- 投稿日:2019-06-25T22:13:47+09:00
Railsチュートリアル完走後に、改めてリソースについてまとめてみた
背景
- Railsチュートリアル完走後に、どのようにして機能を拡張していくか考えたときになんとなく「機能をリソース」として扱えれば、設計がしやすいのでは?というのが発端。また、リソースについてもしっかり理解できていなかったので完走したあとに再度情報整理したかった。
目的
- 「Railsにおけるリソース」について、構成する要素の関係性についてまとめることで理解を深めてオペレーション時にもすぐに活かせる状態にしたい。
RESTの原則
- RailsはRESTの原則に従って設計されている。
- RESTとは、ざっくりいうとwebを設計するための考え方のひとつ。
- Railsでのリソースを理解するためには、土台であるRESTの原則を知る必要がある。
4つの原則
- ステートレスなクライアント/サーバプロトコル
- すべての情報(リソース)に適用できる「よく定義された操作」のセット
- リソースを一意に識別する「汎用的な構文」
- アプリケーションの情報と状態遷移の両方を扱うことができる「ハイパーメディアの使用」
引用元:Representational State Transfer - Wikipedia
1. ステートレスなクライアント/サーバプロトコル
RESTな考え方では、サーバーへのリクエストも、クライアントへのレスポンスも毎回状態を管理しない(ステートレス)HTTPを使う。
メリットとしては、複数のサーバーで複数のクライアントに対してレスポンスする際に効率がよい。
web設計する際に1つ目の原則に関しては、基本的にHTTPを使っていれば意識しなくて遵守される。
HTTP(HTTP/1.1)には、8つのメソッドが定義されており、2つ目の原則と関連してくる。
- GET
- POST
- PUT
- HEAD
- DELETE
- OPTIONS
- TRACE
- CONNECT
引用元:Hypertext Transfer Protocol - Wikipedia
2. すべての情報(リソース)に適用できる「よく定義された操作」のセット
RESTな考え方では、全てのリソースにHTTPメソッド(GET、POST、PUT、DELETEなど)を使ったアクセス可能な共通インターフェイスを持つ。
HTTPメソッドは次の役割を持っており、この役割に当てはめて設計を考える。
HTTPメソッド 役割 GET リソースの取得 POST 子リソースの作成、リソースへのデータ追加、その他の処理 PUT リソースの更新、リソースの作成 DELETE リソースの削除 HEAD リソースのヘッダ(メタデータ)の取得 OPTIONS リソースがサポートしているメソッドの取得 TRACE 自分宛にリクエストメッセージを返す(ループバック)試験 CONNECT プロキシ動作のトンネル接続への変更 3. リソースを一意に識別する「汎用的な構文」
RESTな考え方では、全てのリソースはURI(広い概念でURLとURNが含まれる)で表されるユニークなアドレス持つ
4. アプリケーションの情報と状態遷移の両方を扱うことができる「ハイパーメディアの使用」
今ではHTMLページに他のページへのリンクを貼ることは当たり前だが、そのこと。
これも、意識してなくても基本的に遵守される。RESTfulとは
4つの原則に従って作成されたものを指す。
RailsでRESTfulなリソースを作成するために意識すること
Railsにおいて、RESTの原則の1と4に関しては、現在であれば当たり前なのであまり意識せずともよいが、2と3に関しては意識する必要がある。
2. すべての情報(リソース)に適用できる「よく定義された操作」のセット
Railsにおいて、2に関しては、具体的にRailsチュートリアル内のコラム 2.2で言及されており、
Railsのリソースは、下記に対応する共通インターフェイスを持っているといえる。
- リレーショナルデータベースの作成/取得/更新/削除 (Create/Read/Update/Delete: CRUD) 操作
- 4つの基本的なHTTPメソッド (POST/GET/PATCH/DELETE)
Railsは、RESTの原則を取り入れいち早く対応しているフレームワークでもあり、共通インターフェイスを持たせるために、HTTPメソッドごとにデータベース上のCRUD操作と対応付けを定義している。
Railsのルーティング機能は、RESTの考え方を取り入れる上で、重要。
ルーティングでHTTPメソッドとアクションを紐づけ、webでのCRUD操作を実現する。下記は、photosリソースの例(CRUD操作の列は、HTTPメソッドとデータベースの繋がりが分かりやすいように追加)。
HTTP動詞 パス コントローラ#アクション 目的 CRUD操作 GET /photos photos#index すべての写真の一覧を表示 取得(R) GET /photos/new photos#new 写真を1つ作成するためのHTMLフォームを返す 取得(R) POST /photos photos#create 写真を1つ作成する 作成(C) GET /photos/:id photos#show 特定の写真を表示する 取得(R) GET /photos/:id/edit photos#edit 写真編集用のHTMLフォームを1つ返す 削除(D) PATCH/PUT /photos/:id photos#update 特定の写真を更新する 更新(U) DELETE /photos/:id photos#destroy 特定の写真を削除する 削除(D) 引用元:Rails のルーティング - Rails ガイドの2.2の表参照
HTTPメソッドとURL(パス)を組み合わせて、CRUD操作を実現していることがわかる。
Railsの良いところは、
resources :photosを使えば、RESTの考え方に沿った共通インターフェイスができる点。3. リソースを一意に識別する「汎用的な構文」
RESTの原則の3に関しては、Railsチュートリアルの7章の7.1.2 Usersリソースで少し触れられています。
RESTの原則に従う場合、リソースへの参照はリソース名とユニークなIDを使うのが普通です。
他にチュートリアルで良い例が見つけられなかったが下記が参考になった。
- URLに動詞を含めず、複数形の名詞のみで構成する
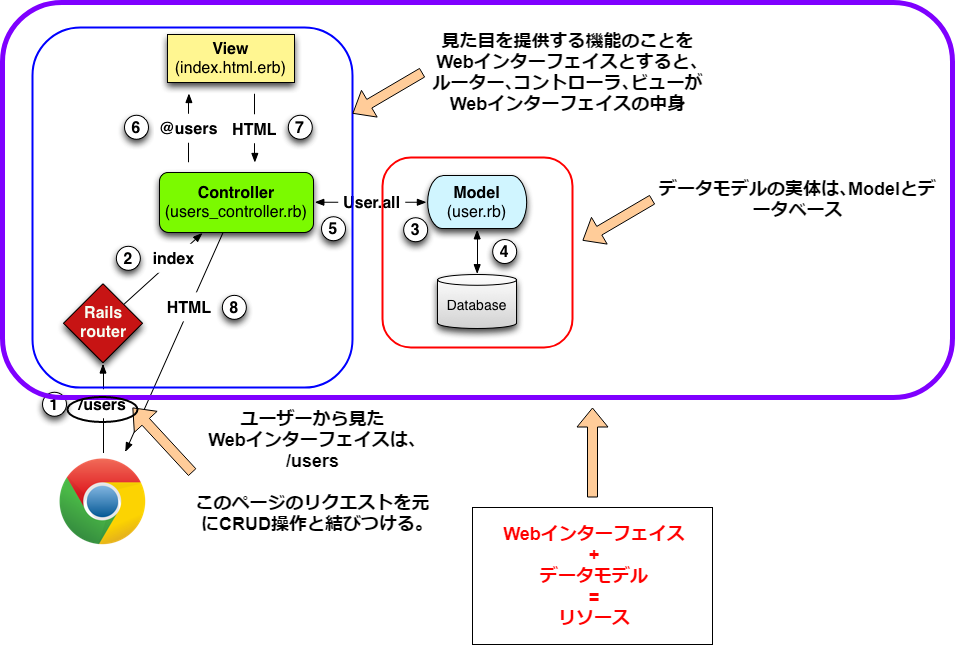
リソースを2.2.2 MVCの挙動のMVCモデルの図と使って説明
これらを踏まえた上で、自分のリソースのイメージは、こんな感じです。
図でいうと、ユーザーから見たインターフェイスは/usersになる。
/usersのページのリクエスト(HTTPメソッド)を元にCRUD操作と結びつける(ルーターとコントローラの役割。モデルも密接に関わっている)。CRUD操作をするためには、データモデルが必要になり、最終的にユーザーから見える/usersに提供するためにビューが必要になる。
これらが組み合わさり、ユーザーにCRUD操作を提供するオブジェクトがリソース。これがリソースの正体。
Railsチュートリアルで出てきたリソースを比較してみる。
一番やりかったのがこれ。
下記ページのP25をみたときに全体像が分かっていれば、少しリソースの設計がわかりやすくと思ったため。
Rest ful api設計入門3章以降で出てくるリソースをRailsのCRUD操作に当てはめてみた(自分が分かりやすいように少し調整)。
1~3行目までは、すべてのリソースに共通する項目で、4行目は、途中で説明したphotosリソースを例として使っている。5行目以降がRailsチュートリアルで出てくるリソース。
すべてのアクションを使っていないリソースがあったり、用途に合わせてパスを調整しているリソースもあったりすることがわかる。
目的 一覧表示 作成フォーム 作成 個別表示 編集フォーム 個別更新 個別削除 HTTPリクエスト GET GET POST GET GET PATCH/PUT DELETE 対応アクション index new create show edit update destroy photos /photos /photos/new /photos /photos/:id /photos/:id/edit /photos/:id /photos/:id users /users /signup /signup /users/:id
/users/:id/following
/users/:id/followers/users/:id/edit /users/:id /users/:id sessions - /login /login - - - /logout account_activations - - - - account_activations#edit - - password_resets - /password_resets/new /password_resets - /password_resets/:id/edit /password_resets/:id - microposts - - /microposts - - - /microposts/:id relationships - - /relationships - - - /relationships/:id まとめ
最後は、良くわからない表になってしまったがなんとなくでしか分からなかったリソースの全体像がわかったと思う。
なにより必要に応じて、分かりやすいように名前付きルートの変更(users/newをsignup)をしている点や全てのアクションを使わなくてもリソースの考え方に則って実装することで、リソースとして扱うという実装方法の統一が図れるという点、14章で出てくるフォローの実装はさらにRESTのリソースをより活用した実装(ルーティングをネストさせている)という点に気づけた。
参考
Representational State Transfer - Wikipedia
ステートフル ステートレスとはどういうことか - Sojiro’s Blog
Hypertext Transfer Protocol - Wikipedia
Representational State Transfer (REST)
「Webを支える技術」を読みました とRESTのまとめ - 大学生からの Web 開発
