- 投稿日:2020-01-13T23:52:39+09:00
[Python3 入門 8日目] 4章 Pyの皮:コード構造(4.1〜4.13)
4.1 #によるコメント
- プログラムの中に含まれるテキストで"#"によるコメントはPythonインタープリンタから無視される。
- Pythonには複数行コメントはないため、コメント行、コメントセクションの冒頭には必ず#を入れなければならない。
4.2 \による行の継続
- 行末に\を置くとPythonはまだ行替えをしていないと思って動く。
#小さい文字列から長い文字列を作りたければ次のように少しずつ作っていく方法がある。 >>> alphabet = "" >>> alphabet +="abcdefg" >>> alphabet +="hijklmnop" >>> alphabet +="qrstuv" >>> alphabet +="wxyz" #継続文字を使えば見づらくせずワンステップで作ることもできる。 >>> alphabet = "abcdefg" + \ ... "hijklmnop" +\ ... "qrstuv"+\ ... "wxyz" #行が複数行にまたがる場合にも行継続が必要になる。 >>> 1+2+ File "<stdin>", line 1 1+2+ ^ SyntaxError: invalid syntax >>> 1+2\ ... 3 File "<stdin>", line 2 3 ^ SyntaxError: invalid syntax >>> 1+2+\ ... 3 64.3 if, elif,elseによる比較
- Pythonではセクション内ではコードが首尾一貫しているはずだと考えて動くため、インデントは同じ大きさで左端が揃っていなければならない。
- PEP8という推奨スタイルは4個のスペースを使っている。
#disasterの内容をチェックして適切なコメントを表示するプログラム >>> disaster = True >>> if disaster: ... print("Woe!") ... else: ... print("Whee!") ... Woe!>>> funny = True >>> small = True #if funnyがTrueならば if smallのテストに入る。 >>> if funny: ... if small: ... print("It's a cat.") ... else: ... print("It's a bear!") ... else: ... if small: ... print("It's a skink!") ... else: ... print("It's a human.Or a hairless bear.") ... It's a cat.#テストが3種類以上に分かれる場合はif,elif(else ifという意味),elseを使う。 >>> color ="puse" >>> if color =="red": ... print("It's a tomato") ... elif color =="green": ... print("It's a green pepper") ... elif color =="bee purple": ... print("I don't know what it is,but only bees can see it") ... else: ... print("I've never heard of the color",color) ... I've never heard of the color puse>>> x =2 #等価性のテスト >>> x ==2 True >>> x ==5 False >>> 4 < x False >>> x<10 True #ブール演算子は比較対象の要素よりも優先順位が低い。 #比較対象となる要素が先に計算されてからブール演算子が行われる。 >>> 1<x and x <10 True >>> 1<x or x <10 True >>> 1<x and x >10 False >>> 1<x and not x >10 True >>> 1<x<10 True >>> 1<x<10<377 True4.3.1 Trueとは何か
- 以下に示すものは全てFalseと見なされる。
- その他のものは全てTrueと見なされる。
Falseと見なされるもの 値 ブール値 False null None 整数のゼロ 0 floatのゼロ 0.0 空文字列 " " 空リスト [ ] 空タプル ( ) 空辞書 { } 空集合 set() >>> some_list = [] >>> if some_list: ... print("There's something in here") ... else: ... print("Hey,it's empty!") ... Hey,it's empty!4.4 whileによる反復処理
- 同じことを2回以上行いたいときはループを使う。
#countの初期化 #countの値と5を比較 #countを1ずつインクリメント(加算) >>> count =1 >>> while count <=5: ... print(count) ... count+=1 ... 1 2 3 4 54.4.1 ブレイクによるループの中止
- ループを中止させたい場合、breakを使う
#無限ループ #input()関数を使ってキーボードから入力行を読み出し、stuffに代入 #入力文字が"q":だった場合にループを抜ける。 #"q"以外は入力文字列の先頭文字を大文字にして表示する。 >>> while True: ... stuff=input("String to capitalize[type q to quit]:") ... if stuff == "q": ... break ... print(stuff.capitalize()) ... String to capitalize[type q to quit]:type Type String to capitalize[type q to quit]:untitarou Untitarou String to capitalize[type q to quit]:q4.4.2 continueによる次のイテレーションの開始
- イテレーションとは反復処理の1回分のことである。
#input()関数を使ってキーボードから入力行を読み出し、valueに代入 #入力文字が"q":だった場合にループを抜ける。 #valueをint型にしてnumberへ代入 #偶数であれば次のイテレーションを開始 >>> while True: ... value=input("Integer,please [q to quit]:") ... if value == "q": ... break ... number =int(value) ... if number %2==0: ... continue ... print(number,"squared is",number*number) ... Integer,please [q to quit]:1 1 squared is 1 Integer,please [q to quit]:2 Integer,please [q to quit]:3 3 squared is 9 Integer,please [q to quit]:q4.4.3 elseによるbreakのチェック
#変数positionの初期化 #偶数であれば"Found even numbers"とその数字を表示させbreakでwhile文を抜ける。 #else節はwhile分が終了したが探し物が見つからなかった場合に実行される。(breakチェッカー) >>> number =[1,3,5] >>> position =0 >>> while position <len(number): ... numbers=number[position] ... if numbers%2 ==0: ... print("Found even numbers",numbers) ... break ... position+=1 ... else: ... print("No even number found") ... No even number found4.5 forによる反復処理
Pythonはイテレータ(イテレーションごとにリスト、辞書などから要素を一つずつ取り出して返すもの)を頻繁に使う。
それはデータ構造を知らなくてもデータ構造の各要素を操作できるから。#while文 >>> rabbits =["a","b","c","d"] >>> current=0 >>> while current<len(rabbits): ... print(rabbits[current]) ... current +=1 ... a b c d #for文 >>> for rabbit in rabbits: ... print(rabbit) ... a b c dリスト、文字列、タプル、辞書、集合、その他とともにPythonのイテラブル(イテレータに対応している)オブジェクトである。
- タプルやリストをforで処理すると一度に一つずつの要素が取り出される。
- 文字列をforで処理すると以下に示すように一度に一つずつ文字が生成される。
>>> word="cat" >>> for letter in word: ... print(letter) ... c a t
- 辞書をforで処理するとキーが返される。
>>> accusation ={"a":"ballroom","b":"weapon","c":"kowai"} >>> for card in accusation: ... print(card) ... a b c
- 値を反復処理させたい場合は辞書のvalues()関数を使う。
>>> for value in accusation.values(): ... print(value) ... ballroom weapon kowai
- キーと値の両方をタプルの形で帰したい場合はitems()関数を使う。
>>> for value in accusation.items(): ... print(value) ... ('a', 'ballroom') ('b', 'weapon') ('c', 'kowai')
- タプルの各要素を個別の変数に代入したい場合は、forの変数を2つ用意する。第一引数に"キー"、第二引数に"値"が代入される。
>>> for card,contents in accusation.items(): ... print("Card",card,"has the contents",contents) ... Card a has the contents ballroom Card b has the contents weapon Card c has the contents kowai4.5.1 breakによる中止
for文の中にbreak文を入れるとwhile分と同様にループを中止できる。
4.5.2 continueによる次のイテレーションの開始
for文にcontinueを入れるとwhile分と同様に次のイテレーションにジャンプする。
4.5.3 elseによるbreakのチェック
whileと同様にforは正常終了したかどうかをチェックするオプションのelseを持っている。breakが呼び出されなければ、else文が実行される。
>>> cheeses=[] >>> for cheese in cheeses: ... print("This shop has some lovely",cheese) ... break ... else: ... print("This is not much of a cheese shop,is it?") ... This is not much of a cheese shop,is it?4.5.4 zip()を使った複数のシーケンス処理
- zip関数を使えば複数のシーケンスを並列的に処理できる。
- zip()は最もサイズが小さいシーケンス要素を処理しつくし時に止まる。
#リストの作成 #dessertsだけが他のリストより長い。他の要素を長くしない限りpuddingをもらえる人はいない。 >>> days =["Monday","Tuesday","Wednesday"] >>> fruits=["coffee","tea","bear"] >>> drinks=["coffee","tea","beer"] >>> desserts=["tiamisu","ice cream","pie","pudding"] #zip()を使い、複数のシーケンスをたどってオフセットが共通する要素からタプルを作ることができる。 >>> for day,fruit,drink,dessert in zip(days,fruits,drinks,desserts): ... print(day,":drink",drink,"- eat",fruit,"-enjoy",dessert) ... Monday :drink coffee - eat coffee -enjoy tiamisu Tuesday :drink tea - eat tea -enjoy ice cream Wednesday :drink beer - eat bear -enjoy pie#zip()から返される値自体はタプルやリストではなく、タプルやリストにできるイテラブルな値である。 >>> english="Monday","Tuesday","Wednesday" >>> french="Lundi","Mardi","Mercredi" #リスト化 >>> list(zip(english,french)) [('Monday', 'Lundi'), ('Tuesday', 'Mardi'), ('Wednesday', 'Mercredi')] #辞書化 >>> dict(zip(english,french)) {'Monday': 'Lundi', 'Tuesday': 'Mardi', 'Wednesday': 'Mercredi'}4.5.5 range()による数値シーケンスの生成
- range()関数を使えば指定した範囲の数値ストリームを返すことができる。
- range()はrange(start: end:step)というスライスと似た形式で使う。 startは省略すると0が先頭になる。唯一の引数はendで、スライスと同様に作成される最後の値はstep-1の値である。 stepのデフォルト値は1だが、−1を指定して逆順にすることができる。
- zip()と同様にrange()はイテラブルなオブジェクトを返すので戻り値はfor...inで反復処理するか、リストなどのシーケンスに変換するが必要ある。
#0から3までの範囲作成 >>> for x in range(0,3): ... print(x) ... 0 1 2 #リスト化 >>> list(range(0,3)) [0, 1, 2] #2から0までの範囲作成 >>> for x in range(2,-1,-1): ... print(x) ... 2 1 0 #リスト化 >>> list(range(2,-1,-1)) [2, 1, 0] #0から10までの偶数を取り出し >>> list(range(0,11,2)) [0, 2, 4, 6, 8, 10]4.6 内包表記
内包表記は一つ以上のイテレータからPythonデータ構造をコンパクトに作れる形式。
4.6.1 リスト内包表記
1から5までの整数のリストは以下のように一つずつ要素を追加しても作れる。
#append()を使い末尾に追加している。 >>> number_list=[] >>> number_list.append(1) >>> number_list.append(2) >>> number_list.append(3) >>> number_list.append(4) >>> number_list.append(5) >>> number_list [1, 2, 3, 4, 5] #range()関数とforでも作れる。 >>> number_list=[] >>> for number in range(1,6): ... number_list.append(number) ... >>> number_list [1, 2, 3, 4, 5] #range()の出力を直接リストに変換しても作れる。 >>> number_list = list(range(1,6)) >>> number_list [1, 2, 3, 4, 5]リスト内包表記を使ったコードを以下に示す。
#[expression for item in iterable]の基本形式 #最初のnumber変数はループの実行結果をnumber_listに格納するためのもの。 #第二のnumberはfor文の一部 >>> number_list = [number for number in range(1,6)] >>> number_list [1, 2, 3, 4, 5] #最初のnumberが式だとわかる。 >>> number_list = [number-1 for number in range(1,6)] >>> number_list [0, 1, 2, 3, 4]>>> a_list=[] >>> for number in range (1,6): ... if number%2 ==1: ... a_list.append(number) ... >>> a_list [1, 3, 5] #[expression for item in iterable if condition]の形式 >>> a_list = [number for number in range(1,6) if number %2 ==1] >>> a_list [1, 3, 5]>>> rows =range(1,4) >>> cols=range(1,3) >>> for row in rows: ... for col in cols: ... print(row,col) ... 1 1 1 2 2 1 2 2 3 1 3 2 #内包表記もネストできる。 #タプルで出力している。 >>> rows =range(1,4) >>> cols=range(1,3) >>> cells = [(row,col) for row in rows for col in cols] >>> for cell in cells: ... print(cell) ... (1, 1) (1, 2) (2, 1) (2, 2) (3, 1) (3, 2) #cellsリストを反復処理しながらタプルからrow,colを引き抜く。 >>> for row,col in cells: ... print(row,col) ... 1 1 1 2 2 1 2 2 3 1 3 24.6.2 辞書包括表記
- 辞書にも内包表記がある。
- {key_item:value_item for item in iterable}の基本形式
#"letters"から一つずつ文字を取り出し"letters"の中に何個含まれているかカウントし、キーとカウント回数をletter_countsに格納 >>> word ="letters" >>> letter_counts={x:word.count(x)for x in word} >>> letter_counts {'l': 1, 'e': 2, 't': 2, 'r': 1, 's': 1} #wordを集合としてみる。 >>> word ="letters" >>> letter_counts={x:word.count(x)for x in set(word)} >>> letter_counts {'e': 2, 'l': 1, 's': 1, 't': 2, 'r': 1}4.6.3 集合内包表記
- {item for item in iterable}の基本形式
- 集合でも長いバージョンが使える。
>>> a_set={number for number in range(1,6) if number %3 ==1} >>> a_set {1, 4}4.6.4 ジェネレータ内包表記
- タプルに内包表記はない
- 普通のかっこで内包表記を作るとジェネレータオブジェクトを返す
- ジェネレータとはイテレータにデータを供給する方法の一つ。
#()間のものはジェネレータ内包表記 >>> number_thing = (number for number in range(1,6)) #ジェネレータオブジェクトを返す。 >>> type(number_thing) <class 'generator'> #ジェネレータオブジェクトはfor文で処理できる。 >>> for number in number_thing: ... print(number) ... 1 2 3 4 5 #ジェネレータ内包表記をlist()呼び出しでラップすればリスト内包表記リスト包括表記のように動作できる。 >>> number_list=list(number_thing) >>> number_list [1, 2, 3, 4, 5] #ジェネレータは一度だけしか実行できない。ジェネレータは一度に一つずつその場で値を作り、イテレータに渡してしまうので作った値を覚えていない。そのためジェネレータをもう一度使ったりバックアップしたりすることはできない。 >>> number_list=list(number_thing) >>> >>> number_list []4.7 関数
プログラマーは関数に対して二つのことをできる。
- 関数の定義
- 関数の呼び出し
Python関数を定義するには defと入力し、関数名を書き、関数に対する入力引数をかっこに囲んでかき、最後に(:)を書く。
#make_a_sound()関数を呼び出すとPythonが定義の中のコードを実行する。この場合は、1個の単語を出力して、メインプログラムに制御を返す。 >>> def make_a_sound(): ... print("quack") ... >>> make_a_sound() quack #引数がないが値を返す関数 >>> def agree(): ... return True ... >>> agree() True #ifを使って戻り値をテストする。 >>> if agree(): ... print("Splendid!") ... else: ... print("That was unexpected.") ... Splendid!>>> def echo(anything): ... return anything+' '+anything ... #echo()関数は"ss"という実引数とともに呼び出されている。 #この値はecho()内のanithingという仮引数にコピーされ、呼び出し元に返される。 >>> echo("ss") 'ss ss'
関数を呼び出すときに関数に渡される値も引数と呼ばれる。
実引数(argument)を渡して関数を呼び出すとき、それらの値は関数内の対応する仮引数(parameter)にコピーされる。
>>> def commtentary(color): ... if color == "red": ... return "It's a tomoato." ... elif color =="green": ... return "It's a green pepper" ... elif color =="bee purple": ... return "I don't know what it is,but only bees can see it." ... else: ... return "I've never heard of te color"+ color+"." ... #"blue"という実引数とともにcommententary関数を呼び出す。 >>> comment=commtentary("blue") >>> print(comment) I've never heard of te colorblue.
- 関数が明示的にreturnを呼び出さなければ呼び出しもとはNoneを受け取る
>>> def do_nothing(): ... pass ... >>> print(do_nothing()) None
- Noneは何もいうべきことがない時に使われる。
- Noneはブール値として評価すると偽になるが、ブール値のFalseと同じではない。
>>> def is_none(thing): ... if thing is None: ... print("It's nothing") ... elif thing: ... print("It's True") ... else: ... print("It's False") ... >>> is_none(None) It's nothing >>> is_none(True) It's True >>> is_none(False) It's False #ゼロの整数とfloat、空文字列、空リスト、空タプル、空辞書、空集合はFalseだが、Noneとは等しくない。 >>> is_none(0) It's False >>> is_none(0.0) It's False >>> is_none(()) It's False >>> is_none([]) It's False >>> is_none({}) It's False >>> is_none(set()) It's False4.7.1 位置引数
- 位置引数とは先頭から順に対応する位置の仮引数にコピーされる引数
>>> def menu(x,y,z): ... return{"wine":x,"entree":y,"dessert":z} ... >>> menu("aaa","bbb","ccc") {'wine': 'aaa', 'entree': 'bbb', 'dessert': 'ccc'}4.7.2 キーワード引数
- 対応する仮引数の名前を指定して実引数を指定すれば良い。
- 位置引数とキーワード引数の両方を使って関数を呼び出す場合は、まず先に位置引数を指定しなければならない。
>>> def menu(x,y,z): ... return{"wine":x,"entree":y,"dessert":z} ... >>> menu("beef","bagel","bordeaux") {'wine': 'beef', 'entree': 'bagel', 'dessert': 'bordeaux'} #仮引数を指定して実引数を指定している。 >>> menu(y="beef",z="bagel",x="bordeaux") {'wine': 'bordeaux', 'entree': 'beef', 'dessert': 'bagel'} #位置引数とキーワード引数の両方を使う場合は位置引数を最初に指定する。 >>> menu("frontenac",z="flan",y="fish") {'wine': 'frontenac', 'entree': 'fish', 'dessert': 'flan'}4.7.3 デフォルト引数値の指定
#デフォルト引数値の指定 >>> def menu(x,y,z="unchi"): ... return{"wine":x,"entree":y,"dessert":z} ... #"dessert"のみ引数指定されていないためデフォルトの引数が入る。 >>> menu("dunkelfelder","chiken") {'wine': 'dunkelfelder', 'entree': 'chiken', 'dessert': 'unchi'} #引数を指定すればそれがデフォルト値の代わりに使われる。 >>> menu("dunkelfelder","duck","doughnut") {'wine': 'dunkelfelder', 'entree': 'duck', 'dessert': 'doughnut'}>>> def buggy(arg,result=[]): ... result.append(arg) ... print(result) ... >>> buggy("a") ['a'] #['ab']としたい... >>> buggy("ab") ['a', 'ab']#buggy()関数呼びだしのたびにresultを[]にして初期化しておくおkとがポイント >>> def buggy(arg): ... result=[] ... result.append(arg) ... return result ... >>> buggy("a") ['a'] #正しく動作した!!!! >>> buggy("b") ['b']#result=[]としてif文を使い、resultを初期化している。 >>> def nonbuggy(arg,result=None): ... if result is None: ... result = [] ... result.append(arg) ... print(result) ... >>> nonbuggy("a") ['a'] >>> nonbuggy("b") ['b']4.7.4 *による位置引数のタプル化
- 関数定義の中で仮引数の一部として*を使うと、可変個の位置引数をタプルにまとめてその仮引数にセットできる。
- *を使うときにタプル仮引数をargsを使うのが慣習的。
>>> def print_args(*args): ... print("Positional argument tuple:",args) ... >>> print_args() Positional argument tuple: () #argsタプルとして表示される >>> print_args(3,2,1,"wait!","uh...") Positional argument tuple: (3, 2, 1, 'wait!', 'uh...') #必須の引数がある場合には、位置引数の最後に*argsを書くと必須引数以外の全ての位置引数を一つにまとめることができる。 >>> def print_more(x1,x2,*args): ... print("Need this one",x1) ... print("Need this one too",x2) ... print("All the rest",args) ... >>> print_more("cap","gloves","scarf","monocle","mustache wax") Need this one cap Need this one too gloves All the rest ('scarf', 'monocle', 'mustache wax')4.7.5 **によるキーワード引数の辞書化
- **を使えばキーワード引数を1個の辞書にまとめることができる。
- 引数の名前は辞書のキー、引数の値は辞書の値となる。
- 位置引数をまとめるargsと*kwargsを併用する場合、この二つはこの順序でまとめなければならない。
>>> def print_kwargs(**kwargs): ... print("Keyward arguments:",kwargs) ... >>> print_kwargs(x="xx",y="yy",z="zz") Keyward arguments: {'x': 'xx', 'y': 'yy', 'z': 'zz'}**4.7.6 docstring
- 関数本題の先頭に文字列を組み込めば、関数定義にドキュメントをつけることができる。これを関数のdocstringと呼ぶ。
>>> def echo(anything): ... 'echoは与えられた入力引数をかえす' ... return anything ... #help()関数を呼び出すと関数のdocstringを表示する。 >>> help(echo) Help on function echo in module __main__: echo(anything) echoは与えられた入力引数をかえす (END)4.7.7 一人前のオブジェクトとしての関数
- 関数もオブジェクトである。
- 関数はリスト、タプル、集合、辞書の要素として使うことができる。
- 関数はイミュータブルなので辞書のキーとしても使うことができる。
>>> def answer(): ... print(43) ... >>> answer() 43 >>> def run_something(func): ... func() ... #answer()ではなくanswerを渡すと他のデータ型と同様に関数をデータ型として使っていることになる。 >>> run_something(answer) 43>>> def add_args(x1,x2): ... print(x1+x2) ... >>> type(add_args) <class 'function'> #funcをオブジェクトとしてrun_something_with_argsに渡している。 >>> def run_something_with_args(func,arg1,arg2): ... func(arg1,arg2) ... >>> run_something_with_args(add_args,5,9) 14#任意の数の位置引数をとり、sum()関数でそれらの合計を計算して返す。 >>> def sum_args(*args): ... return sum(args) ...>>> def run_with_positional_args(func,*args): ... return func(*args) ... >>> run_with_positional_args(sum_args,1,2,3,4) 104.7.8 関数内関数
- 関数を関数内で定義することができる。
>>> def outer(a,b): ... def inner(c,d): ... return c+d ... return inner(a,b) ... >>> outer(4,7) 11 >>> def knights(s): ... def inner(q): ... return "%s" % q ... return inner(s) ... >>> knights("Ni!") 'Ni!'4.7.9 クロージャ
- 関数内関数はクロージャとして機能する。
- クロージャとは他の関数によって動的に生成される関数で、その関数の外で作られた変数の値を覚えていたり、変えたりすることができる。
#inner2()は引数を要求せず、外側の関数に対する引数sを直接使う。 #knights2()はinner2を呼び出すのではなくその関数名を返す。 #inner2はクロージャとして機能している。 >>> def knights2(s): ... def inner2(): ... return "%s" % s ... return inner2 ... >>> a= knights2("Duck") >>> b= knights2("Hasenpfeffer") >>> type(a) <class 'function'> >>> type(b) <class 'function'> #これらは関数だが、クロージャでもある。 >>> a <function knights2.<locals>.inner2 at 0x1006d6ef0> >>> b <function knights2.<locals>.inner2 at 0x1006d60e0> #これらを呼び出すと二つのクロージャはknights2に自分たちが作られていたsの内容を覚えている。 >>> a() 'Duck' >>> b() 'Hasenpfeffer'4.7.10 無名関数:ラムダ関数
- ラムダ関数は一つの文で表現される無名関数。
- 小さな関数をいくつも作って名前を覚えておかなければならないような場面で効果的。
>>> def edit_story(words,func): ... for word in words: ... print(func(word)) ... >>> stairs = ["x","u","z","r"] >>> def enliven(word): ... return word.capitalize()+"!" ... #リストから一文字ずつ取り出し、enlivenで処理している。 >>> edit_story(stairs,enliven) X! U! Z! R! #enliven()関数はとても短いのでラムダに取り替える。 #このラムダは1個の引数 wordをとる。 #":"から末尾までの部分は全て関数定義である。 >>> edit_story(stairs,lambda word:word.capitalize()+"!") X! U! Z! R!4.8 ジェネレータ
- ジェネレータはPythonのシーケンスを作成するオブジェクトである。
- ジェネレータはイテレータのデータソースになることが多い。
#ジェネレータ関数は値をreturnの代わりにyield文で返す。 >>> def my_range(first=0,last=10,step=1): ... number=first ... while number < last: ... yield number ... number +=step ... #my_rangeは通常の関数である。 >>> my_range <function my_range at 0x1009364d0> >>> ranger=my_range(1,5) #ジェネレータオブジェクトを返す。 >>> ranger <generator object my_range at 0x100636ed0> #ジェネレータオブジェクトを対象としてforによる反復処理をすることができる。 >>> for x in ranger: ... print(x) ... 1 2 3 44.9 ※デコレータ
- デコレータは入力として関数を一つとり、別の関数を返す関数。
- 以下のものを使ってデコレータを作成する。
- argsと*kwargs
- 関数内関数
- 引数としての関数
関数に対するデコレータは複数持てる。関数に最も近いデコレータが先に実行され、次にその上のデコレータが実行される。
先日実行した際に①のようなエラーが出ていたため本日、再度実行し直したら②のようなエラーが出てきました。
①に関してはかなり悩みましたが、
最初にadd_intsの引数a,bを定義してから再度document_itを実行したところ通常に結果が返されたため引数a,bを指定していないからエラーが発生したのだと考えております。しかし、本には引数を指定せずとも実行結果が正しく出ているため本当に自分の考えが正しいか分かりません。(③のように引数指定するとエラーでない)②も不明のためご教示ください。
#① >>> def document_it(func): ... def new_function(*args,**kwargs): ... print("Running function:",func.__name__) ... print("Positional arguments:",args) ... print("Keyword arguments:",kwargs) ... result =func(*args,**kwargs) ... print("Result:",result) ... return result ... return new_function() ... >>> def add_ints(a,b): ... return a+b ... >>> add_ints(1,2) 3 >>> cooler_add_ints =document_it(add_ints) Running function: add_ints Positional arguments: () Keyword arguments: {} Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 9, in document_it File "<stdin>", line 6, in new_function TypeError: add_ints() missing 2 required positional arguments: 'a' and 'b'#②なぜかエラーが... #result定義されていると思うのだが。 >>> def document_it(func): ... def new_function(*args,**kwargs): ... print("Running function:",func.__name__) ... print("Positiona.:",func.__name__) ... print("Positional arguments:", args) ... print("Positional arguments:",func.__name__) ... print("Keyword arguments:", kwargs) ... print("Result:",result) ... return result ... return new_function() ... >>> def add_ints(a,b): ... return a+b ... >>> add_ints(3,5) 8 >>> c_add_ints=document_it(add_ints) Running function: add_ints Positiona.: add_ints Positional arguments: () Positional arguments: add_ints Keyword arguments: {} Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 10, in document_it File "<stdin>", line 8, in new_function NameError: name 'result' is not defined上記2点回答いただけるとありがたいです。
