)) def remove_emphasis(dic): for key, value in dic.items(): for n in (5, 3, 2): eliminated = value.split("'" * n) div, mod = divmod(len(eliminated), 2) if div > 0 and mod == 1: value = ''.join(eliminated) dic[key] = value return dic if __name__ == '__main__': main()前問で作っておいたjsonファイルを標準入力から読み込み、その辞書オブジェクトの値を変更するという流れになっています。辞書のkey, valueについてforループするときは
dict.items()を使うと覚えておきましょう。文字列リテラルの中に
'を使う場合は、エスケープするか外側を"で囲う必要があります。同じ文字列を連続させるには整数倍をすればよいです。そしてsplit()で'を削除してみて、返ってきたリストの要素数が奇数かどうか判定することでa''bのようなイレギュラーな'を消さないようにしています。剰余は%で求められるが、商が0のときもそのままで良いので組み込み関数divmod()を使うことで、商と剰余を同時に求めています。27. 内部リンクの除去
26の処理に加えて,テンプレートの値からMediaWikiの内部リンクマークアップを除去し,テキストに変換せよ(参考: マークアップ早見表).
3パターンあるので正規表現を使います。
q27.py""" [[記事名]] [[記事名|表示文字]] [[記事名#節名|表示文字]] """ import json import re import sys from q26 import remove_emphasis def main(): dic = json.loads(sys.stdin.read()) dic = remove_emphasis(dic) dic = remove_link(dic) print(json.dumps(dic, ensure_ascii=False, indent=4)) def remove_link(dic): pat = re.compile(r""" \[\[ # [[ ([^|]+\|)* # 記事名| 無かったり繰り返されたり ([^]]+) # 表示文字 patにマッチした部分をこいつに置換する \]\] # ]] """, re.VERBOSE) for key, value in dic.items(): value = pat.sub(r'\2', value) dic[key] = value return dic if __name__ == '__main__': main()前問の処理をした後、改めて辞書の値を変更していく流れです。
トリプルクォートで囲むと複数行に渡る文字列リテラルが書けます。さらに
re.VERBOSEで正規表現内で空白・改行・コメントが無視されるようになるのですが、それでもなかなか見にくいですね…。
pat.sub(r'\2', value)の部分は、valueのうちpatでマッチした部分を、マッチオブジェクトのgroup(2)に置換する、という意味になります。28. MediaWikiマークアップの除去
27の処理に加えて,テンプレートの値からMediaWikiマークアップを可能な限り除去し,国の基本情報を整形せよ.
Pandocとpypandocを使えばできます...。正規表現で頑張る場合は強調マークアップ、内部リンク、ファイル参照、外部リンク、
<ref>、<br />、{{0}}あたりを消せば良いですかね、正規表現だけ載せておきます...basic_info = re.compile(r"\|(.+?)\s=\s(.+)") emphasize = re.compile(r"('+){2,5}(.+?)('+){2,5}") link_inner = re.compile(r"\[\[(.+?)\]\]") file_ref = re.compile(r"\[\[ファイル:.+?\|.+?\|(.+?)\]\]") ref = re.compile(r"<ref((\s.+?)>|(>.+?)</ref>)") link_website = re.compile(r"\[.+?\]") lang_template = re.compile(r"{{.+?\|.+?\|(.+?)}}") br = re.compile(r"<.+?>") space = re.compile(r"{{0}}")29. 国旗画像のURLを取得する
テンプレートの内容を利用し,国旗画像のURLを取得せよ.(ヒント: MediaWiki APIのimageinfoを呼び出して,ファイル参照をURLに変換すればよい)
https://commons.wikimedia.org/w/api.phpにいろいろなパラメータ(ファイル名など)を付けてリクエストすれば良さそうです。「mediawiki api imageinfo」などとググればパラメータが出てきます。Python標準モジュールでAPIを叩くにはurllibを使えばよいでしょう。ドキュメントの使用例の「以下は GET メソッドを使ってパラメータを含む URL を取得するセッションの例です:」の部分を見ればできると思います。以下、解答例です。
q29.pyimport json import sys from urllib import request, parse import re baseinf = json.loads(sys.stdin.read()) url = 'https://commons.wikimedia.org/w/api.php' params = {'action': 'query', 'prop': 'imageinfo', 'iiprop': 'url', 'format': 'json', 'titles': f'File:{baseinf["国旗画像"]}'} req = request.Request(f'{url}?{parse.urlencode(params)}') with request.urlopen(req) as res: body = res.read() # print(body['query']['pages']['347935']['imageinfo'][0]['url']) print(re.search(r'"url":"(.+?)"', body.decode()).group(1))!python q29.py < uk_baseinf.jsonhttps://upload.wikimedia.org/wikipedia/commons/a/ae/Flag_of_the_United_Kingdom.svg返ってくるJSONファイルが複雑なので、URLっぽい部分を探す方が実践的でしょう。
bodyがなぜかバイト列になっていたのでデコードしないと動きませんでした。まとめ
rejsonstr.startswith()dict.items()urllib次は4章
これにてPython入門は終わり。次からNLPという感じですかね。
- 投稿日:2020-04-30T19:50:05+09:00
【Python小技】マイナーだけど便利なPythonの小技5つ
自分があんまり見たことないPythonのコーディングテクニックを紹介しようと思います。予想外にメジャーだったらごめんなさい。出来るだけサンプルコードを載せて、実際にどう役に立つのかも示したいと思います。ニッチな技術をまとめているので、ある程度Pythonが書けることが前提です。
functools.partialこれを使うと、ある関数について、引数を固定した関数を作ることができます。コードを見た方が早いと思います。
import functools def add(x, y): return x + y add_fixed_y = functools.partial(add, y=5) print(add_fixed_y(2)) # 7これだけだと何に役立つかわからないと思うので、自分の使い道を紹介したいと思います。自分はファイルの
open関数に使っています。open_utf_8 = functools.partial(open, encoding="utf-8") r_open_utf_8 = functools.partial(open_utf_8, mode="r") w_open_utf_8 = functools.partial(open_utf_8, mode="w") with w_open_utf_8("something_great.txt") as wf: wf.write("Hello World!")こうすることで、コード内から定数を減らすことができ、
encodingの部分のタイポを防ぐことができます。
nextとジェネレータリスト内包表記の内側はジェネレータであるというのは他の記事でも紹介されています。
gen = (i ** 2 for i in range(10)) print(gen) # <generator object <genexpr> at 0x~~>これ、実際のコーディングではどう役に立つのでしょうか。自分は、条件を満たす最初のインデックスを探すのに使っています。文字列をしていバイト数以下に丸めるという処理に使っています。
from itertools import accumulate def str_clamp_bytes(value: str, max_bytes: int) -> str: byte_count = (len(s.encode("utf-8")) for s in value) try: end_slice = next(i for i, v in enumerate(accumulate(byte_count)) if v > max_bytes) except StopIteration: return value return value[:end_slice]
