- 投稿日:2019-10-11T22:20:14+09:00
原子分子の動きをパソコンでみてみよう:Atomic Simulation Environmentで遊んでみた
ASE (Atomic Simulation Environment)とは
量子化学計算や、古典分子動力学法をpython上で実行できるライブラリです。以下のサイトを参照していただければ、どのようなコンセプトで作られたか理解できると思います。
https://wiki.fysik.dtu.dk/ase/about.htmlインストールのしかた
以下のURLを参考にしました:
https://wiki.fysik.dtu.dk/ase/install.html
私は、git clone -b 3.18.1 https://gitlab.com/ase/ase.gitで問題なくできました。古典分子動力学をやってみる
まず初めに物理系を作成する
テスト系として窒素分子(N2)を作成してみます。ASEは基本的に
ase.Atomsに物理系の座標情報を入れていきます。from ase import Atoms d = 1.1 molecule = Atoms('2N', positions=[(0., 0., 0.), (0., 0., d)])
moleculeにちゃんと座標データが入っているか確認してみましょう。そのためには、ase.ioを使います:from ase import io write('N2.pdb',molecule)(
.pdbと出力ファイルを指定するとPDBファイル形式を取り扱える。これは生物系の人には便利)
すると以下のような構造が得られます(PyMOLか何かで確認)。確かに窒素の2原子分子が作成されているようです。
分子動力学計算の設定
以下の設定で計算を走らせます
- 積分器:Velocity Verlet
- ポテンシャル:Effective medium theory (EMT)、(https://wiki.fysik.dtu.dk/ase/ase/calculators/emt.html#module-ase.calculators.emt)
- 時間刻み:0.01 fs
- 20 stepsごとに構造の保存from ase.md.verlet import VelocityVerlet from ase import units from ase.calculators.emt import EMT molecule.set_calculator(EMT()) dyn = VelocityVerlet(molecule, dt=0.01 * units.fs) for i in range(100): pot = molecule.get_potential_energy() kin = molecule.get_kinetic_energy() print('%2d: %.5f eV, %.5f eV, %.5f eV' % (i, pot + kin, pot, kin)) H.append(pot + kin) K.append(kin) U.append(pot) dyn.run(steps=20) write(f'traj.pdb',molecule,append=True) # エネルギーの図作成 import matplotlib.pyplot as plt %matplotlib inline plt.plot(H, c='black') plt.plot(K, c='red') plt.plot(U, c='blue') plt.savefig('energy.png')得られたトラジェクトリのエネルギーの確認
下図をみていただくと、たしかに、全エネルギーは保存しており、NVEアンサンブルになっているようです(黒線が全エネルギー、赤線が運動エネルギー、青線がポテンシャルエネルギー)。
感想
かなり簡単に計算結果を得ることができました。オブジェクト指向で書かれているのでソフトウェアの設計の勉強にもなりました。このような形でとある過去の遺産をラップできたらいいのになあ。とりあえず基本的な使い方はりかいしましたが、グラフェンの計算など気になることがあるので、もう少し遊んでみようと思います。


- 投稿日:2019-10-11T21:58:35+09:00
Python+OpenCVで画像処理ツール作成したときに参考になったwebサイトまとめ
はじめに
PythonもOpenCVも業務未経験でした。
Pythonは知ってましたけど、OpenCVなんて名前初めて聞いたくらいでした。笑ネット上から色々情報は拾えて来れましたが、良い記事見つけては試しての繰り返しで作成してたのですが
「この処理は何の記事を参考にしたんだっけ?」
とせっかく調べたのに忘れてしまうのはもったいないと思って参考になったサイトを纏めました。
python + opencvの基本的なこと
画像の明るさ調整に関すること
ガンマ補正
画像のノイズ処理に関すること
ぼかし処理
クラスタリング、フィルタリング処理
その他の処理
2値化画像に関すること
thresholdを使って閾値で2値化
エッジを検出して2値化
モルフォロジー変換
背景差分
画像のセンタリングに関すること
GrabCutに関すること
その他
- 投稿日:2019-10-11T21:51:57+09:00
量子情報理論の基本:シュミット分解
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
量子情報理論の分野においては、環境系と注目系のように複合した全体系の中で、各々の系がどう変化していくとか、どんな性質をもっているとかいう観点で、いろいろな研究がなされてきました。そういった研究を進める中で、有用なツール・知見の蓄積がなされてきたわけですが、今回は、その代表選手の一つである「シュミット分解(Schmidt decomposition)」について勉強してみます。だいたいわかってきたところで、量子計算シミュレータqlazyを使って、そこから導き出される性質を確認しつつ、その面白さを噛み締めてみたいと思います。
参考にさせていただいたのは、以下の文献です。
- ニールセン、チャン「量子コンピュータと量子通信(2)」オーム社(2005年)
- 石坂、小川、河内、木村、林「量子情報科学入門」共立出版(2012年)
- 富田「量子情報工学」森北出版(2017年)
- シュミット分解と量子状態の純粋化・エンタングルメントとの関係 - 物理とか
シュミット分解とは
部分系A,Bからなる全体系ABにおける、ある純粋状態を$\ket{\Phi}^{AB}$とすると、
\ket{\Phi}^{AB} = \sum_{k=1}^{R} \lambda_{k} \ket{\phi_{k}}^{A} \ket{\psi_{k}}^{B} \tag{1}を満たす、負でない実数$\{ \lambda_{k} \}$、および系Aと系Bにおける正規直交基底$\{ \ket{\phi_k}^{A} \}$、$\{ \ket{\psi_{k}}^{B} \}$が必ず存在します。この表現のことを「シュミット分解」と言い、$\{ \lambda_{k}\}$のことを「シュミット係数(Schmidt coefficient)」、$\{ \lambda_{k}\}$の中のゼロでないものの個数を「シュミット・ランク(Schmidt rank)」、正規直交基底$\{\ket{\phi_{k}}^{A}\}$、$\{\ket{\psi_{k}}^{B}\}$のことを、系A、系Bに対する「シュミット基底(Schmidt basis)」と言います。
ここで、$\ket{\Phi}^{AB}$の正規化条件から、
\sum_{k=1}^{R} \lambda_k^{2} = 1 \tag{2}が成り立ちます。
それでは、任意の$\ket{\Phi}^{AB}$が式(1)のように分解できることを証明してみます。
【証明】
$\ket{\Phi}^{AB}$は、ABの純粋状態なので、系Aの正規直交基底$\{ \ket{i}^A\}$と系Bの正規直交基底$\{ \ket{j}^B\}$を使って、一般に以下のように書けます1。
\ket{\Phi}^{AB} = \sum_{i=1}^{M} \sum_{j=1}^{N} c_{ij} \ket{i}^{A} \ket{j}^{B} \tag{3}ここから出発して、式(1)を導ければ証明完了なのですが、それには特異値分解を使います。
いま、式(1)の$c_{ij}$をM行N列の行列$C$の($i,j$)要素とみなすと、M行M列のユニタリ行列$U$、N行N列のユニタリ行列$V$、M行N列の対角行列$D$を用いて、
C = UDV \tag{4}のように特異値分解できます2。つまり、
c_{ij} = \sum_{k=1}^{R} u_{ik} d_{kk} v_{kj} \tag{5}です。ここで、$u_{ik}, \space d_{kk}, \space v_{kj}$は各々$U,D,V$の要素です。また、$R$は、$D$の対角成分に並ぶゼロでない成分の個数を表します。
式(5)を式(3)に代入します。
\ket{\Phi}^{AB} = \sum_{i=1}^{M} \sum_{j=1}^{N} \sum_{k=1}^{R} u_{ik} d_{kk} v_{kj} \ket{i}^{A} \ket{j}^B \tag{6}ここで、
\begin{align} \ket{\phi_{k}}^{A} &= \sum_{i=1}^{M} u_{ik} \ket{i}^{A} \\ \ket{\psi_{k}}^{B} &= \sum_{j=1}^{N} v_{kj} \ket{j}^{A} \tag{7} \end{align}とおくと、
\ket{\Phi}^{AB} = \sum_{k=1}^{R} \lambda_{k} \ket{\phi_{k}}^{A} \ket{\psi_{k}}^{B} \tag{1}となり、式(1)が導けました。また、式(7)より、$\{ \ket{\phi_{k}}^{A} \}$および$\{\ket{\psi_{k}}^{B}\}$は正規直交基底に対するユニタリ変換なので、両方とも正規直交基底です。(証明終)
さて、ここで、出発点とした式(3)とシュミット分解の式(1)を改めて眺めてください。証明の過程で何をやったかというと、要はユニタリ変換で部分系Aと部分系Bの基底を変換しているだけです。どのように変換したかというと、考えるべき基底の数をなるべく少なくなるようにした、ということになります3。と同時に、部分系Aと部分系Bの間のエンタングルメント(もつれ)が最大に見えるように変換したとも言えます。とすると、シュミットランク$R$というのは、ある意味、エンタングルメントの大きさを表す指標と考えることができます。シュミットランクが1というのは、エンタングルメントがない状況、つまり、部分系AとBが積状態(=テンソル積として分割できる状態)になっているということを表しており、シュミットランクが2以上というのは、両者エンタングルしている状況ということです。
部分系の性質
全体系のある部分系をA、残りの部分系をBとすると、全体系で定義されたどんな純粋状態も、式(1)のようにシュミット分解の表式に書き直すことができる、ということがわかりました。この知見を利用すると、部分系に関して以下の性質が導けます。
密度演算子の固有値
全体系の密度演算子$\rho_{AB}=\ket{\Phi}^{AB} \bra{\Phi}^{AB}$の部分トレースをとると、部分系の密度演算子$\rho_{A}, \rho_{B}$は、
\begin{align} \rho_{A} &= Tr_{B} (\ket{\Phi}^{AB} \bra{\Phi}^{AB}) = \sum_{k=1}^{R} \lambda_{k}^{2} \ket{\phi_{k}}^{A} \bra{\phi_{k}}^{A} \\ \rho_{B} &= Tr_{A} (\ket{\Phi}^{AB} \bra{\Phi}^{AB}) = \sum_{k=1}^{R} \lambda_{k}^{2} \ket{\psi_{k}}^{B} \bra{\psi_{k}}^{B} \tag{8} \end{align}となります。したがって、$\rho_{A}$の固有値も$\rho_{B}$の固有値も$\{ \lambda_{k}^2 \}$で、同じということになります。また、固有値(=ユニタリ変換で対角化したときの対角成分)が同じということは、当然ランクも同じで、さらに、その2乗トレースも等しいということになります。つまり、
Tr(\rho_{A}^{2}) = Tr(\rho_{B}^{2}) \tag{9}です。
このことは、全体系をどのように分割したとしても成り立つわけで、とても面白い性質だと思います。どっちの部分系で固有値を計算したとしても全く同じになるということなので、この固有値というのは、何かAとBとの間の分割面というか、関係性を特徴づけるような指標に思えてきます。そういえば、この固有値(の平方根)はシュミット係数そのものでした。つまり、その関係性というのは、要はエンタングルメントのことではないでしょうか、ということが、じんわりとわかってきます。
また、ある純粋状態に対するシュミット係数(あるいはシュッミットランク)を知りたいとすると、想定している部分系(どっちの部分系でも良い)で部分トレースをとって、その密度演算子の固有値を求めれば良い、ということもわかってきます(一つの計算方法として)。
ユニタリの自由度
部分系Aで定義される局所的なユニタリ変換を$U_{A}$、部分系Bで定義される局所的なユニタリ変換を$U_{B}$とすると、それによって全体系の純粋状態$\ket{\Phi}^{AB}$は、
\begin{align} (U_{A} \otimes U_{B}) \ket{\Phi}^{AB} &= (U_{A} \otimes U_{B}) \sum_{k=1}^{R} \lambda_{k} \ket{\phi_{k}}^{A} \ket{\psi_{k}}^{B} \\ &= \sum_{k=1}^{R} \lambda_{k} (U_{A} \ket{\phi_{k}}^{A}) (U_{B} \ket{\psi_{k}}^{B}) \\ &= \sum_{k=1}^{R} \lambda_{k} \ket{\phi_{k}^{\prime}}^{A} \ket{\psi_{k}^{\prime}}^{B} \tag{10} \end{align}のように変換されます。ここで、
\begin{align} \ket{\phi_{k}^{\prime}}^{A} &= U_{A} \ket{\phi_{k}}^{A} \\ \ket{\psi_{k}^{\prime}}^{B} &= U_{B} \ket{\psi_{k}}^{B} \tag{11} \end{align}とおきました。
これより、局所的なユニタリ変換で、シュミット分解の性質(シュミット係数やシュミットランク)は不変であるということがわかります。つまり、部分系AとBの間に存在するエンタングルメントの性質は、局所ユニタリ変換で不変に保たれるということです。こういう不変性は、いろいろ理論計算をする上で、何かと便利に使えるものなので、覚えておくと良いと思います。
シミュレータで確認
それでは、上で述べてきた知見の一部をシミュレータで確認してみたいと思います。全体系の任意の純粋状態に対する部分系の密度演算子の固有値が、全体系をどういう形に2分割したとしても、同じということだったので、本当にそうなるかを確認します。
全体のPythonコードは以下です。
import random import numpy as np from scipy.stats import unitary_group from scipy.linalg import eigh from qlazypy import QState, DensOp MIN_DOUBLE = 0.000001 def random_qstate(qubit_num): dim = 2**qubit_num vec_ini = np.array([0.0]*dim) vec_ini[0] = 1.0 mat = unitary_group.rvs(dim) vec = np.dot(mat, vec_ini) qs = QState(vector=vec) return qs def random_qubit_id(qubit_num): id = list(range(qubit_num)) random.shuffle(id) qubit_num_A = random.randint(1,qubit_num-1) qubit_num_B = qubit_num - qubit_num_A id_A = id[:qubit_num_A] id_B = id[qubit_num_A:] return id_A,id_B def eigen_values(densop): matrix = densop.get_elm() eigvals = eigh(matrix, eigvals_only=True) eigvals_out = [eigvals[i] for i in range(len(eigvals)) if eigvals[i] > MIN_DOUBLE] return eigvals_out if __name__ == '__main__': # whole quantum state qubit_num = 5 qs = random_qstate(qubit_num) de = DensOp(qstate=[qs], prob=[1.0]) # pure state # partial density operators (system A and B) id_A, id_B = random_qubit_id(qubit_num) de_A = de.patrace(id=id_B) de_B = de.patrace(id=id_A) # eigen-values of density operators (system A and B) eval_A = eigen_values(de_A) eval_B = eigen_values(de_B) print("== system A ==") print("- qubit id =", id_A) print("- square trace = ", de_A.sqtrace()) print("- eigen values =", eval_A) print("- rank =", len(eval_A)) print("== system B ==") print("- qubit id =", id_B) print("- square trace = ", de_B.sqtrace()) print("- eigen values =", eval_B) print("- rank =", len(eval_B)) qs.free() de.free() de_A.free() de_B.free()何をやっているか、順に説明します。
# whole quantum state qubit_num = 5 qs = random_qstate(qubit_num) de = DensOp(qstate=[qs], prob=[1.0]) # pure state全体系の量子ビット数を5にして、量子状態をランダムに設定します。関数random_qstateの中で実行しているので、その中身を見てみます。
def random_qstate(qubit_num): dim = 2**qubit_num vec_ini = np.array([0.0]*dim) vec_ini[0] = 1.0 mat = unitary_group.rvs(dim) vec = np.dot(mat, vec_ini) qs = QState(vector=vec) return qs指定された量子ビット数に対応した状態の次元数をdimとして、numpyの配列(ベクトル)を適当に決めます。第0成分のみ1.0、それ以外を0.0としました。ここで、ランダムな量子状態にするために、scipyの関数を召喚します。
from scipy.stats import unitary_group ... mat = unitary_group.rvs(dim)です。これは、ランダムなユニタリ行列を生成するための関数です。ここにドキュメントがあります4。生成されたユニタリ行列をvec_iniに適用して、できたランダムベクトルに基づき、量子状態QStateクラスのインスタンスを作り、リターンします。
もとのmain部に戻ります。できあがったランダム量子状態を用いて、密度演算子DensOpクラスのインスタンスを生成します。これで、全体系に対する純粋状態の密度演算子ができあがりました。
# partial density operators (system A and B) id_A, id_B = random_qubit_id(qubit_num) de_A = de.patrace(id=id_B) de_B = de.patrace(id=id_A)全体系の量子ビット(5量子ビット)を部分系Aと部分系Bにランダムに分割して、各々の量子ビット番号リストを変数id_A,id_Bに格納しています。関数random_qubit_idで実行しています。説明は省きます。関数定義を見てください。この量子ビット番号リストを使って、全体系の密度演算子の部分トレースをとります。結果を各々、変数de_A,de_Bに格納します。
# eigen-values of density operators (system A and B) eval_A = eigen_values(de_A) eval_B = eigen_values(de_B)固有値問題を解いて固有値のリストを求めます。関数eigen_valuesの中で、scipyの関数を使って実行しています。eighはエルミート行列に対する固有値を求める関数です。
from scipy.linalg import eigh ... def eigen_values(densop): matrix = densop.get_elm() eigvals = eigh(matrix, eigvals_only=True) eigvals_out = [eigvals[i] for i in range(len(eigvals)) if eigvals[i] > MIN_DOUBLE] return eigvals_outeigen_values関数の最初の行で、密度演算子DensOpクラスのget_elm()メソッドを使って行列表現(numpyの2次元配列)を取得しています。それを使って、固有値問題を解いています。
メイン部に戻ります。
print("== system A ==") print("- qubit id =", id_A) print("- square trace = ", de_A.sqtrace()) print("- eigen values =", eval_A) print("- rank =", len(eval_A)) ...部分系Aの量子ビット番号、2乗トレース、固有値、ランクを表示します。部分系Bも同様に表示します。
さて、実行結果です。以下のようになりました。
== system A == - qubit id = [4, 1, 2] - square trace = 0.38437171 - eigen values = [0.0822181470819045, 0.1464507832125754, 0.2143642754307335, 0.5569667940374802] - rank = 4 == system B == - qubit id = [0, 3] - square trace = 0.38437171 - eigen values = [0.08221814299667664, 0.14645078689065036, 0.2143642733317681, 0.5569667867809049] - rank = 4部分系Aに3量子ビット、部分系Bに2量子ビットが各々割り当てられました。ランクは4で固有値を見ていただくとわかる通り、きちんと一致しました!5また、2乗トレースは1以下なので、言わずもがなですが混合状態になっています。
もう一回やってみます。
== system A == - qubit id = [2, 3, 0, 4] - square trace = 0.53145101 - eigen values = [0.3745986253398182, 0.6254013753462571] - rank = 2 == system B == - qubit id = [1] - square trace = 0.53145101 - eigen values = [0.37459862198601285, 0.6254013780139871] - rank = 2というわけで、今度は、4量子ビットと1量子ビットに分割されました。ランクは2となり、この場合も固有値は一致しました!全体系の量子ビット数も変えつつ、何度も実行してみましたが、すべての場合で固有値は一致しました!
これは、それほど自明なことではないので、面白がっていただけると幸いです。純粋状態の密度演算子があって、それを2つの部分系に分けたとすると、必ず成り立つ性質です。
おわりに
今回は、純粋状態を部分系にわけるお話でした。その部分系は一般に混合状態になります。では、逆に混合状態に何らかの部分系を追加することで、純粋状態にできるでしょうか。答えはイエスで、それを実行する手続きのことを「純粋化」と言います。今回の記事で一緒に説明しようと思ったのですが、長くなりました。というわけで、次回は「純粋化」の予定です。
以上
これは大丈夫ですよね。任意の状態は適当な基底を使った重ね合わせで表現できます、と言っているだけです。 ↩
特異値分解は、通常$C = UDV^{\dagger}$と書かれたりします。添字を使って式展開するときに、ダガーがあると複素共役とか添字の順番を逆にしないと、、とかちょっと余計な注意をしないといけないので、$V^{\dagger} \rightarrow V$と置き換えました。 ↩
データサンプルの分布特徴を利用して、大量の説明変数をなるべく減らすという統計分析の世界でよく使われる「主成分分析」に似ています。 ↩
中で何をやっているか理解できていませんが(汗)、Haar測度に基づく由緒正しいランダムユニタリ行列を計算しているようです。今回は単に適当な量子状態を作りたかっただけなので、ここまでちゃんとしたランダム性は必要ないですが、ランダムな量子状態をどうやったら作れるんだろうとちょっと調べていたら、ひっかかってきたので試しに使ってみました。採用している手法は、以下の論文に記載されているようです。参考まで。How to generate random matrices from the classical compact groups ↩
小数点以下7桁以降は微妙に違っていたりしますが、計算誤差なので無視します ↩
- 投稿日:2019-10-11T20:38:12+09:00
【自然言語処理のためのWikipediaデータの扱い方(#1) 】Wikipedia記事DBの作成
自然言語処理で遊ぶための学習用データとして魅力的なWikipediaのデータですが、ダウンロード可能なDumpデータは3GB程度と容量が大きくXMLデータだったりして扱うのが大変です。もしDBに格納されていれば条件検索して記事数など確認しながら必要なデータだけ取り出せて便利です。今回はファイルとして持ち運びも可能なSQLiteでWikipediaの記事DBを作成します。
※※ 実行できることは確認していますが、処理時間が長いため記事作成に当たって再確認せずに記憶を頼りに書いています。ディレクトリの指定など違った場合はご一報ください※※
目的
・Wikipediaの記事データをDB(SQLite)に格納する
・記事名でパターン検索して、タイトルに特定の文字を含む記事データを抽出してみる。方法(概要)
・Wikipadiaのダンプデータをダウンロードする
・Wikiextractorでテキストを整形しつつjsonデータとして抽出する
・抽出したjsonデータを拙作のPythonスクリプトwikiextractor2sqliteを用いてsqliteのDBファイルに格納するwikiextractor2sqlite
簡単なPythonスクリプトなので、Qiitaへ貼るだけでも良かったのですがせっかくなので実行環境
- Ubuntu 18.04
- Python 3.6.0
- sqlite3 3.22.0
手順
記事データのダウンロード
次のURLから、pages-articleデータをダウンロードします。
https://dumps.wikimedia.org/jawiki/latestでも良いですが、後で別のデータと結合したい場合など日付付きの方が安全かもしれません。
今回は次のファイルをダウンロードしました。wget https://dumps.wikimedia.org/jawiki/20191001/jawiki-20191001-pages-articles.xml.bz2完了までだいたい25分くらいでした。
wikiextractorをダウンロード
次のコマンドでダウンロードします
git clone https://github.com/attardi/wikiextractorWikiextractorでテキストを整形しつつjsonデータとして抽出
次のコマンドでWikiextractorを実行します。
./wikiextractor/WikiExtractor.py --json -q -o extracted jawiki-latest-pages-articles.xml.bz2正確に覚えていませんが、だいたい30分くらいだったと思います。
処理が完了するとextractedというフォルダ内にAAといったアルファベット2文字のフォルダが作成され、その中に1MB毎に分割された記事データのJsonファイルが作成されます。
いくつもWARNINGが出ますが、対象の記事データも一応出力はされているようです。オプションの説明
- --json: 出力をタグ形式からJSON形式に変更
- -q: メッセージの量を減らす
- -o extracted: 出力先として「extracted」フォルダを指定
Wikiextractorの詳細はこちらから
Wikiextractorwikiextractor2sqlite をダウンロード
次のコマンドでダウンロードします。
合わせて必要ライブラリをインストールします。git clone https://github.com/yuukimiyo/wikiextractor2sqlite.git pip install tqdmWikipedia DBを作成
./wikiextractor2sqlite/wikiextractor2sqlite.py ./extracted -o wikipedia.dbオプションの説明
- ./extracted: wikiextractorで抽出したファイルのディレクトリを指定
- -o wikipedia.db: 出力先のDB名を指定
この処理を実施すると、またWARNINGが出ます。wikiextractorが全ての改行コードを除去しきれていないのではと想像できる出方ですが、大した数ではなさそうなので今回は無視することにします。
オプションとして-qを指定するとWARNINGの表示を出さないようにできます。
データの確認
以上の手順で記事DBが作成されていると思います。
-rw-r--r-- 1 dev-user users 3.2G 10月 11 18:05 wikipedia.db3.2GBと結構大きいですが、次のコマンドなどで圧縮すると大分小さくなるのでコピーする際は参考にしてください。(圧縮には結構時間がかかります)
# tarコマンドで圧縮 tar zxvf wikipedia.db.tar.gz wikipedia.db # 3.2GBが1.1GBまで圧縮されました。 -rw-r--r-- 1 dev-user users 1.1G 10月 11 18:49 wikipedia.db.tar.gzデータの中身を見てみる
SQLite3をインストールする(入っていない場合)
もしインストールされていない場合は適宜インストールしてください。
下記はUbuntuの場合です。sudo apt install sqlite3記事数を確認してみる
sqlite3 wikipedia.db "select count(*) from pages;" >> 1170762約110万件のきじが登録されました。
記事テーブルの構造を確認してみる
sqlite3 wikipedia.db ".schema pages" >> CREATE TABLE `pages` ( >> `id` bigint PRIMARY KEY, >> `url` varchar(512), >> `title` varchar(1024), >> `text` text >> );wikiextractorが出力したJsonに合わせて筆者が軽く作成したTableなのでちょっと素朴すぎる感じがしますが、このようなTableにデータが格納されています。さすがにidがbigintになっているのは恥ずかしいので将来の更新で直すかもしれません。
タイトルに「アニメ」が含まれる記事の一覧を表示する
# まずは件数を確認 sqlite3 wikipedia.db 'select count(title) from pages where title like "%アニメ%";' >> 1073 # 多いので、絞って表示 sqlite3 wikipedia.db 'select title from pages where title like "%アニメ%" limit 30;' >> アニメ >> SFアニメ >> アニメ関係者一覧 >> アニメ作品一覧 >> アダルトアニメ >> 東京を舞台とした漫画・アニメ作品一覧 >> アニメーション >> 魔法少女アニメ >> 宇宙の戦士 (アニメ) >> ロボットアニメ ...タイトルに「アニメ」が含まれる記事の本文データを取得する
やっとここまで来ました。次のコマンドで、anime.txtとして1073件分の記事データを取得できます。
sqlite3 wikipedia.db 'select text from pages where title like "%アニメ%";' > anime.txt中身の確認
# 容量の確認。4.8MBです。 ls -lh anime.txt >> -rw-r--r-- 1 dev-user users 4.8M 10月 11 20:03 anime.txt # 行数 wc -l anime.txt >> 37570 anime.txt # 先頭の10行を表示 head -n 10 anime.txt ---------------------------------------- アニメ アニメは、アニメーションの略語である。アニメーションを用いて構成された映像作品全般を指す。 各種メディアで提供されるサブカルチャーの一つ。 「文化芸術基本法」ではメディア芸術、関連法の「コンテンツの創造、保護及び活用の促進に関する法律」によるとコンテンツの一つと定義されており、い ずれにおいてもアニメと略されてはおらず、アニメーションと正式表記されている。別定義として、多角的芸術分類観点において、美術(映像を含まない) 、映像、音楽、文学、芸能の総合芸術とされるときもある。 単に「アニメ」という場合は、セルアニメーション(セルアニメ)のことを指していることが多い。本項では、主に日本で製作された商業用セルアニメーシ ョンについて解説する。 ----------------------------------------最後に
目的に応じて記事を絞り込むことができるので、特定の話題を対象とした文章の分析や試行錯誤中に使用する軽量の学習データとしてなど、アイディアによっては便利に使えるのではないでしょうか。
いつになるか分かりませんが、次回はカテゴリデータを追加して、カテゴリによる記事の抽出など紹介できればと思います。
- 投稿日:2019-10-11T18:08:36+09:00
[正規表現Tips] Pythonで文字列内のドットをカンマに置換する�(末尾2つが数字なら置換しない)
正規表現って普段書かなくなると、すぐ忘れちゃいますよね
?
めちゃめちゃTipsですが、備忘録も兼ねて投稿します。やりたいこと
- 掲題の通りですが、金額等の文字列の修正を想定しています。
- 例: 金額欄に
1,000.000と入力されたときに、1,000,000に修正したい。
- ただし、
1,000.000.00と入力されたときは1,000,000.00にしたい。- 「そんなケースに遭遇する?」と思われるかもしれませんが、例えばOCRシステム等ではあり得るかと思います。(私の場合、まさにこれ)
コード
import re target_text = '1,000.000.00' replace_rule = re.compile('\.(?!\d{2}$)') text = replace_rule.sub(',', target_text)これでいけました。
なお、このままだと例えば1,000.0は1,000,0となってしまうので、ちゃんと3つ区切りのドットだけを置換したい場合は(そもそもそんなケースが有るかは不明ですが)import re target_text = '1.000.00.00' replace_rule = re.compile('\.(\d{3})') text = replace_rule.sub(r',\1', target_text)でいけました。
以上です。この記事が世界の誰かの役に立てば幸いです
- 投稿日:2019-10-11T17:41:02+09:00
Python: 写真を水彩画風に変換する
SAMPLE
これが
こうなります。
PYTHON
- 画像に減色処理を施した上で任意の画素数で平滑化します。
- 画像からエッジを検出し反転させたものを線画として上記に透過します。
- 2に減色処理後の画像を再度重みづけながら合成します。
初期設定を変更することで水彩画具合を調整できます。
import cv2 import numpy as np import os.path import matplotlib.pyplot as plt from PIL import Image #####初期設定 ##読み込み画像 f = 'filename.jpg' ##平滑化を行う画素のサイズ average_square = (5, 5) ##x軸方向の標準偏差 sigma_x = 0 ##減色処理の際の配列サイズ reshape_size = (-1, 3) ##減色処理の際の停止条件 criteria = (cv2.TERM_CRITERIA_EPS+cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0) ##減色処理数 k=100 ##線画抽出の際の平滑化サイズ line_average = (9, 9) ##線画抽出の際のx軸方向の標準偏差 line_sigma_x = 0 ##エッジ検出の際のthreshold1 threshold1 = 50 ##エッジ検出の際のthreshold2 threshold2 = 55 ##エッジを反転させる際の平滑化サイズ edges_average = (1, 1) ##エッジを反転させる際のx軸方向の標準偏差 edges_sigma_x = 0 ##二値化の際のthresh thresh = 90 ##二値化の際のmax_pixel max_pixel = 255 ##エッジを明るくする際のガンマ gamma = 5.0 ##合成画像の重み multi_w = 0.5 ##彩色表現の重み paint_w = 0.9 ##ガンマ gamma = 1.5 #####初期設定終わり ##画像の読み込み image = cv2.imread(f, 1) ##ファイル名と拡張子を取得 file, ext = os.path.splitext(f) #####彩色表現 def paint(filename): ##画像をぼかす image_blurring = cv2.GaussianBlur(filename, average_square, sigma_x) ##減色処理 z = image_blurring.reshape(reshape_size) z= np.float32(z) ret,label,center=cv2.kmeans(z, k, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS) center = np.uint8(center) res = center[label.flatten()] image_reshape = res.reshape((image_blurring.shape)) ##再度ぼかす return cv2.GaussianBlur(image_reshape, average_square, sigma_x) #####線画抽出 def line(filename): ##エッジを検出 image_preprocessed = cv2.cvtColor(cv2.GaussianBlur(filename, line_average, line_sigma_x), cv2.COLOR_BGR2GRAY) image_edges = cv2.Canny(image_preprocessed, threshold1 = threshold1, threshold2 = threshold2) ##エッジを反転させる image_h = cv2.GaussianBlur(image_edges, edges_average, edges_sigma_x) _, image_binary = cv2.threshold(image_h, thresh, max_pixel, cv2.THRESH_BINARY) image_binary = cv2.bitwise_not(image_binary) return image_binary paint = paint(image) cv2.imwrite(file + "_paint" + ext, paint) line = line(image) cv2.imwrite(file + "_line" + ext, line) ##乗算 def mul(input_color,mul_color): return int(round(((input_color*mul_color)/255),0)) ##合成 def multiple(image1, image2): ##Pillowに変換 pixelSizeTuple = image1.size image3 = Image.new('RGB', image1.size) for i in range(pixelSizeTuple[0]): for j in range(pixelSizeTuple[1]): r,g,b = image1.getpixel((i,j)) r2,g2,b2 = image2.getpixel((i,j)) img_r = mul(r,r2) img_g = mul(g,g2) img_b = mul(b,b2) image3.putpixel((i,j),(img_r,img_g,img_b)) return image3 image1 = Image.open(file + "_paint" + ext).convert("RGB") image2 = Image.open(file + "_line" + ext).convert("RGB") multi = multiple(image1, image2) multi.save(file+"_multi"+ext) ##重みあり合成 def dodge(multi, paint): d = cv2.addWeighted(multi, multi_w, paint, paint_w, gamma) return d multi_image = cv2.imread(file+"_multi"+ext,1) output = dodge(multi_image, paint) cv2.imwrite(file + "_output" + ext, output)EXAMPLE
加工する前の画像です。
減色処理を施し平滑化しました。
画像からエッジを検出し反転しました。
減色処理した画像にエッジを反転させた画像を投下しました。
再度減色処理した画像を重みを調整しながら合成しました。完成です。
女の子の画像です。









- 投稿日:2019-10-11T16:33:13+09:00
FBX SDK Pythonでエクスポート可能なファイル形式一覧
FBX SDK Python 2019 が対応しているファイル形式一覧
公式サイトを見ると、C++版のFBX SDKは大量のファイルフォーマットをサポートしているようなのですが、どうやらPython版はすべて対応しているわけではないみたいでしたので、対応しているフォーマットを調査してみました。
書き込み可能なファイル形式一覧
以下が一覧です。
IndexとDescriptionは、あくまで私の環境(後述)での値です。他の環境では異なる可能性がありますのでご注意ください。
Index Description 0 FBX binary (*.fbx) 1 FBX ascii (*.fbx) 2 FBX encrypted (*.fbx) 3 FBX 6.0 binary (*.fbx) 4 FBX 6.0 ascii (*.fbx) 5 FBX 6.0 encrypted (*.fbx) 6 AutoCAD DXF (*.dxf) 7 Alias OBJ (*.obj) 8 Collada DAE (*.dae) 9 Biovision BVH (*.bvh) 10 Motion Analysis HTR (*.htr) 11 Motion Analysis TRC (*.trc) 12 Acclaim ASF (*.asf) 13 Acclaim AMC (*.amc) 14 Vicon C3D (*.c3d) 15 Adaptive Optics AOA (*.aoa) 16 Superfluo MCD (*.mcd) 読み込み可能なファイル形式一覧
以下が一覧です。
IndexとDescriptionは、あくまで私の環境(後述)での値です。他の環境では異なる可能性がありますのでご注意ください。
Index Description 0 FBX (*.fbx) 1 AutoCAD DXF (*.dxf) 2 Alias OBJ (*.obj) 3 3D Studio 3DS (*.3ds) 4 Collada DAE (*.dae) 5 Alembic ABC (*.abc) 6 Biovision BVH (*.bvh) 7 Motion Analysis HTR (*.htr) 8 Motion Analysis TRC (*.trc) 9 Acclaim ASF (*.asf) 10 Acclaim AMC (*.amc) 11 Vicon C3D (*.c3d) 12 Adaptive Optics AOA (*.aoa) 13 Superfluo MCD (*.mcd) 14 (*.zip) 調査方法
IndexとDescriptionは以下のコードで確認しました。# 書き込み可能な形式一覧を出力 for formatIndex in range(manager.GetIOPluginRegistry().GetWriterFormatCount()): description = manager.GetIOPluginRegistry().GetWriterFormatDescription(formatIndex) print(formatIndex, description) # 読み込み可能な形式一覧を出力 for formatIndex in range(manager.GetIOPluginRegistry().GetReaderFormatCount()): description = manager.GetIOPluginRegistry().GetReaderFormatDescription(formatIndex) print(formatIndex, description)以下の2つの環境で確認しました。
Windows環境
- Windows 10 64bit
- Python 2.7
- FBX SDK Python 2019.5
Linux環境
- Alpine Linux v3.9
- Python 2.7
- FBX SDK Python 2019.2
さいごに
読み込みと書き込みでIndexが変わるのがちょっとややこしいですね。。。
以下のサイトを参考にさせていただきました。ありがとうございます。
- 投稿日:2019-10-11T16:33:13+09:00
FBX SDK Pythonが対応しているファイル形式一覧
FBX SDK Python 2019 が対応しているファイル形式一覧
公式サイトを見ると、C++版のFBX SDKは大量のファイルフォーマットをサポートしているようなのですが、どうやらPython版はすべて対応しているわけではないみたいでしたので、対応しているフォーマットを調査してみました。
書き込み可能なファイル形式一覧
以下が一覧です。
IndexとDescriptionは、あくまで私の環境(後述)での値です。他の環境では異なる可能性がありますのでご注意ください。
Index Description 0 FBX binary (*.fbx) 1 FBX ascii (*.fbx) 2 FBX encrypted (*.fbx) 3 FBX 6.0 binary (*.fbx) 4 FBX 6.0 ascii (*.fbx) 5 FBX 6.0 encrypted (*.fbx) 6 AutoCAD DXF (*.dxf) 7 Alias OBJ (*.obj) 8 Collada DAE (*.dae) 9 Biovision BVH (*.bvh) 10 Motion Analysis HTR (*.htr) 11 Motion Analysis TRC (*.trc) 12 Acclaim ASF (*.asf) 13 Acclaim AMC (*.amc) 14 Vicon C3D (*.c3d) 15 Adaptive Optics AOA (*.aoa) 16 Superfluo MCD (*.mcd) 読み込み可能なファイル形式一覧
以下が一覧です。
IndexとDescriptionは、あくまで私の環境(後述)での値です。他の環境では異なる可能性がありますのでご注意ください。
Index Description 0 FBX (*.fbx) 1 AutoCAD DXF (*.dxf) 2 Alias OBJ (*.obj) 3 3D Studio 3DS (*.3ds) 4 Collada DAE (*.dae) 5 Alembic ABC (*.abc) 6 Biovision BVH (*.bvh) 7 Motion Analysis HTR (*.htr) 8 Motion Analysis TRC (*.trc) 9 Acclaim ASF (*.asf) 10 Acclaim AMC (*.amc) 11 Vicon C3D (*.c3d) 12 Adaptive Optics AOA (*.aoa) 13 Superfluo MCD (*.mcd) 14 (*.zip) 調査方法
IndexとDescriptionは以下のコードで確認しました。# 書き込み可能な形式一覧を出力 for formatIndex in range(manager.GetIOPluginRegistry().GetWriterFormatCount()): description = manager.GetIOPluginRegistry().GetWriterFormatDescription(formatIndex) print(formatIndex, description) # 読み込み可能な形式一覧を出力 for formatIndex in range(manager.GetIOPluginRegistry().GetReaderFormatCount()): description = manager.GetIOPluginRegistry().GetReaderFormatDescription(formatIndex) print(formatIndex, description)
managerにはFbxManager.Create()で生成したインスタンスを入力してください。サンプルプロジェクトはこちらに置きます。
GitHub/segurvita/fbx_sdk_python_sample/convert_fbx/list_format.py以下の2つの環境で試し、同じ値が出力さえることを確認しました。
Windows環境
- Windows 10 64bit
- Python 2.7
- FBX SDK Python 2019.5
Linux環境
- Alpine Linux v3.9
- Python 2.7
- FBX SDK Python 2019.2
さいごに
読み込みと書き込みでIndexが変わるのがちょっとややこしいですね。。。
以下のサイトを参考にさせていただきました。ありがとうございます。
- 投稿日:2019-10-11T16:19:22+09:00
Windows Update後にコマンドラインからpythonを実行するとストアアプリが立ち上がるのを解決する方法
問題
大型のWindows Update後,コマンドラインで
pythonを実行すると,すでにpython環境が構築されている場合でも対話型インタプリタではなく,MS Storeのpythonのページが開くようになった.
詳しい記事解決方法
アプリ実行エイリアスの欄のpythonをはずしてやればよい.
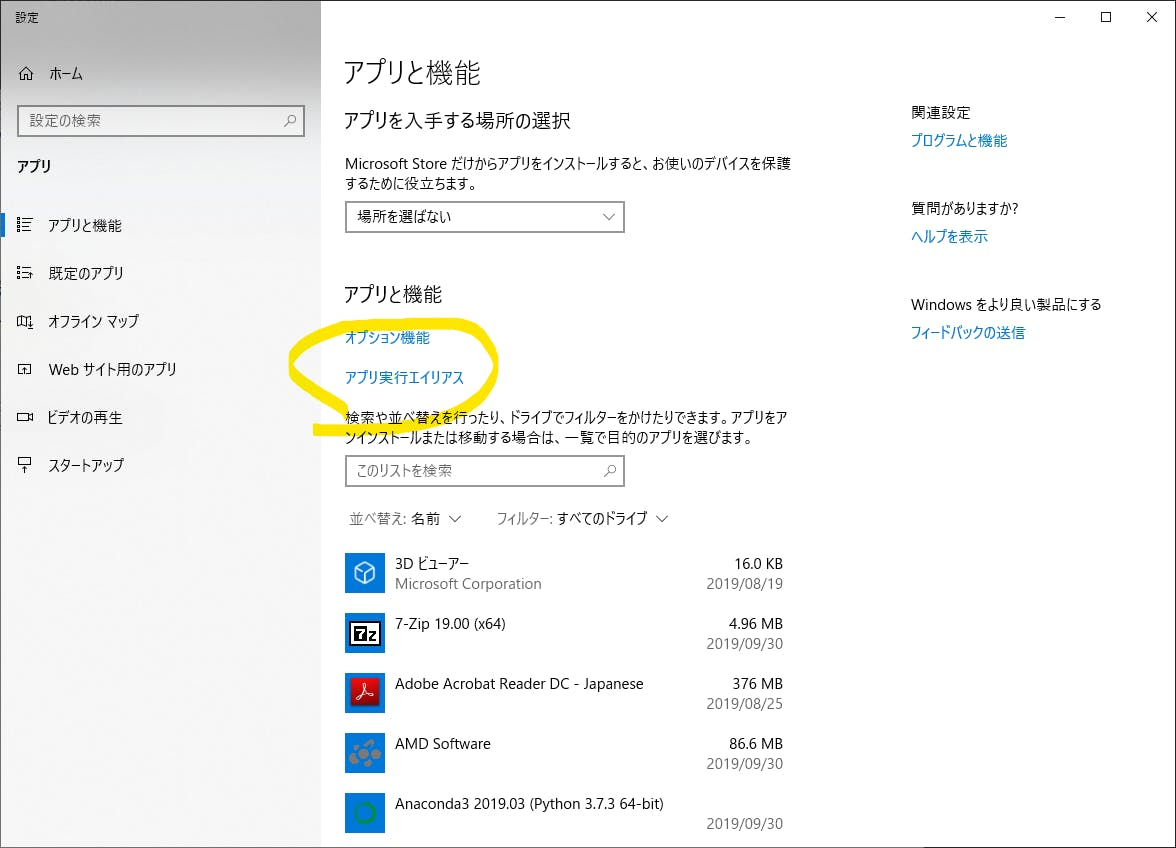

- 投稿日:2019-10-11T16:00:58+09:00
【Python】圧縮されたS3オブジェクトをローカルに保存せず読み込む
S3に保存されたgzip/zip圧縮ファイルを、ローカルファイルとして保存することなく読み込みたい。
前提条件
- Python: 3.7.4
- AWS SDK: boto3-1.9.230以上
ポイント
- 標準の
gzip,zipfileパッケージを使ってファイルを読み込んでファイルオブジェクトに変換する。
(bzip2とかは考えなくて良いんじゃないかな)
つまり、以下のようにして読み込んだ際と同様に扱いたい。
import gzip gz_file = 'path/to/file.csv.gz' file = gzip.open(gz_file, 'rt') file.read() ..パッケージ毎にファイルオブジェクトの変換方法に癖があるので、それぞれ対応する。
ioパッケージのBytesIOやらTextIOWrapperを使う。
ついでに、圧縮形式も正しいかチェックする。コード
gzip圧縮の場合
import boto3 import gzip import io # 圧縮形式が正しいかチェック def valid_gzip_format(obj): file = gzip.open(io.BytesIO(obj), 'rt') try: file.read() return True except OSError: return False s3 = boto3.client('s3') bucket = 'bucket_name' key = 'path/to/file.csv.gz' # S3オブジェクトの取得 obj = s3.get_object( Bucket=bucket, Key=key )['Body'].read() # main if valid_gzip_format(obj): file = gzip.open(io.BytesIO(obj), 'rt') else: raise InvalidCompressError('ファイル拡張子(.gz)に対して圧縮形式が正しくありません。') # 中身確認 for row in file.readlines(): print(row.replace('\n', ''))zip圧縮の場合
import boto3 import io import zipfile # 圧縮形式が正しいかチェック def valid_zip_format(obj): return zipfile.is_zipfile(io.BytesIO(obj)) s3 = boto3.client('s3') bucket = 'bucket_name' key = 'path/to/file.csv.zip' # S3オブジェクトの取得 obj = s3.get_object( Bucket=bucket, Key=key )['Body'].read() # main if valid_zip_format(obj): zf = zipfile.ZipFile(io.BytesIO(obj)) if len(zf.namelist()) > 1: raise InvalidCompressError('zipアーカイブの中にファイルが複数あります。') file = io.TextIOWrapper(zf.open(zf.namelist()[0], 'r')) else: raise InvalidCompressError('ファイル拡張子(.zip)に対して圧縮形式が正しくありません。') # 中身確認 for row in file.readlines(): print(row.replace('\n', ''))
zipfileではopenのモードに'rt'が無いのでTextIOWrapperを使う必要がある。
参考 - ZIP アーカイブの処理 — Python 3.7.5rc1 ドキュメントバージョン 3.6 で変更: Removed support of mode='U'. Use io.TextIOWrapper for reading compressed text files in universal newlines mode.
