- 投稿日:2020-01-13T22:36:21+09:00
AWS認定SysOpsアドミニストレーターアソシエイトを受験した時の話
この記事の概要
2020/01/13に
AWS認定SysOpsアドミニストレーター - アソシエイト
(AWS Certified SysOps Administrator - Associate (SOA))
を受験したので、その時の記録試験の概要
アソシエイトレベル(下から2番目)の管理・運用者向け試験です。
「AWSプラットフォームでのデプロイ、管理および運用に関する技術的な専門知識を認定します。AWSベースのアプリケーションの運用に関する1年以上の実務経験を持つ方が対象です。」
AWS公式より引用:引用元◼︎ 試験要項
問題数 :65問
試験時間 :130分
受験料 :¥15,000(税別)
合格ライン:100~1000点中720点(約69%)
受験資格 :なし◼︎ 出題範囲
分野 出題割合 分野 1: モニタリングとレポート 22% 分野 2: 高可用性 8% 分野 3: 展開とプロビジョニング 14% 分野 4: ストレージおよびデータの管理 12% 分野 5: セキュリティとコンプライアンス 18% 分野 6: ネットワーク 14% 分野 7: 自動化と最適化 12% 2020/01時点の最新バージョン(Ver.1.2)のものです。
バージョンアップで範囲等は変更されるので、受験時は公式で確認してください。
AWS 認定 SysOps アドミニストレーター – アソシエイト | AWS勉強開始前の状態
AWSで動いているアプリ開発の業務経験1年以上、
8ヶ月ほど前にソリューションアーキテクト - アソシエイトを取得、5ヶ月ほど前にデベロッパー - アソシエイトを取得済み
DynamoDB, S3, Lambda, SQSの利用経験あり、SDKによる開発がメイン。
AWSソリューションアーキテクトを受験した時の話
https://qiita.com/aminosan000/items/24c6dff9532658a5c4d5
https://qiita.com/aminosan000/items/89bc76f77626314f3182勉強に使ったもの
1. オンライン練習問題(非公式)その1
AWS WEB問題集で学習しよう | 赤本ではなく黒本の問題集から学習する方向け
ソリューションアーキテクト受験の際に利用したサイト、SysOpsはフリープランだと理解度確認テストがないので、問題数は少ないです。
全問(469問)利用するためにはプラチナプラン:90日/¥4,280(税抜き)の登録が必要なので、今回は無料の問題21問だけ利用。2. オンライン練習問題(非公式)その2
AWS Certified SysOps Administrator Associate | Whizlabs
以前、デベロッパーアソシエイト受験の際に利用して、なかなか良かったので今回も購入。
デベロッパーアソシエイトと同様、最新のバージョンの問題が325問(65問×5パターン)用意されています。
※旧バージョンの試験と合わせると700問以上
今回はクリスマス&ニューイヤークーポンで 19.95USD の50%offで 9.98USD でした。(現在のレートで¥1,138、コスパ抜群!)
前回同様、Google翻訳で翻訳しながら日本語が怪しい部分は原文とあわせながら利用。3. AWS公式模擬試験
4. AWSアカウント
SysOpsに関しては対策本が↓の1種類しかなかったので、一応購入してみましたが、ソリューションアーキテクト、デベロッパーとさほど内容が変わらないように思いました。
「AWS認定アソシエイト3資格対策~ソリューションアーキテクト、デベロッパー、SysOpsアドミニストレーター~」なので、前回同様、公式模擬試験(前回の合格者特典で1回無料)でどれぐらい解けるか一度試してみて、あとはひたすら練習問題を解く!触ったことがないサービス名とかが出てきたら、ググってイメージの湧かないものはマネジメントコンソールでも触ってみる〜の流れでいきました。
勉強時間
トータルで10時間ぐらい
正直、SAAとDVAを持ってる人なら問題集だけで十分かなと思います。受験後
しっかり見直しして30分ほど残して終了。結果スコアは872で合格
印象としては、
- オンプレからの移行やハイブリッドとマルチリージョン(Snowball、ストレージゲートウェイ, VPCピアリング)
- 追跡や構成の保護,管理(VPC Flow, CloudTrail, Amazon Inspector, AWS Config, AWS SSM)
- アプリケーションレイヤーでのセキュリティ(GurdDuty, AWS Sield, WAF)
- サポートプランによる違いや、サポートへの申請が必要な制限の解除
あたりが、SAAとDVAに比べて結構でてきた感じでした。
次は「ソリューションアーキテクト - プロフェッショナル」か「DevOpsエンジニア - プロフェッショナル」のどちらか
受験したらまた載せていきたいと思います。
アソシエイト試験の期限(3年)が切れるまでには受験する予定です。勉強になったことメモ
試験のために勉強したことで、今後どこかで使えそうなことを忘れないようにメモ
Spot Block(スポットインスタンスのオプション):
一定の起動時間の間、価格変動があっても起動し続けられるSpotインスタンスのオプション(最大6時間)
AWS Artifact:
AWSの監査レポートをPDFで取得できる
AWS System Manager(SSM):
EC2インスタンスのOSのパッチ適用やアンチウイルス定義更新などを一括で行える
Egress-Only(下り専用)インターネットゲートウェイ:
IPv6のNATゲートウェイ的な役割をする。NATゲートウェイはIPv6に対応できない。
AD Connector, AWS Managed Microsoft AD:
Active Directoryのユーザに対してAWSマネジメントコンソールへのアクセス権の認可が行える。
AWS Snowball:
オンプレミスからAWSヘ物理ストレージを経由したデータ移行サービス
より高機能なSnowball Edgeもある。(ストレージ容量などが上がっているが、Edgeの方が高い)
Snowballアプライアンス(appliance=器具,装置)はデータ移行用専用デバイスのこと。Route53の加重(重み付け)ルーティング:
加重ルーティングを使うと新しいバージョンのインスタンスに少しだけリクエストを流して、カナリアリリースができる。
AWS Orgatnization:
複数のAWSアカウント(IAMユーザでなく"アカウント")を統合管理できるサービス
共通のポリシーをアカウントにまたがって設定したりできる。その仕組みをSCP(サービスコントロールポリシー)という。Vault Lock(ボールトロック):
S3 Glacierにアーカイブする際に変更不可能にすることができる「write once read many」などのポリシーを設定する機能
ボールトロックポリシーをボールトにアタッチするとボールトロックIDが生成され、24時間以内にこのIDを使用してロックを有効にする。という2段階のプロセスが必要。SSE-S3, SSE-KMS(Server Side Encliption):
S3アクセスログのターゲットバケットを暗号化する場合SSE-S3でないとならない。
AWS WAF:
そのまんまWAF, SQLインジェクションとかXSSとかを防げる
AWS Sield:
DDOS攻撃に対するマネージドセキュリティサービス
Amazon GurdDuty:
AWS環境やAWSアカウントに対する攻撃を検知する。脅威リストと信頼済みIPリストを設定できる。(マスターアカウントのみ)
GurdDutyのルールは無効にしたり、削除はできないがアーカイブすることによって通知を発生しないようにできる。VPC Endpoint for S3:
EC2からS3へアクセスさせるためにはIAMロールだけでなくVPCエンドポイントも必要
AWS Config Rules:
AWS Config Rulesを使ってEC2に適切なタグ付けがされていること、セキュリティグループが関連付けられていること、ポート22が空いていないこと、
CloudWatch:
複数のリージョンにまたがるメトリクスの取得は詳細モニタリング
ストレージゲートウェイ:
S3をオンプレミス環境と接続するための仕組み
・ファイルゲートウェイ:NFSやSMBなどの業界標準ファイルプロトコルを使用できる。VMware ESXi or Hyper-VのVMとしてオンプレにデプロイできる。
・ボリュームゲートウェイ:キャッシュボリュームを使うとオンプレミスサーバからiSCSIとして接続できる。
・テープゲートウェイ:バックアップデータ向け、GLACIER または DEEP_ARCHIVEにアーカイブできる。AWS Config & AWS CloudTrail & Amazon Inspector:
追跡・セキュリティ評価に利用できるサービス達
・AWS Configは構成ルールに関するリソースの変更を追跡できる。リージョンごとに有効にできる。
・AWS CloudTrailはAWSリソースへのAPI呼び出しを追跡できる。デフォルトで有効、グローバルサービス。
・Amazon InspectorはEC2インスタンス上のアプリケーションのポート及びサービスの脆弱性を評価できる。AWS Systems Manager(SSM):
EC2やオンプレサーバに対して、メタデータの取得を行える。
例)インストールされているソフトウェアのリストやOSの更新状況など
OSのパッチ適用などもできる。Amazon QuickSight:
ビジネス分析サービス、StandardとEnterpriseの二つのEditionがある。
StandardはIAMでのアクセス制御、EnterpriseはADでのアクセス制御
Enterpriseのみ保存時の暗号化をサポート。SurgeQueueLengthとSpilloverCount:
CLBのバックエンドインスタンスで処理しきれないリクエストはキューに溜め込まれ、この数はSurgeQueueLengthというメトリックで確認できる。
SurgeQueueLengthは1024を超えるとリクエストが拒否される、メトリックSpilloverCountはこの拒否されたリクエストの数。VPC Flow Logs:
VPC内のトラフィックをキャプチャする機能、キャプチャしたデータはCloudWatch LogsとS3に出力できる。
セキュリティツールとしてのトラフィックの監視や到達しないトラフィックのトラブルシューティングに利用可能。インターフェイスVPCエンドポイント:
インターフェイスVPCエンドポイントを利用するとVPC内のEC2からインターネットを経由せずKinesis Streamにアクセスできる。
Amazon Redshift Enhanced VPC Routing:
Redshiftクラスターに転送されるデータを全てVPC経由にできる。これにより、SG,NACL,IGWなどのVPC標準サービスが適用できる。
S3のクロスリージョンレプリケーション:
S3バケットを異なるリージョンにコピーする条件
・送信元バケットと宛先バケットでともにバージョニングが有効であること。
・バケットのリージョンが異なること。
・Amazon S3に送信先バケットに対するアクセス許可があること。Elastic Beanstalk:
Elastic BeanstalkはWebアプリのデプロイを簡略化するサービス。EC2だけでなくECSもいける。LAMPテンプレートとかいうのもある。
Amazon Data Lifecycle Manager:
EBSボリュームをバックアップするために作成されたスナップショットの作成・保持・削除を自動化できる


- 投稿日:2020-01-13T21:35:24+09:00
横文字が飛び交う世界で無知無知の新卒が一人前のSEになるまで ー1年目ー
要約
- 「IT?何それ?」な新卒社員がIT部署に配属されてからの軌跡
- 一年を通しての振り返り
- 何を見て何を学び、何が出来るようになったのかのまとめ
- 参考になるかは貴方次第
はじめに
こんにちは。タスク管理で予想時間以内にタスクが終わった試しがない、あやしいブロッコリーです。
という紹介文が馴れ馴れしいほどのQiita初心者です。
2019年、皆様はどんな年でしたでしょうか。
個人的な感想としては、題にもある通り新卒ということで沢山の苦悩・苦難があった年でした。
例えば、先輩社員や上司の方々がどこぞのクラウドサービス炎上でドタバタする中、
私はTwitterで現状を追うことしかできなかったり。。
あの時の自分の何もできない感といったらまあもう味わいたくないですね。
アマゾン森林の大火災なんて笑えません全く。そんな2019年でしたが、今回は新年明けての挨拶も兼ねて、
昨年の振り返り、今年の抱負、やりたいこと等々色々考えてみました。
脳内の大掃除なくして2020年は迎えられませんからね。現在携わっているプロダクト
Webサイトにおける様々なログを収集・分析し、そのデータをレポートとして提供するサービス。
現在はその内部システムを担当しているチームに所属しています。2019年振り返り
2019年では「えんじにあ…??」⇒「デプロイ作業やってみよう」まで変化できたかなと思います。
当初はエンジニアになるとは思ってもいなかったため、右も左も分からなかった状態でした。
幸いにも、部署の研修プロセスは基礎の基礎からの叩き上げが重視されていたため、
「理解するまで理解する」ことに集中できました。
やることはひたすら『調べること』『得た知識を発表』
『フィードバックを受けてさらに洗練』のループ&ループ。
調べに調べまくっては発表し、痛い指摘を受けてはまた調べての毎日を送っていました。上長の口癖は「じゃあそれってなんだっけ?」。
どんな説明をしても全てこの一言で一刀両断されます。その切れ味は妖刀紅桜をも凌駕します。
これが本当に痛くて苦しく、そして悔しくて原動力になる言葉でした。
半年ほどかけて最終的に上長からその言葉を聞かなくなった時の達成感は、
今でも糧になっています。現在はシステムのデプロイ作業の練習をしており、
終了後はとうとう自分がハンドルを握る・・・それまでに自分が何を学んできたのか、振り返ってみました。
2019年やってきたこと
業務を中心にひたすらインプットとアウトプットの繰り返し。
Try&Errorの繰り返し、。
とにかく書いて、とにかく触って、とにかく動かしていく毎日.ザックリ言うと以下の通り。
1. IT基礎知識の習得
2. システム問い合わせ対応 / 一部開発・改修作業
3. その他インプット2019年で学んだこと、出来るようになったこと
上記のやってきたことベースで思い出し書き。
IT基礎知識の習得
ITの基礎知識の定着に、配属されてからの約4ヶ月間を費やしました。
主なテーマは以下の通り。
1. 開発プロセス
2. Webシステム
3. http/https通信の違い
4. Webサイト作成開発プロセス
SEとしてシステム開発に携わる前提として、直後に「そもそもシステム開発ってなに?」「ただコード書けばいいの?」とならないように、一般的な開発フェーズやプロセスとは何たるかを学びました。
自分の、そしてチーム全体のスコープを見失わずに開発を進めていくうえで必須な考え方を身に付けました。
- 開発フェーズ
- 上流(要件定義、基本設計)、下流(詳細設計、実装)、テスト(単体、結合、システム、UAT)
- 開発プロセスの種類
- ウォータフォール、プロトタイプ、スパイラル、アジャイル開発
- 開発管理
- プロジェクト管理(Redmine)、構成管理/バージョン管理(Git)、変更管理、QA
Webシステム
Webシステムでは、私が今までChromeやSafari等のブラウザを通して当たり前のように
サイト巡回をしていたその裏の仕組みを学びました。ここが一番重要且つ重いテーマでした。
この時も「そもそもWebってなんだっけ?」で始まりました。
はじめの頃って調べるの慣れておらずこの三文字に1時間かけました。
そして毎テーマ必ず「そもそも・・・」という原点追及を欠かさなかったのが
自分自身で印象に残ってます()大まかにいうと内容はこんな感じ。
- コンピュータの構造
- クライアントサーバシステム、ソフトウェア、ハードウェア、アプリケーション、ミドルウェア
- プロトコル
- プロトコル、ネットワークアーキテクチャの種類や違い、各レイヤーでの役割
- リクエスト/レスポンス
- メソッド、リソース(URL、IPアドレス、FQDN、DNS)、User-Agent、Referrer、Cookie
- サーバ側の処理
- Webサーバ・アプリケーションサーバ・データベースサーバの役割の違い
- レンダリング処理
- レンダリングの流れ(Parse、Scripting、Rendering、Painting)、HTML/CSS
http/https通信の違い
Webシステムから続いて、http/https通信の違いについて学びました。
「電子署名って何なんだよ・・・」でかなり苦戦しましたね。
公開鍵で暗号化するって言ったじゃん!!!!秘密鍵使うなよ!!!!!
