- 投稿日:2019-11-01T23:40:26+09:00
AWSのVPC作成からEC2にsshログインまで
AWS立ち上げ
今回、AWSを使用してEC2インスタンスにsshログインするまでの記事を投稿する
約一年ほど前にAWSでサーバを立ち上げてJavaやRDSを使用してネットワークやプログラムの
学習を行なっていたが諸事情により途絶えたので再開する本記事の基本的な流れとしては下記になる
VPC作成→サブネット作成→EC2配置→sshログインVPC作成(サブネット作成)
アプリケーションのプラットフォームを作成する
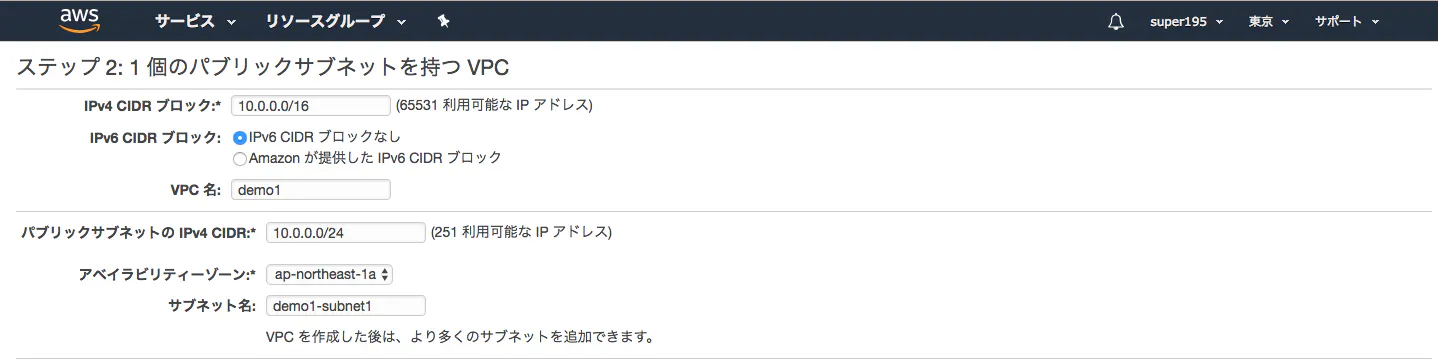
VPC環境をAWSコンソールから作成し、EC2のプラットフォームを作る下記のキャプチャより、AWSコンソール画面のメニュー選択からネットワークとコンテンツ配信からVPCを選択する。
去年作成したが、あまり覚えていない・・・
どうやら下記がメインとなる設定画面のようだ
・使用するネットワークのIPアドレスとCIDRを決定する
・アベイラビリティゾーンの剪定を行うVPCのネットワークとサブネットを同時に作成できるみたい
IPアドレスのプレフィックスは何かの書籍で読んだが、下位16ビットがホスト部として使用することを推奨していたので、VPCのIPは/16を使用する。
サブネットはVPCのプラットフォーム内に/24のものを配置する。
画面を進めていくと下記のような設定画面がある。
アクセスポリシーの設定、ホスト名の有効化、ハードウェアのテナンシー設定である
VPCエンドポイントへのアクセスは基本的にあとで自宅用IPで制限をかけるので、フルアクセス可能にする
ホスト名の有効化は、よく意味がわからないが
おそらくIPアドレスだけでなくVPC用ホスト名を設定できる項目だと思われる
ホスト名は便利なのでとりあえず使用する設定にする最後にテナンシーだが、詳細は公式ドキュメントに書いてある
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/dedicated-instance.html今回はテスト動作用なので、専用ハードを構築する必要はない
よって、デフォルト設定で次へ読み進めていくとVPC作成されていることが確認できる
設定の最後にpemファイルをダウンロードする項目がある
これはsshで接続する際に、身元確認証として必要になるので無くさないように
持っておく必要があるEC2インスタンス作成
次にEC2を作成する
同様にAWSコンソール画面のメニューからEC2の項目を選択する
下記のインスタンスの作成をクリックすると設定画面に移る
AMIを選ぶ
AMIはAWS専用OSのことで、インスタンスで起動する際のOSを選択する
今回は、無料のものを使うので、下記を選択
次にEC2のスペックを決める
こちらも大規模システムを扱うわけでないので、無料枠でインスタンスの詳細設定では、先ほど作成したVPCとサブネットを選択する
こうすることで指定したVPCとそのサブネット内にEC2サーバーが立ち上がる
自動IP割当を行わず、あとで固定IP(EIP)を割り当てる
自動IPの場合、EC2の再起動によってエンドポイント(IP)が変更されてしまうので一意性を保持するためにEPIを使用する
※EIPは有料(月500円程だった気がする
次にストレージのスペックを選ぶ
最後にセキュリティグループの設定だが、設定内容をセキュリティ上公開したくないため、画像はない
セキュリティグループは、EC2単位に設定できるファイアウォールみたいなもので、今回は自宅からのグローバルIPのみ通過するように設定した
また、テスト動作ではsshのみのアクセスとなるので、ポート番号は22番を解放する以上の設定でEC2インスタンスが起動準備する(pending)
EC2作成したEC2インスタンスは自動IP割当を行なっていないため、グローバルIPがない状態で作成される模様
そこでEIPを作成し、割り当てるように設定する
EC2管理画面のメニューからElastic IPを選択して、新しいアドレスの割り当てを行う
下記の設定では、AmazonプールからIPを割り当てる。
詳細は不明だが、AWSがDHCPサーバーを保有していて、可変/固定IPの割り当てを行なっている模様
固定IP(EIP)の設定を行うことでDHCPのIPプールから固定IPを割り当てる
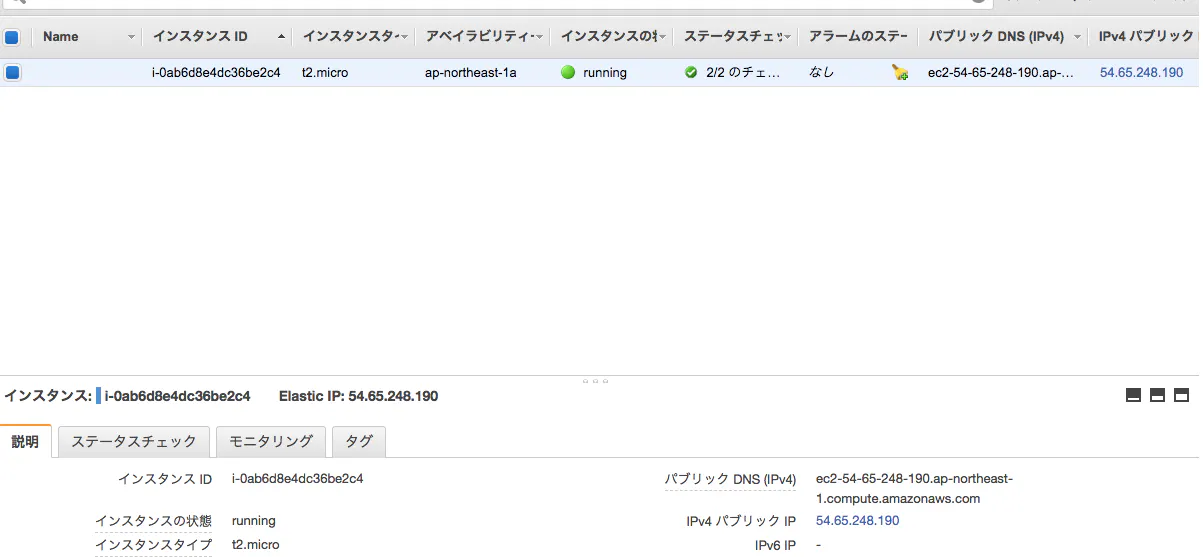
以上、EIPが割り当てられるので作成したEC2に関連付ける
以上の動作で、作成したEC2にグローバルIPとエンドポイントが表示される
ssh接続
Macのターミナル画面よりsshで下記のコマンド入力する
ssh -i [VPCでダウンんロードしたpemファイル].pem ec2-user@ec2-54-65-248-190.ap-northeast-1.compute.amazonaws.com
なにやらエラーが・・・
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: UNPROTECTED PRIVATE KEY FILE! @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
Permissions 0644 for '[VPCでダウンんロードしたpemファイル].pem' are too open.pemファイルは秘密鍵同様、他のユーザーからの書き込み権限があると使用できないみたい
下記のように権限を変更する
chmod 600 [VPCでダウンんロードしたpemファイル].pemもう一度、sshで接続してみる
ssh -i [VPCでダウンんロードしたpemファイル].pem ec2-user@ec2-54-65-248-190.ap-northeast-1.compute.amazonaws.com————————————————————
| _| )
| ( / Amazon Linux 2 AMI
__|_|___|
————————————————————接続できた!!