#③ >>> def document_it(func): ... def new_function(*args,**kwargs): ... print("Running function:",func.__name__) ... print("Positional arguments:",args) ... print("Keyword arguments:",kwargs) ... result =func(*args,**kwargs) ... print("Result:",result) ... return result ... return new_function() ... #デコレートしたい関数の直前に@decorator_name形式で追加する。 >>> @document_it ... def add_ints(a=1,b=2): ... return a+b ... Running function: add_ints Positional arguments: () Keyword arguments: {} Result: 34.10 名前空間とスコープ
- 名前空間とは特定の名前の意味が一意に決まり、他の名前空間と同じ名前とは無関係になる領域のこと。しかし、必要なら他の名前空間にアクセスできる。
- プログラムのメイン部分はグローバル名前空間を定義する。この名前空間の変数はグローバル変数と呼ばれる。
- pythonは名前空間にアクセスするために二つの関数を用意している。
- locals()はローカル名前空間の内容を示す辞書を返す。
- globals()はグローバル名前空間の内容を示す辞書を返す。
#グローバル変数の値は関数内から参照できる。 >>> animal="Z" >>> def print_global(): ... print("inside print_global:",animal) ... >>> print("at the top level:",animal) at the top level: Z >>> print_global() inside print_global: Z #関数内でグローバル変数の値を取得し、書き換えようとするとエラーが起きる。 >>> def changed_and_print_global(): ... print("inside change_and_print_global:",animal) ... animal="wombat" ... print("after the change:",animal) ... >>> changed_and_print_global() Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 2, in changed_and_print_global UnboundLocalError: local variable 'animal' referenced before assignment #change_local()関数もanimalという変数を持っているが、その変数は関数のローカル名前空間内の存在。 >>> animal="Z" >>> def change_local(): ... animal = "W" ... print("inside change_local:",animal,id(animal)) ... #change_local()の中のanimal変数がプログラム内のanimal変数とは別物であることがわかる。 >>> change_local() inside change_local: W 4564475440 >>> animal 'Z' >>> id(animal) 4564751344 #グローバル変数にアクセスするにはglobalキーワードを使ってそのことを明示しなければならない。 >>> animal="Z" >>> def change_and_print_global(): ... global animal ... animal = "wombat" ... print("inside change_and_print_global:",animal) ... >>> animal 'Z' >>> change_and_print_global() inside change_and_print_global: wombat >>> animal 'wombat' #関数内でglobalと書かなければ、Pythonはローカル名前空間を使い、animal変数はローカルになる。関数が終わったら、ローカル変数は消えて無くなる。 >>> animal="Z" >>> def change_local(): ... animal = "wombat" ... print("locals:",locals()) ... >>> animal 'Z' #ローカル名前空間の内容を示す辞書を返す。 >>> change_local() locals: {'animal': 'wombat'} #グローバル名前空間の内容を示す辞書を返す。 >>> print("globals:",globals()) globals: {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'document_it': <function document_it at 0x110146290>, 'add_ints': 3, 'square_it': <function square_it at 0x110146440>, 'animal': 'Z', 'print_global': <function print_global at 0x1101464d0>, 'changed_and_print_global': <function changed_and_print_global at 0x1101465f0>, 'change_local': <function change_local at 0x110146950>, 'change_and_print_global': <function change_and_print_global at 0x110146830>} >>> animal 'Z'4.10.1 名前の中のと_
- 先頭と末尾が2個のアンダースコアになっている名前は、Pythonが使う変数として予約されている。
>>> def amazing(): ... '''これは素晴らしい関数だ ... もう1度見る''' #関数の名前はシステム変数のfunction_name__(基本形式) ... print("この関数の名前:",amazing.__name__) #docstringはシステム変数のfunction_doc__(基本形式) ... print("docstring:",amazing.__doc__) ... >>> amazing() この関数の名前: amazing docstring: これは素晴らしい関数だ もう1度見る4.11 エラー処理とtry,except
- 例外が起きそうなところには全て例外処理を追加して、ユーザーに何が起きるか知らせておくのがグッドプラクティス。
#プログラム強制終了 >>> short_list=[1,2,3] >>> position = 5 >>> short_list[position] Traceback (most recent call last): File "<stdin>", line 1, in <module> IndexError: list index out of range #tryを使って例外が起きそうな場所を囲み、exceptを使って例外処理を提供すべき。 #tryブロックのコードが実行され、そこでエラーが起きると例外は生成されexceptブロックのコードが実行される。例外が起きなければexceptブロックは実行されない。 >>> short_list=[1,2,3] >>> position = 5 >>> try: ... short_list[position] ... except: ... print("Need a position between 0 and",len(short_list)-1,"but got",position) ... Need a position between 0 and 2 but got 5#exceptを使うと全ての例外をキャッチする。 #詳細情報が分かるようにしたい場合、except exceptiontype as nameの基本形式を記述する。 >>> short_list=[1,2,3] >>> while True: ... value=input("Position[q to quit]?") ... if value =="q": ... break ... try: ... position=int(value) ... print(short_list[position]) ... except IndexError as err: ... print("bad index:",position) ... except Exception as other: ... print("Something else broke:",other) ... Position[q to quit]?1 2 Position[q to quit]?0 1 Position[q to quit]?2 3 Position[q to quit]?3 bad index: 3 Position[q to quit]?2 3 Position[q to quit]?two Something else broke: invalid literal for int() with base 10: 'two' Position[q to quit]?q4.12 独自例外の作成
- 独自の例外型を定義できる。
#例外が生成された時に何を表示すべきか親クラスのExceptionに任せている。 >>> class OopsException(Exception): ... pass ... >>> try: ... raise OopsException("panic") ... except OopsException as exc: ... print(exc) ... panic4.13 復習課題
4-1 変数guess_meに7を代入しよう。次にguess_meが7より小さければtoo low、7よりも大きければtoo high、等しければjust right表示しよう。
>>> if guess_me<7: ... print("too low") ... elif guess_me>7: ... print("too high") ... elif guess_me==7: ... print("just right") ... just right4-2 変数guess_meに7、変数startに1を代入し、startとguess_meを比較するwhileループを書こう。
>>> while True: ... if start<guess_me: ... print("too low") ... elif start==guess_me: ... print("found it!") ... break ... elif start>guess_me: ... print("oops") ... break ... start+=1 ... too low too low too low too low too low too low found it!##4-3 forループを使ってリスト[3,2,1,0]の値を表示しよう。
>>> list=[3,2,1,0] >>> for x in list: ... print(list[x]) ... 0 1 2 34-4 リスト内包表記を使ってrange(10)の偶数のリストを作ろう。
>>> list=[number for number in range(10) if number%2==0] >>> list [0, 2, 4, 6, 8]4-5 辞書内包表記を使ってsquaresという辞書を作ろう。ただし、range(10)を使ってキーを返し、各キーの辞書の自乗をその値とする。
>>> squares={number:number*number for number in range(10)} >>> squares {0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}4-6 集合内包表記を使ってrange(10)の奇数からoddという集合を作ろう。
>>> odd= {number for number in range(10) if number%2==1} >>> odd {1, 3, 5, 7, 9}4-7 ジェネレータ内包表記を使ってrange(10)の数値に対しては"Got "と数値を返そう。
>>> for thing in ("Got %s" %number for number in range(10)): ... print(thing) ... Got 0 Got 1 Got 2 Got 3 Got 4 Got 5 Got 6 Got 7 Got 8 Got 94-8 ["H","R","Hermione"]というリストを返すgoodという関数を定義しよう。
>>> def good(): ... print(["H","R","Hermione"]) ... >>> good() ['H', 'R', 'Hermione']4-9 range(10)から奇数を返すget_oddsというジェネレータ関数を定義しよう。また、forループを使って、返された3番目の値を見つけて表示しよう。
#ジェネレータ関数はyieldで返す。 >>> def get_odds(): ... for x in range(1,10,2): ... yield x ... #enumerate()関数を使うと、for文の中でリスト(配列)などのイテラブルオブジェクトの要素と同時にインデックス番号(カウント、順番)を取得できる。インデックス番号, 要素の順に取得できる。 #オフセットを1からに指定。 >>> for count,number in enumerate(get_odds(),1): ... if count==3: ... print("The third number is",number) ... break ... The third number is 54-10 関数が呼び出された時に"start"、終了した時に"end"を表示するデコレータを定義しよう。
>>> def test(func): ... def new_func(*args,**kwargs): ... print("start") ... result = func(*args,**kwargs) ... print("end") ... return result ... return new_func ... >>> @test ... def greeting(): ... print("Hello!") ... >>> greeting() start Hello! end4-11 OopseExceptionという例外を定義しよう。次に何が起きたかを知らせるためにこの例外コードとこの例外をキャッチして"Caught an oops"と表示するコードを書こう。
#OopseExceptionの定義 >>> class OopseException(Exception): ... pass ... >>> raise OopseException() Traceback (most recent call last): File "<stdin>", line 1, in <module> __main__.OopseException >>> try: ... raise OopseException ... except OopseException: ... print("Caught an oops") ... Caught an oops4-12 zip()を使ってmoviesという辞書を作ろう。辞書はtitles=["C","B","A"]、plots=["D","W"]というリストを組み合わせて作るものとする。
>>> titles=["C","B","A"] >>> plots=["D","W"] >>> movies=dict(zip(titles,plots)) >>> movies {'C': 'D', 'B': 'W'}感想
4.9 デコレータが不明だったのでご教示いただければと思います。
よろしくお願いいたします。
4章の復習ボリューム多かったな。1日がかりだった。参考文献
「Bill Lubanovic著 『入門 Python3』(オライリージャパン発行)」
- 投稿日:2020-01-13T23:42:16+09:00
PythonGUI(コンボックス)で行列を作成
GUI(コンボボックス)で行列の要素の値を入力し2次元配列型のデータを取得するソースです。行列のサイズ、コンボボックスのリストも変数により変更可能。
qiita.rbfrom tkinter import * from tkinter import ttk import numpy as np #入力用のGUI def GUI_Input(n,m): root = Tk() root.title('Table Input') #入力用フレーム frame = ttk.Frame(root) frame.grid(row=0, column=0) list_Items = [0]*(n*m) N = n M = m k=0 for i in range(0, n): for j in range(0, m): valuelist = [1,2,3,4,5,6,7,8,9] list_Items[k] = ttk.Combobox(frame,values=valuelist,width = 2) list_Items[k].grid(row=i+1, column=j+1) k+=1 #コンボボックスからデータを取得し2次元配列としてpritnt出力 def ButtonClicked_Run(): B = [0]*(N*M) for i in range(N*M): B[i] = list_Items[i].get() A= np.reshape(B, (N,M)) print(A) #実行ボタンの設置 button_Run = ttk.Button(root, text='実行', padding=5, command=ButtonClicked_Run) button_Run.grid(row=1, column=0) root.mainloop() #n、mの数を変えて、行列のサイズを指定 m = 9 n = 9 GUI_Input(m,n)結果
⬇︎


- 投稿日:2020-01-13T23:42:16+09:00
PythonGUI(コンボボックス)で行列を作成
GUI(コンボボックス)で行列の要素の値を入力し2次元配列型のデータを取得するソースです。行列のサイズ、コンボボックスのリストも変数により変更可能。
qiita.rbfrom tkinter import * from tkinter import ttk import numpy as np #入力用のGUI def GUI_Input(n,m): root = Tk() root.title('Table Input') #入力用フレーム frame = ttk.Frame(root) frame.grid(row=0, column=0) list_Items = [0]*(n*m) N = n M = m k=0 for i in range(0, n): for j in range(0, m): valuelist = [1,2,3,4,5,6,7,8,9] list_Items[k] = ttk.Combobox(frame,values=valuelist,width = 2) list_Items[k].grid(row=i+1, column=j+1) k+=1 #コンボボックスからデータを取得し2次元配列としてpritnt出力 def ButtonClicked_Run(): B = [0]*(N*M) for i in range(N*M): B[i] = list_Items[i].get() A= np.reshape(B, (N,M)) print(A) #実行ボタンの設置 button_Run = ttk.Button(root, text='実行', padding=5, command=ButtonClicked_Run) button_Run.grid(row=1, column=0) root.mainloop() #n、mの数を変えて、行列のサイズを指定 m = 9 n = 9 GUI_Input(m,n)結果
⬇︎
- 投稿日:2020-01-13T23:42:16+09:00
PythonGUI(tkinterコンボボックス)で行列を作成
GUI(tkinterコンボボックス)で行列の要素の値を入力し2次元配列型のデータを取得するソースです。行列のサイズ、コンボボックスのリストも変数により変更可能。
qiita.rbfrom tkinter import * from tkinter import ttk import numpy as np #入力用のGUI def GUI_Input(n,m): root = Tk() root.title('Table Input') #入力用フレーム frame = ttk.Frame(root) frame.grid(row=0, column=0) list_Items = [0]*(n*m) N = n M = m k=0 for i in range(0, n): for j in range(0, m): valuelist = [1,2,3,4,5,6,7,8,9] list_Items[k] = ttk.Combobox(frame,values=valuelist,width = 2) list_Items[k].grid(row=i+1, column=j+1) k+=1 #コンボボックスからデータを取得し2次元配列としてpritnt出力 def ButtonClicked_Run(): B = [0]*(N*M) for i in range(N*M): B[i] = list_Items[i].get() A= np.reshape(B, (N,M)) print(A) #実行ボタンの設置 button_Run = ttk.Button(root, text='実行', padding=5, command=ButtonClicked_Run) button_Run.grid(row=1, column=0) root.mainloop() #n、mの数を変えて、行列のサイズを指定 m = 9 n = 9 GUI_Input(m,n)結果
⬇︎
- 投稿日:2020-01-13T23:16:19+09:00
【Python】 jsonと辞書
はじめに
Pythonでjsonのデータを扱うことがあったのですが、Python標準のdict型と親和性があるので紹介します。
jsonとは
こちらとても参考になります。ありがとうございます。
JavaScript Object Notation
データを表現するための記法です。
JavaScriptの構文に似ていますが、JavaScriptとは独立して扱われます。
JavaScript以外のプログラミング言語でもJSONを扱うことができる機能が準備されています。この記事はJSONを使っていくことを中心な記事なので細かい説明は省略します。
形式は以下のようなものです。keyに対してvalueが紐づいているという感じです。{ "key":value, "key":value, "key":value }keyとvalueのセットというのはPythonのdictと同じですね。
Pythonのjsonモジュール
Pythonにjsonモジュールが存在します。dict⇔jsonの変換を主にやってくれます。
dictからjsonへの変換には
json.dumpsを使います。
dictの型はもちろんdictですが、変換後はstr型になります。import json sample_dict = {"Japan":"Tokyo","UK":"London","USA":"Washington, D.C."} print(type(sample_dict)) print(sample_dict) # 出力 # <class 'dict'> # {'Japan': 'Tokyo', 'UK': 'London', 'USA': 'Washington, D.C.'} # 変換 sample_json = json.dumps(sample_dict) print(type(sample_json)) print(sample_json) # 出力 # <class 'str'> # {"Japan": "Tokyo", "UK": "London", "USA": "Washington, D.C."}pandasからjsonに変換する
pandas DataFrameやpandas Seriesからもjsonに変換することができます。個人的にpandasはよく使うのでありがたいです。
pandasDataFrame(Series)からjsonへの変換はto_json()を使います。import pandas as pd df_sample = pd.DataFrame([[1,1,1],[2,3,4],[8,7,6]],columns=["x","y","z"],index=["A","B","C"]) json_df = df_sample.to_json() print(df_sample) print(json_df) # 出力 x y z A 1 1 1 B 2 3 4 C 8 7 6 {"x":{"A":1,"B":2,"C":8},"y":{"A":1,"B":3,"C":7},"z":{"A":1,"B":4,"C":6}}jsonを読み込む
jsonのデータを読み込むには json.loads を使います。
先ほどのsample_jsonを使います。dict_json = json.loads(sample_json) print(type(dict_json)) print(dict_json) # 出力 # <class 'dict'> # {'Japan': 'Tokyo', 'UK': 'London', 'USA': 'Washington, D.C.'}もちろんdict_jsonはPythonのdictなので
print(dict_json['Japan']) # 出力 # Tokyoこのような形でアクセスできます。
おわりに
jsonはpythonだけでなくほかの言語でも使えるので言語間の通信に便利です。ここでは最低限しか説明してませんがぜひ使ってみてください!
思ったこと
自分が使ってみて、とかの視点で書いているのでまったく網羅的に触れることができていない記事ばかりだなと思いました。とりあえず今後も自分が使ってみたものについて書いてみて、見直す必要があった場合は記事を更新していこうかなと思います。
- 投稿日:2020-01-13T23:16:19+09:00
【Python】 PythonでJSONを使う
はじめに
Pythonでjsonのデータを扱うことがあったのですが、Python標準のdict型と親和性があるので紹介します。
jsonとは
こちらとても参考になります。ありがとうございます。
JavaScript Object Notation
データを表現するための記法です。
JavaScriptの構文に似ていますが、JavaScriptとは独立して扱われます。
JavaScript以外のプログラミング言語でもJSONを扱うことができる機能が準備されています。この記事はJSONを使っていくことを中心な記事なので細かい説明は省略します。
形式は以下のようなものです。keyに対してvalueが紐づいているという感じです。{ "key":value, "key":value, "key":value }keyとvalueのセットというのはPythonのdictと同じですね。
Pythonのjsonモジュール
Pythonにjsonモジュールが存在します。dict⇔jsonの変換を主にやってくれます。
dictからjsonへの変換には
json.dumpsを使います。
dictの型はもちろんdictですが、変換後はstr型になります。import json sample_dict = {"Japan":"Tokyo","UK":"London","USA":"Washington, D.C."} print(type(sample_dict)) print(sample_dict) # 出力 # <class 'dict'> # {'Japan': 'Tokyo', 'UK': 'London', 'USA': 'Washington, D.C.'} # 変換 sample_json = json.dumps(sample_dict) print(type(sample_json)) print(sample_json) # 出力 # <class 'str'> # {"Japan": "Tokyo", "UK": "London", "USA": "Washington, D.C."}pandasからjsonに変換する
pandas DataFrameやpandas Seriesからもjsonに変換することができます。個人的にpandasはよく使うのでありがたいです。
pandasDataFrame(Series)からjsonへの変換はto_json()を使います。import pandas as pd df_sample = pd.DataFrame([[1,1,1],[2,3,4],[8,7,6]],columns=["x","y","z"],index=["A","B","C"]) json_df = df_sample.to_json() print(df_sample) print(json_df) # 出力 x y z A 1 1 1 B 2 3 4 C 8 7 6 {"x":{"A":1,"B":2,"C":8},"y":{"A":1,"B":3,"C":7},"z":{"A":1,"B":4,"C":6}}jsonを読み込む
jsonのデータを読み込むには json.loads を使います。
先ほどのsample_jsonを使います。dict_json = json.loads(sample_json) print(type(dict_json)) print(dict_json) # 出力 # <class 'dict'> # {'Japan': 'Tokyo', 'UK': 'London', 'USA': 'Washington, D.C.'}もちろんdict_jsonはPythonのdictなので
print(dict_json['Japan']) # 出力 # Tokyoこのような形でアクセスできます。
おわりに
jsonはpythonだけでなくほかの言語でも使えるので言語間の通信に便利です。ここでは最低限しか説明してませんがぜひ使ってみてください!
思ったこと
自分が使ってみて、とかの視点で書いているのでまったく網羅的に触れることができていない記事ばかりだなと思いました。とりあえず今後も自分が使ってみたものについて書いてみて、見直す必要があった場合は記事を更新していこうかなと思います。
- 投稿日:2020-01-13T22:48:54+09:00
Pythonのパの字も知らない人間がTensorFlowチュートリアルやりながら"完全に理解"していった記録
まえがき
こんにちは、 Webエンジニアをやっているますみんと申します。機械学習が巷では流行りに流行っていますね。自分も大学の講義でなんとなーくやった記憶があるのですが、もう既に覚えてません。さすがにチュートリアルくらいやっておかないと流行についていけないだろうという若干後ろめたい気持ちがドリブンにドリブンを重ねたので、今回はTensorFlowのニューラルネットワークのチュートリアルをやってみることにします。
注意
この記事は、Pythonを触ったこともない初心者がドキュメントあさりながらあーだこーだやった記録です。やったこと、思ったことをそのまま書いていますので、読みやすさは保証できかねます。
環境構築
何から手を付けたらいいのかすらよく分からないけれど、自分の中ではとりあえず「機械学習といえばPython + TensorFlow」っていうイメージなので、TensorFlowをインストールします。TensorFlowってGoogleが作ってるんですね。初めて知りました。
Pythonバージョン確認
Pythonコマンド打ってみる$ python Python 2.7.16 (default, Apr 12 2019, 15:32:40)Pythonは2.x系と3.x系で全然別モノだから気をつけろって誰かに言われた気もしますが、まだ触ったこともないのでそんなのは知りません。とりあえず既にMacに入っていた2.x系で進めることにします。
pipのアップデート
参考: 公式ドキュメント "Install TensorFlow 2"
公式ドキュメントのインストール手順に従い、インストールを進めていきます。GitHubによると、2020/01/12時点でのTensorFlowの最新Versionは2.1.0のようです。
Pythonではpip(Pip Installs Packages)というパッケージ管理ツールで各種パッケージをインストールできるようですね。TensorFlowもこのpipを使ってインストールします。ちなみにちなむと、pipはRubyでいうところのGem、PHPでいうところのComposerみたいなやつです。まずはpip自体のアップデートをします。
pipのアップデート$ pip install -U pip DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won't be maintained after that date. A future version of pip will drop support for Python 2.7. Collecting pip Downloading https://files.pythonhosted.org/packages/00/b6/9cfa56b4081ad13874b0c6f96af8ce16cfbc1cb06bedf8e9164ce5551ec1/pip-19.3.1-py2.py3-none-any.whl (1.4MB) 100% |████████████████████████████████| 1.4MB 7.8MB/s Installing collected packages: pip Found existing installation: pip 19.0.3 Uninstalling pip-19.0.3: Successfully uninstalled pip-19.0.3 Successfully installed pip-19.3.1いきなり悲しいメッセージが表示されました。なんと2020年1月1日でPython2.7はその生涯に幕を下ろしたとのこと?pipも今後のバージョンアップでPython2.7のサポートを終了すると書いてありますね...。Macにはいっているのはガッツリ2.7系のPythonなので、これは困りました...。
それじゃあせっかくなのでTensorFlowがサポートしている中で最新のPythonをインストールしましょう。
2020/01/12時点でPython自体の最新版はVer. 3.9.0a2ですが、TensorFlowでは3.4〜3.7系をサポートしているようなので、3.7.x系で最新の安定版であるVer. 3.7.6をインストールすることにします。Python 3.7.6のインストール
pyenvのインストール
公式ドキュメントに従って直接Pythonをインストールしてもよいのですが、後々またバージョンの違いに泣かされるのは嫌なので、Pythonのバージョン管理ツールを使ってインストールすることにします。
ツールはいろいろあるみたいですが、自分の周りでも結構触ってる人が多いのでpyenvを使うことにしました。pyenvのREADME曰く、MacならHomebrewでインストールできるようですね。ではさっそくインストールしましょう?
pyenvのインストール$ brew update $ brew install pyenvpyenvがインストール出来たか確認$ pyenv pyenv 1.2.16 ...pyenv 1.2.16が無事インストールされました!
pyenvでPython 3.7.6をインストール
インストールしといてアレなんですが、そもそもpyenvでインストールできるバージョンの中に本当にVer. 3.7.6が含まれているのかが分かりません。インストールできるバージョンを確認してみます。
まずはinstallコマンド自体のヘルプを確認してみます。pyenv installコマンドのヘルプを確認$ pyenv install -h Usage: pyenv install [-f] [-kvp] <version> pyenv install [-f] [-kvp] <definition-file> pyenv install -l|--list pyenv install --version -l/--list List all available versions -f/--force Install even if the version appears to be installed already -s/--skip-existing Skip if the version appears to be installed already python-build options: -k/--keep Keep source tree in $PYENV_BUILD_ROOT after installation (defaults to $PYENV_ROOT/sources) -p/--patch Apply a patch from stdin before building -v/--verbose Verbose mode: print compilation status to stdout --version Show version of python-build -g/--debug Build a debug version For detailed information on installing Python versions with python-build, including a list of environment variables for adjusting compilation, see: https://github.com/pyenv/pyenv#readmeどうやら
pyenv install -lもしくはpyenv install --listでインストールできるバージョン一覧を表示できるようです。
ではこのコマンドを打って、 Ver. 3.7.6がインストールできるか確認してみましょう。pyenvでインストール可能なPythonのバージョン一覧表示$ pyenv install -l Available versions: 2.1.3 2.2.3 ... 3.7.6 ...おお、ちゃんとインストールできるみたいですね!一安心です。では改めて、pyenvでVer. 3.7.6をインストールしましょう。
Python 3.7.6をインストール$ pyenv install 3.7.6 python-build: use openssl@1.1 from homebrew python-build: use readline from homebrew Downloading Python-3.7.6.tar.xz... -> https://www.python.org/ftp/python/3.7.6/Python-3.7.6.tar.xz Installing Python-3.7.6... python-build: use readline from homebrew python-build: use zlib from xcode sdk Installed Python-3.7.6 to /Users/<ユーザー名>/.pyenv/versions/3.7.6インストールが終わったようです。でもインストールしただけではまだバージョンが切り替わっていません。
Pythonのバージョン確認$ python --version Python 2.7.16pyenvで使用するPythonのバージョンを指定
もう2.7系は使わないので、pyenvにてMac全体で使用するPythonのバージョンを3.7.6に指定してしまいましょう。
pyenvでglobalバージョンを3.7.6に指定$ pyenv global 3.7.6指定をしたので、再度シェルからPythonのバージョンを確認してみます。
Pythonのバージョン確認$ python --version Python 2.7.16おや、バージョンが切り替わっていません。よくあるパスの問題ですね。
pyenvでインストールしたPythonにパスが通っておらず、pythonコマンドで使える状態になっていません。pyenvでインストールしたPythonのありかにパスを通す
パスを通しましょう。自分はMacのshellをbashのままにしている(macOS Catalinaからはzshがデフォルトになっている)ので、bash_profileに以下を追記します。
~/.bash_profileに追記export PYENV_ROOT="$HOME/.pyenv" # /Users/<ユーザー名>/.pyenv export PATH="$PYENV_ROOT/bin:$PATH" # パス一覧に最優先で $PYENV_ROOT/bin を追加(パスは左側が優先される) eval "$(pyenv init -)" # $PYENV_ROOT/shimsディレクトリ追加、指定したバージョンのPythonをshimsにコピーする。終わったら$PYENV_ROOT/shimsを$PATHに追加追記が終わったら
sourceコマンドで設定を反映させます。~/.bash_profileに記述した設定を反映$ source ~/.bash_profile設定を反映したので、シェルからpythonコマンドのパスを確認してみます。
pythonコマンドのパス確認$ which python /Users/<ユーザー名>/.pyenv/shims/pythonpyenvでインストールしたPythonの方に向いていますね!これでOKです。再度グローバルのバージョンを設定し、バージョンを確認してみます。
グローバルのPythonバージョン設定と確認$ pyenv global 3.7.6 $ python --version Python 3.7.6ちゃんとバージョンが切り替わってますね!これでようやくTensorFlowのインストールに戻れます!