まとめ
上記のコードで取得したS3オブジェクトは
bytes型で保持されるだけなので、with構文で扱う必要はないと思う(合ってる?)。
あと実際に中身を読み込む際に、末尾に改行コードが含まれるのでそのあたりも考慮が必要(もろちん、バイナリモードでも含まれるけど)。
- 投稿日:2019-10-11T15:42:41+09:00
機械学習初心者が『Pythonではじめる機械学習』についてまとめてみた。 【5章 モデルの評価と改良】
はじめに
モデルの汎化性能を評価する上で、より頑健な手法である交差検証を導入する。また、クラス分類性能と回帰性能を評価する上で、
scoreでのデフォルトのR^2よりも良い手法について議論されてます。
教師あり学習で汎化性能を最大にするように効率的にパラメータを調整するグリッドサーチにも触れます。交差検証
交差検証では、データの分割を何度も繰り返して行うことで、これまでのただの分割よりも安定した評価を実現する。最もよく用いられるのは、k分割交差検証である。例えば、k=5の場合は、分割0から分割4の5つに分割され、分割0から順番にテストセットに、残りの分割を訓練セットにして学習を行い、性能の平均をとる。
(層化)k分割交差検証
from sklearn.model_selection import cross_val_scoreデータをk個に分割する際に、先頭から1/k個取る方法はうまくいくとは限らない。なぜなら、データがクラス0から順番に保存されているデータセットもあるためだ。そのため、scikit-learnでは各分割内でのクラスの比率が全体の比率と同じになるように、層化交差検証を行っている。
cross_val_scoreでは、デフォルトで3分割交差検証を行い、3つの精度を返す。
cv分割数1つ抜き交差検証
from sklearn.model_selection import LeaveOneOutk分割交差検証の個々の分割が1サンプルしかないと考え、毎回、テストセットの中の1サンプルだけをテストセットとして検証する。大規模なデータセットでは非常に時間がかかるが、小さいデータセットではよりよい推定ができる。
シャッフル分割交差検証
from sklearn.model_selection import ShuffleSplitデータセットの中から指定した数・割合の訓練セットとテストセットを選び、指定した回数の検証を行う。サブサンプリングと呼ばれる、データの一部だけを用いるようにすることもでき、データセットが大きい場合に有用である。
train_size訓練セットの数・割合
test_sizeテストセットの数・割合
n_iter繰り返しの回数グループ付き交差検証
from sklearn.model_selection import GroupKFold汎化性能を高めるためには、データとしては異なるものの、訓練セットとテストセットに分かれることが好ましくないことがある。例えば、表情から感情を予測する際に、同じ人のデータが分かれることである。なぜならば、学習済の人の表情の予測は容易になるはずであり、未知の人の表情から感情を予測する汎化性能を計るには適切でないためである。
そのため、配列を用意し、同じグループに属するデータには同じ番号を振ることで、それらのデータをグループ化し、個々のグループはまとまって訓練セットもしくはテストセットに入るように出来る。
groupsグループ分けを行うための配列グリッドサーチ
グリッドサーチとは、基本的にはパラメータのすべての組み合わせに対して試して見る方法である。ただし、それぞれのパラメータに対する評価に対してテストセットを使っていては、汎化性能を適切に評価できているとは言い難い。そのため、訓練セット・検証セット・テストセットとデータセットを3つに分割する。
交差検証を用いたグリッドサーチ
from sklearn.model_selection import GridSearchCVグリッドサーチは一般に用いられているが、データの実際の分割のされ方によって大きく性能が変わる。そのため、それぞれのパラメータの組み合わせに対して交差検証を行うとよい。ただし、パラメータ2つをそれぞれ6つの値で、交差検証を5回行うとすると、6×6×5=180通りのモデルを訓練する必要がある。これには非常に時間がかかることが大きな問題点である。
ネストした交差検証
上記のグリッドサーチでは、データセットを訓練セットとテストセットに一度だけ分け、訓練セット上で交差検証を行い、訓練セットと検証セットに分けた。訓練セットとテストセットの分割が一度だけの場合、その分割の仕方に結果が依存する場合がある。そのため、訓練セットとテストにも交差検証による分割を適用する。この手法をネストした交差検証と呼ぶ。
ネストした交差検証をscikit-learnで行うのは容易で、cross_val_scoreをGridSearchCVのインスタンスをモデルとして呼び出せば良い。評価基準とスコア
機械学習の基準を選ぶときには、そのアプリケーションによって最終的な目的を考える必要がある。横軸を予測ラベル、縦軸を新ラベルとし、あてはまるデータの数を成分とした行列を混同行列と呼ぶ。
2クラス分類
2クラス分類では、2つのクラスを陽性と陰性と呼ぶ。予測・実際の値がともに陽性のときを真陽性(TP)、予測・実際の値がともに陰性のときを真陰性(TN)と呼ぶ。また、陽性と予測したが実際は陰性のときを偽陽性(FP)、この逆のときを偽陰性(FN)と呼ぶ。
from sklearn.metrics import classification_report以下の3つの評価基準をクラスごとにそのクラスを陽性とした場合に値を出力してくれる。同時に支持度と呼ばれる、陽性のデータの数も出力してくれる。
適合率
適合率=\frac{TP}{TP+FP}適合率は、陽性であると予測されたものがどれだけ実際に陽性であったかを表す。偽陽性の数を制限したい場合に基準として用いられる。
再現率
再現率=\frac{TP}{TP+FN}再現率は、実際に陽性のデータのうち、陽性と予測されたものの割合を示す。偽陰性を避けることが重要な場合に基準として用いられる。例えば、ガンの診断。
f-値
F=2×\frac{適合率×再現率}{適合率+再現率}適合率と再現率がトレードオフである。すべてを陽性と判定すれば再現率は100%となるが、適合率は非常に小さくなる。一方、最も真である可能性が高いもの1つだけを真とすれば、適合率は100%となるが、再現率は非常に小さくなる。
適合率と再現率はそれぞれ非常に重要な基準であるが、一方だけでは全体像がつかめない。そのため、これら2つを包括的に評価するf-値という基準がある。これは、適合率と再現率の調和平均によって求められる。(f-値の変種の1つであり、他にもあるらしい)適合率・再現率カーブ
from sklearn.metrics import precision_recall_curve, average_precision_scoreカーブが右上に近いほど、適合率と再現率が同時に高いため、良いクラス分類器であることがわかる。カーブを要約する方法の1つとして、カーブ下の領域(AUC)を積分することがあり、これは平均適合率とも呼ばれる。
受信者動作特性カーブ(ROCカーブ)
from sklearn.metrics import roc_curve, roc_auc_score横軸に偽陽性率、縦軸に真陽性率(再現率)をとる。低い偽陽性率を保ちながら、高い再現率を達成したいので、左上に近いほどよいクラス分類器と言える。同様にして、ROCカーブのAUCを積分することで要約することができる。
予測の不確実性
ほとんどのクラス分類器には、予測の不確実性を評価するための
decision_functionメソッドもしくはpredict_probaメソッドがある。予測の閾値は、デフォルトでは前者が0、後者が0.5となっている。例えば、偽陽性が増えてもよいからより多くの真陽性を得たい場合は、閾値を小さくすることで再現率を上げることができる。他クラス分類
他クラス分類においても、
classification_reportによって適合率・再現率・f-値を求めることができる。クラスごとのf-値を平均する方法は以下の3つがある。
macro重みをつけずにクラスごとのf-値を平均する。個々のクラスを同じように重視している。
weighted各クラスの支持度に応じて重みをつけてクラスごとのf-値を平均する。
microすべてのクラスの偽陽性・偽陰性・真陽性の総数を計算し、その値を用いて計算する。個々のサンプルを同じように重視している。回帰
R^2スコアが最も直観的。
参考文献
Pythonではじめる機械学習
――scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
Andreas C. Muller、Sarah Guido 著、中田 秀基 訳
- 投稿日:2019-10-11T15:34:03+09:00
任意の周波数特性を持ったFIRフィルタの設計
はじめに
マイクで収録した音にFIRフィルタで周波数補正をかけたくなりました。FIRフィルタというとscipy.signal.firwinなどがありますが、今回は単純なローパスフィルタやハイパスフィルタではなく、複雑な周波数特性の実現を目指します。私はFIRフィルタの理論を深く理解しているわけではないので、間違っている箇所があると思います。そのときはコメントで教えていただけるとありがたいです。
参考
東北大学講義資料の以下を参考にさせていただきました。
やる夫で学ぶディジタル信号処理手順
ファイル読み込みなどのコードは省略しました。
1. マイク付属の周波数特性表の読み込み
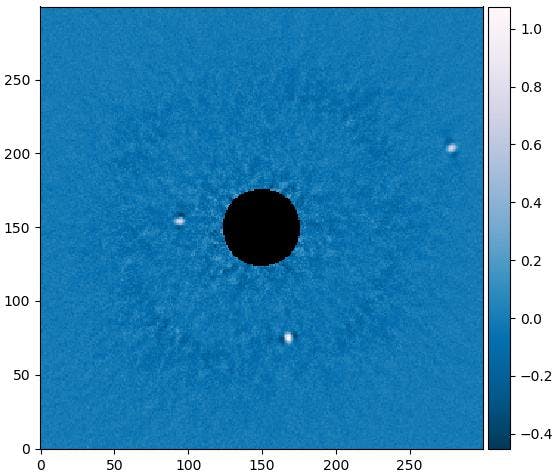
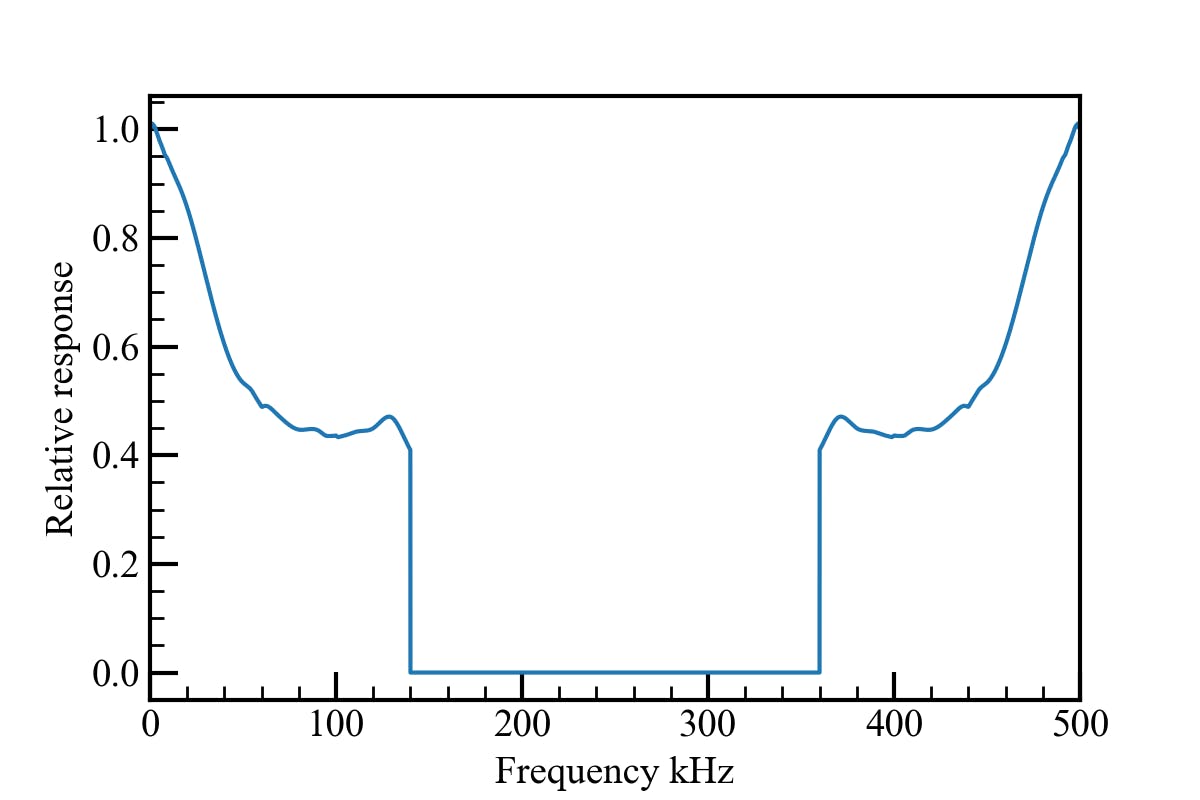
これはとあるマイクの周波数特性と自由音場補正データです。
補正すべき値は以下のようになります。
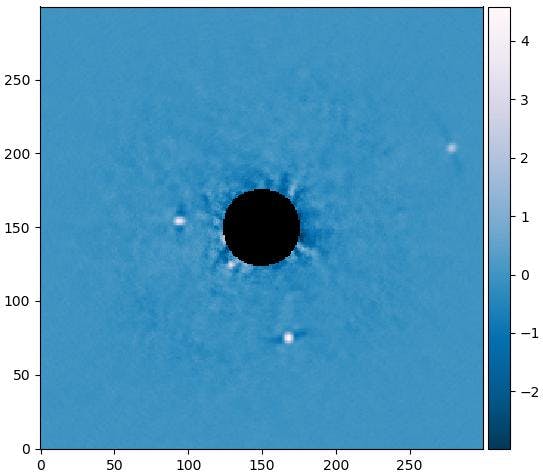
2. 実現したい周波数特性をつくる
ここで、補正値は対数から線形になおしておきます。
このマイクは140 kHzまでが計測可能範囲なので、それより高い周波数ではゲインを0にします。N = 128 #タップ数 + 1 fs = 500.0e3 #補正をかけたいデータのサンプリングレート freq_array = np.linspace(0.0, fs, num=N) gain_correction = np.zeros(N//2) lim_freq = freq_array[freq_array <= 140.0e3] # f_pro_funcとf_pro2_funcはスプライン補間テーブル gain_correction[0:len(lim_freq)] = 10**(-(f_pro_func(lim_freq) + f_pro2_func(lim_freq))/20.0) gain_correction = list(gain_correction) + list(gain_correction[::-1]) #反転して合わせる fig, axes = plt.subplots(figsize=(8,4)) axes.plot(freq_array/1000.0, gain_correction) axes.set_xlabel("Frequency kHz") axes.set_ylabel("Relative response") axes.set_ylim(-0.1, 1.1)
3. FIRフィルタの係数を計算する
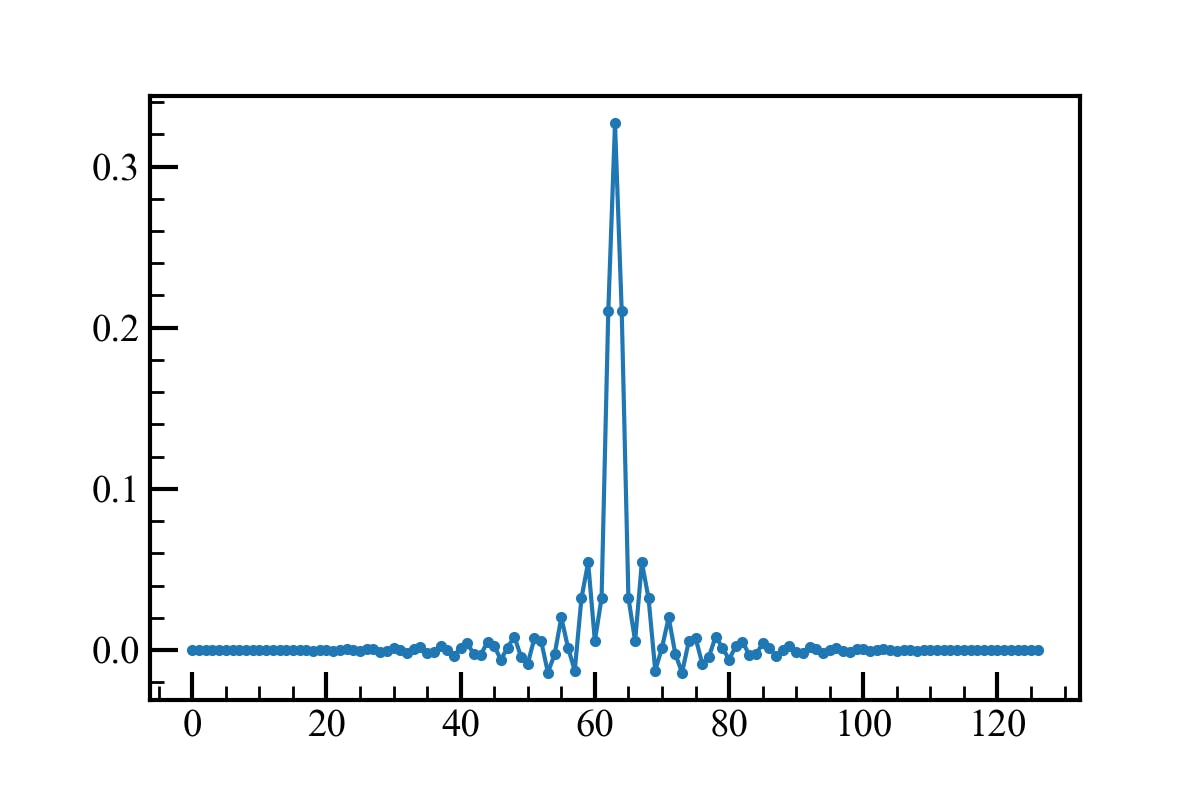
波形データにフィルタ係数を畳み込み計算した結果は、それぞれのデータのフーリエ変換の積になります。フィルタ係数のフーリエ変換は、実現したい周波数特性そのものです。従って、先程の周波数特性を逆フーリエ変換すればフィルタの係数が求まります。また、FIRフィルタの係数は左右対称になります。
b = list(np.real(np.fft.ifft(gain_correction)))[0:N//2] b = b[::-1] + b[1:] b = b * np.hamming(N-1) b /= np.sum(b) # 係数の和を1にする
フィルタ係数をフーリエ変換してみます。
4. FIRフィルタの適用
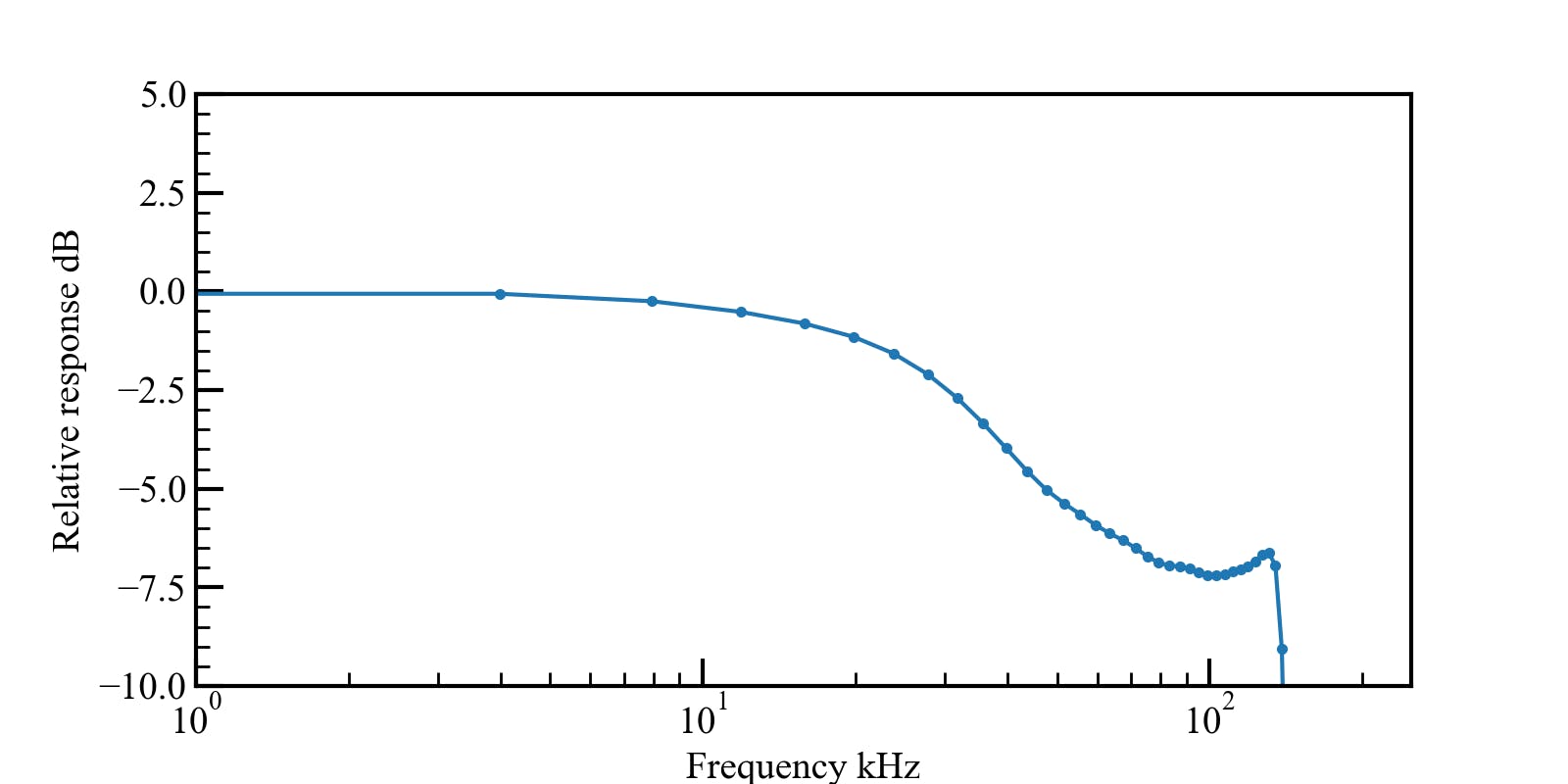
計算したFIRフィルタをホワイトノイズに適用して、適用された波形のスペクトルを確認してみます。
NN = 8192 ave_num = 1000 y = np.random.rand(NN*ave_num) # ホワイトノイズ yy = signal.lfilter(b, 1, y) # FIRフィルタを適用した信号 fft_sum_w = np.zeros(NN) fft_sum_f = np.zeros(NN) for i in range(ave_num): fft_sum_w += np.abs(np.fft.fft(y[NN*i:NN*(i+1)]) / NN) fft_sum_f += np.abs(np.fft.fft(yy[NN*i:NN*(i+1)]) / NN) fft_ave_w = 20.0 * np.log10(fft_sum_w / ave_num) fft_ave_f = 20.0 * np.log10(fft_sum_f / ave_num) fig, axes = plt.subplots(figsize=(8,4)) axes.plot(np.linspace(0.0, 500.0, num=NN), fft_ave_w) axes.plot(np.linspace(0.0, 500.0, num=NN), fft_ave_f) axes.set_xlim(1.0, 250.0) axes.set_ylim(-50.0-15, -50.0) axes.set_xscale("log") axes.set_xlabel("Frequency kHz") axes.set_ylabel("Amplitude dB")ちゃんと実現したかった周波数特性になっています。
まとめ
実現したい周波数特性からFIRフィルタの係数を計算し、波形に適用しました。
今後はリアルタイム信号処理にも挑戦してみたいです。



- 投稿日:2019-10-11T14:16:55+09:00
TrueSkill「まだ Elo レーティングで消耗してるの?」
徒競走のタイムと違って、対戦型ゲームの巧さというのは簡単には数値化できません。 しかし、なんとかしてそれを実現させようとして生まれたのがレーティングです。 古典的にはチェスのために生み出された Elo レーティングが存在し、様々な改良アルゴリズムが生み出されてきました。
TrueSkill は Microsoft が開発したレーティングアルゴリズムです。 Microsoft が開発したとあって Xbox Live のゲームで使用されているようです。 このアルゴリズムには既存のレーティングアルゴリズムと比較して以下のような特徴があるそうです。
- 収束が早い。 レーティングに初めて参加するプレイヤーの実力を推定するのに何度も何度も不適当なマッチングで対戦する必要がない。
- 複数人による対戦に対応している。 勝ちか負けかのみならず順位を定めるようなゲームやチーム戦1のゲームにも使用できる。
- ゲームへの参加に重み付けができる。 例えばチームメンバーのひとりが回線トラブルにより途中でゲームから抜けた場合でも適用できる。
Microsoft の息がかかっている。 特許申請と商標登録がなされており、なんとなく手が出しづらい。 あと一部の狂信的 OSS 主義者が憤死する。ちょろっと論文を読んでみようとは試みたのですが、まず私は英語がてんでダメで、おまけに数学統計学の知識も付け焼き刃なもので、因子グラフとか言われてもさっぱりぽんで無事死亡しました。 私よりはマシという自信がある方は Qiita に投稿されているこちらの記事をお読みいただくと理解を深められると思います。
ぶっちゃけこれと“Computing Your Skill”の和訳記事以外に日本語の資料ないです。 あと Wikipedia もか……?しかし、私たちには他人の褌があります。 そう、ここに TrueSkill の Python 実装があります。 いくら英語がダメな私でも、Google 先生に頼ればリファレンスくらいは読めるでしょう。 ということで一念発起して TrueSkill で遊んでみて簡単な使い方と遊んだ結果を残すことで数少ない TrueSkill の日本語資料の一つとして労せずうまい汁をすすりたいと思います。
誰かがやめ太郎さん風に書き直して「ワイ『TrueSkill? 転職支援サイトかなんかやろか?』」みたいな感じで投稿するとさらにバズるかもしれません。 次のうまい汁は君だ!簡単な統計学と TrueSkill の概要
TrueSkill ではプレイヤーのスキルを正規分布に従う確率密度関数によって表現します。 このように序盤から難しそうな単語を出していくことで読者を威圧していくテクニックが荒んだ現代社会で生きのこるには必須と言われています。
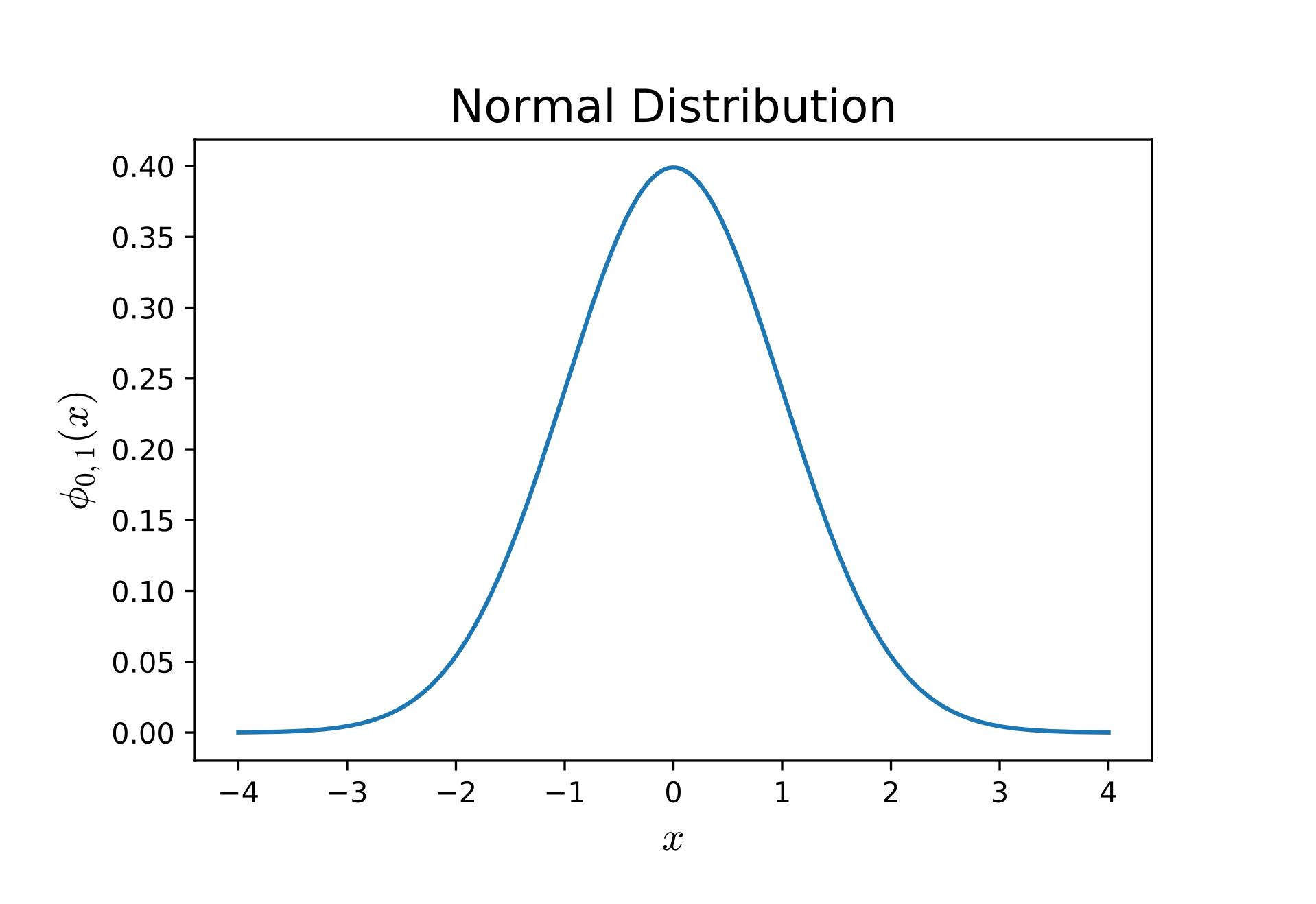
しかし皆さんは私のこの姑息な手法に怯える必要はありません。 まず下の図を見てください。
正規分布とは、まあおおむねこんな形をしたものです。 確率密度関数とは……たとえばそうですね、横軸を「ある値」だとします。 今回の場合はそう、スキルです。 縦軸は……ちょっと違うのですが確率だと思ってください。 正確な話をすると、ちょっとだけ数学的な話になりますが、確率密度関数 $\phi_{\mu, \sigma^2}(x)$ とは2、「ある値」が $x_1$ から $x_2$ の間(ここで $x_1 < x_2$ とします)に収まる確率 $p_{12}$ が $\phi_{\mu, \sigma^2}(x)$ を $x_1$ から $x_2$ まで積分した値、すなわち $p_{12} = \int_{x_1}^{x_2}\phi_{\mu, \sigma^2}(x)$ になるように定めた関数です。 まあ要するに山の頂点周辺の可能性が高いよ関数、と思ってくれればいいです。
ここで私たちが気にしなければいけないことはふたつです。 すなわち、
- 頂点はどこか?
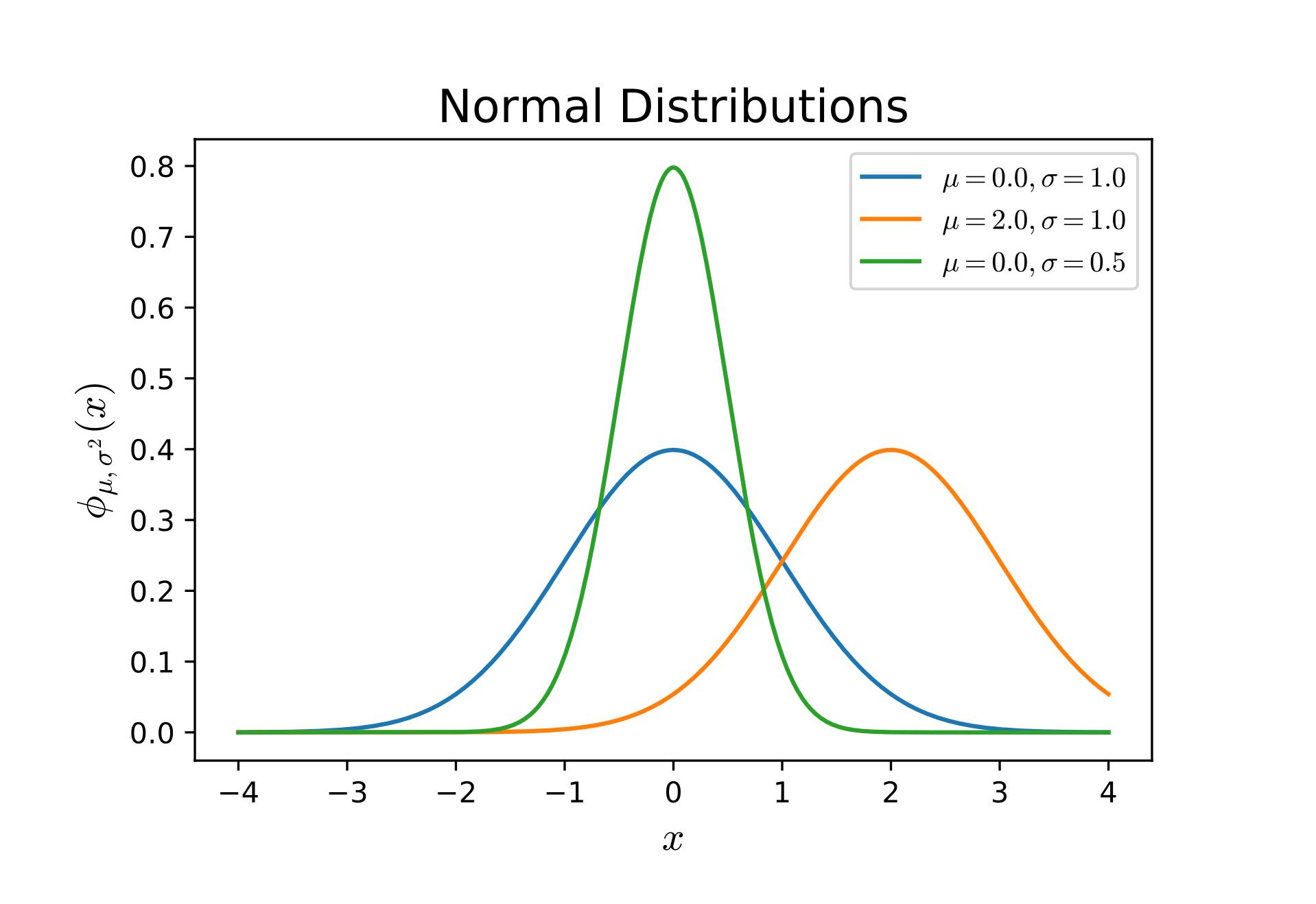
- どれくらい幅があるのか?
頂点が右にあるほうがよりよいスキルを持っている可能性が高いですし(青に対する橙)、横軸に対する頂点が同じでも幅が狭いほど精密な予測になっているといえます(青に対する緑)。 ちなみに定義上、幅が狭くなれば頂点は高くなります。
前者を教えてくれるのが期待値あるいは平均と呼ばれる数値で、ギリシア文字の $\mu$ やラテン文字の $m$ で表されます。 正規分布における期待値はそのまま山の頂点の横軸成分になります。 マイナス無限からプラス無限まで重み付き積分をしたときの平均、ということなんだと……思います……。(統計クソザコマン)
後者を教えてくれるのが標準偏差と呼ばれる数値で、ギリシア文字の $\sigma$ やラテン文字の $s$ で表されます。 ちなみに、「ある値」が $\mu \pm \sigma$ の範囲に収まっている確率は、定義から計算すると約 68% になります。 これが $\mu \pm 3\sigma$ になるとほぼ確実3となり、この $3\sigma$ という指標は実用上よく利用されます。 外れ値の検出とかね。
TrueSkill ではこの 2 種類の値によってプレイヤーのスキルを推測します。
プレイヤーが勝てば $\mu$ は上昇し、負ければ $\mu$ は減少します。 いずれにせよ $\sigma$ は減少し4、推測がより正確になったことを示します。 プレイヤーに提示される数値は $\mu - 3\sigma$ という、期待値をより「控えめ」に見積もった値で、これは Python 実装のリファレンスでは“rating exposure”と表現されています。 どう訳すのが適切かはよくわかりませんが、とりあえず本稿では「顕在化レート / 顕在化レーティング」としておきます。
はじめて TrueSkill のレーティングシステムに参加したプレイヤーの値は $\mu = 25, \sigma = \frac{25}{3}$ で与えられます。 顕在化レーティングはちょうど 0 となります。
利用してみる
堅苦しい理論はここまでにして、実際に TrueSkill を利用してみましょう。
当然の権利のように PyPI に登録されていますので、
pipを使用して簡単にインストールできます。$ pip install trueskillインポートするにはこうです。
In[*]import trueskill環境
TrueSkill によるレーティング計算を行うには、環境を用意します。 環境といってもなにかをインストールするとかそういう意味ではなく、いわば「利用する定数を設定する」くらいの意味合いで考えて下さい。
新しい環境を生成するには
trueskill.TrueSkillコンストラクタを呼び出します。In[*]mu = 25. sigma = mu / 3. beta = sigma / 2. tau = sigma / 100. draw_probability = 0.1 backend = None env = trueskill.TrueSkill( mu=mu, sigma=sigma, beta=beta, tau=tau, draw_probability=draw_probability, backend=backend) envOut[*]trueskill.TrueSkill(mu=25.000, sigma=8.333, beta=4.167, tau=0.083, draw_probability=10.0%)パラメータ
muとsigmaは、より実態に即した表記をすると $\mu_0$ および $\sigma_0$ で、$\mu$ および $\sigma$ の初期値を示します。 デフォルト値は25.および8.333333333333334です。パラメータ
betaは 76% の勝率を保証するスキル差です。 チェスや将棋や囲碁のような、運の要素が絡まないゲームにおいてはこの値は小さく、麻雀のような多少の実力差を運でカバーできるゲームではこの値は大きくするのが理想的です。 デフォルト値は4.166666666666667です。パラメータ
tauはスキルの再計算を行うときに問答無用で $\sigma$ に与えられます。 これは不確かさを示し、ゲームのダイナミクスを表現するとか、$\sigma$ が 0 になって更新が停滞するのを防ぐとかの意味があるようです。 デフォルト値は0.08333333333333334です。パラメータ
draw_probabilityは、名前の通り 2 チーム(あるいはふたり)が引き分けになる確率です。float値で入力することもできますが、floatを返却する関数を与えることもできるそうです(未確認)。 デフォルト値は0.1です。パラメータ
backendは計算に使用するバックエンドを指定します。 利用可能なバックエンドは'scipy'と'mpmath'です。Noneでは TrueSkill モジュール自前のものを使用します。 デフォルト値はNoneです。以降は主にこの環境に対してメソッドを呼び出すことによって TrueSkill を利用していきます。 例えば、以下のような具合です。
In[*]alice = env.create_rating() bob = env.create_rating() (alice,),(bob,), = env.rate(((alice,), (bob,),), ranks=[0, 1,]) print(f'Alice\'s rating exposure: {env.expose(alice):.3f}') print(f' Bob\'s rating exposure: {env.expose(bob):.3f}')Out[*]Alice's rating exposure: 7.881 Bob's rating exposure: -0.910ユーザが生成する環境のほかにも、あらかじめ設定されたグローバル環境を利用することもできます。 グローバル環境は
trueskill.global_env関数で呼び出すことができます。 グローバル環境の初期値は前述のデフォルト値になっています。In[*]trueskill.global_env()Out[*]trueskill.TrueSkill(mu=25.000, sigma=8.333, beta=4.167, tau=0.083, draw_probability=10.0%)グローバル環境を取得してメソッドコールをすることもできますが、多くのメソッドには代替(proxy)関数が存在します。
メソッドコール 代替関数 trueskill.global_env().rate trueskill.rate trueskill.global_env().quality trueskill.quality trueskill.global_env().expose trueskill.expose 生成した環境をグローバル環境に登録するには
make_as_globalメソッドを使用します。In[*]env = trueskill.TrueSkill(mu=50.) env.make_as_global() trueskill.global_env()Out[*]trueskill.TrueSkill(mu=50.000, sigma=8.333, beta=4.167, tau=0.083, draw_probability=10.0%)
trueskill.setup関数を使用すると直接グローバル環境の設定を変更することができます。In[*]trueskill.setup(mu=10., sigma=10./3., beta=10./6., tau=10./300.) trueskill.global_env()Out[*]trueskill.TrueSkill(mu=10.000, sigma=3.333, beta=1.667, tau=0.033, draw_probability=10.0%)レーティングとチーム
環境に対し
create_ratingメソッドを呼び出すことで各プレイヤーのレーティングを示すRatingオブジェクトを生成できます。create_ratingにmuパラメータおよびsigmaパラメータを与えることで初期値以外のレーティングを生成することもできます。 レーティングはmuプロパティおよびsigmaプロパティをもちます。In[*]env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating(mu=30, sigma=4) (r1.mu,r1.sigma,),(r2.mu,r2.sigma,),Out[*]((25.0, 8.333333333333334), (30.0, 4.0))
Ratingオブジェクトのコンストラクタを直接呼び出した場合、グローバル環境が利用されます。In[*]r1 = trueskill.Rating() trueskill.setup(mu=10., sigma=10./3., beta=10./6., tau=10./300.) r2 = trueskill.Rating() r1,r2,Out[*](trueskill.Rating(mu=25.000, sigma=8.333), trueskill.Rating(mu=10.000, sigma=3.333))環境に対し
exposeメソッドを呼び出し、パラメータにレーティングオブジェクトを与えることでそのレーティングオブジェクトの顕在化レーティングを得ることができます。 Wikipedia 情報によると 0 - 50 のスケールが使用されているそうですが、このメソッドの返却値はクリッピングなどは行わないので注意が必要です。In[*]env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating(mu=30, sigma=4) r3 = env.create_rating(mu=10, sigma=5) env.expose(r1),env.expose(r2),env.expose(r3),Out[*](0.0, 18.0, -5.0)ゲームに参加する 1 単位のことをチームといいます。 チームはレーティングオブジェクトのリストまたはタプルか、値にレーティングオブジェクトをもつ辞書です。 たとえ 1 対 1 のゲームであってもチームを形成します。
In[*]env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating() t1 = (r1,r2,) t1Out[*](trueskill.Rating(mu=25.000, sigma=8.333), trueskill.Rating(mu=25.000, sigma=8.333))レーティングの更新
rateメソッドを呼び出すことでレーティングの更新を行います。 第一パラメータにはチームのリストかタプルを、ranksパラメータには順位(プログラムの世界なので 0 始まりです)のリストかタプルを与えます。 更新されたチームのリストが返却されます。 前述したとおりチームには複数の書式がありますが、rateメソッドに渡すチームの書式は統一されている必要があります。In[*]env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating() r3 = env.create_rating() r4 = env.create_rating() t1 = {'player1': r1, 'player2': r2,} t2 = {'player3': r3, 'player4': r4,} t1,t2, = env.rate((t1,t2,), ranks=(1,0,)) t1,t2,Out[*]({'player1': trueskill.Rating(mu=21.892, sigma=7.774), 'player2': trueskill.Rating(mu=21.892, sigma=7.774)}, {'player3': trueskill.Rating(mu=28.108, sigma=7.774), 'player4': trueskill.Rating(mu=28.108, sigma=7.774)})
ranksパラメータを与えなかった場合、記述した通りの順位だったとみなして計算を行います。In[*]env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating() r3 = env.create_rating() r4 = env.create_rating() t1 = {'player1': r1, 'player2': r2,} t2 = {'player3': r3, 'player4': r4,} t1,t2, = env.rate((t1,t2,)) t1,t2,Out[*]({'player1': trueskill.Rating(mu=28.108, sigma=7.774), 'player2': trueskill.Rating(mu=28.108, sigma=7.774)}, {'player3': trueskill.Rating(mu=21.892, sigma=7.774), 'player4': trueskill.Rating(mu=21.892, sigma=7.774)})前述したとおり、たとえ 1 対 1 のゲームであってもチームを形成します。
rateメソッドにレーティングオブジェクトを直接渡すことはできないので注意してください。In[*]# 間違い env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating() r1,r2 = env.rate((r1,r2,)) r1,r2Out[*]--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-11-08f690b7e5cd> in <module> 6 r2 = env.create_rating() 7 ----> 8 r1,r2 = env.rate((r1,r2,)) 9 10 r1,r2 f:\trueskill_test\venv\lib\site-packages\trueskill\__init__.py in rate(self, rating_groups, ranks, weights, min_delta) 475 476 """ --> 477 rating_groups, keys = self.validate_rating_groups(rating_groups) 478 weights = self.validate_weights(weights, rating_groups, keys) 479 group_size = len(rating_groups) f:\trueskill_test\venv\lib\site-packages\trueskill\__init__.py in validate_rating_groups(self, rating_groups) 272 raise TypeError('All groups should be same type') 273 elif group_types.pop() is Rating: --> 274 raise TypeError('Rating cannot be a rating group') 275 # normalize rating_groups 276 if isinstance(rating_groups[0], dict): TypeError: Rating cannot be a rating groupIn[*]# 正解 env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating() ((r1,),(r2,),) = env.rate(((r1,),(r2,),)) r1,r2,Out[*](trueskill.Rating(mu=29.396, sigma=7.171), trueskill.Rating(mu=20.604, sigma=7.171))
rateメソッドのweightsパラメータに 2 次元のリストかタプルを与えることで、ゲームの参加率を加味したレーティングの更新を行います。 チームと異なり、辞書による書式は使用できません。 チームを辞書で記述した場合順序が保証されませんので後述する書式によって参加率を記述するのが基本になります。In[*]env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating() r3 = env.create_rating() r4 = env.create_rating() t1 = (r1,r2,) t2 = (r3,r4,) teams = (t1,t2,) w1 = (1,1,) w2 = (0.5,1,) # プレイヤー3はゲームの半分が経過した時点で回線落ちした、など weights = (w1,w2,) t1,t2, = env.rate(teams, weights=weights) t1,t2,Out[*]((trueskill.Rating(mu=26.738, sigma=7.844), trueskill.Rating(mu=26.738, sigma=7.844)), (trueskill.Rating(mu=24.131, sigma=8.214), trueskill.Rating(mu=23.262, sigma=7.844)))そもそもチーム 2 が不利な状況で負けたためか先程までの例にくらべレーティングの上昇/下降幅が小さく、また参加時間が少なかったプレイヤー 3 の $\sigma$ がほかの 3 人にくらべてあまり減っていないのがわかります。
現実問題としては、ほぼ全員の参加率が 1 で一部のプレイヤーのみが少ない、という傾向になると予想できます。 こういった場合、リストおよびタプルによる参加率の書式は、参加人数が増えたときに煩雑な記述になる問題があります。 そこで、参加率が 1 に満たないプレイヤーだけを辞書によって記述する方法があります。 キーをチーム順とメンバー順(チームの書式がリストまたはタプルの場合)/チーム順とプレイヤー名のキー(チームの書式が辞書の場合)のタプルとすることでプレイヤーを特定し、値として参加率を記述します。 言葉で説明してもイメージしづらいと思うので、以下のコードで確認してください。
In[*]env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating() r3 = env.create_rating() r4 = env.create_rating() t1 = (r1,r2,) t2 = (r3,r4,) teams = (t1,t2,) weights = {(1,0,): 0.5} t1,t2, = env.rate(teams, weights=weights) t1,t2,Out[*]((trueskill.Rating(mu=26.738, sigma=7.844), trueskill.Rating(mu=26.738, sigma=7.844)), (trueskill.Rating(mu=24.131, sigma=8.214), trueskill.Rating(mu=23.262, sigma=7.844)))In[*]env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating() r3 = env.create_rating() r4 = env.create_rating() t1 = {'player1': r1, 'player2': r2,} t2 = {'player3': r3, 'player4': r4,} teams = (t1,t2,) weights = {(1,'player3',): 0.5} t1,t2, = env.rate(teams, weights=weights) t1,t2,Out[*]({'player1': trueskill.Rating(mu=26.738, sigma=7.844), 'player2': trueskill.Rating(mu=26.738, sigma=7.844)}, {'player3': trueskill.Rating(mu=24.131, sigma=8.214), 'player4': trueskill.Rating(mu=23.262, sigma=7.844)})勝率とマッチング品質
驚くべきことに、この Python 実装には勝率を計算する関数が存在しないらしいです。 以下に示すのはリファレンスにも記載がある Juho Snellman によるスニペットを、環境を指定できるように微加筆したものです。 必要なら利用しましょう。
import itertools import math def win_probability(team1, team2, env=None): env = env if env else trueskill.global_env() delta_mu = sum(r.mu for r in team1) - sum(r.mu for r in team2) sum_sigma = sum(r.sigma ** 2 for r in itertools.chain(team1, team2)) size = len(team1) + len(team2) denom = math.sqrt(size * (env.beta * env.beta) + sum_sigma) return env.cdf(delta_mu / denom)In[*]env = trueskill.TrueSkill(beta=1) r1 = env.create_rating(mu=30, sigma=0.1) r2 = env.create_rating(mu=29, sigma=0.1) t1 = (r1,) t2 = (r2,) wp = win_probability(t1, t2, env=env) wpOut[*]0.7591582948828006どれだけ公平にマッチングできているかを示す指標が
qualityメソッドです。 引き分け確率を使用しているようです。weightsパラメータを与えることができます。In[*]env = trueskill.TrueSkill() r1 = env.create_rating(mu=30, sigma=3) r2 = env.create_rating(mu=29, sigma=3) t1 = (r1,) t2 = (r2,) q = env.quality((t1,t2,)) qOut[*]0.8038743995638264ショートカット
TrueSkill の利点が多人数対戦に使えることではあれど、ほかのルールにくらべ 1 対 1 のゲームが圧倒的に多いこともまた事実です5。 そのため 1 対 1 のゲームで利用できるショートカット関数
trueskill.rate_1vs1とtrueskill.quality_1vs1が用意されています。 これらの関数にはレーティングオブジェクトを直接渡すことができます。In[*]env = trueskill.TrueSkill() r1 = env.create_rating() r2 = env.create_rating() # (r1,),(r2,), = env.rate(((r1,),(r2,),)) r1,r2, = trueskill.rate_1vs1(r1, r2, env=env) print(r1) print(r2) print() # (r1,),(r2,), = env.rate(((r1,),(r2,),), ranks=(0,0,)) r1,r2, = trueskill.rate_1vs1(r1, r2, drawn=True, env=env) print(r1) print(r2) print() # q = env.quality(((r1,),(r2,),)) q = trueskill.quality_1vs1(r1, r2, env=env) print(q)Out[*]trueskill.Rating(mu=29.396, sigma=7.171) trueskill.Rating(mu=20.604, sigma=7.171) trueskill.Rating(mu=26.114, sigma=5.678) trueskill.Rating(mu=23.886, sigma=5.678) 0.5770440474290585実にスッキリ書けますね。
文字数は増えてるって? カッコの対応がワケワカメになるほうが面倒だしfrom import記法もあるから多少はね。シミュレーションによるレーティング
「あーなるほどね完全に理解した」したところで、多人数戦ができること、参加率による重み付けができることはわかりましたが、収束が早いというのはどこまで本当なのでしょうか? これは実際に試してみないことにはわかりません。
というわけで、架空のプレイヤーによるゲーム勝敗をシミュレーションし、既存のアルゴリズムと比較してみましょう。
Elo レーティングの理論を利用したシミュレーションの作成
古典的なレーティングアルゴリズムである Elo レーティングは、極めて単純な式でありながらレーティング差から勝率を導き出せるなど、こういったシミュレーションに最適です。
詳細は省きますが、プレイヤー A のレーティングが $R_A$、プレイヤー B のレーティングが $R_B$ であるとき、プレイヤー A の勝率は以下の式で得ることができます。
$$
W_{AB} = \frac{1}{10^{\frac{R_B - R_A}{400}} + 1}
$$
これを利用してシミュレーションスクリプトを書いていきます。今回想定する架空のプレイヤーは以下のとおりです。
プレイヤー 内部レーティング Emu 2700 Parado 2700 Niko 2500 Taiga 2000 Hiiro 2000 Kiriya 1700 Kuroto 1700 Poppy 1500 軒並み Elo レーティングの「標準プレイヤー」値である 1500 以上ですが、
これはファンへの配慮です。あくまでも重要なのはレーティングの差なので上位プレイヤーから下位プレイヤーまでがまんべんなく存在していなくても問題ないと思います。 ただ、この結果を Elo レーティングによりレーティングしたとき、彼らの中での標準を 1500 とするため、設定した内部レーティングよりも低い結果が出るものと思われます6。実際に勝敗のシミュレーションを書いたものがこちらのコードになります。 ランダムに二人ごと対戦させ、これを 500 回繰り返します。 引き分けはありません。 結果は CSV ファイルで出力されます。
結果はこんな感じでした。
index Match 1 Winner Match 1 Loser Match 2 Winner Match 2 Loser Match 3 Winner Match 3 Loser Match 4 Winner Match 4 Loser 1 Emu Parado Taiga Hiiro Niko Poppy Kiriya Kuroto 2 Emu Kuroto Poppy Hiiro Kiriya Taiga Niko Parado 3 Emu Niko Kiriya Kuroto Hiiro Poppy Parado Taiga 4 Parado Poppy Emu Taiga Niko Kuroto Hiiro Kiriya 5 Niko Poppy Hiiro Kiriya Taiga Kuroto Parado Emu ... ... ... ... ... ... ... ... ... 496 Kiriya Taiga Niko Kuroto Hiiro Poppy Emu Parado 497 Kiriya Poppy Emu Hiiro Niko Kuroto Parado Taiga 498 Parado Taiga Niko Kiriya Emu Kuroto Hiiro Poppy 499 Emu Kuroto Niko Taiga Parado Kiriya Hiiro Poppy 500 Kuroto Poppy Parado Hiiro Emu Niko Kiriya Taiga 「Emu が負けるありえない話し!!」とか言い出す
神ファンの存在をのぞけば、問題なさそうな結果です。 実際のデータはこちらになります。Elo レーティングで実験
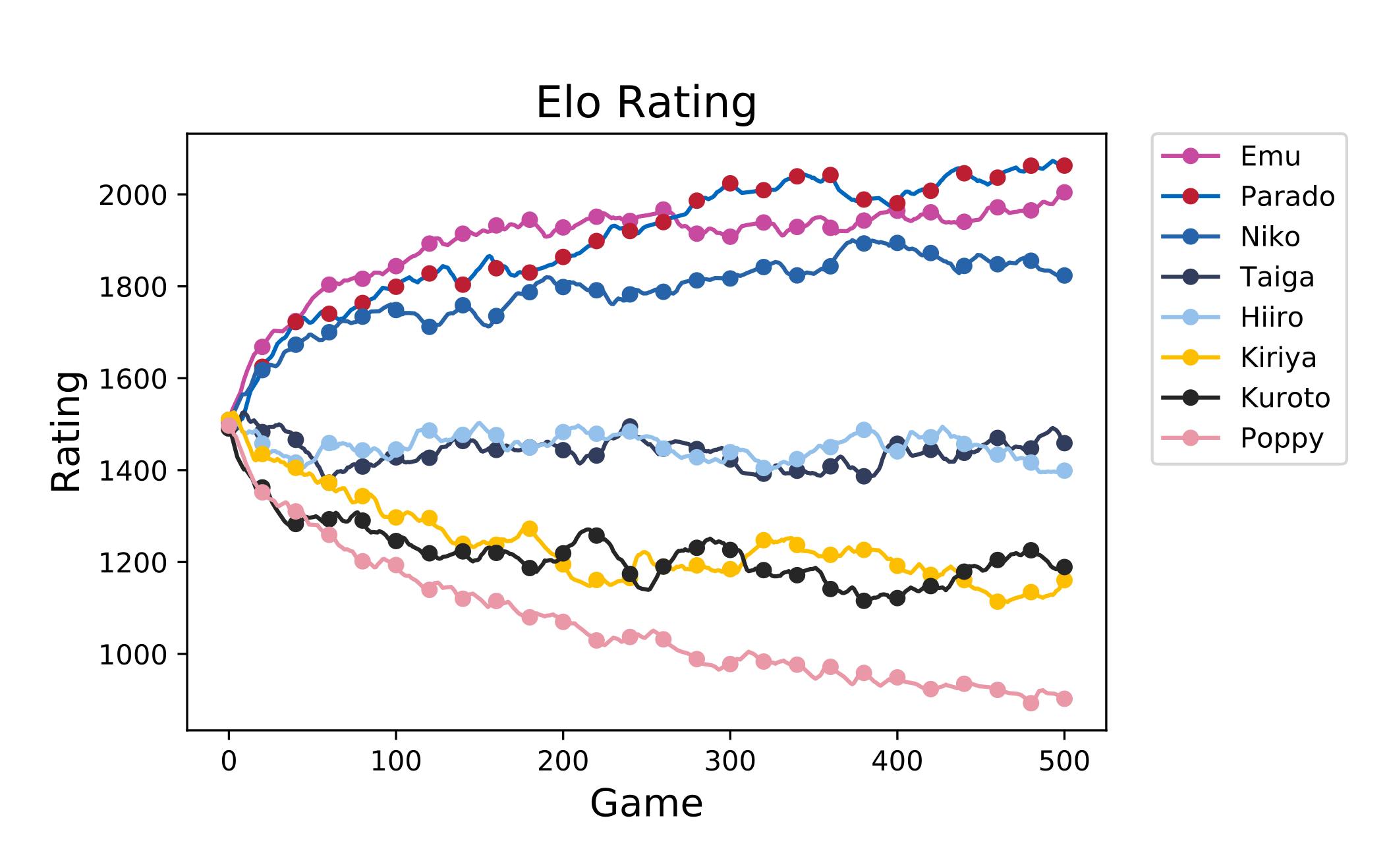
今回比較対象として、Elo レーティングによるレーティングを行ってみます。 こちらのコードを実行し、ゲームごとのレーティングの推移を確認してみます。 Elo レーティングで使用されるレーティング変動の激しさを示す値 $K$ は、最初の 20 ゲームでは 32 を、それ以降は 24 を使用します。
結果は以下のようになりました。
プレイヤー 最終レート Emu 2006.988 Parado 2062.846 Niko 1821.448 Taiga 1449.791 Hiiro 1398.873 Kiriya 1168.829 Kuroto 1190.664 Poppy 900.5602 とはいえ、前述したように設定値より低く見積もられていますので、Emu との差で見てみましょう。
プレイヤー 差 差(真) Emu +0.000 +0.000 Parado +55.858 +0.000 Niko -185.540 -200.000 Taiga -557.197 -700.000 Hiiro -608.115 -700.000 Kiriya -838.159 -1,000.000 Kuroto -816.324 -1,000.000 Poppy -1,106.428 -1,200.000 確かにある程度設定値にしたがった値になっているようです。
一方で推移は以下のようになっています。 生の値はガクガクして見づらいので 5 点移動平均7で平滑化して示しています。
これを見ると、完全に収束しきっておらず、まだまだ伸びしろがあるように思います。 先程の差も、実際のところ設定値まで広がりきっていません。
TrueSkill で実験
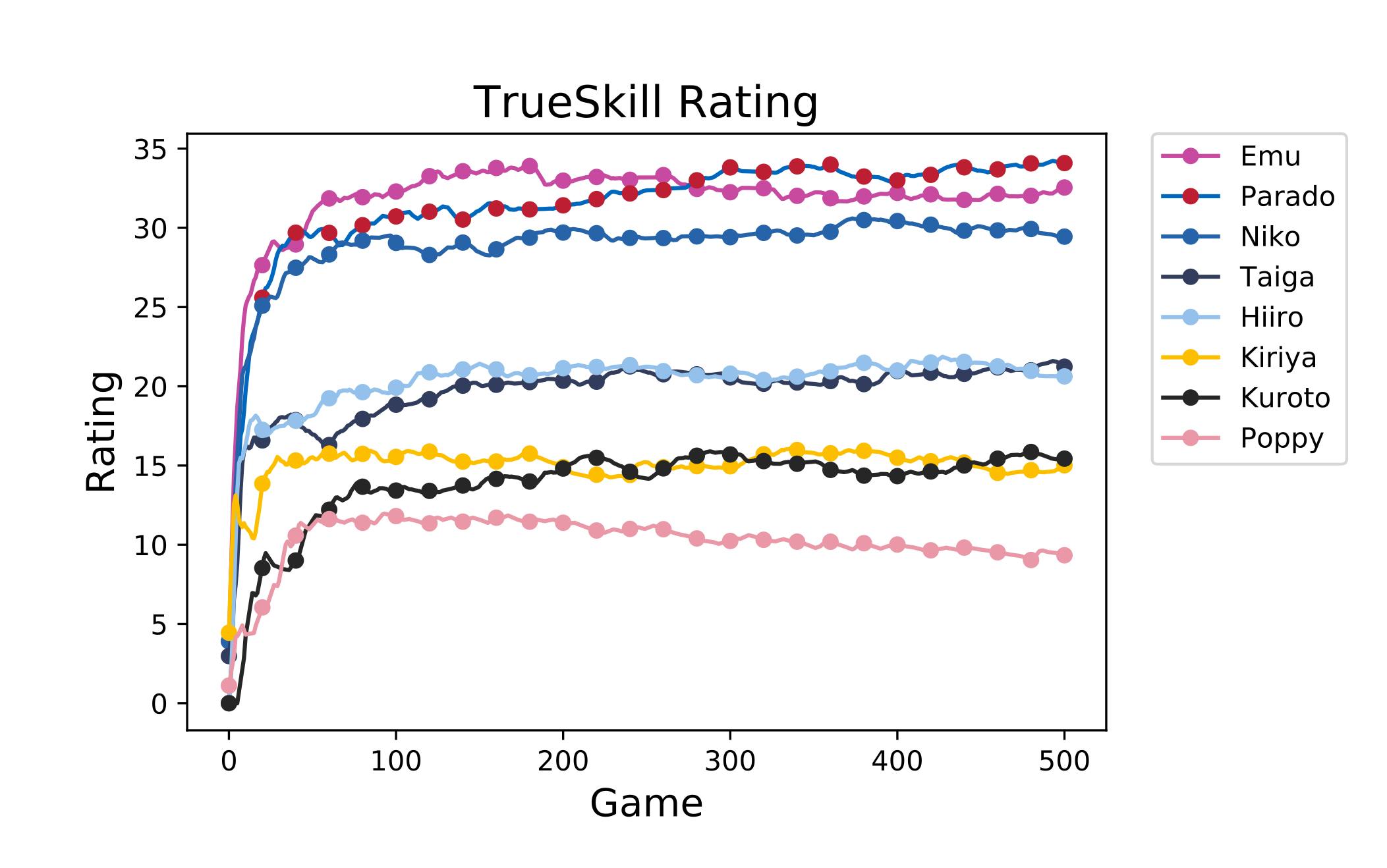
つづいて本命の TrueSkill を試してみましょう。こちらのコードを実行します。
結果は以下のようになりました。
プレイヤー 最終顕在化レート $\mu$ $\sigma$ Emu 32.59123 35.70087 1.036545 Parado 34.08617 37.20115 1.038326 Niko 29.41995 32.34306 0.974371 Taiga 21.1425 23.87729 0.911596 Hiiro 20.62174 23.38207 0.92011 Kiriya 15.11853 17.90101 0.927492 Kuroto 15.4544 18.2791 0.941565 Poppy 9.310735 12.44336 1.044209 おおむね順序通り、内部レーティングを同じ値にしたプレイヤーはだいたい同じ値に落ち着いています。 適切にレーティングできていると言っていいでしょう。
一方で推移は以下のようになりました。 こちらも 5 点移動平均で平滑化して示しています。
見てのとおり、Elo レーティングにくらべて爆速で
アプリをデプロイする方法収束しているのが分かります。 最初の数十ゲームでもうある程度の位置が定まっていますね。 これは確かに「収束が早い」と謳うだけのことはあります。日本プロ野球リーグをレーティングしてみる
いつまでも夢に逃げているとワカメを冷まされるので、いよいよ現実の世界に目を向けてみましょう。
ちょうど最近プロ野球の公式戦が終了いたしましたので、今年度の公式戦データ(セパ交流戦含む)から 12 球団をレーティングしてみましょう。
そんなデータ出したら殺されるのでは?ちなみにセ・リーグとパ・リーグの 2019 年度公式順位は以下のようになっています。
順位 チーム 勝 敗 分 勝率 ゲーム差 1 巨人 77 64 2 .546 0.0 2 DeNA 71 69 3 .507 5.5 3 阪神 69 68 6 .504 6.0 4 広島 70 70 3 .500 6.5 5 中日 68 73 2 .482 9.0 6 ヤクルト 59 82 2 .418 18.0
順位 チーム 勝 敗 分 勝率 ゲーム差 1 西武 80 62 1 .563 0.0 2 ソフトバンク 76 62 5 .551 2.0 3 楽天 71 68 4 .511 7.5 4 ロッテ 69 70 4 .496 9.5 5 日本ハム 65 73 5 .471 13.0 6 オリックス 61 75 7 .449 16.0 野球見ていないマンゆえ贔屓球団とかはないので、この結果を見ても特に感慨がわかないのが残念です。 あえていうなら、DeNA になる前の横浜はひどかったという噂を聞いたことはあるので、いまは上位に食い込んでいるのが面白いなってくらいですかね……。 一応故郷に最も近いのは日ハムです。
ただ、勝率を見ていくと、もちろん順位が付く程度の差はできていますが、たとえばチェスの強い人と初心者レベルの差という程のものはできていない、割と拮抗している8リーグだなあという感じですね。 これはうまくレーティングできるか不安です。
なにはともあれレーティングしてみましょう。 2019 年度の公式戦のデータはこちらに用意しました。 NPB 公式サイトからシコシココピペして作りましたがクッソ面倒でした。 API とか探したらありませんかね?
