- 投稿日:2019-11-01T22:43:48+09:00
gonum/matで単位行列を生成する
コード
idSlice := make([]float64, n*n) for i := 0; i < n; i++ { idSlice[i*(n+1)] = 1 } idMat := mat.NewDense(n, n, idSlice)これでできる。
サンプルコード
go get gonum.org/v1/gonum/matを実行して、コピペすれば動く。package main import ( "fmt" "gonum.org/v1/gonum/mat" ) func matPrint(X mat.Matrix) { fa := mat.Formatted(X, mat.Prefix(""), mat.Squeeze()) fmt.Printf("%v\n", fa) } func main() { n := 4 idSlice := make([]float64, n*n) for i := 0; i < n; i++ { idSlice[i*(n+1)] = 1 } idMat := mat.NewDense(n, n, idSlice) matPrint(idMat) }解説
gonum/matでは、
[]float64を渡して行列を作る。例えば、3x3の単位行列
⎡1 0 0⎤ ⎢0 1 0⎥ ⎣0 0 1⎦を作るには、要素数$3 \times 3 = 9$のスライス
[1 0 0 0 1 0 0 0 1]を渡す。
これは、1を4個の要素ごとに、全部で3個代入したスライスである。4x4の場合、
⎡1 0 0 0⎤ ⎢0 1 0 0⎥ ⎢0 0 1 0⎥ ⎣0 0 0 1⎦を作るには、要素数$4 \times 4 = 16$のスライス
[1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1]を渡す。
これは、1を5個の要素ごとに、全部で4個代入したスライスである。つまり、nxnの場合、1をn+1個の要素ごとに、全部でn個代入したスライスを生成すれば良い。
これをコードに落とし込むと、
idSlice := make([]float64, n*n) for i := 0; i < n; i++ { //全部でn個 idSlice[i*(n+1)] = 1 //1をn+1個の要素ごとに代入 }となるので、あとは
idMat := mat.NewDense(n, n, idSlice)でコンストラクタに渡せば良い。
- 投稿日:2019-11-01T21:21:59+09:00
GO言語でmapの値に構造体を使う時はポインタにすると良いらしい
mapの値に構造体を入れたらエラーが・・・
先日、職場でこんな感じのコードを書いたらエラー。(コードはサンプルです)
umaimono.gopackage main import "fmt" type Food struct { ID int Name string Description string } func main(){ fmt.Println(MakeResult()["うまいもの"]) } func MakeResult() map[string]Food { result := make(map[string]Food) result["うまいもの"] = Food{ ID: 1, Name: "焼肉", } result["うまいもの"].Description = "すこぶるうまい" return result }これを実行すると
cannot assign to struct field result["うまいもの"].Description in mapというエラー。なんでや〜。ポインタ型にしたら解決
色々とググった結果、構造体をポインタ型にしたら解決した。
理屈は一旦置いておいて、これでうまくいく。umaimono.gopackage main import "fmt" type Food struct { ID int Name string Description string } func main(){ fmt.Println(*MakeResult()["うまいもの"]) } func MakeResult() map[string]*Food { result := make(map[string]*Food) result["うまいもの"] = &Food{ ID: 1, Name: "焼肉", } result["うまいもの"].Description = "すこぶるうまい" return result }結果:
{1 焼肉 すこぶるうまい}無事に説明が追加された。
どうしてもポインタ型で返したくない場合は?
他の機能との兼ね合いで、どうしてもポインタ型で返したくないという場合もあるかもしれない。
そんな時は、こう。(自分が思いついたのではなく、先輩がこうしていた)umaimono.gopackage main import "fmt" type Food struct { ID int Name string Description string } func main(){ fmt.Println(MakeResult()["うまいもの"]) } func MakeResult() map[string]Food { pointerResult := make(map[string]*Food) pointerResult["うまいもの"] = &Food{ ID: 1, Name: "焼肉", } pointerResult["うまいもの"].Description = "すこぶるうまい" result := make(map[string]Food) for k, v := range pointerResult{ result[k] = *v } return result }なるほどなあ。
最後に
無事、焼肉はうまいという結果を返す関数が実装できましたね。うれしいです。
ちなみに今回がQiita初投稿なので、どういう口調で書けば良いのかなどが色々と分からない感じでしたが、最後まで読んでくださってありがとうございます。
- 投稿日:2019-11-01T18:42:31+09:00
Goのディレクトリ構成(追記予定)
Goのディレクトリ構成をきっちり知っておきたい
/src 開発用のディレクトリ
- プロジェクトごとにsrc 以下にディレクトリをつくる。
- ソースコード管理プラットフォームごとに切るのがGoの思想的
- go install するとpkgに実行したパッケージをコンパイルしたものが作られる。
- go buildをmainパッケージで実行すると/binに実行可能なバイナリファイルが作られる。
/bin 実行可能ファイル、バイナリ
- 環境変数PATHに設定することが推奨されている。'export PATH:=$GOPATH/bin'
/pkg コンパイルされたファイル
- srcからコンパイルされた非アプリケーション実行ファイルの.aファイル
tips
- githubからgo getするようなものは、実態としてはgit cloneとgo installである。
- 投稿日:2019-11-01T17:00:17+09:00
containerdについて備忘録
「dockerってなに?マジ意味わからん」って思った平成31年n月m日
今までdockerを使って開発していたが実際dockerについて何も知らないことが急に不安になった.
