- 投稿日:2019-10-21T22:50:45+09:00
docker-compose+Rails+Mysqlでサーバー起動まで
はじめに
Dockerを使って開発演習が出来たことに感動したので、その嬉しさの勢いと、アウトプットとして書きます。また、Dockerの仕組みが分からなくても、以下に従っていけば、とりあえず構築できます。
環境
- Docker for Windows
- VScode
- Windows10 Pro
- Mysql
Windowsを使ってますが、基本的にmacの方も、DockerとMysqlがインストールされていれば大丈夫です。
Dockerがインストールされているかの確認
docker --version Docker version 18.09.1, build 4c52b90Dockerの起動
デスクトップにあるクジラのアイコンをクリックすると、起動します。右下のバーにクジラアイコンがあれば、Dockerが起動しています。
Railsアプリ用のディレクトリを作成
例えば現在のディレクトリがrailsというディレクトリだとします。
$ pwd /railsそして、これから作成するアプリ用のディレクトリを以下のように作り、そこに移動します。ここでは、ディレクトリ名をdocker_sample_appとします。
$ mkdir docker_sample_app $ cd docker_sample_app $ pwd /rails/docker_sample_appDockerファイルなどの準備
以下の4つのファイルを作成してください。
$ touch docker-compose.yml Dockerfile Gemfile Gemfile.lockそして、VScode内でファイルを変更していきます。
docker-compose.ymlversion: '3' services: db: image: mysql:5.7 ports: - "3306:3306" restart: always environment: - MYSQL_DATABASE=app_name_db - MYSQL_ROOT_PASSWORD=password volumes: - ./data:/var/lib/mysql:rw command: --innodb_use_native_aio=0 web: build: . command: bundle exec rails s -p 3000 -b '0.0.0.0' volumes: - .:/app_name ports: - "3000:3000" depends_on: - db environment: DB_HOST: dbDockerfile.FROM ruby:2.5.3 ENV LANG C.UTF-8 RUN apt-get update -qq && apt-get install -y build-essential libpq-dev nodejs RUN gem install bundler WORKDIR /tmp ADD Gemfile Gemfile ADD Gemfile.lock Gemfile.lock RUN bundle install ENV APP_HOME /app_name RUN mkdir -p $APP_HOME WORKDIR $APP_HOME ADD . $APP_HOMEdocker-compose.ymlは上から9, 18行目のapp_nameを、Docker.fileは下から4行目の箇所を、先ほど作成したディレクトリ名に変えてください。(ここではdocker_sample_app)
docker-compose.yml内にportが二つあります。db側はmysql workbenchからアクセスするためのポートで、web側はブラウザでlocalhostでアクセスするためのものです。
正直workbenchは今回のサーバ起動までという目的には含まれてないので、気にしなくて大丈夫です。Gemfile.source 'https://rubygems.org' gem 'rails'Gemfile.lockは空で問題ないです。
Railsアプリの作成
ターミナルで、このコマンドをうってください。
$ docker-compose run web rails new . -d mysql --skip-bundle途中で
Overwrite /docker_sample_app/Gemfile? (enter "h" for help) [Ynaqdhm]と聞かれます。そこは、「y」とタイプしてください。 すると、ディレクトリ内にrails newした時と同じようなファイルが作成されているのが分かると思います。 次に、プロジェクトをビルドします。
$ docker-compose buildこのコマンドでDockerfileの内容が実行されます。 おめでとうございます。あと、もうすこしです。
サーバーを立ち上げる
以下のコマンドをうつことで、サーバーを立ち上げれます。
$ docker-compose up -dこの状態でブラウザに行って、localhostにアクセスしようとすると、
Can't connect to local MySQL server through socket '/var/run/mysqld/mysqld.sock' (2 "No such file or directory")といったエラーが出ると思います。これは、まだdatabaseファイルを設定していないからです。なので、変更してあげます。
database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: root password: password host: <%= ENV['DB_HOST'] %> development: <<: *default database: app_name_development test: <<: *default database: app_name_test今回は、本番環境を用意する必要ではないので、Productionは消しました。先ほどと同じように、app_nameをディレクトリ名(docker_sample_app_developmentのように)に変更してください。
そしたら、データベースファイルをいじったので、サーバーを再起動します。
$ docker-compose down $ docker-compose up -dそして、ブラウザをリロードすると、違うエラーが出ます。
Unknown database 'app_name_development'これは、「データベースを作成してください」というエラーなので、言われるがままにデータベースを作りましょう。
docker-compose exec web rails db:createブラウザに戻ってください。localhost:3000にアクセスすると無事、例の画面が出るはずです!!!
これで今回の目標は達成されました!
docker-composeのコマンドについて
rails c, rails db:createなどのコマンドがありますが、docker-composeを使うときは、以下のコマンドを必ずその前に付けなければなりません。
docker-compose exec webなので、例えば、データベースを作りたい時は
docker-compose exec web rails db:createとなります!
ちなみにrails sコマンドは使いません。
docker-compose up -dでサーバが起動するからです。[番外編]
ルーティングファイルなどを変更したらサーバーを再起動させますが、viewsファイルに関しては変更してもサーバの再起動は、必要ないのですが、反映されないことが分かりました。その場合は、development.rbファイルを変更する必要があることが分かりました。
development.rbconfig.file_watcher = ActiveSupport::EventedFileUpdateCheckerのEventedFileUpdateCheckerのところをFileUpdateCheckerに変更します。
development.rbconfig.file_watcher = ActiveSupport::FileUpdateChecker参考にさせていただいた記事


- 投稿日:2019-10-21T21:05:54+09:00
[Ruby]FileUtils.cpの内部処理を調べる
目的
- 以下を実行した際の内部処理を調べる。
sample.rbrequire 'fileutils' FileUtils.cp 'src_file', 'dest_file'
- Rubyのバージョンは2.4.0。
- RubyのソースはGitHubから確認できます。
cpメソッド
- まず、FileUtils.cpを実行すると、fileutils.rbのcpメソッドが呼ばれる。
fileutil_cp.rb346: def cp(src, dest, preserve: nil, noop: nil, verbose: nil) 347: fu_output_message "cp#{preserve ? ' -p' : ''} #{[src,dest].flatten.join ' '}" if verbose 348: return if noop 349: fu_each_src_dest(src, dest) do |s, d| 350: copy_file s, d, preserve 351: end 352: end
- cpメソッドの引数は以下の通り。
引数 説明 src コピー元のファイル、配列でもOK dest コピー後ファイル、ディレクトリでもOK preserve ファイルの属性を保持するかどうか。何も指定しなければ保持しない。 noop ヌープ。ヌープにnil以外を指定すれば、何も実行されない。 verbose nil以外を指定すれば「cp -p src dest」みたいにコピーコマンド調に出力してくれる。
- なお、preserve, noop, verboseはhashで渡す必要あり。
fu_output_messageメソッド
- verboseにnil以外を渡した場合はfu_output_messageメソッドが実行される。
- なので、fu_output_messageメソッドを見てみる。
fileutil_cp.rb1481: @fileutils_output = $stderr 1482: @fileutils_label = '' 1483: 1484: def fu_output_message(msg) #:nodoc: 1485: @fileutils_output ||= $stderr 1486: @fileutils_label ||= '' 1487: @fileutils_output.puts @fileutils_label + msg 1488: end 1489: private_module_function :fu_output_message
- 1481行目で@fileutils_outputに標準エラーを代入する。
- 1482行目で@fileutils_labelに空文字を代入する。
- さらに、fu_output_messageメソッドの中で@fileutils_outputが偽または未定義なら標準エラーを代入する。(今回はエラーは出ていないので、何もなし)
- @fileutils_labelも同様に偽または未定義なら空文字を代入する。
- 最後に@fileutils_outputのputsメソッドを実行する。putsメソッドの引数としては@fileutils_labelとmsgとなる。
- 標準エラーはIOクラスなので、putsメソッドを持っている。
cpメソッド
- cpメソッドに戻ってヌープがnil以外ならその場でリターン
- 次はfu_each_src_destメソッドを実行。
fileutil_cp.rb346: def cp(src, dest, preserve: nil, noop: nil, verbose: nil) 347: fu_output_message "cp#{preserve ? ' -p' : ''} #{[src,dest].flatten.join ' '}" if verbose 348: return if noop 349: fu_each_src_dest(src, dest) do |s, d| 350: copy_file s, d, preserve 351: end 352: endfu_each_src_destメソッド
- fu_each_src_destメソッドは引数がsrc,dest
- その中でfu_each_src_dest0という似た名前のメソッドを呼ぶ。
- その前にfu_same?メソッドでsrc, destが同じファイルがどうかを判断している。
- src, destが同じファイルならArgumentErrorをraiseしている。
fileutil_cp.rb1451: def fu_each_src_dest(src, dest) #:nodoc: 1452: fu_each_src_dest0(src, dest) do |s, d| 1453: raise ArgumentError, "same file: #{s} and #{d}" if fu_same?(s, d) 1454: yield s, d 1455: end 1456: endfu_same?メソッド
- fu_same?メソッドではFileTest.#identical?メソッドを使用。
- その後、fu_each_src_dest0メソッドを呼ぶ。
fileutil_cp.rb1476: def fu_same?(a, b) #:nodoc: 1477: File.identical?(a, b) 1478: endfu_each_src_dest0メソッド
- 1460行目はコピー元ファイルを配列で指定したかの判定
- 1460行目がTRUEの場合
- Array.try_convertは引数をto_aするらしい。
- 引数にto_aがなければnilを返すので、TRUEならsrcが配列、FALSEなら単一ファイルとなる。
- srcが配列なら配列一つ一つに対して、yieldして、その一つ一つが1466行目に行く感じ。
- 1460行目がFALSEの場合
- コピー後ファイルがファイルではなく、ディレクトリだったらコピー元ファイル名を取って、またyieldするので、最終的には1470行目に行く感じ。
fileutil_cp.rb1459: def fu_each_src_dest0(src, dest) #:nodoc: 1460: if tmp = Array.try_convert(src) 1461: tmp.each do |s| 1462: s = File.path(s) 1463: yield s, File.join(dest, File.basename(s)) 1464: end 1465: else 1466: src = File.path(src) 1467: if File.directory?(dest) 1468: yield src, File.join(dest, File.basename(src)) 1469: else 1470: yield src, File.path(dest) 1471: end 1472: end 1473: endfu_each_src_dest0メソッド
- fu_each_src_dest0メソッドに戻ってきました。
- 今回はもちろんfu_same?(s, d)はFALSEなので、エラーは出ません。
- 1454行目でやっと本丸のcopy_fileメソッドが呼ばれる。
fileutil_cp.rb1451: def fu_each_src_dest(src, dest) #:nodoc: 1452: fu_each_src_dest0(src, dest) do |s, d| 1453: raise ArgumentError, "same file: #{s} and #{d}" if fu_same?(s, d) 1454: yield s, d 1455: end 1456: endcopy_fileメソッド
- copy_fileメソッドではコピー元、コピー先、属性保持するかとdereferenceが引数。
- dereferenceっていうのは、何のことかわからず。。
- Entry_クラスのインスタンスを生成している。
- Entry_クラスはinternal use onlyのクラスらしい。。。
fileutil_cp.rb421: def copy_file(src, dest, preserve = false, dereference = true) 422: ent = Entry_.new(src, nil, dereference) 423: ent.copy_file dest 424: ent.copy_metadata dest if preserve 425: end
- copy_fileメソッドではsrcファイルを開いて、IO.copy_streamを行う。
fileutil_cp.rb1281: def copy_file(dest) 1282: File.open(path()) do |s| 1283: File.open(dest, 'wb', s.stat.mode) do |f| 1284: IO.copy_stream(s, f) 1285: end 1286: end 1287: endまとめ
- コピー処理の本質はIOクラスのcopy_streamメソッド。
- 自分が知らないメソッド(File.identical?、File.directory?)やyieldの使い方など、色々勉強になりますね。
- 投稿日:2019-10-21T20:10:58+09:00
【駆け出しWEBエンジニアのメモ】ターミナルへの文字入力と表示_1(Ruby)
