- 投稿日:2019-06-27T23:57:27+09:00
傾向スコアを用いた因果効果推定(IPW,DR推定量)【実験編】
はじめに
理論編で述べた内容を簡単に人工データで試してみよう、という内容です。
実験
因果効果の推定の数値実験はいろいろネットに転がってて、データセットとかも現実のものを使っても良いのですが、問題の性質上、人工データでやったほうが因果と相関がどれくらい異なっているかという真のモデルがわかって結果の解釈がしやすいので、今回は自分でデータを生成して因果効果を推定してみます。
単純にMD(Mean difference)を調べると実際の因果効果よりも大きく見えてしまうデータを生成し、そのようなデータに対してIPW推定量やDR推定量を用いて因果効果の推定を行うと、正しく真の因果効果に近い値を示すことを確認します。
MDの定義は理論編にありますが、念のため再掲します。
詳しくは前回の記事を参照してください。MD=\frac{\sum_i^n z_i y_i}{\sum_i^n z_i}-\frac{\sum_i^n (1-z_i) y_i}{\sum_i^n (1-z_i)}以下のようにデータを生成します。
最初に$z=1,z=0$のデータを半分ずつ作り、それを元に以下のようにして特徴量$x_e,x_{ne}$や結果変数$y$を作ります。
x_e = 3z + \epsilon_1\\ x_{ne} \sim N(1,1)\\ y = 1+2x_e+3x_{ne} + 10z + \epsilon_2\\ \epsilon_1,\epsilon_2 \sim N(0,1)$x_e$は$z$と$y$とともに変化する共変量です。
$x_{ne}$は$z$に影響しません。結果変数は、$z=1$のデータのときは$z=0$の時よりも10だけ大きい値をとるようにします。
このように生成したデータについて、$z$の$y$への因果効果($y$の増加に$z$がどれだけ寄与しているか)は、
- $z$自体が直接$y$に与えている影響 : 10
- $z$とともに変化する$x_e$由来の$y$への影響 : $3\times 2=6$
今回のように$z$が先にあって$x_e$がそれに伴って作られていると2個目の影響も因果効果に見えますが、$x_e$由来の$y$への影響分は純粋な$z$による効果ではないので、因果効果には含みません。
なので、気持ちとしては
単純に集団ごとの平均の差を見ると16程度の偏りがあるが、実際の因果効果はそのうちの10だけで、残りの6は共変量による見かけの影響である
ようなデータです。
このようにして生成したデータに対して、MD,IPW,DRの3つの推定量を計算してみます。
結果がこちら。
指標 値 MD 16.0 IPW 12.4 DR 9.9 単純なMDでは、先に説明した影響の両方(10と6)をどちらも見てしまうので約16になっていて、IPWやDRはそれより小さく10に近い値、すなわち真の因果効果に近い値を正しく推定できています。(IPWはちょっと外れていますが)
おまけに、データ生成の際に乗せていたノイズを小さくした(0.1倍)綺麗なデータについても実験を行いました。
結果がこちら。
指標 値 MD 16.0 IPW 16.0 DR 10.0 面白いことに、IPWがMDとほぼ一致します。
これは、ノイズがなくなったことにより傾向スコアのモデルが$z=1$のデータに対しては$e=1$、$z=0$のデータに対しては$e=0$に近い値を算出するようになったことが原因と考えられます。このような傾向スコアのモデリングは正しくないため、傾向スコアのモデリングの正しさにのみ依存するIPW推定量は、真の因果効果の不偏推定量になってくれず、見かけの相関のMDと一致してしまいます。
実際、定義からそのような傾向スコアを用いてIPW推定量を計算した場合、MDにほぼ一致します。
一方、傾向スコアのモデリングを外していても、潜在結果変数のモデリングが正しくできているため、DR推定量は真の因果効果である10をバイアスなく推定することができています。
ソースコード
因果推論の実験とかだとRを使ったものが多いので、あえてPythonで書いてみました。
データ生成部分。
regression_generator.pyclass RegressionGenerator(GeneratorInterface): """回帰問題用のデータセットを生成するクラス. x_e = s_to_xe * s + coef_noize * epsilon x_ne ~ N(mu,sigma^2) : iid w = [1,2,3,1,2,3,1,2,3...] features_n : x_e と x_neの個数合計 y_1 = w * [x_1, x_i] + c + coef_noize * epsilon y_0 = w * [x_1, x_i] + coef_noize * epsilon """ def __init__(self, s_to_x_e, c, features_n=2, seed=0, p=0.5, mu=1, sigma2=1, coef_noize=1): """Initialize genrator instance.""" w = np.array(([1, 2, 3] * (features_n // 3 + 1))[:features_n + 1]) self.seed = seed self.s_to_x_e = s_to_x_e self.w = w self.mu = mu self.p = p self.sigma2 = sigma2 self.coef_noize = coef_noize self.c = c self.features_n = features_n def run(self, num): """Generate raw dataset.""" seed(self.seed) s1_num = int(self.p * num) s = [1 for _ in range(s1_num)] + [0 for _ in range(num - s1_num)] x_e = [self.s_to_x_e * e + self.coef_noize * randn() for e in s] x_ne = np.array([[normal(self.mu, self.sigma2) for i in range(self.features_n - 1)] for _ in range(num)]) y = [] for i in range(len(s)): x = np.concatenate([np.array([1, x_e[i]]), x_ne[i]]) y.append(np.dot(self.w, x) + s[i] * self.c + self.coef_noize * randn()) df = pd.DataFrame() df["x_e"] = x_e for i in range(self.features_n - 1): df[f"x_ne{i+1}"] = x_ne[:, i] df["s"] = s df["y"] = y df = df.reindex(np.random.RandomState(self.seed).permutation( df.index)).reset_index(drop=True) return df各推定量の計算はこんなかんじ。
analyze.pydef get_md(s, y): """MDを返す. input s(numpy) y(numpy) yはラベル1となる確率が各要素 return md """ ys = y[s == 1] yns = y[s == 0] md = ys.mean() - yns.mean() return md def get_ipw(y, s, e): """IPW推定量を計算する.""" Ey1 = (s * y / e).sum() / (s / e).sum() Ey0 = ((1 - s) * y / (1 - e)).sum() / ((1 - s) / (1 - e)).sum() return Ey1 - Ey0 def get_dr(y, s, e, g0, g1): """DR推定量を計算する.""" Ey1 = (s * y / e + (1 - s / e) * g1).mean() Ey0 = ((1 - s) * y / (1 - e) + (1 - (1 - s) / (1 - e)) * g0).mean() return Ey1 - Ey0おわりに
前回の記事で紹介した因果推論の傾向スコアを用いた推定(IPW,DR推定量)について、人工データを用いて簡単な実験を行いました。
ありがとうございました。
- 投稿日:2019-06-27T23:54:22+09:00
InfluxDBをPythonから使う
InfluxDBをPythonから使う
InfluxDataがInfluxDB-Pythonというライブラリを用意してくれているのでそれを使えば良いだけ。
参考サイト
https://github.com/influxdata/influxdb-python
InfluxDB-Pythonのインストール
pip3 install influxdb --user pip3 install --upgrade influxdb --user依存関係
InfluxDB-PythonディストリビューションはPython 2.7, 3.5, 3.6, 3.7, そしてPyPyとPyPy3上ででサポートされていてテスト済みである。
注意: Python <3.5 は現在テストされていない。
主な依存関係は:
- Requests: HTTP library for human beings (http://docs.python-requests.org/)
他の依存関係は:
- pandas: for writing from and reading to DataFrames (http://pandas.pydata.org/)
- Sphinx: Tool to create and manage the documentation (http://sphinx-doc.org/)
- Nose: to auto-discover tests (http://nose.readthedocs.org/en/latest/)
- Mock: to mock tests (https://pypi.python.org/pypi/mock)
ドキュメント
ドキュメントはココ
例
>>> from influxdb import InfluxDBClient >>> json_body = [ { "measurement": "cpu_load_short", "tags": { "host": "server01", "region": "us-west" }, "time": "2009-11-10T23:00:00Z", "fields": { "value": 0.64 } } ] >>> >>> json_body [{'measurement': 'cpu_load_short', 'tags': {'host': 'server01', 'region': 'us-west'}, 'time': '2009-11-10T23:00:00Z', 'fields': {'value': 0.64}}] >>> client = InfluxDBClient('localhost', 8086, 'root', 'root', 'example') >>> client <influxdb.client.InfluxDBClient object at 0x7f4fea0c4ef0> >>> client.create_database('example') >>> client.write_points(json_body) True >>> result = client.query('select value from cpu_load_short;') >>> print("Result: {0}".format(result)) Result: ResultSet({'('cpu_load_short', None)': [{'time': '2009-11-10T23:00:00Z', 'value': 0.64}]})テスト
toxをインストールする:
$ pip3 install tox --user複数のバージョンのPythonに対してinfluxdb-pythonをテストするためには、Toxを使うことが出来る:
$ tox
- 投稿日:2019-06-27T23:37:30+09:00
我为中国人创作了翻译。
私は中国語への翻訳機を作成しました
日本語の文章を構文解析して日本人が読める偽中国語翻訳機を作った記事『我偽中国語翻訳機作成了』が、たくさんいいねされていてうらやましい。
構文解析しなくても近いものが翻訳APIでちょちょいとできるんじゃね、と思ってやってみた。
以前に使ってみたことがあったので、IBM Cloud の Language Translator を使った。
でも、Language Translator の既存の翻訳言語モデルに
日本語から中国語へ直接変換するモデルは現時点ではないみたい。
英語は各言語に直接変換するモデルがあるみたい。
翻訳言語 モデル 日本語 ⇔ 英語 あり 中国語 ⇔ 英語 あり 日本語 ⇔ 中国語 なし ということで英語を中継して中国語を作成するプログラムにします。
発言 ➡ 中継 ➡ 最終 日本語 ➡ 英語 ➡ 中国語 以前に同じようなことをやりました。
Watson APIを利用してPythonで多言語通訳botをSlackに作るIBM Cloud - Language Translator の利用準備
- IBM Cloudのアカウントを作成
- Language Translator のサービスインスタンス作成
- 作成したインスタンスのサービス資格情報から apikey を取得
こちらの url でインスタンス作成
IBM Cloud - Language Translatorアカウント作成からインスタンス作成まで こちらの記事 参考。サービスのバージョンアップで画面イメージが違っていますが、やることは同じです。
- pythonライブラリ ibm-watson のインストール
pip install --upgrade ibm-watsonIBM Cloud APIを使って翻訳してみる
実装
watson_language_translator.pyfrom ibm_watson import LanguageTranslatorV3 language_translator = LanguageTranslatorV3( version='2018-05-01', iam_apikey='{apikey}', url='https://gateway.watsonplatform.net/language-translator/api' ) langs = [['ja','日'], ['en','英'], ['zh-cn','中']] # langs = [開始言語, 中継言語, 出力言語] for _ in range(10): print('■ 日本語を入力してね。1回英語を中継して、中国語に翻訳するよ。') text = input('%s> ' % (langs[0][1],)) for i in range(len(langs)-1): translation = language_translator.translate( text=text, source=langs[i][0], target=langs[i+1][0]) text = translation.result['translations'][0]['translation'] print('%s:%s' % (langs[i+1][1], text,)) print()結果
>python watson_language_translator.py ■ 日本語を入力してね。1回英語を中継して、中国語に翻訳するよ。 日> 私は中国語への翻訳機を作成しました 英:I have created a translator for Chinese. 中:我为中国人创作了翻译。 ■ 日本語を入力してね。1回英語を中継して、中国語に翻訳するよ。 日> 私はお酒を飲みたい 英:I want to drink. 中:我想喝 ■ 日本語を入力してね。1回英語を中継して、中国語に翻訳するよ。 日> 私は本日定時退社します 英:I'm leaving the company today. 中:我今天要离开公司 ■ 日本語を入力してね。1回英語を中継して、中国語に翻訳するよ。 日> 私は理解しました 英:I understood. 中:我明白了 ■ 日本語を入力してね。1回英語を中継して、中国語に翻訳するよ。 日> 私は明日、伊豆大島に行きたい 英:I want to go to Izu Oshima tomorrow. 中:我明天要去伊豆大岛 ■ 日本語を入力してね。1回英語を中継して、中国語に翻訳するよ。 日> 私は昨日、日本の料理を食べました 英:Yesterday, I ate Japanese food. 中:昨天我吃了日本菜 ■ 日本語を入力してね。1回英語を中継して、中国語に翻訳するよ。 日> 今日は10時に仕事が終わります 英:I'm done at 10 o'clock today. 中:我今天十点就完成了 ■ 日本語を入力してね。1回英語を中継して、中国語に翻訳するよ。 日> あなたは何時に終わりますか? 英:What time do you end up? 中:你几点结束?結論
- 日本人の読める偽中国語は、翻訳APIで作れなかった。
中国語はむずかしいってこと。
- 英語を経由することで中国語に翻訳した時には意味、情報が落ちるケースがあった。
ひとつの英単語で広い意味を持ってたりするため。
例えば drink だけで、酒を飲むという意味がある。
- 投稿日:2019-06-27T23:20:08+09:00
超小ネタ 引数に渡した数値型の全てが0を除き同じ符号かを判定する
コード
def is_same_sign(*numbers) -> bool: return len({x > 0 for x in numbers if x != 0}) <= 1テスト
assert is_same_sign(*[1, 5, 0]) assert not is_same_sign(*[-1, 5, 0]) assert is_same_sign(*[0, 0, 0, 0])解説
関数
is_same_signは、set内包表記を用いて、引数の中で0でないなら、0より大でTrue、0より小ならFalseとするboolのsetを作る。
このsetは
-set(): 長さ0の空set
-{True}か{False}: 長さ1のset
-{True, False}か{False, True}: 長さ2のset
となり、全て符号が同じ =setの要素数が0または1 = 要素数が1以下ということができる。以上。
- 投稿日:2019-06-27T23:12:18+09:00
VRゲームで自身をアバターとして表示して録画する方法と、その撮影するカメラを自動で動かす手段を考えてみた話
VRゲームで自身をアバターとして表示して録画する
手持ち無沙汰でなんとなくTwitterのTLを見ていると、VRのゲームを録画した映像にキャラクターが合成された動画が流れてくることが(多分)何回かはあると思います。
あれはどう実現されているかというとゲームのMODだったりいろいろと手はありますがここではLIVとバーチャルモーションキャプチャーを使った方法について書きます。LIVは、グリーンバック(以下GB)の前に人がいるカメラ映像と三人称視点で表示したVRのゲーム画面を合成するソフトです。
バーチャルモーションキャプチャーは、SteamVRから手や頭の位置情報を取得してアバターを動かしGBで表示するめっちゃ便利なソフトです。あきら氏(@sh_akira)が開発しています。
LIVへの『GB撮影されたカメラ映像』の代わりに『GBの前で動くアバターの映像』を仮想webカメラとして流し込むことで、VRゲームの中でアバターが動いているような映像になります。
撮影するカメラを動かしたい
LIVとバーチャルモーションキャプチャーを使用した動画で今一番出回っているのはBeat Saberだと思われます。
その動画を見ると大体初めから終わりまで背後から固定したカメラでの映像です。
自分で撮影してみると、もっとアバターを別アングルで見てみたいとか絵的に派手にしたいとか欲が出てきます。
Beat Saberに限れば、MODのみでアバターを合成したり三人称視点にしてカメラを動かしたりは可能なようです。https://www.youtube.com/watch?v=ivBVDMMO_YA
しかし、他のゲームでも同じようなことをするためにはMODに頼らずにどうにかする必要があります。
LIVにはVRデバイスに三人称視点のカメラを割り当てる機能があります。
誰かにVIVEのトラッカーやコントローラーを持ってもらってプレイヤーの周りを動いて撮影することはできますが、手ブレの問題があったり、何よりも一人では無理です。コントローラーをプログラム的に動かす手が無いかとぼんやり考えながら過ごしていたところ、VR内から画像ファイルやデスクトップを見れる超絶便利なツールVaNiiMenu開発者のgpsnmeajp氏(@Seg_Faul)がコントローラードライバのサンプルコードを公開されていました。
そのサンプルコードではクライアントがドライバの共有メモリに座標を書き込んで、仮想のコントローラーを移動させることができるようになっていました。
クライアントのC++のコードを参考にPythonで書いてみたのがこれです。
simpleShareMemWrite.pyimport mmap shareMem = mmap.mmap(0,16384,'pip1') cameraPos = [0,1.5,-1] #単位はメートル これで高さ1.5m 前方1m posX = str(cameraPos[0]) posY = str(cameraPos[1]) posZ = str(cameraPos[2]) shareMem.seek(0) shareMem.write(b'{"id":0,"v":['+posX.encode()+b','+posY.encode()+b','+posZ.encode()\ +b'],"vd":[0,0,0],"vdd":[0,0,0],"r":[0,0,0,0],"rd":[0,0,0],"rdd":[0,0,0],"Valid":true}')サンプルのドライバを入れた状態でスクリプトを動かすと目の前にベースステーションのモデルが移動します。
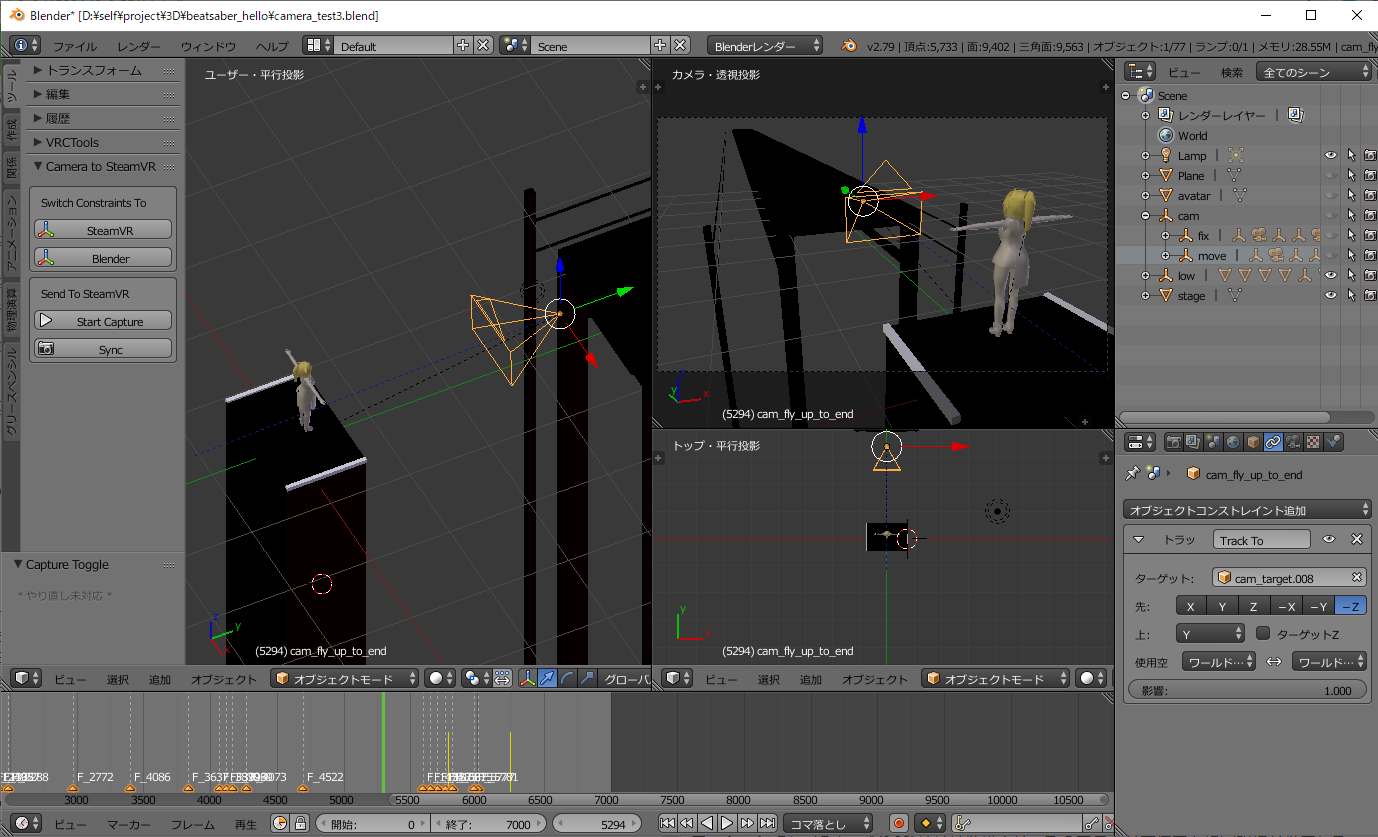
カメラを動かしたいのですが3Dの座標の計算がよくわからないので、Blenderのカメラ位置をそのまま共有メモリに書き込むアドオンとして作りました。
Blender上で何もないとどこをカメラで狙えばいいかわからないので適当にアバターやステージを置きました。
実際に撮れる動画と比べるとどうしてもズレるのであくまでも目安です。フレームが変わるタイミングかsyncボタンを押すと、シーンでアクティブなカメラの位置と回転を仮想コントローラーへ送ることができます。
SteamVRとBlenderで座標の向きが違うようで、揃えるために入れ替えたりしてみたらカメラの方向がおかしくなってしまいました・・・。
多分ちゃんと計算すればいいのですが手動で切り替えることで無理やり動かしてます。
(カメラの回転の向きをTrack Toコンストレイントで決めていて、そこのプロパティを変更することで向きを変えている)blender_to_SteamVR.pyimport bpy import mmap bl_info = { "name" : "camera move test", "author" : "imakami", "version" : (0,1), "blender" : (2, 7, 0), "location" : "", "description" : "", "warning" : "", "wiki_url" : "", "tracker_url" : "", "category" : "" } capture = False shareMem = False class AnimationCaptureToggle(bpy.types.Operator): bl_idname = "imakami.animation" bl_label = "Capture Toggle" bl_description = "Start Capture" bl_options = {'REGISTER', 'UNDO'} def invoke(self, context, event): global capture if capture == False: bpy.app.handlers.frame_change_pre.append(sendCameraPos) capture = True else: bpy.app.handlers.frame_change_pre.clear() capture = False return {'FINISHED'} class CameraSync(bpy.types.Operator): bl_idname = "imakami.camera" bl_label = "Sync" bl_description = "Sync" bl_options = {'REGISTER', 'UNDO'} def invoke(self, context, event): sendCameraPos(self) return {'FINISHED'} def sendCameraPos(self): global shareMem if shareMem == False: shareMem = mmap.mmap(0,16384,'pip1') nowCameraPos, nowCameraRotate, nowCameraScale = bpy.context.scene.camera.matrix_world.decompose() #scaleは使ってない posX = str(nowCameraPos[0]) #XAxis posY = str(nowCameraPos[2]) #ZAxis posZ = str(nowCameraPos[1]*-1) #YAxis rotQuat = [] for i in range(4): if i == 2: rotQuat.append(str(nowCameraRotate[i]*-1)) else: rotQuat.append(str(nowCameraRotate[i])) shareMem.seek(0) wait = shareMem.read(1) if wait != b'x': print('not wait') return shareMem.seek(0) shareMem.write(b'{"id":0,"v":['+posX.encode()+b','+posY.encode()+b','+posZ.encode()+b'],"vd":[0,0,0],"vdd":[0,0,0],"r":['\ +rotQuat[0].encode()+b','+rotQuat[1].encode()+b','+rotQuat[3].encode()+b','+rotQuat[2].encode()\ +b'],"rd":[0,0,0],"rdd":[0,0,0],"Valid":true}') #print(posX,posY,posZ) class TransToVRCameraAxis(bpy.types.Operator): bl_idname = "imakami.to_vr" bl_label = "SteamVR" bl_description = "Switch Constraints To SteamVR" bl_options = {'REGISTER', 'UNDO'} def invoke(self, context, event): changeCameraTrackAxis('TRACK_Y','UP_Z') return {'FINISHED'} class TransToBlenderCameraAxis(bpy.types.Operator): bl_idname = "imakami.to_bl" bl_label = "Blender" bl_description = "Switch Constraints To Blender" bl_options = {'REGISTER', 'UNDO'} def invoke(self, context, event): changeCameraTrackAxis('TRACK_NEGATIVE_Z','UP_Y') return {'FINISHED'} def changeCameraTrackAxis(trackAxis, upAxis): for obj in bpy.data.objects: if obj.type == 'CAMERA': track = obj.constraints.get('Track To') if track != None: track.track_axis = trackAxis track.up_axis = upAxis class addonPanel(bpy.types.Panel): bl_label = "Camera to SteamVR" bl_space_type = "VIEW_3D" bl_region_type = "TOOLS" bl_category = "Tools" def draw(self, context): global capture sc = context.scene layout = self.layout boxAxis = layout.box() boxAxis.label(text = "Switch Constraints To") boxAxis.operator(TransToVRCameraAxis.bl_idname, icon="MANIPUL") boxAxis.operator(TransToBlenderCameraAxis.bl_idname, icon="MANIPUL") boxCap = layout.box() boxCap.label(text = "Send To SteamVR") if capture == False: boxCap.operator(AnimationCaptureToggle.bl_idname, text="Start Capture", icon="PLAY") else: boxCap.operator(AnimationCaptureToggle.bl_idname, text="Stop",icon="REC") boxCap.operator(CameraSync.bl_idname, icon="SCENE") classes = {TransToVRCameraAxis,TransToBlenderCameraAxis,AnimationCaptureToggle,CameraSync,addonPanel} def register(): for cls in classes: bpy.utils.register_class(cls) def unregister(): for cls in classes: bpy.utils.unregister_class(cls) if __name__ == "__main__": register()これでBlender上でアニメーションを再生すると、アクティブなカメラの位置と連動して仮想コントローラーが動くようになりました。
後はLIVでこの仮想コントローラーをカメラに指定して、バーチャルモーションキャプチャーとLIVで読み込むexternalcamera.cfgのx/y/z/rx/ry/rzを全て0にしたファイルを読み込ませるようにします。
そうして書いたBlenderアドオンとgpsnmeajp氏の書いたコントローラードライバのサンプルコードをそのまま使って以下の動画を撮りました。最新版のバーチャルモーションキャプチャーが軽いのでかなり無茶なことができるようになった
— いまかみ (@imakami) 2019年6月27日
Song:Hello by Capsule
Custom Map : Firm Retention#バーチャルモーションキャプチャー #BeatSaber pic.twitter.com/mqUXk0pJiuまとめ
この手法だと対象となるゲームとLIVとバーチャルモーションキャプチャーとOBSとBlenderを同時に動作させないといけません。
LIVとバーチャルモーションキャプチャーの処理が結構重くてカクカクになったりしていたのですが、最新版のバーチャルモーションキャプチャー(V0.32)がかなり軽くなったのでこんな方法でも現実的になりました。
とはいえBeat Saberで最低のグラフィック設定にしたケースでの話です。自分のPC(CPU i7 4770 グラボ GTX1060)だと720pでギリギリでフルHDだと無理な感じです。仮想コントローラーが手に持つコントローラと認識されるということがありました。コントローラの電源を入れなおしたりすると直ったりします。
バーチャルモーションキャプチャーの設定も手動で各コントローラーを指定するとうまく動くようになりました。動画を撮る際、Blenderで普通に動画を作成するようにカメラ切り替えとアニメーションを前もってすべて作成するというめちゃくちゃ面倒なことをしています。
コントローラーを移動させたい座標とクォータニオンでの回転を共有メモリに書き込むだけなのでBlender抜きでコードを書いて、適当なボタンを押すとカメラが動くとかにした方が使いやすいと思われます。
- 投稿日:2019-06-27T23:01:09+09:00
QiitaAPIで各プログラミング言語のタグの記事とフォロワーの数を調べて纏めたりする(pythonとrubyを使う)
今どのプログラミング言語がどれくらい人気なのか気になるので、qiitaで書かれた記事のタグを調べて見ましたが、一々調べるよりもコードを書いてQiitaAPIからデータを取得して分析する方が楽なので、書いてみました。この記事では試してみたこととその結果を纏めてみます。
QiitaAPIについて
QiitaAPIにアクセスしたらタグの記事の数とフォローしている人数を調べることができます。
例えばc++のタグ https://qiita.com/api/v2/tags/c++
QiitaAPIについて詳しくは https://qiita.com/api/v2/docs
このようなjsonデータが出ます
{"followers_count":24875,"icon_url":"https://s3-ap-northeast-1.amazonaws.com/qiita-tag-image/fe7df47710bdae8b8565b323841a6b89e2f66b89/medium.jpg?1515774066","id":"C++","items_count":5919}使うプログラミング言語
基本的にQiitaAPIのようなAPIは色んな言語で簡単に扱えるようですが、今回はrubyとpythonを使ってQiitaAPIを通じて色んなプログラミング言語のタグの記事とフォロワーの数を調べて纏めてみます。
最初は全部rubyでやってみたいと思っていたのですが、データの分析やグラフを描くことがやはりpythonのpandasとmatplotlibを使ったほうがずっと楽です。
なのでrubyでデータをcsvに保存して、pythonでグラフを描くという形になります。
ここで挙げるのは自分が知っている言語だけです。それ以外知らない言語もあるかもしれないです。その他に、私の知っている言語の中にも IDLなどqiitaで全然記事が見つからない言語もあります。
プログラミング言語だけ比べるので、htmlやxmlみたいなマークアップ言語や、cssみたいなスタイルシート言語などは含まれません。
rubyでタグのデータをcsvに保存する
rubyでは標準モジュールとしてopen-uriというスクレイピング用のモジュールがあるので、簡単にQiitaAPIからデータを取得できます。
csvの扱いも簡単にcsvモジュールが使えます。これも標準モジュールなので個別にインストールする必要がありません。
require "open-uri" require "json" require "csv" gengo = %w!c c++ csharp cobol clojure delphi elm erlang fortran golang haskell java javascript julia kotlin lisp lua objective-c pascal perl php prolog python r ruby rust scala swift typescript vb.net! col = %w!id items_count followers_count! CSV.open('qiitaprogramming.csv','w'){|csv| gengo.each{|gg| data = JSON.parse(open('https://qiita.com/api/v2/tags/'+gg).read) csv << col.map{|c|data[c]} } }こういうcsvファイルが出来ます。左の方が記事の数で、右の方がフォロワーの数です。
C,2632,21744 C++,5919,24875 C#,7427,23077 cobol,56,45 Clojure,619,550 Delphi,347,148 Elm,452,463 Erlang,524,446 Fortran,255,196 golang,2886,2025 Haskell,1904,9497 Java,12165,39527 JavaScript,26386,59733 Julia,570,620 Kotlin,2576,2243 lisp,267,358 Lua,452,320 Objective-C,3946,17766 Pascal,82,14 Perl,1469,12188 PHP,16169,37330 Prolog,207,96 Python,28671,55570 R,2727,1912 Ruby,21943,34065 Rust,1298,1527 Scala,2830,10363 Swift,11791,6603 TypeScript,3036,2325 VB.Net,359,322pythonでデータを並べて棒グラフを描く
pythonにもスクレイピング用のモジュールがたくさんあります。ここではrequestsというモジュールを使います。
データを数によって並べるにはpandasでは一番やりやすいです。
グラフを描くにはmatplotlibが一番です。
どれでも標準モジュールではないからインストールする必要がありますが、anacondaとか使っていたら最初から含まれているはずです。
pip install requests pandas matplotlibちなみに、rubyにもdaruというpandasと似ているモジュールが存在します。https://github.com/SciRuby/daru/wiki/pandas-vs-daru
import requests import matplotlib.pyplot as plt import pandas as pd lis_tagid = '''c c++ csharp cobol clojure delphi elm erlang fortran golang haskell java javascript julia kotlin lisp lua objective-c pascal perl php prolog python r ruby rust scala swift typescript vb.net '''.split() gengo = [] n_follow = [] n_item = [] for tagid in lis_tagid: r = requests.get('https://qiita.com/api/v2/tags/'+tagid) r.raise_for_status() data = r.json() gengo.append(data['id']) n_follow.append(data['followers_count']) n_item.append(data['items_count']) df = pd.DataFrame(index=gengo) df['記事'] = n_item df['フォロワー'] = n_follow print(df) y = range(len(df)) plt.figure(figsize=[6,6]) plt.gca(ylim=[min(y)-0.5,max(y)+0.5]) df.sort_values('フォロワー',inplace=True) plt.yticks(y,['%s: %6s'%x for x in df['フォロワー'].iteritems()]) plt.barh(y,df['フォロワー'],color='#882244') plt.title(u'フォロワㄧ',family='AppleGothic') plt.tight_layout() plt.figure(figsize=[6,6]) plt.gca(ylim=[min(y)-0.5,max(y)+0.5]) df.sort_values('記事',inplace=True) plt.yticks(y,['%s: %6s'%x for x in df['記事'].iteritems()]) plt.barh(y,df['記事'],color='#337744') plt.title(u'記事',family='AppleGothic') plt.tight_layout() plt.show()結果
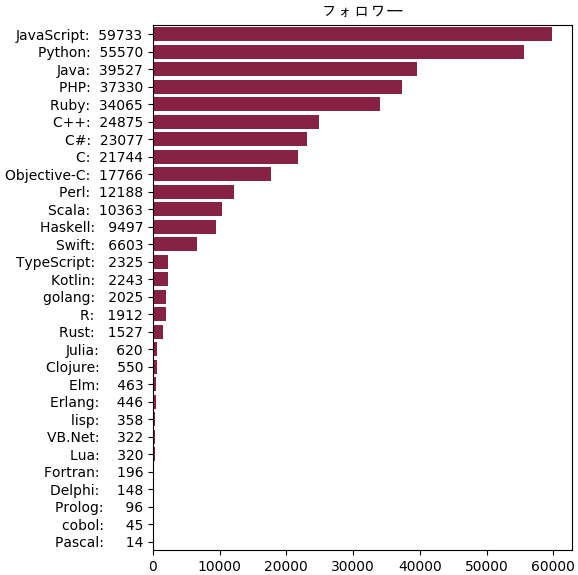
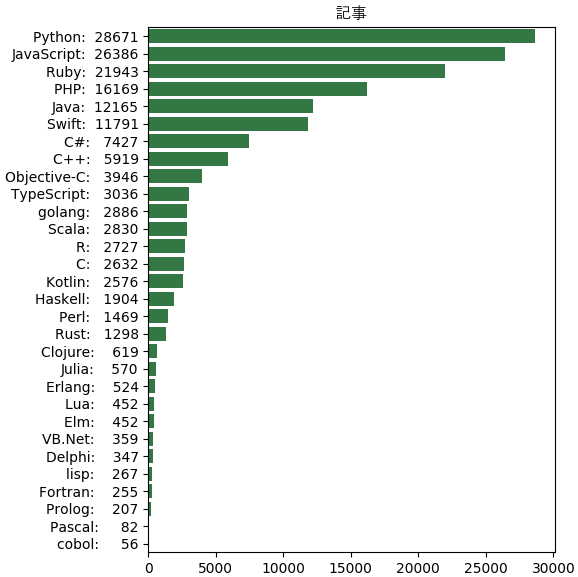
記事 フォロワー C 2632 21744 C++ 5919 24875 C# 7427 23077 cobol 56 45 Clojure 619 550 Delphi 347 148 Elm 452 463 Erlang 524 446 Fortran 255 196 golang 2886 2025 Haskell 1904 9497 Java 12165 39527 JavaScript 26386 59733 Julia 570 620 Kotlin 2576 2243 lisp 267 358 Lua 452 320 Objective-C 3946 17766 Pascal 82 14 Perl 1469 12188 PHP 16169 37330 Prolog 207 96 Python 28671 55570 R 2727 1912 Ruby 21943 34065 Rust 1298 1527 Scala 2830 10363 Swift 11791 6603 TypeScript 3036 2325 VB.Net 359 322
纏め
結果から見ると、フォロワーの数はjavascriptの方が一番ですが、記事の数はpythonの方が一番です。
javascriptはウェブ開発に欠かせない言語ですし、データサイエンスや機械学習のおかげでこの数年の間にpythonはどんどん人気な言語になってきたようです。
二年前のこの記事を調べてみたら https://qiita.com/ty-edelweiss/items/b8172c2e22726bc08aeb
あの時pythonの記事はrubyよりも少なかったようです。javaとphpとrubyもその次に人気のようです。
C言語などはフォロワーが多い割には記事が少ないです。
結果としてフォロワーと記事の数を見ると、この数年間のプログラミング言語の使う傾向をある程度示せるはずです。
編集: 2019年6月28日に、Rustを追加しました
- 投稿日:2019-06-27T22:34:45+09:00
Python bool() の中で何が起こっているか
組み込み関数の1つ、
bool()
引数として渡されたオブジェクトの真偽値を返却します。中で何が起こっているか確認する
オブジェクトの真偽値はどうやって決まるのでしょうか?
