- 投稿日:2020-02-05T15:37:03+09:00
tensorflow.kerasにおけるtf.function-decorated function tried to create variables on non-first call.のエラー
たまに詰まりがちなので備忘録で
エラー部分
class ResNet50(Model): def __init__(self, stride: int = 1, *args, **kwargs): super(ResNet50, self).__init__(*args, **kwargs) self.stride = stride self.avgpool = AveragePooling2D() self.maxpool = MaxPool2D(padding='same') self.ResBlocks: List[Layers] = [] self.softmax = Softmax() self.dense = Dense(1, activation='sigmoid') def call(self, inputs): conv_1 = self.conv(inputs) maxpooled = self.maxpool(conv_1) layers_num = [3, 4, 6, 3] for i in range(len(layers_num)): for _ in range(layers_num[i]): if i==0 and u==0: self.ResBlocks.append(Residual_Block(filters_num=4 * 2 ** (i))(maxpooled)) else: self.ResBlocks.append(Residual_Block(filters_num=4 * 2 ** (i))(self.ResBlocks[-1]))) avgpooled = self.avgpool(maxpooled) value = self.dense(avgpooled) return avgpooled, value的なことをしてtf.function-decorated function tried to create variables on non-first callが出ていました。
調べるとtensorflowの宣言ずみvariableが新しく宣言されてしまうため、ということですが解決後
class ResNet50(Model): def __init__(self, stride: int = 1, *args, **kwargs): super(ResNet50, self).__init__(*args, **kwargs) self.stride = stride self.avgpool = AveragePooling2D() self.maxpool = MaxPool2D(padding='same') self.ResBlocks: List[Layers] = [] layers_num = [3, 4, 6, 3] for i in range(len(layers_num)): for _ in range(layers_num[i]): self.ResBlocks.append(Residual_Block(filters_num=4 * 2 ** (i))) self.conv = Conv2D(filters=16, kernel_size=7, strides=self.stride, padding='same') self.softmax = Softmax() self.dense = Dense(1, activation='sigmoid') def call(self, inputs): conv_1 = self.conv(inputs) maxpooled = self.maxpool(conv_1) for layer in self.ResBlocks: maxpooled = layer(maxpooled) avgpooled = self.avgpool(maxpooled) value = self.dense(avgpooled) return avgpooled, valueとすれば直りました。原因としては、tensorflow.kerasのModelの仕様でLayerを宣言する時にはinitの部分にしなければいけないということでした。
完全に忘れてました。そこらへんと変数の宣言が関係しているのでしょうか。今度時間がある時にでも調べてみたいです。
- 投稿日:2020-02-05T01:51:58+09:00
ディープラーニングをTPUでやった話
どうも,三条です.大学のグループワークでディープラーニングをやったので,その記録です.
概要
実際には自分たちで作成したデータセットを使ってディープラーニングをやりましたが,本記事では簡単のためcifar10を使います.
CNNを用いて学習させ,作ったモデルを視覚的に評価してみます.開発環境
Google Colaboratory + TPU + tensorflow 2.0.0
(Googleアカウントが必要です)ランタイムをPython3 + TPUに変更し,
!pip install tensorflow==2.0.0でtensorflow 2.0.0をインストールしましょう.とりあえずやってみる
コード全体
import os import numpy as np import tensorflow as tf from tensorflow.keras import Sequential from tensorflow.keras.layers \ import Conv2D, MaxPool2D, GlobalAvgPool2D, Dense, \ BatchNormalization, ReLU, Softmax from tensorflow.keras.datasets.cifar10 import load_data from tensorflow.keras.optimizers import SGD from tensorflow.keras.utils import to_categorical import pickle os.environ['TF_CPP_MIN_LOG_LEVEL']='2' os.environ['TCMALLOC_LARGE_ALLOC_REPORT_THRESHOLD'] = '10737418240' def create_model(): model = Sequential([ Conv2D(filters=64, kernel_size=3, strides=1, padding='same', input_shape=(32,32,3)), BatchNormalization(), ReLU(), Conv2D(filters=64, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), Conv2D(filters=128, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=128, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), GlobalAvgPool2D(), Dense(units=4096), BatchNormalization(), ReLU(), Dense(units=4096), BatchNormalization(), ReLU(), Dense(units=10), BatchNormalization(), ReLU(), Softmax() ]) return model def data_augmentation(img): im = tf.image.random_flip_left_right(img) im = tf.image.random_flip_up_down(im) im = tf.pad(im, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") im = tf.image.random_crop(im, size=[32, 32, 3]) return im def train(batch_size, epochs, lr): # Setup tpu print("Setting up TPU ...") tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"] tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url) tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) print("Done!") # Load dataset (x_train, y_train), (x_test, y_test) = load_data() x_val, y_val = x_test[:5000], y_test[:5000] x_test, y_test = x_test[5000:10000], y_test[5000:10000] train_num = len(x_train) val_num = len(x_val) test_num = len(x_test) # Normalize, convert to one-hot x_train, y_train = x_train.astype(np.float32), y_train.astype(np.int32) x_train /= 255.0 x_val, y_val = x_val.astype(np.float32), y_val.astype(np.int32) x_val /= 255.0 x_test, y_test = x_test.astype(np.float32), y_test.astype(np.int32) x_test /= 255.0 y_train = to_categorical(y_train, num_classes=10, dtype=np.int32) y_val = to_categorical(y_val, num_classes=10, dtype=np.int32) y_test = to_categorical(y_test, num_classes=10, dtype=np.int32) # Convert to tf.data trainset = tf.data.Dataset.from_tensor_slices((x_train, y_train)) trainset = trainset.map(lambda image, label: (data_augmentation(image), label)).shuffle(buffer_size=1024).repeat().batch(batch_size) valset = tf.data.Dataset.from_tensor_slices((x_val, y_val)) valset = valset.shuffle(buffer_size=1024).batch(val_num) testset = tf.data.Dataset.from_tensor_slices((x_test, y_test)) testset = testset.batch(test_num) # Train callbacks = [] callbacks.append(tf.keras.callbacks.EarlyStopping('val_loss', patience=10)) op = SGD(lr=lr, momentum=0.9) with strategy.scope(): model = create_model() model.compile(optimizer=op, loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit( trainset, epochs=epochs, validation_data=valset, callbacks=callbacks, steps_per_epoch=train_num // batch_size ) model.evaluate(testset) model.save('model.h5') # Save history save_file = 'history.pkl' with open(save_file, 'wb') as f: pickle.dump(history.history, f) print(f"Saving history to \'{save_file}\'. (epochs: {len(history.epoch)})") train(128, 100, 0.01)CNNを作る
作る前にまずは諸々のインポートとかを書きます.
import os import numpy as np import tensorflow as tf from tensorflow.keras import Sequential from tensorflow.keras.layers \ import Conv2D, MaxPool2D, GlobalAvgPool2D, Dense, \ BatchNormalization, ReLU, Softmax from tensorflow.keras.datasets.cifar10 import load_data from tensorflow.keras.optimizers import SGD from tensorflow.keras.utils import to_categorical import pickle os.environ['TF_CPP_MIN_LOG_LEVEL']='2' os.environ['TCMALLOC_LARGE_ALLOC_REPORT_THRESHOLD'] = '10737418240'TPUの設定ログがうるさく感じる方は,
tf.compat.v1.logging.set_verbosity(tf.compat.v1.logging.WARN)で解決!