※TECH::EXPERTで学び始めた駆け出しエンジニアのメモです!
タイトルの通りですが、ターミナルから文字を入力し、
ターミナル上に入力した文字を表示します。基本的な書き方から、ハッシュを用いて少し応用した書き方までを順々に記載します。
1. 基礎的な入力と表示
まずは、以下の「gets」を使ってコードを書きます。
ちなみにここでは意図しない改行を防ぐべく、「.chomp」を追記してます。a = gets.chomp #aにターミナルからなにかしら入力 b = gets.chomp #bにターミナルからなにかしら入力 c = gets.chomp #cにターミナルからなにかしら入力 puts a puts b puts c以下の通り、「あ」「い」「う」と入力すると、「あ」「い」「う」と表示されます。
maedamasaterunoMacBook-Pro:desktop xxxxxxx$ Ruby sample1.rb あ い う あ い う2. 分かりやすくするために入力指示のコメント追記
puts "なにか入力してよ(1/3)" a = gets.chomp #aにターミナルからなにかしら入力 puts "なにか入力してよ(3/3)" b = gets.chomp #bにターミナルからなにかしら入力 puts "なにか入力してよ(3/3)" c = gets.chomp #cにターミナルからなにかしら入力 puts a puts b puts cそうすると、1つ目の「あ」を入力する前に「なにか入力してよ(1/3)」というコメントができました。
「い」「う」にも同様にコメントをつけました。maedamasaterunoMacBook-Pro:desktop xxxxxxx$ Ruby sample1.rb なにか入力してよ(1/3) あ なにか入力してよ(3/3) い なにか入力してよ(3/3) う あ い う3. さらにハッシュでまとめます
# 空のハッシュを宣言 post = {} # 要素の追加 puts "なにか入力してよ(1/3)" post[:a] = gets.chomp puts "なにか入力してよ(2/3)" post[:b] = gets.chomp puts "なにか入力してよ(3/3)" post[:c] = gets.chomp # レビューの描画 puts post #まとめて表示も可能 puts post[:a] puts post[:b] puts post[:c]同じく、「あ」「い」「う」と入力すると、「あ」「い」「う」と表示されます。
さらに「puts post」だけにすると、
{:a=>"あ", :b=>"い", :c=>"う"}
というように、内部に格納された全てが表示されます。なにか入力してよ(1/3) あ なにか入力してよ(2/3) い なにか入力してよ(3/3) う {:a=>"あ", :b=>"い", :c=>"う"} あ い う4. 表示にもコメントしたい
このままだと、表示は「あ」「い」「う」が並ぶだけの味気ない感じで終わるので、
少しコメントを表示できるようにします。# 空のハッシュを宣言 post = {} # 要素の追加 puts "なにか入力してよ(1/3)" post[:a] = gets.chomp puts "なにか入力してよ(2/3)" post[:b] = gets.chomp puts "なにか入力してよ(3/3)" post[:c] = gets.chomp # レビューの描画 puts post #まとめて表示も可能です puts "入力1つ目 : #{post[:a]}" puts "入力2つ目 : #{post[:b]}" puts "入力3つ目 : #{post[:c]}"こちらも同じく、「あ」「い」「う」と入力すると、「あ」「い」「う」と表示されます。
が、それぞれの文字の前に「入力1つ目 :」「入力2つ目 :」「入力3つ目 :」が表示されました。
”文字 #{ 式 }” とすることで、変数と文字を組み合わせることができます。なにか入力してよ(1/3) あ なにか入力してよ(2/3) い なにか入力してよ(3/3) う {:a=>"あ", :b=>"い", :c=>"う"} 入力1つ目 : あ 入力2つ目 : い 入力3つ目 : う
- 投稿日:2019-10-21T18:26:15+09:00
Railsのcheck_boxにデフォルトでチェックを付ける方法
環境
- Rails 5.2.3
- Ruby 2.6.5
失敗例
check_boxに{ checked: true }をつけるとチェックは付きますが、チェックを外してもtrueがサーバに送られてしまいます。<%= f.check_box :published, { checked: true }, true, false %>成功例
controllerで
newする時にセットします。def new @book = Book.new(published: true) end
check_boxに{ checked: true }は付けない。<%= f.check_box :published, {}, true, false %>
- 投稿日:2019-10-21T18:14:17+09:00
ガチ調査版::2019年プログラミング言語 求人人気ランキング
背景
実求人をクロールし、どの言語がどれだけ求人を保有しているか実数を取得し、年収別の求人数から総合ランキングを作成してみました。個人の恣意的な価値観を反映しないよう、エンジニアとしての個人的な主観は可能な限り省いています。(解説のところで少し主観が入っているのでお気をつけください)
調査方法
Web上にある求人サービスから実求人をクローリングし、言語の頻出数から人気言語のランキングを調査しました。
クローリングとは何か
クローラーとは、ザックリ言うと、web上でデータを集めてくれるロボットです。webにある色々なサイトを飛び周り、こちらの命令(求めているもの)に該当するページで、データを集めてくれます。集まったデータは、各項目ごとに分別され、それぞれ値が抽出されます。抽出されたものは、何かうまいことやってデータベースに格納するなどします。
初心者でも分かる説明
水泳帽をかぶったロボットがプールの中をクロールで泳ぎまくり、「おとな20人」「こども12人」「おとこ20人」「おんな11人」「せいべつふめい1人」みたいな感じで情報、データを集めてくれる便利で良い奴です。
対象データ
調査した実求人総数は10万件ぐらい。
プログラミング言語はWikipediaの一覧から取得し、求人数が100件に満たないものは除外しました。ref https://ja.wikipedia.org/wiki/プログラミング言語一覧
では早速見てみましょう。
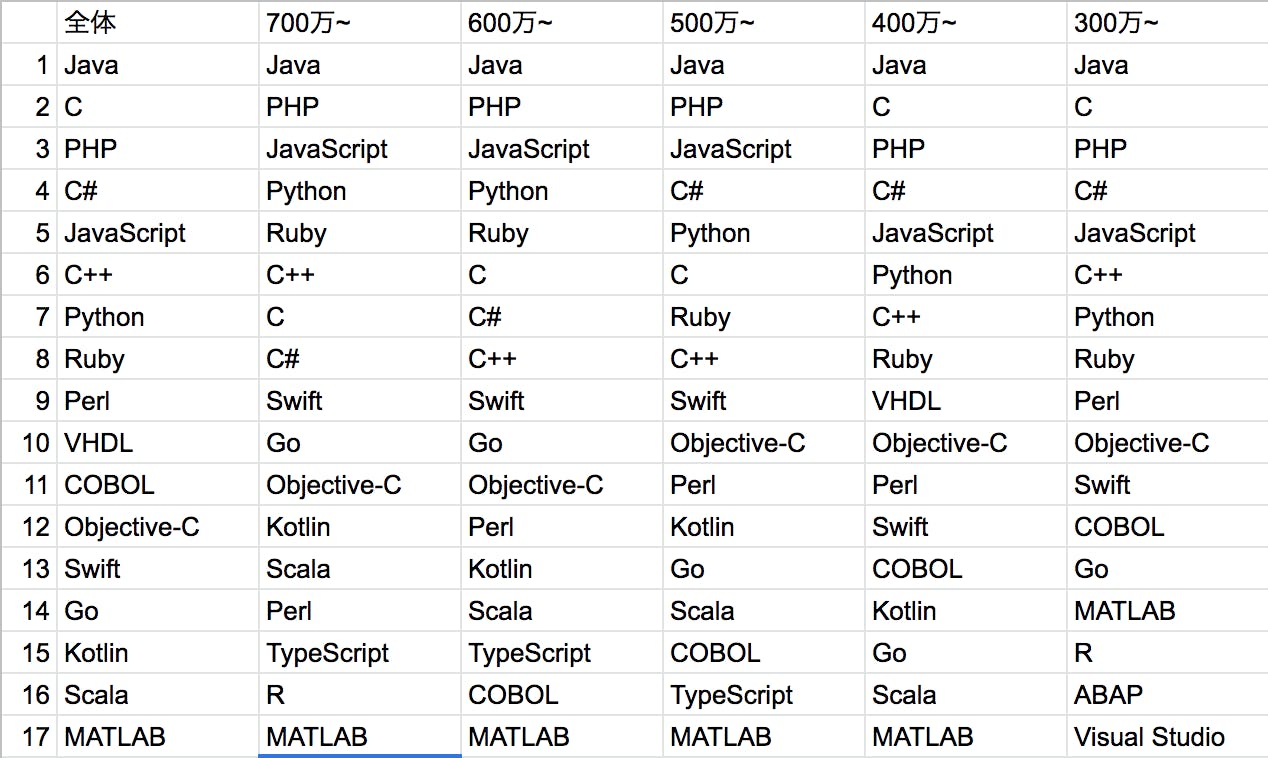
年収別ランキング(絶対数順)
全体的にJava,PHP,JavaScriptが上位に位置しています。特にJavaの案件がダントツに多いことが分かりますね。
この3つの言語は幅広いスキル層に求人を提供しています。専門学校、プログラミングスクールなどを卒業したての駆け出しエンジニアから、バリバリ開発が出来る高レベル層のエンジニアまで幅広い種類の案件がたくさんあります。
傾向
上位はJava、C、PHP, C#, JavaScriptです。市場規模を考えると業務系はWeb系の8倍弱なのでJava,C,C#が上位に来るのは当然です。PHP,JavaScriptが健闘しています。
第2章 我が国における IT 関連産業及び IT 人材の動向
https://www.meti.go.jp/policy/it_policy/jinzai/27FY/ITjinzai_report_2.pdfC言語はJavaに比べ高年収求人が比較的少ない事が分かります。逆にRuby,PythonはC言語と比較するとそれぞれ案件数に比べて高年収求人は比較的多い事分かります。C, C#などは低年収求人が比較的多いようです。組み込み寄りの言語は人あまりが発生しているのかもしれません。
高年収求人はTypeScript, Kotlin, Scalaが高年収求人に偏っています。TypeScriptはJavaScriptの、KotlinとScalaはJavaの後方互換言語で、これから言語学習を始める方はJavaかJavaScriptをやっておけば、高年収の道は確保されていると見て良さそうです。
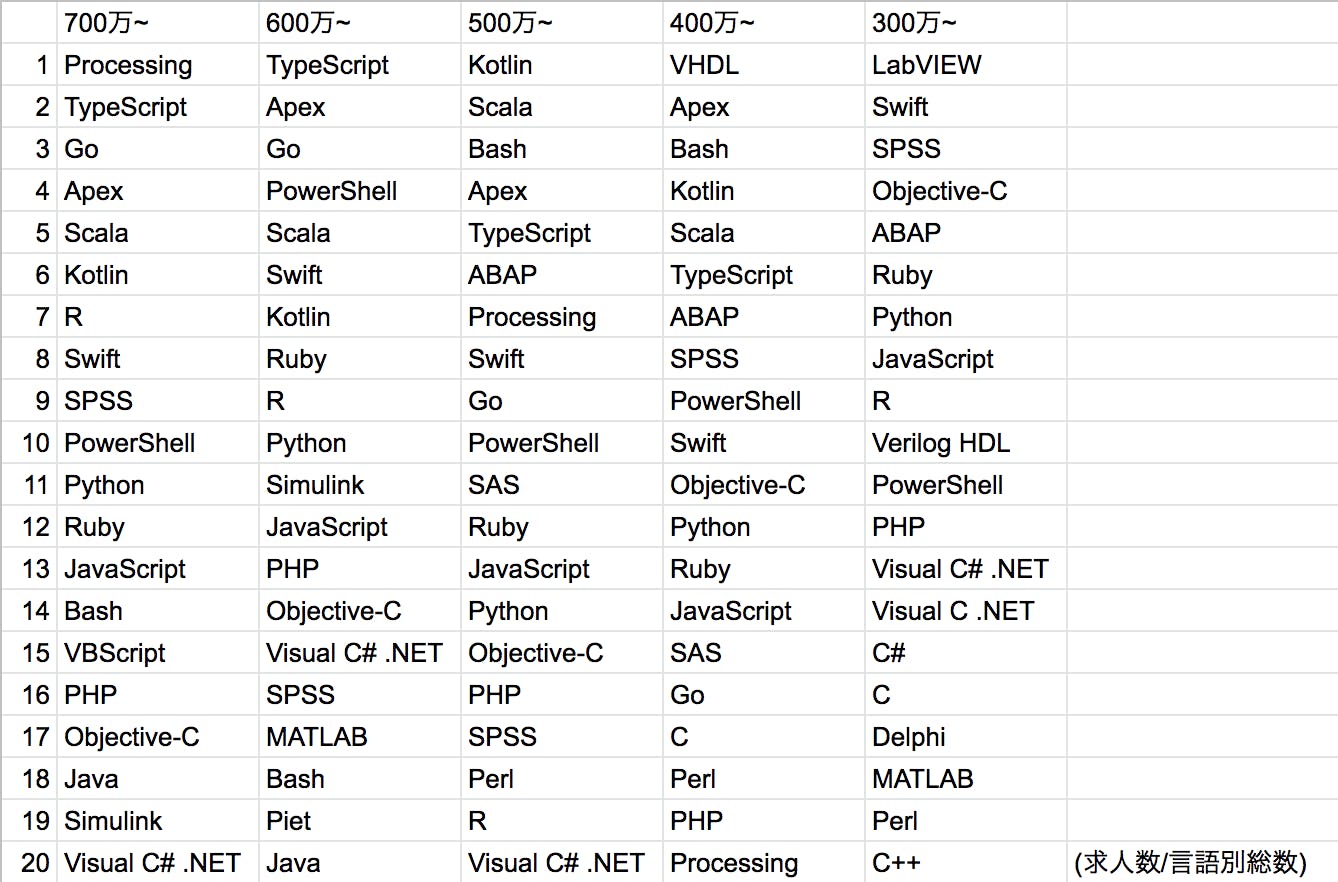
年収別ランキング(相対数順)
単純な求人数だけの比較をしてしまうとどうしても母数の多い言語が有利になってしまうため「言語別の高年収求人の割合」を出して並び替えました。「人気がありかつ人手不足の求人ほど給料が高年収の求人割合が多い」と考えるなら、こちらのほうが人気度の実態を表していると考えられます。
傾向
400万円台までは組み込み系かWeb系、500万円台,600万円台からモダンな言語が増えていきます。700万円台ではProcessingの人気が際立っています。Processingは主に電子アートとビジュアルデザインのための言語です。その他、高年収求人には最近出て来たモダンな言語が割合多く見られます。
2019年 総合ランキング 決定版
絶対評価、相対評価だと結局どの言語が良いのか分からないので、絶対数と相対数から弊社独自の重み付けにより総合ランキングを算出しました。ランキングの仕組みは期待値を出しているだけで単純すぎて恥ずかしいので割愛しますが、要は「高年収求人の割合が多い言語」ほど上位に来る仕組みだと思ってください。(期待値のようなものです。というか期待値です。)
10位:Kotlin
Androidアプリ開発で採用する企業が年々と増えており、Android需要に後押しされた格好です。Androidアプリ開発自体はJavaでもできるため、Kotlinでの開発は選択的でiOS開発におけるSwiftほどのインパクトはなかったと見るべきでしょう。
KotlinはJavaよりもスマートに完結に書けることを目指していて、Javaとの互換性もあり、人気が高まっている言語です。最近は「サーバサイドでもkotlinで実装しよう」という動きが目立ち始めています。
国内のサーバーサイド Kotlin 公開採用事例まとめ
https://qiita.com/ptiringo/items/dd734ab8064f941392949位:Scala
国内ではあまり目立っていませんが「高単価求人の多さ」が援護射撃になり上位にランクイン。開発資産としてJavaライブラリが使用可能で(Kotlinも同じ)、生産性を高めるモダンな書き方も可能です。やや古い話ですが、2009年にはTwitterがバックエンドをRubyからScalaに移行しました。
Twitter、Ruby on RailsからScalaへ
https://it.srad.jp/story/09/04/10/0421223/8位:JavaScript
SPAの需要拡大に伴いTypeScriptと共に上位に浮上しました。Adobe AcrobatがJavaScriptのマクロ機能を積んでいるなど、サードパーティ製ツールもJavaScript解析エンジンを積んでいる例が散見されます。また昨今ではJavaScriptの言語的特性(NonBlocking I/Oと相性が良い)からサーバサイドでもJavaScript(NodeJS)を使う動きが見られています。
githubでは注目度断トツの1位。世界的にも現在、もっとも注目を浴びている言語の1つとして過言ではないでしょう。
https://githut.info/7位:Python
Pythonはシンプルで少ないコードで書けるので、C言語などと比較し扱いやすい人気言語です。近年よく耳にするAI/機械学習/統計解析に必要なライブラリを揃えている事で上位にランクイン。AI需要もありこれからもPython需要は高まっていくかもしれません。
既にAI分野のディファクトスタンダードのような扱いで、Jupyter Notebook(https://jupyter.org/ )など使えば比較的簡単に環境が手に入ります。これから学ぼうという方にも良いかもしれません。
6位:Ruby
日本で開発されたプログラミング言語で、初めて国際電気標準会議(IEC)で国際規格に認証されたことでも有名です。『Y combinator』出身の時価総額上位10社のうち6社が採用している言語で、世界のテクノロジーを支えていると言って過言ではないでしょう。Webアプリケーション開発と非常に相性がよく、日本では下火になったと言われて久しいですが、求人ベースだと人気は健在。国内のスタートアップが積極的に採用している言語の1つです。
ref
https://news.ycombinator.com/item?id=211384225位:TypeScript
TypeScriptはマイクロソフトによって開発されたプログラミング言語。JavaScriptに「型」の概念を持ち込みました。ここから『ReactJS』『VueJS』が生まれたと言って過言ではないでしょう。スパゲティになりがちなフロントエンド開発にオブジェクト指向の概念を持ち込み、優れた保守性を持ったSPAアプリケーション開発を実現します。
4位:Apex
SalseForceのプログラミング言語です。ApexはJavaに似ており、Java言語ユーザには親しみのある記述方法を提供しています。Salesforceは開発者に高いインセンティブを支払うことで有名であり、中小ベンダーにとって採用の敷居が低い人気言語となっています。
実は現在、人材市場ではApex開発者の争奪戦が繰り広げられており、歴3年もあればヘッドハントは当たり前。開発者からすると東京で1000万、大阪でも800万も狙える非常に魅力的なプログラミング言語となっています。
3位:PowerShell
PowerShellは2006年に生まれた言語でMicrosoft発のプログラミング言語です。WindowsやMicrosoft製品のシステム管理を行うためのシェル言語を提供しており、オブジェクト指向で開発ができることでも有名です。Bashで書くかPowerShellで書くかで悩んだ開発者も多いでしょう。現在はオープンソース化されています。
Apexと同様、この2つの言語は使用用途が偏っているため求人数が多くないのですが、その分開発経験者が少なく、高単価になったと考えられます。わざわざこれから始めようという言語ではないかもしれませんが、既に業務で経験されていたり触る機会のある方にはGood Newsかもしれませんね。
2位:Swift
Swiftは、モダンな記述で開発がしたい開発者とiOSアプリの開発需要のダブルアタックで上昇したプログラミング言語です。Swift自体は初心者にも優しく、駆け出しの方にもオススメですが、ある程度ターミナルの知識を求められるので、知識が全くないと環境構築の段階で沼にハマってしまうかもしれません。そして言うまでもないかもしれませんが、Swiftでの開発には「MacBook」が必要です。
1位:Golang
GolangはGoogleによって設計されたプログラミング言語です。動作は軽量でソフトウェアを効率的にシンプルに構築できるとされていてオススメです。Goのツール、コンパイラ、ソースコードは全てオープンソースです。実装はオブジェクト指向にも関数型にも適応しており、優れたメモリ管理アルゴリズムが非常に軽快で高いパフォーマンスを発揮します。ある程度の言語経験者には非常に人気の高いプログラミング言語ではあります。一方で低年収求人には少なく、初心者向きではないので注意が必要です。
まとめ
プログラミング言語別総合ランキングはGolangが一位を獲得しました。今までGolangには興味あるけどなんとなく遠ざけてきた開発者の方は一度Tryしてみる価値はあるかもしれません。しかし入門者が始めるには敷居が高く、これからプログラミング言語を始める人はJava/Ruby/JavaScriptあたりが良いかもしれません。全体的にモダンな言語や用途が限定的ではあるが需要の高い言語が上位に来ており、既に得意になっている言語の延長で取り組めば効率よく年収アップが狙えるかと思います。
プロモーション
『リッターズ』のTwitterアカウントでは世界中の「先端Techビジネス」や技術要素の格付け情報を流しています。気になる方は是非フォローしてみてください。
リッターズ
https://twitter.com/ritters2u『渋谷コード塾』では求人市場の調査結果から最新の技術トレンドを調査取得し、それらを習得するための半年間のコースを提供しています。直近ではReactNativeによるネイティブアプリ開発とRuby/Python/NodeJS/Golangによるサーバサイド開発を半年でマスターする「アプリxAPI開発コース」を提供しています。「精神と時の部屋」で半年間で3年分の成果を出しましょう。HPはまだ用意していないため、興味ある方は直接私のTwitterアカウントにご連絡ください。
https://twitter.com/shiraponsuフォローやお仕事のお問い合わせもお待ちしています。
ここまで読んでいただきありがとうございました。
- 投稿日:2019-10-21T17:42:02+09:00
[Rails]devise、Omniauthを利用したGoogle、facebook認証を実装した
はじめに
久しぶりの更新になります。某スクールを先日卒業したChihaと申します。
某スクールにてチームで某フリマアプリのコピーを作成したため、実装物のコードについて記録を残しつつ、開発チームで共有する目的で当記事を書いています。今回はOmniAuthを利用したGoogle、facebookユーザー認証機能について、私が行った作業を全部まとめて書いていこうと思います。
極力この記事のみで全て実装できるように丁寧な記事にしようと思います。
丁寧な記事が書けるとはとは言ってない対象読者
- SNS認証をアプリケーションに組み込みたい方
- あれこれ色々な記事を確認しながら実装するのに疲れた方
- 某スクールの受講生
後輩受講生が見る可能性があるのでこういう記事書いていいのかな?とも思いますがその辺は考えないそもそもの話、OmniAuthとは?