って2日間くらいなってました。
ただ、個人的にここでの学習が後に大いに役立つとは思ってませんでしたが。以下内容。
- 通信の暗号化
- SSL/TLS、共通鍵方式、公開鍵方式
- サーバ証明書
- 認証局、自己署名証明書、電子署名
Webサイト作成
上記の全てを踏まえて、実際に自分でWebサイトを作成し公開してみました。
サイトのテーマは「ログインサイト」。
単純にログインの機能を持ったサイトをAWSの一部のサービスを用いて作成するということでした。作成スケジュールは以下の通り。
Day1:先輩社員の方をクライアントに見立てて、作成したいWebページの要件を聞き出し設計書におこす。
クライアントと擦り合わせながら設計書を完成させていき、スケジュールを確定させる。
Day2:AWSのプライベートアカウントを作成し、サイトを公開するためのインフラを構築。
Day3:HTML/PHPファイルを作成し、ページの機能を完成。
Day4:CSSを適用し、サイトを完成。単体テストを実施。先輩からレビュー。
Day5:レビューを基に修正。完成。しかしこれが大幅にスケジュールオーバー。
インフラ構築に二日かかってしまい、HTML/PHPの完成に二日費やしてしまいました。
これによってCSSを適用できなかった私のサイトはみすぼらしく、点数は0点。。
悔しすぎて、夏季休暇に暇してた時間全部つぎ込んで「パスワード再設定メールの送信」という
要件にない機能まで付けて無理やり完成させました。(要件にない機能:-10点)ちなみに、設計書の内容は「全体構成概要図」「内部設計」「DB定義」「各画面基本設計」。
以下は完成した実際のサイト(現在はサーバー落としているので画像)。
そして、以下はこのサイトの内部設計。
※画像内のIP/Subnet maskは例
苦労した点は、NATの仕組みと使い方や、セキュリティグループの設定、
パスワード再設定メール送信機能の設定等々、インフラ構築の部分が多かった印象です。
特にメール送信機能では、サブミッションポート587を利用したかったのですがなかなか上手くいかず。
やむなく25番を利用した時の悔しさたるや。CSSの適用にもかなり苦戦しました。
ここで学んだのは、その場しのぎのコードは後に巨大なブラックボックスを生んでしまうこと。
「これでいいじゃん♪開発」で進めて、正しいと思っている位置にCSSが適用されないことが多発しました。
反省した後、ノートに全てのページで適用するデザインフレームワークを作成し、
各パートに要素を入れていく形で進めるとCSSを瞬殺することが出来ました。
(後々にLaravelすげぇってなる男の軌跡)その逆に、https通信の確立に最初は3時間くらいかかっていたものを今では5分で出来るようになり、
研修で身に付けたhttps通信の知識が大いに活きた瞬間でもあります。実際の完成したサイトでテストをした時、もう楽しすぎて30分くらいサイト巡回してました。
システム問い合わせ対応 / 機能開発・改修・結合テスト
研修と併せて所属部署が担当する自社システムに触れる機会が増えていき、
利用者からの問い合わせや結合テストを担当することが多くなりました。最初はパスワードを数回間違えると掛かってしまうアカウントロックの解除しか
対応できませんでしたが、最近ではDBからのデータ抽出や改修対応を担当することも増えました。
先輩方に任せっきりだったところも、解決後に必ず始終の説明を受け自分でも手を動かすことで
どんどん自分が扱える範囲を広げていきました。そして問い合わせ内容から発展し一部開発や改修を担当することもありました。
基本的にはPHP/JS/HTML等のフロント部分が多く、MVCについての知識も得られました。結合テストに関しては、ただテスト項目を消化するのではなく、
「今どんな背景でこのテストが必要とされていて、なぜこの部分をテストするのか」
まで考慮に入れて実施することを念頭に置いて実施していました。
そして口を酸っぱくして言われたのは「テスト項目が100%正ではない」ということ。
項目書も人が作ったもの。システムである以上動かした際の結果が真実。
終了したことには芯の部分からその機能を理解できるようになれました。印象に残っているのは、ChromeのSamesite属性の検証テスト。
上記テストの環境構築も自ら行うことによって、AWSの各サービスについての理解や
インスタンス・コンテナ・ロードバランサー等への理解を深められた重要なテストでした。その他インプット
基本的に言語学習はプログラミング学習サイトを利用しました。
Webアプリケーションの開発部でもあるため、業務で多く利用したのはPHP/HTML/JS。
また、AWSサービスについても様々な場面で触れました。
先に述べたSamesiteテストでの環境構築一つとっても、CloudFront/Route53/ELB/EC2/ECS…等々、
仕組みや繋がりを理解しながら実施していき、どこに何をすればどうなるのかを形にできました。
- プログラミング言語
- PHP
- HTML/CSS
- JavaScript
- Shell Script(主にJenkinsにて)
- AWSサービス
- Athena(CTAS、パーティションの貼り方、クエリチューニング)
- S3(バージョニング、CLIからのバケットコピーシェル作成)
- CloudFront(Behaviors、OriginGroups)
- Route53
- EC2/ECS/ELB(AMI/Snapshot/EBSボリューム、起動設定/AutoScaling、CLBとALBの違い)
来年やりたいこと
そんなこんなで右往左往した1年目でしたが、得るものに余りはありませんでした。
手に落ちてくるものを零さないように必死に飲み干していく毎日。
それは来年も変わらないとは思いますが、その中でもやりたいこと、
やり遂げたいことをまとめてみました。知識面
自社システム構造のドキュメント化
自社のシステムを自分の中で整理することを目的として、様々なドキュメントを作成したい。
これがなかなか難しく時間が取れないけれど、視覚的に頭に入れることは時に絶大な力を
発揮すると信じてやまないので、少しずつ完成させていきます。リリース作業ハンドル
リリース作業を自分がハンドルを握って完結させること。
リリースの内容のみならず、手順全てとトラブル時の対応力、
今まで学んできたことの集大成として、「開発」を完結させる能力を身に付けること。
現在開発環境でのデプロイ作業を練習として行っており、
本番環境のリリースに携われるように勉強しています。Java・Pythonをいじりたい
インタプリタ言語がメインだった2019年。
今年はJava等のコンパイル言語も動かしてみたいです。
Javaは大学の時にいじりましたが正直赤子程度の知識まで風化してしまいました。
ここで一度学びなおし、フロントエンドもバックエンドも扱えるようになり、
簡単なアプリケーションであればサッと開発できるようになることが目標です。
また、Pythonについてもシステム内で使用している点も含めて学習したい言語として見据えています。資格
去年ITパスポートの資格を取得した時、大きい資格とは言えないまでも
確実な自信につながることを実感しました。
何より、身に付けた知識が本当に身についているのかを証明できる一つの形でもあるため、
来年以降も継続していきます。
- 技術系
- 基本情報処理技術者
- AWS
- ソリューションアーキテクト-アソシエイト
- デベロッパー-アソシエイト
- 英語
- TOEIC 800点
まとめ
簡単にですが、配属されてからの8ヶ月間を振り返ってみました。
最初から見てみると、やはり中身が空っぽであった分多くのことを
学んでいたのだなと実感できました。
恐れずに配属希望を出して本当に良かったと、今は心の底から思っています。後輩にバリバリにプログラムが書ける人が入ってくることに恐れながら、
今年も去年より飛躍する年に。


- 投稿日:2020-01-13T21:27:25+09:00
はじめてAWSでデプロイする方法⑦(EC2にgemをインストール)
EC2のメモリを増強する
Swap(スワップ)領域を設定
Swapは、EC2のメモリが限界に達したとき、補う形でメモリの容量を増やす機能です。
デフォルトではSwap領域が設定されていないので、設定しましょう手順
ホームディレクトリに移行
[ec2-user@ip-172-31-25-189 ~]$ cd下記のコマンドを実行
[ec2-user@ip-172-31-25-189 ~]$ sudo dd if=/dev/zero of=/swapfile1 bs=1M count=512うまくいくと、下記の表示が出ます
512+0 レコード入力 512+0 レコード出力 536870912 バイト (537 MB) コピーされました、 5.19011 秒、 103 MB/秒次は権限に制限をかけましょう(chmodコマンド)
[ec2-user@ip-172-31-25-189 ~]$ sudo chmod 600 /swapfile1スワップ(swap)領域を作成する - mkswap
[ec2-user@ip-172-31-25-189 ~]$ sudo mkswap /swapfile1 #成功すると下記の表示が出ます スワップ空間バージョン1を設定します、サイズ = 524284 KiB ラベルはありません, UUID=74a961ba-7a33-4c18-b1cd-9779bcda8ab1スワップ(swap)領域を有効化する - swapon
[ec2-user@ip-172-31-25-189 ~]$ sudo swapon /swapfile1エラーが出なければ成功です。
エラー「swapon: /swapfile1: スワップヘッダの読み込みに失敗しました: 無効な引数です」が表示された場合は、一つ前の手順に戻ってmkswapコマンドを実施してください。下記のコマンドを実施してください。
?長いので、気をつけてください[ec2-user@ip-172-31-25-189 ~]$ sudo sh -c 'echo "/swapfile1 none swap sw 0 0" >> /etc/fstab'これで完了
gemのインストール
まずは、EC2にダウンロードしたWEB Appを開く
[ec2-user@ip-172-31-23-189 www]$ cd /var/www(作成したディレクトリ)/アプリ名Rubyのバージョンを確認する
[ec2-user@ip-172-31-23-189 <アプリ名>]$ ruby -v指定したrubyのバージョンが表示されれば成功です。
ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-linux]ローカル上のターミナルでbundlerのバージョンを確認する
EC2ではなく、ローカル環境のWEB Appを開き、下記コマンドを実施
$ bundler -vするとバージョンが表示されます
Bundler version 2.0.2これと同じバージョンをEC2で入れます。
?下記のバージョンをそのまま (2.0.1)を入れるとエラーが発生するので注意[ec2-user@ip-172-31-23-189 <アプリ名>]$ gem install bundler -v 2.0.1EC2でbundle installをして、gemをインストール
[ec2-user@ip-172-31-23-189 <アプリ名>]$ bundle installエラーがなければ、gemのインストール完了です。
エラーが発生した場合
下記のエラーが表示された場合、インストールするべき bundler -vが間違っています
Traceback (most recent call last): 2: from /home/ec2-user/.rbenv/versions/2.5.1/bin/bundle:23:in `<main>' 1: from /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/2.5.0/rubygems.rb:308:in `activate_bin_path' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/2.5.0/rubygems.rb:289:in `find_spec_for_exe': can't find gem bundler (>= 0.a) with executable bundle (Gem::GemNotFoundException)エラーがある場合は、アプリ側の bundlerのバージョンを確認してください
$ bundler -v >Bundler version 2.0.2 [ec2-user@ip-172-31-23-189 <アプリ名>]$ bundler -v >Bundler version 2.0.1 >バージョンが違うので、エラーがおきますインストール完了後、下記の表示があった場合
Post-install message from chromedriver-helper: +--------------------------------------------------------------------+ | | | NOTICE: chromedriver-helper is deprecated after 2019-03-31. | | | | Please update to use the 'webdrivers' gem instead. | | See https://github.com/flavorjones/chromedriver-helper/issues/83 | | | +--------------------------------------------------------------------+gem'chromedriver-helper'のサポートが終了しているので、代わりとなるgem 'webdrivers'をインストールすることを推奨しているメッセージとなります。
group :test do # ... - gem 'chromedriver-helper' + gem 'webdrivers'
- 投稿日:2020-01-13T21:08:22+09:00
CloudWatch Eventsで別のアカウントをイベントターゲットに出来る「Event Bus」
https://dev.classmethod.jp/cloud/aws/cloudwatch-events-event-bus/
アカウントBでEvent Busへの権限設定
↓
アカウントAでEvent Bus(アカウントB)をターゲットにしたルールを作成
↓
アカウントBでルールを作成(ソースでアカウントAのみに絞るなどできる)
- 投稿日:2020-01-13T20:45:45+09:00
デプロイグループのメモ
アプリ作成
デプロイグループ作成
デプロイコンフィグ作成
リビジョンのアップロード
デプロイ
チェック
リデプロイCodeDeploy アプリケーション用に 1 つ以上のデプロイグループを指定できます。
デプロイグループには、デプロイ中に使用される設定と構成が含まれています。ほとんどのデプロイグループ設定は、アプリケーションで使用される compute platform によって異なります。ロールバック、トリガー、アラームなどの一部の設定は、どの compute platform 用のデプロイグループでも設定できます。
デプロイグループでは、新しいバージョンの Lambda 関数にトラフィックをルーティングする方法を指定します。また、アラームとロールバックを指定する場合もあります。
- 投稿日:2020-01-13T19:20:12+09:00
クラウドアーキテクチャ構築指針 まとめのまとめ
以前書いたクラウド環境構築の指針に関する記事を整理しました。
AWS Well-Architedted フレームワーク ホワイトペーパー
AWS ソリューションアーキテクトのための設計方針。
試験でもベースラインの知識として問われます。AWS Well-Architected Framework ホワイトペーパーまとめ 1 【導入編】
AWS Well-Architected Framework ホワイトペーパーまとめ 2 【運用上の優秀性】
AWS Well-Architected Framework ホワイトペーパーまとめ 3 【セキュリティ】
AWS Well-Architected Framework ホワイトペーパーまとめ 4 【信頼性】
AWS Well-Architected Framework ホワイトペーパーまとめ 5 【パフォーマンス効率】
AWS Well-Architected Framework ホワイトペーパーまとめ 6 【コスト最適化】Azure アーキテクチャガイド
Azure での Well-Architected フレームワークに相当するようなガイドライン。
一読すると AWS との設計哲学の違いみたいなものを感じられます。
そもそもクラウドのアーキテクチャってなんぞ、という方にもおすすめ。Azureアーキテクチャガイドまとめ 1 【はじめに】
Azureアーキテクチャガイドまとめ 2【N層】
Azureアーキテクチャガイドまとめ 3 【Webキューワーカー】
Azureアーキテクチャガイドまとめ 4 【マイクロサービス】
Azureアーキテクチャガイドまとめ 5 【CQRS】
Azureアーキテクチャガイドまとめ 6 【イベントドリブンアーキテクチャ】
Azureアーキテクチャガイドまとめ 7 【ビッグデータアーキテクチャ】
Azureアーキテクチャガイドまとめ 8 【ビッグコンピューティングアーキテクチャ】参考リンク
AWS Well-Architedted フレームワーク 公式ドキュメント
Azure アーキテクチャガイド 公式ドキュメント
- 投稿日:2020-01-13T19:12:15+09:00
コンピューティングサービス
出展:AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
EC2
EC2の概要
・Amazon Elastic Compute Cloudの略
・仮想サーバがサービスとして提供されるEC2の特徴
必要な時に必要なだけの量を使用
・必要なときに必要なだけのインスタンスを稼働させることができる
・必要なEC2インスタンスの数を事前に予測する必要はない使用した分にだけコストが発生
・EC2の料金の構成
・EC2稼働に対しての料金
EC2イオンスタンスが起動中の時間が課金対象となり、停止中は課金が停止する
1時間単位で課金(Amazon Linux、Ubuntuでは秒単位)
・データ転送料金
リージョンの外にデータを転送(アウト)した場合にのみ、データ転送料金が発生する
データ転送料金はリージョンによって異なる
インターネットからAmazon EC2への転送受信(イン)には課金されない
・ストレージ料金
EBS(Amazon Elastic Book Store)の料金
1GBあたりのプロビジョニング(ボリュームのサイズとして確保した容量)した料金変更可能なインスタンスタイプから性能を選択
・使い始めてから状態をモニタリングしてインスタンスタイプを変更できる
・インスタンスタイプによってインスタンスの稼働時間の課金単価が変わる
・運用を開始する前の、誤った性能予測の計算をする必要がなくなる数分でサーバを調達して起動できる
・数分でEC2を起動することができ、一度に複数台を自動で起動することも可能
・調達・起動を自動化することもできる
・経営の俊敏性が向上する世界中のリージョンから起動場所を選択
・数分でEC2を世界中にデプロイできる
AMIからいくつでも同じサーバを起動できる
・EC2インスタンスはAMI(Amazon Machine Image)から起動する
・1つのAMIからいくつでもインスタンスを起動することができる
・同じ構成を持ったEC2インスタンスを複数起動することができる
・AMIの種類
・クイックスタートAMI
・AWSがあらかじめ用意しているAMI
・OSとモジュールがインストール済みで用意されている
・マイAMI
・ユーザが作成するAMI
・ほかのアカウントと共有することも、公開することも可能
・AWS Marketplace
・ソフトウェアやミドルウェアがすでにインストールされている構成済みのAMI
・パートナーベンダーが提供
・コミュニティAMI
・一般公開されているAMIセキュリティグループでトラフィックを制御できる
・EC2インスタンスへのトラフィックはセキュリティグループのインバウンド(受信)で制御する
オペレーティングシステムを管理者権限で操作できる
・起動したEC2では、キーペアを使用してログインすることで、オペレーティングシステムを管理権限で操作できる
・キーペア:
公開鍵と秘密鍵の2つの鍵ファイルをペアにして認証を行う
ユーザはユーザ名と秘密鍵ファイルを使ってログインする
公開鍵はAWSに保管される
秘密鍵はユーザがOSの管理者だけがアクセスできる場所で管理するユースケースに応じた料金オプション
・ユースケースに応じて料金オプションを使い分けることで、コスト効率よくEC2を使用できる
・オンデマンドインスタンス
・料金オプションを使わずにEC2インスタンスを起動すると、オンデマンドインスタンスの単価が適用される
・定価料金
・秒単位、時間単位の課金により、必要なときに必要なインスタンスを起動できる
・リザーブドインスタンス
・24時間365日(またはその75%以上)稼働し続けることが決まっているインスタンスがある場合に使用
・1年または3年の使用期間を事前設定することで割引を受けることができる
・支払方法の選択が可能(全額前払い、一部前払い、前払いなし)
・スポットインスタンス
・未使用のEC2キャパシティに対して支払ってもよい金額をリクエストとして設定し利用する
・スポット料金がリクエスト料金を下回った際に起動、上回ったときに終了する
・処理途中で終了しても問題がないユースケースに向いている
・Dedicated Hosts
・EC2が起動するホストを専用するオプション
・セキュリティ/ガバナンス要件、ライセンス要件を満たす目的で使用する
・インスタンスではなく、ホストに対しての従量課金ELB
**ELBの概要
・Elastic Load Balancing
・EC2インスタンスの可用性を高めるためにELBを使用することができるELBの特徴
ロードバランサータイプ
・Application Load Balancer:HTTPまたはHTTPSのリクエストを負荷分散する
・Network Load Balancer:HTTP、HTTPS以外のTCPプロトコルを使用する場合に選択する
・Classic Load Balancer:以前のタイプのロードバランサー。以前の構成との互換性のために残されているヘルスチェック
・ターゲットとしているインスタンスが正常かどうかのヘルスチェックを行い、正常なインスタンスのみにリクエストを送る
インターネット向け/内部向け
・ELBはインターネット向けにも内部向けにも対応している
・インターネット向けだけでなく内部向けにもELBを挟むことによって、システムの可用性を高めることができる高可用性のマネージドサービス
・ELB自体が高可用性のマネージドサービスなので単一障害点とはならない
クロスゾーン負荷分散
・ターゲットに対してアベイラリティゾーンを超えて負荷分散するかどうかの設定
・有効にしていると、すべてのターゲットインスタンスに対しリクエストが送信される
・リクエストの分散が均等となり、ターゲットインスタンスのリソースを無駄なく使えるAuto Scalling
Auto Scalingの概要
・Auto ScalingによってEC2インスタンスを必要なときに自動で増減できる
・Auto Scalingのメリットは高可用性、耐障害性、コスト効率化垂直スケーリングと水平スケーリング
・垂直スケーリング:
・インスタンスのサイズを変更することによって、スケールアップ/スケールダウンを行う
・システムの設計変更が発生
・影響がないかの検証が必要
・変更時にサーバ単位での停止が発生
・上限はインスタンスタイプの最大サイズ
・水平スケーリング:
・インスタンス数を変更することによって、スケールアウト/スケールインを行う
・システムの設計変更ではない
・変更時にシステム全体に対しての影響なし
・上限なし
・垂直スケーリングよりも水平スケーリングのほうがスケーラビリティを確保しやすい
・Auto Scalingでは水平スケーリングを自動化するAuto Scalingの設定
起動設定(何を)
・どのようなEC2インスタンスを起動するか
・IAM
・インスタンスタイプ
・IAMロール
・ユーザデータ
・ストレージ
・セキュリティグループ
・キーペアAuto Scalingグループ(どこで)
・どこでEC2インスタンスを起動するか
・起動設定名
・アベイラリティゾーン(サブネット)
・ELBのターゲットグループ
・最小/最大/希望するインスタンス数
・通知
・タグAuto Scalingポリシー(いつ)
・いつのタイミングで起動/終了するか
・ターゲットポリシー:
・Auto ScalingグループのEC2インスタンス平均CPU使用率などを決めておくことで、AWSが自動的に最小数と最大数の間でEC2インスタンスを調整する
・シンプルポリシー:
・CloudWatchのアラームに基づいて、Auto Scalingアクションを実行する
・クールダウン:「その後待機」。Auto Scalingアクションが連続して発生し、インスタンスが頻繁に起動/終了されることを防ぐ
・ステップポリシー:
・複数段階でのインスタンスの追加、削除を設定できる
・ウォームアップ:インスタンスが頻繁に追加されることを防ぐ
・Auto Scalingアクションはポリシーだけではなく、時間を指定したスケジュールも実行できるアプリケーションデプロイの自動化
・EC2のユーザデータを使うことでコマンドを自動実行し、デプロイ処理を自動化することができる
・EC2の情報(IPアドレスやインスタンスID)はメタデータから取得できるLambda
Lambdaの特徴
サーバの構築が不要
・実行したいプログラムのランタイムを選択してソースコードをアップロードすれば実行できる(すぐに開発を始められる)
・OSの用意、実行するためのミドルウェアのインストール、環境設定などの作業は不要サーバの管理が不要
・サーバの運用から解放され、開発に注力できる
一般的な言語のサポート
・Lambdaがサポートする言語
・C#/PowerShell/Go/Java/Node.js/Python/Ruby
・Labdaを使うために新しい言語の勉強は不要。使い慣れた言語ですぐに始められる並行処理/スケーリング
・リクエストに応じて水平的にスケーリングして、並行で関数が実行される
・Auto Scalingを設定する必要がない
・初期設定では、アカウント全体で同時実行数1000という制限があるが、同時実行数の制限引き上げをリクエストすることができる柔軟なリソース設定
・メモリを割り当てることで、CPU等、他のリソースの性能も割り当てられる
・設定できるメモリの範囲は128MBから3008MBまで、64MB刻み
・タイムアウト時間は最長で15分ミリ秒単位の無駄のない課金
・実行されている時間に対してミリ秒単位の無駄のない課金がなされる
・実行されていない待機時間には課金されない他のAWSサービスとの連携
・AWSサービスの処理を簡単に自動化できる
・AWSサービスからのトリガーを使用することで、イベントからLambdaを実行できる
- 投稿日:2020-01-13T18:15:25+09:00
【AWS完全に理解したへの道】 ELB 基本編
【AWS完全に理解したへの道】 ELB 基本編
AWS過去記事
IAM 基本編
VPC 基本編
S3 基本編
データベース(RDS/ElastiCache/DynamoDB)基本編
EC2 基本編ELB(Elastic Load Balancing)
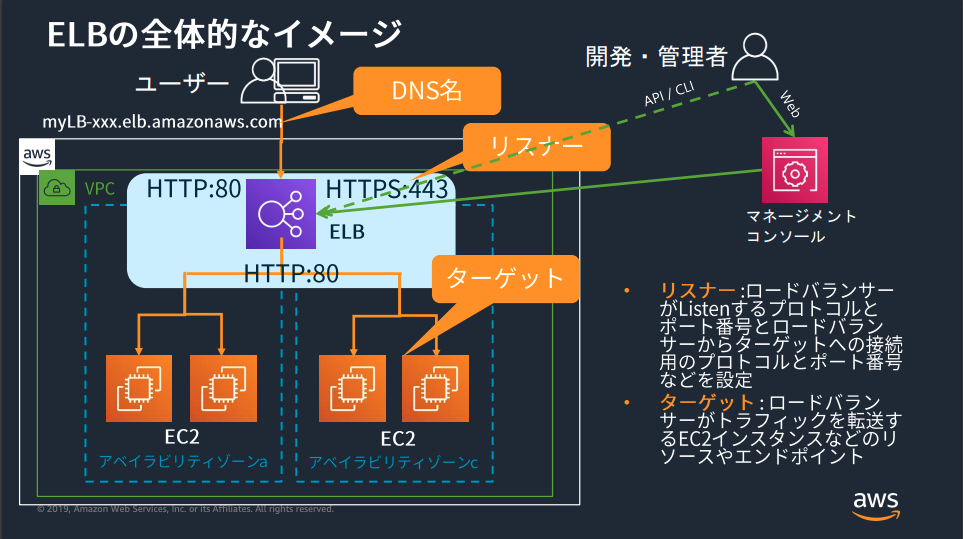
ELBの全体的なイメージは以下の画像のようになる。
AWS Black Belt Online Seminar Elastic Load Balancing (ELB)より画像引用
リスナー
ロードバランサ自体がListenするプロトコルとポート番号。
さらにロードバランサからターゲットへの接続用のプロトコルとポート番号も設定可能。
ターゲット
ロードバランサがトラフィックを転送するEC2インスタンスなどのリソースやエンドポイントを設定する。
そもそもなぜロードバランサ(LB)が必要なの?
