- 投稿日:2019-06-25T23:36:42+09:00
ESP32は深い学習の夢を見るか?(ESP32でMNISTデータの画像認識)
目的
DeepLearningやるのだったら、やっぱりMNISTデータですよね。
実は「アヤメの分類」はDeepLearningとは言えないとの噂が。
(ネットワークが4段以上無いと言わないとか)
◆◆◆ そうだ、ESP32でMNISTデータの画像認識をやるぜ ◆◆◆
うーむ、ESP32でメモリが足りるだろうか経緯
(1)前回 の「アヤメの分類」でneural_network_consoleの使い方は多少分かった。
(2)neural_network_console吐き出したc_sourceを、ESP32,vs2017で走らせEVALUATIONが実行できた。
(3)次に10_deep_mlpで同様にしたが、問題点が....。
1)結果の数値が出力されていない。
2)画像の入力のやり方が良く判らない。
3)メモリ不足でコンパイルできない(学習データがでかい!)
(4)色々やって問題点を潰したら、いい感じで結果らしきものが表示された。前提条件(前回と同様)
以下のソフトを予め導入の事。
(1)neural_network_console (当たり前、for Windows 8.1/10_64bit 1.4.0にて検証)
(2)ESP-IDF (ESP32の開発環境)
(3)VisualStudio(2017) (パソコン上で動作確認したい場合に必要、無くても可)neural_network_consoleでの操作(deep_mlp)
例題とした「10_deep_mlp」は判定の確度しか表示せず、判定の元になる数値を出力していない。
そこで、数値を出力するように変更する。
(1)neural_network_console samples sample_project tutorial basics に在る10_deep_mlp.sdcproj(filesも)を何処かにコピーする。
(2)プロジェクト画面でコピーしたプロジェクトを選択する。
(3)EDIT画面で最下段をSoftMaxに変更。
(4)Affine_4(5),Tanh_4(5)のOutShapeを10に変更。
(5)TRAINING,EVALUATIONを実行。
(6)EVALUATION画面で、y'0 - Y'_9が表示されていることを確認。
(7)c_sourceの内容をコンパイルする各フォルダにコピーする
(8)上記を設定したものを下記に格納しているので参考にされたい。(但しコピー(移動)して動くかどうかは未調査)
10出力deep_mlp
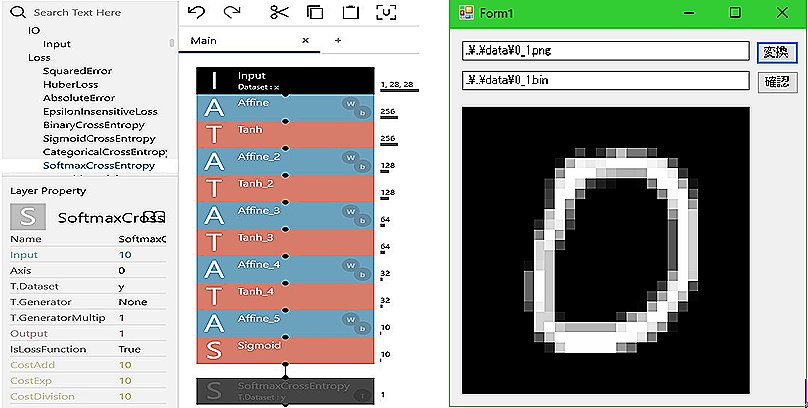
10出力deepmlp設定例 入力画像変換画面
neural_network_consoleでの入力画像変換
c_sourceのMainRuntime_example.cは独自形式の画像入力にのみ対応している。
テストデーター(2個)は存在しているが、作り方の説明が何処にあるのかは判らなかった。
そこでテストデーターを解析し、次のように新たなデータを作成した。
(1)見た感じでテストデータは28x28(784個)のfloatの並びと想定。
(2)上記想定に基づく変換、表示ソフト(VB)を作成して検証。
※変換データ(0,1,2,3を追加、既成分と合わせて計8件)をdataフォルダに格納しています。
※変換プログラム(VB)は下記に格納しています。
入力画像変換
プログラムはVB(2017)で新規プロジェクトを設定し、floatconv内の各ファイルと差し替えれば使える(はずです)。
データ作成方は、入力画面(上図)で上段に変換元(.png)、下段に変換先(.bin)を入れ、「変換」を押す。画像の与え方
前回 記載の「ESP32による「アヤメの分類」のEVALUATION(データーファイル使用バージョン)」と同様に行います。<データーの読み込み>
入力バッファに784個のfloatデータをべた書きする。
float *idbf = nnablart_mainruntime_input_buffer(context, 0); // Input.Data.Buffer
fread(idbf, sizeof(float), NNABLART_MAINRUNTIME_INPUT0_SIZE, input0);ESP32へのプログラム(主に学習データ)の格納
c_sourceをESP32でコンパイルすると悲しい事に、「region `dram0_0_seg' overflowed by ****** bytes」が発生します。
これはMainRuntime_parameters.c内の配列も含めた変数を、100KB程度に収めないとRAMがパンクするからです。