そこからdockerの資料を見てみるとこんな記事を見つけた
https://containerd.io/ この記事を読んで
「dockerの中身ってcontainerdってやつらしい」とわかった.
は?
「docker」いらなくね?って思ったのでcontainerdを触ってみた.まとめ
dockerの中身が気になって調べたらcontainerdってやつがいい感じにコンテナ作ってることを知って興味が湧いて触ってみたくなった.なぜやる
dockerの中身が気になって調べたらcontainerdってやつがいい感じにコンテナ作ってることを知って興味が湧いて触ってみたくなった.
どうやる
いろいろやる
containerdとは
コンテナランタイムの一つでdockerの内部でつかわれている
containerdをinstallする
想定はCentos7
installするならこれだけあれば大丈夫$ yum update $ yum -y install curl wget git vimcontainerdをダウンロードする
ちなみに最新版をバージョンを確認してダウンロードしてくるといいと思う
リリース一覧
記事を書いてる2019/04/10(水)時点での最新はcontainerd 1.2.6だゾ
構築してるときより進んでる....$ wget https://github.com/containerd/containerd/releases/download/v1.2.4/containerd-1.2.4.linux-amd64.tar.gzダウンロードしたcontainerdを解凍すると同時にパスが通ってるところに配置する
ここでは/usr/local/配下に配置する
$ tar zxvf ./containerd-1.2.4.linux-amd64.tar.gz -C /usr/local/ちなみに解凍したファイルの中身は
$ tar zxvf ./containerd-1.2.4.linux-amd64.tar.gz bin/ bin/containerd bin/ctr bin/containerd-shim-runc-v1 bin/containerd-shim bin/containerd-stressbin以下に入っているのでbinディレクトリを移動させればそれで良さそう
上書きされそうなのでbin/*が無難な気がするが....containerdを起動させる
起動のやり方はいろいろあると思うけど
今回はserviceで起動できるようにする.$ containerdとかマジ勘弁
serviceは->containerd.serviceを参考にかく$ systemctl start containerd
- 投稿日:2019-11-01T07:17:29+09:00
goとpythonで始めるgRPCの事始め
gRPCってなんだって思って調べてたら実装してしまっていたので備忘録として残します。
ゴール
このようなディレクトリ構造でpythonクライアントとgoサーバー間でgRPCを実装していくことをゴールとします.
$GOPATH/src/pygo-grpc/ ├ client/ | ├ app.py | ├ hello_pb2_grpc.py (gRPC自動生成) | └ hello_pb2.py (gRPC自動生成) ├ protos/ | └ hello.protc └ server/ ├ grpc-server/hello.pb.go (gRPC自動生成) └ server.goプロトコルを定義
$GOPATHの配下に新しいワーキングディレクトリを作成し、プロトコルを定義します。~ $ cd $GOPATH/src src $ mkdir pygo-grpc;cd $_ pygo-grpc $ mkdir client protocs server server/grpc-server pygo-grpc $ touch protocs/hello.protoprotocs/hello.proto
syntax = "proto3"; package hello; service Hello { rpc PushMsg (MsgStruct) returns (MsgStruct) {} } message MsgStruct { string message = 1; }パラメータ、戻り値、呼び出しメソッドを定義しています。
今回は簡単なメッセージの通信を実装するので、PushMsgというメソッドを定義し、そのパラメータと戻り値をどちらも同じMsgStructで定義します。GoでgRPCサーバーを実装する
GoのgRPC周りのインストール
まだの人はチャチャッとやってしまいましょう。
go version // 1.6以上必要 go get -u google.golang.org/grpc // Install gRPC go get -u github.com/golang/protobuf/protoc-gen-go // Install the protoc pluginGoのgRPCコードを生成
protoファイルの場所とgRPCコードを生成する場所を指定。
pygo-grpc $ protoc -I protocs/ protocs/hello.proto --go_out=plugins=grpc:server/grpc-server/
server/grpc-server/hello.pb.goが自動生成されます。GoのgRPCサーバー実装
pygo-grpc $ touch server/server.goserver/server.go
package main import ( "context" "log" "net" "google.golang.org/grpc" pb "pygo-grpc/server/grpc-server" ) const ( port = ":50051" ) type server struct { pb.UnimplementedHelloServer } func (s *server) PushMsg(ctx context.Context, p *pb.MsgStruct) (*pb.MsgStruct, error) { log.Printf("Received: %v", p.Message) return &pb.MsgStruct{Message: "Hello " + p.Message}, nil } func main() { lis, err := net.Listen("tcp", port) if err != nil { log.Fatalf("failed to listen: %v", err) } s := grpc.NewServer() pb.RegisterHelloServer(s, &server{}) if err := s.Serve(lis); err != nil { log.Fatalf("failed to serve: %v", err) } }PythonでgRPCクライアントを実装する
pythonの仮想環境の立ち上げ
pygo-grpc $ virtualenv venv && source venv/bin/activatevenvはトレースしなくて大丈夫なので .gitignoreにでも
PythonのgRPC周りのインストール
(venv) pygo-grpc $ pip install grpcio (venv) pygo-grpc $ pip install grpcio-toolsPythonのgRPCコードを生成
(venv) pygo-grpc $ python -m grpc_tools.protoc -I protocs --python_out=client --grpc_python_out=client protocs/hello.proto
client/hello_pb2_grpc.pyとclient/hello_pb2.pyが自動生成されますPythonのgRPCクラアイアント実装
client/app.py
from __future__ import print_function import logging import grpc import hello_pb2 import hello_pb2_grpc def run(): msg = input() with grpc.insecure_channel('localhost:50051') as channel: stub = hello_pb2_grpc.HelloStub(channel) stub.PushMsg(hello_pb2.MsgStruct(message=msg)) if __name__ == '__main__': logging.basicConfig() run()動作確認
まずサーバーを立ち上げ
pygo-grpc $ go run server/server.go次にクライアントを立ち上げます
(venv) pygo-grpc $ python client/app.py
うまくいきました?
