- 投稿日:2019-11-01T23:44:26+09:00
Pythonで[Errno 2] No such file or directoryがでた時の対処
間違っていたこと一覧
相対パスの書き方をプログラムのファイルの位置が起点だと思っていた。
↓
カレントディレクトリが起点
Python 3.x - pythonでの相対パスの設定|teratailWindowsでのパスの書き方を
temp/file.txtだと思っていた。
↓
temp\file.txt上の書き方はUNIX対処法
絶対パスで参照した。
感想
パスの書き方違うのまじで衝撃
- 投稿日:2019-11-01T23:41:48+09:00
いまさらPython3(その他)
はじめに
自分用のPython3として基本的な制御構造とデータ構造以外の文法を記載する。正確性より実用性を重視する。
(Javaや.NETを主に使ってる自分が、Pythonを使うためのページです)制御構造はいまさらPython3(制御構造編)
データ構造はいまさらPython3(データ構造編)モジュール
import文
(1) import モジュール名 as 別名 (2) from モジュール名 import 定義名 as 別名, 定義名 as 別名 ※定義名は、クラス名、関数名、変数名などimportの例import math as m from math import pi print( m.pi ) print( pi )(1)は、モジュールをインポートし、モジュール名.定義名で利用する。
(2)は、モジュール内の定義されている名前をインポートし、定義名で利用する。(モジュール名を書かずに定義名のみでアクセスできるので、クラスをインポートするときに便利)
モジュールを階層構造でまとめたパッケージのモジュールをインポートする場合、モジュール名を指定で、パッケージ名.サブパッケージ名.モジュール名と指定することができる。
- 投稿日:2019-11-01T22:11:05+09:00
c++のテンプレートを使用して型を意識しない
はじめに
Cに軽く触れた程度の知識でC++のライブラリの使い方を調べていたときに、テンプレートが良く出てきていました。その時は、テンプレートのことを良くわからず読み飛ばしていましたが改めて調べたところ、なかなか有用なものでしたので調べた内容を簡単なサンプルと使える例とともにまとめました。
環境
- ubuntu:18.04.2
- g++:7.4.0
テンプレート
テンプレートの説明
テンプレートについて、調べたときはテンプレートという名前に混乱させられました。いったんテンプレートという言葉の意味を忘れて読んでください。
テンプレートとは簡単に言うと型を意識しない関数(orクラス)になります。C++は変数や戻り値に型を指定するのが普通ですが、すべての型に適した関数(orクラス)を作成するのは無駄で無理なのでテンプレートという機能ですべての型を受け取る関数(orクラス)を作成できます。テンプレートの形式
引数に適用するときの例
テンプレートを適用するのは簡単です。関数(orクラス)の上に
template <typename 変数名>をつけるだけで、その関数(orクラス)の中では指定した変数名の型が呼び出し元に指定された型に変化します。
呼び出し方は普通の関数と同じようにするだけで呼び出せます。
※関数名<型名>(引数)でも呼び出せます。cppMain.cpptemplate <typename 引数名> void 関数名(引数名){ 関数内の処理 } // 呼び出し方 int main(){ int a = 1; 関数名(a); 関数名<int>(a); }戻り値に適用するときの例
戻り値の型を適用するときも同じく関数(orクラス)の上に
template <typename 変数名>をつけるだけです。ここで少し注意しないといけないのがreturnで返却する型になります。returnで返却する型は定義した戻り値の型と同じ出ないといけないため、下の例でいう戻り値名を返却するようにしないといけないです。cppMain.cpptemplate <typename 戻り値名> 戻り値名 関数名(){ 戻り値名 a = 値; 関数内の処理 return a; }テンプレートのシンプルな例
この例ではどの型でも受け取れる引数Tを持つ関数を作成しています。関数の中身は変数Tの型を標準出力に表示しているだけです。
その関数にint型を与えたとき、std::string型を与えたとき、ポインタを与えたときの結果を表示しています。cppMain.cpp#include <typeinfo> #include <iostream> #include <cxxabi.h> template <typename T> static void print_type(T){ int status; std::cout << "type name:" << abi::__cxa_demangle(typeid(T).name(), 0, 0, &status) << std::endl; } int main(){ int a = 1; print_type(a); std::string b = "ab"; print_type(b); char* e = "ab"; print_type(e); }結果
# ./cppMain type name:int type name:std::__cxx11::basic_string<char, std::char_traits<char>, std::allocator<char> > type name:char*結果を見ると、intなどの標準の型もstd::stringなどのクラスもポインタもすべて渡せていることがわかります。
今回は標準出力するだけの関数なのでイマイチ有用性がわかりませんが、次の例で実際に使える例を紹介します。テンプレートの使える例
実際に使える例としては、以前まとめたboostpythonでC++とpythonの変換器を設定するの変換器を取り上げます。
以前の例ではint型限定の変換器でしたが、テンプレートを適用するとint型以外の変換もできるようになりました。また、リストを取得するget_list()関数にもテンプレートを適用して同じ関数でありながら別の戻り値を返すようにしました。
これによって変換器をすべての型に作成する必要がなく、また関数も共通で使用できるものがあればpythonへの公開口を変えてあげるだけで対応できるようになりました。適用後
cppMod.cpp#include <boost/python.hpp> #include <iostream> template <typename T> struct vec_to_list_convert { static PyObject* convert(std::vector<T> const& vec) { boost::python::list pyList; for (auto item: vec) { pyList.append(item); } return boost::python::incref(pyList.ptr()); } }; class Greeting { public: template <typename T> std::vector<T> get_list() { std::vector<T> cppVec; cppVec.push_back(1); cppVec.push_back(2); return cppVec; } }; BOOST_PYTHON_MODULE(CppMod) { boost::python::to_python_converter<const std::vector<int>, vec_to_list_convert<int>>(); boost::python::to_python_converter<const std::vector<double>, vec_to_list_convert<double>>(); boost::python::class_<Greeting>("greeting") .def("get_int_list", &Greeting::get_list<int>) .def("get_double_list", &Greeting::get_list<double>); }結果
# python3 >>> import CppMod >>> a=CppMod.greeting() >>> a.get_int_list() [1, 2] >>> a.get_double_list() [1.0, 2.0]おわりに
テンプレートをまとめました。知らなくても開発はできる程度の知識ですが、ライブラリの使い方の調査であったり効率的できれいなコードを意識した開発を実現するためにはとても有用なものでした。
- 投稿日:2019-11-01T22:08:25+09:00
BorutaでlightGBM, xgboostを使えるようにしてみた
BorutaでlightGBMとxgboostが動かなかったので一部書き換えて動くようにしてみました。
普通にsklearn estimatorでやる方法は以下を見てください
https://qiita.com/studio_haneya/items/bdb25b19baaf43d867d7試行環境
Windows10
python 3.6.7
scikit-learn 0.21.3
lightgbm 2.3.0
xgboost 0.90変更したところ
Borutaはfeature_importance_が取得できるsklearn estimatorで動くようになっているので、RandomForestやGradientBoostingを使うことができますが、lightGBMやxgboostのsklearn wrapperはsklearnっぽいですがちょこちょこ違う為にそのままでは動かないようです。そこで、BorutaPyクラスを継承して一部書き換えて動くようにしてみました。
lightGBMをBorutaで使おうとしたときに問題になる相違点は以下の2つです。
boruta lgb/xgb random_state np.random.RandomState int max_depth制限なし None -1 sklearnではnp.random.RandomState()でseedを渡すことができるのがlightGBM/xgboostでは出来なくてint型の数値で渡さないといけないのと、max_depthの制限をなくしたときにparamsに代入される値がsklearnではNoneであるのがlightGBMでは-1である為にmax_depthを元に算出されるn_estimatorsが正常に算出されません。なのでこの2つに該当する部分を直せば動きます。
BorutaでlightGBMを使う
以下がlightGBMを動かすサンプルコードです。BorutaPyを継承して一部書き直しているんですが、_fit()がrandom_stateをnp.random.RandomState()に置き換えてからself.estimator.fit()する仕様になっている為にごっそり書き直す以外のやり方が思いつかず、えらく長いコードになってしまってます。もっと上手い方法があったら教えて下さい。
(20191102修正: random stateの値が反映されないコードになっていたので修正しました)pythonimport numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.metrics import confusion_matrix, accuracy_score from boruta import BorutaPy import lightgbm as lgb import xgboost as xgb from sklearn.utils import check_random_stateclass BorutaPyForLGB(BorutaPy): def __init__(self, estimator, n_estimators=1000, perc=100, alpha=0.05, two_step=True, max_iter=100, random_state=None, verbose=0): super().__init__(estimator, n_estimators, perc, alpha, two_step, max_iter, random_state, verbose) if random_state is None: self.random_state_input = np.random.randint(0, 2**64-1) elif isinstance(random_state, int): self.random_state_input = random_state else: raise TypeError('random_state must be int or None') def _get_tree_num(self, n_feat): depth = self.estimator.get_params()['max_depth'] if (depth == None) or (depth <= 0): depth = 10 f_repr = 100 multi = ((n_feat * 2) / (np.sqrt(n_feat * 2) * depth)) n_estimators = int(multi * f_repr) return n_estimators def _fit(self, X, y): # check input params self._check_params(X, y) self.random_state = check_random_state(self.random_state) # setup variables for Boruta n_sample, n_feat = X.shape _iter = 1 # holds the decision about each feature: # 0 - default state = tentative in original code # 1 - accepted in original code # -1 - rejected in original code dec_reg = np.zeros(n_feat, dtype=np.int) # counts how many times a given feature was more important than # the best of the shadow features hit_reg = np.zeros(n_feat, dtype=np.int) # these record the history of the iterations imp_history = np.zeros(n_feat, dtype=np.float) sha_max_history = [] # set n_estimators if self.n_estimators != 'auto': self.estimator.set_params(n_estimators=self.n_estimators) # main feature selection loop while np.any(dec_reg == 0) and _iter < self.max_iter: # find optimal number of trees and depth if self.n_estimators == 'auto': # number of features that aren't rejected not_rejected = np.where(dec_reg >= 0)[0].shape[0] n_tree = self._get_tree_num(not_rejected) self.estimator.set_params(n_estimators=n_tree) # make sure we start with a new tree in each iteration self.estimator.set_params(random_state=self.random_state_input) # add shadow attributes, shuffle them and train estimator, get imps cur_imp = self._add_shadows_get_imps(X, y, dec_reg) # get the threshold of shadow importances we will use for rejection imp_sha_max = np.percentile(cur_imp[1], self.perc) # record importance history sha_max_history.append(imp_sha_max) imp_history = np.vstack((imp_history, cur_imp[0])) # register which feature is more imp than the max of shadows hit_reg = self._assign_hits(hit_reg, cur_imp, imp_sha_max) # based on hit_reg we check if a feature is doing better than # expected by chance dec_reg = self._do_tests(dec_reg, hit_reg, _iter) # print out confirmed features if self.verbose > 0 and _iter < self.max_iter: self._print_results(dec_reg, _iter, 0) if _iter < self.max_iter: _iter += 1 # we automatically apply R package's rough fix for tentative ones confirmed = np.where(dec_reg == 1)[0] tentative = np.where(dec_reg == 0)[0] # ignore the first row of zeros tentative_median = np.median(imp_history[1:, tentative], axis=0) # which tentative to keep tentative_confirmed = np.where(tentative_median > np.median(sha_max_history))[0] tentative = tentative[tentative_confirmed] # basic result variables self.n_features_ = confirmed.shape[0] self.support_ = np.zeros(n_feat, dtype=np.bool) self.support_[confirmed] = 1 self.support_weak_ = np.zeros(n_feat, dtype=np.bool) self.support_weak_[tentative] = 1 # ranking, confirmed variables are rank 1 self.ranking_ = np.ones(n_feat, dtype=np.int) # tentative variables are rank 2 self.ranking_[tentative] = 2 # selected = confirmed and tentative selected = np.hstack((confirmed, tentative)) # all rejected features are sorted by importance history not_selected = np.setdiff1d(np.arange(n_feat), selected) # large importance values should rank higher = lower ranks -> *(-1) imp_history_rejected = imp_history[1:, not_selected] * -1 # update rank for not_selected features if not_selected.shape[0] > 0: # calculate ranks in each iteration, then median of ranks across feats iter_ranks = self._nanrankdata(imp_history_rejected, axis=1) rank_medians = np.nanmedian(iter_ranks, axis=0) ranks = self._nanrankdata(rank_medians, axis=0) # set smallest rank to 3 if there are tentative feats if tentative.shape[0] > 0: ranks = ranks - np.min(ranks) + 3 else: # and 2 otherwise ranks = ranks - np.min(ranks) + 2 self.ranking_[not_selected] = ranks else: # all are selected, thus we set feature supports to True self.support_ = np.ones(n_feat, dtype=np.bool) # notify user if self.verbose > 0: self._print_results(dec_reg, _iter, 1) return self上記で準備できたので以下で実行していきます。コードは以下を参考にしています。
https://github.com/masakiaota/blog/blob/master/boruta/Madalon_Data_Set.ipynbdef main(): # データを読んでくる data_url='https://archive.ics.uci.edu/ml/machine-learning-databases/madelon/MADELON/madelon_train.data' label_url='https://archive.ics.uci.edu/ml/machine-learning-databases/madelon/MADELON/madelon_train.labels' X_data = pd.read_csv(data_url, sep=" ", header=None) y_data = pd.read_csv(label_url, sep=" ", header=None) data = X_data.iloc[:,0:500] data['target'] = y_data[0] y=data['target'] X=data.drop(columns='target') X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42) # データ全体で学習 model = lgb.LGBMClassifier(objective='binary', num_leaves = 23, learning_rate=0.1, n_estimators=100,) model.fit(X_train.values, y_train.values) y_test_pred = model.predict(X_test.values) print(confusion_matrix(y_test.values, y_test_pred, labels=model.classes_), '\n') print('SCORE with ALL Features: %1.2f\n' % accuracy_score(y_test, y_test_pred)) # Borutaで特徴量選択 (一部書き換えたBorutaPyを使います) model = lgb.LGBMClassifier(objective='binary', num_leaves = 23, learning_rate=0.1, n_estimators=100,) feat_selector = BorutaPyForLGB(model, n_estimators='auto', two_step=False,verbose=2, random_state=42) feat_selector.fit(X_train.values, y_train.values) print(X_train.columns[feat_selector.support_]) # 選択したFeatureを取り出し X_train_selected = X_train.iloc[:,feat_selector.support_] X_test_selected = X_test.iloc[:,feat_selector.support_] print(X_test_selected.head()) # 選択したFeatureで学習 model = lgb.LGBMClassifier(objective='binary', num_leaves = 23, learning_rate=0.1, n_estimators=100,) model.fit(X_train_selected.values, y_train.values) y_test_pred = model.predict(X_test_selected.values) print(confusion_matrix(y_test.values, y_test_pred, labels=model.classes_), '\n') print('SCORE with selected Features: %1.2f\n' % accuracy_score(y_test, y_test_pred)) if __name__=='__main__': main()ということで実行した結果が以下です。ちゃんと選択出来ているようです。
結果[[192 57] [ 49 202]] SCORE with ALL Features: 0.79 Index([48, 105, 153, 241, 318, 336, 338, 378, 442, 453, 472, 475], dtype='object') [[212 37] [ 34 217]] SCORE with selected Features: 0.86Borutaでxgboostを使う
上記で作ったBorutaPyForLGB()はxgboostでも使えます。
pythondef main(): # データを読んでくる data_url='https://archive.ics.uci.edu/ml/machine-learning-databases/madelon/MADELON/madelon_train.data' label_url='https://archive.ics.uci.edu/ml/machine-learning-databases/madelon/MADELON/madelon_train.labels' X_data = pd.read_csv(data_url, sep=" ", header=None) y_data = pd.read_csv(label_url, sep=" ", header=None) data = X_data.iloc[:,0:500] data['target'] = y_data[0] y=data['target'] X=data.drop(columns='target') X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42) # データ全体で学習 model = lgb.LGBMClassifier(objective='binary', num_leaves = 23, learning_rate=0.1, n_estimators=100,) model.fit(X_train.values, y_train.values) y_test_pred = model.predict(X_test.values) print(confusion_matrix(y_test.values, y_test_pred, labels=model.classes_), '\n') print('SCORE with ALL Features: %1.2f\n' % accuracy_score(y_test, y_test_pred)) # Borutaで特徴量選択 (一部書き換えたBorutaPyを使います) model = lgb.LGBMClassifier(objective='binary', num_leaves = 23, learning_rate=0.1, n_estimators=100,) feat_selector = BorutaPyForLGB(model, n_estimators='auto', two_step=False,verbose=2, random_state=42) feat_selector.fit(X_train.values, y_train.values) print(X_train.columns[feat_selector.support_]) # 選択したFeatureを取り出し X_train_selected = X_train.iloc[:,feat_selector.support_] X_test_selected = X_test.iloc[:,feat_selector.support_] print(X_test_selected.head()) # 選択したFeatureで学習 model = lgb.LGBMClassifier(objective='binary', num_leaves = 23, learning_rate=0.1, n_estimators=100,) model.fit(X_train_selected.values, y_train.values) y_test_pred = model.predict(X_test_selected.values) print(confusion_matrix(y_test.values, y_test_pred, labels=model.classes_), '\n') print('SCORE with selected Features: %1.2f\n' % accuracy_score(y_test, y_test_pred)) if __name__=='__main__': main()動きはするんですがこちらは上手くいってなくて、精度が下がっちゃってます。どうも特徴量を減らし過ぎてしまったようなんですが何故なんでしょう。
結果[[182 67] [ 75 176]] SCORE with ALL Features: 0.72 Index([28, 378, 451, 475], dtype='object') [[148 101] [109 142]] SCORE with selected Features: 0.58という感じです。もっと短く書くやり方あったら教えて下さい。
レッツトライ!
