SQLでは、データにNULLを入れることができます。 しかし、データには数値であれば「0」、文字列であれば「空白」を入れて表現することもできます。 そこで、データをNULLとするか、「0」や「空白」で表すかを調べて考えてみました。 NULLにする場合 NULLにする場合は簡単です。 基準としては、値が存在しないときにNULLを使います。 例えば、電話番号やメールアドレスなどと存在として不明確な場合にはNULLを使います。 しかし、これが年齢や身長などと存在がはっきりとわかる場合には使えないということです。 「0」や「空白」とする場合 先ほども書いた通りに、年齢や身長などと存在がはっきりとわかる場合には「0」や「空白」を使います。(この場合は「0」ですね) まとめ まとめると、 存在として値が不明確なときは、NULL はっきりと存在がわかる値のときは、「0」や「空白」
SQLでは、データにNULLを入れることができます。 しかし、データには数値であれば「0」、文字列であれば「空白」を入れて表現することもできます。 そこで、データをNULLとするか、「0」や「空白」で表すかを調べて考えてみました。
NULL
NULLにする場合は簡単です。 基準としては、値が存在しないときにNULLを使います。 例えば、電話番号やメールアドレスなどと存在として不明確な場合にはNULLを使います。
しかし、これが年齢や身長などと存在がはっきりとわかる場合には使えないということです。
先ほども書いた通りに、年齢や身長などと存在がはっきりとわかる場合には「0」や「空白」を使います。(この場合は「0」ですね)
まとめると、
うちの新人が知らなかったので、 小ネタとして。。。 見本用に適当にテーブルを作り、データを用意しました。 ※ここでは割愛します。 とりあえずSELECTで中身を見てみます。 mysql> SELECT * FROM sample; +------+----------+------------+-------+-------+-------+-------+-------+-------+-------+---------------------+---------------------+ | id | password | is_deleted | text1 | text2 | text3 | text4 | text5 | text6 | text7 | created | modified | +------+----------+------------+-------+-------+-------+-------+-------+-------+-------+---------------------+---------------------+ | 1 | test | 0 | aaa | bbb | ccc | ddd | eee | fff | ggg | 2019-06-25 20:00:00 | 2019-06-24 20:00:00 | +------+----------+------------+-------+-------+-------+-------+-------+-------+-------+---------------------+---------------------+ 1 row in set (0.00 sec) デフォルトだと横長で表示されるので、 ウィンドウのサイズによって見づらかったりします。 そこで今度は;を\Gに変えます。 そうすると... mysql> SELECT * FROM sample\G *************************** 1. row *************************** id: 1 password: test is_deleted: 0 text1: aaa text2: bbb text3: ccc text4: ddd text5: eee text6: fff text7: ggg created: 2019-06-25 20:00:00 modified: 2019-06-24 20:00:00 1 row in set (0.00 sec) まとめ このように縦に表示されて見やすくなりました。 参考 MySQL 5.6 リファレンスマニュアル https://dev.mysql.com/doc/refman/5.6/ja/mysql-commands.html
うちの新人が知らなかったので、 小ネタとして。。。
見本用に適当にテーブルを作り、データを用意しました。 ※ここでは割愛します。
とりあえずSELECTで中身を見てみます。
mysql> SELECT * FROM sample; +------+----------+------------+-------+-------+-------+-------+-------+-------+-------+---------------------+---------------------+ | id | password | is_deleted | text1 | text2 | text3 | text4 | text5 | text6 | text7 | created | modified | +------+----------+------------+-------+-------+-------+-------+-------+-------+-------+---------------------+---------------------+ | 1 | test | 0 | aaa | bbb | ccc | ddd | eee | fff | ggg | 2019-06-25 20:00:00 | 2019-06-24 20:00:00 | +------+----------+------------+-------+-------+-------+-------+-------+-------+-------+---------------------+---------------------+ 1 row in set (0.00 sec)
デフォルトだと横長で表示されるので、 ウィンドウのサイズによって見づらかったりします。
そこで今度は;を\Gに変えます。 そうすると...
mysql> SELECT * FROM sample\G *************************** 1. row *************************** id: 1 password: test is_deleted: 0 text1: aaa text2: bbb text3: ccc text4: ddd text5: eee text6: fff text7: ggg created: 2019-06-25 20:00:00 modified: 2019-06-24 20:00:00 1 row in set (0.00 sec)
このように縦に表示されて見やすくなりました。
MySQL 5.6 リファレンスマニュアル https://dev.mysql.com/doc/refman/5.6/ja/mysql-commands.html
いろいろ調べたけど下記を修正するだけで通った。 define('PDO_DSN','mysql:dbhost=localhost;dbname=' . DB_DATABASE); ↓ define('PDO_DSN','mysql:host=localhost;dbname=' . DB_DATABASE);
いろいろ調べたけど下記を修正するだけで通った。
define('PDO_DSN','mysql:dbhost=localhost;dbname=' . DB_DATABASE); ↓ define('PDO_DSN','mysql:host=localhost;dbname=' . DB_DATABASE);
Laravelを触り始めて約一ヶ月の初心者です つまづいたのでメモ 結論としてはLaravelクエリビルダのdelete(というかMySQLのDELETE)ではauto_incrementがリセットされないという仕様が分かってなかったっていう話です 1つのUserに対して多数のItemが紐付く構造 userを削除した際はitemも削除するよう外部キーを持たせてあります 2019_06_25_000000_create_item_table.php public function up() { Schema::create('items', function (Blueprint $table) { $table->bigIncrements('id'); $table->text('title'); $table->bigInteger('user_id')->unsigned(); $table->timestamps(); $table->foreign('user_id') ->references('id') ->on('users') ->onDelete('cascade'); }); } ユーザテーブルはLaravelデフォルトなので省略 ↓こちらがseeder UserTableSeeder.php public function run() { DB::table('users')->delete(); App\User::create([ 'name' => 'hoge', 'email' => 'hoge@example.com', 'password' => Hash::make('hogehoge'), ]); App\User::create([ 'name' => 'hage', 'email' => 'hage@example.com', 'password' => Hash::make('hagehage'), ]); } ItemTableSeeder.php public