大きくは以下の2点。
冗長化/可用性
例えば、1台のみサーバで構成している場合、そのサーバがダウンした時にサービスを継続できない。
よって複数台のサーバ(冗長化)とトラフィックをコントロールするLBを組み合わせることによってサービスの安定稼動につなげる(可用性)負荷分散/スケール
バックエンドEC2インスタンスのリクエスト数やコネクション数が均等になるようにすることでトラフィックを効率的にする。
EC2インスタンス一箇所にリクエストなどが集中するとトラフィックの効率が悪い(レイテンシーの増加など)。最適なロードバランサーの選択
選択できるELB製品は以下の3つ。
1. Application Load Balancer(ALB)
2. Network Load Balancer(NLB)
3. Classic Load Balancer(CLB)
1. Application Load Balancer
パスベースのルーティングやHTTPメソッドベースのルーティング、リダイレクトなど柔軟なアプリケーション管理をしたい場合はこれ。
2. Network Load Balancer
非常に高度なパフォーマンスと静的IPが必要な場合はこれ。
3. Classic Load Balancer
EC2-Classicネットワーク内で構築された既存のアプリケーションがある場合はこれ。
VPCの前の古いやつらしいので、今から始めるなら使う必要はなさそう。※各々の詳細は別記事で掘り下げる予定。
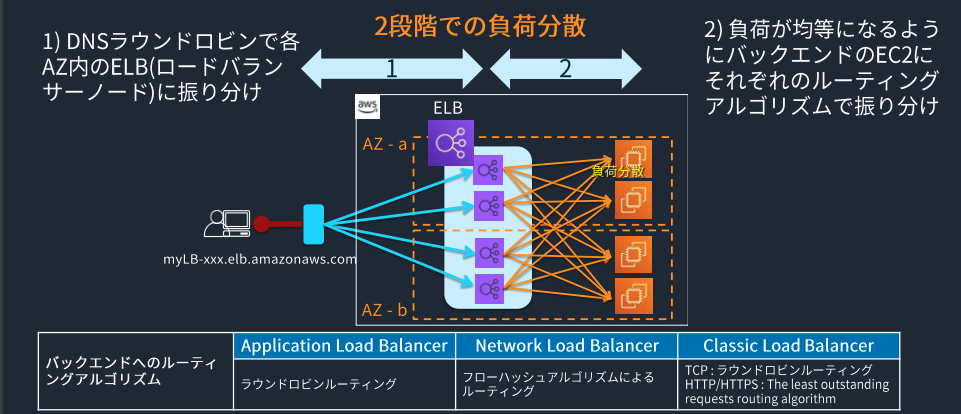
ELBの基本機能
高可用性と負荷分散
負荷分散は以下の2ステップで行われる。
1) DNSラウンドロビン(均等負荷分散)で各AZ内のELBに振り分けられる。
2)負荷が均等になるようにバックエンドのEC2にそれぞれのルーティングアルゴリズムで振り分ける。
AWS Black Belt Online Seminar Elastic Load Balancing (ELB)より画像引用
- ゾーンごとのフェイルオーバー
- クロスゾーン負荷分散
- 同一インスタンスで複数ポートに負荷分散
- IPアドレスをターゲットに設定
- ELB自体のスケーリング
負荷に応じて、ELBを自動でスケールアップ、スケールアウトする
注意点
- リクエストが瞬間的に急増した時にELBのスケーリングが間に合わない場合があり、その時HTTP503が返ってくる。
- NLB以外のELB(ALB/CLB)がスケールするときはIPアドレスが変化するので、ELBヘアクセスするときは必ずDNS名でアクセスすること。
回避方法
事前にALB/CLBをスケールさえておく。
- Pre-Warmingの申請をサポートケースで行う。 ※ 要Business/Enterpriseサポート ※NLBはPre-Warming不要で突発的な数百万リクエスト/秒のトラフィックも捌ける。
- 自前で負荷を段階的にかけてスケールさせておく
モニタリング・ログ
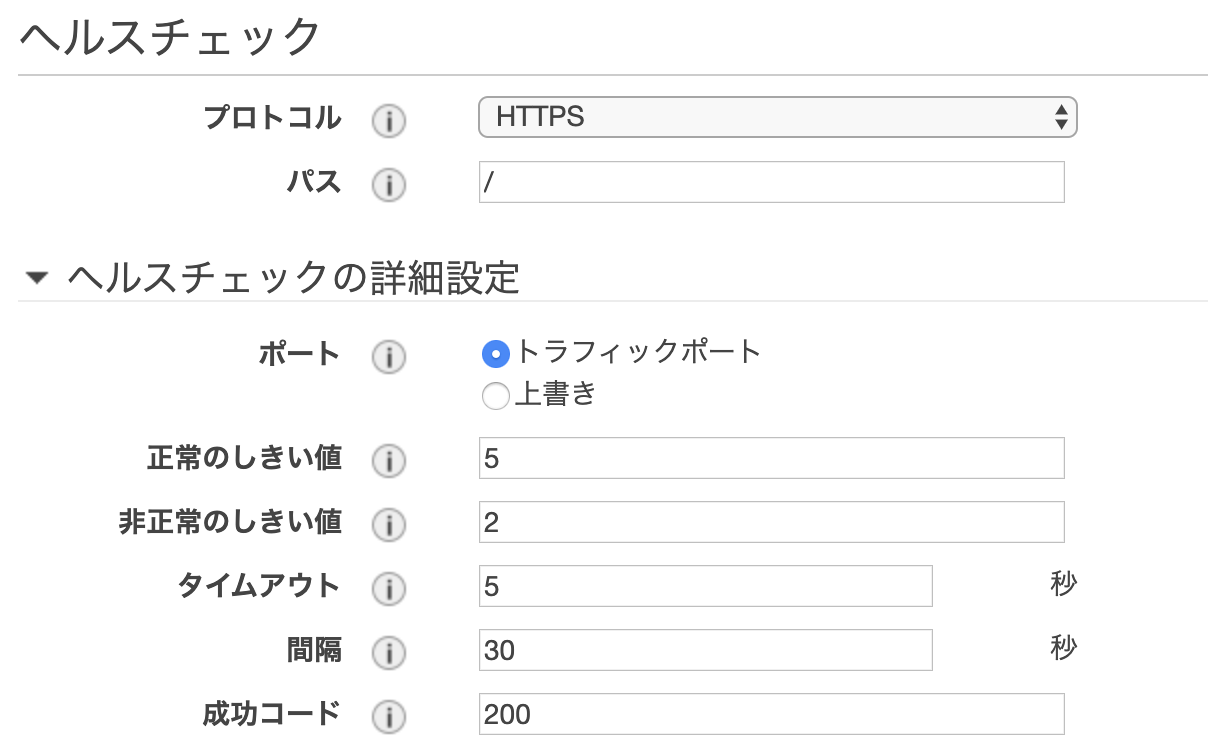
ヘルスチェック
ELBが正常なターゲットのみをトラフィックするようにルーティングできているかチェックする。
正常のしきい値
異常なターゲットが正常であると見なされるまでに必要なヘルスチェックの連続成功回数非正常のしきい値
ターゲットが異常であると見なされるまでに必要なヘルスチェックの連続失敗回数タイムアウト
ヘルスチェックを失敗とみなす、ターゲットからレスポンスがない時間の設定(秒単位)
2~60秒の範囲で設定可能。間隔
個々のターゲットのヘルスチェックの概算間隔(秒単位)
5~300秒の範囲で設定可能。運用のモニタリング
Auto Scalingによるインスタンス増減時のELBへの追加・削除が可能
(Auto Scalingについては別記事に書く予定)アクセスログの記録
- 最短5分間隔でELBのアクセスログを取得可能
- 指定したS3バケットに簡単にログを自動保管可能
- ELBの種類によってアクセスログの出力フィールドも異なる
セキュリティ関連
SSL/TLSサポート
ELB側でSSL/TLS認証ができる。(基本的にはTLSプロトコル)
通信パターン
ELBでSSL Terminationし、バックエンドとはSSLなし(推奨はこれらしい)
バックエンドのEC2インスタンスでSSL処理をしなくて良いので、EC2側の負荷軽減できる。ELBでSSL Terminationし、バックエンドとは別途SSL
SSLをバイパスしてバックエンドにTCPで送信
クライアント証明書認証などを利用するためにはTCPとして扱う
ELB バックエンド(EC2など) 1 HTTPS HTTP 2 HTTPS/SSL HTTPS/SSL 3 TCP TCP Server Name Indication(SNI)
通常はTLS証明書を1つしか設定できないが、複数のTLS証明書を1つのALB/NLBのListenerに設定可能になる。
- SNIをサポートするクライアントには、適切な証明書を選択してTLSで通信を行うことができる。
SNIをサポートしないクライアントにはデフォルト証明書が使用される。
ALB毎にMAX25証明書まで(デフォルト証明書を除く)設定可能。
ACMまたはIAMの全ての証明書が利用可能。
コネクション
ELBのコネクションタイムアウト
- ALB/CLBはデフォルト設定ではコネクションタイムアウト値は60秒(1~4000秒の間隔で設定可能)
- NLBのデフォルト設定ではコネクションタイムアウト値は350秒固定
Connection Draining(登録解除の遅延)
スティッキーセッション
- 同ユーザから来たリクエストを全て同じEC2インスタンスに送信
- デフォルトでは無効
- HTTP/HTTPSのみで利用可能
ステートレスな設計が望ましいので、セッション情報などはキャッシュサーバやDBサーバに持たせるのが望ましい。したがって、この機能は使わなくてよさそう。

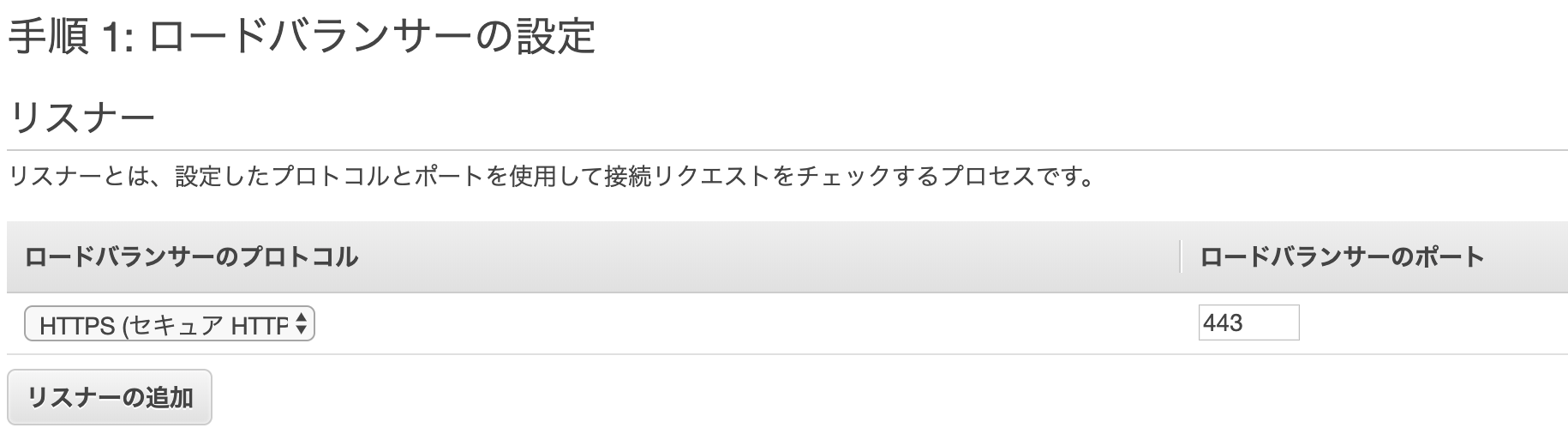
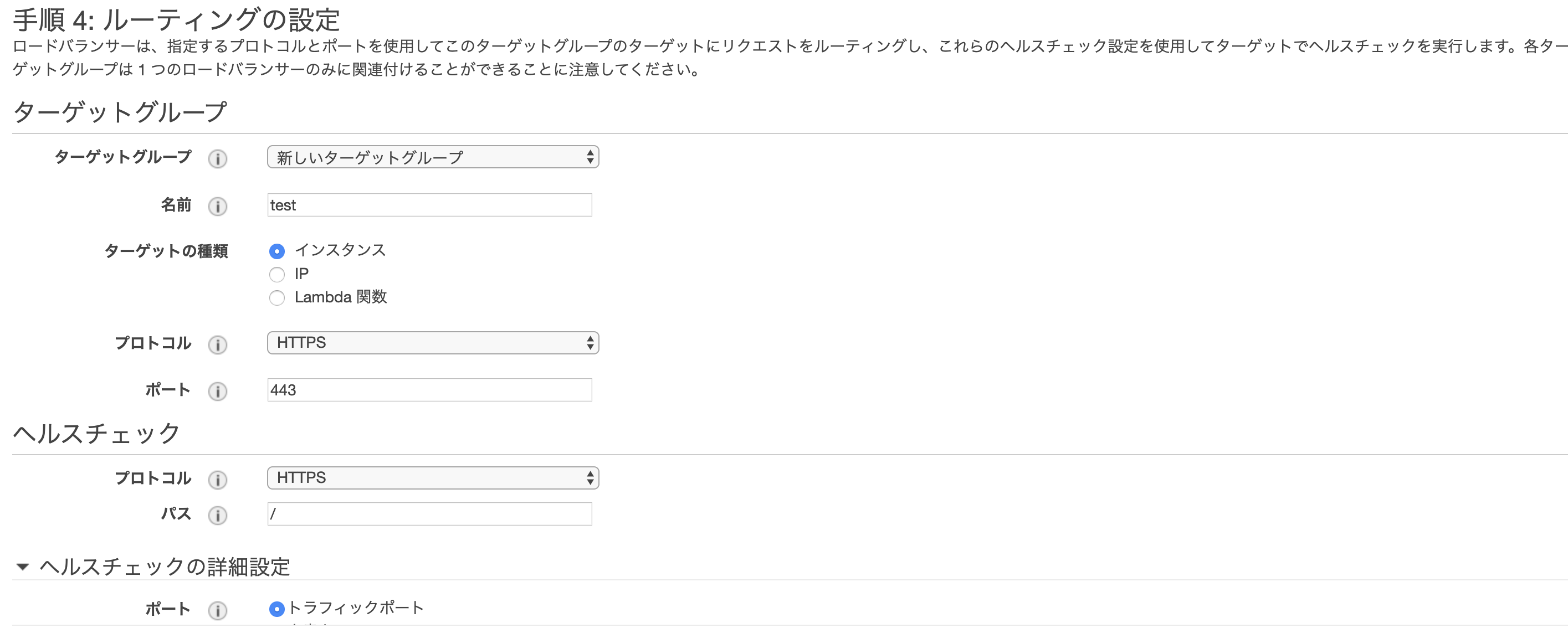
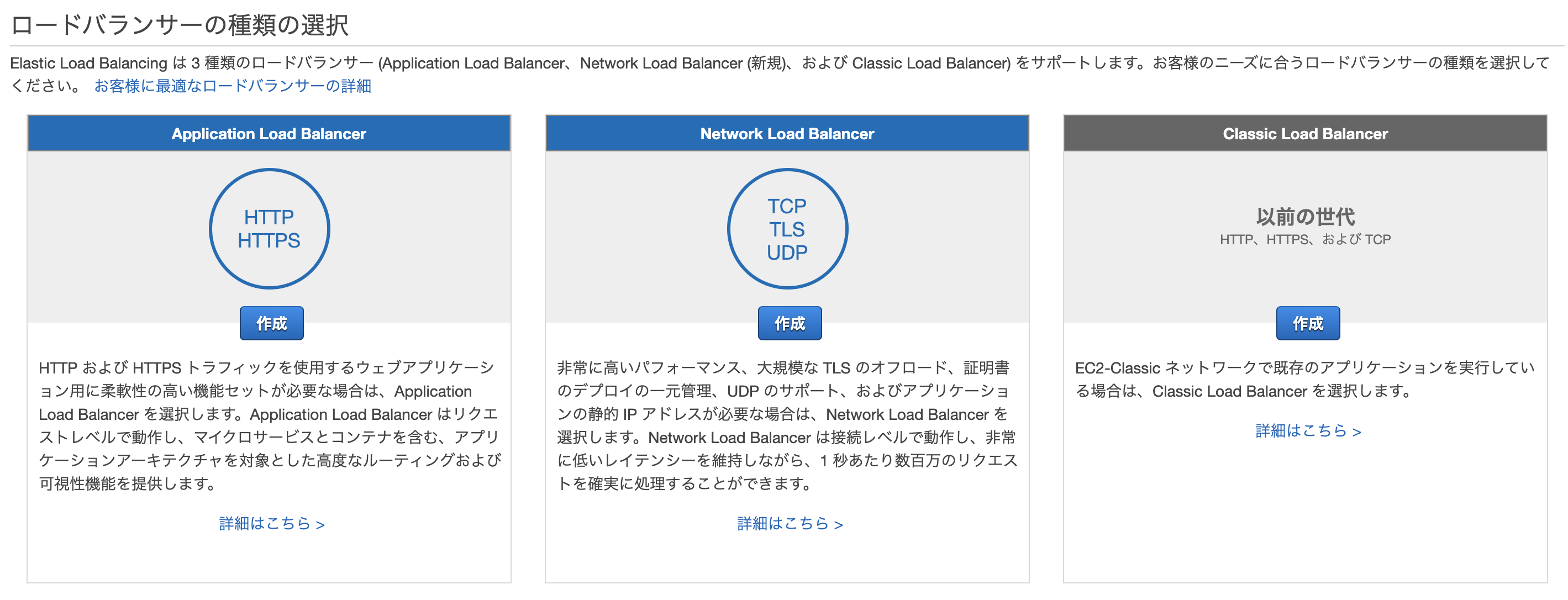
- 投稿日:2020-01-13T17:57:10+09:00
[AWS]ネットワークの構築方法
2020年1月13日現在の内容です。
用語説明
リージョン
AWSの各サービスが提供されている地域のこと
例:東京,オハイオ,ロンドン
- AWSのサービスを利用する際にまずリージョンを決める必要がある
- リージョンごとに使えるサービスが異なる
- 基本的に新しいサービスはアメリカのリージョンから利用可能になり、その後他のリージョンに展開される
- 日本でAWSを利用する際は東京リージョンを選択したほうが良い(応答時間が早いから)
アベイラビリティゾーン
世界各地にあるデータセンターをまとめたもの
- それぞれのリージョンにアベイラビリティゾーンは2つ以上存在する(あるアベイラビリティゾーンが災害で使用不可になっても、他のアベイラビリティゾーンを利用することでサービスを常に稼働させることができる)
VPC(Virtual Private Cloud)
AWS上に仮想ネットワークを作成できるサービス
- リージョンを選択してVPCを作成する(リージョンをまたいでVPCは作成できない)
サブネット
VPCを細かく区切ったネットワーク
- アベイラビリティゾーンの中にサブネットを作成する
- VPCのIPアドレスの中にサブネットのIPアドレスが含まれる
- パブリックサブネットはインターネットから接続できる
- プライベートサブネットはインターネットから接続できない
IPアドレスとは
IPアドレス
ネットワーク上の機器を識別するためのインターネットの住所
- ネットワーク上で重複しない番号
- 32ビットの整数値で構成される
- 一般的に32ビットのIPアドレスを8ビットずつ4組に分けピリオドを入れて10進数で表現する
(0.0.0.0 〜 255.255.255.255)パブリックIPアドレス
- インターネットに接続する際に使用するIPアドレス
- 重複すると正しく通信できなくなるので、ICANN(Internet Corporation for Assigned Names and Numbers)が管理している
- プロパイダやサーバー事業者から貸し出される(AWS上でも貸し出される)
プライベートIPアドレス
- インターネットで使用されないIPアドレス
- 以下範囲内のアドレスを自由に使用できる
- 10.0.0.0 〜 10.255.255.255
- 172.16.0.0 〜 172.31.255.255
- 192.168.0.0 〜 192.168.255.255
- 社内LANの構築やネットワークの実験時はプライベートIPアドレスを使用する
IPアドレスの範囲
ネットワークを構築する際は、そのネットワークで使用するIPアドレスの範囲を決める必要がある。
IPアドレスはネットワーク部とホスト部に区分けして範囲を表記する
例:192.168.128.0 〜 192.168.128.255を使用する場合、共通部分(192.168.128)がネットワーク部、異なる部分(0〜255)がホスト部範囲の表記
CIDR表記
IPアドレスの後ろに「/」を書き、その後ろにネットワーク部が先頭から何ビット目までなのかを記載する
例:ネットワーク部が24ビット → 192.168.128.0/24サブネットマスク表記
IPアドレスの後ろに「/」を書き、ネットワーク部を表すビットと同じ部分を1に、ホスト部を表すビットと同じ部分を0にする
例:ネットワーク部が24ビット → 192.168.128.0/255.255.255.0VPCの作成
リージョンを「東京」に設定し、サービス → VPCを検索
VPCを選択
デフォルトでVPCが作成されているがこれは使用しない
「VPCの作成」をクリック
以下の画像を参考に設定し、「作成」をクリック