Google、Facebook、twitter等のSNSアカウントを用いてユーザー登録やログインを行ってくれるgem。
Gemfilegem "omniauth" gem "omniauth-twitter" gem "omniauth-facebook"のように、使いたいSNSによって"omniauth-snsによって決まった名称"のgemを導入する必要があります。
OmniAuthは、複数の外部サービスのアカウント情報を使ってユーザー登録やログインを提供します。OmniAuthはサービスごとにストラテジー(Strategies)を管理する、いわば元締めのgemです。OmniAuthのストラテジーとは、外部サービスごとにOAuth認証に必要な処理が記述されており、Rackミドルウェアとして提供されます。
ということで、やっていきましょう。
開発環境
- Ruby on Rails 5.2.2
- Ruby 2.5.1
- haml
- gem devise
- gem omniauth
事前準備
使いたいSNSのAPI取得が必要です。
今回はgoogleとfacebookですね。
また、注意事項が数点あります。導入にあたっての注意事項
この辺でハマったから記事書いたまであるgoogle認証の注意事項
OAuthクライアントID(Railsに設定するAPIキーのようなもの)の取得に際して、承認済みのリダイレクトURIを登録する必要がありますが、きちんとしたドメインを設定したURLでないと登録ができません。
※ローカル環境のURLは普通に登録できます。できないのはdevelopment環境での〇〇.〇〇.〇〇のような、数値のみのURLとなるドメイン等になります。
そのため、今回はローカル環境のみの話になります。本番実装するならドメインを取得して登録するなどの対応が必要です。facebook認証の注意事項
こいつも曲者です。
OAuthクライアントID(Railsに設定するAPIキーのようなもの)の取得に際して、承認済みのリダイレクトURIを登録する必要がありますが、SSL通信を行うURLのみ登録することができます。
つまり、httpsから始まるURLでの登録が必要であり、httpで始まるURLでは登録ができません。
※Railsを普通にセッティングして開発してた場合、ローカルサーバーを普通に$rails sすると、httpから始まるパスになります。
そのため、ローカルでもSSL通信となるような設定の変更が必要になります。注意点まとめ
- google認証では、本番環境ではきちんとしたドメインの取得が必要な場合がある
- facebook認証では、httpsから始まるパスによるSSL通信をするURLを登録する必要がある
今回の記事ではローカルでの開発に絞った話をするため、ローカルでのSSL通信化のみ必要となります。
開発環境でのSSL通信化
Rails5 + pumaのローカル環境でSSL/HTTPSを有効にするを参考にしました。
SSL証明書の作成
今回はローカルで動くようにするだけなので適当な証明書をアプリのディレクトリ内に適当に作ります。
ターミナルssl証明書を置くディレクトリ $ openssl genrsa 2048 > server.key ssl証明書を置くディレクトリ $ openssl req -new -key server.key > server.csr #色々入力を求められますが、全部適当で大丈夫です。 ssl証明書を置くディレクトリ $ openssl x509 -days 3650 -req -signkey server.key < server.csr > server.crt作れたらpumaの設定を弄ります。
pumaの設定変更
以下のコードを書き足します。
puma.rb~~中略~~ if ENV.fetch('RAILS_ENV') { 'development' } == 'development' ssl_bind 'localhost', '9292', { key: 'tmp/server.key', cert: 'tmp/server.crt' } end
ssl_bindの後にはURLにしたい番号やらを書くといいです。
今回の場合は生成されるのはhttps://localhost:9292となります。起動時の注意
SSL通信が可能なサーバーを起動する場合、
$ rails sではなく、ターミナル$ bundle exec puma -C config/puma.rbで起動します。
以後はこの起動コマンド及びURLにて作業することになります。続いて認証のためのAPI取得などなど
google認証
まずはクライアントID及びクライアントシークレットを取得します。
クライアントIDの取得
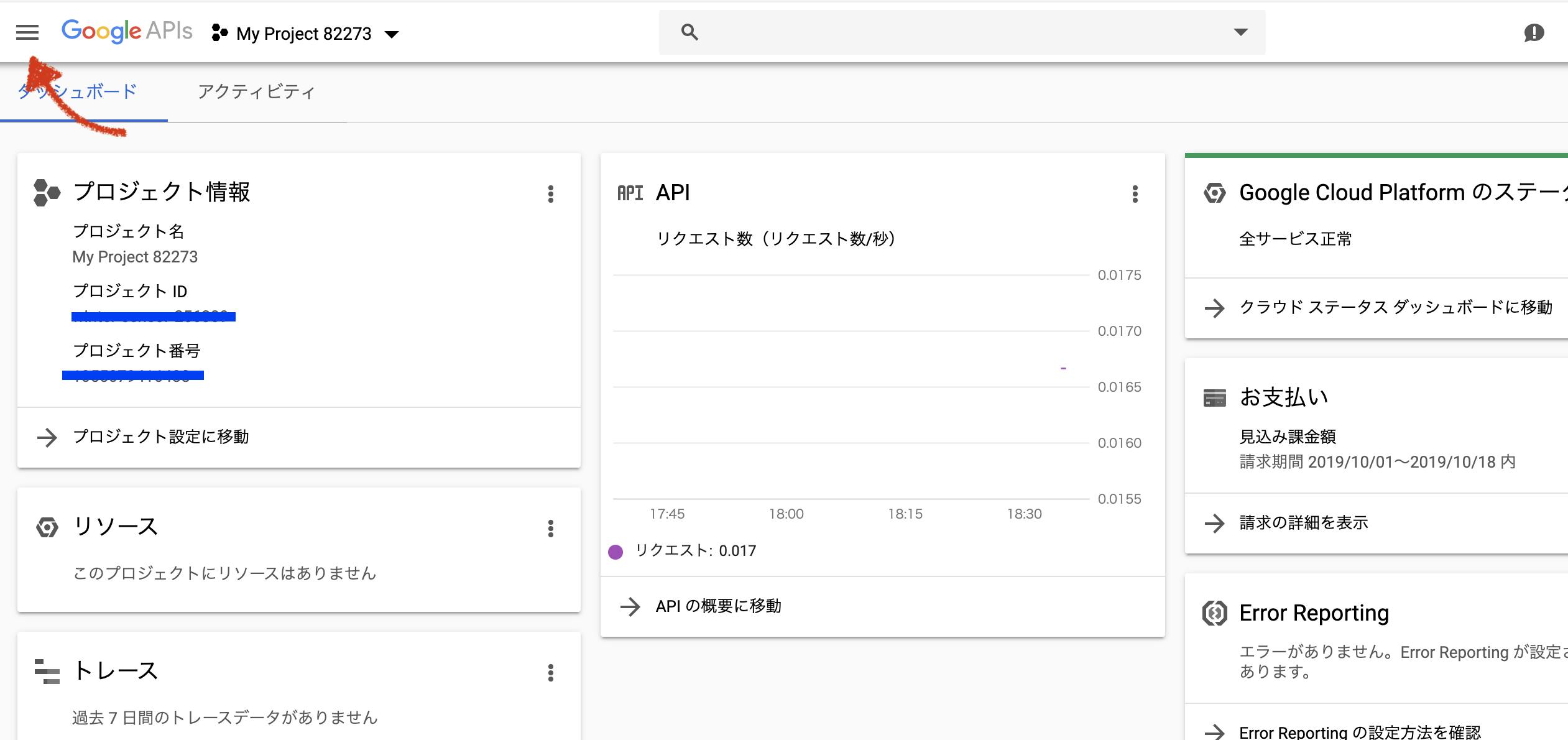
Google Developer Console
にログインし、プロジェクトの選択 > 新しいプロジェクト
導入するアプリに沿ってプロジェクト名を入力し、作成します(今回は記事用のスクリーンショットなのでデフォルト名そのまま)
作成したら以下の画面に遷移するので、左上の三本線(ハンバーガーアイコン)より、ナビゲーションメニューを表示し、APIとサービス > OAuth同意画面 へと遷移し、アプリ名だけ入れて保存を押します。
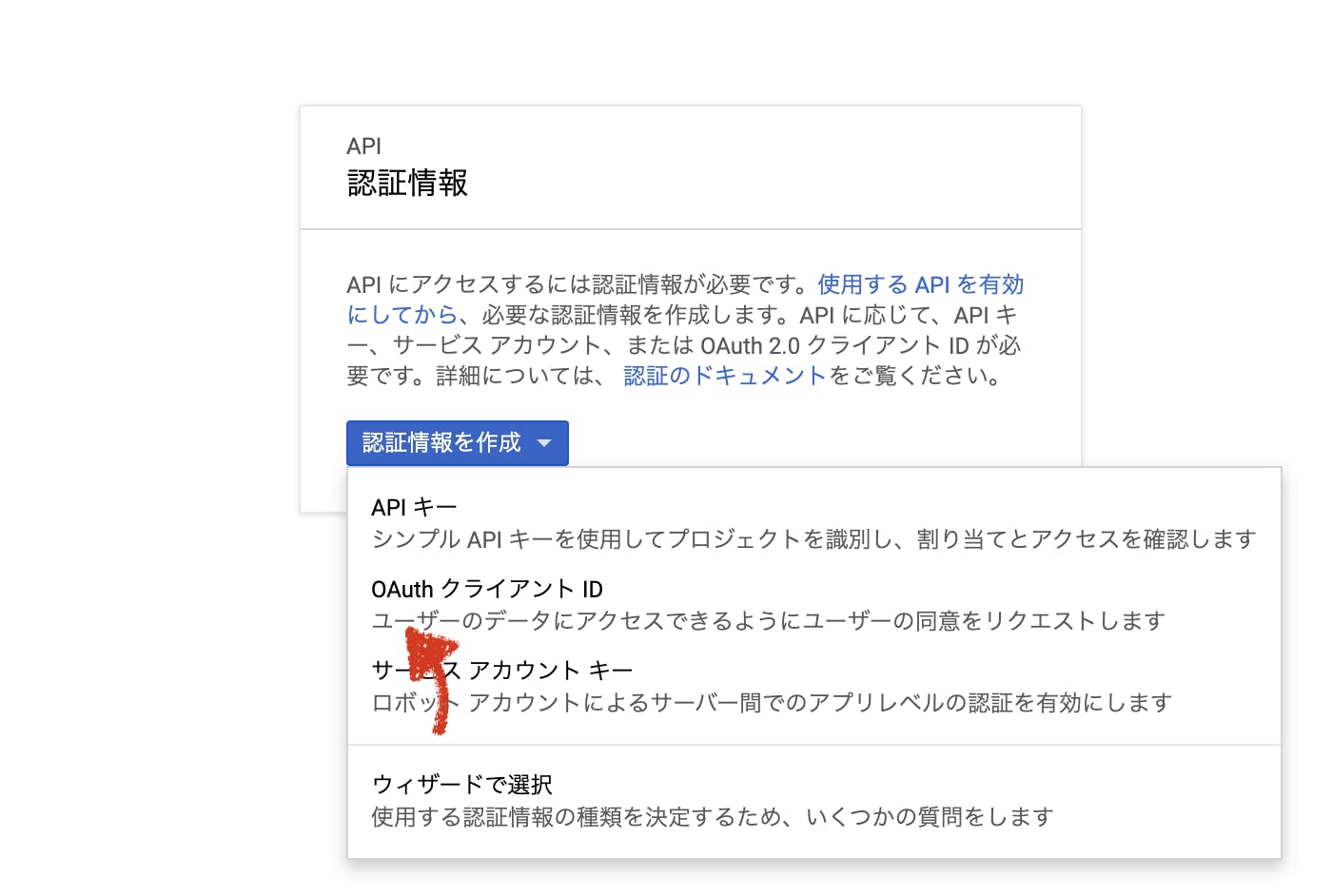
保存ができたら、認証情報 > 認証情報を作成 > OAuth クライアント IDから、ID取得画面へ移動します。
今回は「ウェブ アプリケーション」を選択してください。
選ぶと色々入力項目が出ますが、承認済みのリダイレクトURIにhttps://localhost:9292/users/auth/google_oauth2/callbackを入れて保存してあげましょう。
保存すると、「クライアントID、クライアントシークレット」の2つが表示されます。
この2つをRailsで使用するので控えておきます。取得できたら、認証を利用するためのAPIを有効にしましょう。
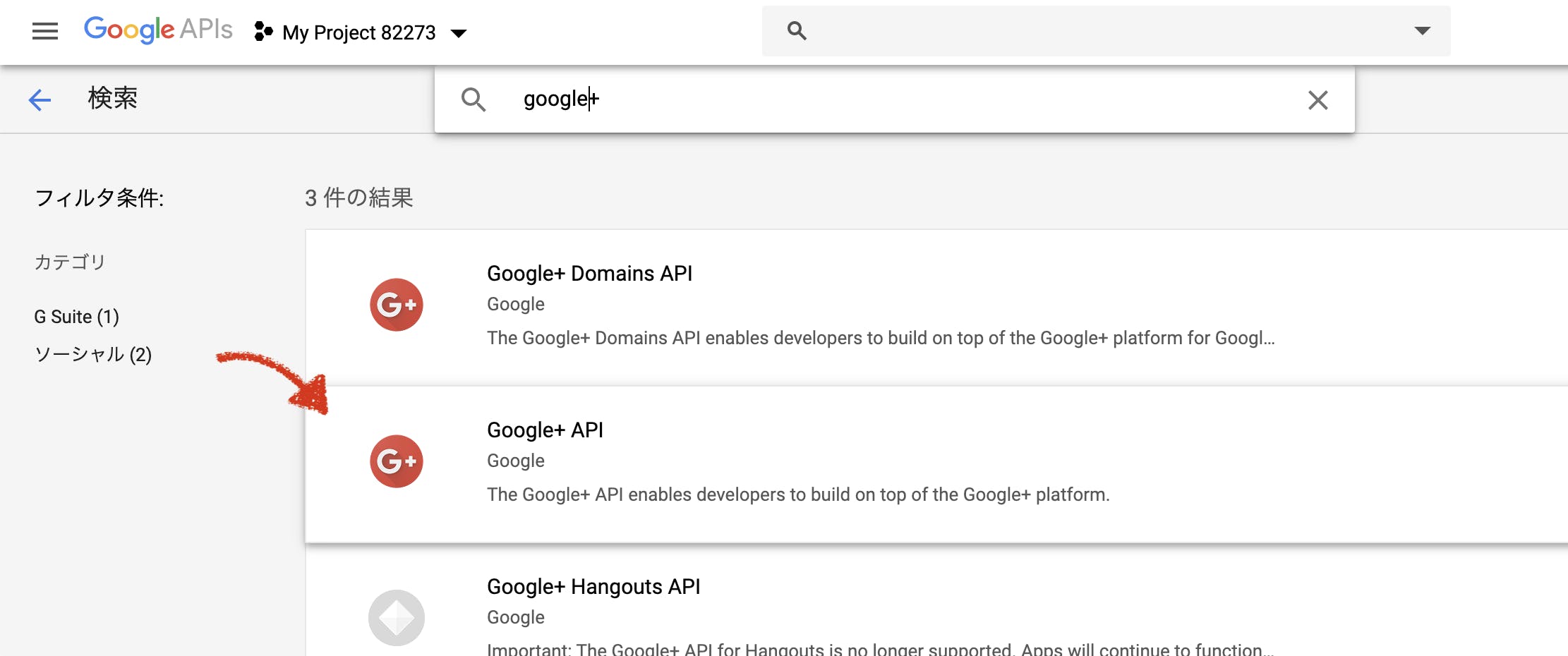
Google+ APIの有効化
左側ナビゲーションメニューからAPIとサービス > ライブラリ へ移動
google+ で検索し、検索結果に出てくるgoogle+ APIを有効にします。
これでGoogleは完了です。
facebook認証
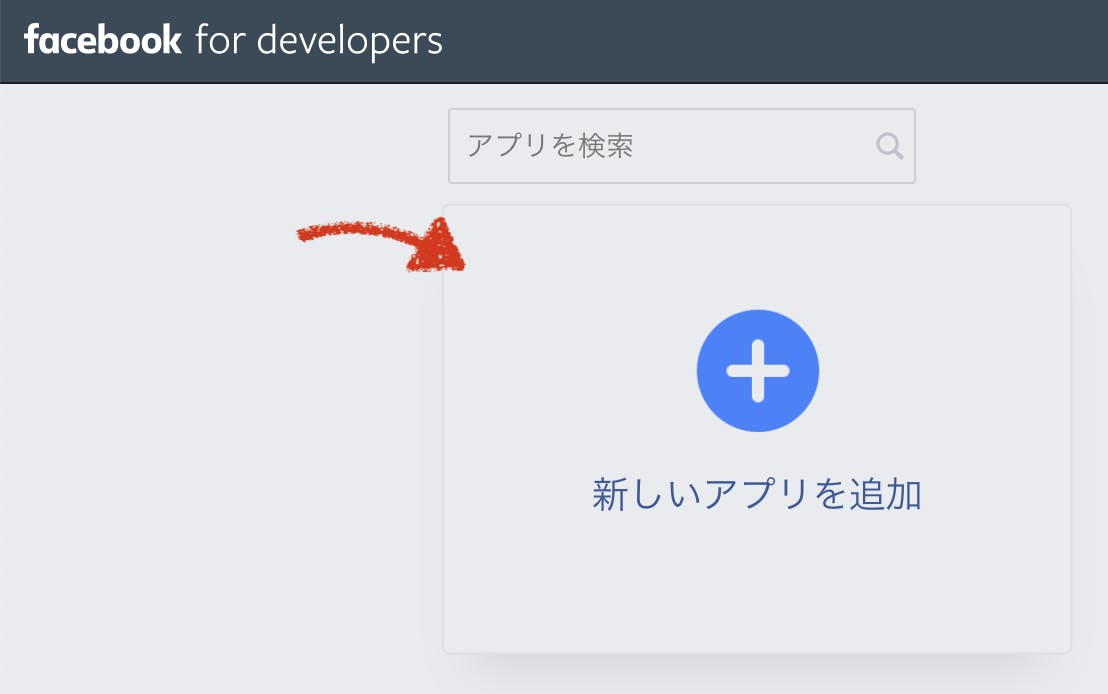
facebook for developersへとアクセスします。
新しいアプリの追加を押してアプリ名とメールアドレスを入力し、アプリIDを作成する。
作成したら、ベーシックへと移動し、「アプリID」「app secret」を控えておきます。
控えたら左側メニューのプロダクトの横にある「+」ボタンからプロダクト追加画面へ。
一番最初に出てくる「Facebookログイン」製品の設定を押すと、左のメニューにFacebookログインの項目が追加されます。
表示されたら、左メニュー「設定」から、OAuthリダイレクトURIを設定します。https://localhost:9292/users/auth/facebook/callback今回はpumaの設定に沿って以下のURIを登録します。問題なければ「変更を保存」して完了です。
何も問題なければ、これでいけると思います。
これでSNS側での設定は完了しました。続いてRails側のコード。
機能実装
今回はdeviseのomniauth_callbackを利用します。
テーブル
devise経由で作成したusersテーブルにuid、providerの2項目を追加します。(ログイン時に認証するために保存が必要になります)
ターミナル$ rails g migrate 適当な名前して適当なmigrateファイルを作成し、uidとproviderカラムを追加する記述をします。
uidは数字だけではないのでstring型にしましょう。integer型だと保存できません。migrateファイルclass AddOmniauthToUsers < ActiveRecord::Migration[5.2] def change add_column :users, :provider, :string add_column :users, :uid, :string end end書いたら
ターミナル$ rails db:migrateして、テーブルの準備は完了です。
最終的なテーブル構成はこんな感じに。テーブル構成
Column Type Options nickname string null: false string null: false,unique: true encrypted_password string null: false uid string provider string アソシエーションや他テーブルは今回の実装に関係ないので割愛します。
ルーティング
deviseで生成されるomniauth_callbacks_controller.rbを使用するため、コントローラを明示する記述を追加します。
routes.rbRails.application.routes.draw do devise_for :users,controllers: {omniauth_callbacks: "users/omniauth_callbacks"} endController
controllers/users/omniauth_callbacks_controller.rbclass Users::OmniauthCallbacksController < Devise::OmniauthCallbacksController #facebookとgoogle_oauth2の2つを定義 def facebook callback_from :facebook end def google_oauth2 callback_from :google end private def callback_from(provider) provider = provider.to_s #プロバイダを定義 @user = User.from_omniauth(request.env['omniauth.auth']) #モデルでSNSにリクエストするメソッド(from_omniauth)を使用し、レスポンスを@userに代入 if @user.persisted? #@userがすでに存在したらログイン処理、存在しなかったら残りの登録処理へ移行 sign_in @user redirect_to root_path else #今回は複数ページに渡る登録項目があるため、情報をsessionに保存し、他のページにも持ち越せるように #この辺りの値は用途に合わせてアレンジしてください。 session[:password] = @user.password session[:password_confirmation] = @user.password session[:provider] = @user.provider session[:uid] = @user.uid redirect_to registration_signup_index_path end end endModel
実際の認証を行う処理部分をモデルに書いています。
user.rbclass User < ApplicationRecord # :omniauthableの記述を追加するのを忘れないように devise :database_authenticatable, :registerable, :recoverable, :rememberable, :validatable, :omniauthable ~~中略~~ # sns認証後、ユーザーの有無に応じて挙動を変更する def self.from_omniauth(auth) # uidとproviderでユーザーを検索 user = User.find_by(uid: auth.uid, provider: auth.provider) if user #SNSを使って登録したユーザーがいたらそのユーザーを返す return user else #いなかった場合はnewします。 new_user = User.new( email: auth.info.email, nickname: auth.info.name, uid: auth.uid, provider: auth.provider, #パスワードにnull制約があるためFakerで適当に作ったものを突っ込んでいます password: Faker::Internet.password(min_length: 8,max_length: 128) ) return new_user end end endView
認証を行いたいページの適当な箇所にcallbackのリンクを仕込むだけです。
new.html.haml#見やすさのためにclassや他の記述は省いています。 = link_to user_facebook_omniauth_authorize_path do = 'Facebookで登録する' = link_to user_google_oauth2_omniauth_authorize_path do = 'Googleで登録する'クライアントIDの設定
secret.ymlに取得したクライアントID・クライアントシークレットを記載します。
secret.ymldevelopment: google_client_id: <%= ENV["GOOGLE_CLIENT_ID"] %> google_client_secret: <%= ENV["GOOGLE_CLIENT_SECRET"] %> facebook_client_id: <%= ENV["FACEBOOK_CLIENT_ID"] %> facebook_client_secret: <%= ENV["FACEBOOK_CLIENT_SECRET"] %>devise.rbに、設定したクライアントID及びシークレットを読み込む記述を追加します。適当にファイル末尾に以下を記載。
devise.rbconfig.omniauth :facebook,Rails.application.secrets.FACEBOOK_CLIENT_ID,Rails.application.secrets.FACEBOOK_CLIENT_SECRET config.omniauth :google_oauth2,Rails.application.secrets.GOOGLE_CLIENT_ID,Rails.application.secrets.GOOGLE_CLIENT_SECRET以上になります。
今回は保存処理などに関しては書いていません。認証処理と認証完了後のデータの取得を中心に記事を書きました。最後に
スクール卒業から身の回りに積もったあれこれを消化していたら久しぶりの記事更新になりました。まだまだ書きたい項目はあるのでじゃんじゃん更新していこうと思います。
就活も頑張ります。まだまだ粗末な点も多いと思いますが、より良いコード、間違った点などがあればご教授頂けると幸いです。


















- 投稿日:2019-10-21T17:35:03+09:00
備忘録:Railsにおける多次元配列のリファクタリングについて(+ jsonでの受渡しについて)
前提
json形式で配列を送りたかったが、配列が別々に2つ存在するため多次元配列(2次元配列)を作る必要があった。
最初
name.rbnames = ["hideki", "takahiro", "miki"] descriptions = ["すごい", "かっこいい", "かわいい"] inventories = [] names.each_with_index do |name, i| inventories.push [name, descriptions[i]] end出力結果
[["hideki", "すごい"], ["takahiro", "かっこいい"], ["miki", "かわいい"]]改善
name.rbnames = ["hideki", "takahiro", "miki"] descriptions = ["すごい", "かっこいい", "かわいい"] inventories = names.zip(descriptions)出力結果
[["hideki", "すごい"], ["takahiro", "かっこいい"], ["miki", "かわいい"]]メモ:受け取り側での処理
上記をjson形式で送る
name.rbrender json: inventoriesループさせる
name.coffeesuccess: (json) -> html = "" for i of json html += "<div class='name'>#{json[i][0]}</div><div class='description'>#{json[i][1]}</div>" $(".names").html(html)上記の[0][1]をループさせる方法がわからずでして、、どなたかわかる方がいらっしゃいましたら教えて頂けるとうれしみです。。
参考にした記事
- 投稿日:2019-10-21T15:42:24+09:00
[Ruby] Hello world より前に出てくる「irb」の意味を知っているか!!
