- 投稿日:2020-02-05T23:36:44+09:00
Android端末1つでDiscordBotを作成し動作させる
「DiscordBotを作ってみたい、だけどPCを持っていない」という人向けにAndroid端末1つでDiscordBotを作って実際に動作させるまでの方法を紹介します。
なるべく初心者向けに説明していますが、Pythonやdiscord.py, Linuxコマンド, Vimコマンドなどの詳しい説明は省略しています。動作環境
- Android 9
- Termux 0.90
- Python 3.8.1
- discord.py 1.3.1
1. Termuxのインストール
TermuxはGoogle Playストアからインストールできます。
https://play.google.com/store/apps/details?id=com.termuxTermuxとはroot化不要でLinux環境を用意することができるエミュレータです。
ここではPythonとVimを使ってDiscordBotを書く方法を説明します。2. Termuxでの準備
まずターミナルで以下のコマンドを実行し、aptの更新とPython, Vimのインストールを行います。($はコマンドラインであることを表すもので入力は不要です)
$ apt update $ apt upgrade $ apt install python $ apt install vim次にPythonで簡単にDiscordBotを動かすことができるdiscord.pyというライブラリをインストールします。
$ pip install discord.py※もしインストールが上手くいかない場合は
pip install yarlで先にyarlをインストールしておくことで解決する場合があります。次に実行するPythonファイルを置くディレクトリを作り、移動します。
※{}で囲まれた部分は説明してる内容で置き換えてください$ mkdir {好きなディレクトリ名} $ cd {上で作ったディレクトリ名}3. Pythonファイルの作成
$ vim {好きなファイル名}.py上のコマンドを実行すると新規ファイルがVimが開かれるので、キーボードで
iと入力し、INSERTモードにします。
ここで下のコードをコピペしてください。(後述のサイトにあるものを一部改変し拝借させていただきました)import discord client = discord.Client() @client.event async def on_ready(): print('Logged in as') print(client.user.name) print(client.user.id) print('------') @client.event async def on_message(message): # 送り主がBotだった場合反応したくないので if message.author.bot: return # 「おはよう」で始まるか調べる if message.content.startswith("おはよう"): # メッセージを書きます m = "おはようございます" + message.author.name + "さん!" # メッセージが送られてきたチャンネルへメッセージを送ります await message.channel.send(m) client.run("token")4. Botアカウントを作成する
Chromeなどのブラウザで「https://qiita.com/PinappleHunter/items/af4ccdbb04727437477f 」のサイトのサイトを開き、「Bot用のトークンを手に入れる」の項に従ってBotアカウントを作成して使用したいサーバーにBotを追加しておきます。
ここで「後で使います」と言われているトークンをコピーしておいてください。
※このトークンはBotを動かすためのパスワードのようなものなので扱いには十分気を付けてください。5. Pythonファイルを実行する
Termuxを開き、
cliant.run("token")のtokenの部分に、先程コピーしてきたトークンをペーストし、ESC→:wqでファイルを保存しVimを閉じます。下のコマンドでPythonファイルを実行します。
$ python {先程作成したファイル名}.pyこれで
Logged in as...のように表示されればBotが動作していることになります。Botを追加したサーバーで
おはようなどを送信して返答が来るか試してみてください。
終了したいときはTermuxを終了すればBotも動かなくなります。もしBotを常時動かしたい場合は、Herokuなどを利用することでできます。
ちなみにTermuxではGitも使えるので、AndroidのみでHerokuにデプロイすることも可能です。参考サイト
Pythonで簡単なDiscord Botの作り方
Android端末上でDiscordのbotを動かす(Termux)
AndroidでTermuxを使いroot化なしでLinux環境を作る!
- 投稿日:2020-02-05T23:26:30+09:00
FastAPIが覇権を取れるかもという話
こんにちは、こんばんは、おはようございます。
K.S.ロジャース の島袋です。以前PythonのWebフレームワークの次期覇権はコレ みたいな記事を書きましたが、それからしばらくPythonから離れたエンジニア生活を過ごしていたところ、なんと FastAPI なるフレームワークが登場しているではないですか!
正直、何番煎じかわからない遅れ方してますが、ぜひとも紹介させてください。
FastAPIの特徴
公式トップページ に書いてあるには、
- 高速 - NodeJSやGoなみに早い
- コード書くの早い - 2倍3倍で書ける!
- バグが減る - 40%くらい減る!
- 直感的 - デバッグが簡単
- 簡単 - 使いやすい。ドキュメント読むのも簡単!
- 短い - 重複が少ない。パラメータ宣言で複数の機能を呼べる
- 堅牢 - 自動生成あるからほんと楽
- スタンダード - OpenAPI標準だから互換性あるよ(Swaggerと互換性あるよ)
とありますが一番下の
OpenAPI標準だから互換性あるよ(Swaggerと互換性あるよ)これが素晴らしすぎる。
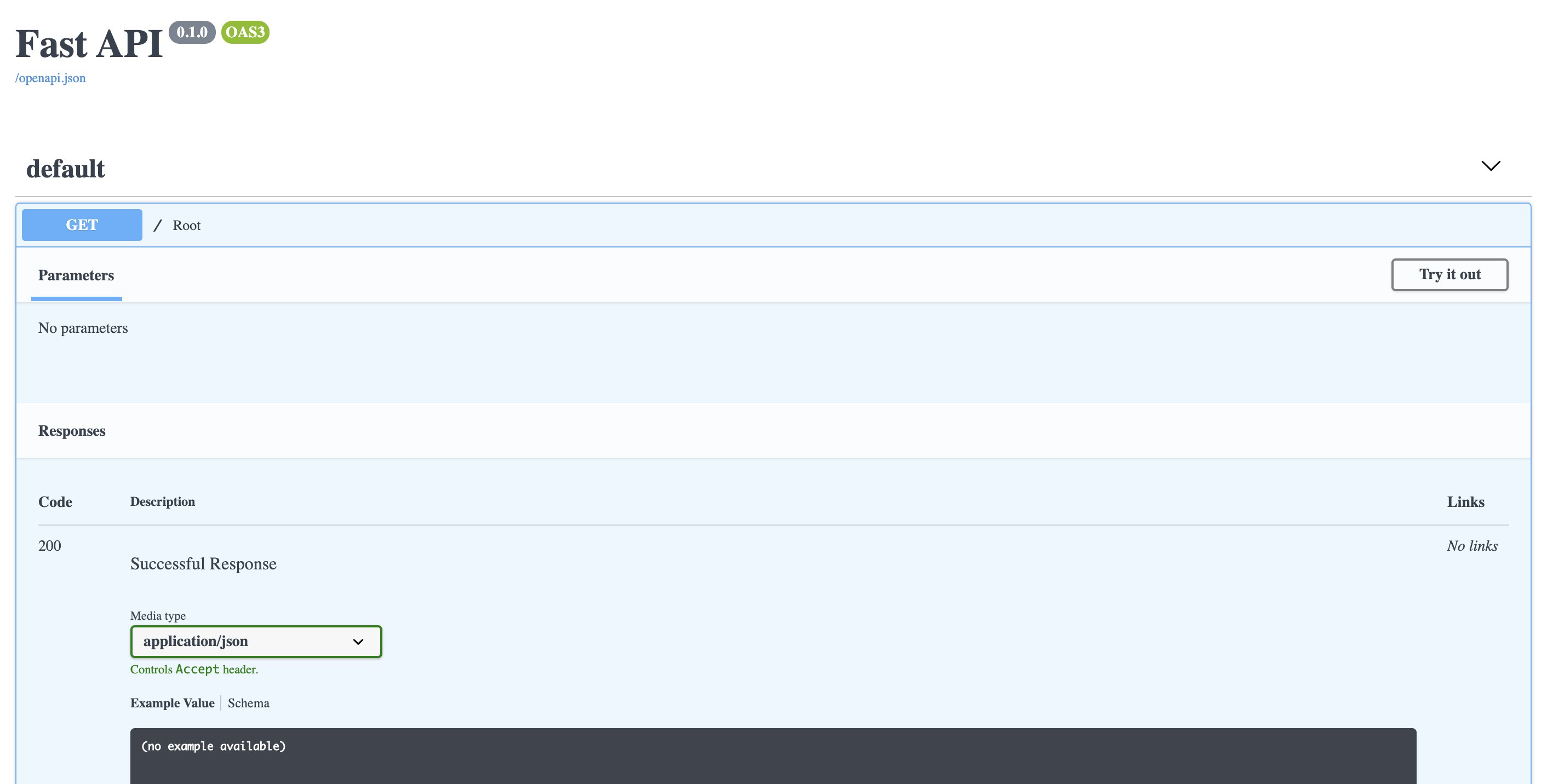
FastAPI、実はSwagger(ドキュメント)の自動生成ができるのです!ドキュメント自動生成
pipで
fastapiとuvicornをインストールしたら早速触ってみます。
ちなみに標準のpipには環境切り分けなどがないので、pipenv を利用することをおすすめします。from fastapi import FastAPI app = FastAPI() @app.get("/") async def root(): return {"message": "Hello World"}上記を
main.pyで作成後にuvicorn main:app --reloadで起動。
http://127.0.0.1:8000/docsを確認すると…
はい!素敵!!
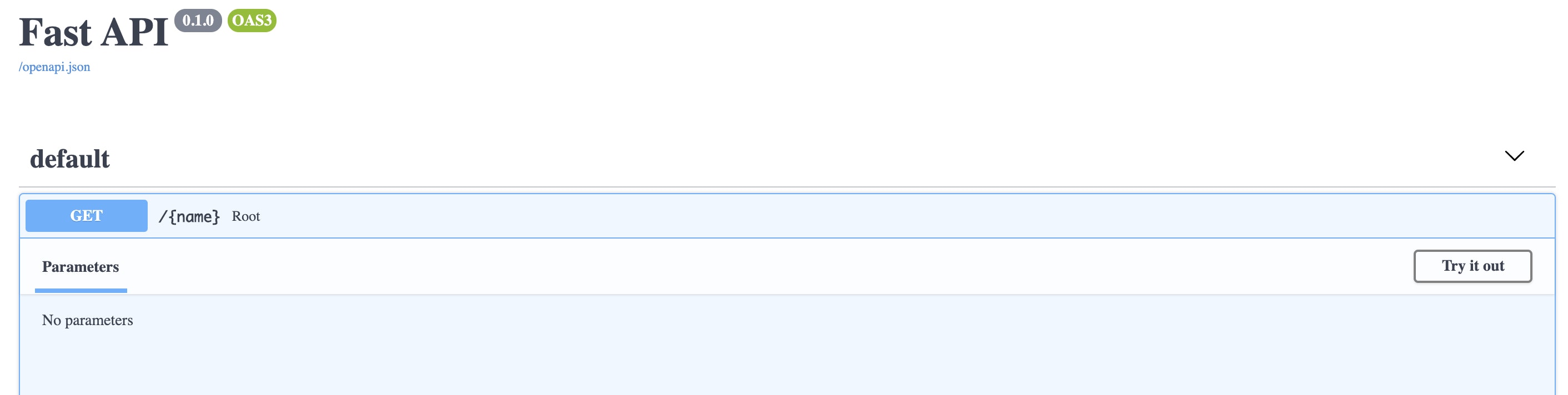
試しにpath parameterを設定すると…Path parameters
@app.get("/{name}") async def root(): return {"message": "Hello " + name}
自動で反映されます。
ドキュメントが自動で作られていくとか最強です。
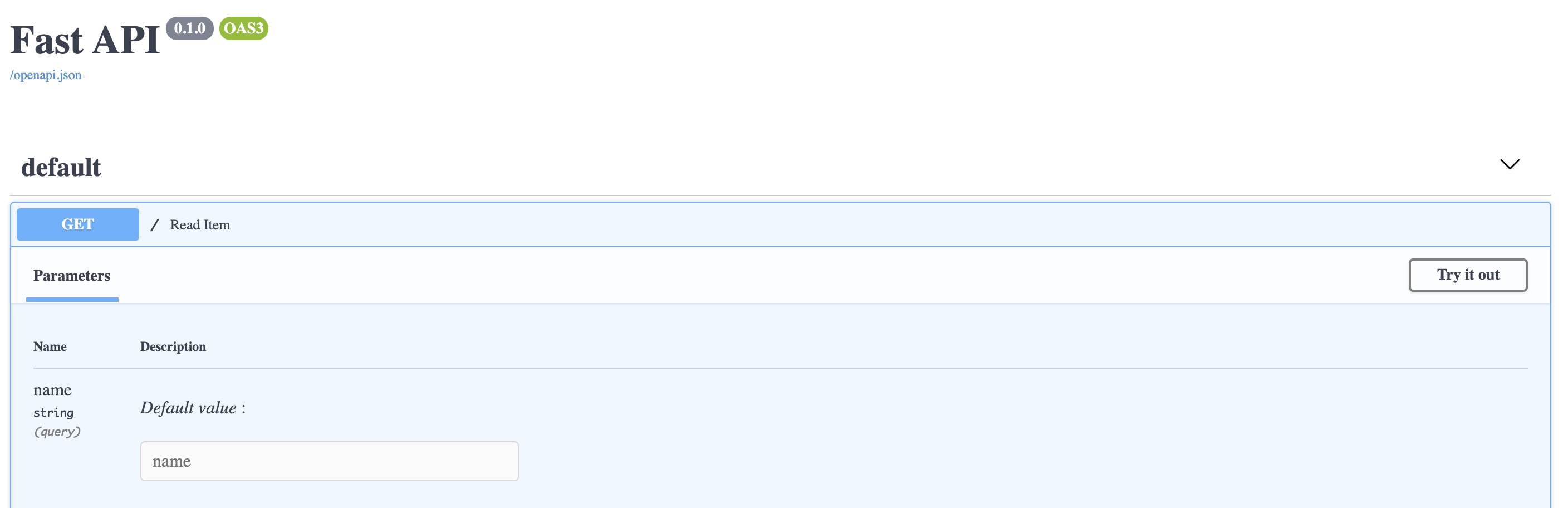
とくにドキュメントを重要視している弊社では便利すぎる機能です。Query Parameters
@app.get("/") async def read_item(name: str = ""): return {"message": "Hello " + name}
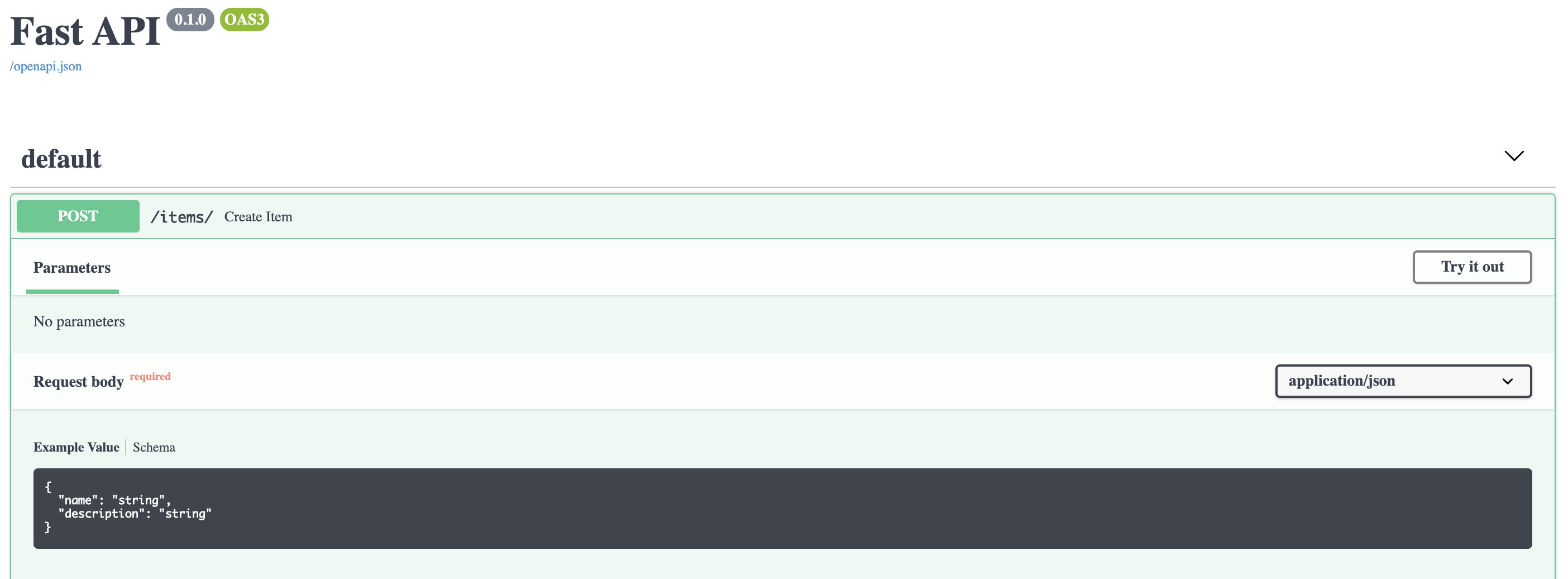
Requests
Modelを使います。
from fastapi import FastAPI from pydantic import BaseModel class Item(BaseModel): name: str description: str = None app = FastAPI() @app.post("/items/") async def create_item(item: Item): return item
さらにModelクラス内でのプロパティにバリデーションを指定できるので、取り回しが凄く良いです。
ここらへんはDjangoのModelと似たような構成ですね。class Item(BaseModel): name: str = Field(None, min_length=2, max_length=5) description: str = Field(None, max_length=100)CRUD (Crate, Read, Update, Delete)
基本のCRUDをざっくり書いてみます。
一部抜粋して書いているので、詳しくは書きリンクをご参考ください。https://github.com/shuto-S/sample-fast-api
DB Connection & Migration
DBへの接続とマイグレーションは
databasesとsqlalchemyを使います。
今回は取り回しのよいSQLiteをDBに使います。さくっとコネクション周りを書いて、
import databases import sqlalchemy DATABASE_URL = "sqlite:///./db.sqlite3" database = databases.Database(DATABASE_URL) engine = sqlalchemy.create_engine(DATABASE_URL, echo=False) metadata = sqlalchemy.MetaData()Schemas
テーブル定義を記述して、同ファイルを実行しておきます。
import sqlalchemy from db import metadata, engine items = sqlalchemy.Table( "items", metadata, sqlalchemy.Column("id", sqlalchemy.Integer, primary_key=True), sqlalchemy.Column("name", sqlalchemy.String), sqlalchemy.Column("description", sqlalchemy.String), ) metadata.create_all(engine)Main
main.pyも改修from fastapi import FastAPI from db import database from starlette.requests import Request from routers import items app = FastAPI() @app.on_event("startup") async def startup(): # DBコネクション開始 await database.connect() @app.on_event("shutdown") async def shutdown(): # DBコネクション切断 await database.disconnect() # routersを登録 app.include_router(items.router) # ミドルウェアでDBコネクション埋め込んでおく(routerで取得できるように) @app.middleware("http") async def db_session_middleware(request: Request, call_next): request.state.connection = database response = await call_next(request) return responseRouters
routerもファイル分割してエンドポイント毎に記述できるようにします。from fastapi import APIRouter, Depends, HTTPException from typing import List from databases import Database from starlette.status import HTTP_204_NO_CONTENT from utils import get_db_connection from schemas import items from models.item import ItemModel router = APIRouter() @router.get("/items", tags=["items"], response_model=List[ItemModel]) async def list_item(database: Database = Depends(get_db_connection)): query = items.select() return await database.fetch_all(query) @router.post("/items", tags=["items"], response_model=ItemModel) async def create_item(data: ItemModel, database: Database = Depends(get_db_connection)): query = items.insert() await database.execute(query, data.dict()) return {**data.dict()} @router.patch("/items/{item_id}", tags=["items"], response_model=ItemModel) async def update_item(item_id: int, data: ItemModel, database: Database = Depends(get_db_connection)): query = items.update().where(items.columns.id==item_id) ret = await database.execute(query, data.dict()) if not ret: raise HTTPException(status_code=404, detail="Not Found") return {**data.dict()} @router.delete("/items/{item_id}", tags=["items"], status_code=HTTP_204_NO_CONTENT) async def delete_item(item_id: int, database: Database = Depends(get_db_connection)): query = items.delete().where(items.columns.id==item_id) ret = await database.execute(query) if not ret: raise HTTPException(status_code=404, detail="Not Found")まとめ
どうでしょう?ドキュメント自動生成はかなり魅力的な機能ではないでしょうか?
Responder もかなり良いフレームワークだと思いますが、FastAPI のほうが癖が少なく書きやすく感じました。あとづけ
ちなみに弊社、Tech系以外にも会社ブログも掲載してますので、気になった方は是非どうぞ。
https://www.wantedly.com/companies/ks-rogers
- 投稿日:2020-02-05T22:49:38+09:00
クラスの多重継承
1class Person(object): def talk(self): print('talk') def run(self): print('person run') class Car(object): def run(self): print('car run') class PersonCarRobot(Person, Car): def fly(self): print('fly') person_car_robot = PersonCarRobot() person_car_robot.talk() person_car_robot.run() person_car_robot.fly()1の実行結果talk person run flyPersonCarRobotクラスは、
PersonクラスとCarクラスの両方を継承している。
なので、
両方のクラスのメソッドを持っている。ここで、
PersonクラスもCarクラスも runというメソッドを持っている。この場合、
class PersonCarRobot(Person, Car)となっており、
先にPersonクラスを継承して、ないものをCarクラスから継承するイメージ。
なので、Carクラスのrunメソッドは継承されない。class PersonCarRobot(Car, Person)と入れ替えると
先にCarクラスを継承して、ないものをPersonクラスから継承する。
Personクラスのrunメソッドは継承されない。2class Person(object): def talk(self): print('talk') def run(self): print('person run') class Car(object): def run(self): print('car run') class PersonCarRobot(Car, Person): def fly(self): print('fly') person_car_robot = PersonCarRobot() person_car_robot.talk() person_car_robot.run() person_car_robot.fly()2の実行結果talk car run fly
- 投稿日:2020-02-05T22:19:04+09:00
【お手軽Python】pandasによるExcelファイル読み込み
pandasとは
pandasとは、Pythonのライブラリです。
pandasは、主にデータを操作する時に使われます。AIや機械学習にpandasは必須です。
ですが、Excelのファイルを操作する機能も搭載されています。
今回は、pandasを使ったExcelファイルの読み込みの仕方について説明していきます。Excelファイル読み込み
最初のシートのみの読み込み
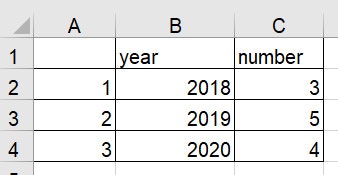
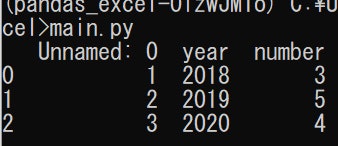
sample.xlsxの中身が
だった場合main.pyimport pandas as pd df = pd.read_excel('sample.xlsx') print(df)上記のmain.pyを実行すると
となり、無事Excelファイルを読み込む事に成功しました。全シートから読み込み
因みに、main.pyの二行目を
df = pd.read_excel('sample.xlsx', sheet_name =None)とすれば、sample.xlsxの全てのシートからデータを取ってくる事ができます。
指定したシート読み込み
番号で指定
sheet_nameをNoneにすると、全シート読み込みとなりました。
sheet_nameに0から始まる番号を指定することで、[指定した数字+1]番目のシートを読み込むことができます。df = pd.read_excel('sample.xlsx', sheet_name =0) #1枚目のシート読み込み df = pd.read_excel('sample.xlsx', sheet_name =2) #3枚目のシート読み込み名前で指定
sheet_nameに文字列を指定することで、その文字列をシート名に持つシートを読み込むことができます。
df = pd.read_excel('sample.xlsx', sheet_name ='sheet1') #名前が'sheet1'のシート読み込みまとめ
pandasを使ってExcelファイルを読み込む方法を紹介しました。
この機能はpandasの全機能の氷山の一角に過ぎません。非常に様々な場面で使われるライブラリなので、気になった方は是非詳しいサイトなどを調べてみてください。
- 投稿日:2020-02-05T21:48:16+09:00
OpenCVで複数動画を連結する!