環境はほぼ初期のまま、引き分け確率のみ過去 3 年度の合計試合数と合計引き分け数から算出して使用します。 こちらにコードを置いておきます。 引き分け数 CSV は一応ここにおいておきますがこれいる?
結果は以下のようになりました。
チーム TrueSkill 公式順位 勝 敗 分 勝率 西武 23.932 パ 1 位 80 62 1 0.563 ソフトバンク 23.083 パ 2 位 76 62 5 0.551 楽天 22.884 パ 3 位 71 68 4 0.511 阪神 22.801 セ 3 位 69 68 6 0.504 巨人 22.726 セ 1 位 77 64 2 0.546 ロッテ 22.714 パ 4 位 69 70 4 0.496 DeNA 22.492 セ 2 位 71 69 3 0.507 中日 22.456 セ 5 位 68 73 2 0.482 広島 22.362 セ 4 位 70 70 3 0.500 オリックス 22.067 パ 6 位 61 75 7 0.449 日本ハム 21.979 パ 5 位 65 73 5 0.471 ヤクルト 21.395 セ 6 位 59 82 2 0.418 野球を見ている皆さん的にはこれは直感に即した結果でしょうかね?
交流戦は全体に比べると数が少ないので、セパ横断順位の信憑性はあんまないと思います。 しかし、リーグ単位で見ても公式順位との入れ替わりがいくつかあるのが見て取れます。 特に阪神はセ・リーグ 3 位にもかかわらずセ・リーグ優勝の巨人を抜いてトップに躍り出ています。
「単に勝率のみを見るのではなく、どれほど強い相手に勝ったかを見る」のがレーティングですが、ランダムマッチングのゲームと違い対戦機会が計画されて平等になっているのがプロ野球ですから、「弱い相手ばっかり選んでるから」みたいなのは発生し得ないはずです。
考えられる可能性としては……単にコピペしただけでちゃんと試合結果を精査したわけではないので推測なのですが、「巨人や DeNA のような成績の良いチームに対する勝率が良かった説」があります。 逆に巨人や DeNA の下位陣相性が悪い説もあります。
やきうのお兄ちゃんたち、実際はどうでした?レーティングは極めて単純な仮定をおいているところがあり、「A さんが B さんに 2 勝 1 敗、B さんが C さんに 3 勝 2 敗ならば、A さんは C さんに $\frac{2}{1} \times \frac{3}{2} = 3$ 倍の勝利を上げる(4 戦して 3 勝 1 敗)だろう」みたいな感じです。 しかし実際の勝負には相性があることがしばしばあり、C さんが A さん相手だと妙に強かったりするわけです。 こういった影響を小さくするためにも、レーティングでは「なるべく多くのプレイヤープールで、かつ同じ相手とばかり戦わない」ことが精度上昇のためにも重要だったりするわけです。 今回とりあげたプロ野球は、プレイヤープール 12 球団と少なく、さらに交流戦があるとはいえリーグが 2 種に分断されているのであまり良い例ではなかったかもしれませんね。
ぶっちゃけ IIDX のアリーナモードとかレーティングしたいけど KONAMI しか試合データ持っていない。ちょっと脇道にそれ過ぎましたので、推移のグラフでも貼っておきましょう。 例によって 5 点移動平均です。
……団子状態過ぎてよくわかりませんね。 $17 \leq y \leq 25$ の範囲だけ拡大してみましょう。
まだ多少見えづらいですがだいぶマシかな?
つかチームカラーが似たりよったり過ぎて区別つきづらいんですが……。パッと見て目立つのは 90 試合前あたりから広島が思いっきり落ち込んでいるところですね……。 今年広島は交流戦で「こいついっぱい貯金持ってるンゴwww」されたらしいのでそれかもしれません。
あと、横浜は今年セ 2 位となりましたが、立ち上がりはかなり遅かったようです。
最後に、各チームごとの勝率も貼っておきます。
マジで殺されるぞ。
○\● 巨人 ヤクルト DeNA 中日 阪神 広島 日本ハム 楽天 西武 ロッテ オリックス ソフトバンク 巨人 - 58.7% 51.6% 51.9% 49.6% 52.5% 55.0% 49.1% 42.0% 50.2% 54.5% 47.8% ヤクルト 41.3% - 42.9% 43.1% 40.9% 43.7% 46.3% 40.4% 33.7% 41.5% 45.8% 39.1% DeNA 48.4% 57.1% - 50.3% 48.0% 50.9% 53.4% 47.5% 40.4% 48.6% 52.9% 46.2% 中日 48.1% 56.9% 49.7% - 47.7% 50.6% 53.2% 47.2% 40.2% 48.3% 52.7% 45.9% 阪神 50.4% 59.1% 52.0% 52.3% - 52.9% 55.4% 49.5% 42.4% 50.6% 54.9% 48.2% 広島 47.5% 56.3% 49.1% 49.4% 47.1% - 52.6% 46.6% 39.6% 47.7% 52.1% 45.3% 日本ハム 45.0% 53.7% 46.6% 46.8% 44.6% 47.4% - 44.1% 37.2% 45.2% 49.5% 42.8% 楽天 50.9% 59.6% 52.5% 52.8% 50.5% 53.4% 55.9% - 42.9% 51.1% 55.5% 48.7% 西武 58.0% 66.3% 59.6% 59.8% 57.6% 60.4% 62.8% 57.1% - 58.2% 62.4% 55.8% ロッテ 49.8% 58.5% 51.4% 51.7% 49.4% 52.3% 54.8% 48.9% 41.8% - 54.3% 47.6% オリックス 45.5% 54.2% 47.1% 47.3% 45.1% 47.9% 50.5% 44.5% 37.6% 45.7% - 43.3% ソフトバンク 52.2% 60.9% 53.8% 54.1% 51.8% 54.7% 57.2% 51.3% 44.2% 52.4% 56.7% - いま示したのは既知のデータに基づく勝敗比ではなく、未知の試合に対する勝利確率ということになります。 まあ、あんまり参考にならないとは思いますが……。 ともあれ、レーティング最上位の西武対レーティング最下位のヤクルトでもそこまで絶望的な数値になっていないというところを見ると、やっぱり拮抗した良いリーグです。
野球見てみようかな?よくばりセット
今回使用したスクリプトやデータを固めたものをここに置いておきました。
Notebook 形式なので JupyterLab などをご用意して頂く必要があります。
まとめ
いかがでしたか?(定型文)
今回使用したのは Python 実装でしたが、どうも様々な言語にフォークされているようなので、あなたが使いたい言語での実装も見つかるかもしれませんし見つからないかもしれません(あいまい)。
私が今回の記事で伝えたかったのは、「既存の Elo レーティングとかにくらべて TrueSkill の理論は、腰を据えて読まないとわからないしそもそもある程度の前提知識がないと厳しいのは確かだけど、使うだけなら脳死でメソッド叩くだけで使えるし性能もいいからめっちゃ使ってほしい」ということです。
Elo を利用した記事は Qiita にも多い9ので、これから TrueSkill でレーティングする記事も増えてほしいと思います。
あと、レーティングといえば Glicko とかも Elo より性能よくて自分で実装するのも難しくないのでオヌヌメです。
Elo 以外のレーティングもっと流行れ!
チームとはいっても、テレビで放送されているプロスポーツのような「チームの構成員がほぼ一定で、ある選手がゲーム単位の短いスパンでチームを変更しない」チームの場合、チームそのものをプレイヤーとして扱うのが理にかなっています。 ここでいうチーム戦とは、例えば Splatoon のようなマッチングしたプレイヤーをランダムにチームに振り分けて行われるようなゲームに向いています。 ↩
$\phi_{\mu, \sigma^2}$ は確率密度関数一般のことではなく正規分布のことなのですが、わかりやすさ重視でここにねじ込んでしまいました。 YURUSHITE。 ↩
具体的には 99.73% 程度。 ↩
実際には、更新前にごく少量の σ が与えられるため、常に減少し続けるわけではありません。 成長やブランクによるスキルの変化を許容できるということだと思います。 ↩
そもそもレーティングの研究はチェスから始まりました。 ↩
そして、これがレーティングという仕組みが本質的に抱えるどうしようもない弱点でもあります。 たとえば、あるリーグのプレイヤーがもつレーティングと、それとは別のリーグに参加しているプレイヤーがもつレーティングは、レーティングの仕組みが同じだったとしても比較できません。 ↩
今回のスムージングでは、端を端点の値で埋めてから
mode='valid'で畳み込んでいます。mode='same'でも良いのでしょうが、まあ「しゅみです」ということで。 ↩この辺は野球見ている人と温度差があると思います。 レーティング視点でということです。 ↩
車輪の再発明系の記事だと TrueSkill は難しいと思いますが。 ↩


- 投稿日:2019-10-11T14:06:20+09:00
IRCの概要から簡易クライアント作成(Python3)まで
みなさんは、IRC(Internet Relay Chat)というワードを聞いたことはあるでしょうか。
今IRCを使っているという人は少ないかもしれません(私の周りにも一人もいません)が、今回はこのIRCについて書いていきます!
(すでにIRCクライアントのコードが載っているQiitaの記事がありましたが、気になる部分がいくつかあったのと、Python2のコードだったので、改めて記事にしようと思いました。)IRC(Internet Relay Chat)とは
IRCとは、サーバを介してクライアントとクライアントが会話をする枠組みで、インスタントメッセンジャーのプロトコルの1つに分類されます。
また、ユーザがクライアントソフトを実行し、サーバは情報の伝達を行うだけなので、サーバの負担が軽くチャットが高速に行えます。
チャットに特化したプロトコルなんですね!なぜIRCの利用は衰退したの?
チャットアプリなんて、今はたくさんありますよね。(Facebook,Twitter,Discord,Slack,...etc.)
これらSNSを利用するほうが、IRCを利用するよりも便利で多機能で使いやすいわけですね。。。
また、SSL/TLSを利用せずにIRCを利用すると、暗号化していないため、第三者に会話の内容を盗み見られる可能性があります。(もちろんSSL/TLSを利用すれば安全です!)
LINEなどのサービスなら、暗号化などは自動でやってくれるから、そんなの普段は意識しないですよね。。IRCを利用するメリットは?
それだけ聞くとIRCを利用するメリットはあまりないように感じるかもしれませんが、そんなことはありません!
まず、IRCは、データ通信に関するプロトコルが簡素で、かつオープンであるため、ユーザ・クライアントに用いるソフトウェアの開発が簡単なんです!今回の記事でも、簡易クライアントをたった100行程度で作っちゃいます!
それだけではなく、IRCサーバを立てるのも、ngircdというものを利用すれば超簡単なんです!(今回はこれには触れません。)今IRCは何に使われてるの?
では今、IRCは何に使われているんでしょうか。
それは、、、ボットネットの通信手段です。(誤解を招きそうなので言っておきますが、もちろん正規の普通の使い方でもたくさん利用されています。)
ボットネットとは、ボットウイルスに感染した端末で構成されるネットワークです。ボットウイルスとは、マルウェアの一種で、感染すると端末が悪意を持った第三者に遠隔操作され、不正アクセスやDDoS攻撃などの犯罪行為に使われてしまいます。
その感染端末と攻撃者の通信手段に、IRCはよく使われています。。。
自分のパソコンをポートスキャンしたり、通信のログを見て、「IRC」という文字を見つけた場合は、ボットウイルスに感染している可能性があるかもしれません。。。有名なIRCクライアントソフト
IRCクライアントソフトはたくさんありますが、ここでは中でも有名(人気)なもの(すべて無料)を紹介します。
LimeChat
おそらく1番有名(人気)なIRCクライアントソフトです。
Windowsの場合はLimeChat 2.x、Macの場合はLimeChat for OSXを利用します。
現行IRCクライアントの中では最も安定しています。ヘルプが充実しているので初心者にもおすすめです。HexChat
XChat(後述)ベースのソフトウェアです。
Windows用、Mac用、Unix系システム用があり、ほぼすべてのOSで利用できます。
海外のさまざまなネットワークが標準設定で入っています。XChat
Linuxのほとんどのディストリビューションに標準で入っているIRCクライアントです。
Windows用、Mac用、Unix系システム用があり、ほぼすべてのOSで利用できます。
海外のさまざまなネットワークが標準設定で入っています。Python3で簡易クライアントを作る
では早速IRCクライアントを作ってみましょう!
IRCクライアントを作るには、まずIRCのコマンドというものについて知る必要があります。IRCのコマンドについて
IRCにおいて、サーバとクライアントは互いにメッセージを送信し合います。
また、メッセージが正しいコマンドを含んでいた場合、クライアントは仕様通りのリプライを期待します。
つまり、あるコマンドを含むメッセージに対するサーバからの応答メッセージの形式は決まっているわけですね。
このIRCコマンドはたくさんありますが、今回は、後で作成する簡易クライアントが実装している、最も基本的なコマンド8つについてのみ説明します。(コマンドは正規表現で示します。)PASSコマンド
PASS <password>IRCサーバにパスワードが設定されている場合は、ユーザは接続を開始しようとする前(NICK/USERの組み合わせを送る前)にPASSコマンドを送る必要があります。
NICKコマンド
NICK :<nickname>ユーザにニックネームを設定したり、今のニックネームを変更したりするのに使います。
USERコマンド
USER <username> <hostname> <servername> <realname>新しいユーザのユーザ名やホスト名、本名を指定するために、接続のはじめに使われます。
QUITコマンド
QUIT (:<Quit Message>)??クライアントセッションを終了します。サーバはクライアントにERRORメッセージを送ることでこれを承認します。
JOINコマンド
JOIN :<channel> ("," <channel>)* (<key> ("," <key>)*)??ユーザによって、特定のチャンネルに接続するリクエストを行うために使用されます。
PRIVMSGコマンド
PRIVMASG <msgtarget> :<text to be sent>ユーザ間のプライベートメッセージを送るのに使います。また、メッセージをチャンネルに送るのにも使われます。msgtargetは通常、メッセージの受け取り手のニックネームか、チャンネル名です。
誰かがメッセージを送った場合は、サーバから次の形式でメッセージが送られてきます。送られてくるとき:<A's nickname>!(~<A's username>)??@<A's gateway-name> PRIVMSG <msgtarget> :<text to be sent>PINGコマンド
PING :<server1> (<server2>)??ネットワーク上のアクティブなクライアントやサーバが、実際につながって動いているかどうかを確認するのに使われます。
サーバは、ネットワークからほかのアクションが届かない場合、一定間隔でPINGメッセージを送出します。
指定時間内にPINGメッセージに返答がない場合、その接続は閉じられます。
PINGメッセージを受け取ったら、server1(PINGメッセージを送ったサーバ)へのリプライとして、可能な限り早く正しいPONGメッセージを送らなくてはなりません。server2パラメータが指定されていれば、それがpingのターゲットとなり、メッセージはそこに転送されます。PONGコマンド
PONG <server1> (<server2>)??PINGメッセージへのリプライです。server2パラメータが指定されれば、メッセージはそこに転送されなくてはなりません。
IRCクライアント(Python3コード)
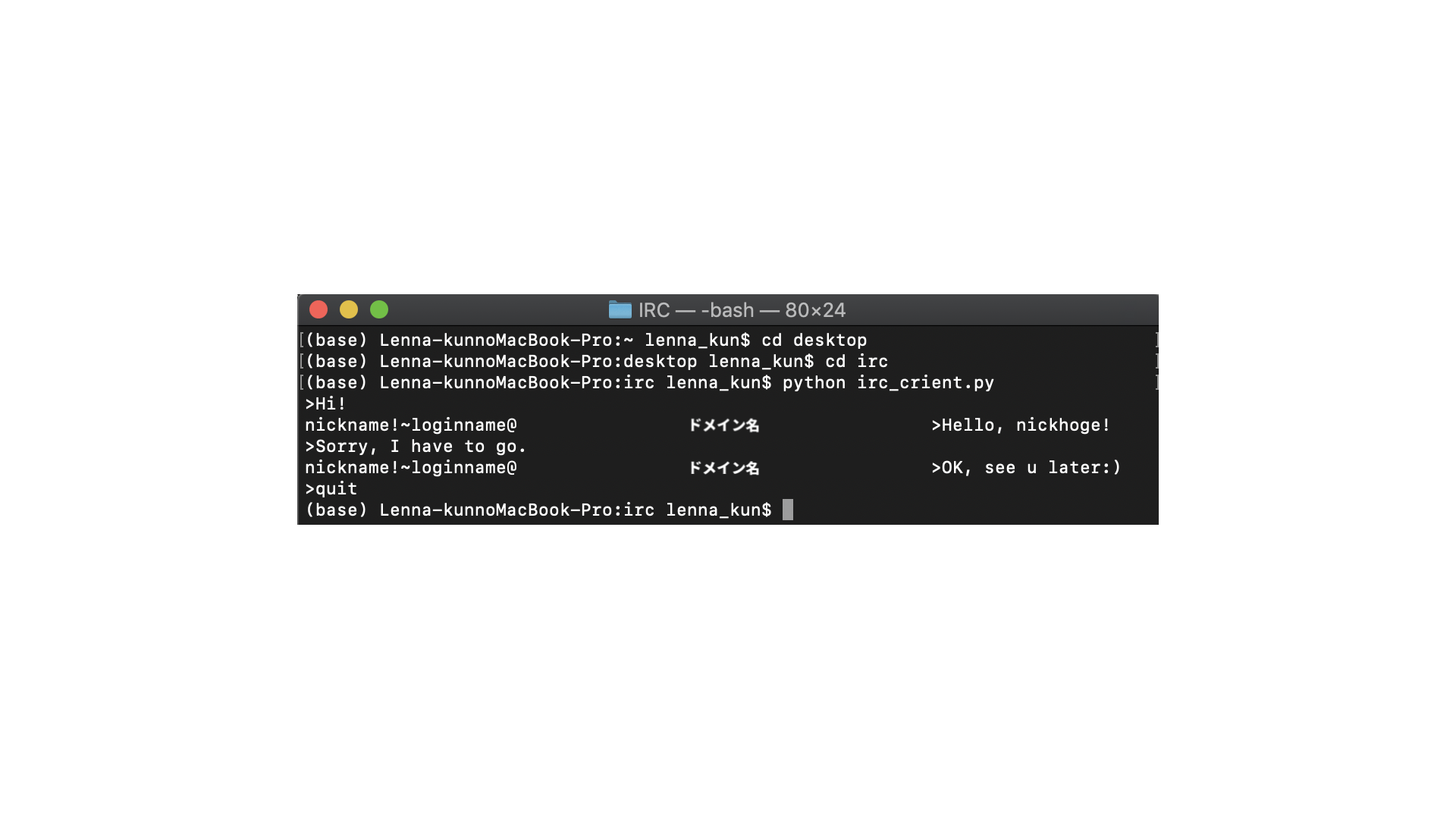
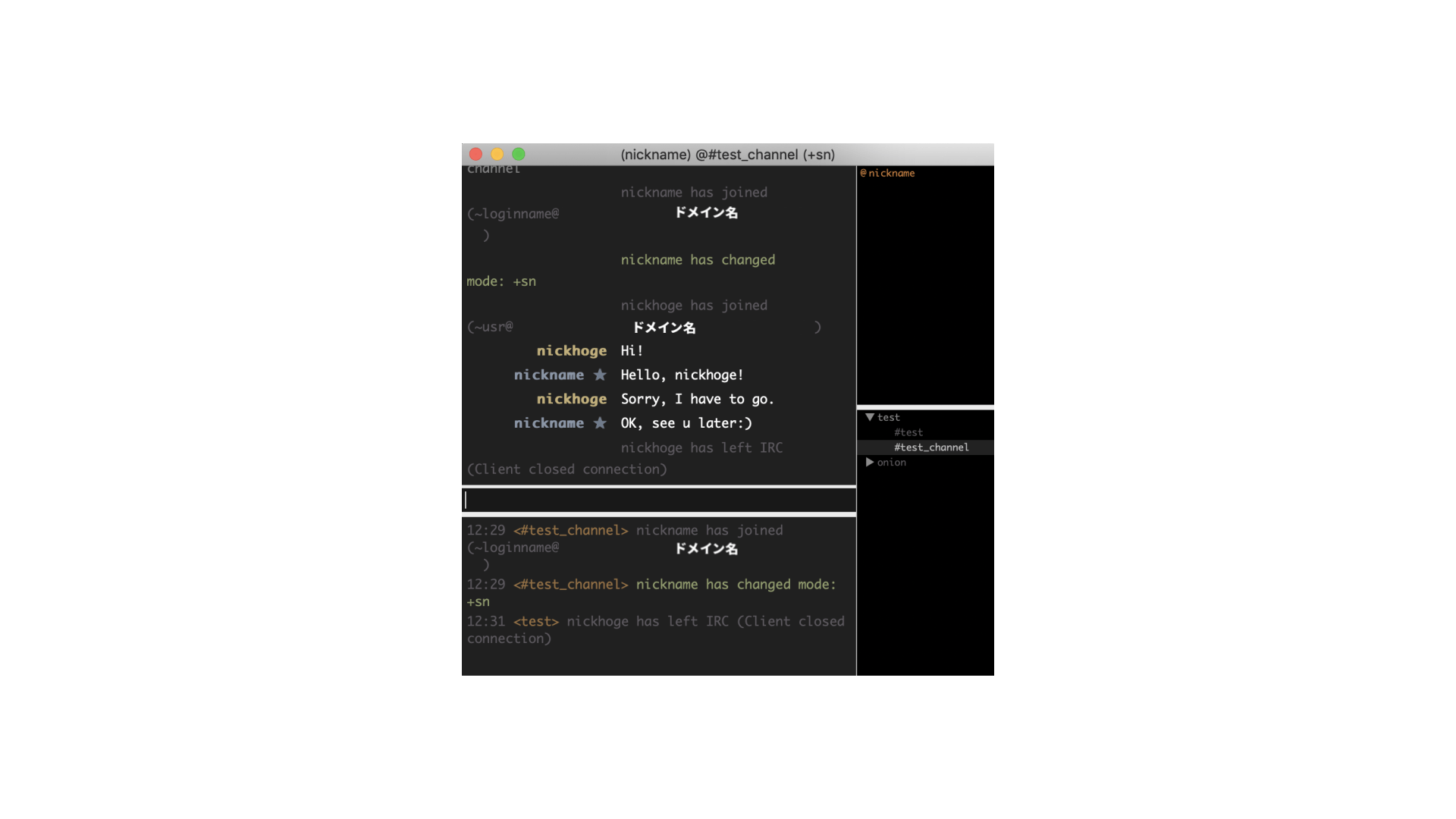
import sys, socket, os, signal HOST = "X.X.X.X" PORT = 6667 #IRCサーバでは一般的に6667番ポートが使われることが多い BUF_SIZE = 1024 class IRC(object): def __init__(self): self.server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) #socketオブジェクトの生成(TCP) def connect(self, host, port): self.server.connect((host, port)) #接続 def login(self, password, nickname, username, realname, hostname = "hostname", servername = "*"): if password is not None: #中にはパスワードがいらないサーバもある pass_message = "PASS " + password + "\n" #PASSメッセージ self.server.send(pass_message.encode('utf-8')) #送信 nick_message = "NICK " + nickname + "\n" #NICKメッセージ user_message = "USER %s %s %s :%s\n" % (username, hostname, servername, realname) #USERメッセージ self.server.send(nick_message.encode('utf-8')) #送信 self.server.send(user_message.encode('utf-8')) #送信 def join(self, channel): join_message = "JOIN " + channel + "\n" #JOINメッセージ self.server.send(join_message.encode('utf-8')) #送信 def pong(self, server1, server2 = None): pong_message = "PONG %s %s" % (server1, server2) #PONGメッセージ pong_message += "\n" self.server.send(pong_message.encode('utf-8')) #送信 def privmsg(self, channel, text): privmsg_message = "PRIVMSG %s :%s\n" % (channel, text) #PRIVMSGメッセージ self.server.send(privmsg_message.encode('utf-8')) #送信 def quit(self): self.server.send(b"QUIT :bye!") #QUITメッセージ送信 def handle_privmsg(self, prefix, text): print("\r" + prefix + ">" + text + "\n>", end="") #受信したPRIVMSGメッセージを処理、表示 def wait_message(self): while(True): msg_buf = self.server.recv(BUF_SIZE) #受信 msg_buf = msg_buf.decode('utf-8').strip() ## ここからメッセージ処理 ## prefix = None if msg_buf[0] == ":": p = msg_buf.find(" ") prefix = msg_buf[1:p] msg_buf = msg_buf[(p + 1):] p = msg_buf.find(":") if p != -1: #":"から始まるパラメータがまだあった場合 last_param = msg_buf[(p + 1):] msg_buf = msg_buf[:p] msg_buf = msg_buf.strip() messages = msg_buf.split() ## ここまで ## command = messages[0] #コマンド名 params = messages[1:] #今回は無視 if command == "PING": self.pong(last_param) #PINGが来たらすぐPONGを返す elif command == "PRIVMSG": text = last_param #PRIVMSGコマンドで送られてきたメッセージ self.handle_privmsg(prefix, text) def client_interface(self, channel, prompt = ">"): while(True): line = input(prompt) if line == "quit": self.quit() break self.privmsg(channel, line) def main(): password = "password" nickname = "nickhoge" username = "usr" realname = "realname" channel = "#test_channel" irc = IRC() irc.connect(HOST, PORT) irc.login(password, nickname, username, realname) irc.join(channel) pid = os.fork() #子プロセス生成 if(pid == 0): #os.fork()は、子プロセスでは0を返す irc.wait_message() else: irc.client_interface(channel) os.kill(pid, signal.SIGTERM) #子プロセスをkill(これをしないと子プロセスがゾンビプロセスになる) if __name__ == "__main__": main()macで実行してみた
実際にLimeChatユーザと会話してみました。
LimeChat側からみるとこんな感じです。
いい感じですね!参考
https://qiita.com/mmttt202/items/d182c6f27f466c923fea
http://jbpe.tripod.com/rfcj/rfc2812.j.sjis.txt
https://www.friend-chat.jp/irc.html
https://wikiwiki.jp/2chIRC/IRC%E3%82%AF%E3%83%A9%E3%82%A4%E3%82%A2%E3%83%B3%E3%83%88%E7%B4%B9%E4%BB%8B
https://ja.wikipedia.org/wiki/Internet_Relay_Chat
https://murashun.jp/blog/20190215-01.html
- 投稿日:2019-10-11T13:34:27+09:00
macOS Catalina にしたら、Anaconda 使えなくなった場合の対処法
楽しみにしていた「macOS Catalina」にアップデート。
あれっ、、アップデートしたらAnacondaが使えなくなってる。。。
そんな方への対処法をまとめました。なんで使えなくなった
Catalinaではルートディレクトリへの書き込みをセキュリティ上推奨しないようです。
一方、Anacondaはディフォルトではルートに生成されています。
OSアップグレードの際にルートディレクトリから丸ごと移動されてしまうため、使えなくなってしまいます。追い出されたanacondaは以下に移動されています。
/Users/Shared/Relocated Items/Security/anaconda3
デスクトップにエイリアス「場所が変更された項目」が生成されているのでそちらからも辿れます。対応方法
詳しくは以下の海外サイト、こちらを参考にしました。
https://superuser.com/questions/1456518/anaconda-not-working-in-mac-catalina対応Step
1 追い出されたanacondaディレクトリをホームディレクトリに移動
#追い出されたanaconda /Users/Shared/Relocated Items/Security/anaconda3 #ホームディレクトリに移動 /Users/[your_user_name]/anaconda32 condaを使用可能にする
#binディレクトリに移動 cd /Users/[your_user_name]/anaconda3/bin/ #condaファイルのshebangを変更 vi conda #1行目 #!/anaconda3/bin/python #↓以下に変更 #!/Users/[your_user_name]/anaconda3/bin/python. #condaファイルを保存3 condaの初期化
初期化することで、依存ファイルが最適化され、shellにanacondaのパスが通ります。conda init bash (conda init zsh) #(catalinaのディフォルトshはzsh。私は取り急ぎbashでしましたが、zsh移行済みの方は、zshで初期化してください) #以下のステータスが走ります。 modified 〜〜〜 ・・・ ・・・ ==> For changes to take effect, close and re-open your current shell. <==4 確認
~/.bash_profileにパスを通す記述が自動追記されます。# >>> conda initialize >>> # !! Contents within this block are managed by 'conda init' !! #<パスを通すコマンドが自動記述される> unset __conda_setup # <<< conda initialize <<<5 読み込み、正常使用を確認
terminalを再度立ち上げるか、
source ~/.bash_profileで設定を再読み込み。これでエラーがなければ、anacondaは正常に使えるようになっていると思います。
anaconda経由のpythonや、ライブラリ、condaも使用できるようになります。まだ、Catalinaがリリースされてから日が浅いので、一部不具合の可能性もあります。心配な方は少し経ってからの移行をおすすめします。
6 anaconda-navigatorの対応
私はanaconda-navigatorを利用してませんが、参考サイトに対応方法ありましたので、ついでに対応してみました。
- anacondaディレクトリに移動
/Users/[your_user_name]/anaconda3/- Anaconda-Navigator.app を右クリック
パッケージの内容を表示を選択- Contents/MacOS/run.sh を開く
- 以下の部分を全て書き換える
#変更前 /anaconda3 ↓ #変更後 /Users/[your_user_name]/anaconda3ファイルを保存する。
これで「Anaconda Navigator」は使用できるようになりました。7 番外
私の場合は、「jupyter notebook」も使えなくっていました。
以前、conda経由でインストールしたのですが、今回のOSアップグレードに関係あるかもしれません。
私の場合ですが、アップグレードしたら使えるようになりました。#conda自体をアップデート conda update conda #jupyter notebookのアップデート conda update jupyterただ、環境により人それぞれ対応方法は異なるかもしれません。
追伸
試してないけど、違うやり方です。
https://medium.com/@justinaugust/upgrading-to-osx-catalina-as-an-anaconda-user-2e71db194764ざっくりこんな方法みたいです。
1. セキュリティディレクトリに避難された、anacondaディレクトリをホームディレクトリに移動するのは同じ。
2. anacondaの公式ページからダウンロードインストーラーをダウンロード
3. Terminalで インストール作業
./<name of anaconda installer> -u
ホームディレクトリを指示してanaconda3をインストール要はインストールすることで設定を上書きするやり方のようです。
おわりに
以上、macOS Catalinaを入れた際のAnacondaの対応方法をまとめてみました。
OSリリースしてまだ日が浅いこともあり、まだ他の不具合が出てくる可能性もありますが、
ひとまず私の環境ではAnaconda/pythonは使えております。稚拙なまとめでしたが、みなさんのお力になれると幸いです。
- 投稿日:2019-10-11T12:56:26+09:00
Python: 町丁目の座標に基づいてmapにマーカーを描画
SAMPLE
REFERENCE
folium 事始め
Folium: Pythonでデータを地図上に可視化DATA
国土交通省国土政策局のページから町丁目レベル位置参照情報とをダウンロードする。
=>ここではテーブル名[locate_lt_lg]としてSQL Serverに格納。PYTHON
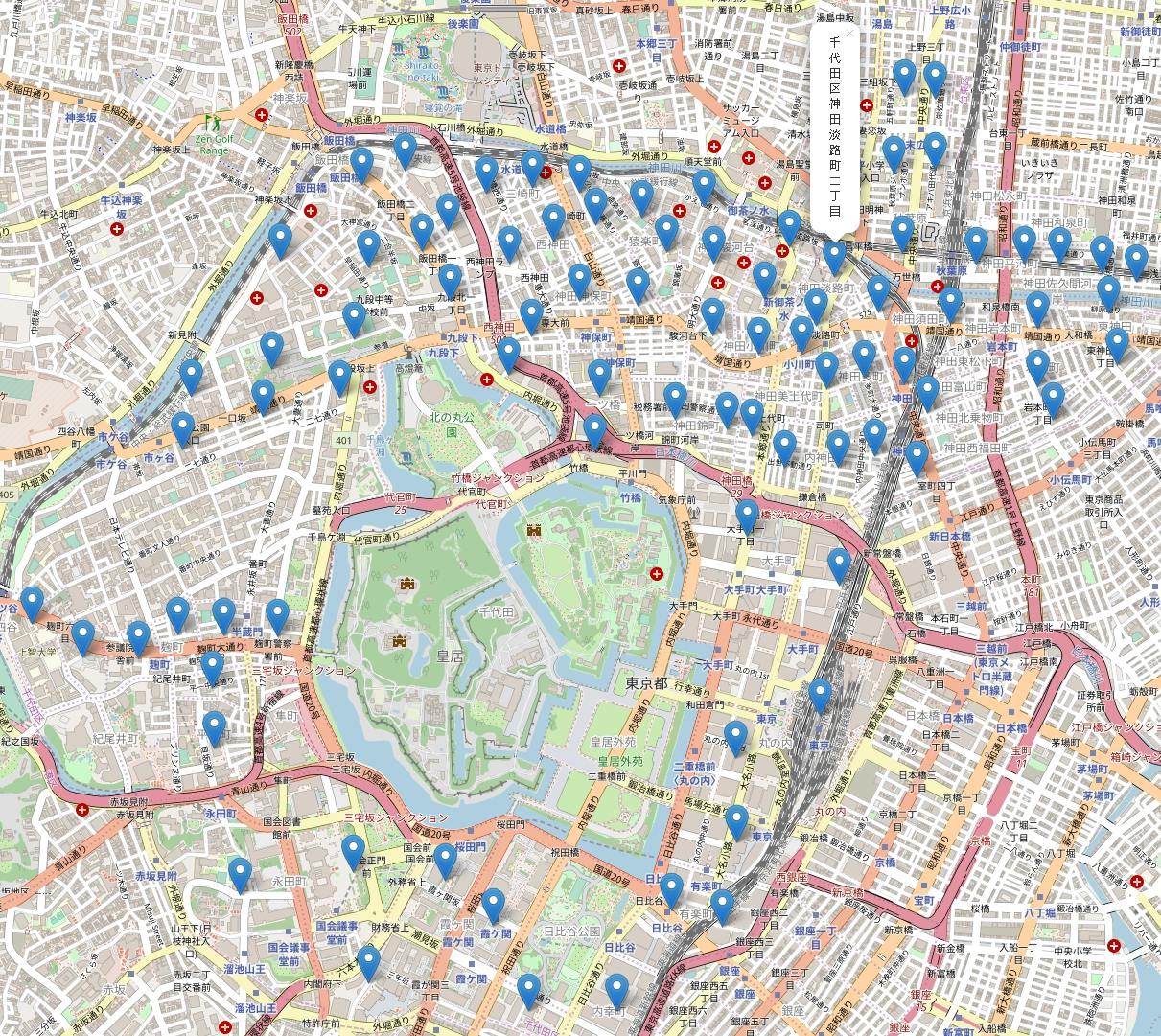
ここでは
・千代田区
・大字・字・丁目区分コード3
のデータのみを利用する。import pypyodbc connection_string ='Driver={SQL Server Native Client 11.0};Server=ServerName;Database=DatabaseName;Uid=UserName;Pwd=Password;' connection = pypyodbc.connect(connection_string) SQL = """ SELECT todofuken_name,shichoson_name,choson_name,lt,lg FROM [locate_lt_lg] WHERE chomoku_code = '3' AND shichoson_name = '千代田区' """ cur = connection.cursor() cur.execute(SQL) rows = cur.fetchall() ltlg_data = [] for row in rows: ltlg_data.append(row) cur.close() connection.close()中心座標を東京駅に設定して丁目ごとの代表座標をマーカーとして設置。htmlとして保存する。
import folium copyright_map = '© <a href="http://osm.org/copyright">OpenStreetMap</a> contributors' map0 = folium.Map(location=[35.681167, 139.767052], attr=copyright_map, zoom_start=15) states = [] for row in ltlg_data: state = {} state['todofuken_name'] = row[0] state['shichoson_name'] = row[1] state['choson_name'] = row[2] state['lt'] = row[3] state['lg'] = row[4] states.append(state) for state in states: folium.Marker( [state['lt'], state['lg']], popup=state['shichoson_name']+state['choson_name'], ).add_to(map0) map0.save('sample0.html')
- 投稿日:2019-10-11T12:53:44+09:00
PEP 572, Assignment expressions
最近、Pythonの新たな実装追っかけを怠っていたので、この時間でお勉強してみた。
吉祥寺でゆるく仕事帰りの勉強会をやっていて、そこで調べたことを記録したノートです。
https://kichipy.connpass.com/event/149625/PEP 572, Assignment expressionsについて
参考 syntax-and-assignment-expressions-what-and-why
:=という表記のAssignment expressions(代入演算子と言ったら良いのかな)が追加されました。例えば、ifやwhileの条件式の条件内で、変数に値を代入しながら処理を実行したりする時に使うと良さげです。まずは、、、、
if statement(if条件式)
今まで
match = pattern.match(line) if match: return match.group(1)Assignment expressions(代入演算)にすると
if match := pattern.match(line): return match.group(1)Infinite while statement(whileの条件式)
今まで:
while True: data = f.read(1024) if not data: break use(data)Assignment expressions(代入演算)にすると
while data := f.read(1024): use(data)だいぶコードがシンプルに書けることがわかります。
こんな処理は実際書くことを無いのですが、動作のおさらい。>>> if a := None: # a に None を代入して、a を評価 ... print(a) ... >>> if a := 1: # a に 1 を代入して、a を評価 ... print(a) ... 1その他stackoverflowに上がっていた例
stuff = [(lambda y: [y,x/y])(f(x)) for x in range(5)]が
stuff = [[y := f(x), x/y] for x in range(5)]こうなります。読みにくい
lambdaを使わなくてよいので、いい感じです。inputを以下様に処理もできます。
command = input("> ") while command != "quit": print("You entered:", command) command = input("> ")が
while (command := input("> ")) != "quit": print("You entered:", command)なります。
感想
実践でも使い所は結構ありそうなのと、そこまで可読性が下がる印象はないので、積極的に使っていこうかなと思った次第。
- 投稿日:2019-10-11T12:21:16+09:00
[IOS](自分用メモ)IOSアプリの評価ランク別の割合をスクレイピングで取得する
自分用メモです
色々調べたらiTunesSearchAPIではトータルの評価数、及び平均評価ランクを取得する事はできるが、ランク別の評価数を取得する事は不可能な模様。
よって、”トータルの評価数*評価ランクの全体中の割合”でなら大まかにだが取得できるだろうという考え。日次で取得すれば、前日の数値との差を算出する事で日別の評価ランク数も取得できる。
AppStoreのアプリ別のページをスクレイピングすればできるできた。
以下、サンプルコード
import urllib.request as url_req import re from html.parser import HTMLParser class AppStoreParser(HTMLParser): def __init__(self): HTMLParser.__init__(self) self.cnt = 5 def handle_starttag(self, name, attrs): attrs = dict(attrs) if name == "div": if 'class' in attrs and attrs['class'] == 'we-star-bar-graph__bar__foreground-bar': h_r = re.match('^width: ([0-9]+)%;$', attrs['style']) h = int(h_r.group(1)) if h_r else 0 print('Rating:{} {}%'.format(self.cnt, h)) self.cnt -= 1 request = url_req.Request( url='https://apps.apple.com/jp/app/id{}'.format('任意のAppStoreID')) tmp = url_req.urlopen(request, timeout=15) parser = AppStoreParser() parser.feed(str(tmp.read()))以上です。
- 投稿日:2019-10-11T12:15:45+09:00
AWS LambdaからPython Boto3を使用してDynamoDBを操作する
バージョン
Python3.7準備
import boto3 dynamoDB = boto3.resource('dynamodb') table= dynamoDB.Table('sample') def main(event, context): search(event) insert(event) update(event) delete(event) return取得処理
def search(event): query_data = table.get_item( Key={ 'id': event['id'] } ) print("GetItem succeeded:") # 取り出す時は sample_value = query_data['Item']['sample_value'] return sample_value登録処理
def insert(event, context): table.put_item( Item = { 'id': event['id'], 'sample_value': event['sample_value'] } ) print("PutItem succeeded:") return更新処理
def update(event): table.update_item( Key= {'id': event['id']}, UpdateExpression='set = :s', ExpressionAttributeValues={ ':s' : event['sample_value'] } ) print("UpdateItem succeeded:") return削除処理
def delete(event): table.delete_item( Key={ 'id': event['id'] } ) print("DeleteItem succeeded:") return参考
ステップ 3: 項目を作成、読み込み、更新、削除する
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/GettingStarted.Python.03.html
- 投稿日:2019-10-11T12:12:36+09:00
UTF-8風の可変長な整数の符号化方法をPythonで実装する
Rubyの中間表現では、こんなのが使われているようです。
2. 整数値の符号化方法を変更
また、出力に含まれていたあらゆる整数値はほぼすべてが固定長で符号化され、4byteや8byteのデータ長で出力されていました。 しかし、出力される整数値はその出現頻度に大きな偏りがあり、多くが 0 や 1 などの少ないbit数で表現できる値です。 そこで、UTF-8を参考に可変長な整数の符号化方法を考え、導入することにしました。
0x0000000000000000 - 0x000000000000007f: 1byte | XXXXXXX1 | 0x0000000000000080 - 0x0000000000003fff: 2byte | XXXXXX10 | XXXXXXXX | 0x0000000000004000 - 0x00000000001fffff: 3byte | XXXXX100 | XXXXXXXX | XXXXXXXX | 0x0000000000020000 - 0x000000000fffffff: 4byte | XXXX1000 | XXXXXXXX | XXXXXXXX | XXXXXXXX | ... 0x0001000000000000 - 0x00ffffffffffffff: 8byte | 10000000 | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | 0x0100000000000000 - 0xffffffffffffffff: 9byte | 00000000 | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX |この方法では、7bitで十分に表現できる値は1byteに、14bitで表現できる値は2byteに、というように符号化する整数の大きさによって必要なバイト長を変化させています。
Ruby中間表現のバイナリ出力を改善する - クックパッド開発者ブログ
https://techlife.cookpad.com/Pythonでこれを実装してみましょう。
実装してみた
実装してみました。
書きやすさ優先で、Rubyのと若干仕様を変えています。
なお、(言うまでもなく)Python標準の数値演算は遅いので、今回のコードはあまり実用的ではないでしょう。
''' Variable width bytes representation of uint64_t. Inspired by Ruby interpreter。 https://techlife.cookpad.com/entry/2019/09/26/143000 > 0x0000000000000000 - 0x000000000000007f: 1byte | 1XXXXXXX | > 0x0000000000000080 - 0x0000000000003fff: 2bytes | 01XXXXXX | XXXXXXXX | > 0x0000000000004000 - 0x00000000001fffff: 3bytes | 001XXXXX | XXXXXXXX | XXXXXXXX | > 0x0000000000020000 - 0x000000000fffffff: 4bytes | 0001XXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | > ... > 0x0001000000000000 - 0x00ffffffffffffff: 8bytes | 00000001 | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | > 0x0100000000000000 - 0xffffffffffffffff: 9bytes | 00000000 | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | XXXXXXXX | ''' from typing import List, Tuple def pack(n: int) -> bytes: if n < 0: raise ValueError("negative number is not supported") l = n.bit_length() if l > 64: raise ValueError("too large") s = (l - 1) // 7 + 1 if s > 8: return b"\0" + n.to_bytes(8, "big") else: packed = bytearray(n.to_bytes(s, "big")) packed[0] = packed[0] | (0x100 >> s) return bytes(packed) def unpack(packed: bytes) -> Tuple[int, int]: size = 8 - packed[0].bit_length() b = bytearray(packed[:size]) b[0] = packed[0] & (0xFF >> size) return int.from_bytes(b, "big"), size def test(): cases = [ (1, 0b10000001 .to_bytes(1, "big")), (0b01111111, 0b11111111 .to_bytes(1, "big")), (0b00111111_11111111, 0b01111111_11111111 .to_bytes(2, "big")), ( 0b00000000_11111111_11111111_11111111_11111111_11111111_11111111_11111111, 0b00000001_11111111_11111111_11111111_11111111_11111111_11111111_11111111 .to_bytes( 8, "big" ), ), ( 0b00000000_11111111_11111111_11111111_11111111_11111111_11111111_11111111_11111111, 0b00000000_11111111_11111111_11111111_11111111_11111111_11111111_11111111_11111111 .to_bytes( 9, "big" ), ), ] for n, packed in cases: assert pack(n) == packed assert unpack(packed) == (n, len(packed))https://gist.github.com/doloopwhile/1419f460fbe2c3561714a4cd3a20c390
補足
Pythonにはビット単位演算 が昔からあります。内容はC言語と同じです(
x ^ y,x & y,x | y,x << n,x >> n,~x)。また、整数←→バイト列の変換をするためのライブラリとして、structも昔から備わっています。
2バイト整数×2 と 4バイト整数×1 のエンコード・デコード >>> from struct import * >>> pack('hhl', 1, 2, 3) b'\x00\x01\x00\x02\x00\x00\x00\x03' >>> unpack('hhl', b'\x00\x01\x00\x02\x00\x00\x00\x03') (1, 2, 3)今回のコードでは、最近(と言っても3.2で)追加されたint型のメンバ関数を使っています。
int.bit_length(): 整数を表現するのに必要なビット数int.to_bytes(length, byteorder): 整数 → バイト列int.from_bytes(bytes, byteorder): バイト列 → 整数開発中に数値のビット表現を見るには組み込み関数の bin(n)や、
format関数、f-string が使えます。>>> bin(3) '0b11' >>> bin(-10) '-0b1010' >>> format(14, '#b'), format(14, 'b') ('0b1110', '1110') >>> f'{14:#b}', f'{14:b}' ('0b1110', '1110')
- 投稿日:2019-10-11T11:24:46+09:00
今更ながらSeleniumIDEのお引越し
はじめに
要点:Firefox 55以前で動いていたSelenium IDEのテストケーススクリプトをSideEXベースのものに変換するPythonツールを作りました。
何とかFirefox 55以前のバージョンを使ってSelenium IDEを使い続けていましたがとうとう使わないでという(ごもっともな)事を言われたのでSideEXベースのSelenium IDEにお引越しすることにしました。テストケースに互換性が無いので変換するPythonツールを今更ながら作りました。
変換ツール
リポジトリ
https://github.com/takuya1981/selenium-ide-scripts-converter
必要なパッケージ
- beautifulsoup4 4.8.1+
- Python 2.7+
Python3系は未評価です。
使い方
Usage: python selenium_convert.py dir_in project_name file_out args: dir_in: Firefox 55 以前で使用したSelenium IDEのスクリプト(.html)が格納されたディレクトリ. project_name: プロジェクト名(新しいテストスクリプト上でのプロジェクト名) file_out: 変換されたスクリプトファイル(.side)のパス注記
割とシンプルな変換しかサポートしていません。
- 対応するコマンドが無い場合があります
- clickAndWaitはclickに, selectAndWaitはselectに置き換えます(必要な時は待ってくれるというのがSideEXの方針らしい)
- 投稿日:2019-10-11T11:20:59+09:00
赤外線アレイセンサAMG8833(Grid-EYE)のデータを表示
今回やること
前回でAMG8833(Grid-EYE)のデータ取得ができましたが、ただ数字が出るだけだったので画像として表示してみようと思います。
2次元配列データの可視化
matplotlibを使って2次元配列を表示させます。
amg8833.py# -*- coding: utf-8 -*- import time import busio import board import adafruit_amg88xx import matplotlib.pyplot as plt # I2Cバスの初期化 i2c_bus = busio.I2C(board.SCL, board.SDA) # センサーの初期化 sensor = adafruit_amg88xx.AMG88XX(i2c_bus, addr=0x68) # センサーの初期化待ち time.sleep(.1) # imshowでsensor.pixelsの2次元配列データを表示させる fig = plt.imshow(sensor.pixels, cmap="inferno") plt.colorbar() plt.show()実行すると画像が表示されます。
センサーの上部で手をパーにしてかざして実行しました。$ python3 amg8833.py
bicubic補間を使ってみる
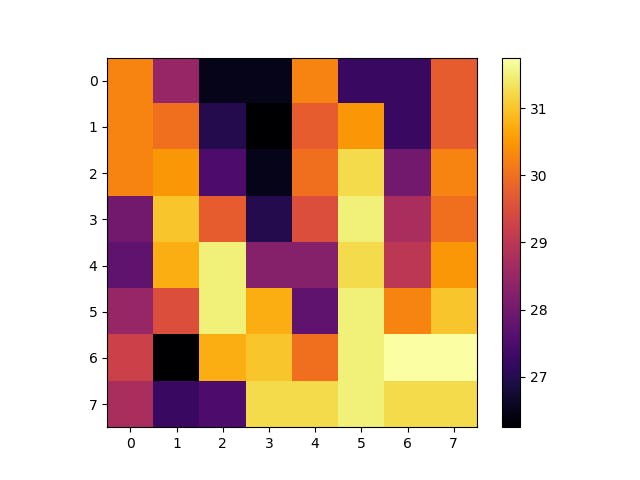
とりあえず熱画像っぽいのは表示することができましたが、AMG8833は8x8ピクセルのため解像度が低すぎてよくわからないので、bicubic補間を使ってみます。
imshowのinterpolationオプションでbicubicを指定すると補間されます。amg8833.py# -*- coding: utf-8 -*- import time import busio import board import adafruit_amg88xx import matplotlib.pyplot as plt # I2Cバスの初期化 i2c_bus = busio.I2C(board.SCL, board.SDA) # センサーの初期化 sensor = adafruit_amg88xx.AMG88XX(i2c_bus, addr=0x68) # センサーの初期化待ち time.sleep(.1) # 8x8ピクセルの画像とbicubic補間をした画像を並べて表示させる plt.subplots(figsize=(8, 4)) # データ取得 sensordata = sensor.pixels # 8x8ピクセルのデータ plt.subplot(1, 2, 1) fig = plt.imshow(sensordata, cmap="inferno") plt.colorbar() # bicubic補間したデータ plt.subplot(1, 2, 2) fig = = plt.imshow(sensordata, cmap="inferno", interpolation="bicubic") plt.colorbar() plt.show()実行すると、オリジナルと補間画像の2枚が並んで表示されます。
$ python3 amg8833.py
少しは手の形がわかるようになったかなと思います。
動画にしてみる
1枚の静止画では何かと不便なので、ループさせて動画にしてみます。
amg8833.py# -*- coding: utf-8 -*- import time import busio import board import adafruit_amg88xx import matplotlib.pyplot as plt # I2Cバスの初期化 i2c_bus = busio.I2C(board.SCL, board.SDA) # センサーの初期化 sensor = adafruit_amg88xx.AMG88XX(i2c_bus, addr=0x68) # センサーの初期化待ち time.sleep(.1) # 8x8ピクセルの画像とbicubic補間をした画像を並べて表示させる plt.subplots(figsize=(8, 4)) # ループ開始 while True: # データ取得 sensordata = sensor.pixels # 8x8ピクセルのデータ plt.subplot(1, 2, 1) fig = plt.imshow(sensordata, cmap="inferno") plt.colorbar() # bicubicのデータ plt.subplot(1, 2, 2) fig = plt.imshow(sensordata, cmap="inferno", interpolation="bicubic") plt.colorbar() # plt.showだと止まってしまうので、pauseを使用 # plt.clfしないとカラーバーが多数表示される plt.pause(.1) plt.clf()手を左から右に動かして撮影してみました。
$ python3 amg88333.py
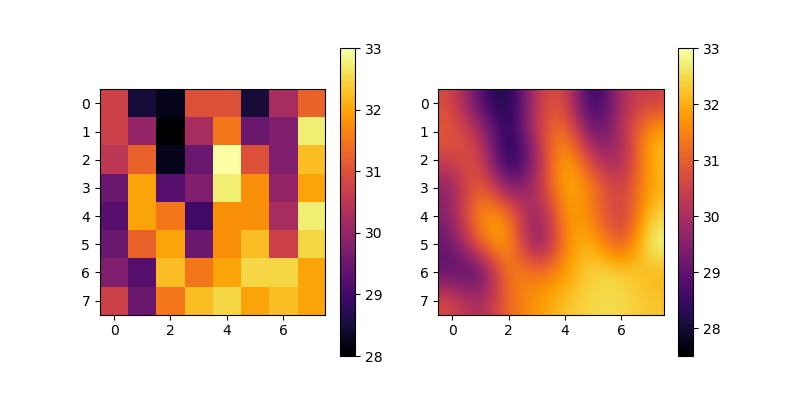

- 投稿日:2019-10-11T10:33:11+09:00
python pandas dataframe の ループ処理が遅すぎる問題
python pandas dataframe の ループ処理が遅すぎる問題
pandas をdf.iterrows()で純粋にループさせると遅すぎでした。
numpy array型に変換してからindexで参照するようにすると爆速になりました。
思わぬところで足を取られました以下のように解決。
def add_pred_in_df(df_input, df_unixepoch_pred): prev_unixepoch = 0 index_pred = 0 df_input["prediction"] = "" array_time_input = df_input.timestamp.values array_time_pred = df_unixepoch_pred.unixepoch.values array_label_pred = df_unixepoch_pred.pred.values list_input_pred = [] for index in range(df_input.shape[0]): if array_time_input[index] > array_time_pred[index_pred]: index_pred += 1 list_input_pred.append(array_label_pred[index_pred]) df_input["prediction"] = list_input_pred return df_input(コードが汚いのはごめんなさい)
参考
https://kunai-lab.hatenablog.jp/entry/2018/04/08/134924
ちなみに
ふつうに iterrows() で回してた時のコードは以下。
def add_pred_in_df(df_input, df_unixepoch_pred): prev_unixepoch = 0 df_input["prediction"] = "null" for index, items in df_unixepoch_pred.iterrows(): if df_input[(df_input["timestamp"] > prev_unixepoch) & (df_input["timestamp"] <= items["unixepoch"])].shape[0] == 0: continue df_input[(df_input["timestamp"] > prev_unixepoch) & (df_input["timestamp"] <= items["unixepoch"])].prediction = items["pred"] prev_unixepoch = items["unixepoch"] return df_inputそのあと、高速化しようと思って Refactoring したのが以下。
ループのたびに df_input を比較を使って抽出するときに、全体スキャンするから遅いと思って下記のように修正したが、
それでも遅かった。def add_pred_in_df(df_input, df_unixepoch_pred): prev_unixepoch = 0 index_pred = 0 df_input["prediction"] = "" for index, items in df_input.iterrows(): print(index, index_pred) if items["timestamp"] > df_unixepoch_pred.unixepoch[index_pred]: index_pred += 1 df_input.prediction[index] = df_unixepoch_pred.pred[index_pred] return df_input
- 投稿日:2019-10-11T10:07:26+09:00
Storing and Retrieving Impression Count Documents
This post is about how I designed the schema for a mongodb collection which will have potentially billions of documents.
I'm working on some code that will allow us to see how many times a user has seen each dish, the main form of content at SnapDish. To do this I designed a new collection called
impression count, which has some requirements.Data Requirements
I want to be able to:
1. query byuser_idand getimpression countdocs for all the dishes that the user has seen
2. query bydish_idand getimpression countdocs for all users who have seen the dish
3. query bycountitself to see which dishes are being viewed the most
4. batch update thousands ofimpression countdocs with a number of database queries that does not scale with the number of documents.Because of these requirements I decided to go with a long form data format. An example looks like this:
{'user_id': ObjectId('5d9d345b0ff2aecca14b7423'), 'dish_id': ObjectId('5d9d345b0ff2aecca14b7424'), 'count': 0}With indexes on the three keys, this data format satisfies requirements 1 through 3, but not 4. To update the count in many
impression countobjects at the same I need a compound key. Since(user_id, dish_id)is a unique combination, I use this as the compound key. I could simple use the tuple I just showed you, but it requires an awful lot of memory. So I decided to use a hash digest of the tuple instead.Picking hashing function
I thought about whether to use the simple
hash()or to usehashlib.sha256().hexdigest().Using
hash()Pros:
- Small data size.hash()generates anint, which only takes 8 bytes when stored in mongo hash
Cons:
- "High" hash collision probability.hash()produces anint, which means there are2**64buckets. Risk of hash collision is larger than withsha256, but still small. And if two dish/user pairs do cause hash collision, it simply means that theimpression countdata gets a little noisy. We can live with that.Using
sha256Pros
- very small risk of hash collisions
Cons
- Large data size. The hexdigest of the
sha256is a 64-character string, which is much larger than the 8 bytes required to storehash()digests.What surprised me a little is that
hash()is only about twice as fast ashashlib.sha256, and that's even including the extra bit of data manipulation required to convert twoObjectIDobjects into a string before calculatingsha256. Still, I went withhash(), because keeping the size of the data stored in the db as small as possible takes priority.Testing
hash()collisionsJust to make sure, I wrote a quick test where I generated 100 million
(user_id, dish_id)tuples, hashed them, and counted the hashes to see if there were any collisions.import time from bson.objectid import ObjectId import pandas as pd start = time.time() hashes = [hash((ObjectId(), ObjectId())) for _ in range(10**8)] end = time.time() pd.Series(hashes).value_counts()[:10] Out[28]: 7865030724768499228 1 3593037806229148232 1 -7578863228603399659 1 5892295761844497950 1 -6940781337181938681 1 -2709651244688460355 1 -3635947529078774682 1 -7736769897498555780 1 -5491088629124975649 1 8601880920309379170 1 dtype: int64So, no collisions. Great! I ran the test around 100 times, but not a single collision occurred. And remember, even if there's a collision at some point, which might really happen, then it just adds a tiny bit of noise to the data, which is not a problem for this kind of data.
Final data format
{'user_id': ObjectId('5d9d345b0ff2aecca14b7423'), 'dish_id': ObjectId('5d9d345b0ff2aecca14b7424'), 'count': 0, 'hash': -8777556310190452075 }Let's take a look at how much memory a single
impression countdocument will use in mongodb
-user_id: BSON ObjectId uses 12 bytes
-dish_id: BSON ObjectId uses 12 bytes
-count: BSON NumberInt uses 4 bytes
-hash: BSON NumberLong uses 8 bytes
