- 投稿日:2020-01-13T21:10:29+09:00
VScodeでJavaウェブアプリケーション開発環境構築(struts2)
VSCodeでJavaのWebアプリケーション開発ができるように開発環境を整えたい。
開発したものはVSCodeからコンパイルして実行したい。デバッグもしたい。テストもしたい。
と色々調べ、使用しているもの全てにおいて初心者なので苦労しましたが、
なんとか実行可能な環境が完成したのでまとめます。
少しでも同じようなことをしたい方の助けになれば幸いです。この記事内では紹介しておりませんが、Tomcatを使用してデバッグも可能です。
動作環境
・macOS Catalina 10.15.2
・Visual Studio Code 1.41.1
・AdoptOpenJDK 1.8.0_232
・Maven 3.6.3
・Tomcat 9.0.30JAVA_HOME設定
これまでOracle提供のJDK1.8.0_221を利用していたのですが、
このタイミングでAdopt提供のOpenJDK1.8.0_232をインストールしたのでまずはこちらを使うためにパスを通します。ターミナル$ open ~/.bash_profile環境変数を記述する
.bash_profileを開きます。.bash_profileexport PATH=$PATH:/Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/Home/bin export JAVA_HOME=/Library/Java/JavaVirtualMachines/adoptopenjdk-8.jdk/Contents/HomePATHとJAVA_HOMEの設定を記述して保存します。
ターミナル$ source ~/.bash_profile
.bash_profileの変更を反映させます。ターミナル$ javac -version $ java -versionターミナル再起動後、設定が反映されたか確認します。
...設定したjdkが表示されればOKだと思います。Apache Tomcatダウンロード
下記URLからダウンロードした圧縮ファイルを解凍して任意の場所に配置します。
自分はApplications配下に配置してます。
http://tomcat.apache.org/Apache Mavenダウンロード
下記URLからダウンロードした圧縮ファイルを解凍して任意の場所に配置します。
自分はApplications配下に配置してます。
https://maven.apache.org/download.cgiVSCodeの拡張機能をインストール
■Java Extension Pack(下記の拡張機能がまとまってる)
・Language Support for Java™ by Red Hat
・Debugger for Java
・Java Test Runner
・Maven for Java
・Java Dependency Viewer
・Visual Studio IntelliCode
■Tomcat For Java
■Generator Junit File(自分はJunitのファイルをワンクリックで作りたかったので入れました。)VSCodeでJAVA_HOMEの設定
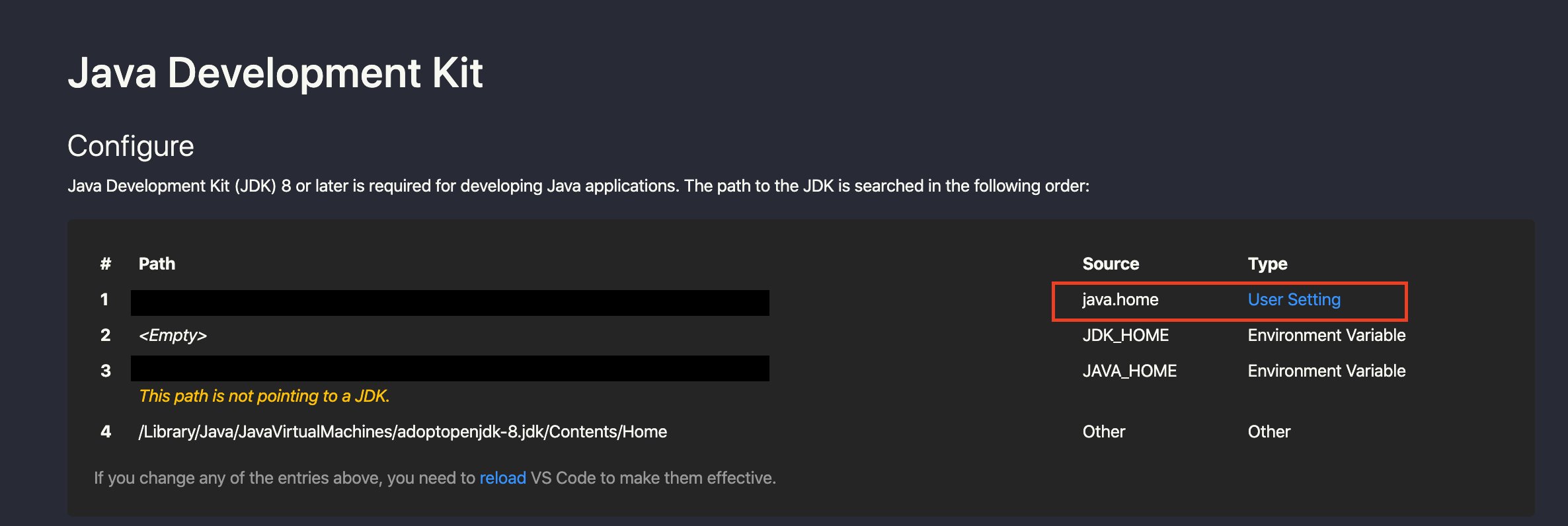
VSCodeでJavaが使えるように設定します。
F1を押し、検索ボックスに画像の様に入力します。
java.homeのUser Settingを選択
settings.jsonで編集を選択
"java.home":の後ろにJAVA_HOMEの場所を記述してVSCodeを再起動Mavenでstruts2のプロジェクト作成
ターミナル$ mkdir MavenProject $ cd MavenProject $ mvn archetype:generateアプリケーション作成用のフォルダ作成
作成したフォルダに移動
mavenプロジェクトを作成するコマンドターミナル...........省略 2545: remote -> us.fatehi:schemacrawler-archetype-maven-project (-) 2546: remote -> us.fatehi:schemacrawler-archetype-plugin-command (-) 2547: remote -> us.fatehi:schemacrawler-archetype-plugin-dbconnector (-) 2548: remote -> us.fatehi:schemacrawler-archetype-plugin-lint (-) 2549: remote -> ws.osiris:osiris-archetype (Maven Archetype for Osiris) 2550: remote -> xyz.luan.generator:xyz-gae-generator (-) 2551: remote -> xyz.luan.generator:xyz-generator (-) 2552: remote -> za.co.absa.hyperdrive:component-archetype (-) Choose a number or apply filter (format: [groupId:]artifactId, case sensitive contains): 1467:struts2と入力してenter
ターミナル...........省略 : Choose archetype: 1: remote -> br.com.address.archetypes:struts2-archetype (an archetype web 3.0 + struts2 (bootstrap + jquery) + JPA 2.1 with struts2 login system) 2: remote -> br.com.address.archetypes:struts2-base-archetype (An Archetype with JPA 2.1; Struts2 core 2.3.28.1; Jquery struts plugin; Struts BootStrap plugin; json Struts plugin; Login System using Session and Interceptor) 3: remote -> com.amazonaws.serverless.archetypes:aws-serverless-struts2-archetype (-) 4: remote -> com.jgeppert.struts2.jquery:struts2-jquery-archetype-base (This Archetype provides a Webapp Configuration ready for the Struts2 jQuery Plugin.) 5: remote -> com.jgeppert.struts2.jquery:struts2-jquery-archetype-mobile (This Archetype provides a Webapp Configuration ready for the Struts2 jQuery Mobile Plugin.) 6: remote -> com.jgeppert.struts2.jquery:struts2-jquery-bootstrap-archetype-grid (This Archetype provides a Webapp Configuration ready for the Struts2 jQuery Grid Plugin and the Struts2 Bootstrap Plugin.) 7: remote -> org.apache.struts:struts2-archetype-angularjs (-) 8: remote -> org.apache.struts:struts2-archetype-blank (-) 9: remote -> org.apache.struts:struts2-archetype-convention (-) 10: remote -> org.apache.struts:struts2-archetype-dbportlet (-) 11: remote -> org.apache.struts:struts2-archetype-plugin (-) 12: remote -> org.apache.struts:struts2-archetype-portlet (-) 13: remote -> org.apache.struts:struts2-archetype-starter (-) Choose a number or apply filter (format: [groupId:]artifactId, case sensitive contains): :88を入力してENTER
ターミナルChoose org.apache.struts:struts2-archetype-blank version: 1: 2.2.1 2: 2.2.1.1 3: 2.2.3 4: 2.2.3.1 5: 2.3.3 6: 2.3.4 7: 2.3.4.1 8: 2.3.7 9: 2.3.8 10: 2.3.12 11: 2.3.14 12: 2.3.14.1 13: 2.3.14.2 14: 2.3.14.3 15: 2.3.15 16: 2.3.15.1 17: 2.3.15.2 18: 2.3.15.3 19: 2.3.16 20: 2.3.16.1 21: 2.3.16.2 22: 2.3.16.3 23: 2.3.20 24: 2.3.20.1 25: 2.3.20.3 26: 2.3.24 27: 2.3.24.1 28: 2.3.24.3 29: 2.3.28 30: 2.3.28.1 31: 2.3.29 32: 2.3.30 33: 2.3.31 34: 2.3.32 35: 2.3.33 36: 2.3.34 37: 2.3.35 38: 2.3.36 39: 2.3.37 40: 2.5-BETA1 41: 2.5-BETA2 42: 2.5-BETA3 43: 2.5 44: 2.5.1 45: 2.5.2 46: 2.5.5 47: 2.5.14 Choose a number: 47:39struts2のバージョンの番号を入力してENTER
ターミナルDefine value for property 'groupId': Hello Define value for property 'artifactId': exsample Define value for property 'version' 1.0-SNAPSHOT: : Define value for property 'package' Hello: : Confirm properties configuration: groupId: Hello artifactId: exsample version: 1.0-SNAPSHOT package: Hello Y: :groupId...Javaのパッケージ的なものの名前を任意で指定する。
artifactId...プロジェクト名を任意で指定する。
version...そのままENTER
package...そのままENTER
Y: :...そのままENTERターミナル[INFO] ---------------------------------------------------------------------------- [INFO] Using following parameters for creating project from Archetype: struts2-archetype-blank:2.3.37 [INFO] ---------------------------------------------------------------------------- [INFO] Parameter: groupId, Value: Hello [INFO] Parameter: artifactId, Value: exsample [INFO] Parameter: version, Value: 1.0-SNAPSHOT [INFO] Parameter: package, Value: Hello [INFO] Parameter: packageInPathFormat, Value: Hello [INFO] Parameter: package, Value: Hello [INFO] Parameter: version, Value: 1.0-SNAPSHOT [INFO] Parameter: groupId, Value: Hello [INFO] Parameter: artifactId, Value: exsample [INFO] Project created from Archetype in dir: /MavenProject/exsample [INFO] ------------------------------------------------------------------------ [INFO] BUILD SUCCESS [INFO] ------------------------------------------------------------------------ [INFO] Total time: 12:24 min [INFO] Finished at: 2020-01-13T18:54:18+09:00 [INFO] ------------------------------------------------------------------------Mavenプロジェクト作成完了
