- 投稿日:2019-10-23T22:08:59+09:00
自分用にpythonでリスト(配列)を初期化する方法をまとめておく
Memo
多次元リストを任意の値で初期化する。
空リスト
要素数0のリスト
lt = [] print(lt) # []一次元のリスト
要素数3のリストを0で初期化する場合
lt=[0*3] print(lt) # [0, 0, 0]※必要に応じて要素数は任意の値(input()等で入力される値)にする
多次元のリスト
ここでは例として二次元のリストを扱い、失敗例もメモしておく。
失敗例
# 失敗例 lt=[[0]*3]*4 print(lt) # [[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]]表示上問題ないように見えるがダメ。
初期化した後に例えばlt[1][2]=5と代入すると期待した結果と異なってしまった。lt=[1][2]=5 print(lt) # 期待値 # [[0, 0, 0], [0, 0, 5], [0, 0, 0], [0, 0, 0]] # 出力 # [[0, 0, 5], [0, 0, 5], [0, 0, 5], [0, 0, 5]]調べたところ
lt=[[0]*3]*4のような書き方だと[0]*3のリストを4つ定義しているからとのこと。
つまり同じオブジェクトを4つもつリストになっているから一つのオブジェクトを変更すると4つすべての要素が変更される。成功例
正しくはリスト内包表記で書く。
lt=[[0]*3 for i in range(4)] lt=[1][2]=5 print(lt) # [[0, 0, 0], [0, 0, 5], [0, 0, 0], [0, 0, 0]]※補足
リスト内包表記[式 for 任意の変数名 in インテラブルオブジェクト]
- 投稿日:2019-10-23T21:20:19+09:00
【Python】Seleniumでスクショを撮らせる
- seleniumで遷移したウェブページのスクショを撮った時のメモ
- 以下のコードと同ディレクトリ内に
imageという名前のディレクトリを作成し実行してくださいimport os import sys from selenium import webdriver from selenium.webdriver.chrome.options import Options # File Name FILENAME = os.path.join(os.path.dirname(os.path.abspath(__file__)), "image/screen.png") # set driver and url driver = webdriver.Chrome('./chromedriver') url = 'https://www.rakuten.co.jp/' driver.get(url) # get width and height of the page w = driver.execute_script("return document.body.scrollWidth;") h = driver.execute_script("return document.body.scrollHeight;") # set window size driver.set_window_size(w,h) # Get Screen Shot driver.save_screenshot(FILENAME) # Close Web Browser driver.quit()撮られたスクショがこのようにディレクトリ
image内に保存されています.

- 投稿日:2019-10-23T21:20:19+09:00
【Python】seleniumでスクリーンショットを撮る
- seleniumで遷移したウェブページのスクショを撮った時のメモ
- 以下のコードと同ディレクトリ内に
imageという名前のディレクトリを作成し実行してくださいimport os import sys from selenium import webdriver from selenium.webdriver.chrome.options import Options # File Name FILENAME = os.path.join(os.path.dirname(os.path.abspath(__file__)), "image/screen.png") # set driver and url driver = webdriver.Chrome('./chromedriver') url = 'https://www.rakuten.co.jp/' driver.get(url) # get width and height of the page w = driver.execute_script("return document.body.scrollWidth;") h = driver.execute_script("return document.body.scrollHeight;") # set window size driver.set_window_size(w,h) # Get Screen Shot driver.save_screenshot(FILENAME) # Close Web Browser driver.quit()撮られたスクショがこのようにディレクトリ
image内に保存されています.
GitHubをクローンして
exe.shを実行するのもありです.
- 投稿日:2019-10-23T20:35:38+09:00
[ゼロから作るDeep Learning]交差エントロピー誤差のバッチ対応・Not One Hot対応の方法を分かりやすく解説してみた
はじめに
この記事はゼロから作るディープラーニング 5章ニューラルネットワークの学習を自分なりに理解して分かりやすくアウトプットしたものです。
文系の自分でも理解することが出来たので、気持ちを楽にして読んでいただけたら幸いです。
また、本書を学習する際に参考にしていただけたらもっと嬉しいです。様々な場合に対応させるために
前回の記事で実装した交差エントロピー誤差は1つのデータを処理する事しか出来ない実装方法を使いました。
このままでは、一つのデータにしか対応ができなくバッチデータ(複数データ)やNotOneHotの正解データなどに対応することができません。
そこで今回は、バッチデータの対応・Not One Hotの対応をそれぞれ行っていこうと思います。バッチデータの対応
バッチデータに対応した交差エントロピー誤差を実装する時に一番重要になるのが平均を求めることです。
今まで通りの実装では、データの数だけ交差エントロピー誤差に処理された値が出力されてしまいます。それを全て人間の処理能力で処理しきるのは不可能です。
そこで、たくさんの処理された値から平均を出す事でその問題を解消します。#複数データに対応した 2次元配列に対応した def cross_entropy_errors(t,y): if y.ndim == 1: t = t.reshape(1,t.size)#データを2次元配列にする y = y.reshape(1,y.size) batch_size = y.shape[0] return -(t*np.log(y + 1e-7)).sum() / batch_size ts = np.array([[0,0,0,0,1],[0,0,1,0,0]])#正解データ ys = np.array([[0.1,0.05,0.05,0.1,0.7],[0.1,0.2,0.4,0.1,0.2]])#softmax関数の出力値 cross_entropy_errors(ts,ys) 0.636482641477893バッチデータへの対応を行うと今までの単体データを処理することができなくなってしまいます。
そこで上の実装では、if文の部分で単体データをバッチデータと同じ2次元配列の形にすることで問題を解消しています。Not One Hotの対応
今までの正解データは全て正解ラベルが1でそれ以外は0のOne Hot法のものを使用して来ましたが、これから使うデータの中に正解ラベルのindex番号がそのまま使用されたラベルデータなどのNot One Hotの正解データがあるかもしれません。
これから下でそのようなデータに対応した実装法を行いたいと思います。
#正解データがone_hot法ではなくラベルデータの場合 def cross_entropy_errors_label(t,y): if y.ndim == 1: y = y.reshape(1,y.size)#データを2次元配列にする batch_size = y.shape[0] return -(np.log(y[np.arange(batch_size),t]).sum()) / batch_size t_label = np.array([4,2])#正解データ y_label = np.array([[0.1,0.05,0.05,0.1,0.7],[0.1,0.2,0.4,0.1,0.2]])#softmax関数の出力値 cross_entropy_errors_label(t_label,y_label) 0.6364828379064438交差エントロピー誤差は数式の性質上、本当に必要なデータは正解ラベルのsoftmax関数の出力値だけです。
交差エントロピー誤差の数式は正解データ✖️logネイピア数(softmax関数の出力値)の総和✖️-1です。
しかし、one hot法の正解データは正解ラベル以外は0のためほとんどが0になります。その為、正解ラベルのsoftmax関数の出力値しかいらないのです。上の実装では、ラベルデータを使って正解ラベルのsoftmax関数の出力値を取得し、計算処理を行っています。
※上の実装はバッチデータにも対応してます。
- 投稿日:2019-10-23T19:16:40+09:00
AWS Cloud9でのpython2からpyhton3に変更する方法(pyenv利用)
概要
aws cloud9でslackbot用のラムダ関数を作成しようとした時に,python2からpython3への変更に手間取ったので,忘れないように書いておきます.結局,cloud9では,「Preference」=> 「Python Support」から2から3への変更が可能だったので,次回からはそうするようにします.
間違えてしまった理由として,前回,EC2サーバを自分で建てたとき,python2しか入っていなかったので,cloud9でサーバを立てた場合でも,python3は入っていないと思ってしまったためです.ですので,python3を入れるのがめんどくさいなら,cloud9を立ててec2を利用するのもいいかもしれません.今回は,python2からpyenvからとってきたpython3.6.2に変えます.
利用環境
amazon linux2
バージョン確認
pythonとpipのバージョンを確認しましょう.
$ python -V Python 2.7.14 $ pip -V pip 9.0.3 from /usr/lib/python2.7/dist-packages (python 2.7)pyenvのインストール
pyenvをgitから落としてきて.bash_profileにpyenvのpathを書き込む
その後sourceコマンドで.bash_profileを改めて読み込み(もしくは再起動)$git clone https://github.com/yyuu/pyenv.git ~/.pyenv $echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $source ~/.bash_profilepyenv へのpathが通っているか確認
$pyenv --version pyenv 1.2.13-19-gf3d008fdpyenvでインストール可能なバージョンを指定
pyenv install --list 2.1.3 2.2.3 2.3.7 2.4.0 2.4.1 2.4.2 2.4.3 2.4.4 2.4.5 2.4.6 2.5.0 2.5.1 2.5.2 2.5.3いろいろ出ますが,今回は3.6.2を選択する.以下に保存される.
$pyenv install 3.6.2 $find . -name python3.6 /home/ec2-user/.pyenv/shims/python3.6 2>/dev/null /home/ec2-user/.pyenv/versions/3.6.2/lib/python3.6 /home/ec2-user/.pyenv/versions/3.6.2/bin/python3.6systemになっているので,3.6.2に変更
$pyenv versions * system 3.6.2 (set by /home/ec2-user/.pyenv/version) $pyenv global 3.6.6 $pyenv rehashこれで
$pyenv versions system * 3.6.2 (set by /home/ec2-user/.pyenv/version)3.6.2のほうにチェックが入りました.
ただ,これでもpython2のままです.$python --V python2.7.?これは,.bash_rcで利用するpythonがすでに決められているためだ.
そこで,$sudo vim ~/.bashrc alias python='python27'上の部分を削除します.
さらに,$find / -name python3.6 2>/dev/null /usr/lib/python3.6 /usr/bin/python3.6 /usr/local/lib/python3.6 /usr/local/lib64/python3.6 /usr/lib64/python3.6 /opt/c9/python3/lib/python3.6 /opt/c9/python3/bin/python3.6 /home/ec2-user/.pyenv/shims/python3.6 /home/ec2-user/.pyenv/versions/3.6.2/lib/python3.6 /home/ec2-user/.pyenv/versions/3.6.2/bin/python3.6 /home/ec2-user/environment/.c9/metadata/environment/calif/venv/lib/python3.6 ~/.pyenv/shims/python3.6とpythonのフォルダは2つ(はじめからあるもの(/usr/bin)と今入れたもの(home/ecs-user/.pyenv)ので,pythonを指定したときに,先に呼び出すファルダを決めます.
今は,$which python /usr/bin/python3.6とかがでます.
そこで,
$ sudo vim /etc/paths /home/ec2-user/.pyenv/shims /usr/bin /bin /usr/local/bin /usr/sbin /sbin /usr/local/sbinとして,pyenvのpythonを先に読み込むようにしましょう.
すると,$which python /home/ec2-user/.pyenv/shims/python3.6となります.
ならないようなら,一度,サーバを落としてください.
これで,pyenvを使ってpython3.6.2を利用できるようになりました.
環境によって,バージョンは変えてください.
ちなみに,現状では,あらかじめ入っているpython3
3.6.8です.
ちなみに,$pip -version pip 19.3.1 from /home/ec2-user/.pyenv/versions/3.6.2/lib/python3.6/site-packages/pip (python 3.6)となっており,pipはpython3を利用されるようになっている.
python2も共存しているので,pipコマンドを利用しているのか確認するとよい.
- 投稿日:2019-10-23T18:45:01+09:00
pythonでcsv出力する際、一文字ずつセルに文字が入力されてしまいます。
pythonでTwitterのトレンドを取得して、その情報をcsvとして保存したいのですが
保存されたデータを見ると、一つのセルに一つのトレンドではなく一文字ずつ入ってしまいます。
例) ”Qiita”の場合
現状:"Q""i""i""t""a"と5つのセルを使う
理想:"Qiita"と1つのセルに収納以下、コード
触り始めたばかりなのでめちゃくちゃだと思います。_____________________________________
import tweepy
import csvconsumer_key =
consumer_secret =
access_token =
access_token_secret =
//OAuth認証
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
//APIのインスタンスを生成
api = tweepy.API(auth)//tweet 範囲指定
woeid = {
"日本": 23424856
}
for area, wid in woeid.items():
print("--- {} ---".format(area))
// リストになっているので取り出す
trends = api.trends_place(wid)[0]
#print(trends.keys()) # trends, as_of, created_at, locations
#print(len(trends["trends"])) # 50
body=[]
for i, content in enumerate(trends["trends"]):
print(i+1, content['name'])
body.append(content['name'])
print("----------")//ヘッダー
header = ['trends']// ファイルを書き込みモードでオープン
with open('sample.csv', 'w',newline="") as f:writer = csv.writer(f,lineterminator='\n') // writerオブジェクトを作成
writer.writerow(header) // ヘッダーを書き込む
writer.writerows(body) // 内容を書き込む
- 投稿日:2019-10-23T17:34:31+09:00
Pythonインストール(Ansible)
はじめに
Ansibleを使用してPythonインストールを行う際の手順を記述します
サンプルアプリケーションはgithubになります前提事項
Ansibleセットアップ手順はREADMEを参照ください
アプリケーション環境構築イメージはアプリケーション環境構築(Ansible)を参照くださいPythonインストール(Ansible)
Pythonインストールを行うplaybookを定義します
ファイル 内容 変数ファイル グループやユーザ名やPythonのインストールバージョン等の変数を定義します タスクファイル Python関連のパッケージやPythonのインストール等を定義します Python関連のパッケージインストール
python関連のパッケージをインストールします
- name: Python関連のパッケージインストール apt: force_apt_get: yes state: latest name: - python-pip - libffi-dev - libmysqlclient-dev - gettext各項目の説明は以下のとおり
項目 内容 force_apt_get 警告を回避するためにapt-get使用を指定します
詳細は#56832を参照くださいstate latestを指定して最新バージョンをインストールします name pip等の必要なパッケージ名を指定します Python及びモジュールインストール
Python及び必要な各種モジュールをインストールします
- block: - name: pyenvの存在チェック command: test -x {{ home_dir }}/.pyenv/bin/pyenv register: pyenv_present ignore_errors: yes - name: pyenvリポジトリ更新 git: repo: https://github.com/pyenv/pyenv.git dest: "{{ home_dir }}/.pyenv" when: pyenv_present is failed - name: pyenv設定追加 lineinfile: dest: "{{ home_dir }}/.bash_profile" state: present create: yes line: "{{ item }}" with_items: - 'export PYENV_ROOT="$HOME/.pyenv"' - 'export PATH="$PYENV_ROOT/bin:$PATH"' - 'if command -v pyenv 1>/dev/null 2>&1; then' - ' eval "$(pyenv init -)"' - 'fi' when: pyenv_present is failed - name: bash_profile読込み shell: /bin/bash -lc "source ~/.bash_profile" - name: Python{{ install_python_version }} インストール shell: /bin/bash -lc "pyenv install {{ install_python_version }}" when: pyenv_present is failed - name: shim更新 shell: /bin/bash -lc "pyenv rehash" when: pyenv_present is failed - name: Pythonインターセプタ変更 set_fact: ansible_python_interpreter={{ home_dir }}/.pyenv/shims/python - name: Python{{ install_python_version }}のglobal指定 shell: /bin/bash -lc "pyenv global {{ install_python_version }}" - name: Python{{ install_python_version }}のpipアップグレード pip: name: pip state: latest - name: Python{{ install_python_version }}のモジュールインストール pip: name: - beautifulsoup4==4.6.0 - Django==2.1.5 - django-admin-tools==0.8.1 - django-bootstrap-form==3.4 - lxml==4.3.0 - mysqlclient==1.4.2 - pytz==2018.9 - PyYAML==3.12 - pytest==4.1.1 - pytest-django==3.4.5 - name: Pythonインターセプタ変更 set_fact: ansible_python_interpreter=/usr/bin/python become: yes become_user: "{{ user_name }}"blockディレクティブ
指定のユーザにスイッチしてPythonをインストールするためblockディレクティブを使用します
- block: ・ ~ 各タスクを記述する ~ ・ become: yes become_user: "{{ user_name }}"各項目の説明は以下のとおり
項目 内容 become yesを指定してsuコマンドを実行します become_user スイッチするユーザを指定します pyenvの存在チェック
pyenvの存在チェックを行います
- name: pyenvの存在チェック command: test -x {{ home_dir }}/.pyenv/bin/pyenv register: pyenv_present ignore_errors: yes各項目の説明は以下のとおり
項目 内容 command testコマンドを実行してファイル有無を取得します register 後続タスクの実行を判定するためファイル有無結果を変数に保持します ignore_errors ファイルが存在しない場合も処理を継続します pyenvリポジトリ更新
gitコマンドでpyenvのリポジトリを取得します
- name: pyenvリポジトリ更新 git: repo: https://github.com/pyenv/pyenv.git dest: "{{ home_dir }}/.pyenv" when: pyenv_present is failed各項目の説明は以下のとおり
項目 内容 repo リポジトリのURLパスを指定します dest リポジトリのダウンロード先を指定します when 変数を参照してpyenvインストール済の場合はスキップします bash_profile設定
bash_profileに設定を追加して読み込みます
- name: pyenv設定追加 lineinfile: dest: "{{ home_dir }}/.bash_profile" state: present create: yes line: "{{ item }}" with_items: - 'export PYENV_ROOT="$HOME/.pyenv"' - 'export PATH="$PYENV_ROOT/bin:$PATH"' - 'if command -v pyenv 1>/dev/null 2>&1; then' - ' eval "$(pyenv init -)"' - 'fi' when: pyenv_present is failed - name: bash_profile読込み shell: /bin/bash -lc "source ~/.bash_profile"各項目の説明は以下のとおり
項目 内容 dest bash_profileのパスを指定します state 設定が追加済の場合はスキップします create ファイルが存在しない場合はファイルを作成します line with_itemsの定義内容をファイルに追記します when 変数を参照してpyenvインストール済の場合はスキップします shell sourceコマンドを実行します Pythonインストール
Pythonをインストールします
- name: Python{{ install_python_version }} インストール shell: /bin/bash -lc "pyenv install {{ install_python_version }}" when: pyenv_present is failed - name: shim更新 shell: /bin/bash -lc "pyenv rehash" when: pyenv_present is failed各項目の説明は以下のとおり
項目 内容 shell pyenvにインストールするPythonのバージョンを指定します when 変数を参照してpyenvインストール済の場合はスキップします Pythonインターセプタ変更
pyenvにモジュールをインストールするためPythonインターセプタを変更します
- name: Pythonインターセプタ変更 set_fact: ansible_python_interpreter={{ home_dir }}/.pyenv/shims/python各項目の説明は以下のとおり
項目 内容 set_fact pyenvのPythonパスを指定します Ansible実行中はPythonインターセプタ変更は保持されるため
モジュールのインストールは以下の流れで行っています
No 内容 1 Pythonパスをシステム→ユーザの参照先に変更する 2 スイッチしたユーザでpipを実行する 3 Pythonパスをユーザ→システムの参照先に変更する Pythonのglobal指定
pyenvのPythonバージョンを変更します
- name: Python{{ install_python_version }}のglobal指定 shell: /bin/bash -lc "pyenv global {{ install_python_version }}"各項目の説明は以下のとおり
項目 内容 shell pyenvのPythonバージョンを指定します pipアップグレード
pipを最新化します
- name: Python{{ install_python_version }}のpipアップグレード pip: name: pip state: latest各項目の説明は以下のとおり
項目 内容 pip モジュール名を指定します state latestを指定してモジュールを最新化します モジュールインストール
pipコマンドを使用してモジュールをインストールします
- name: Python{{ install_python_version }}のモジュールインストール pip: name: - beautifulsoup4==4.6.0 - Django==2.1.5 - django-admin-tools==0.8.1 - django-bootstrap-form==3.4 - lxml==4.3.0 - mysqlclient==1.4.2 - pytz==2018.9 - PyYAML==3.12 - pytest==4.1.1 - pytest-django==3.4.5各項目の説明は以下のとおり
項目 内容 pip アプリケーションに必要なモジュール名を指定します 参考情報
- 投稿日:2019-10-23T16:55:05+09:00
社用PCにpyautoguiを入れる
社用PCにpyautoguiを入れたい(Windows)
#error code C:\Users\xxx>pip install pyautogui管理者権限とプロキシ名を入れることで解決した。
C:\Users\xxx>pip install --user pyautogui --proxy=http://xxx.co.jp Collecting pyautogui Downloading https://files.pythonhosted.org/packages/1c/3c/4711a718371f6a16fd19833abf5feea2b1701722bcecdba782d5db7a9f36/PyAutoGUI-0.9.48.tar.gz (57kB) |████████████████████████████████| 61kB 4.1MB/s Installing collected packages: pymsgbox, PyTweening, pyscreeze, pyrect, pygetwindow, pyperclip, mouseinfo, pyautogui Running setup.py install for pymsgbox ... done Running setup.py install for PyTweening ... done Running setup.py install for pyscreeze ... done Running setup.py install for pyrect ... done Running setup.py install for pygetwindow ... done Running setup.py install for pyperclip ... done Running setup.py install for mouseinfo ... done Running setup.py install for pyautogui ... done Successfully installed PyTweening-1.0.3 mouseinfo-0.1.2 pyautogui-0.9.48 pygetwindow-0.0.7 pymsgbox-1.0.7 pyperclip-1.7.0 pyrect-0.1.4 pyscreeze-0.1.24
- 投稿日:2019-10-23T15:38:24+09:00
【Pycharm】同じ階層のpythonファイルをインポートしようとするとエラーが発生するときの対処法
pythonの問題ではなくpycharmの問題で嵌った話
pythonでは自分で書いたプログラムの関数をライブラリとしてインポートできる便利な機能がある。
同じ階層にある、前に作ったあの関数を使いたい。そんな時にpycharmでエラーが出ました。
No module named ~
原因の切り分け
最初は原因がわからなかったため、とりあえずコンソールからインポートできるか試してみると実行できました。
つまり、この問題はpycharm側の問題であるとわかりました。
原因
調べていく中で、ライブラリとしてインポートするにはプログラムの親ディレクトリがsources rootである必要があるようです。これは一応便利機能の一つだと思います。
このディレクトリをsources rootに指定すると、プロジェクト内のどのディレクトリでインポートしてもsources rootをルートディレクトリとした絶対パスで指定できる、つまりfromなどを使ったパスの指定をする必要がなくなるというものです。
代償としてpure pythonのようにディレクトリの相対パスで指定するとエラーが出るようです。
解決方法
野蛮な方法として、使いたいプログラムがあるディレクトリを右クリック、Mark Directory as でsources rootを指定することでエラーが消えて使えるようになりました
- 投稿日:2019-10-23T14:51:45+09:00
tf.map_fnの使い方
概要
tensorflowライブラリの
map_fnという関数について紹介します.
