- 投稿日:2020-04-30T23:44:20+09:00
LINEBotをみんなで作ろう〜LINEBot is 何?編〜【GWアドベントカレンダー2日目】
この記事は下記の #GWアドベントカレンダー の 2日目の記事になります。
楽しそうなのでやってみる ( @inoue2002 ) | GWアドベントカレンダー
はじめに
こちらの内容は超初心者向けです。
公式ドキュメントを読める方はこちらをお読みいただく方が正確です。昨日の記事をご覧になってない方はぜひ。
こちらの記事はGWアドベントカレンダーを通してLINEBotをサーバレスで作れるようになろう!ということを目標に書いている記事です。LINEBotって何なん?って思われる方にまずお読みいただきたいです。
できるだけ専門用語を使わず、噛み砕いて書いていきます。LINEBotとは
「bot」という単語は robotの短縮形であり、みなさんが想像されるロボットの短縮形という認識で大丈夫です。
ロボット=人間の代わりに仕事をしてくれる
つまり
LINEの中で、人間の代わりにメッセージのやりとりをしてくれるロボット → LINEBot と呼ばれているわけです。「人間の代わりにメッセージのやりとりをしてくれる」というのは具体的にどんなものでしょうか。
よくみなさんも目にするであろう企業のLINE公式アカウントを思い出してみてください。定期的にメッセージが送られてきたり、トーク内でメッセージを送ったりすると、即答でメッセージが返ってくる経験をした事があるはずです。
最近で有名な公式アカウントを例にあげると、ローソン: AIを搭載しており、ユーザーに合った商品をレコメンドしてくれる
https://www.lawson.co.jp/lab/tsuushin/art/1372267_4659.htmlクロネコヤマト: 再配送を依頼したり、荷物がいつ頃届くのか確認したりできる
http://www.kuronekoyamato.co.jp/ytc/campaign/renkei/LINE/日々増え続けているのでぜひ「LINEBot 企業」などで検索をかけてみると面白いBotに出会えるかもしれません。
少しはLINEBotというものがどういうもので、どんな物に活用されているのかを掴んでもらう事ができましたでしょうか。
ここで、企業は色々と客に対して便利なサービスを提供できるけど、個人で開発したところで何の役にもたたんやろ。と思っておられる方もおられるのではないでしょうか。
実際に筆者が、過去2ヶ月で作ったLINEBotをみていただき、個人開発でどんな事ができるのか。可能性を広げていただければなと思います。こちらの動画では5種類の実際にリリースしたbotを紹介しています。↓登壇動画 2020/4/29
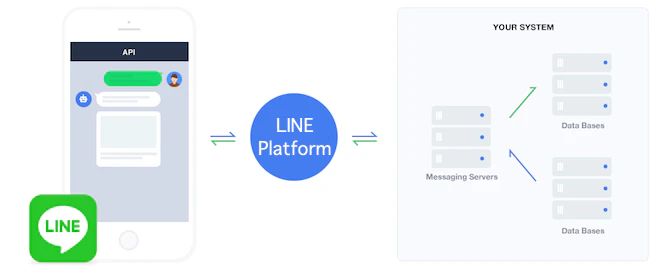
LINEBotが動く(Messaging API)の仕組み
Messaging APIを使い、リクエストは、JSON形式でHTTPSを使って送信されます。
1.ユーザーが、LINEBotにメッセージを送信します。
2.LINEプラットフォームからボットサーバーのWebhook URLに、Webhookイベントが送信されます。
3.Webhookイベントに応じて、ボットサーバーからユーザーにLINEプラットフォームを介して応答します。
LINEBotでできること
・応答メッセージを送る
・プッシュメッセージを送る
・さまざまなタイプのメッセージを送る
・ユーザーが送ったコンテンツを取得する
・ユーザープロフィールを取得する
・グループチャットに参加する
・リッチメニューを使う
・ビーコンを使う
・アカウント連携を使う
・送信メッセージ数を取得するメインで使う機能としては、
・応答orプッシュメッセージを送る
・ユーザープロフィールを取得する
・リッチメニューを使う辺りだと思います。言葉だけでも覚えておくと良いでしょう。
終わりに
明日からサンプルコードを利用しながら、実際にLINEBotを作っていきます!頑張っていきましょう!



