- 投稿日:2019-10-11T23:30:26+09:00
AWS 遊んでみる teraterm ログインする方法
1.teraterm ログインする方法
Hostに下記のアドレスをコピーして、teraterm入力する
User nameに固定ユーザID:ec2-userを入力します。下記の画面のデフォルトを選んでから、ダウンロードしたLightsailDefaultKey-ap-northeast-1.pemを選択します。
2.sudo suでルート権限を入手
3.passwd ec2-userでec2-userのパスワードを変更できます。
4.DB2 V11.5のインストール
4.1 db2のインストール
(1)下記のコマンドでダウンロードしたファイルを解凍します。
#gzip -dc v11.5_linuxx64_dec.tar.gz | tar xvf - tar zxvf v11.5_linuxx64_dec.tar.gz







- 投稿日:2019-10-11T20:37:00+09:00
EC2のRuby/Rails環境構築中のwe're sorry, but something went wrongでハマった話
こんばんは!ポートフォリオをいよいよデプロイしようとした時にハマったエラー
we're sorry, but something went wrong
[ec2-user@ip-172-31-23-189 ~]$ unicorn_rails -c config/unicorn.rb -E production -Dで問題なくunicornが走ったと思い
http://<ElasticIP>:30000にアクセスするとwe're sorry, but something went wrongいつも通り再起動
[ec2-user@ip-172-31-23-189 ~]$ sudo shutdown -r now [ec2-user@ip-172-31-23-189 ~]$ sudo service mysql stop [ec2-user@ip-172-31-23-189 ~]$ sudo service mysql start [ec2-user@ip-172-31-23-189 ~]$ cd /var/www/sample-app [ec2-user@ip-172-31-23-189 sample-app]$ cd /var/www/sample-app [ec2-user@ip-172-31-23-189 sample-app]$ unicorn_rails -c config/unicorn.rb -E production -Dまだnginxの設定していない状態だけど、いつもだとこれでうまくいくはず。だけど今回はダメだった。
production.rbのログ確認
エラーの糸口が掴めずメンターに聞くと教えてくれた
[ec2-user@ip-172-31-23-189 sample-app]$ cd log [ec2-user@ip-172-31-23-189 log]$ cat production.rb
catコマンドでログの内容を確認していくと見覚えのあるエラーを発見。ActionView::Template::Error解決
トップページに設置している画像が存在してないよってことでした。
<%= image_tag("hoge.png"), class:"hoge" %>
hoge.pngはapp/assets/images配下に置いてた画像でgitignoreしてました。ひとまず
img srcに書き換える<img src="http://hogehoge.png" alt="" class-"hoge">これでもう一度、unicornを再起動して走らせたら無事にアクセスできました。
アセットファイルをコンパイル
[ec2-user@ip-172-31-40-237 sample-app]$ rails assets:precompile Yarn executable was not detected in the system. Download Yarn at https://yarnpkg.com/en/docs/install怒られた。
[ec2-user@ip-172-31-40-237 sample-app]$ npm install yarn -g //これでも怒られたら [ec2-user@ip-172-31-40-237 sample-app]$ sudo npm install yarn -g //これでいけるはず [ec2-user@ip-172-31-40-237 sample-app]$ rails assets:precompile ~~ success Saved lockfile. //unicornをkill -9 [pid]してunicorn再起動 [ec2-user@ip-172-31-40-237 sample-app]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D無事にレイアウトも綺麗になりました。
参考
EC2にてnpm install yarn -gが失敗する
https://qiita.com/tsumita7/items/a40a367088018b5bbe33まとめ
2度目のデプロイですが、やはり一筋縄ではいきません。ハマったエラーはメモって次回はハマらないようにしていきます。
終わり
- 投稿日:2019-10-11T19:12:48+09:00
AWS Elastic Beanstalk 環境状態監視
問題
AWS EBでヘルスチェックには問題ないが、一部のインスタンスが障害のままで不安定の状態が続く。
ソリューション
インスタンスを直監視しょうとしたが、環境状態でまとめ評価されるので環境状態を監視する。
Zabbix
AWSプロファイル作成: aws configure --profile [マクロ{$ACCOUNT}]
マクロ
- {$ACCOUNT}: アカウント(複数アカウントがある場合)
- {$EB_APP}: アプリケーション名
アイテム
- 名前:EnvStatus
- タイプ:外部チェック
- キー:cw_eb_status.sh["{\$ACCOUNT}","{\$EB_APP}"]
トリガー
- 条件式: 3回連続「Ok」ではないと障害! {host:cw_eb_status.sh["{\$ACCOUNT}","{\$EB_APP}"].count(#3,'Ok')}=0
#!/bin/bash Account="$1" AppName="$2" export AWS_PROFILE=$Account result=`aws elasticbeanstalk describe-environments --application-name ${AppName} \ | jq '.Environments[0].HealthStatus' | sed 's/^.*"\(.*\)".*$/\1/'` echo $result参考
jq前
{ "Environments": [ { "EnvironmentName": "xxx-env-xxxxxa", "EnvironmentId": "e-xxxxxjvc", "ApplicationName": "xxxx", "VersionLabel": "app-xxxx-xxxxx_170739", "SolutionStackName": "64bit Amazon Linux 2018.03 v2.8.14 running PHP 5.6", "PlatformArn": "arn:aws:elasticbeanstalk:ap-northeast-1::platform/PHP 5.6 running on 64bit Amazon Linux/2.8.14", "Description": "Environment cloned from xxx-env-xxxxxa from the EB CLI using \"eb clone\"", "EndpointURL": "awseb-e-w-AWSEBLoa-xxxxxxxxx-1248087954.ap-northeast-1.elb.amazonaws.com", "CNAME": "xxx-env.elasticbeanstalk.com", "DateCreated": "2019-10-02T08:04:01.469Z", "DateUpdated": "2019-10-10T02:15:31.146Z", "Status": "Ready", "AbortableOperationInProgress": false, "Health": "Green", "HealthStatus": "Ok", "Tier": { "Name": "WebServer", "Type": "Standard", "Version": "1.0" }, "EnvironmentLinks": [], "EnvironmentArn": "arn:aws:elasticbeanstalk:ap-northeast-1:xxxxxxxx396:environment/xxx/xxx-env-xxxxxa" } ] }
- 投稿日:2019-10-11T18:01:00+09:00
downloadCompleteLogFileをbashで実装する
EC2インスタンス上のOSからRDSのログをダウンロードするには、awsのcliのaws rds download-db-log-file-portionが便利かつ簡単であるが、ダウンロードしたログが途切れる現象(仕様?不具合?)が発生する(もともと"portion"という名の通りといえばその通りである)。ログ全体をダウンロードするのに、
downloadCompleteLogFileというAPIが提供されているものの、残念ながらaws rdsには実装されていない。
そこでOSコマンドを駆使してRDSからログを取ってくるシェルスクリプトを作ってみる。
正直なところ、サンプルコードが公開されているpythonを使うほうが楽なのだけれど、現場ではインフラ保守SEはpythonコードのメンテナンスなんてできません、などという状況がままあるので、「普通のシェルスクリプトです」というと通りがよいのだ、、、前提環境
REST APIのサンプルでは、アクセスキーとシークレットをハードコーディングする例が記載されているが、AWSではEC2インスタンスにAPI実行を許可するポリシーを持ったロールを付与しておくことがベストプラクティスとされている。ここでもその前提とする。
具体的には以下のような構成となる。
- EC2インスタンス(Amazon Linux)
- RDS for PostgreSQL11
- EC2インスタンスにアタッチしたロール名は
testec2
testec2ロールにアタッチされているポリシーは以下の通り。ec2_rds_ctl_policy{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "rds:DownloadDBLogFilePortion", "rds:DescribeDBLogFiles", "rds:StopDBInstance", "rds:StartDBInstance" ], "Resource": "*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "rds:DescribeDBInstances", "rds:DownloadCompleteDBLogFile" ], "Resource": "*" } ] }今回のシェルスクリプトに必要なのは、
rds:DownloadCompleteDBLogFileのみ。
downloadCompleteDBLogFileの概要Amazon RDS データベースログファイルに記載してある通り、以下のようなリクエストをRDSのAPIエンドポイントに投げてやればよい。
公式サイトから引用GET /v13/downloadCompleteLogFile/DBInstanceIdentifier/LogFileName HTTP/1.1 Content-type: application/json host: rds.region.amazonaws.comこれだけ見れば、なんだ
curlとかwgetで楽勝と思いきや、実際には認証関連のリクエストヘッダを生成して付与してやる必要がある。公式サイトにも上記の例に続いて、次のようなリクエスト例が記載されていて、見るものを絶望の淵に追いやってくれる。公式サイトから引用GET /v13/downloadCompleteLogFile/sample-sql/log/ERROR.6 HTTP/1.1 host: rds.us-west-2.amazonaws.com X-Amz-Security-Token: AQoDYXdzEIH//////////wEa0AIXLhngC5zp9CyB1R6abwKrXHVR5efnAVN3XvR7IwqKYalFSn6UyJuEFTft9nObglx4QJ+GXV9cpACkETq= X-Amz-Date: 20140903T233749Z X-Amz-Algorithm: AWS4-HMAC-SHA256 X-Amz-Credential: AKIADQKE4SARGYLE/20140903/us-west-2/rds/aws4_request X-Amz-SignedHeaders: host X-Amz-Content-SHA256: e3b0c44298fc1c229afbf4c8996fb92427ae41e4649b934de495991b7852b855 X-Amz-Expires: 86400 X-Amz-Signature: 353a4f14b3f250142d9afc34f9f9948154d46ce7d4ec091d0cdabbcf8b40c558というわけで、これらの値は何なのか、そしてどうやって生成するのか、というのが問題の核心ということになる。
また、仕様なのか不具合なのか不明だが、この通りヘッダを設定しても認証情報が見つからないというエラー(403 Forbidden)になる。以下の情報はAuthorizationヘッダにまとめて渡す必要がある。
X-Amz-SignatureX-Amz-AlgorithmX-Amz-CredentialX-Amz-SignedHeadersX-Amz-Content-SHA256各種セキュリティ情報
前述の通り、以下のセキュリティ情報をHTTPリクエストヘッダに付与してやる必要がある。
X-Amz-Security-Token
今回はEC2インスタンスにロールを付与しているので、これはメタデータから取得可能。
curl http://169.254.169.254/latest/meta-data/iam/security-credentials/$iam_role実行結果抜粋{ "AccessKeyId" : "XXXXXXXXXXXXXXXXX", "SecretAccessKey" : "YYYYYYYYYYYYYYYYYYY", "Token" : "ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ", }
Tokenの値をX-Amz-Security-Tokenヘッダとして渡してやればよい。また、のちにAccessKeyIdとSecretAccessKeyも使うので、これらも取得する必要がある。perlかawkあたりで正規表現を使えば簡単に取り出せる。その他、以降で使用する定数も含めると以下のようなコードになる。# ========== Step 0: 定数設定 ========== LF="__LF__" ## IAMロールからアクセスキー・シークレット・トークンを取得 a=$(curl http://169.254.169.254/latest/meta-data/iam/security-credentials/${iam_role} | grep -e AccessKeyId -e SecretAccessKey -e Token) access_key=$(echo $a | perl -pe 's/"AccessKeyId" : "(.*)", "SecretAccessKey" : "(.*)", "Token" : "(.*)",*$/$1/') secret_key=$(echo $a | perl -pe 's/"AccessKeyId" : "(.*)", "SecretAccessKey" : "(.*)", "Token" : "(.*)",*$/$2/') token=$(echo $a | perl -pe 's/"AccessKeyId" : "(.*)", "SecretAccessKey" : "(.*)", "Token" : "(.*)",*$/$3/') ## サービス関連パラメータ設定 ALGORITHM=AWS4-HMAC-SHA256 region=ap-northeast-1 service=rds host=${service}.${region}.amazonaws.com endpoint="https://${host}" request_path=/v13/downloadCompleteLogFile/${RDS_ID}/${logfilename} amzdate=$(date -u +%Y%m%dT%H%M%SZ) datestamp=$(date -u +%Y%m%d)日付・時刻データは2種類、それぞれUTC時間で必要になる。0時(日本時間9時)をまたいだ場合、つまり
$amzdateと$datestampとで日付が異なるとどうなるかは不明。心配なら一回で日付取得して文字列を切り出すか、値を比較して異なるなら再生成するよう実装するほうがセーフかもしれない。
Authorizationこれがこの記事の核心である。リクエストを認証してもらうのに、署名(HMACのハッシュ値計算)という手続きが必要で、これをリクエストヘッダ(
Authorization)として渡す必要がある。pythonでの実装例を見ればどうやればよいかがわかる。大雑把にいって以下のようになる。
- リクエスト情報をまとめる
- リクエスト情報と時刻、固定文字列から署名対象データを生成する
- 署名対象データに署名する
- リクエストを発行する
以降ではそれぞれについて、
bashでの実装例を記載していく。特に改行文字の扱いには注意が必要で、ダイジェスト値を求める際にecho "hogehoge" | openssl dgstなどとしてしまうと、末尾の改行コードも含めたダイジェスト値となってしまう点に留意する。また、意味のある文字として改行コード(LF)が随所に埋め込まれるので、IFS環境変数の設定によってはスペース文字に変換されてしまう可能性がある。このため、以下では文字列定数LF=__LF__を定義して、ダイジェスト値を求める際に文字変換するように実装している。1. リクエスト情報をまとめる