map_fnがどう動くのかを中心に書きます.
公式ドキュメントは「こちら」です.内容
ある関数にテンソルの要素を一つ一つ与えたいときに使います.
mapは「写像」を意味していると思われます.tf.map_fn( fn, elems, dtype=None, parallel_iterations=None, back_prop=True, swap_memory=False, infer_shape=True, name=None )
elemsに入力テンソルを指定し,fnに適用する関数を指定すると,elemsの要素が連続的にfnに与えられます.
elemsはリスト,タプルにすることも可能ですが,最初の次元は一致させる必要があります.1つのテンソル
簡単な例を次に示します.
test.pyimport numpy as np import tensorflow as tf def func(x): return x*x init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) elems = np.array([1,2,3,4,5,6]) op = tf.map_fn(func, elems) result = sess.run(op) print(type(result)) # <class 'numpy.ndarray'> print(result.shape) # (6,) print(result) # [ 1 4 9 16 25 36]1つのテンソルに対して,関数が適用されていることが分かります.
しかし,これはfunc(elems)のように,関数に引数を与えるときと変わりません.
map_fnの挙動は次の例を見てもらえれば分かると思います.test2.pyimport numpy as np import tensorflow as tf def func(x): return 1 init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) elems = np.array([1, 2, 3]) op = tf.map_fn(func, elems) result = sess.run(op) print(type(result)) # <class 'numpy.ndarray'> print(result.shape) # (3,) print(result) # [1 1 1]1つのテンソルに対して,関数が適用されています.
テンソルは3つの要素を持っており,そのそれぞれに対して「1」が返り値として与えられ,結果としてarray([1, 1, 1])がresultに入ります.複数のテンソル
2つのテンソルをタプルで
elemsに渡したときの例です.test3.pyimport numpy as np import tensorflow as tf def func(x): return 5,6 init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) elems = (np.array([1, 2, 3]), np.array([4,5,6])) op = tf.map_fn(func, elems) result = sess.run(op) print(type(result)) # <class 'tuple'> print(result) # (array([5, 5, 5]), array([6, 6, 6]))2つのテンソルのそれぞれの要素に対し,順番に関数が適用され,1つ目のテンソルには「5」を,2つ目のテンソルには「6」を返しています.
返り値の形や型が,
elemsと異なる場合は,dtypeで指定します.test4.pyimport numpy as np import tensorflow as tf def func(x): return x[0] * x[1] def func2(x): return x[0]+1, x[0]+2, x[1]+1, x[1]+2 init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) elems = (np.array([1, 2, 3]), np.array([4,5,6])) op = tf.map_fn(func, elems, dtype = tf.int32) # dtypeで指定 result = sess.run(op) print(type(result)) # <class 'numpy.ndarray'> print(result) # [ 4 10 18] op2 = tf.map_fn(func2, elems, dtype = (tf.int32, tf.int32, tf.int32, tf.int32)) # dtypeで指定 result2 = sess.run(op2) print(type(result2)) # <class 'tuple'> print(result2) # (array([2, 3, 4]), array([3, 4, 5]), array([5, 6, 7]), array([6, 7, 8]))おまけ
2次元テンソルの場合でも要素が一つずつ順に渡されていることが分かります.
test5.pyimport numpy as np import tensorflow as tf import sys def func2(p, q): return np.dot(p, q) def func(x): a, b = x return func2(a,b) init = tf.global_variables_initializer() sess = tf.Session() sess.run(init) elems = (np.array([[1, 2, 3],[4,5,6]]), np.array([[10, 20, 30],[40,50,60]])) op = tf.map_fn(func, elems, dtype = tf.int32) result = sess.run(op) print(type(result)) # <class 'numpy.ndarray'> print(result) # [[ 10 40 90] [160 250 360]]
- 投稿日:2019-10-23T14:50:09+09:00
pandasで、dfを入力すると相関係数を一列で出力する関数を作ってみた
例えば、irisデータセットに対してpandasのcorrメソッドを使うと、こんな風に相関係数行列が出てくると思います。
pythondf.corr(method='pearson')
ただ、相関係数のランキングを作りたい場合は、こんな感じで1列に並んでいた方が扱いやすかったりします。
そこで、相関係数を上の様に出力する関数を作ってみました。
pythonimport numpy as np import pandas as pd # 引数は、相関係数を作成したいdf def corr(df): # 相関係数行列を作成 corr_mat = df.corr(method='pearson') # 行(列)サイズを取得 n = corr_mat.shape[0] # 項目名を取得 columns = df.columns.tolist() # 変数名1, 変数名2, 値を一つの配列に入れたものを作成 # 相関係数行列の下三角部分(対角成分除く)だけ corr_ary = [] var1_ary = [] var2_ary = [] for i in range(n): for j in range(i): if i == j: continue corr_ary.append(corr_mat.iloc[i,j]) var1_ary.append(columns[i]) var2_ary.append(columns[j]) # dfにする df_new = pd.DataFrame([]) df_new["var1"] = var1_ary df_new["var2"] = var2_ary df_new["corr"] = corr_ary return df_new使用例は以下の通りです。
pythonfrom sklearn import datasets iris = datasets.load_iris() df = pd.DataFrame(data=iris['data'], columns=iris['feature_names']) corr(df)これでさっきのdfが得られます。


- 投稿日:2019-10-23T14:10:01+09:00
AWSでサーバレスな動画解析(Amazon Rekognition)
こんにちは。
日々の業務ではインフラエンジニアをやっています。@hayaosatoです。最近は動画解析などの技術も流行っていてそれらのSaaSも提供されていますね。
AWSではAmazon Rekognition(以下、Rekognition)というサービスが提供されています。
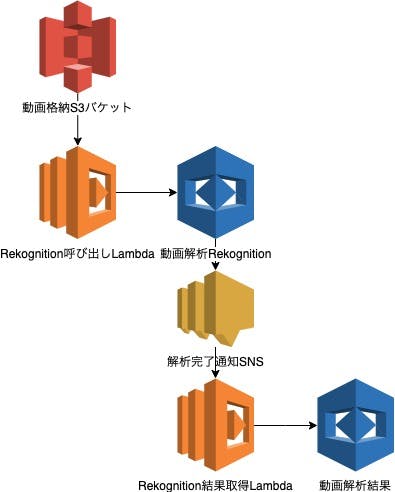
本記事ではこのRekognitionを使うためのサーバレスアーキテクチャを構築してみたいと思います。構成
構成図は以下の通りです。
Rekognitionで動画解析を行うと、動画の長さによりますが解析時間がかかってしまいます。
Rekognitionでは解析時間の完了をAmazon SNS(以下、SNS)のトピックを発行することで通知してくれます。
今回はS3に動画がアップロードされたことをトリガにAWS Lambda(以下、Lambda)からRekognitonの動画解析開始
Rekognitionの動画解析完了後SNSトピックからLambdaを呼び出し、LambdaからRekognitonの解析結果を取得する
というアーキテクチャを作ってみます。S3 -> Lambda
Lambdaファンクションを作成し、トリガを設定します。
この際に注意すべきは動画はファイルサイズが大きくなりがちなので、
マルチパートアップロードの完了時もちゃんとトリガが飛ぶようにしておきましょう。Lambda -> Rekognition -> SNS
Rekognitionで解析を開始するためのLambdaファンクションを作成します。
言語はPythonにしました。ドキュメントはこちら。
今回は顔認識を使ってみることにしたので、start_face_detectionを使用します。response = client.start_face_detection( Video={ 'S3Object': { 'Bucket': 'your-bucket-name', 'Name': 'your-video-name' } }, ClientRequestToken='string', NotificationChannel={ 'SNSTopicArn': 'your-sns-topic-arn', 'RoleArn': 'your-role-arn-for-rekognition' } )ここで、
NotificationChannelにSNSとROLEのARNを指定しています。
SNSTopicArnはその通りRekognitionが解析完了した際に通知を飛ばすためのSNSトピックのARNです。
RoleArnはRekognitionがSNSトピックを飛ばすためのRoleを与える必要があります。SNS -> Lambda -> Rekognition
Rekognitionから発行されたSNSトピックからLambdaが呼び出されるようにサブスクリプションを作成したら、
最後にLambdaからRekognitionに対して動画解析の結果を取得します。Lambdaに届くeventの'Sns'キーのValueは以下のようになっています。
{ 'Type': 'Notification', 'MessageId': 'xxxxxxxx', 'TopicArn': 'arn:aws:sns:your-region:your-account-id:your-topic-arn', 'Subject': None, 'Message': '{"JobId":"xxxxxxxxxx","Status":"SUCCEEDED","API":"APINAME","Timestamp":1571799891913,"Video":{"S3ObjectName":"your-video.mp4","S3Bucket":"your-video-bucket"}}', 'Timestamp': '2019-10-23T03:04:52.660Z', 'SignatureVersion': '1', 'Signature': 'xxxxxxxxx' 'SigningCertUrl': 'https://sns.ap-northeast-1.amazonaws.com/SimpleNotificationService-xxxx.pem', 'UnsubscribeUrl': 'https://sns.ap-northeast-1.amazonaws.com/?Action=Unsubscribe&SubscriptionArn=arn:aws:sns:xxxxxx', 'MessageAttributes': {} }このようにして、Messageを取り出すことでRekognitionから結果を抜き出すための情報が揃います。
MessageからJobIdを抜き出して、(NextTokenは省略しています。)
response = client.get_face_detection( JobId='xxxxxx' )Rekognitionから解析結果のJSONを受け取りことができます。
まとめ
このようにして、Rekognitionを利用してサーバレスなアーキテクチャを作成してみました。
サーバレスでイベントドリブンってやっぱりいいですね
コードはこちら
- 投稿日:2019-10-23T13:19:06+09:00
退屈なことをPythonにやらせたいときに来るところ
随時更新予定
なんかこれどの記事にも書いてる気がするな自分【よく使うライブラリ】
import os import unicodedata import datetime import glob import re import pandas as pd import openpyxl as px from openpyxl.formatting.rule import CellIsRule from openpyxl.styles import Color, PatternFill from openpyxl.utils import get_column_letterPythonを活かすための部品,知識まとめ
osモジュール編
os.chdirでカレントディレクトリを変更
os.listdir()で引数にとったパスのフォルダ、ファイルを列挙Pandas編
pd.read_excel()でExcelファイルを開き、DataFrameに格納
DataFrame.columns.valuesで列名をPandas.Seriesで取得、tolist()でリスト化
locで任意の位置の値を取得、正規表現を併用することでマッチした値を取得する
concat()でDataFrameにDataFrame,Seriesを結合
axis引数でタテヨコを指定
DataFrame.to_excel()で.xlsxに書きこむOpenpyxl編
openpyxl.load_workbook()で.xlsxブックを読み込む
worksheet.conditional_formatting.add()で条件付き書式の設定をする
各パラメータはExcelブックでの条件付き書式設定と同じ設定方法
workbook.save()でExcelブックに書き込み
ws.cell(row=row_num,column=col_num,value=value)で(row_num,col_num)セルにvalueを書き込むその他
コマンドプロンプトにファイルをドラッグ&ドロップするとフルパスが指定できる
windowsのpathに含まれる"\"によってpathの文字がエスケープされてしまうため、pathはrow文字列で指定
path=r"parent\children\current\file"r""の末尾に\があるとエラー
→末尾だけpathlist[n]+="\\"で\を結合
str+strで文字列結合
str.replace(str,str)で文字列置換
input()の引数はprint()と同じく標準出力される使用例
何層にも枝分かれしたフォルダ構造の中から「このファイル探して」と言われたとき
・いちいちエクスプローラーでカチカチクリックするの嫌だな...
・詳細なパスが知りたい
→ファイルの存在確認だけではダメだからフルパスを出力させよう
・どこにあるか分からないけどたぶんこのあたりにあるよ
→pathをリストに入れて全走査しようpathlist=[ r"path1", r"path2", r"path3", r"path4", r"path5" ]・ファイルが.xlsなのか.xlsxなのかも分からない...
→re(正規表現)で探そう,pathに両方文字列結合しようxlsx=".xlsx" xls=".xls"・どの深さのフォルダにあるか分からない...