- 名前タグ:VPCを識別する名前
- IPv4 CIDR ブロック:作成するVPCにおけるIPアドレスの範囲
- テナンシー:物理ハードウェアを専用にする(設定するとEC2の料金が割増になる)
VPCが作成されていることを確認
サブネットの作成
パブリックサブネットの作成
サブネットを選択
デフォルトでサブネットが作成されているがこれは使用しない
「サブネットの作成」をクリック
以下の画像を参考に設定し、「作成」をクリック
- 名前タグ:サブネットを識別する名前
- VPC:サブネットを作成するVPC
- アベイラビリティゾーン:サブネットを作成するアベイラビリティゾーン
- IPv4 CIDR ブロック:作成するサブネットにおけるIPアドレスの範囲
パブリックサブネットが作成されていることを確認
プライベートサブネットの作成
「サブネットの作成」をクリック
以下の画像を参考に設定し、「作成」をクリック
プライベートサブネットが作成されていることを確認
ルーティングの設定
パブリックサブネットからインターネットに接続できるようにしたい
↓
ルーティングを設定するルーティング:IPアドレスからIPアドレスに紐づくルーター(AWSではターゲットと呼ぶ)へつなぐこと
ルートテーブル:IPアドレスとそのルーター情報を一覧化したもの(経路制御表)
デフォルトルート(0.0.0.0/0):ルートテーブルに登録されているアドレスに一致しないときの経路
IPアドレス ルーター(ターゲット) 10.0.1.0/24 local(自身のネットワーク) 10.0.2.0/24 ルーターB 0.0.0.0/0 ルーターC インターネットゲートウェイ:インターネットとVPCをつなぐ仮想ルーター
インターネットゲートウェイを新規作成してVPCに設置する → local以外をインターネットゲートウェイにつなげるようにする
*ルートテーブルはVPCと各サブネットに設定できる
*AWSはサブネットとルートテーブルを定義すると暗黙的にルーターが動作するインターネットゲートウェイを作成し、VPCにアタッチする
「インターネットゲートウェイ」をクリック
「インターネットゲートウェイの作成」をクリック
任意の名前を設定し、「作成」をクリック
作成されたことを確認
作成したインターネットゲートウェイを選択し、「アクション」 → 「VPCにアタッチ」をクリック
作成したVPCを選択し、「アタッチ」をクリック
VPCがアタッチされていることを確認
ルートテーブルを作成し、パブリックサブネットに紐付ける
ルートテーブルの作成
「ルートテーブル」をクリック
現在のルートテーブルを確認(localが作成されている)
「ルートテーブルの作成」をクリック
任意の名前、作成したVPCを選択し、「作成」をクリック
ルートテーブルとパブリックサブネットを紐付ける
作成したルートテーブルはVPCのみ割り当てられているので、パブリックサブネットにも割り当てる
作成したルートテーブルを選択し、「サブネットの関連付け」 → 「サブネットの関連付けの編集」をクリック
パブリックサブネットを選択し、「保存」をクリック
サブネットが追加されていることを確認
デフォルトルートをインターネットゲートウェイに設定する
作成したルートテーブルを選択し、「ルート」 → 「ルートの編集」をクリック
「ルートの追加」をクリック
以下を参考に設定し、「ルートの保存」をクリック
- 送信先:0.0.0.0/0
- ターゲット:Internet Gateway → 作成したインターネットゲートウェイ
ルートが追加されていることを確認
ネットワーク設計で考慮すべきポイント
VPCの設計ポイント
- プライベートIPアドレス範囲から指定する
- VPCでは仮想のプライベートネットワーク空間を作成するので、プライベートIPアドレスの使用が推奨
- IPアドレスのホスト部は大きめに設定する
- ホスト部の範囲は/28 〜 /16と決まっている
- /16が推奨
- オンプレミスや他のVPCレンジと重複しないようにする
- オンプレミスとクラウドを併用している場合、レンジが重複するとどちらに接続すればよいかわからなくなるため
VPCとアカウントの分け方
- 異なるシステムを運用する場合、アカウントは分ける
- 異なるシステムを同一アカウント内に用意すると管理が煩雑になる
- 同一システムで複数環境が存在する場合、同一アカウントでVPCとリージョンを分ける
- VPCを分けるとIAMの設定が一度でよいが、各環境のリソースが見えて事故の元になる
- アカウントを分けると他の環境のリソースが見えず作業しやすいが、環境ごとにIAMの設定が必要
サブネットの設計ポイント
- 将来的に必要なIPアドレス数を見積もって設定する
- /24が標準的
- サブネットの分割はルーティングとアベイラビリティゾーンを基準に行う
- サブネットに割り当てられるルートテーブルは1つ
- インターネットアクセスの有無、拠点アクセスの有無などのルーティングポリシーに応じて分割する
- 高可用性のために2つ以上のアベイラビリティゾーンを使用する
*可能な限り全てのサブネットには明示的に何かしらのルートテーブルを紐づけた方が良い
→ルートテーブルを設定していない場合、デフォルトで存在するルートテーブルが暗黙的に使われるので、
デフォルトルートテーブルが変更された際に意図しない影響が出るリスクが発生するから参考






























- 投稿日:2020-01-13T17:35:15+09:00
EC2上のWordPressの乗っ取りを放置していたら不正利用のメールが来た話
はじめに
WordPressの勉強に、AWSハンズオンのWordPressインスタンスをそのまま利用していました。その後、WordPressにログインすると、身に覚えのない英語の記事が増えていました。その後、放置していたら、AWSから、EC2の不正利用レポートが届きました。
使用していたインスタンスの詳細
- OS
- Amazon Linux AMI release 2016.09
- Apache(httpd)のバージョン
- 2.2.34
- MySQLのバージョン
- 5.5.62
- PHPのバージョン
- 5.3.29
- WordPressのバージョン
- 4.7.2
WordPressの乗っ取り
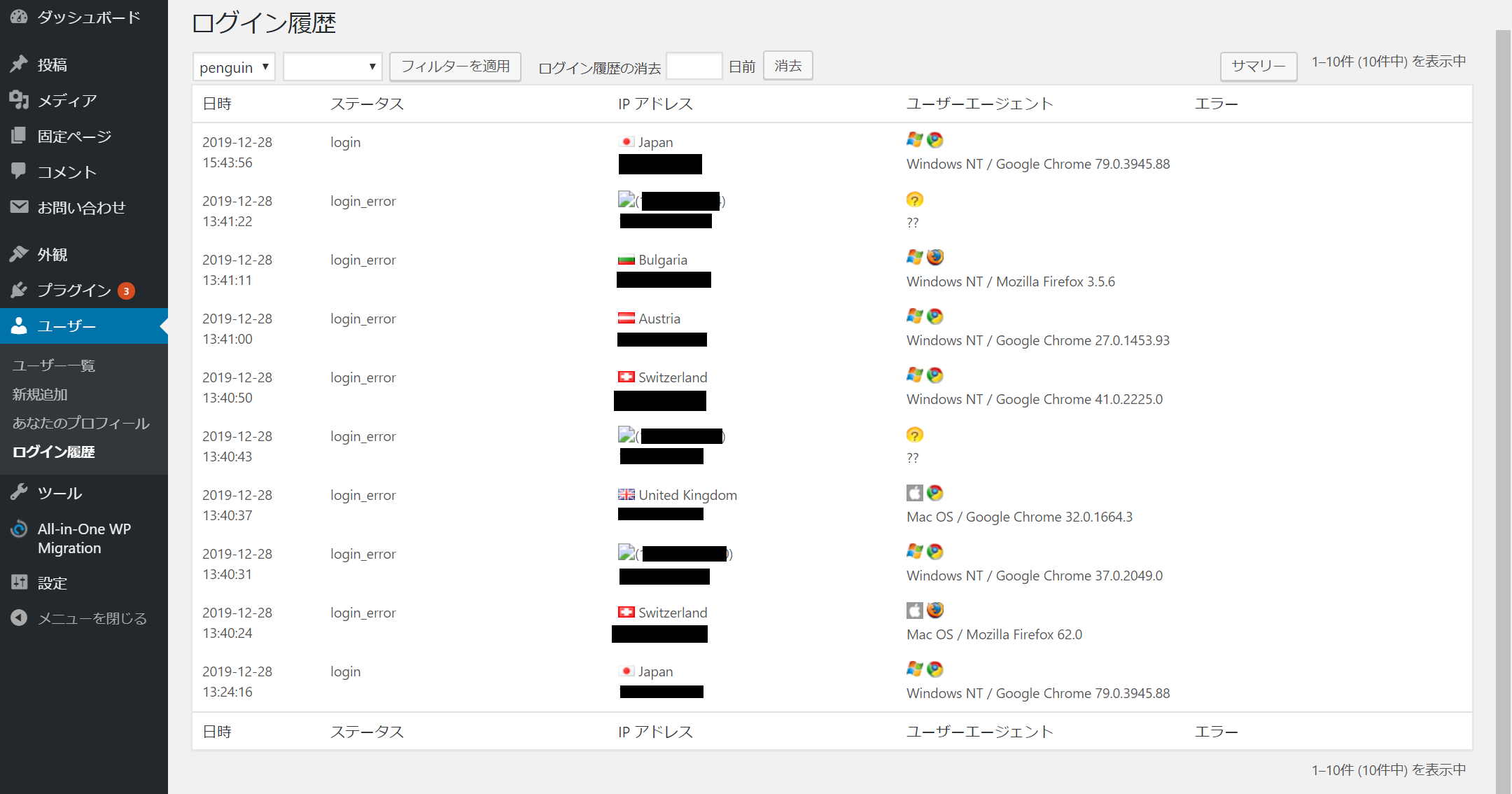
WordPressに1週間ぶりにログインすると、見慣れない記事が増えていました。
簡単なパスワードだったので急いで変更し、ログイン履歴の確認できるCrazy Boneをインストールし、ログイン履歴を確認すると、インストールして約20分ほどで8件のアタック履歴が出てきました。
上記の状況を見て、IP Geo Blockを使用してJPドメイン以外の閲覧と管理画面のログインを禁止しました。
その後、自分の元記事のページを見てみると、不正スクリプトや別のページにジャンプさせる命令が記述されていました。
身に覚えのないスクリプトを削除した後、一安心と思い放置していました。
Amazonから、不正利用のメールが届く
WordPress乗っ取りから、1週間が過ぎた頃、Amazonから、
Your Amazon EC2 Abuse Reportという件名のメールが届きました。
自分が使用しているインスタンスのIPアドレスから、ブルートフォース攻撃とDoS攻撃をしている報告が来ました。
勉強用で消しても問題がないので、急いでインスタンスを削除し、このメールにI stopped and deleted the corresponding EC2.(該当のEC2を停止&削除しました)と送信しました。その後、解決したとメールが届いたので一安心です。
反省点
インスタンスのセキュリティグループ
勉強用で自分しか使わないのにSSHとHTTPが全世界に公開(0.0.0.0/0)していたので、マイIPに設定する。
改ざんされていた時点でインスタンスを停止する
WordPressの改ざんが確認された時点で該当のインスタンスを削除し、新しく作り直すことをしていれば不正利用メールが来なかったと思います。
ソフトウェアのアップデートをして最新バージョンにする
使用していたWordPressのバージョンが古く、脆弱性から踏み台にされたので、脆弱性を減らすためにも、ソフトウェアのアップデートは重要だと思いました。
WordPressのセキュリティプラグインを導入する
ダッシュボードにログインするアドレスを変更したり、ログイン時にCAPTCHA認証が必要にしてボット攻撃に抵抗する必要があります。
パスワードを簡単なものにしない
最初に指定されている複雑なパスワードをそのまま使用するほうが、セキュリティが高い気がします。
さいごに
定期的に自分のサイトやインスタンスを確認して、改ざんや脆弱性がないかを確認する事が重要だと思いました。アタックはボットで無差別に行われているので、常にソフトウェアを最新の状態にして、脆弱性を減らすことが重要です。


- 投稿日:2020-01-13T16:46:17+09:00
AWS IAM について
AWSはサービスが豊富でぽちぽちと簡単に設定できてしまいますが、
1つ1つ理解していないと大変なことになるので拙いですが概要をまとめます。
間違ったこと書いてたらご指摘ください。IAMの概要
IAMとは・・・Identity and Access Management。安全に操作を実施するための認証・認可の仕組み
ユーザ・グループ・ポリシー・ロールと4つの主要トピックがある。
ユーザ
⇨ルートユーザ:AWSアカウント作成時に作られるIDアカウント。全てのサービスにアクセスできるため、
普段からこのルートユーザを使うことは非推奨となる。神様みたいなアカウントなので気をつけましょう!!⇨IAMユーザ:普段から使用されるであろうアカウント。アクセス権があるサービスのみ使用できる。
1アカウントで5000ユーザ、10のグループまでに所属することができるグループ
⇨IAMグループ:IAMユーザの集合体。学校のクラスみたいな!