作成されたプロジェクトのディレクトリ構造
MavenProject/ └── exsample ├── pom.xml └── src ├── main │ ├── java │ │ └── Hello │ │ └── example │ │ ├── ExampleSupport.java │ │ ├── HelloWorld.java │ │ └── Login.java │ ├── resources │ │ ├── Hello │ │ │ └── example │ │ │ ├── Login-validation.xml │ │ │ ├── package.properties │ │ │ └── package_es.properties │ │ ├── example.xml │ │ ├── log4j2.xml │ │ └── struts.xml │ └── webapp │ ├── WEB-INF │ │ ├── example │ │ │ ├── HelloWorld.jsp │ │ │ ├── Login.jsp │ │ │ ├── Menu.jsp │ │ │ ├── Missing.jsp │ │ │ ├── Register.jsp │ │ │ └── Welcome.jsp │ │ └── web.xml │ └── index.html └── test └── java └── Hello └── example ├── ConfigTest.java ├── HelloWorldTest.java └── LoginTest.javaこのままビルドして実行しても、デフォルトで用意されているページは表示されていますが、今回はstruts2を利用した簡単なHelloWorldアプリケーションを作成します。
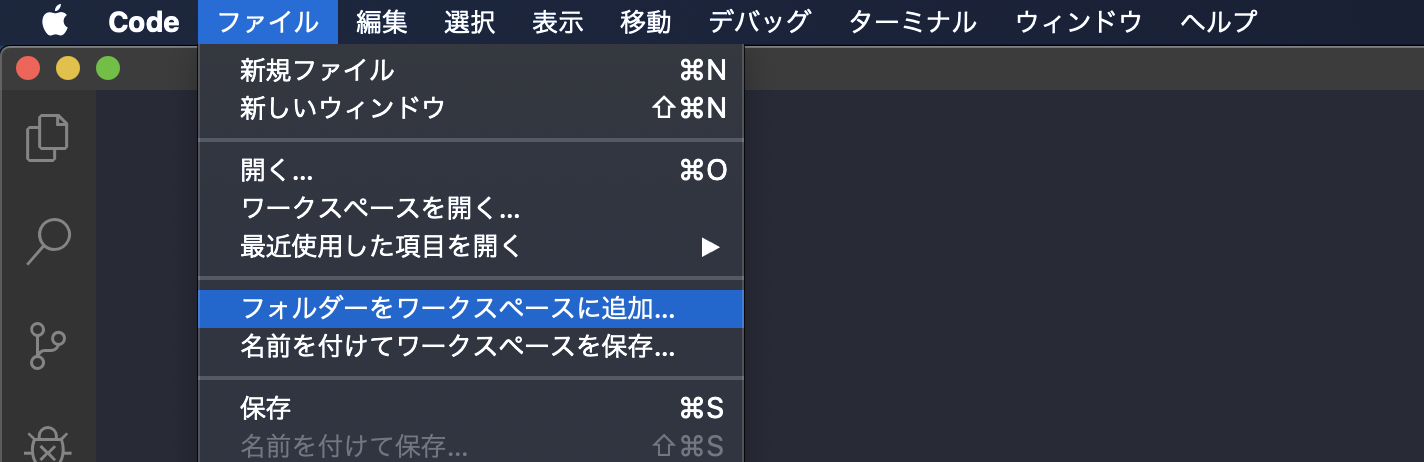
作成したプロジェクトをVSCodeで開く
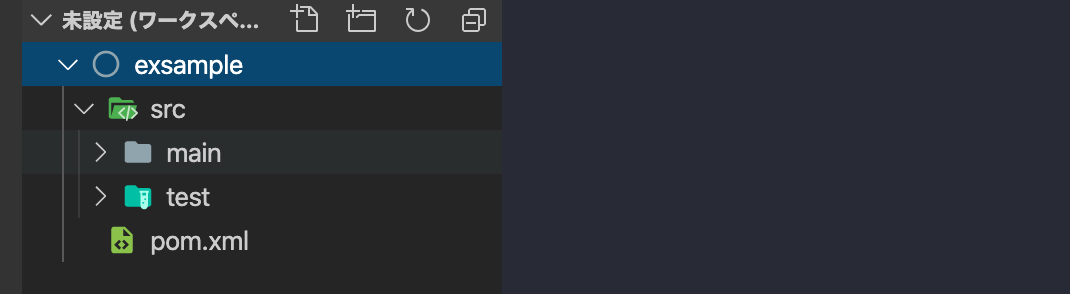
作成したexsampleプロジェクトフォルダをワークスペースに追加します。
追加されました。
簡単なHelloWorldアプリケーションの作成
プロジェクトの内容を、かんたんなHelloWorld表示アプリケーションに変更します。
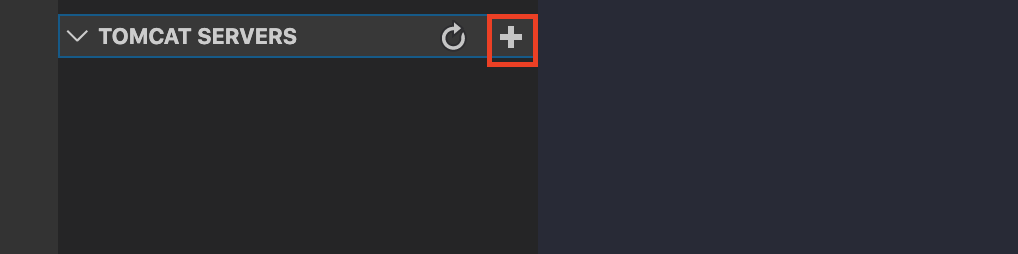
プロジェクト構成MavenProject └── exsample ├── pom.xml └── src ├── main │ ├── java │ │ └── Hello │ │ └── example │ │ └── HelloStrutsAction.java │ ├── resources │ │ └── struts.xml │ └── webapp │ ├── WEB-INF │ │ └── web.xml │ ├── hello.jsp │ └── index.jsp └── test └── java └── Hello └── exampleHelloStrutsAction.javapackage Hello.example; import com.opensymphony.xwork2.ActionSupport; public class HelloStrutsAction extends ActionSupport{ /** * */ private static final long serialVersionUID = 1L; public String execute() { return SUCCESS; } }struts.xml<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE struts PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 2.3//EN" "http://struts.apache.org/dtds/struts-2.3.dtd"> <struts> <constant name = "struts.devMode" value = "true"/> <package name = "com.internousdev.webproj.action" extends = "struts-default"> <action name = "HelloStrutsAction" class = "com.action.HelloStrutsAction" method = "execute"> <result name = "success">hello.jsp</result> </action> </package> </struts>web.xml<?xml version="1.0" encoding="UTF-8"?> <web-app xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://xmlns.jcp.org/xml/ns/javaee" xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd" id="WebApp_ID" version="3.1"> <display-name>WebProj</display-name> <welcome-file-list> <welcome-file>index.jsp</welcome-file> </welcome-file-list> <filter> <filter-name>struts2</filter-name> <filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class> </filter> <filter-mapping> <filter-name>struts2</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> </web-app>hello.jsp<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <%@ taglib prefix = "s" uri = "/struts-tags" %> <!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>HelloStruts</title> </head> <body> <h2>HelloStruts2!</h2> </body> </html>index.jsp<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%> <%@ taglib prefix = "s" uri = "/struts-tags" %> <!DOCTYPE html> <html> <head> <meta charset = "UTF-8"> <title>INDEX</title> </head> <body> <s:form action = "HelloStrutsAction"> <s:submit value = "HelloStruts"/> </s:form> </body> </html>TOMCAT SERVERSの設定
+ボタンから、Tomcatの保存先を選択すると、下記のようにTomcatサーバーが設定できます。
pom.xlmの設定
Mavenでは、pom.xlmという設定ファイル内に、プロジェクトの定義情報が書かれています。
少し設定を変更します。pom.xlm・・・・・・・・・・・・・・・省略 <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.3</version> <configuration> <encoding>UTF-8</encoding> <source>1.5</source> <target>1.5</target> </configuration> </plugin> ・・・・・・・・・・・・・・・省略デフォルトでは、使用するJDKが、jdk1.5に設定されています。
pom.xlm・・・・・・・・・・・・・・・省略 <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.3</version> <configuration> <encoding>UTF-8</encoding> <source>1.8</source> <target>1.8</target> </configuration> </plugin> ・・・・・・・・・・・・・・・省略今回はjdk1.8を使用するように変更します。
pom.xlm・・・・・・・・・・・・・・・省略 <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.48</version> </dependency> ・・・・・・・・・・・・・・・省略今回は必要ありませんが、MySQLなど、他のプラグインを入れるにはこのように書きます。
MAVEN PROJECTSの設定
maven installをします。
pom.xlmで定義されたプラグインなどがインストールされます。コンパイル
コンパイルします。パッケージの作成
warファイルが作成されます。MavenProjct └── exsample ├── pom.xml ├── src │ ├── main │ │ ├── java │ │ │ └── Hello │ │ │ └── example │ │ │ └── HelloStrutsAction.java │ │ ├── resources │ │ │ ├── log4j2.xml │ │ │ └── struts.xml │ │ └── webapp │ │ ├── WEB-INF │ │ │ └── web.xml │ │ ├── hello.jsp │ │ └── index.jsp │ └── test │ └── java │ └── Hello │ └── example └── target ├── classes │ ├── Hello │ │ └── example │ │ └── HelloStrutsAction.class │ ├── log4j2.xml │ └── struts.xml ├── exsample-1.0-SNAPSHOT │ ├── META-INF │ ├── WEB-INF │ │ ├── classes │ │ │ ├── Hello │ │ │ │ └── example │ │ │ │ └── HelloStrutsAction.class │ │ │ └── struts.xml │ │ ├── lib │ │ │ ├── asm-3.3.jar │ │ │ ├── asm-commons-3.3.jar │ │ │ ├── asm-tree-3.3.jar │ │ │ ├── commons-fileupload-1.4.jar │ │ │ ├── commons-io-2.2.jar │ │ │ ├── commons-lang3-3.2.jar │ │ │ ├── freemarker-2.3.28.jar │ │ │ ├── javassist-3.11.0.GA.jar │ │ │ ├── log4j-api-2.3.jar │ │ │ ├── log4j-core-2.3.jar │ │ │ ├── ognl-3.0.21.jar │ │ │ ├── struts2-config-browser-plugin-2.3.37.jar │ │ │ ├── struts2-core-2.3.37.jar │ │ │ └── xwork-core-2.3.37.jar │ │ └── web.xml │ ├── hello.jsp │ └── index.jsp ├── exsample-1.0-SNAPSHOT.war ├── generated-sources │ └── annotations ├── maven-archiver │ └── pom.properties └── maven-status └── maven-compiler-plugin ├── compile │ └── default-compile │ ├── createdFiles.lst │ └── inputFiles.lst └── testCompile └── default-testCompile └── inputFiles.lst全て終わると、上記のようなプロジェクト構造に変化します。