→中間フォルダを考慮してpathにワイルドカードを入れて、いちばん浅いところからいちばん深いところまで再帰的に走査しようtempfilename=primary[i]+"**\\"+filename+xlsx glob.glob(tempfilename, recursive=True)実際の.py
https://github.com/kobayu0902art/work_snippets/blob/master/find.py
何百もあるExcelファイルの「このシートのここに書いてあるファイルの数、種類が正しいか確かめて」といわれたとき
・Excelファイルの中で欲しい情報が書かれている場所がだいたい同じ
→セル範囲を決め、左上のセル番地から右下のセル番地までで欲しい情報と正規表現でマッチしたものを取得例:[C10]~[G30]までの範囲の場合
for col_num in range(3,8): for row_num in range(10,31): if "検索語句" in str(worksheet.cell(row=row_num,column=col_num).value): list.append(worksheet.cell(row=row_num,column=col_num).value)・正しくなかった場合、それがわかりやすいようにしたい
→一致していなかった(False)場合、赤く塗りつぶして強調表示
→→条件付き書式で設定ws.conditional_formatting.add(range, CellIsRule(operator='equal',formula=['FALSE'], fill=PatternFill(start_color='FF0000', end_color='FF0000',fill_type='solid')))【想定環境】
Windows 10
Python 3
- 投稿日:2019-10-23T13:08:20+09:00
Openpyxlで保存したブックがXMLエラー
未解決のため、調べたこと、試したことが増え次第、随時更新予定です
環境
windows 10
Microsoft Excel for Office365
Python 3.7.3
openpyxl 2.6.2事象
xlsをxlsxとして保存し、openpyxlで別ブックとして保存したとき、xmlエラーが発生する
エラーメッセージ
error.xml置き換えられたパーツ: /xl/worksheets/sheet1.xml パーツに XML エラーがありました。 読み込みエラーが発生しました。場所は、行 5、列 0 です。事象発生までの流れ
xls→xlsx
xlsファイルをExcelで開き、「名前を付けて保存」でxlsx(Excelブック)として保存
例)input.xlsを開き、「名前を付けて保存」でinput.xlsxで保存openpyxl
import openpyxl as px #inputファイルのpathをコンソール上にドラッグ&ドロップで取得 origin=input() #openpyxlでxlsxファイルを開く wb=px.load_workbook(origin) ws=wb.active #保存先ファイルとして別名に変更 origin=origin.rstrip(".xlsx") origin+="px.xlsx" #inputファイルを別ブックとして保存 wb.save(origin)例)input.xlsxをopenpyxlを通してinputpx.xlsxで保存
Excelで開く
作成されたxlsxブックをExcelで開くと、
'inputpx.xlsx'の一部の内容に問題が見つかりました。 可能な限り内容を回復しますか?とダイアログが出て、
「はい」をクリックすると、'inputpx.xlsx'の修復 読み取れなかった内容を修復または削除することにより、ファイルを開くことができました。 置き換えられたパーツ: /xl/worksheets/sheet1.xml パーツに XML エラーがありました。 読み込みエラーが発生しました。場所は、行 5、列 0 です。と出る。
開かれたxlsxファイルはすべて空白のセル(新規作成のような状態)になっていた調べたこと、気づいたこと
xls,xlsxについて
- xlsはBIFF(Binary Interchange File Format),xlsxはxml
- xlsxは拡張子をzipに変えると、そのxlsxを構成するxmlを見ることができる
- 一般に、sheet1に対応するxmlは\xl\worksheets\sheet1.xml
zipに変えたものをxlsxに戻して開くと「ファイルが壊れています」となり、開けない
エクスプローラーの「名前の変更」で拡張子をxls→xlsxに変えても、ファイルの中身はxlsのため、開こうとしたときにエラーで開けない
error.xmlについて
xmlを見たとき自分が気づいた点として、
正常に開けるファイル(openpyxlのinput側ファイル)の先頭にある<?xml version="1.0" encoding="UTF-8" standalone="yes"?>がxmlエラーを起こすファイルにない
試したこと
- もともとのxlsファイルの書式を調べる
自分が確認できた範囲で、
セル結合、塗りつぶし、データの入力規則(プルダウン)、改ページプレビュー表示自分の学習範囲で、openpyxlで編集できる書式としてセル結合、塗りつぶしが挙げられる。
塗りつぶしが悪さをするだろうか…と思ったのと、
過去の経験から、pythonでExcelファイルを扱うとき、セル結合はとても厄介だったため、セル結合あり/なしで検証した
xlsxブックを新規作成,openpyxlを通して別名保存
結果:正常に開けるxlsxブックを新規作成(セル結合あり),openpyxlを通して別名保存
結果:正常に開けるxlsブックを新規作成,xlsxで保存後,openpyxlを通して別名保存
結果:正常に開けるxlsブックを新規作成(セル結合あり),xlsxで保存後,openpyxlを通して別名保存
結果:正常に開ける以上の結果から、xls→xlsxの変換、セル結合あり/なしは正常に開けるかどうかに影響しないことが言えそう
- "気づいたこと"より、正常に開けないファイルのxmlにないものを追加してみる
結果:
- zipに変えたものをxlsxに戻して開くと「ファイルが壊れています」となり、開けない
のため、xmlを編集したものをxlsxとして開くことはできなかった
とった対処法
"試したこと"から、新規作成したxlsxファイルについては問題なく開けたため、
もともとのxlsファイルと同じものをxlsxで新規作成(手作業)して、それをinputファイルとすることで、
やりたかった作業をpythonで行うことができた。考察
- openpyxlのバグ?
- openpyxlはもともとxlsxファイル対応のため、xlsが絡むファイルについてうまく扱えないことがある?
- そもそものxlsファイルに異常が隠れている?
今後
未解決のため、今後も調査、検証を行っていくつもりです。
解決法をご存知の方がいらっしゃいましたらご教示いただけると幸いです。
- 投稿日:2019-10-23T12:19:08+09:00
[Python]小ネタ集
はじめに
pythonの小ネタ集的な何かです
まだ完全に理解しきれてないので間違った情報乗っけてたらごめんなさい文字列を任意の回数繰り返し表示させる
# 文字列を十倍にする print("hoge"*10) # 出力>hogehogehogehogehogehogehogehogehogehogehogepythonは文字列に対しても一部の算術演算子が使えます。
#文字列を付け足したい場合は s="hoge" s+=" fuga" print(s) # 出力結果>hoge fugaリストの最後の値を指定する
list = ["a","b","c","d"] print(list[-1]) # 出力結果>d print(list[-2]) # 出力結果>cリストのインデックスにマイナスを付けると後ろから値を指定できます。
リストに格納されている値がわからないときに一番後ろの値を取得したいといった状況で使えるんじゃないですかね?(実際に使ったことはあんまりないです)二つの変数の値を入れ替える
a = "apple" b = "banana" a, b = b, a print(a) # 出力結果 banana print(b) # 出力結果 appleC言語とかだと一時的にaの値を保持する編巣を用意したりでめんどくさかったうえに三行のコードが必要だったのでこれで入れ替えれるのはだいぶ楽だと思います
複数の変数に一定の値を格納
a = b = "apple" print(a) # 出力結果 apple print(b) # 出力結果 apple=でつなげると一括で同じ値を格納できる
複数の変数に複数の値を一括で格納する
a,b = "apple","banana" print(a) # 出力結果 apple print(b) # 出力結果 bananaちなみに変数より値の数が多いと最後の変数がタプルの型に変換されて値が格納される
(タプルの使いかたあんまわかってないです)a , b = "apple","banana","orange" print(a) # 出力結果 apple print(b) # 出力結果 ("banana","orange")変数の型を調べる方法
s = "apple" i = 1 b = False print(type(s)) # 出力結果 <class 'str'> print(type(i)) # 出力結果 <class 'int'> print(type(b)) # 出力結果 <class 'bool'>typeで変数の型を取得できる
代表的な型のリスト
型 説明 int 整数 float 小数 str 文字列 tuple タプル list リスト型 bool 論理値True/False dict 辞書型 これ以外にもまだ結構あるらしい
変数に値が入っているか(Noneかどうか)の確認
if l is None: print("lは空")変数が空かどうかは
変数 is Noneでチェックできる変数 == Noneで比較することはできない-PEP8に反している(PEP8:pythonのコーディング規約)空じゃないかどうかは
if 変数でチェック可能おわり
最後まで読んでくださいありがとうございました
ネタにできそうな仕様はまだ山ほどあるので気が向いたら追加していこうかなぁと思います
まだまだ初心者なんで間違ったコードや説明等があったらコメント欄で指摘してくれると助かります。
あといいねしてくれるとモチベーションの維持にいつながるのでよかったらいいねしていってくださいm(__)m
- 投稿日:2019-10-23T12:17:21+09:00
【画像・音処理用】Jetson Nanoのセットアップ
自分用の備忘録で書いておきます。
(左はjetson Nano。右はRaspberry Pi3 model B。)
ハード関係
ハード関係の購入品は@karaage0703 さんのブログを参考にさせていただきました。
https://karaage.hatenadiary.jp/entry/2019/04/29/073000
https://karaage.hatenadiary.jp/entry/2019/08/19/073000中でもお気に入りはモニタ。ある程度大きくて、組立も楽なので重宝しています。
HDMIケーブルも付属しているので、追加でケーブルを購入する必要もありません。ファン