複数のユーザに対してアクセス許可を設定でき、また管理することができる。
1アカウントで300グループまで作成可能ポリシー
⇨IAMポリシー:ユーザへのアクセス権限をJSON形式で設定できる。
ex)A君:EC2だけ Bグループ:EC2+S3にアクセスできる・ユーザベース⇨アカウント自体に紐づけること
・リソースベース⇨紐付け先がS3バケットなどのAWSサービスに紐づけられること。
アカウントを超したアクセスが可能。ロール
⇨IAMロール:EC2やLambdaなどのAWSリソースに権限を付与できるもの。EC2とS3をアタッチできたりする。
ユーザやグループは人に紐付けされますが、ロールはリソースに紐付けされるイメージ。これからもっと実際に手を動かしながら理解を深めていきます。
アソシエイト資格取得まで頑張ります。
- 投稿日:2020-01-13T12:44:07+09:00
あえて継続的にデプロイしないElasticBeanstalkへのデプロイ環境を構築しました。
お疲れさまです。@naokiurです。
最近ElasticBeanstalkを用いて、
アプリケーションを構築・稼働させることが、たまにあります。開発を続けていく上で、欲しい仕組みの一つとして、
継続的デプロイ(Continuous Deployment)があるかと存じます。
AWSの公式でも、クイックスタートとして
AWS CodePipeline を使用した AWS Elastic Beanstalk 環境へのデプロイが掲載されています。
(Continuous DeploymentとContinuous Deliveryは意味が異なる、ということを初めて認識しました…。)これはとても素晴らしいものだと思うのですが、
局所的な例で恐縮ながら、以下があるとき、
この例を組み替えると、よりマッチしたもの
(いざリリースするときにできなくなったりしなかったり、
作成するリソースを減らすことができたり)
になるのでは、とおもい、検討致しました。
- 前提
- アプリケーションのリリースによるシステム閉塞(数分〜数十分)が認められる
- masterブランチにマージされ、リリース可能となってから、実際にリリースするまで1日以上のラグが発生する場合がある
- リリースフローに承認がいるとか
- そのリリースフローを改善したほうがよい、という話はさておき…
- Manual Approvalは7日間以内に承認・拒否する必要があるので、それ以上間が開くときとか
内容
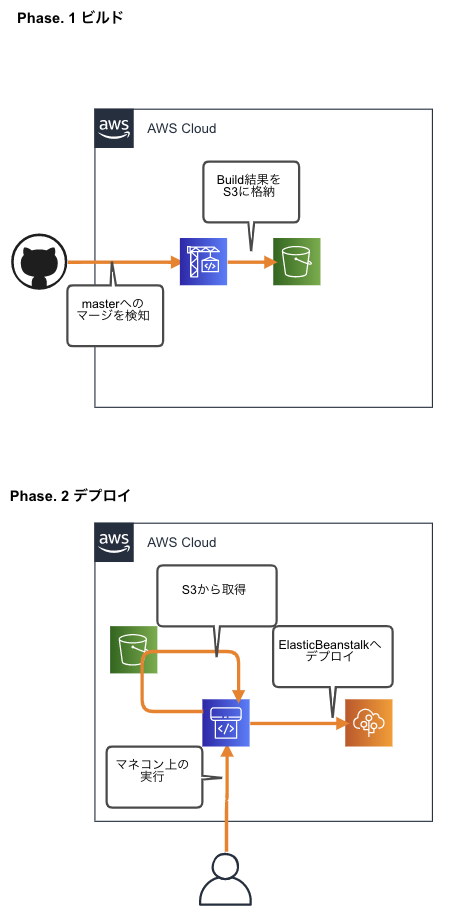
構成図
ビルドまでと、ビルド以降を、CodeBuildとCodePipelineに分けました。
エンジニアがmasterブランチにマージしたら、
CodeBuildによってS3に格納します。その後、
CodePipelineの「変更をリリースする」クリックすることによって、
ElasticBeanstalkにデプロイされる、
という流れです。
最近個人的にAWS CDKが好みなのですが、
今回はCloudFormationで構築しました。
AWS CDKは、ElasticBeanstalkDeployAction的なものがまだ実装されてないとお見受けしたため…。
https://github.com/aws/aws-cdk/issues/2516ElasticBeanstalkサンプルアプリケーション
簡単Djangoアプリケーションを予め稼働させておきます。
* アプリケーション名
* MyApp
* 環境名
* MySampleEnvironment
/quickstartにアクセスすると、
テキストが返ってくる、という単純なものです。
CodeBuild構築
ビルドしてS3に格納するCodeBuildです。
Github Access Tokenは予めSecrets Managerに入れておきます。
デプロイに使用する際、バージョニングが必要なので、
S3のバージョニングはtrueに設定しておきます。Resources: # First: Build Source and Zip, Save to S3(Build Bucket). ## This Need ## * S3 Bucket for after Build. ## * This Bucket need versioning for deploy to ElasticBeanstalk. ## * CodeBuild Project ## * GithubCredential for CodeBuild Project ## * IAM Role for CodeBuild Project DjangoBuildRole: Type: AWS::IAM::Role Properties: RoleName: DjangoBuildRole AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - codebuild.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: DjangoBuildRoleRolePolicy PolicyDocument: Version: "2012-10-17" Statement: - Sid: S3FullAccess Effect: Allow Action: s3:* Resource: - '*' - Sid: CloudWatchLogAccess Effect: Allow Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents Resource: - '*' SysopsBucket: Type: AWS::S3::Bucket Properties: BucketName: !Sub "naokiur-sysops-bucket-${AWS::AccountId}" VersioningConfiguration: Status: Enabled EBBuildGithubCredential: Type: AWS::CodeBuild::SourceCredential Properties: AuthType: PERSONAL_ACCESS_TOKEN ServerType: GITHUB Token: '{{resolve:secretsmanager:personal-secrets:SecretString:github-access-token}}' DjangoAppEBBuild: Type: AWS::CodeBuild::Project Properties: Name: django-app-build-project Source: Auth: Type: OAUTH BuildSpec: buildspec.yml GitCloneDepth: 1 Location: https://github.com/naokiur/django_app.git Type: GITHUB ServiceRole: !GetAtt DjangoBuildRole.Arn Environment: Type: LINUX_CONTAINER ComputeType: BUILD_GENERAL1_SMALL Image: aws/codebuild/standard:2.0 Artifacts: Type: S3 Location: !Ref SysopsBucket Path: /builds Name: django_app.zip Packaging: ZIP Triggers: FilterGroups: - - Type: EVENT Pattern: PULL_REQUEST_CREATED,PULL_REQUEST_UPDATED,PUSH - Pattern: refs/heads/master Type: HEAD_REF Webhook: trueCodePipeline構築
上記のS3からファイルを取得し、
ElasticBeanstalkにデプロイするCodePipelineです。
CodePipelineのArtifactStore用のS3 Bucketも作成しました。
こっちはバージョニングがいらないと考えたためです。
(OutputArtifactsで指定した内容を、S3に蓄積していくという動きをすると思うのですが、毎回別名で保存されるので)# Second: Download Source Zip from S3, Deploy to ElasticBeanstalk. ## This Need ## * S3 Bucket ## * This Bucket is not same with 'First'. It is no need versioning. ## * CodePipeline ## * IAM Role for CodePipeline CodepipelineBucket: Type: AWS::S3::Bucket Properties: BucketName: !Sub "naokiur-codepipeline-bucket-${AWS::AccountId}" VersioningConfiguration: Status: Enabled EBDeployPipelineRole: Type: AWS::IAM::Role Properties: RoleName: EBDeployPipelineRole AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Principal: Service: - codepipeline.amazonaws.com Action: - sts:AssumeRole Policies: - PolicyName: EBDeployPipelineRolePolicy PolicyDocument: Version: "2012-10-17" Statement: - Sid: S3FullAccess Effect: Allow Action: s3:* Resource: - '*' - Sid: EBFullAccess Effect: Allow Action: - elasticbeanstalk:* - cloudformation:* - autoscaling:* - elasticloadbalancing:* Resource: - '*' EBDeployPipeline: Type: AWS::CodePipeline::Pipeline Properties: Name: EBDeployPipeline RoleArn: !GetAtt EBDeployPipelineRole.Arn ArtifactStore: Type: S3 Location: !Ref CodepipelineBucket Stages: - Name: Source Actions: - Name: download-source ActionTypeId: Category: Source Owner: AWS Version: "1" Provider: S3 Configuration: S3Bucket: !Ref SysopsBucket S3ObjectKey: builds/django_app.zip PollForSourceChanges: false OutputArtifacts: - Name: SourceOutput - Name: Deploy Actions: - InputArtifacts: - Name: SourceOutput Name: deploy ActionTypeId: Category: Deploy Owner: AWS Version: "1" Provider: ElasticBeanstalk Configuration: ApplicationName: MyApp EnvironmentName: MySampleEnvironmentトライ
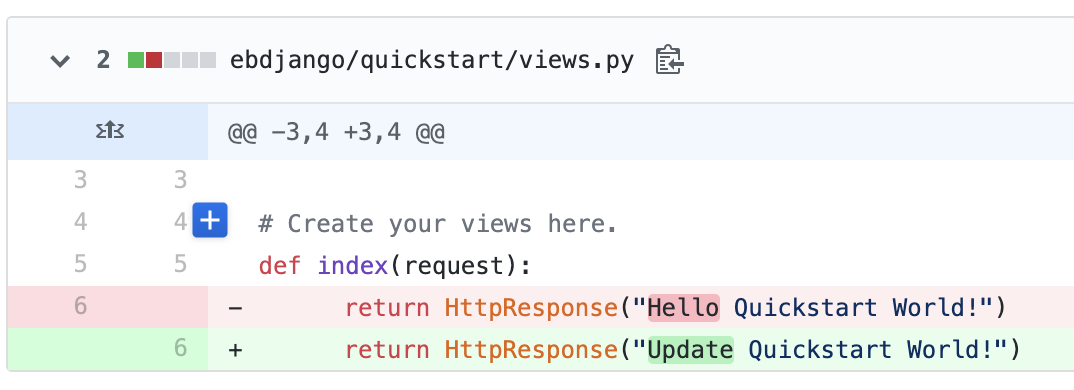
Djangoアプリケーションの内容を変更し、masterへpushします。
CodeBuildがmasterブランチへのpushを検知し、動きます。
CodeBuild完了後、手動で、CodePipelineを実行します。
返却されるテキストが変わりました!
今後
ビジネスに応じて、参考になれば幸いです。
パラメータ化した方が使いやすくなる部分が結構あると思うので、
もし実務で使うときがあったら、そのようなテンプレートにしていけたらと思っています。
デプロイする際に、AWSコンソール上にログインして、ボタンを押さなければならない
というのがめんどうだな…と思うのですが…
機密性と利便性のトレードオフの部分かも…? と考えています(見当違いだったらすみません)参考にさせて頂きました
- https://aws.amazon.com/jp/getting-started/tutorials/continuous-deployment-pipeline/
- https://aws.amazon.com/jp/quickstart/architecture/blue-green-deployment/
- https://www.atlassian.com/continuous-delivery/principles/continuous-integration-vs-delivery-vs-deployment
- https://dev.classmethod.jp/cloud/aws/codepipeline-approve-async-processing/




- 投稿日:2020-01-13T12:19:47+09:00
【API Gateway】HTTP API 使ってみた
AWSのAPI Gatewayで、HTTP API(ベータ版)が利用出来るようになったので、使ってみました。
※正式リリース版ではなくベータ版であることに、ご注意ください。HTTP APIとは
AWSの公式ドキュメントには下記のようなことが書かれています。
HTTP API を使用すると、REST API よりも低いレイテンシーとコストで RESTful API を作成することができます。
HTTP API を使用して、AWS Lambda 関数またはルーティング可能な HTTP エンドポイントにリクエストを送信できます。
APIを低レイテンシー、低コストで利用できるようになるのは、とてもありがたいことですね。
HTTP APIの作成
AWSマネージメントコンソールから作成していきます。
[APIを作成]をクリックします。
作成するAPIの種類の選択画面が表示されます。
HTTP APIの[構築]をクリックします。
APIの作成画面が表示されます。
[統合タイプ]と[統合ターゲット]を指定します。
[統合タイプ]はLambdaまたはHTTPが指定可能です。
今回はLambdaを指定し、ターゲットに「slackNotification」というLambda関数を指定しています。
[API名]を入力し、[次へ]をクリックします。
[メソッド]、[リソースパス]、[統合ターゲット]を指定し、[次へ]をクリックします。
今回は「/slackNotification」に「POST」リクエストがあったら、Lambda関数「slackNotification」にリクエストを送信するよう設定しています。
[ステージ名]を指定し、[次へ]をクリックします。
デフォルトでは「$default」ステージが設定されており、自動デプロイが「有効」になっています。
設定を確認し、[作成]をクリックします。
APIが作成されました。
HTTP APIの実行
curlを使ってAPIにリクエストを送信してみます。
実行方法は当然これまでのAPIと変わりません。curl -X POST -d '{"username": "test-user", "message": "テストメッセージ", "channel": "#work"}' https://XXXXXXXXXX.execute-api.ap-northeast-1.amazonaws.com/slackNotification注目したいのは、API GatewayからLambdaに連携されるデータです。
下記にその例を示します。
リクエストボディが暗号化されているのが分かります。