動画を連結したかったので作ってみた.
シチュエーション
複数の動画が入ったディレクトリあり,その中の動画を連結した一つの動画を作成するプログラム.
ソース
import cv2 import glob def combine_movie(movie_files,out_path): # 形式はmp4 fourcc = cv2.VideoWriter_fourcc('m','p','4','v') #動画情報の取得 movie = cv2.VideoCapture(movie_files[0]) fps = movie.get(cv2.CAP_PROP_FPS) height = movie.get(cv2.CAP_PROP_FRAME_HEIGHT) width = movie.get(cv2.CAP_PROP_FRAME_WIDTH) # 出力先のファイルを開く out = cv2.VideoWriter(out_path, int(fourcc), fps, (int(width), int(height))) for movies in (movie_files): print(movies) movie = cv2.VideoCapture(movies) if movie.isOpened() == True: ret,frame = movie.read() else: ret = False while ret: cv2.putText(frame,' ',(400,400),cv2.FONT_HERSHEY_SIMPLEX,0.75,(0,0,255),2) # 読み込んだフレームを書き込み out.write(frame) # 次のフレーム読み込み ret,frame = movie.read() # ディレクトリ内の動画をリストで取り出す files = sorted(glob.glob("./movie_dir/*.mp4")) # 出力ファイル名 out_path = "movie_out1.mp4" combine_movie(files,out_path)
- 投稿日:2020-02-05T21:48:16+09:00
OpenCVを使って複数動画を一発で連結する!
強化学習結果などの沢山の動画を一発で連結したかったので作ってみた.
シチュエーション
複数の動画が入ったディレクトリあり,その中の動画を連結した一つの動画を作成するプログラム.
ソース
import cv2 import glob def comb_movie(movie_files,out_path): # 形式はmp4 fourcc = cv2.VideoWriter_fourcc('m','p','4','v') #動画情報の取得 movie = cv2.VideoCapture(movie_files[0]) fps = movie.get(cv2.CAP_PROP_FPS) height = movie.get(cv2.CAP_PROP_FRAME_HEIGHT) width = movie.get(cv2.CAP_PROP_FRAME_WIDTH) # 出力先のファイルを開く out = cv2.VideoWriter(out_path, int(fourcc), fps, (int(width), int(height))) for movies in (movie_files): print(movies) movie = cv2.VideoCapture(movies) if movie.isOpened() == True: ret,frame = movie.read() else: ret = False while ret: cv2.putText(frame,' ',(400,400),cv2.FONT_HERSHEY_SIMPLEX,0.75,(0,0,255),2) # 読み込んだフレームを書き込み out.write(frame) # 次のフレーム読み込み ret,frame = movie.read() # ディレクトリ内の動画をリストで取り出す files = sorted(glob.glob("./movie_dir/*.mp4")) # 出力ファイル名 out_path = "movie_out1.mp4" comb_movie(files,out_path)
- 投稿日:2020-02-05T21:40:10+09:00
[Python3 入門 23日目]12章 パイソニスタになろう(12.1〜12.6)
12.1 コードのテスト
12.1.1 pylint、pyflakes、pep8によるチェック
style1a=1 b=2 print(a) print(b) print(c)実行結果$ pylint style1.py ************* Module style1 style1.py:1:1: C0326: Exactly one space required around assignment a=1 ^ (bad-whitespace) style1.py:2:1: C0326: Exactly one space required around assignment b=2 ^ (bad-whitespace) style1.py:1:0: C0114: Missing module docstring (missing-module-docstring) style1.py:1:0: C0103: Constant name "a" doesn't conform to UPPER_CASE naming style (invalid-name) style1.py:2:0: C0103: Constant name "b" doesn't conform to UPPER_CASE naming style (invalid-name) #先頭がEとなっているのはエラーを示す。 style1.py:5:6: E0602: Undefined variable 'c' (undefined-variable) ------------------------------------- Your code has been rated at -10.00/10エラー解消のため、cの値を追加する。
style2.pya=1 b=2 c=3 print(a) print(b) print(c)実行結果$ pylint style2.py ************* Module style2 style2.py:1:1: C0326: Exactly one space required around assignment a=1 ^ (bad-whitespace) style2.py:2:1: C0326: Exactly one space required around assignment b=2 ^ (bad-whitespace) style2.py:3:1: C0326: Exactly one space required around assignment c=3 ^ (bad-whitespace) style2.py:1:0: C0114: Missing module docstring (missing-module-docstring) style2.py:1:0: C0103: Constant name "a" doesn't conform to UPPER_CASE naming style (invalid-name) style2.py:2:0: C0103: Constant name "b" doesn't conform to UPPER_CASE naming style (invalid-name) style2.py:3:0: C0103: Constant name "c" doesn't conform to UPPER_CASE naming style (invalid-name) ------------------------------------ Your code has been rated at -1.67/10変数名を長くしてみる。
style3.pydef func(): first=1 second=2 third=3 print(first) print(second) print(third) func()実行結果$ pylist style3.py -bash: pylist: command not found uemuratntonoAir:bin uemura$ pylint style3.py ************* Module style3 style3.py:3:9: C0326: Exactly one space required around assignment first=1 ^ (bad-whitespace) style3.py:4:10: C0326: Exactly one space required around assignment second=2 ^ (bad-whitespace) style3.py:5:9: C0326: Exactly one space required around assignment third=3 ^ (bad-whitespace) style3.py:1:0: C0114: Missing module docstring (missing-module-docstring) style3.py:1:0: C0116: Missing function or method docstring (missing-function-docstring) ----------------------------------- Your code has been rated at 3.75/1012.1.2 unittestによるテスト
- コードをソース管理システムにコミットする前に、まずテストプログラムを書いて、コードが全てのテストに合格することを確認する作業はグッドプラクティス。
cap.pydef just_do_it(text): return text.capitalize()test_cap.pyimport unittest import cap class TestCap(unittest.TestCase): def setUp(self): pass def tearDown(self): pass def test_one_word(self): text="duck" result=cap.just_do_it(text) self.assertEqual(result, "Duck") def test_multiple_words(self): text="a veritable flock of ducks" result=cap.just_do_it(text) self.assertEqual(result, "A Veritable Flock Of Ducks") #assertで始まる名前を持つメソッドで結果をチェックする。 if __name__=="__main__": unittest.main()実行結果$ python test_cap.py .. ---------------------------------------------------------------------- Ran 2 tests in 0.000s OK $ python test_cap.py .. ---------------------------------------------------------------------- Ran 2 tests in 0.000s OK $ python test_cap.py ..F ====================================================================== FAIL: test_words_with_apostrophes (__main__.TestCap) ---------------------------------------------------------------------- Traceback (most recent call last): File "test_cap.py", line 25, in test_words_with_apostrophes self.assertEqual(result, "I'm Fresh Out Of Ideas") AssertionError: "I'M Fresh Out Of Ideas" != "I'm Fresh Out Of Ideas" #^は実際に文字列が異なっている箇所を示している。 - I'M Fresh Out Of Ideas ? ^ + I'm Fresh Out Of Ideas ? ^ ---------------------------------------------------------------------- Ran 3 tests in 0.001s FAILED (failures=1)capitalize()は先頭の単語のみタイトルケースにする。
cap.py#capitalize()をtitle()に書き換え def just_do_it(text): return text.title()実行結果$ python test_cap.py ... ---------------------------------------------------------------------- Ran 3 tests in 0.000s OKtest_cap.pyimport unittest import cap class TestCap(unittest.TestCase): def setUp(self): pass def tearDown(self): pass def test_one_word(self): text="duck" result=cap.just_do_it(text) self.assertEqual(result, "Duck") def test_multiple_words(self): text="a veritable flock of ducks" result=cap.just_do_it(text) self.assertEqual(result, "A Veritable Flock Of Ducks") #assertで始まる名前を持つメソッドで結果をチェックする。 def test_words_with_apostrophes(self): text="I'm fresh out of ideas" result=cap.just_do_it(text) self.assertEqual(result, "I'm Fresh Out Of Ideas") def test_words_with_quotes(self): text="\"You're despicable,\" said Daffy Duck" result=cap.just_do_it(text) self.assertEqual(result, "\"You're Despicable,\" Said Daffy Duck") if __name__=="__main__": unittest.main()実行結果$ python test_cap.py ...F ====================================================================== FAIL: test_words_with_quotes (__main__.TestCap) ---------------------------------------------------------------------- Traceback (most recent call last): File "test_cap.py", line 30, in test_words_with_quotes self.assertEqual(result, "\"You're Despicable,\" Said Daffy Duck") AssertionError: '"you\'re Despicable," Said Daffy Duck' != '"You\'re Despicable," Said Daffy Duck' - "you're Despicable," Said Daffy Duck ? ^ + "You're Despicable," Said Daffy Duck ? ^ ---------------------------------------------------------------------- Ran 4 tests in 0.002s FAILED (failures=1)12.1.3 noseによるテスト
- noseはサードパーティパッケージ。
test_cap_nose.pyimport cap from nose.tools import eq_ def test_one_word(self): text="duck" result=cap.just_do_it(text) eq_(result, "Duck") def test_multiple_words(self): text="a veritable flock of ducks" result=cap.just_do_it(text) eq_(result, "A Veritable Flock Of Ducks") def test_words_with_apostrophes(self): text="I'm fresh out of ideas" result=cap.just_do_it(text) eq_(result, "I'm Fresh Out Of Ideas") def test_words_with_quotes(self): text="\"You're despicable,\" said Daffy Duck" result=cap.just_do_it(text) eq_(result, "\"You're Despicable,\" Said Daffy Duck")unittestnでテストしたときに見つけたのと同じバグ。
実行結果$ nosetests test_cap_nose.py E ====================================================================== ERROR: Failure: IndentationError (unexpected indent (test_cap_nose.py, line 4)) ---------------------------------------------------------------------- ...(省略) def test_one_word(self): ^ IndentationError: unexpected indent ---------------------------------------------------------------------- Ran 1 test in 0.001s FAILED (errors=1)12.2 Pythonコードのデバッグ
test_dump.pyfrom dump1 import dump @dump def double(*args, **kwargs): "Double every argument" output_list=[2*x for x in args] output_dict={k:2*v for k,v in kwargs.items()} return output_list, output_dict if __name__=="__main__": output=double(3, 5, first=100,next=98.6, last=-40)実行結果$ python test_dump.py Function name: double Input arguments: 3 5 Input keyword arguments: dict_items([('first', 100), ('next', 98.6), ('last', -40)]) Output: ([6, 10], {'first': 200, 'next': 197.2, 'last': -80})12.3 pdbによるデバッグ
capitals.pydef process_cities(filename): with open(filename, "rt") as file: for line in file: line=line.strip() if "quit" in line.lower(): return country, city=line.split(",") city=city.strip() country=country.strip() print(city.title(),country.title(), sep=",") if __name__=="__main__": import sys process_cities(sys.argv[1])実行結果$ python capitals.py cities1.csv Paris,France Caracas,Venuzuela Vilnius,Lithuniacities2.csvを実行中、15行中わずか5行出力したところで停止。
cities2.csv$ python capitals.py cities2.csv Buenos Aires,Argentinam La Paz,Bolivia Brasilia,Brazil Santiago,Chile Bogota,Colombia実行結果$ python -m pdb capitals.py cities2.csv #cと入力すると正常終了もしくはエラーで止まる。 (Pdb) c Buenos Aires,Argentinam La Paz,Bolivia Brasilia,Brazil Santiago,Chile Bogota,Colombia The program finished and will be restarted > /Users/practice/bin/capitals.py(1)<module>() -> def process_cities(filename): #sと入力すると行を順に実行する。 (Pdb) s > /Users/practice/bin/capitals.py(13)<module>() -> import sys (Pdb) s > /Users/practice/bin/capitals.py(14)<module>() -> process_cities(sys.argv[1]) (Pdb) s --Call-- > /Users/practice/bin/capitals.py(1)process_cities() -> def process_cities(filename): (Pdb) s > /Users/practice/bin/capitals.py(2)process_cities() -> with open(filename, "rt") as file: #第6行にブレークポイントセットした。 (Pdb) b 6 Breakpoint 1 at /Users/uemura/practice/bin/capitals.py:6 #ブレークポイントに当たるか、入力行を全て読み出して終了するまでプログラム実行する。 (Pdb) c Buenos Aires,Argentinam La Paz,Bolivia Brasilia,Brazil Santiago,Chile Bogota,Colombia > /Users/practice/bin/capitals.py(6)process_cities() -> return #何を読み出したのか確認する。 (Pdb) p line 'ecuador,quito' (Pdb) b Num Type Disp Enb Where 1 breakpoint keep yes at /Users/uemura/practice/bin/capitals.py:6 breakpoint already hit 1 time #1はコード行、現在位置(->)、ブレークポイント(B)を示す。 #オプションなしのlは前回のlの表示の末尾から表示を始めるのでオプションで指定する。 (Pdb) l 1 1 def process_cities(filename): 2 with open(filename, "rt") as file: 3 for line in file: 4 line=line.strip() 5 if "quit" in line.lower(): 6 B-> return 7 country, city=line.split(",") 8 city=city.strip() 9 country=country.strip() 10 print(city.title(),country.title(), sep=",") 11quitテストが行全体でquitになっているものだけマッチするように書き換える。
capitals2.pydef process_cities(filename): with open(filename, "rt") as file: for line in file: line=line.strip() if "quit" ==line.lower(): return country, city=line.split(",") city=city.strip() country=country.strip() print(city.title(),country.title(), sep=",") if __name__=="__main__": import sys process_cities(sys.argv[1])実行結果$ python capitals2.py cities2.csv Buenos Aires,Argentinam La Paz,Bolivia Brasilia,Brazil Santiago,Chile Bogota,Colombia Quito,Ecuador Stanley,Falkland Islands Cayenne,French Guiana Asuncion,Paraguay Lima,Peru Paramaribo,Suriname Montevideo,Uruguay Caracas,Venezuela12.4 エラーメッセージのロギング
- ロギングのPython標準ライブラリはloggingモジュール。
- ログに保存したいメッセージ
- ランク付けのための優先順位レベルとそれに対応する関数
- モジュールとの主要な通信経路となる一つ以上のロガーオブジェクト
- メッセージを端末、ファイル等そのほかの場所に送るハンドラ
- 出力を作成するフォーマッタ
- 入力に基づいて判断を下すフィルタ
>>> import logging >>> logging.debug("Looks like rain") >>> logging.info("And hill") #デフォルトの優先順位レベルはWARNIGである。 >>> logging.warn("Did I hear thunder?") __main__:1: DeprecationWarning: The 'warn' function is deprecated, use 'warning' instead WARNING:root:Did I hear thunder? >>> logging.critical("Stop fencing and get inside") CRITICAL:root:Stop fencing and get inside #デフォルトレベルはbasicConfig()で設定できる。 #DEBUG以上の全てのレベルがログに書かれる。 >>> import logging >>> logging.basicConfig(level="DEBUG") >>> logger.debug("Timber") DEBUG:bunyan:Timber >>> logging.info("And hill") INFO:root:And hill12.5 コードの最適化
12.5.1 実行時間の計測
time1.py#現在の時刻から処理終了時刻をひく。 from time import time t1=time() num=5 num*=2 print(time()-t1)$ python time1.py 3.0994415283203125e-06 $ python time1.py 1.9073486328125e-06 $ python time1.py 1.6689300537109375e-06time2.pyfrom time import time, sleep t1=time() sleep(1.0) print(time()-t1)実行結果$ python time2.py 1.0051441192626953 uemuratntonoAir:bin uemura$ python time2.py 1.0001447200775146timeitモジュールのtimeit()関数を使うと便利。
timeit1.py#time.timeit("code",number,count)の構文 #timeitの内部で実行するためcodeは""で囲む必要がある。 from timeit import timeit print(timeit("num=5;num*=2", number=1))実行結果$ python timeit1.py 1.63200000000141e-06 uemuratntonoAir:bin uemura$ python timeit1.py 1.252999999999671e-06time2.py#repeat()関数のrepeat引数を使うことで実行回数が増やせる。 from timeit import repeat print(repeat("num=5;num*=2", number=1,repeat=3))実行結果$ python timeit2.py [8.809999999977169e-07, 2.57000000000035e-07, 1.659999999993611e-07]12.5.2 アルゴリズムとデータ構造
リスト内包表記とforループのどちらが早いか。
time_lists.pyfrom timeit import timeit def make1(): result=[] for value in range(1000): result.append(value) return result def make2(): result=[value for value in range(1000)] return result print("make1 takes", timeit(make1, number=1000), "seconds") print("make2 takes", timeit(make2, number=1000), "seconds")リスト内包表記の方が高速である。
実行結果$ python time_lists.py make1 takes 0.07954489899999999 seconds make2 takes 0.035908797000000006 seconds12.6 Gitでのソース管理
#新しいディレクトリ作成後、移動する。 $ mkdir newdir $ cd newdir #カレントディレクトリのnewdirにローカルGitリポジトリを作る。 $ git init Initialized empty Git repository in /Users/practice/bin/newdir/.git/ #Gitリポジトリにファイルを追加する。 $ git add test.py #Gitの状態確認。 $ git status On branch master No commits yet Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: test.py #-m "my first commit"というコミットメッセージをつけてコミットする。 $ git commit -m "my first commit" [master (root-commit) e03cd1c] my first commit 1 file changed, 1 insertion(+) create mode 100644 test.py #変更はコミット済み。 $ git status On branch master nothing to commit, working tree clean感想
1周目ですが約1ヶ月で完走できた。ただ、アウトプットができていないのでアウトプットをメインに次の1ヶ月はやっていく。
参考文献
「Bill Lubanovic著 『入門 Python3』(オライリージャパン発行)」
- 投稿日:2020-02-05T20:58:22+09:00
【Python】無限混合ガウスモデルによるクラスタリング
クラスタリングの手法のひとつに、混合ガウスモデルの推定があります。これは、データセットを複数個のガウス分布で表現、及びクラスタ分けする手法です。通常、これらのガウス分布は有限個を仮定しますが、もし無限個あったとしたら、どんなクラスタリングになるのでしょうか。
本記事では、機械学習プロフェッショナルシリーズ『ノンパラメトリックベイズ 点過程と統計的機械学習の数理』を参考にして、「無限混合ガウスモデル」及び「ノンパラメトリック」の概要と実装を紹介します。この本、非常に分かりやすいのでおすすめです。
詳細な理論の話は省略し、概要とストーリーを重視したいと思います。
また、実装はソースコードを記載する程度に留めます。※前回の記事
【Python】周辺化ギブスサンプリングを実装してみた
ただし、本記事だけ読んでも流れが伝わるように意識しています。無限混合ガウスモデルの導入
通常の混合ガウスモデルでは、データセットが有限個のガウス分布で表現され、各データがその中のガウス分布と紐付いていると考えます。クラスラ数(=ガウス分布数)はあらかじめ決めておく必要がありますが、適切なクラスタ数はデータセットによって変化し、それを把握するのは容易ではありません。
もしクラスタリング中にクラスタ数も自動的に決まれば、上記の課題に悩まずに済みますよね。それを実現するのが、無限混合ガウスモデルです。
無限混合ガウスモデルでは、「ガウス分布は無限個存在し、データセットのデータは、そのうちの有限個と結びついている」という考え方に基づいています。
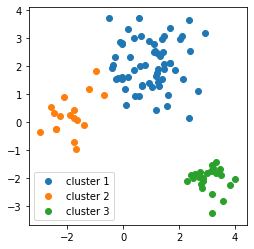
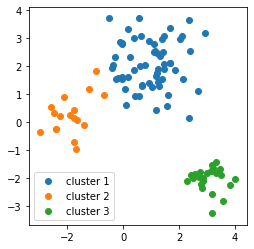
次の図は、後ほどお見せするクラスタリングの結果です。(めんどうなので図を使いまわします。ご了承ください。)
このデータセットは3個のガウス分布で表現されています。
通常の混合ガウスモデルでは、この世界にちょうど3個のガウス分布があると考えるのに対して、無限混合ガウスモデルでは、データセットと結びつかない潜在的なガウス分布が無限個あると考えます。
このように考えることで、データが既存の3個のクラスタに結びつく確率に加え、平均がどこにあるのか分からない未知のクラスタと結びつく確率も計算できるのです。つまり、無限混合ガウスモデルによるクラスタリングでは、データが新しいクラスタに割り当てられたり、一方で既存のクラスタがどのデータとの結びつかず消滅したりと、クラスタ数を増減させながら、最後は適切な数に収束させることができます。
確率分布の算出
ここから計算式を掲載します。
通常の混合ガウス分布では、($x_{1:N}$1を観測しないときの)$z_i$の確率分布にカテゴリカル分布を適用します。P(z_i = k | \pi) = \pi_kここで、$\pi := (\pi_1, \cdots, \pi_K)$は$(K-1)$次元単体上の点です。2
$\pi$の値の決め方として、一様分布を仮定したり、事前分布を仮定してベイズ推定する方法3があります。一方、無限混合ガウスモデルでは、中華料理過程と呼ばれる確率過程を適用します。これは、$i$番目以外のデータのクラスタ$z_{1:N}^{\backslash i}$から、$i$番目のデータのクラスタ$z_i$の確率分布を算出する仕組みです。
P(z_i = k | z_{1:N}^{\backslash i}, \alpha) = \left\{ \begin{array}{ll} \frac{n_k}{N - 1 + \alpha} & (k = 1, \cdots, K) \\ \frac{\alpha}{N - 1 + \alpha} & (k = K + 1) \end{array} \right.$k=1, \cdots, K$が既存のクラスタ、$k=K+1$が新しいクラスタに相当します。ここで、$n_k$は$i \neq j, z_j=k$となる$j$の個数、$\alpha$は正の値を取るハイパパラメータです。式から分かる通り、$\alpha$が大きほど新しいクラスタに割当される確率が大きくなります。今後、この確率分布を${\rm CRP}(k | z_{1:N}^{\backslash i}, \alpha)$と書くことにします。
次に、$x_{1:N}$を観測したときの確率分布を考えます。通常の混合ガウスモデルでは、次のようにして求めることができます。
\begin{align} P(z_i = k | x_{1:N}, \mu_{1:K}, \Sigma_{1:K}, \pi) &= \frac{P(z_i = k | \pi) N(x_i | \mu_k, \Sigma_k)}{\sum_{l=1}^{K}P(z_i = l | \pi) N(x_i | \mu_l, \Sigma_l)} \\ &= \frac{\pi_k N(x_i | \mu_k, \Sigma_k)}{\sum_{l=1}^{K}\pi_l N(x_i | \mu_l, \Sigma_l)} \end{align}$N(x | \mu, \Sigma)$は多変量ガウス分布の確率密度関数です。