ファンは5V用を購入しましょう。
https://qiita.com/yamamo-to/items/bf77048b6f650aad346f取り付けボルトには罠があります。M3は入りません。
(どう頑張ってもM3は入らない。)ネジを「あなたにおススメ」とかで購入するとエライ目に合います。
M3用の穴を加工する方法もありますが、私は不器用なので素直に
M2のボルトを買うことにしました。(まだ、買っていないので、買って
付けたら追記する予定です。)Wifi関係
私はドングルを使ってWifiに接続しました。基本的にjetson Nanoに挿せば認識して
くれますが、何故か再起動しないとネットにつながりませんでした。ソフト関係
JetCardで楽々インストール
JetCardを使えば主要なライブラリ・モジュールが普通に付いてきますので
是非使いましょう。主に以下が添付されています。
- Numpy
- TensorFlow
- matplotlib
- glob など
環境構築
JetCardに入っていないものは手動でインストールします。
コンソールの立ち上げはJetson Nanoのデスクトップから右クリックを
して「Open Terminal」(英語版)から立ち上げます。まずは、いつものアップデートから。
sudo apt-get update sudo apt-get upgradescikit-learnなどのインストール
sudo pip3 install scikit-learn sudo pip3 install pandas sudo pip3 install Jetson.GPIOpandasのインストールは30分くらいかかります。
GPIOはお好みで。
私は、異常検知の良否判定でLEDを光らせたいのでインストールしました。Kerasのインストール
KerasはTensorFlowに内蔵されているので、特にインストールは必要なく
tensorflow.kerasとすればKerasを使うことができます。(こちらを参照)ただ、私はKerasを主体に使うので、
tensorflow.kerasとするのが
面倒くさい!なので、Keras単体をインストールすることにしました。sudo apt install libatlas-base-dev gfortran sudo pip3 install -U cython sudo pip3 install keras音関係のインストール
FFT変換はscipyを使うので、インストールします。
sudo apt-get install python3-scipyまた、録音やリアルタイムな音の処理はpyaudioを使っています。
こちらもインストールします。sudo apt-get install portaudio19-dev sudo pip3 install pyaudiopyqtgraphのインストール
FFTの波形を高速に描画したい場合、matplotlibでは処理が追いつきません。
pyqtgraphを使えば、高速に描画ができます。pyqtgraphの威力はこちらをご覧
いただければ分かるかと思います。sudo pip3 install pyqtgraphまとめ
- ファンは「電源」と「取り付けボルト」を確認して購入する。
- JetCardは凄く便利。


- 投稿日:2019-10-23T12:17:21+09:00
【画像・音処理用】Jetson Nanoのセットアップ方法
自分の備忘録で書いておきます。
(左はjetson Nano。右はRaspberry Pi3 model B。)
ハード関係
ハード関係の購入品は@karaage0703 さんのブログを参考にさせていただきました。
https://karaage.hatenadiary.jp/entry/2019/04/29/073000
https://karaage.hatenadiary.jp/entry/2019/08/19/073000中でもお気に入りはモニタ。ある程度大きくて、組立も楽なので重宝しています。
HDMIケーブルも付属しているので、追加でケーブルを購入する必要もありません。ファン
ファンは5V用を購入しましょう。
https://qiita.com/yamamo-to/items/bf77048b6f650aad346f取り付けボルトには罠があります。M3は入りません。
(どう頑張ってもM3は入らない。)ネジを「あなたにおススメ」とかで購入するとエライ目に合います。
M3用の穴を加工する方法もありますが、私は不器用なので素直に
M2のボルトを買うことにしました。(まだ、買っていないので、買って
付けたら追記する予定です。)Wifi関係
私はドングルを使ってWifiに接続しました。基本的にjetson Nanoに挿せば認識して
くれますが、何故か再起動しないとネットにつながりませんでした。ソフト関係
JetCardで楽々インストール
JetCardを使えば主要なライブラリ・モジュールが普通に付いてきますので
是非使いましょう。主に以下が添付されています。
- Numpy
- TensorFlow
- matplotlib
- OpenCV など
環境構築
JetCardに入っていないものは手動でインストールします。
コンソールの立ち上げはJetson Nanoのデスクトップから右クリックを
して「Open Terminal」(英語版)から立ち上げます。まずは、いつものアップデートから。
sudo apt-get update sudo apt-get upgradescikit-learnなどのインストール
sudo pip3 install scikit-learn sudo pip3 install pandas sudo pip3 install Jetson.GPIOpandasのインストールは30分くらいかかります。
GPIOはお好みで。
私は、異常検知の良否判定でLEDを光らせたいのでインストールしました。Kerasのインストール
KerasはTensorFlowに内蔵されているので、特にインストールは必要なく
tensorflow.kerasとすればKerasを使うことができます。(こちらを参照)ただ、私はKerasを主体に使うので、
tensorflow.kerasとするのが
面倒くさい!なので、Keras単体をインストールすることにしました。sudo apt install libatlas-base-dev gfortran sudo pip3 install -U cython sudo pip3 install keras音関係のインストール
FFT変換はscipyを使うので、インストールします。
sudo apt-get install python3-scipyまた、録音やリアルタイムな音の処理はpyaudioを使っています。
こちらもインストールします。sudo apt-get install portaudio19-dev sudo pip3 install pyaudiopyqtgraphのインストール
FFTの波形を高速に描画したい場合、matplotlibでは処理が追いつきません。
pyqtgraphを使えば、高速に描画ができます。pyqtgraphの威力はこちらをご覧
いただければ分かるかと思います。sudo pip3 install pyqtgraphまとめ
- ファンは「電源」と「取り付けボルト」を確認して購入する。
- JetCardは凄く便利。
- 投稿日:2019-10-23T11:52:47+09:00
【AWS】決定版!最速でpython3.7仮想環境を1から構築
はじめに
今回初めてVPCとEC2を触り、python3.7仮想環境を作成するところまで実施したため、皆さんにナレッジを共有します。(全て無料枠内です。)
ちなみにアーキテクトは以下です。超絶シンプル。
アジェンダ
- VPC作成&設定
- EC2作成&設定
- EC2にPython3.7仮想環境構築
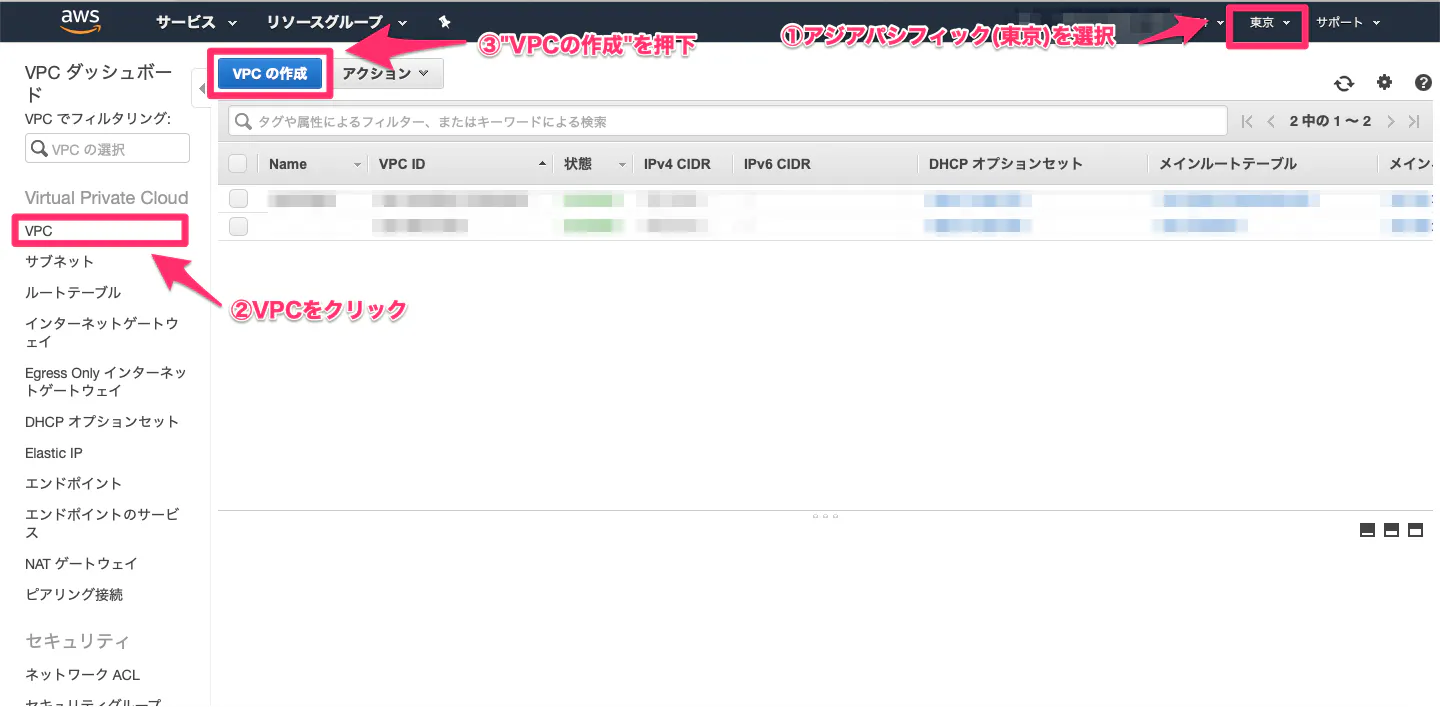
1. VPC作成&設定
大まかな流れとしては、以下です。
①VPC作成
②VPC内にパブリックサブネットを作成
③インターネットゲートウェイを作成し、VPCに結びつける
④ルートテーブルを作成し、パブリックサブネットに割り当て
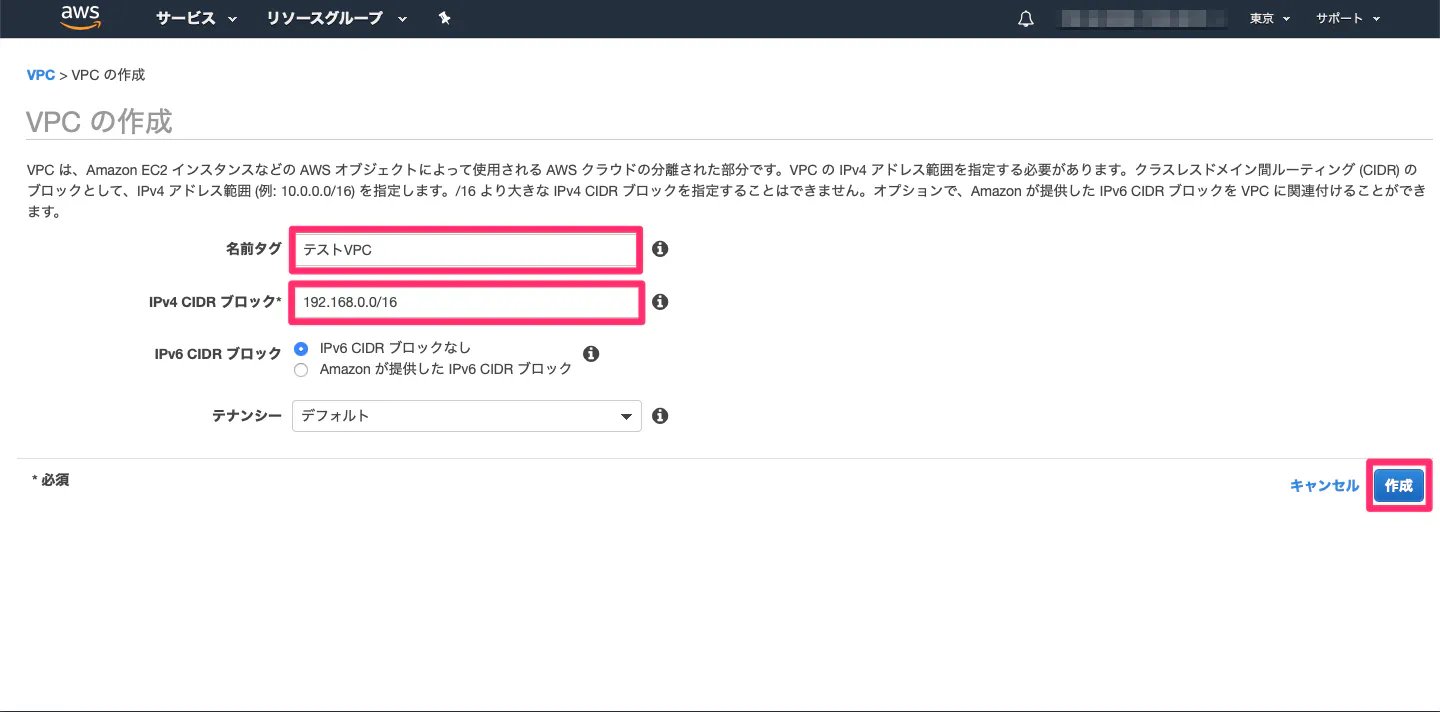
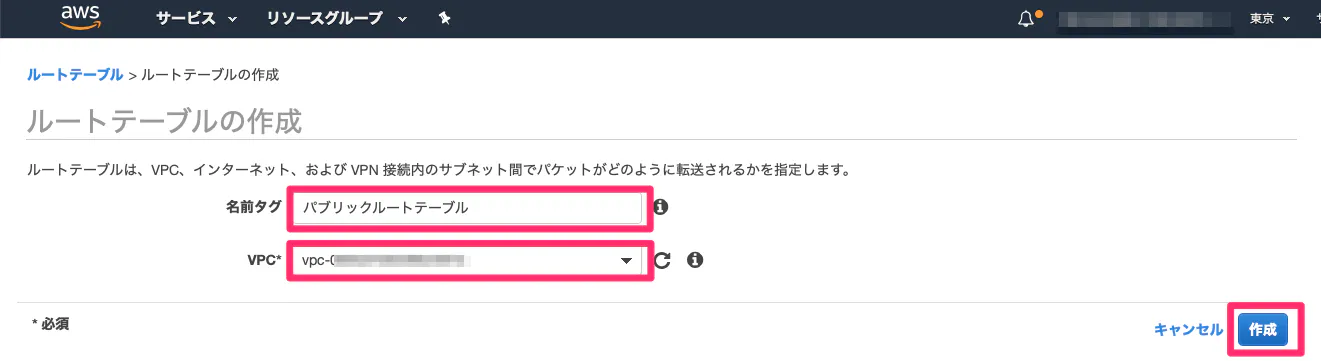
⑤ルートテーブルのデフォルトゲートウェイを、インターネットゲートウェイに設定①VPC作成
・VPC(Virtual Private Cloud)とは?
AWS上に作るプライベートなネットワーク環境。(1)AWSマネジメントコンソールからVPCを開いて、以下の手順を実施。
(2)以下を入力。
項目 値 名前タグ 任意の名前 IPv4 CIDR ブロック 192.168.0.0/16(プライベートIPアドレス1なら他でもOK) IPv6 CIDR ブロック デフォルト テナンシー デフォルト
(3)完成!!
②VPC内にパブリックサブネットを作成
・サブネットとは?
ネットワークをさらに分割したネットワークのこと。(1)以下の手順を実施。
(2)サブネットのCIDRブロック等を入力。以下を参考。
項目 値 名前タグ 任意の名前 VPC 先ほど作成したVPC アベイラビリティーゾーン デフォルト IPv4 CIDR ブロック 192.168.1.0/24(VPCのIPアドレスを分割した値であればOK)
(3)完成!!
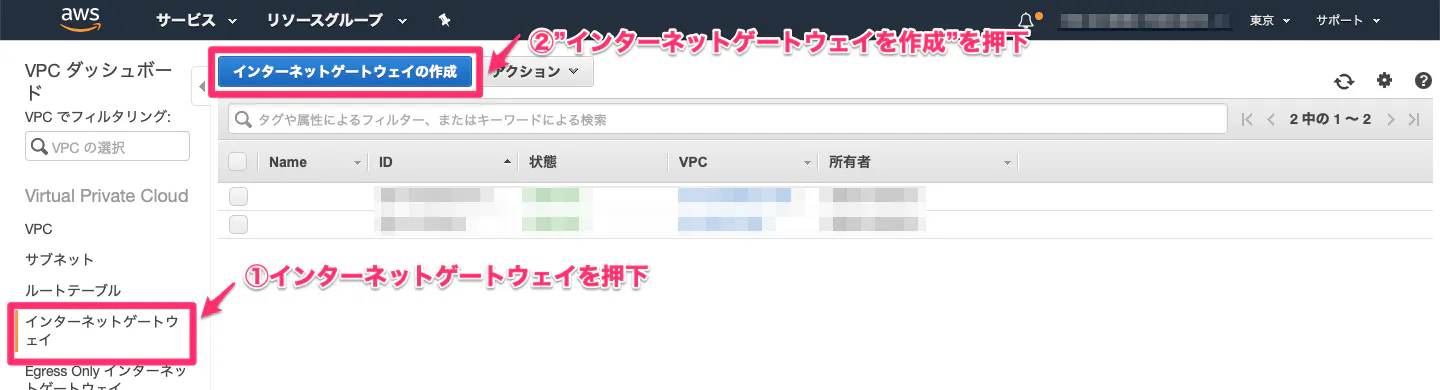
③インターネットゲートウェイを作成し、VPCに結びつける
・インターネットゲートウェイとは?
VPC内のインスタンスとインターネットとの間の通信を可能にするVPCのコンポーネント。(1)インターネットゲートウェイを作成。
(2)インターネットゲートウェイをVPCに結びつける。
(3)完成!!
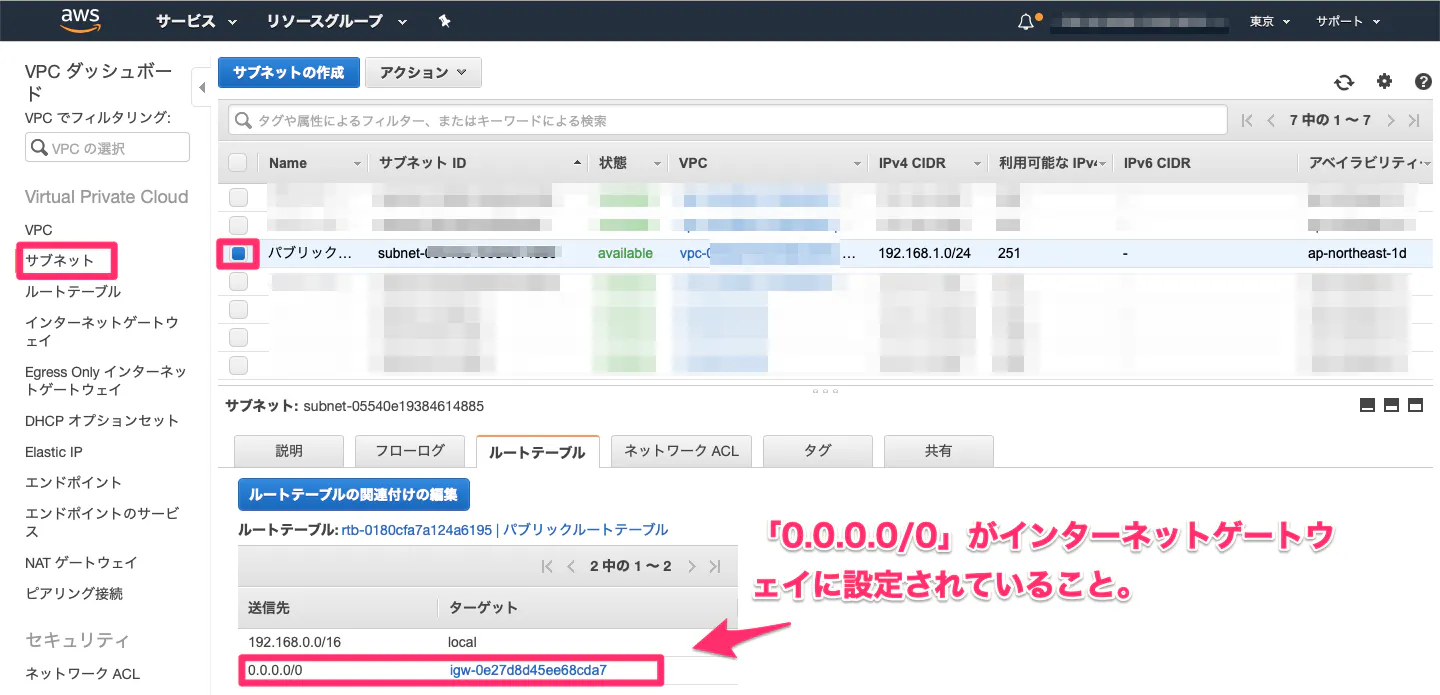
④ルートテーブルを作成し、パブリックサブネットに割り当てる。
・ルートテーブルとは?
通信をどこに流すかを定義するための情報。AWSではルートテーブルを各サブネットに関連付けする。サブネットにはデフォルトで、VPCのデフォルトのルートテーブルのみ適用されている。(今回では、192.168.0.0/16のみ送信可能の状態。)
そのため、ここではインターネットゲートウェイにパケットを送信するように設定する。(1)VPCにルートテーブルを作成。
項目 値 名前タグ 任意の名前 VPC 先ほど作成したVPC
(2)ルートテーブルをパブリックサブネットに割り当てる。
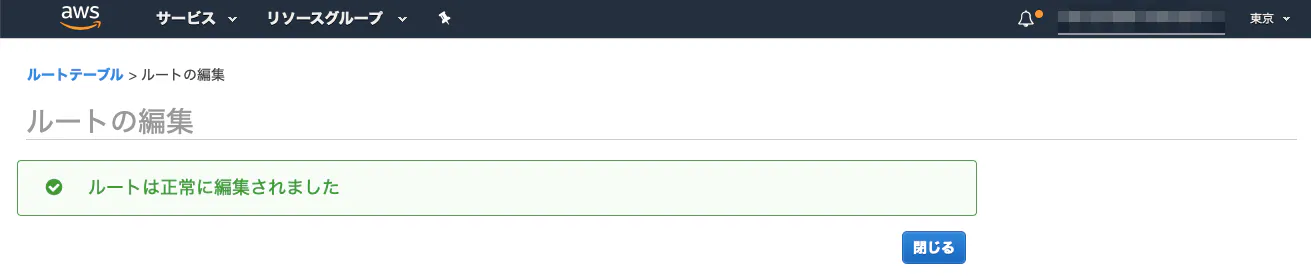
⑤ルートテーブルのデフォルトゲートウェイを、インターネットゲートウェイに設定
・デフォルトゲートウェイとは?
ネットワークから外部のネットワークに接続する際、通信の出入り口となるもの。(1)ルートテーブルのルートを編集。
(2)送信先に全てのIPアドレス範囲を示す「0.0.0.0/0」、ターゲットにインターネットゲートウェイ(igw-XXX)を指定。
(3)完成!!
2. EC2作成&設定
大まかな流れとしては、以下です。
①AMIを選択
②インスタンスタイプを選択
③インスタンスの詳細情報を設定
④ストレージを設定
⑤インスタンスの名前付け
⑥セキュリティグループの設定
⑦設定を確認し、EC2ログインするための秘密鍵をダウンロード①AMIを選択
・AMIとは?