URLとURIは何が違うの? どちらが正しい呼び方? | 初代編集長ブログ―安田英久 | Web担当者Forum
RESTful-APIのURL設計を考えてみる - Qiita
- 投稿日:2019-06-25T21:41:41+09:00
form_forについて
form_forについて
構文の書き方
.hamlform_for(モデルオブジェクト , オプション) do |f| フォームコントロールの設置form_forが生成するフォームコントロール
check_box :チェックボックス
color_field :色の入力欄
date_field :日付の入力欄
datetime_field :日時の入力欄(グローバルタイム)
datetime_local_field :日時の入力欄(ローカルタイム)
email_field :emailアドレスの入力欄
fields_for :form_forの中で別のモデルを指定したフォーム
file_field :画像や文章などのファイルを選択するフォーム
hidden_field :隠しフィールドの生成
label :ラベルの生成
month_field :月の入力欄
number_field :数値入力欄
password_field :パスワード入力欄
phone_field
telephone_field :電話番号入力欄
radio_button :ラジオボタンの生成
range_field :範囲選択バー
search_field :検索ボックスフォーム
text_area :文字列入力欄
text_field :文字列入力欄
time_field :時間入力欄
url_field :URL入力欄
week_field :週の入力欄
submit :送信ボタン以上のようにフォームコントロールに設置するオプションと軽い説明を作成しました。
- 投稿日:2019-06-25T21:29:40+09:00
Rails x Docker環境にテストDBを構築する
Docker上でRailsアプリを開発するにあたり、テスト用のDBと開発用DBをそれぞれ構築する必要があったのでそのときの構築手順を記載。
前提
以下のようなDockerファイルでRailsアプリケーションを構築しているとする。
DockerfileFROM ruby:2.6 RUN apt-get update -qq && apt-get install -y nodejs RUN mkdir /myapp WORKDIR /myapp COPY Gemfile /myapp/Gemfile COPY Gemfile.lock /myapp/Gemfile.lock RUN bundle install COPY . /myapp # Start the main process. CMD ["rails", "server", "-b", "0.0.0.0"]RailsアプリケーションのDB設定を以下のようになっているとする。
database.ymldefault: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> username: <%= ENV.fetch('DB_USERNAME', 'root') %> password: <%= ENV.fetch('DB_PASSWORD', 'pass') %> development: <<: *default host: db database: myapp_development test: <<: *default host: test-db database: myapp_test production: <<: *default database: myapp_productionDockerの設定方法
DBのコンテナ名はdatabase.ymlで設定したhostと一緒にする。
今回の場合、開発用DBのdockerコンテナは'db', テスト用DBのdockerコンテナは'test-db'とする。
MYSQL_USERとMYSQL_PASSWORDはdatabase.ymlで設定したユーザー名とパスワードと一致させる必要がある。
MYSQL_ROOT_PASSWORDはroot用パスワード。設定が必須。
MYSQL_DATABASEはdatabase.ymlで設定したdatabaseと一緒にする。
docker-compose.ymlversion: '3' services: web: build: . env_file: development.env ports: - '3001:3000' volumes: - .:/myapp depends_on: - db - test-db db: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: 'pass' MYSQL_USER: 'webapp' MYSQL_PASSWORD: 'test' MYSQL_DATABASE: myapp_development ports: - '3306:3306' test-db: image: mysql:5.7 environment: MYSQL_ROOT_PASSWORD: 'pass' MYSQL_USER: 'webapp' MYSQL_PASSWORD: 'test' MYSQL_DATABASE: myapp_test ports: - '3307:3306' # ローカルPCから接続するために設定docker-compose.ymlに直接記述してもいいけど、環境変数は外出ししておく。
今回は、webappというユーザーがtestというパスワードでDBに接続できるような設定にする。↓development.envDB_USERNAME=webapp DB_PASSWORD=test接続確認
webのコンテナ名がdocker-rails_web_1という名前で立ち上がっている前提。
$ docker exec -it $(docker ps -f name=docker-rails_web_1 -q) /bin/bash [docker] # rails c -e test irb(main):001:0> ENV['RAILS_ENV'] => "test" [docker] # rails c irb(main):001:0> ENV['RAILS_ENV'] => "development"
- 投稿日:2019-06-25T18:58:58+09:00
【Ruby on Rails】ストロングパラメータって何なの?
【注:Rails初心者記事】
記載に間違いなどがありましたら、指摘いただけると幸いです。はじめに.この記事の目的
ストロングパラメータって何ぞや?
いろいろ調べた結果、頭の中が崩壊したので、一度記事としてまとめます。
これで、少しは理解が深まる・・・はず!!1.ストロングパラメータって何?
ストロングパラメータは、Web上から受けたつけたパラメータが、本当に安全なデータかどうかを検証した上で、取得するための仕組みです。Rails4から実装されています。
2.ストロングパラメータがなぜ必要なのか?
この仕組みを使うことで、意図しない(安全では無い)データの登録・更新を防いでくれるます。
具体的にどうやって防ぐかと言うと、メソッドにあらかじめ登録・更新を許可するカラム名を指定(ホワイトリスト形式)しておきます。そうすると、万が一、未許可のカラムデータが送られてきても、データの登録前に未許可であることを検出し、登録対象として無視することができます。
不特定多数に公開するWebアプリケーションだからこそ、ストロングパラメータの仕組みは必要不可欠な訳ですね。
2−1.「マスアサインメント(Mass Assignment)機能と脆弱性」という問題
ストロングパラメータ機能が実装される以前(rails3)は、実際に意図しないデータの登録・更新が発生していたようです。実例では無いですが、どう言った問題なのか具体例をあげて整理してみました。
・ 問題発生の土壌
以下のとおり、マスアサインメント機能の脆弱性を孕んだWebアプリを作成したことを前提とします。
モデル
ユーザの管理を行うUserテーブル(モデル)
最後の「admin」カラムは管理者ユーザかどうかを識別するために作っています。
(admin=1(管理者))
user_id name admin 1 はむ太郎 hamu@hamu.co.jp 1 ビュー
ユーザ情報の登録を求めるビュー
下図のとおり、Userモデルのname、emailのみの入力を意図して作成しています。
「admin」カラムは管理者ページからのみ操作したいので対象としていません。new.html.erb・・・中略・・・ <%= form_for @user do |f| %> <div class="field"> <%= f.text_field :name, placeholder: "ユーザ名を入力してね!" %> </div> <div class="field"> <%= f.text_field :email, placeholder: "e-mailアドレスを入力してね!" %> </div> <div class="actions"> <%= f.submit %> </div> <% end %> ・・・中略・・・コントローラー
ユーザ情報の登録を行うコントローラ
マスアサインメント機能を使用し、Userモデル丸ごとデータ登録をさせるよう作成されています。test_controller.rbdef create user = User.new(params[:user(モデル名)]) user.save def・ 問題の発生契機と内容
このアプリのWeb公開後、該当のViewから下図のようなパラメータを受け取りました。最後のパラメータ"admin"は、開発者側が意図していない(安全で無い)データでした。
このパラメータは悪意あるユーザによるパラメータの改ざんによって発生したようです。params.{"user"=>{"name"=>"はむ太郎","email"=>"hamu@hamu.co.jp","admin"=>1}} ^^^^^^^^^^^^^^この結果どうなるでしょうか?
「admin」と言うカラムは管理者ユーザかどうかを識別をしています。
そのため、この悪意あるユーザが管理者権限付きのユーザIDを獲得してしまったのです!
