- 投稿日:2019-07-07T23:16:56+09:00
【AWS】API Gateway経由でWebアプリにアクセスした際のレスポンスがBase64形式となる
AWS Lambdaなどに構築したWebアプリにAPI Gateway経由でアクセスした際に、既定の設定ではレスポンスがHTMLコンテンツではなくBase64形式となってしまう。
このような場合は、API Gatewayの設定でAPIの「バイナリメディアタイプ」を追加する必要がある。
解決方法
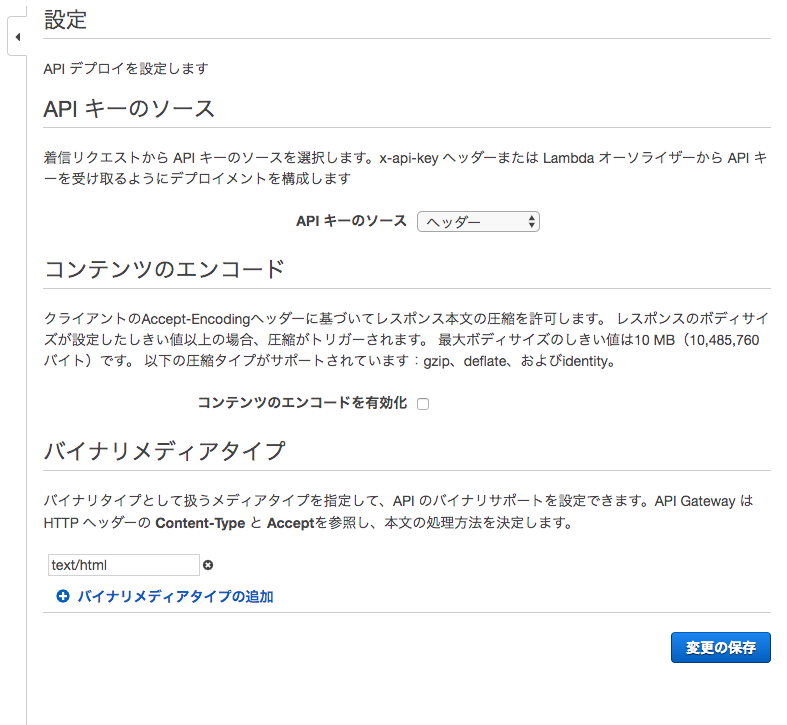
対象のAPIで[設定]-[バイナリメディアタイプ]で[バイナリメディアタイプの追加]をクリックし、
text/htmlまたは*/*を指定して、[変更の保存]をクリック。
ステージに反映させるためにAPIのデプロイを忘れずに行う。
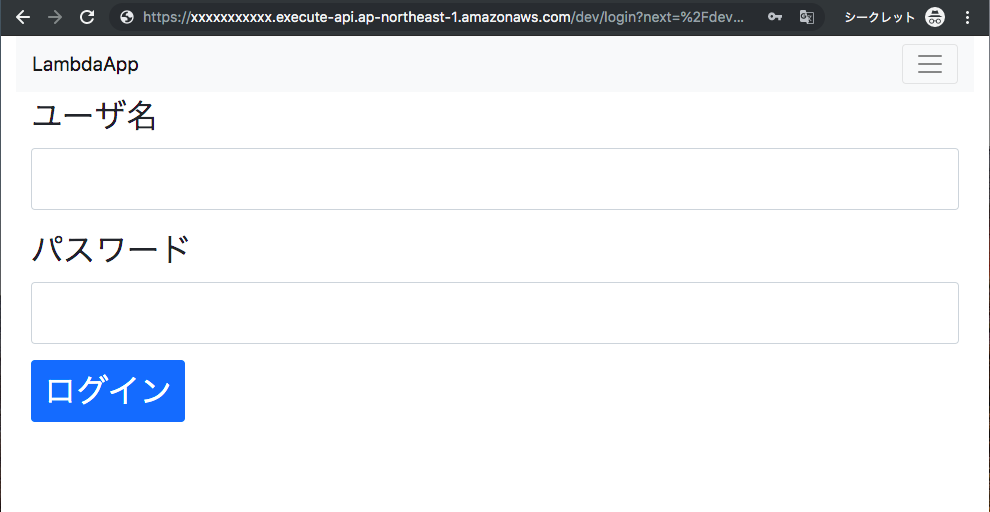
再度Webアプリにアクセスすると正常にHTMLコンテンツが表示された。
以上
- 投稿日:2019-07-07T22:41:23+09:00
Django + Heroku + AWS S3で画像表示させる方法
概要
Djangoアプリで画像をS3に保存し、アプリに表示させる方法を書いてみます。
想定している処理は、①ユーザーが画像投稿→②S3に保存→③S3からアプリに画像表示です。なお、環境は
Python 3.7.3、Django 2.2になります。1. AWS設定
1-1. AWS登録
S3を使用するのに、AWSアカウントが必要になりますので、お持ちでない方はAWS Signupからご登録ください。
1-2. バケット作成
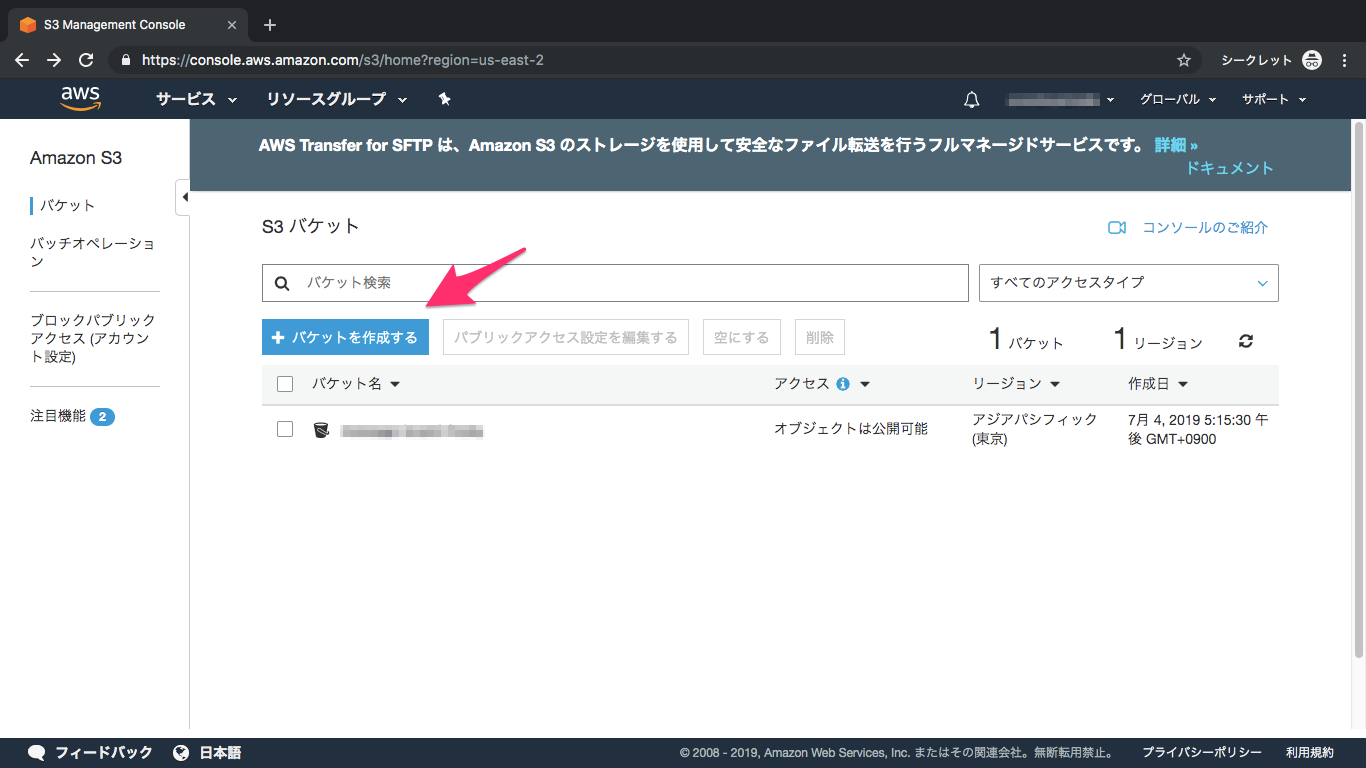
①S3を検索してクリック
②バケット作成
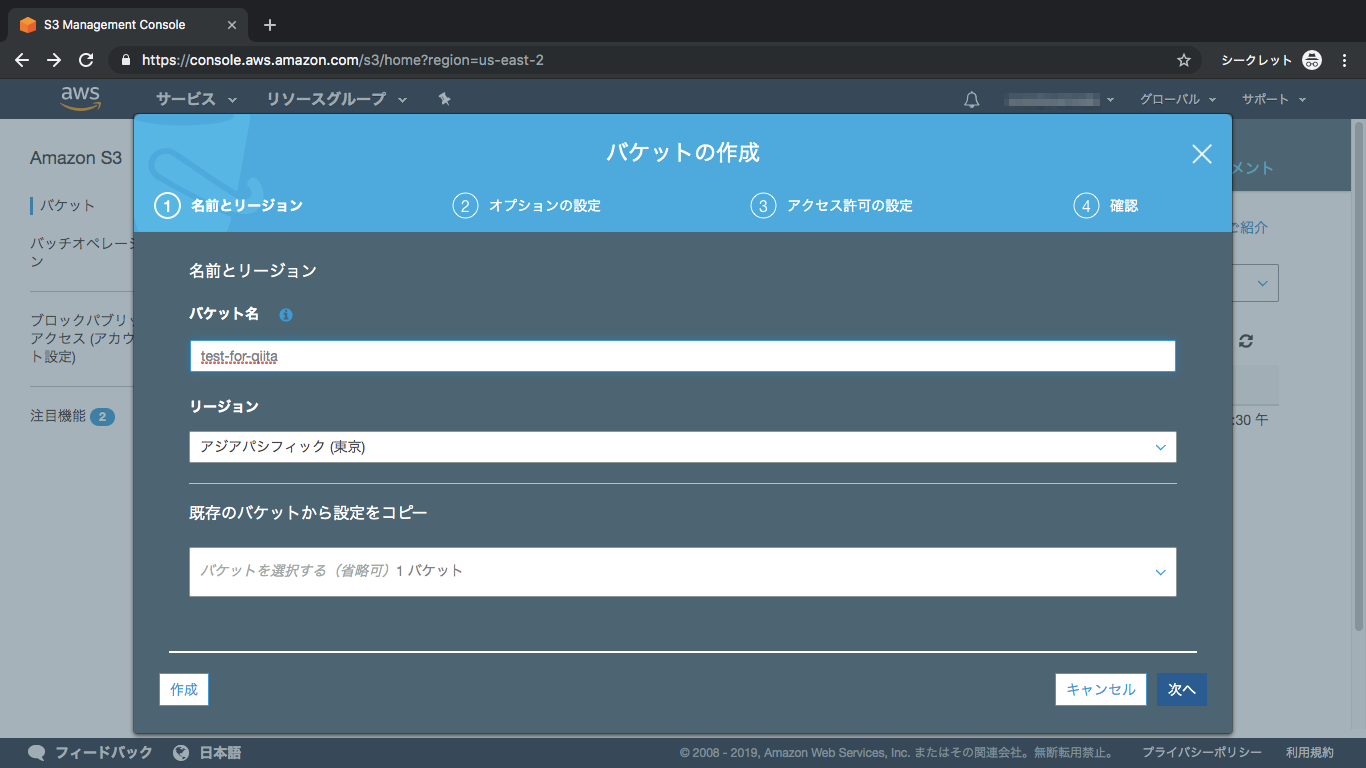
③バケット名とリージョンを選択
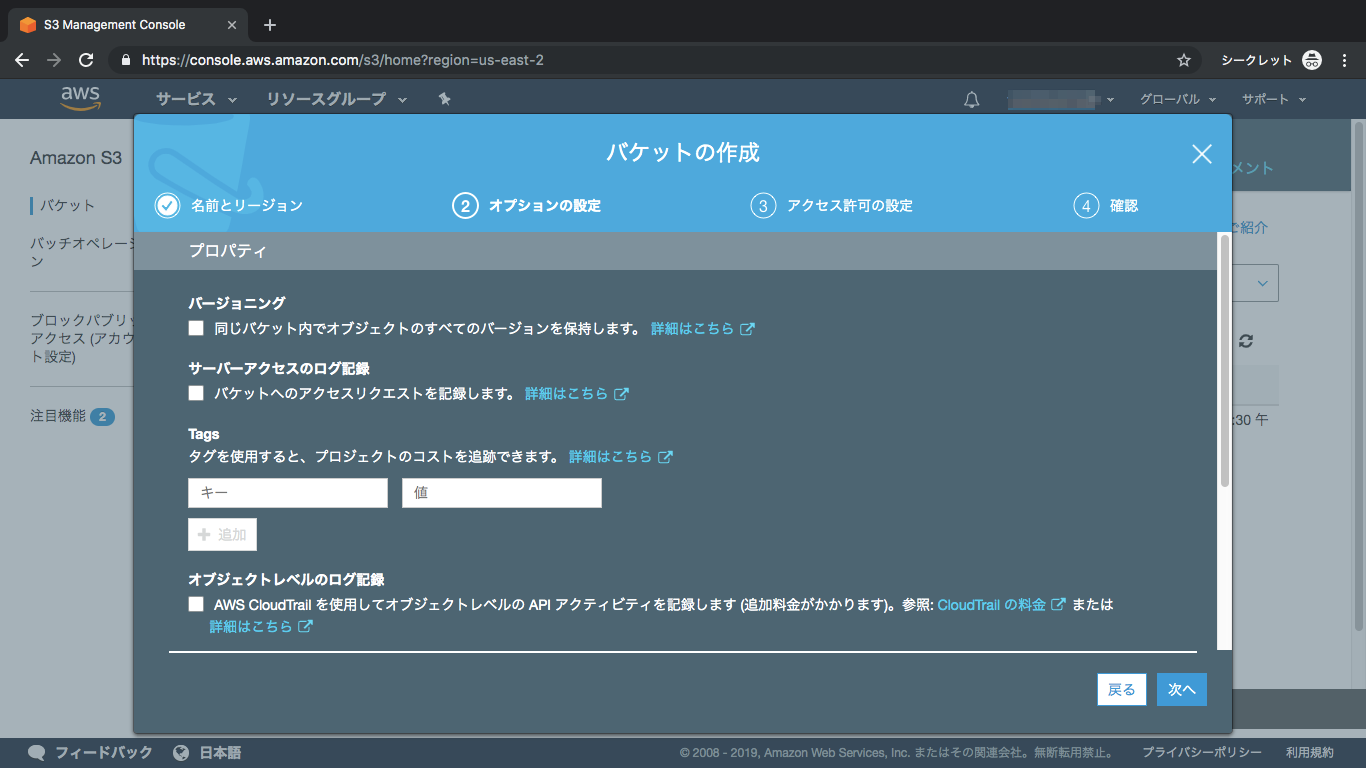
④オプションなし
オプションですが、今回は設定しません
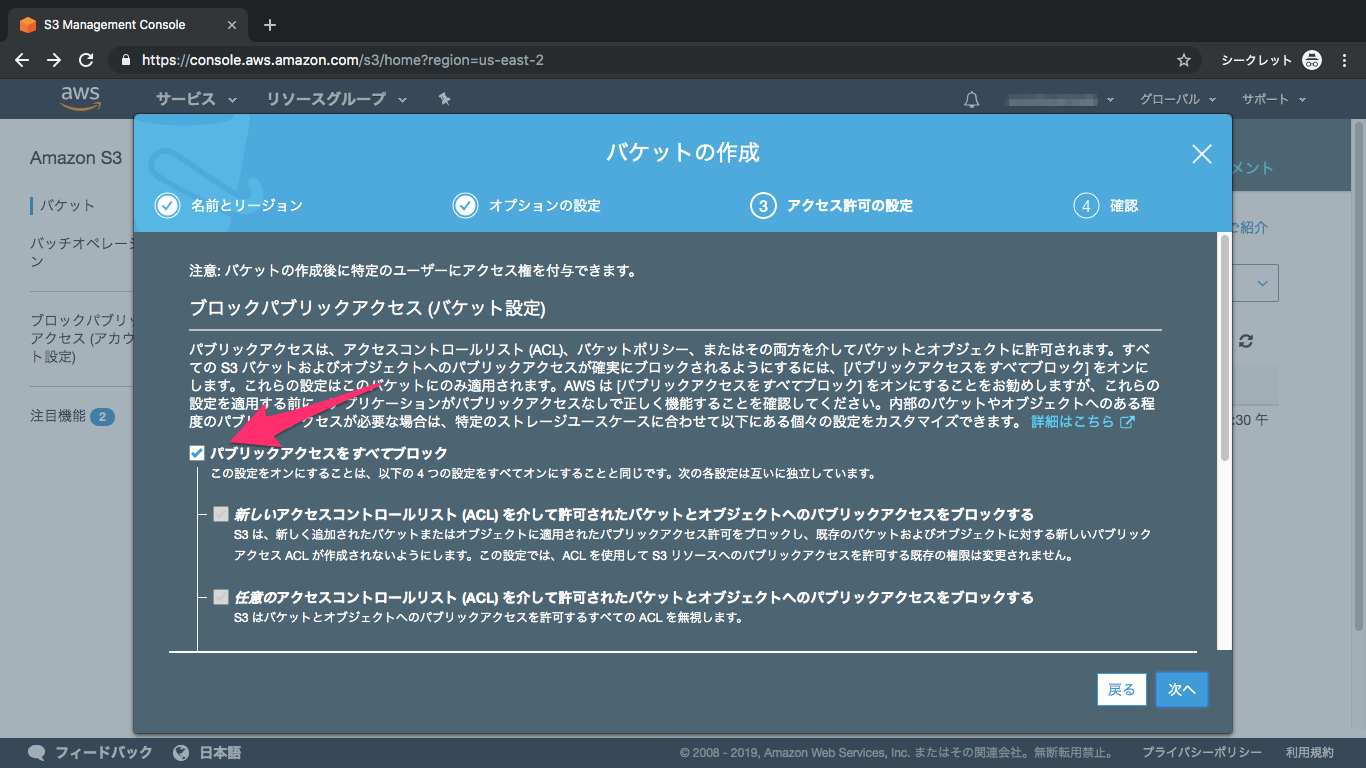
⑤アクセス権限
こちらの項目を外してください、初期設定ではブロックされてしまいます
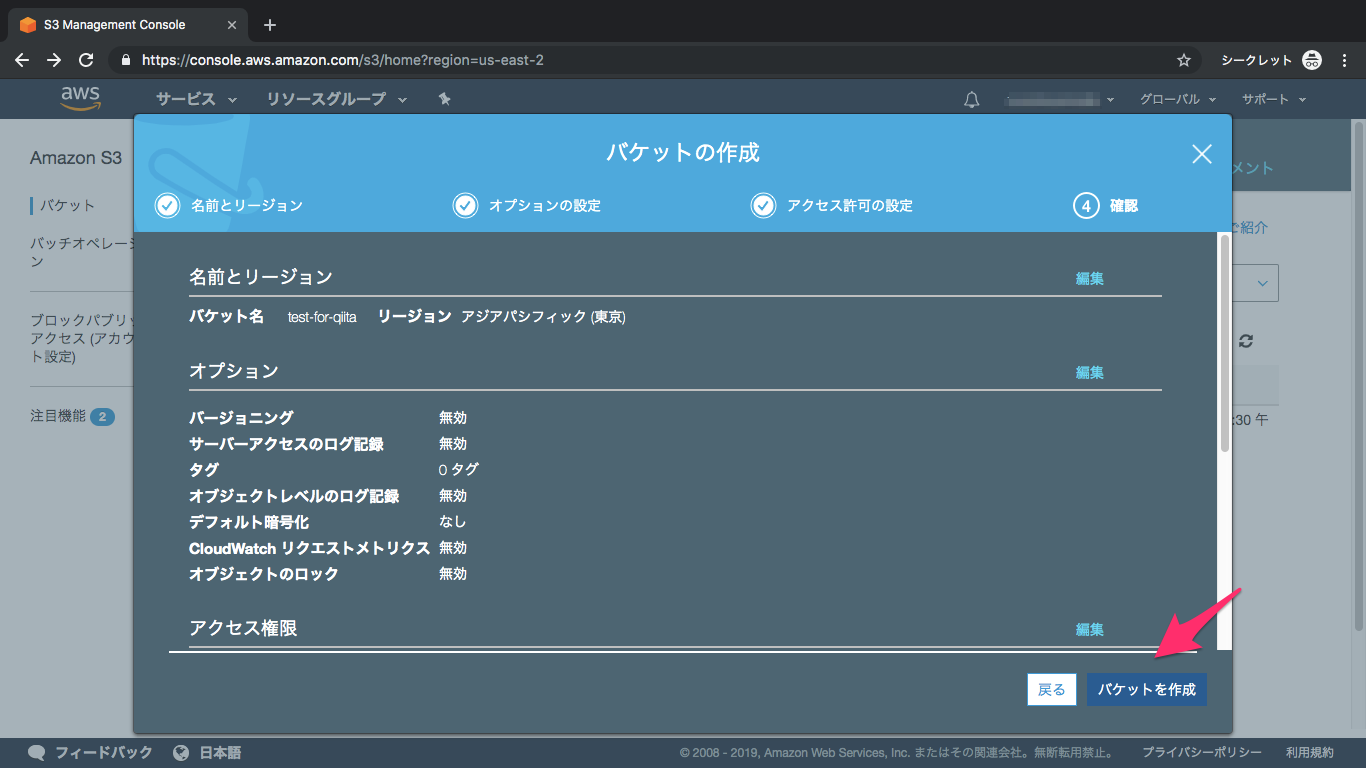
⑥内容を確認して作成
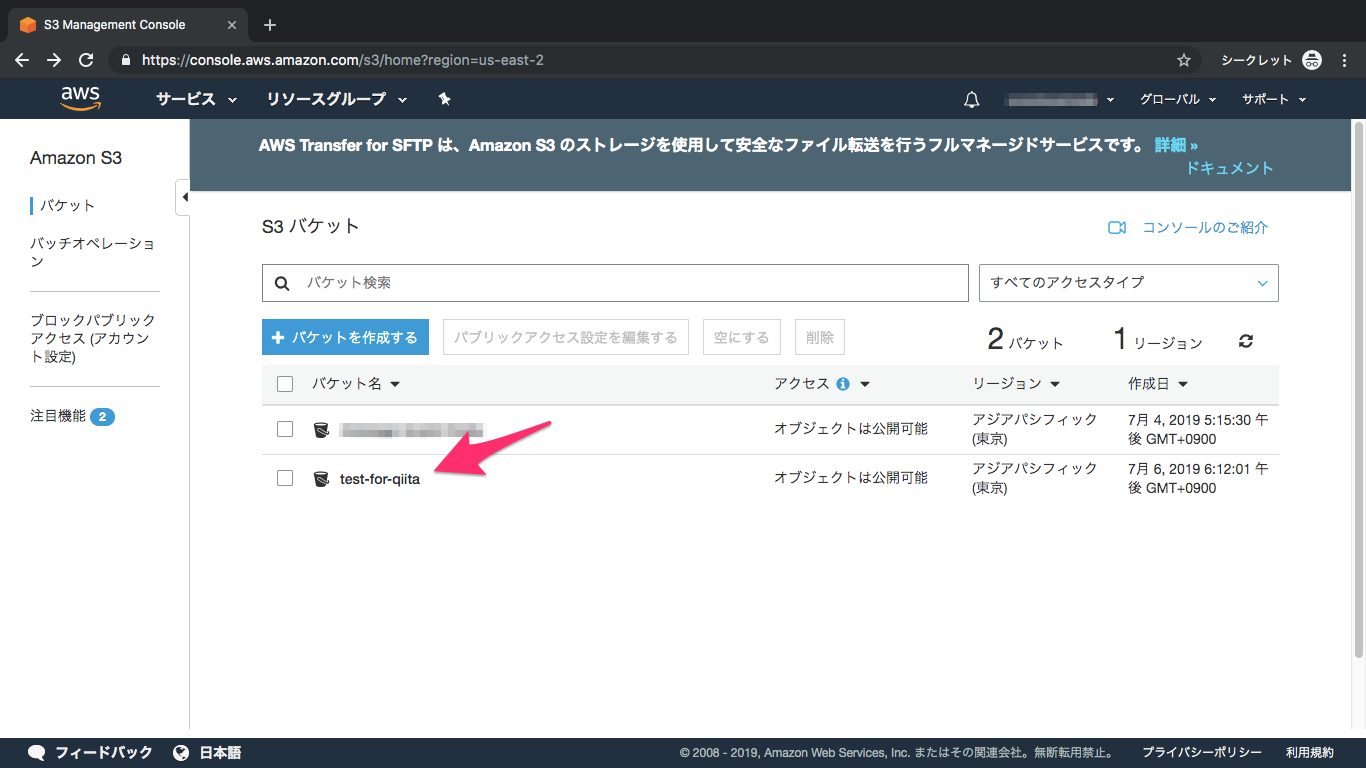
⑦バケット完成
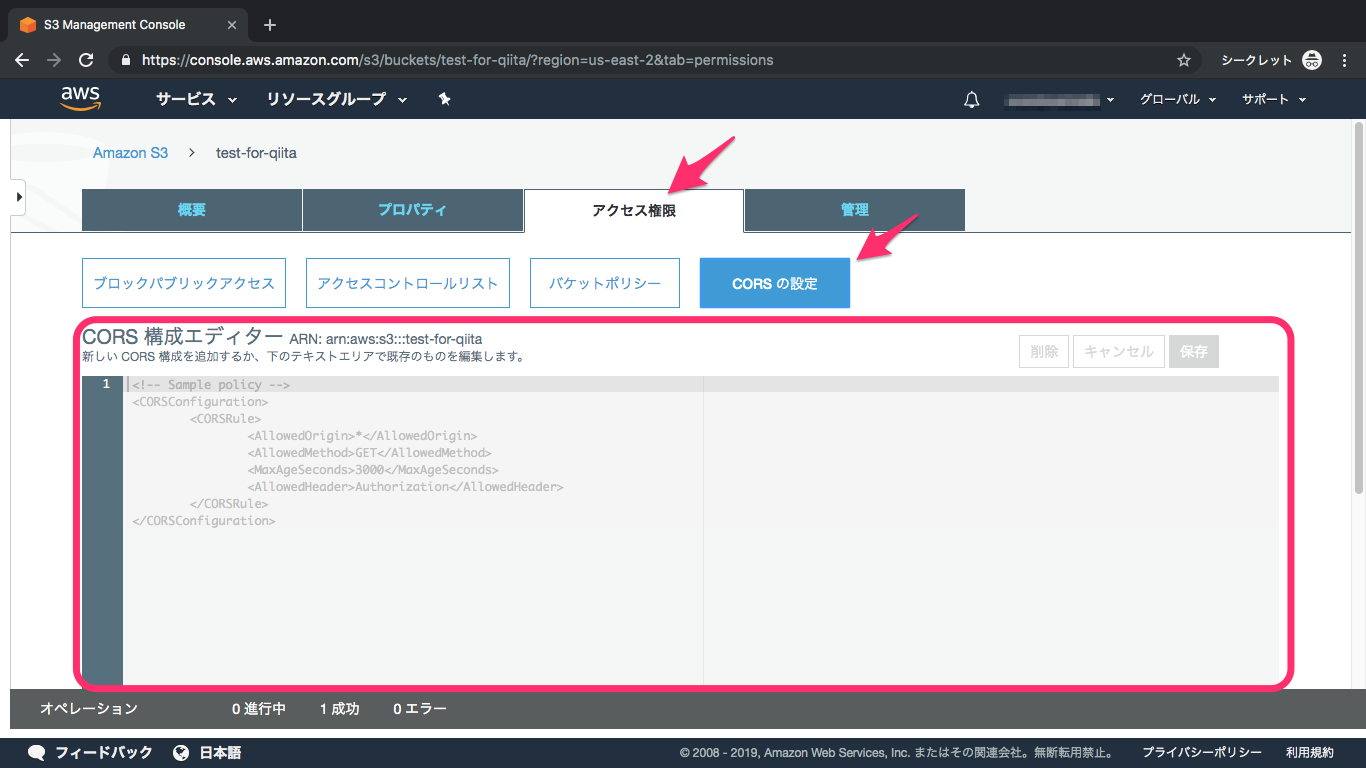
1-3. CORS設定
①CORSの設定に移動
作成したバケットをクリックし、「アクセス制限」の「CORSの設定」に移動します
②CORS構成エディターに追加
下記のように追加してください
CORS<?xml version="1.0" encoding="UTF-8"?> <CORSConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/"> <CORSRule> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>GET</AllowedMethod> <AllowedMethod>POST</AllowedMethod> <AllowedMethod>PUT</AllowedMethod> <AllowedHeader>*</AllowedHeader> </CORSRule> </CORSConfiguration>参照:
Cross-Origin Resource Sharing (CORS)
Direct to S3 File Uploads in Python | S3 Setup1-4. IAM設定
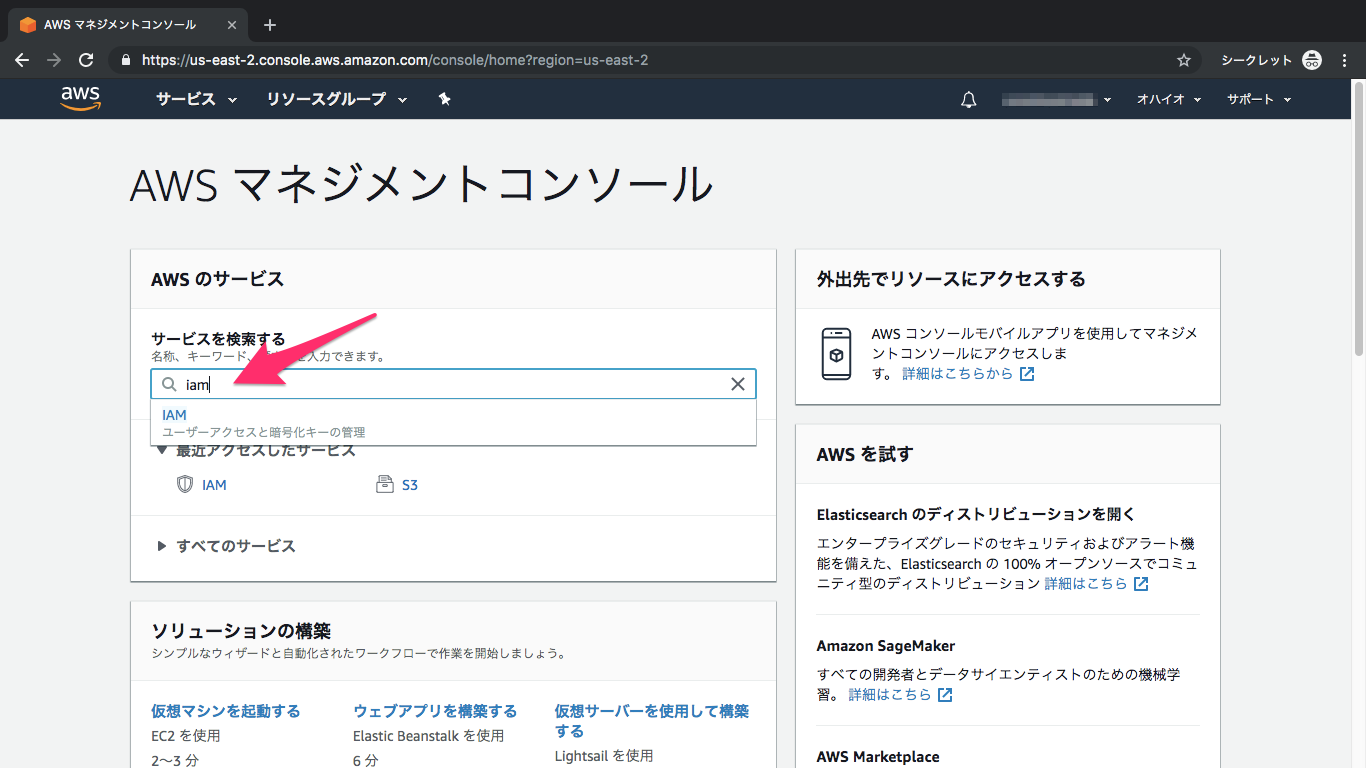
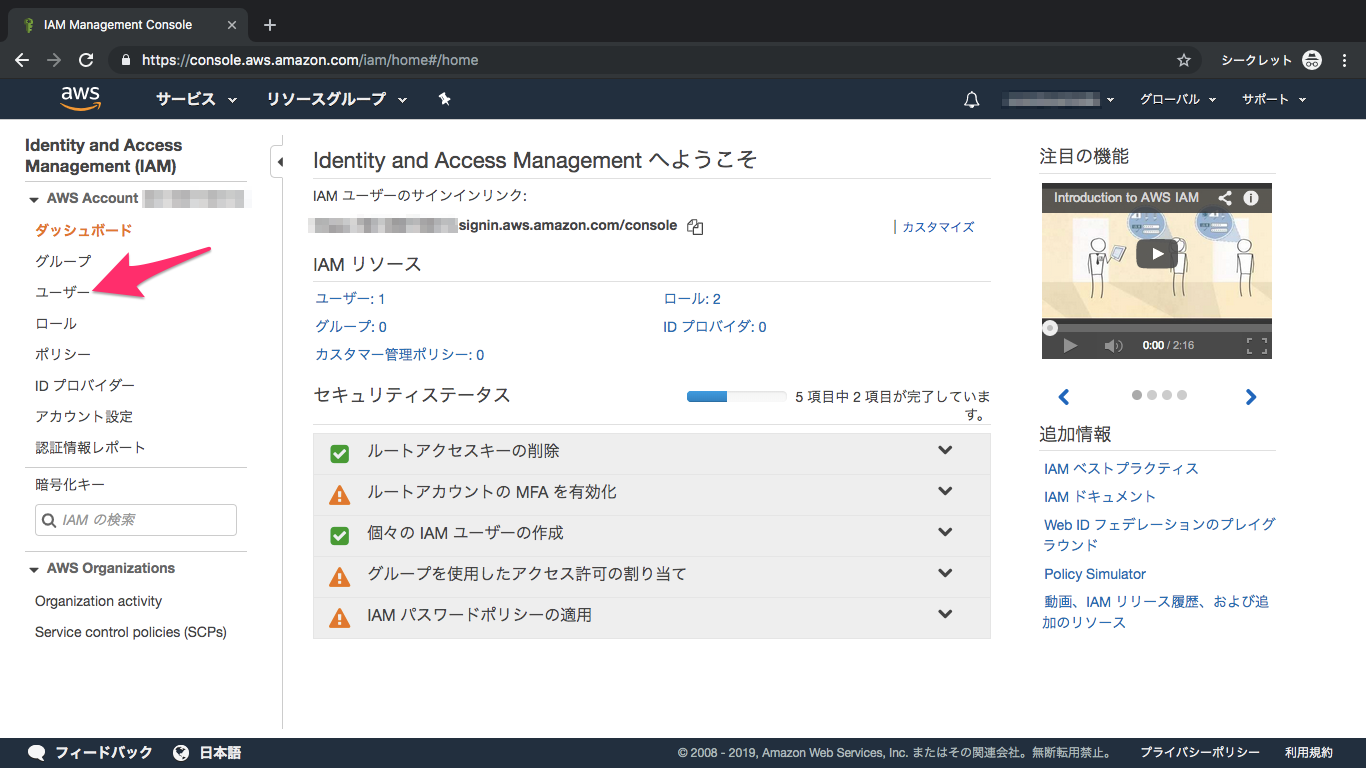
①IAMを検索してクリック
②ユーザーをクリック
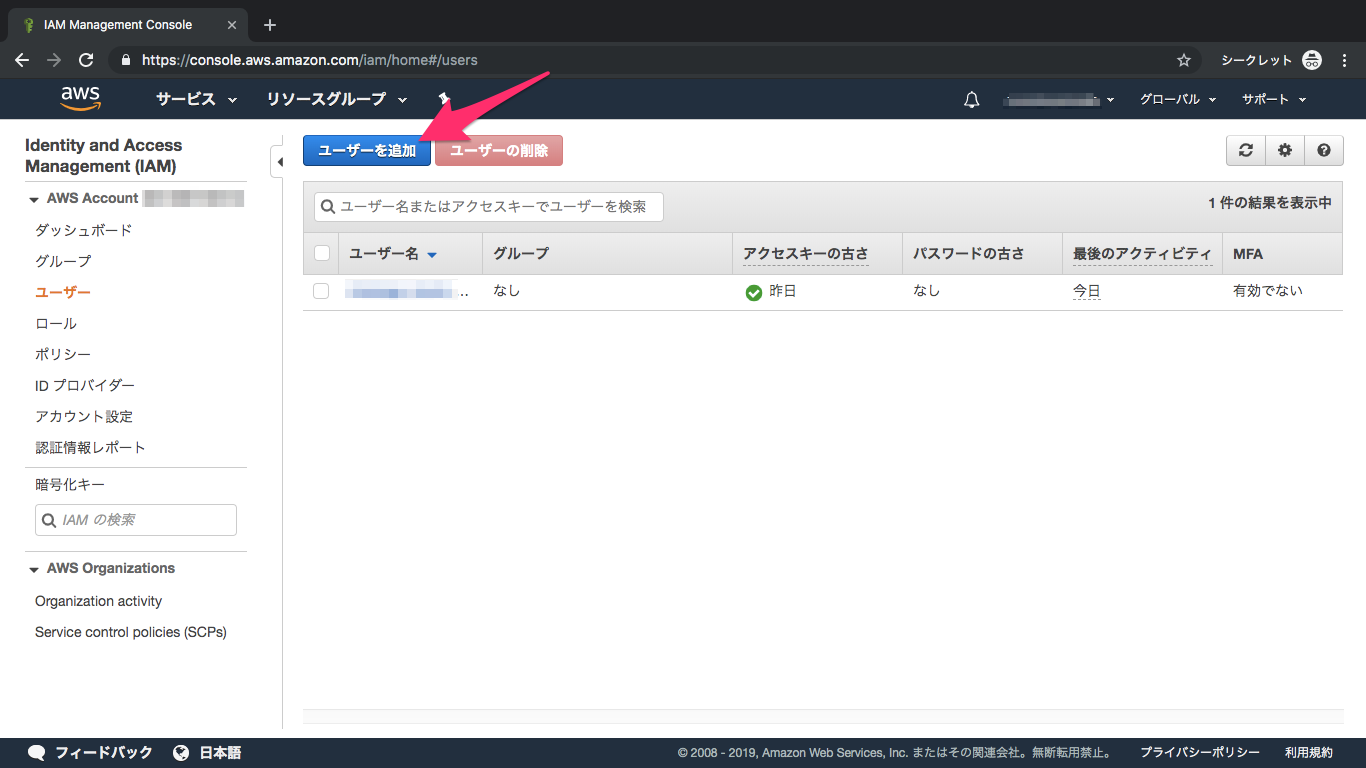
③ユーザー追加をクリック
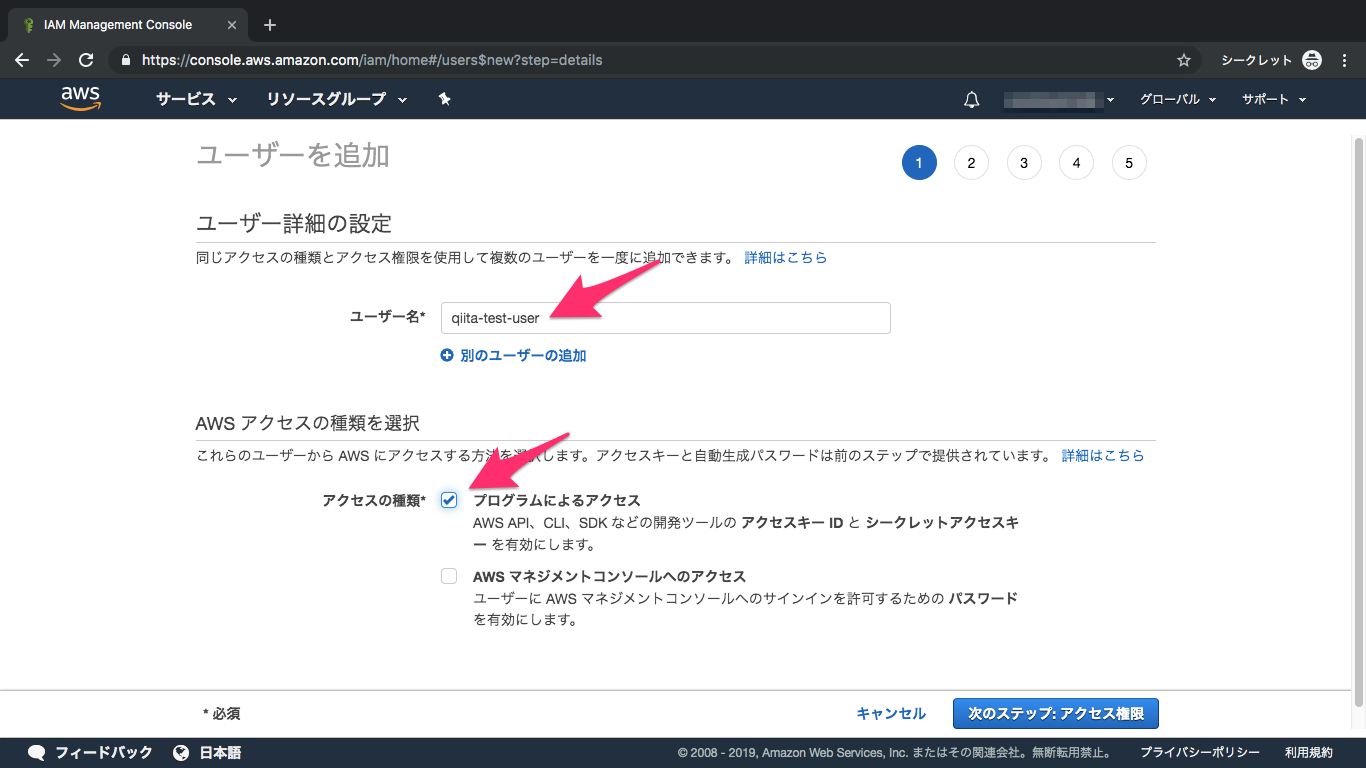
④ユーザー名を入力、プログラムによるアクセスをチェック
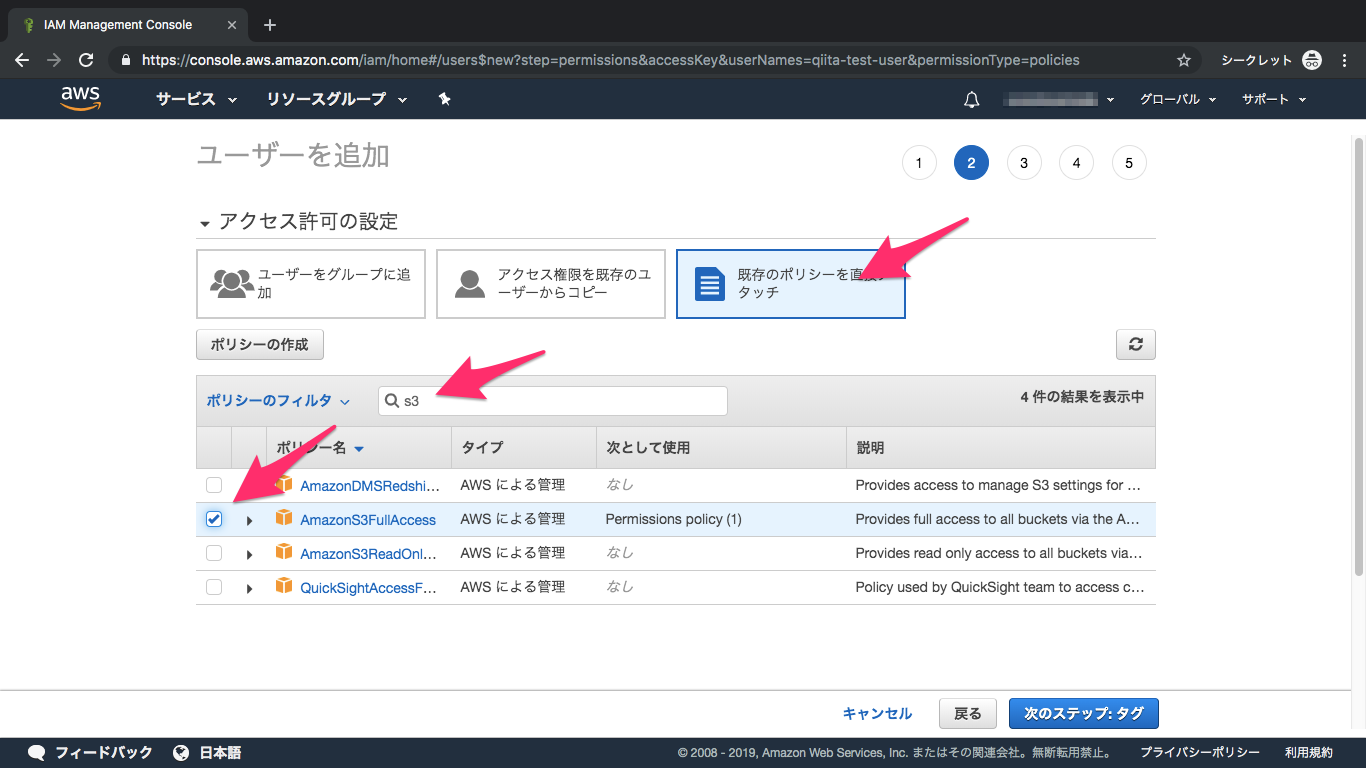
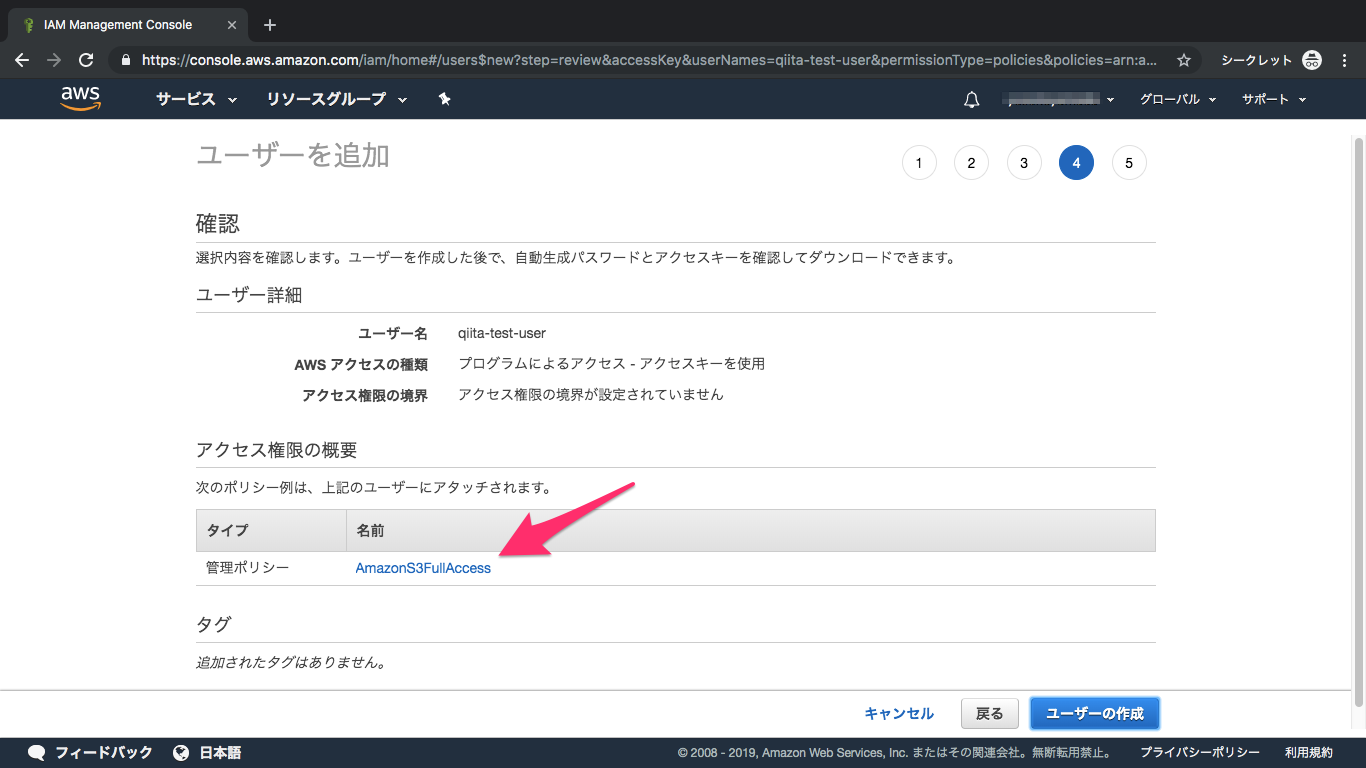
⑤アクセス許可
S3を検索し、AmazonS3FullAccessにチェック
⑥オプションなし
オプションですが、今回は設定しません
⑦内容を確認して作成
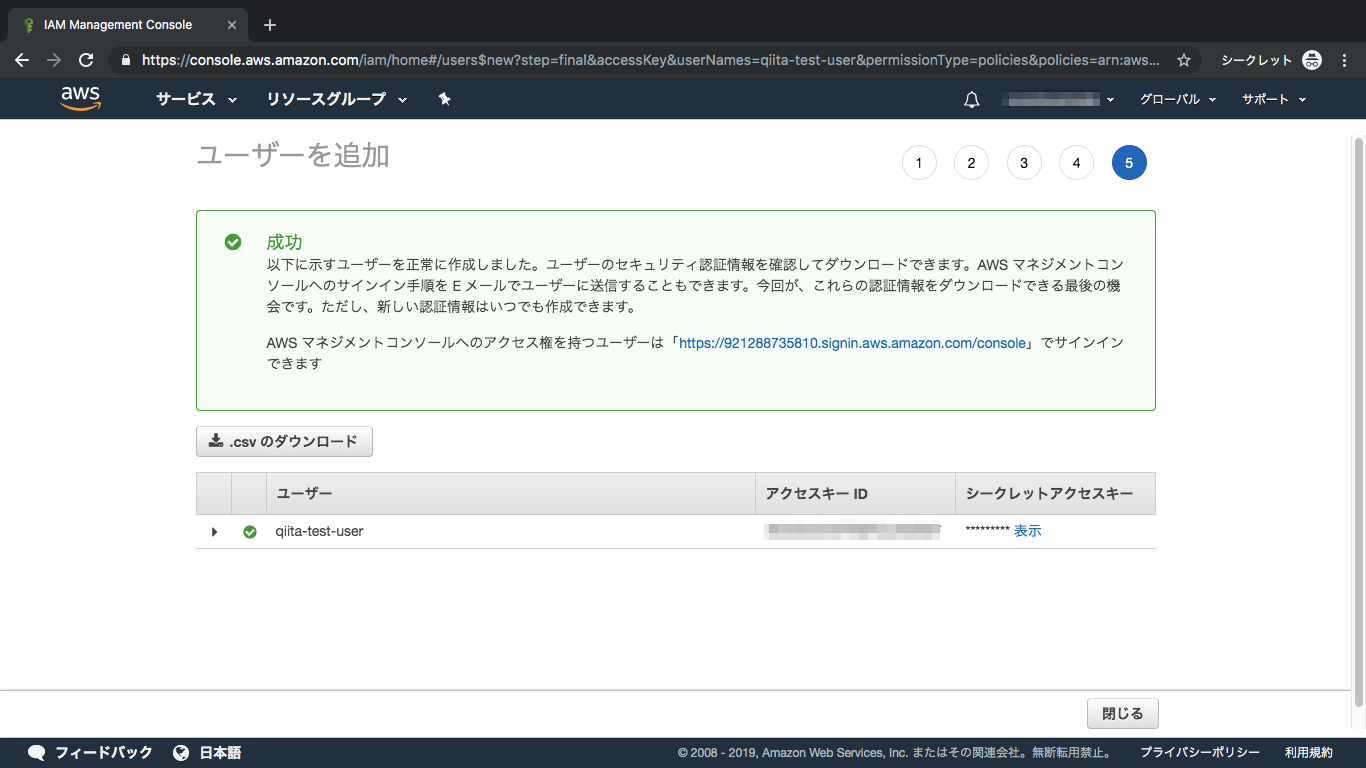
⑧IAM設定完了
後ほど、
アクセスキーIDとシークレットアクセスキーを使いますので、画面を閉じないでください
参照:IAMとは
2. アプリ設定
2-1. インストール
①django-storagesインストール
terminal$ pip install django-storages参照:django-storages | Amazon S3
②boto3インストール
terminal$ pip install boto3参照:
Boto 3 Documentation
AWS SDK for Python (Boto3)2-2. settings.py設定
下記のように追加してください
settings.pyINSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'your_app_name', 'storages', #追加 ] #追加 AWS_ACCESS_KEY_ID = os.environ['AWS_ACCESS_KEY_ID'] AWS_SECRET_ACCESS_KEY = os.environ['AWS_SECRET_ACCESS_KEY'] AWS_STORAGE_BUCKET_NAME = os.environ['AWS_STORAGE_BUCKET_NAME'] DEFAULT_FILE_STORAGE = 'storages.backends.s3boto.S3BotoStorage' S3_URL = 'http://%s.s3.amazonaws.com/' % AWS_STORAGE_BUCKET_NAME MEDIA_URL = S3_URL AWS_S3_FILE_OVERWRITE = False AWS_DEFAULT_ACL = None2-3. 環境変数
Herokuの環境変数を3つ設定します。
①AWS_ACCESS_KEY_IDと②AWS_SECRET_ACCESS_KEYは、IAMユーザーを追加した際に表示された、アクセスキーIDとシークレットアクセスキーになります。
③AWS_STORAGE_BUCKET_NAMEは作成したバケット名です。terminal$ heroku config:set AWS_ACCESS_KEY_ID="ご自身のアクセスキーIDを記入" $ heroku config:set AWS_SECRET_ACCESS_KEY="ご自身のシークレットアクセスキーを記入" $ heroku config:set AWS_STORAGE_BUCKET_NAME="ご自身のバケット名を記入"参照:
Configuration and Config Vars | Heroku
Django Docs | Deployment checklist2-4. requirements.txt
インストールしたモジュールを
requirements.txtに追加します。terminal$ pip freeze > requirements.txt2-5. local_settings.py設定
もし
local_settings.pyを使用している場合は、下記を参考にしてください。ローカル環境では
MEDIA_ROOTで指定したディレクトリから読み込み、HerokuではS3から読み込むことができます。settings.py### 省略 ### DEBUG = False ALLOWED_HOSTS = ['*'] INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'your_app_name', 'storages', ] ### 省略 ### MEDIA_ROOT = os.path.join(BASE_DIR, 'media') MEDIA_URL = '/media/' try: from .local_settings import * except ImportError: pass if not DEBUG: SECRET_KEY = os.environ['SECRET_KEY'] AWS_ACCESS_KEY_ID = os.environ['AWS_ACCESS_KEY_ID'] AWS_SECRET_ACCESS_KEY = os.environ['AWS_SECRET_ACCESS_KEY'] AWS_STORAGE_BUCKET_NAME = os.environ['AWS_STORAGE_BUCKET_NAME'] DEFAULT_FILE_STORAGE = 'storages.backends.s3boto.S3BotoStorage' S3_URL = 'http://%s.s3.amazonaws.com/' % AWS_STORAGE_BUCKET_NAME MEDIA_URL = S3_URL AWS_S3_FILE_OVERWRITE = False AWS_DEFAULT_ACL = None import django_heroku django_heroku.settings(locals()) db_from_env = dj_database_url.config(conn_max_age=600, ssl_require=True) DATABASES['default'].update(db_from_env)local_settings.pyimport os SECRET_KEY = 'ご自身のSECRET_KEYを記入' BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } DEBUG = True最後に
Herokuでのデプロイが曖昧でしたら、下記の記事も参考にしてみてください。
以上
- 投稿日:2019-07-07T20:46:16+09:00
【参加レポート】AWS Summit Tokyo 2019 Day1にいってきた!
めちゃくちゃ出遅れましたが、AWS Summit Tokyo 2019 Day1に参加してきましたので、参加レポートを書きたいと思います。
結論から書くと、去年より遥かにグレードアップしている部分が多数あると感じられました。
具体的に何がグレードアップしていたかについては、記事の中でご紹介させていただこうと思います。AWS Summit Tokyoについて
まずはじめに、AWS Summit Tokyoを知らないという人のために、AWS Summit Tokyoのご説明を致します。
AWS Summit Tokyoは、Amazon Web Serviceが公式で開催しているAWSの祭典です。
IT系のカンファレンスの中では日本最大級の規模になっており、合計 250 以上セッションやデモンストレーション、ハンズオンワークショップを実施しています。年々、来場者数が増加しているらしく、AWS Summit Tokyo 2019では、初の幕張メッセでの開催となりました。
セッション以外でも、AWSのエキスパートに質問や相談ができるブースや、スポンサー企業のブースなど、様々なコンテンツが用意されています。
より詳しい情報は、公式ページに掲載されておりますので、ご興味のある方はご確認ください。
https://aws.amazon.com/jp/summits/tokyo-2019/AWS Summit Tokyo 2019のグレードアップポイント!
今回のAWS Summit Tokyo 2019では今までのものと比較しても、大規模にグレードアップしているポイントがいくつもありました。
その中でも、よりすぐりのグレードアップポイントについて、ピックアップしてご紹介したいと思います。1. 会場がグレードアップ!
まず、大きな変化としては、会場が幕張メッセになったことです。
去年までは、品川プリンスホテルでの開催でした。
品川ということで、職場からのアクセスは大変良かったのですが、セッション会場間の移動が大変だったり、企業ブースがセッション会場と別部屋になっていました。しかし、幕張メッセでの開催になったことで、企業ブースとセッション会場がシームレスに同じ空間に存在する形になりました。
一部のセッション会場を除いた殆どのセッション会場が同じフロアにあるので、セッション会場の移動がとても楽になりました。#AWSSummit の会場全体の様子です!今年は幕張メッセとなり、昨年より広い会場となりました✨#AWSSummit pic.twitter.com/hpf86IGaNd
— AWS / アマゾン ウェブ サービス (@awscloud_jp) 2019年6月12日また、DeepRacerのレース会場があったり、
こちらは AWS EXPOホールの #AWSDeepRacer リーグ会場です。日本で初開催となった #AWSDeepRacer リーグは、初日から大盛況です!!#AWSSummit pic.twitter.com/FSbwn9gT3m
— AWS / アマゾン ウェブ サービス (@awscloud_jp) June 12, 2019空中にNewRelicさんの広告付きの電車が走るなど、豪華さに拍車がかかっていました!
(写真を取り忘れました...)
2. アメニティが豪華
スポンサーブースやExpoブースで貰えるアメニティがとても豪華になっていたように感じました。
#AWSSummit のスポンサブースでは、様々なノベルティをお配りしています。#AWSSummit は最終日となりましたが、ブースにもぜひお立ち寄りください? pic.twitter.com/hAY1KLQp35
— AWS / アマゾン ウェブ サービス (@awscloud_jp) 2019年6月14日去年はアンケートに答えると、PCのカメラ部分を隠すウェブカメラカバーがもらえたのですが、今年は冷感タオルと、アイスがもらえました!
お帰りの際は、アンケートへ回答して、かき氷かアイスクリームを食べるのをお忘れなく??? #AWSSummit pic.twitter.com/pM59ArQOij
— AWS / アマゾン ウェブ サービス (@awscloud_jp) June 12, 2019認定者ラウンジも、去年は認定者シールを貰えましたが、今年はステンレスボトルと、認定者バッチを貰えました。
認定資格者の方が利用できる認定者ラウンジです。お席と電源をご用意しておりますので、お立ち寄り下さい!#AWSSummit pic.twitter.com/pEz6aLdR7n