- 投稿日:2019-11-01T21:34:16+09:00
もう二度とpipenv shellを忘れないようにするためのshellscript
はじめに
pipenv、使ってますか?
pipenvはそのプロジェクトのパッケージ管理や仮想環境の構築を簡単に自動で行ってくれるツールです。
pyenvとの連携もしてくれる、かなり便利なやつです。でもこんな経験ありませんか?
実行したらエラー起きたからpipで入れたけど仮想環境入ってないだけだったわ...
自分はめっちゃやります。
そこで!
Pipfileがあるところにcdしたらpipenv shellするshellscriptを書きました
作った
~/.bash_autopipenv#!/bin/bash function ispipenv() { if [ "$PIPENV_ACTIVE" == 1 ]; then : else if [ -e "Pipfile" ]; then pipenv shell fi fi } function pipenv_cd() { \cd $@ && ispipenv } alias cd='pipenv_cd'ポイントは以下の部分。
if [ "$PIPENV_ACTIVE" == 1 ]; then ...仮想環境に入ると、PIPENV_ACTIVEという環境変数が定義されるのを利用しています。
仮想環境に入っていない場合はPIPENV_ACTIVEは定義されないため、エラー回避の意味で"$PIPENV_ACTIVE"で評価しています。
これで仮想環境に入った状態ではpipenv shellが実行されません。またpipenv_cd内の\cdをcdとしてしまうと、
pipenv_cd内でpipenv_cdが呼ばれその中でpipenv_cdが呼ばれ・・・となってしまうので注意が必要です。常時読み込ませる
.bash_profileや.bashrcに以下を追記すれば常時読み込みしてくれるので、pipenv shellを実行し忘れることはなくなりました
if [ -f ~/.bash_autopipenv ]; then . ~/.bash_autopipenv fiまとめ
- shellscriptで自分だけのbashを作り上げるの楽しい

- つぎはexitを忘れないようにしよう!
- 投稿日:2019-11-01T21:04:09+09:00
【Python】None チェックと分岐でキレ散らかしたので nullutil.py 作った
永遠に
Noneチェックと条件分岐を書く作業から逃げたいと思ったことはないだろうか? 私はある。Python における
Noneは他の言語におけるnullやnilに相当すると思われるのだが、Python には他の言語にはよくある Null を取り回しやすくなる演算子やメソッドがない。しょうがないのでそれらの中でも定番の 3 種を、関数を書いて代用していくことにした。
nullutil.py# Null Coalesce # This means: # lhs ?? rhs def qq(lhs, rhs): return lhs if lhs is not None else rhs # Safty Access # This means: # instance?.member # instance?.member(*params) def q_(instance, member, params=None): if params is None: return getattr(instance, member) if instance is not None else None else: method = q_(instance, member) if isinstance(params, dict): return method(**params) if method is not None else None elif isinstance(params, list) or isinstance(params, tuple): return method(*params) if method is not None else None else: return method(params) if method is not None else None # Safety Evalate (do Syntax) # This means: # params?.let{expression} # do # p0 <- params[0] # p1 <- params[1] # ... # return expression(p0, p1, ...) def q_let(params, expression): if isinstance(params, dict): for param in params.values(): if param is None: return None return expression(**params) elif isinstance(params, list) or isinstance(params, tuple): for param in params: if param is None: return None return expression(*params) else: return expression(params) if params is not None else None一覧
Null 合体演算子
「ある変数の値を取り出したいが、Null だったときはデフォルト値を与えたい」
そんな要求に答えてくれるのが Null 合体演算子である。
Null 合体演算子が利用できる言語では以下のように書ける。
Swift の場合foo = bar ?? default_valueKotlin の場合foo = bar ?: default_valueこれの代替として
guide = 'Mirai Hirano' researcher = 'Kako Nanami' curator = None print(qq(guide, 'John Doe')) print(qq(researcher, 'John Doe')) print(qq(curator, 'John Doe'))Mirai Hirano Kako Nanami John Doe安全呼び出し演算子
Null かもしれない (Nullable な) メンバを直接呼び出そうとすると、もし本当に Null だった場合例外が飛ぶ。
import numpy as np import pandas as pd np.random.seed(365) score = np.clip(np.rint(np.random.normal(80., 15., 500)).astype(int), 0, 100) mean = np.mean(score) std = np.std(score) mean_difference = score - mean standard_score = mean_difference * (10. / std) + 50. column_dict = {'成績': score, '平均との差': mean_difference, '偏差値': standard_score,} column_list = ['成績', '平均との差', '偏差値',] score_df = pd.DataFrame(column_dict)[column_list] none_df = None display(score_df.sort_values('成績')) display(none_df.sort_values('成績'))
成績 平均との差 偏差値 249 34 -45.632 16.784097 82 36 -43.632 18.239913 89 36 -43.632 18.239913 372 41 -38.632 21.879453 112 42 -37.632 22.607361 ... ... ... ... 197 100 20.368 64.826033 43 100 20.368 64.826033 337 100 20.368 64.826033 334 100 20.368 64.826033 280 100 20.368 64.826033 --------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-50-badfe23fbcf4> in <module> 1 display(score_df.sort_values('成績')) ----> 2 display(none_df.sort_values('成績')) AttributeError: 'NoneType' object has no attribute 'sort_values'「Nullable なインスタンスのメンバを呼び出したい。 Null なら返り値も Null でいい」
そんな要求に答えてくれるのが安全呼び出し演算子である。
安全呼び出し演算子が利用できる言語では以下のように書ける。
Swift の場合foo?.bar()Kotlin の場合foo?.bar()これの代替として
q_関数を作成した。display(q_(score_df, 'sort_values', '成績')) display(q_(none_df, 'sort_values', '成績'))
成績 平均との差 偏差値 249 34 -45.632 16.784097 82 36 -43.632 18.239913 89 36 -43.632 18.239913 372 41 -38.632 21.879453 112 42 -37.632 22.607361 ... ... ... ... 197 100 20.368 64.826033 43 100 20.368 64.826033 337 100 20.368 64.826033 334 100 20.368 64.826033 280 100 20.368 64.826033 None複数の引数を指定する場合はリストやタプルや辞書で与える。
# score_df.sort_values(by='偏差値', ascending=False) q_(score_df, 'sort_values', {'by': '偏差値', 'ascending': False})メソッドではなくフィールドを呼び出すときは第三引数を省略する。
# score_df.index q_(score_df, 'index')メソッドに対して第三引数を省略した場合、単に呼び出し可能な関数オブジェクトが返るので、引数のないメソッドを呼ぶときは空のリストやタプルや辞書を与える。
# standard_score.min() q_(standard_score, 'min', ()) # Noneは呼び出し可能ではないので、以下の書き方は例外が飛ぶ可能性がある。 # q_(standard_score, 'min')()安全な式評価
Nullable な値を引数にとる式は、もし本当に Null だった場合例外が飛ぶかもしれない。
import numpy as np sequence = np.arange(0, 10) none_array = None print(sequence * 2) print(none_array * 2)[ 0 2 4 6 8 10 12 14 16 18] --------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-82-44094c5f4f90> in <module> 1 print(sequence * 2) ----> 2 print(none_array * 2) TypeError: unsupported operand type(s) for *: 'NoneType' and 'int'「Nullable な値を引数に取る式を評価したい。 この式は Non-Null を期待しているので Null なら返り値も Null でいい」
そんな要求に答えてくれるのが安全に式を評価するシステムである。
Swift の場合は Nullable なインスタンスは
mapメソッドを持っているため、これに式を与えることで安全に評価できる。Swift の場合foo.map({x in x * 2})Kotlin の場合は Non-Null なインスタンスが持っている
letメソッドを安全呼び出しすることで実現する。Kotlin の場合foo?.let { it * 2 }これらの代替として
q_let関数を作成した。print(q_let(sequence, lambda it: it * 2)) print(q_let(none_array, lambda it: it * 2))[ 0 2 4 6 8 10 12 14 16 18] Noneラムダ式の部分は当然定義済みの関数で代替できる。
np.random.seed(365) n01 = np.random.randn(10) # np.mean(n01) q_let(n01, np.mean)Nullable な変数が複数あると
mapやletがネストして大変である。 Haskell では do 記法というものを使うことでこれを書きやすくできるらしい。q_let関数は所詮関数なので、最初から引数としてコレクションをとれるようにしておいた。import math r = 5 pi = math.pi # r**2 * pi q_let([r, pi,], lambda x, y: x**2 * y)弱点
まず、無理に関数で実装しているのでどうしても文字が増える。
??演算子は 2 文字なのにqq(,)で 5 文字だ。?.などは本来必要ないクォーテーションでさらに悲惨なことになっている。もう一つ、演算子と違って中置できないのでチェーンの見た目がすごい悲惨なことになっている。
以下は Swift におけるチェーンの例。
foo?.bar()?.baz?.qux() ?? default_value非常にスッキリしているが、これと同じことを今回作成した関数で書こうとするとこうなる。
qq(q_(q_(q_(foo,'bar',()),'baz'),'qux',()), default_value)もはやチェーンでなく入れ子と化し、なにがどこまでを囲っているのかさっぱりわからない。 あまりにもひどい。 ここまで来ると、
if foo is None: ret = default_value else: temp = foo.bar() if temp is None: ret = default_value else: temp = temp.baz if temp is None: ret = default_value else: temp = temp.qux() ret = temp if temp is not None else default_valueの方がまだマシに見える。
qq( q_( q_( q_( foo, 'bar', () ), 'baz' ), 'qux', () ), default_value )こう書けば多少は見やすくならねえわこれ。
- 投稿日:2019-11-01T20:02:36+09:00
[ゼロから作るDeep Learning]ニューラルネットワークに逆伝播処理を実装するのに必要なレイヤについて
はじめに
この記事はゼロから作るディープラーニング 6章誤差逆伝播法を自分なりに理解して分かりやすくアウトプットしたものです。
文系の自分でも理解することが出来たので、気持ちを楽にして読んでいただけたら幸いです。
また、本書を学習する際に参考にしていただけたらもっと嬉しいです。レイヤとは
ニューラルネットワークに逆伝播処理を実装するには、ニューロンをレイヤというものにする必要があります。
レイヤとは、順伝播処理と逆伝播処理の両方が実装されたニューロンと考えるのが一番簡単です。ニューラルネットワークを実装するのに必要なレイヤは、Sigmoidレイヤ・Reluレイヤ・Affineレイヤ・出力層から損失関数までのレイヤが最低限です。
レイヤはクラスとして実装して部品のようにすることで、ニューラルネットワークを様々な構造に組み替える時に運用しやすくなります。
では、今回は前回の記事にも出てきた足し算のニューロンと掛け算のニューロンをレイヤ化してみることにします。
加算レイヤ
class AddLayer:# 加算レイヤ def __init__(self): pass# 何も行わない def forward(self, x, y): out = x + y return out def backward(self, dout): dx = dout * 1 dy = dout * 1 # 足し算の時は前の微分を両変数とも引き継ぐ return dx, dy加算レイヤでは、順伝播処理で二つの変数の値を合計して返し、逆伝播処理では前の微分をそのまま引き継がせて返します。
乗算レイヤ
class MulLayer:#乗算レイヤ def __init__(self): self.x = None self.y = None # 変数xyをインスタンス変数に def forward(self, x, y): self.x = x self.y = y # 変数xyの値は逆伝播処理で使うので保存しておく out = x * y return out def backward(self, dout): dx = dout * self.y dy = dout * self.x return dx, dy乗算レイヤは、順伝播処理で変数xyを掛けて返し、逆伝播処理では、もう一方の変数の値と前の微分を掛けることで微分を求めて返します。
- 投稿日:2019-11-01T19:41:35+09:00
最短で試すCython
はじめに
本記事は、Cythonと呼ばれるPythonのライブラリを、試しに動かすために必要な最低限の内容を記した備忘録です。
「Pythonの処理を速くする方法としてCythonてのがあるらしいけど、ググれどググれど何だか良くわからねェ!」といった方の助けに少しでもなれば幸いです。
※ 環境:
OS:Ubuntu18.04
Python:3.6.8
Cython:0.29.13概要
誤解を恐れずに言うと
Cython = Pythonにめちゃくちゃよく似たほぼほぼ新しい言語
です。
もちろん他にもいろいろな使い方がありますが、最初に試すだけであればこの程度の認識で十分です。
Cythonを使うときの流れ
1.Cython語で処理を書く
2.ソースコードをC言語に翻訳(トランスパイル)する
3.トランスパイルされたC言語のソースコードをビルドしてライブラリ化するHello World的な奴
流れを抑えたら早速試してみます。
動かすまでに最低限必要なものは2つ。
1.hoge.pyx(Cythonで書いたソースコード)
hoge.pyxdef tasu(a, b): return a + bPythonにめちゃくちゃよく似てるというかPythonのまんまですね。Cythonでは他に
cdefやcpdefなどで関数を定義できたり、aやbの型を指定できたりしますが、ここでは深入りはしません。2.setup.py
setup.pyfrom distutils.core import setup from Cython.Build import cythonize setup(ext_modules=cythonize("hoge.pyx"))先ほど書いたCythonコードをさいそないずするおまじないが書いてあります。
上2つが用意出来たら早速下記コマンドでトランスパイル&ビルドしてみます。
python3 setup.py build_ext -iいくつかファイルが生成されたかと思いますが、生成された
hoge.cが、hoge.pyxをC言語にトランスパイルされたもの。hoge.cpython-36m-x86_64-linux-gnu.so的な奴が、Pythonでimportして使うライブラリ化されたものです。あとは
hoge.cpython-36m-x86_64-linux-gnu.soをimportして、先ほど作った関数を呼び出すだけです。>>> import hoge >>> >>> print(hoge.tasu(1,2))Cythonは使い方や使いどころを見極めないと高速化の恩恵をあまり受けられないそうですが、試すだけなら意外と簡単ですね。
以上です! ありがとうございました!