ソフトウェア構成(オペレーティングシステム、アプリケーションサーバー、アプリケーションなど)を記録したテンプレート。AWSマネジメントコンソールからEC2を開いて、以下の手順を実施。
今回はLinux2を選択。
②インスタンスタイプを選択
③インスタンスの詳細情報を設定
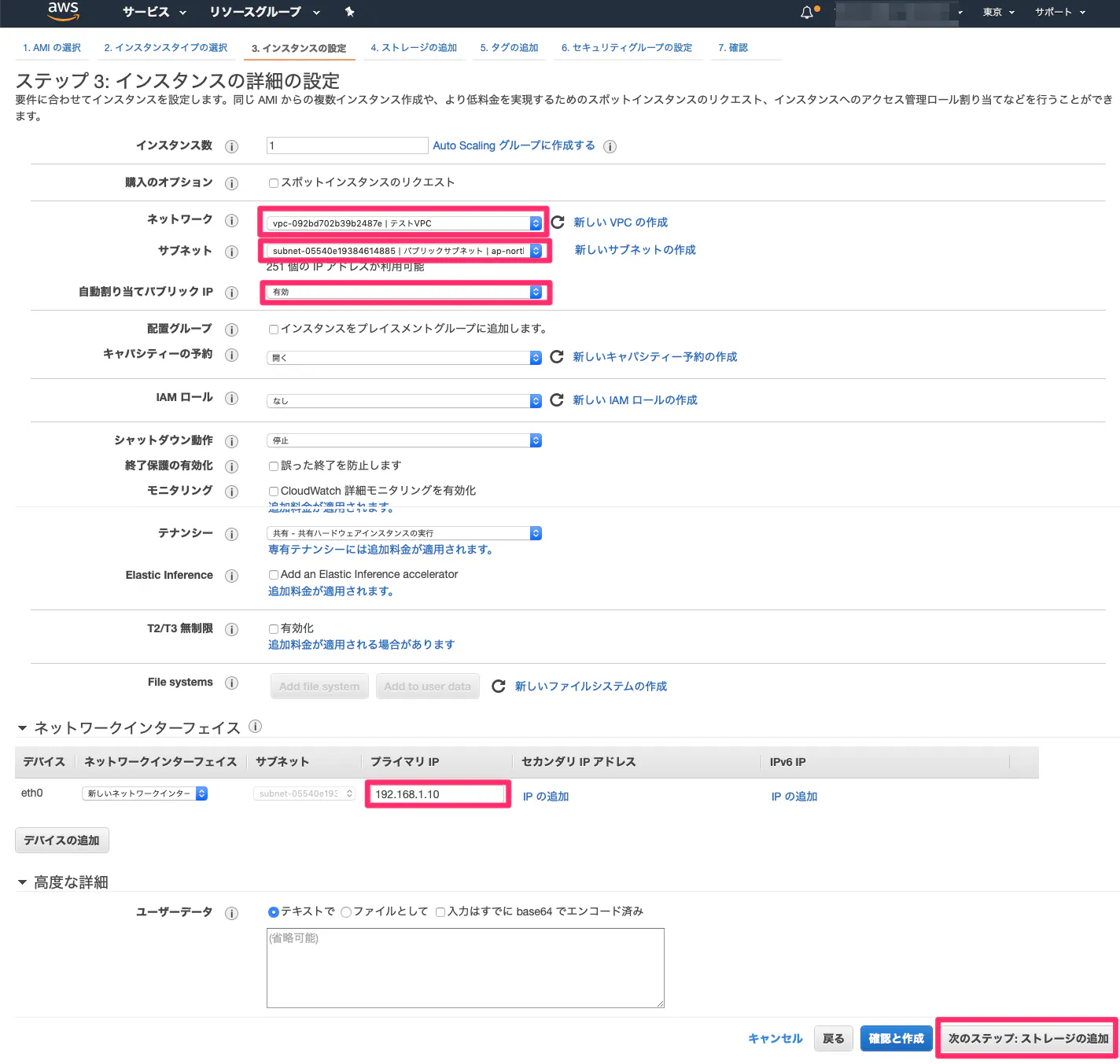
以下の項目を入力。残りの項目はデフォルトのままでOK。
項目 値 ネットワーク 作成したVPC サブネット 作成したパブリックサブネット 自動割り当てパブリックIP 有効化2 プライマリIP(→プライベートIPアドレス) 192.168.1.10
④ストレージを設定
デフォルトのままで何も変更しない。
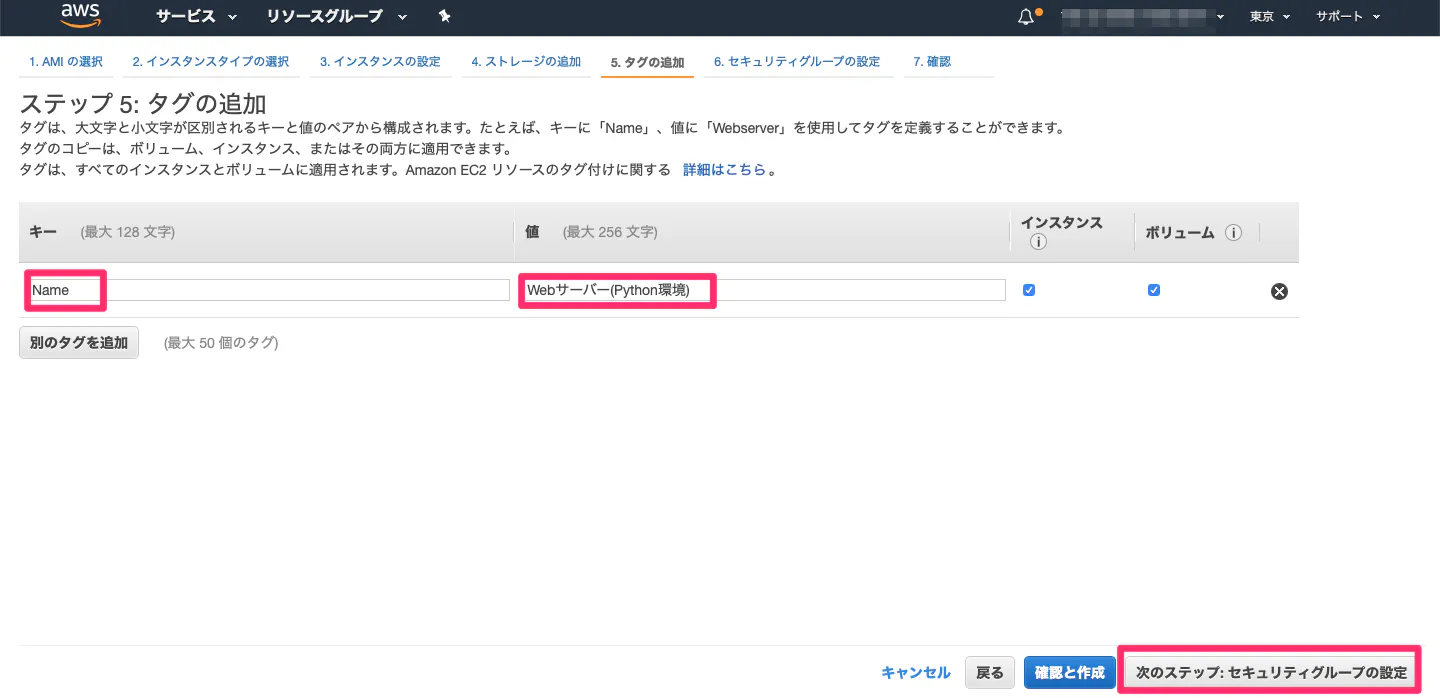
⑤インスタンスの名前付け
任意のキー名/値でOK。
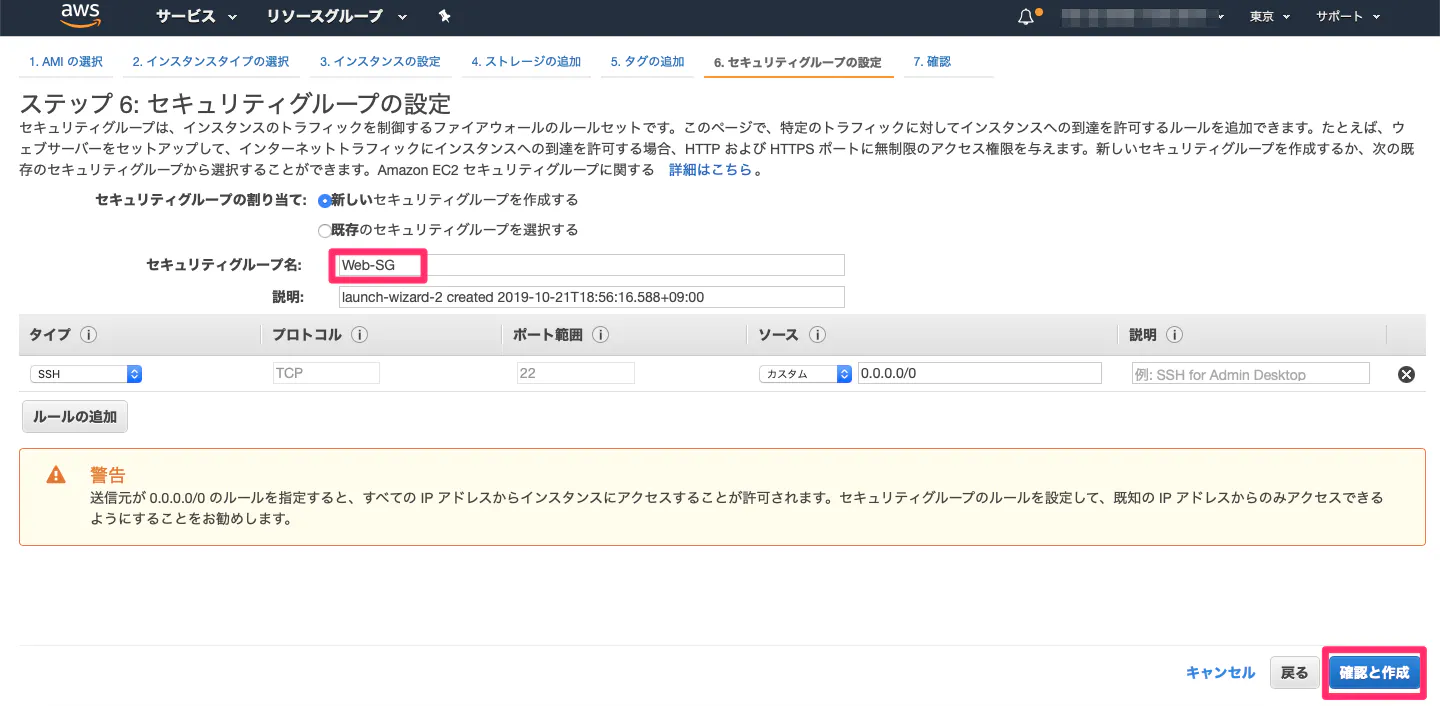
⑥セキュリティグループの設定
・セキュリティグループとは?
所謂、ファイアウォールのこと。デフォルトでは、SSH(22)というプロトコルでどこからでも接続可能になっている。
SSHは後続でPython環境構築する際、PCからEC2にアクセスする時に用いる。任意のセキュリティグループ名でOK。
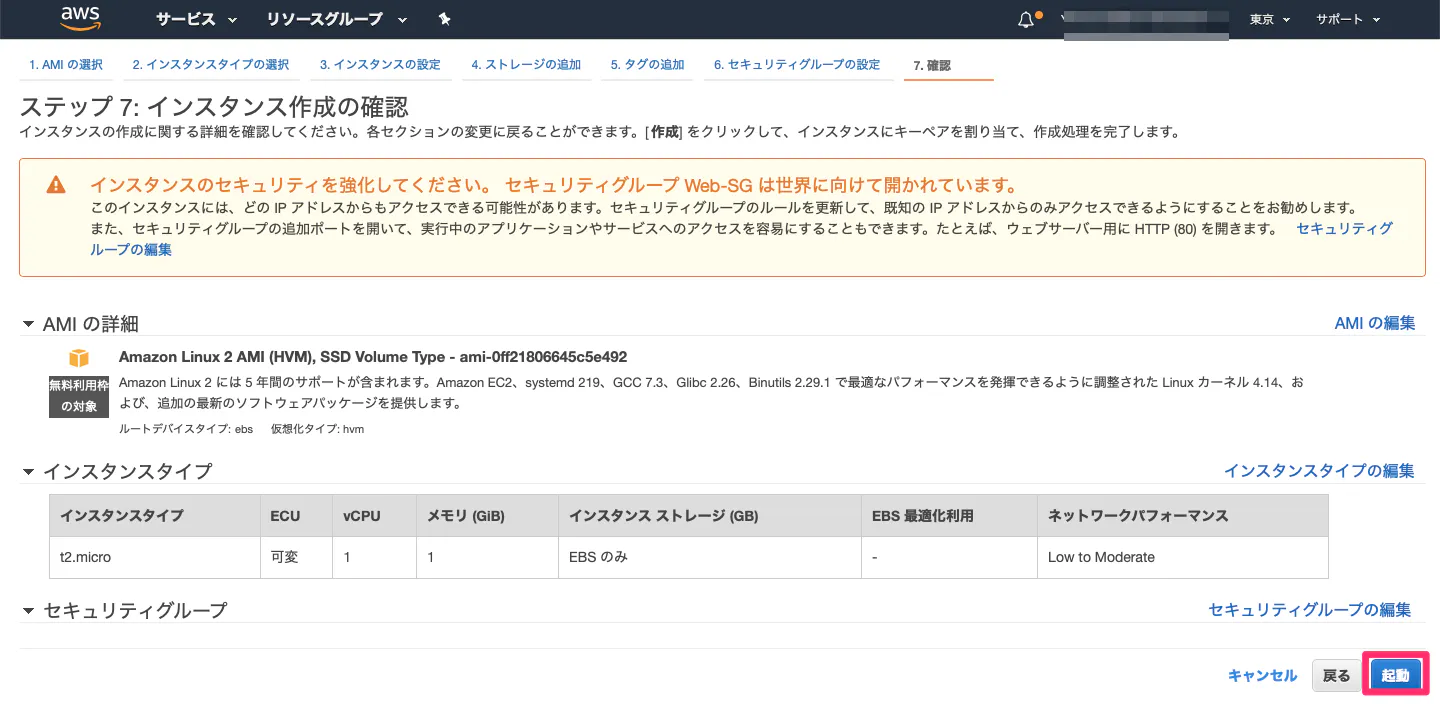
⑦設定を確認し、EC2ログインするための秘密鍵をダウンロード
任意のキーペア名でOK。秘密鍵は一度失くすと再発行不可のため大切に保管する。
1度秘密鍵を作ると、他にEC2を立ち上げる時も共有で利用可能。
設定完了!!
3. Python3.7仮想環境作成
Amazon Linux2ではデフォルトで python2.7系がインストールされていますが、
今回はpython3.7の仮想環境を作成していきます。大まかな流れとしては、以下です。
①秘密鍵を使い、AWSのEC2にSSH接続
②環境構築に必要なパッケージをインストール
③pyenvのインストール
④pyenv-virtualenvのインストール
⑤ライブラリをインストール(任意)①秘密鍵を使い、AWSのEC2にSSH接続
まずはEC2のパブリックIPアドレスを確認。
そしてsshコマンドで接続する。
//1.秘密鍵をホームユーザー配下に格納 $ mv test-my-key.pem.txt ~/.ssh //2.秘密鍵の権限変更 $ chmod 400 ~/.ssh/test-my-key.pem.txt //3.sshでEC2に接続 $ sudo ssh -i ~/.ssh/test-my-key.pem.txt ec2-user@EC2のパブリックIPアドレスAmazon Linux2のデフォルトのユーザー名は「ec2-user」のため、ec2-userを指定。
sshに成功したら以下が表示される。$ sudo ssh -i ~/.ssh/test-my-key.pem.txt ec2-user@EC2のパブリックIPアドレス __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 15 package(s) needed for security, out of 31 available Run "sudo yum update" to apply all updates. [ec2-user@ip-192-168-1-10 ~]$②環境構築に必要なパッケージをインストール
コンパイラ、暗号化、圧縮、コマンドラインなどのライブラリをインストールします。
$ sudo yum -y install gcc gcc-c++ make git openssl-devel bzip2-devel zlib-devel readline-devel sqlite-devel libffi-devel③pyenvのインストール
・pyenvとは?
Pythonのバージョン管理を行なうコマンドラインツールで、複数のバージョンのPythonのインストールや切り替えが容易に可能。Gitからインストール。
$ sudo git clone https://github.com/yyuu/pyenv.git /usr/bin/.pyenv $ sudo mkdir /usr/bin/.pyenv/shims $ sudo mkdir /usr/bin/.pyenv/versions $ sudo chown -R ec2-user:ec2-user /usr/bin/.pyenv環境変数の設定を行う。
$ vi ~/.bashrc ---------------------以下を追記 export PYENV_ROOT="/usr/bin/.pyenv" export PATH=${PYENV_ROOT}/bin:$PATH eval "$(pyenv init -)" ----------------------------- //設定変更を反映 $ source ~/.bashrcpython3.7.3のインストール。
//インストール可能なバージョンを確認 $ pyenv install --list //今回は3.7.3をインストール $ pyenv install 3.7.3 //インストール済みのバージョン一覧 $ pyenv versions //pythonのバージョン確認。インストールしても2.7のまま。 $ python -V Python 2.7.16ちなみに以下で、EC2で利用するデフォルトのバージョンの設定が可能。
//3.7.3バージョンへ切り替え $ pyenv global 3.7.3④pyenv-virtualenvのインストール
・pyenv-virtualenvとは?
分離されたPython環境を作成するツール。環境ごとに違うパッケージを入れることが可能。Gitからインストール。
$ git clone https://github.com/yyuu/pyenv-virtualenv.git /usr/bin/.pyenv/plugins/pyenv-virtualenv環境変数の設定を行う。
$ vi ~/.bashrc ---------------------以下を追記 eval "$(pyenv virtualenv-init -)" ----------------------------- //設定変更を反映 $ source ~/.bashrcpython3.7.3仮想環境を作成
//バージョンpython3.7.3の仮想環境(名前:python3.7)を作成 $ pyenv virtualenv 3.7.3 python3.7 //カレントディレクトリにpython3.7.3の仮想環境を適用 $ pyenv local python3.7 //バージョン確認 (python3.7)$ python --version Python 3.7.3 //仮想環境を設定していないディレクトリに移動すると、EC2デフォルトのバージョン (python3.7)$ cd ~ $ python --version Python 2.7.16ちなみに仮想環境の削除は以下。
$ pyenv uninstall python3.7⑤ライブラリをインストール(任意)
//EC2のデフォルトではpipのバージョンが古いためアップグレード $ pip install --upgrade pip //任意のパッケージをインストール $ pip3 install numpy $ pip3 install sklearn //ライブラリの格納先確認 $ pip3 show numpy終わりに
基本的かつ単純なアーキテクトなので、まだVPCとEC2に触ってみたことがない人はぜひ挑戦してみて下さい。
このアーキテクトに、プライベートサブネットを追加してEC2にDBをインストールするなど、色々と自分でカスタマイズもできます。






















- 投稿日:2019-10-23T10:01:10+09:00
【Python】geventライブライリについて簡単なことを整理する
はじめに
Pythonのgeventライブラリを「入門Python3」で知ったきっかけに,公式ドキュメントなどを参考にしながら,学んだことを備忘録のようにまとめる.
geventライブラリについて
geventライブラリはイベント駆動で,通常の命令型のコードを書くと,geventが手品のように部品をコルーチン(注1)に変換する.
互いに通信して相手がどこにいるのかをつねに把握できるジェネレータのよう動く.
geventはsocketなどのpythonの標準オブジェクトの多くを書き換え,ブロックせずにgeventのメカニズムを使うようにする.(注1.)コルーチンとは処理を中断や再開する仕組みのこと
特徴として通常の関数のとは異なり、
処理を途中で抜けて任意のタイミングで中断部分から処理を再開する.イベント駆動プログラミングについて
以下の資料がわかりやすく参考になった.
イベント駆動プログラミングとI/O多重化
https://www.slideshare.net/mizzy/io-18459625Apache Kafka on Herokuを活用したイベント駆動アーキテクチャの設計と実装
https://www.slideshare.net/DeveloperForceJapan/apache-kafka-on-herokuWhat is gevent?
geventはコルーチンベースのpythonネットワーキングライブラリ.
本稿では,geventの以下の機能について,サンプルコードを確かめながら理解を深める.
- グリーンレットに基づく軽量の実行ユニット
- サードパーティのモジュールに対してモンキーパッチを適応
サンプルコード
グリーンレットの機能
gevent_sample.pyimport gevent from gevent import socket if __name__ == "__main__": hosts = ['www.google.com','www.yahoo.co.jp','www.qiita.com'] jobs = [gevent.spawn(gevent.socket.gethostbyname,host) for host in hosts] gevent.joinall(jobs,timeout=5) # ホスト名のIPアドレスを出力 for job in jobs: print(job.value)$ python gevent_test.py 216.58.197.196 182.22.25.252 52.196.217.245説明
socketモジュールのgethostbyname()関数は,ドメイン名に対応するIPアドレスを返す.同期的なので,世界中のネームサーバーを捕まえて.そのアドレスを解決しようと競い合うときに待ちに入る.しかし,geventバージョンを使用すれば,非同期的に実行し複数のサイトを独立で解決できる.
gevent.spawn()は個々のgevent.socket.gethostbyname(url)を実行するために,グリーンレット(グリーンスレッド,マイクロスレッド)を作る.