— AWS / アマゾン ウェブ サービス (@awscloud_jp) June 12, 2019僕は毎年チャレンジしていたSIOSさんのくじで、ようやくCoatiマグカップをGetすることができました!
Coatiマグカップが当たったw#AWSSummit pic.twitter.com/QYn0aIb4HY
— urmot (@urmot2) June 12, 20193. セッション
セッションもかなり豪華になっていました!
特に基調講演が始まる際にはダンサーによるオープニングアクトがあるなど、本当にテックカンファレンスなのかを疑うほどの豪華さでした。
#AWSSummit 基調講演のオープニングアクトが始まりました!! pic.twitter.com/vIR8iajZKv
— AWS / アマゾン ウェブ サービス (@awscloud_jp) 2019年6月12日基調講演の内容を簡単にまとめると、
- 前年同期比で41%の成長
- クラウドを使う1/2がAWSを選択
- AWSのIT人材の育成
- AWS Loft Tokyo
- AWS Dev Day
- AWS Innvocate
- AWS Educate
- クラウドジャーニー
- Windows対応
- Redshiftのパフォーマンス10倍
- 「全ての開発者に機械学習を」
- SageMaker
- DeepRacer
- トレーニングマテリアルの日本語化
という感じです。
相変わらず、成長率が凄まじいですね...。去年に引き続き機械学習に力を入れていき、IT人材の育成にも力を入れていくみたいですね (ありがたい...)。
まとめ
去年より遥かにグレードアップし、益々成長を遂げているAWS Summitでした!
次は、6/27にAWS Summit Osaka 2019が開催されます。
そして、来年のAWS Summit Tokyoの会場は横浜だそうです!
(今回もだけど、もはやTokyoじゃないw)#AWSSummit が終了しました!本日のまとめビデオをご覧下さい。
— AWS / アマゾン ウェブ サービス (@awscloud_jp) June 14, 2019
今年も多くの出会いがありました。来年は会場をパシフィコ横浜に移し、さらに #AWSSummit Tokyoを盛り上げていければと思います。
そして初開催の #AWSSummit Osaka は6月27日!大阪で皆さまとお会いできるのを、楽しみにしています! pic.twitter.com/gBnCtA6O9Z

- 投稿日:2019-07-07T20:12:47+09:00
EC2とELBで、URLごとに別のサーバにルーティングする
イントロ
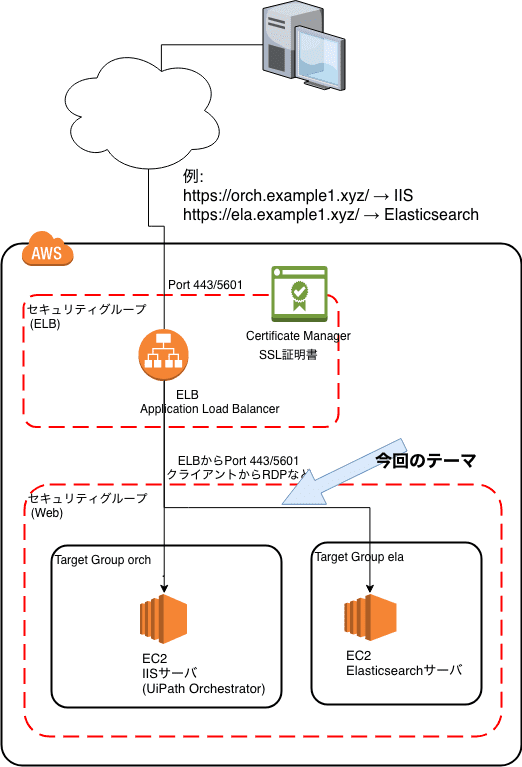
EC2で構築したUiPath Orchestrator サーバを、自己署名じゃない証明書でSSLで公開する(Certificate ManagerとELBを使用) のつづきです。
自己署名証明書で動いているIISのOrchestratorサーバを、ELBを用いて正式な証明書を使ったサーバとして公開するところまでをやりました。残りは、URLが「https://ela.example1.xyz/ 」の時は、Elasticsearchサーバへルーティングする設定の追加です。
もろもろ前提などは、前回の記事 をご確認ください。
やってみる
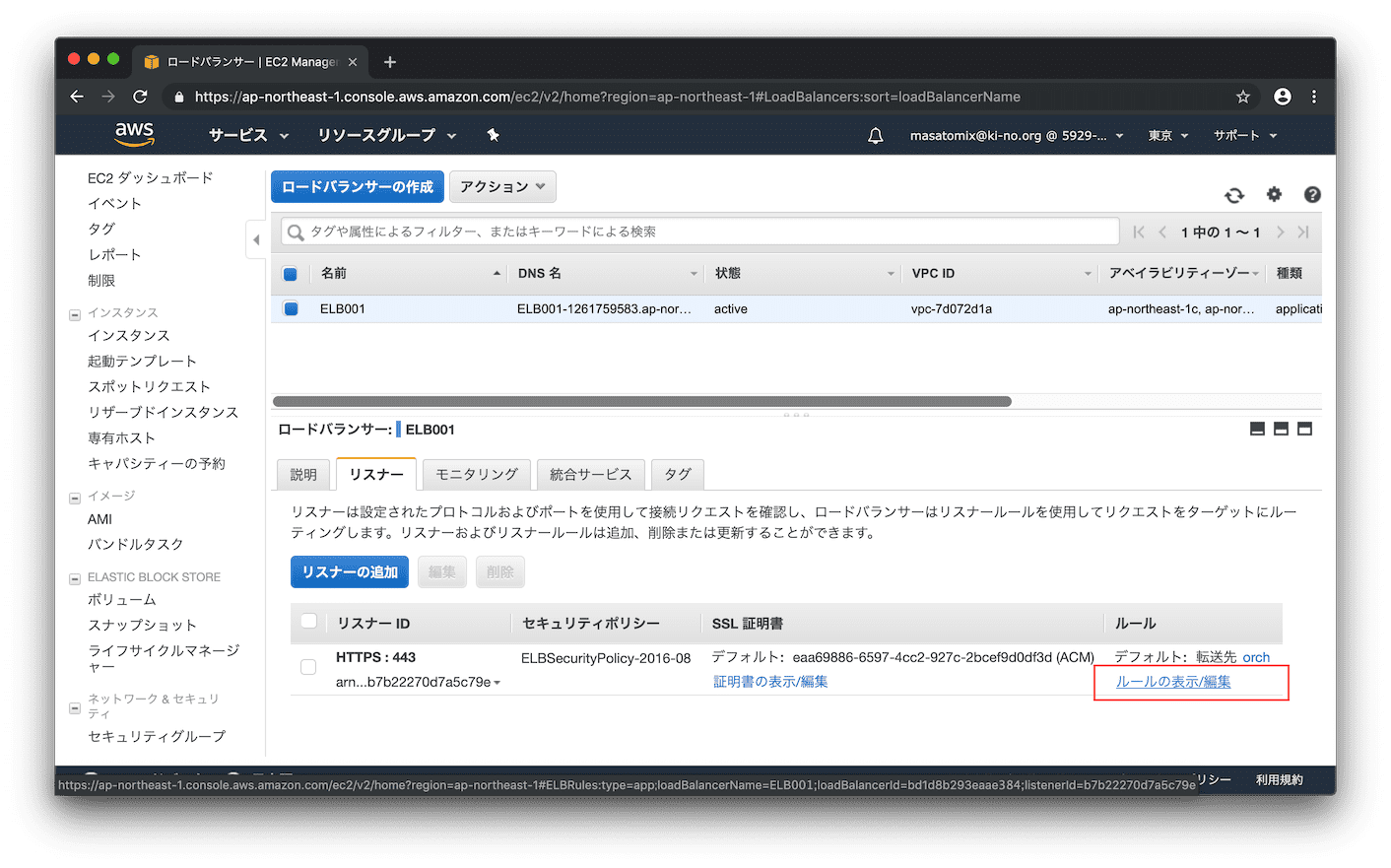
ロードバランサの設定画面で「ルールの表示/編集」をクリック。
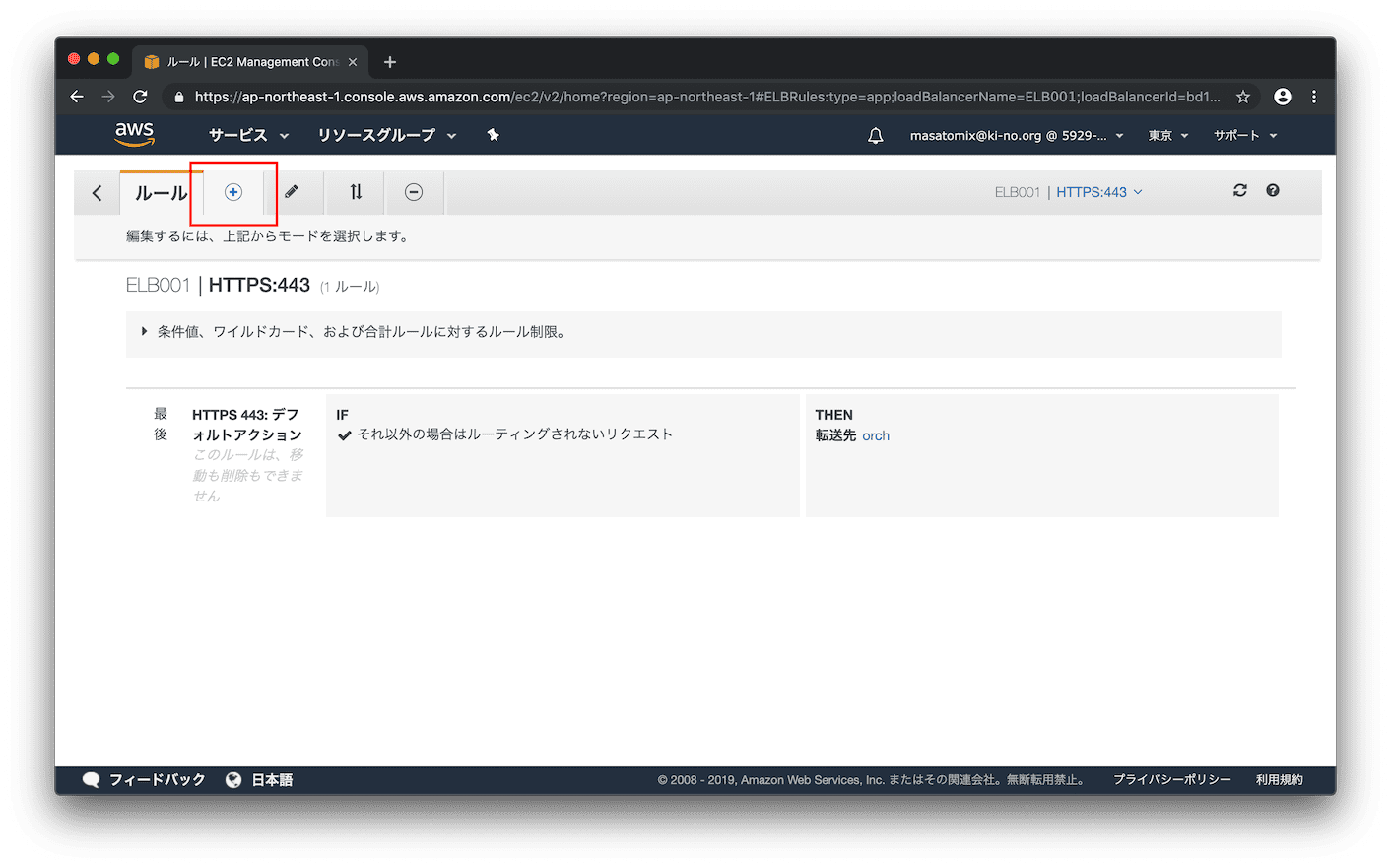
ルーティングを追加するために上部の「プラス」をクリック。
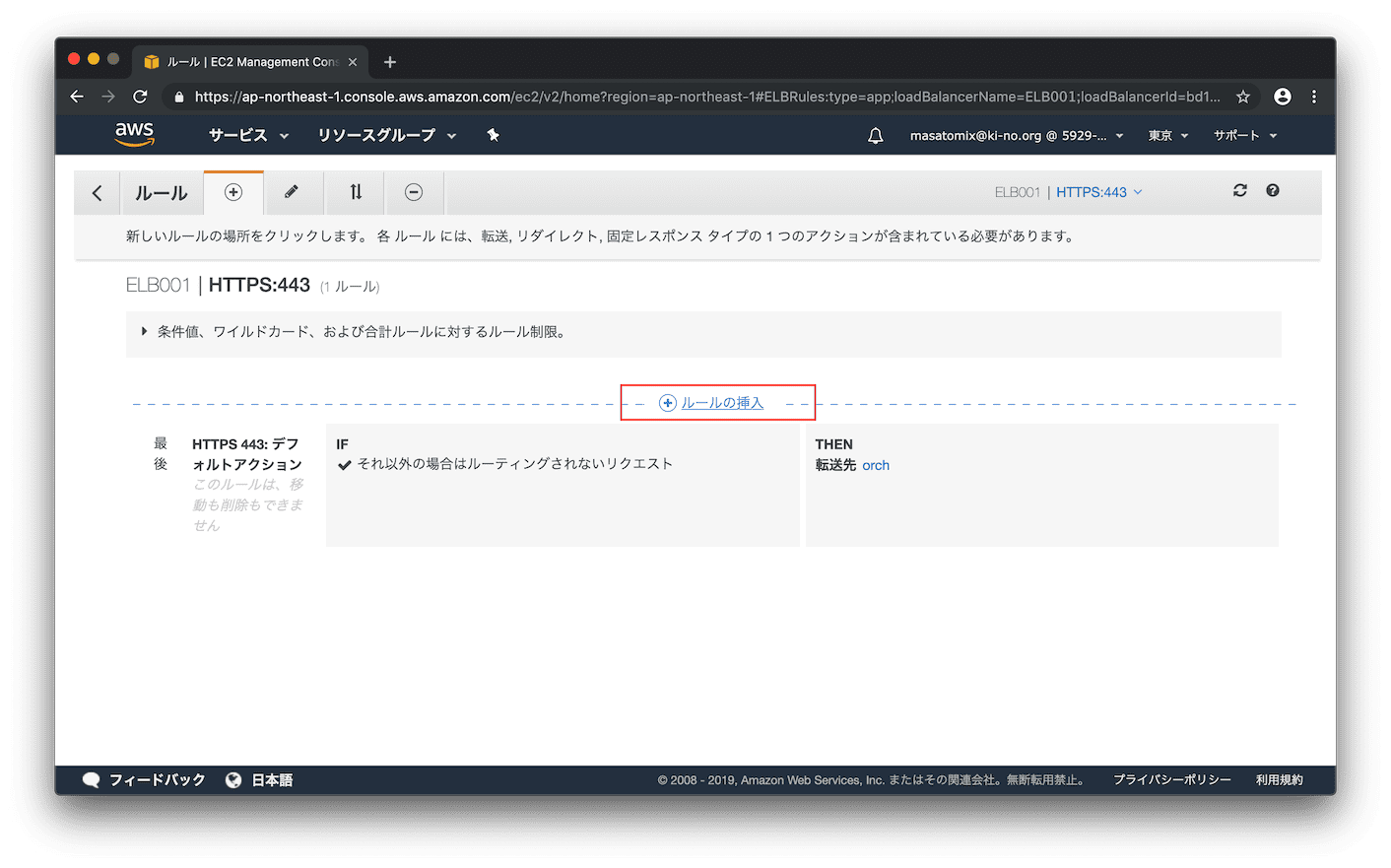
ルールを追加するために「ルールの挿入」をクリック。
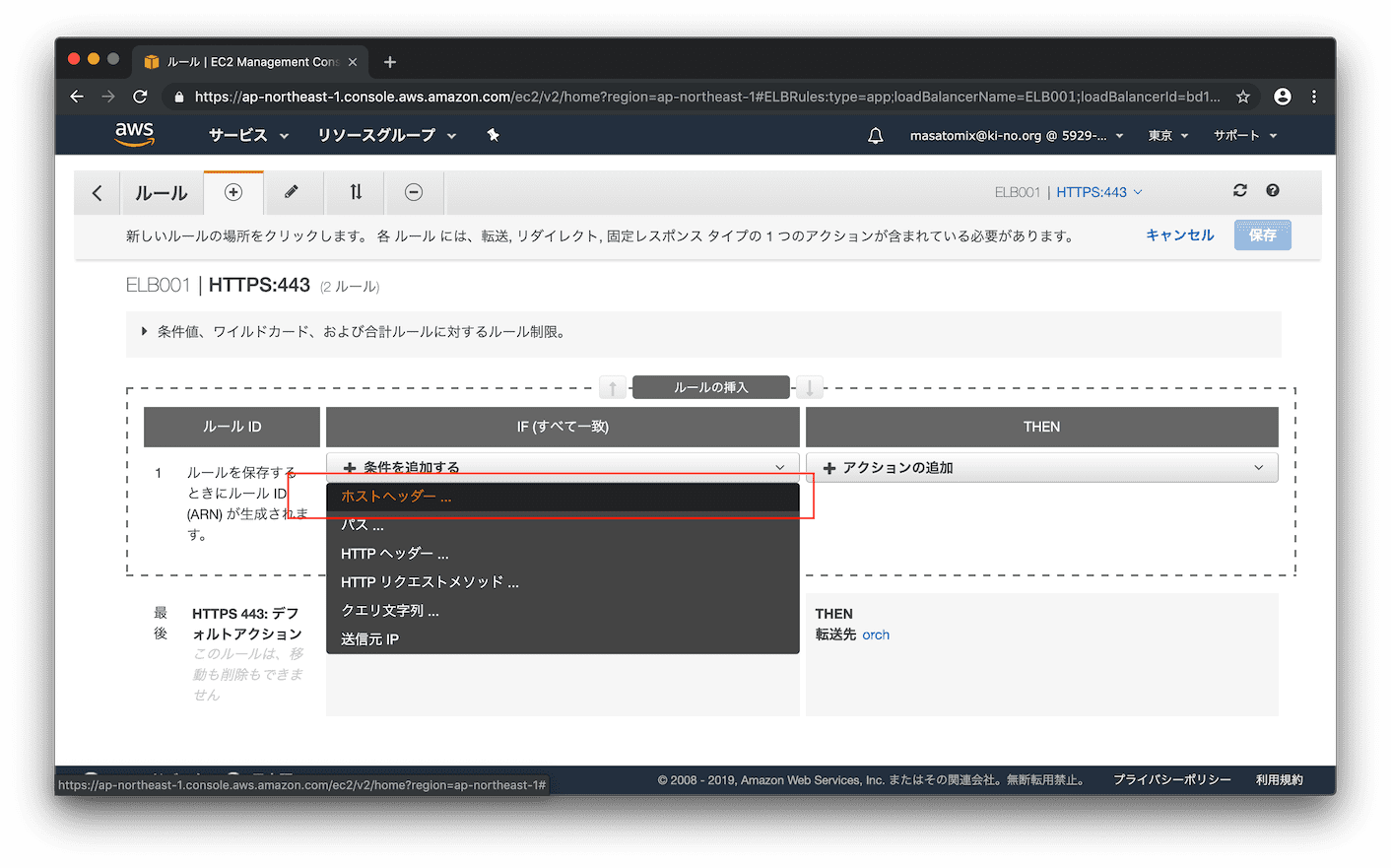
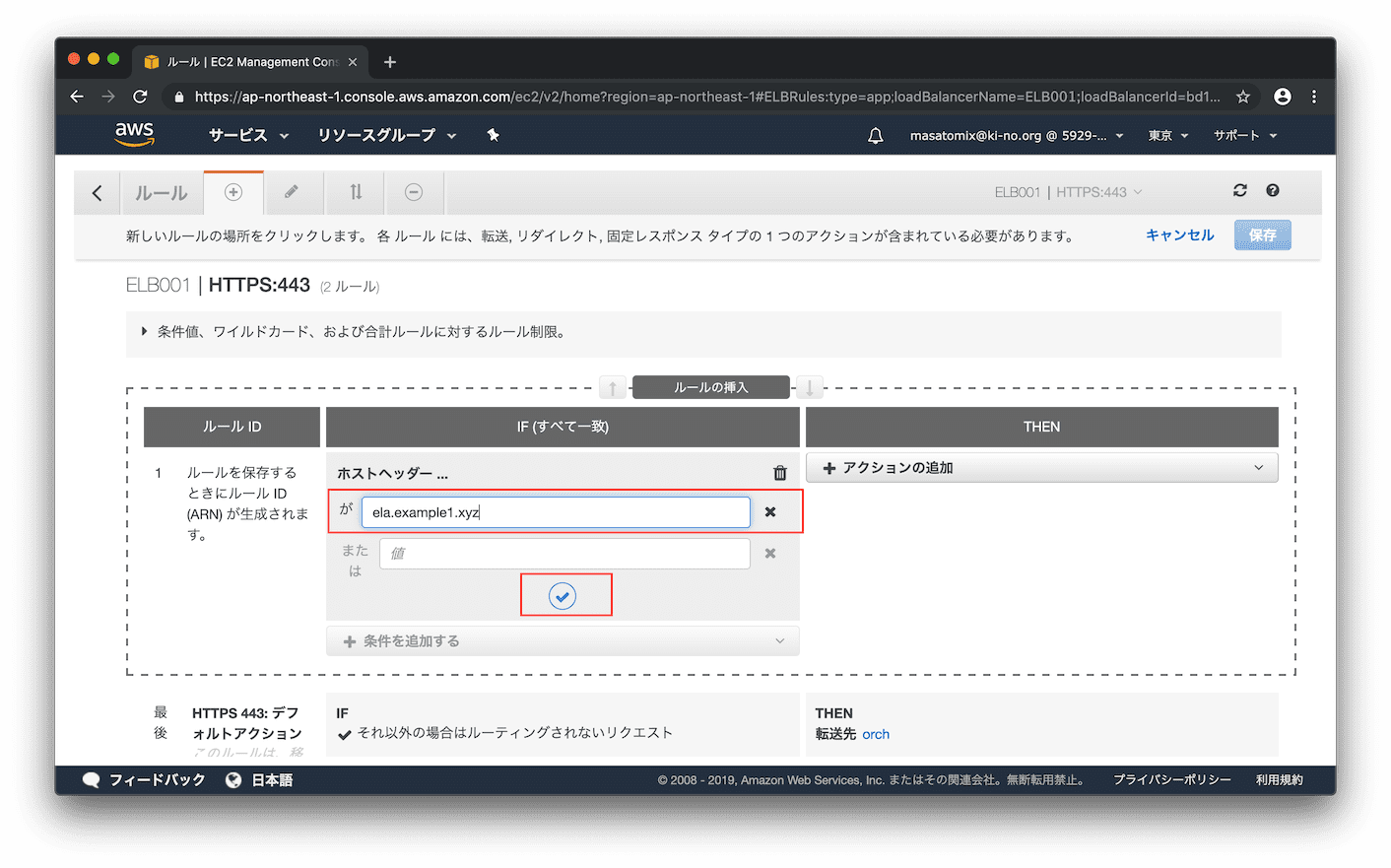
URLが 「https://ela.example1.xyz/ 」の時だったら を追加するため、プルダウンから「ホストヘッダー...」を選択。
「ela.example1.xyz」と入力しチェックマークをクリック。
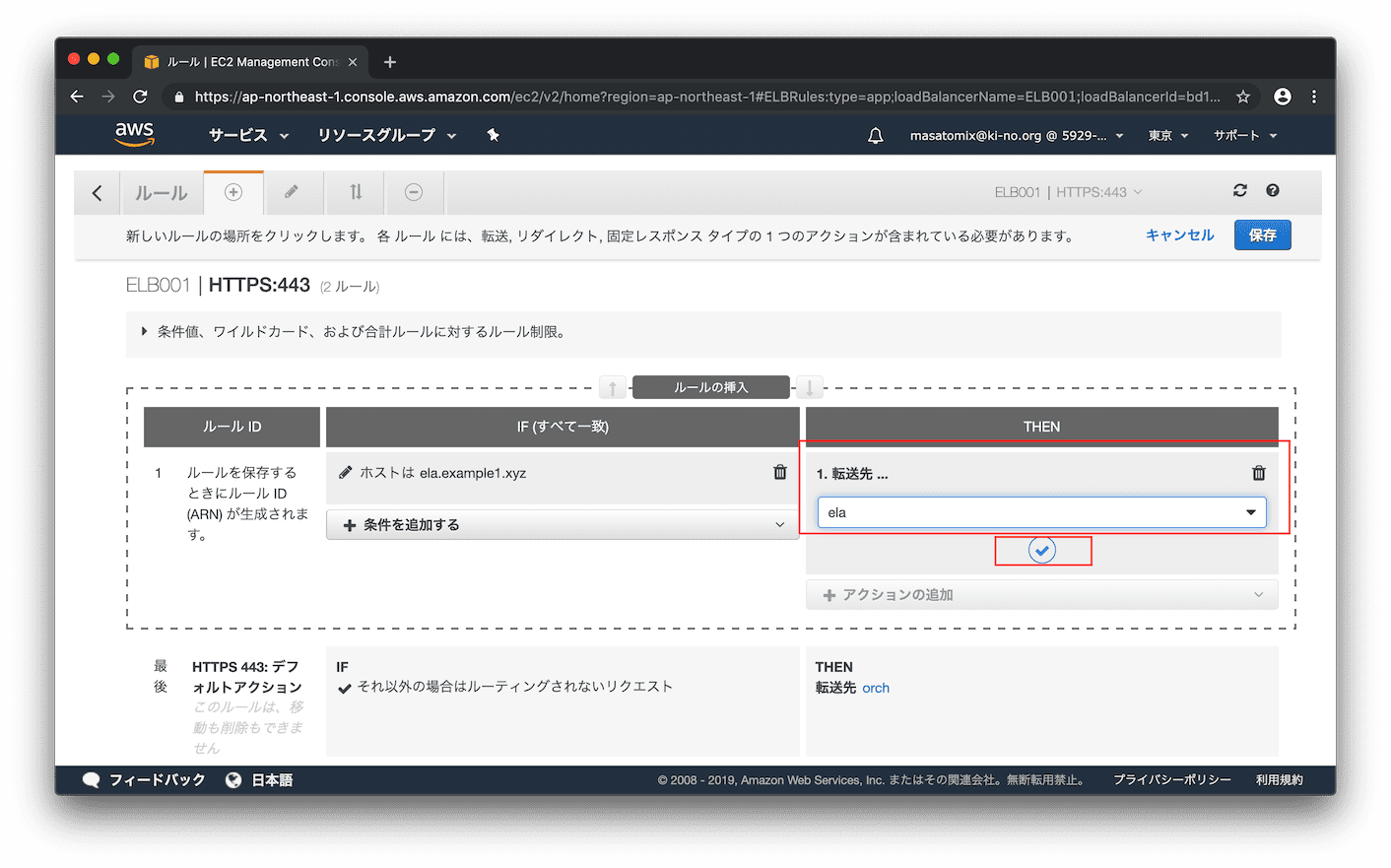
IF(左側)が確定しました。続いてTHEN(右側です) ですが、プルダウンから「転送先」を選択し、転送先のターゲットグループとして前回作成した「ela」を選択。チェックマークをクリックすると、、
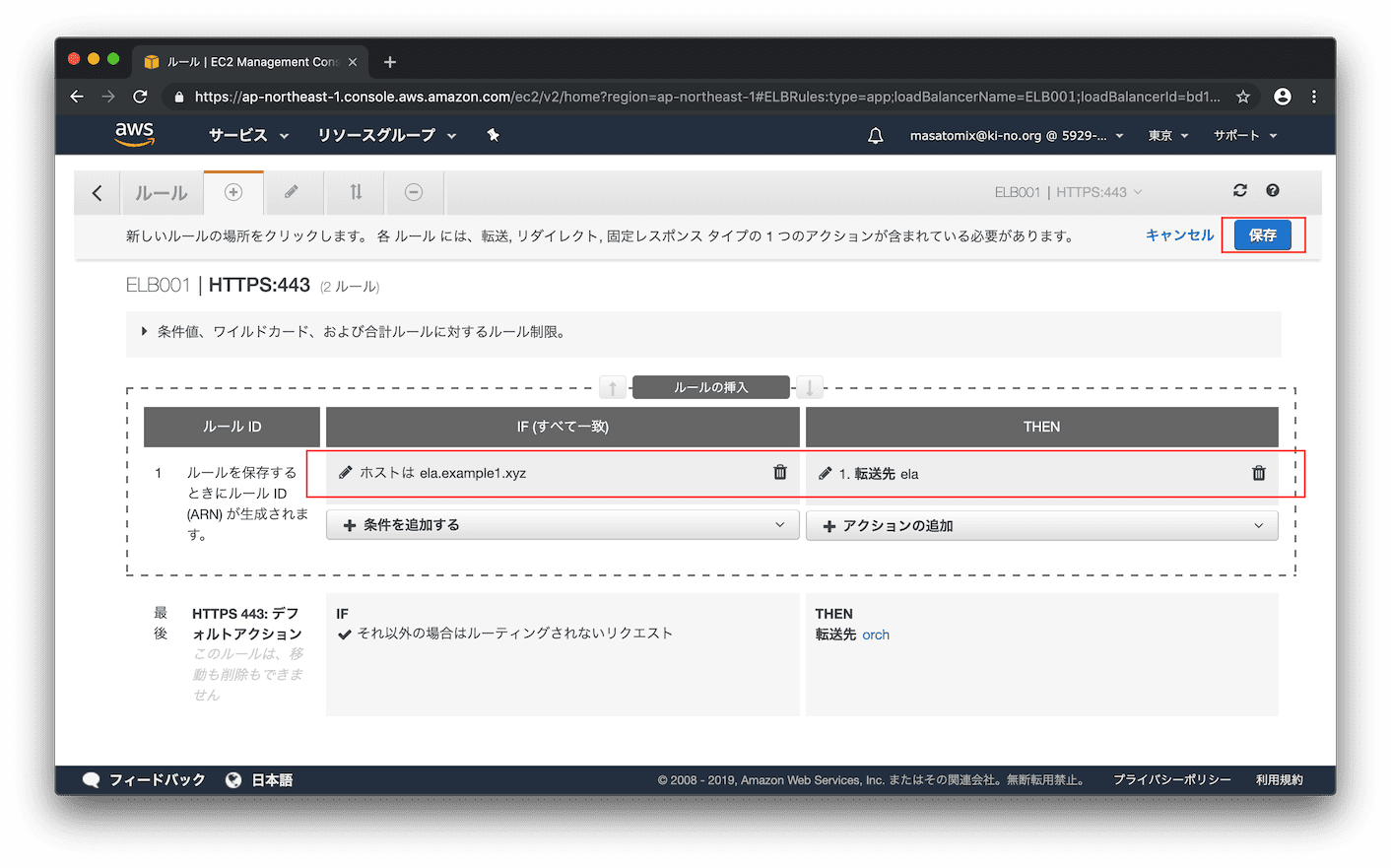
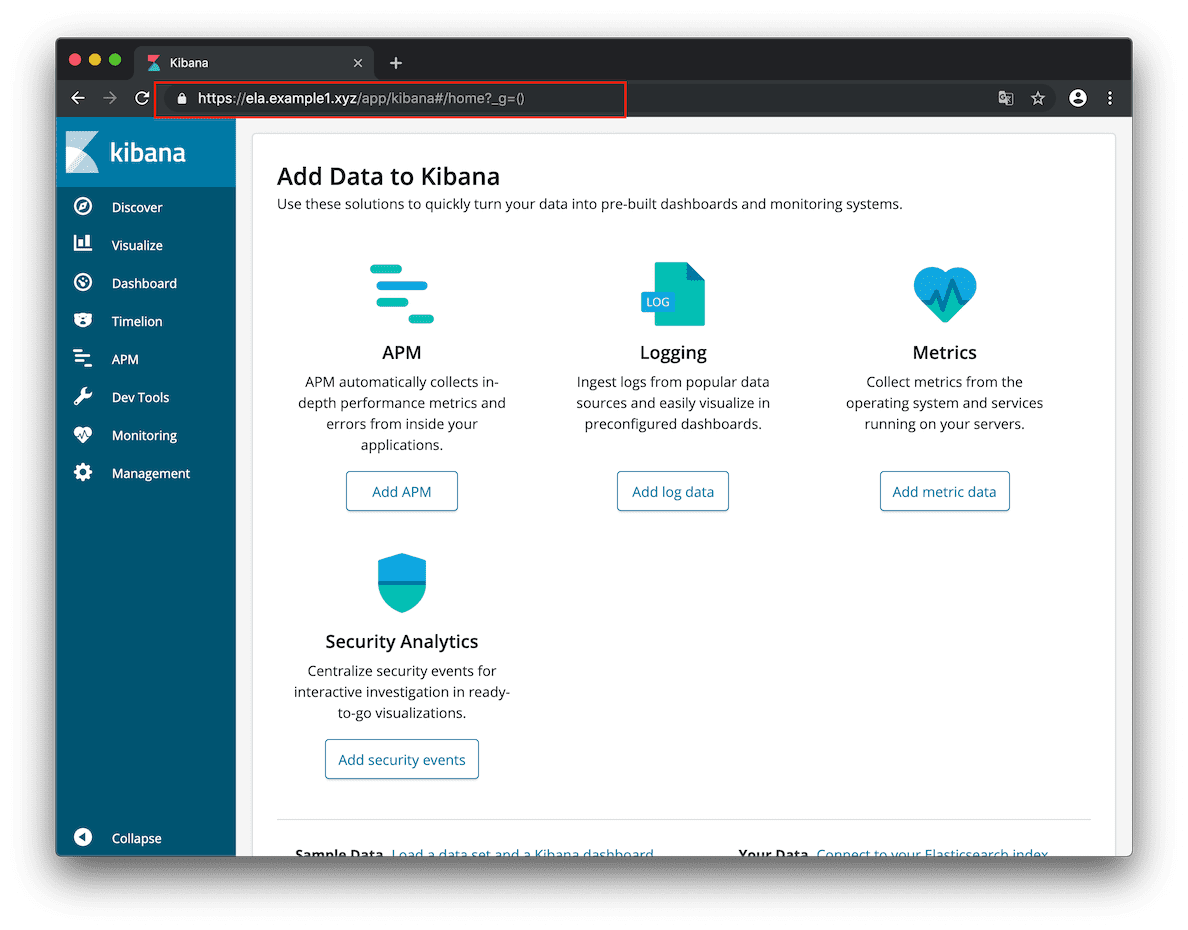
「アクセス先が ela.example1.xyz だったら、ターゲットグループ ela に転送する」という設定が追加されました。右上の「保存」をクリックします。
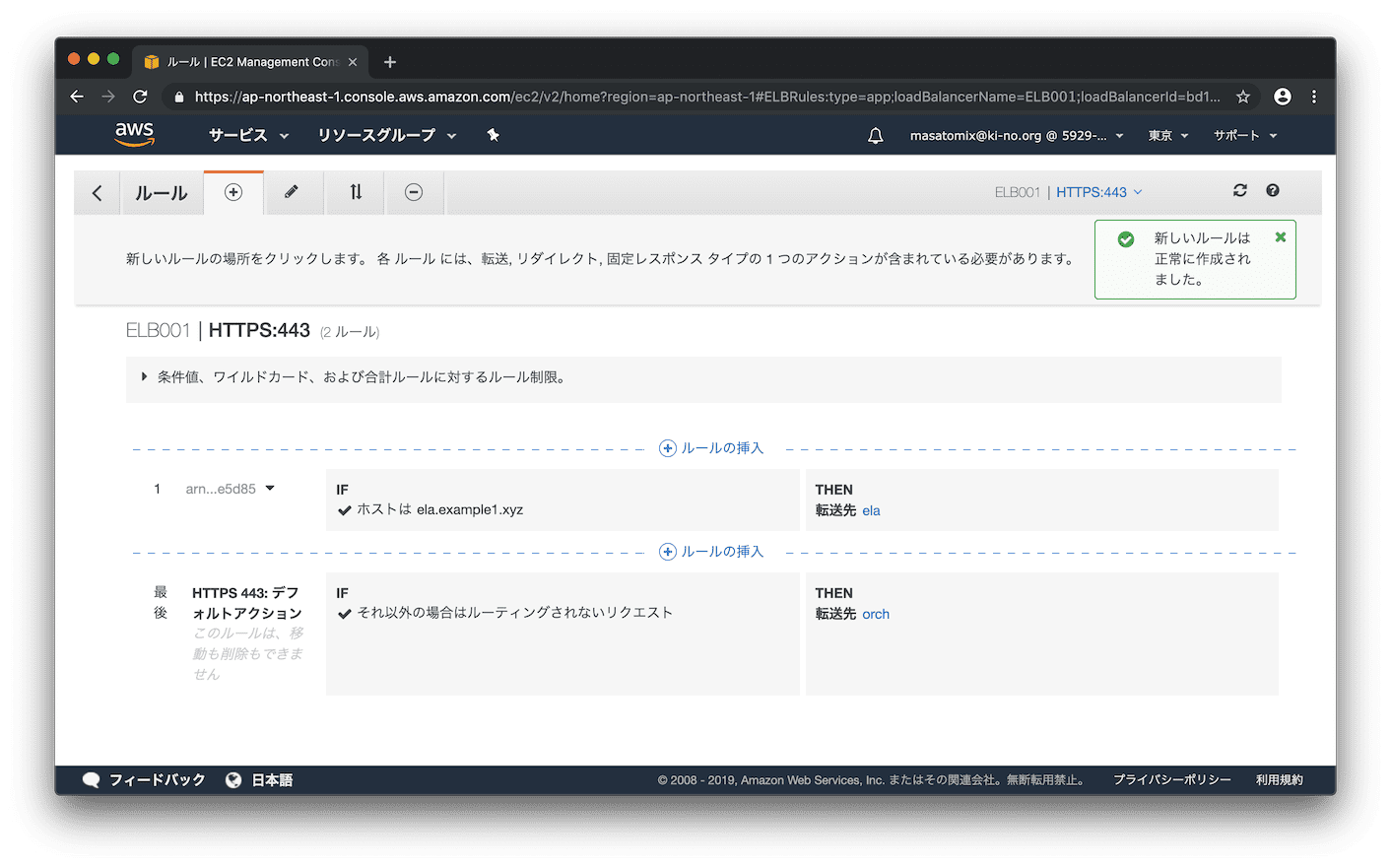
追加されました!
さて https://ela.example1.xyz/ へアクセスしてみると、、表示されましたねーーー。。
この Application Load Balancer の ホスト名ベースのルーティング機能によって、一台のロードバランサを使って、様々なサーバにリバースプロキシできるわけですね。とても便利です。
UiPath Orchestrator の構築の観点からも、メインのOrchestratorサーバとElasticsearchサーバを、一台のロードバランサでURLで振り分けできることが確認出来ましたね。おつかれさまでした。
関連リンク
- 投稿日:2019-07-07T20:01:45+09:00
Terraform - リポジトリ構造と活用範囲を考える
はじめに
Terraform に入門すると、最初に簡単な VPC を作成するまでは早いですが、実運用を見越して
terraform.tfstateの管理方法について考えたり、効率的なディレクトリ構成について考えたりすると手が止まってしまいます。入門時期を終えて、書籍『Pragmatic Terraform on AWS』 を読んで Terraform のお作法について学び直したところなので、これまで得た知見を整理するために記事を書いてみます。
書くこと
- Terraform の使い所
- Terraform で実装したリポジトリの例とサンプルコード(一部)
書かないこと
- Terraform の使い方・インストール方法
Terraform の運用方法
Terraform でクラウド環境を構築するだけなら直ぐですが、「構築した環境の上で動作するアプリケーションのライフサイクルについて」や、「AWSアカウント直後から、対象の環境で Terraform を初めて実行するまで」のことを考えると、色々と考えることが多くなります。
実際の構築順序
今回の記事は「Terraformで全ては構築しない」という前提で記載しています。
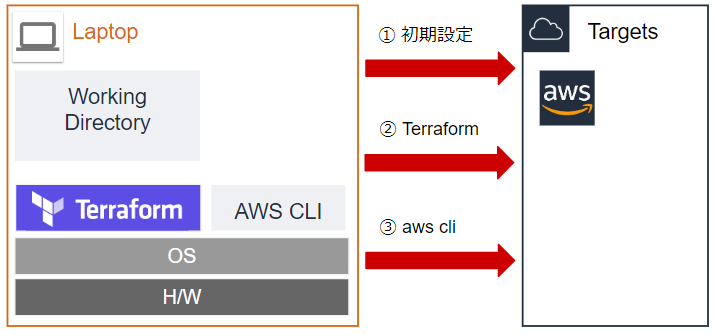
これを踏まえて、「AWSアカウントを取得して基本設定を終わらせた状態」から「アプリケーションをデプロイする」までをまとめると次の3つのステップが必要になります。
- アカウントの基本設定と
tfstate保存領域の確保- Terraform によるインフラの構築
- Terraform 対応範囲外のインフラ構築(GUI、CUI)
このうち、2) のみが Terraform の実行によって環境を構築するフェーズです。
1. アカウントの基本設定と
tfstate保存領域の確保AWSアカウントを取得して、本当の直後は次のようなサイトを参考にして設定を行います。
この設定が終わったら、 Terraform で作業を行うために次のような設定を行います。
- 作業ユーザの作成
access_key,secret_keyの発行- backend 用の S3 Bucket の作成
また、状況に応じて Terraform 実行前にやることとして、以下のようなこともあるかもしれません。
- Elastic IP の発行(外部IF として固定が必要なものなど)
- ドメインの取得 と Route 53 の設定
- ACM を使用した SSL証明書の登録
cf. Multi-account AWS Architecture - Terraform by HashiCorp
ideally the infrastructure that is used by Terraform should exist outside of the infrastructure that Terraform manages.
2. Terraform によるインフラの構築
詳細については、「Module のお作法を整理する」以降の節で記載します。
3. Terraform 対応範囲外のインフラ構築(GUI、CUI)
アプリケーションのデプロイなど、Terraform が構築したシステム・インフラの上にのるリソースのデプロイを行います。
- Elastic Beanstalk アプリケーション
- AWS Lambda アプリケーション
- API Gateway アプリケーション
ただし、この 3) については、自分の中でも悩みの多いところであり、どのように役割分担してゆくか戸惑っている箇所です。
Module のお作法を整理する
まず最初に、Terraform でインフラを構築するにあたって避けては通ることの出来ない module について整理します。
Standard Module Structure
Terraform の公式サイトでは Standard Module Structure ( 標準モジュール構造 ) として次の2つの構成が紹介されています。
cf. Creating Modules - Terraform by HashiCorp
- minimal recommended module
- complete example of a module
構造のルール
構造のルールとして次のようなことが記載されています。
- Root module : リポジトリのルートディレクトリに「Terraform files」を配置しなければならない。
これがモジュールの primary entrypoint となる。- README : Root module と ネストされた moduleは README を配置した方が良い。
input や output はツールで自動生成できるため、記載する必要はない。- LICENSE : Public にモジュール公開するなら、あった方が良い。
- main.tf, variables.tf, outputs.tf : 最小モジュールとして推奨されるファイル名。空でもあったほうが良い。
- Variables and outputs should have descriptions. : 全ての variable と output に1~2行の説明を記載しましょう。
- Nested modules. : module は
modules/配下に配置しましょう。module は可能な限り複雑さを排除した振る舞いを記載し、README に用法を記載しましょう。
Root module が Nested modules を呼ぶ場合、個別のリポジトリにせずに全て1つのリポジトリで管理するようにしましょう。- Examples. : module の使用方法を記載した example は
examples/配下に配置しましょう。
example には README を配置し、用法のゴールを記載しましょう。A minimal recommended module
例)最小構成$ tree minimal-module/ . ├── README.md ├── main.tf ├── variables.tf ├── outputs.tfA complete example of a module
例)全体構成$ tree complete-module/ . ├── README.md ├── main.tf ├── variables.tf ├── outputs.tf ├── ... ├── modules/ │ ├── nestedA/ │ │ ├── README.md │ │ ├── variables.tf │ │ ├── main.tf │ │ ├── outputs.tf │ ├── nestedB/ │ ├── .../ ├── examples/ │ ├── exampleA/ │ │ ├── main.tf │ ├── exampleB/ │ ├── .../Terraform リポジトリの構造を検討する
Terraform によって システムのインフラを構築する際に実装するリポジトリの構造について検討します。
基本コンセプト
検討にあたっての基本コンセプトは次の通りです。
- コンポーネント分割
- 環境分割
- ローカル・モジュール
- Backend は AWS S3 で管理
1. コンポーネント分割
書籍『Pragmatic Terraform on AWS』に「17.4 コンポーネント分割」という節があります。
ここには次のような記載記載があります。
環境は分かりやすい境界です。ひとつの環境につき、ひとつのtfstate ファイルというのは
素直な考え⽅です。しかし、この考え⽅にはデメリットがあります。ひとつのtfstate ファイ
ルでその環境のすべてのリソースを管理すると、ひとつのミスが全体に影響を与えてしまいま
す。また、Terraform の実⾏にも時間がかかります。そこで、環境を複数のコンポーネントに
分割しましょう。
引用:「KOS-MOS(2019).『Pragmatic Terraform on AWS』v1.0.0, 146-149」また、具体的な例として次のような指針が示されています。
- 安定度が高いコンポーネントとそれ以外の分離
- ステートフルなリソース(ストレージやデータストア)の隔離
- (エンドユーザへの)影響範囲が異なるものの分割
- 組織のライフサイクルに関わるリソースの分離
- 関心事の分離
これらの記載を踏まえると、例えば「VPC」「RDS」「EC2」「IAM」といった異なる役割を持つリソースを1つの tfstateファイル で保持することが好ましくないことがわかります。
そのため、今回は記事「terraformはどの単位で分割すべきか - Qiita」を参考にしてコンポーネントの分割を行うことにしました。
2. 環境分割
ここで言う環境とは、Terraform によって構築する対象のサービスが「本番」「検証」「開発」のどの用途で使用されるといった意味で使用します。
この環境の定義の方法は次の2つの方法があります。
- ディレクトリ分割型
- workspace型
インターネット上には「ディレクトリ分割型」で環境を定義する例が多く、記事「Terraform 運用ベストプラクティス 2019 ~workspace をやめてみた等諸々~ - 長生村本郷Engineers'Blog」では「workspace型」のデメリットによって「ディレクトリ分割型」に戻したという旨の記載があります。