- 4 bytes for the document keys, when I changeuser_idtou,dish_idtod,counttocandhashtoh. So a total of12 + 12 + 8 + 4 + 4= 40 bytes. While I could shave off 8 bytes by also hashinguser_idanddish_id, I want to be able to query directly for users and dishes. So now we know that we can store 1 billion user/dishimpression countdocuments with just 40 GiB of database disk used, while still satisfying the original data requirements. Pretty neat!Batch Updating
impression countsfrom typing import List, Dict import pymongo def increment_impression_counts( impression_counts: pymongo.collection.Collection, impressions=List[Dict[str, tuple]] ): """ Accepts a list of impression documents of the form {'u': ObjectId('5d9d41c20ff2aecca14b7427'), 'd': ObjectId('5d9d41c20ff2aecca14b7428')} and increments the count of existing `impression_count` documents that match with the hash, and creates new `impression_count` documents with `c=0` for the rest. """ # user hash to find impression count documents already in collection hash_to_doc = {hash((i["d"], i["u"])): i for i in impressions} hashes_all = list(hash_to_doc.keys()) hashes_in_db = impression_counts.find( {"h": {"$in": hashes_all}}, projection={"_id": False, "h": True} ) hashes_in_db = [ic["h"] for ic in hashes_in_db] # increment count for existing impression count documents impression_counts.update_many({"h": {"$in": hashes_in_db}}, {"$inc": {"c": 1}}) # calculate impression count documents not collection hashes_not_in_db = set(hashes_all) - set(hashes_in_db) docs_to_be_inserted = [ {"h": key, "c": 1, "u": hash_to_doc[key]["u"], "d": hash_to_doc[key]["d"]} for key in hashes_not_in_db ] impression_counts.insert_many(docs_to_be_inserted)I use a total of three queries:
1. Find existingimpression countdocuments
2. Increment count for existingimpression countdocuments
3. Create newimpression countdocuments withcount = 1While it's certainly possible to design the collection with a data format that uses less disk space, the requirement to batch update documents means that having each user/dish pair as a separate document is necessary. And even though this will cause more documents, each document is small (40 bytes), and the user/dish relation matrix is very sparse. We have over 5 million dishes, but most users haven't seen a fraction of these.
This was a fun bit of design work :).
- 投稿日:2019-10-11T06:07:58+09:00
Webアプリケーションの自動化をやってみよう
はじめに
Webアプリケーションに対してある種の繰り返しの操作を行ったり、定型処理を定期的に自動実行したい場合がよくあります。
大きくわけてWebアプリケーションの自動化には3種類のやり方が存在します。1つ目はブラウザのGUI上の操作をプログラム上で真似して自動化する方法
2つ目はブラウザから送信しているデータを真似する方法
3つ目はWebアプリケーションが提供しているAPIを利用する方法1つ目のブラウザのGUI上の操作をプログラム上で真似して自動化する方法は直観的にわかりやすいと言われますが、実際は最も難しい自動化の方法になります。また、アプリケーションのバージョンアップに伴い自動化用のプログラムが動作しなくなる可能性があります。
2つ目のブラウザから送信しているデータを真似する方法はプログラムで実装しやすいやり方ではありますが、Webアプリケーションがどのようなデータを送信しているかなどを調べる必要があります。また、1つ目と同様にアプリケーションのバージョンアップに伴い自動化用のプログラムが動作しなくなる可能性があります。
3つ目のWebアプリケーションが提供しているAPIを利用する方法が最も簡単でかつ正確に自動操作を行えます。ただし、WebアプリケーションのAPIが提供されているかどうかは自動操作対象のWebアプリケーションの仕様次第です。
実験環境
Windows10+PowerShell5.1
Visual Studio 2019 + .NET Framework 4.6
Python 3.7.4
NodeJs v10.16.0
UiPath 2019.8.0-beta 83ブラウザのGUI上の操作をプログラム上で真似して自動化する方法
Windowsの場合、ブラウザを操作して自動化する方法も大きく4つの方法があります。
1つ目の方法はInternetExploreのCOMを利用する方法です。WindowsのInternetExploreに対してならば、なにもインストールすることなく、ブラウザの自動操作が可能になっています。ただし、InternetExploreの寿命自体が、長く持たない可能性があるので注意が必要です。(InternetExplore自体が持っても、対応するWebアプリケーションがInternetExploreのサポートを切る可能性が高いです)
2つ目の方法としてSeleniumを使用する方法です。外部のライブラリが必要になりますが、多くのブラウザがサポートされています。
3つ目の方法としてはブラウザが提供している拡張機能を作成する方法です。ChromeとFirefoxの場合、JavaScriptで作成できるので、外部のライブラリを導入する必要はありません。
4つ目の方法としてRPAツールを使用する方法です。ブラウザ上の要素について深く考えなくても、GUIベースで自動化が行えますが、コストの面で問題になります。
HTMLの要素を調べ方
どのような方法でブラウザを操作するとしても、HTMLがどのような要素で構成されているかを調べる必要があります。
ここではChromeでGoogleで検索する場合を例として画面上の要素を調べる方法を説明します。
1.ChromeにてF12キーを押下して開発者ツールを開きます。その後、「Elements」タブを選択してください。
2.[CTRL]+[Shift]+[C]を押下するか、下記のアイコンをクリックします。
3.調べたい要素にマウスを移動させます。
4.Elementsタブに選択した要素の内容が表示されます。今回の場合、以下のような内容が表示されます。
<input class="gLFyf gsfi" maxlength="2048" name="q" type="text" jsaction="paste:puy29d" aria-autocomplete="both" aria-haspopup="false" autocapitalize="off" autocomplete="off" autocorrect="off" role="combobox" spellcheck="false" title="検索" value="" aria-label="検索" data-ved="0ahUKEwiC0u6iu4nlAhXwyIsBHWwTBHcQ39UDCAQ">inputタグの属性が以下のようになっていることがわかります。
属性 値 class gLFyf gsfi name q 自動操作を行う場合、id、name、classなどを利用して要素を指定することになるので、属性値をメモしておきましょう。
5.同様にボタンについても属性を調べます。その結果は以下のようになります。
<input class="gNO89b" value="Google 検索" aria-label="Google 検索" name="btnK" type="submit" data-ved="0ahUKEwiC0u6iu4nlAhXwyIsBHWwTBHcQ4dUDCAo">
属性 値 class gNO89b name btnK ここで調べた属性を利用して要素を特定して自動操作を行うことになります。。
また、今回はChromeでのやり方を紹介しましたが、他のブラウザでも同様のことが可能です。同じWebアプリケーションを使用していてもブラウザによって出力される内容が異なる可能性もあるので、自動操作を行うブラウザを使用して要素を調べるようにしましょう。InternetExplore11の場合
IE11でもF12キーを押すことで開発者ツールが表示されます。
そこで「DOM Explore」タブを開いて要素の選択を行うことで要素の属性を調べることが可能です。
Edgeの場合
Edgeは将来Chromeベースのものに置き換わる可能性があります。
今回は旧EdgeとChromeベースの新Edge両方について説明します。旧Edge
F12キーで開発者ツールが表示されます。
そこで「要素」タブを開いて要素の選択を行うことで要素の属性を調べることが可能です。
新Edge
2019年10月時点でベータ版としてリリースされているEdgeの場合、F12キーで開発者ツールが表示されます。
Chromeと同様の操作で要素の属性を調べることが可能です。
Firefoxの場合
F12キーで開発者ツールが表示されます。
そこで「インスペクター」タブを開いて要素の選択を行うことで要素の属性を調べることが可能です。
HTMLの要素を調べる方のまとめ
多くのブラウザは開発者ツールをサポートしており、要素の属性を調べることが可能です。
Webアプリケーションの自動化では、この要素を特定して操作する必要があるので、お使いのブラウザでの要素の調べ方は覚えておきましょう。実際の自動操作の例は次章から解説します。
Internet ExploreのCOMを使用した自動化
Internet ExploreのCOMであるmshtmlを経由することでInternetExploreを自動操作できます。
COM(Component Object Model)
Microsoftが提唱した再利用を目的とした技術で、COMを用いて開発した部品はプログラム言語に依存せずに利用できるようになります。たとえば、説明したInternetExploreの操作やOfficeアプリケーションなどが外部から利用できるのは、COMのおかげです。IE操作の単純な例
実際のGoogleのトップページで任意の単語を検索するサンプルを見てみましょう。
WSHやVBAでのIE操作の単純な例
WSHのVBScritpで以下のように実装可能です。
以下コードはWScript.EchoをDebug.Print等に置き換えることでVBAでも流用できると思います。Dim ie Set ie = CreateObject("InternetExplorer.Application") ie.Visible = True call ie.Navigate("https://www.google.com/") 'ページが読み込まれるまで待機 Do While ie.Busy = True Or ie.readyState <> 4 WScript.Sleep 100 Loop Dim doc Set doc = ie.Document Dim txt Set txt = doc.getElementsByName("q") txt.item(0).value = "ドリフターズ" Dim btn Set btn = doc.getElementsByName("btnK") btn.item(0).click() 'ページが読み込まれるまで待機 Do While ie.Busy = True Or ie.readyState <> 4 WScript.Sleep 100 Loop Set doc = ie.Document Dim list Do While True Set list = doc.getElementsByClassName("LC20lb") If Not list is Nothing Then If list.length > 0 Then Exit Do End If End If WScript.Sleep 100 Loop Dim item For Each item In list WScript.Echo item.innerText Next ie.QuitこのサンプルではNavigateで指定のURLに移動したのち、getElementsByNameを使用して属性を取得して、値の設定とクリック操作を行っています。
その後,BusyとreadyStateを監視してページの切り替え完了を待ちます。
その後、検索結果の要素が出現するまで待機して、その要素の内容を出力します。PowerShellでのIE操作の単純な例
実はPowerShellやC#などの.NETでの実装は厄介です。結論から言えばやめといた方がいいです。
たとえば、よく見かける実装でGoogleとはてなブックマークを検索するスクリプトieng1.ps1とieng2.ps1を用意しました。Googleの検索
ieng1.ps1$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://www.google.com/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.getElementsByName("q") $txt[0].value = "ドリフターズ" # ボタン押下 $btn=$doc.getElementsByName("btnK") $btn[0].click() # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc = $ie.Document # LC20lbが表示されるまで待機 while($true) { $list = $doc.getElementsByClassName('LC20lb') if($list -and $list.length -ge 1) { break } Start-Sleep -Milliseconds 100 } foreach($i in $list){ Write-Host($i.innerText) } $ie.Quit() Write-Host("OK")はてなの検索
ieng2.ps1$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://b.hatena.ne.jp/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.getElementsByName("q") $txt[0].value = "ドリフターズ" # ボタン押下 $btn=$doc.getElementsByClassName("gh-search-button") $btn[0].click() # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc = $ie.Document # LC20lbが表示されるまで待機 while($true) { $list = $doc.getElementsByClassName('centerarticle-entry-title') if($list -and $list.length -ge 1) { break } Start-Sleep -Milliseconds 100 } foreach($i in $list){ Write-Host($i.innerText) } $ie.Quit() Write-Host("OK")この実装はいくつか問題を起こす可能性があります。
PowerShellでのIE操作の問題点
環境によっては動作しない
同じコードをPowerShell2.0+Windows7で動かそうとしたところ下記のエラーを表示して動作しません。
PS C:\share\webctrl> $ie.Document.getElementsByName("q") "getElementsByName" のオーバーロードで、引数の数が "1" であるものが見つかりません。 発生場所 行:1 文字:31 + $ie.Document.getElementsByName <<<< ("q") + CategoryInfo : NotSpecified: (:) []、MethodException + FullyQualifiedErrorId : MethodCountCouldNotFinこの問題は下記のフォーラムで議論されていますが、解決はしていません。
COMの解放処理を行っていない
上記のコードはCOMを.NETから利用しているにも関わらずReleaseComObjectを行っていません。
類似の問題として以下を参照してください。.NETを使ったOfficeの自動化が面倒なはずがない―そう考えていた時期が俺にもありました。
https://qiita.com/mima_ita/items/aa811423d8c4410eca71解放処理を行ったコードは以下のようになります。
$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://www.google.com/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.getElementsByName("q") $txt[0].value = "ドリフターズ" [System.Runtime.Interopservices.Marshal]::ReleaseComObject($txt) | Out-Null Remove-Variable txt -ErrorAction SilentlyContinue # ボタン押下 $btn=$doc.getElementsByName("btnK") $btn[0].click() [System.Runtime.Interopservices.Marshal]::ReleaseComObject($btn) | Out-Null Remove-Variable btn -ErrorAction SilentlyContinue ## ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null $doc = $ie.Document # LC20lbが表示されるまで待機 while($true) { $list = $doc.getElementsByClassName('LC20lb') if($list -and $list.length -ge 1) { break } if ($list) { [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null } Start-Sleep -Milliseconds 100 } for($i=0; $i -lt $list.length; $i++) { $item = $list[$i] Write-Host($item.innerText) [System.Runtime.Interopservices.Marshal]::ReleaseComObject($item) | Out-Null Remove-Variable item -ErrorAction SilentlyContinue } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null Remove-Variable list -ErrorAction SilentlyContinue $ie.Quit() Write-Host("OK") [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null Remove-Variable doc -ErrorAction SilentlyContinue [System.Runtime.Interopservices.Marshal]::ReleaseComObject($ie) | Out-Null Remove-Variable ie -ErrorAction SilentlyContinue [System.GC]::Collect() [System.GC]::WaitForPendingFinalizers() [System.GC]::Collect()同一プロセスで複数起動した場合にエラーになる
先にあげた2つのスクリプトはPowerShellを再起動した直後には、それぞれ動作しますが以下のように続けて実行するとエラーになります。
正常に動作する >powershell ./ieng1.ps1 >powershell ./ieng2.ps1 2つ目のスクリプトの実行でエラーになる >./ieng1.ps1 >./ieng2.ps1エラーの内容は下記の通りです。
HRESULT からの例外:0x800A01B6 発生場所 C:\dev\ps\webctrl\ieng2.ps1:14 文字:1 + $txt=$doc.getElementsByName("q") + ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ + CategoryInfo : OperationStopped: (:) [], NotSupportedException + FullyQualifiedErrorId : System.NotSupportedExceptionこの問題は以下の記事で言及されています。
- PowerShell Exception 0x800A01B6 while using getElementsByTagName, getElementsByName or getElementByID
- Exception from HRESULT: 0x800A138A At line......
getElementsByNameをIHTMLDocument3_getElementsByNameに置き換えて、getElementsByClassNameをInvokeMemberで呼び出すようにすれば回避できるようです。
Googleの検索(修正版)
ieok1.ps1$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://www.google.com/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.IHTMLDocument3_getElementsByName("q") $txt[0].value = "ドリフターズ" [System.Runtime.Interopservices.Marshal]::ReleaseComObject($txt) | Out-Null Remove-Variable txt -ErrorAction SilentlyContinue # ボタン押下 $btn=$doc.IHTMLDocument3_getElementsByName("btnK") $btn[0].click() [System.Runtime.Interopservices.Marshal]::ReleaseComObject($btn) | Out-Null Remove-Variable btn -ErrorAction SilentlyContinue ## ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null $doc = $ie.Document # LC20lbが表示されるまで待機 while($true) { $list = [System.__ComObject].InvokeMember("getElementsByClassName", [System.Reflection.BindingFlags]::InvokeMethod, $null, $doc, "LC20lb") if($list -and $list.length -ge 1) { break } if ($list) { [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null } Start-Sleep -Milliseconds 100 } for($i=0; $i -lt $list.length; $i++) { $item = $list[$i] Write-Host($item.innerText) [System.Runtime.Interopservices.Marshal]::ReleaseComObject($item) | Out-Null Remove-Variable item -ErrorAction SilentlyContinue } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null Remove-Variable list -ErrorAction SilentlyContinue $ie.Quit() Write-Host("OK") [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null Remove-Variable doc -ErrorAction SilentlyContinue [System.Runtime.Interopservices.Marshal]::ReleaseComObject($ie) | Out-Null Remove-Variable ie -ErrorAction SilentlyContinue [System.GC]::Collect() [System.GC]::WaitForPendingFinalizers() [System.GC]::Collect()はてなの検索(修正版)
ieok2.ps1$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://b.hatena.ne.jp/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.IHTMLDocument3_getElementsByName("q") $txt[0].value = "ドリフターズ" [System.Runtime.Interopservices.Marshal]::ReleaseComObject($txt) | Out-Null Remove-Variable txt -ErrorAction SilentlyContinue # ボタン押下 $btn=[System.__ComObject].InvokeMember("getElementsByClassName", [System.Reflection.BindingFlags]::InvokeMethod, $null, $doc, "gh-search-button") $btn[0].click() [System.Runtime.Interopservices.Marshal]::ReleaseComObject($btn) | Out-Null Remove-Variable btn -ErrorAction SilentlyContinue ## ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null $doc = $ie.Document #表示されるまで待機 while($true) { $list = [System.__ComObject].InvokeMember("getElementsByClassName", [System.Reflection.BindingFlags]::InvokeMethod, $null, $doc, "centerarticle-entry-title") if($list -and $list.length -ge 1) { break } if ($list) { [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null } Start-Sleep -Milliseconds 100 } for($i=0; $i -lt $list.length; $i++) { $item = $list[$i] Write-Host($item.innerText) [System.Runtime.Interopservices.Marshal]::ReleaseComObject($item) | Out-Null Remove-Variable item -ErrorAction SilentlyContinue } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null Remove-Variable list -ErrorAction SilentlyContinue $ie.Quit() Write-Host("OK") [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null Remove-Variable doc -ErrorAction SilentlyContinue [System.Runtime.Interopservices.Marshal]::ReleaseComObject($ie) | Out-Null Remove-Variable ie -ErrorAction SilentlyContinue [System.GC]::Collect() [System.GC]::WaitForPendingFinalizers() [System.GC]::Collect()PowerShellでのInternetExploreの操作のまとめ
辞めといた方がいいでしょう。
回避策を書いているページは色々見つかりますが、何故その事象が発生しているか、そしてなぜ回避することができたかを説明できているサイトは見つからず、ためしてみたら動作した以上のものではありません。
固定の環境で動かすスクリプトならばともかく、不特定多数の環境で動作するスクリプトでは採用を避けるべきでしょう。また、多くの場合、VBSやVBAで代替できるのでPowerShellにこだわる理由はないでしょう。どうしても、PowerShellで行いたい場合は、IE操作をしたプロセスを終了するようにすると安定しそうです。
すでに起動しているブラウザの操作方法
すでに起動しているIEを操作するにはIEのウィンドウに対してRegisterWindowMessageでWM_HTML_GETOBJECTメッセージを定義して送信することでHTMLDocumentを取得することになります。
Cant create HTML document from Hwnd using C#
https://stackoverflow.com/questions/20873885/cant-create-html-document-from-hwnd-using-c-sharpWin32 APIを直接実行できないWSHでは実現が難しいです。
VBAでの実装例
下記を参考にしてください。
VBAでInternetExplore上のJavaScriptを無理やり動かすよ!
https://qiita.com/mima_ita/items/fdff129a8db1153c9940C#での実装例
.NET経由になるのでCOMの解放処理を入れる必要があります。
(1)参照マネージャーのCOMタブでMicrosoft HTML Object Libraryを追加します。
これにより「Interop.MSHTML.dll」が作成されます。
Interop~.dllはtlbImpコマンドを使用することでコマンドラインで作成できますが、VisualStudioなどの開発ツールをインストールしていないと使えないと思います。(2)以下のような実装をします。下記のコードは.NET2.0でも動作します。
using System; using System.Collections.Generic; using System.Text; using System.Runtime.InteropServices; using MSHTML; using System.Diagnostics; namespace iesample { class Program { [DllImport("user32.dll", EntryPoint = "GetClassNameA")] public static extern int GetClassName(IntPtr hwnd, StringBuilder lpClassName, int nMaxCount); /*delegate to handle EnumChildWindows*/ public delegate int EnumProc(IntPtr hWnd, ref IntPtr lParam); [DllImport("user32.dll")] public static extern int EnumWindows(EnumProc lpEnumFunc, ref IntPtr lParam); [DllImport("user32.dll")] public static extern int EnumChildWindows(IntPtr hWndParent, EnumProc lpEnumFunc, ref IntPtr lParam); [DllImport("user32.dll", EntryPoint = "RegisterWindowMessageA")] public static extern int RegisterWindowMessage(string lpString); [DllImport("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeout(IntPtr hwnd, int msg, int wParam, int lParam, int fuFlags, int uTimeout, out UIntPtr lpdwResult); [DllImport("OLEACC.dll")] public static extern int ObjectFromLresult(UIntPtr lResult, ref Guid _riid, int wParam, ref MSHTML.IHTMLDocument2 _ppvObject); public const int SMTO_ABORTIFHUNG = 0x2; public Guid IID_IHTMLDocument = new Guid("626FC520-A41E-11CF-A731-00A0C9082637"); private static List<IHTMLDocument2> cacheList = new List<IHTMLDocument2>(); public static MSHTML.IHTMLDocument2 FindBrowser(string title) { MSHTML.IHTMLDocument2 ret; if (cacheList.Count == 0) { RefreshBrowserCache(); } ret = FindBrowserInCache(title); if (ret != null) { return ret; } RefreshBrowserCache(); return FindBrowserInCache(title); } public static MSHTML.IHTMLDocument2 FindBrowserInCache(string title) { MSHTML.IHTMLDocument2 ret; foreach(MSHTML.IHTMLDocument2 item in cacheList) { if (item.title.Contains(title)) { return item; } } return null; } public static void RefreshBrowserCache() { foreach (IHTMLDocument2 item in cacheList) { Marshal.ReleaseComObject(item); } cacheList.Clear(); EnumProc proc = new EnumProc(EnumIEWndProc); IntPtr lparam = IntPtr.Zero; EnumWindows(proc, ref lparam); } private static int EnumIEWndProc(IntPtr hWnd, ref IntPtr lParam) { StringBuilder className = new StringBuilder(128); GetClassName(hWnd, className, className.Capacity); EnumProc proc = new EnumProc(EnumIEServerWndProc); if (className.ToString().Equals("IEFrame") || className.ToString().Equals("TabWindowClass")) { IntPtr lparam = IntPtr.Zero; EnumChildWindows(hWnd, proc, ref lparam); } return 1; } private static int EnumIEServerWndProc(IntPtr hWnd, ref IntPtr lParam) { StringBuilder className = new StringBuilder(128); GetClassName(hWnd, className, className.Capacity); if (className.ToString().Equals("Internet Explorer_Server")) { IHTMLDocument2 doc = GetHTMLDocument(hWnd); if (doc != null) { cacheList.Add(doc); } } return 1; } private static IHTMLDocument2 GetHTMLDocument(IntPtr hWnd) { int nMsg = RegisterWindowMessage("WM_HTML_GETOBJECT"); if (nMsg == 0) { return null; } UIntPtr lRes; SendMessageTimeout(hWnd, nMsg, 0, 0, SMTO_ABORTIFHUNG, 1000, out lRes); if (lRes == UIntPtr.Zero) { return null; } Guid IID_IHTMLDocument = new Guid("626FC520-A41E-11CF-A731-00A0C9082637"); IHTMLDocument2 doc = null; int hr = ObjectFromLresult(lRes, ref IID_IHTMLDocument, 0, ref doc); return doc; } static void Main(string[] args) { IHTMLDocument3 doc = FindBrowser("Google") as IHTMLDocument3; IHTMLInputElement txt = doc.getElementsByName("q").item(0) as IHTMLInputElement; txt.value = "ドリフターズ"; IHTMLElement btn = doc.getElementsByName("btnK").item(0) as IHTMLElement; btn.click(); Marshal.ReleaseComObject(btn); Marshal.ReleaseComObject(txt); Marshal.ReleaseComObject(doc); } } }様々なコントロールを含むサンプルの例
様々なコントロールを含む以下のページの入力の自動化について考えてみます。
操作対象として以下のページを使用します。
http://needtec.sakura.ne.jp/auto_demo/form1.htmlこのページは「登録する」ボタンを押下することで確認メッセージが表示されて、「OK」の場合に登録処理を行うものとします。※
※実際はSleepしているだけでなにもしていないです。WSHやVBSでの操作例は以下のようになります。
Dim ie Set ie = CreateObject("InternetExplorer.Application") ie.Visible = True call ie.Navigate("http://needtec.sakura.ne.jp/auto_demo/form1.html") 'ページが読み込まれるまで待機 Do While ie.Busy = True Or ie.readyState <> 4 WScript.Sleep 100 Loop Dim doc Set doc = ie.Document ' INPUTBOX doc.getElementsByName("name").item(0).value = "名前太郎" doc.getElementsByName("mail").item(0).value = "test@co.jp" ' テキストエリア doc.getElementsByName("comment").item(0).innerText = "猫猫子猫" & vbCrLf & "犬犬子犬" ' チェックボックス doc.getElementsByName("q1[]").item(0).Checked = True doc.getElementsByName("q1[]").item(1).Checked = True ' ラジオボタン doc.getElementsByName("men").item(1).Checked = True ' 複数選択リスト Dim objSelect Set objSelect = doc.getElementsByName("osi[]").item(0) objSelect.getElementsByTagName("option").item(1).Selected = True objSelect.getElementsByTagName("option").item(2).Selected = True ' ボタン押下 ' 確認メッセージ処理を偽造する doc.parentWindow.ExecScript("confirm = function () { return true; }") doc.getElementsByTagName("input").item(8).click()確認ダイアログを突破する方法は色々ありますが、上記でやったようなJavaScirptのconfirmやalertを上書きしてしまうのが最も楽だと思います。
確認メッセージの処理を上書きしたくない場合
UIAutomation等を使用します。
確認メッセージが表示されるまで待機してボタンを押下するような処理を別スレッドかプロセスで起動します。WSHやVBAの場合は別プロセスでやった方が楽です。まず、確認メッセージを監視するようなスクリプトを記載します。
これはPowerShellで書いた方が楽だと思います。wait_confirm.ps1Add-Type -AssemblyName UIAutomationClient Add-Type -AssemblyName UIAutomationTypes Add-type -AssemblyName System.Windows.Forms $source = @" using System; using System.Windows.Automation; public class AutomationHelper { public static AutomationElement RootElement { get { return AutomationElement.RootElement; } } public static AutomationElement GetWindowByTitle(string title) { var rootCond = new PropertyCondition(AutomationElement.ClassNameProperty, "Alternate Modal Top Most"); var cond = new PropertyCondition(AutomationElement.NameProperty, title); var elementCollection = RootElement.FindAll(TreeScope.Children, rootCond); foreach(AutomationElement mainForm in elementCollection) { var win = mainForm.FindFirst(TreeScope.Children, cond); if (win != null) { return win; } } return null; } public static AutomationElement WaitWindowByTitle(string title, int timeout = 10) { DateTime start = DateTime.Now; while (true) { AutomationElement ret = GetWindowByTitle(title); if (ret != null) { return ret; } TimeSpan ts = DateTime.Now - start; if (ts.TotalSeconds > timeout) { return null; } System.Threading.Thread.Sleep(100); } } } "@ Add-Type -TypeDefinition $source -ReferencedAssemblies("UIAutomationClient", "UIAutomationTypes") # 5.0以降ならusingで記載した方が楽。 $autoElem = [System.Windows.Automation.AutomationElement] # ウィンドウ以下で指定の条件に当てはまるコントロールを1つ取得 function findFirstElement($form, $condProp, $condValue) { $cond = New-Object -TypeName System.Windows.Automation.PropertyCondition($condProp, $condValue) return $form.FindFirst([System.Windows.Automation.TreeScope]::Element -bor [System.Windows.Automation.TreeScope]::Descendants, $cond) } # 指定のAutomationIDのボタンを押下 function pushButtonById($form, $id) { $buttonElem = findFirstElement $form $autoElem::AutomationIdProperty $id $invElm = $buttonElem.GetCurrentPattern([System.Windows.Automation.InvokePattern]::Pattern) -as [System.Windows.Automation.InvokePattern] $invElm.Invoke() } # $dialog = [AutomationHelper]::WaitWindowByTitle("Web ページからのメッセージ", 30) if ($dialog -eq $null) { Write-Host "タイムアウト" } else { pushButtonById $dialog "1" Write-Host "終了" }あとはWSH側のボタン押下処理を以下のように修正します。
' ボタン押下 ' 確認メッセージ処理を別プロセスで行う Dim shell Set shell = CreateObject("WScript.Shell") shell.Run "C:\Windows\System32\WindowsPowerShell\v1.0\powershell -ExecutionPolicy RemoteSigned -File C:\dev\ps\webctrl\wait_confirm.ps1", 0, False doc.getElementsByTagName("input").item(8).click()Internet ExploreのCOMを使用した自動化のまとめ
VBAやVBSなどの何処でもはいっていそうなプログラミング言語で自動化できるのは強みです。
PowerShellでも行えますが、.NET経由だとCOMの解放処理が面倒だったり、動作が安定しない環境もあるので環境を制御できる場合のみに使用したほうがいいでしょう。また、InternetExploreのサポートがいつまで続くかわからない以上、外部のツールを導入可能である場合は、お勧めしません。
Seleniumを使用した自動化
様々なOS上の様々なブラウザを様々なプログラミング言語で自動操作するためのツールです。
Webアプリケーションをブラウザ操作で自動化する場合、もっともよく使われるツールになります。
Selenium実践入門などの良書が流通しているので、この章は飛ばしてそっちを読んだ方がいいと思います。SeleniumIDEを使用する例
ブラウザの操作を記憶する録画機能が提供されておりGUIベースで自動操作の処理を記載できます。録画した操作内容はスクリプトとして記録され、後で修正が可能です。また、別のプログラム言語で記載されたテストコードに変換することもできます。
以下はGoogle検索の操作をキャプチャした例になります。
SeleniumIDEはChromeまたはFirefoxの拡張機能として提供されています。
「あれ?SeleniumIDEって終わったんじゃなかったっけ?」という人は下記の経緯を参照してください。
Webブラウザ自動化ツール「Selenium IDE」の今までとこれから
https://www.valtes.co.jp/qbookplus/509ChromeでSeleniumIDEを使用する
(1)Chrome用のSeleniumIDEを拡張機能として追加します。
(2)ブラウザの上部にSeleniumIDEのアイコンが表示されるのでクリックします。
(3)SeleniumIDEのポップアップが表示されるので「Record a new test in new project」を選択します。
(4)「Name your new project」ダイアログが表示されるので任意のプロジェクト名を入力して「OK」ボタンを押します。
(5)「Set your projects's base URL」ダイアログが表示されるので操作元になるURLを入力します。たとえばGoogle検索をする例だと「https://www.google.com」を入力して「START RECORDING」ボタンを押下します。
(6)操作の記録が始まると右下に「Selenium IDE is recording...」と書かれた新しいブラウザが開きます。
このブラウザを使用して記録したい任意の操作を行います。(7)操作の記録を終了したい場合、「Selenium IDE」ウィンドウの右上の「Stop recording」アイコンを押します。
(8)「Name your new test」ポップアップが表示されるので任意のテスト名を入力して「OK」を押します。
(9)SeleniumIDE ウィンドウに今回操作した内容がスクリプトとして記録されます。
(10)記録したスクリプトは「Run Current Test」アイコンを押すことで再実行可能です。
また、JUnit や pytest、 JavaScript Mochaといった他のプログラミング言語のユニットテストとしてエクスポートすることが可能です。
FirefoxでSeleniumIDEを使用する
Firefox用のSeleniumIDEを拡張機能として追加します。
あとの操作はChromeと同じです。ただし、記録される操作はFirefoxとChromeで差異があります。
Firefoxの場合、ブラウザのスクロール操作が記録されていましたが、Chromeでは記録されていませんでした。
なお、手で同じコマンドを追加すると、再生はChromeでも動作しました。
プログラムからSeleniumを利用する
C#の場合
まず、NuGetでSelenium.WebDriverとSelenium.Supportに加えて操作したいブラウザのDriverを入手します。今回はChromeを操作したいので、Selenium.Chrome.WebDriverを入手します。
C#でのSeleniumの操作例は以下のようになります。
using OpenQA.Selenium; using OpenQA.Selenium.Chrome; using System; using System.IO; using System.Reflection; namespace chromeSample { class Program { static void Main(string[] args) { using (var driver = new ChromeDriver(Path.GetDirectoryName(Assembly.GetEntryAssembly().Location))) { driver.Url = "http://needtec.sakura.ne.jp/auto_demo/form1.html"; driver.FindElementByName("name").SendKeys("名前太郎"); driver.FindElementByName("mail").SendKeys("test@co.jp"); driver.FindElementByName("comment").SendKeys("猫猫子猫\n\r犬犬子犬"); // チェックボックス var chks = driver.FindElements(By.Name("q1[]")); chks[0].Click(); chks[2].Click(); // オプションボタン var opts = driver.FindElements(By.Name("men")); opts[1].Click(); // 複数選択 var sel = new OpenQA.Selenium.Support.UI.SelectElement(driver.FindElement(By.Name("osi[]"))); sel.DeselectAll(); sel.SelectByIndex(1); sel.SelectByIndex(2); // 登録ボタン押下 driver.FindElement(By.XPath("//input[@value='登録する']")).Click(); // OKボタンを押す var confirm = driver.SwitchTo().Alert(); confirm.Accept(); // 結果の出力 var results = driver.FindElementsByTagName("tr"); foreach(var rec in results) { Console.WriteLine(rec.Text); } Console.ReadLine(); driver.Quit(); } } } }ページの切り替え時に待機処理をいれていませんが、暗黙的にタイムアウトまでDOMをポーリングしています。このタイムアウトについては下記を参照してください。
The default value of timeouts on selenium webdriver
https://stackoverflow.com/questions/30114976/the-default-value-of-timeouts-on-selenium-webdriverPowerShellの場合
PowerShellでもC#と同様な実装が可能です。
下記のページのSelenium Client & WebDriver Language BindingsからC#のクライアントと操作したいブラウザのWebDriverをダウンロードしてください。https://www.seleniumhq.org/download/
クライアントをダウンロードすると以下のようなファイルが入っています。
- Selenium.Support.3.14.0.nupkg
- Selenium.WebDriver.3.14.0.nupkg
- Selenium.WebDriverBackedSelenium.3.14.0.nupkg
これは圧縮されているファイルなので拡張子をzipに変更すればDLLを取り出せます。
サポートしているバージョンが.NET3.5以上なのでWindows7に初期から入っているPowerShellでは動作しません。PowerShellでのサンプルは以下のようになります。
# 以下参考 # https://tech.mavericksevmont.com/blog/powershell-selenium-automate-web-browser-interactions-part-i/ $dllPath = Split-Path $MyInvocation.MyCommand.Path Add-Type -Path "$dllPath\WebDriver.dll" Add-Type -Path "$dllPath\WebDriver.Support.dll" # chromedriver.exeがあるディレクトリを指定 $driver = New-Object OpenQA.Selenium.Chrome.ChromeDriver("C:\tool\selenium\chromedriver_win32\") $driver.Url = "http://needtec.sakura.ne.jp/auto_demo/form1.html" $driver.FindElementByName("name").SendKeys("名前太郎") $driver.FindElementByName("mail").SendKeys("test@co.jp") # テキストエリア $comment = @" 猫猫子猫 犬犬子犬 "@ $driver.FindElementByName("comment").SendKeys($comment) # チェックボックス $chks = $driver.FindElements([OpenQA.Selenium.By]::Name("q1[]")) $chks[0].Click() $chks[2].Click() #オプションボタン $opts = $driver.FindElements([OpenQA.Selenium.By]::Name("men")) $opts[1].Click() #複数選択 $selElem = $driver.FindElement([OpenQA.Selenium.By]::Name("osi[]")) $sel = New-Object OpenQA.Selenium.Support.UI.SelectElement -ArgumentList $selElem $sel.DeselectAll(); $sel.SelectByIndex(1); $sel.SelectByIndex(2); # ボタン押下 $driver.FindElement([OpenQA.Selenium.By]::XPath("//input[@value='登録する']")).Click() $confirm = $driver.SwitchTo().Alert(); $confirm.Accept() # 結果表示 $results = $driver.FindElementsByTagName("tr"); foreach($rec in $results) { Write-Host $rec.Text } $driver.Quit() $driver.Dispose() Write-Host("OK")Pythonの場合
PythonでもSeleniumは使用可能です。まずpipコマンドでseleniumをインストールします。
pip install -U seleniumサンプルコードは以下のようになります。
from selenium import webdriver from selenium.webdriver.support.ui import Select driver = webdriver.Chrome("C:\\tool\\selenium\\chromedriver_win32\\chromedriver.exe") driver.get("http://needtec.sakura.ne.jp/auto_demo/form1.html") driver.find_element_by_name("name").send_keys("名前太郎"); driver.find_element_by_name("mail").send_keys("test@co.jp"); driver.find_element_by_name("comment").send_keys("猫猫子猫\n\r犬犬子犬"); # チェックボックス chks = driver.find_elements_by_name("q1[]") chks[0].click() chks[2].click() # オプションボタン opts = driver.find_elements_by_name("men") opts[1].click() # 選択 sel = Select(driver.find_element_by_name("osi[]")) sel.deselect_all() sel.select_by_index(1) sel.select_by_index(2) # ボタン押下 driver.find_element_by_xpath("//input[@value='登録する']").click() driver.switch_to.alert.accept() # 結果 results = driver.find_elements_by_tag_name("tr") for rec in results: print(rec.text) driver.close()NodeJsの場合
NodeJsでもSeleniumの操作は可能です。npmコマンドを使用してseleniumをインストールします。
npm install selenium-webdriver簡単なサンプルは以下のようになります。
// 以下参考 // https://qiita.com/tonio0720/items/70c13ad304154d95e4bc // https://stackoverflow.com/questions/26191142/selenium-nodejs-chromedriver-path // https://seleniumhq.github.io/selenium/docs/api/javascript/index.html const webdriver = require('selenium-webdriver'); const chrome = require('selenium-webdriver/chrome'); const path = 'C:\\tool\\selenium\\chromedriver_win32\\chromedriver.exe'; const service = new chrome.ServiceBuilder(path).build(); chrome.setDefaultService(service); (async () => { const driver = await new webdriver.Builder() .withCapabilities(webdriver.Capabilities.chrome()) .build(); await driver.get('http://needtec.sakura.ne.jp/auto_demo/form1.html'); await driver.findElement(webdriver.By.name("name")).sendKeys("名前太郎"); await driver.findElement(webdriver.By.name("mail")).sendKeys("test@co.jp"); await driver.findElement(webdriver.By.name("comment")).sendKeys("猫猫子猫\n\r犬犬子犬"); // チェックボックス let chks = await driver.findElements(webdriver.By.name("q1[]")); await chks[0].click(); await chks[2].click(); // オプションボタン let opts = await driver.findElements(webdriver.By.name("men")); await opts[1].click(); // 複数選択 let sel = await driver.findElements(webdriver.By.xpath("//select[@name='osi[]']/option")); await sel[1].click(); await sel[2].click(); // ボタン押下 await driver.findElement(webdriver.By.xpath("//input[@value='登録する']")).click(); await driver.switchTo().alert().accept(); // 結果取得 let results = await driver.findElements(webdriver.By.tagName("tr")); for (let i = 0; i < results.length; ++i) { console.log(await results[i].getText()); } driver.quit(); })();Seleniumで既に起動しているブラウザの操作は行えるか?