function run() { DB::table('items')->delete(); App\Item::create([ 'title' => '君という花', 'user_id' => '1', ]); App\Item::create([ 'title' => 'リライト', 'user_id' => '2', ]); } 2つともseed時は一回deleteで全消ししてからデータを挿入します 一回migrate:refreshを挟まないとdb:seed出来ない問題 refreshせずにシーディングを実行すると1452エラーが出る $ php artisan db:seed Seeding: UsersTableSeeder Seeding: ItemsTableSeeder Illuminate\Database\QueryException : SQLSTATE[23000]: Integrity constraint violation: 1452 Cannot add or update a child row: a foreign key constraint fails refreshを挟むと何故か成功する php artisan migrate:refreshしたあとにphp artisan db:seedを再度実行 $ php artisan migrate:refresh Rolling back: 2019_06_10_190034_create_items_table Rolled back: 2019_06_10_190034_create_items_table Rolling back: 2014_10_12_100000_create_password_resets_table Rolled back: 2014_10_12_100000_create_password_resets_table Rolling back: 2014_10_12_000000_create_users_table Rolled back: 2014_10_12_000000_create_users_table Migrating: 2014_10_12_000000_create_users_table Migrated: 2014_10_12_000000_create_users_table Migrating: 2014_10_12_100000_create_password_resets_table Migrated: 2014_10_12_100000_create_password_resets_table Migrating: 2019_06_10_190034_create_items_table Migrated: 2019_06_10_190034_create_items_table $ php artisan db:seed [~/dev/app/gaogao_gate/likes] Seeding: UsersTableSeeder Seeding: ItemsTableSeeder Database seeding completed successfully. (逆に)なんでや… 再度db:seedを実行、やっぱり1452のエラーが出る… UserTableを確認してみた mysql> select id from users; +----+ | id | +----+ | 3 | | 4 | +----+ 2 rows in set (0.01 sec) id途中から始まってるやんけ! どうやらdeleteではauto_incrementに設定したidがリセットされない様子(無知並感) 既に無いuser_idをitemに与えようとして1452エラーが出ていたようです どうしよう これ見てdeleteじゃなくてtruncate使えばええやん!と思ったけどそうでも無い様子 (1701エラーを眺めながら) 外部キーがあると使えない…だと…(rollbackもできなくなる) deleteと同時にauto_incrementを1に戻してしまえばよい そんな都合のいいクエリは無いみたいなのでdeleteの下にSQLを1行追加 UserTableSeeder.php DB::table('users')->delete(); DB::unprepared("ALTER TABLE users AUTO_INCREMENT = 1 "); これでとりあえず解決したみたいです? ていうかItemSeederでuser_idを数字で与えているのがそもそもダメなのでは…
Laravelを触り始めて約一ヶ月の初心者です つまづいたのでメモ
結論としてはLaravelクエリビルダのdelete(というかMySQLのDELETE)ではauto_incrementがリセットされないという仕様が分かってなかったっていう話です
1つのUserに対して多数のItemが紐付く構造 userを削除した際はitemも削除するよう外部キーを持たせてあります
public function up() { Schema::create('items', function (Blueprint $table) { $table->bigIncrements('id'); $table->text('title'); $table->bigInteger('user_id')->unsigned(); $table->timestamps(); $table->foreign('user_id') ->references('id') ->on('users') ->onDelete('cascade'); }); }
ユーザテーブルはLaravelデフォルトなので省略
↓こちらがseeder
public function run() { DB::table('users')->delete(); App\User::create([ 'name' => 'hoge', 'email' => 'hoge@example.com', 'password' => Hash::make('hogehoge'), ]); App\User::create([ 'name' => 'hage', 'email' => 'hage@example.com', 'password' => Hash::make('hagehage'), ]); }
public function run() { DB::table('items')->delete(); App\Item::create([ 'title' => '君という花', 'user_id' => '1', ]); App\Item::create([ 'title' => 'リライト', 'user_id' => '2', ]); }
2つともseed時は一回deleteで全消ししてからデータを挿入します
refreshせずにシーディングを実行すると1452エラーが出る
$ php artisan db:seed Seeding: UsersTableSeeder Seeding: ItemsTableSeeder Illuminate\Database\QueryException : SQLSTATE[23000]: Integrity constraint violation: 1452 Cannot add or update a child row: a foreign key constraint fails
php artisan migrate:refreshしたあとにphp artisan db:seedを再度実行
php artisan migrate:refresh
php artisan db:seed
$ php artisan migrate:refresh Rolling back: 2019_06_10_190034_create_items_table Rolled back: 2019_06_10_190034_create_items_table Rolling back: 2014_10_12_100000_create_password_resets_table Rolled back: 2014_10_12_100000_create_password_resets_table Rolling back: 2014_10_12_000000_create_users_table Rolled back: 2014_10_12_000000_create_users_table Migrating: 2014_10_12_000000_create_users_table Migrated: 2014_10_12_000000_create_users_table Migrating: 2014_10_12_100000_create_password_resets_table Migrated: 2014_10_12_100000_create_password_resets_table Migrating: 2019_06_10_190034_create_items_table Migrated: 2019_06_10_190034_create_items_table $ php artisan db:seed [~/dev/app/gaogao_gate/likes] Seeding: UsersTableSeeder Seeding: ItemsTableSeeder Database seeding completed successfully.
(逆に)なんでや…
再度db:seedを実行、やっぱり1452のエラーが出る… UserTableを確認してみた
mysql> select id from users; +----+ | id | +----+ | 3 | | 4 | +----+ 2 rows in set (0.01 sec)
id途中から始まってるやんけ!