ドキュメントには「正規リクエスト(canonical request)」と表現されているが、以下の要素を改行文字(LF)で連結した文字列である。
- HTTPリクエストメソッド:今回は
GET- HTTPリクエストパス:今回は
/v13/downloadCompleteLogFile/${RDS_ID}/${logfilename}- HTTPリクエストクエリ文字列:今回はNULL
- 署名対象HTTPリクエストヘッダ:今回は
host:$RDS_API_ENDPOINTとx-amz-date:<リクエスト発行時刻GMT>。複数ある場合は改行文字(LF)で区切る- 署名対象ヘッダ情報:今回は
host;x-amz-date。こちらは複数ある場合セミコロン(;)で区切る- POSTデータのペイロードハッシュ:今回はリクエストメソッドが
GETなのでNULLのSHA-256ハッシュ値ほぼ固定値なので、
bashで簡単に生成できる。ペイロードは空なので常に固定値になるが、opensslコマンドで動的に生成すると以下のようになる。# ========== Step 1: 正規リクエストの生成 ========== header="host:${host}${LF}x-amz-date:${amzdate}${LF}" signed_headers="host;x-amz-date" request_param="" payload_hash=$(printf "" | openssl dgst -sha256 | awk '{print$2}') canonical_request="GET${LF}${request_path}${LF}${request_param}${LF}${header}${LF}${signed_headers}${LF}${payload_hash}"繰返しになるが、この後ダイジェスト値を求めることになるので、たとえば
header変数の中でhost: ${host}というように余分な空白を入れたりすると、まったく異なった署名値ができあがり、無事に(?)403 Forbiddenが返されることになる。2. リクエスト情報と時刻、固定文字列から署名対象データを生成する
署名対象の文字列は以下の要素をこれまた改行文字(LF)で連結して生成する。
- 署名アルゴリズム:
AWS4-HMAC-SHA256固定。ダイジェストアルゴリズムは変更できそうだがわざわざビット数が低いアルゴリズムを選択するメリットはないだろう- 資格情報の有効範囲(スコープ):
YYYYMMDD/<AWSリージョン名>/<AWSサービス名>/aws4_request- 正規リクエストのダイジェスト値
実際のコードは以下のようになる。
# ========== Step 2: 署名対象文字列生成 ========= scope="${datestamp}/${region}/${service}/aws4_request" dgst=$(printf $canonical_request | perl -pe 's/__LF__/\n/g' | openssl dgst -sha256 | awk '{print$2}') str_2B_signed="${ALGORITHM}${LF}${amzdate}${LF}${scope}${LF}${dgst}"正規リクエスト文字列(
$canonical_request})のダイジェスト($dgst)は、改行文字のマーク(${LF})をパイプでperlにつないで改行文字(LF)に変換し、あとはopenssl dgst -sha256に渡して取得できる。
署名対象文字列(str_2B_signed)はこれらをやはり改行文字(LF)で連結したものになる。3. 署名対象データに署名する
上記で生成した署名対処文字列に署名する。使用するアルゴリズム(HMAC)は同じなので、コマンドとしては
openssl dgstで生成可能だが、そのステップは以下のようになる。
# 署名対象データ 鍵データ 1 日付( $datestamp)AWS4${secret_key}2 リージョン名( $region)前のステップで生成したダイジェスト値 3 サービス名( $service)前のステップで生成したダイジェスト値 4 aws4_request前のステップで生成したダイジェスト値 5 署名対象データ( $str_2B_signed)前のステップで生成したダイジェスト値 やっていることは同じだがその意味合いは異なる。1~4までで署名に使用する鍵となる値を生成し、そのダイジェスト値を使用して署名対象データのダイジェスト値(HMACハッシュ値)を計算することになる。
# ========== Step3: 署名生成 ========== ## 署名用鍵生成 kDate=$(printf $datestamp | openssl dgst -sha256 -mac HMAC -macopt key:AWS4${secret_key} | awk '{print$2}') kRegion=$(printf $region | openssl dgst -sha256 -mac HMAC -macopt hexkey:${kDate} | awk '{print$2}') kService=$(printf $service| openssl dgst -sha256 -mac HMAC -macopt hexkey:${kRegion} | awk '{print$2}') sigkey=$(printf "aws4_request" | openssl dgst -sha256 -mac HMAC -macopt hexkey:${kService} | awk '{print$2}') ## 署名 signature=$(printf $str_2B_signed | perl -pe 's/__LF__/\n/g' | openssl dgst -mac HMAC -macopt hexkey:${sigkey} | awk '{print$2}')ところどころに固定文字列が使用されるので若干複雑に感じるものの、いくつかの情報のハッシュチェーンである。
openssl dgst -mac HMACでは鍵を渡すときのオプション(-macopt)として文字列(key:<key_str>)とhex文字列(hexkey:<hex_str>)が利用可能で、一つ目だけは文字列で鍵を渡すので、前者のオプションを使用している。出力はhexdumpなので、以降ではhexkeyとして渡す必要がある。
繰返しになるが、署名を生成するのにハッシュチェーンを使用していて、鍵生成の最初のステップと最後のステップ(#1と#4)で固定文字列(それぞれAWS4とaws4_request)を使用している。$secret_keyをそのまま使わずにソルト文字列の役割を持つAWS4を挿入している点が心憎い。4. リクエストを発行する
あとはリクエストヘッダを付与して実際に
GETするだけ。curlの-Hオプションを使用すれば、リクエストヘッダを追加できる。Authorizationヘッダ値のフォーマットは以下の通り。<署名アルゴリズム> Credential=<アクセスキー>/<スコープ>, SignedHeaders=<署名対象HTTPリクエストヘッダ>, Signature=<署名値>アクセスキーはここで使う。
# ========== Step 4: 署名をリクエストに付与してリクエスト発行 ========== auth_header="${ALGORITHM} Credential=${access_key}/${scope}, SignedHeaders=${signed_headers}, Signature=${signature}" curl \ -H "host: ${host}" \ -H "Accept: text/plain" \ -H "x-amz-security-token: ${token}" \ -H "x-amz-date: ${amzdate}" \ -H "Authorization: ${auth_header}" \ "${endpoint}${request_path}"
Acceptにtext/plainを指定したので、標準出力をリダイレクトするなりすれば、そのままログファイルとして出力できる(指定しなくてもデフォルトはtext/plainで返ってきていたが明示しておいて損はないだろう)。参照資料
付録
引数でIAMロール名、RDSインスタンスID、ログファイルパターンおよび出力先を指定し、マッチするログを全て出力する例。IAM認証情報がいつ期限切れになるかわからないので、ダウンロードするたびに動的に取得するよう実装している。というよりも、上記コードを関数化して繰り返し呼出しするようにしただけなので、あまりきれいにまとまっていない、、、
downloadCompleteLogFile.sh#!/bin/bash # https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/UserGuide/USER_LogAccess.html # https://docs.aws.amazon.com/ja_jp/general/latest/gr/signature-version-4.html # ========== 初期化 ========== while [ $# -gt 0 ]; do case $1 in "-region") shift region=$1 shift;; "-rds") shift rds_id=$1 shift;; "-iam") shift iam_role=$1 shift;; "-out") shift outputfile=$1 shift;; "-file") shift logfilename=$1 shift;; *) echo "Usage: $(basename $0) -region AWS_REGION -rds RDS_IDENTIFIER -iam IAM_ROLE_NAME -file FILENAME_PATTERN_TO_BE_DOWNLOADED -out OUTPUT_FILE" >&2 exit 1;; esac done # assume defaults iam_role=${iam_role:=$(uname -n)} rds_id=${rds_id:=database-1} logfilename=${logfilename:=postgresql.log} outputfile=${outputfile:=/tmp/postgresql.log} region=${region:=$AWS_DEFAULT_REGION} region=${region:=ap-northeast-1} # set constants service=rds metadata_url=http://169.254.169.254/latest/meta-data/iam/security-credentials/${iam_role} LF="__LF__" ALGORITHM=AWS4-HMAC-SHA256 host=${service}.${region}.amazonaws.com endpoint="https://${host}" # ========== 関数 ========= function downloadRDSLog() { local logfilename=$1 # ========== Step 0: 定数設定 ========== ## IAMロールからアクセスキー・シークレット・トークンを取得 a=$(curl $metadata_url | grep -e AccessKeyId -e SecretAccessKey -e Token) access_key=$(echo $a | perl -pe 's/"AccessKeyId" : "(.*)", "SecretAccessKey" : "(.*)", "Token" : "(.*)",*$/$1/') secret_key=$(echo $a | perl -pe 's/"AccessKeyId" : "(.*)", "SecretAccessKey" : "(.*)", "Token" : "(.*)",*$/$2/') token=$(echo $a | perl -pe 's/"AccessKeyId" : "(.*)", "SecretAccessKey" : "(.*)", "Token" : "(.*)",*$/$3/') if [ -z "$access_key" -o -z "$secret_key" -o -z "$token" ]; then echo "security credentials not available" >&2 curl $metadata_url >&2 exit 1 fi ## リクエスト関連パラメータ設定 request_path=/v13/downloadCompleteLogFile/${rds_id}/${logfilename} amzdate=$(date -u +%Y%m%dT%H%M%SZ) datestamp=$(date -u +%Y%m%d) # ========== Step 1: 正規リクエストの生成 ========== header="host:${host}${LF}x-amz-date:${amzdate}${LF}" signed_headers="host;x-amz-date" request_param="" payload_hash=$(printf "" | openssl dgst -sha256 | awk '{print$2}') canonical_request="GET${LF}${request_path}${LF}${request_param}${LF}${header}${LF}${signed_headers}${LF}${payload_hash}" # ========== Step 2: 署名対象文字列生成 ========= scope="${datestamp}/${region}/${service}/aws4_request" dgst=$(printf $canonical_request | perl -pe 's/__LF__/\n/g' | openssl dgst -sha256 | awk '{print$2}') str_2B_signed="${ALGORITHM}${LF}${amzdate}${LF}${scope}${LF}${dgst}" # ========== Step3: 署名生成 ========== ## 署名用鍵生成 kDate=$(printf $datestamp | openssl dgst -sha256 -mac HMAC -macopt key:AWS4${secret_key} | awk '{print$2}') kRegion=$(printf $region | openssl dgst -sha256 -mac HMAC -macopt hexkey:${kDate} | awk '{print$2}') kService=$(printf $service| openssl dgst -sha256 -mac HMAC -macopt hexkey:${kRegion} | awk '{print$2}') sigkey=$(printf "aws4_request" | openssl dgst -sha256 -mac HMAC -macopt hexkey:${kService} | awk '{print$2}') ## 署名 signature=$(printf $str_2B_signed | perl -pe 's/__LF__/\n/g' | openssl dgst -mac HMAC -macopt hexkey:${sigkey} | awk '{print$2}') # ========== Step 4: 署名をリクエストに付与してリクエスト発行 ========== auth_header="${ALGORITHM} Credential=${access_key}/${scope}, SignedHeaders=${signed_headers}, Signature=${signature}" curl \ -H "host: ${host}" \ -H "Accept: text/plain" \ -H "x-amz-security-token: ${token}" \ -H "x-amz-date: ${amzdate}" \ -H "Authorization: ${auth_header}" \ "${endpoint}${request_path}" if [ $? -ne 0 ]; then echo "download error" >&2 exit 1 fi } # ========== 主処理 ========== ## ファイル初期化 > $outputfile if [ $? -ne 0 ]; then echo "file access error(${outputfile})" >&2 exit 1 fi ## ログファイルリストを取得 logfiles=$( aws rds describe-db-log-files --db-instance-identifier $rds_id --filename-contains $logfilename \ --query "DescribeDBLogFiles[*].[LogFileName]" --output text | sort ) if [ $? -ne 0 ]; then echo "log list not available" >&2 exit 1 fi ## ログをダウンロード for logfile in $logfiles; do echo "downloading $logfile" downloadRDSLog $logfile >>$outputfile done
- 投稿日:2019-10-11T17:59:49+09:00
最低限の労力でLaravelのタスクスケジュール ( Task Scheduling ) + AWS ECS
最低限の労力でLaravelのタスクスケジュール ( Task Scheduling ) + AWS ECS
※ ある程度LaravelのCommandやECSを利用している人向けの記事です
※ イメージにはphp:7.3-fpm-alpineベースで、他にミドルウェアを色々入れたものを利用
※ Laravelは6.0を利用EC2 + cron + Laravelで動いていた定期処理実行サーバを、ECSに移すことになりました。
以前から、WebはECS + Laravel (+ Nginx)で動かしてました
まあ、インフラ管理方法が2種類あるのは負担でしかないですよね。。。それで、方法を考えると、ECSの"タスクのスケジューリング"だろうとは思ったのですが
- たくさんECSのスケジュールタスクを作るのは面倒...