はじめに
みなさん,Ruby入門書の初めの方に「Rubyを動かしてみよう」ってな感じで,[irb]とターミナルで記述することがあったかと思います.
そんな記憶はあるものの,ファイルから実行するそこまで,深く考える人はいないと思うので,ほんの少しだけ深掘りしてみよと思います.irb(Interactive Ruby)
ちなみにですが,略称は上の方になっています.
ここで,念の為英単語の意味を確認しておきましょう.・interactive 対話方式
つまりは,,対話方式に実行するためのコマンドということになります.
もう少し一般化した言葉で記述すると,REPL
REPL(Read-eval-print loop) : 対話型評価環境
上にも書いてありますが,[irb]とはRubyにおける対話型評価環境ということです.
入力・評価・出力のループのこと.主にインタプリタ言語において,ユーザーとインタプリタが対話的にコードを実行する.
Wikipediaにはこのように書いてあります.
まとめ
irb⊂REPL
ということになります.
みなさんは"Hello world!"以外でどんな使い方をしているのでしょうか?
もし,テキスト出力以外で使っている人がいましたらコメント頂けると嬉しいです〜では!
- 投稿日:2019-10-21T15:30:27+09:00
JSON内の特定の値をマスクする
目的
APIリクエスト・レスポンスをログに吐きだす際など用のメモ書き
例
javascript
const MASK_KEYS = ['email', 'password'] const maskJson = obj => MASK_KEYS.reduce( (memo, key) => memo.replace(new RegExp(`"${key}":"[^,}]*"`), `"${key}":"XXXXXX"`), JSON.stringify(obj) )console
maskJson({ email: 'sample@email.com', password: 'password' }) => "{"email":"XXXXXX","password":"XXXXXX"}"ruby
MASK_KEYS = %w[email password].freeze def mask_json(hash) MASK_KEYS.inject(JSON.generate(hash)) { |memo, key| memo.gsub(/("#{key}":"[^,}]*")/, "\"#{key}\":\"XXXXXX\"") } endconsole
mask_json({ email: 'sample@email.com', password: 'password' }) => "{\"email\":\"XXXXXX\",\"password\":\"XXXXXX\"}"
- 投稿日:2019-10-21T15:06:31+09:00
Tama.rb に行ってモブプロをやって feature spec をリファクタリングした話
ブログ記事からの転載です。
と、いうことで最近噂の Tama.rb が前々から気になったので初めて参加してモブプロをやってきました!
今回の Tama.rb の内容は Everyday Rails - RSpecによるRailsテスト入門 を読みながらグループに分かれてモブプロを行う、という内容でした。
ぶっちゃけモブプロはやったことがなかったのでどうなるのか不安でしたが、Vim グループというとても居心地がいいグループに入った事でもう好き勝手言いまくってました!!そしてその結果、書籍の内容そっちのけで最初から最後までひたすら feature spec のコードをリファクタリングしていただけという結果になり…。
もう途中からモブプロはそっちのけで全員であーだこーだ言いながらみんなでわいわいいいながらコードを書く会になっていましたね…。
はやモブプロとは…という感じだったんですが、結果的には RSpec の知識を共有したりわいわい言いながらみんなでコードを書くことが出来てめっちゃ楽しかったです!最終的には個人的にかなりいい感じのリファクタリングになったので、そこに至るまでの流れを簡単にまとめてみたいと思います。
結構うろ覚えなので話の流れとか間違ってたらごめんなさい!元の feature spec
書籍に載っていたのは元々以下のような rspec でした。
require 'rails_helper' RSpec.feature "Projects", type: :feature do # ユーザーは新しいプロジェクトを作成する scenario "user creates a new project" do user = FactoryBot.create(:user) visit root_path click_link "Sign in" fill_in "Email", with: user.email fill_in "Password", with: user.password click_button "Log in" expect { click_link "New Project" fill_in "Name", with: "tama.rb" fill_in "Description", with: "omotesando" click_button "Create Project" # MEMO: click_button とはまだ処理が完了していない可能性がある # そこで以下のようなテストを実行することで「次のページがレンダリングされている」ことを保証する expect(page).to have_content "Project was successfully created" expect(page).to have_content "tama.rb" expect(page).to have_content "Owner: #{user.name}" }.to change(user.projects, :count).by(1) end endこのテスト自体はそこまで複雑ではなくて以下のような流れになっています。
1. テストで使用する
Userを生成する
2.visit root_pathで root にアクセスして生成したUserでpasswordを入力して"Log in"ボタンをクリックする
3. (expectのブロック内に入る)
4."New Project"をクリックしてNew Projectのページに移動する
5."Name"と"Description"のフォームを入力して"Create Project"をクリックする
6. クリック後に"Project was successfully created"等が表示されているかどうかのテストを行う
7. 最後にuser.projectsが増えていることを確認するこれはこれで流れがわかりやすくて悪くはないと思うんですが、最初にコードを見たときに以下の点が気になりました。
scenarioの中身が長い
- 別
contextのテストを追加しようとするとつらいexpect {}の中でexpectしている…
- これは待ち処理を行っているのでしょうがない部分もあるがうーん…
と、いうような話をモブプロ内で行っていたら「じゃあ、リファクタリングするべ」という流れになり書籍を読むのはやめてひたすらこのコードのリファクタリングを行っていました。
このときの共通の意識としては、
- フォームに変な入力を行った場合のテストを書きたいよね
- 失敗したときのテストを書きたいよね
expect {}の中でexpectしてるのがきもいっていうのがあったと思うのでこのあたりを中心にリファクタリングしていきました。
userをlet化するまず最初は、
「
user.nameが空の場合のテストとかしたいよねー」
「じゃあ、let(:name)とかに切り出すべー」みたいな話になり、まずは
userをletに切り出しました。require 'rails_helper' RSpec.feature "Projects", type: :feature do # コンテキストで切り分けそうな値を切り出す let(:user) { FactoryBot.create(:user) } let(:email){ user.email } let(:password){ user.password } let(:name){ user.name } scenario "user creates a new project" do visit root_path click_link "Sign in" fill_in "Email", with: email fill_in "Password", with: password click_button "Log in" expect { click_link "New Project" fill_in "Name", with: "tama.rb" fill_in "Description", with: "omotesando" click_button "Create Project" # MEMO: click_button とはまだ処理が完了していない可能性がある # そこで以下のようなテストを実行することで「次のページがレンダリングされている」ことを保証する expect(page).to have_content "Project was successfully created" expect(page).to have_content "tama.rb" expect(page).to have_content "Owner: #{name}" }.to change(user.projects, :count).by(1) end end割と妥当なやり方ですね。
ログイン処理を
beforeに切り出す今回テストするのは『
New Projectからプロジェクトを生成した場合にどうなるのか』を検証するテストになります。
なので最初の方にある『ログイン処理』はscenarioから切り出してbeforeで定義する事になりました。
また、ここで気づいたんですが「あれ、ログイン処理が今回のテストに関係ないなら別に
passwordはletで切り出さなくてよくね」
「じゃあ、無駄なletは定義しないでuser.emailとかで参照するべ」という流れになり、今回必要がない
letは消すことにしました。require 'rails_helper' RSpec.feature "Projects", type: :feature do let(:user) { FactoryBot.create(:user) } let(:name){ user.name } # ログイン処理を before に切り出し before do visit root_path click_link "Sign in" # let 経由ではなくて user 経由で参照する fill_in "Email", with: user.email fill_in "Password", with: user.password click_button "Log in" end scenario "user creates a new project" do expect { click_link "New Project" fill_in "Name", with: "tama.rb" fill_in "Description", with: "omotesando" click_button "Create Project" # MEMO: click_button とはまだ処理が完了していない可能性がある # そこで以下のようなテストを実行することで「次のページがレンダリングされている」ことを保証する expect(page).to have_content "Project was successfully created" expect(page).to have_content "tama.rb" expect(page).to have_content "Owner: #{name}" }.to change(user.projects, :count).by(1) end endめっちゃライブ感がありますね!
プロジェクトの生成を subject に切り出すこれはわたしが強い気持ちで、
「
scenarioの中身が長いのでsubjectに切り出そう!!!」と言って『プロジェクトを生成する処理』をまるっと
subjectに切り出しました。
ここでポイントなのは『subjectがlambdaを返している点』です。
これはsubjectがlambdaを返すことでscenario "user creates a new project" do expect { subject.call }.to change(user.projects, :count).by(1) endを
scenario "user creates a new project" do is_expected.to change(user.projects, :count).by(1) endと言う風に
is_expectedで記述することが出来るからです。
また、「もう
scenarioの中身が1行しかないからitのほうがよくない?」みたいな話になり全員が特に強い気持ちがなかったので
scenarioからitに変更し、更に引数も省略しました。
「あーみんなもそういう意識があるんだー」と「自分の書き方もそこまで間違ってないんだなー」と思いました。
一人で書いていると何が正しいのかがわからなくなるのでこういう『共通の認識』みたいなのを共有できるとだいぶ安心感があっていいですねー。
で、以下のようになりました。it { is_expected.to change(user.projects, :count).by(1) }結果的に出来上がったのは以下のような
subjectになります。require 'rails_helper' RSpec.feature "Projects", type: :feature do let(:user) { FactoryBot.create(:user) } let(:name){ user.name } before do visit root_path click_link "Sign in" fill_in "Email", with: user.email fill_in "Password", with: user.password click_button "Log in" end # 『プロジェクトを生成する』という処理を subject に切り出し subject { -> { click_link "New Project" fill_in "Name", with: "tama.rb" fill_in "Description", with: "omotesando" click_button "Create Project" # MEMO: click_button とはまだ処理が完了していない可能性がある # そこで以下のようなテストを実行することで「次のページがレンダリングされている」ことを保証する expect(page).to have_content "Project was successfully created" expect(page).to have_content "tama.rb" expect(page).to have_content "Owner: #{name}" } } # その結果、 scenario はやめて it 1行だけに it { is_expected.to change(user.projects, :count).by(1) } end各々の処理の役割が明確になってきましたね。
it(scenario)が1行だけになりだいぶスッキリしてきました。
describeで別スコープ化ここまで来ると
「上位スコープにあんまりletとか定義したくないよねー」
「describeでテストの意味を切り分けよう!」
ということでdescribeでテストを切り分けました。require 'rails_helper' RSpec.feature "Projects", type: :feature do # 『プロジェクトを生成した場合』のテストとして切り分ける describe "project create" do let(:user) { FactoryBot.create(:user) } let(:name){ user.name } before do visit root_path click_link "Sign in" fill_in "Email", with: user.email fill_in "Password", with: user.password click_button "Log in" end subject { -> { click_link "New Project" fill_in "Name", with: "tama.rb" fill_in "Description", with: "omotesando" click_button "Create Project" # MEMO: click_button とはまだ処理が完了していない可能性がある # そこで以下のようなテストを実行することで「次のページがレンダリングされている」ことを保証する expect(page).to have_content "Project was successfully created" expect(page).to have_content "tama.rb" expect(page).to have_content "Owner: #{name}" } } it { is_expected.to change(user.projects, :count).by(1) } end endこうすることで今後『プロジェクトを削除した場合のテスト』などを追加する場合に
letが切り分けることが出来るので便利です。
click_button "Create Project"したあとの待ち処理をどうするかさて、今回一番悩んだ点です。
click_button "Create Project"した後にどうやって『ページ遷移が終了したのか』の判定を行うのか、です。
現状はexpect(page).to have_content "Project was successfully created"を行い『"Project was successfully created"が content に表示されるまで待つ』という処理を行っています。「現状は
"Project was successfully created"で判定しているけどバリデーションエラーになった場合とかに必ずしも"Project was successfully created"が表示されるとは限らない」
「失敗した時のページ遷移の条件をどうするか…」
「今回の程度ならもうsleep 1でいいんじゃね?」
「待ち処理の為にexpect使いたくなりなり〜」みたいな話をしていたんですが、結果的には『
have_contentに渡す文字列をコンテキストによって変える(:letで定義しておく)』という事にしました。
また、「
expect {}内でexpectを行っているのはあくまでも『待ち処理を行う』という目的じゃん?」
「expect {}内でテストを行う必要性はないんじゃなかろうか」と、言うことで一旦『
expect {}内で行うexpectは1回だけ』にすることにしました。
ついでにfill_in "Name"に渡す文字列もコンテキストによって変えたいのでletで定義することに。require 'rails_helper' RSpec.feature "Projects", type: :feature do describe "project create" do let(:user) { FactoryBot.create(:user) } let(:name){ user.name } # コンテキストで変わりそうな値を let で定義する let(:have_content_notice) { "Project was successfully created" } let(:project_name) { "tama.rb" } let(:project_description) { "omotesando" } before do visit root_path click_link "Sign in" fill_in "Email", with: user.email fill_in "Password", with: user.password click_button "Log in" end subject { -> { click_link "New Project" fill_in "Name", with: project_name fill_in "Description", with: project_description click_button "Create Project" # MEMO: click_button とはまだ処理が完了していない可能性がある # そこで以下のようなテストを実行することで「次のページがレンダリングされている」ことを保証する expect(page).to have_content have_content_notice } } it { is_expected.to change(user.projects, :count).by(1) } end endなかなか整ってきましたね
contextを追加するもう少しです!
project_nameが空の場合project_descriptionが空の場合のテストを追加していきたいと思います!
require 'rails_helper' RSpec.feature "Projects", type: :feature do describe "project create" do let(:user) { FactoryBot.create(:user) } let(:name){ user.name } let(:have_content_notice) { "Project was successfully created" } let(:project_name) { "tama.rb" } let(:project_description) { "omotesando" } before do visit root_path click_link "Sign in" fill_in "Email", with: user.email fill_in "Password", with: user.password click_button "Log in" end subject { -> { click_link "New Project" fill_in "Name", with: project_name fill_in "Description", with: project_description click_button "Create Project" # MEMO: click_button とはまだ処理が完了していない可能性がある # そこで以下のようなテストを実行することで「次のページがレンダリングされている」ことを保証する expect(page).to have_content have_content_notice } } # project_name と description が存在する場合のテスト context "with project name and description" do it { is_expected.to change(user.projects, :count).by(1) } end # project_name が空の場合のテスト context "with empty project name" do let(:have_content_notice) { "Name can't be blank" } let(:project_name) { "" } it { is_expected.not_to change(user.projects, :count) } end # project_description が空の場合のテスト context "with empty project description" do let(:project_description) { "" } it { is_expected.to change(user.projects, :count).by(1) } end end endおおーだいぶ簡単にテストが追加できましたね。
余談ですが、アプリ側の挙動が全然わかってなくて「
project_descriptionが空だとエラーになるよねー」
「いや、でもdescriptionが空でも別に大丈夫なんじゃない?」
「じゃあ、試しにやってみよう!」と、言う感じでやってみたら実は
descriptionが空でもプロジェクトが生成されるということがわかりました。
テストからアプリ側の挙動がわかるのがちょっとおもしろかったです。
letは DRY にしないこれも RSpec あるあるかもしれませんが
letはあまり DRY にしたくありません。
と、いうのも「
letはデフォルトで定義するんじゃなくて各contextで明示的に定義したいよね」
「contextの外にletがあると目線が上に言ったりきたりしてつらい」
「コードが重複してもいいのでなるべく狭い範囲(context)でletを定義しよう!」と、言うことで
let(:have_content_notice)などは各context内で明示的に定義するようにしました。
これも強い反対意見などなくて割とみんな共通の意識なのかなーと思いました。require 'rails_helper' RSpec.feature "Projects", type: :feature do describe "project create" do let(:user) { FactoryBot.create(:user) } let(:name){ user.name } before do visit root_path click_link "Sign in" fill_in "Email", with: user.email fill_in "Password", with: user.password click_button "Log in" end subject { -> { click_link "New Project" fill_in "Name", with: project_name fill_in "Description", with: project_description click_button "Create Project" # MEMO: click_button とはまだ処理が完了していない可能性がある # そこで以下のようなテストを実行することで「次のページがレンダリングされている」ことを保証する expect(page).to have_content have_content_notice } } context "with project name and description" do let(:have_content_notice) { "Project was successfully created" } let(:project_name) { "tama.rb" } let(:project_description) { "omotesando" } it { is_expected.to change(user.projects, :count).by(1) } end context "with empty project name" do let(:have_content_notice) { "Name can't be blank" } let(:project_name) { "" } let(:project_description) { "omotesando" } it { is_expected.not_to change(user.projects, :count) } end context "with empty project description" do let(:have_content_notice) { "Project was successfully created" } let(:project_name) { "tama.rb" } let(:project_description) { "" } it { is_expected.to change(user.projects, :count).by(1) } end end end
have_contentのテストを追加する最後に先程削除した
expect(page).to have_content "tama.rb"のテストをどうするのか考えました。
これ、expect(page)を呼び出しているのでちょっとテストの仕方に工夫が必要になります。
最初は、it { is_expected.to change { page }.to have_content "tama.rb" }みたいに書いてみたんですが、これだとうまく行きませんでした。
「これで動くといいなー」
「あー動かなかったー」
「pageが返す値が同じになっているのかなあ…」
「じゃあ、subjectを直接呼び出せばいいんじゃない?」で、まずは以下のようなテストにしました。
it "shows project_name" do subject.call expect(page).to have_content project_name endこれはこれでいいのですが、
「
subject.callっていう呼び出しが意味不明過ぎる」
「これはつらい」
「じゃあsubjectに名前つければいいんじゃね?」
「「それだ!」」という事で
subject(:new_project)と定義し、new_project.callと呼び出すことに。
ぶっちゃけsubjectに引数が渡せることは完全に失念していたいので「なるほどなー」とめっちゃ関心してました。
そして、最終的に出来上がったので次のコードになります!require 'rails_helper' RSpec.feature "Projects", type: :feature do describe "project create" do let(:user) { FactoryBot.create(:user) } let(:name){ user.name } before do visit root_path click_link "Sign in" fill_in "Email", with: user.email fill_in "Password", with: user.password click_button "Log in" end subject(:new_project) { -> { click_link "New Project" fill_in "Name", with: project_name fill_in "Description", with: project_description click_button "Create Project" # MEMO: click_button とはまだ処理が完了していない可能性がある # そこで以下のようなテストを実行することで「次のページがレンダリングされている」ことを保証する expect(page).to have_content have_content_notice } } context "with project name and description" do let(:have_content_notice) { "Project was successfully created" } let(:project_name) { "tama.rb" } let(:project_description) { "omotesando" } it { is_expected.to change(user.projects, :count).by(1) } it "shows project_name" do new_project.call expect(page).to have_content project_name end end context "with empty project name" do let(:have_content_notice) { "Name can't be blank" } let(:project_name) { "" } let(:project_description) { "omotesando" } it { is_expected.not_to change(user.projects, :count) } end context "with empty project description" do let(:have_content_notice) { "Project was successfully created" } let(:project_name) { "tama.rb" } let(:project_description) { "" } it { is_expected.to change(user.projects, :count).by(1) } end end endもう最初のコードのかけらもないですね!
ちょうどここでモブプロの時間も終了して個人的にはかなり満足したコードがかけたと思います。まとめ
はじめてモブプロをやったんですが、これがモブプロとして正しいのかどうかは置いておいて多人数でコードを書くのはやっぱり楽しいですね。
普段は基本的に1人だけでコードを書いているのでこういう『他人のコードの書き方』や『コードを書く上での知見』みたいなのを得るのはとても貴重な機会でした。
意外というか意見を出しながらコードを書いていたんですが、あんまりコードの書き方の方向性で殴り合い揉めなかったことですね。これは自分の声がデカかったのかもしれませんが、『あーみんなもそう思っているんだー』みたいな安心感の方が大きかった気がします。
1人でコードを書いていると何が正しいのかがわからなくなる事が多いんですが、こういう機会があると『自分のコードの書き方は間違ってなかったんや!!』みたいに思えるのでめっちゃいいですね。あと今回は 1つの PC をみんなで使いまわしていたんですが、自分の Vim に慣れすぎてて他人の Vim がめっちゃつらいという事が体験できました…。
いかにしてに自分の Vim が自分の使いやすいようにカスタマイズされているのか改めて実感しました。今回参加してみてモブプロ自体がかなりよくて、そのあともいろいろと Ruby について話が出来たので次もぜひぜひ参加してみたいですね!