参考
https://grpc.io/docs/quickstart/go/
https://grpc.io/docs/quickstart/python/

- 投稿日:2019-11-01T07:09:23+09:00
Golangらしいコードを書こう
はじめに
この記事は未完成です。Golangらしいコードというのは文化のようなものだと考えているので、様々な方の意見を取り込みながら、この記事を充実させていきたいと考えています。よろしくお願いいたします。
Goらしいコードの前に
全言語共通のルールについてまとめます。きれいなコードを学びたい方へのおすすめはリーダブルコードです。というよりかは、エンジニアなら絶対に読んでほしい本です。
可読性の高いコード
読むときに覚えておくことが少ない
- シンプルに作られている
- 変数のスコープはできるだけ小さく
- ネストは浅く、関数は短く
意図が理解しやすい
- 適切なコメントが添えてある
- 設計の背景などがドキュメントにまとまっている
再現性がとりやすい
- ライブラリのバージョン管理がきっちりされている
- ビルドやテストがMakefileやスクリプトで再現できる
- 適度に抽象化されていてテストが外部依存してない
Goらしいコード
静的解析ツール
基本的に静的解析ツールは導入しないとプルリクは通りません。
静的解析ツール 役割 gofmt, goimports コードフォーマッター go vet, golint コードチェッカー, リンター gocode コード補完 errcheck エラー処理チェッカー コメントアウト
コメントは、記述されているものの名前で始まり、ピリオドで終わる必要があります。
// Request represents a request to run a command. type Request struct { ... // Encode writes the JSON encoding of req to w. func Encode(w io.Writer, req *Request) { ...Context
APIおよびプロセスの一連の流れで保持しておく必要のある値をコンテキストで管理します。具体的にはセキュリティ資格情報、トレース情報、期限、キャンセルのシグナルなどが挙げられます。
Contextを利用するほとんどの関数で一番最初の引数にしています。func F(ctx context.Context, /* other arguments */) {}スライス
var t []string t := []string{}上はnilスライスを返し、下は非nilスライスを返します。どちらもcap,lenともにゼロですが、上のnilスライスが優先スタイルです。しかしJSONオブジェクトをエンコードするときは非nilスライスが優先されます。
また、インターフェイスを設計するときは、ちょっとしたプログラミングエラーにつながる可能性があるので、nilスライスと非nil、長さゼロのスライスを区別しないでください。math/rand
基本的にこのパッケージはキーを生成するときには利用しないでください。シードなしでは予測可能な値が出てしまいます。代わりに、crypto/randのリーダーを使用し、テキストが必要な場合は、16進数またはbase64で印刷します。
import ( "crypto/rand" // "encoding/base64" // "encoding/hex" "fmt" ) func Key() string { buf := make([]byte, 16) _, err := rand.Read(buf) if err != nil { panic(err) // out of randomness, should never happen } return fmt.Sprintf("%x", buf) // or hex.EncodeToString(buf) // or base64.StdEncoding.EncodeToString(buf) }panicは使わない
通常のエラー処理にpaincを使用しないでください。エラーと複数の戻り値を使用します。
エラーの文字列について
エラー文字列は、通常、他のコンテキストに従って出力されるため、大文字にしないでください。ただし、固有名詞や頭文字で始まる場合は大文字にしてください。
//これはよくない fmt.Errorf("Something bad") //通常はこのようにフォーマットされて出力されます。 fmt.Errorf("something bad") log.Printf("Reading %s: %v", filename, err)エラーハンドリングについて
関数の戻り値としてエラーが返ってくるときに、絶対に受け取り、処理をする必要があります。本当に例外の時だけpanicを利用して下さい。また、エラーが発生したときは先にエラーハンドリングを書きます。
if文があるときのエラーハンドリングについて。//これはよくない例 if x, err := f(); err != nil { // error handling return } else { // use x } //こっちがよい例 x, err := f() if err != nil { // error handling return } // use ximportについて
名前の衝突を避けるため以外は、インポートの名前を変更しないでください。衝突を避ける場合には、プロジェクト固有の名前にしてください。
変数や関数について
IDやHTTP、URLなど一貫して大文字の名前を付けることが一般的です。例えば「URL」はUrlとは命名せず、URLとします。ユーザIDに関してもuserIDのように命名します。また、golangはキャメルケースで書きます。