- CloudFormationを書くには、このプロジェクトは遅すぎた。cloudformationの運用も面倒...
そんなわけで、Laravelのタスクスケジュールと、ECSの”タスクのスケジューリング”を組み合わせてみました。
両方似たような名前で頭がオカシクなりそうです。注意事項
これから紹介する方法は、以下を許容できる処理に限定した方が良いと思います
- スケジュールが多少いい加減で良い
- イメージの内容によるが、コンテナ(タスク)が立ち上がるまでに数十秒かかる
- 時間に対応したスケジュールが一個ずつ実行されるため、全ての処理が完了するまでに時間がかかる
- ちなみに
runInBackground()を利用したら処理完了前にコンテナが終了すると思います(戒め)- 時間がかかる処理では、同じコマンドが並列実行されるリスクがある
- つまり、コンテナが多重起動している状態もあるということ
- 多重でScheduleを実行させないための実装がLaravelにあり
onOneServer(),withoutOverlapping()onOneServer()の方が良さそう(小並感)- コンテナ(ECSタスク)の多重起動をECS側で禁止する方法もあるが、大事なタイミングでコマンドが実行されない危険性があるので、おすすめしない
重要な処理は、個別にECSタスク定義とECSスケジュールタスクを作った方が良いかと思います。
(同じタスク定義を利用しても設定でCMDを上書きできます。しかし、タスクの設定でタスク定義のリビジョンを上げるたびに再度指定することになります。おすすめしません。)全体像
Laravelのタスクスケジュールで、定期実行の設定を記述
以下を参考に、淡々と記述すればOK。
https://readouble.com/laravel/6.0/ja/scheduling.htmlEC2なんかでcronですでに設定されていれば、
cron()使えば楽にスケジュールを指定可能。ECSのスケジュールタスクを設定
- ECSでLaravelが動くDockerイメージが作成できていれば、それを利用してバッチ処理用のタスク定義を作成
- タスク定義では、コンテナ設定でCMDを
php artisan schedule:runに変更
- すでにLaravelがPHP-FPMとかで動くイメージを利用する場合、起動時の動作(CMD)を上書きできる状態に変更
- ENTRYPOINTが指定されていた場合、ENTRYPOINTは実行時に上書きできないし、CMDはENTRYPOINTの引数扱いとなり、実行時の挙動を上書きできない
- ベースがphp-fpmのイメージなら、DockerfileでENTRYPOINTを
[]に上書き(無効化)して、CMDを["docker-entry-point","php-fpm"]とかに変えればいいと思いますECSで"タスクのスケジューリング"を設定
上記のタスクを毎分起動するように設定。
(おまけ) エラー通知
例外発生時には、通知はもちろんスタックトレースとかも確認できるようにしたい。
LaravelのScheduleには、before, after, onFailuereといったフックがあるんですが、出力を参照できないっぽいから、こいつらは大した事はできないです。これはすごい悩んだ。いやまあ、杞憂でしたけどorz。
エラー時には、普通にHandlerに引っかかります。
つまり、app/Exceptions/Handler.php内の処理。
既にSlack通知なりが設定されてれば、ECSスケジュールタスクでの例外発生時にも、同様にSlack通知されます。
定期処理だけ特別な処理をしたいなら、タスク定義に定期処理フラグ的な環境変数でも適当に設定して、その環境変数の値をもってHandlerの処理を分岐させれば良いと思われます。
- 投稿日:2019-10-11T17:39:38+09:00
AWS Step FunctionsのDynamic Parallelismを試してみる
AWS Step Functions とは
SNS, SQS等のイベントやLambdaやECS Task、AWS Batchなどの実行・制御を定義したワークフローを作成できるAWSのサービスです。
https://docs.aws.amazon.com/ja_jp/step-functions/index.htmlワークフローはjsonで記述し、自動的にビジュアライズされます。
Step Functionsの記述とビジュアライズされたワークフローの例AWS Step FunctionsがDynamic Parallelismをサポートしたという発表が9月18日にありました。
https://aws.amazon.com/jp/blogs/aws/new-step-functions-support-for-dynamic-parallelism/これまでも複数のタスクを並列に動かすことは可能でしたが、並列処理の内容は静的に定義しておく必要がありました。
今回サポートされたDynamic Parallelismでは、実行時の条件に応じて個数の変わる複数のアイテムに対して、同じ処理を並列に実行することができます。
これまで可能だった並列処理の例
今回からサポートされた並列処理の例Dynamic Parallelismの記述方法
新たに追加された
Mapという状態を使用します。Mapで指定できるフィールド
Mapには全ての状態で共通のフィールドや、Task, Parallelと共通のRetry, Catchといったフィールドの他に、下記の独自のフィールドがあります。
フィールド名 必須 内容 Iterator * 与えられた配列の各要素に対して実行する処理 ItemsPath - イテレート対象の配列への参照パス MaxConcurrency - 並列処理の最大同時実行数 ResultPath - 結果の出力先への参照パス InputPath, ItemsPathによる入力値のマッピング
MapのInputPathおよびItemsPathフィールドの設定例"InputPath": "$.result", "ItemsPath": "$.files",↑のような設定で
Mapに渡されるjsonの例{ "result": { "files": [ {"filepath":"/path/to/1.csv"}, {"filepath":"/path/to/2.csv"}, {"filepath":"/path/to/3.csv"} ] } }↑のような入力がMapにあった時
Iteratorのステートマシンに与えられるjsonの例{"filepath":"/path/to/1.csv"}↑のようなjsonがイテレータ内の処理に入力されます。
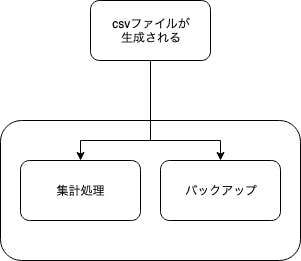
Dynamic Parallelismを利用したステートマシンの例
複数のCSVファイルの情報が渡された時に、それぞれ計算およびバックアップを行うステートマシンを例として記述します。
(Iterator内で起動するLambdaの実装についてはここでは割愛します)複数のcsvファイルそれぞれに対して計算およびバックアップを行うステートマシンの記述例{ "StartAt":"csv-processes", "States": { "csv-processes": { "Type": "Map", "InputPath": "$.result", "ItemsPath": "$.files", "MaxConcurrency": 10, "Iterator": { "StartAt":"csv-process", "States": { "csv-process": { "Type": "Parallel", "End": true, "Branches": [ { "StartAt": "Calcurate", "States": { "Calcurate": { "Type": "Task", "Resource": "arn:aws:lambda:{REGION}:{ACCOUNT_ID}:function:{FUNCTION_NAME}", "End": true } } }, { "StartAt": "Backup", "States": { "Backup": { "Type": "Task", "Resource": "arn:aws:lambda:{REGION}:{ACCOUNT_ID}:function:{FUNCTION_NAME}", "End": true } } } ] } } }, "End": true } } }MapやParallel状態はStatesを内包するので、ネストすると記述が複雑になります。
状態の名称やフィールドの順序などに注意し、できるだけわかりやすい記述をできるよう心がけたいです。
例示のjsonからこのようなステートマシンが作成できます。まとめ
Step Functionsの中でイテレーションが行えるようになったことにより、Lambda FunctionやECS Taskなどをよりシンプルに作ることができるようになったと思います。
複数のLambda FunctionやECS Taskを連携させて行うバッチ処理などで活用していきたいです。



- 投稿日:2019-10-11T16:06:59+09:00
ECS(Fargate)のバッチをCloudFormationで作成する
お試しで作ったものの備忘メモ
- 以下のリソースが作成されます
- ECS
- クラスタ
- タスク定義
- Fargateタイプ
- ネットワークモードはawsvpc
- タスクスケジュール(CloudWatch Events)
- 毎日12時に動く
- ECR
- 直近2イメージのみ保持
- 以下が前提になります
- プライベートサブネット、セキュリティグループが作成済
- ecsTaskExecutionRoleが作成済
- SSMのパラメーターストアにて
your_secrets_valueという名前のシークレットが作成済
- 必要なければ
Secretsを消せばOK- 本日時点で、AWS::Events::Rule EcsParametersの日本語記事を読むと
NetworkConfigurationなどの指定ができないように思えますが、英語版には普通に書いてある...ということを伝えたくて書きました
- フィードバックは送り済みなのでそのうち直るかも
sample.ymlAWSTemplateFormatVersion: "2010-09-09" Parameters: ResourceName: Type: String Description: Resource Name RepositoryName: Type: String Description: Repository Name ImageTagName: Type: String Description: Image Tag Name TaskDefinitionCpu: Type: Number Description: TaskDefinition Cpu TaskDefinitionMemory: Type: Number Description: TaskDefinition Memory TaskExecutionSecurityGroups: Type: List<AWS::EC2::SecurityGroup::Id> Description: Service SecurityGroups TaskExecutionSubnets: Type: List<AWS::EC2::Subnet::Id> Description: Service Subnets Resources: Cluster: Type: AWS::ECS::Cluster Properties: ClusterName: Ref: ResourceName Repository: Type: AWS::ECR::Repository Properties: RepositoryName: Ref: RepositoryName LifecyclePolicy: # https://dev.classmethod.jp/cloud/aws/cfn-for-ecr-lifecyclepolicy/ LifecyclePolicyText: | { "rules" : [ { "rulePriority" : 1, "description" : "Delete more than 2 images", "selection" : {"countType" : "imageCountMoreThan", "countNumber" : 2, "tagStatus" : "any"}, "action" : {"type" : "expire"} } ] } TaskDefinition: Type: AWS::ECS::TaskDefinition Properties: Family: Ref: ResourceName Cpu: Ref: TaskDefinitionCpu Memory: Ref: TaskDefinitionMemory NetworkMode: awsvpc ExecutionRoleArn: Fn::Sub: arn:aws:iam::${AWS::AccountId}:role/ecsTaskExecutionRole RequiresCompatibilities: - FARGATE ContainerDefinitions: - Name: Ref: ResourceName Image: Fn::Sub: ${AWS::AccountId}.dkr.ecr.${AWS::Region}.amazonaws.com/${RepositoryName}:${ImageTagName} Secrets: # https://dev.classmethod.jp/cloud/aws/ecs-secrets/ - Name: YOUR_SECRETS_VALUE ValueFrom: your_secrets_value LogConfiguration: LogDriver: awslogs Options: "awslogs-region": Ref: AWS::Region "awslogs-stream-prefix": ecs "awslogs-group": Fn::Sub: /aws/ecs/${ResourceName} TaskSchedule: Type: AWS::Events::Rule Properties: Name: sample_task State: ENABLED ScheduleExpression: cron(0 3 * * ? *) Targets: - Id: sample_task Arn: Fn::GetAtt: [Cluster, Arn] RoleArn: Fn::Sub: arn:aws:iam::${AWS::AccountId}:role/ecsTaskExecutionRole EcsParameters: # https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-properties-events-rule-ecsparameters.html TaskDefinitionArn: Ref: TaskDefinition LaunchType: FARGATE PlatformVersion: LATEST NetworkConfiguration: AwsVpcConfiguration: AssignPublicIp: DISABLED Subnets: Ref: TaskExecutionSubnets SecurityGroups: Ref: TaskExecutionSecurityGroups Input: # コマンドは任意に設定してください! Fn::Sub: | { "containerOverrides" : [ { "name" : "${ResourceName}", "command" : ["python3", "-m", "sample_task"] } ] } LogGroup: Type: AWS::Logs::LogGroup Properties: LogGroupName: Fn::Sub: /aws/ecs/${ResourceName} RetentionInDays: 30以下のような設定ファイルを定義して
parameters.iniResourceName=sample-resource RepositoryName=sample-repository ImageTagName=smpl TaskDefinitionCpu=256 TaskDefinitionMemory=512 TaskExecutionSecurityGroups=sg-xxxx TaskExecutionSubnets=subnet-yyyy,subnet-zzzz以下のような感じで実行すると楽
ターミナル# 作成 $ aws cloudformation deploy \ --stack-name sample-stack \ --template-file sample.yml \ --no-fail-on-empty-changeset \ --parameter-overrides $(cat parameters.ini | tr '\n' ' ') # オマケ # DockerイメージをビルドしてECRにpush(99999999はアカウントID) $ $(aws ecr get-login --no-include-email) $ docker build -t 99999999.dkr.ecr.ap-northeast-1.amazonaws.com/sample-repository:smpl . $ docker push 99999999.dkr.ecr.ap-northeast-1.amazonaws.com/sample-repository:smpl結構面倒でしたが、実際に定義から環境ができると楽しいですね!
