- 投稿日:2019-10-23T23:50:55+09:00
AWSを使ってホームページを公開するまで。
AWSで新規プロジェクトを立ち上げようとしたらよくわからない不具合で止まったのでその全貌のメモ。
1 AWSでアカウントを作る。
リージョンは東京。
別の地域、特に現在地から遠いところだと最大0.1秒程度のラグが出るらしい。2 EC2インスタンス立ち上げ。
- EC2を起動
- キーペア作成
- インスタンスIDをコピーしてメモしとく
- Elastic IPとインスタンスIDを関連付ける
- セキュリティグループを開いてポートの開放
- インバウンドタブを開いて編集
- ルールの追加
- HTTPを選択して保存
terminal$ cd $ mv Downloads/XXX.pem .ssh/ $ cd .ssh/ $ chmod 600 XXX.pem $ ssh -i XXX.pem ec2-user@Elastic IPこれでSSH接続完了。
[ヒント]
terminal-bash: warning: setlocale: LC_CTYPE: cannot change locale (UTF-8): No such file or directory上記のようなエラーが出た場合は、
- ターミナルをいったん閉じる。
- Terminal -> Preferences -> Profiles -> Advanced
- 最下部の Set locale environment variables on startup のチェックを外す。
- もう一度SSH接続し直す。
これで改善される。
3 環境づくり
まずパッケージのアップデートを行う。
terminal$ sudo yum update次に一度に必要なものをインストール。
terminal$ sudo yum install \ git make gcc-c++ patch \ libyaml-devel libffi-devel libicu-devel \ zlib-devel readline-devel libxml2-devel libxslt-devel \ ImageMagick ImageMagick-devel \terminal$ sudo yum install -y openssl-develNode.jsをインストール
terminal$ sudo curl -sL https://rpm.nodesource.com/setup_6.x | sudo bash - $ sudo yum install nodejsrbenvとruby-buildをインストール
terminal$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv $ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile $ source .bash_profile $ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build $ rbenv rehash $ rbenv install X.X.X $ # これはかなり長くかかる場合もあるので痺れを切らせて閉じたり変な入力をしないように! $ rbenv global X.X.X $ rbenv rehash $ ruby -v $ # 入れたバージョンと同じなら問題なし。MySQLのインストール
今回は5.6を入れる。
terminal$ sudo yum install mysql56-server mysql56-devel mysql56 $ sudo service mysqld start $ sudo service mysqld status $ # ここで running と出れば大丈夫。 $ sudo /usr/libexec/mysql56/mysqladmin -u root password 'XXXpasswordxxx' $ mysql -u root -p $ # パスワードを入れて問題なければ quit で終了。SSH鍵ペアを作る
terminal$ ssh-keygen -t rsa -b 4096 $ cat ~/.ssh/id_rsa.pub $ # これで出てきた文字列をコピーする。
- GitHubのhttps://github.com/settings/keysに行く。
- New SSH key を押してタイトルを入れ、keyのところに先ほどコピーした文字列を入力する。
terminal$ ssh -T git@github.comunicorn導入
gemfilegroup :production do gem 'unicorn', '5.4.1' endconfig/unicorn.rb を作成。
config/unicorn.rbapp_path = File.expand_path('../../', __FILE__) worker_processes 1 working_directory app_path pid "#{app_path}/tmp/pids/unicorn.pid" listen 3000 stderr_path "#{app_path}/log/unicorn.stderr.log" stdout_path "#{app_path}/log/unicorn.stdout.log" timeout 60 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection endと入力する。
terminal$ sudo mkdir /var/www/ $ sudo chown ec2-user /var/www/ $ cd /var/www/ $ git clone リポジトリURL $ # このリポジトリURLは各リポジトリを選択した際に右のほうに出る clone or download という緑色のボタンのところに出る。gemのインストール
terminal$ cd /var/www/リポジトリ名 $ # 以降はこのディレクションで作業する $ ruby -vローカルでの開発環境で bundler のバージョンを確認。
local_terminal$ bundler -vterminal$ gem install bundler -v X.X.X $ # 先ほど確認したバージョンのものを入れる。 $ bundler install $ # この作業もかなり時間がかかる場合がある。環境変数の設定
terminal$ rake secret $ # これで表示された文字列をコピーしておく。 $ sudo vim /etc/environment $ # 入力後に i を押してインサートモードにし、 DATABASE_PASSWORD='MySQLのパスワード' SECRET_KEY_BASE='さっきの文字列'入力後は esc を押した後に :wq で保存して終了。
[ヒント]
:q!で保存せずに終了。
出られなくなったりめちゃくちゃになった時はこれ!その後 exit でいったんログアウトする。
terminal$ env | grep SECRET_KEY_BASE $ env | grep DATABASE_PASSWORDこれで現在の環境変数を確認できる。
セキュリティグループを選択してインバウンドタブの編集から、
カスタムTCP、3000番ポートを開放する設定を追加。4 データベースを作る
config/database.ymlproduction: <<: *default database: XXX username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sock変更を加えた時は必ず
termianl$ git pull origin masterをする。
そして現在(2019/10/23)の問題点……
terminal$ rails db:create Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) Couldn't create 'XXX_development' database. Please check your configuration. rails aborted! Mysql2::Error::ConnectionError: Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) /var/www/XXX/bin/rails:9:in `<top (required)>' /var/www/XXX/bin/spring:15:in `<top (required)>' bin/rails:3:in `load' bin/rails:3:in `<main>' Tasks: TOP => db:create (See full trace by running task with --trace)以前まではこれで普通にデータベースを作れていたのだが、
何故か今回このような表示が出てデータベースが作れなくなってしまった。
エラー画面を元に様々な解決法を検索して試してみたが、
(2)が別の数字に変わるだけで依然進展せず、
インスタンスをかれこれ3回も初めからやり直すことに……解決法が分かり次第更新するが、もしこれを見て解決法が分かりそうな方は是非お力を貸していただきたいです!
- 投稿日:2019-10-23T22:57:33+09:00
JAWS-UG初心者支部第20回勉強会に参加してきた
10/23日に開催されたJAWS-UG初心者支部第20回勉強会に参加してきました
ブログに書いたら薄い本くれるって@dkfjさんがおっしゃってたので書いてみます
記事書く気なかったので写真と全くなく見辛い、、
セッションやLTごとに大事だと思った部分や印象に残った部分を3行で書くので気になったらスライドみてくださいセッション①:AWS流アウトプットの秘訣
AWSJ舘岡 守さん
- アウトプットは大事
- アウトプットしないのは知的な便秘
- オススメのアウトプット方法はLT
AWSの方ってなんとなくお固そうなイメージだったんですが愉快な方でしたw
スライド⬇︎ (Qiitaって埋め込みできないのか?)
https://speakerdeck.com/qphoney/output-techniqueセッション②:LTのコツと心得
森川晃さん @ariaki4dev
- まずはアウトプットをなぜやるのか(自分のため or 他人のため)モチベーションを探る
- アウトプットしようとすると調べるので、アウトプットは良質なインプットのチャンス
- LTするときは聞き手の知らないことを内容の3割程度にすると聴きやすく刺激的
LTのTipsみたいなのがすごかったので自分がやるときには是非参考にさせていただきます!
スライド⬇︎
https://speakerdeck.com/ariaki/how-to-begin-output-jawsug-bgnrパネルディスカッション:
JAWSの運営コアメンバーから初心者にお届けするJAWSなアウトプットについて
モデレーター:
AWSJ沼口さん
各支部運営:
・Security-JAWS大竹さん
・X-Tech JAWS吉江さん
・Fin-JAWS釜山さん
・CLI専門支部波田野さんみなさんかなりの熱量で濃いお話をしてくれましたが個人的にはCLIの波田野さんの
- 負のフィードバックをどれだけもらえるかが大事
- AWS CLIではコピペで動くので強烈なインプットを与えて、帰ってから復習してもらう
- 何度やっても動くので復習効率がいい
という話がなるほどなあという感じでした
LT:誰でもできる簡単なアウトプット法!!IAMのマニアックな話に添えて
佐々木拓郎さん @dkfj
- アウトプットのハードルを下げる。最初はツイッターや1行のブログでもOK
- 継続する。質より量。量が増えれば質は上がる。
- 計測する。成果が目に見えることで励みや工夫に繋がる。
この方のIAMの本が欲しくてこれ書いてますw
スライド⬇︎
https://speakerdeck.com/takuros/jawsugchu-xin-zhe-zhi-bu-shui-demodekirujian-dan-naautopututofaLT:意識低いインプットでもできるアウトプット
近藤佑子さん @kondoyuko
- 技術を扱った経験が少なくてもアウトプット力があれば知識をつけられる
- かっこ悪いアウトプットでもOK
- 出してみることは正義
5分間をとんでもない勢いで駆け抜けっていったエネルギッシュな方でした
スライド⬇︎
https://speakerdeck.com/kondoyuko/output-that-can-be-achieved-even-with-beginners-inputまとめ!
AWSの話が聞けると思って行ったんですが実際にはほとんど聞けませんでしたw
ただアウトプットの大切さについて思い知ることができました!
おれもどっかでLTやるぞ当日のツイッターの様子はこちら
#jawsug_bgnr
- 投稿日:2019-10-23T21:36:49+09:00
CircleCI+Code4兄弟でFargateで動くGoプログラムをデプロイする
はじめに
Go言語で書かれたプログラムをFargateでサービス実行していて、そこにCI/CDを設定する
手順の紹介記事です。
構成は以下の通り
- GitHub
- CircleCI
- CodePipeline(CodeCommit/CodeBuild/CodeDeploy)
- ECS(Fargate)
CircleCIを経由しないフローでもいいですが、CircleCI 2.1での新しい書き方を試したかった
のもあり、こんな構成にしました。 参考:CircleCI2.1Qiita検索結果
なお、手順の紹介に重点を置いたので、各種設定ファイルについては概要説明に止めます。前提
環境
- QA/Production環境それぞれ別のAWSアカウントで利用
- 東京リージョン(ap-northeast-1)を利用
- FargateでサービスとしてGoプログラムを実行している
- CirceCIのconfig.ymlはversion2.1を使用
- executors/commands/parametersを使いたいので
- Golangのバージョンは1.13~
- Go Modulesを使っているので
デプロイフロー
GitHubでは3種類のブランチを使います。
それを、以下のように動作するよう設定します。
- masterブランチ
- developブランチのマージ先
- PRマージされるとProduction環境のCodeCommitへPushされる
- CodeCommitへのPushをトリガにCodePipelineによりECSへデプロイされる
- developブランチ
- 開発用ブランチのマージ先
- 開発を始める場合はここから新しい開発用ブランチを作成
- PRマージされるとQA環境のCodeCommitへPushされる
- CodeCommitへのPushをトリガにCodePipelineによりECSへデプロイされる
- 開発用ブランチ(ここではfeature_hogeブランチ)
- GitHubにPushされるとLint/Testが実行される
なので、マージの流れは、 feature_hoge -> develop -> master の順
イメージ図
今回利用するGoプログラム
sample-go
プログラムの内容は適当(個人的な検証プログラム)です。
ECSにサービス登録して実行する前提なので、デーモンとして動く実装であればどんなコードでもOK。ファイル構成
sample-go├── .circleci │ └── config.yml # CircleCI設定ファイル ├── Dockerfile # Goプログラム実行用コンテナ作るやつ(マルチステージビルド!!) ├── Makefile # Goプログラムのビルドに使う ├── bin # リポジトリには含まれません │ └── sample-go # make bin/sample-go を実行して生成されるバイナリ ├── buildspec.yml # CodeBuildが実行するコマンドを記述したファイル ├── main.go ├── main_test.go ├── go.mod └── go.sumCI設定に関わる下記ファイルの概要説明
- .circleci/config.yml
- GitHubへのPushをトリガに動くCircleCIワークフローの設定ファイル
- buildspec.yml
- CodeBuildが実行するコマンドなどを指定したファイル
- docker build してイメージをECRへPushするという内容
- Dockerfile
- Goプログラムのビルド、及び実行バイナリを格納したコンテナイメージを作成するDockerfile
- buildspec.yml内で指定されている
手順
GitHub - CircleCI 連携設定
https://circleci.com/ にアクセス
まだGitHub - CircleCI 連携設定していない場合は下記手順を実施
GitHubアカウントでログイン
下記ボタンをクリック
CircleCIからGitHubへのアクセスを許可
下記のような確認画面が表示されるので画面下の
Authorize circleciボタンをクリック
CIをセットアップするリポジトリを指定