Seleniumを介さず起動していたブラウザの自動操作については公式にはサポートしていません。
下記に幾つかの回避法が紹介されていますが、あくまで非公式の内容になります。Can Selenium interact with an existing browser session?
https://stackoverflow.com/questions/8344776/can-selenium-interact-with-an-existing-browser-sessionSeleniumを使用する方法のまとめ
Seleniumを使用することで様々なブラウザを様々なプログラミング言語で操作できることができます。
またSeleniumIDEを使用することでプログラミングをせずにブラウザの自動操作がおこなえます。ただし、Flashページなどの画像認識を必要とする操作の場合は他の方法を検討してください。
たとえば以下のような方法があります。Sikulix1.1.4を使って画面の自動操作をする
https://qiita.com/mima_ita/items/8f653042ac9140e5023fC#やPowerShellで画面上の特定の画像の位置をクリックする方法
https://qiita.com/mima_ita/items/f7d2c38767bda8b35cbd拡張機能を作成する方法
ChromeやFirefoxで利用できる拡張機能を使用して表示中のページを自動操作することが可能です。
Chromeの拡張機能
https://developer.chrome.com/extensionsFirefoxの拡張機能
https://developer.mozilla.org/ja/docs/Mozilla/Add-ons/WebExtensions/Your_first_WebExtension以下はChromeの拡張機能を使用してページを自動操作後、操作結果をメッセージボックスで表示しています。
操作対象のページ
http://needtec.sakura.ne.jp/auto_demo/form1.html拡張機能を使った自動操作の仕組みは下記の通りです。
default_popupからcontent_scriptsに対して自動操作の開始指示をメッセージを使用して行います。
入力ページのcontent_scriptsは項目の入力とボタンの押下を行います。
出力ページのcontent_scriptsは出力ページの内容を取得してメッセージを使用してdefault_popupに内容を送信します。なお、ChromeとFirefoxの拡張機能は同じような実装で作成できます。
Chromeの拡張機能で自動操作
Chrome拡張機能での自動操作のサンプル
https://github.com/mima3/auto_sample/tree/master/auto_chrome_sample以下が実際の自動操作を行っているcontent_scriptになります。
content_input.jschrome.runtime.onMessage.addListener( function(request, sender, sendResponse) { console.log(request); let nameElem = document.getElementsByName('name'); nameElem[0].value = '名前太郎'; let mailElem = document.getElementsByName('mail'); mailElem[0].value = 'test@co.jp'; let commentElem = document.getElementsByName('comment'); commentElem[0].value = '猫猫子猫\n犬犬子犬'; // チェックボックス let chkElem = document.getElementsByName('q1[]'); chkElem[0].click(); chkElem[2].click(); // ラジオボタン let radioElem = document.getElementsByName('men'); radioElem[1].click(); // 選択項目 var itr = document.evaluate("//select[@name='osi[]']/option", document, null, XPathResult.UNORDERED_NODE_ITERATOR_TYPE, null ); var node = itr.iterateNext(); while(node) { if (node.textContent === '千鶴さん' || node.textContent === 'さおりん') { node.selected = true; } node = itr.iterateNext(); } // ボタン押下 // contents.jsでwindows.confirmを書き換えてもブラウザ側の処理に影響を与えない // そのため、window.confirmを書き換えるscritpをタグとして挿入する // 考え方は以下を参考 // https://qiita.com/suin/items/5e1aa942e654bce442f7 let scr = document.createElement("script"); scr.setAttribute('type', 'text/javascript'); scr.innerText = 'window.confirm = function () { return true; }'; document.body.appendChild(scr); setTimeout(function(){ //ここでやってもブラウザ上のwindow.confirmは影響ない。 var btnElem = document.evaluate("//input[@value='登録する']", document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null); btnElem.singleNodeValue.click(); }, 0); } );JavaScriptのDOM操作で入力項目を設定後、登録ボタンを押下します。
この際、confirmで確認ダイアログが表示されるため、window.confirmの処理を上書きしてダイアログが出ないようにしています。
content_scriptからブラウザで使用しているJavaScriptを更新するため、scriptタグを埋め込んでいます。
この考え方は下記を参考にしました。Chrome拡張開発: 拡張からページにJavaScriptを送り込みたい
https://qiita.com/suin/items/5e1aa942e654bce442f7Firefoxの拡張機能で自動操作
Firefox拡張機能での自動操作のサンプル
https://github.com/mima3/auto_sample/tree/master/auto_firefox_sample拡張機能での自動操作のまとめ
ブラウザの拡張機能を利用することでブラウザの自動操作が行えます。
この方法のメリットとしてはインターネットの接続がなくてもテキストエディタのみで自動操作を行うためのスクリプトが作成できることです。(ブラウザを開発者モードで動かしていいという条件は必要)もし、自動操作中にネイティブのアプリと連携が必要になった場合はNative Messagingを使用してください。このNaitiveMessageを使用したサンプルは以下にあります。
RPAツールを使用する方法
お高いRPAツールはブラウザの操作をサポートしている商品が多いです。
今回は小規模事業や個人利用なら無料でしようできるUiPath Communityを利用してChromeの操作を行います。ChromeをUiPathで操作する場合、Chromeの拡張機能をインストールする必要があるので、下記を参考にインストールしてください。
https://docs.uipath.com/studio/lang-ja/docs/installing-the-chrome-extension(1)UIPathで新規プロジェクトを作成します。言語はC#を選択します。
(2)「ブラウザを開く」アクティビティを追加します。
プロパティ 値 url "http://needtec.sakura.ne.jp/auto_demo/form1.html" ブラウザの種類 Chrome (3)「文字を入力」アクティビティを追加して「画面上で指定」でブラウザ上のテキスト入力項目を指定します。
(4)「文字を入力」アクティビティのプロパティを設定します。
(5)(3)~(4)を繰り返して「名前:」、「メールアドレス:」、「コメント:」を入力します。
プロパティ 値 表示名 文字を入力 'INPUT-名前' テキスト "名前太郎" フィールド内を削除 ON ウィンドウメッセージを送信 OFF 入力をシミュレート OFF
プロパティ 値 表示名 文字を入力 'INPUT-メールアドレス' テキスト "test@mail.co.jp" フィールド内を削除 ON ウィンドウメッセージを送信 ON ※デフォルトの挙動だとIMEが有効となり全角で入力されてしまう 入力をシミュレート OFF
プロパティ 値 表示名 文字を入力 'TEXTAREA-コメント' テキスト "猫猫子猫\n\r犬犬子犬" フィールド内を削除 ON ウィンドウメッセージを送信 OFF 入力をシミュレート OFF (6)「クリック」アクティビティを追加して「画面上で指定」でブラウザ上のクリックが必要な項目をを指定します。
(7)「クリック」アクティビティのプロパティを設定します。
(8)(5)~(6)を繰り返して「その1」、「その3」、「そば」をクリックします。
プロパティ 値 表示名 クリック 'INPUTーその1' ウィンドウメッセージを送信 ON(デフォルトだと挙動が安定しない) 入力をシミュレート OFF
プロパティ 値 表示名 クリック 'INPUTーその3' ウィンドウメッセージを送信 ON(デフォルトだと挙動が安定しない) 入力をシミュレート OFF
プロパティ 値 表示名 クリック 'INPUTーそば' ウィンドウメッセージを送信 ON(デフォルトだと挙動が安定しない) 入力をシミュレート OFF (9)リストを複数選択するために「JSスクリプトを挿入」アクティビティを追加します。
選択したJSスクリプトは下記の通りです。
select_multi.jsfunction selectmulti(e, aryStr) { var ary = JSON.parse(aryStr); var itr = document.evaluate("//select[@name='osi[]']/option", document, null, XPathResult.UNORDERED_NODE_ITERATOR_TYPE, null ); var node = itr.iterateNext(); while(node) { if (ary.indexOf(node.textContent) >= 0) { node.selected = true; } node = itr.iterateNext(); } }
プロパティ 値 スクリプトコード select_multi.js 入力パラメータ "[\"千鶴さん\",\"さおりん\"]" CTRLキーを押しながらのリスト項目をクリックする操作や、「複数の項目を選択」アクティビティを使用した実装だと動作しない場合がありました。
Web上のリストボックスで複数選択したい
https://forum.uipath.com/t/web/113531/9また、ここで指定したJavaScript中で日本語やハングルは使用しないでください。文字化けします。日本語などが必要な場合は引数で渡すようにしてください。
たとえば「alert("千鶴さん");」とかいうコードを埋め込むと以下のようになります。
(10)登録ボタンを押下するために「クリック」アクティビティを追加します。
プロパティ 値 表示名 クリック 'INPUT-登録' ウィンドウメッセージを送信 ON(デフォルトだと挙動が安定しない) 入力をシミュレート OFF (11)登録ボタン押下後の確認メッセージを閉じるために「画像をクリック」アクティビティを追加します。
なお、「select_multi.js」に以下のコードを追加してconfirm関数を上書きして確認メッセージを表示させないことも可能です。
let scr = document.createElement("script"); scr.setAttribute('type', 'text/javascript'); scr.innerText = 'window.confirm = function () { return true; }'; document.body.appendChild(scr);(12)登録後のページのデータを取得するために「データスクレイピング」を行います。
「データスクレイピング」アイコンを押下します。
「取得ウィザード」で「次へ」ボタンを押下します。
要素の選択が可能になるのでテーブルのセルを選択します。
「表全体からデータを抽出しますか?」の確認メッセージには「はい」を選択します。
「取得ウィザード」で「終了」ボタンを押下します。
「次へのリンクを指定」の確認メッセージには「いいえ」を選択します。
「データスクレイピング用のアクティビティが追加されます。
(13)「構造化データを抽出」アクティビティの「出力」プロパティに対してCTRL+Kを押下してresult変数を追加します
(14)「繰り返し(各行)」アクティビティを追加します。この際、コレクションには「result」変数を指定してください。
(15)「繰り返し(各行)」アクティビティに「一行を書き込み」アクティビティを追加します。
プロパティ 値 Text row[0].ToString() + " " + row[1].ToString() (16)これまでの操作を再生すると以下のようになります。
UiPathでのブラウザの自動操作のまとめ
UiPathを使用したメリットは以下の通りです。
・要素を画面から選択できる
・画像認識による自動操作ができる
・ブラウザ以外の自動操作が同じ操作感で行える。
・今回は説明してませんがUiPath Orchestratorで資産管理が容易になる逆にデメリットは以下の通りです。
・GUIでのプログラミングになるので、複雑な実装が困難である
・GUIなので変更点の差分を見るのが困難で、コードレビューが負担になる。※結局はxamlなのでテキストで差分はとれるが…
・なれないとハマるポイントが多い。
・UiPathの操作でDOMの要素を変更したりしているのでシステム試験等で使用する場合、妥当性を考える必要がある。
例:UiPathで操作した要素には以下のように「uipath_custom_id」という属性が追加されている。
UiPathは外部プログラムを呼び出す機能やPowerShellの実行が可能なのでブラウザの操作は別の手法で行うことも可能です。
なお、RPAで未経験者でもお手軽自動操作とかいう言説が大きくなっていますが、正直、WebアプリケーションやWindowsアプリケーションを組んだことのない人が簡単に使えると言われると大きな疑問が残ります。
逆にRPAツール不要論もありますが、UiPath Orchestratorの存在や、簡単なフローが頻繁に変わる業務形態における仕事の分担という観点で、そのRPA不要論についても絶対的な真理とは言えないでしょう。状況にあわせた組み合わせが必要と思います。
ブラウザのGUI上の操作をプログラム上で真似して自動化する方法のまとめ
ここまでで、ブラウザのGUI上の操作をプログラム上で真似して自動化する方法について紹介しました。
RPAツールを使える環境の場合、RPAツールは自動化を行う上で便利ではありますが、それを使うことを目的にしない方がいいです。必要に応じて別の方法をミックスして使うようにしましょう。
外部ライブラリを使用できる環境の場合、Seleniumを採用するのが一番楽だと思います。ChromeやFirefoxならSeleniumIDEで録画機能もついているので生産性は高いでしょう。
外部ライブラリが使用できない環境の場合、InternetExploreのCOM又は、ブラウザの拡張機能を使用することになります。
IEを使用する場合、操作対象のWebアプリケーションのサポート状況をよく確認しましょう。いずれの方法でブラウザ操作を自動化するにせよ以下の点は気をつけてください。
安易なSleepを使用しない
たとえば、適当に2秒待つという処理をいれた場合、ネットワークやPCの負荷状況によって動作しない可能性があります。
Sleepよりも以下で判断するようにしましょう。・ document.readyStatusなどを活用する
・ 特定の要素が出現したか、消えたかを見て判断する。
→SeleniumやUiPathでは、要素の出現消滅の検出をサポートする機能が提供されているテキスト入力は手動入力と異なる挙動をする可能性がある
テキスト入力を行う場合、手動で入力した場合と異なる挙動をする可能性があります。
たとえばキーボード操作のイベントで何らかの処理していたり、フォーカスの移動で何らかの処理をしていたりする場合です。
UiPathの場合、入力モードに以下の3種類があるので必要に応じて使いわけてください。・デフォルト:デバイスドライバ経由なので手入力にもっとも近い
・WindowsMessage:Windowsのメッセージを利用してテキストを入力している。
・Simulate:コントロールを直接操作しているそれ以外の場合は、JavaScriptのコード上でアプリが期待するイベントを無理やり起こす必要があります。
必要に応じてJavaScriptを利用する
複雑なUIの場合、画面要素を一々クリックするより、WebアプリケーションのJavaScriptを直接実行した方が早い場合があります。
また、いままでの例にでてきたように、alertやconfirmのような自動操作がし辛いポップアップの出現を抑止することが可能になります。テストの自動化についてはテスト方針をよく確認する
ツールをつかったテストは強力ですが、それはユーザが動かしたものと全く同一にならないことに注意してください。
たとえば、先にあげたJavaScriptを呼び出して処理を行った場合、それがテストとして妥当かどうかはテストの方針や観点しだいになります。UIの軽微な変更で動作しなくなることを忘れないこと
ブラウザの自動テストはUIの軽微な変更で簡単に動かなくなります。
たとえばリストの2番目と3番目の項目を選択するという実装だと、リストの項目が追加された場合に簡単に動作しなくなります。
これがなるべく影響を受けないような書き方をすることも可能ですが、限界はあります。もしブラウザの自動化スクリプトを重要な業務で使用している場合は、前に動いたスクリプトだからと安心せずWebアプリケーションの変更にともなって定期的に以前に書いた自動化スクリプトが動作するか確認するようにしてください。
ブラウザから送信しているデータを真似する方法
ブラウザの送受信データの確認方法
ブラウザから送信しているデータを真似して自動化する前にブラウザからどんなデータを送受信しているか調べる方法を説明します。
下記のページで登録ボタンを押した場合にどのようなデータを送信しているか確認してみましょう。
http://needtec.sakura.ne.jp/auto_demo/form1.htmlChromeでの送受信データの確認方法
(1)F12で開発者ツールを開き、「Network」タブを選択します。
(2)画面上で入力操作を行い「登録する」ボタンを押します。しばらくすると受信ファイルの一覧が表示されます。
(3)「regist1.php」などの受信ファイルを選択後に、Headersタブを選択すると送信データが確認できます。
(4)Responseタブを選択すると受信内容が確認できます。
Firefoxでの送受信データの確認方法
(1)F12で開発者ツールを開き、「ネットワーク」タブを選択します。
(2)画面上で入力操作を行い「登録する」ボタンを押します。しばらくすると受信ファイルの一覧が表示されます。
(3)「regist1.php」などの受信ファイルを選択します。
(4)パラメータタブでFormの送信情報を確認できます。
(5)応答タブでサーバーからのレスポンスデータを確認できます。
IE11での送受信データの確認方法
(1)F12で開発者ツールを開き、「ネットワーク」タブを選択します。
(2)画面上で入力操作を行い「登録する」ボタンを押します。しばらくすると受信ファイルの一覧が表示されます。
(3)「regist1.php」などの受信ファイルを選択します
(4)本文タブを選択し、さらに「要求本文」タブを選択するとFormの送信情報を確認できます。
(5)本文タブを選択し、さらに「応答本文」タブを選択するとサーバーからのレスポンスデータを確認できます。
旧Edgeでの送受信データの確認方法
(1)F12で開発者ツールを開き、「ネットワーク」タブを選択します。
(2)画面上で入力操作を行い「登録する」ボタンを押します。しばらくすると受信ファイルの一覧が表示されます。
(3)「regist1.php」などの受信ファイルを選択します
(4)本文タブを選択し、さらに「要求本文」タブを選択するとFormの送信情報を確認できます。
(5)本文タブを選択し、さらに「応答本文」タブを選択するとサーバーからのレスポンスデータを確認できます。
新Edgeでの送受信データの確認方法
Chromeと同じです。
単純なFormデータの送信例
下記のページのような単純なフォームのデータの送信例を説明します。
http://needtec.sakura.ne.jp/auto_demo/form1.htmlcurlコマンド
macやlinux系のOSならcurlコマンドを使用することで単純なフォームデータをPOSTすることが可能です。
windos10でもプリインストールされるようになったようですが、文字コードの問題があるので注意が必要です。また、PowerShellを使用しているとcurlコマンドが利用できますが、これはInvoke-WebRequestの別名です。以下はCentOS7でcurlコマンドを実行した例となります。
>curl -F "name=名前太郎" -F "mail=test@co.jp" -F "comment=コメント" -F "q1[]=その1" -F "q1[]=その3" -F "men=soba" -F "osi[]=千鶴さん" -F "osi[]=さおりん" http://needtec.sakura.ne.jp/auto_demo/regist1.php <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>sample</title> </head> <body> <table border="1"> <tr> <td>名前</td><td>名前太郎</td> </tr> <tr> <td>メールアドレス</td><td>test@co.jp</td> </tr> <tr> <td>コメント</td><td>コメント</td> </tr> <tr> <td>チェック</td> <td> その1, その3<br> </td> </tr> <tr> <td>めん</td><td>soba</td> </tr> <tr> <td>おし</td><td>千鶴さん,さおりん</td> </tr> </table> </body> </html>powershellの例
PowerShellではInvoke-WebRequestを利用してFormデータを送信可能です。
$data = @{ name='名前太郎'; mail='test'; comment=@" 猫猫子猫 犬犬子犬 "@; 'q1[0]'='その1'; 'q1[1]'='その3'; men='soba'; 'osi[0]'='千鶴さん'; 'osi[1]'='さおりん' } $ret = Invoke-WebRequest http://needtec.sakura.ne.jp/auto_demo/regist1.php -Method POST -Body $data -ContentType "application/x-www-form-urlencoded" $html = $ret.ParsedHtml $list = $html.getElementsByTagName("tr") for($i=0; $i -lt $list.length; $i++) { $item = $list[$i] Write-Host($item.innerText) [System.Runtime.Interopservices.Marshal]::ReleaseComObject($item) | Out-Null Remove-Variable item -ErrorAction SilentlyContinue } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null Remove-Variable list -ErrorAction SilentlyContinue [System.Runtime.Interopservices.Marshal]::ReleaseComObject($html) | Out-Null Remove-Variable html -ErrorAction SilentlyContinue [System.GC]::Collect() [System.GC]::WaitForPendingFinalizers() [System.GC]::Collect()ParsedHtmlはmshtmlになっているので、構文解析を容易に行えます。
なお、mshtmlはCOMなのでReleaseComObjectを実施して解放処理をしておいた方が無難です。なお、ページによっては文字化けする場合があります。この場合は以下のように文字コードを変換して出力します。
# 以下参考 # https://qiita.com/zaki-lknr/items/1ae3258d7b77c5e2a2ba $ret = Invoke-WebRequest http://needtec.sakura.ne.jp/auto_demo/form1.html $content = [System.Text.Encoding]::UTF8.GetString( [System.Text.Encoding]::GetEncoding("ISO-8859-1").GetBytes($ret.Content) ) Write-Host $contentVBAまたはVBSの場合
MSXML2.XMLHTTPを利用することでFormデータを送信可能です。
受信したHTMLはMSHTML.HTMLDocumentで解析しています。以下はVBSのサンプルになっていますがWScript.EchoをDebug.Print等に置き換えることでVBAでも流用できると思います。
' 参考: ' https://outofmem.tumblr.com/post/63052619242/vbaexcel-vba%E3%81%A7http%E9%80%9A%E4%BF%A1 ' https://stackoverflow.com/questions/9931429/parse-html-file-using-mshtml-in-vbscript Dim httpReq Set httpReq = CreateObject("MSXML2.XMLHTTP") Call httpReq.Open("POST", "http://needtec.sakura.ne.jp/auto_demo/regist1.php", False) Call httpReq.setRequestHeader("Content-Type", "application/x-www-form-urlencoded;charset=utf-8") Dim postData postData = "name=名前太郎&mail=test@co.jp&comment=猫猫" & vbCrLf & "子犬&q1[]=その1&q1[]=その2&men=soba&osi[]=千鶴さん&osi[]=さおりん" Call httpReq.Send(postData) Dim objHtml Set objHtml = CreateObject("htmlfile") call objHtml.write(httpReq.responseText) Dim list Set list = objHtml.getElementsByTagName("tr") Dim item For Each item In list WScript.Echo item.innerText NextPythonの例
http.clientを使用してFormデータを送信して結果を受信可能です。html.parserを利用することでHTMLの解析も行えます。おそらく、python3xが入っている環境ならどこでも使えると思います。
import http.client, urllib.parse from html.parser import HTMLParser # 結果ページを解析するパーサー class ResultParser(HTMLParser): def __init__(self): HTMLParser.__init__(self) self.flag = False def handle_starttag(self, tag, attrs): if tag == "td": self.flag = True def handle_data(self, data): if self.flag: print (data) self.flag = False conn = http.client.HTTPConnection('needtec.sakura.ne.jp') headers = { 'Content-type': ' application/x-www-form-urlencoded' } data = { 'name': '名前太郎', 'mail': 'test@co.jp', 'comment' : '猫猫子猫\n\r犬犬子犬', 'q1[0]' : 'その1', 'q1[1]' : 'その3', 'men' : 'soba', 'osi[0]' : '千鶴さん', 'osi[1]' : 'さおりん' } #r = requests.post('http://needtec.sakura.ne.jp/auto_demo/regist1.php', data=data) #print(r) #print(r.text) params = urllib.parse.urlencode(data) conn.request('POST', '/auto_demo/regist1.php', params, headers) response = conn.getresponse() print(response.status, response.reason) parser = ResultParser() # trの内容を出力 parser.feed(response.read().decode()) conn.close()外部ライブラリを使う場合
requestsパッケージを使うとデータの送受信が、Beautiful Soupを使うとHTMLの解析が楽になります。
import requests from bs4 import BeautifulSoup data = { 'name': '名前太郎', 'mail': 'test@co.jp', 'comment' : '猫猫子猫\n\r犬犬子犬', 'q1[0]' : 'その1', 'q1[1]' : 'その3', 'men' : 'soba', 'osi[0]' : '千鶴さん', 'osi[1]' : 'さおりん' } r = requests.post('https://needtec.sakura.ne.jp/auto_demo/regist1.php', data=data) print(r.status_code, r.reason) soup = BeautifulSoup(r.text) for tr in soup.find_all('tr'): print('------------------------') print(tr.text)認証があるページの例
単純なフォームの送信例はPOSTを一回送信するだけで済みましたが、認証処理やページの不正遷移防止が行われているWebアプリについてはサーバからの情報を受け取ってそれを基にデータを送信する必要があります。
今回はbitnamiから取得できるRedmineのVMでチケット登録を行うサンプルを見てみます。
VMのもろもろの設定はTestLinkで設定したときと同様に行えます。Redmineでログインしてチケットを登録するには以下の手順を踏む必要があります。
- ログインページを取得する。
- サーバーはヘッダーにセッションID、HTML中に認証トークン文字を埋め込んでログイン用のページを返す。
- セッションIDをリクエストヘッダに設定し、リクエストボディに認証トークン、ユーザ名、パスワード、ログイン後の遷移ページ(チケット登録画面)を指定してログイン処理を行う。
- サーバーはログインに成功したらチケット登録画面を返す。この際、認証トークン文字が新しいものに変更される。
- セッションIDをリクエストヘッダに設定し、リクエストボディに認証トークン、チケット情報を指定してチケット登録処理を行う。
PowerShellの例
PowerShellでRedmineのチケットを登録するには以下のようになります。
# エラーが起きたらとめる $ErrorActionPreference = "Stop" # サーバから取得したCookieの値からキーを指定して値を取得する function get_key_value($value, $key) { $tmp = $value.substring($value.indexof($key) + $key.length) $ret = $tmp.substring(0, $tmp.indexof(';')) return $ret } # DOMを解析して指定の名前の指定の属性を取得する function get_attribyte_value($html, $elem_name, $attr_name) { $elems = $html.getElementsByName($elem_name) $elem = $elems[0] $attrs = $elem.attributes $attr = $attrs[$attr_name] $ret = $attr.value [System.Runtime.Interopservices.Marshal]::ReleaseComObject($elems) | Out-Null [System.Runtime.Interopservices.Marshal]::ReleaseComObject($elem) | Out-Null [System.Runtime.Interopservices.Marshal]::ReleaseComObject($attrs) | Out-Null [System.Runtime.Interopservices.Marshal]::ReleaseComObject($attr) | Out-Null return $ret } ################################## #Redmineの設定値 ################################## $redmine_host = "192.168.0.200" # サーバ名 $redmine_project = "test1" # プロジェクト名 $username = "user" $password = "pass" ################################## # ログインページを初回アクセスしてセッションIDとcsrf-tokenを取得する ################################## $ret = Invoke-WebRequest "http://$redmine_host/login" -Method GET # セッションID取得 $cookie = $ret.Headers['Set-Cookie'] $session_id = get_key_value $ret.Headers['Set-Cookie'] '_redmine_session=' # ログインページのcsrf-token取得 $html = $ret.ParsedHtml $csrf_token = get_attribyte_value $html 'csrf-token' 'content' [System.Runtime.Interopservices.Marshal]::ReleaseComObject($html) | Out-Null # セッション情報作成 $session = New-Object Microsoft.PowerShell.Commands.WebRequestSession $cookie = New-Object System.Net.Cookie $cookie.Name = "_redmine_session" $cookie.Value = $session_id $cookie.Domain = $redmine_host $session.Cookies.Add($cookie); ################################## # ログイン処理。 # ログイン後はチケット登録画面へ ################################## $login_data = @{ authenticity_token = $csrf_token; back_url = "http://$redmine_host/projects/$redmine_project/issues/new"; username = $username; password = $password; } $ret = Invoke-WebRequest "http://$redmine_host/login" -Method POST -WebSession $session -Body $login_data -ContentType "application/x-www-form-urlencoded" # csrf-token取得 $html = $ret.ParsedHtml $csrf_token = get_attribyte_value $html 'csrf-token' 'content' [System.Runtime.Interopservices.Marshal]::ReleaseComObject($html) | Out-Null ################################## # チケット登録 ################################## Write-Host "チケット登録........................................................" $title = Get-Date -format "yyyyMMddHHmmss" $ticket_data = @{ 'utf8' = '✓'; authenticity_token = $csrf_token; 'issue[is_private]' = 0; 'issue[tracker_id]' = 1; 'issue[subject]' = "自動登録 $title"; 'issue[description]' = "わっふるわっふる"; 'issue[status_id]' = 1; 'was_default_status' = 1; 'issue[priority_id]' = 2; 'issue[start_date]' = '2019-10-10'; 'issue[due_date]' = ''; 'issue[done_ratio]' = 0; 'commit' = '作成' } $ret = Invoke-WebRequest "http://$redmine_host/projects/$redmine_project/issues" -Method POST -WebSession $session -Body $ticket_data -ContentType "multipart/form-data" $html = $ret.ParsedHtml Write-Host $html.title [System.Runtime.Interopservices.Marshal]::ReleaseComObject($html) | Out-NullPythonの例
HTMLの解析がしんどいのでBeautiful Soupを使用した方がいいでしょう。
import requests from bs4 import BeautifulSoup import datetime ############################################## # redmineの情報 ############################################## redmine_host = "192.168.0.200" # サーバ名 redmine_project = "test1" # プロジェクト名 username = "user" password = "password" # セッションの作成 session = requests.session() # ログインページの取得 ret = session.get('http://' + redmine_host + '/login') print(ret.status_code, ret.reason) ret.raise_for_status() session_id = ret.cookies['_redmine_session'] soup = BeautifulSoup(ret.text, 'html.parser') elem_token = soup.find('meta', {'name': 'csrf-token'}) csrf_token = elem_token['content'] # ログイン処理 cookies = { redmine_host : session_id } login_data = { 'authenticity_token' : csrf_token, 'back_url' : "http://' + redmine_host + '/projects/' + redmine_project + '/issues/new", 'username' : username, 'password' : password } ret = session.post('http://' + redmine_host + '/login', data=login_data, cookies=cookies) print(ret.status_code, ret.reason) ret.raise_for_status() # チケット登録 print('チケット登録................................') soup = BeautifulSoup(ret.text, 'html.parser') elem_token = soup.find('meta', {'name': 'csrf-token'}) csrf_token = elem_token['content'] ticket_data = { 'utf8' : '✓', 'authenticity_token' : csrf_token, 'issue[is_private]' : 0, 'issue[tracker_id]' : 1, 'issue[subject]' : "自動登録 " + str(datetime.datetime.now()), 'issue[description]' : "わっふるわっふる", 'issue[status_id]' : 1, 'was_default_status' : 1, 'issue[priority_id]' : 2, 'issue[start_date]' : '2019-10-10', 'issue[due_date]' : '', 'issue[done_ratio]' : 0, 'commit' : '作成' } ret = session.post('http://' + redmine_host + '/projects/' + redmine_project + '/issues', data=ticket_data, cookies=cookies) print(ret.status_code, ret.reason) ret.raise_for_status() soup = BeautifulSoup(ret.text, 'html.parser') print(soup.title)ブラウザから送信しているデータを真似する方法のまとめ
ブラウザを介さないのでブラウザより簡単にかつ高速で自動操作が行えます。
同時にそれは、デメリットになる場合があります。
たとえば、JavaScriptでクライアントサイドで動的にページを作成している場合、その処理は動作しません。つまり、ブラウザで操作したときと同様のDOMの構成が返ってくるとは限りません。この手法を結合試験やシステム試験で使用する場合は、注意してください。
仮にテストデータの入力に使う場合であっても、システム上本来作成できないデータが作成されてしまう場合があるからです。試験の観点に合わせて慎重に導入してください。また、ブラウザの自動操作と同様にWebアプリケーションの変更によって今まで動いていた自動化スクリプトが動作しなくなるリスクはあるので注意してください。
Webアプリケーションが提供しているAPIを利用する方法
もっともリスクの少ないWebアプリケーションの自動化の方法です。
ただしWebアプリケーションがAPIを提供しているかどうかは個別の仕様次第になります。Redmineのチケット登録の例
これまでにRedmineでチケット登録を行うサンプルをいくつか記述しました、Redmineが提供しているAPIを利用することでシンプルに実装することができます。
まずRedmineの管理画面でRESTAPIを有効にしてください。
すると個人設定画面でAPIキーが表示されます。このAPIを使用してRedmineを操作します。
PowerShellの例
チケット用のXMLを作成してPOSTするだけです。
この際、APIキーをヘッダに付与して送信します。################################## #Redmineの設定値 ################################## $redmine_host = "192.168.0.200" # サーバ名 $apikey = "60076966cebf71506ae3f2391da649235a2b1d46" $title = Get-Date -format "yyyyMMddHHmmss" $xml = @" <issue> <project_id>1</project_id> <subject>RESTAPIテスト $title</subject> <description>試験</description> </issue> "@ # セッション情報作成 $headers = @{ 'X-Redmine-API-Key' = $apikey; 'Content-Type' = 'text/xml'; } # 文字化けして登録されるなら以下をいれる $sendData = [System.Text.Encoding]::UTF8.GetBytes($xml) $ret = Invoke-WebRequest http://$redmine_host/issues.xml -Headers $headers -Method POST -WebSession $session -Body $sendData Write-Host $ret.ContentPythonの場合
import requests import datetime xml = """ <issue> <project_id>1</project_id> <subject>RESTAPIテスト python {0}</subject> <description>試験</description> </issue> """.format(str(datetime.datetime.now())) headers = { 'X-Redmine-API-Key' : '60076966cebf71506ae3f2391da649235a2b1d46', 'Content-Type' : 'text/xml' } r = requests.post('http://192.168.0.200/issues.xml', data=xml.encode('utf-8'), headers=headers) print(r.status_code, r.reason) print(r.text)なお、PythonでやるならPython Redmineあたりのライブラリを使用したほうが楽だと思います。
共通的な注意事項
ここまででWebアプリケーションの自動化の方法についていくつか方法を説明しました。
最後に共通的な注意事項を述べておきたいと思います。できることと、やっていいことは違う
おそらくここまでで、多くのWebアプリケーションを自動で操作することが可能になったと思います。
しかしながら、できることと、やっていいことは違うということを常に心がけてください。API経由以外の自動操作はWebアプリケーション側が想定していない操作になる可能性があります。つまり、いつ動かなくなってもおかしくありませんし、仮に動くからといってやっていい操作とは限りません。
場合によっては規約違反に問われることになります。たとえば広告ブロックして云々とか、複数人で遊ぶブラウザゲームの自動化は、かなりの確率で規約違反になります。
Webアプリケーションを自動化する際は必ず規約を確認してから行うようにしましょう。また、そういった規約が明記されておらず、不正に当たらないと考えられる場合であっても自動操作はWebアプリケーション側に想定外の負荷を与えることがあります。たとえば、2010年には情報取得目的に図書館の蔵書検索システムに高頻度(1秒に1アクセス程度)のリクエストを送信して偽計業務妨害容疑で逮捕された岡崎市立中央図書館事件があったことは心に留めておくべきでしょう。
特に社内システムの場合、品質が悪い傾向があるので、根回しをしつつやっておくか、すぐに停止てきる状況かで実施し始めた方が無難です。
武器や流派にこだわるな
「武器や流派にこだわるな」という格言は、およそ20年前の名著「アジャイルソフトウェア開発 (The Agile Software Development Series) 」の「付録B3 武蔵」の項目にでてきた格言です。
今回、色々な自動化の方法を紹介はしましたが、それは自動化を行うための選択肢を増やして「こだわりを捨ててもらう」意図がありました。
RPAツールは素晴らしく自動化の手助けになります。しかしながら、あきらかに別の方法でやったほうが楽な場合でもRPAツールにこだわるケースがよくみられます。例えばブラウザ画面を介しての自動操作に慣れ親しんだ人はcurlコマンドで済むようなことまで慣れ親しんだという理由だけで困難な技法を選択してしまうケースをよく見かけます。
逆にcurlコマンドでは行うのが困難なことを、それだけでやろうとするケースも同じくらいよく見ます。普段は使用しない技法であっても必要があるなら採用すべきですし、逆に最も自分が慣れ親しんだ技法であっても状況にそぐわなければ捨てるべきです。
自動化スクリプトの管理方法を考えよう
1度動かせばすむスクリプトなのか、定期的に動かすスクリプトなのかによって、スクリプトの管理方法が変わります。
定期的に動かすスクリプトの場合、常にWebアプリケーションのバージョンアップで動作しなくなるというリスクがあります。
このリスクをどう扱うか考えましょう。たとえば、実際やってエラーとなった時点で修正する時間的余裕のあるものであれば、その時に考えればいいでしょう。
しかし、そういう時間的余裕が確保できないようなスクリプトの場合は、事前にそれを検出する必要があります。
定期的にスモークテストを行う計画を立てるか、Webアプリケーションのリリースノートをチェックする工数をとるか、いずれにせよなんらかの対策が必要になります。あとは、自動化スクリプトの意図を複数の人間が理解して、メンテナンスできる体制を作るよう必要があります。人間は割と簡単にいなくなります。一誰も意図が分からない自動化スクリプトが動き続ける状態にならないように気を付けましょう。
自動化のコストを見積もる場合、これらの作ったあとのメンテナンスのコストについて忘れずに考えておきましょう。
自動化を目的にするのはやめよう
慣れてくると、なんらかの方法で多くのことが自動化できるようになりますが、それを目的とするのはやめましょう。
重大な障害対応を放置して、優先度の低い自動化スクリプトを書いても意味はありません。
全体の状況をみて、効果のありそうなところを自動化しましょう。無理ならあきらめよう
どうしても自動化できないこともあります。
素直にあきらめて別の事をしましょう。参考
- Internet Explorer C++ Reference
- powershellのIEを操作するスクリプトの中のgetElementByIdを使う箇所でエラーが起こる
- PowerShell Exception 0x800A01B6 while using getElementsByTagName, getElementsByName or getElementByID
- Exception from HRESULT: 0x800A138A At line......
- Cant create HTML document from Hwnd using C#
- Selenium実践入門
- Webブラウザ自動化ツール「Selenium IDE」の今までとこれから
- The default value of timeouts on selenium webdriver
- https://www.seleniumhq.org/
- PowerShell & Selenium: Automate Web Browser Interactions – Part I
- Nodejsを使ってSeleniumでChromeを動かす
- Selenium Nodejs CHROMEDRIVER path
- selenium-webdriver
- Can Selenium interact with an existing browser session?