無限混合ガウスモデルでは、上式の$P(z_i = k | \pi)$を中華料理過程の式に変えることで確率分布を求めることができます。\begin{align} P(z_i = k | x_{1:N}, \mu_{1:K}, \Sigma_{1:K}, z_{1:N}^{\backslash i}, \alpha) &= \frac{{\rm CRP}(k | z_{1:N}^{\backslash i}, \alpha) N(x_i | \mu_k, \Sigma_k)}{\sum_{l=1}^{K+1}{\rm CRP}(l | z_{1:N}^{\backslash i}, \alpha) N(x_i | \mu_l, \Sigma_l)} \end{align}ここで、ひとつ注意があります。既存のクラスタ$k=1, \cdots, K$については、各クラスタに所属するデータから平均$\mu_k$と分散共分散行列$\Sigma_k$を推定することが可能です。
ところが、新しいクラスタ$k=K+1$については、クラスタに所属するデータがないため、直接的な平均と分散共分散行列の推定ができません。
そこで、今回は次の方法を採用します。
- $\mu_k$に事前分布を仮定し、同時分布$P(x_i, \mu_k| \cdots)$を周辺化して、$\mu_k$を陽に推定せずに確率分布を求める
- $\Sigma_k$を全てのクラスタで共通の行列$\sigma^2 I$とする。($\sigma^2$はハイパパラメータ)
平均に関して、ベイズ推定と周辺化によって、事前分布のみから確率分布を計算します。
分散共分散行列に関して、上記のように固定してもクラスタリングには十分なので、今回は推定なしにします。4もちろん、分散を推定してクラスタリングすることも可能です。場合分けするのはナンセンスなので、この手法を$k=1, \cdots, K+1$のときにも適用します。
なお、周辺化については前回の記事をご参照ください。ノンパラメトリックベイズによるクラスタリング
$N$個のデータのクラスタ$z_{1 :N}$を推定するため、$z_1$から$z_N$まで一つずつ順次確率的にサンプリングすることにします。この方法をギブスサンプリングといい、今回のように、無限次元の確率分布をもとにした方法を特にノンパラメトリックベイズといいます。
この方法を実行するため、初期のクラスタリング$z_{1:N}$を何かしら仮定する必要があります。今回は全て同じクラスタ$k=1$を初期クラスタリングとして、$z_1$から$z_N$までのサンプリングを複数回反復することにします。最初は1つしかクラスタがありませんが、平均から遠いデータが新しいクラスタと結びついて、クラスタ数を増やしながらクラスリングが進むイメージです。
実装
無限混合ガウスモデルによるクラスタリングを実装しました。
前回の実装をベースにしていますが、全体的にブラッシュアップしており、差分が大きいかもしれません。
ソースコード
from collections import Counter from functools import partial from typing import Sequence, Tuple import numpy as np from scipy.special import logsumexp def _log_gaussian(x: np.ndarray, mu: np.ndarray, var: float) -> np.ndarray: # 前回記事では2*np.piを省略していましたが、分かりやすさのため今回は計算に入れます d = x.shape[0] norm_squared = ((x - mu) * (x - mu)).sum(axis=1) return - d * np.log(2 * np.pi * var) / 2 - norm_squared / (2 * var) # クラスタを格納する配列クラス class InfiniteClusterArray(object): def __init__(self, array: Sequence[int]): self._array = np.array(array, dtype=int) self._counter = Counter(array) self._n_clusters = max(array) + 1 def update(self, i: int, k: int): assert k <= self._n_clusters pre_value = self._array[i] if pre_value == k: return if self._counter[pre_value] > 0: self._counter[pre_value] -= 1 self._array[i] = k self._counter[k] += 1 if k == self._n_clusters: self._n_clusters += 1 if not self._counter[pre_value]: self._array -= 1 * (self._array > pre_value) self._counter = Counter(self._array) self._n_clusters -= 1 @property def array(self) -> np.ndarray: return self._array.copy() @property def n_clusters(self) -> int: return self._n_clusters def count(self, k: int, excluded=None) -> int: assert (excluded is None) or isinstance(excluded, int) if excluded is None: return self._counter[k] counted = self._counter[k] - bool(self._array[excluded] == k) return counted def __getitem__(self, i: int) -> int: return self._array[i] # データセットを格納する配列クラス class DataArray(object): def __init__(self, array: np.ndarray): assert array.ndim == 2 self._array = array @property def n(self) -> int: return self._array.shape[0] @property def d(self) -> int: return self._array.shape[1] def mean(self, excluded=None) -> np.ndarray: assert (excluded is None) or isinstance(excluded, Sequence) if excluded is None: return self._array.mean(axis=0) else: return self._array[excluded].mean(axis=0) def __getitem__(self, i): return self._array.__getitem__(i) def __iter__(self): for i in range(self.n): yield self._array[i] def __str__(self) -> str: return f'DataArray({self._array})' # 無限混合ガウスのギブスサンプリングクラス class IGMMGibbsSampling(object): def __init__(self, var: float, var_pri: float, alpha: float, seed=None): # 事前分布の平均は、データセット全体の平均に設定されます。 assert (var > 0) and (var_pri > 0) assert alpha > 0 self.var = var self.var_pri = var_pri self.alpha = alpha self._random = np.random.RandomState(seed) def predict_clusters(self, X: np.ndarray, n_iter: int, init_z=None) -> np.ndarray: # クラスタを推定するメソッド assert X.ndim == 2 X = DataArray(X) mu_pri = X.mean() if init_z is None: init_z = np.zeros(X.n, dtype=int) z = InfiniteClusterArray(init_z) for _ in range(n_iter): compute_probs = partial(self._compute_pmf_zi, X, z, mu_pri) for i in range(X.n): probs = compute_probs(i) z_i = self._random.multinomial(1, probs) z_i = np.where(z_i)[0][0] # One-hot to index z.update(i, z_i) return z.array def _compute_pmf_zi(self, X: DataArray, z: InfiniteClusterArray, mu_pri: np.ndarray, i: int) -> np.ndarray: mu, var = self._compute_marginal_distribution(X, z, mu_pri, i) pi = np.array([ z.count(k, excluded=i) / (X.n - 1 + self.alpha) if k < z.n_clusters else self.alpha / (X.n - 1 + self.alpha) for k in range(z.n_clusters + 1) ]) log_pdf_xi = _log_gaussian(X[i], mu, var) with np.errstate(divide='ignore'): pmf_zi = np.exp(np.log(pi) + log_pdf_xi - logsumexp(np.log(pi) + log_pdf_xi)[np.newaxis]) return pmf_zi def _compute_marginal_distribution(self, X: DataArray, z: InfiniteClusterArray, mu_pri: np.ndarray, i: int) -> Tuple[np.ndarray, float]: n_vec = np.array([ z.count(k, excluded=i) for k in range(z.n_clusters + 1) ], dtype=np.int) tmp_vec = 1 / (n_vec / self.var + 1 / self.var_pri) mu = np.tile(mu_pri / self.var_pri, (z.n_clusters + 1, 1)) # Shape (z.n_clusters + 1, X.d) for k in range(z.n_clusters): excluded_list = [ j for j in range(X.n) if (j != i) and (z[j] == k) ] if excluded_list: mean = X.mean(excluded=excluded_list) mu[k] += n_vec[k] * mean / self.var mu *= tmp_vec[:, np.newaxis] var = tmp_vec + self.var return mu, varクラスタリングの実践
試しに、実装した自作クラスを使ってクラスタリングしてみます。
今回は、次のデータセットに適用します。
ソースコード
Jupyter Notebookを使用しています。
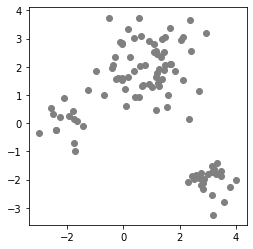
import numpy as np import matplotlib.pyplot as plt import matplotlib.patches as patches %matplotlib inline np.random.seed(0) cmap = plt.rcParams['axes.prop_cycle'].by_key()['color'] pi = [0.6, 0.2, 0.2] mu = np.array([[1, 2], [-2, 0], [3, -2]]) var = [0.8, 0.4, 0.2] size = 100 ndim = 2 def make_data(): z = np.random.multinomial(1, pvals=pi) z = np.where(z==1)[0][0] cov = var[z] * np.eye(2) return np.random.multivariate_normal(mu[z], cov) X = np.array([make_data() for _ in range(100)]) fig = plt.figure() ax = plt.axes() ax.scatter(X[:, 0], X[:, 1], color='gray') ax.set_aspect('equal') plt.show()
序盤でお見せしたデータセットの、まだクラスタリングされていない状態のものです。
データの個数は100個で、3つのガウス分布からランダムに選んで作成しています。
したがって、3つのクラスタに分けるのが適切です。それでは、クラスタリングしてみましょう。
model = IGMMGibbsSampling(var=0.5, var_pri=4, alpha=0.1, seed=0) # ハイパパラメータをコンストラクタにわたす clusters = model.predict_clusters(X, n_iter=10) #クラスタリングの実行 # 可視化 fig = plt.figure() ax = plt.axes() for k in range(max(clusters) + 1): data = np.array([ X[i, :] for i in range(X.shape[0]) if clusters[i] == k ]) ax.scatter(data[:, 0], data[:, 1], label=f'cluster {k + 1}', color=cmap[k]) ax.set_aspect('equal') plt.legend() plt.show()クラスタで共通の分散
varはデータセット小さめの$0.5$、平均の事前分布の分散var_priは、一様分布っぽくするために大きめの$4$、中華料理過程のパラメータalphaは$0.1$にしています。
ちなみに、平均の事前分布の平均は、データセット全体の平均になるように実装されています。
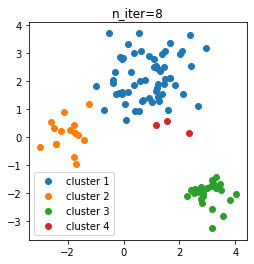
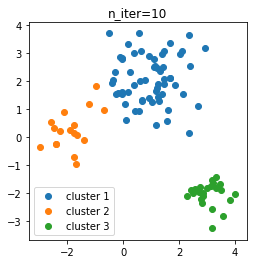
クラスタリングメソッドpredict_clustersに、データセットと反復回数n_iterを渡しています。ここで、反復回数を10としました。結果は、次のようになりました。
クラスタ数を指定せず、全て同じクラスタの状態からスタートしたのにもかかわらず、3個のクラスタに分かれてくれました。
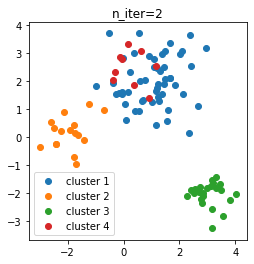
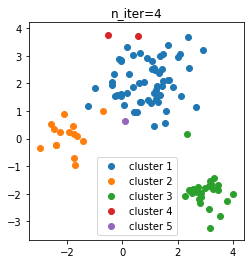
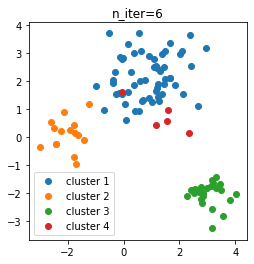
せっかくなので、反復回数ごとのクラスタリングの推移を調べてみます。
n_iter=2, 4, 6, 8, 10におけるクラスタリング結果を図示しました。
- n_iter = 2
- n_iter = 4
- n_iter = 6
- n_iter = 8
- n_iter = 10
初期状態から多めにクラスタができ、そこから徐々にクラスタが減って3個になったようです。
ちなみに、ここからn_iterを増やしても、クラスタ数は基本的に3個の状態を維持していました。
※たまにデータが1個だけのクラスタができて、クラスタ数が4個になることもありました。ハイパパラメータの調整
中華料理過程のハイパパラメータ$\alpha$は、上述した通り、大きほど新しいクラスタが出来やすくなります。
もともとクラスタ数の推定を省略するという動機があり、この$\alpha$の調整に苦戦してしまったら導入した意義が薄れてしまいます。
$\alpha$を変えながら試行したところ、基本的には小さめにすれば問題ないという印象を受けました。
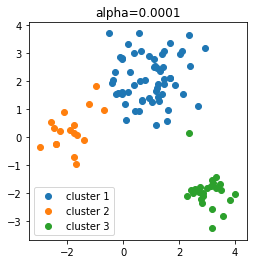
次の図は、$\alpha=0.0001$、反復回数10回の結果です。
しっかり3つのクラスタに分かれています。
$\alpha$をかなり小さめにしても、反復回数に大きなインパクトなく、適切にクラスタリングできるようです。ちなみに、$\alpha=1$にすると、10回反復時点で5個のクラスタができ、その後も3個に減ることはありませんでした。$\alpha$が大きすぎるとうまくクラスタ数が決まらないようです。
機械学習で使われる最適化アルゴリズムのステップ幅と同じ性質を持っていますね。おわりに
以上、無限混合ガウスモデルによるクラスタリングを試してみました。
狙い通りのクラスタ数に分かれてくれたのでおもしろかったです。
$N$個の変数$x_1, \cdots, x_N$を、省略して$x_{1:N}$と書くことにします。また、その中から$i$番目を除いた$N-1$個の変数を$x_{1:N}^{\backslash i}$と書くことにします。 ↩
$\pi_1, \cdots, \pi_K \ge 0$及び$\sum_{k=1}^K\pi_k=1$を満たす$(\pi_1, \cdots, \pi_K)$の集合を$(K-1)$次元単体と言います。もともとは幾何学で使われる集合で、$0$次元単体は1点、$1$次元単体は線分、$2$次元単体は三角形を表しています。ベイズ推定の本を読んでると、確率の文脈でこの集合が使われるのを目にします。 ↩
$\pi$を$z_{1:N}^{\backslash i}$の観測から最尤推定する方法もありますが、この方法ではクラスタ$k$が消滅するすると常に$\pi_k=0$となり、クラスタが復活しなくなるため注意が必要です。 ↩
$\Sigma_k$をクラスタ共通の固定値にしても、k-meansと同様の精度でクラスタリングができると思います。なぜなら、k-means法は、上記のように分散を固定した混合ガウスモデルにおいて、各$\mu_k$や$z_i$を最尤推定した場合と同等だからです。 ↩
- 投稿日:2020-02-05T20:51:31+09:00
ABC134-Dから学んだ計算量の求め方
問題
https://atcoder.jp/contests/abc134/tasks/abc134_d
難しかった。というか問題文を読むことが難しかった。
今回の学び
- 任意の整数=全ての整数のようなニュアンス
- 後ろから順に解いていくと一意に確定する
- $O(\sum(N/i)) = O(NlogN)$
計算量の求め方
発生した疑問:$O(\sum(N/i))$って間に合うの?
今回の問題では任意のiにおいて$N/i$を求める必要がある。これを考えるとき、積分を行うと良い。$\int(1/N) = logN$であることから最悪でもlogNで押さえつけることができる。
まとめ
- 数学的な文章になれる
- 配列を前もしくは後ろから判定するのはよくあるし気づかなければいけない
- 積分を考えると面積から計算時間を求めることができる。
コード
N = int(input()) a = list(map(int, input().split())) a.insert(0, 0) b = [0] * N M = 0 for i in range(N, 0, -1): ball = 0 for j in range(i + i, N + 1, i): ball ^= b[j - 1] b[i - 1] = ball ^ a[i] M = sum(b) print(M) for i in range(N): if b[i]: print(i + 1, end = ' ')
- 投稿日:2020-02-05T20:21:30+09:00
嘘つき族と正直族の問題
嘘つき族と正直族の問題を
Pythonで解いてみた。
答え合わせはしていない。Python楽。import itertools # 嘘つきなら反対を答える def ans( person, liars, b): if person in liars: b = not b return b def print_res(liars, cards): print('-----') for i in range(4): print( '{}:{} {}'.format('ABCD'[i], '嘘' if i in liars else '正', cards[i])) # 嘘つきな人 と カードの組み合わせ liars_g = itertools.combinations(list(range(4)),2) # 嘘つきな人 cards_g = itertools.permutations(list(range(1,5))) # カード for liars, cards in itertools.product(liars_g,cards_g): # Aさん:私のカードは,偶数です. # Bさん:私のカードは,3か4のどちらかです. # Cさん:Bさんは,正直族です. # Dさん:私のカードは,1です. if ans( 0, liars, cards[0] % 2 == 0) and \ ans( 1, liars, cards[1] in (3,4)) and \ ans( 2, liars, 1 not in liars) and \ ans( 3, liars, cards[3] == 1): print_res(liars, cards)答え
----- A:嘘 1 B:正 3 C:正 2 D:嘘 4 ----- A:嘘 1 B:正 3 C:正 4 D:嘘 2 ----- A:嘘 1 B:正 4 C:正 2 D:嘘 3 ----- A:嘘 1 B:正 4 C:正 3 D:嘘 2 ----- A:嘘 3 B:正 4 C:正 1 D:嘘 2 ----- A:正 4 B:嘘 2 C:嘘 3 D:正 1
- 投稿日:2020-02-05T20:20:10+09:00
PythonでmongoDBを操作する~その6:aggregate編~
当記事の記載範囲
この記事ではPythonでmongodbに接続してから、aggregate(SQLで言うところの集計関数)の使い方について記載します。
mongodbの起動やpymongoのインストール方法については以下の記事をご覧いただければ幸いです。
https://qiita.com/bc_yuuuuuki/items/2b92598434f6cc320112準備データ
準備データは以下の記事でmongoDBに突っ込んだQiitaの記事情報を使用します
[Python]Qiitaの記事情報をmongoDBに突っ込んだaggregateの使い方
mongoDBのaggregateの使い方はSQLに慣れているとイマイチピンと来ないです。
下表がSQLとaggregateの対比表です。
SQL aggregate WHERE $match GROUP BY $group HAVING $match SELECT $project ORDER BY $sort LIMIT $limit SUM() $sum COUNT() $sum mongoDBの操作クラス
pymongoを使用して色々とmongoDBを使用するクラスを作ってます。
mongo_sample.pyfrom pymongo import MongoClient class MongoSample(object): def __init__(self, dbName, collectionName): self.client = MongoClient() self.db = self.client[dbName] #DB名を設定 self.collection = self.db.get_collection(collectionName) def aggregate(self, filter, **keyword): return self.collection.aggregate(filter, keyword)aggregate呼び出し用の関数を作っているだけです。
mongoDBからデータを取得する
まずは、コードです。
aggregate_sample.pyfrom mongo_sample import MongoSample import pprint # arg1:DB Name # arg2:Collection Name mongo = MongoSample("db", "qiita") # 最大値 pipeline = [ {"$group":{ "_id":"title","page_max_view":{"$max":"$page_views_count"}}} ] results = mongo.aggregate(pipeline) print("------------------------最大値-----------------------------") pprint.pprint(list(results)) # 最小値 pipeline = [ {"$group":{ "_id":"title","page_min_view":{"$min":"$page_views_count"}}} ] results = mongo.aggregate(pipeline) print("------------------------最小値-----------------------------") pprint.pprint(list(results)) # 平均値 pipeline = [ {"$group":{ "_id":"average","page_average_view":{"$avg":"$page_views_count"}}} ] # 合計 pipeline = [ {"$group":{"_id":"page_total_count","total":{"$sum":"$page_views_count"}}} ] results = mongo.aggregate(pipeline) print("------------------------平均値-----------------------------") pprint.pprint(list(results)) # tag毎の出現回数カウント pipeline = [ { "$unwind": "$tag_list"}, { "$group": { "_id": "$tag_list", "count": { "$sum":1}}}, { "$sort": {"count": -1, "_id":1}} ] results = mongo.aggregate(pipeline) print("------------------------集計値-----------------------------") pprint.pprint(list(results))やっていることは大したことはありません。
最大値、最小値、平均値、タグ毎のカウントを取得しています。pprintはinstallする必要があります。
pip install pprintそれぞれ、mongoDBの操作方法と見比べていきます。
最大値/最小値/平均値/合計値
まずは、mongoDBのコマンド
例は最大値のみとします。maxをminやavg、sumに変えれば最小値/平均値/最大値になります。db.qiita.aggregate([{$group:{_id:"page_max_views",total:{$max:"$page_views_count"}}}])aggregate_sample.pypipeline = [ {"$group":{ "_id":"title","page_max_view":{"$max":"$page_views_count"}}} ]実行結果
[{'_id': 'title', 'page_max_view': 2461}]このやり方だと、"_id"を"title"に固定して、全レコード中の最大値を取得するという結果になりました。
ただ、どの記事が一番読まれているのかを知りたいので記事のタイトルを表示したいです。
mongoDBコマンド
> db.qiita.aggregate([{$project:{title:1,page_views_count:1}},{$group:{_id:"$title", total:{$max:"$page_views_count"}}},{$sort:{total:-1}}]) { "_id" : "Pythonでmongodbを操作する~その2:find編~", "total" : 2461 } { "_id" : "Pythonでmongodbを操作する~その3:update編~", "total" : 1137 } { "_id" : "Pythonでmongodbを操作する~その4:insert編~", "total" : 1102 } { "_id" : "pymongoを使った様々な検索条件(AND/OR/部分一致/範囲検索)", "total" : 1019 } (略)このコマンドだと、記事のタイトルとページの閲覧回数を見れました。
当たり前ですが、記事名でグループ化されているのであまり意味のない集計ですね。。
グループ化が必要ない最大値であれば、findでsortしてlimitをかけるのが良さそうです。tag1毎の最大値を取得してみます。
> db.qiita.aggregate([{$group:{_id:"$tag1", total:{$max:"$page_views_count"}}},{$sort:{total:-1}}]) { "_id" : "Python", "total" : 2461 } { "_id" : "Vagrant", "total" : 946 } { "_id" : "Java", "total" : 617 } { "_id" : "Hyperledger", "total" : 598 } { "_id" : "solidity", "total" : 363 } { "_id" : "Ethereum", "total" : 347 } { "_id" : "ブロックチェーン", "total" : 232 } { "_id" : "Blockchain", "total" : 201 } { "_id" : "coverage", "total" : 199 }はい。良い感じで取得出来ました。
一応、pythonのコードも変えてみます。
aggregate_sample.py# 最大値 pipeline = [ {"$group":{ "_id":"$tag1","page_max_view":{"$max":"$page_views_count"}}} ] results = mongo.aggregate(pipeline) print("------------------------最大値-----------------------------") pprint.pprint(list(results))タグ毎の集計
タグ毎に何個記事を書いているか集計したいと思います。
集計はtag_listという項目を使用しますが、このデータは以下のようになっています。> db.qiita.find({},{_id:0,tag_list:1}) { "tag_list" : [ "Python", "MongoDB", "Python3", "pymongo" ] } { "tag_list" : [ "Python", "Python3" ] } { "tag_list" : [ "Python", "Python3", "Blockchain", "ブロックチェーン", "Hyperledger-Iroha" ] } { "tag_list" : [ "Blockchain", "ブロックチェーン", "Hyperledger-Iroha" ] } { "tag_list" : [ "Blockchain", "Ethereum", "Hyperledger", "Hyperledger-sawtooth" ] } { "tag_list" : [ "ブロックチェーン", "Hyperledger", "Hyperledger-sawtooth" ] } { "tag_list" : [ "Java", "ブロックチェーン", "Hyperledger", "Hyperledger-Iroha" ] } { "tag_list" : [ "ブロックチェーン", "Hyperledger", "Hyperledger-Iroha" ] } { "tag_list" : [ "Java", "Ethereum", "ブロックチェーン", "Hyperledger", "Hyperledger-Iroha" ] } { "tag_list" : [ "Java", "ブロックチェーン", "Hyperledger", "Hyperledger-Iroha" ] } { "tag_list" : [ "Hyperledger", "Hyperledger-Iroha", "Hyperledger-burrow", "Hyperledger-sawtooth", "Hyperledger-besu" ] } { "tag_list" : [ "Vagrant", "VirtualBox", "Hyper-V" ] } { "tag_list" : [ "Java", "Ethereum", "solidity", "ブロックチェーン", "web3j" ] } { "tag_list" : [ "Java", "Ethereum", "ブロックチェーン", "web3j" ] } { "tag_list" : [ "Java", "Ethereum", "ブロックチェーン", "web3j" ] } { "tag_list" : [ "Java", "Ethereum", "ブロックチェーン", "web3j" ] } { "tag_list" : [ "Java", "Ethereum", "solidity", "ブロックチェーン", "web3j" ] } { "tag_list" : [ "Java", "Ethereum", "ブロックチェーン", "web3j" ] } { "tag_list" : [ "Java", "Ethereum", "ブロックチェーン", "web3j" ] } { "tag_list" : [ "Ethereum", "ブロックチェーン" ] }SQLでこんな形式で格納されているデータを集計するとかなり面倒くさいですね。。
mongoDBではunwindというものを使うことでLIST形式のデータを分割して集計可能になります。
> db.qiita.aggregate( { $project:{tag_list:1}}, { $unwind: "$tag_list"}, { $group: { _id: "$tag_list", count: { $sum:1}}},{ $sort: {"count": -1, "_id":1}} ) { "_id" : "ブロックチェーン", "count" : 16 } { "_id" : "Ethereum", "count" : 11 } { "_id" : "Java", "count" : 10 } { "_id" : "Python", "count" : 9 } { "_id" : "Python3", "count" : 9 } { "_id" : "Hyperledger", "count" : 7 } { "_id" : "Hyperledger-Iroha", "count" : 7 } { "_id" : "MongoDB", "count" : 7 } { "_id" : "web3j", "count" : 7 } { "_id" : "solidity", "count" : 4 } { "_id" : "Blockchain", "count" : 3 } { "_id" : "Hyperledger-sawtooth", "count" : 3 } { "_id" : "Hyper-V", "count" : 1 } { "_id" : "Hyperledger-besu", "count" : 1 } { "_id" : "Hyperledger-burrow", "count" : 1 } { "_id" : "Vagrant", "count" : 1 } { "_id" : "VirtualBox", "count" : 1 } { "_id" : "coverage", "count" : 1 } { "_id" : "pymongo", "count" : 1 } { "_id" : "truffle", "count" : 1 }pythonのコードは「{ "$project": {"tag_list": 1}}」を入れていません。
あっても無くても、結果が変わりませんでした。
イマイチ、このprojectの使い方がよくわからない。感想
SQLに慣れていると分かり辛い部分が多々あるが、unwindなどを使用することで柔軟な集計が出来そう
関連記事
- 投稿日:2020-02-05T20:15:39+09:00
PySparkDataFrameからPandasDataFrameへの変換でメモリエラーになるときの対処法
はじめに
SparkのDataFrameで作ったデータをPythonの各モジュールで使いたい時、
toPandas()メソッドを利用してPandasのDataFrameに変換するが、その際にメモリエラーが起きる場合がしばしばある。
メモリに載せられるように試行錯誤した中で、有効そうなものをまとめた。もっといい手段がありそうなので、ご存じの方は是非教えてください!
