- 投稿日:2020-04-30T23:42:01+09:00
文字列の中に変数を入れる記法
自分はもともとRubyでプログラミングに触れて、eRubyでCGIを書いたりしてたから文字列の中に
{}でくくった変数を入れるのを多用していたのですが。HelloWorld.rbstr1 = "Hello" str2 = "World!" print "#{str1}, #{str2}\n"これをC#で書こうとしたらこうなります。
HelloWorld.csvar str1 = "Hello"; var str2 = "World!"; Console.Write($"{str1}, {str2}\n") ;別解でこういう風にも書けるようです。
HelloWorldAlt.csvar str1 = "Hello"; var str2 = "World!"; Console.Write("{0}, {1}\n", str1, str2);ところで、最近Javaをはじめたのですが、Javaだとこういう風に書くみたいです。
HelloWorld.javavar str1 = "Hello"; var str2 = "World!"; System.out.printf("%s, %s\n", str1, str2);後で書いた
HelloWorldAlt.csのC#のパターンに近いですね。
ぶっちゃけJavaが一番わかりづらいので、今後C#で書く時もJava表記に近い後者の記法を書いていこうかなと思いました。
- 投稿日:2020-04-30T23:29:52+09:00
こんなコードは嫌だ!現場で実際に見たアンチパターン集
はじめに
内容はタイトルの通りなのですが、アンチパターンなコードを書いた人をこき下ろす意図は一切ありません。コードを憎んで人を憎まずという言葉もありますしね。1
そのようなネガティブな動機ではなく、アンチパターンからできるだけ教訓を汲み取って前に進もうというポジティブな動機で筆を執っています。全体的に古い話が多いので、最近はこのようなコードや状況が減っていたらいいな、と願っているところです。
環境
- 主にJava 6
内容
Struts1を拡張したオレオレフレームワークの使用
ご存知の方も多いでしょうけど、Struts1はもう何年も前にサポートが切れているので、この時点で嫌な予感しかしないところです。
Strutsをそのまま使うならまだいいんですが、そのプロジェクトでは見出しの通りStrutsを拡張したオレオレフレームワークを使っていました。そのフレームワークでは、1リクエストの処理を書くのに大量のクラスを作成する必要があり、StrutsのActionやFormBean、ビジネスロジックを記述するBLogic、BLogicへの入力のためのBLogicInputBean、出力のためのBLogicOutputBean、JSP、場合によってはDAOやDAOに渡すためのDAOBeanも必要など盛り沢山でした。他にもstruts-config、Strutsのvalidation、Springの定義、iBATISのsqlMapとXMLファイルの修正もてんこもり。
特に、同じようなBeanを何種類も作る必要があるのは謎でしたが、それらのBeanはフレームワークの規約として嫌でも作るしかなく、それに中身はほぼ同じなのに型としては別なので、Beanの詰め替えを手動で書く必要があって時間をとられました。2
しかも、これらを「1リクエストごと」に作成するので、表示のリクエスト、新規登録や更新のリクエスト、画面の一部項目を更新するためのリクエストなど、それぞれに対して上記を作成する必要がありました。とにかく修正量が多いので非常に生産性が低かったです。どうすれば良かったのか
当時はまだStrutsに代わるような有力なフレームワークがあまりなかったので、Strutsの採用自体はある程度は仕方がなかったのかなと思います。ただ、素のStrutsでは不要な大量のクラスの作成を強制するように魔改造してしまったのは謎です。素のStrutsをそのまま使えばよかったのではと思います。
簡単に調べてみると、そういうフレームワークは生産性を上げることではなく、開発者のスキルが低くてもなんとかなるようにすることが目的なのだとか。3
もしかしたら、そのようなフレームワークを採用した上で単価の安い新人をアサインし、コストを削減していたのかもしれません。(実際、新人が多かったです)
このフレームワークの選定がそういった政治的な理由によるものだとすると、もはやどうしようもないですね。逃げ出すくらいしか対処方法が思いつきません。技術力が高い人なら参考リンク先の方のように技術的に頑張ることもできるかもしれないですが、当時の私は思いつかなかったです。私はまともなプログラマじゃないかもしれません。とりあえず、今から新規開発するならStrutsを選ぶ理由はないでしょう。やっぱりSpring Bootがいいんでしょうかね。
コピープログラミングの横行
既存の機能と似たような機能を作る時についやってしまうのがコピープログラミングです。既存のコードをコピペして差分だけ修正するというアレです。私もやってしまうことがあるので偉そうなことは言えないし、コピープログラミングが常に悪だと言う気はありませんが、それでもコピープログラミングには欠点があることを指摘せざるをえません。
コピープログラミングを行うと、自分がよく理解していないコードでもあっという間に機能が実装できてしまうため、ある種の快感がありますし、さらに一見すると生産性が高そうに見えますが、メンテナンス時に地獄を見ます。
まず、何か修正があったらコピーした部分の全てに対して同じ修正をしなければなりません。それに、コピーした際の修正漏れで、変なバグを発生させるリスクがあります。コピーによって、内容をよく理解していないのに一気に組み立てられてしまったコードは読むのが大変に億劫なので確認が疎かになりがちで、修正漏れが発生することはよくあります。コードの修正漏れは問題ですが、コメントの修正漏れもまた問題です。コメントの修正が漏れても動作に影響しないため、ある意味ではコードの修正漏れよりもたちが悪いかもしれません。私が見たプロジェクトではコピープログラミングが横行しており、というかコーディングの大半がコピープログラミングによってなされていたのではと思われます。そのプロジェクトではコメントの修正漏れがとにかく多くて、もはやコメントが全く信用できない状態になっていました。それではコメントがないのと同じです。コメントが全くないコードをメンテナンスすることの辛さは、皆様もよくご存知のことだろうと思います。
どうすれば良かったのか
同じ処理なら、コピーするのではなくメソッド等に抽出して共有すべきでした。それなら修正が発生しても一箇所だけ直せばいいですし、そもそもコピーしないので修正漏れも発生しません。
ただし、逆に言えば一箇所修正するだけで複数箇所に影響が及ぶようになるため、「本当に共有していいのか?」ということはよく検討しなければいけません。4修正内容をコメントアウトして全て残す
諸悪の根源です。皆様も一度は聞いたことがあるであろう、悪名高いやつです。一時的にコメントアウトするくらいならいいですが、ここで言っているのは全ての修正について永続的にコメントアウトしたままにするということです。その上、そのプロジェクトでは修正時のルールとして、修正開始を示すコメントと修正終了を示すコメントも挿入しなければならないこととなっていました。修正をするたびにゴミが増えるため、非常に邪魔です。とても読みづらいですし、検索のノイズにもなります。全ての修正が残るため、コードは汚くなる一方です。修正が多い箇所ではカオス過ぎて読めたものではありません。
言うまでもなく、コードを読むというのは非常に高頻度で行われる作業ですから、これも生産性がガタ落ちする原因の一つでした。百害あって一利なしとはこのことです。どうすれば良かったのか
SVNでもGitでも何でもいいですが、何らかのバージョン管理システムを使うべきです。バージョン管理システムがあればこのようなことは一切する必要はありません。今時、バージョン管理システムを使わずに開発しているプロジェクトなどないでしょう。…ない…ですよね………?
もっとも、そのプロジェクトではSVNでバージョン管理していたにもかかわらず上記のルールだったので、全くもって意味不明だったのですが…JSPのスクリプトレットに大量のJavaコード
JSPにビジネスロジックが大量に記述されているという場面がよくありました。HTMLとJavaが混在して非常に読みにくかったです。あと、一つのJSPファイルに記述するコード量が多すぎてエラーになる5場合があったため、一つの画面でJSPを分割していて、これまた読みにくかったです。適切な単位で分割するのはいいんですが、この場合は巨大なJSPを適当に2つや3つにぶった切ってファイル名に連番を付けるというやり方だったので、適切な単位での分割とは言い難かったです。
それと、条件によって画面の表示が変わるのを実装するために、愚直に条件分岐を使って全部べた書きしていました。これもコード量が膨れ上がって読みづらくなる原因となっていました。どうすれば良かったのか
ビジネスロジックはモデルに書きましょう。MVCの基本です。
また、条件によって画面の表示が変わるのならサブのJSPを作って読み込ませるなど、一つのファイルが肥大化しないようにするための工夫をすべきです。ちなみに、今は新規開発でJSPを採用することはあまりないのではと思います。今主流なのはやっぱりThymeleafですかね。
リファクタリングしない
触らぬコードに祟りなしということで、コード上問題があっても、動作上の問題がなければ触ってはならないことになっていました。そのためちょっとした問題は修正されず、どんどん増えていきました。警告が出ていても修正できないので、警告が溜まりに溜まっていました。警告が大量にあると、本当に問題がある警告が埋もれてしまうので、これは非常に良くないです。
また、TODOコメントも大量に放置されていました。長期間TODOのままで放置されていると、どう扱っていいのか地味に困ります。また、個人的に追加したTODOが埋もれてしまうので邪魔でもあります。
どうすれば良かったのか
多少時間を割いてでもリファクタリングを行うべきでした。時間がないからやらないというのは一見正しそうに聞こえますが、そうではありません。やることはたくさんあるので、自然に時間ができるなんてことはまずありません。他の作業を調整して時間を作るという思考でないと時間なんてできません。ないのは時間ではなくやる気です。6
また、コードを触るとテストしなくてはならないので嫌という話もあります。それはわかるのですが、テストしてでもリファクタリングすべき場合もあります。また、バグ修正や機能追加によってコードを修正した際に、どうせテストしなければならないので、ついでにリファクタリングも行うなどの工夫も、その気になればできますし、そうすべきだったと思います。
ちょっとした修正であればUT実行で担保できそうなものですが、このプロジェクトではそもそもUTなんて全く書きませんでした。まずはそこからですね…もっとも、修正内容をコメントアウトして全て残すルールがある限り、リファクタリングもくそもありません。最低でもこのルールだけは何としても破棄しないといけません。
定数病
一般的に、何度も出現する固定値を定数で扱うようにするのは良いこととされていますが、その意図がわからずに意味不明な定数が作られてしまうことがあります。
public static final int INT_0 = 0; public static final int INT_1 = 1; // 以下同じようなのがずらずらと続くこれではリテラルを使うのと何も変わりませんね。謎ですが、これを書いた人は誤った教育によってリテラルを直接使うのは悪であると刷り込まれてしまったのかもしれません。
定数病という言葉は自分で考えたつもりだったのですが、既に同じことを考える人もいたようです。まさにこんな感じです。
【ソース編】「DIV病」とは、何事もやり過ぎると危険であることの代名詞であるどうすれば良かったのか
あまり解説するまでもないような気もしますが、定数とは本来は将来変更されるかもしれない値に対して使うものだと思います。定数を定義して、その値が必要な箇所では定数を参照するようにしておくことで、何か変更があっても定数の初期化の部分だけ修正すれば済みます。
また、将来変更するかもしれないという性質から、定数名はどのような意味の値なのかということを元に命名すべきで、具体的にどのような値が入っているのかということを元に命名するのはナンセンスです。
簡単な例を示します。// ダメな例 public static final String LF = "\n"; // 良い例 public static final String LINE_SEPARATOR = "\n";ダメな例のほうだと、将来変更されることになった際に困りますよね。下の例のように、値が変わっても違和感がない命名にしましょう。
あと、将来変更される可能性があまりない値であれば、無理に定数を使わずにそのまま使えばいいと思います。こちらも例を示します。
public static boolean isEven(int num) { return num % 2 == 0; }ご覧の通り、数値が偶数かどうかを判定するコードです。「2」や「0」といった数値リテラルをそのまま使っていますが、この例であればこれらの数値が将来変更されるとは考えづらいです。そのため、リテラルをそのまま使っても特に問題はないと思います。
拡張for文を使わない
拡張for文を使える箇所で、普通のfor文で頑張っているコードもよく見かけました。ループカウンタが必要ないのであれば、拡張for文を使いましょう。そのほうが書きやすく、バグが入り込む余地が少なく、読みやすくなります。使える場面で使わない理由があまり思いつかないのですが、おそらく存在を知らないでしょう。
そんな人いる!?と思われたかもしれませんが、普通にいると思います。でも最初に書いたように、そういった方をこき下ろす意図は全くありません。知らないのであればこれから知っていけばいいだけですからね。
また、Java8以降であればStream APIの使用も検討しましょう。クラス名に機能IDが使われている
クラスにはクラスの責務がわかるような名前をつけるのが一般的ですが、あるプロジェクトでは全てのクラスが機能IDで命名されていました。適当に考えた例ですが、たとえば「AP060.java」「AP060BLogic.java」「AP060Bean.java」とかそんな感じです。これでは各クラスが何なのかサッパリわかりません。まあ、どの機能IDが何の機能なのかを覚えてしまえば意外と大丈夫だったりするので、人間ってすごいなーと思ったのですが、一般的には異常な命名規則であると認識しておく必要があります。
どうすれば良かったのか
これも書くまでもないでしょうけど、そのクラスが何なのかわかるような名前を付けましょう。名前重要。
if文の中のコードが長すぎる
if文の中の行数が長すぎて、何がどこに書かれているのかよくわからないというコードもよく見ました。if文の中に何百行と処理が書かれていて、終わったと思ったら今度はelseの中に似たようなコードが延々と続くみたいな。
分岐の条件は、新規登録の場合と更新の場合など、大半は同じ処理だけど一部だけ値が異なるみたいな感じのが多かったです。差分に対してだけif文を使えよと…どうすれば良かったのか
ちょっと書いちゃいましたが同じ処理ならif文の外に出して、差分だけ条件分岐すべきです。また、意味をなす条件分岐だとしても長いのはやはり辛いので、そのような場合はif文の中の処理をメソッドに切り出してわかりやすい名前を付けるなど、ちょっとした工夫で読みやすさを追求したいところです。場合によっては、ポリモーフィズムを活用して条件分岐そのものを消せないかどうか検討してもいいでしょう。
スコープが無駄に広い
ローカル変数をメソッドの先頭で定義しているが、その変数を実際に使うのはずっと下みたいなコードをよく見かけました。C言語(の古いバージョン)であればそうしないとコンパイルエラーになりますが、Javaにはそのような制約はないので、何の意味もありません。ただ変数の定義部分と使用する部分が離れてわかりづらくなるだけです。
また、ローカル変数で事足りるのにわざわざフィールドとして定義している変数も散見されました。フィールドだと他のメソッドから読み書きされている可能性もあるので、値の変遷を追うのが辛くなります。どうすれば良かったのか
ローカル変数は必要になってから定義しましょう。また、1つのメソッド内でしか使わない変数はフィールドではなくローカル変数として定義しましょう。まあ、この辺りはIDEが警告を出してくれるかもしれませんが。
変数の使い回しによるリソース解放漏れ
疑似コードですが、こんな感じのコードをよく見かけました。何がダメなのかおわかりでしょうか?