公式リファレンスによると
https://docs.python.org/ja/3/library/stdtypes.html#truthオブジェクトは、デフォルトでは真と判定されます。ただしそのクラスが
__bool__()メソッドを定義していて、それが False を返す場合、または__len__()メソッドを定義していて、それが 0 を返す場合は偽と判定されます。だそうです。試してみます。
# __bool__() __len__()を定義している場合 >>> class Class1: ... def __bool__(self): ... print('__bool__が呼ばれたよ') ... return False ... def __len__(self): ... print('__len__が呼ばれたよ') ... return 0 ... >>> hoge = Class1() >>> bool(hoge) __bool__が呼ばれたよ False # __bool__()が定義されていない場合 >>> class Class2: ... def __len__(self): ... print('__len__が呼ばれたよ') ... return 0 ... >>> piyo = Class2() >>> bool(piyo) __len__が呼ばれたよ False # __bool__()__len__()が定義されていない場合 >>> class Class3(): ... pass >>> fuga = Class3() # デフォルトどおり真が返る >>> bool(fuga) True応用してみる
組み込み型のクラスであれば
__bool__()か__len__()のどちらかは定義されています。
組み込み型を継承して自作クラスをつくる場合はこれらの特殊メソッドをオーバーライドできます。
例えば↓こんな感じ# 通常のリストの場合、要素が1つ以上あれば真になる >>> list = list([0]) >>> bool(list) True # 要素それぞれの真偽値判定をし、真になるものが1つ以上あれば真を返す >>> class MyList(list): ... def __bool__(self): ... return any(self) ... >>> my_list = MyList([0]) >>> bool(my_list) False
bool()の中で何が起こっているか理解していると、こういったアレンジができちゃいます。
(特殊メソッドをオーバーライドすると影響範囲が大きくなるので、やるときは慎重に!)
- 投稿日:2019-06-27T22:03:53+09:00
【後編】KaggleのKarnel上でtitanic問題を解いてみた ~モデル作成~
前回の続き。今回は実際に予測モデルの構築、kaggleへのサブミットまでを行う。
動作環境
・Kaggle kernel上
準備
ライブラリのインポート
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns import plotly.offline as py import plotly.graph_objs as go import cufflinks as cf py.init_notebook_mode(connected=True) # デフォルトでPlotlyがオンラインモードになっているので、オフラインモードへと変更 #cf.go_offline()# 恒久的にデフォルトをオフラインモードにデータセットの読み込み
train=pd.read_csv("../input/train.csv") test=pd.read_csv("../input/test.csv") data=[train,test]前処理
どう前処理するか
・欠損値を何らかの形で埋める
・不必要と思しきデータを排除する
・連続した数字データをカテゴライズ
(例えば、0~99までの数字を含むデータをそのまま扱うと100クラスに区別されたことになり、大雑把に多い、少ないを把握できない)
・文字データを数字におきかえる(分類器は数字しか受け付けない)
分類器につっこむ前に上記の処理が必要...具体的には....
欠損値を数えた結果、欠損しているのはAge, Cabin, Embarked。
●Cabinは891人中687人のデータが欠損しているので、あんまり使えなさそう
●Embarkedが欠損しているのは高々2名分なので、これはそれほど影響はなさそう。
●Name・・・生死には関係ないと思われる。ただし、Mr.やMrs.などの敬称は人物の属性を表すので関係あるかも。
●PassengerId・・・通し番号なので、関係が薄いと思われる。(断言はできないが)今回は排除。
●ticket・・・分類器には数字化したデータしか用いることができないことを考えると、規則性がわからない文字列に頼るのはあまり得策ではなさそう。使用する分類器
今回は、ランダムフォレストによって、予測モデルを構築する。
そのため、ゴールとしてはrandom forest classifierに突っ込むことだが、分類器は基本的には数字のデータにしておかなければいけない。
今回のデータセットの意味を考えると、氏名が生死に影響するとは考えにくい。
しかし、"Name"にはすべて、"Mr"や"Mrs"といった敬称が含まれており、これはその人の属性を表すものとして、結果に影響を与えそうである。(性別や年齢のセグメントで敬称が変わるため)
そこで、"Name"から全員分の敬称を抜き出すことを考える。敬称は多岐に渡るようであるから、いくつかのパターンに分類する。名前は敬称だけ抜き取る
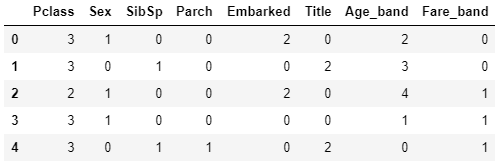
import re def get_title(name): title_search = re.search(' ([A-Za-z]+)\.', name) if title_search: return title_search.group(1) return "" #"Title"という列を作り、その中に全員分の敬称を収録する for df in [train,test]: df['Title'] = df['Name'].apply(get_title)train.info() #確認
train.Title
#trainに対して train.Title.value_counts()
#testに対して test.Title.value_counts()
#Mr, Miss, Others(その他)におきかえ for df in data: df['Title'] = df['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Others') df['Title'] = df['Title'].replace(["Mlle","Ms"],"Miss") df['Title'] = df['Title'].replace("Mme","Mrs")train.Title.value_counts() #改めて、どの敬称がいくつずつ含まれているのかを調べる
欠損値を埋める
train.isnull().sum() #改めてtrain、testそれぞれについて各列における欠損値の個数を確認
test.isnull().sum()
欠損しているのは
●trainについて・・・Embarked、Age、Cabinの3種類
●testについて・・・Fare、Age、Cabinの3種類まずはtrainのembarkedから埋めていく。
欠けているのは高々二人分なので、一番乗ってきた人が多い港で補完する。
train.Embarked.value_counts() #train.Embarkedの値とその個数を一覧にして表示する
train.Embarked=train.Embarked.fillna("S") #"S"が最も多かったので、欠損値に"S"を代入train.Embarked.value_counts() #確認する
Ageを補完する。(train,test両方)
一番荒っぽいが手っ取り早い方法は、 全ての年齢の欠損値を「年齢のデータが残っている乗客の平均年齢」で埋めてしまうことである。 しかし、これでは若干雑すぎるので「敬称ごとの平均で埋める」という方法を採用する。 敬称の区別は年齢の情報を含んだものであると考えられるため、有効だと思われる。
敬称別での年齢の平均をとって、欠損値を埋めよう。 for文を用いることで、train、test両方に対して一気に処理をしてしまおう。
for df in data: for title in train.Title.unique(): df.loc[(df.Age.isnull())&(df.Title==title),"Age"] = df.loc[df.Title==title,'Age'].mean() #unique()は重複しない値をリストにして返すpandasの関数#参考 df.loc[df.Title=='Mr','Age'].mean()
#参考unique関数 train.Title.unique()
testのFareが1箇所欠けているので、これを埋める
高々1箇所なので、testの他のFare列の中央値を入れてしまえば十分。
#testのFareを埋める test.Fare=test.Fare.fillna(test.Fare.median())残るはCabinの情報だが・・・
Cabinは欠損値の方が多いため、今回はCabinの情報は使えないものと判断し、あとで丸ごと削除することとする。
これでCabin以外の欠損値はすべて補完できたはずである。
念のため確認を行う。train.isnull().sum()
test.isnull().sum()
データのカテゴリ化
バラバラの値をとるデータをカテゴリ化する。
運賃の額(Fare)と、年齢(Age)のデータはそれぞれバラバラの値をとっているが、分類器にデータを投入することを考えると、これらのデータをカテゴリ化しておく必要がある。
分類器は数字のみ受け付けるため、カテゴリ名には数字を割り当てることとするが、分類器はfloat型(浮動小数)には対応しないため、必ずint型に整形しておく必要があることに注意。for df in data:#train,testともに適用 # "Age"を5クラスにわけ、"Age_band"列を新たに作り、クラスの値を代入 df.loc[ df['Age'] <= 22, 'Age_band'] = 0 df.loc[(df['Age'] > 22) & (df['Age'] <= 30), 'Age_band'] = 1 df.loc[(df['Age'] > 30) & (df['Age'] <= 37), 'Age_band'] = 2 df.loc[(df['Age'] > 37) & (df['Age'] <= 59), 'Age_band'] = 3 df.loc[ df['Age'] > 59, 'Age_band'] = 4 df.Age_band = df.Age_band.astype(int)''' for df in data: # "Fare"を4クラスにわけ、"Fare_band"列を新たに作り、クラスの値を代入 df.loc[ df['Fare'] <= 8, 'Fare_band'] = 0. df.loc[(df['Fare'] > 8) & (df['Fare'] <= 15), 'Fare_band'] = 1 df.loc[(df['Fare'] > 15) & (df['Fare'] <= 31), 'Fare_band'] = 2 df.loc[ df['Fare'] > 31, 'Fare_band'] = 3 df.Fare_band = df.Fare_band.astype(int) ''' #上の方法でもよいがここではqcutを用いた手法を用いる for df in data: df['Fare_band']=pd.qcut(df.Fare,4,labels=range(4))少し寄り道
新しい列Title,Age_band,Fare_bandを作ったことで
新たな切り口でデータを視覚化することが可能になった。
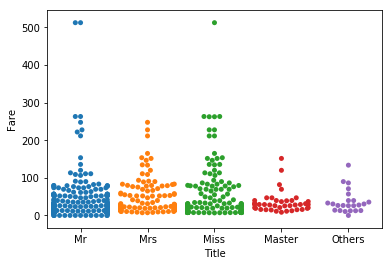
ここで、Title、Age_band、Fare_bandを切り口としていくつかグラフを作成する。敬称(Title)と支払った運賃(Fare)の関係を調べて視覚化してみよう。
sns.swarmplot("Title","Fare",data=train) #敬称(Title)と支払った運賃(Fare)の関係
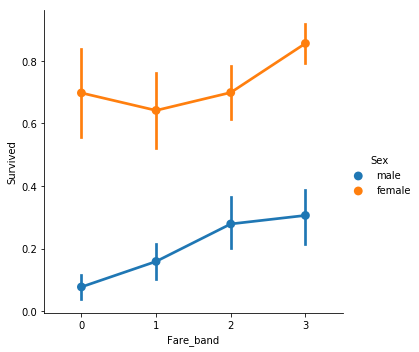
運賃のクラス(Fare_band)と性別(Sex)で生存率がどう変わるかを調べよう。
sns.factorplot("Fare_band","Survived",data=train,hue="Sex") #運賃のクラス(Fare_band)・性別(Sex)と生存率の関係
不要と思しきデータの削除
・PassengerId・・・形式が扱いにくい(クラス分類しにくい)上に、あまり生死と関係がなさそう
・Name・・・敬称を集めたTitle列を作ったので用済み
・Ticket・・・規則性が見出せず扱いに困る
・Cabin・・・欠損値が多すぎるので不採用
・Age・・・Age_bandを作ったので用済み
・Fare・・・Fare_bandを作ったので用済みdrop_columns = ['PassengerId', 'Name', 'Ticket', 'Cabin','Age','Fare'] # 上の6つのcolumn名をリストに。train.info()
train = train.drop(drop_columns, axis = 1) test = test.drop(drop_columns, axis = 1) ''' for df in data: df=df.drop(drop_columns,axis=1) '''データをすべて数字になおす
いま文字列の形で記述されているのは
・Sex列
・Title列
・Embarked列
である。いずれもカテゴリであるので、ラベルとして数字を割り当ててあげればよい。
(例) Mr:0, Miss:1, Mrs:2 ・・・などdata=[train,test]#for文でdropした場合には不要 for df in data: # 性別を数字でおきかえ df.loc[df['Sex']=="female", "Sex"]=0 df.loc[df['Sex']=='male','Sex']=1 # 敬称を数字で置き換え df.loc[df['Title']=='Mr', 'Title']=0 df.loc[df['Title']=='Miss', 'Title']=1 df.loc[df['Title']=='Mrs', 'Title']=2 df.loc[df['Title']=='Master', 'Title']=3 df.loc[df['Title']=='Others', 'Title']=4 # 乗船した港3種類を数字でおきかえ df.loc[df['Embarked']=='S', 'Embarked']=0 df.loc[df['Embarked']=='C', 'Embarked']=1 df.loc[df['Embarked']=='Q', 'Embarked']=2train #データの確認
データを分類器につっこむ
from sklearn.model_selection import train_test_splittrain.head()
test.head()
testのデータには答え("Survived")がついておらず、これを用いて学習器の良し悪しを確かめる術がないので、
trainの一部のデータを分類器の検証用に用いることとする。train→tr_train、tr_test に分割
(tr_trainデータ数):(tr_testのデータ数)=7:3
となるように指定する。tr_train,tr_test=train_test_split(train, test_size=0.3) #tr_train,tr_testに振り分けられるデータはランダムに決まるprint(tr_train.info()) print(tr_test.info())
tr_train_Xにはtr_trainの"Survived"列【以外】のデータを、
tr_train_Yにはtr_trainの"Survived"列のみを、
tr_test_Xにはtr_testの"Survived"列【以外】のデータを、
tr_test_Yにはtr_testの"Survived"列のみを納める。tr_train_X = tr_train[train.columns[1:]] tr_train_Y = tr_train[train.columns[0]] tr_test_X = tr_test[train.columns[1:]] tr_test_Y = tr_test[train.columns[0]]決定木(DecisionTreeClassifier)
決定木のモデルを設定。from sklearn.tree import DecisionTreeClassifier model=DecisionTreeClassifier()このモデルにtr_train_Xのデータを学習させ、tr_train_Yのデータを分類し判別率を算出
model.fit(tr_train_X,tr_train_Y) predict= model.predict(tr_test_X)判別率をsklearn.metricsを用いて見てみる
from sklearn import metrics print('判別率:',metrics.accuracy_score(predict, tr_test_Y))
ランダムフォレスト(RandomForestClassifier)
ランダムフォレストのモデルを設定。とりあえず、n_estimatorは100としておく。from sklearn.ensemble import RandomForestClassifier model=RandomForestClassifier(n_estimators=100)このモデルにtr_train_Xのデータを学習させ、tr_train_Yのデータを分類し判別率を算出
model.fit(tr_train_X,tr_train_Y) predict= model.predict(tr_test_X)判別率をsklearn.metricsで確認
from sklearn import metrics print('判別率:',metrics.accuracy_score(predict, tr_test_Y))
K-分割交差検証
from sklearn.model_selection import KFold, cross_val_score, cross_val_predict kf=KFold(n_splits=5, random_state=30, shuffle=True) x=train[train.columns[1:]] y=train["Survived"] cv_result = cross_val_score(model, x, y, cv = kf) print(cv_result) print("平均精度:{}".format(cv_result.mean()))
グリッドサーチ
ハイパーパラメータチューニングの最も基本的な手法
from sklearn.model_selection import GridSearchCV param={'n_estimators':range(100,1000,100),"max_depth":range(1, 10, 1)}#100から1000の100区切り GS_rf=GridSearchCV(estimator=RandomForestClassifier(random_state=0),param_grid=param,verbose=True,cv=5) GS_rf.fit(x,y) print(GS_rf.best_score_) print(GS_rf.best_estimator_)
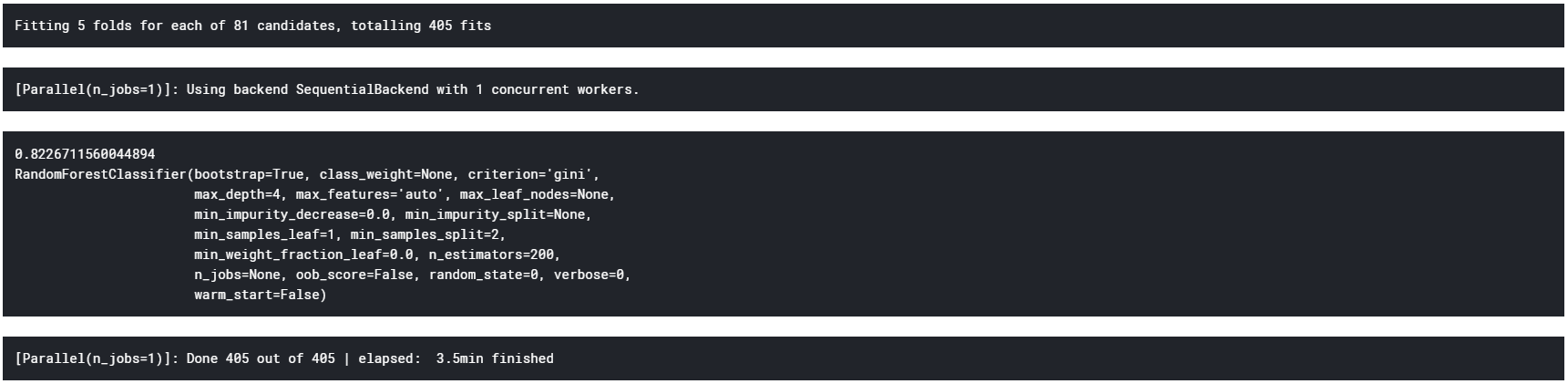
ランダムフォレストのパラメタチューニングの結果、試した条件の中では、
決定木の数:200
が最適で、このとき
精度:約81%
の分類器が得られることがわかった。補足:GridSearchCVはパラメタチューニングを行う際、引数cvをn(整数)と設定すれば
どのパラメタの組み合わせが「最適」であるかを求めるために、裏でデータをn分割して交差検証を行ってくれる。test
これまではtrainデータセットの一部を精度予測のテスト用に用いていたが、最後はtrainデータセット全てで学習を行う。
前準備として、
train_Xにはtrainの"Survived"列【以外】のデータを、
train_Yにはtrainの"Survived"列のみを、格納する。train_X=train[train.columns[1:]] train_Y=train[train.columns[0]]test用のデータセット(test.csv)をこのモデルに従って分類。
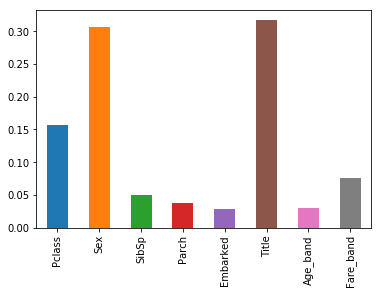
また、分類結果を提出する形式にまとめる(csv形式)model=RandomForestClassifier(max_depth=4, n_estimators=200) model.fit(train_X,train_Y)test_prediction = model.predict(test) passenger_id = np.arange(892,1310) test = pd.DataFrame( { 'PassengerId': passenger_id , 'Survived': test_prediction } ) test.shape test.head() test.to_csv( 'titanic_forsubmisson.csv' , index = False )pd.Series(model.feature_importances_, index=tr_train_X.columns).plot.bar()
test_prediction
# PassengerIdを取得 PassengerId = np.array(test["PassengerId"]).astype(int) # my_prediction(予測データ)とPassengerIdをデータフレームへ落とし込む my_solution = pd.DataFrame(test_prediction, PassengerId, columns = ["Survived"]) # my_tree_one.csvとして書き出し my_solution.to_csv("my_tree_one.csv", index_label = ["PassengerId"])最終結果
2019/6/27時点




















- 投稿日:2019-06-27T21:57:29+09:00
量子アルゴリズムの基本:算術演算の確認(加算)
$$
\def\bra#1{\mathinner{\left\langle{#1}\right|}}
\def\ket#1{\mathinner{\left|{#1}\right\rangle}}
\def\braket#1#2{\mathinner{\left\langle{#1}\middle|#2\right\rangle}}
$$はじめに
前々回の記事で「量子フーリエ変換」、前回の記事で「位相推定アルゴリズム」の確認ができたので、次は「Shorのアルゴリズム」と思っていたら、「べき剰余」も必要なのでした。で、べき剰余を実行するためには、いくつかの算術演算の基礎も必要ということなので、以後しばらくは、算術演算を順に確認していこうと思います。今回はもっとも簡単な「加算」です。アルゴリズムを説明した後、自作の量子計算シミュレータqlazyで、動作の確認をします。
参考にさせていただいた論文・記事は以下の通りです。
- V. Vedral,A. Barenco,A. Ekert; "Quantum Networks for Elementary Arithmetic Operations" (arXiv:quant-ph/9511018)
- 量子コンピュータ(シミュレータ)でモジュール化可能な加算器を作る
加算の実現方法
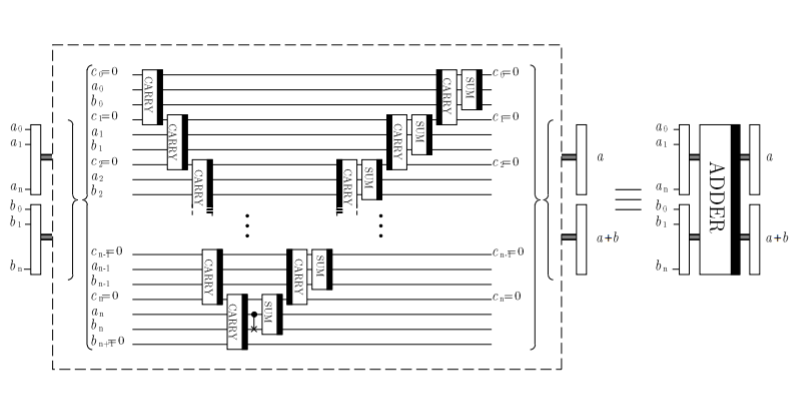
参考論文に全体の回路図が出ているので、まずそれを掲載します。
論文には、
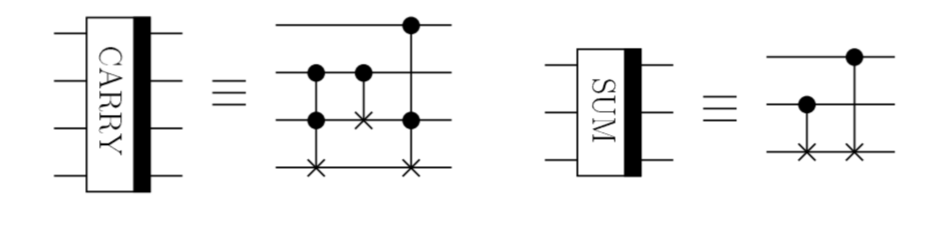
\ket{a,b} \rightarrow \ket{a,a+b}を計算する回路と説明されています。ここで、$a_0,a_1,...$と$b_0,b_1,...$は、整数$a,b$を2進数で表したときの各桁の値{0,1}を下の桁から順に並べた数列です。$c_0,c_1,...$は、各桁を加算したときに発生する桁上げ情報を格納するための補助量子ビットです。また、CARRYとSUMと書いてあるボックスは各々以下のような量子回路で定義されます。
これで本当に加算が実現できるのでしょうか。まずは各部品(CARRYとSUM)の動作から地道に見ていくことにします。
CARRYの動作
CARRYの量子レジスタは4つあり、1つのCNOTゲートと2つのToffoliゲートから構成されています。入力状態を上から$\ket{x},\ket{y},\ket{z},\ket{w}$としたとき、最初のToffoliゲート、CNOTゲート、2番目のToffoliゲートを通っていくに従い、どのように状態が変化するかを以下の表に示してみます。
初期状態 Toffoli[1] CNOT Toffoli[2] $x$ $x$ $x$ $x$ $y$ $y$ $y$ $y$ $z$ $z$ $y \oplus z$ $y \oplus z$ $w$ $(yz) \oplus w$ $(yz) \oplus w$ $(xy \oplus yz \oplus zx) \oplus w$ 最終的に$x,y$のレジスタは変化せず、$z$のレジスタには$y,z$の加算(ただしmod 2)が入り、一番下のレジスタは、
\ket{w} \rightarrow \ket{(xy \oplus yz \oplus zx) \oplus w}となることがわかります。ここで、$(xy \oplus yz \oplus zx)$は、$x,y,z$のどれか2つ以上が1をとるときに1になり、そうでない場合0になります。ということは、$x,y,z$を全部足した結果、桁上げがある場合、$\ket{1 \oplus w}$、桁上げがない場合$\ket{0 \oplus w}$となりますので、一番下のレジスタは桁上げを表していると言えそうです。
改めて全体の回路図を見てみてください。CARRYの入力レジスタの状態は$c_{i},a_{i},b_{i},c_{i+1}$となっていますので、$a$と$b$の$i$番目の桁を足して、さらに$i-1$番目までの桁から来る桁上げの値(0または1)を足したものが、$c_{i+1}$のレジスタに入ります。どうでしょう。加算の桁上げの役割を果たしているような気がしてきますよね。
後の議論のため、上の表の記号を$x,y,z,w$ではなく、$c_{i},a_{i},b_{i},c_{i+1}$に変えて記載しておきます。
初期状態 Toffoli[1] CNOT Toffoli[2] $c_{i}$ $c_{i}$ $c_{i}$ $c_{i}$ $a_{i}$ $a_{i}$ $a_{i}$ $a_{i}$ $b_{i}$ $b_{i}$ $a_{i} \oplus b_{i}$ $a_{i} \oplus b_{i}$ $c_{i+1}$ $(a_{i}b_{i}) \oplus c_{i+1}$ $(a_{i}b_{i}) \oplus c_{i+1}$ $c_{i+1}^{\prime}$ ここで、
c_{i+1}^{\prime} = (c_{i}a_{i} \oplus a_{i}b_{i} \oplus b_{i}c_{i}) \oplus c_{i+1}とおきました。つまり、$c_{i}^{\prime}$は下の桁からやってくる桁上げの値を表しています。
ついでに、CARRYの逆演算(以下i-CARRYと呼ぶことにします)も見てみましょう。上の表を逆から読むだけです。
初期状態 Toffoli[2] CNOT Toffoli[1] $c_{i}$ $c_{i}$ $c_{i}$ $c_{i}$ $a_{i}$ $a_{i}$ $a_{i}$ $a_{i}$ $a_{i} \oplus b_{i}$ $a_{i} \oplus b_{i}$ $b_{i}$ $b_{i}$ $c_{i}^{\prime}$ $(a_{i}b_{i}) \oplus c_{i+1}$ $(a_{i}b_{i}) \oplus c_{i+1}$ $c_{i+1}$ となります。
SUMの動作
SUMは簡単です。3つの量子レジスタに対する入力を$c_{i},a_{i},b_{i}$とすると、量子状態は以下のように変化します。
初期状態 CNOT[1] CNOT[2] $c_{i}$ $c_{i}$ $c_{i}$ $a_{i}$ $a_{i}$ $a_{i}$ $b_{i}$ $a_{i} \oplus b_{i}$ $a_{i} \oplus b_{i} \oplus c_{i}$ ということで、$b_{i}$のレジスタに下の桁の桁上げも含めた加算(ただしmod 2)の結果が入ることがわかります。つまり、SUMは各桁の加算を表しています。
1量子ビットの加算
部品の動作が確認できたところで、これを組み合わせて本当に$a+b$が実行できるかを、具体的に確認してみます。まずは1量子ビットの場合です。全体の回路図を参照すると、$a,b$各々の入力が1量子ビットの場合は、以下のような回路になります。
c0=0 ---|C||------|S||--- c0=0 a0 ---|A||--*---|U||--- a0 b0 ---|R||--CX--|M||--- b0 c1=0 ---|R||------------- b1各部品の動作を表す上の表を参照しながら、この回路での状態変化を表にすると、
初期状態 CARRY CNOT SUM $c_{0}=0$ $c_{0}=0$ $c_{0}=0$ $c_{0}=0$ $a_{0}$ $a_{0}$ $a_{0}$ $a_{0}$ $b_{0}$ $a_{0} \oplus b_{0}$ $b_{0}$ $a_{0} \oplus b_{0}$ $c_{1}=0$ $c_{1}^{\prime}$ $c_{1}^{\prime}$ $c_{1}^{\prime} = b_{1}$ となります。この最終状態でレジスタ($b_{0},b_{1}$)を観測すると、ちょうど$a+b$を実行した結果に等しくなることがわかると思います(ここで$b_{0}$は下位、$b_{1}$は上位ビットを表します。この加算回路では補助量子ビット$c$の最上位を$b$の最上位ビットと同一視するようにしています)。
2量子ビットの加算
次に、2量子ビットです。回路図は、以下の通りです。
c0=0 --|C||------------------||C|--|S||-- c0=0 a0 --|A||------------------||A|--|U||-- a0 b0 --|R||------------------||R|--|M||-- b0 c1=0 --|R||--|C||------|S||--||R|-------- c1=0 a1 --------|A||--*---|U||-------------- a1 b1 --------|R||--CX--|M||-------------- b1 c2=0 --------|R||------------------------ b2先程と同様に、状態変化を表にしてみます。
初期状態 1番目のCARRY 2番目のCARRY CNOT 1番目のSUM i-CARRY 2番目のSUM $c_{0}=0$ $c_{0}$ $c_{0}$ $c_{0}$ $c_{0}$ $c_{0}$ $c_{0}=0$ $a_{0}$ $a_{0}$ $a_{0}$ $a_{0}$ $a_{0}$ $a_{0}$ $a_{0}$ $b_{0}$ $a_{0} \oplus b_{0}$ $a_{0} \oplus b_{0}$ $a_{0} \oplus b_{0}$ $a_{0} \oplus b_{0}$ $b_{0}$ $a_{0} \oplus b_{0}$ $c_{1}=0$ $c_{1}^{\prime}$ $c_{1}^{\prime}$ $c_{1}^{\prime}$ $c_{1}^{\prime}$ $c_{1}$ $c_{1}=0$ $a_{1}$ $a_{1}$ $a_{1}$ $a_{1}$ $a_{1}$ $a_{1}$ $a_{1}$ $b_{1}$ $b_{1}$ $a_{1} \oplus b_{1}$ $b_{1}$ $c_{1}^{\prime} \oplus a_{1} \oplus b_{1}$ $c_{1}^{\prime} \oplus a_{1} \oplus b_{1}$ $c_{1}^{\prime} \oplus a_{1} \oplus b_{1}$ $c_{2}=0$ $c_{2}$ $c_{2}^{\prime}$ $c_{2}^{\prime}$ $c_{2}^{\prime}$ $c_{2}^{\prime}$ $c_{2}^{\prime}=b_{2}$ となります。この最終状態でレジスタ($b_{0},b_{1},b_{2}$)を観測すると、ちょうど$a+b$を実行した結果に等しくなることがわかります。
N量子ビットの加算
3量子ビット以上の場合は、上の議論を延長してちょっと考えてみれば、確かに足し算を実行していることがわかります(2進数の足し算を筆算でやることを頭の中でイメージしていただければ、わかりやすいと思います)。
シミュレータで動作確認
重ね合わせ無し
さて、それではシミュレータで、この加算の動作を確認してみます。まず、重ね合わせがない一つの純粋状態を入力した場合です。全体のPythonコードは以下の通りです。