- 投稿日:2020-04-30T19:47:51+09:00
初心者がWordPressでタイピングのリアルタイム対戦ゲームを作ってみました
はじめに
この記事は、WordPressでしかホームページを作れないプログラミング初心者が、無理やりWordPressを使って、タイピングのリアルタイム対戦ゲームを作ってみた記事です。
タイピング初心者用に、70近くあるステージをクリアしていくモードもあります。IT系の集まりで、「WordPressでこのサイト作ったよ」って言ったらどよめきが起こり、「Qiitaに書いてみれば?」と言われたので書いてみます。
ちなみに、タイピンガーZというサイトです。
このサイトをWordPressでどうやって作ったのかを、ざっくり書いていこうと思います。
テーマのテンプレート
はるか昔に購入した有料テンプレートを使ってみましたが、改造しすぎて原型をとどめていないので、なんでも良かったと思います。
記事投稿と固定ページテンプレート
タイピンガーZは、対人対戦を除いて、ステージをクリアしていく仕組みになっているのですが、それらのステージはWordPressの記事投稿で作りました。
記事には、敵キャラのセリフだったり、敵の強さだったり、音楽・背景だったりのパラメーターを記入します。
↓こんな感じ<!--セリフ--> <span id="pan2serifu"> (たけしさんブリーフ増えてる・・・)brbr なんすかそれ, ブリーフ型ターバンヲ発明シマシタ。22, ヨガタケシデース22, カレーガンジーヨガファイア22, インド人に謝れ, ヨガソーリー22, さて、今回もがんばろう。 ,*-,*del,((</span> <!--速度基準--> <span id="speedlinesetting1">20</span><!--遅い--> <span id="speedlinesetting2">30</span> <span id="speedlinesetting3">40</span><!--早い--> <!--ミス基準--> <span id="misslinesettei1">60</span><!--正確性低い--> <span id="misslinesettei2">70</span> <span id="misslinesettei3">85</span><!--正確性高い-->それぞれのパラメーターは、Javascriptでゲットできるように、idかclassを付けておきます。
セリフに「22」とか、「*del」とか書いてますが、これはJavascript側に何かしてほしいときの自作コマンドみたいなものです。
このコマンドで、セリフを話してるキャラが消えたり、セリフが大きくなったり、BGMが変わったりと、いろいろ操作することができるようにしてます。また、これだけではただのブログ記事のデザインにしかならないので、自分で作った固定ページテンプレートを当てます。
「初心者練習ステージテンプレート」「CPU対戦用テンプレート」などをPHPで書いて用意しました。
あとはパラメーターを書いた記事を大量に投稿して、それぞれに固定ページテンプレートを当てれば、ステージがどんどん増えていきます。
リアルタイム対戦
リアルタイム対戦を導入するにあたってNode.jsを使いたかったのですが、僕が使っているロリポップレンタルサーバーが対応してなかったので、仕方なくAWSも使うことにしました。
AWSを「オッス」と読んでたくらい何も知識がなかったのですが、1年目が無料なのと、2年目以降もだいぶ格安っぽい感じだったので使うことにしました。
AWSでNode.jsを導入するにあたって、下記の記事をそのままやりました。
この記事でやってることが何なのか、何も理解しないまま人形のように作業したのですが、なんと普通にNode.jsが動きました。
記事の筆者さんありがとう。しかし、この記事のままだとhttpsでのやり取りができず、そこではまりました。
何も理解しないまま進めると、応用が利かないから困ります。なんとか解決したものの、どうやって解決したのか忘れてしまったという。。。
たしかロードバランサ―の部分でhttpsを受け入れてなかったとか、そんな感じだった気がします。Socket.io
Node.jsのライブラリであるSocket.ioを使って、リアルタイム対戦を実現しました。
Socket.ioまじですごい。アホでも使えるようにしてくれてる。基本的には、下の四つだけ覚えたら使えました。
.on() 受信
.emit() 送信
.broadcast() 自分以外に送信
.join() 部屋作るFirebaseとやらがもっと簡単という噂を聞きましたが、Socket.ioも初心者でも扱えるとてもシンプルなものでした。
処理のフローをまとめると
無理やりWordpress使って、サーバーも2つ使ってるという構造なので、無駄に複雑です。
リアルタイム対戦の処理をまとめると・・・
1、サーバー1(WordPress)からクライアントにページ情報を送信
2、クライアント側でHTMLとかJavascriptが動く
3、クライアントからサーバー2(AWS、Node.js)に情報送信
4、サーバー2から対戦相手のクライアントに情報送信
5、以下サーバー2を通してクライアント同士で情報送受信という流れです。
Qiitaの天才達、ありがとう
開発前は、プログラミング素人の自分が、リアルタイム対戦なんてできるのか?