最後の2行もうるさいから黙らせる系のやつです.さて,VGG16をベースにして適当にCNNを作っていきましょう.
model = Sequential([ Conv2D(filters=64, kernel_size=3, strides=1, padding='same', input_shape=(32,32,3)), BatchNormalization(), ReLU(), Conv2D(filters=64, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), Conv2D(filters=128, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=128, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), GlobalAvgPool2D(), Dense(units=4096), BatchNormalization(), ReLU(), Dense(units=4096), BatchNormalization(), ReLU(), Dense(units=10), BatchNormalization(), ReLU(), Softmax() ])なんかそれっぽい(小並感).本家と違う点は,主にバッチ正規化ですね.これを噛ませることで精度が格段に違ってくるので入れます.GlobalAvgPoolは単にDenseと形状を合わせるために入れてるので,FlattenでもReshapeでも何でもいいです.
TPUを使えるようにする
TPUの設定をします.
# Setup tpu print("Setting up TPU ...") tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"] tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url) tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) print("Done!")合言葉とかおまじないとかその類なので,詳しいことは省きます.2.0.0ではまだ実験段階なので,将来的に
experimentalが外れる可能性はあります.cifar10を加工する
データセットを取ってきます.trainデータとtestデータしか用意されていないので,testデータを分割してvalidationデータを用意します.
# Load dataset (x_train, y_train), (x_test, y_test) = load_data() x_val, y_val = x_test[:5000], y_test[:5000] x_test, y_test = x_test[5000:10000], y_test[5000:10000] train_num = len(x_train) val_num = len(x_val) test_num = len(x_test)cifar10は
tf.keras.datasets.cifar10.load_data()で取得できます.ダウンロードは実行すれば勝手にやってくれるので,自分で引っ張ってくるとか面倒なことはしなくていいです.ここで注意して欲しいのが,この取得したデータは正規化されてないし,one-hot表現になってないことです.なので,正規化とone-hot化を施します.
# Normalize, convert to one-hot x_train, y_train = x_train.astype(np.float32), y_train.astype(np.int32) x_train /= 255.0 x_val, y_val = x_val.astype(np.float32), y_val.astype(np.int32) x_val /= 255.0 x_test, y_test = x_test.astype(np.float32), y_test.astype(np.int32) x_test /= 255.0 y_train = to_categorical(y_train, num_classes=10, dtype=np.int32) y_val = to_categorical(y_val, num_classes=10, dtype=np.int32) y_test = to_categorical(y_test, num_classes=10, dtype=np.int32)データ型をしっかり指定してあげないとTPUを使うときに怒られるので,注意しましょう.TPUがuint8に対応してないのが主な原因です.
さらに,tensorflow 2.0.0っぽくtf.dataを使います.これは好みです.
# Convert to tf.data trainset = tf.data.Dataset.from_tensor_slices((x_train, y_train)) trainset = trainset.map(lambda image, label: (data_augmentation(image), label)).shuffle(buffer_size=1024).repeat().batch(batch_size) valset = tf.data.Dataset.from_tensor_slices((x_val, y_val)) valset = valset.shuffle(buffer_size=1024).batch(val_num) testset = tf.data.Dataset.from_tensor_slices((x_test, y_test)) testset = testset.batch(test_num)ざっくり言うと,numpyテンソルからtf.dataの形式に変換したのち,シャッフルしてバッチサイズ分を取り分けるといった感じです.詳細は公式ドキュメントを見てください.
学習させる
# Train callbacks = [] callbacks.append(tf.keras.callbacks.EarlyStopping('val_loss', patience=10)) op = SGD(lr=lr, momentum=0.9) with strategy.scope(): model = create_model() model.compile(optimizer=op, loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit( trainset, epochs=epochs, validation_data=valset, callbacks=callbacks, steps_per_epoch=train_num // batch_size ) model.evaluate(testset) model.save('model.h5') # Save history save_file = 'history.pkl' with open(save_file, 'wb') as f: pickle.dump(history.history, f) print(f"Saving history to \'{save_file}\'. (epochs: {len(history.epoch)})")コールバックにEarlyStoppingを設定して,学習が停滞したときに打ち切るようにします.また,オプティマイザとしてMoment SGDを採用します.
TPUを使う際には
with strategy.scope():で囲います.また,今回はone-hot表現なので,categorical_crossentropyを使います.単に正解ラベルの羅列の場合には逆にsparse_categorical_crossentropyを使います.次に,fitでモデルに学習させます.tf.dataを採用しているので,steps_per_epochはちゃんと指定しないと怒られます.最後にtestデータでモデルを評価して,モデル構成を保存しておきます.
ついでに,ログも保存しておきます.
