- 投稿日:2019-10-23T23:05:53+09:00
golang vscodeのデバッグで変数をのぞいたときに値が省略されているやつ
... +4160 more じゃねー!
vscでブレークポイントを貼っても変数の値が省略されてしまい、内容が最後まで見られませんでした。
- jsonとかだと全体をみたいよね
- 省略されても嬉しくないよね
それで解決方法をggったけどなかなか見つからなかったのでメモっときます。
BEFORE
settings.jsonを編集
「 // ← これ」のところを編集
settings.json{ "go.delveConfig": { "dlvLoadConfig": { "followPointers": true, "maxVariableRecurse": 1, "maxStringLen": 10000, // ← これ "maxArrayValues": 500, "maxStructFields": -1 } } }AFTER
他の
dlvLoadConfigの項目については以下のリンクからどうぞ
https://github.com/Microsoft/vscode-go/wiki/Debugging-Go-code-using-VS-Code


- 投稿日:2019-10-23T21:42:03+09:00
Zero Scale Abstraction in Knative Serving - Part1
Serverless Days Tokyo 2019 の Zero Scale Abstraction in Knative Serving というセッションの内容を書き起こしたものです。スピーカーノートをベースに、セッションの時間内で話せなかった内容も含めて、Knative Serving についてまとめています。思った以上に長くなってしまったので、2つの記事に分割します。
いくつかリンクを貼っていますが、Google Slide や Docs は knative-users@ への参加が必要です。
Table of contents
- Knative プロジェクトとは (Part1)
- Knative Serving
- 紹介と簡単なデモ (Part1)
- ゼロスケールの仕組み (Part1)
- 優れた点
- 制約と課題
- Knative Serving の本番導入に向けて
- Why Knative?
- High-level architecture walkthrough
- gRPC load balancing
- Strategy for upgrading EKS cluster
- Event driven system
- Resource requests and limits
Introduction
Knative プロジェクトの大枠を紹介します。
Knative は Kubernetes 固有のプラットフォームで、モダンな Serverless アプリケーションをビルド、デプロイ、管理します。Knative の名前の由来は Kubernetes native platform から来ています。Knative は次の 3 つの主要なプロジェクトを中心に構成されています。
- HTTP リクエスト駆動でゼロスケール可能なコンテナベースのアプリケーションを管理します。
- イベント駆動でアプリケーションを動作させるための機構です。
- Eventing で取り扱われるイベントは HTTP リクエストベースのものが多く、GitHub の webhook や
- Kubernetes のイベントから AWS SQS や Cloud Pub/Sub、Kafka など多様です。
“Kubernetes はクラウドの世界の Linux になるだろう”と Linux Foundation の Jim Zemlin が発言しています。K8S を中心に CaaS (≒ IaaS) / PaaS / FaaS をマッピングしてみました。
諸説あるのであくまで個人の見解ですが、Knative 自体は PaaS よりの基盤に見えます。Knative の上に独自の Runtime を構築することで、FaaS の機能を提供することができます。そういう意味では、Cloud Foundry の Eirini プロジェクト (Kubernetes クラスター上で Cloud Foundry Application Runtime を管理) が最も近い存在かもしれません。
余談ですが、フルマネージドな Cloud Run は、オープンソースとして公開されている Knative を使って構築されている訳ではありません。Knative Serving の API に準拠しつつ、Google のインフラ (gVisor on Borg) に合わせて内部の実装が異なっています。ただ、Cloud Run for Anthos (Cloud Run on GKE) では、オープンソースとして公開している Knative と Istio を GKE クラスター上にデプロイすることになります。Cloud Run (fully managed) と Cloud Run for Anthos に関する詳細な情報は、公式ドキュメントを確認して下さい。
Knative の目指すべきゴールは、Cloud Foundry や Heroku と同じに見えます。
Knative — Kubernetes-native PaaS with Serverless の引用ですが、Knative プロジェクトが提供する機能はこれまでの PaaS が提供してきた機能に近いものばかりです。それらを可能な限り疎結合なコンポーネントとして提供することで、サービスプロバイダが柔軟にそれらのコンポーネントを組み立てて、自分だけのプラットフォームを構築できるようにしています。
Knative が目指している世界も PaaS がかつて目指した世界と同じで、アプリケーションのソースコードの場所を指定すれば、サービスが公開できる未来です。アプリ開発者がより自身のアプリケーションの開発に注力できるようになります。
Knative serverless Kubernetes bypasses FaaS to revive PaaS からの引用ですが、Knative の強みは Kubernetes というコンテナオーケストレーション基盤の上に構築したことです。Kubernetes の Primitive なコンポーネントを Custom Resource Definition を用いて拡張することで、Kubernetes のネイティブなプラットフォームに仕立てています。Knative を利用しても、Kubernetes の Primitive なリソースが使えなくなる訳ではありません。自身のワークロードに併せて、Knative の抽象化されたリソースを使う部分と、Kubernetes のリソースを使う部分を分けることができます。例えば、ステートフルなアプリケーションをデプロイしたい場合は、単純に Kubernetes の StatefulSet を利用すれば良いのです。
What Exactly Is Knative? からの引用ですが、CloudFoundry のメンバーも Knative プロジェクトの開発に関わっています。
Knative は、Kubernetes をより実用的に抽象化したプラットフォームです。Kubernetes を利用する上でのベストプラクティスを盛り込みつつ抽象化を試みています。Knative Serving のリードである Matt Moore のツイートにも書いてあるように、多くのユーザーがハマりがちな問題を単純化することも Knative プロジェクトの重要な要素になっています。ただ、抽象化している分、型にはまって、柔軟性の欠ける部分はあります。
Knative は様々なプラットフォームを構築するための部品の集まりです。デフォルトの Knative way に削ぐわない場合は、自身の用途に合わせてコントローラを自作すれば良いのです。私のような小さな組織の人間がコントローラを自作/管理していくのは骨が折れます。ですので、Knative way が全員ではないが大多数のベストプラクティス集として成長していくことを願いつつ、Knative への貢献を始めました。
Knative は Google 主体で様々なベンダーと協力して開発が進められています。Kubernetes の PodAutoscaler (sig/autoscaling) や既存の FaaS (OpenWisk, Kubeless) の開発メンバー、CNCF の Sandbox プロジェクト入りした CloudEvent のメンバーなど多方面から参加しています。開発も活発に行われており、6ヶ月サイクルで新バージョンがリリースされています。
それぞれのベンダーが Knative をベースに Serverless プラットフォームを提供しています。そして、ユーザーに利用してもらい、そのフィードバックを Knative に還元する形で開発を進めています。
また、プラットフォームの中には Knative の機能をフル活用しているものもあれば、Knative の一部の機能のみを利用している場合もあります。例えば、Rancher Rio は Knative Serving のオートスケーリングの機能だけを切り出して利用しています。このように Knative の特徴として各コンポーネントの疎結合性が挙げられます。必要なコンポーネントを好きに組み合わせて Serverless プラットフォームを作ることができます。
本セッションでは、Knative Serving を取り上げます。
Knative Serving
Knative Serving は Kubernetes 上に構築した Serverless プラットフォームです。
ステートレスなアプリケーションを対象に、HTTP イベント駆動で自動スケールする仕組みを提供します。Before talking about Knative Serving...
本題に入る前に、軽く Kubernetes について触れておきます。
Kubernetes は、コンテナオーケストレーションプラットフォームのデファクトスタンダードで、様々な機能を提供します。
本日のセッションでは、kube-proxy という Kubernetes のコンポーネントが出てきます。サービスディスカバリの処理を行なっているコンポーネントの一つです。Kubernetes 内部でのみ利用可能な VIP に対するリクエストは、kube-proxy に一旦送られ、Netfilter のルールと照合します。(この処理は、ルールの数を N として、O(N) の処理になります。) そして、転送先のバックエンドをランダムに決定します。(statistic mode random probability)
本セッションに登場する Kubernetes の主要なリソースは次の 3 つです。
- Pod は、アプリケーションをホストするための最小単位のリソースです。複数のコンテナを含めることができ、ひとつの PodIP とポート空間を共有します。
- Deployment は、複数の Pod のライフサイクルを抽象化して管理します。Pod は時間とともに変動する短寿命なリソースなので、Deployment で自己回復できる仕組みを提供しています。アプリケーション開発者が触るリソースになります。
- Service は、ネットワーク関連のリソースです。クラスター内部でのみ使える VIP の提供やサービスディスカバリ、L4 レイヤーでの負荷分散など、アプリケーションをクラスター内外に公開する際に利用されます。
Kubernetes でサービスを外部に公開しようと思うと、多くのリソースを定義する必要があります。
VirtualService
- L7 レイヤーの機能を提供する Istio のリソースです。
- サービスに対するリクエストを制御するためのリソースです。
- トラフィック分割や Circuit Breking などの設定を行うことができます。
Horizontal Pod Autoscaler
- Pod がリソースの使用量によって自動的にスケールアウト/インするためのポリシーを定義します。
これとは別に ConfigMap や Secret などのアプリケーション設定に関するリソース、ServiceAccount や Role などセキュリティ関連のリソースも定義する必要があります。
先ほどのマニフェストは、次の Knative Service リソースの定義とほぼ等価です。一部異なる部分は、Horizontal Pod Autoscaler (HPA) がリソース消費量でスケールするのに対して、Knative Pod Autoscaler (KPA, Knative の独自リソース) は、リクエストの処理数でスケールします。KPA はデフォルトだと、Pod の同時処理数が 70 リクエストを越えるとスケールします。(
container-concurrency-target-defaultxcontainer-concurrency-target-percentage= 100 x 0.7 = 70) 前者は Knative Service 単位で指定が可能です。詳細は、Configuring the Autoscaler を確認して下さい。また、
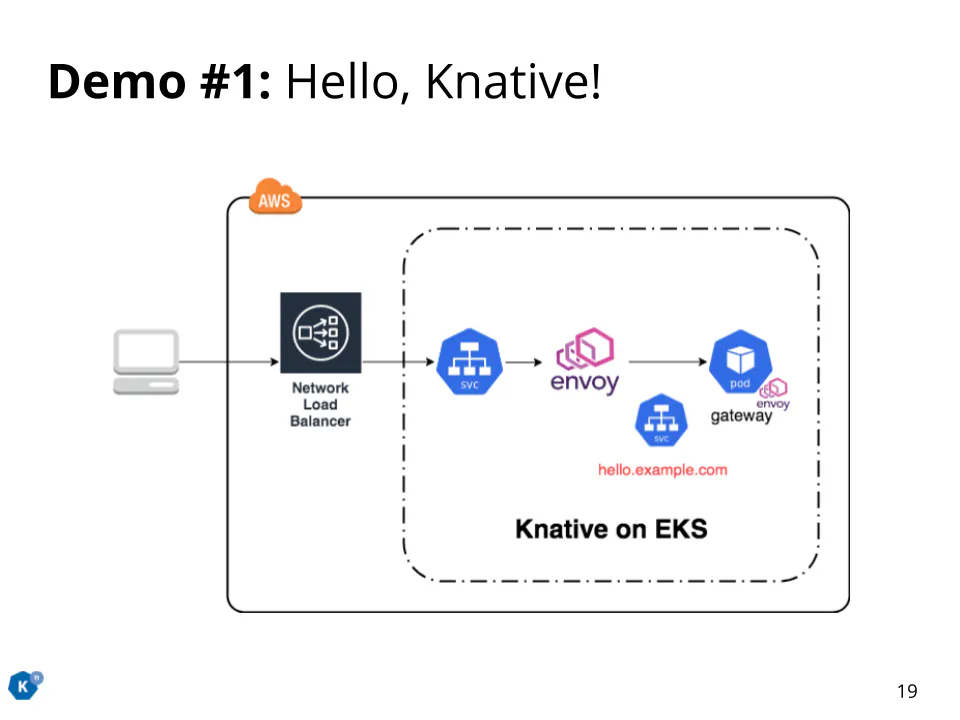
spec.template.metadata.annotationsで Pod のスケールに関する設定を行なっています。上から最小スケール数と最大スケール数を指定しています。Demo#1 Hello Knative!