- 投稿日:2019-10-11T15:28:07+09:00
mongomirrorを用いてAWS上のMongoDBからAtlasにデータをインポートする
関連
MongoDB AtlasのLiveMigrationを用いるときの覚書
AWS上のMongoDBをAtlasにLiveMigrationする
NLBでTLS終端を行いAtlasのLiveMigrationを行う
経緯
Atlas提供の、LiveMigrationを利用した場合にエラーが発生することが何回かあった。
LiveMigration側でエラーが発生するとユーザー的にはブラックボックスで Troubleshootingやチャットサポートでは解決策を見い出せなかったので、mongomirrorを用いてデータをインポートすることにした。
手順
mongomirrorを動かすインスタンスを用意する
https://docs.atlas.mongodb.com/reference/mongomirror/#performance
To avoid contention for network and CPU resources, do not run mongomirror on the same hosts that provide your replica set’s mongod instances.
mongomirror must have network access to the source replica set.
mongomirror must have network access to the target cluster.
mongomirror has approximately the same performance impact on your source replica set as a secondary:
For the initial sync stage, the load scales with the size of your data set.
Once an initial sync completes, the load scales with oplog gigabytes used per hour.EC2上のDB、およびAtlasに接続できる場所である必要がある = appサーバと同じサブネット内に、 DBサーバと同じスペックでインスタンスを作成する
mongomirrorのインストール
mkdir mongomirror_work cd mongomirror_work curl https://s3.amazonaws.com/mciuploads/mongomirror/binaries/linux/mongomirror-linux-x86_64-enterprise-amzn64-0.8.0.tgz -o mongomirror-linux-x86_64-enterprise-amzn64-0.8.0.tgz tar -zxvf mongomirror-linux-x86_64-enterprise-amzn64-0.8.0.tgz curl https://downloads.mongodb.org/linux/mongodb-shell-linux-x86_64-amazon-4.2.0.tgz -o mongodb-shell-linux-x86_64-amazon-4.2.0.tgz tar -zxvf mongodb-shell-linux-x86_64-amazon-4.2.0.tgzソース側のDB(EC2)に移行用のユーザーを作成する。
Set up MongoDB user in the source replica set
use admin db.createUser( { user: "mySourceUser", pwd: "mySourceP@$$word", roles: [ "clusterMonitor", "readAnyDatabase" ] } )Atlas側にAtlasAdmin権限でユーザーを作成する
Set up MongoDB user in the target Atlas cluster
ここで作成するユーザーは、
Save as temporary userにチェックを入れる疎通確認
mongodb-linux-x86_64-amazon-4.2.0/bin/mongo "mongodb+srv://<Atlasのホスト>/admin" --username <Atlasに作成したユーザー>mongomirrorの起動
nohup mongomirror-linux-x86_64-enterprise-amzn64-0.8.0/bin/mongomirror \ --host <srcのレプリカセット名>/srcのホスト1:27017,srcのホスト2:27017,srcのホスト3:27017 \ --username "<srcに作成した移行用のユーザー>" \ --password "<srcに作成した移行用のユーザーのパスワード>" \ --authenticationDatabase "admin" \ --destination "<Atlas上のレプリカセット名>/<Atlasクラスターのホスト1>:27017,<Atlasクラスターのホスト2>:27017,<Atlasクラスターのホスト3>:27017" \ --destinationUsername "<Atlas側に作成したユーザー>" \ --destinationPassword "<Atlas側に作成したユーザーのパスワード>" \ --httpStatusPort 8000 \ -j 16 > mongomirror.log 2>&1 &この際、Atlas上のレプリカセット名や、接続情報の確認方法は
https://docs.atlas.mongodb.com/import/mongomirror/#copy-the-target-cluster-host-information
をよく読む。接続情報が間違っていると
2019-10-08T05:27:30.881+0000 Error initializing mongomirror: could not initialize destination connection: could not connect to server: server selection error: server selection timeout current topology: Type: ReplicaSetNoPrimary Servers:のようなエラーがでてmongomirrorが止まる
-jオプションについて
collectionコピーの並列度を決める。
numParallelCollections--numParallelCollections , -j
Default: 4The number of collections to copy and restore in parallel.
サポートに聞いたところ、
we recommend this parameter to be in line with the number of CPU cores on the host machine hosting mongomirror.
とのことなので、CPUサイズに合わせる。
デフォルトは4。おそらくLiveMigrationも裏ではmongomirrorを4で起動しているのではないかと思う。
今回16にすると、LiveMigrationでは16hかかっていたものが6hほどに短縮された。mongomirrorのログの読み方
initializing~initial syncのログnohup: ignoring input mongomirror version: 0.8.0 git version: a5cbb2d5babea8ed87191b31b12ffc6f3a3fa485 Go version: go1.12.4 os: linux arch: amd64 compiler: gc 2019-10-08T05:31:42.724+0000 Initializing HTTP status service on port 8000 2019-10-08T05:31:42.801+0000 Attempting initial sync from: 10.0.1.17:27017 2019-10-08T05:31:43.015+0000 Creating collection <DB名>.<コレクション名AAA> 2019-10-08T05:31:43.015+0000 Creating collection <DB名>.<コレクション名BBB> 2019-10-08T05:31:43.078+0000 Copying documents to collection <DB名>.<コレクション名AAA> 2019-10-08T05:31:43.116+0000 Copying documents to collection <DB名>.<コレクション名BBB> 2019-10-08T05:31:46.015+0000 [........................] <DB名>.<コレクション名AAA> 39316/1033602 (3.8%) 2019-10-08T05:31:46.015+0000 [#.......................] <DB名>.<コレクション名BBB> 50015/1161614 (4.3%)コレクション毎の進捗がインジゲーター風に3秒ごとに出力される。
ここでJオプションで指定した並列度が効いてくる。indexのコピー
documentのコピーが終わるとindexの構築が始まる
2019-10-08T05:43:32.944+0000 Copied 11043565 documents to <DB名>.<コレクション名AAA> 2019-10-08T05:43:32.944+0000 [########################] <DB名>.<コレクション名AAA> 11043565/11043565 (100.0%) 2019-10-08T05:43:32.993+0000 Tailing the oplog on the source cluster starting at timestamp: {1570512697 1} 2019-10-08T05:43:32.994+0000 Oplog tailer has shut down. Oplog applier will exit. 2019-10-08T05:43:32.994+0000 Current lag until the end of initial sync: 0s 2019-10-08T05:43:33.032+0000 createIndexes for collection: `<DB名>.<コレクション名AAA>`, finished in 36.390104ms 2019-10-08T05:43:33.032+0000 createIndexes for collection: `<DB名>.<コレクション名BBB>`, finished in 36.834095msここで注意したいのが、
createIndexes for collectionのログ出力は、index構築完了後に表示されるので、大きなコレクションでIndex作成自体に数分かかるものがある場合、ログの出力が止まってしまう。
ログ出力がない場合でもmongomirrorのプロセスは生きているのでそんなときはhttpサーバー機能(後述)で現在のステータスを確認できるので慌てない。
initial sync~oplog syncのログdocumentのコピー、Indexの構築がおわると、mongomirrorは
oplog sync状態にはいる。
このlag時間が0sの場合にカットオーバーすることができる。2019-10-08T06:00:48.161+0000 Index builds completed. 2019-10-08T06:00:48.161+0000 Initial sync from 10.0.1.17:27017 completed at oplog timestamp: {{1570513407 1} {1570513407 1}} 2019-10-08T06:00:48.161+0000 Proceeding to tail oplog. 2019-10-08T06:00:48.174+0000 Current lag from source: 17m20s 2019-10-08T06:00:48.174+0000 Tailing the oplog on the source cluster starting at timestamp: {1570513407 1} 2019-10-08T06:00:58.185+0000 Current lag from source: 0s 2019-10-08T06:01:08.175+0000 Current lag from source: 0shttpサーバー機能によるステータス確認
起動オプションで指定した、
--httpStatusPort 8000に対して、GETリクエストを行うことで、mongomirrorのプロセスの現在の状態を知ることができる。curl -X GET http://localhost:8000 | python -m json.tool{ "details": { "<DB名>.<コレクション名AAA>": { "complete": true, "createIndexes": 2 }, "<DB名>.<コレクション名AAA>": { "complete": true, "createIndexes": 4 }, .... }, "phase": "copying indexes", "stage": "initial sync" }