これは Ruby の話に飢えているんだ…もっと Ruby の話がしてえんだ…。そんな感じで簡単に初参加した Tama.rb の内容をまとめてみました。
同じグループでワイワイしていた方々、運営の方々ありがとうございましたー!その後
で、いまブログ記事を書きながら先程動かねーと言っていた
it { is_expected.to change { page }.to have_content "tama.rb" }をどうにか出来ないかいろいろと試していたんですが、
pageではなくてpage.htmlを参照することで解決出来ました。it { is_expected.to change { page.html }.to include "tama.rb" }これでかなりすっきりしましたね!
- 投稿日:2019-10-21T14:51:55+09:00
Railsで論理削除(soft delete)を実装する
環境
- Rails 5.2.3
- Ruby 2.6.5
- Discard 1.1.0
注意:Gemの選択
(※)非推奨の背景
- ActiveRecordの
deleteやdestroyをoverrideしているため、開発者が予期しない挙動をする。dependent: :destroy関連のレコードは削除(物理削除)される。- バグフィックスと、Railsの新しいバージョンへの対応は行うが、新しいfeatureは受け付けない。
Discardの導入
Gemのインストール
Gemfilegem "discard"$ bundle installdb migration
$ rails generate migration add_discarded_at_to_posts discarded_at:datetime:index以下のようなファイルが生成される。
class AddDiscardedAtToCatalogs < ActiveRecord::Migration[5.2] def change add_column :catalogs, :discarded_at, :datetime add_index :catalogs, :discarded_at end end$ rails db:migrateモデルに定義追加
class Post < ApplicationRecord include Discard::Model end使い方
削除
destroyの代わりに、discardを使う。@post.discardコマンド実行例
# 削除 post.discard # => true # 確認 post.discarded? # => true # 強制削除。既に削除済の場合は、exceptionが発生する。 post.discard! # => true post.discard! # Discard::RecordNotDiscarded: Failed to discard the record # 削除したレコードを元に戻す post.undiscard # => true post.undiscard! # => Discard::RecordNotUndiscarded: Failed to undiscard the record post.discarded_at # => nil # 削除した日時を確認 post.discarded_at # => Mon, 21 Oct 2019 14:34:41 JST +09:00 # 削除されたレコード一覧 Post.discarded # => [#<Post:0x00007fc04dbe3010 ...] # 削除されていないレコード一覧 Post.kept # => []default_scopeの導入について
デフォルトでは、
Post.allは削除されたレコードも含めて返す。
この挙動を変えて削除されていないものだけ返すようにするには、default_scope -> { kept }を設定する。class Post < ApplicationRecord include Discard::Model default_scope -> { kept } end Post.all # 削除さけていないレコードのみ Post.with_discarded # 全てのレコード Post.with_discarded.discarded # 削除されたレコードのみ
- 投稿日:2019-10-21T14:51:55+09:00
Railsで論理削除(soft delete)を実装する(discard版)
環境
- Rails 5.2.3
- Ruby 2.6.5
- Discard 1.1.0
Gemの選択に要注意
(※)非推奨の背景
- ActiveRecordの
deleteやdestroyをoverrideしているため、開発者が予期しない挙動をする。dependent: :destroy関連のレコードは削除(物理削除)される(※期待動作ではない)。上記に伴い、バグフィックスと、Railsの新しいバージョンへの対応は行うが、新しいfeatureは受け付けていない。
Discardの導入
Gemのインストール
Gemfilegem "discard"$ bundle installdb migration
$ rails generate migration add_discarded_at_to_posts discarded_at:datetime:index以下のようなファイルが生成される。
class AddDiscardedAtToCatalogs < ActiveRecord::Migration[5.2] def change add_column :catalogs, :discarded_at, :datetime add_index :catalogs, :discarded_at end end$ rails db:migrateモデルに定義追加
class Post < ApplicationRecord include Discard::Model end使い方
削除
destroyの代わりに、discardを使う。@post.discardコマンド実行例
# 削除 post.discard # => true # 確認 post.discarded? # => true # 強制削除。既に削除済の場合は、exceptionが発生する。 post.discard! # => true post.discard! # Discard::RecordNotDiscarded: Failed to discard the record # 削除したレコードを元に戻す post.undiscard # => true post.undiscard! # => Discard::RecordNotUndiscarded: Failed to undiscard the record post.discarded_at # => nil # 削除した日時を確認 post.discarded_at # => Mon, 21 Oct 2019 14:34:41 JST +09:00 # 削除されたレコード一覧 Post.discarded # => [#<Post:0x00007fc04dbe3010 ...] # 削除されていないレコード一覧 Post.kept # => []default_scopeの導入について
デフォルトでは、
Post.allは削除されたレコードも含めて返す。
この挙動を変えて削除されていないものだけ返すようにするには、default_scope -> { kept }を設定する。class Post < ApplicationRecord include Discard::Model default_scope -> { kept } end Post.all # 削除さけていないレコードのみ Post.with_discarded # 全てのレコード Post.with_discarded.discarded # 削除されたレコードのみ
- 投稿日:2019-10-21T14:51:55+09:00
Railsで論理削除(soft delete)を実装する(discard gem利用)
環境
- Rails 5.2.3
- Ruby 2.6.5
- Discard 1.1.0
Gemの選択に要注意
(※)非推奨の背景
- ActiveRecordの
deleteやdestroyをoverrideしているため、開発者が予期しない挙動をする。dependent: :destroy関連のレコードは削除(物理削除)される(※期待動作ではない)。上記に伴い、バグフィックスと、Railsの新しいバージョンへの対応は行うが、新しいfeatureは受け付けていない。
Discardの導入
Gemのインストール
Gemfilegem "discard"$ bundle installdb migration
$ rails generate migration add_discarded_at_to_posts discarded_at:datetime:index以下のようなファイルが生成される。
class AddDiscardedAtToCatalogs < ActiveRecord::Migration[5.2] def change add_column :catalogs, :discarded_at, :datetime add_index :catalogs, :discarded_at end end$ rails db:migrateモデルに定義追加
class Post < ApplicationRecord include Discard::Model end使い方
削除
destroyの代わりに、discardを使う。@post.discardコマンド実行例
# 削除 post.discard # => true # 確認 post.discarded? # => true # 強制削除。既に削除済の場合は、exceptionが発生する。 post.discard! # => true post.discard! # Discard::RecordNotDiscarded: Failed to discard the record # 削除したレコードを元に戻す post.undiscard # => true post.undiscard! # => Discard::RecordNotUndiscarded: Failed to undiscard the record post.discarded_at # => nil # 削除した日時を確認 post.discarded_at # => Mon, 21 Oct 2019 14:34:41 JST +09:00 # 削除されたレコード一覧 Post.discarded # => [#<Post:0x00007fc04dbe3010 ...] # 削除されていないレコード一覧 Post.kept # => []default_scopeの導入について
デフォルトでは、
Post.allは削除されたレコードも含めて返す。
この挙動を変えて削除されていないものだけ返すようにするには、default_scope -> { kept }を設定する。class Post < ApplicationRecord include Discard::Model default_scope -> { kept } end Post.all # 削除さけていないレコードのみ Post.with_discarded # 全てのレコード Post.with_discarded.discarded # 削除されたレコードのみ
- 投稿日:2019-10-21T14:48:19+09:00
〜誰ワカ〜 MVC ルーティング・コントローラー・ビューの基本関係(ついでにモデル)
「MVC」 (コントローラー、ビュー + モデル)の関係・流れの基本(基礎編)
Ruby on Railsにおいて、画面を表示させるまでに知っておくべきこと(2)
こんにちは。 〜誰ワカ〜 Ruby on Rails攻略 のコムリンです。
このページでは、Ruby on Rails攻略において必須だけど必須じゃない!?「MVC」についてです。
「MVC」は、Ruby on Railsの基礎、基本的な概念です。が、
でも、知っていて損はありませんが、知らなくても問題ないかと思います。(学習しているうちにいつの間にか分かるので)
初学者にはなかなか飲み込む事が難しいと思うし、実際に手を動かさないとイメージが湧かないからです。
なので、とりあえず的な感じでさらっと行きましょう!
MVCとは、
「モデル」「ビュー」「コントローラー」の略。モデル(Model) はデータを管理するところ。
ビュー(View) は表示画面を管理するところ。
コントローラー(Controller) はモデルとビューを繋げたり処理したりするところ。です!!
こういう関係があるから、複雑な処理が必要なアプリやサイトがうまく動くのです!!!
それをわざわざ「MVC」なんていうかっこいい名前をつけるから・・・なんか難しく感じちゃいません!?w
なんかすごいシステムの仕組みかと思ってましたが、よくよく考えたらしごく単純明快な概念でした。難しい説明がないことが売りの〜誰ワカ〜なので、めちゃめちゃ簡単なイメージでお伝えしました。
↓Ruby on Rails の基本的な流れ↓
https://qiita.com/comlin_memo/items/617a6e5bbe96b55c57cf
- 投稿日:2019-10-21T14:44:46+09:00
find, find_by, whereの違いと特徴を丁寧に
勉強会にて
-findfind_bywhereの使い分け
- それぞれどんな時に使うのか
- 取れるデータはどんな形かが理解できていない人が多かったので勉強会用資料として書きます。
※初心者向けですのでわかりやすさ重視を心掛けましたfindメソッド
自動で作られて勝手に連番になってくれる
idってありますよね。
このidを絞り込みの条件にしてデータを取得する
こんな感じで作ると
id title created_at updated_at 1 ああああ 2019-10-18 04:05:36.776003 2019-10-18 04:05:36.776003 2 買い物 2019-10-18 04:05:43.090180 2019-10-18 04:05:43.090180 3 帰宅 2019-10-18 04:05:51.098753 2019-10-18 04:05:51.098753 こんな感じでデータベースに登録されます。
で、その最初の列のidを使って検索します。2.5.3 :001 > Todo.find(1) Todo Load (0.2ms) SELECT "todos".* FROM "todos" WHERE "todos"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]] => #<Todo id: 1, title: "ああああ", created_at: "2019-10-18 04:05:36", updated_at: "2019-10-18 04:05:36">データが
1件取れます。同じidは存在しないので1件しか取れないのが当たり前ですが一応。試しに
idが10を条件にして探してみる。2.5.3 :002 > Todo.find(10) Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."id" = ? LIMIT ? [["id", 10], ["LIMIT", 1]] Traceback (most recent call last): 1: from (irb):2 ActiveRecord::RecordNotFound (Couldn't find Todo with 'id'=10)そんなデータないです!
というエラーが出る。これ注意です。whereではエラーは出ません。find_byではnilです。whereで存在しない
idを条件に検索してみる2.5.3 :003 > Todo.where(id: 10) Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."id" = ? LIMIT ? [["id", 10], ["LIMIT", 11]] => #<ActiveRecord::Relation []>カラの配列
[]が取得されてます。
同じようなことをしても動作が少し違います。find_byメソッド
一概には言えないですけど
findの上位版とでもいうべきかも。ただし記述が少し長くなる。
findはidのみでしたが、find_byはid以外もOK- もちろんidでの検索もできる
- 条件を複数設定することが可能
- 取得できるデータが最初に見つかった
1件(超重要!!)
id title created_at updated_at 1 ああああ 2019-10-18 04:05:36.776003 2019-10-18 04:05:36.776003 2 買い物 2019-10-18 04:05:43.090180 2019-10-18 04:05:43.090180 3 帰宅 2019-10-18 04:05:51.098753 2019-10-18 04:05:51.098753 4 ああああ 2019-10-18 04:05:56.098753 2019-10-18 04:05:56.098753 例えばさっきのデータに同じ
titleのデータを追加します。2.5.3 :001 > Todo.find_by(title: "ああああ") Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."title" = ? LIMIT ? [["title", "ああああ"], ["LIMIT", 1]] => #<Todo id: 1, title: "ああああ", created_at: "2019-10-18 04:05:36", updated_at: "2019-10-18 09:17:15">
1件目のデータを取得しています。あと、データがない場合に
エラーでなくてnil です。2.5.3 :004 > Todo.find_by(title: "いいいい") Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."title" = ? LIMIT ? [["title", "いいいい"], ["LIMIT", 1]] => nilfindで予期しないでnilが返ってくるとよろしくない場合あり、書くにしても少し長くなるなどfindの使い道はあります。間違いも減りますので基本的には
idで検索するときはfindでいく方がいいと思います。whereメソッド
前述の2つは似てましたがwhereは少し違います。
- 該当データをすべて取得 ※一件でないです
- 取得した件数が
一件でも配列(取り出し方注意)普通やらないですが、試しに
idが1の場合を検索して変数に入れます。2.5.3 :006 > todo = Todo.where(id: 1) Todo Load (0.2ms) SELECT "todos".* FROM "todos" WHERE "todos"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 11]] => #<ActiveRecord::Relation [#<Todo id: 1, title: "ああああ", created_at: "2019-10-18 04:05:36", updated_at: "2019-10-18 09:17:15">]>
[#<Todo id: 1, title: "テスト", created_at: "2019-10-18 04:05:36", updated_at: "2019-10-18 09:17:15">]配列で囲われていますね。→
[]
というわけでTodo.where(id: 1).idみたいに取り出すことできません。
findとfind_byは2.5.3 :007 > Todo.find(1).title Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 1]] => "ああああ"みたいに取り出せます。
whereなら
2.5.3 :009 > todo = Todo.where(id: 1) Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."id" = ? LIMIT ? [["id", 1], ["LIMIT", 11]] => #<ActiveRecord::Relation [#<Todo id: 1, title: "ああああ", created_at: "2019-10-18 04:05:36", updated_at: "2019-10-18 09:17:15">]> 2.5.3 :010 > todo[0].id Todo Load (0.3ms) SELECT "todos".* FROM "todos" WHERE "todos"."id" = ? [["id", 1]] => 1こんな感じで取り出します。全て配列で取得するので何番目かを指定しないといけないわけです。
今回取得できたのが1件なので分かりにくいかもしれませんので複数件取得できる条件で試してみます。
Todo.where(title: "ああああ")は2件ヒットします2.5.3 :010 > todo = Todo.where(title: "ああああ") Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."title" = ? LIMIT ? [["title", "テスト"], ["LIMIT", 11]] => #<ActiveRecord::Relation [#<Todo id: 1, title: "ああああ", created_at: "2019-10-18 04:05:36", updated_at: "2019-10-18 09:17:15">, #<Todo id: 5, title: "ああああ", created_at: "2019-10-21 04:04:05", updated_at: "2019-10-21 04:04:05">]>ちょっと整理すると
#<ActiveRecord::Relation [ #<Todo id: 1, title: "ああああ", created_at: "2019-10-18 04:05:36", updated_at: "2019-10-18 09:17:15">, #<Todo id: 5, title: "ああああ", created_at: "2019-10-21 04:04:05", updated_at: "2019-10-21 04:04:05"> ]>こんなデータ取れてます。
Todo.where(title: "ああああ").titleとするとidが1とidが5にデータ2つあるからどっちかわからないわけです。というわけで最初に
todo = Todo.where(id: 1)としてデータを取得した後に
todo[0].idとして配列の0番目のidを取り出しました。ついでにさっきのtitleが「ああああ」の例なら
todo = Todo.where(title: "ああああ")としてデータを取得した後に
todo[0].title結果:"テスト"
todo[0].created_atなら結果:Fri, 18 Oct 2019 04:05:36 UTC +00:00
こんな感じで取れます。(Datetimeなのでこんな形式)
検索条件に一致しなかった場合
先ほどfindのところで説明しましたが、エラーでもnilでもなく
カラ配列です。2.5.3 :003 > Todo.where(id: 10) Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."id" = ? LIMIT ? [["id", 10], ["LIMIT", 11]] => #<ActiveRecord::Relation []>whereの取り出し方
2.5.3 :027 > todos = Todo.where(title: "ああああ") Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."title" = ? LIMIT ? [["title", "テスト"], ["LIMIT", 11]] => #<ActiveRecord::Relation [#<Todo id: 1, title: "ああああ", created_at: "2019-10-18 04:05:36", updated_at: "2019-10-18 09:17:15">, #<Todo id: 5, title: "ああああ", created_at: "2019-10-21 04:04:05", updated_at: "2019-10-21 04:04:05">]> 2.5.3 :028 > todos.each do |todo| 2.5.3 :029 > puts todo.title 2.5.3 :030?> end テスト テスト
todos.each do |todo|をつかって取り出しています。
todosに配列形式で入っているので1つの要素ずつtodoという変数に代入しています。繰り返し1回目の変数
todo:
#<Todo id: 1, title: "ああああ", created_at: "2019-10-18 04:05:36", updated_at: "2019-10-18 09:17:15">繰り返し2回目の変数
todo:
#<Todo id: 5, title: "ああああ", created_at: "2019-10-21 04:04:05", updated_at: "2019-10-21 04:04:05">このように1つずつの要素が
todoに入っていて、1回目、2回目の要素の中にはtitleが一つしかありません。
なのでtodo.titleとすればデータを特定できるので取り出すことができます。ついでにRailsで書くと
たぶんRailsで使うと思いますので、参考程度に。
todos_controller.rbdef index @todos = Todo.where(title: "テスト") endindex.html.erb<h1>ToDo一覧</h1> <table> <% @todos.each do |todo| %> <tr> <th><%= todo.title %></th> </tr> <% end %> </table>
テストというtitleを検索して表示している例です。余談:エラーに気が付きにくいので注意
※ 少し難しいので省いてOKです。
whereだとデータなくてもエラーでもnilでもないので注意必要です。
条件に使いたいからデータあるかどうかで条件式書こうとか言っているとエラー起こるかもしれません。2.5.3 :015 > todo = Todo.where(title: "いいいい") Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."title" = ? LIMIT ? [["title", "いいいい"], ["LIMIT", 11]] => #<ActiveRecord::Relation []> 2.5.3 :016 > !!todo => true 2.5.3 :017 > todo = Todo.find_by(title: "いいいい") Todo Load (0.1ms) SELECT "todos".* FROM "todos" WHERE "todos"."title" = ? LIMIT ? [["title", "いいいい"], ["LIMIT", 1]] => nil 2.5.3 :018 > !!todo => falsewhereとfind_byで返ってくるもの違うことに注意
【まとめ】それぞれの使い分けと注意
種類 使い分け 注意 find idで特定の1件取得すればいい場合 idのみ find_by id以外で特定の1件取得すればいい場合 最初の1件のみ & データなしでnil where 複数のデータを取得する場合 取り出し方 & データなしでカラ配列


- 投稿日:2019-10-21T14:41:21+09:00
realineのエラー
要約
- railsプロジェクトで
rails sのときにreadlineのエラーが出たimage not foundエラー- rbenv使っている
- readlineのバージョンが上がったのが原因
- rbenvからビルドしなおせば直った
エラー