from qlazypy import QState def sum(self,q0,q1,q2): self.cx(q1,q2).cx(q0,q2) return self def carry(self,q0,q1,q2,q3): self.ccx(q1,q2,q3).cx(q1,q2).ccx(q0,q2,q3) return self def i_carry(self,q0,q1,q2,q3): self.ccx(q0,q2,q3).cx(q1,q2).ccx(q1,q2,q3) return self def plain_adder(self,id_a,id_b,id_c): depth = len(id_a) for i in range(depth): self.carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.cx(id_a[depth-1],id_b[depth-1]) self.sum(id_c[depth-1],id_a[depth-1],id_b[depth-1]) for i in reversed(range(depth-1)): self.i_carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.sum(id_c[i],id_a[i],id_b[i]) return self def encode(self,decimal,id): for i in range(len(id)): if (decimal>>i)%2 == 1: self.x(id[i]) return self def decode(self,id): iid = id[::-1] return self.m(id=iid,shots=1).lst def create_register(digits): num = 0 id_a = [i for i in range(digits)] num += len(id_a) id_b = [i+num for i in range(digits+1)] num += len(id_b) id_c = [i+num for i in range(digits+1)] id_c[digits] = id_b[digits] # share the qubit id's num += (len(id_c)-1) return (num,id_a,id_b,id_c) if __name__ == '__main__': # add metthods QState.encode = encode QState.decode = decode QState.sum = sum QState.carry = carry QState.i_carry = i_carry QState.plain_adder = plain_adder # create registers digits = 4 num,id_a,id_b,id_c = create_register(digits) # set input numbers a_list = [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15] b = 12 for a in a_list: # initialize quantum state qs = QState(num) qs.encode(a,id_a) qs.encode(b,id_b) # execute plain adder qs.plain_adder(id_a,id_b,id_c) res = qs.decode(id_b) print("{0:}+{1:} -> {2:}".format(a,b,res)) qs.free()何をやっているか簡単に説明します。
def sum(self,q0,q1,q2): self.cx(q1,q2).cx(q0,q2) return self def carry(self,q0,q1,q2,q3): self.ccx(q1,q2,q3).cx(q1,q2).ccx(q0,q2,q3) return self def i_carry(self,q0,q1,q2,q3): self.ccx(q0,q2,q3).cx(q1,q2).ccx(q1,q2,q3) return selfで、上で説明したCARRY,i-CARRY,SUMの動作を関数として定義しています。QStateクラスのメソッドとして動的追加することを想定し、第1引数をselfにしています。
def plain_adder(self,id_a,id_b,id_c): depth = len(id_a) for i in range(depth): self.carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.cx(id_a[depth-1],id_b[depth-1]) self.sum(id_c[depth-1],id_a[depth-1],id_b[depth-1]) for i in reversed(range(depth-1)): self.i_carry(id_c[i],id_a[i],id_b[i],id_c[i+1]) self.sum(id_c[i],id_a[i],id_b[i]) return selfで、それら部品関数を組み合わせた加算器をplain_adder関数として定義しています。これも、QStateクラスのメソッドとして動的追加するため、第1引数はselfです。第2引数以降のid_a,id_b,id_cはそれぞれa,b,cに対応した量子レジスタ番号のリストを表しています(量子レジスタの生成は別の関数create_registerで行います)。関数内部の処理は、上で説明した回路図そのものです。
def encode(self,decimal,id): for i in range(len(id)): if (decimal>>i)%2 == 1: self.x(id[i]) return selfは、入力量子ビットを設定する関数です。decimalという10進整数を、量子レジスタidに設定します(つまり、量子レジスタidを$\ket{desimal}$という状態にします)。関数内部では、decimalを2進数に直してビットが立っている桁に相当する量子レジスタのビットをXゲートで反転しています。
def decode(self,id): iid = id[::-1] return self.m(id=iid,shots=1).lstは、encodeと逆に最終状態の量子レジスタidを観測して得られた{0,1}系列から10進整数を構成してリターンします。idに相当する量子ビットだけを1回観測し、lstプロパティによってその結果(10進整数)を得ています。
def create_register(digits): num = 0 id_a = [i for i in range(digits)] num += len(id_a) id_b = [i+num for i in range(digits+1)] num += len(id_b) id_c = [i+num for i in range(digits+1)] id_c[digits] = id_b[digits] # share the qubit id's num += (len(id_c)-1) return (num,id_a,id_b,id_c)は、今回の量子レジスタの配置を決めてそのリストおよび全体で必要となる量子ビット数をリターンする関数です。digitsは入力として想定するビット数です。
一連の関数が定義できたところで、プログラムのmain部を見ていきます。まず、
QState.encode = encode QState.decode = decode QState.sum = sum QState.carry = carry QState.i_carry = i_carry QState.plain_adder = plain_adderで、上で定義した関数を、QStateクラスのメソッドとして追加しています。
digits = 4 num,id_a,id_b,id_c = create_register(digits)で、量子レジスタを決定して変数num,id_a,id_b,id_cに格納しています。量子計算(加算)の実体部分は以下です。
# set input numbers a_list = [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15] b = 12 for a in a_list: # initialize quantum state qs = QState(num) qs.encode(a,id_a) qs.encode(b,id_b) # execute plain adder qs.plain_adder(id_a,id_b,id_c) res = qs.decode(id_b) print("{0:}+{1:} -> {2:}".format(a,b,res)) qs.free()量子ビット数はdigit=4と設定してあるので、4ビット同士の加算を実行します。ここでは、aの値を0から15まで変化させながら、固定値b=12との足し算結果を表示します。
実行結果を以下に示します。
0+12 -> 12 1+12 -> 13 2+12 -> 14 3+12 -> 15 4+12 -> 16 5+12 -> 17 6+12 -> 18 7+12 -> 19 8+12 -> 20 9+12 -> 21 10+12 -> 22 11+12 -> 23 12+12 -> 24 13+12 -> 25 14+12 -> 26 15+12 -> 27というわけで、正しく計算できることがわかりました。
重ね合わせ有り
さて、上に示したように逐次実行するのは、実は、あまり賢いやり方ではありません。量子計算では、入力値を量子重ね合わせとして用意しておけば、逐次的にぐるぐるforループを回さなくても、多数の入力値を一気に計算することができます。というわけで、やってみます。
まず、先程のencode関数の代わりに、
def superposition(self,id): for i in range(len(id)): self.h(id[i]) return selfという、入力状態を重ね合わせとして用意する関数superpositionを定義します。内部では引数として指定した量子レジスタのすべてに対してアダマールをかけています。入力が重ね合わせなので、出力も重ね合わせになります。そこから結果を引き出す関数も必要になるので、以下のように定義します。
def result(self,id_a,id_b): # measurement id_ab = id_a + id_b iid_ab = id_ab[::-1] freq = self.m(id=iid_ab).frq # set results a_list = [] r_list = [] for i in range(len(freq)): if freq[i] > 0: a_list.append(i%(2**len(id_a))) r_list.append(i>>len(id_a)) return (a_list,r_list)プログラムのmain部は以下のようになります。「重ね合わせなし」の場合との違いに注目してください。forループがないですよね。先程は15回、量子状態を初期化して量子計算をぐるぐると実行しましたが、今回は1回しか実行していません。
if __name__ == '__main__': # add methods QState.encode = encode QState.decode = decode QState.sum = sum QState.carry = carry QState.i_carry = i_carry QState.plain_adder = plain_adder # add methods (for superposition) QState.superposition = superposition QState.result = result # create registers digits = 4 num,id_a,id_b,id_c = create_register(digits) # set input numbers b = 12 # initialize quantum state qs = QState(num) qs.superposition(id_a) # set superposition of |0>,|1>,..,|15> for |a> qs.encode(b,id_b) # execute plain adder qs.plain_adder(id_a,id_b,id_c) a_list,r_list = qs.result(id_a,id_b) for i in range(len(a_list)): print("{0:}+{1:} -> {2:}".format(a_list[i],b,r_list[i])) qs.free()結果は以下の通りです。
0+12 -> 12 1+12 -> 13 2+12 -> 14 3+12 -> 15 4+12 -> 16 5+12 -> 17 6+12 -> 18 7+12 -> 19 8+12 -> 20 9+12 -> 21 10+12 -> 22 11+12 -> 23 12+12 -> 24 13+12 -> 25 14+12 -> 26 15+12 -> 27というわけで、4ビットのaの値すべてに対して一気に加算が実行できました。めでたしめでたし、と言いたいところですが、注意しておきたいことが一つあります。一気に結果が表示できるように見せかけていますが、これはシミュレータだからできることでありまして、実際の量子コンピュータでは、こんなことはできません。最終的な量子状態に対して測定をしたらば、基本一つの結果しか得られません。例えば"5+12->17"でした、という結果です。すべての加算結果を得るためには、やはり何度も何度も入力状態を用意して測定する必要があります。「なーんだ、量子コンピュータ、速くないじゃん」と思われるかもしれませんが、この例の場合は、確かにその通りかもしれません。
実際の量子計算では、求めたい結果に相当する状態の確率がなるべく高くなるように量子回路を構成し最後に測定することで、何度も計算実行しなくても、欲しい結果を効率よく得られるようにしています。量子アルゴリズムがこれまでにいろいろと提案されていますが、ざっくり言うと、要はそういうことをやっているわけです。
おわりに
今回、算術演算の中でもっとも簡単な「加算」の動作を確認しました。「Shorのアルゴリズム」で必要になる「べき剰余」に至るまで、あと何ステップかありますが、参考論文に従い、以後、順に確認していこうと思います。具体的には「剰余加算」→「制御剰余乗算」→「べき剰余」を予定しています。果たして最終ゴールまでたどり着けるかどうか...。ちょっとドキドキしてきましたが、何とか(できるところまでかもしれませんが)頑張ってみたいと思います。
以上
- 投稿日:2019-06-27T21:21:01+09:00
「魚の名前で小さな恋のうた」生成器作ってみた
「魚の名前で小さな恋のうた」生成器作ってみた
概略
Twitter 上で「魚の名前で小さな恋のうた」が話題になっていました.
これは面白い.本当に面白い.ということで作ってみました.
歌詞(日本語) を入れる入力すると,発音がそれっぽい魚の名前に変換してくれるスクリプトです.「小さな恋のうた」以外でも何でも変換できます.
結果
広い -> シロウ 宇宙の -> ウバウオ 数 -> アユ ある -> アユ ひとつ -> イトウ 青い -> サヨリ 地球の -> シラウオ 広い -> シロウ 世界で -> メカジキ 小さな -> チンアナゴ 恋の -> コイチ 思いは -> コモンハタ 届く -> ドジョウ 小さな -> チンアナゴ 島の -> シシャモ あなたの -> アカハナ もとへ -> オオセ完全版は下の方に乗せておきます.
構成
歌詞ファイル(.txt)から歌詞を分節に分解して,ローマ字化します.
似てる発音となる魚名は事前に用意した辞書ファイル(.csv)から探します.文節に分割した歌詞と魚の名前の,ローマ字のレーベンシュタイン距離が最小のものを探します.
それらをつなげて完成です.簡単.
def main(): # read lyrics if(len(sys.argv) <= 1): print("Specify a lyrics file") sys.exit(1) lyrics_file_name = sys.argv[1] lyrics_lines = [] with open(lyrics_file_name, "r") as f: lyrics_lines = f.readlines() # chunknize chunknized_lyrics = [] for lyrics_line in lyrics_lines: chunknized_lyrics += chunknize(lyrics_line) # map to romaji romaji_lyrics = [romajinize(chunk) for chunk in chunknized_lyrics] # search fish fishnized_lyrics = [fishnize(romaji_chunk) for romaji_chunk in romaji_lyrics] # print result for i in range(len(fishnized_lyrics)): print( "{} \t-> {} \t ".format(chunknized_lyrics[i], fishnized_lyrics[i]))魚の辞書の用意
まず,魚の名前の辞書を用意します.
こちらのサイトを参考にさせていただきました.
WEB 魚図鑑 和名一覧スクレイピングして魚名だけ取り出します.
こちらの際は単純に魚名だけではなく「アオダイ属未同定種」といったように
名前以外の種に関する記述が入っている場合があるのでそれは取り除きます.各魚名に関してローマ字変換したものも合わせて csv に保存しておきます.
#!/usr/bin/env python # -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from pykakasi import kakasi kakasi = kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') conv = kakasi.getConverter() URL = "https://zukan.com/fish/level5" res = requests.get(URL) soup = BeautifulSoup(res.text, 'html.parser') soup = soup.select( "#alphabetal_order a") with open('fish_name_list.csv', 'w') as f: f.write("name,romaji\n") # set header for s in soup: t = s.text t = t if t.find("属") == -1 else t[:t.find("属")] t = t if t.find("科") == -1 else t[:t.find("科")] t = t if t.find("群") == -1 else t[:t.find("群")] t = t if t.find("L") == -1 else t[:t.find("L")] t = t if t.find("太") == -1 else t[:t.find("太")] t = t if t.find("日") == -1 else t[:t.find("日")] t = t if t.find("」") == -1 else t[:t.find("」")] t = t if t.find("「") == -1 else t[t.find("「")+1:] if t != "": f.write(t + ","+conv.do(t)+"\n")歌詞の文節分割
CaboCha というものを用いました.
CaboCha/南瓜CaboCha はまともなドキュメントがなく大変でした.
感謝して読みました.
CaboCha/南瓜 Python Document (CaboCha.py)どうやら分節ごと区切れるけど,そのまま出力する機能はない?ようなので,
一つづつチャンク(文節)を読み込んでいって
token_size(含まれている単語の数)分だけ単語を読んで足します.chunk の先頭の場所を表すのに chunk.token_pos だったり,単語の文字自体を
出すのが token.surface だったりとよくわかりませんでした.なんとかやっつけました.for i in range(t.chunk_size()): chunk = "" token_pos = t.chunk(i).token_pos for j in range(t.chunk(i).token_size): chunk += t.token(token_pos+j).surface chunknized_string.append(chunk)全体的にはこんなふうになりました.
def chunknize(string): chunknized_string = [] c = CaboCha.Parser() t = c.parse(string) for i in range(t.chunk_size()): chunk = "" token_pos = t.chunk(i).token_pos for j in range(t.chunk(i).token_size): chunk += t.token(token_pos+j).surface chunknized_string.append(chunk) return chunknized_stringCaboCha はハマりポイントが 2 つあって
環境が /usr/local/lib にパスが通っていなかったため Not Found のエラーが出続けていました.
また,CaboCha の前に MeCab をインストールする際に辞書を UTF-8 でやっておかないと辞書関連でエラーが出ます.(詳しく覚えてなくてすみません.)適用部分はこのようになっています.
# read lyrics if(len(sys.argv) <= 1): print("Specify a lyrics file") sys.exit(1) lyrics_file_name = sys.argv[1] lyrics_lines = [] with open(lyrics_file_name, "r") as f: lyrics_lines = f.readlines() # chunknize chunknized_lyrics = [] for lyrics_line in lyrics_lines: chunknized_lyrics += chunknize(lyrics_line)lyrics_file を直接文節に区切るのではなく一度 readline()してから分節化したのには理由があります.
歌詞は文法に則った正確な日本語ではないため,自立語と付属語の区別に失敗し,上手にパースされないことがあります.
「小さな恋のうた」を例に上げると,ただ あなたにだけ届いて欲しい 響け恋の歌 ほら ほら ほら 響け恋の歌この部分の「ほら」が正確に解釈されなかったりしました.
一行ごと分節化することで「ほら」のみ分節化対象にできるのでこの問題が解決できます.文節のローマ字化
pykakasi というものを用います.
pip を使うとエラーが出るらしいので使わず自分でビルドしました.参考 漢字をローマ字に変換できる Python ライブラリ "pykakasi" を使ってみた。
kakasi = pykakasi.kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') conv = kakasi.getConverter()こんなものを定義しておいて次のように用意すれば良いです.
def romajinize(string): return conv.do(string)適用部分はこのようになっています.
# map to romaji romaji_lyrics = [romajinize(chunk) for chunk in chunknized_lyrics]検索
一番中核なところ.ローマ字の文節とローマ字の魚名のレーベンシュタイン距離をもとに
文節を魚名に変換します.レーベンシュタイン距離
レーベンシュタイン距離は名前だけすごそうですが,定義自体は難しくありません.
何文字変えればその文字になりますか?というものです.
小さいほどその文字は似ているということになります.詳しくはこちら
編集距離(レーベンシュタイン距離)を理解し、実装するLevenshtein というライブラリがあるので import して,
Levenshtein.distance(str1, str2)で,求めることができます.
今回のの実装では n_levenshtein_distance_with_threshold 関数内部で使用しています.
n(正規化した)_levenshtein_distance(レーベンシュタイン距離)_with_threshold(母音数の制限あり)
という実装にしました.
これは本当にいきあたりばったりで実装した部分で余分に複雑なので後ほど解説します.ともかく,ここで歌詞の文節と魚名の距離を算出しているというところが大切です.
変換部分
文節に対し,各魚のローマ字名との距離をリストに格納します.
その中で最小のものを取り出すようにしています.index()の挙動上,最短距離であるものが複数ある場合は,辞書内で一番若いものになります.
いちいち全部の魚名に対して距離を計算するのは遅くなってしまうので褒められた方法ではありません.おそらくこれが原因でとても遅いです.
ただ,冗長性とかもない気がするので難しいですが考え中です.実装はこのようになっています.
def fishnize(string): fish_table["distance"] = [] for romaji_fish_name in fish_table["romaji"]: fish_table["distance"].append( n_levenshtein_distance_with_threshold(romaji_fish_name, string)) index = fish_table["distance"].index(min(fish_table["distance"])) return fish_table["name"][index]適用部分はこのようになっています.
# search fish fishnized_lyrics = [fishnize(romaji_chunk) for romaji_chunk in romaji_lyrics]結果
あとは出力するだけです.
# print result for i in range(len(fishnized_lyrics)): print( "{} \t-> {} \t ".format(chunknized_lyrics[i], fishnized_lyrics[i]))
小さな恋の歌全体を変換するとこのようになります.
広い -> シロウ
宇宙の -> ウバウオ
数 -> アユ
ある -> アユ
ひとつ -> イトウ
青い -> サヨリ
地球の -> シラウオ
広い -> シロウ
世界で -> メカジキ
小さな -> チンアナゴ
恋の -> コイチ
思いは -> コモンハタ
届く -> ドジョウ
小さな -> チンアナゴ
島の -> シシャモ
あなたの -> アカハナ
もとへ -> オオセ
あなたと -> ハナタツ
出会い -> ヘダイ
時は -> トミヨ
流れる -> マガレイ
思いを -> ウメイロ
込めた -> コボラ
手紙も -> タマギンポ
増える -> ブリル
いつしか -> イシダイ
二人 -> ニタリ
互いに -> タラキヒ
響く -> チチブ
時に -> トウジン
激しく -> アメギス
時に -> トウジン
切なく -> セトダイ
響くは -> ヒシコバン
遠く -> ポラック
遥かかなたへ -> ホカケアナハゼ
やさしい -> ナガサギ
歌は -> ワタカ
世界を -> メカジキ
変える -> カツオ
ほら -> ヒラ
あなたにとって -> アカタナゴ
大事な -> ハシキンメ
人ほど -> カナド
すぐ -> スギ
そばに -> サバヒー
いるの -> キレンコ
ただ -> アラ
あなたにだけ -> アカタナゴ
届いて欲しい -> ソコイトヨリ
響け -> ヒラメ
恋の -> コイチ
歌 -> スマ
ほら -> ヒラ
ほら -> ヒラ
ほら -> ヒラ
響け -> ヒラメ
恋の -> コイチ
歌 -> スマ
あなたは -> アカタチ
気付く -> スズキ
二人は -> カワビシャ
歩く -> カラス
暗い -> キダイ
道でも -> ギチベラ
日々 -> ギギ
照らす -> カラス
月 -> ダツ
握りしめた -> キビレミシマ
手離す -> カワマス
こと -> コイ
なく -> アユ
思いは -> コモンハタ
強く -> ウツボ
永遠誓う -> キチヌ
永遠の -> キリンミノ
淵きっと -> ウシエイ
僕は -> コクレン
言う -> ギス
思い変わらず -> アメリカナマズ
同じ -> マアジ
言葉を -> コトヒキ
それでも -> オキエソ
足りず -> カラス
涙に -> ナミハタ
変わり -> カンダリ
喜びに -> モロコシハギ
なり -> アラ
言葉に -> コトヒキ
できず -> メギス
ただ -> アラ
抱きしめる -> アカヒメジ
ただ抱きしめる -> タカサゴヒメジ
ほら -> ヒラ
あなたにとって -> アカタナゴ
大事な -> ハシキンメ
人ほど -> カナド
すぐ -> スギ
そばに -> サバヒー
いるの -> キレンコ
ただ -> アラ
あなたにだけ -> アカタナゴ
届いて欲しい -> ソコイトヨリ
響け -> ヒラメ
恋の -> コイチ
歌 -> スマ
ほら -> ヒラ
ほら -> ヒラ
ほら -> ヒラ
響け -> ヒラメ
恋の -> コイチ
歌 -> スマ
夢ならば -> ユメカサゴ
覚めないで -> サメガレイ
夢ならば -> ユメカサゴ
覚めないで -> サメガレイ
あなたと -> ハナタツ
過ごした -> アゴハタ
時 -> コイ
永遠の -> キリンミノ
星と -> シシャモ
なる -> アユ
ほら -> ヒラ
あなたにとって -> アカタナゴ
大事な -> ハシキンメ
人ほど -> カナド
すぐ -> スギ
そばに -> サバヒー
いるの -> キレンコ
ただ -> アラ
あなたにだけ -> アカタナゴ
届いて欲しい -> ソコイトヨリ
響け -> ヒラメ
恋の -> コイチ
歌 -> スマ
ほら -> ヒラ
あなたにとって -> アカタナゴ
大事な -> ハシキンメ
人ほど -> カナド
すぐ -> スギ
そばに -> サバヒー
いるの -> キレンコ
ただ -> アラ
あなたにだけ -> アカタナゴ
届いて欲しい -> ソコイトヨリ
響け -> ヒラメ
恋の -> コイチ
歌 -> スマ
ほら -> ヒラ
ほら -> ヒラ
ほら -> ヒラ
響け -> ヒラメ
恋の -> コイチ
歌 -> スマ
いかがでしょうか?
コード全体は以下のようになりました.
もしかしたら GitHub 上のものは書き換えるかも,というか書き換えたい.
import sys import pandas as pd import CaboCha import pykakasi import Levenshtein import re def romajinize(string): return conv.do(string) def normalized_levenshtein_distance(str1, str2): max_len = max([len(str1), len(str2)]) return Levenshtein.distance(str1, str2)/max_len def count_vowels(string): n_vowel = 0 for vowel in ["a", "i", "u", "e", "o"]: n_vowel += len(re.findall(vowel, string)) return n_vowel def n_levenshtein_distance_with_threshold(str1, str2, threshold=0): n_str1_vowel = count_vowels(str1) n_str2_vowel = count_vowels(str2) return normalized_levenshtein_distance(str1, str2) if n_str2_vowel >= 5 or abs(n_str1_vowel - n_str2_vowel) <= threshold else 100 def fishnize(string): fish_table["distance"] = [] for romaji_fish_name in fish_table["romaji"]: fish_table["distance"].append( n_levenshtein_distance_with_threshold(romaji_fish_name, string)) index = fish_table["distance"].index(min(fish_table["distance"])) return fish_table["name"][index] def chunknize(string): chunknized_string = [] c = CaboCha.Parser() t = c.parse(string) for i in range(t.chunk_size()): chunk = "" token_pos = t.chunk(i).token_pos for j in range(t.chunk(i).token_size): chunk += t.token(token_pos+j).surface chunknized_string.append(chunk) return chunknized_string def main(): # read lyrics if(len(sys.argv) <= 1): print("Specify a lyrics file") sys.exit(1) lyrics_file_name = sys.argv[1] lyrics_lines = [] with open(lyrics_file_name, "r") as f: lyrics_lines = f.readlines() # chunknize chunknized_lyrics = [] for lyrics_line in lyrics_lines: chunknized_lyrics += chunknize(lyrics_line) # map to romaji romaji_lyrics = [romajinize(chunk) for chunk in chunknized_lyrics] # search fish fishnized_lyrics = [fishnize(romaji_chunk) for romaji_chunk in romaji_lyrics] # print result for i in range(len(fishnized_lyrics)): print( "{} \t-> {} \t ".format(chunknized_lyrics[i], fishnized_lyrics[i])) conv = None fish_table = None if __name__ == "__main__": kakasi = pykakasi.kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') conv = kakasi.getConverter() fish_table = {"name": [], "romaji": []} with open("fish_name_list.csv", "r") as f: for line in f.readlines()[1:]: # skip the headr line values = line.split(",") fish_table["name"].append(values[0]) fish_table["romaji"].append(values[1][:-1]) # remove \n main()hoge.py とかで保存して
$python hoge.py lyrics.txtってすればどんな歌詞でも変換できます.ぜひ試してみてください.
改善点
改善点もやっぱりあります.
「恋の歌」はひとかたまりとして扱いたいですが,文節として区切ってしまうと別れてしまうので,まとめて扱うものを指定する機能とかあったらいいですね,
歌詞は記号とかを現段階では想定してないので対応したい.
レーベンシュタイン距離よりもよい距離を見つける.
上 2 つはできそうですが 3 つ目は難しいです.
レーベンシュタイン距離よりもよい距離を見つける.
ほら -> ヒラ
友人「ボラじゃないじゃん」
僕「...はい」確かに,「ヒラ」よりも「ボラ」のほうがチカイ気がします.
レーベンシュタイン距離というのはそもそも何文字編集すればいいか,という数
なので音声ではなくテキストベースの距離だと言えます.
