- 投稿日:2019-07-10T23:22:46+09:00
pythonのf-stringとformatとパーセント%の書式の速度の比較
pythonで文字列を書く時はいつも%書式を使ってたのですが、python3.6からはf-stringという新しい表記があります。
f-stringについてこの記事を参考に https://qiita.com/shirakiya/items/2767b30fd4f9c05d930b
で、二ヶ月前にこの記事を書いた時にhttps://qiita.com/phyblas/items/9a087ad1f73aca5dcbe5
@shiracamusさんに指示してもらったのはきっかけで、f-stringを興味を持ち始めたのですが、今でも時々python2.7を使う必要がまだあるので、互換性のことを考慮するとやはり今はまだf-stringに乗り換える時ではないと思ってました。しかし、先日この記事を見つけました。https://qiita.com/Nakamurus/items/9171a37014d9b25eece0
記事ではf-stringが高速だと説明したのです。とても早ければ乗り換えるメリットがあるし、いいかもしれないと思ったので、結局自分も実験してみたのです。
今回は3つの方法の速度を測って比べることにしました。
- %書式
- format
- f-string
色々試してみたのですが、結果は意外でした。ここでその結果を発表します。
%書式からf-stringに乗り換えるべきかどうか迷っている人に参考になれたらと思います
比較対象
データの種類によって結果は随分違います。
今回で実験してみたのは
- 文字列をそのまま出力する(%s、{})
- intを文字列に変換する(%d、{})
- intを指定の桁数で0埋めて文字列に変換する(%010d、{:010})
- floatを指数形式で小数部の桁数を指定しずに文字列に変換する(%e、{:e})
- floatを指数形式で指定の小数部の桁数で文字列に変換する(%.10e、{:.10e})
- floatをfで小数部の桁数を指定しずに文字列に変換する(%f、{:f})
- floatをfで指定の小数部の桁数で文字列に変換する(%.10f、{:.10f})
- floatを形式を指定しずに文字列に変換する(%s、{})
- Noneを文字列に変換する(%s、{})
- listを文字列に変換する(%s、{})
小数(float)の場合は色々違う形で変換できるのです。
コード
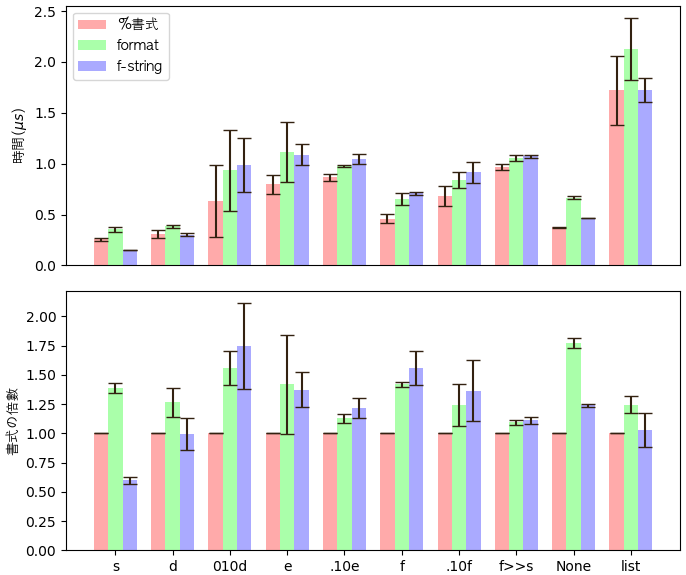
3つの方法で10つの場合毎に五回実行して平均値と標準偏差を求めて棒グラフを書いてみす。
import time import numpy as np import matplotlib.pyplot as plt tt =[] n = 100000 t = [[],[],[]] for j in range(5): a = 'あい' b = 'まい' t0 = time.time() for i in range(n): '%s%s'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{}{}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a}{b}' t[2].append(time.time()-t0) tt.append(t) t = [[],[],[]] for j in range(5): a = 10 b = 200 t0 = time.time() for i in range(n): '%d%d'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{}{}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a}{b}' t[2].append(time.time()-t0) tt.append(t) t = [[],[],[]] for j in range(5): a = 10 b = 200 t0 = time.time() for i in range(n): '%010d%010d'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{:010}{:010}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a:010}{b:010}' t[2].append(time.time()-t0) tt.append(t) t = [[],[],[]] for j in range(5): a = 1.522555 b = 3.125 t0 = time.time() for i in range(n): '%e%e'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{:e}{:e}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a:e}{b:e}' t[2].append(time.time()-t0) tt.append(t) t = [[],[],[]] for j in range(5): a = 1.522555 b = 3.125 t0 = time.time() for i in range(n): '%.10e%.10e'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{:.10e}{:.10e}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a:.10e}{b:.10e}' t[2].append(time.time()-t0) tt.append(t) t = [[],[],[]] for j in range(5): a = 1.522555 b = 3.125 t0 = time.time() for i in range(n): '%f%f'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{:f}{:f}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a:f}{b:f}' t[2].append(time.time()-t0) tt.append(t) t = [[],[],[]] for j in range(5): a = 1.522555 b = 3.125 t0 = time.time() for i in range(n): '%.10f%.10f'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{:.10f}{:.10f}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a:.10f}{b:.10f}' t[2].append(time.time()-t0) tt.append(t) t = [[],[],[]] for j in range(5): a = 1.522555 b = 3.125 t0 = time.time() for i in range(n): '%s%s'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{}{}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a}{b}' t[2].append(time.time()-t0) tt.append(t) t = [[],[],[]] for j in range(5): a = None b = None t0 = time.time() for i in range(n): '%s%s'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{}{}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a}{b}' t[2].append(time.time()-t0) tt.append(t) t = [[],[],[]] for j in range(5): a = list(range(1,6)) b = list(range(11,16)) t0 = time.time() for i in range(n): '%s%s'%(a, b) t[0].append(time.time()-t0) t0 = time.time() for i in range(n): '{}{}'.format(a, b) t[1].append(time.time()-t0) t0 = time.time() for i in range(n): f'{a}{b}' t[2].append(time.time()-t0) tt.append(t) tt = np.array(tt)/n*1000000 plt.figure(figsize=[7,6]) plt.subplot(211) for i,c in enumerate(['#ffaaaa','#aaffaa','#aaaaff']): plt.bar(np.arange(10)+(i-1)/4.,tt[:,i].mean(1),width=0.25,yerr=tt[:,i].std(1),capsize=5,color=c,ecolor='#332211') plt.legend(['%書式','format','f-string'],prop={'family':'AppleGothic'}) plt.ylabel('時間($\mu s$)',family='AppleGothic') plt.xticks([]) plt.subplot(212) for i,c in enumerate(['#ffaaaa','#aaffaa','#aaaaff']): plt.bar(np.arange(10)+(i-1)/4.,(tt[:,i]/tt[:,0]).mean(1),width=0.25,yerr=(tt[:,i]/tt[:,0]).std(1),capsize=5,color=c,ecolor='#332211') plt.ylabel('書式の倍數',family='AppleGothic') plt.xticks(np.arange(10),['s','d','010d','e','.10e','f','.10f','f>>s','None','list']) plt.tight_layout() plt.show()結果
結果は以上です。上図はマイクロ秒単位の一回毎の過ごす時間で、下図は%書式の場合と比べる倍数です。
ちなみに、macでpython 3.7.1で実行したのですが、環境によって違う可能性があるかもしれません。
まとめ
結果から見ると、殆どの場合は%書式の方が早いです。
直接文字列をそのまま出力する場合ははf-stringの方が早いですが、それ以外は勝つことがありません。
formatについてですが、この記事を読んだことがあります。https://qiita.com/amedama/items/8635aff8729a248bad16
記事によると、formatの方が推奨さられていたようですが、結果から見ると、どんな場合でも%書式より遅いようですし書く時も一番冗長だから、そもそもformatを使う理由はあるのでしょうか?と不思議に思っています。
文字列をそのまま出力する時はf-stringはとても高速ですし、短く書けるから便利です。
整数やリストを形式を指定しないで文字列に変換する場合もあまり変わらないようです。
ただ、形式指定で整数と小数を変換することはf-stringは向いていないようです。どんな場合でもformatよりも遅いです。
書き方もこの場合では%書式と同じくらいの長さになります。
というわけで、速度のことにこだわるのなら使い分けしたらいいかもしれません。
とは言っても、速度の違いはそんなに大きいっていうわけではないから、好きなように選ぶといいと思います。
- 投稿日:2019-07-10T23:09:31+09:00
Anacondaのインストール(Windows編)
Pythonとは?
Pythonとはプログラミング言語の1つです。
分かりやすい文法が特徴で、最近では、AI(人工知能)と呼ばれる分野でPythonが利用されることで注目を浴びています。なぜPythonなのか?
Pythonはライブラリと呼ばれるモジュール群が豊富に準備されています。
モジュールとは一連の関連した関数を埋め込んだPythonプログラムのことです。
ライブラリを使うことで、身の丈以上の機能を実装することが可能になります。Anacondaとは?
私はPythonプログラミングの開発環境として「Anaconda」(アナコンダ)をインストールしています。
AnacondaはPython本体だけでなく、NumPy等の定番ライブラリや便利なツールをパッケージとして配布している便利なディストリビューションです。Anacondaのインストール
AnacondaのWebサイトからDownloadをクリック。
Pythonには2系と3系がありますが、2系と3系は互換性がありません。
はじめてプログラミングを学ぶ初心者の人は、最新版のPython3系を選んでおくと無難だといわれていますので、Python3系をインストールしたいと思います。私はWindows環境なので、WindowsのPython3系をDownloadします。
ダウンロードしたインストーラ(Anaconda3-2019.03-Windows-x86_64.exe)をクリックし、インストールを開始します。
インスールパスに日本語が含まれているとモジュールによっては不具合が起きる恐れもあると聞いたことがあるので、インストールフォルダはC:\Anaconda3にしましたが、それ以外は全てデフォルト設定でインストール。
後はインストールが完了するのをお待ち下さい。
インストールの確認
インストールが完了すると、スタートメニューにAnaconda3のフォルダが登録されますので、
Anaconda Pronptを選択します。
Anaconda Pronptのウィンドウが開いたら、python --versionでPythonのバージョンを確認してみましょう。
Pythonのバージョンが表示されたら、インストールが無事に完了しています。$ python --version Python 3.7.3Pythonインタプリタに入力する
次に、Pythonインタプリタでコードを入力してみます。
Anaconda Pronptにpythonと入力するとpythonインタプリタが起動します。
(左側が「>>>」に変わります。)$ python Python 3.7.3 (default, Mar 27 2019, 17:13:21) [MSC v.1915 64 bit (AMD64)] :: Anaconda, Inc. on win32 Type "help", "copyright", "credits" or "license" for more information. >>>「>>>」の後ろにprint("Hello World!")と入力します。
>>> print("Hello World!") Hello World! >>>今、入力したのは、print関数です。
print関数はプログラミング言語を習得する際に最初に覚える関数の一つですので、覚えておきましょう。
print("出力したい文字列")Pythonインタプリタの終了
Pythonインタプリタを終了させるときは、exit()+[Enter]を入力します。
>>> exit()以上、Anacondaのインストールでした。







- 投稿日:2019-07-10T22:18:13+09:00
0.1ぐらいから始めるProjectEuler@python Problem 2
どもども、今日髪を切りに行ったら切られすぎてしまったとある学生です。
というわけで、2問目書いていきます。
まぁまぁ今回も簡単ですかね。Problem_2.py#フィボナッチ数列の項は前の2つの項の和である. #最初の2項を 1, 2 とすれば, 最初#の10項は以下の通りである. #1, 2, 3, 5, 8, 13, 21, 34, 55, 89, ... #数列の項の値が400万以下の, 偶数値の項の総和を求めよ. a=0 b=1 c=a+b d=0 MAX=4000000 while c<=MAX: c=(a+b) a=b b=c if c>MAX: break elif c % 2 ==0: d+=c print(d)解 4613732
はい、私はこう書きました。解き方の解説をしていきます。
グローバル関数のa,bが数列の最初の数ですね。cがそれらを足したやつ。
dは、数値を入れておくための箱です。
後は、whileでa,bを足し続け、2で割って余りが0だったら、dに足していき、最後にcが4百万になったら止めるって感じです。こんな感じですかね?もしわからないやアドバイス等あればコメントしていただければと思います(答えるとは言っていない)
というわけで気が向いたら次のも見てってください。よろしくお願いします。
- 投稿日:2019-07-10T21:29:45+09:00
python IDE
anaconda (Jupyter Notebook)
https://www.anaconda.com/distribution/#download-sectionvisualstudio code
https://code.visualstudio.com/pycharm free for student
https://www.jetbrains.com/pycharm/
- 投稿日:2019-07-10T19:09:19+09:00
PythonのPDF処理まとめ(結合・分割, 画像変換, パスワード解除)
はじめに
PythonでPDFを扱う方法を目的別にまとめます。
シンプルなファイル読み書き、画像への変換やパスワードロック解除等について記載します。PDFファイル読み書き
基本的な読み書きについてはPyPDF2というライブラリを使う事で実装可能です。
pip install PyPDF2以下は、複数のPDFファイルをひとつのPDFに結合する関数の参考例です。
def integratePdf(fileList): merger = PyPDF2.PdfFileMerger() for file in fileList: merger.append(file) OUTPUT_DIR = os.path.dirname(fileList[0]) merger.write(OUTPUT_DIR + '/output.pdf') merger.close()mergerでPyPDF2のPdfFileMergerクラスのインスタンスを生成し、そこにPDFファイルのパスを渡しています。
merger.write()関数により結合後のPDFファイルを出力します。
もし特定のページを追加したいのであれば以下のとおり書けば良いです。merger.append(file, pages=(0,2))この場合、1ページ目から3ページ目までを、mergerに追加しています。
PDF同士の結合のパターンを紹介しましたが、シンプルなRead&Writeにも対応しています。
しかしながら、PDFをPDFのまま扱う場合の処理というのは、結合・分割にほぼ限られるのかな、と思います。画像への変換
pdf2imageというライブラリで非常にシンプルに書けます。
※pillowとpopplerというライブラリに依存pip install pdf2image pip install pillow pip install popplerこれでインストールして
from pdf2image import convert_from_pathでライブラリをインポートし
imgs = convert_from_path(pdf_filepath) for img in imgs: img.save('output.png','png')例えばこんな感じで、pngファイルとして保存する事ができます。非常にかんたん。
パスワードロックの解除
pikepdfというライブラリを使います。
GitHub/pikepdfpip install pikepdffrom pikepdf import PdfでPdfクラスをインポート
以下は「(パスワードの文字列).pdf」を読み込んで、パスワードロックを解除した別ファイル「decrypted.pdf」として保存する関数の参考例です。
def unlockPdf(filepath): PSWD = os.path.basename(filepath)[0:-4] pdffile = Pdf.open(filepath, password=PSWD) newPdf = Pdf.new() newPdf.pages.extend(pdffile.pages) OUTPUT_DIR = os.path.dirname(filepath) newPdf.save(OUTPUT_DIR + '/decrypted.pdf')パスワードは既知である必要があります(パスワードのわからないPDFファイルのロックを解除するものではない)。
pdffile = Pdf.open(filepath, password=PSWD)この行で、パスワードが必要なPDFを、そのパスワードを用いて読み込んでいます。
そして以下の行で新たなPDFファイルとして出力しています。
とてもシンプルに書けますね。ちなみに、Windows32bit環境で動作する実行ファイルを作ってあります。
GitHub - Kanahiro/PdfUnlocker終わりに
以上、実装したい処理別にライブラリを紹介しました。
他には、PDFファイルからのデータマイニング(OCR機能を用いてPDFファイルからテキストデータへの変換)なんかも需要があるようです。
今後紹介できればと考えています。
さて本記事は結局、PDFを○○したいときにはどのライブラリを使うべきか、という記事になっております。
先人が、「こういう機能があれば便利」と思って書いてくれたライブラリ、活用しない手はありません。
でもいつかはそういったライブラリを提供する側に回りたいなと思うこの頃です。
- 投稿日:2019-07-10T19:06:31+09:00
.envのCredentialsでboto3を使う
動機
.envにAWSのCredentialsを記述してs3からファイルをダウンロードしたい。前提
pipenvをつかってpython環境を構築する。
手順
準備
.envを作成してアクセストークンなどを入力する。AWS_ACCESS_KEY_ID=xxx AWS_SECRET_ACCESS_KEY=yyy読み込み
.envを作成したら仮想環境を作成、立ち上げる。$ pipenv install boto3 $ pipenv shell仮想環境を立ち上げると
.envを自動で読み込み環境変数に設定できる。
スクリプト中ではosモジュールから環境変数にアクセスする。# REPLを立ち上げ >>> import os >>> os.environ['AWS_ACCESS_KEY_ID'] 'xxx'ファイルダウンロード
client = boto3.client( 's3', aws_access_key_id=os.environ['AWS_ACCESS_KEY_ID'], aws_secret_access_key=os.environ['AWS_SECRET_ACCESS_KEY'] ) client.download_file(AWS_S3_BUCKET_NAME, s3_key, file_path)管理
.envはgitで管理せずに.gitignoreに追加する。
かわりに値を空白にした.env.sampleをgitで管理しておく。
- 投稿日:2019-07-10T19:05:36+09:00
ラズパイで熱帯夜を乗り切ろう!
エアコン操作を自動化して室温を一定に
上限温度に達すればオン
下限ならオフ
これをひたすら繰り返します笑対象
ターミナル接続でLinuxを触ったことのある人向け。
用意するもの
ラズパイzero: 電源まで付いたスターターキットがオススメ。
リモコンアドバンス:パワフルで操作簡単なリモコンモジュール。
BME280:温度湿度気圧センサー。要ハンダ付け。
ブレッドボードケーブル(メス-メス)20cmぐらい。
USBケーブル:リモコンアドバンス(miniB) - ラズパイzero(microB)ラズパイのセットアップに必要なもの
電源
microSD
おすすめキーボード・マウス(あったほうが楽)
HDMIケーブルラズパイzeroの注意点
ラズパイzeroは小ささや消費電力の点で魅力的なのですが反面USBやHDMIの規格が小さくなってます。
黄丸にはブレッドボードケーブルでBME280をつなぎます。
赤の左からミニHDMI、USB-microB、USB-microB
赤真ん中にリモコンアドバンス、赤右に電源をつなぎます。
ラズパイzeroをセットアップして下さい。
OSインストール
パスワードの変更
wifi設定
SSH Enable
I2C Enable
起動時にCUIで立ち上げる設定
できればipアドレスの固定化までできれば大丈夫です。
先人の偉い方々の記事がたくさんありますので参考にして下さい。
この後はリモートで作業しましょう。ここではPiユーザーで設定しますが任意のユーザーを作成したほうがいいと思います。
センサーやリモコンアドバンスの接続時は念の為電源を切っておいてください。BME280とラズパイzero
ピンがハンダ付けされてない場合はハンダ付けしてください。
BME280.VCC -> ラズパイ.1ピン
BME280.GND -> ラズパイ.6ピン
BME280.SCL -> ラズパイ.5ピン
BME280.SDA -> ラズパイ.3ピン
BME280.SDO -> ラズパイ.9ピンSCLとSDAがI2C通信をするピン。
こんな感じでブレッドボードケーブルで指して繋げばOK。
BME280の設定
hawk777さんの記事が参考になります。ありがとうございます。
ラズパイ+BME280でIoT環境センサー構築(その1)
4.サンプルコードの実行はこちらと読み替えて下さい。sudo apt install -y python-smbus cd /home/pi/ダウンロード wget https://github.com/SWITCHSCIENCE/BME280/archive/master.zip unzip master.zip sudo pip install smbus2 python BME280-master/Python27/bme280_sample.py無事スイッチサイエンスさんのサンプルが動いたら次へ行きましょう。
リモコンアドバンスの設定
参考にさせていただきました。ありがとうございます。
エアコンを外出先から遠隔操作(by MQTT)
6. 赤外線リモコン信号送信まででOKです。作業フォルダ
/home/pi/aircon
以下の作業は先程作成したairconフォルダ内でやります。リモコン信号の記憶
#受信開始 $ bto_advanced_USBIR_cmd -r #受信終了 $ bto_advanced_USBIR_cmd -s #ファイル書き出し $ bto_advanced_USBIR_cmd -g | tee aircon_XX.txt22度設定でon -> aircon_22.txt
25度設定でon -> aircon_25.txt
オフ -> aircon_off.txt
上を参考に3種類のリモコン信号をファイル化してください。
書き出しのところでエラーがでたときはもう一度試すと成功することがあります。BME280のライブラリをダウンロード
Raspberry PiとBME280モジュールで自動で温度・湿度・気圧を測定してグラフ化する
からあげさんの記事を参考に改変させていただきました。git clone https://github.com/fell-procir2/bme280.git cp ./bme280/bme280_sensor.py ./フラグファイルの作成
off.aircon
というファイル名で空ファイルを作成して下さい。auto_pirot.py
#!/usr/bin/env python # -*- coding: utf-8 -*- import time, datetime import bme280_sensor import sys import os #温度設定 upper = 27.8 under = 26.4 on_files = ['aircon_25.txt'] strong_files = ['aircon_22.txt'] off_files = ['aircon_off.txt'] def ir_cmd(code_files): for code_file in code_files: _cmd = "bto_advanced_USBIR_cmd -d `cat " + code_file + "`" while not 0 == os.system(_cmd): time.sleep(1) print(_cmd + ' -> ' + str('done')) time.sleep(1) #湿度による微調整 def clearance(hu): clr = 0 if 60 <= hu: clr = -0.5 elif 58 <= hu and hu < 60: clr = -0.3 elif 50 <= hu and hu < 58: clr = 0 elif hu < 50: clr = 0.2 return clr #初期設定 -> エアコン状態off -> フラグoff ir_cmd(off_files) if os.path.isfile('on.aircon'): os.rename('on.aircon', 'off.aircon') before_temp = 35 while True: (temp, humi, press) = bme280_sensor.get_value() temp_is_over = upper + clearance(humi) < temp and os.path.isfile('off.aircon') temp_is_under = temp < under + clearance(humi) and os.path.isfile('on.aircon') #冷房中に温度があがったか? temp_is_back = before_temp < temp and os.path.isfile('on.aircon') #冷えにくくなったらstrong_file送信 if temp_is_back: ir_cmd(strong_files) if temp_is_over: ir_cmd(on_files) os.rename('off.aircon', 'on.aircon') if temp_is_under: ir_cmd(off_files) os.rename('on.aircon', 'off.aircon') now = datetime.datetime.fromtimestamp(time.time()) log = now.strftime("%H:%M") + ": Temp: " + str(round(temp, 2)) + "C Humi: " + str(round(humi, 2)) + "% Press: " + str(round(press, 2)) + "hPa: " print(log) before_temp = temp time.sleep(60)テスト起動
全てのファイルが作業フォルダ上にあることを確認して下さい。
auto_pirot.py
off.aircon
aircon_22.txt
aircon_25.txt
aircon_off.txt
bme280_sensor.pypython auto_pirot.py1分おきに気温・湿度・気圧が表示されauto_pirot.pyの設定温度になるとリモコン信号が照射されます。
ctrl-cで中断できます。リモコン設定温度等、色々調整してみて下さい。
湿度によっても微調整するようにしています。自動起動
aircon_auto_pirot.sh を作成して作業フォルダに保存します。
vi aircon_auto_pirot.sh#!/bin/sh cd /home/pi/aircon/ python auto_pirot.pyrc.configを編集。
sudo vi /etc/rc.config・・・ sh /home/pi/aircon/aircon_auto_pirot.sh exit 0これで再起動すると自動起動でエアコン操作が始まります。
プロセスが動いているかは下記コマンドで確認できます。pgrep -l pythonケースに入れてみました
センサーが外でブラブラしてるのはラズパイの温度の影響を受けないためです笑
このぐらいの半透明でもこのリモコンはよく効きますね。とりあえず2日ほどつけっぱなしでいますが特に不具合もなく動いています。




- 投稿日:2019-07-10T18:24:11+09:00
ABC133 灰色コーダーの精進日記[3日目]
概要
ABC133をA~Dまで、pythonでの正解例を見ながら解いていった。
目標
- まずは自分でどういう方針で行けばいいのかを考えてから、コードを読む(こういうことをしたいけど、どう描くんだろうと思ったときは、それを明示的に意識する)
- コードを読んだ時に、こういう考え方をしたら、自分もこんなコードが書けるな。みたいな学びを書くようにする
実践
ABC133
自分でA~Dまでは友達と一緒にといたので、答え合わせの気持ちで読む。
A min(n*a,b)を出力する。
自分のコードと同じ
B
ポイント 自分が悩んだ点
- 2重配列をどう受け取るか
- リストのリストで処理。(固定長で挿入、欠失がないので、配列の方が良さそうだけど、全体の計算時間には英kyほうがないからかな。)
p = [list(map(int,input().split())) for _ in range(n)]- 整数かどうかの判定はどうする?
- 僕は
int(n) - n == 0で判定した- math内のceil (切り上げ)、floor(切り捨て)で判断する。
ceil(n)==floor(n)C [l,r]内の2つの整数の掛け算で2019 の剰余が最小になるものをさがす。
- 単純に全てでループを回すとTLE(計算時間制限)に引っかかる
- 僕の方針
- r-lが2019以上なら必ず[r,l]に2019の倍数があるので積の余りの最小値は0になる。
- 2019未満の時には、ループを回す。4*10^6なので大丈夫そう。
- ループの境界条件などで色々と時間がかかった。
- 方針は同じ
- ループを回して、最小値を更新していく。
- tips: 2019は素数でないので、3*673 r-lが673以上なら必ず積が割切れる事は証明できる。計算量が1/9倍になる。
D n(n=奇数)の連立方程式を解く問題
- 僕の方針
- 考えつくまでだいぶ時間がかかった。
- なぜ偶数ではダメなんだろう?
- 偶数だと奇数番目、偶数番目のダムに入る総和が等しくなるという制約条件があるので、nこの変数にn-1個の式になり、式が1つ足りな苦なり、数学的に解けない。
- `Ans[i]=sum[a]-2*(sum[a[j] if i-j %2 == 0 )で良い気がしていた。
- が、それだと、i以外の全ての要素を消せてないことに気づいた。
- また、計算量も毎回のnのloopを回るので間に合わない。o(n^2)
- 1つを求めたら、あとは、連立法廷sきから連鎖的に求められる。o(1)*n
- 方針は最後の僕のものと同じ。」
- 配列をspace 区切りで出力するときに、
print(*Ans)で可能なのはすごい。感想
100分ぐらいかかったので、想定より時間がかかった。
主な原因はD問題で問題で問われていないことを考えたり、そもそも方針が思いつかなかって悩んでいたこと。
10分経って進捗が(新たな方針が立つ気配がなかったら)解説を見るべき。あとは、以外に、解説を見ながらならd問題でも難しくは思わなかった。
今回が簡単だったのもあるかもだけど、考察力に比べて実装力が圧倒的に足りていないのが推測できる。
- 投稿日:2019-07-10T18:24:11+09:00
n次の連立方程式、2019は素数でない! 灰色コーダーの精進日記[3日目]ABC133
概要
ABC133をA~Dまで、pythonでの正解例を見ながら解いていった。
目標
- まずは自分でどういう方針で行けばいいのかを考えてから、コードを読む(こういうことをしたいけど、どう描くんだろうと思ったときは、それを明示的に意識する)
- コードを読んだ時に、こういう考え方をしたら、自分もこんなコードが書けるな。みたいな学びを書くようにする
実践
ABC133
自分でA~Dまでは友達と一緒にといたので、答え合わせの気持ちで読む。
A min(n*a,b)を出力する。
自分のコードと同じ
B
ポイント 自分が悩んだ点
- 2重配列をどう受け取るか
- リストのリストで処理。(固定長で挿入、欠失がないので、配列の方が良さそうだけど、全体の計算時間には英kyほうがないからかな。)
p = [list(map(int,input().split())) for _ in range(n)]- 整数かどうかの判定はどうする?
- 僕は
int(n) - n == 0で判定した- math内のceil (切り上げ)、floor(切り捨て)で判断する。
ceil(n)==floor(n)C [l,r]内の2つの整数の掛け算で2019 の剰余が最小になるものをさがす。
- 単純に全てでループを回すとTLE(計算時間制限)に引っかかる
- 僕の方針
- r-lが2019以上なら必ず[r,l]に2019の倍数があるので積の余りの最小値は0になる。
- 2019未満の時には、ループを回す。4*10^6なので大丈夫そう。
- ループの境界条件などで色々と時間がかかった。
- 方針は同じ
- ループを回して、最小値を更新していく。
- tips: 2019は素数でないので、3*673 r-lが673以上なら必ず積が割切れる事は証明できる。計算量が1/9倍になる。
D n(n=奇数)の連立方程式を解く問題
- 僕の方針
- 考えつくまでだいぶ時間がかかった。
- なぜ偶数ではダメなんだろう?