しかしこの作業は、学習データを小さくすることであり、極端な性能低下を招く可能性が高いと思われます。
そこで、色々調べたが解決策が見当たらず、暗礁に乗り上げてしまい深い学習の夢は立たれるかと思われました。
しかし、意外に簡単な方法で解決することが分かって、事なきを得ました。
学習データはMainRuntime_parameters.cに配列の形で格納しています。
ESP32では配列は変数であり、起動時にDRAM領域にコピーされる事により(推測)、貴重なRAMが食いつぶされます。
そこで配列を定数とする事により、配列はプログラム領域に留まり、貴重なRAMが生き残ります。
具体的には、MainRuntime_parameters.c内の配列の先頭にconstを追記してconst floatとする事により、これを実現します。
これにより、下記に示すようなメモリ使用量となりました。
プログラムエリアはpartitions_example.csvにより約3MB確保しており、あと3倍程度に学習強化が可能でしよう。$ make size Total sizes: DRAM .data size: 8592 bytes DRAM .bss size: 2008 bytes Used static DRAM: 10600 bytes ( 170136 available, 5.9% used) ← 配列を変数にするとここが使われる Used static IRAM: 34560 bytes ( 96512 available, 26.4% used) Flash code: 99064 bytes Flash rodata: 1001396 bytes Total image size:~1143612 bytes (.bin may be padded larger)ESP32によるdeep_mlpのEVALUATION
ESP32のesp-idfでコンパイル可能な形で下記に格納しています。
ESP32によるdeep_mlp
前回プログラムとの共用を図っているため、プログラムの移動が必要となっています。
(1)esp-nnc main 内のcomponent.mk以外をすべて削除
(2)eps-nnc main_mnistのプログラムを esp-nnc main に全てコピー
(3)make cleanを実行後、make flash monitorを実行する。
(4)下記が表示されれば成功Start Spiffs.Dir.Info 0_1.bin 1_1.bin 2_1.bin 3_1.bin 4_1.bin 4_2.bin 9_1.bin 9_2.bin : : Partition size: total: 956561, used: 210589 0_1.bin +1.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 ( 0 ) 1_1.bin +0.000 +1.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 ( 1 ) 2_1.bin +0.000 +0.000 +1.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 ( 2 ) 3_1.bin +0.000 +0.000 +0.000 +1.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 ( 3 ) 4_1.bin +0.000 +0.000 +0.000 +0.000 +1.000 +0.000 +0.000 +0.000 +0.000 +0.000 ( 4 ) 4_2.bin +0.000 +0.000 +0.000 +0.000 +1.000 +0.000 +0.000 +0.000 +0.000 +0.000 ( 4 ) 9_1.bin +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +1.000 ( 9 ) 9_2.bin +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +0.000 +1.000 ( 9 ) Stop※0_1.binでは最初の数値が+1.000(他は+0.000)となっており、「0」である確率が高いことを示している。
()内は各ファイルにおいての、一番確率の高い数値を示しています。ESP32もNeuralNetworkConsoleもDeepLearningも、深く理解していないので、 考え違いをしているかもしれませんよ。
でも、次はカメラを繋いだESP32でDeepLearningをやってみたいかな。(Please expect the next work?)