また、書籍『Pragmatic Terraform on AWS』には、2018 年9 ⽉に⾏われたHashiCorpJapan Meetup において、workspace型の利用者は少数派で、多くのユーザがディレクトリ分割を行っていたとの記載があります。
一方で、workspace型の活用例も確かに存在し、そちらの実例の方が魅力に感じたため、今回は workspace型 を採用することにします。
3. ローカル・モジュール
「Module Sources - Terraform by HashiCorp」によると、module block が
sourceとして指定出来るものとして次の方法が紹介されています。
- Local paths
- Terraform Registry
- GitHub
- Bitbucket
- Generic Git, Mercurial repositories
- HTTP URLs
- S3 buckets
- GCS buckets
今回、この中で使用するのは「Local paths」です。
4. Backend は AWS S3 で管理
これはもう当然の選択ですが、Backend に AWS S3 を指定して
terraform.tfsateを管理する方式を採用します。プロジェクト構成
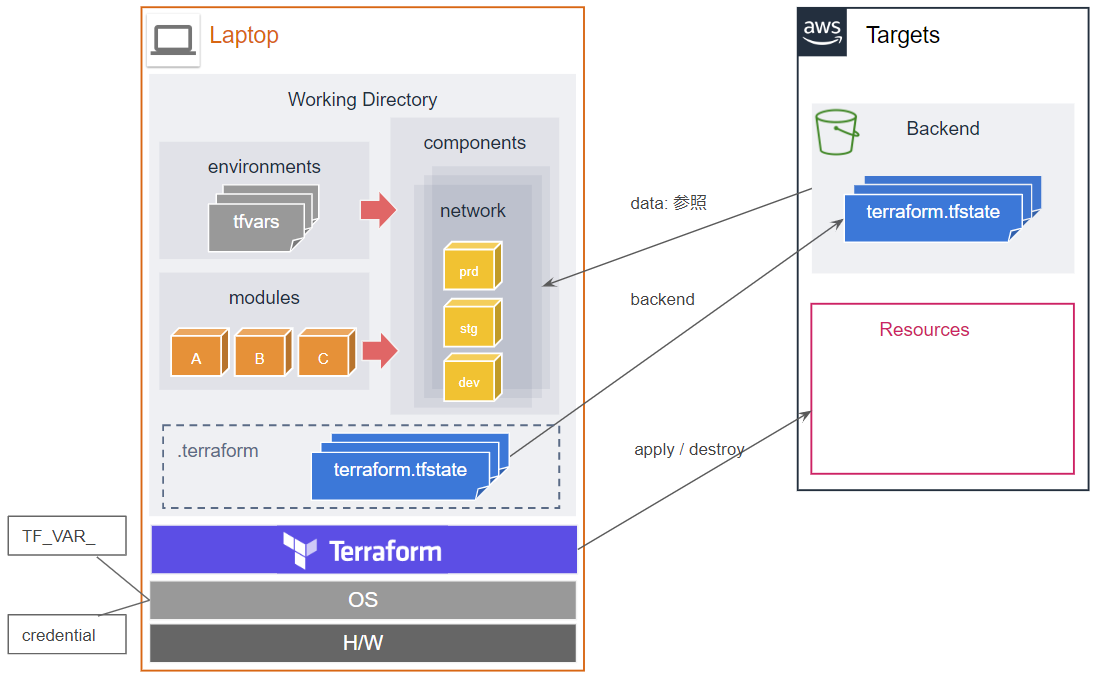
Standard Module Structure をベースに、前述の基本コンセプトを考慮して設計したディレクトリ構成が以下です。
構成例$ tree sample-project/ . ├── README.md ├── LICENSE ├── .secret ├── .gitignore ├── ... ├── bin <--- リポジトリの初期化 │ ├── init_components.sh │ ├── init_s3.sh │ ├── init_s3.bat │ ├── config/ ├── environments/ <--- 環境ごとの変数を定義 │ ├── common │ │ ├── terraform.tfvars │ ├── product │ │ ├── terraform.tfvars │ ├── staging │ ├── develop │ ├── default ├── modules/ <--- Local Module │ ├── nestedA/ │ │ ├── README.md │ │ ├── variables.tf │ │ ├── main.tf │ │ ├── outputs.tf │ ├── nestedB/ │ ├── .../ ├── components/ <--- コンポーネント分割した設定群 │ ├── network/ │ │ ├── README.md │ │ ├── main.tf <--- 基本となる処理を記載 │ │ ├── variables.tf <--- variables を記載 │ │ ├── outputs.tf <--- output ブロックを記載 │ │ ├── backend.tf <--- リモートステートを記載(terraformブロック、dataブロック) │ │ ├── provider.tf <--- provider を記載 │ │ ├── .terraform │ ├── firewall/ │ ├── iam/ │ ├── s3/ │ ├── datastore/ │ ├── application/ │ ├── operation/ │ ├── .../Terraform を実際に実行するのは、
components配下にある任意のコンポーネント・ディレクトリの下で実施します。大雑把な構成図は以下の通りです。
Sample Code
firewallコンポーネントを例に、コンポーネント配下のコード例を記載します。backend
リモートステート情報を定義する
components/firewall/backend.tfの例は次の通りです。components/firewall/backend.tfterraform { required_version = "0.12.3" backend "s3" { region = "ap-northeast-1" encrypt = true bucket = "<unique-bucket-name>" key = "firewall/terraform.tfstate" profile = "profile-name" } } data "terraform_remote_state" "network" { backend = "s3" config = { bucket = "<unique-bucket-name>" key = "env:/${terraform.workspace}/network/terraform.tfstate" region = "ap-northeast-1" profile = "profile-name" } }terraformブロックの backend を指定すると、以下のような PATH で remote state が作成されます。
unique-bucket-name/env:/${terraform.workspace}/firewall/terraform.tfstate
variables
変数情報を定義する
components/firewall/variables.tfの例は次の通りです。components/firewall/variables.tfvariable "common" { type = map(string) default = { "default.region" = "ap-northeast-1" "default.project" = "project-name" } }main
基本となる処理を定義する
components/firewall/main.tfの例は次の通りです。components/firewall/main.tfmodule "firewall" { source = "../../modules/nestedB" common = var.common vpc = data.terraform_remote_state.network.outputs.vpc }provider
providerを定義する
components/firewall/provider.tfの例は次の通りです。components/firewall/provider.tfvariable "aws_access_key" { } variable "aws_secret_key" { } provider "aws" { version = "= 2.18.0" access_key = var.aws_access_key secret_key = var.aws_secret_key region = "ap-northeast-1" }terraform.tfvars
環境ごとに定義する変数ファイル
environments/common/terraform.tfvarsの例は次の通りです。environments/common/terraform.tfvarsregion = "ap-northeast-1" cidrs = [ "10.0.0.0/16", "10.1.0.0/16" ] amis = { "ap-northeast-1a" = "ami-abc123" "ap-northeast-1c" = "ami-def456" }workspace
各コンポーネント・ディレクトリ配下に次の4つの workspace を作成します。
commandterraform workspace list * default develop product stagingAWS CLI profile
backendで指定する AWS S3 にアクセスするための profile 情報を設定します。.aws/credentials[profile-name] aws_access_key_id = AKIAXXXXXXXXXXXXXXXXXX aws_secret_access_key = XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXBackend用 AWS S3 Bucket 作成スクリプト
AWS CLI を使用して S3 Bucket を作成します。
bin/init_s3.bat@echo off set profile_name=%1 set bucket_name=%2 aws s3 mb s3://%bucket_name% ^ --profile %profile_name% aws s3api put-bucket-versioning ^ --profile %profile_name% ^ --bucket %bucket_name% ^ --versioning-configuration Status=Enabled aws s3api put-bucket-encryption ^ --profile %profile_name% ^ --bucket %bucket_name% ^ --server-side-encryption-configuration file://config/config-public-access-block.json aws s3api put-public-access-block ^ --profile %profile_name% ^ --bucket %bucket_name% ^ --public-access-block-configuration file://config/config-public-access-block.jsonbin/config/config-public-access-block.json{ "Rules": [{ "ApplyServerSideEncryptionByDefault": { "SSEAlgorithm": "AES256" } }] }bin/config/config-bucket-encryption.json{ "BlockPublicAcls": true, "IgnorePublicAcls": true, "BlockPublicPolicy": true, "RestrictPublicBuckets": true }実行
terraformコマンドを実行する際は以下のようにします。
コマンドを実装するフォルダに注意してください。command_bash// 環境変数の設定を確認 export TF_VAR_aws_access_key="AKIAXXXXXXXXXXXXXXXXXX" export TF_VAR_aws_secret_key="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" echo $TF_VAR_aws_access_key echo $TF_VAR_aws_secret_key // workspace の選択 terraform workspace select [ default / product / staging / develop ] // 初期化 terraform init // Dry run terraform plan \ -var-file="../../environments/common/terraform.tfvars" \ -var-file="../../environments/$(terraform workspace show)/terraform.tfvars"command_Powershell// 環境変数の設定を確認 $env:TF_VAR_aws_access_key="AKIAXXXXXXXXXXXXXXXXXX" $env:TF_VAR_aws_secret_key="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX" $env:TF_VAR_public_key_path=".\.secret\public" $env:TF_VAR_aws_access_key; $env:TF_VAR_aws_secret_key; $env:TF_VAR_public_key_path; Get-ChildItem env: // workspace の選択 terraform workspace select [ default / product / staging / develop ] // 初期化 terraform init // Dry run terraform plan ` -var-file="../../environments/common/terraform.tfvars" ` -var-file="../../environments/$(terraform workspace show)/terraform.tfvars"まとめ
この記事のまとめです。
実現したこと
- コンポーネント分割によって、tfstateファイルで管理するリソースを分割
- Workspaces を使用して環境(本番、検証、開発)分割
- ローカル・モジュールしてリソースを定義
- AWS S3 を使用した
terraform.tfstateの管理とバージョニング課題
- 一つのリポジトリに複数のコンポーネントを管理する形になっており、
terraform initの度に、実行ディレクトリにproviderツールがインストールされる。- Module Repogitory が良くわからない。
- 全体的に手探り
対策
- コンポーネントごとにリポジトリ設計した方が良いのかもしれない。
- これは使ってみるしかない。
- (悩ましい)
おわりに
記事を書いている途中に
v0.11.xからv0.12.xに Terraform のバージョンを上げたら、書いていたコードが全然動かなくなってかなり焦りました。terraform 0.12upgradeコマンドを実行しましたが、万能ではないようです。さすがにメジャーバージョンがまだ 0系だけあって、破壊的な変更というのがあるのですね。
Terraform が持つコアの機能は素晴らしくイメージも付きやすいものですが、実際に触ってみると HCL の記法や各構築対象サービスのお作法を押さえておく必要があり、最初の壁を乗り越えるまでが大変だという印象を受けます。
また、まだツール自体が成長段階ということもあり、次々の新しい記法やお作法が生まれており、そういった情報を把握して追従することにも一手間が生まれそうです。ただ、そのコスト以上に、Terraform から得られるメリットの方が大きいため、もっと Terraform について知って行きたいと思います。
参考
今回の記事を作成するにあたって参考にした情報です。
ディレクトリ構造
- Terraform Best Practices in 2017 - Qiita
- Terraformにおけるディレクトリ構造のベストプラクティス - Developers.IO
- shogomuranushi/oreno-terraform - GitHub
- DevOpsを支える今話題のHashiCorpツール群についてに登壇してきました - てっくぼっと!