- 偶数だと奇数番目、偶数番目のダムに入る総和が等しくなるという制約条件があるので、nこの変数にn-1個の式になり、式が1つ足りな苦なり、数学的に解けない。
- `Ans[i]=sum[a]-2*(sum[a[j] if i-j %2 == 0 )で良い気がしていた。
- が、それだと、i以外の全ての要素を消せてないことに気づいた。
- また、計算量も毎回のnのloopを回るので間に合わない。o(n^2)
- 1つを求めたら、あとは、連立法廷sきから連鎖的に求められる。o(1)*n
- 方針は最後の僕のものと同じ。」
- 配列をspace 区切りで出力するときに、
print(*Ans)で可能なのはすごい。感想
100分ぐらいかかったので、想定より時間がかかった。
主な原因はD問題で問題で問われていないことを考えたり、そもそも方針が思いつかなかって悩んでいたこと。
10分経って進捗が(新たな方針が立つ気配がなかったら)解説を見るべき。あとは、以外に、解説を見ながらならd問題でも難しくは思わなかった。
今回が簡単だったのもあるかもだけど、考察力に比べて実装力が圧倒的に足りていないのが推測できる。
- 投稿日:2019-07-10T18:06:29+09:00
pythonにおけるlist、arrayの扱い
数値計算をしていると、次のような操作をしたいときがあります。
- ある配列を複製して、複製元の配列を変えずに複製した配列の成分の値のみを変えたい。
- 全ての成分が同じ値(例えば0)である配列を作って、その配列のとある成分の値のみを変えたい。
pythonで数値計算をしていたところ、listやarrayを複製したり、各成分の値を書き換えたりする際に少しつまずいたので、list、arrayのその辺りの性質についてまとめます。listやarrayの詳しい仕様については触れていません。
本記事中で使っているarrayは、numpyのndarrayです。
結論
ある配列を複製する際、複製した配列の成分の値を変えても元の配列の値が変わらない複製方法を「配列の複製」にまとめました。また、とある成分の値を変えても他の成分の値が変わらない0埋めされた配列の作製方法は「0埋めされた配列の作製」にまとめてあります。
配列の複製
配列aを複製した配列copy_aを作り、aの各成分の値を変えずにcopy_aの各成分の値のみを変えるには、
- aが1次元listの場合は次の方法(2)〜(5)でcopy_aを作りましょう。
copy_a = a[:] # (2) copy_a = a.copy() # (3) copy_a = list(a) # (4) copy_a = [elem for elem in a] # (5)
- aが2次元listの場合は次の方法(5.2)〜(5.5)が有効です。
copy_a = [elem[:] for elem in a] # (5.2) copy_a = [elem.copy() for elem in a] # (5.3) copy_a = [list(elem) for elem in a] # (5.4) copy_a = [[_elem for _elem in elem] for elem in a] # (5.5)
- 一方で、aがarrayの場合は、aが1次元、2次元であるかを問わず次の方法(3)〜(5)で複製元aの値を変えずに各成分の値を変えられるcopy_aを作ることが出来ます。
copy_a = a.copy() # (3) copy_a = np.array(a) # (4) copy_a = np.array([elem for elem in a]) # (5)0埋めされた配列の作製
ある成分の値を変えても他の成分の値が変わらない0埋めされた配列を作るには、
- 1次元listの場合、次の方法(1)、(2)が有効です。
# Kは自然数 a = [0 for _ in range(K)] # (1) a = [0]*K # (2)
- 2次元listの場合は方法(1.1)、(1.2)を使いましょう。
a = [[0 for _ in range(K)] for _ in range(K)] # (1.1) a = [[0]*K for _ in range(K)] # (1.2) # a = [[0]*K]*K # (2.2)方法(2.2)が使えないことには注意して下さい。
- 1次元arrayの場合は、次の方法が有効です。
a = np.zeros(K, int) a = [0 for _ in range(K)] # (1) a = [0]*K # (2)
- 2次元arrayの場合は次の方法が使えます。
a = np.zeros((K, K), int) a = np.array([[0 for _ in range(K)] for _ in range(K)]) # (1.1) a = np.array([[0]*K for _ in range(K)]) # (1.2) a = np.array([[0]*K]*K) # (2.2)2次元listの場合は、方法(2.2)は有効でありませんでしたが、作った2次元listをarrayに変換すると、とある成分の値を変えても他の成分の値が変わらない0埋めされた配列になります。
実験1
実験1では、1次元list・array及び2次元list・arrayの様々な複製方法を試しました。
1次元listの複製
1次元list aを複製したlist copy_aを作って、copy_aの第0成分の値を変える場合、
>>> a = [0, 1] >>> copy_a = a # (1) >>> id(copy_a) == id(a) True >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = [0, 1] >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = list(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = [elem for elem in a] # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False上述のように、(1)以外の方法ならば、copy_aの成分の値を変えてもaの成分の値は変わりません。
1次元arrayの複製
一方で、aが1次元arrayの場合は以下のような結果になります。
>>> a = np.array([0, 1]) >>> copy_a = a # (1) >>> id(copy_a) == id(a) True >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = np.array(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = np.array([elem for elem in a]) # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) Trueaがlistだった場合と異なる点は、
- (2)の方法で複製した場合にcopy_aの成分の値を変えると、aの成分の値も変わる。
- (3)〜(5)の方法では、copy_aの成分の値を変えてもaの成分の値は変わらないが、変えた成分のidは等しい。
の2点です。
2次元listの複製
2次元list aを複製したlist copy_aを作り、aの値を変えずに、copy_aの(0,0)成分の値のみを変えたいとします。1次元listの場合に試した方法の内、効果のあった(2)〜(5)の方法を使いましょう。
>>> a = [[1, 0],[0, 1]] >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = list(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = [elem for elem in a] # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) Trueこのように、list aが1次元の場合に有効だった(2)〜(5)の方法では、copy_aの(0,0)成分の値のみを変えることは出来ませんでした。更に以下の方法を試してみます。
>>> a = [[1, 0],[0, 1]] >>> copy_a = [elem[:] for elem in a] # (5.2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [elem.copy() for elem in a] # (5.3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [list(elem) for elem in a] # (5.4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [[_elem for _elem in elem] for elem in a] # (5.5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False上の結果から、(5)の方法でlistであるaの要素を呼び出し、その要素に対して(2)〜(4)の方法を用いると無事aの値を変えずにcopy_aの(0,0)成分の値のみを変えられることが分かりました。
2次元arrayの複製
2次元listの場合と同様に、2次元array a対しても1次元arrayの場合に効果のあった(3)〜(5)の方法で、copy_aの(0,0)成分の値のみを変えられるか試してみます。
>>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array([elem for elem in a]) # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True2次元listの場合には有効でなかった(3)〜(5)の方法ですが、2次元arrayの場合には、aの値を変えずにcopy_aの(0,0)成分の値のみを変えることが出来ました。
実験2
実験2では、0埋めされた配列を作製する幾つかの方法を試しました。
0埋めされたlistの作製
0埋めされた1次元listを作り、第0成分の値を1にする場合、
>>> a = [0 for _ in range(2)] # (1) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a [1, 0] >>> id(a[0]) == id(a[1]) False >>> a = [0]*2 # (2) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a [1, 0] >>> id(a[0]) == id(a[1]) False上のように、方法(1)、(2)のどちらで0埋めされたlist aの第0成分の値のみを1にすることが出来ました。
一方で、0埋めされた2次元listの場合は、
>>> a = [[0 for _ in range(2)] for _ in range(2)] # (1.1) >>> id(a[0]) == id(a[1]) False >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [0, 0]] >>> id(a[0][0]) == id(a[1][0]) False >>> a = [[0]*2 for _ in range(2)] # (1.2) >>> id(a[0]) == id(a[1]) False >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [0, 0]] >>> id(a[0][0]) == id(a[1][0]) False >>> a = [[0]*2]*2 # (2.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [1, 0]] >>> id(a[0][0]) == id(a[1][0]) Trueのように演算子
*を2回用いて0埋めされた2次元listを作ると、(0,0)成分の値のみを1にすることが出来ません。0埋めされたarrayの作製
0埋めされた1次元arrayを作り、第0成分の値のみを1に変えるには、方法(1)、(2)で0埋めされた1次元listを作ってarrayに変換する以外に、
np.zeros()を利用する方法があります。>>> a = np.zeros(2, int) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a array([1, 0]) >>> id(a[0]) == id(a[1]) True0埋めされた2次元arrayを作る場合も、同様に
np.zeros()を使うことで、(0,0)成分の値のみを1にすることが出来ます。0埋めされた2次元listを作った場合と異なる点は、方法(2.2)を用いても(0,0)成分の値のみを1にすることが出来る点です。>>> a = np.zeros((2, 2), int) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0 for _ in range(2)] for _ in range(2)]) # (1.1) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0]*2 for _ in range(2)]) # (1.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0]*2]*2) # (2.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True考察
listの複製に関しては、1次元、2次元のいずれにせよ、数値型の値を格納しているlistのidが異なれば複製元の配列の成分の値を変えずに複製した配列の成分を変えることが出来ます。一方でarrayの場合は、複製した配列のidが複製元の配列のidと異なっているだけで、複製した配列の各成分の値のみを変えられるようです。実験1の2次元arrayの実験では、copy_aに格納された数値型の値1つを変える操作をしましたが、例えば、次のように配列を渡してaの各成分の値を変えずに、copy_aの各成分の値のみを変えることが出来ます。
>>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = [0, 1] >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = np.array([0, 1]) >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = 0, 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True実験2で0埋めされたarray配列を作った際にも見られましたが、idが等しいのに数値が異なるというarrayの仕様を理解するには、より詳しく調べる必要があります。
実験2の0埋めされたlistを作る実験からは、listに演算子
*を作用させることは、次の操作と等しいという直感が得られるでしょう。# Kは自然数 >>> temp = 0 >>> a = [temp for _ in range(K)] # a = [0]*K >>> temp = [0]*K >>> b = [temp for _ in range(K)] # b = [[0]*K]*Kリンク
- 投稿日:2019-07-10T18:06:29+09:00
pythonにおけるlist、numpy.arrayの扱い
数値計算をしていると、次のような操作をしたいときがあります。
- ある配列を複製して、複製元の配列を変えずに複製した配列の成分の値のみを変えたい。
- 全ての成分が同じ値(例えば0)である配列を作って、その配列のとある成分の値のみを変えたい。
pythonで数値計算をしていたところ、listやarrayを複製したり、各成分の値を書き換えたりする際に少しつまずいたので、list、arrayのその辺りの性質についてまとめます。listやarrayの詳しい仕様については触れていません。
本記事中で使っているarrayは、numpyのndarrayです。
結論
ある配列を複製する際、複製した配列の成分の値を変えても元の配列の値が変わらない複製方法を「配列の複製」にまとめました。また、とある成分の値を変えても他の成分の値が変わらない0埋めされた配列の作製方法は「0埋めされた配列の作製」にまとめてあります。
配列の複製
配列aを複製した配列copy_aを作り、aの各成分の値を変えずにcopy_aの各成分の値のみを変えるには、
- aが1次元listの場合は次の方法(2)〜(5)でcopy_aを作りましょう。
copy_a = a[:] # (2) copy_a = a.copy() # (3) copy_a = list(a) # (4) copy_a = [elem for elem in a] # (5)
- aが2次元listの場合は次の方法(5.2)〜(5.5)が有効です。
copy_a = [elem[:] for elem in a] # (5.2) copy_a = [elem.copy() for elem in a] # (5.3) copy_a = [list(elem) for elem in a] # (5.4) copy_a = [[_elem for _elem in elem] for elem in a] # (5.5)今回は扱いませんでしたが、copyモジュールのdeepcopyを使うことでも複製元の各成分の値を変えずに複製したlistの各成分の値のみを変えることが出来るようです(リンクを参照)。
- 一方で、aがarrayの場合は、aが1次元、2次元であるかを問わず次の方法(3)〜(5)で複製元aの値を変えずに各成分の値を変えられるcopy_aを作ることが出来ます。
copy_a = a.copy() # (3) copy_a = np.array(a) # (4) copy_a = np.array([elem for elem in a]) # (5)0埋めされた配列の作製
ある成分の値を変えても他の成分の値が変わらない0埋めされた配列を作るには、
- 1次元listの場合、次の方法(1)、(2)が有効です。
# Kは自然数 a = [0 for _ in range(K)] # (1) a = [0]*K # (2)
- 2次元listの場合は方法(1.1)、(1.2)を使いましょう。
a = [[0 for _ in range(K)] for _ in range(K)] # (1.1) a = [[0]*K for _ in range(K)] # (1.2) # a = [[0]*K]*K # (2.2)方法(2.2)が使えないことには注意して下さい。
- 1次元arrayの場合は、次の方法が有効です。
a = np.zeros(K, int) a = [0 for _ in range(K)] # (1) a = [0]*K # (2)
- 2次元arrayの場合は次の方法が使えます。
a = np.zeros((K, K), int) a = np.array([[0 for _ in range(K)] for _ in range(K)]) # (1.1) a = np.array([[0]*K for _ in range(K)]) # (1.2) a = np.array([[0]*K]*K) # (2.2)2次元listの場合は、方法(2.2)は有効でありませんでしたが、作った2次元listをarrayに変換すると、とある成分の値を変えても他の成分の値が変わらない0埋めされた配列になります。
実験1
実験1では、1次元list・array及び2次元list・arrayの様々な複製方法を試しました。
1次元listの複製
1次元list aを複製したlist copy_aを作って、copy_aの第0成分の値を変える場合、
>>> a = [0, 1] >>> copy_a = a # (1) >>> id(copy_a) == id(a) True >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = [0, 1] >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = list(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = [elem for elem in a] # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False上述のように、(1)以外の方法ならば、copy_aの成分の値を変えてもaの成分の値は変わりません。
1次元arrayの複製
一方で、aが1次元arrayの場合は以下のような結果になります。
>>> a = np.array([0, 1]) >>> copy_a = a # (1) >>> id(copy_a) == id(a) True >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = np.array(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = np.array([elem for elem in a]) # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) Trueaがlistだった場合と異なる点は、
- (2)の方法で複製した場合にcopy_aの成分の値を変えると、aの成分の値も変わる。
- (3)〜(5)の方法では、copy_aの成分の値を変えてもaの成分の値は変わらないが、変えた成分のidは等しい。
の2点です。
2次元listの複製
2次元list aを複製したlist copy_aを作り、aの値を変えずに、copy_aの(0,0)成分の値のみを変えたいとします。1次元listの場合に試した方法の内、効果のあった(2)〜(5)の方法を使いましょう。
>>> a = [[1, 0],[0, 1]] >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = list(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = [elem for elem in a] # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) Trueこのように、list aが1次元の場合に有効だった(2)〜(5)の方法では、copy_aの(0,0)成分の値のみを変えることは出来ませんでした。更に以下の方法を試してみます。
>>> a = [[1, 0],[0, 1]] >>> copy_a = [elem[:] for elem in a] # (5.2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [elem.copy() for elem in a] # (5.3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [list(elem) for elem in a] # (5.4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [[_elem for _elem in elem] for elem in a] # (5.5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False上の結果から、(5)の方法でlistであるaの要素を呼び出し、その要素に対して(2)〜(4)の方法を用いると無事aの値を変えずにcopy_aの(0,0)成分の値のみを変えられることが分かりました。
2次元arrayの複製
2次元listの場合と同様に、2次元array a対しても1次元arrayの場合に効果のあった(3)〜(5)の方法で、copy_aの(0,0)成分の値のみを変えられるか試してみます。
>>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array([elem for elem in a]) # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True2次元listの場合には有効でなかった(3)〜(5)の方法ですが、2次元arrayの場合には、aの値を変えずにcopy_aの(0,0)成分の値のみを変えることが出来ました。
実験2
実験2では、0埋めされた配列を作製する幾つかの方法を試しました。
0埋めされたlistの作製
0埋めされた1次元listを作り、第0成分の値を1にする場合、
>>> a = [0 for _ in range(2)] # (1) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a [1, 0] >>> id(a[0]) == id(a[1]) False >>> a = [0]*2 # (2) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a [1, 0] >>> id(a[0]) == id(a[1]) False上のように、方法(1)、(2)のどちらで0埋めされたlist aの第0成分の値のみを1にすることが出来ました。
一方で、0埋めされた2次元listの場合は、
>>> a = [[0 for _ in range(2)] for _ in range(2)] # (1.1) >>> id(a[0]) == id(a[1]) False >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [0, 0]] >>> id(a[0][0]) == id(a[1][0]) False >>> a = [[0]*2 for _ in range(2)] # (1.2) >>> id(a[0]) == id(a[1]) False >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [0, 0]] >>> id(a[0][0]) == id(a[1][0]) False >>> a = [[0]*2]*2 # (2.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [1, 0]] >>> id(a[0][0]) == id(a[1][0]) Trueのように演算子
*を2回用いて0埋めされた2次元listを作ると、(0,0)成分の値のみを1にすることが出来ません。0埋めされたarrayの作製
0埋めされた1次元arrayを作り、第0成分の値のみを1に変えるには、方法(1)、(2)で0埋めされた1次元listを作ってarrayに変換する以外に、
np.zeros()を利用する方法があります。>>> a = np.zeros(2, int) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a array([1, 0]) >>> id(a[0]) == id(a[1]) True0埋めされた2次元arrayを作る場合も、同様に
np.zeros()を使うことで、(0,0)成分の値のみを1にすることが出来ます。0埋めされた2次元listを作った場合と異なる点は、方法(2.2)を用いても(0,0)成分の値のみを1にすることが出来る点です。>>> a = np.zeros((2, 2), int) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0 for _ in range(2)] for _ in range(2)]) # (1.1) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0]*2 for _ in range(2)]) # (1.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0]*2]*2) # (2.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True考察
listの複製に関しては、1次元、2次元のいずれにせよ、数値型の値を格納しているlistのidが異なれば複製元の配列の成分の値を変えずに複製した配列の成分を変えることが出来ます。一方でarrayの場合は、複製した配列のidが複製元の配列のidと異なっているだけで、複製した配列の各成分の値のみを変えられるようです。実験1の2次元arrayの実験では、copy_aに格納された数値型の値1つを変える操作をしましたが、例えば、次のように配列を渡してaの各成分の値を変えずに、copy_aの各成分の値のみを変えることが出来ます。
>>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = [0, 1] >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = np.array([0, 1]) >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = 0, 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True実験2で0埋めされたarray配列を作った際にも見られましたが、idが等しいのに数値が異なるというarrayの仕様を理解するには、より詳しく調べる必要があります。
実験2の0埋めされたlistを作る実験からは、listに演算子
*を作用させることは、次の操作と等しいという直感が得られるでしょう。# Kは自然数 >>> temp = 0 >>> a = [temp for _ in range(K)] # a = [0]*K >>> temp = [0]*K >>> b = [temp for _ in range(K)] # b = [[0]*K]*Kリンク
- 投稿日:2019-07-10T18:06:29+09:00
pythonにおけるlist、numpy.arrayの扱い (複製、初期化)
数値計算をしていると、次のような操作をしたいときがあります。
- ある配列を複製して、複製元の配列を変えずに複製した配列の成分の値のみを変えたい。
- 全ての成分が同じ値(例えば0)である配列を作って、その配列のとある成分の値のみを変えたい。
pythonで数値計算をしていたところ、listやarrayを複製したり、各成分の値を書き換えたりする際に少しつまずいたので、list、arrayのその辺りの性質についてまとめます。listやarrayの詳しい仕様については触れていません。
本記事中で使っているarrayは、numpyのndarrayです。
結論
ある配列を複製する際、複製した配列の成分の値を変えても元の配列の値が変わらない複製方法を「配列の複製」にまとめました。また、とある成分の値を変えても他の成分の値が変わらない0埋めされた配列の作製方法は「0埋めされた配列の作製」にまとめてあります。
配列の複製
配列aを複製した配列copy_aを作り、aの各成分の値を変えずにcopy_aの各成分の値のみを変えるには、
- aが1次元listの場合は次の方法(2)〜(5)でcopy_aを作りましょう。
copy_a = a[:] # (2) copy_a = a.copy() # (3) copy_a = list(a) # (4) copy_a = [elem for elem in a] # (5)
- aが2次元listの場合は次の方法(5.2)〜(5.5)が有効です。
copy_a = [elem[:] for elem in a] # (5.2) copy_a = [elem.copy() for elem in a] # (5.3) copy_a = [list(elem) for elem in a] # (5.4) copy_a = [[_elem for _elem in elem] for elem in a] # (5.5)今回は扱いませんでしたが、copyモジュールのdeepcopyを使うことでも複製元の各成分の値を変えずに複製したlistの各成分の値のみを変えることが出来るようです(リンクを参照)。
- 一方で、aがarrayの場合は、aが1次元、2次元であるかを問わず次の方法(3)〜(5)で複製元aの値を変えずに各成分の値を変えられるcopy_aを作ることが出来ます。
copy_a = a.copy() # (3) copy_a = np.array(a) # (4) copy_a = np.array([elem for elem in a]) # (5)1次元arrayに対して、1次元listのように方法(2)が使えない点に注意しましょう。
0埋めされた配列の作製
ある成分の値を変えても他の成分の値が変わらない0埋めされた配列を作るには、
- 1次元listの場合、次の方法(1)、(2)が有効です。
# Kは自然数 a = [0 for _ in range(K)] # (1) a = [0]*K # (2)
- 2次元listの場合は方法(1.1)、(1.2)を使いましょう。
a = [[0 for _ in range(K)] for _ in range(K)] # (1.1) a = [[0]*K for _ in range(K)] # (1.2) # a = [[0]*K]*K # (2.2)方法(2.2)が使えないことには注意して下さい。
- 1次元arrayの場合は、次の方法が有効です。
a = np.zeros(K, int) a = [0 for _ in range(K)] # (1) a = [0]*K # (2)
- 2次元arrayの場合は次の方法が使えます。
a = np.zeros((K, K), int) a = np.array([[0 for _ in range(K)] for _ in range(K)]) # (1.1) a = np.array([[0]*K for _ in range(K)]) # (1.2) a = np.array([[0]*K]*K) # (2.2)2次元listの場合は、方法(2.2)は有効でありませんでしたが、作った2次元listをarrayに変換すると、とある成分の値を変えても他の成分の値が変わらない0埋めされた配列になります。
実験1
実験1では、1次元list・array及び2次元list・arrayの様々な複製方法を試しました。
1次元listの複製
1次元list aを複製したlist copy_aを作って、copy_aの第0成分の値を変える場合、
>>> a = [0, 1] >>> copy_a = a # (1) >>> id(copy_a) == id(a) True >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = [0, 1] >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = list(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = [elem for elem in a] # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False上述のように、(1)以外の方法ならば、copy_aの成分の値を変えてもaの成分の値は変わりません。
1次元arrayの複製
一方で、aが1次元arrayの場合は以下のような結果になります。
>>> a = np.array([0, 1]) >>> copy_a = a # (1) >>> id(copy_a) == id(a) True >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = np.array(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = np.array([elem for elem in a]) # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) Trueaがlistだった場合と異なる点は、
- (2)の方法で複製した場合にcopy_aの成分の値を変えると、aの成分の値も変わる。
- (3)〜(5)の方法では、copy_aの成分の値を変えてもaの成分の値は変わらないが、変えた成分のidは等しい。
の2点です。
2次元listの複製
2次元list aを複製したlist copy_aを作り、aの値を変えずに、copy_aの(0,0)成分の値のみを変えたいとします。1次元listの場合に試した方法の内、効果のあった(2)〜(5)の方法を使いましょう。
>>> a = [[1, 0],[0, 1]] >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = list(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = [elem for elem in a] # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) Trueこのように、list aが1次元の場合に有効だった(2)〜(5)の方法では、copy_aの(0,0)成分の値のみを変えることは出来ませんでした。更に以下の方法を試してみます。
>>> a = [[1, 0],[0, 1]] >>> copy_a = [elem[:] for elem in a] # (5.2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [elem.copy() for elem in a] # (5.3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [list(elem) for elem in a] # (5.4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [[_elem for _elem in elem] for elem in a] # (5.5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False上の結果から、(5)の方法でlistであるaの要素を呼び出し、その要素に対して(2)〜(4)の方法を用いると無事aの値を変えずにcopy_aの(0,0)成分の値のみを変えられることが分かりました。
2次元arrayの複製
2次元listの場合と同様に、2次元array a対しても1次元arrayの場合に効果のあった(3)〜(5)の方法で、copy_aの(0,0)成分の値のみを変えられるか試してみます。
>>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array([elem for elem in a]) # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True2次元listの場合には有効でなかった(3)〜(5)の方法ですが、2次元arrayの場合には、aの値を変えずにcopy_aの(0,0)成分の値のみを変えることが出来ました。
実験2
実験2では、0埋めされた配列を作製する幾つかの方法を試しました。
0埋めされたlistの作製
0埋めされた1次元listを作り、第0成分の値を1にする場合、
>>> a = [0 for _ in range(2)] # (1) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a [1, 0] >>> id(a[0]) == id(a[1]) False >>> a = [0]*2 # (2) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a [1, 0] >>> id(a[0]) == id(a[1]) False上のように、方法(1)、(2)のどちらで0埋めされたlist aの第0成分の値のみを1にすることが出来ました。
一方で、0埋めされた2次元listの場合は、
>>> a = [[0 for _ in range(2)] for _ in range(2)] # (1.1) >>> id(a[0]) == id(a[1]) False >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [0, 0]] >>> id(a[0][0]) == id(a[1][0]) False >>> a = [[0]*2 for _ in range(2)] # (1.2) >>> id(a[0]) == id(a[1]) False >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [0, 0]] >>> id(a[0][0]) == id(a[1][0]) False >>> a = [[0]*2]*2 # (2.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [1, 0]] >>> id(a[0][0]) == id(a[1][0]) Trueのように演算子
