- 投稿日:2019-10-21T19:14:10+09:00
AWS ElastiCache Redisエンジンにて cache.r5.4xlarge(105.81GiB) から cache.r4.8xlarge(203.26GiB) へのスケールアップができない件
タイトルの通りです。
とり急ぎサポートに上げ、詳細が分かれば後日追記します。
- 投稿日:2019-10-21T17:53:22+09:00
[AWS Amplify][AppSync] API_KEYによる認証を使っている場合に発生しうる "Error: No credentials" と出る問題の対処
API_KEYを使ってAppSyncを叩いている環境でハマりました。
他人の既存環境のソースを引っ張って来た場合や、ステージング環境のデプロイなどでamplify add envを使って環境をスイッチした場合に表題のエラーが起こりえます。
特にソースの変更を行っていないにも関わらず、envを切り替えたら動かなくなった、という事象に遭遇した方は、この記事の内容が該当するかもしれません。
amplifyのバージョンは以下の通りです。
"aws-amplify": "^1.2.2", "aws-amplify-vue": "^0.3.2",GraphQLを叩いている部分のコードスニペットを例示します。
graphqlOperationを用いています。let listItems = `query listBenchmarkHistory { listBenchmarkResultHistorys(team: "${this.team}",limit: 10000){ items { epochMilliSeconds score status comment } } }` const lists = await API.graphql(graphqlOperation(listItems))背景
初期の開発では
dev環境を利用していました。当初は一人で開発していましたし特に困ることもなかったのですが、本番デプロイを迎えてまっさらな本番環境を用意する必要が出ました。(本番環境にAPI Keyを使うんじゃない、というご指摘は甘んじて受け入れます。。。1日限りで利用するアプリケーションだし・・・と手抜いた結果がこのザマです)
amplify env add
で
prodを追加し、publishしようとすると、publish自体は成功するものの以下のようなエラーが出ます。
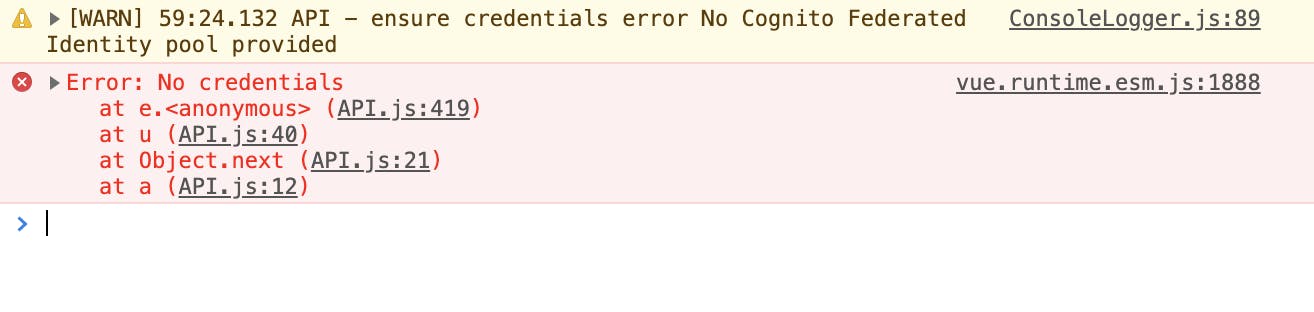
[WARN] 59:24.132 API - ensure credentials error No Cognito Federated Identity pool providedvue.runtime.esm.js:1888 Error: No credentials at e.<anonymous> (API.js:419) at u (API.js:40) at Object.next (API.js:21) at a (API.js:12)フロントをざっと見た限りでは、AppSyncに対するQueryやSubscriptionがコケているようでした。
Cognitoも使っていないし、Credentialでもないのに、はて何のことやら?と思っていましたがどうもamplify-jsのバグに近い挙動のようです。
対処方法
Amplifyのクライアントを初期化する際に、AppSync APIリクエストを行うときに使用する認証方法を指定する属性があります。env切り替えを行った場合にこのプロパティが何故か抜け落ちます。これが原因でAPIの疎通不具合が発生しています。
ワークアラウンド的な対処となりますが、私の見解としては以下の2つのいずれかが良いように思います。
src/aws-exports.js の追記
Amplifyの初期化時にこのファイルのexportを参照しています。認証方法の指定もここで指定できます。一例として、変更後のaws-exportsは以下のような内容になります。
// src/aws-exports.js // WARNING: DO NOT EDIT. This file is automatically generated by AWS Amplify. It will be overwritten. const awsmobile = { "aws_project_region": "ap-northeast-1", "aws_content_delivery_bucket": "your.hosting.bucket.com", "aws_content_delivery_bucket_region": "ap-northeast-1", "aws_content_delivery_url": "http://your-subdomain.s3-website-ap-northeast-1.amazonaws.com", "aws_appsync_graphqlEndpoint": "https://your-api.appsync-api.ap-northeast-1.amazonaws.com/graphql", "aws_appsync_region": "ap-northeast-1", "aws_appsync_apiKey": "your-api-key", "aws_appsync_authenticationType": "API_KEY" // この1行を追加する }; export default awsmobile;Amplifyの初期化時に aws_appsync_authenticationType を明示的に指定
アプリからのGraphQLリクエストをAPI_KEYによる方法のみに仮定することになりますが、Amplify初期化時の引数に明示してしまうという手もあります。
通常Amplifyの初期化はmain.jsで実行することになると思います。コードの一例は以下。
import Vue from 'vue' import App from './App.vue' import router from './router' import store from './store' import vuetify from './plugins/vuetify'; import Amplify, * as AmplifyModules from 'aws-amplify' import { AmplifyPlugin, components } from 'aws-amplify-vue' import awsconfig from './aws-exports' /* 次のコードが該当部分。通常はawscondfigを引数に指定するところ、 aws_appsync_authenticationType を明示的に追加することで対処 */ Amplify.configure({ ...awsconfig, aws_appsync_authenticationType: "API_KEY" }) Vue.use(AmplifyPlugin, AmplifyModules) Vue.config.productionTip = false new Vue({ router, store, vuetify, render: h => h(App), components: { ...components } }).$mount('#app')解説
自分なりに調べたことを書くので、以降は読みたい人だけ読んでください。
Amplifyクライアントの初期化は
Amplify.configure(arg)で行います。argはオブジェクト型です。APIの認証方法を指定する引数を、aws_appsync_authenticationTypeプロパティで受け取ることができます。Amplify CLIで開発しているならば、argには通常 aws-exports.js のexportを指定して初期化することになると思います。このとき、envの切り替えを経由してデプロイしようとした場合に どういうわけか この
aws_appsync_authenticationTypeが抜け落ちます。GraphQL APIの呼び出し方法に話を変えます。多くの場合はAmplify.API.graphqlを以下のような形で呼び出すことになると思います。
await API.graphql(graphqlOperation(listItems)) // listItemsはクエリのtemplate string
API.graphqlはオブジェクト型の引数を受け取ります。そのオブジェクトのキーとして許容されるのは、query, variables, authMode の3つです。authModeがAppSyncへのリクエストに使用する認証方法の指定になります。graphqlOperationの実態はGraphQL APIへのリクエストパラメータを組み立てるためのユーティリティで、
{query, value}の形を持つobjectを返します(authModeは含みません)。authModeが無指定の場合、API.graphqlはAmplifyの初期化時に指定された認証方式を使ってAPIリクエストを行います。2つの話を総合すると、
- envを切り替えるとexportsから
aws_appsync_authenticationTypeが抜け落ちてしまい、AmplifyがGraphQL APIにリクエストするときに使用する認証方式が未指定(デフォルト値は AWS_IAM) になる- Ampilfyはデフォルト指定の認証方式(AWS_IAM)を利用してGraphQL APIリクエストを実行ようとするが、実際にはAPI_KEYを使うのが正しく、リクエストは失敗する
という状況が発生します。最終的に
No credentialsという例外が生成されることになります。なお、該当のExceptionを上げている部分のソースはこちらです。
https://github.com/aws-amplify/amplify-js/blob/master/packages/api/src/API.ts#L303-L308
case 'AWS_IAM'の分岐に入っているのがわかると思います。aws-exportsに認証方式の指定がないために、ここの分岐に入ってしまいます。(蛇足)なお、この問題はAPI.graphql の呼び出し時にauthModeを明示的に指定する、でも回避可能です。以下。
await API.graphql({ ...graphqlOperation(listItems), authMode: "API_KEY" })ただし、複数の認証方式をフロントエンドで使い分けたいケース(あるのか..??)でもなければこんなことをする必要はないです。おとなしくaws-exportsに追記した方が良いです。
まとめ
Amplifyの想定ユースケースの中で使う分には非常に便利に感じることが多いです。が、結局、リゾルバ周りやデータソースのスキーマやらをちゃんと作り込もうとすると労力が掛かるしあまりメリットはないかなと。そのへんまでやりたくなったらそのときはAmplifyを卒業すべきなのでしょうね。
Amplify、クセが強い。
- 投稿日:2019-10-21T17:53:22+09:00
[AWS Amplify][AppSync] API_KEYによる認証を使っている場合に発生しうる "Error: No credentials" 問題の対処
API_KEYを使ってAppSyncを叩いている環境でハマりました。
他人の既存環境のソースを引っ張って来た場合や、ステージング環境のデプロイなどでamplify add envを使って環境をスイッチした場合に表題のエラーが起こりえます。
特にソースの変更を行っていないにも関わらず、envを切り替えたら動かなくなった、という事象に遭遇した方は、この記事の内容が該当するかもしれません。
amplifyのバージョンは以下の通りです。
"aws-amplify": "^1.2.2", "aws-amplify-vue": "^0.3.2",GraphQLを叩いている部分のコードスニペットを例示します。
graphqlOperationを用いています。let listItems = `query listBenchmarkHistory { listBenchmarkResultHistorys(team: "${this.team}",limit: 10000){ items { epochMilliSeconds score status comment } } }` const lists = await API.graphql(graphqlOperation(listItems))背景
初期の開発では
dev環境を利用していました。当初は一人で開発していましたし特に困ることもなかったのですが、本番デプロイを迎えてまっさらな本番環境を用意する必要が出ました。(本番環境にAPI Keyを使うんじゃない、というご指摘は甘んじて受け入れます。。。1日限りで利用するアプリケーションだし・・・と手抜いた結果がこのザマです)
amplify env add
で
prodを追加し、publishしようとすると、publish自体は成功するものの以下のようなエラーが出ます。
[WARN] 59:24.132 API - ensure credentials error No Cognito Federated Identity pool providedvue.runtime.esm.js:1888 Error: No credentials at e.<anonymous> (API.js:419) at u (API.js:40) at Object.next (API.js:21) at a (API.js:12)フロントをざっと見た限りでは、AppSyncに対するQueryやSubscriptionがコケているようでした。
Cognitoも使っていないし、Credentialでもないのに、はて何のことやら?と思っていましたがどうもamplify-jsのバグに近い挙動のようです。
対処方法
Amplifyのクライアントを初期化する際に、AppSync APIリクエストを行うときに使用する認証方法を指定する属性があります。env切り替えを行った場合にこのプロパティが何故か抜け落ちます。これが原因でAPIの疎通不具合が発生しています。
ワークアラウンド的な対処となりますが、私の見解としては以下の2つのいずれかが良いように思います。
src/aws-exports.js の追記
Amplifyの初期化時にこのファイルのexportを参照しています。認証方法の指定もここで指定できます。一例として、変更後のaws-exportsは以下のような内容になります。
// src/aws-exports.js // WARNING: DO NOT EDIT. This file is automatically generated by AWS Amplify. It will be overwritten. const awsmobile = { "aws_project_region": "ap-northeast-1", "aws_content_delivery_bucket": "your.hosting.bucket.com", "aws_content_delivery_bucket_region": "ap-northeast-1", "aws_content_delivery_url": "http://your-subdomain.s3-website-ap-northeast-1.amazonaws.com", "aws_appsync_graphqlEndpoint": "https://your-api.appsync-api.ap-northeast-1.amazonaws.com/graphql", "aws_appsync_region": "ap-northeast-1", "aws_appsync_apiKey": "your-api-key", "aws_appsync_authenticationType": "API_KEY" // この1行を追加する }; export default awsmobile;aws-exportsはpublishした際にAmplify CLIが勝手によしなに上書きしてくれる自動生成ファイルです。環境の固有名が入っているコンテンツなのでgitignoreの対象にもなっています。
Amplifyの初期化時に aws_appsync_authenticationType を明示的に指定
アプリからのGraphQLリクエストをAPI_KEYによる方法のみに仮定することになりますが、Amplify初期化時の引数に明示してしまうという手もあります。
前述のやり方との違いはパラメータを宣言する場所が異なるだけです。 DO NOT EDIT と書かれているソースの変更に抵抗があればこちらで。ただし、こっちのやり方ではAppSyncの認証方式を変えた場合にコードの変更が必要になりますし、あまり推奨はしません。
通常Amplifyの初期化はmain.jsで実行することになると思います。コードの一例は以下。
import Vue from 'vue' import App from './App.vue' import router from './router' import store from './store' import vuetify from './plugins/vuetify'; import Amplify, * as AmplifyModules from 'aws-amplify' import { AmplifyPlugin, components } from 'aws-amplify-vue' import awsconfig from './aws-exports' /* 次のコードが該当部分。通常はawscondfigを引数に指定するところ、 aws_appsync_authenticationType を明示的に追加することで対処 */ Amplify.configure({ ...awsconfig, aws_appsync_authenticationType: "API_KEY" }) Vue.use(AmplifyPlugin, AmplifyModules) Vue.config.productionTip = false new Vue({ router, store, vuetify, render: h => h(App), components: { ...components } }).$mount('#app')解説
自分なりに調べたことを書くので、以降は読みたい人だけ読んでください。
Amplifyクライアントの初期化は
Amplify.configure(arg)で行います。argはオブジェクト型です。APIの認証方法を指定する引数を、aws_appsync_authenticationTypeプロパティで受け取ることができます。Amplify CLIで開発しているならば、argには通常 aws-exports.js のexportを指定して初期化することになると思います。このとき、envの切り替えを経由してデプロイしようとした場合に どういうわけか この
aws_appsync_authenticationTypeが抜け落ちます。GraphQL APIの呼び出し方法に話を変えます。多くの場合はAmplify.API.graphqlを以下のような形で呼び出すことになると思います。
await API.graphql(graphqlOperation(listItems)) // listItemsはクエリのtemplate string