mongomirrorの停止ps aux | grep mongomirror kill <pid>2019-10-08T06:10:28.175+0000 Current lag from source: 0s 2019-10-08T06:10:38.175+0000 Current lag from source: 0s 2019-10-08T06:10:48.130+0000 signal 'terminated' received; attempting to shut down 2019-10-08T06:10:48.130+0000 Quitting... 2019-10-08T06:10:48.131+0000 Current lag from source: 0s 2019-10-08T06:10:49.130+0000 Timestamp file written to /home/ec2-user/mongomirror_work/mongomirror.timestamp.このとき作成された
mongomirror.timestampは次回のmongomirror実行時に、bookmarkFileオプションとして指定することで、続きから実行することができる。
--bookmarkFileを指定して起動したときのログは以下のような出力となる。git version: a5cbb2d5babea8ed87191b31b12ffc6f3a3fa485 Go version: go1.12.4 os: linux arch: amd64 compiler: gc 2019-10-10T01:51:16.723+0000 Initializing HTTP status service on port 8000 2019-10-10T01:51:16.791+0000 Read timestamp from bookmark file: {1570671675 1} 2019-10-10T01:51:16.791+0000 Proceeding to tail oplog. 2019-10-10T01:51:16.792+0000 Current lag from source: 10m0s 2019-10-10T01:51:16.792+0000 Tailing the oplog on the source cluster starting at timestamp: {1570671675 1} 2019-10-10T01:51:26.803+0000 Current lag from source: 0s 2019-10-10T01:51:36.793+0000 Current lag from source: 0s

- 投稿日:2019-10-11T14:51:09+09:00
anyenvをシステムワイドにインストール:aws linux2
背景
anyenvは個人でも便利でよく使うものですが、主に開発環境のところで利用していました。今回は本番などでウェブサーバー(phpenv)を利用する場合を想定してシステムワイドにインストールする方法をやってみます。
参考:https://qiita.com/mikesorae/items/e8e2d13b6b46b60ef4c4概要
- Versionのインストールはrootユーザー
- 利用は全ユーザー
インストール
上記の参考URLの内容にすると以下のエラーに出ました。
ANYENV_DEFINITION_ROOT(/*********/.config/anyenv/anyenv-install) doesn't exist. You can initialize it by:解決方法として調べた内容がこちらです。sudo及びrootで実装で実行します。
cd /opt git clone https://github.com/riywo/anyenv echo 'export PATH="/opt/anyenv/bin:$PATH"' >> /etc/profile.d/anyenv.sh echo 'export ANYENV_ROOT="/opt/anyenv"' >> /etc/profile.d/anyenv.sh echo 'export ANYENV_DEFINITION_ROOT="/opt/anyenv/share/anyenv-install"' >> /etc/profile.d/anyenv.sh echo 'eval "$(anyenv init -)"' >> /etc/profile exec exec $SHELL -lAWS Linux2での注意点
phpenvでphp7.3.*をインストールする際に以下の物を先にインストールしました。
sudo yum -y install gcc libxml2 libxml2-devel libcurl libcurl-devel libpng libpng-devel libmcrypt libmcrypt-devel libtidy libtidy-devel libxslt libxslt-devel openssl-devel bison libjpeg-turbo-devel readline-devel autoconf bzip2-devel libicu-devel gcc-c++ libzip libzip-devel re2c libtidyだが、AWS Linux2では以下のエラーでlibtidyが出来ませんでした。
$ yum -y install libtidy libtidy-devel Loaded plugins: extras_suggestions, langpacks, priorities, update-motd 26 packages excluded due to repository priority protections No package libtidy available. No package libtidy-devel available.原因は「amzn-main?」ではlibtidyがないことでした。それで以下のコンマンドでインストールがでいました。
参考:https://dev.classmethod.jp/cloud/aws/amazon-linux-2-enable-epel-repository-with-amazon-linux-extras/amazon-linux-extras install -y epel yum --enablerepo=epel install libtidy-devel
- 投稿日:2019-10-11T14:23:34+09:00
gitの仕組みとか細かいことはいいから、とにかく使いたい人用
はじめに
これまで、gitってあまり触れてこなかったんですが、
codecommitにlambdaコードを管理してるので、デプロイとかいろいろ便利なので
使ってみました。gitってしっかり使いこなそうと思うと結構複雑なんだなとー理解はあとでいいから、とにかく使う!というところを書いて行きます。
登場人物
codecommit
jenkins(デプロイでつかう。今回はほとんど登場しないです)
sourcetree使った流れ
codecommit(AWS)に、リポジトリを作って、ブランチを切ります。
↓
sourcetreeというgitを使うためのツールを使って、
そのブランチにコードを置きます。
↓
jenkinsに作ったジョブでデプロイをします。という流れでつかいました。
今回は、gitコマンドを中心にしていきます。
他のツールは説明に必要な部分だけ使いかたとか書きます。
細かく知りたい方は他のページをご参考に実際にやったこと
codecommitでリポジトリを作る
(これは、ブランチを入れるための箱のようなものです。)その中で、ブランチを作成。
(これは、コードの置き場と作業場所のようなものです。
と今は思っていただければいいかと思います。)sourcetreeを使って、リポジトリを自分のローカルに持ってきます。
(ツールはgitが使えて、codecommitに繋げればなんでもいいかと)で、
sourcetreeのホーム画面の右上にある、
端末を使います。
すると、黒い画面(CUI)が出ます。
GUIよりも実はとっつきやすかったりしますよ。
こういうやつ
ここで、
git checkout -b 新しいブランチ名 :新しいブランチを作成して、そのブランチに移動します。masterという名前のブランチがあると思いますが、基本そこには何も置かないし作業もしないと思ってもらえれば
いいと思います。(運用の仕方にもよるので一概には言えないですが、基本的にはということで)git branch -a : リモートとローカルブランチの両方のあるなしが確認できます。あと、自分が今いるブランチの場所を*で教えてくれます。ざっくり、リモートブランチは、codecommitにあるブランチ
ローカルブランチは自分のPCにあるという感じのイメージです。
ローカルブランチにcodecommitに置きたいファイルなどを持ってきます。たとえば、ファイルダウンロードして、そのディレクトリから、ローカルブランチにコピー
とかで持ってきます。
そしたら、git add .します。これは、今自分がいる階層にあるファイルをaddするよって意味です。
git commit -m "最初のコミット"これで、コミット(確定させるみたい感じの意味です)して、これはなにをしたのかを -mオプションをつけて書いておきます。
他の人が見た時に概要が掴めるようにです。git push -n :実際にpushするときは -nを取って実行する。最後にpushします。-nはdry-run(実際にはpushしないで、もししたらどうなるかの結果を表示してくれます)
これで、codecommit上に、自分が更新、作成をしたファイルを置くことができます。そしたら、デプロイしましょう。
まとめ
リポジトリ作成
↓
リポジトリクローン
↓
ブランチ作成
↓
git add
↓
git commit
↓
git push
↓
デプロイ現場からは以上です。


- 投稿日:2019-10-11T14:16:34+09:00
AWSのEC2+RDSの構築
最初からの構築
最初の状態から構築はなかったので、今回会社の構築内容をまとめてみました。個人的にGCPの方を経験したかったですが貴重な経験ではあると思います。
前提条件
- AWSアカウントの取得
- Mac環境
構成図
一応、本番で利用するサーバーとして構成しようかと思います。サーバーの障害耐性や冗長化、負荷分散、オートスケーリングなどは入れてない、なるべくコストが掛からない構成です(バンバン入れたいけど)。
図のRDSのSlaveの方は実際入れてないです。RDSの設定でサブネットグルプが必要ですが、そこで複数のアベイラビリティーゾーンが必要なので作るしかないです。実際余裕があればSlaveSlaveとして利用するようです。DBサーバーはMulti-AZ構成という物理的に離れたデータセンターにホットスタンバイ用のサーバーをもう一つ建てることで、障害対応やバックアップなどの対応が可能
アベイラビリティーゾーンとVPCの構造は実際はVPCの中にアベイラビリティーゾーンが入る形ですかね。
ウェブサーバーのサブネットは「public subnet」はネットからの接続するために「Elastic IP」によってグローバルIPを付与します。
VPC環境の構築
「Start VPC Wizard」を始めると詳細な設定をしなくても良いらしいですが、今回は一つ一つ設定を行いましょう!!
VPCの作成
- 左メニューから「VPC」を選択し、「VPCの作成」という青いボタンをクリック
- 今回作成のネットワーク全体を表す「CIDR」を「192.168.0.0/16]と設定
- 「作成」の青いボタンをクリック
- あとで見分けがつくようにタグに適当な名前をつける
[VPC作成画面]
[VPCのタグの記入]
サブネットの作成
EC2 インスタンス(Webサーバー)用と RDS インスタンス(MySQL)用、RDS Multi-AZ 構成用とで計3つ作成します。
1. 左メニューから「サブネット」を選択し、「サブネットの作成」という青いボタンをクリック
2. VPCは先ほど作成した物を指定
3. アベイラビリティーゾーンは「ap-northeast-1a」に設定
4. CIDRは「192.168.0.0/24」に設定
5. あとで見分けがつくようにタグに適当な名前をつける
各サブネットの作成内容は以下になります。
Name VPC アベイラビリティーゾーン IPv4 CIDR public subnet: web example-vpc ap-northeast-1a 192.168.0.0/24 private subnet: DB example-vpc ap-northeast-1a 192.168.1.0/24 private subnet: DB(Slave) example-vpc ap-northeast-1c 192.168.2.0/24 3つ目のサブネットは、RDS の Multi-AZ 構成で利用するものなので、2つ目のサブネットとは異なるアベイラビリティーゾーンを指定します。本エントリーの構成では RDS を単一 AZ 構成で構築しますので、このサブネットは今回は利用しません。
インターネットゲートウェイ
インターネットゲートウェイはVPC内のサーバがインターネットと接続するための出入口です。
1. 左メニューから「インターネットゲートウェイ」を選択し、「インターネットゲートウェイの作成」という青いボタンをクリック
2. あとで見分けがつくように「名前タグ」に適当な名前をつける
3. 「作成」ボタンをクリック
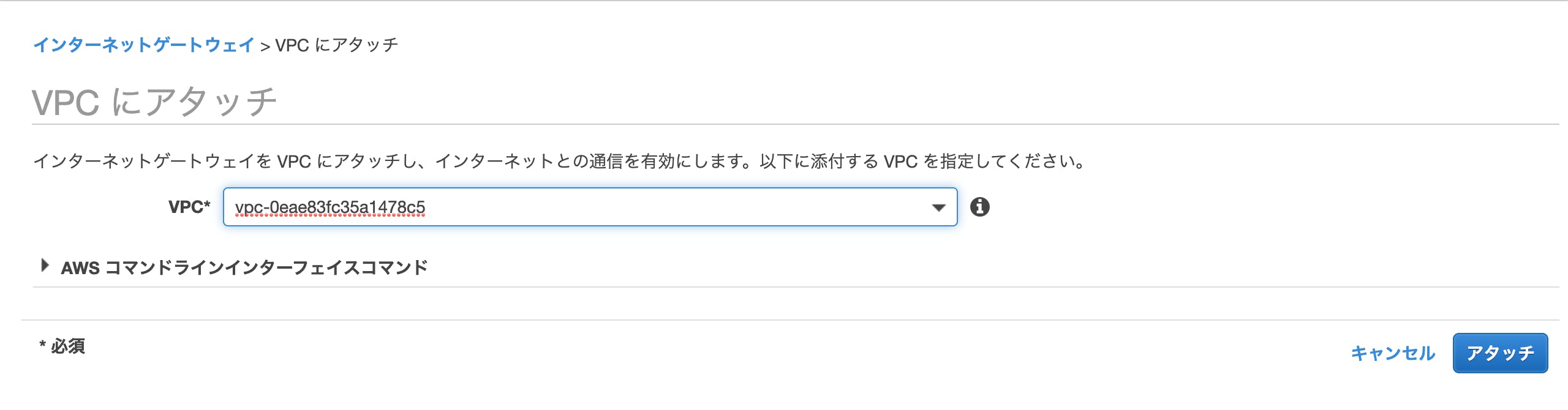
次に作成したインターネットゲートウェイをVPCと紐付けます。
1. 「アクション」メニューの「VPCにアタッチ」を選択
2. 「VPCにアタッチ」画面で、先ほど作成したVPCを選択