こんな事しちゃうユーザです。その後の更なるセキュリティ攻撃に発展しそうな予感大ですね。。。こうした問題が「マスアサインメント機能と脆弱性の問題」でした。多分。
ただ、Rails4以降はストロングパラメータの使用が必須になっていて、上であげたような記述は出来ないようです。以下に実際の事象に関する記事がありましたので、参考までに。。。【マスアサインメント機能の脆弱性問題に関する記事】
https://www.infoq.com/jp/news/2012/03/GitHub-Compromised/3.ストロングパラメータの適用対象
3-1.適用対象について
ユーザがフォームから入力する情報がストロングパラメータの適用対象となります。
観点としては、以下2つを覚えておくと迷わないと思います。・対象のデータ
ユーザフォーム(View)から送られてきたデータ。
コントローラ上の表記で言う”params”
※ただし、1カラムずつparams内のデータを指定する場合は不要
・対象の機能:対象のデータに対する登録・更新機能
コントローラ上に定義された”create/update"などのメソッド3-2.適用対象外について
対象となる機能・データ以外であれば、ストロングパラメータを介する必要はないようです。
・不要なデータ
ユーザフォームから入力された情報ではない(=params以外)データ。
例えば、current_user(devise利用時に使える変数)を登録する場合などです。ただし、敢えて、ストロングパラメータの対象とすることも可能です。・不要な機能
データの登録・更新が発生しない機能はもちろんですが、View/controllerを介さない機能も不要です。例えば、テストデータの一括登録、データ移行、バッチ処理などは不要。と言うより、機能自体使えないですね。きっと。4.ストロングパラメータの書き方
前置きが長くなりましたが、ストロングパラメータの書き方について整理してみましょう。
4-1. 基本構文
ストロングパラメータは以下のように記述します。
メソッド名に命名規則は無いようですが[ モデル名_params ]とするのが一般的なようです。
また、実行結果として、許可されたカラムの値だけを抽出し、ハッシュ形式で呼び出し元に値を返してくれます。user_controller.rbprivate def user_params params.require(:キー(モデル名)).permit(:カラム名1,:カラム名2,・・・).marge(カラム名: 入力データ) end4-2.requireメソッド
requireメソッドを使用する事で、params内の特定のキーに紐付く値だけを抽出する事ができます。そのため、引数には取り出したい値のキーを指定する必要があります。
例)キー値userに対するデータを抽出したい場合は、以下のように設定します
params.require(:user).permit(・・・略・・・)・ キーの設定元
View上でform_forメソッドを使用した場合のキー設定箇所を見てみましょう。下図の例ではform_forに続く”@user"がrequireメソッドで指定すべきキーです。
なお、form_forメソッドは、モデルに基づくformを作成する際に使うヘルパーメソッドで"@user"が対象のモデル名をさしています。new.html.erb・・・中略・・・ <%= form_for @user do |f| %> <%= f.text_field :name, placeholder: "ユーザ名を入力してね!" %> <%= f.submit %> <% end %> ・・・中略・・・4-3.permitメソッド
permitメソッドを使用する事で、許可された値のみを取得することができます。
そのため、permitメソッドの引数には登録を許可する全てのカラム名を指定しておく必要があります。もし、許可されいないカラムがparams内に存在した場合、そのデータは取得されず無視されます。例)Userモデルに存在するnameおよび、emailカラムのみ入力を受け付けたい場合
(他のカラム(admin)は受け付けないたくない)params.require(:user).permit(:name,:email)※ユーザの入力項目を増やした場合は、ストロングパラメータへの項目追加も忘れずに!
もし、忘れたら・・・何と明示的にエラーとなりません!(エラーキャッチとかしてるとなるのかな?)
必須項目だった場合、DB自体に保存されませんし、必須項目でない場合も、該当データのみDBに反映されない歯抜けの状態になっちゃいます。4-4.mergeメソッド
mergeメソッドを使用することでハッシュ同士を結合することができます。
例えば、paramsに含まれない値をストロングメソッドに加えたい場合などに、ストロングパラメータの後に記述することができます。params.require(:user).permit(:name,:email).merge(user_id: current_user.id)4-5.privateメソッド
privateメソッド配下に記述したメソッドは、クラス外からのアクセスができません。
基本的にストロングパラメータは、クラス外からのアクセスをさせないようにprivateメソッド配下に書くようです。5.ストロングパラメータの呼び出し方
折角定義したストロングパラメータのメソッドですが、呼び出して使わないと意味がありません。どのように呼び出すか、記述例を見てみましょう。
なお、呼び出し方には大きく2パターンあります。(もっとあるかもしれませんが・・・)5-1. 丸投げパターン
このパターンが多いと思います。ストロングパラメータに全てお任せパターンです。
user_controller.rbdef create User.create(user_params) end5-2. 部分投げパターン
params以外のデータを含む場合などに使うようです。
ただ、このパターンでは、そもそもマスアサインメント機能を使っていません。そのため、ストロングパラメータ自体不要ですね。実際にストロングパラメータを使わなくても登録が可能です。
なお、params以外のデータもストロングパラメータとして指定できるので、丸投げパターンで呼び出すことも可能です。(4-4.margeメソッド参照)post_controller.rbdef create Post.create(image: post_params[:image], text: post_params[:text],user_id: current_id) endまとめ
ストロングパラメータは、マスアサインメント機能の脆弱性問題を回避するために作られた機能。
そのため、対象はparamsを使用したデータの登録、更新のみ。
さらに言うと、paramsを使っていたとしても、1カラムずつ定義する場合は、ストロングパラメータの利用が必須ではない!これでストロングパラメータと少しは仲良くなれたかな。。。
参考
・Ruby on Rails5 アプリケーションプログラミング 山田祥寛 (参考書)
・https://kirohi.com/strong_parameters_rails
・https://diveintocode.jp/tips/strong_parameter
- 投稿日:2019-06-25T17:09:21+09:00
後置ifについて!
後置ifについて
本日は後置ifを使うことのメリットやデメリットを考えてみたいと思います!
テキスト上の説明
後置ifとは、、、
最後のendを省略してif文を処理の後方に配置する書き方です。
elsif, elseにあたる条件分岐が無く、かつ処理が一行で完結する場合に用います。
とあります。少しでも短く、且つ分かりやすいコードで誰がみても理解できるコードを目指す私にとっては是非とも使いこなしたい書き方です!テキスト上の通常if文と後置if文の比較です↓↓
app/controllers/tweets_controller.rb#通常のif表記 def destroy tweet = Tweet.find(params[:id]) if tweet.user_id == current_user.id tweet.destroy end end #後置if表記 def destroy tweet = Tweet.find(params[:id]) tweet.destroy if tweet.user_id == current_user.id end考えられるメリット・デメリット
メリット
- 文字の分量的には通常表記と後置表記の大差は無いですが、endが一つ無くなったことで少しスッキリして可読性がUPします!
- 通常表記時のifで始まった時のendが後置時は不要なのでつけ忘れ防止→うっかりエラー回避にも役立ってくれそうです!
デメリット
テキスト上に書いていますが、
- 条件文が長くなった際(elseやelsifがある際)は使用できません。
- 処理が一行で完結できる場合にしか使用できません。結果
使える場面はそんなに多く無い感じがしましたが、短いif文では積極的に使っていきたいと思います!
- 投稿日:2019-06-25T16:56:46+09:00
TECH ~Day3~
学習三日目を終え、やはり新しく覚える用語も難しくなってきたように感じます。
前回から引き続きrubyのレビュー管理アプリケーションの開発カリキュラムを行いました。
後半部分に入りましたが新たな壁にぶつかり、スムーズには進まなくなってきました。学習内容
・if文、条件分岐(elsif)
・to_iメソッド
・メソッドの定義方法
・繰り返し処理(while)
・配列オブジェクト、<<メソッド・if文、条件分岐(elsif)
条件分岐を行う際、rubyではifを使用する。
ifは条件式を書き、その条件式が正か負かで処理を行う。(エクセルの時と同じ)
書き方
if 条件式1 ther
#この部分は、上の条件式1が真の場合の実行処理を書く
elsif 条件式2 ther
#条件式1が偽の場合かつ、
#条件式2が真の場合の実行処理
else
#ここは条件式1と2どちらも偽の場合の実行処理
end ←最後はendで閉じる・to_iメソッド
文字列オブジェクトにこの「to_i」を使うと、その文字列を数値オブジェクトに変換することができる。書き方
string = "30"←これは文字列の30
number = string.to_i←数値の30に変換
puts number + 20←数値の30に変換後の30と計算されるためこの結果は50になる・メソッドの定義方法(def)
defでメソッドを定義しておくことで、定義後にメソッド名を打ち込んだ際に簡単にそのメソッドで処理された状態の文書を出すことができる。書き方
def メソッド名
#この部分に実行する処理を書く
end!defの横に書いた文字がメソッド名になる。メソッド名は自分で好きにつけることができるが小文字英語から始まり、単語と単語を繋げる時は、「_」で繋げる。
・繰り返し処理(while)
書き方
while 条件式 do
#ここに実行処理を記入
endwhileは条件式の部分で繰り返し処理を行うのか決める。
条件式が真の場合はすっと処理を続けることになる。・配列オブジェクト、<<メソッド
様々なデータを入れて管理できるオブジェクトである。
配列オブジェクトに入れられたデータを要素という。
要素は順番を持ち、最初に書いた要素から順番がつく。書き方
配列オブジェクト = [an,in,on] ←配列をする時は大括弧配列オブジェクトに新たにデータを追加するためのメソッドを「<<メソッドという」
書き方
pencil_case = [an,in,on]
pemcil_case << "en" ←これによって追加される。この後に出てくる「引数」というのが個人的に今も理解に苦しんでいて、時間を取られています。妥協せず引き続き気合いを入れて学習したいと思います。
- 投稿日:2019-06-25T16:54:47+09:00
「Gemfile」は「gemfile」じゃだめだよ!