また、Golangは他の言語とは違い、長い名前を好まず、ある程度省略が許されています。
さらに、golangはスコープに厳しいので、変数を使う直前で宣言してください。interface
使用する予定がない関数はinterfaceで定義しないでください。
値を渡す場合
大きな構造体や大きくなる見込みのあるスライス以外は、引数はポインタ型にしないでください。
メソッドのレシーバ
一貫性を保ち、短い名前、そのアイデンティティを反映していれば十分です。clientならば「c」や「cl」で十分です。メソッドの引数は説明的要素を含まなければなりませんが、レシーバは役割が明確なので、簡潔さが一番好まれます。
また、メソッドに特別な意味を与えるオブジェクト指向言語の典型的な識別子である「me」、「this」、「self」などの一般的な名前は使用しないようにしてください。レシーバのタイプ
ポインタレシーバを使うか否かの判断基準
- レシーバがmap、func、またはchanの場合、それらへのポインターを使用しないでください。レシーバーがスライスであり、メソッドがスライスの再スライスまたは再割り当てを行わない場合、そのポインターを使用しないでください。
- メソッドがレシーバーを変更する必要がある場合、レシーバーはポインターでなければなりません。
- レシーバがsync.Mutexまたは同様の同期フィールドを含む構造体である場合、受信者はコピーを避けるためにポインターでなければなりません。
- レシーバーが大きな構造体または配列の場合、ポインターレシーバーの方が効率的です。
- レシーバーが構造体、配列、またはスライスであり、その要素のいずれかが変化している可能性のある場合は、ポインターレシーバーを優先します。
- 受信者が小さな配列または構造体の場合や可変フィールドとポインターがない場合、またはintやstringなどの単純な基本型である場合、ポインタレシーバは必要ないです。
- 疑わしい場合はポインタレシーバを使います。
Getter
GetXxxではなくXxxと命名しましょう。
参考にしたサイト
- 投稿日:2019-11-01T04:17:27+09:00
今すぐ「レイヤードアーキテクチャ+DDD」を理解しよう。(golang)
今すぐ「レイヤードアーキテクチャ+DDD」を理解しよう。(golang)
とはいっても記事を読み終わるのに三時間くらいかかる気がします。
対象読者
- レイヤードアーキテクチャ+DDDの実装に困っている方
- バックエンドエンジニアを目指す学生
- APIサーバを開発したことがある方
はじめに
アーキテクチャは学習コストが高いと言われています。その要因の一つとして考えられるのはアーキテクチャの概念を学んだとしても、アーキテクチャの細かい部分は実装者に左右されるので、ネット上にあるプログラムは概念とはズレがあるので混乱しやすいことだと思います。それに加えて他のサイトを参考にした時もやはり実装者による違いで混乱してしまうからです。
したがって、概念とズレがある部分はしっかり言及したうえで解説することが良いと思います。アーキテクチャを採用する意味
- レイヤ間が疎結合になるため、ユニットテストが行いやすいこと。
- 責務がはっきりしているので、保守性が高いこと。
- 途中からフレームワーク等を入れたとしても影響範囲が限定されるので外部の技術の変更が容易なこと。
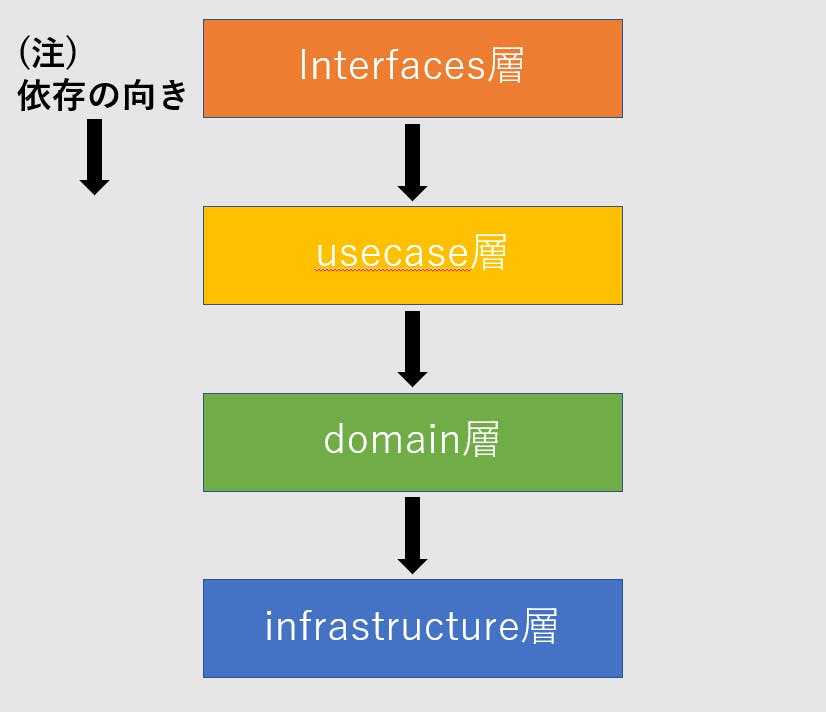
レイヤードアーキテクチャとは
レイヤードアーキテクチャは図のようにレイヤを上下で表現します。上位のレイヤは下位のレイヤに依存するのが特徴です。図では直下のレイヤにのみ依存していますが、上位のレイヤが下位のレイヤに依存していれば、直下でなくてもOKです。例えば、usecase層がinfrastructure層に依存するケースやinterfaces層がdomain層に依存している場合があります。基本的にアーキテクチャを導入すると依存関係を守るために冗長化をする必要がありますが、小規模でそれほど複雑でない時や、チームで話し合って、冗長化することによるメリットよりもコードをシンプルにした方がいいという結論に至れば一つ飛ばしの層に依存しても問題はありません。DDD(domain driven design)とは
こちらの記事を参考に理解を深めてください。
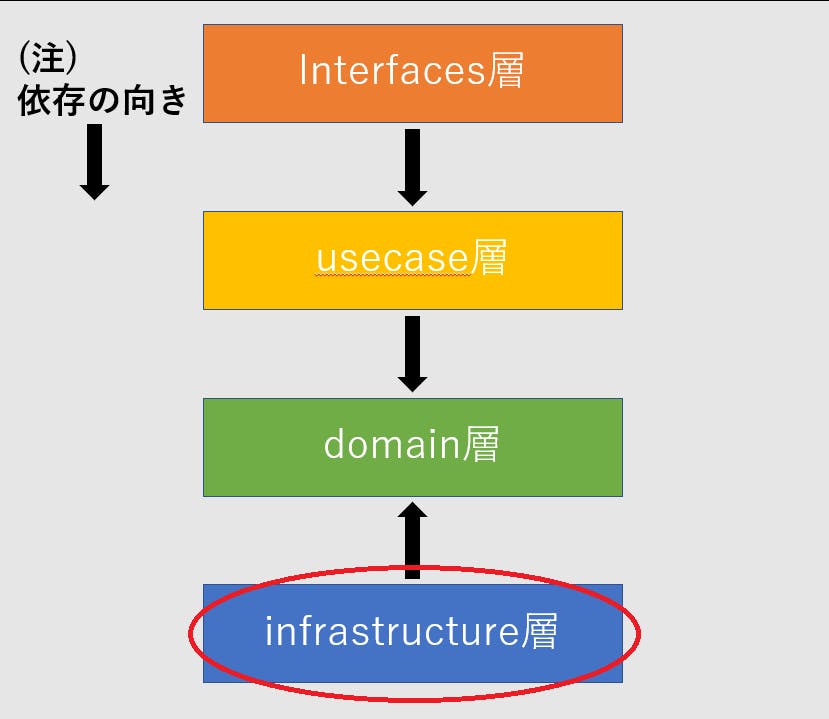
レイヤードアーキテクチャにドメイン駆動設計の考えを取り込むと次の図のような依存関係になります。
純粋なレイヤードアーキテクチャと違う点はdomainとinfrastructureの依存関係が逆になっていることです。
ここでは説明を省きますが、もっと知りたければエリック・エヴァンス氏の書籍ドメイン駆動設計を読むことをおすすめします。前置きはこのくらいにして、以降はコードベースで解説していきます。
ディレクトリ構成
レイヤードアーキテクチャの層は本来は一番上から、
Presentation → Application → Domain → Infrastructure
という名前が付いていますが責務のイメージが浮かびずらいと思うので今回は
Interfaces → Usecase → Domain → Infrastructure
という名前で進めさせていただきます。LayeredArchitecture ├── cmd │ └── api │ └── main.go ├── domain │ └── repository | | └── user_repository.go | └── user.go ├── config //DBの起動など │ └── database.go ├── interfaces │ └── handler │ | └── user.go | └── response │ └── response.go ├── infrastructure │ └── persistence │ └── user.go └── usecase └── user.godomain層