なかなか忘れている部分が多く時間がかかったが、なんとか接続できた
次回は、AWSのEC2を使って何かしようと思う
以上














- 投稿日:2019-11-01T23:31:47+09:00
Alexaスキル(APL対応&スキル内課金あり)を開発したときにハマった5つのポイント(スキル名:マッチファンタジー)
初投稿です。
この度、初めてのAlexaスキルをストアに出しました。
今回は、画面付きのデバイスが増えている背景もあり画面付きデバイスに対応したスキルを開発したのですが、実装時にハマったポイントを共有しようと思います。どんな人が書いたの?
・Alexaスキルの開発は初めて
・個人でのWebアプリやスマホアプリ開発経験あり
・業務としての開発経験無し
・使える(触ったことある)言語はC#,F#,js,python,ruby,C,Dart,etc...対象読者
・Alexaスキルをこれから作ってみたいと思ってる人
・画面付きデバイス(Echo Show 5 等)用のスキルを開発したい人
・javascriptが読める人or何かしらプログラミングしたことある人作ったスキル
マッチ売りの少女をモチーフとした様々な物語を毎日一話ずつ(スキル内課金すればいくつでも)聴くことが出来るスキルです。
また、物語の途中で選択肢が現れ、その選択肢によって後半のストーリーが変わるというアドベンチャーゲームのような要素もあります。「マッチファンタジー」という名前で現在Amazonのスキルストアにて公開中なので興味ある方はぜひ!
https://www.amazon.co.jp/Acerola-Production-%E3%83%9E%E3%83%83%E3%83%81%E3%83%95%E3%82%A1%E3%83%B3%E3%82%BF%E3%82%B8%E3%83%BC/dp/B07YNCVQZH画面イメージ
スキルのアイコン
ハマった5つのポイント
まず、ハマったポイントの一覧をあげておきます。
1. 音声ファイルの個数制限
2. 外部サイトの音声ファイル利用の制限
3. ユーザーが選択した選択肢の統計情報の保持
4. 適切なタイミングでの画面遷移
5. 各ストーリー用文章の構造化1. 音声ファイルの個数制限
マッチファンタジーの性質上、登場人物の話し言葉や背景音等が必要だったため
自前またはAlexaのサウンドライブラリの音声ファイルをAlexaのデフォルトの読み上げの間に埋め込む必要があったのですが、
スキルからの一度のレスポンスに埋め込める音声の個数が5個という制限がありました。
そこで、複数の音声ファイルが必要な箇所をまとめて1つのファイルにしたり、そもそも音声ファイルが必要ないように工夫するなど、ストーリーの構造を変更することで制限を回避しました。2. 外部の音声ファイル利用の制限
これはAlexaのサウンドライブラリのみを使えば特に起きない問題なのですが、Alexaスキルでは外部ファイルを利用する場合はファイルのホストがHTTPSかつ自己署名NGという制約があります。
ただし、Alexaスキルプロジェクトごとに自動で用意してもらえるS3容量があるので、配置できない理由がない限り(特に開発初期は)そこにファイルを配置するのがよいかと思います。(Alexaスキルの開発プロジェクト立ち上げる時の設定でバックエンドリソースをAlexa-Hostedのどちらか(Node.jsかPython)を選ぶ必要あり?)3. ユーザーが選択した選択肢の統計情報の保持
マッチファンタジーでは上記の通りストーリーの途中で選択肢が出てくるのですが、それに関連して、他のユーザーがどの選択肢を選んだかの統計情報をグラフ等で示すという機能があります。
このような機能を実現するためにはDBを利用したデータ永続化が必須です。
もちろん自前でDBを用意してやればそれほど複雑な実装では無いんですが、プロジェクトの制約上、実装コストを落として(極力無料)かつ素早く実装する必要があったため、
今回は、上記の2.で触れた自動で用意されるS3を利用して永続化できる ask-sdk-s3-persistence-adapter というライブラリを利用しました。
このライブラリをそのまま使うだけでも、ユーザー毎のセッション情報の保存/読込することは出来るのですが、統計データのようにユーザー間をまたいでの保存/読込は出来ないので、
上記のライブラリのソースコードを参考にして、統計情報の保存、読込をするメソッドを実装しました。以下、実際のコードを公開します。1ファイルとしてモジュール化しています。
const AWS = require( 'aws-sdk' ); // S3上で統計情報を保持するJSONファイルの保存先ディレクトリパス const TOTALING_PATH = 'totalings' // ストーリー毎に統計情報を保存するためにストーリー毎のキーを不可して各ファイルパスを生成 const _getTotalignPath = ( storyKey ) => `${TOTALING_PATH}/${storyKey}`; const s3Client = new AWS.S3( { apiVersion: 'latest' } ); // 統計情報を取得するメソッド storyKey:ストーリーに割り当てられたキー module.exports.getStore = async function getStore( storyKey ) { const bucketName = process.env.S3_PERSISTENCE_BUCKET; try { const params = { Bucket: bucketName, Key: _getTotalignPath( storyKey ), }; // S3からstoryKeyに応じた統計情報ファイル(JSON)を取得する const data = await s3Client.getObject( params ).promise(); const json = JSON.parse( data.Body ); return json } catch ( err ) { console.log( err ); return undefined; } } // ユーザーが選択した結果を統計情報に反映させるメソッド choiceNum:ユーザーが選択した選択肢の番号 module.exports.addCount = async function addCount( storyKey, choiceNum ) { const bucketName = process.env.S3_PERSISTENCE_BUCKET; try { if ( choiceNum !== 1 && choiceNum !== 2 ) throw ReferenceError( `choiceNum ${choiceNum}: Invalid number` ); const params = { Bucket: bucketName, Key: _getTotalignPath( storyKey ), }; // S3からstoryKeyに応じた統計情報ファイル(JSON)を取得する const data = await s3Client.getObject( params ).promise(); const json = JSON.parse( data.Body ); // 統計情報ファイルの該当する選択肢のcount値を+1 json[ choiceNum ].count = parseInt( json[ choiceNum ].count ) + 1; params.Body = JSON.stringify( json ); // S3に保存 await s3Client.putObject( params ).promise(); return json; } catch ( err ) { console.log( err ); return undefined; } }この場合のS3の構造は以下のようになります。