helloworld アプリをデプロイして Knative のイメージを掴みましょう。EKS クラスターに Istio と Knative をインストールしています。
helloworld アプリをデプロイして、作成されたリソースを確認してみます。
- kn コマンドを使って、helloworld アプリをデプロイします。
- イメージと Revision の名前を指定しています。Revision は、アプリケーションのコードと設定の不変のスナップショットです。
- デプロイした helloworld アプリには
hello.example.comのホストヘッダーでアクセスできます。
- ConfigMap リソース (config-network) を編集して、
domainTemplate: '{{.Name}}.{{.Domain}}'としています。- 下のウィンドウで、http://hello.example.com にリクエストを投げて、
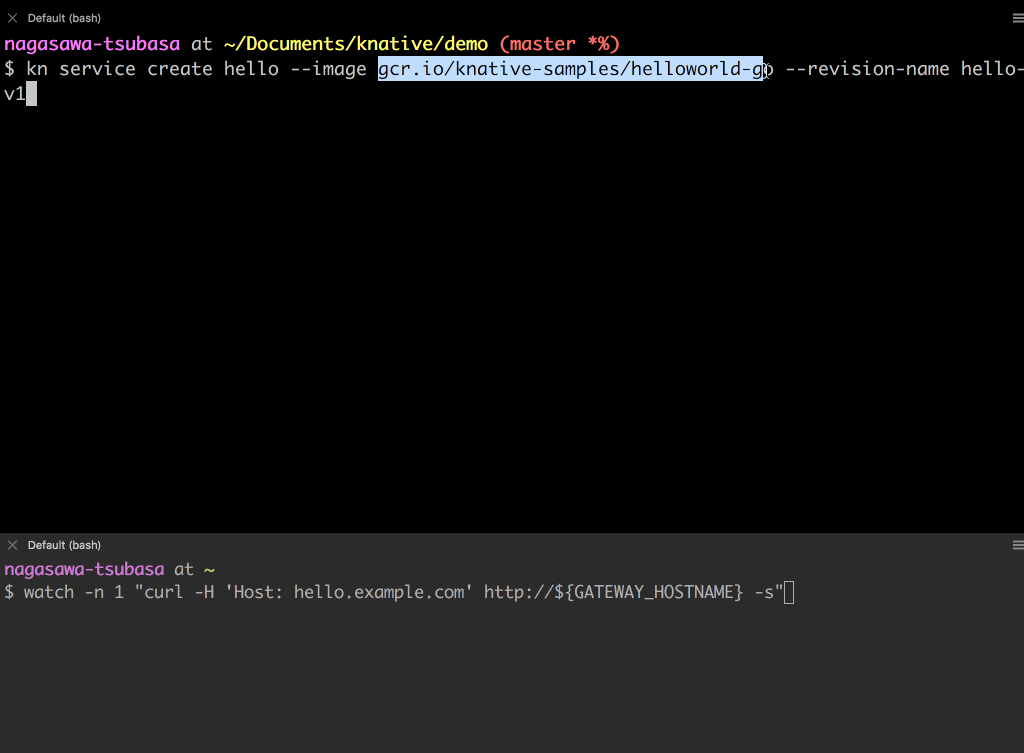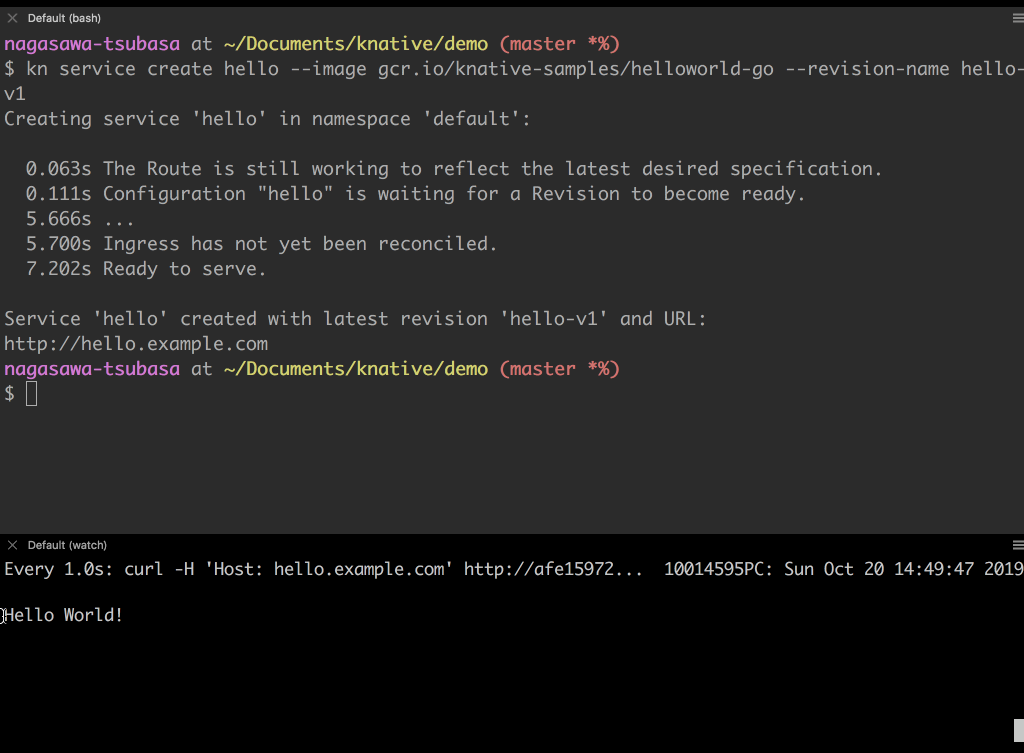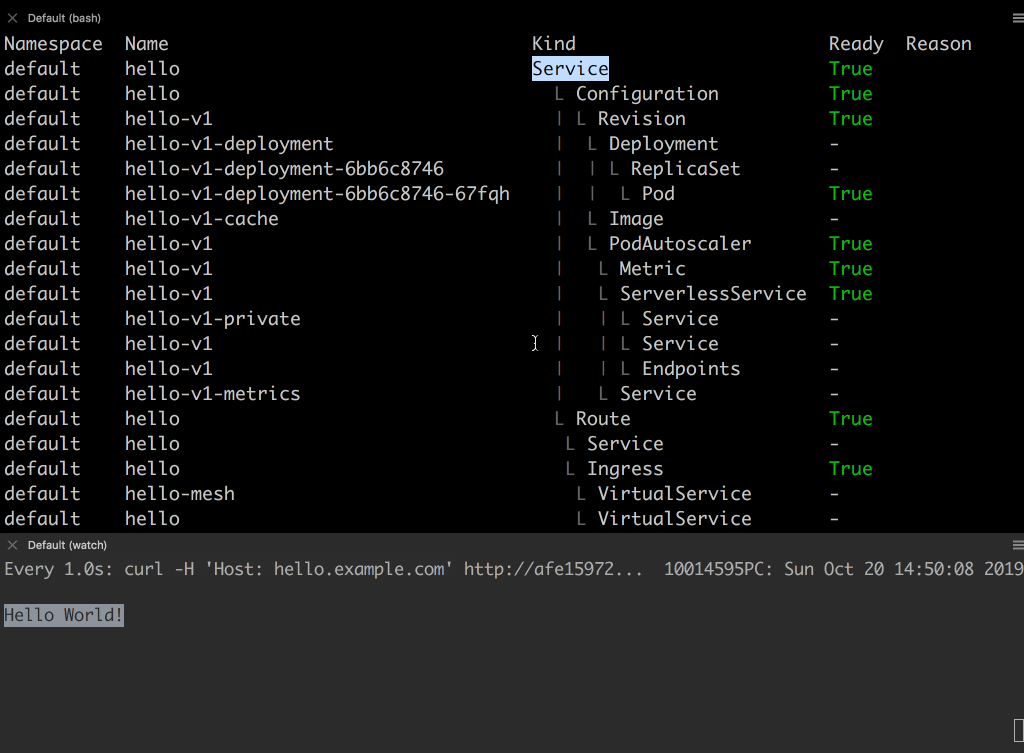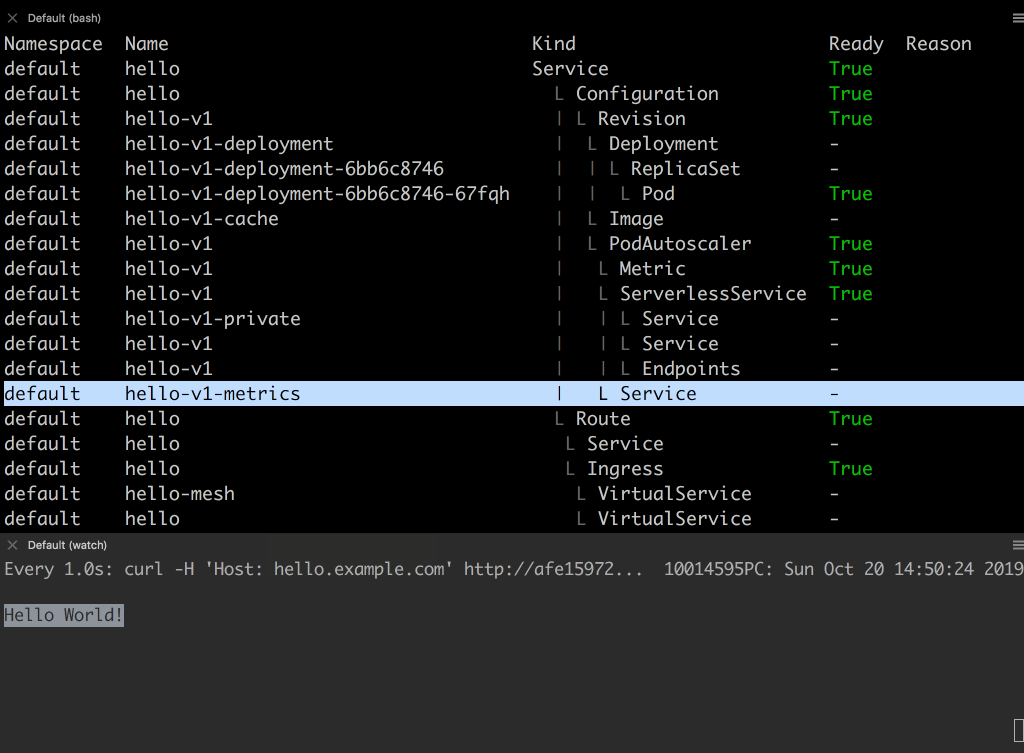
Hello Worldのレスポンスが返って来ていることが確認できます。- デプロイした helloworld アプリに対して knative-inspect を使って、Knative が裏側で作成したリソース一覧を確認しましょう。
- 1 つのアプリケーションに対して 20 個のリソースが裏側で作成されています。
- トップリソースは Knative Service リソースです。
- それ以外の Service は全て K8S Service リソースになります。
- K8S Service が複数作成されていることを確認して下さい。
- これらはスケール時に使われるリソースで、後ほど用途を説明します。
helloworld アプリのアップデートしてみます。
- 環境変数として TARGET=ServerlessDays を指定しています。これによりレスポンスの中身が
Hello ServerlessDaysに変わります。- 新しい Revision を
hello-v2という名前で作成します。- hello-v2 という名前の Revision に
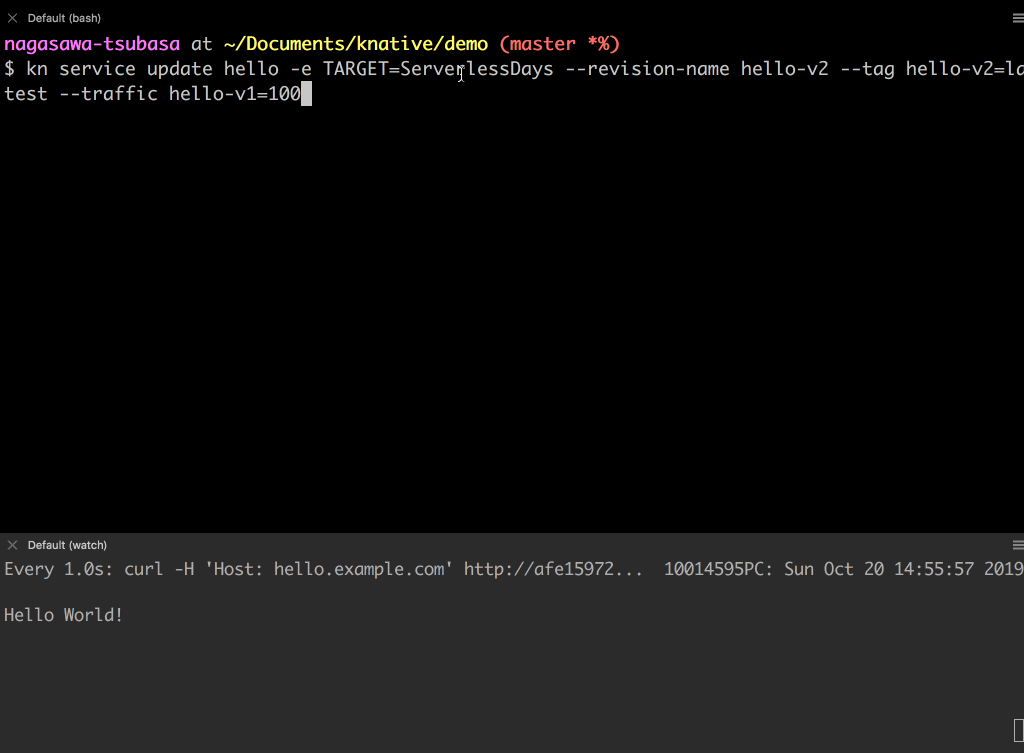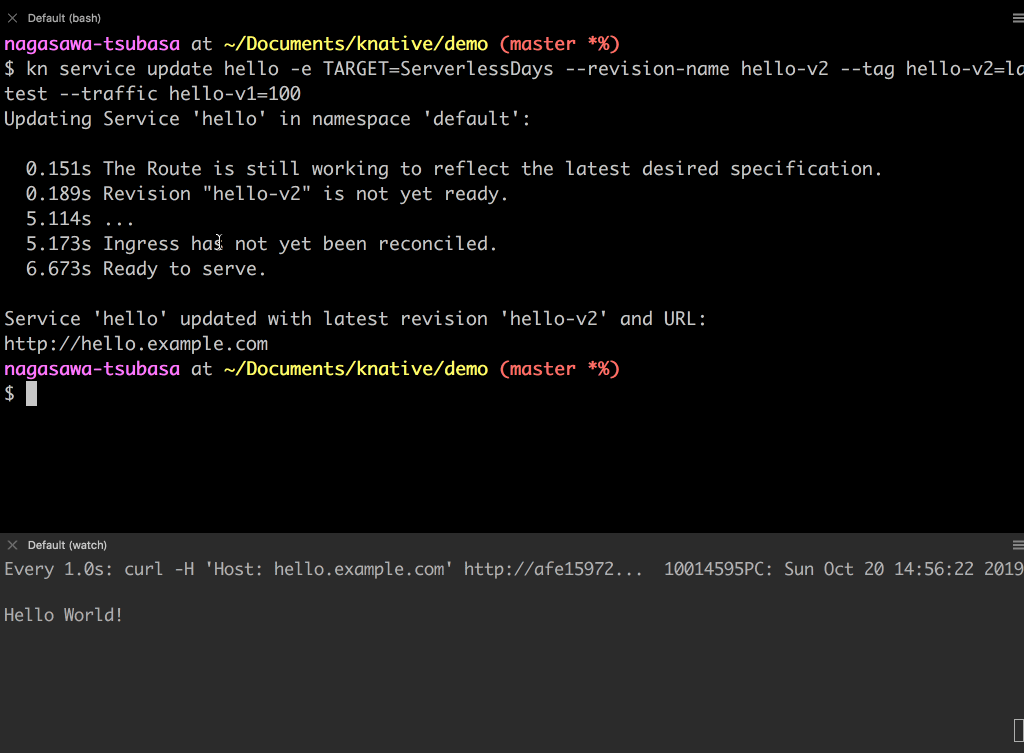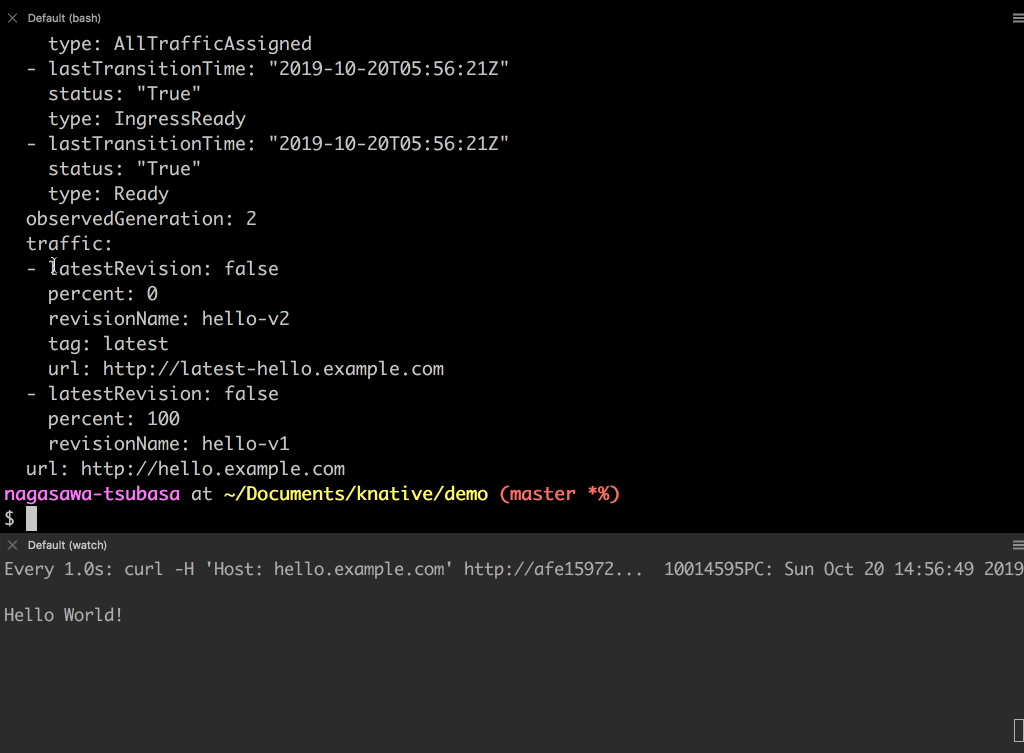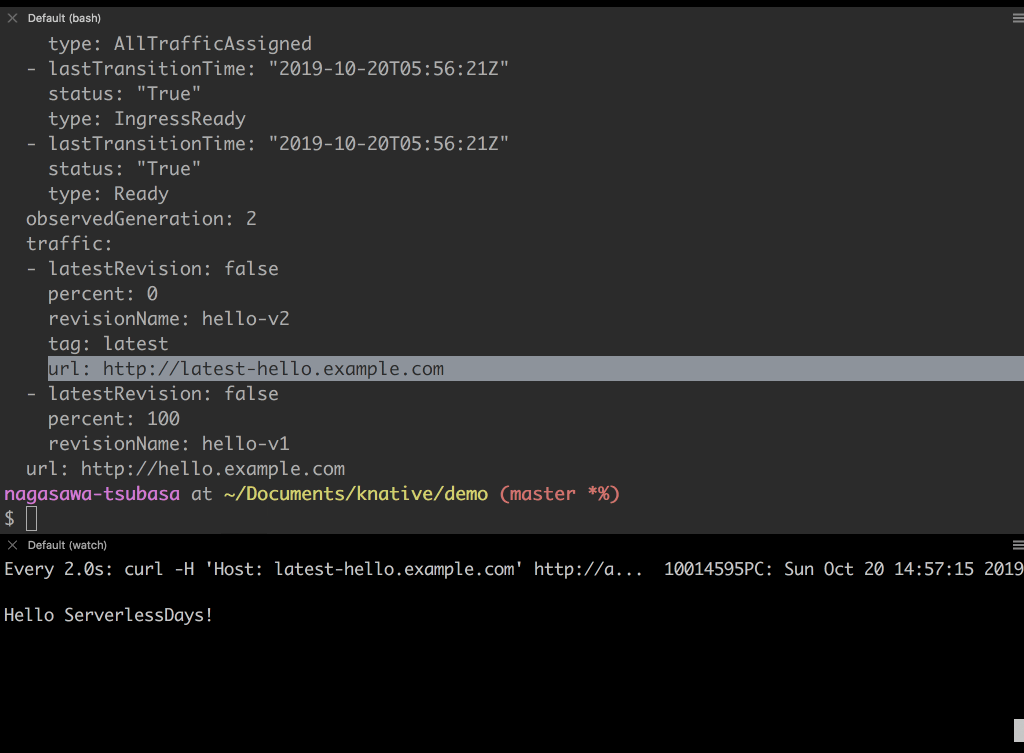
latestという名前のタグを付けます。タグを付けることで、latest-hello.example.com({{.Tag}}-{{.Name}}.{{.Domain}}) という名前のエンドポイントが払い出されます。- http://latest-hello.example.com にアクセスすると新しい Revision のレスポンス Hello ServerlessDays が返ってきます。
- トラフィックは古い Revision を向けたままにします。http://hello.example.com にアクセスしても、古い Revision のレスポンスが返ってきます。
2 つの Revision
hello-v1とhello-v2へトラフィックを分割してみましょう。
- 現在は、
hello-v1Revision にトラフィックが 100% 向いています。hello-v1とhello-v2の Revision にそれぞれ 50%の割合でトラフィックを流します。- レスポンスが
Hello WorldとHello ServerlessDaysが大体交互に表示されることが確認できます。
新しい Revision
hello-v2にトラフィックを 100% 流してみましょう。レスポンスが全てHello ServerlessDaysに切り替わったことが確認できます。Knative Primitives
Knative Serving の主要なコンポーネントは 4 つあります。
Knative Service
- 多くの開発者が触れ合うことになる、Knative Serving の中で最も抽象度の高いリソースです。
- 単一の Stateless なアプリケーション (e.g. マイクロサービス) の環境をインスタンス化します。
- アプリケーションのコードと設定それからアプリケーションに接続可能なエンドポイントを保持します。
- コントローラーは内部的に Configuration と Route リソースを生成します。
Configuration
- 自動でスケールする単一のアプリケーションの理想的な姿を定義したものです。
- Revision リソースを生成するためのテンプレートを定義します。
- コントローラーは内部的に Revision リソースを生成します。
- Knative のリードである Matt Moore によると、Configuration は Git におけるブランチに近いものであると、Online Meetup 2 - Aug 29, 2019 - Knative and Gloo で発言しています。
Revision
- Stateless で自動スケールするアプリケーションのある時点での不変なスナップショットです。
- アプリケーションのコードと設定を保持します。
- アプリケーションの変更に伴うロールアウト/ロールバックを HTTP のルーティングを変更することで実現します。
- ルーティング先の Revision はサービス名と Revision 名で決定されるため、一意の Revision から生成された Pod にリクエストを流すことができます。
- Revision は不変なため、直接変更することはできません。
- 例外として、Secret/ConfigMap などの変更可能なリソースに変更が入った場合や、Knative Serving のバージョン更新によりデフォルト値が変わった場合が考えられます。
- Revision を変更したい場合は、Configuration 経由で新しい Revision を生成する必要があります。
- コントローラーは内部的には KPA (or HPA) と Deployment を生成します。
Route
- Revision に対する HTTP リクエストルーティングの状態を管理します。
- Service Mesh の機能が有効な場合、複数の Revision に対してパーセントベースでリクエストを分配します。
- コントローラーは内部的に IstioGateway からのリクエストを受けるための Service リソースを生成します。
v0.9.0 時点での Knative の Custom Resource Definitions (Kubernetes を独自に拡張したリソース) は 10 個あります。
certificates.networking.internal.knative.dev (Optional) configurations.serving.knative.dev images.caching.internal.knative.dev ingresses.networking.internal.knative.dev metrics.autoscaling.internal.knative.dev podautoscalers.autoscaling.internal.knative.dev revisions.serving.knative.dev routes.serving.knative.dev serverlessservices.networking.internal.knative.dev services.serving.knative.dev
Knative Service のマニフェストに戻ります。
spec.template.metadata.name を指定しない場合、metadata.name + ランダム文字列で Revision の名前が自動的に生成されます。また、spec.traffic を明示的に指定しなくても、デフォルトでは最新の Revision に 100 パーセントのリクエストがルーティングされます。
先ほどの Knative Service 定義は次の Knative Service 定義と等価です。
Knative Service でアプリケーションをローリングアップデートしてみましょう。
template.metadata.name に新しい Revision の名前を指定します。traffic ブロックでは、明示的に Revision 名を指定してルーティングの割合を指定します。まずは、古いバージョンの Revision (アプリケーション) に 100 パーセントのトラフィックを向けた状態にしておきます。