API.graphqlはオブジェクト型の引数を受け取ります。そのオブジェクトのキーとして許容されるのは、query, variables, authMode の3つです。authModeがAppSyncへのリクエストに使用する認証方法の指定になります。graphqlOperationの実態はGraphQL APIへのリクエストパラメータを組み立てるためのユーティリティで、
{query, value}の形を持つobjectを返します(authModeは含みません)。authModeが無指定の場合、API.graphqlはAmplifyの初期化時に指定された認証方式を使ってAPIリクエストを行います。2つの話を総合すると、
- envを切り替えるとexportsから
aws_appsync_authenticationTypeが抜け落ちてしまい、AmplifyがGraphQL APIにリクエストするときに使用する認証方式が未指定(デフォルト値は AWS_IAM) になる- Ampilfyはデフォルト指定の認証方式(AWS_IAM)を利用してGraphQL APIリクエストを実行ようとするが、実際にはAPI_KEYを使うのが正しく、リクエストは失敗する
という状況が発生します。最終的に
No credentialsという例外が生成されることになります。なお、該当のExceptionを上げている部分のソースはこちらです。
https://github.com/aws-amplify/amplify-js/blob/master/packages/api/src/API.ts#L303-L308
case 'AWS_IAM'の分岐に入っているのがわかると思います。aws-exportsに認証方式の指定がないために、ここの分岐に入ってしまいます。まとめ
Amplify、クセが強い。
今回のトラブルの内容から推測するに、あくまでもAPI_KEYは単独での動作検証等に用いることを前提に設計されている感じがしました。だから別環境に持っていったり、他人との共同開発で同じ環境をシェアするような使い方で支障が出るのかなと。
- 投稿日:2019-10-21T17:53:22+09:00
[AWS Amplify][AppSync] API_KEYの認証方式でenvの切り替えを行った場合にGraphQLが通らなくなった
API_KEYを使ってAppSyncを叩いている環境でハマりました。
特にソースの変更を行っていないにも関わらず、envを切り替えたら動かなくなった、という事象に遭遇した方は、この記事の内容が該当するかもしれません。
amplifyのバージョンは以下の通りです。
"aws-amplify": "^1.2.2", "aws-amplify-vue": "^0.3.2",GraphQLを叩いている部分のコードスニペットを例示します。
graphqlOperationを用いています。let listItems = `query listBenchmarkHistory { listBenchmarkResultHistorys(team: "${this.team}",limit: 10000){ items { epochMilliSeconds score status comment } } }` const lists = await API.graphql(graphqlOperation(listItems))背景
初期の開発では
dev環境を利用していました。当初は一人で開発していましたし特に困ることもなかったのですが、本番デプロイを迎えてまっさらな本番環境を用意する必要が出ました。(本番環境にAPI Keyを使うんじゃない、というご指摘は甘んじて受け入れます。。。1日限りで利用するアプリケーションだし・・・と手抜いた結果がこのザマです)
amplify env add
で
prodを追加し、publishしようとすると、publish自体は成功するものの以下のようなエラーが出ます。
[WARN] 59:24.132 API - ensure credentials error No Cognito Federated Identity pool providedvue.runtime.esm.js:1888 Error: No credentials at e.<anonymous> (API.js:419) at u (API.js:40) at Object.next (API.js:21) at a (API.js:12)フロントをざっと見た限りでは、AppSyncに対するQueryやSubscriptionがコケているようでした。
Cognitoも使っていないし、Credentialでもないのに、はて何のことやら?と思っていましたがどうもamplify-jsのバグに近い挙動のようです。
対処方法
Amplifyのクライアントを初期化するために利用する src/aws-exports.js に、AppSync APIを使うときの認証方法を指定する属性があります。この指定が何故か抜け落ちており、これが原因でAPIの疎通不具合が発生しています。
// src/aws-exports.js // WARNING: DO NOT EDIT. This file is automatically generated by AWS Amplify. It will be overwritten. const awsmobile = { "aws_project_region": "ap-northeast-1", "aws_content_delivery_bucket": "your.hosting.bucket.com", "aws_content_delivery_bucket_region": "ap-northeast-1", "aws_content_delivery_url": "http://your-subdomain.s3-website-ap-northeast-1.amazonaws.com", "aws_appsync_graphqlEndpoint": "https://your-api.appsync-api.ap-northeast-1.amazonaws.com/graphql", "aws_appsync_region": "ap-northeast-1", "aws_appsync_apiKey": "your-api-key", "aws_appsync_authenticationType": "API_KEY" // この1行を追加する }; export default awsmobile;解説
自分なりに調べたことを書くので、以降は読みたい人だけ読んでください。
Amplifyクライアントの初期化は
Amplify.configure(arg)で行います。argはオブジェクト型です。APIの認証方法を指定する引数を、aws_appsync_authenticationTypeプロパティで受け取ることができます。Amplify CLIで開発しているならば、argには通常 aws-exports.js のexportを指定して初期化することになると思います。このとき、envの切り替えを経由してデプロイしようとした場合に どういうわけか この
aws_appsync_authenticationTypeが抜け落ちます。また、GraphQL APIの呼び出し方法に話を変えます。Amplify.API.graphqlを使って以下のような形で呼出します。
await API.graphql(graphqlOperation(listItems)) / listItemsはクエリのtemplate string
API.graphqlはオブジェクト型の引数を受け取ります。そのオブジェクトのキーとして許容されるのは、query, variables, authMode の3つです。authModeがAppSyncへのリクエストに使用する認証方法の指定になります。graphqlOperationの実態はGraphQL APIへのリクエストパラメータを組み立てるためのユーティリティで、{query, value}の形を持つobjectを返します(authModeはここに含まれません)。authModeが無指定の場合、API.graphqlはAmplifyクライアントの初期化時に指定された認証方式を使ってAPIリクエストを行います。2つの話を総合すると、
- envを切り替えるとexportsから
aws_appsync_authenticationTypeが抜け落ちてしまい、APIリクエストに使用する認証方式が未指定(デフォルト値は AWS_IAM) になる- Ampilfyはクライアント生成時のデフォルト指定の認証方式(AWS_IAM)を利用しようとする。しかしクライアント側でIAMに対応した設定はしていない(また、AppSync側にも定義されていない)
という状況が発生します。最終的に
No credentialsという例外が生成されることになります。なお、該当のExceptionを上げている部分のソースはこちらです。
https://github.com/aws-amplify/amplify-js/blob/master/packages/api/src/API.ts#L303-L308
case 'AWS_IAM'の分岐に入っているのがわかると思います。aws-exportsに認証方式の指定がないために、ここの分岐に入ってしまいます。(蛇足)なお、この問題はAPI.graphql の呼び出し時にauthModeを明示的に指定する、でも回避可能です。以下。
await API.graphql({ ...graphqlOperation(listItems), authMode: "API_KEY" })ただし、複数の認証方式をフロントエンドで使い分けたいケース(あるのか..??)でもなければこんなことをする必要はないです。おとなしくaws-exportsに追記した方が良いです。
まとめ
Amplifyの想定ユースケースの中で使う分には非常に便利に感じることが多いです。が、結局、リゾルバ周りやデータソースのスキーマやらをちゃんと作り込もうとすると労力が掛かるしあまりメリットはないかなと。そのへんまでやりたくなったらそのときはAmplifyを卒業すべきなのでしょうね。
Amplify、クセが強い。
- 投稿日:2019-10-21T17:53:22+09:00
[AWS Amplify][AppSync] API_KEYの認証方式でenvの切り替えを行った場合に "Error: No credentials" と出る問題の対処
API_KEYを使ってAppSyncを叩いている環境でハマりました。
特にソースの変更を行っていないにも関わらず、envを切り替えたら動かなくなった、という事象に遭遇した方は、この記事の内容が該当するかもしれません。
amplifyのバージョンは以下の通りです。
"aws-amplify": "^1.2.2", "aws-amplify-vue": "^0.3.2",GraphQLを叩いている部分のコードスニペットを例示します。
graphqlOperationを用いています。let listItems = `query listBenchmarkHistory { listBenchmarkResultHistorys(team: "${this.team}",limit: 10000){ items { epochMilliSeconds score status comment } } }` const lists = await API.graphql(graphqlOperation(listItems))背景
初期の開発では
dev環境を利用していました。当初は一人で開発していましたし特に困ることもなかったのですが、本番デプロイを迎えてまっさらな本番環境を用意する必要が出ました。(本番環境にAPI Keyを使うんじゃない、というご指摘は甘んじて受け入れます。。。1日限りで利用するアプリケーションだし・・・と手抜いた結果がこのザマです)
amplify env add
で
prodを追加し、publishしようとすると、publish自体は成功するものの以下のようなエラーが出ます。
[WARN] 59:24.132 API - ensure credentials error No Cognito Federated Identity pool providedvue.runtime.esm.js:1888 Error: No credentials at e.<anonymous> (API.js:419) at u (API.js:40) at Object.next (API.js:21) at a (API.js:12)フロントをざっと見た限りでは、AppSyncに対するQueryやSubscriptionがコケているようでした。
Cognitoも使っていないし、Credentialでもないのに、はて何のことやら?と思っていましたがどうもamplify-jsのバグに近い挙動のようです。
対処方法
Amplifyのクライアントを初期化する際に、AppSync APIリクエストを行うときに使用する認証方法を指定する属性があります。env切り替えを行った場合にこのプロパティが何故か抜け落ちます。これが原因でAPIの疎通不具合が発生しています。
ワークアラウンド的な対処となりますが、私の見解としては以下の2つのいずれかが良いように思います。
src/aws-exports.js の追記
Amplifyの初期化時にこのファイルのexportを参照しています。認証方法の指定もここで指定できます。一例として、変更後のaws-exportsは以下のような内容になります。
// src/aws-exports.js // WARNING: DO NOT EDIT. This file is automatically generated by AWS Amplify. It will be overwritten. const awsmobile = { "aws_project_region": "ap-northeast-1", "aws_content_delivery_bucket": "your.hosting.bucket.com", "aws_content_delivery_bucket_region": "ap-northeast-1", "aws_content_delivery_url": "http://your-subdomain.s3-website-ap-northeast-1.amazonaws.com", "aws_appsync_graphqlEndpoint": "https://your-api.appsync-api.ap-northeast-1.amazonaws.com/graphql", "aws_appsync_region": "ap-northeast-1", "aws_appsync_apiKey": "your-api-key", "aws_appsync_authenticationType": "API_KEY" // この1行を追加する }; export default awsmobile;Amplifyの初期化時に aws_appsync_authenticationType を明示的に指定
アプリからのGraphQLリクエストをAPI_KEYによる方法のみに仮定することになりますが、Amplify初期化時の引数に明示してしまうという手もあります。
通常Amplifyの初期化はmain.jsで実行することになると思います。コードの一例は以下。
import Vue from 'vue' import App from './App.vue' import router from './router' import store from './store' import vuetify from './plugins/vuetify'; import Amplify, * as AmplifyModules from 'aws-amplify' import { AmplifyPlugin, components } from 'aws-amplify-vue' import awsconfig from './aws-exports' /* 次のコードが該当部分。通常はawscondfigを引数に指定するところ、 aws_appsync_authenticationType を明示的に追加することで対処 */ Amplify.configure({ ...awsconfig, aws_appsync_authenticationType: "API_KEY" }) Vue.use(AmplifyPlugin, AmplifyModules) Vue.config.productionTip = false new Vue({ router, store, vuetify, render: h => h(App), components: { ...components } }).$mount('#app')解説
自分なりに調べたことを書くので、以降は読みたい人だけ読んでください。
Amplifyクライアントの初期化は
Amplify.configure(arg)で行います。argはオブジェクト型です。APIの認証方法を指定する引数を、aws_appsync_authenticationTypeプロパティで受け取ることができます。Amplify CLIで開発しているならば、argには通常 aws-exports.js のexportを指定して初期化することになると思います。このとき、envの切り替えを経由してデプロイしようとした場合に どういうわけか この
aws_appsync_authenticationTypeが抜け落ちます。また、GraphQL APIの呼び出し方法に話を変えます。Amplify.API.graphqlを使って以下のような形で呼出します。
await API.graphql(graphqlOperation(listItems)) / listItemsはクエリのtemplate string
API.graphqlはオブジェクト型の引数を受け取ります。そのオブジェクトのキーとして許容されるのは、query, variables, authMode の3つです。authModeがAppSyncへのリクエストに使用する認証方法の指定になります。graphqlOperationの実態はGraphQL APIへのリクエストパラメータを組み立てるためのユーティリティで、{query, value}の形を持つobjectを返します(authModeはここに含まれません)。authModeが無指定の場合、API.graphqlはAmplifyクライアントの初期化時に指定された認証方式を使ってAPIリクエストを行います。2つの話を総合すると、
- envを切り替えるとexportsから
aws_appsync_authenticationTypeが抜け落ちてしまい、APIリクエストに使用する認証方式が未指定(デフォルト値は AWS_IAM) になる- Ampilfyはクライアント生成時のデフォルト指定の認証方式(AWS_IAM)を利用しようとする。しかしクライアント側でIAMに対応した設定はしていない(また、AppSync側にも定義されていない)
という状況が発生します。最終的に
No credentialsという例外が生成されることになります。なお、該当のExceptionを上げている部分のソースはこちらです。
https://github.com/aws-amplify/amplify-js/blob/master/packages/api/src/API.ts#L303-L308