├──[スキルID] │ └── totaling │ │ ├── storyKey1 │ │ ├── storyKey2 │ │ ├── ... │ │ ...尚、参考にしたライブラリのソースは以下です。ライブラリのgetAttributesがgetStoreと、saveAttributesがaddCountと対応しています。
https://github.com/alexa/alexa-skills-kit-sdk-for-nodejs/blob/2.0.x/ask-sdk-s3-persistence-adapter/lib/attributes/persistence/S3PersistenceAdapter.ts4. 適切なタイミングでの画面遷移
Alexaスキルでは、APL(Alexa Presentation Language)という独自の画面用フォーマットで記述したものをレスポンスとしてデバイスに送信することで画面表示をコントロールするのですが、ユーザー発話のレスポンスとして返す構造上、基本的にはユーザー発話のタイミングでしか画面を切り替えることが出来ません。
本来はマッチファンタジーでは物語の展開に応じて画面を切り替えたかったのですが、この仕様があるためにかなり枚数を減らすことになってしまいました。
また、動画の再生終了イベントをトリガーとしてデバイスからスキルに対してリクエストを送れるので、動画を上手く入れることで画面の切り替えを増やす工夫もしました。他のイベントをトリガーしたりイベントのdelayオプションを駆使する等すれば、もっと柔軟に画面をコントール出来るかもしれませんが、少し複雑化するため今回は断念しました。
この問題はリッチな画面を提供したいスキルでは比較的起こりやすそうな気がするので、画面遷移を柔軟にコントロールできる機能がそのうち追加されないかと期待しています。
5. 各ストーリー用文章の構造化
これはハマったというより、やらないと後々大変になってただろうなあというポイントなんですが、
早い段階でストーリーのテキストを物語上出てくる地の文や登場人物の声、音声ファイル等ごとに識別できるようにJSONファイルに構造化して記述しておいたので、ストーリーごとに手動でタグや属性値を付加する必要がなくなり、ストーリーの追加や変更がかなり楽でした。以下、構造化JSONファイルの一部です。
// スキル起動して最初の読み上げ "intro": { // builderのspeakに対応 "speak": [ // seはAlexaのサウンドライブラリ valueがパス { "type": "se", "value": "weather/wind/wind_10" }, // narratorは地の文 { "type": "narrator", "value": "一人の少女が薄暗い寒空の下、 マッチを売っている、" }, // audio_outer はS3以外の音声ファイル descriptionはわかりやすいように付加してあるだけで実行時には無視される { "type": "audio_outer", "value": "自前の音声ファイルのパス", "description": "はーさむいなあ" }, { "type": "narrator", "value": "寒さに耐えかねた少女は、 マッチに火をつけたいようです、" }, { "type": "narrator", "value": "火をつける、と言ってください、" } ], // builderのrepromptに対応(ユーザーからの発話がなかった場合に再読み上げする際の文言) "reprompt": [ { "type": "narrator", "value": "火をつける、と言ってみてください、" } ] },他にも'man'や'boy','old_woman'といったtypeを用意してあり、プログラム側でタイプに応じてssml(読み上げ用のフォーマット)のタグや属性を付加するメソッドを用意することで音量やピッチ、話す速度等の指定をしやすくしています。
ssmlの文法エラーが出た場合、間違っている箇所がログでは追いづらいため、エラーを減らせるのも構造化しておくことメリットの1つです。その他
Alexaスキルに限らず音声デバイスでは、いかにVUI(音声ユーザーインターフェース)を設計するかがよりよいユーザー体験を目指す上でかなり重要なポイントです。
というのも、一般的なアプリやPCのような画面で操作するデバイスと違い、ユーザーのアクションを制限することが出来ないからです。(例えば、アプリではボタンを開発者が設置しない限りボタンを押すというアクションはできません。)
つまり、ユーザーが行うであろうあらゆる行動(発話)に柔軟に対応できるように設計する必要があります。マッチファンタジーでは、VUIを考えるにあたり、以下のようなフローチャートを使いました。(画面遷移を考える上でも利用しています。)
フローチャートは特に状態管理が必要な場合に有効だと思います。
このフローチャートは正常系(ユーザーが期待通りの行動(発話)をした場合)のみしか記載していませんが、ユーザー体験を向上させるには異常系でのレスポンスもリッチにする必要があります。
また、VUIを考える際は、ユーザーの発話とスキルからのレスポンスを1セットとして組み立てていくのが良いかと思います。
今後やりたいこと
今回は、「Alexaスキルのコンテストに出す」という目的があり期限が限られていたため、まだまだ実装不十分な部分があります。
・すべてのストーリーの登場人物の声をAlexaの読み上げ音声ではなく肉声に(現在は自作の音源を一話分だけ実装済み。出来れば声優さんに頼みたい)
・すべてのストーリーにイラストを入れる&場面を追加する
・ストーリー数を増やす(現在10話)
・選択するフェーズで画面を切り替える(出来ていないのは、ハマったポイントの4番目が理由)
etc.まとめ
ここまでハマったポイントを色々説明してきましたが、Alexaスキル開発を一通りしてみた上で、難易度はそれほど高くないように感じます。
マッチファンタジーは企画から含めて約一ヶ月程度で公開していますが、プログラムの実装自体は学習も含めて1~2週間程度で、むしろ企画や音源やイラスト等の素材作りのほうが時間がかかりました。また、スキル公開のための審査提出のレスポンスが早く(私達の場合は営業日で1~2日程度でした)、審査が通らない場合でもどこをどう直せばよいのかをとても丁寧に教えてくれるので、
Alexaスキルに興味ある方は、とりあえず1つスキル作って審査出してみるのがおすすめです。以上です!