次に、新しい Revision (アプリケーション) に Traffic を向けます。古い Revision のアプリケーションの中でリクエストの処理を終えたものから次々に新しい Revision に置き換わって行きます。 正確に言うと、リクエストの処理数が 0 になって特定の時間 (デフォルトでは Terminate するかの判断に 60 秒、Graceful Shutdown の猶予期間で最大 30 秒の合計 90 秒) が経過したものから Pod が Terminate され、新しい Revision の Pod が立ち上がっていきます。
リクエストが一定期間ルーティングされず、以下の条件 (デフォルト) を満たした Revision は、GC によってお掃除されます。GC の設定は、config-gc で変更可能です。
- Revision が生成されてから 24 時間が経過している。
- Route が Revision を最後にルーティング先として指定してから 15 時間経過している。
- GC 対象と見なす Revision の保持世代数 (デフォルトで 1 世代) の範囲外である。
- Revision を GC するか判断する間隔は、5 時間毎です。Revision の annotations に付与されている。
serving.knative.dev/lastPinned: “<EpochTime Seconds>”で一つ前の GC がいつ起きたかが分かります。Demo#2 Rolling Update
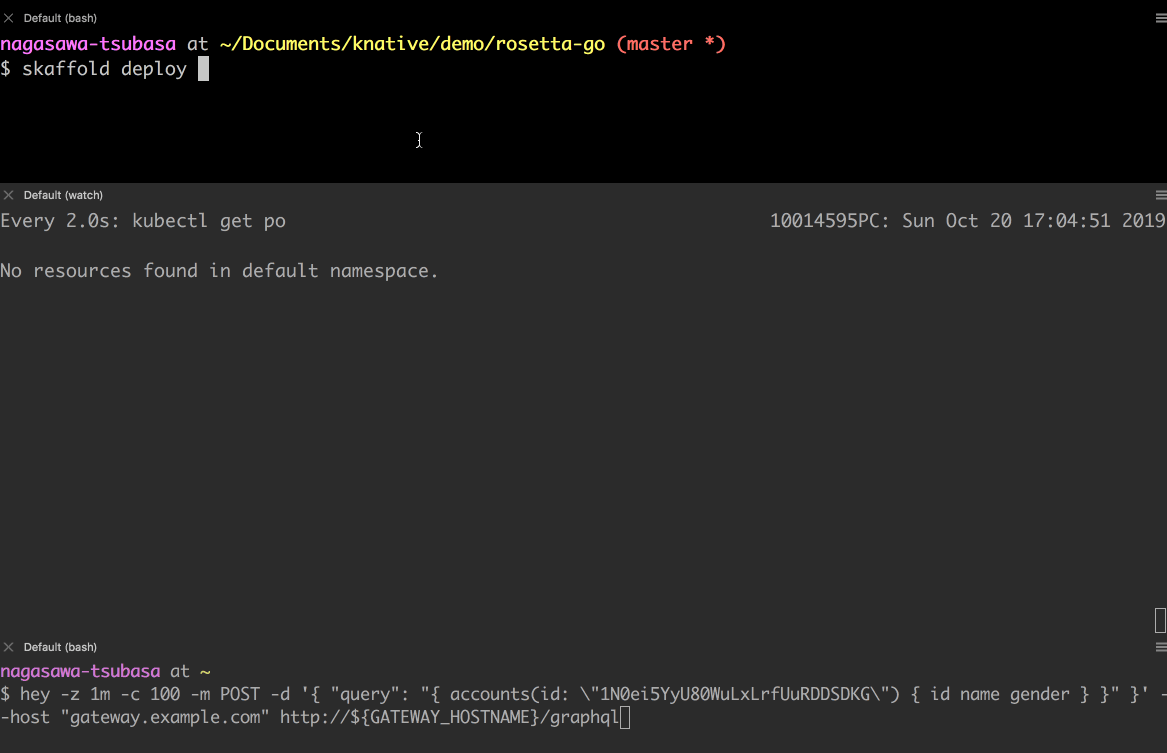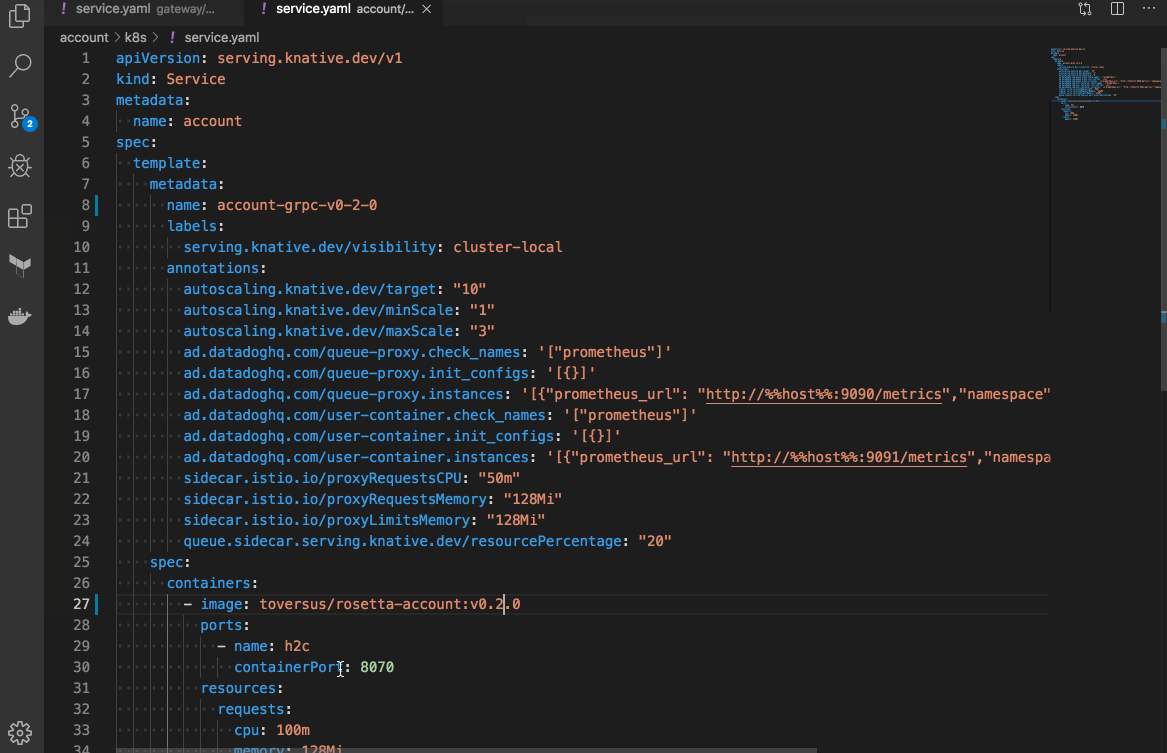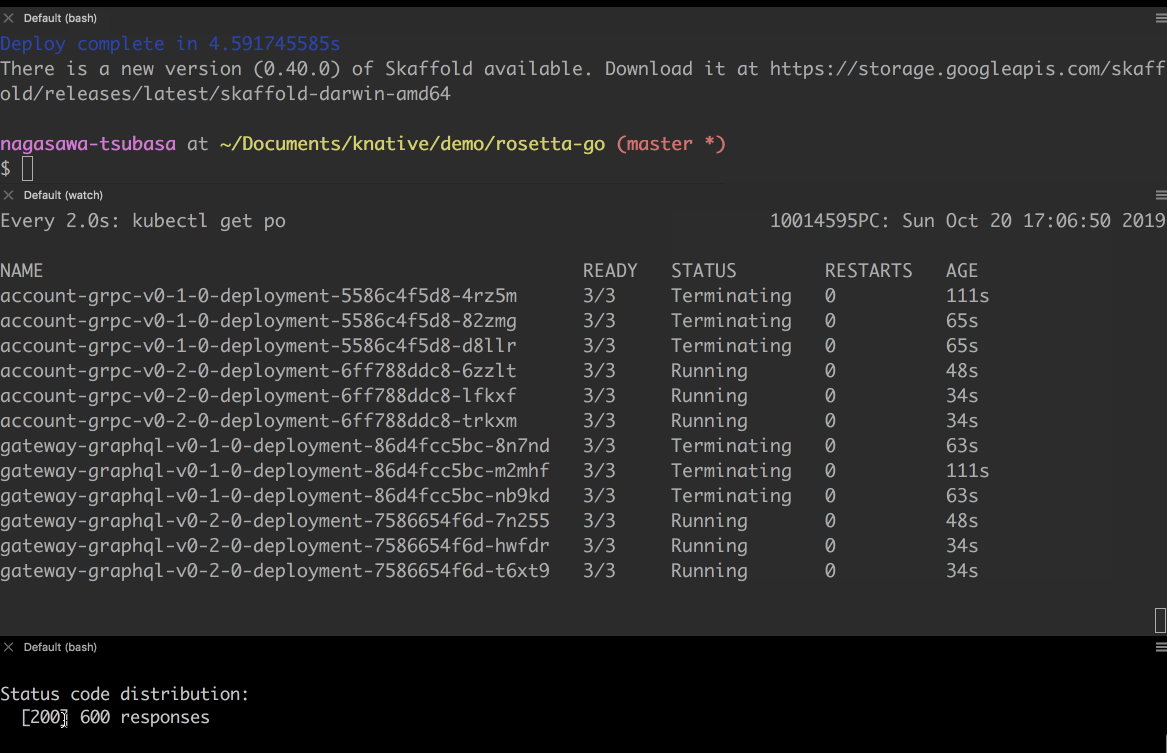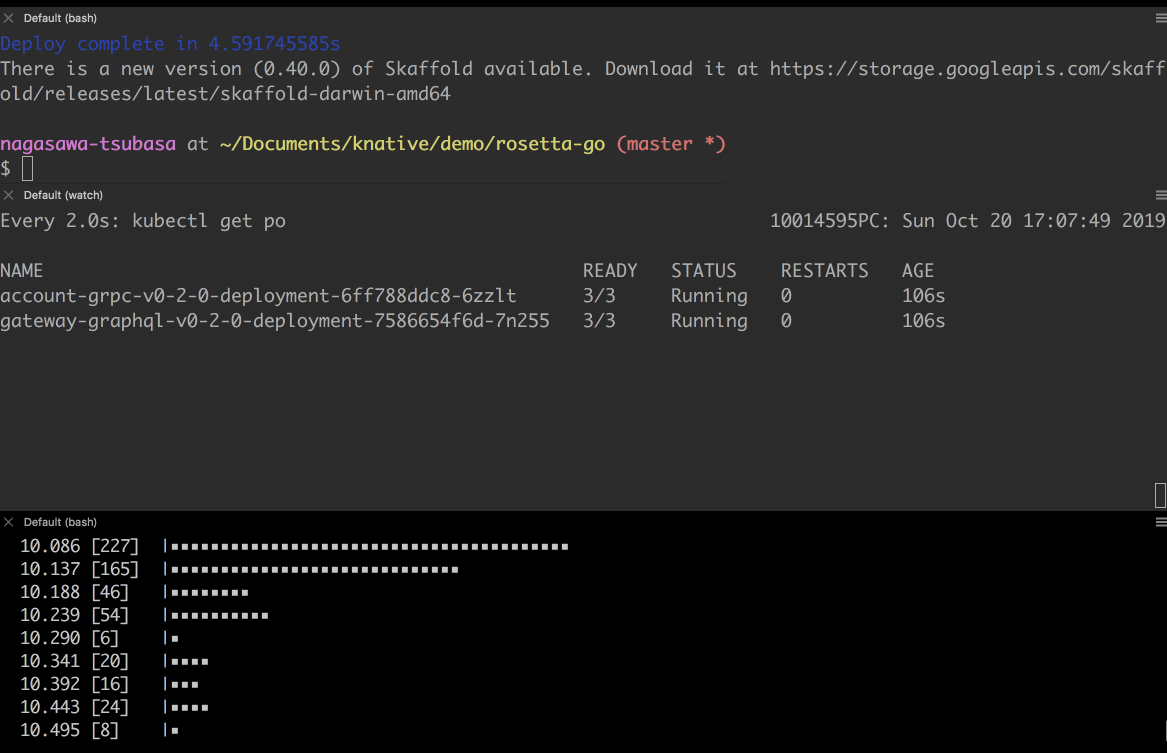
helloworld アプリよりも少しだけ現実に即したマイクロサービスの一部を用意しました。負荷を与えながらローリングアップデートしてみましょう。
- gateway サービスは GraphQL サーバです。バックエンドにある account サービスにリクエストを振り分けます。
- account サービスは gRPC サーバです。gateway サービスから送られてきた HTTP/2 のリクエストを処理します。
- account サービスは DynamoDB から必要な情報を取り出して、レスポンスを返します。ただ、今回のデモではレスポンスを返す前に 10 秒間意図的にスリープさせています。
gateway サービスと account サービスのデプロイに使ったマニフェストです。(一部 annotation を省略しています。)
autoscaling.knative.dev/targetは、1 つの Pod で同時に処理可能なリクエスト数です。この値にcontainer-concurrency-target-percentageのパーセントを掛け合わせた 7 個のリクエストを Pod が処理していると、Autoscaler が account/gateway サービスをスケールアウトします。autoscaling.knative.dev/minScaleとautoscaling.knative.dev/maxScaleは、それぞれサービスのスケールアウトの最小値と最大値です。この場合、account/gateway サービスの Pod 数は最小で 1 台、最大で 3 台までスケールアウトします。sidecar.istio.io/proxyRequestCPUやsidecar.istio.io/proxyRequestMemory、sidecar.istio.io/proxyLimitMemoryは、それぞれ istio-proxy に割り当てるリソースを調整します。istio-injector が istio-proxy を忍ばせる際のテンプレートを修正しています。詳細は、Issue コメント を参照して下さい。queue.sidecar.serving.knative.dev/resourcePercentageは、アプリのコンテナに割り当てたリソース制限に対する割合で queue-proxy に割り当てるリソースを決定します。ただ、queue-proxy に割り当てるリソースの上限がハードコードされているため、こちらの値と比較して最終的に決定されます。- account サービスに付与されているラベル
serving.knative.dev: cluster-localはサービスを外部に公開せずクラスター内部に留めるために利用します。このラベルがあるサービスは、Istio IngressGateway ではなく、Cluster IngressGateway を経由してバックエンドの Pod にリクエストが流れます。
新しい Revision を作成して、そちらにリクエストを向けます。イメージの中身は特に変更していないですが、タグを変えています。
- まず skaffold を利用して、サービスをデプロイします。リソースが作成されます。
- エンドポイントにアクセスして、レスポンスを確認しています。レスポンスが返ってくるのが遅いのは、アプリの実装で意図的に 10 秒間スリープさせているからです。
- マニフェストを変更します。イメージのタグを変更していますが、アプリの実装に変更はありません。
- v1 のサービスに負荷を掛けます。新しい Pod が立ち上がってきます。
- 負荷を掛けながら新しいサービスをデプロイし、そちらにリクエストを向けます。
- 新しい Revision の Pod が一つ作成されます。古い Revision の Pod の処理が終わり、新しい Revision へのリクエストが増えると、新しい Revision の Pod が追加されていきます。
- 古い Revision の Pod が処理を終え、一定期間リクエストを受けつけないと、Pod が停止されていきます。
- 負荷を掛け終わりました。アップグレード時にリクエストを取りこぼすことなく、新しい Revision にリクエストを向けることができました。
- 新しい Revision へのリクエストがなくなったので、Pod が停止されていきます。
- 新しい Revision の Pod が 1 台だけ残ります。
Knative Serving の内部コンポーネントやゼロスケールの仕組みを知りたい方は、KubeCon China 2019 の Inside Knative Servin の講演をまずは視聴してみて下さい。既存のデプロイ方式との比較から始まり、Activator や Autoscaler など重要なコンポーネントの概要が素晴らしく良くまとまっています。
Inside Zero Scale Abstraction
Knative Serving のゼロスケールの仕組みを見ていきましょう。
ゼロスケールした状態から必要な数の Pod がスケールアップしてくるまで、リクエストをどうやって保持すれば良いでしょうか?
ゼロスケールを実現する重要な要素はいくつかあります。
- Pod の起動待ちで処理できないリクエストを保持するためのキュー
- リクエストがタイムアウトする前にスケールアウト
- Pod へリクエストを流すパスとキューにリクエストを溜めるパスの切り替え
- 同時処理数のメトリクスを監視
- メトリクスからスケールを決定
Knative の主要なコンポーネントは次の 3 つです。
- Activator
- 中央集権的なリクエストキューです。
- Activator という名前は歴史的な背景によるもので、役割上 KQueue と呼ばれることもあります。
- 過去に一度名前の変更を試みていますが、変更箇所が大量にあり断念しています。Rename Activator to KBuffer #2380
- リクエストを適切にバックエンドにルーティング、負荷分散します。
- Activator に送られたリクエスト数をメトリクスとして Prometheus 形式で公開します。
- Autoscaler
- Activator や queue-proxy からメトリクスを収集します。
- 収集したメトリクスから必要な Pod 数を計算し、スケールの決定を下します。
- 収集する Pod の数が増えると、全ての Pod からメトリクスを収集することがボトルネックになってしまいます。そのため、統計的に収集が必要なサンプル数を動的に算出しています。詳細は、Dynamically change autoscaling metrics scraping sample size based on pod size #3831 を確認して下さい。
- queue-proxy
- 分散リクエストキューです。
- Pod の中でリクエストを最初に受ける部分です。