通常のスレッドとの違いはグリーンレットならブロックしないこと.ブロック処理とは他のスレッドがその資源にアクセスできないようする処理で,排他処理や排他制御ともいう.通常のスレッドをブロックしてしまうようなことが起きても,geventはほかのグリーンレットのどれかを制御を切り替える.
gevent.joinall()メソッドは派生させたすべてのジョブが終了するのを待つ.geventのモンキーパッチ機能
geventバージョンのsocketではなく,モンキーパッチング関数を使うことができる.
これらはgevetnバージョンのモジュールを呼び出すのでなく,socketなどの標準モジュールがグリーンレットを使うように書き換える.
Pythonコードには機能するが,Cで書かれたライブラリには適用しない.モンキーパッチングについて
- 元のコードを変更することなく、動的にコードを拡張/変更する事の総称のこと.(メタプログラミングの一種)
- ライブラリのコードを直接変えたくない時とかに利用される
- テスト系ライブラリでよく利用される
gevent_monkey.pyimport gevent from gevent import monkey;monkey.patch_all() import socket import time if __name__ == "__main__": hosts = ['www.google.com','www.yahoo.co.jp','www.qiita.com'] #gevent.spawn()の引数にはsocket.gethostbynameを指定しているが,ここがモンキーパッチング対象 jobs = [gevent.spawn(socket.gethostbyname,host) for host in hosts] gevent.joinall(jobs,timeout=5) gevent.spawn() for job in jobs: print(job.value)説明
genvent_test.pyでは,gevent.socketモジュールを明示的にインポートしていた.
一方,gevent_monkey.pyでは,標準ライブラリであるsocketモジュールを明示的インポートした.monkey.patch_all()を使用しない場合,import socketの段階では,gevent版のsocketモジュールではなく,標準ライブラリとしてのsocketモジュールである.
モンキーパッチング関数(サンプルコードではmonkey.patch_all())を使用することで,標準ライブラリをgevent版(gevent.socket)に書き換えることができる.所感
ここに記述したことは全然実践的でないし,もっと調べていきたい.
知らべてわかったことを追加していく予定.参考文献
- 入門Python3
- http://www.gevent.org/
- 投稿日:2019-10-23T07:11:50+09:00
SimPyで離散事象シミュレーション(2) リソースを理解しよう:Container編
はじめに
SimPyというPythonの離散事象シミュレーション用のパッケージを見つけて試してみたら気に入ったので自分用の備忘録も兼ねて使い方をまとめていく.
- SimPyのドキュメント
- SimPyのソース
- 前回の記事(はじめの一歩)
第2回目の今回は,前回触れられなかった「resources関連のモジュール群」で提供されているリソースについてみていこう.この使い方としては,シミュレーションの対象システムのモデルの部品に使うというようなイメージだと思う.
どんな部品でも,SimPyに用意されているリソースを使わずに実装することはできるが,使った方が便利ならそれに越したことはない.このとき,デフォルトのリソースをそのまま使うのではなく,少しカスタマイズしたくなることもあるかもしれない.ちょっとしたカスタマイズならできそうだと思えるぐらいまで理解することを目指そう.
モジュール群の構成
「resources関連のモジュール群」をまとめたフォルダには,container.py,store.py,resource.py,base.pyの4つのモジュールが含まれている.
container.pyには,なんらかのオブジェクトを蓄えておく容器のような役割を果たすリソース(Containerクラス)が定義されている.蓄えられるオブジェクトは,1つ,2つと数えられるものでもいいし,液体などの連続的なものでもよい.ただし,離散的なオブジェクトの場合でもオブジェクトはどれも同一で,個体間の区別はできない.
store.pyに定義されているリソース(Store,PriorityStore,FilterStoreの3クラス)もなんらかのオブジェクトを蓄えておくものである.これらのリソースに蓄えられるものは離散的なオブジェクトのみで,個体間の区別が可能な点がContainerとの違いである.
resource.pyには,プロセスが何かの処理を進めるために使用する道具,機械,担当者などのリソースが定義されている(Resource,PriorityResource,PreemptiveResourceの3クラス).このリソースは数が限られていて,複数のプロセスが同時にそれを必要とした場合には取り合いが生じることがある.
base.pyには,上の3つのリソースの基盤となるBaseResourceクラス(とそれが利用する事象PutとGet)が定義されている.上のリソースはいずれもこのBaseResourceを継承したサブクラスになっているので,最初にbase.pyモジュールからみていこう.
ただし,「BaseResourceの仕組み」の節は少しテクニカルなので,もしリソースをデフォルトのまま,あるいは微修正して使えれば十分という場合はスキップしてもいいと思う.
BaseResourceの仕組み
BaseResourceはプロセスからの依頼に対応して何かを受け入れたり,払い出したりする装置としてモデル化されている.受け入れたことを表すシグナルをGet,払い出したことを表すシグナルをPutと考えよう.PutとGetはどちらも事象の一種で,Eventクラスを継承したサブクラスとして実装されている.そして,いずれも依頼元のプロセス(
proc)と依頼先のリソース(resource)への参照をもつ.BaseResourceクラスは,環境
envへの参照,容量を表す変数(capacity),Put/Getを格納するリスト(put_queue/get_queue)をもち,put()/get(),_do_put()/_do_get(),_trigger_put()/_trigger_get()という6つのメソッドを備えている.
put()/get()メソッドは,Put/Getクラスのインスタンス事象p/gを生成し,それをリストput_queue/get_queueに追加する.そして,事象p/gのコールバック関数のリストに_trigger_get()/_trigger_put()を追加してから_trigger_put()/_trigger_get()を呼ぶ.ここに,
_trigger_put()/_trigger_get()メソッドは,対応するリストput_queue/get_queueを「先頭から順に」走査していく.そして,各要素についてその事象に対応する受入れ処理もしくは払出し処理(_do_put()/_do_get()メソッド)を呼ぶ.なお,これらのメソッドからFalseが返ってきた場合は,リストの途中であってもそこでリストの走査を抜ける.BaseResourceクラスには
_do_put()/_do_get()メソッドのスケルトンが用意されているのみで,それらの具体的な実装はサブクラスで行うようになっている.例えば,対象の要素(事象Put/Get)が所定の条件(例えば,Putなら容量にまだ余裕があるかどうかなど)を満たしていれば,それをok=Trueでトリガーする.条件を満たしていなければFalseを返す,といった実装が考えられる.慣れていないとわかりにくいと思うので,この場合の流れを簡単に説明しよう.例えば,あるPut事象
pが生成されたとしよう.これは受入れ処理のリクエストが届いたことに該当する.この場合,事象pはput_queueの末尾に追加され,p.callbacksに_trigger_get()を入れた後,_trigger_put()が呼ばれる.このとき仮に,事象
pが届く前にはput_queueにもリソースの中にも何も入っていなかったとしよう.この場合,今はput_queueにはpだけが入っていることになる._trigger_put()は,このpを取り出して_do_put()を呼ぶ._do_put()は,リソースの容量にまだ余裕がある(今は空だから)ことを確認して,p.succeed()を呼ぶ(p.ok=Trueでpをトリガーする).これで,pに対応する受入れ処理のリクエストは無事処理された.その後,イベントカレンダから
pが取り出されその生起処理が実行される(すなわち,p.callbacksに入っているコールバック関数が順に呼ばれる).この際,_trigger_get()も呼ばれ,もしget_queueが空でなければ,_do_get()が呼ばれる.すると,上記のpによって受け入れられたオブジェクト(しかリソースの中には存在しないから,それが)が払い出される,というような流れになる.また,補足として,事象Put/Getは,リスト
put_queue/get_queue内で待っている間に依頼元プロセスから取り消しが入った場合(OR結合の事象を待っていて別の事象が先に生起した場合やInterrupt例外を受け取った場合など),cancel()処理を呼んでリストから取り除く必要がある.ただし,プロセス側でyieldする際に,withブロックでコンテキスト化しておくと必要に応じてcancel()が自動的に呼ばれるようになる(cancel()せずに再度同じ事象をyieldして待ち続けることもできるが,その場合はプロセス側のコードにそれを明示すること).リソースのフレームワークとしてうまく設計されているなと思う.個人的に1つだけ限界を感じたのは,
_trigger_put()/_trigger_get()メソッドがリストを先頭から順に走査して,Falseでブレークするように実装されている点.デフォルトだとput_queue/get_queueはFIFOキューになるが,後で見るように,適切なキーでリストがソートされるようにしておけば単純なディスパッチングルールなどは簡単に表現できる.しかし,ダイナミックなロジックを組み込みたいときは,_trigger_put()/_trigger_get()メソッド自体を本格的にオーバーライドする必要が出てくるかもしれない.Containerとその使用例
最初にContainerクラスが上のBaseResourceクラスをどのように継承しているかを確認しておこう.まず,Put/Getの代わりにそれらのサブクラスContainerPut/ContainerGetが用いられている.違いは,これらのサブクラスに,受入れ・払出しの要求量を表す変数(
amount,負数はNG)が追加されている点である.Containerクラス自体には,リソース内に蓄えられているオブジェクトの総数,もしくは総量を表す変数(
level)が追加されている.また,_do_put()メソッドは,capacity-levelがamount以上であればトリガー,そうでなければFalseを返すという形で,_do_get()メソッドは,levelがamount以上であればトリガー,そうでなければFalseを返すという形で,それぞれ実装されている.Containerクラスのインスタンスは,
simpy.resources.container.Container(env, capacity=float('inf'), init=0) simpy.Container(env, capacity=float('inf'), init=0)のいずれかで生成できる(2つ目はショートカット).生成時に特に指定しないと,
capacityは無限に,levelの初期値は0にそれぞれ設定される.標準的な使い方
一例として,前回の在庫管理の例を微修正したモデルをContainerを用いて作成してみた.コードの後に解説があるので,それを参照しながら眺めてみてほしい.
import random import simpy def manager(env): env.model.ordered = False # no back order to receive env.stocktake = env.event() # create the first signal (event) while True: yield env.stocktake report(env) if not env.model.ordered and env.model.level <= 10: # only when no back order to receive # reorder point = 10 env.process(deliverer(env)) # activate deliverer env.model.ordered = True # back order will be received env.stocktake = env.event() # create the next signal (event) def deliverer(env): yield env.timeout(5) # delivery lead time = 5 env.model.put(20) # back order is recieved env.model.ordered = False # no back order to receive def customer(env): while True: time_to = random.expovariate(1) yield env.timeout(time_to) how_many = random.randint(1, 3) env.model.get(how_many) env.stocktake.succeed() # signal for stocktaking (event) def report(env): print('[{}] current level: {}, orderd: {}, queue length: {} '.format(round(env.now), env.model.level, env.model.ordered, len(env.model.get_queue))) def main(): env = simpy.Environment() env.model = simpy.Container(env, init=10) # model is marely a Container env.process(manager(env)) env.process(customer(env)) env.run(until=200) if __name__ == "__main__": main()前回のコードと比べると,Modelクラスの定義がなくなっていることがわかる.
main()の中を見てみるとわかるように,Containerのインスタンスをそのままenv.modelとして利用しているからである.デフォルトのContainerでは,バックオーダのリストを保持しにくいので,同時に高々1個のオーダしか出せないように微修正を加えた.また,Containerの特徴を確認するために,顧客が買っていく品物の数は1個には限定せず,3個以下の乱数で個数を定めるようにしてある.それにあわせて配送のリードタイムも5に短縮した.結果表示のメソッドは関数に変更して,プロセス
manager()から直接呼び出している.カスタマイズの例
最後に,興味のある人向けにContainerクラスを少しカスタマイズした例を示しておこう.
import random import simpy class Model(simpy.Container): def __init__(self, env, capacity=float('inf'), init=0): self.env = env super(Model, self).__init__(env, capacity, init) def _trigger_get(self, put_event): if len(self.get_queue) > 0: e = self.get_queue[len(self.get_queue) -1] if not hasattr(e, 'now'): e.now = self.env.now super(Model, self)._trigger_get(put_event) def _do_get(self, event): if self._level >= event.amount: print('I waited for {} time units.'.format(round(self.env.now -event.now))) super(Model, self)._do_get(event) def report(self): print('[{}] current level: {}, orderd: {}, queue length: {} '.format(round(self.env.now), self.level, self.ordered, len(self.get_queue))) def manager(env): env.model.ordered = False env.stocktake = env.event() while True: yield env.stocktake env.model.report() # changed to model's method if not env.model.ordered and env.model.level <= 10: env.process(deliverer(env)) env.model.ordered = True env.stocktake = env.event() def deliverer(env): yield env.timeout(5) env.model.put(20) env.model.ordered = False def customer(env): while True: time_to = random.expovariate(1) yield env.timeout(time_to) how_many = random.randint(1, 3) env.model.get(how_many) env.stocktake.succeed() def main(): env = simpy.Environment() env.model = Model(env, init=10) # changed to customized model env.process(manager(env)) env.process(customer(env)) env.run(until=200) if __name__ == "__main__": main()Modelクラスは,Containerを継承したサブクラスになっている.それ以降の部分は,上の例とほぼ同じである.
Modelクラスの定義を見てみると,もともと独立した関数だった画面表示のための
report()をメソッドとして取り込んでいることがわかる.ただ,この変更はシミュレーションの機能自体にはまったく影響を与えない,単に好みの問題だ.もう1つの変更点は,Get事象がトリガーされたときに,それに対応する各顧客の待ち時間を画面に表示させるようにしたことである.
_do_get()メソッドをオーバーライドして実現していることがわかる.なお,待ち始めた時刻をGet事象に属性nowとしてもたせるために,_trigger_get()メソッドにもちょっとしたトリックを仕込んだ.まとめ
今回はSimPyの「resources関連のモジュール群」のうち,base.pyとcontainer.pyの内容についてまとめた.Conteinerクラスの標準的な使い方と簡単なカスタマイズの具体例も紹介したので,機会があればぜひ試してみてほしい.残りの2つのモジュールについても,次回以降にまとめたいと思う.