- https://developer.chrome.com/extensions
- https://developer.mozilla.org/ja/docs/Mozilla/Add-ons/WebExtensions/Your_first_WebExtension
- Chrome拡張開発: 拡張からページにJavaScriptを送り込みたい
- UiPath Community
- Installing the Chrome Extension
- Web上のリストボックスで複数選択したい
- https://kashika.biz/uipath_orchestrator_01/
- https://curl.haxx.se/docs/manpage.html
- Windows 10 に curl がプリインストールされてた
- Invoke-WebRequestの文字化け
- http.client
- requestsパッケージ
- Beautiful Soup
- https://bitnami.com/stack/redmine/virtual-machine)
- 岡崎市立中央図書館事件
- アジャイルソフトウェア開発 (The Agile Software Development Series) 」
- [VBA]Excel VBAでHTTP通信
- Parse html file using MSHTML in VBScript


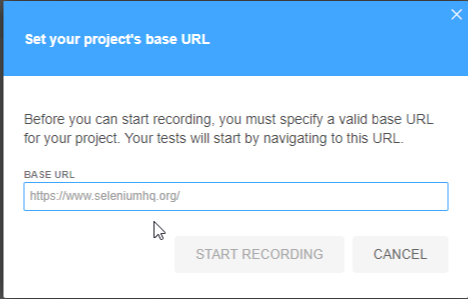
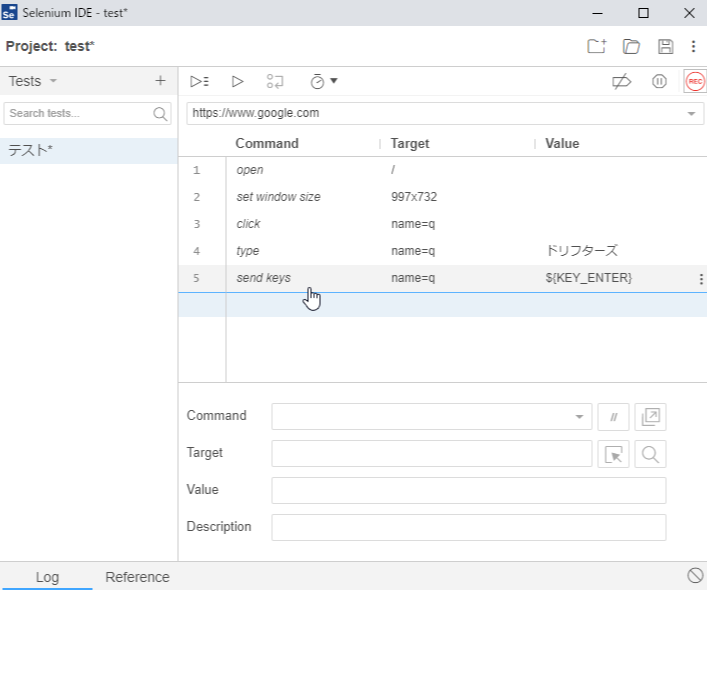

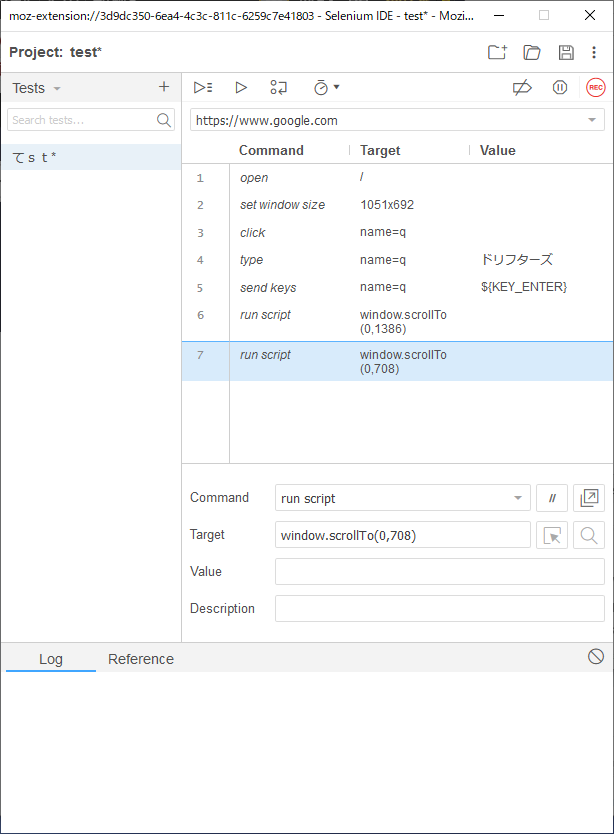

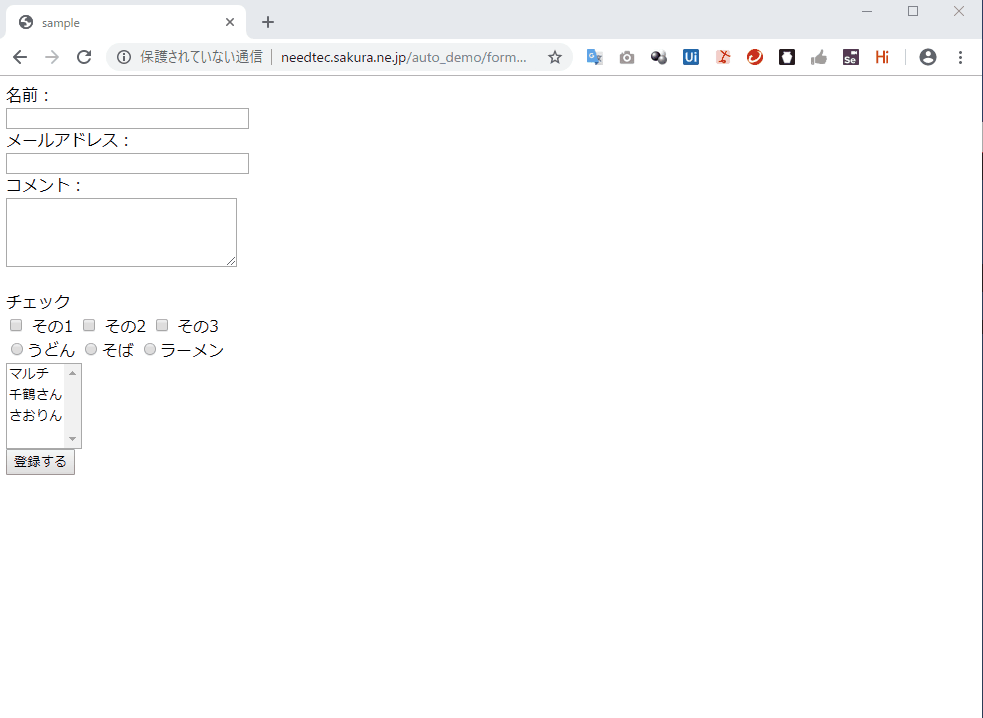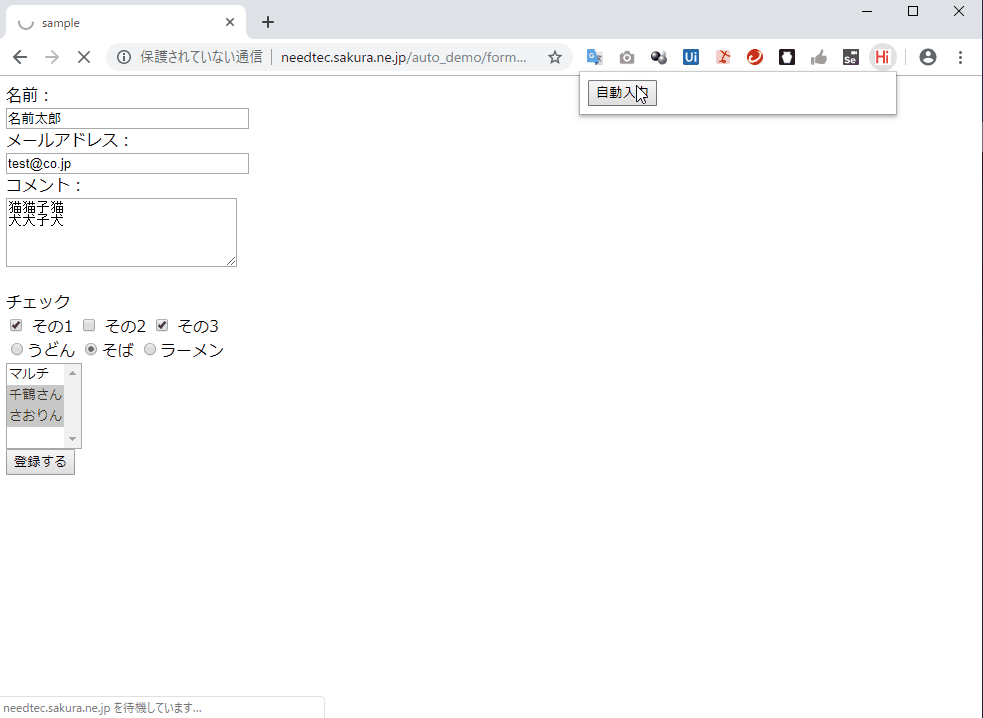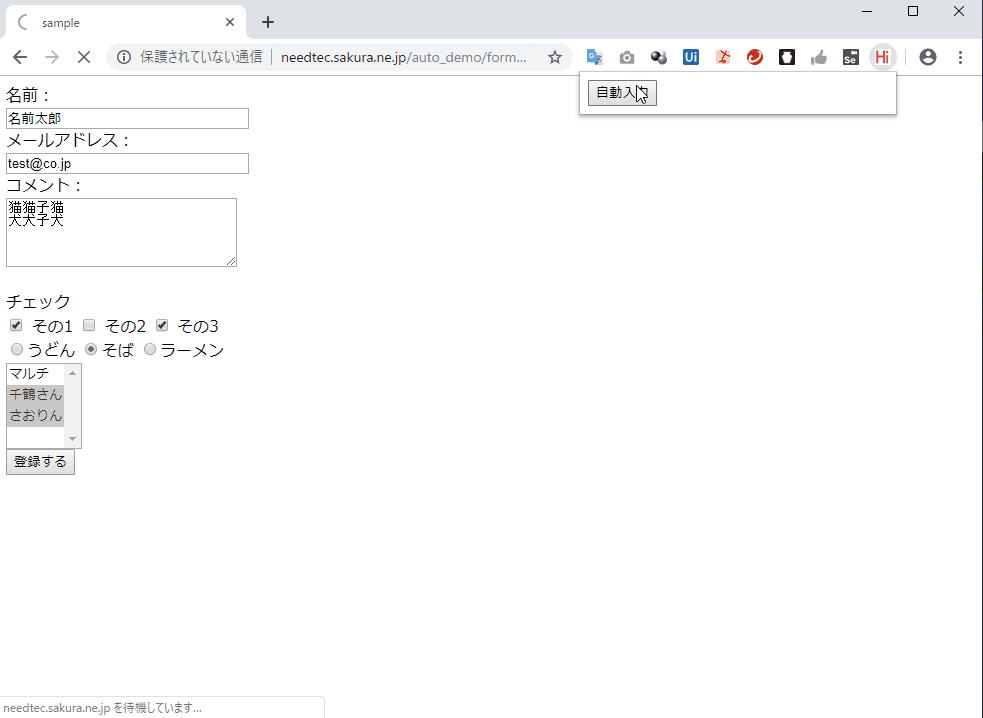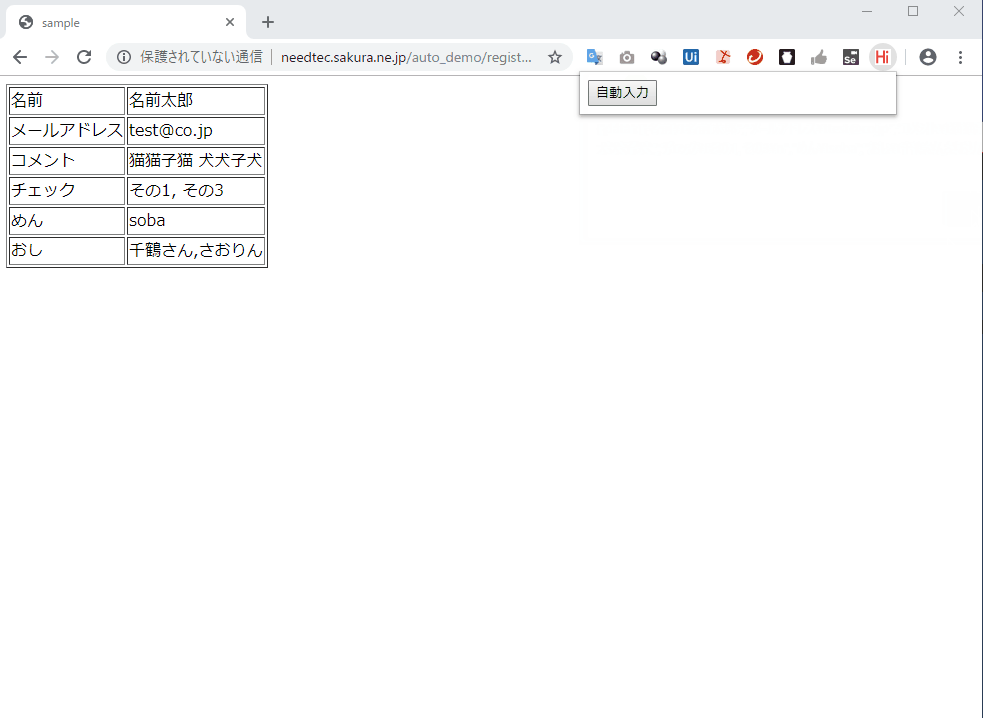
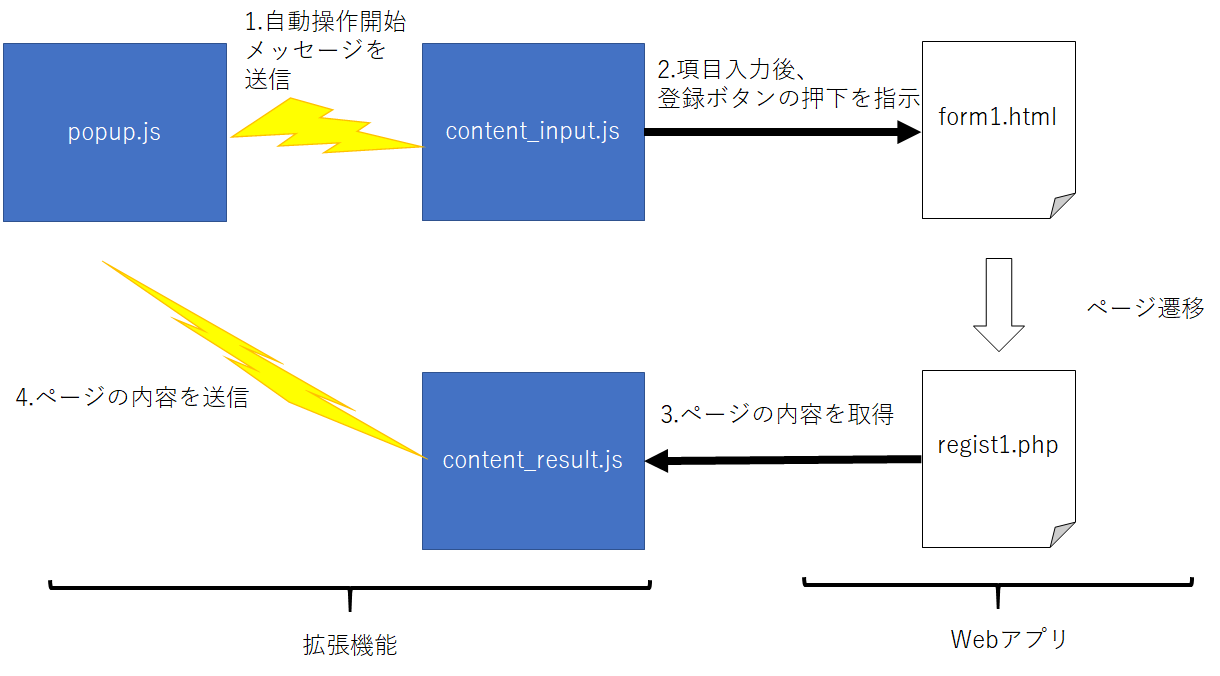
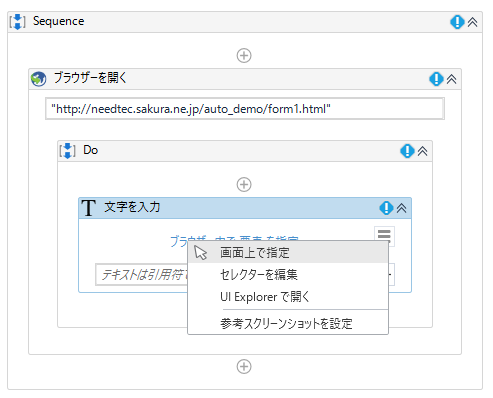
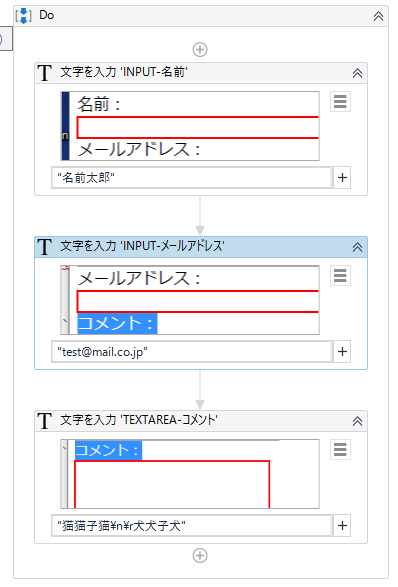
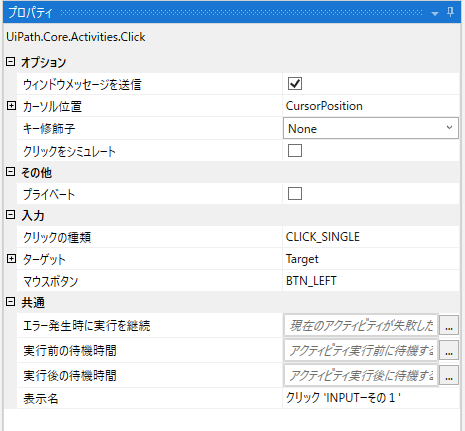

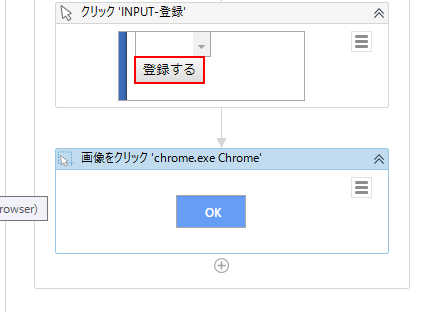
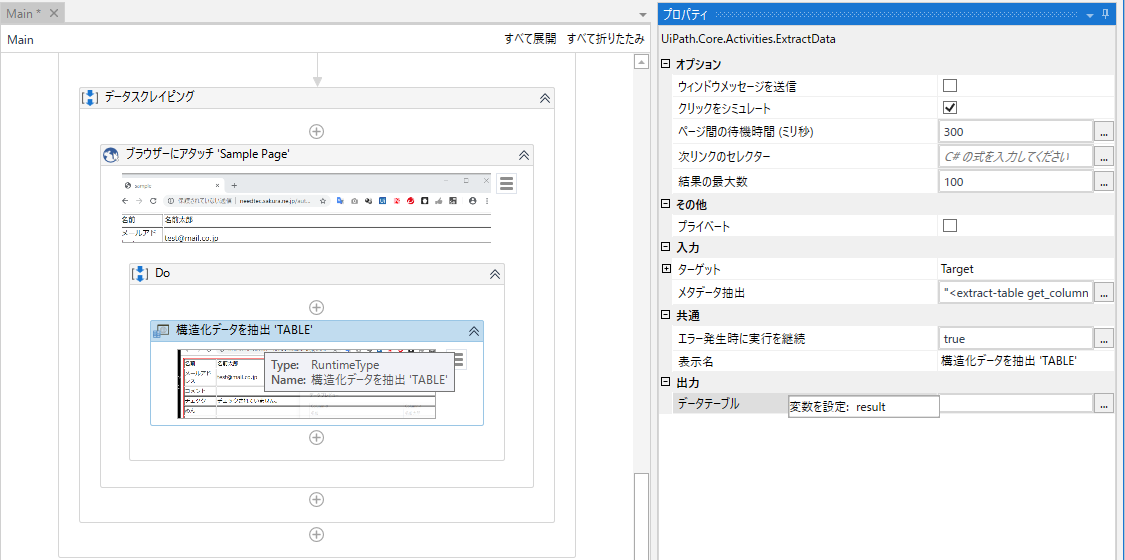


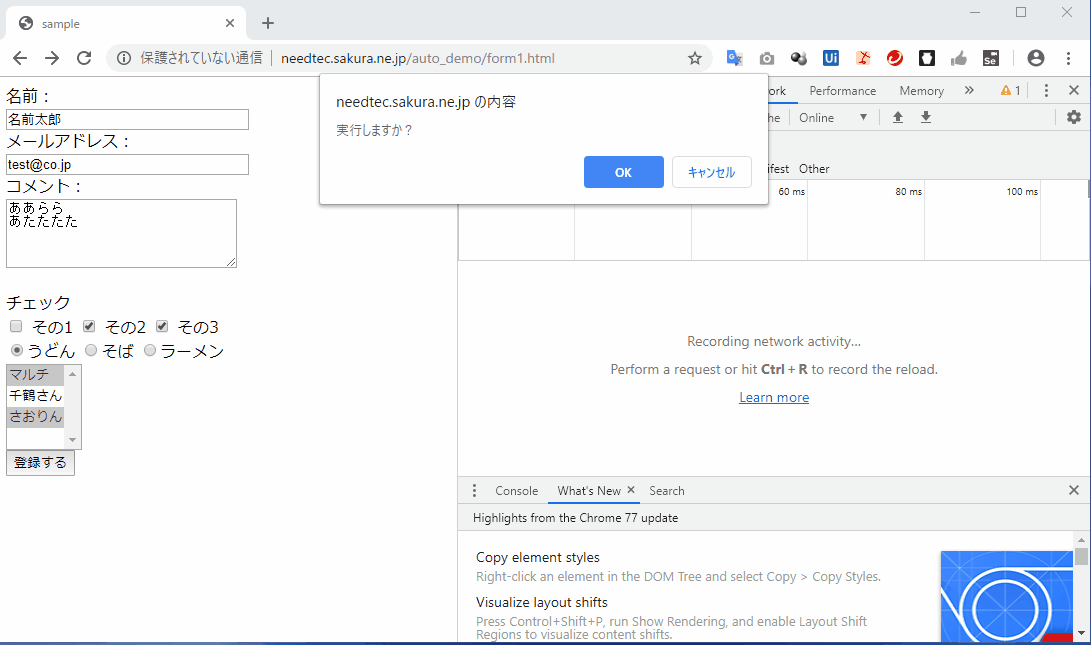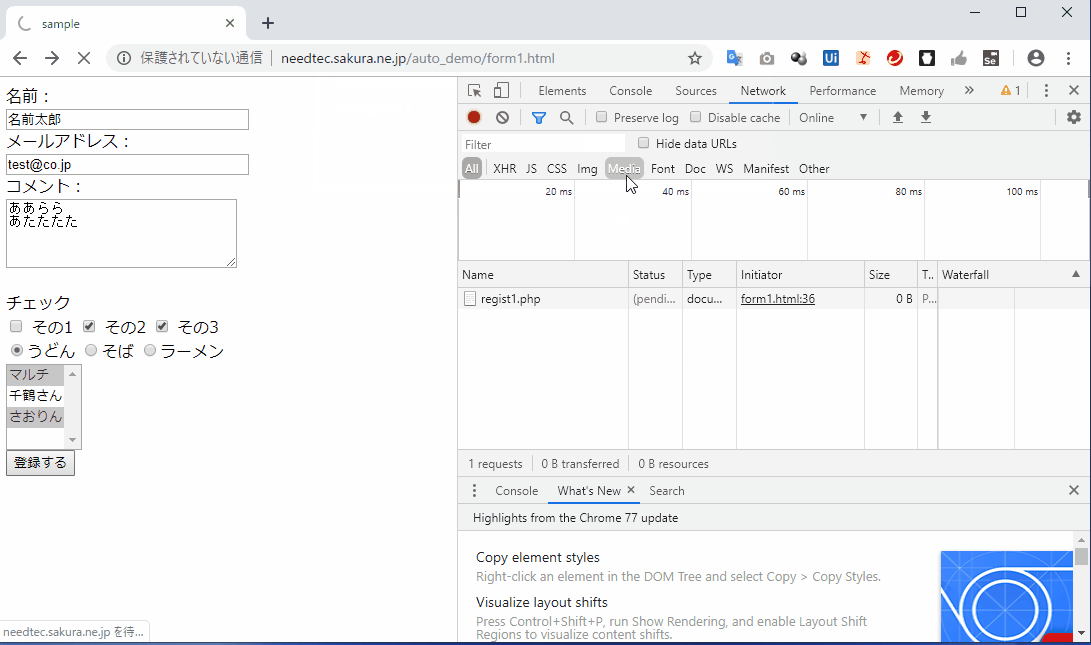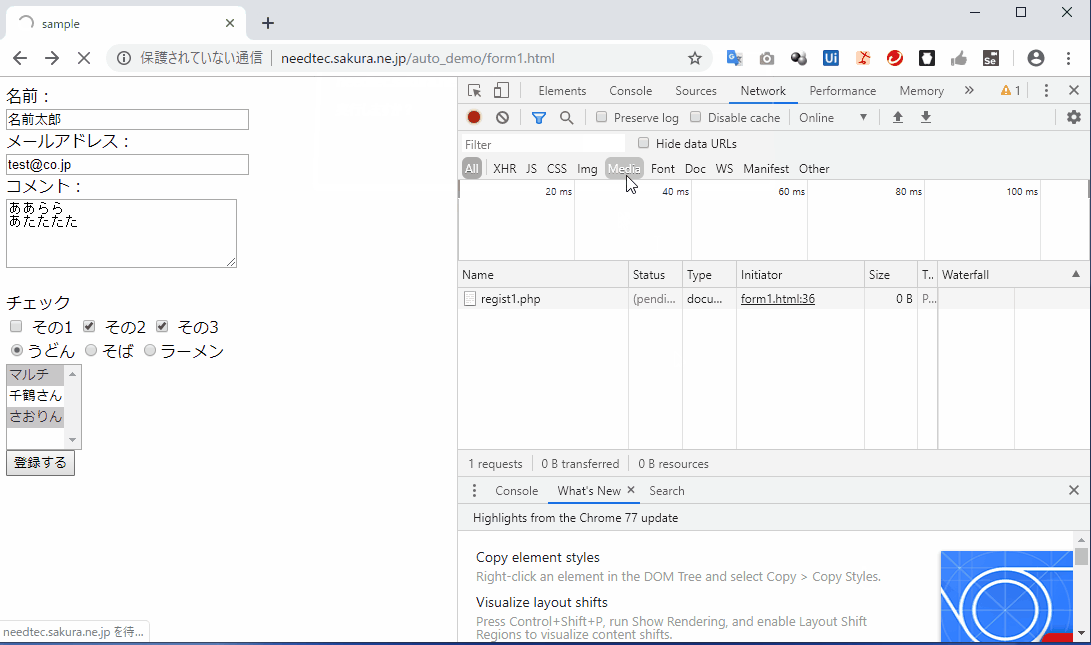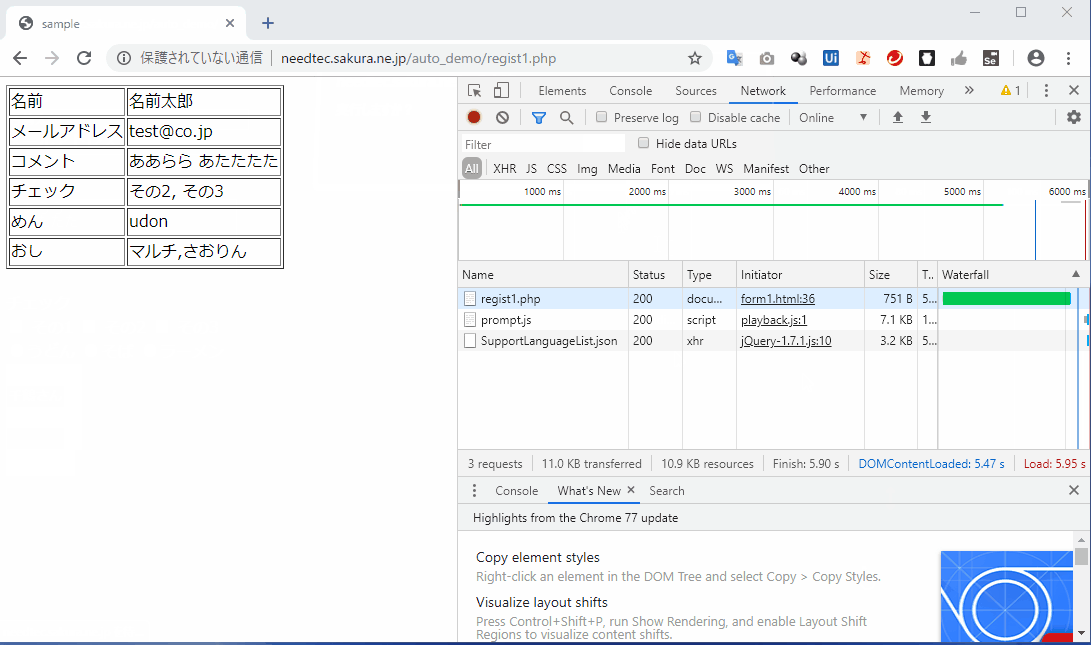
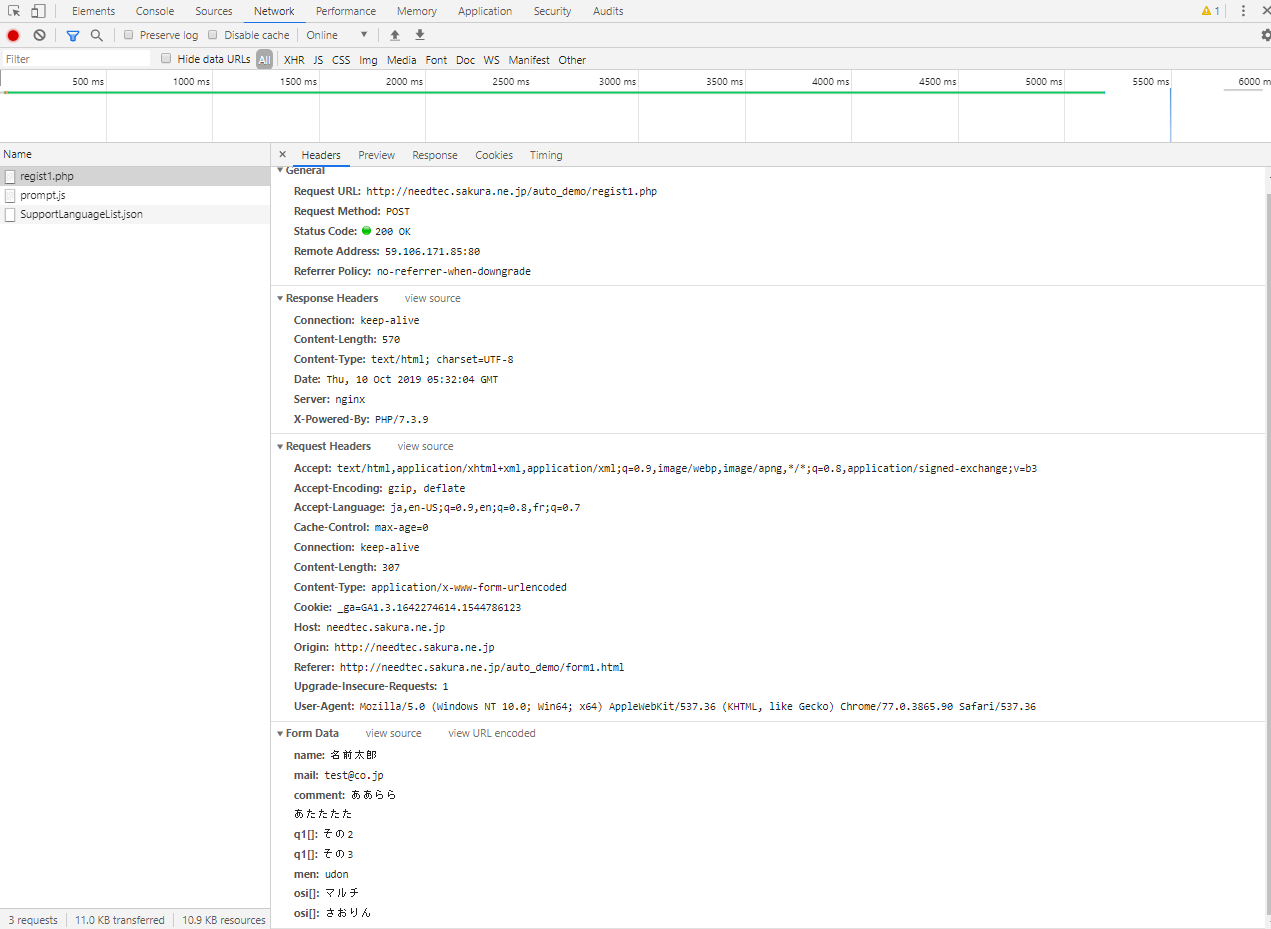
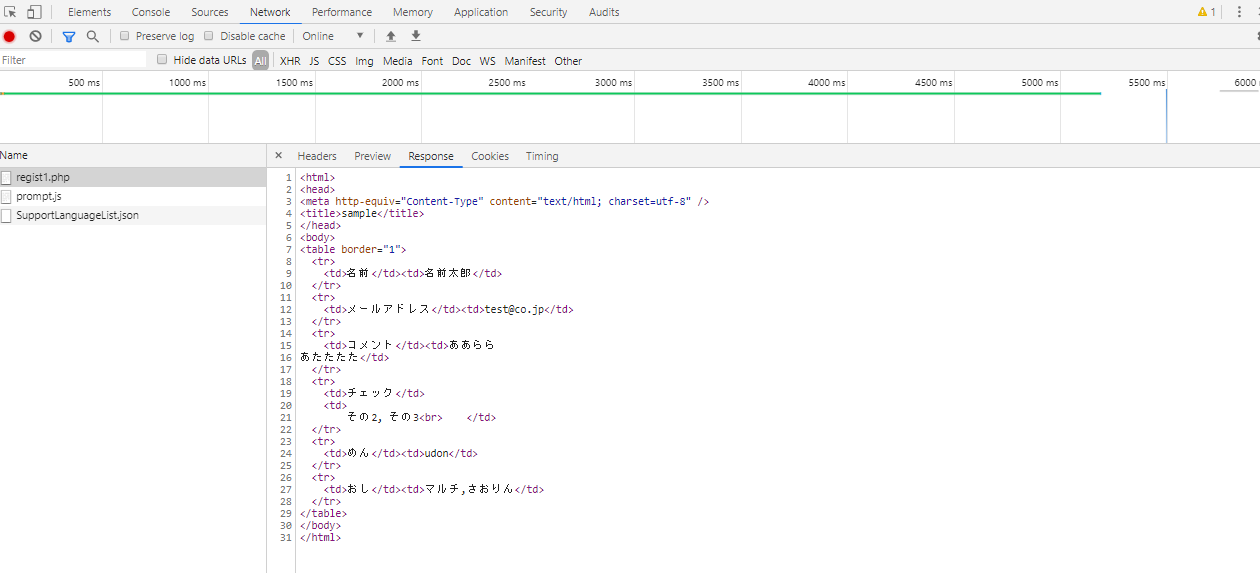
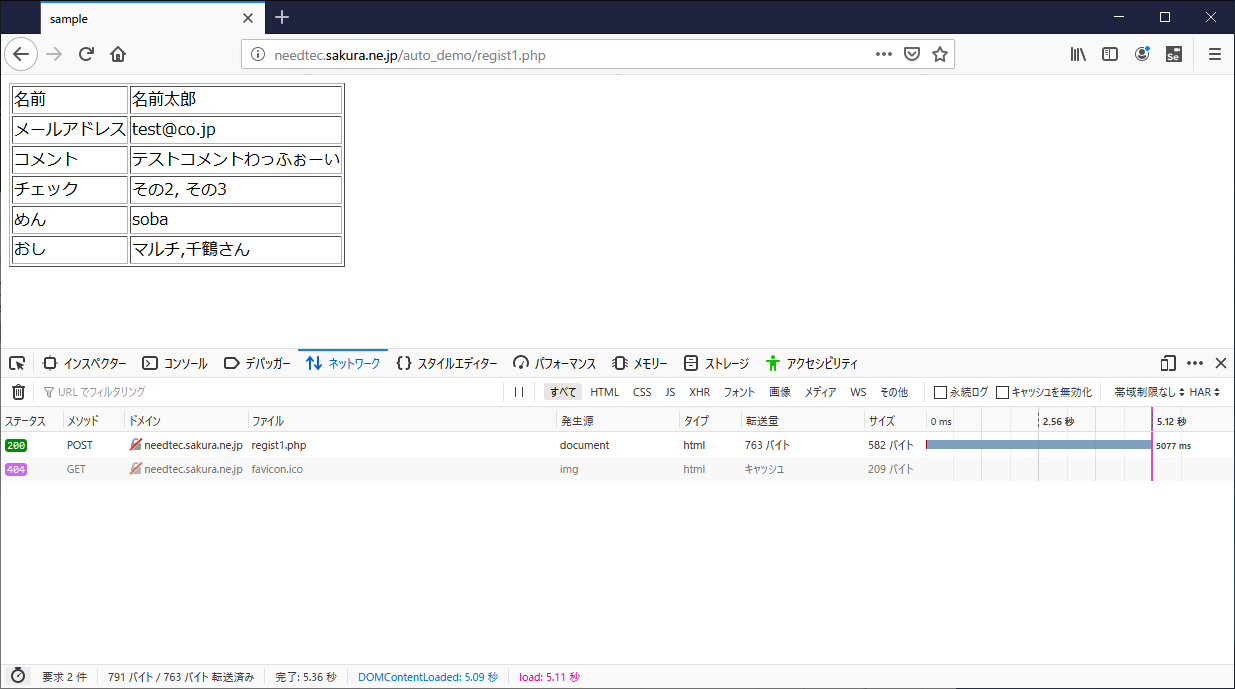
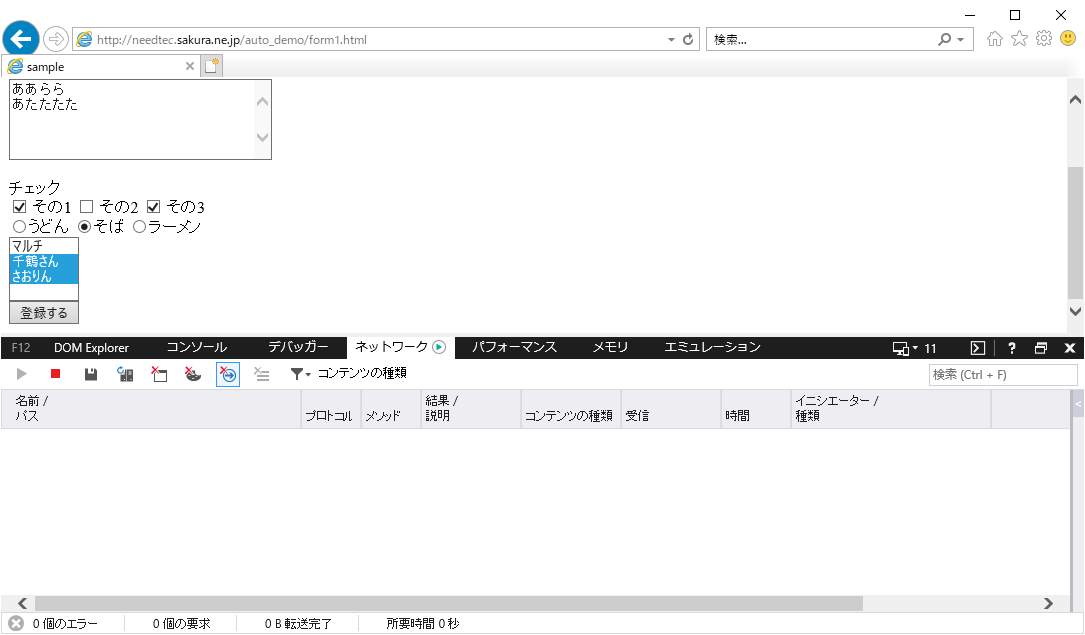
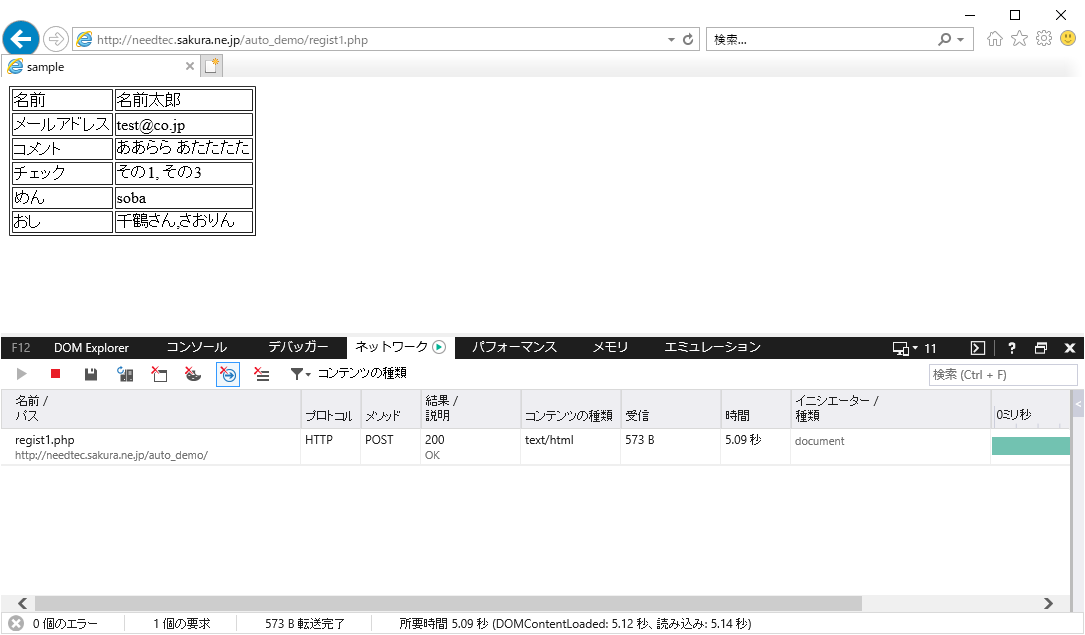
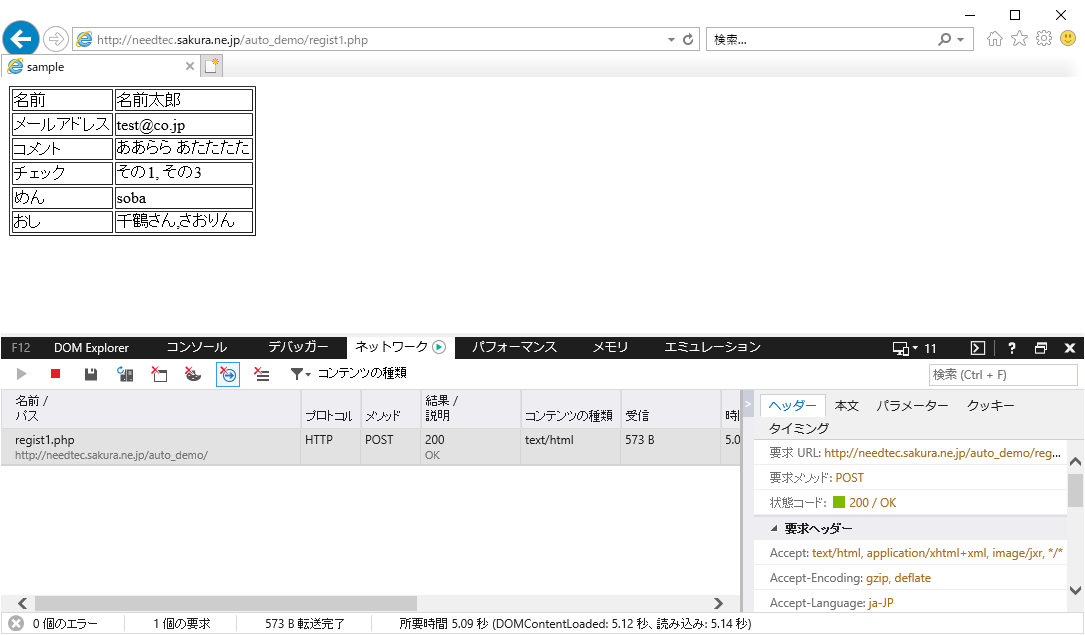
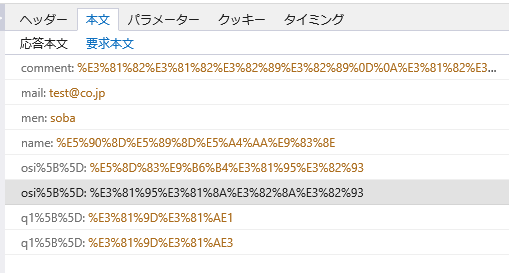
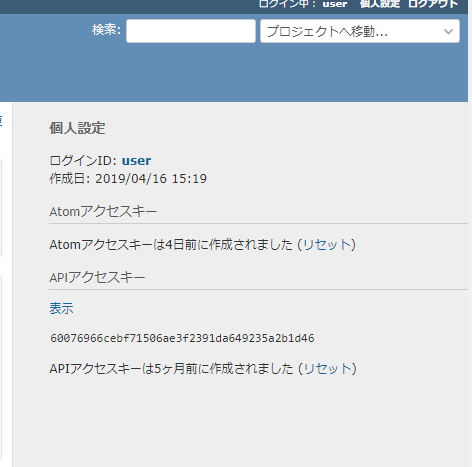
- 投稿日:2019-10-11T06:07:58+09:00
Webアプリケーションを自動で操作してみよう
はじめに
Webアプリケーションに対してある種の繰り返しの操作を行ったり、定型処理を定期的に自動実行したい場合がよくあります。
大きくわけてWebアプリケーションの自動化には3種類のやり方が存在します。1つ目はブラウザのGUI上の操作をプログラム上で真似して自動化する方法
2つ目はブラウザから送信しているデータを真似する方法
3つ目はWebアプリケーションが提供しているAPIを利用する方法1つ目のブラウザのGUI上の操作をプログラム上で真似して自動化する方法は直観的にわかりやすいと言われますが、実際は最も難しい自動化の方法になります。また、アプリケーションのバージョンアップに伴い自動化用のプログラムが動作しなくなる可能性があります。
2つ目のブラウザから送信しているデータを真似する方法はプログラムで実装しやすいやり方ではありますが、Webアプリケーションがどのようなデータを送信しているかなどを調べる必要があります。また、1つ目と同様にアプリケーションのバージョンアップに伴い自動化用のプログラムが動作しなくなる可能性があります。
3つ目のWebアプリケーションが提供しているAPIを利用する方法が最も簡単でかつ正確に自動操作を行えます。ただし、WebアプリケーションのAPIが提供されているかどうかは自動操作対象のWebアプリケーションの仕様次第です。
実験環境
Windows10+PowerShell5.1
Visual Studio 2019 + .NET Framework 4.6
Python 3.7.4
NodeJs v10.16.0
UiPath 2019.8.0-beta 83ブラウザのGUI上の操作をプログラム上で真似して自動化する方法
Windowsの場合、ブラウザを操作して自動化する方法も大きく4つの方法があります。
1つ目の方法はInternetExploreのCOMを利用する方法です。WindowsのInternetExploreに対してならば、なにもインストールすることなく、ブラウザの自動操作が可能になっています。ただし、InternetExploreの寿命自体が、長く持たない可能性があるので注意が必要です。(InternetExplore自体が持っても、対応するWebアプリケーションがInternetExploreのサポートを切る可能性が高いです)
2つ目の方法としてSeleniumを使用する方法です。外部のライブラリが必要になりますが、多くのブラウザがサポートされています。
3つ目の方法としてはブラウザが提供している拡張機能を作成する方法です。ChromeとFirefoxの場合、JavaScriptで作成できるので、外部のライブラリを導入する必要はありません。
4つ目の方法としてRPAツールを使用する方法です。ブラウザ上の要素について深く考えなくても、GUIベースで自動化が行えますが、コストの面で問題になります。
HTMLの要素を調べ方
どのような方法でブラウザを操作するとしても、HTMLがどのような要素で構成されているかを調べる必要があります。
ここではChromeでGoogleで検索する場合を例として画面上の要素を調べる方法を説明します。
1.ChromeにてF12キーを押下して開発者ツールを開きます。その後、「Elements」タブを選択してください。
2.[CTRL]+[Shift]+[C]を押下するか、下記のアイコンをクリックします。
3.調べたい要素にマウスを移動させます。
4.Elementsタブに選択した要素の内容が表示されます。今回の場合、以下のような内容が表示されます。
<input class="gLFyf gsfi" maxlength="2048" name="q" type="text" jsaction="paste:puy29d" aria-autocomplete="both" aria-haspopup="false" autocapitalize="off" autocomplete="off" autocorrect="off" role="combobox" spellcheck="false" title="検索" value="" aria-label="検索" data-ved="0ahUKEwiC0u6iu4nlAhXwyIsBHWwTBHcQ39UDCAQ">inputタグの属性が以下のようになっていることがわかります。
属性 値 class gLFyf gsfi name q 自動操作を行う場合、id、name、classなどを利用して要素を指定することになるので、属性値をメモしておきましょう。
5.同様にボタンについても属性を調べます。その結果は以下のようになります。
<input class="gNO89b" value="Google 検索" aria-label="Google 検索" name="btnK" type="submit" data-ved="0ahUKEwiC0u6iu4nlAhXwyIsBHWwTBHcQ4dUDCAo">
属性 値 class gNO89b name btnK ここで調べた属性を利用して要素を特定して自動操作を行うことになります。。
また、今回はChromeでのやり方を紹介しましたが、他のブラウザでも同様のことが可能です。同じWebアプリケーションを使用していてもブラウザによって出力される内容が異なる可能性もあるので、自動操作を行うブラウザを使用して要素を調べるようにしましょう。InternetExplore11の場合
IE11でもF12キーを押すことで開発者ツールが表示されます。
そこで「DOM Explore」タブを開いて要素の選択を行うことで要素の属性を調べることが可能です。
Edgeの場合
Edgeは将来Chromeベースのものに置き換わる可能性があります。
今回は旧EdgeとChromeベースの新Edge両方について説明します。旧Edge
F12キーで開発者ツールが表示されます。
そこで「要素」タブを開いて要素の選択を行うことで要素の属性を調べることが可能です。
新Edge
2019年10月時点でベータ版としてリリースされているEdgeの場合、F12キーで開発者ツールが表示されます。
Chromeと同様の操作で要素の属性を調べることが可能です。
Firefoxの場合
F12キーで開発者ツールが表示されます。
そこで「インスペクター」タブを開いて要素の選択を行うことで要素の属性を調べることが可能です。
HTMLの要素を調べる方のまとめ
多くのブラウザは開発者ツールをサポートしており、要素の属性を調べることが可能です。
Webアプリケーションの自動化では、この要素を特定して操作する必要があるので、お使いのブラウザでの要素の調べ方は覚えておきましょう。実際の自動操作の例は次章から解説します。
Internet ExploreのCOMを使用した自動化
Internet ExploreのCOMであるmshtmlを経由することでInternetExploreを自動操作できます。
COM(Component Object Model)
Microsoftが提唱した再利用を目的とした技術で、COMを用いて開発した部品はプログラム言語に依存せずに利用できるようになります。たとえば、説明したInternetExploreの操作やOfficeアプリケーションなどが外部から利用できるのは、COMのおかげです。IE操作の単純な例
実際のGoogleのトップページで任意の単語を検索するサンプルを見てみましょう。
WSHやVBAでのIE操作の単純な例
WSHのVBScritpで以下のように実装可能です。
以下コードはWScript.EchoをDebug.Print等に置き換えることでVBAでも流用できると思います。Dim ie Set ie = CreateObject("InternetExplorer.Application") ie.Visible = True call ie.Navigate("https://www.google.com/") 'ページが読み込まれるまで待機 Do While ie.Busy = True Or ie.readyState <> 4 WScript.Sleep 100 Loop Dim doc Set doc = ie.Document Dim txt Set txt = doc.getElementsByName("q") txt.item(0).value = "ドリフターズ" Dim btn Set btn = doc.getElementsByName("btnK") btn.item(0).click() 'ページが読み込まれるまで待機 Do While ie.Busy = True Or ie.readyState <> 4 WScript.Sleep 100 Loop Set doc = ie.Document Dim list Do While True Set list = doc.getElementsByClassName("LC20lb") If Not list is Nothing Then If list.length > 0 Then Exit Do End If End If WScript.Sleep 100 Loop Dim item For Each item In list WScript.Echo item.innerText Next ie.QuitこのサンプルではNavigateで指定のURLに移動したのち、getElementsByNameを使用して属性を取得して、値の設定とクリック操作を行っています。
その後,BusyとreadyStateを監視してページの切り替え完了を待ちます。
その後、検索結果の要素が出現するまで待機して、その要素の内容を出力します。PowerShellでのIE操作の単純な例
実はPowerShellやC#などの.NETでの実装は厄介です。結論から言えばやめといた方がいいです。
たとえば、よく見かける実装でGoogleとはてなブックマークを検索するスクリプトieng1.ps1とieng2.ps1を用意しました。Googleの検索
ieng1.ps1$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://www.google.com/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.getElementsByName("q") $txt[0].value = "ドリフターズ" # ボタン押下 $btn=$doc.getElementsByName("btnK") $btn[0].click() # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc = $ie.Document # LC20lbが表示されるまで待機 while($true) { $list = $doc.getElementsByClassName('LC20lb') if($list -and $list.length -ge 1) { break } Start-Sleep -Milliseconds 100 } foreach($i in $list){ Write-Host($i.innerText) } $ie.Quit() Write-Host("OK")はてなの検索
ieng2.ps1$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://b.hatena.ne.jp/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.getElementsByName("q") $txt[0].value = "ドリフターズ" # ボタン押下 $btn=$doc.getElementsByClassName("gh-search-button") $btn[0].click() # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc = $ie.Document # LC20lbが表示されるまで待機 while($true) { $list = $doc.getElementsByClassName('centerarticle-entry-title') if($list -and $list.length -ge 1) { break } Start-Sleep -Milliseconds 100 } foreach($i in $list){ Write-Host($i.innerText) } $ie.Quit() Write-Host("OK")この実装はいくつか問題を起こす可能性があります。
PowerShellでのIE操作の問題点
環境によっては動作しない
同じコードをPowerShell2.0+Windows7で動かそうとしたところ下記のエラーを表示して動作しません。
PS C:\share\webctrl> $ie.Document.getElementsByName("q") "getElementsByName" のオーバーロードで、引数の数が "1" であるものが見つかりません。 発生場所 行:1 文字:31 + $ie.Document.getElementsByName <<<< ("q") + CategoryInfo : NotSpecified: (:) []、MethodException + FullyQualifiedErrorId : MethodCountCouldNotFinこの問題は下記のフォーラムで議論されていますが、解決はしていません。
COMの解放処理を行っていない
上記のコードはCOMを.NETから利用しているにも関わらずReleaseComObjectを行っていません。
類似の問題として以下を参照してください。.NETを使ったOfficeの自動化が面倒なはずがない―そう考えていた時期が俺にもありました。
https://qiita.com/mima_ita/items/aa811423d8c4410eca71解放処理を行ったコードは以下のようになります。
$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://www.google.com/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.getElementsByName("q") $txt[0].value = "ドリフターズ" [System.Runtime.Interopservices.Marshal]::ReleaseComObject($txt) | Out-Null Remove-Variable txt -ErrorAction SilentlyContinue # ボタン押下 $btn=$doc.getElementsByName("btnK") $btn[0].click() [System.Runtime.Interopservices.Marshal]::ReleaseComObject($btn) | Out-Null Remove-Variable btn -ErrorAction SilentlyContinue ## ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null $doc = $ie.Document # LC20lbが表示されるまで待機 while($true) { $list = $doc.getElementsByClassName('LC20lb') if($list -and $list.length -ge 1) { break } if ($list) { [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null } Start-Sleep -Milliseconds 100 } for($i=0; $i -lt $list.length; $i++) { $item = $list[$i] Write-Host($item.innerText) [System.Runtime.Interopservices.Marshal]::ReleaseComObject($item) | Out-Null Remove-Variable item -ErrorAction SilentlyContinue } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null Remove-Variable list -ErrorAction SilentlyContinue $ie.Quit() Write-Host("OK") [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null Remove-Variable doc -ErrorAction SilentlyContinue [System.Runtime.Interopservices.Marshal]::ReleaseComObject($ie) | Out-Null Remove-Variable ie -ErrorAction SilentlyContinue [System.GC]::Collect() [System.GC]::WaitForPendingFinalizers() [System.GC]::Collect()同一プロセスで複数起動した場合にエラーになる
先にあげた2つのスクリプトはPowerShellを再起動した直後には、それぞれ動作しますが以下のように続けて実行するとエラーになります。
正常に動作する >powershell ./ieng1.ps1 >powershell ./ieng2.ps1 2つ目のスクリプトの実行でエラーになる >./ieng1.ps1 >./ieng2.ps1エラーの内容は下記の通りです。
HRESULT からの例外:0x800A01B6 発生場所 C:\dev\ps\webctrl\ieng2.ps1:14 文字:1 + $txt=$doc.getElementsByName("q") + ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ + CategoryInfo : OperationStopped: (:) [], NotSupportedException + FullyQualifiedErrorId : System.NotSupportedExceptionこの問題は以下の記事で言及されています。
- PowerShell Exception 0x800A01B6 while using getElementsByTagName, getElementsByName or getElementByID
- Exception from HRESULT: 0x800A138A At line......