とか思ってましたが、やってみればできるもんです。
10年前だったら不可能だったと思いますが、先人の天才達が素人でもできるように、資料やライブラリを公開してくれているので、なんとかなった感があります。
Qiita、めちゃくちゃ参考にしました。天才達、ありがとう。
Twitter:@pant2taicho
ホームページ:タイピンガーZ


- 投稿日:2020-04-30T17:08:49+09:00
Node.jsを使ってサーバにアクセスログを出力してみた
はじめに
この記事はなんとなくJSなどを勉強している学生がメモ代わりに書いている記事です。内容は期待しないでください。
1.仮想環境を構築する。
今回はUbuntuで行うのでiTerm2で仮想環境を起動する。
起動したところで
1.Virtual Box(バーチャルボックス)
2.Vagrant(ベイグラント)
という2つのソフトウェアを使った仮想環境でUbuntuを使用します。
cd ~/vagrant/ubuntu
vagrant up
vagrant sshUbuntuがインストールされたディレクトリに移動。vagrant upは仮想的なPCにインストールされたUbuntuを起動するコマンドで,vagrant sshはVagrantの仮想マシンがセットされている状態でSSHに接続します。
2.作成したサーバにログを表示する
以下の内容をhttp.createServerのアロー関数内に記述します。
console.info(
'[' + new Date() + '] Requested by ' + reqest.connection.remoteAddress
);
今回はreqestという変数にサーバへのリクエストを代入しています。今回はリクエストが送られたIP情報を出力します。console.infoというものを使用していますがinfoは以下のように分類されます。
関数名 内容 出力 info,log 普段から残す情報 標準出力 warn,error 警告 エラー標準出力 3.作成したサーバにエラーを出力する
on('error', (e) => {
console.error('[' + new Date() + '] Server Error', e);
以上のon関数をアロー関数後に記述します。4.実際にサーバを起動してみる
node ファイル名
実際にサーバを起動してエラー等のコンソールが表示されれば成功です。
- 投稿日:2020-04-30T16:32:41+09:00
さくらVPSにmaria db + nginx + headlessCMSのstrapiを入れる
さくらインターネットでVPSを契約
基本環境はCentOS7を選択
nginx インストール
yum -y install nginxmarina dbをインストール
yum install mariadb-server systemctl enable mariadb systemctl start mariadbNode.js インストール
curl -L git.io/nodebrew | perl - setup echo 'export PATH=$HOME/.nodebrew/current/bin:$PATH' >> ~/.bash_profile source ~/.bash_profile nodebrew install-binary stable nodebrew use stablestrapiのインストール
npm install strapi@alpha -g cd /usr/share/nginx/html strapi new blognginxの設定の追加
/etc/nginx/nginx.conflocation / { proxy_pass http://localhost:1337; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; }pm2による自動起動の設定
https://qiita.com/kuryus/items/fbdc373f23d3236ebb04
nuxtのプロジェクト作成
$ yarn create nuxt-app my_blog yarn create v1.15.2 [1/4] ? Resolving packages... warning create-nuxt-app > sao > download-git-repo > download > mkdirp@0.5.4: Legacy versions of mkdirp are no longer supported. Please update to mkdirp 1.x. (Note that the API surface has changed to use Promises in 1.x.) warning create-nuxt-app > sao > micromatch > snapdragon > source-map-resolve > resolve-url@0.2.1: https://github.com/lydell/resolve-url#deprecated warning create-nuxt-app > sao > micromatch > snapdragon > source-map-resolve > urix@0.1.0: Please see https://github.com/lydell/urix#deprecated [2/4] ? Fetching packages... [3/4] ? Linking dependencies... [4/4] ? Building fresh packages... warning Your current version of Yarn is out of date. The latest version is "1.22.4", while you're on "1.15.2". info To upgrade, run the following command: $ brew upgrade yarn success Installed "create-nuxt-app@2.15.0" with binaries: - create-nuxt-app create-nuxt-app v2.15.0 ✨ Generating Nuxt.js project in my_blog ? Project name my_blog ? Project description My world-class Nuxt.js project ? Author name Rickey ? Choose programming language JavaScript ? Choose the package manager Yarn ? Choose UI framework Vuetify.js ? Choose custom server framework None (Recommended) ? Choose Nuxt.js modules Axios ? Choose linting tools ESLint ? Choose test framework None ? Choose rendering mode Universal (SSR) ? Choose development tools (Press <space> to select, <a> to toggle all, <i> to invert selection)Netlifyの登録
https://qiita.com/isihigameKoudai/items/e3b136e9964f1d30d73d
https://ja.unflf.com/tech/netlify/route53/
- 投稿日:2020-04-30T14:16:53+09:00
Node.jsのrequest-promiseモジュールでresponseの内容が表示できずはまった件
やりたかったこと
Node-REDでリビングのGoogle homeにメッセージを喋らせるREST APIを作り、Node.jsでそのREST APIを呼び出すプログラムを作りたかった。REST APIの呼び出しにはrequest-promiseモジュールを利用。
はまったところ
REST APIを以下のコードで呼び出したが、responseの内容を表示しようとしてもコンソールに
undefinedと表示されてしまう。var options = { url: 'http://XXX.XXX.XXX.XXX:1880/sendtogh', method: 'POST', form: {"message": message}, //前段の処理でmessageにgoogle homeに喋らせたい内容をセット } request(options) .then(function(response){ console.log(response.statusCode); //コンソールに「undefined」と表示される }) .catch(function(err){ (省略)解決方法
request-promiseのドキュメントを見ると、optionsに
resolveWithFullResponse: trueを指定しないと、bodyの内容しか返却されないとのこと。
https://github.com/request/request-promise#get-the-full-response-instead-of-just-the-body
- 投稿日:2020-04-30T12:53:06+09:00
Node - ES6 imports cannot find module
Problem
index.jsimport HttpConnect from './src/Library/Connect/HttpConnect'; ... ... ...node --experimental-modules index.js$ node --experimental-modules index.js internal/modules/run_main.js:54 internalBinding('errors').triggerUncaughtException( ^ Error [ERR_MODULE_NOT_FOUND]: Cannot find module '\home\johnny\test\src\Library\Connect\HttpConnect' imported from \home\johnny\test\index.js at finalizeResolution (internal/modules/esm/resolve.js:272:11) at moduleResolve (internal/modules/esm/resolve.js:652:10) at Loader.defaultResolve [as _resolve] (internal/modules/esm/resolve.js:695:13) at Loader.resolve (internal/modules/esm/loader.js:97:40) at Loader.getModuleJob (internal/modules/esm/loader.js:243:28) at ModuleWrap.<anonymous> (internal/modules/esm/module_job.js:42:40) at link (internal/modules/esm/module_job.js:41:36) { code: 'ERR_MODULE_NOT_FOUND'Solution
index.jsimport HttpConnect from './src/Library/Connect/HttpConnect.js'; <- including the file extension ... ... ...https://stackoverflow.com/questions/60059121/nodejs-es6-imports-cannot-find-module
- 投稿日:2020-04-30T11:45:50+09:00
Puppeteerでexampleコードsearch.jsを試すときにハマったこと(動的サイトのセレクタ確認、Headless解除でのデバッグ)
はじめに
スクレイピングをnode.jsでできるPuppeteer(スペルミス多発)を初心者が使ってみたところ、
私的なハマりどころが複数あったので備忘録として残します。ハマりポイント(順番に)
- search.jsは2018年に作成されたものなので、一部スクレイピング対象サイトのセレクタが変わっていた。
- 検索窓に入力した際のポップアウトが動的で、developer toolでDOMをelementを見つけるのに苦労した。