音声的にチカイ単語を検索したい今回では最適とは言い難いです.英語では Soundex や Metaphone といったスペルから発音に変換する
アルゴリズムが存在しますが,
ざっと探した限りでは日本語ではそれに当たるものが見当たりませんでした.
- IPA
基本的にはこちらの論文を参考にしました.ほぼ読んでいないですが,国際発音記号の IPA の
レーベンシュタイン距離を計測して空耳を作成していました.しかし,日本語を IPA に変換するツールでポピュラーなものはなさそうなのでこの手法は採用しませんでした.
- カタカナ
そもそもカタカナは表音文字であることを思い出し,レーベンシュタイン距離出やりました.
とてもじゃないですが載せられないくらい制度が悪かったです.
文節は文字数が少ないです.4 文字の場合一文字変えるだけで 25%違う単語になります.
候補が大量に出て,トオイ文字に変換されてしまいました.
(結果残しておけばよかった)
- ローマ字
文字数が少ないことが問題になったので文字数を増やしつつ,発音を表せるローマ字を選択.
割と改善しました.(結果残しておけばよかった)
しかしながら,似てはいるものの次は日本語にした時の文字数が合わなかったりしました.
歌なので文字数が増えてしまうと歌いにくいです.
- 標準化レーベンシュタイン距離
4 文字中の 1 文字変更は影響が大きいですが,10 文字中の 1 文字変更は影響が小さいです.
標準化レーベンシュタイン距離はどのくらいの割合変更すると一方の文字になれるかを表していると言えます.標準化レーベンシュタイン距離は値の範囲が 0~1 になるので候補の数が減らせるのではないかと期待して導入しました.
https://qiita.com/Ishio/items/d52b9221c92bd4ebb344
こんなふうに実装できます.
def normalized_levenshtein_distance(str1, str2): max_len = max([len(str1), len(str2)]) return Levenshtein.distance(str1, str2)/max_len候補 1 と候補 2 の文字数とレーベンシュタイン距離距離が同じ場合,複数の候補になってしまいます.
- 母音の数を考慮に入れてローマ字
現在のスタイルです.歌いづらいのは音節の数が揃っていないからなので,
両者の母音の数が等しいまたは近いもののみ候補に入れて距離を計算します.文字数が多い場合はちょっとくらいずれていても問題ないので母音が 5 個以上ある場合は
母音数を考慮して距離計算していません.逆に言えば母音数 4 個以下(カタカナで 4 文字以下くらい)の歌詞は必ず母音数が一致します.
割と良かったです.
実装はこのようになりました.
def count_vowels(string): n_vowel = 0 for vowel in ["a", "i", "u", "e", "o"]: n_vowel += len(re.findall(vowel, string)) return n_vowel def n_levenshtein_distance_with_threshold(str1, str2, threshold=0): n_str1_vowel = count_vowels(str1) n_str2_vowel = count_vowels(str2) return normalized_levenshtein_distance(str1, str2) if n_str2_vowel >= 5 or abs(n_str1_vowel - n_str2_vowel) <= threshold else 100いい距離の条件
- 音声ベースの計測方法であること.
レーベンシュタイン距離はテキストベースなので変更したいですが,そんなものが存在するのか知らないので
教えください.
- 複数候補が出ることがない
標準化レーベンシュタイン距離は実数なのでバラけることを期待しましたが,
全体的に文字数が似ているので距離が一致してしまうものもありました.
「ヒラ」と「ボラ」などもっとバラける実数値だと良いんだと思います.
- かぶって変換しない
異なる単語に対しては異なる魚名に変換して欲しいです.
歌詞のリズムが崩れてしまいます.数 -> アユ
ある -> アユ見つかったらいいな.
感想
なんか改善点長いですね.
GitHub にあげておいたので改良するかも.
SingFishでも,できました.意外と楽しくできてよかったです.
届いて欲しい -> ソコイトヨリ
なんて結構お気に入りです.ちょうどよい無理矢理感です.
- 投稿日:2019-06-27T18:54:26+09:00
【Airflow on Kubernetes】DockerイメージのbuildとPodのdeployの仕組みについて
概要
Airflowでは、Kubernetes用のDockerイメージの作成スクリプトと、Podのdeploy用のスクリプトが用意されている。
GitHUB: https://github.com/apache/airflowこれらのスクリプトが実際にどのような処理を行っているのかを調べた。
関連記事
おおまかな処理の流れ
処理の流れを大きく分けると、以下の2つに分けられる。
- Dockerイメージをbuildする
- Podをdeployをする
以降で、それぞれの詳細な処理について追っていく。
Dockerイメージをbuildする
Dockerイメージをbuildするための、build.shの処理内容を追う。
実際に実行させる場合は、以下の様にする。
$ sudo ./scripts/ci/kubernetes/docker/build.shbuild.shを実行してairflowのDockerイメージを作成する
build.sh#L46でcompile.shが実行される。
scripts/ci/kubernetes/docker/build.sh#L46docker run -it --rm -v ${AIRFLOW_ROOT}:/airflow \ -w /airflow ${PYTHON_DOCKER_IMAGE} ./scripts/ci/kubernetes/docker/compile.shbuild.shの中でcompile.shが実行される
compile.sh#L32でsetup.pyが実行されると、ホストOSに
~/airflow/dist/というディレクトリが生成され、その下にapache-airflow-2.0.0.dev0.tar.gzというファイルが生成される。
これが、airflowのソースコードとなるものである。scripts/ci/kubernetes/docker/compile.sh#L32# apache-airflow-2.0.0.dev0.tar.gzが生成される python setup.py compile_assets sdist -qcompile.shでairflowのtarファイルが作成されると、build.sh#L51で、先程生成された
apache-airflow-2.0.0.dev0.tar.gzが、scripts/ci/kubernetes/docker/airflow.tar.gzにリネームしてコピーされる。scripts/ci/kubernetes/docker/build.sh#L51cp $AIRFLOW_ROOT/dist/*.tar.gz ${DIRNAME}/airflow.tar.gzbuild.shの中でairflowのDockerイメージをbuildする
build.sh#L52で、
docker buildが実行される。build.sh#L52cd $DIRNAME && docker build --pull $DIRNAME --tag=${IMAGE}:${TAG}このときに、このDockerfileが読み込まれる。
Dockerfileの処理
Dockerfile#L43で、先程生成されたホストOSの
scripts/ci/kubernetes/docker/airflow.tar.gzがコンテナ内にCOPYされる。Dockerfile#L43# コンテナ内にCOPY COPY airflow.tar.gz /tmp/airflow.tar.gzDockerfileの中でairflow-test-env-init.shが実行される
次にDockerfile#L46で、airflow-test-env-init.shが実行される。
Dockerfile#L46COPY airflow-test-env-init.sh /tmp/airflow-test-env-init.shすると、airflow-test-env-init.sh#L23で、コンテナ内の
/usr/local/lib/python3.6/site-packages/airflow/example_dags/を、PersistentVolumeのmount先である/root/airflow/dags/にコピーする。airflow-test-env-init.sh#L23# example_dags/とcontrib/example_dags/をPersistentVolumeにコピー cd /usr/local/lib/python3.6/site-packages/airflow && \ cp -R example_dags/* /root/airflow/dags/ && \ cp -R contrib/example_dags/example_kubernetes_*.py /root/airflow/dags/ && \ cp -a contrib/example_dags/libs /root/airflow/dags/ && \build.shの処理はこれで完了。
Deploy
Podをdeployするための、deploy.shの処理内容を追う。
実際に実行させる場合は、以下の様にする。
-dオプションで、dags_folderの追加方法をpersistent_modeかgit_modeのどちらかから選ぶ。usage: ./scripts/ci/kubernetes/kube/deploy.sh options OPTIONS: -d Use PersistentVolume or GitSync for dags_folder. Available options are "persistent_mode" or "git_mode"実行
$ sudo ./scripts/ci/kubernetes/kube/deploy.sh -d {persistent_mode,git_mode}deploy.shを実行
deploy.shを実行して、Podをdeployする。
実行されると、scripts/ci/kubernetes/kube/templates以下のmanifestのテンプレートファイルの必要箇所が置換されて、
scripts/ci/kubernetes/kube/buildの下に生成される。
生成されたmanifestファイルを使ってkubectl applyが実行される。$ ls -1 scripts/ci/kubernetes/kube/templates/ airflow.template.yaml configmaps.template.yaml init_git_sync.template.yamlInitContainer
ci/kubernetes/kube/templates/airflow.template.yamlを元にして生成された、scripts/ci/kubernetes/kube/build/airflow.yamlをapplyすると、airflow.yaml#L69で定義されているInitContainerが実行され、deployの際にInitContainerでもairflow-test-env-init.shが実行される。
ここで、コンテナ内の
/usr/local/lib/python3.6/site-packages/airflow/example_dags/が、PodのPersistentVolumeのmount先である/root/airflow/dags/にコピーされる。airflow.template.yaml#一部抜粋spec: initContainers: - name: "init" image: {{AIRFLOW_IMAGE}}:{{AIRFLOW_TAG}} imagePullPolicy: IfNotPresent volumeMounts: - name: airflow-configmap mountPath: /root/airflow/airflow.cfg subPath: airflow.cfg - name: {{INIT_DAGS_VOLUME_NAME}} mountPath: /root/airflow/dags - name: test-volume mountPath: /root/test_volume env: - name: SQL_ALCHEMY_CONN valueFrom: secretKeyRef: name: airflow-secrets key: sql_alchemy_conn command: - "bash" args: - "-cx" - "./tmp/airflow-test-env-init.sh"deploy.shの処理はこれで完了。
dagsの確認
Pod内を確認。/root/airflow/dags/だけでなく、/usr/local/lib/python3.6/site-packages/airflow/example_dags/にもファイルがあることがわかる。
Pod内に入って確認してみる。
$ sudo kubectl exec -it airflow-xxxxxxxxxx-xxxxx /bin/bashPod内の/usr/local/lib/python3.6/site-packages/airflow/example_dags/を確認。
root@airflow-xxxxxxxxxx-xxxxx:/# ls -1 /usr/local/lib/python3.6/site-packages/airflow/example_dags/ __init__.py __pycache__ docker_copy_data.py example_bash_operator.py example_branch_operator.py example_branch_python_dop_operator_3.py example_docker_operator.py example_http_operator.py example_latest_only.py example_latest_only_with_trigger.py example_passing_params_via_test_command.py example_pig_operator.py example_python_operator.py example_short_circuit_operator.py example_skip_dag.py example_subdag_operator.py example_trigger_controller_dag.py example_trigger_target_dag.py example_xcom.py subdags test_utils.py tutorial.pyPod内の/root/airflow/dags/以下を確認。
root@airflow-xxxxxxxxxx-xxxxx:/# ls -1 /root/airflow/dags/ __init__.py __pycache__ docker_copy_data.py example_bash_operator.py example_branch_operator.py example_branch_python_dop_operator_3.py example_docker_operator.py example_http_operator.py example_kubernetes_executor.py example_kubernetes_executor_config.py example_kubernetes_operator.py example_latest_only.py example_latest_only_with_trigger.py example_passing_params_via_test_command.py example_pig_operator.py example_python_operator.py example_short_circuit_operator.py example_skip_dag.py example_subdag_operator.py example_trigger_controller_dag.py example_trigger_target_dag.py example_xcom.py libs subdags test_utils.py tutorial.pyどちらにもdagファイルがあるが、/root/airflow/dags/のほうがファイルが多い。
これはairflow-test-env-init.shを見ると分かるが、example_dags/だけでなく、contrib/example_dags/以下のファイルもコピーされているためである。airflow-test-env-init.sh#L23cp -R example_dags/* /root/airflow/dags/ && \ cp -R contrib/example_dags/example_kubernetes_*.py /root/airflow/dags/ && \ cp -a contrib/example_dags/libs /root/airflow/dags/ && \Hackする
同期されるdagファイルを変更する場合
airflow-test-env-init.sh#L23
の以下の箇所を変更することで、同期されるdagファイルを変更することができる。airflow-test-env-init.sh#L23cp -R example_dags/* /root/airflow/dags/ && \ cp -R contrib/example_dags/example_kubernetes_*.py /root/airflow/dags/ && \ cp -a contrib/example_dags/libs /root/airflow/dags/ && \PersistentVolumeのmount先を変更する方法
以下2つのvolumeの定義を変更する。
- airflowのファイル群のmount先
- scripts/ci/kubernetes/kube/volumes.yaml
- postgresのデータのmount先
- scripts/ci/kubernetes/kube/postgres.yaml
参考
- 投稿日:2019-06-27T17:46:33+09:00
[Heroku]Django WEB App デプロイ(完)2019/6(下書き)
Django製アプリを「Heroku」へのデプロイ
はじめに
この記事を見てくださっている方はいくつものサイトを見ては、エラーを繰り返している方も多いと思います。
僕はデプロイに丸一日を要しました。他サイトを見ながら試行錯誤してやっとデプロイできましたが、なんせ、拡張子なしのファイル(後で出てきます)の作り方すら知らなかった僕にとっては、もう少し詳しく教えて欲しい!というところも多かったです。
もちろん、記事を書いてくださる方には感謝していますし、この記事よりも専門的な知識は多く得られます。
ですので、この記事では細かな説明もしつこいくらいに入れていきながら解説したいと思います。
読んでくださる方が多くても数時間でデプロイできるようにしたいと思います。(一回もエラーが出ないなら、30分もかかりません。)前提条件(対象者)
- データベース(MySQL, phpMyAdmin)を用いたアプリ
- ローカルホストではきちんと動作するアプリが完成している
- Herokuのアカウントを持っている(無料)
- GitHub, git のコマンドを使える(僕のように調べながらでも使えればいいと思います)
開発環境
Mac OS python 3.7.3 dj-database-url 0.5.0 #後でインストールします Django 2.1 django-bootstrap4 0.0.8 gunicorn 19.9.0 #後でインストールします pip 19.1.1 psycopg2-binary 2.8.3 #後でインストールします PyMySQL 0.9.3 pytz 2019.1 #後でインストールします setuptools 41.0.1 sqlparse 0.3.0 whitenoise 3.3.1 #後でインストールします #「後でインストール」以外のものは、必要かはわかりません。 #ローカルで動いているのなら、この[pip list]はそんなに気にすることもないと思います。最終的なファイル構成
どこのファイルかわからない(説明不足)時は、この画像で判断してください。
紫色の線のファイルはこの後追加します。他のファイルはみなさんあると思います。(場合によって、staticファイルとかはないかも)
必要なものをインストールする
下記のように、必要なものをインストールしてください。
※注意(下の文を必ず読んでください)
「whitenoise」はバージョン3を指定してください。指定しないと4がインストールされ、この記事の方法だとうまくいきません。
また、「psycopg2」のインストールができない場合は「pip install psycopg2-binary」をインストールしてください。
pip install gunicorn django-herokuで下記のものを一括インストールできるらしいが、僕はできませんでした。