- Terraform workspaceを利用する。環境ごとのリソース名の分岐など - Goldstine研究所
- TerraformのModuleソースとしてTerraform Enterprise’s Private Module Registryを利用する - GMOメディア エンジニアブログ
Terraform の分割単位
- terraformはどの単位で分割すべきか - Qiita
- Terraformと変数(variable)の話 - CUPSULE CLOUD
- Feature: Conditionally load tfvars/tf file based on Workspace #15966 - GitHub
- Variable Definitions (.tfvars) Files - Input Variables - Configuration Language - Terraform by HashiCorp
State の管理
サンプル
- cloudposse/terraform-aws-elastic-beanstalk-application - GitHub
- terraform-aws-modules/terraform-aws-vpc - GitHub
Terraform v0.12.x
AWS S3 for terraform.tfstate
- 投稿日:2019-07-07T19:03:21+09:00
TerraformでFargateを扱う際にはまったポイントまとめ
はじめに
Terraformでインフラ構築(AWS)を勉強していて、Fargateを扱う際にはまったポイントをまとめました。
バージョン
- Terraform v0.12.1
はまったポイント
エラー内容
Error: ClientException: No Fargate configuration exists for given values.原因
タスク定義でFargate起動タイプを選択している場合、CPU, Memoryは以下の組み合わせから選ばなくてはならないが、
cpu = 128 memory = 256のように設定していた。
CPU value Memory value (MiB) 256 (.25 vCPU) 512 (0.5GB), 1024 (1GB), 2048 (2GB) 512 (.5 vCPU) 1024 (1GB), 2048 (2GB), 3072 (3GB), 4096 (4GB) 1024 (1 vCPU) 2048 (2GB), 3072 (3GB), 4096 (4GB), 5120 (5GB), 6144 (6GB), 7168 (7GB), 8192 (8GB) 2048 (2 vCPU) Between 4096 (4GB) and 16384 (16GB) in increments of 1024 (1GB) 4096 (4 vCPU) Between 8192 (8GB) and 30720 (30GB) in increments of 1024 (1GB) 参考
No Fargate configuration exists for given values
https://code.thebur.net/2018/05/11/no-fargate-configuration-exists-for-given-values/指定された CPU またはメモリの値が無効
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/developerguide/task-cpu-memory-error.html
エラー内容
Error: ClientException: Fargate requires task definition to have execution role ARN to support ECR images.原因
execution_role_arnを指定する必要があった参考
terraformのmoduleで定義したresouseにアクセスするにはoutputしないとダメ
http://www.mpon.me/entry/2016/12/13/030907https://github.com/ContainerSolutions/unifi-fargate
エラー内容
Error: InvalidParameterException: Network Configuration must be provided when networkMode 'awsvpc' is specified.原因
network_configurationを設定する必要があった参考
https://github.com/ContainerSolutions/unifi-fargate
エラー内容
Error: Incorrect attribute value type Inappropriate value for attribute "subnets": element 0: string required.解決方法
flattenを用いる
参考
Terraform 0.12 + vpc module v2.2 (Inappropriate value for attribute "subnet_ids": element 0: string required.) #271
https://github.com/terraform-aws-modules/terraform-aws-vpc/issues/271その他はまったポイント
0.11と0.12での記述の仕方の違い
- 主に ブロックタイプ (attr { … } という波括弧で記述する属性)と マップ (attr = { key = value } という記述をする属性) ではまりました
- 参考
- Terraformを0.11から0.12に移行するときの注意点とは
- https://apps-gcp.com/terraform-011-to-012/#i-2
タイポ
- 疲れていると謎のタイポをしています
- 投稿日:2019-07-07T17:15:40+09:00
AWS IoT AnalyticsでCSVインポートの処理を作る
AWS IoT Analyticsをあまり利用したことがなかったので、利用した備忘録。ただ色々といじってみたかったので本来のIoT Analyticsの用途からは離れていることは受け入れる感じで。
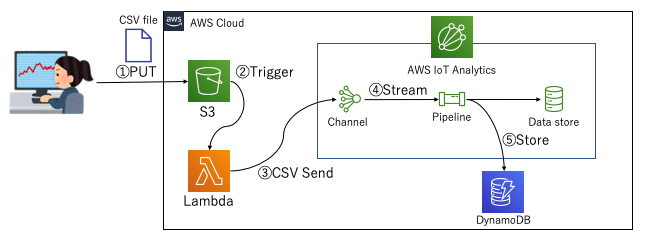
こんな感じのことをやりたい
こういうのを実現するためにAWS IoT Analyticsは使えるんじゃないかな、と。(向いているとは言っていない)
- とあるバケットにCSVファイルが置かれる
- CSVファイル配置をトリガとしてLambdaがキックされ、中身をAWS IoT AnalyticsのChannelに送付する。(この際渡す量をAPI側で調整してあげれば、Pipeline内の処理性能はある一定以上は不要になるので、サイジングをシビアに考える必要がない)
- あとはStream処理でPipelineの中でやりたい処理を実施する。(今回はDynamoDBへのデータ格納)
Pipeline(AWS IoT Analytics)はVPCの中でLambda処理を動かすことはできないようなので、PipelineのLambdaからVPC内に配置したデータストアへのデータ格納はできないようですが、とりあえずこれができるだけでも色々とメリットを得られるので良さそうです。
- Channelはデータの受信したデータをバックアップとして保持しておくことが可能。それを用いてPipeline処理を再度実施することもできる。(例えばPipeline処理を更新したので再度同じデータを通しておく、と言うことも可能。この際データストアに保持されるデータは追加されるのではなく上書きされる仕組みも個人的には嬉しい)
- Pipelineを通したデータの一覧をデータセットとして確認することができる。なんならデータセットを利用して他の処理(AWS Batchなどを使った定期的な重めの処理)を実行することも可能。
全体の成果物は以下
とりあえず以降に説明する内容の成果物は以下に保存
https://github.com/kojiisd/aws-iot-csv-importer
データ配置後トリガで起動するLambdaの実装
早速実装に取り掛かります。図で言うところの②のトリガが発生した以降に起動されるLambdaの実装はこんな感じになります。
data_sensor.pydef convert_from_csv_to_json(file_path, bucket_name, header=False): df = pd.read_csv(file_path) tmp_json ={} if header: tmp_json = df.to_json(orient='records') else: tmp_json = df.to_json(orient='values') result_json_array = [] for ele_json in json.loads(tmp_json): logger.info(ele_json) result_json = {} result_tmp_json = {} result_tmp_json['s3_bucket'] = bucket_name result_tmp_json['data'] = ele_json result_json['messageId'] = str(ele_json['account_number']) result_json['payload'] = json.dumps(result_tmp_json) result_json_array.append(result_json) return result_json_array def send_data_lambda(event, context): bucket_str = event['Records'][0]['s3']['bucket']['name'] bucket = s3_client.Bucket(bucket_str) key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') file_path = TMP_PATH + key os.makedirs(os.path.dirname(file_path), exist_ok=True) bucket.download_file(key, file_path) json_array = convert_from_csv_to_json(file_path, bucket_str, True) for json_sub in chunked(json_array, DATA_BATCH_SIZE): response = iot_analytics_client.batch_put_message( channelName = 'csv_import_sample_channel', messages = json_sub ) return 'All data sending finished.'だいぶ雑なつくりですが、これでChannelに対してCSVデータを送付することができます。今回扱っているデータはElasticsearchのサンプルで使われるデータの
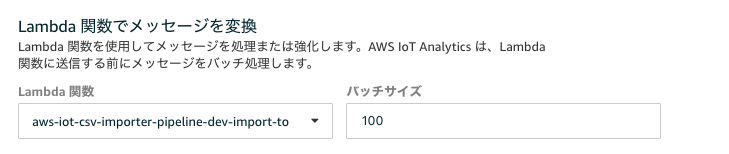
accounts.csvを利用しています。こんな感じのデータです。accounts.csvaccount_number,address,age,balance,city,email,employer,firstname,gender,lastname,state 1,880 Holmes Lane,32,39225,Brogan,amberduke@pyrami.com,Pyrami,Amber,M,Duke,IL 6,671 Bristol Street,36,5686,Dante,hattiebond@netagy.com,Netagy,Hattie,M,Bond,TN 13,789 Madison Street,28,32838,Nogal,nanettebates@quility.com,Quility,Nanette,F,Bates,VA 18,467 Hutchinson Court,33,4180,Orick,daleadams@boink.com,Boink,Dale,M,Adams,MDこれをそれぞれIoT Analyticsに流し込むことになりますが、IoT Analytics側は1データずつ送付されるとそれだけでPipelineの起動数が多すぎになってしまうため、Batch Sizeを調整してまとめてStream処理を走らせられるようにIoT AnalyticsのPipeline部分に設定をしています。
これでデータが送られてきた際、Pipelineに100データずつ流し込んでくれるようになります。
Pipelineで呼び出されるLambda処理
無事Channelへのデータ送付がされたら、次にPipeline処理が呼ばれます。このようなコードを書きました。
csv_importer_store.pydef store_data_lambda(event, context): logger.info("Start store data: {}".format(event)) bucket = s3_client.Bucket(event[0]['s3_bucket']) key = CONF_PATH file_path = TMP_PATH + key os.makedirs(os.path.dirname(file_path), exist_ok=True) bucket.download_file(key, file_path) conf_file = open(file_path, 'r') conf_json = json.load(conf_file) logger.info(conf_json) result_json_array = [] tmp_json = {} for ev in event: tmp_json = {} for key, value in ev['data'].items(): if key in conf_json.keys(): tmp_json[conf_json[key]] = value result_json_array.append(tmp_json) ddb_table = ddb_client.Table(DYNAMODB_TABLE) with ddb_table.batch_writer() as batch: for item_json in result_json_array: batch.put_item( Item=item_json ) return result_json_arrayこれで実行結果がDynamoDBに格納され、かつIoT Analyticsの時系列DBにも格納されるようになります。
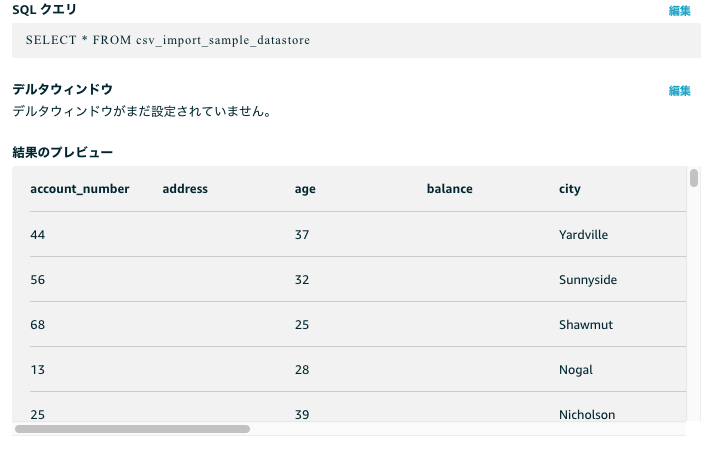
実際に実行してみた結果
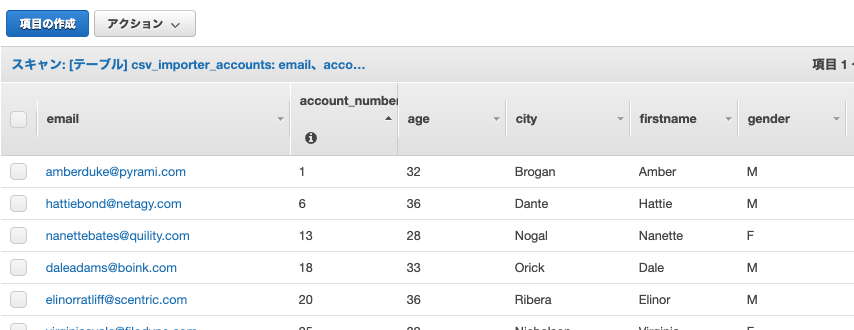
実際にCSVファイルをS3に配置して、この処理を通してみました。IoT Analyticsのデータセット部でクエリを発行することで実施結果が確認できました。(もちろんDynamoDBにもデータは入っていました。)
DynamoDBにも問題なくデータが格納されています。
これで無事に処理を通すことができました。
Pipelineの再処理を実施したくなったら?
もしPippeline内の処理を更新した、などで再度データを流したい場合は、AWS IoT Analyticsでポチポチするだけで実現できます。(もちろんCLIで実施することも可能です)
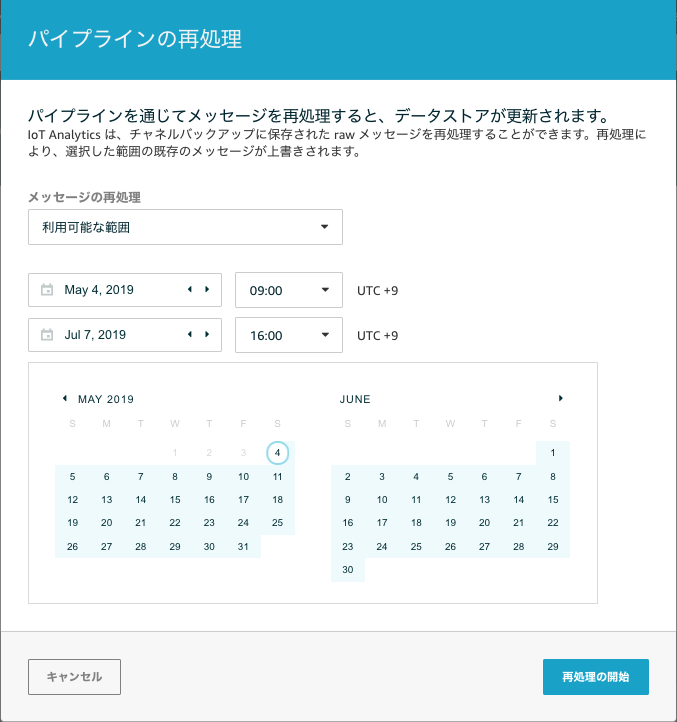
Channelの右側から「メッセージの再処理」を選択します。
期間でしか絞れないのが惜しいところですが、ここで期間を指定して、その期間でChannelが受信したメッセージをPipelineに再度流すことができます。
ちなみにCLIの場合はstart-pipeline-reprocessingで実施できます。
まとめ
今回はAWS IoT Analyticsが本来期待されている目的とは少し異なる利用法を試してみましたが、IoT ANayticsが持っているメッセージ再処理などの特徴をうまく利用することで、CSVインポート処理を任せてみることもできそうだ、と言うこともわかりました。様々な活用法があるとは思うので、模索していきたいところです。

- 投稿日:2019-07-07T16:33:41+09:00
Zappa利用時のトラブルシューティング集
そもそもZappaとは
Github(英語): https://github.com/Miserlou/Zappa
日本語訳: https://githubja.com/miserlou/zappaZappa makes it super easy to build and deploy server-less, event-driven Python applications (including, but not limited to, WSGI web apps) on AWS Lambda + API Gateway. Think of it as "serverless" web hosting for your Python apps.
とのこと。FlaskやDjangoなどのWebアプリケーションフレームワークを利用したPythonアプリをAWS Lambdaへデプロイする際にとても役に立つ。
Zappa利用時のトラブルシューティング集
以下、Zappa利用時に遭遇した事象とトラブルシューティング方法を記載していく。
zappaコマンド(templateなど)を実行すると
NoRegionErrorとなる事象
$ zappa template dev -l ${your-lambda-arn} -r ${your-role-arn} Calling template for stage dev.. Warning! AWS Lambda may not be available in this AWS Region! Warning! AWS API Gateway may not be available in this AWS Region! Oh no! An error occurred! :( ============== Traceback (most recent call last): (中略) botocore.exceptions.NoRegionError: You must specify a region. ============== Need help? Found a bug? Let us know! :D File bug reports on GitHub here: https://github.com/Miserlou/Zappa And join our Slack channel here: https://slack.zappa.io Love!, ~ Team Zappa!対処法
zappa_settings.jsonに"aws_region": "aws-region-name"を記載する。zappa_settings.json{ "dev": { "app_function": "server.app", "aws_region": "ap-northeast-1", ... } }
zappa templateコマンドを実行するとAttributeError: 'ZappaCLI' object has no attribute 'apigateway_policy'となる事象
$ zappa template dev -l ${your-lambda-arn} -r ${your-role-arn} Calling template for stage dev.. Oh no! An error occurred! :( ============== Traceback (most recent call last): File "/root/.local/share/virtualenvs/application-NgYdrrUH/lib/python3.6/site-packages/zappa/cli.py", line 2779, in handle sys.exit(cli.handle()) File "/root/.local/share/virtualenvs/application-NgYdrrUH/lib/python3.6/site-packages/zappa/cli.py", line 509, in handle self.dispatch_command(self.command, stage) File "/root/.local/share/virtualenvs/application-NgYdrrUH/lib/python3.6/site-packages/zappa/cli.py", line 553, in dispatch_command json=self.vargs['json'] File "/root/.local/share/virtualenvs/application-NgYdrrUH/lib/python3.6/site-packages/zappa/cli.py", line 666, in template policy=self.apigateway_policy, AttributeError: 'ZappaCLI' object has no attribute 'apigateway_policy' ============== Need help? Found a bug? Let us know! :D File bug reports on GitHub here: https://github.com/Miserlou/Zappa And join our Slack channel here: https://slack.zappa.io Love!, ~ Team Zappa!対処法
zappaのバージョンを
0.47.0に下げる必要がある。$ zappa -v 0.48.2 $ pipenv install zappa==0.47.0 --skip-lock Installing zappa==0.47.0… Adding zappa to Pipfile's [packages]… ✔ Installation Succeeded Installing dependencies from Pipfile… ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 1/1 — 0
zappa deployやupdateコマンドを実行するとStatus check on the deployed lambda failed. A GET request to '/' yielded a 500 response code.となる事象
$ zappa deploy dev Calling deploy for stage dev.. Downloading and installing dependencies.. - markupsafe==1.1.1: Using locally cached manylinux wheel - sqlite==python3: Using precompiled lambda package Packaging project as zip. Uploading app-dev-1560529924.zip (8.5MiB).. 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 8.91M/8.91M [00:00<00:00, 20.6MB/s] Scheduling.. Scheduled app-dev-zappa-keep-warm-handler.keep_warm_callback with expression rate(4 minutes)! Uploading app-dev-template-1560529930.json (1.6KiB).. 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.60K/1.60K [00:00<00:00, 24.2KB/s] Waiting for stack app-dev to create (this can take a bit).. 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:15<00:00, 5.84s/res] Deploying API Gateway.. Error: Warning! Status check on the deployed lambda failed. A GET request to '/' yielded a 500 response code.対処法
コマンドでのデプロイ時に動作確認としてAPI Gatewayの
/リソースに対してGETリクエストが行われるが、そのリクエストに対するLambdaからのレスポンスが500エラーとなっている。
Lambda側の実行ロールの権限やソースコードに問題がないか確認をする。参考
https://github.com/Miserlou/Zappa/issues/1747
以上
- 投稿日:2019-07-07T16:33:41+09:00
Zappa利用時におけるトラブルシューティング集
そもそもZappaとは
Github(英語): https://github.com/Miserlou/Zappa
日本語訳: https://githubja.com/miserlou/zappaZappa makes it super easy to build and deploy server-less, event-driven Python applications (including, but not limited to, WSGI web apps) on AWS Lambda + API Gateway. Think of it as "serverless" web hosting for your Python apps.
とのこと。FlaskやDjangoなどのWebアプリケーションフレームワークを利用したPythonアプリをAWS Lambdaへデプロイする際にとても役に立つ。
Zappaによるサーバーレスアプリ開発でのトラブルシューティング集
以下、Zappaによるサーバーレスアプリ開発時に遭遇したトラブル事象とそのシューティング方法を記載していく。
1. zappaコマンド(templateなど)を実行すると
NoRegionErrorとなる事象
$ zappa template dev -l ${your-lambda-arn} -r ${your-role-arn} Calling template for stage dev.. Warning! AWS Lambda may not be available in this AWS Region! Warning! AWS API Gateway may not be available in this AWS Region! Oh no! An error occurred! :( ============== Traceback (most recent call last): (中略) botocore.exceptions.NoRegionError: You must specify a region. ============== Need help? Found a bug? Let us know! :D File bug reports on GitHub here: https://github.com/Miserlou/Zappa And join our Slack channel here: https://slack.zappa.io Love!, ~ Team Zappa!対処方法
zappa_settings.jsonに"aws_region": "aws-region-name"を記載する。zappa_settings.json{ "dev": { "app_function": "server.app", "aws_region": "ap-northeast-1", ... } }2.
zappa templateコマンドを実行するとAttributeError: 'ZappaCLI' object has no attribute 'apigateway_policy'となる事象
$ zappa template dev -l ${your-lambda-arn} -r ${your-role-arn} Calling template for stage dev.. Oh no! An error occurred! :( ============== Traceback (most recent call last): File "/root/.local/share/virtualenvs/application-NgYdrrUH/lib/python3.6/site-packages/zappa/cli.py", line 2779, in handle sys.exit(cli.handle()) File "/root/.local/share/virtualenvs/application-NgYdrrUH/lib/python3.6/site-packages/zappa/cli.py", line 509, in handle self.dispatch_command(self.command, stage) File "/root/.local/share/virtualenvs/application-NgYdrrUH/lib/python3.6/site-packages/zappa/cli.py", line 553, in dispatch_command json=self.vargs['json'] File "/root/.local/share/virtualenvs/application-NgYdrrUH/lib/python3.6/site-packages/zappa/cli.py", line 666, in template policy=self.apigateway_policy, AttributeError: 'ZappaCLI' object has no attribute 'apigateway_policy' ============== Need help? Found a bug? Let us know! :D File bug reports on GitHub here: https://github.com/Miserlou/Zappa And join our Slack channel here: https://slack.zappa.io Love!, ~ Team Zappa!対処方法
zappaのバージョンを
0.47.0に下げる。$ zappa -v 0.48.2 $ pipenv install zappa==0.47.0 --skip-lock Installing zappa==0.47.0… Adding zappa to Pipfile's [packages]… ✔ Installation Succeeded Installing dependencies from Pipfile… ▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉▉ 1/1 — 0参考
https://github.com/Miserlou/Zappa/issues/1747
3.
zappa deployやupdateコマンドを実行するとStatus check on the deployed lambda failed. A GET request to '/' yielded a 500 response code.となる事象
$ zappa deploy dev Calling deploy for stage dev.. Downloading and installing dependencies.. - markupsafe==1.1.1: Using locally cached manylinux wheel - sqlite==python3: Using precompiled lambda package Packaging project as zip. Uploading app-dev-1560529924.zip (8.5MiB).. 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 8.91M/8.91M [00:00<00:00, 20.6MB/s] Scheduling.. Scheduled app-dev-zappa-keep-warm-handler.keep_warm_callback with expression rate(4 minutes)! Uploading app-dev-template-1560529930.json (1.6KiB).. 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.60K/1.60K [00:00<00:00, 24.2KB/s] Waiting for stack app-dev to create (this can take a bit).. 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████| 4/4 [00:15<00:00, 5.84s/res] Deploying API Gateway.. Error: Warning! Status check on the deployed lambda failed. A GET request to '/' yielded a 500 response code.対処方法
コマンドでのデプロイ時に動作確認としてAPI Gatewayの
/リソースに対してGETリクエストが行われるが、そのリクエストに対するLambdaからのレスポンスが500エラーとなっている。
Lambda側の実行ロールの権限やソースコード自体に問題がないか確認をする。4.