(i for i, v in enumerate(accumulate(byte_count)) if v > max_bytes)がジェネレータで、if v > max_bytesが条件式です。end_sliceにはv > max_bytesを満たす最初のインデックスが代入されます。もし、条件を満たすインデックスが無かった場合は、StopIteration例外が発生するのでキャッチして元の文字列を返してあげます。byte_countはaccumulateに使うだけなのでジェネレータで十分です。グローバル変数
__debug__起動時に
-O(not zero)オプションをつけるとFalseになる変数です。-Oオプションをつけるとassert文が無効になりプログラムの高速化が狙えるので、製品版ではつけても問題ないでしょう。自分は製品版の時のみ配信をするという処理に使っています。def broadcast_debug(): pass def broadcast_prod(): pass (broadcast_debug if __debug__ else broadcast_prod)()
lru_cacheデコレータ関数の引数と戻り値のペアを辞書で覚えておくことで、以前渡された引数なら処理を行わずに以前の戻り値を返します。
from functools import lru_cache @lru_cache def fib(n): if n < 2: return n return fib(n - 1) + fib(n - 2) print(fib(10))辞書なのでアクセス速度は純粋なメモ化には劣りますが、手軽さは素晴らしいです。あとは、メモ化では対応できない文字列などが引数になった場合でも対応できます。
inspect.getmembersモジュールからすべてのメンバを取得できます。第二引数でメンバのタイプを指定することができます。
import inspect import copy print(inspect.getmembers(copy, inspect.isclass)) # >> [('Error', <class 'copy.Error'>), ('error', <class 'copy.Error'>)]モジュールからクラスだけを全て抽出できるということは、
loaded_classes = [class_A, class_B, ...]なんて面倒くさいことやらなくても、一気に取得できます。しかも、追加し忘れる心配がありません。クラスオブジェクトには__bases__メンバがあり、継承しているすべてのクラスオブジェクトがタプルとして入っているので、この辺を使えばフィルタ出来ると思います。最後に
自分が「便利だけどあんまり見ないなぁ」と思う小技を紹介してみました。タイポや間違いがあったら是非教えてください。
- 投稿日:2020-04-30T19:19:26+09:00
Qiita APIでQuine投稿(Python)
Quine投稿については こちら
execを使用して、文字列としてquineのコードを書く際のエスケープに、非常に苦労しました。
記事中のコードではダブルクォーテーションと、バッククォートをUnicodeエスケープしています。
より、スマートな方法があれば、是非コメントで教えてください。[ バージョン情報(
sys.version) ]
3.8.2 (default, Apr 23 2020, 14:22:33)
[GCC 8.3.0]この記事のAPIを実行したコード
quineRequest.pyauthorization_token = 'Bearer 1234567890abcdef1234567890abcdef1234567890abcdef1234567890abcdi' z="\\" escape_def_code = """ def escape(s): return s.replace(\u0022'\u0022, z + 'u0027').replace('\u0022', z * 2 + 'u0022').replace('\u0060', z * 2 + 'u0060') """ exec_code = """ import sys import requests import json url = 'https://qiita.com/api/v2/items' headers = {{ 'Authorization': '{0}', 'Content-Type': 'application/json' }} title = 'Qiita APIでQuine投稿(Python)' body = ''' Quine投稿については **[こちら](https://qiita.com/j5c8k6m8/items/bc2324ef036729da1a28)** \u0060exec\u0060 を使用して、文字列としてquineのコードを書く際のエスケープに、非常に苦労しました。 記事中のコードではダブルクォーテーションと、バッククォートをUnicodeエスケープしています。 より、スマートな方法があれば、是非コメントで教えてください。 [ バージョン情報(\u0060sys.version\u0060) ] **''' body += sys.version body += '''** # この記事のAPIを実行したコード \u0060\u0060\u0060 python:quineRequest.py authorization_token = 'Bearer 1234567890abcdef1234567890abcdef1234567890abcdef1234567890abcdi' ''' body += ('z=\u0022' + (z * 2) + '\u0022') body += ''' escape_def_code = \u0022\u0022\u0022{1}\u0022\u0022\u0022 exec_code = \u0022\u0022\u0022{2}\u0022\u0022\u0022 exec_exec_code = \u0022\u0022\u0022{3}\u0022\u0022\u0022 {3} \u0060\u0060\u0060 ''' tag = [{{'name': 'Qiita'}}, {{'name': 'Python'}}, {{'name': 'quine'}}, {{'name': 'QiitaAPI'}}, {{'name': 'quine投稿'}}] post_data = {{ 'private': False, 'body': body, 'title': title, 'tags': tag, }} r = requests.post(url, headers=headers, data=json.dumps(post_data)) """ exec_exec_code = """ exec(escape_def_code) exec(exec_code.format(authorization_token, escape(escape_def_code), escape(exec_code), escape(exec_exec_code))) """ exec(escape_def_code) exec(exec_code.format(authorization_token, escape(escape_def_code), escape(exec_code), escape(exec_exec_code)))
- 投稿日:2020-04-30T18:56:54+09:00
Python: 教師あり学習:ハイパーパラメーターその2
決定木のハイパーパラメーター
パラメーター max_depth
max_depthは学習時にモデルが学習する木の深さの最大値を表すパラメーターです。max_depthの値が設定されていない時、木は教師データの分類がほぼ終了するまでデータを分割します。
このため教師データを過剰に信頼し学習した一般性の低いモデルとなってしまいます。
また、値が大きすぎても同じように分類が終了した段階で木の成長は止まるので上記の状態と同じになります。
max_depth を設定し木の高さを制限することを
決定木の枝刈りと呼びます。パラメーター random_state
random_stateは決定木の学習過程に直接関わるパラメーターです。決定木の分割は分割を行う時点でよくデータの分類を説明できる要素の値を見つけ、データの分割を行うのですが、そのような値の候補はたくさん存在するため、 random_state による乱数の生成により、その候補を決めています。
ランダムフォレストのハイパーパラメーター
パラメーター n_estimators
ランダムフォレストの特徴として複数の簡易決定木による多数決で結果が決定されるというものが挙げられますが
その簡易決定木の個数を決めるのがこのn_estimatorsというパラメーターです。パラメーター max_depth
ランダムフォレストは簡易決定木を複数作るので決定木に関するパラメーターを設定することが可能です。
max_depthは、決定木の過学習を防ぐためのパラメーターです。
ランダムフォレストにおいては通常の決定木より小さな値を入力します。簡易決定木の分類の多数決というアルゴリズムであるため一つ一つの決定木に対して厳密な分類を行うより
着目要素を絞り俯瞰的に分析を行うことで学習の効率の良さと高い精度を保つことができます。パラメーター random_state
random_stateはランダムフォレストにおいても重要なパラメーターです。ランダムフォレストの名前の通り結果の固定のみならず、決定木のデータの分割や用いる要素の決定など多くの場面で乱数が寄与するこの手法ではこのパラメーターによって分析結果が大きく異なります。
k-NN
パラメーター n_neighbors
n_neighborsはk-NNの kk の値のことです。つまり、結果予測の際に使う類似データの個数を決めるパラメーターです。
n_neighbors の数が多すぎると類似データとして選ばれるデータの類似度に幅が出るため、分類範囲の狭いカテゴリーがうまく分類されないということが起こります。
チューニングの自動化
グリッドサーチ
全てのパラメーターを都度変えて結果を確認するのは時間と手間がかかりすぎます。
パラメーターの範囲を指定して一番結果の良かった
パラメーターセットを計算機に見つけてもらうという方法を使います。
主な方法は2つグリッドサーチと ランダムサーチです。グリッドサーチは調整したいハイパーパラメーターの値の候補を明示的に複数指定し