上記POSTリクエストの'{"username": "test-user", "message": "テストメッセージ", "channel": "#work"}'にあたる部分です。
HTTP APIではデフォルトで、Base64エンコードが有効になっています。
Lambda側の処理でデコードしてあげる必要があるので、注意が必要です。{ 'version': 2, 'path': '/slackNotification', 'httpMethod': 'POST', 'headers': { (省略) }, 'multiValueHeaders': { (省略) }, 'queryStringParameters': None, 'multiValueQueryStringParameters': None, 'requestContext': { (省略) }, 'pathParameters': None, 'stageVariables': None, 'body': 'eyJ1c2VybmFtZSI6ICJ0ZXN0LXVzZXIiLCAibWVzc2FnZSI6ICLjg4bjgrnjg4jjg6Hjg4Pjgrvjg7zjgrgiLCAiY2hhbm5lbCI6ICIjd29yayJ9', 'isBase64Encoded': True }使ってみた感想
これまでのREST APIは設定方法がかなり難しい印象があったが、HTTP APIは直感的にかなり分かりやすいと感じました。
Base64エンコードの部分は少しハマりました。。。







- 投稿日:2020-01-13T12:11:39+09:00
EFS ファイルサーバーへの移行 - Nextcloud 環境の構築を通じて AWS での環境構築を体験する③
「Nextcloud 環境の構築を通じて AWS での環境構築を体験する」 の第 3 回となります。
これまでの記事が下記からどうぞ。
- 【第 1 回】EC2 と RDS を利用した Nextcloud 環境の構築
- 【第 2 回】ElastiCache サービスの導入
はじめに
今回は、前回記事 で作成した環境構成から Nextcloud に保管されているファイル群を Amazon Elastic File System (EFS) を利用した外部のファイルサーバーに移してみます。
これを分離することで、将来的に EC2 サーバーをロードバランサ等を利用して複数台運用としても、Nextcloud 保管ファイルを Web サーバーで共有することができるようになります。# EFS ってなかなか 東京リージョンに下りてこなかったので、追加が発表されたときには「いよいよ!」と歓喜した思い出 w
今回構築する Nextcloud on AWS 環境
次のような構成となります。EC2 から ファイルサーバーをマウントする形となります。
今回追加で利用する AWS サービス
サービス名 役割 Amazon Elastic File System (EFS) シンプルでスケーラブル、かつ伸縮自在な完全マネージド型の NFS ファイルシステム。 変更手順
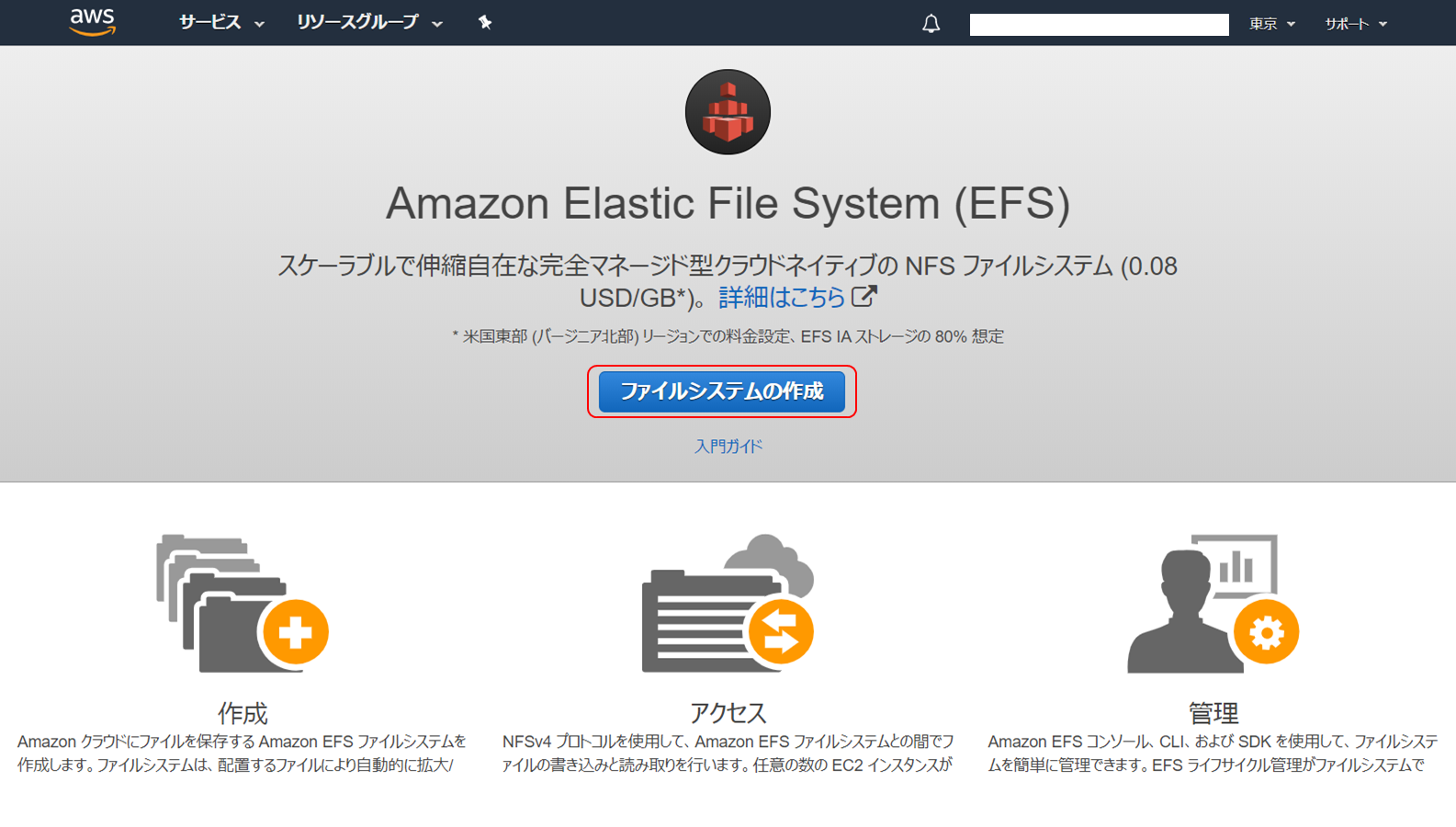
EFS サービスを起動する
AWS マネジメントコンソールにログインし、EFS サービスを選択します。「作成」をクリックします。
サービスを起動するための設定情報をいくつか設定します。
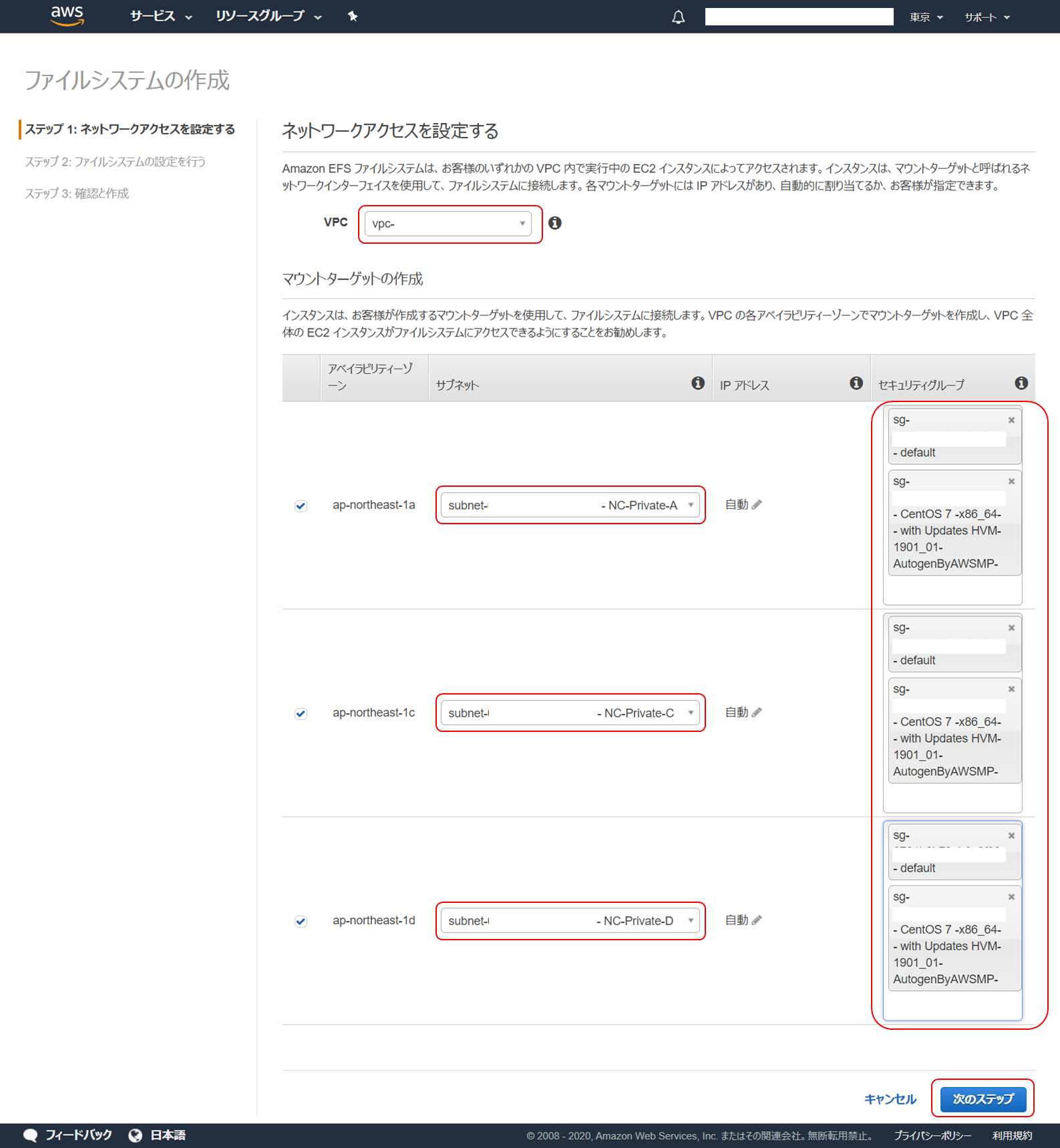
ネットワークアクセスの設定です。
まず、「 VPC 」は、EFS をどの VPC でアクセスできるようにするかを選択します。EC2 と同じ VPC を選択してください。デフォルト VPC でも問題ありません。
次にマウントターゲットの作成です。マウントターゲットは EC2 インスタンスから EFS に接続するための接続先となります。現時点では、EC2 を作成しているアベイラビリティゾーンのみあれば問題ありませんが、将来的にどこのアベイラビリティゾーンの EC2 でも接続できるようにするため、この時点ですべてのアベイラビリティゾーンの EC2 インスタンスに接続できるようにしてしまいます。表示されているすべてのアベイラビリティゾーンについてチェックをして有効にします。
そのほかの項目は以下のように設定し、「次のステップ」をクリックします。
項目 内容 サブネット EFS のマウントポイントをどのサブネットで作成するかを選択します。今回は EC2 と接続することができれば問題ないので、プライベートサブネットで OK です。 セキュリティグループ マウントターゲットに関連付けるセキュリティグループを設定します。Nextcloud EC2 に設定されているセキュリティグループを追加して、このセキュリティグループを持つ EC2 と疎通できるようにします。
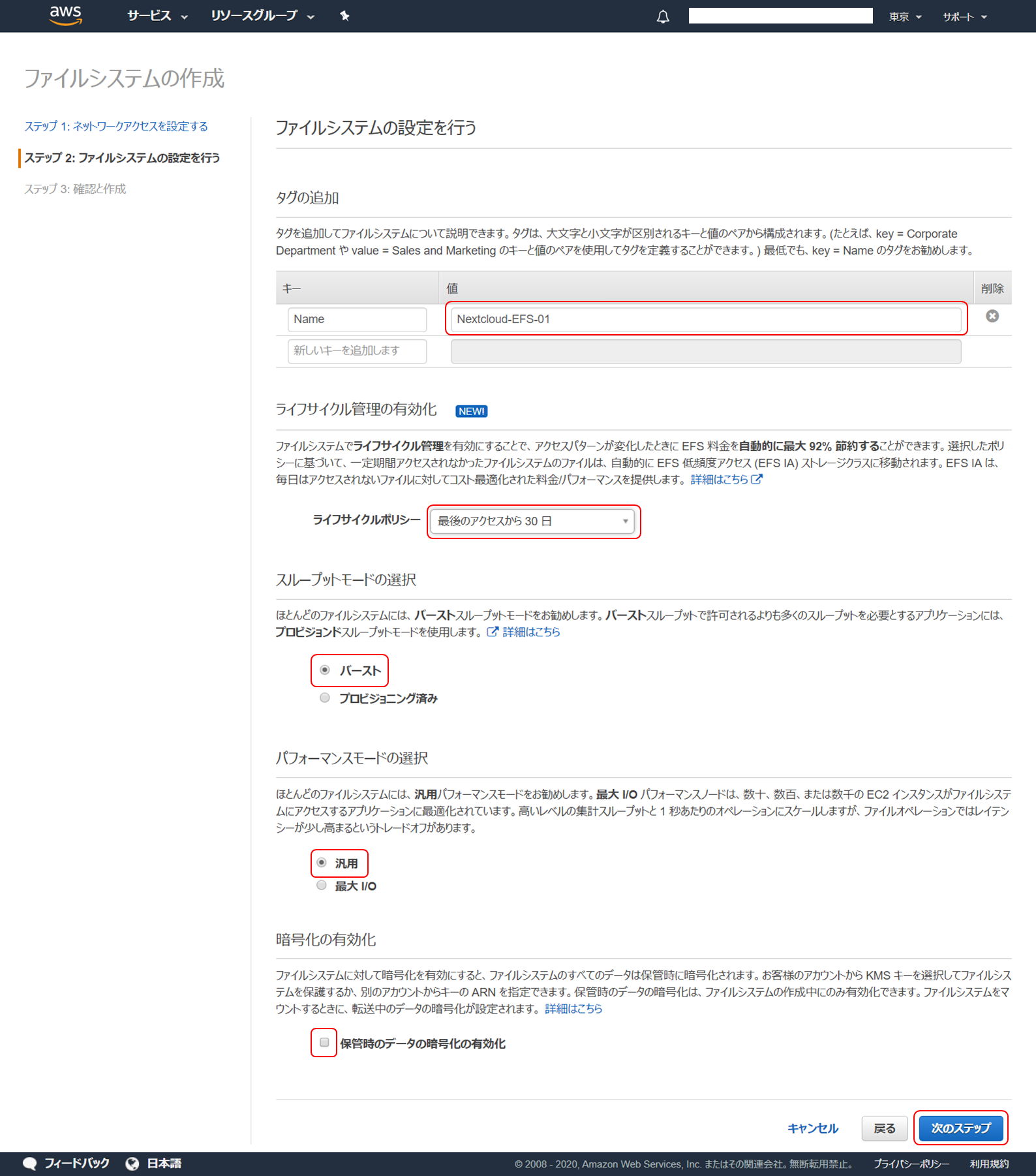
ファイルシステムの設定です。
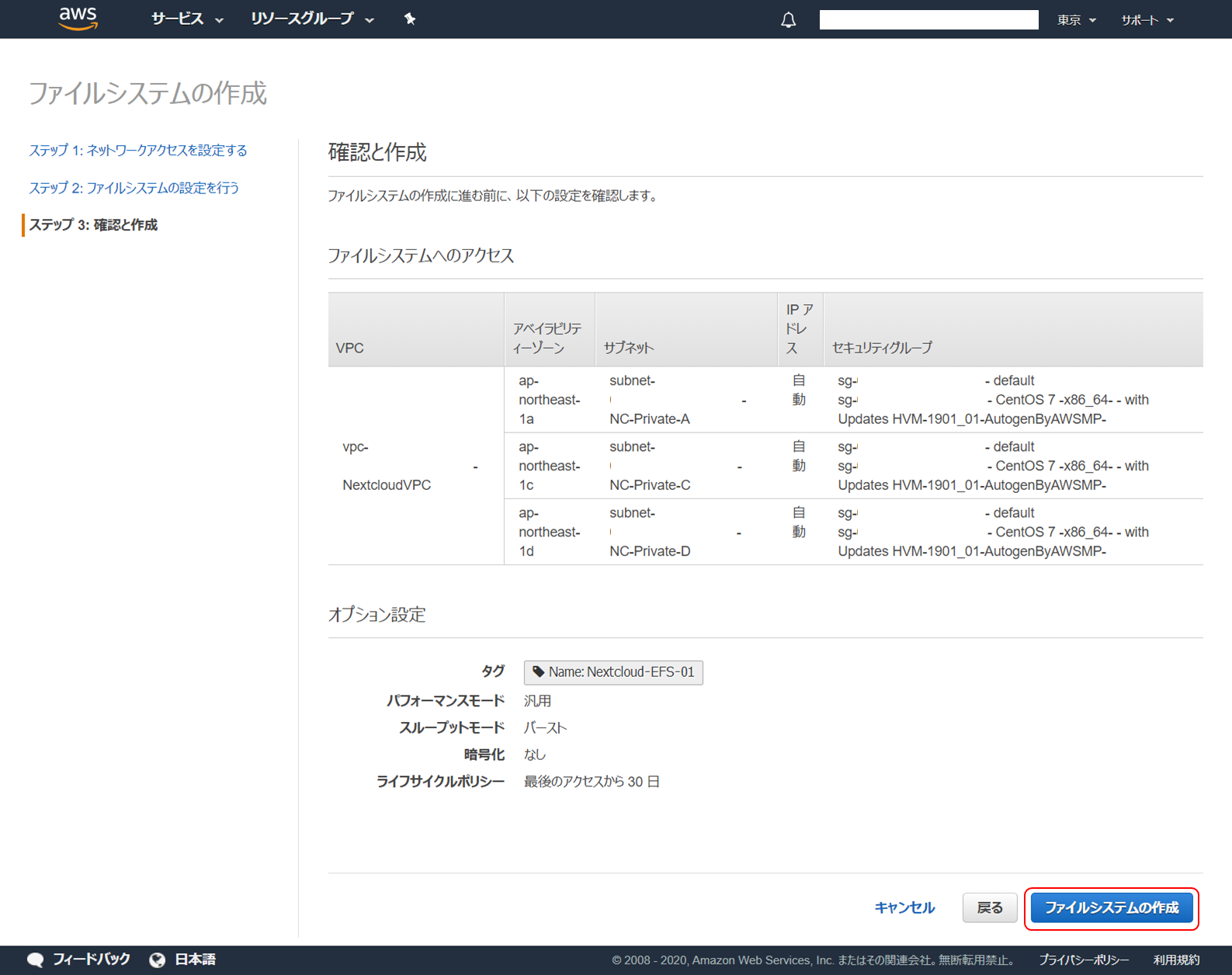
以下のように設定し、「次のステップ」をクリックします。
項目 内容 タグの追加 作成する EFS にタグを追加します。Name キーとしてこの EFS の名前を最低限追加しておきます。その他必要なタグがあれば追加しておきます。 ライフサイクル管理の有効化 ここでは、「最後のアクセスから 30 日」を選択し、30 日アクセスされなかったファイルを移動するようにします。ライフサイクル管理は最近追加された機能で、 EFS に保管されているファイルを自動的に EFS 低頻度アクセスストレージクラスに移動する機能です。EFS 低頻度アクセスストレージクラスは S3 の低頻度アクセスタイプみたいな感じで、容量当たりの利用料金が安い代わりに取り出しにコストがかかるやつです。 スループットモードの選択 「バースト」を選択します。要件などでより高いスループットが必要でなければこれで問題ありません。 パフォーマンスモードの選択 「汎用」を選択します。 暗号化の有効化 チェックがついていたら外します。ファイルシステムの暗号化をするかどうかを選択するもので、セキュリティ要件などで暗号化が必要であればチェックします。
これまでの設定内容を確認します。問題なければ「ファイルシステムの作成」をクリックします。
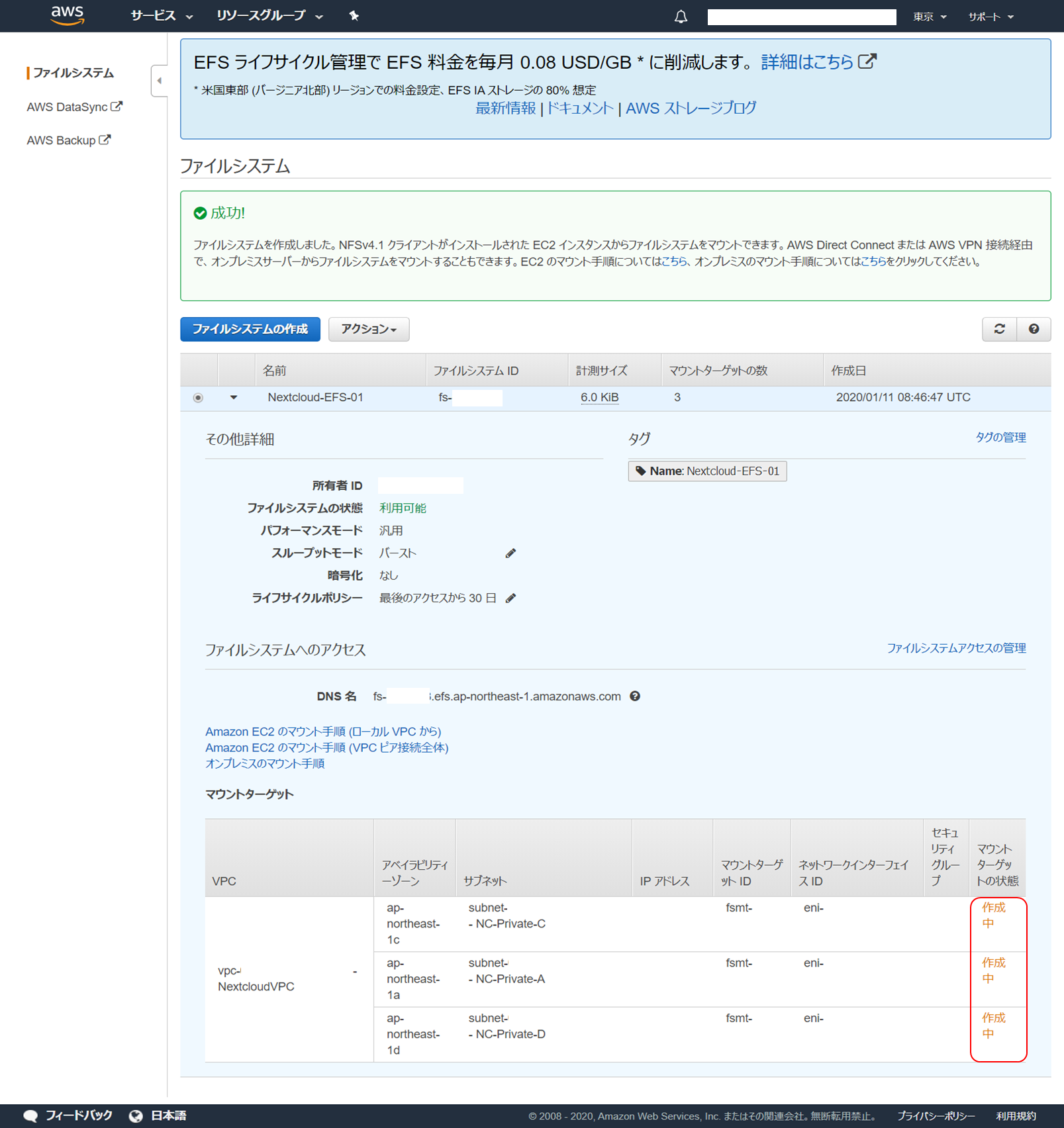
EFS ファイルシステムの作成が開始されます。マウントターゲットの状態が「作成中」の場合はまだ使えないので気長に待ちます。
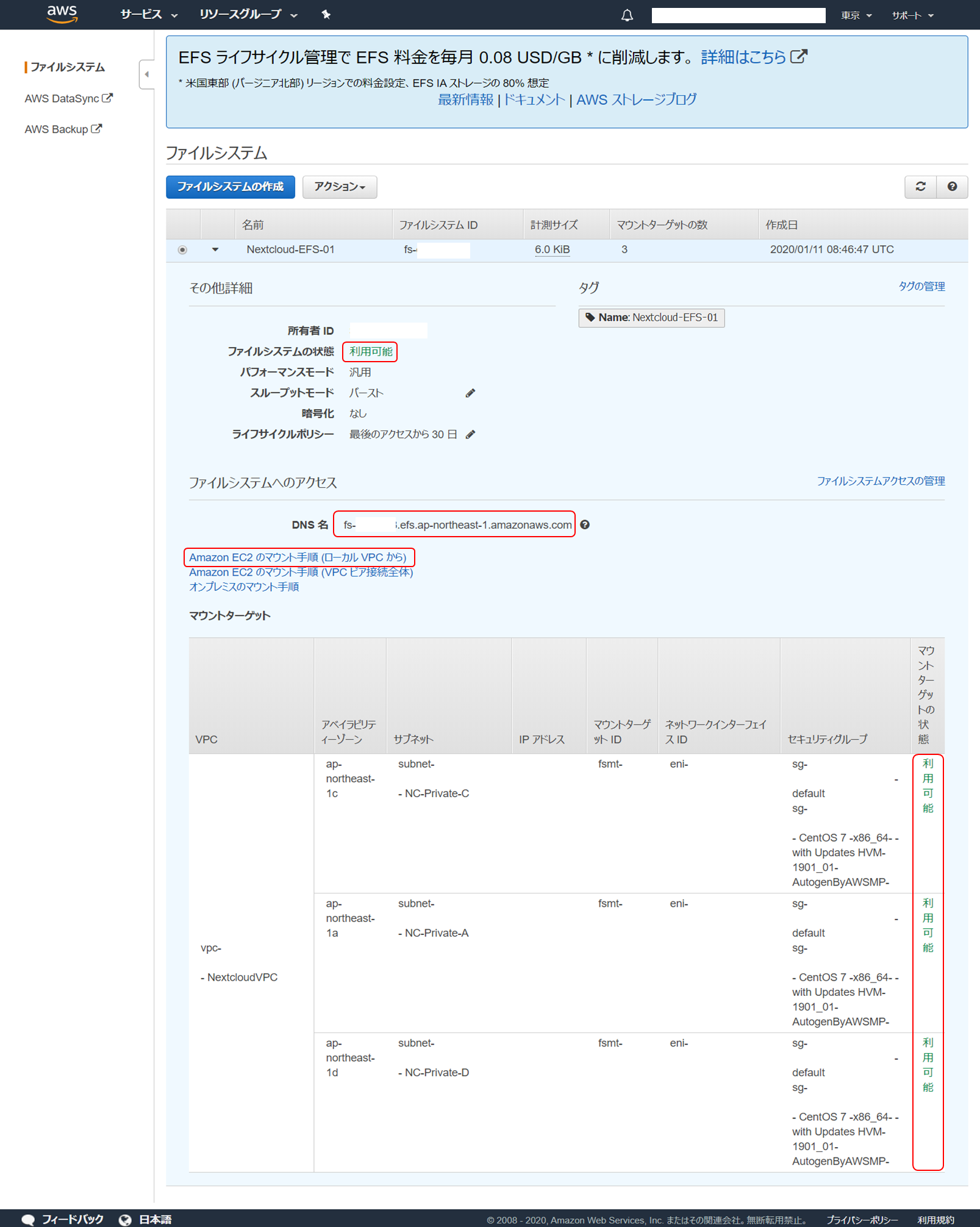
ブラウザ再読み込みをしてファイルシステムの状態、マウントターゲットの状態が「利用可能」となったら作成完了です。
「ファイルシステムへのアクセス」の「DNS 名」がこの EFS へのアクセスポイントとなりますので確認しておきます。
この後、 Nextcloud EC2 サーバーにこれをマウントするのですが、この手順は「 Amazon EC2 のマウント手順 (ローカル VPC から)」のリンクに親切にも記載されていますのでこれを参照して設定していきます。
EC2 サーバーにEFS サービスをマウント
これまでで作成した EC2 の Nextcloud サーバーにこの EFS をマウントして、EC2 に保管されている Nextcloud 保管ファイルをここに移動します。
Nextcloud サーバーに SSH 接続して作業を行います。
サービスの一時停止
設定変更中に不用意にアクセス等が行われないように、一部サービスを停止しておきます。
Nextcloud バックグラウンドジョブの停止。
sudo mv /etc/cron.d/nextcloud-cron-php /etc/cron.d/.nextcloud-cron-phpNginx の停止。
sudo systemctl stop nginxPHP-FPM の停止。
sudo systemctl stop php-fpm既存の Nextcloud 保管ファイルを退避
既存の Nextcloud データファイルが保管されているディレクトリを一時退避します。
データ保管ディレクトリの名前を変更。
sudo -i mv /DATA /DATA_back exitEFS を接続(マウント)
作成した EFS をこのサーバーのファイルシステムとして利用できるようにマウントを行います。
マウント先ディレクトリの作成。
sudo mkdir /DATA作成したディレクトリをマウントポイントとして EFS をマウント。
sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport 【EFS の DNS 名】:/ /DATA接続されているか確認。
df -Th※以下の表示を確認します。
項目 内容 ファイルシス 【EFS の DNS 名】:/ タイプ nfs4 マウント位置 /DATA サーバーが再起動しても自動的にマウントするように設定追加。
sudo echo "【EFS の DNS 名】:/ /DATA nfs4 defaults 0 0" >> /etc/fstab設定が追加されているか確認。
cat /etc/fstab※「【EFS の DNS 名】:/ /DATA nfs4 defaults 0 0」の 1 行が追加されていることを確認します。
※指定を誤っているとサーバーが起動しなくなる可能性があるので、確認はしっかり行ってください。Nextcloud 保管ファイルを退避先からコピー
マウントした EFS に退避していた Nextcloud 保管ファイルをコピーして復元します。
先に名前変更したディレクトリの中身を EFS にコピー。
sudo cp -piR /DATA_backup/. /DATA※隠しファイルもあるため、コピー元の指定には注意してください。
サービスの起動
一時停止しているサービスを起動します。
PHP-FPM の起動。
sudo systemctl start php-fpmNginx の起動。
sudo systemctl start nginxNextcloud バックグラウンドジョブの起動。
sudo mv /etc/cron.d/.nextcloud-cron-php /etc/cron.d/nextcloud-cron-phpNextcloud の動作確認
Nextcloud が動作しているか確認します。Nextcloud にログインしてファイルアップロード、ダウンロード等を試してみます。
お疲れさまでした! これですべての設定が完了です。
あとがき
EFS 東京リージョン追加に歓喜した割には、なかなか利用する機会に恵まれず、前回同様、今回の記事を起こすにあたって、初めて EFS を利用してみたのですが、こちらもけっこうあっさり起動、マウントまで完了ました。
当然ですが、このサービスを使わないで、EC2 で NFS ファイルサーバーを追加で立てて運用することも可能です。ですが、フルマネジメントで保管領域を気にしたり EC2 障害などを普段は面倒見なくてもいいように、あえて EFS サービスを利用します。ここまでで、次回に向けての準備はできましたので、次回は EC2 を複数にし、ロードバランサを追加することで、Nextcloud の可用性を高めていきます。
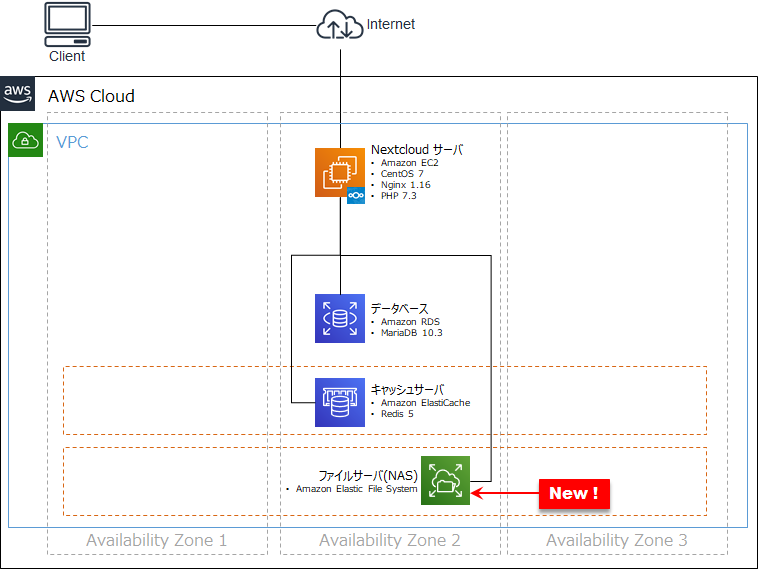
- 投稿日:2020-01-13T11:24:10+09:00
S3にAWS CLIからアップロードすると「Access Denied」が発生した
概要
ラズパイで撮影した画像をS3に送る時に、「Access Denied」が発生してS3にアクセスすることができず、解消に手間取ったので備忘録。
事象
aws s3 cp test.jpg s3://test/上記のコマンドでS3へ画像を送ると以下のエラーが発生する。
upload failed: ./kaitlyn-baker-vZJdYl5JVXY-unsplash.jpg to s3://test/kaitlyn-baker-vZJdYl5JVXY-unsplash.jpg An error occurred (AccessDenied) when calling the PutObject operation: Access DeniedIAMポリシーとか、IAMロールとかいろいろ見たけどどれも問題なさそう。
ちなみにIAMユーザーに対してS3フルアクセスの権限を与えているので、ポリシーレベルでは問題ないはず。
原因
MFAでの認証が取れていないため、アクセス拒否されていた。
会社のAWS環境でなく個人のAWS環境で同じようにS3へアップロードしたところ問題なくUPすることができた。唯一の差分といえばIAMユーザーに対しMFAが割り当てられているかどうかぐらいだった。
解消法
CLIでMFAの認証を通してから、S3へアップロードしたところ本事象が解消した。
MFAが有効になっているかどうかは、Identity and Access Management (IAM)の画面で確認することができる。
IAMユーザーの一覧画面でMFA項目が「仮想」になっていたらMFAが有効になっている。
その場合、AWS CLIでaws configureコマンドで設定を行ったあと、一時的なアクセスキーとシークレットキーを払い出し、環境変数に設定する必要がある。以下のリンク先を参考にすればMFAの認証を行うことができる。
「AWS CLIのみでMFAを有効にする方法」
http://blog.serverworks.co.jp/tech/2019/08/16/cli-mfa/
※上記リンクの「6.CLIでのMFA認証方法」から参照してください。実行例
例として、「ターミナルを開いてからS3へアップするまでのコマンド」を上げておきます。
1.AWSへの接続情報を準備
$ aws configure AWS Access Key ID [none]: {アクセスキー} AWS Secret Access Key [none]: {シークレットキー} Default region name [none]: {リージョン} Default output format [none]: {フォーマット形式}上記のキー設定・取得方法は以下を参照
「AWS CLIのインストールから初期設定メモ」
https://qiita.com/n0bisuke/items/1ea245318283fa118f4a2.環境変数に接続情報を設定
$ export AWS_ACCESS_KEY_ID= {アクセスキー} $ export AWS_SECRET_ACCESS_KEY={シークレットキー} $ export AWS_DEFAULT_REGION= {リージョン} $ export AWS_DEFAULT_OUTPUT= {フォーマット形式}ここは1をやっていればやらなくても大丈夫かもしれないが念のため。
たとえばすでに別のAWSアカウントでCLIの接続をしたことがある場合。
環境変数に古い値が設定されていると1で設定した内容よりも環境変数で設定されている内容をAWS側で優先して見てしまうので念のため設定しておくことをお勧めする。3.一時情報の取得
$ aws sts get-session-token --serial-number {IAMユーザーのユーザーの ARN} --token-code {MFAの認証コード6桁}MFAの認証コード6桁については以下を参照
「AWSでMFA(二段階認証)を有効にする方法を超丁寧に説明するよ」
https://qiita.com/viptakechan/items/6d19aee635b2ab189e474.取得した一時情報を環境変数に設定する
3を実行すると以下のような結果が取得できる
"Credentials": { "SecretAccessKey": "シークレットアクセスキー", "SessionToken": "セッショントークン", "Expiration": "2020-01-13T13:33:35Z", "AccessKeyId": "アクセスキー" }それを環境変数に以下のような形式で設定する。
export AWS_ACCESS_KEY_ID={アクセスキー} export AWS_SECRET_ACCESS_KEY={シークレットアクセスキー} export AWS_SESSION_TOKEN={セッショントークン}5.S3へアップロードする