ResultSet rs = null; try { for(HogeBean bean : beanList) { // なんかbeanを使った処理... rs = stmt.executeQuery(); // なんかrsを使った処理... } } finally { if(rs != null) { rs.close(); } }まあ見出しで察しがつくかもしれませんが、リソース解放がきちんと実行されていません。ループの中で変数rsを使い回しているので、close()がちゃんと呼ばれるのは最後の1つだけです。
どうすれば良かったのか
try-finallyをfor文の中に入れるなどして、全てに対してclose()が呼ばれるようにしましょう。加えて、Java7以降ならtry-with-resourcesを使いましょう。まあ、これは静的解析ツールで検出されるとは思いますが。
インデントが適当
インデントは重要です。インデントが適当なソースは本当に読むのに苦労します。if文やfor文などがネストしている場合は特に。
何もないところでインデントしていたり、インデントが必要な箇所なのにしていなかったり、酷いコードをよく見かけました。前述のif文の中のコードが長すぎるのと相まって本当に読みづらかったです。おそらく、書いた人自身も混乱してしまっているのでしょう。コードが何百行とあるのが元凶ですね…
しかし、それだけではありません。修正内容をコメントアウトして全て残すという問題があります。ほとんどのメンバーは先頭行に「// 」を付ける形式でコメントアウトしていたのですが、これをやるとコメントアウトされたコードが少し後ろにズレます。これも混乱の元になりました。さらに、インデントくらい勝手に直したいものですが、コメントアウトで残すルールのせいでなんとなく修正しづらいと感じてしまいました。
なんかもう、複数の原因が絡まり合って酷いことになっていてため息しか出ませんでした。どうすれば良かったのか
根が深い問題ですが、コメントアウトルールの廃止と、何百行とあるコードの削減がまず必要です。それができれば、インデントも自然に直るのではと思います。
無駄にStringBuffer
別にスレッドセーフが求められるわけでもない箇所で、文字列の連結にStringBuilderではなくStringBufferを使っているコードもよく見かけました。これも拡張for文を使わないと同じで、StringBuilderの存在を知らないのでしょう。まあ、それで性能問題が発生したわけでもないので、どうでもいいのかもしれませんが。
ラッパークラス同士を
==で比較しているこれは厄介なバグに繋がりかねない問題です。ラッパークラス同士だと参照を比較するため、基本的には別のインスタンスの場合は同値であっても
falseが返ってきます。ここまではString同士を==で比較してはいけないのと同じです。
しかし、厄介なのは値によってはtrueが返ってくることもあるということです。具体的には-128〜127の値だと、同値であれば別インスタンスであってもtrueが返ります。小さい値でテストした時は問題なかったからといって==で比較したコードをリリースしたりすると痛い目にあうかもしれません。要注意です。どうすれば良かったのか
Stringと同様に
equalsを使って比較しましょう。ちなみに、この問題は静的解析ツールで検出されると思います。ロジック上、絶対にthrowされないチェック例外がthrows宣言されている
見たことがあります。メソッドの定義上はthrowされるように見えるけど、ロジック上は絶対に投げられない例外がthrows宣言されていることにより、例外処理のコードが爆発的に増殖していく様を…
それはあちこちから呼ばれる重要なメソッドだったので、それはもう大変に増殖していました。その例外は絶対に投げられないのに。絶対に投げられない例外を処理するためのコードなんてゴミとしか言いようがありません。こうしてまたコードが無駄に肥大化するのでした。
むしゃくしゃして無断で消してまわりました。とても楽しかったです。どうすればよかったのか
throws節の定義は慎重に設計しましょう。その例外は本当に投げられることがあるのか、よく確認しましょう。Javaのチェック例外は、呼び出し元に例外処理を強制するという強い力を持っています。その例外の処理を呼び出し元に強制させるのは本当に適切なのか、よくよく考えましょう。
その他(コード以外)
iBATISの使用
iBATISは便利なORマッパーなのですが、とっくの昔にサポート切れしており、Raw型のListを返すなど仕様も古いです。後続のMyBatisに移行すべきでしょう。
Excelを使った設計書で、修正前の内容をグループ化して残す
Excelでは特定の行や列をグループ化することができ、グループ化した箇所はワンクリックで表示・非表示を切り替えることができます。この機能を使って、修正前の内容を非表示状態で残すということです。
こいつも百害あって一利くらいしかない代物です。まず、修正内容を全て残すためファイルが重くなり、表示に時間がかかって生産性が落ちます。また、普段は非表示とはいえ存在はしているため検索ノイズになりますし、オートフィル機能で連番などを作る時に、途中にそのグループがあると、その中身にも連番が作成されてしまって非常に邪魔です。
なんか、修正内容をコメントアウトして全て残すのと似ていますね。基本的に、修正履歴をそのファイル自体に持たせるのは悪いアイデアなのかもしれません。
なお、一利くらいはあると書きましたが、ワンクリックで修正前の内容を閲覧できるのは一応便利です。でもメリットはそれくらいしか思いつかず、デメリットのほうが多いです。どうすれば良かったのか
設計書をSVNなどでバージョン管理すればいいのではと思います。もちろんExcelファイルはバイナリファイルなので、そのままバージョン管理してもあまりうれしくありません。なので、設計書をExcelではなくMarkdownやAsciiDocで作成すればいいと思います。それならテキストファイルなのでバージョン管理しやすいですし、どうしてもExcelがいいなら、MarkdownやAsciiDocをExcelファイルに変換すればいいです。(ちゃんと調べてないですが、たぶんできると思います)
使い勝手の悪いオレオレカバレッジ計測ツール
プロジェクトで使用するように指示されたカバレッジ計測ツールが、元のコードを全コピーしてカバレッジ計測用のソースコードを埋め込むというなかなか大胆な方法をとるツールでした。(カバレッジ計測ツールには詳しくないのですが、バイトコードレベルで見るのが一般的のような気が…)
テスト(UTではなく手動のテスト)を実施する際に、そのツールが生成したソースコードをビルドしてテストを実行するというルールとなっていたのですが、そのツールがコピーして配置してくれるのはJavaのファイルだけなので、その他のXMLやJSPなどは全部手動コピーしなければならず、テストが実施できるようになるまでに時間がかかって非常に不便でした。
それに、元のソースとツールが生成したソースの2つがあるので、2つのファイルの同期がとれているように気を使わないといけません。ソースを少し修正したあとに、その修正を計測用ソースのほうに反映させるのを忘れて、テストをやり直すハメになるといった事故が何度か起こりました。
さらに、カバレッジを計測するには謎のSwingアプリケーションを起動させておかなければならず、重くて邪魔でした。
さらにさらに、そのSwingアプリケーションを立ち上げてなくても正常に動作してしまう(動作はするがカバレッジは計測されない)ため、ここでも後で気づいてテストやり直しという事故が起こりました。
このように使い勝手の悪いツールの使用を強制され、また生産性が下がるのでした。どうすれば良かったのか
正直なところカバレッジ計測ツールに詳しくないのですが、自社でしか使われていないようなオレオレツールではなく、JaCoCoとか有名なツールを使えば良かったのではと思います。今の私の職場で使っているカバレッジ計測ツールはたしかJaCoCoなんですが、ソースコードレベルで計測コードを埋め込むなどという事故を誘発するような処理はなかったと思います。
というか、カバレッジ計測って手動テスト時ではなくてUT実行時に計測するのが一般的ですよね。そもそも、UTを全く書いていないのが問題なのかもしれません。7SVNで1ファイルずつコミットする人
これも謎なんですがいらっしゃったのですよね、そういうお方。一つの修正なのにコミットが複数(それも2つや3つではなくたくさん)に分散するので、修正履歴を見るのが面倒です。おそらくバージョン管理システムの意義がよくわかっておらず、単にみんなでソースを共有できる仕組みくらいにしか思っていないのでしょう。
それだけならまだいいほうで、中には全部コミットし終わってないのに離席しちゃうような猛者もいます。その間にチェックアウトしてしまうと、もちろん中途半端な状態で取得されてしまって、消えないコンパイルエラーに悩まされることになります。どうすれば良かったのか
バージョン管理システムはどのようなもので、上記のような振る舞いがどういう影響をもたらすか、言って聞かせるしかないでしょうかね。他社の人だったり、自社の先輩だったりするから面倒ですが…(※今の職場ではありません)
終わりに
コードと言いつつコード以外の内容も含まれていてごった煮のようになってしまいましたが、何か一つでも参考になった項目があれば幸いです。
ググってみたら本当にありました。 ↩
後に、似てるけど型が違うBeanの内容をコピーしてくれるライブラリがあることを知ったので、その点は多少楽になったのですが。 ↩
参考: 侵略的なフレームワーク ↩
参考: javaの制限である1メソッド内でコンパイル結果が65535バイトを越すと、実行できない問題を即時解決してほしい。 ↩
時期にかかわらず全員が毎日22時くらいまで働いていて、たまに休出もあるという状況だったので、時間がないというのは本当でした。ただ、全体的に非効率的な開発手法だったり、体調不良で頻繁に休む人がいたり、自席を立ってから30分くらい戻ってこない人がいたり等、諸々合算されて時間がなくなっていたので、その気になれば時間の捻出は可能だったと思います。 ↩
UTがないのは間違いなく問題ですが、カバレッジの計測という観点から見ても同様、ということです。 ↩
- 投稿日:2020-04-30T22:32:29+09:00
「徹底攻略 Java SE 11 Silver 問題集」から学ぶオブジェクト指向設計
前置き
現在参画している現場でJavaの案件に携わることになりました。
しかし、エンジニア歴15年目になるにも関わらずずっと.NET周りの技術しか扱ってこなかったので、今回が初のJava案件になります。
そこでJavaの基礎知識をゼロベースで学ぶために、Java SE 11 Silver/Goldの取得を目標とした学習を始めることにしました。学習を始めるに当たり、まずは徹底攻略 Java SE 11 Silver 問題集(いわゆる「黒本」を購入しました。
回答の解説が非常に丁寧に記載されているので、試験対策だけでなく基礎知識を学ぶのに最適な教材だと感じたのですが、自分は書籍内で「参考(試験対策と直接関係ないが、知っておくと有益な情報)」と記載されている箇所に注目しました。
「参考」の箇所でも、特に今後「オブジェクト指向」を深堀りしていくのであれば非常に重要となる記述が散見されたので、今回の記事ではそれらをまとめてみようと思います。
P51より:不変(immutable)オブジェクト
「第2章 Javaの基本データ型と文字列操作」のStringオブジェクトに関する問題の解説からです。
データが不適切に変更されることを防ぐための「不変(immutable)オブジェクト」の実装例が記載されています。これはDDD(ドメイン駆動設計)における「Value Object(値オブジェクト)」の実装に必須となる知識です。参考:設計要件をギッチギチに詰めたValueObjectで低凝集クラスを爆殺する
P203より:引数が多いほどメソッドは使いにくくなる
「第6章 インスタンスとメソッド」における、呼び出し元メソッドとメソッド宣言で定義している引数の数についての問題の解答からです。
- 引数が多いほどそのメソッドは使いにくくなってしまう
- たくさんの引数を受け取るメソッドを定義するのであれば、それらの引数をフィールドに持つ1つのオブジェクトを受け取るようにしたほうが、より簡潔で変更にも強くなる
といった参考情報が記載されています。
私が最近見かけた具体例ですと
ドメイン駆動設計入門 ボトムアップでわかる!ドメイン駆動設計の基本
のサンプルコードで引数をフィールドに持つオブジェクト「〜Command」と定義する「コマンドオブジェクト」戦略が非常にわかりやすい良例だと思います。引数をフィールドに持つ「〜Command」オブジェクト例
https://github.com/nrslib/itddd/blob/master/Layered/SnsApplication/Users/Get/UserGetCommand.cs
「〜Command」オブジェクトを呼び出すメソッド例
https://github.com/nrslib/itddd/blob/master/Layered/WebApplication/Controllers/UserController.cs#L36
こちらのサンプルコードでは戻り値も「〜Result」オブジェクトとしてまとめていることで、簡潔で変更に強い設計になってい点も参考になると思います。
P220より:カプセル化
「第6章 インスタンスとメソッド」における、カプセル化の概念に関する問題の解説からです。
こちらの問題は「コードが提示されていてそこにカプセル化を適用したい。以下から最適なコードを選べ」といった内容です。
よって、「カプセル化」に関する知識は試験対策としても必須な知識となるのですがオブジェクト指向においても同様の知識と思われます。
カプセル化については以下のように解説されています。カプセル化は、ソフトウェアを分割する際に、関係するデータとそのデータを必要する処理を1つにまとめ、無関係なものや関係性の低いものをクラスから排除することで「何のためのクラスなのか?」というクラスの目的を明確化するために行い、ほかのクラスに重複するデータや処理がない状態を目指すものです。
前述のValue Objectはまさに「カプセル化」を実現するための手法の1つです。
そして、「カプセル化」したオブジェクトを実装するためには「データ隠蔽」、Javaにおいてはオブジェクト内のフィールドはprivateで修飾(隠蔽)し、フィールドの値を使ったメソッドを公開(public)することと、といったことも記載されています。P244より:「継承」は使われなくなってきている
「第7章 クラスの継承、インターフェース、抽象クラス」における、クラスの継承に関する問題の解説からです。
クラスの継承はオブジェクト指向言語においては必須となる知識ですが最近では、継承を使うことで保守性が低下する可能の高まりが指摘されています。
と記述されています。
継承を安易にしようしてしまうとどのような事が起きてしまうかは、以下の投稿で解りやすく解説されています。あなたが保守しているシステムにも「AbstractController」とか「AbstractService」みたいな共通処理が多数実装された「神・基底クラス」が存在していたりしませんか?