実行結果
Setting up TPU ... INFO:tensorflow:Initializing the TPU system: 10.111.159.218:8470 INFO:tensorflow:Initializing the TPU system: 10.111.159.218:8470 INFO:tensorflow:Clearing out eager caches INFO:tensorflow:Clearing out eager caches INFO:tensorflow:Finished initializing TPU system. INFO:tensorflow:Finished initializing TPU system. INFO:tensorflow:Found TPU system: INFO:tensorflow:Found TPU system: INFO:tensorflow:*** Num TPU Cores: 8 INFO:tensorflow:*** Num TPU Cores: 8 INFO:tensorflow:*** Num TPU Workers: 1 INFO:tensorflow:*** Num TPU Workers: 1 INFO:tensorflow:*** Num TPU Cores Per Worker: 8 INFO:tensorflow:*** Num TPU Cores Per Worker: 8 INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:CPU:0, CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:CPU:0, CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0) Done! Train on 390 steps, validate on 1 steps Epoch 1/100 390/390 [==============================] - 28s 71ms/step - loss: 1.6188 - accuracy: 0.4342 - val_loss: 2.0326 - val_accuracy: 0.2442 Epoch 2/100 390/390 [==============================] - 11s 29ms/step - loss: 1.2757 - accuracy: 0.5581 - val_loss: 1.9118 - val_accuracy: 0.4016 Epoch 3/100 390/390 [==============================] - 11s 29ms/step - loss: 1.1264 - accuracy: 0.6105 - val_loss: 1.2568 - val_accuracy: 0.5498 Epoch 4/100 390/390 [==============================] - 11s 29ms/step - loss: 1.0150 - accuracy: 0.6484 - val_loss: 1.3001 - val_accuracy: 0.5564 Epoch 5/100 390/390 [==============================] - 11s 29ms/step - loss: 0.9265 - accuracy: 0.6820 - val_loss: 0.9689 - val_accuracy: 0.6802 Epoch 6/100 390/390 [==============================] - 11s 29ms/step - loss: 0.8634 - accuracy: 0.7041 - val_loss: 1.3286 - val_accuracy: 0.5624 Epoch 7/100 390/390 [==============================] - 11s 29ms/step - loss: 0.8024 - accuracy: 0.7261 - val_loss: 1.0214 - val_accuracy: 0.6676 Epoch 8/100 390/390 [==============================] - 11s 28ms/step - loss: 0.7602 - accuracy: 0.7416 - val_loss: 0.9298 - val_accuracy: 0.6804 Epoch 9/100 390/390 [==============================] - 11s 29ms/step - loss: 0.7220 - accuracy: 0.7575 - val_loss: 0.9745 - val_accuracy: 0.6784 Epoch 10/100 390/390 [==============================] - 11s 29ms/step - loss: 0.6771 - accuracy: 0.7717 - val_loss: 0.7908 - val_accuracy: 0.7244 Epoch 11/100 390/390 [==============================] - 11s 29ms/step - loss: 0.6520 - accuracy: 0.7819 - val_loss: 0.9043 - val_accuracy: 0.6934 Epoch 12/100 390/390 [==============================] - 11s 29ms/step - loss: 0.6146 - accuracy: 0.7947 - val_loss: 0.7787 - val_accuracy: 0.7446 Epoch 13/100 390/390 [==============================] - 11s 28ms/step - loss: 0.5933 - accuracy: 0.7997 - val_loss: 0.7505 - val_accuracy: 0.7528 Epoch 14/100 390/390 [==============================] - 11s 28ms/step - loss: 0.5710 - accuracy: 0.8072 - val_loss: 0.7057 - val_accuracy: 0.7644 Epoch 15/100 390/390 [==============================] - 11s 29ms/step - loss: 0.5457 - accuracy: 0.8174 - val_loss: 0.8235 - val_accuracy: 0.7312 Epoch 16/100 390/390 [==============================] - 11s 29ms/step - loss: 0.5243 - accuracy: 0.8262 - val_loss: 0.6631 - val_accuracy: 0.7672 Epoch 17/100 390/390 [==============================] - 11s 28ms/step - loss: 0.5073 - accuracy: 0.8307 - val_loss: 0.6935 - val_accuracy: 0.7734 Epoch 18/100 390/390 [==============================] - 11s 29ms/step - loss: 0.4879 - accuracy: 0.8380 - val_loss: 0.6700 - val_accuracy: 0.7748 Epoch 19/100 390/390 [==============================] - 11s 28ms/step - loss: 0.4698 - accuracy: 0.8414 - val_loss: 0.6904 - val_accuracy: 0.7714 Epoch 20/100 390/390 [==============================] - 11s 29ms/step - loss: 0.4508 - accuracy: 0.8479 - val_loss: 0.6207 - val_accuracy: 0.8012 Epoch 21/100 390/390 [==============================] - 12s 31ms/step - loss: 0.4416 - accuracy: 0.8536 - val_loss: 0.7352 - val_accuracy: 0.7684 Epoch 22/100 390/390 [==============================] - 11s 29ms/step - loss: 0.4235 - accuracy: 0.8586 - val_loss: 0.9226 - val_accuracy: 0.7102 Epoch 23/100 390/390 [==============================] - 11s 29ms/step - loss: 0.4118 - accuracy: 0.8635 - val_loss: 0.6872 - val_accuracy: 0.7864 Epoch 24/100 390/390 [==============================] - 11s 29ms/step - loss: 0.4054 - accuracy: 0.8633 - val_loss: 0.6349 - val_accuracy: 0.7980 Epoch 25/100 390/390 [==============================] - 11s 29ms/step - loss: 0.3873 - accuracy: 0.8716 - val_loss: 0.5795 - val_accuracy: 0.8112 Epoch 26/100 390/390 [==============================] - 11s 29ms/step - loss: 0.3743 - accuracy: 0.8762 - val_loss: 0.7991 - val_accuracy: 0.7580 Epoch 27/100 390/390 [==============================] - 11s 28ms/step - loss: 0.3623 - accuracy: 0.8811 - val_loss: 0.6132 - val_accuracy: 0.8048 Epoch 28/100 390/390 [==============================] - 11s 28ms/step - loss: 0.3537 - accuracy: 0.8821 - val_loss: 0.6159 - val_accuracy: 0.8034 Epoch 29/100 390/390 [==============================] - 11s 29ms/step - loss: 0.3451 - accuracy: 0.8871 - val_loss: 0.5890 - val_accuracy: 0.8172 Epoch 30/100 390/390 [==============================] - 11s 29ms/step - loss: 0.3341 - accuracy: 0.8888 - val_loss: 0.5170 - val_accuracy: 0.8312 Epoch 31/100 390/390 [==============================] - 11s 29ms/step - loss: 0.3217 - accuracy: 0.8930 - val_loss: 0.6331 - val_accuracy: 0.7992 Epoch 32/100 390/390 [==============================] - 11s 29ms/step - loss: 0.3161 - accuracy: 0.8941 - val_loss: 0.6867 - val_accuracy: 0.7958 Epoch 33/100 390/390 [==============================] - 11s 29ms/step - loss: 0.3062 - accuracy: 0.8975 - val_loss: 0.6233 - val_accuracy: 0.8064 Epoch 34/100 390/390 [==============================] - 11s 28ms/step - loss: 0.3011 - accuracy: 0.8990 - val_loss: 0.5072 - val_accuracy: 0.8326 Epoch 35/100 390/390 [==============================] - 11s 29ms/step - loss: 0.2936 - accuracy: 0.9028 - val_loss: 0.5389 - val_accuracy: 0.8330 Epoch 36/100 390/390 [==============================] - 11s 28ms/step - loss: 0.2840 - accuracy: 0.9071 - val_loss: 0.6223 - val_accuracy: 0.8054 Epoch 37/100 390/390 [==============================] - 11s 29ms/step - loss: 0.2734 - accuracy: 0.9085 - val_loss: 0.5799 - val_accuracy: 0.8176 Epoch 38/100 390/390 [==============================] - 11s 28ms/step - loss: 0.2720 - accuracy: 0.9092 - val_loss: 0.5513 - val_accuracy: 0.8324 Epoch 39/100 390/390 [==============================] - 11s 28ms/step - loss: 0.2625 - accuracy: 0.9120 - val_loss: 0.6154 - val_accuracy: 0.8116 Epoch 40/100 390/390 [==============================] - 11s 29ms/step - loss: 0.2576 - accuracy: 0.9140 - val_loss: 0.5031 - val_accuracy: 0.8404 Epoch 41/100 390/390 [==============================] - 11s 28ms/step - loss: 0.2503 - accuracy: 0.9162 - val_loss: 0.5218 - val_accuracy: 0.8374 Epoch 42/100 390/390 [==============================] - 11s 29ms/step - loss: 0.2441 - accuracy: 0.9186 - val_loss: 0.5802 - val_accuracy: 0.8216 Epoch 43/100 390/390 [==============================] - 11s 29ms/step - loss: 0.2317 - accuracy: 0.9229 - val_loss: 0.5359 - val_accuracy: 0.8374 Epoch 44/100 390/390 [==============================] - 11s 29ms/step - loss: 0.2345 - accuracy: 0.9208 - val_loss: 0.5335 - val_accuracy: 0.8386 Epoch 45/100 390/390 [==============================] - 11s 29ms/step - loss: 0.2283 - accuracy: 0.9241 - val_loss: 0.4964 - val_accuracy: 0.8444 Epoch 46/100 390/390 [==============================] - 11s 28ms/step - loss: 0.2186 - accuracy: 0.9274 - val_loss: 0.6013 - val_accuracy: 0.8216 Epoch 47/100 390/390 [==============================] - 11s 28ms/step - loss: 0.2146 - accuracy: 0.9275 - val_loss: 0.5554 - val_accuracy: 0.8246 Epoch 48/100 390/390 [==============================] - 11s 29ms/step - loss: 0.2064 - accuracy: 0.9315 - val_loss: 0.4062 - val_accuracy: 0.8742 Epoch 49/100 390/390 [==============================] - 11s 29ms/step - loss: 0.2040 - accuracy: 0.9327 - val_loss: 0.5200 - val_accuracy: 0.8416 Epoch 50/100 390/390 [==============================] - 11s 28ms/step - loss: 0.1994 - accuracy: 0.9340 - val_loss: 0.4557 - val_accuracy: 0.8644 Epoch 51/100 390/390 [==============================] - 11s 29ms/step - loss: 0.1911 - accuracy: 0.9371 - val_loss: 0.5573 - val_accuracy: 0.8282 Epoch 52/100 390/390 [==============================] - 11s 28ms/step - loss: 0.1883 - accuracy: 0.9366 - val_loss: 0.5349 - val_accuracy: 0.8404 Epoch 53/100 390/390 [==============================] - 11s 28ms/step - loss: 0.1818 - accuracy: 0.9392 - val_loss: 0.6524 - val_accuracy: 0.8090 Epoch 54/100 390/390 [==============================] - 11s 28ms/step - loss: 0.1822 - accuracy: 0.9387 - val_loss: 0.5043 - val_accuracy: 0.8514 Epoch 55/100 390/390 [==============================] - 11s 28ms/step - loss: 0.1825 - accuracy: 0.9401 - val_loss: 0.5196 - val_accuracy: 0.8500 Epoch 56/100 390/390 [==============================] - 11s 28ms/step - loss: 0.1696 - accuracy: 0.9433 - val_loss: 0.4863 - val_accuracy: 0.8546 Epoch 57/100 390/390 [==============================] - 11s 28ms/step - loss: 0.1662 - accuracy: 0.9452 - val_loss: 0.6238 - val_accuracy: 0.8246 Epoch 58/100 390/390 [==============================] - 11s 28ms/step - loss: 0.1617 - accuracy: 0.9466 - val_loss: 0.5467 - val_accuracy: 0.8404 1/1 [==============================] - 2s 2s/step - loss: 0.5631 - accuracy: 0.8316 Saving history to 'history.pkl'. (epochs: 58)83.16%でした.まあ,こんなもんかって感じですね.では,もう少しちゃんとやってみましょう.