https://circleci.com/add-projects/gh/{GitHubアカウント名} にアクセス
対象リポジトリのSet Up Projectボタンを押すSet Up Project 画面からビルドを一度実行する
- Operating System -> Linux
- Language -> Go
を選択し、Next StepsセクションのStart buildingをクリック

初回はエラーになるがこのまま進めます
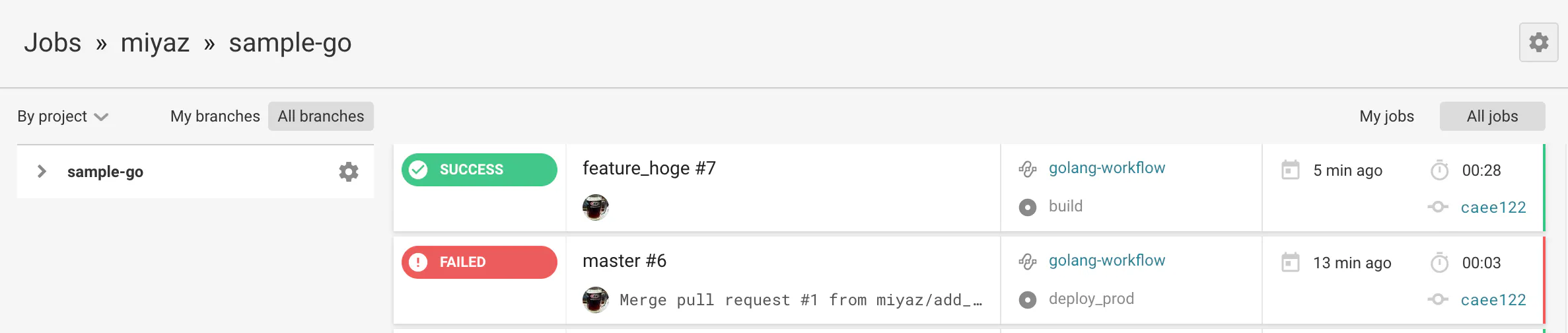
CI(Lint/Test)動作確認
feature_hogeブランチを作成してPushgit checkout -b feature_hoge git push origin feature_hogehttps://circleci.com/gh/{GitHubアカウント名}
にアクセスして上記のPushをトリガに最新Job(一番上)が動いていることを確認します。
SUCCESSであれば、Lint/Testにパスしたということになります。
もし、FAILEDであれば、対象のJobをクリックして、Lint/Test結果を確認し、必要な修正を行ってください。以降の設定は、QA/Productionの両方のAWSアカウントで実施する必要があります。
QA用AWSアカウントの手順のみ記載しますが、Productionにも同様に設定する必要がありますFargate設定
ECRにリポジトリを作成してコンテナイメージをPush
# awsクレデンシャルのプロファイルを指定 export AWS_PROFILE={プロファイル名} # ECRにリポジトリを作成 aws ecr create-repository --region ap-northeast-1 --repository-name sample-go # コンテナイメージをECRにPush ACCOUNT_ID=$(aws sts get-caller-identity | jq -r .Account) $(aws ecr get-login --no-include-email --region ap-northeast-1) docker build -t sample-go . docker tag sample-go:latest $ACCOUNT_ID.dkr.ecr.ap-northeast-1.amazonaws.com/sample-go:latest docker push $ACCOUNT_ID.dkr.ecr.ap-northeast-1.amazonaws.com/sample-go:latestFargate設定(詳細割愛)
ここでは下記を作成した前提で進めます
- クラスタ名:sample-go
- サービス名:sample-go
- タスク定義名:sample-go
- コンテナ定義のイメージURL:123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/sample-go:latest
CodeCommit設定
CodePipelineのトリガとなる、CodeCommitの設定を行います。
CI設定時に、事前にCodeCommitにブランチを作成する必要があるのでそのセットアップも行います。CodeCommitにPushするためのIAMユーザ作成
IAMユーザ作成
ユーザ名:codecommit-pusher(任意)
アクセスの種類:プログラムによるアクセスにチェック
アタッチポリシー:AWSCodeCommitPowerUser
※ここでは権限広めですが、適切に絞ってくださいー後は、デフォルト値で進めてユーザ作成まで実行
CodeCommitのSSHキーを作成
注)ここで発行するSSHキーは、CodeCommitブランチ作成、及びCircleCIのSSH Permissionsでも使用します
ローカル端末でSSHキーペアを作成します
(後述するCircleCIへの鍵アップロードではPEM形式にしか対応していないので-m pemを忘れずに!)cd ~/.ssh/ ssh-keygen -t rsa -b 2048 -f codecommit-pusher-key -m pem ls codecommit-pusher-key* → codecommit-pusher-key, codecommit-pusher-key.pubが存在することを確認(鍵ファイル名を変えて、QA/Production用に別々に発行してください)
IAMユーザ画面の
認証情報タブを開き、SSHパブリックキーのアップロードボタンをクリックし
codecommit-pusher-key.pubの内容を貼り付けてアップロードする
表示されたSSHキーIDを控えておいてください
CodeCommitリポジトリ作成
- AWSマネジメントコンソールからCodeCommit画面を開き、
リポジトリを作成ボタンをクリック- リポジトリ名に
sample-goを入力して作成ボタンをクリックdevelopブランチを作成する
GitHubとCodeCommitでコミット履歴が同じ状態である必要があるので、git remoteにCodeCommitリポジトリを追加
する形でブランチを追加します。# CodeCommitにgitでアクセスできるようにssh_config設定 IAM_SSH_KEY_ID={SSHキーIDを指定} echo -e "Host git-codecommit.*.amazonaws.com\n User ${IAM_SSH_KEY_ID}\n StrictHostKeyChecking no\n UserKnownHostsFile=/dev/null\n IdentityFile ~/.ssh/codecommit-pusher-key" >> ${HOME}/.ssh/config # githubからcloneしたsample-goローカルリポジトリへ移動 cd sample-go # CodeCommitのリポジトリをremote追加 git remote add codecommit ssh://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/sample-go # developブランチをPush git checkout develop git pull codecommit develop git push codecommit develop git remote remove codecommit(Productionの場合はmasterブランチに読み替えてください)
CodeCommitにPushするためのCircleCI設定
.circleci/config.ymlを見るとわかりますが、今回QA/ProductionでAWSアカウントが別れている関係で
CircleCIからPushするCodeCommitは2アカウント分となるため、SSHキー&秘密鍵が2つ必要になります。
今回は、環境ごとにdeploy_qaとdeploy_prodの2つのジョブに分けて、IAM_SSH_KEY_ID_QA / IAM_SSH_KEY_IDという
環境変数で使用するSSHキーを使い分ける形にしました。.circleci/config.ymlの該当箇所抜粋deploy_qa: 〜略〜 steps: - checkout - run: name: deploy for qa command: | echo -e "Host git-codecommit.*.amazonaws.com\n User ${IAM_SSH_KEY_ID_QA}\n StrictHostKeyChecking no\n UserKnownHostsFile=/dev/null" >> ${HOME}/.ssh/config git push ssh://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/sample-go develop deploy_prod: 〜略〜 steps: - checkout - run: name: deploy for production command: | echo -e "Host git-codecommit.*.amazonaws.com\n User ${IAM_SSH_KEY_ID}\n StrictHostKeyChecking no\n UserKnownHostsFile=/dev/null" >> ${HOME}/.ssh/config git push ssh://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/sample-go masterCircleCIの環境変数追加
Project Settings画面(https://circleci.com/gh/{GitHubアカウント名}/sample-go/edit) にアクセス
Environment Variablesをクリック
Add Variableボタンをクリック
IAM_SSH_KEY_ID/IAM_SSH_KEY_ID_QAという環境変数として、QA/Production環境で発行したSSHキーIDを追加します
CircleCIのSSH鍵追加
Project Settings画面(https://circleci.com/gh/{GitHubアカウント名}/sample-go/edit) にアクセス
SSH Permissionsをクリック
Add SSH Keyボタンをクリック
Private Key欄に codecommit-pusher-keyの内容を貼り付けます(Hostnameは空欄でOK)
Add SSH KeyボタンをクリックQA/Production環境用に発行した2つのキーを登録します
コードパイプライン設定
コードパイプライン作成
AWSマネジメントコンソールからコードパイプライン画面を開き、
パイプラインを作成するボタンをクリックパイプラインの設定を選択する
パイプライン名を入力して、
次にをクリック
ロール名は自動的に入力されます(手入力は不要です)
ソースステージを追加する
ソースプロバイダーに
AWS CodeCommitを選択
リポジトリ名にsample-goを指定し、ブランチ名にdevelopを指定して、次にをクリック
ビルドステージを追加する
プロバイダー:AWS CodeBuild
リージョン:アジアパシフィック(東京)
を選択し、プロジェクトを作成するボタンをクリックビルドプロジェクトを作成する
プロジェクト名:sample-go
環境イメージ:マネージド型イメージ
オペレーティングシステム:Ubuntu
ランタイム:Standard
イメージ:aws/codebuild/standard:2.0
特権付与:チェックOn
サービスロール:新しいサービスロール
ロール名:codebuild-sample-go-service-role
※あとで権限変更するため、ロール名を控えておくこと<追加設定>を開いて環境変数として下記入力
名前 値 入力 AWS_DEFAULT_REGION ap-northeast-1 プレーンテキスト AWS_ACCOUNT_ID 123456789012 プレーンテキスト 以降、Buildspec、ログ設定はデフォルトのまま
CodePipelineに進むをクリック
ビルドステージを追加する画面に戻るので、次にボタンをクリック
この画像には、特権付与にチェック入っていませんが必要です m(_ _)m
デプロイステージを追加する
デプロイプロバイダーに
Amazon ECSを選択
リージョン:アジアパシフィック(東京)
クラスター名:sample-go
サービス名:sample-go
次にボタンをクリック
確認画面が表示されるので、
パイプラインを作成するボタンをクリック
パイプラインが作成されると、最初のパイプライン処理が実行されます。
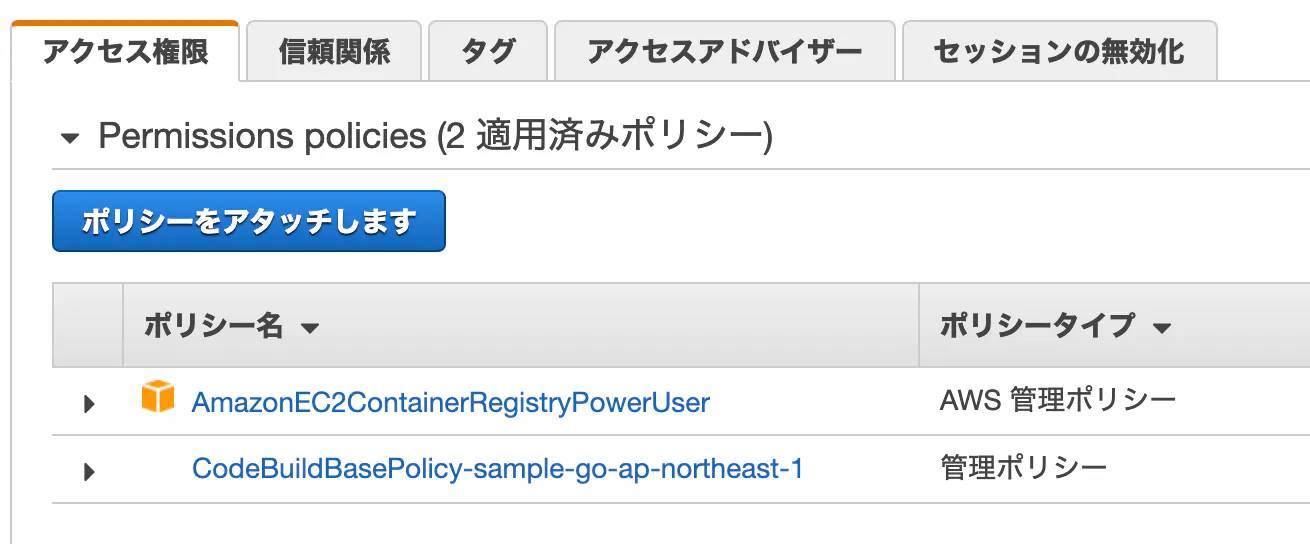
まだ設定完了ではないのでエラーになりますが、気にせずに。ECRアクセス権限付与
CodeBuildがビルドしたイメージをECRにPushするための権限を付与します。
IAMロール[codebuild-sample-go-service-role]に権限追加
※デフォルトでは、codebuild-{プロジェクト名}-service-roleというロール名になります
IAMコンソールで、上記ロールを開きます
アクセス権限タブを開きます
AmazonEC2ContainerRegistryPowerUserポリシーをアタッチします
※ここでは権限広めですが、適切に絞ってくださいー
CI/CD動作確認
feature_hogeブランチをPushした際に、golangci-lintやgo testの結果がNGであれば、その旨GitHubのプルリク上
で表示されます。CircleCIのジョブ画面でエラー詳細が確認できます。
developブランチにMergeした時には、自動的にQA環境のECS(Fargate)のサービスが更新(デプロイ)されます。
また、手順省略しましたが、Production環境用の設定も行えば、masterにMergeした時に、自動的にProductionの
ECS(Fargate)のサービスが更新(デプロイ)されるようになります。まとめ
ビルドが早い、マルチステージビルドでコンテナイメージがコンパクトにできる、ワンバイナリで動く、ということで
もともとGoとコンテナ実行の相性はいいですが、これにCI/CDができるとさらにデリバリスピードが上がるので最高ですねー。
さらに、サーバの存在を意識しなくてよいECS(Fargate)へのデプロイも、Code4兄弟が面倒をみてくれるので、
開発者だけでなく、SREにもメリットのあるかなりよい構成なので、今後もこの構成推しでいこうと思っています。あと、今回は長々とコンソールを操作する手順を紹介しましたが、本来こういう設定はCloudFormationでテンプレートを
作って自動でセットアップするのがいいと思います(実際に、弊社でもテンプレート化してそれを使って構築しています)
ですが、コンソールで操作してみるとAWS/GitHub/CircleCIの連携部分の理解が進むので、一度やってみるのを
オススメします!















- 投稿日:2019-10-23T21:10:50+09:00
AWS認定 SysOps アドミニストレーター アソシエイト(SOA)の合格記録
2019/10/21に試験に合格しました。
9/23にソリューションアーキテクトプロフェショナルに合格したので、その勢いで勉強しました。
AWS認定 ソリューションアーキテクト プロフェッショナル(SAP-C01)の合格記録ネットでは、SAAに合格できたら、他のアソシエイト資格はさほど学習しなくても合格できると書かれてたので、SAPに合格するレベルだったら楽勝だろうと思って勉強始めたのですが、意外とわからないことが多く、ちゃんと勉強としてなかったら落ちてたと思います
やはり、分野が異なるので、それなりに学習した方がより確実に合格できるかと思います。学習内容
1. 試験ガイドの確認
まずは試験ガイドを確認します。
https://aws.amazon.com/jp/certification/certified-sysops-admin-associate/
(ざっと読む程度でいいです。)
試験ガイドより、こちらの
https://aws.amazon.com/jp/certification/certification-prep/
sysopsの欄にある、「AWSホワイトペーパーおよびよくある質問」が参考になります。
ここに掲載されているホワイトペーパーやよくある質問、対象サービスのBlackbeltは読んだ方がいいです。
ここに記載はないですが、CloudFormationに関する問題もよく出たのでそちらのサービスも学習した方がいいです。2.黒本で学習
https://aws.koiwaclub.com/
前回SAPの為に契約した期間(3ヶ月)のうち、1ヶ月余っていたので、こちらでまず勉強しました。
簡単かと思って始めたのですが、初回の正解率が50%ほどで少し焦りました。
3回ほど繰り返して9割以上正解できるようにします。3.Udemyで学習
https://www.udemy.com/course/aws-certified-sysops-administrator-associate-practice-exams-soa-c01/
黒本だけだと不安だったのでこちらも解いて覚えました。
こちらも4,5回繰り返して9割以上正解できるようにしました。試験振り返り
813/1000で合格しました。
SAPの時は手探り状態だったこともあり、4ヶ月ほどかかりましたが、こちらは1ヶ月で合格できました。
アーキテクトと違い、コマンドや定数名が問題に出てきますが、数は多くないので問題集で出たものを都度覚えていくで問題ないかと。
今回の試験でも、コマンドラインを問う問題は1問だけでした。
- 投稿日:2019-10-23T19:16:40+09:00
AWS Cloud9でのpython2からpyhton3に変更する方法(pyenv利用)
概要
aws cloud9でslackbot用のラムダ関数を作成しようとした時に,python2からpython3への変更に手間取ったので,忘れないように書いておきます.結局,cloud9では,「Preference」=> 「Python Support」から2から3への変更が可能だったので,次回からはそうするようにします.