実装方法が継承よりもハードルが高いかもしれませんが、継承を使いたくなったら「移譲」や「合成」を検討するのが現代のオブジェクト指向設計のベストプラクティスなのかもしれません。
p259より:リスコフの置換原則
「第7章 クラスの継承、インターフェース、抽象クラス」における、メソッドのオーバーライドに関する問題の解説からです。
参考情報として「サブクラスはスーパークラスと置き換え可能でなければいけない」という原則、「リスコフの置換原則(LSV:Liskov Substitution Principle)」が紹介されています。
オブジェクト指向にはほかにもたくさんの原則があること、より良い設計をするためにはこれらの原則をしっかりと学習することを勧める、といった記載もあります。
これらの原則の代表例といえば「リスコフの置換原則」も含めた5つの原則、いわゆる「SOLID原則」です。
- Single Responsibility Principle:単一責任の原則
- Open/closed principle:オープン/クロースドの原則
- Liskov substitution principle:リスコフの置換原則
- Interface segregation principle:インターフェース分離の原則
- Dependency inversion principle:依存性逆転の原則
SOLID原則については、以下の投稿がコード例も添えて解りやすく解説されています。
P283より:デザインパターンとStrategyパターン
「第8章 関数型インターフェース、ラムダ式」のおけるラムダ式の基本的な宣言方法に関する問題の解説からです。
本設問のコード自体が、Strategyパターンをラムダ式を使って実現したものとなっており、そこからGoFのデザインパターンの紹介とStrategyパターンの解説が記載されています。Javaとデザインパターンと言えば、もう15年前の出版物となってしまいますが
増補改訂版 Java言語で学ぶデザインパターン入門
を思い出しました。
当時、Javaは扱っていませんでしたがデザインパターンの実装例がサンプルコードともに掲載されており、非常に勉強になりました。
Amazonのレビュー上ではここ1〜2年の間でも高評価のレビューが投稿されているので、今も変わらず名著と評価されているようです。まとめ
以上、「徹底攻略 Java SE 11 Silver 問題集」の「参考」情報からより深くオブジェクト指向設計を学ぶための補足となるような形でまとめてみました。
本問題集を読んだJavaおよびプログラミング初心者(あるいはベテランの方も?)の方が、本記事にたまたまたどり着いてオブジェクト指向をより深く学んでいくきっかけに繋がったら幸いです。
- 投稿日:2020-04-30T21:29:21+09:00
【Java】Resource interpreted as Stylesheet but transferred with MIME type text/html
CSSが適用されなくてずっとハマっていた時の話。せっかくなのでここに書き留めておく。
ちなみに、Javaのコードに原因があった話なので関係ない方は参考にならないと思います。環境
OS: Windows10
サーバー: Apache Tomcat 9.0.26
Java: JDK13
HTML: HTML5
CSS: CSS3ブラウザで警告が出ていた
CSSは正しくダウンロードされているのに、適用されていない。ブラウザの開発ツールを見ると、この警告が出ていた。
Resource interpreted as Stylesheet but transferred with MIME type text/html*Internet ExplorerやMicrosoft Edgeだと次のような警告になる。
SEC7113: CSS は、MIME の種類が一致しないため、無視されましたいくつかのブラウザで試しても同じだったので、サーバー側に問題があることは察しがついた。
行きついた原因
原因は、次のコードにあった。クラス名やメソッド名から分かる通り、フィルターである。
EncodingFilter.javaimport java.io.IOException; import javax.servlet.Filter; import javax.servlet.FilterChain; import javax.servlet.FilterConfig; import javax.servlet.ServletException; import javax.servlet.ServletRequest; import javax.servlet.ServletResponse; public class EncodingFilter implements Filter{ public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException{ request.setCharacterEncoding("UTF-8"); //↓ここが原因箇所! response.setContentType("text/html; charset=UTF-8"); //↑ここが原因箇所! chain.doFilter(request, response); } public void init(FilterConfig filtercConfig){}; public void destroy(){} }web.xmlでこのフィルターを通るように設定していて、CSSファイルに関して、どうもこれでContentTypeが「text/html; charset=UTF-8」になってしまっていたようだった。
ちなみに、web.xmlとCSSファイルの読み取りはそれぞれ以下のようなコード。
web.xml<?xml version="1.0" encoding="UTF-8"?> <web-app version="4.0" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"> <filter> <filter-name>EncodingFilter</filter-name> <filter-class>tool.EncodingFilter</filter-class> </filter> <filter-mapping> <filter-name>EncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> </web-app><link href="background.css" rel="stylesheet" type="text/css">解決方法
EncodingFilter.javaで原因箇所の部分を次のように書き換える。
response.setCharacterEncoding("UTF-8");
これで無事直った。サーバーの設定に問題があるかと思ったよ…。*ブラウザでCtrl+F5を行わないと反映されないのでお忘れなく。キャッシュを消去して更新。
余談
EncodingFilter.javaは本に倣って書いていたものでした。こんな罠があるとは…。
- 投稿日:2020-04-30T19:36:14+09:00
読みやすいコードを意識するために
読みやすいコードを意識する
気を抜くと冗長なコードになりがちになるので、意識づけのために
可読性の高くなるポイントについてまとめました。条件式を簡潔化
javaif (a == 1 && b == 2 && c == 3 && d == 4){ System.out.println("test"); } //if 文の条件式を折り返す if (a == 1 && b == 2 && c == 3 && d == 4){ System.out.println("test"); } //メソッドを作り可読性をあげる if (output()){ System.out.println("test"); } private boolean isValidType(){ //処理 return true; }ネストが深すぎる
java//NG if(a == 1){ if(b == 2){ if(c == 3){ if(d == 4){ if(e == 5){ System.out.println("test"); } } } } } //OK ////同じくメソッドを作り可読性をあげる if (isValidType()){ System.out.println("test"); } private boolean isValidType(){ //処理 return true; }変数名やメソッド名が不適切
命名規則にそって宣言
スネークケース
javaString user_name = "太郎"ローワーキャメルケース
javaString userName = "太郎"アッパーキャメルケース
javaString UserName = "太郎"チェインケース
javaString user-name = "太郎"codicを使って自動で変数名を作成
スコープ有効範囲の意識
java//NG class Calculator { public static int num = 0; public static void alterNumber(int _num) { num = _num; } public static void main(String args[]) { alterNum(23); } } //OK //アクセス制御子によりクラスの中だけでしか実行できない class Calculator { private static int num = 0; private static void alterNumber(int _num) { num = _num; } public static void main(String args[]) { alterNum(23); } }コードの統合化
java//NG public class StandAction extends BaseAction { public void Stand(Account account) { if(account.getFirstName() == null || account.getFirstName().length()== 0) { return; } if(account.getLastName() == null || account.getLastName().length() == 0) { return; } } } //OK //メソッドを追加したので可読性の向上 public class Stand extends BaseAction { public void Stand(Account account){ if(isEmpty(account.getFirstName())){ return; } if(isEmpty(account.getLastName())) { return; } } public boolean isEmpty(String str) { return str == null || str.length() == 0; } }

- 投稿日:2020-04-30T19:15:47+09:00
AWS LambdaのJavaは遅い?
AWS Lambdaで動作するJavaは初回が遅いですが、速くする方法がないか調べました。
末尾にある参考サイトの内容にたどり着いて、実際に試してみたのでその記録です。レイテンシ情報はX-Rayにて取得しました。
テスト対象
S3にファイルをPUTするだけのものです
S3Client s3 = S3Client.builder().region(Region.AP_NORTHEAST_1).build(); PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("filename.txt").build(), RequestBody.fromString("contents"));検証1 普通に実行
まずは普通に試してみます。
ソース全体
package helloworld; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import software.amazon.awssdk.core.sync.RequestBody; import software.amazon.awssdk.regions.Region; import software.amazon.awssdk.services.s3.S3Client; import software.amazon.awssdk.services.s3.model.PutObjectRequest; import software.amazon.awssdk.services.s3.model.PutObjectResponse; public class TestTarget0429 implements RequestHandler<Object, Object> { public Object handleRequest(final Object input, final Context context) { String ENV_BUCKET = System.getenv("BUCKET"); S3Client s3 = S3Client.builder().region(Region.AP_NORTHEAST_1).build(); PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("filename.txt").build(), RequestBody.fromString("contents")); System.out.println(result); return null; } }
回数 レイテンシ(ms) 処理内容 1 6200 2 422 3 217 4 210 5 315 1回目だけ遅い、いわゆるコールドスタートが遅い状態ですね。
S3に1ファイル作成するだけで6秒は遅いですよねぇ。検証2 Provisioned Concurrencyを有効化
では昨年末に登場した
Provisioned Concurrencyを使うとどうでしょう。
https://aws.amazon.com/jp/blogs/news/new-provisioned-concurrency-for-lambda-functions/ソースコードは検証1と同じものです。
回数 レイテンシ(ms) 処理内容 1 5500 2 266 3 274 4 402 5 304 初回が遅いままじゃないか。。
同時実行1をプロビジョンドしただけでも月$14.42かかるのに、あんまりじゃないか。。。なので、以降はProvisioned Concurrencyを無効にして検証を続けます
検証3 処理の分離(Provisioned Concurrencyなし)
初回に遅い原因を探るため、Lambda初回起動時と2回目起動時で処理を分けてみました。
staticな
count変数を作って、初回呼び出し時のみ速攻returnしてみます。if (count == 1) { count++; return null; }
ソース全体
package helloworld; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import software.amazon.awssdk.core.sync.RequestBody; import software.amazon.awssdk.regions.Region; import software.amazon.awssdk.services.s3.S3Client; import software.amazon.awssdk.services.s3.model.PutObjectRequest; import software.amazon.awssdk.services.s3.model.PutObjectResponse; public class TestTarget0429 implements RequestHandler<Object, Object> { private static int count = 1; public Object handleRequest(final Object input, final Context context) { if (count == 1) { count++; return null; } String ENV_BUCKET = System.getenv("BUCKET"); S3Client s3 = S3Client.builder().region(Region.AP_NORTHEAST_1).build(); PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("filename.txt").build(), RequestBody.fromString("contents")); System.out.println(result); return null; } }結果
回数 レイテンシ 処理内容 1 625ms Initialization処理のみ 2 5600ms S3 PUT(1回目) 3 393ms S3 PUT(2回目) 4 401ms S3 PUT(3回目) 5 311ms S3 PUT(4回目) Initialization処理が遅いわけじゃないことがわかりました。
S3 PUT(初回)に時間がかかっているようです。検証4 初期化処理をstaticにする(Provisioned Concurrencyなし)
S3Clientを作る部分をstatic化してみます。
private static String ENV_BUCKET = System.getenv("BUCKET"); private static S3Client s3 = S3Client.builder().region(Region.AP_NORTHEAST_1).build();
ソース全体
package helloworld; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import software.amazon.awssdk.core.sync.RequestBody; import software.amazon.awssdk.regions.Region; import software.amazon.awssdk.services.s3.S3Client; import software.amazon.awssdk.services.s3.model.PutObjectRequest; import software.amazon.awssdk.services.s3.model.PutObjectResponse; public class TestTarget0429 implements RequestHandler<Object, Object> { private static int count = 1; private static String ENV_BUCKET = System.getenv("BUCKET"); private static S3Client s3 = S3Client.builder().region(Region.AP_NORTHEAST_1).build(); public Object handleRequest(final Object input, final Context context) { if (count == 1) { count++; return null; } PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("filename.txt").build(), RequestBody.fromString("contents")); System.out.println(result); return null; } }結果
回数 レイテンシ 処理内容 1 2400ms Initialization処理 と S3Clientインスタンスの生成 2 2200ms S3 PUT(1回目) 3 43ms S3 PUT(2回目) 4 46ms S3 PUT(3回目) 5 78ms S3 PUT(4回目) お!少し1回目の処理時間がかかるようになって、2回目が少し早くなりましたね。
3回目以降も早くなってますがこれもなにか影響があるのでしょうか?検証5 staticイニシャライザで1回やっちゃう(Provisioned Concurrencyなし)
staticで処理をすれば早くなることがわかりました。
一旦staticイニシャライザでダミーファイルを作成してみます。static{ PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("dummy.txt").build(), RequestBody.fromString("contents")); System.out.println(result); }
ソース全体
package helloworld; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import software.amazon.awssdk.core.sync.RequestBody; import software.amazon.awssdk.regions.Region; import software.amazon.awssdk.services.s3.S3Client; import software.amazon.awssdk.services.s3.model.PutObjectRequest; import software.amazon.awssdk.services.s3.model.PutObjectResponse; public class TestTarget0429 implements RequestHandler<Object, Object> { private static int count = 1; private static String ENV_BUCKET = System.getenv("BUCKET"); private static S3Client s3 = S3Client.builder().region(Region.AP_NORTHEAST_1).build(); static{ PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("dummy.txt").build(), RequestBody.fromString("contents")); System.out.println(result); } public Object handleRequest(final Object input, final Context context) { if (count == 1) { count++; return null; } PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("filename.txt").build(), RequestBody.fromString("contents")); System.out.println(result); return null; } }結果
回数 レイテンシ 処理内容 1 4000ms Initialization処理 と staticメソッドによるS3 PUT(1回目)ダミーファイル 2 42ms S3 PUT(2回目) 3 125ms S3 PUT(3回目) 4 42ms S3 PUT(4回目) 5 44ms S3 PUT(5回目) めでたく2回目以降が速くなりましたよ~!
検証6 検証5+Provisioned Concurrency
検証5で早くなったので、Provisioned Concurrencyも組み合わせたら、1回目から速くなるのか?!
ソースは検証5と同じものです。
回数 レイテンシ 処理内容 1 80ms Initialization処理 2 370ms S3 PUT(2回目)※Provisionedの際にstaticイニシャライザで1回実行済みのため 3 43ms S3 PUT(3回目) 4 72ms S3 PUT(4回目) 5 84ms S3 PUT(5回目) やりましたよ!