- 投稿日:2019-10-23T01:58:55+09:00
Djangoで作ったWEBアプリにPWAを導入する方法
概要
Django,Python初学者の自分がDjangoで作ったWEBアプリにPWAを導入する際にPWAについての日本語の記事はいくつかあれど、DjangoでPWAを導入している例を挙げているような記事がほとんどなく、導入に非常に手間取ったので自分用の忘備録としても記事に残しておこうと思った次第です。
PWAとは
Progressive Web Appsの略で、googleが開発したWEBアプリなどをネイティブなアプリケーションのように動作させるモバイル向けの仕組み、と理解しています。
これを導入することによっていちいちブラウザからアクセスしてもらう必要がなくなり、ホームに追加されたアイコンをタップするだけでWEBアプリにアクセスしてもらうことができます。DjangoのWEBアプリに導入する
本題です。
今回はPWAを導入してデスクトップ版、Android版のChromeでPWAをインストールできるとこまでを目標とし、バージョンはDjango 2.2.4で作っていきます。
完成したコードはGithubに公開しています。
https://github.com/kitune-chan-250r/pwa-sampleDjangoのプロジェクトとアプリを作成
django-admin startproject mypwamypwaへ移動しアプリケーションpwatestを作成
python manage.py startapp pwatestmypwa/mypwa/setting.py にアプリを追加
#省略 INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'pwatest', #追加 ] #省略サーバーの起動
python manage.py runserver下記のように表示されれば問題ないです。
Watching for file changes with StatReloader Performing system checks... System check identified no issues (0 silenced). You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. October 22, 2019 - 23:52:56 Starting development server at http://127.0.0.1:8000/ Quit the server with CTRL-BREAK.最低限のwebアプリケーションを作成
mypwa/mypwa/urls.py
from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('', include('pwatest.urls')) ]mypwa/pwatest/urls.py (新規作成します)
from django.urls import path, include from .views import * urlpatterns = [ path('', index, name='index') ]mypwa/pwatest/views.py
from django.shortcuts import render def index(request): return render(request, 'index.html')mypwa/pwatest/templates/index.html (templatesフォルダを作成し、その中にindex.htmlを作成)
<!DOCTYPE html> <html> <head> <title></title> </head> <body> <h1>PWA test page</h1> </body> </html>この状態で http://127.0.0.1:8000/ へアクセスするとでかでかとPWA test pageと書かれているページが出現するはずです。
PWAに必要な設定、ファイルを追加
ここまで作ってきた最低限のwebアプリにpwaを導入していきます。
始めにPWAをインストールできるようにするために必要最低限の項目がこちらです(https://developers.google.com/web/fundamentals/app-install-banners より抜粋)Includes a web app manifest that includes: ・short_name or name ・icons must include a 192px and a 512px sized icons ・start_url ・display must be one of: fullscreen, standalone, or minimal-ui Served over HTTPS (required for service workers) Has registered a service worker with a fetch event handler簡単に説明すると、manifest.jsonにはshort_name、nameのどちらか(自分の環境では両方必要でした)、192px と 512pxサイズのアイコンの設定、start_url、display(fullscreen, standalone, minimal-uiのうちどれか一つ)が含まれており、HTTPSで配信されていて且つservice workerが登録されていること、とのことです。(localhostの場合はhttpでも動作するようです)
この条件を満たすよう先ほどのwebアプリに手を加えていきます。mypwa/pwatest/templates/index.html
<!DOCTYPE html> <html> <head> <title>pwa test</title> <!-- ここから --> <link rel="manifest" href="static/manifest.json"> <script> if ('serviceWorker' in navigator) { navigator.serviceWorker.register('sw.js').then(function() { console.log('Service Worker Registered'); }); } </script> <!-- ここまで追加 --> </head> <body> <h1>PWA test pwage</h1> </body> </html>mypwa/mypwa/setting.py (一番下に追加)
#省略 STATICFILES_DIRS = ( os.path.join(BASE_DIR, 'static'), )mypwa/mypwa/urls.py
from django.contrib import admin from django.urls import path, include #追加 from django.views.generic import TemplateView from django.views.decorators.cache import cache_control urlpatterns = [ path('admin/', admin.site.urls), path('', include('pwatest.urls')), #追加 path('sw.js', (TemplateView.as_view(template_name="sw.js", content_type='application/javascript', )), name='sw.js'), ]↑このurls.pyの部分が一番重要な部分であり、調べてもほとんど出てこなくて詰まったポイントでした。
ここからはPWAに必要なファイルを作成していきます。
mypwa/static/manifest.json (staticフォルダを作成し、その中にmanifest.jsonを作成)
{ "background_color": "#1f1f1f", "description": "pwa test", "display": "standalone", "theme_color": "aliceblue", "icons": [{ "src": "icon-192x192.png", "sizes": "192x192", "type": "image/png" },{ "src": "icon-512x512.png", "sizes": "512x512", "type": "image/png" }], "name": "pwaapp", "short_name": "pwaapp", "start_url": "http://127.0.0.1:8000" }mypwa/pwatest/templates/sw.js (staticではなくtemplatesフォルダ内に作成する点に注意してください)
self.addEventListener('fetch', function(event) {});最後にstaticフォルダ内にicon-192x192.pngとicon-512x512.pngを追加するとPWAの導入は完了です。
動作確認
デスクトップ
導入が成功していればデスクトップ版のChromeでアクセスした場合にURLの右端に+マークが出てくるようになり、それをクリックすることによってインストールすることが可能になります。インストール後はデスクトップに設定したアイコンが出現しそれをクリックすることによってwebアプリに直接アクセスすることが可能になります。
Android版Chrome
herokuなどのPaaSにデプロイして確認することもできます。その場合、ホームにアプリ追加バナーが出るようになります、通常は5分以上の間隔をあけて2度目にアクセスした際に表示されますが、デバッグする際は chrome://flags/#bypass-app-banner-engagement-checks にアクセスして有効化することで1度目のアクセスでバナーが表示されるようになります。
おまけ
iOS端末しか持っていない!デバッグできねぇじゃん!って方もいるかと思います(自分です)
自分の環境ではNoxなどのエミュレータでも動作確認することができず非常に困っていたのですが、Chromeの拡張機能にApkOnlineというブラウザ上で動作するAndroidエミュが存在し、これでPWAのインストールまで動作確認することができます、びっくりですね(ただし動作は非常に遅いです)もしどうしようもなければ試してみてください。最後に
初心者が書いた初Qiita記事でしたが少しはお役に立てたでしょうか、自分は深いところの解説ができないのでdjango + pwaの日本語記事が増えればなと思っています。
Vtuberファン向けの生放送一覧が確認できるwebアプリを作っています(PWAもここで使いました)
興味がある方は使ってみてください。
https://vlsapi-web.herokuapp.com参考ページ
Add to Home Screen (英語)
https://developers.google.com/web/fundamentals/app-install-banners
はじめてのプログレッシブウェブアプリ
https://developers.google.com/web/fundamentals/codelabs/your-first-pwapp
【3ステップではじめる】PWAによる「ホーム画面に追加」バナーの実装
https://amymd.hatenablog.com/entry/2017/10/12/001612スタックオーバーフローも参考にしたんですがどこかにいきました....

- 投稿日:2019-10-23T01:27:14+09:00
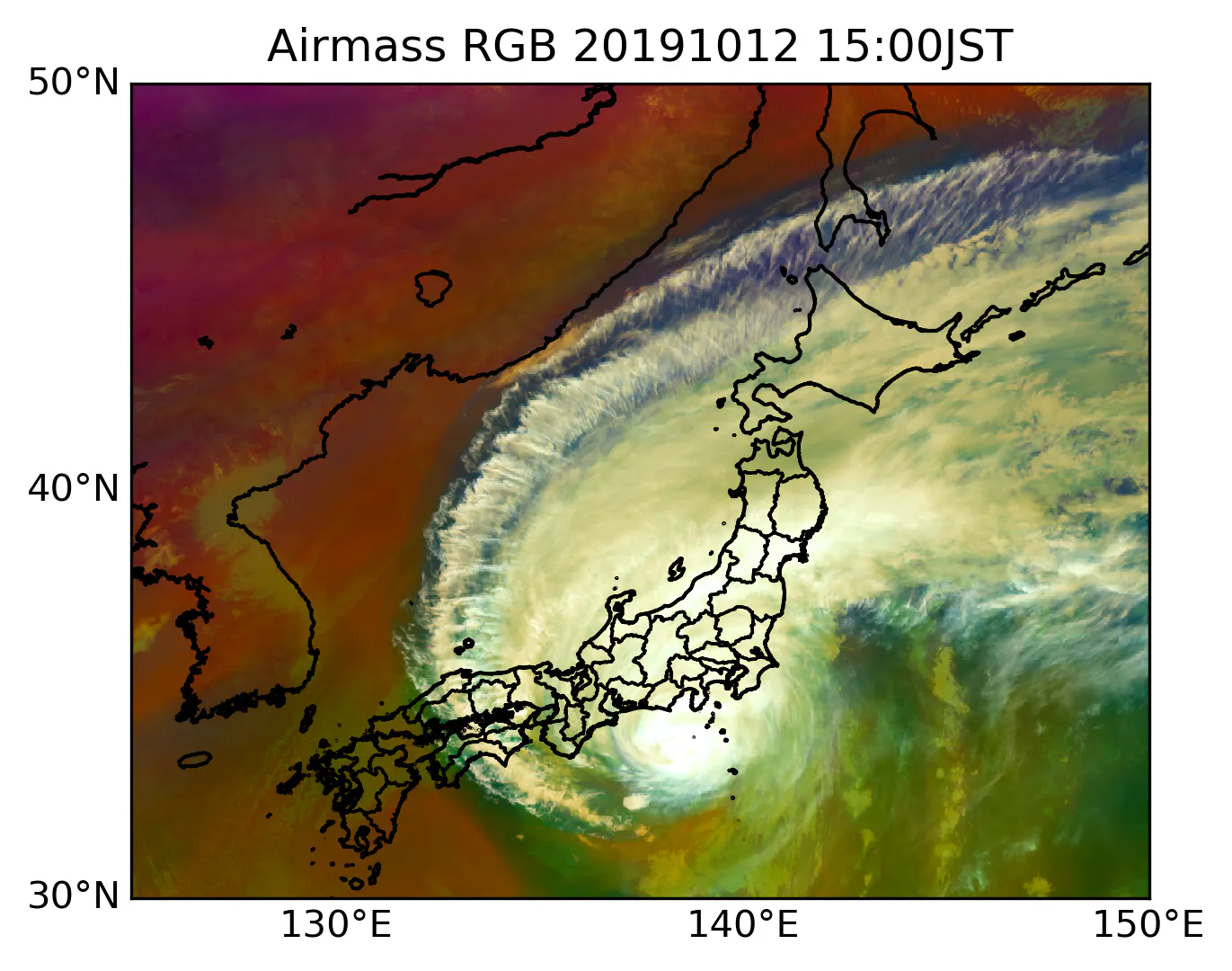
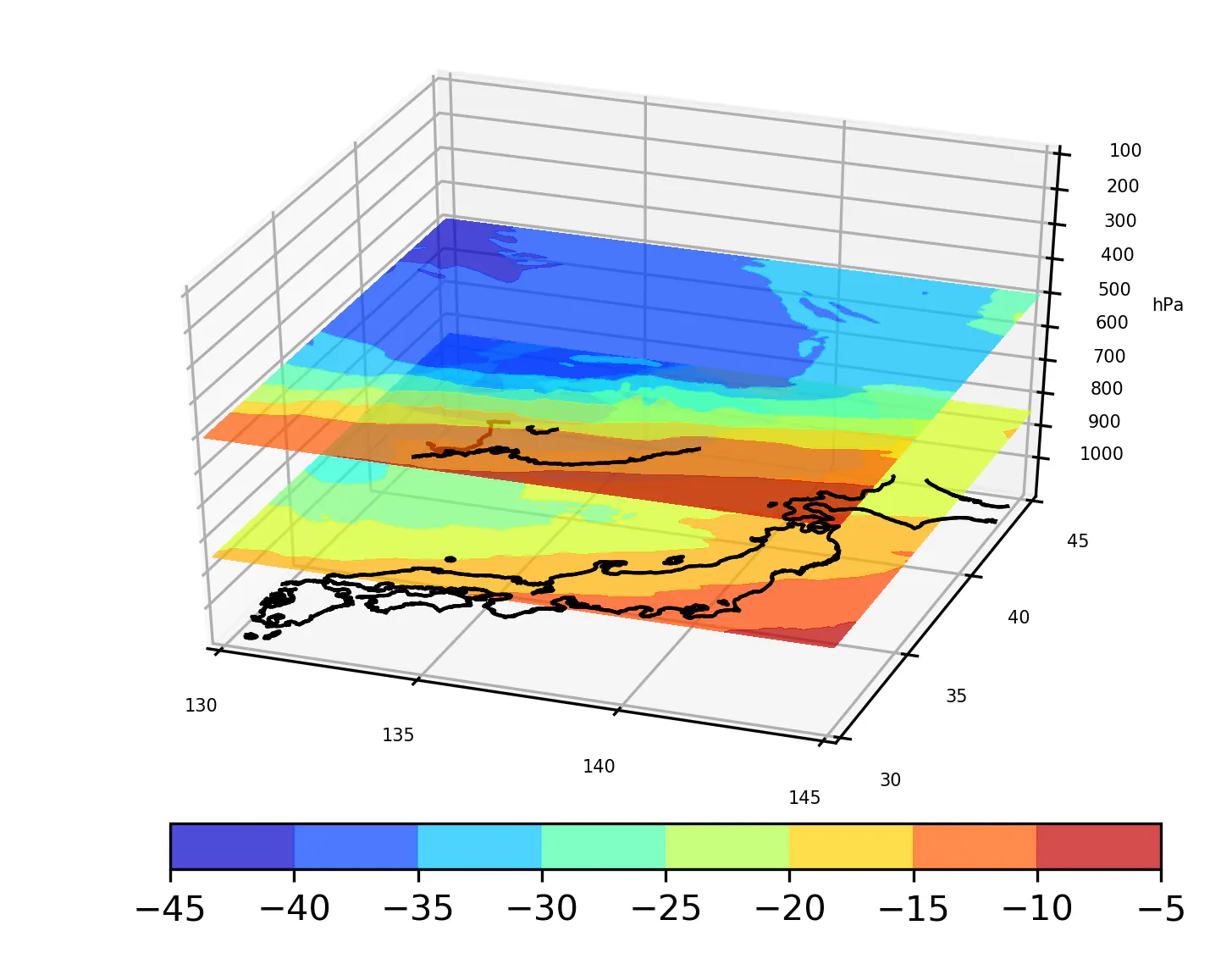
気象×Python 〜気象衛星ひまわり8号を用いたRGB合成〜
気象衛星ひまわりグリッドデータの描画です。とりあえず自分の備忘録として、雑に書きます。
1. 静止気象衛星ひまわり8号の概要
▶2014年10月7日に打ち上げられ、2015年7月7日に運用を開始した。世界最先端の観測能力を有する可視赤外放射計(AHI:Advanced Himawari Imager)を搭載し、可視域〜赤外域の16バンドを記録することができる。(気象庁より)
▶可視域の赤・青・緑それぞれに感度を持つバンドの画像を合成することで、強調して表示したい現象を分かりやすく表示することができるようになった。https://www.jma-net.go.jp/sat/himawari/satobs.html#rgb-composite2. 使用データ
▶千葉大学環境リモートセンシング研究センター「ひまわり8/9号」の全球スキャン (FD) の gridded data (緯度経度直行座標系による精密幾何補正済データ)→詳細はこちらのページ
▶ちなみに今回選んだ事例は東日本に記録的な大雨をもたらした2019/10/12の台風19号。2. RGB画像作成コード
こちらの資料を参考に実装しました。
あと、生データを輝度温度,反射率へ変換するためのルックアップテーブルは必要です。
ftp://hmwr829gr.cr.chiba-u.ac.jp/gridded/FD/support/(1)Airmass RGB
画像の特徴と画像作成レシピ
気団の解析、ジェット気流の位置、上層トラフや上層渦、大気沈降域などの推定に用いられる。
色 赤 緑 青 利用するバンドの種類 バンド8 - バンド10 バンド12 - バンド13 バンド8 (反転) 階調の設定 -25~0K -40~5K 243~208K ガンマ値 1.0 1.0 1.0 airmass.py# -*- coding: utf-8 -*- import matplotlib matplotlib.rcParams['backend'] = 'TkAgg' import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np from mpl_toolkits.basemap import Basemap #必要なバンドの読み込み band08 = np.fromfile("201910120600.tir.06.fld.geoss", dtype='>u2').reshape(6000, 6000) band10 = np.fromfile("201910120600.tir.08.fld.geoss", dtype='>u2').reshape(6000, 6000) band12 = np.fromfile("201910120600.tir.10.fld.geoss", dtype='>u2').reshape(6000, 6000) band13 = np.fromfile("201910120600.tir.01.fld.geoss", dtype='>u2').reshape(6000, 6000) #欠損値置換 band08 = np.where(band08 > 2000, 2000, band08) band10 = np.where(band10 > 4050, 4050, band10) band12 = np.where(band12 > 4050, 4050, band12) band13 = np.where(band13 > 4050, 4050, band13) #ルックアップテーブル参照 #日本領域にトレミング(50→30, l25→150) band08 = np.loadtxt('./count2tbb/tir.06',usecols=(1,))[band08][500:1500, 2000:3250] band10 = np.loadtxt('./count2tbb/tir.08',usecols=(1,))[band10][500:1500, 2000:3250] band12 = np.loadtxt('./count2tbb/tir.10',usecols=(1,))[band12][500:1500, 2000:3250] band13 = np.loadtxt('./count2tbb/tir.01', usecols=(1,))[band13][500:1500, 2000:3250] #差分をとって階調域の限定 R = (band08 - band10).clip(-25, 0) G = (band12 - band13).clip(-40, 5) B = band08.clip(208, 243) #最小値0、最大値1にする数量正規化するメソッド def normalization(x): x_min = x.min() x_max = x.max() x_norm = (x - x_min) / (x_max - x_min) return x_norm #正規化した配列を返す #階調反転メソッド def reverse(color, min, max): for x in color[:]: y = ((0-1)/(max-min))*x + (max/(max-min)) color = np.where(color == x, y, color) return color R = normalization(R) G = normalization(G) B = reverse(B, 208, 243) rgb = np.dstack((R, G, B)) rgb = np.power(rgb, 1.0) fig = plt.figure(facecolor='white',dpi=300) m = Basemap(projection="cyl", resolution="i", llcrnrlat=30, urcrnrlat=50, llcrnrlon=125, urcrnrlon=150, area_thresh=100, fix_aspect=True) m.imshow(rgb, origin="upper") m.drawcoastlines(color='k') m.drawmeridians(np.arange(0, 360, 10), labels=[True, False, False, True], linewidth=0) m.drawparallels(np.arange(-90, 90, 10), labels=[ True,False, True, False],linewidth=0) plt.title("Airmass RGB 20191012 15:00JST")それっぽいのはできた、、
ちなみに気象衛星センターによると、暖気側の温かい気団は緑系色、寒気側の冷たい気団は青紫系色、トラフ後面の大気沈降域は赤系色で表されるとのこと。(2)Day convective storm RGB
画像の特徴と画像作成レシピ
突風や竜巻等のシビア現象を伴う対流雲の判別に用いられる。
色 赤 緑 青 利用するバンドの種類 バンド8 - バンド10 バンド7 - バンド13 バンド5 - バンド3 階調の設定 -35~5K -5~60K -75~25% ガンマ値 1.0 1.0 1.0 コードは省略しますが結果だけ。シビア現象を伴う積乱雲は黄色表示となるみたい。
Day convective storm & Radar 地上天気図 天気図はtenki.jpより引用してます。
データ容量は大きいので注意です。
以上!!!