タイトル通り、Gemfileの「G」は大文字じゃないとデプロイの際、エラーになります。
僕は「gemfile」のファイル名のままデプロイして12時間ハマりました。
僕みたいにハマる方がこれ以上生まれないよう、念のため共有しておきます。ふと新しいwebアプリケーションを作りたいと思い、以下の記事にしたがってrails newしました。
https://qiita.com/yuitnnn/items/b45bba658d86eabdbb26ただ、以下の記事で説明されているように、gemを--path vendor/bundle配下で管理する必要は別にないかもしれないです。
https://qiita.com/jnchito/items/99b1dbea1767a5095d85原因はわかりませんがrails newして新しいrailsアプリを作成した時になぜかファイル名が「Gemfile」ではなく「gemfile」(先頭の文字が小文字のg)になっていました。
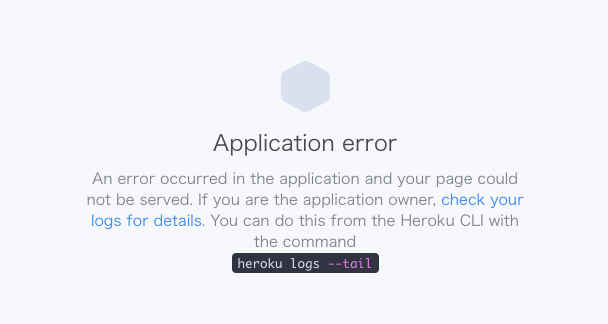
多分、自分が何かおかしいことをやったんだと思います。その状態でリモートリポジトリにpush、Herokuにデプロイして、https://×××××.herokuapp.comにアクセスするとエラーが発生しています。
heroku使っている人なら一度は見たことがあるであろうおなじみの画面ですよね!
そこで試しにheroku run rails cをしてみるとTraceback (most recent call last): 4: from /app/bin/rails:3:in `<main>' 3: from /app/bin/rails:3:in `load' 2: from /app/bin/spring:8:in `<top (required)>' 1: from /usr/lib/ruby/2.5.0/rubygems/core_ext/kernel_require.rb:59:in `require' /usr/lib/ruby/2.5.0/rubygems/core_ext/kernel_require.rb:59:in `require': cannot load such file -- bundler (LoadError)bundlerがないと怒られてます。
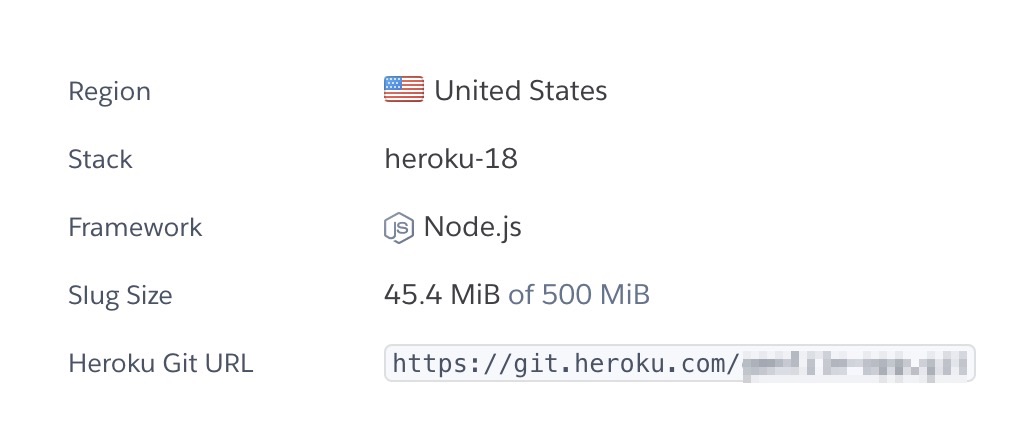
HerokuダッシュボードのSettingsを見てみると
RailsアプリをデプロイしたのにFrameworkがNode.jsになっています。
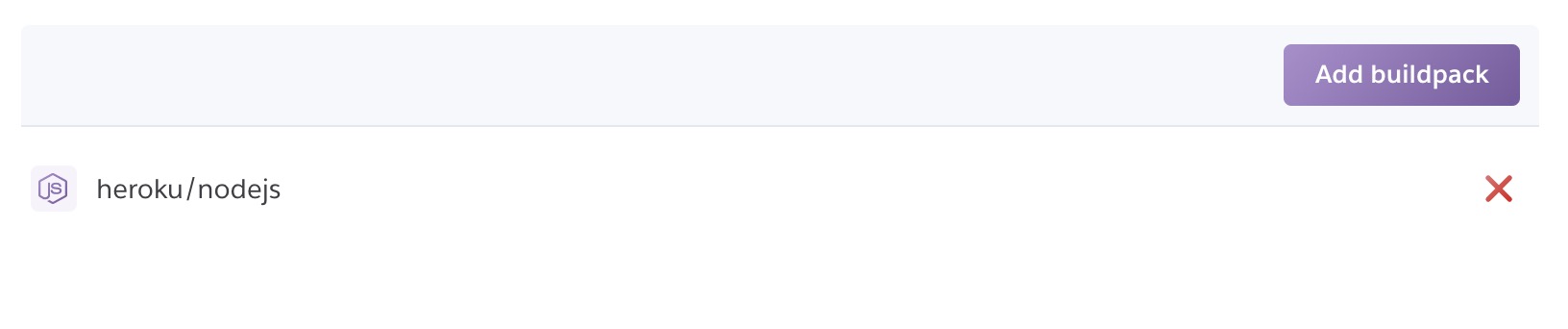
HerokuのBuildpacksを見てみると、RailsでWebpackerを利用するために必要なNode.jsのbuildpackしか使われていないことが分かります。
肝心なrubyのbuildpackがないため、rubyのbuildpackを追加してもう一度Herokuへデプロイしてみました。
remote: -----> Build succeeded! remote: ! This app may not specify any way to start a node process remote: https://devcenter.heroku.com/articles/nodejs-support#default-web-process-type remote: remote: -----> App not compatible with buildpack: https://buildpack-registry.s3.amazonaws.com/buildpacks/heroku/ruby.tgz remote: More info: https://devcenter.heroku.com/articles/buildpacks#detection-failure remote: remote: ! Push failed remote: Verifying deploy... remote: remote: ! Push rejected to ×××××××××××××. remote: To https://git.heroku.com/×××××××××××××.git ! [remote rejected] master -> master (pre-receive hook declined) error: failed to push some refs to 'https://git.heroku.com/×××××××××××××.git'なぜかデプロイできない!!!
ここからが長かった。。。
buildpackについて調べたり、bundlerについて調べたり色々したけど、
結局、原因は「Gemfile」のファイル名が「gemfile」と先頭の「g」がなぜか小文字になっていることが原因でした。https://devcenter.heroku.com/articles/buildpacks#detection-failure
上記URL先に「アプリケーションのルートフォルダにGemfileがないといけない」と記載されていますが、まさか小文字の「gemfile」だと正しく読み込んでくれないとは気づかなかったです。ってかなんで小文字の「gemfile」になってたんだ...どこかの記事に「エラーで長時間詰まるときは大体単純なミスが多い」と書いてあったのを読んだことがありますが、今回はまさにそれでした。
今回みたいになぜかファイル名が小文字で「gemfile」となっているようなことが他の方に起こることはほぼないと思いますが、一応投稿して共有させて頂きました。
- 投稿日:2019-06-25T16:21:26+09:00
【初心者向け】i18nを利用して、enumのf.selectオプションを日本語化する[Rails]
こんにちは、エンジニアとして就職を目指しています、タヌキです。
前回の記事では、haml, form_withを利用して、f.selectの入力フォームを作るために色々と試行錯誤した話、
さらに、enumを利用してデータを利用しやすくした話を書きました。▼前回の記事はこちら
【初心者向け】form_with, haml, enumを使ってselectによるプルダウンリストを作った話[Rails]
https://qiita.com/tanutanu/items/1bb5f12ac8ae90e71352その中で、f.selectの入力フォームは実装できたのですが、
最後に選択肢が英語になってしまうという課題が残りました。そのため、今回はenum利用時に、f.selectの選択肢を日本語にするための方法をご紹介したいと思います。
合わせて、日本語化したデータをビューなど他の場所でも使うための方法もご紹介いたします。
どうぞよろしくお願いいたします。今回参考にした記事
まず、今回参考にさせていただいた記事はこちらです。
参考というよりも、こちらの記事がとても良すぎて、ほとんどこのままの内容で実装できましたので、
本記事の内容も下記の記事とほぼ同じです。ページ下方の、selectオプション以外への使用方法の項だけ、内容が異なります。
自分自身のまとめのために、やったことを記しているので、
selectオプションへの使用方法だけが知りたい!という方は下記の記事を参照された方が良いと思います。▼参考にした記事はこちら
https://qiita.com/tomoharutsutsumi/items/272a10f4fefb555944f2必要なファイル
enumを日本語化する上で必要だったファイルは下記の通りです。
- (gem) enum_help, rails-i18n
- model ←今回は restaurant.rb
- ja.yml
- application.rb
その他、enumを日本語化して記載したいビューファイルです。
gem ファイルのインストール
まずは、enumをI18n(国際化)対応させるgem
enum_help をインストールします。rails-i18nの方はまだしっかり言語化できていないのですが、
i18nの機能が使いやすくなるそうです。Gemfilegem 'rails-i18n' gem 'enum_help'bundle lnstall します。
model に enumを記載する
次に、modelにenumを記載します。
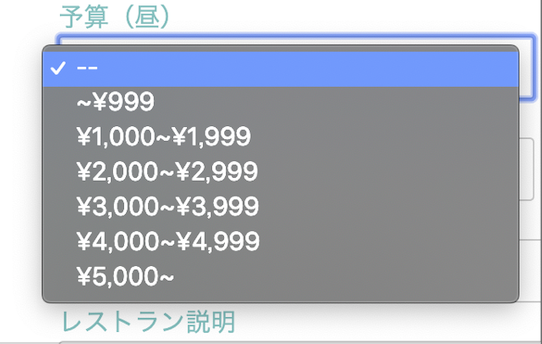
今回は、レストラン情報を載せるrestaurantsテーブルの、昼の予算のカラム budget_d に対して、下記のようにenumを記載しました。models/restaurant.rbenum budget_d: { default: 0, till_1000: 1, till_2000: 2, till_3000: 3, till_4000: 4, till_5000: 5, over_5000: 6 }, _prefix: true最後の prefix: true は、同じ値をもつ複数のenumが存在するときにつけるものです。
今回は、夜の予算を定義する budgetn も同じアプリ内に存在していたので、 _prefix:true をつけました。▼詳しくは、こちらをご覧ください。
https://qiita.com/emacs_hhkb/items/fce19f443e5770ad2e13ja.ymlに翻訳情報を記載する
翻訳情報を記したファイル、ja.ymlを
config/locales/ 内に作成し、下記のように記します。config/locales/ja.ymlja: enums: restaurant: budget_d: default: "--" till_1000: "~¥999" till_2000: "¥1,000~¥1,999" till_3000: "¥2,000~¥2,999" till_4000: "¥3,000~¥3,999" till_5000: "¥4,000~¥4,999" over_5000: "¥5,000~"上記は、enumのデータを翻訳したい時の記載方法ですので、その他の場所を翻訳したいときには、別の記載方法となります。
▼詳しくは、こちらの記事をご覧ください。
https://qiita.com/shi-ma-da/items/7e5c3d75c9a9f51abdd5デフォルトの言語を日本語化する
application.rb の設定を変更して、デフォルトの言語を日本語にします。
config/application.rb# 前略 module SomeApp class Application < Rails::Application # 中略 config.i18n.default_locale = :ja # デフォルトのlocaleを日本語(:ja)にする end endパスを通して、i18nのロケールファイルが読み込まれるようにする。
以下の記述も application.rb に追記して、locales フォルダ内のファイルが全て読み込まれるようにします。
config/application.rb# 前略 module SomeApp class Application < Rails::Application # 中略 config.i18n.default_locale = :ja config.i18n.load_path += Dir[Rails.root.join('my', 'locales', '*.{rb,yml}').to_s] # 追記 end endこれで、enumを日本語化するための設定は完了です!
設定だけでかなり長かったです・・・。最終的なコード
そして、今回 f.select に使用したコードは下記のようになりました。