3. 「アタッチ」ボタンをクリック
ルートテーブルの確認&作成
各サブネットに対して仮想的に配置されるルーターのルーティングテーブルのようなものです。左メニューからサブネットを選択し、作成したサブネット一覧を見てみましょう。自動作成された Route Table がデフォルトで割り当てられているのがわかります(下の図ではrtb-******c41となっています)
ルートテーブルは、「Public subnet」に関してはインターネット(外界)への出口(Internet Gateway)が必要であり、「Private subnet」に関しては不要となります。したがって、自動生成された ルートテーブルは「Private subnet」用として使います。ルートテーブルの作成
- 左メニューから「ルートテーブル」を選択し、「ルートテーブルの作成」という青いボタンをクリック
- VPCに先ほど作成した物を指定
- 「作成」ボタンをクリック
次に今作成したルートテーブルを「Public subnet」に設定します。
- 一覧から今作成したルートテーブルを選択し、画面下部の「ルート」タブを開いて、「ルートの編集」ボタンをクリック
- 「送信先」に「0.0.0.0/0」と入力
- 「ターゲット」に「Internet Gateway」を選択
- 表示されるインターネットゲートウェイの中で、先ほど作成したインターネットゲートウェイを選択
- 「ルートの保存」ボタンをクリック
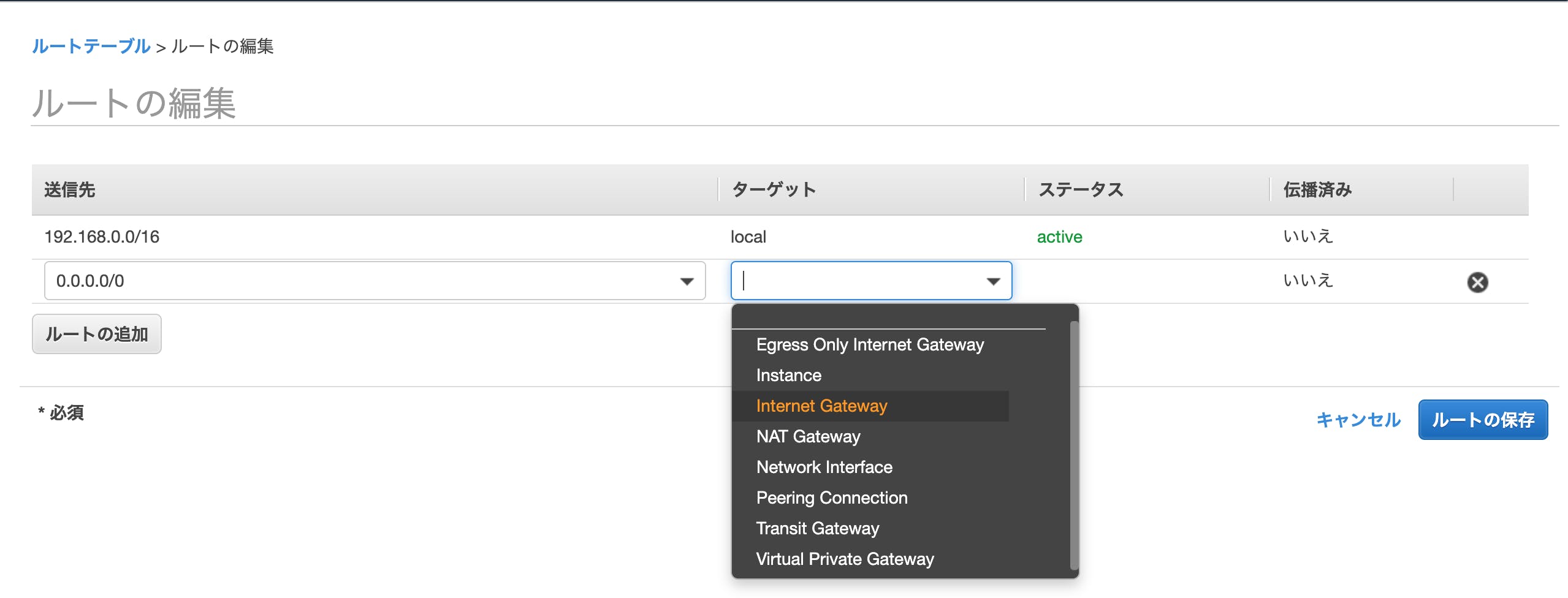
最後に今作成したルートテーブルを先ほど作成した「public subnet」に設定します。
- 左メニューから「サブネット」を選択し、サブネット一覧から「public subnet」を選択
- 下部の「ルートテーブル」のタブを開いて「ルートテーブルの関連付けの編集」という青いボタンをクリック
- 「ルートテーブルの関連付けの編集」の「ルートテーブルID」から作成したルートテーブルを選択して一覧に追加されたのを確認
- 「保存」ボタンをクリック
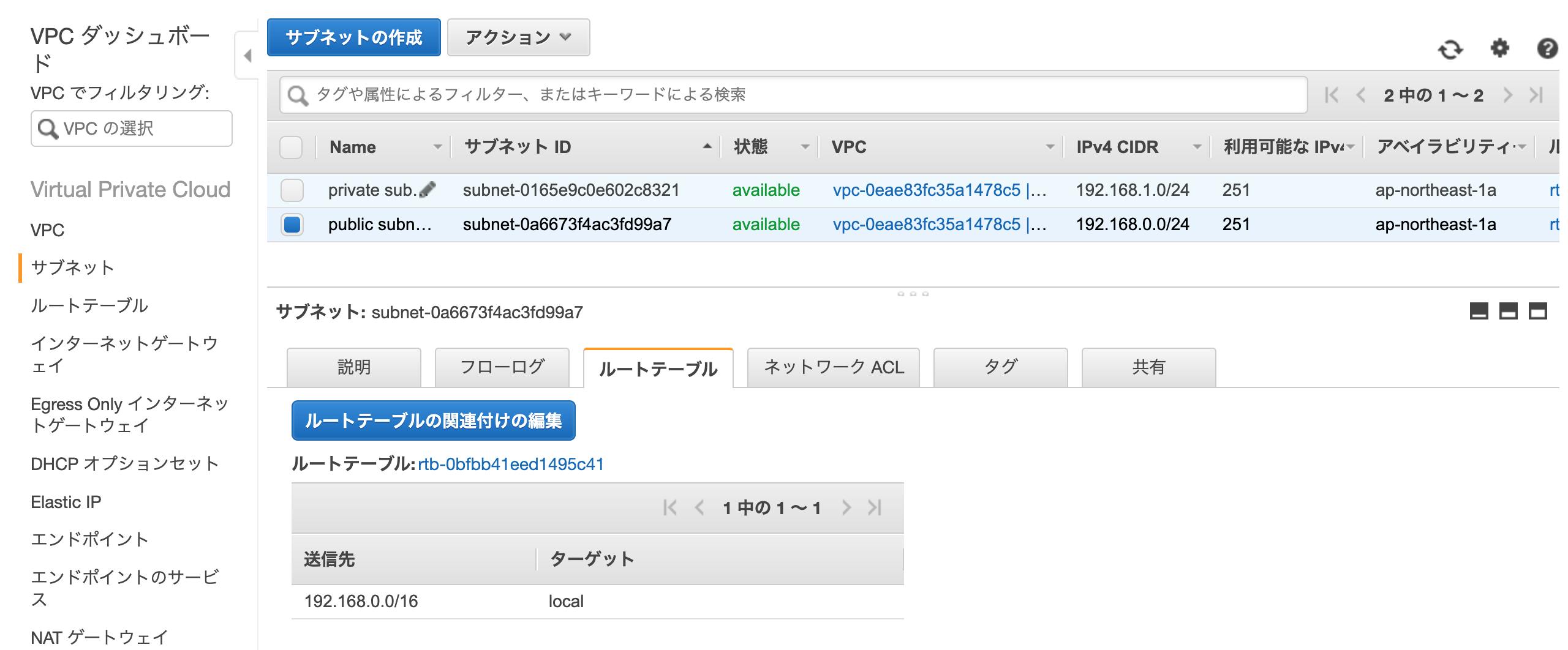


セキュリティグループの作成
セキュリティグループは用途に合わせて複数作成します。今回は2つ作成します。
- ウェブサーバー用のセキュリティグループ
- DB用のセキュリティグループ:ウェブサーバー用のセキュリティグループからの接続(3306)
左メニューから「セキュリティグループ」を選択します。既にセキュリティグループが一個ありますが、それはおいて新しく作成します。
入力したら「作成」ボタンをクリックします(説明は日本語だとダメでした。)。
1. 作成されたセキュリティグループに名前を適当に記入
2. 下部にある「インバウンドルール」タブを選択し、「編集」ボタンをクリック
3. 「インバウンドのルールの編集」画面で適当なルールを入れて「ルールを保存」をクリック
DB用のセキュリティグループは以下のようにソースにウェブサーバー用のセキュリティグループIDを記入します。
DBのサブネットグループ:RDSからVPCを利用するための設定
RDS管理コンソールを開きます。
1. 左メニューから「サブネットグループ」を選択
2. 「DBサブネットグループの作成」のオレンジ色のボタンをクリック
3. 「名前」と「説明」に適当に入力
4. 「VPC」に先ほど作成したものを指定
5. 「アベイラビリティーゾーン」と「サブネットID」(private subnet: DB)を選択して「サブネットを追加します」をクリック
6. 先と違う「アベイラビリティーゾーン」を選択し、「サブネットID」(public subnet: DB(Slave))を選択して「サブネットを追加します」をクリック
7. 「作成」ボタンをクリック
アベイラビリティーゾーン サブネットID CIDRブロック ap-northeast-1a private subnet: DB 192.168.1.0/24 ap-northeast-1c private subnet: DB(Slave) 192.168.2.0/24 EC2、RDSの構築
以下の設定は省略します。以下のところだけ設定すれば大丈夫だと思います。
- EC2の「ステップ3:インスタンスの詳細設定」で「public subne」を「ステップ6:セキュリティグループの設定」でウェブサーバー用のものを設定
- RDSは先ほど作成したサブネットグループが設定















- 投稿日:2019-10-11T13:37:49+09:00
s3 パブリックからファイルアップロードや削除はできないが、パブリックからファイル閲覧できるという確認をダメパターンも含めて実際に試す
目的
- s3のブロックパブリックアクセスとアクセスコントロールリスト(ACL)、バケットポリシー(Policy)の関連性がややこしくてイマイチピンとこない
- s3のドキュメントがカオス
- なので把握も兼ねて、実際のユースケースを元にセキュリティ的にダメなパターンと、どんな設定でできるのかを試す
ユースケース
- awscliでサーバ等から画像をS3へアップロードさせて、S3のオブジェクトURL( https://[バケット名].s3-ap-northeast-1.amazonaws.com/[オブジェクト名] )でパブリックから画像を閲覧させたい場合
- = パブリックからファイルアップロードや削除はできないが、パブリックからファイル閲覧できる という確認をダメパターンも含めて実際に試す
前提条件
s3リージョン:ap-northeast-1パブリックからファイルアップロードされてしまうことの確認(ダメパターン)
パターンA
- ブロックパブリックアクセス -> パブリックアクセスをすべてブロック
オフ且つ- ACL -> パブリックアクセス -> グループ Everyone -> オブジェクトの書き込み
はい(他は-) 且つPolicy
何も記述しないアップロードされてしまう事を確認
- 確認用HTML
<html> <body> <form action="https://[バケット名].s3-ap-northeast-1.amazonaws.com/" method="post" enctype="multipart/form-data" > <input type="hidden" name="key" value="uploads/[アップロードファイル名]"> <input type="file" name="file"> <br> <input type="submit" value="送信"> </form> </body> </html>
- Webページアクセスし、ファイルアップロード マネコンからアプロードしたファイルを確認
パターンB
- ブロックパブリックアクセス -> パブリックアクセスをすべてブロック
オフ且つ- ACL -> パブリックアクセス -> グループ Everyone -> オブジェクトの書き込み
-(他も-) 且つ- Policy
{ "Version": "2012-10-17", "Statement": [ { "Sid": "PublicReadForGetBucketObjects", "Effect": "Allow", "Principal": "*", "Action": "s3:PutObject", "Resource": "arn:aws:s3:::[バケット名]/*" } ] }ポイントは
PutObject
- アップロードされてしまう事を確認
- HTMLは上記同様
- Webページアクセスし、ファイルアップロード
- マネコンからアプロードしたファイルを確認
結論
パブリックからファイルをアップロードされてしまう設定(ダメパターン)
- ブロックパブリックアクセス -> パブリックアクセスをすべてブロック
オフ且つ- ACL、ポリシーどちらかで書き込み/PutObjectが許可
パブリックからファイルアップロードされることはない設定
- ブロックパブリックアクセス -> パブリックアクセスをすべてブロック
オン- ACL -> パブリックアクセス -> グループ Everyone
-- Policy
PutObjectを許可しないアップロード(PutObject)以外にオブジェクト閲覧(GetObject)、削除(DeleteObject)の場合も同様
パブリックからファイル閲覧させる確認
パターンC
- ブロックパブリックアクセス -> パブリックアクセスをすべてブロック
オン且つ- ACL -> パブリックアクセス -> グループ Everyone -> 全て
-且つPolicy
何も記述しないアップロードされてるオブジェクトへWebアクセス
https://[バケット名].s3-ap-northeast-1.amazonaws.com/[オブジェクト]
- Access Deniedでオブジェクトが表示されない
これだとCLIからアップロードされても、閲覧できないので、、
パターンD
- ブロックパブリックアクセス -> 任意のパブリックバケットポリシーを介して、バケットとオブジェクトへのパブリックアクセスとクロスアカウントアクセスをブロックする のみ
オフ(他はオン) 且つ- ACL -> パブリックアクセス -> グループ Everyone -> 全て
-且つPolicy
何も記述しないアップロードされてるオブジェクトへWebアクセス
https://[バケット名].s3-ap-northeast-1.amazonaws.com/[オブジェクト]
- Access Deniedでオブジェクトが表示されない
これでもCLIからアップロードされても、閲覧できないので、、
パターンE
- ブロックパブリックアクセス -> 任意のパブリックバケットポリシーを介して、バケットとオブジェクトへのパブリックアクセスとクロスアカウントアクセスをブロックする のみ
オフ(他はオン) 且つ- ACL -> パブリックアクセス -> グループ Everyone -> 全て
-且つ- Policy
{ "Version": "2012-10-17", "Statement": [ { "Sid": "PublicReadForGetBucketObjects", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::[バケット名]/*" } ] }ポイントは
GetObject
- アップロードされてるオブジェクトへWebアクセス https://[バケット名].s3-ap-northeast-1.amazonaws.com/[オブジェクト]
- オブジェクトが表示される
念のためこの設定で、パブリックからファイルアップロードできないことも確認
結論
パブリックからファイル閲覧させつつ、アップロード/削除はさせたくない場合
パターンEの設定でOK
- 投稿日:2019-10-11T12:17:01+09:00
【AWS】ECR, ECS(Fargate), StepFunctions, CloudWatch でバッチ処理~前編~
はじめに
本記事は、AWS FargateタスクとActivityステートマシンを利用して
・ソースの管理用リポジトリ(ECR)
・Activityをポーリングするワーカー
・アクティビティの処理内容
を実装しつつ、CloudWatchで定期実行するバッチ処理を作成するための概要(&備忘録)です。筆者自身、まだ理解が追いついていないと感じる部分はありますが、初学者の方の一助にでもなれば幸いです。
誤字・脱字などあればご指摘いただけると幸いです。m(_ _)m
前提
まず、前提となる技術要素のおさらいです。
Amazon ECR
Amazon ECR とは Elastic Container Registry の略で、AWSが提供するDockerレジストリサービスです。IAMを使用する点を除けば、通常のDocker同様、
リポジトリを通してコンテナイメージを管理できます。
ECR レジストリはAWSアカウントごとに用意されており、レジストリ内にイメージ用のリポジトリを作成して各イメージを管理します。AWS Fargate
AWS Fargate は Amazon ECS(以下、ECS) 同様、コンテナベースのサービスとなります。
ECS が裏で EC2 インスタンスを起動しているのに対し、Fargate ではそれを行っていません。
つまり、コンテナベースサービスとはいえ実質サーバ(EC2)のリソースをきにする必要があったECSに対し、Fargateでは純粋にコンテナの上で稼働するアプリケーションの設計のみに注力できるという利点があります。
(「アプリが大きくなってきたし、コンテナのEC2のメモリを増やそうかな。。。」などと検討する必要が無いのはとても嬉しいですね)詳細は公式を確認すれば大体のイメージは掴めると思います。
ちなみに、マネジメントコンソールからクラスタ作成時に起動タイプを選択するだけで利用できます。
AWS StepFunctions
AWS Step Functions とは
視覚的なワークフローを使用して、分散アプリケーションとマイクロサービスのコンポーネントを調整できるウェブサービス
です。個人的には、読むより触ってみる方が理解は早いかと思いますし、AWS の各種サービスの中でもそれほど習得の難易度は高くない方だと思います。
Step Functions を理解するために重要な概念であるステートマシンについてですが、これは主に
- ステートマシン全体への最初のInput
- ステートマシン内部での状態遷移
- ステートマシンから最後に出力されるOutput
で構成されています。
各情報はJSON形式で定義ファイルを作成することで設定していくことができますが、
マネジメントコンソール上では定義内容を以下の例のようにグラフィカルに確認することができます。
定義内容にミスがあっても気付きやすくていいですね。