- レスポンシブデザインのbreakpointのサイズを考えずに組んでいたので、Headlessで立ち上がっているChromeと挙動の差異があったことに気付いていなかった(Navigation Drawerが出てきてしまっていた)。
解決策
- ちゃんとdeveloper toolでelementを確認する。
- JavaScriptのdebugと同じ要領でBreakpointを設定してポップアウトが出た瞬間に止めて、elementを確認する。
- Headlessモードを解除し、実際にChromeが動いている様子を確認してロジックを組む。
3についてはpuppeteerにより立ち上がるChromeのブラウザサイズを指定することで対応できないかと思ったのですが、
自分が調べた範囲では、スクリーンショットのサイズは変更可能ですが、ブラウザサイズの変更はできないみたいです。
(もしどなたか、やり方を知っていたら教えてください)結局のところ
- developer toolsを使って対象サイトの構成をしっかり把握しよう
- Breakpointを駆使しよう(JS書くならデバッグのやり方把握しないとですよね)
- HeadfullでChromeの挙動を確認しよう
対象
- Puppeteerの初心者
- Puppeteerのexampleのsearch.jsを試そうとしたけどそのままでは動かなかった人
私のレベルとしてはDOM操作の一通りの知識があり、バックエンドはnodeとExpressを少し触った程度です。
用語の正確性がボロボロかもしれませんのでよろしければご指摘ください。開発環境
- puppeteer@3.0.2
- node.js v12.16.1
- npm 6.13.4
- macOS Catalina 10.15.4
一つ一つ見ていきます
Puppeteerの導入については公式のgithubをご覧ください
https://github.com/puppeteer/puppeteerexamplesの実行については以下となります。
Assuming you have a checkout of the Puppeteer repo and have run npm i (or yarn) to install the dependencies, the examples can be run from the root folder like so:
NODE_PATH=../ node examples/search.jshttps://github.com/puppeteer/puppeteer/tree/master/examples
こちらからsearch.jsを見てみます。search.js'use strict'; const puppeteer = require('puppeteer'); (async() => { const browser = await puppeteer.launch(); const page = await browser.newPage(); await page.goto('https://developers.google.com/web/'); // Type into search box. await page.type('#searchbox input', 'Headless Chrome'); // Wait for suggest overlay to appear and click "show all results". const allResultsSelector = '.devsite-suggest-all-results'; await page.waitForSelector(allResultsSelector); await page.click(allResultsSelector); // Wait for the results page to load and display the results. const resultsSelector = '.gsc-results .gsc-thumbnail-inside a.gs-title'; await page.waitForSelector(resultsSelector); // Extract the results from the page. const links = await page.evaluate(resultsSelector => { const anchors = Array.from(document.querySelectorAll(resultsSelector)); return anchors.map(anchor => { const title = anchor.textContent.split('|')[0].trim(); return `${title} - ${anchor.href}`; }); }, resultsSelector); console.log(links.join('\n')); await browser.close(); })();コードの説明は省きますが、コメントアウトで書かれている通りの流れとなっています。
https://developers.google.com/web にアクセスして検索窓に入力し、出てくるポップアウトの中のボタンを押し、遷移したページの結果を取得するというものです。1. スクレイピング対象サイトのHTML Elementが変わっていた問題への対応
さて、このまま実行すると
UnhandledPromiseRejectionWarning: Error: No node found for selector: #searchbox inputといったエラーが出ます。2018年段階ではsearchboxというIDで選択できたのですが、2020/4/29時点では変更されています。
修正しなければいけない部分は以下になります。検索窓を見つけてpage.type()で入力する処理です。search.js'use strict'; const puppeteer = require('puppeteer'); (async() => { // 省略 // Type into search box. await page.type('#searchbox input', 'Headless Chrome'); //<- ここ! //省略 })();ChromeのDeveloper toolsを開き、検索窓をinspectします。