試してみるのもありかもしれないです。terminal(dj)$ pip install dj-database-url (dj)$ pip install gunicorn (dj)$ pip install whitenoise==3.3.1 ?バージョンを指定しないと whitenoise4.x.x がインストールされる (dj)$ pip install psycopg2 ?エラーが出る可能性あり (dj)$ pip install pytzファイルを追加する
Herokuへデプロイするのに必要なファイルを作成していきます。
(.gitignore, Procfile, requirements.txt, runtime.txtを追加します。)「.gitignore」を追加する
terminal#いつもの開発環境(venv)で実行してください。 (dj)$ cd myapp7 ?プロジェクトに移動(外側のディレクトリであることに注意)(myapp7のところは自分のに変える) (dj)myapp7 $ touch .gitignore ?これを実行すると「.gitignore」が作られる Mac の場合は、Finderで「Shift + cmd + .」で見えるようになる「.gitignore」を編集する
「.gitignore」を開いて、以下のように編集
(dj の部分は人によって異なる).gitignoredj ?これは自分の開発環境の名前(terminalの$マークの後ろの文字) __pycache__ staticfiles db.sqlite3 *.py[co]「Procfile」を追加する
terminal#先ほどの続きで問題ないです。ディレクトリは外側のmyapp7 (dj)myapp7 $ touch Procfile ?これを実行すると「Procfile」が作られる Mac の場合は、Finderで「Shift + cmd + .」で見えるようになる「Procfile」を編集する
Procfileはこの1行だけです。
スペースなどを省略するとエラーの原因になるため、コピペをお勧めします。
そのあとに、myapp7の部分を自分のプロジェクト名に変更してください。Procfileweb: gunicorn myapp7.wsgi --log-file -「requirements.txt」を追加する
下のコマンドを実行するだけでOK
terminal(dj)myapp7 $ pip freeze > requirements.txt念の為、下のように記載されたファイルができているか確認してください。
requirements.txtdj-database-url==0.5.0 Django==2.1 django-bootstrap4==0.0.8 gunicorn==19.9.0 psycopg2-binary==2.8.3 PyMySQL==0.9.3 pytz==2019.1 sqlparse==0.3.0 whitenoise==3.3.1 psycopg2==2.7.6.1 ?上で「psycopg2」がインストールできなかった人は追加「runtime.txt」を追加する
これは、CotEditorなり、普通のテキストエディタなりを開いて以下の1行を書きこんで保存してください。(このファイルは、Procfile同様に1行だけ)
保存場所は上の最初の画像を参照。
pythonのバージョンは自分が使用しているものに置き換えてください。
ただし、python2は想定していません。ご了承ください。python-3.7.3「local_settings.py」を作成する
settings.pyのデータベース接続部分をコピーして、新たに作成する「local_settings.py」に貼り付けします。(このファイルの保存場所は上の画像を確認してください。)
①settings.pyからDATABASEの部分をコピーする(DATABASEの部分は人によって異なると思います。)
②local_settings.pyという名前で新たに作成したファイルに、貼り付け(下のような感じになります。少しも省略していないため、local_settings.pyはこれが全てです。)
「?」の部分以外は人によって異なると思います。(Django2, MySQL, phpMyAdminの組み合わせの人は、
"NAME": "kiitedb",以外は下と全く同じになっても不思議ではありません。)local_settings.pyimport os ? BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) ? import pymysql pymysql.install_as_MySQLdb() DATABASES = { 'default': { #'ENGINE': 'django.db.backends.sqlite3', #'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), "ENGINE": "django.db.backends.mysql", "NAME": "kiitedb", "USER": "root", "PASSWORD": "root", "HOST": "127.0.0.1", "PORT": "3306", } } DEBUG = True ?
- 投稿日:2019-06-27T17:46:33+09:00
[Heroku]Django WEB App デプロイ(完)2019/6月版
Django製アプリを「Heroku」へのデプロイ
コード:https://github.com/MachinoTensei/kiite-kikasete
はじめに
この記事を見てくださっている方はいくつものサイトを見ては、エラーを繰り返している方も多いと思います。
僕はデプロイに丸一日を要しました。他サイトを見ながら試行錯誤してやっとデプロイできましたが、なんせ、拡張子なしのファイル(後で出てきます)の作り方すら知らなかった僕にとっては、もう少し詳しく教えて欲しい!というところも多かったです。
もちろん、記事を書いてくださる方には感謝していますし、この記事よりも専門的な知識は多く得られます。
ですので、この記事では細かな説明もしつこいくらいに入れていきながら解説したいと思います。
そのため、長めの記事ですが、やっていることはそんなに多くありません。
読んでくださる方が、多くても数時間でデプロイできるようにしたいと思います。(一回もエラーが出ないなら、30分もかかりません。)前提条件(対象者)
- データベース(MySQL, phpMyAdmin)を用いたアプリを作成済み
- ローカルホストではきちんと動作するアプリが完成している
- Herokuのアカウントを持っている(無料)
- GitHub, git のコマンドを使える(僕のように調べながらでも使えればいいと思います)
開発環境
Mac OS python 3.7.3 dj-database-url 0.5.0 #後でインストールします Django 2.1 django-bootstrap4 0.0.8 gunicorn 19.9.0 #後でインストールします pip 19.1.1 psycopg2-binary 2.8.3 #後でインストールします PyMySQL 0.9.3 pytz 2019.1 #後でインストールします setuptools 41.0.1 sqlparse 0.3.0 whitenoise 3.3.1 #後でインストールします #「後でインストール」以外のものは、必要かはわかりません。 #ローカルで動いているのなら、この[pip list]はそんなに気にすることもないと思います。最終的なファイル構成
どこのファイルかわからない(説明不足)時は、この画像で判断してください。
紫色の線のファイルはこの後追加します。他のファイルはみなさんあると思います。(場合によって、staticファイルとかはないかも)
(1)必要なものをインストールする
下記のように、必要なものをインストールしてください。
※注意(下の文を必ず読んでください)
「whitenoise」はバージョン3を指定してください。指定しないと4がインストールされ、この記事の方法だとうまくいきません。
また、「psycopg2」のインストールができない場合は「pip install psycopg2-binary」をインストールしてください。
pip install gunicorn django-herokuで下記のものを一括インストールできるらしいが、僕はできませんでした。
試してみるのもありかもしれないです。terminal(dj)$ pip install dj-database-url (dj)$ pip install gunicorn (dj)$ pip install whitenoise==3.3.1 ?バージョンを指定しないと whitenoise4.x.x がインストールされる (dj)$ pip install psycopg2 ?エラーが出る可能性あり (dj)$ pip install pytz(2)ファイルを追加する
Herokuへデプロイするのに必要なファイルを作成していきます。
(.gitignore, Procfile, requirements.txt, runtime.txtを追加します。)(2-1)「.gitignore」を新規作成
terminal#いつもの開発環境(venv)で実行してください。 (dj)$ cd myapp7 ?プロジェクトに移動(外側のディレクトリであることに注意)(myapp7のところは自分のに変える) (dj)myapp7 $ touch .gitignore ?これを実行すると「.gitignore」が作られる Mac の場合は、Finderで「Shift + cmd + .」で見えるようになる(2-2)「.gitignore」を編集する
「.gitignore」を開いて、以下のように編集
(dj の部分は人によって異なる).gitignoredj ?これは自分の開発環境の名前(terminalの$マークの後ろの文字) __pycache__ staticfiles db.sqlite3 *.py[co](2-3)「Procfile」を新規作成
terminal#先ほどの続きで問題ないです。ディレクトリは外側のmyapp7 (dj)myapp7 $ touch Procfile ?これを実行すると「Procfile」が作られる Mac の場合は、Finderで「Shift + cmd + .」で見えるようになる(2-4)「Procfile」を編集する
Procfileはこの1行だけです。
スペースなどを省略するとエラーの原因になるため、コピペをお勧めします。
そのあとに、myapp7の部分を自分のプロジェクト名に変更してください。Procfileweb: gunicorn myapp7.wsgi --log-file -(2-5)「requirements.txt」を新規作成
下のコマンドを実行するだけでOK
terminal(dj)myapp7 $ pip freeze > requirements.txt念の為、下のように記載されたファイルができているか確認してください。
requirements.txtdj-database-url==0.5.0 Django==2.1 django-bootstrap4==0.0.8 gunicorn==19.9.0 psycopg2-binary==2.8.3 PyMySQL==0.9.3 pytz==2019.1 sqlparse==0.3.0 whitenoise==3.3.1 psycopg2==2.7.6.1 ?上で「psycopg2」がインストールできなかった人は追加(2-6)「runtime.txt」を新規作成
これは、CotEditorなり、普通のテキストエディタなりを開いて以下の1行を書きこんで保存してください。(このファイルは、Procfile同様に1行だけ)
保存場所は上の最初の画像を参照。
pythonのバージョンは自分が使用しているものに置き換えてください。
ただし、python2は想定していません。ご了承ください。python-3.7.3(3)「local_settings.py」を新規作成
settings.pyのデータベース接続部分をコピーして、新たに作成する「local_settings.py」に貼り付けします。(このファイルの保存場所は上の画像を確認してください。)
①settings.pyからDATABASEの部分をコピーする(DATABASEの部分は人によって異なると思います。)
②local_settings.pyという名前で新たに作成したファイルに、貼り付け(下のような感じになります。少しも省略していないため、local_settings.pyはこれが全てです。)
「?」の部分以外は人によって異なると思います。(Django2, MySQL, phpMyAdminの組み合わせの人は、
"NAME": "kiitedb",以外は下と全く同じになっても不思議ではありません。)local_settings.py#この上には何もありません import os ? BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) ? import pymysql pymysql.install_as_MySQLdb() DATABASES = { 'default': { #'ENGINE': 'django.db.backends.sqlite3', #'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), "ENGINE": "django.db.backends.mysql", "NAME": "kiitedb",?ここは人によって違う "USER": "root",?場合によっては違う "PASSWORD": "root",?場合によっては違う "HOST": "127.0.0.1", "PORT": "3306", } } DEBUG = True ? #この下には何もありません「.gitignore」に「local_settings.py」を追加
先ほど作成した、「.gitignore」に「local_settings.py」の1行を追加してください。
.gitignoredj __pycache__ staticfiles local_settings.py ?追加 db.sqlite3 *.py[co](4)「settings.py」を編集する(4ステップ)
(蛇足な部分がある可能性あり)
(4−1)ステップ1
下のコードを、settings.pyの一番下に貼り付けてください。
"@@@@@@@@@@"の部分は自分のパソコンのユーザー名に変更してください。settings.py#この上は省略してあります STATIC_URL = '/static/'?(静的ファイルがある方のみ) STATIC_ROOT = os.path.join(BASE_DIR, 'kiite/static')?kiiteの部分は自分のアプリ名(静的ファイルがある方のみ) from socket import gethostname hostname = gethostname() if "@@@@@@@@@@" in hostname: # デバッグ環境 DEBUG = True #=====ここから...===== import pymysql pymysql.install_as_MySQLdb() DATABASES = { 'default': { #'ENGINE': 'django.db.backends.sqlite3', #'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), "ENGINE": "django.db.backends.mysql", "NAME": "kiitedb",?ここは人によって違う "USER": "root",?場合によっては違う "PASSWORD": "root",?場合によっては違う "HOST": "127.0.0.1", "PORT": "3306", } } #=====...ここまでは、使用しているデータベースに置き換えてください。===== ALLOWED_HOSTS = [] else: # 本番環境 DEBUG = True LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console': { 'class': 'logging.StreamHandler', }, }, 'loggers': { 'django': { 'handlers': ['console'], 'level': os.getenv('DJANGO_LOG_LEVEL', 'DEBUG'), }, }, } # DB設定 import dj_database_url PROJECT_ROOT = os.path.dirname(os.path.abspath(__file__)) db_from_env = dj_database_url.config() DATABASES = { 'default': dj_database_url.config() } ALLOWED_HOSTS = ['*'] #この下には何もありません(4−2)ステップ2
WSGI_APPLICATION = '<プロジェクトネーム>.wsgi.application'を探して、その下に下記のコードを貼り付けsettings.pyimport dj_database_url db_from_env = dj_database_url.config() DATABASES = { 'default': dj_database_url.config() }(4−3)ステップ3
MIDDLEWAREを探して、下の1行を追加してください。settings.pyMIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'whitenoise.middleware.WhiteNoiseMiddleware',?この1行だけを追加 'django.contrib.sessions.middleware.SessionMiddleware',(4−4)ステップ4
下のように変更(最初からなっている人も多いと思いますが、一応)
settings.pyALLOWED_HOSTS = ["*"](5)「wsgi.py」を編集
「wsgi.py」を下記のコードに変えてください。(追記ではなく、全変えです。)
wsgi.py#この上には何もありません import os from django.core.wsgi import get_wsgi_application os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'myapp7.settings')?myapp7は自分のアプリ名に変更 application = get_wsgi_application() from whitenoise.django import DjangoWhiteNoise application = DjangoWhiteNoise(application) #この下には何もありません(6)「Heroku CLI」をインストール
ここからインストールしてください。
インストーラーを起動後、「OK」や「完了」を押して、次々に進んでいけば大丈夫だと思います。
(7)デプロイ
下のコマンドをデプロイするアプリがある開発環境で順番に実行。
myapp7やkiiteは適宜変更してください。terminal(dj)$ cd myapp7 ?外側のディレクトリに移動 (cd)myapp7 $ git init ?「.git」ディレクトリが作成される (cd)myapp7 $ git config user.name <自分の名前> ?<>はいらない (cd)myapp7 $ git config user.email *+*+*+@info.com (cd)myapp7 $ git add -A . (cd)myapp7 $ git commit -m "First Django App, OK" (cd)myapp7 $ heroku login ?Herokuアカウントは事前に作成しておいてください (cd)myapp7 $ heroku create kiite ?kiiteは自由に変更(省略も可能) (cd)myapp7 $ git push heroku master (cd)myapp7 $ heroku ps:scale web=1 (cd)myapp7 $ heroku run python manage.py migrate (cd)myapp7 $ heroku run python manage.py createsuperuser (cd)myapp7 $ heroku open終了
参考サイト







- 投稿日:2019-06-27T15:49:44+09:00
Azure Databricks: 4. PySpark基本操作
サンプルデータセット
今回はkaggleのデータセット「Brazilian E-Commerce Public Dataset by Olist」をサンプルとして、Azure Databricksを使ったSparkの操作を行っていきます。
このデータはOlist StoreというブラジルのECサイトで行われた2016年から2018年までの約10万件の注文に関するデータが含まれています。
データ量としてはビッグデータというほどに多くありませんが、注文の商品明細やレビューなどが複数のCSVに分かれて保存され、それぞれがIDで紐づけられているため、PySparkやSpark SQLの練習に適しています。CSVの読み込み
注文ごとの商品の明細情報「olist_order_items_dataset.csv」を使ってデータの読み込みとPySparkの操作を行っていきます。
DataFrameに読み込み
下記スクリプトでCSVをSpark DataFrameとして読み込みます。
読み込むCSVはカラム名を示す行が先頭にあるため、読み込みオプションとして「header="true"」、またカラムのデータ型を自動推定するため「inferSchema="true"」として読み込んでいます。