viewfile= f.select :budget_d, Restaurant.budget_ds_i18n.keys.map{|k| [I18n.t("enums.restaurant.budget_d.#{k}"), k]}まず、budget_d の中身を含む配列、budget_ds に対し、
keys メソッドを実施し、[["default": "--"], ["till_1000": "~¥999"], ...] などのキーだけ(["default", "till_1000"])を配列の形で取り出します。そして、その値一つ一つに対して、mapを使い処理をしています。
処理の内容は、
I18n.t ... enumの内容を翻訳するメソッド
を使って、["翻訳した内容":"value"]の配列を作る処理です。enums.restaurant.budget_d のように、
ja.ymlに書いたenumの翻訳情報の位置をきちんと記します。結果
その結果、できたドロップダウンリストがこちら。
生成されたコードがこちらです。
valueがdefaultやtill_1000などになっていますが^^;これで正しくvalueはデータベースに保存されます。
その他の場所で、翻訳したデータを使う。
最後に、ビューのその他の場所で翻訳したファイルを使う方法をご紹介します。
基本的には、「カラム名_i18n」をつけた表記にすればokです。view%p= restaurant.budget_d_i18n #これで、昼の予算が日本語で表示されるenumの日本語化といい、f.selectの表記といい、なかなか時間のかかった実装でした。
それでは、ここまで読んでくださり、ありがとうございました。

- 投稿日:2019-06-25T15:55:44+09:00
Railsでのsqliteの基本操作
超基本操作
--コンソールの起動--
$ rails dbconsole--テーブルの確認--
sqlite> .tables--スキーマの確認--
sqlite> .schemaテーブルのカラムの追加・削除
rails g migrationでファイルを作成して、rails db:migration でDBに反映させる流れ
--カラムの追加--
rails g migration[Addカラム名Toテーブル名] [カラム名:型]
※Addの後のカラム名とテーブル名の表記に注意
※カラム名にしてはいけないワード[img]$ rails g migration AddSurlToLists surl:string $ rake db:migrate---カラムの削除--
$ rails g migration RemoveAreaFromLists area:int $ rake db:migrate
- 投稿日:2019-06-25T15:44:44+09:00
Crystal の Lucky という WebFramework 使ってみた with Mac
はじめに
友人から Ruby ライクな Crystal 言語が書きやすくて良いと聞いて興味が出てきたので、
CrystalShards というサイトで Crystal の各種ライブラリを眺めていたところ、
Lucky というウェブフレームワークを発見したので勉強がてら触ってみました(本当は amber という Crystal の WebFramework を触ってみようとしてたのですが、
Lucky という名前に惹かれて Lucky 触ってみることにした感じです。。。笑)開発環境
- macOS Mojave 10.14.5
- PostgreSQL 11.2
- OpenSSL 1.0.2s
- Crystal 0.29.0
- Lucky 0.15.0
Crystal & Lucky プロジェクトのセットアップ作業
1. Crystal のインストール
crenv という Crystal のバージョンマネージャでインストール作業を進めていきます。
anyenv 経由でのインストール推奨のようなので anyenv 経由で crenv を入れます。brew install anyenv anyenv init # ANYENV_DEFINITION_ROOT(/Users/riywo/.config/anyenv/anyenv-install) doesn't exist. You can initialize it by: # コマンド実行時に ↑ が都度出力される場合は anyenv install --init を実行 # anyenv install --init anyenv install crenv # shell 再起動後、↓ のコマンドを実行して crenv コマンドが使えることを確認する crenv install --list正常に
crenvコマンドが使用できるようになったことが確認できたら、
本記事で使用する Crystal バージョンである 0.29.0 をインストールします。# Crystal のバージョン 0.29.0 をインストール crenv install 0.29.0 # デフォルトで使用する Crystal のバージョンを 0.29.0 に設定 crenv global 0.29.0 $ crystal --version Crystal 0.29.0 (2019-06-05) LLVM: 3.9.1 Default target: x86_64-apple-macosx↑ の出力がターミナルで確認できれば Crystal のインストール作業は完了です
2. Lucky のインストール
brewを使用して Lucky をインストールします。ついでに openssl も Lucky のビルド時に必要になるのでインストールします。
また PostgreSQL もユーザデータの登録などに使用するのでインストールしておきます。brew update brew install openssl brew tap luckyframework/homebrew-lucky brew install lucky # Lucky の確認 (↓ のコマンドを実行した際に Usage が表示されていればインストール済み) $ lucky # PostgreSQL サーバの起動を行う (起動してなかった時) brew services start postgresqlまた
PKG_CONFIG_PATHに/usr/local/opt/openssl/lib/pkgconfigを追加します。bash を使用している方は
.bash_profile内に、
export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/opt/openssl/lib/pkgconfigを追記しておけば OK です。~/.bash_profileexport PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/opt/openssl/lib/pkgconfigfish を使用している方は
~/.config/fish/config.fish内に、
set -x PKG_CONFIG_PATH "$PKG_CONFIG_PATH:/usr/local/opt/openssl/lib/pkgconfig"を追記しておきます。~/.config/fish/config.fishset -x PKG_CONFIG_PATH "$PKG_CONFIG_PATH:/usr/local/opt/openssl/lib/pkgconfig"各種ライブラリのインストール & 設定が確認できたら、
Lucky のプロジェクトをluckyコマンドを使用して作成します。3. Lucky プロジェクトのセットアップ
luckyコマンドを使用することで、
プロジェクトの作成からモデルの作成等々を行うことが出来ます。
(rails コマンドみたいな役割ですね)まずは
lucky-backendという名前のプロジェクトを作成します。$ lucky init Project name? lucky-backend Lucky can generate different types of projects Full (recommended for most apps) ● Great for server rendered HTML or Single Page Applications ● Webpack included ● Setup to compile CSS and JavaScript ● Support for rendering HTML API ● Specialized for use with just APIs ● No webpack ● No static file serving or public folder ● No HTML rendering folders API only or full support for HTML and Webpack? (api/full): full Lucky can be generated with email and password authentication ● Sign in and sign up ● Mixins for requiring sign in ● Password reset ● Generated files can easily be removed/customized later Generate authentication? (y/n): y ----------------------- Done generating your Lucky project ▸ cd into lucky-backend ▸ check database settings in config/database.cr ▸ run script/setup ▸ run lucky dev to start the server↑ の出力が確認できたら、コマンドを実行したディレクトリに、
lucky-backendというプロジェクトフォルダが生成されているはずです。次に Lucky のビルドスクリプトを実行して、
lucky devというコマンドで開発が進められるようにしていくのですが、
その前に予めチェックしておくべき項目が 3点あるので確認していきます1
1. .crystal-version を確認する
lucky-backend内に.crystal-versionを確認して0.29.0と記載されているか確認します。lucky-backend/.crystal-version0.29.02. shard.yml を確認する
Crystal には shards というパッケージマネージャが公式で用意されているのですが、パッケージの依存関係が
shard.ymlというファイルに記載されています。この
shard.ymlにはパッケージのビルドを行う際の Crystal バージョンも記載されているのですが、これが現在自分の使用している Crystal バージョン (0.29.0) と一致している確認します。lucky-backend/shared.ymlname: lucky_backend version: 0.1.0 authors: - hoge <fuga@test.com> targets: lucky_backend: main: src/lucky_backend.cr # ここの表記が 0.29.0 であることを確認する # 私の環境では 0.27.2 になっていてビルドに失敗し続けていた。。 crystal: 0.29.0 dependencies: lucky: github: luckyframework/lucky version: ~> 0.15.0 authentic: github: luckyframework/authentic version: ~> 0.3.0 carbon: github: luckyframework/carbon version: ~> 0.1.0 dotenv: github: gdotdesign/cr-dotenv lucky_flow: github: luckyframework/lucky_flow version: ~> 0.4.13. yarn をインストールする