- 投稿日:2019-10-23T01:26:59+09:00
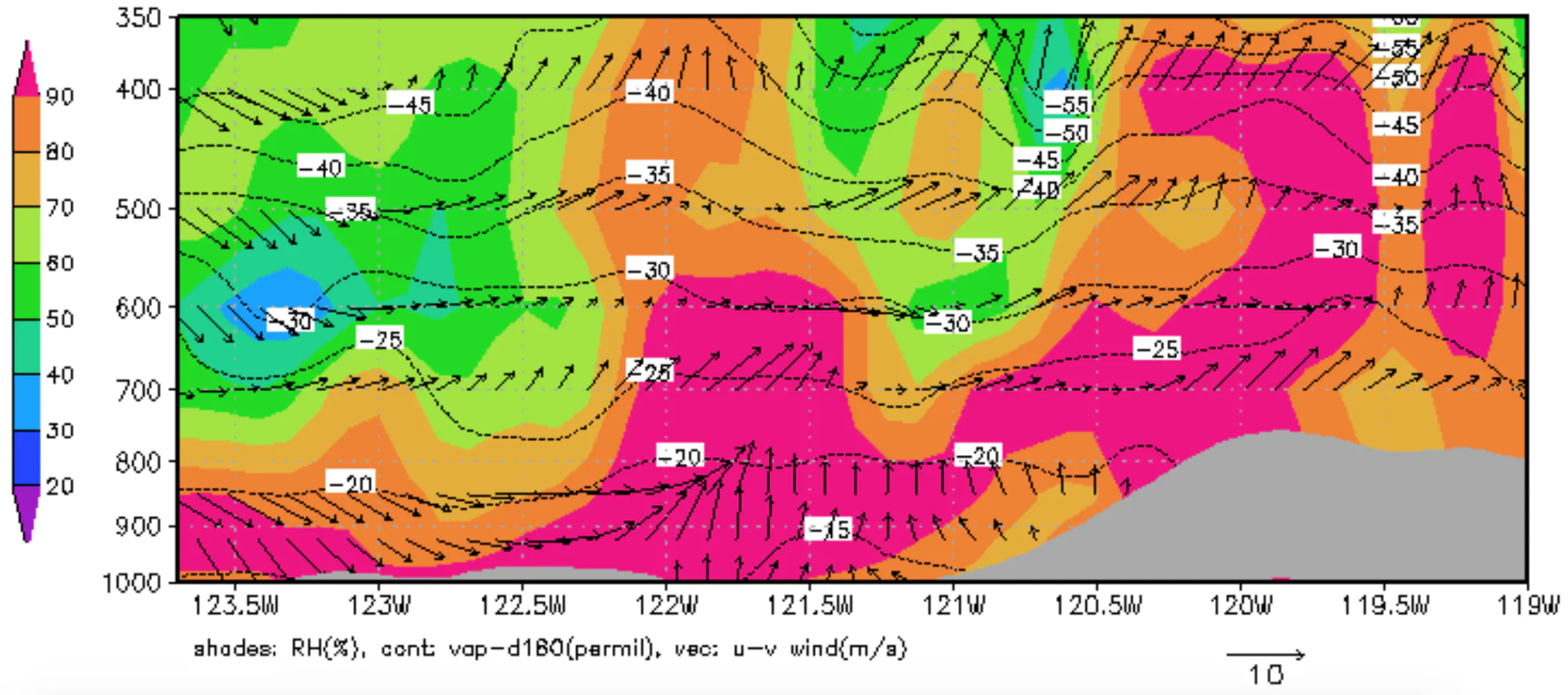
気象×Python 〜地形のマスクアウト〜
鉛直断面図を書く時に下の図のような地形マスクをかけたいと思ったので、 pythonでもやってみました(ネットにもあまり記載されてなかったので、、、)。とりあえず自分の備忘録として、雑に書きます。
↓完成イメージはこんなかんじ↓
http://isotope.iis.u-tokyo.ac.jp/~kei/?IT%20memo/GrADS%20memo#zca6364e1. 使用データ
▶京都大学生存圏研究所(RISH: Research Institute for Sustainable Humanosphere)から取得したメソ数値予報モデルGPV(MSM)
▶NetCDF形式
ちなみに2014/12/17は雪がめっちゃ降った日。
2. コード
結論、地上気圧が等圧面の気圧よりも低いとき、その気圧面を塗りつぶすというロジック。ただし地上と等圧面データの解像度を合わせること。
maskout.py# -*- coding: utf-8 -*- import matplotlib matplotlib.rcParams['backend'] = 'TkAgg' import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np import netCDF4 from mpl_toolkits.basemap import Basemap nc_p = netCDF4.Dataset('20141217_p.nc', 'r') nc_s = netCDF4.Dataset('20141217_s.nc', 'r') sp = nc_s['sp'][0][:][:] / 100 temp = nc_p['temp'][0][:][:][:] - 273.15 z_temp = temp[:,120,:] #lat=35.6 def maskout(hpa): mask_hpa = (sp[::2,::2] - hpa).reshape(1,253,241) return mask_hpa mask_p = np.zeros((0,253,241)) for hpa in [1000,975,950,925,900,850,800,700,600,500,400,300,250,200,150,100]: mask_hpa = maskout(hpa) mask_p = np.vstack((mask_p,mask_hpa)) X, Y = np.meshgrid(lon_p,nc_p['p'][:]) fig = plt.figure(facecolor='white',dpi=300) im = plt.contourf(X, Y, z_temp, cmap=cm.bwr) cmap2=cm.Greys cmap2.set_over('w', alpha=0)#範囲外は透過 im2 = plt.contourf(X, Y, mask_p[:,120,:],cmap=cmap2,vmin=-100000,vmax=0)#vminは適当に plt.gca().invert_yaxis() plt.xlim(127,139) plt.colorbar(im) plt.title("lat=35.6 9:00JST 17DEC2014") plt.show()
ついでに水平分布についても地形マスクかけてみた。
maskout.pync_p = netCDF4.Dataset('20141217_p.nc', 'r') nc_s = netCDF4.Dataset('20141217_s.nc', 'r') #['time']['p']['lat']['lon'] temp850 = nc_p['temp'][0][5][:][:] -273.15 #850hPa sp = nc_s['sp'][0][:][:] / 100 mask_s = sp[::2,::2] - 850 lat_p = nc_p['lat'][:] lon_p = nc_p['lon'][:] X, Y = np.meshgrid(lon_p,lat_p) fig = plt.figure(facecolor='white',dpi=300) m = Basemap(projection="cyl", resolution="i", llcrnrlat=30,urcrnrlat=45, llcrnrlon=130, urcrnrlon=145) m.drawcoastlines(color='black') m.drawmeridians(np.arange(0, 360, 5), labels=[True, False, False, True],linewidth=0.0) m.drawparallels(np.arange(-90, 90, 5), labels=[True, False, True, False],linewidth=0.0) im = plt.contourf(X, Y, temp850,cmap=cm.jet) cmap2=cm.gray cmap2.set_over('w', alpha=0) im2 = plt.contourf(X, Y, mask_s,cmap=cmap,vmin=-100000,vmax=0) cb = m.colorbar(im) plt.title("temp850hPa 9:00JST 17DEC2014") plt.show()中部山岳とかマスクされたぽい
以上!!!



- 投稿日:2019-10-23T01:26:59+09:00
気象×Python 〜地形マスクアウト〜
鉛直断面図を書く時に下の図のような地形マスクをかけたいと思ったので、 pythonでもやってみました(ネットにもあまり記載されてなかったので、、、)。とりあえず自分の備忘録として、雑に書きます。
↓完成イメージはこんなかんじ↓
http://isotope.iis.u-tokyo.ac.jp/~kei/?IT%20memo/GrADS%20memo#zca6364e1. 使用データ
▶京都大学生存圏研究所(RISH: Research Institute for Sustainable Humanosphere)から取得したメソ数値予報モデルGPV(MSM)
▶NetCDF形式
ちなみに2014/12/17は雪がめっちゃ降った日。
2. コード
結論、地上気圧が等圧面の気圧よりも低いとき、その気圧面を塗りつぶすというロジック。ただし地上と等圧面データの解像度を合わせること。
maskout.py# -*- coding: utf-8 -*- import matplotlib matplotlib.rcParams['backend'] = 'TkAgg' import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np import netCDF4 from mpl_toolkits.basemap import Basemap nc_p = netCDF4.Dataset('20141217_p.nc', 'r') nc_s = netCDF4.Dataset('20141217_s.nc', 'r') sp = nc_s['sp'][0][:][:] / 100 temp = nc_p['temp'][0][:][:][:] - 273.15 z_temp = temp[:,120,:] #lat=35.6 def maskout(hpa): mask_hpa = (sp[::2,::2] - hpa).reshape(1,253,241) return mask_hpa mask_p = np.zeros((0,253,241)) for hpa in [1000,975,950,925,900,850,800,700,600,500,400,300,250,200,150,100]: mask_hpa = maskout(hpa) mask_p = np.vstack((mask_p,mask_hpa)) X, Y = np.meshgrid(lon_p,nc_p['p'][:]) fig = plt.figure(facecolor='white',dpi=300) im = plt.contourf(X, Y, z_temp, cmap=cm.bwr) cmap2=cm.Greys cmap2.set_over('w', alpha=0)#範囲外は透過 im2 = plt.contourf(X, Y, mask_p[:,120,:],cmap=cmap2,vmin=-100000,vmax=0)#vminは適当に plt.gca().invert_yaxis() plt.xlim(127,139) plt.colorbar(im) plt.title("lat=35.6 9:00JST 17DEC2014") plt.show()
ついでに水平分布についても地形マスクかけてみた。
maskout.pync_p = netCDF4.Dataset('20141217_p.nc', 'r') nc_s = netCDF4.Dataset('20141217_s.nc', 'r') #['time']['p']['lat']['lon'] temp850 = nc_p['temp'][0][5][:][:] -273.15 #850hPa sp = nc_s['sp'][0][:][:] / 100 mask_s = sp[::2,::2] - 850 lat_p = nc_p['lat'][:] lon_p = nc_p['lon'][:] X, Y = np.meshgrid(lon_p,lat_p) fig = plt.figure(facecolor='white',dpi=300) m = Basemap(projection="cyl", resolution="i", llcrnrlat=30,urcrnrlat=45, llcrnrlon=130, urcrnrlon=145) m.drawcoastlines(color='black') m.drawmeridians(np.arange(0, 360, 5), labels=[True, False, False, True],linewidth=0.0) m.drawparallels(np.arange(-90, 90, 5), labels=[True, False, True, False],linewidth=0.0) im = plt.contourf(X, Y, temp850,cmap=cm.jet) cmap2=cm.gray cmap2.set_over('w', alpha=0) im2 = plt.contourf(X, Y, mask_s,cmap=cmap,vmin=-100000,vmax=0) cb = m.colorbar(im) plt.title("temp850hPa 9:00JST 17DEC2014") plt.show()中部山岳とかマスクされたぽい
以上!!!
- 投稿日:2019-10-23T01:26:46+09:00
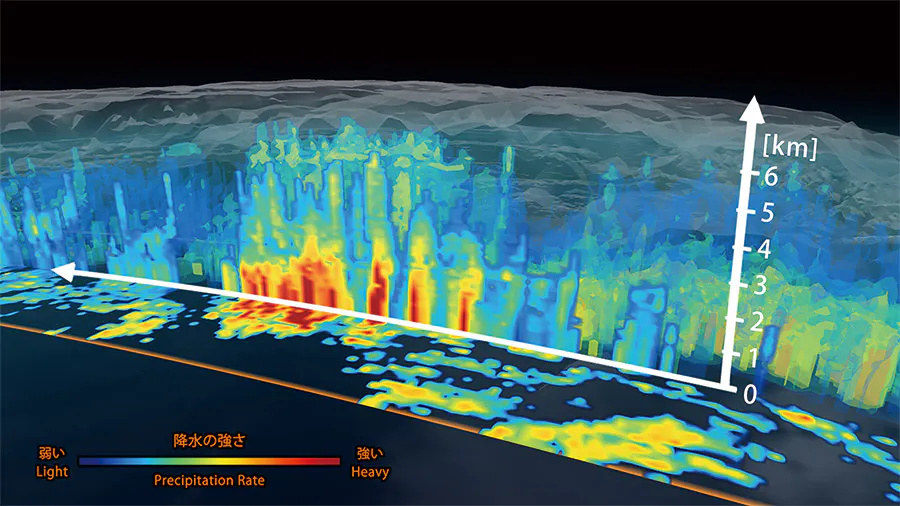
気象×Python 〜3次元描画〜
気象データは地上だけじゃなくて、何層にも等圧面データがあるんで3次元的に描けるか試してみました。とりあえず自分の備忘録として、雑に書きます。
3次元の降水データはこんなん(JAXAより引用してます。)
1. 使用データ
▶京都大学生存圏研究所(RISH: Research Institute for Sustainable Humanosphere)から取得したメソ数値予報モデルGPV(MSM)
▶NetCDF形式
16層からなる(1000,975,950,925,900,850,800,700,600,500,400,300,250,200,150,100)
ちなみに2014/12/17は雪がめっちゃ降った日。
2. コード
temp_3d.py# -*- coding: utf-8 -*- import matplotlib matplotlib.rcParams['backend'] = 'TkAgg' import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np import netCDF4 from mpl_toolkits.basemap import Basemap from mpl_toolkits.mplot3d import Axes3D nc_p = netCDF4.Dataset('20141217_p.nc', 'r') temp = nc_p['temp'][0][:][:][:] -273.15 p = nc_p['p'][:] lat_p = nc_p['lat'][:] lon_p = nc_p['lon'][:] fig = plt.figure(facecolor='white',dpi=300) ax = fig.gca(projection='3d') m = Basemap(projection="cyl", resolution="i", llcrnrlat=30,urcrnrlat=45, llcrnrlon=130, urcrnrlon=145,fix_aspect=False, ax=ax) ax.add_collection3d(m.drawcoastlines(linewidth=1)) ax.add_collection3d(m.drawcountries(linewidth=1)) ax.view_init(azim=290, elev=35) meridians = np.arange(130, 145 + 5, 5) parallels = np.arange(30, 45 + 5, 5) pressure = np.arange(100, 1000 + 100 , 100) ax.set_xticks(meridians) ax.set_xticklabels(meridians,fontsize=5) ax.set_yticks(parallels) ax.set_yticklabels(parallels,fontsize=5) ax.set_zticks(pressure) ax.set_zticklabels(pressure, fontsize=5) ax.set_zlabel('hPa', labelpad=0.5,fontsize=5) ax.invert_zaxis() X, Y = np.meshgrid(lon_p , lat_p) level = np.arange(-45,20,5) #試しに2層で。 #1000,975,950,925,900,850,800,700,600,500,400,300,250,200,150,100 m.contourf(X,Y, temp[5,:,:], offset=850, cmap=cm.jet , alpha=0.7) #850hPa img = m.contourf(X, Y, temp[9,:,:], offset=500, cmap=cm.jet , alpha=0.7) #500hPa # (left,bottom,right,top) cax = fig.add_axes([0.22, 0.05, 0.65, 0.045]) fig.colorbar(img,cax, orientation="horizontal")日本地図の位置が事案
ちょいと修正。new_temp_3d.py#途中から meridians = np.arange(130, 145 + 5, 5) parallels = np.arange(30, 45 + 5, 5) pressure = np.arange(100, 1000 + 100 , 100) ax.set_xticks(meridians) ax.set_xticklabels(meridians,fontsize=5) ax.set_yticks(parallels) ax.set_yticklabels(parallels,fontsize=5) ax.set_zticks(pressure) ax.set_zticklabels(pressure[::-1], fontsize=5) ax.set_zlabel('hPa', labelpad=0.5,fontsize=5) X, Y = np.meshgrid(lon_p , lat_p) level = np.arange(-45,20,5) m.contourf(X,Y, temp[5,:,:], offset=1100-850, cmap=cm.jet , alpha=0.7) #850hPa img = m.contourf(X, Y, temp[9,:,:], offset=1100-500, cmap=cm.jet , alpha=0.7) #500hPa cax = fig.add_axes([0.22, 0.05, 0.65, 0.045]) fig.colorbar(img,cax, orientation="horizontal")正しい位置には戻ったが、正直微妙。
もっとそれっぽい可視化方法ありそうだけど、、誰か教えてくださいまし。
以上!!!


- 投稿日:2019-10-23T01:22:24+09:00
Ansibleでハマりがちなミスの自分用メモ
開発環境
Git Lab
Source Tree
Visulal Studio Code
Docker
Ansible作業環境
1.Git LabのリポジトリをoriginにしてSource Treeにリモートリポジトリ設定
2.Source Treeでブランチを切ってローカルに保存
3.ローカルのリポジトリをVSCodeで読ませてコード編集
4.編集したらコミット、プル
5.サーバにログインしてDockerを立ち上げて同期・コンテナ起動
6.Ansibleでdry run(diffオプションで特定のノードグループとの比較を取る)1,2は事前設定なので実作業としては3~6を繰り返すことになる。
ハマった箇所と原因と対策
・一括変換によるコーディングミス
The error appears to have been in '///.yml': line *, column *, but may
be elsewhere in the file depending on the exact syntax problem.The offending line appears to be:
********:
^ hereだいたいこういう感じでシンタックスエラーが出る。
エラー箇所そのものを表示してくれるわけではないのできちんと前後関係を読まなければいけない。
この場合、変数にエラーがあったということだが、実際は変数の次の行でダブルクォートの囲みミスがあった。
before - /usr/local/src/.rpm"
after - "/usr/local/src/.rpm"
ダブルクォートの囲みミスは一括変換でやりがちなので気をつけたい。・半角スペースの文字コードエラー
VSCode上で編集中は気づかないが、文字コードが混在していてサーバに同期したときに半角スペースが???と表示されていることがあった。
前任者から引き継いだ作業だったが前任者と会話をしたことはなかったので確認していなかった。
度々起きたエラー。・ansible.cfgがない
ERROR! the role '**' was not found in **The error appears to have been in '****.yml': line *, column *, but may
be elsewhere in the file depending on the exact syntax problem.The offending line appears to be:
roles:
- { role: ****** , tags: [ '*****' ] }
^ hereそんなロールはないと言われている。
roles_pathの場所が定義されていない。rolesの変数はあってもどこにrolesはあるのか?と問われている状態。
原因はansible.cfgを配置していなかったこと。
ここが一番ハマったが、他の環境からコピーして解決した。・スペルミス
そんなロールはないその2。ありがち。
directoryならdirectolyなどと書いているようなもの。・node_groupが存在しない
そんなロールはないその3。
特定のノードグループと比較しながらdry runを流していたが、
あるノードグループだけ、ymlファイルはあるのにそんなロールはないと言われてしまう。
ノードグループの数をチェックしていたら、そのノードグループはディレクトリごと存在していなかったというオチ。他にもあったら追記するかもしれない。