ちょっと脱線「パスって何?」
「パスって何?」っていう人は、「コマンド名を打った時に実際に実行されるファイルのありか」って覚えておけばOKです。
今回はpythonって打った時にpyenvでインストールしたPythonを使いたかったのですが、実際に実行されるファイルのありかにpyenvでインストールしたPythonのありかが入っていなかったので使えなかった、ということになります。もちろん実行ファイル自体は存在していますので、実行ファイルを直指定すれば使うことができます。pyenvでインストールしたPythonの実行ファイルを直指定してバージョン確認$ ~/.pyenv/versions/3.7.6/bin/python --version Python 3.7.6pipのアップデート
pipもpyenv配下のものを使うように変わったので、改めてアップデートをしておきます。
pipコマンドの実態のありかがpyenv配下になっている$ pip --version pip 19.2.3 from /Users/<ユーザー名>/.pyenv/versions/3.7.6/lib/python3.7/site-packages/pip (python 3.7)pipのアップデート$ pip install -U pip Collecting pip Using cached https://files.pythonhosted.org/packages/00/b6/9cfa56b4081ad13874b0c6f96af8ce16cfbc1cb06bedf8e9164ce5551ec1/pip-19.3.1-py2.py3-none-any.whl Installing collected packages: pip Found existing installation: pip 19.2.3 Uninstalling pip-19.2.3: Successfully uninstalled pip-19.2.3 Successfully installed pip-19.3.1アップデートが完了しました!
TensorFlowをインストール
だいぶ遠回りをしてしまいましたが、ようやく諸問題が片付きました。ではpipでTensorFlowをインストールしてみましょう。
TensorFlowの公式ドキュメント曰く、
- 最新の安定版をインストールする場合 ...
pip install tensorflow- 最新の開発版をインストールする場合 ...
pip install tf−nightlyとするようです。最新の安定版をインストールしたいので、今回は前者のコマンドになります。
TensorFlowをインストール$ pip install tensorflowインストールが完了しました!いい感じ!!
Pythonスクリプトを実行してみる
全くの初心者なので、そもそもPythonをどうやって動かすのかよく分かっていません。なのでまず最初にHello Worldしてみたいと思います。
試しにHello, Worldとだけ表示するスクリプトを書いてみます。Pythonでは変数の標準出力はprint()関数で行えるようです。sample.pyprint('Hello, World')このPythonスクリプトをコマンドラインから実行してみます。
sample.pyを実行$ python sample.py Hello, Worldおおっ、Hello Worldができました!調子いいですね?
ちなみにpythonとだけ打つと、対話型のPython実行環境が立ち上がります。いちいちスクリプト書いて実行するの面倒ならこちらでもいいかもしれません。TensorFlowのチュートリアルをやってみる
TensorFlow 公式ドキュメント "はじめてのニューラルネットワーク:分類問題の初歩"
さ、ようやく本題のTensorFlowのチュートリアルです?
初心者向けチュートリアルの中に「身につけるモノの写真分類」といういかにもそれっぽいお題があったので、今回はそれをやってみることにします。ちなみにこのチュートリアルで取り上げられている機械学習の手法はニューラルネットワークといって、生物の神経回路に似せた構造になっています。tutorial.pyfrom __future__ import absolute_import, division, print_function, unicode_literals # TensorFlow と tf.keras のインポート import tensorflow as tf from tensorflow import keras # ヘルパーライブラリのインポート import numpy as np import matplotlib.pyplot as plt print(tf.__version__)ふむふむ。はじめにPythonのインポートシステムというのを使って他のモジュールを使えるようにしているのですね。fromはモジュールの中の特定属性だけimportするときに使う構文のようです。
__future__というモジュールが提供しているいろいろな機能を使えるようにしているわけですね。で次に、pipでさっきインストールしたtensorflowをインポートするわけですが、名前が長いから
tfという名前でモジュールを扱えるようにしてある、と。なるほど。このへんはJavaScriptとかでも見るやつですね。PHPもuse asで名前空間のエイリアス作成できますね。おんなじや!次の行をみると、tensorflowの中にkerasという機能が盛り込まれているようですね。これもそのままインポートすると
tf.kerasってなるはずですが、頻繁に使われるからkerasだけで呼べるようにしてある、ということですかね。ふむ〜。あとは同じですね。
numpyをnpで呼べるようにした上でインポート、matplotlib.pyplotをpltで呼べるようにした上でインポートしています。な〜んだ、初期化だけじゃんか!
そして最後にtf.__version__で、インストールしたTensorFlowのバージョンを表示して終了です。楽勝楽勝!?では一旦これで実行してみましょう。
tutorial.pyの実行$ python tutorial.py Traceback (most recent call last): File "tutorial.py", line 9, in <module> import matplotlib.pyplot as plt ModuleNotFoundError: No module named 'matplotlib'お、楽勝かと思っていたらさっそくエラー。コピペでうまく動かない箇所が出てきました。
matplotlibというパッケージがインストールされていないようですね。どうやらこのmatplotlibというパッケージは標準パッケージではないので、pipでのインストールが必要だったみたいです。
numpyも標準パッケージではないようですが、こちらはPythonのインストールの仕方によっては同梱されてるらしいです。以前ちらっとだけPython触ったときにもしかすると入っちゃったのかな?(無知)matplotlibパッケージをインストール
pipでmatplotlibパッケージをインストール$ pip install matplotlib無事にインストールが完了したら、再度tutorial.pyを実行します。
tutorial.pyの実行$ python tutorial.py 2.1.0今度はうまくいきました!バージョン2.1.0のTensorFlowがインストールされていることを確認できました!
ファッションMNISTデータセットのダウンロード
機械学習には、学習するためのデータセットが必要です。チュートリアルで使用するデータセットをダウンロードする行をスクリプトに追加しましょう。追記した行だけ表示すると、以下のようになります。
tutorial.pyfashion_mnist = keras.datasets.fashion_mnist (train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()kerasっていうのはPythonで使えるニューラルネットワークライブラリのことらしく、TensorFlowにも組み込まれています。読み方は「ケラス」っぽいです(公式ドキュメントで名前に触れている部分と、ギリシャ語表記の方のGoogle翻訳結果)。TensorFlowでは、よく使われるデータセットはこのtf.keras.datasets モジュールのAPIで呼び出せるようです。
ってか公式のドキュメント見てて思ったんですが、TensorFlow公式も自身のこと
tfって略して表記するの推奨なんですね。まぁ確かに、何回もコード内に出てきたらちょっと見づらいかもです?まま、さっそくダウンロードをば。
ファッションMNISTデータセットのダウンロード$ python tutorial.py 2.1.0 Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 2s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 8192/5148 [===============================================] - 0s 1us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/stepダウンロードが完了しました!一度ダウンロードしてしまったあとは、もうダウンロードの必要はないみたいですね。
ちなみにダウンロードしてきたファイルは~/.keras/datasets/<データセット名>/に保存されます。keras APIのドキュメントを見ると保存先のパスを渡せるみたいなので、TensorFlowで用意されたラッパーではなく元のAPIを使えば任意の場所に保存できます。データセットの保存先$ ls ~/.keras/datasets/fashion-mnist/ t10k-images-idx3-ubyte.gz t10k-labels-idx1-ubyte.gz train-images-idx3-ubyte.gz train-labels-idx1-ubyte.gzちょっと脱線「MNISTデータセット(MNIST Database)って何?」
機械学習では、大量のデータ群を学習させることでモデルを作り出します。この大量のデータ群というのがミソで、数十というオーダーではまず足りません。さらに集めたデータ群は入力のフォーマットが揃うように前処理が必要となるため、データ集めだけで骨が折れるというのがこの分野でよく言われること(らしい)です。これでは初心者の参入障壁が爆上がりしてしまう(学習させられるだけのデータ群を用意できずに挫折する)ということで、初学者向けのチュートリアル等では予め用意されたデータセットを使うことが多いようです。
機械学習界隈で有名なデータセットの1つにNIST Databaseがあります。これはもともとアメリカ国立標準技術研究所(NIST)のSRD(Standard Reference Data)で頒布されていた手書き文字のデータ群であり、このNIST Databaseをより使いやすく改修したのがMNIST Database(MNISTのMはModifiedのM)です。MNIST Databaseは機械学習のいわばHello Worldといえます。TensorFlowのtf.keras.datasetsモジュールでももちろんMNIST Databaseが使えます。
TensorFlowのチュートリアルでは、単純かつ使われすぎてしまったMNISTデータセットを置き換える目的で作られたファッションMNISTデータセットを使用しています。学習データの用意
機械学習の大枠の流れとしては、
- モデルを作成
- 学習データをモデルに流し、学習させる
- 学習が済んだモデルにテストデータを流し、精度を確認する
- 学習が済んだモデルに実データを流す
という感じです。ただモデルを作っただけではダメで、分類やらなんやらのコツを学習するための学習データ、モデルの精度を確認するためのテストデータが必要ということですね。ファッションMNISTデータセットには、学習データとテストデータの両方が含まれています。試しに以下を
tutorial.pyに追記して、学習データの1番目を表示してみます。tutorial.py(学習データを表示する)plt.figure() plt.imshow(train_images[0]) plt.colorbar() plt.grid(False) plt.show()
pltはimport matplotlib.pyplot as pltでインポートした機能でした。matplotlibはおそらくmatrix plot libraryの略称かと思われますが、要は行列に格納されたデータからいい感じの図を作ってくれるモジュールです。このモジュールのうち、pyplotっていう機能を使うやで〜ってことですね。公式曰くpyplotはMATLABライクなインターフェースで図を描くことができるとのことで、用意された関数やその使い方は確かにMATLABっぽさがある...かも。
新しい図を作成して、図に画像を貼り付けてカラーバー表示して、グリッド消して図を表示する。MATLABのimagesc()とかそのへんに近いですね。じゃあスクリプトを実行して学習データの1番目を表示してみましょう。
これは...ブーツですね!こんな感じで、0〜255の値が入った28px × 28pxの画像が60,000枚入っています。じゃあこれをさっそくニューラルネットワークに...といきたいところですが、それぞれの画素の値を0〜1の値にしてから突っ込みたいのでここでちょっとデータを加工。いわゆる前処理というやつですね。なるほど。
tutorial.py(データの前処理)train_images = train_images / 255.0 test_images = test_images / 255.0なにげな〜く書いていますが、配列の各要素を一気に割り算できるあたり、やはりPythonだな〜って感じがします。PHPとかRubyとかだとfor文で要素を1つずつ割っていかないといけないですからね。Pythonだと行列計算しやすいっていうのはこういう実装がされているからなんだな〜としみじみ感じます。
さて、各データセットには「その画像が実際何の画像なのか」を表す
ラベルが付いています。しかしラベルは文字列ではなく整数で格納されているので、クラス(それぞれの振る舞いを表すもの)の名称に衣料品の名前を付け、クラスとラベルとを対応付けます。tutorial.py(クラス名定義)class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']例えば
class_names[0]はT-shirt/top、class_names[1]はTrouser(ズボンのこと)といった具合になります。念の為、正しいクラス名になっているかどうかを確認しましょう。
tutorial.py(クラス名の確認)plt.figure(figsize=(10,10)) for i in range(25): plt.subplot(5,5,i+1) plt.xticks([]) plt.yticks([]) plt.grid(False) plt.imshow(train_images[i], cmap=plt.cm.binary) plt.xlabel(class_names[train_labels[i]]) plt.show()先に結果を見てみるとこんな感じ。
おお、チュートリアルページに載っているのと同じですね!(当たり前)
正しいラベルが振られていることが確認できました。後はモデルを作ってデータをブチ込むだけです!?コードをちょっと追ってみます。といってもほぼ「matplotlib.pyplotのドキュメント読め」で終わる話ではあるんですが?
figsizeはインチ指定です。この場合10インチ * 10インチの図を作るってことですね。ドキュメントによると、デフォルトは6.4インチ * 4.8インチです。
range()関数(正確には、作成後値が変更できない(イミュータブルという)Pythonの型)は、引数1こ(nとする)だけ取った場合n未満を常に満たすようにして、0から1ずつカウントアップしたものを返します。先述の通りrangeは型扱いなので、配列とはちょっと違うみたいですね。といってもインデックス指定して要素取ってくる操作は配列のそれと何ら変わりありませんが。for文まで来ました。Pythonのfor文は結構独特な書き方するんですね?他の言語のcase文っぽさがあります。Pythonにおいてインデントは非常に重要らしく、for文でインデントがないとエラーになってしまいます。まぁRubyとかと違ってendとかないし、そりゃそうだよねって感じです。
で画像を1枚1枚図に貼り付けていきます。5行5列の配置場所に対し、左上から始まり右端へ向けて画像を貼っていき、右端にきたら次の行に進む、という感じですね。plot()関数は1つの画像やグラフ表示、subplot()関数は複数の画像やグラフを表示するときに使うようですね。
xticks()、yticks()はそれぞれグラフの縦軸の目盛り、横軸の目盛りの刻みを取得 or 設定します。空の配列を渡すことで目盛りなしに出来ます。今回は画像を貼るので目盛りはいらないですね。なので空配列を渡しています。グリッド表示もいらないので、grid()にはFalseを渡しています。Pythonのbool型って頭文字が大文字なんですね。小文字でも判定できるようにするモジュールも用意されているようですが、使う時明示しないといけないのでちと面倒ですね。なんでこういう実装なんだろう。
imshow()はさっきやったので、xlabel()を見てみましょう。ってかgrid()もさっきあったな。まぁいいや。
xlabel()はx軸方向(今は横方向)に表示するラベルです。画像が属するクラスの名前を表示していますね。これをylabel()に変えると、y軸方向にラベルが表示されます。参考までに、4行7列で画像を表示してy軸方向にラベルをつけるとこんな具合になります。
だんだんわかってきたぞ!?
モデルを構築する
ここからは主にkeras APIを使うことになるので、説明はしょった部分はAPIのドキュメントみて補完してください。
いよいよモデルの構築に入ります。このチュートリアルではニューラルネットワークを構築しているといいましたが、ニューラルネットワークにおいて重要なのが
層と呼ばれる概念です。入力があったらなにかしら重み付けをして出力するものだと思ってもらえればいいかと。この層を順に積んで作るモデルを、kerasではSequentialと呼んでいるようですね。tutorial.py(モデル構築)model = keras.Sequential([ keras.layers.Flatten(input_shape=(28, 28)), keras.layers.Dense(128, activation='relu'), keras.layers.Dense(10, activation='softmax') ])モデルの中身がそれぞれ何をしているかはチュートリアルのページを是非見てほしい(逃げの姿勢!)のですが、平たく言うと
- 入力された画像(要素数28 * 28の2次元配列)を、1次元配列に変換(厳密にはこの層はニューラルネットワークの前処理をする層)
- 128個の人工ニューロンからなる全結合層を作り、ReLUという種類の伝達関数(活性化関数)に入力し値を加工、出力する
- 10個の人工ニューロンからなる全結合層を作り、ソフトマックスという種類の伝達関数(活性化関数)に入力し値を加工、出力する(出力は各ラベルに属する確率になる)
って感じです。まぁなんとなく分かったところで、モデルをコンパイルしてみましょう。
tutorial.py(モデルのコンパイル指示)model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])ここもなんとなく理解する程度にとどめておきます(ホントはこのあたりが一番面白いところだけど、ガッツリ数学なので)。ざっくり見ると、コンパイルには以下の3つが必要だということらしいですね。
- 損失関数(loss function) ... 誤差関数とも呼ばれるやつ。学習中のモデルの正確さを表す。値が低いほど正確。今回はsparse_categorical_crossentropyというやつを使う
- オプティマイザ(optimizer) ... モデルの更新方法。今回はAdamというアルゴリズムを用いている。
- メトリクス(metrics) ... モデルの更新ステップで何を監視するかを指定。今回はモデルの正解率を監視する
なんのこっちゃって感じになってきましたね。でも「機械学習を使ってとりあえず何かする」だけなら、この辺はあまり深く追わなくてOKです。何層で何をして、どういう更新方法使って...とかいう部分は全て、正解率を上げるための変数の1つに過ぎません。より正解率の高いモデルを作りたくなったら、その時初めて数学を学べばよいでしょう。ということで、今はこの辺スルーでいきます?
モデルに学習させる
学習用のデータセットをモデルに読み込ませて、学習をさせます。ニューラルネットワークに大量の画像を突っ込み、「この画像はこのクラスに分類されるやで〜?」っていうのを覚えさせるわけですね。かんたんかんたん!やってみましょう。
tutorial.py(モデルに学習させる)model.fit(train_images, train_labels, epochs=5)学習用のデータセットとラベルを使って、同じデータで5回学習させるわけですね。ふむふむ。いざ実行!
学習を実行する$ python tutorial.py 2020-01-12 23:53:12.524687: I tensorflow/core/platform/cpu_feature_guard.cc:142] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA 2020-01-12 23:53:12.684666: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7ff1c0a736e0 initialized for platform Host (this does not guarantee that XLA will be used). Devices: 2020-01-12 23:53:12.684725: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version Train on 60000 samples Epoch 1/5 60000/60000 [==============================] - 4s 65us/sample - loss: 0.4982 - accuracy: 0.8242 Epoch 2/5 60000/60000 [==============================] - 3s 50us/sample - loss: 0.3763 - accuracy: 0.8648 Epoch 3/5 60000/60000 [==============================] - 3s 48us/sample - loss: 0.3373 - accuracy: 0.8773 Epoch 4/5 60000/60000 [==============================] - 3s 48us/sample - loss: 0.3142 - accuracy: 0.8849 Epoch 5/5 60000/60000 [==============================] - 3s 54us/sample - loss: 0.2967 - accuracy: 0.8902「GPUではなくCPUで頑張って学習しちゃってるけど大丈夫か〜?」ってPythonに言われてるけど、大丈夫なので無視します。ちゃんと学習できてるみたいですね!素晴らしい!最終的には正解率89%くらいのモデルが出来上がりました!
正解率の評価
学習に使っていないテスト用データセットにも、ラベルがついています。これを学習が終わったモデルに流し込むことで、モデルにデータ突っ込んだら実際どのくらいの正解率になるのかを予測してみます。
tutorial.pytest_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2) print('\nTest accuracy:', test_acc)正解率の予測をしてみる$ python tutorial.py 10000/10000 - 0s - loss: 0.3457 - accuracy: 0.8752 Test accuracy: 0.8752ほほう、87.5%...学習の最後のステップよりちょっと正解率下がりましたね。チュートリアル曰く、この差はいわゆる過学習の一例とのことです。学習用データセットで正解率が高くなるような学習の仕方をしすぎたせいで、他のデータが入ってきたときにモデルが「オレが知ってるデータと違う...」と疑心暗鬼になってしまう状態のことですね。な〜るほど。まぁここも今はスルーして、とりあえず実際にデータ突っ込んで結果を見てみましょう。
学習が終わったモデルで新しいデータを分類してみる
とうとうチュートリアルのゴールにたどり着きました!完成したモデルにデータを投げて、ちゃんと分類されているか見てみましょう。
tutorial.py(分類)predictions = model.predict(test_images) print(predictions[0]) print('\n This image shows ', class_names[np.argmax(predictions[0])])分類の実行$ python tutorial.py [1.1950669e-06 2.0900355e-08 8.5691376e-08 2.0669324e-07 5.3152036e-07 1.7759526e-02 7.3810802e-06 3.2051697e-02 1.6501182e-05 9.5016277e-01] This image shows Ankle boot数字だらけの配列は
入力された画像がそれぞれのラベルに分類される確率を表しています。で、結果としてこのモデルは入力された画像群の1番目をブーツであると分類したわけですね。確認のためにtest_images[0]を図示してみると...
うむ、ブーツですね!!素晴らしい!!?
ということで、チュートリアルを終え無事に身につけるモノ画像分類器が完成しました!基礎の基礎ができたので、今回はここまで!PythonもTensorFlowも完全に理解した!?(初心者特有の謎の自信)
学習に使う関数とかは確かに難しいのですが、「機械学習でなんやかんやする」だけなら細かいロジック覚えなくてもまぁなんとかなりそうだなっていうことが分かりました。
ただどっかにも書きましたが、実際にモデル構築するときはとにかくデータセット作成がめちゃくちゃ大変だなって気がします。チュートリアルでは既存のデータセットを使ったので簡単に実装できますけど、これ1から自分でデータ用意するのまじで骨折れますね...ま、次は自前でなんか作ってみます?




- 投稿日:2020-01-13T22:33:26+09:00
ジェネレーター
forループでl = ['おはよう', 'こんにちは', 'こんばんは'] for i in l: print(i)forループでの実行結果おはよう こんにちは こんばんはこれをジェネレーターを使って書くと、
ジェネレーター1def greeting(): yield 'おはよう' yield 'こんにちは' yield 'こんばんは' g = greeting() print(next(g)) print(next(g)) print(next(g))ジェネレーター1の実行結果おはよう こんにちは こんばんはジェネレーターを2つにすると、
ジェネレーター2つdef greeting(): yield 'おはよう' yield 'こんにちは' yield 'こんばんは' g = greeting() def counter(num=10): for i in range(num): yield 'ががががががー!!!' c = counter() print(next(g)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(g)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(c)) print(next(g))ジェネレーター2つの実行結果おはよう ががががががー!!! ががががががー!!! ががががががー!!! ががががががー!!! ががががががー!!! こんにちは ががががががー!!! ががががががー!!! ががががががー!!! ががががががー!!! ががががががー!!! こんばんはforループの様に一気に処理するのではなく、
要素の生成を保持したまま、
他の処理をする事ができる。なので、
例えば下記のコードの様に、
重たい処理が途中に入っていた場合、
一気に全ての処理をするよりも、
小分けにして実装する事ができる。ジェネレーター重いdef greeting(): yield 'おはよう' for i in range(1000000): print(i) yield 'こんにちは' for i in range(1000000): print(i) yield 'こんばんは'yield 'おはよう' を処理。
for i in range(1000000):
print(i) を処理しなくもよい。次に
for i in range(1000000):
print(i)
yield 'こんにちは' を処理。という具合に小分けに処理できる。
ジェネレーターエラーdef greeting(): yield 'おはよう' yield 'こんにちは' yield 'こんばんは' g = greeting() for i in range(4): print(next(g))ジェネレーターエラーの実行時エラーTraceback (most recent call last): File "Main.py", line 9, in <module> print(next(g)) StopIterationおはよう、こんにちは、こんばんは の3つなのに、
4つprint(next(g))をしたので、
StopIteration でエラーが返ってくる。
- 投稿日:2020-01-13T22:27:20+09:00
Python初心者がとりあえず動くものを書いてみた(復習用)part1
はじめに
こんにちは。プログラミング(Python)歴約4か月の初心者です。
具体的には、TechAcademyさんの「Pythonコース」と「データサイエンスコース」を各2ヶ月ずつ受講しました。
本記事は、これまで私が学習したことを整理する目的で書きました。上記コースでどのようなことが学べるのか、また受講後にどのようなことが出来るようになるのか、参考になれば幸いです。(特に本記事では「Pythonコース」の内容を書かせて頂きます)。
不格好な部分も多々あると思いますが、よろしくお願いいたします。Pythonコースで学んだ内容
変数、オブジェクト、関数、メソッドとは?というような基礎から始まり、よく使用する構文(条件分岐if-elif-else, 繰り返しfor/while, 例外処理try-except)、シーケンス(リスト・タプル・セット・辞書)の種類と扱い、オブジェクト指向プログラミング、各ライブラリ(Numpy・Pandas・Matplotlib・Pillow・Imageio・scikit-learn)の使い方を学ぶことができました。定期的に演習課題があり、モデルデータを使用した機械学習(犬猫の画像判別、乳がんの良性悪性予測)の課題などもありました。おそらく基礎的な部分は網羅されているように思いますが、逆にDjangoやFlaskといったWebアプリケーション用のフレームワークについては範囲外になります。
さて、一通り学び終えたところで、復習も兼ねて下記の成績管理プログラムを作成してみました。もちろんテキストを見直しながら、習っていないところはググりながらですが、一応動くものを作ることが出来ました。もし私と同じように、一通りインプットを終えて何かアウトプットしてみたい方がいらっしゃいましたら、是非下記の要件だけ読んでプログラムを書いてみて下さい!きっと良い復習になると思います。
生徒の成績管理プログラム
<要件>
①“save 生徒名 点数“とすると、その生徒の点数を保存。生徒名がすでに保存されている時は、点数を上書きするか警告文を出して、yes/noで上書きの選択を行う。
②“get 生徒名“とするとその生徒の点数を表示。生徒が登録されていない場合はErrorと出力させて処理を継続。
③“quit” とするとプログラムが終了する。
④“average” すでに保存されいる生徒全員の平均点を表示する。“登録されている生徒XX人の平均点はXX.XX点です”せっかくオブジェクト指向プログラミングを学んだ(正直一番理解に苦しんだ部分でした)ため、クラスを定義しそのメソッドとして各処理を行うようにしました。
class_Score.pyclass Score: def __init__(self): self.dict={} def save(self,name,score): try: score= int(score) except : print("整数値を入力してください") else : if name in self.dict : print("生徒名:",name,"は登録されています。") ans = input("得点を上書きしますか?(yes/no):") if ans == "yes" or "Yes" or "YES": self.dict[name] = int(score) print("データが更新されました。") else : self.dict[name] = int(score) print("データが更新されました。") def get(self,name): if name in self.dict : print(name, "の得点は", self.dict[name], "点です。") else: print("エラー:データが登録されていません。") def average(self): try: ave = sum(self.dict.values())/len(self.dict.values()) except ZeroDivisionError: print("エラー:データが登録されていません。") else: print("登録されている生徒", len(self.dict), "人の平均点は", ave, "点です。")続けて別ファイルにて、上記で作ったクラスをインポート。Scoreクラスのインスタンスを作成し、条件分岐で各メソッドを実行させるよう書いてきます。
test_score.pyfrom class_Score import Score Score_data = Score() while True: data = input("コマンドを入力してください:") if data == "quit": break elif "save" in data: a, b, c = data.split() Score_data.save(name = b, score = c) elif "get" in data: d, e = data.split() Score_data.get(name = e) elif data == "average": Score_data.average() else: print("エラー:コマンドを正しく入力してください。") print("処理を終了します。")さて、実際に動くか試してみましょう。test_score.pyを実行してみると・・・
コマンドを入力してください:average エラー:データが登録されていません。 コマンドを入力してください:save Yamada 88 データが更新されました。 コマンドを入力してください:save Ishii 79 データが更新されました。 コマンドを入力してください:save Tanaka 69 データが更新されました。 コマンドを入力してください:save Yamada 89 生徒名: Yamada は登録されています。 得点を上書きしますか?(yes/no):yes データが更新されました。 コマンドを入力してください:get Yamada Yamada の得点は 89 点です。 コマンドを入力してください:average 登録されている生徒 3 人の平均点は 79.0 点です。 コマンドを入力してください:quit 処理を終了します。正常に動いていますね!
おわりに
正直なところ、動くものができただけでだいぶ感動しました(笑)。スクールの課題では、テキストを部分的に変えればできてしまうようなものも多かったため、やはり1から自分で考えてやってみるとハードな分とても勉強になるなと実感しました。また別の課題についても今後投稿してみようと思います。
まだまだ駆け出しですが、マイペースに楽しみながら学習を楽しみたいと思います!ご一読いただきありがとうございました!