どうやらdeleteではauto_incrementに設定したidがリセットされない様子(無知並感) 既に無いuser_idをitemに与えようとして1452エラーが出ていたようです
これ見てdeleteじゃなくてtruncate使えばええやん!と思ったけどそうでも無い様子 (1701エラーを眺めながら) 外部キーがあると使えない…だと…(rollbackもできなくなる)
そんな都合のいいクエリは無いみたいなのでdeleteの下にSQLを1行追加
DB::table('users')->delete(); DB::unprepared("ALTER TABLE users AUTO_INCREMENT = 1 ");
これでとりあえず解決したみたいです?
ていうかItemSeederでuser_idを数字で与えているのがそもそもダメなのでは…
はじめに AWS上のAmazon Aurora(MySQL)を MySQL Workbenchで外からいじってみました。 Amazon Auroraとは AWSが提供しているフルマネージドなデータベースサービス。 可用性99.99% 最低でも3つのAZにデータを6個複製、継続的にAmazon S3にバックアップ MySQL、PostgreSQL互換 いろいろ自動でやってくれる(プロビジョニングとかバックアップとか) ストレージが64TBまで自動で増える。 Aurora Serverlessを使えばインスタンスの性能まで自動で管理してくれる。 詳しくはこちら Amazon Aurora データベースのセットアップ AWSコンソールのRDSからいきます。 データベースの作成からAmazonAuroraを選択します。 エディションはMySQLです。 接続のところの追加の接続設定で「パブリックアクセス可能」を「あり」にします これをしないとVPC外から接続できません。 あと付与するセキュリティグループでインスタンスのポートに接続可能にしておくのも忘れずに(デフォルトだと3306) 他の設定は適当で大丈夫です。 作成できたらエンドポイントをメモっておいてください。 MySQL Workbenchを起動 起動したら下の矢印の+ボタンを押します。 そしたらこの画面が出てくるので先程のエンドポイントとユーザー名、パスワードを入力してOKを押します。 スキーマの作成 接続できたらこんな画面 左上のアイコンをクリックするとスキーマが作成できます。 テーブルの作成 適当にスキーマを作成したら 今度はテーブルを作成します。 右隣のボタンです。 PKとかNNとかなんやっておもったら右下のStorageってところに書いてありました。 PrimaryKeyとかの設定ですね。 