もっとやってみる
コード全体
import os import numpy as np import tensorflow as tf from tensorflow.keras import Sequential from tensorflow.keras.layers \ import Conv2D, MaxPool2D, GlobalAvgPool2D, Dense, \ BatchNormalization, ReLU, Softmax from tensorflow.keras.datasets.cifar10 import load_data from radam import RAdam from tensorflow.keras.utils import to_categorical import pickle os.environ['TF_CPP_MIN_LOG_LEVEL']='2' os.environ['TCMALLOC_LARGE_ALLOC_REPORT_THRESHOLD'] = '10737418240' def create_model(): model = Sequential([ Conv2D(filters=64, kernel_size=3, strides=1, padding='same', input_shape=(32,32,3)), BatchNormalization(), ReLU(), Conv2D(filters=64, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), Conv2D(filters=128, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=128, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), GlobalAvgPool2D(), Dense(units=4096), BatchNormalization(), ReLU(), Dense(units=4096), BatchNormalization(), ReLU(), Dense(units=10), BatchNormalization(), ReLU(), Softmax() ]) return model def data_augmentation(img): im = tf.image.random_flip_left_right(img) im = tf.image.random_flip_up_down(im) im = tf.pad(im, tf.constant([[2, 2], [2, 2], [0, 0]]), "REFLECT") im = tf.image.random_crop(im, size=[32, 32, 3]) return im def train(batch_size, epochs, lr): # Setup tpu print("Setting up TPU ...") tpu_grpc_url = "grpc://" + os.environ["COLAB_TPU_ADDR"] tpu_cluster_resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu_grpc_url) tf.config.experimental_connect_to_cluster(tpu_cluster_resolver) tf.tpu.experimental.initialize_tpu_system(tpu_cluster_resolver) strategy = tf.distribute.experimental.TPUStrategy(tpu_cluster_resolver) print("Done!") # Load dataset (x_train, y_train), (x_test, y_test) = load_data() x_val, y_val = x_test[:5000], y_test[:5000] x_test, y_test = x_test[5000:10000], y_test[5000:10000] train_num = len(x_train) val_num = len(x_val) test_num = len(x_test) # Normalize, convert to one-hot x_train, y_train = x_train.astype(np.float32), y_train.astype(np.int32) x_train /= 255.0 x_val, y_val = x_val.astype(np.float32), y_val.astype(np.int32) x_val /= 255.0 x_test, y_test = x_test.astype(np.float32), y_test.astype(np.int32) x_test /= 255.0 y_train = to_categorical(y_train, num_classes=10, dtype=np.int32) y_val = to_categorical(y_val, num_classes=10, dtype=np.int32) y_test = to_categorical(y_test, num_classes=10, dtype=np.int32) # Convert to tf.data trainset = tf.data.Dataset.from_tensor_slices((x_train, y_train)) trainset = trainset.map(lambda image, label: (data_augmentation(image), label)).shuffle(buffer_size=1024).repeat().batch(batch_size) valset = tf.data.Dataset.from_tensor_slices((x_val, y_val)) valset = valset.shuffle(buffer_size=1024).batch(val_num) testset = tf.data.Dataset.from_tensor_slices((x_test, y_test)) testset = testset.batch(test_num) # Train callbacks = [] callbacks.append(tf.keras.callbacks.EarlyStopping('val_loss', patience=10)) op = RAdam(lr=lr) with strategy.scope(): model = create_model() model.compile(optimizer=op, loss='categorical_crossentropy', metrics=['accuracy']) history = model.fit( trainset, epochs=epochs, validation_data=valset, callbacks=callbacks, steps_per_epoch=train_num // batch_size ) model.evaluate(testset) model.save('model2.h5') # Save history save_file = 'history2.pkl' with open(save_file, 'wb') as f: pickle.dump(history.history, f) print(f"Saving history to \'{save_file}\'. (epochs: {len(history.epoch)})") train(128, 100, 0.01)CNNをもっと複雑に
model = Sequential([ Conv2D(filters=64, kernel_size=3, strides=1, padding='same', input_shape=(32,32,3)), BatchNormalization(), ReLU(), Conv2D(filters=64, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), Conv2D(filters=128, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=128, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=256, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), Conv2D(filters=512, kernel_size=3, strides=1, padding='same'), BatchNormalization(), ReLU(), MaxPool2D(pool_size=2, strides=2, padding='same'), GlobalAvgPool2D(), Dense(units=4096), BatchNormalization(), ReLU(), Dense(units=4096), BatchNormalization(), ReLU(), Dense(units=10), BatchNormalization(), ReLU(), Softmax() ])VGG16本家にもっと近づけました.まあ他にもResnetとかXceptionとか優秀なのがありますが,まあいいでしょう.
最新のオプティマイザを使う
radam.pyclass RAdam(Optimizer): """RAdam optimizer. Default parameters follow those provided in the original Adam paper. # Arguments lr: float >= 0. Learning rate.\\ beta_1: float, 0 < beta < 1. Generally close to 1.\\ beta_2: float, 0 < beta < 1. Generally close to 1.\\ epsilon: float >= 0. Fuzz factor. If `None`, defaults to `K.epsilon()`.\\ decay: float >= 0. Learning rate decay over each update.\\ amsgrad: boolean. Whether to apply the AMSGrad variant of this algorithm from the paper "On the Convergence of Adam and Beyond". # References - [RAdam - A Method for Stochastic Optimization] (https://arxiv.org/abs/1908.03265) - [On The Variance Of The Adaptive Learning Rate And Beyond] (https://arxiv.org/abs/1908.03265) """ def __init__(self, learning_rate=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, weight_decay=0.0, name='RAdam', **kwargs): super(RAdam, self).__init__(name, **kwargs) self._set_hyper('learning_rate', kwargs.get('lr', learning_rate)) self._set_hyper('beta_1', beta_1) self._set_hyper('beta_2', beta_2) self._set_hyper('decay', self._initial_decay) self.epsilon = epsilon or K.epsilon() self.weight_decay = weight_decay def _create_slots(self, var_list): for var in var_list: self.add_slot(var, 'm') for var in var_list: self.add_slot(var, 'v') def _resource_apply_dense(self, grad, var): var_dtype = var.dtype.base_dtype lr_t = self._decayed_lr(var_dtype) m = self.get_slot(var, 'm') v = self.get_slot(var, 'v') beta_1_t = self._get_hyper('beta_1', var_dtype) beta_2_t = self._get_hyper('beta_2', var_dtype) epsilon_t = tf.convert_to_tensor(self.epsilon, var_dtype) t = tf.cast(self.iterations + 1, var_dtype) m_t = (beta_1_t * m) + (1. - beta_1_t) * grad v_t = (beta_2_t * v) + (1. - beta_2_t) * tf.square(grad) beta2_t = beta_2_t ** t N_sma_max = 2 / (1 - beta_2_t) - 1 N_sma = N_sma_max - 2 * t * beta2_t / (1 - beta2_t) # apply weight decay if self.weight_decay != 0.: p_wd = var - self.weight_decay * lr_t * var else: p_wd = None if p_wd is None: p_ = var else: p_ = p_wd def gt_path(): step_size = lr_t * tf.sqrt( (1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2) ) / (1 - beta_1_t ** t) denom = tf.sqrt(v_t) + epsilon_t p_t = p_ - step_size * (m_t / denom) return p_t def lt_path(): step_size = lr_t / (1 - beta_1_t ** t) p_t = p_ - step_size * m_t return p_t p_t = tf.cond(N_sma > 5, gt_path, lt_path) m_t = tf.compat.v1.assign(m, m_t) v_t = tf.compat.v1.assign(v, v_t) with tf.control_dependencies([m_t, v_t]): param_update = tf.compat.v1.assign(var, p_t) return tf.group(*[param_update, m_t, v_t]) def _resource_apply_sparse(self, grad, handle, indices): raise NotImplementedError("Sparse data is not supported yet") def get_config(self): config = super(RAdam, self).get_config() config.update({ 'learning_rate': self._serialize_hyperparameter('learning_rate'), 'decay': self._serialize_hyperparameter('decay'), 'beta_1': self._serialize_hyperparameter('beta_1'), 'beta_2': self._serialize_hyperparameter('beta_2'), 'epsilon': self.epsilon, 'weight_decay': self.weight_decay, }) return config人気のAdamもいいですが,その改良版であるRAdamというのを採用してみます.ざっくり言えば,MomentSGDとAdamを組み合わせたようなやつです.