case 'AWS_IAM'の分岐に入っているのがわかると思います。aws-exportsに認証方式の指定がないために、ここの分岐に入ってしまいます。(蛇足)なお、この問題はAPI.graphql の呼び出し時にauthModeを明示的に指定する、でも回避可能です。以下。
await API.graphql({ ...graphqlOperation(listItems), authMode: "API_KEY" })ただし、複数の認証方式をフロントエンドで使い分けたいケース(あるのか..??)でもなければこんなことをする必要はないです。おとなしくaws-exportsに追記した方が良いです。
まとめ
Amplifyの想定ユースケースの中で使う分には非常に便利に感じることが多いです。が、結局、リゾルバ周りやデータソースのスキーマやらをちゃんと作り込もうとすると労力が掛かるしあまりメリットはないかなと。そのへんまでやりたくなったらそのときはAmplifyを卒業すべきなのでしょうね。
Amplify、クセが強い。
- 投稿日:2019-10-21T17:38:49+09:00
GetLowestPricedOffersForASINをpythonで実行する話
本記事について
MWSのAPIについてpythonで遊んでいるが、そのうちの「GetLowestPricedOffersForASIN」というAPIがなぜか全然動かなくて詰んだ話。とりあえず解決したのでもし同じ悩みを抱えているエンジニアの助けになれば・・・
とりあえず解決したコード
まず動いたコードを載せよう。
MWS_API.py### 初期モジュール宣言 import os, sys, time import base64 import datetime import hashlib import hmac import urllib.parse import requests import six import xmltodict import json from time import gmtime, strftime import pandas as pd import pandas as np from pathlib import Path ###★アクセス用key===個人のやつを入れてね=== AMAZON_CREDENTIAL = { 'SELLER_ID': '★', 'ACCESS_KEY_ID': '★', 'ACCESS_SECRET': '★', } DOMAIN = 'mws.amazonservices.jp' ENDPOINT = '/Products/2011-10-01' ### 関数宣言 ## 使用するAPIの宣言と必須パラメータを与える関数 def GetLowestPricedOffersForASIN(ItemCondition='New'): print('Funcition : GetLowestPricedOffersForASIN', flush=True) ## GetLowestPricedOffersForASINの必須パラメータを作成 q = { 'Action' : 'GetLowestPricedOffersForASIN', 'MarketplaceId' : 'A1VC38T7YXB528',#日本 'ASIN' : 'B000xxxx',#調べたいASINを入れる 'ItemCondition' : ItemCondition, } return q ##POST関数 def PostMWS(q): timestamp = datetime.datetime.utcnow().strftime('%Y-%m-%dT%H:%M:%SZ') ##POSTするのに必要なパラメータの作成 data = { 'AWSAccessKeyId' : AMAZON_CREDENTIAL['ACCESS_KEY_ID'], 'SellerId' : AMAZON_CREDENTIAL['SELLER_ID'], 'SignatureVersion' : '2', 'Timestamp' : timestamp, 'Version' : '2011-10-01', 'SignatureMethod' : 'HmacSHA256', } print(type(data['Timestamp'])) data.update(q) query_string = urllib.parse.urlencode(sorted(data.items())) canonical = "{}\n{}\n{}\n{}".format( 'POST', DOMAIN, ENDPOINT, query_string ) h = hmac.new( six.b(AMAZON_CREDENTIAL['ACCESS_SECRET']), six.b(canonical), hashlib.sha256 ) signature = urllib.parse.quote(base64.b64encode(h.digest()), safe='') url = 'https://{}{}'.format( DOMAIN, ENDPOINT) data = '{}&Signature={}'.format( query_string, signature) headers = {'Content-Type': 'application/x-www-form-urlencoded'} res = requests.post(url,data,headers=headers) return res if __name__ == '__main__': q = GetLowestPricedOffersForASIN() res = PostMWS(q) response_xml = res.text print(response_xml)なにが起きたのか?
これから下の文は愚痴のようなものなので、動いた!サンキュー!って方は無視して大丈夫です。
解決するまでは以下のようなコードで実行していた。MWS_API.py### 初期モジュール宣言 import os, sys, time import base64 import datetime import hashlib import hmac import urllib.parse import requests import six import xmltodict import json from time import gmtime, strftime import pandas as pd import pandas as np from pathlib import Path ###★アクセス用key===個人のやつを入れてね=== AMAZON_CREDENTIAL = { 'SELLER_ID': '★', 'ACCESS_KEY_ID': '★', 'ACCESS_SECRET': '★', } DOMAIN = 'mws.amazonservices.jp' ENDPOINT = '/Products/2011-10-01' ### 関数宣言 ## ASINに応じた結果を返す関数 def GetLowestPricedOffersForASIN(ItemCondition='New'): print('Funcition : GetLowestPricedOffersForASIN', flush=True) ## GetLowestPricedOffersForASINの必須パラメータを作成 q = { 'MarketplaceId' : 'A1VC38T7YXB528',#日本 'ASIN' : 'B000xxxx',#調べたいASINを入れる 'ItemCondition' : ItemCondition, } return q ##POST関数 def PostMWS(q): timestamp = datetime.datetime.utcnow().strftime('%Y-%m-%dT%H:%M:%SZ') ##POSTするのに必要なパラメータの作成 data = { 'AWSAccessKeyId' : AMAZON_CREDENTIAL['ACCESS_KEY_ID'], 'Action' : 'GetLowestPricedOffersForASIN', 'SellerId' : AMAZON_CREDENTIAL['SELLER_ID'], 'SignatureVersion' : '2', 'Timestamp' : timestamp, 'Version' : '2011-10-01', 'SignatureMethod' : 'HmacSHA256', } print(type(data['Timestamp'])) data.update(q) query_string = urllib.parse.urlencode(sorted(data.items())) canonical = "{}\n{}\n{}\n{}".format( 'POST', DOMAIN, ENDPOINT, query_string ) h = hmac.new( six.b(AMAZON_CREDENTIAL['ACCESS_SECRET']), six.b(canonical), hashlib.sha256 ) signature = urllib.parse.quote(base64.b64encode(h.digest()), safe='') ##★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ url = 'https://{}{}?{}&Signature={}'.format( DOMAIN, ENDPOINT,query_string, signature) res = requests.post(url) ##★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ return res if __name__ == '__main__': q = GetLowestPricedOffersForASIN() res = PostMWS(q) response_xml = res.text print(response_xml)★で囲っている部分が異なるところである。
例えばGoogleなどでmwsのAPIの送り方を調べると上記のような形で書かれている。事実私もそれを参考に作成し、ほかのAPIではうまくいっていた。
そうほかのAPIではうまくいっていたのである。
ちなみに上のコードを実行すると400エラーが返ってくる。これは必須パラメータが足りないことを示しているようだ。
解決への道
調べていたらこんな記事を見つけた
https://teratail.com/questions/127617クエストリング・・・?リクエストボディ・・・?なんのこっちゃ・・・
調べてみたらダメなやり方はPOSTで指定しているのはURLのみ、確かにURL上はデータがあるように見えるがこれだとリクエストボディ上は空になるらしい。
なるほど、つまりこうか!!MWS_API.py##★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ url = 'https://{}{}'.format( DOMAIN, ENDPOINT) data = '{}&Signature={}'.format( query_string, signature) res = requests.post(url,data=data) ##★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★・・・が、ダメ!!!
なんでだ・・・さらに調べる。するとこんな記事が
https://sellercentral.amazon.com/forums/t/getlowestpricedoffersforasin-service-call-with-no-xml-response/252922この方はheaderをつけることで解決したらしい。
なるほど、つまりこうか!!MWS_API.py##★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ url = 'https://{}{}'.format( DOMAIN, ENDPOINT) data = '{}&Signature={}'.format( query_string, signature) headers = {'Content-Type': 'application/x-www-form-urlencoded'} res = requests.post(url,data=data,headers=headers) ##★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★・・・が、ダメ!!!!!!なんでやああああああああああああ!!!!!
このとき結果を見ていて気付いたが、どうにもデータがうまく入っていないように見える・・・?まさか?
MWS_API.py##★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★ url = 'https://{}{}'.format( DOMAIN, ENDPOINT) data = '{}&Signature={}'.format( query_string, signature) headers = {'Content-Type': 'application/x-www-form-urlencoded'} res = requests.post(url,data,headers=headers) ##★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★・・・う、動いた・・?
課題事項
とりあえず動いて助かったのだが、疑問が残る。
・ほかのAPIはクエストリングだけで動くのに、なぜこいつはリクエストボディやヘッダーをつけなければ動かないのか?
(もしかしたらボディやヘッダーをつけるのが正規なのかもしれない・・・)・requests.postのdata引数について。クイックスタートやほかの投稿をみるとdata引数に送るデータを渡していたのでなにも考えずdata=dataとしていたがダメっぽい。。。よく読むとdata引数に渡すのは辞書と書いてある、要調査。
2019/10/21時点。
- 投稿日:2019-10-21T17:24:08+09:00
docker-credential-ecr-login can only be used with Amazon Elastic Container Registry. のエラーを消す
docker-credential-ecr-loginとは?
docker-credential-ecr-loginっていうのは、 Amazon ECR (Amazon が提供している Dockerレジストリサービス)に、PCからアクセスする際に必要になるログイン作業を、自動化してくれるツールです。
amazon-ecr-credential-helperと同じものです。(多分)インストール方法等、詳細はこちらをご覧ください。
amazon-ecr-credential-helperをWindowsにインストールするプルしたら
docker-credential-ecr-loginでエラーが発生した新しいPCに
docker-credential-ecr-loginをインストールして、docker pull node:12.3.1-alpineを実行したところ、以下のエラーが発生しました。$ docker pull node:12.3.1-alpine ERRO[0000] Error parsing the serverURL error="docker-credential-ecr-login can only be used with Amazon Elastic Container Registry." serverURL="https://index.docker.io/v1/"
docker-credential-ecr-login使ってhttps://index.docker.io/v1/(Docker Hubのこと) にアクセスしようとしてますけど、docker-credential-ecr-loginはAmazon ECRでしか使えませんよ!みたいな意味だと思います。
credsStoreじゃなくてcredHelpersを使わなきゃダメらしいこちらの記事に同じ症状のことが記載されてました。
docker-credential-ecr-login can only be used with Amazon Elastic Container Registryどうやら、
config.jsonでcredsStoreを使うのはダメで、credHelpersを使わなきゃいけないみたいです。
config.jsonを修正した
%USERPROFILE%\.docker\config.jsonを確認したところ、以下のようになっていました。{ // 省略 "credsStore": "ecr-login", // 省略 }この
credsStoreの行を削除して、以下のように書き換えます。{ // 省略 "credHelpers": { "{AWSアカウントID}.dkr.ecr.{リージョン名}.amazonaws.com": "ecr-login" }, // 省略 }例えば、
AWSアカウントIDが00000000000000リージョン名がap-northeast-1の場合、
00000000000000.dkr.ecr.ap-northeast-1.amazonaws.comとなります。ちなみに、
*等のワイルドカードは使えませんので、ご注意ください。
例えば、*.dkr.ecr.*.amazonaws.comみたいなのはNGです。(私の環境で試したところ、ダメでした。)これで再度、
docker pull node:12.3.1-alpineを実行したところ、無事にプルすることができました。念のため、 ECRからもプルを試してみたところ、そちらも大丈夫でした。
さいごに
以下のサイトを参考にさせていただきました。
- 投稿日:2019-10-21T16:57:21+09:00
MongoDB Atlas → AWSへのVPC Peering
概用
- Atlas側のVPCからマイVPCにVPC Peeringのリクエスト
- マイVPC側でAccept
- マイVPC側のセキュリティグループにAtlasのVPCを追加
※基本的にAtlasの公式ドキュメント通りに作業します。
1. Atlas側のVPCからマイVPCにVPC Peeringをリクエスト
2. マイVPC側でAccept
マネジメントコンソールからVPC Peeringのメニューを開き、VPC PeeringのリクエストをAcceptします。
3. マイVPC側のセキュリティグループにAtlasのVPCを追加
ここがポイント。手動でRoute Tableの設定を修正してもいいですが、CFnで冪等に管理します。
スクリプト