期待してたのはこれです。最終結果
最終形はこうなりました。
- staticメソッドでダミーファイル作成を一回やっちゃう
- Provisioned Concurrency有効
ソース全体
package helloworld; import com.amazonaws.services.lambda.runtime.Context; import com.amazonaws.services.lambda.runtime.RequestHandler; import software.amazon.awssdk.core.sync.RequestBody; import software.amazon.awssdk.regions.Region; import software.amazon.awssdk.services.s3.S3Client; import software.amazon.awssdk.services.s3.model.PutObjectRequest; import software.amazon.awssdk.services.s3.model.PutObjectResponse; public class TestTarget0429 implements RequestHandler<Object, Object> { private static String ENV_BUCKET = System.getenv("BUCKET"); private static S3Client s3 = S3Client.builder().region(Region.AP_NORTHEAST_1).build(); static{ PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("dummy.txt").build(), RequestBody.fromString("contents")); System.out.println(result); } public Object handleRequest(final Object input, final Context context) { PutObjectResponse result = s3.putObject( PutObjectRequest.builder().bucket(ENV_BUCKET).key("filename.txt").build(), RequestBody.fromString("contents")); System.out.println(result); return null; } }
回数 レイテンシ 処理内容 1 552ms S3 PUT(2回目)※Provisionedの際にstaticイニシャライザで1回実行済みのため 2 118ms S3 PUT(3回目) 3 44ms S3 PUT(4回目) 4 86ms S3 PUT(5回目) 5 146ms S3 PUT(6回目) めでたし、めでたし。
考察
どうも、Javaのクラスローダーは初めてクラスが呼ばれたタイミングでクラスを読み込むようで、クラスの初期ロードに時間がかかるらしいです。
なので、一回読み込んじゃって、クラスをロード済みにしてしまえば次から速いということのようです。呼ばれたタイミングじゃなくて、はじめに全部クラスをロードしてくれたらいいんですが、そんなことはできないのですかねぇ。
参考サイトはこちらです。
クラスメソッドさんのブログ
https://dev.classmethod.jp/articles/report-best-practive-for-java-on-lambda/re:Invent 2019でのセッション資料
https://d1.awsstatic.com/events/reinvent/2019/REPEAT_1_Best_practices_for_AWS_Lambda_and_Java_SVS403-R1.pdf
https://youtu.be/ddg1u5HLwg8他に見つけたブログ
https://pattern-match.com/blog/2020/03/14/springboot2-and-aws-lambda-provisioned-concurrency/
- 投稿日:2020-04-30T18:37:50+09:00
MacOSでのPostgresSQLを用いたJDBCの始め方
はじめに
JDBCを触る機会があったのですが、個人用の環境でも練習したいと思い、PostgreSQLを導入した際の手順です。基本的には備忘録です。
各種バージョン等
- macOS : 10.15.4 - JDK : 13.0.1 - PostgreSQL : 12.2 - JDBC Driver : 42.4.12 - ターミナル : bashHomebrewを用いてPostgreSQLをインストール
上記の記事を参考にPostgreSQLをインストールします。
以下では、userとpasswordはpostgresqlとして説明します。PostgreSQL JDBC Driverをダウンロード
上記ページからJDBC Driverをダウンロードします。
JDBC Driver(jarファイル)の設置とCLASSPATHの設定
MacOSかつ、JDKのバージョンが8以下であれば、Java外部ライブラリ(jarファイル等)を
/Library/Java/Extensionsに設置するとクラスローダーがコンパイル時にJDBCのクラスファイルを探してくれます。
しかし、今回はJDK13を用いているためCLASSPATHを設定する必要があります。1. JDBC Driverの設置
ダウンロードした
postgresql-42.2.12.jarを/Library/Java/Extensionsに設置します。2. CLASSPATHの設定
コンパイル時にクラスローダーに反応させるために、環境変数CLASSPATHを設定します。
ターミナルを起動し、以下コマンドを実行します。CLASSPATHの設定及び再読み込みecho 'export CLASSPATH=.:/Library/Java/Extensions/postgresql-42.2.12.jar:$CLASSPATH' >> .bash_profile source ~/.bash_profile1行目は
.bash_profileへのCLASSPATHの書き込み
2行目は.bash_profileの再読み込み
をそれぞれ行っています。JDBCを用いたPostgreSQLへの接続テスト
最後に、テストテーブルの作成とデータベースへの接続及びデータの取得のデモを行います。
1. テスト用テーブルの作成
テストテーブル作成用SQLの作成
任意の場所に以下のファイルを作成します。
以下では~/Desktopに作成したものとします。createTestTable.sqlcreate table test( id serial primary key, name varchar(255), point real ); insert into test(name,point) values ('foo', 41.2), ('bar',55.1), ('baz', 10.7), ('qux', 98.0), ('quux', 22.2), ('foobar', 35.6);PostgreSQLの起動とデータベースの作成
ターミナルを起動し、以下コマンドを実行します。
PostgreSQLの起動とデータベースの作成brew services start postgresql createdb test psql testテスト用テーブルの作成
PostgreSQLのコンソールが起動したら、以下コマンドを実行します。
テスト用テーブルの作成\i ~/Desktop/createTestTable.sql \q2. JDBCからDBへの接続及びデータの取得
呼び出し用のJavaファイルの作成
任意の場所に以下のファイルを作成します。
以下では~/Desktopに作成したものとします。Main.javaimport java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; public class Main { public static void main(String[] args) { String url = "jdbc:postgresql://localhost/test"; String user = "postgresql"; String password = "postgresql"; String sql = "select * from test"; try(Connection con = DriverManager.getConnection(url, user, password)){ try(PreparedStatement ps = con.prepareStatement(sql)){ ResultSet rs = ps.executeQuery(); while (rs.next()){ System.out.print(rs.getString("name")); System.out.print(" gets "); System.out.println(rs.getInt("point")); } } catch(SQLException e){ e.printStackTrace(); } } catch(SQLException e){ e.printStackTrace(); } } }Javaファイルのコンパイルと実行
Javaファイルのコンパイルと実行cd ~/Desktop javac Main.java java Main出力結果
foo gets 41.2 bar gets 55.1 baz gets 10.7 qux gets 98.0 quux gets 22.2 foobar gets 35.6おわりに
初めてJDBCを用いてデータベースアクセスを行う方の手助けになればと思います。
誤り等あればご指摘頂けると幸いです。参考文献
- 投稿日:2020-04-30T17:44:15+09:00
Ruby と Perl と Java と Python で解く AtCoder ATC 002 A
はじめに
AtCoder Typical Contest(ATC) とは、競技プログラミングにおける、典型問題を出題するコンテストです。
AtCoder さん、ありがとうございます。今回のお題
AtCoder Typical Contest 002 A - 幅優先探索
今回のテーマ、幅優先探索
Ruby
DFS(深さ優先探索)とBFS(幅優先探索)の違いについて、いろいろあると思いますが、ここではデータの流れに注目します。
DFS BFS 後入れ先出し 先入れ先出し データ構造 スタック キュー データを入れる push push データを取り出す pop shift ruby.rbr, c = gets.split.map(&:to_i) sy, sx = gets.split.map(&:to_i) gy, gx = gets.split.map(&:to_i) cm = Array.new(r + 1).map{Array.new(c + 1, 0)} 1.upto(r) do |i| s = gets.chomp 1.upto(c) do |j| cm[i][j] = -1 if s[j - 1] == '.' end end que = [] que.push(sy) que.push(sx) cm[sy][sx] = 0 while que.size > 0 y = que.shift x = que.shift if cm[y + 1][x] == -1 cm[y + 1][x] = cm[y][x] + 1 que.push(y + 1) que.push(x) end if cm[y - 1][x] == -1 cm[y - 1][x] = cm[y][x] + 1 que.push(y - 1) que.push(x) end if cm[y][x + 1] == -1 cm[y][x + 1] = cm[y][x] + 1 que.push(y) que.push(x + 1) end if cm[y][x - 1] == -1 cm[y][x - 1] = cm[y][x] + 1 que.push(y) que.push(x - 1) end end puts cm[gy][gx]que に push して shift して que が空になるまで while で回す要領です。
末尾にデータを追加 先頭のデータを取り出す push shift que.rbque.push(sy) que.push(sx)xy 座標を別々に push していますが、リファレンスで配列ごと渡してもいいと思います。
array.rbif cm[y + 1][x] == -1 if cm[y - 1][x] == -1 if cm[y][x + 1] == -1 if cm[y][x - 1] == -1上下左右をチェックしていますが、出題によっては右と下のみに減ったりします。
Python
python.pyfrom collections import deque r, c = map(int, input().split()) sy, sx = map(int, input().split()) gy, gx = map(int, input().split()) cm = [[0 for j in range(c + 1)] for i in range(r + 1)] for i in range(1, r + 1): s = input() for j in range(1, c + 1): if s[j - 1] == ".": cm[i][j] = -1 que = deque([]) que.append(sy) que.append(sx) cm[sy][sx] = 0 while len(que) > 0: y = que.popleft() x = que.popleft() if cm[y + 1][x] == -1: cm[y + 1][x] = cm[y][x] + 1 que.append(y + 1) que.append(x) if cm[y - 1][x] == -1: cm[y - 1][x] = cm[y][x] + 1 que.append(y - 1) que.append(x) if cm[y][x + 1] == -1: cm[y][x + 1] = cm[y][x] + 1 que.append(y) que.append(x + 1) if cm[y][x - 1] == -1: cm[y][x - 1] = cm[y][x] + 1 que.append(y) que.append(x - 1) print(cm[gy][gx])deque の場合
末尾にデータを追加 先頭のデータを取り出す append popleft Perl
perl.plchomp (my ($r, $c) = split / /, <STDIN>); chomp (my ($sy, $sx) = split / /, <STDIN>); chomp (my ($gy, $gx) = split / /, <STDIN>); my @cm; for my $i (1..$r) { chomp (my $s = <STDIN>); for my $j (1..$c) { $cm[$i][$j] = -1 if substr($s, $j - 1, 1) eq '.'; } } my @que; push @que, $sy; push @que, $sx; $cm[$sy][$sx] = 0; while(@que) { my $y = shift @que; my $x = shift @que; if ($cm[$y + 1][$x] == -1) { $cm[$y + 1][$x] = $cm[$y][$x] + 1; push @que, $y + 1; push @que, $x; } if ($cm[$y - 1][$x] == -1) { $cm[$y - 1][$x] = $cm[$y][$x] + 1; push @que, $y - 1; push @que, $x; } if ($cm[$y][$x + 1] == -1) { $cm[$y][$x + 1] = $cm[$y][$x] + 1; push @que, $y; push @que, $x + 1; } if ($cm[$y][$x - 1] == -1) { $cm[$y][$x - 1] = $cm[$y][$x] + 1; push @que, $y; push @que, $x - 1; } } print $cm[$gy][$gx], "\n";
末尾にデータを追加 先頭のデータを取り出す push shift Java
java.javaimport java.util.*; class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int r = Integer.parseInt(sc.next()); int c = Integer.parseInt(sc.next()); int sy = Integer.parseInt(sc.next()); int sx = Integer.parseInt(sc.next()); int gy = Integer.parseInt(sc.next()); int gx = Integer.parseInt(sc.next()); int cm[][] = new int[r + 1][c + 1]; for (int i = 1; i <= r; i++) { String s = sc.next(); for (int j = 1; j <= c; j++) { if (".".equals(s.substring(j - 1, j))) { cm[i][j] = -1; } } } sc.close(); Deque<Integer> que = new ArrayDeque<>(); que.add(sy); que.add(sx); cm[sy][sx] = 0; while (que.size() > 0) { int y = que.poll(); int x = que.poll(); if (cm[y + 1][x] == -1) { cm[y + 1][x] = cm[y][x] + 1; que.add(y + 1); que.add(x); } if (cm[y - 1][x] == -1) { cm[y - 1][x] = cm[y][x] + 1; que.add(y - 1); que.add(x); } if (cm[y][x + 1] == -1) { cm[y][x + 1] = cm[y][x] + 1; que.add(y); que.add(x + 1); } if (cm[y][x - 1] == -1) { cm[y][x - 1] = cm[y][x] + 1; que.add(y); que.add(x - 1); } } System.out.println(cm[gy][gx]); } }Deque の場合
末尾にデータを追加 先頭のデータを取り出す add poll
Ruby Python Perl Java コード長 791 Byte 935 Byte 915 Byte 1660 Byte 実行時間 10 ms 24 ms 5 ms 106 ms メモリ 1788 KB 3436 KB 512 KB 23636 KB まとめ
- ATC 002 A を解いた
- Ruby に詳しくなった
- Python に詳しくなった
- Perl に詳しくなった
- Java に詳しくなった
- 投稿日:2020-04-30T16:45:33+09:00
IBMの「Liberty」について整理する
IBMから提供されているJava EE対応のアプリケーションサーバー「WebSphere Application Server」には,2012年からLibertyという新しいランタイムが提供されています。このLibertyという言葉はいろいろな意味で使われることがあり,混乱しているケースが(IBM社員でも)しばしばみられますので,整理してみたいと思います。
ランタイム
- Libertyプロファイル / WebSphere Liberty
前者はWAS V8.5の時の名称で,後者はV9.0での名称です。2012年に出荷されたV8.5から新しく追加されたランタイムです。クラウド自体に対応するために新たに開発されたランタイムで,完全モジュール化された軽量・高速なランタイムで,DevOpsやコンテナなどのモダンな環境にも適しています。
現在も活発に新機能の開発や新仕様への対応などが続けられています。
- Fullプロファイル / WebSphere traditional
前者はWAS V8.5の時の名称で,後者はV9.0での名称です。tWASとよばれることもあります。
1998年の登場以来バージョンアップが続けられている,従来型のランタイムです。過去との互換性に優れており,古いJava EEの仕様や,従来提供されていたIBM独自APIなどもほとんどそのまま利用できます。管理概念やツールなどもWAS V5.0のころからのものをほとんどそのまま継承しています。
ただ,モノリシックな実装が限界に達しており,現在提供されているものが最終バージョンで,今後は新機能の実装などはおこなわれません。
ライセンス
IBMから購入するライセンスとしては,三種類のエディションがあります。
- WebSphere Application Server Network Deployment(通称WAS ND)
- WebSphere Application Server(通称WAS Base)
- WebSphere Application Server Liberty Core(通称Liberty Core)
じつは,WAS BaseエディションやWAS NDエディションでも,WebSphere Libertyランタイムは使用できます。これらのエディションのライセンスは,購入いただいたCPU数の範囲で,WebSphere LibertyランタイムとWebSphere traditionalランタイムを自由に選択してご利用いただけます。
Liberty Coreエディションは,安価なWebSphere Libertyランタイム専用のライセンスです。このライセンスでは,WebSphere traditionalランタイムは使用できません。またWebSphere Libertyランタイムも,利用できるAPIがJava EEのサブセット,Web Profileに限定されています。
まとめ
表にまとめるとこのようになります。
Libertyという名前が,Liberty Coreというエディション名とWebSphere Libertyというランタイム名で混同されて使われることがありますので気をつけましょう。

- 投稿日:2020-04-30T16:18:29+09:00
触って覚えるgradle
gradleって何が嬉しいの?