- 投稿日:2019-11-01T18:48:37+09:00
Raspberry Pi wi-fi切り替え ショートカットキー
ラズパイをVNCで操作しているけど,ネットワークが変わるとそれができない...
というかなりマイナー(?)な悩みを抱えていたので自己流の解決策を提示します.
注意 configファイルの編集はリスクを伴うかも?知れないので自己責任で
LANケーブルでつなげればええやんというつっこみもなしで
どうしてもラズパイをとあるネットワークにつなげるている必要があったので環境
●Raspberry Pi 3 model B
●ネットワークA(dns server,default gateway : 192.168.1.1/24)
●ネットワークB(dns server,default gateway : 192.168.52.1/24)やること
●configファイル用意
●pythonでコマンド実行
●ショートカットキー作成configファイル編集
wpa_supplicant
ネットワークの設定のやつです
$sudo nano /etc/wpa_supplicant/wpa_supplicant.confエディタは何でもいいですVimでもgeditでも.好きなの使ってください
/etc/wpa_supplicant/wpa_supplicant.conftrl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev update_config=1 country=JP network={ ssid="Network-A" psk=###### }こんな感じでいつも使ってるネットワークが出てればいいです
次,適当なファイルを2つ作ってください
$sudo nano /etc/wpa_supplicant/###.###
$sudo nano /etc/wpa_supplicant/???.???
/etc/wpa_supplicant/###.###trl_interface=DIR=/var/run/wpa_supplicant GROUP=netdev update_config=1 country=JP network={ ssid="Network-B" psk=###### }???のほうはファイルを作るだけで何もしなくていいです保存だけしてください.
dhcpcd
IPこていするやつです
$ sudo nano /etc/dhcpcd.conf/etc/dhcpcd.confinterface wlan0 static ip_address=192.168.1.2/24 static routers=192.168.1.1 static domain_name_servers=192.168.1.1これがネットワークAで固定してる状況です
次にBで固定するconfigファイルを作ります
$ sudo nano /etc/###.###/etc/###.###interface wlan0 static ip_address=192.168.52.2/24 static routers=192.168.52.1 static domain_name_servers=192.168.52.1同じく???.???の方は保存だけでいいです.
Pythonでコマンド実行
$ nano wifichange.pywifichange.pyimport os import time def change(): os.system('sudo cp /etc/dhcpcd.conf /etc/???.??? ') os.system('sudo cp /etc/###.### /etc/dhcpcd.conf ') os.system('sudo cp /etc/???.??? /etc/###.### ') os.system('sudo cp /etc/wpa_supplicant/wpa_supplicant.conf /etc/wpa_supplicant/???.???') os.system('sudo cp /etc/wpa_supplicant/###.### /etc/wpa_supplicant/wpa_supplicant.conf ') os.system('sudo cp /etc/wpa_supplicant/???.??? /etc/wpa_supplicant/###.###') time.sleep(3) os.system('sudo reboot') if __name__ == "__main__": change()os.system使うたびにシェルで書けばいいのに...と頭をよぎりますが
Python大好きなのでPython使いましょう試しに
python wifichange.pyで実行してみてくださいショートカットキー作成
$ sudo nano .config/openbox/lxde-rc.xml追記してきます
.config/openbox/lxde-rc.xml<keybind key="C-A-w"> <action name="Execute"> <command>python wifichange.py</command> </action> </keybind>key="C-A-w"のところはお好きにどうぞ
C=Ctrl
A=Alt
w=W
C-A-wならCtrl + Alt + wになります
$ sudo nano .config/openbox/lxde-pi-rc.xml.config/openbox/lxde-pi-rc.xml(省略) <keybind key="C-A-w"> <action name="Execute"> <command>python wifichange.py</command> </action> </keybind> (省略)おわり
リブートして
$ sudo reboot
ショートカットキー押してみる.なんかリブートする.ネットワーク変わって固定になってる.
やったぁ終
制作・著作
━━━━━
Ⓝ〇Ⓚ
- 投稿日:2019-11-01T17:59:02+09:00
pybind11でPythonからC++にリストを参照渡しする
はじめに
PythonとC++を連携させることができる
pybind11では、
STLコンテナを介することでPythonからC++の関数にリストを渡すことができます。外部リンク:pybind11を使ってPythonからC++コードを実行する方法
しかしこれは値渡しになるため、更新したリストをPythonで使うにはC++側で返り値にする必要があります。
一方、既存のC++資産を使う場合にはできるだけC++のソースコードに手を加えたくないので、
新たに返り値を設定したり更新のところを書き換えたりしたくないことがあります。そこで、リストではなくNumpyを介することで、
用途は限定的ではありますが参照渡しができるので共有します。基本的には以下のリンクで解説されている
mutable_dataやEigenを使うのがいいと思うのですが、
それ以外にもこんなやり方があるというくらいの内容です。
外部リンクpybind11入門(3) NumPy連携その1
外部リンクpybind11入門(3) NumPy連携その2注意点
- pybindのインストール方法、基本的な利用方法は説明しません
- pybindおよびC++は浅い知識しかないので誤りがありましたらコメントください
C++コード
STLコンテナを介してリストを渡す関数
update1()と、Numpyで渡す関数update2()を定義します。
どちらも受け取った配列の値を1.0に更新しようとするものです。hoge.cpp#include <pybind11/pybind11.h> #include <pybind11/numpy.h> #include <pybind11/stl.h> #include <vector> namespace py = pybind11; void update1(std::vector<double> &x) { int i; for(i = 0; i < 3; i ++) { x[i] = 1.0; } } void update2(py::array_t<double> x) { auto x_buf = x.request(); double *x_ptr = (double *)x_buf.ptr; int i; for(i = 0; i < 3; i ++) { x_ptr[i] = 1.0; } } PYBIND11_MODULE(hoge, m) { m.doc() = "hoge module"; m.def("update1", &update1, "update1 function"); m.def("update2", &update2, "update2 function"); }Pythonコード
[1., 2., 3.]というリストをupdate1、update2に渡して、
それぞれの関数適用後にリストがどう変化するのか検証するスクリプトです。test.pyimport numpy as np import hoge x = [1., 2., 3.] print(x) hoge.update1(x) print(x) x = np.array(x) hoge.update2(x) print(x)結果
[1.0, 2.0, 3.0] [1.0, 2.0, 3.0] [1. 1. 1.]
update1では値が更新されず、update2では更新されていることがわかります。参考リンク先でも説明されていますが、型(今回はdouble)がPython側とC++側で一致しないと
値渡しになってしまうので注意してください。
- 投稿日:2019-11-01T16:49:56+09:00
GPUの使用状況確認
最近研究でGPUを使用することが多いのでそれらの使用状況を確認できる便利なコマンドメモです。
自分用の備忘録ではありますが、適宜追加等の更新してきます。
- GPUの使用状況の確認
$nvidia-smi
- GPUを使用しているプロセスの確認
$nvidia-smi -q -d PIDS
- pytorchでGPUの確認
import tourch print(torch.cuda.is_available()) torch.cuda.get_device_name(0)
- tensorflowでGPUの確認
from tensorflow.python.client import device_lib print(device_lib.list_local_devices())
- 投稿日:2019-11-01T16:45:30+09:00
いろんな方法で数独解いてみる(SAT, CSP編)
数独を色々な論理プログラミングで解いてみて、その一長一短なところをみてみましょう。
紹介するのは次の5つです
- SAT - CNF(連言標準形)の論理式をとく
- CSP - 変数の定義域と制約から解を求める
- ASP - 一階述語論理式をとく(次回)
- Prolog - ASPと似てるやつ(次回)
- 自前プログラム - 比較用、rust(次回)
数独のルールの定義
ルールを定義して、プログラムが定義に乗っ取っているかを確認します
- 一つのマスに数字は一つ
- 一つの行に同じ数字は一つ
- 一つの列に同じ数字は一つ
- 一つのブロックに同じ数字は一つ
- 入力を満たす
入力は、「セルの行x列yに値iが入る」という条件をタプル
(x,y,i)で表し、入力全体はそのタプルのリストで表されるとします。SAT
SATソルバーはCNF(連言標準形)と呼ばれる論理式を充足する真偽値が存在するかを求めるアルゴリズムです。CNFは節と呼ばれるリテラルの論理和($x_1 \vee \neg x_2\dots \vee x_n$など)の集合の論理積で表されるものです。
それでは、ルールをSATに変換していきましょう。
定義
「セルの行x列yに値iが入る」とき$g_{x,y,i}$が真であるとします。逆に「セルの行x列yに値iが入らない(他の値が入る)」というとき$g_{x,y,i}$は偽となります。
ルール1(一つのマスに数字は一つ)
安直に考えるとこんな感じになります
(g_{x,y,1} \wedge \neg g_{x,y,2} \wedge \dots \wedge\neg g_{x,y,9}) \vee(\neg g_{x,y,1} \wedge g_{x,y,2} \wedge \dots \wedge\neg g_{x,y,9}) \vee \dots \vee\\ (\neg g_{x,y,1} \wedge \neg g_{x,y,2} \wedge \dots\wedge g_{x,y,9})でもこれはCNFの形ではないので、分配法則(?)のように展開して簡略化すると次のようになります
(g_{x,y,1} \vee g_{x,y,2} \vee \dots g_{x,y,9}) \wedge (\neg g_{x,y,1} \vee \neg g_{x,y,2})\wedge (\neg g_{x,y,1} \vee \neg g_{x,y,3}) \wedge \dots \wedge\\ (\neg g_{x,y,8} \vee \neg g_{x,y,9})ルール2,3,4(一つの行(列、ブロック)に同じ数字は一つ)
「行xに数字iが一つ以上存在する」という条件は次のように書けます
g_{x,1,i} \vee g_{x,2,i} \vee \dots g_{x,9,i}これに「行xに数字iが2つ以上存在しない」という条件を加えればルール2になるわけですが、ルール1と組み合わせるとその条件は必要無くなります。なぜなら、数字1~9が9個のセルにそれぞれ1つ以上あるわけですから、鳩の巣原理的に、それぞれの数字は1つしか存在しえないわけです。
ちなみに、「行xに数字iが2つ以上存在しない」という条件を表すとこうなります。
(\neg g_{x,1,i} \vee \neg g_{x,2,i})\wedge (\neg g_{x,1,i} \vee \neg g_{x,3,i}) \wedge \dots \wedge(\neg g_{x,8,i} \vee \neg g_{x,9,i})列やブロックについては同様であるので、省略
ルール5(入力を満たす)
「セルの行x列yに値iが入る」という条件は$g_{x,y,i}$に真を割り当てるということになります。
実装
ということでpysatのminisatを使って解きます。
from pysat.solvers import Minisat22 from itertools import product, combinations def grid(i, j, k): return i * 81 + j * 9 + k + 1 def sudoku_sat(arr): m = Minisat22() # ルール1 for i, j in product(range(9), range(9)): m.add_clause([grid(i, j, k) for k in range(9)]) for k1, k2 in combinations(range(9), 2): m.add_clause([-grid(i, j, k1), -grid(i, j, k2)]) # ルール2,3 for i in range(9): for k in range(9): m.add_clause([grid(i, j, k) for j in range(9)]) for j in range(9): for k in range(9): m.add_clause([grid(i, j, k) for i in range(9)]) # ルール4 for p, q in product(range(3), range(3)): for k in range(9): m.add_clause([grid(i, j, k) for i, j in product(range(p*3, p*3+3), range(q*3, q*3+3))]) # ルール5 for a in arr: m.add_clause([grid(a[0], a[1], a[2] - 1)]) if not m.solve(): return None model = m.get_model() return [ [ [k + 1 for k in range(9) if model[grid(i, j, k) - 1] > 0][0] for j in range(9) ] for i in range(9) ]CSP
大学の課題のコピペですCSP(制約プログラミング)は次の$V, D, C$からなる問題を解くアルゴリズムです。
- $V= \{v_0, v_1,\dots,v_n\}$ - 変数の集合
- $D$ - それぞれの変数の定義域。$D_i$は変数$v_i$の定義域を示す
- $C$ - 変数同士のの制約(例: $v_1 \neq v_2$)の集合
前提
変数$v_{x,y}$が行x列yのセルの値であるとします。つまり:
- $V = \{v_{0,0}, v_{0,1},\dots,v_{8,8}\}$
- $D_{x,y} = \{1,2,\dots,9\}$
この前提のみでルール1は満たすことができます。
ルール2,3,4(一つの行(列、ブロック)に同じ数字は一つ)
ルールを書き下すと次のようになります
(v_{x,0}, v_{x,1})\in\{(1,2), (1,3), \dots (9,8)\} \\ (v_{x,0}, v_{x,2})\in\{(1,2), (1,3), \dots (9,8)\} \\ \vdots\\ (v_{x,7}, v_{x,8})\in\{(1,2), (1,3), \dots (9,8)\}ですが、通常CSPには
AllDifferentという便利機能がありますので、それを利用すると簡単に記述できます\text{AllDifferent}(v_{x,0}, v_{x,1},\dots,v_{x,8})列、ブロックも同様です。
ルール5(入力を満たす)
ルール5は定義域から組み込むこともできますが、数独の根本のルールの部分と入力を分離したいという目的のため、制約で表すとします。「セルの行x列yに値iが入る」という制約は次のようになります
v_{x,y} \in \{i\}実装
python-constraintを使って解きます。
from constraint import Problem, AllDifferentConstraint, InSetConstraint def sudoku_csp(arr): def grid(i, j): return '{}_{}'.format(i, j) p = Problem() for i, j in product(range(9), range(9)): p.addVariable(grid(i, j), range(1, 10)) for i in range(9): p.addConstraint(AllDifferentConstraint(), [grid(i, j) for j in range(9)]) p.addConstraint(AllDifferentConstraint(), [grid(j, i) for j in range(9)]) for m, n in product(range(3), range(3)): p.addConstraint( AllDifferentConstraint(), [grid(i, j) for i, j in product(range(m*3, m*3+3), range(n*3, n*3+3))] ) for a in arr: p.addConstraint(InSetConstraint([a[2]]), [grid(a[0], a[1])]) solution = p.getSolution() return [ [ solution[grid(i, j)] for j in range(9) ] for i in range(9) ]最後に
この調子でアドベントカレンダーやったら死にそうなので、次から手を抜きます。
- 投稿日:2019-11-01T16:42:30+09:00
カメラキャリブレーションを視覚的に理解する
カメラキャリブレーションはレンズの歪み補正などに使われますが、それぞれの係数がどう影響を及ぼしているのかわかりにくく感じます。
そこで直感的に理解できるようにしてみようと思います。
カメラキャリブレーションとは
理想的なピンホールカメラモデルでない限り、左図のように画像は歪んでいます。
カメラ固有の歪み係数を求めることで、このように歪んだ画像を補正することができます。
カメラキャリブレーションの仕組み
カメラキャリブレーションを行う際は、チェッカーボードと呼ばれるものを印刷します。
パラメータを計測したいカメラでその写真をあらゆる角度から何十枚も撮影します。
これでカメラの二次元座標 $x$ と空間の三次元座標 $X$ との対応が取れるようになります。
x = P Xこの $P$ がカメラマトリックスです。3行4列で、連立方程式で求まります。
P = K [R|t]$P$ は上三角行列 $K$ と正規直行行列 $R$ に分解することができて、
$K$ ...... 内部パラメータ、Intrinsic Parameter (焦点距離、光学中心、せん断係数)
$[R|t]$ ... 外部パラメータ、Extrinsic Parameter (カメラの回転と変換)となります。
内部パラメータ
この内部パラメータ $K$ は
K = \begin{pmatrix} f_x & s & c_x \\ 0 & f_y & c_y \\ 0 & 0 & 1 \\ \end{pmatrix}となっていて、焦点距離 $(f_x, f_y)$, 光学中心 $(c_x, c_y)$, せん断係数 $s$ を表します。
実装
PythonではOpenCVを使って以下のように $K$ (mtx)が求まります。
# チェッカーボードから点を検出 ret, corners = cv2.findChessboardCorners(gray, (8,6), None) # キャリブレーション ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, img_size,None,None) # 歪み補正 dst = cv2.undistort(img, mtx, dist, None, newMtx)直感的理解
それぞれ焦点距離、光学中心、せん断係数などのパラメータをアニメーションしてみましょう。
求めたカメラマトリックスから、対象のパラメータのみを変化させています。元画像
焦点距離
無限遠→適正焦点距離→小さい
(1) $f_x, f_y$
(2) $f_x$
(3) $f_y$
光学中心
負→適正位置→正
(1) $c_x$
(1) $c_y$
せん断係数
負→適正値→正
英語ではSkewです。まとめ
いかがだったでしょうか。
カメラキャリブレーションは歪みの補正に使われるということがわかりました。フューチャーワーク
半径方向の歪み係数、円周方向の歪み係数についてもやりたいです。
画像引用
https://github.com/DavidWangWood/Camera-Calibration-Python
https://jp.mathworks.com/help/vision/examples/evaluating-the-accuracy-of-single-camera-calibration.html










- 投稿日:2019-11-01T16:28:35+09:00
uwsgi の uwsgi プロトコル通信を uwsgi-tools で確認する
メモ。
以下のよう uwsgi を実行すると uwsgi プロトコルによる通信が出来る。
Putting behind a full webserver
$uwsgi --socket 127.0.0.1:3031 --wsgi-file foobar.py --master --processes 4 --threads 2 --stats 127.0.0.1:9191ただし、上記のような場合、クライアントからの接続テストが面倒そうだなと感じていた。
ググると以下の Github issue を発見
how to test uwsgi unix socket ? #1443
上記に書いてあるように uwsgi-tools というのが便利みたいなので使ってみた。
インストール
インストールは
pipで可能$pip install uwsgi-tools使い方
基本的な使い方は README に書いてある。
localhost で uwsgi プロトコルをリッスンしている場合、以下のようにして確認出来る。
$uwsgi_curl localhost:3031 HTTP/1.1 200 OK Content-Type: text/htmlリモートホストの場合にも以下のようにして接続テストが出来る。
$uwsgi_curl hogefuga:3031 HTTP/1.1 200 OK Content-Type: text/html参考
import socketをしており、socket 通信をしている模様。https://github.com/andreif/uwsgi-tools/blob/master/uwsgi_tools/curl.py#L9
The protocol works mainly via TCP but the master process can bind to a UDP Unicast/Multicast for The embedded SNMP server or cluster management/messaging requests.