セルの一番上に%%writefile radam.pyとつけて実行するとそのファイルに上書き保存(なければ新規作成)されます.作るとfrom radam import RAdamで参照できます.学習させる
同様にcompileしてfitさせます.
実行結果
Setting up TPU ... INFO:tensorflow:Initializing the TPU system: 10.111.159.218:8470 INFO:tensorflow:Initializing the TPU system: 10.111.159.218:8470 INFO:tensorflow:Clearing out eager caches INFO:tensorflow:Clearing out eager caches INFO:tensorflow:Finished initializing TPU system. INFO:tensorflow:Finished initializing TPU system. INFO:tensorflow:Found TPU system: INFO:tensorflow:Found TPU system: INFO:tensorflow:*** Num TPU Cores: 8 INFO:tensorflow:*** Num TPU Cores: 8 INFO:tensorflow:*** Num TPU Workers: 1 INFO:tensorflow:*** Num TPU Workers: 1 INFO:tensorflow:*** Num TPU Cores Per Worker: 8 INFO:tensorflow:*** Num TPU Cores Per Worker: 8 INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:CPU:0, CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:CPU:0, CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0) INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0) Done! Train on 390 steps, validate on 1 steps Epoch 1/100 390/390 [==============================] - 59s 151ms/step - loss: 1.8134 - accuracy: 0.3453 - val_loss: 5.4962 - val_accuracy: 0.2774 Epoch 2/100 390/390 [==============================] - 15s 40ms/step - loss: 1.5007 - accuracy: 0.4666 - val_loss: 4.3148 - val_accuracy: 0.3578 Epoch 3/100 390/390 [==============================] - 16s 40ms/step - loss: 1.3087 - accuracy: 0.5373 - val_loss: 2.2541 - val_accuracy: 0.4854 Epoch 4/100 390/390 [==============================] - 15s 40ms/step - loss: 1.1609 - accuracy: 0.5954 - val_loss: 1.6294 - val_accuracy: 0.5296 Epoch 5/100 390/390 [==============================] - 16s 41ms/step - loss: 1.0613 - accuracy: 0.6346 - val_loss: 1.2080 - val_accuracy: 0.6104 Epoch 6/100 390/390 [==============================] - 16s 40ms/step - loss: 0.9717 - accuracy: 0.6696 - val_loss: 1.3208 - val_accuracy: 0.5942 Epoch 7/100 390/390 [==============================] - 16s 40ms/step - loss: 0.9017 - accuracy: 0.6955 - val_loss: 1.3902 - val_accuracy: 0.5940 Epoch 8/100 390/390 [==============================] - 16s 40ms/step - loss: 0.8464 - accuracy: 0.7188 - val_loss: 0.9953 - val_accuracy: 0.6920 Epoch 9/100 390/390 [==============================] - 16s 40ms/step - loss: 0.7957 - accuracy: 0.7360 - val_loss: 1.1091 - val_accuracy: 0.6478 Epoch 10/100 390/390 [==============================] - 16s 40ms/step - loss: 0.7436 - accuracy: 0.7546 - val_loss: 0.8850 - val_accuracy: 0.7030 Epoch 11/100 390/390 [==============================] - 16s 40ms/step - loss: 0.7095 - accuracy: 0.7634 - val_loss: 0.7887 - val_accuracy: 0.7370 Epoch 12/100 390/390 [==============================] - 16s 40ms/step - loss: 0.6654 - accuracy: 0.7831 - val_loss: 0.8152 - val_accuracy: 0.7310 Epoch 13/100 390/390 [==============================] - 16s 41ms/step - loss: 0.6306 - accuracy: 0.7942 - val_loss: 0.9708 - val_accuracy: 0.6908 Epoch 14/100 390/390 [==============================] - 16s 40ms/step - loss: 0.6042 - accuracy: 0.8034 - val_loss: 0.9384 - val_accuracy: 0.6928 Epoch 15/100 390/390 [==============================] - 16s 40ms/step - loss: 0.5818 - accuracy: 0.8109 - val_loss: 0.6889 - val_accuracy: 0.7816 Epoch 16/100 390/390 [==============================] - 15s 40ms/step - loss: 0.5588 - accuracy: 0.8199 - val_loss: 0.7431 - val_accuracy: 0.7612 Epoch 17/100 390/390 [==============================] - 16s 40ms/step - loss: 0.5267 - accuracy: 0.8310 - val_loss: 0.8451 - val_accuracy: 0.7414 Epoch 18/100 390/390 [==============================] - 16s 41ms/step - loss: 0.5040 - accuracy: 0.8382 - val_loss: 0.9923 - val_accuracy: 0.6854 Epoch 19/100 390/390 [==============================] - 16s 40ms/step - loss: 0.4935 - accuracy: 0.8424 - val_loss: 0.6350 - val_accuracy: 0.7880 Epoch 20/100 390/390 [==============================] - 16s 40ms/step - loss: 0.4707 - accuracy: 0.8472 - val_loss: 0.5511 - val_accuracy: 0.8188 Epoch 21/100 390/390 [==============================] - 16s 40ms/step - loss: 0.4546 - accuracy: 0.8539 - val_loss: 0.5996 - val_accuracy: 0.8056 Epoch 22/100 390/390 [==============================] - 16s 40ms/step - loss: 0.4357 - accuracy: 0.8615 - val_loss: 0.6641 - val_accuracy: 0.7864 Epoch 23/100 390/390 [==============================] - 16s 40ms/step - loss: 0.4259 - accuracy: 0.8637 - val_loss: 0.5961 - val_accuracy: 0.8134 Epoch 24/100 390/390 [==============================] - 16s 40ms/step - loss: 0.4054 - accuracy: 0.8689 - val_loss: 0.5884 - val_accuracy: 0.8190 Epoch 25/100 390/390 [==============================] - 16s 41ms/step - loss: 0.3913 - accuracy: 0.8750 - val_loss: 0.5741 - val_accuracy: 0.8238 Epoch 26/100 390/390 [==============================] - 16s 41ms/step - loss: 0.3784 - accuracy: 0.8774 - val_loss: 0.5228 - val_accuracy: 0.8368 Epoch 27/100 390/390 [==============================] - 16s 40ms/step - loss: 0.3645 - accuracy: 0.8838 - val_loss: 0.6014 - val_accuracy: 0.8166 Epoch 28/100 390/390 [==============================] - 16s 40ms/step - loss: 0.3498 - accuracy: 0.8893 - val_loss: 0.5302 - val_accuracy: 0.8298 Epoch 29/100 390/390 [==============================] - 16s 40ms/step - loss: 0.3323 - accuracy: 0.8917 - val_loss: 0.6008 - val_accuracy: 0.8098 Epoch 30/100 390/390 [==============================] - 16s 40ms/step - loss: 0.3362 - accuracy: 0.8923 - val_loss: 0.5984 - val_accuracy: 0.8048 Epoch 31/100 390/390 [==============================] - 16s 40ms/step - loss: 0.3225 - accuracy: 0.8971 - val_loss: 0.4980 - val_accuracy: 0.8364 Epoch 32/100 390/390 [==============================] - 16s 40ms/step - loss: 0.3095 - accuracy: 0.9016 - val_loss: 0.4806 - val_accuracy: 0.8426 Epoch 33/100 390/390 [==============================] - 16s 41ms/step - loss: 0.3046 - accuracy: 0.9034 - val_loss: 