/nishizaki/.rbenv/versions/2.5.5/lib/ruby/2.5.0/x86_64-darwin18/readline.bundle, 9): Library not loaded: /usr/local/opt/readline/lib/libreadline.7.dylib (LoadError) Referenced from: /Users/nishizaki/.rbenv/versions/2.5.5/lib/ruby/2.5.0/x86_64-darwin18/readline.bundle Reason: image not found - /Users/nishizaki/.rbenv/versions/2.5.5/lib/ruby/2.5.0/x86_64-darwin18/readline.bundle背景
rbenvでrubyの2.6.4をインストールした後に、2.5.5に戻したらエラー
rbenvを最新バージョンリストに更新するために
brew update && brew upgrade ruby-buildreadlineが8にアップデート→
readline7がロードされなくなる→
readline7でビルドしていたrbenvの中のrubyがエラーになるみたい。
こうやってビルドし直せば復活した
RUBY_CONFIGURE_OPTS=--with-readline-dir=`brew --prefix readline` rbenv install 2.5.5
- 投稿日:2019-10-21T14:23:39+09:00
Mac環境でopenssl@1.1があると古いRubyのインストールに失敗する
OSSのサンプルプログラムを確認するために、古い Ruby をインストールしようとしてハマりました。
発生したこと
macOS Catalina (10.15) で Ruby 2.3.1 をインストールしようとしたところ、以下のようなエラーが発生しました。
The Ruby openssl extension was not compiled. ERROR: Ruby install aborted due to missing extensions Configure options used: --prefix=/Users/username/.rbenv/versions/2.3.1 --with-openssl-dir=/usr/local/opt/openssl@1.1 --with-readline-dir=/usr/local/opt/readline CC=clang LDFLAGS=-L/Users/username/.rbenv/versions/2.3.1/lib CPPFLAGS=-I/Users/username/.rbenv/versions/2.3.1/include解決方法
以下のように環境変数で openssl@1.1 ではなく openssl のディレクトリを指定するとインストールに成功しました。
RUBY_CONFIGURE_OPTS="--with-openssl-dir=/usr/local/opt/openssl" rbenv install 2.3.1通常はより新しいバージョンを使用するべきなので、あくまで検証時などローカルで動作させたい場合の迂回策としての解決方法です。
そもそも、Ruby 2.3 はサポートが終了しているので本番環境等で使用するべきではないです。参考
https://github.com/rbenv/ruby-build/issues/1353
ruby-build の issues に上がっていました。
2.4 よりも古い ruby は、openssl@1.1 がインストールされた環境ではビルドに失敗するようです。
- 投稿日:2019-10-21T14:08:12+09:00
libxml-ruby 3.1.0 install on macOS 10.15 Catalina
xml2をhomebrewなどからインストールせずに、macOS 10.15 でOSのライブラリ(Xcode)を使ってlibxml-rubygem をインストールgem install
% gem install libxml-ruby -v '3.1.0' -- \ --with-xml2-dir=/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr \ --with-xml2-lib=/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/lib \ --with-xml2-include=/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/include/libxml2bundle install
bundler を使う場合は
--with-xml2-includeだけでないとダメだった% bundle config build.libxml-ruby --with-xml2-include=/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/include/libxml2 % bundle
libxml2 の場所は
xml2-config --cflagsで参照できる。
GCCなど用に-Iフラグがついてしまうので、そのままでは使えないので今回は上記のようにベタがきにした。% xml2-config --cflags -I/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/include/libxml2 % xml2-config --libs -L/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/usr/lib -lxml2 -lz -lpthread -licucore -lm参考
- 投稿日:2019-10-21T13:50:37+09:00
世界のナベアツをRubyで書いてみた
二日酔いで頭が回らないので、とりあえずなんか書こうと思い作りました。
Nabeatsuインスタンスにjudgementメソッドを実行すると、3の倍数と3がつく数字はアホになります(黄色で出力します)。nabeatsu.rbclass String def be_fool "\e[33m#{self}\e[0m" end end class Nabeatsu < Range def judgement self.each do |n| if n % 3 == 0 || n.to_s.include?("3") puts n.to_s.be_fool else puts n end end puts "Hey, OMORO!" end end Nabeatsu.new(1, 40).judgement出力結果は長いし、面白くないので割愛します。
お世話になりました
- 投稿日:2019-10-21T13:04:57+09:00
Rails6環境の本番環境でBlocked hostエラーが発生したときの対処法
結論
下記のいずれかでエラーを回避できます。
※ひとまずエラーを回避するための方法として記載しておりますが、これがベストな対処法かは判断し兼ねます。対応は自己責任でお願いいたします。
エラー回避策①
config/environments/development.rbに下記を記載し、ホワイトリストに許可したいhostを追加する。config/environments/development.rbRails.application.configure do (中略) config.hosts << "<許可したいホスト名>" (中略) end後述するエラーメッセージにしたがった方法です。
今回の私の場合、config.hosts << "thawing-caverns-37676.herokuapp.com"を記載しました。エラー回避策②
同じく
config/environments/development.rbに下記を記載し、ホワイトリスト全体をクリアする。
これにより、すべてのホスト名に対するリクエストを通過させることができる。config/environments/development.rbRails.application.configure do (中略) config.hosts.clear (中略) endただし、せっかくRails6で追加された保護機能を無効化してしまうため、推奨は①のような気がします。
発生したエラー
Rails6で開発した環境をherokuへプッシュしてアクセスしようとしたところ、下記のようなエラーが発生した。
Blocked host: thawing-caverns-37676.herokuapp.com To allow requests to thawing-caverns-37676.herokuapp.com, add the following to your environment configuration: config.hosts << "thawing-caverns-37676.herokuapp.com"※thawing-caverns-37676.herokuapp.comはherokuのアプリ名
原因
調べてみると、Rails6へのアップデート時の変更点の一つである
DNSリバインディング攻撃からの保護
という機能が原因のようです(Railsガイド〜Ruby on Rails 6.0 リリースノート〜参照)。上記機能のPull Requestによると、攻撃を保護するための
ActionDispatch::HostAuthorizationという新しいミドルウェアが導入されたことにより、許可するホストは自分で設定しなくてはならなくなったようです。
(デフォルトでは0.0.0.0、::、およびlocalhostからのリクエストを許可)まとめ
対処法として、
config/environments/development.rbに下記のいずれかを記載する。対処法① ホワイトリストに許可したいhostを追加
config.hosts << "<許可したいホスト名>"対処法② ホワイトリスト全体をクリア
`config.hosts.clear`参考

- 投稿日:2019-10-21T13:01:18+09:00
テーブルを設計する際に必要となる要素を知り、それらの要素をどういった場合に使えばいいのかを理解する
テーブルの構成要素
データベースのテーブルがどのような要素から構成されているかを学習する。
テーブルとエンティティ
エンティティ = テーブルと考えてほとんと差し支えない。
成績管理アプリを作る場合を感えると生徒、科目、成績といったエンティティが存在する。
データベースにはそれらのエンティティに対応した生徒テーブル、科目テーブル、成績テーブルを作成することになる。テーブルの行と列
テーブルは名前の通り表の形式で構成されている。テーブルの行はレコード、列はカラムを言うがそれぞれ表している意味が異なる。
- テーブルの行(レコード)はエンティティの具体的なデータを表す
- テーブルの列(カラム)はエンティティの属性を表す
テーブルの行(レコード)
レコードとはエンティティの具体的なデータである。例で以下のような生徒テーブルのレコードを考えてみる。
id name 1 山田太郎 taro@example.com 2 鈴木次郎 jiro@example.com idが1である1行目は山田太郎さんという生徒のデータを管理している。idが2である2行目は鈴木次郎さんという生徒のデータである。
このようにレコーそはそのテーブルの表す具体的なデータ(山田太郎さん、鈴木次郎さん)を表している。テーブルの列(カラム)
カラムとはエンティティの属性である。上記の表の例だと生徒テーブルにはid, name, email (それぞれ識別子、名前、メールアドレスの意味)という3つの属性を持っているということになる。
テーブル同士の関連性
エンティティ間には関係性のある場合がある。「エンティティ = テーブル」と考えて良いので、テーブル同士にも関係性がある場合がある。この関係性がリレーションにあたる。
例えば、生徒を成績の間には関係性がある。生徒は必ず成績を持っており、成績も必ず生徒に紐づいている(Aさんは70点、Bさんは90点など)。このような場合、生徒テーブルを成績テーブルの間にはリレーションがある。データを識別するための特殊な属性値
属性の中にはキーと呼ばれる特殊なデータが存在する。キーは同じテーブルのレコード同士を識別するためのデータである。多くの場合、idをいう名前のつく属性がキーとなる。
キーの役割
エンティティの属性であるカラムの中にはキーと呼ばれる特殊なデータが存在する。キーの役割はレコードを識別することである。
● キー
テーブルにおけるキーとはレコードを識別するための特別なカラムのことを指す。キーは識別子であるので同じテーブル内の他のレコードとは絶対に被らないように設定する。キーの種類
キーには以下の2種類がある。
- 主キー
- 外部キー
主キー
主キーはあるテーブルのなかで他のレコードとの区別をつける識別子となるカラムである。そのため、同じ主キーの値を持つレコードがテーブル内に存在してはならない。
以下の生徒テーブルのidカラムが主キーになる。この時、鈴木次郎さんのレコードのidが1であってはならない。
id name 1 山田太郎 taro@example.com 2 鈴木次郎 jiro@example.com 外部キー
外部キーは関連する他のテーブルのレコードの主キーを値として持つカラムである。外部キーは他のテーブルのレコードとの関係性を表すために用いる。
主キーの説明であげた生徒テーブルには2名の生徒がいる。主キーとなるカラムはidであったが。。。
id name 1 山田太郎 taro@example.com 2 鈴木次郎 jiro@example.com 生徒テーブルと関係性を持つテーブルとして成績テーブルがあると仮定する。成績テーブルにはそれぞれの生徒に対応する成績が保存されている。
id score student_id 1 70 2 2 90 1 成績テーブルのidは主キーです。その他にstudent_idという属性が存在する。成績テーブルでは、このstudent_idは外部キーに当たる。これはその成績をとった生徒のレコードの主キーと対応している。
つまり成績テーブルのidが1であるレコードは生徒テーブルのidが2であるレコードと対応しており、このことから 「鈴木次郎さんは70点である」 ことが分かる。制約で安全なテーブルを設計する
テーブルのカラムに対して制約をかけることで不正なデータや予期せぬデータが保存されることを防ぐことができる。
制約とは
制約とは特定のデータの保存を許さないためのバリデーションである。例えば同じメールアドレスのユーザーを登録できないようにする、名前のデータが空のユーザーを保存できないようにするといったことができるようになる。
制約の種類
- NOT NULL制約
- 一異性制約
- 主キー制約
- 外部キー制約
この4つの制約の挙動を具体的に確認するために実際に実装してみることにする。そこで学習するためのサンプルアプリを作成する。
● 以下の手順で 「DataBaseDesignSample」という名前のRailsアプリケーションを作成する
1. アプリケーションの作成以下のコマンドを順々に実行する。
ターミナル$ cd #ホームディレクトリに移動 $ rails _5.0.7.2_ new DataBaseDesignSample -d mysql #mysqlでRailsアプリケーションを作成 $ cd DataBaseDesignSample $ bundle exec rake db:create #DBの作成2. userモデルを作成
ターミナル$ rails g model userここから4つの制約を説明しつつ実際に実装してみる。
NOT NULL制約
NOT NULL制約はカラムに設定する制約である。 NOT NULL制約を設定すると、そのカラムの値にはNULL (空の値) を入れることができなくなる。絶対に値があるカラムに対して使う制約である。
● NOT NULL制約
NOT NULL制約はテーブルの属性値にNULL (空の値) が入ることを許さない制約である。例えば、 usersテーブルのnameというカラムに NOT NULL制約を設定すると、 nameが空(nil)レコードは保存できなくなる。
実際にNOT NULL制約の挙動を確認してみる。usersテーブルにNOT NULL制約を付けたnameカラムを作成する
Railsでは、マイグレーションファイルでカラムを追加するときに
null: falseと記述することでNOT NULL制約を設定することができる。マイグレーションファイルclass CreateUsers < ActiveRecord::Migration def change create_table :users do |t| t.string :name, null: false t.timestamps null: false end end end記述ができたらターミナルでマイグレーションを実行
ターミナル$ bundle exec rake db:migrateマイグレーションが実行されてusersテーブルが作成されたら、
rails cを使い実際の挙動を確認してみる。ターミナル$ rails c irb(main):001:0> User.create(name: "keita") //=> ユーザーが作成される irb(main):002:0> User.create(name: nil) //=> エラーこのようにNOT NULL制約が設定されたカラムがnilであるとエラーが発生する。
一意性制約
一意性制約はカラムに設定する制約である。一意性とはユニークで他とは違う意味である。一意性制約を設定したカラムには同じ値をできなくなる。例にあげるとAさんのemailが「test@gmail.com」だった場合、他にemailが「test@gmail.com」のレコードを保存できなくなる。
● 一意性制約
一意性制約はテーブル内で重複するデータを禁止する制約である。
emailカラムに対して一意性制約を設定すると同じemailのレコードは保存できなくなる。
実際に一意性制約の挙動を確認してみるusersテーブルに一意性制約を付けたemailカラムを作成する
emailカラムを作成するためのマイグレーションファイルを作成する。
ターミナル$ rails g migration AddEmailToUsers email:stringRailsでは、カラムに対して
add_indexメソッドを用いることで一意性制約を付けることができる。
一異性制約add_index :テーブル名, :カラム名, unique: true生成されたマイグレーションファイルを以下のように編集してemailカラムに一異性制約を設定する。
マイグレーションファイルclass AddEmailToUsers < ActiveRecord::Migration def change add_column :users, :email, :string add_index :users, :email, unique: true end end記述したらターミナルでマイグレーションを実行
ターミナル$ bundle exec rake db:migrate実際の挙動を
rails cで確認してみる。ターミナル$ rails c irb(main):001:0> User.create(name: "taro", email: "taro@yamada.com") //=> ユーザーが作成される irb(main):002:0> User.create(name: "yamada", email: "taro@yamada.com") //=> エラー2回目のUser.createでエラーが起きる。これは1回目のUser.createと2回目のUser.createで同じemailでユーザーを作成していることで、一異性制約に引っかかってしまったためである。
このように一異性制約を設定したカラムの値は、唯一の値でなくてはいけない。主キー制約
主キー制約とは、レコードが必ず主キーを持っていなくてはいけないことを保証するための制約である。
●主キー制約
主キー制約は、主キーである属性値が必ず存在してかつ重複していないことを保証する制約である。主キーに対してNOT NULL制約と一意性制約を両方設定するのと同義になる。
Railsでテーブルを作成する際、主キー制約は元々実装されている。Railsでは主キーはidカラムとして自動で作成される。つまり、idカラムの値は重複しないようにできている。外部キー制約
外部キー制約とは、外部キー制約とは、外部キーに対応するレコードが必ず存在することを保証する制約である。例えばstudent_idが3のレコードを保存するためにはstudentsテーブルにidが3のレコードが存在してなくてはならない。
● 外部キー制約
外部キー制約は、外部キーの対応するレコードが必ず存在しなくてはいけないという制約である。外部キーのカラムに値があっても、その値を主キーとして持つ他のテーブルのレコードがなければいけない。
実際に外部キー制約の挙動を確認してみる。外部キー制約を実装してみる
usersテーブルの外部キーを持つためのscoreテーブルを作成する。このscoresテーブルはユーザーの成績を保存するためのテーブルである。そのため、scoresテーブルのレコードはuser_idという外部キーのカラムを持ち、どのユーザーの得点なのかがわかるようにする。
ターミナル$ rails g model scoreRailsでは、マイグレーションファイルで外部キーとなるカラムを追加するときに
foreign_key: trueと記述することで外部キー制約を設定することができる。
では、生成されたマイグレーションファイルを以下のように編集してuserとのアソシエーションに外部キー制約を設定する。マイグレーションファイルclass CreateScores < ActiveRecord::Migration def change create_table :scores do |t| t.string :name t.integer :score t.references :user, foreign_key: true t.timestamps null: false end end end記述ができたらターミナルでマイグレーションを実行する。
ターミナル$ bundle exec rake db:migrateマイグレーションを実行するとscoreテーブルにはuser_idというカラムが作成されている。このuser_idカラムは外部キーであり、外部キー制約が設定されている。
rails cで挙動を確認してみよう。usersテーブルが以下のような状態と仮定して説明する。
id name 1 山田太郎 taro@example.com 2 鈴木次郎 jiro@example.com ターミナル$ rails c irb(main):001:0> Score.create(name: "English", score: 80, user_id: 2) //レコードが生成される irb(main):002:0> Score.create(name: "Math", score: 90, user_id: 4) //エラー3行目では、 user_idに4を指定している。しかし、 usersテーブルにはidが4のユーザーは存在しませんから外部キー制約によってエラーが発生する。このように外部キー制約は関連先のテーブルに存在する主キーのみしか外部キーに指定することができない。
インデックスでデータの検索を高速化する
サービスでよく起きるテーブル操作の中でレコードの検索がある。例えばusersテーブル内で検索が頻繁に行われるカラムにインデックスを設定することで検索の高速化を図ることができる。
インデックスとは
インデックスはデータベースの機能の一つで、テーブル内のデータ検索を高速化することができる。インデックスはカラムに対して設定することができ、設定したカラムでの検索が高速になる。
※ インデックスを設定することを、「インデックスを貼る」と言う。● インデックス
インデックスとはテーブル内のデータの検索を高速にするための仕組みである。インデックスはカラムに対して設定する。インデックスをカラムに設定するとそのカラムで検索をした場合に検索速度が向上する。インデックスのデメリット
インデックスで速度が上がるからといってすべてのカラムにインデックスを設定してはならない。インデックスには以下の2つのデメリットがある。
- データを保存・更新する速度が遅くなる
- データベースの容量を使う
データを保存・更新する速度が遅くなる
データを保存する際に、設定されているインデックスの数だけ追加でデータを作成する。インデックスを設定するカラムが増えるだけ保存するデータが増え、処理の速度が遅くなる。
データベースの容量を使う
インデックスはそのカラムで検索しやすいための特別なデータを保存するために検索速度が向上する仕組みです。そのため、インデックスを多く設定すればその分、データが必要になり容量が圧迫される。
1つのカラムに対するインデックス
テーブル内の1つのカラムにインデックスを貼る場合は、そのカラムで検索した場合に検索速度が向上する。
インデックスはmigrationファイル内で以下のように記述することで設定することができる。migrationファイルclass AddIndexToテーブル名 < ActiveRecord::Migration def change add_index :テーブル名、 :カラム名 end end1つのカラムに対するインデックスを設定してみる
DataBaseDesignSampleアプリケーションを使ってインデックスを実践してみる。 scoreテーブルに対してインデックスを貼るためのマイグレーションファイルを作成する。
ターミナル$ rails g migration AddIndexToScores記述したらターミナルでマイグレーションを実行する。問題なく実行できたらscoresテーブルのnameカラムに対してインデックスが設定できている。
以下のような検索の場合、検索速度が向上する。__nameカラムによる検索
Score.where(name: '山田太郎')複数のカラムに対するインデックス
インデックスは1つのカラムだけではなく、複数のカラムにも設定ができる。例えば、ユーザーを姓と名で検索するシステムを作っていることを想定しよう。SQLは以下のようになる。
姓と名によるユーザー検索
SELECT * FROM users WHERE family_name = '山田' AND first_name = '太郎'このように検索時に2つのカラムを使う場合が多い時に複数カラムに対してインデックスを設定する。
複数のカラムにインデックスを設定するためには、migrationファイル内で以下のように記述する。migrationファイルclass AddIndexToテーブル名 < ActiveRecord::Migration def change add_index :テーブル名, [:カラム名, :カラム名] end end複数のカラムに対するインデックスを設定してみる
DataBaseDesignSampleアプリケーションを使ってインデックスの設定を実践してみる。usersテーブルに対してインデックスを貼るためにマイグレーションファイルを作成する。
ターミナル$ rails g migration AddIndexToUsers作成したマイグレーションファイルを編集してnameカラムとemailカラムの2つに対してインデックスを貼ることにする。
migrationファイルclass AddIndexToUsers def change add_index :users, [:name, :email] end end記述ができたらターミナルでマイグレーションを実行する。問題なく実行できたらusersテーブルのnameカラムをemailカラムの2つで検索する場合に対するインデックスが設定できている。
以下のような検索の場合、検索速度が向上する。nameカラムによる検索
User.where(name: '山田太郎', email: 'taro@mail.com')※この方法でインデックスを貼るとき、emailカラム単体で検索する場合には検索速度は向上しないので注意すること。
まとめ
- エンティティをテーブルとして定義する
- エンティティの持つ属性をカラムとして定義する
- カラムには主キーを必ず持たせる
- 他のテーブルのレコードと関連がある場合、外部キーという形で他のテーブルとの関係を保存する
- カラムの値には制約をつけてデータの正しさを保証する
- 値が必ず設定されていることを保証する時にはNOT NULL制約を用いる
- 値に重複がないように設定するには一意性制約を用いる
- キーの存在を保証する時には主キー制約、外部キー制約を用いる
- 検索する際に使うカラムにはインデックスを設定する
- 投稿日:2019-10-21T12:50:36+09:00
GoとGAEでWebhookを使ったプライベートなShopifyアプリを作る
今回はShopifyアプリをGoogle Cloud PlatformのGAE(Google App Engine)を使ってGoで書いてみました。
Shopifyとは?