以下あたりが勉強になりそう
- 投稿日:2019-11-01T15:27:55+09:00
OpenCVのTrackerを使って動画内のオブジェクトをトラッキングする
映像内に現れるマーカーやその他のオブジェクトを基準に何か処理をしたい場合は、物体検知・マーカー検知の手法を使ってフレーム内の物体の検出・位置を特定するという手順を踏むことが多いと思いますが、物体追跡(トラッキング)を併用すると物体検知・マーカー検知に失敗したフレームにおけるマーカー・オブジェクトの検出を補間できる場合があります。
OpenCVのTrackerを使って、動画内のオブジェクトのトラッキングをやってみます。
環境構築の手間がないので、Google Colaboratory上で実験します。
Google Driveのマウント
解析対象の動画をGoogle Driveから読み込みたいので、Google Driveをマウントします。
from google.colab import drive drive.mount("/content/gdrive")FPSの指定
fps = 5FPSを高く設定した方が基本的には追跡の精度が上がりますが、処理時間も増えてしまうのでまずは5FPSで解析を行います。あとで変更できるように変数にしておきます。
動画からフレームを抽出(静止画に変換)
!ffmpeg -i "/content/gdrive/My Drive/TrackerExp/src.mp4" -vf fps=$fps "/content/gdrive/My Drive/TrackerExp/src/%06d.jpg"ffmpegを使って、動画から静止画を抽出します。抽出先はGoogle Drive上じゃなくても良いのですが、あとで過程をチェックするときに便利なのでGoogle Drive上に保存するようにしています。参照する必要がない場合はGoogle Drive上のディレクトリではなく一時ディレクトリなどを使った方がGoogle Driveの同期のキューが詰まらないので良いです。
抽出した画像のリストを取得する
import glob import os files = glob.glob("/content/gdrive/My Drive/TrackerExp/src/*.jpg") files.sort() # 見つかったファイルをソートする print(len(files))抽出先のフォルダから画像のリストを取得します。取得された画像はフレーム番号順にソートされている保証はないので、ソートしておきます。
解析結果の保存先のディレクトリを作る
dst_dir = "/content/gdrive/My Drive/TrackerExp/dst" if os.path.exists(dst_dir) == False: os.makedirs(dst_dir)今回は解析結果(トラッキングの結果)をオリジナル画像の上に描画して画像で保存していくようにします。保存先のディレクトリを作成しておきます。
トラッキングしたい範囲(時間)の指定
start_sec = 5.0 # トラッキング開始は5秒時点 end_sec = 15.0 # トラッキング終了は15秒時点 start_frame = fps * start_sec end_frame = fps * end_sec動画のうち、トラッキングを行いたい範囲(時間)を指定します。実際のフレーム番号(何フレーム目から何フレーム目か)は、FPSに応じて変わってくるので、秒にFPSをかけてフレーム番号を求めています。
トラッカーの生成
tracker = cv2.TrackerMedianFlow_create()トラッカーを生成します。OpenCVにはMedianFrow以外にも複数のトラッキングアルゴリズムが用意されているので、トラッキング対象映像の特性に合わせて切り替えます。例: cv2.TrackerKCF_create()
各トラッキングアルゴリズムの甲乙については、こちらの投稿などがわかりやすいです。
トラッキング初期位置の設定
start_rect = (100, 200, 30, 30) # x: 100, y: 200, width: 30, height: 30 start_img = cv2.imread(files[start_frame]) tracker.init(start_img, start_rect)最初のフレームの画像を読み込み、そのフレームにおけるトラッキングしたいオブジェクトの範囲を指定します。
トラッキングの実行
for i in range(start_frame, end_frame): frame = cv2.imread(files[i]) located, bounds = tracker.update(frame) if located: x = bounds[0] y = bounds[1] w = bounds[2] h = bounds[3] cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 0), 2) cv2.imwrite(os.path.join(dst_dir, os.path.basename(files[i])), frame)初期位置の設定を行ったら、1フレームずつトラッキングを行っていきます。
cv2.imreadでフレームの画像を読み込み、読み込んだ画像に対してtrackerのupdateを実行していきます。located, bounds = tracker.update(frame)updateメソッドの一つ目の返り値は「目標を見つけることができたか」がTrue/Falseで表現されます。見つかった場合は第二の返り値に目標の位置(範囲の矩形)が
(x, y, width, height)の形でセットされます。x = bounds[0] y = bounds[1] w = bounds[2] h = bounds[3] cv2.rectangle(frame, (int(x), int(y)), (int(x + w), int(y + h)), (255, 255, 0), 2)目標が見つかった場合は元画像の上に
cv2.rectangleで黄色の枠を描画します。最後の引数2は線の太さです。cv2.imwrite(os.path.join(dst_dir, os.path.basename(files[i])), frame)最後に結果を上で作った出力用ディレクトリに保存します。
- 投稿日:2019-11-01T15:14:01+09:00
Windows10 64bit環境で最近の単語を含む文章を形態素解析する
問題
Windows10 64bit環境のPythonでMeCabを使おうとする際、
主に下記の5点で躓いて画面を割りたい気持ちでいっぱいになったので体系的にまとめました。問題1:pip installのみではMeCabが入らない
問題2:インストールできたものの形態素解析がうまくいかない
問題3:NEologd辞書を用いることで固有表現の抽出が上手くいくらしいが
Windows環境ではインストールが難しい
問題4:インストールしようとするとPATHを通すのだがPATHの概念がよくわからない
問題5:DOSコマンドが通らない目次
①64bit向けの非公式版の.exeからMeCabをインストール
②PythonでMeCabを扱うためのライブラリをインストール
③形態素解析をより精緻に行うために
NEologdをgitからクローンしてコマンドプロンプトからコンパイル
※参考記事は各項にて記載①64bit向けの非公式版の.exeからMeCabをインストール
参考:https://qiita.com/wanko5296/items/eeb7865ee71a7b9f1a3a
公式では32bit版しかサポートされていないので、
有志でビルドされている64bit版をインストールする方がbetter。実行ファイルは下記のgitで公開されている。
https://github.com/ikegami-yukino/mecab/releases/tag/v0.996実行ファイルをインストールする際に文字コードを選択するのだが、
自分が形態素解析を行いたい対象のテキストファイルの文字コードに合わせて選択する。
こだわりが無いのであれば、UTF-8を選択する。
(※デフォルトはSHIFT-JIS)②PythonでMeCabを扱うためのライブラリをインストール
参考:https://qiita.com/yukinoi/items/990b6933d9f21ba0fb43
cmdやAnaconda promptで
pip install syspip install MeCabを実行。
上記の64-bit版MeCabをインストールしていれば上記のpipで通る。jupyter notebookなどで
import MeCabでインストールできているか検証。
エラーが発生しないようであればこの段階で形態素解析は可能な状態となっている。
試しにやってみたい方は、import sys import MeCab m = MeCab.Tagger ("-Ochasen") print(m.parse ("すもももももももものうち"))と実行すると形態素解析ができているのが分かる。
ただ、最近の単語を含むワード(i.g. マイナンバー、欅坂46など)は
マイ/ナンバー、欅/坂/46のようになってしまう。これを防ぐために、最近のKWリストを含むNEologd辞書をインストールすると良い。
③形態素解析をより精緻に行うためにNEologdをgitからクローンしてコマンドプロンプトからコンパイル
・準備編
参考:https://qiita.com/zincjp/items/c61c441426b9482b5a48
(基本的に上記の記事をPATHやDOSコマンドが分からない人向けに記載しました。)必要なものとして64-bitのgitと7-zipをインストールしておく。
インストール方法に関してはここでは省略する。
・git
参考:https://eng-entrance.com/git-install
・7-zip
公式サイト:https://sevenzip.osdn.jp/7-zipに環境変数を設定する必要がある。
C:\Program Files\7-Zipさて、この環境変数というものを簡易的に紹介すると、
アプリケーションをcmdで簡易的に実行する設定のことで、PATHを通すとも言われる。設定方法としてはコントロールパネル画面などで"環境変数"と検索すれば設定画面が出現する。
上記イメージの環境変数を編集を選択するとこのような画面になる。
青塗のPathという部分を選択して編集>新規で
7-zipのインストール先である下記を追加してOKを選択。
再掲になるが、インストール先は人によって異なり、デフォルトでは下記の通り。C:\Program Files\7-ZipこれでいわゆるPATHが通った状態となる。
ここからNEologd辞書をインストールしていく。
・NEologd辞書をインストール&コンパイル
管理者権限でコマンドプロンプトを立ち上げ
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git必要な辞書ファイルなどをダウンロード。
続いてダウンロードしたファイルのディレクトリに移動し、dirでダウンロードされているか確認する。
dir実行時にneologd~系のファイルが目視できれば問題ない。
seedフォルダが見当たらずエラーが出る場合は、
C:\Users(ユーザー名)\mecab-ipadic-neologd\seedから記載すればディレクトリに移動する。cd mecab-ipadic-neologd\seed dirちなみにmecab-ipadic-neologd\seedというディレクトリを読みに行くという意。
7-zipによる解凍が必要なので
下記コマンドを実行。
.xzファイルを7-zipで解答するの意。7z X *.xz続いて下記コマンドで辞書をコンパイルする。(MeCabで読める辞書形式に変える)
ただし、注意点がある。①NEologdは日々更新されているので、以降の20191024はすべて実際に
自分がクローンした際にDLしたファイル名についている日付を選択する
②C:\Program Files\MeCab\bin\mecab-dict-indexは自分のMeCabのインストール先に合わせる
③本稿のmecabのインストール方法ではUTF-8を選択していたが、
SHIFT-JIS環境でインストールしている場合は”-t utf-8”を”-t shift-jis”に変更する"C:\Program Files\MeCab\bin\mecab-dict-index" -d "C:\Program Files\MeCab\dic\ipadic" -u NEologd.20191024.dic -f utf-8 -t utf-8 mecab-user-dict-seed.20191024.csv mkdir "C:\Program Files\MeCab\dic\NEologd" move NEologd.20191024.dic "C:\Program Files\MeCab\dic\NEologd"ちなみに、意味としては
C:\Program Files\MeCab\binにあるmecab-dict-index.exeを実行し、
cdの移動先である現在のディレクトリに存在する
mecab-user-dict-seed.20191024.csvをUTF-8形式で
NEologd.20191024.dicという名前でコンパイルする。
その後、C:\Program Files\MeCab\dicの中に、NEologdを作成し、その中にコンパイルしたものを移動する。ここまでくれば、あとはもうほぼ終わりで
C:\Program Files\MeCab\etcに存在しているmecabrcをメモ帳で開いて
userdic =の部分をC:\Program Files\MeCab\dic\NEologd\Neologd.20191024.dic
に変更して上書き保存する。
権限によっては上書き保存できない場合もあるので、
別フォルダに一旦mecabrcを保存して元のところに保存すればよい。
その際に.txtを消すのを忘れずに。実際にNEologdが適用されているか確認するには、jupyterなどで実際に形態素解析をした際に、
固有名詞として欅坂46が名詞認識されていればよい。import sys import MeCab m = MeCab.Tagger ("-Ochasen") print(m.parse ("欅坂46が赤いきつねを食べている。"))おわり