domain層はドメインロジックを実装する責務を持ちます。ドメインロジックに関してはこちらの資料を参考にしてください。domain層はDBアクセスなどの技術的な実装は持たず、それらはinfrastructure層が担当します。
/domain/user.gopackage domain type User struct { UserID string Name string Email string }続いてリポジトリの実装です。
domain/repository/user_repository.gopackage repository import ( "database/sql" "LayeredArchitecture/domain" ) type UserRepository interface { Insert(DB *sql.DB, userID, name, email string) error GetByUserID(DB *sql.DB, userID string) ([]*domain.User, error) }domain層はどの層にも依存しないのでこの層だけで完結します。
infrastructure層
infrastructure層は、DBアクセスなどの技術的関心を記述します。この層はdomain層に依存しています。純粋なレイヤードアーキテクチャの場合、依存の向きがdomain → infrastructureですが、今回はDDDを取り込んだ設計になるので、依存の向きが逆転します。そのためinfrastructure層はdomain層のrepositoryで定義したインタフェースを実装します。/infrastructure/persistence/user.gopackage persistence import ( "LayeredArchitecture/domain" "LayeredArchitecture/domain/repository" "database/sql" ) type userPersistence struct{} func NewUserPersistence() repository.UserRepository { return &userPersistence{} } //ユーザ登録 func (up userPersistence) Insert(DB *sql.DB, userID, name, email string) error { stmt, err := DB.Prepare("INSERT INTO user(user_id, name, email) VALUES(?, ?, ?)") if err != nil { return err } _, err = stmt.Exec(userID, name, email) return err } //userIDによってユーザ情報を取得する func (up userPersistence) GetByUserID(DB *sql.DB, userID string) (*domain.User, error) { row := DB.QueryRow("SELECT * FROM user WHERE user_id = ?", userID) //row型をgolangで利用できる形にキャストする。 return convertToUser(row) } //row型をuser型に紐づける func convertToUser(row *sql.Row) (*domain.User, error) { user := domain.User{} err := row.Scan(&user.UserID, &user.Name, &user.Email) if err != nil { if err == sql.ErrNoRows { return nil, nil } return nil, err } return &user, nil }domain層で定義した
GetByUserIDとInsert関数の引数や返り値を満たしながら中身を実装しているので確かにinfrastructure層がdomain層に依存しています。実はこの手法はDIP(依存性逆転の原則)といいます。golangでつまずく人が多いinterface(interfaces層とは全くの別物)というものを使って実体を抽象に依存させることで依存性を逆転しています。ここでいう抽象とは名前、引数、返り値だけ決まっている関数のことで、実体とは、その関数の具体的な処理内容のことです。
interfaceが全く分からないという方はこちらの記事を参考に、ある程度分かってきたらこちらの記事を参考にしてください。interfaceに慣れる
interfaceになれている方は読み飛ばしていただいて結構です。
interfaceになれていない方はおそらく以下の部分で混乱してしまうと思うので補足説明しておきます。infrastructure/persistence/user.gotype userPersistence struct{} func NewUserPersistence() repository.UserRepository { return &userPersistence{} }
NewUserPersistence()の返り値がrepository.UserRepository型になっています。interfaceを理解していない方はここでつまずくのではないでしょうか。「返り値はUserRepositoryなのに、返却しているのがuserPersistence型?」と思ってしまいますよね。