*を2回用いて0埋めされた2次元listを作ると、(0,0)成分の値のみを1にすることが出来ません。0埋めされたarrayの作製
0埋めされた1次元arrayを作り、第0成分の値のみを1に変えるには、方法(1)、(2)で0埋めされた1次元listを作ってarrayに変換する以外に、
np.zeros()を利用する方法があります。>>> a = np.zeros(2, int) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a array([1, 0]) >>> id(a[0]) == id(a[1]) True0埋めされた2次元arrayを作る場合も、同様に
np.zeros()を使うことで、(0,0)成分の値のみを1にすることが出来ます。0埋めされた2次元listを作った場合と異なる点は、方法(2.2)を用いても(0,0)成分の値のみを1にすることが出来る点です。>>> a = np.zeros((2, 2), int) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0 for _ in range(2)] for _ in range(2)]) # (1.1) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0]*2 for _ in range(2)]) # (1.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0]*2]*2) # (2.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True考察
listの複製に関しては、1次元、2次元のいずれにせよ、数値型の値を格納しているlistのidが異なれば複製元の配列の成分の値を変えずに複製した配列の成分を変えることが出来ます。一方でarrayの場合は、複製した配列のidが複製元の配列のidと異なっているだけで、複製した配列の各成分の値のみを変えられるようです。実験1の2次元arrayの実験では、copy_aに格納された数値型の値1つを変える操作をしましたが、例えば、次のように配列を渡してaの各成分の値を変えずに、copy_aの各成分の値のみを変えることが出来ます。
>>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = [0, 1] >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = np.array([0, 1]) >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = 0, 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True実験2で0埋めされたarray配列を作った際にも見られましたが、idが等しいのに数値が異なるというarrayの仕様を理解するには、より詳しく調べる必要があります。
実験2の0埋めされたlistを作る実験からは、listに演算子
*を作用させることは、次の操作と等しいという直感が得られるでしょう。# Kは自然数 >>> temp = 0 >>> a = [temp for _ in range(K)] # a = [0]*K >>> temp = [0]*K >>> b = [temp for _ in range(K)] # b = [[0]*K]*Kリンク
- 投稿日:2019-07-10T18:06:29+09:00
pythonにおけるlist、numpy.arrayの扱い(複製、初期化)
数値計算をしていると、次のような操作をしたいときがあります。
- ある配列を複製して、複製元の配列を変えずに複製した配列の成分の値のみを変えたい。
- 全ての成分が同じ値(例えば0)である配列を作って、その配列のとある成分の値のみを変えたい。
pythonで数値計算をしていたところ、listやarrayを複製したり、各成分の値を書き換えたりする際に少しつまずいたので、list、arrayのその辺りの性質についてまとめます。listやarrayの詳しい仕様については触れていません。
本記事中で使っているarrayは、numpyのndarrayです。
結論
ある配列を複製する際、複製した配列の成分の値を変えても元の配列の値が変わらない複製方法を「配列の複製」にまとめました。また、とある成分の値を変えても他の成分の値が変わらない0埋めされた配列の作製方法は「0埋めされた配列の作製」にまとめてあります。
配列の複製
配列aを複製した配列copy_aを作り、aの各成分の値を変えずにcopy_aの各成分の値のみを変えるには、
- aが1次元listの場合は次の方法(2)〜(5)でcopy_aを作りましょう。
copy_a = a[:] # (2) copy_a = a.copy() # (3) copy_a = list(a) # (4) copy_a = [elem for elem in a] # (5)
- aが2次元listの場合は次の方法(5.2)〜(5.5)が有効です。
copy_a = [elem[:] for elem in a] # (5.2) copy_a = [elem.copy() for elem in a] # (5.3) copy_a = [list(elem) for elem in a] # (5.4) copy_a = [[_elem for _elem in elem] for elem in a] # (5.5)今回は扱いませんでしたが、copyモジュールのdeepcopyを使うことでも複製元の各成分の値を変えずに複製したlistの各成分の値のみを変えることが出来るようです(リンクを参照)。
- 一方で、aがarrayの場合は、aが1次元、2次元であるかを問わず次の方法(3)〜(5)で複製元aの値を変えずに各成分の値を変えられるcopy_aを作ることが出来ます。
copy_a = a.copy() # (3) copy_a = np.array(a) # (4) copy_a = np.array([elem for elem in a]) # (5)1次元arrayに対して、1次元listのように方法(2)が使えない点に注意しましょう。
0埋めされた配列の作製
ある成分の値を変えても他の成分の値が変わらない0埋めされた配列を作るには、
- 1次元listの場合、次の方法(1)、(2)が有効です。
# Kは自然数 a = [0 for _ in range(K)] # (1) a = [0]*K # (2)
- 2次元listの場合は方法(1.1)、(1.2)を使いましょう。
a = [[0 for _ in range(K)] for _ in range(K)] # (1.1) a = [[0]*K for _ in range(K)] # (1.2) # a = [[0]*K]*K # (2.2)方法(2.2)が使えないことには注意して下さい。
- 1次元arrayの場合は、次の方法が有効です。
a = np.zeros(K, int) a = [0 for _ in range(K)] # (1) a = [0]*K # (2)
- 2次元arrayの場合は次の方法が使えます。
a = np.zeros((K, K), int) a = np.array([[0 for _ in range(K)] for _ in range(K)]) # (1.1) a = np.array([[0]*K for _ in range(K)]) # (1.2) a = np.array([[0]*K]*K) # (2.2)2次元listの場合は、方法(2.2)は有効でありませんでしたが、作った2次元listをarrayに変換すると、とある成分の値を変えても他の成分の値が変わらない0埋めされた配列になります。
実験1
実験1では、1次元list・array及び2次元list・arrayの様々な複製方法を試しました。
1次元listの複製
1次元list aを複製したlist copy_aを作って、copy_aの第0成分の値を変える場合、
>>> a = [0, 1] >>> copy_a = a # (1) >>> id(copy_a) == id(a) True >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = [0, 1] >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = list(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False >>> a = [0, 1] >>> copy_a = [elem for elem in a] # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0, 1] copy_a = [1, 1] >>> id(copy_a[0]) == id(a[0]) False上述のように、(1)以外の方法ならば、copy_aの成分の値を変えてもaの成分の値は変わりません。
1次元arrayの複製
一方で、aが1次元arrayの場合は以下のような結果になります。
>>> a = np.array([0, 1]) >>> copy_a = a # (1) >>> id(copy_a) == id(a) True >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [1 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = np.array(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) True >>> a = np.array([0, 1]) >>> copy_a = np.array([elem for elem in a]) # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> copy_a[0] = 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [0 1] copy_a = [1 1] >>> id(copy_a[0]) == id(a[0]) Trueaがlistだった場合と異なる点は、
- (2)の方法で複製した場合にcopy_aの成分の値を変えると、aの成分の値も変わる。
- (3)〜(5)の方法では、copy_aの成分の値を変えてもaの成分の値は変わらないが、変えた成分のidは等しい。
の2点です。
2次元listの複製
2次元list aを複製したlist copy_aを作り、aの値を変えずに、copy_aの(0,0)成分の値のみを変えたいとします。1次元listの場合に試した方法の内、効果のあった(2)〜(5)の方法を使いましょう。
>>> a = [[1, 0],[0, 1]] >>> copy_a = a[:] # (2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = list(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = [[1, 0],[0, 1]] >>> copy_a = [elem for elem in a] # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[0, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) Trueこのように、list aが1次元の場合に有効だった(2)〜(5)の方法では、copy_aの(0,0)成分の値のみを変えることは出来ませんでした。更に以下の方法を試してみます。
>>> a = [[1, 0],[0, 1]] >>> copy_a = [elem[:] for elem in a] # (5.2) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [elem.copy() for elem in a] # (5.3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [list(elem) for elem in a] # (5.4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False >>> a = [[1, 0],[0, 1]] >>> copy_a = [[_elem for _elem in elem] for elem in a] # (5.5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) False >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1, 0], [0, 1]] copy_a = [[0, 0], [0, 1]] >>> id(copy_a[0][0]) == id(a[0][0]) False上の結果から、(5)の方法でlistであるaの要素を呼び出し、その要素に対して(2)〜(4)の方法を用いると無事aの値を変えずにcopy_aの(0,0)成分の値のみを変えられることが分かりました。
2次元arrayの複製
2次元listの場合と同様に、2次元array a対しても1次元arrayの場合に効果のあった(3)〜(5)の方法で、copy_aの(0,0)成分の値のみを変えられるか試してみます。
>>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = a.copy() # (3) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) # (4) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array([elem for elem in a]) # (5) >>> id(copy_a) == id(a) False >>> id(copy_a[0]) == id(a[0]) True >>> id(copy_a[0][0]) == id(a[0][0]) True >>> copy_a[0][0] = 0 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 0] [0 1]] >>> id(copy_a[0][0]) == id(a[0][0]) True2次元listの場合には有効でなかった(3)〜(5)の方法ですが、2次元arrayの場合には、aの値を変えずにcopy_aの(0,0)成分の値のみを変えることが出来ました。
実験2
実験2では、0埋めされた配列を作製する幾つかの方法を試しました。
0埋めされたlistの作製
0埋めされた1次元listを作り、第0成分の値を1にする場合、
>>> a = [0 for _ in range(2)] # (1) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a [1, 0] >>> id(a[0]) == id(a[1]) False >>> a = [0]*2 # (2) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a [1, 0] >>> id(a[0]) == id(a[1]) False上のように、方法(1)、(2)のどちらで0埋めされたlist aの第0成分の値のみを1にすることが出来ました。
一方で、0埋めされた2次元listの場合は、
>>> a = [[0 for _ in range(2)] for _ in range(2)] # (1.1) >>> id(a[0]) == id(a[1]) False >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [0, 0]] >>> id(a[0][0]) == id(a[1][0]) False >>> a = [[0]*2 for _ in range(2)] # (1.2) >>> id(a[0]) == id(a[1]) False >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [0, 0]] >>> id(a[0][0]) == id(a[1][0]) False >>> a = [[0]*2]*2 # (2.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a [[1, 0], [1, 0]] >>> id(a[0][0]) == id(a[1][0]) Trueのように演算子
*を2回用いて0埋めされた2次元listを作ると、(0,0)成分の値のみを1にすることが出来ません。0埋めされたarrayの作製
0埋めされた1次元arrayを作り、第0成分の値のみを1に変えるには、方法(1)、(2)で0埋めされた1次元listを作ってarrayに変換する以外に、
np.zeros()を利用する方法があります。>>> a = np.zeros(2, int) >>> id(a[0]) == id(a[1]) True >>> a[0] = 1 >>> a array([1, 0]) >>> id(a[0]) == id(a[1]) True0埋めされた2次元arrayを作る場合も、同様に
np.zeros()を使うことで、(0,0)成分の値のみを1にすることが出来ます。0埋めされた2次元listを作った場合と異なる点は、方法(2.2)を用いても(0,0)成分の値のみを1にすることが出来る点です。>>> a = np.zeros((2, 2), int) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0 for _ in range(2)] for _ in range(2)]) # (1.1) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0]*2 for _ in range(2)]) # (1.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True >>> a = np.array([[0]*2]*2) # (2.2) >>> id(a[0]) == id(a[1]) True >>> id(a[0][0]) == id(a[1][0]) True >>> a[0][0] = 1 >>> a array([[1, 0], [0, 0]]) >>> id(a[0][0]) == id(a[1][0]) True考察
listの複製に関しては、1次元、2次元のいずれにせよ、数値型の値を格納しているlistのidが異なれば複製元の配列の成分の値を変えずに複製した配列の成分を変えることが出来ます。一方でarrayの場合は、複製した配列のidが複製元の配列のidと異なっているだけで、複製した配列の各成分の値のみを変えられるようです。実験1の2次元arrayの実験では、copy_aに格納された数値型の値1つを変える操作をしましたが、例えば、次のように配列を渡してaの各成分の値を変えずに、copy_aの各成分の値のみを変えることが出来ます。
>>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = [0, 1] >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = np.array([0, 1]) >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> a = np.array([[1, 0],[0, 1]]) >>> copy_a = np.array(a) >>> id(a) == id(copy_a) False >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True >>> copy_a[0] = 0, 1 >>> print(f'a = {a}\ncopy_a = {copy_a}') a = [[1 0] [0 1]] copy_a = [[0 1] [0 1]] >>> id(a[0]) == id(copy_a[0]) True >>> id(a[0][0]) == id(copy_a[0][0]) True実験2で0埋めされたarray配列を作った際にも見られましたが、idが等しいのに数値が異なるというarrayの仕様を理解するには、より詳しく調べる必要があります。
実験2の0埋めされたlistを作る実験からは、listに演算子
*を作用させることは、次の操作と等しいという直感が得られるでしょう。# Kは自然数 >>> temp = 0 >>> a = [temp for _ in range(K)] # a = [0]*K >>> temp = [0]*K >>> b = [temp for _ in range(K)] # b = [[0]*K]*Kリンク
- 投稿日:2019-07-10T18:00:41+09:00
Jetson Nano で簡単な画像認識・骨格姿勢検知を動かす基本設定色々デモ
はじめに
株式会社ProsCons (https://proscons.co.jp/) のエンジニアチームです。
弊社では、エッジAIデバイスとして注目されているJetson Nanoを用いて製造業等向けに提供しております。本体価格1万円強と廉価かつ手のひらサイズという極小スケールのデバイスでディープラーニングをも動作させることが可能です。
今回はこのJetson Nanoを容易に環境設定する方法と基本的な画像認識・骨格姿勢検知を動作させる方法を公開いたします。参考動画URL
教師なし異常検知:https://www.youtube.com/watch?v=-NMPNE5-sco&feature=youtu.be
骨格姿勢検知:https://www.youtube.com/watch?v=IVLhe_cjYwE手順
弊社githubより、以下のリポジトリをcloneします。
https://github.com/ProsConsInc/jetson-nano00〜13番までの手順を順番に踏めば、
一通りJetson Nanoが動作する感動を味わえるはずです!始めに補足と注意事項を挙げておきます。
補足:shellスクリプトは失敗したらエラーで落ちるように設定しております。
他に不具合等発生しましたら、想定外の動作となりますので、
弊社githubへ issue を上げて頂けますと幸いです。
注意事項1:電源はmicro USBでは無く、5V 4Aの電源を使用するようにして下さい。
そうでないと、電源供給が不十分になり意図しない電源OFFが起きます。
注意事項2:マイクロSDカードは16GBが最小の構成になりますが、最低でも32GBは欲しいです(the larger the better)。●以下shellスクリプト概要
00_init.sh
gitリポジトリのsubmoduleをcloneします。
thirdpartyディレクトリ配下にダウンロードされます。cmakeのみversionを指定しております。これは、現時点で動作確認が取れているものに固定したいが為です(他のsubmoduleも本来は固定すべきかもしれません)。
01_run_power_up.sh
Jetson Nanoは初めは5Wモードで動作しています。
ですので、10Wで動作するように変更し、ハイパフォーマンスで動作するようにします(Jetson Nanoは 5W/10W をコマンドで簡単に切り替える事が出来る仕様です)。
02_install_swapfile_and_reboot.sh
Jetson Nanoは搭載メモリが LPDDR4 4GBと貧弱な為、スワップ領域を作ってあげる必要があります。再起動しないと有効にならないようですので、スクリプト内でrebootするようにしてあります。
03_install_deps_for_openpose.sh
Jetson Nano向けに色々と依存パッケージを入れてくれて便利なので、openposeの組み込みスクリプトを採用しました。
お茶でも飲みながら、終わるのを待ちます。04_test_pi_camera.sh
Raspberry Pi カメラモジュール v2を繋いであれば、画面にカメラの画像が映るはずです。ここでカメラのエラーが起きる場合は、カメラの接触の不具合を疑う、若しくは電源ケーブルを挿し直す(電源OFF→ON)と映るようになるケースがあります。
Ctrl + c で終了します。05_install_cmake.sh
cmakeをソースからインストールします。ビルドする際にPPAからインストールしたcmakeだとバージョンが低いと怒られるアプリケーションが存在する為です。
お茶受けでも頂きながら、終わるのを待ちます。06_install_tensorflow.sh
公式のJetson Nano対応のTensorFlow v1.13.1をインストールします。
テレビでも見ながら、終わるのを待ちます。07_install_tf_pose.sh
tf-pose-estimationをインストールします。これは骨格・姿勢検知を行うものです。
動画サイトでも見ながら、終わるのを待ちます。08_prepare_for_webcam_and_reboot.sh
カメラの映像をストリームとして受け取る為に必要なので、インストールするものです。ここで機能を有効にする為、再起動させています。
09_build_darknet.sh
darknetをビルドします。主にGPUの力を引き出す為にpatchを当てたりもしています。
まとめサイトでも見ながら、終わるのを待ちます。10_run_darknet.sh
darknetでYOLO v3 Tinyモデルを利用して、Object Detectionを行います。
15FPS 前後になるはずです。Raspberry Pi カメラモジュール v2のフレームレートは21FPS なので、ほぼ性能を出し切っていると言えると思います。
Ctrl + c で終了します。11_build_openpose.sh
お試しとして、本家のopenposeをビルドします。
お酒でも飲みながら、終わるのを待ちます。12_run_openpose.sh
サンプルの動画に対して、openposeによる骨格・姿勢検知を行います。手持ちのMacbookではレンダリングに 66 分ほど掛かりました。
Jetson Nanoでは7、8分で処理が完了し、動画が生成されるはずです。
軽く運動でもしながら、終わるのを待ちます。13_run_tf_pose.sh
tf-pose-estimationを用いて、骨格・姿勢検知を行います。10FPS前後のフレームレートとなることが期待されます。Escで終了します。
※終了する際は必ず Escキー を押して終了させるようにして下さい。理由はTensorFlowがリソースを掴んだ状態になり、カメラモジュールが検出出来なくなったり、メモリ不足に陥ったり、と不具合が起きます。
おわりに
お疲れ様でした。
以上で、このリポジトリの説明を終了します。なお、この環境を整備する際に多くの先人の知恵にお世話になりました。この場を借りて御礼申し上げます。
- 投稿日:2019-07-10T15:50:41+09:00
virtualenvwrapperで仮想環境を作成してからjupyter kernelに追加するまで
目的
virtualenvwrapperを用いて作成した仮想環境をjupyterで利用するために必要な手順をまとめました.
(仮想環境の作成部はvirtualenvやvenvで行っても問題ありません.ただ,ここではvirtualenvwrapperのコマンドのみを記載します.)
(ここではjupyter notebookを扱っていますが,jupyter labなどでも同様の手順でカーネル追加できるはずです.)想定環境
- (何らかの環境に)jupyter (notebook) がインストール済
- virtualenvがインストール済
- virtualenvwrapperがインストール済
手順
仮想環境の作成
root環境のインストール済パッケージを用いる場合
$ mkvirtualenv --system-site-packages --python=python3 hoge_envroot環境のインストール済パッケージを用いない場合
$ mkvirtualenv --no-site-packages --python=python3 hoge_env仮想環境への
ipykernelのインストールもし仮想環境に入っていない場合は,仮想環境に入ります.
$ workon hoge_envその後,
ipykernelをインストールします.(hoge_env) $ pip install ipykerneljupyterへのカーネル追加
(hoge_env) $ ipython kernel install --user --name=hoge_env Installed kernelspec hoge_env in <new kernel path>カーネル追加の確認
カーネルに追加できているか確認する場合,jupyter notebookを立ち上げる環境(自分の場合root環境)でカーネルのリストを確認します.
$ jupyter kernelspec list Available kernels: hoge_env <kernel_dir_path> ...この
<kernel_dir_path>はカーネルの情報が格納されたJupyterによって作成されたディレクトリです.また,正しく想定した仮想環境のカーネルが追加されているかどうか確認するためには,各カーネルのディレクトリ内にある
kernel.jsonを確認します.(kernel_dir_path)/kernel.json{ "argv": [ "<home_path>/.virtualenvs/hoge_env/bin/python3.6", "-m", "ipykernel_launcher", "-f", "{connection_file}" ], "display_name": "hoge_env", "language": "python" }この
"argv"の一行目はkernelの実行に使う環境のpythonのパスを表しており,環境<home_path>/.virtualenvs/hoge_env/がkernelに追加しようとした仮想環境と一致しているかどうか確認してください.
kernel.jsonに記されたpythonのパスの環境が追加したい仮想環境と異なる場合
kernel.jsonに登録されるpythonのパスは,先ほど(hoge_env) $ipython kernel install ...と実行した際にipythonが依存するpythonのパスとなります.
そのため,カーネル登録に用いるipythonが正しく仮想環境にインストールされたipythonであることを確認してください.(hoge_env) $ which ipython # OK: <home_path>/.virtualenvs/hoge_env/bin/ipython # NG: /usr/local/bin/ipythonこのような症状は,新しく仮想環境を作成した際に新たに
ipykernelのインストール(hoge_env) $ pip install ipykernelをし忘れた場合に起こりがちです.
jupyter notebookの起動
jupyterを起動したい環境でjupyter notebookを起動します.
$ jupyter notebook以上の手順で,各notebookから
Kernel -> Change kernelで仮想環境も指定できるようになっているはずです.(番外編)
jupyterからのカーネルの削除
カーネル追加の確認と同じ手順でjupyterに追加されたカーネルのディレクトリ(
<kernel_dir_path)を調べ,そのディレクトリを削除するだけでOKです.作成した仮想環境の削除
一旦
(hoge_env) $ deactivateによって仮想環境から抜けた後,
$ rmvirtualenv hoge_encで仮想環境が保存されたディレクトリを削除します.
- 投稿日:2019-07-10T15:44:19+09:00
リッジ回帰とラッソ回帰の理論と実装を初めから丁寧に
はじめに
- 前回の記事で重回帰分析の導入をしてみたので、今回はその続きということで、2つ同時にやってみたいと思います。
- ベクトルの微分公式については下記のブログが参考になります。
- 個人的な話ですが、統計検定2級に成績優秀者(A)で合格してた様です。機械学習に関しては年始からの未経験スタートでしたが、勉強をしてきた成果が見えてきて素直に嬉しかったです。これからもっと知識を身に付けたい。
参考記事
重回帰分析
リッジ回帰について考える際に、重回帰分析の理解はマストになるのでここでも見ていこうと思います。式変形については、前回の記事で詳しく導入したので少しだけ端折っていきます。
準備
- 説明変数$x_1, x_2, x_3, \cdots, x_m$を$\boldsymbol{x}$($x$のベクトル)とする
- 予測値を$\hat{y}$とする($\hat{y}$はスカラー)
- 回帰係数を$w_1, w_2, w_3, \cdots, w_m$を$\boldsymbol{w}$($w$のベクトル)とする
この時、目的変数は以下の式で表すことができます。$$\hat{y}=w_1x_1 + w_2x_2 + \cdots + w_mx_m$$
この式に切片を加えるのですが、切片については$w_0x_0$と表します。(この線型結合の形で表される関数をアフィン関数と言います。)
$$\hat{y}= w_0x_0 + w_1x_1 + w_2x_2 + \cdots + w_mx_m$$
$$(w_0 ,切片 : x_0=1)$$
ベクトルで表すと以下の通りになります。
\hat{y} = (\begin{array} xx_0&x_1&\cdots&x_m \end{array}) \begin{pmatrix} w_0 \\ w_1 \\ \vdots \\ w_m \\ \end{pmatrix}$$\hat{y} = \boldsymbol{x}^T \boldsymbol{w}$$
$x$ベクトルは一つではありません。多数の教師データから、回帰係数を予測します。よって、$x$横ベクトルをサンプル数だけ縦方向に並べた行列を$X$とします。また、教師データの数だけ予測値も出てくるので、その値を並べたベクトルを$y$ベクトルと定義します。式で表した方が分かりやすいと思います。サンプル数を$n$として式に表してみます。
\begin{pmatrix} y_1 \\ y_2 \\ y_3 \\ y_4 \\ y_5 \\ \vdots \\ y_n \end{pmatrix} = \begin{pmatrix} 1 & x_{11} & \cdots & x_{m1} \\ 1 & x_{12} & \cdots & x_{m2} \\ 1 & x_{13} & \cdots & x_{m3} \\ 1 & x_{14} & \cdots & x_{m4} \\ 1 & x_{15} & \cdots & x_{m5} \\ \vdots & \vdots & \ddots & \vdots \\ 1 & \cdots & \cdots & x_{mn} \end{pmatrix} \begin{pmatrix} w_0 \\ w_1 \\ \vdots \\ w_m \end{pmatrix}$$\boldsymbol{\hat{y}} = X\boldsymbol{w}$$
最小二乗法
予測値$\hat{y}$と実際の$y$に隔離が無いように、重み$w$を求めて行きますが、重回帰分析では最小二乗法を使います。以下の通りに表される損失関数$L$を最小化させる様にパラメータを決定します。
$$L=\sum_{i=1}^{n}(y_i - \hat{y_i})^2$$
$y_i - \hat{y_i}$ については、 $\hat{y}$ベクトルと $y$ベクトルの成分同士の引き算と見ることができると思います。また、上式はベクトルの内積、若しくはL2ノルムの二乗で表すことが出来ます。(\begin{array} yy_1 - \hat{y_1}&y_2 - \hat{y_2} &\cdots&y_n - \hat{y_n} \end{array}) \begin{pmatrix} y_1 - \hat{y_1} \\ y_2 - \hat{y_2} \\ \vdots \\ y_n - \hat{y_n} \end{pmatrix}$$ (\boldsymbol{y} - \boldsymbol{\hat{y}})^T(\boldsymbol{y} - \boldsymbol{\hat{y}})$$
$$ ||\boldsymbol{y} - \boldsymbol{\hat{y}}||^2 $$上記の式と先ほどの⑴式から以下の通りに損失関数を導くことができます
$$ L = (\boldsymbol{y} - X\boldsymbol{w})^T (\boldsymbol{y} - X\boldsymbol{w})$$
$$ L = (\boldsymbol{y}^T - \boldsymbol{w}^T X^T)(\boldsymbol{y} - X\boldsymbol{w})$$
$$ L = \boldsymbol{w} ^T X^T X \boldsymbol{w} - \boldsymbol{w} ^T X^T \boldsymbol{y} - \boldsymbol{y}^T X \boldsymbol{w} + \boldsymbol{y}^T \boldsymbol{y} $$
ここで第2項と第3項は同値であり、以下の通りに式変形することが可能です。(理由;2項と3項は転置の関係にあり、更に両方ともスカラーであることから、同値である事が分かる)
$$ L = \boldsymbol{w} ^T X^T X \boldsymbol{w} - 2\boldsymbol{y}^T X \boldsymbol{w} + \boldsymbol{y}^T \boldsymbol{y} $$
この式を$\boldsymbol{w}$の各成分で偏微分し、一次導関数が0ベクトルとなる$w$を求めます。
$$ \frac{\partial L}{\partial \boldsymbol{w}} = 2X^T X \boldsymbol{w} - 2X^T \boldsymbol{y} + O \cdots (1)$$
$\frac{\partial L}{\partial \boldsymbol{w}} = O$とすると
$$ 2X^T X \boldsymbol{w} = 2X^T \boldsymbol{y}$$
今、$X^T X$は正方行列であり逆行列が存在するため
$$ \boldsymbol{w} = (X^T X)^{-1} X^T \boldsymbol{y} $$
これで求めるべき$\boldsymbol{w}$が分かりました。尚、$X^T X$に逆行列が存在しない場合、上式の解は定まりません。これが言わゆる多重共線性問題に繋がってきます。
リッジ回帰
正則化項
重回帰分析の損失関数に正則化項を加えたものがリッジ回帰、及びラッソ回帰になります。
$$ L = (\boldsymbol{y} - X\boldsymbol{w})^T (\boldsymbol{y} - X\boldsymbol{w}) + \alpha|| \boldsymbol{w} ||_{2}^2\cdots (2)$$
(2)式はリッジ回帰の式になるのですが、右に出てきているのが正則化項となります。尚、リッジ回帰ではL2ノルムの二乗、ラッソ回帰ではL1ノルムを正則化項として使います。リッジ回帰では正則化項を加えることで、パラメータ$\boldsymbol{w}$の各成分を全体的に滑らかにする事ができます。(ノルムをなるべく小さくしようとするので)
因みに、$\alpha$はハイパーパラメータとなり、自由に決めてよい値になります。値が大きほど正則化項の影響が大きくなりますので、モデルの精度を見ながら変えていきます。
〜L2ノルムとL1ノルム〜
- L2ノルム...いわゆるユークリッド距離と呼ばれるもので、ベクトル成分同士の差の二乗和の平方根になります。
- L1ノルム...マンハッタン距離と呼ばれます。ベクトル成分同士の差の絶対値の和になります。上記(2)式の正則化項は$\alpha\boldsymbol{w}^T\boldsymbol{w}$と表されることが分かります。先ほどの重回帰分析を参考にして微分していくと最終的に以下の通りになります。
$$ \frac{\partial L}{\partial \boldsymbol{w}} = 2X^T X \boldsymbol{w} - 2X^T \boldsymbol{y} + O + 2\alpha\boldsymbol{w}$$これが0ベクトルとなるようなパラメータ$\boldsymbol{w}$は結局
$$ \boldsymbol{w} = (X^T X + \alpha I)^{-1} X^T \boldsymbol{y} $$
となります。(Eは単位行列)リッジ回帰の実装
前回の重回帰分析でも実装をしてみましたが、今回の同じようにリッジ回帰を実装してみます。使うデータセットはscikit-learnのボストンハウジング、環境はJupyterNotebookです。まずは普通にscikit-learnで