- 投稿日:2019-11-01T23:29:03+09:00
Rails6のActionDispatch::HostAuthorizationとELBのヘルスチェックの共存
Rails6のActionDispatch::HostAuthorization設定とokcomputerを利用した
Nginx - Rails - RDSという経路のヘルスチェックの共存に少しコツが必要だったので記事にしました。ActionDispatch::HostAuthorization
https://github.com/rails/rails/pull/33145
Rails6から追加された、DNSリバインディング攻撃から保護する新機能です。下記のように設定することで、指定したホスト以外からのアクセスはエラーとなります。
Rails.application.config.hosts << "product.com"okcomputer
https://github.com/sportngin/okcomputer
HealthCheck系のgemです。
2019/10/26(執筆時点の一週間前)にRails6対応がリリースされました。
Rails - DBという経路のヘルスチェックを簡単に追加することができます。
例えば、下記のような設定で、/custom_pathというパスにDBまでのヘルスチェック機能を追加することができます。# config/initializers/okcomputer.rb OkComputer.mount_at = false # config/routes.rb, at any priority that suits you mount OkComputer::Engine, at: "/custom_path"発生した問題
Rails6 + AWSで下記の構成のようなアプリを開発していました。
ECS +----------------+ ALB---|--Nginx--Rails--|---RDS +----------------+Rails6の
HostAuthorizationとokcomputergemを利用し、/healthcheckというパスでALBからのヘルスチェックをDBまで通して行おうとしました。
しかし、Railsが403エラーを返し、ヘルスチェックが失敗してしまいました。問題の原因
Nginx、Railsの設定はそれぞれ下記のようになっていました。
Nginxの設定
# healthcheck部分のみ抜粋 server { location /healthcheck { access_log off; proxy_pass http://rails:3000; } }Railsの設定
Rails.application.config.hosts << "product.com"原因はシンプルで、「ヘルスチェック時のホスト名が
product.comでないからエラーになっていた」というものです。対策
いくつか対策方法が考えられますが、今回はシンプルにNginxでHostヘッダを設定する対策を採用しました。
Nginxの設定
server { location /healthcheck { access_log off; # 以下を追加 proxy_set_header Host healthcheck.localhost; proxy_pass http://rails:3000; } }Railsの設定
Rails.application.config.hosts << "product.com" Rails.application.config.hosts << "healthcheck.localhost"この設定で無事、ALBからのhealthcheckでhealthyとなりました!
もう少しスマートな対応方法ありましたら、教えていただけると嬉しいです
- 投稿日:2019-11-01T22:51:16+09:00
AWSで作成したWordPressのサイトをSSL化する
はじめに
自分はインターネット初心者です。
無料枠が残っているAWSを有効活用するためにEC2を使い、WordPressでブログでも書こうと思った際、SSL化がよくわからなかったので記事に残しておく事にしました。
正直なぜこれで動いてるのかわかりません。(色々な記事を参考にしてもうまくいかなかった)
この記事を参考にしてSSL化する際は自己責任でお願いします。いろいろやる
Certificate Managerで証明書を発行し、ロードバランサーの作成、Route 53でドメイン名とELBとの関連付けまでは他の方々と同じです。
WordPressにログインし、プラグインをインストール
WordPressにログイン後、メニューの「プラグイン」から「新規追加」を選択。
「プラグインの検索」に「ssl」と入力し、「Really Simple SSL」をインストール後有効化。
サーバーにSSHでアクセス
アクセス後、以下の方法で「wp-config.php」ファイルを書き込み可能にする。
chmod 4273 /opt/bitnami/apps/wordpress/htdocs/wp-config.php実行後、WordPressに戻りページを再読み込みしてSSL化ができてるか確認。
確認後、権限を一応戻しておく。
chmod 4253 /opt/bitnami/apps/wordpress/htdocs/wp-config.phpこれでSSL化は完了。
さいごに
ほぼツールに頼ってSSL化しました。
セキリュティ的によろしくなかったらコメントで教えてもらえると助かります。
よろしくお願いします。
そして、この一言に尽きます。とりあえず動いてるからヨシ!!


- 投稿日:2019-11-01T21:56:08+09:00
AWS Cloud9でherokuコマンドがnot foundになった時の対処法
Railsチュートリアルの6.4でherokuコマンドを見失ったので対処法のメモ。
1.herokuコマンドみつからないエラー
■入力したコマンド
$ heroku run rails db:migrate■エラー内容
bash: heroku: command not found■やったこと
Cloud9でHerokuが使えない時の対処法■結果
上記記事内のコマンドを上から実行していったときに、新たなエラーに遭遇。2.herokuをアップデートしなさいエラー
■エラー内容
$ heroku -v
› Warning: heroku-cli update available from 7.0.9
› to 7.29.0.■やったこと
$ heroku update■結果
heroku-cli: Updating CLI... not updatable3.herokuアップデートできませんエラー
■やったこと
AWS Cloud9でHerokuのインストールが毎回必要?になる(Railsチュートリアル )
※補足※ということで「$HOME/.bash_profile」に$PATHの設定を追加して再起動してみる。
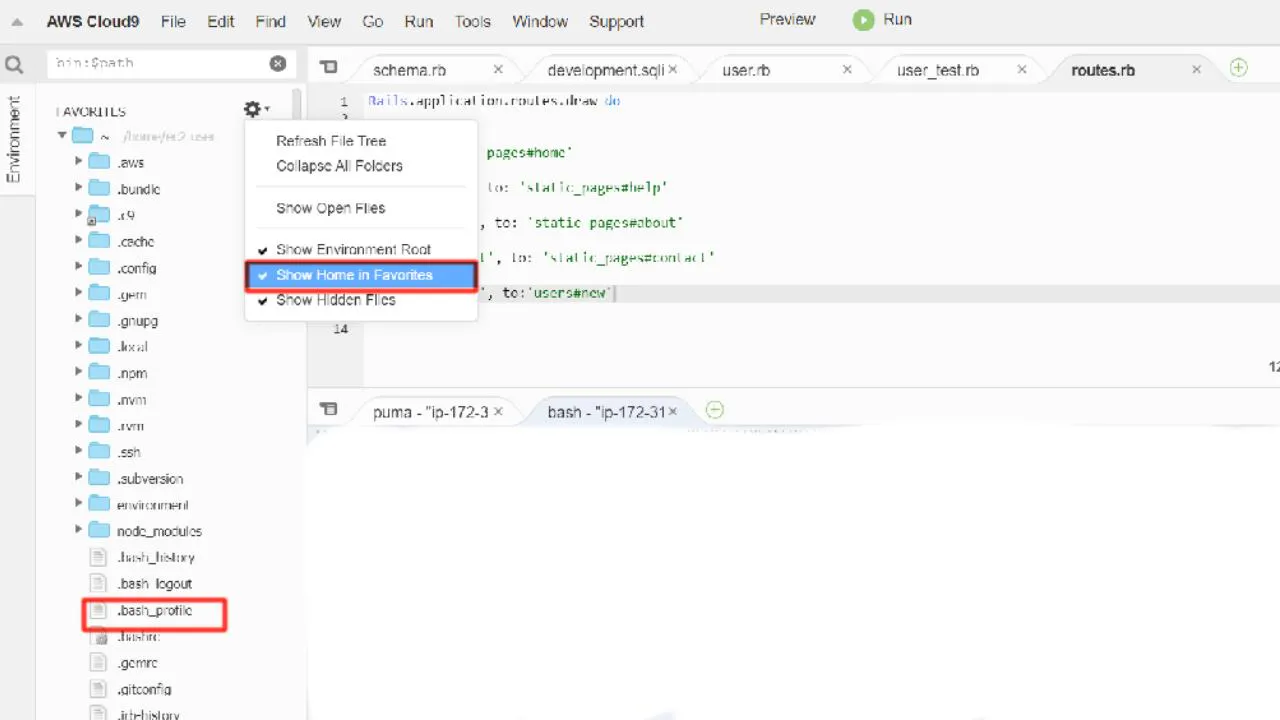
上記記述がよくわからなかったんですが、いろいろ調べながら以下の作業を実施。
・以下の画像とおり、Cloud9のコンソールの左ペインの歯車をクリックして、全てのファイルを表示させる。
・.bash_profileファイルが表示されるのでダブルクリックして開く。
・10行目くらいにすでにPATHの記述があるのでコメントアウト(以降の作業で環境がおかしくなった時に、アンコメントして元に戻すため)
・以下の記述を足して保存する。
PATH=/usr/local/heroku/bin:$PATH
・EC2のコンソールを開き、インスタンスを再起動する。(詳細な説明は割愛します。)
・再起動後rails sしようとしたらエラーが出たので、bundle isntallを実行