これが許される理由は、interfaceであるUserRepositoryを満たすようにuserPersistenceを実装しているからです。どういうことかというと、①UserRepositoryはGetByUserIDとInsert関数を持っている。(関数名、引数、返り値だけ決まっている)
②userPersistenceをレシーバに持つGetByUserIDとInsert関数(関数名、引数、返り値がUserRepositoryで指定されているものと同じ)を実装する。
③userPersistenceがinterfaceのUserRepositoryを満たしていることになる。
④interfaceの性質上、型(今回に関してはレシーバの型)は不問。
⑤返り値はUserRepositoryというinterfaceなのでそれを満たしているので返り値として満たされる。
という事になります。そのため、userPersistenceをレシーバに持つUserRepositoryで定義した関数を満たしている必要があります。その実装がこのコードより下の部分で行っています。
純粋なレイヤードアーキテクチャの場合
ここで、「じゃあ純粋なレイヤードアーキテクチャの場合はどのように依存関係をdomain層 → infrastructure層にしているの?」と疑問をもつ方のためにDDDの概念を持ち込まない純粋なレイヤードアーキテクチャの実装も載せておきます。
方針としては、infrastructure層にdomainのモデルと同じ構造体を用意することです。DDDを採用しようがしまいが各レイヤの責務は変わらないのでinfrastructureはDBアクセスの技術的な関心事を記述します。しかし、domainで定義されたモデルを扱うことができないのでDTOを利用します。DTOに関してはこちらの記事が分かりやすかったので参考にしてください。今回の場合は依存関係を保つためにDTOを利用するという形になっています。解説はGetByUserIDについてのみになります。infrastructure/user.gopackage infrastructure import "database/sql" type UserDTO struct { UserID string Name string Email string } //ユーザ情報を取得 func GetByUserID(DB *sql.DB, userID string) (*UserDTO, error) { //DB にアクセスするロジック row := DB.QueryRow("SELECT * FROM user WHERE user_id=?", userID) return convertToUser(row) } //row型をuserDTO型に紐づける func convertToUser(row *sql.Row) (*UserDTO, error) { userDTO := UserDTO{} err := row.Scan(&userDTO.UserID, &userDTO.Name, &userDTO.Email) if err != nil { if err == sql.ErrNoRows { return nil, nil } return nil, err } return &userDTO, nil }infrastructure層でentityを扱うことになるので、
User構造体を利用したいですが、それではdomainに依存してしまうので中身が全く同じのUserDTOという構造体を定義し、domain層にUser構造体に紐づける処理を加えます。そのため、domain層の実装は次のようになります。domain/user.gopackage domain import ( "LayeredArchitecture/infrastructure" "database/sql" ) type User struct { UserID string Name string Email string } func GetUserByID(DB *sql.DB, userID string) (*User, error) { //インフラストラクチャレイヤの実装を利⽤する。 userDTO, err := infrastructure.GetUserByID(DB, userID) if err != nil { return nil, err } user := &User{ UserID: userDTO.UserID, Name : userDTO.Name, Email : userDTO.Email } return user, nil }依存関係を実装に落とし込むことができていない人はこのあたりでつまずくと思ったので詳しく解説しました。以降は話をレイヤードアーキテクチャ+DDDに戻します。
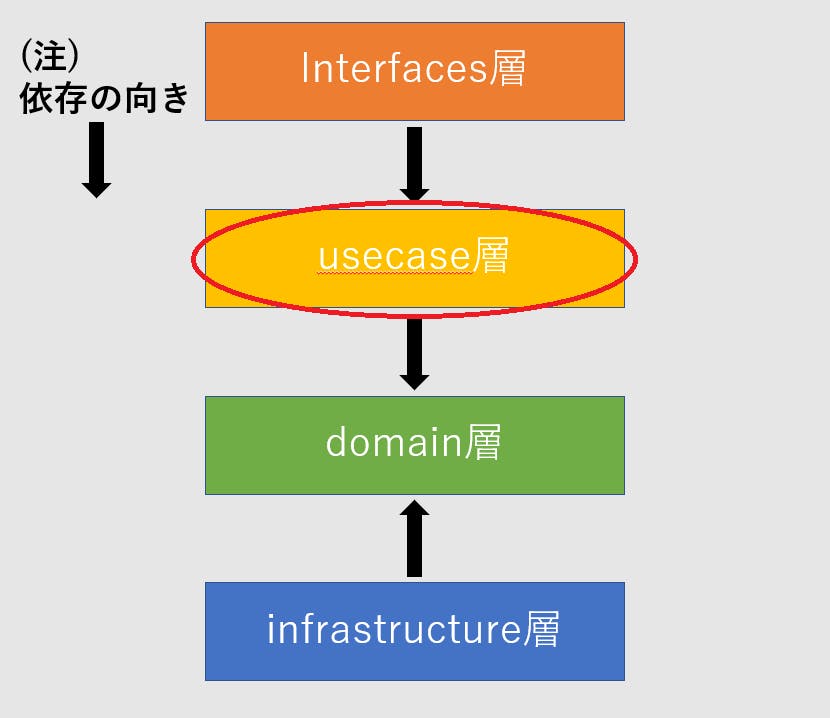
usecase層
usecase層の責務はinterfaces層から情報を受け取り、domain層で定義してある関数を用いて任意のビジネスロジックを実行することです。