これはDockerを人に勧める時にも同じことを思ったんだけど、正直口で言って良さを伝えるのは難しい。
gradleにしてもDockerにしてもどの部分に魅力を感じるかは人それぞれってのもあるし、便利を伝えてみても実感として伴わない。聞いてる方は「なるほど、便利そうだね」という位置に留まる。
そもそも「マジかよ! じゃあ早速使ってみるよ!」って人は、自分でガシガシ触ってみて、どういうものか掴もうとするから説明の必要がない。
自分で「とりあえず使う」が出来るればいい。しかしそれをやれるスキルに至っていないという事が多々ある。とりあえず……何をすればいいんだろう?よってこの記事のタグには「研修」をつけている。
世界に数多ある有用なツールを自分で戦力化できるようになるためには、いくつかのツールを戦力化するという実績を積むのが一番の近道だろう。この記事は、gradleを自分の戦力として扱うための手助けをする。
何が嬉しいか分かった時、その時にはすでに武器を一つ手に入れている。gradleのインストール
この記事では開発マシンのOSはWindowsを想定している。またIDEはEclipseだ。よっていくらかそれに特化した手順や記述が出てくる。
インストールがまだの人は、是非ともパッケージマネージャを使ってみよう。
MacではHomebrewなどあるが、Windowsを想定しているためscoopでの手順を記す。
まずは管理者権限でパワーシェルを立ち上げよう。スクリプト実行を許可する
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser -Forcescoopをインストールする
iex (new-object net.webclient).downloadstring('https://get.scoop.sh')gradleをインストールする
scoop install gradleプロキシを通る場合はもう少し手順が増えるが(PowerShellでプロキシを潜る方法は拙稿Docker for Windowのインストールから利用までの(ほぼ)CUI手順にあるので参照願いたい)コマンド3行コピペすればインストールできるのだから、便利な時代になったものだ。
scoopというパッケージマネージャは入れておいて損はない。この機会に入れておくと後々幸せかも知れない。プロジェクトのフォルダを作る
早速gradleを使ってみよう。なにはともあれプロジェクトのフォルダを作る。
プロジェクト名でフォルダを作る。今回は「Yebisu」とした。勿論、今飲んでいるビールである。作ったらエクスプローラでYebisuフォルダの中に入り、Shift+右クリックでメニューを出そう。PowerShell ウィンドウをここで開くというメニューがあるはずだ。それを選択してPowerShellを起動しよう。gradleプロジェクトの作成
gradle initこれを実行するといくつかのアンケートがある。今回はjava-appicationという事で以下のように入力してみよう。
- Select type of project to generate -> 2 (application)
- Select implementation language -> 3 (Java)
- Select build script DSL -> 1 (Groovy)
- Select test framework -> 4 (JUnit Jupiter)
- Project name -> そのままエンター(default)
- Source package -> 任意 (今回はyebisuとした)
PS D:\git-private\Yebisu> gradle init Starting a Gradle Daemon, 1 busy Daemon could not be reused, use --status for details Select type of project to generate: 1: basic 2: application 3: library 4: Gradle plugin Enter selection (default: basic) [1..4] 2 Select implementation language: 1: C++ 2: Groovy 3: Java 4: Kotlin 5: Swift Enter selection (default: Java) [1..5] 3 Select build script DSL: 1: Groovy 2: Kotlin Enter selection (default: Groovy) [1..2] 1 Select test framework: 1: JUnit 4 2: TestNG 3: Spock 4: JUnit Jupiter Enter selection (default: JUnit 4) [1..4] 4 Project name (default: Yebisu): Source package (default: Yebisu): yebisu > Task :init Get more help with your project: https://docs.gradle.org/6.1/userguide/tutorial_java_projects.html BUILD SUCCESSFUL in 1m 28s 2 actionable tasks: 2 executedこれでプロジェクトが作成できた。
このPowerShellウィンドウは閉じずに置いといて欲しい。Eclipseプロジェクトにする
今回のIDEはEclipseである。EclipseプロジェクトにするためにはEclipseプラグインを使う。この辺はお決まりの手順である。
すでにフォルダの中にはbuild.gradleがあるはずなので、テキストエディタで開いてみよう。
pluginsにeclipseを追加する。id 'application'の次行にid 'eclipse'を追記すればよい。尚、私は分かり切ったコメントが嫌いなので、コメントはとっとと消してしまっている。build.gradleplugins { id 'java' id 'application' id 'eclipse' } repositories { jcenter() } dependencies { implementation 'com.google.guava:guava:28.1-jre' testImplementation 'org.junit.jupiter:junit-jupiter-api:5.5.2' testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.5.2' } application { mainClassName = 'yebisu.App' } test { useJUnitPlatform() }編集が終わったらPowerShellで以下のコマンドを走らせよう。
./gradlew eclipse
これで.project .classpathファイル等が作られ、Eclipseに取り込める形となる。
Eclipseにインポートする
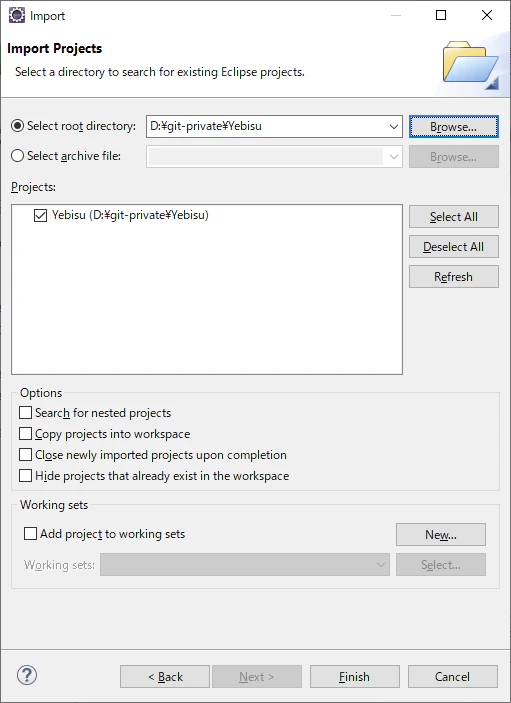
メニューバーの[File] -> Importでインポートウィザードを出そう。
Existing Projects into Workspaceを選択してNextだ。
Select root directoryにさっき作ったプロジェクトのパスを入力する。
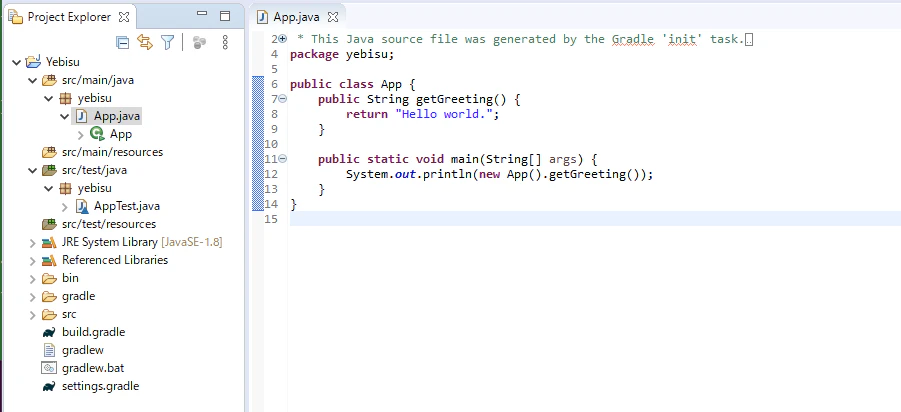
Projectsでチェックが入っている事を確認してFinishボタンを押そう。App.javaというソースファイルがあり、そこにmainが出来ているはずである。
- src/main/java 本体のソースファイル
- src/main/resources 本体のリソースファイル
- src/test/java 単体テストのソースファイル
- src/test/resources 単体テストのリソースファイル
ライブラリを追加する
Apache Commons IOのFilenameUtilsが使いたい!
こういう場合どうしていただろうか? もしかしたらCommons IOのjarをダウンロードしてプロジェクトの依存関係に追加していたかも知れない。
gradleではそんな事は必要ない。これを使うための一行を見つけてくればいいのだ。
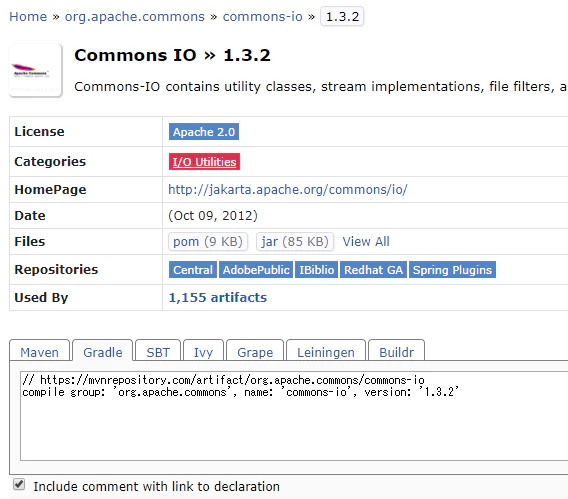
検索ワードは、FilenameUtils mavenとしてググってみよう。
MVNrepositoryというサイトを見つけられるはずだ。
Gradleタブを選択すると、その下のテキストボックスに呪文が出てくる。この呪文をコピーしよう。
これをbuild.gradleのdependenciesに貼り付ける。本当はcompileはimplementationにした方がいいのだが、今回はこのままベタリと貼り付けよう。build.gradledependencies { implementation 'com.google.guava:guava:28.1-jre' // https://mvnrepository.com/artifact/org.apache.commons/commons-io compile group: 'org.apache.commons', name: 'commons-io', version: '1.3.2' testImplementation 'org.junit.jupiter:junit-jupiter-api:5.5.2' testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine:5.5.2' }build.gradleをセーブしたら、PowerShellに戻って以下のコマンドだ。
./gradlew eclipseこれでFilenameUtilsはもう使える
Eclipseに戻って、プロジェクトをF5で更新しよう。プロジェクトを右クリックしてリフレッシュでも構わない。
Referenced Librariesのツリーを開いてみると、commmons-io-1.3.2.jarがある。
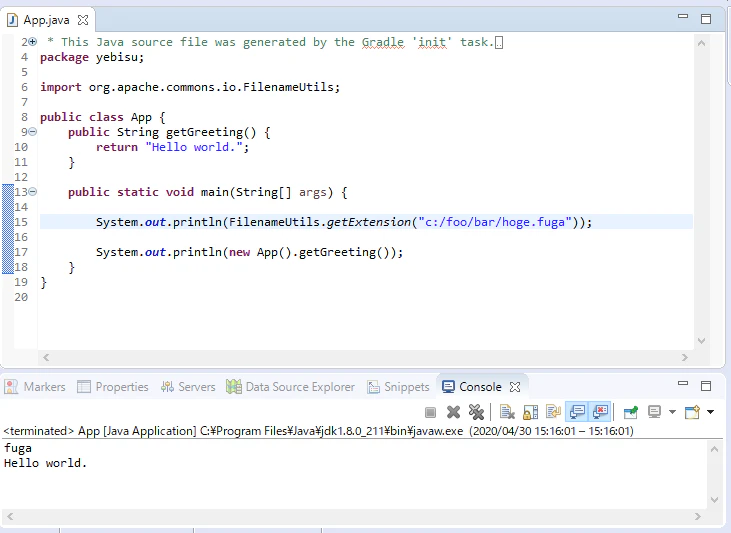
試しに使ってみよう。App.javaのmainに以下の行を書くと・・・
System.out.println(FilenameUtils.getExtension("c:/foo/bar/hoge.fuga"));Ctrl+Shift+'O'でimport org.apache.commons.io.FilenameUtils;が自動挿入されると思う。
早速実行してみよう。
画像ではEclipseから実行したが、gradleから実行する事もできる。
./gradlew run> Task :run fuga Hello world. BUILD SUCCESSFUL in 2s 2 actionable tasks: 1 executed, 1 up-to-date一応正しく書き直す
compileは実は古い書き方だ。group, name, versionの記述ももっとシンプルにできる。
build.graldecompile group: 'org.apache.commons', name: 'commons-io', version: '1.3.2' ↓ implementation 'org.apache.commons:commons-io:1.3.2'また複数のimplementationはまとめて書くことができる。
implementation('com.google.guava:guava:28.1-jre' ,'org.apache.commons:commons-io:1.3.2')Lombokを追加する
ほとんどのライブラリは上のやり方で取り込めるのだが、アノテーションプロセッサはやり方が変わってくる。私はLombokがないと知らぬ間に築いてた自分らしさの檻の中でもがいてしまうため無条件でdependenciesに以下を追加する。
build.gradlecompileOnly 'org.projectlombok:lombok:1.18.4' annotationProcessor "org.projectlombok:lombok:1.18.4" testCompileOnly 'org.projectlombok:lombok:1.18.4' testAnnotationProcessor "org.projectlombok:lombok:1.18.4"もしLombokのインストールが済んでいない場合は、インストールが必要だ。説明はLombokの使い方を説明してあるサイトに委ねるが、簡単にいうとLombok.jarをダブルクリックで起動させてインストールすればよい。eclipse.iniに記述されるため一回インストールしとけば、プロジェクトでの使用は上記の4行を頭空っぽにしてベトンと貼り付ければ良い。
Jarを作る
ここまででも、世界にあるライブラリが簡単に取り込めて使える、しかも依存関係ごと取り込んでくれるという素敵な感じが伝わったと思う。伝わっていて欲しい。伝わっているといいな。
springBootを使うようになるとgradleをより崇拝するようになるのだが、今回の記事はJarを作って最後とする。
実はいま時点でもJarは作れてしまう。
./gradlew jarこれだけだ。
./build/libsフォルダの下にjarが出来ていると思う。
これはただjarにしただけなので-jarでは動かないし、manifestにも何も書かれていない。そして今回は一つのjarファイルに依存関係を全部ぶちこみ、それだけで動作可能な実行可能jarにしてみよう。(普段はやんないんだけどね)
build.gradleに以下の記述を追加する。build.gradlejar { manifest { attributes('Implementation-Title': 'Yebisu' , 'Implementation-Version': 1.0 , 'Main-Class': 'yebisu.App') } from configurations.runtimeClasspath.collect { it.isDirectory() ? it : zipTree(it) } }こうして
./gradlew jarでjarを生成し、以下のコマンドを実行するとちゃんと動作すると思う。java -jar .\build\libs\Yebisu.jarMANIFEST.MFにバージョンやタイトルもちゃんと入っている。
MANIFEST.MFManifest-Version: 1.0 Implementation-Title: Yebisu Implementation-Version: 1.0 Main-Class: yebisu.App最後に
この次のステップは、単体テストを記述する、Jacocoでカバレッジを取るといったところになるだろうか。build.gradleはGroovyという言語で書かれている。(Kotlinでも書ける)
だからといってGroovyやKotlinの読み書きが必須という事はない。もちろんあるに越したことはないが。しかしまあ、gradleでやりたい事が出来たならば、googleを使って世界に問いかけてみれば、大体の答えはそこにある。そういうものだ。だってgraldeは新しい技術ではないもの。
世界にはまだまだ便利なものが山程ある。
その多くは学習コストによって嫌われていると私は思っている。しかし世の中で多く使われているライブラリやツールは、学習コストを払うに見合うものが殆どだ。今の方法でも出来ているから問題ないという考えは悪癖である。
是非とも積極的に、武器を探し、手に取り、自分のものとして戦力化して欲しい。そうやって培った生産力の差が、五年後十年後には莫大なものになる。
かも知れない。

- 投稿日:2020-04-30T16:05:26+09:00
Eclipseのm2eプラグインとMavenの関係
タイトル通りですが、初心者すぎて私がわからなかったのでメモっておきます。
m2eプラグイン
これは、Eclipse上からMavenを実行するためのプラグインです。
今回、JavaEE開発用のEclipseを使いましたが、その場合はデフォルトで入っています。わからなかったポイント
Eclipse上で右クリックしてMavenの実行を行うと、ポップアップが表示され、ゴールを指定する画面が出てきます。
一方で、世に出回っているMavenの記事を参照すると
mvn compileのようなコマンドが良く出てきます。
私はこの関連性がよくわからず、mvnコマンドを実行したいんだけど、コマンド引数はどこに設定すればいいんだろう?と思ってました。Eclipse上でMavenを実行するには
m2eプラグインで表示されるポップアップのゴールに設定するのは、上記で言えば「compile」の部分です。
mavenではmvnコマンドの後にゴールを指定するという書式になっており、ものすごく大雑把に言うとmvnコマンドの引数=ゴールというイメージになります。また、2つ以上ゴールがある場合、例えば
mvn package deployのような場合もポップアップのゴール欄に「package deploy」と入力すればOKです。
つまり、m2eプラグインのポップアップの画面でゴールにmvnの引数部分を指定することで、mvnコマンドが実行できるのです!(※ハイフンで始まる引数は別枠)
- 投稿日:2020-04-30T15:23:10+09:00
SpringBootプロジェクトのGradleタスクを眺める
Gradleのタスクを眺める
下のコマンドでタスクの一覧を見ることができる。
.\gradlew.bat task --all下のように表示される。
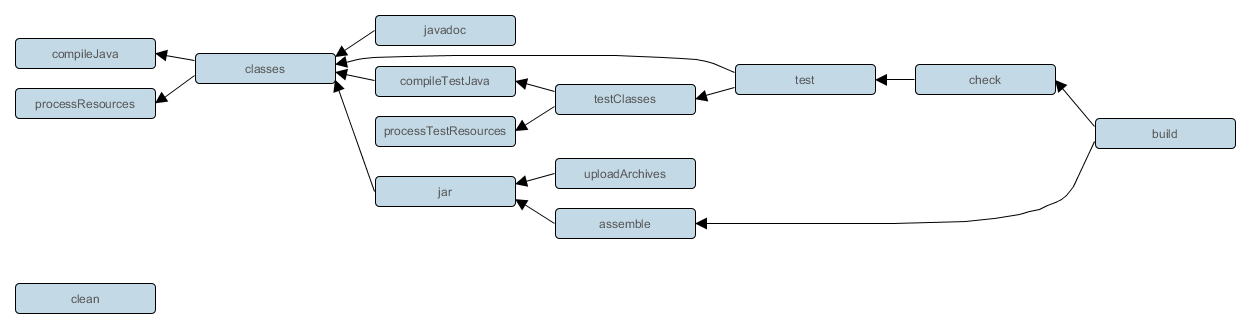