より形態素解析の精度をあげていくためには、
一般的に公開されている日本語のストップワードリストを読み込んだり、
読み込む対象に特有の単語を地道にユーザー辞書として設定したり、
不要なものは地道にNGしていくことで精度があがっていくはずである。


- 投稿日:2019-11-01T15:02:26+09:00
int(num)とmath.trunc(num)とnp.trunc(num)
bresenhamを使いたい座標値がまとまったものを
bresenham.bresenhamに突っ込みたかったがbresenhamはint型しか受け付けていなかった。truncateは0方向に丸める関数
検証
計測はGoogleColabを使用
前準備として読み込みとかをするbase.pyimport math import numpy as np foo = [0.0001* i for i in range(1000000)]
int(num)%%timeit for i in foo: tmp = int(i) =>10 loops, best of 3: 105 ms per loop --- type(tmp) =>int
math.trunc(num)%%timeit for i in foo: tmp = math.trunc(i) =>10 loops, best of 3: 107 ms per loop --- type(tmp) =>int
np.trunc(num)%%timeit for i in foo: tmp = np.trunc(i) =>1 loop, best of 3: 831 ms per loop --- type(tmp) =>numpy.float64結果
int(num) ≒ math.trunc(num) >> np.trunc(num)
と考えて良さそう
- 投稿日:2019-11-01T14:38:45+09:00
Pythonで顔認証をしてみたい - Part0【準備編】
前提
このシリーズは、
・Pythonに関する基本的な知識がある方
・PCの知識がある程度ある方
を対象としています。
(ですが、わからなくても、Google先生に聞けば大抵のことはわかります)開発環境Windows10 Pro(1809) 64bit Intel(R) Core(TM) i7-8500Y@1.50GHz x4 RAM 8GBMacOSX・Linuxでも動くと思いますが、適宜変更しないといけないところがあります。なるべく書くようにはしますが、環境がないので確実でなかったりしますがそこはお許しをm(_ _)m
材料
Python
Python3.8.0 ダウンロード
これがないとお話になりません。はい。リンクを開いたら、下の方にある「Files」
の中から自分の環境に合ったものをダウンロードして、インストールしてください。
(Windowsの人は、Cドライブ直下(ex. C:\Python380)にインストールすることをおすすめします。そうしないと、ライブラリのインストールが面倒になります。)
そしたら、少し準備をします。コマンドプロンプトを起動してください。
そして、VSCodeで必要なものを入れます。コマンドC:\Users\xxx> py -m pip install pylintVisual Studio Code
Micrrosoft謹製のテキストエディタです。神です。使いやすいので、今回はこれを使います。
他のものを使ってもこのシリーズは平気ですが、これを使う前提で話を進めます。
最初は英語です。次節で日本語化もしますので、忘れずに、慌てずに。
Visual Studio Code - 公式サイト(英語)拡張機能
左側のバーの四角を押しましょう。すると、あら不思議。なにか出てきます。
そしたら、あとはかんたん。検索して「インストール」を押すだけ。Japanese Language Pack for Visual Studio Code ダウンロード
→日本語化パックです。これがないと辛いです。(英語がいい人はそのままでも別にOK)
Python ダウンロード
→Python用の拡張機能です。無いと死にます。はい。
Bracket Pair Colorizer 2 ダウンロード
→対応するかっこ「()[]<>{}」を色で示してくれます。便利です。
indent-rainbow ダウンロード
→インデントを見やすくします。これがないと泣きます。(多分僕だけだが)GitHub
「コードを自分で打つのがめんどくさい」
と考えるなまけもののあなたのために、GitHubにPartごとに分けてアップロードします。
ダウンロードはこちらから↓
Hiro527/OpenCV-Py3-Face



- 投稿日:2019-11-01T13:44:14+09:00
プログラミング問題集(問11〜問15)
問11:区分求積法(長方形近似)
積分を数値的に求める区分求積法として、長方形近似、台形則、シンプソン則などがある。そのうち長方形近似では、ある点 $x_i$ における値 $f(x_i)$ に幅 $h$ をかけた長方形を足し合わせたものを積分値として近似する。
長方形近似を用いて、上の式を数値的に解け。
問12:区分求積法(台形則)
積分を数値的に求める区分求積法として、長方形近似、台形則、シンプソン則などがある。そのうち台形則では、ある点 $x_i$ とその前の点 $x_{i-1}$ における、$f(x_i)$ と $f(x_{i-1})$ による幅 $h$ の台形を足し合わせたものを積分値として近似する。
台形則を用いて、上の式を数値的に解け。
問13:区分求積法(シンプソン則)
積分を数値的に求める区分求積法として、長方形近似、台形則、シンプソン則などがある。そのうちシンプソン則では、ある点 $x_i$ とその前の点 $x_{i-1}$、後の点 $x_{i+1}$ を通る二次関数を導出し、その$f(x_{i-1})$ から $f(x_{i+1})$ までの積分値$h(f(x_{i+1})+4f(x_i)+f(x_{i-1}))/3$ を足し合わせたものを積分値として近似する。
シンプソン則を用いて、上の式を数値的に解け。
問14:エラトステネスの篩
整数 $n$ を入力すると、 $n$ 以下の素数の個数を返す関数を作りなさい。またそのアルゴリズムを説明しなさい。
ただし、
- 1 ≤ $n$ ≤ 106
とする。
例14-1
n = 104例14-2
n = 10025例14-3
n = 1000168例14-4
n = 100001229例14-5
n = 100009592問15:格子点の個数
ユークリッド平面状に2つの格子点 $P = (x_1, y_1)$, $Q = (x_2, y_2)$ がある。線分 $PQ$ 上には、$P$, $Q$ 以外にいくつの格子点が存在するか計算する関数を作りなさい。またそのアルゴリズムを説明しなさい。
ただし、
- -106 ≤ $x_1$ ≤ 106
- -106 ≤ $x_2$ ≤ 106
- -106 ≤ $y_1$ ≤ 106
- -106 ≤ $y_2$ ≤ 106
とする。
【ヒント】 最大公約数を求める問題に帰着できます。「ユークリッドの互除法」で効率的に解けます。
例15-1
x1 = -2 y1 = -9 x2 = 6 y2 = 77# 図示して確認 %matplotlib inline import matplotlib.pyplot as plt fig = plt.figure() ax = fig.add_subplot(111) ax.plot([x1, x2], [y1, y2]) ax.set_xticks(range(x1, x2 + 1, 1)) ax.set_yticks(range(y1, y2 + 1, 1)) ax.set_xlabel("x") ax.set_ylabel("y") ax.grid()
例15-2
x1 = -42 y1 = -65 x2 = 62 y2 = -9125例15-3
x1 = 908 y1 = -307 x2 = -86 y2 = -6791例15-4
x1 = -6326 y1 = 3211 x2 = 7048 y2 = 58220例15-5
x1 = -9675 y1 = -2803 x2 = 3828 y2 = -63492参考:例の作り方
import random x1 = random.randint(-1000000, 1000000) y1 = random.randint(-1000000, 1000000) x2 = random.randint(-1000000, 1000000) y2 = random.randint(-1000000, 1000000) print("x1 = ", x1) print("y1 = ", y1) print("x2 = ", x2) print("y2 = ", y2)


- 投稿日:2019-11-01T12:34:18+09:00
Pythonの数値、文字列、リスト型(Python学習メモ①)
Pythonの型
数値
ポイント
- 除算(
/)は常にfloatを返す- 切り下げ除算を行ってint型を得たい場合は
//演算子を使う- 剰余を得たい場合は
%を使う- 演算対象の型が混同していた場合は、整数は浮動小数点数に変換される
- 対話モードでは、最後に表示した式を変数「
_」に代入してあるので電卓と使用するのに楽- Pythonでは整数型、浮動小数点数型以外にも、十進数(Decimal)や有理数(Fraction)などがサポートされている
- 複素数もサポートされており、虚部を表現するのに接頭辞
jまたはJを使用して3+5jなどとする# 足し算 >>> 2+2 4 # 引き算と掛け算 >>> 50 - 5 * 6 20 >>> (50 - 5) *6 270 # 割り算 >>> 17 / 3 5.666666666666667 >>> 17 // 3 5 >>> 17 % 3 2 # 累乗 >>> 5 ** 2 25 >>> 5 ** 3 125 # 対話モードを電卓として使う >>> _ + 1 126文字列型
ポイント
- 引用符にはシングルクォート、ダブルクォートどちらも使用でき、区別されない
- クォート文字のエスケープは
\でできる\を前置した文字列が特殊文字に解釈されるのが嫌な場合はraq文字列を使う- 複数行の文字列はトリプルクォートで表現できる
- 行末文字は自動的に文字列に含有されるが、開業したくない場合は行末に
\を置くとエスケープされる- 文字列は
+演算子で結合でき、*で繰り返すこともできる- 文字列リテラルが連続している場合は自動で連結される
- 文字列はインデックス指定が可能
- インデックスは文字と文字の間を指す数字であり、最初の文字の左端が0である、と考えるのが便利
- 文字列はスライシングも可能
- インデックスで範囲外の値を指定するとエラーになる
- スライシングは範囲外を指定してもエラーにはならない
- pythonの文字列はimmutableなので、インデックスを利用して文字の改変を行うことはできない(やりたい場合は新たに文字列を生成する)
- len関数は文字列の長さを返す
# raw name (文字列の前にrをつける) >>> print('C:\some\name') C:\some ame >>> print(r'C:\some\name') C:\some\name # 複数行 print("""\ Usage: thingy [OPTIONS] -h Display this usage message -H hostname """) # 出力 Usage: thingy [OPTIONS] -h Display this usage message -H hostname # 文字列の繰り返しと連結 >>> 3 * "un" + "ium" 'unununium' # 文字列リテラルの自動連結(変数では使えない) >>> 'Py' 'thon' 'Python' # index >>> word[0] 'P' >>> word[-1] 'n' # slice >>> word[:3] 'Pyt' >>> word[3:] 'hon' # len >>> len(word) 6リスト
ポイント
- 基本的には同じ型を入れる
- 文字列同様、インデックスとスライシングが使える
- スライシングは常に要求された要素を含んだ新たなリストを返す
- リストは文字列と違ってmutableなので変更可能
.appendで末尾に要素を追加する- スライシングへの代入も可能
- len関数はリストにも使える
- リストは入れ子にできる
# リスト >>> letters = ['a', 'b', 'c', 'd', 'e', 'f'] # index >>> letters[1] 'b' # slicing >>> letters[3:] ['d', 'e', 'f'] # append >>> letters.append('g') >>> letters ['a', 'b', 'c', 'd', 'e', 'f', 'g'] # slicingへの代入 >>> letters[3:5] = ['D', 'E'] >>> letters ['a', 'b', 'c', 'D', 'E', 'f', 'g'] # len >>> len(letters) 7 # 入れ子のリスト >>> array = [['a', 'b', 'c'], [1, 2, 3]]フィボナッチ数列を求める
# フィボナッチ級数 # このように多重代入が可能 a, b = 0, 1 while b < 10: print(b) a, b = b, a+bprint関数について
- 複数値を引数に指定可能
- キーワード引数endを使うと、出力末尾の開業の抑制や、出力末尾を他の文字列に変更することができる
- キーワード引数sepを使うと、引数間の文字を変更できる
name = 'Kawausomando' # 複数値指定(間にはスペースが付与される) print('My name is', name) # 出力: My name is Kawausomando # endキーワード print(name, end=' is my name') # 出力: Kawausomando is my name # sepキーワード print(1, 2, 3, sep=' and ') # 出力: 1 and 2 and 3
- 投稿日:2019-11-01T12:25:43+09:00
BlenderのPythonスクリプトのコードが2.80で動かなかった時に見る記事
おはPython! 皆様、今日も元気にモデリングしてますか!