間違えてしまった理由として,前回,EC2サーバを自分で建てたとき,python2しか入っていなかったので,cloud9でサーバを立てた場合でも,python3は入っていないと思ってしまったためです.ですので,python3を入れるのがめんどくさいなら,cloud9を立ててec2を利用するのもいいかもしれません.今回は,python2からpyenvからとってきたpython3.6.2に変えます.
利用環境
amazon linux2
バージョン確認
pythonとpipのバージョンを確認しましょう.
$ python -V Python 2.7.14 $ pip -V pip 9.0.3 from /usr/lib/python2.7/dist-packages (python 2.7)pyenvのインストール
pyenvをgitから落としてきて.bash_profileにpyenvのpathを書き込む
その後sourceコマンドで.bash_profileを改めて読み込み(もしくは再起動)$git clone https://github.com/yyuu/pyenv.git ~/.pyenv $echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $source ~/.bash_profilepyenv へのpathが通っているか確認
$pyenv --version pyenv 1.2.13-19-gf3d008fdpyenvでインストール可能なバージョンを指定
pyenv install --list 2.1.3 2.2.3 2.3.7 2.4.0 2.4.1 2.4.2 2.4.3 2.4.4 2.4.5 2.4.6 2.5.0 2.5.1 2.5.2 2.5.3いろいろ出ますが,今回は3.6.2を選択する.以下に保存される.
$pyenv install 3.6.2 $find . -name python3.6 /home/ec2-user/.pyenv/shims/python3.6 2>/dev/null /home/ec2-user/.pyenv/versions/3.6.2/lib/python3.6 /home/ec2-user/.pyenv/versions/3.6.2/bin/python3.6systemになっているので,3.6.2に変更
$pyenv versions * system 3.6.2 (set by /home/ec2-user/.pyenv/version) $pyenv global 3.6.6 $pyenv rehashこれで
$pyenv versions system * 3.6.2 (set by /home/ec2-user/.pyenv/version)3.6.2のほうにチェックが入りました.
ただ,これでもpython2のままです.$python --V python2.7.?これは,.bash_rcで利用するpythonがすでに決められているためだ.
そこで,$sudo vim ~/.bashrc alias python='python27'上の部分を削除します.
さらに,$find / -name python3.6 2>/dev/null /usr/lib/python3.6 /usr/bin/python3.6 /usr/local/lib/python3.6 /usr/local/lib64/python3.6 /usr/lib64/python3.6 /opt/c9/python3/lib/python3.6 /opt/c9/python3/bin/python3.6 /home/ec2-user/.pyenv/shims/python3.6 /home/ec2-user/.pyenv/versions/3.6.2/lib/python3.6 /home/ec2-user/.pyenv/versions/3.6.2/bin/python3.6 /home/ec2-user/environment/.c9/metadata/environment/calif/venv/lib/python3.6 ~/.pyenv/shims/python3.6とpythonのフォルダは2つ(はじめからあるもの(/usr/bin)と今入れたもの(home/ecs-user/.pyenv)ので,pythonを指定したときに,先に呼び出すファルダを決めます.
今は,$which python /usr/bin/python3.6とかがでます.
そこで,
$ sudo vim /etc/paths /home/ec2-user/.pyenv/shims /usr/bin /bin /usr/local/bin /usr/sbin /sbin /usr/local/sbinとして,pyenvのpythonを先に読み込むようにしましょう.
すると,$which python /home/ec2-user/.pyenv/shims/python3.6となります.
ならないようなら,一度,サーバを落としてください.
これで,pyenvを使ってpython3.6.2を利用できるようになりました.
環境によって,バージョンは変えてください.
ちなみに,現状では,あらかじめ入っているpython3
3.6.8です.
ちなみに,$pip -version pip 19.3.1 from /home/ec2-user/.pyenv/versions/3.6.2/lib/python3.6/site-packages/pip (python 3.6)となっており,pipはpython3を利用されるようになっている.
python2も共存しているので,pipコマンドを利用しているのか確認するとよい.
- 投稿日:2019-10-23T15:06:52+09:00
AmazonLinux2でkubectlコマンドを使う
参考
https://kubernetes.io/docs/tasks/tools/install-kubectl/#install-kubectl-on-linux
コマンドダウンロード
curl -LO https://storage.googleapis.com/kubernetes-release/release/`curl -s https://storage.googleapis.com/kubernetes-release/release/stable.txt`/bin/linux/amd64/kubectl実行権限つける
chmod +x ./kubectl実行できるパスへ移動
sudo mv ./kubectl /usr/local/bin/kubectl実行できるかチェック
kubectl version出力結果
Client Version: version.Info{Major:"1", Minor:"16", GitVersion:"v1.16.2", GitCommit:"c97fe5036ef3df2967d086711e6c0c405941e14b", GitTreeState:"clean", BuildDate:"2019-10-15T19:18:23Z", GoVersion:"go1.12.10", Compiler:"gc", Platform:"linux/amd64"} The connection to the server localhost:8080 was refused - did you specify the right host or port?
- 投稿日:2019-10-23T14:10:01+09:00
AWSでサーバレスな動画解析(Amazon Rekognition)
こんにちは。
日々の業務ではインフラエンジニアをやっています。@hayaosatoです。最近は動画解析などの技術も流行っていてそれらのSaaSも提供されていますね。
AWSではAmazon Rekognition(以下、Rekognition)というサービスが提供されています。
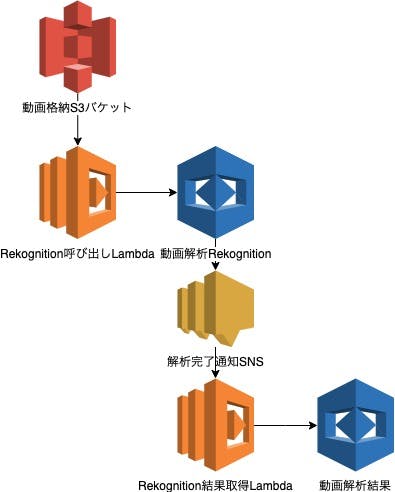
本記事ではこのRekognitionを使うためのサーバレスアーキテクチャを構築してみたいと思います。構成
構成図は以下の通りです。
Rekognitionで動画解析を行うと、動画の長さによりますが解析時間がかかってしまいます。
Rekognitionでは解析時間の完了をAmazon SNS(以下、SNS)のトピックを発行することで通知してくれます。
今回はS3に動画がアップロードされたことをトリガにAWS Lambda(以下、Lambda)からRekognitonの動画解析開始
Rekognitionの動画解析完了後SNSトピックからLambdaを呼び出し、LambdaからRekognitonの解析結果を取得する
というアーキテクチャを作ってみます。S3 -> Lambda
Lambdaファンクションを作成し、トリガを設定します。
この際に注意すべきは動画はファイルサイズが大きくなりがちなので、
マルチパートアップロードの完了時もちゃんとトリガが飛ぶようにしておきましょう。Lambda -> Rekognition -> SNS
Rekognitionで解析を開始するためのLambdaファンクションを作成します。
言語はPythonにしました。ドキュメントはこちら。
今回は顔認識を使ってみることにしたので、start_face_detectionを使用します。response = client.start_face_detection( Video={ 'S3Object': { 'Bucket': 'your-bucket-name', 'Name': 'your-video-name' } }, ClientRequestToken='string', NotificationChannel={ 'SNSTopicArn': 'your-sns-topic-arn', 'RoleArn': 'your-role-arn-for-rekognition' } )ここで、
NotificationChannelにSNSとROLEのARNを指定しています。
SNSTopicArnはその通りRekognitionが解析完了した際に通知を飛ばすためのSNSトピックのARNです。
RoleArnはRekognitionがSNSトピックを飛ばすためのRoleを与える必要があります。SNS -> Lambda -> Rekognition
Rekognitionから発行されたSNSトピックからLambdaが呼び出されるようにサブスクリプションを作成したら、
最後にLambdaからRekognitionに対して動画解析の結果を取得します。Lambdaに届くeventの'Sns'キーのValueは以下のようになっています。
{ 'Type': 'Notification', 'MessageId': 'xxxxxxxx', 'TopicArn': 'arn:aws:sns:your-region:your-account-id:your-topic-arn', 'Subject': None, 'Message': '{"JobId":"xxxxxxxxxx","Status":"SUCCEEDED","API":"APINAME","Timestamp":1571799891913,"Video":{"S3ObjectName":"your-video.mp4","S3Bucket":"your-video-bucket"}}', 'Timestamp': '2019-10-23T03:04:52.660Z', 'SignatureVersion': '1', 'Signature': 'xxxxxxxxx' 'SigningCertUrl': 'https://sns.ap-northeast-1.amazonaws.com/SimpleNotificationService-xxxx.pem', 'UnsubscribeUrl': 'https://sns.ap-northeast-1.amazonaws.com/?Action=Unsubscribe&SubscriptionArn=arn:aws:sns:xxxxxx', 'MessageAttributes': {} }このようにして、Messageを取り出すことでRekognitionから結果を抜き出すための情報が揃います。
MessageからJobIdを抜き出して、(NextTokenは省略しています。)
response = client.get_face_detection( JobId='xxxxxx' )Rekognitionから解析結果のJSONを受け取りことができます。
まとめ
このようにして、Rekognitionを利用してサーバレスなアーキテクチャを作成してみました。
サーバレスでイベントドリブンってやっぱりいいですね
コードはこちら
- 投稿日:2019-10-23T13:57:02+09:00
AWS Cloud9 に Ruby 開発環境をセットアップする
AWS Cloud9 で Rubyのプログラム開発をする際の開発環境をセットアップしてみました。
結論
初めから Ruby2.6 がインストールされているので、特に何もしなくても Rubyによるプログラミングが始められそうです。
環境
- AWS Cloud9
前提条件
- AWS アカウント登録済み
- AWS Cloud9 サービス利用中
AWS Cloud9 に Ruby の開発環境をセットアップする
作業用ディレクトリの作成
実行中の Cloud9 環境に作業用のディレクトリを作成します。
- 左側ツリーのトップディレクトリを右クリックして [New Folder] を選択
- フォルダ名を入力します
Ruby のバージョンを確認
ターミナルを開き、現在の環境のRubyのバージョンを確認します。
$ ruby -v ruby 2.6.3p62 (2019-04-16 revision 67580) [x86_64-linux]今回はこのままで進めます。
gem のリストを確認
現在の環境にインストール済みのgems一覧を確認します。
思ったより沢山インストール済みです。$ gem list --local *** LOCAL GEMS *** actioncable (5.0.0) actionmailer (5.0.0) actionpack (5.0.0) actionview (5.0.0) activejob (5.0.0) activemodel (5.0.0) activerecord (5.0.0) activesupport (5.0.0) arel (7.1.4) bigdecimal (default: 1.4.1) builder (3.2.3) bundler (default: 1.17.3) bundler-unload (1.0.2) cmath (default: 1.0.0) concurrent-ruby (1.1.5) crass (1.0.4) csv (default: 3.0.9) date (default: 2.0.0) did_you_mean (1.3.0) e2mmap (default: 0.1.0) erubis (2.7.0) etc (default: 1.0.1) executable-hooks (1.6.0) fcntl (default: 1.0.0) fiddle (default: 1.0.0) fileutils (default: 1.1.0) forwardable (default: 1.2.0) gem-wrappers (1.4.0) globalid (0.4.2) i18n (0.9.5) io-console (default: 0.4.7) ipaddr (default: 1.2.2) irb (default: 1.0.0) json (default: 2.1.0) logger (default: 1.3.0) loofah (2.3.0) mail (2.7.1) matrix (default: 0.1.0) method_source (0.9.2) mini_mime (1.0.2) mini_portile2 (2.4.0) minitest (5.11.3) mutex_m (default: 0.1.0) net-telnet (0.2.0) nio4r (1.2.1) nokogiri (1.10.4) openssl (default: 2.1.2) ostruct (default: 0.1.0) power_assert (1.1.3) prime (default: 0.1.0) psych (default: 3.1.0) rack (2.0.7) rack-test (0.6.3) rails (5.0.0) rails-dom-testing (2.0.3) rails-html-sanitizer (1.3.0) railties (5.0.0) rake (12.3.2) rdoc (default: 6.1.0) rexml (default: 3.1.9) rss (default: 0.2.7) rubygems-bundler (1.4.5) rvm (1.11.3.9) scanf (default: 1.0.0) sdbm (default: 1.0.0) shell (default: 0.7) sprockets (4.0.0) sprockets-rails (3.2.1) stringio (default: 0.0.2) strscan (default: 1.0.0) sync (default: 0.5.0) test-unit (3.2.9) thor (0.20.3) thread_safe (0.3.6) thwait (default: 0.1.0) tracer (default: 0.1.0) tzinfo (1.2.5) webrick (default: 1.4.2) websocket-driver (0.6.5) websocket-extensions (0.1.4) xmlrpc (0.3.0) zlib (default: 1.0.0)bunder を更新