getElementsByNameをIHTMLDocument3_getElementsByNameに置き換えて、getElementsByClassNameをInvokeMemberで呼び出すようにすれば回避できるようです。
Googleの検索(修正版)
ieok1.ps1$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://www.google.com/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.IHTMLDocument3_getElementsByName("q") $txt[0].value = "ドリフターズ" [System.Runtime.Interopservices.Marshal]::ReleaseComObject($txt) | Out-Null Remove-Variable txt -ErrorAction SilentlyContinue # ボタン押下 $btn=$doc.IHTMLDocument3_getElementsByName("btnK") $btn[0].click() [System.Runtime.Interopservices.Marshal]::ReleaseComObject($btn) | Out-Null Remove-Variable btn -ErrorAction SilentlyContinue ## ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null $doc = $ie.Document # LC20lbが表示されるまで待機 while($true) { $list = [System.__ComObject].InvokeMember("getElementsByClassName", [System.Reflection.BindingFlags]::InvokeMethod, $null, $doc, "LC20lb") if($list -and $list.length -ge 1) { break } if ($list) { [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null } Start-Sleep -Milliseconds 100 } for($i=0; $i -lt $list.length; $i++) { $item = $list[$i] Write-Host($item.innerText) [System.Runtime.Interopservices.Marshal]::ReleaseComObject($item) | Out-Null Remove-Variable item -ErrorAction SilentlyContinue } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null Remove-Variable list -ErrorAction SilentlyContinue $ie.Quit() Write-Host("OK") [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null Remove-Variable doc -ErrorAction SilentlyContinue [System.Runtime.Interopservices.Marshal]::ReleaseComObject($ie) | Out-Null Remove-Variable ie -ErrorAction SilentlyContinue [System.GC]::Collect() [System.GC]::WaitForPendingFinalizers() [System.GC]::Collect()はてなの検索(修正版)
ieok2.ps1$ie = New-Object -ComObject InternetExplorer.Application # IE起動 $ie.Visible = $true $ie.Navigate("https://b.hatena.ne.jp/") # ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } $doc=$ie.Document # 検索文字入力 $txt=$doc.IHTMLDocument3_getElementsByName("q") $txt[0].value = "ドリフターズ" [System.Runtime.Interopservices.Marshal]::ReleaseComObject($txt) | Out-Null Remove-Variable txt -ErrorAction SilentlyContinue # ボタン押下 $btn=[System.__ComObject].InvokeMember("getElementsByClassName", [System.Reflection.BindingFlags]::InvokeMethod, $null, $doc, "gh-search-button") $btn[0].click() [System.Runtime.Interopservices.Marshal]::ReleaseComObject($btn) | Out-Null Remove-Variable btn -ErrorAction SilentlyContinue ## ページが読み込まれるまで待機 while ($ie.Busy -or $ie.readyState -ne 4) { Start-Sleep -Milliseconds 100 } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null $doc = $ie.Document #表示されるまで待機 while($true) { $list = [System.__ComObject].InvokeMember("getElementsByClassName", [System.Reflection.BindingFlags]::InvokeMethod, $null, $doc, "centerarticle-entry-title") if($list -and $list.length -ge 1) { break } if ($list) { [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null } Start-Sleep -Milliseconds 100 } for($i=0; $i -lt $list.length; $i++) { $item = $list[$i] Write-Host($item.innerText) [System.Runtime.Interopservices.Marshal]::ReleaseComObject($item) | Out-Null Remove-Variable item -ErrorAction SilentlyContinue } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null Remove-Variable list -ErrorAction SilentlyContinue $ie.Quit() Write-Host("OK") [System.Runtime.Interopservices.Marshal]::ReleaseComObject($doc) | Out-Null Remove-Variable doc -ErrorAction SilentlyContinue [System.Runtime.Interopservices.Marshal]::ReleaseComObject($ie) | Out-Null Remove-Variable ie -ErrorAction SilentlyContinue [System.GC]::Collect() [System.GC]::WaitForPendingFinalizers() [System.GC]::Collect()PowerShellでのInternetExploreの操作のまとめ
辞めといた方がいいでしょう。
回避策を書いているページは色々見つかりますが、何故その事象が発生しているか、そしてなぜ回避することができたかを説明できているサイトは見つからず、ためしてみたら動作した以上のものではありません。
固定の環境で動かすスクリプトならばともかく、不特定多数の環境で動作するスクリプトでは採用を避けるべきでしょう。また、多くの場合、VBSやVBAで代替できるのでPowerShellにこだわる理由はないでしょう。どうしても、PowerShellで行いたい場合は、IE操作をしたプロセスを終了するようにすると安定しそうです。
すでに起動しているブラウザの操作方法
すでに起動しているIEを操作するにはIEのウィンドウに対してRegisterWindowMessageでWM_HTML_GETOBJECTメッセージを定義して送信することでHTMLDocumentを取得することになります。
Cant create HTML document from Hwnd using C#
https://stackoverflow.com/questions/20873885/cant-create-html-document-from-hwnd-using-c-sharpWin32 APIを直接実行できないWSHでは実現が難しいです。
VBAでの実装例
下記を参考にしてください。
VBAでInternetExplore上のJavaScriptを無理やり動かすよ!
https://qiita.com/mima_ita/items/fdff129a8db1153c9940C#での実装例
.NET経由になるのでCOMの解放処理を入れる必要があります。
(1)参照マネージャーのCOMタブでMicrosoft HTML Object Libraryを追加します。
これにより「Interop.MSHTML.dll」が作成されます。
Interop~.dllはtlbImpコマンドを使用することでコマンドラインで作成できますが、VisualStudioなどの開発ツールをインストールしていないと使えないと思います。(2)以下のような実装をします。下記のコードは.NET2.0でも動作します。
using System; using System.Collections.Generic; using System.Text; using System.Runtime.InteropServices; using MSHTML; using System.Diagnostics; namespace iesample { class Program { [DllImport("user32.dll", EntryPoint = "GetClassNameA")] public static extern int GetClassName(IntPtr hwnd, StringBuilder lpClassName, int nMaxCount); /*delegate to handle EnumChildWindows*/ public delegate int EnumProc(IntPtr hWnd, ref IntPtr lParam); [DllImport("user32.dll")] public static extern int EnumWindows(EnumProc lpEnumFunc, ref IntPtr lParam); [DllImport("user32.dll")] public static extern int EnumChildWindows(IntPtr hWndParent, EnumProc lpEnumFunc, ref IntPtr lParam); [DllImport("user32.dll", EntryPoint = "RegisterWindowMessageA")] public static extern int RegisterWindowMessage(string lpString); [DllImport("user32.dll", EntryPoint = "SendMessageTimeoutA")] public static extern int SendMessageTimeout(IntPtr hwnd, int msg, int wParam, int lParam, int fuFlags, int uTimeout, out UIntPtr lpdwResult); [DllImport("OLEACC.dll")] public static extern int ObjectFromLresult(UIntPtr lResult, ref Guid _riid, int wParam, ref MSHTML.IHTMLDocument2 _ppvObject); public const int SMTO_ABORTIFHUNG = 0x2; public Guid IID_IHTMLDocument = new Guid("626FC520-A41E-11CF-A731-00A0C9082637"); private static List<IHTMLDocument2> cacheList = new List<IHTMLDocument2>(); public static MSHTML.IHTMLDocument2 FindBrowser(string title) { MSHTML.IHTMLDocument2 ret; if (cacheList.Count == 0) { RefreshBrowserCache(); } ret = FindBrowserInCache(title); if (ret != null) { return ret; } RefreshBrowserCache(); return FindBrowserInCache(title); } public static MSHTML.IHTMLDocument2 FindBrowserInCache(string title) { MSHTML.IHTMLDocument2 ret; foreach(MSHTML.IHTMLDocument2 item in cacheList) { if (item.title.Contains(title)) { return item; } } return null; } public static void RefreshBrowserCache() { foreach (IHTMLDocument2 item in cacheList) { Marshal.ReleaseComObject(item); } cacheList.Clear(); EnumProc proc = new EnumProc(EnumIEWndProc); IntPtr lparam = IntPtr.Zero; EnumWindows(proc, ref lparam); } private static int EnumIEWndProc(IntPtr hWnd, ref IntPtr lParam) { StringBuilder className = new StringBuilder(128); GetClassName(hWnd, className, className.Capacity); EnumProc proc = new EnumProc(EnumIEServerWndProc); if (className.ToString().Equals("IEFrame") || className.ToString().Equals("TabWindowClass")) { IntPtr lparam = IntPtr.Zero; EnumChildWindows(hWnd, proc, ref lparam); } return 1; } private static int EnumIEServerWndProc(IntPtr hWnd, ref IntPtr lParam) { StringBuilder className = new StringBuilder(128); GetClassName(hWnd, className, className.Capacity); if (className.ToString().Equals("Internet Explorer_Server")) { IHTMLDocument2 doc = GetHTMLDocument(hWnd); if (doc != null) { cacheList.Add(doc); } } return 1; } private static IHTMLDocument2 GetHTMLDocument(IntPtr hWnd) { int nMsg = RegisterWindowMessage("WM_HTML_GETOBJECT"); if (nMsg == 0) { return null; } UIntPtr lRes; SendMessageTimeout(hWnd, nMsg, 0, 0, SMTO_ABORTIFHUNG, 1000, out lRes); if (lRes == UIntPtr.Zero) { return null; } Guid IID_IHTMLDocument = new Guid("626FC520-A41E-11CF-A731-00A0C9082637"); IHTMLDocument2 doc = null; int hr = ObjectFromLresult(lRes, ref IID_IHTMLDocument, 0, ref doc); return doc; } static void Main(string[] args) { IHTMLDocument3 doc = FindBrowser("Google") as IHTMLDocument3; IHTMLInputElement txt = doc.getElementsByName("q").item(0) as IHTMLInputElement; txt.value = "ドリフターズ"; IHTMLElement btn = doc.getElementsByName("btnK").item(0) as IHTMLElement; btn.click(); Marshal.ReleaseComObject(btn); Marshal.ReleaseComObject(txt); Marshal.ReleaseComObject(doc); } } }様々なコントロールを含むサンプルの例
様々なコントロールを含む以下のページの入力の自動化について考えてみます。
操作対象として以下のページを使用します。
http://needtec.sakura.ne.jp/auto_demo/form1.htmlこのページは「登録する」ボタンを押下することで確認メッセージが表示されて、「OK」の場合に登録処理を行うものとします。※
※実際はSleepしているだけでなにもしていないです。WSHやVBSでの操作例は以下のようになります。
Dim ie Set ie = CreateObject("InternetExplorer.Application") ie.Visible = True call ie.Navigate("http://needtec.sakura.ne.jp/auto_demo/form1.html") 'ページが読み込まれるまで待機 Do While ie.Busy = True Or ie.readyState <> 4 WScript.Sleep 100 Loop Dim doc Set doc = ie.Document ' INPUTBOX doc.getElementsByName("name").item(0).value = "名前太郎" doc.getElementsByName("mail").item(0).value = "test@co.jp" ' テキストエリア doc.getElementsByName("comment").item(0).innerText = "猫猫子猫" & vbCrLf & "犬犬子犬" ' チェックボックス doc.getElementsByName("q1[]").item(0).Checked = True doc.getElementsByName("q1[]").item(1).Checked = True ' ラジオボタン doc.getElementsByName("men").item(1).Checked = True ' 複数選択リスト Dim objSelect Set objSelect = doc.getElementsByName("osi[]").item(0) objSelect.getElementsByTagName("option").item(1).Selected = True objSelect.getElementsByTagName("option").item(2).Selected = True ' ボタン押下 ' 確認メッセージ処理を偽造する doc.parentWindow.ExecScript("confirm = function () { return true; }") doc.getElementsByTagName("input").item(8).click()確認ダイアログを突破する方法は色々ありますが、上記でやったようなJavaScirptのconfirmやalertを上書きしてしまうのが最も楽だと思います。
確認メッセージの処理を上書きしたくない場合
UIAutomation等を使用します。
確認メッセージが表示されるまで待機してボタンを押下するような処理を別スレッドかプロセスで起動します。WSHやVBAの場合は別プロセスでやった方が楽です。まず、確認メッセージを監視するようなスクリプトを記載します。
これはPowerShellで書いた方が楽だと思います。wait_confirm.ps1Add-Type -AssemblyName UIAutomationClient Add-Type -AssemblyName UIAutomationTypes Add-type -AssemblyName System.Windows.Forms $source = @" using System; using System.Windows.Automation; public class AutomationHelper { public static AutomationElement RootElement { get { return AutomationElement.RootElement; } } public static AutomationElement GetWindowByTitle(string title) { var rootCond = new PropertyCondition(AutomationElement.ClassNameProperty, "Alternate Modal Top Most"); var cond = new PropertyCondition(AutomationElement.NameProperty, title); var elementCollection = RootElement.FindAll(TreeScope.Children, rootCond); foreach(AutomationElement mainForm in elementCollection) { var win = mainForm.FindFirst(TreeScope.Children, cond); if (win != null) { return win; } } return null; } public static AutomationElement WaitWindowByTitle(string title, int timeout = 10) { DateTime start = DateTime.Now; while (true) { AutomationElement ret = GetWindowByTitle(title); if (ret != null) { return ret; } TimeSpan ts = DateTime.Now - start; if (ts.TotalSeconds > timeout) { return null; } System.Threading.Thread.Sleep(100); } } } "@ Add-Type -TypeDefinition $source -ReferencedAssemblies("UIAutomationClient", "UIAutomationTypes") # 5.0以降ならusingで記載した方が楽。 $autoElem = [System.Windows.Automation.AutomationElement] # ウィンドウ以下で指定の条件に当てはまるコントロールを1つ取得 function findFirstElement($form, $condProp, $condValue) { $cond = New-Object -TypeName System.Windows.Automation.PropertyCondition($condProp, $condValue) return $form.FindFirst([System.Windows.Automation.TreeScope]::Element -bor [System.Windows.Automation.TreeScope]::Descendants, $cond) } # 指定のAutomationIDのボタンを押下 function pushButtonById($form, $id) { $buttonElem = findFirstElement $form $autoElem::AutomationIdProperty $id $invElm = $buttonElem.GetCurrentPattern([System.Windows.Automation.InvokePattern]::Pattern) -as [System.Windows.Automation.InvokePattern] $invElm.Invoke() } # $dialog = [AutomationHelper]::WaitWindowByTitle("Web ページからのメッセージ", 30) if ($dialog -eq $null) { Write-Host "タイムアウト" } else { pushButtonById $dialog "1" Write-Host "終了" }あとはWSH側のボタン押下処理を以下のように修正します。
' ボタン押下 ' 確認メッセージ処理を別プロセスで行う Dim shell Set shell = CreateObject("WScript.Shell") shell.Run "C:\Windows\System32\WindowsPowerShell\v1.0\powershell -ExecutionPolicy RemoteSigned -File C:\dev\ps\webctrl\wait_confirm.ps1", 0, False doc.getElementsByTagName("input").item(8).click()Internet ExploreのCOMを使用した自動化のまとめ
VBAやVBSなどの何処でもはいっていそうなプログラミング言語で自動化できるのは強みです。
PowerShellでも行えますが、.NET経由だとCOMの解放処理が面倒だったり、動作が安定しない環境もあるので環境を制御できる場合のみに使用したほうがいいでしょう。また、InternetExploreのサポートがいつまで続くかわからない以上、外部のツールを導入可能である場合は、お勧めしません。
Seleniumを使用した自動化
様々なOS上の様々なブラウザを様々なプログラミング言語で自動操作するためのツールです。
Webアプリケーションをブラウザ操作で自動化する場合、もっともよく使われるツールになります。
Selenium実践入門などの良書が流通しているので、この章は飛ばしてそっちを読んだ方がいいと思います。SeleniumIDEを使用する例
ブラウザの操作を記憶する録画機能が提供されておりGUIベースで自動操作の処理を記載できます。録画した操作内容はスクリプトとして記録され、後で修正が可能です。また、別のプログラム言語で記載されたテストコードに変換することもできます。
以下はGoogle検索の操作をキャプチャした例になります。
SeleniumIDEはChromeまたはFirefoxの拡張機能として提供されています。
「あれ?SeleniumIDEって終わったんじゃなかったっけ?」という人は下記の経緯を参照してください。
Webブラウザ自動化ツール「Selenium IDE」の今までとこれから
https://www.valtes.co.jp/qbookplus/509ChromeでSeleniumIDEを使用する
(1)Chrome用のSeleniumIDEを拡張機能として追加します。
(2)ブラウザの上部にSeleniumIDEのアイコンが表示されるのでクリックします。
(3)SeleniumIDEのポップアップが表示されるので「Record a new test in new project」を選択します。
(4)「Name your new project」ダイアログが表示されるので任意のプロジェクト名を入力して「OK」ボタンを押します。
(5)「Set your projects's base URL」ダイアログが表示されるので操作元になるURLを入力します。たとえばGoogle検索をする例だと「https://www.google.com」を入力して「START RECORDING」ボタンを押下します。
(6)操作の記録が始まると右下に「Selenium IDE is recording...」と書かれた新しいブラウザが開きます。
このブラウザを使用して記録したい任意の操作を行います。(7)操作の記録を終了したい場合、「Selenium IDE」ウィンドウの右上の「Stop recording」アイコンを押します。
(8)「Name your new test」ポップアップが表示されるので任意のテスト名を入力して「OK」を押します。
(9)SeleniumIDE ウィンドウに今回操作した内容がスクリプトとして記録されます。
(10)記録したスクリプトは「Run Current Test」アイコンを押すことで再実行可能です。
また、JUnit や pytest、 JavaScript Mochaといった他のプログラミング言語のユニットテストとしてエクスポートすることが可能です。
FirefoxでSeleniumIDEを使用する
Firefox用のSeleniumIDEを拡張機能として追加します。
あとの操作はChromeと同じです。ただし、記録される操作はFirefoxとChromeで差異があります。
Firefoxの場合、ブラウザのスクロール操作が記録されていましたが、Chromeでは記録されていませんでした。
なお、手で同じコマンドを追加すると、再生はChromeでも動作しました。
プログラムからSeleniumを利用する
C#の場合
まず、NuGetでSelenium.WebDriverとSelenium.Supportに加えて操作したいブラウザのDriverを入手します。今回はChromeを操作したいので、Selenium.Chrome.WebDriverを入手します。
C#でのSeleniumの操作例は以下のようになります。
using OpenQA.Selenium; using OpenQA.Selenium.Chrome; using System; using System.IO; using System.Reflection; namespace chromeSample { class Program { static void Main(string[] args) { using (var driver = new ChromeDriver(Path.GetDirectoryName(Assembly.GetEntryAssembly().Location))) { driver.Url = "http://needtec.sakura.ne.jp/auto_demo/form1.html"; driver.FindElementByName("name").SendKeys("名前太郎"); driver.FindElementByName("mail").SendKeys("test@co.jp"); driver.FindElementByName("comment").SendKeys("猫猫子猫\n\r犬犬子犬"); // チェックボックス var chks = driver.FindElements(By.Name("q1[]")); chks[0].Click(); chks[2].Click(); // オプションボタン var opts = driver.FindElements(By.Name("men")); opts[1].Click(); // 複数選択 var sel = new OpenQA.Selenium.Support.UI.SelectElement(driver.FindElement(By.Name("osi[]"))); sel.DeselectAll(); sel.SelectByIndex(1); sel.SelectByIndex(2); // 登録ボタン押下 driver.FindElement(By.XPath("//input[@value='登録する']")).Click(); // OKボタンを押す var confirm = driver.SwitchTo().Alert(); confirm.Accept(); // 結果の出力 var results = driver.FindElementsByTagName("tr"); foreach(var rec in results) { Console.WriteLine(rec.Text); } Console.ReadLine(); driver.Quit(); } } } }ページの切り替え時に待機処理をいれていませんが、暗黙的にタイムアウトまでDOMをポーリングしています。このタイムアウトについては下記を参照してください。
The default value of timeouts on selenium webdriver
https://stackoverflow.com/questions/30114976/the-default-value-of-timeouts-on-selenium-webdriverPowerShellの場合
PowerShellでもC#と同様な実装が可能です。
下記のページのSelenium Client & WebDriver Language BindingsからC#のクライアントと操作したいブラウザのWebDriverをダウンロードしてください。https://www.seleniumhq.org/download/
クライアントをダウンロードすると以下のようなファイルが入っています。
- Selenium.Support.3.14.0.nupkg
- Selenium.WebDriver.3.14.0.nupkg
- Selenium.WebDriverBackedSelenium.3.14.0.nupkg
これは圧縮されているファイルなので拡張子をzipに変更すればDLLを取り出せます。
サポートしているバージョンが.NET3.5以上なのでWindows7に初期から入っているPowerShellでは動作しません。PowerShellでのサンプルは以下のようになります。
# 以下参考 # https://tech.mavericksevmont.com/blog/powershell-selenium-automate-web-browser-interactions-part-i/ $dllPath = Split-Path $MyInvocation.MyCommand.Path Add-Type -Path "$dllPath\WebDriver.dll" Add-Type -Path "$dllPath\WebDriver.Support.dll" # chromedriver.exeがあるディレクトリを指定 $driver = New-Object OpenQA.Selenium.Chrome.ChromeDriver("C:\tool\selenium\chromedriver_win32\") $driver.Url = "http://needtec.sakura.ne.jp/auto_demo/form1.html" $driver.FindElementByName("name").SendKeys("名前太郎") $driver.FindElementByName("mail").SendKeys("test@co.jp") # テキストエリア $comment = @" 猫猫子猫 犬犬子犬 "@ $driver.FindElementByName("comment").SendKeys($comment) # チェックボックス $chks = $driver.FindElements([OpenQA.Selenium.By]::Name("q1[]")) $chks[0].Click() $chks[2].Click() #オプションボタン $opts = $driver.FindElements([OpenQA.Selenium.By]::Name("men")) $opts[1].Click() #複数選択 $selElem = $driver.FindElement([OpenQA.Selenium.By]::Name("osi[]")) $sel = New-Object OpenQA.Selenium.Support.UI.SelectElement -ArgumentList $selElem $sel.DeselectAll(); $sel.SelectByIndex(1); $sel.SelectByIndex(2); # ボタン押下 $driver.FindElement([OpenQA.Selenium.By]::XPath("//input[@value='登録する']")).Click() $confirm = $driver.SwitchTo().Alert(); $confirm.Accept() # 結果表示 $results = $driver.FindElementsByTagName("tr"); foreach($rec in $results) { Write-Host $rec.Text } $driver.Quit() $driver.Dispose() Write-Host("OK")Pythonの場合
PythonでもSeleniumは使用可能です。まずpipコマンドでseleniumをインストールします。
pip install -U seleniumサンプルコードは以下のようになります。
from selenium import webdriver from selenium.webdriver.support.ui import Select driver = webdriver.Chrome("C:\\tool\\selenium\\chromedriver_win32\\chromedriver.exe") driver.get("http://needtec.sakura.ne.jp/auto_demo/form1.html") driver.find_element_by_name("name").send_keys("名前太郎"); driver.find_element_by_name("mail").send_keys("test@co.jp"); driver.find_element_by_name("comment").send_keys("猫猫子猫\n\r犬犬子犬"); # チェックボックス chks = driver.find_elements_by_name("q1[]") chks[0].click() chks[2].click() # オプションボタン opts = driver.find_elements_by_name("men") opts[1].click() # 選択 sel = Select(driver.find_element_by_name("osi[]")) sel.deselect_all() sel.select_by_index(1) sel.select_by_index(2) # ボタン押下 driver.find_element_by_xpath("//input[@value='登録する']").click() driver.switch_to.alert.accept() # 結果 results = driver.find_elements_by_tag_name("tr") for rec in results: print(rec.text) driver.close()NodeJsの場合
NodeJsでもSeleniumの操作は可能です。npmコマンドを使用してseleniumをインストールします。
npm install selenium-webdriver簡単なサンプルは以下のようになります。
// 以下参考 // https://qiita.com/tonio0720/items/70c13ad304154d95e4bc // https://stackoverflow.com/questions/26191142/selenium-nodejs-chromedriver-path // https://seleniumhq.github.io/selenium/docs/api/javascript/index.html const webdriver = require('selenium-webdriver'); const chrome = require('selenium-webdriver/chrome'); const path = 'C:\\tool\\selenium\\chromedriver_win32\\chromedriver.exe'; const service = new chrome.ServiceBuilder(path).build(); chrome.setDefaultService(service); (async () => { const driver = await new webdriver.Builder() .withCapabilities(webdriver.Capabilities.chrome()) .build(); await driver.get('http://needtec.sakura.ne.jp/auto_demo/form1.html'); await driver.findElement(webdriver.By.name("name")).sendKeys("名前太郎"); await driver.findElement(webdriver.By.name("mail")).sendKeys("test@co.jp"); await driver.findElement(webdriver.By.name("comment")).sendKeys("猫猫子猫\n\r犬犬子犬"); // チェックボックス let chks = await driver.findElements(webdriver.By.name("q1[]")); await chks[0].click(); await chks[2].click(); // オプションボタン let opts = await driver.findElements(webdriver.By.name("men")); await opts[1].click(); // 複数選択 let sel = await driver.findElements(webdriver.By.xpath("//select[@name='osi[]']/option")); await sel[1].click(); await sel[2].click(); // ボタン押下 await driver.findElement(webdriver.By.xpath("//input[@value='登録する']")).click(); await driver.switchTo().alert().accept(); // 結果取得 let results = await driver.findElements(webdriver.By.tagName("tr")); for (let i = 0; i < results.length; ++i) { console.log(await results[i].getText()); } driver.quit(); })();Seleniumで既に起動しているブラウザの操作は行えるか?
Seleniumを介さず起動していたブラウザの自動操作については公式にはサポートしていません。
下記に幾つかの回避法が紹介されていますが、あくまで非公式の内容になります。Can Selenium interact with an existing browser session?
https://stackoverflow.com/questions/8344776/can-selenium-interact-with-an-existing-browser-sessionSeleniumを使用する方法のまとめ
Seleniumを使用することで様々なブラウザを様々なプログラミング言語で操作できることができます。
またSeleniumIDEを使用することでプログラミングをせずにブラウザの自動操作がおこなえます。ただし、Flashページなどの画像認識を必要とする操作の場合は他の方法を検討してください。
たとえば以下のような方法があります。Sikulix1.1.4を使って画面の自動操作をする
https://qiita.com/mima_ita/items/8f653042ac9140e5023fC#やPowerShellで画面上の特定の画像の位置をクリックする方法
https://qiita.com/mima_ita/items/f7d2c38767bda8b35cbd拡張機能を作成する方法
ChromeやFirefoxで利用できる拡張機能を使用して表示中のページを自動操作することが可能です。
Chromeの拡張機能
https://developer.chrome.com/extensionsFirefoxの拡張機能
https://developer.mozilla.org/ja/docs/Mozilla/Add-ons/WebExtensions/Your_first_WebExtension以下はChromeの拡張機能を使用してページを自動操作後、操作結果をメッセージボックスで表示しています。
操作対象のページ
http://needtec.sakura.ne.jp/auto_demo/form1.html拡張機能を使った自動操作の仕組みは下記の通りです。
default_popupからcontent_scriptsに対して自動操作の開始指示をメッセージを使用して行います。
入力ページのcontent_scriptsは項目の入力とボタンの押下を行います。
出力ページのcontent_scriptsは出力ページの内容を取得してメッセージを使用してdefault_popupに内容を送信します。なお、ChromeとFirefoxの拡張機能は同じような実装で作成できます。
Chromeの拡張機能で自動操作
Chrome拡張機能での自動操作のサンプル
https://github.com/mima3/auto_sample/tree/master/auto_chrome_sample以下が実際の自動操作を行っているcontent_scriptになります。
content_input.jschrome.runtime.onMessage.addListener( function(request, sender, sendResponse) { console.log(request); let nameElem = document.getElementsByName('name'); nameElem[0].value = '名前太郎'; let mailElem = document.getElementsByName('mail'); mailElem[0].value = 'test@co.jp'; let commentElem = document.getElementsByName('comment'); commentElem[0].value = '猫猫子猫\n犬犬子犬'; // チェックボックス let chkElem = document.getElementsByName('q1[]'); chkElem[0].click(); chkElem[2].click(); // ラジオボタン let radioElem = document.getElementsByName('men'); radioElem[1].click(); // 選択項目 var itr = document.evaluate("//select[@name='osi[]']/option", document, null, XPathResult.UNORDERED_NODE_ITERATOR_TYPE, null ); var node = itr.iterateNext(); while(node) { if (node.textContent === '千鶴さん' || node.textContent === 'さおりん') { node.selected = true; } node = itr.iterateNext(); } // ボタン押下 // contents.jsでwindows.confirmを書き換えてもブラウザ側の処理に影響を与えない // そのため、window.confirmを書き換えるscritpをタグとして挿入する // 考え方は以下を参考 // https://qiita.com/suin/items/5e1aa942e654bce442f7 let scr = document.createElement("script"); scr.setAttribute('type', 'text/javascript'); scr.innerText = 'window.confirm = function () { return true; }'; document.body.appendChild(scr); setTimeout(function(){ //ここでやってもブラウザ上のwindow.confirmは影響ない。 var btnElem = document.evaluate("//input[@value='登録する']", document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null); btnElem.singleNodeValue.click(); }, 0); } );JavaScriptのDOM操作で入力項目を設定後、登録ボタンを押下します。
この際、confirmで確認ダイアログが表示されるため、window.confirmの処理を上書きしてダイアログが出ないようにしています。
content_scriptからブラウザで使用しているJavaScriptを更新するため、scriptタグを埋め込んでいます。
この考え方は下記を参考にしました。Chrome拡張開発: 拡張からページにJavaScriptを送り込みたい
https://qiita.com/suin/items/5e1aa942e654bce442f7Firefoxの拡張機能で自動操作
Firefox拡張機能での自動操作のサンプル
https://github.com/mima3/auto_sample/tree/master/auto_firefox_sample拡張機能での自動操作のまとめ
ブラウザの拡張機能を利用することでブラウザの自動操作が行えます。
この方法のメリットとしてはインターネットの接続がなくてもテキストエディタのみで自動操作を行うためのスクリプトが作成できることです。(ブラウザを開発者モードで動かしていいという条件は必要)もし、自動操作中にネイティブのアプリと連携が必要になった場合はNative Messagingを使用してください。このNaitiveMessageを使用したサンプルは以下にあります。
RPAツールを使用する方法
お高いRPAツールはブラウザの操作をサポートしている商品が多いです。
今回は小規模事業や個人利用なら無料でしようできるUiPath Communityを利用してChromeの操作を行います。ChromeをUiPathで操作する場合、Chromeの拡張機能をインストールする必要があるので、下記を参考にインストールしてください。
https://docs.uipath.com/studio/lang-ja/docs/installing-the-chrome-extension(1)UIPathで新規プロジェクトを作成します。言語はC#を選択します。
(2)「ブラウザを開く」アクティビティを追加します。
プロパティ 値 url "http://needtec.sakura.ne.jp/auto_demo/form1.html" ブラウザの種類 Chrome (3)「文字を入力」アクティビティを追加して「画面上で指定」でブラウザ上のテキスト入力項目を指定します。
(4)「文字を入力」アクティビティのプロパティを設定します。
(5)(3)~(4)を繰り返して「名前:」、「メールアドレス:」、「コメント:」を入力します。
プロパティ 値 表示名 文字を入力 'INPUT-名前' テキスト "名前太郎" フィールド内を削除 ON ウィンドウメッセージを送信 OFF 入力をシミュレート OFF
プロパティ 値 表示名 文字を入力 'INPUT-メールアドレス' テキスト "test@mail.co.jp" フィールド内を削除 ON ウィンドウメッセージを送信 ON ※デフォルトの挙動だとIMEが有効となり全角で入力されてしまう 入力をシミュレート OFF
プロパティ 値 表示名 文字を入力 'TEXTAREA-コメント' テキスト "猫猫子猫\n\r犬犬子犬" フィールド内を削除 ON ウィンドウメッセージを送信 OFF 入力をシミュレート OFF (6)「クリック」アクティビティを追加して「画面上で指定」でブラウザ上のクリックが必要な項目をを指定します。
(7)「クリック」アクティビティのプロパティを設定します。
(8)(5)~(6)を繰り返して「その1」、「その3」、「そば」をクリックします。
プロパティ 値 表示名 クリック 'INPUTーその1' ウィンドウメッセージを送信 ON(デフォルトだと挙動が安定しない) 入力をシミュレート OFF
プロパティ 値 表示名 クリック 'INPUTーその3' ウィンドウメッセージを送信 ON(デフォルトだと挙動が安定しない) 入力をシミュレート OFF
プロパティ 値 表示名 クリック 'INPUTーそば' ウィンドウメッセージを送信 ON(デフォルトだと挙動が安定しない) 入力をシミュレート OFF (9)リストを複数選択するために「JSスクリプトを挿入」アクティビティを追加します。
選択したJSスクリプトは下記の通りです。
select_multi.jsfunction selectmulti(e, aryStr) { var ary = JSON.parse(aryStr); var itr = document.evaluate("//select[@name='osi[]']/option", document, null, XPathResult.UNORDERED_NODE_ITERATOR_TYPE, null ); var node = itr.iterateNext(); while(node) { if (ary.indexOf(node.textContent) >= 0) { node.selected = true; } node = itr.iterateNext(); } }
プロパティ 値 スクリプトコード select_multi.js 入力パラメータ "[\"千鶴さん\",\"さおりん\"]" CTRLキーを押しながらのリスト項目をクリックする操作や、「複数の項目を選択」アクティビティを使用した実装だと動作しない場合がありました。
Web上のリストボックスで複数選択したい
https://forum.uipath.com/t/web/113531/9また、ここで指定したJavaScript中で日本語やハングルは使用しないでください。文字化けします。日本語などが必要な場合は引数で渡すようにしてください。
たとえば「alert("千鶴さん");」とかいうコードを埋め込むと以下のようになります。
(10)登録ボタンを押下するために「クリック」アクティビティを追加します。
プロパティ 値 表示名 クリック 'INPUT-登録' ウィンドウメッセージを送信 ON(デフォルトだと挙動が安定しない) 入力をシミュレート OFF (11)登録ボタン押下後の確認メッセージを閉じるために「画像をクリック」アクティビティを追加します。
なお、「select_multi.js」に以下のコードを追加してconfirm関数を上書きして確認メッセージを表示させないことも可能です。
let scr = document.createElement("script"); scr.setAttribute('type', 'text/javascript'); scr.innerText = 'window.confirm = function () { return true; }'; document.body.appendChild(scr);(12)登録後のページのデータを取得するために「データスクレイピング」を行います。
「データスクレイピング」アイコンを押下します。
「取得ウィザード」で「次へ」ボタンを押下します。
要素の選択が可能になるのでテーブルのセルを選択します。
「表全体からデータを抽出しますか?」の確認メッセージには「はい」を選択します。
「取得ウィザード」で「終了」ボタンを押下します。
「次へのリンクを指定」の確認メッセージには「いいえ」を選択します。
「データスクレイピング用のアクティビティが追加されます。
(13)「構造化データを抽出」アクティビティの「出力」プロパティに対してCTRL+Kを押下してresult変数を追加します
(14)「繰り返し(各行)」アクティビティを追加します。この際、コレクションには「result」変数を指定してください。
(15)「繰り返し(各行)」アクティビティに「一行を書き込み」アクティビティを追加します。
プロパティ 値 Text row[0].ToString() + " " + row[1].ToString() (16)これまでの操作を再生すると以下のようになります。
UiPathでのブラウザの自動操作のまとめ
UiPathを使用したメリットは以下の通りです。
・要素を画面から選択できる
・画像認識による自動操作ができる
・ブラウザ以外の自動操作が同じ操作感で行える。
・今回は説明してませんがUiPath Orchestratorで資産管理が容易になる逆にデメリットは以下の通りです。
・GUIでのプログラミングになるので、複雑な実装が困難である
・GUIなので変更点の差分を見るのが困難で、コードレビューが負担になる。※結局はxamlなのでテキストで差分はとれるが…
・なれないとハマるポイントが多い。
・UiPathの操作でDOMの要素を変更したりしているのでシステム試験等で使用する場合、妥当性を考える必要がある。
例:UiPathで操作した要素には以下のように「uipath_custom_id」という属性が追加されている。
UiPathは外部プログラムを呼び出す機能やPowerShellの実行が可能なのでブラウザの操作は別の手法で行うことも可能です。
なお、RPAで未経験者でもお手軽自動操作とかいう言説が大きくなっていますが、正直、WebアプリケーションやWindowsアプリケーションを組んだことのない人が簡単に使えると言われると大きな疑問が残ります。
逆にRPAツール不要論もありますが、UiPath Orchestratorの存在や、簡単なフローが頻繁に変わる業務形態における仕事の分担という観点で、そのRPA不要論についても絶対的な真理とは言えないでしょう。状況にあわせた組み合わせが必要と思います。
ブラウザのGUI上の操作をプログラム上で真似して自動化する方法のまとめ
ここまでで、ブラウザのGUI上の操作をプログラム上で真似して自動化する方法について紹介しました。
RPAツールを使える環境の場合、RPAツールは自動化を行う上で便利ではありますが、それを使うことを目的にしない方がいいです。必要に応じて別の方法をミックスして使うようにしましょう。
外部ライブラリを使用できる環境の場合、Seleniumを採用するのが一番楽だと思います。ChromeやFirefoxならSeleniumIDEで録画機能もついているので生産性は高いでしょう。
外部ライブラリが使用できない環境の場合、InternetExploreのCOM又は、ブラウザの拡張機能を使用することになります。
IEを使用する場合、操作対象のWebアプリケーションのサポート状況をよく確認しましょう。いずれの方法でブラウザ操作を自動化するにせよ以下の点は気をつけてください。
安易なSleepを使用しない
たとえば、適当に2秒待つという処理をいれた場合、ネットワークやPCの負荷状況によって動作しない可能性があります。
Sleepよりも以下で判断するようにしましょう。・ document.readyStatusなどを活用する
・ 特定の要素が出現したか、消えたかを見て判断する。
→SeleniumやUiPathでは、要素の出現消滅の検出をサポートする機能が提供されているテキスト入力は手動入力と異なる挙動をする可能性がある
テキスト入力を行う場合、手動で入力した場合と異なる挙動をする可能性があります。
たとえばキーボード操作のイベントで何らかの処理していたり、フォーカスの移動で何らかの処理をしていたりする場合です。
UiPathの場合、入力モードに以下の3種類があるので必要に応じて使いわけてください。・デフォルト:デバイスドライバ経由なので手入力にもっとも近い
・WindowsMessage:Windowsのメッセージを利用してテキストを入力している。
・Simulate:コントロールを直接操作しているそれ以外の場合は、JavaScriptのコード上でアプリが期待するイベントを無理やり起こす必要があります。
必要に応じてJavaScriptを利用する
複雑なUIの場合、画面要素を一々クリックするより、WebアプリケーションのJavaScriptを直接実行した方が早い場合があります。
また、いままでの例にでてきたように、alertやconfirmのような自動操作がし辛いポップアップの出現を抑止することが可能になります。テストの自動化についてはテスト方針をよく確認する
ツールをつかったテストは強力ですが、それはユーザが動かしたものと全く同一にならないことに注意してください。
たとえば、先にあげたJavaScriptを呼び出して処理を行った場合、それがテストとして妥当かどうかはテストの方針や観点しだいになります。UIの軽微な変更で動作しなくなることを忘れないこと