zappa deployやupdateコマンドを実行するとProvided role 'role_arn' cannot be assumed by principal 'events.amazonaws.com'.となる事象
$ zappa update dev Calling update for stage dev.. Downloading and installing dependencies.. - markupsafe==1.1.1: Using locally cached manylinux wheel - sqlite==python3: Using precompiled lambda package Packaging project as zip. Uploading app-dev-1560527282.zip (8.5MiB).. 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 8.91M/8.91M [00:00<00:00, 23.3MB/s] Updating Lambda function code.. Updating Lambda function configuration.. Uploading app-dev-template-1560527288.json (1.6KiB).. 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.60K/1.60K [00:00<00:00, 14.9KB/s] Waiting for stack app-dev to update.. 6res [00:09, 1.48s/res] Deploying API Gateway.. Scheduling.. Unscheduled app-dev-zappa-keep-warm-handler.keep_warm_callback. Oh no! An error occurred! :( ============== Traceback (most recent call last): (中略) cannot be assumed by principal 'events.amazonaws.com'. ============== Need help? Found a bug? Let us know! :D File bug reports on GitHub here: https://github.com/Miserlou/Zappa And join our Slack channel here: https://slack.zappa.io Love!, ~ Team Zappa!対処方法
Lambda関数の実行ロールとしたいIAMロールの信頼されたエンティティに
events.amazonaws.comを追加する必要がある。https://console.aws.amazon.com/iam/home より、対象のIAMロールで[信頼関係]タブ-[信頼関係の編集]から、ポリシードキュメントの
events.amazonaws.comを追記し、[信頼ポリシーの更新]をクリック。以下はポリシードキュメントの編集例。
PolicyDocument_example.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "lambda.amazonaws.com", "events.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }参考
https://silvaneves.org/provided-role-cannot-be-assumed-by-principal-eventsamazonawscom.html
以上
- 投稿日:2019-07-07T12:52:52+09:00
S3でパブリックアクセス可能なファイルを投稿する
はじめに
久しぶりに AWS で新規アプリケーション開発したらハマった。
2018/11 から S3 のパブリックアクセス機能がリリースされ、一工夫必要になったらしい。
https://aws.amazon.com/jp/blogs/news/amazon-s3-block-public-access-another-layer-of-protection-for-your-accounts-and-buckets/ではどうすればいいのかという話。
パブリックアクセス機能についてはこちらを参照。
https://dev.classmethod.jp/cloud/aws/s3-block-public-access/設定手順
下記の3つのいずれかの設定でパブリックアクセス可能なオブジェクトにできる。
公開権限を委任しアップロード時にパブリックアクセスを許可する
権限の委任以外は従来と同じ。
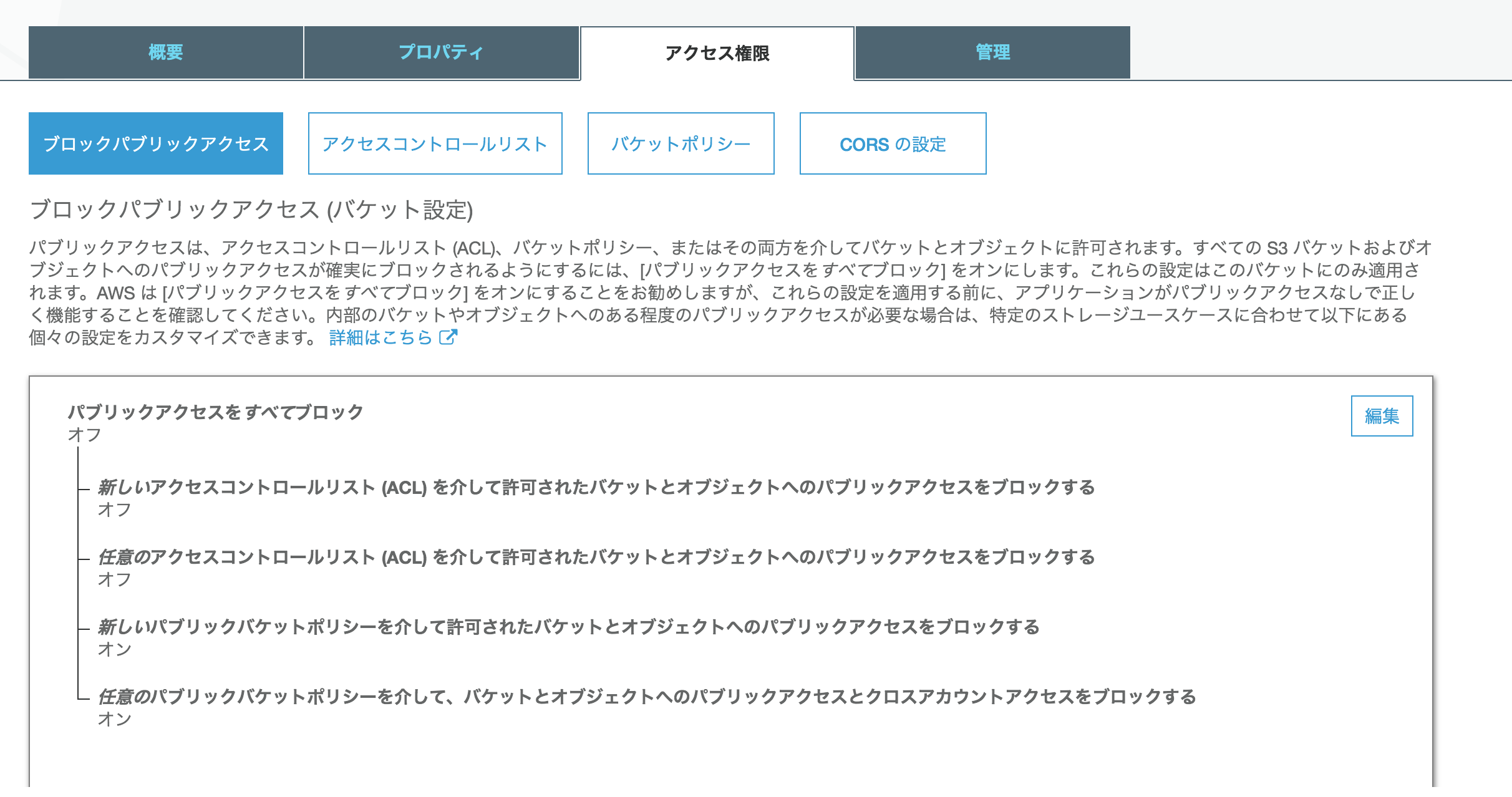
パブリックアクセス設定
- 新しいアクセスコントロールリスト (ACL) を介して許可されたバケットとオブジェクトへのパブリックアクセスをブロックする
- 任意のアクセスコントロールリスト (ACL) を介して許可されたバケットとオブジェクトへのパブリックアクセスをブロックする
の 2つをオフにする。
あとは、ファイルアップロード時に acl でパブリックアクセスにすればOK。
aws s3 cp [任意のファイル] s3://s3-public-access-test/ --acl public-readバケットポリシーで許可
下記のポリシーで、s3-public-access-test バケットの public フォルダ以下についてパブリックアクセスを許可している。
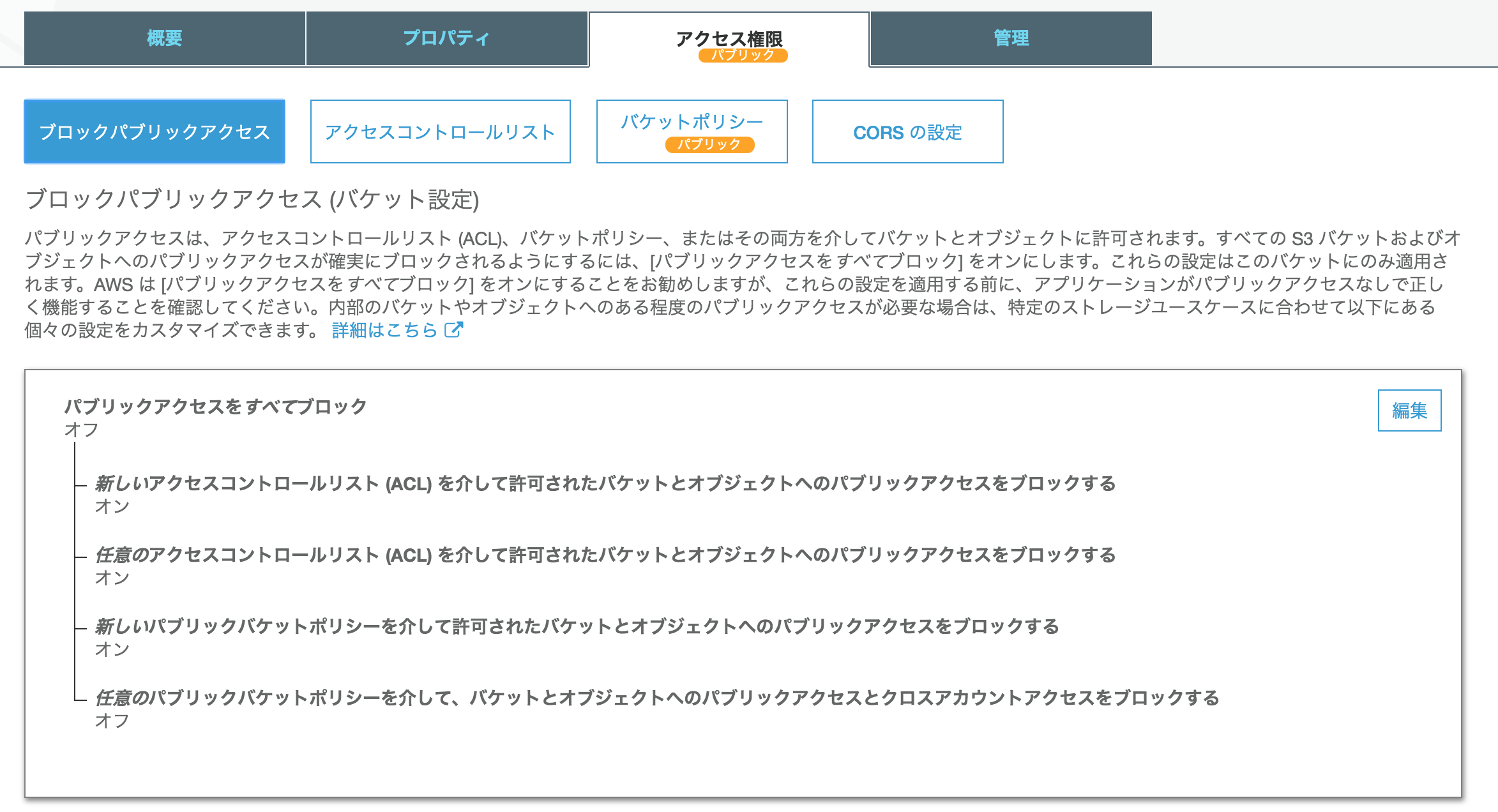
パブリックアクセス設定
下記の 2つを許可しておく。
- 新しいパブリックバケットポリシーを介して許可されたバケットとオブジェクトへのパブリックアクセスをブロックする
- 任意のパブリックバケットポリシーを介して、バケットとオブジェクトへのパブリックアクセスとクロスアカウントアクセスをブロックする
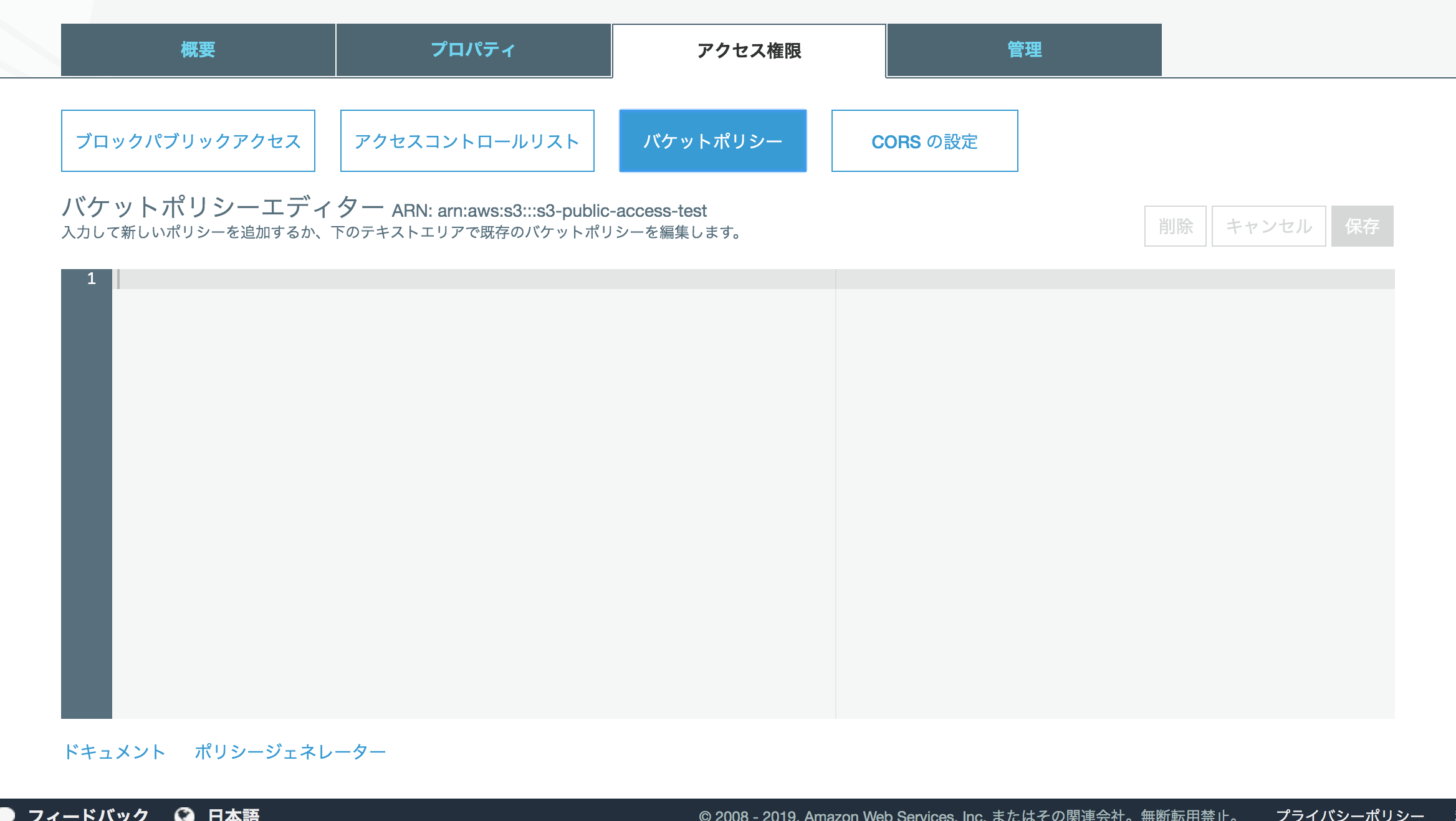
ポリシー