やり方
daskを利用して変換する
sparkによる変換は、
spark.driver.memoryやspark.driver.maxResultSizeの影響を受けるが、daskの場合はそれがないため、エラーを回避しやすい。daskを利用した変換import dask.dataframe as dd df.write.parquet(parquet_path) dask_df = dd.read_parquet(parquet_path) pandas_df = dask_df.compute()データ型を変更する
バイト数を削減するように、変数のデータ型を変更する。
※勿論、バイト数を削減することで、その後の演算の精度は損なわれる
データ型を変更# 例えば、int32型(4バイト)をint8型(1バイト)へ変換する dask_df = dask_dt.astype({k: 'int8' for k in dask_df.dtypes[dask_df.dtypes == 'int32'].index})
- 投稿日:2020-02-05T20:00:50+09:00
SIRモデルを使って新型肺炎の感染を予測してみた:武漢編
最近,新型肺炎が流行っていますね.
以前にSIRモデルという感染症の数理モデルを使った研究をしていたので,新型肺炎のモデルに当てはめてみました.数理モデルを使うと,感染症の未来を予測できます.今回は,発生の中心である 武漢 に注目して,感染症のモデル化と感染症の未来を予測します.
keyword
疫学, SIR model, nCoV-2019, 新型肺炎, 新型コロナウィルス
SIRモデル
SIRモデルは,感染した人数の推移を微分方程式として表したモデルです(Wikipediaでもわかりやすく解析されています). SIRモデルでは,感染症に対して人は3つの状態を取ると考えられます.
- 感染する可能性がある人 : S
- 感染している人:I
- 感染から治って免疫を獲得した人,または死亡した人 : R
時刻tにおける感染する可能性のある人,感染している人と感染から治った人をそれぞれS(t), I(t)とR(t)表記すると,SIRモデルは,
$$
\dot{S}(t) = -\beta S(t)I(t),\
\dot{I}(t) = \beta S(t)I(t) - \gamma I(t)\
\dot{R}(t) = \gamma I(t)
$$と記述されます.
ここで,βは感染率を表し,γは回復率(+死亡率)を表しています.
感染者の増え方は,感染率β,感染する可能性がある人S(t)と感染している人I(t)に比例します.死亡した人も感染を引き起こさないので,感染から治った人と同一視することに注意してください.
ここで,
$$
S(t) + I(t) + R(t) = N
$$
は一定となり,その地域の人口と一致します.
今回は,武漢の人口を使います.武漢における新型肝炎の感染データをつかって,感染率βと回復率γを学習し,武漢の未来を予測します.
使ったデータ
感染データはkaggleに公開されているこちらから引用しています.
また,武漢の人口データは,こちらのに記述されている2017年の人口統計データを用いています.SIRモデルを使ったパラメーターの学習
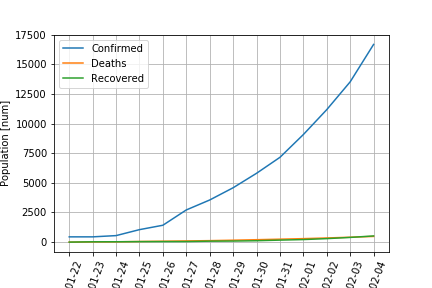
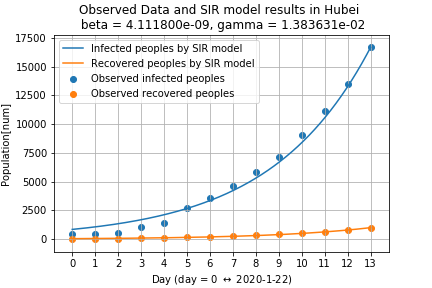
武漢における,2020年1月22日から2月4日までの感染の推移は,以下のようになります.
青線が感染者数,オレンジ線が死者数,緑線が回復した人数です.
回復した人数と死者数がだいたい同じであることは,少しおかしいかな?と思います.このデータを表現できるように,SIRモデルでフィッティングしてみました.
Recovered peopleは回復した人と死者数の和としています.
また,青点が実際に観測されている感染者数,青線がSIRモデルで近似した結果です.
オレンジ点とオレンジ線は回復した人数の実測値と予測値です.十分に近似できていそうです.
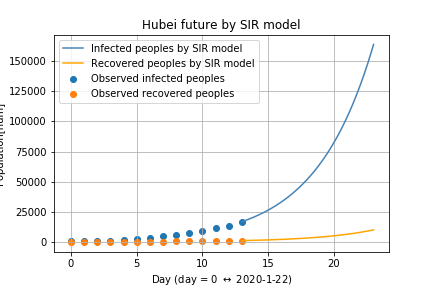
武漢の感染の未来を予測
十分に近似できていそうなので,学習したパラメータを使って,武漢の感染の未来を予測してみました.
次の図が,2月4日から10日間の予測になります.
点が実測値,線が予測値です.
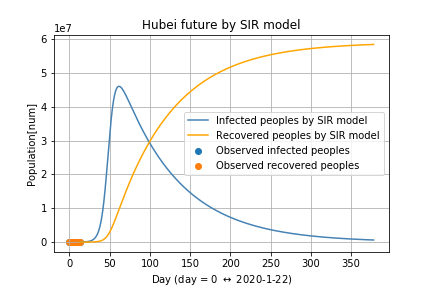
SIRモデルよれば,まだまだ増加するようです.次が2月4日から一年間の予測になります.
感染が全然止まらいようです.
考察
- SIRモデルを用いて武漢における新型肺炎の感染の拡大を予測してみましたが,拡大が止まらないという予測結果になりました.
- 武漢において回復した人数が正確に計量されていないことが原因だと思われます.
- 他のデータを用いて,回復率γを正確に測定できれば,より良い予測ができると考えられます.
今後の課題
次は,交通量をもとに,中国全土の感染の広がりを予測しようと思います.
コード
- 投稿日:2020-02-05T19:28:38+09:00
MaxPooling2DをConv2Dのみで表現する
はじめに:
CNNモデルにおいてよくPooling処理は畳み込み処理(Conv2D)と区別して解説が行われます。
しかし、勘の良い人なら(2,2)サイズのAveragePooling2D()は畳み込みフィルタ((0.25,0.25),(0.25,0.25))をstrides=2で畳み込み処理させたものに等しいことに既に気付いているでしょう。
一方でMaxPooling2DをConv2Dの畳み込み処理だけで表現することが可能かと問いかければ一見不可能に思えます。しかし、よくよく考えてみると実はConv2DのみでMaxpooling2Dを表現可能でしたので、それについて書いてみます。max関数とreluの関係:
$max(a,b)$を$relu(x)$を使って表現することを考えます。
max(a,b) = relu(a-b) + b上記の時、$a>b$で$max(a,b)=a$で、$a\leqq b$で$max(a,b)=b$であることが分かります。
つまり、$max$関数は$relu$関数を利用して表現可能ということです。さて、MaxPooling2Dを考えるにあたり、pool_size(2,2)として4つの要素から最大値を取り出す作業を考えます。$max(a,b,c,d)$を考えた場合、$relu$関数を利用して下記のように記述可能です。
\begin{align} max(a,b,c,d) &= max(max(a,b), max(c,d))\\ &=max(relu(a-b)+b,relu(c-d)+d)\\ &=relu((relu(a-b)+b)-(relu(c-d)+d))+relu(c-d)+d\\ &=relu(relu(a-b) - relu(c-d) + (b - d)) + relu(c-d) + d \end{align}さて、ここで$relu(a-b)$を畳み込みフィルタが((1,-1),(0,0))をstrides=2掛けた結果に活性化関数$relu$を掛けたもの見なすとしましょう。
同様に$relu(c-d)$は畳み込みフィルタが((0,0),(1,-1))に活性化関数$relu$を、
$b$は畳み込みフィルタが((0,1),(0,0))に活性化関数に恒等関数を、
$d$は畳み込みフィルタが((0,0),(0,1))に活性化関数に恒等関数を掛けたものとみなします。
これらの足し合わせ結果に$relu$と恒等関数を掛けた結果を足し合わせればMaxpoolingを再現できるのです。実証コード:
下記のように式から求まった畳み込みフィルタ重みを定義してやり、その重みを.set_weightsで設定しました。
import numpy as np from keras.layers import Input, Conv2D, Add, Concatenate from keras.models import Model inputs = Input(shape=(16,16,1)) x1 = Conv2D(1, (2, 2), strides=2, padding='same', activation='relu', use_bias=False)(inputs) x2 = Conv2D(1, (2, 2), strides=2, padding='same', activation='relu', use_bias=False)(inputs) x3 = Conv2D(1, (2, 2), strides=2, padding='same', activation='linear', use_bias=False)(inputs) x4 = Conv2D(1, (2, 2), strides=2, padding='same', activation='linear', use_bias=False)(inputs) x5 = Concatenate()([x1, x2, x3, x4]) x6 = Conv2D(1, (1, 1), activation='relu', use_bias=False)(x5) x7 = Conv2D(1, (1, 1), activation='linear', use_bias=False)(x5) outputs = Add()([x6, x7]) model = Model(inputs=inputs, outputs=outputs) model.summary() weight1 = np.array([[[[1]],[[-1]]],[[[0]],[[0]]]]) # relu(a-b) weight2 = np.array([[[[0]],[[0]]],[[[1]],[[-1]]]]) # relu(c-d) weight3 = np.array([[[[0]],[[1]]],[[[0]],[[0]]]]) # b weight4 = np.array([[[[0]],[[0]]],[[[0]],[[1]]]]) # d weight5 = np.array([[[[1],[-1],[1],[-1]]]]) # relu(a-b) - relu(c-d) + b - d weight6 = np.array([[[[0],[1],[0],[1]]]]) # relu(c-d) + d model.get_layer(name='conv2d_1').set_weights([weight1]) model.get_layer(name='conv2d_2').set_weights([weight2]) model.get_layer(name='conv2d_3').set_weights([weight3]) model.get_layer(name='conv2d_4').set_weights([weight4]) model.get_layer(name='conv2d_5').set_weights([weight5]) model.get_layer(name='conv2d_6').set_weights([weight6]) X = np.random.randint(-10,11,(1,16,16,1)) Y = model.predict(X) print('X=\n',X[0,:,:,0]) print('Y=\n',Y[0,:,:,0])適当な入力を与えた時、その出力が(2,2)サイズのMaxpooling2D()と等価であることを確認しました。
モデルにはConv2D()とConcatenate()とAdd()しか使っていません。X= [[ -7 7 0 -8 8 -3 -1 7 -6 9 4 -10 8 7 -6 10] [ -4 -5 -5 0 -10 7 1 8 1 -9 10 -3 5 -10 5 -9] [ -7 9 6 -9 0 -7 3 0 4 9 -6 -1 9 1 0 0] [ 1 -3 -7 -5 7 3 6 7 -4 -2 6 -8 7 -6 0 -2] [ -2 -6 9 4 4 3 10 3 9 9 -5 2 0 2 9 -3] [ 2 7 5 -3 9 -7 -1 -10 7 -5 -4 -6 0 7 8 -10] [ 1 -3 -3 9 -5 -6 -7 -7 -4 9 -7 -9 -6 2 1 -9] [ -1 -5 -3 1 -2 9 0 10 -10 5 -9 -8 -2 8 -4 3] [ 1 -4 -2 -5 -2 3 5 4 -5 3 -6 9 0 2 -3 6] [ 6 1 4 -8 -6 7 -8 4 -10 -10 -5 7 -8 -7 -1 5] [ 8 -2 4 9 6 9 -10 -4 -3 -9 7 1 -7 4 7 0] [ -6 5 6 -1 -8 -2 0 0 6 3 10 -3 3 9 1 -2] [ 2 3 -6 6 -1 1 9 -2 -3 2 4 5 -10 -7 5 4] [ -5 5 0 9 4 2 -10 -8 7 4 -7 2 -8 7 -3 3] [ 5 0 3 2 -4 2 -3 10 1 -7 -7 2 7 5 -4 2] [ 0 -9 6 2 1 -2 -4 3 -4 7 9 -9 7 -5 4 -1]] Y= [[ 7. 0. 8. 8. 9. 10. 8. 10.] [ 9. 6. 7. 7. 9. 6. 9. 0.] [ 7. 9. 9. 10. 9. 2. 7. 9.] [ 1. 9. 9. 10. 9. -7. 8. 3.] [ 6. 4. 7. 5. 3. 9. 2. 6.] [ 8. 9. 9. 0. 6. 10. 9. 7.] [ 5. 9. 4. 9. 7. 5. 7. 5.] [ 5. 6. 2. 10. 7. 9. 7. 4.]]まとめ:
Maxpooling2D()とてConv2d()を用いて等価なモデルを記述可能である。
a,b,c,dの最大値の取り方は$max(max(a,b), max(c,d))$の代わりに$max(max(a,c), max(b,d))$でもいいので他の係数でもMaxpooling2D()を再現できるかもしれない。
とはいえ、活性化関数に恒等関数を選ぶ必要があるので(あまり見掛けない)、普通のモデルでConv2d()のみで偶然にMaxpooling2D()と等価なレイヤーを作ってしまうことはあまりないかと思われます。
(identityの結合があればあり得るのでしょうか?)
- 投稿日:2020-02-05T18:13:19+09:00
書籍「15Stepで踏破 自然言語処理アプリケーション開発入門」をやってみる - 3章Step10メモ
内容
15stepで踏破 自然言語処理アプリケーション入門 を読み進めていくにあたっての自分用のメモです。
今回は3章Step10で、自分なりのポイントをメモります。準備
- 個人用MacPC:MacOS Mojave バージョン10.14.6
- docker version:Client, Server共にバージョン19.03.2
章の概要
8章では単純パーセプトロンから発展して多層パーセプトロンを導入し、9章では多クラス識別器を実装してみた。
10章ではニューラルネットワークの改善を目指す。
- ニューラルネットワークの層を深くする難しさ
- 重みの最適化手法
- ニューラルネットワークのチューニング方法
10.1 Deep Neural Networks
もともとは3層以上のニューラルネットワークをdeepと呼んでいた。
層を増やすのはmodel.addで層を増やすだけで良い。ニューラルネットワークの層を深くする難しさ
項目 解決策 過学習しやすくなる ・Early stopping
・層が多いとニューラルネットワークの表現力が高いため、学習データへ過剰に適合しやすい
・エポック単位で学習を繰り返すが、テストデータに対する精度が下がる前に学習を切り上げること
・Dropout
・学習時に一部のユニットを一定の割合でランダムに無視し、予測時には全ユニットを使う
・1回の学習で有効になるユニットの数が少ないので過学習しづらい
・複数のニューラルネットワークの足し合わせに似た予測の仕方が、アンサンブル学習と同様の効果を発揮する学習がうまく進まない ・Batch normalization
・内部共変量シフトが起きる
・手前の層の重みの更新のせいで、後ろの層の重みの更新が妨げられる
・データの分布が平均0で分散1になるよう正規化する
・新たな層として追加したり、層中の活性化関数の前で実行したりする計算量の増大 高速に並列処理ができるGPUを利用してニューラルネットワークを学習する EarlyStoppingmodel.fit(X, y, epochs = 100, validation_split = 0.1, callbacks = [EarlyStopping(min_delta = 0.0, patience = 1)]) # epochs:ある程度大きくして、EarlyStoppingで切り上げるより前に終わらないようにする # validation_split:入力した学習データのうち、学習データとバリデーションデータの割合を指定できる # callbacks:listで指定したコールバックが学習中に逐次呼び出されるDropoutmodel = Sequential() model.add(Dense(..)) model.add(Dropout(0.5)) model.add(Dense(..)) model.add(Dropout(0.5)) model.add(Dense(..)) model.add(Dropout(0.5)) model.add(Dense(.., activation = 'softmax') model.compile(..) # Dropoutのコンストラクタ引数はユニットを無視する割合BatchNormalizationmodel = Sequential() # 新たな層として追加 model.add(Dense(.., activation = 'relu')) model.add(BatchNormalization(0.5)) # 活性化関数の前に追加 model.add(Dense(..)) model.add(BatchNormalization(0.5)) model.add(Activation('relu') model.add(Dense(.., activation = 'softmax') model.compile(..)10.2 ニューラルネットワークの学習
勾配降下法
誤差関数を重みで微分することで傾きを求め、傾きの逆方向に重みの値を更新し、ニューラルネットワークの学習を進める。
大域最適解と局所最適解
- 大域最適解:求めたい最適解。取りうる重みの中で最も誤差が最小となる重み(最適解)
- 局所最適解:部分的に見れば最適解だが、最も適した解が他にも存在する
確率的勾配降下法とミニバッチ法
- 勾配降下法(バッチ法)
- 一度に全データを投入して全データの平均に対して重みを更新する
- 学習が進みづらい
- 局所最適解に陥りやすい
- 確率的勾配降下法(SGD)
- 一度に一個だけランダムに選んだ学習データを投入し、それに対して重みを更新する
- ノイズに対して弱く、重みの更新が悪い方向にブレると学習が安定しない
- ミニバッチ法
- バッチ法とSGDの中間
- 一度に数個だけランダムに選んだ学習データを投入し、それらのデータの平均に対して重みを更新する
10.3 ニューラルネットワークのチューニング
項目 内容 バッチサイズ ・学習時のバッチサイズで、Kerasのデフォルトは32
・2のべき乗が多いがこれはただの慣習だが、小さい値は密に大きい値は疎に探索することに意味があるOptimizer ・よく使われるのは後発のAdamだが、問題によってはシンプルなSGDが一番いい場合もある
・下の学習率とともにチューニングする学習率 ・一度に更新する重みの比率で、KerasのAdamのデフォルトは0.001 活性化関数 ・広く使われるのはReLU(Rectified Linear Unit)だが、改良版のやLeaky ReLUやSeLU(Scaled Exponential Unit)も検討の余地あり。
・Leaky ReLU:入力が0以下の場合、傾きが小さな線形関数で変換
・ELU:入力が0以下の場合、指数関数から1引いた値で変換正則化/荷重減衰 ・過学習を避けるために重みが大きくなりすぎないよう制約をかけ、下記のようなノルムを損失関数に加える
・l1ノルム:重みの各要素の絶対値の和
・l2ノルム:重みの各要素の2乗和
・l∞ノルム:重みの各要素の最大絶対値重みの初期化 ・Kerasのデフォルトは乱数で初期化される
・分布を指定することも可能活性化関数model = Sequential() model.add(Dense(.., activation = 'selu')) model.add(Dense(.., activation = LeakyReLU(0.3))) model.add(Dense(.., activation = 'softmax') model.compile(..)正則化model = Sequential() model.add(Dense(.., activation = 'relu', kernel_regularizer = regularizers.l2(0.1))) model.add(Dense(.., activation = 'softmax', kernel_regularizer = regularizers.l2(0.1))) model.compile(..)重みの初期化model = Sequential() model.add(Dense(.., activation = 'relu', kernel_initializer = initializers.glorot_normal())) model.add(Dense(.., activation = 'softmax', kernel_initializer = initializers.glorot_normal())) model.compile(..)glorot_normal():Glolotの正規分布のことで、Xavierの正規分布とも呼ばれる(こっちの方が聞いたことがあった)。
Xavierの初期値はsigmoid関数やtanh関数に適しているが、活性化関数にReLUを用いる場合はReLUに特化したHeの初期値の方が良さそう。
- 投稿日:2020-02-05T18:01:05+09:00
LinuxでAnacondaインストール中に固った場合
はじめに
CentOSにAnacondaをインストール中にトラブったのでメモ
環境
- CentOS 7
- Anaconda 2019.10-Linux-x86_64.