> Task :tasks ------------------------------------------------------------ Tasks runnable from root project ------------------------------------------------------------ Application tasks ----------------- bootRun - Runs this project as a Spring Boot application. Build tasks ----------- assemble - Assembles the outputs of this project. bootJar - Assembles an executable jar archive containing the main classes and their dependencies. build - Assembles and tests this project. buildDependents - Assembles and tests this project and all projects that depend on it. buildNeeded - Assembles and tests this project and all projects it depends on. classes - Assembles main classes. clean - Deletes the build directory. jar - Assembles a jar archive containing the main classes. testClasses - Assembles test classes. Build Setup tasks ----------------- init - Initializes a new Gradle build. wrapper - Generates Gradle wrapper files. Documentation tasks ------------------- javadoc - Generates Javadoc API documentation for the main source code. Help tasks ---------- buildEnvironment - Displays all buildscript dependencies declared in root project 'demo'. components - Displays the components produced by root project 'demo'. [incubating] dependencies - Displays all dependencies declared in root project 'demo'. dependencyInsight - Displays the insight into a specific dependency in root project 'demo'. dependencyManagement - Displays the dependency management declared in root project 'demo'. dependentComponents - Displays the dependent components of components in root project 'demo'. [incubating] help - Displays a help message. model - Displays the configuration model of root project 'demo'. [incubating] outgoingVariants - Displays the outgoing variants of root project 'demo'. projects - Displays the sub-projects of root project 'demo'. properties - Displays the properties of root project 'demo'. tasks - Displays the tasks runnable from root project 'demo'. Verification tasks ------------------ check - Runs all checks. test - Runs the unit tests. Other tasks ----------- compileJava - Compiles main Java source. compileTestJava - Compiles test Java source. prepareKotlinBuildScriptModel processResources - Processes main resources. processTestResources - Processes test resources. Rules ----- Pattern: clean<TaskName>: Cleans the output files of a task. Pattern: build<ConfigurationName>: Assembles the artifacts of a configuration. Pattern: upload<ConfigurationName>: Assembles and uploads the artifacts belonging to a configuration.ビルド関連のタスク
ビルドタスクだけでも、9つもある。
javaプラグイン由来のタスクとorg.springframework.bootプラグイン由来のタスクがある。Build tasks ----------- assemble - Assembles the outputs of this project. bootJar - Assembles an executable jar archive containing the main classes and their dependencies. build - Assembles and tests this project. buildDependents - Assembles and tests this project and all projects that depend on it. buildNeeded - Assembles and tests this project and all projects it depends on. classes - Assembles main classes. clean - Deletes the build directory. jar - Assembles a jar archive containing the main classes. testClasses - Assembles test classes.タスクの依存関係は、下の画像を見れば分かりやすい。
(https://docs.gradle.org/current/userguide/java_plugin.html#sec:java_tasks から転載)
assembleタスク
jarファイルを生成した上で、さらにarchivesで設定されている生成物も生成する。
zipを生成するタスクを作って、archivesに追加しておけば、ビルド時にカスタムのzipファイルを作成することもできる。アウトプット
> Task :compileJava > Task :processResources > Task :classes > Task :bootJar > Task :jar SKIPPED > Task :assemblebootJarタスク
メインクラスとその全ての依存関係を含む、実行可能な
jarファイルを生成するタスク。
テストを実行せず、jarファイルだけ欲しいときは、このタスクを実行する。アウトプット
> Task :compileJava > Task :processResources > Task :classes > Task :bootJarbuildタスク
普通にビルドするときは、このタスクを実行する。マルチプロジェクト時は、現在のプロジェクトだけをビルドする。テストも実行され、
build\reportsディレクトリの下にテストリポートが生成される。アウトプット
> Task :compileJava > Task :processResources > Task :classes > Task :bootJar > Task :jar SKIPPED > Task :assemble > Task :compileTestJava > Task :processTestResources NO-SOURCE > Task :testClasses > Task :test 2020-04-30 13:26:22.615 INFO 5520 --- [extShutdownHook] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor' > Task :processTestResources NO-SOURCE > Task :testClassesbuildDependentsタスク
マルチプロジェクト時のビルドのやり方の一つ。
buildDependentsでビルドすれば、今のプロジェクトにtestRuntimeClasspath設定の依存関係を持っている全てのプロジェクトもビルドされる。アウトプット
> Task :compileJava > Task :processResources > Task :classes > Task :bootJar > Task :jar SKIPPED > Task :assemble > Task :compileTestJava > Task :processTestResources NO-SOURCE > Task :testClasses > Task :test 2020-04-30 13:27:15.725 INFO 16828 --- [extShutdownHook] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor' > Task :check > Task :build > Task :buildDependentsbuildNeededタスク
マルチプロジェクト時のビルドのやり方の一つ。今のプロジェクトだけではなく、そのプロジェクトが
testRuntimeClasspath設定で依存している全てのプロジェクトもビルドされる。アウトプット
> Task :compileJava > Task :processResources > Task :classes > Task :bootJar > Task :jar SKIPPED > Task :assemble > Task :compileTestJava > Task :processTestResources NO-SOURCE > Task :testClasses > Task :test 2020-04-30 13:27:40.483 INFO 9032 --- [extShutdownHook] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor' > Task :check > Task :build > Task :buildNeededclassesタスク
Javaの
mainのソースコードをコンパイルし、クラスファイルを作成するタスク。
IntelliJにはデコンパイラが付いていて、IDE上でクラスファイルの中身を解析できるが、実体はコンパイルされたバイトコード。アウトプット
> Task :compileJava > Task :processResources > Task :classescleanタスク
buildディレクトリを削除するタスク。アウトプット
> Task :cleanjarタスク
mainのソースセットをコンパイルし、jarファイルを生成する。
今回のプロジェクトでは、bootJarタスクがあるからか、jarタスクはスキップされている。アウトプット
> Task :compileJava > Task :processResources > Task :classes > Task :jar SKIPPEDtestClassesタスク
Javaの
testのソースコードをコンパイルし、テストのクラスファイルを作成するタスク。アウトプット
> Task :compileJava > Task :processResources > Task :classes > Task :compileTestJava > Task :processTestResources NO-SOURCE > Task :testClasses
- 投稿日:2020-04-30T15:17:52+09:00
JavaでDB接続をしてみる
JavaでDBを操作するには
Javaで使うMySQLをドライバーを入手し、プロジェクトに追加する
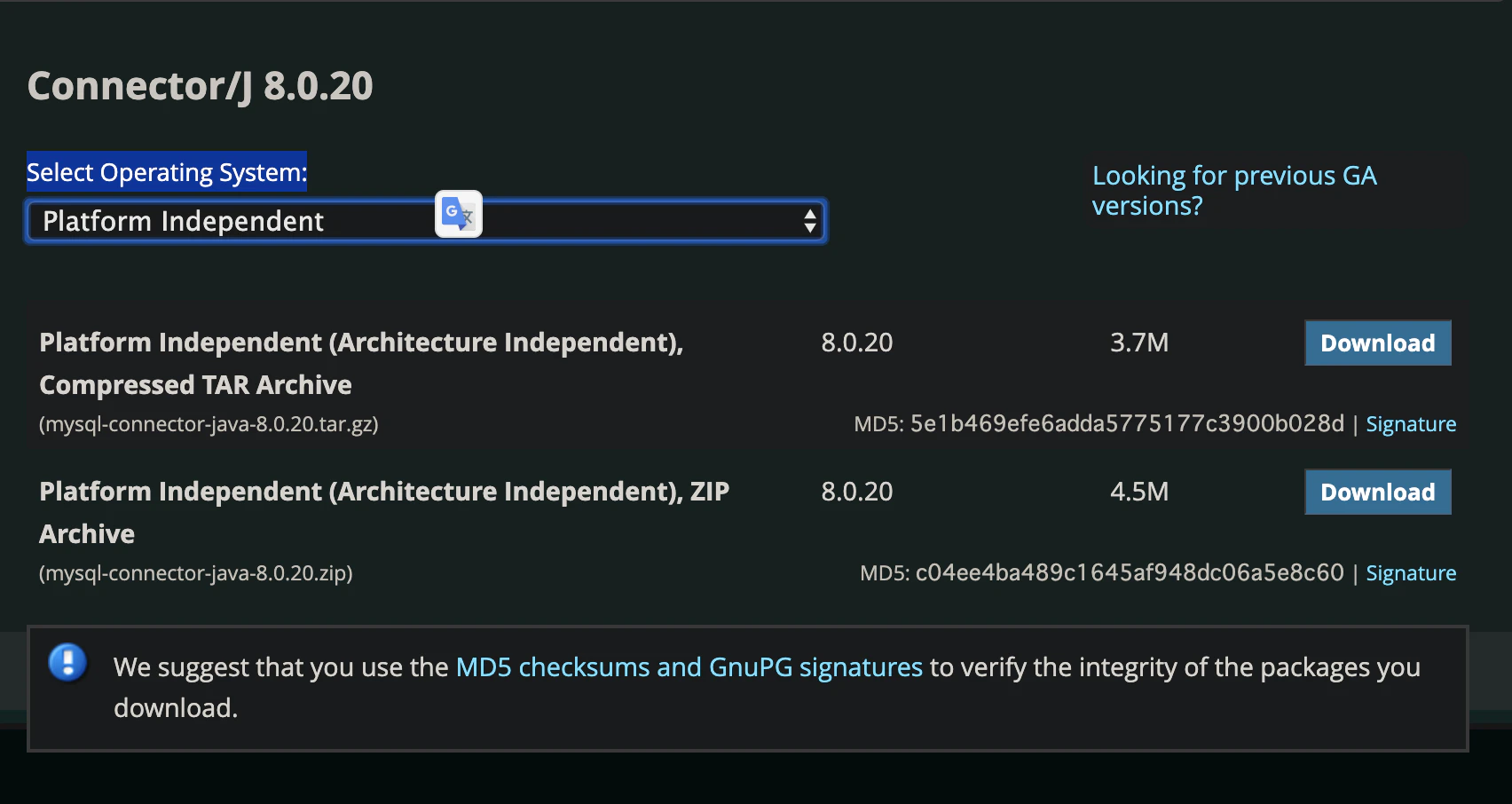
SQLドライバーを入手
以下のURLにアクセスし、
Select Operating System:の下にあるセレクトボックスをPlatform Independentにして
zipをダウンロードし、解凍する。(ダウンロード先はどこでもOK)
SQLドライバー
解凍したら
jarファイルができる。プロジェクトに追加
解凍したSQLドライバーをプロジェクトに追加する。
Eclipseで作ったプロジェクトのWebContent->WEB-INF->libにドラッグ&ドロップ
以下のようになる。
ビルドパスの構成を設定
`
プロジェクト右クリック->ビルド・パス->ビルド・パスの構成を開き、ライブラリタブから外部JARの追加を選択し、先ほどWebContent->WEB-INF->libに追加したjarファイルを選択し、追加させる。
追加させた時の画面が以下の通り。
DBの接続確認
以下の実装でDB接続を図る
DBConnect.javaimport java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; public class DBManager { public static Connection getConnection(){ Connection con = null; // 初期化 try{ Class.forName("com.mysql.jdbc.Driver"); con = DriverManager.getConnection("jdbc:mysql://localhost:ポート番号/データベース名","ユーザー名","パスワード"); System.out.println("DB接続成功!!!"); return con; }catch(ClassNotFoundException e){ throw new IllegalMonitorStateException(); // クラスがなかった時の例外処理 } catch (SQLException e) { throw new IllegalMonitorStateException(); // SQLでエラーが起きた時の例外処理 } } }DBConnect.javaClass.forName("com.mysql.jdbc.Driver"); con = DriverManager.getConnection("jdbc:mysql://localhost:ポート番号/データベース名","ユーザー名","パスワード"); System.out.println("DB接続成功!!!"); // 成功したら出力するようになっている なくてもOK return con; // 接続結果を返すClass.forName("com.mysql.jdbc.Driver");
Classクラス
クラスクラス・・・w
すべてのクラスのスーパークラスである java.lang.Object クラスにgetClass()というメソッドが実装されており、サブクラスのインスタンス生成時に該当のサブクラスのClass情報をClassクラスのインスタンスとして生成し、保持します。
クラス読み込み用クラスみたいなイメージかな
forName("com.mysql.jdbc.Driver");
()内はクラス名 ここではSQLドライバーを指定している。
forName()することにより、DBドライバクラスがロードされ、staticイニシャライザが実行されます。DBドライバクラスは全て、java.sql.Driverを実装しており、各DBドライバクラスでは、staticイニシャライザでDriverManagerクラスというドライバを管理するクラスにDBドライバクラス自身を登録しに行くという処理を実施しています。
forNameでSQLドライバーを探しに行って勝手に登録してくれるみたい
参考:知ってるようで知らないClassクラス(基本編)以上でDBの接続は完了する。


- 投稿日:2020-04-30T14:59:36+09:00
#Scala: vol2: 【akka-grpcでgoogle/protobuf/*.proto をimportする方法】
#Scala: vol2: 【akka-grpcでgoogle/protobuf/*.proto をimportする方法】
問題
akka-grpcで開発時に、
google/protobuf/*.protoのimportができずに、sbt-consoleImport "google/protobuf/timestamp.proto" was not found or had errors "google.protobuf.Timestamp" is not defined.となってしまったので、その解決策についてご紹介します。
解決策
https://github.com/akka/akka-grpc/issues/681
Find the ones you need in protocolbuffers/protobuf:src/google/protobuf@master , download and put them alongside your projects' .proto resources
ダウンロードして、プロジェクトの.protoリソースと並べて配置
と書いてありましたが、 もっと簡単に対応可能です。
build.sbt に以下を追加すれば解決です。
libraryDependencies ++= Seq( "com.google.protobuf" % "protobuf-java" % "3.6.1" % "protobuf" )
- 投稿日:2020-04-30T11:19:40+09:00
Ruby と Perl と Java と Python で解く AtCoder ABC 047 C
はじめに
AtCoder Problems の Recommendation を利用して、過去の問題を解いています。
AtCoder さん、AtCoder Problems さん、ありがとうございます。今回のお題
AtCoder Beginner Contest 047 C - 一次元リバーシ
Difficulty: 650今回のテーマ、正規表現
Ruby
例えば、
WWWWBBWBBBを W B でそれぞれまとめますとWBWBとなり、3回で一色にできることが分かります。
こういう文字列の処理は正規表現を使用すると簡単に解けます。
AtCoder に登録したら次にやること ~ これだけ解けば十分闘える!過去問精選 10 問 ~で有名な C - 白昼夢 も正規表現ですとスッキリ解けます。ruby.rbs = gets.chomp s.gsub!(/W+/, "W") s.gsub!(/B+/, "B") puts s.size - 1
W+は1文字以上の連続したW を表現しています。Python
python.pyimport re s = input() s = re.sub(r'W+', "W", s) s = re.sub(r'B+', "B", s) print(len(s) - 1)Python で正規表現を使用する場合、
import reが必要です。Perl
perl.plchomp (my $s = <STDIN>); $s =~ s/W+/W/g; $s =~ s/B+/B/g; print length($s) - 1, "\n";Java
java.javaimport java.util.*; class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); String s = sc.next(); sc.close(); s = s.replaceAll("W+", "W"); s = s.replaceAll("B+", "B"); System.out.println(s.length() - 1); } }
Ruby Python Perl Java コード長 71 Byte 97 Byte 87 Byte 310 Byte 実行時間 36 ms 38 ms 21 ms 239 ms メモリ 10076 KB 4468 KB 640 KB 35160 KB まとめ
- ABC 063 C をスッキリ解いた
- Ruby に詳しくなった
- Python に詳しくなった
- Perl に詳しくなった
- Java に詳しくなった
参照したサイト
pythonで、とっても便利な正規表現を!