下記のポリシーを「アクセス権限」タブ内のバケットポリシーで設定する。
{ "Version":"2012-10-17", "Statement":[ { "Sid":"AddPerm", "Effect":"Allow", "Principal": "*", "Action":["s3:GetObject"], "Resource":["arn:aws:s3:::s3-public-access-test/public/*"] } ] }public ディレクトリ以下にアップロードされたファイルは常にパブリックアクセス許可された状態になる。
aws s3 cp [任意のファイル] s3://s3-public-access-test/public/バケットポリシー & タグで制御
特定のタグが付与されたオブジェクトについて、パブリックアクセス許可のポリシーを適用する方法。
一括で権限を変更できるので一番スマートかもしれない。タグの利用には別途料金がかかる。
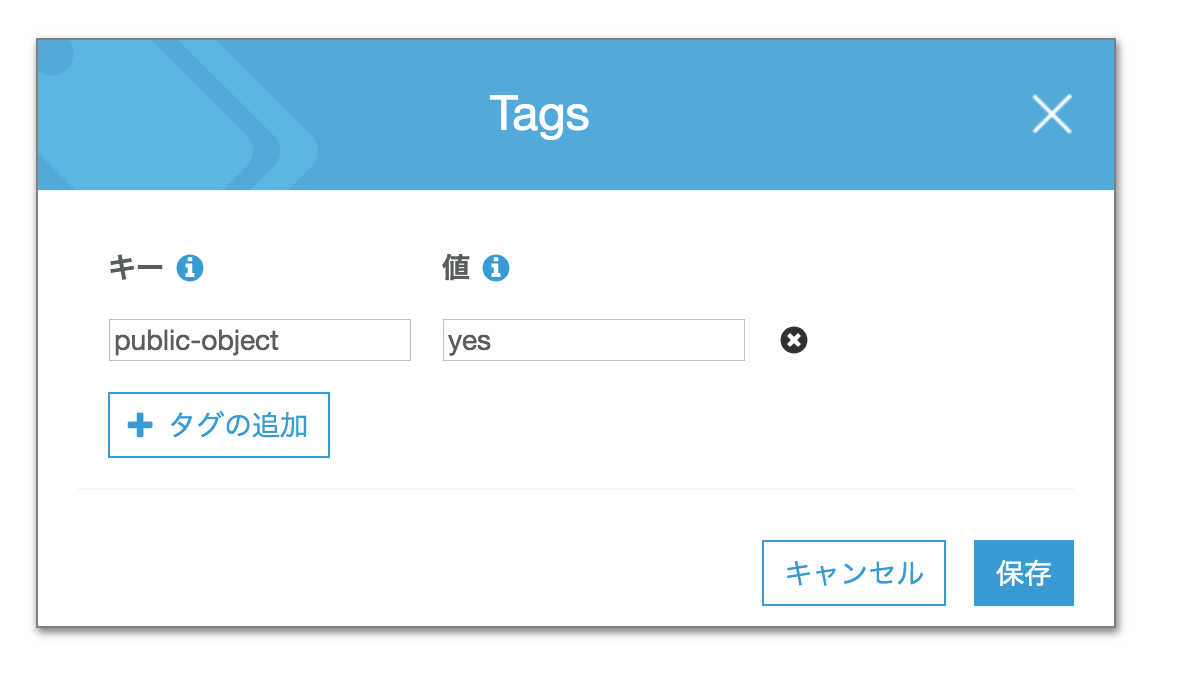
https://aws.amazon.com/jp/s3/pricing/#S3_Storage_Management_pricingタグの追加
バケット内の「プロパティ」タブから、タグを追加
key: public-object
value: yes
パブリックアクセス設定
[バケットポリシーで許可]と同じ。
ポリシー
設定方法は[バケットポリシーで許可]と同じ。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::s3-public-access-test/*", "Condition": { "StringEquals": { "s3:ExistingObjectTag/public-object": "yes" } } } ] }コマンド
cp 時に付与できないようでちょっと面倒。プログラムでアップロードするなら関係ないかも。
# ファイルアップロード aws s3 cp ~/Downloads/5c886538.jpg s3://s3-public-access-test/public/ --profile=kol # タグを付与 aws s3api put-object-tagging --bucket s3-public-access-test --key "public/[任意のファイル]" --tagging 'TagSet={Key=public-object,Value=yes}'終わりに
AWS S3 でパブリックアクセス可能なファイルを投稿するための設定方法を記述した。
Techブログを書くなら数ヶ月前の自分に向けて書くと良いとどこかで読んだが、マジで自分に届け。
- 投稿日:2019-07-07T10:21:26+09:00
EC2で構築したUiPath Orchestrator サーバを、自己署名じゃない証明書でSSLで公開する(Certificate ManagerとELBを使用)
イントロ
UiPath Orchestrator を構築するにあたって、久しぶりにEC2でSSL証明書を取って環境構築したので、そのときの備忘。
タイトルは UiPath OrchestratorサーバをSSLで公開するってなってますが、実際はOrchestratorに特化した話ではなく一般的なEC2サーバのSSL公開の話って感じです。
前提
- ドメインを持っている(example1.xyz としました)
- そのドメインは、AWSのRoute 53で管理している
- UiPath Orchestratorが、AWS上のEC2で(WindowsサーバのIIS上で)ポート443ですでに動いている
- 今時点では Orchestratorサーバ(以下Orchサーバ)へは https://[IPアドレス]/ でアクセスしている
- 保守のためそのEC2サーバへは 443の他RDP(ポート3389)やKibana(ポート5601)も許可している
- Orchestratorが動くIISサーバは、SSL証明書が自己署名証明書なので、ちゃんとした証明書を用いるようにしたい
- 監視とか冗長構成とかは、とりあえず今回は省略
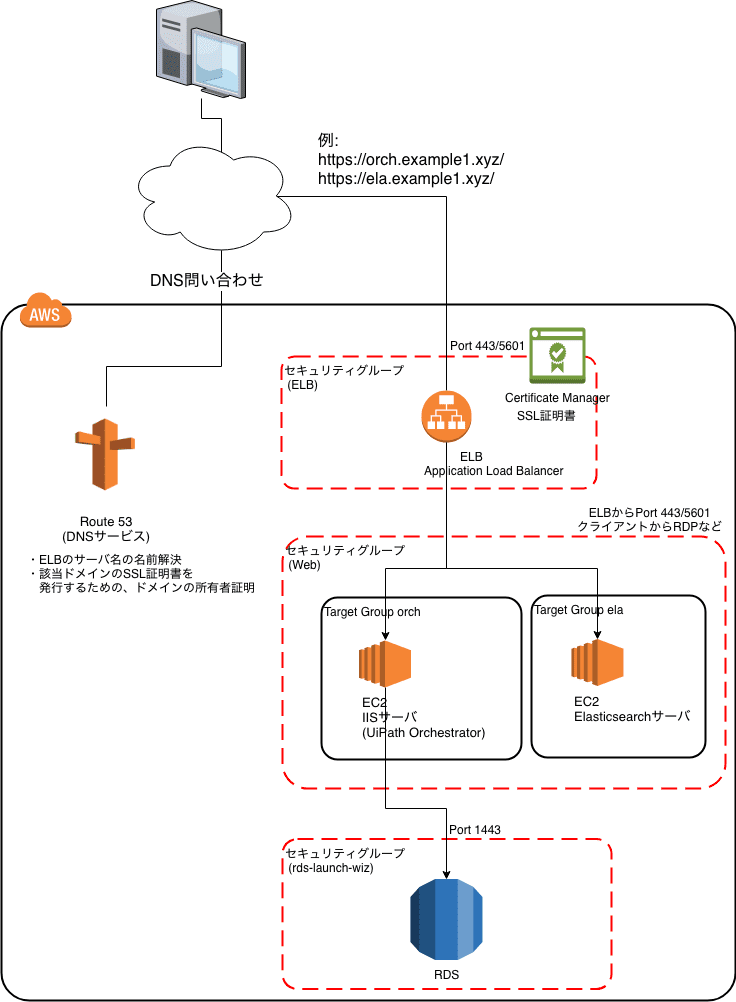
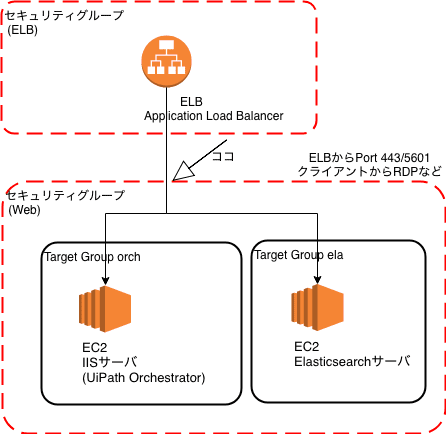
記事開始時点を図示するとこんな感じ。
さてさて今回、UiPath Orchestratorを自己署名証明書で構築するところは省略していて、すでに構築済みとしています。そのOrchサーバを自己署名じゃない証明書で公開するのに
- 証明書を正規に取得して自己署名証明書から置き換え Orchサーバをそのまま外部に「 https://orch.example1.xyz 」などで公開
してもよいのですが、今回は
- Orchサーバの手前にELB(Elastic Load Balancer)を置いて、AWS上で無料で取得できるSSL証明書を用いる
ことにしました。ELBは特定のネットワークからのポート443,5601への接続のみ許可するモノとします。
図示するとこうです。
ほんとはSSLをほどいてルーティングしたい、、
-- 2019/07/07追記 --
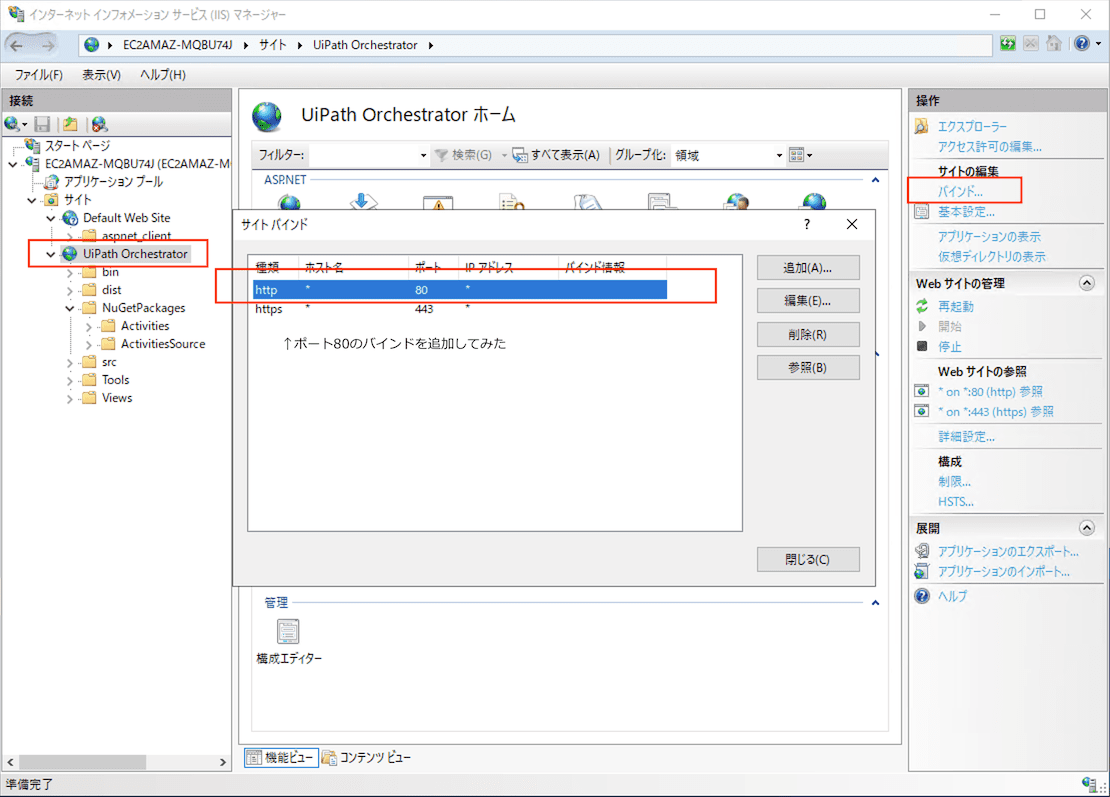
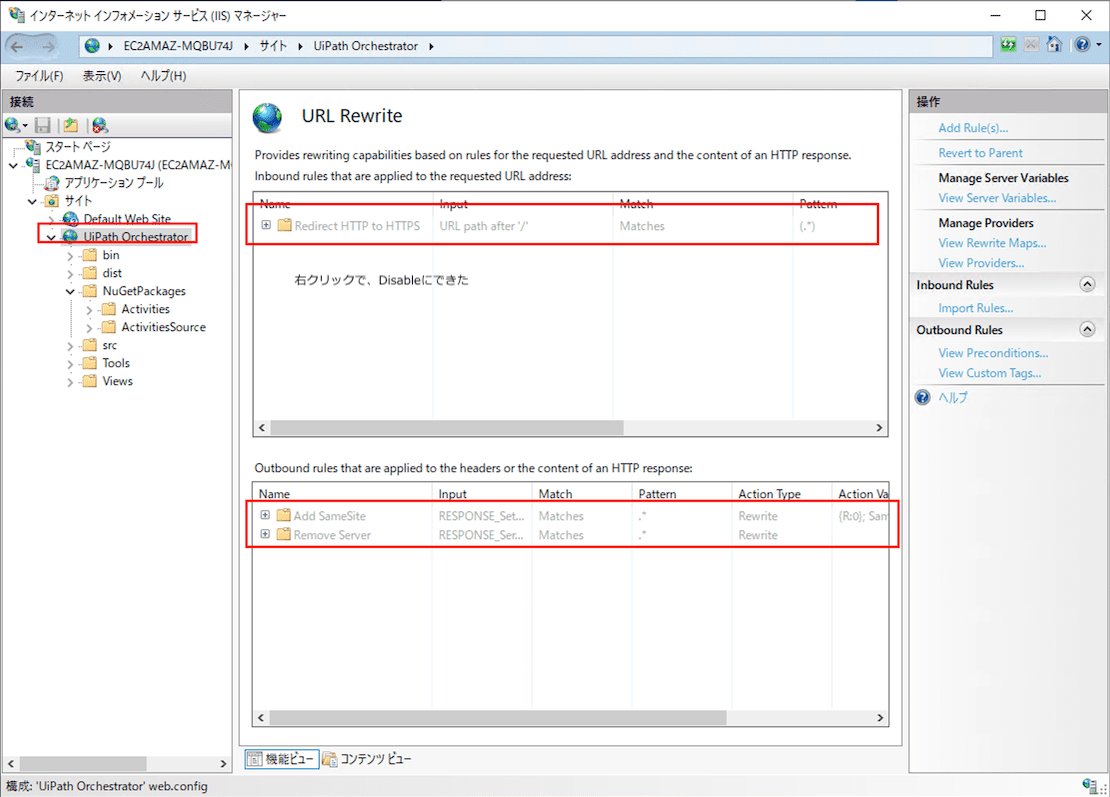
ちなみに本当は、ELBでSSLをほどいて IISにはHTTPのポート80で流したかったのですが、UiPath OrchestratorのインストーラがIIS上にSSL付きで構築してくれてしまうのと、さらにはURL Rewrite機能を用いて HTTPアクセスをHTTPSにリダイレクトまでしてくれていて、、、、これらをオフってIIS上にHTTPのOrchestratorを構築する手順が明確ではなかったからです、、、。バインドを80に替えて、URL RewriteをすべてDisableにすれば行けるのかもしれませんが未検証ですorz。
-- 2019/07/07追記 以上 ---- 2019/07/07追記2 --
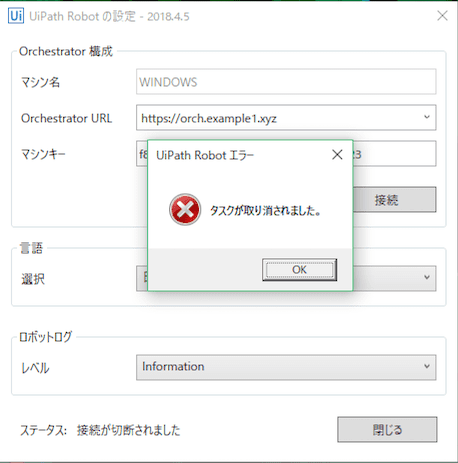
バインドをポート80を追加して、URL RewriteをOFFにしてみたのですが、