ちなみに、図中の点線枠のブロックは各ステートとなりますが、定義ファイルの中では日本語も使用できるので、分かりやすい方を使えば良いと思います。
States内の実行パラメータであるResourceには実行するジョブのARNを指定します。
- LambdaファンクションARN
- DynamoDBのAPI
- 別ステートマシンのARN
など様々なジョブを登録することができます。詳細はこちらも公式を参照してください。
アクティビティとは
StepFunctionsの代表的な機能として、ステートマシンともう一つ、アクティビティがあります。
ステートマシンに設定できるLambdaファンクションは最大で15分(2019/10時点)の実行時間が設けられていますが、それを越えるとタイムアウトしてしまいます。
長時間かかることがあらかじめ分かっている処理などは、アクティビティを使用するのが得策でしょう。開発者ガイドのマニュアルでは
ワーカーによって作業が実行されるステートマシンでタスクを実行できるようにする AWS Step Functions 機能です。
と説明されていますが、個人的にはサンプルのソースを読む方が理解は早い気がします。
Amazon CloudWatch Events
Amazon CloudWatch はログの収集、アラート検知、リソースモニタリングなど、運用・保守・監視といった業務にて主に使用されるサービスです。
CloudWatch Events は Amazon CloudWatch の機能の一つであり、主に次の二種類があります。
- 【イベントパターン】...特定のイベント(AWS環境内で起きた何らかの変化・イベント)をトリガーにしてターゲットを実行
- 【スケジュール】...一定の間隔、あるいは(AWS独自の)Cron構文にて定義されたターゲットを実行
ターゲットとはイベントを処理するための機能であり、EC2インスタンスの操作(起動/停止など)、Lambda関数の実行、StepFunctionsステートマシンの呼び出しなど様々なイベントをJSON形式で定義することで使用可能です。
本編
ではいよいよ本題となる「FargateとStepFunctionsアクティビティでバッチ処理を実装」していきたいと思います。
大まかな流れは以下のようになります。
- ECR リポジトリの作成
- アクティビティステートマシンの作成
- アクティビティの作成
- アクティビティステートマシン用のタスク定義ファイルを作成
- アクティビティステートマシンの作成
- docker イメージの準備
- ソースのbuildとタグ付け
- リポジトリへpush
- ECS クラスターの作成
- ECS タスク定義の作成
- コンテナに登録するタスク定義ファイルの作成
- Fargateタスク定義の登録
- CloudWatch Event 設定
- Fargateタスク起動用ルールの作成
- Fargateタスク起動用ターゲットの作成と割り当て
- アクティビティステートマシン用ルールの作成
- アクティビティステートマシン用ターゲットの作成と割り当て
少し長くなるので、本記事では
2-3. アクティビティステートマシンの作成までを行い、以降は後編とします。0. 事前準備
以降の手順はブラウザ/CLIでの手順となりますが、CLIにて実施する場合、aws-cli を別途インストールしておく必要があります。
awscli のインストールには大きく分けてpipを使用する方法、使用しない方法の2通りがあります。各環境に合わせて AWS CLI をインストールしましょう。
以降の手順はWebコンソール経由での手順を記載しつつ、同様の作業を行うためのコマンドも記載しますが、コマンド手順で進める場合、CLI環境では
- プロファイルの設定が行われ、
- IAMリソースに適切なポリシーが都度割り当てられている
という前提にしております。エラーが出た場合などは必要なポリシーが割り当てられているか適宜確認してください(今回はIAM周りは省略します)。
1. ECR リポジトリの作成 : ブラウザ
マネジメントコンソールにログインしたら、ECRコンソールにて画面右上の [リポジトリの作成] をクリックし、空のリポジトリを作成します。
リポジトリ名は任意ですが、ここでは
demo-repoとしておきます。ECR リポジトリの作成(コマンド)
aws ecr create-repository --repository-name $REPOSITORY_NAME
以降、
$変数名は任意の値を設定するか、適切な値に読み替えて下さい。2. アクティビティステートマシンの作成
リポジトリが作成できたら、ワーカーからのポーリングを待機するためのアクティビティを作成します。
2-1. アクティビティの作成 : ブラウザ
Step Functionsコンソール(以下、SFNコンソール)から、アクティビティを作成します。
ここでは
demo-activityという名前にしておきます。アクティビティの作成(コマンド)
aws stepfunctions create-activity --name $ACTIVITY_NAME
2-2. アクティビティステートマシン用のタスク定義ファイルを作成 : ブラウザ
続いて、アクティビティをポーリングするためのタスク定義(JSON)を作成します。
ECRコンソールから [新しいタスク定義の作成] を選択し、起動タイプには "FARGATE" を指定します。
次に、タスクの詳細を定義していきます。
入力項目が多いため、JSON形式のサンプルの一部と、各パラメータの意味を# 以降に記載します。サンプル{ "Rule": "$RULE_NAME", # CloudWatchEventRule名 "Targets": [ { "Id": "", # 任意の文字列 "Arn": "$CLUSTER_ARN", # コンテナが起動するクラスタのARN。クラスタについては後編で。 "RoleArn": "arn:aws:iam::$ACCOUNT_ID:role/$ROLE_NAME", # 実行用のロールのARN "EcsParameters": { "TaskDefinitionArn": "$TASK_DEFINITION_ARN", "TaskCount": 1, "LaunchType": "FARGATE", # task 起動タイプ "NetworkConfiguration": { "awsvpcConfiguration": { "Subnets": [ "subnet-XXXXXXXXXXXXXX" # 使用するSubnetID ], "SecurityGroups": [ "sg-ABCABCABCABCABCAB", # 使用するSecurityGroup "sg-XYZXYZXYZXYZXYZXY" # 使用するSecurityGroup ], "AssignPublicIp": "ENABLED" # public IP アドレスの割り当て } } } } ]定義ファイルの全体像と各パラメータの詳細な内容についてはこちらを参照してください。
アクティビティステートマシン用のタスク定義ファイルを作成(コマンド)
# JSON 形式のSkeletonパラメータファイルを取得 aws ecs register-task-definition --generate-cli-skeleton # 編集したJSONパラメータファイルを指定して、タスク定義を登録する aws ecs register-task-definition --cli-input-json file://$TASK_DEFINITION_FILE_PATHここまでで、ワーカーからのポーリングを待つアクティビティと、ワーカーが実行する実際のタスクの定義を作成しました。
最後に、アクティビティを起動し待機させるためのステートマシンを作成します。
2-3. アクティビティステートマシンの作成 : ブラウザ
SFNコンソールに戻り、ステートマシンメニューを開きステートマシンを作成します。
ここでは、サンプル作成のためテンプレートからの作成を選び、Hello Worldを選択した状態にします。
下にスクロールするとJSON形式の "ステートマシンの定義" が表示されているため、これを編集していきます。
ステート要素内にある
"Results"要素を"Resource"に書き換え、valueには2-1. アクティビティの作成で作成したアクティビティのARNを指定しておきます。アクティビティステートマシンの作成(コマンド)
# 作成 aws stepfunctions create-state-machine --name $STATE_MACHINE_NAME --definition file://$JSON_FILE --role-arn "arn:aws:iam::$ACCOUNT_ID:role/$ROLE_NAME" # 確認 aws stepfunctions describe-state-machine --state-machine-arn $STATE_MACHINE_ARNここまででアクティビティステートマシンの準備ができました。
後編では、サンプルコードを用いて、実際にアクティビティをポーリングしてタスクを実行するワーカーを作成していきます。
(近日中に投稿予定です)






- 投稿日:2019-10-11T12:15:45+09:00
AWS LambdaからPython Boto3を使用してDynamoDBを操作する
バージョン
Python3.7準備
import boto3 dynamoDB = boto3.resource('dynamodb') table= dynamoDB.Table('sample') def main(event, context): search(event) insert(event) update(event) delete(event) return取得処理
def search(event): query_data = table.get_item( Key={ 'id': event['id'] } ) print("GetItem succeeded:") # 取り出す時は sample_value = query_data['Item']['sample_value'] return sample_value登録処理
def insert(event, context): table.put_item( Item = { 'id': event['id'], 'sample_value': event['sample_value'] } ) print("PutItem succeeded:") return更新処理
def update(event): table.update_item( Key= {'id': event['id']}, UpdateExpression='set = :s', ExpressionAttributeValues={ ':s' : event['sample_value'] } ) print("UpdateItem succeeded:") return削除処理
def delete(event): table.delete_item( Key={ 'id': event['id'] } ) print("DeleteItem succeeded:") return参考
ステップ 3: 項目を作成、読み込み、更新、削除する
https://docs.aws.amazon.com/ja_jp/amazondynamodb/latest/developerguide/GettingStarted.Python.03.html
- 投稿日:2019-10-11T12:12:43+09:00
【AWS】MacからEC2へSSH接続する際に、Permission denied (publickey,gssapi-keyex,gssapi-with-mic).と出た際の対処法
MacからEC2インスタンスにssh接続する際に、
$ ssh ec2-user@x.xxx.xxx.xx -i /Users/xxxx/.ssh/xxxx.pem @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNING: UNPROTECTED PRIVATE KEY FILE! @ @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ Permissions 0644 for '/Users/xxxx/.ssh/xxxx.pem' are too open. It is required that your private key files are NOT accessible by others. This private key will be ignored. Load key "/Users/xxxx/.ssh/xxxx.pem": bad permissions
pemファイルの権限が甘いよとエラーが出ました。$ chmod 400 /Users/xxxx/.ssh/xxxx.pem400番は、
所有者のみが読み込み可能という権限を与えます。chomdコマンドについて詳しくはこちら
として権限に制限を与えると
$ ssh ec2-user@x.xxx.xxx.xx -i /Users/xxxx/.ssh/xxxx.pem Last login: Fri Oct 4 02:52:48 2019 from 58.138.187.2 __| __|_ ) _| ( / Amazon Linux 2 AMI ___|\___|___| https://aws.amazon.com/amazon-linux-2/ 1 package(s) needed for security, out of 3 available Run "sudo yum update" to apply all updates. [ec2-user@ip-xxx-xxx-xx ~]$接続できました!