※pom.xlmで設定されている情報を基に、ライブラリも追加されています。
※srcの内容を編集すると、コンパイル時にtargetの内容に反映されます。
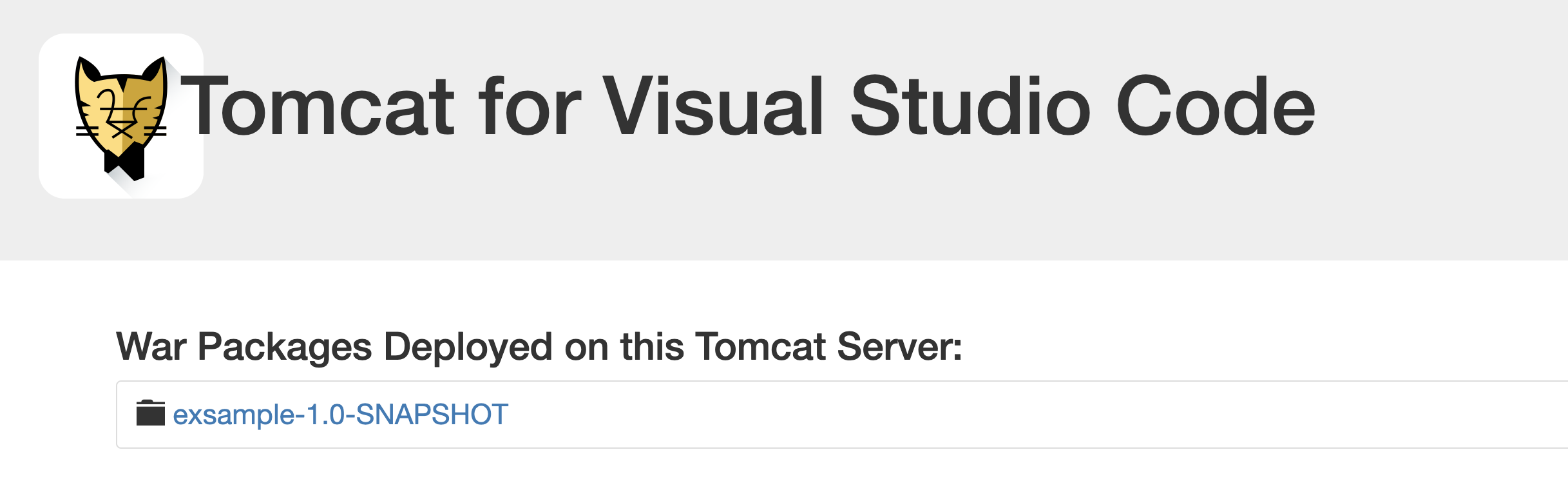
tergetディレクトリが作られ、配下に、exsample-1.0-SNAPSHOT.warが作成されます。プロジェクト実行
warファイルを右クリックして、Run on Tomcat Serverを選択します。
Tomcat上で右クリック
Open in Browserを選択すると、ブラウザで下の画面が開かれます。
プロジェクト名をクリックします。
index.jspが表示されました! 「HelloStruts」ボタンをクリックすると...
hello.jspに遷移しました!










- 投稿日:2020-01-13T19:53:08+09:00
組み合わせ計算(フェルマーの小定理、事前計算による高速化)
はじめに
フェルマーの小定理を利用した組み合わせ計算の理論と、javaの実装例を書きました。
また複数回組み合わせを求める際に利用する、事前計算による高速化の実装例も載せています。
実装例はソースに貼り付けて汎用的に利用できます。計算方法
組み合わせ $_nC_r$ の求め方
- nが小さい時
パスカルの三角形を用いて行います。
n=4000くらいまでは計算できます。
考え方や実装例はこちらに書きました。
- nが大きい時
nが大きい時の組み合わせは、ある大きな素数modの法の元で計算します。
nが小さい時には純粋な計算しかできませんでしたが、modを法にするとき、n!やr!などをオーバーフローしないまま計算できるので、以下の公式通りに計算することができます。nCr=\frac{n!}{r!{(n-r)!}}ただしmod計算では割り算を自由に行えないので、フェルマーの小定理を用いて掛け算に変形することで解決します。
{\displaystyle a^{p-2}\equiv a^{-1}{\pmod {p}}} //フェルマーの小定理$r!$に対して、上式を用いると法pの元で以下の変形ができます。
\frac{1}{r!} = (r!)^{p-2}従って、$_nC_r$は法pの元で、以下のように計算できることになります。
nCr=\frac{n!}{r!{(n-r)!}}=n! (r!)^{p-2}((n-r)!)^{p-2}実装
法とする定数名はソース上、modとします。(100_000_007などが問題から与えられます。)
階乗計算はmodpowというメソッドで、繰り返し二乗法により高速化しています。
また、公式を以下のように少し変形して計算しています(手計算する時と同じです)。nCr=\frac{n(n-1)(n-2)\cdots(n-r+1)}{r(r-1)(r-2)\cdots 2*1}フェルマーの小定理を用いた組み合わせ計算//Fermat Combination static int mod = (int) 1e9 + 7; static long fermatComb(long a, long b) { if (b > a - b) return fermatComb(a, a - b); long mul = 1; //分子 long div = 1; //分母 for (int i = 0; i < b; i++) { mul *= (a - i); mul %= mod; div *= (i + 1); div %= mod; } long ans = mul * modpow(div, mod - 2) % mod; //フェルマーの小定理を利用して掛け算で計算 return ans; } //mod条件下の高速pow static long modpow(long a, long p) { if (p == 0) return 1; if (p % 2 == 0) { long root = modpow(a, p / 2); return root * root % mod; } else return a * modpow(a, p - 1) % mod; }利用例
利用例public static void main(String[] args) { System.out.println(fermatComb(5, 2)); //5C2を計算 -> 出力10 System.out.println(fermatComb(50000, 3000)); //50000C3000を計算 -> 出力890850597 (1e9+7で割った余り) }事前計算による高速化
上記の組み合わせ計算の最悪計算量は$O(nlog(mod))$ですが、
繰り返し組み合わせ計算を行うときには、毎回求めると制限時間に間に合わなくなることがあります。
例えば、以下の問題ではn回組み合わせ計算をするとTLEします。
ABC-E - Max-Min Sumsこういった場合の解決策として、組み合わせで利用するだけの階乗を事前に$O(N)$で計算しておくことで、組み合わせ計算を$O(1)$まで高速化できます。
以下の実装例では、pre_factorials(int n)というメソッドの中で階乗を事前に計算し、配列factorials[]に結果を格納しています。
組合せ計算は、この配列の値を参照して行います。事前計算を行う、高速化した組み合わせ計算//Fast Fermat Combination static int mod = (int) 1e9 + 7; static long factorials[]; //事前に階乗計算の結果を格納しておく配列 static void pre_factorials(int n) { factorials = new long[n + 1]; factorials[0] = 1; for (int i = 0; i < n; i++) { factorials[i + 1] = (long)(i + 1) * factorials[i] % mod; } } static long fastFermatComb(long a, long b) { if (factorials.length == 0) System.err.println("error : factorials has not been culculated!! do [pre_factorials] method"); long af = factorials[(int) a]; long bf = factorials[(int) b]; long abf = factorials[(int) (a - b)]; long res = af * modpow(bf, mod - 2) % mod * modpow(abf, mod - 2) % mod; return res; } //mod条件下の高速pow static long modpow(long a, long p) { if (p == 0) return 1; if (p % 2 == 0) { long root = modpow(a, p / 2); return root * root % mod; } else return a * modpow(a, p - 1) % mod; }利用方法
利用例public static void main(String[] args) { int n = 1_000_000; //n=100万まで求めるとする pre_factorials(n); //1!からn!までの値を持った配列を準備する System.out.println(fastFermatComb(5, 2)); //5C2を計算 -> 出力10 System.out.println(fastFermatComb(50000, 3000)); //50000C3000を計算 -> 出力890850597 (1e9+7で割った余り) }
- 投稿日:2020-01-13T19:53:08+09:00
組み合わせ計算(フェルマーの小定理、事前計算による高速化)(Java)
はじめに
フェルマーの小定理を利用した組み合わせ計算の理論と、javaの実装例を書きました。
また複数回組み合わせを求める際に利用する、事前計算による高速化の実装例も載せています。
実装例はソースに貼り付けて汎用的に利用できます。計算方法
組み合わせ $_nC_r$ の求め方
- nが小さい時
パスカルの三角形を用いて行います。
n=4000くらいまでは計算できます。
考え方や実装例はこちらに書きました。
ただしnが小さくても、modを法として計算できる時は、nが大きい時と同様にフェルマーの小定理を用いて計算して良いです。
- nが大きい時
nが大きい時の組み合わせは、ある大きな素数modの法の元で計算します。
modを法にするとき、n!やr!などもオーバーフローしないまま計算できるので、以下の公式通りに計算することができます。nCr=\frac{n!}{r!{(n-r)!}}ただしmod計算では割り算を自由に行えないので、フェルマーの小定理を用いて掛け算に変形することで解決します。
{\displaystyle a^{p-2}\equiv a^{-1}{\pmod {p}}} //フェルマーの小定理$r!$に対して、上式を用いると法pの元で以下の変形ができます。
\frac{1}{r!} = (r!)^{p-2}従って、$_nC_r$は法pの元で、以下のように計算できることになります。
nCr=\frac{n!}{r!{(n-r)!}}=n! (r!)^{p-2}((n-r)!)^{p-2}実装
法とする定数名はソース上、modとします。(100_000_007などが問題から与えられます。)
階乗計算はmodpowというメソッドで、繰り返し二乗法により高速化しています。
また、公式を以下のように少し変形して計算しています(手計算する時と同じです)。nCr=\frac{n(n-1)(n-2)\cdots(n-r+1)}{r(r-1)(r-2)\cdots 2*1}フェルマーの小定理を用いた組み合わせ計算//Fermat Combination static int mod = (int) 1e9 + 7; static long fermatComb(long a, long b) { if (b > a - b) return fermatComb(a, a - b); long mul = 1; //分子 long div = 1; //分母 for (int i = 0; i < b; i++) { mul *= (a - i); mul %= mod; div *= (i + 1); div %= mod; } long ans = mul * modpow(div, mod - 2) % mod; //フェルマーの小定理を利用して掛け算で計算 return ans; } //mod条件下の高速pow static long modpow(long a, long p) { if (p == 0) return 1; if (p % 2 == 0) { long root = modpow(a, p / 2); return root * root % mod; } else return a * modpow(a, p - 1) % mod; }利用例
利用例public static void main(String[] args) { System.out.println(fermatComb(5, 2)); //5C2を計算 -> 出力10 System.out.println(fermatComb(50000, 3000)); //50000C3000を計算 -> 出力890850597 (1e9+7で割った余り) }事前計算による高速化
上記の組み合わせ計算の最悪計算量は$O(nlog(mod))$ですが、
繰り返し組み合わせ計算を行うときには、毎回求めると制限時間に間に合わなくなることがあります。
例えば、以下の問題ではn回組み合わせ計算をするとTLEします。
ABC-E - Max-Min Sumsこういった場合の解決策として、組み合わせで利用するだけの階乗を事前に$O(N)$で計算しておくことで、組み合わせ計算を$O(log(mod))$まで高速化できます。
以下の実装例では、pre_factorialsというメソッドの中で階乗を事前に計算し、配列factorialsに結果を格納しています。