おお、Web画面も動くしなんかうまくいってそうな感じ、、、とおもったら、PC上からのロボットトレイからの接続・切断がNGに、、┐('〜`;)┌。。
検証はまた後日かな、、、。
-- 2019/07/07追記2 以上 --やってみる
さて構築の流れとしては、
- AWSのCertificate ManagerでSSL証明書をあらかじめ取得しておき
- ELBが使用するターゲットグループを作成
- ELBを構築してSSL証明書を配置
- 最後にELBのサーバ名をAWS Route 53(DNSサービス)で名前解決
すればよさそうです。ついでに同じELBを用いて
も入れてみます。
Certificate ManagerでSSL証明書をあらかじめ取得
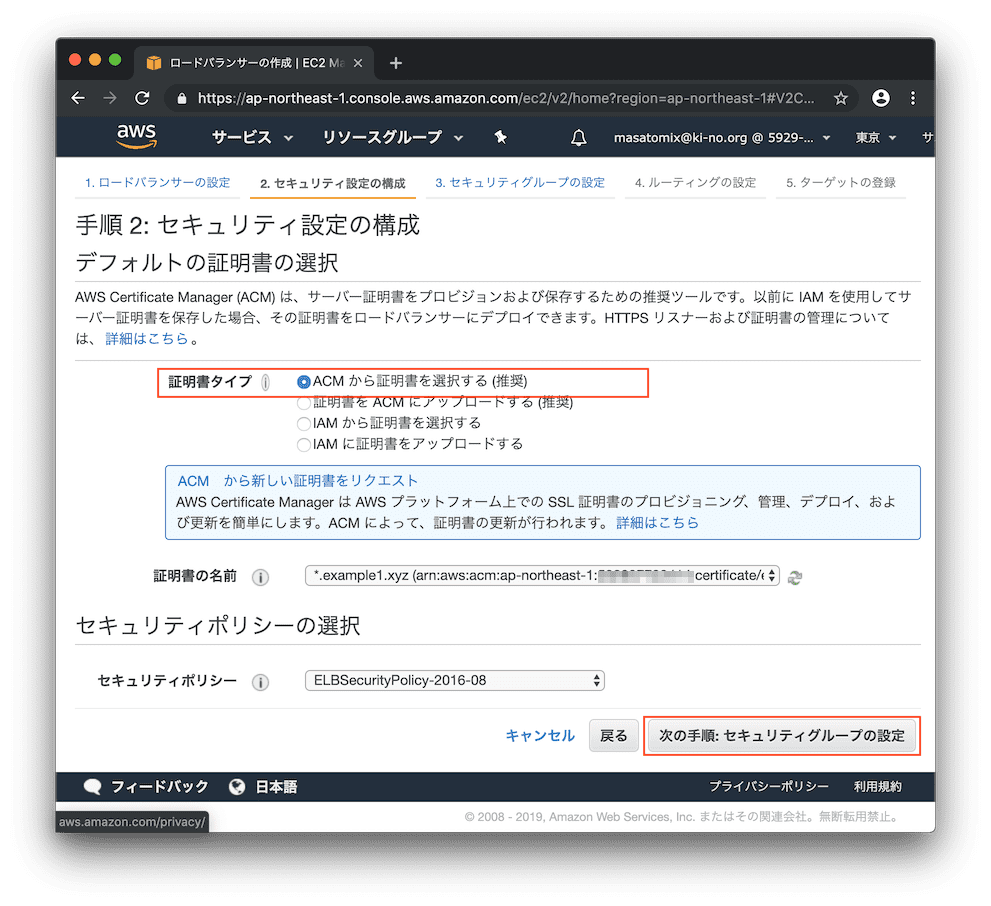
AWS Certificate Managerを使って無料でSSL証明書を発行する にまとめました。証明書取得まではそれで行けると思います。
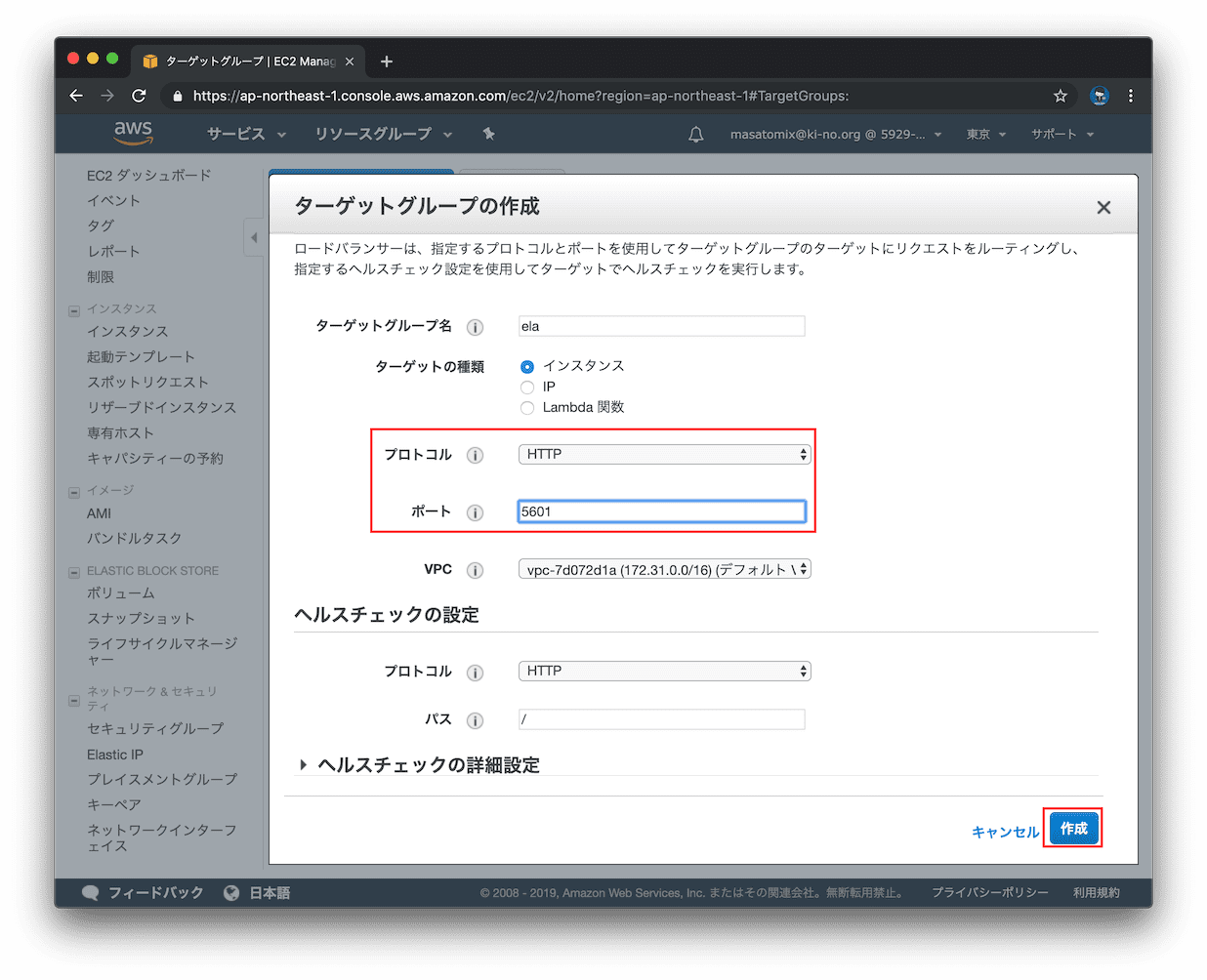
ELBの構築(の前のターゲットグループ作成)
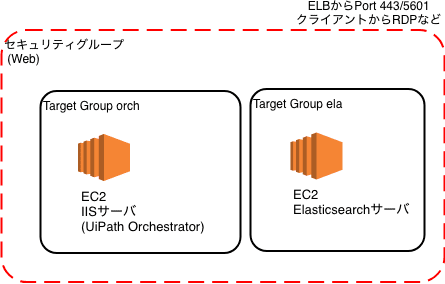
ELBは処理を転送するのに、ターゲットグループというEC2インスタンスのグルーピングを用います。今回 Orchサーバのインスタンスをもつグループ「orch」と、あとで使うElasticsearchサーバのインスタンスをもつ「ela」というグループを作成します。先の図のココです。
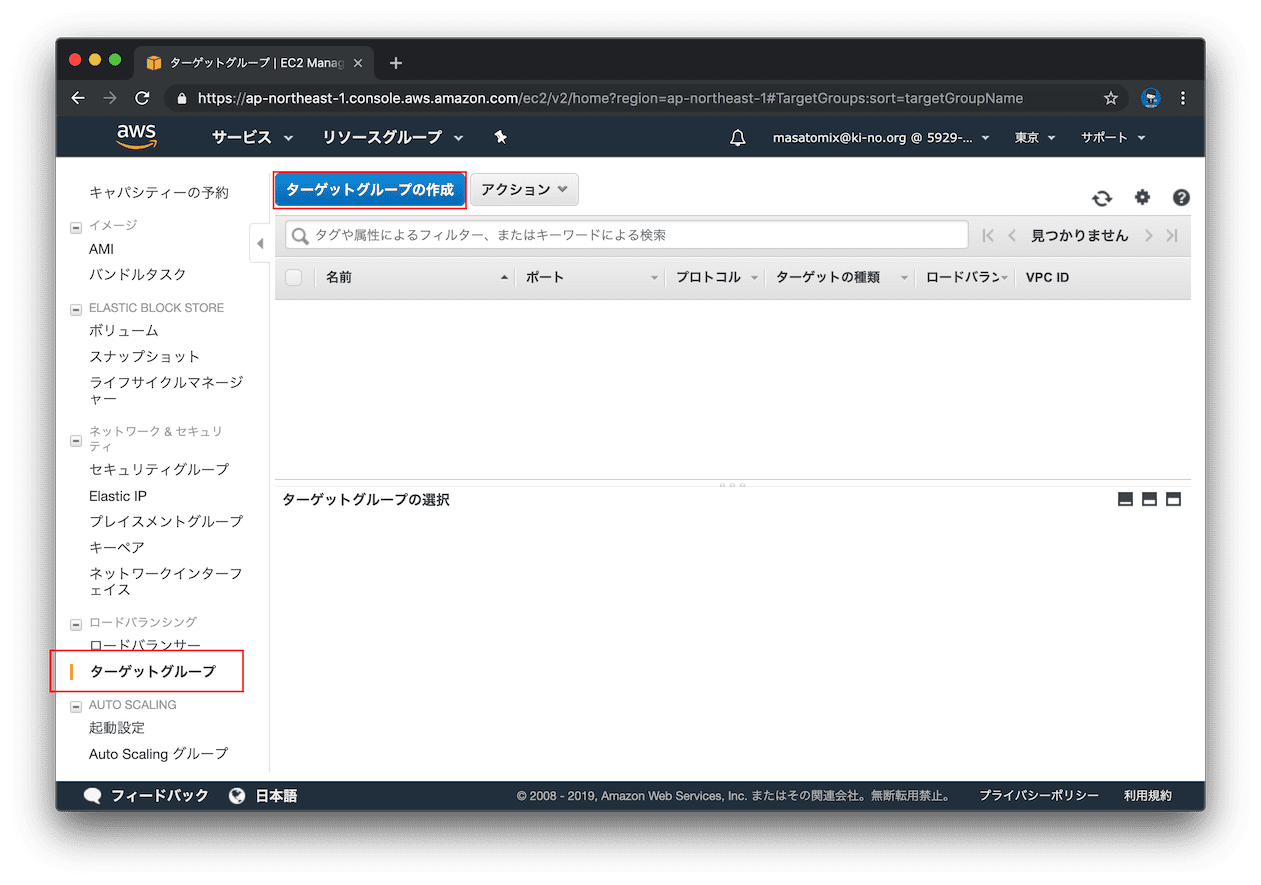
EC2 >> ターゲットグループ を表示して「ターゲットグループの作成」をクリック。
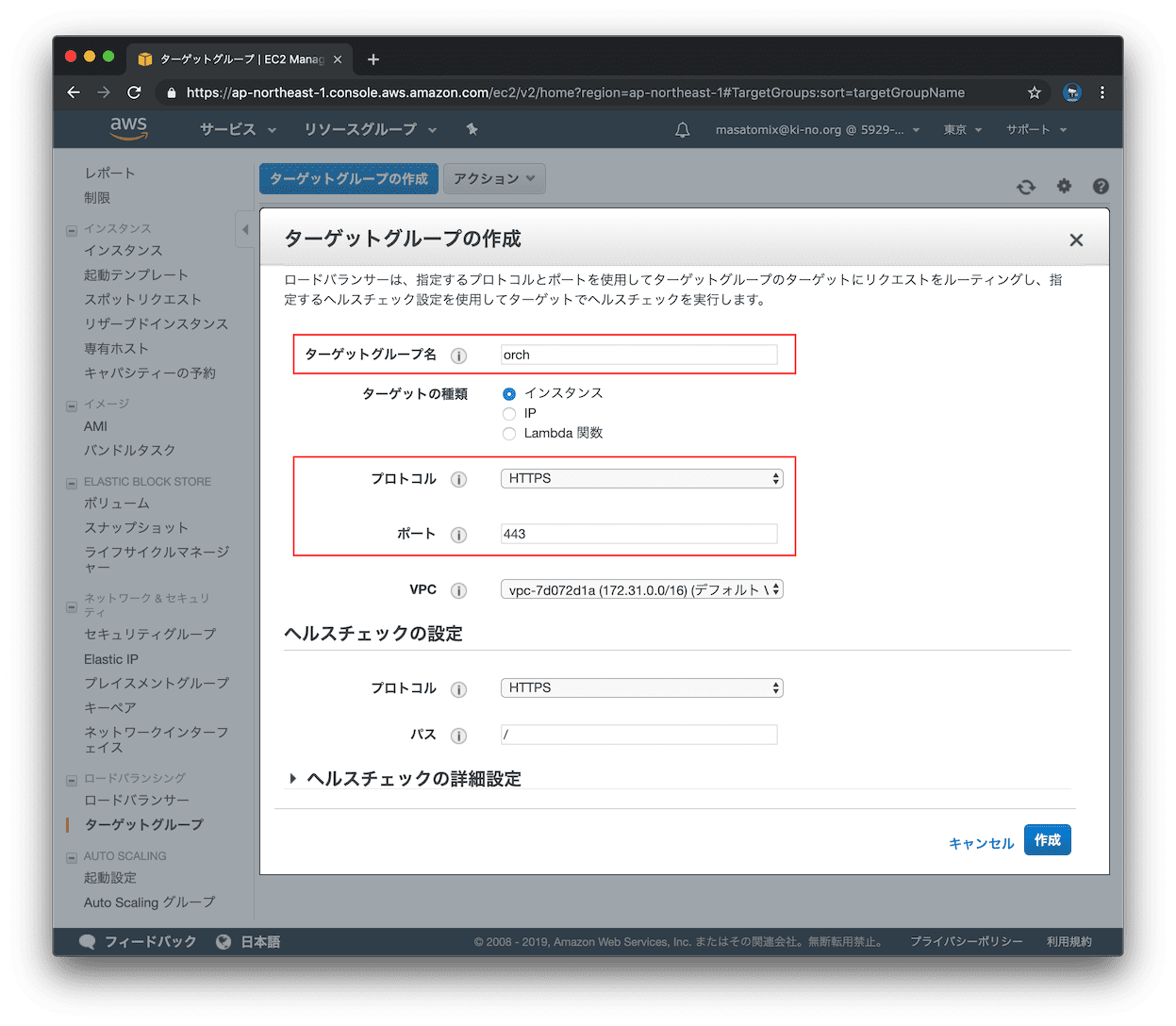
今回はELBから、そのままHTTPS(ポート443) で待ち受けているIISサーバに転送するので、プロトコルはHTTPS、ポートは443とします。IISサーバではHTTPで待ち受けている場合は、プロトコルはHTTP、ポートはIISのポート(通常80かな)を設定します。
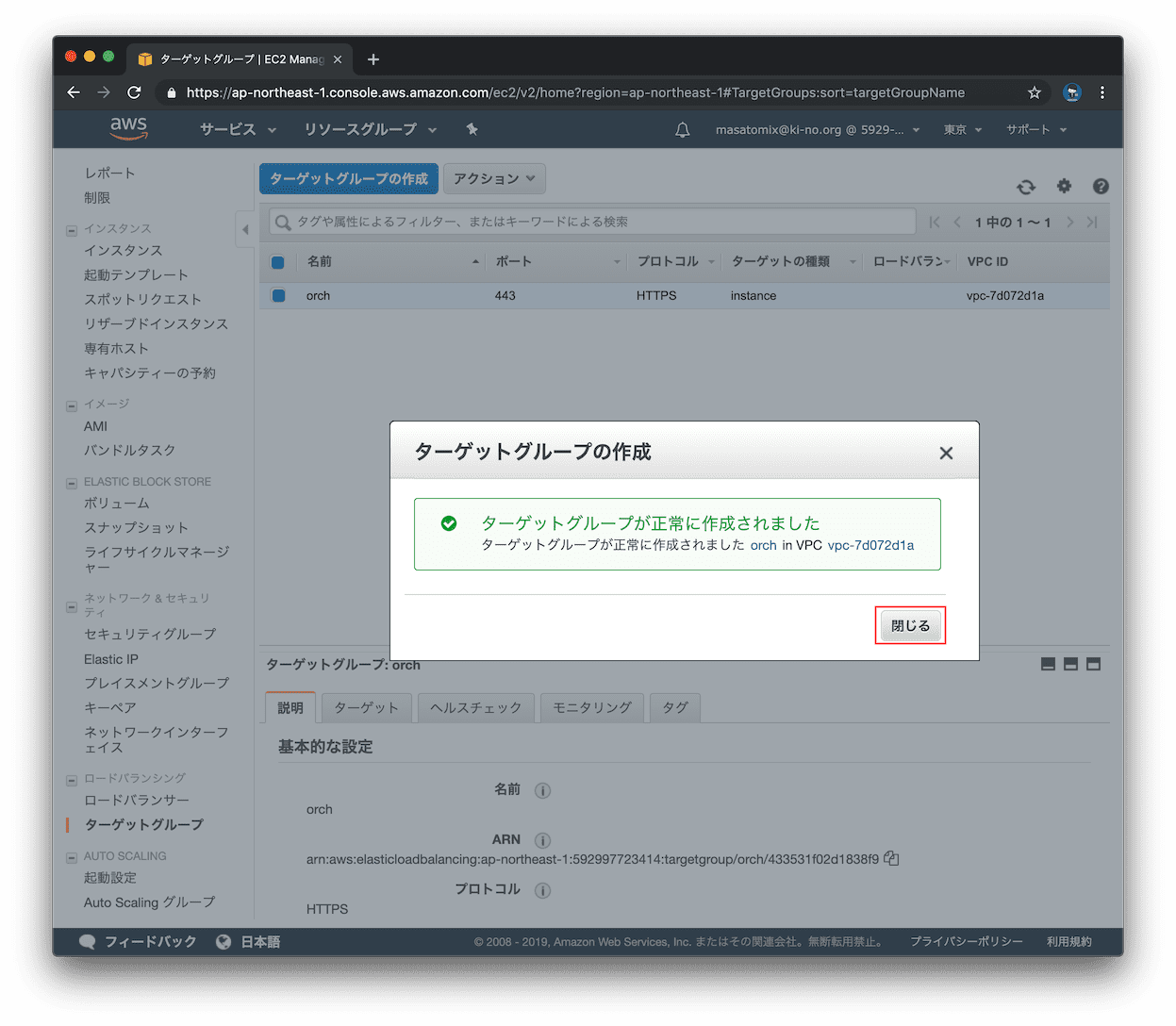
作成が完了したら「閉じる」をクリック。
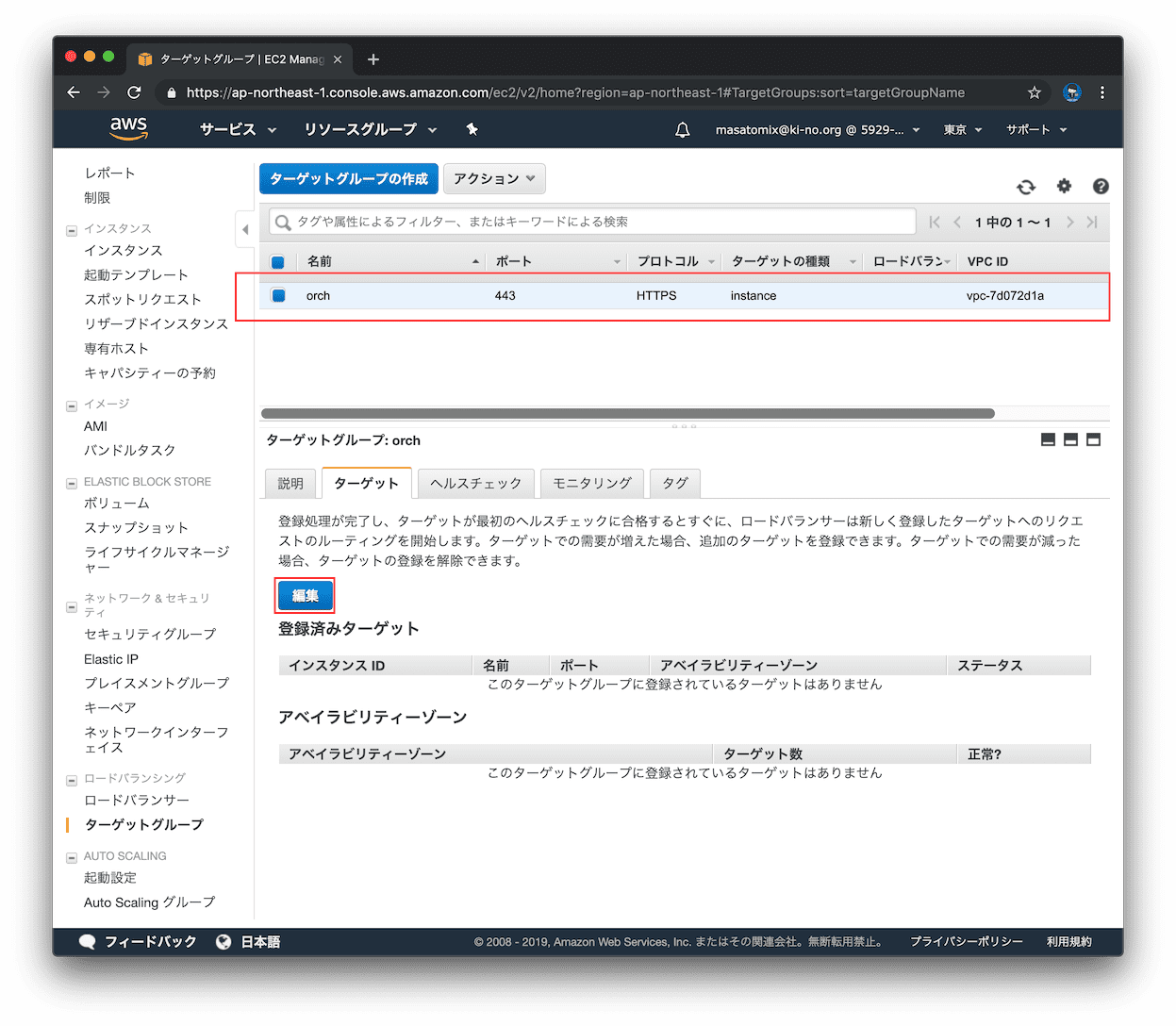
つづいてターゲットグループにOrchサーバを登録するため「編集」をクリックします。
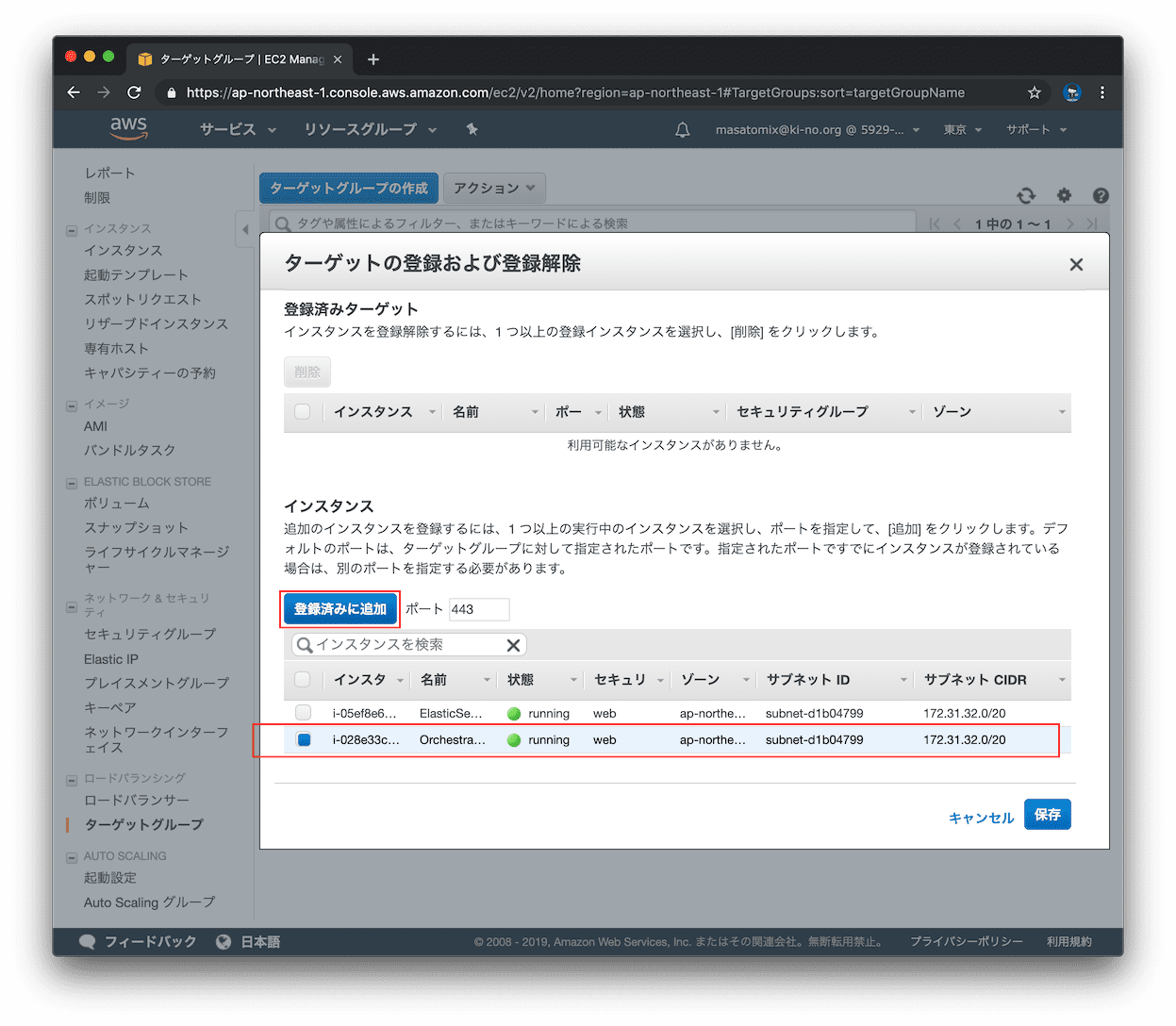
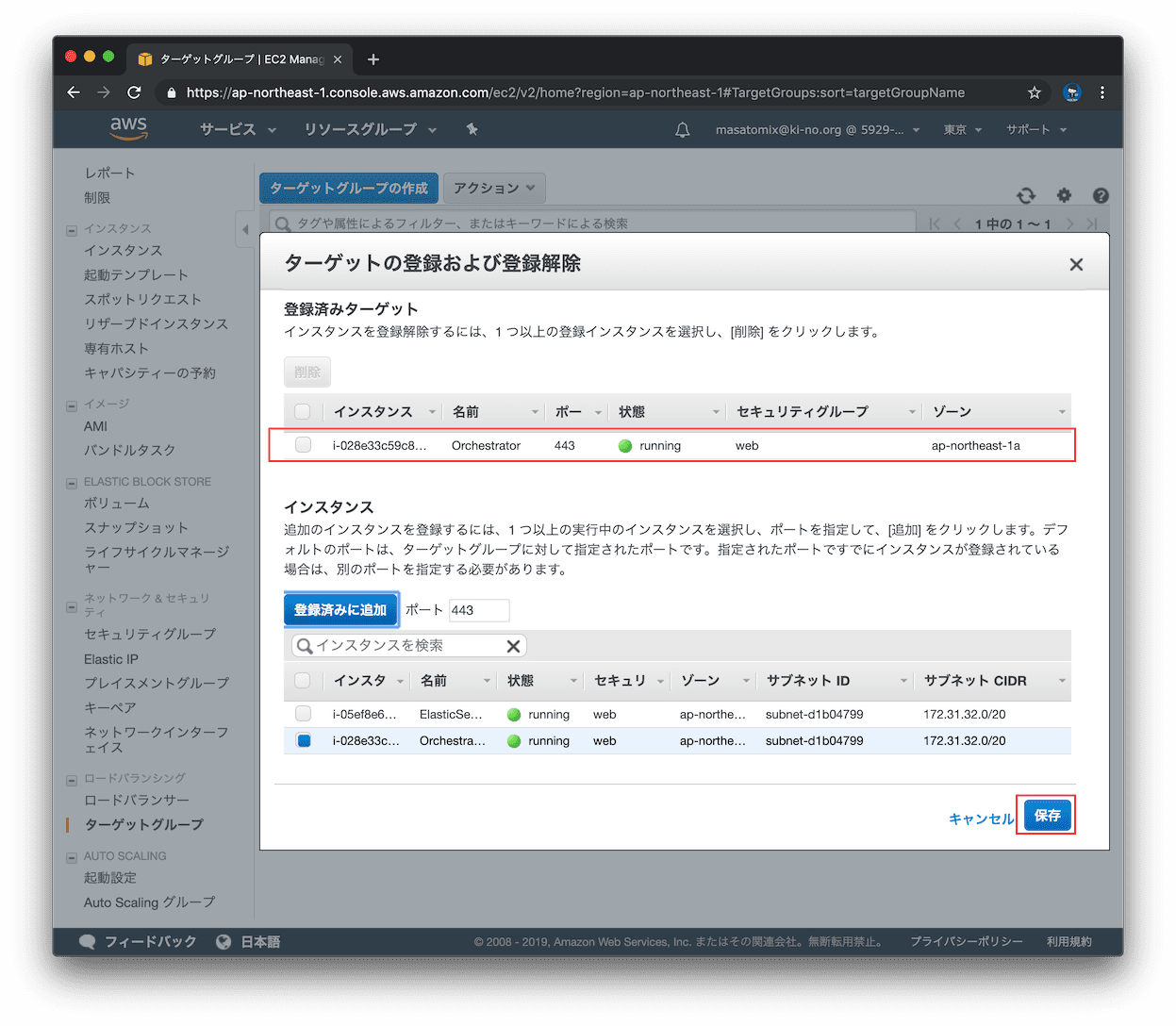
Orchestratorサーバを選択して「登録済みに追加」をクリック。待ち受けるポートをインスタンスごとに個別に指定出来ますが、今回はターゲットグループに指定したポートと同じなのでそのままでOK。
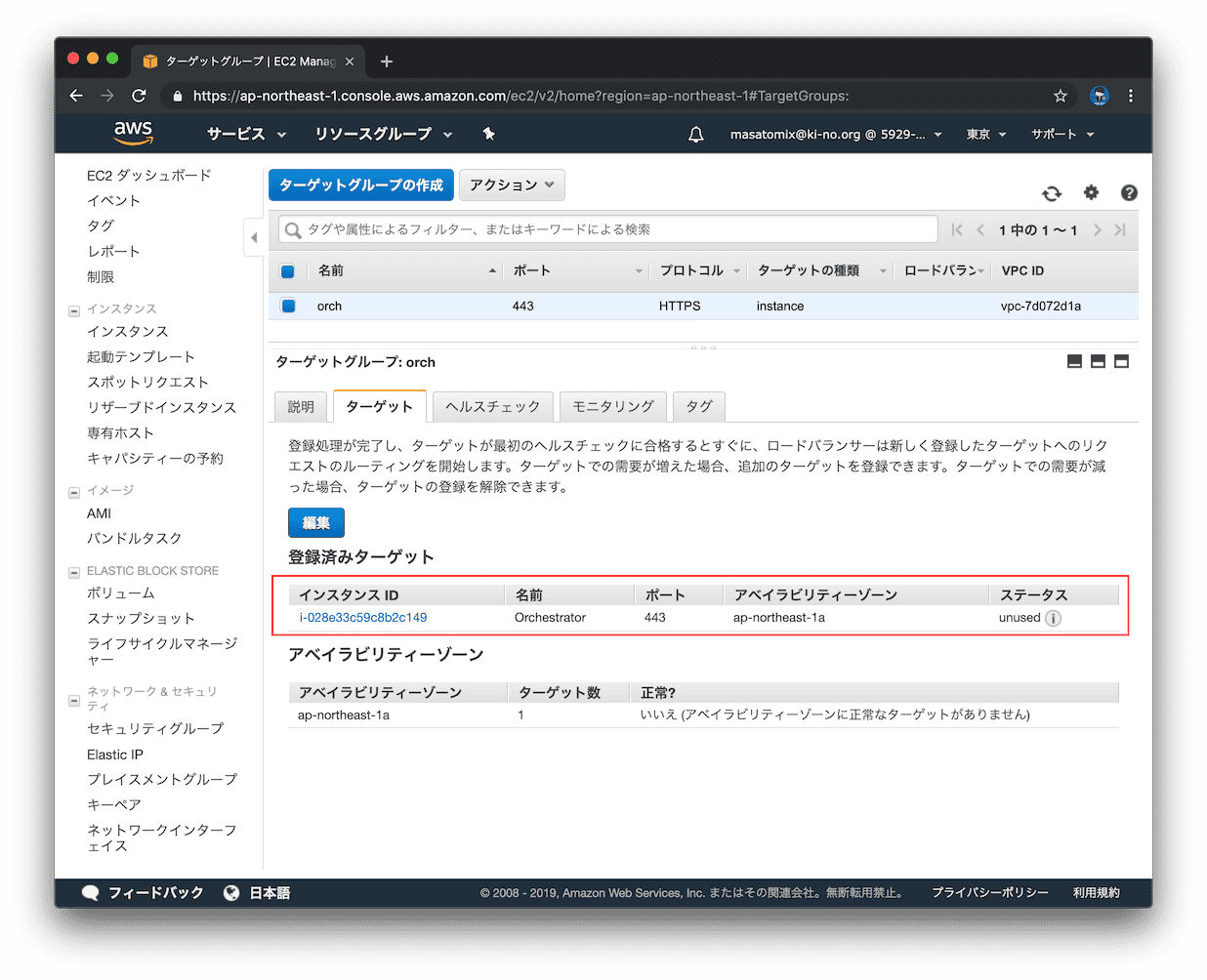
上に追加されたので、「保存」をクリック。
保存されました。
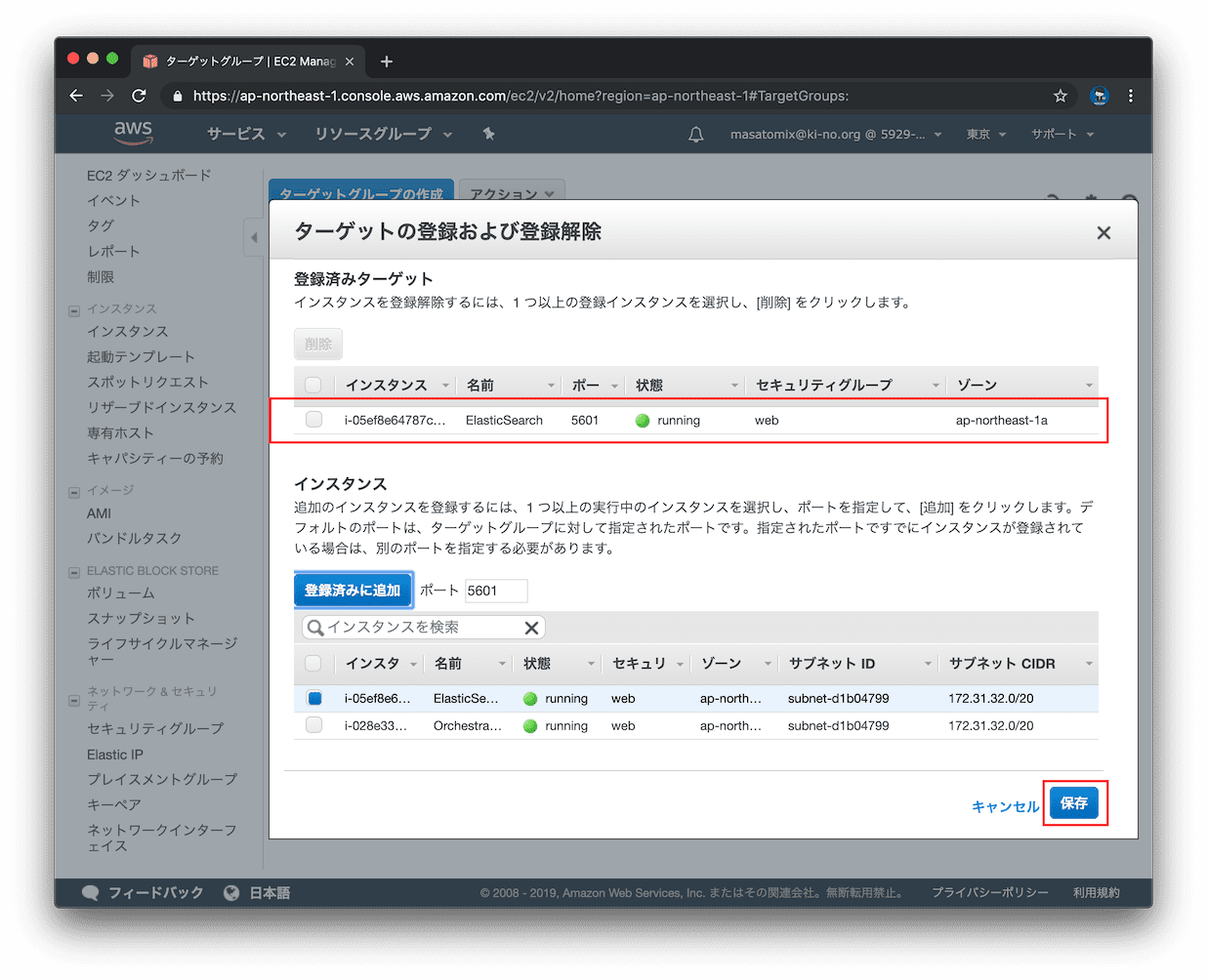
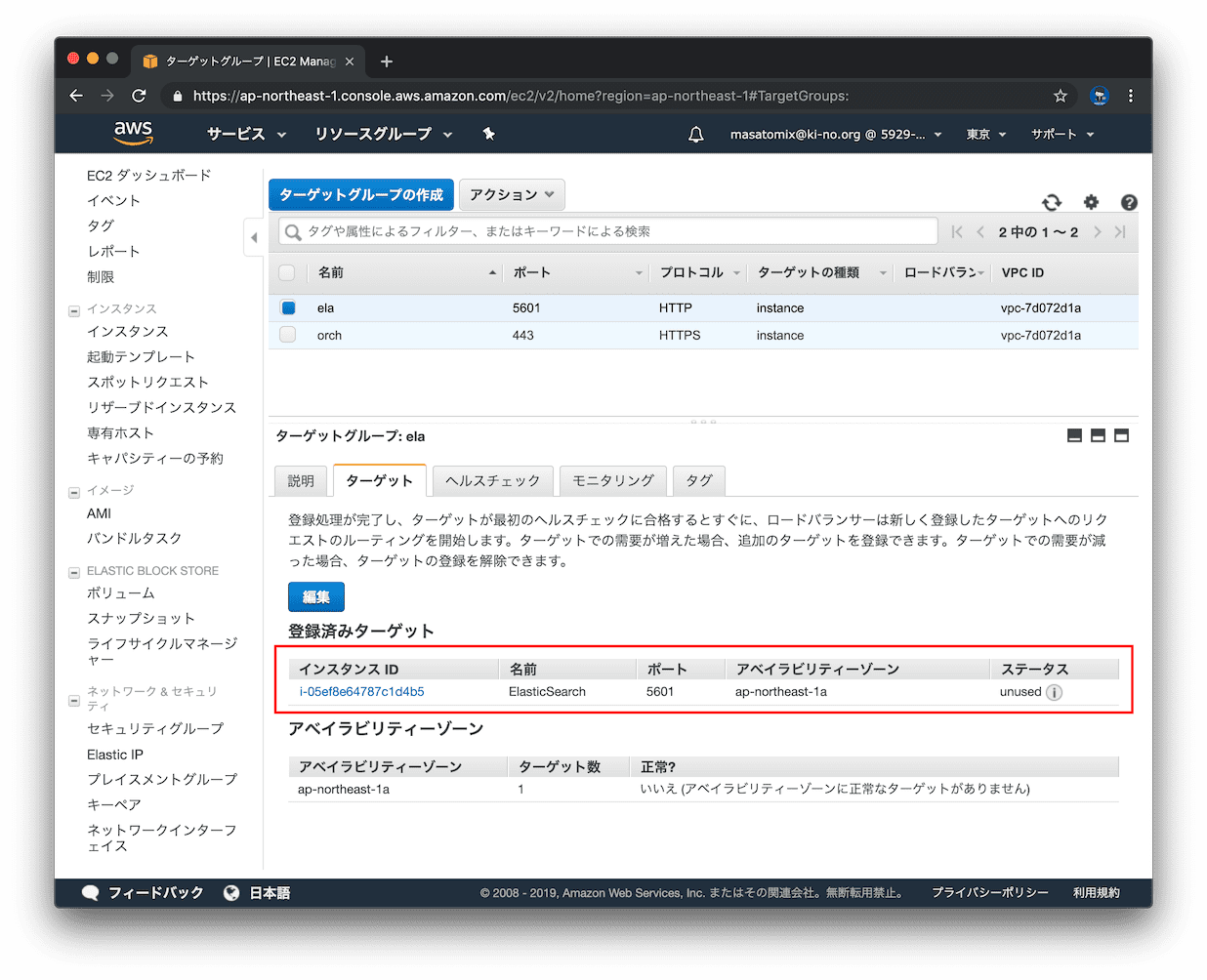
同様に、ela のターゲットグループも作ります。違うところは、ELBがHTTPSで受けた後、こちらのターゲットグループにはHTTPでポート5601でルーティングしますので、そのように設定します。
ターゲットグループへのElasticsearchサーバの登録も忘れずに。。
保存できました。
以上で、各ターゲットグループの作成は完了です。
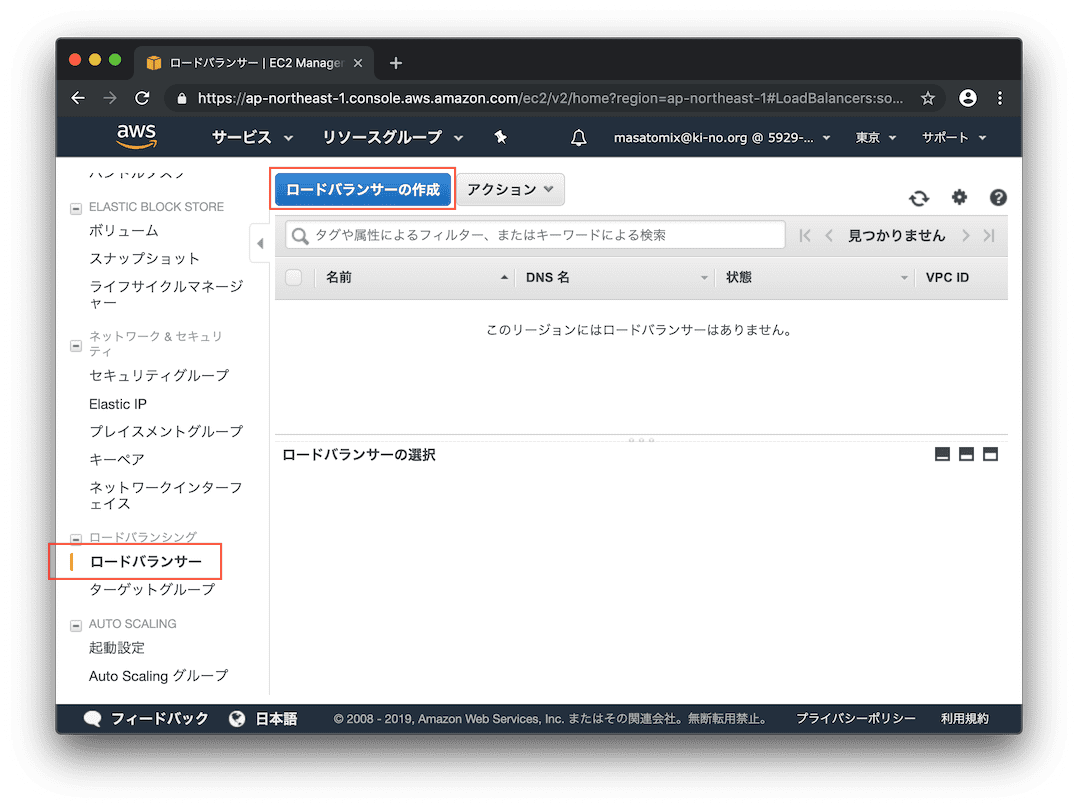
ELBの構築(Application Load Balancerの作成)
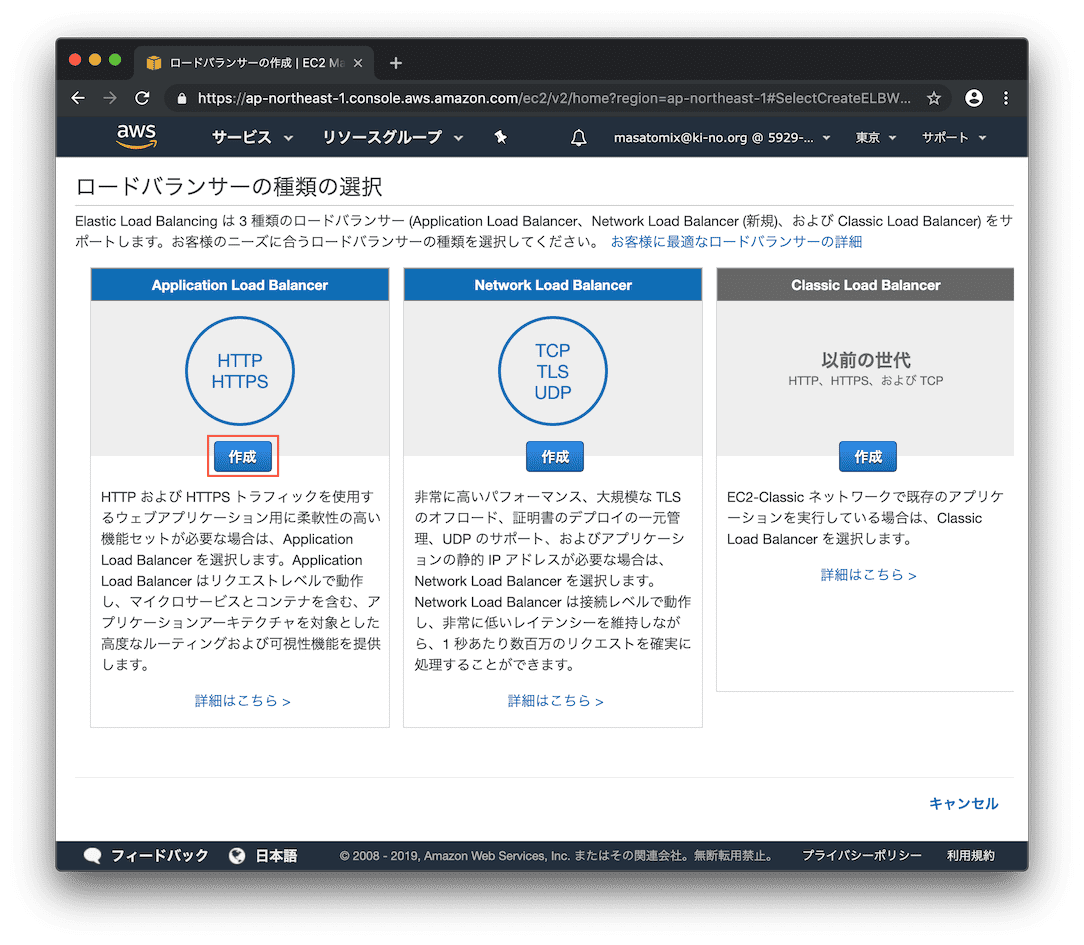
つづいて、主役のロードバランサの作成です。
Application Load Balancerを選択。
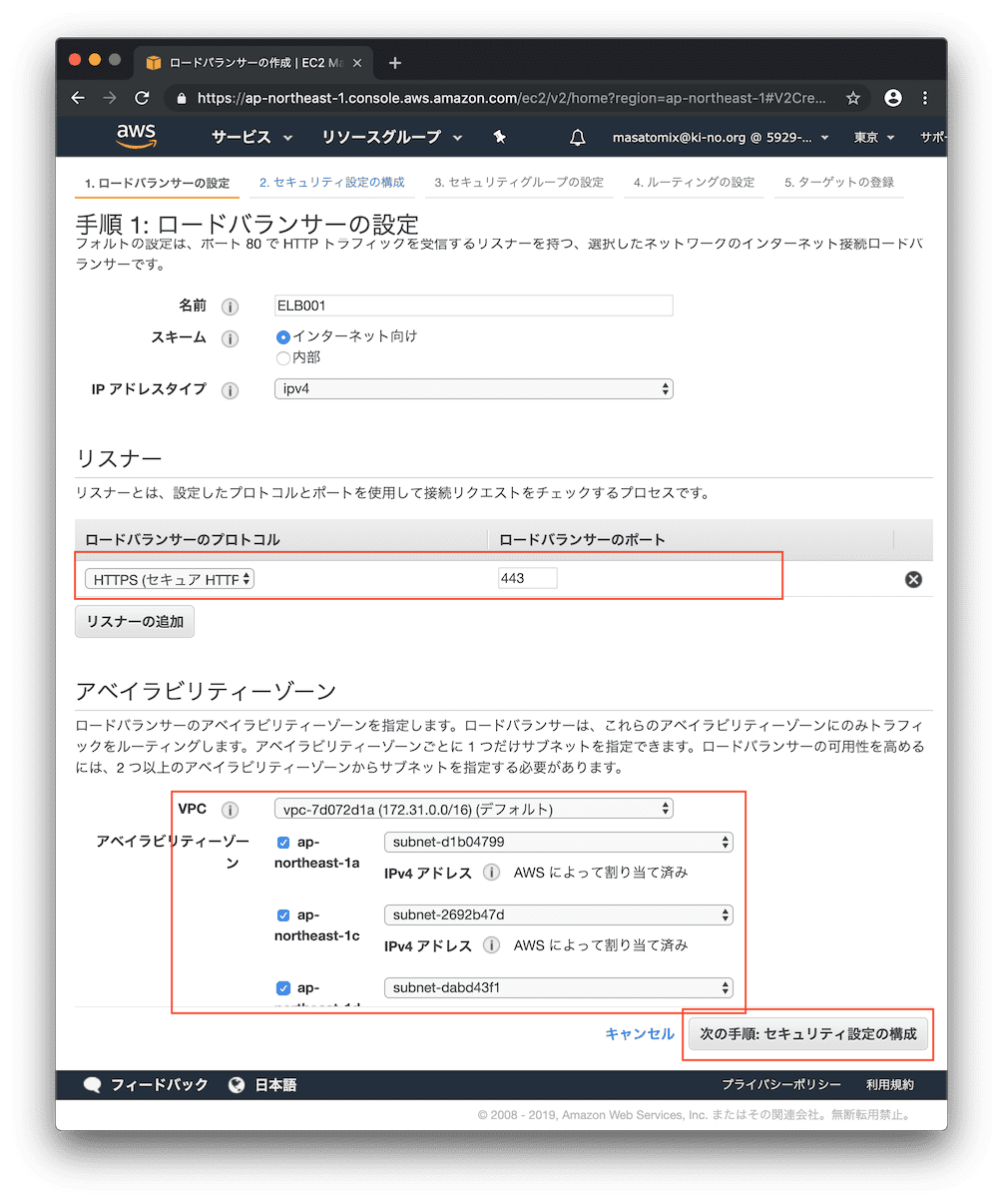
今回はHTTPSのみを受け付けるので、HTTPS/443を選択。アベイラビリティゾーンはとりあえず、自分が持ってるサブネットを指定しておきましょう。
SSLの設定です。すでにさきほど作成済みであれば、ココに証明書として出てくるはずなのでそれを選択して次へ。
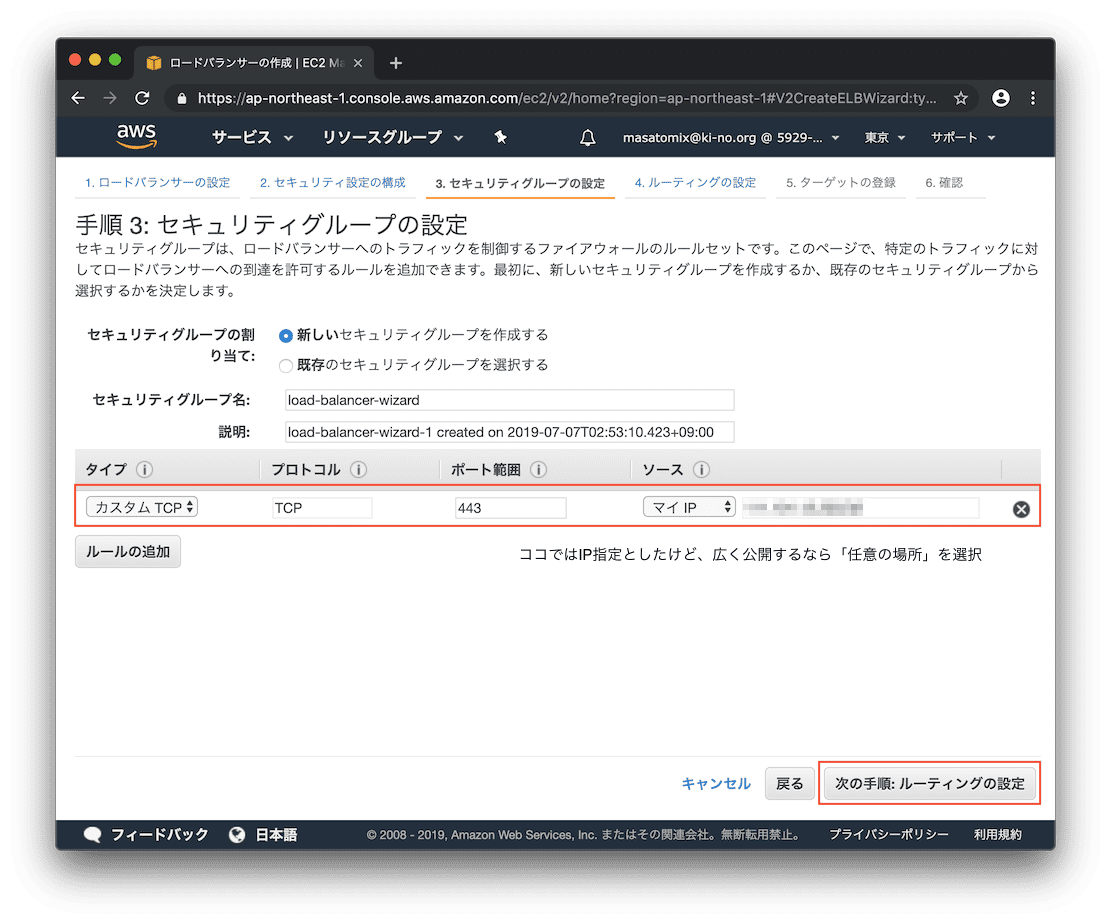
ELBが属するセキュリティグループについて、グループはELB用に新規に作成します。このグループは外部からアクセスされるところになるので慎重に。今回はOrchestratorサーバを構築する記事なのであるIPアドレスたちからの接続のみを許可する設定としていますが、広く公開する場合は「任意の場所」を選択しましょう。
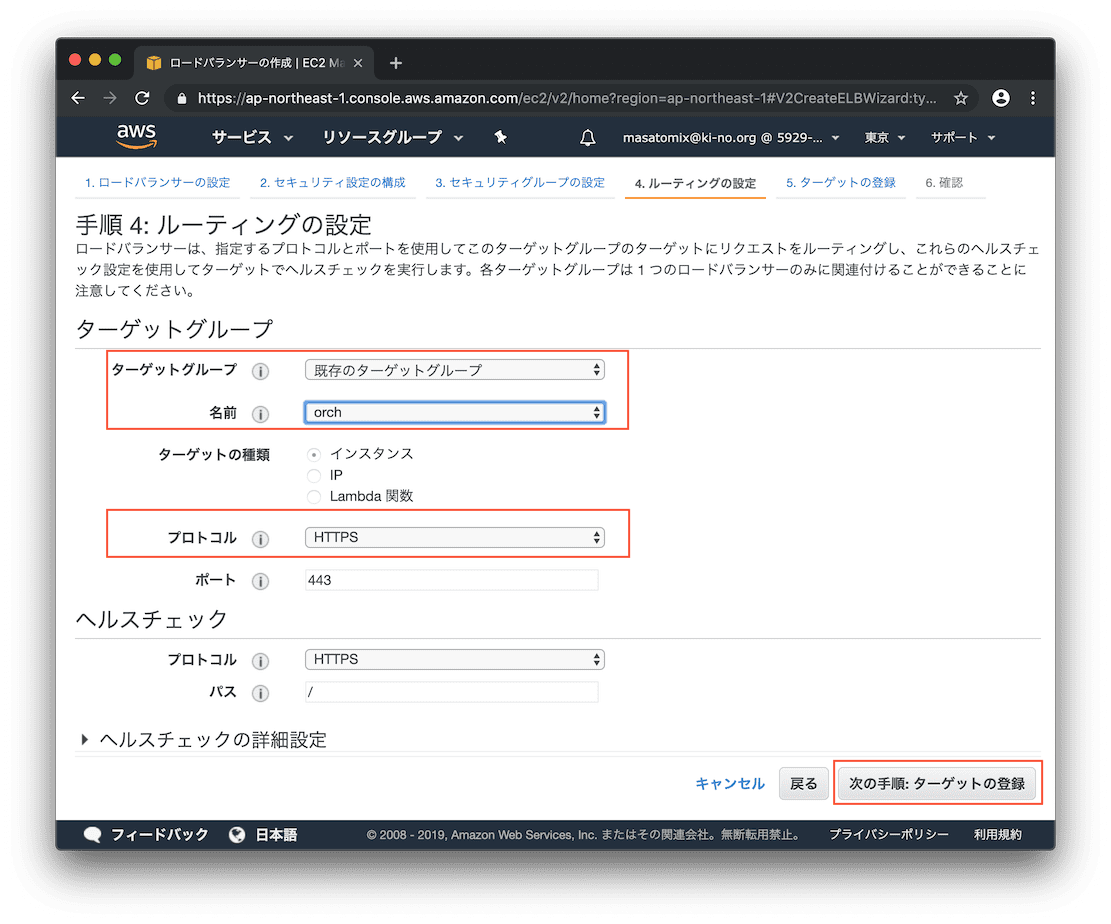
さて、ルーティングするターゲットグループを指定します。まずはシンプルに、全てのリクエストを「orch」グループにルーティングするように設定します。
のちに「 https://ela.example1.xyz/ 」へのリクエストはSSLをほどいて別のグループ「ela」にルーティングさせますが、あと回しで。
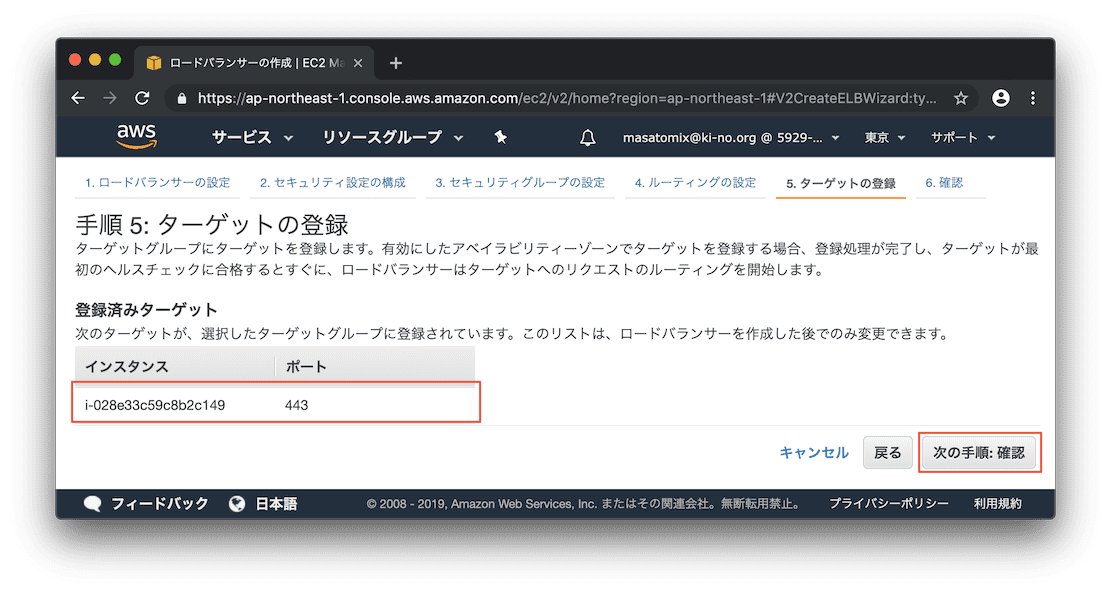
インスタンスとポート番号を確認します。
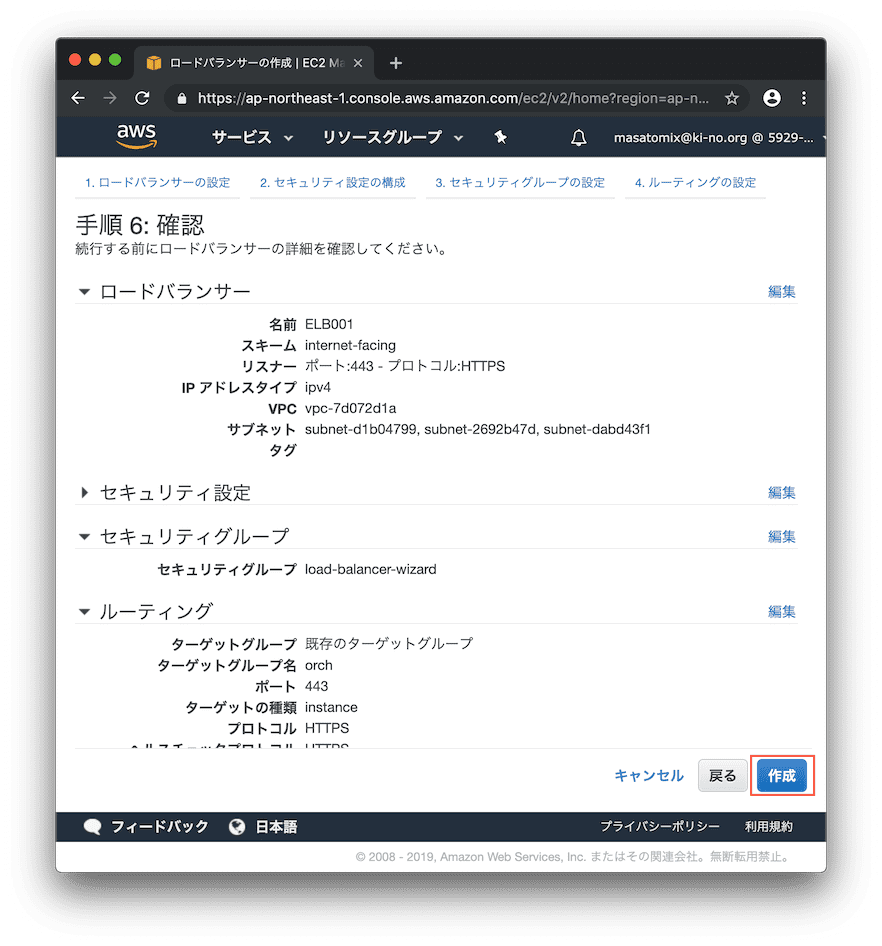
最終確認。よければ「作成」をクリック。
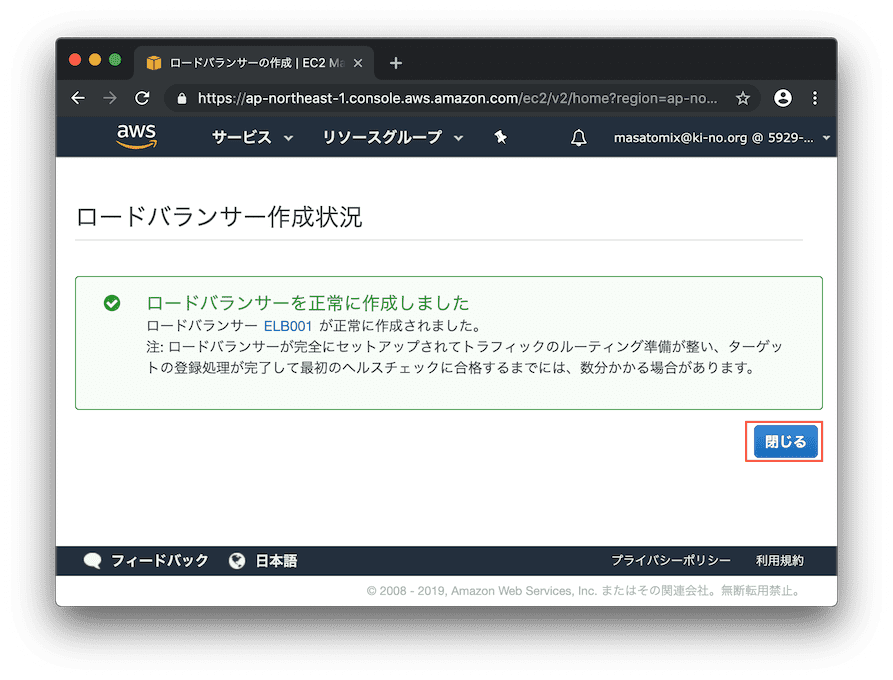
おお、作成できたようですね。
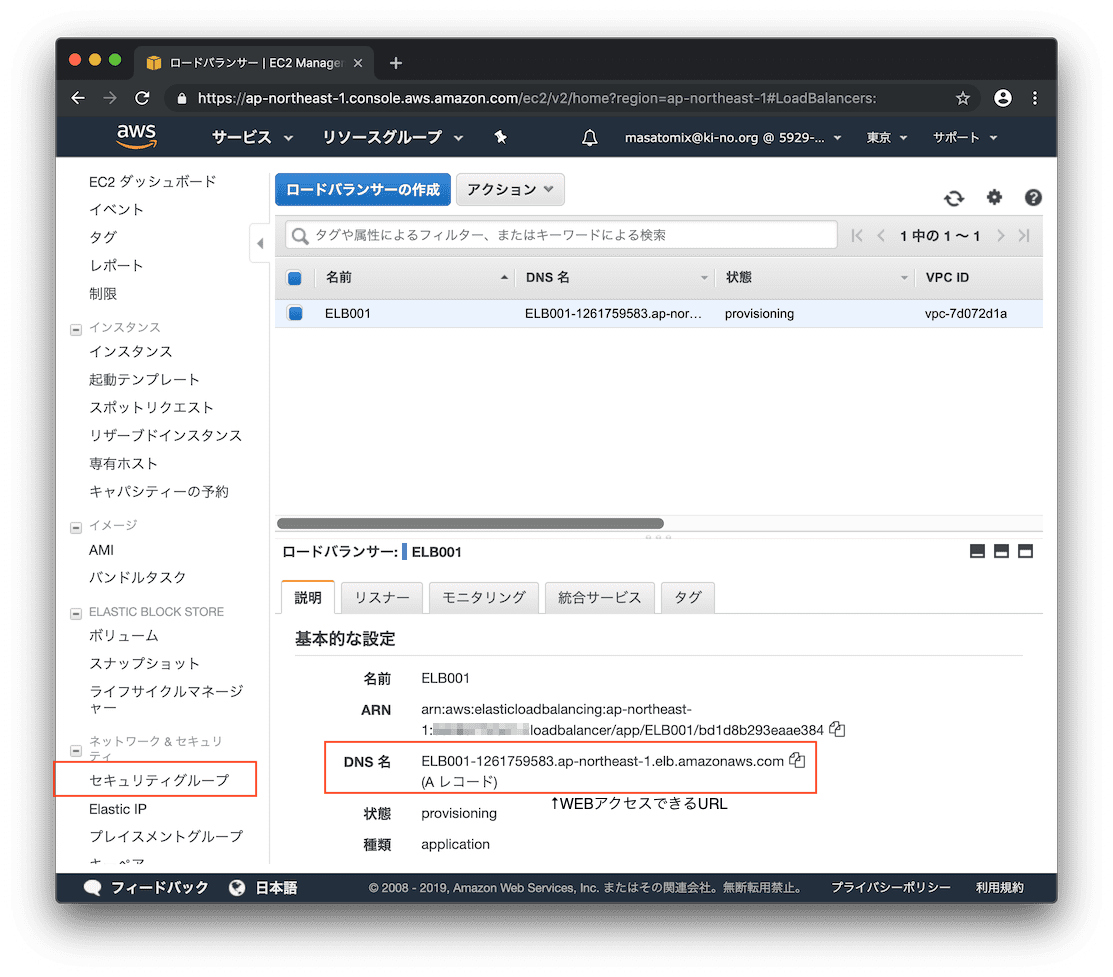
一覧に戻ってみると、確かにELB001というロードバランサが作成できています。下の詳細にDNS名が表示されていますが、このサーバ名がロードバランサに割り振られたサーバ名になります。あとでもっとわかりやすいエイリアスをつけますが、これでアクセスできるようになったということですね。
ここまででほぼ、ELBの構築は完了です。
ELBのセキュリティグループ → EC2のグループへの通信許可
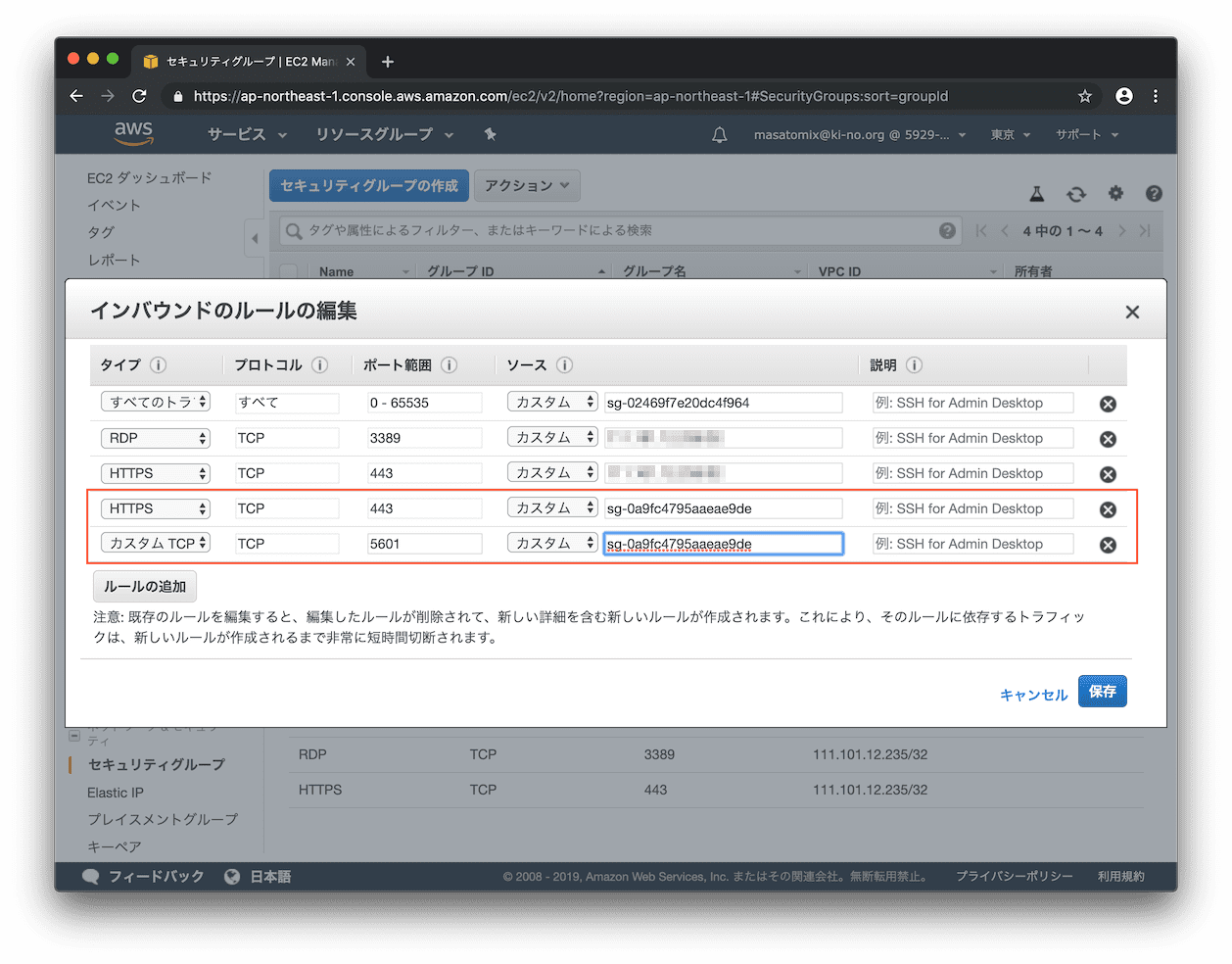