- 投稿日:2019-10-11T11:09:52+09:00
コマンドラインでアカウント作成
- 投稿日:2019-10-11T10:35:11+09:00
AWSでF5のAdvancedWAFを構築する-動くものを作る編-
概要
とある事情でAWS上にF5Networks社のAdvanced WAFを構築する機会があったのですが
- WAFというものはなんとなくわかるけど、AWSのWAFしか構築したことがない
- どうやって構築するのか、できるとどんなものなのかわからない
- 前例がない
状態だったので、まずは起動できることを目標に構築してみることにしました。
今回はその構築方法についてまとめます。F5のAdvancedWAFってどんなもの?
- 従来F5が提供していたWAF(Web Application Firewall)に、以下の機能が強化されたもの
- ボット対策
- DDoS対策
- クレデンシャルスタッフィング対策
もっと詳しく知りたい方はこちら
- アプライアンス、仮想アプライアンス、クラウドサービスで提供されている
- AWSではMarketPlaceでAMIが提供されている
AMIを選ぶ
AWS MarketPlaceで提供しているAdvancedWAFのAMIにはいくつか種類があるのですが、
今回はその中の3種類を比較してみます。
F5 Advanced WAF (PAYG, 25Mbps)
- シンプルにAdvancedWAF
F5 Per-App VE - Advanced WAF (PAYG, 25Mbps)
- Advanced WAFにPer-Appとついているパターン
- アプリケーションごとのADC(Application Deliverly Controller)+WAFの機能を提供する
- ADCは簡単にいうとロードバランサ(負荷分散装置)の機能を高度化したもの
- 具体的にはHTTP圧縮で帯域の有効活用、SSLアクセラレーションができたりする
アプリケーションごとのADCってなんだ?と思った人はこちらを。
本当になんとなくですが、 イメージがつきます。
- F5 Per-App VE - Advanced WAF + LTM (PAYG, 25Mbps)
- Advanced WAFにPer-Appと+LTMがついているパターン
- Per-App VE - Advanced WAFにLTMが追加されたもの
- LTMが何かと言うと、Ipv6対応でプログラマブルなロードバランサ機能
今回最終的にやりたいことは
- シンプルにWAFとして使う
- ロードバランシングはしない
- ALBから受けたトラフィックを検疫するのみ
なので、F5 Advanced WAF (PAYG, 25Mbps)を使ってみることにしました。
構築する
今回はWAFとして機能するかはさておき、まずはインスタンスを立ち上げてみます。
以下のAWSリソースはすでに作成されているものとします。
- VPC
- サブネット
- EIP
- キーペア(SSH接続するために必要)
インスタンスを作る
1.AMIの選択
- F5 Advanced WAF (PAYG, 25Mbps)
2.インスタンスタイプの選択
- t2.medium ←選択できる一番小さいインスタンス
3.インスタンスの設定
- 自動割り当てパブリックIPのみ無効にする ←EIPを使うので
4.ストレージの追加
- 何もしない
5.タグの追加
- 何もしない
6.セキュリティグループの設定
- 以下のように設定
セキュリティグループの名前とディスクリプションは任意で設定してください。
これでインスタンスを作成し、完了したらネットワークインターフェイスにEIPを割り当てます。インスタンスにSSH接続する
AdvancedWAFにはwebコンソールが用意されるのですが
デフォルトパスワードが設定されており、そのままだとログインできません。そのため、以下のコマンドを実行し、デフォルトパスワードを変更します。
$ ssh -i test-waf.pem admin@パブリックDNS名 admin@(ip-xxx-xx-xx-xx)(cfg-sync Standalone)(ModuleNotLicensed::Active)(/Common)(tmos)# modify auth password admin changing password for admin new password: confirm password:設定を保存します。
save sys configwebコンソールに接続する
ブラウザに https://EIPのアドレス:8443 と入力するとログイン画面が表示されるので
ユーザ名とパスワードを入力します。ログインすると、、、
この状態だと左上に Provisioning Waring と出ていて健全ではなさそうなので
調査が必要そうです。(続く...)構築してみてわかったこと
- BIGIPと書かれたドキュメントはたくさんあるが、それはAdvanedWAFのことなのか、、?
- 基本的に問い合わせ先はF5
- 最終的にはALBの下にぶら下げたいのでなんらかのエンドポイントでヘルスチェックができる必要がある。webコンソールのログイン画面を使おうとしたが、AdvancedWAFのデフォルトはHTTPSの8443ポート。でも、IPを使って接続しているので、curl https://EIP:8443 だと証明書がないと言われる。 (実現方法が見えない)
参考
https://clouddocs.f5.com/cloud/public/v1/aws/AWS_singleNIC.html
https://www.networld.co.jp/files/5415/5262/7356/F5_BIG-IP_license_activation_v13.1.x.pdf



- 投稿日:2019-10-11T09:00:14+09:00
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #10 (モバイル)
Amazon Web Services (AWS)のサービスで正式名称や略称はともかく、読み方がわからずに困ることがよくあるのでまとめてみました。
Amazon Web Services (AWS) - Cloud Computing Services
https://aws.amazon.com/まとめルールについては下記を参考ください。
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #1 (コンピューティング) - Qiita
https://qiita.com/kai_kou/items/a6795dbab7e707b0d1a6間違いや、こんな呼び方あるよーなどありましたらコメントお願いします!
Mobile - モバイル
AWS Amplify
- 正式名称: AWS Amplify
- https://docs.aws.amazon.com/amplify/?id=docs_gateway
- 読み方: アンプリファイ
- 略称: なし
- 俗称: なし
AWS AppSync
- 正式名称: AWS AppSync
- https://docs.aws.amazon.com/appsync/index.html
- 読み方: アップシンク
- 略称: なし
- 俗称: なし
AWS Device Farm
- 正式名称: AWS Device Farm
- https://docs.aws.amazon.com/devicefarm/?id=docs_gateway
- 読み方: デバイス ファーム
- 略称: なし
- 俗称: なし
Amazon Pinpoint
- 正式名称: Amazon Pinpoint
- https://docs.aws.amazon.com/pinpoint/?id=docs_gateway
- 読み方: ピンポイント
- 略称: なし
- 俗称: なし
Amazon Simple Notification Service (Amazon SNS)
- 正式名称:
- https://docs.aws.amazon.com/sns/?id=docs_gateway
- 読み方: シンプル ノーティフィケイション サービス
- 略称: Amazon SNS
- 俗称: なし
- 投稿日:2019-10-11T02:09:33+09:00
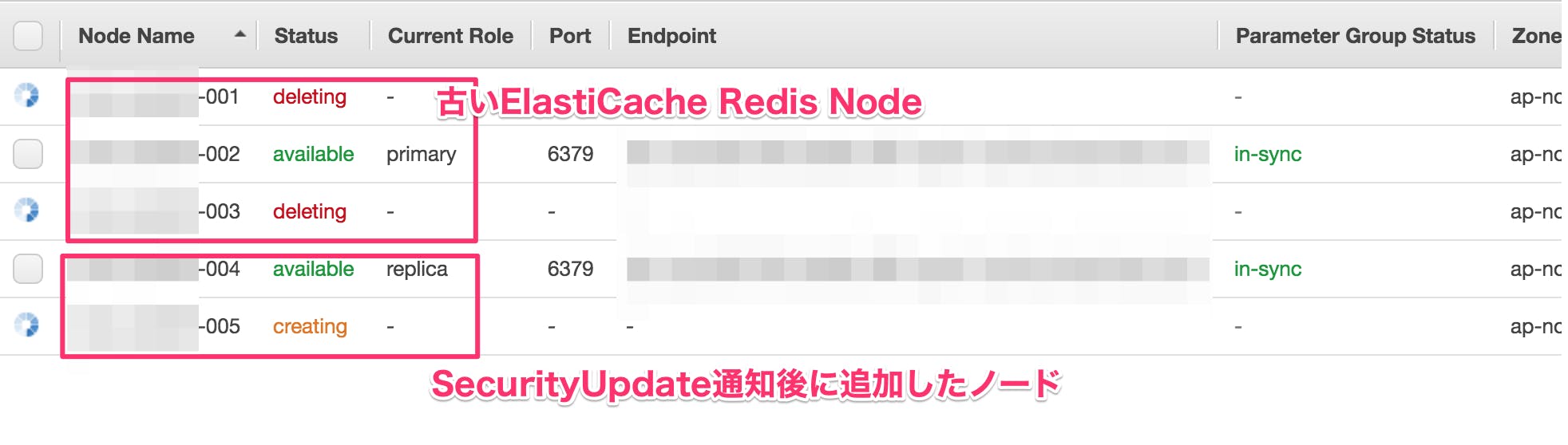
ElastiCache Redis Service Update をApply Service Updateにおまかせしないで俺が対処する方法
俺です。
ElastiCache Redis Self Service Update通知を受けて興奮がさめやらない俺たちのためにメモを残します。
眠れない夜をありがとうelc-20191007-001↓のこいつをポチらずElastiCache RedisのUpdateを行う方法です。
2019/10/11 2:17JST時点ではElastiCache Redis Multi-AZモードを俺俺Service Updateした内容を書いてます。Clusterは別日に書く力があれば多分書きます。
Apply Service Updateを使うとローリングで適用されていきます。途中で停止することもできます。
が、Eventを眺めていないとどのノードにService Updateが適用されているのかわからずprimary failoverタイミングが読めません。
failoverタイミングを制御する方法を検証した結果のメモを残しておきます。
Multi-AZモードのRedisを俺俺Service Updateしてわかったこと
- Service UpdateはNode単位に適用される
- Service Update通知を受けたクラスタへ、新規ノードを追加するとup to dateなノードとして起動する
検証に使ったElastiCache Redis
- ElastiCache Redis(Multi-AZ)
- Instance Type cache.t2.micro
- Engine Version Compatibility: v5.0.0
検証内容
- Redisクラスタ内にReplica Nodeを追加する(旧ノード数分のReplica Nodeを追加する)
古いReplica Nodeを消す
failover primaryして[1]で追加したReplicaノードのいずれかをPrimaryにする
[3]でfailoverしてReplicaになったNodeを消す
Update Action Statusが
update availableからup to dateになる
旧ノード削除前もしくは削除中
旧ノード削除後
最高
良いフルマネージドサービスの俺ージドライフを!