from sklearn.linear_model import LinearRegression, Ridge from sklearn.datasets import load_boston import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from sklearn.preprocessing import StandardScaler %matplotlib inline sns.set() boston = load_boston() X, y = boston.data, boston.target X = StandardScaler().fit_transform(X) clf1 = LinearRegression().fit(X, y) clf2 = Ridge(alpha=10).fit(X, y) clf3 = Ridge(alpha=100).fit(X, y) plt.figure(figsize=(18, 10)) plt.plot(clf1.coef_, label='alpha=0', color='r', linestyle=':') plt.plot(clf2.coef_, label='alpha=10', color='g', linestyle='-.') plt.plot(clf3.coef_, label='alpha=100', color='b', linestyle='--') plt.xlabel('Features') plt.ylabel('Coefficient') plt.legend();
次に、scikit-learnを使わずに書いてみます。
class Ridge2: def __init__(self, alpha=1): self.w_ = None self.alpha = alpha def fit(self, X, y): X = np.insert(X, 0, 1, axis=1) I = np.eye(X.shape[1]) self.w_ = np.linalg.inv(X.T @ X + self.alpha*I) @ X.T @ y def predict(self, X): X = np.insert(X, 0, 1, axis=1) return X @ self.w_ clf4 = Ridge2(alpha=10) clf4.fit(X, y) coef_df = pd.DataFrame({'clf2': clf2.coef_, 'clf4': clf4.w_[1:]}, index=boston.feature_names) coef_df
scikit-learnの結果と一致している事が分かります。
ラッソ回帰
数値最適化
ラッソ回帰ではその損失関数を以下の通りに定義します。
$$ L = \frac{1}{2}(\boldsymbol{y} - X\boldsymbol{w})^T (\boldsymbol{y} - X\boldsymbol{w}) + \alpha|| \boldsymbol{w} ||_{1}\cdots (3) $$
L1ノルムはその定義からも分かる通り、絶対値が出てきており、L2ノルムのように一気にベクトルで微分してその最適解を求めるという処理が出来ません。左微分と右微分を駆使して最適化を行っていくのですが、重回帰やリッジよりも少し難しいです。
ラッソ回帰の最適化アルゴリズムはいくつか種類があるらしいのですが、自分はCD(Coordinate Descent;座標降下法)と言う手法しか勉強していないので、こちらの手法で手順を追っていきたいと思います。
座標降下法は名前の割に単純なアイデアです。まず$\boldsymbol{w}$の初期値を決めます。そこからまず$ \frac{\partial L}{\partial w_1} = 0 $となる様な$w_1$を求めます。次に$\frac{\partial L}{\partial w_2} = 0$となる$w_2$を求めます。この操作を全ての$w_d$で行い少しずつ$L$の最小化を目指していく形になります。全ての変数を同時に動かして$\frac{\partial L}{\partial \boldsymbol{w}} = 0$となる様な変数を求める事が難しいので、一つずつ攻めて行って、近似解を求めようと行った手法です。
損失関数の式変形
損失関数を微分していくのですが、ここで気をつけるべきこととして、$w_0$の切片項だけ正則化項が働かないと言う条件が挙げられます。つまり上の(3)式は$w_1$ 〜 $w_d$までにしか適用されず、$w_0$に関しては、正則化項を無視して良い形になります。なので$w_0$から式変形をしていきたいと思います。
他サイトでは式変形を省略して導出していますが、なるべく丁寧にやっていこうとして行ったら、すごく長くなりました。。。
取り敢えず重回帰分析で導出した(1)から始めて行きたいと思います。$$ \frac{\partial L}{\partial \boldsymbol{w}} = 2X^T X \boldsymbol{w} - 2X^T \boldsymbol{y} + O \cdots (1)$$
ラッソでは損失関数に1/2が掛けられているためこの式は以下の通りに変形されます。
$$ \frac{\partial L}{\partial \boldsymbol{w}} = X^T X \boldsymbol{w} - X^T \boldsymbol{y}$$
= \begin{pmatrix} 1 & x_{11} & \cdots & x_{1j} \\ 1 & x_{21} & \cdots & x_{2j} \\ 1 & x_{31} & \cdots & x_{3j} \\ \vdots & \vdots & \ddots & \vdots \\ 1 & x_{i1} & \cdots & x_{ij} \end{pmatrix}^T \left[ \begin{pmatrix} 1 & x_{11} & \cdots & x_{1j} \\ 1 & x_{21} & \cdots & x_{2j} \\ 1 & x_{31} & \cdots & x_{3j} \\ \vdots & \vdots & \ddots & \vdots \\ 1 & x_{i1} & \cdots & x_{ij} \end{pmatrix} \begin{pmatrix} w_0 \\ w_1 \\ \vdots \\ w_j \end{pmatrix} - \begin{pmatrix} y_1 \\ y_2 \\ y_3 \\ \vdots \\ y_i \end{pmatrix} \right]= \begin{pmatrix} 1 & 1 & \cdots & 1 \\ \cdots & \cdots & \cdots & \cdots \\ \cdots & \cdots & \cdots & \cdots \\ \vdots & \vdots & \ddots & \vdots \\ \cdots & \cdots & \cdots & \cdots \end{pmatrix} \left[ \begin{pmatrix} 1 & x_{11} & \cdots & x_{1j} \\ 1 & x_{21} & \cdots & x_{2j} \\ 1 & x_{31} & \cdots & x_{3j} \\ \vdots & \vdots & \ddots & \vdots \\ 1 & x_{i1} & \cdots & x_{ij} \end{pmatrix} \begin{pmatrix} w_0 \\ w_1 \\ \vdots \\ w_j \end{pmatrix} - \begin{pmatrix} y_1 \\ y_2 \\ y_3 \\ \vdots \\ y_i \end{pmatrix} \right]= \begin{pmatrix} 1 & 1 & \cdots & 1 \\ \cdots & \cdots & \cdots & \cdots \\ \cdots & \cdots & \cdots & \cdots \\ \vdots & \vdots & \ddots & \vdots \\ \cdots & \cdots & \cdots & \cdots \end{pmatrix} \left[ \begin{pmatrix} w_0 + w_1x_{11} + \cdots \\ \cdots \\ \cdots \\ \cdots \\ \cdots \end{pmatrix} - \begin{pmatrix} y_1 \\ y_2 \\ y_3 \\ \vdots \\ y_i \end{pmatrix} \right]いい感じで、左項の1行目が全て1になってくれます。よって$w_0$で微分した結果($ = \frac{\partial L}{\partial \boldsymbol{w}}$ベクトルの第一成分)に関しては、右のベクトルで出てきた成分の単純な和になる事が分かります。よって以下の通りになる事が分かります。
$$
\frac{\partial L}{\partial w_0} = \sum^n_{i=1}\left(w_0 + \sum^d_{j=1}x_{ij}w_{j} - y_i \right) \cdots (4)
$$$n$は全データの数(つまり$i$の最後の数)、$d$はデータの次元数(つまり$j$の最後の数)になります。
(↑本当はこのルールに沿って考えた場合、上の長い行列にも$n$と$d$を書かなくてはいけませんが、見えにくいので、敢えて文字を減らしています。)
この式を$=0$として、$w_0$以外の文字を移行すると以下の様になります。
$$
w_0 = \frac{1}{n} \sum^n_{i=1} \left(y_i - \sum^d_{j=1}x_{ij}x_{j} \right)
$$次に$w_0$以外で微分していきますが、こちらは正則化項が出てくるので、右側微分と左側微分を考えていかなければなりません。正則化項の微分に関しては以下の写真を参考にしてください。
正の方向と負の方向、どちらから極限を取るかによって、結果が違ってくる事、更に0でその微分が定義できないことに気をつけます。以上の点と、(4)を参考に$w_k$について、右微分と左微分を求めると(表記が誤っている可能性あります。)
$$
\frac{\partial^+ L}{\partial w_k} = \sum^n_{i=1} \left(w_0 + \sum^d_{j=1}x_{ij}w_{j} - y_i \right)x_{ik} + \alpha \cdots (5.1)
$$$$
\frac{\partial^- L}{\partial w_k} = \sum^n_{i=1} \left(w_0 + \sum^d_{j=1}x_{ij}w_{j} - y_i \right)x_{ik} - \alpha \cdots (5.2)
$$先程の$w_0$と違い、積を取るべき$X^T$の行が全て1ではないので、$x_{ik}$の変数が式に出てきています。
更にこの式を$=0$として、$w_k$以外の文字を移行すると以下の様になります。
$$
w_k^+ = \frac{\displaystyle\sum^n_{i=1} \left(y_i - w_0- \sum^d_{j=1(j≠k)}x_{ij}w_{j} \right)x_{ik} - \alpha}
{\displaystyle\sum^n_{i=1}x_{ik}^2}
\cdots (6.1)
$$$$
w_k^- = \frac{\displaystyle\sum^n_{i=1} \left(y_i - w_0- \sum^d_{j=1(j≠k)}x_{ij}w_{j} \right)x_{ik} + \alpha}
{\displaystyle\sum^n_{i=1}x_{ik}^2}
\cdots (6.2)
$$$(j≠k)$の記号ですが、$w_k$は左項に移行しているので、それ以外の$w$を足していくと言う意味です。ブログとは関係ないですが、Latexの練習になりました。。。
ここで、再確認ですが(6.1)は$w_k$が正の値の場合における、$w_k$の更新後の値になります。ところが、下記の条件に当てはまる場合、$w_k$は正にならない事がわかると思います。
$$ \displaystyle\sum^n_{i=1} \left(y_i - w_0- \sum^d_{j=1(j≠k)}x_{ij}w_{j} \right)x_{ik} < \alpha $$
つまり通常の重回帰分析で$w_k$の値が正になる様な場合でも、上式の条件に入ってしまった場合、$w_k$は更新できなくなってしまいます。その場合、$w_k$は初期値0のまま更新されません。負の場合も同様です。まとめると以下の様な形になります。
【条件1】
$ \displaystyle\sum^n_{i=1} \left(y_i - w_0- \sum^d_{j=1(j≠k)}x_{ij}w_{j} \right)x_{ik} > \alpha $の場合、
$w_k^+ = \frac{\displaystyle\sum^n_{i=1} \left(y_i - w_0- \sum^d_{j=1(j≠k)}x_{ij}w_{j} \right)x_{ik} - \alpha}
{\displaystyle\sum^n_{i=1}x_{ik}^2}
\cdots(6.1)$
【条件2】
$ -\alpha < \displaystyle\sum^n_{i=1} \left(y_i - w_0- \sum^d_{j=1(j≠k)}x_{ij}w_{j} \right)x_{ik} < \alpha $の場合、
$w_k = 0$
【条件3】
$ \displaystyle\sum^n_{i=1} \left(y_i - w_0- \sum^d_{j=1(j≠k)}x_{ij}w_{j} \right)x_{ik} < -\alpha $の場合、
$
w_k^- = \frac{\displaystyle\sum^n_{i=1} \left(y_i - w_0- \sum^d_{j=1(j≠k)}x_{ij}w_{j} \right)x_{ik} + \alpha}
{\displaystyle\sum^n_{i=1}x_{ik}^2}
\cdots (6.2)
$
以上が$w_k$の更新後の値となります。以上の事からも分かりますが、L1ノルムを正則化項として加えた場合、パラメータ$\boldsymbol{w}$の多くが0になってしまう事が分かると思います。これがいわゆる『スパースな解』になります。
scikit-learnでの実装
先程のボストンハウジングでラッソ回帰の挙動を確認してみようと思います。
clf5 = Lasso(alpha=1).fit(X, y) plt.figure(figsize=(18, 10)) plt.plot(clf1.coef_, label='LinearRegression', color='r', linestyle=':') plt.plot(clf5.coef_, label='Lasso alpha=1', color='g', linestyle='-.') plt.plot(clf3.coef_, label='Ridge alpha=100', color='b', linestyle='--') plt.xlabel('Features', fontsize=30) plt.ylabel('Coefficient', fontsize=30) plt.legend();
通常の重回帰分析やリッジ回帰と比較すると各特徴量における回帰係数が0になっている事が確認できます。よりシンプルで分かりやすいモデルとも言えます。
終わりに
今回、ブログを通してイマイチ理解できてなかった部分を少しだけクリアにできた。(まだ分かってない部分も多いですが・・・)
L1、L2ノルムによる正則化はリッジやラッソに関わらず頻出なので、勉強してよかった。
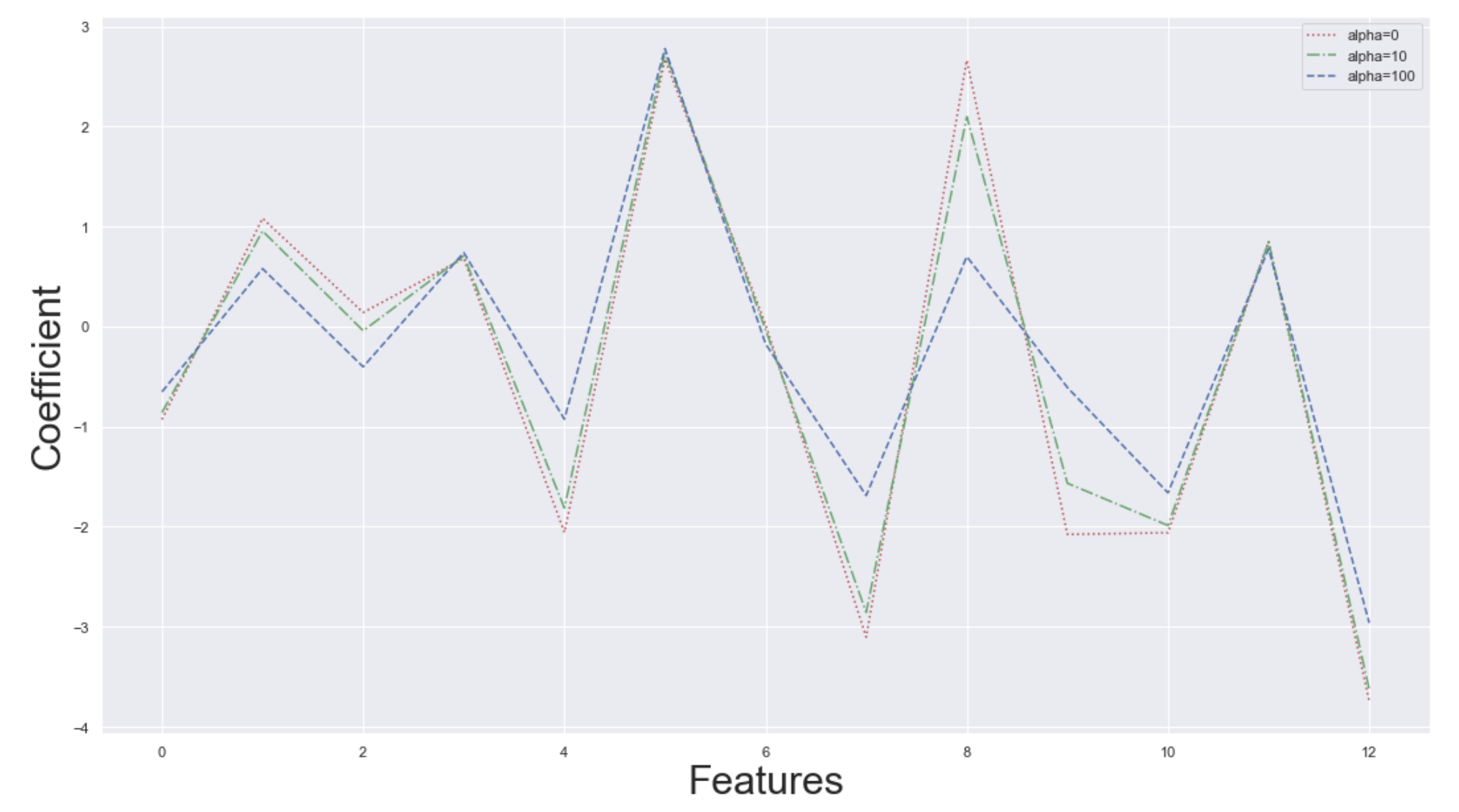

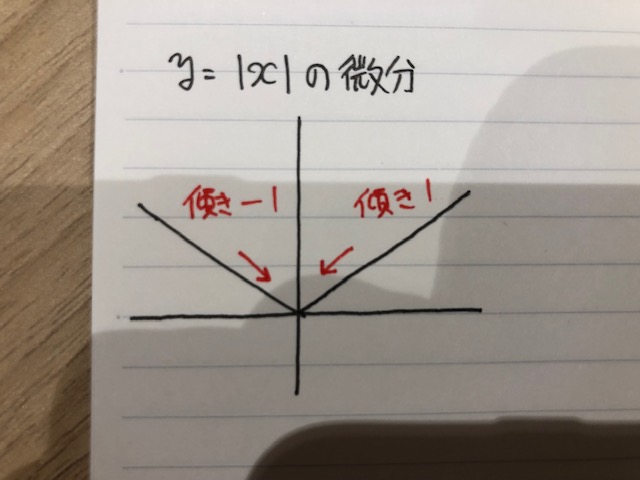
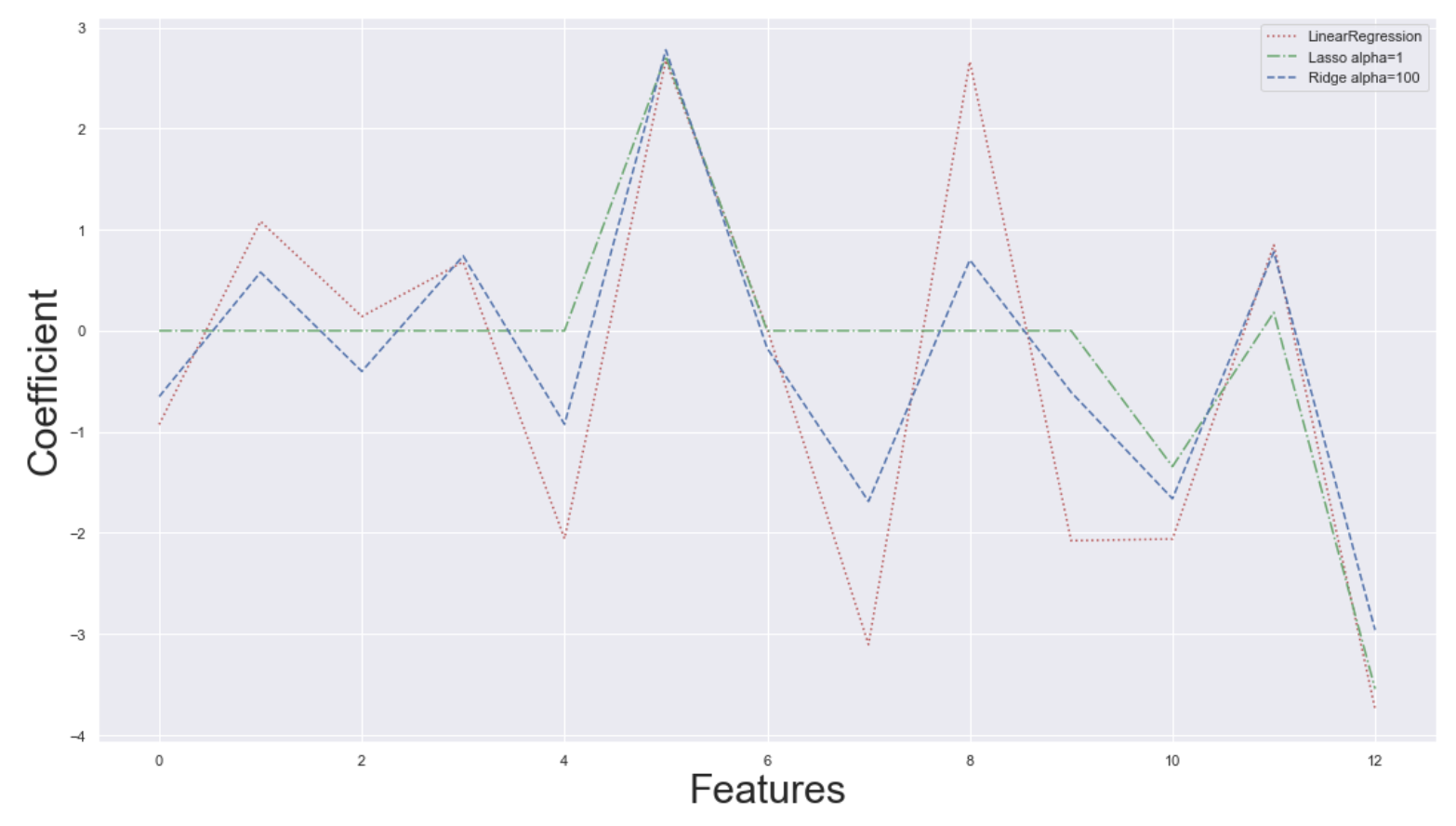
- 投稿日:2019-07-10T14:03:40+09:00
Pythonによるlistの数値⇄文字列変換,組み合わせ,順列 競技プログラミング用
タイトル通りです。
ただの備忘録なので、内容が飛び飛びだぉ。
競技プログラミングをやるときに使ったりすると便利って事で残しておく。数値 ⇄ 文字列 変換
その前に、この2つの型の判定をする関数を作成。
手法として、要素の一番最初を取り出し、それによってintかstrに分けるという処理としている。
get_dataはlist型である。def judge(get_data): if isinstance(get_data[0], int): return True elif isinstance(get_data[0], str): return Falseまぁこんな感じで実装できますかね。
んで、次に実際の変換の処理。def is_change(get_data): # intならTrue,strならFalseとする res = judge(get_data) # res == Trueと同じ,int→str変換 if res: s_data = [str(i) for i in get_data] return s_data # res == Falseと同じ,str→int変換 elif not res: i_data = [int(i) for i in get_data] print('strを通ったよ') return i_dataって感じ。書き方はお好みでどうぞ。2つの型判定しかしない場合だとif-elseで分岐した方がいいね、うん。
型を少し増やしたいとき用にそうしたかったんだ。。。
まぁ、ならなぜboolで管理してるのかって話だけど、ただの忘備録なので御愛嬌。上二つの処理をまとめた関数も書いておく~
# 返り値はlist型 def is_change2(get_data): # intならTrue,strならFalseとする res = false if isinstance(get_data[0], int): res = True elif isinstance(get_data[0], str): res = False # int→str変換 if res: s_data = [str(i) for i in get_data] return s_data # str→int変換 elif not res: i_data = [int(i) for i in get_data] print('strを通ったよ') return i_dataまぁ、態々二つにわけるまでもなかったね。
ただ、分けた方がis_changeが見やすくなるからってだけ。
拡張して、全部の型どれでも対応させるのなら意味あったけど。
まぁ忘備録で見て思い出せればいいから。。。
って言い訳。
気が向いたらjudgeも拡張しておく。部分集合の求め方
['a', 'b', 'c']からなる集合を考える。これは2の3乗で8通りの部分集合を持つ。
3bitで表せるだとか、難しい話は他の詳しい方の記事を参考にして頂きたい。
https://docs.python.org/ja/3/library/itertools.html
より、combinations('ABCD', 2) --> AB AC AD BC BD CD combinations(range(4), 3) --> 012 013 023 123のような使い方がされる。
なお、これをそのままコピーして動かないとか言われても困るので、一応書いておく...hoge = combinations('ABCD',2) hogehoge = conbinarions(range(4),3)後はこれをfor文なりで展開してくれ。
今回は、任意の桁で全ての部分集合を取得したいので、for文で回してあげる。
外側のループは、回す回数である。
combinations(任意のリスト,何文字から構成されているか)というようになっている。
ここで、空集合から、全てを含んだ部分集合と、全ての集合が必要だとすると、要素数ga
3の場合、0~3まで回してあげる必要がある。よって、+1としてあげることで、全ての部分集合を取得できる。
内側のループは、要素数の選択である。from itertools import combinations def length(items): get_pettern = [] for i in range(len(items) + 1): for j in combinations(items, i): get_pettern.append(j) return get_pettern以上で、全ての組み合わせ(部分集合を求めることができた。)
ちなみに、
python3
combinations_with_replacement('ABC', 2) --> AA AB AC BB BC CC
のようにすることで、重複を許して選ぶこともできる。
これは、カードを戻してから引き直す。数学の重複を許す組み合わせってことですね、
ちなみに、重複を許さない組み合わせは、くじ引きなどをして、箱に戻さない場合に利用できそうですね♩んで、次に今度は順列を求めてみる
まずは重複無しのパターンdef permutation(items): pattern = [] for i in range(len(items)): for j in itertools.permutations(items, i): pattern.append(j) return pattern説明は面倒なので端折ります。
まぁ上の組み合わせの説明と変わらないからね。次に重複ありパターン
pattern = [] for i in range(len(items)): for j in itertools.product(items, repeat=i): pattern.append(j) return patternはい、これが重複あり順列。
以上をまとめて僕はこうやって実装した# 順列を返す関数 0と1により,重複ありと重複無しを選ぶ、0なら重複無し # 欲しい方に応じてselectに数値を投げ入れる def permutation(select, items): if select == 0: pattern = [] for i in range(len(items)): for j in itertools.permutations(items, i): pattern.append(j) return pattern elif select == 1: pattern = [] for i in range(len(items)): for j in itertools.product(items, repeat=i): pattern.append(j) return pattern # 組み合わせを返す関数 selectが0なら重複無し def combination(select, items): if select == 0: pattern = [] for i in range(len(items)): for j in itertools.combinations(items, i): pattern.append(j) return pattern else: pattern = [] for i in range(len(items)): for j in combinations_with_replacement(items, i): pattern.append(j) return patternって感じです。長くなったなぁ。
もし使いたいという人が居たなら勝手に使ってどうぞ〜
以上!
- 投稿日:2019-07-10T12:38:31+09:00
[UE4]Pythonによるインスタンシング
GTMF2019にてPython / BlueprintによるUnreal Engineの自動化という内容で講演いたしました。
本記事はその中で紹介した実装例、Pythonによるインスタンシングのサンプル公開用記事です。発表内容については以下のスライドをご覧ください。
[GTMF2019] Python / BlueprintによるUnreal Engineの自動化
https://www.slideshare.net/EpicGamesJapan/gtmf2019-python-blueprintunreal-engine/1Unreal EngineではInstanced Static Meshを使うことでインスタンスを作成することができます。
Merge Actorsというツールを使うことで選択アクタを一気にインスタンス化することもできますが、いずれにしても大量のアクタをグループ分けしつつインスタンス化していくのは非常に手間です。そこで、Pythonの外部ライブラリに含まれるK-meansを使ってクラスタリング&インスタンシングをしてみました。
事前準備
Python側
Python2.7が入っていない場合は公式サイトからダウンロード、インストールしておいてください。
インストール時、Add python.exe to Pathを有効にしておきます。
Python外部ライブラリのインストールはコマンドプロンプトでpipを使って行います。
ややこしいですが、まずはそのpipをインストールします。コマンドプロンプトを起動して"python -m pip install pyinstaller"と入力
色々ログが流れてインストールされたようなメッセージが出ればOKです。
これで外部ライブラリをインストールする準備ができたので、今度は以下のように入力してscikit learnをインストールします。
"python -m pip install scikit-learn"
インストールされたライブラリはC:\Python2.7\lib\site-packagesに入ります。
同じ階層がEngine\Binaries\ThirdParty\Python\Win64\Lib内にもあるので、site-packagesフォルダを丸ごとコピーしてください。
これで、Unreal Pythonで外部ライブラリを使えるようになります。Unreal Engine側
検証バージョンはUE4.22です。
Python Editor Script Pluginを有効にしておく必要があります。
次にインスタンスとして使うアクタを用意しておきます。
Blueprintを新規作成。
Actorクラスを親にします。
名前はとりあえずBP_Instanceにしてください。
作成したらBlueprintを開いて、Add ComponentからInstanced Static Meshを追加しておきます。
K-meansによるインスタンシング
こちらが実際に動作している結果になります。
コードはこちら
qiita.pyimport unreal import numpy as np import sklearn from sklearn.cluster import KMeans #用意したインスタンス用Blueprintクラスをロード bp_instance = unreal.EditorAssetLibrary.load_blueprint_class('/Game/BP_Instance.BP_Instance') #選択したStatic Mesh Actorを取得 list_actors = unreal.EditorLevelLibrary.get_selected_level_actors() list_static_mesh_actors = unreal.EditorFilterLibrary.by_class(list_actors,unreal.StaticMeshActor) list_unique = np.array([]) #選択したアクタに含まれるStatic Meshの種類を調べる for lsm in list_static_mesh_actors: static_mesh = lsm.get_component_by_class(unreal.StaticMeshComponent).get_editor_property("StaticMesh") list_unique = np.append(list_unique,static_mesh) list_unique = np.unique(list_unique) for lu in list_unique: list_transform = np.array([]) list_locations = np.array([[0,0,0]]) #クラスタリング用の位置情報と、インスタンスに追加するトランスフォームの配列を作成 for lsm in list_static_mesh_actors: if lsm.get_component_by_class(unreal.StaticMeshComponent).get_editor_property("StaticMesh") == lu: list_transform = np.append(list_transform,lsm.get_actor_transform()) location = np.array([[lsm.get_actor_location().x,lsm.get_actor_location().y,lsm.get_actor_location().z]]) list_locations = np.append(list_locations,location,axis=0) list_locations = np.delete(list_locations,0,axis=0) #クラスタ数を指定 num_clusters = 5 #位置情報を元にクラスタリング pred = KMeans(n_clusters=num_clusters).fit_predict(list_locations) instanced_components = np.array([]) #インスタンス用アクタをスポーン for i in range(num_clusters): instanced_actor = unreal.EditorLevelLibrary.spawn_actor_from_class(bp_instance,(0,0,0),(0,0,0)) instanced_component = instanced_actor.get_component_by_class(unreal.InstancedStaticMeshComponent) instanced_components = np.append(instanced_components,instanced_component) #クラスタ番号を元にインスタンスを追加 for j, pd in enumerate(pred): instanced_components[pd].add_instance(list_transform[j]) #インスタンスにStatic Meshを割り当て for k in range(num_clusters): instanced_components[k].set_editor_property("StaticMesh",lu) #最初に選択したアクタを削除 for lsm in list_static_mesh_actors: lsm.destroy_actor()※Scikit-learnライブラリがインストールされていない場合は動作しません。
※実行時にnum_clusters以上の数のアクタを選択していないと動作しません。6行目、load_blueprint_class('/Game/BP_Instance.BP_Instance')の()内には事前準備したBlueprintのパスを入れます。
qiita.pybp_instance = unreal.EditorAssetLibrary.load_blueprint_class('/Game/BP_Instance.BP_Instance')アセット右クリックからCopy Referenceでコピーして貼り付けてください。
インスタンスを個別のStatic Meshに変換
一度インスタンス化してしまうと再調整ができないので、インスタンスからバラバラな状態に戻すスクリプトも作ってみました。
コードはこちら。
qiita.pyimport unreal import numpy as np #選択したアクタを取得 selected_actors = unreal.EditorLevelLibrary.get_selected_level_actors() #インスタンスコンポーネントを取得 for sa in selected_actors: instanced_components = np.array([]) instanced_component = sa.get_components_by_class(unreal.InstancedStaticMeshComponent) instanced_components = np.append(instanced_components,instanced_component) #コンポーネントに含まれるインスタンス数を取得 for ic in instanced_components: instance_transform = np.array([]) instance_count = ic.get_instance_count() #インスタンスの数分Static Mesh Actorをスポーンし、トランスフォーム割り当て、Static Mesh割り当てを繰り返す for j in range(instance_count): instance_transform = np.append(instance_transform,ic.get_instance_transform(j,1)) spawned_actor = unreal.EditorLevelLibrary.spawn_actor_from_class(unreal.StaticMeshActor,(0,0,0),(0,0,0)) spawned_actor.set_actor_transform(instance_transform[j],0,0) smc = spawned_actor.get_component_by_class(unreal.StaticMeshComponent) smc.set_editor_property("StaticMesh",ic.get_editor_property("StaticMesh")) #最初に選択していたアクタを削除 for sa in selected_actors: sa.destroy_actor()※大量のインスタンスが含まれる場合、処理時間がかなり長くなる場合があります。
こちらのスクリプトはフォリッジに対しても実行可能です。
参考
Python を使用したエディタのスクリプティング
https://api.unrealengine.com/JPN/Engine/Editor/ScriptingAndAutomation/Python/index.htmlUnreal Python API Documentation
https://api.unrealengine.com/INT/PythonAPI/


- 投稿日:2019-07-10T12:23:35+09:00
社内勉強会 機械学習入門(2.「Jupyter Notebook」を使ってみよう)
新規にNotebookを作る
右のほうにある[New]をクリックし、Python3を選びます。
簡単なコードを書いてみる
グラフ表示するコードを書いてみる
新しくセルを挿入してみましょう。
新しいセルに以下のコードを書いて、Runしてみましょう。
グラフを表示するコードimport numpy as np import matplotlib.pyplot as plt x = np.arange(0, 10, 0.1) y = np.sin(x) plt.plot(x,y) plt.show()最初は以下のようなエラーになると思います。
これは、仮想環境に「numpy」と「matplotlib」のライブラリがインストールされていないからです。
- ライブラリをインストールしてみよう。
「Jupyter Notebook」上でライブラリをインストールする場合は、次のように「!」を先頭に付けてください。
!pip install numpyインストールが成功すると以下のように表示されます。
同じように「matplotlib」もインストールしてください。(こっちは、ちょっと時間が掛かります。)
!pip install matplotlib※もちろん、コマンドプロンプトからライブラリをインストールしてもOKです。(「!」はいらないので注意)
- ライブラリのインストールが成功したら、もう一度グラフ表示のコードを実行してみよう。
以下のようなグラフが表示されたらOKです。
- 【補足】今回インストールしたライブラリについて
ライブラリ 読み方 説明 numpy ナムパイ 学術計算をするためのライブラリ。ベクトルや行列など、機械学習で必要となる形式のデータを簡単に扱うことができる。 matplotlib マットプロットリブ グラフ描写ライブラリ。折れ線グラフ、ヒストグラムなど、様々なグラフを簡単に描写することできる。

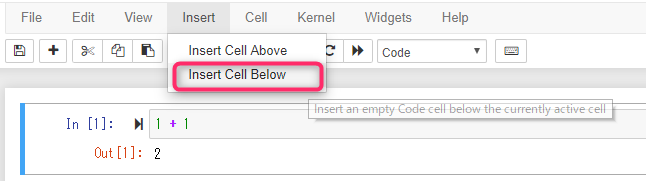
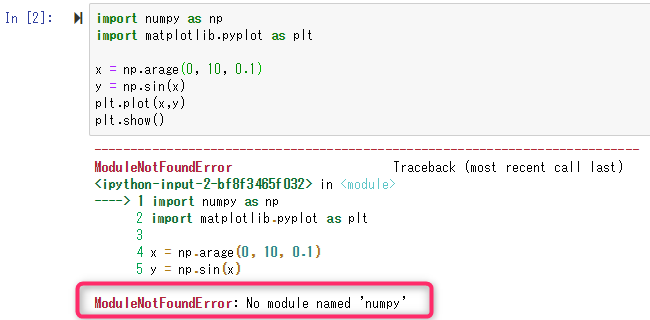


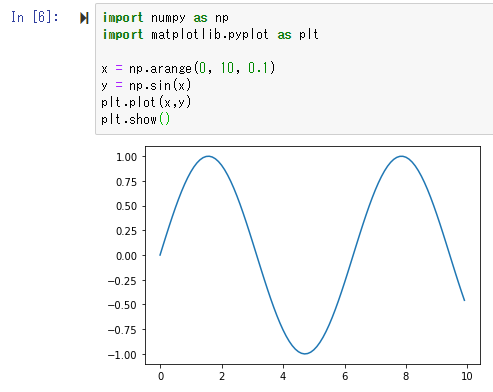
- 投稿日:2019-07-10T12:03:02+09:00
Visual Studio Code Remote - WSL extensionの導入
はじめに
この記事はVisual Studio Codeの拡張機能"Visual Studio Remote- WSL extension"を導入した際のメモです.
Visual Studio Remote - WSL extension
Windows上で走らせているVisual Studio Codeから,Windows Subsystem for Linux (WSL)を使うことができるようになる拡張機能です.詳細については下記をご参照ください.
https://code.visualstudio.com/docs/remote/wsl実施環境
OS:
- Name: Microsoft Windows 10 Pro
- Version: 10.0.17763 build 17763WSL:
- Distribution ID: Ubuntu
- Description: Ubuntu 18.04.2 LTS
- Release: 18.04
- Codename: bionicWSLの導入や環境の整備
WSLはすでに導入しています.さらに,WSL上にAnacondaを導入して,自然言語処理の環境を構築(juman, juman++, KNP, pyknp)しています.詳細は過去記事をご参照ください.
https://qiita.com/mocha-N/items/aa397a5bfec758cfebd0動機など
これまでpythonを使った処理は,Windowsマシンに直接導入したpython (Anaconda)と,WSL上に導入したpythonを状況に応じて使い分けていました.しかし,いちいち使い分けるのに煩わしさを感じておりました.最近,ラップトップを新調したのを機に,python系の処理はすべてWSL上で行うことにしました.さらに,pythonを含めたWSL上の処理もWindows側で行っている処理もひとつの開発環境(Visual Studio Code)で行いたかったため,Visual Studio Code Remote - WSL extensionを導入しました.
導入の方法と経緯
以下のステップで導入しました.基本的には公式で紹介されている方法です.
- Remote - WSL extensionのインストール
- プロジェクトフォルダを開いて初期設定
- コードの実行
WSLやVisual Studio Codeのインストール,Remote - WSLの導入はすでに行っていますので省略します.詳細は公式ホームページや過去記事をご覧ください.
Remote - WSL extensionのインストール
公式ホームページの通りです.
https://code.visualstudio.com/docs/remote/wsl#_getting-started私の環境では,VS Codeを起動した直後のWelcomeページ(Help -> Welcome)で,Customizeの欄をクリック→左側に現れる検索バーに「Remote - wsl」と入力し,インストールしました.
お試しなので.gitattributesの設定は行っていません.
プロジェクトフォルダを開いて初期設定を行う
こちらも公式ホームページの通りです.
https://code.visualstudio.com/docs/remote/wsl#_getting-started
code .を実行して新しいウィンドウが立ち上がり,しばらくすると使えるようになります.ウィンドウ左下の角に「WSL」というインジケーターが表示されるはずです.
なお,pythonのコードを開いた場合,python extensionの導入もおすすめされます.ついでに導入しておきました.pythonコードの実行
terminalを立ち上げて(ctrl + @),コードの場所まで移動して以下のように実行しました.
$ python3 my_script.pyおわりに
PyCharmでも同様のことができるようですが,お金がかかるようなので諦めました.
https://pleiades.io/help/pycharm/using-wsl-as-a-remote-interpreter.html以上です.
- 投稿日:2019-07-10T11:21:51+09:00
Detectronの中身を一部を理解してみる2
親記事はVideopose3Dを理解してみる(メモ)です.