(※CSV読み込みオプションの詳細はDatabricksドキュメントも参照してください)order_items_csv = "dbfs:/mnt/my_blob_container/brazilian-ecommerce/olist_order_items_dataset.csv" df = spark.read\ .format("csv")\ .options(header="true", inferSchema="true")\ .load(order_items_csv) display(df)
スキーマを指定して読み込み
スキーマを指定して読み込みを行う場合は下記のようにします。
※指定できる型はSparkドキュメントも参照カラムのデータ型指定にinferSchemaを使用した場合、型推定のため1回余計に読み込むことになり、読み込みのパフォーマンスが低下します。
データのスキーマがわかっている場合は、スキーマを指定して読み込むことを推奨します。from pyspark.sql.types import * # order_items_csv = "dbfs:/mnt/my_blob_container/brazilian-ecommerce/olist_order_items_dataset.csv" # スキーマ指定 schema = StructType([ StructField("order_id", StringType(), False), StructField("order_item_id", StringType(), False), StructField("product_id", StringType(), False), StructField("seller_id", StringType(), False), StructField("shipping_limit_date", StringType(), False), StructField("price", DoubleType(), False), StructField("freight_value", DoubleType(), False), ]) df_spec = spark.read\ .format("csv")\ .options(header="true")\ .load(order_items_csv, schema=schema) display(df_spec)
データ型の確認
display(df.dtypes)
PySparkでのDataFrameの基本操作
読み込んだCSVでPySparkの基本操作を実行します。
- 指定行数抽出して表示
display(df.head(5))
- 全レコード数のカウント
df.count()
- 計算列の追加
# 送料込合計列追加 df = df.withColumn("total_price", df["price"] + df["freight_value"]) display(df)
- カラムを指定して抽出
display(df.select( df["product_id"], df["shipping_limit_date"].alias("limit_date"), # aliasでカラム名の変更が可能 df["price"] ))
- 条件でレコード抽出
# 2018/01/01 ~ 2018/01/31のデータを抽出 from datetime import datetime df_jan = df.filter((df["shipping_limit_date"] >= datetime(2018, 1, 1)) & (df["shipping_limit_date"] < datetime(2018, 2, 1))) display(df_jan)
- レコードのカウント
# product_idごとの売り上げの個数 df_count = df_jan.groupBy("product_id").count() display(df_count)
- レコードの集計
# product_idごとの売り上げの合計 df_sum = df_jan.groupBy("product_id").agg({"price": "sum"}) display(df_sum)
Spark SQLを使用した操作
DataFrameをTemp Tableに登録することでSpark SQLを使用した集計が可能になります。
- Temp Tableの登録
df.createOrReplaceTempView("order_items")
- Spark SQLによるカラム抽出
query = """ SELECT product_id, shipping_limit_date, price FROM order_items """ display(spark.sql(query))
- %sqlマジックコマンドを使用する場合
%sql SELECT product_id, shipping_limit_date, price FROM order_items
DataFrameの結合
データセットに含まれる他のCSVファイルと組み合わせて商品カテゴリごとの売り上げを集計してみます。
各商品の詳細情報「olist_products_dataset.csv」をDataFrameに読み込みます。
products_csv = "dbfs:/mnt/my_blob_container/brazilian-ecommerce/olist_products_dataset.csv" df_prod = spark.read\ .format("csv")\ .options(header="true", inferSchema="true")\ .load(products_csv) display(df_prod)
# カラム名の変更 df_prod = df_prod.withColumnRenamed("product_id", "product_id_2") # DataFrame結合 df_join = df.join(df_prod, df["product_id"] == df_prod["product_id_2"]) display(df_join)
2018年1月の商品カテゴリごとの売り上げ金額を集計します。
「sum(price)」をソートすると「relogios_presentes」の売り上げが最も高いことがわかりますが、ポルトガル語なので何の商品カテゴリかわかりません。df_category = df_join.filter((df["shipping_limit_date"] >= datetime(2018, 1, 1)) & (df["shipping_limit_date"] < datetime(2018, 2, 1)))\ .groupBy("product_category_name")\ .agg({"price": "sum"}) display(df_category)
データセットにカテゴリを英語翻訳したCSVファイルがあるため、これも読み込みます。
translation_csv = "dbfs:/mnt/my_blob_container/brazilian-ecommerce/product_category_name_translation.csv" df_translate = spark.read\ .format("csv")\ .options(header="true", inferSchema="true")\ .load(translation_csv) display(df_translate)
結合して翻訳します。
df_category = df_category.join(df_translate, df_category["product_category_name"] == df_translate["product_category_name"])\ .select(df_translate["product_category_name_english"], df_category["sum(price)"]) display(df_category)
Databricksではデータの可視化も簡単にできます。
売り上げが最も高いのは「watches_gifts」であることがわかりました。
CSVの書き出し
DataFrameを書き出す場合は下記コマンドを使用します。
# DataFrameCSV書き出し output_path = "/mnt/my_blob_container/brazilian-ecommerce/order_items_with_detail.csv" df.join.write\ .format("csv")\ .options(header="true")\ .save(output_path)
CSVは指定したパスに直接書き出されるのではなく、指定パスのディレクトリが作成され、直下に分割されたCSVファイルとして出力されます。
display(dbutils.fs.ls(output_path))
ファイルを1つのCSVとして出力する場合は、HadoopのFileUtil.copyMergeを使用し、上記で出力したファイルをマージして1ファイルにまとめます。
%scala import org.apache.hadoop.conf.Configuration import org.apache.hadoop.fs._ var sourceDir = "/mnt/blob_container/output.csv" var mergedFileName = "/mnt/blob_container/output_merge.csv" val hadoopConfig = new Configuration() val hdfs = FileSystem.get(hadoopConfig) FileUtil.copyMerge(hdfs, new Path(sourceDir), hdfs, new Path(mergedFileName), true, hadoopConfig, null)
import os display(dbutils.fs.ls(os.path.dirname(output_path)))
Clusterのメモリ量に余裕がある場合は、下記スクリプトで1ファイルにデータを書き出すことができます。
この場合でも「output.csv/part-00000-xxxxxxxxx.csv」のような名称でファイルが出力されるため、出力後必要に応じてファイルの移動を行います。output_path = "/mnt/my_blob_container/brazilian-ecommerce/order_items_with_detail_rep1.csv" # DataFrameを1つのCSVに書き出し() df.repartition(1).write\ .format("csv")\ .options(header="true")\ .save(output_path)
display(dbutils.fs.ls(output_path))
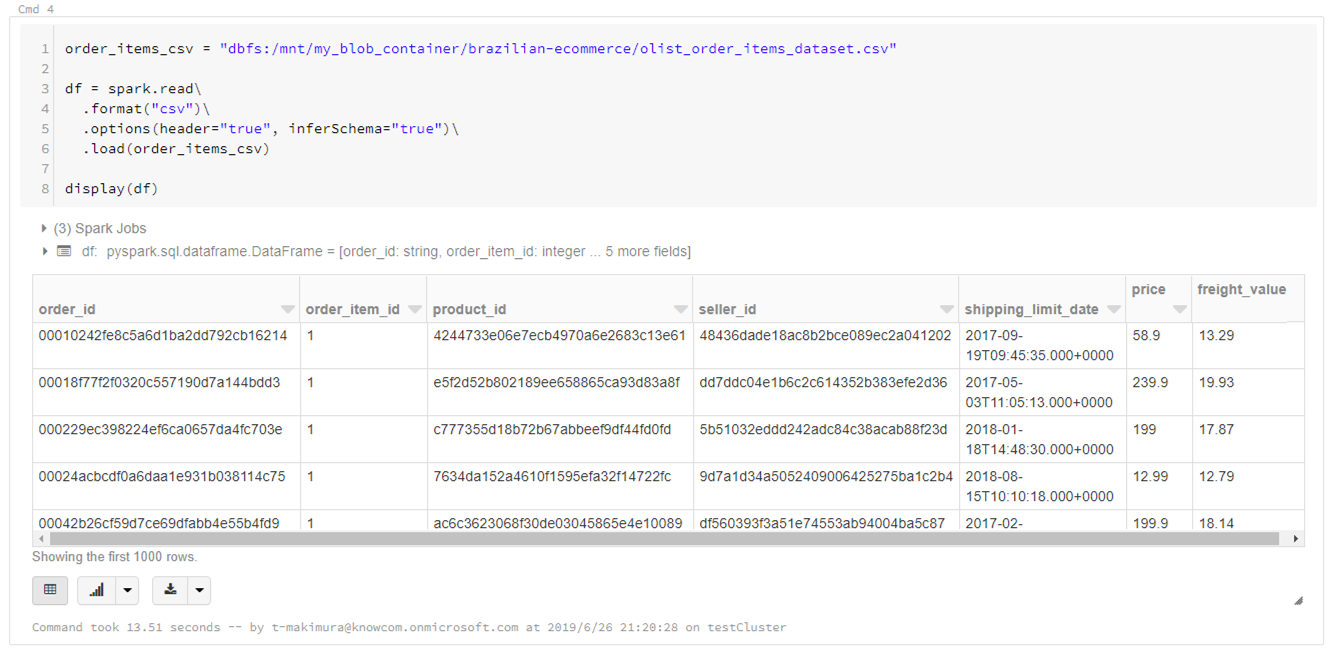
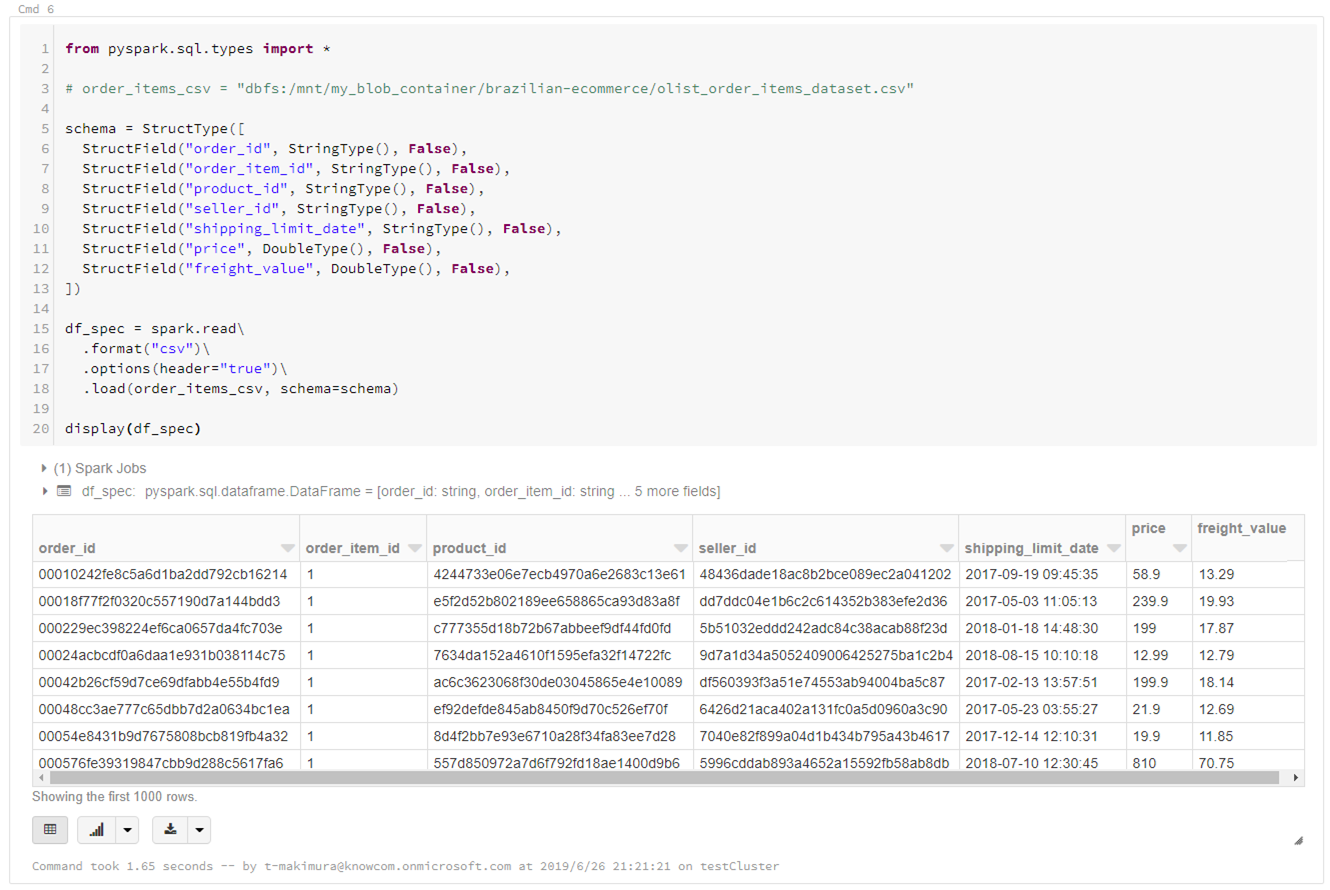
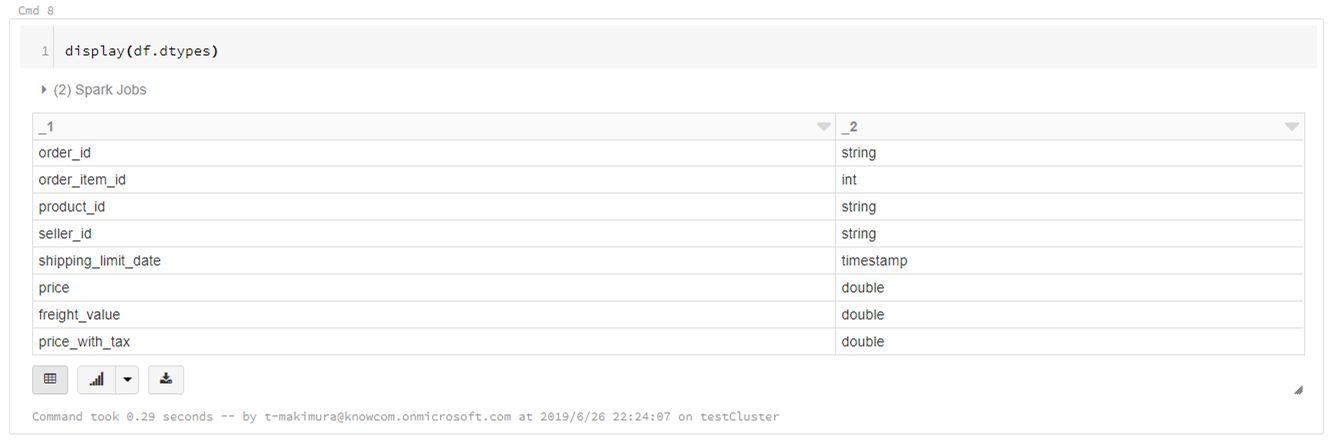
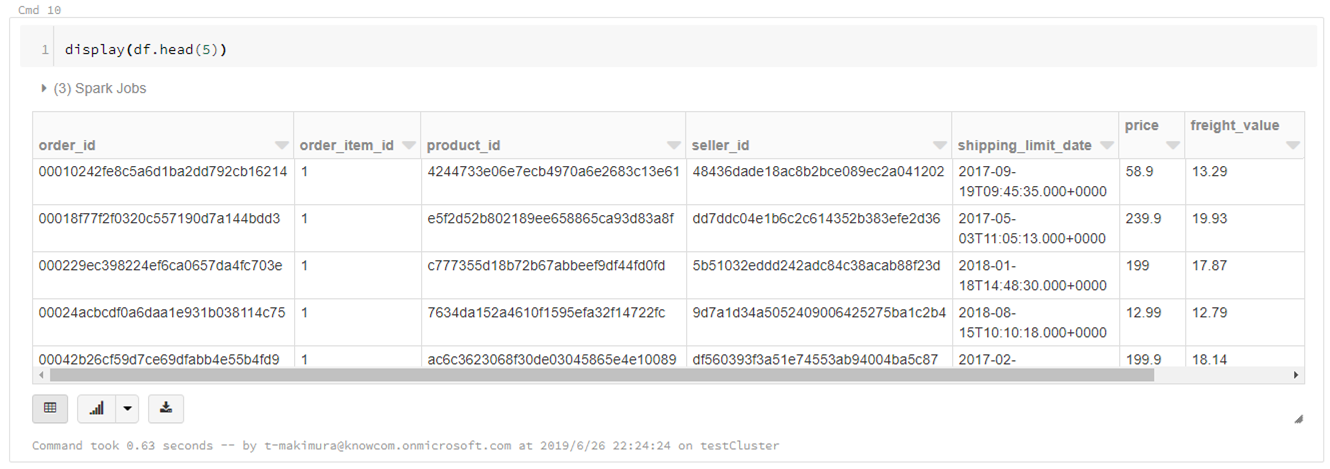

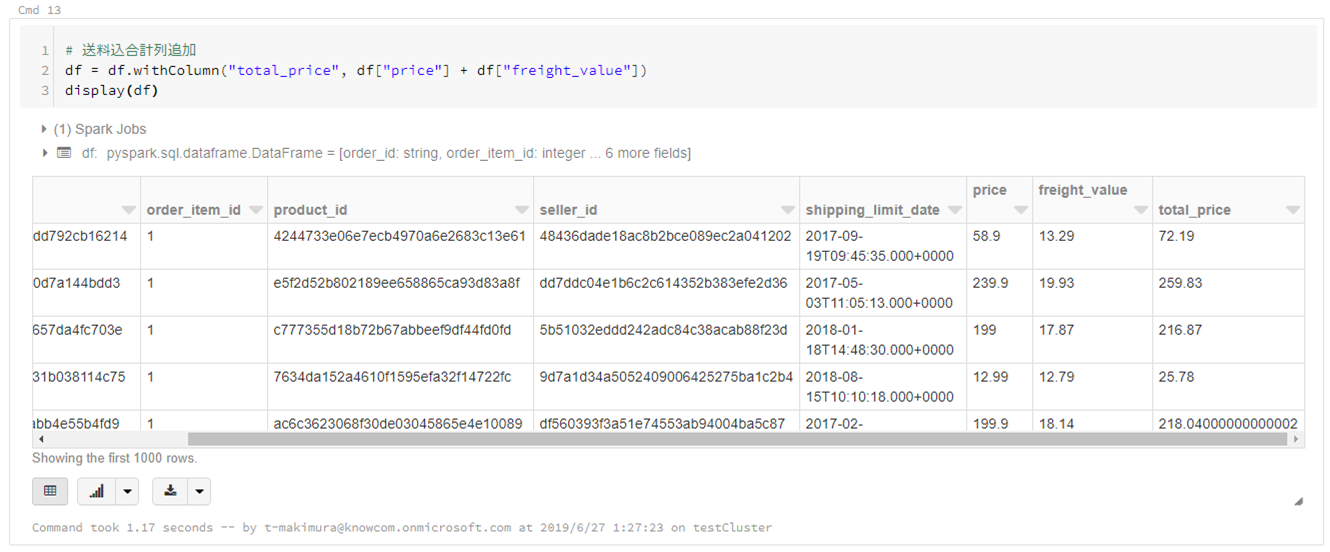
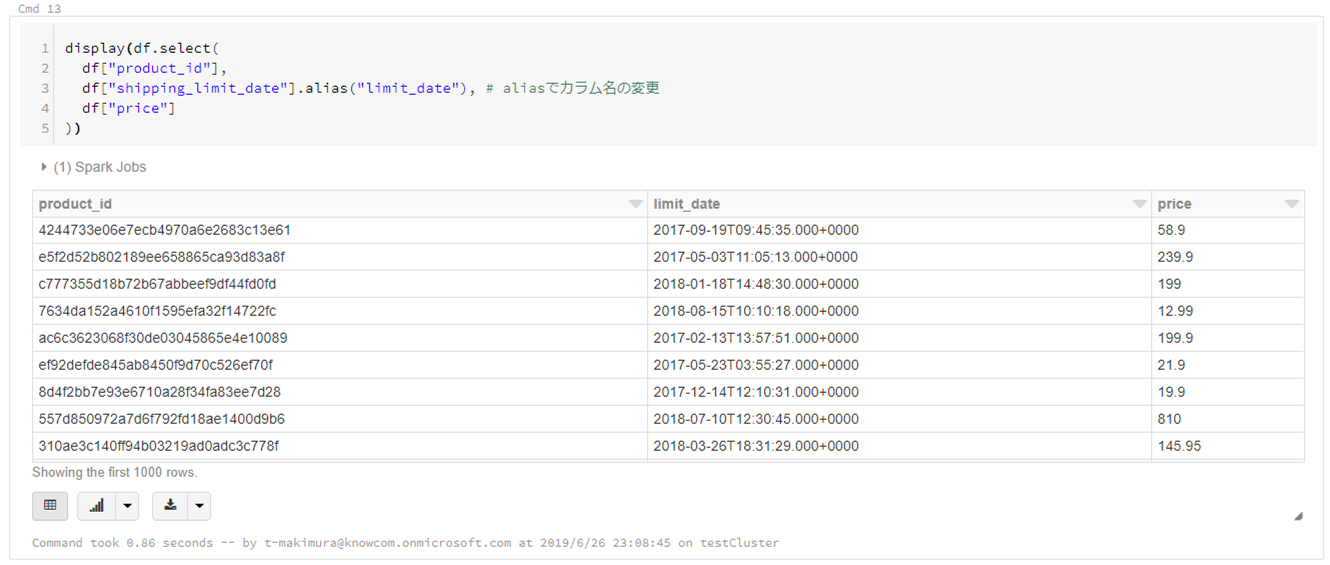
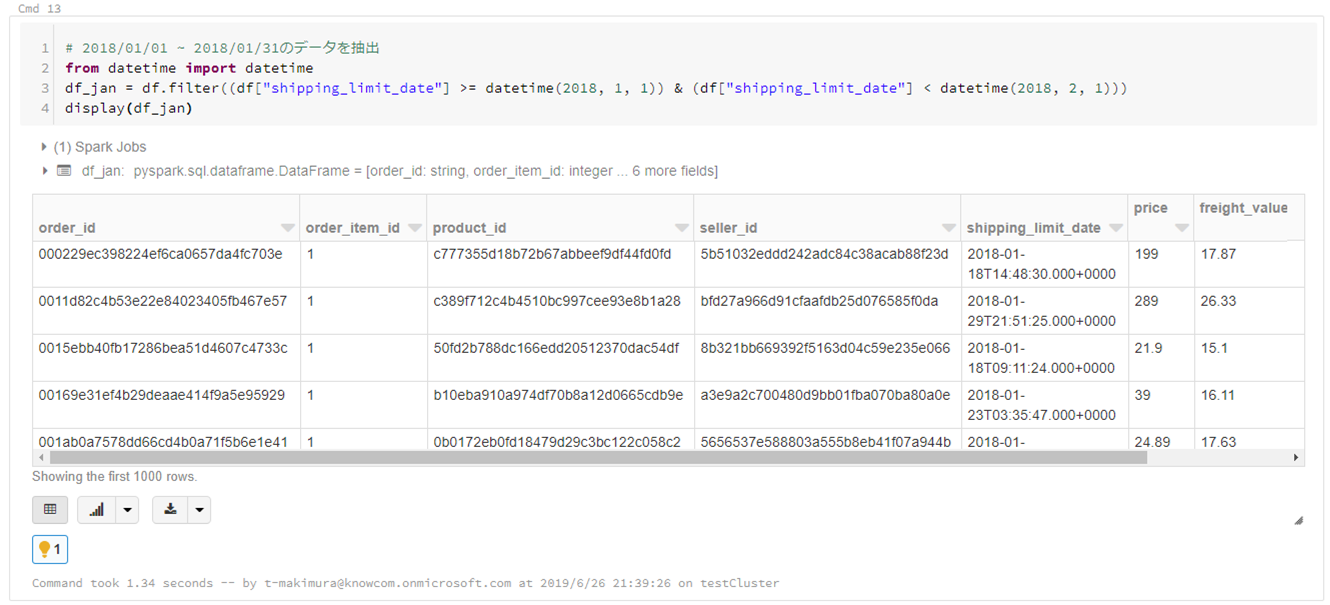
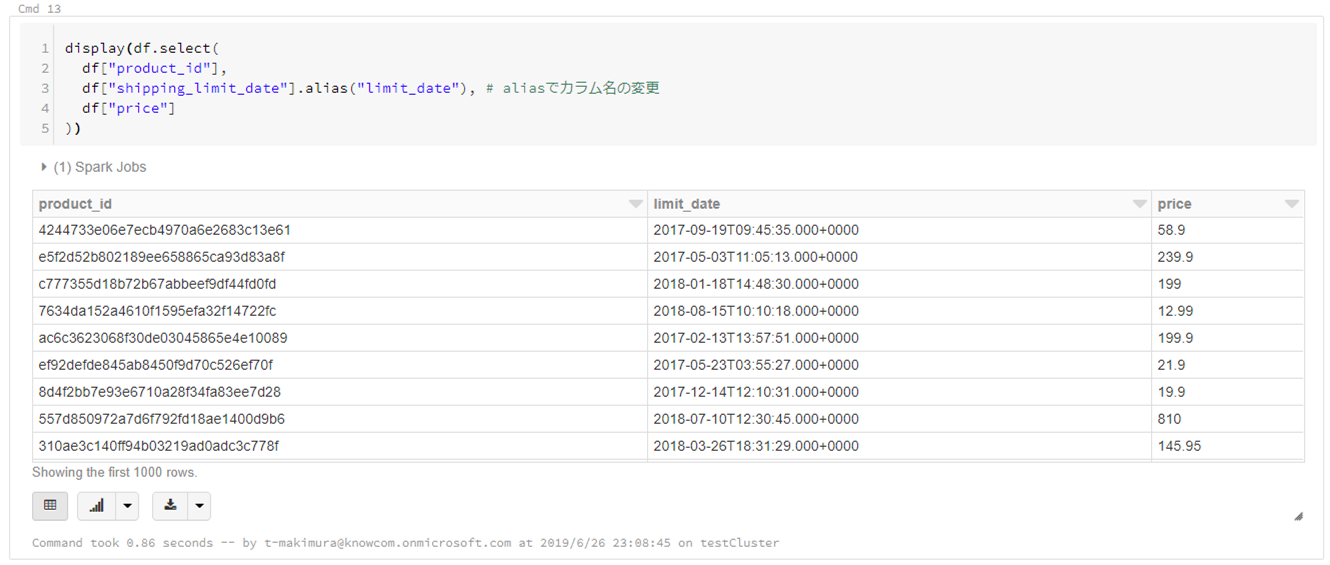
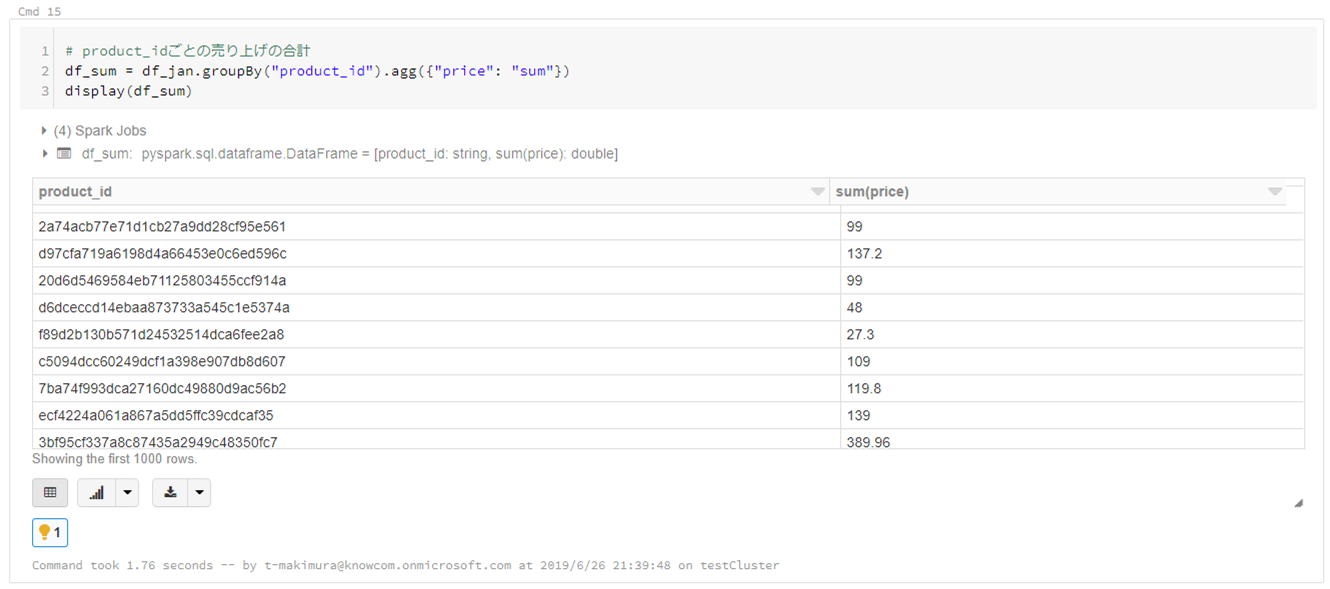

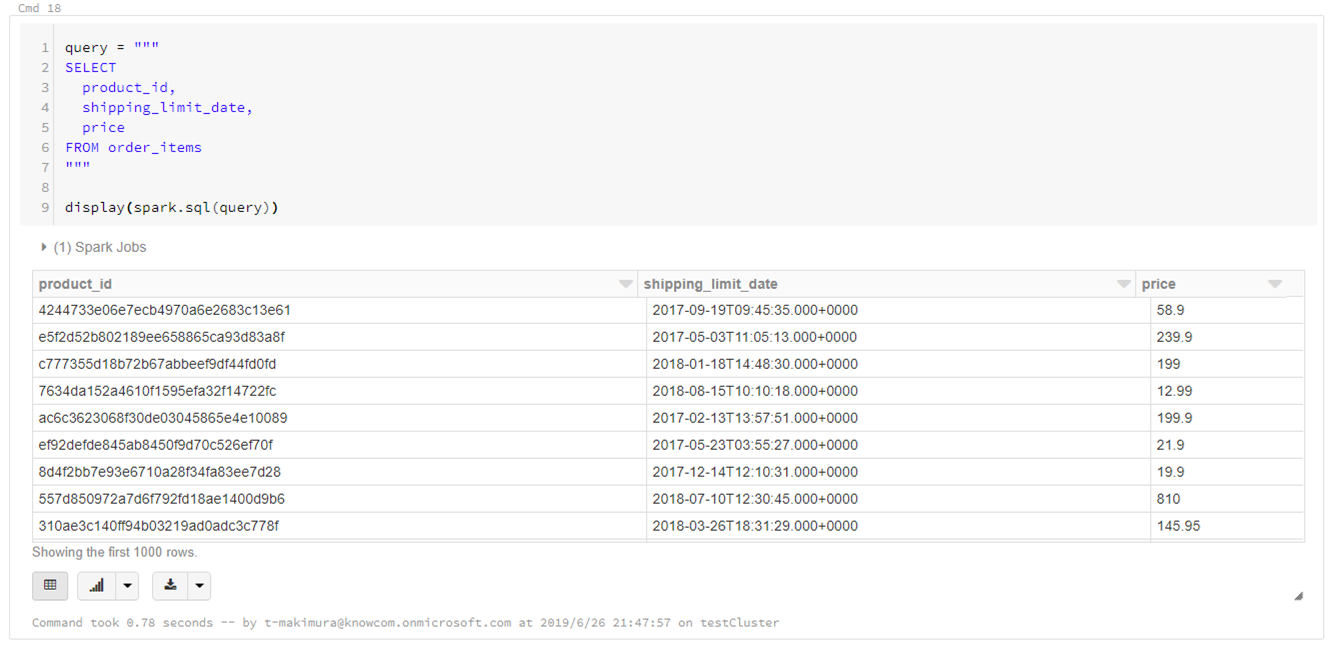
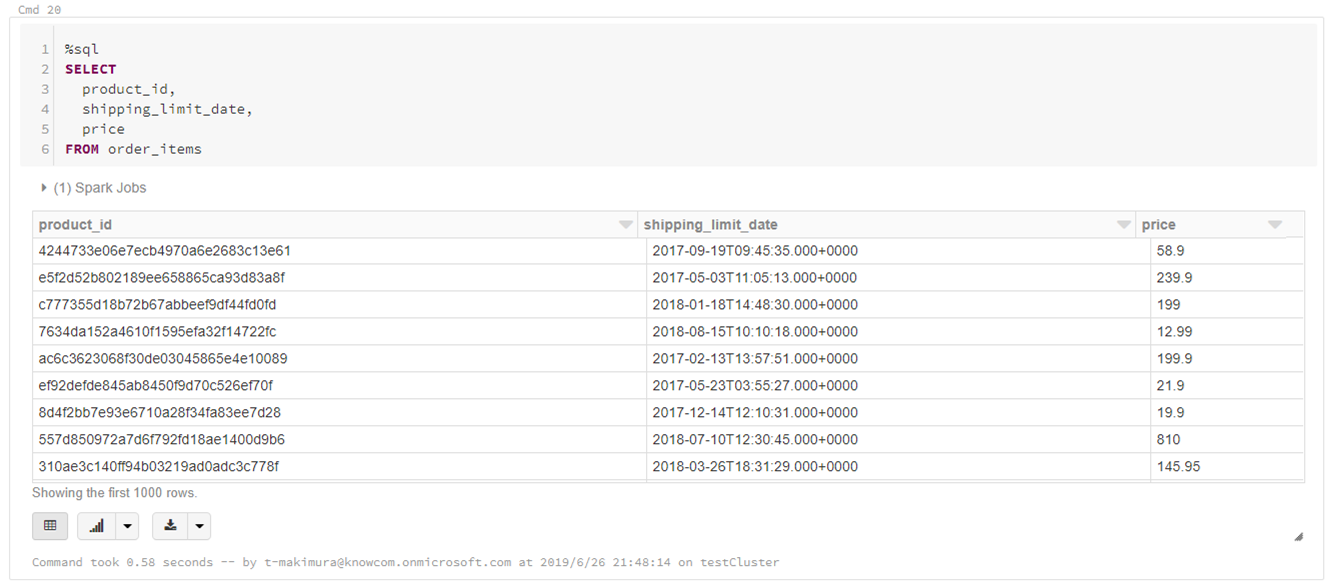
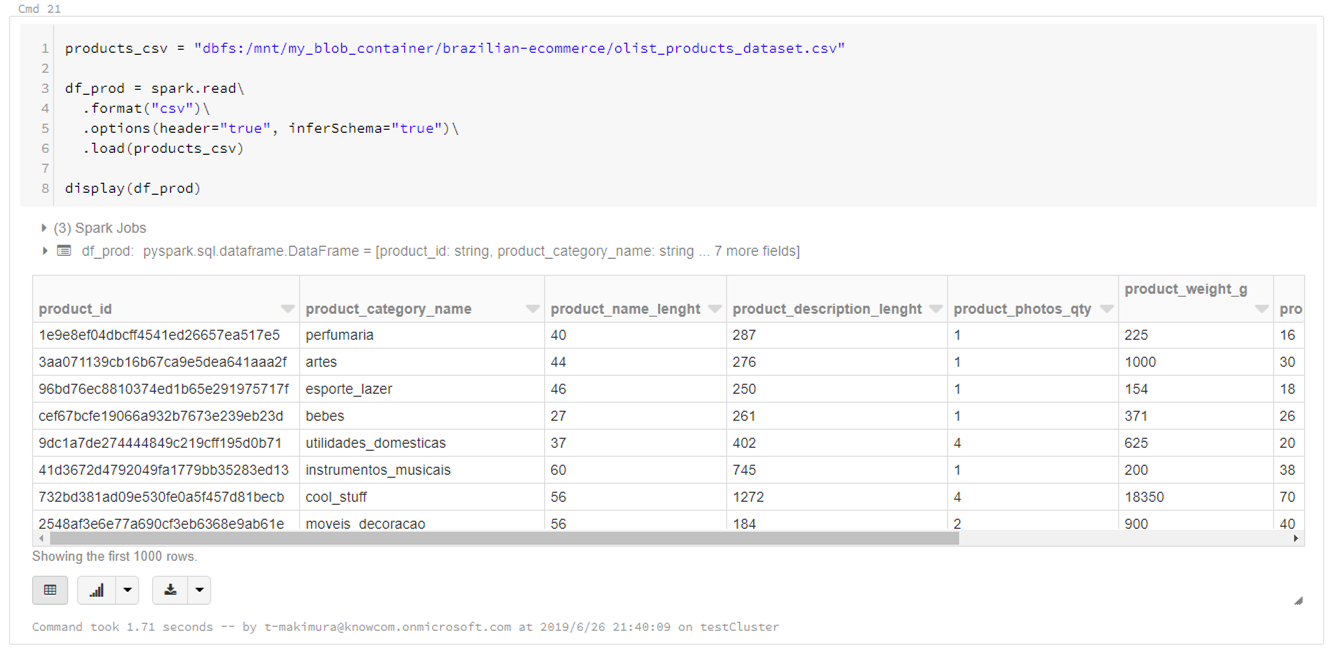
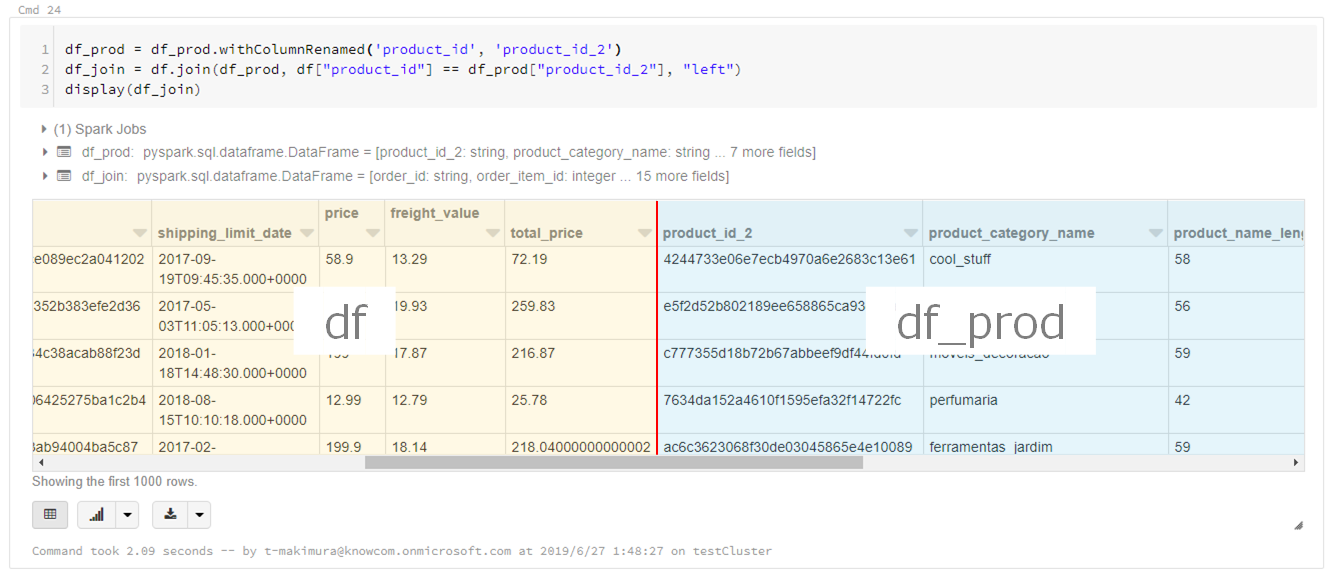
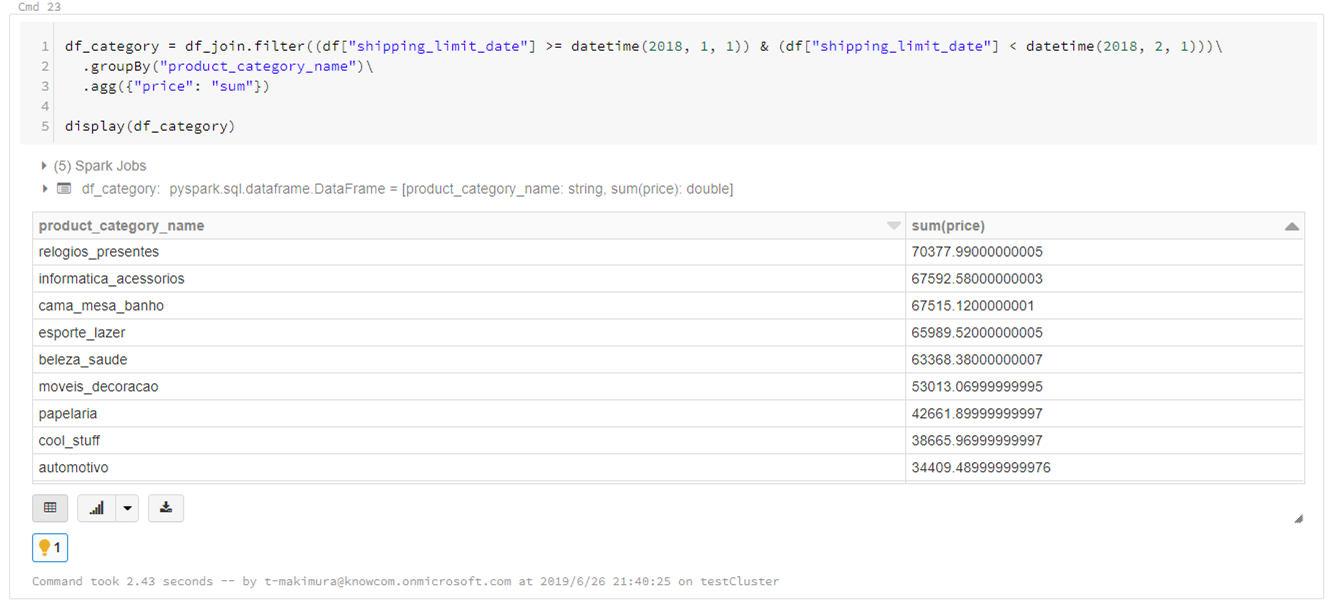
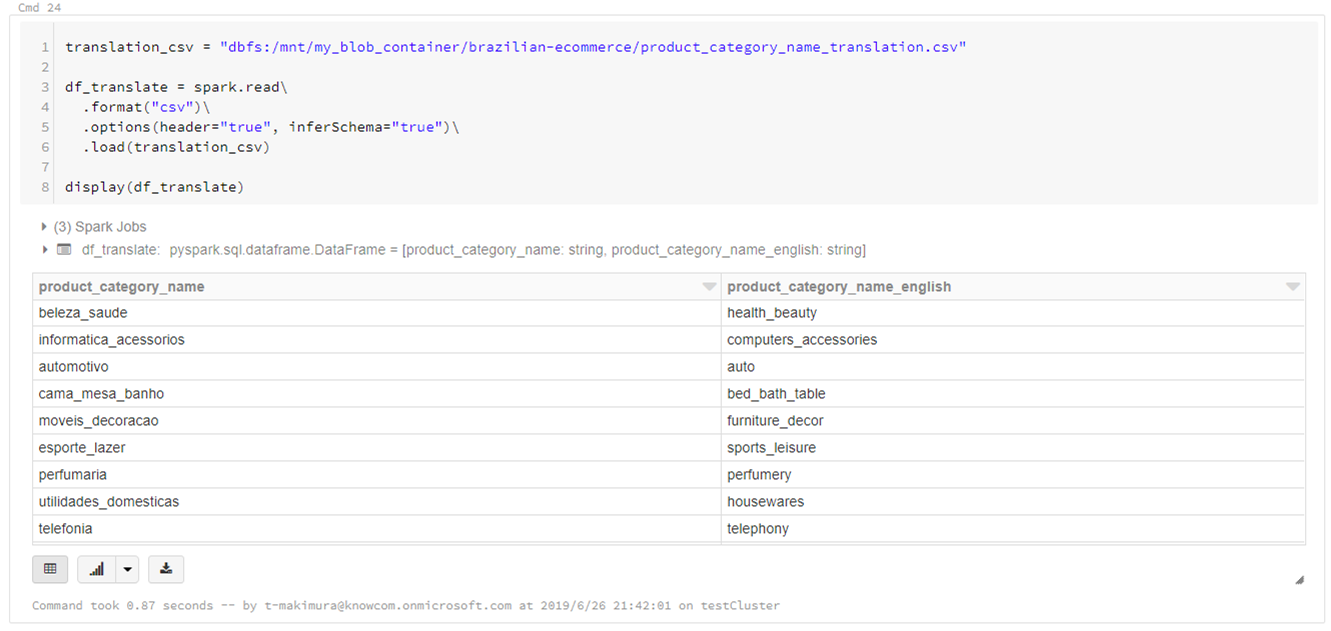
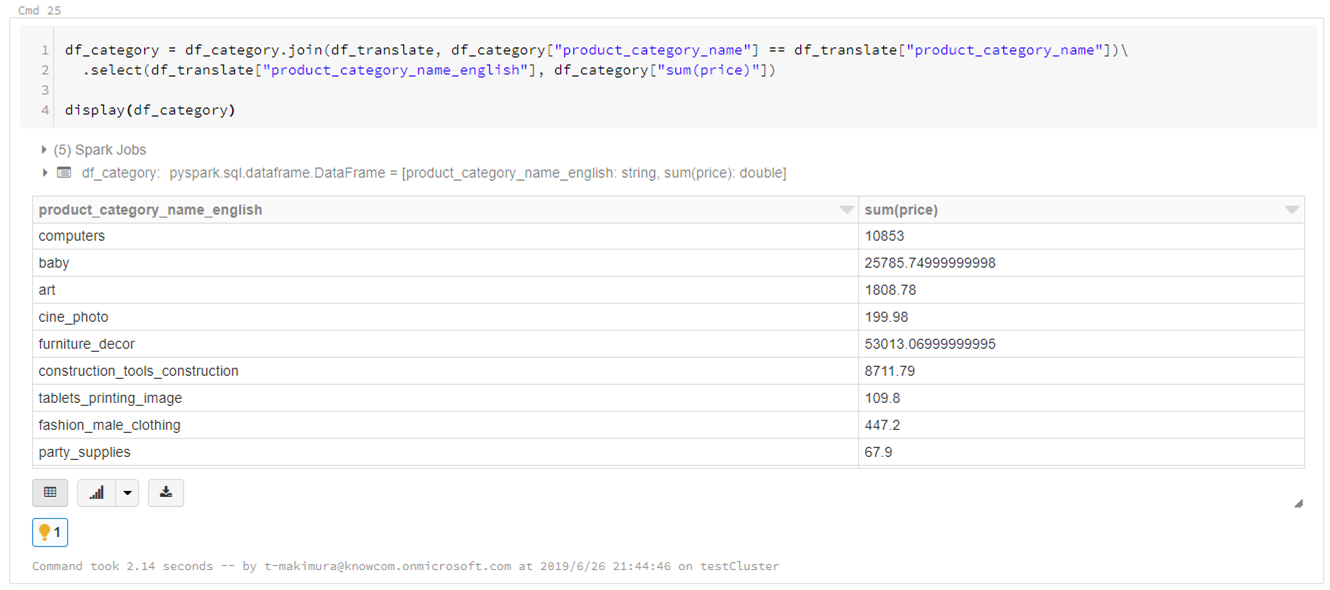
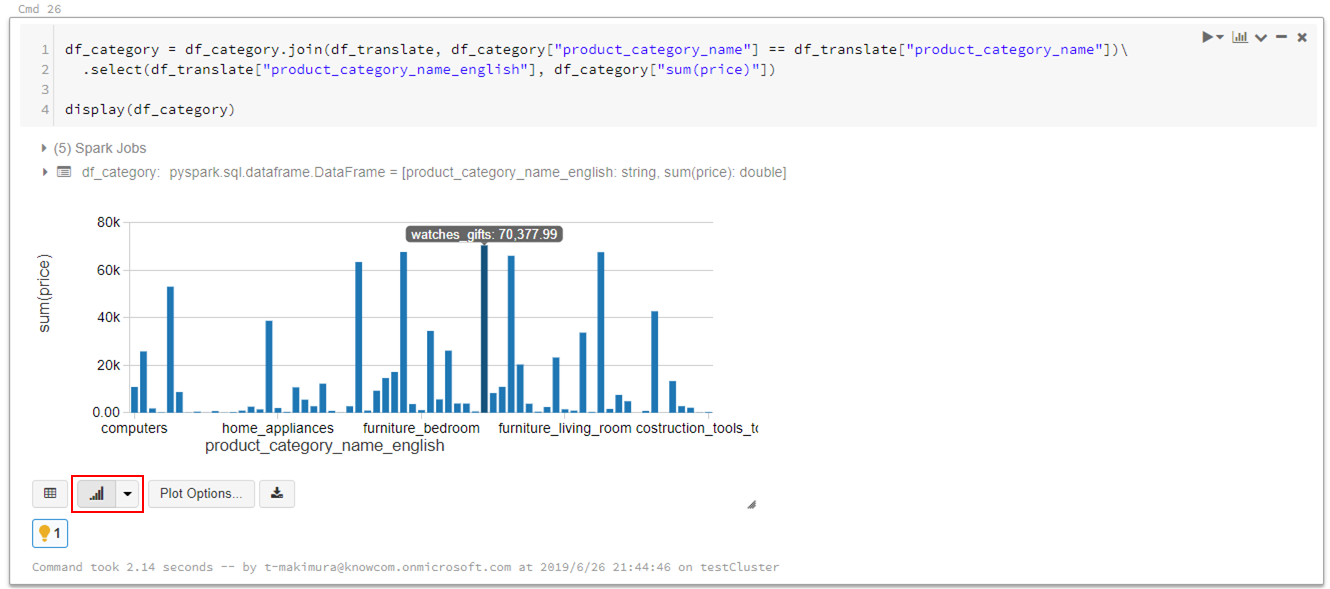

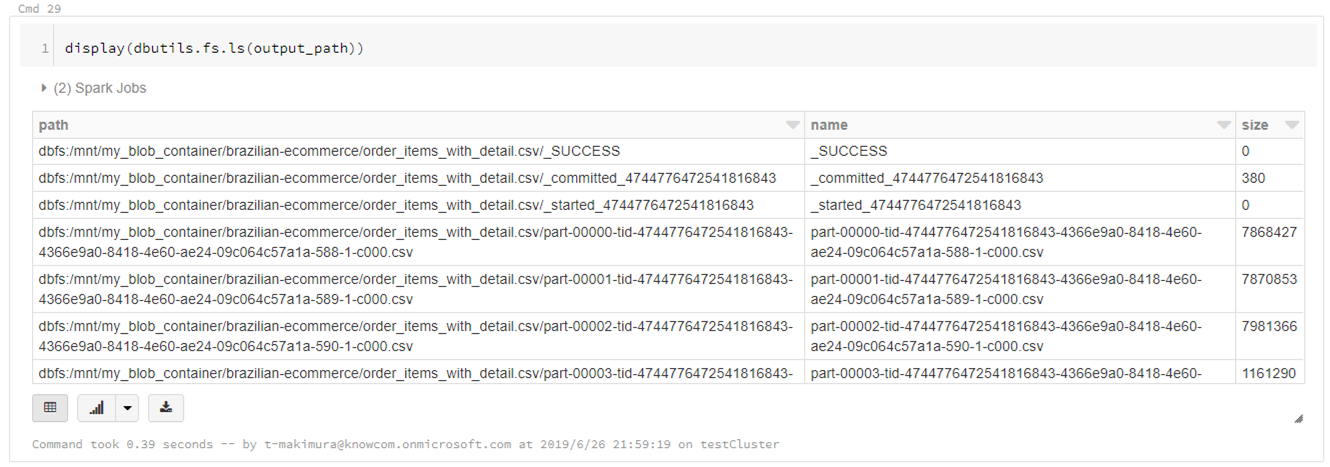
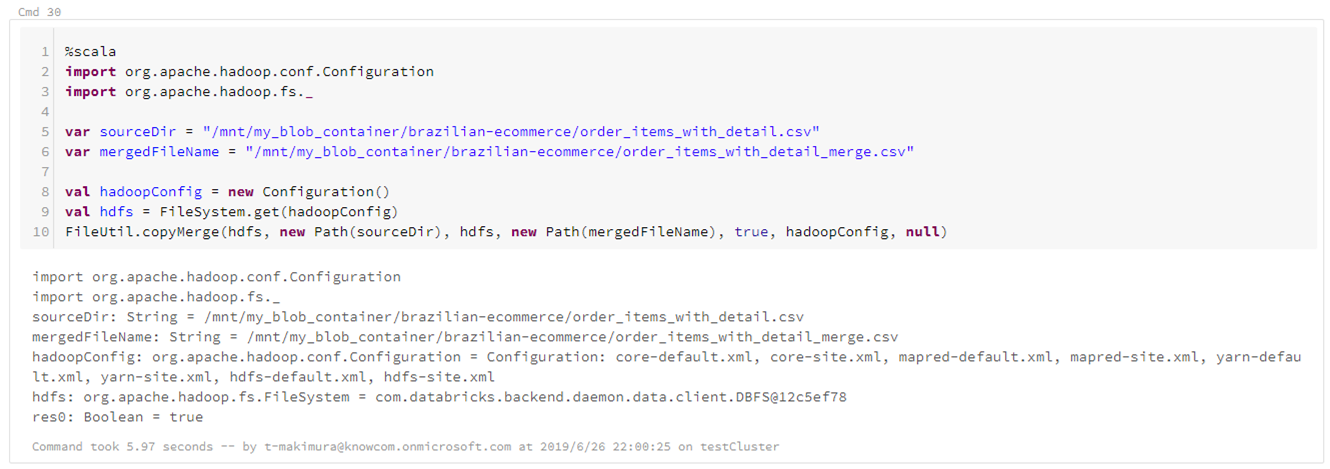
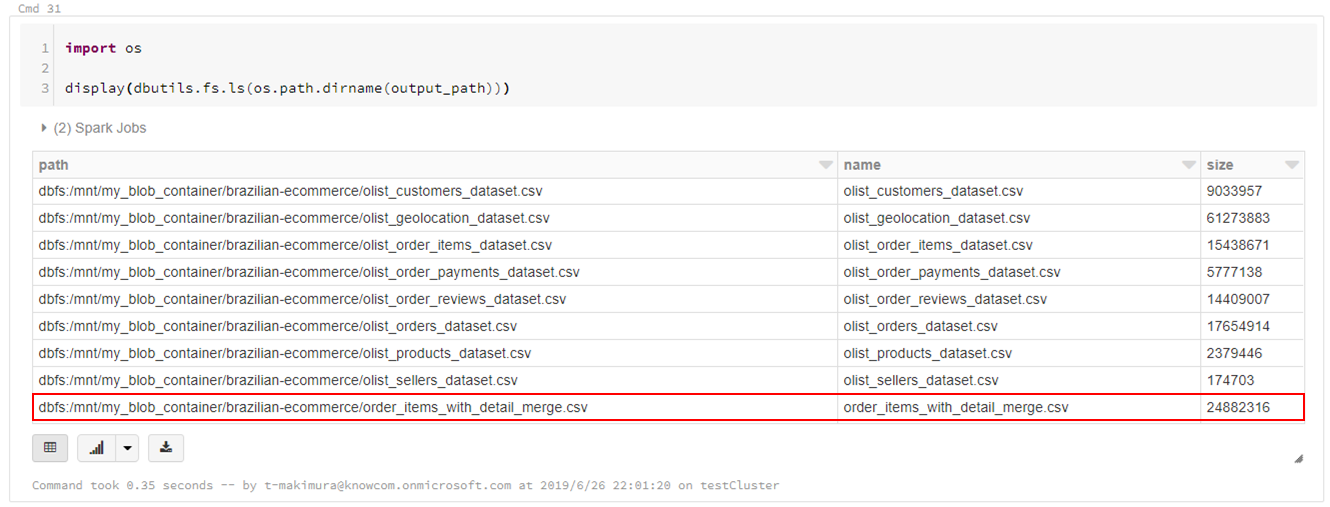
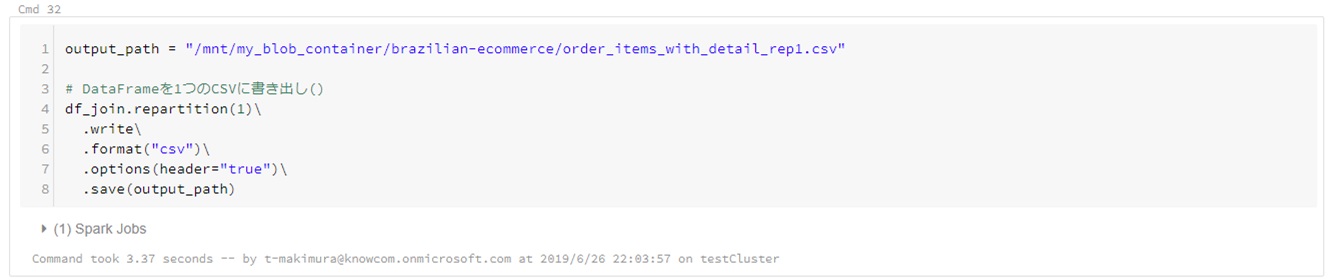
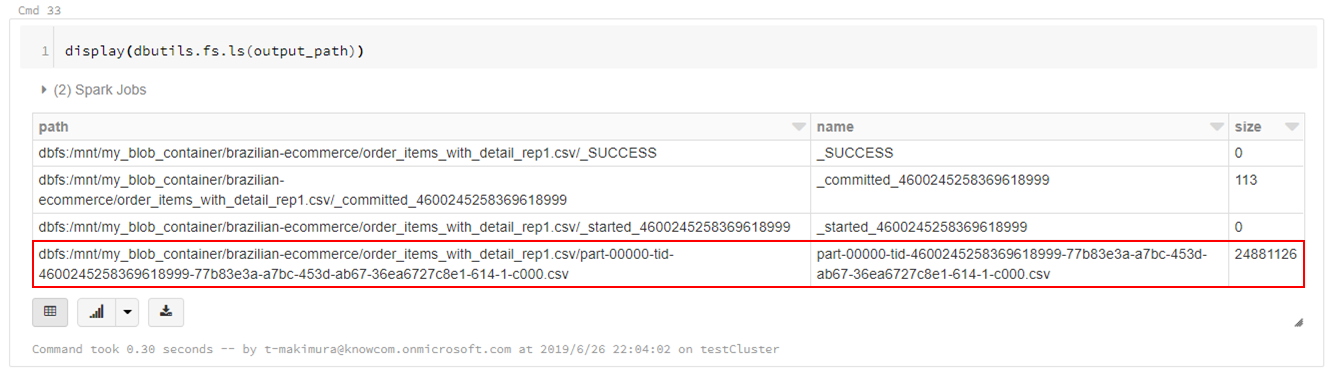
- 投稿日:2019-06-27T15:14:27+09:00
QuantXで指値注文
はじめに
QuantXが新エンジンにバージョンアップしました!
旧バージョンと比べて機能追加や変わった点などいくつかあります!
以下の記事にまとめたのでよかったら参照ください!(いいねくださると嬉しいです...)
https://qiita.com/katakyo/items/12b41fec940a3bac1142今回やること
今回は前回の記事であまり触れなかった指値注文をQuantXで実装する方法を紹介します!!
説明することとしては
- 指値注文とは何か?
- 指値注文と成行注文のメリットデメリットの比較
- 実際の実装方法
- 結果検証
以上の4点になります
指値注文について
株取引の注文方法は大きく2つで値段を指定する指値(さしね)注文と、指定しない成行(なりゆき)注文にわかれます。
注文方法 概要 指値(さしね)注文 希望価格を指定して発注する方法 成行(なりゆき)注文 希望価格を指定せず、どんな価格でもいいので取引したいという注文方法 旧エンジンではシグナルが出た株価が金額的に注文可能であれば約定していたため成行注文であるということがわかります。
希望価格を指定して発注する指値取引ですが、その中でも指値(さしね)注文と逆指値(ぎゃくさしね)注文の大きく二つに分けることができます。
注文方法 購入 売却 指値(さしね)注文 希望価格より安くなったら購入 希望価格より高くなったら売却 逆指値(ぎゃくさしね)注文 希望価り高くなったら購入 希望価格より安くなったら売却 イメージだと以下の図のようになります。
指値注文と成行注文のメリットデメリットの比較
指値注文
指値注文は自分で希望金額で取引可能です。(実際の相場は値幅制限があります。)よって、株価が自分が指定した金額にならない限りは約定(取引が成立すること)しません。自分が思った通りの値段で取引ができる点がメリットとなります。
逆に言えば、相場と離れた金額を設定してしまうとなかなか取引が成立しません。成行注文
成行注文は注文してしまえば*ほぼ購入可能です。
しかし、希望金額を指定していないので、株価の暴騰や暴落により自分の想定していない金額で取引が成立してしまうことがあります。*ほぼと言ったのは、売買が殺到して注文数が足りない場合に関しては取引が成立しないからです。(ストップ高、ストップ安とかいうアレです。)
まとめ
注文方法 メリット デメリット 指値(さしね)注文 自分の希望した金額で取引ができる 相場と離れた金額を指定していると取引が成立しにくい 成行(なりゆき)注文 取引が成立しやすい 自分の想定していない金額で取引が成立してしまうことがある QuantXでの実装方法
現状は逆指値注文はできなさそうなので指値注文のやり方だけ書きます
注)今回は使い方のための記事なのでパフォーマンスは無視します。
指値注文はhandle_signals関数内のorderの部分で以下のような書き方をします。
order(amount, comment, order_type = maron.OrderType.LIMIT , limit_price , comment = "指値注文")順に見ていきます
外側のorderは以下のリンクを参照にしてください
https://factory.quantx.io/handbook/ja/api.html#Security実装は非常にシンプルで
order_type = maron.OrderType.LIMITと記述すれば指値注文が可能です。
そのあとカンマで希望の約定価格をlimit_priceに記述します。指値注文
まず、シグナルが出た日の終値の価格で指値注文をしてみます。
アルゴリズムはコチラ
handle_signal以下のオーダー方法を以下のようにします(利確5%,損切り−3%で設定)# 約定(買い) buy = market_sig[market_sig > 0.0] for (sym, val) in buy.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=maron.OrderType.LIMIT,limit_price = (current["close_price"][sym]), comment="SIGNAL BUY") #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) pass # 約定(売り) sell = market_sig[market_sig < 0.0] for (sym, val) in sell.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot,limit_price = (current["close_price"][sym]), comment="SIGNAL SELL") #ctx.logger.debug("SELL: %s, %f" % (sec.code(), val)) pass作成したアルゴリズムのファーストリテイリング社の取引状況をみてみましょう。
6月27日の終値の価格(50,580円)で注文を出し、翌日その価格で約定されていることがわかります。
ファーストリテイリングの株価
日付 始値 高値 安値 終値 前日比 前日比% 売買高(株) 18/06/29 51,160 51,450 50,640 50,910 -30 -0.1 605,600 18/06/28 50,670 50,980 49,690 50,940 +360 +0.7 647,200 18/06/27 49,990 50,690 49,880 50,580 +370 +0.7 551,400 18/06/26 50,960 51,030 50,190 50,210 -1,430 -2.8 695,400 前場寄成
同様の条件で、シグナルが出た日の始値の価格で成行注文をしてみます。
アルゴリズムはコチラ
handle_signal以下のオーダー方法を以下のようにします(利確5%,損切り−3%で設定)# 約定(買い) buy = market_sig[market_sig > 0.0] for (sym, val) in buy.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=maron.OrderType.MARKET_OPEN, comment="SIGNAL BUY") #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) pass # 約定(売り) sell = market_sig[market_sig < 0.0] for (sym, val) in sell.items(): if sym in done_syms: continue sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=maron.OrderType.MARKET_OPEN, comment="SIGNAL SELL") #ctx.logger.debug("SELL: %s, %f" % (sec.code(), val)) pass翌日のマーケットの始値の値で約定すると以下のように成ります。
6月28日の始値(50,670)で約定されていることがわかります。
ここで気づくかもしれませんが、成行注文では6月7日に買いの約定が執行されていますが指値では執行されていません。
以下の表に6月6日(買いシグナルが出た日)と6月7日(約定が執行された日)のファーストリテイリングの株価情報を載せます。
日付 始値 高値 安値 終値 前日比 前日比% 売買高(株) 18/06/07 48,550 49,490 48,550 49,190 +880 +1.8 793,500 18/06/06 47,490 48,500 47,220 48,310 +1,170 +2.5 608,700 指値注文では買いシグナルが出た終値(48,310円)で注文を出します。
しかし、翌日は始値(48,550円)、安値(48,550円)と始値の値を安値が切ることがありませんでした。
よって希望の約定価格になることがなく取引しなかったということになります。少し指値をいじってみる
先ほどの指値注文の条件を少し変えてみます。
シグナルが出た日の終値-10を指値としてみます.アルゴリズムはコチラ
変更した部分
sec.order(sec.unit() * 1, orderType=maron.OrderType.LIMIT,limit_price = (current["close_price"][sym]-10), comment="SIGNAL BUY")
先ほど50580円で約定されていたものが50570円で約定されました。
同タイミングで売りを出せば10×100=1000円の利益の違いが出ますね。まとめ
希望価格を自由に設定できるというのが利点だと思います。
シグナルが出た日の高値、安値でとってパラメータ調整すると面白いかもしれませんね。
ただ、成行注文と違ってキャッシュがあったとしても約定しないケースもあるので注意が必要ですね。宣伝
勉強会やってます!