データ挿入 テーブルが作れたらデータの挿入です 左側のテーブル名のところにカーソルを当てると表っぽいアイコンが出てきてそれをクリックするとテーブルの中身が見えます。 真ん中らへんのEditのところでいろいろ挿入したり削除したりできます。 変更したら右下のApplyで実際のコマンドとして入力するとテーブルが更新されます。 コマンドで表を操作したり、GUI上でポチポチとテーブルを操作したりできます。 すぐに反映された結果のテーブルが見えるので便利です。 まとめ Amazon AuroraをGUIのMySQLクライアントから触ってみました。 いろいろ機能が豊富そうなので研究しがいがありそうです
AWS上のAmazon Aurora(MySQL)を
MySQL Workbenchで外からいじってみました。
詳しくはこちら Amazon Aurora
AWSコンソールのRDSからいきます。
データベースの作成からAmazonAuroraを選択します。 エディションはMySQLです。
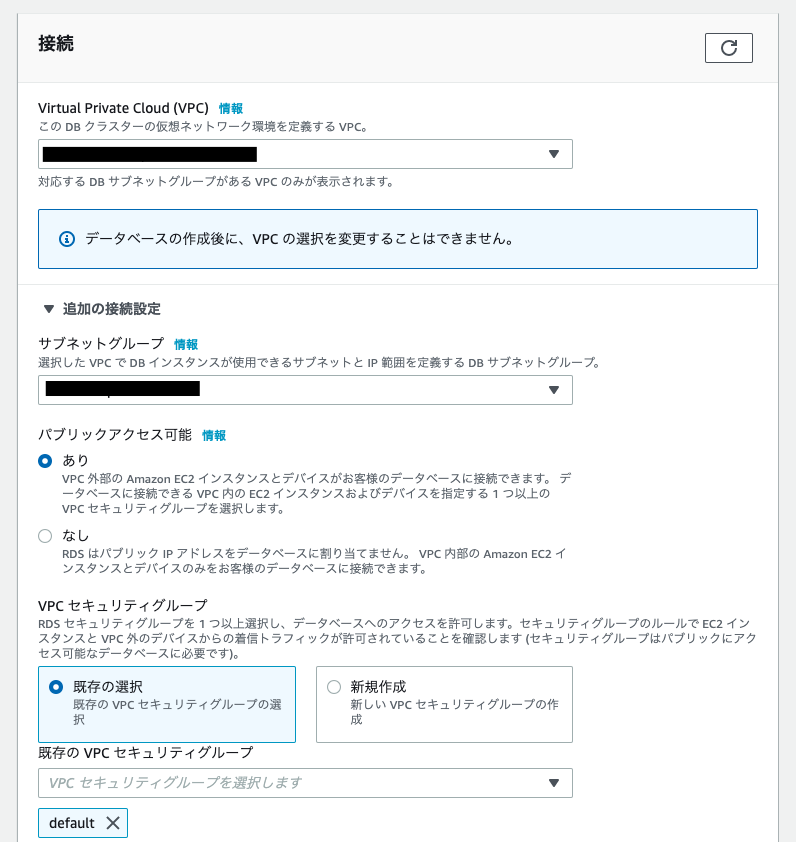
接続のところの追加の接続設定で「パブリックアクセス可能」を「あり」にします これをしないとVPC外から接続できません。 あと付与するセキュリティグループでインスタンスのポートに接続可能にしておくのも忘れずに(デフォルトだと3306) 他の設定は適当で大丈夫です。
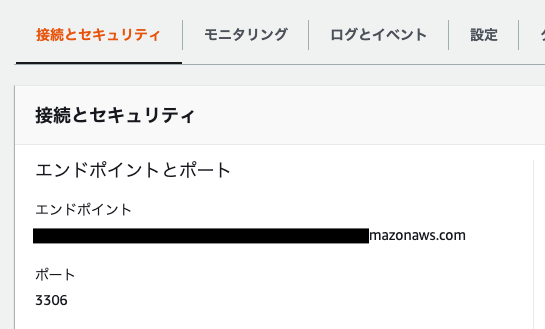
作成できたらエンドポイントをメモっておいてください。
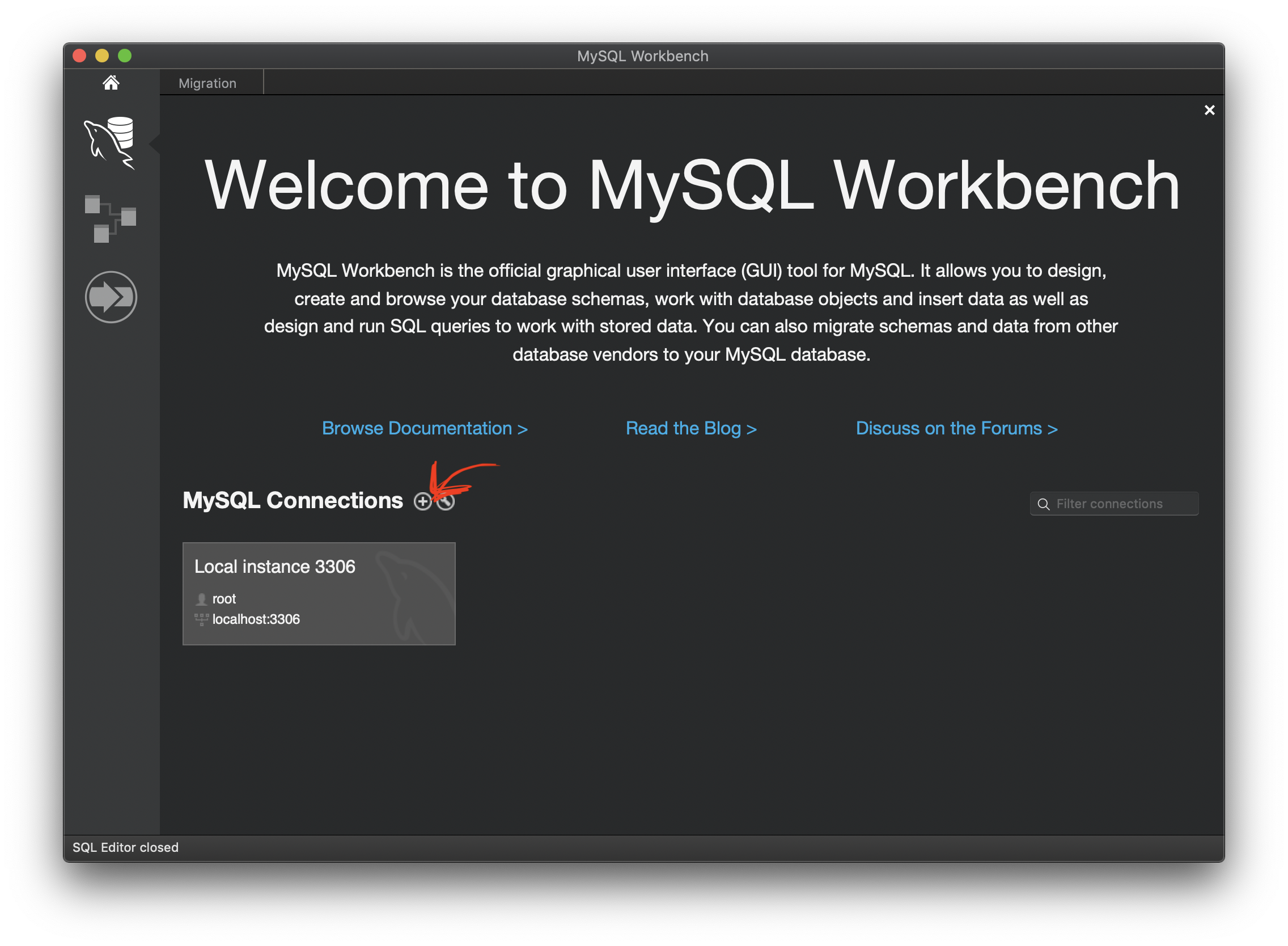
起動したら下の矢印の+ボタンを押します。
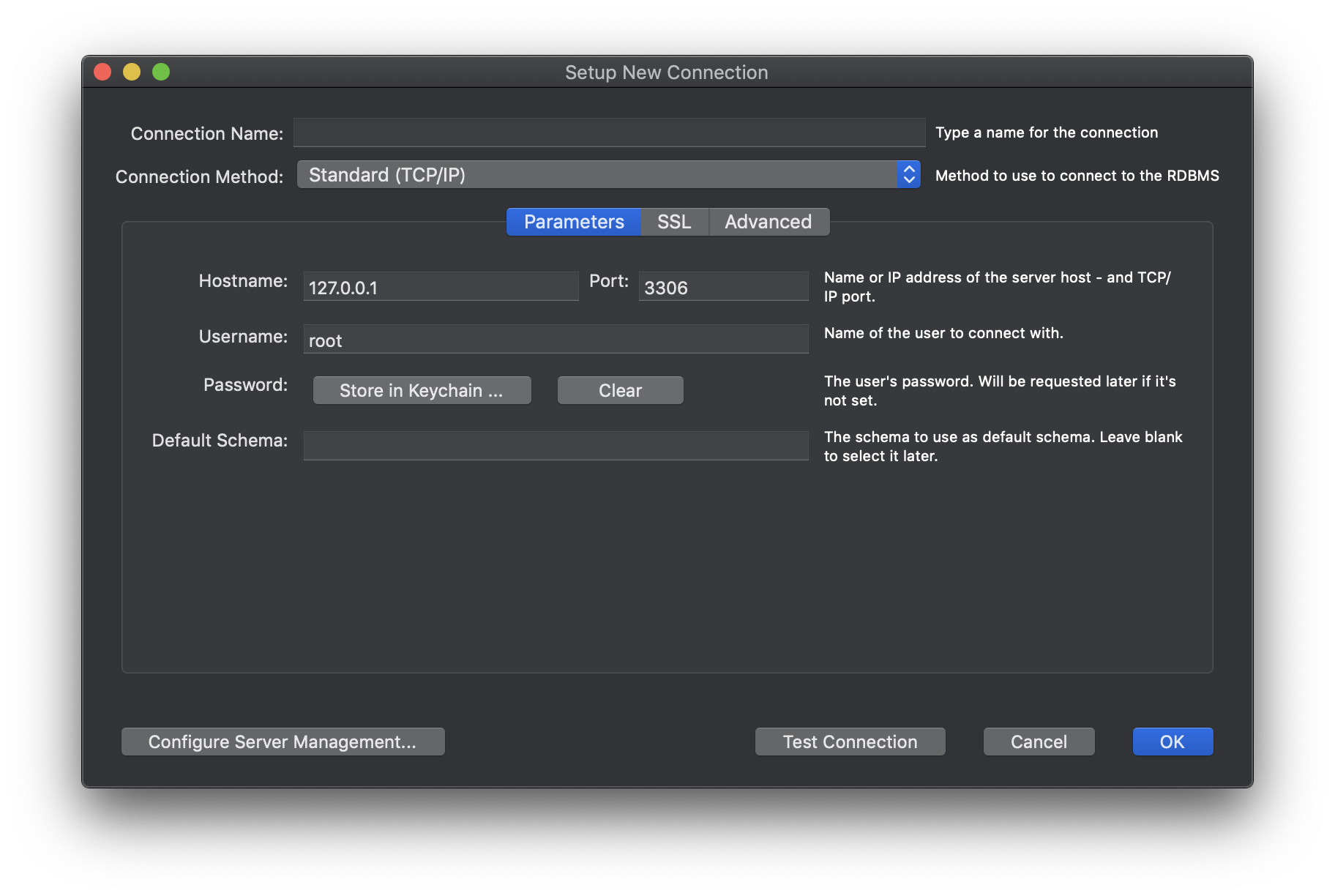
そしたらこの画面が出てくるので先程のエンドポイントとユーザー名、パスワードを入力してOKを押します。
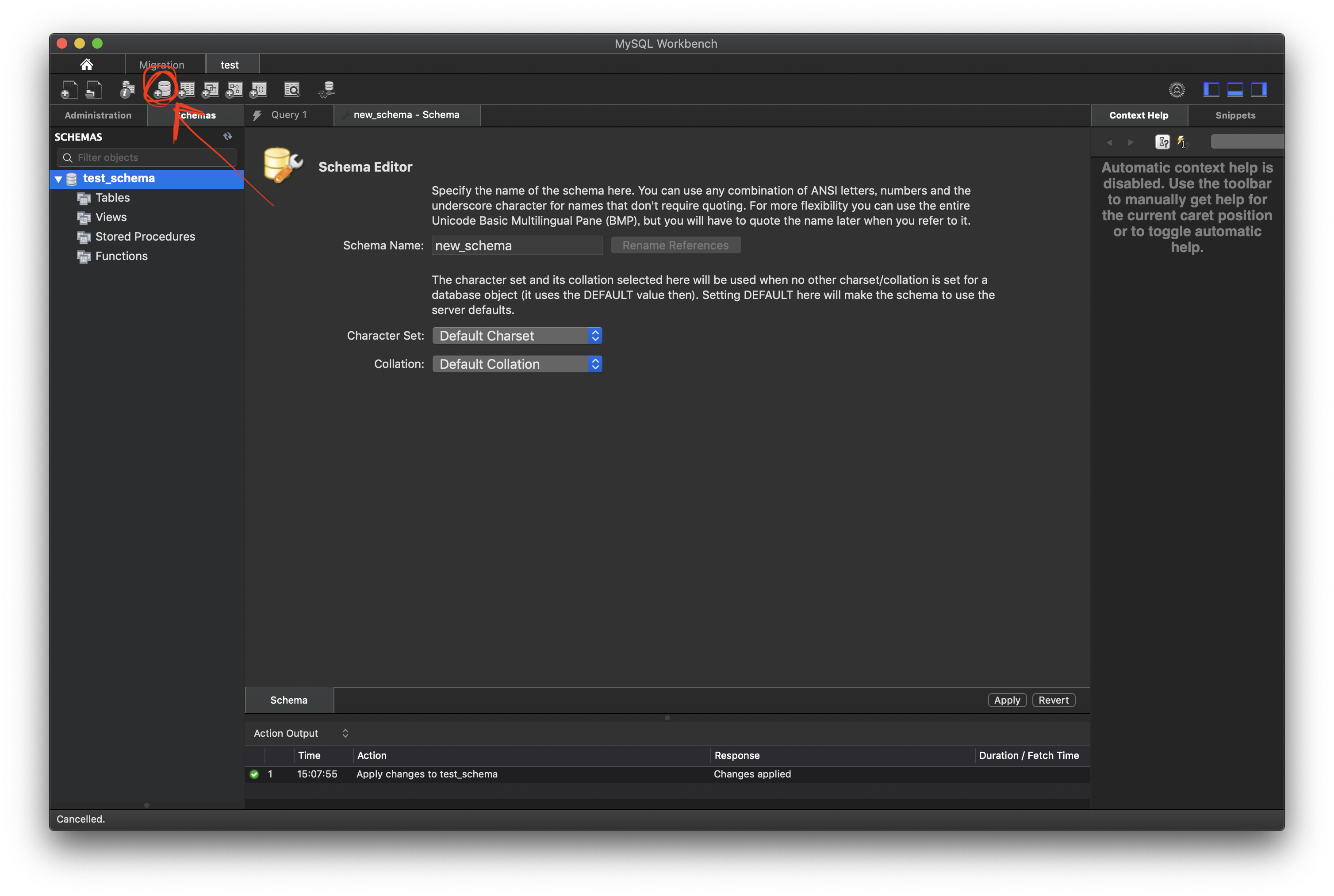
接続できたらこんな画面 左上のアイコンをクリックするとスキーマが作成できます。
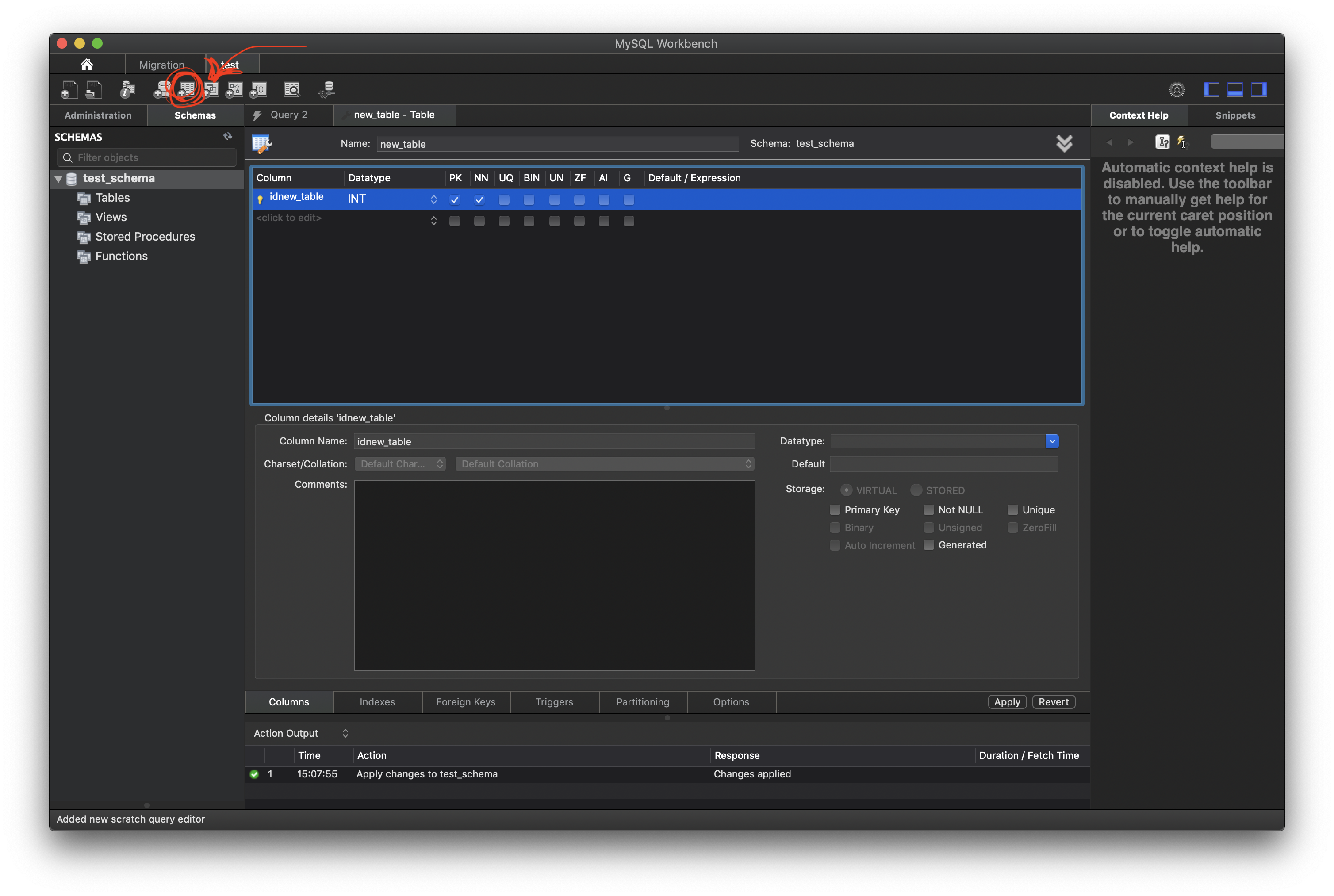
適当にスキーマを作成したら 今度はテーブルを作成します。 右隣のボタンです。
PKとかNNとかなんやっておもったら右下のStorageってところに書いてありました。
PrimaryKeyとかの設定ですね。
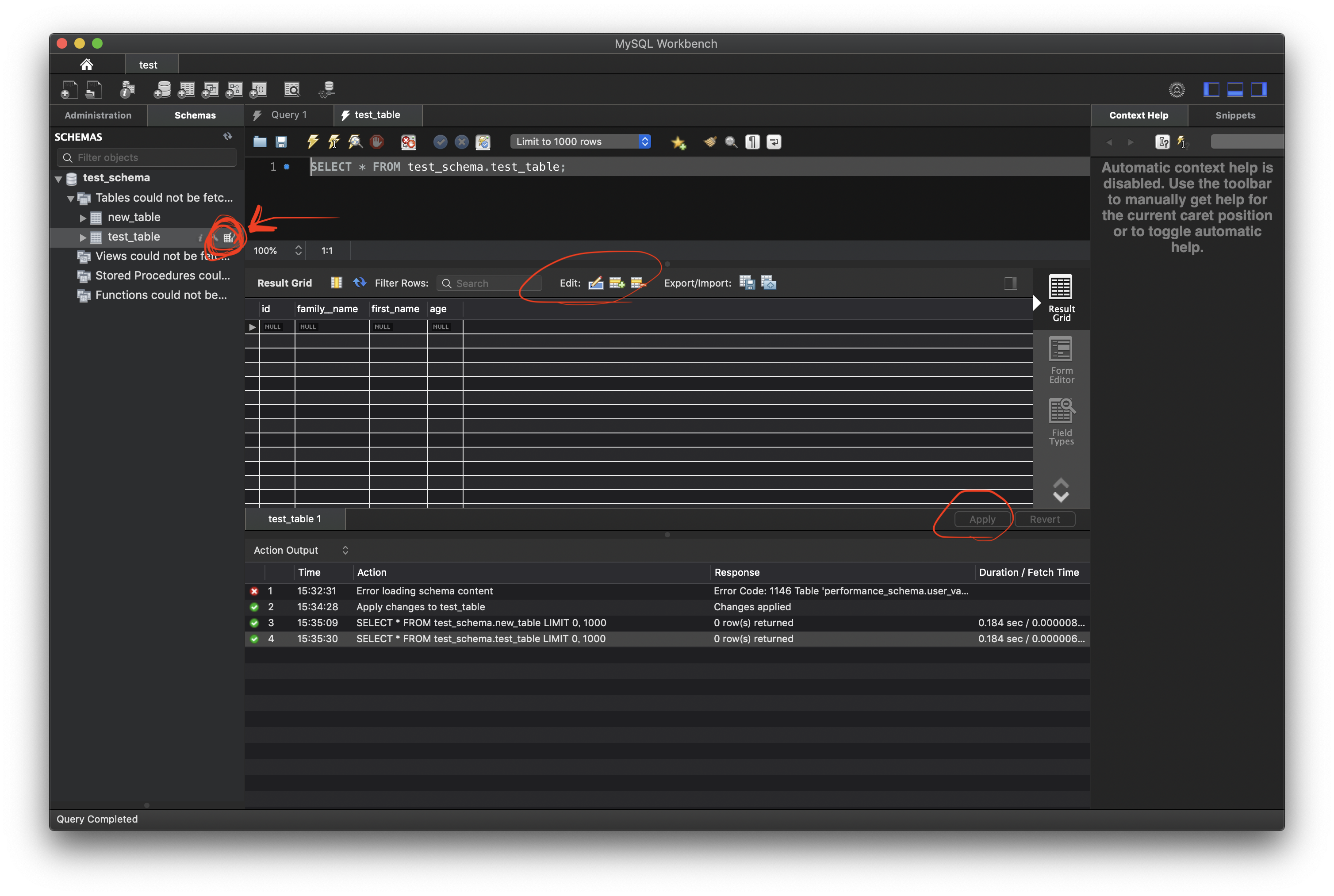
テーブルが作れたらデータの挿入です
左側のテーブル名のところにカーソルを当てると表っぽいアイコンが出てきてそれをクリックするとテーブルの中身が見えます。 真ん中らへんのEditのところでいろいろ挿入したり削除したりできます。 変更したら右下のApplyで実際のコマンドとして入力するとテーブルが更新されます。