0.4721 - val_accuracy: 0.8520 Epoch 34/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2891 - accuracy: 0.9079 - val_loss: 0.4913 - val_accuracy: 0.8418 Epoch 35/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2826 - accuracy: 0.9099 - val_loss: 0.5302 - val_accuracy: 0.8274 Epoch 36/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2779 - accuracy: 0.9103 - val_loss: 0.6216 - val_accuracy: 0.8034 Epoch 37/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2630 - accuracy: 0.9176 - val_loss: 0.4146 - val_accuracy: 0.8638 Epoch 38/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2558 - accuracy: 0.9187 - val_loss: 0.4989 - val_accuracy: 0.8408 Epoch 39/100 390/390 [==============================] - 16s 41ms/step - loss: 0.2507 - accuracy: 0.9185 - val_loss: 0.5337 - val_accuracy: 0.8370 Epoch 40/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2417 - accuracy: 0.9237 - val_loss: 0.4495 - val_accuracy: 0.8574 Epoch 41/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2313 - accuracy: 0.9254 - val_loss: 0.5956 - val_accuracy: 0.8180 Epoch 42/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2328 - accuracy: 0.9250 - val_loss: 0.4339 - val_accuracy: 0.8634 Epoch 43/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2285 - accuracy: 0.9263 - val_loss: 0.3959 - val_accuracy: 0.8734 Epoch 44/100 390/390 [==============================] - 16s 41ms/step - loss: 0.2123 - accuracy: 0.9323 - val_loss: 0.4857 - val_accuracy: 0.8392 Epoch 45/100 390/390 [==============================] - 16s 41ms/step - loss: 0.2045 - accuracy: 0.9331 - val_loss: 0.4265 - val_accuracy: 0.8634 Epoch 46/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2062 - accuracy: 0.9326 - val_loss: 0.5432 - val_accuracy: 0.8358 Epoch 47/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1986 - accuracy: 0.9359 - val_loss: 0.5131 - val_accuracy: 0.8394 Epoch 48/100 390/390 [==============================] - 16s 40ms/step - loss: 0.2002 - accuracy: 0.9362 - val_loss: 0.3935 - val_accuracy: 0.8746 Epoch 49/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1851 - accuracy: 0.9389 - val_loss: 0.5090 - val_accuracy: 0.8490 Epoch 50/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1819 - accuracy: 0.9405 - val_loss: 0.5670 - val_accuracy: 0.8300 Epoch 51/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1794 - accuracy: 0.9417 - val_loss: 0.4944 - val_accuracy: 0.8570 Epoch 52/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1784 - accuracy: 0.9406 - val_loss: 0.4221 - val_accuracy: 0.8712 Epoch 53/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1666 - accuracy: 0.9455 - val_loss: 0.4772 - val_accuracy: 0.8522 Epoch 54/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1657 - accuracy: 0.9454 - val_loss: 0.3937 - val_accuracy: 0.8782 Epoch 55/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1663 - accuracy: 0.9463 - val_loss: 0.4190 - val_accuracy: 0.8710 Epoch 56/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1589 - accuracy: 0.9485 - val_loss: 0.3726 - val_accuracy: 0.8840 Epoch 57/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1583 - accuracy: 0.9474 - val_loss: 0.4746 - val_accuracy: 0.8538 Epoch 58/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1526 - accuracy: 0.9502 - val_loss: 0.5419 - val_accuracy: 0.8432 Epoch 59/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1543 - accuracy: 0.9506 - val_loss: 0.3782 - val_accuracy: 0.8840 Epoch 60/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1448 - accuracy: 0.9526 - val_loss: 0.4636 - val_accuracy: 0.8556 Epoch 61/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1404 - accuracy: 0.9545 - val_loss: 0.4362 - val_accuracy: 0.8754 Epoch 62/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1391 - accuracy: 0.9543 - val_loss: 0.5420 - val_accuracy: 0.8528 Epoch 63/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1409 - accuracy: 0.9531 - val_loss: 0.3796 - val_accuracy: 0.8848 Epoch 64/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1328 - accuracy: 0.9563 - val_loss: 0.5381 - val_accuracy: 0.8344 Epoch 65/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1347 - accuracy: 0.9562 - val_loss: 0.4141 - val_accuracy: 0.8744 Epoch 66/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1289 - accuracy: 0.9577 - val_loss: 0.3722 - val_accuracy: 0.8888 Epoch 67/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1263 - accuracy: 0.9587 - val_loss: 0.4023 - val_accuracy: 0.8812 Epoch 68/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1181 - accuracy: 0.9612 - val_loss: 0.4208 - val_accuracy: 0.8778 Epoch 69/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1216 - accuracy: 0.9598 - val_loss: 0.4888 - val_accuracy: 0.8556 Epoch 70/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1160 - accuracy: 0.9625 - val_loss: 0.6075 - val_accuracy: 0.8378 Epoch 71/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1214 - accuracy: 0.9598 - val_loss: 0.4046 - val_accuracy: 0.8742 Epoch 72/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1121 - accuracy: 0.9627 - val_loss: 0.4819 - val_accuracy: 0.8662 Epoch 73/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1128 - accuracy: 0.9629 - val_loss: 0.4114 - val_accuracy: 0.8804 Epoch 74/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1101 - accuracy: 0.9646 - val_loss: 0.4471 - val_accuracy: 0.8756 Epoch 75/100 390/390 [==============================] - 16s 41ms/step - loss: 0.1040 - accuracy: 0.9655 - val_loss: 0.4560 - val_accuracy: 0.8752 Epoch 76/100 390/390 [==============================] - 16s 40ms/step - loss: 0.1099 - accuracy: 0.9641 - val_loss: 0.4584 - val_accuracy: 0.8724 1/1 [==============================] - 2s 2s/step - loss: 0.4376 - accuracy: 0.8698 Saving history to 'history2.pkl'. (epochs: 76)86.98%でした.大して変わりませんね.まあそんなもんです.実際のところ数%上げるのも難しい世界なので,良い結果なのではないでしょうか.