Lucky ではデフォで
webpackを使用しており、ビルドスクリプトの実行するのにyarnコマンドが必要なので、インストールされていない方はbrew install yarnで予めインストールしておきます。brew install yarn4. データベースの接続情報を設定する (PostgreSQL)
config/database.crの中を見ると、データベースへの接続状況として環境変数のDATABASE_URLやDB_HOSTを利用していることが確認できます。lucky-backend/config/database.cr# Lucky の実行環境に応じてデータベース名を設定する database_name = "lucky_backend_#{Lucky::Env.name}" Avram::Repo.configure do |settings| if Lucky::Env.production? # 本番環境では DATABASE_URL という環境変数の設定が必須になっている settings.url = ENV.fetch("DATABASE_URL") else # DATABASE_URL は設定しなくとも Avram::PostgresURL.build を使用することで、 # データベースのユーザ名やホストを指定することで適切な PostgreSQL URL を生成する settings.url = ENV["DATABASE_URL"]? || Avram::PostgresURL.build( database: database_name, hostname: ENV["DB_HOST"]? || "localhost", username: ENV["DB_USERNAME"]? || "postgres", password: ENV["DB_PASSWORD"]? || "postgres" ) end # 後述の説明では DATABASE_URL に値を適切に設定することで DB への接続を実現していますが、 # 環境変数に情報をセットしておくのが面倒な方でとにかく動かしたいは、 # ここに決め打ちで ↓ の用な感じで PostgreSQL の URL を設定してしまっても良いです。 # settings.url = "postgresql://localhost:5432/#{database_name}?user=<ユーザ名>&password=<パスワード>" settings.lazy_load_enabled = Lucky::Env.production? end今回は
DATABASE_URLに一括でデータベースへの接続情報を設定したいと思いますので ↓ コマンドで PostgreSQL の URL をセットします。export DATABASE_URL=postgresql://localhost:5432/lucky_backend_development?user=<ユーザ名>&password=<パスワード>fish を使用している方は ↓ コマンドで
DATABASE_URLに PostgreSQL の URL を環境変数にセットします。set -x DATABASE_URL "postgresql://localhost:5432/lucky_backend_development?user=<ユーザ名>&password=<パスワード>"また PostgreSQL のロールは
CREATEDBのものを使用してください。
PostgreSQL のロールの作り方はこちらのサイトを参考にされると良いと思います。筆者はターミナル開いて
psql postgres実行後CREATE ROLE <ユーザ名> WITH CREATEDB LOGIN PASSWORD '<パスワード>';を入力してユーザの作成を行いました
3.5, Lucky プロジェクトのセットアップ (続き)
ここまで来たら、あとは Lucky プロジェクトのセットアップ用ビルドスクリプトを実行するのみです
# lucky プロジェクトに入っている setup シェルスクリプトを実行する $ sh script/setup ▸ Installing node dependencies yarn install v1.16.0 [1/4] Resolving packages... success Already up-to-date. Done in 0.35s. ▸ Compiling assets yarn run v1.16.0 $ yarn run webpack --progress --hide-modules --color --config=node_modules/laravel-mix/setup/webpack.config.js $ /Users/nika/Desktop/qiita/lucky-backend/node_modules/.bin/webpack --progress --hide-modules --color --config=node_modules/laravel-mix/setup/webpack.config.js 98% after emitting SizeLimitsPlugin DONE Compiled successfully in 1039ms00:56:04 Done in 3.03s. ▸ Installing shards Fetching https://github.com/luckyframework/lucky.git Fetching https://github.com/luckyframework/lucky_cli.git Fetching https://github.com/mosop/teeplate.git Fetching https://github.com/luckyframework/habitat.git Fetching https://github.com/luckyframework/wordsmith.git Fetching https://github.com/luckyframework/avram.git Fetching https://github.com/kostya/blank.git Fetching https://github.com/crystal-lang/crystal-db.git Fetching https://github.com/will/crystal-pg.git Fetching https://github.com/luckyframework/dexter.git Fetching https://github.com/luckyframework/lucky_router.git Fetching https://github.com/luckyframework/shell-table.cr.git Fetching https://github.com/paulcsmith/cry.git Fetching https://github.com/mosop/cli.git Fetching https://github.com/mosop/optarg.git Fetching https://github.com/mosop/callback.git Fetching https://github.com/mosop/string_inflection.git Fetching https://github.com/crystal-loot/exception_page.git Fetching https://github.com/luckyframework/authentic.git Fetching https://github.com/luckyframework/carbon.git Fetching https://github.com/gdotdesign/cr-dotenv.git Fetching https://github.com/luckyframework/lucky_flow.git Fetching https://github.com/ysbaddaden/selenium-webdriver-crystal.git Using lucky (0.15.1) Using lucky_cli (0.15.0) Using teeplate (0.7.0) Using habitat (0.4.3) Using wordsmith (0.2.0) Using avram (0.10.0) Using blank (0.1.0) Using db (0.5.1) Using pg (0.16.1) Using dexter (0.1.1) Using lucky_router (0.2.2) Using shell-table (0.9.2 at refactor/setter) Using cry (0.4.0) Using cli (0.7.0) Using optarg (0.5.8) Using callback (0.6.3) Using string_inflection (0.2.1) Using exception_page (0.1.2) Using authentic (0.3.0) Using carbon (0.1.0) Using dotenv (0.2.0) Using lucky_flow (0.4.1) Using selenium (0.4.0 at a6d0e63ab7ddc6a20923bf4157bc6247c1fa2acc) ▸ Checking that a process runner is installed ✔ Done ▸ Setting up the database Already created lucky_backend_development ▸ Migrating the database Did not migrate anything because there are no pending migrations. ▸ Seeding the database with required and sample records Done adding required data Done adding sample data ✔ All done. Run 'lucky dev' to start the app↑ のような出力が確認できれば正常に実行出来てセットアップ完了です
また出力を確認すると、データベースの作成/マイグレーション、
シードデータの投入まで全てが一括で実行されていることが分かります。ちなみにマイグレーションファイルは
db/migrationsフォルダに生成されていきます。
初期はメールアドレスとパスワードのみを扱うusersテーブルを定義したファイルが存在しています↓lucky-backend/db/migrations/00000000000001_create_users.cr# ちなみに Lucky 内部では Avram という ORM が使用されています class CreateUsers::V00000000000001 < Avram::Migrator::Migration::V1 def migrate create :users do # メールアドレスとパスワードを扱う users テーブルが PostgreSQL 内に生成される add email : String, unique: true add encrypted_password : String end end def rollback drop :users end endそれでは早速