- 投稿日:2020-01-13T22:21:50+09:00
グラフ理論の基礎をmatplotlibアニメーションで
- グラフ理論の基礎
- matplotlibを使ったアニメーション作成
をここでは取り扱います。
グラフ理論の基礎
グラフ理論の基礎
https://qiita.com/maskot1977/items/e1819b7a1053eb9f7d61という記事を過去に書きまして、たくさんの方から「いいね」をいただいておりますが、今回はその内容をアニメーションで分かりやすくしたいと思います。
matploblib を用いたアニメーション
簡単なアニメーションは次のようにして描けます。
# -*- coding: UTF-8 -*- import math import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML fig = plt.figure() ims = [] # 動画=静止画の集合を格納するリスト for i in range(360): rad = math.radians(i) x1, y1 = math.cos(rad), math.sin(rad) x2, y2 = math.cos(rad * 2), math.sin(rad * 2) im = plt.scatter(x1, y1) # 静止画の部品1(リスト型ではないもの) im2 = plt.scatter(x2, y2) # 静止画の部品2(リスト型ではないもの) im3 = plt.plot([x1, x2], [y1, y2]) # 静止画の部品3(リスト型のもの) image = [im, im2] + im3 # 1つのリストが1つの静止画を表す ims.append(image) # 静止画を1つ追加する # 動画に変換する ani = animation.ArtistAnimation(fig, ims, interval=10, repeat_delay=1000) ani.save("Animation1.gif", writer='pillow') # gif ファイルとして保存 HTML(ani.to_jshtml()) # HTML上で表示
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。日本の県庁所在地データ
グラフ理論の基礎と同じデータを使います。県庁所在地の都市の座標データ(緯度・経度)が書かれています。県庁所在地の都市を「頂点」、都市と都市を結ぶ直線を「辺」と呼ぶことにします。辺で結ばれている都市は「隣接している」といいます。
import urllib.request url = 'https://raw.githubusercontent.com/maskot1977/ipython_notebook/master/toydata/location.txt' urllib.request.urlretrieve(url, 'location.txt') # データのダウンロード('location.txt', <http.client.HTTPMessage at 0x11c9c2320>)グラフ理論の基礎では使わなかった pandas を用いて読み込んでみます。
import pandas as pd japan = pd.read_csv('location.txt') japan
Town Longitude Latitude 0 Sapporo 43.06417 141.34694 1 Aomori 40.82444 140.74000 2 Morioka 39.70361 141.15250 3 Sendai 38.26889 140.87194 4 Akita 39.71861 140.10250 5 Yamagata 38.24056 140.36333 ... ... ... ... 45 Kagoshima 31.56028 130.55806 46 Naha 26.21250 127.68111 図示します。
%matplotlib inline import matplotlib.pyplot as plt plt.figure(figsize=(10, 8)) plt.scatter(japan['Latitude'], japan['Longitude']) for city, x, y in zip(japan['Town'], japan['Latitude'], japan['Longitude']): plt.text(x, y, city, alpha=0.5, size=12) plt.grid()
以上のデータを使って、グラフ理論の基礎アルゴリズムである深さ優先探索・幅優先探索・最良優先探索のアニメーションを作ってみましょう。
距離行列
グラフ理論の基礎では使いませんでしたが、scipyを使えば距離行列(頂点間の距離)は次のようにして求められます。
import numpy as np from scipy.spatial import distance mat = japan[['Latitude', 'Longitude']].values dist_mat = distance.cdist(mat, mat, metric='euclidean') # ユークリッド距離2点間の直線を引くために座標を得る関数
グラフの描画で2点間の直線を引くため、辺(頂点の組)の組から座標を求める関数を自作します。
def get_edges(routes): edges = [] for route in routes: if len(route) == 2: town1, y1, x1 = [value for value in japan.values][route[0]] town2, y2, x2 = [value for value in japan.values][route[1]] edges.append([[x1, x2], [y1, y2]]) return edges使用例はこのような感じです。
get_edges([[1, 2], [3, 4], [5, 6]])[[[140.74, 141.1525], [40.82444, 39.70361]], [[140.87194, 140.1025], [38.26889, 39.71861]], [[140.36333, 140.46778], [38.240559999999995, 37.75]]]深さ優先探索
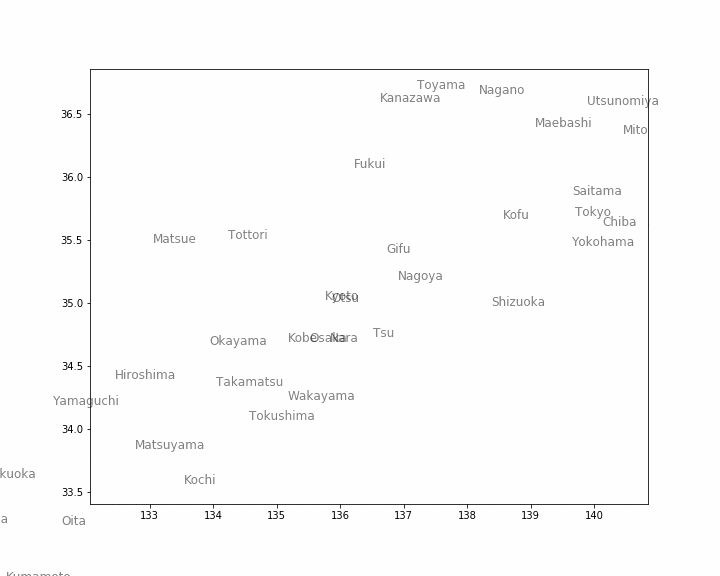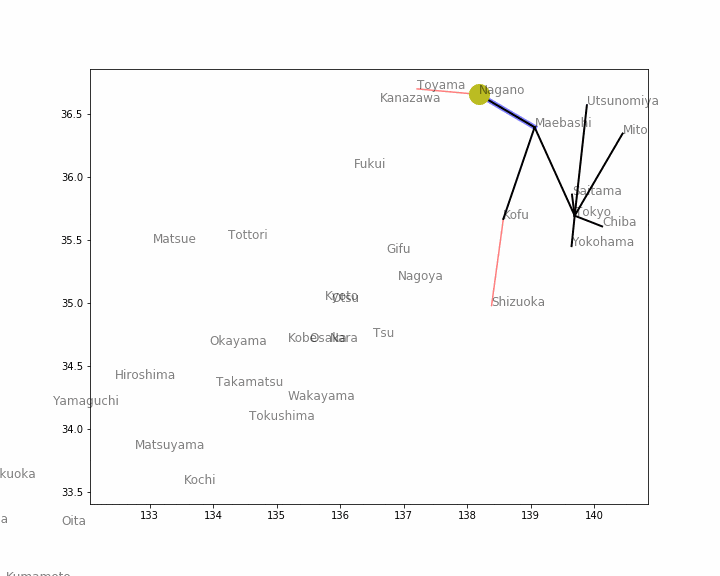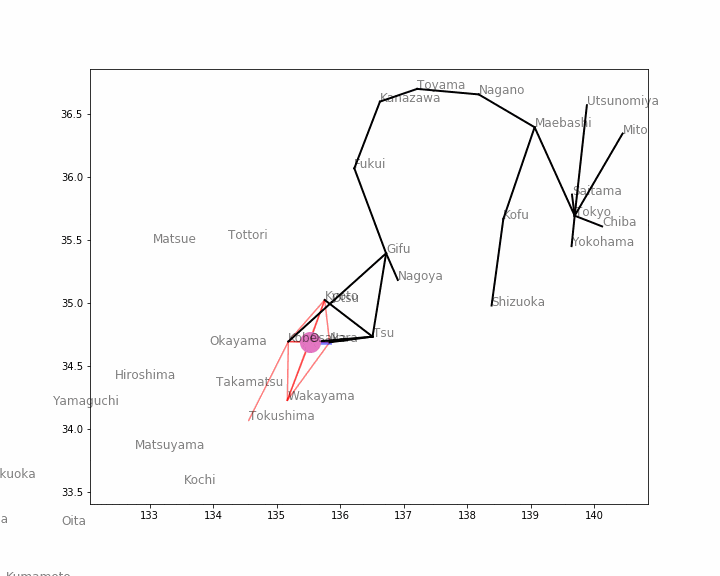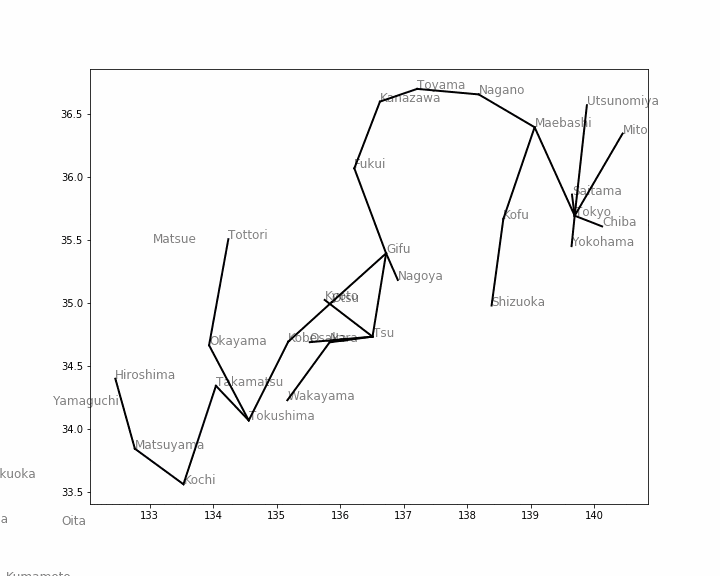
それでは、グラフ探索アルゴリズムの最初として、深さ優先探索をやります
隣接リストを得る関数1
グラフ探索では「隣接リスト」(どの頂点からどの頂点に行けるか)の作り方が非常に大切なわけですが、まずは 「ある距離(threshold)以下の頂点間に辺を結ぶ」 という方針で行ってみたいと思います。グラフ理論の基礎では使わなかったnumpyと距離行列を使えば次のようにして求められます。
def neighbor(town, dist_mat=dist_mat, threshold=1): # 隣接リストを得る関数1 return [x[0] for x in enumerate(np.where(dist_mat[town] <= threshold, True, False)) if x[1]]使用例はこんな感じ。
neighbor(12) # 東京から距離1以内の都市は?[7, 8, 9, 10, 11, 12, 13]グラフ探索関数1
グラフ理論の基礎では while 文を使ってグラフ探索問題を解いていましたが、ここでは、ステップごとに途中経過を図示したいため、探索の1ステップを進めるための関数を以下のように定義しました。
def traverse(i=0): # 深さ優先探索の1ステップ if len(stack) != 0: # スタックが空でなければ next_town, current_town = stack.pop() # 次の経路(現在地と次の都市)を得る current_direction = [[next_town, current_town]] # 描画用 if next_town not in visited_towns: # 次の都市が未訪問ならば used_routes.append([next_town, current_town]) # その経路を登録 visited_towns.append(next_town) # 訪問済みにする for nei in neighbor(next_town): # 訪問した都市に隣接する都市を1個ずつ取り出す if nei not in visited_towns: # 未訪問ならば stack.append([nei, next_town]) # 経路をスタックに入れる return current_direction # 描画用深さ優先探索アニメーション1
では、アニメーション化しましょう。
# -*- coding: UTF-8 -*- import math import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML fig = plt.figure(figsize=(10, 8)) stack = [[12, 12]] # 始点は東京 visited_towns = [] # 訪問済みの都市を蓄える配列 used_routes = [] # 実際に使用した経路を蓄える配列 current_direction = [] # 現在チェック中の経路 ims = [] # 静止画を蓄える配列 i = 0 while len(stack) > 0: # スタックが空でなければ if i != 0: # 最初の1回は初期値を表示するため探索を進めない current_direction = traverse() # 探索を1ステップ進める image = [] # 1つの静止画に書き込む部品を蓄える配列 for edge in get_edges(stack): # 赤い線は stack に入っている「候補」の経路 image += plt.plot(edge[0], edge[1], 'r', alpha=0.5) for edge in get_edges(current_direction): # 青い線は 現在チェック中の経路 image += plt.plot(edge[0], edge[1], 'b', lw=5, alpha=0.5) for edge in get_edges(used_routes): # 黒い線は 使用済みの経路 image += plt.plot(edge[0], edge[1], 'k', lw=2) for city, x, y in zip(japan['Town'], japan['Latitude'], japan['Longitude']): image.append(plt.text(x, y, city, alpha=0.5, size=12)) # 都市名を表示 if len(current_direction) > 0: current_town = current_direction[0][0] image += plt.plot(japan.iloc[current_town, :]['Latitude'], japan.iloc[current_town, :]['Longitude'], markersize=20, marker='o') # 丸は 現在チェック中の都市 ims.append(image) # 静止画を1つ蓄える i += 1 # 動画に変換 ani = animation.ArtistAnimation(fig, ims, interval=500, repeat_delay=1000) ani.save("Animation2.gif", writer='pillow') # gifファイルとして保存 HTML(ani.to_jshtml()) # HTML上で表示深さ優先探索アニメーション1
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。隣接リストを得る関数2
上の深さ優先探索では、「最後にスタックに入った都市」が次の行き先候補になります。ある都市に移動すると、それに隣接する(複数の)都市がスタックに入ります。このとき、スタックに入れる順序を考慮することで、同じ深さ優先探索でも挙動が変わります。距離の近い都市を優先的に行き先候補に選ぶように修正しましょう。
import numpy as np def neighbor(town, dist_mat=dist_mat, threshold=1): # 隣接リストを得る関数2 return np.argsort(dist_mat[town])[1:np.where(dist_mat[town] <= threshold, 1, 0).sum()][::-1]深さ優先探索アニメーション2
以下のコードは、先ほどの「深さ優先探索アニメーション1」と同一です(保存する動画のファイル名が違うだけです)。 関数
neighborを変えると、挙動がどう変わるか確認してみましょう。# -*- coding: UTF-8 -*- # -*- coding: UTF-8 -*- import math import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML fig = plt.figure(figsize=(10, 8)) stack = [[12, 12]] # 始点は東京 visited_towns = [] # 訪問済みの都市を蓄える配列 used_routes = [] # 実際に使用した経路を蓄える配列 current_direction = [] # 現在チェック中の経路 ims = [] # 静止画を蓄える配列 i = 0 while len(stack) > 0: # スタックが空でなければ if i != 0: # 最初の1回は初期値を表示するため探索を進めない if stack[0] != []: # 最後の表示のときも探索を進めない current_direction = traverse() # 探索を1ステップ進める image = [] # 1つの静止画に書き込む部品を蓄える配列 for edge in get_edges(stack): # 赤い線は stack に入っている「候補」の経路 image += plt.plot(edge[0], edge[1], 'r', alpha=0.5) for edge in get_edges(current_direction): # 青い線は 現在チェック中の経路 image += plt.plot(edge[0], edge[1], 'b', lw=5, alpha=0.5) for edge in get_edges(used_routes): # 黒い線は 使用済みの経路 image += plt.plot(edge[0], edge[1], 'k', lw=2) for city, x, y in zip(japan['Town'], japan['Latitude'], japan['Longitude']): image.append(plt.text(x, y, city, alpha=0.5, size=12)) # 都市名を表示 if len(current_direction) > 0: current_town = current_direction[0][0] image += plt.plot(japan.iloc[current_town, :]['Latitude'], japan.iloc[current_town, :]['Longitude'], markersize=20, marker='o') # 丸は 現在チェック中の都市 ims.append(image) # 静止画を1つ蓄える if len(stack) == 0: # 最後の表示用 current_direction = [] stack.append([]) elif stack[0] == []: # 最後の脱出用 break i += 1 # 動画に変換 ani = animation.ArtistAnimation(fig, ims, interval=500, repeat_delay=1000) ani.save("Animation3.gif", writer='pillow') # gifファイルとして保存 HTML(ani.to_jshtml()) # HTML上で表示深さ優先探索アニメーション2
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。幅優先探索
次に、幅優先探索をしてみましょう。基本アルゴリズムはほぼ同一で、スタック(先入れ後出し)をキュー(待ち行列:先入れ先出し)にするだけです。
グラフ探索関数2
関数
traverseを書き換えます。書き換える部分は「変更点」として示した1点だけです。スタックとして用いていたリストがキューに変わるので変数名stackを変えたいところですが、そうすると書き換える部分が多くなってしまうので、stackはそのままにしときましょう。def traverse(i=0): # 幅優先探索の1ステップ if len(stack) != 0: next_town, current_town = stack.pop(0) # 変更点 current_direction = [[next_town, current_town]] if next_town not in visited_towns: used_routes.append([next_town, current_town]) visited_towns.append(next_town) for nei in neighbor(next_town): if nei not in visited_towns: stack.append([nei, next_town]) return current_direction隣接リストを得る関数3
隣接リストを得る関数も書き換えますが、基本的には前のものとほとんど同一です。スタックがキューになるので、順番をひっくり返すだけです。
import numpy as np def neighbor(town, dist_mat=dist_mat, threshold=1): # 隣接リストを得る関数3 return np.argsort(dist_mat[town])[1:np.where(dist_mat[town] <= threshold, 1, 0).sum()] # 末尾だけ変更幅優先探索アニメーション
以下のコードも、先ほどの「深さ優先探索アニメーション1」「深さ優先探索アニメーション2」と同一です(保存する動画のファイル名が違うだけです)。 関数
traverseを変えると、挙動がどう変わるか確認してみましょう。# -*- coding: UTF-8 -*- import math import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML fig = plt.figure(figsize=(10, 8)) stack = [[12, 12]] # 始点は東京 visited_towns = [] # 訪問済みの都市を蓄える配列 used_routes = [] # 実際に使用した経路を蓄える配列 current_direction = [] # 現在チェック中の経路 ims = [] # 静止画を蓄える配列 i = 0 while len(stack) > 0: # スタックが空でなければ if i != 0: # 最初の1回は初期値を表示するため探索を進めない if stack[0] != []: # 最後の表示のときも探索を進めない current_direction = traverse() # 探索を1ステップ進める image = [] # 1つの静止画に書き込む部品を蓄える配列 for edge in get_edges(stack): # 赤い線は stack に入っている「候補」の経路 image += plt.plot(edge[0], edge[1], 'r', alpha=0.5) for edge in get_edges(current_direction): # 青い線は 現在チェック中の経路 image += plt.plot(edge[0], edge[1], 'b', lw=5, alpha=0.5) for edge in get_edges(used_routes): # 黒い線は 使用済みの経路 image += plt.plot(edge[0], edge[1], 'k', lw=2) for city, x, y in zip(japan['Town'], japan['Latitude'], japan['Longitude']): image.append(plt.text(x, y, city, alpha=0.5, size=12)) # 都市名を表示 if len(current_direction) > 0: current_town = current_direction[0][0] image += plt.plot(japan.iloc[current_town, :]['Latitude'], japan.iloc[current_town, :]['Longitude'], markersize=20, marker='o') # 丸は 現在チェック中の都市 ims.append(image) # 静止画を1つ蓄える if len(stack) == 0: # 最後の表示用 current_direction = [] stack.append([]) elif stack[0] == []: # 最後の脱出用 break i += 1 # 動画に変換 ani = animation.ArtistAnimation(fig, ims, interval=500, repeat_delay=1000) ani.save("Animation4.gif", writer='pillow') # gifファイルとして保存 HTML(ani.to_jshtml()) # HTML上で表示幅優先探索アニメーション
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。最良優先探索と最小木
最後に、最良優先探索 です。上2つの探索では、スタック(またはキュー)に追加するときに、距離の短い都市が優先的に取り出されるように追加しました。最良優先探索では、追加された後のスタック(実際はキュー)全体をソートして、その中から距離の短い都市を優先的に取り出すようにします。その結果として「最小木」ができあがります。
スタックを並び直す関数
これまでとの変更点は、スタック全体をソートし直すだけです。
def sort_stack(stack): return [stack[i] for i in np.argsort([dist_mat[edge[0]][edge[1]] for edge in stack])]最良優先探索アニメーション
以下のコードは、今までのと基本的に同じです。変更点は関数
sort_stackが追加されたことと、動画を保存するファイル名を変えただけです。# -*- coding: UTF-8 -*- import math import matplotlib.pyplot as plt import matplotlib.animation as animation from IPython.display import HTML fig = plt.figure(figsize=(10, 8)) stack = [[12, 12]] # 始点は東京 visited_towns = [] # 訪問済みの都市を蓄える配列 used_routes = [] # 実際に使用した経路を蓄える配列 current_direction = [] # 現在チェック中の経路 ims = [] # 静止画を蓄える配列 i = 0 while len(stack) > 0: # スタックが空でなければ if i != 0: # 最初の1回は初期値を表示するため探索を進めない if stack[0] != []: # 最後の表示のときも探索を進めない stack = sort_stack(stack) # 最良優先探索のためにスタックをソート current_direction = traverse() # 探索を1ステップ進める image = [] # 1つの静止画に書き込む部品を蓄える配列 for edge in get_edges(stack): # 赤い線は stack に入っている「候補」の経路 image += plt.plot(edge[0], edge[1], 'r', alpha=0.5) for edge in get_edges(current_direction): # 青い線は 現在チェック中の経路 image += plt.plot(edge[0], edge[1], 'b', lw=5, alpha=0.5) for edge in get_edges(used_routes): # 黒い線は 使用済みの経路 image += plt.plot(edge[0], edge[1], 'k', lw=2) for city, x, y in zip(japan['Town'], japan['Latitude'], japan['Longitude']): image.append(plt.text(x, y, city, alpha=0.5, size=12)) # 都市名を表示 if len(current_direction) > 0: current_town = current_direction[0][0] image += plt.plot(japan.iloc[current_town, :]['Latitude'], japan.iloc[current_town, :]['Longitude'], markersize=20, marker='o') # 丸は 現在チェック中の都市 ims.append(image) # 静止画を1つ蓄える if len(stack) == 0: # 最後の表示用 current_direction = [] stack.append([]) elif stack[0] == []: # 最後の脱出用 break i += 1 # 動画に変換 ani = animation.ArtistAnimation(fig, ims, interval=500, repeat_delay=1000) ani.save("Animation5.gif", writer='pillow') # gifファイルとして保存 HTML(ani.to_jshtml()) # HTML上で表示最良優先探索アニメーション
※ アニメーションが終了し停止してしまった場合、画像をクリックするともう一度動かせると思います。




- 投稿日:2020-01-13T22:15:07+09:00
pipって何、どう使うの?
pipってなに?