・rails sが実行されたら、再度以下のコマンドを実施
git push heroku
・herokuにログインを促されるので、以下の情報を入力
-Username:herokuのログインID(メールアドレス)
-Password:Herokuの[Account settings]ページ内にある、[API Key
]のRevealをクリックしたときに表示されるコードをコピペ
・[Opening browser to https://cli-auth.heroku.com/auth/browser/[id]]と表示されるので、別ウィンドウでURLを開く上記の手順でやっと[$ heroku run rails db:migrate]ができました。
調べながらあっちやったりこっちやったりしたので、上記の流れのとおりじゃなかったかもしれませんが、今後の自分のためと同じようにつまづいた人のためにメモ。
何かご指摘があれば遠慮なく教えてください。初投稿なのでお手柔らかにお願いします。
- 投稿日:2019-11-01T17:01:47+09:00
CloudFormation備忘録
現存する環境から複製するために部分的に書けたテンプレートを起こすというようなタスクがアレで個人的な覚書を。
・なんでこれで?
→ほかのあらゆるInfrastracture as a codeと同様に見える化と省力化とミス防止などいろいろメリットがある。当初の担当者が既にいないがブラックボックスな状況を多少は防げると思われるしわかる人どうしなら引き継ぎがしやすい。
強いて言うとクラウドプロバイダ謹製だから新サービス対応が早い
わかる人がみるとエクセル資料などをあさって確認せずとも環境を確認・俯瞰しやすいリアルな資料がわりに。
乖離してなければ。・Terraformとなにが違うか
テスト結果の確認しやすさはTerraformが上かもしれないけども、CFでも変更検知は可能。
Terraformもマルチクラウドでできるといってもそれぞれのクラウドのことを知らずに使えるわけでもなく、
リソースの書き方はクラウドによって独特な感じなので、使う人々が使いやすい広めやすい方でよくてケースバイケースかな。・一度始めたら手動対応するとめんどくさいことになる件
乖離してるときは手で変えた環境を手で戻してドリフトステータス再度確認する感じ。
そうしないとスタックが消せなくなる。スタックが消せないと中途半端に残った同名のリソースを作り直すとかできないことに。
作りかけとか消すのに失敗してるステータスだと問い合わせるかだいぶ待つかしないとロールバックしてくれなかったりも。
まあそれは他のツールでもあまり変わらないけどTerraformだとimportとかできるのはいい。それが良し悪しという意見もありそうだけど。・動的パラメータが可能な種類が限られる件
ざっくりいうとRDBのパスワードは大体いけたりするがそれ以外は結構無理だったりなど。
パラメータストアとセキュリティマネージャは結構違い、どっちかにすぐできるという感じでもなくて
コードから変えないといけなかったりするため既存をある程度踏襲したいという場合には不向き。これは書けるが
DBMasterUserPassword: Description: from system manater parameter. Default: "{{resolve:ssm-secure:stg-admin-DB_PASSWORD:1}}" Type: String NoEcho: trueこれは無理だった。webhookのトークンとかも。
DatadogApikey: Description: "datadog apikey from system manager parameterstore(manual, its support not yet)" # Default: "{{resolve:ssm-secure:datadog_APIKEY:1}}" Type: String NoEcho: true・アカウントIDやらリージョンやらはいきなり使える
Resource: !Sub 'arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/kinesisfirehose/${KinesisFirehoseName}:log-stream:*'・パラメータからリストで取り出して番号指定して使う
何度もテストするのに既存にあるものから選ぶほうが運用しやすくてたぶん便利という動機からこんなかんじに。
Parameters: EfsSecurityGroup: Description: 'select sg-efs-xxx' Type: "List<AWS::EC2::SecurityGroup::Id>" Subnets: Type: "List<AWS::EC2::Subnet::Id>" Description: "The list of SubnetIds in your Virtual Private Cloud (VPC)" Resources: FileSystem: Type: AWS::EFS::FileSystem Properties: PerformanceMode: generalPurpose FileSystemTags: - Key: Name Value: efs-xxxx-stg Encrypted: false MountTarget1: Type: AWS::EFS::MountTarget Properties: FileSystemId: Ref: "FileSystem" SubnetId: !Select [0, !Ref Subnets] SecurityGroups: !Ref EfsSecurityGroup MountTarget2: Type: AWS::EFS::MountTarget Properties: FileSystemId: Ref: "FileSystem" SubnetId: !Select [1, !Ref Subnets] SecurityGroups: !Ref EfsSecurityGroup・文字列を結合して値とするにはSubとJoin
Policies: - PolicyName: KinesisFirehosePolice PolicyDocument: Version: "2012-10-17" Statement: - Effect: Allow Resource: !Sub 'arn:aws:logs:${AWS::Region}:${AWS::AccountId}:log-group:/aws/kinesisfirehose/${KinesisFirehoseName}:log-stream:*' Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEventsResourceId: !Join ['', [service/, !Ref 'ECSCluster', /, !GetAtt [service, Name]]]・パラメータはデフォルト値を定義したりDescriptionに書くと便利
固定の値ならデフォルト値書いとくと指定しなくていいので楽。TypeとDescriptionが必須。
InstanceType: Description: "(Required)" Default: "t3a.medium" Type: "String"パスワード的なものはNoEchoで定義したやつを見られないようにするのが定石っぽい
・OutputsとImportValueでテンプレート間のリレーション
OutPutしてImportすると親子的なリレーション依存関係のあるテンプレを作れる