組合せ計算は、この配列の値を参照して行います。事前計算を行う、高速化した組み合わせ計算//Fast Fermat Combination static int mod = (int) 1e9 + 7; static long factorials[]; //事前に階乗計算の結果を格納しておく配列 static void pre_factorials(int n) { //0!〜n!まで求めておく factorials = new long[n + 1]; factorials[0] = 1; for (int i = 0; i < n; i++) { factorials[i + 1] = (long)(i + 1) * factorials[i] % mod; } } static long fastFermatComb(long a, long b) { if (factorials.length == 0) System.err.println("error : factorials has not been culculated!! do [pre_factorials] method"); long af = factorials[(int) a]; long bf = factorials[(int) b]; long abf = factorials[(int) (a - b)]; long res = af * modpow(bf, mod - 2) % mod * modpow(abf, mod - 2) % mod; return res; } //mod条件下の高速pow static long modpow(long a, long p) { if (p == 0) return 1; if (p % 2 == 0) { long root = modpow(a, p / 2); return root * root % mod; } else return a * modpow(a, p - 1) % mod; }利用方法
利用例public static void main(String[] args) { int n = 1_000_000; //n=100万まで求めるとする pre_factorials(n); //1!からn!までの値を持った配列を準備する System.out.println(fastFermatComb(5, 2)); //5C2を計算 -> 出力10 System.out.println(fastFermatComb(50000, 3000)); //50000C3000を計算 -> 出力890850597 (1e9+7で割った余り) }
- 投稿日:2020-01-13T16:22:49+09:00
【Java】ファイステルネットワークの実装
【概要】
共通鍵暗号方式の1つであるDESでは、ファイステルネットワークという構造を使用しています。
簡単に説明すると、ラウンド関数という関数と排他的論理和を使用した暗号化方式です。
DESでは入力の平文は64ビット、鍵のビット長は56ビットなどの決まりがありますが、今回はファイステルネットワークを実装してみたかっただけなので、そのような制約は排除しています。【コード】
ここで掲載しているコードは、下記リンク先のGitHubに載せています。
feistelNetworkMain.javapackage main; import common.AbstractEncryption; import encryption.Decryption; import encryption.Encryption; public class Main { // ラウンド回数 public static int ROUND_EXEC_TIME = 3; // ラウンド関数で使用する秘密鍵 // ラウンド関数はビットシフト演算をしているため、8よりも小さい数を指定しなければ暗号化ができない // 攻撃者に解読されないようにするため、この鍵は秘密にしなければならない private static int[] SECRET_KEY = {2, 3, 6}; public static void main(String[] args) { // 秘密データ String secretData = "testcase"; AbstractEncryption encryption = new Encryption(); AbstractEncryption decryption = new Decryption(); // 暗号化 String encryptionData = encryption.execEncryption(secretData, SECRET_KEY); // 復号化 String deryptionData = decryption.execEncryption(encryptionData, SECRET_KEY); System.out.println("暗号化データ:" + encryptionData); System.out.println("復号化データ:" + deryptionData); } }AbstractEncryption.javapackage common; import main.Main; /** * 暗号化と復号化の両方を受け持つクラス * @author nobu * */ public abstract class AbstractEncryption { /** * 暗号化と復号化を実行する * @param secretData 秘密データ * @param key 秘密鍵 */ public String execEncryption(String secretData, int key[]) { String left = secretData.substring(0, secretData.length() / 2); String right = secretData.substring(secretData.length() / 2, secretData.length()); // 左側の文字列データ、暗号化されたデータを入れるための変数 byte leftArray[][]; // 左側の文字は秘密データの文字数が偶数、奇数の場合を考慮している if (secretData.length() % 2 == 0) { leftArray = new byte[Main.ROUND_EXEC_TIME+1][left.length()]; } else { leftArray = new byte[Main.ROUND_EXEC_TIME+1][left.length() + 1]; } // 右側の文字列データ、暗号化されたデータを入れるための変数 byte rightArray[][] = new byte[Main.ROUND_EXEC_TIME+1][right.length()]; // 入力値の初期化 for (int i = 0; i < left.length(); i++) { leftArray[0][i] = (byte) left.charAt(i); } for (int i = 0; i < right.length(); i++) { rightArray[0][i] = (byte) right.charAt(i); } // 暗号化, 復号化 for (int i = 0; i < Main.ROUND_EXEC_TIME; i++) { for (int j = 0; j < right.length(); j++) { rightArray[i + 1][j] = encryption(leftArray[i][j], rightArray[i][j], key, i); leftArray[i + 1][j] = rightArray[i][j]; } // 最終ラウンドでは、左右を交換しないため、既に交換済みのデータを元に戻す if (i == Main.ROUND_EXEC_TIME - 1) { byte tmp[]; tmp = leftArray[i + 1]; leftArray[i + 1] = rightArray[i + 1]; rightArray[i + 1] = tmp; } } String returnData = ""; for (int i = 0; i < right.length(); i++) { returnData = returnData + String.valueOf((char)leftArray[Main.ROUND_EXEC_TIME][i]); } for (int i = 0; i < right.length(); i++) { returnData = returnData + String.valueOf((char)rightArray[Main.ROUND_EXEC_TIME][i]); } return returnData; } /** * 暗号化 * @param left 左側のデータ * @param right 右側のデータ * @param key 秘密鍵 * @param roundNumber * @return 暗号化の結果 */ abstract protected byte encryption(byte left, byte right, int[] key, int roundNumber); /** * ラウンド関数、秘密鍵で指定された値だけ右シフトする * @param right 右側データ * @param key 秘密鍵 * @return ラウンド関数の結果 */ protected byte roundFunction(byte right, int key) { return (byte) (right << key); } }Encryption.javapackage encryption; import common.AbstractEncryption; /** * 暗号化クラス * @author nobu * */ public class Encryption extends AbstractEncryption { @Override protected byte encryption(byte left, byte right, int[] key, int roundNumber) { return (byte) (left ^ roundFunction(right, key[roundNumber])); } }Decryption.javapackage encryption; import common.AbstractEncryption; import main.Main; /** * 復号化クラス * @author nobu * */ public class Decryption extends AbstractEncryption { @Override protected byte encryption(byte left, byte right, int[] key, int roundNumber) { return (byte) (left ^ roundFunction(right, key[Main.ROUND_EXEC_TIME - roundNumber - 1])); } }【実行結果】
"testcase"という文字列を暗号化および、その暗号化したデータを復号化した結果です。
※暗号化データの一部は文字化けにより空白になっています。暗号化データ:8ᄀᅠᆪiヒe 復号化データ:testcase【参考書籍】
- 投稿日:2020-01-13T15:21:25+09:00
JavaのAssertionとは?まとめ。
概要
JavaのIntegrationTestをやったので、忘れないようアウトプットします。
目次
- Assertionとは
- Assertionのメソッドたち
1. Assertionとは
Assertionとは
アサーションとは、プログラムに関する前提をテストできるようにするJavaプログラミング言語の文です。
Assertionのライフサイクル
アサーションは常にBoolean型となっており、trueを前提としてテストをしていきます。
falseの場合、AssertionErrorをthrowします。カバレッジ
また、機能をテストでどの程度カバーできているかをカバレッジといいます。
カバレッジの質が高いほどバグが減ります。2. Assertionのメソッドたち
assertEqual()
期待される結果と実際の結果が同じかどうか判定
EqualIntegrationTest.java/** * expected: 期待値 * actual: 実際の値 * message: メッセージ(期待値と実際の値が一致しない場合表示) */ Assert.assertEqual(expected, actual); Assert.assertEqual(message, expected, actual);assertTrue()
与えられた条件が正しいかどうか判定する
TrueIntegrationTest.java/** * actual: 実際の値 * message: メッセージ(与えられた条件が正しくない場合表示) */ Assert.assertTrue(expected > 1); Assert.assertTrue(message, expected > 1);assertNotNull()
与えられたObjectがnullでないかどうか判定する
NotNullIntegrationTest.java/** * object: 期待値 * message: メッセージ(objectがnullの場合表示) */ Assert.assertNotNull(object); Assert.assertNotNull(message, object);assertNull()
与えられたObjectがnullか判定する
NullIntegrationTest.java/** * object: 期待値 * message: メッセージ(objectがnullではない場合表示) */ Assert.assertNull(object); Assert.assertNull(message, object);assertSame()