コマンドで表を操作したり、GUI上でポチポチとテーブルを操作したりできます。 すぐに反映された結果のテーブルが見えるので便利です。
Amazon AuroraをGUIのMySQLクライアントから触ってみました。 いろいろ機能が豊富そうなので研究しがいがありそうです
実践ハイパフォーマンスMySQLを読んで考えたことをまとめました。 通常は小さい方がいい 当たり前だがデータ型が小さい方がパフォーマンスが良くなるので、なるべく小さいデータ型を使うよううにする。 しかし、この時にデータ型の大きさを過小評価すると、あとでデータ型の範囲を広げる必要が出てくる。 単純なものがいい データ型が単純であるほど、操作に時間がかからない。 例えば、日付と時刻は文字列ではなくMySQLの組み込み型として格納すべき。 IPアドレスは文字列でなく整数型で格納すべき。(.は人間が認識しやすいようにつけられているだけだから) できればNULLを使用しない NULL値を設定できる列はインデックス、インデックス統計、値の比較を複雑にするので、それらを参照するクエリをMySQLで最適化するのは難しい。NULL値を格納できる列はより多くの記憶域を使用し、内部でも特殊な処理を要求するから。 ただし通常NULL値を格納できる列をNOT NULLにしてもパフォーマンスの向上はわずかなので、列にインデックスをつける予定がある時以外は優先しなくていい。 ここのリンクにも書いてある通り、NOT NULLを使わずに例えば''を使うことはSQLアンチパターンとして知られているので、慎重に考える必要がありそう。 NOT NULLを使わずに''とかでNULLを表現すると''がNULLであることを開発者が覚えておく必要があるので、生産性を下げる原因になりうる。 整数 整数型には - TINYINT - SMALLINT - MEDIUMINT - INT - BIGINT がある。 整数型はUNSIGNED属性を持つことで、格納できる正の数の上限を約2倍にすることができる。 実数 実数とは少数部分を持つ数字のこと。 BIGINTに収まらない大きな整数を格納するためにDECIMALを使うこともできる。 不正確な型 FLOAT DOUBLE どちらも標準の浮動小数点演算の近似計算をサポートする。 それぞれの違いについては https://www.cc.kyoto-su.ac.jp/~yamada/programming/float.html に詳しく書いている。 正確な型 DECIMAL型 http://dcx.sap.com/1201/ja/dbreference/decimal.html 記憶域と計算のコストが増えるため、財務データを格納するなど少数部分の正確な結果が必要な時だけにする 文字列型 VARCHAR型 可変長の文字列を格納する最も一般的なデータ型。 