Videopose3Dの中のdetectronの機能を使うinfer_simple.pyを理解するために少しこちらに遷移してきました。
infer_simple.py内で呼び出された宣言について軽く理解していきたいと思います。主にこの記事でみるのは、この関数の戻り値の一つであるcls_boxesの値です。
人を検知して得られた箱の4点の座標を表すための値と、確率を表すスコアが入っていると想定しています。確認してみます。im_detect_allを理解してみる
この関数内の条件は主にこのコードでの入力のarg.cfg(=e2e_keypoint_rcnn_R-101-FPN_s1x.yaml)のBoolean型の変数のTrue,Falseになっています。
このコードを確認して、条件文で当てはまらないところはコメントアウトしています。
test.pydef im_detect_all(model, im, box_proposals, timers=None): if timers is None: timers = defaultdict(Timer) # Handle RetinaNet testing separately for now #if cfg.RETINANET.RETINANET_ON: #cls_boxes = test_retinanet.im_detect_bbox(model, im, timers) #return cls_boxes, None, None timers['im_detect_bbox'].tic() #if cfg.TEST.BBOX_AUG.ENABLED: #scores, boxes, im_scale = im_detect_bbox_aug(model, im, box_proposals) #else: scores, boxes, im_scale = im_detect_bbox( model, im, cfg.TEST.SCALE, cfg.TEST.MAX_SIZE, boxes=box_proposals ) timers['im_detect_bbox'].toc()なおこのとき、cfg.TEST.SCALE=800, cfg.TEST.MAX_SIZE=1333です。
すこしdetectron/core/test_retinanet.py内で定義されているim_detect_bboxに遷移してみます。
(長いです)test_retinanet.pydef im_detect_bbox(model, im, timers=None): """Generate RetinaNet detections on a single image.""" if timers is None: timers = defaultdict(Timer) # Although anchors are input independent and could be precomputed, # recomputing them per image only brings a small overhead anchors = _create_cell_anchors() timers['im_detect_bbox'].tic() k_max, k_min = cfg.FPN.RPN_MAX_LEVEL, cfg.FPN.RPN_MIN_LEVEL A = cfg.RETINANET.SCALES_PER_OCTAVE * len(cfg.RETINANET.ASPECT_RATIOS) inputs = {} inputs['data'], im_scale, inputs['im_info'] = \ blob_utils.get_image_blob(im, cfg.TEST.SCALE, cfg.TEST.MAX_SIZE) cls_probs, box_preds = [], [] for lvl in range(k_min, k_max + 1): suffix = 'fpn{}'.format(lvl) cls_probs.append(core.ScopedName('retnet_cls_prob_{}'.format(suffix))) box_preds.append(core.ScopedName('retnet_bbox_pred_{}'.format(suffix))) for k, v in inputs.items(): workspace.FeedBlob(core.ScopedName(k), v.astype(np.float32, copy=False)) workspace.RunNet(model.net.Proto().name) cls_probs = workspace.FetchBlobs(cls_probs) box_preds = workspace.FetchBlobs(box_preds) # here the boxes_all are [x0, y0, x1, y1, score] boxes_all = defaultdict(list)boxes_allにはhere the boxes_all are [x0, y0, x1, y1, score]と書かれています。
それでは目的のcls_boxesまでもう少し!detectionsを中心に見ていきましょう。test_retinanet.pycnt = 0 for lvl in range(k_min, k_max + 1): # create cell anchors array stride = 2. ** lvl cell_anchors = anchors[lvl] # fetch per level probability cls_prob = cls_probs[cnt] box_pred = box_preds[cnt] cls_prob = cls_prob.reshape(( cls_prob.shape[0], A, int(cls_prob.shape[1] / A), cls_prob.shape[2], cls_prob.shape[3])) box_pred = box_pred.reshape(( box_pred.shape[0], A, 4, box_pred.shape[2], box_pred.shape[3])) cnt += 1 #if cfg.RETINANET.SOFTMAX: #cls_prob = cls_prob[:, :, 1::, :, :] cls_prob_ravel = cls_prob.ravel() # In some cases [especially for very small img sizes], it's possible that # candidate_ind is empty if we impose threshold 0.05 at all levels. This # will lead to errors since no detections are found for this image. Hence, # for lvl 7 which has small spatial resolution, we take the threshold 0.0 th = cfg.RETINANET.INFERENCE_TH if lvl < k_max else 0.0 candidate_inds = np.where(cls_prob_ravel > th)[0] if (len(candidate_inds) == 0): continue pre_nms_topn = min(cfg.RETINANET.PRE_NMS_TOP_N, len(candidate_inds)) inds = np.argpartition( cls_prob_ravel[candidate_inds], -pre_nms_topn)[-pre_nms_topn:] inds = candidate_inds[inds] inds_5d = np.array(np.unravel_index(inds, cls_prob.shape)).transpose() classes = inds_5d[:, 2] anchor_ids, y, x = inds_5d[:, 1], inds_5d[:, 3], inds_5d[:, 4] scores = cls_prob[:, anchor_ids, classes, y, x] boxes = np.column_stack((x, y, x, y)).astype(dtype=np.float32) boxes *= stride boxes += cell_anchors[anchor_ids, :] if not cfg.RETINANET.CLASS_SPECIFIC_BBOX: box_deltas = box_pred[0, anchor_ids, :, y, x] else: box_cls_inds = classes * 4 box_deltas = np.vstack( [box_pred[0, ind:ind + 4, yi, xi] for ind, yi, xi in zip(box_cls_inds, y, x)] ) pred_boxes = ( box_utils.bbox_transform(boxes, box_deltas) if cfg.TEST.BBOX_REG else boxes) pred_boxes /= im_scale pred_boxes = box_utils.clip_tiled_boxes(pred_boxes, im.shape) box_scores = np.zeros((pred_boxes.shape[0], 5)) box_scores[:, 0:4] = pred_boxes box_scores[:, 4] = scores for cls in range(1, cfg.MODEL.NUM_CLASSES): inds = np.where(classes == cls - 1)[0] if len(inds) > 0: boxes_all[cls].extend(box_scores[inds, :]) timers['im_detect_bbox'].toc() # Combine predictions across all levels and retain the top scoring by class timers['misc_bbox'].tic() #detectionsを定義 detections = [] for cls, boxes in boxes_all.items(): cls_dets = np.vstack(boxes).astype(dtype=np.float32)ここで疑問です!npモジュールのvstack関数って何するの?
np.vstackって何?
配列同士を縦方向に連結する関数
example_vstack.pyIn [1]: import numpy as np In [2]: a = np.arange(12).reshape(-1,1) # 12個の要素を持つ縦ベクトル In [3]: b = np.arange(2).reshape(-1,1) # 2個の要素を持つ縦ベクトル In [4]: a Out[4]: array([[ 0], [ 1], [ 2], [ 3], [ 4], [ 5], [ 6], [ 7], [ 8], [ 9], [10], [11]])こんな感じです。
test_retinanet.py# do class specific nms here #if cfg.TEST.SOFT_NMS.ENABLED: #cls_dets, keep = box_utils.soft_nms( #cls_dets, #sigma=cfg.TEST.SOFT_NMS.SIGMA, #overlap_thresh=cfg.TEST.NMS, #score_thresh=0.0001, #method=cfg.TEST.SOFT_NMS.METHOD #) #else: keep = box_utils.nms(cls_dets, cfg.TEST.NMS) cls_dets = cls_dets[keep, :] out = np.zeros((len(keep), 6)) out[:, 0:5] = cls_dets out[:, 5].fill(cls) detections.append(out) # detections (N, 6) format: # detections[:, :4] - boxes # detections[:, 4] - scores # detections[:, 5] - classes detections = np.vstack(detections) # sort all again inds = np.argsort(-detections[:, 4]) detections = detections[inds[0:cfg.TEST.DETECTIONS_PER_IM], :] # Convert the detections to image cls_ format (see core/test_engine.py) num_classes = cfg.MODEL.NUM_CLASSES #空のリストのリストをつくる cls_boxes = [[] for _ in range(cfg.MODEL.NUM_CLASSES)] #0はあけておく for c in range(1, num_classes): inds = np.where(detections[:, 5] == c)[0] cls_boxes[c] = detections[inds, :5] timers['misc_bbox'].toc() return cls_boxes戻ります。
test.py# score and boxes are from the whole image after score thresholding and nms # (they are not separated by class) # cls_boxes boxes and scores are separated by class and in the format used # for evaluating results timers['misc_bbox'].tic() scores, boxes, cls_boxes = box_results_with_nms_and_limit(scores, boxes) timers['misc_bbox'].toc() if cfg.MODEL.MASK_ON and boxes.shape[0] > 0: timers['im_detect_mask'].tic() if cfg.TEST.MASK_AUG.ENABLED: masks = im_detect_mask_aug(model, im, boxes) else: masks = im_detect_mask(model, im_scale, boxes) timers['im_detect_mask'].toc() timers['misc_mask'].tic() cls_segms = segm_results( cls_boxes, masks, boxes, im.shape[0], im.shape[1] ) timers['misc_mask'].toc() else: cls_segms = None if cfg.MODEL.KEYPOINTS_ON and boxes.shape[0] > 0: timers['im_detect_keypoints'].tic() if cfg.TEST.KPS_AUG.ENABLED: heatmaps = im_detect_keypoints_aug(model, im, boxes) else: heatmaps = im_detect_keypoints(model, im_scale, boxes) timers['im_detect_keypoints'].toc() timers['misc_keypoints'].tic() cls_keyps = keypoint_results(cls_boxes, heatmaps, boxes) timers['misc_keypoints'].toc() else: cls_keyps = None return cls_boxes, cls_segms, cls_keypsbox:箱の位置情報・人の確率
seg:何も入ってない
key:関節の二次元の座標が入っている
(segmentation:ピクセル単位でクラスラベルを付ける)
with:https://www.sejuku.net/blog/24672
- 投稿日:2019-07-10T11:16:57+09:00
django heroku
実行環境
win10
python3.7.2
herokuゴール
ローカルでdjangoを利用するのではなく、サーバにデプロイしweb公開(herokuを利用しdjangoをデプロイ)する事を目的としてみました。出来るイメージは以下です。
djangoで作成したアプリをweb公開する
https://firstkenosin.herokuapp.com/myapp/
これ以上ない程シンプルですが中身はdjango+herokuが稼働しています。
herokuとは
Heroku はpaasです。Paasはアプリケーションの開発から実行、運用までのすべてをクラウドで完結できるサービスです。一言で言うとサーバやOS、データベースなどプラットフォーム部分を簡単に設定する事ができます。アプリの構築、提供、監視、スケールが容易でインフラストラクチャの管理問題から大部分は解放されるとても便利なサービスです。
詳細は以下をご覧ください。
https://jp.heroku.com/whatherokuのプランやプライスは以下を参考にしてください。
https://jp.heroku.com/pricing1 herokuユーザ登録
まずユーザ登録しましょう。
heroku CLI Heroku Dev Center
https://devcenter.heroku.com/articles/heroku-cli
【Winodwsの場合】
インストーラを起動させたら『Next >』をクリック任意のインストール先(デフォルトで良い)を設定して『Install』します。
正常終了したらPowerShellかコマンドプロンプトでバージョン確認します。
heroku --version heroku/7.22.9 win32-x64 node-v11.10.1バージョンが表示していればOKです。
Herokuにログイン
heroku loginコマンドを叩くとブラウザ起動してログインを求められるのでエンターを押してください。> heroku login heroku: Press any key to open up the browser to login or q to exit: Opening browser to https://cli-auth.heroku.com/auth/browser/xxxxxxxxxxxxxxxxxxxxx Logging in... done Logged in as xxxxxxxxxxxx@xxxxx.com
六本木
Loginを押すと自動的にloggedinされます。
Logged in が表示されていれば正常にログインできています。
2 各ライブラリインストール
ローカル環境上(win10)で必要となるライブラリをインストールします。
django
dj-database-url
django-heroku
gunicorn
whitenoisepsycopg2
pytzpip install django dj-database-url gunicorn whitenoise django-herokudjangoでプロジェクトとアプリを作成する
djangoをインストールしたらプロジェクトとアプリを作成し各種設定をしましょう。djangoにはプロジェクトとアプリという概念があります。ここでは説明は割愛します。
プロジェクト名:first
アプリ名:myappプロジェクトを作る
$ django-admin startproject firstfirstというプロジェクトが作成されました。firstフォルダは違う階層に2つできややこしいですが正常稼働ですので注意してください。
first/ first/ manage.py mysite/ __init__.py settings.py urls.py wsgi.pysettings.pyと新しく作るlocal_settings.pyの作成方法は後述します。
urls.py
"""first URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/2.0/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: path('', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.urls import include, path 2. Add a URL to urlpatterns: path('blog/', include('blog.urls')) """ from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('myapp/', include('myapp.urls')) ]アプリを作る
$ python manage.py startapp myappmyappというアプリが作成されます。
myapp/ __init__.py admin.py apps.py migrations/ __init__.py models.py tests.py views.pyアプリの中の各ファイルを修正・追加していきます。
views.pyは以下のように修正しています。
from django.shortcuts import render def index(request): """/ トップページ""" context = { 'name': 'Kenosin', } return render(request, 'myapp/index.html', context) def about(request): """/about アバウトページ""" return render(request, 'myapp/about.html') def info(request): """/info インフォページ""" return render(request, 'myapp/info.html')apps.py
from django.apps import AppConfig class MyappConfig(AppConfig): name = 'myapp'urls.pyは新規にファイルを作成します。
from django.urls import path from . import views app_name = 'myapp' urlpatterns = [ path('', views.index, name='index'), # 127.0.0.1:8000/myapp path('about/', views.about, name='about'), # 127.0.0.1:8000/myapp/about path('info/', views.info, name='info'), # 127.0.0.1:8000/myapp/info ]起動を確認する
必ずmanage.pyがある場所ディレクトリに移動してサーバーを起動してみる。$ python manage.py runserver3 herokuを利用する為herokuで利用する各設定ファイルを追加する
新しく3つのファイルを作成する必要があります。
ファイル名 役割 一言TIPS runtime.txt Pythonのバージョン指定 ローカルでtxt作成すればOKです Procfile Herokuプロセスの起動コマンド 拡張子はないので注意してください requirements.txt 依存パッケージのリスト ローカルtxt作成すればokです プロジェクト名:first
アプリ名:app
※今後はみなさんの環境で上記を読み替えてください。
3つのファイルがどこに格納するべきかを以下のディレクトリ構造をチェックし再度確認してください。
first │ db.sqlite3 │ manage.py │ Procfile????? │ requirements.txt????? │ runtime.txt????? │ __init__.py │ ├─first │ settings.py │ urls.py │ wsgi.py │ __init__.py │ └─app │ admin.py │ apps.py │ models.py │ tests.py │ urls.py │ views.py │ __init__.py │ ├─migrations │ ├─static │ └─app │ style.css │ └─templates └─app detail.html index.html results.htmlruntime.txt
Pythonのバージョンはお使いのPythonのバージョンに変更してください。python --versionでOKです。
python-3.7.2Procfile
firstと書いてある部分はあなたのプロジェクト名に変更して下さい。
web: gunicorn first.wsgi --log-file -requirements.txt
必ずディレクトリをfirstフォルダ(上の階層の方)にcdで移動してから以下コマンドを入力します。pip freeze > requirements.txtちゃんとrequirements.txtの中身が入っているかを確認してください。
4 django側ファイル作成
django側は2ファイルを作成・修正します。local_settings.pyは新規にファイルを作ります。
settings.pyは既存にある設定ファイルを編集します。
ファイル名 役割 first/local_settings.py 新規作成です。開発環境用設定ファイル first/settings.py 本番環境用設定ファイル first │ db.sqlite3 │ manage.py │ Procfile │ requirements.txt │ runtime.txt │ __init__.py │ ├─first │ settings.py????? │ local_settings.py????? │ urls.py │ wsgi.py │ __init__.py │ └─app │ admin.py │ apps.py │ models.py │ tests.py │ urls.py │ views.py │ __init__.py │ ├─migrations │ ├─static │ └─app │ style.css │ └─templates └─app detail.html index.html results.htmlfirst/local_settings.py
ローカル環境でアプリを動かすための設定です。プロジェクトの下の「first」フォルダの下に、「local_settings.py」を作成して以下のように編集します。import os BASE_DIR = os.path.dirname(os.path.dirname(__file__)) DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } DEBUG = Truefirst/settings.py
Herokuで動くための設定を追加します。settings.pyの最後に以下を追加します。なお以下ファイルをまるまるコピーするではありませんので気を付けてくださいね。あくまで以下コードは最後に追加してください。import dj_database_url DATABASES['default'] = dj_database_url.config() SECURE_PROXY_SSL_HEADER = ('HTTP_X_FORWARDED_PROTO', 'https') ALLOWED_HOSTS = ['*'] STATIC_ROOT = 'staticfiles' DEBUG = False try: from .local_settings import * except ImportError: pass.gitignore ファイル作成
.gitignoreというファイルを作成します。しかし.gitignoreの最初は[.]です。windowsでは通常のファイルの作成方法だと名前の一番最初に[.]が付くファイルは以下のようにエラーがでます。
そこで以下方法で.gitignoreファイルを作成します。
1gitignore.txtを作る。(gitignore.txtは.gitignoreファイルを保存したいフォルダに保存しておく。)
2gitignore.txtに.gitignoreに書きたい内容を書く。
3gitignore.txtを保存したフォルダ上を、SHIFTを押しながら右クリックして、"コマンドウインドウをここで開く"を選択。
コマンドプロンプト(黒い画面)を開いたら以下コマンドを入力してEnterを押してください。ren gitignore.txt .gitignoreファイルの格納場所は以下になります。
実際の.gitignoreファイルの中身は以下を入力しましょう
### Django ### __pycache__ staticfiles local_settings.py db.sqlite3 *.py[co]5 Gitでリモートリポジトリにプッシュ
※heroku, gitコマンドはあらかじめwindows環境変数のpathを追加しておきます。以下のパスを環境変数に追加してください。
C:\Program Files\Git\bin C:\Program Files\heroku\binwindowsで環境変数を開き上記パスをpath欄に追加してください。
ファイルを格納する場所は以下を参照してください。
first │ .gitignore???????新規作成します。 │ db.sqlite3 │ manage.py │ Procfile │ requirements.txt │ runtime.txt │ __init__.py │ ├─first │ local_settings.py?????????新規作成します。 │ settings.py????????既存ファイルの修正です。 │ urls.py │ wsgi.py │ __init__.py │ └─app │ admin.py │ apps.py │ models.py │ tests.py │ urls.py │ views.py │ __init__.py │ ├─migrations │ ├─static │ └─app │ style.css │ └─templates └─app detail.html index.html results.htmlherokuにログインします。
heroku login 結果 heroku: Press any key to open up the browser to login or q to exit: Opening browser to https://cli-auth.heroku.com/auth/browser/66295473-1184-419f-b9c7-1bac9c80edb7 Logging in... done Logged in as keno@gmail.comログインしたら、まず作成したプロジェクトの直下にディレクトリをcdで移動します。
cd first 作ったプロジェクトの直下に移動します。(manag.pyと並列の階層です)git init Initialized empty Git repository in C:/Users/kenosin/first/.git/ご自身の名前で登録します。例えばgit config user.name "kenosin"
git config user.name "Your Name"メールアドレスを入力します。例えばgit config user.email keno@gmail.com
git config user.email xxxxx@mail.comgit add -A . 結果以下のようなワーニングが出るかもしれません。 warning: LF will be replaced by CRLF in first/settings.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in first/urls.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in first/wsgi.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in manage.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/admin.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/apps.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/models.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/templates/myapp/about.html. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/templates/myapp/base.html. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/templates/myapp/index.html. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/templates/myapp/info.html. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/tests.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/urls.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/views.py. The file will have its original line endings in your working directoryコミット用のコメントを入力します。
git commit -m "first commit" 結果 [master (root-commit) 76d9fbd] first commit 21 files changed, 364 insertions(+) create mode 100644 .gitignore create mode 100644 Procfile create mode 100644 first/__init__.py create mode 100644 first/settings.py create mode 100644 first/urls.py create mode 100644 first/wsgi.py create mode 100644 manage.py create mode 100644 myapp/__init__.py create mode 100644 myapp/admin.py create mode 100644 myapp/apps.py create mode 100644 myapp/migrations/__init__.py create mode 100644 myapp/models.py create mode 100644 myapp/templates/myapp/about.html create mode 100644 myapp/templates/myapp/base.html create mode 100644 myapp/templates/myapp/index.html create mode 100644 myapp/templates/myapp/info.html create mode 100644 myapp/tests.py create mode 100644 myapp/urls.py create mode 100644 myapp/views.py create mode 100644 requirements.txt create mode 100644 runtime.txtHerokuへデプロイ
重複しないURLを入力してください。ここでURLが決まります。
heroku create firstkenosin 結果 Creating ⬢ firstkenosin... done https://firstkenosin.herokuapp.com/ | https://git.heroku.com/firstkenosin.githerokuのアプリにローカルリポジトリからpushします。
git push heroku master 結果 Enumerating objects: 26, done. Counting objects: 100% (26/26), done. Delta compression using up to 4 threads Compressing objects: 100% (21/21), done. Writing objects: 100% (26/26), 5.71 KiB | 307.00 KiB/s, done. Total 26 (delta 1), reused 0 (delta 0) remote: Compressing source files... done. remote: Building source: remote: remote: -----> Python app detected remote: ! Python has released a security update! Please consider upgrading to python-3.7.3 remote: Learn More: https://devcenter.heroku.com/articles/python-runtimes remote: -----> Installing python-3.7.2 remote: -----> Installing pip remote: -----> Installing SQLite3 remote: -----> Installing requirements with pip 省略 remote: -----> Compressing... remote: Done: 207.4M remote: -----> Launching... remote: Released v5 remote: https://firstkenosin.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To ssh://heroku.com/firstkenosin.git * [new branch] master -> master続いて以下コマンドを打ちます。push した後はアプリケーションのプロセスを動かす必要がありますので以下のコマンドで起動します。
heroku ps:scale web=1 結果 Scaling dynos... done, now running web at 1:Freeデータベースが空の状態なので、ローカルにデータベースをセットアップした時のように、再度migrate コマンドを実行します。
heroku run python manage.py migrate 結果 Running python manage.py migrate on ⬢ firstkenosin... up, run.2676 (Free) Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length... OK Applying auth.0010_alter_group_name_max_length... OK Applying auth.0011_update_proxy_permissions... OK Applying sessions.0001_initial... OK任意でsuperuserを作成し管理画面にログインできるように設定してください。
heroku run python manage.py createsuperuser 結果 Running python manage.py createsuperuser on ⬢ firstkenosin... up, run.8935 (Free) ユーザー名 (leave blank to use 'u18723'): xxxxxx メールアドレス: keno@gmail.com Password: Password (again): Superuser created successfully.最後に下記を入力すると、ブラウザが立ち上がり、自分で作ったアプリが表示されます。
heroku openhttps://firstkenosin.herokuapp.com/myapp/
6 herokuのURLをムームードメイン独自ドメインと紐づける
djangoのweb公開ができたら次は独自ドメインを設定しましょう。
ムームードメイン側:
1.「ドメイン管理」→「ムームーDNS」→設定したい独自ドメインの「変更」を選択します。
2.「カスタム設定のセットアップ方法はこちら」というボタンを押してください。
3.設定2が現れるのでサブドメインを「www」、種別を[CNAME]、内容を[www.アプリの名前.herokudns.com]にしますサブドメイン:www
種別:CNAME
内容:agile-cephalopod-adここはそれぞれ違いますfakjnefhoo60.herokudns.com
※内容はherokuのDNS Targetをそのまま入れて下さい。
4.「セットアップ情報変更」を押し完了です。
5.24~48時間ほどで適用されます。
heroku側:
続いてheroku側の設定をGUI上で実施します。まずはDomains and certificatesページでドメインを登録してください。登録しようとした時にもしも以下のようなエラーが出たらheroku側にクレジットカード登録が済んでいない可能性があります。請求ページに行きクレジットカードを登録してください。
https://dashboard.heroku.com/account/billingDomain "xxx.com" could not be created: Please verify your account in order to add domain s (please enter a credit card) For more information, seeここからクレジットカードを登録します。
アプリのドメインが設定されているかをコマンドプロンプトで確認しましょう。
C:\Users\kenosin>heroku domains -a firstkenosin === firstkenosin Heroku Domain firstkenosin.herokuapp.com === firstkenosin Custom Domains Domain Name DNS Record Type DNS Target ──────────── ─────────────── ───────────────────────────────────────────────────── sinukasu.com ALIAS or ANAME agile-cephalopod-joghoehgoehgoehgoehgoe.herokudns.comしばらく待ってから独自ドメインでweb公開されているか確認しましょう。
番外編
gitにメール、ユーザを登録していないと、commit時にエラーになります。
*** Please tell me who you are. Run git config --global user.email "you@example.com" git config --global user.name "Your Name" to set your account's default identity. Omit --global to set the identity only in this repository.fatal: unable to auto-detect email address (got 'ycnp4@DESKTOP-B5N6I3B.(none)')
その場合は登録してください。git config --global user.email "hogehoge@gmail.com" git config --global user.name "taro yamada"settings.py
""" Django settings for first project. Generated by 'django-admin startproject' using Django 2.0. For more information on this file, see https://docs.djangoproject.com/en/2.0/topics/settings/ For the full list of settings and their values, see https://docs.djangoproject.com/en/2.0/ref/settings/ """ import os # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # Quick-start development settings - unsuitable for production # See https://docs.djangoproject.com/en/2.0/howto/deployment/checklist/ # SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = 'urfaj;foanjdfnaewlufnawefhnawoenfawefaj'?????#ここは毎回違うので注意してください。 # SECURITY WARNING: don't run with debug turned on in production! DEBUG = True????? ALLOWED_HOSTS = []????? # Application definition INSTALLED_APPS = [ 'myapp.apps.MyappConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ] MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] ROOT_URLCONF = 'first.urls' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ] WSGI_APPLICATION = 'first.wsgi.application' # Database # https://docs.djangoproject.com/en/2.0/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } # Password validation # https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators AUTH_PASSWORD_VALIDATORS = [ { 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', }, { 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', }, { 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', }, { 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', }, ] # Internationalization # https://docs.djangoproject.com/en/2.0/topics/i18n/ LANGUAGE_CODE = 'ja' ?????#変更対象です。 TIME_ZONE = 'Asia/Tokyo' ?????#変更対象です。 USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/2.0/howto/static-files/ STATIC_URL = '/static/' # 今回heroku用に以下を追加します DEBUG = False try: from .local_settings import * except ImportError: pass if not DEBUG: import django_heroku django_heroku.settings(locals())以上、お疲れ様でした。