与えられた2つのObjectが同じObjectを参照しているか判定する
SameIntegrationTest.java/** * expectedObject: 期待値 * actualObject: 実際値 * message: メッセージ(objectがnullではない場合表示) */ Assert.assertSame(expectedObject, actualObject); Assert.assertSame(message, expectedObject, actualObject);assertThat()
基本的に比較だが、その使用方法は多岐に渡る 詳細
参考資料
- 投稿日:2020-01-13T12:12:37+09:00
kuromoji を Win10 + Eclipse + Java の環境で動かす (2020年1月版)
さすがはJava製のkuromojiはOSに依存することもなくMavenにも対応しているので、とても導入しやすくて使いやすいです。
本投稿のタイトルにはWin10とEclipseと入れておりますが、kuromojiはどちらにも依存していません。
Maven
セットアップはたったこれだけ。
モデルデータもダウンロードされます。<!-- https://mvnrepository.com/artifact/com.atilika.kuromoji/kuromoji --> <dependency> <groupId>com.atilika.kuromoji</groupId> <artifactId>kuromoji</artifactId> <version>0.9.0</version> <type>pom</type> </dependency> <dependency> <groupId>com.atilika.kuromoji</groupId> <artifactId>kuromoji-ipadic</artifactId> <version>0.9.0</version> </dependency>Code
サンプルコードそのままです。
// https://www.atilika.com/ja/kuromoji/ package hello.kuromoji; import com.atilika.kuromoji.ipadic.Token; import com.atilika.kuromoji.ipadic.Tokenizer; import java.util.List; public class KuromojiExample { public static void main(String[] args) { Tokenizer tokenizer = new Tokenizer(); List<Token> tokens = tokenizer.tokenize("お寿司が食べたい。カレーも食べたい。"); for (Token token : tokens) { System.out.println(token.getSurface() + "\t" + token.getAllFeatures()); } } }実行結果
お 接頭詞,名詞接続,*,*,*,*,お,オ,オ 寿司 名詞,一般,*,*,*,*,寿司,スシ,スシ が 助詞,格助詞,一般,*,*,*,が,ガ,ガ 食べ 動詞,自立,*,*,一段,連用形,食べる,タベ,タベ たい 助動詞,*,*,*,特殊・タイ,基本形,たい,タイ,タイ 。 記号,句点,*,*,*,*,。,。,。 カレー 名詞,一般,*,*,*,*,カレー,カレー,カレー も 助詞,係助詞,*,*,*,*,も,モ,モ 食べ 動詞,自立,*,*,一段,連用形,食べる,タベ,タベ たい 助動詞,*,*,*,特殊・タイ,基本形,たい,タイ,タイ 。 記号,句点,*,*,*,*,。,。,。所感
Kuromoji はとても使いやすいです。
参照
参考にしたページ
kuromoji | Atilika
https://www.atilika.com/ja/kuromoji/
- 投稿日:2020-01-13T10:25:49+09:00
NLP4J [006-034] NLP4J で言語処理100本ノック #34 「AのB」
やってみます。
34. 「AのB」
2つの名詞が「の」で連結されている名詞句を抽出せよ.
Maven
現在開発中のバージョンを利用します。
<dependency> <groupId>org.nlp4j</groupId> <artifactId>nlp4j-core</artifactId> <version>1.1.1.0-SNAPSHOT</version> </dependency>Text Data
デフォルトで利用している形態素解析(Yahoo! Japan デベロッパーネットワーク 日本語形態素解析) では、リクエストサイズの上限が900KBであり、回数に制限もあるので小さなサイズのテキストファイルを利用しています。
一 吾輩は猫である。 名前はまだ無い。 どこで生れたかとんと見当がつかぬ。 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。 吾輩はここで始めて人間というものを見た。 しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。 この書生というのは時々我々を捕えて煮て食うという話である。 しかしその当時は何という考もなかったから別段恐しいとも思わなかった。 ただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。 掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始であろう。 この時妙なものだと思った感じが今でも残っている。 第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。 その後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。 のみならず顔の真中があまりに突起している。 そうしてその穴の中から時々ぷうぷうと煙を吹く。 どうも咽せぽくて実に弱った。 これが人間の飲む煙草というものである事はようやくこの頃知った。Java Code
package nlp4j.nokku.chap4; import java.util.List; import nlp4j.Document; import nlp4j.DocumentAnnotator; import nlp4j.DocumentAnnotatorPipeline; import nlp4j.Keyword; import nlp4j.crawler.Crawler; import nlp4j.crawler.TextFileLineSeparatedCrawler; import nlp4j.impl.DefaultDocumentAnnotatorPipeline; import nlp4j.index.DocumentIndex; import nlp4j.index.SimpleDocumentIndex; import nlp4j.yhoo_jp.YJpMaAnnotator; public class Nokku31 { public static void main(String[] args) throws Exception { // NLP4Jが提供するテキストファイルのクローラーを利用する Crawler crawler = new TextFileLineSeparatedCrawler(); crawler.setProperty("file", "src/test/resources/nlp4j.crawler/neko_short_utf8.txt"); crawler.setProperty("encoding", "UTF-8"); crawler.setProperty("target", "text"); // ドキュメントのクロール List<Document> docs = crawler.crawlDocuments(); // NLPパイプライン(複数の処理をパイプラインとして連結することで処理する)の定義 DocumentAnnotatorPipeline pipeline = new DefaultDocumentAnnotatorPipeline(); { // Yahoo! Japan の形態素解析APIを利用するアノテーター DocumentAnnotator annotator = new YJpMaAnnotator(); pipeline.add(annotator); } // アノテーション処理の実行 pipeline.annotate(docs); // キーワードをカウントするためにDocumentIndexを利用します。 SimpleDocumentIndex index = new SimpleDocumentIndex(); // ドキュメントの追加 index.addDocuments(docs); List<Keyword> kwds = index.getKeywordsWithoutCount(); // 「AのB」を探す String meishi_a = null; String no = null; for (Keyword kwd : kwds) { if (meishi_a == null && kwd.getFacet().equals("名詞")) { meishi_a = kwd.getLex(); } // else if (meishi_a != null && no == null && kwd.getLex().equals("の")) { no = kwd.getLex(); } // else if (meishi_a != null && no != null && kwd.getFacet().equals("名詞")) { System.err.println(meishi_a + no + kwd.getLex()); meishi_a = null; no = null; } // else { meishi_a = null; no = null; } } } }結果
彼の掌 掌の上 書生の顔 はずの顔 顔の真中 穴の中続き
この記事には続きがあります。
NLP4J [006-034b] NLP4J で言語処理100本ノック #34 「AのB」の Annotator を作ってみるまとめ
NLP4J を使うと、Javaで簡単に自然言語処理ができますね!
プロジェクトURL

- 投稿日:2020-01-13T03:43:13+09:00
幅優先探索で迷路の距離を測る
ABC151に参加してD問題解けなかった復習としてまとめる
幅優先探索と深さ優先探索
wikiの図がすごいわかりやすいから見て・・・
まぁこんな感じに木があると思って
親A ├子AA │ ├孫AAA │ └孫AAB ├子AB │ └孫ABA └子AC ├孫ACA ├孫ACB └孫ACC幅優先探索
https://ja.wikipedia.org/wiki/%E5%B9%85%E5%84%AA%E5%85%88%E6%8E%A2%E7%B4%A2
親ノードにぶら下がってる子ノードを全部探索してから、探索した子ノードにぶら下がってる全部の孫ノードを探索する
キューを使って解く
- キューに親Aを入れる ( キューの状態:親A )
- 親Aを取り出す ( キューの状態:空 )
- 親Aにぶら下がってる子AA,AB,ACを全部キューに入れる ( キューの状態:子AA 子AB 子AC )
- 子AAを取り出す ( キューの状態:子AB 子AC )
- 子AAにぶら下がってる孫AAA,AABを全部キューに入れる ( キューの状態:子AB 子AC 孫AAA 孫AAB )
- キューが空っぽになるまで繰り返し
探索する順番は
親A→子AA→子AB→子AC→孫AAA→孫AAB→孫ABA→孫ACA→孫ACB→孫ACC親→子→孫の順番に探索するのが幅優先探索
深さ優先探索
https://ja.wikipedia.org/wiki/%E6%B7%B1%E3%81%95%E5%84%AA%E5%85%88%E6%8E%A2%E7%B4%A2
親ノードから行けるとこまで行ってから、他に孫ノードがないか、また戻って他に子ノードがないか探索する
こっちはスタック使う こっちは先入れ先出し
- スタックに親Aを入れる ( スタックの状態:親A )
- 親Aを取り出す ( スタックの状態:空 )
- 親Aにぶら下がってる子AA,AB,ACをスタックに入れる ( スタックの状態:子AA 子AB 子AC )
- 子ACを取り出す ( スタックの状態:子AA 子AB )
- 子ACにぶら下がってる孫ACA,ACB,ACCをスタックに入れる ( スタックの状態:子AA 子AB 孫ACB 孫ACB 孫ACC )
- スタックが空になるまで繰り返し
探索する順番は
親A→子AC→孫ACC→孫ACB→孫ACA→子AB→孫ABA→子AA→孫AAA→孫AAB木の図の外周を順番に見てくイメージなんだけど伝われ・・・
スタックを使うとは書いたけど再帰で探索すると深さ優先探索になる(一概にはそうとは言えない?)