必要な記憶域しか使用しないので、固定長の型ほど多くの記憶域を使用しない。 格納する値が短ければ短いほど使用する記憶域も小さい。 VARCHAR型は値の長さを保存するために1か2バイトを使用する。 CHAR型 固定長の文字列データ型。 nバイトに満たない場合は文字列の右側に空白が追加され、10バイトぴったりに調整される。 BLOB型とTEXT型 BLOB型は大量のバイナリデータを格納する。 TEXT型は大量の文字列データを保存する。 他のすべてのデータ型と異なり、MySQLはBLOB型とTEXT型の値を独自のIDを持つオブジェクトとして処理する。 VARCHAR型とTEXT型どちらを使うべき? ここのサイトに詳しく書いてある。 ストレージエンジンごとに違いはあるが、TEXT型は外部記憶領域を使ってDBにはそのポインタが格納される。 一方VARCHAR型は値そのものをDB内に保存するためアクセス速度が早い。 基本的にはVARCHAR型を使った方がいい。 日付と時刻型 DATETIME 1001~9999年までの値を格納することができる。精度は1秒。YYYYMMDDHHMMSS形式で整数にアンパックする。これには8バイトの記憶域が使用される。 TIMESTAMP型 1970年1月1日午前0時からの経過時間を秒数で格納する。記憶域を4バイトしか使用しないのでDATETIME型より範囲はずっと狭い(1970年から2038年の途中まで) 他のデータ型と違いTIMESTAMP型の列はデフォルトでNOT NULL。 どちらを使うべき? 記憶域が小さいことを考えると基本的にTIMESTAMPだが2038年問題や特集な挙動があるようなので注意が必要。
実践ハイパフォーマンスMySQLを読んで考えたことをまとめました。
当たり前だがデータ型が小さい方がパフォーマンスが良くなるので、なるべく小さいデータ型を使うよううにする。 しかし、この時にデータ型の大きさを過小評価すると、あとでデータ型の範囲を広げる必要が出てくる。
データ型が単純であるほど、操作に時間がかからない。 例えば、日付と時刻は文字列ではなくMySQLの組み込み型として格納すべき。 IPアドレスは文字列でなく整数型で格納すべき。(.は人間が認識しやすいようにつけられているだけだから)
NULL値を設定できる列はインデックス、インデックス統計、値の比較を複雑にするので、それらを参照するクエリをMySQLで最適化するのは難しい。NULL値を格納できる列はより多くの記憶域を使用し、内部でも特殊な処理を要求するから。 ただし通常NULL値を格納できる列をNOT NULLにしてもパフォーマンスの向上はわずかなので、列にインデックスをつける予定がある時以外は優先しなくていい。