Shopifyとは、カナダ産のEC(e-Commerce)のSaaSです。ひと昔前風に言うと、GMOメイクショップや、フューチャーショップ、Baseの様なEC向けのASPです。
現在、カナダだけではなく、北米はもとより世界中で利用されており、昨年くらいからアジアオセアニア地域でのマーケティングにお力を入れ始めた、ECプラットフォーム界の巨人です。
グローバルに展開しているサービスなので、世界中のローカルの決済等が利用でき、越境EC向けのECプラットフォームです。標準機能も素晴らしいのですが、Shopifyアプリというサードパーティーのアプリでその機能を拡張できる点も魅力的な点です。
すでに世界中で様々なShopifyアプリが開発されており、日本国内でも増えてきています。
Shopifyアプリとは?
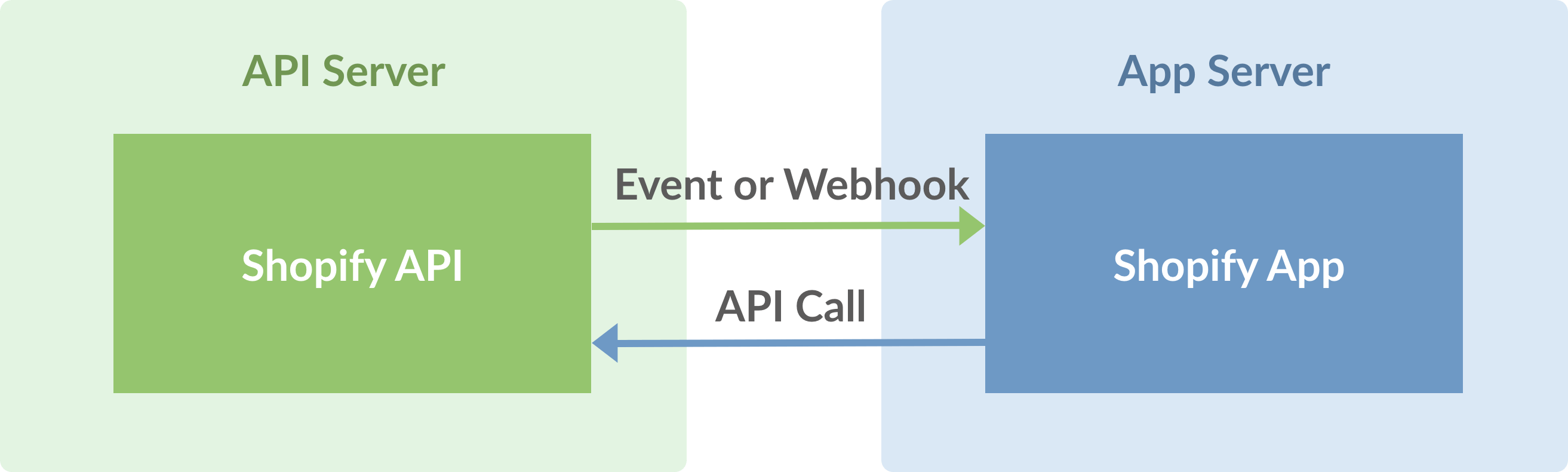
じゃあ、具体的にShopifyアプリってどうなってんの?というと、基本的にShopifyのWebAPIを叩くsomethingです。
APIには伝統的なRESTのAPIと最近流行りのGraphQLがあります。
Shopify内の何かしらのイベントに対応したEventかWebhookでキックされる感じです。
APIとアプリにはいくつか種類があって、全体的なAPIと、管理画面上の要素をごにょごにょするAPIとかフロント用のAPIとか実店舗や倉庫向けのPOSアプリ用のAPIとかもありますよくわかりません。とりあえず今回の要件に必要な分だけ調べました。Shopifyアプリには、大きく分けて公開されてて誰でも利用することができるPublic Appsと、その店舗専用みたいなPrivate Appsがあります。
Private Apps
ShopifyのAppストアに出さないそのショップ専用のアプリ。Public Appと違って、認証周りが楽。トークンとか取得しなくて良い。
https://{API_key}:{password}@{shop}.myshopify.com/admin/api/2019-10/shop.jsonみたいにBasic認証でリクエストして処理できる。今回使ったのはこれPublic Apps
ShopifyのAPPストアからインストールできる。APIの接続には認証とトークンが必要。一般的なAppsといったらこっち。
App Storeに公開しなくても使える。その場合はPrivate Appsっぽい扱いができる。Private Appじゃないメリットは後述のEmbedded SDKとかが使えること。管理画面系のアプリはPublicにしないとできない。自分が作ったアプリを広く売りたいなら通常のShopify App
Public AppsはShopifyの利用者に向け販売できます。だいたいのアプリがサブスクリプション方式なので、定期的な収入が欲しい方は作ってみてはいかがでしょうか?
英語など多言語に対応すれば市場はものすごく大きいので、ポテンシャルは高いです。ただ、現状だと日本語と日本にしか対応していないアプリは厳しそうです。実際、現在日本語で提供されているアプリも、決済系かロジ系が多く、アプリじゃなくて自社サービスと連携させるアプリを出して、自社サービスで利益を出すタイプが多い様です。Embedded apps
なぜこれがPublic AppsとPrivate Appsと同じレベルで説明されているのかわからないけど、上記のPublic Appsで使える管理画面系のアプリのためのSDKがあり、これらを使う様なアプリはEmbedded appsと呼ばれる。
- Embedded App SDK
- 管理画面に埋め込む系の何かを作る時用のSDK
POS App SDK
- iPadとかのタブレットなどで使えるShopify POSアプリがあり、それ用のSDK。今は非推奨。iOS9以降は対応してないっぽい。
- Shopify App Bridge
- Embedded App SDK、POS SDKに代わる新しいしくみ。JavaScriptのライブラリで、管理画面やShopify POS Appのフロントエンド向け。
どの言語でShopify Appを作るか?
ぶっちゃけどれでも良い。APIとのやり取りがメインなので、何だったらCでもアセンブラでも良い。
RESTかGraphQL叩ければ良い。ただ、いろんな言語でShopify API用のライブラリが出てるのでそれらを使うと楽。公式に推してるのはRuby on Rails
https://github.com/Shopify/shopify_app
最初、Railsで書いてたけど、Railsが動くApp Serverを立てるのとそのメンテが面倒だったので途中でやめた。たぶんHerokuとか使えば良いんだろうけど、嫌いなのでテンション下がってやめた。今回はクライアントにとってもHerokuとRailsを使うメリットはあまり無かった。Shopify自体がRubyで書かれていて、UAがRubyでAPPにアクセスしてくる。
Shopifyって中は何で書いてるんだろう?って思ってたんですが、Wenhookに関してはアクセスしてくるUAがRubyとなってるので、中でも結構Rubyが使われてるのかも。 Matzすごい
Ruby以外の言語のライブラリ
Ruby on Railsで書くのを止めた段階で候補はGoかPHPしかなかったんだけど、ざっくり調べて見た。
- Go
- go-shopify(今回使ったやつ)
- PHP
- Shopify公式 (メンテされてない)
- Laravel Shopify App
- Symfony Shopify Bundle (最近コミットされてなくて怪しい)
- node
- Java
- Shopify SDKちゃんとメンテされてるっぽい
- Shopify4J - Caffeinated Shopify BindingsAndroid用(メンテされてない)
- Elixir
世界中で使われてるSaaSなだけあって、とにかくいっぱいある。ただ、日本語対応とか日本向けはまだまだ少ないので、日本人的には辛い。日本人頑張らねば
PHPが公式のリポジトリにあるにも関わらずメンテされていなかったので、何となく避けた。Laravelのライブラリは開発が盛んで盛り上がっているみたいだったので、少し興味を持ったけど今回はLaravel使うほどのものでもなかったのでGoでベタ書きすることにした。結局100行ちょいのmain.go1ファイルで終わった。go-shopifyを使ってgolangでShopify Appを書く
goでShopify Appを書く場合、go-shopifyを使うと色々と便利。大体のShopifyのオブジェクトの構造体が準備されてるし、
.Create()で追加したり色々できる。
とりあえずgo getしてインポートする。$ go get github.com/bold-commerce/go-shopifypackage main import ( "encoding/json" "fmt" "io/ioutil" "log" "net/http" "os" "strings" "time" goshopify "github.com/tao-s/go-shopify"//これ )go-shoipfyの基本的な使い方
まずはAPIの認証。 Private AppとPublic Appで少し違う
Public AppのShopify APIの認証
API KeyとAPI Secretをセットしてトークンを取得する// Create an app somewhere. app := goshopify.App{ ApiKey: "abcd", ApiSecret: "efgh", RedirectUrl: "https://example.com/shopify/callback", Scope: "read_products,read_orders", }
API KeyとAPI SecretはShopifyのパートナーページのアプリ管理で取得できる。
次にトークン取得
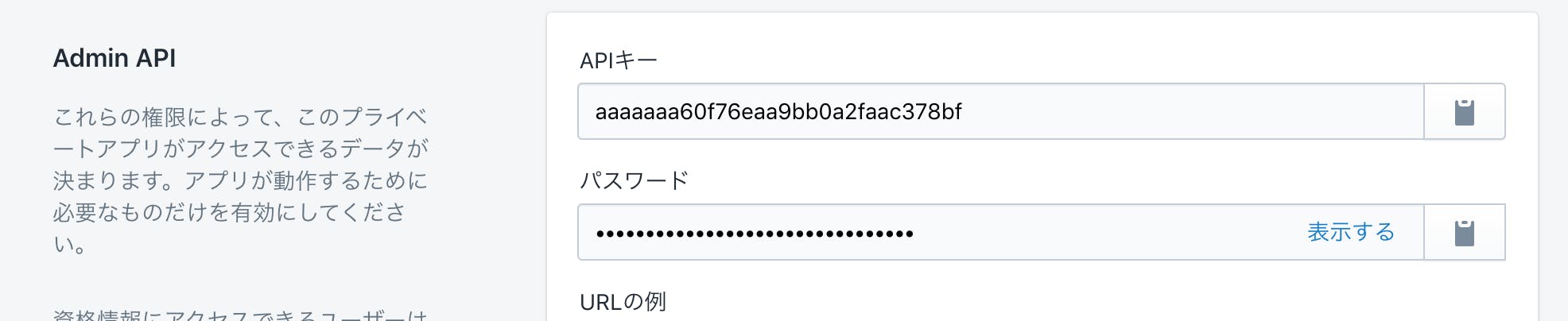
// Create an oauth-authorize url for the app and redirect to it. // In some request handler, you probably want something like this: func MyHandler(w http.ResponseWriter, r *http.Request) { shopName := r.URL.Query().Get("shop") authUrl := app.AuthorizeURL(shopName)//shopNameはストアの管理画面のドメイン。 http.Redirect(w, r, authUrl, http.StatusFound)//アプリ認証画面にリダイレクトさせる } // 認証画面からの戻りの画面 func MyCallbackHandler(w http.ResponseWriter, r *http.Request) { // Check that the callback signature is valid if ok, _ := app.VerifyAuthorizationURL(r.URL); !ok {//戻りの検証 http.Error(w, "Invalid Signature", http.StatusUnauthorized) return } query := r.URL.Query() shopName := query.Get("shop") code := query.Get("code") token, err := app.GetAccessToken(shopName, code)//トークンを取得。ここで取得したトークンはDBとかに保存しとく // Do something with the token, like store it in a DB. }トークンが取得できたらAPI叩ける。
// Create an app somewhere. app := goshopify.App{ ApiKey: "abcd", ApiSecret: "efgh", RedirectUrl: "https://example.com/shopify/callback", Scope: "read_products", } // Create a new API client client := goshopify.NewClient(app, "shopname", "token")//取得したshopnameとトークンを渡してクライアントを初期化 // Fetch the number of products. numProducts, err := client.Product.Count(nil)//APIをCallするPrivate AppのShopify APIの認証
Private Appの場合は、APIキー取得するとこが違う。Public Appはパートナーページだったけど、Pricvate Appはショップのアプリ管理から取得する。
取得した** API Key*とパスワード*で初期化。トークンは空文字ですぐクライアント作れる。
このプライベートアプリがどのAPIにアクアセスできるか?とかはストアのプライベートアプリの管理画面で設定する。// Create an app somewhere. app := goshopify.App{ ApiKey: "apikey", Password: "apipassword",//API Secretじゃなくてpassword } // Create a new API client (notice the token parameter is the empty string) client := goshopify.NewClient(app, "shopname", "")アプリの起動はWebhookで
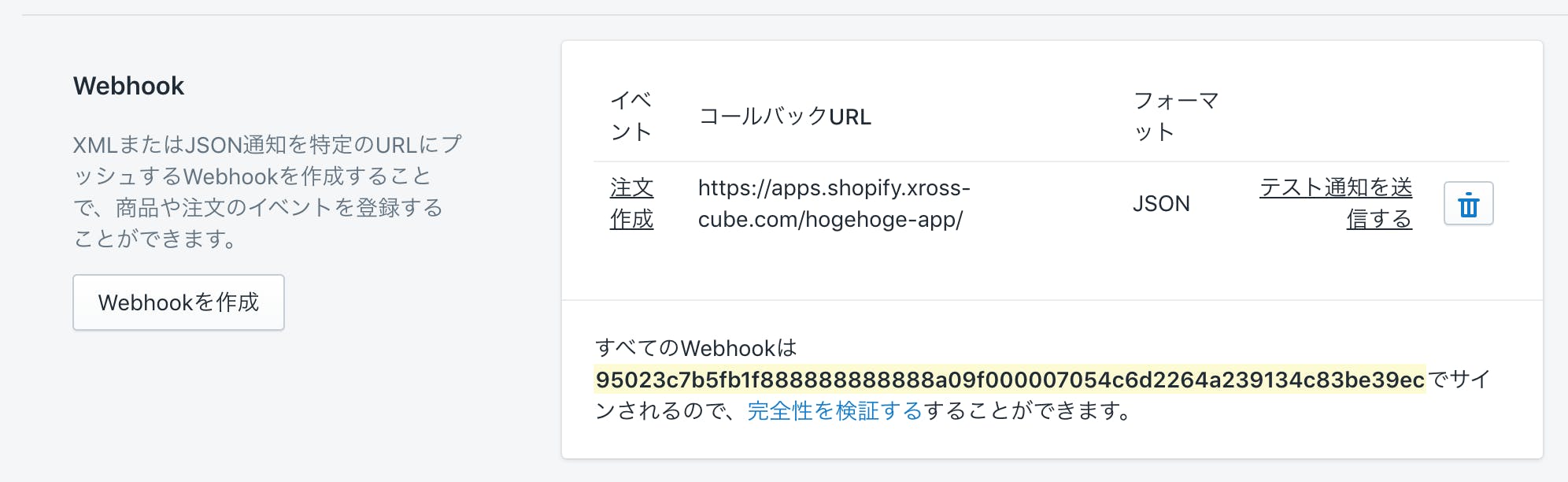
アプリの起動方法は2種類あって、あらかじめshopifyのEventに登録しておく方法と、Webhookを使う方法。プライベートアプリならWebhookが楽。
Webhookの設定は、ストアの管理画面の通知メニューから設定する。
ここでWebhookの送信先とかリクエストの検証用キーとかが設定できる。
Private Appはトークンいらない代わりにWebhookリクエストの検証が必要。じゃないとショップ以外の悪意ある第三者からのリクエストも処理しちゃう。
func ValidateWebhook(httpRequest *http.Request) (bool) { shopifyApp := goshopify.App{ApiSecret: "ratz"} return shopifyApp.VerifyWebhookRequest(httpRequest) }Webhookを起点にShopify APIを叩く
Webhookのパース
今回は受注のタイミングで支払いステータスを変更したいって要件だったので、注文作成のWebhookを設定した。その際、作成された注文の情報がWebhookのリクエストに入ってくるので、必要な情報だけを取得する。
go-shopifyでもできるんだけど、諸事情によりここだけ手作業でやった。b, err := ioutil.ReadAll(r.Body)//リクエストのbodyをパース defer r.Body.Close() if err != nil { panic(err) } var jsonData Webhook//jsonの形式に合わせたstructを初期化 if err := json.Unmarshal(b, &jsonData); err != nil {//jsonをパースして構造体に値を入れる。 panic(err) } //Webgook Webhookの構造体 type Webhook = struct { ID json.Number `json:id`//これがID。受注番号とは違う。 Gateway string `json:gateway` FinancialStatus string `json:financial_status`//支払いステータス 読み取り専用 }Shopify Admin APIを叩いてTransactionを追加する
Shopifyの受注データの支払いステータスは読み取り専用で直接変更できない。変更するためにはTransactionという支払いデータを追加して、そのステータスを
successに設定する必要がある。具体的にはOrderのIDを使ってtransactionを追加する。ntr := goshopify.Transaction{ ParentID: &tr[0].ID,//親のトランサクションID、受注時に正成される Status: "success", Kind: "sale",//必須項目 Amount: tr[0].Amount, Gateway: tr[0].Gateway, Currency: tr[0].Currency, OrderID: orderID, SourceName: "external", Source: "external",//ここが今回のハマりポイント } rtr, err := client.Transaction.Create(orderID, ntr) //API叩いて追加ここで今回最大にハマったのが、この
Sourceってパラメータ。なんと公式ドキュメントに書いてないw
なのに必須要素で、'external'に指定しないとTransactionが追加できない。公式のドキュメントにも載ってないのでgo-shopifyにも定義されてないw
仕方が無いのでgo-shopifyをいじって、Sourceを設定できる様にして解決。そのPRこれで無事、受注ステータスをShopify Appから変更できる様になりました。いやー、最後の最後でハマった...
環境はまたGAE使いました
Goの簡単な環境作るならこれがGoogle Cloud PlatformのApp Engineが一番楽ですね。運用も楽だし、速い、安い。
[PR]株式会社クロスキューブではShopifyアプリの開発も請け負っております!
最後に、弊社株式会社クロスキューブでは、Shopifyアプリ開発やShopifyを使ったECサイト構築のお仕事も大募集中です!
何かShopifyアプリでお困りの方がいらっしゃいましたらぜひお問合せ願います。


- 投稿日:2019-10-21T12:41:30+09:00
フレームワークと言語の関係性は、インスタント食品と料理の違いと言える
はじめに
- フレームワークとはいったいなんなのか?