日時:毎週金曜日19時〜
場所:神田 千代田共同ビル4階 SmartTrade社オフィス
内容:初心者(プログラミングってものを知らなくてもOK)向けに初心者(私とか)がこんな内容をハンズオン(一緒にやる事)で解説しています
備考:猛者の方も是非御鞭撻にいらして下さい、そして開発・伝導者になりましょう!もくもく会もやってます!
日時:毎週水曜日18時〜
場所:神田 千代田共同ビル4階 SmartTrade社オフィス
内容:基本黙々と自習しながら猛者の方に質問して強くなっていく会
備考:お菓子と終わりにお酒を飲みながら参加者と歓談できます!詳細はこちらです
週によっては開催されない週もあります。
また勉強会参加、もくもく会参加には基本的に事前に参加登録をしてください!
Pythonアルゴリズム勉強会HP:https://python-algo.connpass.com/
(connpassって言うイベントサイトに飛びます)ストアもあります
システムトレードの開発者が作ったアルゴリズムがQuantX Storeで販売されています!
詳細は以下のリンクから
https://quantx.io/免責注意事項
このコードや購入したアルゴリズム及び知識を使った実際の取引で生じた損益に関しては一切の責任を負いかねますので御了承下さい
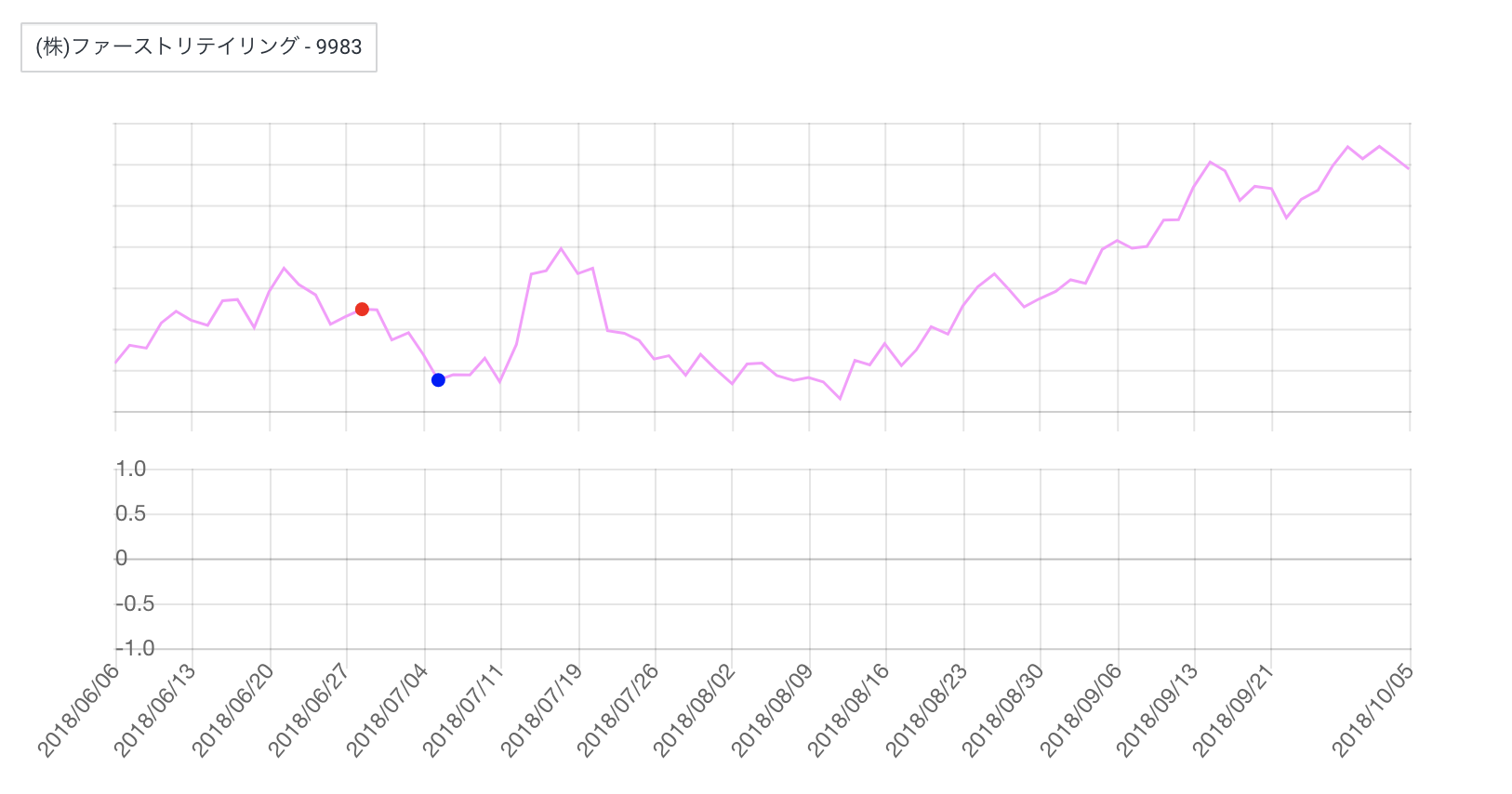

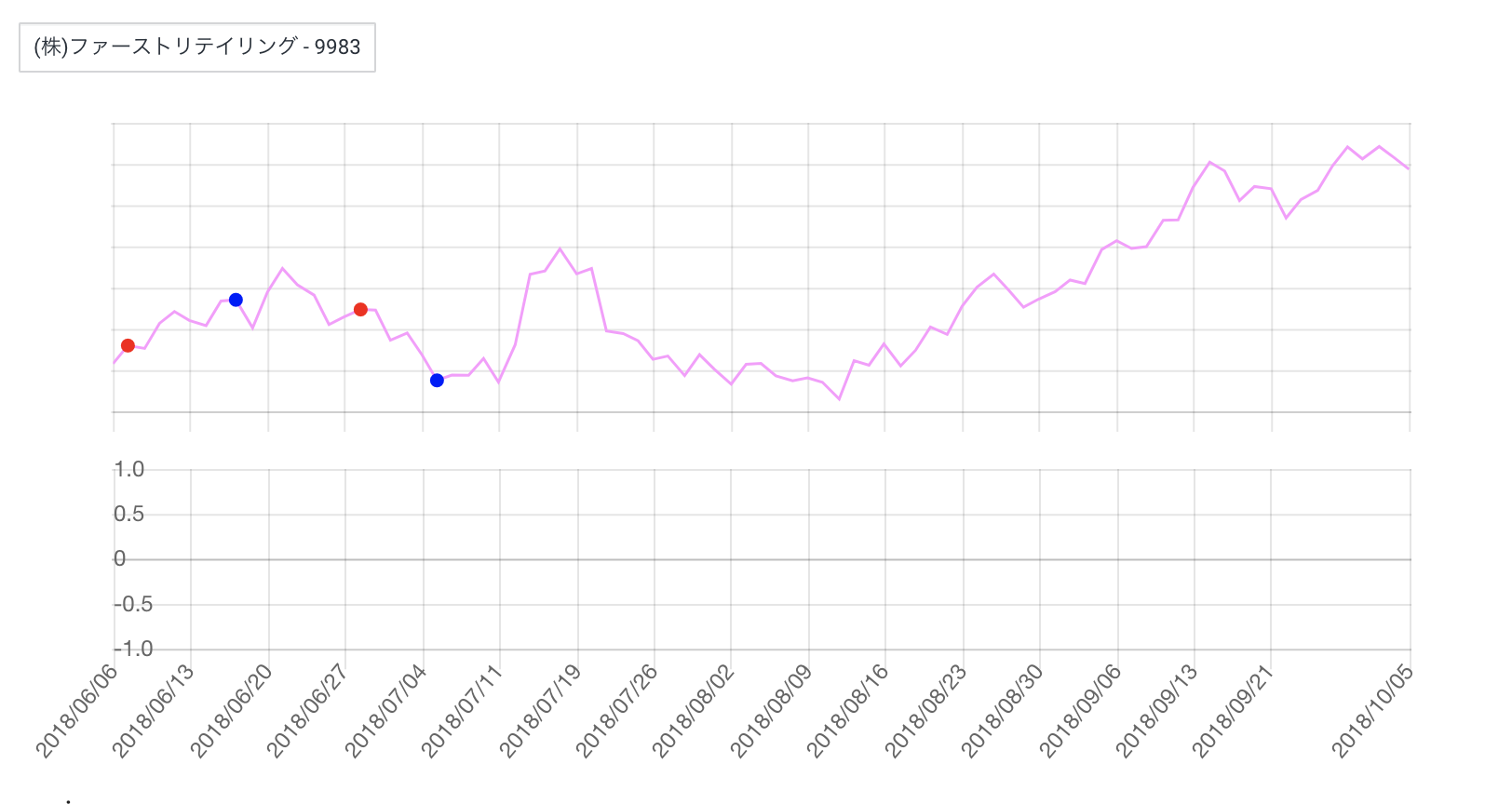
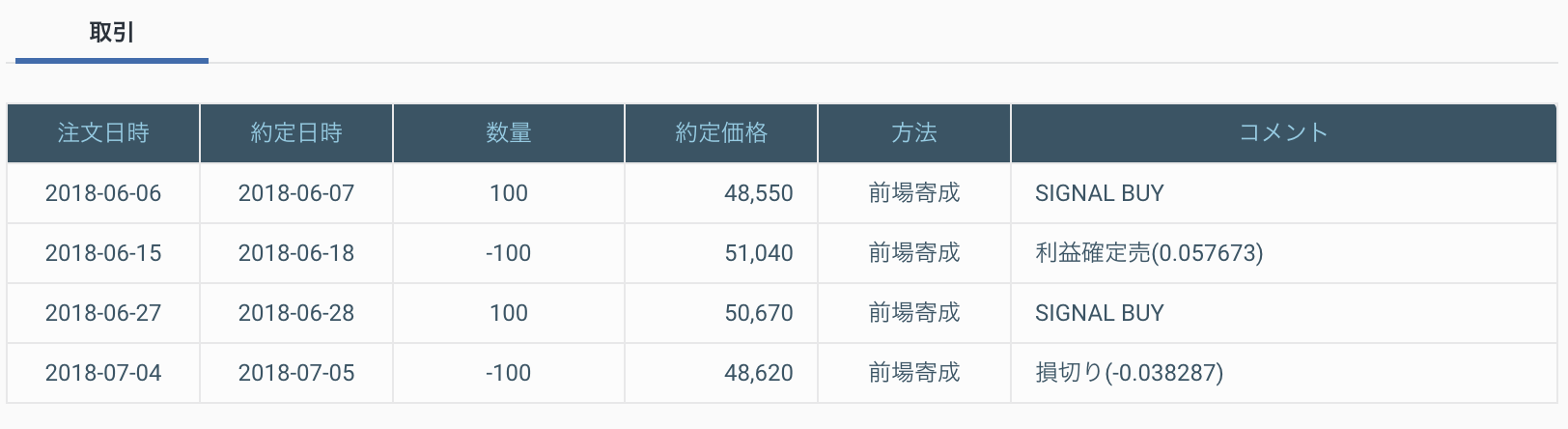

- 投稿日:2019-06-27T14:53:53+09:00
Python3 (Jupyter Notebook) で Google BigQuery を操作し, parquet 形式で保存
概要
データ分析を行う上で Python3 で Google BigQuery を操作することが多いです.
操作には下記の 2 つの手法が存在します.
- Python の BigQuery 連携ライブラリを使う
- Google Cloud Datalab を使う
今回は, Python の BigQuery 連携ライブラリを使う手法の内 pandas.io.gbq を使う手法について説明します.今回は Apache Parquet 形式で取ってきたデータを保存します.
Apache Parquet 形式とは
csvなどの行志向のデータフォーマットと違い、列志向のフォーマットで、列単位でデータを取り出す分析用途に向いています。この記事で他の形式との比較をしています. 特に大規模データファイルを圧縮する際に効率が良くなるのでビッグデータの分析データの保存に用いられます.
pandas.io.gbq ことはじめ
自分ははじめにこの記事を参考にして, pandas.io.gbq を使おうとしていましたが, 下記のエラーが発生し, 上手くいきませんでした.
GenericGBQException: Reason: 400 Invalid table name: `project.dataset.table` [Try using standard SQL (https://cloud.google.com/bigquery/docs/reference/standard-sql/enabling-standard-sql)].おそらく 2016 年の記事なので, 2019 年の仕様と異なってしまうことがエラーの原因であると考えられます.
さらにエラー文を読んでみると StandardSQL に設定できていないことが考えられるわけです.操作手法
以下の方法で Python から Google BigQuery を操作します.この方式を利用することにより, オンプレミス環境においてクエリを叩く回数を減らしコストを削減可能で, Parquetファイルとgzipを利用し圧縮効率をあげローカルに落とすデータの容量を削減することが可能です.
- ローカルに .parquet ファイル(データを保存したファイル)がないとき
- ローカル .sql ファイルを読み込む
- 読み込んだクエリで, BigQuery を叩く
- データフレームに格納する
- 列志向形式 (Apache Parquet) に圧縮して, .parquet 形式でローカルに保存する
- ローカルに .parquet ファイルがあるとき
- ローカルの .parquet ファイルを読み込む
- データフレームに格納する
コード説明
自分は下記のようなコードを書いて, 上の条件を満たすようにしました.
test.pynbimport os from google.cloud import bigquery import pandas as pd import pyarrow as pa import pyarrow.parquet as pq #parquetを入手,ある場合は取得しない filePath = "../input/test.parquet" sqlPath = "../script/test.sql" if(not os.path.isfile(filePath)): #1 with open(sqlPath, 'r') as fd: query = fd.read() #2 df = pd.read_gbq(query, 'project名', dialect='standard') #3 table = pa.Table.from_pandas(df) #4 pq.write_table(table, filePath, compression='gzip') #5 else: table = pq.read_table(filePath) #6 df = table.to_pandas() #7軽く説明すると,
- #1 では os ライブラリを用いて指定したパスにデータファイルがあるかないかを確認し, なかったら if 文内の処理に移行します
- #2 では #1 で指定されたパスの .sql ファイルから, クエリを変数 query に代入します.
- #3 では #2 で取得したクエリを BigQuery 上で実行します
- #4 では #3 で実行したクエリの結果をデータフレーム型に代入します.
- #5 では #4 で作ったデータフレームを parquet ファイルで gzip 形式に圧縮し保存します.
- #6 では指定されたパスにデータファイルがあったとき, table にロードします
- #7 では #6 でロードした table をデータフレーム型に変更します
実行結果
これを実行すると Jupyter Notebook 上で, 下記のような画面が出力されます.
リンクを踏み, 認証を行うことで, 認証コードが発行されます. そのコードを Jupyter Notebook 上のフォームに入力することで, Python3 の PandasGBQ で BigQuery を操作することができるようになります.
まとめ
以上より, Python を用いてGoogle BigQuery を操作することができます.また上記のようなコードを書くことで, コストを削減し, 圧縮効率をあげ, 効率よくデータを取ってくることが可能です.

- 投稿日:2019-06-27T14:53:53+09:00
Python3 (Jupyter Notebook) で Google BigQuery を操作し parquet 形式で保存
概要
データ分析を行う上で Python3 で Google BigQuery を操作することが多いです.
操作には下記の 2 つの手法が存在します.
- Python の BigQuery 連携ライブラリを使う
- Google Cloud Datalab を使う
今回は, Python の BigQuery 連携ライブラリを使う手法の内 pandas.io.gbq を使う手法について説明します.
今回の目標
BigQuery などのオンプレミス環境においてクエリを叩く回数を減らし, コストを削減することおよび, ローカル環境を圧迫しないようなデータの保持を行うことを目標にします. そのため Apache Parquet 形式で取ってきたデータを保存することにしました.
Apache Parquet 形式とは
csvなどの行志向のデータフォーマットと違い、列志向のフォーマットで、列単位でデータを取り出す分析用途に向いています。この記事で他の形式との比較をしています. 特に大規模データファイルを圧縮する際に効率が良くなるのでビッグデータの分析データの保存に用いられます.
pandas.io.gbq ことはじめ
自分ははじめにこの記事を参考にして, pandas.io.gbq を使おうとしていましたが, 下記のエラーが発生し, 上手くいきませんでした.
GenericGBQException: Reason: 400 Invalid table name: `project.dataset.table` [Try using standard SQL (https://cloud.google.com/bigquery/docs/reference/standard-sql/enabling-standard-sql)].おそらく 2016 年の記事なので, 2019 年の仕様と異なってしまうことがエラーの原因であると考えられます.
さらにエラー文を読んでみると StandardSQL に設定できていないことが考えられるわけです.操作手法
以下の方法で Python から Google BigQuery を操作します.この方式を利用することにより, オンプレミス環境においてクエリを叩く回数を減らしコストを削減可能で, Parquetファイルとgzipを利用し圧縮効率をあげローカルに落とすデータの容量を削減することが可能です.
- ローカルに .parquet ファイル(データを保存したファイル)がないとき
- ローカル .sql ファイルを読み込む
- 読み込んだクエリで, BigQuery を叩く
- データフレームに格納する
- 列志向形式 (Apache Parquet) に圧縮して, .parquet 形式でローカルに保存する
- ローカルに .parquet ファイルがあるとき
- ローカルの .parquet ファイルを読み込む
- データフレームに格納する
コード説明
自分は下記のようなコードを書いて, 上の条件を満たすようにしました.
test.pynbimport os from google.cloud import bigquery import pandas as pd import pyarrow as pa import pyarrow.parquet as pq #parquetを入手,ある場合は取得しない filePath = "../input/test.parquet" sqlPath = "../script/test.sql" if(not os.path.isfile(filePath)): #1 with open(sqlPath, 'r') as fd: query = fd.read() #2 df = pd.read_gbq(query, 'project名', dialect='standard') #3 table = pa.Table.from_pandas(df) #4 pq.write_table(table, filePath, compression='gzip') #5 else: table = pq.read_table(filePath) #6 df = table.to_pandas() #7軽く説明すると,
- #1 では os ライブラリを用いて指定したパスにデータファイルがあるかないかを確認し, なかったら if 文内の処理に移行します
- #2 では #1 で指定されたパスの .sql ファイルから, クエリを変数 query に代入します.
- #3 では #2 で取得したクエリを BigQuery 上で実行します
- #4 では #3 で実行したクエリの結果をデータフレーム型に代入します.
- #5 では #4 で作ったデータフレームを parquet ファイルで gzip 形式に圧縮し保存します.
- #6 では指定されたパスにデータファイルがあったとき, table にロードします
- #7 では #6 でロードした table をデータフレーム型に変更します
実行結果
これを実行すると Jupyter Notebook 上で, 下記のような画面が出力されます.
リンクを踏み, 認証を行うことで, 認証コードが発行されます. そのコードを Jupyter Notebook 上のフォームに入力することで, Python3 の PandasGBQ で BigQuery を操作することができるようになります.
まとめ
以上より, Python を用いてGoogle BigQuery を操作することができます.また上記のようなコードを書くことで, コストを削減し, 圧縮効率をあげ, 効率よくデータを取ってくることが可能です.
- 投稿日:2019-06-27T14:17:24+09:00
【Python】10行未満のコードで作る「インターバル通知」
はじめに
こんにちは。
今回は、Tkinterのmessageboxモジュールを使って、一定時間ごとに通知をしてくれるものを作っていきます。
この記事では一時間ごとに通知がくるようにしています。
これで時間間隔を意識しながら、作業を進めることができますね!こんな感じに通知がきます!
完成したプログラム
こちらが完成したプログラムになります。
IntervalAlert.pyimport tkinter as tk import tkinter.messagebox as mb import time win = tk.Tk() win.withdraw() #ウィンドウ非表示 while True: time.sleep(3600) #秒単位 mb.showinfo("通知","1時間経ったよ!!")実際に通知がくるかどうかを試してみるために、time.sleepに渡す引数を10にしてみてください。
10秒後に通知が来ましたか?ここまで読んでいただき、ありがとうございました。
- 投稿日:2019-06-27T14:04:55+09:00
EC2にgit、docker、docker-compose、pip、pythonコマンドをインストールする方法
EC2を立ち上げた際にやることを忘れがち&チームに共有としてメモしておきます。
準備まではQiitaの「(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまで」という記事がわかりやすかった。
コマンドのインストール
git
$ sudo yum install gitgitの連携方法は以下
# gotconfigを作成、編集 $ vi .gitconfig [user] name = your_name email = hoge@hoge.com # githubに公開鍵を登録するために公開鍵作成 $ chmod 700 ~/.ssh $ cd ~/.ssh $ ssh-keygen -t rsaあとは、Github/Gitlabに公開鍵を登録してcloneするだけ。
docker
# yum の更新 $ sudo yum update -y # yum から docker をインストール $ sudo yum install -y docker # docker サービスの起動 $ sudo service docker start # ec2-user を docker グループに追加する $ sudo usermod -a -G docker ec2-user # ログインしなおして以下を実行しインストールされていることを確認 $ docker infodocekrコマンドをsudo無しで実行する場合は以下を実行
# dockerグループがなければ作る $ sudo groupadd docker # 現行ユーザをdockerグループに所属させる $ sudo gpasswd -a $USER docker # dockerデーモンを再起動する (CentOS7の場合) $ sudo systemctl restart docker # exitして再ログインすると反映される。 $ exitdocker-compose
$ sudo curl -L "https://github.com/docker/compose/releases/download/1.23.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose $ sudo chmod +x /usr/local/bin/docker-compose $ docker-compose --version他のリンクにしたい場合以下から探す
https://github.com/docker/compose/releases/byobu
$ sudo yum update -y $ wget https://launchpad.net/byobu/trunk/5.119/+download/byobu_5.119.orig.tar.gz $ tar xzf byobu*.tar.gz $ cd byobu-* && ./configure $ sudo make && sudo make installpip
$ curl -O https://bootstrap.pypa.io/get-pip.py $ python get-pip.py --user # or python3python
# 依存関係インストール $ sudo yum install gcc zlib-devel bzip2 bzip2-devel readline readline-devel sqlite sqlite-devel openssl openssl-devel -y # 本体インストール $ pyenv install 3.6.5 # このOSで使用するPythonのバージョンを宣言 $ pyenv global 3.6.5 $ pyenv rehash $ python --version
- 投稿日:2019-06-27T13:44:35+09:00
awscli を pip でインストールするときは Python 3 を使ってください
Python 2 は 2020-01-01 に EOL を迎えます。
しかし、いまだに PyPI からのダウンロードの50%強は Python 2 からのものです。
from PyPI Statsこの膨大なPython 2からのダウンロード数は、 Python のライブラリをメンテナンスしている人たちに Python 2 のサポートを続けさせるプレッシャーになっています。 Python 2 の EOL までにこのダウンロード数をなるべく下げたいところです。
だれがこんなに Python 2 で
pip installをしているのでしょうか。OS別ダウンロード数統計にヒントがあります。
過半数の Python ユーザーが macOS か Windows を使っているのに対して、ダウンロードの90%くらいが Linux からのものです。 CI, CD, サーバーのプロビジョニングで実行される
pip installが多いのでしょう。ではどのパッケージが多くダウンロードされているのでしょうか。 PyPI Stats のランキング を見てみましょう。
トップ20のうち、pip とその依存ライブラリである setuptools を除いた 18 パッケージは、 awscli かその依存パッケージです!
そして awscli パッケージの 80% 以上が Python 2 から
pip installされています!!もし多くの人に読まれているドキュメントや Dockerfile のサンプルなどで awscli を Python 2 から pip install しているのを見かけたら、この記事か 英語版 のURLを紹介して Python 3 に移行するように提案してみてください。
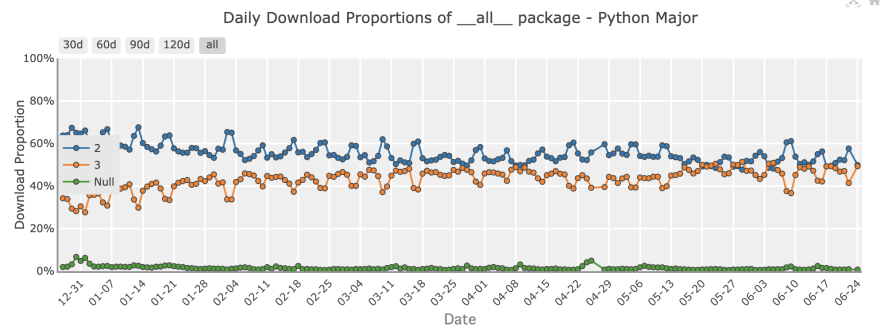
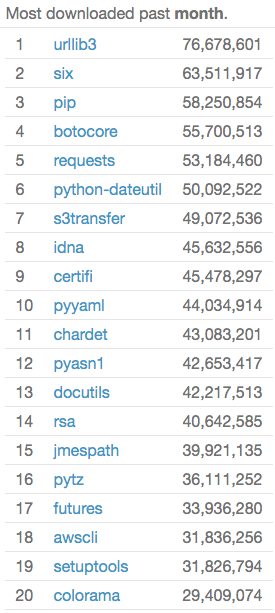
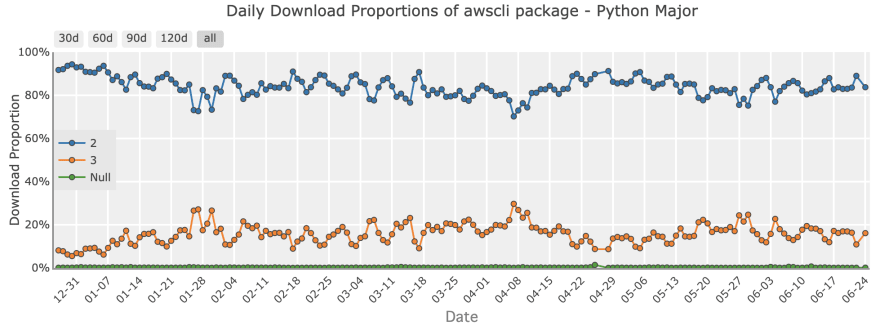
- 投稿日:2019-06-27T13:33:05+09:00
anacondaでcondaするときにHTTPErrorが出るのそれproxyの問題じゃない??
それproxyが悪さしてるんじゃない?
$ conda install -c anaconda pydot -y CondaHTTPError: HTTP 000 CONNECTION FAILED for url <~~~~~~> An HTTP error occurred when trying to retrieve this URL. HTTP errors are often intermittent, and a simple retry will get you on your way. If your current network has https://www.anaconda.con blocked, please file a support request with your network engineering team. ConnectTimeout(MaxRetryError(.......別にインターネットはhttp://anaconda.com をブロックしているわけでもない.
proxyは設定しているはずなのにcondaのインストールが通らない…….もしかして:proxy
設定してると思いきや設定してないことがある
謎のHTTPErrorに悩まされている場合は,一度.condarcファイルを確認してほしい.proxy設定が別にあるってマジ?
anacondaでは環境設定とは別に,condaとしてproxyを設定する必要があるみたい.
なんだそのクソ仕様.condarcを探す or 作る
anacondaの設定ファイル.condarcにproxyの設定を書き込む.
anacondaのルート直下に作るのが正しい.
windowsであれば通常ユーザールートの直下にAnaconda3のディレクトリC:\Users\[ユーザー名]\Anaconda3があるのでそこに.condarcを作るか,すでにあれば追記する.
Unix系OSは/opt/conda/の下に作るか追記する.無ければ適当なエディタ1で作成してください.
.condarcを記述する
.condarcproxy_servers: http: http://[ユーザ名]@[ホスト名]:[ポート番号] https: http://[ユーザ名]@[ホスト名]:[ポート番号] # 例 http: http:keisuke@hoge.jp:8080dockerでanacondaを使っている場合は,毎回記述するのがめんどくさいのでDockerfileに直接
DockerfileRUN echo 'proxy_servers:\n http: http://[ユーザ名]@[ホスト名]:[ポート番号]\n https: http://[ユーザ名]@[ホスト名]:[ポート番号] >> /opt/conda/.condarcとか書くといい.