ここのリンクにも書いてある通り、NOT NULLを使わずに例えば''を使うことはSQLアンチパターンとして知られているので、慎重に考える必要がありそう。 NOT NULLを使わずに''とかでNULLを表現すると''がNULLであることを開発者が覚えておく必要があるので、生産性を下げる原因になりうる。
''
整数型には - TINYINT - SMALLINT - MEDIUMINT - INT - BIGINT がある。 整数型はUNSIGNED属性を持つことで、格納できる正の数の上限を約2倍にすることができる。
UNSIGNED
実数とは少数部分を持つ数字のこと。 BIGINTに収まらない大きな整数を格納するためにDECIMALを使うこともできる。
どちらも標準の浮動小数点演算の近似計算をサポートする。 それぞれの違いについては https://www.cc.kyoto-su.ac.jp/~yamada/programming/float.html に詳しく書いている。
DECIMAL型
http://dcx.sap.com/1201/ja/dbreference/decimal.html
記憶域と計算のコストが増えるため、財務データを格納するなど少数部分の正確な結果が必要な時だけにする
可変長の文字列を格納する最も一般的なデータ型。 必要な記憶域しか使用しないので、固定長の型ほど多くの記憶域を使用しない。 格納する値が短ければ短いほど使用する記憶域も小さい。 VARCHAR型は値の長さを保存するために1か2バイトを使用する。
固定長の文字列データ型。 nバイトに満たない場合は文字列の右側に空白が追加され、10バイトぴったりに調整される。
BLOB型は大量のバイナリデータを格納する。 TEXT型は大量の文字列データを保存する。
他のすべてのデータ型と異なり、MySQLはBLOB型とTEXT型の値を独自のIDを持つオブジェクトとして処理する。
ここのサイトに詳しく書いてある。
ストレージエンジンごとに違いはあるが、TEXT型は外部記憶領域を使ってDBにはそのポインタが格納される。 一方VARCHAR型は値そのものをDB内に保存するためアクセス速度が早い。 基本的にはVARCHAR型を使った方がいい。
1001~9999年までの値を格納することができる。精度は1秒。YYYYMMDDHHMMSS形式で整数にアンパックする。これには8バイトの記憶域が使用される。
1970年1月1日午前0時からの経過時間を秒数で格納する。記憶域を4バイトしか使用しないのでDATETIME型より範囲はずっと狭い(1970年から2038年の途中まで) 他のデータ型と違いTIMESTAMP型の列はデフォルトでNOT NULL。