#!/bin/sh -e ### # VPC PeeringをAcceptした側のVPCに、VPC Peeringが存在する場合のみRouteを追加するスクリプト。 ### REQUESTER_VPC_ID=$1 REQUESTER_FRIENDLY_NAME=$2 DESCRIBE_VPC_PEER="aws ec2 describe-vpc-peering-connections --filters Name=status-code,Values=active Name=requester-vpc-info.vpc-id,Values=${REQUESTER_VPC_ID}" echo ${DESCRIBE_VPC_PEER} export VpcPeeringConnectionId=$(${DESCRIBE_VPC_PEER} \ --query VpcPeeringConnections[0].VpcPeeringConnectionId \ --output text) export RequesterVpcCidr=$(${DESCRIBE_VPC_PEER} \ --query VpcPeeringConnections[0].RequesterVpcInfo.CidrBlock \ --output text) if [ ${VpcPeeringConnectionId} != None ]; then aws ec2 modify-vpc-peering-connection-options \ --vpc-peering-connection-id ${VpcPeeringConnectionId} \ --accepter-peering-connection-options '{"AllowDnsResolutionFromRemoteVpc":true}' \ --region ${AWS_DEFAULT_REGION} aws cloudformation deploy \ --template-file cfn/vpc-peer-acceptor-config.yml \ --stack-name vpc-peer-with-${REQUESTER_FRIENDLY_NAME} \ --parameter-overrides \ VpcPeeringConnectionId=${VpcPeeringConnectionId} \ RequesterVpcCidr=${RequesterVpcCidr} \ --tags date="$(date '+%Y%m%d%H%M%S')" fiCloudFormationテンプレート
AWSTemplateFormatVersion: '2010-09-09' Description: VPC Peering Accepter Config Parameters: VpcPeeringConnectionId: Type: String RequesterVpcCidr: Type: String Resources: XXXRouteToVPCPeer: Type: AWS::EC2::Route Properties: RouteTableId: { "Fn::ImportValue": !Sub "XXXRouteTable-Id" } DestinationCidrBlock: !Ref RequesterVpcCidr VpcPeeringConnectionId: !Ref VpcPeeringConnectionId4. 疎通チェック
今回はAmazon Linuxにmongoコマンドをインストールします。
ダウンロードリンクはここから。
https://www.mongodb.com/download-center/enterprise?jmp=docs# 絶対もっと効率いいやり方あります。 MONGO_SHELL=https://downloads.mongodb.org/linux/mongodb-shell-linux-x86_64-amazon-4.2.1.tgz curl -O $MONGO_SHELL tar -zxvf mongodb-shell-linux-x86_64-amazon-4.2.1.tgz sudo cp mongodb-linux-x86_64-amazon-4.2.1/bin/mongo /usr/bin/mongo# 接続確認 mongo "mongodb+srv://<your_mongodb_host>.mongodb.net/test" --username <username> ... MongoDB Enterprise <your_mongodb_host>-0:PRIMARY>


- 投稿日:2019-10-21T16:51:26+09:00
AWS EC2でhello world
AWSアカウントを作成してからEC2にApacheを入れてhello worldを表示するまでのメモ
使用OSはWindows
EC2インスタンスの作成方法とElasticIPの関連付けなどは省略キーペア作成
画面左の選択欄から キーペア > キーペアの作成 を選択、適当なキーペア名を入力後作成ボタンをクリックし、「キーペア名.pem」をダウンロード
インスタンス一覧画面のキー名のところに作成したキーペアが登録されていることを確認
TeraTermで接続
接続先のインスタンスのIPv4パブリックIPを入力してOKボタンをクリック
ユーザ名にec2-userを入力、先ほどダウンロードした認証キーを設定
接続完了
Apacheをインストールして起動
// パッケージ更新 $ sudo yum update -y // Apacheのインストール $ sudo yum install -y httpd // Apacheの起動 $ sudo service httpd start// htmlファイル作成 $ sudo vim /var/www/html/index.html $ cat /var/www/html/index.html hello world!ブラウザから確認
その前にポートを開いておく
セキュリティグループ > アクション > インバウンドのルールの編集
タイプをHTTPにして追加
インスタンス > パブリックDNS(IPv4)にあるアドレスにブラウザからアクセスすれば、hello worldが表示される

- 投稿日:2019-10-21T16:31:25+09:00
Aws cli ebcliでエラー、動かない時にはまずpipパッケージのバージョンを確認しよう
なんだかんだ1年以上運用したので
定期的にどんな作業が発生するかというのが溜まってきたのでまとめてみます。環境周りのコマンドを実行する作業になるので
不安がある場合は仮想環境のコピーを作成するのをお勧めします。私の個人的な経験ではほとんどが依存関係のバージョンが食い違っているというものが大半でしたので
バージョンアップのメンテナンス内容をメインに書きます。これから導入を考えている方に
こんな作業が発生するんだとか
こんなスキルセットが必要になるんだとか
参考になれば嬉しいです。※ここに書いてあることが全てではないのでその点はご注意を
定期的に必要となるお手入れ
コマンドラインツールもそれぞれバージョンアップをしてくれています。
ゆえに突然エラーが出てくるということもしばしばそんな時はまずは現状確認しましょう。
※pipを使っていることが前提ですpiplisto.shellpip list -o続きましてpip自身のアップグレード
upgrade.pippip install --upgrade pipawscliのアップグレード
awscliupgrade.shellpip install awscli --upgrade --user参考URL
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/installing.htmleb cliのアップグレード
ebcliupgrade.shellpip install awsebcli --upgrade --userbotocoreのアップグレード
aws cliもアップグレードが同時に必要のような状態の場合
piplist.shell$ pip list -o Package Version Latest Type awscli 1.16.97 1.16.99 wheel botocore 1.12.87 1.12.89 wheel以下のコマンドでbotocoreとaws cliの両方がアップデートされた
awscliup.shellpip install awscli --upgrade --userその他pip管理のプラグインアップデート
pipでプラグインを個別にアップデートしないといけない場合もある。
pipupdate.shsudo pip install プラグイン名 -U #以下tabulateというpipパッケージをアップデートする場合 sudo pip install tabulate -U再インストール
運用している中で何度かawscli,ebコマンド自体を再インストールしたら
治ったということがありましたのでそれも書いてみます。aws cliの再インストール
pythonモジュールのpipが入っていれば以下でアンインストールできます。
uninstallaws.sh$ pip uninstall awscliebコマンドの再インストール
ebコマンドのアンインストール
uninstallaws.sh$ pip uninstall awscli再度インストール
installeb.shpip install awsebcli --upgrade --userエラーが表示されたら
ebコマンドのデバッグ
debug.shEb deploy --debugpipパッケージのダウングレード
稀に以下のようなエラーが表示されることがあります。
error.shERROR: awscli 1.16.253 has requirement botocore==1.12.243, but you'll have botocore 1.12.253 which is incompatible. ERROR: awscli 1.16.253 has requirement rsa<=3.5.0,>=3.1.2, but you'll have rsa 4.0 which is incompatible.これはawscliが使っているパッケージのバージョンがあっていませんよ〜というもので
バージョンをあげる場合は前述のコマンドでいけますが
バージョンを下げろという場合もあります。
ダウングレードということになりますが
コマンド的にはバージョンを指定してインストールという形でダウングレードできます。downgrade.shpip install botocore==1.12.243linuxの時間がずれた時もエラーが出ます。
当方の環境としてCentOS7の仮想環境に置いている状態で
定期的にLinuxの時間がずれるという現象があり
ebコマンドが動かなくなる時があります。
私の環境では以下の方法で解決しています。
>>CentOS7の時間がずれる
- 投稿日:2019-10-21T14:57:17+09:00
AWSの有料サポートプランについてまとめ
AWSのサポートについて、問い合わせした内容をまとめておきます。
いくつかのサポートの中で得た知識をまとめただけの備忘録です。1つの契約で全ての質問に対応してもらえるか
他のアカウントの件についてはサポートを受けることはできない。(当たり前ですね笑)
サポートに加入しているアカウントについてのサポートのみのため、
複数のアカウントを契約しており、それぞれに対してサポートが必要な場合は、
それぞれのアカウントでサポート契約を結ぶ必要があります。サポートのケース作成数に上限があるか
ケースの作成数には上限はなく、無制限のケースをオープン可能。
ケースをクローズしたのち、新たに不明点が見つかった場合には、
同じケースを再度オープンにする、または、新たなケースを作ることができます。サードパーティ製ソフトウェアサポートについて
ビジネス以上のプランにて、サードパーティ製ソフトウェアサポートをベストエフォートで対応してもらえる。
今回は、Nginx まわりの原因調査をお願いした場合に、このように回答されました。
なお、今回は、原因が Nginx ではない(サーバの設定で解決できる)場合の可能性があったため、
その点については回答をもらうことができました。実際に環境にアクセスして原因究明に当たってもらえるか
SSHなどでサーバにログインし、確認しながらのサポートはしてもらえない。
環境にアクセスするようなサポートが必要な場合には、
AWSサポートではなく、AWSパートナーの利用をオススメされました。
※ AWSパートナーを探したい場合には、こちらからも相談可能なようです最低利用期間はあるか
30日間です。
最低30日契約すれば、40日目でも50日目でも、好きなタイミングでのサポートの解約が可能です。
月をまたいで30日契約した場合に料金はどのように計算されるか
料金を決定するためのAWSの月額料金は、月ごとに計算されるようです。
仮に、10月21日〜11月19日(30日)のみ契約していた場合、
- 10月21日〜10月31日の利用料金をもとに計算され、10月ご利用分として課金
- 11月1日〜11月19日の利用料金をもとに計算され、11月ご利用分として課金
一度解約したあと、再度契約することは可能か
可能です。
問題が起こったときだけサポートプランを契約するような利用方法も可能とのことです。
※ ただし、毎回30日間の最低利用期間が発生します
とりあえず、ここまで。
また増えたら追加します
- 投稿日:2019-10-21T14:17:19+09:00
Serverless FrameworkでTypeScriptにしつつLambda Layersを使う方法
serverless framework自体をインストールする
npm install -g serverlessプロジェクトを作成する
serverless create --template aws-nodejs-typescript --path my-serviceプラグインインストール
serverless plugin install -n serverless-webpacknpm installデプロイ
serverless deploy --aws-profile sandbox -vデプロイされると、
endpointsにURLが表示されています。そのURLにcurlでアクセスしてみます。
curl https://hsnfe8svli.execute-api.us-east-1.amazonaws.com/dev/hello | jq実行すると下記の結果が得られます。(抜粋)
{ "message": "Go Serverless Webpack (Typescript) v1.0! Your function executed successfully!" }実行してみる
serverless invoke -f hello -l --aws-profile sandbox出力
{ "statusCode": 200, "body": "{\n \"message\": \"Go Serverless Webpack (Typescript) v1.0! Your function executed successfully!\",\n \"input\": {}\n}" } -------------------------------------------------------------------- START RequestId: d2d32d7e-7c23-448d-ac57-45133fcf6422 Version: $LATEST END RequestId: d2d32d7e-7c23-448d-ac57-45133fcf6422 REPORT RequestId: d2d32d7e-7c23-448d-ac57-45133fcf6422 Duration: 2.07 ms Billed Duration: 100 ms Memory Size: 1024 MB Max Memory Used: 76 MBLayersプラグインを使う
npx sls plugin install --name serverless-layersS3 Bucketを指定する
serverless info -vで表示される、
ServerlessDeploymentBucketNameを、serverless.yamlのcustomセクションに追加custom: serverless-layers: layersDeploymentBucket: 'ここにServerlessDeploymentBucketNameの値を入れる'(いちいちこの方法を使わないでも直接参照したい…。だれか知っている人がいたら教えてください)
- 投稿日:2019-10-21T14:17:19+09:00
Serverless FrameworkでTypeScriptを使い、Lambda Layersを使う方法
serverless framework自体をインストールする
npm install -g serverlessプロジェクトを作成する
serverless create --template aws-nodejs-typescript --path my-serviceプラグインインストール
serverless plugin install -n serverless-webpacknpm installデプロイ
serverless deploy --aws-profile sandbox -vデプロイされると、
endpointsにURLが表示されています。そのURLにcurlでアクセスしてみます。
curl https://hsnfe8svli.execute-api.us-east-1.amazonaws.com/dev/hello | jq実行すると下記の結果が得られます。(抜粋)
{ "message": "Go Serverless Webpack (Typescript) v1.0! Your function executed successfully!" }実行してみる
serverless invoke -f hello -l --aws-profile sandbox出力
{ "statusCode": 200, "body": "{\n \"message\": \"Go Serverless Webpack (Typescript) v1.0! Your function executed successfully!\",\n \"input\": {}\n}" } -------------------------------------------------------------------- START RequestId: d2d32d7e-7c23-448d-ac57-45133fcf6422 Version: $LATEST END RequestId: d2d32d7e-7c23-448d-ac57-45133fcf6422 REPORT RequestId: d2d32d7e-7c23-448d-ac57-45133fcf6422 Duration: 2.07 ms Billed Duration: 100 ms Memory Size: 1024 MB Max Memory Used: 76 MBLayersプラグインを使う
npx sls plugin install --name serverless-layersS3 Bucketを指定する
serverless info -vで表示される、
ServerlessDeploymentBucketNameを、serverless.yamlのcustomセクションに追加custom: serverless-layers: layersDeploymentBucket: 'ここにServerlessDeploymentBucketNameの値を入れる'(いちいちこの方法を使わないでも直接参照したい…。だれか知っている人がいたら教えてください)
- 投稿日:2019-10-21T12:32:54+09:00
AWS EKSでPersistentVolumeClaim経由でEFSを使う
Amazon EFSCSI ドライバー
EKSからEFSを操作するためのツール的な?