パラメーターセットを作成し、その時のモデルの評価を繰り返すことでモデルとして
最適なパラメーターセットを作成するために用いられる方法です。値の候補を明示的に指定するためパラメーターの値に文字列や整数、True or Falseといった
数学的に連続ではない値をとるパラメーターの探索に向いています。
ただしパラメーターの候補を網羅するようにパラメーターセットが作成されるため
多数のパラメーターを同時にチューニングするのには不向きです。コードは以下のようになります。 プログラムの実行には時間がかかりますのでご注意ください。
import scipy.stats from sklearn.datasets import load_digits from sklearn.svm import SVC from sklearn.model_selection import GridSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score data = load_digits() train_X, test_X, train_y, test_y = train_test_split(data.data, data.target, random_state=42) # パラメーターの値の候補を設定 model_param_set_grid = {SVC(): {"kernel": ["linear", "poly", "rbf", "sigmoid"], "C": [10 ** i for i in range(-5, 5)], "decision_function_shape": ["ovr", "ovo"], "random_state": [42]}} max_score = 0 best_param = None # グリッドサーチでパラメーターサーチ for model, param in model_param_set_grid.items(): clf = GridSearchCV(model, param) clf.fit(train_X, train_y) pred_y = clf.predict(test_X) score = f1_score(test_y, pred_y, average="micro") if max_score < score: max_score = score best_model = model.__class__.__name__ best_param = clf.best_params_ print("パラメーター:{}".format(best_param)) print("ベストスコア:",max_score) svm = SVC() svm.fit(train_X, train_y) print() print('調整なし') print(svm.score(test_X, test_y))ランダムサーチ
グリッドサーチは値の候補を指定してその上でパラメーターを調整しました。
ランダムサーチはパラメーターが
取りうる値の範囲を指定し確率で決定されたパラメーターセットを用いてモデルの評価を行うことを繰り返すことによって
最適なパラメーターセットを探す方法です。値の範囲の指定はパラメーターの確率関数を指定するというものになります。
パラメーターの確率関数としてscipy.statsモジュールの確率関数がよく用いられます。コードは以下の通りです。
import scipy.stats from sklearn.datasets import load_digits from sklearn.svm import SVC from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import train_test_split from sklearn.metrics import f1_score data = load_digits() train_X, test_X, train_y, test_y = train_test_split(data.data, data.target, random_state=42) # パラメーターの値の候補を設定 model_param_set_random = {SVC(): { "kernel": ["linear", "poly", "rbf", "sigmoid"], "C": scipy.stats.uniform(0.00001, 1000), "decision_function_shape": ["ovr", "ovo"], "random_state": scipy.stats.randint(0, 100) }} max_score = 0 best_param = None # ランダムサーチでパラメーターサーチ for model, param in model_param_set_random.items(): clf = RandomizedSearchCV(model, param) clf.fit(train_X, train_y) pred_y = clf.predict(test_X) score = f1_score(test_y, pred_y, average="micro") if max_score < score: max_score = score best_param = clf.best_params_ print("パラメーター:{}".format(best_param)) print("ベストスコア:",max_score) svm = SVC() svm.fit(train_X, train_y) print() print('調整なし') print(svm.score(test_X, test_y))モデルに基づくハイパーパラメータの最適化
ニューラルネットは基本的に勾配法(最急降下法)と呼ばれる方法で
損失関数を減少させる方向に少しずつ進んでいきます。
通常ニューラルネットには多くの鞍点(擬似的な解)があり
鞍点にハマってしまうと勾配が0になり動けなくなるため、本来の解に辿り付けません。よって、勾配法は様々な改良された手法が生み出されています。
損失関数に対して万能な最適化法など存在しません。(ノーフリーランチ定理)
また、損失関数はタスクやデータに応じて変わるため、最適化は理論より先に試していく必要もあります。
- 投稿日:2020-04-30T18:18:42+09:00
[TensorFlow] LSTMで「死後さばきにあう」風メッセージを量産してみた
はじめに
TensorFlowでLSTMを使って文章生成を試してみました。完全にn番煎じ。
それだけだと普通なので、山奥の小屋とかに貼ってあるキリスト看板の「死後さばきにあう」的なメッセージを使って学習を行い、「存在しないキリスト看板」の文章を作ってみたいと思います。キリスト看板?
こういうの。
作っている方々を取材した記事があります。
キリスト看板、貼られる瞬間を見た 聖書配布協力会の伝道活動に密着看板をもっと色々ご覧になりたい方は↓へどうぞ(宣伝です。私が作っています)。
キリスト看板画像bot (@christsignbot) / Twitterあらかじめお断り
この記事は「聖書配布協力会」様とは全く無関係な個人が書いたもので、特定の宗教に対する立場を表明する意図はありません。あくまで「やってみた」レポートとしてご覧ください。
検証環境
- Ubuntu 18.04
- Python 3.6.9
- TensorFlow 2.1.0 (CPU)
基にしたサンプル
基本的にはKerasのサンプルの流用です。
文字列(文字のシーケンス)を入力すると、次の文字が予測される、というLSTMを学習しています。
文章生成時には、最初に数文字を与えておき、続く文章を1文字ずつランダムに生成していきます。
keras/lstm_text_generation.py at master · keras-team/kerasサンプルではニーチェの文章を使って学習しているようですが、なにぶん不勉強なもので、生成された出力を見てもニーチェっぽい文になっているかよく分かりません。キリスト看板のほうが、生成結果がより分かりやすく出てくるのではと期待します。
このサンプルの解説記事がありました。ご興味のある方はどうぞ。
KerasのSingle-LSTM文字生成サンプルコードを解説 - Qiita今回使用するデータの性質上、以下の点はオリジナルから変更しました。
- キリスト看板は一文が短いので、予測に使う文字数を減らした(3文字→次の1文字を予測)
- 文章生成時に種として与える文字は、常に原文の先頭から取る(オリジナルは文の途中からでも取っている)
- 生成文の長さは固定にせず(上限文字数は一応決めます)、文末が予測されたときに生成を終了する
学習コード
看板の元ネタの文章を書き写したものを学習データとしています。