現象
Anaconda3-2019.10-Linux-x86_64.shでインストール中に以下のUnpacking payloadのところで固まった状態になった。
Anaconda3 will now be installed into this location: /home/kimisyo/anaconda3 - Press ENTER to confirm the location - Press CTRL-C to abort the installation - Or specify a different location below [/home/kimisyo/anaconda3] >>> PREFIX=/home/kimisyo/anaconda3 Unpacking payload ...対応
シングルコアの場合に発生するらしい。仮想環境の場合は仮想マシンのCPUのコア数を2以上にするとうまくいった。
参考
- 投稿日:2020-02-05T18:01:05+09:00
LinuxでAnacondaインストール中に固まった場合
はじめに
CentOSにAnacondaをインストール中にトラブったのでメモ
環境
- CentOS 7
- Anaconda 2019.10-Linux-x86_64.
現象
Anaconda3-2019.10-Linux-x86_64.shでインストール中に以下のUnpacking payloadのところで固まった状態になった。
Anaconda3 will now be installed into this location: /home/kimisyo/anaconda3 - Press ENTER to confirm the location - Press CTRL-C to abort the installation - Or specify a different location below [/home/kimisyo/anaconda3] >>> PREFIX=/home/kimisyo/anaconda3 Unpacking payload ...対応
シングルコアの場合に発生するらしい。仮想環境の場合は仮想マシンのCPUのコア数を2以上にするとうまくいった。
参考
- 投稿日:2020-02-05T18:01:05+09:00
LinuxでAnacondaインストール中に固まった場合の対処
はじめに
CentOSにAnacondaをインストール中にトラブったのでメモ
環境
- CentOS 7
- Anaconda 2019.10-Linux-x86_64.
現象
Anaconda3-2019.10-Linux-x86_64.shでインストール中に以下のUnpacking payloadのところで固まった状態になった。
Anaconda3 will now be installed into this location: /home/kimisyo/anaconda3 - Press ENTER to confirm the location - Press CTRL-C to abort the installation - Or specify a different location below [/home/kimisyo/anaconda3] >>> PREFIX=/home/kimisyo/anaconda3 Unpacking payload ...対応
シングルコアの場合に発生するらしい。仮想環境の場合は仮想マシンのCPUのコア数を2以上にするとうまくいった。
参考
- 投稿日:2020-02-05T17:51:02+09:00
CentOS7 + Python3 + netmikoでCisco Catalystにssh接続してローカルにコンフィグを保存する
概要
Ciscoのスイッチ(Catalyst2960など)にsshアクセスしコンフィグを自動で取得するプログラムを書く必要が生じ情報収集すると、どうもnetmikoというpythonライブラリで実現できそうなので環境構築しプログラムを作成してみました。
なおCentOS7にデフォルトのリポジトリでyumインストールできるpythonのヴァージョンは2系でそのままではnetmikoが動作しないため、python3をインストールする手順も記載します。
インポート
IUSリポジトリを追加します。
# yum install -y https://centos7.iuscommunity.org/ius-release.rpm確認
以下コマンドを実行しインストール可能なマイナーヴァージョンを確認します。
# yum search python3インストール
現時点で最新のpython3.6(本体+ライブラリ、開発、パッケージ管理等)をインストールします。
# yum install -y python36u python36u-libs python36u-devel python36u-pip # python -V Python 3.6.8 # pip -V pip 9.0.3 from /usr/lib/python3.6/site-packages (python 3.6)netmikoのインストール
netmikoライブラリをインストールします。
# pip install netmikoサンプルプログラム
サンプルプログラムとしてIPアドレスとパスワードをカンマ区切りで記載したcsvファイルを読み込み
running-configを指定ディレクトリに保存するpythonコードを記載します。devices.csv192.168.1.254,password1234 172.16.1.254,password5678backup.py#!/usr/bin/env python from netmiko import ConnectHandler import csv import datetime # コンフィグのバックアップファイルに日付を含ませるための日付取得処理 now = datetime.datetime.now() today = now.strftime('%Y%m%d') with open('devices.csv') as f: reader = csv.reader(f) # csvファイルを1行読み込んでIPアドレスとパスワードを取得し処理を回す for row in reader: cisco_ios = { 'device_type': 'cisco_ios', # sshの場合左記を指定 'ip': row[0], # csvファイルの1カラム目 'username': 'user_name', # 実際のユーザー名 'password': row[1], # csvファイルの2カラム目 'port' : 22, # ポート番号 'secret': row[1], # enable secretのパスワード 'verbose': False, } net_connect = ConnectHandler(**cisco_ios) # 特権モードに移行 net_connect.enable() # write memoryコマンドでrunning configをstartup configに保存 net_connect.send_command('wr') # running-configの取得 output = net_connect.send_command('show running-config') # ホスト名の取得 prompt = net_connect.find_prompt() hostname = prompt[:-1] # 先頭の不要行を除外 list = output.split('\n') list = list[3:] config = '\n'.join(list) # ファイル名の作成 file = 'store/' + hostname + '-' + today + '.txt' # ファイルをstoreディレクトリに保存 with open(file, 'w') as backup: backup.write(config) print(hostname + ' : ' + 'succeeded') net_connect.disconnect()またコンフィグファイルの保存先ディレクトリを作成しておきます。
# mkdir storepyファイルとcsvファイル、storeディレクトリを同じディレクトリに設置しpyファイルを実行するとstoreディレクトリに「ホスト名-年月日.txt」の形式でrunning configが保存されます。
# ls backup.py devices.csv store # python backup.py switch1 : succeeded switch2 : succeeded # ls store/ switch1-20200205.txt switch2-20200205.txt
- 投稿日:2020-02-05T17:32:16+09:00
これだけ知っていればPythonのテストコードが書ける! 〜超入門編〜
この記事を読んだらどうなれるか
この記事を読み終わった後に、読者が以下の三つを達成できるような記事になっています。
1.ソースコードをテストすることの意義を理解する
2.Pythonのテストコードをどのように書くのか、雰囲気をつかむ
3.Pythonによるテストコードの書かれたファイルを単一で実行できる実行環境
OS: macOS Mojava 10.14.6
Pythonバージョン: 3.7.1テストコードを書く意義
テストはソースコードの品質を保証するために書きます。
バグのない完璧なソースコードを書きました〜と言われて渡されたソースコードを信用できるでしょうか。
全くミスしない人がいるとしたら、信用してもいいのかもしれません。しかし、人は往々にしてミスするものです。テストがある程度書かれていれば、ソースコードの品質を信用することができます。
また、テストがあれば、ソースコードが正しく作られているかを判断する基準として利用することもできます。それではPythonでテストを書いていきましょう!
最大公約数を算出するメソッドのテストを書く
1. テストするメソッドの仕様
テストする対象として、最大公約数を算出するメソッドを考えます。
最大公約数を英語で言うとGreatest Common Divisorです。頭文字をとってファイル名をgcd.pyとしましょう。gcd.pydef gcd(a, b): # なんかしてa,bの最大公約数を算出 return # 戻り値は最大公約数gcd()の引数a,bは整数が入力されることを想定するものとし、戻り値としてa,bの最大公約数を返します。
テストする関数の仕様が固まったところで、テストコードを書いていきましょう。
2. テストコードを書くために
importするのはこれ!今回、Pythonでテストコードを記述するために使用するのは、
unittestと呼ばれるモジュールです。
標準搭載のため、インストールする必要はありません。
早速importしてみましょう。test_gcd.pyimport unittest from gcd import gcdテスト対象であるgcd()をテストするために
gcd.pyの関数gcdもインポートしておきましょう。
これでテストコードを書く準備が整いました。3. テストケースを作成しよう
次にテストケースを作成していきます。
テストケースというのは、あるモジュールや、あるクラスに備わっている機能が正しく動作することを確認するために入力と、入力から想定される出力を一つ以上定義したものです。
まずはテストケースを内包するクラスを作成します。
test_gcd.pyimport unittest from gcd import gcd class GCDTest(unittest.TestCase): passテストケースはunittestモジュールのTestCaseクラスを継承して宣言します。
unittest.TestCaseを継承することによって、テストケースを作成する上で必要なメソッド類を利用できるようになります。クラス名(テストケース名)は、最大公約数をテストするものなので、GCDTestにしてみました。
4. テストを書いてみる
それでは最大公約数を算出するメソッドのテストを書いてみましょう。
test_gcd.pyimport unittest from gcd import gcd class GCDTest(unittest.TestCase): def test_gcd(self): self.assertEqual(15, gcd(30, 15)) pass
test_gcdと呼ばれるメソッドを実装しました。今回は二つの整数の最大公約数を算出するメソッドを実装したいのですから、a = 30, b = 15が入力されたのであれば、戻り値は15にならなければなりません。
これをチェックしているのが、
self.assertEqual(15, gcd(30, 15))です。
gcd(30, 15)の結果が15であることを確認しています。assertという英語は、「断言する」というような意味を持つ単語であることを踏まえると、理解が容易になります。
self.assertEqual(15, gcd(30, 15))は、「gcd(30,15)の結果は15と等しくなる」ということを断言しているのです。わかりやすいですね。5. テストを実行してみよう
テストの実行には以下のコマンドを利用します。
python -m unittest `作成したモジュール名`今回作成したモジュールは、
test_gcd.pyです。
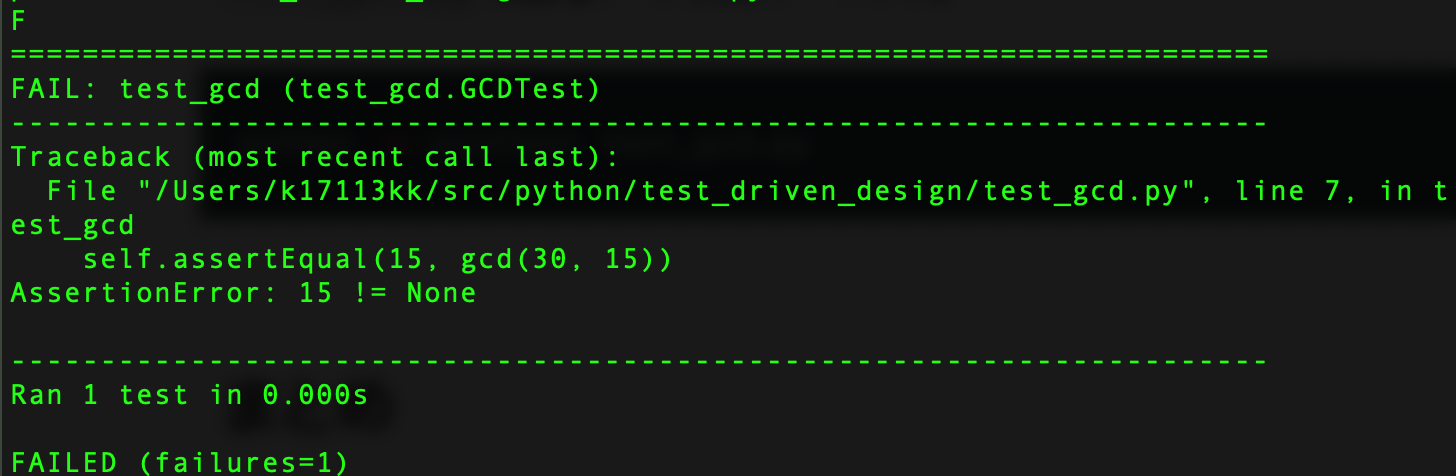
test_gcd.pyを指定して、実行してみます。python -m unittest test_gcd.py実行結果
失敗していますが、実装していないので当然ですね。
どこでテストが失敗したのか、実行されたテストの個数、実行時間などが示されます。gcdメソッドを実装してもう一度実行してみましょう。
gcd.pydef gcd(a, b): return b if a%b == 0 else gcd(b, a%b)実装についてはユークリッドの互除法というのを使っています。ユークリッドの互除法は、最大公約数を高速に求められるアルゴリズムです。
ここでは触れませんので、気になる人は調べてみてください。それでは、実装できたところで、
python -m unittest test_gcd.pyを実行!
テストが通過したため、OKと表示されました。やったね。
テストを書く上で注意すること
今回書いたテストは、
self.assertEqual(15, gcd(30, 15))だけでした。
これは、テストケースとして十分でしょうか。答えは否です。一つだけのチェックで対象のメソッドが正しく実装できているとは言えません。
なぜなら、今回のチェック項目だけでは以下のような実装でもテストケースを通過してしまうからです。gcd.pydef gcd(a, b): return 15これではどんな入力だったとしても最大公約数は15であるということになってしまいます。
ケーステストを書く際には、入力と出力のパターンにどのようなものがあるのかを考え、網羅するように心がけましょう。
まとめ
・テストはソースコードの品質を保証するために記述する
・Pythonのテストを作成するのにはunittestモジュールを使用する
・テストケースを作成するときは、unittest.TestCaseを継承する。
・テストケースとは、入力と、入力から想定される出力のあつまり
・python -m unittestモジュール名で該当ファイルのテストケースを実行できる
・テストケースは入力と出力のパターンにどのようなものがあるのかを考え、十分に網羅するようにする次の記事
本記事の内容は、とにかく雰囲気を掴む、という観点で書きました。
そのため、細かいお作法などについて触れられていません。これについては、次の記事で補足していく予定です。
Coming Soon!

- 投稿日:2020-02-05T17:29:23+09:00
Pythonでスクリプトのパスを得る
Pythonでスクリプトのパスを得る方法。
get-script-path.pyimport os, json, datetime # スクリプトのパス BASE_DIR = os.path.dirname(__file__) # データファイルの指定 DATA_FILE = BASE_DIR + '/data.txt'
- 投稿日:2020-02-05T17:28:40+09:00
スクラッチからのディープラーニング(フォワードプロパゲーション編)
はじめに
DeepLearningを学び出してから2週間ほど経ちました。そろそろ学んだことが頭から零れ落ちる音がしてきたので、整理がてらにアウトプットしたいと思います。今回から複数回に渡ってDNNを構築していきます。今回はフォワードプロパゲーション編です。
作成するDNNについて
画像が猫である(1)かそれ以外である(0)かを判定するネットワークを構築します。
使用するデータ
209枚の画像をトレーニングデータとし、50枚の画像をテストデータとして使用します。それぞれの画像のサイズは64 * 64です。
Number of training examples : 209 Number of testing examples : 50 Each image is of size : 64 * 64また、正解データと不正解データの割合は以下のようになっています。
Number of cat-images of training data : 72 / 209 Number of cat-images of test data : 33 / 50構築するDNN
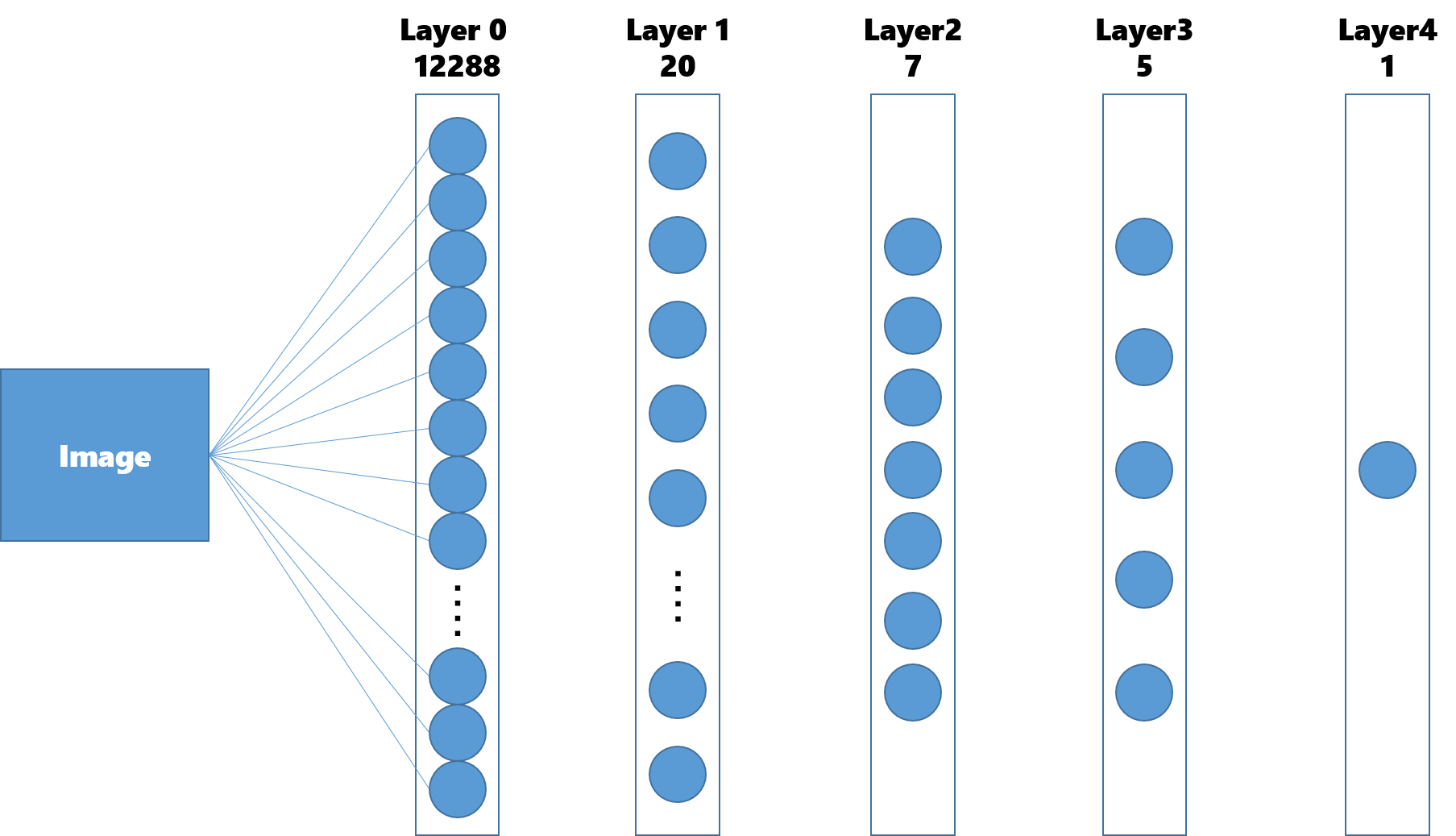
レイヤ数
12288(64 * 64)の入力ノードと一つの出力ノードを持つ4層のネットワークを構築します。それぞれのノードを線で結ぶつもりだったのですがパワポで作るのは過酷だったのであきらめました。
Dimention of each layer : [12288, 20, 7, 5, 1]活性化関数
今回は中間層にReLU関数を使い、出力層にsigmoid関数を使用します。
Relu関数
Relu関数は入力値が0以下であれば0を、それ以外であれば入力値をそのまま出力する関数です。以下のように書けます。
y = np.maximum(0, x)
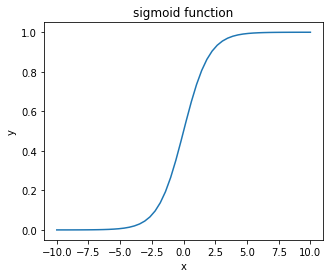
sigmoid関数
sigmoid関数は入力値を1から0の値に変換して出力する関数です。以下のように書けます。式で表すと次のようになります。