pipはpythonのパッケージマネージャの一つです、他にはcondaやpipenvなどがあります。
python3系ではバージョン3.4以降であれば、pythonのインストールと共にpipもインストールされます。
pythonの標準ライブラリに含まれないパッケージのインストールや管理をすることができます。仮想環境でpipの使い方を見ていきましょう
pipを使えるかチェック:
$ pip --version pip 10.0.1 from /Users/場所/venv/lib/python3.7/site-packages/pip (python 3.7)pipのアップデート
$ pip install --upgrade pippipのバージョン再チェック
$ pip --version pip 19.3.1 from /Users/場所/venv/lib/python3.7/site-packages/pip (python 3.7)pipで使えるコマンド達を見てみましょう:
$ pip help Usage: pip <command> [options] Commands: install Install packages. download Download packages. uninstall Uninstall packages. freeze Output installed packages in requirements format. list List installed packages. show Show information about installed packages. check Verify installed packages have compatible dependencies. config Manage local and global configuration. search Search PyPI for packages. wheel Build wheels from your requirements. hash Compute hashes of package archives. completion A helper command used for command completion. debug Show information useful for debugging. help Show help for commands. General Options: -h, --help Show help. --isolated Run pip in an isolated mode, ignoring environment variables and user configuration. -v, --verbose Give more output. Option is additive, and can be used up to 3 times. -V, --version Show version and exit. -q, --quiet Give less output. Option is additive, and can be used up to 3 times (corresponding to WARNING, ERROR, and CRITICAL logging levels). --log <path> Path to a verbose appending log. --proxy <proxy> Specify a proxy in the form [user:passwd@]proxy.server:port. --retries <retries> Maximum number of retries each connection should attempt (default 5 times). --timeout <sec> Set the socket timeout (default 15 seconds). --exists-action <action> Default action when a path already exists: (s)witch, (i)gnore, (w)ipe, (b)ackup, (a)bort. --trusted-host <hostname> Mark this host or host:port pair as trusted, even though it does not have valid or any HTTPS. --cert <path> Path to alternate CA bundle. --client-cert <path> Path to SSL client certificate, a single file containing the private key and the certificate in PEM format. --cache-dir <dir> Store the cache data in <dir>. --no-cache-dir Disable the cache. --disable-pip-version-check Don't periodically check PyPI to determine whether a new version of pip is available for download. Implied with --no-index. --no-color Suppress colored outputパッケージをpipでインストール
pythonの標準ライブラリは充実していますが、それ以外にも世界中の開発者が製作したpythonのフレームワーク、ツール、ライブラリなどがPython Package Index(PyPI)にて公開されています。(パイピーアイと読みます、パイパイではないです。)
現在の環境にインストールされているパッケージをpip listでチェック(まだ何もインストールしていない状態):$ pip list Package Version ---------- ------- pip 19.3.1 setuptools 39.0.1PyPIから使いたいパッケージをインストールするためにはpip installコマンドを使います。
機械学習ライブラリscikit-learnを使いたいとなったら:$ pip install scikit-learn Collecting scikit-learn Downloading https://files.pythonhosted.org/packages/82/d9/69769d4f79f3b719cc1255f9bd2b6928c72f43e6f74084e3c67db86c4d2b/scikit_learn-0.22.1-cp37-cp37m-macosx_10_6_intel.whl (11.0MB) |████████████████████████████████| 11.0MB 851kB/s Collecting scipy>=0.17.0 Using cached https://files.pythonhosted.org/packages/85/7a/ae480be23b768910a9327c33517ced4623ba88dc035f9ce0206657c353a9/scipy-1.4.1-cp37-cp37m-macosx_10_6_intel.whl Collecting joblib>=0.11 Downloading https://files.pythonhosted.org/packages/28/5c/cf6a2b65a321c4a209efcdf64c2689efae2cb62661f8f6f4bb28547cf1bf/joblib-0.14.1-py2.py3-none-any.whl (294kB) |████████████████████████████████| 296kB 1.1MB/s Collecting numpy>=1.11.0 Using cached https://files.pythonhosted.org/packages/2f/5b/2cc2b9285e8b2ca8d2c1e4a2cbf1b12d70a2488ea78170de1909bca725f2/numpy-1.18.1-cp37-cp37m-macosx_10_9_x86_64.whl Installing collected packages: numpy, scipy, joblib, scikit-learn Successfully installed joblib-0.14.1 numpy-1.18.1 scikit-learn-0.22.1 scipy-1.4.1現在の環境にインストールされているパッケージをチェック:
$ pip list Package Version ------------ ------- joblib 0.14.1 numpy 1.18.1 pip 19.3.1 scikit-learn 0.22.1 scipy 1.4.1 setuptools 39.0.1scikit-learnをインストールしただけなのにscikit-learn以外にjoblib、numpy、scipyがインストールされている。これはscikit-learnが他のパッケージjoblib、numpy、scipyに依存しているからです。つまりscikit-learn単体では動かないので、必要とされる他のパッケージを一緒にインストールしてくれたのです。
pip show コマンドでインストールしたパッケージのバージョンや依存情報を確認できます:
$ pip show scikit-learn Name: scikit-learn Version: 0.22.1 Summary: A set of python modules for machine learning and data mining Home-page: http://scikit-learn.org Author: None Author-email: None License: new BSD Location: /Users/場所/venv/lib/python3.7/site-packages Requires: scipy, joblib, numpy Required-by:Requires: scipy, joblib, numpyなのでscikit-learnはscipy, joblib, numpyに依存していることが確認できます。
Required-by: が空欄になっているので、今の所scikit-learnに依存しているパッケージはないことを確認できます。一緒にインストールされたscipyも見てみましょう:
$ pip show scipy Name: scipy Version: 1.4.1 Summary: SciPy: Scientific Library for Python Home-page: https://www.scipy.org Author: None Author-email: None License: BSD Location: /Users/場所/venv/lib/python3.7/site-packages Requires: numpy Required-by: scikit-learnscipyはnumpyが必要で、scikit-learnに必要とされていることがわかります。
pip installは常に公開されている最新のバージョンをインストールするため、ある決まったバージョンのパッケージをインストールしたい時は、バージョンを明記する必要がある。
例えばscikit-learnの最新バージョンは0.22.1だが、バージョン0.21.3をインストールしたければ:$ pip install scikit-learn==0.21.3 Collecting scikit-learn==0.21.3 Using cached https://files.pythonhosted.org/packages/e9/57/8a9889d49d0d77905af5a7524fb2b468d2ef5fc723684f51f5ca63efed0d/scikit_learn-0.21.3-cp37-cp37m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl Requirement already satisfied: scipy>=0.17.0 in ./venv/lib/python3.7/site-packages (from scikit-learn==0.21.3) (1.4.1) Requirement already satisfied: joblib>=0.11 in ./venv/lib/python3.7/site-packages (from scikit-learn==0.21.3) (0.14.1) Requirement already satisfied: numpy>=1.11.0 in ./venv/lib/python3.7/site-packages (from scikit-learn==0.21.3) (1.18.1) Installing collected packages: scikit-learn Found existing installation: scikit-learn 0.22.1 Uninstalling scikit-learn-0.22.1: Successfully uninstalled scikit-learn-0.22.1 Successfully installed scikit-learn-0.21.3scikit-learn-0.22.1をすでにインストールしていた状態でも、まずアンインストールしてから指定したバージョンをインストールしてくれます。joblib、numpy、scipyに関しては、すでにインストールしている、かつscikit-learn-0.21.3が必要としている条件を満たしているのでそのままにしてくれます。
複数のパッケージのバージョンを指定してインストールしたい時、まとめてrequirements.txt(名前はなんでもいい)に書いてpip installできます。
$ cat requirements.txt joblib==0.14.1 numpy==1.18.1 scikit-learn==0.21.3 scipy==1.4.1$ pip install -r requirements.txt Collecting joblib==0.14.1 Using cached https://files.pythonhosted.org/packages/28/5c/cf6a2b65a321c4a209efcdf64c2689efae2cb62661f8f6f4bb28547cf1bf/joblib-0.14.1-py2.py3-none-any.whl Collecting numpy==1.18.1 Using cached https://files.pythonhosted.org/packages/2f/5b/2cc2b9285e8b2ca8d2c1e4a2cbf1b12d70a2488ea78170de1909bca725f2/numpy-1.18.1-cp37-cp37m-macosx_10_9_x86_64.whl Collecting scikit-learn==0.21.3 Using cached https://files.pythonhosted.org/packages/e9/57/8a9889d49d0d77905af5a7524fb2b468d2ef5fc723684f51f5ca63efed0d/scikit_learn-0.21.3-cp37-cp37m-macosx_10_6_intel.macosx_10_9_intel.macosx_10_9_x86_64.macosx_10_10_intel.macosx_10_10_x86_64.whl Collecting scipy==1.4.1 Using cached https://files.pythonhosted.org/packages/85/7a/ae480be23b768910a9327c33517ced4623ba88dc035f9ce0206657c353a9/scipy-1.4.1-cp37-cp37m-macosx_10_6_intel.whl Installing collected packages: joblib, numpy, scipy, scikit-learn Successfully installed joblib-0.14.1 numpy-1.18.1 scikit-learn-0.21.3 scipy-1.4.1現在の環境を別のプロジェクトなどに複製したい時はpip freezeコマンドで現在の環境を丸ごとファイルに書き出すことができます:
$ pip freeze > requirements.txt $ cat requirements.txt joblib==0.14.1 numpy==1.18.1 scikit-learn==0.21.3 scipy==1.4.1'==' 以外にも'<='、 '>='などの条件をつけることができます。requirement-specifiers
例えばscikit-learn>=0.21.3という条件にした場合:$ cat requirements.txt joblib==0.14.1 numpy==1.18.1 scikit-learn>=0.21.3 scipy==1.4.1現在の環境チェック:
$ pip list Package Version ------------ ------- joblib 0.14.1 numpy 1.18.1 pip 19.3.1 scikit-learn 0.21.3 scipy 1.4.1 setuptools 39.0.1pip install -r requirements.txtしてみる:
$ pip install -r requirements.txt Requirement already satisfied: joblib==0.14.1 in ./venv/lib/python3.7/site-packages (from -r requirements.txt (line 1)) (0.14.1) Requirement already satisfied: numpy==1.18.1 in ./venv/lib/python3.7/site-packages (from -r requirements.txt (line 2)) (1.18.1) Requirement already satisfied: scikit-learn>=0.21.3 in ./venv/lib/python3.7/site-packages (from -r requirements.txt (line 3)) (0.21.3) Requirement already satisfied: scipy==1.4.1 in ./venv/lib/python3.7/site-packages (from -r requirements.txt (line 4)) (1.4.1)requirements.txtに記述されている条件を満たしていると言われる。まーscikit-learn 0.21.3はscikit-learn>=0.21.3を確かに満たしている。
条件を満たす最新のバージョンにアップデートして欲しい時には--upgrade:$ pip install --upgrade -r requirements.txt Requirement already up-to-date: joblib==0.14.1 in ./venv/lib/python3.7/site-packages (from -r requirements.txt (line 1)) (0.14.1) Requirement already up-to-date: numpy==1.18.1 in ./venv/lib/python3.7/site-packages (from -r requirements.txt (line 2)) (1.18.1) Collecting scikit-learn>=0.21.3 Using cached https://files.pythonhosted.org/packages/82/d9/69769d4f79f3b719cc1255f9bd2b6928c72f43e6f74084e3c67db86c4d2b/scikit_learn-0.22.1-cp37-cp37m-macosx_10_6_intel.whl Requirement already up-to-date: scipy==1.4.1 in ./venv/lib/python3.7/site-packages (from -r requirements.txt (line 4)) (1.4.1) Installing collected packages: scikit-learn Found existing installation: scikit-learn 0.21.3 Uninstalling scikit-learn-0.21.3: Successfully uninstalled scikit-learn-0.21.3 Successfully installed scikit-learn-0.22.1また、requirementsファイルの中にrequirementsファイルを書くこともできます:
$ cat requirements_old.txt numpy==1.18.1 scipy==1.4.1$ cat requirements_new.txt -r requirements_old.txt scikit-learn>=0.21.3$ pip install -r requirements_new.txt Collecting numpy==1.18.1 Using cached https://files.pythonhosted.org/packages/2f/5b/2cc2b9285e8b2ca8d2c1e4a2cbf1b12d70a2488ea78170de1909bca725f2/numpy-1.18.1-cp37-cp37m-macosx_10_9_x86_64.whl Collecting scipy==1.4.1 Using cached https://files.pythonhosted.org/packages/85/7a/ae480be23b768910a9327c33517ced4623ba88dc035f9ce0206657c353a9/scipy-1.4.1-cp37-cp37m-macosx_10_6_intel.whl Collecting scikit-learn>=0.21.3 Using cached https://files.pythonhosted.org/packages/82/d9/69769d4f79f3b719cc1255f9bd2b6928c72f43e6f74084e3c67db86c4d2b/scikit_learn-0.22.1-cp37-cp37m-macosx_10_6_intel.whl Collecting joblib>=0.11 Using cached https://files.pythonhosted.org/packages/28/5c/cf6a2b65a321c4a209efcdf64c2689efae2cb62661f8f6f4bb28547cf1bf/joblib-0.14.1-py2.py3-none-any.whl Installing collected packages: numpy, scipy, joblib, scikit-learn Successfully installed joblib-0.14.1 numpy-1.18.1 scikit-learn-0.22.1 scipy-1.4.1$ pip list Package Version ------------ ------- joblib 0.14.1 numpy 1.18.1 pip 19.3.1 scikit-learn 0.22.1 scipy 1.4.1 setuptools 39.0.1パッケージの探し方
pip searchでPyPIで公開されているパッケージを検索できます。
例えばQiitaを検索してみる:$ pip search qiita qiita (0.1.1) - Qiita api wrapper for Python qiita-spots (0.2.0) - Qiita: Spot Patterns qiita_v2 (0.2.1) - Python Wrapper for Qiita API v2 qiitacli (1.1.0) - CLI Application for Qiita API v2 qiitap (1.3.1) - Add include function to Qiita Markdown qiita_api_wrapper (0.1.0) - Qiita API V2 wrapper for Python qiidly (1.0.0) - Sync Qiita feeds for followees and following tags to Feedly. -> Qiita&# 12391;フォロӦ 0;中のタグ&# 12392;ユーザӦ 0;をFeedlyに同 399;。しかし、この方法だとパッケージの詳細がわからないので、ほとんどの場合はPyPIのウェブサイトで検索します。
パッケージをpipでアンインストール
現在の環境チェック:
$ pip list Package Version ------------ ------- joblib 0.14.1 numpy 1.18.1 pip 19.3.1 scikit-learn 0.22.1 scipy 1.4.1 setuptools 39.0.1パッケージをアンインストールする前にpip showでこのパッケージを必要とする他のパッケージがないことを確認してからpip uninstallしましょう。
scikit-learnはもういらないとなったら:$ pip show scikit-learn Name: scikit-learn Version: 0.22.1 Summary: A set of python modules for machine learning and data mining Home-page: http://scikit-learn.org Author: None Author-email: None License: new BSD Location: /Users/場所/venv/lib/python3.7/site-packages Requires: joblib, scipy, numpy Required-by:$ pip uninstall scikit-learn Uninstalling scikit-learn-0.22.1: Would remove: /Users/場所/venv/lib/python3.7/site-packages/scikit_learn-0.22.1.dist-info/* /Users/場所/venv/lib/python3.7/site-packages/sklearn/* Proceed (y/n)? y Successfully uninstalled scikit-learn-0.22.1$ pip list Package Version ---------- ------- joblib 0.14.1 numpy 1.18.1 pip 19.3.1 scipy 1.4.1 setuptools 39.0.1scikit-learnをインストールした時にはjoblib、numpy、scipyもついてきたのに、アンインストール時は残していくれるんですね!
的な-yで確認を飛ばせます:
$ pip uninstall joblib -y $ pip uninstall scipy -y $ pip uninstall numpy -y複数アンインストール:
$ pip uninstall -y joblib scipy numpyrequirementsファイルで指定してアンインストール:
pip uninstall -r requirements.txt -y依存関係を満たしているかチェック
pip checkコマンドでインストールされているパッケージ間の依存をチェックしてくれます。
scipyとscikit-learnはnumpyに依存するが、numpyがない場合:$ pip list Package Version ------------ ------- joblib 0.14.1 pip 19.3.1 scikit-learn 0.22.1 scipy 1.4.1 setuptools 39.0.1$ pip check scipy 1.4.1 requires numpy, which is not installed. scikit-learn 0.22.1 requires numpy, which is not installed.numpyがないよと教えてくれる。
参考


- 投稿日:2020-01-13T21:58:05+09:00
Word2Vecを理解する
はじめに
今や自然言語処理の定番手法となっているWord2Vecについて勉強したことをまとめました。
そのアルゴリズムの概要を整理しライブラリを用いてモデルを作成しています。参考
Word2Vecを理解するに当たって下記を参考にさせていただきました。
- ゼロから作るDeep Learning ❷ ―自然言語処理編 斎藤 康毅 (著)
- 絵で理解するWord2vecの仕組み
- Efficient Estimation of Word Representations in Vector Space (元論文)
- gensimのAPIリファレンス
Word2Vec概要
下記ではWord2Vecの前提となっている自然言語処理の考え方について記載しています。
単語の分散表現
単語を固定長のベクトルで表現することを「単語の分散表現」と呼びます。単語をベクトルで表現することができれば単語の意味を定量的に把握することができるため、様々な処理に応用することができます。Word2Vecも単語の分散表現の獲得を目指した手法です。
分布仮説
自然言語処理の世界では様々なベクトル化手法が研究されていますが、主要な手法は「単語の意味は周囲の単語によって形成される」というアイデアに基づいており分布仮説と呼ばれています。本記事でご紹介するWord2Vecも分布仮説に基づいています。
カウントベースと推論ベース
単語の分散表現を獲得する手法としては、大きく分けてカウントベースの手法と推論ベースの手法の二つがあります。カウントベースの手法は周囲の単語の頻度によって単語を表現する方法で、コーパス全体の統計データから単語の分散表現を獲得します。一方で、推論ベースの手法はニューラルネットワークを用いて少量の学習サンプルをみながら重みを繰り返し更新する手法です。Word2Vecは後者に該当します。
Word2vecのアルゴリズム
以下ではWord2Vecのアルゴリズムの中身を説明していきます。
Word2vecで使用するニューラルネットワークのモデル
Word2vecでは下記2つのモデルが使用されています。
- CBOW(continuous bag-of-words)
- skip-gram
それぞれのモデルの仕組みについて説明していきます。
CBOWモデル
概要
CBOWモデルはコンテクストからターゲットを推測することを目的としたニューラルネットワークです。このCBOWモデルをできるだけ正確な推測ができるように訓練することで単語の分散表現を獲得することができます。
前後のコンテクストをどの程度利用するかはモデル作成ごとに判断しますが、前後1単語をコンテクストとする場合、例えば下記だと「毎朝」「を」から「?」の単語を推測することになります。
私 は 毎朝 ? を 飲み ます 。 CBOWのモデル構造を図示すると下記のようになります。入力層が二つあり、中間層を経て出力層へとたどり着きます。
上記図の中間層は各入力層の全結合による変換後の値が「平均」されたものになります。一つ目のの入力層が$h_1$二つ目の入力層が$h_2$に変換されたとすると中間層のニューロンは$\frac{1}{2}(h_1+h_2)$になります。
入力層から中間層への変換は、全結合層(重みは$W_{in}$)によって行われます。この時は全結合層の重み$W_{in}$は$8×3$の形状の行列になっていますが、この重みこそがCBOWを用いて作る単語の分散表現になります。
CBOWモデルの学習
CBOWモデルは出力層において各単語のスコアを出力しますが、そのスコアに対してSoftmax関数を適応することで「確率」を得ることができます。この確率は前後の単語を与えた時にその中央にどの単語が出現するのかを表します。
上記の例ではコンテクストは「毎朝」「を」、ニューラルネットワークが予想したい単語が「コーヒー」である例です。この時適切な重みを持ったニューラルネットワークでは「確率」を表すニューロンにおいて正解ニューロンが高くなっていることが期待できます。CBOWの学習では正解ラベルとニューラルネットワークが出力した確率の交差エントロピー誤差を求め、それを損失としてその損失を少なくしていく方向に学習を進めます。
CBOWモデルの損失関数は下記のように表されます。
(モデルを作成するに当たって用いるコンテクストを前後1単語とした場合)L = -\frac{1}{T}\sum_{t=1}^{T}logP(w_{t}|w_{t-1},w_{t+1})上記損失関数をできるだけ小さくしていく方向で学習していくことで、その時の重みを単語の分散表現として獲得することができます。
skip-gramモデル
skip-gramモデルはCBOWで扱うコンテクストとターゲットを逆転させたようなモデルになります。下記のように中央の単語から前後の複数のコンテクストを予測するモデルです。
私 は ? コーヒー ? 飲み ます 。 skip-Gramのモデルのイメージは下記のようになります。
skip-gramの入力層はひとつで出力層はコンテクストの数だけ存在します。それぞれの出力層で個別に損失を求め、それらを足し合わせたものを最終的な損失とします。
また、skip-gramモデルの損失関数は下記の式で表されます。
(モデルを作成するに当たって用いるコンテクストを前後1単語とした場合)L = -\frac{1}{T}\sum_{t=1}^{T}(logP(w_{t-1}|w_{t}) + logP(w_{t+1}|w_{t}))skip-gramモデルはコンテクストの数だけ推測を行うためその損失関数は各コンテクストで求めた損失の総和を求める必要があります。
CBOWとskip-gram
CBOWとskip-gramではskip-gramモデルの方が良い結果が得られるとされており、コーパスが大規模になるにつれて程頻出の単語や類推問題の性能の点において優れた結果が得らるとのことです。一方でskip-gramはコンテクストの数だけ損失を求める必要があるため学習コストが大きく、CBOWの方が学習は高速です。
ライブラリを用いたWord2vecモデルの作成
以下ではライブラリを用いて実際にWord2Vecのモデルを作成していきます。
データセット
pythonのライブラリであるgensimを用いて簡単にWord2Vecのモデルを簡単に作成することが可能です。今回データセットは「livedoor ニュースコーパス」を使用させていただきます。データセットの詳細やその形態素解析の方法は以前投稿した記事で投稿しているの気になる方そちらをご参照いただければと思います。
日本語の場合は事前に文章を形態素単位に分解する前処理が必要となるため、全ての文章を形態素に分解した後下記のようなデータフレームに落とし込んでいます。
一番右のカラムが文章を全て形態素解析して半角スペースごとに区切ったものになります。こちらを用いてWord2Vecモデルを作成します。
モデルの学習
gensimを用いてWord2vecのモデルの作成を行います。下記がモデルを作成するに当たっての主要なパラメータになります。
パラメーター名 パラメータの意味 sg 1ならskip-gramで0ならCBOWで学習する size 何次元の分散表現を獲得するかを指定 window コンテクストとして認識する前後の単語数を指定 min_count 指定の数以下の出現回数の単語は無視する 下記がWord2Vecのモデルを作成するコードになります。投入するテキストさえ作成できていれば一行でモデルの作成が可能です。
sentences = [] for text in df[3]: text_list = text.split(' ') sentences.append(text_list) from gensim.models import Word2Vec model = Word2Vec(sentences, sg=1, size=100, window=5, min_count=1)Word2Vecでできること
Word2Vecのモデルによって単語の分散表現を獲得することができました。単語の分散表現を用いると単語間の意味的な距離を定量的に表したり、単語同士で意味の足し算や引き算ができたりします。
先ほど作成したモデルを用いて「家族」に近い単語を確認してみます。
for i in model.most_similar('家族'): print(i)('親子', 0.7739133834838867) ('恋人', 0.7615703344345093) ('絆', 0.7321233749389648) ('友人', 0.7270181179046631) ('団らん', 0.724891185760498) ('友だち', 0.7237613201141357) ('ふたり', 0.7198089361190796) ('夫婦', 0.6997368931770325) ('同士', 0.6886075735092163) ('深める', 0.6761922240257263)「親子」や「恋人」など何となく「家族」と意味合いの近そうな単語が上位に上がってきました。
次は単語同士で算術計算をしていみます。「人生」ー「幸福」を計算してみたのが下記になります。for i in model.most_similar(positive='人生',negative='幸福'): print(i)('現金', 0.31968846917152405) ('おら', 0.29543358087539673) ('修理', 0.29313164949417114) ('募金', 0.2858077883720398) ('ユーザー', 0.2797638177871704) ('頻度', 0.27897265553474426) ('適正', 0.2780274450778961) ('税金', 0.27565300464630127) ('かから', 0.273759663105011) ('予算', 0.2734326720237732)今回は学習させたコーパス自体がそこまで大きなものではないため、微妙な感じにはなっていますが「現金」という単語が最も上位に来ています。単語の分散表現がどのようなものになるかは投入するコーパスに依存するため、Word2Vecを使用したい局面に応じて投入するコーパスをどういったものにするかの検討が必要だと思います。
Next
Word2Vecについて概要をざっくりと理解することができました。Word2Vecの発展であるDoc2vecについても次回以降でまとめることができたらと思っています。最後までご覧いただきありがとうございました。



- 投稿日:2020-01-13T21:30:34+09:00
シャドバの勝ち負けを画像認識で判定する
この記事は リンク情報システム の「2020新春アドベントカレンダー TechConnect!」のリレー記事です。
TechConnect! は勝手に始めるアドベントカレンダーとして、engineer.hanzomon という勝手に作ったグループによってリレーされます。
(リンク情報システムのFacebookはこちらから)
テーマが自由だったので自由な記事となります。(使用技術は真面目です。)
チュートリアルを駆使し、頑張って画像認識をしました。出来たもの
Shadowverse(Steam版)のWin/Lose判定を行うプログラムが出来ました。
(gifの画面はLose判定を確認するために描画しています。判定は描画しなくても可能です。)見ての通り、Win/Lose画像とキャプチャ画面を比較して判定しているだけなので、
「特定のアプリケーションのキャプチャに、指定画像が出現しているかをリアルタイムで判定する」
ことがしたい人の参考にもなるかと思います。使ったもの
- Python 3.7.4
- pip 19.3.1
- numpy 1.17.3
- opencv-contrib-python 4.1.1.26
- Pillow 6.2.0
導入方法は後述する参考記事を参照してください。
片っ端からpipでインストールするだけで出来たので特に詰まった所は無かったです。やり方
- ゲーム画面をスクリーンキャプチャする
- キャプチャした画像と、Win/Lose画像を比較
- 特徴点をDistanceで足切りし、一定以上の特徴点がマッチしていればWin/Loseと判断
- 一定回数以上Win/Lose判定が連続した場合に、Win画面/Lose画面と判定
ゲーム画面をスクリーンキャプチャする
以下の記事を参考にPILを使用してキャプチャを行いました。
[Python][Windows] Pythonでスクリーンキャプチャを行うfrom PIL import ImageGrab import numpy as np TARGET_NAME = 'Shadowverse' handle = win32gui.FindWindow(None, TARGET_NAME) while True: rect = win32gui.GetWindowRect(handle) img = ImageGrab.grab(rect) ocv_im = np.asarray(img) #OpenCV用に色変換 ocv_im = cv2.cvtColor(ocv_im, cv2.COLOR_BGR2RGB) #画面に描画(確認用) cv2.imshow("images", ocv_im, ) #適当な方法でWaitをかける(描画時間の確保) cv2.waitKey(10)キャプチャした画像と、Win/Lose画像を比較
(あらかじめWin/Lose画像はスクリーンショットから切り抜いておきます。)
以下の記事を参考に、AKAZEで特徴量マッチングを行います。
OpenCV 3とPython 3で特徴量マッチング(A-KAZE, KNN)def MatchResultCheck(ocv_img): win_img = cv2.imread(WIN_IMAGE_PATH) lose_img = cv2.imread(LOSE_IMAGE_PATH) akaze = cv2.AKAZE_create() kp2, des2 = akaze.detectAndCompute(ocv_img, None) kp1_l, des1_l = akaze.detectAndCompute(lose_img, None) kp1_w, des1_w = akaze.detectAndCompute(win_img, None) is_win = False is_lose = False bf = cv2.BFMatcher() if not des2 is None : #Lose画像とキャプチャ画像で特徴量マッチング matches_l = bf.knnMatch(des1_l,des2, k=2) #Win画像とキャプチャ画像で特徴量マッチング matches_w = bf.knnMatch(des1_w,des2, k=2) #Lose判定 good_l = [] for match1, match2 in matches_l: if match1.distance < 0.75*match2.distance: good_l.append([match1]) #Win判定 good_w = [] for match1, match2 in matches_w: if match1.distance < 0.75*match2.distance: good_w.append([match1]) #確認用の画像を作成 akaze_matches = cv2.drawMatchesKnn(lose_img,kp1_l,ocv_img,kp2,good_l,None,flags=2) #画面に描画(確認用) cv2.imshow("match", akaze_matches, ) if len(good_l) > 20 : print("is lose") is_lose = True if len(good_w) > 20 : print("is win") is_win = True return is_win, is_loseWin/Loseの判定
マッチング結果にはDistance(どれだけマッチしているか)が格納されているので、Distanceで足切りを行います。
#Lose判定 good_l = [] for match1, match2 in matches_l: #Distanceが一定以上の特徴点だけを抜き出す if match1.distance < 0.75*match2.distance: good_l.append([match1])足切り後、一定以上特徴点が残っていれば、Win/Lose画像が存在していると判断します。
if len(good_l) > 20 : print("is lose") is_lose = TrueWin画面/Lose画面の判定
誤検知を抑止するために、一定回数以上連続でWin/Lose画像と判断した場合のみWin/Lose画面と判定します。
(python使ってるんだからもっと簡素に書けそう……)is_win, is_lose = MatchResultCheck(ocv_im) if is_lose : cnt_lose_match += 1 if cnt_lose_match >= 4: print("is lose match") cnt_lose_match = 0 cv2.waitKey(1000) else : cnt_lose_match = 0出来なかったこと
同様に先攻/後攻も判定しよう!と思ったら上手く出来ませんでした……
Win/Loseと違って判定画像が小さすぎるのと、漢字なのが辛いのかなって思ってます。
引き続き精進していきます。まとめ
スクリーンキャプチャに特定の画像が存在しているか判定できました。
判定結果をリアルタイムに描画できると面白いですね。次回は@rysk001さんです。

- 投稿日:2020-01-13T21:29:14+09:00
Jupyter学習ノート_007
google colabにpytestを試して見る
下記の手順で実施する
- ソースコードを用意する
- ネーミングルール
- 「test」で始まるメソッドにする
- 結果がOKかNGかはassert条件式の結果より判断する
pytest01.pydef add(a, b): return a + b def sub(a, b): return a - btest_pytest01.pyfrom pytest01 import add, sub def test_add(): assert add(1, 2) == 4 # NGになる def test1_sub(): assert sub(3, 1) == 2 # OKになる def atest_sub(): assert sub(3, 1) == 2 # pytestが認識できない
- 実施した結果

- 投稿日:2020-01-13T21:28:59+09:00
pandasで「A value is trying to be set on a copy of a slice from a DataFrame.」warningが発生する例と対策
この記事で書いていること
pandasでデータ分析をしていると、
A value is trying to be set on a copy of a slice from a DataFrame.