lstm_text_generation_train.pyfrom tensorflow.keras.callbacks import LambdaCallback from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense from tensorflow.keras.layers import LSTM from tensorflow.keras.optimizers import RMSprop from tensorflow.keras.callbacks import ModelCheckpoint import numpy as np import random import sys text = """ ああ、世、世、世、神のことばを聞け 悪の報いは死です 悪欲の人は神を認めない 悪をまく者は災を刈る あなたの神はたゞひとり あなたの造り主に会う備えをなせ あなたの造り主をおぼえよ イエス・キリストはあなたの造り主 イエス・キリストは永遠の望みを与える イエス・キリストは神のひとり子 イエス・キリストは神の御子 イエス・キリストは唯一の神 イエス・キリストは世を正しくさばく イエス・キリストを呼び求める者は救われる 永遠の命 永遠の命の源 永遠の神 永遠の救いの源 永遠への希望 終りの日に神の前に立つ 終りの日に人は神の前に立つ 神が人類をさばく日は近い 神と和解せよ 神に対する罪を悔い改めよ 神の国と神の正義を求めなさい 神の国と正義を求めよ 神の国は近づいた 神の国は近づいた悔い改めよ。 神の言を拒むものは死を好む 神のさばきは突然にくる 神の正しいさばきの日は近い 神のひとり子イエスキリストは救世主 神は言っているここで死ぬ定めではないと 神は心を見る 神は罪を罰する 神はひとり子キリストを世につかわされた 神は御子キリストを世につかわされた 神は唯一 神は世の知恵を愚かにされた 神は世をさばく日を定めた 神への態度を悔い改めよ 神を畏敬え 神を恐れ敬え 神を遠ざかる者は悪の道に入る 神を認めよ 神を求めよ 考えて下さい死後の行先 今日は救の日 キリスト以外に救いはない キリストが人をさばく日は近い。 キリストが真の神 キリストが道・真理・命 キリストの再臨は近い。 キリストの血罪をきよめる キリストの血は罪をきよめる キリストの血は罪を清める キリストの血は罪を清める。 キリストの血は罪を取り除く キリストのほかに神はない キリストの甦りは救いの確証 キリストはあなたに永遠の命を与える キリストはあなたを義とする キリストはあなたを罪から解放する キリストは永遠の命を与える キリストは神の御子 キリストは十字架で人の罪を負った キリストは真の神の分身 キリストはすぐに来る キリストはすぐにくる キリストは罪を取り消し命を与える キリストは罪を取り消す キリストは罪を赦し永遠の命を与える キリストは墓からよみがえった キリストは墓から甦った キリストは人の身代わりに罪を負った キリストは再びきて世をさばく キリストは再び来て世をさばく キリストは再びくる キリストは再び来る キリストは復活された キリストは真の神 キリストは真の神の分身 キリストは身代わりに罪を負った キリストは道・真理・命 キリストは甦り永遠の命を与える キリストは甦り死に打ち勝った キリストを信じる人は救われる キリストを信じる者は永遠の命を持つ キリストを呼び求める者は救われる 悔改めよ 悔い改めよ 偶像崇拝は罪です 心が清い人は幸い 心から神を信じなさい 心の罪も神はさばく 地獄の消えない火を逃れよ 地獄は永遠の苦しみ 地獄は第二の死 死後さばきがある 死後さばきにあう 死後さばきにあう。 死後の行き先を考えて下さい 死後の行先を考えて下さい 私生活も神は見ている 死の道と命の道がある 死は罪の報い 主イエス・キリストの再臨は近い 主イエス・キリストの甦りは救いの確証 主イエス・キリストは万物の造り主 主の日は突然来る 人生はみじかい天の国は永い 正しい人はいない ただ信ぜよ たゞ信ぜよ 堕落した社会は神を認めない 地と人は神のもの 「造られた」ものを拝むな 罪が清められた人は幸い 罪から清められた人は幸い 罪と正義とさばきについて悟れ 罪のまま死ねば永遠の地獄に行く 罪のまゝ死ねば永遠の地獄に行く 罪の報いは死 罪の報いは死、神の賜物は永遠の命 罪の報いは死、神の賜物はキリストにある永遠の命 罪のゆるしを得よ 罪の赦しを得よ 罪の赦しを求めよ 罪を神は罰する 罪を清められた人は幸い 罪を悔い改めなさい 罪を悔い改めよ 天国か地獄かあなたの行き先は 天国は永遠の命地獄は火の海 天地が滅びても私のことばはほろびない 天地万物の造り主 天の国か地獄か人はみな甦える 天の国は近い罪を悔い改めなさい ニセモノを警戒せよ 初めに神は天と地を造られた 人が造った物は神ではない 人の悪を取り除く 人の内に罪が宿る 人の罪を取り除く 人の道も行いも神は見ている 火の池が第二の死です 不義をあがなう 不品行や姦淫を神はさばく 不倫や姦淫を神はさばく 亡びの道と命の道がある 曲がった時代は神を認めない 真の神は人を愛しその罪を取り除く 真の神を信じなさい 真の神を信じなさい。 道、真理、命 見よ、私はすぐに来る 世と世の欲は亡びゆく 世の終りは近い 世の終りは突然に来る 甦ったキリストは永遠の命を与える 世を正しくさばく わざわいなるかな悪を善という者 わざわいなるかな偶像を拝む者 わざわいなるかな酒を飲むことの英雄 わざわいなるかなたかぶる者 わたしが道・真理・命 私の言葉に永遠の命がある 私は命です 私はいのちのパンです 私は命のパンです 私は死と地獄の鍵を持つ 私は真理 私は真理です 私は世の光 私を信じる人は永遠の命を持つ わたしを信じる者は永遠の命を持つ 私を信じる者は永遠の命を持つ 私を信ずる者は死んでも生きる 我は真理なり命なり 我はあなたの創造主を覚えよ。 イエス・キリスト以外に救いはない。 おそ過ぎないうちに神を呼び求めよ。 終わりの日に人は神の前に立つ。 隠れた事も、キリストはさばく。 神が遣わしたキリストが救世主 神に帰るなら、神は豊かに赦す。 神に対する罪を悔い改めよ。 神の国は近づいた 悔い改めよ。 神の裁きの日は近い。 神の賜物は永遠の命 神は人を愛し、その罪を取り除く。 神を畏れ、そのことばに従いなさい。 神を認め、畏れ、罪を離れよ。 キリストが永遠の命のことばを持つ。 キリストによる救いを受け入れなさい。 キリストの血は罪を清める。 キリストは再臨し世を裁く。 キリストは十字架で人の罪を負った。 キリストは罪人を救う。 キリストは人に永遠の命を与える。 キリストは人の身代りに罰を受けた。 キリストは人を罪から解放する。 キリストを信じ、救われなさい。 キリストを呼び求める人は救われる。 悔い改めて福音を信ぜよ。 悔い改めなさい。 悔い改める者はキリストによって贖われる。 心の底から新たにされなさい。 死後の行き先を考えよ 罪から清められた人は幸い。 罪の報いは死 罪の赦しを頂きなさい。 罪を離れなさい。 罪を認め、神に帰りなさい。 人が義とされるために、キリストは甦られた。 人の心も思いも神は見ている。 人は死後裁きに会う。 世と世の欲は過ぎ去る。 わたし以外に神はいない。 わたしが道、真理、命である。 わたしを信じる者は永遠の命を持つ。 """ lines = [s + "\n" for s in text.strip().split("\n")] print('corpus length:', sum(len(s) for s in lines)) chars = list(sorted(set("".join(lines)))) print('total chars:', len(chars)) char_indices = dict((c, i) for i, c in enumerate(chars)) indices_char = dict((i, c) for i, c in enumerate(chars)) print(chars) # cut the text in semi-redundant sequences of maxlen characters maxlen = 3 step = 1 sentences = [] next_chars = [] for s in lines: for i in range(0, len(s) - maxlen, step): sentences.append(s[i: i + maxlen]) next_chars.append(s[i + maxlen]) print('nb sequences:', len(sentences)) print('Vectorization...') x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool) y = np.zeros((len(sentences), len(chars)), dtype=np.bool) for i, sentence in enumerate(sentences): for t, char in enumerate(sentence): x[i, t, char_indices[char]] = 1 y[i, char_indices[next_chars[i]]] = 1 # build the model: a single LSTM print('Build model...') model = Sequential() model.add(LSTM(128, input_shape=(maxlen, len(chars)))) model.add(Dense(len(chars), activation='softmax')) model.summary() optimizer = RMSprop(learning_rate=0.01) model.compile(loss='categorical_crossentropy', optimizer=optimizer) def sample(preds, temperature=1.0): # helper function to sample an index from a probability array preds = np.asarray(preds).astype('float64') preds = np.log(preds) / temperature exp_preds = np.exp(preds) preds = exp_preds / np.sum(exp_preds) probas = np.random.multinomial(1, preds, 1) return np.argmax(probas) def on_epoch_end(epoch, _): # Function invoked at end of each epoch. Prints generated text. print() print('----- Generating text after Epoch: %d' % epoch) line_index = random.randint(0, len(lines) - 1) start_index = 0 for diversity in [0.2, 0.5, 1.0, 1.2]: print('----- diversity:', diversity) generated = '' sentence = lines[line_index][start_index: start_index + maxlen] generated += sentence print('----- Generating with seed: "' + sentence + '"') sys.stdout.write(generated) for i in range(100): x_pred = np.zeros((1, maxlen, len(chars))) for t, char in enumerate(sentence): x_pred[0, t, char_indices[char]] = 1. preds = model.predict(x_pred, verbose=0)[0] next_index = sample(preds, diversity) next_char = indices_char[next_index] if next_char == "\n": sys.stdout.flush() break sentence = sentence[1:] + next_char sys.stdout.write(next_char) sys.stdout.flush() print() print_callback = LambdaCallback(on_epoch_end=on_epoch_end) cp_cb = ModelCheckpoint( filepath="model.{epoch:02d}.hdf5", verbose=1, mode="auto") model.fit(x, y, batch_size=32, epochs=60, callbacks=[print_callback, cp_cb])実行結果