- リクエストをユーザーコンテナ (アプリ) に転送します。
- containerConcurrency で指定されたリクエストと現在処理中のリクエスト数を比較して、大量のリクエストが一度にアプリケーションに届かないように調整しています。
- queue-proxy に転送されたリクエスト数をメトリクスとして Prometheus 形式で公開します。
- サイドカーコンテナとしてデプロイされます。
A journey through initial scaling to zero
Istio と Knative Serving を K8S クラスターにインストールした後の状態です。まだ、Knative Service をデプロイしていません。
- Autoscaler は、WebSocket サーバを起動してメトリクスが届くのを待ちます。
- Activator は、起動時に Autoscaler に対して WebSocket のコネクションを張ります。
- Activator が提供するメトリクスは、Activator にルーティングされたリクエスト数の平均値です。
Knative Service をデプロイすると、
Revision コントローラが Knative Pod Autoscaler (KPA) を作成します。
- KPA は、HTTP リクエストに関係するメトリクスをもとに自動スケールするための、Knative の独自リソースです。
- KPA では、処理中のリクエスト数か秒間のリクエスト数 (RPS) をもとに自動スケールさせることができます。
- Horizontal Pod Autoscaler (HPA) をベースにしていますが、HPA は CPU やメモリなどのリソース使用率をベースにスケールします。
- HPA は、Pod のリソース使用率を直接監視する必要がありますが、ゼロスケール時には Pod が存在しないため、ゼロからスケールアップする判断が下せません。HPA のゼロスケールは未実装で、HPA scale-to-zero #3064 の Issue で議論が進められています。
Serverless-style Service は、K8S Service リソースを Serverlss なワークロードに合わせて抽象化したリソースです。
Serverless-style Service を作ることになった背景は、
- K8S の Service リソースは、Pod のラベルを使って Service Discovery することで、Endpoint (IP:Port) を更新します。
- K8S の Service リソースでは、Serverless なワークロードに必要なゼロスケールに対応できません。
- ゼロスケールした場合、Pod の Endpoint を紐付けることが出来ず、トラフィックを落としてしまいます。
- 実際にアプリケーションがリクエストを処理できる状態 (Serve Mode) とアプリケーションがリクエストを処理できない状態 (Proxy Mode) の切り替えが必要です。
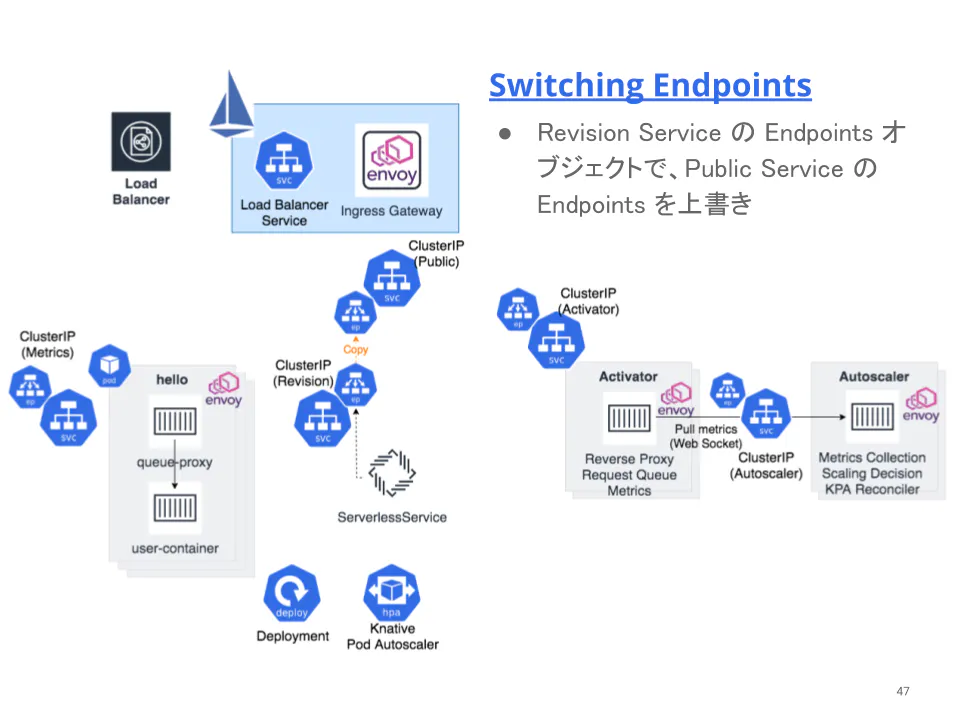
前ページで触れたように Knative はゼロスケールを実現するために、Serve Mode と Proxy Mode を切り替えます。すなわち、Public サービスがスイッチの役割を担っています。
切り替えは、3 つの ClusterIP Service を使って行います。K8S では、通常外部公開するアプリと Service リソースは 1:1 の関係ですが、Knative では、1:3 の関係であることに注意して下さい。
- Service without selector (Public Service)
- without selector な Service であるため、Endpoints オブジェクトは自動で紐付きません。
- リクエストをアプリにルーティングするために実際に使われるスイッチの役割を担う Service です。
- Revision backed Service (Private Service)
- selector で特定の Revision ラベルを指定した Service です。
- Serve Mode 時に、Public Service に Endpoints オブジェクトをコピーするために使います。
- Endpoints オブジェクトには Revision に属する Pod 群の PodIP が含まれています。
- Metrics Service
- queue-proxy から Revision に属する Pod のメトリクスを収集するための K8S Service です。
- 通常のメトリクスとユーザーが定義可能なカスタムメトリクス用の 2 つのポートが紐付いています。
- Activator backed Service
- selector で Activator 群を指定した Service です。
- Proxy Mode 時に、Public Service に Endpoints オブジェクトをコピーするために使います。
- Endpoints オブジェクトには Activator 群の PodIP が含まれています。
Serverless-style K8S Service のデザインドキュメントは、Revision-based activation or Serverless k8s Style Services です。Revision K8S Service は、このドキュメントにおける Private Service のことです。細かい実装の部分は変わってしまっていますが、大枠がまとまっています。
Knative Service をデプロイした直後なので、アプリがリクエストを受け取る準備がまだできていません。そのため、Serverless Service はリクエストパスを ActivaPublic Service に Activator を向いている Service の Endpoint オブジェクトを紐付けます。
Activator は、Revision Backend Manager という機構を持っており、Activator からユーザーアプリケーションにリクエストを転送しても良いかを監視しています。正確に言うと、以下の 2 つのヘルスチェックを並列して行い、より早く正常性が確認できた IP に対してリクエストを転送します。
- Revision K8S Service の ClusterIP
- Revision K8S Service の Endpoints から得られる PodIP
- 正確には PodIP を使って queue-proxy のヘルスチェックを送っています。
なぜ、2つのヘルスチェックを並列して行なっているかと言うと、
- Endpoints の ClusterIP への反映は kube-proxy の iptables の更新が必要
- iptables の更新タイミングは kube-proxy の iptables-min-sync-period によって決まる
ネットワークプログラミングのオーバーヘッドにより ClusterIP に対するヘルスチェックの通過が遅れるからです。iptables-min-sync-period の指定はクラウドプロバイダー毎に異なります。GKE の場合だと 10s になっているようですが、EKS の場合は 0s です。
EKS の場合
I1004 07:40:39.361635 1 flags.go:33] FLAG: --iptables-min-sync-period="0s"詳細は、iptables-min-sync-period が Knative に与えた影響については、Cold start latency exacerbated by iptables-min-sync-period を確認して下さい。
Pod 内部の全てのコンテナの readinessProbe が成功して初めて、kubelet によって Pod が正常だと判断されます。
Activator が PodIP か ClusterIP どちらかの正常性を確認できました。
Serverless Service は、Revision Service の Endpoints オブジェクトを監視しているので、同時もしくは少し遅れた段階で、Public Service の Endpoints オブジェクトを Revision Service の Endpoints オブジェクトで上書きします。これにより、それ以降のリクエストは IngressGateway から Activator を経由せず、直接 Revision に属する Pod に向かいます。
queue-proxy は、受け取ったリクエスト数や user-container に転送したリクエスト数などの情報を Prometheus 形式で公開しています。詳細は、queue-proxy のコードを確認して下さい。
- queue-proxy が受け取ったリクエスト数