bundler (default: 1.17.3) を更新します。
最新は (2.0.2)$ gem update bundler Updating installed gems Updating bundler Fetching bundler-2.0.2.gem Successfully installed bundler-2.0.2 Parsing documentation for bundler-2.0.2 Installing ri documentation for bundler-2.0.2 Installing darkfish documentation for bundler-2.0.2 Done installing documentation for bundler after 5 seconds Parsing documentation for bundler-2.0.2 Done installing documentation for bundler after 2 seconds Gems updated: bundlerbundler で ライブラリをインストール
bundle init
$ bundle init Writing new Gemfile to /home/ec2-user/environment/ruby_test/GemfileGemfile に インストールするライブラリを追加
gem "dotenv"bundle install
$ bundle install Fetching gem metadata from https://rubygems.org/.. Resolving dependencies... Using bundler 2.0.2 Fetching dotenv 2.7.5 Installing dotenv 2.7.5 Bundle complete! 1 Gemfile dependency, 2 gems now installed. Use `bundle info [gemname]` to see where a bundled gem is installed. $ gem list --local *** LOCAL GEMS *** actioncable (5.0.0) actionmailer (5.0.0) actionpack (5.0.0) actionview (5.0.0) activejob (5.0.0) activemodel (5.0.0) activerecord (5.0.0) activesupport (5.0.0) arel (7.1.4) bigdecimal (default: 1.4.1) builder (3.2.3) bundler (2.0.2, default: 1.17.3) bundler-unload (1.0.2) cmath (default: 1.0.0) concurrent-ruby (1.1.5) crass (1.0.4) csv (default: 3.0.9) date (default: 2.0.0) did_you_mean (1.3.0) dotenv (2.7.5) e2mmap (default: 0.1.0) erubis (2.7.0)dotenv がインストールされました。
テスト
ライブラリが読み込めて利用できることをテストします。
hello.rbrequire 'rubygems' require 'bundler/setup' require 'dotenv/load' def hello(name) puts "#{ENV['HELLO']} #{name}!!" end hello("ruby").envファイル
HELLO=Hello実行結果
$ ruby -cw hello.rb Syntax OK $ ruby -w hello.rb Hello ruby!!kintone のアプリの情報の取得
フィールドの一覧を取得する
https://developer.cybozu.io/hc/ja/articles/204783170#anchor_getform_fields拙稿からコードをコピーして実行してみます。
https://qiita.com/sy250f/items/82f84904daf7601eeb08#%E3%83%95%E3%82%A9%E3%83%BC%E3%83%A0%E3%81%AE%E8%A8%AD%E5%AE%9A%E3%81%AE%E5%8F%96%E5%BE%97アプリID=100のアプリのフィールド一覧を取得します。
実行結果
$ ruby -cw get_app_fields.rb Syntax OK $ ruby -w get_app_fields.rb {"revision"=>"24", "properties"=> {"備考"=> {"type"=>"MULTI_LINE_TEXT", "code"=>"備考", "label"=>"備考", "noLabel"=>false, "required"=>false, "defaultValue"=>""}, "レコード番号"=> {"type"=>"RECORD_NUMBER", "code"=>"レコード番号", "label"=>"レコード番号", "noLabel"=>false}, "作業者"=> {"type"=>"STATUS_ASSIGNEE", "code"=>"作業者", "label"=>"作業者", "enabled"=>true}, "割引率"=> {"type"=>"NUMBER", "code"=>"割引率", "label"=>"割引率", "noLabel"=>false, "required"=>false, "minValue"=>"", "maxValue"=>"", "digit"=>false, "unique"=>false, "defaultValue"=>"", "displayScale"=>"", "unit"=>"", "unitPosition"=>"BEFORE"}, "更新者"=> {"type"=>"MODIFIER", "code"=>"更新者", "label"=>"更新者", "noLabel"=>false}, "作成者"=>{"type"=>"CREATOR", "code"=>"作成者", "label"=>"作成者", "noLabel"=>false}, "ステータス"=> {"type"=>"STATUS", "code"=>"ステータス", "label"=>"ステータス", "enabled"=>true}, "更新日時"=> {"type"=>"UPDATED_TIME", "code"=>"更新日時", "label"=>"更新日時", "noLabel"=>false}, "金額"=> {"type"=>"NUMBER", "code"=>"金額", "label"=>"金額", "noLabel"=>false, "required"=>false, "minValue"=>"", "maxValue"=>"", "digit"=>true, "unique"=>false, "defaultValue"=>"", "displayScale"=>"", "unit"=>"", "unitPosition"=>"BEFORE"}, "カテゴリー"=> {"type"=>"CATEGORY", "code"=>"カテゴリー", "label"=>"カテゴリー", "enabled"=>false}, "file"=> {"type"=>"FILE", "code"=>"file", "label"=>"file", "noLabel"=>false, "required"=>false, "thumbnailSize"=>"150"}, "商品名"=> {"type"=>"SINGLE_LINE_TEXT", "code"=>"商品名", "label"=>"商品名", "noLabel"=>false, "required"=>false, "minLength"=>"", "maxLength"=>"64", "expression"=>"", "hideExpression"=>false, "unique"=>true, "defaultValue"=>""}, "備考_0"=> {"type"=>"MULTI_LINE_TEXT", "code"=>"備考_0", "label"=>"備考", "noLabel"=>false, "required"=>false, "defaultValue"=>""}, "備考_4"=> {"type"=>"MULTI_LINE_TEXT", "code"=>"備考_4", "label"=>"備考", "noLabel"=>false, "required"=>false, "defaultValue"=>""}, "備考_3"=> {"type"=>"MULTI_LINE_TEXT", "code"=>"備考_3", "label"=>"備考", "noLabel"=>false, "required"=>false, "defaultValue"=>""}, "作成日時"=> {"type"=>"CREATED_TIME", "code"=>"作成日時", "label"=>"作成日時", "noLabel"=>false}, "備考_2"=> {"type"=>"MULTI_LINE_TEXT", "code"=>"備考_2", "label"=>"備考", "noLabel"=>false, "required"=>false, "defaultValue"=>""}, "備考_1"=> {"type"=>"MULTI_LINE_TEXT", "code"=>"備考_1", "label"=>"備考", "noLabel"=>false, "required"=>false, "defaultValue"=>""}}}rubyプログラムから kintoneアプリのフィールド一覧を取得できました。
関連リンク
Ruby関連
- 投稿日:2019-10-23T12:53:40+09:00
サーバレスで動く研究室のHPを1年間運用してみて
指導教員の無茶振りで作り始めたサーバレス+SPA+GraphQL+ChatOpsで研究室のHPが完成してからだいたい1年が経過しました。(参考: 研究室のHPをサーバレス、SPA、GraphQL、ChatOpsで作った)研究室という、人が数年でほとんど入れ替わる特殊な組織内でどのようにHPを継続的に運用していったのか振り返ります。
HPの概要
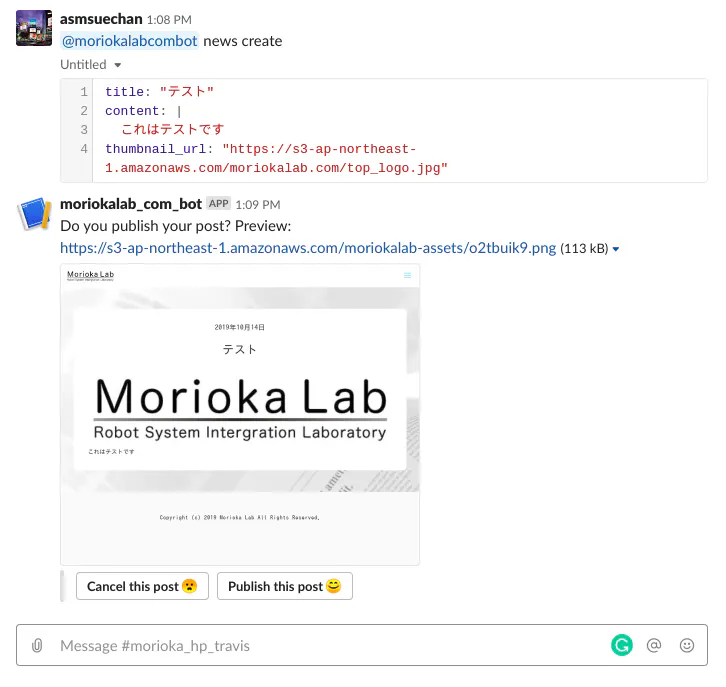
Slack Botで更新する研究室のHPです。YAMLを添付して
@labbot posts createのようにメンションを飛ばすと記事が作成されます。更新、削除もできます。
このHPは、(1) 研究室のみんなが更新できる, (2) 運用、ID/PASS周りの管理コストを最小限にする, の2点を要件として開発したものです。
大きく分けてフロントエンド、サーバーサイド、Slack Botの3つの部分で構成されており、フロントエンドはNuxt(Vue.js)、Buefy、AtomicDesign、ApolloClientなど、サーバサイドはNodejs、GraphQL、DynamoDBなど、Slack BotはNodejsやjestなどから作られています。そしてこれら全てのインフラをserverless framework(Lambda)で動かしています。以下の図は現在のシステム構成概要です。
_人人人人人人人人人人人人人_
> 全部sererless framework <
 ̄Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^Y^ ̄serverless frameworkの開発者達には足を向けて寝られない。
数字で見るこの1年間
(1) アクセス数
GAでトラックしていたのでそのキャプチャです。去年書いた記事がバズった時以外はだいたい週20アクセス前後です。いや20人も誰が見とんねんって感じですが。
(2) 運用費
運用費はRoute53とS3が毎月\$0.5ずつかかって年間\$12です。ドメイン代の\$12を合わせても年間\$24で運用できています。とても財布に優しいですね。
たぶん月100万アクセスくらいまではこんな感じの値段になると思います。
(3) 記事数
週一で記事を追加するので4 x 12 = 48になるはずですが、長期休暇等があって書いてない人もいるので37件でした。思ったより多くて満足しています。
HPの成果
一番大きな目的は、学科内の研究室配属の時に「うちの研究室はこんなアクティビティがあるよ」というのを紹介するというものでした。これは去年の研究室選択の時期に指導教員がみんなに見せていたので役割は果たせたと思います。
あと、うちの研究室に院試受けて入ろうという人の参考にもなったみたいです。
この1年の開発
以下はこの1年で行った開発に関する取り組みです。
- (1) Vue.jsのSPAからNuxtでのSSRへリプレイス
- (2) 毎週担当者をアサインするBotの稼働
- (3) 投稿前にインタラクティブに内容を確認できる
- (4) Algoliaでの記事検索
- (5) 指導教員に内緒でシークレットモードを追加
- (6) serverless slack botのバグ修正
そういえば、今でもちょくちょく指導教員から「ここ機能追加して欲しいです」みたいな要望があって興が乗った時にガリガリ作っているのですが、しばらく触っていなくてもすんなり触れる感じのコードになっていて(自分が書いたので当たり前といえば当たり前だけど)大変喜ばしい限りです。
(1) Nuxtへのリプレイス
上の記事の通り、最初はVue.jsによるSPAとして動かしていたのですが、以下の辛みを感じたので勢いに任せてNuxtへ置き換えました。
- 頭を使わずにSPAしてたからレスポンスが返ってくるまでの0.5秒くらい何も表示されない
- SPAだから記事ごとにOG設定できない
- 勢いだけで書いたからかなり雑でテストが書きにくい(リプレイスの後押しとなった要因)
書いて動かしてる感触なんですが、NuxtはプレーンなVue.jsで書くよりも適度な規約があってとても書きやすかったです。
なお、このNuxtアプリケーションについてもLambdaの上で動かしています。NuxtをLambda上で動かす仕組みはNuxt.js on AWS Lambda with Serverless Frameworkとほとんど同じ物を採用しました。
(2) 週次アサインBotの作成
研究室の仲間たち(合計20人くらい)で継続的に更新を続けていくために、週に一回担当者を決めて更新してもらうようにしました。この週一の担当者決めはSlack Botが担当します。
これもサーバレスで動いています。去年のre:InventでLambdaのRubyサポートが始まったので試してみたかったのでRubyで書きました。
(3) 投稿前の確認
ある日研究室で隣の席の人が「投稿時に確認画面が欲しい」と言ったのでガガっと実装したのがこの機能です。
こういう風に、Slack BotにSnipetとして送信するとプレビュー画像と共に「これ本当に投稿する?キャンセルする?」の2択を迫ってくるようにしました。
投稿プレビューの仕組みは擬似的なもので、実はプレビュー段階で本番環境にデータが作成されます。そしてPublishボタンを押すと作成済みデータの
published_atに現在時刻が代入されてニュース一覧で見られるようになり、Cancelボタンを押すとこのデータが削除されます。つまりプレビュー時はURL直打ちだと見える状態になっており、プレビューのスクリーンショットはここに直接アクセスして取得したものを返すようにしています。
ここで必要になったのが、任意のWebページのスクリーンショットを撮影してその画像を取得するという仕組みです。
スクリーンショット撮影部分
欲しかったのは「あるURLを渡すとそのサイトのスクリーンショットが返ってくる」機能だったので、作りました(asmsuechan/sshot)。
これもサーバレスで動かしています。ヘッドレスchromeを無理やりLambdaに押し込んでAPI Gateway経由で呼ぶような形式です。
以下のURLは公開されているもので、誰でもアクセスすることができます。あ、このままだとスクショは研究室のAWSアカウントのS3に保存されるので、保存されたくない方は自分で立てるかbase64オプション使うかで。
$ curl "https://vckvs9l162.execute-api.ap-northeast-1.amazonaws.com/production/screenshot?url=https://github.com/asmsuechan" {"screenshot":{"url":"https://s3-ap-northeast-1.amazonaws.com/sshot-images/kvd6ajor2hbprpb9.png"}}urlをパラメータに入れたcurlを投げるとそのサイトのスクリーンショットがアップロードされたS3のURLが返ってきます(このバケットは研究室のAWSアカウント上のものです)。また、base64パラメータをtrueに設定する事によってbase64にエンコードした画像を返すようにする事もできます。