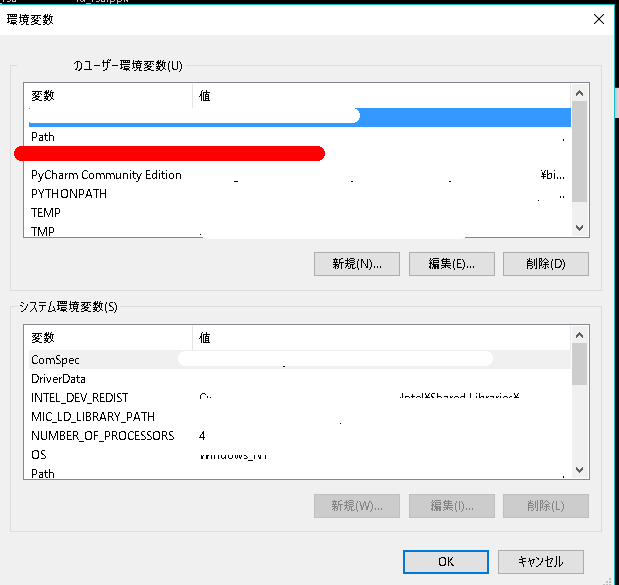

- 投稿日:2019-07-10T11:16:57+09:00
herokuでdjango
実行環境
win10
python3.7.2
herokuゴール
ローカルでdjangoを利用するのではなく、サーバにデプロイしweb公開(herokuを利用しdjangoをデプロイ)する事を目的としてみました。出来るイメージは以下です。
djangoで作成したアプリをweb公開する
https://firstkenosin.herokuapp.com/myapp/
これ以上ない程シンプルですが中身はdjango+herokuが稼働しています。
herokuとは
Heroku はpaasです。Paasはアプリケーションの開発から実行、運用までのすべてをクラウドで完結できるサービスです。一言で言うとサーバやOS、データベースなどプラットフォーム部分を簡単に設定する事ができます。アプリの構築、提供、監視、スケールが容易でインフラストラクチャの管理問題から大部分は解放されるとても便利なサービスです。
詳細は以下をご覧ください。
https://jp.heroku.com/whatherokuのプランやプライスは以下を参考にしてください。
https://jp.heroku.com/pricing1 herokuユーザ登録
まずユーザ登録しましょう。
heroku CLI Heroku Dev Center
https://devcenter.heroku.com/articles/heroku-cli
【Winodwsの場合】
インストーラを起動させたら『Next >』をクリック任意のインストール先(デフォルトで良い)を設定して『Install』します。
正常終了したらPowerShellかコマンドプロンプトでバージョン確認します。
heroku --version heroku/7.22.9 win32-x64 node-v11.10.1バージョンが表示していればOKです。
Herokuにログイン
heroku loginコマンドを叩くとブラウザ起動してログインを求められるのでエンターを押してください。> heroku login heroku: Press any key to open up the browser to login or q to exit: Opening browser to https://cli-auth.heroku.com/auth/browser/xxxxxxxxxxxxxxxxxxxxx Logging in... done Logged in as xxxxxxxxxxxx@xxxxx.com
Loginを押すと自動的にloggedinされます。
Logged in が表示されていれば正常にログインできています。
2 各ライブラリインストール
ローカル環境上(win10)で必要となるライブラリをインストールします。
django
dj-database-url
django-heroku
gunicorn
whitenoisepsycopg2
pytzpip install django dj-database-url gunicorn whitenoise django-herokudjangoでプロジェクトとアプリを作成する
djangoをインストールしたらプロジェクトとアプリを作成し各種設定をしましょう。djangoにはプロジェクトとアプリという概念があります。ここでは説明は割愛します。
プロジェクト名:first
アプリ名:myappプロジェクトを作る
$ django-admin startproject firstfirstというプロジェクトが作成されました。firstフォルダは違う階層に2つできややこしいですが正常稼働ですので注意してください。
first/ first/ manage.py mysite/ __init__.py settings.py urls.py wsgi.pysettings.pyと新しく作るlocal_settings.pyの作成方法は後述します。
urls.py
"""first URL Configuration The `urlpatterns` list routes URLs to views. For more information please see: https://docs.djangoproject.com/en/2.0/topics/http/urls/ Examples: Function views 1. Add an import: from my_app import views 2. Add a URL to urlpatterns: path('', views.home, name='home') Class-based views 1. Add an import: from other_app.views import Home 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home') Including another URLconf 1. Import the include() function: from django.urls import include, path 2. Add a URL to urlpatterns: path('blog/', include('blog.urls')) """ from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('myapp/', include('myapp.urls')) ]アプリを作る
$ python manage.py startapp myappmyappというアプリが作成されます。
myapp/ __init__.py admin.py apps.py migrations/ __init__.py models.py tests.py views.pyアプリの中の各ファイルを修正・追加していきます。
views.pyは以下のように修正しています。
from django.shortcuts import render def index(request): """/ トップページ""" context = { 'name': 'Kenosin', } return render(request, 'myapp/index.html', context) def about(request): """/about アバウトページ""" return render(request, 'myapp/about.html') def info(request): """/info インフォページ""" return render(request, 'myapp/info.html')apps.py
from django.apps import AppConfig class MyappConfig(AppConfig): name = 'myapp'urls.pyは新規にファイルを作成します。
from django.urls import path from . import views app_name = 'myapp' urlpatterns = [ path('', views.index, name='index'), # 127.0.0.1:8000/myapp path('about/', views.about, name='about'), # 127.0.0.1:8000/myapp/about path('info/', views.info, name='info'), # 127.0.0.1:8000/myapp/info ]起動を確認する
必ずmanage.pyがある場所ディレクトリに移動してサーバーを起動してみる。$ python manage.py runserver3 herokuを利用する為herokuで利用する各設定ファイルを追加する
新しく3つのファイルを作成する必要があります。
ファイル名 役割 一言TIPS runtime.txt Pythonのバージョン指定 ローカルでtxt作成すればOKです Procfile Herokuプロセスの起動コマンド 拡張子はないので注意してください requirements.txt 依存パッケージのリスト ローカルtxt作成すればokです プロジェクト名:first
アプリ名:app
※今後はみなさんの環境で上記を読み替えてください。
3つのファイルがどこに格納するべきかを以下のディレクトリ構造をチェックし再度確認してください。
first │ db.sqlite3 │ manage.py │ Procfile????? │ requirements.txt????? │ runtime.txt????? │ __init__.py │ ├─first │ settings.py │ urls.py │ wsgi.py │ __init__.py │ └─app │ admin.py │ apps.py │ models.py │ tests.py │ urls.py │ views.py │ __init__.py │ ├─migrations │ ├─static │ └─app │ style.css │ └─templates └─app detail.html index.html results.htmlruntime.txt
Pythonのバージョンはお使いのPythonのバージョンに変更してください。python --versionでOKです。
python-3.7.2Procfile
firstと書いてある部分はあなたのプロジェクト名に変更して下さい。はまりポイントです。さりげなくwsgiファイル名称が異なるのでご自身のファイル名称を記載するよう注意してくださいね。
web: gunicorn first.wsgi --log-file -requirements.txt
必ずディレクトリをfirstフォルダ(上の階層の方)にcdで移動してから以下コマンドを入力します。pip freeze > requirements.txtちゃんとrequirements.txtの中身が入っているかを確認してください。
4 django側ファイル作成
django側は2ファイルを作成・修正します。local_settings.pyは新規にファイルを作ります。
settings.pyは既存にある設定ファイルを編集します。
ファイル名 役割 first/local_settings.py 新規作成です。開発環境用設定ファイル first/settings.py 本番環境用設定ファイル first │ db.sqlite3 │ manage.py │ Procfile │ requirements.txt │ runtime.txt │ __init__.py │ ├─first │ settings.py????? │ local_settings.py????? │ urls.py │ wsgi.py │ __init__.py │ └─app │ admin.py │ apps.py │ models.py │ tests.py │ urls.py │ views.py │ __init__.py │ ├─migrations │ ├─static │ └─app │ style.css │ └─templates └─app detail.html index.html results.htmlfirst/local_settings.py
ローカル環境でアプリを動かすための設定です。プロジェクトの下の「first」フォルダの下に、「local_settings.py」を作成して以下のように編集します。
import os BASE_DIR = os.path.dirname(os.path.dirname(__file__)) DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } DEBUG = Truefirst/settings.py
Herokuで動くための設定を追加します。settings.pyの最後に以下を追加します。なお以下ファイルをまるまるコピーするではありませんので気を付けてくださいね。あくまで以下コードは最後に追加してください。
# 今回heroku用に以下を追加します DEBUG = False try: from .local_settings import * except ImportError: pass if not DEBUG: import django_heroku django_heroku.settings(locals()).gitignore ファイル作成
.gitignoreというファイルを作成します。しかし.gitignoreの最初は[.]です。windowsでは通常のファイルの作成方法だと名前の一番最初に[.]が付くファイルは以下のようにエラーがでます。
そこで以下方法で.gitignoreファイルを作成します。
1gitignore.txtを作る。(gitignore.txtは.gitignoreファイルを保存したいフォルダに保存しておく。)
2gitignore.txtに.gitignoreに書きたい内容を書く。
3gitignore.txtを保存したフォルダ上を、SHIFTを押しながら右クリックして、"コマンドウインドウをここで開く"を選択。
コマンドプロンプト(黒い画面)を開いたら以下コマンドを入力してEnterを押してください。ren gitignore.txt .gitignoreファイルの格納場所は以下になります。
実際の.gitignoreファイルの中身は以下を入力しましょう
### Django ### __pycache__ staticfiles local_settings.py db.sqlite3 *.py[co]5 Gitでリモートリポジトリにプッシュ
※heroku, gitコマンドはあらかじめwindows環境変数のpathを追加しておきます。以下のパスを環境変数に追加してください。
C:\Program Files\Git\bin C:\Program Files\heroku\binwindowsで環境変数を開き上記パスをpath欄に追加してください。
ファイルを格納する場所は以下を参照してください。
first │ .gitignore???????新規作成します。 │ db.sqlite3 │ manage.py │ Procfile │ requirements.txt │ runtime.txt │ __init__.py │ ├─first │ local_settings.py?????????新規作成します。 │ settings.py????????既存ファイルの修正です。 │ urls.py │ wsgi.py │ __init__.py │ └─app │ admin.py │ apps.py │ models.py │ tests.py │ urls.py │ views.py │ __init__.py │ ├─migrations │ ├─static │ └─app │ style.css │ └─templates └─app detail.html index.html results.htmlherokuにログインします。
heroku login 結果 heroku: Press any key to open up the browser to login or q to exit: Opening browser to https://cli-auth.heroku.com/auth/browser/66295473-1184-419f-b9c7-1bac9c80edb7 Logging in... done Logged in as keno@gmail.comログインしたら、まず作成したプロジェクトの直下にディレクトリをcdで移動します。
cd first 作ったプロジェクトの直下に移動します。(manag.pyと並列の階層です)git init Initialized empty Git repository in C:/Users/kenosin/first/.git/ご自身の名前で登録します。例えばgit config user.name "kenosin"
git config user.name "Your Name"メールアドレスを入力します。例えばgit config user.email keno@gmail.com
git config user.email xxxxx@mail.comgit add -A . 結果以下のようなワーニングが出るかもしれません。 warning: LF will be replaced by CRLF in first/settings.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in first/urls.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in first/wsgi.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in manage.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/admin.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/apps.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/models.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/templates/myapp/about.html. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/templates/myapp/base.html. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/templates/myapp/index.html. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/templates/myapp/info.html. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/tests.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/urls.py. The file will have its original line endings in your working directory warning: LF will be replaced by CRLF in myapp/views.py. The file will have its original line endings in your working directoryコミット用のコメントを入力します。
git commit -m "first commit" 結果 [master (root-commit) 76d9fbd] first commit 21 files changed, 364 insertions(+) create mode 100644 .gitignore create mode 100644 Procfile create mode 100644 first/__init__.py create mode 100644 first/settings.py create mode 100644 first/urls.py create mode 100644 first/wsgi.py create mode 100644 manage.py create mode 100644 myapp/__init__.py create mode 100644 myapp/admin.py create mode 100644 myapp/apps.py create mode 100644 myapp/migrations/__init__.py create mode 100644 myapp/models.py create mode 100644 myapp/templates/myapp/about.html create mode 100644 myapp/templates/myapp/base.html create mode 100644 myapp/templates/myapp/index.html create mode 100644 myapp/templates/myapp/info.html create mode 100644 myapp/tests.py create mode 100644 myapp/urls.py create mode 100644 myapp/views.py create mode 100644 requirements.txt create mode 100644 runtime.txtHerokuへデプロイ
重複しないURLを入力してください。ここでURLが決まります。
heroku create firstkenosin 結果 Creating ⬢ firstkenosin... done https://firstkenosin.herokuapp.com/ | https://git.heroku.com/firstkenosin.githerokuのアプリにローカルリポジトリからpushします。
git push heroku master 結果 Enumerating objects: 26, done. Counting objects: 100% (26/26), done. Delta compression using up to 4 threads Compressing objects: 100% (21/21), done. Writing objects: 100% (26/26), 5.71 KiB | 307.00 KiB/s, done. Total 26 (delta 1), reused 0 (delta 0) remote: Compressing source files... done. remote: Building source: remote: remote: -----> Python app detected remote: ! Python has released a security update! Please consider upgrading to python-3.7.3 remote: Learn More: https://devcenter.heroku.com/articles/python-runtimes remote: -----> Installing python-3.7.2 remote: -----> Installing pip remote: -----> Installing SQLite3 remote: -----> Installing requirements with pip 省略 remote: -----> Compressing... remote: Done: 207.4M remote: -----> Launching... remote: Released v5 remote: https://firstkenosin.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To ssh://heroku.com/firstkenosin.git * [new branch] master -> master続いて以下コマンドを打ちます。push した後はアプリケーションのプロセスを動かす必要がありますので以下のコマンドで起動します。
heroku ps:scale web=1 結果 Scaling dynos... done, now running web at 1:Freeデータベースが空の状態なので、ローカルにデータベースをセットアップした時のように、再度migrate コマンドを実行します。
heroku run python manage.py migrate 結果 Running python manage.py migrate on ⬢ firstkenosin... up, run.2676 (Free) Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length... OK Applying auth.0010_alter_group_name_max_length... OK Applying auth.0011_update_proxy_permissions... OK Applying sessions.0001_initial... OK任意でsuperuserを作成し管理画面にログインできるように設定してください。
heroku run python manage.py createsuperuser 結果 Running python manage.py createsuperuser on ⬢ firstkenosin... up, run.8935 (Free) ユーザー名 (leave blank to use 'u18723'): xxxxxx メールアドレス: keno@gmail.com Password: Password (again): Superuser created successfully.最後に下記を入力すると、ブラウザが立ち上がり、自分で作ったアプリが表示されます。
heroku openhttps://firstkenosin.herokuapp.com/myapp/
6 herokuのURLをムームードメイン独自ドメインと紐づける
djangoのweb公開ができたら次は独自ドメインを設定しましょう。
ムームードメイン側:
1.「ドメイン管理」→「ムームーDNS」→設定したい独自ドメインの「変更」を選択します。
2.「カスタム設定のセットアップ方法はこちら」というボタンを押してください。
3.設定2が現れるのでサブドメインを「www」、種別を[CNAME]、内容を[www.アプリの名前.herokudns.com]にしますサブドメイン:www
種別:CNAME
内容:agile-cephalopod-adここはそれぞれ違いますfakjnefhoo60.herokudns.com
※内容はherokuのDNS Targetをそのまま入れて下さい。
4.「セットアップ情報変更」を押し完了です。
5.24~48時間ほどで適用されます。
heroku側:
続いてheroku側の設定をGUI上で実施します。まずはDomains and certificatesページでドメインを登録してください。登録しようとした時にもしも以下のようなエラーが出たらheroku側にクレジットカード登録が済んでいない可能性があります。請求ページに行きクレジットカードを登録してください。
https://dashboard.heroku.com/account/billingDomain "xxx.com" could not be created: Please verify your account in order to add domain s (please enter a credit card) For more information, seeここからクレジットカードを登録します。
アプリのドメインが設定されているかをコマンドプロンプトで確認しましょう。
C:\Users\kenosin>heroku domains -a firstkenosin === firstkenosin Heroku Domain firstkenosin.herokuapp.com === firstkenosin Custom Domains Domain Name DNS Record Type DNS Target ──────────── ─────────────── ───────────────────────────────────────────────────── sinukasu.com ALIAS or ANAME agile-cephalopod-joghoehgoehgoehgoehgoe.herokudns.comしばらく待ってから独自ドメインでweb公開されているか確認しましょう。
番外編
gitにメール、ユーザを登録していないと、commit時にエラーになります。
*** Please tell me who you are. Run git config --global user.email "you@example.com" git config --global user.name "Your Name" to set your account's default identity. Omit --global to set the identity only in this repository.fatal: unable to auto-detect email address (got 'ycnp4@DESKTOP-B5N6I3B.(none)')
その場合は登録してください。git config --global user.email "hogehoge@gmail.com" git config --global user.name "taro yamada"settings.py
""" Django settings for first project. Generated by 'django-admin startproject' using Django 2.0. For more information on this file, see https://docs.djangoproject.com/en/2.0/topics/settings/ For the full list of settings and their values, see https://docs.djangoproject.com/en/2.0/ref/settings/ """ import os # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) # Quick-start development settings - unsuitable for production # See https://docs.djangoproject.com/en/2.0/howto/deployment/checklist/ # SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = 'urfaj;foanjdfnaewlufnawefhnawoenfawefaj'?????#ここは毎回違うので注意してください。 # SECURITY WARNING: don't run with debug turned on in production! DEBUG = True????? ALLOWED_HOSTS = []????? # Application definition INSTALLED_APPS = [ 'myapp.apps.MyappConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ] MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] ROOT_URLCONF = 'first.urls' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ] WSGI_APPLICATION = 'first.wsgi.application' # Database # https://docs.djangoproject.com/en/2.0/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } # Password validation # https://docs.djangoproject.com/en/2.0/ref/settings/#auth-password-validators AUTH_PASSWORD_VALIDATORS = [ { 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', }, { 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', }, { 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', }, { 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', }, ] # Internationalization # https://docs.djangoproject.com/en/2.0/topics/i18n/ LANGUAGE_CODE = 'ja' ?????#変更対象です。 TIME_ZONE = 'Asia/Tokyo' ?????#変更対象です。 USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/2.0/howto/static-files/ STATIC_URL = '/static/' # 今回heroku用に以下を追加します????? DEBUG = False try: from .local_settings import * except ImportError: pass if not DEBUG: import django_heroku django_heroku.settings(locals())以上、お疲れ様でした。今回はherokuとdjangoのデプロイを中心に独自ドメインの設定までを記載してみました。今後は具体的webサービスについて公開していきたいと思います。御忙しい所最後までご覧いただきありがとうございました。
- 投稿日:2019-07-10T10:51:57+09:00
Pythonの基本
1.Pythonの特徴
Pythonは機械学習に使われることが多い言語ですが、その特徴としてデバッグの手軽さと実行速度の速さがあります。通常のプログラミング言語ではコンパイルという作業が必要ですが、Pythonはコンパイルなしに実行できます。また、コンパイルを必要としない言語の中ではPythonの実行速度が比較的早いことから多くの計算が必要となる科学技術分野で重宝されています。
2.文法と作法
C言語やjava、PHPなどのプログラミング言語にはそれぞれ記述するためのルールがあります。こおれをいわゆる文法と呼びますが、その他にも独特の作法がある場合もあります。今回はPythonを触るにあたって最低限の文法と作法を紹介します。
(1)文法の前に
プログラミング言語にはそれぞれ独自の文法(作法)があります。
正しい文法でプログラムを記述しないと正確に実行することはできません。
ここではPyhtonの基本的な文法を説明します。プログラムの実行はanacondaのspyderを使います。下にspyderの画面で解説すると、
画面の赤枠①にプログラムを記述し、青枠②の実行ボタンでプログラムを実行します。実行結果は緑枠③のコンソールに表示されます。
(2)なにはともあれ"Hello World!"
anacondaからspyderを起動し、左側のエディタに次のコードを入力してください。
print("Heloo Wrold!")入力が終わったら、実行ボタンを押すと右下のコンソールに実行結果が表示されます。
Hello World!入力したprint("Hello World!")はHello World!とコンソールへ出力しなさい。という命令です。このように、プログラミングは命令を組み合わせることで、コンピュータに何かを実行させることができるのです。基本的な命令を順を追って説明して行きます。
(3)変数と演算子
プログラミングにおける変数とは、数値などを記憶しておくための入れ物に例えることができます。変数には「型(データ型)」と呼ばれる種類があり、整数、小数、文字列や行列など、用途に合った変数の型を使うことでコンピュータ内で効率的に計算を行うことができるようになっています。ただし、pythonを含む最近のプログラミング言語では、この型を特に意識しなくても計算を行うことができてしまうのが現状です。(この型については後程解説します)
演算子とはその名のとおり変数を演算するための記号です、とは言っても普通の四則演算と同じで、+、-、*(アスタリスク:掛け算)、/(スラッシュ:割り算)のことなどを指します。実際に変数と演算子を使って簡単な計算をしてみましょう。下のコードをエディタに入力してください。
a = 1 b = 2 c = 0 c = a + b print(c)入力できたら、実行ボタンを押すと、3と表示されるはずです。
今入力したa,b,cは変数、=,+,は演算子になります。
a = 1 という記述はaに1を代入しなさいという意味です。数学で使う=とは意味合いが違うので注意が必要です。
c = a + b はaとbを足した結果をcに代入しなさいという意味です。
print(c)はcの内容を表示しなさいという意味です。このprint()という関数は()内をコンソールへ表示するための命令(関数)で、単にprint(c)となっている場合にはcに代入されている数値(この場合はa+bの計算結果の3)を表示します。cという文字や文字列を表示したい場合には"(ダブルクォーテーション)で囲うことで、その文字列を表示することができます。(先ほどのprint("Helo World!")もダブルクォーテーションで囲まれているのが分かります)(4)関数
関数はプログラム内で実行される命令のことです。最初からpythonやライブラリに実装されている関数と、自分で定義する関数があります。
最初にHello World!と表示するために使用した「print()」はpythonに最初から実装されている関数の一つです。
・引数と返り値(戻り値)
関数には引数と返り値(戻り値とも言う)と呼ばれるものがあります。pythonで使われる関数も、一般的な数学の関数と同じ仕組みで、何かの入力に対して何かの出力を行う機能を有しています。
例えば、数学のy=2x+1という関数では、xが入力、yが出力になります。同じようにpythonにおけるsinの値を計算する関数を例にするとy = math.sin(x)という関数は、math.sin(x)のxが入力でyが出力になります。正確には、入力xに対して、math.sin(x)は計算結果(出力)を返す仕組みのため、返された計算結果をyに代入しています。プログラムのルールでは、関数の入力を引数、出力を返り値と呼ぶことになっています。
(5)型(データ型)
pythonには、int(整数)、float(浮動小数)、str(文字列)などの型(データ型)が定義されています。異なる型同士を扱う場合には注意が必要となります。
例えば、int型の変数とfloat型の変数を足す場合に、足した結果がint型になるのかfloat型になるのかは、実行環境によって異なる場合があります。また、int型とstr型を+演算子で足すことはできません。このため、各変数がどの型であるかを確認するための関数が用意されています。
以下のコードを実行するとコンソールに変数aの型が表示されます。a = 1 print(type(a))コンソール表示
<class 'int'>変数aはint型であることが確認できました。では次のようなコードではどうなるでしょうか。
b = 1.0 print(type(b))実行結果は以下のとおりとなりました。bはfloat型でした。
<class 'float'>それではさらに、次のような場合はどうでしょうか、結果はint型でしょうか、float型でしょうか。
a = 1 b = 1.0 c = a + b print(type(c))結果はfloat型でした。
<class 'float'>昔のプログラミング言語では、同じ型同士でないと計算ができない場合もありましたが、pythonは賢いので自動的に適切な型に計算結果を合わせてくれます。しかしながら、機械学習で行う複雑な数値演算を行う場合には、型の違いが予期せぬ結果やエラーを引き起こすことがよくあります。
実際に皆さんが機械学習を行う際に計算すべき変数の型について注意を払うと予期せぬエラーを回避することができることがあります。(6)制御文
制御文とは、条件によって実行する命令を選択したり、命令を必要な回数繰り返すための仕組みです。
・if
ifはもし~であれば、という条件を示して命令を実行するかどうかを決める制御文です。
次のプログラムは、もしaが0であれば、print(a)を実行します。ifの次のaと0の間にある==は左右の値が同じかどうかを比較する演算子です。また、プログラムの[TAB]はTABキーのことです。a = 0 if a == 0: [TAB]print(a)このプログラムでは、まずa=0でaに0という値を代入し、if a==0:によってaと0の値を比較し、同じ値であれば、:以降の命令(print(a))を実行しなさいという意味になります。
ここで注意が必要なことは、ifなどの制御文によって実行される命令の範囲は、TABキーによって字下げが行われている範囲となります。TABキーによって制御文などの実行範囲を指定する書き方はPythonの特徴の一つであり、必ず覚えておく必要があります。・for
forは指定した回数命令を実行するための制御文です。書き方の例を以下に示します。繰り返す命令はTABキーによって字下げする必要があります。
a = 10 for i in range(a): [TAB]print(i)このプログラムでは、aに10を代入して、aの回数だけ命令を実行します。range(a)によって命令を実行する回数を指定します。(ここでは10)また、何回実行しているかは、forの後にあるiという変数に毎回記憶されます。このため、このプログラムを実行すると、a回(10回)print(i)が実行されるため、iの数値が実行回数によって変わります。
(7)クラス
クラスとは、関数や変数をひとまとまりにした塊のことです。このクラスを利用することで、効率的にプログラムを記述することができます。例えば下のmath.sin(x)はmathクラスの関数sin()を呼び出す形式となっています。このmathクラスは他にも数学に関係する関数を多く持っており、わざわざ自分で関数を作らなくても、簡単に関数を利用することができます。
y = math.sin(x)このクラスを利用するためには、あらかじめプログラムの先頭でクラスを使うことを宣言する必要があります。実際にmath.sin()を利用しとうとすると、以下のようなプログラムになります。
import math y = math.sin(x)importとは、必要なクラス(モジュールとも言う)を利用するための命令で、ここではmathというクラス(モジュール)を利用することを宣言しています。pythonには様々なクラス(モジュール)が用意されており、機械学習関係のものもあります。
(8)Numpy
Numpyは数値計算を行うために用意されているモジュールで、機械学習では特に重要な役割を果たします。このNumpyでよく使うのが配列とよばれる仕組みです。配列とは、複数の変数を一つにまとめて扱うための仕組みです。例として1,2,3の3つの値を持つ配列を作成してみます。
import numpy as np a = np.array([1,2,3]) print(a)上のプログラムを実行すると[1,2,3]と表示されます。1,2,3の3つの値が入った配列が作られました。この配列は一つ一つの変数を操作することもできます。以下は配列の最初の数値のみを表示するプログラムです。
import numpy as np a = np.array([1,2,3]) print(a[0])このように、配列は配列名のあとに[]を付けることで、個別の変数を操作できます。ここで注意が必要なのは、変数につけられた名前は0から始まります。上のプログラムでは、1という変数に付けられた名前はa[0]になります。同様に2はa[1]、3はa[2]になります。以下のプログラムはforを使って配列の中身を順番に表示します。
import numpy as np a = np.array([1,2,3]) for i in range(3): [TAB]print(a[i])配列は、行列のように多次元に拡張することができます。以下のプログラムでは、2×2の配列を作成しています。
import numpy as np a = np.array([[1,2],[3,4]]) print(a)多次元配列の場合に各変数を操作したい場合には、配列の後ろに[]をつなげることで操作が可能です。
import numpy as np a = np.array([[1,2],[3,4]]) for i in range(2): [TAB]for j in range(2): [TAB][TAB]print(a[i][j])この配列操作は機械学習で膨大なデータを扱う場合に大変重要な役割を果たします。
機械学習を実践する場合には配列の扱いに慣れているかどうかで効率が大きく異なります。3.最後に
以上、必要最低限のPythoの使い方について説明しました。
実際には制御文や演算子、関数やモジュールなど機械学習を実践するために必要な知識はまだまだ多くありますが、全てを完璧に習得してから何かに取り組むのではなく、必要になった段階で調べて習得する方が効率的であると考えます。

- 投稿日:2019-07-10T10:12:33+09:00
AWSLambda + Python3 でLINEに通知してくれるToDoリストを作った話
作り始めた経緯
一か月前ほどからJavaを使ってandroidアプリ開発の勉強を始めたのですが、ToDoリストを作っている途中で
「よく考えたら普段使いはPCとiPhoneだった」
ということに気づき、このまま使いもしないandroidアプリを作るくらいだったらとりあえずPCからタスク管理ができるものを作ろうということで作り始めました。AWSを使う
AWS(Amazon Web Service)はクラウドで様々なことを行えるサービスです
登録後12か月は無料枠がありますし、個人で使う分には利用料金もそこまでしないので安心です。AWS登録はこちら
https://aws.amazon.com/jp/
今回は様々なサービスがある中でLambdaとS3とCloudWatchEventsを使っていきます。
Lambda:関数を作って何かのトリガーで実行する機能
S3:ファイルを保存するストレージ
CloudWatchEvents:指定した時間に関数を叩いてくれるくらいの認識で大丈夫だと思います。
システム概要
分かりにくいですがこんな感じに作っていきます。Lambda関数を作る
まずはLambdaの関数を作らなければ何も始まりませんので作っていきます。
まず関数の作成を押します。
一から作成を選択します。
すぐ下にこのような画面が出るので関数名と使う言語を入力し関数の作成を押します。
なんかこんな画面が出てきたらOKです。
ロールの設定
ロールにポリシーをアタッチしておかないと許可がなく実行できなかったりするのでロールの設定をしていきます。
先ほどのページを下がっていくと実行ロールの欄に既存のロールというというところがあります。そこのhogehogeロールを表示しますというところをクリックしてください。
すると、このようなページが出てくると思うのでポリシーをアタッチしますをクリックしてください。
その先のページで下記3つのポリシーをアタッチしてください。
これでポリシーの設定は完了です。PythonでAWSを扱う
PythonでAWSを扱うためにはboto3というライブラリを使用します。
初期設定などは少し難しいので偉大なる先人様の記事を参考にしました。
ココミテ
boto3を使ってS3をごにょごにょするS3にタスクをアップロードする
まずはクライアント側のプログラムを作ります。
細かいプログラムは人に見せられるような代物ではないので、ここでは僕が作っていて詰まった点とその解決法を書いていきます。受け渡しデータ
CSVファイルに渡すデータはタスク名、日付、時間の三つのデータです。
年のデータを渡していないので一年以内のタスクしか扱えません。ClientErrorが出る
これはtry-exceptで例外処理できるのですが、素の状態だとエラー名が見つからないので
from botocore.exceptions import ClientErrorしてから
try: hogehoge except(ClientError): hugahugaしてください。
データの受取型
with open した後に
reader = csv.reader(f)するのですが、readerにはreaderオブジェクトとして帰るのでそのままは使えません。
僕はfor文を使って二重ループで内容を回収しました。通知時間に到達しているかチェックする関数
ここからはLambda側で作っていきます。
なおLambdaにライブラリとコードをまとめたZIP形式でアップロードするためコーディングは自分側で行います。プログラム概要
データを保存するディレクトリ