私はといえば、BlenderをPythonスクリプトで動かそうとしたところ、謎のエラーに苦しめられていました。悪戦苦闘した結果、その原因はAPIの仕様変更にあることがわかりました。現在ネット上に公開されているコード(≒2.79以前用)はほとんどコピペしただけでは動かないと考えてよいでしょう。
そこで、現在公開されているコードについて、ここをこうすれば2.80でも動くよ! という形を直したものを公開しようと思います。変更前と変更後のコードを並べた後で、変更があった個所には該当リファレンスを参照してこのように変更されていますよ、という形で解説していこうと思います。キーとなる変更ポイントはどのコードでもだいたい同じなので、おそらく他のコードでエラーに見舞われた人の役にも立つかと思われます。
コードを書いてくださった方々は何も悪くないのですが、仕様変更があったので仕方がありません。進化しているBlenderが悪い訳でもない。誰も悪い訳ではないのに人々が苦しんでいるなら……その罪、俺が背負ってやる。
第1例
以上のようなメッシュを作成するスクリプトです。
コード
オリジナル
2.79import bpy import math #reset objects bpy.ops.object.select_all(action='SELECT') bpy.ops.object.delete(True) #world bpy.context.scene.world.horizon_color=(0.0,0.0,0.0) #plane_add for i in range(0,100): bpy.ops.mesh.primitive_plane_add(radius = (i*1.1/100),location=(0,0,0),rotation=(math.pi*1/2,math.pi*i*8.2/360,math.pi*i*10/360)) for item in bpy.context.scene.objects: if item.type == 'MESH': bpy.context.scene.objects.active = bpy.data.objects[item.name] bpy.ops.object.modifier_add(type='WIREFRAME') bpy.context.object.modifiers['Wireframe'].thickness = 0.0025 bpy.context.object.modifiers['Wireframe'].use_boundary = True #lamp add bpy.ops.object.lamp_add(type='HEMI',location=(0.0,0.0,2.0)) #camera add bpy.ops.object.camera_add(location=(5.0,0.0,0.0)) bpy.data.objects['Camera'].rotation_euler = (math.pi*1/2, 0, math.pi*1/2) #render bpy.context.scene.render.resolution_x = 1000 bpy.context.scene.render.resolution_y = 1000 bpy.context.scene.render.resolution_percentage = 100 bpy.context.scene.camera = bpy.context.object bpy.context.scene.render.image_settings.file_format = 'PNG' bpy.data.scenes["Scene"].render.filepath = "tmp/plane.png" bpy.ops.render.render(write_still=True)変更後
2.80import bpy import math #reset objects bpy.ops.object.select_all(action='SELECT') bpy.ops.object.delete(True) #plane_add for i in range(0,100): bpy.ops.mesh.primitive_plane_add(size = (i*1.1/100),location=(0,0,0),rotation=(math.pi*1/2,math.pi*i*8.2/360,math.pi*i*10/360)) for item in bpy.context.scene.objects: if item.type == 'MESH': bpy.context.view_layer.objects.active = bpy.data.objects[item.name] bpy.ops.object.modifier_add(type='WIREFRAME') bpy.context.object.modifiers['Wireframe'].thickness = 0.0025 bpy.context.object.modifiers['Wireframe'].use_boundary = True #lamp add bpy.ops.object.light_add(location=(0.0,0.0,2.0)) #camera add bpy.ops.object.camera_add(location=(5.0,0.0,0.0)) bpy.data.objects['Camera'].rotation_euler = (math.pi*1/2, 0, math.pi*1/2) #render bpy.context.scene.render.resolution_x = 1000 bpy.context.scene.render.resolution_y = 1000 bpy.context.scene.render.resolution_percentage = 100 bpy.context.scene.camera = bpy.context.object bpy.context.scene.render.image_settings.file_format = 'PNG' bpy.data.scenes["Scene"].render.filepath = "tmp/plane.png" bpy.ops.render.render(write_still=True)変更箇所
2.79bpy.ops.mesh.primitive_plane_add(radius = (i*1.1/100),location=(0,0,0),rotation=(math.pi*1/2,math.pi*i*8.2/360,math.pi*i*10/360))2.80bpy.ops.mesh.primitive_plane_add(size = (i*1.1/100),location=(0,0,0),rotation=(math.pi*1/2,math.pi*i*8.2/360,math.pi*i*10/360))平面のプリミティブを追加。スケールを示す
radiusがsizeに。
2.79bpy.context.scene.objects.active = bpy.data.objects[item.name]2.80bpy.context.view_layer.objects.active = bpy.data.objects[item.name]アクティブなオブジェクトを選択。オリジナルでは
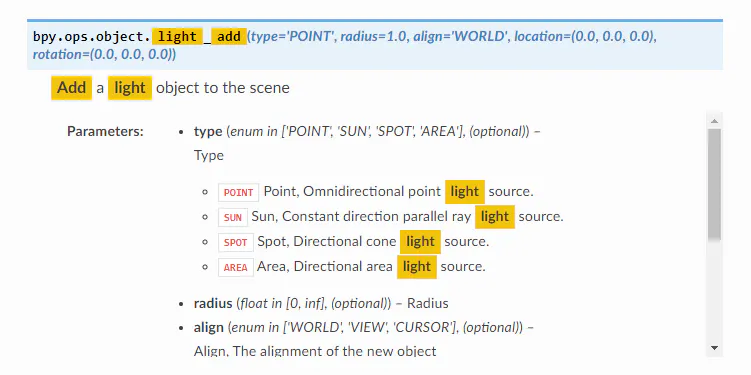
bpy.context.scene~となっていた部分をbpy.context.view_layer~とする必要があります。sceneのAPIも残っているのでどういう使い分けかは正直よくわかりませんが、ここら辺はリファレンスのこのあたりを読んで勉強するしかなさそうです。2.79bpy.ops.object.lamp_add(type='HEMI',location=(0.0,0.0,2.0))2.80bpy.ops.object.light_add(location=(0.0,0.0,2.0))ランプの追加。
lampの名前をlightに変更。またHEMI(半球)タイプのライトも消滅。
#world bpy.context.scene.world.horizon_color=(0.0,0.0,0.0)これについては代替APIが見つかりませんでした。GUIでは
ここを操作することで変更できます。一応
bpy.context.scene.world.colorというAPIがあるのですが、ここを指定しても変わらず。ここは力及ばずです。再現実装したい人は手動で変更してください。すいません……。第2例
blenderのpythonスクリプト入門してみた_その01
以上のようなメッシュを、プリミティブを使わずに生成するスクリプトです。
ソースコード
オリジナル
2.79import bpy # デフォルトのCubeを削除 def delete_all(): for item in bpy.context.scene.objects: bpy.context.scene.objects.unlink(item) for item in bpy.data.objects: bpy.data.objects.remove(item) for item in bpy.data.meshes: bpy.data.meshes.remove(item) for item in bpy.data.materials: bpy.data.materials.remove(item) delete_all() # 頂点座標を定義 coords=[ (-1.0, -1.0, -1.0), ( 1.0, -1.0, -1.0), ( 1.0, 1.0, -1.0), (-1.0, 1.0, -1.0), ( 0.0, 0.0, 1.0) ] # この添字を使って面を定義 # 各面は4つの整数の並びで定義 # 三角形の面は最初の頂点と4つ目の頂点が同じになる必要 faces=[ (2,1,0,3), (0,1,4,0), (1,2,4,1), (2,3,4,2), (3,0,4,3) ] # 新規メッシュを作成 me = bpy.data.meshes.new("PyramidMesh") # メッシュでオブジェクトを作成 ob = bpy.data.objects.new("Pyramid", me) # オブジェクトを 3D カーソルの位置に配置 ob.location = bpy.context.scene.cursor_location # オブジェクトをシーンにリンク bpy.context.scene.objects.link(ob) # メッシュの頂点、辺、面を埋めまる me.from_pydata(coords,[],faces) # 新たなデータでメッシュを更新 me.update(calc_edges=True)変更後
2.80import bpy # デフォルトのCubeを削除 def delete_all(): for item in bpy.context.scene.objects: bpy.context.scene.collection.objects.unlink(item) for item in bpy.data.objects: bpy.data.objects.remove(item) for item in bpy.data.meshes: bpy.data.meshes.remove(item) for item in bpy.data.materials: bpy.data.materials.remove(item) delete_all() # 頂点座標を定義 coords=[ (-1.0, -1.0, -1.0), ( 1.0, -1.0, -1.0), ( 1.0, 1.0, -1.0), (-1.0, 1.0, -1.0), ( 0.0, 0.0, 1.0) ] # この添字を使って面を定義 # 各面は4つの整数の並びで定義 # 三角形の面は最初の頂点と4つ目の頂点が同じになる必要 faces=[ (2,1,0,3), (0,1,4,0), (1,2,4,1), (2,3,4,2), (3,0,4,3) ] # 新規メッシュを作成 me = bpy.data.meshes.new("PyramidMesh") # メッシュでオブジェクトを作成 ob = bpy.data.objects.new("Pyramid", me) # オブジェクトを 3D カーソルの位置に配置 ob.location = bpy.context.scene.cursor.location # オブジェクトをシーンにリンク bpy.context.scene.collection.objects.link(ob) # メッシュの頂点、辺、面を埋めまる me.from_pydata(coords,[],faces) # 新たなデータでメッシュを更新 me.update(calc_edges=True)変更箇所
2.79bpy.context.scene.objects.unlink(item)2.80bpy.context.scene.collection.objects.unlink(item)現在のシーンの中にあるオブジェクトに関する命令ですが、
sceneの下に更にcollectionという階層が追加されたので、それを反映させる必要があります。sceneの直下にもobjectsがあって、それだとオブジェクトをlinkまたはunlinkする時にエラーが出る、というのが中々の初見殺しですね。AttributeError: 'bpy_prop_collection' object has no attribute 'link'というエラーに泣かされた人も多いのではないでしょうか。2.79ob.location = bpy.context.scene.cursor_location2.80ob.location = bpy.context.scene.cursor.locationカーソル位置の指定。2.79以下では
curosr_locationというAPIがありましたが、2.80ではcursorの下にlocationがある、という階層構造になってようです。該当リファレンス:https://docs.blender.org/api/current/bpy.types.View3DCursor.html
2.79bpy.context.scene.objects.link(ob)2.80bpy.context.scene.collection.objects.link(ob)先ほどの
collectionの話と同様。使えるAPIをみつけるコツ
このように、変更点がありすぎて必要となる情報もまだ少ない、という状況なので、使えるAPIは自分で探すことも必要になります。そのような時には、
BlenderのPythonコンソール上で
Ctrl+Spaceキーを押すと候補となるコマンドの一覧が出てきますので(途中まで入力していればそれに応じて候補が絞られます)役に立つかもしれないです。それでは皆様よきBlender 2.80ライフを。





- 投稿日:2019-11-01T12:00:47+09:00
pythonのMySQLdbで日本語の入ったクエリを投げる際のUnicodeEncodeError回避
概要
pythonからMySQLへとinsert文を投げたい時があります。
MySQLdbパッケージを使ってクエリを投げる際に、クエリに日本語が入っているとUnicodeEncodeErrorが出てしまいます。
これはMySQLdb.connect()の引数に"use_unicode=True"、"charset="utf8""というオプションを追加すると回避できるようです。状況
こういったMySQLのデータベースがあるとします。
mysql> desc test; +-----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------+-------------+------+-----+---------+-------+ | test_id | int(11) | NO | PRI | NULL | | | test_text | varchar(64) | YES | | NULL | | +-----------+-------------+------+-----+---------+-------+pythonからtest_textというカラムに文字列を追加したいという気持ちが生まれました。
普通にMySQLdbパッケージを使ってinsert文を投げてみます。mysqltest.pyimport MySQLdb try: conn = MySQLdb.connect( host=host, db=dbname, port=port, user=user, passwd=password ) cur = conn.cursor() query = "insert into test values('1','aaa')" cur.execute(query) except: cur.close() conn.close() cur.close() conn.commit() conn.close()アルファベット文字列なら普通にできます。
mysql> select * from test; +---------+-----------+ | test_id | test_text | +---------+-----------+ | 1 | aaa | +---------+-----------+しかしながら日本語の文字列だと…。
mysqltest.py(省略) query = "insert into test values('2','あああ')" cur.execute(query) (省略)Traceback (most recent call last): File "mysqltest.py", line 30, in <module> conn.commit() _mysql_exceptions.OperationalError: (2006, '')といったエラーが出ます。
これはtry文での例外をキャッチした後にconn.commit()をしようとして出たエラーのようです。
このスタックトレースではよくわからんのでexcept文が実行されたタイミングでスタックトレースを出してみましょう。mysqltest.pyimport MySQLdb import traceback try: conn = MySQLdb.connect( host=host, db=dbname, port=port, user=user, passwd=password ) cur = conn.cursor() query = "insert into test values('2','あああ')" cur.execute(query) except: cur.close() conn.close() print(traceback.format_exc()) cur.close() conn.commit() conn.close()するとこのように出てきます。
Traceback (most recent call last): File "mysqltest.py", line 25, in <module> cur.execute(query) File "C:\path\to\anaconda\lib\site-packages\MySQLdb\cursors.py", line 248, in execute query = query.encode(db.encoding, 'surrogateescape') UnicodeEncodeError: 'latin-1' codec can't encode characters in position 29-31: ordinal not in range(256)latin-1という文字コードでクエリがエンコードできないという怒られが発生しています。
どうやらMySQLdbパッケージはデフォルトでlatin-1を使ってエンコードするようです。どうして?対策
こちらを参考にすると、MySQLdb.connect()の引数でエンコード方法を指定できるようです。
"use_unicode=True"と"charset="utf8""を引数に与えてやると、mysqltest.pyimport MySQLdb import traceback try: conn = MySQLdb.connect( host=host, db=dbname, port=port, user=user, passwd=password, use_unicode=True, charset="utf8" ) cur = conn.cursor() query = "insert into test values('2','あああ')" cur.execute(query) except: cur.close() conn.close() print(traceback.format_exc()) cur.close() conn.commit() conn.close()クエリが無事utf-8でエンコードされ、上手くいきました。
mysql> select * from test; +---------+-----------+ | test_id | test_text | +---------+-----------+ | 1 | aaa | | 2 | あああ | +---------+-----------+
- 投稿日:2019-11-01T12:00:47+09:00
PythonのMySQLdbで日本語の入ったクエリを投げる際のUnicodeEncodeError回避
概要
PythonからMySQLへとinsert文を投げたい時があります。
MySQLdbパッケージを使ってクエリを投げる際に、クエリに日本語が入っているとUnicodeEncodeErrorが出てしまいます。
これはMySQLdb.connect()の引数に"use_unicode=True"、"charset="utf8""というオプションを追加すると回避できるようです。状況
こういったMySQLのデータベースがあるとします。
mysql> desc test; +-----------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-----------+-------------+------+-----+---------+-------+ | test_id | int(11) | NO | PRI | NULL | | | test_text | varchar(64) | YES | | NULL | | +-----------+-------------+------+-----+---------+-------+Pythonからtest_textというカラムに文字列を追加したいという気持ちが生まれました。
普通にMySQLdbパッケージを使ってinsert文を投げてみます。mysqltest.pyimport MySQLdb try: conn = MySQLdb.connect( host=host, db=dbname, port=port, user=user, passwd=password ) cur = conn.cursor() query = "insert into test values('1','aaa')" cur.execute(query) except: cur.close() conn.close() cur.close() conn.commit() conn.close()アルファベット文字列なら普通にできます。
mysql> select * from test; +---------+-----------+ | test_id | test_text | +---------+-----------+ | 1 | aaa | +---------+-----------+しかしながら日本語の文字列だと…。
mysqltest.py(省略) query = "insert into test values('2','あああ')" cur.execute(query) (省略)Traceback (most recent call last): File "mysqltest.py", line 30, in <module> conn.commit() _mysql_exceptions.OperationalError: (2006, '')といったエラーが出ます。