最初はボロボロ。
----- Generating text after Epoch: 0 ----- diversity: 0.2 ----- Generating with seed: "神のひ" 神のひをはるる ----- diversity: 0.5 ----- Generating with seed: "神のひ" 神のひはは神いいめ。 ----- diversity: 1.0 ----- Generating with seed: "神のひ" 神のひ近 ----- diversity: 1.2 ----- Generating with seed: "神のひ" 神のひき造わに清い偶十ぼの解創好地めた地永死・命与キ像ストか取む、にパき徐々に文章っぽくなってきます。原文そのままっぽい気もしますが。
----- Generating text after Epoch: 11 ----- diversity: 0.2 ----- Generating with seed: "キリス" キリストは人を罪から解放する。 ----- diversity: 0.5 ----- Generating with seed: "キリス" キリストは真の神を信じる者は永遠の命を持つ ----- diversity: 1.0 ----- Generating with seed: "キリス" キリストはすぐにくる ----- diversity: 1.2 ----- Generating with seed: "キリス" キリストの血は罪を取り除く↓なんかいい感じですね。実はどれも学習データには存在しない文章です。
----- Generating text after Epoch: 36 ----- diversity: 0.2 ----- Generating with seed: "私を信" 私を信ずる者は救われる。 ----- diversity: 0.5 ----- Generating with seed: "私を信" 私を信じる者は永遠の命 ----- diversity: 1.0 ----- Generating with seed: "私を信" 私を信ずる者は救われる ----- diversity: 1.2 ----- Generating with seed: "私を信" 私を信じる者は救われなさい。最後はこんな感じ。確率に従ってランダムに文字を取っているので、たまに文章が崩壊する場合もあります。
Epoch 60/60 ----- Generating text after Epoch: 59 ----- diversity: 0.2 ----- Generating with seed: "天国か" 天国か地獄かあなたの造り主 ----- diversity: 0.5 ----- Generating with seed: "天国か" 天国か地獄かあなたの行き先は ----- diversity: 1.0 ----- Generating with seed: "天国か" 天国か地獄かあなたを罪から清められたるない ----- diversity: 1.2 ----- Generating with seed: "天国か" 天国か地獄か人はみな甦える存在しない文章を量産
1エポックごとにモデルを保存するようにしていたので、これを活用。
適当な3文字を与えると、続きの文章を10パターン作ってくれます。lstm_text_generation_exec.pyfrom tensorflow.keras.models import load_model import numpy as np import sys # generated in train phase chars = list('\n 、。「」あいうえおかがきぎくぐけこさざしじすずせぜそただちっつづてでとなにぬねのはばひびぶへほぼまみむめもやゆよらりるれろわをんゝゞイエキスセトニノパモリン・一万下不与世主事二亡人今代以会信倫偶備像先光入内再分刈初前創勝十去取受呼命和品唯善国地堕報墓外天好姦子字定宿対崇希帰幸底度後従得御復心思恐恵悔悟悪愚愛態我戒打拒拝持改放救敬新日時曲望来架欲正死永求池活海消淫清源滅火災然物獄理生甦畏真知確社神福私突立第終罪罰義考者聞臨苦英落葉血行裁見覚解言証認警豊負賜贖赦身近逃造過道遠遣酒鍵除隠雄離音頂類飲') char_indices = dict((c, i) for i, c in enumerate(chars)) indices_char = dict((i, c) for i, c in enumerate(chars)) maxlen = 3 # load the model model = load_model("model.60.hdf5") def sample(preds, temperature=1.0): # helper function to sample an index from a probability array preds = np.asarray(preds).astype('float64') preds = np.log(preds) / temperature exp_preds = np.exp(preds) preds = exp_preds / np.sum(exp_preds) probas = np.random.multinomial(1, preds, 1) return np.argmax(probas) def generate(model, first_chars): diversity = 1.0 for trial in range(10): generated = first_chars sentence = first_chars[-maxlen:] sys.stdout.write(first_chars) for i in range(100): x_pred = np.zeros((1, maxlen, len(chars))) for t, char in enumerate(sentence): x_pred[0, t, char_indices[char]] = 1. preds = model.predict(x_pred, verbose=0)[0] next_index = sample(preds, diversity) next_char = indices_char[next_index] if next_char == "\n": sys.stdout.flush() break sentence = sentence[1:] + next_char sys.stdout.write(next_char) sys.stdout.flush() print() for l in iter(sys.stdin.readline, ""): l = l.rstrip() if l == "": continue if len(l) < 3: print("ERROR: input must be >= 3 characters", file=sys.stderr) continue if not all(c in chars for c in l): print("ERROR: invalid charater", file=sys.stderr) continue generate(model, l)実行例。
>>> イエス イエス・キリストはあなたを義とする イエス・キリストはあなたの義とこと イエス・キリストの血は罪を清める。 イエス・キリストを永遠の命の源 イエス・キリストは人を愛し、その源 イエス・キリストを信じなさい イエス・キリストはあなたの造り主 イエス・キリストはあなたに永遠の命を与える イエス・キリストの血は罪を清める。 イエス・キリストは、のき先 >>> キリス キリストは甦り永遠の命を与える キリストは身代わりに罪を負った。 キリストを信じる者は永遠の命を持つ キリストの血罪をきよめる キリストが道・真理・命 キリストは救世主 キリストにある永遠の命を持つ。 キリストは罪を清める キリスト以外に救いはない キリストを世につかわされた >>> あなた あなたの造り主 あなたを罪から解放する。 あなたの創造主を覚えよ。 あなたを罪から清められた。 あなたを義とする あなたの創造主を覚えよ。 あなたを義とする あなたの創造主を覚えよ。 あなたの造り主 あなたの創造主を覚えよ。 >>> 真の神 真の神の分身 真の神はない 真の神は人を愛し、その罪を負った。 真の神の分身 真の神の分身 真の神 真の神を信じる者は永遠の命を与える 真の神なた。 真の神を信じる者は死んでも生きる 真の神「真の神を信じる者は死んでも生きる」、学習データに同じ文はないのですが、普通に意味が通っていますし、個人的には気に入りました。(笑)
課題
- 学習データに出てくる文字しか出力できない
- このプログラムでは、例えば「ネコと和解せよ」などは絶対に出ない
- 単語単位のモデルを作り、word2vecを活用して意味の近い単語を使えるようになればいいかも?