というエラーが出ることが良くあります。直訳すると、「データフレームからのスライスのコピーに値が代入されようとしています。」ということ。
データフレームから何らかの条件でデータを抽出した先のデータフレームに、値を代入しようとすると発生します。
抽出先のデータフレームに値が代入したときに、元のデータフレームに値が反映されるかどうか、不明確になっている書き方の時に、これが出るようです。
これに関して、わたしが出会った事例と対策についてまとめておきます
環境
- python 3.7.4
- pandas 0.25.3
- numpy 1.16.1
コードの例
warningが出るコードの例
# DataFrameをつくる df = pd.DataFrame(np.arange(20).reshape((4,5)), columns = list("abcde")) print(df) # a b c d e # 0 0 1 2 3 4 # 1 5 6 7 8 9 # 2 10 11 12 13 14 # 3 15 16 17 18 19 df["f"] = 3 # これはsliceへの代入とみなされず、エラーは出ない # DataFrameから".loc"を作ってデータを抽出 # 条件を指定して抜き出し → これがsliceとみなされる df_sub = df.loc[df["e"] % 2 == 0] df_sub["g"] = 100 # sliceへの代入とみなされて、warningが出る print(df_sub) # a b c d e f g # 0 0 1 2 3 4 3 100 # 2 10 11 12 13 14 3 100 # c:\program files\python37\lib\site-packages\ipykernel_launcher.py:1: SettingWithCopyWarning: # A value is trying to be set on a copy of a slice from a DataFrame. # Try using .loc[row_indexer,col_indexer] = value instead # See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy対策例 - .copy()で別のDataFrameであることを明示
条件指定で抽出するところで、以下のように.copy()で、スライスではなくコピーであることを明示すれば、warningは出なくなります。
これは、コピー先にデータを反映し、コピー元には反映しないことを明示する、ということになります。df_sub = df.loc[df["e"] % 2 == 0].copy() df_sub["g"] = 100コピー元にデータを反映したい場合には、pd.merge()などすればよいと思われます。
- 投稿日:2020-01-13T21:25:11+09:00
学習記録 その21(25日目)
学習記録(25日目)
勉強開始:12/7(土)〜
教材等:
・大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年):12/7(土)〜12/19(木)読了
・Progate Python講座(全5コース):12/19(木)〜12/21(土)終了
・Andreas C. Müller、Sarah Guido『(邦題)Pythonではじめる機械学習』(オライリージャパン、2017年):12/21(土)〜12月23日(土)読了
・Kaggle : Real or Not? NLP with Disaster Tweets :12月28日(土)投稿〜1月3日(金)まで調整
・Wes Mckinney『(邦題)Pythonによるデータ分析入門』(オライリージャパン、2018年):1/4(水)〜1/13(月)読了『Pythonによるデータ分析入門』
1月13日読了
11章 時系列データ
・ある時点において観測されたデータはどのようなものでも時系列を構成する。
特徴付けの例 タイムスタンプ、一定の期間、時間の感覚によるものなど。
何に応用するかで方法は変わってくる。
pandasは時系列のためのツールを多く提供している。金融やログデータ分析等に応用が効く。・datetime、time、calendarモジュール
strやstrftimeで書式を指定できる。%Yは4桁の年、%yは2桁の年 など。
datetime.strftime('%Y-%m-%d')のように使う。・インデックス参照 date['2000']のようにすれば、該当する年月日のデータを参照できる。
範囲指定での生成 date_range
データの移動 shift、オフセットを指定して移動もできる。・時系列は協定世界時UTCで扱うのがほとんど。
pytz.timezoneでタイムゾーンオブジェクトを取得、生成
tz_localizeでローカライズ、tz_convertで別のタイムゾーンに変換する。
タイムスタンプを生成するときにタイムゾーンも指定できる。・時系列の頻度は変換できる。resampleメソッドを用いる。
より低い頻度のデータに集約するダウンサンプリング、逆はアップサンプリング
resample('5min',closed = XXX), closedは左右どちらを閉区間(値に含まない)か決める。
OHLC(Open-High-Low-Close)関数、始値・終値・最高値・最安値を集約できる。
・窓関数:指数関数的に減少する重み付けをデータに行う。ある有限区間以外では0となる関数。
ノイズや隙間データを軽減するのに役立つ。rolling, expanding, span, applyで独自関数を適用できる。12章 pandas:応用編
・pandasのCategorical(カテゴリ型)
活用することで処理速度やメモリ使用量を改善できる可能性がある。
・特定のデータセットを用いて大量の分析をする場合はカテゴリ変数で性能向上が得られる。
データフレームの列をカテゴリ表現に置き換えると、メモリも少量に抑えられる。
astype('category')・カテゴリメソッド 追加、大小関係を設定、削除など。
add_categories, as_ordered,remove_categories・機械学習ツール等を使用する場合には、ダミー変数形式に変換しなければならないことがある。
(one-hotエンコーディングのこと。) 0か1かで表現
get_dummiesで変換できる。・groupbyは指定した要素に対し、共通の処理を行える。
lambda x : x.mean()のように、lambda式を用いればtransformでも同じことができる。
df.transform(lambda x:x.mean())
transformを活用することでグループ演算も可能
normalized = (df['A'] - b.transform('mean'))/b.transform('std') など。
グループごとの集約が複数回発生する場合があるか、ベクトル演算のメリットが全体的に上回る。13章 Pythonにおけるモデリングライブラリ入門
・pandasと分析ライブラリの接点は、通常はNumPy配列。
データフレームをNumPyに変換するには.value属性を用いる。(ndarrayになる。)
data.values
戻す時は2次元のndarrayを渡し、列名を指定する。
pd.DataFrame(data.values, columns=['one', 'two', 'three']・列の一部のみ使う場合 locでインデックス参照をしながらvaluesを使うとよい。
model_cols = ['x0', 'x1']
data.loc[:, model_cols].values
これで全行のx0,x1のみをarrayで抽出できる。一部をダミー変数で置き換えるdummies = pd.get_dummies(data.category, prefix='category') data_with_dummies = data.drop('category', axis=1).join(dummies) #ダミーを作成、dropで元々あった列を削除し、joinで追加する。
- 投稿日:2020-01-13T20:46:09+09:00
アルキメデスの円周率計算手法の正確さについて
はじめに
アルキメデスは円に外接する正6角形、正12角形、正24角形、正48角形、正96角形と順に周囲の長さを計算することで、円周率の近似値を求めたとのことです。
tsujimotterさんノートブック "アルキメデスと円周率"
当時は小数点は未だ発明されておらず、整数の比で表現していたとのことです。
こんな制限があってもアルキメデスは、3と1/7より小さく、3と10/71より大きいことを求めていました。(小数点で表現すると、3.1428571428571429と3.1408450704225352?の間)
アルキメデスの手法をそのまま進めると何所まで正確に円周率を計算できるかプログラミングの力を借りてをやってみました。アルキメデスの手法
アルキメデスの手法そのものは、先のtujimotterさんのノートブックに正確に記載されていますので、興味のある方はそちらをご覧ください。ここでは、プログラム作りにあたって、必要な証明のみ記載します。
正n角形の周囲の長さをL、外接する円の半径を1とすると、円周は2πなので、正n角形を元にした円周率の近似値は L÷2となります。
【正6角形の場合】
L=F(0)B×2×6
F(0)B =1/√3 ※ ∠F(0)OBが30°なので(△OF(0)Cは正三角形)
正6角形を元にした円周率の近似値は
L÷2=1/√3×2×6÷2=2×√3 ≒ 3.464 となる。【正12角形の場合】
L=F(1)B×2×12
F(1)B = OB× F(0)B ÷(OB+F(0)O)= F(0)B ÷(1+√(1+F(0)B× F(0)B))
正12角形をもとにした円周率の近似値は、
L÷2=F(1)B×2×12÷2 ≒ 3.215 となる。
証明
F(1)Oと平行なF(0)を通る直線を引き、OBの延長線との交点をAとする。
△OBF(1) と △ABF(0) は相似であるから、以下が成り立つ。
F(1)B:OB = F(0)B:(OB+OA)
更に、△OF(0)Aは二等辺三角形であることから、F(0)O = OA
F(0)Oはピタゴラスの定理を使って、√(OB×OB+ F(0)B× F(0)B) より求められる。【正n角形の場合】
同様にして、正n角形を元にした円周率の近似値は以下のようになる。
L÷2=F(n)B×2×n÷2 = F(n-1)B÷(1+√(1+F(n-1)B× F(n-1)B))×nPythonによる実装
以上の結果をPythonで実装すると下記のようになる。
import math import itertools def f(n): if n == 0: return math.sqrt(3)/3 return f(n-1)/(1+math.sqrt(1+f(n-1)**2)) N = int(input()) for n in range(N): print(f(n)*6*2**n)ただし、正n角形を正確に入力するのはメンドウなので、入力値Nは以下のようにしている。
0 … 正6角形を計算
1 … 正12角形まで計算
2 … 正24角形まで計算
以下同様。
上記のアルゴリズムではO(2**n)の計算量が必要になるため、次のようにDPで書き直してみました。また、2進数では小数点以下を正確に表現できない(※)ので、15桁ほど大きな数字にして、出力の際に整形するプログラムとしました。
※プログラミングで小数はヤバイんだぜ?という話。import math import itertools def pi2s(pi): return str(pi)[0] + "." + str(pi)[1:] def regN(n): return format(n, '10d') + ": " R = 1732050807568877 B = 1000000000000000 pi = "3.14159265358979323846264338327950288" N = int(input()) F = [0.0 for n in range(N)] F[0] = B for n in range(1, N): F[n] = F[n-1]*R/(R+math.sqrt(F[n-1]**2+R**2)) for n, v in enumerate(F): print(regN(6*2**n) + pi2s(int(v*6*2**n*B/R))) print(format("pi: ", '>12') + pi[:17])正3145728角形まで計算した結果です。
最後の行にπを出力しています。結構正確な値が計算できていることが分かります。さいごに
アルキメデスの手法をプログラミングでなぞってみました。勝手な予想に反して結構早い段階(48角形)で既に3.14に近似できていて驚きでした。
これを、手でしかも整数の比(分数)で計算したアルキメデスには、ひたすら脱帽です。


- 投稿日:2020-01-13T20:42:33+09:00
pandasのgroupbyで文字列の操作
概要
pandasで数値の平均や、最小値、最大値を取得する例はよく見つかりますが、
グループを作ってそこに対して処理することも多かったので自分の備忘録がわりにまとめ。
何番煎じだと突っ込まれそうな気もしますが・・・必要なもの
- python 3.7.2
- pandas
- numpy
動作確認にはJupyterNotebookを使っています。
処理内容
使用データはJADERの有害事象のデータを使用しています。
import pandas as pd import numpy as np reacs=pd.read_csv('reac.csv',dtype='str',encoding='shift-jisx0213')まずは症例ごとにユニークになるように 識別番号でグルーピング
groupCaseNo=reacs.groupby('識別番号')識別番号ごとにグルーピングされているので、以下のように
groupsを使用すればグルーピングしているキーを取得できる。groupCaseNo.groups.keys()以下のようにすることでそれぞれのキー単位で処理ができる。
get_groupはグルーピングのキーを使うことで中身を取得することができます。for case in groupCaseNo.groups.keys(): print(groupCaseNo.get_group(case))以下のように
applyを使用することで関数を使って文字列を結合したりすることが可能です。
lambdaを使って無名関数も可能ですが、込み入ったことをするときは別途関数を作成することになるかと思います。def getRecordAe(data): return data.有害事象連番+':'+data.有害事象 groupCaseNo.apply(getRecordAe)
- 投稿日:2020-01-13T20:08:20+09:00
AtCoder Beginner Contest 124 過去問復習
所要時間
感想
50番から70番くらいの問題をやっていて飽きたので全然違う番号の問題をやってみました。
A問題
大きい方を常に押すというのを言い換える
answerA.pya,b=map(int,input().split()) if a==b: print(2*a) else: print(2*max(a,b)-1)B問題
それぞれの旅館から実際に見えるのかを確かめる。
その旅館よりも大きい旅館が海側にあるのかどうかで場合分けをすれば良い。answerB.pyn=int(input()) h=list(map(int,input().split())) c=0 for i in range(n): for j in range(i): if h[j]>h[i]: break else: c+=1 print(c)C問題
こういう塗り替える系の問題は最終状態に注目すると良い。
010101…か101010…のどちらかしかありえないので両方を試して書き換える数が少ないものを解とすれば良い。answerC.pys=input() l=len(s) sa="" sb="" for i in range(l): if i%2==0: sa+="0" sb+="1" else: sa+="1" sb+="0" ca=0 cb=0 for i in range(l): if sa[i]!=s[i]: ca+=1 if sb[i]!=s[i]: cb+=1 #print(ca) #print(cb) print(min(ca,cb))D問題
今回の問題では、サンプルで実験をすればわかるようにn回の指示で逆立ちさせることができるのはn箇所の連続している人たちということになります。(けんちょんさんの記事を参照すれば、確かに交差する区間への操作は交差しない区間への操作を分割した操作と同値であることがわかります。)
したがって、k箇所の連続している人たちの合計の人数を求めればいいことがわかり、それぞれの連続してる箇所の人たちはgroupby関数で一つにまとめると良さそうなことがわかります。
ここで、groupby関数の返り値は[[0,n1],[1,n2],....]または[[1,n1],[0,n2],....](配列Gとする、n1,n2....はそれぞれの連続する人数)のどちらかの形になります。さらに、連続する人数の合計が大きくなるようにK箇所の連続している人たちを配列Gからとるには、0を1に変える操作が逆立ちに相当するので、1で始まり1で終わるような2K+1個の要素を配列Gから取ってくれば良いこともわかります。
しかし、返り値の一つ目のパターンは初めの要素が0なので(初めの要素を含みかつ)1で始まり1で終わるような2K+1個の要素を取ってくることができません。そこで、初めの0を含むK箇所を変化させる箇所として選ぶと、(初めの要素を含みかつ)0で始まり1で終わるような2K個の要素を考えることになります。そして、その後は、初めの0をのぞいて考えることで二つ目のパターンに帰着できます。
また、二つ目のパターンを考える際は、要素を二つずつずらしていくことと最後の要素が0の場合もあるのでその時は場合分けが必要であることに注意が必要です。
以上のことを実装すると以下のようになります。(ややこしすぎて実装がきつかった上に判定の条件を適当にやってしまいデバッグに時間がかかりました。)answerD.pyfrom sys import exit #groupby関数の定義 def groupby(a): a2=[[a[0],1]] for i in range(1,len(a)): if a2[-1][0]==a[i]: a2[-1][1]+=1 else: a2.append([a[i],1]) return a2 n,k=map(int,input().split()) s=list(input()) #groupby関数を適用して"0"と"1"がそれぞれ何個ずつ連続して並ぶかを記録する x=groupby(s) l=len(x) #sum(y)をしやすくしたかったので y=[x[i][1] for i in range(l)] #groupby関数の返り値の二つ目のパターンに帰着 if x[0][0]=="0": su=sum(y[:2*k]) ans=su y.pop(0) #削除するのでlを-1するの忘れずに l-=1 else: ans=0 #初めの2k+1個の合計を考える。(ここから尺取り法で数えていくので) su=sum(y[:2*k+1]) #ansの更新を忘れずに ans=max(ans,su) #二つずつ尺取るので2で割ることを忘れずに l_sub=(l-(2*k+1))//2 #2k+1個以上ない場合もあるので、その時はこの時点でmaxがわかる。 if l_sub<=0: print(ans) exit() #実際に尺を取って最後の要素までたどってく for i in range(l_sub): #二つずつ尺とる su-=y[2*i] su-=y[2*i+1] su+=y[2*k+1+(2*i)] su+=y[2*k+1+(2*i+1)] ans=max(su,ans) #最後の要素が0の場合は以下の条件を満たす #この場合は1で始まり0で終わることに注意(引き算は二回して足し算は一回しかできない) if 2*k+1+2*l_sub<l: su-=y[2*l_sub] su-=y[2*l_sub+1] su+=y[2*k+1+2*l_sub] ans=max(su,ans) print(ans)

- 投稿日:2020-01-13T20:07:11+09:00
【入門】open3dの使い方
1.はじめに
1-1.記事を書くきっかけ
仕事でopen3dを使うことになったが、初期導入から基本的な機能の把握に
時間がかかったので、把握内容をまとめたい。1-2.対象読者
・Open3Dを仕事で使うことになったが、何から手をつければいいかわからない人
・RGBだけではなくDepthも取り扱いたいが、まず何をしたらいいかわからない人
・上記に加えて、英語が苦手な人2.関連サイト
読んだサイトは以下の通り。
https://blog.negativemind.com/2018/10/17/open3d/
http://robonchu.hatenablog.com/entry/2018/02/24/200635
https://qiita.com/n_chiba_/items/fc9605cde5c19a8c7dad3.Tutorial
3-1.一番大事なこと。
他のライブラリ、フレームワークと同様に、公式サイトのチュートリアルが一番詳しく、正しく、最新の情報が載っている。
まずは公式サイトを読もう。3-2.公式ドキュメント
URL: http://www.open3d.org/docs/release/index.html
Get startedを読むと手順が記載されている。
http://www.open3d.org/docs/release/getting_started.html3-3.動作確認
red-woodのテストプログラム
http://redwood-data.org/indoor_lidar_rgbd/download.html
4 Point Cloudの注意点
Point cloud のままだとデータ量が莫大。
3d surfaceに変換して使うことが多い。点のデータだけでは分析には使いにくいため、
・segmentationによるクラス、インスタンス分類
・surface化による表面形状の設定
などを行うことが多い。5 次のアクション
・以下のプロジェクトに、3Dデータのリンクを貼り付けていくと、3Dデータのコミュニティに貢献できるので、やっていきたい。
https://github.com/awesomedata/awesome-public-datasets/tree/master
- 投稿日:2020-01-13T20:03:25+09:00
[BigQuery] BigQueryのPython用APIの使い方 -テーブル作成編-
5行で
- データサイエンティストは普段はJupyterで分析をしている
- 故にDBに対する処理もJupyter上で行いたい欲望がある
- 故にBigQueryもWebUIやRESTAPIではなくライブラリ経由でJupyter上で使えた方が便利
- 上に書いたことを実現するために公式のライブラリ
google.cloud.bigqueryの機能を調べることにした- 下にBigQueryにおけるテーブル作成の方法をまとめた
下準備
from google.cloud import bigquery # 自身のGCPProjectIDを指定 project_id = 'YourProjectID' client = bigquery.Client(project=project_id)Colaboratoryで認証を通す方法がわからない場合には、前に記事書いたのでそれを参照いただければと思います。
GCE環境で実行するならばそもそも認証についてはデフォルトで通っているはず。
他の環境でアクセスするならば下記の公式のAPIリファレンスに従って認証用JSONを作成して読み込ませましょう。
ColaboratoryでBigQueryにアクセスする3つの方法
公式APIリファレンス前提
google.cloud.bigquery: Ver. 1.20.0
* GCE上で構築されたJupyterで実行されることを前提に記載します言うまでもないけどこんな感じでインストールしておいてください
pip install google-cloud-bigquery==1.20.0DataSetはUSリージョンで作成することを前提とします
DataSet操作
すでにDataSetが用意されているPJであればこの部分は完全にすっ飛ばしてOK。
まだDataSetがなくてもDataSetを色々と作り変えることは基本的にはないので、一度処理してしまえばここら辺の機能は忘れてOK。ちなみに、BigQueryのDataSetは他のDBで言う所の「スキーマ」に該当する。でもBQではスキーマに別の意味を与えているのでここではDataSetの事はスキーマとは呼ばない。
DataSetの作成
Dataset作成する# [demo]という名称でDataSetを作成 dataset_name = "demo" dataset_id = "{}.{}".format(client.project, dataset_name) dataset = bigquery.Dataset(dataset_id) # locationはUSが一番安いのでいつもこれにしている. リージョンにこだわりがあれば変更してください dataset.location = "US" client.create_dataset(dataset)Table操作
テーブルの作成やテーブルへのデータをロードする処理について
- テーブルの作成
- テーブルの確認
- テーブルへのData Import
- テーブルからのData Export
- テーブルの削除
基本的には↓公式リファレンスを読めば全部書いてあるけど、まぁ。。。うん。。。Qiitaで書いといてもいいじゃん。。。
-参考-
Managing Tables
データ定義言語ステートメントの使用テーブルの作成
ここでは仮に下の様な商品の購入履歴テーブルを作成する事を想定してコード例を記載していく
# カラム名 型 モード コメント 1 TRANSACTION_ID STRING REQUIRED 購入履歴ID 2 ORDER_TS TIMESTAMP REQUIRED 購入時間 3 ORDER_DT DATE REQUIRED 購入日 4 ITEM_CODE STRING REQUIRED 商品ID 5 ITEM_NAME STRING NULLABLE 商品名 6 QUANTITY INTEGER NULLABLE 購入数量 7 AMOUNT FLOAT NULLABLE 購入金額 8 DISCOUNT FLOAT NULLABLE 値引金額 9 CUSTOMER_ID STRING REQUIRED 顧客ID 10 ITEM_TAG RECORD REPEATED 商品タグリスト 10.1 TAG_ID STRING NULLABLE タグID 10.2 TAG_NAME STRING NULLABLE タグ名称 *ネストされた情報を扱いたくない場合は#10のフィールドは無視する
テーブル定義を作成する(スキーマを作成する)
BigQueryではテーブルの定義のことをスキーマと読んでいる
よって、
bigquery.SchemaFieldのメソッドに色々定義をぶち込んでいくことになるフィールド名と型は省略不可
タグ情報はネストされた形式で定義
from google.cloud import bigquery # Schemaを定義 schema = [ bigquery.SchemaField('TRANSACTION_ID', 'STRING', mode='REQUIRED', description='購入履歴ID'), bigquery.SchemaField('ORDER_TS', 'TIMESTAMP', mode='REQUIRED', description='購入時間'), bigquery.SchemaField('ORDER_DT', 'DATE', mode='REQUIRED', description='購入日'), bigquery.SchemaField('ITEM_CODE', 'STRING', mode='REQUIRED', description='商品ID'), bigquery.SchemaField('ITEM_NAME', 'STRING', mode='NULLABLE', description='商品名'), bigquery.SchemaField('QUANTITY', 'INTEGER', mode='NULLABLE', description='購入数量'), bigquery.SchemaField('AMOUNT', 'FLOAT', mode='NULLABLE', description='購入金額'), bigquery.SchemaField('DISCOUNT', 'FLOAT', mode='NULLABLE', description='値引金額'), bigquery.SchemaField('CUSTOMER_ID', 'STRING', mode='NULLABLE', description='顧客ID'), bigquery.SchemaField('ITEM_TAG', 'RECORD', mode='REPEATED', description='タグ情報', fields= [ bigquery.SchemaField('TAG_ID', 'STRING', mode='NULLABLE', description='タグID'), bigquery.SchemaField('TAG_NAME', 'STRING', mode='NULLABLE', description='タグ名称'), ] ) ]実際にテーブルを作成する
スキーマを作成したら次はテーブルを実際に作成
スキーマ以外に検討しておくべき要素としては
- 分割テーブルにするか(日付2000日を超えるデータを入れる予定ならば分割テーブルにはしない方が良い)
- クラスターテーブルにするか(分割テーブルでしか適用できないので注意)
今回は分割&クラスターテーブルとしてテーブルを作成します
テーブル作成from google.cloud import bigquery # project_id = 'YourProjectID' # client = bigquery.Client(project=project_id) # dataset_name = "demo" # dataset_id = "{}.{}".format(client.project, dataset_name) # テーブル名を決める table_name = "demo_transaction" table_id = "{}.{}.{}".format(client.project, dataset_id, table_name) # スキーマは上で定義したものを利用 table = bigquery.Table(table_id, schema=schema) # 分割テーブルの設定(ここではORDER_DT) table.time_partitioning = bigquery.TimePartitioning( type_=bigquery.TimePartitioningType.DAY, field="ORDER_DT" ) # クラスターテーブルの設定 table.clustering_fields = ["ITEM_CODE", "CUSTOMER_ID"] table.description = "Demo Data" # テーブル作成を実行 table = client.create_table(table)Web上のコンソールで確認するとこんな感じで定義されていることが分かる
テーブル一覧確認
テーブルの一覧を確認するにはDataSet名を確定するか、もしくはDataSetオブジェクトを指定するか
で確認可能# [demo]DataSetに入っているテーブルを確認する # DataSet名を指定してテーブル名を確認するパターン dataset_id = "demo" for table in client.list_tables(dataset=dataset_id): print(table.table_id) # DataSetオブジェクトを指定して確認するパターン dataset_object = client.get_dataset("demo") for table in client.list_tables(dataset=dataset_object): print(table.table_id)テーブルへのデータロード
データサイエンティストはデータをImport/Exportを頻繁に繰り返すので、このあたりもちゃんと理解しておきたいところ
- ローカルファイルをImportする
- CSVを読み込む
- JSONを読み込む
- GCSファイルをImportする
ローカルファイルをImport
CSVでファイルを格納しているパターンとJSONで格納している2つのパターンを記載しておきます
CSVファイルを読み込む
CSVファイルでデータを保管していることはよくあると思うので、このパターンはフォローしておく。
ただし、ネストされたフィールドがあるテーブルではCSVでネストされた情報を表現できないので、CSVでは対応不可ネストされた情報が含まれていないテーブル名を
demo_transacitonとしてロードしてみるcsvをImport# ローカルファイルを指定 filename = 'demo_transaction.csv' # データセット名 detaset_id = "demo" # Importする対象のテーブル名 table_id = "demo_transaction_csv" dataset_ref = client.dataset(dataset_id) table_ref = dataset_ref.table(table_id) # Importする上での設定 job_config = bigquery.LoadJobConfig() # CSVがソースであることを指定 job_config.source_format = bigquery.SourceFormat.CSV # ファイルにヘッダーが含まれている場合は一行目をスキップする job_config.skip_leading_rows = 1 with open(filename, "rb") as source_file: job = client.load_table_from_file(source_file, table_ref, job_config=job_config) # 実行 job.result()ちなみに何らかの理由でエラーになった場合は、
job.errorsでエラーの中身を確認してロードし直してくださいJSONファイルを読み込み
ネストされたデータを含むテーブルはjsonでImportします
jsonでImport可能な形式は決まっていて下記のように改行で1レコードを判断する形でデータが入っている必要がある
json形式{"TRANSACTION_ID":"t0001","ORDER_TS":"2019-11-02 12:00:00 UTC","ORDER_DT":"2019-11-02","ITEM_CODE":"ITEM001","ITEM_NAME":"YYYYY1","QUANTITY":"29","AMOUNT":2200,"DISCOUNT":0,"CUSTOMER_ID":"F0002","ITEM_TAG":[{"TAG_ID":"XXX1", "TAG_NAME":"XYZ1"},{"TAG_ID":"XXX2", "TAG_NAME":"XYZ2"}]} {"TRANSACTION_ID":"t0002","ORDER_TS":"2019-11-03 12:00:00 UTC","ORDER_DT":"2019-11-03","ITEM_CODE":"ITEM002","ITEM_NAME":"YYYYY2","QUANTITY":"35","AMOUNT":5700,"DISCOUNT":0,"CUSTOMER_ID":"F0002","ITEM_TAG":[]} {"TRANSACTION_ID":"t0003","ORDER_TS":"2019-11-04 12:00:00 UTC","ORDER_DT":"2019-11-04","ITEM_CODE":"ITEM003","ITEM_NAME":"YYYYY3","QUANTITY":"48","AMOUNT":4200,"DISCOUNT":0,"CUSTOMER_ID":"F0002","ITEM_TAG":[{"TAG_ID":"XXX3", "TAG_NAME":"XYZ3"}]}こういう状態でjson化されたデータがあった場合にローカルファイルはこうやってImportできる
jsonをImport# ローカルファイル名を指定 filename = 'demo_transaction.json' # データセット名 detaset_id = "demo" # ネスト情報ありのテーブル名 table_id = "demo_transaction" dataset_ref = client.dataset(dataset_id) table_ref = dataset_ref.table(table_id) job_config = bigquery.LoadJobConfig() # jsonが元ファイルであることを教えてあげる job_config.source_format = bigquery.SourceFormat.NEWLINE_DELIMITED_JSON with open(filename, "rb") as source_file: job = client.load_table_from_file(source_file, table_ref, job_config=job_config) # 実行 job.result()ちなみにネストされたデータなので、コンソールで見るとこんな感じで見える
-参考-
gist:Google BigQuery の JSON投入を軽く試すGCSファイルをImport
ローカルファイルでBigQueryにデータをImportすることもあるにはあるが、GCPを使っているのでGCSをフル活用した方が良い
ということで、GCSに置いてあるデータをImportする方法も確認しておく
GCSに格納してあるファイルのパスさえ把握しておけば、GCS関連のライブラリを呼び出す必要がないのは素敵
CSVファイルを
demo_transaction_csvテーブルにImportするのを想定した例↓GCSからロード# データセット、テーブル名を指定 detaset_id = "demo" table_id = "demo_transaction_csv" dataset_ref = client.dataset(dataset_id) table_ref = dataset_ref.table(table_id) # CSVをロードするので諸々設定 job_config = bigquery.LoadJobConfig() job_config.skip_leading_rows = 1 job_config.source_format = bigquery.SourceFormat.CSV # GCSのファイルが置いてあるパスを指定 uri = "gs://{yourbacketname}/demo_transaction.csv" # ジョブを生成 load_job = client.load_table_from_uri( uri, table_ref, job_config=job_config ) # ロードを実行 load_job.result()(たぶん邪教)pandasの機能でDataFrameをBQに突っ込む
公式のAPIの機能ではないがpandas側の機能を使って
pd.DataFrameのデータをBigQueryのテーブルに挿入することもできる既存のテーブルに追加で挿入することも出来るけど、どちからというと色々加工した後のDataFrameを新しいテーブルにして書き出す為に使う方が多い気がする
例として先ほど作成した
demo.demo_transaction_csvのデータを一部引っこ抜いて別のテーブルとして書き出してみるto_gbqでDataFrameを書き出す# データの一部を取得するクエリを用意する query = """ SELECT TRANSACTION_ID , ORDER_TS , ITEM_CODE , QUANTITY , AMOUNT FROM `{YourProjectID}.demo.demo_transaction_csv` LIMIT 200 ; """ # クエリジョブを生成 query_job = client.query( query, location='US' ) # データフレームで結果を受け取る df = query_job.to_dataframe() # データフレームを[demo_transaciton_csv_extracted]の名前で書き出す # if_exists:append -> すでにテーブルがあれば追記、なければ新規作成 # if_exists:fail -> すでにテーブルがあればFail、なければ新規作成 # if_exists:replace -> すでにテーブルがあれば置き換え、なければ新規作成 detaset_id = "demo" table_id = "demo_transaciton_csv_extracted" df.to_gbq(destination_table='{dataset}.{table}'.format(dataset=dataset_id, table=table_id),project_id=project_id, if_exists='append')Importがうまくいっているかを一応確認しておく
一応テーブルにデータが入っているか確認するdetaset_id = "demo" dataset_ref = client.dataset(dataset_id) table_id = "demo_transaciton_csv_extracted" table_ref = dataset_ref.table(table_id) table = client.get_table(table_ref) print("Table has {} rows".format(table.num_rows)) > Table has 200 rowsAPIネイティブな機能でpd.DataFrameのデータをImport
邪法を先に書いてしまったが、APIでもDataFrameを入れることが可能
サンプルコードではSchemaを定義しているが無くても実行可能
pd.DataFrameをImportimport pandas as pd detaset_id = "demo" dataset_ref = client.dataset(dataset_id) table_id = "demo_pandas_data" table_ref = dataset_ref.table(table_id) # 適当にpd.DataFrameデータを作成 rows = [ {"item_id": "xx1", "quantity": 1}, {"item_id": "xx2", "quantity": 2}, {"item_id": "xx3", "quantity": 3}, ] dataframe = pd.DataFrame( rows, columns=["item_id", "quantity"] ) # スキーマを定義(無くてもImport出来るけど書いておいたほうが安全) job_config = bigquery.LoadJobConfig( schema=[ bigquery.SchemaField("item_id", "STRING"), bigquery.SchemaField("quantity", "INTEGER"), ], ) # pd.DataFrameデータをテーブルに格納する job = client.load_table_from_dataframe( dataframe, table_ref, job_config=job_config, location="US", ) # 実行 job.result()既存のテーブルデータをImport
邪教的にDataFrameを介して既存のテーブルからデータを引っこ抜いて、新しいテーブルとして書き込んだけど、基本的には公式の機能で実装しておきたいところ
- APIの機能を使って既存のテーブルの情報を抜き出して新たに書き込む
- クエリで直接、新たに書き込む
APIネイティブな機能でクエリ結果を書き込む
APIの機能を使って書き込む場合は、
QueryJobConfig.destinationに新たなテーブル名を指定してあげれば良いだけシンプル!!!