解けなかった問題
https://atcoder.jp/contests/abc151/tasks/abc151_d
D - Maze Master
問題文
高橋君は、縦Hマス、横WマスのH×Wマスからなる迷路を持っています。
上からi行目、左からj列目のマス(i,j)は、Sijが'#'のとき壁であり、'.'のとき道です。
道のマスからは、上下左右に隣接する道のマスに移動することができます。
迷路の外に移動すること、壁のマスへ移動すること、斜めに移動することはできません。
高橋君は、道のマスからスタートとゴールを自由に決め、迷路を青木君に渡します。
青木君は、移動回数が最小になるようにしてスタートからゴールまで移動します。
高橋君がスタートとゴールの位置を適切に定めたとき、青木君の移動回数は最大で何回になるでしょうか?制約
1≤H,W≤20
Sijは'.'か'#'
Sは'.'を2つ以上含む
任意の道のマスから任意の道のマスまで0回以上の移動で到達できる入力
入力は以下の形式で標準入力から与えられる。
H W S11...S1W : SH1...SHW回答
import java.util.*; public class Main { public static void main(String[] args) { Scanner in = new Scanner(System.in); String[] params = in.nextLine().split(" "); int h = Integer.parseInt(params[0]); int w = Integer.parseInt(params[1]); String[][] ss = new String[h][w]; for (int i = 0; i < h; i++) { params = in.nextLine().split(""); for (int j = 0; j < w; j++) { ss[i][j] = params[j]; } } // 全ての場所をスタート地点として最長距離を回答とする int maxDistance = 0; for (int i = 0; i < h; i++) { for (int j = 0; j < w; j++) { maxDistance = Math.max( maxDistance , getMaxDistanceWithBfs( ss , i , j ) ); } } System.out.println(maxDistance); } /** * 幅優先探索で最長距離を返す * @param ss 迷路の配列 * @param startY スタート地点のY座標 * @param startX スタート地点のX座標 * @return 最長距離 */ private static int getMaxDistanceWithBfs( String[][] ss , int startY , int startX ) { int[][] distances = new int[ss.length][ss[0].length]; Queue<Integer> queue = new ArrayDeque<>(); // 四方の距離の定義 順に左上右下 int[] dx = { -1 , 0 , 1 , 0 }; int[] dy = { 0 , 1 , 0 , -1 }; int maxDistance = 0; // スタート位置をキューに追加しておく queue.add( startX ); queue.add( startY ); // キューが空になった時 = 探索できる場所がなくなった時 // ループ回数 = スタート位置からの距離 while( !queue.isEmpty() ) { int x = queue.remove(); int y = queue.remove(); // 今いる場所が壁の場合処理しない if( "#".equals( ss[y][x] ) ){ continue; } maxDistance = Math.max( maxDistance , distances[y][x] ); // 四方を確認 for( int i = 0 ; i < 4 ; i++ ){ // 確認先の座標 int xx = x + dx[i]; int yy = y + dy[i]; // 確認先の座標が配列外にいないこと if( !( 0 <= yy && yy < ss.length && 0 <= xx && xx < ss[0].length ) ) { continue; } // 確認先の座標が壁でないこと if( !".".equals( ss[yy][xx] ) ) { continue; } // 既に通った道でないこと if( distances[yy][xx] != 0 ){ continue; } // スタート地点でないこと if( xx == startX && yy == startY ){ continue; } queue.add( xx ); queue.add( yy ); distances[yy][xx] = distances[y][x] + 1; } } return maxDistance; } }キューから取り出した座標から四方を確認して、通れる道ならキューに追加
その時に、今いる距離+1を通れる場所に格納するっていう通ったかどうかの判定配列をスタート地点からの距離を格納しとく配列と一緒にして書いたから
確認先の座標がスタート地点かどうかも見る必要があった3 5 ##### #..## #####こういう入力だった場合にS22をスタート地点、S23をゴール地点とした回答1が正解なんだけど、
スタート地点からの距離を測っていくと、##### #0.## ########## #01## ########## #21## #####こんな感じにスタート地点(スタート地点からの距離:0)がまだ通ってない判定されて行って戻ってくるのが最長ルートになっちゃう
判定の中にも上記と同じようなのがあったみたいで、チェック外したらちゃんとWAになったJavaには標準でPointっていう座標クラスがあるからそっち使えばよかったかも
キューにはX→Yの順で追加+2つずつ追加/取り出しって決めて書いたからいらなかったけど備考
全座標をスタート地点として総なめするのどうにかならないか?
今回の問題は二次元配列のサイズが最大20×20
座標すべての場所をスタート地点として確認しても実行時間に余裕があった
もっと広くなったら無理か?
同じルートの計算は使いまわせないか?
この書き方より速くなるのか?他の人の回答いくつか見て回ったけど
この問題としては総なめする必要があるらしい幅優先探索使った他の問題見てみた方がいいかも
1/13 回答ソース修正
この記事を書くにあたり、最初はこういう風に書いてた
https://atcoder.jp/contests/abc151/submissions/9485696修正箇所のポイント
自分なりのね
各座標の距離を測る配列を用意することになったから
System.arraycopyが必要なくなった修正前.java// 探索の中で配列を操作するので、コピーを渡す for( int k = 0 ; k < h ; k++ ){ copy[k] = new String[w]; System.arraycopy( ss[k] , 0 , copy[k] , 0 , w ); } int distance = getMaxDistanceWithBfs( copy , i , j );Mathクラス使うようにした
便利だ・・・
修正前.javaint distance = getMaxDistanceWithBfs( copy , i , j ); if (maxDistance < distance) { maxDistance = distance; }キューにX→Yの順で入れるって決めてしまえば座標用クラスいらない
修正前.java/** * 座標用クラス */ public static class Position { int x; int y; public Position( int x , int y ) { this.x = x; this.y = y; } } Queue<Position> queue = new ArrayDeque<>(); queue.add( new Position( startX , startY ) );ループ処理変えた
修正前.javareturn distance - 1;この帳尻合わせみたいなのほんと嫌い
元々は
1. キューが空になるまでループ
2. 取り出した距離と同じ距離のものをすべて確認するためにループ
3. 四方を確認(なんでfor使わなかった)
っていう3重ループ各座標の距離を格納しとくための配列を用意したことで、2のループが必要なくなった
2のループは距離を測るのに必要だったけどこいつの所為で最終的にdistance-1する必要があった
- 投稿日:2020-01-13T02:43:53+09:00
【初心者】Java オブジェクト指向/インスタンスフィールド/インスタンスメソッド/オーバーロード【備忘録24】
オブジェクト指向
楽にプログラムを組み立て、修正できるように存在する指向のこと。
プログラムの中に人間がいるかのようにし、それぞれに自己紹介をさせるような形。オブジェクト(別名:インスタンス)
情報と振る舞いに分けられる。
情報の種類としては、名前・年齢など。
振る舞いの種類としては、hello・walkなど。※情報=インスタンスフィールド
※振る舞い=インスタンスメソッドクラス(メソッドをまとめる部品)
インスタンスの設計図を意味する。
インスタンス
インスタンスを生成する際は基本的には変数に代入して用いる。
「クラス型 変数名 = new クラス名();」
※大文字・小文字の違いに気を付ける。
※変数名に1、2、3など数字を付ける事で大量に作ることが可能。インスタンスフィールド
情報を格納しておく変数のこと。
基本的にクラスの一番上で定義する。class Person{ public String name; }呼び出し方としては
/*<Main.java>にて*/ ... Person person1 = new Person(); person1.name = "Suzuki"; System.out.println(person1.name);インスタンスメソッド
一般的な定義の仕方として↓
class Person { public void hello(){ //「static」はつかないので気を付ける System.out.println("こんにちは"); } }呼び出し方としては
/*<Main.java>にて*/ Person person1 = new Person(); Person person2 = new Person(); person1.hello(); person2.hello(); /*インスタンスを生成した後でないと呼び出せないので注意!*/thisの使い方
this.変数名 とすることで、このクラスの変数と特定することができる。
【例】class Person{ public String name; public void hello(){ System.out.println ("こんにちは"+ this.name + "です"); /*ここで、下記の「Suzuki」に置き換えられる↑*/ } }/*<Main.java>にて*/ Person person = new Person(); person.name = "Suzuki"; person.hello(); //←ここで出力!コンストラクタ
newを使ってインスタンスを生成した後、自動で呼び出されるメソッドのこと。
定義として下記のような決まりがあるので気を付ける。
<1>コンストラクタ名はクラス名を同じにする
<2>戻り値を書いてはダメ!(voidも)class Person{ public String name; Person (String name){ /*↑コンストラクタ名*/ this.name = name; } }呼び出し方↓
/*<Main.java>にて*/ Person person = new Person("Suzuki"); System.out.println(person.name);自己紹介文を書いてみる
※引数ではなく、thisで書いていくこと。
class Person{ /*まずクラスの一番上で定義*/ public String firstName; public String lastName; public int age; public double height; public double weight; /*コンストラクタで複数を定義・並び順間違えないよう注意!*/ Person(String firstName,String lastName,int age, double height, double weight){ this.firstName = firstName; this.lastName = lastName; this.age = age; this.height = height; this.weight = weight; } public String fullName(){ return this.firstName + " " + this.lastName; } public double bmi(){ return this.weight/this.height/this.height; } /*出力用にprintDataを定義!!↓*/ public void printData(){ System.out.println("私の名前は"+this.fullName()+"です"); System.out.println("年齢は"+this.age+"歳です"); System.out.println("BMIは"+Math.round(this.bmi())+"です"); }/*fullNameとbmiの後に()を忘れない!/Math.roundは四捨五入用*/ }呼び出し↓
/*<Main.java>にて*/ ... Person person1=new Person("Kate","Jones",27,1.6,50.0); person1.printData(); ...オーバーロード
ここで意味するオーバーロードとは、
person1がミドルネーム無し、person2がミドルネーム有りという場合
2つのコンストラクタを定義することで解決ができる。
【例】class Person{ //...略 public String middleName; //インスタンスフィールドの定義しているところにプラス。 Person(String firstName,String lastName, ...); //1つ目のパターン //...※略 Person(String firstName,String middleName,String lastName, ...); //2つ目のパターン //...※略上記の「※略」のところは、ほぼ重複するので、2つ目の方は省略の書き方として
... this(firstName,lastName,...weight); //ここで他のコンストラクタを呼び出す this.middleName = middleName; //追加したい物はここに書く振り返り・気を付ける事
・()を付けるのか、付けないのかなどがこんがらがってしまうので
しっかり確認しながら書いていく。
・以前の記事で、スペースの使い方やインデントのアドバイスをいただいたので
しっかり癖付けていきたいと思った。
- 投稿日:2020-01-13T00:55:14+09:00
Java Dynamic Proxy
前言:Java标准库提供的动态代理(Dynamic Proxy)功能,允许在运行期动态创建一个接口的实例。动态代理实际上是通过JDK在运行期动态创建class字节码并加载的过程。
代理模式
关于代理模式
代理模式(Proxy pattern)是经典的23种设计模式之一,Java的动态代理就是代理模式。首先来看看什么是代理模式?下面是代理模式的UML图:
该模式的参与者:
- Proxy
- 保存一个引用使得代理可以访问实体。Proxy引用Subject。
- 控制实体的存取,负责创建和删除它。
- 提供一个与Subject的接口相同的接口,这样代理可以用来代替实体。
- Suject
- 定义RealSubject和Proxy的共用接口,这样就在任何使用RealSubject的地方都可以使用Proxy。
- RealSubject
- 定义Proxy所代表的的实体。
代理模式的例子
首先定义一个代表“可移动”交通工具的接口:
public interface Moveable { /** * 移动指定距离, 以kilometer为单位 * @param km 移动的距离 */ void move(Integer km); }接下来创建一个接口实现类:Metro(地铁),该类实现了Moveable接口的move方法,并模拟了调用该方法后的运行时间。
public class Metro implements Moveable { @Override public void move(Integer km) { try { System.out.println("Metro is moving ..."); Thread.sleep(km * 1000); // 模拟移动时间 } catch (InterruptedException e) { e.printStackTrace(); } } }然后创建一个可以测试方法性能的PerformanceProxy:
public class PerformanceProxy implements Moveable { private Moveable m; public PerformanceProxy(Moveable m) { this.m = m; } @Override public void move(Integer km) { long start = System.currentTimeMillis(); // 记录方法调用开始时间 m.move(km); // 方法调用 long end = System.currentTimeMillis(); // 方法结束的时间 System.out.println("耗时: " + (end - start)/1000.0); // 计算耗时 } }测试代理模式:
public static void main(String[] args) { new PerformanceProxy(new Metro()).move(5); }---- 测试的结果 ---- Metro is moving ... 耗时: 5.005这样一个简单的代理模式的例子就完成了。这个模式的好处是以后需要测试其他的交通工具(如飞机、高铁)的性能的时候,只需要让它们(飞机、高铁)实现Moveable接口,测试的时候将它们的实例传给PerformanceProxy代理即可(每个类不需要自己实现测试代码)。
这样,PerformanceProxy可以检测所有实现Moveable的实体类。如果还想实现其他代理,比如给某方法埋点(跟踪该方法的调用次数)、日志打印等等,只需要创建TrackingProxy、LoggingProxy等代理。当然因为这些代理都是实现的Moveable接口,所以它们可以链式使用:
public static void main(String[] args) { Plane plane = new Plane(); PerformanceProxy pp = new PerformanceProxy(plane); LoggingProxy lp = new LoggingProxy(PerformanceProxy); lp.move(); }静态代理
什么是静态代理?
像上面的例子,先编辑好源代码,自己手动实现代理,再对其编译。这样,在程序运行前,代理类就已经确定,代理类的.class文件(二进制文件)就已经存在了,这就是所谓的静态代理。
动态代理
Java标准库提供的动态代理(Dynamic Proxy)功能,允许在运行期动态创建一个接口的实例。动态代理实际上是通过JDK在运行期动态创建class字节码并加载的过程。将上面静态代理的例子用动态代理实现如下:
public static void main(String[] args) { final Metro metro = new Metro(); Moveable m = (Moveable) Proxy.newProxyInstance(Metro.class.getClassLoader(), // 被代理的class loader new Class[]{Moveable.class}, // 传入要实现的接口 new InvocationHandler() { // 传入处理调用方法的InvocationHandler (匿名类) @Override public Object invoke(Object proxy, Method method, Object[] args) throws Throwable { // 1 long start = System.currentTimeMillis(); Object res = method.invoke(metro, args); // 2 long end = System.currentTimeMillis(); System.out.println("耗时: " + (end - start)/1000.0); return res; // 3 } }); m.move(5); } // 1. invoke中的参数proxy就是动态创建的proxy;method为接口的方法:可根据不同的方法做不同的处理。 // 2. method.invoke(metro, args)等价于这里的metro.move(),这和js中的function.call(obj, param)类似。 // 3. 2中方法的返回值,如果是void方法返回null,如果是基本数据类型则会自动装箱(例如:int会自动转换成Integer)。上面的代码测试可以得到和上面静态代理同样的结果。从动态代理可以看出主要是调用了
Proxy.newProxyInstance(...)操作以及InvocationHandler的invoke的方法的实现。要查看JDK运行时做了什么,可以在测试代码上加上以下代码:// env: JDK1.8 / IntelliJ IDEA 15 / macOS Majave System.getProperties().put("sun.misc.ProxyGenerator.saveGeneratedFiles", "true");运行之后可以看到IDEA多了个
com文件夹,动态生成的proxy就在里面:# 动态生成代理的位置 ... |-- com/ | |--sun/ | | |--proxy/ | | | |--$Proxy0.class ...下面是反编译
$Proxy0.class后的部分代码:可以看出该代理继承于Proxy类并实现了Moveable接口。主要实现了Object类的equals、hashCode和toString基本方法和Moveable的接口方法move。// ----- $Proxy0.class public final class $Proxy0 extends Proxy implements Moveable { ... public $Proxy0(InvocationHandler var1) throws { super(var1); } public final void move(Integer var1) throws { try { super.h.invoke(this, m3, new Object[]{var1}); // 1 } ... } public final boolean equals(Object var1) throws { ... } public final String toString() throws { ... } public final int hashCode() throws { ... } static { try { m1 = Class.forName("java.lang.Object").getMethod("equals", new Class[]{Class.forName("java.lang.Object")}); m3 = Class.forName("proxy.lizi.Moveable").getMethod("move", new Class[]{Class.forName("java.lang.Integer")}); ... } ... } }上面代码中(1位置)的super.h就是手动编写的InvocationHandler实例,m3可以从后面的代码看出就是move方法。所以调用动态代理的move实际就是调用InvocationHandler实例的invoke方法。下面的时序图简易的描述了上述动态代理的创建及执行过程:
注:由JDK源码可了解到动态代理的实现的方式是:Java的反射机制+ASM(一个可操作字节码的框架)。反射机制可动态获取类及其方法,但仅限于获取及调用;ASM是可以直接操作字节码(.class文件),以此来实现动态创建代理类。
动态代理的应用例子
动态代理的运用之MyBatis
MyBatis是一款优秀的持久层框架,它支持定制化SQL、存储过程以及高级映射。使用MyBatis时一般只需要写好Mapper.xml配置及接口文件XXXMapper.java,如下:
<!-- XXXMapper.xml --> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="tk.mybatis.simple.mapper.UserMapper"> <select id="selectById" resultMap="userMap"> SELECT * from sys_user where id = #{id} </select> <select id="selectAll" resultType="tk.mybatis.simple.model.SysUser"> select id, user_name userName from sys_user </select> ... </mapper>// ---- UserMapper.java public interface UserMapper { /** * 通过 id 查询用户 * * @param id * @return */ SysUser selectById(Long id); /** * 查询所有用户 * * @return */ List<SysUser> selectAll(); }Mapper接口没有实现类却能被正常调用接口方法,这是因为MyBaits在Mapper接口上使用了动态代理的。基本原理就是通过获取XML文件的配置信息再根据Mapper接口定义实现其接口方法。
动态代理运用之Spring
Spring框架的核心是IoC(Inversion of Control)和AOP(Aspect Oriented Programming)。Spring bean的依赖注入(DI:可以通过XML方式和注解方式)以及面向切面的方法织入,实质是使用了cglib的动态代理。cglib(Code Generation Library)的原理是动态生成了一个要代理类的子类,子类重写要代理的类的所有不是final的方法,在子类中采用方法拦截的技术拦截所有父类方法的调用,顺势织入横切逻辑。cglib的底层也是使用了ASM框架。


- 投稿日:2020-01-13T00:44:26+09:00
NLP4J [006-033] NLP4J で言語処理100本ノック #33 サ変名詞
やってみます。
33. サ変名詞
サ変接続の名詞をすべて抽出せよ.
Maven
現在開発中のバージョンを利用します。
<dependency> <groupId>org.nlp4j</groupId> <artifactId>nlp4j-core</artifactId> <version>1.1.1.0-SNAPSHOT</version> </dependency>Text Data
デフォルトで利用している形態素解析(Yahoo! Japan デベロッパーネットワーク 日本語形態素解析) では、リクエストサイズの上限が900KBであり、回数に制限もあるので小さなサイズのテキストファイルを利用しています。
一 吾輩は猫である。 名前はまだ無い。 どこで生れたかとんと見当がつかぬ。 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。 吾輩はここで始めて人間というものを見た。 しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。 この書生というのは時々我々を捕えて煮て食うという話である。 しかしその当時は何という考もなかったから別段恐しいとも思わなかった。 ただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。 掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始であろう。 この時妙なものだと思った感じが今でも残っている。 第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。 その後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。 のみならず顔の真中があまりに突起している。 そうしてその穴の中から時々ぷうぷうと煙を吹く。 どうも咽せぽくて実に弱った。 これが人間の飲む煙草というものである事はようやくこの頃知った。Java Code
package nlp4j.nokku.chap4; import java.util.List; import nlp4j.Document; import nlp4j.DocumentAnnotator; import nlp4j.DocumentAnnotatorPipeline; import nlp4j.Keyword; import nlp4j.crawler.Crawler; import nlp4j.crawler.TextFileLineSeparatedCrawler; import nlp4j.impl.DefaultDocumentAnnotatorPipeline; import nlp4j.index.DocumentIndex; import nlp4j.index.SimpleDocumentIndex; import nlp4j.yhoo_jp.YJpMaAnnotator; public class Nokku31 { public static void main(String[] args) throws Exception { // NLP4Jが提供するテキストファイルのクローラーを利用する Crawler crawler = new TextFileLineSeparatedCrawler(); crawler.setProperty("file", "src/test/resources/nlp4j.crawler/neko_short_utf8.txt"); crawler.setProperty("encoding", "UTF-8"); crawler.setProperty("target", "text"); // ドキュメントのクロール List<Document> docs = crawler.crawlDocuments(); // NLPパイプライン(複数の処理をパイプラインとして連結することで処理する)の定義 DocumentAnnotatorPipeline pipeline = new DefaultDocumentAnnotatorPipeline(); { // Yahoo! Japan の形態素解析APIを利用するアノテーター DocumentAnnotator annotator = new YJpMaAnnotator(); pipeline.add(annotator); } // アノテーション処理の実行 pipeline.annotate(docs); // キーワードをカウントするためにDocumentIndexを利用します。 SimpleDocumentIndex index = new SimpleDocumentIndex(); // ドキュメントの追加 index.addDocuments(docs); List<Keyword> kwds = index.getKeywordsWithoutCount(); String meishi = null; // かっこいいやり方ではないが、今回は単純に名詞+するを探すとする。 for (Keyword kwd : kwds) { if (kwd.getFacet().equals("名詞")) { meishi = kwd.getLex(); } // else if (meishi != null && kwd.getLex().equals("する")) { System.err.println(meishi + kwd.getLex()); meishi = null; } // else { meishi = null; } } } }結果
記憶する 装飾する 突起する所感
サ変動詞でなくてサ変名詞なのですね。
まとめ
NLP4J を使うと、Javaで簡単に自然言語処理ができますね!