aws s3 cp {ローカル状の画像の配置パス} s3://{バケット名}/あとがき
この手順でS3にアップロードできるかと思います。
もしAccess Deniedが発生して、「ポリシーもロールも問題ないんだけどなぁ」って感じであれば、試してみてください!
- 投稿日:2020-01-13T10:01:58+09:00
AWS プレフィックス「mi-」が付いたマシン
AWS Management Console で、プレフィックス「mi-」が付いたマシンは、オンプレミスサーバーまたは仮想マシン (VM) マネージドインスタンスです。
https://docs.aws.amazon.com/ja_jp/systems-manager/latest/userguide/managed_instances.html
- 投稿日:2020-01-13T09:49:47+09:00
Lambdaを使用し、最新 AMI の ID を取得する関数を作成
1.最新 AMI の ID を取得する関数をLambdaで作成
2.カスタムリソースを作成カスタムリソースは関連付けられた Lambda 関数を起動します。関数をカスタムリソースと関連付けるには、Fn::GetAtt 組み込み関数を使用して、ServiceToken プロパティ用に関数の Amazon リソースネーム (ARN) を指定します。AWS CloudFormation は、カスタムリソースの宣言に含まれている追加のプロパティ (Region や Architectureなど) を入力として Lambda 関数に送信します。Lambda 関数は、これらの入力プロパティの正しい名前と値を判断します。
3.リージョンとインスタンスタイプの組み合わせを指定することで最新AMIを起動
Amazon Elastic Compute Cloud (Amazon EC2) インスタンスを宣言する AWS CloudFormation テンプレートでは、インスタンスの起動に使用される、オペレーティングシステムまたはその他のソフトウェアと構成情報が含まれた Amazon マシンイメージ (AMI) の ID も指定する必要があります。適切な AMI ID は、スタックを起動するインスタンスタイプおよびリージョンによって異なる場合があります。ID は定期的に変更される可能性があります (AMI が更新されてソフトウェアアップデートが追加されたときなど)。
通常は、特定のインスタンスタイプとリージョンに AMI ID をマップできます。ID を更新するには、各テンプレートで手動で更新します。カスタムリソースと AWS Lambda (Lambda) を使用すると、使用するリージョンとインスタンスタイプの最新 AMI の ID を取得する関数を作成でき、マッピングを維持する必要がなくなります。
- 投稿日:2020-01-13T09:34:36+09:00
AWS Trusted Advisor
結構いろんなことができる
一例
- 関連付けられていない Elastic IP Address
- EC2 リザーブドインスタンスの最適化
- 使用率の低いAmazon EC2 Instances
- 利用頻度の低いAmazon EBSボリューム
- アイドル状態の Load Balancer
Trusted Advisor チェック結果を Amazon CloudWatch Events でモニタリングする
https://docs.aws.amazon.com/ja_jp/awssupport/latest/user/cloudwatch-events-ta.html
CloudWatch イベント を使用する際には、Trusted Advisor ワークフローの一部として次のターゲットタイプを選択できます。
- AWS Lambda 関数
- Amazon Kinesis ストリーム
- Amazon Simple Queue Service キュー
- 組み込みターゲット (CloudWatch アラームアクション)
- Amazon Simple Notification Service のトピック
次にユースケースをいくつか示します。
- Lambda 関数を使用して、チェックステータスが変更されたときに Slack チャネルに通知を渡します。
- チェックに関するデータを Kinesis ストリームにプッシュして、包括的でリアルタイムのステータスモニタリングを支援します。
- 投稿日:2020-01-13T09:18:09+09:00
CodeDeployフックのベストプラクティス
アーカイブが展開された時点で実行権限があるように、アーカイブ化前に実行権限を与えましょう。
https://dev.classmethod.jp/cloud/aws/best-practice-of-code-deploy-hooks/
- 投稿日:2020-01-13T08:24:56+09:00
はじめてAWSでデプロイする方法⑤(EC2の環境構築、Ruby, MySQL)
前回までの記事
はじめてAWSでデプロイする方法①(インスタンスの作成)
はじめてAWSでデプロイする方法②(Elastic IPの作成と紐付け)
はじめてAWSでデプロイする方法③(AWSセキュリティグループの設定)
はじめてAWSでデプロイする方法④(EC2インスンタンスにSSHログイン)EC2インスタンス(サーバー)を作成し、パブリックIPをElastic IPで固定。
一般ユーザーがアクセスできるように、セキュリティグループの設定を追加(入り口を作成)
IDとPWを使って、EC2にログインざっくり説明すると、こんなところです。
今回の内容
ssh接続でログインをして、環境構築をする。
[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y update[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install git make gcc-c++ patch libyaml-devel libffi-devel libicu-devel zlib-devel readline-devel libxml2-devel libxslt-devel ImageMagick ImageMagick-devel openssl-develNode.jsをインストール
[ec2-user@ip-172-31-25-189 ~]$ sudo curl -sL https://rpm.nodesource.com/setup_6.x | sudo bash -[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install nodejsrbenvとruby-buildをインストール
[ec2-user@ip-172-31-25-189 ~]$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv[ec2-user@ip-172-31-25-189 ~]$ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile[ec2-user@ip-172-31-25-189 ~]$ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile[ec2-user@ip-172-31-25-189 ~]$ source .bash_profile上記をしないと エラー『 -bash: rbenv: コマンドが見つかりません 』が表示
[ec2-user@ip-172-31-25-189 ~]$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build[ec2-user@ip-172-31-25-189 ~]$ rbenv rehashRubyをインストール
[ec2-user@ip-172-31-25-189 ~]$ rbenv install 2.5.1ここでエラー
「-bash: rbenv: コマンドが見つかりません」が表示された場合、rbenvとruby-buildをインストールを見直してください。
インストールには時間がかかります。
このまま待ちましょう[ec2-user@ip-172-31-25-189 ~]$ rbenv global 2.5.1[ec2-user@ip-172-31-25-189 ~]$ rbenv rehash[ec2-user@ip-172-31-25-189 ~]$ ruby -vバージョンが表示されれば、
無事にインストールされています
MySQLをインストール
[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install mysql56-server mysql56-devel mysql56(mysql56は、MySQLのバージョン5.6をインストールすることを意味)
MySQLを起動
[ec2-user@ip-172-31-25-189 ~]$ sudo service mysqld startMySQLの起動確認
[ec2-user@ip-172-31-25-189 ~]$ sudo service mysqld status
runningが表示されていれば、稼働しています。MySQLのrootパスワードの設定
この操作はPW設定をします
>PWを入力してから、コマンドを実行してください[ec2-user@ip-172-31-25-189 ~]$ sudo /usr/libexec/mysql56/mysqladmin -u root password 'PWを入力'ここでエラーが表示された場合
EC2 MySQL 初期設定 root にパスワードの設定MySQLに接続(ターミナルでコマンド操作可能)
[ec2-user@ip-172-31-25-189 ~]$ mysql -u root -pここでPWが要求されます。
>登録したPWを入力してみて、無事に開かれるか確認しましょう!下記が表示されたら、成功です
PWが正しく登録できたことを確認できたので、
$ exitでMySQLの接続を解除しましょう





- 投稿日:2020-01-13T06:42:11+09:00
Aurora グローバルデータベースの利点
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-global-database.html
Aurora グローバルデータベースの利点
Aurora グローバルデータベースは、専用のインフラストラクチャを使用して、プライマリ DB クラスターとセカンダリクラスターの間で変更をレプリケートします。Aurora グローバルデータベースには以下の利点があります。Aurora グローバルデータベースによるレプリケーションは、プライマリ DB クラスターのパフォーマンスに対する影響が一切ないか、限定されます。DB インスタンスのリソースは、全面的に読み取りおよび書き込みのワークロードに当てられます。
変更は、最小限の遅れ (通常は 1 秒未満) で AWS リージョン間でレプリケートされます。
セカンダリクラスターは、災害対策の高速なフェイルオーバーを可能にします。通常、1 分未満でセカンダリクラスターを昇格させて書き込みに対応できます。
★リモートの AWS リージョンのアプリケーションは、セカンダリクラスターから読み取ると、クエリのレイテンシーが低くなります。
セカンダリクラスターには最大 16 個の Aurora レプリカを追加できるため、単一の Aurora クラスターの容量を超えて読み取りをスケールできます。
- 投稿日:2020-01-13T01:06:58+09:00
【AWS Cloud9 / Laravel 5.8】make:authして認証画面を作ったらリンク先に飛ばなくてハマった話
こんにちは、にゃーんです。昨日Laravelを始めたばかりの者です。
たぶん初心者すぎて笑える内容です。どうか温かい目で見てあげてください。
間違いやまずい部分があれば訂正しますので、ご指摘あればお待ちしています。トラブル内容
以下のサイトを参考にAWS Cloud9に登録して開発環境を整えた。
(バージョンはphp7.1、Laravelは5.8)
次にデータベースを構築した。
そのあとLaravelのドキュメント通りに認証機能をつけた。
ソース: https://readouble.com/laravel/5.8/ja/authentication.html
そして何事もなく初期画面に"Login"と"Register"が表示された。
と思ったら、
"LOGIN"をクリックしても全く反応がない。
調べまくってもみんなログイン画面にちゃんと飛んでいるのに、なぜか飛ばない。
エラーも出ないので、原因が分からなくてしばらく泣いた。原因
route()で吐き出されるURIがhttpになってたので、Cloud9を立ち上げているブラウザ(Chrome)側で遮断されていた。
解決策
常時SSLになるように"app/Providers/AppServiceProvider.php"を書き換えたところ、とりあえずリンクが機能するようになった。
app/Providers/AppServiceProvider.phpuse Illuminate\Routing\UrlGenerator; class AppServiceProvider extends ServiceProvider public function boot(UrlGenerator $url) { $url->forceScheme('https'); } }ご意見お待ちしています。
エンジニアになって日が浅いのでこれが正しいのか分からないところもあります。色々まずいよーってことがあればぜひお知らせください。



- 投稿日:2020-01-13T01:06:58+09:00
【AWS Cloud9 / Laravel 5.8】make:authして認証画面を作ったけどリンク先が反応しない
こんにちは、にゃーんです。昨日Laravelを始めたばかりの者です。
たぶん初心者すぎて笑える内容です。どうか温かい目で見てあげてください。
間違いやまずい部分があれば訂正しますので、ご指摘あればお待ちしています。トラブル内容
以下のサイトを参考にAWS Cloud9に登録して開発環境を整えた。
(バージョンはphp7.1、Laravelは5.8)
次にデータベースを構築した。
そのあとLaravelのドキュメント通りに認証機能をつけた。
引用元: https://readouble.com/laravel/5.8/ja/authentication.html
そして何事もなく初期画面に"Login"と"Register"が表示された。
と思ったら、
"LOGIN"をクリックしても全く反応がない。
調べまくってもみんなログイン画面にちゃんと飛んでいるのに、なぜか飛ばない。
エラーも出ないので、原因が分からなくてしばらく泣いた。原因
route()で吐き出されるURIが"http:〜"になってたので、Cloud9のプレビューだとリンク先に飛ばない模様。
解決策
常時SSLになるように"app/Providers/AppServiceProvider.php"を書き換えたところ、とりあえずリンクが機能するようになった。
app/Providers/AppServiceProvider.phpuse Illuminate\Routing\UrlGenerator; class AppServiceProvider extends ServiceProvider public function boot(UrlGenerator $url) { $url->forceScheme('https'); } }ご意見お待ちしています。
エンジニアになって日が浅いのでこれが正しいのか分からないところもあります。色々まずいよーってことがあればぜひお知らせください。



- 投稿日:2020-01-13T01:01:22+09:00
Amazon Linux2にPython3 -Django - mod_wsgi をインストール
Pythonを使う案件が増えてきた!