/usecase/user.gopackage usecase import ( "database/sql" "errors" "github.com/google/uuid" "LayeredArchitectuer/domain" "LayeredArchitectuer/domain/repository" ) // User における UseCase のインターフェース type UserUseCase interface { GetByUesrID(DB *sql.DB, userID string) (domain.User, error) Insert(DB *sql.DB, userID, name, email string) error } type userUseCase struct { userRepository repository.UserRepository } // Userデータに対するusecaseを生成 func NewUserUseCase(ur repository.UserRepository) UserUseCase { return &userUseCase{ userRepository: ur, } } func (uu UserUsecase) GetByUserID(DB *sql.DB, userID string) (*domain.User, error) { user, err := uu.userRepository.GetByUserID(DB, userID) if err != nil { return nil, err } return user, nil } func (uu UserUsecase) Insert(DB *sql.DB, name, email string) error { //本来ならemailのバリデーションをする //一意でランダムな文字列を生成する userID, err := uuid.NewRandom()//返り値はuuid型 if err != nil { return err } //domainを介してinfrastructureで実装した関数を呼び出す。 // Persistence(Repository)を呼出 err = uu.userRepository.Insert(DB, userID.String(), name, email) if err != nil { return err } return nil }このように、usecase層はバリデーション、ユーザIDの生成などのビジネスロジックを記述したり、infrastructure層で実装したDBアクセスに関する処理をdomain層を介して間接的に呼んだりします。ここに関してはイメージがしずらいと思います。「実際に利用するのはinfrastructure層の具体的な内容が実装されている関数だから結局usecase層はinfrastructure層に依存するんじゃないの?」と思う人が多いと思います。
そこで先ほどから出てきているNewXxxXxxやここでもUserUsecaseでinterfaceを定義していることによって間接的に呼びだしているように実装できるんです。アーキテクチャの話をするとよく聞くDI(依存性の注入)というものに利用します。それらについては後で説明します。interfaces層
今回実装したinterfaces層の責務は、HTTPリクエストを受け取り、UseCaseを使って処理を行い、結果をクライアントに返したり、サーバのログに出力することです。今回はレイヤの責務がイメージしやすいようにHTTPリクエストに限定していますが、外部データとの差異を吸収してusecaseに渡し、結果を返却する役割を担うのがこの層の役割です。/interfaces/handler/user.gopackage interfaces import ( "LayeredArchitecture/config" "LayeredArchitecture/interfaces/response" "LayeredArchitecture/usecase" "encoding/json" "io/ioutil" "log" "net/http" "github.com/julienschmidt/httprouter" ) // Userに対するHandlerのインターフェース type UserHandler interface { HandleUserGet(http.ResponseWriter, *http.Request, httprouter.Params) HandleUserSignup(http.ResponseWriter, *http.Request, httprouter.Params) } type userHandler struct { userUseCase usecase.UserUseCase } //Userデータに関するHandlerを生成 func NewUserHandler(uu usecase.UserUseCase) UserHandler { return &userHandler{ userUseCase: uu, } } //ユーザ情報取得 func (uh userHandler) HandleUserGet(writer http.ResponseWriter, request *http.Request, _ httprouter.Params) { // Contextから認証済みのユーザIDを取得 ctx := request.Context() userID := dddcontext.GetUserIDFromContext(ctx) //usecaseレイヤを操作して、ユーザデータ取得 user, err := usecase.UserUsecase{}.SelectByPrimaryKey(config.DB, userID) if err != nil { response.Error(writer, http.StatusInternalServerError, err, "Internal Server Error") return } //レスポンスに必要な情報を詰めて返却 response.JSON(writer, http.StatusOK, user) } // ユーザ新規登録 func (uh userHandler) HandleUserSignup(writer http.ResponseWriter, request *http.Request, _ httprouter.Params) { //リクエストボディを取得 