また、設定ファイルをよしなにいじる事で自分のAWSアカウント上にデプロイすることもできます。
開発で一番大変だったのが日本語フォントへの対応で、かなり無理くりやって何とか対応しました。が、上の画像を見る通りフォントがダサいのでここもうちょっとどうにかならんかったんか・・・って感想です。
(4) Algoliaでの記事検索
Algolia使ってみたくて、なんとなく興が乗った時に記事検索機能を https://moriokalab.com/news に追加しました。誰が使うんだろう、って感じですが。。。
NuxtへのAlgoliaの導入は公式のexampleと公式ドキュメント以外特に参照せず実装できました。すごく簡単。Algoliaめちゃくちゃ速くてびっくりです。Algoliaすごい。
(5) 指導教員に内緒でシークレットモードを追加
トップページにある指導教員の顔を30回クリックするとシークレットモードが発動し、イカしたデザインになります。なお画面から元に戻す方法はありません。戻したい方は
LocalStorageでそれっぽいフラグをdeleteしてください。研究室のHP、指導教員には内緒で指導教員の顔を30回クリックしたらイカしたデザインになるようにした pic.twitter.com/kdxvheWfqh
— asmsuechan (@suenaga_ryota) May 23, 2019(6) serverless slack botのバグ修正
Slack Botはjohnagan/serverless-slackbotを元に作ったのですが、画像を2回以上連続でSlackにアップロードするとBotが落ちてしまうという問題がありました。最初は放置していたのですがあまりにも不便だったので原因を探したところserverless-slackbot側のバグだったので直してPRを送りました。
https://github.com/johnagan/serverless-slackbot/pull/3サーバレスで良かったこと・悪かったこと
良かったことは
- serverless frameworkを使うとコマンド1つで簡単にデプロイできる
- インフラのメンテコストがかからない
- 料金が安い
悪かったことは
- ローカル環境構築が大変
- DB選択が悩ましい
- 初回アクセスが遅い
1年経ちましたが、あんまりずっと面倒を見続けるようなシステムではないのでサーバレスを選択して良かったな、と思っています。
運用を振り返る
また、更新操作をSlackで完結させることで、CMSと比べて誰でも手軽に更新できる仕組みとなったのが良かったです。CMSだとどうしてもID/Passの問題があって、ここの管理が面倒でだんだん更新されなくなる未来が見えていました。
また、サーバレスな構成にしてサーバーサイドのインフラの面倒を見なくても動き続けるようにしたので「管理/運用したくない」という目標は達成したと思います。
更新を続ける仕組み
研究室の愉快な仲間たちみんなで更新していくための仕組みとして、毎週月曜日の18時にその週の更新担当者をアサインするCronを動かすようにしました。
これ最初は「みんな無視するんじゃね」って思ってたんですが案外そんなことはなく、当てられた人は結構マジメに更新してくれています。
打ち捨てられないための仕組み
このようなHPというのは作ったっきりで打ち捨てられてしまうことがままあります。これはだいたいの場合「めんどくさい」という気持ちと「優先度が低い」という状況のどちらか、またはどちらもが原因になります。この辺りで意識したことについて運用面と開発面の両方で書きます。
運用面
Botに指名されているのにも関わらずHPの更新をしていない人には指導教員が面談中に「書いてくれ」と言っていたことで、(その人の中での)優先度をあげていました。とにかくあたった人に、書くまでpingを送るという戦法ですね。
なるべく記事のハードルを下げるというのも気をつけたことです。目的は「アクティビティがあることを示すこと」なので内容のクオリティはそもそも問うていません。クオリティは必要になってから考えます。
あ、あと、こういうのはやる気がありすぎても飽きて打ち捨てられてしまう事があるのでほどほどのやる気で取り組んだというのも良かったと思います。指導教員に「これ欲しいから作って」と言われた時に「興が乗ったら作ります」と言って数カ月後ガリガリ作り出す、みたいな感じのゆるさ。
開発面
開発上では研究室のGitHubオーガナイゼーションを作りそこに全てのコードを置いてどこからでもコマンド1つでデプロイできるような仕組みを最初から作り、デプロイがめんどくさくてコードいじる気がなくなるという状況を緩和しました。
そしてコードも最初から予めある程度の決まった枠組みを作り、何か機能を追加する時には既存のものを見ながら思考停止でも基本はコピペで動くものができるようにすることで「コードの書き始めのだるさ、めんどくささ」を軽減しました。既存システムへの機能追加って、どうしても「壊すかもしれない」という気持ちがあって最初は億劫なものなので。最初さえ頭を使わずサクッとできればあとは流れに乗って書けるはずです。
現状の問題点
去年も同じこと言ってたじゃねえか!って話もありますが、今の問題点です。
(1) ローカル環境が適当
インフラのローカル環境が全然構築できていなくて、毎回デプロイしてテスト用Slackチャンネルで直接いじるという形にしていて非常にめんどくさいです。いい感じにDocker環境立ててやるとうまくできるのでしょうが、そこまでやる体力がなくてそのままにしています・・・
(2) 後任の不在
研究室は人間の流動性が高く、1人の学生がずっと面倒を見続けるわけにはいきません。このHPももちろんそうなのですが、指導教員と話していてこれから先Web人材が研究室に入ってきて自分の残したコードを読み保守運用してくれる人が現れる確率は低そうという結論になったので、卒業後はたまに報酬(うまい焼肉)を貰いながら私が運用していくという感じの話をしています。
(3) LambdaでSSRすると初回アクセス遅い
Lambdaがcold standbyしている時にアクセスすると表示に5秒くらいかかってしまうという残念な問題があります・・・解決策は10分に1回だかヘルスチェック回して常にHot standbyな状態にしてやることです。そんなに難しくはないと思うのですが気持ちが乗らないので手をつけていません。
(4) UIの改善は特になし
やはり仕事のコードではないのでUI上の細かい部分はおざなりになりがちです。どこかであまり良くない部分を改善したいとは思っているのですが後回しにしています。もっとカッコよくしていきたい。
まとめ
この手のHPの目的はだいたい「自分たちの組織がマトモに活動していることを対外的にアピールして印象を悪くしないこと」であることが多いので、作って公開することより公開して更新し続けることがよっぽど重要だと思います。ですのでここで書いた継続する仕組みや打ち捨てられないための仕組みというのが、私と似たような状況に置かれた人の助けになれば幸いです。



- 投稿日:2019-10-23T12:24:48+09:00
AWSのDNS障害でDebianパッケージがインストールできなかった話
やろうとしたこと
Dockerファイルをビルドしようとしていました。
FROM php:7.1.11-fpm WORKDIR /var/local RUN apt-get update && apt-get install -y \ apt-transport-https \ lsb-release \ ca-certificates \ wget ...エラー発生
Step 3/13 : RUN apt-get update && apt-get install -y apt-transport-https lsb-release ca-certificates wget ---> Running in 50a658d96e1f Get:1 http://security.debian.org jessie/updates InRelease [44.9 kB] Err http://deb.debian.org jessie InRelease Err http://deb.debian.org jessie-updates InRelease Err http://deb.debian.org jessie Release.gpg Could not resolve 'cdn-fastly.deb.debian.org' Err http://deb.debian.org jessie-updates Release.gpg Could not resolve 'cdn-fastly.deb.debian.org' Get:2 http://security.debian.org jessie/updates/main amd64 Packages [893 kB] Fetched 938 kB in 4s (192 kB/s) Reading package lists... W: Failed to fetch http://deb.debian.org/debian/dists/jessie/InRelease W: Failed to fetch http://deb.debian.org/debian/dists/jessie-updates/InRelease W: Failed to fetch http://deb.debian.org/debian/dists/jessie/Release.gpg Could not resolve 'cdn-fastly.deb.debian.org' W: Failed to fetch http://deb.debian.org/debian/dists/jessie-updates/Release.gpg Could not resolve 'cdn-fastly.deb.debian.org' W: Some index files failed to download. They have been ignored, or old ones used instead. Reading package lists... Building dependency tree... Reading state information... Package lsb-release is not available, but is referred to by another package. This may mean that the package is missing, has been obsoleted, or is only available from another source E: Package 'lsb-release' has no installation candidate The command '/bin/sh -c apt-get update && apt-get install -y apt-transport-https lsb-release ca-certificates wget' returned a non-zero code: 100 make: *** [build] Error 100原因調査
deb.debian.orgのサーバーが死んだのかな?と思いきや、エラーメッセージに下記を発見。
Could not resolve 'deb.debian.org'ネームサーバー変わったのかなと思っていたら、社内のエンジニアからSlackが飛んできました。
AWSでDNS周りの障害が起きていたみたいです。https://www.theregister.co.uk/2019/10/22/aws_dns_ddos/
その障害によって、deb.debian.orgの名前解決ができず、パッケージのダウンロードができなくなっていたんですね。
障害復旧後
下記のステータスを、AWSで確認しました。
[RESOLVED] Intermittent DNS Resolution Errors Between 10:30 AM and 6:30 PM PDT, we experienced intermittent errors with resolution of some AWS DNS names. Beginning at 5:16 PM, a very small number of specific DNS names experienced a higher error rate. These issues have been resolved.その後再ビルドすると、無事にdebianパッケージもインストールされ、ビルドできました!
考察
おそらくdeb.debian.orgはRoute53あたりを使っているんでしょうか。
今後debianパッケージ取得の際に名前解決関係のエラーが出たら、AWSの障害を疑ってみることも一つの手ですね。
- 投稿日:2019-10-23T12:23:52+09:00
GCPのGCRとAWSのECR併用時に no basic auth credentials エラー
環境
- MacOS
- docker desktop community 2.1.0.1(37199) stable
- aws-cli/1.16.166 Python/2.7.15 Darwin/18.7.0 botocore/1.12.156
事象
以下のコマンドでECRにログインする。
$ $(aws ecr get-login --no-include-email --region ap-northeast-1)そして、docker buildしようとすると以下のようなエラーメッセージが出た。
no basic auth credentials原因
結論から言うと、その前にGCPのGCRにログインしていたことが原因だった。
~/.docker/config.jsonの中身を見ると、以下のようにECRとGCRの設定が混在していた。{ "auths": { "xxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com": {}, "asia.gcr.io": {}, "eu.gcr.io": {}, "gcr.io": {}, "https://asia.gcr.io": {}, "https://eu.gcr.io": {}, "https://gcr.io": {}, "https://marketplace.gcr.io": {}, "https://staging-k8s.gcr.io": {}, "https://us.gcr.io": {}, "marketplace.gcr.io": {}, "staging-k8s.gcr.io": {}, "us.gcr.io": {} }, "HttpHeaders": { "User-Agent": "Docker-Client/19.03.1 (darwin)" }, "credsStore": "desktop", "credHelpers": { "asia.gcr.io": "gcloud", "eu.gcr.io": "gcloud", "gcr.io": "gcloud", "marketplace.gcr.io": "gcloud", "staging-k8s.gcr.io": "gcloud", "us.gcr.io": "gcloud" } }そこで
~/.docker/config.jsonを削除した後、再度$(aws ecr get-login --no-include-email --region ap-northeast-1)によりログインするとうまく行った。うまくいったときの
~/.docker/config.jsonは以下のようであった{ "auths": { "xxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com": {} }, "HttpHeaders": { "User-Agent": "Docker-Client/19.03.1 (darwin)" }, "credsStore": "osxkeychain" }もっとスマートな回避方法はあると思いますが、分かり次第追記します。
一旦内容共有まで。
- 投稿日:2019-10-23T11:52:47+09:00
【AWS】決定版!最速でpython3.7仮想環境を1から構築
はじめに
今回初めてVPCとEC2を触り、python3.7仮想環境を作成するところまで実施したため、皆さんにナレッジを共有します。(全て無料枠内です。)
ちなみにアーキテクトは以下です。超絶シンプル。
アジェンダ
- VPC作成&設定
- EC2作成&設定
- EC2にPython3.7仮想環境構築
1. VPC作成&設定
大まかな流れとしては、以下です。
①VPC作成
②VPC内にパブリックサブネットを作成
③インターネットゲートウェイを作成し、VPCに結びつける
④ルートテーブルを作成し、パブリックサブネットに割り当て
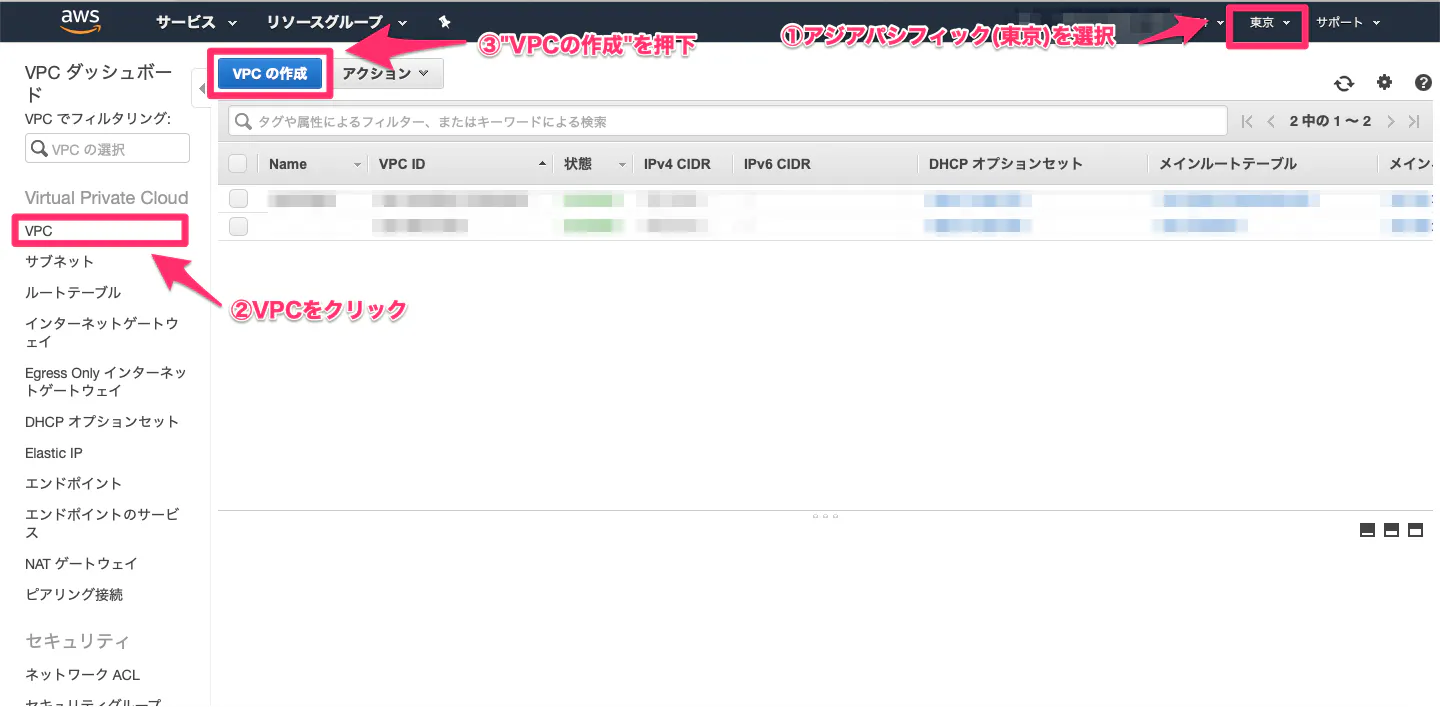
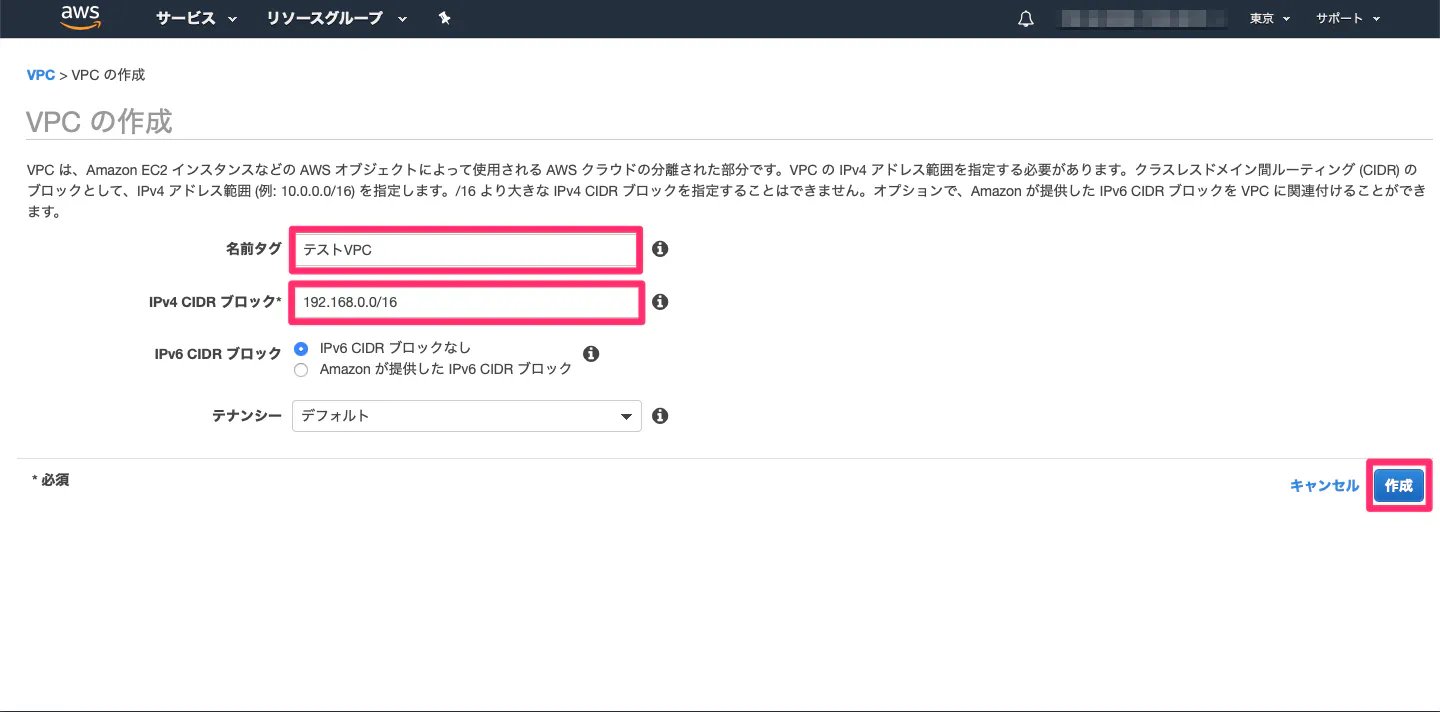
⑤ルートテーブルのデフォルトゲートウェイを、インターネットゲートウェイに設定①VPC作成
・VPC(Virtual Private Cloud)とは?