便利なケースもそれだと取り回しづらいというケースもあるOutputs: S3BucketName: Description: Bucket used for CodePipeline temp files Value: !Ref S3Bucket Export: Name: !Sub "${AWS::StackName}-S3BucketName"CodePipeline: Type: "AWS::CodePipeline::Pipeline" DependsOn: - CodeBuild - CodePipelineRole Properties: Name: !Ref AWS::StackName RoleArn: !GetAtt [ CodePipelineRole, Arn ] ArtifactStore: Location: !ImportValue pipeline-dependencies-stg-S3BucketName Type: S3・既存のリソースを使うときはARNを指定する書き方だと消して作り直されることはない
気を付ける点として、テンプレートとその設定した環境が乖離した状況になると
環境を手で戻して再度確認するなどの手順を踏まないと更新や削除が一切できなくなる。
なので、自由奔放な運用方法はできない。手動対応を規制する必要がある。Parameterとして指定することで厳密に管理され固定的になるのを防ぐという手もなくはない。
ただパラメータにしてしまうと動的にとか複数環境に対応できるように抽象的にするということは難しいような気がする。たぶん。
・mappingで複数環境対応もできる
が、これも運用しやすいかどうかは対応する人によるので、誰がどうするかとか考えて書いたほうがいいかも
Mappings: RDS: stg: ClusterName: rds-xxxxx-dbcluster ClusterNameShort: rds-xxxxx Instance1Name: rds-xxxxx-a Instance2Name: rds-xxxxx-c InstanceType: db.t2.medium BackupRetentionPeriod: 5 PreferredBackupWindow: "15:07-15:37" PreferredMaintenanceWindow: "sun:23:00-sun:23:30" AvailabilityZone1: "ap-northeast-1a" AvailabilityZone2: "ap-northeast-1c" MonitoringInterval: 60 ~~~ DBCluster: Type: "AWS::RDS::DBCluster" DeletionPolicy: Snapshot Properties: AvailabilityZones: - !FindInMap [RDS, !Ref "EnvName", "AvailabilityZone1"] - !FindInMap [RDS, !Ref "EnvName", "AvailabilityZone2"] BackupRetentionPeriod: !FindInMap [RDS, !Ref "EnvName", "BackupRetentionPeriod"]・Conditionで条件分岐する
あんまやりすぎると複雑になるので必要な分だけでいいかなあというか。
以下は、パラメータにスナップショットが指定さなかった場合に新規作成アトリビュートができて、
スナップショットは空に、ユーザとパスワードが設定されるがスナップショットがあったらそれが設定されて
ユーザとパスは無視される的な見本。Conditions: isBrandNewDB: !Equals [ !Ref DBSnapshotArn, "" ] ~~~ SnapshotIdentifier: !If [isBrandNewDB, !Ref "AWS::NoValue", !Ref "DBSnapshotArn" ] ~~~ MasterUsername: !If [isBrandNewDB, !Ref "DBMasterUserName", !Ref "AWS::NoValue" ] MasterUserPassword: !If [isBrandNewDB, !Ref "DBMasterUserPassword", !Ref "AWS::NoValue" ]・対応しているリソースやロードマップを確認できる
https://github.com/aws-cloudformation/aws-cloudformation-coverage-roadmap/projects/1
リソースのTypeで指定できるかどうかという話を↑でみられる
こういうの↓Type: "AWS::AutoScaling::LaunchConfiguration"マニュアル検索するときに↑のTypeで検索する
・一回ブラックベルトよむとだいぶわかった気にはなりそう
https://dev.classmethod.jp/cloud/aws/blackbelt-cloudformation-2018/
・Jsonだったらデザイナーでyamlに置換しとくと楽
yamlの可読性がjsonに比べたら大変すばらしいし置換はデザイナーでできる。
・同様のツール
GCPだとCloud Deployment Manager、AzureだとAzure Resource Managerなど。(つかったことはない。使えと強制されたことがないのが大きいと思う。)
- 投稿日:2019-11-01T15:14:55+09:00
CloudWatchLogsのログをElasticSearchに流す
概要
CloudWatchLogsからElasticSearchにログを流します。
ログを流す際にLambdaを経由する形になります。
CloudWatchLogsのアクションからロググループを選んで「Amazon Elasticsearch Serviceへのストリーム」を選択します。
あとは画面に従って設定するだけです。
注意点
ロール
VPC内のElasticSearchに書き込みたい場合はLambdaにAWSLambdaVPCAccessExecutionRoleをつけましょう。
セキュリティーグループ
ElasticSearchにアクセスできるようにセキュリティグループを設定してください。
Lambdaの関数が古い
ElasticSearchにCloudWatchLogsのログを投げるNode.jsで書かれているLambdaの関数がES7.xに対応していないのでLogの流し込みに失敗する場合があります。
具体的にはElasticSearchのindexのマッピングをdynamicではなく、自分で指定した場合に、index.typeがlogEvent.logGroupとなっていますが、ElasticSearch7.xでは複数のtypeに対応していないために落ちます。ここは
var action = { "index": {} }; action.index._index = indexName; action.index._type = '_doc'; // changed for ES 7.x action.index._id = logEvent.id;として、変更しておきます。

- 投稿日:2019-11-01T13:19:03+09:00
【AWS EC2】Amazon Linux 2にJenkinsをインストールする
概要
AWS EC2(AMI: Amazon Linux 2)にJenkinsをインストールして8081番ポートでアクセスできるようにする
環境
- AWS EC2
- OS: Amazon Linux 2
- AMI ID: amzn2-ami-hvm-2.0.20190823.1-x86_64-gp2
- セキュリティグループ: SSH 22 / TCP 8080 / TCP 8081 を開けておく
- Jenkins
- version: 2.202
構築手順
1. JDK 8 をインストール
- Amazon Linux 2にはデフォルトでJavaが入っていないのでインストールする
- Jenkins 2.164(2019-02)以降はJava 8 or Java 11が必要