プロジェクトURL
- 投稿日:2020-01-13T00:31:09+09:00
NLP4J [006-032] NLP4J で言語処理100本ノック #32 動詞の原形
やってみます。
32. 動詞の原形
動詞の原形をすべて抽出せよ.
Maven
現在開発中のバージョンを利用します。
<dependency> <groupId>org.nlp4j</groupId> <artifactId>nlp4j-core</artifactId> <version>1.1.1.0-SNAPSHOT</version> </dependency>Text Data
デフォルトで利用している形態素解析(Yahoo! Japan デベロッパーネットワーク 日本語形態素解析) では、リクエストサイズの上限が900KBであり、回数に制限もあるので小さなサイズのテキストファイルを利用しています。
一 吾輩は猫である。 名前はまだ無い。 どこで生れたかとんと見当がつかぬ。 何でも薄暗いじめじめした所でニャーニャー泣いていた事だけは記憶している。 吾輩はここで始めて人間というものを見た。 しかもあとで聞くとそれは書生という人間中で一番獰悪な種族であったそうだ。 この書生というのは時々我々を捕えて煮て食うという話である。 しかしその当時は何という考もなかったから別段恐しいとも思わなかった。 ただ彼の掌に載せられてスーと持ち上げられた時何だかフワフワした感じがあったばかりである。 掌の上で少し落ちついて書生の顔を見たのがいわゆる人間というものの見始であろう。 この時妙なものだと思った感じが今でも残っている。 第一毛をもって装飾されべきはずの顔がつるつるしてまるで薬缶だ。 その後猫にもだいぶ逢ったがこんな片輪には一度も出会わした事がない。 のみならず顔の真中があまりに突起している。 そうしてその穴の中から時々ぷうぷうと煙を吹く。 どうも咽せぽくて実に弱った。 これが人間の飲む煙草というものである事はようやくこの頃知った。Java Code
package nlp4j.nokku.chap4; import java.util.List; import nlp4j.Document; import nlp4j.DocumentAnnotator; import nlp4j.DocumentAnnotatorPipeline; import nlp4j.Keyword; import nlp4j.crawler.Crawler; import nlp4j.crawler.TextFileLineSeparatedCrawler; import nlp4j.impl.DefaultDocumentAnnotatorPipeline; import nlp4j.index.DocumentIndex; import nlp4j.index.SimpleDocumentIndex; import nlp4j.yhoo_jp.YJpMaAnnotator; public class Nokku31 { public static void main(String[] args) throws Exception { // NLP4Jが提供するテキストファイルのクローラーを利用する Crawler crawler = new TextFileLineSeparatedCrawler(); crawler.setProperty("file", "src/test/resources/nlp4j.crawler/neko_short_utf8.txt"); crawler.setProperty("encoding", "UTF-8"); crawler.setProperty("target", "text"); // ドキュメントのクロール List<Document> docs = crawler.crawlDocuments(); // NLPパイプライン(複数の処理をパイプラインとして連結することで処理する)の定義 DocumentAnnotatorPipeline pipeline = new DefaultDocumentAnnotatorPipeline(); { // Yahoo! Japan の形態素解析APIを利用するアノテーター DocumentAnnotator annotator = new YJpMaAnnotator(); pipeline.add(annotator); } // アノテーション処理の実行 pipeline.annotate(docs); // キーワードをカウントするためにDocumentIndexを利用します。 SimpleDocumentIndex index = new SimpleDocumentIndex(); // ドキュメントの追加 index.addDocuments(docs); List<Keyword> kwds = index.getKeywords(); kwds = kwds.stream() // .filter(o -> o.getFacet().equals("動詞")) // 品詞が動詞 .collect(Collectors.toList()); for (Keyword kwd : kwds) { System.err.println(kwd.getLex()); // ←ここだけ変更 } } }結果
生れる つく する 泣く 始める いう 見る 聞く いう いう 捕える 煮る 食う いう 思う 載せる 持ち上げる する ある 落ちつく 見る いう 思う 残る もつ する 逢う 出会う する 吹く 咽せる くう 弱る 飲む いう 知るまとめ
NLP4J を使うと、Javaで簡単に自然言語処理ができますね!
プロジェクトURL
- 投稿日:2020-01-13T00:26:41+09:00
NLP4J [006-031] NLP4J で言語処理100本ノック #31 動詞
やってみます。
31. 動詞
動詞の表層形をすべて抽出せよ.
Maven
現在開発中のバージョンを利用します。
<dependency> <groupId>org.nlp4j</groupId> <artifactId>nlp4j-core</artifactId> <version>1.1.1.0-SNAPSHOT</version> </dependency>Text Data
デフォルトで利用している形態素解析(Yahoo! Japan デベロッパーネットワーク 日本語形態素解析) では、リクエストサイズの上限が900KBであり、回数に制限もあるので小さなサイズのテキストファイルを利用しています。
Java Code
package nlp4j.nokku.chap4; import java.util.List; import nlp4j.Document; import nlp4j.DocumentAnnotator; import nlp4j.DocumentAnnotatorPipeline; import nlp4j.Keyword; import nlp4j.crawler.Crawler; import nlp4j.crawler.TextFileLineSeparatedCrawler; import nlp4j.impl.DefaultDocumentAnnotatorPipeline; import nlp4j.index.DocumentIndex; import nlp4j.index.SimpleDocumentIndex; import nlp4j.yhoo_jp.YJpMaAnnotator; public class Nokku31 { public static void main(String[] args) throws Exception { // NLP4Jが提供するテキストファイルのクローラーを利用する Crawler crawler = new TextFileLineSeparatedCrawler(); crawler.setProperty("file", "src/test/resources/nlp4j.crawler/neko_short_utf8.txt"); crawler.setProperty("encoding", "UTF-8"); crawler.setProperty("target", "text"); // ドキュメントのクロール List<Document> docs = crawler.crawlDocuments(); // NLPパイプライン(複数の処理をパイプラインとして連結することで処理する)の定義 DocumentAnnotatorPipeline pipeline = new DefaultDocumentAnnotatorPipeline(); { // Yahoo! Japan の形態素解析APIを利用するアノテーター DocumentAnnotator annotator = new YJpMaAnnotator(); pipeline.add(annotator); } // アノテーション処理の実行 pipeline.annotate(docs); // キーワードをカウントするためにDocumentIndexを利用します。 SimpleDocumentIndex index = new SimpleDocumentIndex(); // ドキュメントの追加 index.addDocuments(docs); List<Keyword> kwds = index.getKeywords(); kwds = kwds.stream() // .filter(o -> o.getFacet().equals("動詞")) // 品詞が動詞 .collect(Collectors.toList()); for (Keyword kwd : kwds) { System.err.println(kwd.getStr()); } } }結果
生れ つか し 泣い 始め いう 見 聞く いう いう 捕え 煮 食う いう 思わ 載せ 持ち上げ し あっ 落ちつい 見 いう 思っ 残っ もっ し 逢っ 出会わ し 吹く 咽せ く 弱っ 飲む いう 知っまとめ
NLP4J を使うと、Javaで簡単に自然言語処理ができますね!
プロジェクトURL
- 投稿日:2020-01-13T00:15:12+09:00
javaでAtCoder Beginner Contest 151を解く
AtCoder Beginner Contest 151お疲れ様でした!
公式ページ今回の自分の書いたコードはこちら
以下簡単に解説します。問題A
入力文字列の次のアルファベットを出力する問題。
javaのcharはインクリメントすると次のcharになることを知っていたので、そのまま記載。問題B
テストの点数が与えられ、目標点に到達するには何点とればよいか、という問題。
テストの点数を順番に足していって、目標点と引き算すればOKです。目標点に頑張っても到達できない場合と既に到達している場合があるので、注意。
問題C
個人的にちょっと骨がありました。
問題番号とACかWAが与えられ、正解した問題数とペナルティ数を数える問題。ペナルティ数は正解した問題にしか適用されないので注意。(これで一度不正解なってしまいました。)
問題D
手つけてません
問題E
数の組み合わせから特定の数を選んで、その最大値と最小値の差を、組み合わせの数だけ足し合わせる問題。
最大値と最小値を別々に求める発想にいたらず、TLEでした。コンテスト後に最大値と最小値別々に求めるように変更したらTLEがなおらないままWAになって迷宮入りしたので、あきらめました。
最大値と最小値を別々に求めるって考え方があるって学べたからヨシとします。(二項係数の算出方法が遅いのかな・・・)問題F
一定の数の点を包含する最小の円の半径を求めよ、という問題。
全ての点の最大の長さを求めて半分したのですが、それでは考慮不足でした。点の数が50だったので、多少計算量膨らんでもよいって気づけばよかった・・・残念。
残念ながら今回はじめてレーティングが下がってしまいました。
今までほぼ丸腰で挑んでいましたが、ぼちぼちセオリーを学び始めようかと思います。。