上記記載内容は無保証であり、各自の責任においてご利用願います。
- 投稿日:2019-06-25T22:07:59+09:00
機械学習のモデルの評価 - 交差検証、バイアスとバリアンス、学習曲線、適合率と再現率
最近数学をやり直していてふと機械学習がどういう仕組みなのか知りたくなって、Courseraでスタンフォード大学が提供している機械学習講座を受けている。第6週まで終わったので思い出しながら軽くまとめる。講座はこちら Coursera Machine Learning
week1 機械学習とは何か、単線形回帰、仮説関数、コスト関数、最急降下法
week2 重線形回帰、スケーリング、多項式回帰、正規方程式
week3 ロジスティック回帰、共役勾配法・BFGS・L-BFGS、多クラス分類 、過学習と正則化
week4 ニューラルネットワークの基礎
week5 ニューラルネットワークのコスト関数とバックプロパゲーション
week6 機械学習のモデルの評価 - 交差検証、バイアスとバリアンス、学習曲線、適合率と再現率Week 6 機械学習のモデルの評価 - 交差検証、バイアスとバリアンス、学習曲線、適合率と再現率
交差検証 - Cross Validation
あるデータセットに学習アルゴリズムがよく適合しているからと言って、それがいいモデルであるとは言えない。なぜならそのモデルに新しいデータセットを与えた時、同じようによく適合するとは言えないからである。
この問題を改善するために、以下のように3つにデータセットを分ける。