終わりに
死ぬほどはまって時間を溶かした.
windowsのプロキシ設定をしているとhttpだけ書いてくれていたりする.なんだその微妙な仕様はそもそもanacondaを使うやつが悪いって?それはそう……(研究室の都合です)
メモ帳はエディタではない ↩
- 投稿日:2019-06-27T13:12:09+09:00
pythonで文字列リストをnp.arrayに変換する時の速度比較
概要
自然言語処理などでは、文や文書を分散表現に変換する際、文字列のリストに単語ベクトルを適用して変換する必要がある。
これをできるだけ速く行いたいので、速度比較して見た。
方法はこのページを参考にした問題設定・評価
jupyterの
%%timeitで評価をおこなった
擬似問題として以下を用意し、足し合わせが最も速くなるものを比較したa = ['a', 'b', 'c'] b = {'a': np.arange(3), 'b': np.ones(3), 'c': np.zeros(3)}各種実行方法
for文
%%timeit c = np.zeros(3) for x in a: c += b[x]内包表記
%%timeit np.add.reduce(np.array([b[x] for x in a]))map
%%timeit np.add.reduce(np.array(list(map(lambda x: b[x], a))))np.frompyfunc
def d(x): return b[x] f = np.frompyfunc(d, 1, 1)%%timeit np.sum(f(a))結果
何と、普通にfor文が速いという結果になった。
- for文:5.78 µs ± 39.8 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
- 内包表記:7.24 µs ± 189 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
- map:8.02 µs ± 500 ns per loop (mean ± std. dev. of 7 runs, 100000 loops each)
- np.frompyfunc:18 µs ± 766 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
- 投稿日:2019-06-27T13:05:18+09:00
Python の時間計測便利ツール
Motivation
python であるメソッドとか処理の一部分とかを計測するのに、毎回
start = time.time() some_process() end = time.time() print('process time = {} [sec]'.format(end - start))とかってしてたんだけど、いい加減面倒になってきたのでデコレータ作って
@stop_watch def some_process(...): ...ってしたり、
__enter__と__exit__を実装したクラス作ってwithステートメントでwith TimeMeasure(): ...ってしたいなぁーって思ってた。
まぁそれ自体はすぐできて、せっかくだから公開しようかなーって思ったところで、laudaというツールを見つけた。github にソースがあったので、覗いてみたら自分で実装したものとほとんど同じだったので、そちらのツールを使うことにした。Installation
https://github.com/astagi/lauda
$ pip install laudaHow to Use
使い方は大きくわけて
decoratorでメソッドをラップするか、withステートメントで囲うかの 2通り。Decorator
stopwatchをインポートして、デコレーションするだけ。from lauda import stopwatch @stopwatch def some_process(): ...ちなみに callback を引数に取るので、次のように表示を変更したりできる。
import time from lauda import stopwatch def print_fn(watch, function): print ('{0}秒もかかっちゃった'.format(watch.elapsed_time)) @stopwatch(callback=print_fn) def some_process(): time.sleep(1) some_process() # => 1.0046770572662354秒もかかっちゃったWith statement
こちらは
withで対象部分を囲うだけ。from lauda import stopwatchcm with stopwatchcm(): some_process()Conclusion
世の中には便利ツールがたくさん埋もれている。
- 投稿日:2019-06-27T12:54:53+09:00
Python 3.8 に追加した per opcode cache について
Python 3.8 に導入1した LOAD_GLOBAL 命令用の per-opcode cache について紹介します。
LOAD_GLOBAL 命令
Python のグローバル変数のロードはローカル変数のロードに比べて遅いです。そのためにグローバル変数に繰り返しアクセスする場合は一旦ローカル変数に格納するというテクニックがあったりします。
$ python3 -m timeit -s ' > def foo(): > for _ in range(1000): > sum > ' -- 'foo()' 10000 loops, best of 5: 29.9 usec per loop $ python3 -m timeit -s ' def foo(): _sum = sum for i in range(1000): _sum ' -- 'foo()' 20000 loops, best of 5: 16.7 usec per loopこの例では速度比は2倍弱ですが、これはループのオーバーヘッドを含んでいるので、ロード命令単体での速度比は3倍くらいはあります。
ローカル変数は関数をコンパイルする時に整数のインデックスがつけられ、ローカル変数用の配列からそのインデックスでアクセスしているので高速です。
>>> def foo(): ... s = 1 ... s ... >>> import dis >>> dis.dis(foo) 2 0 LOAD_CONST 1 (1) 2 STORE_FAST 0 (s) 3 4 LOAD_FAST 0 (s) # 0 番目のローカル変数をロードする命令 6 POP_TOP 8 LOAD_CONST 0 (None) 10 RETURN_VALUE一方、グローバル変数をロードは次のように実現されています。
- コンパイル時に名前一覧の配列が作られる
- LOAD_GLOBAL 命令の引数に名前のインデックスが渡される
- 名前一覧配列からインデックスアクセスで名前を取り出す
- その名前をモジュールのグローバル変数 dict から探索する
- (存在しなかった場合)ビルトイン変数 dict から探索する
>>> def foo(): ... sum ... >>> dis.dis(foo) 2 0 LOAD_GLOBAL 0 (sum) # 0番目の名前 (="sum") でグローバル変数をロードする 2 POP_TOP 4 LOAD_CONST 0 (None) 6 RETURN_VALUE >>> foo.__code__.co_names # 名前一覧配列 ('sum',)配列アクセスよりも遅いdict の探索を多ければ2回実行するのでグローバル変数アクセスには時間がかかってしまいます。
dict のバージョン
Python 3.6 で dict の実装を変更したタイミングで、
ma_versionという変数が dict に追加されました。グローバルなカウンタを dict を変更するたびにインクリメントし、それを ma_version にセットするという実装になっています。そのため、別の dict や、同じ dict でも何かが変更されていると ma_version は異なります。これを使ってグローバル変数dictとビルトイン変数dictのバージョンを覚えておけば、2回目以降は前回の探索結果を再利用できます。
per opcode cache
LOAD_GLOBAL 命令だけを高速化したい場合は LOAD_GLOBAL 命令の引数でアクセスされる名前一覧配列のインデックスをキーにキャッシュを実装することもできます。しかし今後他の命令にもキャッシュを実装することを考えて、 per opcode cache (opcache) を実装しました。
Python の opcode は一命令あたり2バイト (word code とも呼ばれます) になっています。関数が1000回実行された時にキャッシュ用の領域を確保します。キャッシュは比較的大きいデータが必要になる2ので、1命令あたり1バイトのインデックステーブルをこのときに作成します。最終的に 命令数1 + LOAD_GLOBAL命令数(キャッシュエントリサイズ) バイトの領域を利用します。
効果
$ local/py38/bin/python3 -m timeit -s ' > def foo(): > for _ in range(1000): > sum > ' -- 'foo()' 10000 loops, best of 5: 20.4 usec per loop $ local/py38/bin/python3 -m timeit -s ' > def foo(): > _sum = sum > for _ in range(1000): > _sum > ' -- 'foo()' 20000 loops, best of 5: 18.1 usec per loop違う条件でコンパイルしたバイナリなので最初の Python 3.7 の結果と直接は比較できませんが、ローカル変数アクセスとの違いがかなり小さくなっているのが分かります。高速化のために一旦ローカル変数に置いておくというテクニックはあまり推奨されなくなっていくでしょう。
実際のライブラリを利用したベンチマークスイート (pyperformance) の結果はこのキャッシュ導入前後でこうなっています。
$ ./cpython/python -m perf compare_to master.json opcache_load_global.json -G --min-speed=2 Slower (2): - pickle: 19.1 us +- 0.2 us -> 19.7 us +- 0.8 us: 1.03x slower (+3%) - unpickle_list: 8.66 us +- 0.04 us -> 8.85 us +- 0.06 us: 1.02x slower (+2%) Faster (23): - scimark_lu: 424 ms +- 22 ms -> 384 ms +- 4 ms: 1.10x faster (-9%) - regex_compile: 359 ms +- 4 ms -> 330 ms +- 1 ms: 1.09x faster (-8%) - django_template: 250 ms +- 3 ms -> 231 ms +- 2 ms: 1.08x faster (-8%) - unpickle_pure_python: 802 us +- 12 us -> 754 us +- 9 us: 1.06x faster (-6%) - pickle_pure_python: 1.04 ms +- 0.01 ms -> 991 us +- 15 us: 1.05x faster (-5%) - hexiom: 20.8 ms +- 0.2 ms -> 19.8 ms +- 0.1 ms: 1.05x faster (-5%) - logging_simple: 18.4 us +- 0.2 us -> 17.6 us +- 0.2 us: 1.05x faster (-4%) - sympy_expand: 774 ms +- 5 ms -> 741 ms +- 3 ms: 1.04x faster (-4%) - json_dumps: 28.1 ms +- 0.2 ms -> 27.0 ms +- 0.2 ms: 1.04x faster (-4%) - logging_format: 20.4 us +- 0.2 us -> 19.6 us +- 0.3 us: 1.04x faster (-4%) - richards: 147 ms +- 2 ms -> 141 ms +- 1 ms: 1.04x faster (-4%) - meteor_contest: 189 ms +- 1 ms -> 182 ms +- 1 ms: 1.04x faster (-4%) - xml_etree_iterparse: 226 ms +- 2 ms -> 217 ms +- 2 ms: 1.04x faster (-4%) - sympy_str: 358 ms +- 3 ms -> 345 ms +- 4 ms: 1.04x faster (-4%) - sqlalchemy_imperative: 44.0 ms +- 1.2 ms -> 42.4 ms +- 1.2 ms: 1.04x faster (-4%) - sympy_sum: 167 ms +- 1 ms -> 161 ms +- 1 ms: 1.04x faster (-4%) - nqueens: 217 ms +- 1 ms -> 211 ms +- 1 ms: 1.03x faster (-3%) - fannkuch: 1.09 sec +- 0.01 sec -> 1.07 sec +- 0.00 sec: 1.03x faster (-3%) - raytrace: 1.11 sec +- 0.02 sec -> 1.08 sec +- 0.01 sec: 1.03x faster (-3%) - dulwich_log: 122 ms +- 1 ms -> 119 ms +- 1 ms: 1.03x faster (-3%) - logging_silent: 419 ns +- 5 ns -> 410 ns +- 5 ns: 1.02x faster (-2%) - sympy_integrate: 33.5 ms +- 0.1 ms -> 32.8 ms +- 0.2 ms: 1.02x faster (-2%) - pathlib: 40.8 ms +- 0.4 ms -> 40.0 ms +- 0.5 ms: 1.02x faster (-2%)今後について
LOAD_GLOBALよりも動作が複雑で難しいのですが、属性アクセスのLOAD_ATTR, LOAD_METHODに対するキャッシュは実現したいです。
他には
{"a": foo(), "b": bar()}のようにキーが文字列だけで構成された dict display を構築する CONST_MAP_KEY という命令があるのですが、この命令を使う時にハッシュテーブルを毎回構築するのではなく構築済みのハッシュテーブルから dict を高速に作成するようにするアイデアもあります。一方で、1000回実行したらキャッシュを構築するという今のやり方はシンプルすぎるのでその辺の改良は必要になってくるかもしれません。
- 投稿日:2019-06-27T11:35:11+09:00
CentOSへPython、pipをインストール
書いてあること
- CentOSへのPython、pipのインストール手順
環境
- CentOS Linux release 7.6.1810 (Core)
- Python
- pip
リポジトリを作成
バージョン番号(安定版)を確認
リポジトリを作成
bash$ yum install -y https://centos7.iuscommunity.org/ius-release.rpmリポジトリが作成されたことを確認
bash$ ls -l /etc/yum.repos.dリポジトリからインストール可能なバージョンを確認
最新の安定版は3.7だったが、この時点でリポジトリからインストール可能なのは3.6
bash$ yum search python37 警告: 一致するものが見つかりません: python37 No matches found $ yum search python36インストール
Pythonをインストール
bash$ yum install -y python36u python36u-libs python36u-devel python36u-pippipを最新バージョンにアップグレード
bash$ python3.6 -m pip install --upgrade pipバージョン確認
bash$ python3.6 --version $ python3.6 -m pip --versionエイリアス
3.6と毎回打つのが若干面倒な場合はエイリアス登録
エイリアス登録
bashalias puthon3='python3.6'エイリアス削除
bashunalias puthon3参考
注意
CentOSはデフォルトでPython2.7をインストール済だが、yumコマンド等でPythonを利用しているため削除しないこと!
- 投稿日:2019-06-27T11:28:21+09:00
Discord.py(rewrite版)の使い方メモ(順次追加)
プログラム初心者向けのDiscord.pyの使用方法メモ
APIリファレンスをできるだけ初心者に分かりやすいレベルまでかみ砕いて書いてみる。簡単な例のコードも書いておく。暇なときに追加していく。
バージョン
- discord.py 1.2.3
- Python 3.7.x
イベントリファレンス
Discord上である特定の動作が行われたとき、これらが呼ばれる。
APIリファレンスと同じ順番で記述していく。
推奨されていないものや、使いどころが無さそうなものは飛ばすかも。discord.on_connect()
botがDiscordサーバーに接続できたときに呼ばれる。
discord.on_connect()@client.event async def on_connect(): print("Connection OK")discord.on_disconnect()
botがDiscordから切断したときに呼び出される。
discord.on_disconnect()@client.event async def on_disconnect(): print("Bye")discord.on_ready()
on_connectと違う点は、
- on_connect「とりあえず目的のサーバーと通信ができたよ~!」
- on_ready「準備万端だから、botくんいつでも動いていいよ~!」 って感じのイメージ
discord.on_ready()@client.event async def on_ready(): print("ready")discord.on_shard_ready(shard_id)
on_ready()とほぼ一緒。いろんなサーバー(1000個くらい?)でbotが使われる場合はこれ使ったほうがいいらしい。使ったことがないのでわからん。
discord.on_error(event, *args, **kwargs)
discordサーバー側のエラーをこれでキャッチできるんだと思う。
discord.on_error()@client.event async def on_error(e): print(e) #エラーの名前表示discord.on_typing(channel, user, when)
ユーザーにタイピング中ですよ~っていうマークが付いてるときにこれが呼び出される。
パラメータ
- channel (abc.Messageable) -- 入力が行われたチャンネル。 TextChannel,DMChannel, GroupChannelのいずれかのオブジェクトを返す。
- user (Union[User, Member]) -- 入力を始めたユーザー。Userオブジェクト、Memberオブジェクトの集合を返す。
- when (datetime.datetime) -- 入力が開始された時刻。UTC時間でdatetime型のオブジェクトを返す。
以下の例ではchannelがTextChannelの場合
discord.on_typing()@client.event async def on_typing(channel, user, when): if channel.__class__.__name__ is "TextChannel": #入力しようとしているところがテキストチャンネルなら print(channel.name) #ユーザーが入力しようとしているチャンネル名 print(user.id) #タイピング中のユーザーのID print(when)#UTCになっているので、日本時間なら+9時間してdiscord.on_message(message)
誰かがメッセージを送信したときに呼ばれる。自分がメッセージを送信した際も呼ばれるため、無限ループしてしまう処理には注意。
パラメータ
- message (Message)
discord.on_message(message)@client.event async def on_message(message): if client.user != message.author: #ここで自分以外の送信者に絞る。 if message.content is "こんにちは": #message.contentで本文を取得。本文が「こんにちは」なら await message.channel.send(f'{message.author.mention} うるさい') #送信者に「うるさい」と発言discord.on_message_delete(message):
誰かがメッセージを削除したときに呼ばれる。(bot起動前のmessageを削除した場合は呼ばれない。要はbotを起動してからのメッセージのみ反応する。)
パラメータ
- message (Message)
discord.on_message_delete(message)@client.event async def on_message_delete(message): print(f'{message.author} deleted {message.content}')discord.on_bulk_message_delete(messages)
複数のメッセージを一気に削除したときに呼ばれる。bot起動前のmessageを削除した場合は呼ばれない。 削除されたメッセージのリストを渡してくれる。
パラメータ
- messages (List[message])
on_bulk_message_delete(messages)@client.event async def on_bulk_message_delete(messages): for x in messages: print(i.content+" :Deleted\n")discord.on_raw_message_delete(payload)
メッセージを削除したとき呼ばれる。bot起動前のmessageを削除した場合も呼ばれる。
パラメータ
- payload (RawMessageDeleteEvent)
discord.on_raw_message_delete(payload)@client.event async def on_raw_message_delete(payload): print(payload.cached_message.content)discord.on_raw_bulk_message_delete(payload)
メッセージを一括削除したとき呼ばれる。bot起動前のmessageを削除した場合も呼ばれる。
パラメータ
- payload(RawBulkMessageDeleteEvent)
discord.on_raw_bulk_message_delete(payload)@client.event async def on_raw_bulk_message_delete(payload): for x in payload.cached_messages: print(x.content)discord.on_message_edit(before, after)
メッセージが以下の更新を受け取ったときに呼ばれる。
- メッセージをピン留め、または解除した。
- メッセージの内容を変更した。
- メッセージが埋め込みを受け取った。
- 通話呼び出しメッセージの参加者や終了時刻が変わった。
編集されたメッセージがbot起動前のものの場合は呼び出されない。
パラメータ
- before (Message) -- 更新前のメッセージ。
- after (Message) -- 更新後のメッセージ。
discord.on_message_edit(before,after)@client.event async def on_message_edit(before, after) if before.content != after.content: await message.channel.send("メッセージが変更されました。")discord.on_raw_message_edit(payload)
メッセージが編集されたときに呼び出される。編集されたメッセージがbot起動前のものでも呼び出される。
メッセージが見つかった際はpayload.cached_messageでMessageにアクセスできる。discord.on_raw_message_edit(payload)@client.event async def discord.on_raw_message_edit(payload): if payload != None: payload.cached_message.channel.send("メッセージが変更されました")discord.on_reaction_add(reaction, user)
メッセージにリアクションが追加された際に呼ばれる。botが起動前のメッセージでは呼び出されない。
リアクションの付いたメッセージにアクセスしたい場合は reaction.messagediscord.on_reaction_add(reaction,user)@client.event async def on_reaction_add(reaction, user): message = reaction.message print(message.content) #リアクションをつけたメッセージを表示 if reaction.emoji == u"\U0001F4CC": #リアクションがピンマークなら await message.pin()
以下はそのうち追記
discord.on_raw_reaction_add(payload)
discord.on_reaction_remove(reaction, user)
discord.on_raw_reaction_remove(payload)
discord.on_reaction_clear(message, reactions)
discord.on_raw_reaction_clear(payload)
discord.on_private_channel_create(channel)
discord.on_private_channel_update(before, after)
discord.on_private_channel_pins_update(channel, last_pin)
discord.on_guild_channel_create(channel)
discord.on_guild_channel_update(before, after)
discord.on_guild_channel_pins_update(channel, last_pin)
discord.on_guild_integrations_update(guild)
discord.on_member_join(member)
discord.on_member_remove(member)
discord.on_member_update(before, after)
discord.on_user_update(before, after)
Q & A
- Q. リアクションとかの絵文字(emoji)はどうやって出力したり判定すればいいの?
- A. ここでemojiを検索してUnicode文字列を取得してください。検索すると
Python source codeという欄があるのでそれを使うと楽です- Q. なんかほかのサイトと書き方が違うような気がする。例えば、メッセージを送信する際に他の記事では
client.send_message(message.channel,"送りたいメッセージ")となっているのに、ここではclient.channel.send("送りたいメッセージ")みたいになってる。
- A. バージョンの違いです。前者の書き方は古いバージョンで用いられます。今回紹介しているのは新しいrewrite版のものです。
- 投稿日:2019-06-27T11:10:46+09:00
競プロであったら嬉しいと思ったスニペットのまとめ
はじめに
競プロやっててほしいなと思ったスニペットとかをまとめて行くつもりです。そのうち増えていく予定です。
メインがPythonサブがC++なので、基本Pythonで書いていきますが余裕があったらC++のコードも足して行こうと思います。また、全境界条件等検討できているとは限らないので責任はおえません。あしからず。
GCD(最大公約数),LCM(最小公倍数)
最大公約数はユークリッドの互除法によって構成します。LCMは2数の積/最大公約数です。
2数に関してのGCD及びLCMを繰り返すことで配列で与えた整数群に関してのGCD,LCMを計算します。def gcd_core(a, b): if b == 0: return a else: return gcd_core(b, a % b) def gcd(arr): g = gcd_core(arr[0], arr[1]) for i in range(2, len(arr)): g = gcd_core(g, arr[i]) return g def lcm_core(a,b): g = gcd_core(a,b) return (a*b)//g def lcm(arr): l = lcm_core(arr[0],arr[1]) for i in range(2,len(arr)): l = lcm_core(l,arr[i]) return lUnion-Find木(連結要素)
UF木です。経路圧縮などは根をたどるときのつなぎ直ししか入れていないため、もっと最適化が必要な場面が出てくるかもしれません。indep()で連結要素の数を数えることができます。ノードが1 indexから始まる場合はn+1でインスタンスを作成して、ノード0を捨てます。
class uf_tree(): def __init__(self,n): self.n = n self.par = [i for i in range(n)] def indep(self): dep =0 for i in range(self.n): if i == self.par[i]: dep += 1 return dep def unite(self,child,mas): if self.root(child) == self.root(mas): return else: self.par[self.root(child)] = self.root(mas) def root(self,i): if self.par[i] == i: return i else: self.par[i] = self.root(self.par[i]) return self.par[i] def same(self,x,y): if self.root(x) == self.root(y): return True else: return False
- 投稿日:2019-06-27T10:27:08+09:00
業界初!Webデータを自動収集できるWebスクレイピングテンプレート
今では、副業としてAmazonと楽天市場に出店している人がたくさんいるでしょう。Amazonの販売者だった場合、競合店がどのような価格で同様の製品を販売しているのかを調査しなければなりませんね。Amazonデータベースに直接アクセスすることはできないので、出品者と価格のテーブルを作成するためにすべてのページを閲覧する必要があります。もちろん、Pythonを書いて、製品名、レビュー、価格などのような望ましい情報を抽出するためにスクレイピングロボットを作ることもできます。しかし、プログラミング技術を持っていない販売者にとって、Webから有用なデータを取得するためのコーディング方法を学ぶことは、自分の能力を遥かに超えています。
もしパワーポイントテンプレートのようにWebスクレイピングにもテンプレートがあれば、対象となるWebサイトのテンプレートを選択して、収集したいデータを選択してスクレイピングを開始できますよね。そこはOctoparseの出番です。Octoparseは業界初の革新的なWebスクレイピングテンプレートという機能をリリースしました。
Octoparseについて
Octoparseは、初心者から高級者向けのWebスクレイピングツールです。直感的に操作できる操作画面、コーディングせず簡単なポイントアンドクリック操作をして、Webサイトからすべてのテキストを収集ことが可能です。取得したデータはExcel、HTML、CSV、またはご指定のデータベースのような構造化フォーマットに保存されます。
Webスクレイピングテンプレートとは?
Webスクレイピングテンプレートは非常にシンプルで強力な機能です。テンプレートを使うと、プログラミング知識の少ない/ない人でも簡単にWebスクレイピングを達成できます。具体的には、Octoparseのソフトには数十種類のあらかじめ作成されたテンプレートがあり、パラメータ(ターゲットWebサイトのURL、検索キーワードなど)を入力するだけで、データが抽出されてきます。そのため、スクレイピングタスクやコードを書く必要はありません。例えば、eBayで「イヤフォン」に関する製品情報を収集したい場合は、パラメータに「イヤフォン」と入力してタスクを実行して、数秒でアイテム番号、価格、送料などを含む製品情報を得ることができます。
なぜテンプレートモードが特別なの?
Webクローラーを作成するのにどれほどの技術スキルが必要でしょうか?新しくリリースされたWebスクレイピングテンプレートでは「必要なし」です。伝統的なWebスクレイピング手法では、1つのWebクローラーを完成させるためにPythonを学ぶ必要があります。しかし、Pythonの学習にはかなり時間がかかります。例えば、Pythonの書くことを、Adobe Photoshopを使って写真を編集するようなものだと考えてみてください。VSCOのような写真加工アプリと比べると、Adobe Photoshopはパラメータのセットが非常に複雑です。OctoparseのWebスクレイピングテンプレートは、Webスクレイピングに苦労している人々のためのソリューションです。必要あるのはWebサイトのURLを入力することだけです。それからの作業はOctoparseが全部やります。
これは誰向けなの?
誰でも!はい、データを迅速かつ簡単に入手したい人のために。この時点でテンプレートはAmazon、Instagram、Twitter、YouTube、楽天市場、Googleマップなど多くの人気サイトがカバーされています。
ほかのWebスクレイピングツールと比べてOctoparseの特徴は?
- Octoparseは、内蔵ブラウザを介して、データを閲覧、検索、抽出するという人間の操作をシミュレートします。スクロールダウン、実行前の待機などの高度な設定により、抽出プロセス全体が人間化されて順調になります。
- Webサイトにブロックを回避するために、Octoparseはプロキシサーバー、IPローテーション、ユーザーエージェント、CAPTCHA回避、Cookieクリアなどを提供して、Webスクレイピングの中断を防止します。
- 抽出時間と頻度を設定することで、定期のスクレイピング作業をOctoparseに任せることができます。あるいは、クラウド上でタスクを実行して、ローカルリソース(パソコンのメモリーやIPなど)を占有しないようにすることもできます。
- Octoparse内蔵の正規表現ツールで抽出したデータを再フォーマットすることができ、XPathツールは、プログラミングに詳しくない人のために要素を正確に見つけることができます。
本当の意味での自動Webスクレイピングを実現するために、Octoparseチームはデータをより入手しやすくし、誰でも利用できるように取り込んでいます。ビッグデータの時代では、誰でもビッグデータの力を利用するためにデータを収集するスキルを身に付けるべきです。正確なデータベースがあれば、データ分析、マーケティング戦略、センチメント分析、広告キャンペーン、見込み顧客の生成などを実行できます。
- 投稿日:2019-06-27T09:09:41+09:00
これ知らないデータサイエンティストって損してんなって思う汎用的なツール
教えてください。
これ知らないプログラマって損してんなって思う汎用的なツールみたいな感じで。
- 投稿日:2019-06-27T06:56:56+09:00
【Python】Juman × PyKNPで解析結果から引用符(")が消える。
実行環境$ python3 -V Python 3.6.4 $ pip3 show pyknp Name: pyknp Version: 0.4.1 $ juman -v juman 7.01引用符が消える
以下のようなPythonスクリプトで分かち書きを行なった。
tokenizer.pyfrom pyknp import Juman t = Juman(jumanpp=False) text = "彼は\"Hello!\"と言った。" print("Input : {}".format(text)) tokens = [token.midasi for token in t.analysis(text).mrph_list()] print("Tokenized : {}".format(tokens))実行結果$ python3 tokenizer.py Input : 彼は"Hello!"と言った。 Tokenized : ['彼', 'は', 'Hello!', 'と', '言った', '。']よく見るとHello!を囲っていた引用符(")がなくなっている。
レアな現象ではあるもの、オフセットがずれる原因になっていた。
一時的な対策
アポストロフィーなら消えないようなので置換する。
tokenizer.pyの一部text = "彼は\"Hello!\"と言った。".replace("\"","'")実行結果$ python3 tokenizer.py Input : 彼は'Hello!'と言った。 Tokenized : ['彼', 'は', "'Hello!'", 'と', '言った', '。']引用符にこだわりがないならこれで良い。
コードから原因を推測して直す。
pyknpの中にあるpyknp/juman/morpheme.pyにおいて引用符が閉じている場合、引用符を意図的に消していることがわかった。
これは、コマンドで実行したjumanの解析結果のパースに絡んだ処理のよう。
コマンドでjumanを実行すると以下のようになる。実行結果$ juman 彼は"Hello!"と言った。 彼 かれ 彼 名詞 6 普通名詞 1 * 0 * 0 "代表表記:彼/かれ 漢字読み:訓 カテゴリ:人" は は は 助詞 9 副助詞 2 * 0 * 0 NIL "Hello!" "Hello!" "Hello!" 未定義語 15 その他 1 * 0 * 0 NIL と と と 助詞 9 格助詞 1 * 0 * 0 NIL 言った いった 言う 動詞 2 * 0 子音動詞ワ行 12 タ形 10 "代表表記:言う/いう 補文ト" 。 。 。 特殊 1 句点 1 * 0 * 0 NIL EOS代表表記の部分を見ると引用符で囲まれているのがわかる。
引用符内は空白が使用可能であるため、パースをする際引用符で囲まれた範囲内の空白を無視する必要がある。
そんなわけで引用符で囲まれた範囲を抽出可能なよう設計してあり、また抽出後に引用符は取り除かれるようになっている。
そのため、見出し語の引用符も消されてしまっている。pyknp/juman/morpheme.pyの一部のif文を次のように直す。
pyknp/juman/morpheme.pyの一部if part != "" and char == ' ' and not inside_quotes: #if part.startswith('"') and part.endswith('"') and len(part) > 1: if part.startswith('"') and part.endswith('"') and len(part) > 1 and len(parts) > 2: parts.append(part[1:-1]) else: parts.append(part)これで"Hello!" "Hello!" "Hello!"の部分の引用符は消されなくなった。
実行結果$ python3 tokenizer.py Input : 彼は"Hello!"と言った。 Tokenized : ['彼', 'は', '"Hello!"', 'と', '言った', '。']治った。やったね。
ちなみに引用符がらみで他の問題もある。
実行結果$ python3 tokenizer.py Input : 彼は" Hello!" と言った。 Tokenized : ['彼', 'は', '"', '\\ ', 'Hello!" Hello!"', '\\ ', 'と', '言った', '。']Hello! Hello!とテンション高い人みたいになってしまった。
コマンドでjumanを実行した場合はこう。実行結果juman 彼は" Hello!" と言った。 彼 かれ 彼 名詞 6 普通名詞 1 * 0 * 0 "代表表記:彼/かれ 漢字読み:訓 カテゴリ:人" は は は 助詞 9 副助詞 2 * 0 * 0 NIL " " " 未定義語 15 その他 1 * 0 * 0 NIL \ \ 特殊 1 空白 6 * 0 * 0 NIL Hello!" Hello!" Hello!" 未定義語 15 その他 1 * 0 * 0 NIL \ \ 特殊 1 空白 6 * 0 * 0 NIL と と と 助詞 9 格助詞 1 * 0 * 0 NIL 言った いった 言う 動詞 2 * 0 子音動詞ワ行 12 タ形 10 "代表表記:言う/いう 補文ト" 。 。 。 特殊 1 句点 1 * 0 * 0 NIL EOSお分りいただけただろうか。
実行結果の一部Hello!" Hello!" Hello!" 未定義語 15 その他 1 * 0 * 0 NIL引用符が来ると次の引用符まで問答無用でまとめられるので、
Hello!" Hello!"
Hello!" 未定義語 15 その他 1 * 0 * 0 NIL
にしかパースされなくなってしまう。
だからpyknpでの解析結果がおかしくなっている。これは以下のようにpyknp/juman/morpheme.pyの1行を修正する。
pyknp/juman/morpheme.pyの一部#if inside_quotes and char == ' ' and part == '"': if inside_quotes and char == ' ' and part[-1] == '"': inside_quotes = False今までは引用符単体の次に空白がこないと機能しなかったが、引用符の次に空白がこれば良いようにした。
実行結果$ python3 tokenizer.py Input : 彼は" Hello!" と言った。 Tokenized : ['彼', 'は', '"', '\\ ', 'Hello!"', '\\ ', 'と', '言った', '。']治った。やったね。
githubに置いておく。
取り急ぎk141303/juman_temporarilyにJumanを継承する形で書いた修正コードを挙げておきます。
あとで本家にプルリクしたいと思います。
=> お粗末ですが修正させていただきプルリクParse bug fixes for Juman analysis results. しました。以上。