lucky devとターミナルに入力してみます。$ lucky dev [OKAY] Loaded ENV .env File as KEY=VALUE Format 01:07:58 assets.1 | yarn run v1.16.0 01:07:58 assets.1 | $ yarn run webpack --watch --hide-modules --color --config=node_modules/laravel-mix/setup/webpack.config.js 01:07:58 assets.1 | 01:07:58 assets.1 | $ /Users/nika/Desktop/qiita/lucky-backend/node_modules/.bin/webpack --watch --hide-modules --color --config=node_modules/laravel-mix/setup/webpack.config.js 01:08:00 assets.1 | webpack is watching the files… 01:08:01 assets.1 | DONE Compiled successfully in 1359ms01:08:01 01:08:04 web.1 | yarn run v1.16.0 01:08:04 web.1 | $ /Users/nika/Desktop/qiita/lucky-backend/node_modules/.bin/browser-sync start -c bs-config.js --port 3001 -p http://0.0.0.0:5000 01:08:05 web.1 | [Browsersync] Proxying: http://0.0.0.0:5000 01:08:05 web.1 | [Browsersync] Access URLs: 01:08:05 web.1 | ---------------------------- 01:08:05 web.1 | Local: http://localhost:3001 01:08:05 web.1 | ---------------------------- 01:08:05 web.1 | [Browsersync] Watching files...実行したらブラウザを開いて http://localhost:3001 にアクセスすると、
↓ の画面が確認出来るはずです
ユーザの登録/ログインを行ってみる
lucky initを行った際に、ユーザ認証の仕組みを入れて、
登録/ログインについても既にページが用意された状態でプロジェクトについてセットアップ済みなので、
すぐにユーザの登録からログインまでの動作確認を行うことが可能です。
lucky devでサーバを起動してから、http://localhost:3001/sign_up にアクセスします。
すると ↓ のユーザ情報入力画面が出てくるので、必要な情報を入力してSign Upボタンをクリックします。
ユーザの登録に成功すると自動的に http://localhost:3001/me に遷移して、
登録したユーザ情報が確認できる画面が表示されます。
また http://localhost:3001/sign_in でユーザのログイン画面に遷移します。
ユーザ登録時に入力した情報でログインすることが可能です。
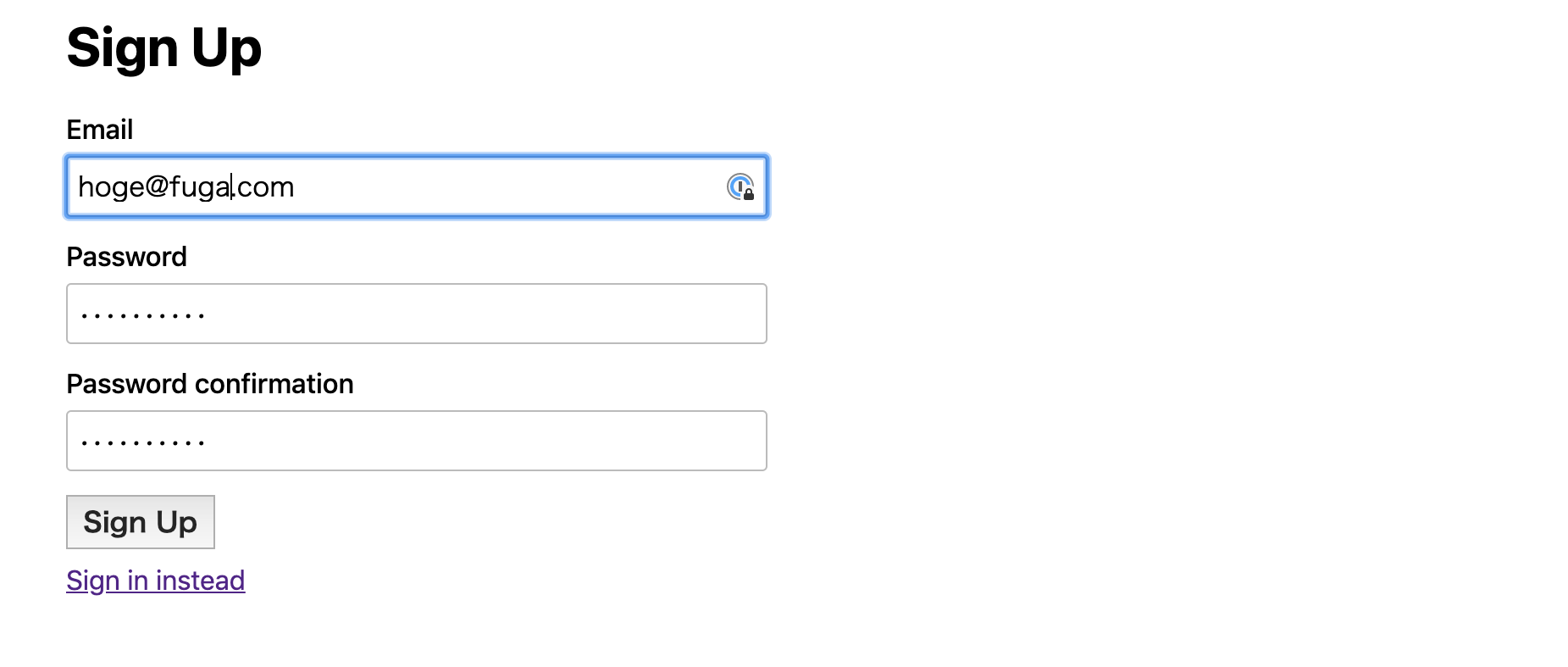
ログイン成功後は http://localhost:3001/me に遷移します。正しくユーザ登録が行えているかターミナルから
psqlコマンドでデータベースの中を見てみます。psql lucky_backend_development psql (11.2) Type "help" for help. lucky_backend_development=# select * from users; id | created_at | updated_at | email | encrypted_password ----+------------------------+------------------------+---------------+-------------------------------------------------------------- 2 | 2019-06-25 13:59:09+09 | 2019-06-25 13:59:09+09 | hoge@fuga.com | $2a$04$TA1q9jt4U2MPSP3Fi5uwm.qCQcIFd7syy6WJ/SCwz6QC7WDLt6bwm (1 row)正しくデータベースにユーザの情報が登録出来ているようです
おわりに
Crystal はまだアルファ版ということもあり、(2019/06/25 時点では)
言語仕様の変更が頻繁に入っているようなので、現段階での本番採用は難しいかもしれません。。しかし Crystal がコンパイル型言語である &
Lucky が Rails 並の書きやすさでサクサク開発出来そうという点が非常に魅力的に見えたので、
引き続き動向をウォッチしていきたいと考えていますまた現段階の記事内容だと、ただプロジェクトのサンプルを動かしただけなので、
今後は本記事に追記する形でビューやルーティング、モデルの追加等も行う予定です。参考リンク
https://github.com/pine/crenv/blob/master/README.ja.md
https://luckyframework.org/guides/getting-started/installing
https://luckyframework.org/guides/getting-started/starting-project
https://luckyframework.org/guides/database/intro-to-avram-and-orms
https://luckyframework.org/guides/database/managing-and-migrating
https://qiita.com/pinemz/items/e71903532c24cbeb200a
https://github.com/anyenv/anyenv
https://www.dbonline.jp/postgresql/role/index2.html
この項目内容をチェックしていなかったせいで、Lucky を動かすのに長時間を犠牲にしました。。。 ↩


- 投稿日:2019-06-25T15:21:42+09:00
rspecの導入+カバレッジを出力する
概要
Ruby on Railsの開発で単体試験、カバレッジを測りたいという時のための手順
すでにRailsが起動してるよ!という状態からスタート環境
Ruby on Rails自体はDockerの上で起動(Dockerじゃなくても同じように動くはず)
* Ruby : 2.6
* Rails : 5.2.3
* rspec-rails : 3.8.2
* simplecov : 0.16.1やったこと
Gemfileの編集
Gemfileに
rspec-railsとsimplecovを追加する
test`モードのときにのみインストールするように設定Gemfilegroup :test do gem 'rspec-rails' gem 'simplecov' endrspecをインストールする
gemをダウンロードする(今回はdocker-compose使ってます)
docker-compose buildDocker使ってないと
bundle installかなbundle installrspecをインストール(generate)する
rails generate rspec:installこんなファイル構成が生まれてばOK
.spec spec/ spec/spec_helper.rb spec/rails_helper.rb設定を書き換える
Railsのモード指定をする
spec_helper.rbRSpec.configure do |config| ENV['RAILS_ENV'] = 'test' (略) endカバレッジレポート作成を設定する
spec_helper.rbrequire 'simplecov' RSpec.configure do |config| (略) if ENV['CIRCLE_ARTIFACTS'] dir = File.join(ENV['CIRCLE_ARTIFACTS'], 'coverage') SimpleCov.coverage_dir(dir) end SimpleCov.start endテストクラス作成
テスト対象のクラスを作る
本来はrails generate model item ・・・というようにrails generateしたときにテストクラス(〜_spec.rb)が作られる
けど、すでに存在するクラスに対しては作られないので主導で作成
以下のようなファイル構成で作る(例はitemというモデルがあった場合)spec/models/item_spec.rbファイルの中身はこんな感じ
item_spec.rbrequire 'rails_helper' RSpec.describe Item, type: :model do # describeはテストの大きな枠で、クラスが持つ機能(メソッド)ごとに作るといいかも # 文字列のところは任意で決められ、表すものを書けばOK describe 'aaa test' do # itはテストケース単位 # 文字列のところは任意で決められ、表すものを書けばOK it 'bbb test' do # テスト内容を記載 end end end試験データを作成するときは
factory_bot_railsを使うと良い
(今回は説明しません)テスト実行
テスト実行は1コマンド
rspec # テストケースを指定する場合は引数でファイル名を渡す(対象ファイルが多いと時間がかかるため、開発中は限定したい) rspec spec/models/item_spec.rb結果がベローって出て、全部緑ならOK
最後にカバレッジが出るので、試験結果とカバレッジ結果を両方確認できるFinished in 0.03117 seconds (files took 3.09 seconds to load) 1 example, 0 failures Coverage report generated for RSpec to /sample_app/coverage. 187 / 194 LOC (96.39%) covered.カバレッジ結果は
caverage/index.htmlに出力されるので、通過していない箇所をブラウザで確認できる注意点
specファイルが書かれていないクラスはカバレッジ計測されません
(他のテストケースを実行したときに呼ばれれば計測される)
全テスト対象クラスを最初から用意しておくことを激しくお勧めします
テスト結果が正しくないまま「カバレッジが高いぞ!」ってはしゃぐことになります応用編
手動で実行すると忘れるものです
なので、リポジトリにpushしたときにテストが実行されるよう自動化をお勧めします
(github → circleCIとかgitlabのスクリプトで十分効果が発揮できる)
テスト結果をslackなどのコミュニケーションツールに投げ込むと失敗に気づけると思います
考えたら色々きりがないので、色々な環境で試してみてください。
- 投稿日:2019-06-25T14:26:02+09:00
Rails6 のちょい足しな新機能を試す41(MailDeliveryJob 編)
はじめに
Rails 6 に追加されそうな新機能を試す第41段。 今回は、
MailDeliveryJob編です。
Rails 6 では、ActionMailer::DeliveryJobを使うとDEPRECATION WARNINGが表示されるようになります。