Java での正規表現の使い方メモ
instance method String#gsub
ABC049C - 白昼夢を簡単に導く方法が知りたい(Golang)
- 投稿日:2020-04-30T11:03:24+09:00
Android - AsyncTaskの直列処理と並列処理の順番は保証されるのか??
Android開発において、AsyncTaskで直列処理と並列処理について、ほぼ同時に動いた時はどのような動きになるのか、実際に順番は保証されるのかわからなかったので、軽くコードを組んでみて確認してみましたので、メモとして残しておきたいと思います。
【参考URL】
developer - AsyncTask
Android - AsyncTaskの直列処理?並列処理?
AsyncTaskの非同期処理はどのように実現しているのか【試作1】タスク1:直列処理、タスク2:並列処理の場合
task1:execute()
task2:executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR)// 1つ目の非同期タスク AsyncTask task1 = new AsyncTask() { @Override protected Object doInBackground(Object[] objects) { Log.v("task1", "start!!!"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } return null; } @Override protected void onPostExecute(Object o) { super.onPostExecute(o); Log.v("task1", "done!!!"); } } .execute(); // 2つ目の非同期タスク AsyncTask task2 = new AsyncTask() { @Override protected Object doInBackground(Object[] objects) { Log.v("task2", "start!!!"); try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } return null; } @Override protected void onPostExecute(Object o) { super.onPostExecute(o); Log.v("task2", "done!!!"); } } .executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR);実行結果
順番通りになっているかを確認するため、数回実行してみました。
【1回目】 5970-5995/com.example.testcode V/task2: start!!! 5970-5994/com.example.testcode V/task1: start!!! 5970-5970/com.example.testcode V/task2: done!!! 5970-5970/com.example.testcode V/task1: done!!! 【2回目】 7138-7157/com.example.testcode V/task2: start!!! 7138-7156/com.example.testcode V/task1: start!!! 7138-7138/com.example.testcode V/task2: done!!! 7138-7138/com.example.testcode V/task1: done!!! 【3回目】 7383-7403/com.example.testcode V/task1: start!!! 7383-7404/com.example.testcode V/task2: start!!! 7383-7383/com.example.testcode V/task2: done!!! 7383-7383/com.example.testcode V/task1: done!!!2回目のスタートが逆になっていますね。。。
【試作2】タスク1:並列処理、タスク2:直列処理の場合
task1:executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR)
task2:execute()
※ソースコードは試作1とほぼ変わりません。// 1つ目の非同期タスク AsyncTask task1 = new AsyncTask() { @Override protected Object doInBackground(Object[] objects) { Log.v("task1", "start!!!"); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } return null; } @Override protected void onPostExecute(Object o) { super.onPostExecute(o); Log.v("task1", "done!!!"); } } .execute(); // 2つ目の非同期タスク AsyncTask task2 = new AsyncTask() { @Override protected Object doInBackground(Object[] objects) { Log.v("task2", "start!!!"); try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); } return null; } @Override protected void onPostExecute(Object o) { super.onPostExecute(o); Log.v("task2", "done!!!"); } } .executeOnExecutor(AsyncTask.THREAD_POOL_EXECUTOR);実行結果
こちらも順番通りになっているかを確認するため、数回実行してみました。
【1回目】 7267-7273/com.example.testcode V/task2: start!!! 7267-7272/com.example.testcode V/task1: start!!! 7267-7267/com.example.testcode V/task2: done!!! 7267-7267/com.example.testcode V/task1: done!!! 【2回目】 7643-7662/com.example.testcode V/task1: start!!! 7643-7663/com.example.testcode V/task2: start!!! 7643-7643/com.example.testcode V/task2: done!!! 7643-7643/com.example.testcode V/task1: done!!! 【3回目】 7871-7891/com.example.testcode V/task1: start!!! 7871-7892/com.example.testcode V/task2: start!!! 7871-7871/com.example.testcode V/task2: done!!! 7871-7871/com.example.testcode V/task1: done!!!こちらの実行結果も試作1と似たような結果となっています。
まとめ
直列処理と並列処理をほぼ同時に実行した場合の処理の順番は保証されないようです。
確実に順番を保証したい場合は、両方とも直列処理で行ったほうが良いですね。最後に
それ違うぞ!っという点もあるかと思いますが、参考程度になれば幸いです。
以上です。
- 投稿日:2020-04-30T00:07:21+09:00
実践プログラミング入門 ~変数からオブジェクト指向まで~
はじめに
これは、入門書などの無味乾燥な例題では納得して理解できない初学者のためのプログラミングチュートリアルである。
この記事では、プログラミングはプログラムを書くことによって学ぶという視点に立ち実践を重視する。楽器の演奏や車の運転のように本を読んだだけで出来るようにはならない。ここではオセロとカードゲームUNOの実装を通してプログラミングの重要な概念を伝える。オセロでは値と型、メソッドについて。UNOではオブジェクト指向を取り扱う。
オセロ実装
1つ目の題材はオセロである。オセロはゲームの状態やプレイヤーの操作が少ないが、ひっくり返すという操作は複雑であり練習にちょうど良い。
オセロをプログラムするためには何が必要になるだろうか。十分な考察ののち、プログラマはその答えをネットの海に求める。検索の技術はプログラマにとって最も重要な技術の一つである。既存の技術を活用し時間や集中力といった資源をより重要な問題に充てることができるからである。検索の技術とは、検索によって得られた情報の中から必要なものを抽出し活用する技術のことである。
では最初の実践である。
実践1 オセロゲームをプログラムする。ただし、次の要求を満たすこと。
- 日本語Wikipedia(https://ja.wikipedia.org/wiki/オセロ_(ボードゲーム)#ルール ) に記載された基本ルールに基づくこと。
- オセロ板の状態が表示される。
- コマを置ける。
- 修了条件を満たしたとき、結果を表示して終了する。
あえて難易度の高い問題を最初に出した。できる範囲で実践1に取り組むことで、以降の内容に説得力を持たせる狙いがある。ぜひ取り組んでほしい。
状態を表現する
課題にあたるとき、最初の一歩は問題の整理である。十分な考察がなければどんな情報も混乱のもとになる。
オセロをプレイするとは何か。プログラムを組むためにはそのすべてを理解していることが求められる。まずオセロのボードとコマが必要になる。そしてゲームをプレイするためには二人のプレイヤーが必要である。
ボードとコマとプレイヤーがあればオセロができる。次の問題は、「プログラムの世界と現実の世界をどう結び付けるか」だ。プログラムで扱えるものは数値のみである。しかしボードやプレイヤーは数値じゃない。ここに飛躍がある。プログラムでオセロを作るのではない、オセロと見なせるプログラムを作るのである。ボードもコマもプレイヤーも必要ない、ボードに見えるもの、コマに見えるもの等々があればよい。つまり、数値でもってボード等を表現すればよいということだ。
ボードとコマとプレイヤーを表現するためにはどうするべきだろうか。ボードには64のマスが存在しコマには裏と表が存在する。プレイヤーは白か黒の番を持ちボードにコマを置く。次は実践だ。
実践2 ボードとコマを表現する。ただし、次の要求を満たすこと。
- 64マスの状態を保存できる。
- マスには「何も置いていない」、「白が置かれている」、「黒が置かれている」を区別できる情報を持たせる。
- 基本ルールに従って中央に4つのコマを配置する。
- ボードの状態を確認できる。
方法は無数に存在するが、ここでは2次元配列を用いる。下のプログラムでは1と2でコマの白黒を表現した。
回答例
class Othello { public static void main(String[] args) { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } } }このプログラムの実行結果とみなす。次はプレイヤーを表現する。
状態を変化させる
プレイヤーの要件を確認する。白か黒のコマを置くことである。ただし、置くマスには「ひっくり返せるか」という条件が付く。コマを置いたときひっくり返せないマスにはコマを置けない。
条件に従って動作を変える仕組みは制御構文と呼ばれる。ここでの条件は「コマを置いたときひっくり返せるコマが存在する」かどうかである。
動作を実現する手段は何だろうか。プレイヤーの操作をユーザーが行う場合は、プログラムがユーザーの入力を受け付ける必要がある。そして入力に従ってプログラムを動作させる。「右からx番目、左からy番目のマスに黒のコマを置け」といった入力を受け、プログラムはそのマスに黒のコマを置けるか確認し、置けるときはボードの情報を更新し、置けないときはそれをユーザーに伝える。
入力を受け付けるとき、多くの場合は事前に用意された機能に頼ることになる。JavaではScannerクラスを用いる。入力の詳細に関しては入門の範囲を超えるためここでは扱わない。
コマを置くという動作を整理すると複数の要素からできていることがわかる。
- 入力を受け取る。
- コマを置けるか確認する。
- コマを置き、ひっくり返す。
複雑な問題は分割すると把握が容易になる。ここでは上のように3つの要素ごとに問題を分けて考える。要素の上から順に実践する。
実践3 コマを置くマスの座標を入力として受け取る。
入力を受け付けるためにScannerクラスを用いている。Scannerクラスの用い方は公式のドキュメント(https://docs.oracle.com/javase/jp/8/docs/api/java/util/Scanner.html)を参照する。
回答例
import java.util.Scanner; class Othello { public static void main(String[] args) { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } // Scannerクラスのインスタンスを作成 // 引数で標準入力System.inを指定する Scanner scanner = new Scanner(System.in); // 入力を促すメッセージ System.out.print("x y の順で入力してください > "); int x = scanner.nextInt(); int y = scanner.nextInt(); //入力された内容を画面に表示 System.out.println("x=" + x + " y="+y); // Scannerクラスのインスタンスをクローズ scanner.close(); } }実践4 コマを置けるか確認する。ただし、置くコマは黒(2)とする。
回答例
import java.util.Scanner; class Othello { public static void main(String[] args) { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } // Scannerクラスのインスタンスを作成 // 引数で標準入力System.inを指定する Scanner scanner = new Scanner(System.in); // 入力を促すメッセージ System.out.print("x y の順で入力してください > "); int x = scanner.nextInt(); int y = scanner.nextInt(); //入力された内容を画面に表示 System.out.println("x=" + x + " y="+y); //範囲チェック if (0<x&&x<8 && 0<y&&y<8) { //マスが開いているか if (borad[y][x] == 0) { //八方向のリスト int[] dx = {-1, 0, 1, 1, 1, 0, -1, -1}; int[] dy = {-1, -1, -1, 0, 1, 1, 1, 0}; //八方向を順に試す for (int i=0; i<8; i++) { //置くマスの隣を(nx, ny)とする int nx = x+dx[i]; int ny = y+dy[i]; //範囲チェック if (0<nx&&nx<8 && 0<ny&&ny<8) { //隣に白のコマがあるかどうか if (borad[ny][nx] == 1) { //黒のコマを見ている方向で探す while (0<nx+dx[i]&&nx+dx[i]<8 && 0<ny+dy[i]&&ny+dy[i]<8) { if (borad[ny][nx] == 2) { //OK System.out.println("OK"); System.out.println("dx=" + dx[i] + " dy="+dy[i]); } nx += dx[i]; ny += dy[i]; } } } } } } // Scannerクラスのインスタンスをクローズ scanner.close(); } }実践5 コマを置き、ひっくり返す。
回答例
import java.util.Scanner; class Othello { public static void main(String[] args) { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } // Scannerクラスのインスタンスを作成 // 引数で標準入力System.inを指定する Scanner scanner = new Scanner(System.in); // 入力を促すメッセージ System.out.print("x y の順で入力してください > "); int x = scanner.nextInt(); int y = scanner.nextInt(); //入力された内容を画面に表示 System.out.println("x=" + x + " y="+y); //範囲チェック if (0<x&&x<8 && 0<y&&y<8) { //マスが開いているか if (borad[y][x] == 0) { //八方向のリスト int[] dx = {-1, 0, 1, 1, 1, 0, -1, -1}; int[] dy = {-1, -1, -1, 0, 1, 1, 1, 0}; //八方向を順に試す for (int i=0; i<8; i++) { //置くマスの隣を(nx, ny)とする int nx = x+dx[i]; int ny = y+dy[i]; //範囲チェック if (0<nx&&nx<8 && 0<ny&&ny<8) { //隣に白のコマがあるかどうか if (borad[ny][nx] == 1) { //黒のコマを見ている方向で探す while (0<nx+dx[i]&&nx+dx[i]<8 && 0<ny+dy[i]&&ny+dy[i]<8) { if (borad[ny][nx] == 2) { //OK System.out.println("OK"); System.out.println("dx=" + dx[i] + " dy="+dy[i]); while (x!=nx || y!=ny) { borad[y][x] = 2; x += dx[i]; y += dy[i]; } } nx += dx[i]; ny += dy[i]; } } } } } } for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } // Scannerクラスのインスタンスをクローズ scanner.close(); } }このように分岐やループが重なり構造が複雑なコードを美しくないという。
プログラムを分ける
操作としては簡単なはずだが、それを表現するコードは複雑になった。この操作を繰り返すことでオセロをプレイできるが面倒だし間違いのもとである。同じ処理をまとめ、名前を付ける機能がJava(とその他たいていの言語)に備わっている。
同じ処理をまとめることで繰り返しが書きやすくなる。Javaではメソッドと呼ばれ、ほかに関数やサブルーチンといった呼ばれ方もする。メソッドを用いてオセロの完成を目指す。コマを交互に置き、置けなくなったら勝敗を表示するということだ。
実践6 オセロの完成。ただし白と黒が交互に入力し、入力の方法は自由とする。
回答例