- 言語との違いや関係性はなんなのか?
- アプリの開発力を高めるためには フレームワークをたくさん勉強するべき?
初心者が勉強を進めていくと一度はぶつかるこの疑問について。
たまにある、
「Ruby on Railsでの開発力を高めたいと思っている。RailsはRubyの”上位の技術”だから、Railsの勉強を集中して行うべき?」
という疑問にも回答すべく、今回はRubyとRailsを例に使って言語とフレームワークの関係性や違いを分かりやすく解説しました。
フレームワークについて
フレームワークと言語に上下関係はない
ちなみにRailsとRubyに技術的な上下関係はありません。
また、ある程度まで上達してなおRailsの開発力を高めたかったら、むしろRuby言語の勉強を優先して行った方がいいと言えます。フレームワークでこんなものが簡単に作れる
Ruby on Railsを構築するプログラミング言語Rubyは、Webアプリを作る以外にも以下のような様々なことができます。
- チャットボット
- スマホアプリ
- ゲーム
- Webスクレイピング
- Webクローリング
Ruby on Railsは「Webアプリケーションを」「決まった流れに従って」構築することに特化したフレームワークです。
フレームワークはインスタント食品
Ruby on RailsとRubyの関係は、料理における「インスタント食品」と「生の食材」との関係に近いと私は考えます。
Railsのようなフレームワークは、インスタント食品に該当します。例えばインスタント食品であるカップラーメンは
- お湯を沸かす
- お湯を注いで数分待つ
の手順を踏襲するだけで、我々は
- お湯を注いだときカップラーメン内部で何が起こっているか
- カップ麺にはどのような具材が入っているか
- 調味法はどうするのか
- 麺はどのように作られたのか
を「食べる側は一切気にする必要がなく」美味しく食べることができます。
Railsフレームワークの良いところの一つは、「決まりきった方法に従って実装を行うのであれば、開発者側が内部構造を深く理解する必要がない」ことです。なぜこのようなことが可能かというと「Railsの設計者が内部で、開発者側が深く実装を意識しなくて済むよう親切に」設計をしてくださっているからです。
言語はオーダーメイドの料理
Ruby言語そのものは生の食材に該当します。
生の食材で料理をしようと思うと、例えば肉じゃがを作るときに
- 何の具材を入れるか
- 調味料の割合
- 具材の切り方
- 煮込む時間
- 盛り付け方
などを逐一考慮しなければならず相応の手間がかかります。
加えてその過程で包丁や火の扱い方、栄養素についての知識が必要とされるかもしれません。Ruby言語そのものは「多様なことができる」故に、「用途によって深い基礎知識を持って逐一考慮し開発者側が設計を行う」必要があります。
Railsの開発力をあげようと思ったら、Rails内部でどのような実装が行われているかを理解する必要がありますが、それはRailsライブラリ内のRubyコードを読むことに他なりません。
当然Ruby言語の文法知識が要求されます。料理に例え直すと、「食材であるジャガイモ本来の性質を理解し、具材の切り方や煮込み時間などを考慮する」ことでより美味しい肉じゃがを作れる、といったところでしょうか。
また、インスタント食品と生の食材に上下関係が無いように、フレームワークと言語に上下関係はありません。
あくまで言語の用途特化機能群がフレームワークです。
まとめ
言語とフレームワークの関係性や違いについて解説しました。
アプリ開発の経験も浅くて慣れていない最初は、もちろんフレームワークをガンガン使ってアプリ開発の経験と学びを積みましょう。そこからさらにアプリ開発のスキルを深めていきたい場合にはぜひ言語に対する理解を深めていくのがいいかと思われます。
参考
この記事は「CodeShip」内での実際の質疑応答や指導・アドバイスの一部を基に作成しています。
- 投稿日:2019-10-21T12:17:55+09:00
本日の学び #5
sum一番早いらしい
ary = [1, 2, 3, 4, 5] p ary.sum #=> 15
shift配列の先頭の要素を取り除いてそれを返します。 引数を指定した場合はその個数だけ取り除き、それを配列で返します。破壊的メソッド。
ary = [1, 2, 3, 4, 5] p ary.shift #=> 1 p ary #=> [2, 3, 4, 5]
pop
shiftの末尾版
freeze破壊的操作を禁止する
ary = [1, 2, 3, 4, 5] ary.freeze p ary.shift #=> in `shift': can't modify frozen Array (FrozenError) p ary #=> [1, 2, 3, 4, 5]お世話になりました
Rubyで配列の要素を合計するベストな方法
Rubyで定数を扱う場合はfreezeするべき
【Ruby】「!」が付かない破壊的メソッドまとめ
Array#shift
Array#pop感想
shiftは破壊的メソッドなのになんで感嘆符!がついてないんだと思い悩みハゲましたが、破壊的な一面と、そうでない一面を持つDV夫のようなメソッドだけ感嘆符をつけるらしい。DVダメ、ゼッタイ!
- 投稿日:2019-10-21T09:16:01+09:00
Rubyビルド時の OpenSSL の PATH指定方法
Ruby ビルド時の OpenSSLのPATH指定方法について
なかなかたどり着かなかったためメモ。
--with-opt-dirを指定すると良い。1.8.7# ruby 1.8.7 ./configure --prefix=/opt/ruby \ --enable-pthread \ --with-opt-dir=/opt/openssl-1.0.2t #--with-opt-dir=/opt/openssl-0.9.8zh
- 投稿日:2019-10-21T06:26:27+09:00
bundlerで sqlite3がinstallできない
はじめに
sinatraでactiverecordを使ってなんやかんやのアプリケーションを作ろうとしているが、Bundlerでsqlite3をインストールしようとすると下記のエラーが出て処理が終わる。
An error occurred while installing sqlite3 (1.4.1), and Bundler cannot continue. Make sure that `gem install sqlite3 -v '1.4.1' --source 'https://rubygems.org/'` succeeds before bundling.試したこと
調べてみるとbundle install時にsqlite周りが原因でエラーが出る人が中々に多かった。
ヴァージョン指定してみた
始めはエラーコードをろくに読んでなかった(読め)ので、ヴァージョン指定とかの話かと思って試してみたが、ダメだった。
具体的にはこの記事とかを参考に、gemfileを以下のように書き換えてみた。gem 'sqlite3' ⇒ gem 'sqlite3', '~> 1.3.6'結局うまくいかないので次の手を試すことに。
yumコマンドでsqlite3の依存パッケージをインストールする
ずっとここで止まっててようやくエラーコードを読んでないことを思い出したのでログを少しさかのぼってみた。
Try 'brew install sqlite3', 'yum install sqlite-devel' or 'apt-get install libsqlite3-dev' and check your shared library search path (the location where your sqlite3 shared library is located).あった。
とりあえず
yum install sqlite-develを実行するが、yumコマンドがインストールされていない。sudo apt install yumyumインストール後に再度
sudo yum install sqlite-develを実行するが、segmentaition違反だとかで断念。
これについては解決方法ほんとにわからなかったので助けてほしい。
分からんこと調べてるときに分からんこと出てくると訳の分からないことになって訳が分からない...ついに解決
で、疲れたのでコーヒーブレイクしていたが、そういえばもう一つ選択肢なかった?ってことで
sudo apt install libsqlite3-devしてみたところ、なんだかいい感じ。
改めて
bundle install --path vendor/bundle・
・
・
・
・できた。
おわりに
なんだか凄い遠回りをして時間を無駄にした気がするが、エラーコードはちゃんと読めってことですね。
これでようやく先へ進める。
- 投稿日:2019-10-21T03:17:38+09:00
無料で使えるツールを調査しよう!
まえがき
日々、大量の情報に埋もれている無料で使用できるツールの情報...
これらの優秀なツールを1つでも知らないというのは、エンジニアとして選択肢を狭めていると思います。
そこで本記事では、そのような情報を収集するプログラムを作成し、整理をして見やすくするところまでを行います。集めた情報をどう使うかは本記事では紹介しません。あなた次第です。
手段
筆者の感覚では無料ツールに関する情報は、はてなブックマークで知ることが多い気がします。
そこで、はてなブックマーク検索APIで「無料 ツール」を検索した結果を収集し、集計・ソートなどで見やすい形にするというところまでを行います。使用言語がバラバラかつプログラムがスマートでないのは、筆者の怠慢です。
道筋
- はてなブックマーク検索APIを用いて、情報を集める (Ruby)
- 見やすい形にする (Python)
情報を集める (Ruby)
ここではRubyを用いて、はてなブックマーク検索APIからの結果をCSVファイルに保存するという処理を行います。
貪欲に集められる限りの情報が欲しいので、はてなブックマークで集められる2009年から2019年まで各日に関してそれぞれAPIを投げます。
今回はカテゴリーが「テクノロジー」もののみ収集します。hoge.rbrequire "rss" require "uri" require "nokogiri" keyword = "無料 ツール" # 検索ワード years = 2009..2019 for year in years dt = DateTime.new(year, 1, 1) days = dt.leap? ? 366 : 365 # 閏年のときは366日 days.times do |day| sleep(1) # 負担をかけないよう1秒間隔を空ける date_begin = (dt + day).strftime("%Y-%m-%d") url = "https://b.hatena.ne.jp/search/title?q={#{keyword}}&sort=popular&mode=rss&date_begin=#{date_begin}&date_end=#{date_begin}" begin # URLに日本語が混じるのでパーセントエンコーディングを行う url = URI.encode(url) rss = RSS::Parser.parse(url) aritcle_info = rss.items aritcle_info.each do |x| if x.dc_subject == "テクノロジー" sleep(1) # ブックマーク数を問い合わせる bookmarkcount_link = "http://api.b.st-hatena.com/entry.count?url=#{x.link}" doc_b = Nokogiri::HTML(open(bookmarkcount_link, :read_timeout => 10)) bookmarkcount = doc_b.xpath('/html/body/p')[0].children.text.to_i # CSVのフォーマットに即した出力を行う title = x.title.gsub!(",", " ") # タイトルからコンマを除去 if title == nil # タイトルにコンマがない場合、元のタイトルを保存 print x.title else print title end print "," print x.link print "," print bookmarkcount print "," puts date_begin end end rescue => e next end end end上記の処理の結果をCSVファイルに保存します。
ターミナルruby hoge.rb > hoge.csvこれでhoge.csvに無料ツールに関する情報が収集できました。
収集した情報を見やすくする (Python)
上記で作成したCSVファイルをpandasを用いて、見やすい形に変えます。
はてなブックマークの仕様上、同じ記事が別日で保存されている場合があるので、タイトルが同じものは除去します。Pythonimport pandas as pd df = pd.read_csv('./hoge.csv', header=None) df = df.rename(columns={0: 'title', 1: 'link', 2: 'bookmark', 3: 'date'}) # カラム名を指定 df = df.drop_duplicates(subset='title') # タイトルが同じものを除去 df.head()以上の最低限の前処理を行うと下のような結果が得られたと思います。
今回は千件以上の情報があるうえに、人によってはいらない情報もあるかもしれません。
そこで、情報を見やすくしましょう。
例えば、年別でブックマーク数でソートしてみます。Pythondf_markdown_sorted = df.sort_values("bookmark", ascending=False) df_markdown_sorted.query('date.str.startswith("2019")', engine='python').head()pandasの条件抽出を簡単にするために下記の記事を参考にしています。
pandas.DataFrameの行を条件で抽出するquery上記の処理で下のような結果が得られたと思います。
あとがき・今後の展望
本記事では「無料 ツール」の情報を収集するため、はてなブックマーク検索APIを用いた情報検索と情報整理を行いました。
欲しい情報は得られたでしょうか?
今後の展望としては
- 収集した記事をクラスタリングし、興味のある分野のクラスタを抽出する。
- 記事についているタグの情報も収集する
などあるかと思います。


- 投稿日:2019-10-21T01:38:25+09:00
Rubyローカル環境構築:Homebrew、rbenv、ruby-buildを使った構築方法
概要
ここではHomebrewのインストールについて記載する。
環境
Mac OS Catalina 10.15
前提
・Xcodeのインストール
・Command Line Toolsのインストール(xcode-select --install)インストール
1.Homebrewをコマンドラインでインストールする
ターミナルで以下を記載して実行する
$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"$ ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" ==> This script will install: /usr/local/bin/brew /usr/local/Library/... /usr/local/share/doc/homebrew /usr/local/share/man/man1/brew.1 /usr/local/share/zsh/site-functions/_brew /usr/local/etc/bash_completion.d/brew ==> The following directories will be made group writable: /usr/local/. /usr/local/bin ==> The following directories will have their owner set to nakaotakahiro: /usr/local/. /usr/local/bin ==> The following directories will have their group set to admin: /usr/local/. /usr/local/bin Press RETURN to continue or any other key to abort ==> /usr/bin/sudo /bin/chmod g+rwx /usr/local/. /usr/local/bin Password:Mac PCのパスワードを入力して実行する
: : ==> Installation successful! ==> Homebrew has enabled anonymous aggregate formulae and cask analytics. Read the analytics documentation (and how to opt-out) here: https://docs.brew.sh/Analytics ==> Homebrew is run entirely by unpaid volunteers. Please consider donating: https://github.com/Homebrew/brew#donations ==> Next steps: - Run `brew help` to get started - Further documentation: https://docs.brew.shInstallation successfulと表示され、インストールが成功する
2.Homebrewを最新にする
$ brew upgrade3.rbenv、ruby-build のインストール
$ brew install rbenv ruby-build4.Rubyのインストール
$ rbenv install 2.6.3 Downloading openssl-1.1.1b.tar.gz... -> https://dqw8nmjcqpjn7.cloudfront.net/5c557b023230413dfb0756f3137a13e6d726838ccd1430888ad15bfb2b43ea4b Installing openssl-1.1.1b... Installed openssl-1.1.1b to /Users/xxx/.rbenv/versions/2.6.3 Downloading ruby-2.6.3.tar.bz2... -> https://cache.ruby-lang.org/pub/ruby/2.6/ruby-2.6.3.tar.bz2 Installing ruby-2.6.3... Installed ruby-2.6.3 to /Users/xxx/.rbenv/versions/2.6.3インストール後、標準で利用するRubyのバージョンを2.6.3にする。
$ rbenv global 2.6.3ターミナルでRubyのバージョンを確認する。
$ ruby -v ruby 2.6.3p62 (2019-04-16 revision 67580) [x86_64-darwin19]
- 投稿日:2019-10-21T01:37:24+09:00
RubyでXMLのAPIへリクエスト
はじめに
現在公開されているほとんどのAPIがデータフォーマットJSONでリクエストを送るAPIかと思いますが、
稀にデータフォーマットがXMLのAPIがありますので、そのリクエスト方法をメモとして残しておきたいと思います。環境
- Ruby 2.5.0
今回はRailsなどは使用せず、ピュアなRubyのみで実装を行なっていきたいと思います。
ファイル構成
- index.rb
- hoge_api.rb
ファイル名などは適当ですmm
リクエスト用のクラスを作成
このクラスでxml引数にとりをAPIへリクエストを行わせます。
Rubyの標準ライブラリを使用するため、特別何かのインストールは必要ありません。# hoge_api.rb require 'net/http' require 'uri' require 'json' require 'rexml/document' require 'open-uri' class HogeApi attr_reader :body, :code, :json def initialize(xml) # リクエストヘッダ headers = { 'Content-Type' => 'application/xml' } # 環境変数にエンドポイントを設定しておく uri = URI.parse("#{ENV['API_URL']}") # xmlのAPIは仕様が古くsslに対応していないものが多いので、以下のように80番ポートでアクセス。sslに対応している場合はsslに対応するように設定を変更してください http = Net::HTTP.new(uri.host, 80) http.use_ssl = false response = http.post("#{uri.path}?#{uri.query}", xml, headers) @body = response.body # APIからのresponseのxmlをそのまま返す @code = response.code # ステータスコードを返す @json = xml_to_json(response.body) # xmlをjsonに変換したデータを返す end # xmlフォーマットのデータを扱い易いようにjsonデータに変換するメソッド def xml_to_json(xml) doc = REXML::Document.new(xml) hash = Hash.from_xml(doc.to_s) hash.to_json end end実行用のファイル
リクエスト用のxml
<?xml version='1.0' encoding='UTF-8' ?> <foods> <food> <name>バナナ</name> <color>黄色</color> </food> <food> <name>リンゴ</name> <color>赤</color> </food> </foods>上記のようなxmlを使用します。
require 'json' require 'net/http' require './hoge_api' # 作成したリクエスト用のクラスを読み込み def main food_name = 'アップル' food_color = '赤' # 上記のxmlデータを文字列にして変数に格納 xml = "<?xml version='1.0' encoding='UTF-8' ?><foods><food><name>#{food_name}</name><color>#{food_color}</color></food></foods>" # HogeApiクラスでリクエストを行い、返却された結果を変数responseに代入 response = HogeApi.new(xml) # 返却されたデータが必要ない場合は、以下でもいい HogeApi.new(xml) end以上となります。
xmlでリクエストを送る方法でわかりやすいのがなかなかなかったので、参考になれば幸いです。
- 投稿日:2019-10-21T01:37:24+09:00
APIへxmlでリクエストをする方法
はじめに
現在公開されているほとんどのAPIがデータフォーマットJSONでリクエストを送るAPIかと思いますが、
稀にデータフォーマットがXMLのAPIがありますので、そのリクエスト方法をメモとして残しておきたいと思います。環境
- Ruby 2.5.0
今回はRailsなどは使用せず、ピュアなRubyのみで実装を行なっていきたいと思います。
ファイル構成
- index.rb
- hoge_api.rb
ファイル名などは適当ですmm
リクエスト用のクラスを作成
このクラスでxml引数にとりをAPIへリクエストを行わせます。
Rubyの標準ライブラリを使用するため、特別何かのインストールは必要ありません。# hoge_api.rb require 'net/http' require 'uri' require 'json' require 'rexml/document' require 'open-uri' class HogeApi attr_reader :body, :code, :json def initialize(xml) # リクエストヘッダ headers = { 'Content-Type' => 'application/xml' } # 環境変数にエンドポイントを設定しておく uri = URI.parse("#{ENV['API_URL']}") # xmlのAPIは仕様が古くsslに対応していないものが多いので、以下のように80番ポートでアクセス。sslに対応している場合はsslに対応するように設定を変更してください http = Net::HTTP.new(uri.host, 80) http.use_ssl = false response = http.post("#{uri.path}?#{uri.query}", xml, headers) @body = response.body # APIからのresponseのxmlをそのまま返す @code = response.code # ステータスコードを返す @json = xml_to_json(response.body) # xmlをjsonに変換したデータを返す end # xmlフォーマットのデータを扱い易いようにjsonデータに変換するメソッド def xml_to_json(xml) doc = REXML::Document.new(xml) hash = Hash.from_xml(doc.to_s) hash.to_json end end実行用のファイル
リクエスト用のxml
<?xml version='1.0' encoding='UTF-8' ?> <foods> <food> <name>バナナ</name> <color>黄色</color> </food> <food> <name>リンゴ</name> <color>赤</color> </food> </foods>上記のようなxmlを使用します。
require 'json' require 'net/http' require './hoge_api' # 作成したリクエスト用のクラスを読み込み def main food_name = 'アップル' food_color = '赤' # 上記のxmlデータを文字列にして変数に格納 xml = "<?xml version='1.0' encoding='UTF-8' ?><foods><food><name>#{food_name}</name><color>#{food_color}</color></food></foods>" # HogeApiクラスでリクエストを行い、返却された結果を変数responseに代入 response = HogeApi.new(xml) # 返却されたデータが必要ない場合は、以下でもいい HogeApi.new(xml) end以上となります。
xmlでリクエストを送る方法でわかりやすいのがなかなかなかったので、参考になれば幸いです。