$ sudo yum install -y java-1.8.0-openjdk-devel.x86_64 $ sudo alternatives --config java $ java -version openjdk version "1.8.0_222" OpenJDK Runtime Environment (build 1.8.0_222-b10) OpenJDK 64-Bit Server VM (build 25.222-b10, mixed mode)2. Jenkinsのyumリポジトリを追加
$ sudo wget -O /etc/yum.repos.d/jenkins.repo https://pkg.jenkins.io/redhat/jenkins.repo $ sudo rpm --import https://pkg.jenkins.io/redhat/jenkins.io.key接続先のbaseurlがhttpだとinstallでコケるのでhttpsに変更する
$ sudo vi /etc/yum.repos.d/jenkins.repo [jenkins] name=Jenkins baseurl=https://pkg.jenkins.io/redhat gpgcheck=13. Jenkinsをインストール
$ sudo yum install -y jenkins $ rpm -qa | grep jenkins jenkins-2.202-1.1.noarch4. Jenkinsを起動
$ sudo systemctl start jenkins Starting jenkins : [ OK ]5. Jenkinsの設定
初期設定
http://(public IP address):8080にアクセスして画面に従ってまず初期設定する$ sudo less /var/lib/jenkins/secrets/initialAdminPassword
- Unlock Jenkinsは初期パスワードを確認して入力する
- Customize JenkinsはとりあえずInstall suggested pulginsを選択
- Create First Admin Userで管理者ユーザーを登録
- Instance Configurationで
http://(public IP address):8081/jenkins/と入力- Save and Finishで設定完了
URLとportの設定を変更する
初期設定の4に書いたように
http://(public IP address):8081/jenkins/で動かしたいので、設定を変更してJenkinsを再起動する$ sudo vi /etc/sysconfig/jenkins JENKINS_PORT="8081" JENKINS_ARGS="--prefix=/jenkins" $ sudo systemctl restart jenkins
http://(public IP address):8081/jenkins/にアクセスして初期設定した管理者ユーザーでログインできれば完成感想
最初はQiitaの参考記事を見ながらやってたんだけど、installのときにサイトに接続できない的なエラーが出て進まなくて。
RedHatの公式ページ見たらURLが変わってたからhttpsで接続するようにしたらうまくいったのでメモ。参考
- 投稿日:2019-11-01T07:59:00+09:00
マルチクラウド環境におけるサーバ証明書の運用 Let's Encrypt/AWS/Azure
はじめに
本記事は、マルチクラウド環境におけるサーバ証明書の運用についての記事になります。
マルチクラウド環境でサーバ証明書を使用している場合は、環境によって対応手順が異なります。また、ワイルドカードでサーバ証明書を取得していている場合は、留意事項があるケースが多いので注意が必要です。
本記事では、実際に運用での失敗を経験した上で、サーバ証明書の運用時のポイントなどを簡潔にまとめています。
サーバ証明書の発行
Let's Encrypt
Let's Encryptでサーバ証明書を発行する場合は、certbotをインストールして発行します。Standaloneプラグインを使用する際は、以下のコマンドを実行します。Webサーバーを停止させずにサーバ証明書を取得したい場合は、Webrootプラグインを使用します。
# certbot certonly -a standalone -d <URL> --email <メールアドレス>ワイルドカードの場合は、以下のコマンドを実行します。
# certbot certonly --manual -d ‘*.<URL>’ -d <URL> -m ‘<メールアドレス>’ --agree-tos --preferred-challenges dns-01 --server https://acme-v02.api.letsencrypt.org/directoryまた、ワイルドカードで発行する際はDNS-01 チャレンジによる認証が必要になるため、_acme-challenge.の値としてTXTレコードを設定します。
AWSのAmazon Route 53などでTXTレコードを更新する際は、反映されるまでラグがあるので、TXTレコード設定後続けてcertbotの処理を行うと、認証に失敗する場合があります。
AWS
AWSはACM(AWS Certificate Manager)でサーバ証明書の発行ができます。料金は無料です。
ACMで取得したサーバ証明書の有効期限は、発行日から13か月後になり、有効期限の60日前に更新プロセスが開始されます。
ACM使用時の留意事項としてワイルドカードの場合は、手動更新が必要になります。自動更新されないため、注意が必要です。
- AWS Certificate Manager のよくある質問
- ACM 証明書の自動更新が失敗するのはなぜですか ?
- ワイルドカードとサブドメインを使用する E メール検証の証明書の場合、ACM が管理する更新プロセスはどのように行われますか?
Microsoft Azure
Microsoft Azureは、APP Service 証明書を使用してアプリケーションのHTTPS化を行うことができます。
Microsoft Azure PortalでAPP Service証明書の自動更新が「オン」になっている場合は、自動的に更新が行われます。
APP Service証明書の自動更新が「オン」の場合は、基本的に対応不要ですが、使用しない場合は無駄に課金されるので注意が必要です。
レンタルサーバのサーバ証明書
お名前.comなどのレンタルサーバによっては、自動的にサーバ証明書を更新してくれるサービスもあります。自動的に更新されるため、対応は不要です。料金も無料です。仕様が不明な場合はレンタルサーバのサポートに確認すれば教えてくれます。
レンタルサーバでサーバ証明書を利用する場合は導入時にきちんと確認しましょう。
サーバ証明書の運用
サーバ証明書の更新切れ対策
サーバ証明書の更新切れを防ぐために、メールの通知設定はきちんと行いましょう。
例えば、AWSなどアカウント登録時に普段使用しないメールアドレスを指定すると、更新切れに気づくことができません。
その様な状況を考慮し、AWSの場合は代替のメールアドレスで宛先を追加して対策ができます。また、メールアドレスは個人の担当者のメールアドレスではなく、メーリングリストなどにしておくと良いでしょう。
更に念を入れる場合は、サーバ証明書の期限をチェックし、期限が近くなったら通知する仕組みを作るのも有効な一手です。AWSの場合CLIのコマンドを使用すれば実現できます。
サーバ証明書更新時の確認
サーバ証明書更新後は、Webサイトにアクセスしてサーバ証明書の有効期限が更新されたことだではなく、サーバ証明書の検証エラーが出てないことも確認することをお勧めします。