AWS上に作るプライベートなネットワーク環境。(1)AWSマネジメントコンソールからVPCを開いて、以下の手順を実施。
(2)以下を入力。
項目 値 名前タグ 任意の名前 IPv4 CIDR ブロック 192.168.0.0/16(プライベートIPアドレス1なら他でもOK) IPv6 CIDR ブロック デフォルト テナンシー デフォルト
(3)完成!!
②VPC内にパブリックサブネットを作成
・サブネットとは?
ネットワークをさらに分割したネットワークのこと。(1)以下の手順を実施。
(2)サブネットのCIDRブロック等を入力。以下を参考。
項目 値 名前タグ 任意の名前 VPC 先ほど作成したVPC アベイラビリティーゾーン デフォルト IPv4 CIDR ブロック 192.168.1.0/24(VPCのIPアドレスを分割した値であればOK)
(3)完成!!
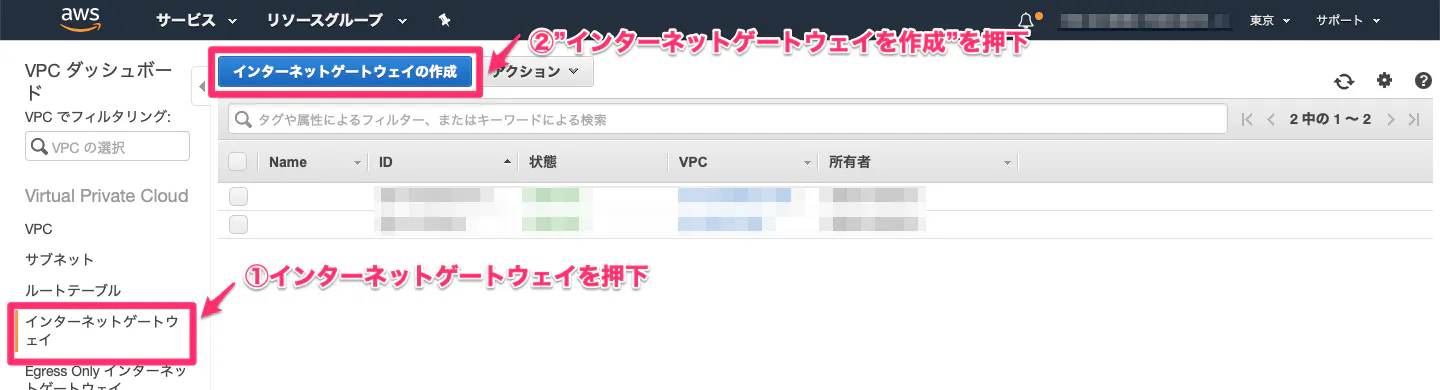
③インターネットゲートウェイを作成し、VPCに結びつける
・インターネットゲートウェイとは?
VPC内のインスタンスとインターネットとの間の通信を可能にするVPCのコンポーネント。(1)インターネットゲートウェイを作成。
(2)インターネットゲートウェイをVPCに結びつける。
(3)完成!!
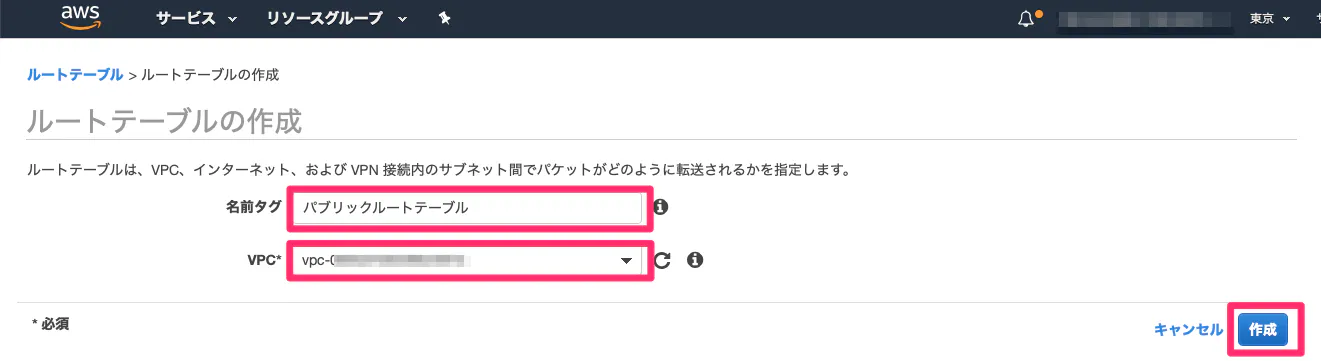
④ルートテーブルを作成し、パブリックサブネットに割り当てる。
・ルートテーブルとは?
通信をどこに流すかを定義するための情報。AWSではルートテーブルを各サブネットに関連付けする。サブネットにはデフォルトで、VPCのデフォルトのルートテーブルのみ適用されている。(今回では、192.168.0.0/16のみ送信可能の状態。)
そのため、ここではインターネットゲートウェイにパケットを送信するように設定する。(1)VPCにルートテーブルを作成。
項目 値 名前タグ 任意の名前 VPC 先ほど作成したVPC
(2)ルートテーブルをパブリックサブネットに割り当てる。
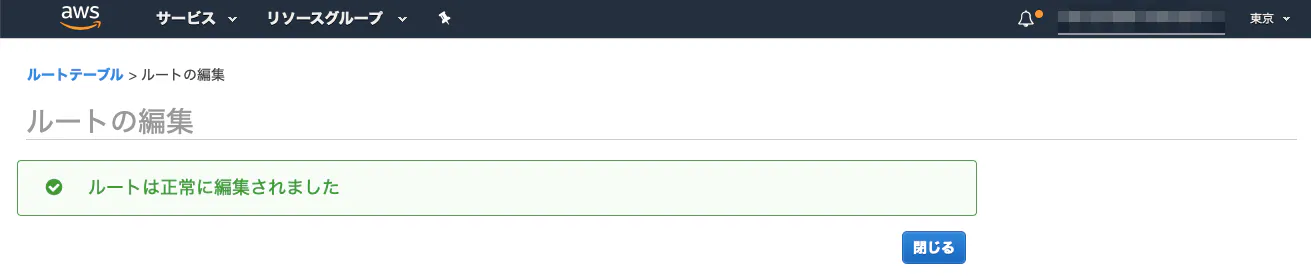
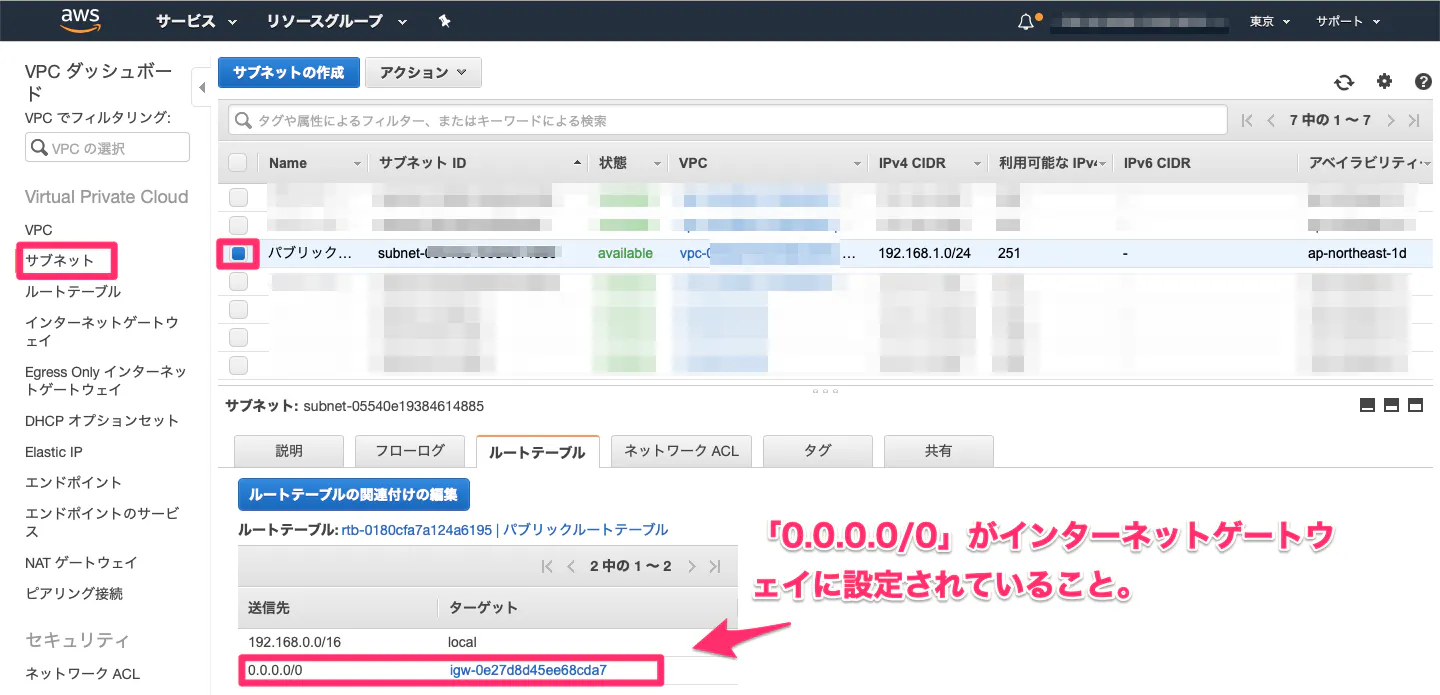
⑤ルートテーブルのデフォルトゲートウェイを、インターネットゲートウェイに設定
・デフォルトゲートウェイとは?
ネットワークから外部のネットワークに接続する際、通信の出入り口となるもの。(1)ルートテーブルのルートを編集。
(2)送信先に全てのIPアドレス範囲を示す「0.0.0.0/0」、ターゲットにインターネットゲートウェイ(igw-XXX)を指定。
(3)完成!!
2. EC2作成&設定
大まかな流れとしては、以下です。
①AMIを選択
②インスタンスタイプを選択
③インスタンスの詳細情報を設定
④ストレージを設定
⑤インスタンスの名前付け
⑥セキュリティグループの設定
⑦設定を確認し、EC2ログインするための秘密鍵をダウンロード①AMIを選択
・AMIとは?