ブラウザの自動テストはUIの軽微な変更で簡単に動かなくなります。
たとえばリストの2番目と3番目の項目を選択するという実装だと、リストの項目が追加された場合に簡単に動作しなくなります。
これがなるべく影響を受けないような書き方をすることも可能ですが、限界はあります。もしブラウザの自動化スクリプトを重要な業務で使用している場合は、前に動いたスクリプトだからと安心せずWebアプリケーションの変更にともなって定期的に以前に書いた自動化スクリプトが動作するか確認するようにしてください。
ブラウザから送信しているデータを真似する方法
ブラウザの送受信データの確認方法
ブラウザから送信しているデータを真似して自動化する前にブラウザからどんなデータを送受信しているか調べる方法を説明します。
下記のページで登録ボタンを押した場合にどのようなデータを送信しているか確認してみましょう。
http://needtec.sakura.ne.jp/auto_demo/form1.htmlChromeでの送受信データの確認方法
(1)F12で開発者ツールを開き、「Network」タブを選択します。
(2)画面上で入力操作を行い「登録する」ボタンを押します。しばらくすると受信ファイルの一覧が表示されます。
(3)「regist1.php」などの受信ファイルを選択後に、Headersタブを選択すると送信データが確認できます。
(4)Responseタブを選択すると受信内容が確認できます。
Firefoxでの送受信データの確認方法
(1)F12で開発者ツールを開き、「ネットワーク」タブを選択します。
(2)画面上で入力操作を行い「登録する」ボタンを押します。しばらくすると受信ファイルの一覧が表示されます。
(3)「regist1.php」などの受信ファイルを選択します。
(4)パラメータタブでFormの送信情報を確認できます。
(5)応答タブでサーバーからのレスポンスデータを確認できます。
IE11での送受信データの確認方法
(1)F12で開発者ツールを開き、「ネットワーク」タブを選択します。
(2)画面上で入力操作を行い「登録する」ボタンを押します。しばらくすると受信ファイルの一覧が表示されます。
(3)「regist1.php」などの受信ファイルを選択します
(4)本文タブを選択し、さらに「要求本文」タブを選択するとFormの送信情報を確認できます。
(5)本文タブを選択し、さらに「応答本文」タブを選択するとサーバーからのレスポンスデータを確認できます。
旧Edgeでの送受信データの確認方法
(1)F12で開発者ツールを開き、「ネットワーク」タブを選択します。
(2)画面上で入力操作を行い「登録する」ボタンを押します。しばらくすると受信ファイルの一覧が表示されます。
(3)「regist1.php」などの受信ファイルを選択します
(4)本文タブを選択し、さらに「要求本文」タブを選択するとFormの送信情報を確認できます。
(5)本文タブを選択し、さらに「応答本文」タブを選択するとサーバーからのレスポンスデータを確認できます。
新Edgeでの送受信データの確認方法
Chromeと同じです。
単純なFormデータの送信例
下記のページのような単純なフォームのデータの送信例を説明します。
http://needtec.sakura.ne.jp/auto_demo/form1.htmlcurlコマンド
macやlinux系のOSならcurlコマンドを使用することで単純なフォームデータをPOSTすることが可能です。
windos10でもプリインストールされるようになったようですが、文字コードの問題があるので注意が必要です。また、PowerShellを使用しているとcurlコマンドが利用できますが、これはInvoke-WebRequestの別名です。以下はCentOS7でcurlコマンドを実行した例となります。
>curl -F "name=名前太郎" -F "mail=test@co.jp" -F "comment=コメント" -F "q1[]=その1" -F "q1[]=その3" -F "men=soba" -F "osi[]=千鶴さん" -F "osi[]=さおりん" http://needtec.sakura.ne.jp/auto_demo/regist1.php <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>sample</title> </head> <body> <table border="1"> <tr> <td>名前</td><td>名前太郎</td> </tr> <tr> <td>メールアドレス</td><td>test@co.jp</td> </tr> <tr> <td>コメント</td><td>コメント</td> </tr> <tr> <td>チェック</td> <td> その1, その3<br> </td> </tr> <tr> <td>めん</td><td>soba</td> </tr> <tr> <td>おし</td><td>千鶴さん,さおりん</td> </tr> </table> </body> </html>powershellの例
PowerShellではInvoke-WebRequestを利用してFormデータを送信可能です。
$data = @{ name='名前太郎'; mail='test'; comment=@" 猫猫子猫 犬犬子犬 "@; 'q1[0]'='その1'; 'q1[1]'='その3'; men='soba'; 'osi[0]'='千鶴さん'; 'osi[1]'='さおりん' } $ret = Invoke-WebRequest http://needtec.sakura.ne.jp/auto_demo/regist1.php -Method POST -Body $data -ContentType "application/x-www-form-urlencoded" $html = $ret.ParsedHtml $list = $html.getElementsByTagName("tr") for($i=0; $i -lt $list.length; $i++) { $item = $list[$i] Write-Host($item.innerText) [System.Runtime.Interopservices.Marshal]::ReleaseComObject($item) | Out-Null Remove-Variable item -ErrorAction SilentlyContinue } [System.Runtime.Interopservices.Marshal]::ReleaseComObject($list) | Out-Null Remove-Variable list -ErrorAction SilentlyContinue [System.Runtime.Interopservices.Marshal]::ReleaseComObject($html) | Out-Null Remove-Variable html -ErrorAction SilentlyContinue [System.GC]::Collect() [System.GC]::WaitForPendingFinalizers() [System.GC]::Collect()ParsedHtmlはmshtmlになっているので、構文解析を容易に行えます。
なお、mshtmlはCOMなのでReleaseComObjectを実施して解放処理をしておいた方が無難です。なお、ページによっては文字化けする場合があります。この場合は以下のように文字コードを変換して出力します。
# 以下参考 # https://qiita.com/zaki-lknr/items/1ae3258d7b77c5e2a2ba $ret = Invoke-WebRequest http://needtec.sakura.ne.jp/auto_demo/form1.html $content = [System.Text.Encoding]::UTF8.GetString( [System.Text.Encoding]::GetEncoding("ISO-8859-1").GetBytes($ret.Content) ) Write-Host $contentVBAまたはVBSの場合
MSXML2.XMLHTTPを利用することでFormデータを送信可能です。
受信したHTMLはMSHTML.HTMLDocumentで解析しています。以下はVBSのサンプルになっていますがWScript.EchoをDebug.Print等に置き換えることでVBAでも流用できると思います。
' 参考: ' https://outofmem.tumblr.com/post/63052619242/vbaexcel-vba%E3%81%A7http%E9%80%9A%E4%BF%A1 ' https://stackoverflow.com/questions/9931429/parse-html-file-using-mshtml-in-vbscript Dim httpReq Set httpReq = CreateObject("MSXML2.XMLHTTP") Call httpReq.Open("POST", "http://needtec.sakura.ne.jp/auto_demo/regist1.php", False) Call httpReq.setRequestHeader("Content-Type", "application/x-www-form-urlencoded;charset=utf-8") Dim postData postData = "name=名前太郎&mail=test@co.jp&comment=猫猫" & vbCrLf & "子犬&q1[]=その1&q1[]=その2&men=soba&osi[]=千鶴さん&osi[]=さおりん" Call httpReq.Send(postData) Dim objHtml Set objHtml = CreateObject("htmlfile") call objHtml.write(httpReq.responseText) Dim list Set list = objHtml.getElementsByTagName("tr") Dim item For Each item In list WScript.Echo item.innerText NextPythonの例
http.clientを使用してFormデータを送信して結果を受信可能です。html.parserを利用することでHTMLの解析も行えます。おそらく、python3xが入っている環境ならどこでも使えると思います。
import http.client, urllib.parse from html.parser import HTMLParser # 結果ページを解析するパーサー class ResultParser(HTMLParser): def __init__(self): HTMLParser.__init__(self) self.flag = False def handle_starttag(self, tag, attrs): if tag == "td": self.flag = True def handle_data(self, data): if self.flag: print (data) self.flag = False conn = http.client.HTTPConnection('needtec.sakura.ne.jp') headers = { 'Content-type': ' application/x-www-form-urlencoded' } data = { 'name': '名前太郎', 'mail': 'test@co.jp', 'comment' : '猫猫子猫\n\r犬犬子犬', 'q1[0]' : 'その1', 'q1[1]' : 'その3', 'men' : 'soba', 'osi[0]' : '千鶴さん', 'osi[1]' : 'さおりん' } #r = requests.post('http://needtec.sakura.ne.jp/auto_demo/regist1.php', data=data) #print(r) #print(r.text) params = urllib.parse.urlencode(data) conn.request('POST', '/auto_demo/regist1.php', params, headers) response = conn.getresponse() print(response.status, response.reason) parser = ResultParser() # trの内容を出力 parser.feed(response.read().decode()) conn.close()外部ライブラリを使う場合
requestsパッケージを使うとデータの送受信が、Beautiful Soupを使うとHTMLの解析が楽になります。
import requests from bs4 import BeautifulSoup data = { 'name': '名前太郎', 'mail': 'test@co.jp', 'comment' : '猫猫子猫\n\r犬犬子犬', 'q1[0]' : 'その1', 'q1[1]' : 'その3', 'men' : 'soba', 'osi[0]' : '千鶴さん', 'osi[1]' : 'さおりん' } r = requests.post('https://needtec.sakura.ne.jp/auto_demo/regist1.php', data=data) print(r.status_code, r.reason) soup = BeautifulSoup(r.text) for tr in soup.find_all('tr'): print('------------------------') print(tr.text)認証があるページの例
単純なフォームの送信例はPOSTを一回送信するだけで済みましたが、認証処理やページの不正遷移防止が行われているWebアプリについてはサーバからの情報を受け取ってそれを基にデータを送信する必要があります。
今回はbitnamiから取得できるRedmineのVMでチケット登録を行うサンプルを見てみます。
VMのもろもろの設定はTestLinkで設定したときと同様に行えます。Redmineでログインしてチケットを登録するには以下の手順を踏む必要があります。
- ログインページを取得する。
- サーバーはヘッダーにセッションID、HTML中に認証トークン文字を埋め込んでログイン用のページを返す。
- セッションIDをリクエストヘッダに設定し、リクエストボディに認証トークン、ユーザ名、パスワード、ログイン後の遷移ページ(チケット登録画面)を指定してログイン処理を行う。
- サーバーはログインに成功したらチケット登録画面を返す。この際、認証トークン文字が新しいものに変更される。
- セッションIDをリクエストヘッダに設定し、リクエストボディに認証トークン、チケット情報を指定してチケット登録処理を行う。
PowerShellの例
PowerShellでRedmineのチケットを登録するには以下のようになります。
# エラーが起きたらとめる $ErrorActionPreference = "Stop" # サーバから取得したCookieの値からキーを指定して値を取得する function get_key_value($value, $key) { $tmp = $value.substring($value.indexof($key) + $key.length) $ret = $tmp.substring(0, $tmp.indexof(';')) return $ret } # DOMを解析して指定の名前の指定の属性を取得する function get_attribyte_value($html, $elem_name, $attr_name) { $elems = $html.getElementsByName($elem_name) $elem = $elems[0] $attrs = $elem.attributes $attr = $attrs[$attr_name] $ret = $attr.value [System.Runtime.Interopservices.Marshal]::ReleaseComObject($elems) | Out-Null [System.Runtime.Interopservices.Marshal]::ReleaseComObject($elem) | Out-Null [System.Runtime.Interopservices.Marshal]::ReleaseComObject($attrs) | Out-Null [System.Runtime.Interopservices.Marshal]::ReleaseComObject($attr) | Out-Null return $ret } ################################## #Redmineの設定値 ################################## $redmine_host = "192.168.0.200" # サーバ名 $redmine_project = "test1" # プロジェクト名 $username = "user" $password = "pass" ################################## # ログインページを初回アクセスしてセッションIDとcsrf-tokenを取得する ################################## $ret = Invoke-WebRequest "http://$redmine_host/login" -Method GET # セッションID取得 $cookie = $ret.Headers['Set-Cookie'] $session_id = get_key_value $ret.Headers['Set-Cookie'] '_redmine_session=' # ログインページのcsrf-token取得 $html = $ret.ParsedHtml $csrf_token = get_attribyte_value $html 'csrf-token' 'content' [System.Runtime.Interopservices.Marshal]::ReleaseComObject($html) | Out-Null # セッション情報作成 $session = New-Object Microsoft.PowerShell.Commands.WebRequestSession $cookie = New-Object System.Net.Cookie $cookie.Name = "_redmine_session" $cookie.Value = $session_id $cookie.Domain = $redmine_host $session.Cookies.Add($cookie); ################################## # ログイン処理。 # ログイン後はチケット登録画面へ ################################## $login_data = @{ authenticity_token = $csrf_token; back_url = "http://$redmine_host/projects/$redmine_project/issues/new"; username = $username; password = $password; } $ret = Invoke-WebRequest "http://$redmine_host/login" -Method POST -WebSession $session -Body $login_data -ContentType "application/x-www-form-urlencoded" # csrf-token取得 $html = $ret.ParsedHtml $csrf_token = get_attribyte_value $html 'csrf-token' 'content' [System.Runtime.Interopservices.Marshal]::ReleaseComObject($html) | Out-Null ################################## # チケット登録 ################################## Write-Host "チケット登録........................................................" $title = Get-Date -format "yyyyMMddHHmmss" $ticket_data = @{ 'utf8' = '✓'; authenticity_token = $csrf_token; 'issue[is_private]' = 0; 'issue[tracker_id]' = 1; 'issue[subject]' = "自動登録 $title"; 'issue[description]' = "わっふるわっふる"; 'issue[status_id]' = 1; 'was_default_status' = 1; 'issue[priority_id]' = 2; 'issue[start_date]' = '2019-10-10'; 'issue[due_date]' = ''; 'issue[done_ratio]' = 0; 'commit' = '作成' } $ret = Invoke-WebRequest "http://$redmine_host/projects/$redmine_project/issues" -Method POST -WebSession $session -Body $ticket_data -ContentType "multipart/form-data" $html = $ret.ParsedHtml Write-Host $html.title [System.Runtime.Interopservices.Marshal]::ReleaseComObject($html) | Out-NullPythonの例
HTMLの解析がしんどいのでBeautiful Soupを使用した方がいいでしょう。
import requests from bs4 import BeautifulSoup import datetime ############################################## # redmineの情報 ############################################## redmine_host = "192.168.0.200" # サーバ名 redmine_project = "test1" # プロジェクト名 username = "user" password = "password" # セッションの作成 session = requests.session() # ログインページの取得 ret = session.get('http://' + redmine_host + '/login') print(ret.status_code, ret.reason) ret.raise_for_status() session_id = ret.cookies['_redmine_session'] soup = BeautifulSoup(ret.text, 'html.parser') elem_token = soup.find('meta', {'name': 'csrf-token'}) csrf_token = elem_token['content'] # ログイン処理 cookies = { redmine_host : session_id } login_data = { 'authenticity_token' : csrf_token, 'back_url' : "http://' + redmine_host + '/projects/' + redmine_project + '/issues/new", 'username' : username, 'password' : password } ret = session.post('http://' + redmine_host + '/login', data=login_data, cookies=cookies) print(ret.status_code, ret.reason) ret.raise_for_status() # チケット登録 print('チケット登録................................') soup = BeautifulSoup(ret.text, 'html.parser') elem_token = soup.find('meta', {'name': 'csrf-token'}) csrf_token = elem_token['content'] ticket_data = { 'utf8' : '✓', 'authenticity_token' : csrf_token, 'issue[is_private]' : 0, 'issue[tracker_id]' : 1, 'issue[subject]' : "自動登録 " + str(datetime.datetime.now()), 'issue[description]' : "わっふるわっふる", 'issue[status_id]' : 1, 'was_default_status' : 1, 'issue[priority_id]' : 2, 'issue[start_date]' : '2019-10-10', 'issue[due_date]' : '', 'issue[done_ratio]' : 0, 'commit' : '作成' } ret = session.post('http://' + redmine_host + '/projects/' + redmine_project + '/issues', data=ticket_data, cookies=cookies) print(ret.status_code, ret.reason) ret.raise_for_status() soup = BeautifulSoup(ret.text, 'html.parser') print(soup.title)ブラウザから送信しているデータを真似する方法のまとめ
ブラウザを介さないのでブラウザより簡単にかつ高速で自動操作が行えます。
同時にそれは、デメリットになる場合があります。
たとえば、JavaScriptでクライアントサイドで動的にページを作成している場合、その処理は動作しません。つまり、ブラウザで操作したときと同様のDOMの構成が返ってくるとは限りません。この手法を結合試験やシステム試験で使用する場合は、注意してください。
仮にテストデータの入力に使う場合であっても、システム上本来作成できないデータが作成されてしまう場合があるからです。試験の観点に合わせて慎重に導入してください。また、ブラウザの自動操作と同様にWebアプリケーションの変更によって今まで動いていた自動化スクリプトが動作しなくなるリスクはあるので注意してください。
Webアプリケーションが提供しているAPIを利用する方法
もっともリスクの少ないWebアプリケーションの自動化の方法です。
ただしWebアプリケーションがAPIを提供しているかどうかは個別の仕様次第になります。Redmineのチケット登録の例
これまでにRedmineでチケット登録を行うサンプルをいくつか記述しました、Redmineが提供しているAPIを利用することでシンプルに実装することができます。
まずRedmineの管理画面でRESTAPIを有効にしてください。
すると個人設定画面でAPIキーが表示されます。このAPIを使用してRedmineを操作します。
PowerShellの例
チケット用のXMLを作成してPOSTするだけです。
この際、APIキーをヘッダに付与して送信します。################################## #Redmineの設定値 ################################## $redmine_host = "192.168.0.200" # サーバ名 $apikey = "60076966cebf71506ae3f2391da649235a2b1d46" $title = Get-Date -format "yyyyMMddHHmmss" $xml = @" <issue> <project_id>1</project_id> <subject>RESTAPIテスト $title</subject> <description>試験</description> </issue> "@ # セッション情報作成 $headers = @{ 'X-Redmine-API-Key' = $apikey; 'Content-Type' = 'text/xml'; } # 文字化けして登録されるなら以下をいれる $sendData = [System.Text.Encoding]::UTF8.GetBytes($xml) $ret = Invoke-WebRequest http://$redmine_host/issues.xml -Headers $headers -Method POST -WebSession $session -Body $sendData Write-Host $ret.ContentPythonの場合
import requests import datetime xml = """ <issue> <project_id>1</project_id> <subject>RESTAPIテスト python {0}</subject> <description>試験</description> </issue> """.format(str(datetime.datetime.now())) headers = { 'X-Redmine-API-Key' : '60076966cebf71506ae3f2391da649235a2b1d46', 'Content-Type' : 'text/xml' } r = requests.post('http://192.168.0.200/issues.xml', data=xml.encode('utf-8'), headers=headers) print(r.status_code, r.reason) print(r.text)なお、PythonでやるならPython Redmineあたりのライブラリを使用したほうが楽だと思います。
共通的な注意事項
ここまででWebアプリケーションの自動化の方法についていくつか方法を説明しました。
最後に共通的な注意事項を述べておきたいと思います。できることと、やっていいことは違う
おそらくここまでで、多くのWebアプリケーションを自動で操作することが可能になったと思います。
しかしながら、できることと、やっていいことは違うということを常に心がけてください。API経由以外の自動操作はWebアプリケーション側が想定していない操作になる可能性があります。つまり、いつ動かなくなってもおかしくありませんし、仮に動くからといってやっていい操作とは限りません。
場合によっては規約違反に問われることになります。たとえば広告ブロックして云々とか、複数人で遊ぶブラウザゲームの自動化は、かなりの確率で規約違反になります。
Webアプリケーションを自動化する際は必ず規約を確認してから行うようにしましょう。また、そういった規約が明記されておらず、不正に当たらないと考えられる場合であっても自動操作はWebアプリケーション側に想定外の負荷を与えることがあります。たとえば、2010年には情報取得目的に図書館の蔵書検索システムに高頻度(1秒に1アクセス程度)のリクエストを送信して偽計業務妨害容疑で逮捕された岡崎市立中央図書館事件があったことは心に留めておくべきでしょう。
特に社内システムの場合、品質が悪い傾向があるので、根回しをしつつやっておくか、すぐに停止てきる状況かで実施し始めた方が無難です。
武器や流派にこだわるな
「武器や流派にこだわるな」という格言は、およそ20年前の名著「アジャイルソフトウェア開発 (The Agile Software Development Series) 」の「付録B3 武蔵」の項目にでてきた格言です。
今回、色々な自動化の方法を紹介はしましたが、それは自動化を行うための選択肢を増やして「こだわりを捨ててもらう」意図がありました。
RPAツールは素晴らしく自動化の手助けになります。しかしながら、あきらかに別の方法でやったほうが楽な場合でもRPAツールにこだわるケースがよくみられます。例えばブラウザ画面を介しての自動操作に慣れ親しんだ人はcurlコマンドで済むようなことまで慣れ親しんだという理由だけで困難な技法を選択してしまうケースをよく見かけます。
逆にcurlコマンドでは行うのが困難なことを、それだけでやろうとするケースも同じくらいよく見ます。普段は使用しない技法であっても必要があるなら採用すべきですし、逆に最も自分が慣れ親しんだ技法であっても状況にそぐわなければ捨てるべきです。
自動化スクリプトの管理方法を考えよう
1度動かせばすむスクリプトなのか、定期的に動かすスクリプトなのかによって、スクリプトの管理方法が変わります。
定期的に動かすスクリプトの場合、常にWebアプリケーションのバージョンアップで動作しなくなるというリスクがあります。
このリスクをどう扱うか考えましょう。たとえば、実際やってエラーとなった時点で修正する時間的余裕のあるものであれば、その時に考えればいいでしょう。
しかし、そういう時間的余裕が確保できないようなスクリプトの場合は、事前にそれを検出する必要があります。
定期的にスモークテストを行う計画を立てるか、Webアプリケーションのリリースノートをチェックする工数をとるか、いずれにせよなんらかの対策が必要になります。あとは、自動化スクリプトの意図を複数の人間が理解して、メンテナンスできる体制を作るよう必要があります。人間は割と簡単にいなくなります。一誰も意図が分からない自動化スクリプトが動き続ける状態にならないように気を付けましょう。
自動化のコストを見積もる場合、これらの作ったあとのメンテナンスのコストについて忘れずに考えておきましょう。
自動化を目的にするのはやめよう
慣れてくると、なんらかの方法で多くのことが自動化できるようになりますが、それを目的とするのはやめましょう。
重大な障害対応を放置して、優先度の低い自動化スクリプトを書いても意味はありません。
全体の状況をみて、効果のありそうなところを自動化しましょう。無理ならあきらめよう
どうしても自動化できないこともあります。
素直にあきらめて別の事をしましょう。参考
- Internet Explorer C++ Reference
- powershellのIEを操作するスクリプトの中のgetElementByIdを使う箇所でエラーが起こる
- PowerShell Exception 0x800A01B6 while using getElementsByTagName, getElementsByName or getElementByID
- Exception from HRESULT: 0x800A138A At line......
- Cant create HTML document from Hwnd using C#
- Selenium実践入門
- Webブラウザ自動化ツール「Selenium IDE」の今までとこれから
- The default value of timeouts on selenium webdriver
- https://www.seleniumhq.org/
- PowerShell & Selenium: Automate Web Browser Interactions – Part I
- Nodejsを使ってSeleniumでChromeを動かす
- Selenium Nodejs CHROMEDRIVER path
- selenium-webdriver
- Can Selenium interact with an existing browser session?
- https://developer.chrome.com/extensions
- https://developer.mozilla.org/ja/docs/Mozilla/Add-ons/WebExtensions/Your_first_WebExtension
- Chrome拡張開発: 拡張からページにJavaScriptを送り込みたい
- UiPath Community
- Installing the Chrome Extension
- Web上のリストボックスで複数選択したい
- https://kashika.biz/uipath_orchestrator_01/
- https://curl.haxx.se/docs/manpage.html
- Windows 10 に curl がプリインストールされてた
- Invoke-WebRequestの文字化け
- http.client
- requestsパッケージ
- Beautiful Soup
- https://bitnami.com/stack/redmine/virtual-machine)
- 岡崎市立中央図書館事件
- アジャイルソフトウェア開発 (The Agile Software Development Series) 」
- [VBA]Excel VBAでHTTP通信
- Parse html file using MSHTML in VBScript















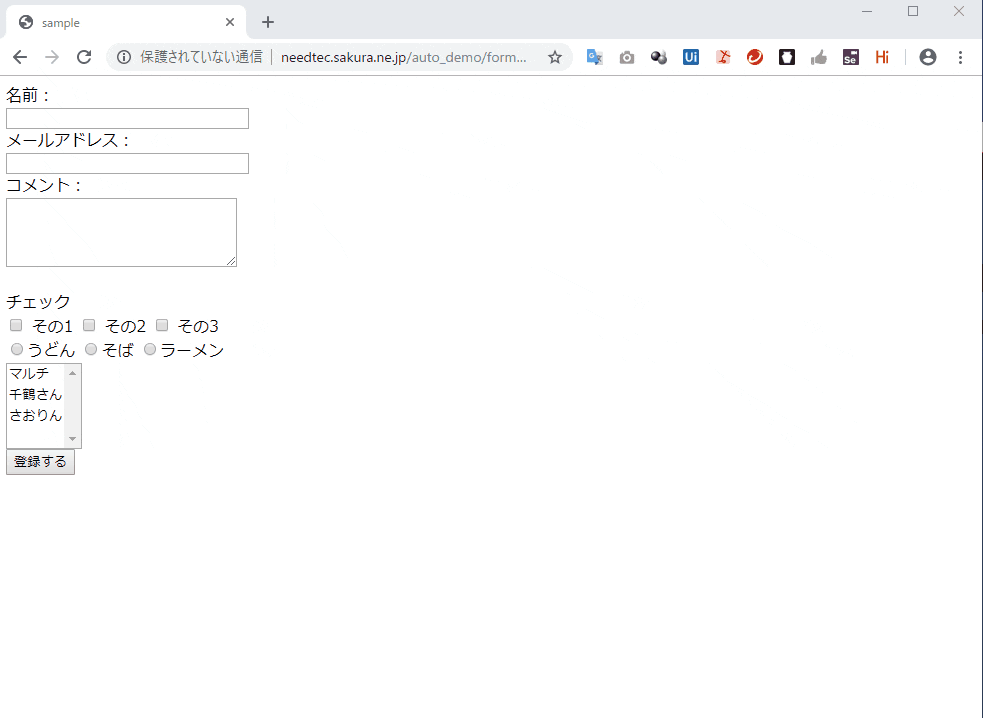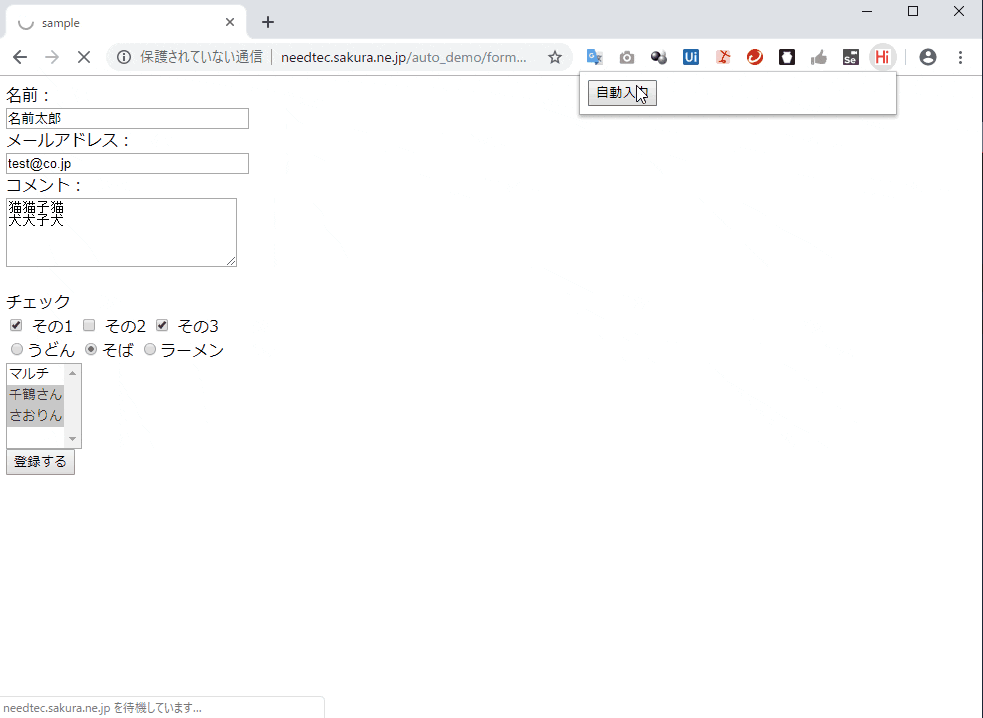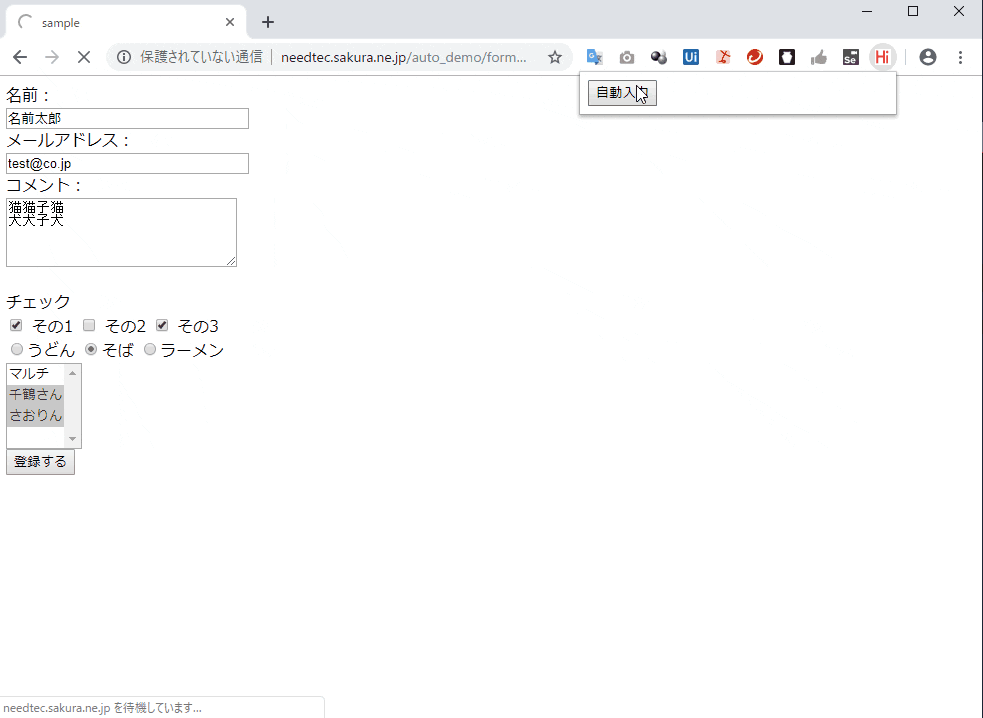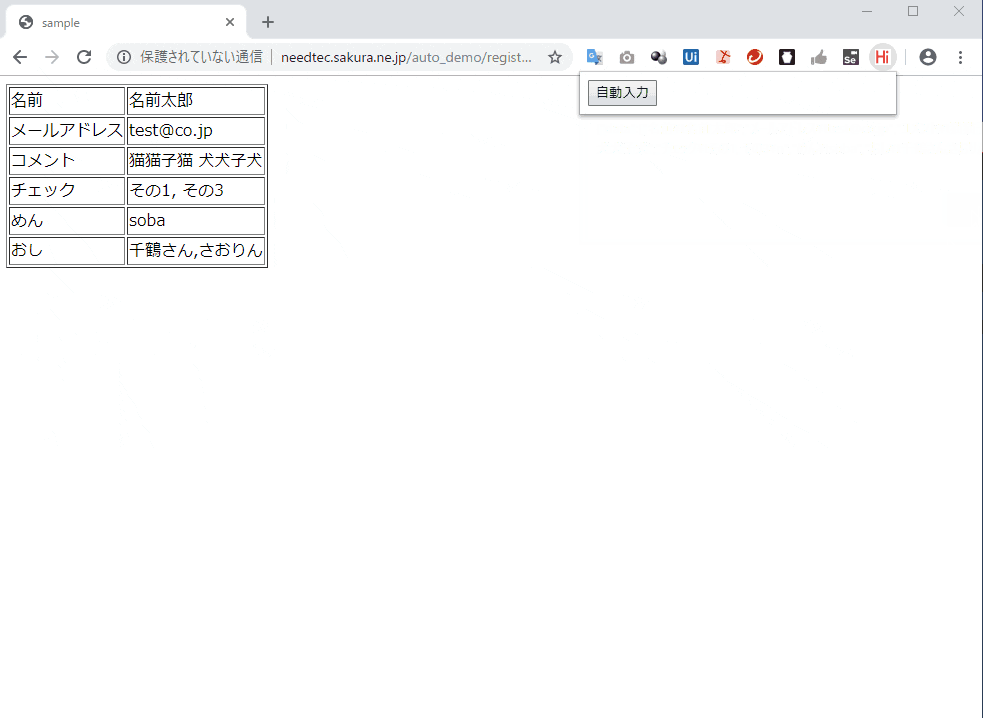






































- 投稿日:2019-10-11T05:30:38+09:00
AttributeError: 'AutoSchema' object has no attribute 'get_link' と出てきてDRFのdocsが使えない場合の対処
はじめに
Django REST framework(DRF)のdocsとはざっくり言うとブラウザ上でわかりやすくスキーマを見れるようにするためのモジュールです.
こういう感じでurls.pyに記述するだけで実装できます.urls.pyfrom django.urls import path, include from rest_framework.documentation import include_docs_urls docs_view = include_docs_urls( title='my drf API', description='This is an awesome API', ) urlpatterns = [ path('docs/', docs_view), ]エラーがでた
docs/にアクセスして確認してみると
AttributeError: 'AutoSchema' object has no attribute 'get_link'
と表示されエラーになりました.なんでや環境
Python 3.7 django 2.2.5 djangorestframework 3.10.3 coreapi 2.3.3DRF 3.10以上だと発生するエラー
3.10 Announcement
こちらによるとdrf3.10からはSchema生成にCoreAPIからOpenAPIを用いるようになり,将来的にはバージョン3.12でCoreAPIはDRFから削除される方針とのことです.
docsはCoreAPIを使っているんですね.CoreAPIを用いたものをつかうためには
settings.pyに以下を書き加えます.settings.pyREST_FRAMEWORK = { ... 'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema' }動いた!!!
まとめ
drf3.10以降で
AttributeError: 'AutoSchema' object has no attribute 'get_link'とエラーが出たり,CoreAPIが必要なモジュールを使うときは以下を記述する.settings.pyREST_FRAMEWORK = { ... 'DEFAULT_SCHEMA_CLASS': 'rest_framework.schemas.coreapi.AutoSchema' }最後までお読みいただきありがとうございます.
- 投稿日:2019-10-11T01:34:50+09:00
主成分分析(PCA)を使う、系外惑星探索
はじめに
この前の記事では直接撮像法による系外惑星探索について説明しました
https://qiita.com/phyblas/items/52dc1bd113aff3745a8d今回は、機械学習の方法の一つである主成分分析(principle component analysis、PCA)を加えて、もっと系外惑星をはっきり見える方法について説明します。
主成分分析(PCA)とは
主成分分析(PCA)の基本については色んな記事で説明してあるので省略します。
理論や簡単な使い方はこの記事を参考に
- https://qiita.com/NoriakiOshita/items/460247bb57c22973a5f0
- https://qiita.com/Hatomugi/items/d6c8bb1a049d3a84feaaPCAは画像処理に使かわれることも多いです。これについてこの記事の説明がいいです。
- https://qiita.com/kenmatsu4/items/c61ce5d85667f499c3c8
- https://qiita.com/supersaiakujin/items/138c0d8e6511735f1f45今回は天文写真の処理に使うことになります。
PCAを使う前に標準偏差で割る場合が多いが、画像処理にとっては普通は必要ないのです。
これについてこの記事参照
https://qiita.com/koshian2/items/2e69cb4981ae8fbd3bdaPCAを使うには普通はsklearnのsklearn.decomposition.PCAを使うことが便利ですが、実際にその中のPCAの計算は特異値分解(singular value decomposition、SVD)で行われます。
PCAとSVDの関係についてはこの記事の説明がいいです。 https://qiita.com/horiem/items/71380db4b659fb9307b4
ここでsklearnを使わずに直接scipyでSVDの計算をします。
SVDを計算する方法は色々あり、例えば
- numpy.linalg.svd
- scipy.linalg.svd
- scipy.sparse.linalg.svdsデータサイズが大きい場合、scipy.sparse.linalg.svdsを使う方がずっと早いので、今回もこれを使います。
使い方についてこの記事も参考に
https://qiita.com/mizunototori/items/38291518110849e91a4c主成分分析を使うところ
この前の記事にも説明した通り、直接系外惑星の姿を撮りたい時、PSF(point spread function = 点拡がり関数)やスペックルノイズなどのノイズを消滅するために普段はADI(angular differential imaging = 角度差分撮像)という方法で何枚の写真を連続で撮影して後で合成するのです。
本来のADIの方法では、PSFはあまり時間によって変わらないと考えて、何枚の写真を合わせて中央値を求めてそれを全ての写真のPSFの値として扱って、そして全ての写真からひくと、PSFが消えて惑星の姿がはっきり見える。
こういう方法は簡単ですが、実際にPSFは時間と共に少しずつ変わっていくもので、その違いも考慮して、違う値でひいたらもっといい結果になるはずです。
ノイズのパターンを掴むことは重要なポイントです。
そのために色んな方法が提案されますが、その中でよく使われる方法はPCAを使うという方法です。
もともとADIという方法は2006年にマロワ(Marois)等によって提案されたものです。その後LOCIやANDROMEDAなどのADIの改善する方法も引き続き提案されました。
初めてADIにPCAを使ったのは2012年に別々に発表された2つの論文
- PYNPOINT: an image processing package for finding exoplanets, Amara & Sascha (2012)
- Detection and Characterization of Exoplanets and Disks Using Projections on Karhunen-Loève Eigenimages, Soummer et al. (2012)これを皮切りにして、その後PCAはADIによく使われる方法になってきたのです。
ADIにPCAを加えるという方法はKLIP(Karhunen-Loève image projection、もしくはprocessing)と呼ばれることも多いです。
やり方
写真は二次元の明るさのデータで、違う時間で何枚も連続撮ったものだから、時間と空間を合わせたら三次元データになります。波長(あるいは、色)を分けたら四次元になるが、ここでは簡単のために一色の明るさを考慮します。
PCAでは普通は二次元(各データ×各特徴)配列を入力として使われるので、二次元の空間を一次元に変形する必要があります。
画像が広さ$m_x$、高さ$m_y$ピクセルで$n$枚あるとしたら、データは$n \times m_x\times m_y$の配列になりますが、ここでまずは1ピクセルは1つの特徴にします。$m = m_x \times m_y$ピクセルが$m$特徴にしたら、データは$n \times m$の配列になります。
このようなn行m列の行列に書けます。
Z = \begin{bmatrix} z_{1,1} & z_{1,2} & \cdots & z_{1,m} \\ \\ z_{2,1} & z_{2,2} & \cdots & z_{2,m} \\ \\ \vdots & \vdots & \ddots & \vdots \\ \\ z_{n,1} & z_{n,2} & \cdots & z_{n,m} \\ \end{bmatrix}$z_{i,j}$はi番目の画像のj番目のピクセルの明るさ。
各枚の画像の各ピクセルの明るさは、恒星のPSFやスペックルノイズや惑星など、色んな要因から成されるもので、色んな成分の足し合わせに見なすことができます。
このように分割できます。
\begin{align} z_{i,j} = \sum_{h=1}^{m} \xi_{i,h} w_{h,j} \end{align}$\xi_{i,h}$は$i$番目の画像での$h$番目の成分の値。$w_{h,j}$は$j$番目ピクセルに対する$h$番目の成分の重み。
こうやってデータはこのように、かけ合った2つの行列に分解できます。
\begin{align} X_{[n\times m]} &= \Xi_{[n\times m]}W_{[m\times m]} \\ \begin{bmatrix} z_{1,1} & z_{1,2} & \cdots & z_{1,m} \\ \\ z_{2,1} & z_{2,2} & \cdots & z_{2,m} \\ \\ \vdots & \vdots & \ddots & \vdots \\ \\ z_{n,1} & z_{n,2} & \cdots & z_{n,m} \\ \end{bmatrix} &= \begin{bmatrix} \xi_{1,1} & \xi_{1,2} & \cdots & \xi_{1,m} \\ \\ \xi_{2,1} & \xi_{2,2} & \cdots & \xi_{2,m} \\ \\ \vdots & \vdots & \ddots & \vdots \\ \\ \xi_{n,1} & \xi_{n,2} & \cdots & \xi_{n,m} \\ \end{bmatrix} \begin{bmatrix} w_{1,1} & w_{1,2} & \cdots & w_{1,m} \\ \\ w_{2,1} & w_{2,2} & \cdots & w_{2,m} \\ \\ \vdots & \vdots & \ddots & \vdots \\ \\ w_{m,1} & w_{m,2} & \cdots & w_{m,m} \\ \end{bmatrix} \end{align}ここで$W$は直交行列である重みの行列です。直交行列の性質で
\begin{align} W^TW = W^{-1}W = I \end{align}それで
\begin{align} Z &=& \Xi W \\ ZW^T &=& \Xi W W^T &=& \Xi \\ ZW^T W &=& \Xi W &=& X \end{align}これはつまり、$Z$は$W^T$でかけたら$\Xi$になり、そしてまた$W$でかけたら$Z$に戻るということです。
しかし、ここでの目的はPSFの影響をたくさん受ける成分を求めることです。PSFによるノイズは時間と共に変化していくといっても、何か固定な傾向がある変化です。そのような変化は主成分に捉えられやすいです。
PCAでは主成分は何か一定の変化の傾向を持っている説明能力の高い成分のことです。
つまり、その主成分は、PCAのノイズの影響をたくさん受ける成分だと考えることができます。その主成分を求めて、元のデータからひいたら、ノイズが大分消されて、惑星の姿は残されてはっきり見えるようになります。
説明能力が高い最初の$k$成分だけ取ったら、重みの行列は$k$行だけ残ります。
P = \begin{bmatrix} w_{1,1} & w_{1,2} & \cdots & w_{1,m} \\ \\ w_{2,1} & w_{2,2} & \cdots & w_{2,m} \\ \\ \vdots & \vdots & \ddots & \vdots \\ \\ w_{k,1} & w_{k,2} & \cdots & w_{k,m} \\ \end{bmatrix}ここで$P$は主成分ばかりの重みで、$k=m$の場合$P$は$W$となり、$P^TP=I$になりますが、$k<m$の場合は、これはつまりただ主成分だけ取って再構成するということになります。
Z_p = Z P^T P$Z_p$は主成分だけ使って再構成されたデータの配列で、$i$番目の画像の$j$番目のピクセルの再構成された値は
\begin{align} z_{p(i,j)} = z_{i,j}\sum_{h=1}^k w_{h,j}^2 \end{align}元のデータ$Z$から$Z_p$をひいたら残るのは惑星と他のノイズです。(ガウス雑音のノイズは主成分に含まれることはないのでまだ残る)
ただ、主成分の数$k$はどれくらいでいいかは問題によって違うので、これも又よく考慮しなければならないハイパーパラメータです。
それともう一つの問題は、中心の部分が値のノイズが大きいため、PCAの計算に邪魔することが多いので、中心部が必要ない場合この部分を除外することでいい結果になることもあります。なので、これももう一つ考慮するかもしれないハイパーパラメータです。
実装
ここで流れを纏めると、
- 中心の部分を除外
- 画像データを二次元の$n$行$m$列の行列にする
- 各枚の間の平均値を計算してそれをひいて、平均値を0にする
- 主成分(最も説明能力の高い$k$成分)の重み行列$P$を求める
- $ZP^TP$を計算して、それを元のデータからひく
- 全ての画像を視差角によって回転し、最後に中央値を求める
次は実装。
使うデータはこの前の記事で使ったHR8799という星のデータにします。
その記事と同じ流れで生データの解析をしたら、HR8799_20150928/products/science_cube.fitsとscience_parang.fitsができます。
次の段階は、普通に中央値を取るという方法の代わりに、PCAを使います。
使っているSPHERE/IRDISは2つの波長がありますが、今回では0番目の波長(このHR8799_20150928のデータセットでは2110μm)だけを使います。
もっと詳しい説明はコードの中のコメントで
import matplotlib.pyplot as plt import numpy as np from astropy.io import fits from skimage.transform import rotate from scipy.sparse.linalg import svds import os rmin = 25 # 除外する中心部の半径 n_pc = 12 # 主成分の数 folder = 'HR8799_20150928/products' # 解析が完了した画像データ path_sc = os.path.join(folder,'science_cube.fits') # データは四次元だが、一番目の次元は波長で、今回は短い方の波長 (0番目) だけ使う z = fits.getdata(path_sc)[0,:,150:-150,150:-150] # 視差角 path_parang = os.path.join(folder,'science_parang.fits') parang = fits.getdata(path_parang) z -= z.mean(0) # 平均值をひく shape = z.shape z = z.reshape(shape[0],-1) # 二次元の画像を一次元に変形する xc,yc = (shape[2]-1)/2.,(shape[1]-1)/2. # 中心の位置 my,mx = np.indices([shape[1],shape[2]]) mx,my = mx.ravel()-xc,my.ravel()-yc mr = np.sqrt(mx**2+my**2) # 中心からの距離 z[:,mr<rmin] = np.nan # 中心部を除外 p = svds(z[:,mr>=rmin],n_pc)[2] # 中心部以外だけを取ってSVDを実行して重み行列を求める z[:,mr>=rmin] -= z[:,mr>=rmin].dot(p.T).dot(p) # 主成分だけでデータ再構成 z = z.reshape(shape) # データ形を二次元の画像に戻す # 視差角による回転 for i,parang_i in enumerate(parang): z[i] = rotate(z[i],-parang_i,cval=np.nan) # 中央値 res = np.median(z[:,100:-100,100:-100],0) # 結果を描く plt.figure(figsize=[6,5]).gca(facecolor='k') plt.imshow(res,origin='bottom',cmap='PuBu_r') plt.colorbar(pad=0.01) plt.tight_layout() plt.savefig('adi_pca%d.png'%n_pc) plt.close()ここでは主成分の数が12で、このような結果ができます。
ここから4つの明るい点が見えます。中心から一番遠いものから近いものまで並ぶと、HR8799b、HR8799c、HR8799d、HR8799e。
元の方法ではHR8799eを見ることが難しいが、今回でPCAを使ったらこのようにはっきり見えるようになりました。
主成分の数が変われば結果も大きく変わります。
例えば8にする場合
6
4
2
主成分の数が少なすぎるとノイズがたくさん残って惑星は見えにくくなります。
逆に主成分が多すぎると、惑星の信号もたくさん主成分に含められて薄くなります。
例えば、50にする場合
100
こんな風にHR8799eの姿は随分薄くなってしまいます。
環状のPCA
PCAを使う時、計算の参考に使うデータと、後で結果を使って再構成するデータとは、必ずしも同じものであるわけではないのです。
上述の方法では、ただ簡単に全部のデータを参考に使って、そしてそのデータ自身の主成分で再構成したのです。
ADIでの惑星探しでは、惑星の影響が主成分に巻き込まれることがあります。こうなったら残る惑星の信号が薄くなるので、できるだけ避けるべきことです。
そのため、n番目の画像の主成分を求める時にPCAの計算にn番目の画像と、近い視差角を持つ画像を参考データに含めないようにするという方法も提案されたのです。
2つの写真のフレームの視差角が近いというのはその写真の中での惑星の位置が近くにあるということです。なので視差角が目標のフレームから惑星の範囲より大きく離れるフレームだけ使う方が無難です。
ここで惑星の範囲というのは、惑星が画像に写っている範囲です。実際に惑星もPSFによってエアリーディスクの姿になりますが、簡単に二次元ガウス関数に見なすこともできます。
f(x,y) = a\exp{\left(-\frac{(x-x_c)^2+(y-y_c)^2}{2\sigma^2}\right)}普通は半値全幅(FWHM)が惑星の範囲を示すのによく使われます。
ガウス関数のFWHMと$\sigma$との関係は
\mathrm{FWHM} = 2\sqrt{2\ln 2}\sigma \approx 2.355\sigmaSPHEREデータでは、products/psf_cube.fitsにある解析されたOBJECT,FLUXのデータを使ったら、PSFの様子とFWHMを求めることができますが、今回は便宜上、FWHM=5ピクセルにします。(SPHEREデータのFWHMは大体が4~5ピクセルくらいだから大きく間違わない)
ただ、惑星の移動は中心に近いほど大きくなるものなので、除外するべきフレームは中心からの距離によって違います。
距離と角度の関係はこの画像通りです。
ここで$r$は中心からの距離で、$\Delta \theta$はFWHM内の角度の範囲です。こうやって計算できます。
\begin{align} \Delta\theta > 2\arcsin\left(\frac{FWHM}{2r}\right) \end{align}だからいくつかの円環(アニュラス、annulus)に分けて別々にPCAの計算を行うということになります。
このように円環一つずつ取って別々に計算します。
次はpythonで実装。コードは随分複雑になるし、かかる時間も何倍も長くなります。詳しくはコートの中のコメントで
import matplotlib.pyplot as plt import numpy as np from astropy.io import fits from skimage.transform import rotate from scipy.sparse.linalg import svds import os,time t0 = time.time() fwhm = 5 d_ann = 4 # 円環の広さ rmin = 25 # 除外する中心部の半径 n_pc = 12 # 主成分の数 folder = 'HR8799_20150928/products' path_sc = os.path.join(folder,'science_cube.fits') path_parang = os.path.join(folder,'science_parang.fits') z = fits.getdata(path_sc)[0,:,150:-150,150:-150] parang = fits.getdata(path_parang) n_f = len(z) z -= z.mean(0) # 平均値をひく shape = z.shape z = z.reshape(shape[0],-1) # 二次元の配列に変形する xc,yc = (shape[2]-1)/2.,(shape[1]-1)/2. # 中心の位置 rmax = int(min(xc,yc)) my,mx = np.indices([shape[1],shape[2]]) mx,my = mx.ravel()-xc,my.ravel()-yc mr = np.sqrt(mx**2+my**2) # 中心からの距離 n_ann = int((rmax-rmin)/d_ann) # 円環の数 print('円環の数: %d'%n_ann) r_ann_io = np.linspace(rmin,rmax,n_ann+1) r_ann_out = r_ann_io[1:] # 円環の最も外 r_ann_in = r_ann_io[:-1] # 円環の最も中 r_ann_cen = (r_ann_in+r_ann_out)/2. # 円環の半ば dthetamin = 2*np.degrees(np.arctan(fwhm*0.5/r_ann_cen)) # 使える最天元の視差角 zp = np.full_like(z,np.nan) d_parang = np.abs(parang-parang[:,None]) # 視差角の差 # 円環一つずつ for i_ann in range(n_ann): # 視差角が十分大きいかどうかを示すブールの配列 dthetafar = d_parang>dthetamin[i_ann] # この円環の範囲にあるピクセルだけ取る in_xy_a = (r_ann_in[i_ann]<=mr)&(mr<r_ann_out[i_ann]) z_i = z[:,in_xy_a] # 1フレームずつ主成分分析を行う for i_f in range(n_f): w = svds(z_i[dthetafar[i_f]],n_pc)[2] # その円環とそのフレームの主成分での再構成 zp[i_f,in_xy_a] = z_i[i_f].dot(w.T).dot(w) print('%d番目完成。%.2f分経過'%(i_ann+1,(time.time()-t0)/60)) z -= zp # 主成分で再構成された値をひく z = z.reshape(shape) # 形をもとに戻す # 視差角による回転 for i,parang_i in enumerate(parang): z[i] = rotate(z[i],-parang_i,cval=np.nan) res = np.median(z[:,100:-100,100:-100],0) # 中央値 # 結果を描く plt.figure(figsize=[6,5]).gca(facecolor='k') plt.imshow(res,origin='bottom',cmap='PuBu_r') plt.colorbar(pad=0.01) plt.tight_layout() plt.savefig('adi_pca%d_ann.png'%n_pc) plt.close()結果
すでにあるpythonモジュール
PCAはよくADIに使われる方法なので、簡単に実装できるpythonモジュールがあります。
終わりに
以上は系外惑星探索におけるPCAの用途の一つです。
最近機械学習の方法が系外惑星探索を含めて色んな分野によく使われています。
PCAの他にのにNMFなどの方法もADIに使われることがあります。