例として、WebサービスとiPhoneアプリ及びAndroidアプリを提供するサービスにおいて、サーバ証明書更新時に中間証明書の登録漏れなどの不備があった場合、WebブラウザやiPhoneアプリはアクセスできるけど、Androidアプリのみアククセスできないという事象が発生します。
実際に経験しましたが当事象が発生すると、Androidアプリが真っ白になり、何も操作ができなくなりました。デバッグについてもWebブラウザやiPhoneアプリからはアクセスができ、Androidのみ当事象が発生している状況だったので調査にも少し時間を要しました。これについてはAndroid DevelopersのDocsより、HTTPS と SSL を使用したセキュリティが参考になります。以下はドキュメントからの引用です。
興味深い点として、パソコン用ブラウザでこのサーバーにアクセスしても、ほとんどの場合、「未知の CA」や「自己署名サーバー証明書」の場合に発生するようなエラーは発生しません。エラーが発生しないのは、パソコン用ブラウザの多くが、信頼できる中間 CA を時間をかけてキャッシュしているためです。ブラウザがあるサイトにアクセスして中間 CA に関する情報を得ると、次回からは証明書チェーン内にその中間 CA が存在していなくてもエラーにはなりません。
よって、サーバ証明書更新後はサーバ証明書が適切に更新されたことを確認しましょう。
簡単にできるサーバ証明書の確認方法について以下に記載します。
opensslコマンドとSSL Server Testによる二つの方法があります。
- opensslコマンド
# openssl s_client -connect <URL>:443上記opensslコマンドを実行し、出力結果にverify errorが出力される場合は、サーバ証明書の検証に失敗しているため、エラーが発生しています。また、出力結果がdepth=0となっているため、中間証明書がないことが分かります。以下はサーバ証明書に中間証明書が登録されていないときの出力例になります。サーバ証明書はLet's Encryptを使用しています。
CONNECTED(00000005) depth=0 CN = *.test.com verify error:num=20:unable to get local issuer certificate verify return:1 depth=0 CN = *.test.com verify error:num=21:unable to verify the first certificate verify return:1 --- Certificate chain 0 s:/CN=*.test.com i:/C=US/O=Let's Encrypt/CN=Let's Encrypt Authority X3 ---サーバ証明書に不備がない場合は以下の様に出力されます。
CONNECTED(00000005) depth=2 O = Digital Signature Trust Co., CN = DST Root CA X3 verify return:1 depth=1 C = US, O = Let's Encrypt, CN = Let's Encrypt Authority X3 verify return:1 depth=0 CN = *.test.com verify return:1 --- Certificate chain 0 s:/CN=*.test.com i:/C=US/O=Let's Encrypt/CN=Let's Encrypt Authority X3 1 s:/C=US/O=Let's Encrypt/CN=Let's Encrypt Authority X3 i:/O=Digital Signature Trust Co./CN=DST Root CA X3 --- Server certificate
- SSL Server Test
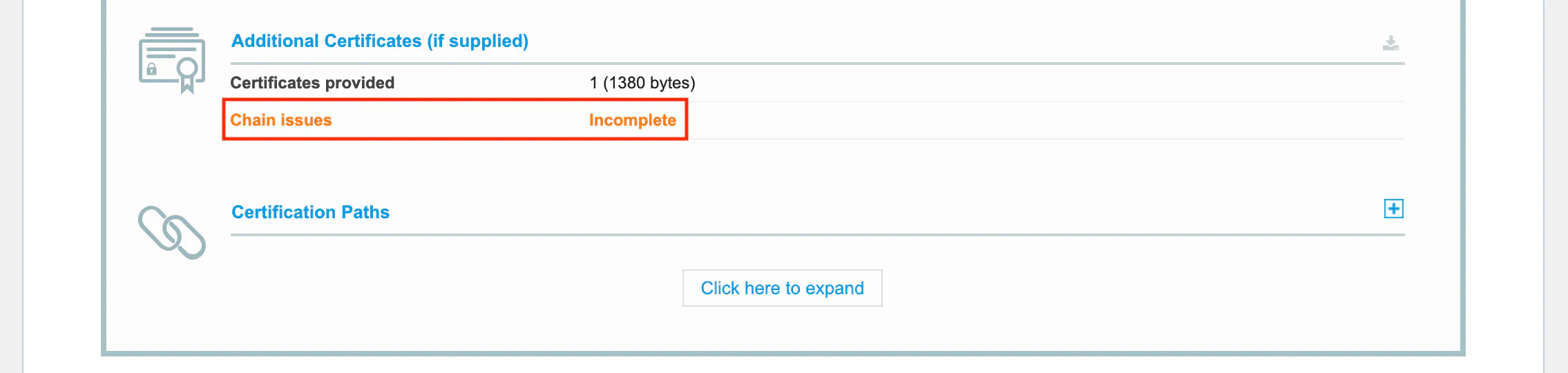
上記と同じく、サーバ証明書に中間証明書が登録されていないときに、SSL Server Testで検証すると、以下の様にChain issuesにincompleteと出力されます。
サーバ証明書に不備がない場合は以下の様にChain issuesにNoneと出力されます。
その他
クラウド環境のロードバランサーにサーバ証明書を登録し、HTTPとHTTPSのリスナーがいて、HTTPのリクエストは受け付けるけど、リダイレクトしたいというケースもあると思います。
Webサーバだけの話なら、Webサーバの機能でリダイレクトで処理を行うことができますが、クラウド環境のロードバランサーの仕様によっては対応してない場合もあります。
その様な場合は、Webサーバの機能でリダイレクトを行うか、ロードバランサーのHTTPリスナーを削除するなどの対応が必要です。
おわりに
サーバ証明書の更新切れに注意し、これからもHTTPSと上手に付き合っていきましょう。


- 投稿日:2019-11-01T00:52:20+09:00
AWS Lambdaでのコールドスタートのメモリの罠と、Invoke Lambdaでのタイムアウトの罠
問題の経緯
API Gateway経由、ALB経由でAPI化しているLambdaを構築していた。
ALB経由Lambdaの中には、VPCに含んでいるものもあった。
そのLambdaからは別のLambdaもいくつかInvokeしていた。
実装を一通り終わってテストしていると、どうもレスポンスが早いときと、遅いとき、酷いとタイムアウト(API Gatewayは30秒制約あるし。。)することがあった。調査した結果
調査してみると、どうにもInvokeしている部分が怪しかった。
やっぱりVPC Lambdaだとコールドスタートのせいで遅いのかなぁと思いながらログから調査していった。
Invoke自体は実行されているが、何故かInvoke先のLambdaにログが来ていない。。。。
もしかして、コールドスタートから起き上がる前にタイムアウトしてる??と思い、Lambda関連のドキュメントを漁りながら、やっぱりLambdaを定期実行して、コールドスタート回避するしかないのかなぁと思っていると下記の記事を発見。。。。
VPC Lambdaのコールドスタートにお悩みの方へ捧ぐコールドスタート予防のハック Lambdaを定期実行するならメモリの割り当ては1600Mがオススメ?!マジですか。。
Lambdaのメモリって単に必要分があれば良い程度にしか思ってませんでした。。
こんなことが出来るんですね。。。ただ、上記設定してみても、それでも若干レスポンスに差がでる。
そこで、Invokeのタイムアウトについて調べると、以下の公式Docが。AWS SDK を使用して Lambda 関数を呼び出す際の再試行とタイムアウトの問題をトラブルシューティングする方法
なんと。。
私はNodeJSでSDKを使っていたのですが、デフォルトの接続タイムアウトはないと。。。
というか、接続でミスることあるのか。。。同じサービス(AWS)内じゃん。。。。何故。。。とりあえず、下記のように設定したら、レスポンスは正常になりました。。
色々罠だった。。XXX.jsAWS.config.update({ region: "ap-northeast-1", maxRetries: 2, // 最大再試行回数 httpOptions: { timeout: 30000, // ソケットタイムアウト connectTimeout: 2000 // 接続タイムアウト } });結論
- LambdaをInvokeするときは必ず「最大再試行回数」「ソケットタイムアウト」「接続タイムアウト」を設定する
- Lambdaのメモリは多すぎず、少なすぎず、処理を必ず見てちょうど良いところで設定する(この時、Lambdaの実行時にENIもちゃんと見る)