プログラミング系の雑誌ではPythonがよく取り上げられていましたが、実案件でもPythonを使うことが増えてきました。
Pythonを使う大きな理由は、AI(機械学習)ライブラリが充実していることです。
今回もAIを使うのでPythonを使います。
WEBのアプリケーション・サーバー(中継?)としてはDjangoを使います。また、インフラ側のクラウドはAWS(Amazon Web Service)です。
AWSを使う理由は。。。流行でしょうか。。。
他のクラウドでもいいと思うのですが、皆使っているという理由が多いような気が。。。EC2サーバーの準備
AWSのEC2インスタンス(仮想サーバー)を作成します。
あらかじめアプリケーションに特化したAMI(マシンイメージ)を選ぶこともでき、PythonやDjangoに特化したBitnami等のイメージも用意されているのですが、今回は一般的な、Amazon Linux2 (64bit版)を使い、Djangoをインストールします。
Amazon Linux2はCentOS7ベースに近いので、この記事はCentOS7での構築にも参考になると思います。
サーバーの構築からログインまで準備ができたという前提で進めます。サーバーの環境構築
まずはログインして環境設定です。
rootログインをしている状態での説明ですので、sudoを使う場合は適宜読み替えてください。
実行コマンドを羅列していますが、実行結果(表示出力されるテキスト)はカットしています。Amazon Linuxの初期状態ではスワップファイルが無い状態ですので、スワップファイルを有効にします。
# fallocate -l 4096m /swapfile # mkswap /swapfile # swapon /swapfile # chmod 600 /swapfile起動時にスワップファイルが有効になるように、/etc/fstab の最終行に下記の行を追記します。
/swapfile none swap sw 0 0タイムゾーンを日本標準時に設定します。
# timedatectl set-timezone Asia/Tokyo念の為既存モジュールのアップデートと、epelレポジトリ、開発環境をインストールしておきます。
# yum -y update # amazon-linux-extras install epel # yum -y groupinstall "Development Tools"Python3のインストール
Pythonはver2系とver3系がありますが、今回のプロジェクトで使用するのはver3系です。
単純にver2系のPythonを削除やアップデートすればいいのでは~と思えますが、ver2系はOS標準のコマンドやスクリプトで多数使用されているため、削除したりアップデートしたりできません。面倒でトラブルも多いのですが、今回はPython2(ver2系)とPython3(ver3系)を共存させて環境を構築します。
pyenvでPython環境を切り替える方法もあるのですが、Djangoで動作する時のみPython3が使えればいいので、今回はpyenvは使用しません。
それでは、Python3をインストールします。
# amazon-linux-extras install python3 # yum -y install python3-develこれでPython3がインストールされました。
現時点でインストールされたバージョンはPython3.7.4でした。これ以降、Python3を使う場合は、
# python3Python3のパッケージのインストールをする場合は、
# pip3を必ず使い、Python2とPython3を使い分けなくてはなりません。
Python3用にpymysqlモジュールをインストールします。
#pip3 install pymysqlエラーが出なければ問題ありません。
Djangoのインストール
次にPythonをWEBサーバーで使用するために、アプリケーションフレームワークのDjangoをインストールします。
pymysqlモジュールが、最新のDjangoに対応していないということなので、バージョン2.1指定でインストールします。# pip3 install django==2.1正常にインストールされているのかと、Djangoのバージョンを確認するには
# python3 -m django --versionで確認できます。
Djangoの動作テスト
任意の場所(今回は/var/www/cgi-bin)にDjangoのプロジェクトmyprojectを作成して動作テストを行います。
# cd /var/www/cgi-bin # django-admin startproject mysite # cd mysiteカレントディレクトリ(例では/var/www/cgi-bin)以下に、mysiteというプロジェクトディレクトリが作成されます。
プロジェクトディレクトリのmysiteディレクトリ以下にある、setting.pyの1行を修正("*"の追加)してデフォルトのアクセス制限を外します。mysite/settings.pyALLOWED_HOSTS = ["*"]プロジェクトディレクトリ内で、以下のコマンドを実行し、Djangoの内部WEBサーバーを起動します。
# python3 manage.py runserver 0.0.0.0:8000データベースの設定をしていないので、migrateしていないとかの警告が出ますが、Djangoのインストールと動作確認だけ進めていますので、後回しにして無視します。
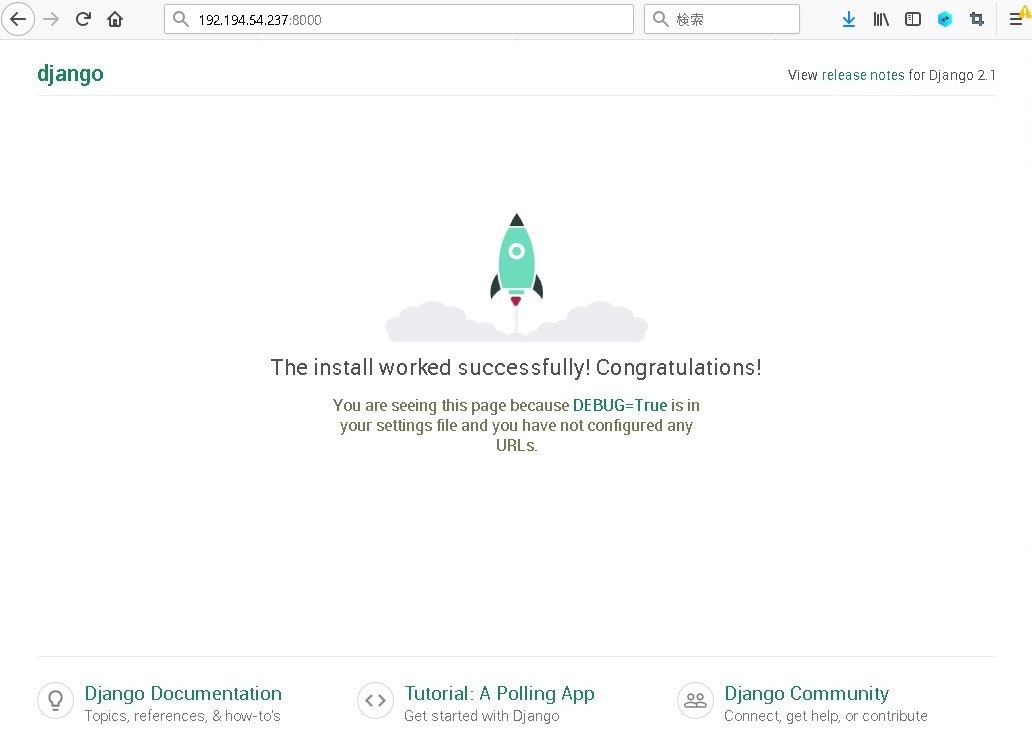
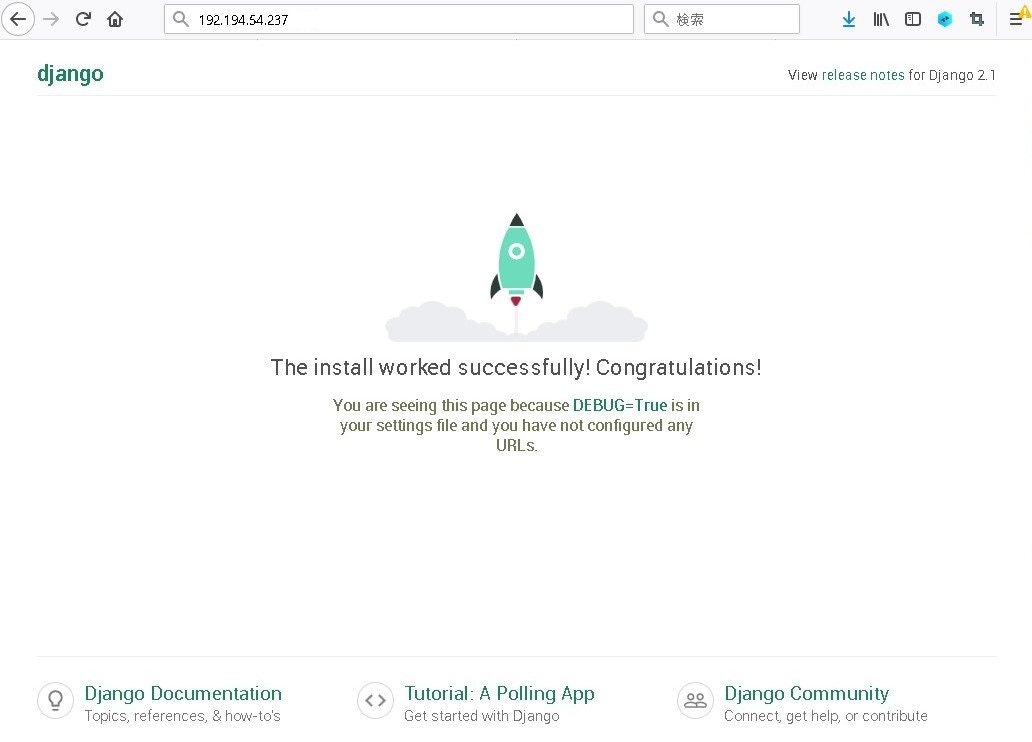
それではPCのブラウザのアドレス欄に下記を入力します。
http://サーバーのIPアドレス:8000
以下のようにブラウザでDjangoの画面が出れば正常です。
タイムアウトなどが起こる場合、ファイアーウォール(AWSではセキュリティグループのインバウンド)でポート8000を通すようにして下さい。
8000の部分を80に変更すれば、ポート80のhttpに変更できますが、Apacheなどが先に起動していると衝突してエラーになります。Webサーバーを停止するには、CONTROLキーとCを同時に押します。
ここまででDjangoがインストールして正常に動作しているのを確認できました。
Apacheとの連携 mod_wsgi
Djangoの内部Webサーバーでの動作は確認できましたが、実際にサービスとして使う場合はApacheやnginx等のWebサーバーを使用します。
今回はApacheを使いますが、WebサーバーとDjangoの橋渡しをするのが、mod_wsgiモジュールです。Apache(httpd)とmod_wsgiをインストールします。
# yum install -y httpd httpd-devel # pip3 install mod_wsgi # pip3 install mod_wsgi-httpdwsgiのApacheモジュールが作成されましたが、どこにモジュールが生成されたのか表示されないので探します。
find /usr -name "mod_wsgi*.so"
モジュールを見つけたら、新規に作成する /etc/httpd/conf.d/wsgi.conf ファイルの1行目で読み込みの指定をします。
/etc/httpd/conf.d/wsgi.confLoadModule wsgi_module /usr/local/lib64/python3.7/site-packages/mod_wsgi/server/mod_wsgi-py37.cpython-37m-x86_64-linux-gnu.so WSGIPythonHome /usr WSGIScriptAlias / /var/www/cgi-bin/mysite/misite/wsgi.py WSGIPythonPath /var/www/cgi-bin/mysite:/var/www/cgi-bin/mysite/mysite:/usr/lib/python3.7/site-packages:/usr/lib64/python3.7/site-packages:/usr/local/lib/python3.7/site-packages:/usr/local/lib64/python3.7/site-packages <Directory /var/www/cgi-bin/mysite/mysite> Options ExecCGI MultiViews Indexes MultiViewsMatch Handlers AddHandler wsgi-script .py AddHandler wsgi-script .wsgi DirectoryIndex index.py app.wsgi index.html Order allow,deny Allow from all <Files wsgi.py> Require all granted </Files> </Directory>このファイルを作成したら、反映させるためにApacheを再起動します。
自動起動設定にしていなければ、ここでApacheの自動起動設定をします。# systemctl restart httpd # systemctl enable httpd.servicePCのブラウザのアドレス欄に下記を入力します。今回はポート80なのでポート指定はしません。
http://サーバーのIPアドレス
Djangoのページが表示されれば正常です。
タイムアウトになる場合はポート80のファイアーウォールの確認、Internal Server Errorの表示場合は、Apacheのエラーログを確認して下さい。
Pythonプログラムファイルやモジュールのパスに注意
ここまでのインストールの道のりは簡単そうですが、実はかなり試行錯誤しています。
ともかく、Pythonはパスが重要だと再認識しました。ファイルを置いてあるパスやモジュールのパスです。当記事では、毎度sudoを使って説明するのが面倒なので、rootユーザーで記述説明しています。
実際のインストールや開発には管理者でない一般ユーザーでログインし、sudoを使いインストールや、インストール後にライブラリモジュール等の
インストールをしています。このモジュールのパスがApache/wsgiから認識されない、あるいはApacheの読み取り権限が無い等に気づかずはまりました。
Apacheのプロセスはapacheユーザー権限にて起動しているので、コマンドライン環境とも異なります。結果として、wsgi.confファイルの、WSGIPythonPath に、この後多数のパスを追加することになりました。
- 投稿日:2020-01-13T00:29:44+09:00
AWS Amplify フレームワークの使い方Part3〜API設定編〜
はじめに
AmpifyシリーズのPart3はAppSyncを利用できるようになるまでを解説していきます。
APIの設定
$amplify add apiから$amplify pushまで。AmplifyにAPIを追加
まずはおなじみのコマンドから実行し、APIの設定を進めていきます。
$ amplify add apiサービスを選択
今回は、AppSyncを利用したいので、GraphQLを選択します。
? Please select from one of the below mentioned services GraphQLAPI名設定
何でもいいですが、管理しやすいプロジェクト名などでいいと思います。
? Provide API name: API名認証形式
今回は、Cognitoを使った認証設定にしています。特段CRUDの権限を制限しない場合は、API KEYでOKです。(その他の選択肢は未検証)
Cognitoを選択すると、まだAuth設定をしていない場合は、amplify add authと同じ操作がここから始まります。? Choose an authorization type for the API Amazon Cognito User Pool■参考
AWS Amplify フレームワークの使い方Part1〜Auth設定編〜スキーマ設定
このあたりのスキーマ設定は後で変更ができる(むしその変更が超絶肝!!)ので、デフォルト連打でOK。
? Do you have an annotated GraphQL schema? No ? Do you want a guided schema creation? Yes ? What best describes your project: Single object with fields (e.g., “Todo” with ID, name, description) ? Do you want to edit the schema now? Yesスキーマファイルの編集
amplify pushの前にamplify/backend/api/<api名>/schema.graphqlを編集していきます。
push後もある程度の更新、変更は可能ですが、思わぬところでエラーが起きて更新できなかったりするので、ある程度考えた上でpushしましょう。
ただ、テストで試す場合は、そのエラーを知ることも大切ですので、基本的なスキーマ設計をしたら次へ進みましょう。※スキーマファイルの書き方については別途記事にまとめる予定です。
リソースの作成
そして、push。これで、設定完了です!!
$ amplify pushおわりに
まずは、スキーマのデフォルトで選べるTODOのスキーマなどでお試しで触ってみることをおすすめします。次の記事では、push後の実際の利用方法について記事を書いていきます。
関連記事
AWS amplify フレームワークの使い方Part1〜Auth設定編〜
AWS Amplify フレームワークの使い方Part2〜Auth実践編〜