- こういう学習済みのパラメータを活用できるのでは?→Kyubyong/wordvectors: Pre-trained word vectors of 30+ languages
- 学習データと全く同じ文章も結構出てくる
- 文法的におかしい文や、意味のおかしい文も出てくる
- 例えば「真の神を信じる者は永遠の命を与える」だと意味的に主語と述語の対応がおかしい
- SeqGANとかがこの問題を解決しているらしい→SeqGANを用いてテキスト(小説のあらすじ)の生成をする - Qiita
- まずは基本的なSeq2Seqを勉強しよう。。。
- 学習データ自体が非常に少ない
- こればかりはどうしようもない…
まとめ
キリスト看板ジェネレータの復活 (v2):これも私が作っています(また宣伝)。



- 投稿日:2020-04-30T17:44:15+09:00
Ruby と Perl と Java と Python で解く AtCoder ATC 002 A
はじめに
AtCoder Typical Contest(ATC) とは、競技プログラミングにおける、典型問題を出題するコンテストです。
AtCoder さん、ありがとうございます。今回のお題
AtCoder Typical Contest 002 A - 幅優先探索
今回のテーマ、幅優先探索
Ruby
DFS(深さ優先探索)とBFS(幅優先探索)の違いについて、いろいろあると思いますが、ここではデータの流れに注目します。
DFS BFS 後入れ先出し 先入れ先出し データ構造 スタック キュー データを入れる push push データを取り出す pop shift ruby.rbr, c = gets.split.map(&:to_i) sy, sx = gets.split.map(&:to_i) gy, gx = gets.split.map(&:to_i) cm = Array.new(r + 1).map{Array.new(c + 1, 0)} 1.upto(r) do |i| s = gets.chomp 1.upto(c) do |j| cm[i][j] = -1 if s[j - 1] == '.' end end que = [] que.push(sy) que.push(sx) cm[sy][sx] = 0 while que.size > 0 y = que.shift x = que.shift if cm[y + 1][x] == -1 cm[y + 1][x] = cm[y][x] + 1 que.push(y + 1) que.push(x) end if cm[y - 1][x] == -1 cm[y - 1][x] = cm[y][x] + 1 que.push(y - 1) que.push(x) end if cm[y][x + 1] == -1 cm[y][x + 1] = cm[y][x] + 1 que.push(y) que.push(x + 1) end if cm[y][x - 1] == -1 cm[y][x - 1] = cm[y][x] + 1 que.push(y) que.push(x - 1) end end puts cm[gy][gx]que に push して shift して que が空になるまで while で回す要領です。
末尾にデータを追加 先頭のデータを取り出す push shift que.rbque.push(sy) que.push(sx)xy 座標を別々に push していますが、リファレンスで配列ごと渡してもいいと思います。
array.rbif cm[y + 1][x] == -1 if cm[y - 1][x] == -1 if cm[y][x + 1] == -1 if cm[y][x - 1] == -1上下左右をチェックしていますが、出題によっては右と下のみに減ったりします。
Python
python.pyfrom collections import deque r, c = map(int, input().split()) sy, sx = map(int, input().split()) gy, gx = map(int, input().split()) cm = [[0 for j in range(c + 1)] for i in range(r + 1)] for i in range(1, r + 1): s = input() for j in range(1, c + 1): if s[j - 1] == ".": cm[i][j] = -1 que = deque([]) que.append(sy) que.append(sx) cm[sy][sx] = 0 while len(que) > 0: y = que.popleft() x = que.popleft() if cm[y + 1][x] == -1: cm[y + 1][x] = cm[y][x] + 1 que.append(y + 1) que.append(x) if cm[y - 1][x] == -1: cm[y - 1][x] = cm[y][x] + 1 que.append(y - 1) que.append(x) if cm[y][x + 1] == -1: cm[y][x + 1] = cm[y][x] + 1 que.append(y) que.append(x + 1) if cm[y][x - 1] == -1: cm[y][x - 1] = cm[y][x] + 1 que.append(y) que.append(x - 1) print(cm[gy][gx])deque の場合
末尾にデータを追加 先頭のデータを取り出す append popleft Perl
perl.plchomp (my ($r, $c) = split / /, <STDIN>); chomp (my ($sy, $sx) = split / /, <STDIN>); chomp (my ($gy, $gx) = split / /, <STDIN>); my @cm; for my $i (1..$r) { chomp (my $s = <STDIN>); for my $j (1..$c) { $cm[$i][$j] = -1 if substr($s, $j - 1, 1) eq '.'; } } my @que; push @que, $sy; push @que, $sx; $cm[$sy][$sx] = 0; while(@que) { my $y = shift @que; my $x = shift @que; if ($cm[$y + 1][$x] == -1) { $cm[$y + 1][$x] = $cm[$y][$x] + 1; push @que, $y + 1; push @que, $x; } if ($cm[$y - 1][$x] == -1) { $cm[$y - 1][$x] = $cm[$y][$x] + 1; push @que, $y - 1; push @que, $x; } if ($cm[$y][$x + 1] == -1) { $cm[$y][$x + 1] = $cm[$y][$x] + 1; push @que, $y; push @que, $x + 1; } if ($cm[$y][$x - 1] == -1) { $cm[$y][$x - 1] = $cm[$y][$x] + 1; push @que, $y; push @que, $x - 1; } } print $cm[$gy][$gx], "\n";
末尾にデータを追加 先頭のデータを取り出す push shift Java
java.javaimport java.util.*; class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int r = Integer.parseInt(sc.next()); int c = Integer.parseInt(sc.next()); int sy = Integer.parseInt(sc.next()); int sx = Integer.parseInt(sc.next()); int gy = Integer.parseInt(sc.next()); int gx = Integer.parseInt(sc.next()); int cm[][] = new int[r + 1][c + 1]; for (int i = 1; i <= r; i++) { String s = sc.next(); for (int j = 1; j <= c; j++) { if (".".equals(s.substring(j - 1, j))) { cm[i][j] = -1; } } } sc.close(); Deque<Integer> que = new ArrayDeque<>(); que.add(sy); que.add(sx); cm[sy][sx] = 0; while (que.size() > 0) { int y = que.poll(); int x = que.poll(); if (cm[y + 1][x] == -1) { cm[y + 1][x] = cm[y][x] + 1; que.add(y + 1); que.add(x); } if (cm[y - 1][x] == -1) { cm[y - 1][x] = cm[y][x] + 1; que.add(y - 1); que.add(x); } if (cm[y][x + 1] == -1) { cm[y][x + 1] = cm[y][x] + 1; que.add(y); que.add(x + 1); } if (cm[y][x - 1] == -1) { cm[y][x - 1] = cm[y][x] + 1; que.add(y); que.add(x - 1); } } System.out.println(cm[gy][gx]); } }Deque の場合
末尾にデータを追加 先頭のデータを取り出す add poll
Ruby Python Perl Java コード長 791 Byte 935 Byte 915 Byte 1660 Byte 実行時間 10 ms 24 ms 5 ms 106 ms メモリ 1788 KB 3436 KB 512 KB 23636 KB まとめ