以下の画像のようになっています。赤い部分が検索窓に対応するHTML Elementです。
ここで注意することとしては、複数のElementと被らないIDやclassをセレクタすることです。
私が試したパターンは以下の三つとなります。
search.js// await page.type('input[name="q"]', 'Headless Chrome'); //OK // await page.type('.devsite-search-field', 'Headless Chrome'); //OK await page.type('.devsite-search-query', 'Headless Chrome'); //OK以上のどれかに変更することで第一関門は突破できました。
この時は以下のコードをpage.type()の下に記述して確認しておりました。await console.log('type success')もしくはスクリーンショットを以下のように撮ることで確認しておりました。
await page.screenshot({path: 'search.png', fullPage: true});しかし、後述しますが、デバッグはHeadlessを解除して行えば一発です。
2. 検索窓入力後のポップアウトのHTML Elementの取得
developer toolsで普通にやるとポップアウト部分のHTML Elementを見ようとするとポップアウトが消えてしまいます。
そこで、以下の記事を参考にしてBreak inを設定します。そうすることによって、JavaScriptが中断され、ポップアウトが開いたままになります。
How to Inspect Dynamic HTML Elements (that keep disappearing!) in Chrome
ここでは結果的に、以下のexampleコードのままで良いことが判明しました。
classが2018年と変更なしということです。search.js'use strict'; const puppeteer = require('puppeteer'); (async() => { //省略 // Wait for suggest overlay to appear and click "show all results". const allResultsSelector = '.devsite-suggest-all-results'; await page.waitForSelector(allResultsSelector); await page.click(allResultsSelector); //省略 })();Breakpointsは
DOM Breakpointsから削除しておきます。もしくは更新すれば消えます。
3.Headlessを解除してHeadfullでデバッグを行う
ここまでクリアすれば問題ないと思っていたのですが、以下のエラーが出てきてしまいました。
UnhandledPromiseRejectionWarning: TimeoutError: waiting for selector ".devsite-suggest-all-results" failed: timeout 30000ms exceeded結果的に解決策としては、
puppeteer.launch()でpuppteer.launch({slowMo:100})として、一つ一つの実行に100ms挟むか、
もしくは、以下のようにtypeする前の部分で、検索アイコンをクリックして検索窓を開かせることで解決しました。search.js'use strict'; const puppeteer = require('puppeteer'); (async() => { // 省略 const searchIconSelector = '.devsite-search-button' await page.waitForSelector(searchIconSelector); await page.click(searchIconSelector); // Type into search box. await page.type('.devsite-search-query', 'Headless Chrome'); //省略 })();重要なのは
Headfullにして、実際に動いているChromeの挙動を確認することでした。Headlessを解除してHeadfullにするには以下のようにします。
puppeteer.launch({headless:false})そうすると、Headfullで立ち上がり、挙動を確認することができます。
このブラウザのサイズは800px × 600pxで固定とのことです。
私が調べた範囲ではスクリーンショットサイズは変更できましたが、ブラウザサイズは変えられませんでした。
レスポンシブデザインの場合は横幅が800pxの状態でどう表示されるか確認する必要があると思います。また、他の私のハマったところとしては、検索アイコンをクリックして検索窓を開かせる場合に、Navigation Drawerにも適用されているclassを指定してしまったことです。
const searchIconSelector = '.devsite-search-button' //OK // const searchIconSelector = '.devsite-header-icon-button' // NG上のNGの方を使うと、以下のようにNavigation Drawerを開いてしまい、入力はできても、サジェストの全結果を開くボタンを押すことができませんでした。
最終結果は以下のように出力されたら成功です。