Lambdaにデータを受け渡すためにS3にいったんCSV形式でタスクのデータを送っているため、それを受け取らなければいけません。
その際ダウンロードをする場所を/tmp/hogehoge.csvとしなければなりません。s3 = boto3.resource('s3') bucket = s3.Bucket('hoge') bucket.download_file('hogehoge.csv','/tmp/hogehoge.csv')のようにします。
handleについて
Lambdaは呼び出されたときhandle設定した関数にeventとcontextを渡して実行します。
今回はS3からデータを持ってきて利用するのでこの受け取った内容は使用しませんが、受け取らないとエラーを吐くのでしっかりとdef handle(event, context):と記述する必要があります。
また、handle名は自由につけることができ
上記のようにハンドラの欄から プログラム名.ハンドル名 の形式で設定します。Lambda上でのタイムゾーン
Lambda上では(多分)リージョンにかかわらずtimeモジュールで持ってくる時間がグリニッジ標準時(GMT)になっています。当然僕は日本でこのプログラムを利用するため日本時間(JST)になおす必要があります。
そのために環境変数の欄にキーをTZ、値をAsia/Tokyoと設定します。
するとtimeモジュールで持ってくる値が日本時間に変更されます。LambdaからLambdaを叩く
Lambda関数から別のLambda関数を叩くには
import boto3 import json clientLambda = boto3.client("lambda") clientLambda.invoke( FunctionName="send_line", #送る先の関数名 InvocationType="Event", #EventかRequestResponseどちらを受け取るか選ぶ Payload=json.dumps(event) )ここも少し難しかったので下記の先人様の記事を参考にさせていただきました。
AWS LambdaからLambda呼んでハマった話。
AWSのLambdaからLambdaを呼んで、Slackにメッセージを送信するLambdaにZIP形式でアップロードする
ライブラリをインポートして使用している場合Lambdaで扱うためにはライブラリとプログラム本体をまとめたZIP形式のファイルでアップロードする必要があります。
C:\Users\user\programfile> pip install hogehoge -t ./とかでプログラムと同階層に利用したライブラリを入れてください。
その後ZIP圧縮するのですが、この際ファイルの置いてあるディレクトリを圧縮すると階層が一つ深くなってhandleを掴めなくなってしまうようなので、ファイル自体を全選択して圧縮します。
あとはここに投げて保存して終了です。
一応、ハンドルがつかめているか確認するためにテストイベントを実行します。
テストイベントの設定を押して
空のテストイベントを作成します。
その後テストから実行します。handleを掴めていてほかのエラーが出ていればとりあえずOKです。CloudWatchEventsのcron式
cron式の記法は[分 時間 日 月 曜日 年]の形式で書きます。
cron式の日フィールドと曜日フィールドは同時に指定することができないとCloudWatchEventsのガイドに書いてあるので、どちらか一方でワイルドカード?(疑問符)を使用する必要があります。ルールのスケジュール式 - Amazon CloudWatch Events
このプログラムは一時間に一回、00分に叩かれる必要があるので
[0 * * * ? *]
のように記述しました。LINE Notifyの設定をする
設定はこちらから
ラインに通知を行うためにLINEのAPIサービスのLINE Notifyの登録を行います。
ページを見ればわかるとは思いますが詰まった場合は
[超簡単]LINE notify を使ってみる
のページを参考にすることをお勧めします。LINE送信部
アクセストークンが発行出来たら、先ほどのLambda関数でメッセージが生成されたときに叩かれるsend_line関数を作成していきます。
権限
ロールにアタッチする権限はS3のreadonly権限のみでOKです。
初期設定
url = "https://notify-api.line.me/api/notify" token ="accesstoken" #各個取得したアクセストークン headers = {"Authorization" : "Bearer "+ token}これをスクリプト内に記述します。
プログラム概要
メッセージのCSVファイルを受け取って読み取って各メッセージごとにラインに送るだけ。
メッセージ複数送信
for mess in mess_lis: message = mess payload = {"message" : message} r = requests.post(url ,headers = headers ,params=payload)こうしておけば複数送信も可能です。
最後に
今回はAWSのさわりとしてこのようなToDoリストを作ってみました。
初めての投稿で読みずらい箇所多々あったとは思いますが、また何か作った際にはもっと改善して読みやすい記事を書けるようになってきますのでよろしくお願いします。余談なのですが、最近「ほんとに使える「ユーザービリティ」(エリック・L.ライス著)」という本を読みました。振り返ってみるとこの記事は写真が多すぎた気がします。
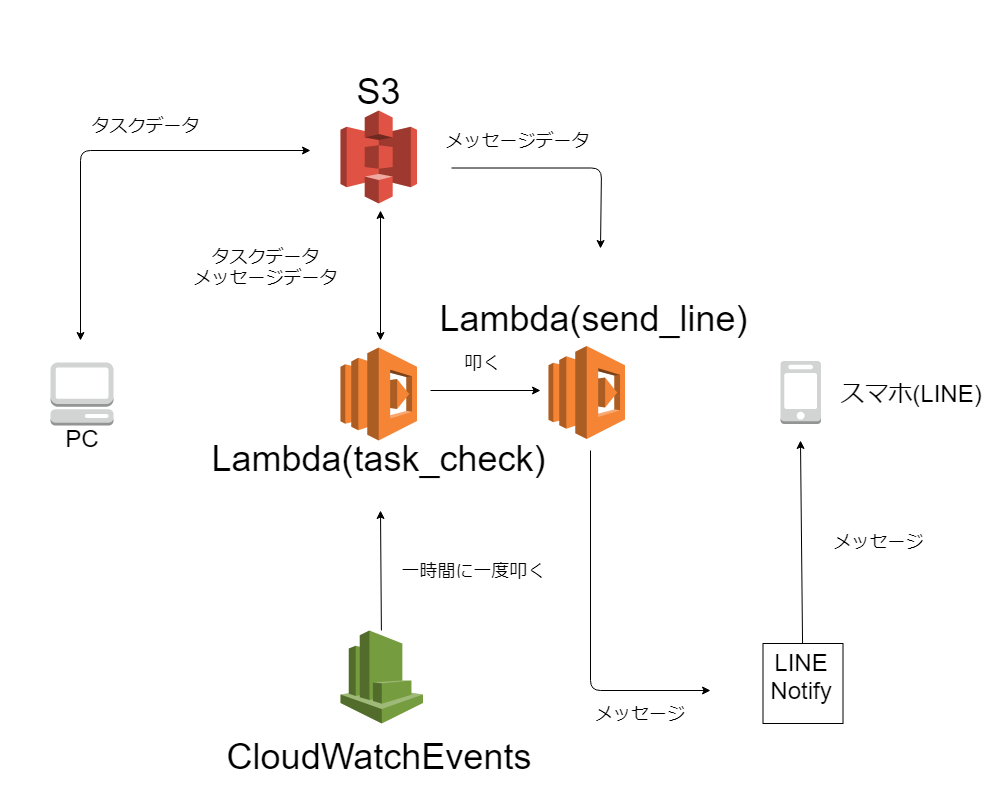

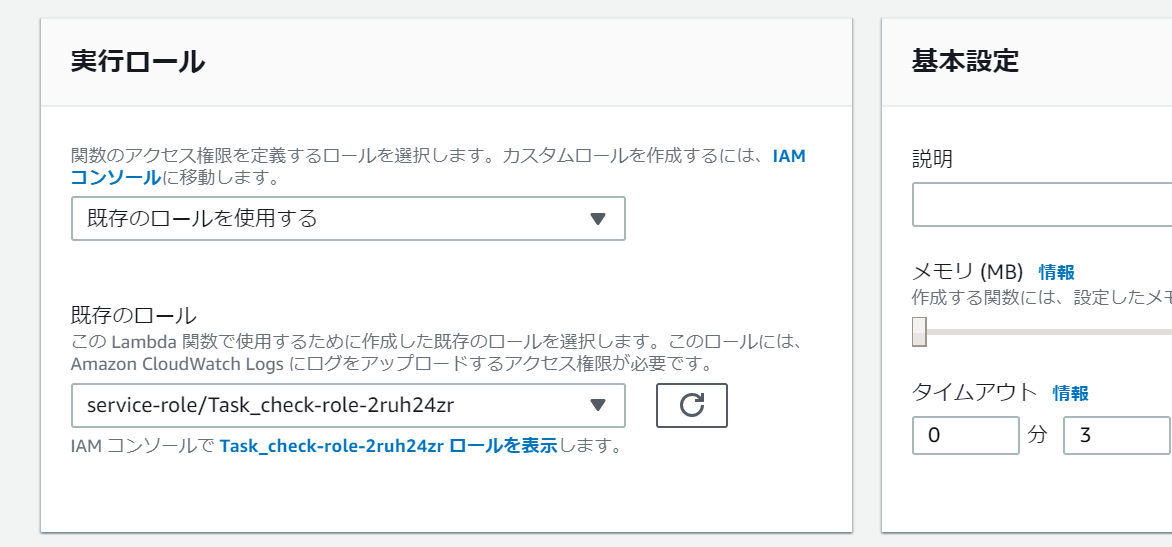
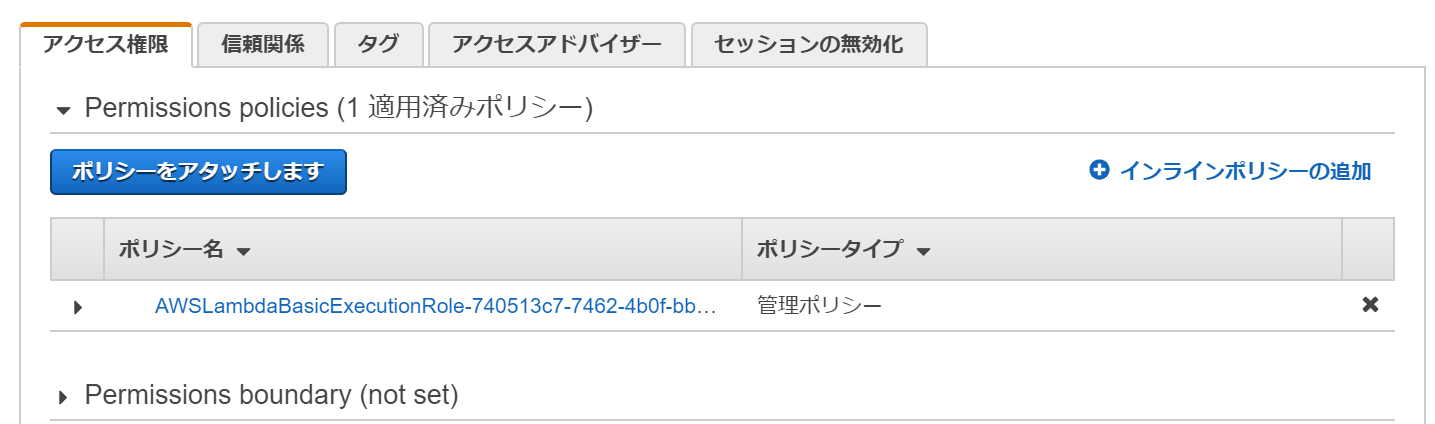
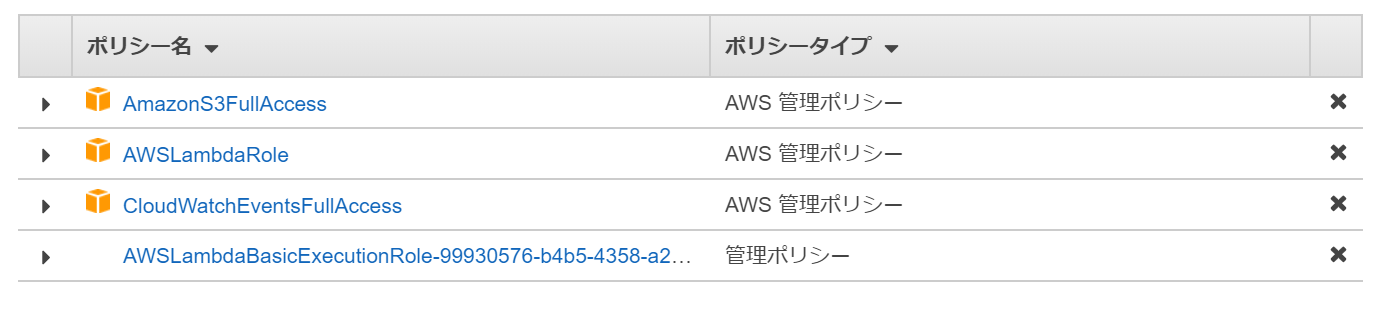
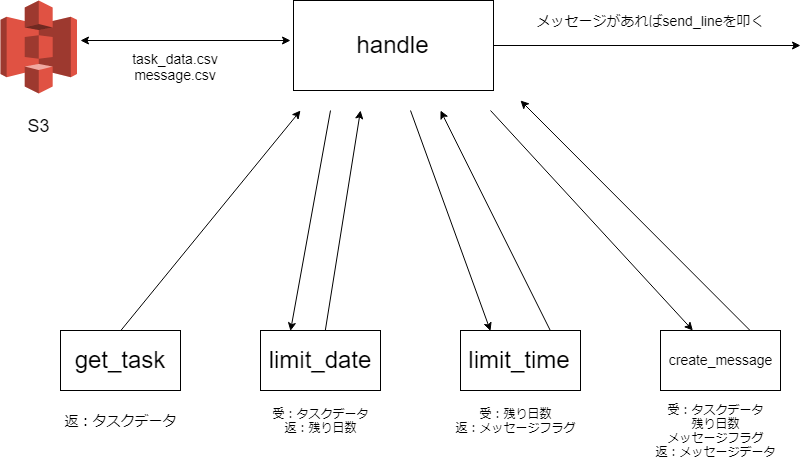

- 投稿日:2019-07-10T09:17:12+09:00
OpenCVのMat型オブジェクトどうしをテストコードで比較する
OpenCVで
cv2.imread()などを行うと、Mat型のオブジェクトが返ります。
cv::Mat Class Reference二つのMatオブジェクトをPythonの
unittestのテストコードで単純に比較しようとしたらエラーが出てしまいました。動作確認してません.pyfrom unittest import TestCase import cv2 class hogehoge(TestCase): def hoge(self): mat1 = cv2.imread('hoge1.jpg') # mat1を何か処理 mat2 = cv2.imread('hoge2.jpg') # mat2を何か処理 # mat1とmat2が同じになってるか確かめたい self.assertEqual(mat1, mat2) # ValueError: The truth value of an array with more than one element is ambiguous. Use a.any() or a.all()エラーメッセージに書いてある通り、Mat型のような中身がたくさんあるオブジェクト(曖昧)は単純な比較ができないようです。
Use a.any() or a.all()と書いてあるように、素直にそれらを使いましょう。次のようにテストコードを修正することで、いい感じにテストを実行できるようになりました。
動作確認してません.pyfrom unittest import TestCase import cv2 class hogehoge(TestCase): def hoge(self): mat1 = cv2.imread('hoge1.jpg') # mat1を何か処理 mat2 = cv2.imread('hoge2.jpg') # mat2を何か処理 # mat1とmat2が同じになってるか確かめたい self.assertTrue((mat1 == mat2).all()) # Ran 1 tests in 0.037s # # OK
- 投稿日:2019-07-10T09:00:15+09:00
AWS CloudFormationのLambda-Backedカスタムリソースでリソース作成を待ち受けできるようにする
AWS CloudFormation(CFn)のLambda-Backedカスタムリソースを利用するとCFnが対応していないリソースでもAWS Lambdaを利用して管理できます。
AWS Lambda-backed カスタムリソース - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-custom-resources-lambda.htmlその際に、リソース作成するとレスポンスはすぐに返ってくるけど、リソースが利用できるまでに時間がかかるものを取り扱えるようにしてみました。
テンプレート
CFnでリソース作成を待ってから関連するリソース作成などができるようにするテンプレートです。
Resources: CreateResource: Type: Custom::CustomResource Properties: ServiceToken: !GetAtt CreateResourceFunction.Arn CustomResource: Type: Custom::CustomResource Properties: ServiceToken: !GetAtt CustomResourceFunction.Arn ResourceId: !GetAtt CreateResource.Id DependsOn: CreateResource CreateResourceFunction: Type: AWS::Lambda::Function Properties: Handler: index.handler Role: !GetAtt FunctionExecutionRole.Arn Code: ZipFile: !Sub | import cfnresponse def handler(event, context): response = {} if event['RequestType'] == 'Create': try: # ほんとはここでリソース作成 response = { "Id": "hoge" } except Exception as e: response = {'error': str(e)} cfnresponse.send(event, context, cfnresponse.FAILED, response) return cfnresponse.send(event, context, cfnresponse.SUCCESS, response) Runtime: python3.7 CustomResourceFunction: Type: AWS::Lambda::Function Properties: Handler: index.handler Role: !GetAtt FunctionExecutionRole.Arn Code: ZipFile: !Sub | import cfnresponse import time def handler(event, context): Id = event['ResourceProperties']['ResourceId'] # リソース作成完了を待ち受ける response = {} while True: # ホントはここでリソース取得 response = { "Id": Id, "Status": "AVAILABLE" } # 特定のステータスになったら抜ける if response['Status'] == 'AVAILABLE': break print('create wait...') time.sleep(60) cfnresponse.send(event, context, cfnresponse.SUCCESS, response) Runtime: python3.7 Timeout: 900 FunctionExecutionRole: Type: AWS::IAM::Role Properties: AssumeRolePolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Principal: Service: - lambda.amazonaws.com Action: - sts:AssumeRole Path: "/" Policies: - PolicyName: root PolicyDocument: Version: '2012-10-17' Statement: - Effect: Allow Action: - logs:CreateLogGroup - logs:CreateLogStream - logs:PutLogEvents Resource: "arn:aws:logs:*:*:*"ポイント
カスタムリソースを2つ用意する
リソースを作成する
CreateResourceとリソース情報を取得するCustomResourceのカスタムリソースを定義することで、リソース作成を待ち受けできるようにしています。Lambda関数のタイムタウト x 3回まで待ち受けできる
AWS Lambdaの関数は最大15分のタイムタウト設定ができます。またLambda-Backedカスタムリソースで関数実行に失敗すると3回までリトライしてくれるのでそれを利用して最大45分間待ち受けできるようになります。
AWS Lambda の制限 - AWS Lambda
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/limits.html※Lambda-Backedカスタムリソースでのリトライ回数について必ず3回実行されるのかはドキュメントが見当たらず不明確となります。
AWS Lambda 再試行動作 - AWS Lambda
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/retries-on-errors.html
DependsOn属性を利用してリソース作成順を制御するCFnの
DependsOn属性を利用することで、リソース作成CreateResource後、リソース情報取得CustomResourceが実行されるようにします。
後続するリソースはCustomResourceをDependsOn属性に指定することでリソース作成完了してから実行されるようにできます。DependsOn 属性 - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-attribute-dependson.htmlカスタムリソースの更新・削除と絡めて利用する
下記記事の内容と組み合わせることで、カスタムリソースの更新・削除が実現できます。
AWS CloudFormationのLambda-backedカスタムリソースでリソースの更新・削除をする方法 - Qiita
https://qiita.com/kai_kou/items/7be2eb9a36611bb5da12参考
AWS Lambda-backed カスタムリソース - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/template-custom-resources-lambda.htmlAWS Lambda の制限 - AWS Lambda
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/limits.htmlAWS Lambda 再試行動作 - AWS Lambda
https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/retries-on-errors.htmlDependsOn 属性 - AWS CloudFormation
https://docs.aws.amazon.com/ja_jp/AWSCloudFormation/latest/UserGuide/aws-attribute-dependson.htmlAWS CloudFormationのLambda-backedカスタムリソースでリソースの更新・削除をする方法 - Qiita
https://qiita.com/kai_kou/items/7be2eb9a36611bb5da12
- 投稿日:2019-07-10T08:54:23+09:00
SphinxとGitHub Pagesで技術ノートを公開しよう!
はじめに
なんからの技術的な調査(もちろん技術的でなくてもよいのですが)をしたときに、なんらかの形でアウトプットすることが多いと思います。たとえばQiitaやはてなブログ、Wikiといったものです。
今回は Sphinx+GitHub Pages を用いることで比較的簡単にWebで技術ノートを作れてアウトプットできるよ、ということを紹介します。Webページだけでなく、PDFなんかも生成することができます。
なお想定する環境は Windows10 です。試してはいないですが MacOS でも問題ないと思います。
ライトな Web ページからしっかりしたドキュメントまでいろいろな用途で用いることができます。例えば Docker ドキュメント日本語化プロジェクト には Sphinx が使われています。
Sphinxとは?
Sphinx は知的で美しいドキュメントを簡単に作れるようにするツールです。Georg Brandl によって開発された Python 製のツールです。
インストール方法
ということでさっそく Python をインストールします。こちら から Python3 をダウンロードしてインストールしましょう。
D:\>python --version Python 3.7.3続いて
pip installで Sphinx をインストールしましょう。基本的に Sphinxの最初の一歩 のUser's ドキュメントに沿って実施します。D:\>pip install sphinx使い方
プロジェクト作成
まずはプロジェクトを作りましょう。
sphinx-quickstartコマンドでプロジェクトを作成することができます。なんやかんや聞かれますが、基本的にはそのまま Enter を押せばOKです。D:\note>sphinx-quickstart Welcome to the Sphinx 2.1.2 quickstart utility. Please enter values for the following settings (just press Enter to accept a default value, if one is given in brackets). Selected root path: . You have two options for placing the build directory for Sphinx output. Either, you use a directory "_build" within the root path, or you separate "source" and "build" directories within the root path. > Separate source and build directories (y/n) [n]: y The project name will occur in several places in the built documentation. > Project name: sample-project > Author name(s): tsuji > Project release []: If the documents are to be written in a language other than English, you can select a language here by its language code. Sphinx will then translate text that it generates into that language. For a list of supported codes, see https://www.sphinx-doc.org/en/master/usage/configuration.html#confval-language. > Project language [en]: ja Creating file .\source\conf.py. Creating file .\source\index.rst. Creating file .\Makefile. Creating file .\make.bat. Finished: An initial directory structure has been created. You should now populate your master file .\source\index.rst and create other documentation source files. Use the Makefile to build the docs, like so: make builder where "builder" is one of the supported builders, e.g. html, latex or linkcheck.プロジェクトの作成が完了すると以下のような構成のファイルが生成されていることがわかります。
D:\note>tree /f D:. │ make.bat │ Makefile │ ├─build └─source │ conf.py │ index.rst │ ├─_static └─_templates
make.batを用いて HTML ファイルを生成したり、ローカルで Preview ができます。ドキュメント作成
それでは、ドキュメントを作成します。まずは Web サイトのトップページ、ノートの目次となるような index ドキュメントを作成しましょう。(といってもファイルは自動生成されています)
ポイントは reStructuredText というマークアップ言語を用いて記述することです。ドキュメントの記述といえば markdown! という方も多いと思います。私もそうでした。最初は reStructuredText の記述方法がちょっと慣れないかも知れませんが、reStructuredText はシンプルに設計された、控えめなマークアップ言語なので、すぐに慣れると思います。reStructuredText は reST と省略することが多いようで、reST と省略することにします。
index となるファイルは
index.rstです。中を見ると以下のようになっていることがわかります。index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search`早速ビルドしてHTMLファイルを生成しましょう。ビルドは
make.batを用いてmake htmlコマンドでビルドできます。D:\note>make html Running Sphinx v2.1.2 loading translations [ja]... done making output directory... done building [mo]: targets for 0 po files that are out of date building [html]: targets for 1 source files that are out of date updating environment: 1 added, 0 changed, 0 removed reading sources... [100%] index looking for now-outdated files... none found pickling environment... done checking consistency... done preparing documents... done writing output... [100%] index generating indices... genindex writing additional pages... search copying static files... done copying extra files... done dumping search index in Japanese (code: ja) ... done dumping object inventory... done build succeeded. The HTML pages are in build\html.
build\html配下にindex.htmlというファイルが生成されていることがわかります。アクセスすると以下のようになっていることがわかります。
コンテンツの追加
index ページが作成できたらコンテンツを追加したいですよね?追加してみます。以下のように
index.rstに追記し、hello.rstというファイルを作成します。「はじめてのSphinx」というページを追加します。index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: + hello Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search`hello.rst+はじめてのSphinx +=============================== + +Hello Sphinx!!!
make htmlでビルドして、再度index.htmlにアクセスすると以下のようになります。
「はじめてのSphinx」 のページが追加されていることがわかります。このページにアクセスしてみましょう。
ちゃんとページのコンテンツが表示されています。
階層のあるコンテンツ
階層のあるコンテンツを追加することも簡単にできます。先ほどの
index.rstに段落のあるページを追加してみます。index.rstへの追記と新しいファイルhierarchy.rstを作成します。index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: hello + hierarchy Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search`hierarchy.rst+段落 +================================== + +--------------------------------- +段落1 +--------------------------------- + +AAAAAA + +--------------------------------- +段落2 +--------------------------------- + +BBBBBB + +--------------------------------- +段落3 +--------------------------------- + +CCCCCC + +--------------------------------- +段落4 +--------------------------------- + +DDDDDD
hierarchy.rstは reST で書かれています。必要になったときに こちら を見てみると良いかもしれません。
make htmlでビルドして、アクセスします。すると、階層のあるページが追加されたことがわかります。
コードの記述
コードを記述して、シンタックスハイライトで表示することももちろん可能です。
index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: hello hierarchy + code Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search`コードは
.. code-block::を用いて記述することができます。source/code.rst+コードを記述 +================================== + +`` .. code-block:: `` を用いることでコードをハイライトすることができます。 + +.. code-block:: go + :caption: hello.go + + package main + + import "fmt" + + func main() { + fmt.Println("Hello, world!") + }以下のように表示されます。
ポイントは、正しく インデントと 空行 が必要ということです。(
.. code-block::) だけに限った話ではないですが。インデントと空行を含めないと表示されません。たとえば以下のようにすると表示されません。気づきにくいと思うので注意が必要です。私は最初にハマりました。
source/code.rstコードを記述 ================================== `` .. code-block:: `` を用いることでコードをハイライトすることができます。 .. code-block:: go コードを記述 ================================== + +表示されるコード +------------------------------------------------- ``` .. code-block:: ``` を用いることでコードをハイライトすることができます。 .. code-block:: go :caption: hello.go package main import "fmt" func main() { fmt.Println("Hello, world!") } + +正しく表示されないコード(その1:インデントがない) +-------------------------------------------------- + +.. code-block:: go + +package main + +import "fmt" + +func main() { + fmt.Println("Hello, world!") +} + +正しく表示されないコード(その2:空行がない) +------------------------------------------------- + +.. code-block:: go + package main + + import "fmt" + + func main() { + fmt.Println("Hello, world!") + }こんな感じになります。
その他いろいろな記述方法
階層以外にも reST を用いていろいろな記述ができます。その中の一部である以下の記述方法を紹介します。
- テーブル
- 脚注
- 数式
- TODO
index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: hello hierarchy code + other Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search` +.. todolist::source/other.rst+その他の機能 +================================== + +--------------------------------- +テーブル +--------------------------------- + +===== ===== ======= +A B A and B +===== ===== ======= +False False False +True False False +False True False +True True True +===== ===== ======= + +--------------------------------- +脚注 +--------------------------------- + +これは 脚注 [#]_ です。 + +.. [#] 本文の下の方につける注記 + +--------------------------------- +数式 +--------------------------------- + +数式を有効にするには、``conf.py`` に ``sphinx.ext.mathjax`` という拡張モジュールを追加する必要があります。以下のような感じです。モジュールを有効にすれば、LaTeX で数式を記述することができます。 + +.. code-block:: python + :caption: conf.py + + # Add any Sphinx extension module names here, as strings. They can be + # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom + # ones. + extensions = ['sphinx.ext.mathjax' + ] + +`N` 個の整数 :math:`d[0], d[1], \dots, d[N-1]` が与えられます。これは数式のサンプルです。 + +--------------------------------- +TODO +--------------------------------- + +TODOも拡張モジュール ``sphinx.ext.todo`` を有効にすると記述できるようになります。あとでやりたいことを残しておくときに便利ですね。 + +.. code-block:: none + :caption: conf.py + + # Add any Sphinx extension module names here, as strings. They can be + # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom + # ones. + extensions = ['sphinx.ext.mathjax', 'sphinx.ext.todo' + ] + + [extensions] + todo_include_todos = True + +.. todo:: + + これは TODO なので、後ほど調査する + +TODOを表示する場所も選ぶことができます。今回は index ページに記載しておきましょう。表示させたい場所に ``` .. todolist:: ``` と記述しておけばよいです。 + +.. code-block:: rest + + .. sample-project documentation master file, created by + sphinx-quickstart on Mon Jul 8 22:38:47 2019. + You can adapt this file completely to your liking, but it should at least + contain the root `toctree` directive. + + Welcome to sample-project's documentation! + ========================================== + + .. toctree:: + :maxdepth: 2 + :caption: Contents: + + hello + hierarchy + code + other + + Indices and tables + ================== + + * :ref:`genindex` + * :ref:`modindex` + * :ref:`search`こんな感じで見えます。きれいですね。
プレビュー
先ほどまではページについての記述方法でした。今度はビルドするときの便利な方法を紹介します。
いままではファイルを修正するたびに
make htmlとビルドして、HTML を生成して確認する、、、としていました。何度も変更するとちょっと面倒です。ファイルの変更が自動的に Web ページに反映されると嬉しいですよね。Sphinxの
sphinx-autobuildを用いると、ファイルを変更すると自動的にビルドが実行され、更新が反映されます。便利です。これを使ってみましょう。
sphinx-autobuildモジュールが必要なので、pip でインストールします。pip install sphinx-autobuildインストールできたら、
sphinx-autobuildコマンドで起動させます。$ sphinx-autobuild -b html source build/html +--------- manually triggered build --------------------------------------------- | Running Sphinx v2.1.2 | loading translations [ja]... done | building [mo]: targets for 0 po files that are out of date | building [html]: targets for 5 source files that are out of date | updating environment: 5 added, 0 changed, 0 removed | reading sources... [ 20%] code | reading sources... [ 40%] hello | reading sources... [ 60%] hierarchy | reading sources... [ 80%] index | reading sources... [100%] other | | looking for now-outdated files... none found | pickling environment... done | checking consistency... done | preparing documents... done | writing output... [ 20%] code | writing output... [ 40%] hello | writing output... [ 60%] hierarchy | writing output... [ 80%] index | writing output... [100%] other | | generating indices... genindex | writing additional pages... search | copying static files... done | copying extra files... done | dumping search index in Japanese (code: ja) ... done | dumping object inventory... done | build succeeded. | | The HTML pages are in build\html. +-------------------------------------------------------------------------------- [I 190709 08:34:05 server:296] Serving on http://127.0.0.1:8000 [I 190709 08:34:05 handlers:62] Start watching changes [I 190709 08:34:05 handlers:64] Start detecting changesするとローカルで Web サーバが 8000 ポートで listen するようになることがわかります。ブラウザから以下にアクセスすると、先ほどまでローカルでビルドしてHTMLを生成していた内容が表示されていることがわかります。
http://localhost:8000/
sphinx-autobuildのコマンドを覚えるのがちょっと面倒という方はmake.batに追記すると便利かもしれません。
以下のようにmake.batに追記しておきます。make.bat@ECHO OFF pushd %~dp0 REM Command file for Sphinx documentation if "%SPHINXBUILD%" == "" ( set SPHINXBUILD=sphinx-build ) set SOURCEDIR=source set BUILDDIR=build if "%1" == "" goto help if "%1" == "preview" ( echo.Running sphinx-autobuild. View live edits at: echo. http://0.0.0.0:8000 sphinx-autobuild -b html %SOURCEDIR% %BUILDDIR%/html if errorlevel 1 exit /b 1 goto end ) %SPHINXBUILD% >NUL 2>NUL if errorlevel 9009 ( echo. echo.The 'sphinx-build' command was not found. Make sure you have Sphinx echo.installed, then set the SPHINXBUILD environment variable to point echo.to the full path of the 'sphinx-build' executable. Alternatively you echo.may add the Sphinx directory to PATH. echo. echo.If you don't have Sphinx installed, grab it from echo.http://sphinx-doc.org/ exit /b 1 ) +:html +%SPHINXBUILD% -b html %SOURCEDIR% "docs" %SPHINXOPTS% %O% +goto end %SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% goto end :help %SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% :end popd起動するときは以下のように
make previewとすれば良いです。
GitHub Pages との連携
さて、ローカルでドキュメントを作成することができたので、これを GitHub Pages で公開してみましょう。GitHub でドキュメントのソースを管理しつつ、簡単に公開できるのがよいですね。
まずは作成したドキュメントを GitHub にアップしておきます。GitHub のリポジトリ名は sphinx-sample としておきます。
.gitignore+build/doctrees +.DS_Storegit init git add -A git commit -m "init" git remote add origin https://github.com/d-tsuji/sphinx-sample.git git push -u origin masterGitHub Pages で公開するにあたって今回は master ブランチの docs ディレクトリを用いて公開することにします。
そのためにビルドしたときに出力されるディレクトリを少し修正します。ビルドするときのコマンドはmake htmlとしておきます。make.bat@ECHO OFF pushd %~dp0 REM Command file for Sphinx documentation if "%SPHINXBUILD%" == "" ( set SPHINXBUILD=sphinx-build ) set SOURCEDIR=source set BUILDDIR=build if "%1" == "" goto help if "%1" == "preview" ( echo.Running sphinx-autobuild. View live edits at: echo. http://0.0.0.0:8000 sphinx-autobuild -b html %SOURCEDIR% %BUILDDIR%/html if errorlevel 1 exit /b 1 goto end ) %SPHINXBUILD% >NUL 2>NUL if errorlevel 9009 ( echo. echo.The 'sphinx-build' command was not found. Make sure you have Sphinx echo.installed, then set the SPHINXBUILD environment variable to point echo.to the full path of the 'sphinx-build' executable. Alternatively you echo.may add the Sphinx directory to PATH. echo. echo.If you don't have Sphinx installed, grab it from echo.http://sphinx-doc.org/ exit /b 1 ) +:html +%SPHINXBUILD% -b html %SOURCEDIR% "docs" %SPHINXOPTS% %O% +goto end %SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% goto end :help %SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% :end popd
make htmlでビルドするとdocsディレクトリに HTML ファイルが生成されたことがわかります。buildディレクトリは不要なので削除しておきます。ディレクトリ構成は以下のようになっています。( HTML ファイルや doctree ファイルは省略)
D:. │ .gitignore │ make.bat │ Makefile ├─docs │ ├─.doctrees │ ├─_sources │ └─_static └─sourceコミットして GitHub にアップします。
GitHub の GUI から GitHub Pages の設定をしておきます。以下のようになります。
設定したら、URL(https://d-tsuji.github.io/sphinx-sample/) にアクセスします。
そうすると、CSS が見事きいていないことがわかります。悲しいですね。
GitHi Pages は、デフォルトで JekyII でホスティングを行います。しかし、JekyII は Sphinx に対応していないため、
_staticなどにあるパスを読み取ることができません。対応として.nojekyllのディレクトリを作成する必要があります。手動で作成しても問題ないですが、今回はsphinx.ext.githubpagesを用いて対応することができます。
sphinx.ext.githubpagesプラグインは GitHub Pages で公開するために、.nojekyllファイルをHTMLディレクトリ内に作成します。source/conf.py... # -- General configuration --------------------------------------------------- # Add any Sphinx extension module names here, as strings. They can be # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom # ones. -extensions = ['sphinx.ext.mathjax', 'sphinx.ext.todo' +extensions = ['sphinx.ext.mathjax', 'sphinx.ext.todo', 'sphinx.ext.githubpages' ] # Add any paths that contain templates here, relative to this directory. templates_path = ['_templates'] ...
conf.pyでプラグインの有効化したのち、再度make htmlでビルドします。そうするとdocs/.nojekyllのディレクトリが作成されていることがわかります。この状態で GitHub にプッシュします。
再度 https://d-tsuji.github.io/sphinx-sample/ にアクセスしてみます。
無事に CSS がきいて、いい感じになっていることがわかります!!!