参考
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/storage-classes.html
https://docs.aws.amazon.com/ja_jp/eks/latest/userguide/efs-csi.htmlStorageClassがデプロイされているか確認
1.14以降であればデフォルトでデプロイされている
未満であれば、上記URLから手動でデプロイする必要があるkubectl get storageclass出力結果
NAME PROVISIONER AGE gp2 (default) kubernetes.io/aws-ebs 11hEFSCSIドライバーをデプロイ
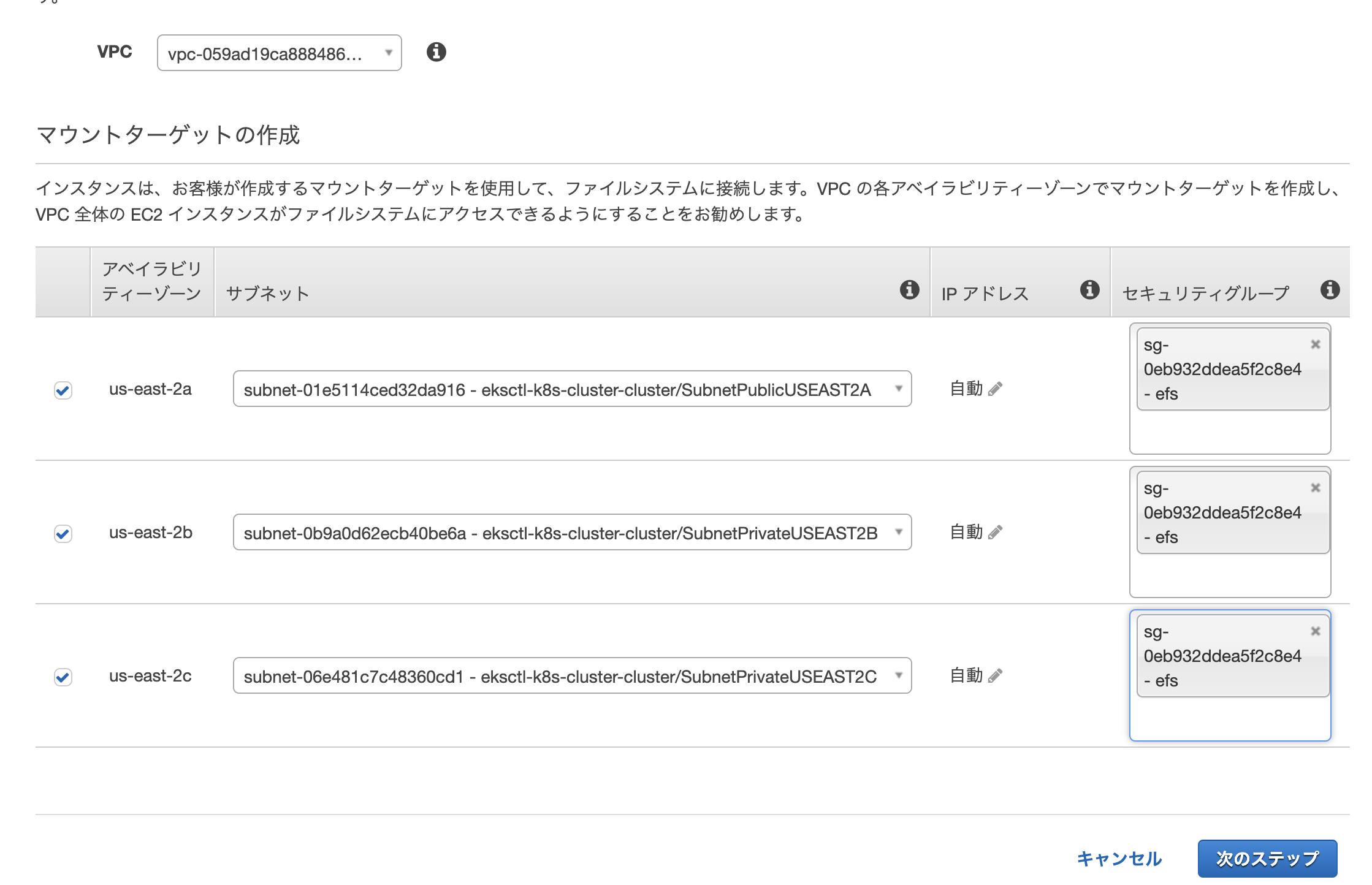
kubectl apply -k "github.com/kubernetes-sigs/aws-efs-csi-driver/deploy/kubernetes/overlays/stable/?ref=master"EKSが動作しているVPCIDを確認
aws eks describe-cluster --name k8s-cluster --query cluster.resourcesVpcConfig.vpcId --output text出力結果
vpc-059ad19ca888486c4IP範囲(CIDRブロック)を確認
aws ec2 describe-vpcs --vpc-ids vpc-059ad19ca888486c4出力結果
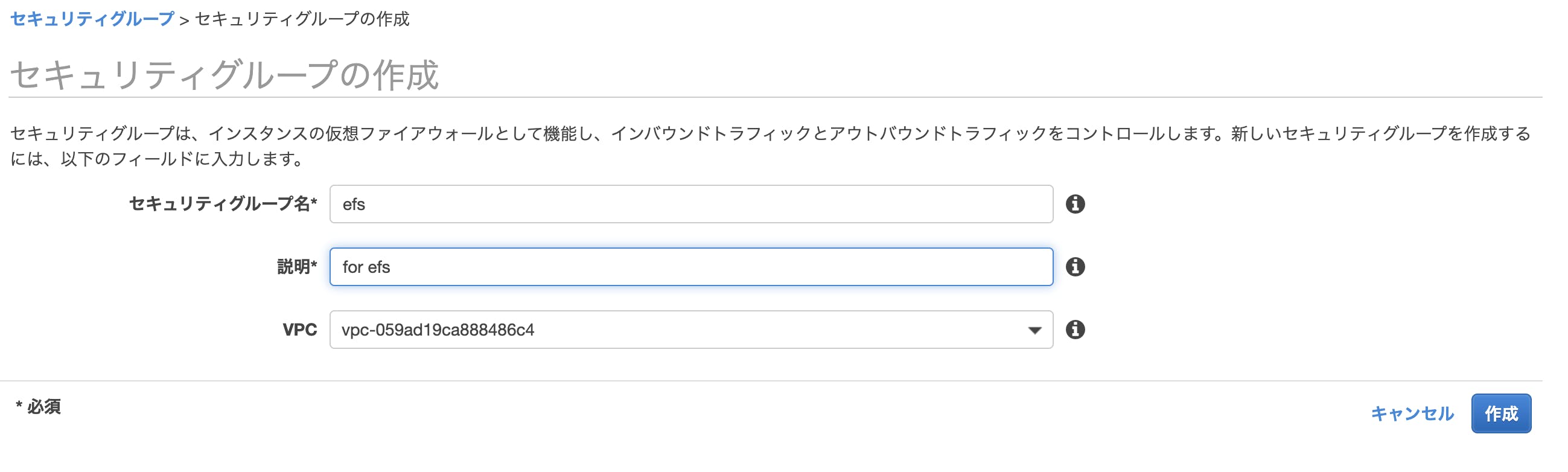
"CidrBlockAssociationSet": [ { "AssociationId": "vpc-cidr-assoc-0a2a4f054ca33b5f0", "CidrBlock": "192.168.0.0/16", "CidrBlockState": { "State": "associated" } }セキュリティグループの作成
インバウンドルールの作成
EFSの作成
サンプルアプリをデプロイして動作確認
ドライバーのクローン
git clone https://github.com/kubernetes-sigs/aws-efs-csi-driver.gitディレクトリ移動
cd aws-efs-csi-driver/examples/kubernetes/multiple_pods/ファイルシステムID確認
aws efs describe-file-systems --query "FileSystems[*].FileSystemId" --output text出力結果
fs-32b4854bpv.yamlの
volumeHandleを上記のファイルシステムIDへ変更specs/pv.yamlapiVersion: v1 kind: PersistentVolume metadata: name: efs-pv spec: capacity: storage: 5Gi volumeMode: Filesystem accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: efs-sc csi: driver: efs.csi.aws.com volumeHandle: fs-32b4854bpv,pvc.storageclass,sampleappデプロイ
kubectl apply -f specs/出力結果
persistentvolumeclaim/efs-claim created pod/app1 created pod/app2 created persistentvolume/efs-pv created storageclass.storage.k8s.io/efs-sc createdpvがデプロイされているか確認
kubectl get pv出力結果
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE efs-pv 5Gi RWX Retain Bound default/efs-claim efs-sc 93spvの詳細情報表示
kubectl describe pv efs-pv出力結果
EFSファイルシステムはVolumeHandleで表示Name: efs-pv Labels: <none> Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"v1","kind":"PersistentVolume","metadata":{"annotations":{},"name":"efs-pv"},"spec":{"accessModes":["ReadWriteMany"],"capaci... pv.kubernetes.io/bound-by-controller: yes Finalizers: [kubernetes.io/pv-protection] StorageClass: efs-sc Status: Bound Claim: default/efs-claim Reclaim Policy: Retain Access Modes: RWX VolumeMode: Filesystem Capacity: 5Gi Node Affinity: <none> Message: Source: Type: CSI (a Container Storage Interface (CSI) volume source) Driver: efs.csi.aws.com VolumeHandle: fs-32b4854b ReadOnly: false VolumeAttributes: <none> Events: <none>Podがボリュームにデータを書き込んでいるかを確認
kubectl exec -ti app1 -- tail /data/out1.txt出力結果
Mon Oct 21 02:44:10 UTC 2019 Mon Oct 21 02:44:15 UTC 2019 Mon Oct 21 02:44:20 UTC 2019 Mon Oct 21 02:44:25 UTC 2019 Mon Oct 21 02:44:30 UTC 2019 Mon Oct 21 02:44:35 UTC 2019 Mon Oct 21 02:44:40 UTC 2019 Mon Oct 21 02:44:45 UTC 2019 Mon Oct 21 02:44:50 UTC 2019 Mon Oct 21 02:44:55 UTC 2019Pod2もついでに確認しておく
kubectl exec -ti app2 -- tail /data/out1.txt

- 投稿日:2019-10-21T10:51:17+09:00
「Node.js 8.10を使用するAWSのLambda関数が非推奨になるよ」というお知らせを読んで考えたこと
はじめに
社内向けにお知らせを書いていたけど、残念な弊社では議論できそうな人がいなかったので、保守とか更新についての考えとかを指摘があればQiitaでコメントもらいたいなと思って投稿した記事です。
なので、コメントがあればいただけますと幸いです。
AWS Lambdaのサービス利用に関するお知らせ
2019年10月19日 午前 4:10:00 UTC+9にPersonal Helth Dashboardにて通知がありました。
通知内容
We are contacting you as we have identified that your AWS Account currently has one or more Lambda functions using Node.js 8.10, which will reach its EOL at the end of 2019.
このAWSアカウントには現在、Node.js 8.10を使用するLambda関数があり、2019年末にEOLに達することを確認したため、お知らせします。What’s happening?
The Node community has decided to end support for Node.js 8.x on December 31, 2019 [1]. From this date forward, Node.js 8.x will stop receiving bug fixes, security updates, and/or performance improvements. To ensure that your new and existing functions run on a supported and secure runtime, language runtimes that have reached their EOL are deprecated in AWS [2].
どうゆうことですか? Nodeコミュニティは、Node.js 8.xのサポートを2019年12月31日に終了することを決定しました。[1] この日以降、Node.js 8.xはバグ修正、セキュリティアップデート、および/またはパフォーマンス改善の受信を停止します。サポートされている安全なランタイムで新しい関数と既存の関数を実行することは、EOLに達した言語ランタイムはAWSで非推奨になりました。[2]For Node.js 8.x, there will be 2 stages to the runtime deprecation process:
1. Disable Function Create – Beginning January 6, 2020, customers will no longer be able to create functions using Node.js 8.10
2. Disable Function Update – Beginning February 3, 2020, customers will no longer be able to update functions using Node.js 8.10Node.js 8.x の場合、ランタイムは2段階のプロセスで非推奨になります。 1. 関数を無効にする 2020年1月6日以降、お客様はNode.js 8.10を使用して関数を作成できなくなります。 2. 関数の更新を無効にする 2020年2月3日以降、お客様はNode.js 8.10を使用している関数を更新できなくなります。After this period, both function creation and updates will be disabled permanently. However, existing Node 8.x functions will still be available to process invocation events.
この期限が過ぎると、関数の作成と更新の両方が永久に無効になります。 ただし、既存のNode 8.x関数は、呼び出しイベントによる利用は引き続き可能です。What do I need to do?
We encourage you to update all of your Node.js 8.10 functions to the newer available runtime version, Node.js 10.x[3]. You should test your functions for compatibility with the Node.js 10.x language version before applying changes to your production functions.
何をする必要がありますか? Node.js 8.10のすべての関数を利用可能な新しいランタイムバージョン(Node.js 10.x)に更新することをお勧めします。 実動関数に変更を適用するために、Node.js 10.x言語バージョンとの互換性について関数をテストする必要があります。What if I have issues/What if I need help?
Please contact us through AWS Support [4] or the AWS Developer Forums [5] should you have any questions or concerns.