- queue-proxy のレスポンス時間
- user-container に転送されたリクエスト数
- user-container のレスポンス時間
- queue-proxy で溜めているリクエストキューの深さ
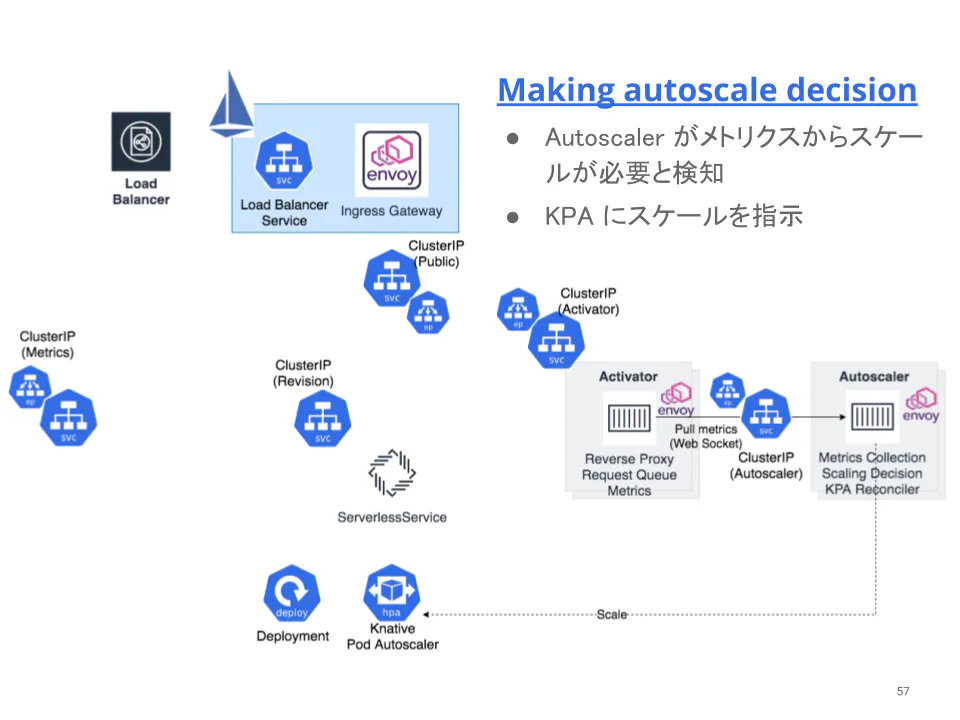
Autoscaler はこれらの情報をスクレイプし、Activator からのメトリクスと合わせてスケールの判断を下します。
Autoscaler のスケールの決定を決定する際に全ての queue-proxy からメトリクスを収集しているとレイテンシが悪化します。そのため、統計的に信頼できるサンプル数を計算して、その数だけスクレイプします。詳細は、Autoscaler のコード を確認して下さい。サンプリングする対象のサイズは、統計を元に決定しています。
ゼロスケールする前に今度は、Activator の Endpoints オブジェクトで Public Service の Endpoints オブジェクトを上書きします。これにより、ゼロスケール時にリクエストが入ってきても Activator のリクエストキューに溜めることができます。
Knative Service をデプロイして外部からリクエストが一切入って来なかったので、そのままゼロスケールしました。
A journey through scaling from zero
初めて Knative Service をデプロイし、ゼロスケールした後の状態です。
外部からリクエストが来ると、クラウドロードバランサーがリクエストを受け、Kubernetes のワーカーノードにリクエストを振り分けます。
Service type LoadBalancer は、Kubernetes のワーカーノードで特定のポートへのリクエストを待ち受けており、クラウドロードバランサーから振り分けられたリクエストをキャッチします。
Service type LoadBalancer は、nodePort で受けたリクエストを Istio Ingress Gateway (Front Envoy) に転送します。
Istio Ingress Gateway は、リクエストのホストヘッダーを見て、転送先の Knative Service を識別し、その Public Service にリクエストを転送します。
Public Service の Endpoints は Activator を向いているため、リクエストを Activator に転送します。Activator は、送られてきたリクエストをキューに溜めます。また、Activator は自身が公開しているメトリクスを更新します。
Autoscaler は、Activator のメトリクスを収集し、特定の Knative Service の Pod をスケールする必要があることに気付きます。Autoscaler は、KPA をリコンサイルして必要な Pod 数を指定します。
KPA は Deployment のレプリカ数をゼロから必要数に変更します。Pod が起動され始めます。
Activator は、以下の2つのタスクを並列実行し、健全な IP アドレスを見つけ、ユーザーリクエストの転送先を決定します。
- Revision K8S Service の Cluster IP に対して HTTP Get リクエストを送信し、queue-proxy の正常性を監視します。
- Revision K8S Service のイベントを監視し、Endpoints オブジェクトが紐づけられるのを待ちます。紐付けられた場合、その Endpoints に対して HTTP Get リクエストを送信し、queue-proxy の正常性を確認します。
Activator は、ClusterIP もしくは PodIP に対してユーザーリクエストを転送します。転送されたリクエストは queue-proxy を経由してアプリケーションに送られます。
Serverless Service は、Public Service の Endpoints オブジェクトを Revision Service の Endpoints で上書きします。
以降のリクエストは Activator を経由せず、Revision の Pod をバックエンドに持つ ClusterIP に転送します。
スケール時など Activator にリクエストが Proxy される場合のトレーシング結果と Activator を経由しない通常時のトレーシング結果です。ゼロスケール時は 2 度
proxyされているのが分かります。逆に通常時は 1 度だけproxyされています。Autoscaling ultimate goal
Autoscaling Working Group の究極的なゴールは、ゼロスケールの仕組みを Kubernetes に取り込む or 還元することです。L4 リソースの K8S Service もしくは L7 リソースの Ingress を使って、ゼロスケールする仕組みを作り上げたいのです。そのため、Ingress v2 の Proposal である [PUBLIC] A sketch of the API にも早い段階からフィードバックを積極的に行なっています。
Kubernetes の HPA の現状は、API レベルで
minReplicas: 0をサポートした段階です。まだ、Kubernetes のリソースとしてリクエストをバッファする仕組みはありません。そのため、外部のメトリクスをベースにゼロスケールを判断する必要があります。また、Knative のコアメンバーで、現在は kubernetes/sig-autoscaling のメンバーである Joe Burnett が Slack で発言しているように、HPA のスケールは遅いです。
hpa will scale up from zero when it notices the custom or external metric warrants a scale-up. the controller evaluates every hpa each 15 seconds, so the delay could be that long, which is why knative scale-from-zero is "faster". the activator (or similar component) is required to serve synchronous request traffic because it "holds" the request until a pod is available. another component could be used, such as kubeproxy (see the knative scaling wg when Rajat Sharma presented such a design: https://docs.google.com/document/d/1FoLJqbDJM8_tw7CON-CJZsO2mlF8Ia1cWzCjWX8HDAI/edit#heading=h.w7c11tvi3emt) the activator is not strictly necessary for scale-from-zero, it just provides a fast signal that the metric has changed and should be reevaluated. @markusthoemmes has proposed (https://docs.google.com/document/d/1jARPGYAwievgzFTN7YYZ7a8Jaz2NUGq-fXTeeBHk5X0/edit#) a custom metrics watch api which could be used to provide the same fast signal to the hpa. with such a mechanism, the activator could inform the knative metric controller about pending requests, which could notify the hpa via the watch api, which could immediately evaluate the hpa for a new scale. this would make the hpa "fast" like the kpa and could be a path toward converging the autoscaler implementations. (note: cm watch and hpa use of watch are not implemented or planned for implementation currently).