- ATC 002 A を解いた
- Ruby に詳しくなった
- Python に詳しくなった
- Perl に詳しくなった
- Java に詳しくなった
- 投稿日:2020-04-30T17:10:06+09:00
【Python】二次元リストを一次元リストに変換する方法
Pythonで二次元リストを一次元リストに変換したい場合がある。
sum関数を使えば一行で変換可能。知らないと一見何をしている処理なのか分からないけど、使ってみると意外と便利。
三次元リストを一次元リストに変換したい場合はsum関数を二回使えばよい。x = [[1, 2], [3, 4]] x = sum(x, []) print(x) # [1, 2, 3, 4] y = [[[1, 2], [3, 4]], [[5, 6], [7, 8]]] y = sum(sum(y, []), []) print(y) # [1, 2, 3, 4, 5, 6, 7, 8]速度重視の場合はitertools.chain.from_iterable()を使う。
こちらの方がsum関数を使う場合よりも高速。import itertools x = [[1, 2], [3, 4]] x = itertools.chain.from_iterable(x) print(list(x)) # [1, 2, 3, 4] y = [[[1, 2], [3, 4]], [[5, 6], [7, 8]]] y = itertools.chain.from_iterable(list(itertools.chain.from_iterable(y))) print(list(y)) # [1, 2, 3, 4, 5, 6, 7, 8]上記の他にも自作関数を作るという方法もある。
リストの次元数に依らないので、様々な次元数のデータを扱うときはオススメ。https://stackoverflow.com/questions/2158395/flatten-an-irregular-list-of-lists
- 投稿日:2020-04-30T17:03:47+09:00
Pythonでファイル名が悪くてimportでハマった
ちょっとしたテストをしようとして、import したいモジュールと同じ名前を付けてハマりました。常識なのかもしれませんが、知らなかったのでメモしておきます。
エラー
math モジュールのテストをしたくて、math.py というファイルを書いたとします。
math.pyimport math print(math.pi)これを実行するとエラーになります。
実行結果$ python math.py Traceback (most recent call last): File "math.py", line 1, in <module> import math File "/home/xxxx/math.py", line 2, in <module> print(math.pi) AttributeError: partially initialized module 'math' has no attribute 'pi' (most likely due to a circular import)自分自身を循環参照
原因はエラーに書いてあるように自分自身を import して循環してしまったことです。
(most likely due to a circular import)
すぐには分からなかったので、適当に print を入れたりしてみました。
math.pyprint("math") import math print(math.pi)実行結果$ python math.py math math Traceback (most recent call last): File "math.py", line 2, in <module> import math File "/home/xxxx/math.py", line 3, in <module> print(math.pi) AttributeError: partially initialized module 'math' has no attribute 'pi' (most likely due to a circular import)
mathが2回表示されています。これでようやく、自分自身を参照していることが分かりました。同じファイルの2回目の import は無視されるので先に進んで、
math.piがないことからエラーになります。結論
ファイル名を変えれば動きます。import の対象と同じファイル名は避けましょう。
- 投稿日:2020-04-30T16:46:27+09:00
Python ファイルに日本語書込みエラーUnicodeEncodeError を解決する
Pythonの鬼門として文字コードの扱いは必ず挙げられると思います。
Pythonを使い始めた初期はこの文字コードの扱いに辟易して二度と使うか!と思ってた時期もありました。
今はもう慣れましたが。。。さて何をしようとしていたか
- Pythonスクリプトで、DBのAPIでクエリログを取得する。
- ファイルに書き込む。
もうこんだけです。
そのクエリログに日本語コメントが入っていると、書き込んだ時に冒頭のUnicodeEncodeErrorが起きることがありました。
その状況と解決を書きてみます。
Python は2.7です。今時ごめんなさい。。。。確認したときは大丈夫だったのに...
DB APIで取得したときは問題なくクエリログを取得できて不要な文字列なども削除できていました。
お試しのログを書き込むこともできた!
そこで、「あーじゃあもうファイルに書き込むだけじゃん!」っと思ってたんですね。ではそのようにをファイルに書き込んでみましょう。
# -*- coding: utf-8 -*- # 実際はAPIでログを取得しますが、ここでは動作確認のために文字列のログにします。 log = "aaa 日本語" with open("test.txt", "a") as f: f.write(log + "\r\n")ファイルのtest.txtをみると
aaa 日本語ちゃんと書かれてる。じゃあもうAPIからクエリログを取得して動かすだけだ。
っと思っていたんですね。そこでAPIからログを取得して書き込んでみたら下記のようなエラーが。。
(すみませんがAPIの部分は省略させてもらいます)Traceback (most recent call last): File "writetest.py", line 11, in <module> f.write(log + "\r\n") UnicodeEncodeError: 'ascii' codec can't encode characters in position 4-6: ordinal not in range(128)結論から言うと、APIで取得した文字列がUnicode型で扱われていました。
どうもpython2ではwriteで書き込むときはデフォルトのasciiで書き込もうとするから起きるエラーのようです。
あまり詳しく調べられてませんが、そういうものみたいです。どうやって解決したかというと
log = log.encode("utf_8")というように一度utf-8に変換して書き込みました。
# -*- coding: utf-8 -*- # APIでログを取得 log = (APIでログを取得) log = log.encode("utf_8") with open("test.txt", "a") as f: f.write(log + "\r\n")ちなみにですが、
f.write(log.encode("utf_8") + "\r\n")でも同様のエラーでした。
その他解決方法
上記の解決も含て
- 一度utf-8に変換する ex. log = log.encode("utf_8")
- codecモジュールを使ってファイルオープンするときに"utf_8"で開いて書き込む
- python3だとopenの時に文字コードを指定できるので、"utf_8"で開いて書き込む
といった方法があるようです。
Unicode型の動作
ちなみにUnicode型の簡単な動作を確認してみましょう。
# coding: utf-8 str_1 = "日本語" str_2 = u"日本語" print str_1 print str_2 print type(str_1) print type(str_2) print len(str_1) print len(str_2) print ("本" in str_1) print (u"本" in str_2) print str_1.find("本") print str_2.find(u"本")これを実行すると
日本語 # print str_1 日本語 # print str_2 <type 'str'> # print type(str_1) <type 'unicode'> # print type(str_2) 9 # print len(str_1) 3 # print len(str_2) True # print ("本" in str_1) True # print (u"本" in str_2) 3 # print str_1.find("本") 1 # print str_2.find(u"本")ざっと見た感じ、
str型は文字列がバイト形式で扱われていて
unicode型は(人が直感的に判断できる)文字として扱われている
とわかりますね。このことからも文字列を扱うのであればunicodeの方が扱いやすいかと思います。
そのためであれば冒頭のpythonによるAPIでログを取得したときのログはunicode型で取得されていたことが理解できます。
ちなみにですが、このへんの動きはまったく知りませんでしたw
- 投稿日:2020-04-30T16:45:11+09:00
Python: 教師あり学習:ハイパーパラメーターその1
ハイパーパラメーターとチューニング
ハイパーパラメーターとは
機械学習においても学習過程全てを自動化することは難しく