書き込みテーブルを指定してクエリ結果を書き込む# ジョブコンフィグを生成 job_config = bigquery.QueryJobConfig() detaset_id = "demo" dataset_ref = client.dataset(dataset_id) # 書き込み先のテーブル名を定義 table_id = "demo_transaciton_csv_direct_extracted" table_ref = dataset_ref.table(table_id) # (重要)書き込み先のテーブルを指定 job_config.destination = table_ref # 書き込み対象のクエリを定義 query = """ SELECT TRANSACTION_ID , ORDER_TS , ITEM_CODE , QUANTITY , AMOUNT FROM `{YourProjectID}.demo.demo_transaction_csv` LIMIT 300 ; """ # クエリジョブを生成 query_job = client.query( query, location="US", job_config=job_config, ) # 実行 query_job.result()クエリ(CREATE TABLE [TABLE_NAME] AS SELECT)で作るパターン
QueryJobConfig.destinationで新規テーブルを定義するパターンで十分な気もするが、お馴染みの方法(CREATE TABLE ~ AS SELECT)もフォローしておく。結局、意外と使うし。。。
クエリで新規テーブルを作成するdetaset_id = "demo" # 書き込み先のテーブル名を定義 table_id = "demo_transaciton_csv_as_select" # 書き込み対象のクエリを定義 query = """ DROP TABLE IF EXISTS {dataset}.{table} ; CREATE TABLE {dataset}.{table} AS SELECT TRANSACTION_ID , ORDER_TS , ITEM_CODE , QUANTITY , AMOUNT FROM `{YourProjectID}.demo.demo_transaction_csv` LIMIT 400 ; """.format(dataset=dataset_id, table=table_id) # クエリジョブを生成 job_config = bigquery.QueryJobConfig() query_job = client.query( query, location="US", job_config=job_config, ) # 実行(もちろん何も返ってこないけどちゃんと書き込まれている) query_job.result()これで一通り、データをImportする方法は網羅したはず。。。
分割テーブルの作成
BigQueryは列単位の従量課金形態なので、
Limitを設定しても課金額は変わらないWhereで条件を絞っても課金額は変わらない- 列(カラム)を増やすごとに課金されていく
というサービス上の特徴がある
データボリュームが小さいうちはどうでも良いことなのだけれど(月あたり1TBはクエリ無料なので)、数十TB以上のデータを扱う場合にはそれなりに気を使う必要が出てくる
じゃあ、どうするのが良いかというと
- 分割テーブルを設定する
- クラスタテーブルを設定する
が基本的な対処方法となる
数TBデータがあるようなテーブルには必ず何らかの時系列情報が含まれるはずなので、その情報を分割対象のフィールドとして設定して分割テーブルを作成する
なお、分割テーブルとしてテーブル作成時に定義しておかないとあとで変更は出来ないので注意
-参考-
パーティション分割テーブルの概要テーブル定義に分割オプションを入れるパターン
まずは、テーブルを作成する段階で分割オプションを設定するパターンを記載しておく
分割オプションを設定# テーブル定義を記述(時系列カラムは必須) schema = [ bigquery.SchemaField('TRANSACTION_ID', 'STRING', mode='REQUIRED', description='購入履歴ID'), bigquery.SchemaField('ORDER_TS', 'TIMESTAMP', mode='REQUIRED', description='購入時間'), bigquery.SchemaField('ORDER_DT', 'DATE', mode='REQUIRED', description='購入日'), ] detaset_id = "demo" table_id = "demo_transaction_time_partition1" dataset_ref = client.dataset(dataset_id) table_ref = dataset_ref.table(table_id) # Tableオブジェクト生成 table = bigquery.Table(table_ref, schema=schema) # 分割オプションを設定する table.time_partitioning = bigquery.TimePartitioning( # 日単位で分割 type_=bigquery.TimePartitioningType.DAY, # 対象のフィールドを設定 field="ORDER_DT" ) table.description = "Time Partition Data" # 分割テーブルを作成 table = client.create_table(table)クエリ(CREATE TABLE [TABLE_NAME] AS SELECT)で作るパターン
既存のテーブルから
CREATE TABLE [TABLE_NAME] AS SELECTでも分割テーブルは作成可能一番の使いどころは、分割テーブルとして設定してないのに肥大化してしまったテーブルを作り直す場合
AS SELECTの前にPARTITION BY [Time Partition Field]を入れればOK分割オプション付きテーブル作成クエリdetaset_id = "demo" # 書き込み先のテーブル名を定義 table_id = "demo_transaciton_csv_as_select_time_partition" query = """ DROP TABLE IF EXISTS {dataset}.{table} ; CREATE TABLE {dataset}.{table} PARTITION BY ORDER_DT AS SELECT TRANSACTION_ID , ORDER_TS , ORDER_DT , ITEM_CODE , QUANTITY , AMOUNT FROM `{YourProjectID}.demo.demo_transaction_csv` LIMIT 500 ; """.format(dataset=dataset_id, table=table_id) # クエリジョブを生成 query_job = client.query( query, location="US" ) # 実行 query_job.result()簡単!!
クラスタテーブルの作成
分割テーブルにはさらにクラスタフィールドを設定できる
分割テーブルのオプションにクラスタフィールドを指定するだけなので、抜粋して記載
-参考-
クラスタ化テーブルの作成と使用クラスターオプションを設定するとどんな効果があるかは以下を参考にしてください
テーブル定義にクラスタオプションを入れるパターン
クラスタフィールドを追加で指定する"""クラスタテーブルは分割テーブルである必要がある table = bigquery.Table(table_ref, schema=schema) table.time_partitioning = bigquery.TimePartitioning( type_=bigquery.TimePartitioningType.DAY, field="ORDER_DT" ) """ table.clustering_fields = ["ITEM_CODE", "CUSTOMER_ID"]クエリ(CREATE TABLE [TABLE_NAME] AS SELECT)で作るパターン
SQLで指定する場合もクラスタオプション
CLUSTER BYを追加するだけクラスタオプション追加部分を抜粋query = """ DROP TABLE IF EXISTS {dataset}.{table} ; CREATE TABLE {dataset}.{table} PARTITION BY ORDER_DT CLUSTER BY ITEM_CODE, CUSTOMER_ID AS SELECT * FROM `{YourProjectID}.demo.demo_transaction_csv` LIMIT 500 ; """.format(dataset=dataset_id, table=table_id)テーブルのデータをExport
ふぅ。。。ようやく、データを入れる部分が終わった。。。
次はExportの部分ですが、テーブルそのものをExportする方法はGCSに吐き出すのが基本
GCSにExport
テーブルの中身をGCSのバケットを指定して書き出す
特にjob_configを指定しなければcsvファイルとして書き出される通常はcsvになるので、ネストされたカラムを含むテーブルはcsvでは書き出せない
csv形式で書き出す# 書き出し対象のテーブルを指定 detaset_id = "demo" dataset_ref = client.dataset(dataset_id) table_id = "demo_transaciton_csv" table_ref = dataset_ref.table(table_id) # 指定バケットにファイルを格納 bucket_name = "{Your Bucket Name}" output_name = "{}.csv".format(table_id) destination_uri = "gs://{}/{}".format(bucket_name, output_name) # 書き出しジョブを生成 extract_job = client.extract_table( table_ref, destination_uri, location="US", ) # 実行 extract_job.result()ファイルを圧縮してExport
テーブルをそのままExportするとそれなりにデータ量が大きくなってしまうので、圧縮オプションは設定しておきたい
ExtractJobConfigで出力のオプションを設定して圧縮する
print_headerオプションを設定するとヘッダーを書き出すか否かを制御可能(デフォルトはTrue)圧縮オプションを追加(gzipで圧縮)destination_uri = "gs://{YourBucket}/{filename}.gz" job_config = bigquery.ExtractJobConfig( compression="GZIP", print_header=True ) # 書き出しジョブを生成 extract_job = client.extract_table( table_ref, destination_uri, job_config=job_config, location="US", ) # 実行 extract_job.result()ネストされたデータを含むテーブルをjson(avro)でExport
ネストされたカラムがある場合はcsvでは書き出せないのでjsonもしくはavroで書き出す
jsonならば圧縮可能だが、avroは圧縮オプションはサポートされていない
ネストされたテーブルはjsonかAvroでoutput_name = "{}.json".format(table_id) destination_uri = "gs://{}/{}".format(bucket_name, output_name) # jsonで書き出す(ヘッダーは出力しない) job_config = bigquery.ExtractJobConfig( destination_format = "NEWLINE_DELIMITED_JSON", print_header = False ) # 実行 extract_job = client.extract_table( table_ref, destination_uri, job_config=job_config, ) extract_job.result()tsvでExport
ちなみにデフォルトはcsvだが、tsvでも書き出し可能
tsvオプションを設定# job_configにデリミタオプションを加える job_config = bigquery.ExtractJobConfig( field_delimiter="\t" )テーブルの削除
テーブルを削除したい場合は、テーブル名を指定するだけでOK
テーブルを削除# from google.cloud import bigquery # project_id = 'YourProjectID' # client = bigquery.Client(project=project_id) detaset_id = "{YourDataSetId}" dataset_ref = client.dataset(dataset_id) table_id = "{YourTableId}" table_ref = dataset_ref.table(table_id) # テーブルの削除 client.delete_table(table_ref)テーブル作成周りの話は一旦これでおしまい

- 投稿日:2020-01-13T19:58:57+09:00
PythonGUIで行列を作成
GUIで行列の要素の値を入力し2次元配列型のデータを取得するソースです。
qiita.rbfrom tkinter import * from tkinter import ttk import numpy as np #入力用のGUI def GUI_Input(n,m): root = Tk() root.title('Table Input') #入力用フレーム frame = ttk.Frame(root) frame.grid(row=0, column=0) list_Items = [0]*(n*m) N = n M = m k=0 for i in range(0, n): for j in range(0, m): list_Items[k] = ttk.Entry(frame,width=2) list_Items[k].grid(row=i+1, column=j+1) k+=1 #コンボボックスからデータを取得し2次元配列としてprint出力 def ButtonClicked_Run(): B = [0]*(N*M) for i in range(N*M): B[i] = list_Items[i].get() A= np.reshape(B, (N,M)) print(A) #実行ボタンの設置 button_Run = ttk.Button(root, text='実行', padding=5, command=ButtonClicked_Run) button_Run.grid(row=1, column=0) root.mainloop() #n,mの数を変えて、表の行数を変える m = 9 n = 9 GUI_Input(m,n)
- 投稿日:2020-01-13T19:58:57+09:00
PythonGUI(コンボボックス)で行列を作成
GUIで行列の要素の値を入力し2次元配列型のデータを取得するソースです。
qiita.rbfrom tkinter import * from tkinter import ttk import numpy as np #入力用のGUI def GUI_Input(n,m): root = Tk() root.title('Table Input') #入力用フレーム frame = ttk.Frame(root) frame.grid(row=0, column=0) list_Items = [0]*(n*m) N = n M = m k=0 for i in range(0, n): for j in range(0, m): list_Items[k] = ttk.Entry(frame,width=2) list_Items[k].grid(row=i+1, column=j+1) k+=1 #コンボボックスからデータを取得し2次元配列としてprint出力 def ButtonClicked_Run(): B = [0]*(N*M) for i in range(N*M): B[i] = list_Items[i].get() A= np.reshape(B, (N,M)) print(A) #実行ボタンの設置 button_Run = ttk.Button(root, text='実行', padding=5, command=ButtonClicked_Run) button_Run.grid(row=1, column=0) root.mainloop() #n,mの数を変えて、表の行数を変える m = 9 n = 9 GUI_Input(m,n)
- 投稿日:2020-01-13T19:58:57+09:00
PythonGUI(テキストボックス)で行列を作成
GUI(テキストボックス)で行列の要素の値を入力し2次元配列型のデータを取得するソースです。行列は、変数により任意のサイズに変更可能。
qiita.rbfrom tkinter import * from tkinter import ttk import numpy as np #入力用のGUI def GUI_Input(n,m): root = Tk() root.title('Table Input') #入力用フレーム frame = ttk.Frame(root) frame.grid(row=0, column=0) list_Items = [0]*(n*m) N = n M = m k=0 for i in range(0, n): for j in range(0, m): list_Items[k] = ttk.Entry(frame,width=2) list_Items[k].grid(row=i+1, column=j+1) k+=1 #コンボボックスからデータを取得し2次元配列としてprint出力 def ButtonClicked_Run(): B = [0]*(N*M) for i in range(N*M): B[i] = list_Items[i].get() A= np.reshape(B, (N,M)) print(A) #実行ボタンの設置 button_Run = ttk.Button(root, text='実行', padding=5, command=ButtonClicked_Run) button_Run.grid(row=1, column=0) root.mainloop() #n,mの数を変えて、表の行数を変える m = 9 n = 9 GUI_Input(m,n)結果
↓


- 投稿日:2020-01-13T19:24:41+09:00
pandas 1.0.0 での pd.NA の特徴
2020-01-13 時点で pandas 1.0.0rc が公開されているが、大きな特徴の一つに missing value として
pd.NAが導入される。この性質や使い方についてまとめる。Disclaimer: pandas 1.0.0 rc での動作確認であり、将来的にも変更の可能性が十分ある。
検証環境 は最後に。
要約
pd.NAは missing value の意味として登場。pd.NAが 使えるのは IntegerArray, BooleanArray, StringArraypd.NA導入により int class にも missing value が表現可能となった(不用意な float への変換がなくなった)。pd.NAは singleton object で 全ての data types と一貫性をもつ。- pd.NA に対する比較演算子の返り値は全て
pd.NA(Julia のmissingobject, R のNA) と同じ挙動)- 論理演算子での演算は、いわゆる three-valued logic に従う
data type
pandas 内に新たに
NATypeという class が導入される。目的は missing value としての値を示す。>>> pd.NA <NA> >>> type(pd.NA) <class 'pandas._libs.missing.NAType'>pd.Series, pd.DataFrame では型を指定しないと object 型、明示するとその型として扱われる。なお
Int64Dtypeとは pandas 0.24 から導入された Nullable interger (An ExtensionDtype for int64 integer data. Array of integer (optional missing) values) である。int64ではなくInt64と大文字で dtype の指定が必要なことに注意が必要。 技術的にはPandas Extension Arraysの導入により ExtensionDType の利用が可能となった。
- https://pandas.pydata.org/pandas-docs/stable/reference/arrays.html
- https://dev.pandas.io/pandas-blog/pandas-extension-arrays.html>>> pd.Series([pd.NA]).dtype dtype('O') # O means Object >>> pd.Series([pd.NA], dtype="Int64").dtype Int64Dtype() >>> pd.Series([pd.NA], dtype="boolean").dtype BooleanDtype >>> pd.Series([pd.NA], dtype="string").dtype StringDtype
NATypeの実装はこちら。興味深いところだが hash value は
2 ** 61 - 1 == 2305843009213693951で定義されている。 dictionary の key では衝突しないので問題ない。pd.NAに関係ない話だが、実は python の 整数値の hash は2**61 - 1で一巡してしまう。>>> hash(pd.NA) == 2 ** 61 -1 True >>> {pd.NA: "a", 2305843009213693951: "b"} {<NA>: 'a', 2305843009213693951: 'b'} >>> (hash(2**61 - 2), hash(2**61 - 1), hash(2**61)) (2305843009213693950, 0, 1)
pd.Series, pd.DataFrame での型
型の確定について、
int64ではなく、大文字のInt64で指定が必要。>>> pd.Series([1, 2]) + pd.Series([pd.NA, pd.NA]) 0 <NA> 1 <NA> dtype: object >>> pd.Series([1, 2]) + pd.Series([pd.NA, pd.NA], dtype="Int64") 0 <NA> 1 <NA> dtype: Int64
int64の指定は error となる。>>> pd.Series([pd.NA], dtype="int64").dtype Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/lib/python3.7/site-packages/pandas/core/series.py", line 304, in __init__ data = sanitize_array(data, index, dtype, copy, raise_cast_failure=True) File "/usr/local/lib/python3.7/site-packages/pandas/core/construction.py", line 438, in sanitize_array subarr = _try_cast(data, dtype, copy, raise_cast_failure) File "/usr/local/lib/python3.7/site-packages/pandas/core/construction.py", line 535, in _try_cast subarr = maybe_cast_to_integer_array(arr, dtype) File "/usr/local/lib/python3.7/site-packages/pandas/core/dtypes/cast.py", line 1502, in maybe_cast_to_integer_array casted = np.array(arr, dtype=dtype, copy=copy) TypeError: int() argument must be a string, a bytes-like object or a number, not 'NAType'
boolean との演算の結果は Julia の
missingや R のNAと同じ挙動。>>> pd.Series([True, False, pd.NA]) & True 0 True 1 False 2 NA dtype: bool >>> pd.Series([True, False, pd.NA]) | True 0 True 1 True 2 True dtype: bool >>> pd.NA & True NA >>> pd.NA & False False >>> pd.NA | True True >>> pd.NA | False NA>>> pd.Series([1, 2, pd.NA], dtype="Int64") 0 1 1 2 2 <NA> dtype: Int64>>> pd.Series([True, False, pd.NA], dtype="boolean") 0 True 1 False 2 <NA> dtype: boolean
sum 演算の結果は
NA伝播 (propagate) するが、引数を指定しないpd.Series.sum()は0として取り扱い propagate しない。 propagate 扱いするためにはsum(skipna=False)を指定する必要がある。ところが'Int64'の型の指定ではNAではなくnp.nanが出力された。これは想定した挙動なのかバグなのか issue を検索したが不明だった。なので無謀にも issue ticket を作成してみた。# python >>> sum([1, pd.NA]) <NA> >>> pd.Series([1, pd.NA], dtype="Int64").sum(skipna=False) nanpow 関数
累乗の扱いは R の
NA_integer_と整合的。 julia の挙動は謎い。>>> pd.NA ** 0 1 >>> 1 ** pd.NA 1 >>> -1 ** pd.NA -1> R.version.string [1] "R version 3.6.1 (2019-07-05)" > NA_integer_ ^ 0L [1] 1 > 1L ^ NA_integer_ [1] 1 > -1L ^ NA_integer_ [1] -1julia> VERSION v"1.3.1" julia> missing ^ 0 missing julia> 1 ^ missing missing julia> -1 ^ missing missing
全ての元凶は numpy に missing value が存在していなかったこと。なので pandas のレイヤーで導入する必要があった。
そもそも私が知ったきっかけ
twitter のどなたかからの retweet で気づいた
https://mobile.twitter.com/jorisvdbossche/status/1208476049690046465
要約
pd.NAは missing value の意味として登場。pd.NAが 使えるのは IntegerArray, BooleanArray, StringArraypd.NA導入により int class にも missing value が表現可能となった(不用意な float への変換がなくなった)。pd.NAは singleton object で 全ての data types と一貫性をもつ。- pd.NA に対する比較演算子の返り値は全て
pd.NA(Julia のmissingobject, R のNA) と同じ挙動)- 論理演算子での演算は、いわゆる three-valued logic に従う
最後に
こういうマニアックな話が大好きな方、ぜひ justInCase へ遊びに来て下さい。https://www.wantedly.com/companies/justincase
参考URL
- https://dev.pandas.io/docs/user_guide/missing_data.html
- https://hackmd.io/@jorisvandenbossche/Sk0wMeAmB
- https://github.com/pandas-dev/pandas/blob/493363ef60dd9045888336b5c801b2a3d00e976d/pandas/_libs/missing.pyx#L335-L485
検証環境
docker上で確認した。
FROM python:3.7.6 WORKDIR /home RUN pip install pandas==1.0.0rc0 CMD ["/bin/bash"]$ docker build -t pdna . $ docker run -it --rm -v $(pwd):/home/ pdnaInside Docker
root@286578c2496b:/home# cat /etc/issue Debian GNU/Linux 10 \n \l root@286578c2496b:/home# uname -a Linux 286578c2496b 4.9.184-linuxkit #1 SMP Tue Jul 2 22:58:16 UTC 2019 x86_64 GNU/Linuxroot@286578c2496b:/home# python -c "import pandas as pd; pd.show_versions()" INSTALLED VERSIONS ------------------ commit : None python : 3.7.6.final.0 python-bits : 64 OS : Linux OS-release : 4.9.184-linuxkit machine : x86_64 processor : byteorder : little LC_ALL : None LANG : C.UTF-8 LOCALE : en_US.UTF-8 pandas : 1.0.0rc0 numpy : 1.18.1 pytz : 2019.3 dateutil : 2.8.1 pip : 19.3.1 setuptools : 44.0.0 Cython : None pytest : None hypothesis : None sphinx : None blosc : None feather : None xlsxwriter : None lxml.etree : None html5lib : None pymysql : None psycopg2 : None jinja2 : None IPython : None pandas_datareader: None bs4 : None bottleneck : None fastparquet : None gcsfs : None lxml.etree : None matplotlib : None numexpr : None odfpy : None openpyxl : None pandas_gbq : None pyarrow : None pytables : None pytest : None s3fs : None scipy : None sqlalchemy : None tables : None tabulate : None xarray : None xlrd : None xlwt : None xlsxwriter : None numba : None

- 投稿日:2020-01-13T19:24:41+09:00
pandas 1.0.0 (rc0) での pd.NA の特徴
2020-01-13 時点で pandas 1.0.0rc0 が公開されているが、大きな特徴の一つに missing value として
pd.NAが導入される。この性質や使い方についてまとめる。Disclaimer: pandas 1.0.0 rc0 での動作確認であり、将来的にも変更の可能性が十分ある。
検証環境 は最後に。
要約
pd.NAは missing value の意味として登場。pd.NAが 使えるのは IntegerArray, BooleanArray, StringArraypd.NA導入により int class にも missing value が表現可能となった(不用意な float への変換がなくなった)。pd.NAは singleton object で 全ての data types と一貫性をもつ。pd.NAに対する比較演算子の返り値は全てpd.NA(Julia のmissingobject, R のNA) と同じ挙動)- 論理演算子での演算は、いわゆる three-valued logic に従う
pd.read_csv()ではInt64,stringの指定は可能だがbooleanは error となる。この挙動がバグなのか仕様なのかは不明。(おそらく仕様)data type
pandas 内に新たに
NATypeという class が導入される。目的は missing value としての値を示す。>>> import pandas as pd >>> pd.NA <NA> >>> type(pd.NA) <class 'pandas._libs.missing.NAType'>pd.Series, pd.DataFrame では型を指定しないと object 型、明示するとその型として扱われる。なお
Int64Dtypeとは pandas 0.24 から導入された Nullable interger (An ExtensionDtype for int64 integer data. Array of integer (optional missing) values) である。int64ではなくInt64と大文字で dtype の指定が必要なことに注意が必要。 技術的にはPandas Extension Arraysの導入により ExtensionDType の利用が可能となった。
- https://pandas.pydata.org/pandas-docs/stable/reference/arrays.html
- https://dev.pandas.io/pandas-blog/pandas-extension-arrays.html>>> pd.Series([pd.NA]).dtype dtype('O') # O means Object # dtype の指定は文字列エイリアスでも type そのものでもどちらでもいける。以下は文字列での指定。 >>> pd.Series([pd.NA], dtype="Int64").dtype Int64Dtype() >>> pd.Series([pd.NA], dtype="boolean").dtype BooleanDtype >>> pd.Series([pd.NA], dtype="string").dtype StringDtype
NATypeの実装はこちら。興味深いところだが hash value は
2 ** 61 - 1 == 2305843009213693951で定義されている。 dictionary の key では衝突しないので問題ない。pd.NAに関係ない話だが、実は python の 整数値の hash は2**61 - 1で一巡してしまう。>>> hash(pd.NA) == 2 ** 61 -1 True >>> {pd.NA: "a", 2305843009213693951: "b"} {<NA>: 'a', 2305843009213693951: 'b'} >>> (hash(2**61 - 2), hash(2**61 - 1), hash(2**61)) (2305843009213693950, 0, 1)
pd.Series, pd.DataFrame での型
型の確定について、
int64ではなく、大文字のInt64で指定が必要。>>> pd.Series([1, 2]) + pd.Series([pd.NA, pd.NA]) 0 <NA> 1 <NA> dtype: object >>> pd.Series([1, 2]) + pd.Series([pd.NA, pd.NA], dtype="Int64") 0 <NA> 1 <NA> dtype: Int64
int64の指定は error となる。>>> pd.Series([pd.NA], dtype="int64").dtype Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/lib/python3.7/site-packages/pandas/core/series.py", line 304, in __init__ data = sanitize_array(data, index, dtype, copy, raise_cast_failure=True) File "/usr/local/lib/python3.7/site-packages/pandas/core/construction.py", line 438, in sanitize_array subarr = _try_cast(data, dtype, copy, raise_cast_failure) File "/usr/local/lib/python3.7/site-packages/pandas/core/construction.py", line 535, in _try_cast subarr = maybe_cast_to_integer_array(arr, dtype) File "/usr/local/lib/python3.7/site-packages/pandas/core/dtypes/cast.py", line 1502, in maybe_cast_to_integer_array casted = np.array(arr, dtype=dtype, copy=copy) TypeError: int() argument must be a string, a bytes-like object or a number, not 'NAType'
boolean との演算の結果は Julia の