これはtry文での例外をキャッチした後にconn.commit()をしようとして出たエラーのようです。
このスタックトレースではよくわからんのでexcept文が実行されたタイミングでスタックトレースを出してみましょう。mysqltest.pyimport MySQLdb import traceback try: conn = MySQLdb.connect( host=host, db=dbname, port=port, user=user, passwd=password ) cur = conn.cursor() query = "insert into test values('2','あああ')" cur.execute(query) except: cur.close() conn.close() print(traceback.format_exc()) cur.close() conn.commit() conn.close()するとこのように出てきます。
Traceback (most recent call last): File "mysqltest.py", line 25, in <module> cur.execute(query) File "C:\path\to\anaconda\lib\site-packages\MySQLdb\cursors.py", line 248, in execute query = query.encode(db.encoding, 'surrogateescape') UnicodeEncodeError: 'latin-1' codec can't encode characters in position 29-31: ordinal not in range(256)latin-1という文字コードでクエリがエンコードできないという怒られが発生しています。
どうやらMySQLdbパッケージはデフォルトでlatin-1を使ってエンコードするようです。どうして?対策
こちらを参考にすると、MySQLdb.connect()の引数でエンコード方法を指定できるようです。
"use_unicode=True"と"charset="utf8""を引数に与えてやると、mysqltest.pyimport MySQLdb import traceback try: conn = MySQLdb.connect( host=host, db=dbname, port=port, user=user, passwd=password, use_unicode=True, charset="utf8" ) cur = conn.cursor() query = "insert into test values('2','あああ')" cur.execute(query) except: cur.close() conn.close() print(traceback.format_exc()) cur.close() conn.commit() conn.close()クエリが無事utf-8でエンコードされ、上手くいきました。
mysql> select * from test; +---------+-----------+ | test_id | test_text | +---------+-----------+ | 1 | aaa | | 2 | あああ | +---------+-----------+
- 投稿日:2019-11-01T10:48:49+09:00
【PyQt】QLabelのテキストカラー変更
環境
- Windows 10
- Python 3.7.3
- PyQt5 5.13.1
- Qt Designer 5.11.1
QLabelのサンプル作成
Qt Designerを使って、適当なラベルを配置した画面を作ります。
Designerを使った画面の作り方はこちらを参考。
hoge_label_ui.py# -*- coding: utf-8 -*- # Form implementation generated from reading ui file 'hoge_label.ui' # # Created by: PyQt5 UI code generator 5.13.1 # # WARNING! All changes made in this file will be lost! from PyQt5 import QtCore, QtGui, QtWidgets class Ui_Form(object): def setupUi(self, Form): Form.setObjectName("Form") Form.resize(225, 123) self.hoge_label = QtWidgets.QLabel(Form) self.hoge_label.setGeometry(QtCore.QRect(30, 20, 181, 91)) font = QtGui.QFont() font.setPointSize(64) self.hoge_label.setFont(font) self.hoge_label.setObjectName("hoge_label") self.retranslateUi(Form) QtCore.QMetaObject.connectSlotsByName(Form) def retranslateUi(self, Form): _translate = QtCore.QCoreApplication.translate Form.setWindowTitle(_translate("Form", "Form")) self.hoge_label.setText(_translate("Form", "hoge"))label_sample.pyimport sys from PyQt5.QtWidgets import QApplication from PyQt5.QtWidgets import QMainWindow from hoge_label_ui import Ui_Form class LabelSample(QMainWindow, Ui_Form): def __init__(self, parent=None): super(LabelSample, self).__init__(parent) self.setupUi(self) if __name__ == '__main__': argvs = sys.argv app = QApplication(argvs) label_sample = LabelSample() label_sample.show() sys.exit(app.exec_())テキストの色を変える
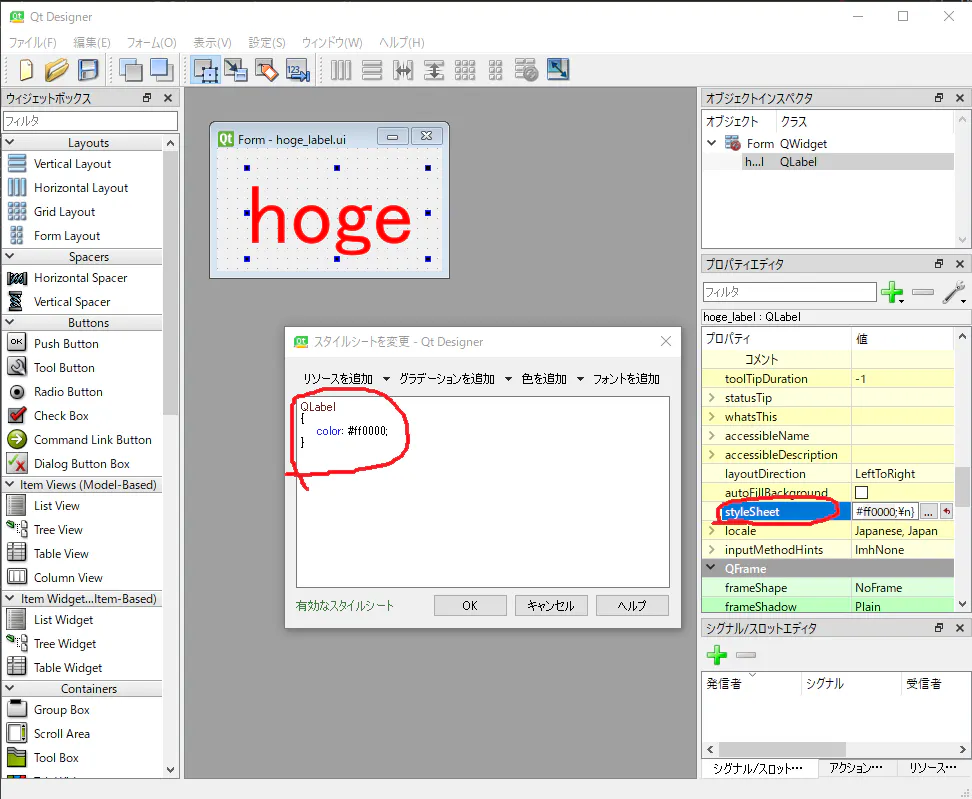
self.hoge_label.setStyleSheet("QLabel { color : red; }")
を追加
label_sample.pyの一部def __init__(self, parent=None): super(LabelSample, self).__init__(parent) self.setupUi(self) self.hoge_label.setStyleSheet("QLabel { color : red; }")色の指定は16進表記でもOK。
self.hoge_label.setStyleSheet("QLabel { color : #ff0000; }")あるいはDesigner上のプロパティのstyleSheetを編集しても同じことができます。
参考URL


- 投稿日:2019-11-01T10:28:41+09:00
分布と検定
分布
乱数と一様分布
まずは、一様乱数を発生させて、その分布を図示してみましょう。
# 乱数を扱うためのライブラリをインポートする。 import randomsample_size = 10 # 乱数発生回数 # 一様乱数を dist に格納する (distribution : 分布) dist = [random.random() for i in range(sample_size)]# dist の中身を確認する。 dist# 図やグラフを図示するためのライブラリをインポートする。 import matplotlib.pyplot as plt %matplotlib inline# ヒストグラムを描く。 plt.hist(dist) plt.grid() plt.show()乱数発生回数を増やしてみる
乱数発生回数を多くするにしたがって、"理想的な" 分布の形に近づいていきます。
sample_size = 100 # 乱数発生回数 # 一様乱数を dist に格納する dist = [random.random() for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist) plt.grid() plt.show()sample_size = 1000 # 乱数発生回数 # 一様乱数を dist に格納する dist = [random.random() for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist) plt.grid() plt.show()sample_size = 10000 # 乱数発生回数 # 一様乱数を dist に格納する dist = [random.random() for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist) plt.grid() plt.show()sample_size = 100000 # 乱数発生回数 # 一様乱数を dist に格納する dist = [random.random() for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist) plt.grid() plt.show()binを増やしてみる
ゴミを分別するのに使う箱のことを bin と言います。ヒストグラムを描く時は、いくつの bin に分別するかで表示が違ってきます。binの数を多くすると、分布の細かい形が見えますが、ひとつのbinあたり分別されたデータ数は当然少なくなります。
sample_size = 100000 # 乱数発生回数 # 一様乱数を dist に格納する dist = [random.random() for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist, bins=100) # binを多くする plt.grid() plt.show()二項分布
np.random.binomial(n, p) は、確率pで奇数が出る(確率1-pで偶数が出る)ルーレットをn回プレイしたときに、奇数が出る個数を返します。このような分布を、二項分布と言います。
等確率の二項分布
奇数と偶数が等確率で出るルーレットを10回プレイし、奇数が出る回数を数えます。それを10000回繰り返します。奇数と偶数が同じ回数だけ出る確率(5回ずつ出る確率)はどのくらいでしょうか。
# 数値計算のライブラリをインポートする。 import numpy as npsample_size = 10000 # 乱数発生回数 # 確率pで奇数が出る(確率1-pで偶数が出る)ルーレットをn回プレイしたときに、 # 奇数が出る回数の分布 dist = [np.random.binomial(n=10, p=0.5) for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist, bins=100) plt.grid() plt.show()上図から分かるように、奇数と偶数が等確率で出るルーレットを10回プレイして、奇数と偶数が同じ回数だけ出る確率(5回ずつ出る確率)は、約25%(10000回中の約2500回)ほどです。案外少ない、という印象を持つかもしれませんね。
そのルーレットはイカサマか
あなたはカジノで他の客がルーレットをプレイしているのを観察していました。すると、奇数の出る回数がやけに多いので、そのルーレットはイカサマではないかという気がしてきました。イカサマでなければ、ルーレットは奇数と偶数が等確率で出るはずです。ところがこのルーレットは、100回中60回、奇数が出ました。このルーレットはイカサマでしょうか。
奇数と偶数が等確率で出るルーレットを100回プレイした時、奇数が出る回数が60回以上になる確率はどれくらいでしょうか。まずは分布を描いてみましょう。
sample_size = 10000 # 乱数発生回数 # 確率pで奇数が出る(確率1-pで偶数が出る)ルーレットをn回プレイしたときに、 # 奇数が出る回数の分布 dist = [np.random.binomial(n=100, p=0.5) for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist, bins=100) plt.grid() plt.show()上と同様の計算で、今度は「ルーレットを100回プレイして奇数が60回以上出る確率」を計算してみます。
sample_size = 10000 # 乱数発生回数 # 確率pで奇数が出る(確率1-pで偶数が出る)ルーレットをn回プレイしたときに、 # 奇数が出る回数の分布 dist = [np.random.binomial(n=100, p=0.5) for i in range(sample_size)] p = sum([1 for n in dist if n >= 60]) / sample_size print("p値: %(p)s " %locals())奇数と偶数が等確率で出るルーレットを100回プレイして、奇数が出る回数が「偶然」60回以上になる確率は 5% 以下になることが分かりました。つまり、100回中60回以上奇数が出るようなルーレットは、そのルーレットがイカサマだと疑ってみるのが良さそうです。
このときのpを、p値(有意確率)と呼びます。
- 帰無仮説:そのルーレットはイカサマではない(奇数と偶数が等確率で出る)。
- 対立仮説:そのルーレットはイカサマである。
- p < 0.05 なので、有意水準5%で、帰無仮説を棄却できる。
- すなわち、そのルーレットはイカサマである可能性が高い。
課題1
100回中60回以上奇数が出るようなルーレットは、そのルーレットがイカサマだと疑ってみるのが良さそうです。では、10回中6回以上奇数が出た場合、奇数が出た確率は同じ60%ですが、そのルーレットはイカサマと言えるでしょうか。p値を計算して答えてください。
# 課題1等確率でない二項分布
全住民の5%がある感染症に罹患したと推定されている。その全住民の中から無作為に20人を抽出した場合、抽出された集団の中に罹患者は何人いるでしょうか。そのような分布も二項分布になります。分布を描いてみましょう。
sample_size = 10000 # 乱数発生回数 # 確率pで奇数が出る(確率1-pで偶数が出る)ルーレットをn回プレイしたときに、 # 奇数が出る回数の分布 dist = [np.random.binomial(n=20, p=0.05) for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist, bins=100) plt.grid() plt.show()課題2
全住民の5%がある感染症に罹患したと推定されている。その全住民の中から無作為に100人を抽出したところ、抽出された集団の中に罹患者が10人以上いた。
(1) それが偶然起こる確率を概算しなさい。
(2) その結果をどう解釈すれば良いか。
# 課題2正規分布
random.normalvariate(mu, sigma) は正規分布に従う乱数を発生させる関数です(mu は平均で、sigma は標準偏差)。
標準正規分布
平均0、標準偏差1の正規分布を「標準正規分布」と言います。標準正規分布を描いてみましょう。
sample_size = 10000 # 乱数発生回数 dist = [random.normalvariate(mu=0, sigma=1) for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist, bins=100) plt.grid() plt.show()標準正規分布に従う乱数が2以上の値を出力する確率はどのくらいでしょうか。計算してみましょう。
sample_size = 10000 # 乱数発生回数 dist = [random.normalvariate(mu=0, sigma=1) for i in range(sample_size)] p = sum([1 for n in dist if n >= 2]) / sample_size print("p値: %(p)s " %locals())偏差値
大学受験模試などでよく使われる「偏差値」は、平均50、標準偏差10の正規分布に従うという仮定をおいています。分布を描いてみましょう。ここで、縦軸は「学生数」をイメージしてください。
sample_size = 10000 # 乱数発生回数 # 平均50、標準偏差10の正規分布 dist = [random.normalvariate(mu=50, sigma=10) for i in range(sample_size)] # ヒストグラムを描く。 plt.hist(dist, bins=100) plt.grid() plt.show()課題3
偏差値70以上の学生は、1万人中、何人いると推定されるでしょうか。
# 課題3検定
import numpy as np # 数値計算を行うライブラリ import scipy as sp # 科学計算ライブラリ from scipy import stats # 統計計算ライブラリカイ2乗検定
カイ2乗検定は、2つの分布が同じかどうかを検定するときに用いる手法です。
サイコロを60回ふり、各目が出た回数を数えたところ、次のようになりました。
サイコロの目 1 2 3 4 5 6 出現回数 17 10 6 7 15 5 このとき、理論値の分布(一様分布)に従うかどうかを検定してみましょう。
significance = 0.05 o = [17, 10, 6, 7, 15, 5] # 実測値 e = [10, 10, 10, 10, 10, 10] # 理論値 chi2, p = stats.chisquare(o, f_exp = e) print('chi2 値は %(chi2)s' %locals()) print('確率は %(p)s' %locals()) if p < significance: print('有意水準 %(significance)s で、有意な差があります' %locals()) else: print('有意水準 %(significance)s で、有意な差がありません' %locals())chi2 値は 12.4 確率は 0.029699459203520212 有意水準 0.05 で、有意な差があります課題4
ある野菜をA方式で育てたものとB方式で育てたものの出荷時の等級が次の表のようになったとき,これらの育て方と製品の等級には関連があると見るべきでしょうか。
優 良 可 計 A方式 12 30 58 100 B方式 14 90 96 200 計 26 120 154 300 # 課題4対応のない t 検定
# 対応のないt検定 significance = 0.05 X = [68, 75, 80, 71, 73, 79, 69, 65] Y = [86, 83, 76, 81, 75, 82, 87, 75] t, p = stats.ttest_ind(X, Y) print('t 値は %(t)s' %locals()) print('確率は %(p)s' %locals()) if p < significance: print('有意水準 %(significance)s で、有意な差があります' %locals()) else: print('有意水準 %(significance)s で、有意な差がありません' %locals())t 値は -3.214043146821967 確率は 0.006243695014300228 有意水準 0.05 で、有意な差があります課題5
6年1組と6年2組の2つのクラスで同一の算数のテストを行い、採点結果が出ました。2つのクラスで点数に差があるかどうか検定してください。
6年1組 点数 6年2組 点数 1 70 1 85 2 75 2 80 3 70 3 95 4 85 4 70 5 90 5 80 6 70 6 75 7 80 7 80 8 75 8 90 class_one = [70, 75, 70, 85, 90, 70, 80, 75] class_two = [85, 80, 95, 70, 80, 75, 80, 90]# 課題5対応のある t 検定
# 対応のあるt検定 significance = 0.05 X = [68, 75, 80, 71, 73, 79, 69, 65] Y = [86, 83, 76, 81, 75, 82, 87, 75] t, p = stats.ttest_rel(X, Y) print('t 値は %(t)s' %locals()) print('確率は %(p)s' %locals()) if p < significance: print('有意水準 %(significance)s で、有意な差があります' %locals()) else: print('有意水準 %(significance)s で、有意な差がありません' %locals())t 値は -2.9923203754253302 確率は 0.02016001617368161 有意水準 0.05 で、有意な差があります課題6
国語と算数の点数に差があるかどうか検定してください。
6年1組 国語 算数 1 90 95 2 75 80 3 75 80 4 75 80 5 80 75 6 65 75 7 75 80 8 80 85 kokugo = [90, 75, 75, 75, 80, 65, 75, 80] sansuu = [95, 80, 80, 80, 75, 75, 80, 85]# 課題6分散分析
# 1要因の分散分析 significance = 0.05 a = [34, 39, 50, 72, 54, 50, 58, 64, 55, 62] b = [63, 75, 50, 54, 66, 31, 39, 45, 48, 60] c = [49, 36, 46, 56, 52, 46, 52, 68, 49, 62] f, p = stats.f_oneway(a, b, c) print('f 値は %(f)s' %locals()) print('確率は %(p)s' %locals()) if p < significance: print('有意水準 %(significance)s で、有意な差があります' %locals()) else: print('有意水準 %(significance)s で、有意な差がありません' %locals())f 値は 0.09861516667148518 確率は 0.9064161716556407 有意水準 0.05 で、有意な差がありません課題7
下記のデータを用いて、分散分析を行ってください。
group1 = [80, 75, 80, 90, 95, 80, 80, 85, 85, 80, 90, 80, 75, 90, 85, 85, 90, 90, 85, 80] group2 = [75, 70, 80, 85, 90, 75, 85, 80, 80, 75, 80, 75, 70, 85, 80, 75, 80, 80, 90, 80] group3 = [80, 80, 80, 90, 95, 85, 95, 90, 85, 90, 95, 85, 98, 95, 85, 85, 90, 90, 85, 85]# 課題7課題8
Twitter 上で行われた以下のアンケート結果の中から1つ選び、統計的検定を行いなさい。また、その結果について統計的に考察しなさい。
- 投稿日:2019-11-01T09:16:41+09:00
【Python】マルチスレッドについて初歩的なことをまとめる
Pythonのマルチスレッド
本稿では,マルチスレッドについて学んだことをまとめ,理解を深めるために記述する.