import java.util.Scanner; import sun.launcher.resources.launcher; class Othello { static boolean turn(int player, int x, int y, int[][] borad, boolean check) { int opponent = 1; if (player == 1) { opponent = 2; } boolean res = false; //範囲チェック if (0<x&&x<8 && 0<y&&y<8) { //マスが開いているか if (borad[y][x] == 0) { //八方向のリスト int[] dx = {-1, 0, 1, 1, 1, 0, -1, -1}; int[] dy = {-1, -1, -1, 0, 1, 1, 1, 0}; //八方向を順に試す for (int i=0; i<8; i++) { //置くマスの隣を(nx, ny)とする int nx = x+dx[i]; int ny = y+dy[i]; //範囲チェック if (0<nx&&nx<8 && 0<ny&&ny<8) { //隣に白のコマがあるかどうか if (borad[ny][nx] == opponent) { //黒のコマを見ている方向で探す while (0<nx+dx[i]&&nx+dx[i]<8 && 0<ny+dy[i]&&ny+dy[i]<8) { if (borad[ny][nx] == player) { //OK res = true; if (!check) { System.out.println("OK"); System.out.println("dx=" + dx[i] + " dy="+dy[i]); while (x!=nx || y!=ny) { borad[y][x] = player; x += dx[i]; y += dy[i]; } } } nx += dx[i]; ny += dy[i]; } } } } } } return res; } static void print_borad(int[][] borad) { for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } } static boolean can_put(int[][] borad, int player) { boolean res = true; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { res &= turn(player, i, j, borad, true); } } return res; } static int[][] init() { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; print_borad(borad); return borad; } public static void main(String[] args) { int [][] borad = init(); int player = 2; boolean is_game_end = false; // Scannerクラスのインスタンスを作成 // 引数で標準入力System.inを指定する Scanner scanner = new Scanner(System.in); int x, y; while (!is_game_end) { // 入力を促すメッセージ System.out.println("Player = " + player); System.out.print("x y の順で入力してください > "); x = scanner.nextInt(); y = scanner.nextInt(); //入力された内容を画面に表示 System.out.println("x=" + x + " y="+y); if (turn(player, x, y, borad, false)) { if(player == 2) player = 1; else player = 2; is_game_end = can_put(borad, player); print_borad(borad); } } // Scannerクラスのインスタンスをクローズ scanner.close(); int black = 0, white = 0; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { if (borad[i][j] == 1) { white++; } else if (borad[i][j] == 2) { black++; } } } if (black>white) { System.out.println("Blackの勝ち"); } else if(black<white) { System.out.println("Whiteの勝ち"); } else { System.out.println("引き分け"); } } }ウノ実装
ただいま編集中
ユーザー定義型
アクセス制御
継承、実行時ポリモーフィズム
オブジェクト指向プログラミングの利点
終わりに
参考資料
- 投稿日:2020-04-30T00:07:21+09:00
実践プログラミング入門
はじめに
これは、入門書などの無味乾燥な例題では納得して理解できない初学者のためのプログラミングチュートリアルである。
この記事では、プログラミングはプログラムを書くことによって学ぶという視点に立ち実践を重視する。楽器の演奏や車の運転のように本を読んだだけで出来るようにはならない。ここではオセロとカードゲームUNOの実装を通してプログラミングの重要な概念を伝える。オセロでは値と型、メソッドについて。UNOではオブジェクト指向を取り扱う。
オセロ実装
1つ目の題材はオセロである。オセロはゲームの状態やプレイヤーの操作が少ないが、ひっくり返すという操作は複雑であり練習にちょうど良い。
オセロをプログラムするためには何が必要になるだろうか。十分な考察ののち、プログラマはその答えをネットの海に求める。検索の技術はプログラマにとって最も重要な技術の一つである。既存の技術を活用し時間や集中力といった資源をより重要な問題に充てることができるからである。検索の技術とは、検索によって得られた情報の中から必要なものを抽出し活用する技術のことである。
では最初の実践である。
実践1 オセロゲームをプログラムする。ただし、次の要求を満たすこと。
- 日本語Wikipedia(https://ja.wikipedia.org/wiki/オセロ_(ボードゲーム)#ルール ) に記載された基本ルールに基づくこと。
- オセロ板の状態が表示される。
- コマを置ける。
- 修了条件を満たしたとき、結果を表示して終了する。
あえて難易度の高い問題を最初に出した。できる範囲で実践1に取り組むことで、以降の内容に説得力を持たせる狙いがある。ぜひ取り組んでほしい。
状態を表現する
課題にあたるとき、最初の一歩は問題の整理である。十分な考察がなければどんな情報も混乱のもとになる。
オセロをプレイするとは何か。プログラムを組むためにはそのすべてを理解していることが求められる。まずオセロのボードとコマが必要になる。そしてゲームをプレイするためには二人のプレイヤーが必要である。
ボードとコマとプレイヤーがあればオセロができる。次の問題は、「プログラムの世界と現実の世界をどう結び付けるか」だ。プログラムで扱えるものは数値のみである。しかしボードやプレイヤーは数値じゃない。ここに飛躍がある。プログラムでオセロを作るのではない、オセロと見なせるプログラムを作るのである。ボードもコマもプレイヤーも必要ない、ボードに見えるもの、コマに見えるもの等々があればよい。つまり、数値でもってボード等を表現すればよいということだ。
ボードとコマとプレイヤーを表現するためにはどうするべきだろうか。ボードには64のマスが存在しコマには裏と表が存在する。プレイヤーは白か黒の番を持ちボードにコマを置く。次は実践だ。
実践2 ボードとコマを表現する。ただし、次の要求を満たすこと。
- 64マスの状態を保存できる。
- マスには「何も置いていない」、「白が置かれている」、「黒が置かれている」を区別できる情報を持たせる。
- 基本ルールに従って中央に4つのコマを配置する。
- ボードの状態を確認できる。
方法は無数に存在するが、ここでは2次元配列を用いる。下のプログラムでは1と2でコマの白黒を表現した。
回答例
class Othello { public static void main(String[] args) { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } } }このプログラムの実行結果とみなす。次はプレイヤーを表現する。
状態を変化させる
プレイヤーの要件を確認する。白か黒のコマを置くことである。ただし、置くマスには「ひっくり返せるか」という条件が付く。コマを置いたときひっくり返せないマスにはコマを置けない。
条件に従って動作を変える仕組みは制御構文と呼ばれる。ここでの条件は「コマを置いたときひっくり返せるコマが存在する」かどうかである。
動作を実現する手段は何だろうか。プレイヤーの操作をユーザーが行う場合は、プログラムがユーザーの入力を受け付ける必要がある。そして入力に従ってプログラムを動作させる。「右からx番目、左からy番目のマスに黒のコマを置け」といった入力を受け、プログラムはそのマスに黒のコマを置けるか確認し、置けるときはボードの情報を更新し、置けないときはそれをユーザーに伝える。
入力を受け付けるとき、多くの場合は事前に用意された機能に頼ることになる。JavaではScannerクラスを用いる。入力の詳細に関しては入門の範囲を超えるためここでは扱わない。
コマを置くという動作を整理すると複数の要素からできていることがわかる。
- 入力を受け取る。
- コマを置けるか確認する。
- コマを置き、ひっくり返す。
複雑な問題は分割すると把握が容易になる。ここでは上のように3つの要素ごとに問題を分けて考える。要素の上から順に実践する。
実践3 コマを置くマスの座標を入力として受け取る。
入力を受け付けるためにScannerクラスを用いている。Scannerクラスの用い方は公式のドキュメント(https://docs.oracle.com/javase/jp/8/docs/api/java/util/Scanner.html)を参照する。
回答例
import java.util.Scanner; class Othello { public static void main(String[] args) { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } // Scannerクラスのインスタンスを作成 // 引数で標準入力System.inを指定する Scanner scanner = new Scanner(System.in); // 入力を促すメッセージ System.out.print("x y の順で入力してください > "); int x = scanner.nextInt(); int y = scanner.nextInt(); //入力された内容を画面に表示 System.out.println("x=" + x + " y="+y); // Scannerクラスのインスタンスをクローズ scanner.close(); } }実践4 コマを置けるか確認する。ただし、置くコマは黒(2)とする。
回答例
import java.util.Scanner; class Othello { public static void main(String[] args) { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } // Scannerクラスのインスタンスを作成 // 引数で標準入力System.inを指定する Scanner scanner = new Scanner(System.in); // 入力を促すメッセージ System.out.print("x y の順で入力してください > "); int x = scanner.nextInt(); int y = scanner.nextInt(); //入力された内容を画面に表示 System.out.println("x=" + x + " y="+y); //範囲チェック if (0<x&&x<8 && 0<y&&y<8) { //マスが開いているか if (borad[y][x] == 0) { //八方向のリスト int[] dx = {-1, 0, 1, 1, 1, 0, -1, -1}; int[] dy = {-1, -1, -1, 0, 1, 1, 1, 0}; //八方向を順に試す for (int i=0; i<8; i++) { //置くマスの隣を(nx, ny)とする int nx = x+dx[i]; int ny = y+dy[i]; //範囲チェック if (0<nx&&nx<8 && 0<ny&&ny<8) { //隣に白のコマがあるかどうか if (borad[ny][nx] == 1) { //黒のコマを見ている方向で探す while (0<nx+dx[i]&&nx+dx[i]<8 && 0<ny+dy[i]&&ny+dy[i]<8) { if (borad[ny][nx] == 2) { //OK System.out.println("OK"); System.out.println("dx=" + dx[i] + " dy="+dy[i]); } nx += dx[i]; ny += dy[i]; } } } } } } // Scannerクラスのインスタンスをクローズ scanner.close(); } }実践5 コマを置き、ひっくり返す。
回答例
import java.util.Scanner; class Othello { public static void main(String[] args) { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } // Scannerクラスのインスタンスを作成 // 引数で標準入力System.inを指定する Scanner scanner = new Scanner(System.in); // 入力を促すメッセージ System.out.print("x y の順で入力してください > "); int x = scanner.nextInt(); int y = scanner.nextInt(); //入力された内容を画面に表示 System.out.println("x=" + x + " y="+y); //範囲チェック if (0<x&&x<8 && 0<y&&y<8) { //マスが開いているか if (borad[y][x] == 0) { //八方向のリスト int[] dx = {-1, 0, 1, 1, 1, 0, -1, -1}; int[] dy = {-1, -1, -1, 0, 1, 1, 1, 0}; //八方向を順に試す for (int i=0; i<8; i++) { //置くマスの隣を(nx, ny)とする int nx = x+dx[i]; int ny = y+dy[i]; //範囲チェック if (0<nx&&nx<8 && 0<ny&&ny<8) { //隣に白のコマがあるかどうか if (borad[ny][nx] == 1) { //黒のコマを見ている方向で探す while (0<nx+dx[i]&&nx+dx[i]<8 && 0<ny+dy[i]&&ny+dy[i]<8) { if (borad[ny][nx] == 2) { //OK System.out.println("OK"); System.out.println("dx=" + dx[i] + " dy="+dy[i]); while (x!=nx || y!=ny) { borad[y][x] = 2; x += dx[i]; y += dy[i]; } } nx += dx[i]; ny += dy[i]; } } } } } } for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } // Scannerクラスのインスタンスをクローズ scanner.close(); } }このように分岐やループが重なり構造が複雑なコードを美しくないという。
プログラムを分ける
操作としては簡単なはずだが、それを表現するコードは複雑になった。この操作を繰り返すことでオセロをプレイできるが面倒だし間違いのもとである。同じ処理をまとめ、名前を付ける機能がJava(とその他たいていの言語)に備わっている。
同じ処理をまとめることで繰り返しが書きやすくなる。Javaではメソッドと呼ばれ、ほかに関数やサブルーチンといった呼ばれ方もする。メソッドを用いてオセロの完成を目指す。コマを交互に置き、置けなくなったら勝敗を表示するということだ。
実践6 オセロの完成。ただし白と黒が交互に入力し、入力の方法は自由とする。
回答例
import java.util.Scanner; import sun.launcher.resources.launcher; class Othello { static boolean turn(int player, int x, int y, int[][] borad, boolean check) { int opponent = 1; if (player == 1) { opponent = 2; } boolean res = false; //範囲チェック if (0<x&&x<8 && 0<y&&y<8) { //マスが開いているか if (borad[y][x] == 0) { //八方向のリスト int[] dx = {-1, 0, 1, 1, 1, 0, -1, -1}; int[] dy = {-1, -1, -1, 0, 1, 1, 1, 0}; //八方向を順に試す for (int i=0; i<8; i++) { //置くマスの隣を(nx, ny)とする int nx = x+dx[i]; int ny = y+dy[i]; //範囲チェック if (0<nx&&nx<8 && 0<ny&&ny<8) { //隣に白のコマがあるかどうか if (borad[ny][nx] == opponent) { //黒のコマを見ている方向で探す while (0<nx+dx[i]&&nx+dx[i]<8 && 0<ny+dy[i]&&ny+dy[i]<8) { if (borad[ny][nx] == player) { //OK res = true; if (!check) { System.out.println("OK"); System.out.println("dx=" + dx[i] + " dy="+dy[i]); while (x!=nx || y!=ny) { borad[y][x] = player; x += dx[i]; y += dy[i]; } } } nx += dx[i]; ny += dy[i]; } } } } } } return res; } static void print_borad(int[][] borad) { for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { System.out.print(borad[i][j] + " "); } System.out.print("\n"); } } static boolean can_put(int[][] borad, int player) { boolean res = true; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { res &= turn(player, i, j, borad, true); } } return res; } static int[][] init() { int [][] borad = new int[8][8]; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { borad[i][j] = 0; } } borad[4][4] = 1; borad[4-1][4] = 2; borad[4][4-1] = 2; borad[4-1][4-1] = 1; print_borad(borad); return borad; } public static void main(String[] args) { int [][] borad = init(); int player = 2; boolean is_game_end = false; // Scannerクラスのインスタンスを作成 // 引数で標準入力System.inを指定する Scanner scanner = new Scanner(System.in); int x, y; while (!is_game_end) { // 入力を促すメッセージ System.out.println("Player = " + player); System.out.print("x y の順で入力してください > "); x = scanner.nextInt(); y = scanner.nextInt(); //入力された内容を画面に表示 System.out.println("x=" + x + " y="+y); if (turn(player, x, y, borad, false)) { if(player == 2) player = 1; else player = 2; is_game_end = can_put(borad, player); print_borad(borad); } } // Scannerクラスのインスタンスをクローズ scanner.close(); int black = 0, white = 0; for (int i=0; i<8; i++) { for (int j=0; j<8; j++) { if (borad[i][j] == 1) { white++; } else if (borad[i][j] == 2) { black++; } } } if (black>white) { System.out.println("Blackの勝ち"); } else if(black<white) { System.out.println("Whiteの勝ち"); } else { System.out.println("引き分け"); } } }ウノ実装
ただいま編集中
ユーザー定義型
アクセス制御
継承、実行時ポリモーフィズム
オブジェクト指向プログラミングの利点
終わりに
参考資料