missingや R のNAと同じ挙動。>>> pd.Series([True, False, pd.NA]) & True 0 True 1 False 2 NA dtype: bool >>> pd.Series([True, False, pd.NA]) | True 0 True 1 True 2 True dtype: bool >>> pd.NA & True NA >>> pd.NA & False False >>> pd.NA | True True >>> pd.NA | False NA>>> pd.Series([1, 2, pd.NA], dtype="Int64") 0 1 1 2 2 <NA> dtype: Int64>>> pd.Series([True, False, pd.NA], dtype="boolean") 0 True 1 False 2 <NA> dtype: boolean
sum 演算の結果は
NA伝播 (propagate) するが、引数を指定しないpd.Series.sum()は0として取り扱い propagate しない。 propagate 扱いするためにはsum(skipna=False)を指定する必要がある。ところが'Int64'の型の指定ではNAではなくnp.nanが出力された。これは想定した挙動なのかバグなのか issue を検索したが不明だった。なので無謀にも issue ticket を作成してみた。>>> sum([1, pd.NA]) <NA># pd.Series object >>> pd.Series([1, pd.NA]) 0 1 1 <NA> dtype: object >>> pd.Series([1, pd.NA]).sum() 1 >>> pd.Series([1, pd.NA]).sum(skipna=False) <NA># pd.Series Int64 >>> pd.Series([1, pd.NA], dtype='Int64') 0 1 1 <NA> dtype: Int64 >>> pd.Series([1, pd.NA], dtype='Int64').sum() 1 >>> pd.Series([1, pd.NA], dtype='Int64').sum(skipna=False) nanpow 関数
累乗の扱いは R の
NA_integer_と整合的。 julia の挙動は謎い。>>> pd.NA ** 0 1 >>> 1 ** pd.NA 1 >>> -1 ** pd.NA -1> R.version.string [1] "R version 3.6.1 (2019-07-05)" > NA_integer_ ^ 0L [1] 1 > 1L ^ NA_integer_ [1] 1 > -1L ^ NA_integer_ [1] -1julia> VERSION v"1.3.1" julia> missing ^ 0 missing julia> 1 ^ missing missing julia> -1 ^ missing missing
read_csv での指定
次の csv ファイルで実験。 (
test.csv)X_int,X_bool,X_string 1,True,"a" 2,False,"b" NA,NA,"NA"dtypeの指定無しでは、 pandas 0.25.3 の挙動と同じ。
>>> df1 = pd.read_csv("test.csv") >>> df1 X_int X_bool X_string 0 1.0 True a 1 2.0 False b 2 NaN NaN NaN >>> df1.dtypes X_int float64 X_bool object X_string object dtype: objectdtype に
Int64,stringは指定可能.# dtype は 文字リテラルでなく次の type class でも可能。 # df2 = pd.read_csv("test.csv", dtype={'X_int': pd.Int64Dtype(), 'X_string': pd.StringDtype()}) >>> df2 = pd.read_csv("test.csv", dtype={'X_int': 'Int64', 'X_string': 'string'}) >>> df2 X_int X_bool X_string 0 1 True a 1 2 False b 2 <NA> NaN <NA> >>> df2.dtypes X_int Int64 X_bool object X_string string dtype: object一方で
'boolean'pd.BooleanDtype()を指定しても boolean NA としての読み込みは失敗。当然'bool'の指定もエラー。>>> df3 = pd.read_csv("test.csv", dtype={'X_bool': 'boolean'}) Traceback (most recent call last): File "pandas/_libs/parsers.pyx", line 1191, in pandas._libs.parsers.TextReader._convert_with_dtype File "/usr/local/lib/python3.7/site-packages/pandas/core/arrays/base.py", line 232, in _from_sequence_of_strings raise AbstractMethodError(cls) pandas.errors.AbstractMethodError: This method must be defined in the concrete class type During handling of the above exception, another exception occurred: Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 676, in parser_f return _read(filepath_or_buffer, kwds) File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 454, in _read data = parser.read(nrows) File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 1133, in read ret = self._engine.read(nrows) File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 2037, in read data = self._reader.read(nrows) File "pandas/_libs/parsers.pyx", line 859, in pandas._libs.parsers.TextReader.read File "pandas/_libs/parsers.pyx", line 874, in pandas._libs.parsers.TextReader._read_low_memory File "pandas/_libs/parsers.pyx", line 951, in pandas._libs.parsers.TextReader._read_rows File "pandas/_libs/parsers.pyx", line 1083, in pandas._libs.parsers.TextReader._convert_column_data File "pandas/_libs/parsers.pyx", line 1114, in pandas._libs.parsers.TextReader._convert_tokens File "pandas/_libs/parsers.pyx", line 1194, in pandas._libs.parsers.TextReader._convert_with_dtype NotImplementedError: Extension Array: <class 'pandas.core.arrays.boolean.BooleanArray'> must implement _from_sequence_of_strings in order to be used in parser methods>>> df3 = pd.read_csv("test.csv", dtype={'X_bool': pd.BooleanDtype()}) Traceback (most recent call last): File "pandas/_libs/parsers.pyx", line 1191, in pandas._libs.parsers.TextReader._convert_with_dtype File "/usr/local/lib/python3.7/site-packages/pandas/core/arrays/base.py", line 232, in _from_sequence_of_strings raise AbstractMethodError(cls) pandas.errors.AbstractMethodError: This method must be defined in the concrete class type During handling of the above exception, another exception occurred: Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 676, in parser_f return _read(filepath_or_buffer, kwds) File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 454, in _read data = parser.read(nrows) File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 1133, in read ret = self._engine.read(nrows) File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 2037, in read data = self._reader.read(nrows) File "pandas/_libs/parsers.pyx", line 859, in pandas._libs.parsers.TextReader.read File "pandas/_libs/parsers.pyx", line 874, in pandas._libs.parsers.TextReader._read_low_memory File "pandas/_libs/parsers.pyx", line 951, in pandas._libs.parsers.TextReader._read_rows File "pandas/_libs/parsers.pyx", line 1083, in pandas._libs.parsers.TextReader._convert_column_data File "pandas/_libs/parsers.pyx", line 1114, in pandas._libs.parsers.TextReader._convert_tokens File "pandas/_libs/parsers.pyx", line 1194, in pandas._libs.parsers.TextReader._convert_with_dtype NotImplementedError: Extension Array: <class 'pandas.core.arrays.boolean.BooleanArray'> must implement _from_sequence_of_strings in order to be used in parser methods>>> df3 = pd.read_csv("test.csv", dtype={'X_bool': 'bool'}) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 676, in parser_f return _read(filepath_or_buffer, kwds) File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 454, in _read data = parser.read(nrows) File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 1133, in read ret = self._engine.read(nrows) File "/usr/local/lib/python3.7/site-packages/pandas/io/parsers.py", line 2037, in read data = self._reader.read(nrows) File "pandas/_libs/parsers.pyx", line 859, in pandas._libs.parsers.TextReader.read File "pandas/_libs/parsers.pyx", line 874, in pandas._libs.parsers.TextReader._read_low_memory File "pandas/_libs/parsers.pyx", line 951, in pandas._libs.parsers.TextReader._read_rows File "pandas/_libs/parsers.pyx", line 1083, in pandas._libs.parsers.TextReader._convert_column_data File "pandas/_libs/parsers.pyx", line 1114, in pandas._libs.parsers.TextReader._convert_tokens File "pandas/_libs/parsers.pyx", line 1231, in pandas._libs.parsers.TextReader._convert_with_dtype ValueError: Bool column has NA values in column 1(感想)
全ての元凶は numpy に missing value が存在していなかったこと。なので pandas のレイヤーで導入には色々矛盾が・・・。
ここに色々書いてあります。 https://dev.pandas.io/docs/user_guide/gotchas.html#why-not-make-numpy-like-rそもそも私が知ったきっかけ
twitter のどなたかからの retweet で気づいた
https://mobile.twitter.com/jorisvdbossche/status/1208476049690046465
要約
pd.NAは missing value の意味として登場。pd.NAが 使えるのは IntegerArray, BooleanArray, StringArraypd.NA導入により int class にも missing value が表現可能となった(不用意な float への変換がなくなった)。pd.NAは singleton object で 全ての data types と一貫性をもつ。- pd.NA に対する比較演算子の返り値は全て
pd.NA(Julia のmissingobject, R のNA) と同じ挙動)- 論理演算子での演算は、いわゆる three-valued logic に従う
pd.read_csv()ではInt64,stringの指定は可能だがbooleanは error となる。この挙動がバグなのか仕様なのかは不明。(おそらく仕様)最後に
こういうマニアックな話が大好きな方、ぜひ justInCase へ遊びに来て下さい。https://www.wantedly.com/companies/justincase
参考URL
- https://dev.pandas.io/docs/user_guide/missing_data.html
- https://dev.pandas.io/docs/user_guide/gotchas.html#nan-integer-na-values-and-na-type-promotions
- https://hackmd.io/@jorisvandenbossche/Sk0wMeAmB
- https://github.com/pandas-dev/pandas/blob/493363ef60dd9045888336b5c801b2a3d00e976d/pandas/_libs/missing.pyx#L335-L485
検証環境
docker上で確認した。
FROM python:3.7.6 WORKDIR /home RUN pip install pandas==1.0.0rc0 CMD ["/bin/bash"]$ docker build -t pdna . $ docker run -it --rm -v $(pwd):/home/ pdnaInside Docker
root@286578c2496b:/home# cat /etc/issue Debian GNU/Linux 10 \n \l root@286578c2496b:/home# uname -a Linux 286578c2496b 4.9.184-linuxkit #1 SMP Tue Jul 2 22:58:16 UTC 2019 x86_64 GNU/Linuxroot@286578c2496b:/home# python -c "import pandas as pd; pd.show_versions()" INSTALLED VERSIONS ------------------ commit : None python : 3.7.6.final.0 python-bits : 64 OS : Linux OS-release : 4.9.184-linuxkit machine : x86_64 processor : byteorder : little LC_ALL : None LANG : C.UTF-8 LOCALE : en_US.UTF-8 pandas : 1.0.0rc0 numpy : 1.18.1 pytz : 2019.3 dateutil : 2.8.1 pip : 19.3.1 setuptools : 44.0.0 Cython : None pytest : None hypothesis : None sphinx : None blosc : None feather : None xlsxwriter : None lxml.etree : None html5lib : None pymysql : None psycopg2 : None jinja2 : None IPython : None pandas_datareader: None bs4 : None bottleneck : None fastparquet : None gcsfs : None lxml.etree : None matplotlib : None numexpr : None odfpy : None openpyxl : None pandas_gbq : None pyarrow : None pytables : None pytest : None s3fs : None scipy : None sqlalchemy : None tables : None tabulate : None xarray : None xlrd : None xlwt : None xlsxwriter : None numba : None
- 投稿日:2020-01-13T18:32:53+09:00
pythonの組み込み例外一覧を取得する方法
ステップ1: 次のようなpythonファイルを作成する。
print_exc_tree.pyfrom __future__ import print_function import platform def classtree(cls, depth=0): if depth == 0: prefix = '' else: prefix = '.' * (depth * 3) + ' ' if cls.__name__.lower() == 'error': print('{0}{1} ({2})'.format(prefix, cls.__name__, cls)) else: print('{0}{1}'.format(prefix, cls.__name__)) for subcls in sorted(cls.__subclasses__(), key=lambda c: c.__name__): classtree(subcls, depth+1) if __name__ == '__main__': print('Python Version: {0}'.format(platform.python_version())) print() classtree(BaseException)ステップ2:
上記のpythonファイルを作成したら、コマンドプロンプトに次のコードを入力する。python print_exc_tree.pyステップ3:
次のようにpythonの組み込み例外の一覧を取得することができる。Python Version: 3.7.4 BaseException ... Exception ...... ArithmeticError ......... FloatingPointError ......... OverflowError ......... ZeroDivisionError ...... AssertionError ...... AttributeError ...... BufferError ...... EOFError ...... Error (<class 'locale.Error'>) ...... ImportError ......... ModuleNotFoundError ......... ZipImportError ...... LookupError ......... CodecRegistryError ......... IndexError ......... KeyError ...... MemoryError ...... NameError ......... UnboundLocalError ...... OSError ......... BlockingIOError ......... ChildProcessError ......... ConnectionError ............ BrokenPipeError ............ ConnectionAbortedError ............ ConnectionRefusedError ............ ConnectionResetError ......... FileExistsError ......... FileNotFoundError ......... InterruptedError ......... IsADirectoryError ......... NotADirectoryError ......... PermissionError ......... ProcessLookupError ......... TimeoutError ......... UnsupportedOperation ...... ReferenceError ...... RuntimeError ......... BrokenBarrierError ......... NotImplementedError ......... RecursionError ......... _DeadlockError ...... StopAsyncIteration ...... StopIteration ...... StopTokenizing ...... SubprocessError ......... CalledProcessError ......... TimeoutExpired ...... SyntaxError ......... IndentationError ............ TabError ...... SystemError ......... CodecRegistryError ...... TokenError ...... TypeError ...... ValueError ......... UnicodeError ............ UnicodeDecodeError ............ UnicodeEncodeError ............ UnicodeTranslateError ......... UnsupportedOperation ...... Verbose ...... Warning ......... BytesWarning ......... DeprecationWarning ......... FutureWarning ......... ImportWarning ......... PendingDeprecationWarning ......... ResourceWarning ......... RuntimeWarning ......... SyntaxWarning ......... UnicodeWarning ......... UserWarning ...... _OptionError ...... error (<class 're.error'>) ... GeneratorExit ... KeyboardInterrupt ... SystemExit
- 投稿日:2020-01-13T18:17:46+09:00
銀行を辞めてエンジニアになるまでについてまとめてみた
はじめに
はじめまして。しゅんたと申します。
私は新卒から約2年働いた銀行を2019年4月末に退職し、5月から半年間プログラミングスクールに通い、11月からデータアナリストとして就職しました。
私にとって2019年は自分の人生が大きく変わる一年となったため、一年の振り返りと今後の自分の覚悟として今思っていることを記事として書いて見ることにしました。概要
私が銀行を辞め、エンジニアになった理由と今後の展望について記載しました。この記事が、どこかの悩める若者の一つの参考になって頂ければ幸いです。
銀行に入るまでの自分
銀行を辞めた理由を書くまえに、簡単に銀行に入った時の自分について紹介します。
私は生まれてから就職するまでの人生、THE日本の教育で育った人間でした。
勉強して良い高校に入って、良い大学に入って、良い会社に入ればなんとなく幸せになれるのかなくらいにしか人生を考えていませんでした。
勉強したいことがあって大学に入ったわけではなかったため、大学生活はひたすら麻雀しているようなクズ学生でした。
そんな人生を過ごしてきたため、就職活動の時は非常に迷いました。やりたいことがない…
それでもなんとか自分自身のことをよく考えて以下のような理由で銀行への就職を決めました。
・数字を扱うのが好きなので、財務関係のことを勉強できるのは面白そう?将来的にも何かに活かせそう?
・離職率も高いため辞めるときに苦労しなさそう?比較的転職に有利そう?
・世間的に見れば高収入?最後に?がついているのはそれくらいアバウトにしか考えていなかったことの表れです(笑)
今考えるとこの程度の選考理由であれば、他の選択肢も色々ありそうな気もしますが、ギリギリまで就職活動をしていなかったり、視野がまだまだ狭かったため、最終的には働いてみればなんとかなるだろうという気持ちで就職を決めました。銀行に入って思ったこと
まず銀行に入って私が思ったことは、思考が合わない…
一つだけ断りを入れさせてもらうと、私は働いていた銀行で嫌いだった人もいませんし、
その人たちのことを否定するつもりも全くありません(ただ、苦手だった人はいました…笑)。
もちろん、尊敬できる先輩方もたくさんいらっしゃいました。
ただ、銀行という組織の考え方は、全く合わず、入って数ヶ月でどこかで絶対辞めるんだろうなと思っていました。参考までに、自分が振り返ってストレスだったなと思うところは以下のようなことです。こういうことでストレスを感じる人には、銀行員は向いていないのかなと思います。
・上下関係や風通しの悪さ
・非生産的な作業が多すぎる。
・単純にワクワクしない。
・自己都合の数字しか追っていない
しかし、やりたいことがある訳ではない私は、せっかく入った銀行ですし、業務をある程度経験してから辞めようと思って働き続けていました(きっとこうやって、なんとなく働いていく人も一定層いるのかなと思います)。銀行を辞めエンジニアを目指した理由
私の決意が急速に固まったのは2019年の1月頃でした。
私は元々、一攫千金を夢見て仮想通貨を購入していました(世間を騒がせたコインチェックの騒動で私のXEMも盗まれました笑)。
2018年にはBTC-FXをはじめて、ビギナーズラックを経た後に、痛い目を見るというありがちな失敗をしました。
負けず嫌いの私は何としても勝つと誓ううと共に、ネットを通して様々な生き方をする人たちの考えを知り、世界の広さを痛感するようになりました。そんな中、私の気持ちを大きく動かしたのはbotterと呼ばれる方々です。彼らは自身で作成した自動売買botで、日々爆益画像をあげていました。Twitterには爆益画像をあげる人はたくさんいるため(加工も簡単にできます)、私が惹かれたのは自動売買botでトレードをするという、知的好奇心をくすぐられる行為でした。
これが私がプログラミングに興味を持ったきっかけでした(私がpythonを選んだ理由にもなります)。
それから、プログラミングについて調べていくうちに、ITの世界ってめちゃくちゃ夢あって面白そうだなと感じるようになり、転職を決意しました。プログラミングスクールでの半年間
仙台で働いており転職活動も難しく、プログラミング知識の全くなかった私は、プログラミングスクールに通って転職をすることにしました。
私は半年間.Proというスクールで勉強をしました。
スクールは土曜日週1で、半年間で2回の発表会がありました。
スクールに通って良かったことは、実際にものを作ることができたこと、IT業界で働く優秀な方々の話を聞くことができたことです。簡単に半年間を振り返ると、まず最初にpythonの基本的な文法について一生懸命勉強しました。と言いたいところですが…
最初の2ヶ月間は、個人的にどうしてもやりたかったトレードの方に集中して、片手間に勉強という過ごし方をしていました。これについては話すと長くなってしまうので割愛しますが、この2ヶ月間は自分の人生観を改めて見つめ直す良いきっかけになったと思います。それからは、以下のようなことをしました。
自動売買botの作成。
linebotの作成
Djangoでメモアプリの作成
機械学習の勉強
機械学習での価格予測モデルの作成こういった勉強をしている中で、自分はやはり数学が好きなのでそういった勉強をもっとしていきたいと思うようになり、データサイエンティストを目指すことを決めました。
入社した会社について
11月から主に分析業務の人材派遣を行う会社に入社しました。
2ヶ月間は研修であったため、業務についての感想はまだ無いのですが、一つだけ言えることは、周りの人が非常に向上心があって良いなと感じています。今後の展望
12月の半ばから、E資格の認定講座となっているジョブカレのディープラーニング講座を受講しています。
当面の目標としては、機械学習やディープラーニングの勉強をして、フリーランスとして仕事ができる人間になることです。
やりたいことはたくさんあるので、一つ一つそれを叶えていけるよう頑張っていきたいと思います。
最初は不安な部分もありましたが、今は自分の人生がどうなっていくのかなというワクワクした気持ちの方が大きいです。終わりに
銀行員に限らず、現状に疑問を抱いていたり、現状に満足できずに働いている人はたくさんいると思います。
この記事が、そうした人たちの人生を見つめ直す一つのきっかけになれば幸いです。
人それぞれ価値観も環境も違うと思いますが、やりたいことがあったり、現状を変えたいという気持ちがある方は、是非思い切って行動を起こしてみてほしいです。つらつらと長い文章になってしまいましたが、改めて思考が整理できる良い機会になったと思います。
今後とも、アウトプットの意味も込めて、定期的に記事も書いていきたいと思いますので、ぜひ読んでいただけたら嬉しいです!
- 投稿日:2020-01-13T17:34:12+09:00
2020年に読むべきデータサイエンスに関する書籍
こちらの記事は、Przemek Chojecki 氏により2019年 11月に公開された『 Data Science Books you should read in 2020 』の和訳です。
本記事は原著者から許可を得た上で記事を公開しています。データサイエンスは間違いなく今最もホットな市場の1つです。ほとんどすべての企業が、データサイエンスの職種を募集している、もしくは検討しています。
つまり、データサイエンティストになるのには最適な時期です。もしくはすでにデータサイエンスティストであり、上級職に昇格したい場合は、スキルを磨くのに最適な時期です。
この記事では、データサイエンスに関する最も人気のある書籍のいくつかを扱っています。
入門レベル
データサイエンスの冒険を始めたばかりなら、ぜひ試してみてください
Data Science from Scratch は、その名の通り、全くの初心者向けのデータサイエンスの入門書です。Pythonを知っていなくても始めることができます。
※訳注:日本語訳はゼロからはじめるデータサイエンス ―Pythonで学ぶ基本と実践
全くの初心者であるが、機械学習寄りのことをもっと知りたい場合は、Introduction to Machine Learning with Python がおすすめの書籍です。この書籍もPythonを知っていることは想定していません。
訳注:日本語訳はPythonではじめる機械学習中級レベル
すでに1冊か2冊データサイエンスの書籍を読んでおり、1つか2つのプロジェクトを自分で行って、データの操作に少し慣れている場合は、さらに成長させてくれるこちらの書籍をどうぞ。
Python for Data Analysis はNumPyやpandasのような標準Pythonライブラリに詳しくなるのには申し分ないです。Pythonの動作を思い出させてくれるところから始まり1冊で完結する本です。訳注:日本語訳はPythonによるデータ分析入門
Python Data Science Handbookは、NumPy、pandas、Matplotlib、Scikit-learnも含む全ての標準Pythonライブラリの優れた入門書です。訳注:日本語訳はPythonデータサイエンスハンドブック
Python Machine Learningは、中級レベルから専門家レベルの間です。専門家および中級レベル以上の人の両方に適しています。緩やかに始まり、機械学習と深層学習の最新情報にまで触れています。読んでみてください!訳注:日本語訳はPython機械学習プログラミング
Python for Financeは、金融とデータサイエンスに興味がある場合は必読です。データサイエンスツールを使用して金融市場を分析する方法に焦点を当てており、それを示す多くの素晴らしい例があります。これは非常に実用的であり、日常的に金融で働いていない人にも適します。訳注:日本語訳はPythonによるファイナンス
専門家レベル
専門家レベルに近づいている場合、本を読むよりも実際に科学論文を読むほうが意味があることが多いです。ただし、従来の統計学を超えるために、ディープラーニングを学習し、ソリューションの中でこの本は緩やかに始まり、非常に実用的で、すぐに使用できるコードを提供し、ディープラーニングを使用するにあたっての一般的に役立つヒントを多数提供しています。
実装するときでもあります。素晴らしく、かつ現在標準となっている3つの参考書は次のとおりです。
Deep Learning with Pythonは、Pythonで最も人気のある機械学習ライブラリの1つであるKerasの作成者によって書かれました。ディープラーニングにおいては必読書です。
訳注:日本語訳はPythonとKerasによるディープラーニング
Deep Learning は、ディープラーニングのアルゴリズムの素晴らしい参考書です。コードはあまり含まれていませんが、機械学習の問題にどのように取り組むべきかについての深い洞察があります:ディープラーニングの先駆者によって書かれました。訳注:日本語訳は深層学習
数学に興味があるなら、Machine Learning: a Probabilistic Perspective はとても気に入ると思います。これは、すべての機械学習方法の背景にある数学を網羅した力作です。おそらく一度に読むことはできないでしょうが、機械学習研究の参考資料として非常に役立ちます。訳注:日本語訳不明
おわりに
これで全てです!
この記事がおもしろかったら、データサイエンティストになる方法についての他の私の投稿を見てみてください。
- Complete guide to become a Data Scientist
- Practical guide to become a Data Scientist
- Data Science Books and Courses recommendations
訳注:「Data Science Books and Courses recommendations」は原著からリンクが飛べないためリンクを消しています
翻訳協力
Original Author: Przemek Chojecki
Thank you for letting us share your knowledge!この記事は以下の方々のご協力により公開する事が出来ました。
改めて感謝致します。
選定担当: yumika tomita
翻訳担当: @satosansato3
監査担当: @nyorochan
公開担当: @aoharu私たちと一緒に記事を作りませんか?
私たちは、海外の良質な記事を複数の優秀なエンジニアの方の協力を経て、日本語に翻訳し記事を公開しています。
活動に共感していただける方、良質な記事を多くの方に広めることに興味のある方は、ぜひご連絡ください。
Mailでタイトルを「参加希望」としたうえでメッセージをいただく、もしくはTwitterでメッセージをいただければ、選考のちお手伝いして頂ける部分についてご紹介させていただく事が可能です。
※ 頂いたメッセージには必ずご返信させて頂きます。ご意見・ご感想をお待ちしております
今回の記事は、いかがだったでしょうか?
・こうしたら良かった、もっとこうして欲しい、こうした方が良いのではないか
・こういったところが良かった
などなど、率直なご意見を募集しております。
いただいたお声は、今後の記事の質向上に役立たせていただきますので、お気軽にコメント欄にてご投稿ください。Twitterでもご意見を受け付けております。
みなさまのメッセージをお待ちしております。










- 投稿日:2020-01-13T17:17:43+09:00
TensorFlow 1.0のコードを2.0で動かす方法
行頭に以下のように記載する
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()