body, err := ioutil.ReadAll(request.Body) if err != nil { response.Error(writer, http.StatusBadRequest, err, "Invalid Request Body") return } //リクエストボディのパース var requestBody userSignupRequest json.Unmarshal(body, &requestBody) //usecaseの呼び出し err = usecase.UserUsecase{}.Insert(config.DB, requestBody.Name, requestBody.Email) if err != nil { response.Error(writer, http.StatusInternalServerError, err, "Internal Server Error") return } // レスポンスに必要な情報を詰めて返却 response.JSON(writer, http.StatusOK, "") }HTTPリクエストのリクエストボディや、ヘッダーから情報を取得し、そのデータをusecaseで扱うデータ型にキャストして渡しています。そして、usecaseの処理結果をサーバ出力やクライアントへ返却しています。
ユーザ情報取得のAPIでアーキテクチャを説明すると、userIDを取得する部分など、余計な部分で実装が複雑になるので、よく紹介されているのはInsertやGetAllみたいな関数ですね。わかりずらい例を挙げてしまい申し訳ございません。
//Contextから認証済みのユーザIDを取得という部分について今回はコンテキストにユーザIDをセットするまでの流れは省いていますが一応説明しておきます。この部分はアーキテクチャの部分とは関係ないので読みとばしていただいて結構です。
本来ならmiddlewareを実装しmiddleware(HandleUserGet())のようにミドルウェアを挟んでmiddleware内でクライアント側から送られてきた認証トークンからアクセスしたユーザIDを特定する操作をし、コンテキストに入れます。middlewareはinterfaces層で実装するのが良いと思います。responseパッケージについて
内容は省略しますが、レスポンスなのでパッケージはinterfaces層にあり、サーバにログ出力する部分と、クライアントへステータスコードとレスポンスメッセージを返却する関数を定義しています。
configパッケージについて
DBの初期化などの部分を実装しています。今回扱っている
DBという変数はこの中で初期化しています。main.go
ここではサーバの起動やルーティング、usecaseの時に後ほど説明すると述べたDI(依存性の注入)を行います。
/cmd/api/main.gopackage main import ( "fmt" "log" "net/http" "github.com/julienschmidt/httprouter" "LayeredArchitecture/interfaces/handler" "LayeredArchitecture/infrastructure/persistence" "LayeredArchitecture/usecase" ) func main() { // 依存関係を注入(DI まではいきませんが一応注入っぽいことをしてる) userPersistence := persistence.NewUserPersistence() userUseCase := usecase.NewUserUseCase(userPersistence) userHandler := handler.NewUserHandler(userUseCase) //ルーティングの設定 router := httprouter.New() router.GET("/api/v2/get", userHandler.HandleUserGet) router.POST("/api/v2/signup", userHandler.HandleUserSignup) // サーバ起動 fmt.Println("Server Running at http://localhost:8080") log.Fatal(http.ListenAndServe(":8080", router)) }main関数の一番最初の三行で、依存関係を注入しています。
①DBアクセスの実体を持っていたuserPersistence(repository.UserRepositoryを満たす)を生成する。
②そのuserPersistenceをusecase層のuserUsecase(repository.UserRepositoryをフィールドに持つ)に注入する。
③生成したuserUsecaseをuserHandler(userUsecaseをフィールドに持つ)に注入するこうすることで、各レイヤの依存関係を守ることができ、かつそれぞれの責務を果たすことができます。
規模が小さいと冗長化するメリットがあまりわからないと思いますが、アーキテクチャを意識することはとても大事だと思うのでぜひ取り組んでみてください。最後に
今回はエラーハンドリングの部分は雑にやってしまったので参考にはしないほうがいいと思います。
この記事を作成するにあたって参考にしたサイトはこちらです。
①【Golang + レイヤードアーキテクチャ】DDD を意識して Web API を実装してみる
②githubのリポジトリ個人的には①のサイトがめちゃくちゃわかりやすかったです。
まだまだ甘い部分があると思うので、アーキテクチャについてはもっと深堀りして、自分でケースに合ったアーキテクチャを採用できるくらいになりたいと思います。