ページのデザインは
conf.pyから設定することができます。( Sphinx に組み込まれていないテーマを選択する場合はtheme.confなどの追加の設定が必要です。)デフォルトだと以下のようにalabasterになっています。source/conf.py... # -- Options for HTML output ------------------------------------------------- # The theme to use for HTML and HTML Help pages. See the documentation for # a list of builtin themes. # html_theme = 'alabaster' ...以下にテーマごとのサンプルがあります。
一番最初に紹介した Docker ドキュメント日本語化プロジェクト のテーマは
sphinx_rtd_themeになっています。好みに合わせて選ぶことができます。まとめ
Sphinx を用いて技術ノートのような静的 Web ページを作成し、GitHub Pages で公開することができました。
今回は紹介しませんでしたが同じソースファイルから HTML ファイルだけでなく PDF ファイルも作成することができます。シンプルなツールで使いやすく、みなさんもたくさんドキュメントを書きたくなるのではないでしょうか。
参考資料



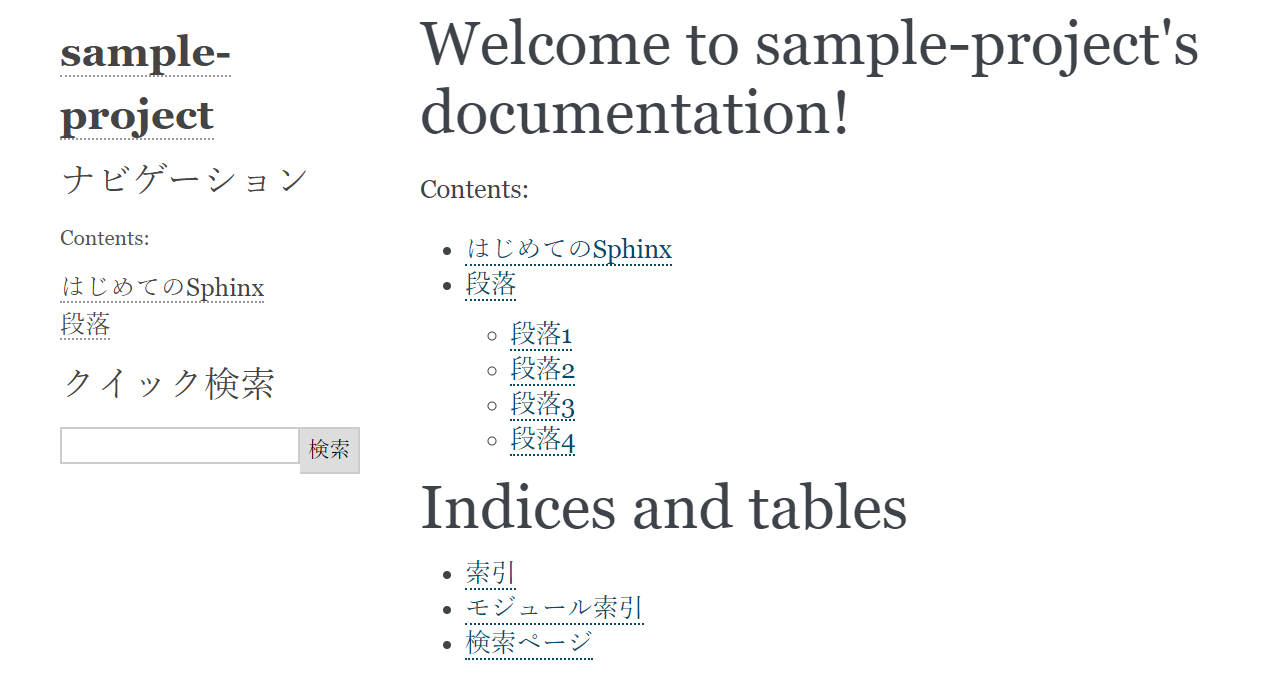

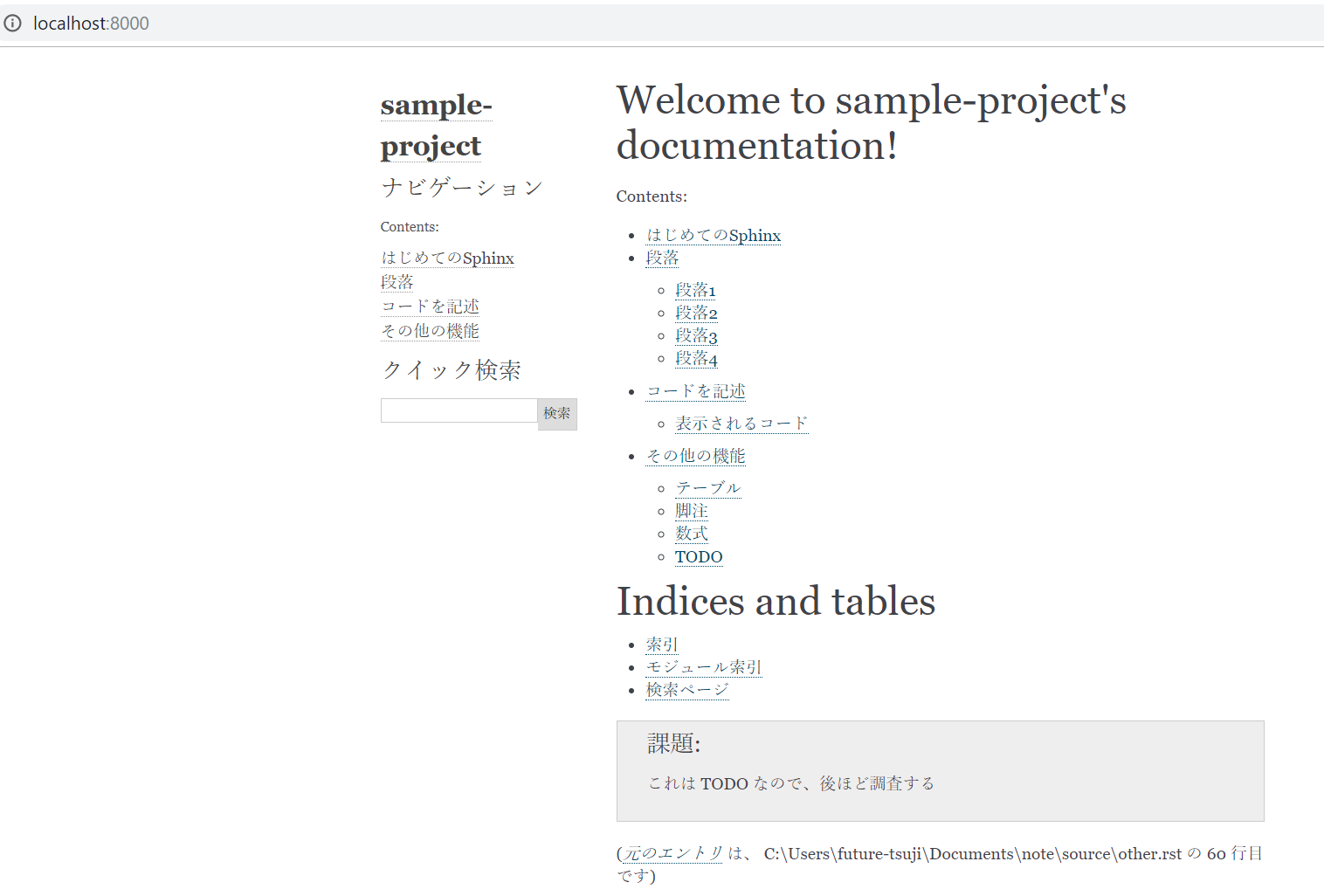
- 投稿日:2019-07-10T08:54:23+09:00
Sphinxで技術ノートを公開しよう!
はじめに
なんからの技術的な調査(もちろん技術的でなくてもよいのですが)をしたときに、なんらかの形でアウトプットすることが多いと思います。たとえばQiitaやはてなブログ、Wikiといったものです。
今回は Sphinx+GitHub Pages を用いることで比較的簡単にWebで技術ノートを作れてアウトプットできるよ、ということを紹介します。Webページだけでなく、PDFなんかも生成することができます。
なお想定する環境は Windows10 です。試してはいないですが MacOS でも問題ないと思います。
ライトな Web ページからしっかりしたドキュメントまでいろいろな用途で用いることができます。例えば Docker ドキュメント日本語化プロジェクト には Sphinx が使われています。
Sphinxとは?
Sphinx は知的で美しいドキュメントを簡単に作れるようにするツールです。Georg Brandl によって開発された Python 製のツールです。
インストール方法
ということでさっそく Python をインストールします。こちら から Python3 をダウンロードしてインストールしましょう。
D:\>python --version Python 3.7.3続いて
pip installで Sphinx をインストールしましょう。基本的に Sphinxの最初の一歩 のUser's ドキュメントに沿って実施します。D:\>pip install sphinx使い方
プロジェクト作成
まずはプロジェクトを作りましょう。
sphinx-quickstartコマンドでプロジェクトを作成することができます。なんやかんや聞かれますが、基本的にはそのまま Enter を押せばOKです。D:\note>sphinx-quickstart Welcome to the Sphinx 2.1.2 quickstart utility. Please enter values for the following settings (just press Enter to accept a default value, if one is given in brackets). Selected root path: . You have two options for placing the build directory for Sphinx output. Either, you use a directory "_build" within the root path, or you separate "source" and "build" directories within the root path. > Separate source and build directories (y/n) [n]: y The project name will occur in several places in the built documentation. > Project name: sample-project > Author name(s): tsuji > Project release []: If the documents are to be written in a language other than English, you can select a language here by its language code. Sphinx will then translate text that it generates into that language. For a list of supported codes, see https://www.sphinx-doc.org/en/master/usage/configuration.html#confval-language. > Project language [en]: ja Creating file .\source\conf.py. Creating file .\source\index.rst. Creating file .\Makefile. Creating file .\make.bat. Finished: An initial directory structure has been created. You should now populate your master file .\source\index.rst and create other documentation source files. Use the Makefile to build the docs, like so: make builder where "builder" is one of the supported builders, e.g. html, latex or linkcheck.プロジェクトの作成が完了すると以下のような構成のファイルが生成されていることがわかります。
D:\note>tree /f D:. │ make.bat │ Makefile │ ├─build └─source │ conf.py │ index.rst │ ├─_static └─_templates
make.batを用いて HTML ファイルを生成したり、ローカルで Preview ができます。ドキュメント作成
それでは、ドキュメントを作成します。まずは Web サイトのトップページ、ノートの目次となるような index ドキュメントを作成しましょう。(といってもファイルは自動生成されています)
ポイントは reStructuredText というマークアップ言語を用いて記述することです。ドキュメントの記述といえば markdown! という方も多いと思います。私もそうでした。最初は reStructuredText の記述方法がちょっと慣れないかも知れませんが、reStructuredText はシンプルに設計された、控えめなマークアップ言語なので、すぐに慣れると思います。reStructuredText は reST と省略することが多いようで、reST と省略することにします。
index となるファイルは
index.rstです。中を見ると以下のようになっていることがわかります。index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search`早速ビルドしてHTMLファイルを生成しましょう。ビルドは
make.batを用いてmake htmlコマンドでビルドできます。D:\note>make html Running Sphinx v2.1.2 loading translations [ja]... done making output directory... done building [mo]: targets for 0 po files that are out of date building [html]: targets for 1 source files that are out of date updating environment: 1 added, 0 changed, 0 removed reading sources... [100%] index looking for now-outdated files... none found pickling environment... done checking consistency... done preparing documents... done writing output... [100%] index generating indices... genindex writing additional pages... search copying static files... done copying extra files... done dumping search index in Japanese (code: ja) ... done dumping object inventory... done build succeeded. The HTML pages are in build\html.
build\html配下にindex.htmlというファイルが生成されていることがわかります。アクセスすると以下のようになっていることがわかります。
コンテンツの追加
index ページが作成できたらコンテンツを追加したいですよね?追加してみます。以下のように
index.rstに追記し、hello.rstというファイルを作成します。「はじめてのSphinx」というページを追加します。index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: + hello Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search`hello.rst+はじめてのSphinx +=============================== + +Hello Sphinx!!!
make htmlでビルドして、再度index.htmlにアクセスすると以下のようになります。
「はじめてのSphinx」 のページが追加されていることがわかります。このページにアクセスしてみましょう。
ちゃんとページのコンテンツが表示されています。
階層のあるコンテンツ
階層のあるコンテンツを追加することも簡単にできます。先ほどの
index.rstに段落のあるページを追加してみます。index.rstへの追記と新しいファイルhierarchy.rstを作成します。index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: hello + hierarchy Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search`hierarchy.rst+段落 +================================== + +--------------------------------- +段落1 +--------------------------------- + +AAAAAA + +--------------------------------- +段落2 +--------------------------------- + +BBBBBB + +--------------------------------- +段落3 +--------------------------------- + +CCCCCC + +--------------------------------- +段落4 +--------------------------------- + +DDDDDD
hierarchy.rstは reST で書かれています。必要になったときに こちら を見てみると良いかもしれません。
make htmlでビルドして、アクセスします。すると、階層のあるページが追加されたことがわかります。
コードの記述
コードを記述して、シンタックスハイライトで表示することももちろん可能です。
index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: hello hierarchy + code Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search`コードは
.. code-block::を用いて記述することができます。source/code.rst+コードを記述 +================================== + +`` .. code-block:: `` を用いることでコードをハイライトすることができます。 + +.. code-block:: go + :caption: hello.go + + package main + + import "fmt" + + func main() { + fmt.Println("Hello, world!") + }以下のように表示されます。
ポイントは、正しく インデントと 空行 が必要ということです。(
.. code-block::) だけに限った話ではないですが。インデントと空行を含めないと表示されません。たとえば以下のようにすると表示されません。気づきにくいと思うので注意が必要です。私は最初にハマりました。
source/code.rstコードを記述 ================================== `` .. code-block:: `` を用いることでコードをハイライトすることができます。 .. code-block:: go コードを記述 ================================== + +表示されるコード +------------------------------------------------- ``` .. code-block:: ``` を用いることでコードをハイライトすることができます。 .. code-block:: go :caption: hello.go package main import "fmt" func main() { fmt.Println("Hello, world!") } + +正しく表示されないコード(その1:インデントがない) +-------------------------------------------------- + +.. code-block:: go + +package main + +import "fmt" + +func main() { + fmt.Println("Hello, world!") +} + +正しく表示されないコード(その2:空行がない) +------------------------------------------------- + +.. code-block:: go + package main + + import "fmt" + + func main() { + fmt.Println("Hello, world!") + }こんな感じになります。
その他いろいろな記述方法
階層以外にも reST を用いていろいろな記述ができます。その中の一部である以下の記述方法を紹介します。
- テーブル
- 脚注
- 数式
- TODO
index.rst.. sample-project documentation master file, created by sphinx-quickstart on Mon Jul 8 22:38:47 2019. You can adapt this file completely to your liking, but it should at least contain the root `toctree` directive. Welcome to sample-project's documentation! ========================================== .. toctree:: :maxdepth: 2 :caption: Contents: hello hierarchy code + other Indices and tables ================== * :ref:`genindex` * :ref:`modindex` * :ref:`search` +.. todolist::source/other.rst+その他の機能 +================================== + +--------------------------------- +テーブル +--------------------------------- + +===== ===== ======= +A B A and B +===== ===== ======= +False False False +True False False +False True False +True True True +===== ===== ======= + +--------------------------------- +脚注 +--------------------------------- + +これは 脚注 [#]_ です。 + +.. [#] 本文の下の方につける注記 + +--------------------------------- +数式 +--------------------------------- + +数式を有効にするには、``conf.py`` に ``sphinx.ext.mathjax`` という拡張モジュールを追加する必要があります。以下のような感じです。モジュールを有効にすれば、LaTeX で数式を記述することができます。 + +.. code-block:: python + :caption: conf.py + + # Add any Sphinx extension module names here, as strings. They can be + # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom + # ones. + extensions = ['sphinx.ext.mathjax' + ] + +`N` 個の整数 :math:`d[0], d[1], \dots, d[N-1]` が与えられます。これは数式のサンプルです。 + +--------------------------------- +TODO +--------------------------------- + +TODOも拡張モジュール ``sphinx.ext.todo`` を有効にすると記述できるようになります。あとでやりたいことを残しておくときに便利ですね。 + +.. code-block:: none + :caption: conf.py + + # Add any Sphinx extension module names here, as strings. They can be + # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom + # ones. + extensions = ['sphinx.ext.mathjax', 'sphinx.ext.todo' + ] + + [extensions] + todo_include_todos = True + +.. todo:: + + これは TODO なので、後ほど調査する + +TODOを表示する場所も選ぶことができます。今回は index ページに記載しておきましょう。表示させたい場所に ``` .. todolist:: ``` と記述しておけばよいです。 + +.. code-block:: rest + + .. sample-project documentation master file, created by + sphinx-quickstart on Mon Jul 8 22:38:47 2019. + You can adapt this file completely to your liking, but it should at least + contain the root `toctree` directive. + + Welcome to sample-project's documentation! + ========================================== + + .. toctree:: + :maxdepth: 2 + :caption: Contents: + + hello + hierarchy + code + other + + Indices and tables + ================== + + * :ref:`genindex` + * :ref:`modindex` + * :ref:`search`こんな感じで見えます。きれいですね。
プレビュー
先ほどまではページについての記述方法でした。今度はビルドするときの便利な方法を紹介します。
いままではファイルを修正するたびに
make htmlとビルドして、HTML を生成して確認する、、、としていました。何度も変更するとちょっと面倒です。ファイルの変更が自動的に Web ページに反映されると嬉しいですよね。Sphinxの
sphinx-autobuildを用いると、ファイルを変更すると自動的にビルドが実行され、更新が反映されます。便利です。これを使ってみましょう。
sphinx-autobuildモジュールが必要なので、pip でインストールします。pip install sphinx-autobuildインストールできたら、
sphinx-autobuildコマンドで起動させます。$ sphinx-autobuild -b html source build/html +--------- manually triggered build --------------------------------------------- | Running Sphinx v2.1.2 | loading translations [ja]... done | building [mo]: targets for 0 po files that are out of date | building [html]: targets for 5 source files that are out of date | updating environment: 5 added, 0 changed, 0 removed | reading sources... [ 20%] code | reading sources... [ 40%] hello | reading sources... [ 60%] hierarchy | reading sources... [ 80%] index | reading sources... [100%] other | | looking for now-outdated files... none found | pickling environment... done | checking consistency... done | preparing documents... done | writing output... [ 20%] code | writing output... [ 40%] hello | writing output... [ 60%] hierarchy | writing output... [ 80%] index | writing output... [100%] other | | generating indices... genindex | writing additional pages... search | copying static files... done | copying extra files... done | dumping search index in Japanese (code: ja) ... done | dumping object inventory... done | build succeeded. | | The HTML pages are in build\html. +-------------------------------------------------------------------------------- [I 190709 08:34:05 server:296] Serving on http://127.0.0.1:8000 [I 190709 08:34:05 handlers:62] Start watching changes [I 190709 08:34:05 handlers:64] Start detecting changesするとローカルで Web サーバが 8000 ポートで listen するようになることがわかります。ブラウザから以下にアクセスすると、先ほどまでローカルでビルドしてHTMLを生成していた内容が表示されていることがわかります。
http://localhost:8000/
sphinx-autobuildのコマンドを覚えるのがちょっと面倒という方はmake.batに追記すると便利かもしれません。
以下のようにmake.batに追記しておきます。make.bat@ECHO OFF pushd %~dp0 REM Command file for Sphinx documentation if "%SPHINXBUILD%" == "" ( set SPHINXBUILD=sphinx-build ) set SOURCEDIR=source set BUILDDIR=build if "%1" == "" goto help if "%1" == "preview" ( echo.Running sphinx-autobuild. View live edits at: echo. http://0.0.0.0:8000 sphinx-autobuild -b html %SOURCEDIR% %BUILDDIR%/html if errorlevel 1 exit /b 1 goto end ) %SPHINXBUILD% >NUL 2>NUL if errorlevel 9009 ( echo. echo.The 'sphinx-build' command was not found. Make sure you have Sphinx echo.installed, then set the SPHINXBUILD environment variable to point echo.to the full path of the 'sphinx-build' executable. Alternatively you echo.may add the Sphinx directory to PATH. echo. echo.If you don't have Sphinx installed, grab it from echo.http://sphinx-doc.org/ exit /b 1 ) +:html +%SPHINXBUILD% -b html %SOURCEDIR% "docs" %SPHINXOPTS% %O% +goto end %SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% goto end :help %SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% :end popd起動するときは以下のように
make previewとすれば良いです。
GitHub Pages との連携
さて、ローカルでドキュメントを作成することができたので、これを GitHub Pages で公開してみましょう。GitHub でドキュメントのソースを管理しつつ、簡単に公開できるのがよいですね。
まずは作成したドキュメントを GitHub にアップしておきます。GitHub のリポジトリ名は sphinx-sample としておきます。
.gitignore+build/doctrees +.DS_Storegit init git add -A git commit -m "init" git remote add origin https://github.com/d-tsuji/sphinx-sample.git git push -u origin masterGitHub Pages で公開するにあたって今回は master ブランチの docs ディレクトリを用いて公開することにします。
そのためにビルドしたときに出力されるディレクトリを少し修正します。ビルドするときのコマンドはmake htmlとしておきます。make.bat@ECHO OFF pushd %~dp0 REM Command file for Sphinx documentation if "%SPHINXBUILD%" == "" ( set SPHINXBUILD=sphinx-build ) set SOURCEDIR=source set BUILDDIR=build if "%1" == "" goto help if "%1" == "preview" ( echo.Running sphinx-autobuild. View live edits at: echo. http://0.0.0.0:8000 sphinx-autobuild -b html %SOURCEDIR% %BUILDDIR%/html if errorlevel 1 exit /b 1 goto end ) %SPHINXBUILD% >NUL 2>NUL if errorlevel 9009 ( echo. echo.The 'sphinx-build' command was not found. Make sure you have Sphinx echo.installed, then set the SPHINXBUILD environment variable to point echo.to the full path of the 'sphinx-build' executable. Alternatively you echo.may add the Sphinx directory to PATH. echo. echo.If you don't have Sphinx installed, grab it from echo.http://sphinx-doc.org/ exit /b 1 ) +:html +%SPHINXBUILD% -b html %SOURCEDIR% "docs" %SPHINXOPTS% %O% +goto end %SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% goto end :help %SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O% :end popd
make htmlでビルドするとdocsディレクトリに HTML ファイルが生成されたことがわかります。buildディレクトリは不要なので削除しておきます。ディレクトリ構成は以下のようになっています。( HTML ファイルや doctree ファイルは省略)
D:. │ .gitignore │ make.bat │ Makefile ├─docs │ ├─.doctrees │ ├─_sources │ └─_static └─sourceコミットして GitHub にアップします。
GitHub の GUI から GitHub Pages の設定をしておきます。以下のようになります。
設定したら、URL(https://d-tsuji.github.io/sphinx-sample/) にアクセスします。
そうすると、CSS が見事きいていないことがわかります。悲しいですね。
GitHi Pages は、デフォルトで JekyII でホスティングを行います。しかし、JekyII は Sphinx に対応していないため、
_staticなどにあるパスを読み取ることができません。対応として.nojekyllのディレクトリを作成する必要があります。手動で作成しても問題ないですが、今回はsphinx.ext.githubpagesを用いて対応することができます。
sphinx.ext.githubpagesプラグインは GitHub Pages で公開するために、.nojekyllファイルをHTMLディレクトリ内に作成します。source/conf.py... # -- General configuration --------------------------------------------------- # Add any Sphinx extension module names here, as strings. They can be # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom # ones. -extensions = ['sphinx.ext.mathjax', 'sphinx.ext.todo' +extensions = ['sphinx.ext.mathjax', 'sphinx.ext.todo', 'sphinx.ext.githubpages' ] # Add any paths that contain templates here, relative to this directory. templates_path = ['_templates'] ...
conf.pyでプラグインの有効化したのち、再度make htmlでビルドします。そうするとdocs/.nojekyllのディレクトリが作成されていることがわかります。この状態で GitHub にプッシュします。
再度 https://d-tsuji.github.io/sphinx-sample/ にアクセスしてみます。
無事に CSS がきいて、いい感じになっていることがわかります!!!
ページのデザインは
conf.pyから設定することができます。( Sphinx に組み込まれていないテーマを選択する場合はtheme.confなどの追加の設定が必要です。)デフォルトだと以下のようにalabasterになっています。source/conf.py... # -- Options for HTML output ------------------------------------------------- # The theme to use for HTML and HTML Help pages. See the documentation for # a list of builtin themes. # html_theme = 'alabaster' ...以下にテーマごとのサンプルがあります。
一番最初に紹介した Docker ドキュメント日本語化プロジェクト のテーマは
sphinx_rtd_themeになっています。好みに合わせて選ぶことができます。まとめ
Sphinx を用いて技術ノートのような静的 Web ページを作成し、GitHub Pages で公開することができました。
今回は紹介しませんでしたが同じソースファイルから HTML ファイルだけでなく PDF ファイルも作成することができます。シンプルなツールで使いやすく、みなさんもたくさんドキュメントを書きたくなるのではないでしょうか。
参考資料
- 投稿日:2019-07-10T08:21:59+09:00
shields.ioを使って技術系アイコンを量産した
概要
shields.ioを用いて技術系アイコンを量産しました。
とりあえず完成したのがこちらです。
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
これでスキルマップを作ってみたらいい感じになりました。
shields.ioについて
GitHubのREADMEでよく見かけるアレです。
shields.ioはSVG形式のバッジサービスです。カスタムバッジを作る
特徴的な機能の1つとして
URLのパターンでカスタムバッジを作ることができます。https://img.shields.io/badge/${subject}-${status}-${color}.svgsubject : バッジの左側に入る文言
status : バッジの右側に入る文言
color : 色Color
以下のようなものが用意されています。
16進数形式で指定することも可能です。
カスタムスタイル
いくつかのスタイルが用意されています。
?style=plastic&logo=appveyor
?style=flat&logo=appveyor
?style=flat-square&logo=appveyor
?style=for-the-badge&logo=appveyor
?style=popout&logo=appveyor
?style=popout-square&logo=appveyor
?style=social&logo=appveyor
simpleicons
バッジではいくつかのアイコンが使えます。
これについてはsimpleiconsを参考になります。そして一例がこれです。
全部で数えたら648ありました。
おすすめアイコンを作った
おすすめしたいアイコンを作りました。
言語系
ライブラリ・フレームワーク
OS
ミドルウェア
エディタ・IDE
クラウド・他
参考
付録 : アイコンのURL
各アイコンのURLです。1
### 言語系 <img src="https://img.shields.io/badge/PHP-ccc.svg?logo=php&style=flat"> <img src="https://img.shields.io/badge/Javascript-276DC3.svg?logo=javascript&style=flat"> <img src="https://img.shields.io/badge/-TypeScript-007ACC.svg?logo=typescript&style=flat"> <img src="https://img.shields.io/badge/-Python-F9DC3E.svg?logo=python&style=flat"> <img src="https://img.shields.io/badge/-CSS3-1572B6.svg?logo=css3&style=flat"> <img src="https://img.shields.io/badge/-HTML5-333.svg?logo=html5&style=flat"> ### ライブラリ・フレームワーク <img src="https://img.shields.io/badge/-CakePHP-D3DC43.svg?logo=cakephp&style=flat"> <img src="https://img.shields.io/badge/-Rails-CC0000.svg?logo=rails&style=flat"> <img src="https://img.shields.io/badge/-Django-092E20.svg?logo=django&style=flat"> <img src="https://img.shields.io/badge/-Flask-000000.svg?logo=flask&style=flat"> <img src="https://img.shields.io/badge/-Bootstrap-563D7C.svg?logo=bootstrap&style=flat"> <img src="https://img.shields.io/badge/-React-555.svg?logo=react&style=flat"> <img src="https://img.shields.io/badge/-jQuery-0769AD.svg?logo=jquery&style=flat"> ### OS <img src="https://img.shields.io/badge/-Linux-6C6694.svg?logo=linux&style=flat"> <img src="https://img.shields.io/badge/-Ubuntu-6F52B5.svg?logo=ubuntu&style=flat"> <img src="https://img.shields.io/badge/-Windows-0078D6.svg?logo=windows&style=flat"> <img src="https://img.shields.io/badge/-RedHat-EE0000.svg?logo=red-hat&style=flat"> <img src="https://img.shields.io/badge/-Debian-A81D33.svg?logo=debian&style=flat"> <img src="https://img.shields.io/badge/-Raspberry%20Pi-C51A4A.svg?logo=raspberry-pi&style=flat"> <img src="https://img.shields.io/badge/-Arch%20Linux-EEE.svg?logo=arch-linux&style=flat"> ### ミドルウェア <img src="https://img.shields.io/badge/-Apache-D22128.svg?logo=apache&style=flat"> <img src="https://img.shields.io/badge/-Nginx-bfcfcf.svg?logo=nginx&style=flat"> <img src="https://img.shields.io/badge/-Oracle-f80000.svg?logo=oracle&style=flat"> <img src="https://img.shields.io/badge/-Redis-D82C20.svg?logo=redis&style=flat"> <img src="https://img.shields.io/badge/-Elasticsearch-005571.svg?logo=elasticsearch&style=flat"> <img src="https://img.shields.io/badge/-PostgreSQL-336791.svg?logo=postgresql&style=flat"> ### エディタ・IDE <img src="https://img.shields.io/badge/-Visual%20Studio%20Code-007ACC.svg?logo=visual-studio-code&style=flat"> <img src="https://img.shields.io/badge/-Vim-019733.svg?logo=vim&style=flat"> <img src="https://img.shields.io/badge/-Emacs-EEE.svg?logo=spacemacs&style=flat"> <img src="https://img.shields.io/badge/-Atom-66595C.svg?logo=atom&style=flat"> <img src="https://img.shields.io/badge/-Xcode-EEE.svg?logo=xcode&style=flat"> <img src="https://img.shields.io/badge/-intellij%20IDEA-000.svg?logo=intellij-idea&style=flat"> ### クラウド・他 <img src="https://img.shields.io/badge/-Amazon%20AWS-232F3E.svg?logo=amazon-aws&style=flat"> <img src="https://img.shields.io/badge/-Google%20Cloud-EEE.svg?logo=google-cloud&style=flat"> <img src="https://img.shields.io/badge/-Ansible-EE0000.svg?logo=ansible&style=flat"> <img src="https://img.shields.io/badge/-GitHub-181717.svg?logo=github&style=flat"> <img src="https://img.shields.io/badge/-Docker-EEE.svg?logo=docker&style=flat">