$$ y = \frac{1}{1+e^{-z}} $$
Pythonで書くと以下のようになります。y = 1 / (1 + np.exp(-x))
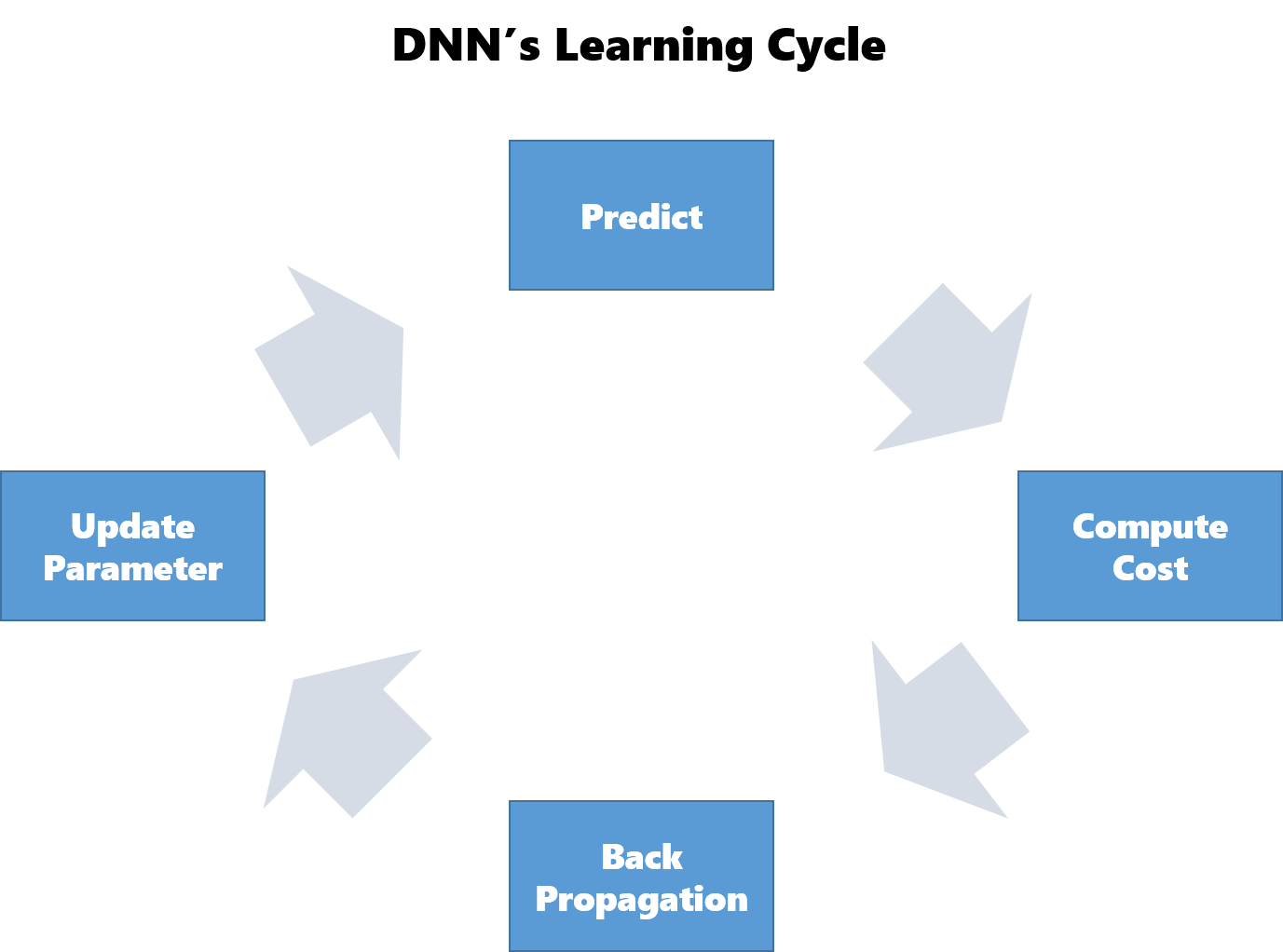
学習の全体像
DNNの全体設計がわかったところで、DNNの学習について復習しておきます。
DNNでは以下の手順で学習を行います。2から5を繰り返し実行することで徐々にパラメータを最適化させていきます。
- パラメータの初期化
- 予測(Forward Propagation)
- 誤差を計算
- 誤差の逆伝播(Back Propagation)
- パラメータの更新
- 2に戻る
パラメータの初期化
今回は全てのレイヤでXivierの初期値を使って初期化しました。relu関数を使う場合にはHeの初期化を使うべきだそうですが、この辺の違いは正直まだよくわかっていないです。
Xivierの初期化
Xivierの初期化は、初期パラメータを平均$0$、標準偏差$\frac{1}{\sqrt{n}}$の正規分布からランダムに取り出します。標準正規分布から取り出す場合と比べ、狭い範囲から取り出すことで各層のアクティベーションが0と1付近に偏ることを防ぎ、勾配消失を起こりにくくします。詳細は「ゼロから作るDeepLearning」の182ページを参照してください。
4層あるので4層分のパラメータを初期化する必要があります。各層のレイヤ数をベクトル化したものを引数としてパラメータを返す関数を作成します。def initialize_parameters(layers_dims): np.random.seed(1) parameters = {} L = len(layers_dims) for l in range(1, L): parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1]) / np.sqrt(layers_dims[l-1]) parameters['b' + str(l)] = np.zeros((layers_dims[l], 1)) return parameters予測(Forward Propagation)
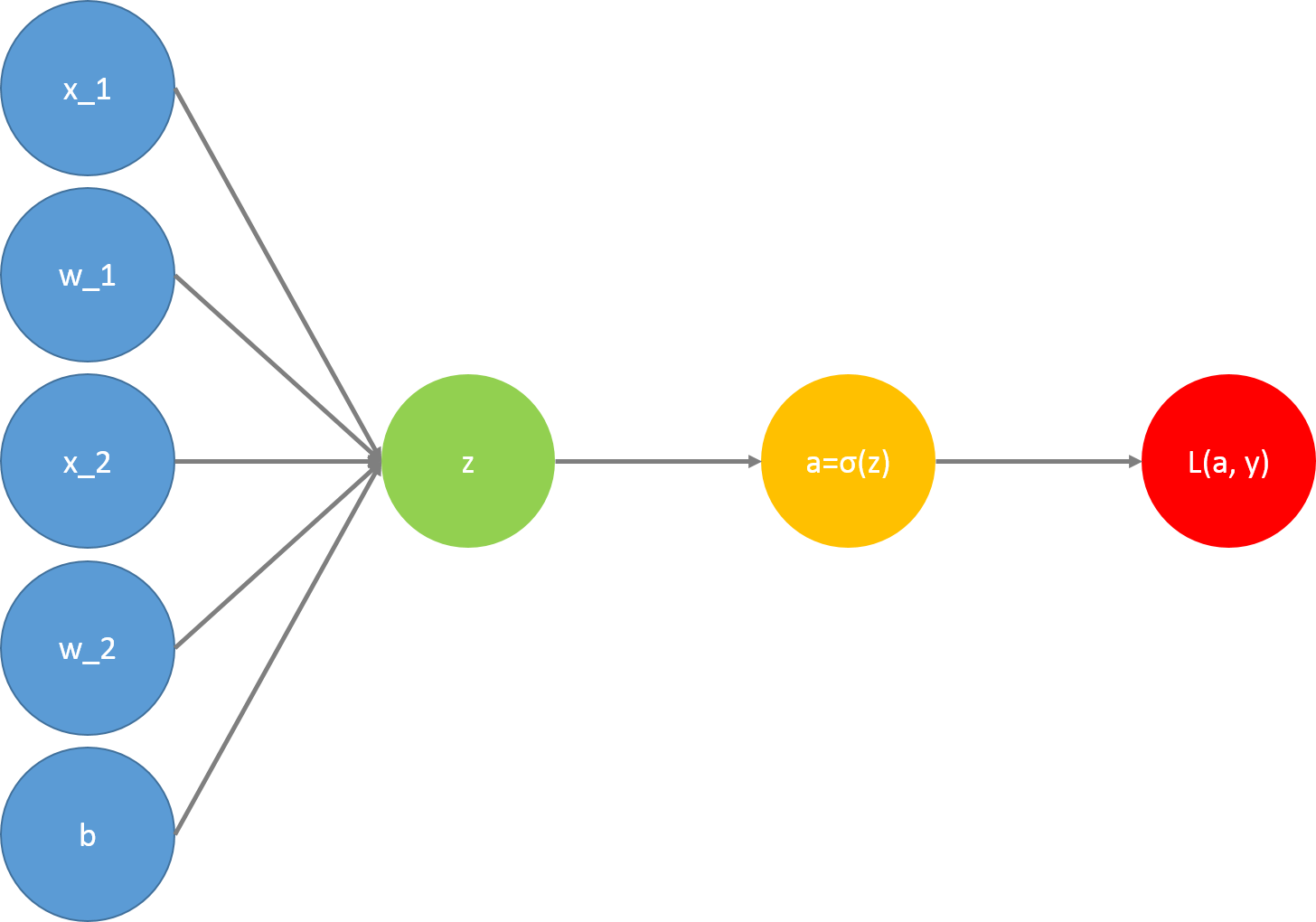
用意したパラメータを使って正解ラベルの予測を行います。全てのレイヤに対して以下の作業を行います。別の投稿で使用した図を流用しているのでコスト関数$L(a, y)$まで描画していますが、Forwad Propagationでは意識しなくてもよいので無視してください。
これを行うのに必要な関数は以下です。たまに出てくるcache、cachesはバックプロパゲーションの実装時に使用する変数です。
- 入力値XとパラメータWの内積+バイアス項を計算する関数
- activation関数(sigmoid(), relu())
- 1と2をまとめた関数
- 3をレイヤ数回繰り返す関数
入力値XとパラメータWの内積+バイアス項を計算する関数
def linear_forward(A, W, b): Z = np.dot(W, A) + b cache = (A, W, b) return Z, cacheactivation関数
def sigmoid(Z): A = 1 / (1+np.exp(-Z)) cache = Z return A, cache def relu(Z): A = np.maximum(0, Z) cache = Z return A, cache1と2をまとめた関数
def linear_activation_forward(A_prev, W, b, activation): if activation == 'relu': Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = relu(Z) elif activation == 'sigmoid': Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = sigmoid(Z) cache = (linear_cache, activation_cache) return A, cache3をレイヤ数繰り返す関数
def L_model_forward(X, parameters): caches = [] A = X L = len(parameters) // 2 for l in range(1, L): A_prev = A A, cache = linear_activation_forward(A_prev, parameters['W'+str(l)], parameters['b'+str(l)], activation='relu') caches.append(cache) AL, cache = linear_activation_forward(A, parameters['W'+str(L)], parameters['b'+str(L)], activation = 'sigmoid') caches.append(cache) return AL, cachesL_model_forwardを実行することで初期パラメータでの予測が行えます。
まとめ
今回はフォワードプロパゲーションまでの実装を行いました。次回はコストの計算を行いたいと思います。

- 投稿日:2020-02-05T17:28:40+09:00
ゼロからのディープラーニング(フォワードプロパゲーション編)
はじめに
DeepLearningを学び出してから2週間ほど経ちました。そろそろ学んだことが頭から零れ落ちる音がしてきたので、整理がてらにアウトプットしたいと思います。今回から複数回に渡ってDNNを構築していきます。今回はフォワードプロパゲーション編です。
作成するDNNについて
画像が猫である(1)かそれ以外である(0)かを判定するネットワークを構築します。
使用するデータ
209枚の画像をトレーニングデータとし、50枚の画像をテストデータとして使用します。それぞれの画像のサイズは64 * 64です。
Number of training examples : 209 Number of testing examples : 50 Each image is of size : 64 * 64また、正解データと不正解データの割合は以下のようになっています。
Number of cat-images of training data : 72 / 209 Number of cat-images of test data : 33 / 50構築するDNN
レイヤ数
12288(64 * 64)の入力ノードと一つの出力ノードを持つ4層のネットワークを構築します。それぞれのノードを線で結ぶつもりだったのですがパワポで作るのは過酷だったのであきらめました。
Dimention of each layer : [12288, 20, 7, 5, 1]活性化関数
今回は中間層にReLU関数を使い、出力層にsigmoid関数を使用します。
Relu関数
Relu関数は入力値が0以下であれば0を、それ以外であれば入力値をそのまま出力する関数です。以下のように書けます。
y = np.maximum(0, x)
sigmoid関数
sigmoid関数は入力値を1から0の値に変換して出力する関数です。以下のように書けます。式で表すと次のようになります。
$$ y = \frac{1}{1+e^{-z}} $$
Pythonで書くと以下のようになります。y = 1 / (1 + np.exp(-x))
学習の全体像
DNNの全体設計がわかったところで、DNNの学習について復習しておきます。
DNNでは以下の手順で学習を行います。2から5を繰り返し実行することで徐々にパラメータを最適化させていきます。
- パラメータの初期化
- 予測(Forward Propagation)
- 誤差を計算
- 誤差の逆伝播(Back Propagation)
- パラメータの更新
- 2に戻る
パラメータの初期化
今回は全てのレイヤでXivierの初期値を使って初期化しました。relu関数を使う場合にはHeの初期化を使うべきだそうですが、この辺の違いは正直まだよくわかっていないです。
Xivierの初期化
Xivierの初期化は、初期パラメータを平均$0$、標準偏差$\frac{1}{\sqrt{n}}$の正規分布からランダムに取り出します。標準正規分布から取り出す場合と比べ、狭い範囲から取り出すことで各層のアクティベーションが0と1付近に偏ることを防ぎ、勾配消失を起こりにくくします。詳細は「ゼロから作るDeepLearning」の182ページを参照してください。
4層あるので4層分のパラメータを初期化する必要があります。各層のレイヤ数をベクトル化したものを引数としてパラメータを返す関数を作成します。def initialize_parameters(layers_dims): np.random.seed(1) parameters = {} L = len(layers_dims) for l in range(1, L): parameters['W' + str(l)] = np.random.randn(layers_dims[l], layers_dims[l-1]) / np.sqrt(layers_dims[l-1]) parameters['b' + str(l)] = np.zeros((layers_dims[l], 1)) return parameters予測(Forward Propagation)
用意したパラメータを使って正解ラベルの予測を行います。全てのレイヤに対して以下の作業を行います。別の投稿で使用した図を流用しているのでコスト関数$L(a, y)$まで描画していますが、Forwad Propagationでは意識しなくてもよいので無視してください。
これを行うのに必要な関数は以下です。たまに出てくるcache、cachesはバックプロパゲーションの実装時に使用する変数です。
- 入力値XとパラメータWの内積+バイアス項を計算する関数
- activation関数(sigmoid(), relu())
- 1と2をまとめた関数
- 3をレイヤ数回繰り返す関数
入力値XとパラメータWの内積+バイアス項を計算する関数
def linear_forward(A, W, b): Z = np.dot(W, A) + b cache = (A, W, b) return Z, cacheactivation関数
def sigmoid(Z): A = 1 / (1+np.exp(-Z)) cache = Z return A, cache def relu(Z): A = np.maximum(0, Z) cache = Z return A, cache1と2をまとめた関数
def linear_activation_forward(A_prev, W, b, activation): if activation == 'relu': Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = relu(Z) elif activation == 'sigmoid': Z, linear_cache = linear_forward(A_prev, W, b) A, activation_cache = sigmoid(Z) cache = (linear_cache, activation_cache) return A, cache3をレイヤ数繰り返す関数
def L_model_forward(X, parameters): caches = [] A = X L = len(parameters) // 2 for l in range(1, L): A_prev = A A, cache = linear_activation_forward(A_prev, parameters['W'+str(l)], parameters['b'+str(l)], activation='relu') caches.append(cache) AL, cache = linear_activation_forward(A, parameters['W'+str(L)], parameters['b'+str(L)], activation = 'sigmoid') caches.append(cache) return AL, cachesL_model_forwardを実行することで初期パラメータでの予測が行えます。
まとめ
今回はフォワードプロパゲーションまでの実装を行いました。次回はコストの計算を行いたいと思います。
- 投稿日:2020-02-05T16:32:06+09:00
動的計画法とナップサック問題の基礎をアニメーションで
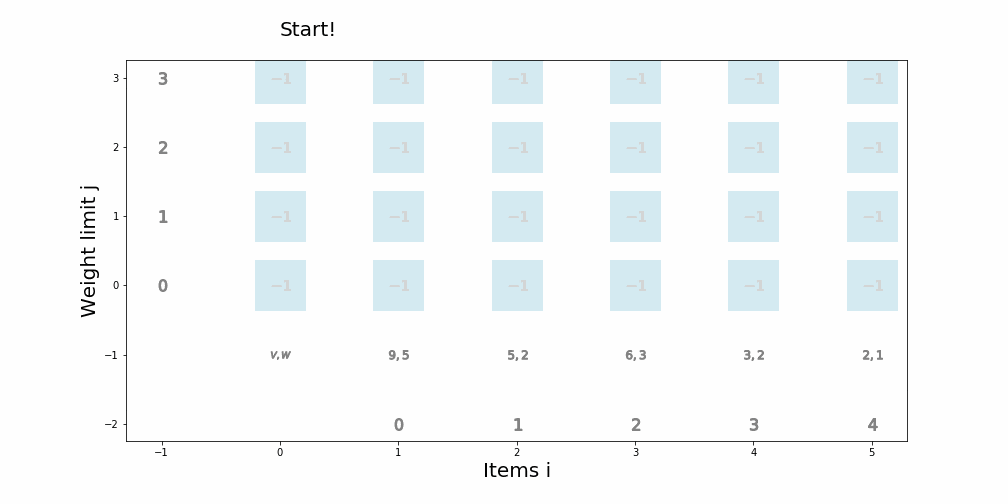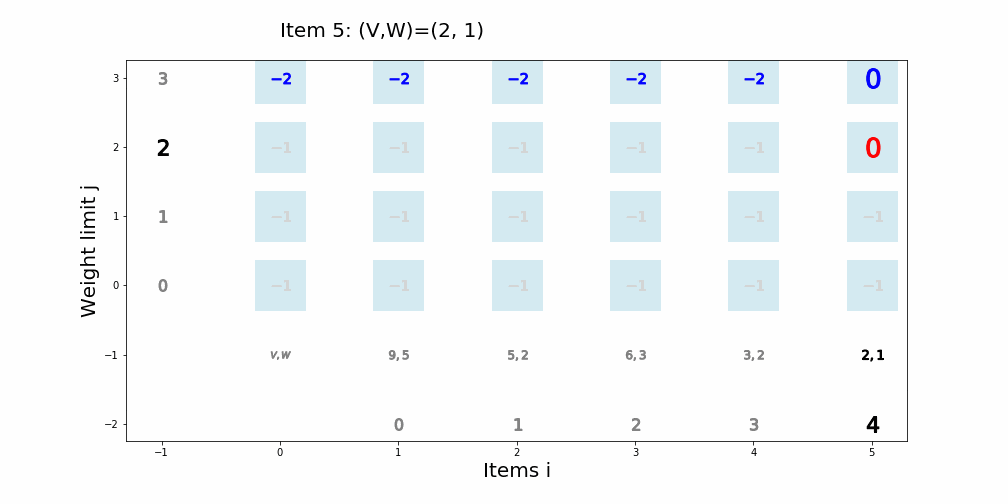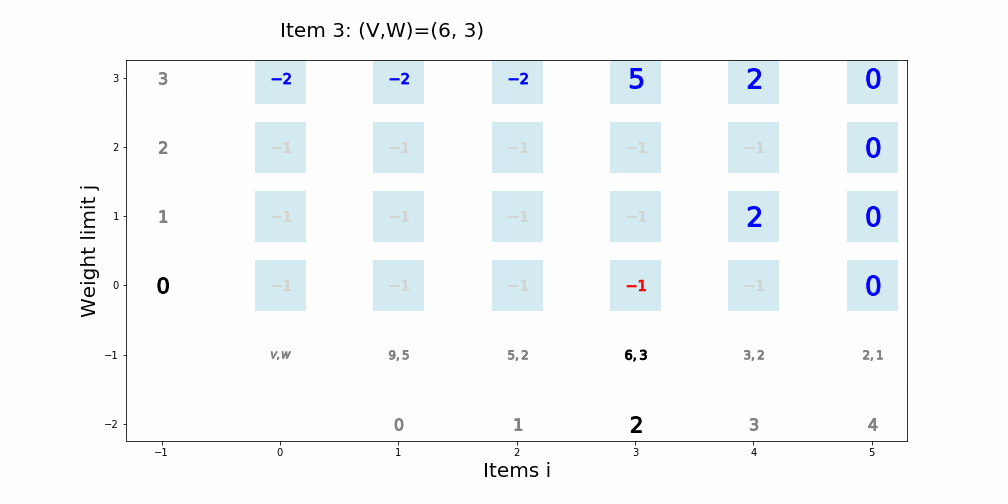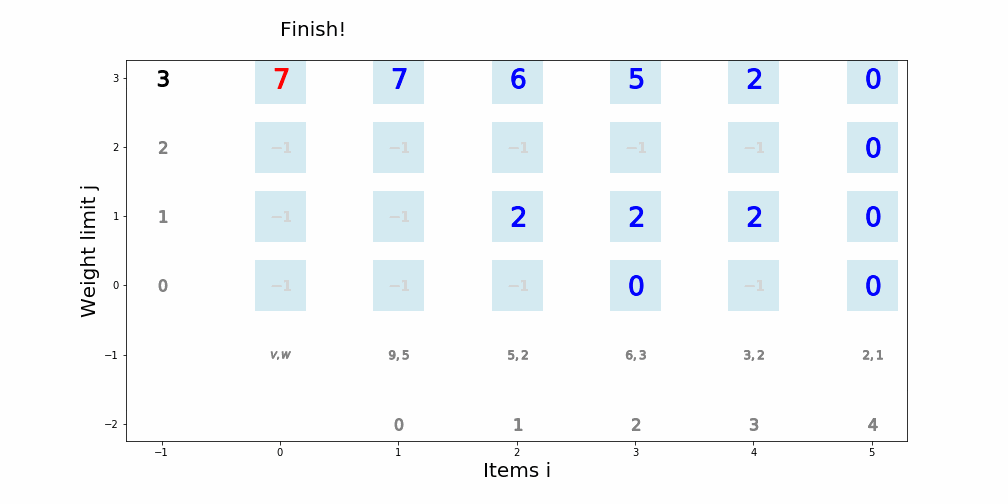
個数制限なしナップサック問題
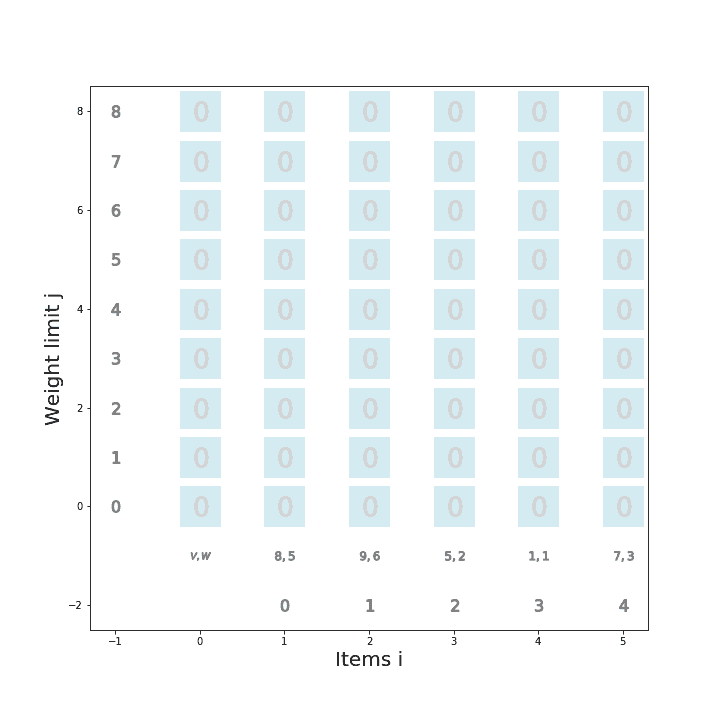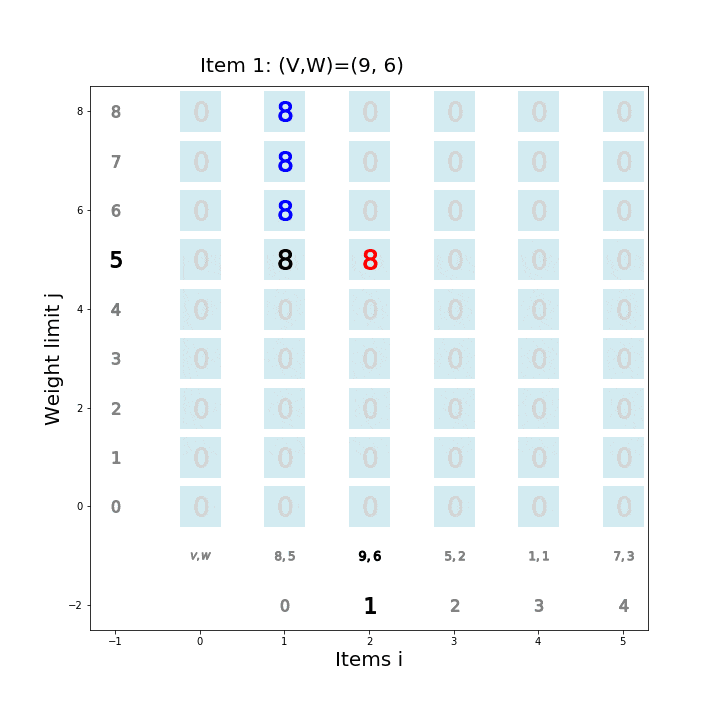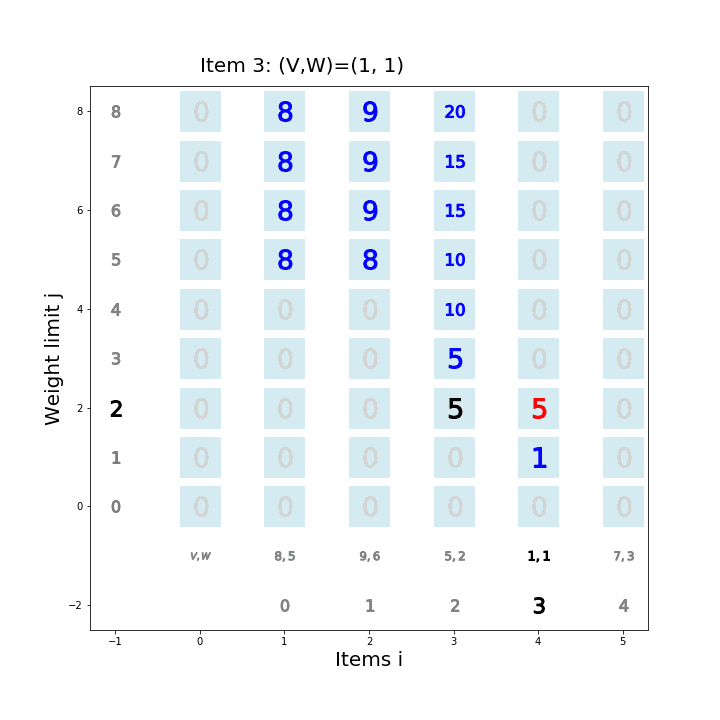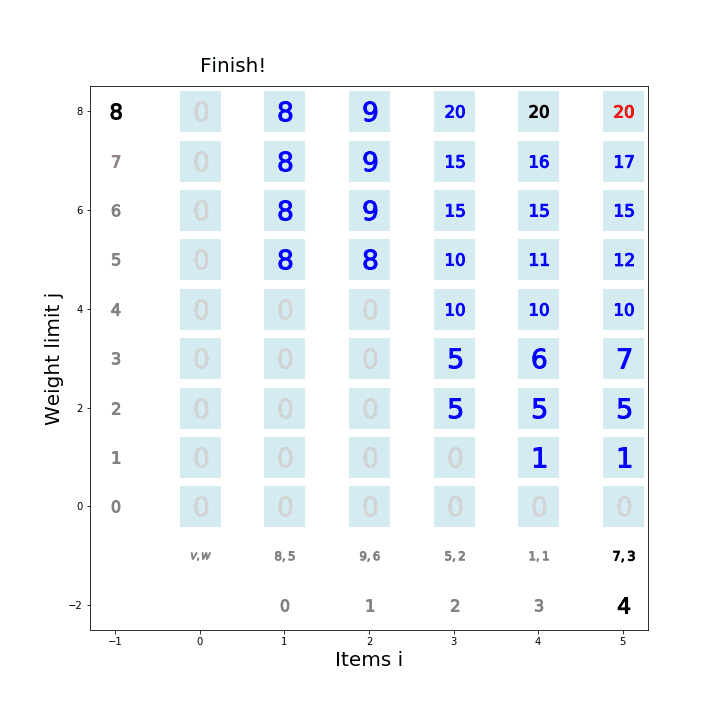
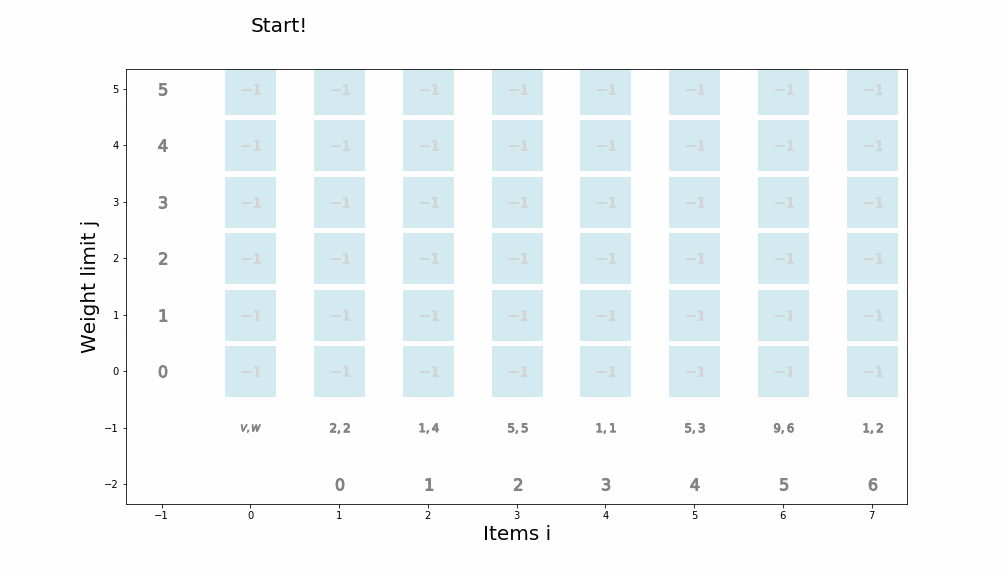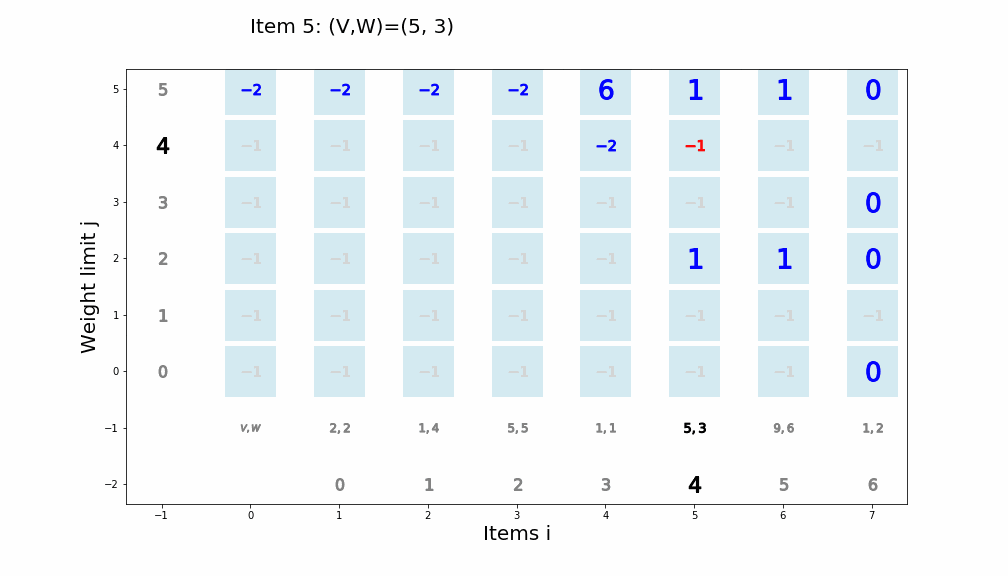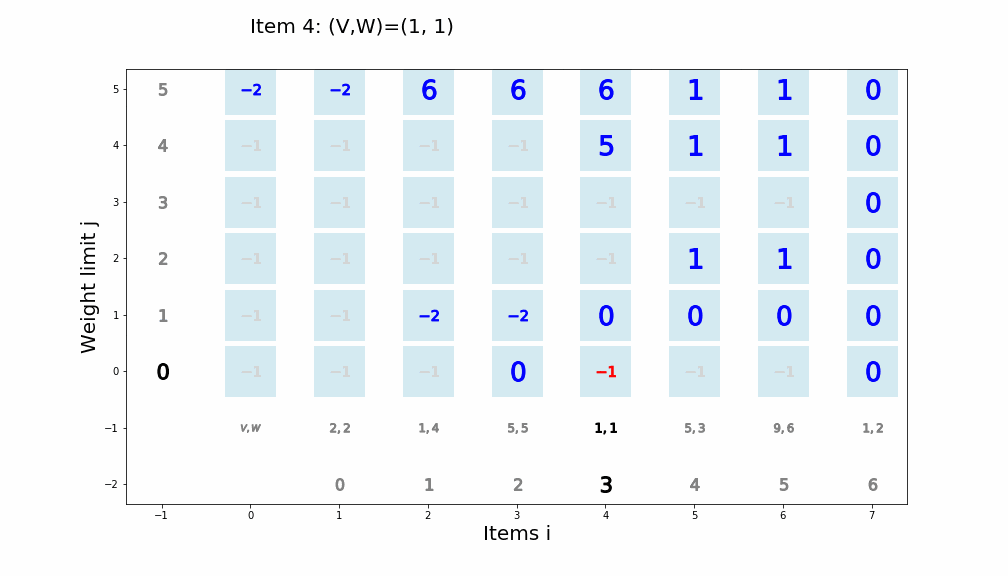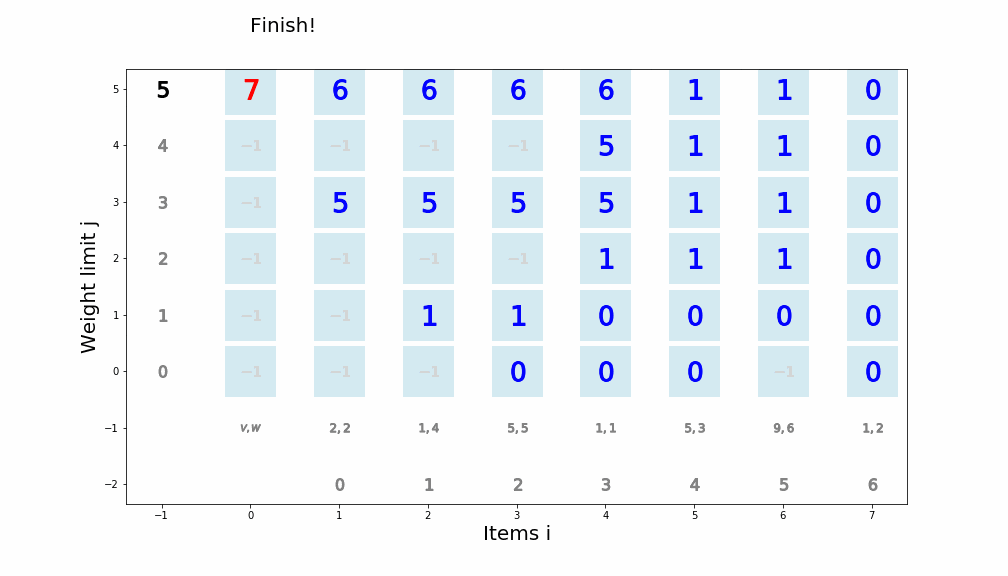
個数制限なしナップサック問題を動的計画法で解くアルゴリズム
def knapsack02(x, W, V): for i in range(len(W)): for j in range(x + 1): if j < W[i]: dp_table[i + 1][j] = dp_table[i][j] else: dp_table[i + 1][j] = max(dp_table[i][j], dp_table[i + 1][j - W[i]] + V[i]) movie.append(draw02(dp_table, i, j)) return dp_table[len(W)][x]アニメーション描画
def draw02(dp_table, i, j): image = [] if i == 0 and j == 0: im_text = plt.text(0, weight_limit * 1.1, "Start!", size=20) image.append(im_text) elif i == len(V) - 1 and j == weight_limit: im_text = plt.text(0, weight_limit * 1.1, "Finish!", size=20) image.append(im_text) elif i >= 0: im_text = plt.text(0, weight_limit * 1.1, "Item " + str(i) + ": (V,W)=(" + str(V[i]) + ", " + str(W[i]) + ")" , size=20) image.append(im_text) for w in range(weight_limit + 1): if j == w: w_lmt = plt.plot(-1, w, markersize=16, marker="$" + str(w) + "$", c="black") else: w_lmt = plt.plot(-1, w, markersize=12, marker="$" + str(w) + "$", c="gray") image += w_lmt for v in range(len(V) + 1): if v < len(V): if i == v: item_vw = plt.plot(v + 1, -1, markersize=22, marker="$" + str(V[v]) + "," + str(W[v]) + "$", c="black") image += item_vw item_id = plt.plot(v + 1, -2, markersize=16, marker="$" + str(v) + "$", c="black") image += item_id else: item_vw = plt.plot(v + 1, -1, markersize=20, marker="$" + str(V[v]) + "," + str(W[v]) + "$", c="gray") image += item_vw item_id = plt.plot(v + 1, -2, markersize=12, marker="$" + str(v) + "$", c="gray") image += item_id else: vw = plt.plot(0, -1, markersize=20, marker="$V,W$", c="gray") image += vw for w in range(weight_limit + 1): if v == i and w == j: color="black" elif v == i + 1 and w == j: color="red" elif dp_table[v][w] == 0: color="lightgray" else: color="blue" square = plt.plot(v, w, markersize=40, marker="s", c="lightblue", alpha=0.5) image += square numeral = plt.plot(v, w, markersize=20, marker="$" + str(dp_table[v][w]) + "$", c=color) image += numeral image.append(plt.ylabel("Weight limit j", size=20)) image.append(plt.xlabel("Items i", size=20)) return image実行例1