記憶域が小さいことを考えると基本的にTIMESTAMPだが2038年問題や特集な挙動があるようなので注意が必要。
はじめに Node.js + Expressを使って開発を行った際に、sequelizeを使ってモデル内のカラムからENUMの値を取得した時のやり方をメモしておきます。 モデルの定義確認 以下のように簡易モデルを定義したとします。 sequelize.define('model', { animals: { type: Sequelize.ENUM, values: ['dog', 'cat', 'bird'] } }) 取得方法 Model.rawAttributes.states.valuesでENUMの値を取得できます。 var Model = sequelize.define('model', { states: { type: Sequelize.ENUM, values: ['dog', 'cat', 'bird'] } }); console.log(Model.rawAttributes.states.values); // logs ['dog', 'cat', 'bird'] in console カラムからENUMの値を取得する場合は、model.column.rawAttributes.states.valuesなどのようにすると同様に取得可能です。
Node.js + Expressを使って開発を行った際に、sequelizeを使ってモデル内のカラムからENUMの値を取得した時のやり方をメモしておきます。
以下のように簡易モデルを定義したとします。
sequelize.define('model', { animals: { type: Sequelize.ENUM, values: ['dog', 'cat', 'bird'] } })
Model.rawAttributes.states.valuesでENUMの値を取得できます。
Model.rawAttributes.states.values
var Model = sequelize.define('model', { states: { type: Sequelize.ENUM, values: ['dog', 'cat', 'bird'] } }); console.log(Model.rawAttributes.states.values); // logs ['dog', 'cat', 'bird'] in console
カラムからENUMの値を取得する場合は、model.column.rawAttributes.states.valuesなどのようにすると同様に取得可能です。
model.column.rawAttributes.states.values