問題がある場合/助けが必要な場合はどうなりますか? 質問や懸念がある場合は、AWSサポート[4]またはAWS開発者フォーラム[5]からご連絡ください。[1] https://github.com/nodejs/Release
[2] https://docs.aws.amazon.com/lambda/latest/dg/runtime-support-policy.html
[3] https://aws.amazon.com/about-aws/whats-new/2019/05/aws_lambda_adds_support_for_node_js_v10/
[4] https://aws.amazon.com/support
[5] https://forums.aws.amazon.com/forum.jspa?forumID=186考えたこと
今回はNode.jsのため弊社では影響はないので問題はないでしょう。(利用していないので)
ただし、これがPythonになった場合は話が変わります。
既存のLambda関数の更新およびテスト
現在、保守/運用している顧客のAWS環境においては、Python 3.6で動くLambda関数をいくつか利用しています。
先日、2019年10月14日に Python 3.8の正式リリースが発表されました。
詳細な機能についてはまとめてくれているものがあるので参考にするとよいでしょう。
Python3.8の新機能 (まとめ)現在AWS Lambdaでデフォルトで利用できるPythonのランタイムバージョンは3.6と3.7です。
AWSでの他の言語ランタイムのサポートの雰囲気を鑑みると、1 or 2 バージョンにのみをサポートとし3つ前のバージョンはサポート非推奨とする流れでしょう。
つまり、現在利用中のLambda関数はすべて、更新準備に向けてテストを実施しなければなりません。
ランタイムポリシー
[2] https://docs.aws.amazon.com/lambda/latest/dg/runtime-support-policy.html
を覗いてみました。
AWS Lambda ランタイムは、メンテナンスとセキュリティの更新の対象となるオペレーティングシステム、プログラミング言語、およびソフトウェアライブラリの組み合わせを中心に構築されています。ランタイムのコンポーネントがセキュリティアップデートでサポート対象外となった場合、Lambda はこのランタイムを廃止します。
廃止は、2 つのフェーズで行われます。最初のフェーズでは、廃止予定のランタイムを使用する関数を作成することはできません。少なくとも 30 日間は、廃止予定のランタイムを使用する既存の関数を引き続き更新することができます。この期間が過ぎると、関数の作成と更新のいずれも、完全に無効になります。ただし、この関数は呼び出しイベントの処理に引き続き使用することができます。
お知らせ内容のことですね。
ほとんどの場合、言語バージョンまたはオペレーティングシステムのサポート終了日は事前に通知されます。今後 60 日以内に廃止予定の関数がランタイムで実行されている場合は、関数をサポートされているランタイムに移行して準備する必要があることが Lambda より E メールで通知されます。下位互換性のない更新を必要とするセキュリティ上の問題、または長期サポート (LTS) スケジュールをサポートしないソフトウェアなど、場合によっては事前通知が不可能な場合があります。
『下位互換性のない更新を必要とするセキュリティ上の問題、または長期サポート (LTS) スケジュールをサポートしないソフトウェアなど、場合によっては事前通知が不可能な場合があります。』
ですよねー。
ということは、概ね新しいランタイムバージョンが正式リリースされた場合は、身構えておく必要があるということですかね。ランタイムが廃止されると、Lambda は呼び出しを無効にすることで終了する可能性があります。廃止予定のランタイムは、セキュリティアップデートやテクニカルサポートの対象にはなりません。ランタイムを終了する前に、Lambda によって、影響を受けるお客様に追加の通知が送信されます。現時点では、ランタイムの廃止予定はありません。
ちょっと日本語理解が難しいような気がする文章。
呼び出し すなわち、 CloudWatchとかのイベントトリガーのことを指しているのかな。
あ、違うのかな。AWS様が呼び出し機能を無効にした場合、その時点からランタイムが終了するから気を付けてねって方かな。しかも廃止予定のランタイムについては、更新とかはサポートしませんよっと。
お知らせ通知から廃止になるまでの期間
最低でも30日間の利用は可能。
今回の通知が、2019年10月19日 で、2020年2月3日以降更新不可ということは、
テストできる期間は約3か月ほどって感じでしょうか。カスタムランタイム利用して、自分たちで面倒みるのは運用面であったりバージョンの管理性とか
もろもろ良いやり方って感じではないですもんねえ。まとめ
とりあえず、AWS Lambdaのランタイムの廃止予定については、
事前には通知はするけど、すべて顧客で対応してねということ。今後やっておくべきこと(やっておきたいこと)
- 利用している言語の新規バージョンリリースをウォッチする。
- AWSのランタイムに合わせて関数を更新する
- Lambda関数の一覧をランタイムバージョン付きでリストアップしておくこと。
こんなところでしょうか。
- 投稿日:2019-10-21T10:25:00+09:00
Kubernetes歴1週間の初心者から見た景色
機械学習のKubeflowというものに興味があってKubernetesの勉強を始めた。1週間くらい触ってみた感想をまとめてみる。
コメントや補足あれば遠慮せずどうぞ。Kubernetes歴〇年の先輩方お待ちしております。
1. 読み方がよくわからん
Kubernetesで最初に躓くポイントはおそらく読み方だろう。
KubernetesそのものはGoogleの人が下記の通りTweetしているので統一されているはず。@imdsm @gregde @francesc @jbeda @developerluke most people on the team say: koo-ber-net-ees, or just 'k8s' or k-eights
— brendandburns (@brendandburns) April 7, 2015問題はそのほかのKube◯◯◯ファミリーだ。ここは海外でも色々議論がされているが、決定打になりそうなTweetがいくつかある。
kubectl is pronounced "kube control" not "cube control". It's Kubernetes not Cube-rnetes. Regardless of whatever Brian Grant says. Don't @ me
— Ian Lewis (@IanMLewis) October 4, 2018Canonical pronunciation of “kubectl” is kube-control, not kube-cuttle ... @bgrant0607 keeping us honest as #KubeCon last keynote speaker. Reminds of Bill Shannon for JEE va #JavaEE ;) pic.twitter.com/dAo5gc5pMj
— Arun Gupta (@arungupta) December 8, 2017結局のところあまり統一されていないようだ。ただYoutubeの動画を見ると、キューブ〇〇と発音している人が多い気がする。
僕は考えた結果、Kubernetesは明確に”ク”、それ以外は気持ちcuっぽく"クュ"1と発音することにした。
代表的なものをまとめるとこうなる。
単語 読み方 補足 Kubernetes クーバネテス koo-ber-nay'-tace Kubectl クューブコントロール koob-control Kubelet クューブレット - Kubeadm クューブエーディーエム - KubeCon クューブコン - 2. 学習コスト、特に初期コストが高い
参考書やWeb上の入門記事を読むと最初はひたすら環境構築から始まる。
正直「Kubernetesって結構めんどくさいな」と思ってしまう人が多数だろう。
僕もその一人だった。もし今その時の自分にアドバイスを送れるならこうだ。
"kubectlが出来るようになるまで何とか頑張れ"kubectlが出来るようになればKubernetesの世界での可動域がぐっと広がる。極端なことを言ってしまうとkubectlでyamlファイルをゴニョゴニョするところからがスタートラインだと思う。
Introduction · The Kubectl Book
Kubernetesを触る前はダッシュボード2とかでクールに操作できると思っていたが、現実はコマンドをいろいろ送信するという地味な作業だった。
3. kubectl apply したときに成功したかどうかわからない
さぁ、ようやくkubectlというスキルを身につけたが、次の問題にぶつかる。
▶kubectl apply -f xxxxxx.yml pod "xxxxxx" created!やったー!成功だ!どれどれ確認してみよう。
$kubectl get pod NAME READY STATUS RESTARTS AGE nginx-pod 0/1 ErrImagePull 0 6sErrImagePull!でうまく起動していない!!
どうやらDockerイメージのpullが失敗しているようだ。
kubectlのapplyが成功したからといって本当に動いているかどうかは保証されない。結局
kubectl get xxxして確認しないとダメらしい。ついでに各リソースを消す時も
▶kubectl delete -f xxxxxx.yml pod "xxxxxx" deletedとだけ表示されるだけだ。
ホントに全ての関連リソースが消えたのか?依存関係で不具合が起きないか?自分で確認しないといけないのか…4. yamlの書き方がわからない
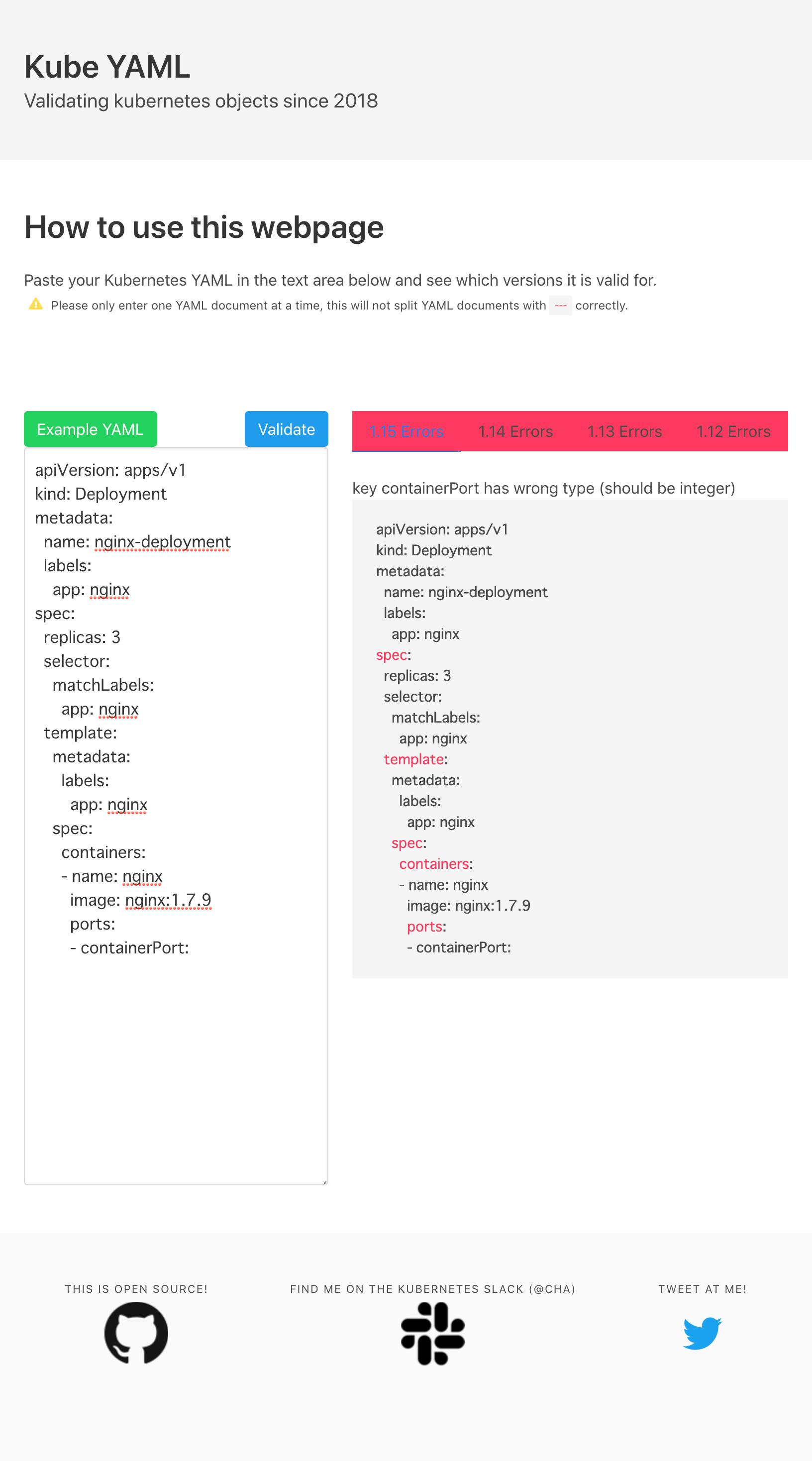
yamlファイルを自分で書けば、コンテナの設定や構成を自由に制御できるのはわかったぞ。早速書いてみよう。
とりあえずサンプルコードを確認…apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment labels: app: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: - containerPort: 80コンテナ3つで…
LBをつけて…
あとはコンテナイメージも自分の作ったやつにしないとなぁ…んー…どこをどう直せば良いんだ?
Githubかどこかでyamlファイルが配布されていればサルでも環境構築できる。
だが、自分で書こうとするとまずどこにどう手をつければいいのか途端にわからなくなる。この書き方で大丈夫?
矛盾とかないか?
こんな簡単で大丈夫?そもそも宣言型管理に慣れていないから、初手が指せないんだよなぁ。
特にapiversionはそもそもそれが何なのかわかっていないので、一行目からどうすればいいのかわからなかった。
結論としては
kubectl api-resources
で自分の作りたいリソースに応じて確認すると言うことらしい。3色々探しているうちにKubernetes YAML Validationというサイトを発見した。めちゃ便利。
5. 具体的なデモが少な過ぎる
yamlファイルの作法はわかったし、頑張れば色々自分でカスタマイズできそうだというのはわかった。だが、自分の描く構成をyamlファイルに落とし込むにはどうすればいいか、まだまだ具体的なイメージがわかない。
なんか良さげなデモはないのか?
企業での導入事例はたくさんあるけど、具体的にどういう設定or構成でやればいいのかは謎に包まれている。
初心者的に見たいのはyamlファイルの書き方とかdockerファイルの中身の方だ。コンテナのポートの開け方とか。kindの指定とか。Nginxをデプロイしてデモ画面を表示する。ほうほう、それで終わり?
それだけではkubernetesの凄さがわからない。
自動ヒーリングやスケーリングをさせるデモとかないかね。6. クラウドマネージドサービスとの連携が難しい
Kubernetesはオープンソースなのでいろんなクラウドでサービス化されている。
今回はAWSのEKSというマネージドサービスを触ってみたが、Route53やVPCの設定はめんどくさかった。CloudFormationで環境構築は自動化出来るとはいえ、Kubernetes初心者はどんなリソースが何のために作成されるのかを理解しなければならないので結局時間がかかる。
あと認証周りは本当にめんどくさい。オープンソースを持ってきてそのままくっつけた合体ロボ状態だ。ドキュメントも未整備で体系的にまとまっていない気がする。ここらへんはやっぱりGCPの方がスマートに使えるのだろうか…?
下記のワークショップで一通りの作業は紹介されているが、AWSの基礎知識がある程度身についている人向け。
Amazon EKS Workshop :: Amazon EKS Workshop
ALBの設定とか未だによくわからないので要勉強。
7. コスト感覚が掴みにくい
これまたEKSで申し訳ないが、Kubernetesを使うとEC2やらCloudWatchやらいろんなリソースが複合的に生成される。
それ一体いくらくらいかかるんだ?
EBSとか一緒に消えるの?自動ヒーリングとか言ってゾンビみたいに復活しないよね?
yamlファイル一撃でいろんなリソースが生成されるので、コスト感覚が把握しづらい。
おそらくここはGCPだろうがAzureだろうがIBMだろうがAlibabaだろうが変わらないところだと思う。yamlファイルでリソースに自動でタグ付け出来ればコストの追跡もしやすいが…
ここも今後調査しないといけないところか。
8. 情報の陳腐化が速い
色々勉強してきて最終的に思ったのがこれだ。
この知識いつまで通用するの?