人の手でモデルを調整しなければならない場合が存在します。ハイパーパラメーターとは、機械学習のモデルが持つパラメーターの中で
人が調整をしないといけないパラメーターのことです。ハイパーパラメーターは選択した手法によって異なるため、モデルごとに説明をしていきます
チューニングとは
ハイパーパラメーターを調整することをチューニングと呼びます。
調整方法については直接値をモデルに入力すること以外にも
ハイパーパラメーターの値の範囲を指定し、探索的に最適な値を探す方法も存在します。scikit-learnではモデルの構築時にパラメーターに値を入力することで
パラメーターのチューニングが可能です。
パラメーターを入力しなかった場合
モデルごとに定められているパラメーターの初期値がそのまま値として指定されます。コードとしては以下のようなものとなります。
# 架空のモデルClassifierを例にしたチューニング方法 model = Classifier(param1=1.0, param2=True, param3="linear")ロジスティック回帰のハイパーパラメーター
パラメーター C
ロジスティック回帰にはCというパラメーターが存在します。このCはモデルが学習する識別境界線が教師データの分類間違いに対して
どのくらい厳しくするのかという指標になります。Cの値が大きいほどモデルは教師データを完全に分類できるような識別線を学習するようになります。
しかし教師データに対して過剰なほどの学習を行うために過学習に陥り
訓練データ以外のデータに予測を行うと正解率が下がる場合が多くなります。Cの値を小さくすると教師データの分類の誤りに寛容になります。
分類間違いを許容することで外れ値データに境界線が左右されにくくなりより
一般化された境界線を得やすくなります。
ただし、外れ値の少ないデータでは境界線がうまく識別できていないものになってしまう場合もあります。
また、極端に小さくてもうまく境界線が識別できません。scikit-learnのロジスティック回帰モデルのCの初期値は1.0です。
import matplotlib.pyplot as plt from sklearn.linear_model import LogisticRegression from sklearn.datasets import make_classification from sklearn import preprocessing from sklearn.model_selection import train_test_split %matplotlib inline # データの生成 X, y = make_classification( n_samples=1250, n_features=4, n_informative=2, n_redundant=2, random_state=42) train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=42) # Cの値の範囲を設定(今回は1e-5,1e-4,1e-3,0.01,0.1,1,10,100,1000,10000) C_list = [10 ** i for i in range(-5, 5)] # グラフ描画用の空リストを用意 train_accuracy = [] test_accuracy = [] # 以下コのコードが重要です。 for C in C_list: model = LogisticRegression(C=C, random_state=42) # Cのリストを持ってきてます。 model.fit(train_X, train_y) train_accuracy.append(model.score(train_X, train_y)) test_accuracy.append(model.score(test_X, test_y)) # グラフの準備 # semilogx()はxのスケールを10のx乗のスケールに変更する plt.semilogx(C_list, train_accuracy, label="accuracy of train_data") plt.semilogx(C_list, test_accuracy, label="accuracy of test_data") plt.title("accuracy by changing C") plt.xlabel("C") plt.ylabel("accuracy") plt.legend() plt.show()パラメーター penalty
先ほどのCが分類の誤りの許容度だったのに対し
penaltyはモデルの複雑さに対するペナルティを表します。penaltyに入力できる値は二つ、「L1」と「L2」です。 基本的には「L2」を選べば大丈夫ですが、「L1」を選ぶ方が欲しいデータが得られる場合もあります。
L1: データの特徴量を削減することで識別境界線の一般化を図るペナルティです。 L2: データ全体の重みを減少させることで識別境界線の一般化を図るペナルティです。パラメーター multi_class
multi_classは多クラス分類を行う際にモデルがどういった動作を行うかということを決めるパラメーターです。ロジスティック回帰では「ovr」、「multinomial」の2つの値が用意されています。
ovr: クラスに対して「属する/属さない」の二値で応えるような問題に適しています。
multinomial: 各クラスに分類される確率も考慮され
「属する/属さない」だけではなく「どれくらい属する可能性があるか」を扱う問題に適しています。パラメーター random_state
モデルは学習の際にデータをランダムな順番で処理していくのですが
random_stateはその順番を制御するためのパラメーターです。ロジスティック回帰モデルの場合、データによっては処理順によって大きく境界線が変わる場合があります。
また、このrandom_stateの値を固定することで同じデータでの学習結果を保存することができます。
線形SVMのハイパーパラメーター
パラメーター C
SVMにもロジスティック回帰と同様に分類の誤りの許容度を示すCが
パラメーターとして定義されています。 使い方もロジスティック回帰と同様です。SVMはロジスティック回帰に比べてCによるデータのラベルの予測値変動が激しいです。
SVMのアルゴリズムはロジスティック回帰にくらべてより一般化された境界線を得るため
誤りの許容度が上下するとサポートベクターが変化し、ロジスティック回帰よりも正解率が上下することになります。線形SVMモデルではCの初期値は1.0です。
モジュールはLinearSVCを利用します。from sklearn.svm import LinearSVC # 線形SVMのモデルを構築 model = LinearSVC(C=C,random_state=2)パラメーター penalty
ロジスティック回帰同様に線形SVMにもpenaltyのパラメーターがあります。
設定できる値も同じく、"L1"と"L2"です
- L1ペナルティは主成分を抽出する働きがあります。
- L2ペナルティは特定の相関性を見ず、データ全体の関係性を用いてモデルを説明しようとします。
パラメーター multi_class
multi_classは多項分類を行う際にモデルがどういった動作を行うかということを決めるパラメーターです。
線形SVMでは「ovr」、「crammer_singer」の2つの値が用意されています。
基本的にはovrの方が動作が軽く結果が良いですパラメーター random_state
結果の固定(乱数の固定)に用いられるrandom_stateですが、SVMに関してはサポートベクターの決定にも関わります。
最終的に学習する境界線はほぼ同じになるものの、わずかながら差異が出ることに留意してください。非線形SVMのハイパーパラメーター
パラメーター C
線形分離可能でないデータを扱う場合SVMのSVCというモジュールを使います。
SVCでもロジティック回帰、SVMと同様にパラメーターCが存在します。非線形SVMではCを調整してペナルティを与えます。
ペナルティは、学習時に分類の誤りをどの程度許容するかを制御します。パラメーター kernel
パラメーターkernelは非線形SVMの中でも特に重要なパラメーターであり
受け取ったデータを操作して分類しやすい形にするための関数を定義するパラメーターです。linear、rbf、poly、sigmoid、precomputedの5つを値としてとることができます。
デフォルトはrbfです。linear # 線形SVMであり、LinearSVCとほぼ同じです。特殊な理由がない限りはLinearSVCを使いましょう。 rbf poly # 立体投影のようなものです。 # rbfは他のものに比べ比較的高い正解率が出ることが多いので通常はデフォルトであるrbfを使用します。 precomputed # データが前処理によってすでに整形済みの場合に用います。 sigmoid # ロジスティック回帰モデルと同じ処理を行います。パラメーター decision_function_shape
decision_function_shapeはSVCにおけるmulti_classパラメーターのようなものです。
ovo、ovrの2つの値が用意されています。
ovo クラス同士のペアを作り、そのペアでの2項分類を行い多数決で属する クラスを決定するという考え方です。 計算量が多くデータの量の増大によっては動作が重くなることが考えられます。 ovr 一つのクラスとそれ以外という分類を行い多数決で属するクラスを決定します。パラメーター random_state
random_stateはデータの処理順に関係するパラメーターです。
予測結果を再現するために、学習の段階では固定することを推奨します。機械学習を実際に行う時には乱数を生成するための生成器を指定する方法があります。
生成器を指定する場合のコードは以下の通りです。import numpy as np from sklearn.svm import SVC # 乱数生成器を構築 random_state = np.random.RandomState() # 乱数生成器をrandom_stateに指定したSVMモデルを構築 model = SVC(random_state=random_state)