代わりにActionMailer::MailDeliveryJobが用意されています。Ruby 2.6.3, Rails 6.0.0.rc1 で確認しました。Rails 6.0.0.rc1 は
gem install rails --prereleaseでインストールできます。$ rails --version Rails 6.0.0.rc1
- parameterized mail に対応するために、
ActionMailer::Parameterized::DeliveryJobが導入される。ActionMailer::DeliveryJobとActionMailer::Parameterized::DeliveryJobの2つがあるのはややこしいから、1つのクラスActionMailer::MailDeliveryJobに統合しよう。- クラスが変わってしまうから、
ActionMailer::DeliveryJobやActionMailer::Parameterized::DeliveryJobを使った場合にDEPRECATION WARNINGを表示しよう。という流れだったみたいです。
今回の準備
今回は、 Rails6 のちょい足しな新機能を試す27(perform_deliveries 編) のソースに手を加えていくことにより動作確認します。
MyMailDeliveryJob を作る
メール送信のジョブを差し変えるため、
MyMailDeliveryJobクラスを作ります。
このとき派生元のクラスをDEPRECATION WARNINGを出すために、意図的にActionMailer::DeliveryJobにします。app/jobs/my_mail_delivery_job.rbclass MyMailDeliveryJob < ActionMailer::DeliveryJob before_perform :logger_info def logger_info Rails.logger.info('BEFORE MyMailDeliveryJob perform') end endMyMailDeliveryJob を使う
MyMailDeliveryJob を使うように
UserMailerを修正します。app/mailers/user_mailer.rbclass UserMailer < ApplicationMailer self.delivery_job = MyMailDeliveryJob # この行を追加 ... endユーザーを登録する
ブラウザから User を登録してメールを送信します。
development.log に
DEPRECATION WARNINGが表示されます。また、MyMailDeliveryJobを設定したにも関わらず、ActionMailer::Parameterized::DeliveryJobが動作していることにも注意してください。log/development.log... [ActiveJob] [ActionMailer::Parameterized::DeliveryJob] [...] DEPRECATION WARNING: Sending mail with DeliveryJob and Parameterized::DeliveryJob is deprecated and will be removed in Rails 6.1. Please use MailDeliveryJob instead. (called from instance_exec at /usr/local/bundle/gems/activesupport-6.0.0.rc1/lib/active_support/callbacks.rb:429) ...MyMailDeliveryJob クラスの親クラスを変更する
MyMailDeliveryJob の親クラスを
ActionMailer::MailDeliveryJobに変更します。app/job/my_mail_delivery_job.rbclass MyMailDeliveryJob < ActionMailer::MailDeliveryJob ... end再度ユーザーを登録する
ブラウザから User を登録してメールを送信します。
今度は、
DEPRECATION WARNINGも消えて、MyMailDeliveryJobが動作していることがわかります。log/development.log... [ActiveJob] [MyMailDeliveryJob] [...] Performing MyMailDeliveryJob ... [ActiveJob] [MyMailDeliveryJob] [...] BEFORE MyMailDeliveryJob perform ...結論
ActionMailer::DeliveryJobやActionMailer::Parameterized::DeliveryJobを使っている場合や独自のメール送信ジョブのクラスを作っている場合は、ActionMailer::MailDeliveryJobから派生させたメール送信ジョブのクラスに変更するのが良いでしょう。試したソース
試したソースは以下にあります。
https://github.com/suketa/rails6_0_0rc1/tree/try041_mail_delivery_job参考情報
- 投稿日:2019-06-25T11:46:54+09:00
なぜかActiveRecord::RecordNotUniqueで怒られる
状況
rails初心者です。
railsでdeviseを使ってログイン機能を作った際に新規登録のUIを変更し実行した際に
ActiveRecord::RecordNotUniqueで怒られた。原因
主な原因はテーブルのindexにありそうでした。
schema.rb#~~省略 t.index ["username"], name: "index_users_on_username", unique: true t.index ["nil"], :name "index_users_on_name", unique: trueこのようにnilに対してのインデックスがなぜに出来たのかもどのような効果があるのかもはっきりとは分かっていませんが用意されていました。
解決策
直前に'username'というカラムを追加していました。
そこで一旦$ rails db:rollbackテーブルを1つ前の状態に戻し
$ rails db:migratemigrateし直した結果見事にnilに対してのindexは削除されていました!
終わりに
nilに対してのindexをremove_indexで消す方法もありなのかなと思いましたがあんまりやり方が分からず今回のやり方でうまくいったのでよしとしました。
どうしてnilに対してのindexが作られていたのかあんまり分かっていないのでどなたか詳しい方教えていただけたら嬉しいです。
- 投稿日:2019-06-25T07:10:35+09:00
ローカルでrails sが止まらない!
ユースケース
railsのゾンビプロセスを発生させる手法
- tmux, terminalを閉じてしまった場合
- railsをバックグラウンドで実行する方法
railsのバックグラウンド実行
$ rails server -d
- process idを消す
$ rm ./tmp/pids/server.pidサーバーを止める方法
process id(以下pid)を消す必要があります。
消し方としては以下の3つの方法があります。
- ポートからpidを探す
- tmpのserver.pidからpidを探す
- pumaのprocessからpidを探す
ポートからpidを探す
$ lsof -i:3000 COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME ruby 31584 _user_name_ 10u IPv4 0xac1c1f275d70c41 0t0 TCP localhost:hbci (LISTEN) ruby 31584 _user_name_ 11u IPv6 0xac1c1f26fce7e19 0t0 TCP localhost:hbci (LISTEN) $ kill -kill 31584tmpのserver.pidからpidを探す
$ ls tmp/pids/server.pid tmp/pids/server.pid $ cat tmp/pids/server.pid 31584 $ kill -kill 31584pumaのprocessからpidを探す
$ ps aux | grep puma _user_name_ 32578 0.0 0.0 xxx xxx s000 S+ xx:xxAM 0:00.00 grep puma _user_name_ 31584 0.0 0.8 xxx xxx s005 S+ xx:xxAM 0:02.52 puma 3.12.1 (tcp://localhost:3000) [project_name] $ kill -kill 31584参考文献
- 投稿日:2019-06-25T05:25:10+09:00
スクレイピング
用途
ウェブサイト上のHTMLからデータを抜き出す処理
使用例
例えばこのようなHTMLのサイトがあったとして
<ul> <li>TEST1</li> <li>TEST2</li> <li>TEST3</li> </ul>TEST1
TEST2
TEST3
の値を取り出す事ができる必要なGem
Mechanize
Mechanizeクラスが使えるようになる
Gemfileの最後の行に以下のコードを記述する
Gemfile.gem 'mechanize'Gemfileに記述されたgemをインストールする
$ bundle installMechanizeクラスのインスタンスを生成
スクレイピングするにはまず、Mechanizeクラスのインスタンスを生成する
例.agent = Mechanize.new #Mechanizeクラスのインスタンスを生成して、agentへ代入webサイトのHTML情報を取得する
getメソッド
getメソッドはMechanizeクラスのインスタンスメソッド
get(スクレイピングしたいウェブサイトのURL)例.agent = Mechanize.new page = get("https://qiita.com/") #QiitaのHTMLを取得HTMLの文字列ではなく、ウェブサイトのHTMLの情報を持ったMechanize::Pageオブジェクトを取得
※オブジェクト
関連する変数(値)とメソッド(動作)をまとめて、そのまとまりに名前を付けたもの
- 投稿日:2019-06-25T00:36:01+09:00
Ruby On Railsチュートリアル
Ruby on rails始まります!
※自分の日記的な
背景
わしは何か武器を身に着けたかったの。
そんな時に進められたのがこれ■チュートリアルやで
https://railstutorial.jp/chapters/beginning?version=5.1#fig-cloud9_gemfileとりあえずこれを制覇してrailsエンジニアになりたいの!!!
本日の進捗
普段のお仕事で死んでるので進捗はとてつもなく遅いと思うの。
とりあえず本日は触りの冒頭と環境構築をちょこちょこ。
これで終わらないようにがんばruby!!!環境構築はローカルに作成するかAWSのクラウド環境かvagrantで仮想環境にするか色々悩んだけどとりあえずvagrantで構築してるの。vagrantで環境作るのってこんなに時間かかるんだっけって感じなの。
明日まで掛かりそうな勢いなの。まだ途中ではあるけど1.2.2 Railsをインストールするまでが今日の進捗かな。
とりま、今日はここまで
ばいの~