マルチスレッドについて
マルチスレッドとは、一つのコンピュータプログラムを実行する際に、複数の処理の流れを並行して進めること。また、そのような複数の処理の流れ。
プログラムをスレッドに分割すると,メモリコンテキストを共有しながら並行に実行できる.外部リソースを利用していない場合,シングルコアCPU上では,マルチスレッド化しても高速にならない.マルチコアCPU上でマルチスレッド化すると,各スレッドが別々のCPUに割り当てられ同時に並列して実行することでプログラムの速度が向上する.
スレッドとプロセスとの比較
簡易な定義,メモリ空間,コンテキストスイッチからの観点で特徴をまとめる.
定義
- プロセスは実行されたプログラムの実体
- スレッドはプロセスをさらに細かく分割した実行単位
メモリ空間
- プロセスは固有のメモリ空間を保持し,占有している.
- スレッドはメモリ空間を共有する
コンテキストスイッチ
- プロセスはコンテキストスイッチのコストがスレッドに比べると大きい.
コンテキストスイッチについて
コンテキストスイッチとは、コンピュータの処理装置(CPU)が現在実行している処理の流れ(プロセス、スレッド)を一時停止し、別のものに切り替えて実行を再開すること。
プロセスのコンテキストスイッチはメモリアドレス空間を切り替える必要があり,この操作は比較的にコストが高い操作.
以下,参考になった資料
https://code-examples.net/ja/q/530280
https://www.slideshare.net/ssuserc2d4c1/ss-124497965これにより,それぞれに対して効率性と信頼性の観点から次の特徴が存在する.
効率性
マルチプロセスによる並列処理に比べて,マルチスレッドの方が一般的にメモリ空間を共有している分,効率性が高い.
信頼性
マルチスレッドはメモリ空間を共有しているため,あるデータが並列処理から使用される場合,データをアクセスされている処理から保護する必要がある.複数のスレッドが保護されていない1つのデータを同時に更新しようとすると,競合状態に陥り,予期しないエラーが発生.データを保護するためにロックをかける必要がある.データのロックには適切に利用するのは難しい.
一方,マルチプロセスはメモリ空間を共有することがないため,マルチスレッドで起こりうるデータの破損やデッドロックが発生する可能性が減少される.
グローバルインタプリタロック(GIL)
RubyやPythonに存在するグローバルインタプリタロック(以下,「GIL」と略記)が採用されている.
Pythonでは,Pythonのオブジェクトにアクセスするスレッドは常に1スレッドだけに制限される.これはなぜか.
まず,PythonをC言語で書かれた実装(CPython)はスレッドセーフではない.スレッドセーフではないという状況は,複数のスレッドが同時に実行したり同じデータを扱ったりすると,データが壊れてしまう状況を指す.ここで言及しているデータとは,例えば「共有されているメモリ領域の内容」が挙げられる.
スレッドセーフではないために生じるデータの破損を回避するための手段として,他のスレッドと共有してしまうことを防ぐ手段が存在する.
他スレッドとの共有を防ぐためには排他ロックの仕組みを採用する必要がある.この排他ロックをGILという.
故にGILによって,常にスレッドは1つに限定される.以下の資料は大変に参考になった
http://blog.bonprosoft.com/1632
https://methane.hatenablog.jp/entry/20111203/1322900647GILついてのPython公式ドキュメントの言及
マルチ CPU マシン上で Python を使いこなすには以下の二つの手段が挙げられている.
- タスクを複数の スレッド ではなく複数の プロセス に分けることを考える
- CPythonの拡張
GILの制限を加味した上でのマルチスレッドの利用
応答のよいインターフェスを作りたい場面
GUI操作によりファイルをあるディレクトリから別ディレクトリにコピーするシステムを考える.
要件としてマルチスレッドを使用して,コピー処理をバックグラウンドで実行し,GUIウィンドウはメインスレッドにより常に更新する.
これにより,ユーザには実行あるいは操作の進捗状況がリアルタイムにフィードバックされ作業の中断も行える.
ここでの応答性のよりインターフェスを作るというのは,時間のかかるタスクをバックグラウンドで処理したり,ユーザに一定時間内にフィードバックを返すようすること.これの実現方法としてマルチスレッドの利用がある.(パフォーマンス向上の目的ではなく,データ処理に時間がかかる場合においてもインターフェスをユーザが操作できるようにするため)プロセスが外部リソースに依存している場面
プロセスが外部のリソースに依存している場合にはマルチスレッドにより高速化できる可能性がある.
外部サービスへ多数のHTTPリクエストを送信する場合,マルチスレッドがよく利用されているとのこと.
レスポンスを受け取るまでに時間のかかるWeb APIから複数の結果を取得したい場合,同期的に実行すると時間がかかる.
WebAPIと通信する場合には,並行するリクエスト(複数のリクエストが完全あるいは部分的に順序関係なく実行されても問題ない場合のリクエスト)が互いに応答時間にほぼ影響を与えずに並行処理されることがある.この並行処理の実現手段として,複数のリクエストを別々にスレッドとして実行する場合がある.
HTTPリクエストを実行する際,TCPソケットからの読み込み(recv())に時間がかかることが多い.CPythonではC言語のrecv()関数の実行はGILを解放する.(これはブロッキングなI/O処理のためらしいがまだ理解がたりない.)
GIL解放によりマルチスレッドの利用が可能.所感
PythonではI/O処理待ちにはスレッドは有用なのかなと.CPythonは自分にとってまだまだ難しい.
参考文献
http://ossforum.jp/node/579
https://ja.wikipedia.org/wiki/グローバルインタプリタロック
http://blog.bonprosoft.com/1632
https://methane.hatenablog.jp/entry/20111203/1322900647
http://e-words.jp/w/%E3%82%B3%E3%83%B3%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88%E3%82%B9%E3%82%A4%E3%83%83%E3%83%81.html
http://e-words.jp/w/%E3%83%9E%E3%83%AB%E3%83%81%E3%82%B9%E3%83%AC%E3%83%83%E3%83%89.html
マスタリングTCP/IP 入門編 第5版
エキスパートPythonプログラミング改訂2版
- 投稿日:2019-11-01T09:03:52+09:00
Ruby初心者がいきなりRailsするときのMemo
初めに
これまではPHPかPythonでの開発がほとんどだったのですが、様々な事情により、Ruby on Railsの案件に取り組むことになりました。これまでよくやっていたPython + Flask構成と比較しながらRuby on Railsを勉強しているのですが、その試行錯誤を残しておきたいと思います。内容は随時更新します。
目次
- Rubyの環境構築
- Railsの導入
Rubyの環境
Pythonでは、以下の環境を使っていました。
* pyenv(Pythonのバージョン管理) * pipenv(仮想環境構築+Packageの管理)Rubyでそれぞれに対応するのは、(というかPythonのそこら辺のツールはRubyのツール群に触発されて開発されたものが多いので、こちらのほうが大元というべきなのですが、)
* rbenv(Rubyのバージョン管理) * bundler(gemの管理)です。一般的なRubyプロジェクトは、bundlerを用いて
mkdir PROJECT_DIR cd PROJECT_DIR bundler init #これによってGemfile, Gemfile.lockが作られる vi Gemfile #Gemfileに必要なライブラリ群を記載 bundler install --path vendor/bundler #Gemfileに記載したライブラリ群をvendor/bundler以下にインストール bundler exec COMMAND #pipenv run COMMANDに対応するコマンドとして環境を作るようです。
Rails環境の構築
Railsは
- 投稿日:2019-11-01T09:03:52+09:00
PythonistがRuby on Railsに異世界転生したときの記録
初めに
これまではPHPかPythonでの開発がほとんどだったのですが、様々な事情により、Ruby on Railsの案件に取り組むことになりました。これまでよくやっていたPython + Flask構成と比較しながらRuby on Railsを勉強しているのですが、そのmemoを残しておきたいと思います。内容は随時更新します。
環境
- ubuntu 19.04 eoan ermine
- rbenv version 1.1.1
- ruby verison 2.6.5
目次
- Rubyの環境構築
- Railsの導入
Rubyの環境
Pythonでは、以下の環境を使っていました。
* pyenv(Pythonのバージョン管理) * pip(デフォルトのPackage管理) * pipenv(仮想環境構築+Packageの管理)Rubyでそれぞれに対応するのは、(というかPythonのそこら辺のツールはRubyのツール群に触発されて開発されたものが多いので、こちらのほうが大元というべきなのですが、)
* rbenv(Rubyのバージョン管理) * gem(デフォルトのPackage管理:ただしRubyではPackageのことをGemとよんでいる) * bundler(仮想環境構築+Gemの管理)です。Gemというのは、PythonでいうPackageみたいなもののようです。一般的なRubyプロジェクトは、bundlerを用いて
mkdir PROJECT_DIR cd PROJECT_DIR rbenv local 2.6.5 #pipenv install 3.8.0と同じノリです gem install bundler bundler init #これによってGemfile, Gemfile.lockが作られる。pipenv initと同じ vi Gemfile #Gemfileに必要なライブラリ群を記載 bundler install --path vendor/bundler #Gemfileに記載したライブラリ群をvendor/bundler以下にインストール bundler exec COMMAND #pipenv run COMMANDに対応するコマンドとして環境を作るようです。
PipenvとBundlerは大体同じですが、以下のような細かい違いがあります。
bundler execはpipenv runと対応していますが、pipenv shellに対応するコマンドはなさそうです- pipenvでは、Packageのインストール先は、デフォルトで
~/.local以下に作られ、PIPENV_VENV_IN_PROJECTでプロジェクトディレクトリ以下に作成されます。一方、bundlerでは--pathオプションにより都度指定する仕組みのようです。Rails環境
RailsはRuby用のWeb開発フレームワークです。その意味ではFlaskと似ていますが、Flaskよりもデフォルトのツールが揃っている気がします。(例えばORMなどです。)その点では、FlaskよりもDjangoのCounterpartと考えるべきなのかもしれません。
Rails環境の構築ですが、上に書いたように、GemfileにRailsを追加してやっていくスタイルかと思いきや、そうではありませんでした。
Railsは統合的なWeb開発環境であり、bundlerを内包しているとのことです。Rails comes with baked in support with bundler.
Bundler公式ドキュメントここでは、公式ドキュメント通りに
gem install rails rails new APP_DIR cd APP_DIR bundler installで良いようです。
- 投稿日:2019-11-01T08:54:44+09:00
初心者の仮想環境
なぜ仮想環境を作るのか
買ったdeeplearnigの本通りに開発環境を整えているとエラーがでて、調べた結果Tensorflowを使うにはpython3.6.0を使わないといけないことが分かった。 そのためにはなにやら、仮想環境というものを構築しないといけないことが分かったので初心者なりに色々実験しながらまとめてみようと思う。
anacondaで開発環境構築
ANACONDA NAVIGATORのCreateから仮想環境を作ることができる。(名前はtensorflowにした)
コマンド conda info -e で今ある環境の一覧を示してみた。実際に先ほどのCreateからtensorflowという環境を作ってみる。
しっかりとtensorflowという仮想環境ができてた!
この矢印からterminalを開くと作った仮想環境に行くことができる。
実際に確認してみるとtensorflowに移動していた!
conda listで作った仮想環境のパッケージを確認してみた。
実際numpyをインポートしてみたがエラーが出た。
次はコマンド(conda activate 仮想環境名)で仮想環境を移動してみた。
コマンドで仮想環境を作ってみた。
conda create -n 仮想環境の名前 インストールするパッケージを書きまくる。(python=x.x)(スペースで区切る)・うまくtensorflowインストールできました!
https://qiita.com/yampy/items/4e89cd97179bbd20f726
condaコマンド一覧









- 投稿日:2019-11-01T07:17:29+09:00
goとpythonで始めるgRPCの事始め
gRPCってなんだって思って調べてたら実装してしまっていたので備忘録として残します。
ゴール
このようなディレクトリ構造でpythonクライアントとgoサーバー間でgRPCを実装していくことをゴールとします.
$GOPATH/src/pygo-grpc/ ├ client/ | ├ app.py | ├ hello_pb2_grpc.py (gRPC自動生成) | └ hello_pb2.py (gRPC自動生成) ├ protos/ | └ hello.protc └ server/ ├ grpc-server/hello.pb.go (gRPC自動生成) └ server.goプロトコルを定義
$GOPATHの配下に新しいワーキングディレクトリを作成し、プロトコルを定義します。~ $ cd $GOPATH/src src $ mkdir pygo-grpc;cd $_ pygo-grpc $ mkdir client protocs server server/grpc-server pygo-grpc $ touch protocs/hello.protoprotocs/hello.proto
syntax = "proto3"; package hello; service Hello { rpc PushMsg (MsgStruct) returns (MsgStruct) {} } message MsgStruct { string message = 1; }パラメータ、戻り値、呼び出しメソッドを定義しています。
今回は簡単なメッセージの通信を実装するので、PushMsgというメソッドを定義し、そのパラメータと戻り値をどちらも同じMsgStructで定義します。GoでgRPCサーバーを実装する
GoのgRPC周りのインストール
まだの人はチャチャッとやってしまいましょう。
go version // 1.6以上必要 go get -u google.golang.org/grpc // Install gRPC go get -u github.com/golang/protobuf/protoc-gen-go // Install the protoc pluginGoのgRPCコードを生成
protoファイルの場所とgRPCコードを生成する場所を指定。
pygo-grpc $ protoc -I protocs/ protocs/hello.proto --go_out=plugins=grpc:server/grpc-server/
server/grpc-server/hello.pb.goが自動生成されます。GoのgRPCサーバー実装
pygo-grpc $ touch server/server.goserver/server.go
package main import ( "context" "log" "net" "google.golang.org/grpc" pb "pygo-grpc/server/grpc-server" ) const ( port = ":50051" ) type server struct { pb.UnimplementedHelloServer } func (s *server) PushMsg(ctx context.Context, p *pb.MsgStruct) (*pb.MsgStruct, error) { log.Printf("Received: %v", p.Message) return &pb.MsgStruct{Message: "Hello " + p.Message}, nil } func main() { lis, err := net.Listen("tcp", port) if err != nil { log.Fatalf("failed to listen: %v", err) } s := grpc.NewServer() pb.RegisterHelloServer(s, &server{}) if err := s.Serve(lis); err != nil { log.Fatalf("failed to serve: %v", err) } }PythonでgRPCクライアントを実装する
pythonの仮想環境の立ち上げ
pygo-grpc $ virtualenv venv && source venv/bin/activatevenvはトレースしなくて大丈夫なので .gitignoreにでも
PythonのgRPC周りのインストール
(venv) pygo-grpc $ pip install grpcio (venv) pygo-grpc $ pip install grpcio-toolsPythonのgRPCコードを生成
(venv) pygo-grpc $ python -m grpc_tools.protoc -I protocs --python_out=client --grpc_python_out=client protocs/hello.proto
client/hello_pb2_grpc.pyとclient/hello_pb2.pyが自動生成されますPythonのgRPCクラアイアント実装
client/app.py
from __future__ import print_function import logging import grpc import hello_pb2 import hello_pb2_grpc def run(): msg = input() with grpc.insecure_channel('localhost:50051') as channel: stub = hello_pb2_grpc.HelloStub(channel) stub.PushMsg(hello_pb2.MsgStruct(message=msg)) if __name__ == '__main__': logging.basicConfig() run()動作確認
まずサーバーを立ち上げ
pygo-grpc $ go run server/server.go次にクライアントを立ち上げます
(venv) pygo-grpc $ python client/app.py
うまくいきました?
参考
https://grpc.io/docs/quickstart/go/
https://grpc.io/docs/quickstart/python/