つづいて上記のセキュリティグループのリンクをクリックして、ELB側でなくEC2インスタンス達側のセキュリティグループの設定を変更します。
このままではELBからの接続が許可されていないことになるので 、ELBのセキュリティグループからEC2側のセキュリティグループへ、HTTPSのためのポート443と、Elasticsearch/Kibanaのためのポート5601 への通信を許可します。また下記のイメージの下から3つめ、元々あったHTTPS/443への直接通信はホントは削除した方がよいでしょう。EC2インスタンス直接アクセスは遮断し、ELBからのアクセスに限定するほうがよいからですね。
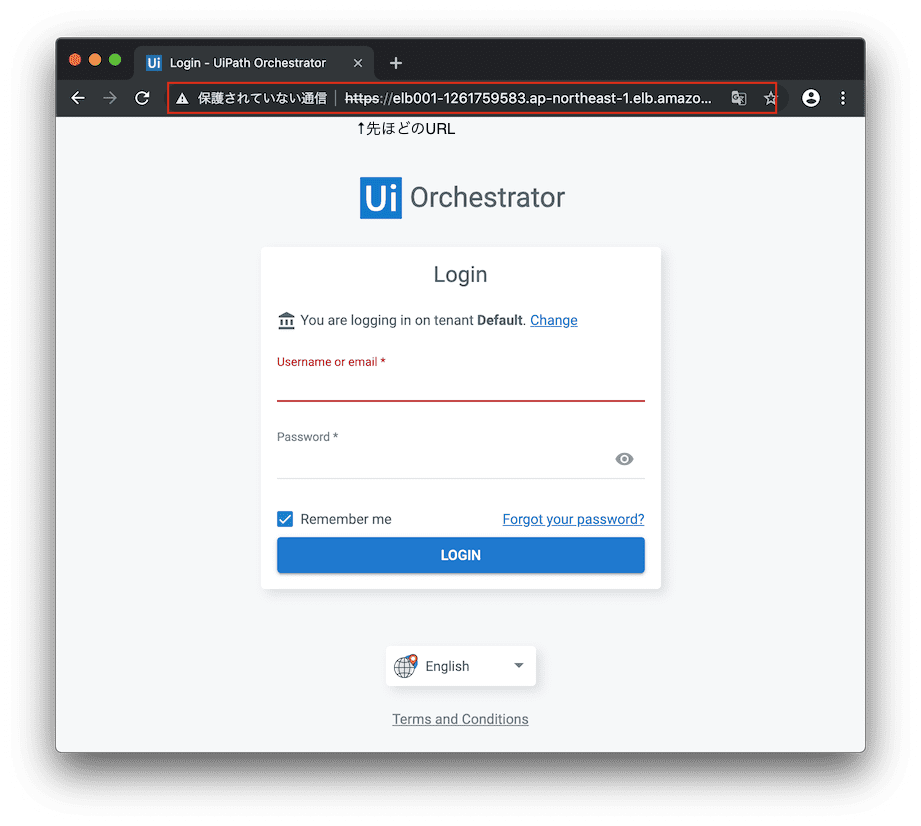
いったん疎通確認
さてさてELBからのルーティングやセキュリティグループによる通信設定もできたので、いったんブラウザで https://[長いELBのDNS名]/ へアクセスしてみましょう。
おなじみのUiPath Orchestrator画面が表示されましたねーー。。今のところ、サーバ名が証明書のCommon Nameと不一致のためSSL的にはエラーになってますが、アクセス自体はできるようになりましたね。
いやー記事にすると長くなりました。。
ELBのサーバ名をAWS Route 53(DNSサービス)で名前解決
さてさて、あとすこし。
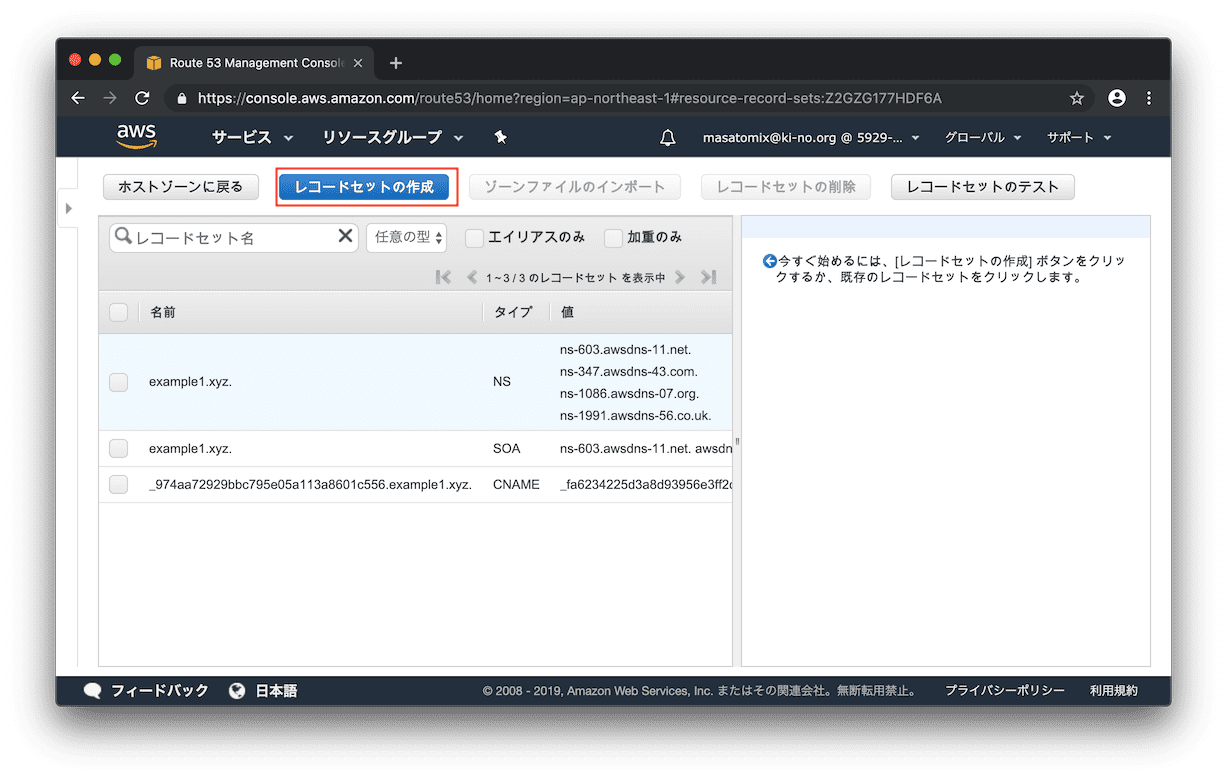
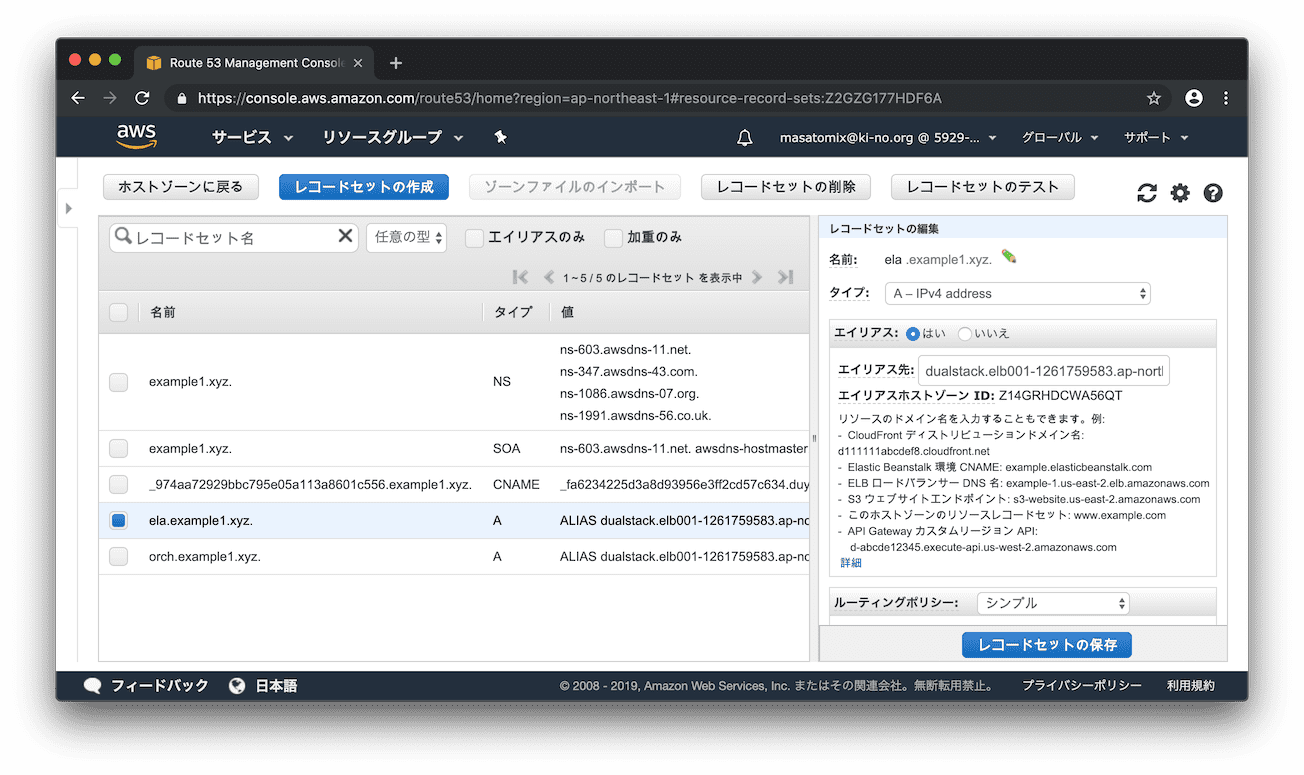
先ほどの長ーいELBのサーバ名を、たとえば orch.example1.xyz とか ela.example.xyz などでアクセスできるよう、DNSサービスで名前解決します。Route 53にアクセスして、該当ホストゾーンの設定画面を開き「レコードセットの作成」をクリック。
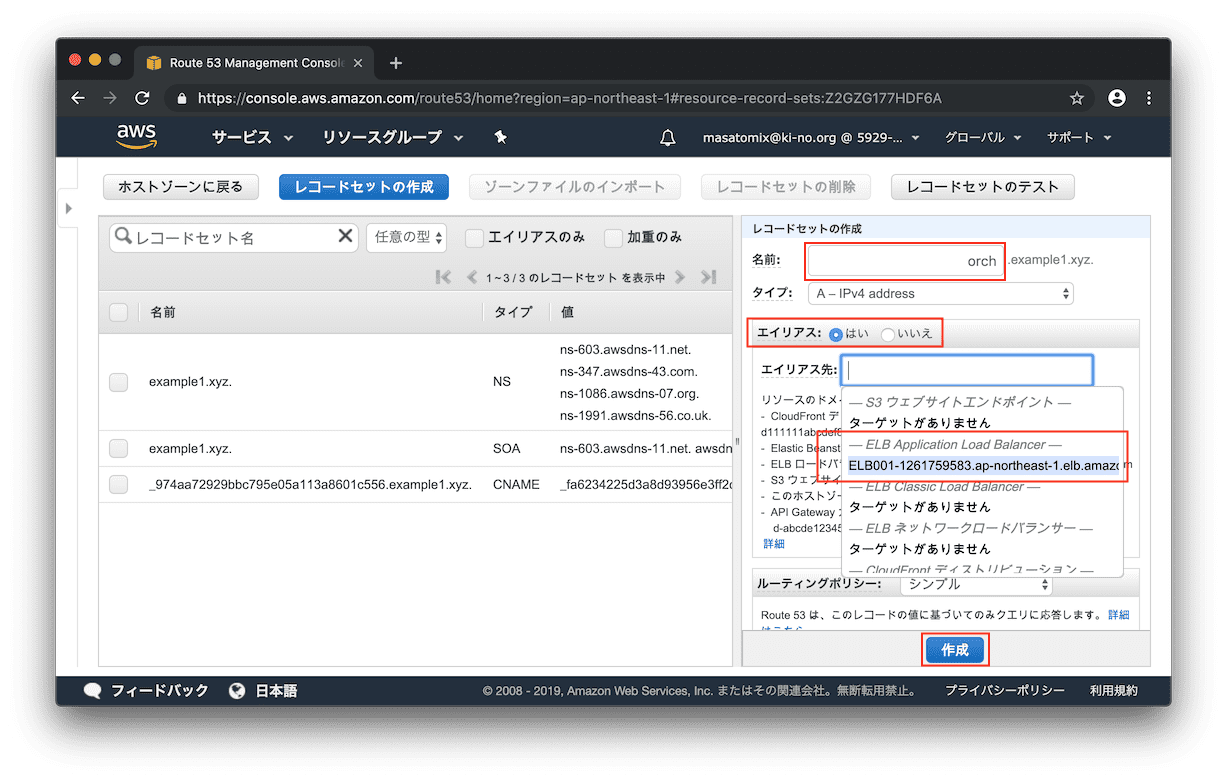
名前に「orch」、エイリアスを「はい」にするとエイリアス先に、ELBのレコードが選択出来るようになるので、それを選択し「作成」をクリック。
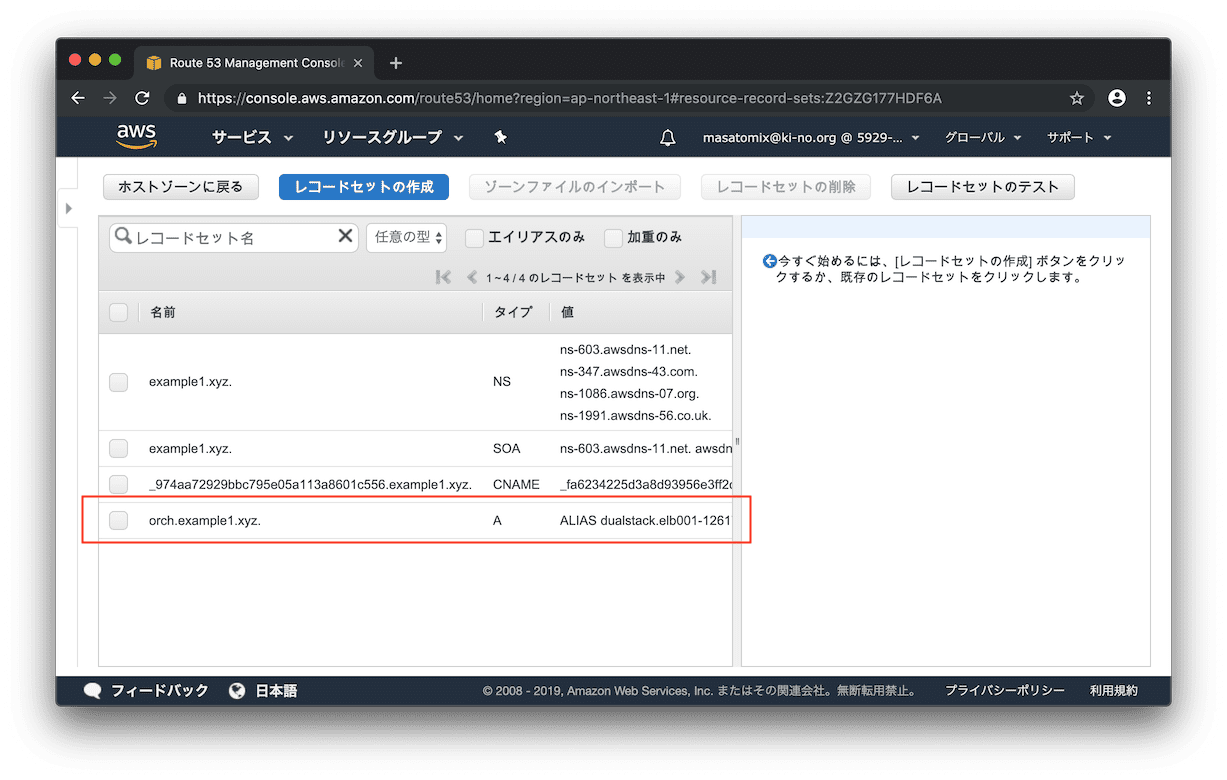
レコードが追加されました。簡単ですね。
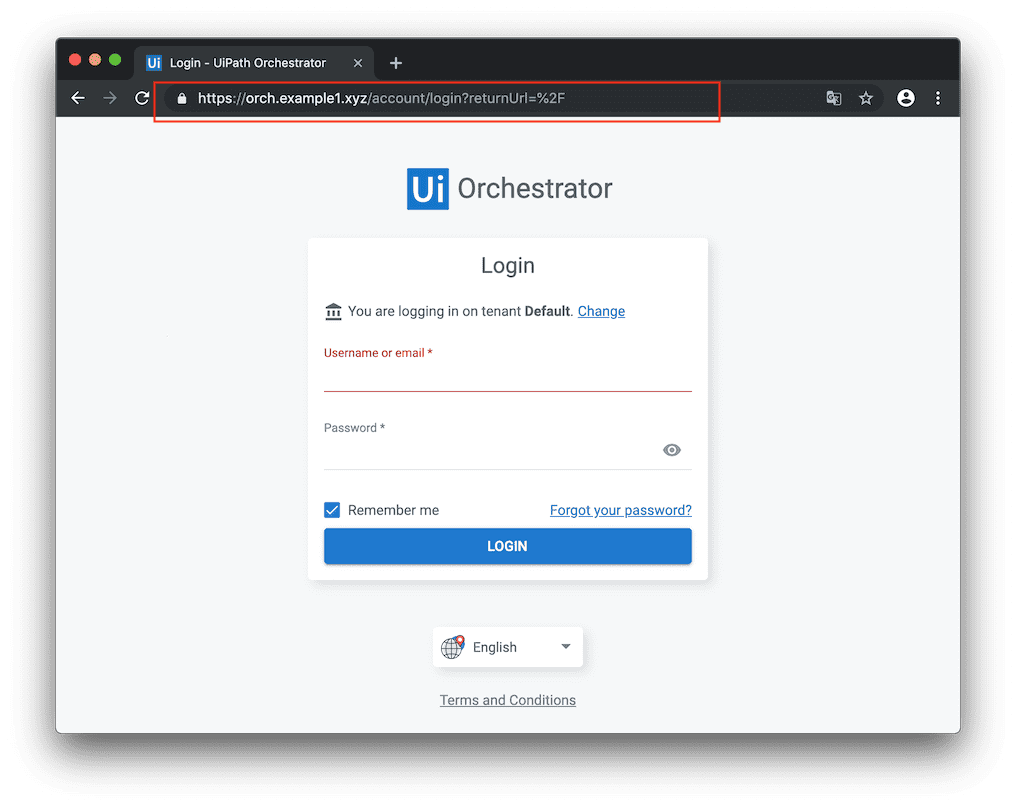
さてさて「 https://orch.example1.xyz/ 」 でアクセスしてみましょう。
表示されましたねーー。。
サーバ名がSSL証明書のCommon Name: *.example1.xyz と一致しているため、先ほどのELBのサーバ名の時は発生していた証明書が不正っていうエラーも、今回は出ていない状態になりました!最後に、ついでに同じ設定で「ela」というサーバ名も追加しておきます。
Elasticsearchサーバのルーティングと疎通
ほぼ環境構築は完了です。まだ「 https://ela.example1.xyz へのアクセスは、Elasticsearch/Kibana サーバにHTTPでポート5601へルーティングする」という設定が入ってないのですが、改めて別記事で書こうと思います。
-- 2019/07/07 追記--
別記事書きました :-)
EC2とELBで、URLごとに別のサーバにルーティングする
-- 2019/07/07 追記 以上--おつかれさまでした。
関連リンク

- 投稿日:2019-07-07T07:57:53+09:00
Datadog入門:AWS IAMロール作成とIntegrationのインストール
AWS:IAMロールの作成
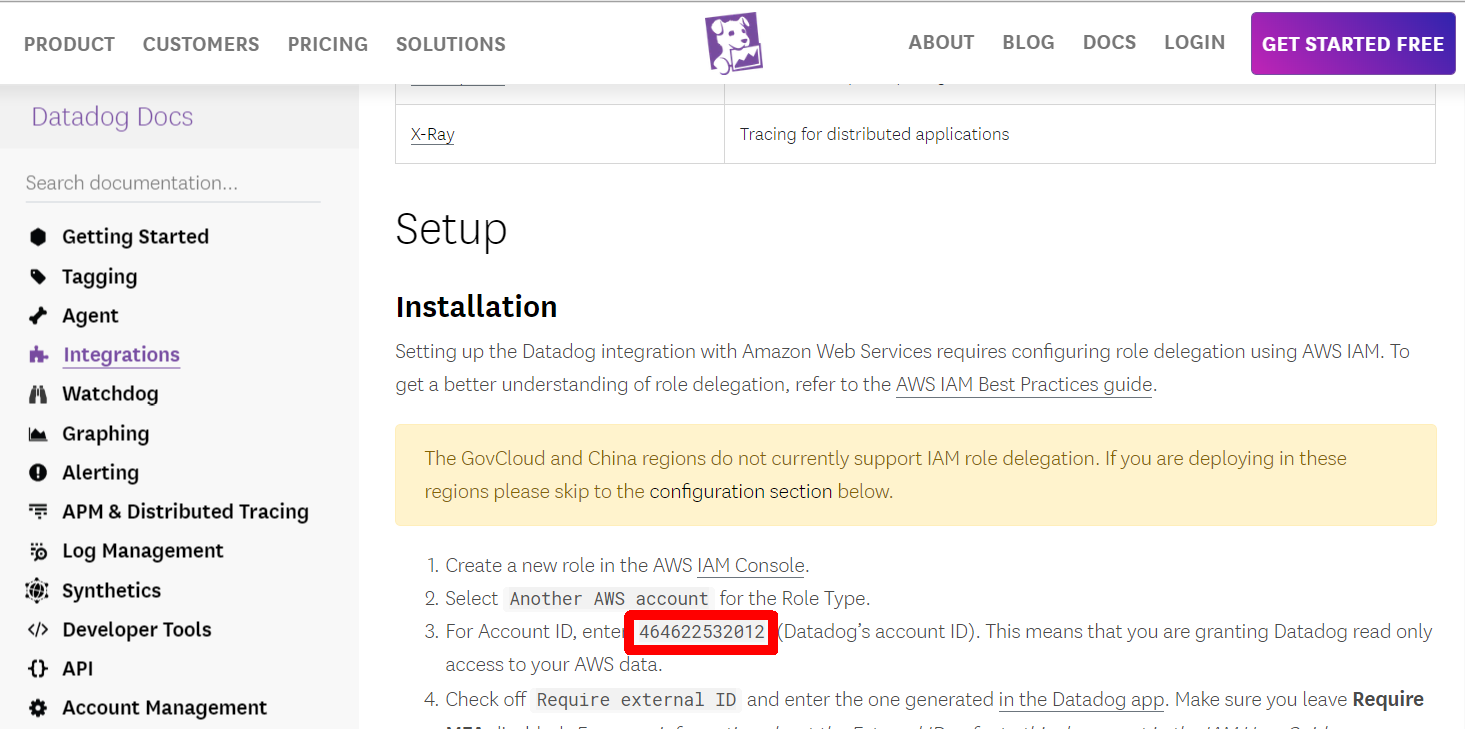
1. DatadogのAWS accuntIDを確認する
- 公式の Datadog Docs から AWS accuntID を控える
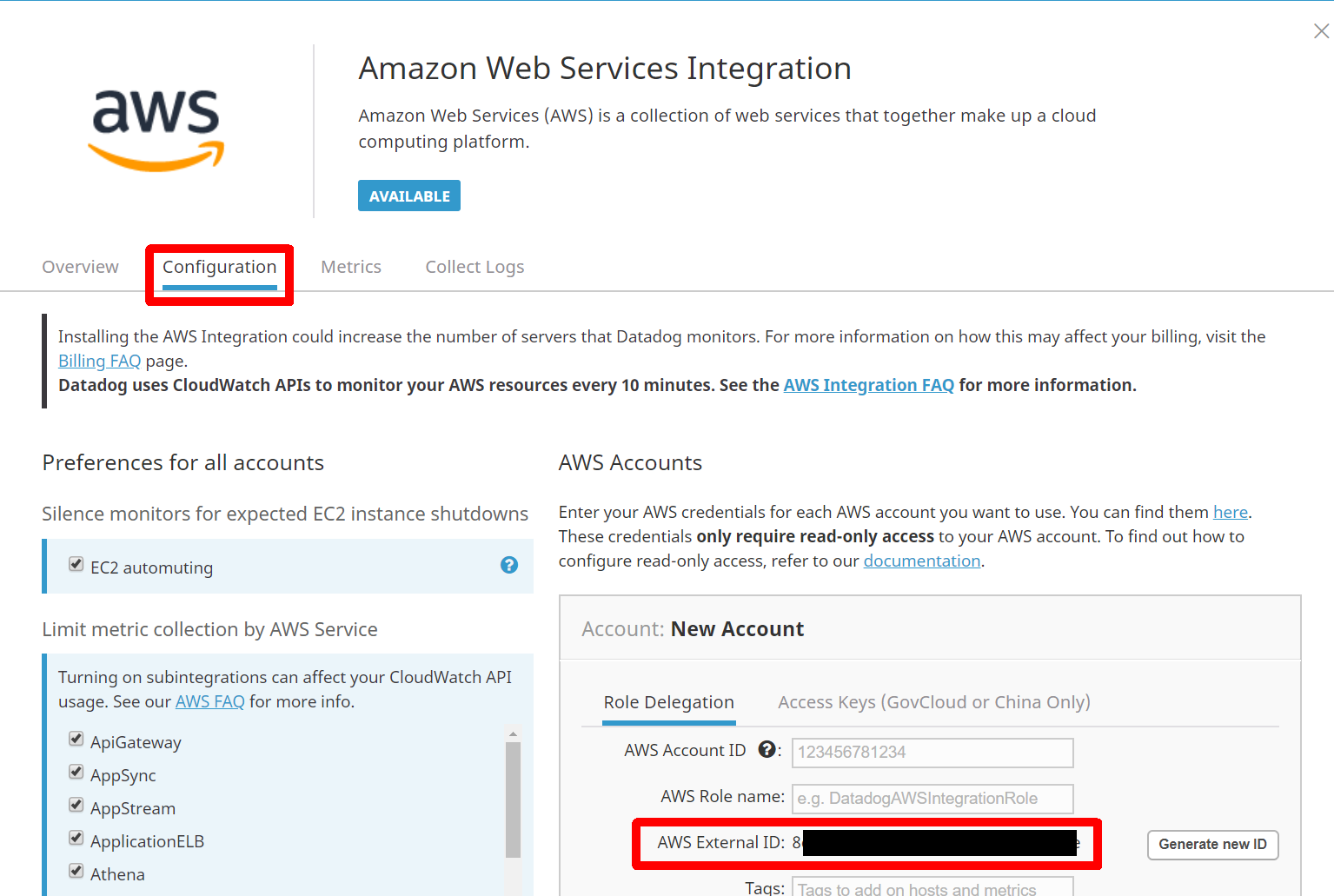
2. AWS External ID を確認する
Datadogのマイページから [Integrations] - [Integrations]
AWSアイコンをクリック
[configration]をクリックし、[AWS External ID]を控える
3.AWS IAM管理画面 を開く
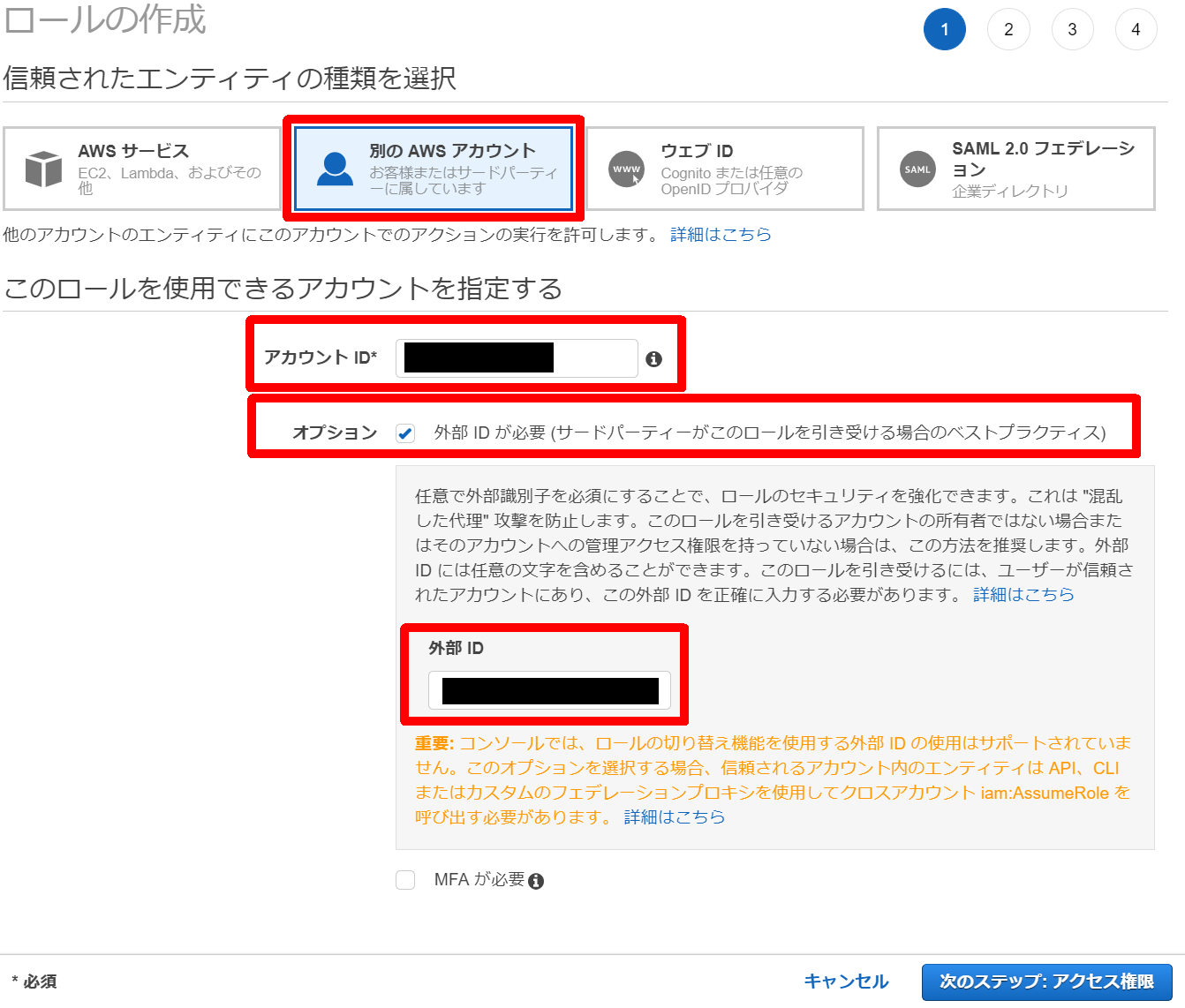
[ロール]- [ロールの作成]をクリック
[別のAWSアカウント]をクリック
- [アカウントID]に、上記で控えた「DatadogのAWS accuntID」を入力
- オプション「外部 ID が必要」にチェック
- [外部ID]に、上記で控えた「AWS External ID」を入力
- [次のステップ:アクセス権限]をクリック

[ポリシーの作成]をクリック
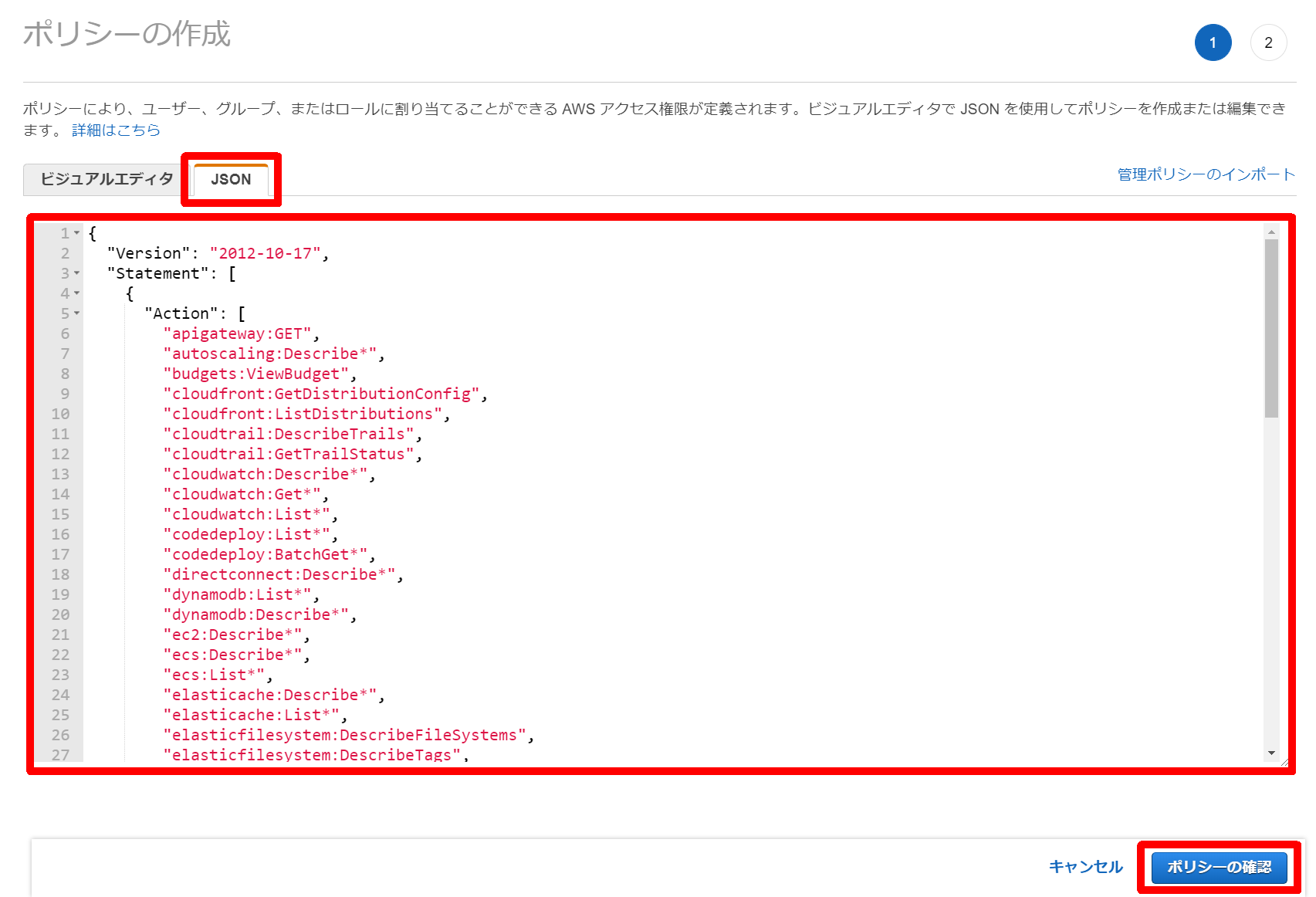
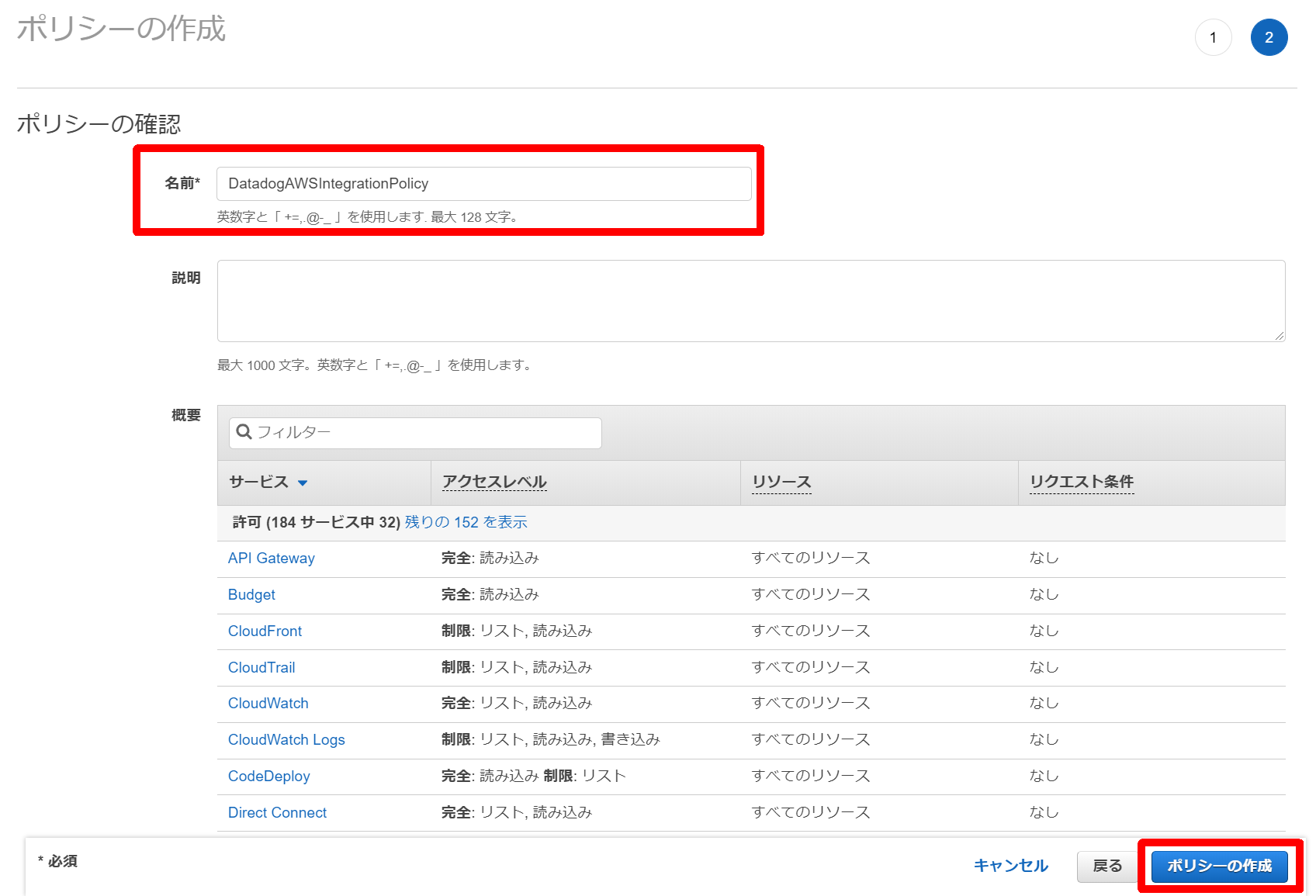
4.[JSON]をクリックし、JSONでポリシーを定義。[ポリシーの確認]をクリック
5.[名前]を入力(例:DatadogAWSIntegrationPolicy)し、[ポリシーの作成]をクリック
6.ポリシーの作成が完了
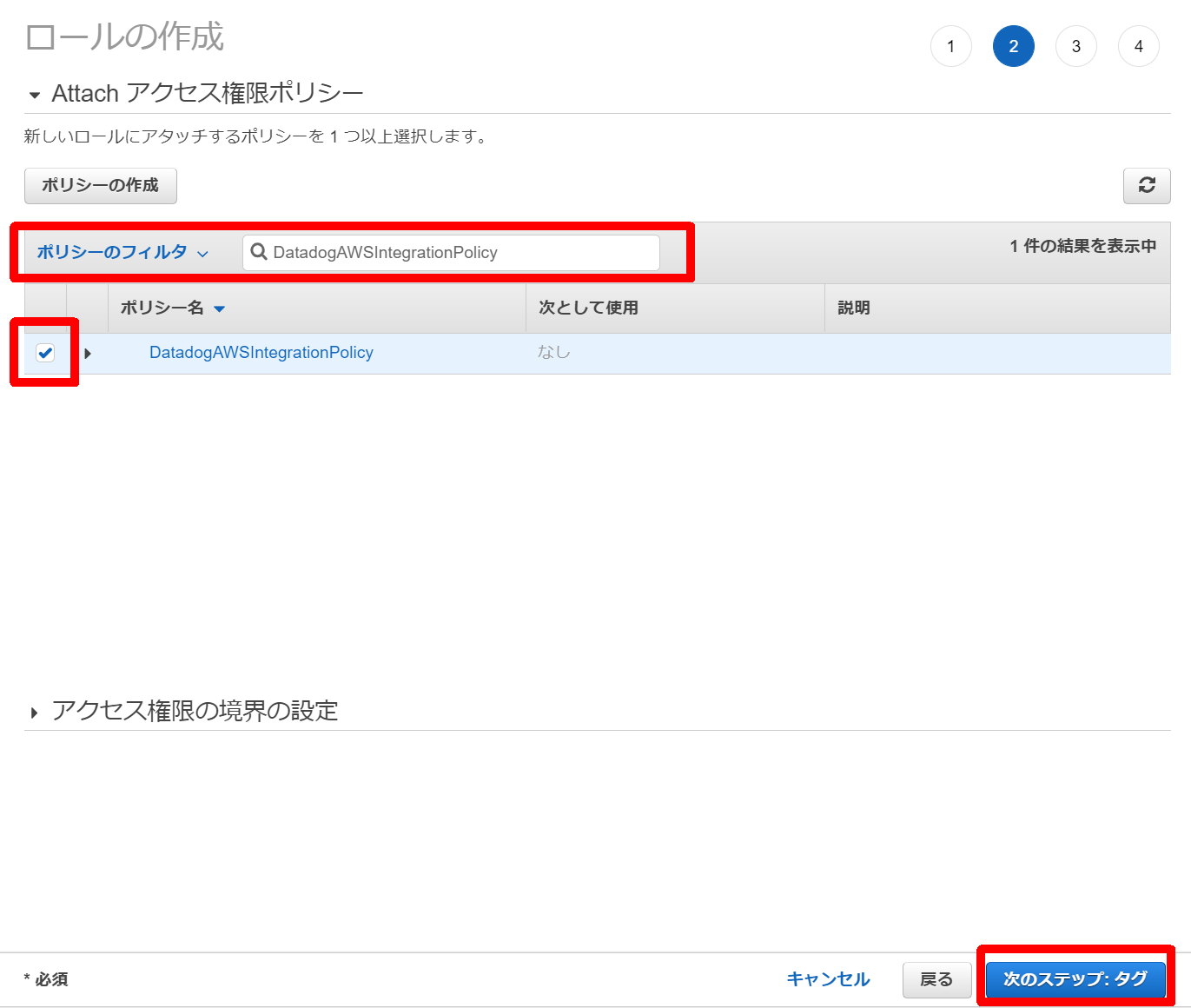
7.先程作成したポリシー名でフィルタしてチェックする。[次のステップ:タグ]をクリック
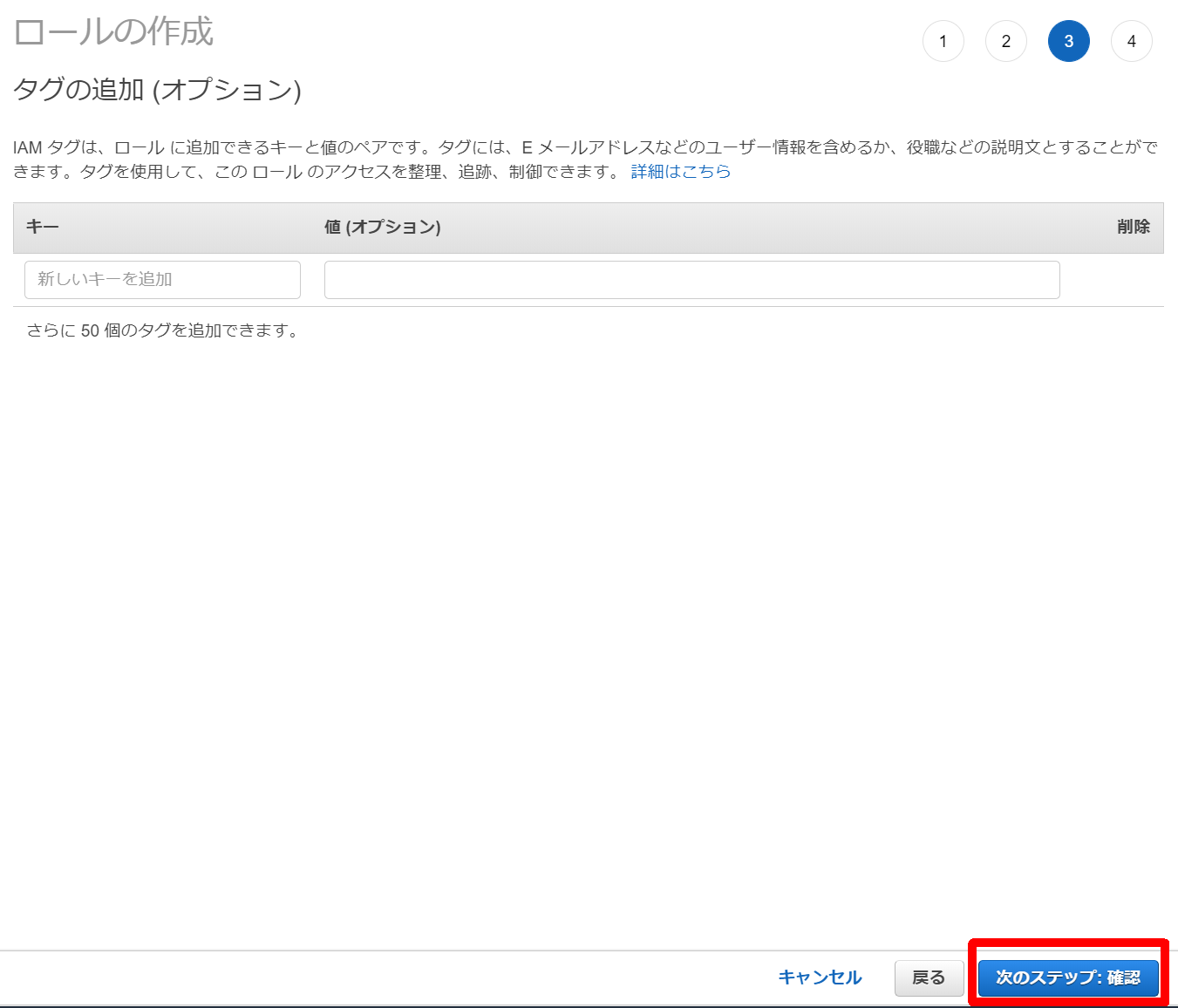
8.[次のステップ:確認]をクリック
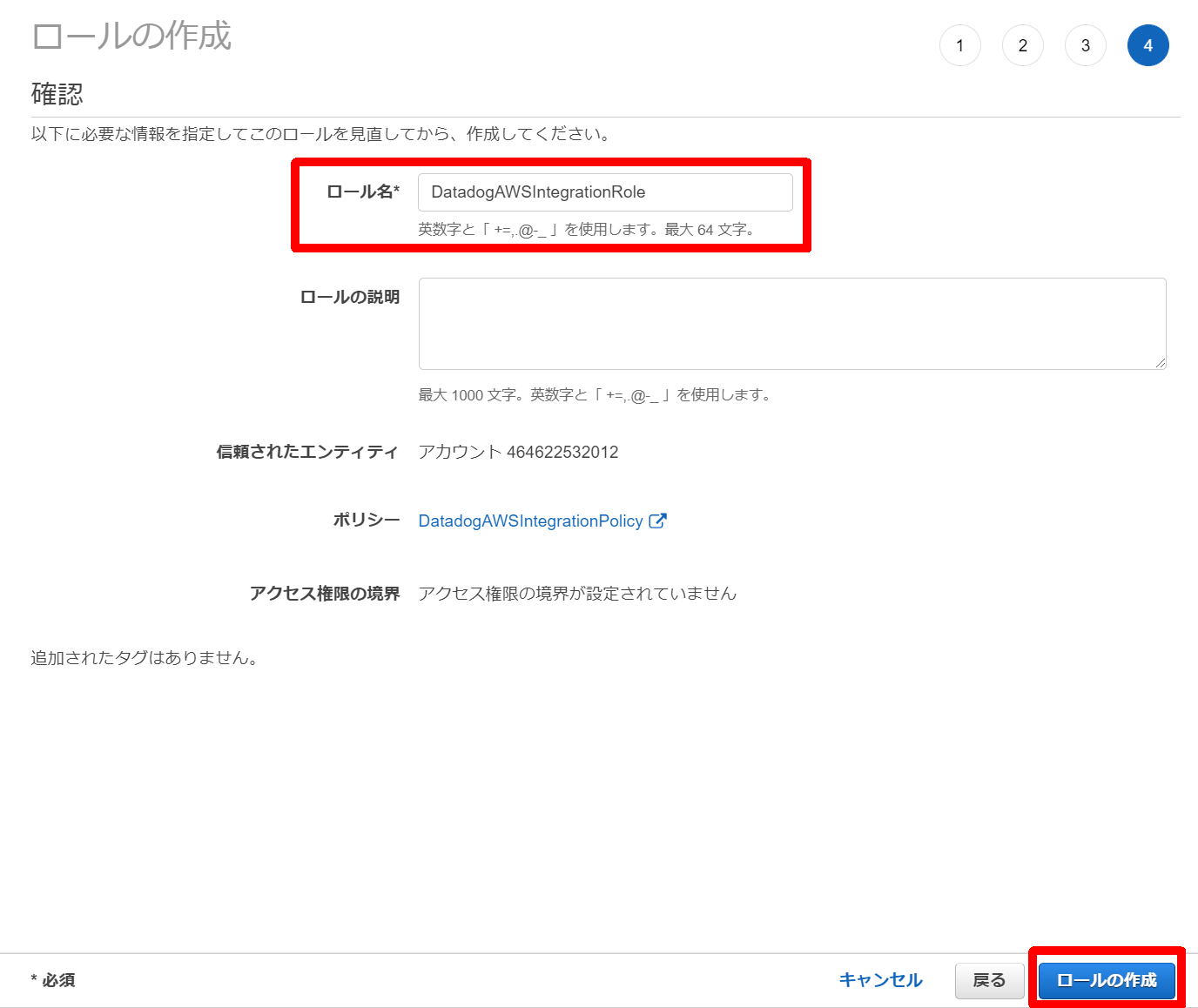
9.[名前]を入力(例:DatadogAWSIntegrationRole)し、[ロールの作成]をクリック
10.ロールが作成されたことを確認
Datadog:AWS Integrationの設定
- Datadogのマイページから [Integrations] - [Integrations]
- AWS accuntID を入力
- ロール名を入力(例:DatadogAWSIntegrationRole)
- [Install Configuration]をクリック
- 反映まで30~60分程かかるまで待つこと。
以上。