Kubernetes自体の開発サイクルが速いため、ウェブ上の入門記事や参考書はトコロドコロ古い部分がある。
毎月のようにミートアップがあるし、Slackの投稿も鬼のように溜まる。正直ついていくの結構キツい…頑張って身につけた知識が一年後には「あ、それもう使えませんよ。こっち使ってください。」となってしまいそうだ。
これはkubernetesに限ったことではないと思うが、Qiitaの記事や個人のブログを盲目的に信頼するのは良くないと実感した。4
きっとこの記事自体もすぐに陳腐化してしまうのだろう。
当たり前だが、一番信頼できるのは公式ドキュメントだ。
公式ドキュメントを読もう。
Kubernetesドキュメント - Kubernetes
九州の”キュ”ではなく、FuckYouの"キュ"。気持ち喉の奥の方で「ュ」を絞り出す感じで。 ↩
各メトリクスを確認するダッシュボードはあるみたいなんだけど ↩
Kubernetesの apiVersion に何を書けばいいか - Qiitaこの記事が参考になりました。感謝。 ↩
Qiitaではしっかりと「上部に出てくるこの記事は〇〇年前のものです」と出てくるから素晴らしい。 ↩

- 投稿日:2019-10-21T09:52:23+09:00
CloudWatch Logsエージェントのログがtimestamp is more than 2 hours in futureで 止まってしまう件について
こんにちわ。
本日はCloudWatch Logsエージェントのログがtimestamp is more than 2 hours in futureで
止まってしまう件について書きます。現在の環境はFuelPHPで、主にFuelPHPのローテートログをCloudWatchエージェントで
PUSHさせたいって内容になっています。
が、恐らく他の環境のログの場合で起きた事象もこれに近しいのではないかと思います。CloudWatchLogsエージェントは導入済みで、ローテート時にうまく動かない人向けなので、
そもそもCloudWatchLogsにログが反映されていない場合は別の要因によるのではないかと思います。[/server/fuelphp/logs] datetime_format = %Y-%m-%d %H:%M:%S file = /path/to/fuel/app/logs/20*/*/* buffer_duration = 5000 log_stream_name = {instance_id} initial_position = start_of_file log_group_name = /server/fuelphp/logs他にマルチラインの設定などが必要かと思いますが、簡単に書くとこんな感じに設定。
CloudWatch側では、log_group_nameで検索ができるようになりますが、翌日
「 timestamp is more than 2 hours in future.」とエラーが出ており
PUSHイベントが動いていません。色々調べていて、皆大好きStackOverflowを見て見ると、以下のような記事が。https://stackoverflow.com/questions/40604940/cloudwatch-logs-acting-weird
https://forums.aws.amazon.com/thread.jspa?threadID=243092この記事の人に激しく同意
>Yes I'm experiencing the issue too. Is there a way to reset the state file without doing this?
うん。私もそう思うわ。それやらないでResetしたいんだよぉぉぉぉ。はい。じゃあ。本題です。
awslogsのPUTイベントが失敗する原因は以下です。
PutLogEvents オペレーションの制約に従って、次の問題によりログイベントまたはバッチがスキップされる場合があります。
以下本家のマニュアルから抜粋
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/logs/WhatIsCloudWatchLogs.html注記
1.データがスキップされた場合、CloudWatch Logs エージェントはログに警告を書き込みます。
2.ログイベントのサイズが 256 KB を超過した場合、ログイベントは完全にスキップされます。
3.ログイベントのタイムスタンプが 2 時間以上未来の場合、ログイベントはスキップされます。
4.ログイベントのタイムスタンプが 14 日以上過去の場合、ログイベントはスキップされます。
5.ログイベントがロググループの保持期間よりも古い場合、バッチはすべてスキップされます。
単一の PutLogEvents リクエストでログイベントのバッチが 24 時間実行されている場合、PutLogEvents オペレーションは失敗します。上記の3がこの「 timestamp is more than 2 hours in future.」というエラーにあたります。
タイムスタンプが実行時間より2時間以上未来日になっているので、スキップしますとのことで、最初は
UTCと日本時間のズレのせいかと考えたのですが、どうもズレている時刻が異なります。実行タイムスタンプの調べ方はStackOverflowに書いてある通りで「/var/lib/awslogs/agent-state」を
sqlite3で検索(JSON形式で保存されているので実行された体の時刻を調べます)
調べるストリームIDは/var/log/awslogs.logに出ています。2019-09-28 06:01:02,041 - cwlogs.push.stream - INFO - 12879 - Thread-1 - Removing dead reader [77cbf636732d4f124469c8ccb0f71abe, /logs/2019/09/27.php] 2019-09-28 06:01:02,041 - cwlogs.push.stream - INFO - 12879 - Thread-1 - Removing dead publisher [77cbf636732d4f124469c8ccb0f71abe, /logs/2019/*/*.php] 2019-09-28 06:01:02,044 - cwlogs.push.stream - INFO - 12879 - Thread-1 - Starting publisher for [77cbf636732d4f124469c8ccb0f71abe, /logs/2019/09/28.php] 2019-09-28 06:01:02,044 - cwlogs.push.stream - INFO - 12879 - Thread-1 - Starting reader for [77cbf636732d4f124469c8ccb0f71abe, /logs/2019/09/28.php] 上記の77cbf636732d4f124469c8ccb0f71abeです。(PATHはサイトの詳細が記載してあるので少し削りました)これを検索します。
[root@server]# sqlite3 /var/lib/awslogs/agent-state SQLite version 3.7.17 2013-05-20 00:56:22 Enter ".help" for instructions Enter SQL statements terminated with a ";" sqlite> select * from push_state where k="8deaef1856dda2abe912ceedc4180f53";上記のkの部分にストリームIDを入れると、JSONからPUSHした時にイベントが出てきます。
8deaef1856dda2abe912ceedc4180f53|{"start_position": 248, "source_id": "8deaef1856dda2abe912ceedc4180f53", "first_timestamp": 1570412666000, "first_timestamp_status": 1, "sequence_token": "49599891918873079124975725871068904036184047788058782002", "batch_timestamp": 1570412666866, "end_position": 369}|2019-10-06T21:00:13|2019-10-07T01:44:32このFirstTimestampとbatchtimestampが明らかに前日になっています。
前日になっていますが、9時間ズレとかではありません。なのでUTCの問題ではありません。
なんでかなーと調べていくと、書き込まれない時に、ローテートされた後のログストリームIDがずっと変わらないではありませんか。2019-09-28 06:00:58,041 - cwlogs.push.reader - INFO - 12879 - Thread-1346 - Reader is leaving as requested... 2019-09-28 06:01:02,041 - cwlogs.push.stream - INFO - 12879 - Thread-1 - Removing dead reader [77cbf636732d4f124469c8ccb0f71abe, /logs/2019/09/27.php] 2019-09-28 06:01:02,041 - cwlogs.push.stream - INFO - 12879 - Thread-1 - Removing dead publisher [77cbf636732d4f124469c8ccb0f71abe, /logs/2019/*/*.php] 2019-09-28 06:01:02,044 - cwlogs.push.stream - INFO - 12879 - Thread-1 - Starting publisher for [77cbf636732d4f124469c8ccb0f71abe, /logs/2019/09/28.php] 2019-09-28 06:01:02,044 - cwlogs.push.stream - INFO - 12879 - Thread-1 - Starting reader for [77cbf636732d4f124469c8ccb0f71abe, /logs/2019/09/28.php] 2019-09-28 06:01:02,045 - cwlogs.push.reader - INFO - 12879 - Thread-1348 - Replay events end at 384. 2019-09-28 06:01:02,045 - cwlogs.push.reader - INFO - 12879 - Thread-1348 - Start reading file from 74. 2019-09-28 06:01:02,045 - cwlogs.push.batch - WARNING - 12879 - Thread-1348 - Skip event: {'timestamp': 1569618001000, 'start_position': 74L, 'end_position': 153L}, reason: timestamp is more than 2 hours in future. 2019-09-28 06:09:30,216 - cwlogs.push.batch - WARNING - 12879 - Thread-1348 - Skip event: {'timestamp': 1569618569000, 'start_position': 153L, 'end_position': 229L}, reason: timestamp is more than 2 hours in future.ダメだった時のログはこんな感じで。Removing dead publisherしてるのにStarting publisherのストリームIDが変わらない。77cbf636732d4f124469c8ccb0f71abeこの場合、翌日になっているのにずっとタイムスタンプ上9月27日の朝6時とかになっているので、9月28日のPUSHとならずに、スキップされてしまいます。
原因は、FuelPHPのログって、一番上位に
<?php defined('COREPATH') or exit('No direct script access allowed'); ?>こんな感じの固定文言が出ているんですけど、こいつが前日とまったく同じなものだから、
Startを前日のログから検索してしまって、日付がリセットされないーって内容でした。
なので、FuelPHPはCoreの LogsClassをOverwriteして2019-10-01 08:26:02<?php defined('COREPATH') or exit('No direct script access allowed'); ?>タイムスタンプを突っ込んでやりました。
2019-10-07 06:00:08,256 - cwlogs.push.stream - INFO - 14088 - Thread-1 - Removing dead reader [729a61c49dafeeb9472f9bc030510546, /logs/2019/10/06.php] 2019-10-07 06:00:08,261 - cwlogs.push.stream - INFO - 14088 - Thread-1 - Starting reader for [8deaef1856dda2abe912ceedc4180f53, /logs/2019/10/07.php]すると、ログに設定した日付を判別して、勝手にローテートされるようになりました。
うまくローテーションがかからなくてログの一部が翌日になったら送れなくなった人はお試しください。こちらの記事は自社のブログに書いたものの転記になります
https://core-tech.jp/blog/article431/
- 投稿日:2019-10-21T09:36:56+09:00
Amazon ECRにdocker pushする
はじめに
Amazon ECRに
docker pushするには少し覚えておくことがある気がしたので、調べて直してまとめておきます。手順
マネジメントコンソールからリポジトリを作成します。ここではhelloとします。
あとはCLIでやります。人によって変わる部分を環境変数として設定します。export AWS_REGION=ap-northeast-1 export AWS_ACCOUNT_ID=123456789012ECRにログインします。
command$(aws ecr get-login --region $AWS_REGION --no-include-email)outputWARNING! Using --password via the CLI is insecure. Use --password-stdin. Login Succeededdocker imageをビルドします。タグにリポジトリ名を設定します。
docker build -t $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/hello:v1 .docker pushします。
docker push $AWS_ACCOUNT_ID.dkr.ecr.$AWS_REGION.amazonaws.com/hello:v1以上です。
参考
- 投稿日:2019-10-21T02:38:11+09:00
EKSでIngressControllerを使ってALBを作成して、サービスを公開する
Ingress Controllerとは
- 必要になったらALBを作成してくれるPodのこと
- いずれかのNodeで起動する
- Ingressを使う場合GCPでは意識しなくて良いが、AWSではこのように手動で作成する必要がある
- ALBを作成せずにCluster内にNginxをデプロイすることでサービス公開するNginx Ingressというのもあるみたい
参考
https://dev.classmethod.jp/cloud/aws/eks-aws-alb-ingress-controller/
クラスタ作成
eksctl create cluster --name=k8s-cluster --nodes=2 --node-type=t2.medium出力結果
[ℹ] eksctl version 0.7.0 [ℹ] using region us-east-2 [ℹ] setting availability zones to [us-east-2c us-east-2a us-east-2b] [ℹ] subnets for us-east-2c - public:192.168.0.0/19 private:192.168.96.0/19 [ℹ] subnets for us-east-2a - public:192.168.32.0/19 private:192.168.128.0/19 [ℹ] subnets for us-east-2b - public:192.168.64.0/19 private:192.168.160.0/19 [ℹ] nodegroup "ng-ac8bfd87" will use "ami-082bb518441d3954c" [AmazonLinux2/1.14] [ℹ] using Kubernetes version 1.14 [ℹ] creating EKS cluster "k8s-cluster" in "us-east-2" region [ℹ] will create 2 separate CloudFormation stacks for cluster itself and the initial nodegroup [ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=us-east-2 --name=k8s-cluster' [ℹ] CloudWatch logging will not be enabled for cluster "k8s-cluster" in "us-east-2" [ℹ] you can enable it with 'eksctl utils update-cluster-logging --region=us-east-2 --name=k8s-cluster' [ℹ] 2 sequential tasks: { create cluster control plane "k8s-cluster", create nodegroup "ng-ac8bfd87" } [ℹ] building cluster stack "eksctl-k8s-cluster-cluster" [ℹ] deploying stack "eksctl-k8s-cluster-cluster" [ℹ] building nodegroup stack "eksctl-k8s-cluster-nodegroup-ng-ac8bfd87" [ℹ] --nodes-min=2 was set automatically for nodegroup ng-ac8bfd87 [ℹ] --nodes-max=2 was set automatically for nodegroup ng-ac8bfd87 [ℹ] deploying stack "eksctl-k8s-cluster-nodegroup-ng-ac8bfd87" [✔] all EKS cluster resources for "k8s-cluster" have been created [✔] saved kubeconfig as "/Users/yuta/.config/k3d/k3s-default/kubeconfig.yaml" [ℹ] adding identity "arn:aws:iam::241161305159:role/eksctl-k8s-cluster-nodegroup-ng-a-NodeInstanceRole-MPUARSLLOYNO" to auth ConfigMap [ℹ] nodegroup "ng-ac8bfd87" has 0 node(s) [ℹ] waiting for at least 2 node(s) to become ready in "ng-ac8bfd87" [ℹ] nodegroup "ng-ac8bfd87" has 2 node(s) [ℹ] node "ip-192-168-39-153.us-east-2.compute.internal" is ready [ℹ] node "ip-192-168-75-177.us-east-2.compute.internal" is ready [ℹ] kubectl command should work with "/Users/yuta/.config/k3d/k3s-default/kubeconfig.yaml", try 'kubectl --kubeconfig=/Users/yuta/.config/k3d/k3s-default/kubeconfig.yaml get nodes' [✔] EKS cluster "k8s-cluster" in "us-east-2" region is readyサービスアカウント作成、ロールのバインド
kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.0.0/docs/examples/rbac-role.yaml出力結果
clusterrole.rbac.authorization.k8s.io/alb-ingress-controller configured clusterrolebinding.rbac.authorization.k8s.io/alb-ingress-controller configured serviceaccount/alb-ingress createdAWS ALB Ingress Controllerのデプロイ
マニュフェストファイルをダウンロード
curl -sS "https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.0.0/docs/examples/alb-ingress-controller.yaml" > alb-ingress-controller.yamlcluster-nameの部分をデプロイしているクラスタ名へ変更