kube-proxy を使ったゼロスケールの仕組みも Proposal 段階ですが、存在します。先ほどの Joe Burnett に当時 Knative で議論した内容の録画が載っているので興味があれば見てみると良いと思います。
Knative のゼロスケールの仕組みは Osiris による影響が大きいです。Endpoints を手動で付け替える部分は Osiris を参考にしています。ただ、Osiris の場合は、2 つの K8S Service を使ってリクエストパスを切り替えているようで、K8S Service のネットワークプログラミングのラグが影響しないのか気になるところです。



















































- 投稿日:2019-10-23T21:36:49+09:00
CircleCI+Code4兄弟でFargateで動くGoプログラムをデプロイする
はじめに
Go言語で書かれたプログラムをFargateでサービス実行していて、そこにCI/CDを設定する
手順の紹介記事です。
構成は以下の通り
- GitHub
- CircleCI
- CodePipeline(CodeCommit/CodeBuild/CodeDeploy)
- ECS(Fargate)
CircleCIを経由しないフローでもいいですが、CircleCI 2.1での新しい書き方を試したかった
のもあり、こんな構成にしました。 参考:CircleCI2.1Qiita検索結果
なお、手順の紹介に重点を置いたので、各種設定ファイルについては概要説明に止めます。前提
環境
- QA/Production環境それぞれ別のAWSアカウントで利用
- 東京リージョン(ap-northeast-1)を利用
- FargateでサービスとしてGoプログラムを実行している
- CirceCIのconfig.ymlはversion2.1を使用
- executors/commands/parametersを使いたいので
- Golangのバージョンは1.13~
- Go Modulesを使っているので
デプロイフロー
GitHubでは3種類のブランチを使います。
それを、以下のように動作するよう設定します。
- masterブランチ
- developブランチのマージ先
- PRマージされるとProduction環境のCodeCommitへPushされる
- CodeCommitへのPushをトリガにCodePipelineによりECSへデプロイされる
- developブランチ
- 開発用ブランチのマージ先
- 開発を始める場合はここから新しい開発用ブランチを作成
- PRマージされるとQA環境のCodeCommitへPushされる
- CodeCommitへのPushをトリガにCodePipelineによりECSへデプロイされる
- 開発用ブランチ(ここではfeature_hogeブランチ)
- GitHubにPushされるとLint/Testが実行される
なので、マージの流れは、 feature_hoge -> develop -> master の順
イメージ図
今回利用するGoプログラム
sample-go
プログラムの内容は適当(個人的な検証プログラム)です。
ECSにサービス登録して実行する前提なので、デーモンとして動く実装であればどんなコードでもOK。ファイル構成
sample-go├── .circleci │ └── config.yml # CircleCI設定ファイル ├── Dockerfile # Goプログラム実行用コンテナ作るやつ(マルチステージビルド!!) ├── Makefile # Goプログラムのビルドに使う ├── bin # リポジトリには含まれません │ └── sample-go # make bin/sample-go を実行して生成されるバイナリ ├── buildspec.yml # CodeBuildが実行するコマンドを記述したファイル ├── main.go ├── main_test.go ├── go.mod └── go.sumCI設定に関わる下記ファイルの概要説明
- .circleci/config.yml
- GitHubへのPushをトリガに動くCircleCIワークフローの設定ファイル
- buildspec.yml
- CodeBuildが実行するコマンドなどを指定したファイル
- docker build してイメージをECRへPushするという内容
- Dockerfile
- Goプログラムのビルド、及び実行バイナリを格納したコンテナイメージを作成するDockerfile
- buildspec.yml内で指定されている
手順
GitHub - CircleCI 連携設定
https://circleci.com/ にアクセス
まだGitHub - CircleCI 連携設定していない場合は下記手順を実施
GitHubアカウントでログイン
下記ボタンをクリック
CircleCIからGitHubへのアクセスを許可
下記のような確認画面が表示されるので画面下の
Authorize circleciボタンをクリック
CIをセットアップするリポジトリを指定
https://circleci.com/add-projects/gh/{GitHubアカウント名} にアクセス
対象リポジトリのSet Up Projectボタンを押すSet Up Project 画面からビルドを一度実行する
- Operating System -> Linux
- Language -> Go
を選択し、Next StepsセクションのStart buildingをクリック

初回はエラーになるがこのまま進めます
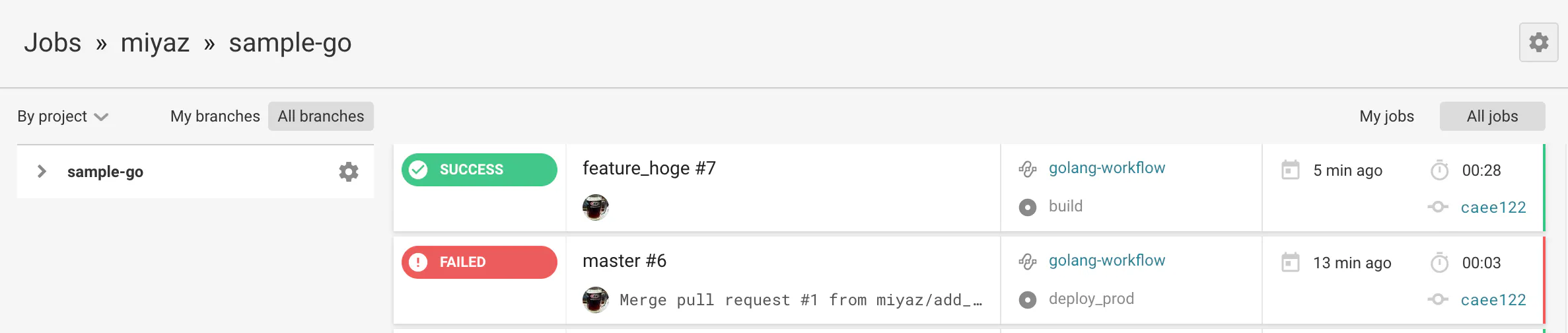
CI(Lint/Test)動作確認
feature_hogeブランチを作成してPushgit checkout -b feature_hoge git push origin feature_hogehttps://circleci.com/gh/{GitHubアカウント名}
にアクセスして上記のPushをトリガに最新Job(一番上)が動いていることを確認します。
SUCCESSであれば、Lint/Testにパスしたということになります。
もし、FAILEDであれば、対象のJobをクリックして、Lint/Test結果を確認し、必要な修正を行ってください。以降の設定は、QA/Productionの両方のAWSアカウントで実施する必要があります。
QA用AWSアカウントの手順のみ記載しますが、Productionにも同様に設定する必要がありますFargate設定
ECRにリポジトリを作成してコンテナイメージをPush
# awsクレデンシャルのプロファイルを指定 export AWS_PROFILE={プロファイル名} # ECRにリポジトリを作成 aws ecr create-repository --region ap-northeast-1 --repository-name sample-go # コンテナイメージをECRにPush ACCOUNT_ID=$(aws sts get-caller-identity | jq -r .Account) $(aws ecr get-login --no-include-email --region ap-northeast-1) docker build -t sample-go . docker tag sample-go:latest $ACCOUNT_ID.dkr.ecr.ap-northeast-1.amazonaws.com/sample-go:latest docker push $ACCOUNT_ID.dkr.ecr.ap-northeast-1.amazonaws.com/sample-go:latestFargate設定(詳細割愛)
ここでは下記を作成した前提で進めます
- クラスタ名:sample-go
- サービス名:sample-go
- タスク定義名:sample-go
- コンテナ定義のイメージURL:123456789012.dkr.ecr.ap-northeast-1.amazonaws.com/sample-go:latest
CodeCommit設定
CodePipelineのトリガとなる、CodeCommitの設定を行います。
CI設定時に、事前にCodeCommitにブランチを作成する必要があるのでそのセットアップも行います。CodeCommitにPushするためのIAMユーザ作成
IAMユーザ作成
ユーザ名:codecommit-pusher(任意)
アクセスの種類:プログラムによるアクセスにチェック
アタッチポリシー:AWSCodeCommitPowerUser
※ここでは権限広めですが、適切に絞ってくださいー後は、デフォルト値で進めてユーザ作成まで実行
CodeCommitのSSHキーを作成
注)ここで発行するSSHキーは、CodeCommitブランチ作成、及びCircleCIのSSH Permissionsでも使用します
ローカル端末でSSHキーペアを作成します
(後述するCircleCIへの鍵アップロードではPEM形式にしか対応していないので-m pemを忘れずに!)cd ~/.ssh/ ssh-keygen -t rsa -b 2048 -f codecommit-pusher-key -m pem ls codecommit-pusher-key* → codecommit-pusher-key, codecommit-pusher-key.pubが存在することを確認(鍵ファイル名を変えて、QA/Production用に別々に発行してください)
IAMユーザ画面の
認証情報タブを開き、SSHパブリックキーのアップロードボタンをクリックし
codecommit-pusher-key.pubの内容を貼り付けてアップロードする
表示されたSSHキーIDを控えておいてください
CodeCommitリポジトリ作成
- AWSマネジメントコンソールからCodeCommit画面を開き、
リポジトリを作成ボタンをクリック- リポジトリ名に
sample-goを入力して作成ボタンをクリックdevelopブランチを作成する
GitHubとCodeCommitでコミット履歴が同じ状態である必要があるので、git remoteにCodeCommitリポジトリを追加
する形でブランチを追加します。# CodeCommitにgitでアクセスできるようにssh_config設定 IAM_SSH_KEY_ID={SSHキーIDを指定} echo -e "Host git-codecommit.*.amazonaws.com\n User ${IAM_SSH_KEY_ID}\n StrictHostKeyChecking no\n UserKnownHostsFile=/dev/null\n IdentityFile ~/.ssh/codecommit-pusher-key" >> ${HOME}/.ssh/config # githubからcloneしたsample-goローカルリポジトリへ移動 cd sample-go # CodeCommitのリポジトリをremote追加 git remote add codecommit ssh://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/sample-go # developブランチをPush git checkout develop git pull codecommit develop git push codecommit develop git remote remove codecommit(Productionの場合はmasterブランチに読み替えてください)
CodeCommitにPushするためのCircleCI設定
.circleci/config.ymlを見るとわかりますが、今回QA/ProductionでAWSアカウントが別れている関係で
CircleCIからPushするCodeCommitは2アカウント分となるため、SSHキー&秘密鍵が2つ必要になります。
今回は、環境ごとにdeploy_qaとdeploy_prodの2つのジョブに分けて、IAM_SSH_KEY_ID_QA / IAM_SSH_KEY_IDという
環境変数で使用するSSHキーを使い分ける形にしました。.circleci/config.ymlの該当箇所抜粋deploy_qa: 〜略〜 steps: - checkout - run: name: deploy for qa command: | echo -e "Host git-codecommit.*.amazonaws.com\n User ${IAM_SSH_KEY_ID_QA}\n StrictHostKeyChecking no\n UserKnownHostsFile=/dev/null" >> ${HOME}/.ssh/config git push ssh://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/sample-go develop deploy_prod: 〜略〜 steps: - checkout - run: name: deploy for production command: | echo -e "Host git-codecommit.*.amazonaws.com\n User ${IAM_SSH_KEY_ID}\n StrictHostKeyChecking no\n UserKnownHostsFile=/dev/null" >> ${HOME}/.ssh/config git push ssh://git-codecommit.ap-northeast-1.amazonaws.com/v1/repos/sample-go masterCircleCIの環境変数追加
Project Settings画面(https://circleci.com/gh/{GitHubアカウント名}/sample-go/edit) にアクセス
Environment Variablesをクリック
Add Variableボタンをクリック
IAM_SSH_KEY_ID/IAM_SSH_KEY_ID_QAという環境変数として、QA/Production環境で発行したSSHキーIDを追加します
CircleCIのSSH鍵追加
Project Settings画面(https://circleci.com/gh/{GitHubアカウント名}/sample-go/edit) にアクセス
SSH Permissionsをクリック
Add SSH Keyボタンをクリック
Private Key欄に codecommit-pusher-keyの内容を貼り付けます(Hostnameは空欄でOK)
Add SSH KeyボタンをクリックQA/Production環境用に発行した2つのキーを登録します
コードパイプライン設定
コードパイプライン作成
AWSマネジメントコンソールからコードパイプライン画面を開き、
パイプラインを作成するボタンをクリックパイプラインの設定を選択する
パイプライン名を入力して、
次にをクリック
ロール名は自動的に入力されます(手入力は不要です)
ソースステージを追加する
ソースプロバイダーに
AWS CodeCommitを選択
リポジトリ名にsample-goを指定し、ブランチ名にdevelopを指定して、次にをクリック
ビルドステージを追加する
プロバイダー:AWS CodeBuild
リージョン:アジアパシフィック(東京)
を選択し、プロジェクトを作成するボタンをクリックビルドプロジェクトを作成する
プロジェクト名:sample-go
環境イメージ:マネージド型イメージ
オペレーティングシステム:Ubuntu
ランタイム:Standard
イメージ:aws/codebuild/standard:2.0
特権付与:チェックOn
サービスロール:新しいサービスロール
ロール名:codebuild-sample-go-service-role
※あとで権限変更するため、ロール名を控えておくこと<追加設定>を開いて環境変数として下記入力
名前 値 入力 AWS_DEFAULT_REGION ap-northeast-1 プレーンテキスト AWS_ACCOUNT_ID 123456789012 プレーンテキスト 以降、Buildspec、ログ設定はデフォルトのまま
CodePipelineに進むをクリック
ビルドステージを追加する画面に戻るので、次にボタンをクリック
この画像には、特権付与にチェック入っていませんが必要です m(_ _)m
デプロイステージを追加する
デプロイプロバイダーに
Amazon ECSを選択
リージョン:アジアパシフィック(東京)
クラスター名:sample-go
サービス名:sample-go
次にボタンをクリック
確認画面が表示されるので、
パイプラインを作成するボタンをクリック
パイプラインが作成されると、最初のパイプライン処理が実行されます。
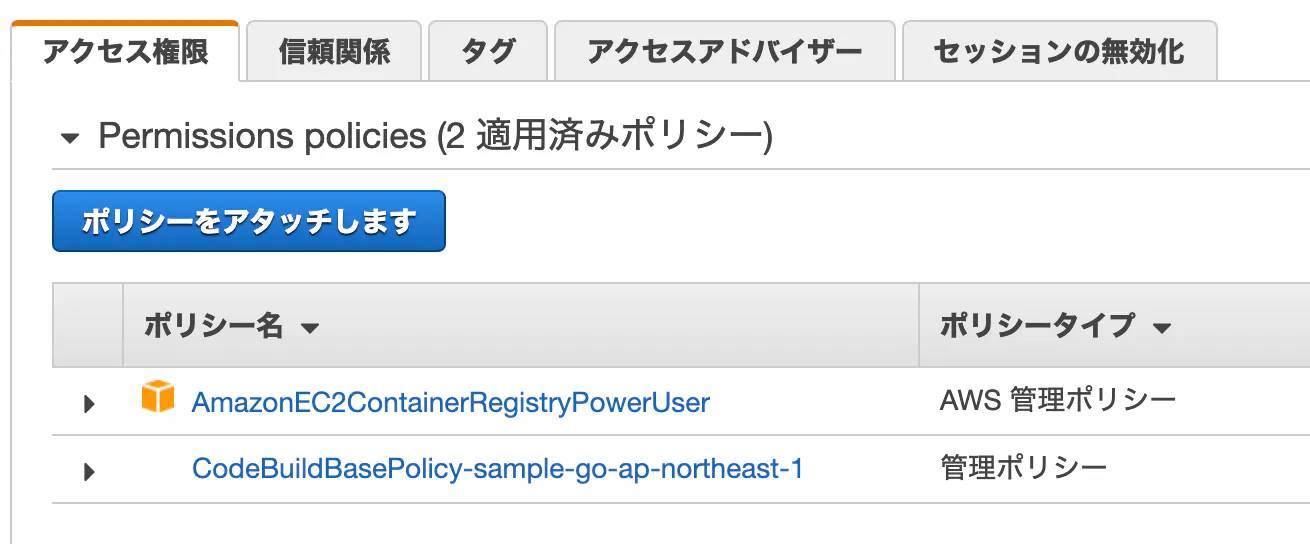
まだ設定完了ではないのでエラーになりますが、気にせずに。ECRアクセス権限付与
CodeBuildがビルドしたイメージをECRにPushするための権限を付与します。
IAMロール[codebuild-sample-go-service-role]に権限追加
※デフォルトでは、codebuild-{プロジェクト名}-service-roleというロール名になります
IAMコンソールで、上記ロールを開きます
アクセス権限タブを開きます
AmazonEC2ContainerRegistryPowerUserポリシーをアタッチします
※ここでは権限広めですが、適切に絞ってくださいー
CI/CD動作確認
feature_hogeブランチをPushした際に、golangci-lintやgo testの結果がNGであれば、その旨GitHubのプルリク上
で表示されます。CircleCIのジョブ画面でエラー詳細が確認できます。
developブランチにMergeした時には、自動的にQA環境のECS(Fargate)のサービスが更新(デプロイ)されます。
また、手順省略しましたが、Production環境用の設定も行えば、masterにMergeした時に、自動的にProductionの
ECS(Fargate)のサービスが更新(デプロイ)されるようになります。まとめ
ビルドが早い、マルチステージビルドでコンテナイメージがコンパクトにできる、ワンバイナリで動く、ということで
もともとGoとコンテナ実行の相性はいいですが、これにCI/CDができるとさらにデリバリスピードが上がるので最高ですねー。
さらに、サーバの存在を意識しなくてよいECS(Fargate)へのデプロイも、Code4兄弟が面倒をみてくれるので、
開発者だけでなく、SREにもメリットのあるかなりよい構成なので、今後もこの構成推しでいこうと思っています。あと、今回は長々とコンソールを操作する手順を紹介しましたが、本来こういう設定はCloudFormationでテンプレートを
作って自動でセットアップするのがいいと思います(実際に、弊社でもテンプレート化してそれを使って構築しています)
ですが、コンソールで操作してみるとAWS/GitHub/CircleCIの連携部分の理解が進むので、一度やってみるのを
オススメします!