import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML movie = [] weight_limit = 9 W = [5, 2, 1] V = [9, 5, 2] n = len(W) fig = plt.figure(figsize=(10, 10)) dp_table = [[0 for _ in range(weight_limit + 1)] for _ in range(len(W) + 1)] movie.append(draw02(dp_table, -1, -1)) knapsack02(weight_limit, W, V) ani = animation.ArtistAnimation(fig, movie, interval=1000, repeat_delay=1000) ani.save("knapsack02-1.gif", writer='pillow') HTML(ani.to_jshtml())
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。実行例2
import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML movie = [] weight_limit = 8 W = [5, 6, 2, 1, 3] V = [8, 9, 5, 1, 7] n = len(W) fig = plt.figure(figsize=(10, 10)) dp_table = [[0 for _ in range(weight_limit + 1)] for _ in range(len(W) + 1)] movie.append(draw02(dp_table, -1, -1)) knapsack02(weight_limit, W, V) ani = animation.ArtistAnimation(fig, movie, interval=1000, repeat_delay=1000) ani.save("knapsack02-2.gif", writer='pillow') HTML(ani.to_jshtml())
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。文字列マッチング
def stringmatch(s, t): movie.append(draw_s(dp_table, -1, -1)) for i in range(len(s)): for j in range(len(t)): if s[i] == t[j]: dp_table[i + 1][j + 1] = dp_table[i][j] + 1 else: dp_table[i + 1][j + 1] = max(dp_table[i][j + 1], dp_table[i + 1][j]) movie.append(draw_s(dp_table, i, j)) return dp_table[len(s)][len(t)]アニメーション描画
def draw_s(dp_table, i, j): image = [] for w in range(len(t)): if j == w: w_lmt = plt.plot(-1, w + 1, markersize=16, marker="$" + t[w] + "$", c="black") else: w_lmt = plt.plot(-1, w + 1, markersize=12, marker="$" + t[w] + "$", c="gray") image += w_lmt for v in range(len(s) + 1): if v < len(s): if i == v: item_vw = plt.plot(v + 1, -1, markersize=22, marker="$" + s[v] + "$", c="black") image += item_vw else: item_vw = plt.plot(v + 1, -1, markersize=20, marker="$" + s[v] + "$", c="gray") image += item_vw for w in range(len(t) + 1): if v >= 1 and w >= 1 and s[v - 1] == t[w - 1]: color = "orange" else: color = "lightblue" square = plt.plot(v, w, markersize=40, marker="s", c=color, alpha=0.5) image += square if v == i and w == j: color="black" elif v == i and w == j + 1: color="black" elif v == i + 1 and w == j: color="black" elif v == i + 1 and w == j + 1: color="red" elif dp_table[v][w] == 0: color="lightgray" else: color="blue" numeral = plt.plot(v, w, markersize=20, marker="$" + str(dp_table[v][w]) + "$", c=color) image += numeral return image実行例1
s = "PENCILS" t = "PENGUINS" fig = plt.figure(figsize=(10, 10)) movie = [] dp_table = [[0 for _ in range(len(t) + 1)] for _ in range(len(s) + 1)] stringmatch(s, t) ani = animation.ArtistAnimation(fig, movie, interval=500, repeat_delay=1000) ani.save("knapsack_s-1.gif", writer='pillow') HTML(ani.to_jshtml())
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。0-1ナップサック問題
def knapsack01(i, j): movie.append(draw01(dp_table, i, j)) if dp_table[i][j] >= 0: return dp_table[i][j] if j == 0: ret = 0 elif i == n: ret = 0 else: dp_table[i ][j] = -2 if W[i] > j: ret = knapsack01(i + 1, j) else: ret = max(knapsack01(i + 1, j), knapsack01(i + 1, j - W[i]) + V[i]) dp_table[i][j] = ret movie.append(draw01(dp_table, i, j)) return retアニメーション描画
def draw01(dp_table, i, j): image = [] if i > 0: if W[i - 1] <= j: arrow = " <= " else: arrow = " > " im_text = plt.text(0, weight_limit * 1.2, "Item " + str(i) + ": (V,W)=(" + str(V[i - 1]) + ", " + str(W[i - 1]) + ")" , size=20) image.append(im_text) else: if dp_table[i][j] == -1: im_text = plt.text(0, weight_limit * 1.2, "Start!", size=20) image.append(im_text) else: im_text = plt.text(0, weight_limit * 1.2, "Finish!", size=20) image.append(im_text) for w in range(weight_limit + 1): if j == w: w_lmt = plt.plot(-1, w, markersize=16, marker="$" + str(w) + "$", c="black") else: w_lmt = plt.plot(-1, w, markersize=12, marker="$" + str(w) + "$", c="gray") image += w_lmt for v in range(len(V) + 1): if v < len(V): if i == v + 1: item_vw = plt.plot(v + 1, -1, markersize=22, marker="$" + str(V[v]) + "," + str(W[v]) + "$", c="black") image += item_vw item_id = plt.plot(v + 1, -2, markersize=16, marker="$" + str(v) + "$", c="black") image += item_id else: item_vw = plt.plot(v + 1, -1, markersize=20, marker="$" + str(V[v]) + "," + str(W[v]) + "$", c="gray") image += item_vw item_id = plt.plot(v + 1, -2, markersize=12, marker="$" + str(v) + "$", c="gray") image += item_id else: vw = plt.plot(0, -1, markersize=20, marker="$V,W$", c="gray") image += vw for w in range(weight_limit + 1): if v == i and w == j: color="red" elif dp_table[v][w] == -1: color="lightgray" else: color="blue" square = plt.plot(v, w, markersize=50, marker="s", c="lightblue", alpha=0.5) image += square numeral = plt.plot(v, w, markersize=20, marker="$" + str(dp_table[v][w]) + "$", c=color) image += numeral image.append(plt.ylabel("Weight limit j", size=20)) image.append(plt.xlabel("Items i", size=20)) return image実行例1
import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML movie = [] weight_limit = 3 W = [5, 2, 3, 2, 1] V = [9, 5, 6, 3, 2] n = len(W) fig = plt.figure(figsize=(14, 7)) dp_table = [[-1 for _ in range(weight_limit + 1)] for _ in range(len(W) + 1)] movie.append(draw01(dp_table, -1, -1)) knapsack01(0, weight_limit) ani = animation.ArtistAnimation(fig, movie, interval=2000, repeat_delay=1000) ani.save("knapsack01-1.gif", writer='pillow') HTML(ani.to_jshtml())
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。実行例2
import random import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML movie = [] weight_limit = 5 W = [2, 4, 5, 1, 3, 6, 2] V = [2, 1, 5, 1, 5, 9, 1] n = len(W) fig = plt.figure(figsize=(14, 8)) dp_table = [[-1 for _ in range(weight_limit + 1)] for _ in range(len(W) + 1)] movie.append(draw01(dp_table, -1, -1)) knapsack01(0, weight_limit) ani = animation.ArtistAnimation(fig, movie, interval=2000, repeat_delay=1000) ani.save("knapsack01-2.gif", writer='pillow') HTML(ani.to_jshtml())
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。


- 投稿日:2020-02-05T15:37:03+09:00
tensorflow.kerasにおけるtf.function-decorated function tried to create variables on non-first call.のエラー
たまに詰まりがちなので備忘録で
エラー部分
class ResNet50(Model): def __init__(self, stride: int = 1, *args, **kwargs): super(ResNet50, self).__init__(*args, **kwargs) self.stride = stride self.avgpool = AveragePooling2D() self.maxpool = MaxPool2D(padding='same') self.ResBlocks: List[Layers] = [] self.softmax = Softmax() self.dense = Dense(1, activation='sigmoid') def call(self, inputs): conv_1 = self.conv(inputs) maxpooled = self.maxpool(conv_1) layers_num = [3, 4, 6, 3] for i in range(len(layers_num)): for _ in range(layers_num[i]): if i==0 and u==0: self.ResBlocks.append(Residual_Block(filters_num=4 * 2 ** (i))(maxpooled)) else: self.ResBlocks.append(Residual_Block(filters_num=4 * 2 ** (i))(self.ResBlocks[-1]))) avgpooled = self.avgpool(maxpooled) value = self.dense(avgpooled) return avgpooled, value的なことをしてtf.function-decorated function tried to create variables on non-first callが出ていました。
調べるとtensorflowの宣言ずみvariableが新しく宣言されてしまうため、ということですが解決後
class ResNet50(Model): def __init__(self, stride: int = 1, *args, **kwargs): super(ResNet50, self).__init__(*args, **kwargs) self.stride = stride self.avgpool = AveragePooling2D() self.maxpool = MaxPool2D(padding='same') self.ResBlocks: List[Layers] = [] layers_num = [3, 4, 6, 3] for i in range(len(layers_num)): for _ in range(layers_num[i]): self.ResBlocks.append(Residual_Block(filters_num=4 * 2 ** (i))) self.conv = Conv2D(filters=16, kernel_size=7, strides=self.stride, padding='same') self.softmax = Softmax() self.dense = Dense(1, activation='sigmoid') def call(self, inputs): conv_1 = self.conv(inputs) maxpooled = self.maxpool(conv_1) for layer in self.ResBlocks: maxpooled = layer(maxpooled) avgpooled = self.avgpool(maxpooled) value = self.dense(avgpooled) return avgpooled, valueとすれば直りました。原因としては、tensorflow.kerasのModelの仕様でLayerを宣言する時にはinitの部分にしなければいけないということでした。
完全に忘れてました。そこらへんと変数の宣言が関係しているのでしょうか。今度時間がある時にでも調べてみたいです。
- 投稿日:2020-02-05T15:21:39+09:00
【Qiita】バックアップのために記事と画像をエクスポート
明日Qiitaに隕石が衝突するかもしれない, もしものために.
環境
- Windows 10
記事バックアップ
- Python 3.8.1
- Git for Windows 2.5.3(Command Lineで実行)
画像取得
- サクラエディタ Ver2.2.0.1
- DS Downloader Ver2.12.0
Mac環境でもできると思います. 試していないため, あくまで提案です.