Getting Started with Headless Chrome - https://developers.google.com/web/updates/2017/04/headless-chrome Automated testing with Headless Chrome - https://developers.google.com/web/updates/2017/06/headless-karma-mocha-chai Headless Chrome: an answer to server-side rendering JS sites - https://developers.google.com/web/tools/puppeteer/articles/ssr Puppeteer - https://developers.google.com/web/tools/puppeteer Chrome DevTools Protocol - https://developers.google.com/chrome-developer-tools/docs/debugger-protocol Examples - https://developers.google.com/web/tools/puppeteer/examples New in Chrome 59 - https://developers.google.com/web/updates/2017/05/nic59 All Updates tagged: headless - https://developers.google.com/web/updates/tags/headless?hl=ja Running the examples - https://developers.google.com/web/tools/puppeteer/examples?hl=ja Troubleshooting - https://developers.google.com/web/tools/puppeteer/troubleshooting?hl=jaこの後の調査予定
- 他のexampleも試し、詰まりながら仕様を理解していく。
長くなりましたが以上となります。お疲れ様でした。
参考記事まとめ






- 投稿日:2020-04-30T10:44:46+09:00
Node.jsを使ってHTTPサーバを作ってみる
はじめに
この記事はなんとなくJSとかを勉強している学生がメモ代わりに書いているものです。内容は期待しないでください。
1.仮想環境を構築する
今回はUbuntuで行うのでiTerm2で仮想環境を起動する。
起動したところで
1.Virtual Box(バーチャルボックス)
2.Vagrant(ベイグラント)
という2つのソフトウェアを使った仮想環境でUbuntuを使用します。
cd ~/vagrant/ubuntu
vagrant up
vagrant sshUbuntuがインストールされたディレクトリに移動。vagrant upは仮想的なPCにインストールされたUbuntuを起動するコマンドで,vagrant sshはVagrantの仮想マシンがセットされている状態でSSHに接続します。
2.プログラムのひな形(テンプレート)を用意する
ディレクトリ内に以下を記述します。
yarn init
echo "'use strict';" > ファイル名
1行目はyarnで新しいプロジェクトを始める際に記述するものです。
3.プログラムを書く
先ほど記述したファイルに以下を記述します。
'use strict';
const http = require('http');
const server = http.createServer((request, response) => {
response.writeHead(200, {
'Content-Type': 'text/plain; charset=utf-8'
});
response.write(request.headers['なんでもいい']);
response.end();
});
server.listen(8000, () => {
console.log('Listening on 8000' );
});
1行目はJSをstrictモードで利用するための記述です。
2行目はhttpモジュールを引数httpに代入しています。
3~9行目はサーバに関する記述です。
引数に代入したhttpモジュールを使ってサーバを構築しています。記述方法は以下参照。
http.createServer( サーバー側の処理 )
今回はサーバ側の処理でアロー関数を使用しており,引数の一つ目にはリクエストが二つ目にはレスポンスが代入されています。
res.writeHead(200, {
'Content-Type': 'text/plain; charset=utf-8'
});
このコードは200という成功を示すステータスコードと共に、サーバが扱う情報の設定をレスポンスヘッダを書き込んでいます。
7行目はwrite関数を使用してリクエストのヘッダーに文字列を表示しています。表示したい内容によっては以下のように書くこともできます。
res.write(
'<!DOCTYPE html><html lang="ja"><body><h1>文字列</h1></body></html>'
);
8行目はサーバの書き出しが終わったことを示しています。10行目以降はサーバ起動するポートを8000としてlisten関数で特定のポートからリクエストがないかを永続的に調べています。今回はリクエストがあり次第コンソールで文字列を表示しています。
4.サーバを起動してみる
以下を記述してREPLで動作を確認します。
node ファイル名
先ほどのコンソールの文字列が表示されたら成功です。お疲れ様でした!!yarnとは
yarnはnodeをインストールすると自動でインストールされるnpmと役割は同様のパッケージマネージャー(https://yarnpkg.com/en/)。
並行処理でのインストールによってnpmよりも高速にパッケージをインストールできる。httpモジュールとは
「httpモジュール」はHTTPサーバーやHTTPクライアントとしての機能を構築するために使われます。自分のwebサイトをネット上に公開したり、フォームなどからデータを送受信できます。もちろん、静的なWebサイトだけでなくTwitterのような大きなWebサービスを構築することも可能になります。
ポートとは(参照:https://www.nic.ad.jp/ja/basics/terms/port-number.html)
TCP/IP通信においては,IPアドレスがあればネットワーク上のコンピュータを一意に識別することができますが,該当コンピュータのどのプログラムに通信パケットを届けるかは,IPアドレスだけでは決定できません。どのプログラムに通信パケットを渡すのかを決定するために,ポート番号を使用します。