# Name of your cluster. Used when naming resources created # by the ALB Ingress Controller, providing distinction between # clusters. - --cluster-name=k8s-clusterデプロイ
kubectl apply -f alb-ingress-controller.yamlデプロイ確認
AWS ALB IngressController用のPodが作成されている
kubectl get pod --all-namespaces | grep alb-ingress kube-system alb-ingress-controller-574db97b5f-2j7hb 1/1 Running 0 32sサンプルアプリケーションデプロイ
ECR経由でEKSへデプロイする
ECR作成
aws ecr create-repository --repository-name eks-test-app出力結果
{ "repository": { "repositoryUri": "241161305159.dkr.ecr.us-east-2.amazonaws.com/eks-test-app", "registryId": "241161305159", "imageTagMutability": "MUTABLE", "repositoryArn": "arn:aws:ecr:us-east-2:241161305159:repository/eks-test-app", "repositoryName": "eks-test-app", "createdAt": 1571584240.0 } }ECRログイン情報を取得
aws ecr get-login --no-include-email上記の出力結果を実行する
docker login -u AWS -p XXXXXXローカルにサンプルアプリケーションを作成
server.gopackage main import ( "fmt" "log" "net/http" "os" ) func main() { http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "healthy!") }) http.HandleFunc("/target1", func(w http.ResponseWriter, r *http.Request) { fmt.Fprintf(w, "/target1:" + os.Getenv("POD_NAME")) }) log.Fatal(http.ListenAndServe(":8080", nil)) }FROM golang ADD . /go/src/ EXPOSE 8080 CMD ["/usr/local/go/bin/go", "run", "/go/src/server.go"]ビルド
docker build -t eks-test-app:target1 .タグ変更
docker tag eks-test-app:target1 241161305159.dkr.ecr.us-east-2.amazonaws.com/eks-test-app:target1ECRへPush
docker push 241161305159.dkr.ecr.us-east-2.amazonaws.com/eks-test-app:target1target2用のアプリも同じ手順で作成
docker build -t eks-test-app:target2 . docker tag eks-test-app:target2 241161305159.dkr.ecr.us-east-2.amazonaws.com/eks-test-app:target2 docker push 241161305159.dkr.ecr.us-east-2.amazonaws.com/eks-test-app:target2Pushされているイメージ一覧
マニュフェスト作成
apiVersion: v1 kind: Namespace metadata: name: "test-app" --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: "test-app-deployment-target1" namespace: "test-app" spec: replicas: 2 template: metadata: labels: app: "test-app-target1" spec: containers: - image: XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/eks-test-app:target1 imagePullPolicy: Always name: "test-app-target1" ports: - containerPort: 8080 env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name --- apiVersion: extensions/v1beta1 kind: Deployment metadata: name: "test-app-deployment-target2" namespace: "test-app" spec: replicas: 2 template: metadata: labels: app: "test-app-target2" spec: containers: - image: XXXXXXXXXXXX.dkr.ecr.ap-northeast-1.amazonaws.com/eks-test-app:target2 imagePullPolicy: Always name: "test-app-target2" ports: - containerPort: 8080 env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name --- apiVersion: v1 kind: Service metadata: name: "test-app-service-target1" namespace: "test-app" spec: ports: - port: 80 targetPort: 8080 protocol: TCP type: NodePort selector: app: "test-app-target1" --- apiVersion: v1 kind: Service metadata: name: "test-app-service-target2" namespace: "test-app" spec: ports: - port: 80 targetPort: 8080 protocol: TCP type: NodePort selector: app: "test-app-target2"アプリケーションのデプロイ
kubectl apply -f test-app.yaml出力結果
namespace/test-app created deployment.extensions/test-app-deployment-target1 created deployment.extensions/test-app-deployment-target2 created service/test-app-service-target1 created service/test-app-service-target2 createdデプロイ確認
kubectl get all --all-namespaces | grep test-app出力結果
test-app pod/test-app-deployment-target1-66498868db-67zdw 1/1 Running 0 56s test-app pod/test-app-deployment-target1-66498868db-tvfgx 1/1 Running 0 56s test-app pod/test-app-deployment-target2-646fd4978f-282qj 1/1 Running 0 55s test-app pod/test-app-deployment-target2-646fd4978f-xjqw7 1/1 Running 0 55s test-app service/test-app-service-target1 NodePort 10.100.82.136 <none> 80:31922/TCP 55s test-app service/test-app-service-target2 NodePort 10.100.208.75 <none> 80:32280/TCP 55s test-app deployment.apps/test-app-deployment-target1 2/2 2 2 57s test-app deployment.apps/test-app-deployment-target2 2/2 2 2 56s test-app replicaset.apps/test-app-deployment-target1-66498868db 2 2 2 57s test-app replicaset.apps/test-app-deployment-target2-646fd4978f 2 2 2 56sALB作成
ingress.yamlapiVersion: extensions/v1beta1 kind: Ingress metadata: name: "ingress" namespace: "test-app" annotations: kubernetes.io/ingress.class: alb alb.ingress.kubernetes.io/scheme: internet-facing labels: app: test-app spec: rules: - http: paths: - path: /target1 backend: serviceName: "test-app-service-target1" servicePort: 80 - path: /target2 backend: serviceName: "test-app-service-target2" servicePort: 80ALBマニュフェストのapply
kubectl apply -f ingress.yamlALBが作成されないっぽい
ログ確認
kubectl logs -n kube-system alb-ingress-controller-5bfd896bd9-hctqk怪しいエラー
E1020 16:46:07.820806 1 :0] kubebuilder/controller "msg"="Reconciler error" "error"="failed to build LoadBalancer configuration due to failed to get AWS tags. Error: AccessDeniedException: User: arn:aws:sts::241161305159:assumed-role/eksctl-k8s-cluster-nodegroup-ng-a-NodeInstanceRole-MPUARSLLOYNO/i-0c18a25d7a5c8e53c is not authorized to perform: tag:GetResources\n\tstatus code: 400, request id: 7225892f-f803-4a10-86a3-c4769ff83a2d" "Controller"="alb-ingress-controller" "Request"={"Namespace":"test-app","Name":"ingress"}export REGION=us-east-2 export ALB_POLICY_ARN=$(aws iam create-policy --region=$REGION --policy-name aws-alb-ingress-controller --policy-document "https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/master/docs/examples/iam-policy.json" --query "Policy.Arn" | sed 's/"//g') export NODE_ROLE_NAME=eksctl-k8s-cluster-nodegroup-ng-a-NodeInstanceRole-MPUARSLLOYNO aws iam attach-role-policy --region=$REGION --role-name=$NODE_ROLE_NAME --policy-arn=$ALB_POLICY_ARNNODE_ROLE_NAMEの箇所
再度デプロイ
kubectl delete pod alb-ingress-controller-5bfd896bd9-hctqk -n kube-system kubectl apply -f alb-ingress-controller.yamlALBが無事作成された
動作確認
target1へのアクセス
~/D/ingress ❯❯❯ curl http://b0a25c21-testapp-ingress-1d16-1953215674.us-east-2.elb.amazonaws.com/target1 /target1:test-app-deployment-target1-66498868db-tvfgx% ~/D/ingress ❯❯❯ curl http://b0a25c21-testapp-ingress-1d16-1953215674.us-east-2.elb.amazonaws.com/target1 /target1:test-app-deployment-target1-66498868db-67zdw%target2へのアクセス
~/D/ingress ❯❯❯ curl http://b0a25c21-testapp-ingress-1d16-1953215674.us-east-2.elb.amazonaws.com/target2 /target2:test-app-deployment-target2-646fd4978f-xjqw7% ~/D/ingress ❯❯❯ curl http://b0a25c21-testapp-ingress-1d16-1953215674.us-east-2.elb.amazonaws.com/target2 /target2:test-app-deployment-target2-646fd4978f-282qj%



- 投稿日:2019-10-21T00:15:13+09:00
FargateでFireLensログドライバを使い自前で用意したfluentdを動かす
背景
FargateのログドライバはCloudWatch Logs,Splunkしか使用できず、その他のログ基盤に連携を行いたい場合はCloudWatch Logsから転送するか(CloudWatch Logsの料金がかかる)、ログドライバを使用せず共有ボリュームにログファイルを出力してサイドカーのFluentdで収集する(ボリュームは8GBまで)といろいろと制約があり、なかなかFargateに移行ができないでいました。
この度、FireLensがGAになり、自前のFluentdに転送できるとのことだったので試してみたところ、色々と詰まりましたのでメモとして残します。
開発
0. FireLensについて
クラスメソッド様の記事がとてもわかり易いと思います。
1. 概要
作成、使用した環境はGitHubにあります。
構成としてはFargateでnginxのログをFirelens(fluentd)を使い、S3に出力しています。
nginx -> firelens(fluentd) -> S32. パッケージ構成
ざっくりとしたパッケージ構成とその説明です。
. ├── fluentd │ ├── conf.in <-- fluentdのcofigディレクトリ。input情報を書いている │ ├── conf.out <-- fluentdのcofigディレクトリ。output情報を書いている │ ├── Dockerfile <-- fluentdのDockerfile │ ├── build.sh <-- Dockerfileでbuildし、ECRにpushしています │ └── fluent.conf <-- fluentdのcofigファイル。conf.inとconf.outをincludeしている ├── nginx │ ├── Dockerfile <-- nginxのDockerfile │ └── build.sh <-- Dockerfileでbuildし、ECRにpushしています ├── terraform <-- AWS環境一式をterraform化してあります └── README.md3. メモ
fluentdのDockerfileです。
firelensに対応するため、COPY fluent.conf /fluentd/etc/fluent-custom.confと名前を変更しています。これは後述のtask-definition.jsonで使用するためです。DockerfileFROM fluent/fluentd:v1.7-1 # Use root account to use apk USER root # below RUN includes plugin as examples elasticsearch is not required # you may customize including plugins as you wish RUN apk add --no-cache --update --virtual .build-deps \ sudo build-base ruby-dev \ && sudo gem install fluent-plugin-rewrite-tag-filter -v 2.2.0 \ && sudo gem install fluent-plugin-s3 -v 1.1.11 \ && sudo gem sources --clear-all \ && apk del .build-deps \ && rm -rf /tmp/* /var/tmp/* /usr/lib/ruby/gems/*/cache/*.gem COPY fluent.conf /fluentd/etc/fluent-custom.conf COPY conf.in /fluentd/etc/conf.in COPY conf.out /fluentd/etc/conf.out USER fluent次に
fluent.confですが、input情報である<source>の記述を消しています。理由は記述するともうポートが空いているとerrorになるため削除しています。おそらく、AWS側で記述があるためだと思われます。fluent.conf<match> @type relabel @label @firelens_log @id in_forward_all </match> @include conf.in/*.conf @include conf.out/*.conf最後に
task-definition.jsonですが、
config-file-type->fileconfig-file-value->/fluentd/etc/fluent-custom.confとしています。
fluent.confと記述してしまうと予約後なのか、errorになるため、このような記述になります。
公式ドキュメントには特に記述は見当たりませんでした。task-definition.json[ { "name": "nginx", "image": "xxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/infra/nginx-1.17.4:latest", "cpu": 256, "memory": 512, "essential": true, "portMappings": [ { "containerPort": 80, "protocol": "tcp", "hostPort": 80 } ], "logConfiguration": { "logDriver": "awsfirelens" } }, { "name": "fluentd", "image": "xxxxxxxxxxx.dkr.ecr.ap-northeast-1.amazonaws.com/infra/fluentd-1.7:latest", "cpu": 256, "memory": 512, "essential": true, "logConfiguration": { "logDriver": "awslogs", "options": { "awslogs-group": "/ecs/firelens-fluentd", "awslogs-region": "ap-northeast-1", "awslogs-stream-prefix": "ecs" } }, "firelensConfiguration": { "type": "fluentd", "options": { "config-file-type": "file", "config-file-value": "/fluentd/etc/fluent-custom.conf" } } } ]他に気をつけることとしては、tagが
コンテナ名-firelens-コンテナIDとハイフン区切りで渡されてきます。
fluentdはドット区切りなため、rewrite_tag_filterを使い、正規表現でtagをrewriteしています。
ソースコードを見たのですが、こちらから上書きする手段はなさそうです。
Fluent Bitだったらドット区切りではないため、困らないからでしょう。
ECSのfluentdログドライバだったらoptionでtagを渡せたため、そうしてくれるとありがたいと思いました。in-match.conf<label @firelens_log> <filter> @type record_transformer <record> tag ${tag} </record> </filter> <match> @type rewrite_tag_filter @label @create_tag <rule> key tag pattern /^nginx-firelens-(\w.+)$/ tag "nginx.sample.$1" </rule> </match> </label> 〜〜省略〜〜まとめ
色々と書きましたが、十分本番環境に耐えられる状態として提供されたのではないでしょうか。
既存のログ基盤がすでにあるサービスにとっては、Fargateへの移行に関しての懸念事項がまた一つ消えたと思います。