- 投稿日:2019-10-23T14:37:38+09:00
Golang構成参考リンク
Goのpackage構成と開発のベタープラクティス - Tech Blog - Recruit Lifestyle Engineer
https://engineer.recruit-lifestyle.co.jp/techblog/2018-03-16-go-ddd/go言語でクリーンアーキテクチャっぽいもの | IIJ Engineers Blog
https://eng-blog.iij.ad.jp/archives/2442Goでクリーンアーキテクチャを試す | POSTD
https://postd.cc/golang-clean-archithecture/Go × Clean Architectureのサンプル実装 - 爆速でGo!
http://nakawatch.hatenablog.com/entry/2018/07/11/181453golang のレイヤ構造において、他のコードに影響なくインフラレイヤのデータソース実装を差し替えることは可能か? - pospomeのプログラミング日記
https://www.pospome.work/entry/2017/11/24/163149Goとクリーンアーキテクチャとトランザクションと - Qiita
https://qiita.com/miya-masa/items/316256924a1f0d7374bb
- 投稿日:2019-10-23T13:54:50+09:00
AtCoder過去問精選10問でGolangと触れ合ってみませんか?
【概要】
「AtCoder に登録したら次にやること ~ これだけ解けば十分闘える!過去問精選 10 問 ~」 の記事にて @drken さんがまとめてくださっているAtCoderに登録したてのエンジニアが解くべき精選10問をGolangで解答します。
Golangをこれから学習する方は Tour of Go などで入門した次のステップとして問題に取り組んでみることをオススメします。【対象者】
- Golangの基礎構文は勉強したけど、実装に自信がない方
- Golangで競技プログラミングをやってみたい方(Golangに拘りなく競技プログラミングをやってみたい方は@drkenさんの記事の方をオススメします)
【本題】
第 1 問: ABC 086 A - Product (100 点)
- 問題概要
二つの正整数 $a$ , $b$ が与えられます。 $a$ と $b$ の積が偶数か奇数か判定してください。
- 制約
- $1 ≤ a,b ≤ 10000$
- $a, b$ は整数
- 考え方
偶数判定のアルゴリズムとしては剰余算を使ったものとビット演算を使ったものの2種類が存在します。ここではよりポピュラーである剰余算を使って実装します。
fmt.Printlnはよく使うので標準出力の方法は知っていましたが、Golangで標準入力をしたことがなかったためそこだけ調べました。fmt.Scanの詳細は Go 言語で標準入力から読み込む競技プログラミングのアレ --- 改訂第二版 を参照していただければと思います。なお実際の開発においては整数以外が入力されたらとか例外を考える必要がありますが、競技プログラミングにおいては考える必要がありません。
- 解答
package main import ( "fmt" ) func main(){ var a,b int fmt.Scan(&a, &b) if a*b%2==0 { fmt.Println("Even") } else { fmt.Println("Odd") } }第 2 問: ABC 081 A - Placing Marbles (100 点)
- 問題概要
0 と 1 のみから成る 3 桁の番号 s が与えられます。1 が何個含まれるかを求めてください。
- 考え方
文字列をループで回して一文字づつ判定を行うのもいいですが、せっかくなのでstringsパッケージに何かいい関数がないかと思い調べてみました。そしたらPHPで言うところの substr_count のような関数である
strings.Count という関数を発見しました。- 解答
package main import ( "fmt" "strings" ) func main(){ var a string fmt.Scan(&a) fmt.Println(strings.Count(a, "1")) }第 3 問: ABC 081 B - Shift Only (200 点)
- 問題概要
黒板に $N$ 個の正の整数 $a_1, ..., a_N$ が書かれています。
すぬけ君は,黒板に書かれている整数がすべて偶数であるとき,次の操作を行うことができます。
- 黒板に書かれている整数すべてを, 2 で割ったものに置き換える。
すぬけ君は最大で何回操作を行うことができるかを求めてください。
- 考え方
各$a_i$に対して割り切れなくなるまで2で除算を繰り返して除算を行った回数の最小値を求めます。
最小値の初期値は非常に大きい数値としたいためInt64の最大値である 9223372036854775807 としています。
完全に私感ですがこういう問題は再帰で解答したくなります。(追記)
Int64の最大値である 9223372036854775807 を数値リテラルとして扱っていましたが、 @c-yan さんのご指摘を参考にmath.MaxInt64を使用するよう修正しております。- 制約
- $1 ≤ N ≤ 200$
- $1 ≤ A_i ≤ 10^9$
- 解答
package main import ( "fmt" "math" ) func visit(cnt, a int) int { if a%2 == 1 { return cnt } return visit(cnt+1, a/2) } func main() { var n, a, cnt int var min int = math.MaxInt64 fmt.Scan(&n) for i := 0; i < n; i++ { fmt.Scan(&a) cnt = visit(0, a) if cnt < min { min = cnt } } fmt.Println(min) }第 4 問: ABC 087 B - Coins (200 点)
- 問題概要
500 円玉を $A$ 枚、100 円玉を $B$ 枚、50 円玉を $C$ 枚持っています。これらの硬貨の中から何枚かを選び、合計金額をちょうど $X$ 円にする方法は何通りあるでしょうか?
- 制約
- $0 ≤ A,B,C ≤ 50$
- $A + B + C ≥ 1$
- $50 ≤ X ≤ 20000$
- $A,B,C$ は整数である
- $X$ は $50$ の倍数である
- 考え方
$A,B,C$ の制約が緩いため3重ループを行ったとしても 計算量は 51^3 = 132651 と非常に小さいため愚直に3重ループを行います(時間制約、メモリ制約にもよるのですが $10^8$ 程度なら時間内に実行し終えるかなという認識です)
- 解答
package main import "fmt" func main() { var a, b, c, x int fmt.Scan(&a, &b, &c, &x) cnt := 0 for i := 0; i <= a; i++ { for j := 0; j <= b; j++ { for k := 0; k <= c; k++ { if i*500+j*100+k*50 == x { cnt++ } } } } fmt.Println(cnt) }第 5 問: ABC 083 B - Some Sums (200 点)
- 問題概要
$1$ 以上 $N$ 以下の整数のうち、$10$ 進法で各桁の和が $A$ 以上 $B$ 以下であるものについて、総和を求めてください。
- 制約
- $1 ≤ N ≤ 10^4$
- $1 ≤ A ≤ B ≤ 36$
- 入力はすべて整数
- 考え方
10進数の取り扱いに関しての問題です。今回は各桁の値を扱う必要があるので 10 による剰余算と除算の繰り返しを行います。3問目と同じく再帰関数を用いて解答していますがforループでも問題ないです。
- 解答
package main import ( "fmt" ) func visit(x int) int { if x == 0 { return 0 } return visit(x/10) + x%10 } func main() { var n, a, b int fmt.Scan(&n, &a, &b) res := 0 for i := 1; i <= n; i++ { sum := visit(i) if a <= sum && sum <= b { res += i } } fmt.Println(res) }第 6 問: ABC 088 B - Card Game for Two (200 点)
- 問題概要
$N$ 枚のカードがあり、$i$ 枚目のカードには $a_i$ という数が書かれています。
Alice と Bob はこれらのカードを使ってゲームを行います。ゲームでは 2 人が交互に 1 枚ずつカードを取っていきます。Alice が先にカードを取ります。
2 人がすべてのカードを取ったときゲームは終了し、取ったカードの数の合計がその人の得点になります。2 人とも自分の得点を最大化するように最適戦略をとったとき、Alice は Bob より何点多くの得点を獲得できるかを求めてください。- 制約
- $N$ は $1$ 以上 $100$ 以下の整数
- $a_i$ は $1$ 以上 $100$ 以下の整数
- 考え方
2 人とも自分の得点を最大化するように最適戦略をとったとき
というのは各手番において場に残っているカードの中から最大値のカードを選択するとなります。ちなみに部分問題(今回の場合は各手番)において局所最適解を求める(今回の場合は最大値のカードを選択する)ということを繰り返すアルゴリズムを貪欲法と言います。
また最終的な解答はAlice, Bobそれぞれ何点獲得出来るか?ではなくてAliceはBobより何点多くの得点を獲得できるかなので、それぞれの得点を求めて差分を求める方法でもAliceの得点を加点・減点を繰り返す方法でもどちらでもいいです。例えば、カードが $1, 3, 5, 7, 9$だった場合に
- $(9 + 5 + 1) - (7 + 3) = 5$
- $+ 9 - 7 + 5 - 3 + 1 = 5$
のどちらのアルゴリズムであっても最終的な値は変わらないということです。(私は後者でアルゴリズムで解答しております。)
各手番において最大値を求めるとオーダーが増加するのでソートを行います。
- 解答
package main import ( "fmt" "sort" ) func main() { var n int fmt.Scan(&n) cards := make([]int, n) for i := 0; i < n; i++ { fmt.Scan(&cards[i]) } sort.Ints(cards) res := 0 operator := 1 for i := n - 1; i >= 0; i-- { res += cards[i] * operator operator *= -1 } fmt.Println(res) }第 7 問: ABC 085 B - Kagami Mochi (200 点)
- 問題概要
$X$ 段重ねの鏡餅 $(X ≥ 1)$ とは、$X$ 枚の円形の餅を縦に積み重ねたものであって、どの餅もその真下の餅より直径が小さい(一番下の餅を除く)もののことです。例えば、直径 $10$、$8$、$6$ センチメートルの餅をこの順に下から積み重ねると $3$ 段重ねの鏡餅になり、餅を一枚だけ置くと $1$ 段重ねの鏡餅になります。
ダックスフンドのルンルンは $N$ 枚の円形の餅を持っていて、そのうち $i$ 枚目の餅の直径は $d_i$ センチメートルです。これらの餅のうち一部または全部を使って鏡餅を作るとき、最大で何段重ねの鏡餅を作ることができるでしょうか。- 制約
- 1 ≤ N ≤ 100
- 1 ≤ d_i ≤ 100
- 入力値はすべて整数である。
- 考え方
競技プログラミングの問題は国語能力を問われているのか、やたら文章が冗長で要約されていない事が多々あります。この問題もやたら長いですが要約すると
$N$ 個の整数 $d[0],d[1],…,d[N−1]$ が与えられます。
この中に何種類の異なる値があるでしょうか?となります。
(追記)
@c-yan さんの指摘によりmapとlenを活用すると分かりやすいと気づきました。なおmapの要素に使用している $1$ は特に意図はないです。- 解答
package main import "fmt" func main() { var n int fmt.Scan(&n) nums := map[int]int{} for i := 0; i < n; i++ { var tmp int fmt.Scan(&tmp) nums[tmp] = 1 } fmt.Println(len(nums)) }第 8 問: ABC 085 C - Otoshidama (300 点)
- 問題概要
10000 円札と、5000 円札と、1000 円札が合計で $N$ 枚あって、合計金額が $Y$ 円であったという。このような条件を満たす各金額の札の枚数の組を 1 つ求めなさい。そのような状況が存在し得ない場合には -1 -1 -1 と出力しなさい。
- 制約
- $1 ≤ N ≤ 2000$
- $1000 ≤ Y ≤ 2∗10^7$
- $N$ は整数
- $Y$ は $1000$ の倍数
- 考え方
第4問目と同じように3重ループで解答してしまうと最大の計算量は $2000 * 2000 * 2000 = 8000000000$ となり、タイムアウトエラーしてしまいます。なので愚直に3重ループで解答するのではなく、一工夫が必要になります。
今回の場合、合計枚数が20枚で10000円札が10枚、5000円札が8枚だったとしたら1000円札は $20-(10+8)=2$ 枚となります。したがって合計枚数、10000円札の枚数、5000円札の枚数が決まれば1000円札の枚数が決まるので、2重ループで十分であり最大の計算量は $2000 * 2000 = 4000000$ となり時間内に解答できる計算量となります。
- 解答
package main import "fmt" func main() { var n, y int fmt.Scan(&n, &y) for i := 0; i <= n; i++ { for j := 0; i+j <= n; j++ { if 10000*i+5000*j+1000*(n-i-j) == y { fmt.Println(i, j, (n - i - j)) return } } } fmt.Println(-1, -1, -1) }第 9 問: ABC 049 C - Daydream (300 点)
- 問題概要
英小文字からなる文字列 $S$ が与えられます。
$T$ が空文字列である状態から始めて、以下の操作を好きな回数繰り返すことで $S=T$ とすることができるか判定してください。$T$ の末尾に "dream", "dreamer", "erase", "eraser" のいずれかを追加する。
- 制約
- $1≤|S|≤10^5$
- $S$ は英小文字からなる
- 考え方
空文字列の末尾に "dream", "dreamer", "erase", "eraser" のいずれかを追加することを繰り返して最終的に $S$ になるかを調べるよりも、 $S$ から "dream", "dreamer", "erase", "eraser" のいずれかを空文字列に置換することを繰り返して最終的に空文字列になるかを調べた方が楽です。
難しい点としては 例えば $S$ が "dreamerase" だった場合に "dream" を空文字列に置換して、残った "erase" を空文字列に置換すれば $S$ が空文字列とできるのに対して、 "dreamer" を空文字列に置換してしまうと "ase" が残ってしまうため $S$ を空文字列に置換できない点にあります。したがって単純に貪欲法を採用してしまうと各手順だけでは局所最適解を求めることが出来ません。
この問題のアルゴリズムは2つあると思いますので、どちらも紹介したいと思います。
- $S$ の末尾から置換を繰り返す
- "dream", "dreamer", "erase", "eraser"の末尾3文字に注目すると "eam", "mer", "ase", "ser" となり、いずれも重複していないことがわかります。したがって末尾から置換していけば重複を意識することなく貪欲法が採用できます。
- 先ほどの例でいうと "dreamerase" の末尾を置換できるのは "erase" だけであり、残った "dream" を置換できるのは "dream" だけになります。
- 段階的に置換を繰り返す
- "dream" と "dreamer" および "erase" と "eraser" のどちらを空文字列に置換すればいいのかが、その手順においては分からないというのが難しいので一気に空文字列に置換するのではなく適当な文字(英小文字以外)に置換して段階を踏めば正しく置換することが出来ます。その手順を以下に示します。
- まず "dream" を "A" に、 "erase" を "B" に置換します