モデルを視覚的に評価してみる
学習させたモデルを視覚的に評価してみましょう.今回はヒートマップを使います.一応精度が一番良かったRAdamのモデルでやってみましょう.
コード全体
from sklearn.metrics import confusion_matrix, classification_report import matplotlib.pyplot as plt import seaborn as sns import pandas as pd import numpy as np from tensorflow.keras.datasets.cifar10 import load_data from tensorflow.keras.models import load_model def plot_cmx(y_true, y_pred, labels): cmx_data = confusion_matrix(y_true, y_pred) df_cmx = pd.DataFrame(cmx_data, index=labels, columns=labels) fig = plt.figure(figsize=(12.8, 9.6)) sns.heatmap(df_cmx, annot=True, fmt='.0f', linecolor='white', linewidths=1) plt.xlabel("Predict") plt.ylabel("True") plt.show() def eval(): # Set Labels labels = [ 'Airplane', 'Automobile', 'Bird', 'Cat', 'Deer', 'Dog', 'Frog', 'Horse', 'Ship', 'Truck' ] # Load dataset (_, _), (x_test, y_test) = load_data() x_test, y_test = x_test[5000:10000], y_test[5000:10000] # Normalize, flatten x_test, y_test = x_test.astype(np.float32), y_test.astype(np.int32) x_test /= 255.0 y_test = y_test.flatten() model = load_model('model2.h5') y_pred = model.predict_classes(x_test, batch_size=128) print(classification_report(y_test, y_pred, target_names=labels)) plot_cmx(y_test, y_pred, labels) eval()ヒートマップを作る
cmx_data = confusion_matrix(y_true, y_pred) df_cmx = pd.DataFrame(cmx_data, index=labels, columns=labels) fig = plt.figure(figsize=(12.8, 9.6)) sns.heatmap(df_cmx, annot=True, fmt='.0f', linecolor='white', linewidths=1) plt.xlabel("Predict") plt.ylabel("True") plt.show()混同行列を作って,それをプロットするだけです.google colaboratoryでは.
plt.show()でグラフや画像をインライン表示することができます.データを加工する
# Load dataset (_, _), (x_test, y_test) = load_data() x_test, y_test = x_test[5000:10000], y_test[5000:10000] # Normalize, convert to one-hot x_test, y_test = x_test.astype(np.float32), y_test.astype(np.int32) x_test /= 255.0 y_test = y_test.flatten()学習の際にはone-hot表現にしましたが,confusion_matrixを使うので平滑化する必要があります.つまり,ラベルの羅列(1次元ベクトル)にします.
flatten()を使えば良いです.
testデータは5000個だったのでそれに統一します.モデルを評価する
model = load_model('model2.h5') y_pred = model.predict_classes(x_test, batch_size=128) print(classification_report(y_test, y_pred, target_names=labels)) plot_cmx(y_test, y_pred, labels)predict_classesで推測ラベルのベクトルy_predを取り出します.これと正解ラベルのベクトルy_testの比較をすることで,F1スコア等が得られます.
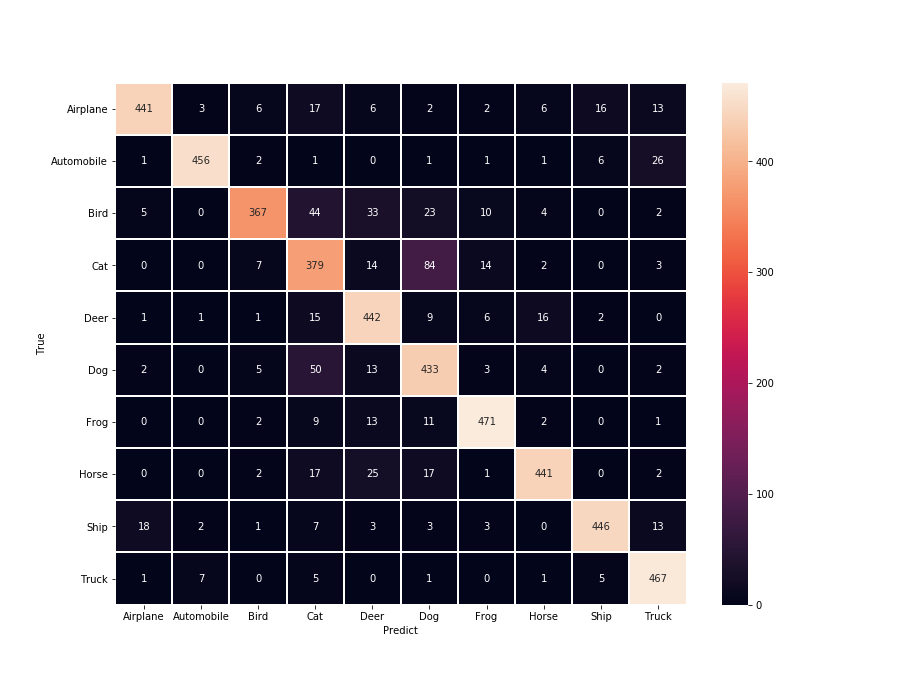
では,実際にヒートマップを表示してみましょう.今回作ったモデルでは,以下の図が得られました.
犬と猫の判別が難しいようですね.あとは,鳥なのに猫と判定していることがややあるようです.他は概ね良さそう.
ちなみに,F1スコア等は以下のようになりました.
precision recall f1-score support Airplane 0.94 0.86 0.90 512 Automobile 0.97 0.92 0.95 495 Bird 0.93 0.75 0.83 488 Cat 0.70 0.75 0.72 503 Deer 0.81 0.90 0.85 493 Dog 0.74 0.85 0.79 512 Frog 0.92 0.93 0.92 509 Horse 0.92 0.87 0.90 505 Ship 0.94 0.90 0.92 496 Truck 0.88 0.96 0.92 487 accuracy 0.87 5000 macro avg 0.88 0.87 0.87 5000 weighted avg 0.88 0.87 0.87 5000supportは母数のことです.猫と犬の判別が課題になりそう.
まとめ
TPUを使ってディープラーニングが出来ました.皆さんも,Resnetや他のニューラルネットワークを採用したり,エポック数やオプティマイザ等を変えて精度を向上させてみてください.
参考サイト