ソフトウェア構成(オペレーティングシステム、アプリケーションサーバー、アプリケーションなど)を記録したテンプレート。AWSマネジメントコンソールからEC2を開いて、以下の手順を実施。
今回はLinux2を選択。
②インスタンスタイプを選択
③インスタンスの詳細情報を設定
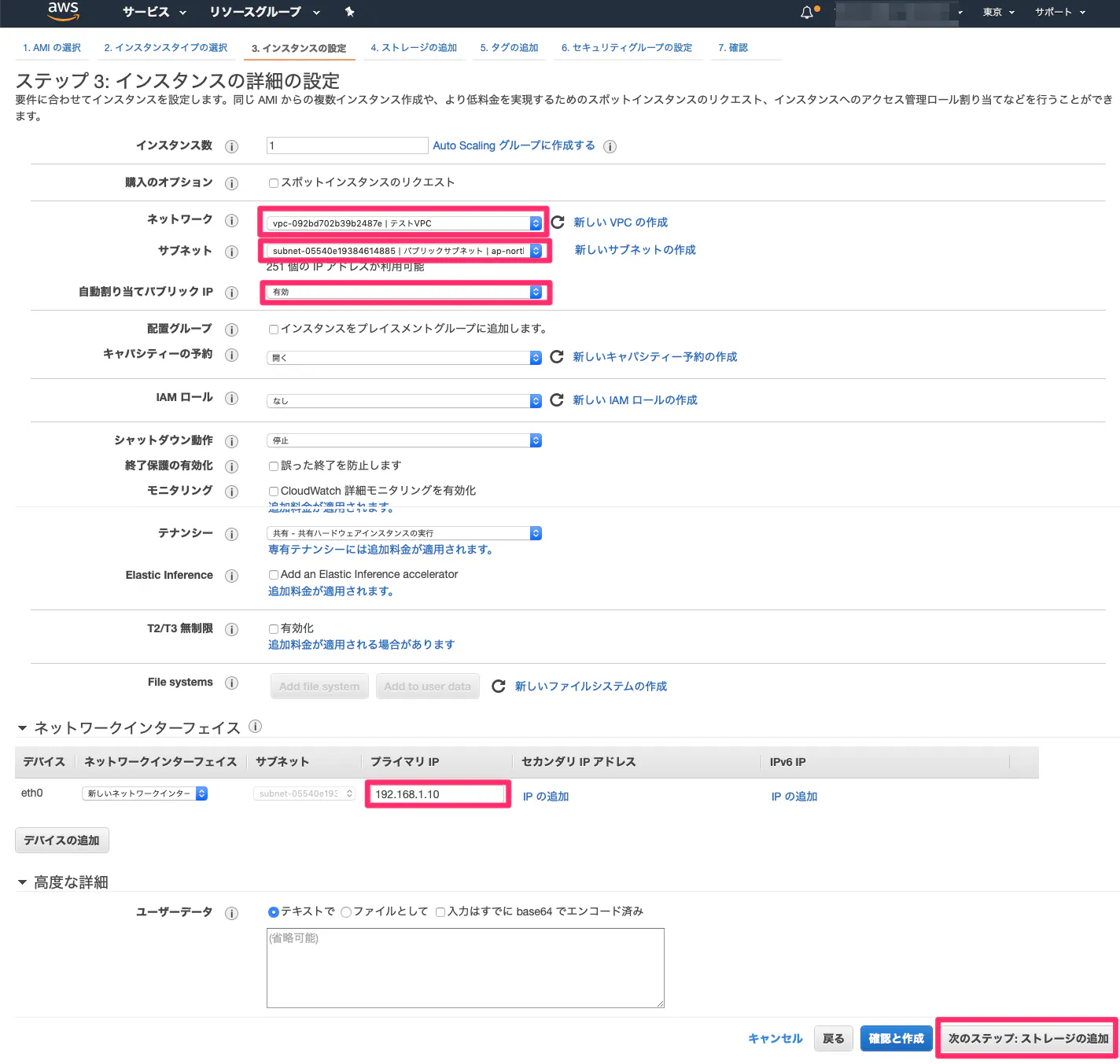
以下の項目を入力。残りの項目はデフォルトのままでOK。
項目 値 ネットワーク 作成したVPC サブネット 作成したパブリックサブネット 自動割り当てパブリックIP 有効化2 プライマリIP(→プライベートIPアドレス) 192.168.1.10
④ストレージを設定
デフォルトのままで何も変更しない。
⑤インスタンスの名前付け
任意のキー名/値でOK。
⑥セキュリティグループの設定
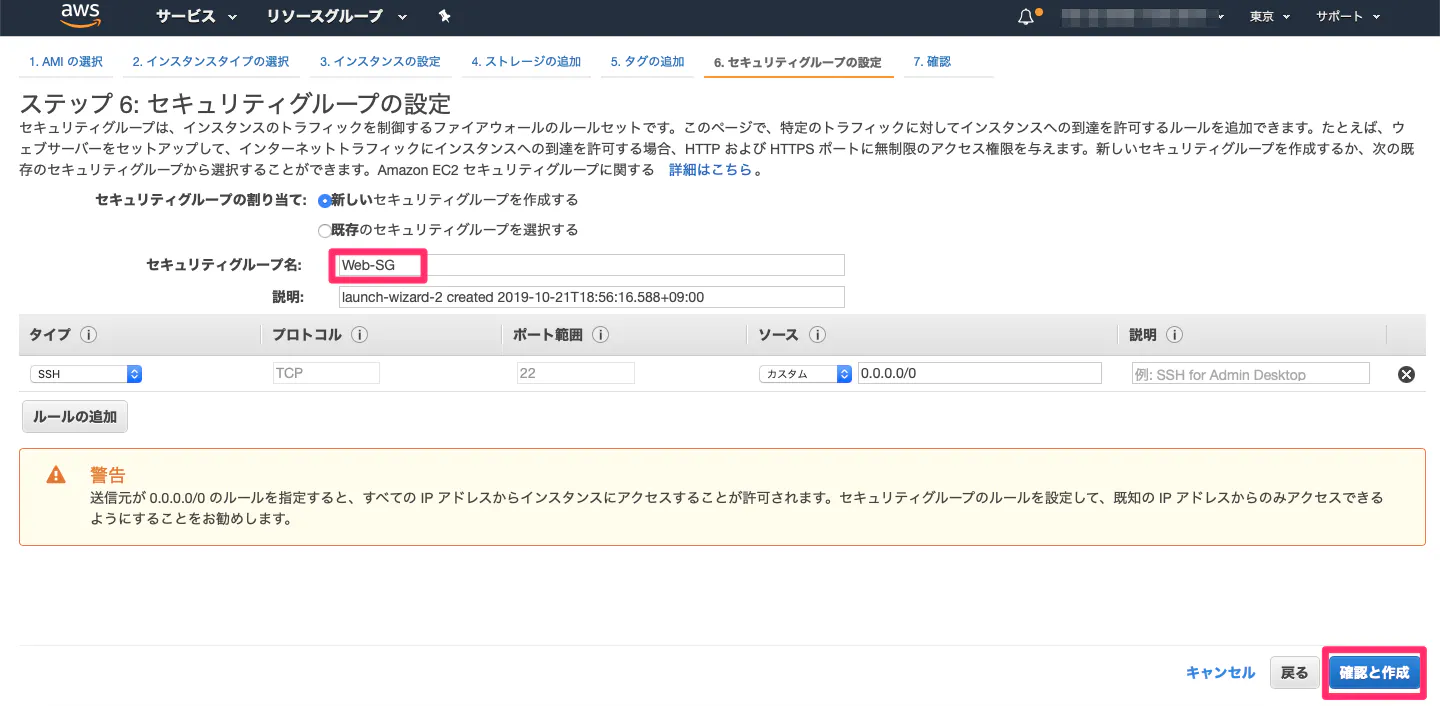
・セキュリティグループとは?
所謂、ファイアウォールのこと。デフォルトでは、SSH(22)というプロトコルでどこからでも接続可能になっている。
SSHは後続でPython環境構築する際、PCからEC2にアクセスする時に用いる。任意のセキュリティグループ名でOK。
⑦設定を確認し、EC2ログインするための秘密鍵をダウンロード
任意のキーペア名でOK。秘密鍵は一度失くすと再発行不可のため大切に保管する。
1度秘密鍵を作ると、他にEC2を立ち上げる時も共有で利用可能。
設定完了!!
3. Python3.7仮想環境作成
Amazon Linux2ではデフォルトで python2.7系がインストールされていますが、
今回はpython3.7の仮想環境を作成していきます。大まかな流れとしては、以下です。
①秘密鍵を使い、AWSのEC2にSSH接続
②環境構築に必要なパッケージをインストール
③pyenvのインストール
④pyenv-virtualenvのインストール
⑤ライブラリをインストール(任意)①秘密鍵を使い、AWSのEC2にSSH接続
まずはEC2のパブリックIPアドレスを確認。
そしてsshコマンドで接続する。
//1.秘密鍵をホームユーザー配下に格納 $ mv test-my-key.pem.txt ~/.ssh //2.秘密鍵の権限変更 $ chmod 400 ~/.ssh/test-my-key.pem.txt //3.sshでEC2に接続 $ sudo ssh -i ~/.ssh/test-my-key.pem.txt ec2-user@EC2のパブリックIPアドレスAmazon Linux2のデフォルトのユーザー名は「ec2-user」のため、ec2-userを指定。
sshに成功したら以下が表示される。$ sudo ssh -i ~/.ssh/test-my-key.pem.txt ec2-user@EC2のパブリックIPアドレス __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 15 package(s) needed for security, out of 31 available Run "sudo yum update" to apply all updates. [ec2-user@ip-192-168-1-10 ~]$②環境構築に必要なパッケージをインストール
コンパイラ、暗号化、圧縮、コマンドラインなどのライブラリをインストールします。
$ sudo yum -y install gcc gcc-c++ make git openssl-devel bzip2-devel zlib-devel readline-devel sqlite-devel libffi-devel③pyenvのインストール
・pyenvとは?
Pythonのバージョン管理を行なうコマンドラインツールで、複数のバージョンのPythonのインストールや切り替えが容易に可能。Gitからインストール。
$ sudo git clone https://github.com/yyuu/pyenv.git /usr/bin/.pyenv $ sudo mkdir /usr/bin/.pyenv/shims $ sudo mkdir /usr/bin/.pyenv/versions $ sudo chown -R ec2-user:ec2-user /usr/bin/.pyenv環境変数の設定を行う。
$ vi ~/.bashrc ---------------------以下を追記 export PYENV_ROOT="/usr/bin/.pyenv" export PATH=${PYENV_ROOT}/bin:$PATH eval "$(pyenv init -)" ----------------------------- //設定変更を反映 $ source ~/.bashrcpython3.7.3のインストール。
//インストール可能なバージョンを確認 $ pyenv install --list //今回は3.7.3をインストール $ pyenv install 3.7.3 //インストール済みのバージョン一覧 $ pyenv versions //pythonのバージョン確認。インストールしても2.7のまま。 $ python -V Python 2.7.16ちなみに以下で、EC2で利用するデフォルトのバージョンの設定が可能。
//3.7.3バージョンへ切り替え $ pyenv global 3.7.3④pyenv-virtualenvのインストール
・pyenv-virtualenvとは?