- Boot Camp
- Wineで実行.
- (仮想化ソフトウェア(VirtualBox等))
- Macでサクラエディタ
- grep機能があるエディタ
- SiteSucker for MacOS記事エクスポート
@i-tanaka730さんのみんな大好きQiitaのバックアップツールを作ったので公開
の力を借ります.Qiitaのバックアップツール
Gitインストール
- Git-2.5.3-64-bit.exeをダウンロード、実行する. Git for Windows 2.5.3
- Command Lineを選択する.(参考[1]:自分用 Git For Windowsのインストール手順)
バージョンは合わせました.
Pythonインストール
- python-3.8.1-amd64-webinstall.exeをダウンロード、実行する. Python 3.8.1
あとはREADME.mdをよく読んで、記事のエクスポートを実行する.
画像エクスポート
[3]を参考にしました.
- 〇〇.mdをサクラエディタで開く
- Ctrl + G (検索メニューの中にあるGrep(G))
- 条件を入力する.(コピペ)
grep.txthttps://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/.*png|https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/.*jpg|https://qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/.*gif
Grep条件入力 実行結果 4.赤枠をコピーし, DS Downloaderに貼り付ける.
5.オプションで保存先, 最大登録数を設定する.
6.Downloadを押せば、保存先に画像をダウンロードしてきます.
補足
- メリット:画像が多い場合は, 効率良い.
- デメリット:
camo.qiitausercontent.com(参考[4])参考文献
[1] みんな大好きQiitaのバックアップツールを作ったので公開
[2] 自分用 Git For Windowsのインストール手順
[3] はてなブログ内の画像を一括でダウンロードする簡単な方法
[4] Camoでプロキシした画像の元URLを展開するワンライナー
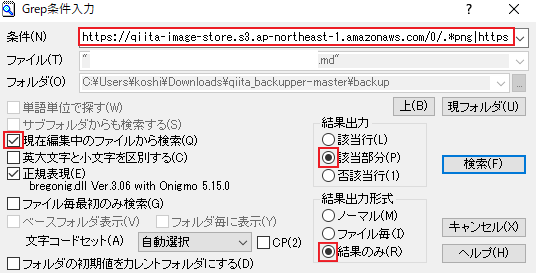
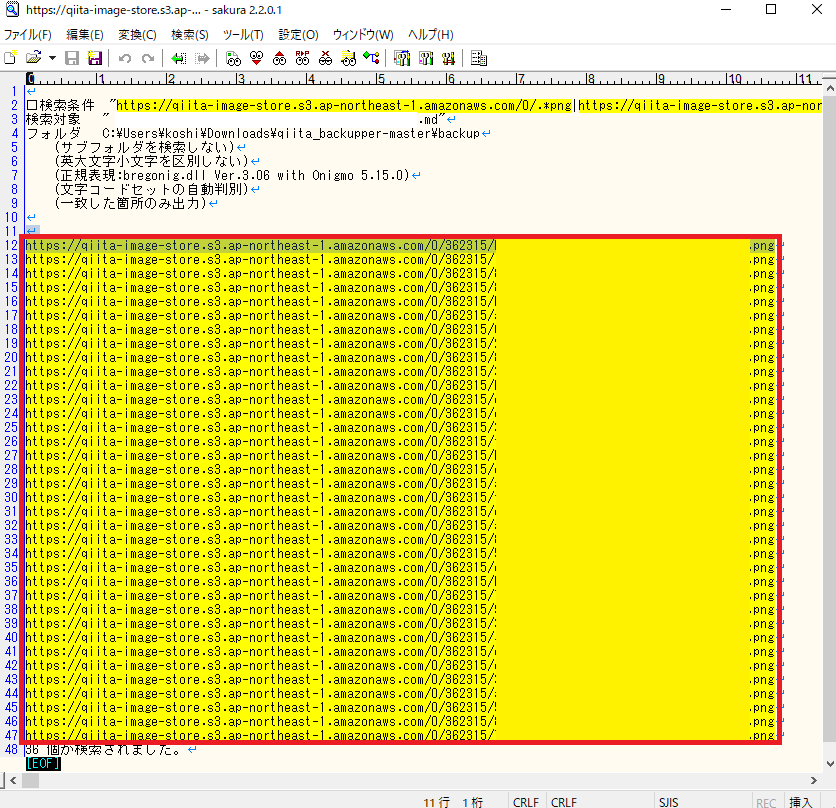
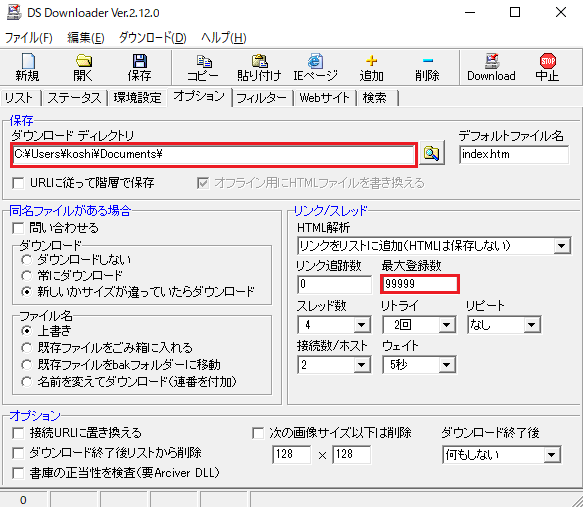
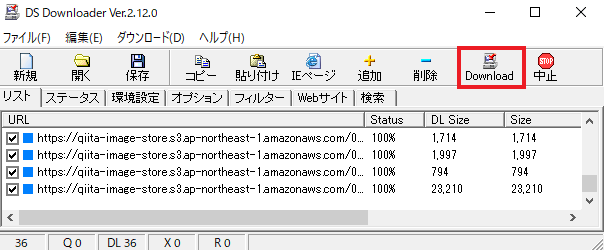
- 投稿日:2020-02-05T15:15:26+09:00
auth0第三方认证认可服务学习
auth0第三方认证认可服务学习
https://auth0.com/官方github提供的例子
Auth0 Python Web App Login
https://github.com/auth0-samples/auth0-python-web-app/tree/master/01-LoginAuth0 + Python + Flask API Seed
https://github.com/auth0-samples/auth0-python-api-samples/tree/master/00-Starter-Seedapi client + test
https://github.com/auth0/auth0-python/blob/master/auth0/v3/test/management/test_rest.py官访文档提供的解决方案
Python + Flask + RESTful API 开发
https://auth0.com/blog/jp-developing-restful-apis-with-python-and-flask/如何应用Auth0的Rules,在Access Token中增加[Role]
https://dev.classmethod.jp/server-side/auth0/add-roles-to-access-token/
- 投稿日:2020-02-05T14:46:58+09:00
CNN+メルスペクトグラム使って言語識別してみた
言語識別とは?
一言でいうと、音声データから言語を特定すること。
例えば、「おはようございます、いい天気ですね」という音声データから、「この音声データは日本語!」とか、
「Buenas Tardes」という音声データから、「この音声データはスペイン語!」って感じです。使用用途としては、何語を話してるか分からい相手に対して、言語を特定することとか。
今ある自動翻訳機とかって、基本的に予め「英語だよ」「スペイン語だよ」って情報を与えないといけっぽい。
だから、そもそも何語を話してるか分からない相手に対しては翻訳しようがない。(と思う。)だから、何語を話しているか分からない相手に対しては、
言語識別を使って言語を特定 → 翻訳
みたいな感じで使われたりする。(と思う。)CNNを使った理由
言語識別には色々な手法があるけれど、今回はCNN使ってみました。
理由は英語の分かり易い記事をたまたま見つけたから。
(http://yerevann.github.io/2015/10/11/spoken-language-identification-with-deep-convolutional-networks/)この記事はトップコーダで2015年に行われた言語識別のコンテストで10位だったらしいでの、勉強がてらやってみました。
使用したデータセット
上の記事では、予め用意された66,176個の10秒のMP3ファイルに対し、176言語分類する問題でした。
でも今回私はVoxForge(http://www.voxforge.org/)
から取得した、英語、フランス語、スペイン語のwav形式の音声ファイルを使用しました。
それぞれ下記のURLからダウンロードできます。
音声データが大量なので、私はwgetコマンドで入手しました。http://www.repository.voxforge1.org/downloads/SpeechCorpus/Trunk/Audio/Main/16kHz_16bit/ http://www.repository.voxforge1.org/downloads/fr/Trunk/Audio/Main/16kHz_16bit/ http://www.repository.voxforge1.org/downloads/es/Trunk/Audio/Main/16kHz_16bit/前処理
CNNを使うので、上で手に入れた各言語のwav形式の音声ファイルを画像に変換します。
今回は「メルスペクトグラム」という、横軸が時間、縦軸が周波数、画像の濃淡が強さを示すものを使用しました。
librosaというライブラリを使えば、簡単にwavファイルからメルスペクトグラムを得ることができます。以下がwavファイルをメルスペクトログラムの画像に変換するコード。
(mp3ファイルでも同じコードで動くと思います)# 入力:音声ファイルのパス # 出力:音声データのメルスペクトグラム画像(192×192) import librosa as lr def wav_to_img(path, height=192, width=192): signal, sr = lr.load(path, res_type='kaiser_fast') if signal.shape[0] < sr: # wavファイルが3秒以下の場合 return False, False else: signal = signal[:sr*3] # 前半3秒だけ抽出 hl = signal.shape[0]//(width*1.1) spec = lr.feature.melspectrogram(signal, n_mels=height, hop_length=int(hl)) img = lr.amplitude_to_db(spec)**2 start = (img.shape[1] - width) // 2 return True, img[:, start:start+width]先程のデータセットには数秒~数十秒のデータが含まれています。
今回はそのデータの中の3秒以上のデータから、初めの3秒だけ抽出し使用しました。
3秒以下のデータは使用しません。以下の関数で指定したフォルダ内の音声データを全てメルスペクトグラム画像に変換して保存します。
# 指定したフォルダの音声ファイルを全てスペクトログラム画像に変換し、指定したフォルダに保存 import os import glob import imageio def process_audio(in_folder, out_folder): os.makedirs(out_folder, exist_ok=True) files = glob.glob(in_folder) start = len(in_folder) files = files[:] for file in files: bo, img = mp3_to_img(file) if bo == True: imageio.imwrite(out_folder + '.jpg', img)以下に示すように、第一引数に各言語の音声データがフォルダ、第二引数に出力先のフォルダを選択して実行してください。
全ての言語に対して行い、全ての音声ファイルをメルスペクトグラムに変換してください。# 以下は音声ファイルの保存先のパスと、出力先のパスを指定 process_audio('data/voxforge/english/*wav', 'data/voxforge/english_3s_imgp/')データの分割
上で取得した、各言語に対するメルスペクトグラムのフォルダを扱いやすいように1つのHDF5ファイルに保存します。
ちょっと不格好ですが、上で保存した各言語に対するメルスペクトグラム画像を以下のパスにHDF5形式で保存します。
保存先のパス:'data/voxforge/3sImg.h5'import dask.array.image import h5py dask.array.image.imread('data/voxforge/english_3s_img/*.jpg').to_hdf5('data/voxforge/3sImg.h5', english) dask.array.image.imread('data/voxforge/french_3s_img/*.jpg').to_hdf5('data/voxforge/3sImg.h5', french) dask.array.image.imread('data/voxforge/spanish_3s_img/*.jpg').to_hdf5('data/voxforge/3sImg.h5', spanish)トレーニングデータ、バリデーションデータ、テストデータに分割します。
import h5py # データサイズなどは得られたメルスペクトグラム画像などを考慮して自分で決めてください data_size = 60000 tr_size = 50000 va_size = 5000 te_size = 5000 x_english = h5py.File('data/voxforge/3sImg.h5')['english'] x_french = h5py.File('data/voxforge/3sImg.h5')['french'] x_spanish = h5py.File('data/voxforge/3sImg.h5')['spanish'] x = np.vstack((x_english[:20000], x_french[:20000], x_spanish[:20000])) del x_french del x_english del x_spanish x = da.from_array(x, chunks=1000) # 正解データのための準備 y = np.zeros(data_size) # 英語、フランス語、スペイン語のラベルをそれぞれ0,1,2 y[0:20000] = 0 y[20000:40000] = 1 y[40000:60000] = 2 # データのシャッフルと分割 import numpy as np shfl = np.random.permutation(data_size) training_size = tr_size validation_size = va_size test_size = te_size # トレーニングデータ,評価用,テストサイズでそれぞれ分割のために,ランダムに用意したインデックスshflを割り当て. train_idx = shfl[:training_size] validation_idx = shfl[training_size:training_size+validation_size] test_idx = shfl[training_size+validation_size:] # 割り当てたindexでトレーニングデータ,評価用,テストサイズを作成 x_train = x[train_idx] y_train = y[train_idx] x_vali = x[validation_idx] y_vali = y[validation_idx] x_test = x[test_idx] y_test = y[test_idx] # 画像の正規化 x_train = x_train/255 x_vali = x_vali/255 x_test = x_test/255 # 学習のための形の変形 x_train = x_train.reshape(tr_size, 192, 192, 1) x_vali = x_vali.reshape(va_size, 192, 192, 1) x_test = x_test.reshape(te_size, 192, 192, 1) # 教師データのワンホットベクトル y_train = y_train.astype(np.int) y_vali = y_vali.astype(np.int) y_test = y_test.astype(np.int)以上の処理で学習データとバリデーションデータ、テストデータに分割できます。
使用したCNNの構造
使用したネットワーク構造は次の通りです。
ここは自由に変えてみてもいいかもしれません。
フレームワークはkerasを用いました。import tensorflow as tf from tensorflow.python import keras from tensorflow.python.keras import backend as K from tensorflow.python.keras.models import Model, Sequential, load_model from tensorflow.python.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten, Dropout, Input, BatchNormalization, Activation from tensorflow.python.keras.preprocessing.image import load_img, img_to_array, array_to_img, ImageDataGenerator i = Input(shape=(192,192,1)) m = Conv2D(16, (7, 7), activation='relu', padding='same', strides=1)(i) m = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(m) m = BatchNormalization()(m) m = Conv2D(32, (5, 5), activation='relu', padding='same', strides=1)(m) m = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(m) m = BatchNormalization()(m) m = Conv2D(64, (3, 3), activation='relu', padding='same', strides=1)(m) m = MaxPooling2D()(m) m = BatchNormalization()(m) m = Conv2D(128, (3, 3), activation='relu', padding='same', strides=1)(m) m = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(m) m = BatchNormalization()(m) m = Conv2D(128, (3, 3), activation='relu', padding='same', strides=1)(m) m = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(m) m = BatchNormalization()(m) m = Conv2D(256, (3, 3), activation='relu', padding='same', strides=1)(m) m = MaxPooling2D(pool_size=(3, 3), strides=2, padding='same')(m) m = BatchNormalization()(m) m = Flatten()(m) m = Activation('relu')(m) m = BatchNormalization()(m) m = Dropout(0.5)(m) m = Dense(512, activation='relu')(m) m = BatchNormalization()(m) m = Dropout(0.5)(m) o = Dense(3, activation='softmax')(m) model = Model(inputs=i, outputs=o) model.summary()以下で学習しました。
トレーニングデータ数が少ないのか、モデルが悪いのか、すぐに過学習してしまう傾向にあったので、
エポック数は5くらいで十分です。
ここらへんは考察が全然できてなくて申し訳ありません。model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=32, epochs=5, verbose=1, validation_data=(x_vali, y_vali), shuffle = True)結果
テストデータに対して行った結果です。
model.evaluate(x_test, y_test)[0.2763474455833435, 0.8972]
約90%でちゃんと予測できてる感じですかね。
ただ実際、学習データとテストデータに同じ人間の音声データが多く混じっているので、精度は高く出ていると思います。
より正確に精度を調べるのであれば、
'data/voxforge/english_3s_imgp/'
のシャッフルする前のデータで使用してないデータ、今回の例でいうと、x_english = h5py.File('data/voxforge/3sImg.h5')['english'] x_french = h5py.File('data/voxforge/3sImg.h5')['french'] x_spanish = h5py.File('data/voxforge/3sImg.h5')['spanish'] x = np.vstack((x_english[20000:], x_french[20000:], x_spanish[20000:]))のデータを使うとより、正確な精度が調べられると思います。
ちなみにその時の、各言語に対する正答率は次の通りでした。英語:0.8414201183431953
フランス語:0.7460106382978723
スペイン語:0.8948035487959443フランス語はあんまりうまく識別できてないですね。
まとめ
今回は勉強がてらCNNを使って音声認識をやってみました。
途中駆け足になって説明が不十分の場所があるかもしれません、申し訳ありません。
基本的な考え方は、冒頭でも紹介しましたが、以下のURLから確認できるので、英語が得意な方はそっちを見たほうがいいかもしれませんね。
(http://yerevann.github.io/2015/10/11/spoken-language-identification-with-deep-convolutional-networks/)最後まで読んでいただきありがとうございました。
- 投稿日:2020-02-05T14:23:02+09:00
python3.7でThunderbirdから保存したEMLファイルのテンプレートを抜き出す
私は小企業(30名ほど)の総務をしています。
当然、勤怠管理システムなんか導入する金はない、そもそも勤怠管理システムって何?という会社なので、エクセル方眼紙で作ったフォーマットに入力された有休届や休日出勤届などが毎月大量に送られてきます。
そこで、thuderbird(強制)からメールを日付で検索し、それをドラッグ&ドロップで保存し添付ファイルをまとめて抜き出す方法を、勉強がてら考えました。emlファイルの読み込み
https://qiita.com/denzow/items/a42d344fa343cd80cf86
を参考に、日付を抜き出せるよう下記のように変更eml_read.pyimport sys import email from email.header import decode_header import datetime class MailParser(object): """ メールファイルのパスを受け取り、それを解析するクラス """ def __init__(self, mail_file_path): self.mail_file_path = mail_file_path # emlファイルからemail.message.Messageインスタンスの取得 with open(mail_file_path, 'rb') as email_file: self.email_message = email.message_from_bytes(email_file.read()) self.subject = None self.to_address = None self.cc_address = None self.from_address = None self.body = "" self.date = None # 添付ファイル関連の情報 # {name: file_name, data: data} self.attach_file_list = [] # emlの解釈 self._parse() def get_attr_data(self): """ メールデータの取得 """ result = """\ DATE: {} FROM: {} TO: {} CC: {} ----------------------- BODY: {} ----------------------- ATTACH_FILE_NAME: {} """.format( self.date, self.from_address, self.to_address, self.cc_address, self.body, ",".join([ x["name"] for x in self.attach_file_list]) ) return result def _parse(self): """ メールファイルの解析 __init__内で呼び出している """ self.subject = self._get_decoded_header("Subject") self.to_address = self._get_decoded_header("To") self.cc_address = self._get_decoded_header("Cc") self.from_address = self._get_decoded_header("From") # 変更したところ self.date = datetime.datetime.strptime( self._get_decoded_header("Date"), "%a, %d %b %Y %H:%M:%S %z" ) # メッセージ本文部分の処理 for part in self.email_message.walk(): # ContentTypeがmultipartの場合は実際のコンテンツはさらに # 中のpartにあるので読み飛ばす if part.get_content_maintype() == 'multipart': continue # ファイル名の取得 attach_fname = part.get_filename() # ファイル名がない場合は本文のはず if not attach_fname: charset = str(part.get_content_charset()) if charset: self.body += part.get_payload(decode=True).decode(charset, errors="replace") else: self.body += part.get_payload(decode=True) else: # ファイル名があるならそれは添付ファイルなので # データを取得する self.attach_file_list.append({ "name": attach_fname, "data": part.get_payload(decode=True) }) def _get_decoded_header(self, key_name): """ ヘッダーオブジェクトからデコード済の結果を取得する """ ret = "" # 該当項目がないkeyは空文字を戻す raw_obj = self.email_message.get(key_name) if raw_obj is None: return "" # デコードした結果をunicodeにする for fragment, encoding in decode_header(raw_obj): if not hasattr(fragment, "decode"): ret += fragment continue # encodeがなければとりあえずUTF-8でデコードする if encoding: ret += fragment.decode(encoding) else: ret += fragment.decode("UTF-8") return ret if __name__ == "__main__": result = MailParser(sys.argv[1]).get_attr_data() print(result)フォルダ内のemlファイルの添付ファイルを抜き出すコードを作成
素人なので変数のつけ方などの書き方が変なのはお許しください。
save_attachmentfile.pyimport eml_read import glob import os from email.header import decode_header import datetime PATH = r"C:\Users\toshi\***" + "\\" # emlファイルを保存した場所 save_file_path = r"C:\Users\***" + "\\" # 添付ファイルを保存したい場所 def save_attachmentfile(file_path_list): # search_emlからリストを受け取って添付ファイルをsave_pathに保存 for file_path in file_path_list: obj_eml = eml_read.MailParser(file_path) from_adderss = obj_eml.from_address[0:3] eml_date = obj_eml.date print(eml_date) # 日付 str_year = eml_date.strftime("%y") str_month = eml_date.strftime("%m").lstrip("0") str_day = eml_date.strftime("%d").lstrip("0") str_date = str_year + "." + str_month + "." + str_day for a in obj_eml.attach_file_list: print(type(decode_header(a["name"])[0][0])) if type(decode_header(a["name"])[0][0]) == bytes: file_name = str_date + from_adderss + decode_header(a["name"])[0][0].decode(decode_header(a["name"])[0][1]) else: file_name = str_date + from_adderss + decode_header(a["name"])[0][0] file_name = ( file_name ).translate(str.maketrans( {'<': '', '>': '', '!': '', '/': '', ':': '', '*': '', '"': '', '|': ''} )) with open(save_file_path + file_name, mode="bw") as f: f.write(a["data"]) def search_eml(file_path): # emlファイル名のリストを返す emlPATHS = [] filepaths = glob.glob(os.path.join(file_path, '*.eml')) for filepath in filepaths: emlPATHS.append(filepath) filepaths = None return emlPATHS if __name__ == "__main__": lst = search_eml(PATH) save_attachmentfile(lst)参考リンク
https://qiita.com/denzow/items/a42d344fa343cd80cf86
https://stackoverflow.com/questions/21711404/how-to-get-decode-attachment-filename-with-python-email
※添付ファイル名のデコードで困ったので
- 投稿日:2020-02-05T13:56:17+09:00
CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'が出たときの解決方法
conda activateを実行したところ以下のエラーが発生したので,そのときの対処をメモ.CommandNotFoundError: Your shell has not been properly configured to use 'conda activate'. To initialize your shell, run $ conda init <SHELL_NAME> Currently supported shells are: - bash - fish - tcsh - xonsh - zsh - powershell See 'conda init --help' for more information and options. IMPORRANT: You may need to close and restart your shell after running 'conda init'.エラーメッセージに従って
conda initを実行し,ターミナルを再起動するも再びエラー.
conda init zsh(私のシェルの環境がzshのため) を実行し,ターミナルを再起動すると正常に動作することができました.
zshの部分を上記のCurrently supported shells are:から各個人の環境に合わせて選択し,書き換えればうまくいくと思います.