- 次に "Aer" および "Br" を空文字列に置換します
- 最後に "A" および "B" を空文字列に置換します
- 先ほどの例でいうと "dreamerase" を "AB" に置換して、 "AB" を空文字列に置換します
今回は $S$ の末尾から置換を繰り返す で実装しています。また競技プログラミングにおいてはパフォーマンスの観点で悪手だと思いましたが、Golangの勉強のためにあえて正規表現を使った解答をしております。
※あくまで個人的な主観ですが精選10問の中でこの問題が一番難しいように感じます。
(追記)
@c-yan さんに指摘して修正していただいたコードが読みやすかったため、修正していただいたコードをそのまま採用させていただいております。- 解答
package main import ( "fmt" "regexp" ) func main() { var str string fmt.Scan(&str) reps := []*regexp.Regexp{regexp.MustCompile("dream$"), regexp.MustCompile("dreamer$"), regexp.MustCompile("erase$"), regexp.MustCompile("eraser$")} for { flg := false for _, rep := range reps { if rep.MatchString(str) { str = rep.ReplaceAllString(str, "") flg = true } } if !flg { break } } if str == "" { fmt.Println("YES") } else { fmt.Println("NO") } }第 10 問: ABC 086 C - Traveling (300 点)
- 問題概要
シカの AtCoDeer くんは二次元平面上で旅行をしようとしています。AtCoDeer くんの旅行プランでは、時刻 $0$ に 点 $(0,0)$ を出発し、$1$ 以上 $N$ 以下の各 $i$ に対し、時刻 $t_i$ に 点 $(x_i,y_i)$ を訪れる予定です。
AtCoDeer くんが時刻 $t$ に 点 $(x,y)$ にいる時、 時刻 $t+1$ には 点 $(x+1,y),(x−1,y),(x,y+1),(x,y−1)$ のうちいずれかに存在することができます。その場にとどまることは出来ないことに注意してください。AtCoDeer くんの旅行プランが実行可能かどうか判定してください。
- 制約
- $1 ≤ N ≤ 10^5$
- $0 ≤ x_i,y_i ≤ 10^5$
- $1 ≤ t_i ≤ t_{i+1} ≤ 10^5$
- 入力はすべて整数
- 考え方
問題を読んですぐに思いつくアルゴリズムは深さ優先探索ではないかと思います。ただし各手順において取れる行動は $4$ 通りあり、かつ手順は最大で $10^5$ あるので最大計算量は $4^{10^5}$ で Google先生で値を求めようとしたところInfinityとなったため、タイムアウトエラーしてしまうでしょう。
この問題で着目すべき点は2点あります。
- $(x_i, y_i)$ に最短で向かった場合に $t_i$ までに到達できるかどうか
- 例えば $t_1$ が 1 で、 $x_1$ = 100, $y_1$ = 100 である場合に、 $t_1$ に到達できるのは $(0, 1), (1, 0)$ のいずれかであるため到底 $(100, 100)$ に到達することはできません
- $(x_i, y_i)$ に最短で向かった場合に 到達した時刻と $t_i$ の差分が偶数かどうか
- 例えば $t_1$ が 10 で、 $x_1$ = 2, $y_1$ = 4 である場合に、 $(2, 4)$ に最短で到達できる時刻は 6 になります(これを仮に $t_j$ とします)。余った時刻は $(2, 4)$ と $(2, 5)$ を往復した場合に $t_i$ に $(x_i, y_i)$ に到達できるのは $t_i$ と $t_j$ の差分が偶数の場合のみです
したがって条件としては全ての $x_i, y_i, t_i$ に関して以下を満たすことになります
- $|x_i - x_{i-1}| + |y_i - y_{i-1}| <= t_i - t_{t-1}$
- $mod(|x_i - x_{i-1}| + |y_i - y_{i-1}|, 2) = mod(t_i - t_{t-1}, 2)$
- 解答
package main import ( "fmt" "math" ) func main() { var n int fmt.Scan(&n) t := map[int]int{0: 0} x := map[int]int{0: 0} y := map[int]int{0: 0} for i := 1; i <= n; i++ { var xi, yi, ti int fmt.Scan(&ti, &xi, &yi) t[i] = ti x[i] = xi y[i] = yi } res := true for i := 1; i <= n; i++ { dx := int(math.Abs(float64(x[i] - x[i-1]))) dy := int(math.Abs(float64(y[i] - y[i-1]))) dt := int(math.Abs(float64(t[i] - t[i-1]))) if dx+dy > dt || (dx+dy)%2 != dt%2 { res = false } } if res { fmt.Println("Yes") } else { fmt.Println("No") } }【まとめ】
これであなたもGolang入門卒業!!
- 投稿日:2019-10-23T09:50:21+09:00
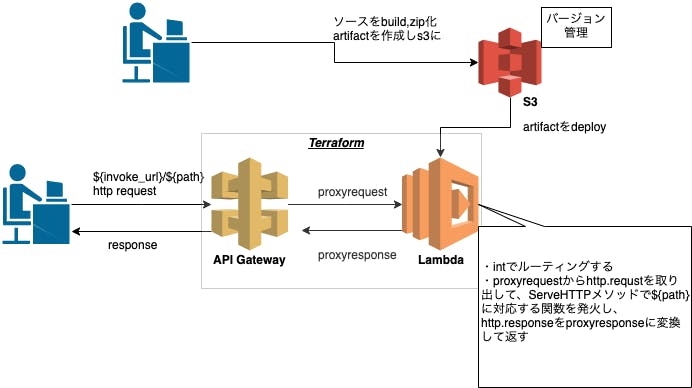
Lambda proxy integration×Go(echo)×Terraformでお手軽Web API(サーバレス)
はじめに
サーバレスで手軽にWeb APIを立てたい場合、API Gatewayのproxy integrationとlambdaアプリケーションソースでのルーティングでこんなに簡単にお安く構築できるんだな〜と感心してしまったのでそのご紹介と、そのリソース群のTerraform moduleを作ってTerraform Registryに公開したのでその内容の紹介で記事を書いてみました。
(しかも最近VPC Lambdaのコールドスタートが大幅に改善されたばかり -> [発表] Lambda 関数が VPC 環境で改善されます | Amazon Web Services ブログ )lambda proxy integrationのmodule,S3のartifact指定できるやつなかったので作って、Terraform Registryに公開した?https://t.co/jJxfruBDQ6
— nari@BOOTHで好評発売中「GoとAWS CDKで作る本格SlackBot入門」 (@fukubaka0825) October 22, 2019後はついでに、Terraform入門資料(v0.12.0対応) ~基本知識から設計や運用、知っておくべきtipsまで~ - Qiitaでは詳しく書けなかったlambdaリソースのアプリとインフラのデプロイの疎結合化についてもSampleを紹介しています。
対象
- AWS Lambdaを使ってWeb API立ててみたいなと思っていた方
- AWS Lambdaリソースのアプリとインフラのデプロイの疎結合化のサンプルに興味がある方
前提
- 標準のnet/httpを用いたルーティングでも可能ですが、今回はフレームワークとしてechoを使用しています
- Lambda proxy integrationとは? -> API Gateway の Lambda プロキシ統合をセットアップする - Amazon API Gateway
- 今回作成したterraformのmoduleはこちら
開発環境
- Terraform v0.12.6
- Go v1.12.4
システム全体像
リポジトリ構成
├── Makefile ├── README.md ├── go.mod ├── go.sum ├── main.tf ├── modules │ ├── iam_role │ │ ├── main.tf │ │ ├── outputs.tf │ │ └── valiables.tf │ └── sg │ ├── main.tf │ ├── outputs.tf │ └── valiables.tf ├── outputs.tf └── source └── main.goまた、サンプルコードは、公開したmoduleのexampleとして公開しています
terraform-aws-lambda-proxy-integration/go1.x_examples at master · fukubaka0825/terraform-aws-lambda-proxy-integration · GitHubTerraformのコード紹介
main.tfmodule "sample_api"{ source = "fukubaka0825/lambda-proxy-integration/aws" //❶ version = "1.0.2" apigw_name = "sample-api" function_name = "sample-api" lambda_role = module.lambda_role.iam_role_arn // The repo's name and object key where source code artifact exists s3_bucket = data.terraform_remote_state.storage.outputs.s3_serverless_app_bucket.name s3_key = "lambda/sample.zip" // If you want to use vpc lambda,required security_group_ids = [module.http_sg.security_group_id] //❷ subnet_ids = module.vpc.app_subnets }❶ 今回API proxy integration+S3のartifactをlambdaのソースとして指定できるmoduleを作成したので、そちらを指定しています(Terraform Registry)
❷ security_group_idsとsubnet_idsは、VPC lambaのモードならば指定します。Goのコード紹介
main.gopackage main import ( "github.com/labstack/echo" "log" "context" "net/http" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" echolamda"github.com/awslabs/aws-lambda-go-api-proxy/echo" ) var echoLambda *echolamda.EchoLambda //❶ func init() { // stdout and stderr are sent to AWS CloudWatch Logs log.Printf("Echo cold start") e := echo.New() //❷ //ここでルーティング e.GET("/ping", func(c echo.Context) error{ return c.NoContent(http.StatusNoContent) }) echoLambda = echolamda.New(e) } func Handler(ctx context.Context, req events.APIGatewayProxyRequest) (events.APIGatewayProxyResponse, error) { // If no name is provided in the HTTP request body, throw an error // 中でServeHTTPを叩いている return echoLambda.ProxyWithContext(ctx, req) //❸ } func main() { lambda.Start(Handler) }❶ コールドスタートの関係上、globalにechoLambdaを宣言するのがセオリーっぽいです。
❷ initでroutingを設定します。ここではechoを使っていますが、もちろん自由なフレームワークなりnet/httpなりで設定可能です。
❸ 本来ならば、proxyrequestからhttp.requstを取り出して、ServeHTTPメソッドで${path}に対応する関数を発火し、http.responseをproxyresponseに変換して返す処理を自前で書く必要がありますが、GitHub - awslabs/aws-lambda-go-api-proxy: lambda-go-api-proxy makes it easy to port APIs written with Go frameworks such as Gin (https://gin-gonic.github.io/gin/ ) to AWS Lambda and Amazon API Gateway.という素晴らしいawslabsが提供しているmoduleで同じようなことをやってくれるものがあるのでそれを利用しています。(なんとgin,echo,net/httpなど主要なパッケージには対応してくれている、最高)lambdaリソースのアプリとインフラのデプロイを疎結合にする運用
Terraform入門資料(v0.12.0対応) ~基本知識から設計や運用、知っておくべきtipsまで~ - Qiitaの3.4 lambdaリソースを扱う場合のインフラとアプリの密結合問題でも扱いましたが、Terraformのみでデプロイを完結させるとインフラとアプリが密結合になってしまいます。その解消法の具体例の話をここではしようと思います。
Makefileを作成する
MakefileLAMDA_SOURRE_REPO=serverless-app LAMDA_SOURRE_KEY=lambda/sample.zip LAMDA_SOURCE_PATH=s3://${LAMDA_SOURRE_REPO}/${LAMDA_SOURRE_KEY} deploy_dummy_code: //❶ aws s3 cp .build/dummy.zip ${LAMDA_SOURCE_PATH} build_update: //❷ GOOS=linux GOARCH=amd64 go build -o .build/main source/main.go cd .build && zip -r sample.zip ./ aws s3 cp .build/sample.zip ${LAMDA_SOURCE_PATH} aws lambda update-function-code --function-name sample-search-api --s3-bucket ${LAMDA_SOURRE_REPO} --s3-key ${LAMDA_SOURRE_KEY} echo 'Success to lambda update!'❶ dummyのzipを
LAMDA_SOURCE_PATHにあげる処理をdeploy_dummy_codeコマンドに仕込んでいます。
❷ 本当のlambdaソースのコードを、buildしてzipにし、LAMDA_SOURCE_PATHにあげて、aws lambda update-function-codeコマンドでlambdaのソースをアップデートする処理をbuild_updateコマンドに仕込んでいます。Makefileを用いたデプロイ運用
// Put dummy code into S3 repo. make deploy_dummy_code //❶ // deploy infra terraform init //❷ terraform plan terraform apply // deploy app(lambda) make build_update //❸❶ まず
deploy_dummy_codeコマンドで、S3にdummyのコードをあげます。
❷ ❶のコードを参照させる形で、lambdaのインフラ部分をデプロイします。
❸ 最後に、build_updateで本当のlambdaのアプリ部分をデプロイします。終わりに
VPC lambdaはコールドスタートの改善によって、レスポンスの要件が非常にシビアでないWeb APIの構築ツールとして、かなり魅了的なものになってきたと思います。
データソースとのつなぎこみは、RDSのようにスケールしづらく、コネクション制限があるものとのやりとりはまだまだ使い勝手が悪い(internalなAPI経由にすれば解決しますが)ですが、スケールしやすい分散型のデータソース(DynamoDB、ElasticSearch,redis)とのやりとりなら全然使っていけそうだなという印象です。
また、この記事で使ったmoduleは、初めてPublic ModuleをTerraform Registry公開してみましたが、これからもどんどん公開できるものは公開していきたいと思います。
参考文献