分離されたPython環境を作成するツール。環境ごとに違うパッケージを入れることが可能。Gitからインストール。
$ git clone https://github.com/yyuu/pyenv-virtualenv.git /usr/bin/.pyenv/plugins/pyenv-virtualenv環境変数の設定を行う。
$ vi ~/.bashrc ---------------------以下を追記 eval "$(pyenv virtualenv-init -)" ----------------------------- //設定変更を反映 $ source ~/.bashrcpython3.7.3仮想環境を作成
//バージョンpython3.7.3の仮想環境(名前:python3.7)を作成 $ pyenv virtualenv 3.7.3 python3.7 //カレントディレクトリにpython3.7.3の仮想環境を適用 $ pyenv local python3.7 //バージョン確認 (python3.7)$ python --version Python 3.7.3 //仮想環境を設定していないディレクトリに移動すると、EC2デフォルトのバージョン (python3.7)$ cd ~ $ python --version Python 2.7.16ちなみに仮想環境の削除は以下。
$ pyenv uninstall python3.7⑤ライブラリをインストール(任意)
//EC2のデフォルトではpipのバージョンが古いためアップグレード $ pip install --upgrade pip //任意のパッケージをインストール $ pip3 install numpy $ pip3 install sklearn //ライブラリの格納先確認 $ pip3 show numpy終わりに
基本的かつ単純なアーキテクトなので、まだVPCとEC2に触ってみたことがない人はぜひ挑戦してみて下さい。
このアーキテクトに、プライベートサブネットを追加してEC2にDBをインストールするなど、色々と自分でカスタマイズもできます。
















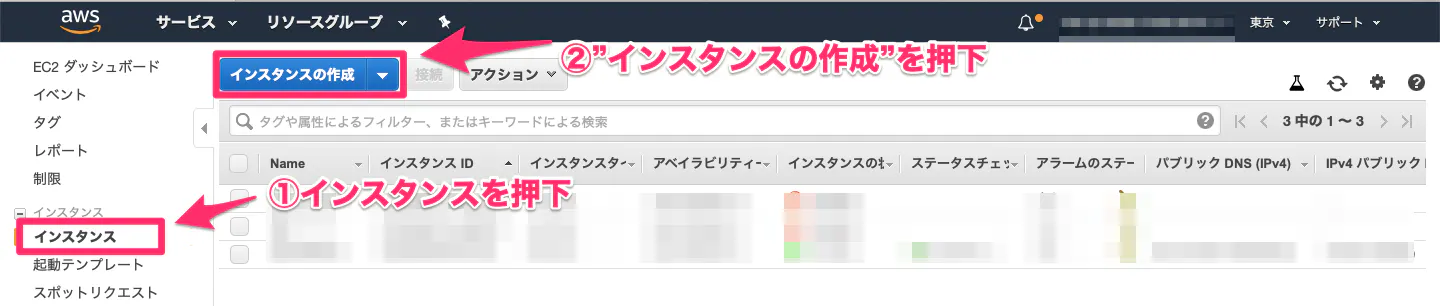






- 投稿日:2019-10-23T10:52:06+09:00
SERPOSCOPEのネットワークエラー解消手順(ERROR_NETWORK)
無料の検索順位取得ツールをAWS(EC2)上で運用しはじめました。
サーバー上で運用できるため、PCを開いていなくても検索順位の定時実行ができることは魅力的なのですが、いくつかのエラーの壁を超える必要があります。本記事では、ネットワークエラーの解消手順について解説します。
環境
- SERPOSCOPE 2.10.0
- AWS EC2
エラーの確認方法
トップページを確認すると、検索がうまくいっていませんね。(Failure)
検索順位がうまくいっていない時はエラーを確認します。
ログよりエラーの種類を確認できます。
トップページ > Logs
私が遭遇した主なエラーは下記の2種類です。
- ネットワークエラーなら
ERROR_NETWORK- キャプチャ認証エラーなら
ERROR CAPTCHA NO SOLVERネットワークエラーの解決方法
Githubにネットワークエラーの解決方法の記載がありました。
These errors are due to Google restrictions / captchas. Solutions are : increase the pause between request, add proxies, add credit to all captcha solver API because they are always overloaded so serposcope can fallback on an API which work
https://github.com/serphacker/serposcope/issues/180#issuecomment-381414112ざっくりと日本語に訳すと、
ネットワークエラーはGoogleの規制によるもので、解決策は下記の通り
- リクエストの待ち時間を増やす
- プロキシを追加する
- 全てのキャプチャ認証のクレジットを追加するとのことです。
それぞれの解決策を見ていきます。
リクエストの待ち時間を増やす
ADMIN > GENERAL > NETWORKING OPTIONS > Pause
リクエストの待ち時間とは、キーワード1個あたりのGoogleの検索順位を取得するための時間のことで、元々
MIN 120, MAX 130でしたが増やしました。プロキシを追加する
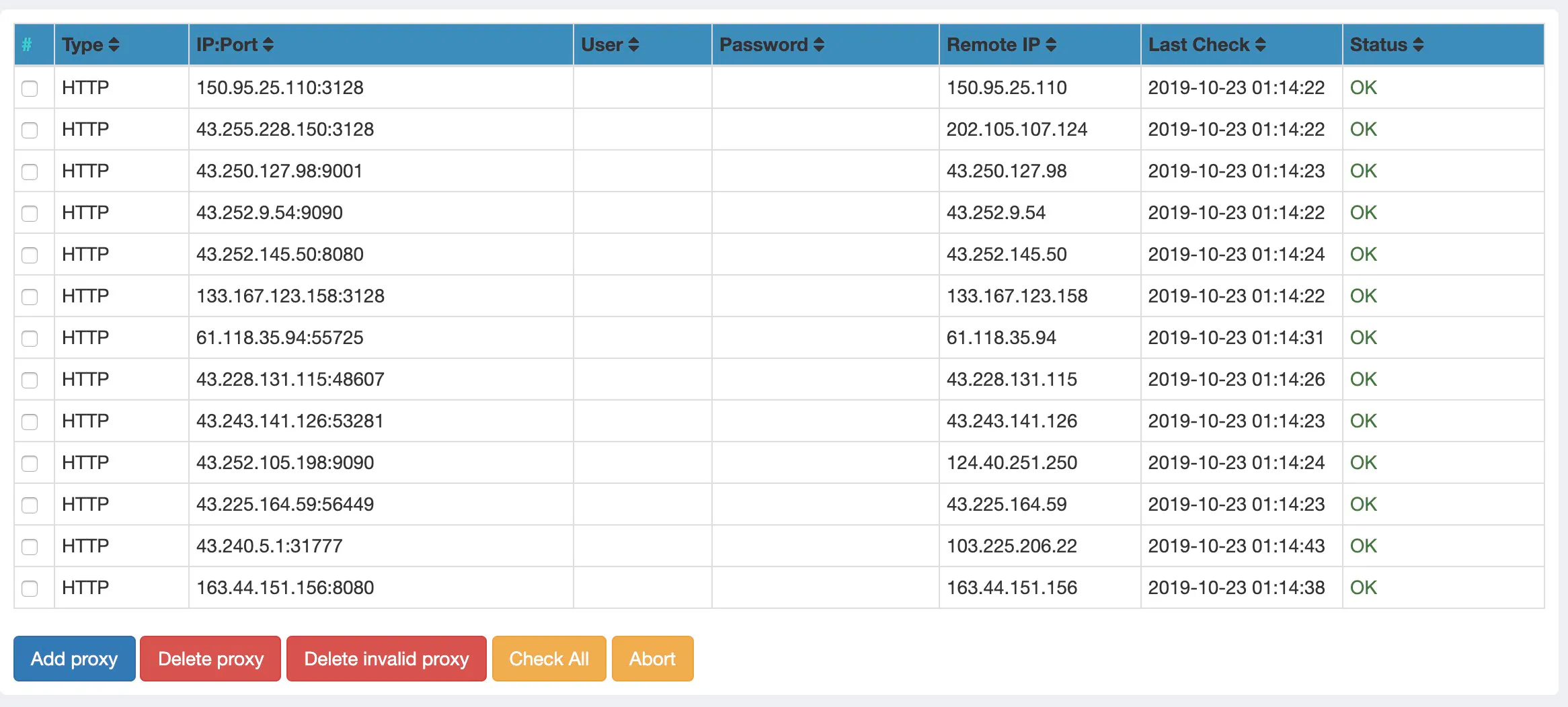
運用している、AWSのサーバーではなく代理のサーバーから検索順位を取得できるように代理(プロキシ)サーバーを追加します。
ADMIN > PROXIES > Add proxy無料のhttpプロキシサーバーを利用する場合はログインユーザー名やパスワードは不要なので、
http proxy : http#127.0.0.1#80の型で入力すれば良いです。
無料のプロキシFREE PROXY LISTSを調べ追加します。(下記は追加例)
追加できましたね。
全てのキャプチャ認証のクレジットを追加する
意外にもキャプチャ認証のクレジットがネットワークエラーと関係しているようですね。
私は下記の記事を参考に、AntiCaptchaのみ導入しました。まとめ
3点全ての対策を施し、様子を見たいと思います。




- 投稿日:2019-10-23T09:50:21+09:00
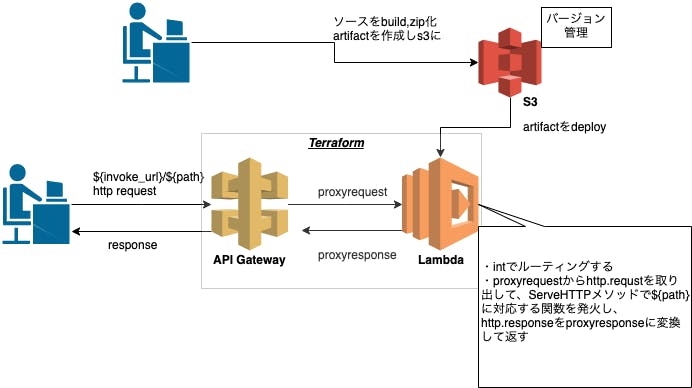
Lambda proxy integration×Go(echo)×Terraformでお手軽Web API(サーバレス)
はじめに
サーバレスで手軽にWeb APIを立てたい場合、API Gatewayのproxy integrationとlambdaアプリケーションソースでのルーティングでこんなに簡単にお安く構築できるんだな〜と感心してしまったのでそのご紹介と、そのリソース群のTerraform moduleを作ってTerraform Registryに公開したのでその内容の紹介で記事を書いてみました。
(しかも最近VPC Lambdaのコールドスタートが大幅に改善されたばかり -> [発表] Lambda 関数が VPC 環境で改善されます | Amazon Web Services ブログ )lambda proxy integrationのmodule,S3のartifact指定できるやつなかったので作って、Terraform Registryに公開した?https://t.co/jJxfruBDQ6
— nari@BOOTHで好評発売中「GoとAWS CDKで作る本格SlackBot入門」 (@fukubaka0825) October 22, 2019後はついでに、Terraform入門資料(v0.12.0対応) ~基本知識から設計や運用、知っておくべきtipsまで~ - Qiitaでは詳しく書けなかったlambdaリソースのアプリとインフラのデプロイの疎結合化についてもSampleを紹介しています。
対象
- AWS Lambdaを使ってWeb API立ててみたいなと思っていた方
- AWS Lambdaリソースのアプリとインフラのデプロイの疎結合化のサンプルに興味がある方
前提
- 標準のnet/httpを用いたルーティングでも可能ですが、今回はフレームワークとしてechoを使用しています
- Lambda proxy integrationとは? -> API Gateway の Lambda プロキシ統合をセットアップする - Amazon API Gateway
- 今回作成したterraformのmoduleはこちら
開発環境
- Terraform v0.12.6
- Go v1.12.4
システム全体像
リポジトリ構成
├── Makefile ├── README.md ├── go.mod ├── go.sum ├── main.tf ├── modules │ ├── iam_role │ │ ├── main.tf │ │ ├── outputs.tf │ │ └── valiables.tf │ └── sg │ ├── main.tf │ ├── outputs.tf │ └── valiables.tf ├── outputs.tf └── source └── main.goまた、サンプルコードは、公開したmoduleのexampleとして公開しています
terraform-aws-lambda-proxy-integration/go1.x_examples at master · fukubaka0825/terraform-aws-lambda-proxy-integration · GitHubTerraformのコード紹介
main.tfmodule "sample_api"{ source = "fukubaka0825/lambda-proxy-integration/aws" //❶ version = "1.0.2" apigw_name = "sample-api" function_name = "sample-api" lambda_role = module.lambda_role.iam_role_arn // The repo's name and object key where source code artifact exists s3_bucket = data.terraform_remote_state.storage.outputs.s3_serverless_app_bucket.name s3_key = "lambda/sample.zip" // If you want to use vpc lambda,required security_group_ids = [module.http_sg.security_group_id] //❷ subnet_ids = module.vpc.app_subnets }❶ 今回API proxy integration+S3のartifactをlambdaのソースとして指定できるmoduleを作成したので、そちらを指定しています(Terraform Registry)
❷ security_group_idsとsubnet_idsは、VPC lambaのモードならば指定します。Goのコード紹介
main.gopackage main import ( "github.com/labstack/echo" "log" "context" "net/http" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" echolamda"github.com/awslabs/aws-lambda-go-api-proxy/echo" ) var echoLambda *echolamda.EchoLambda //❶ func init() { // stdout and stderr are sent to AWS CloudWatch Logs log.Printf("Echo cold start") e := echo.New() //❷ //ここでルーティング e.GET("/ping", func(c echo.Context) error{ return c.NoContent(http.StatusNoContent) }) echoLambda = echolamda.New(e) } func Handler(ctx context.Context, req events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { // If no name is provided in the HTTP request body, throw an error // 中でServeHTTPを叩いている return echoLambda.ProxyWithContext(ctx, req) //❸ } func main() { lambda.Start(Handler) }❶ コールドスタートの関係上、globalにechoLambdaを宣言するのがセオリーっぽいです。
❷ initでroutingを設定します。ここではechoを使っていますが、もちろん自由なフレームワークなりnet/httpなりで設定可能です。
❸ 本来ならば、proxyrequestからhttp.requstを取り出して、ServeHTTPメソッドで${path}に対応する関数を発火し、http.responseをproxyresponseに変換して返す処理を自前で書く必要がありますが、GitHub - awslabs/aws-lambda-go-api-proxy: lambda-go-api-proxy makes it easy to port APIs written with Go frameworks such as Gin (https://gin-gonic.github.io/gin/ ) to AWS Lambda and Amazon API Gateway.という素晴らしいawslabsが提供しているmoduleで同じようなことをやってくれるものがあるのでそれを利用しています。(なんとgin,echo,net/httpなど主要なパッケージには対応してくれている、最高)lambdaリソースのアプリとインフラのデプロイを疎結合にする運用
Terraform入門資料(v0.12.0対応) ~基本知識から設計や運用、知っておくべきtipsまで~ - Qiitaの3.4 lambdaリソースを扱う場合のインフラとアプリの密結合問題でも扱いましたが、Terraformのみでデプロイを完結させるとインフラとアプリが密結合になってしまいます。その解消法の具体例の話をここではしようと思います。
Makefileを作成する
MakefileLAMDA_SOURRE_REPO=serverless-app LAMDA_SOURRE_KEY=lambda/sample.zip LAMDA_SOURCE_PATH=s3://${LAMDA_SOURRE_REPO}/${LAMDA_SOURRE_KEY} deploy_dummy_code: //❶ aws s3 cp .build/dummy.zip ${LAMDA_SOURCE_PATH} build_update: //❷ GOOS=linux GOARCH=amd64 go build -o .build/main source/main.go cd .build && zip -r sample.zip ./ aws s3 cp .build/sample.zip ${LAMDA_SOURCE_PATH} aws lambda update-function-code --function-name sample-search-api --s3-bucket ${LAMDA_SOURRE_REPO} --s3-key ${LAMDA_SOURRE_KEY} echo 'Success to lambda update!'❶ dummyのzipを
LAMDA_SOURCE_PATHにあげる処理をdeploy_dummy_codeコマンドに仕込んでいます。
❷ 本当のlambdaソースのコードを、buildしてzipにし、LAMDA_SOURCE_PATHにあげて、aws lambda update-function-codeコマンドでlambdaのソースをアップデートする処理をbuild_updateコマンドに仕込んでいます。Makefileを用いたデプロイ運用
// Put dummy code into S3 repo. make deploy_dummy_code //❶ // deploy infra terraform init //❷ terraform plan terraform apply // deploy app(lambda) make build_update //❸❶ まず
deploy_dummy_codeコマンドで、S3にdummyのコードをあげます。
❷ ❶のコードを参照させる形で、lambdaのインフラ部分をデプロイします。
❸ 最後に、build_updateで本当のlambdaのアプリ部分をデプロイします。終わりに
VPC lambdaはコールドスタートの改善によって、レスポンスの要件が非常にシビアでないWeb APIの構築ツールとして、かなり魅了的なものになってきたと思います。
データソースとのつなぎこみは、RDSのようにスケールしづらく、コネクション制限があるものとのやりとりはまだまだ使い勝手が悪い(internalなAPI経由にすれば解決しますが)ですが、スケールしやすい分散型のデータソース(DynamoDB、ElasticSearch,redis)とのやりとりなら全然使っていけそうだなという印象です。
また、この記事で使ったmoduleは、初めてPublic ModuleをTerraform Registry公開してみましたが、これからもどんどん公開できるものは公開していきたいと思います。
参考文献