- トレーニングセット 60%
- 交差検証セット 20%
- テストセット 20%
そして、以下のようなステップで誤差を計算していく。
- トレーニングセットを使って、$\Theta$を最適化する。
- 交差検証セットを使って、誤差が最も小さい多項式の次数$d$を探す。
- テストセットを使って、$J_{test}(\Theta^{(d)})$の誤差を見積もる。
バイアスとバリアンス - Bias and Variance
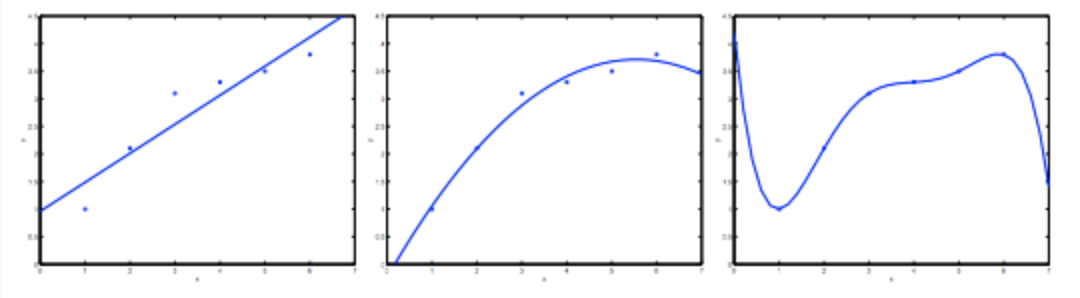
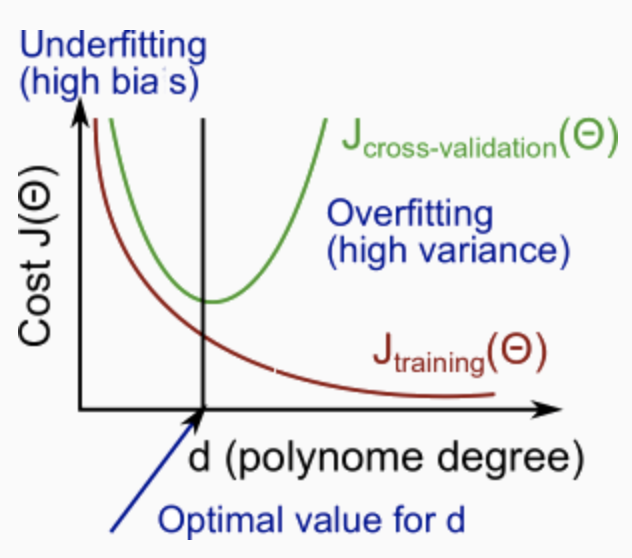
多項式の次数
左 中央 右 高バイアス - High Bias 高バリアンス - High Variance 未学習 - Underfit Justfit 過学習 - Overfit $y=\theta_0+\theta_1x$ $y=\theta_0+\theta_1x+\theta_2x^2$ $y=\sum_{j=0}^5\theta_jx^j$ 上の図から分かるように、次数が大きくなるほどトレーニングセットの誤差は小さくなる。
同時に、交差検証の誤差は、ある点までは次数が大きくなるにつれて減少し、さらに次数が大きくなると増加する。つまり、以下のように次数$d$と$J(\Theta)$の関係をグラフにした場合、下に凸曲線を形成する。
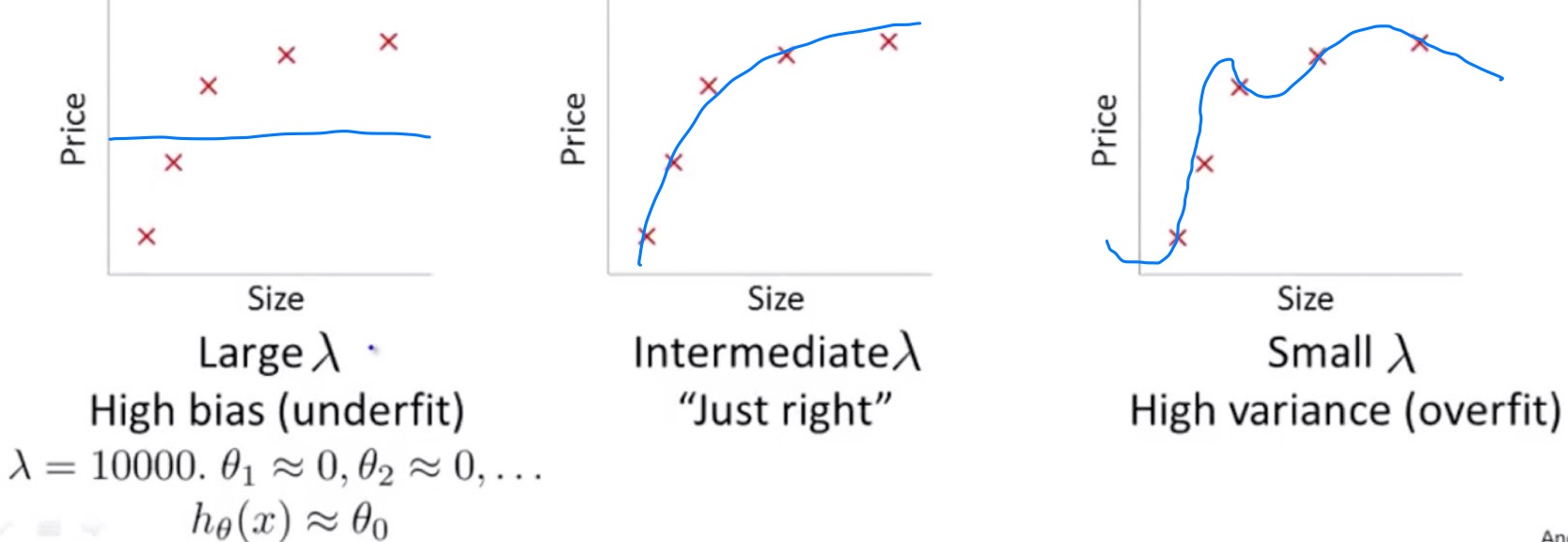
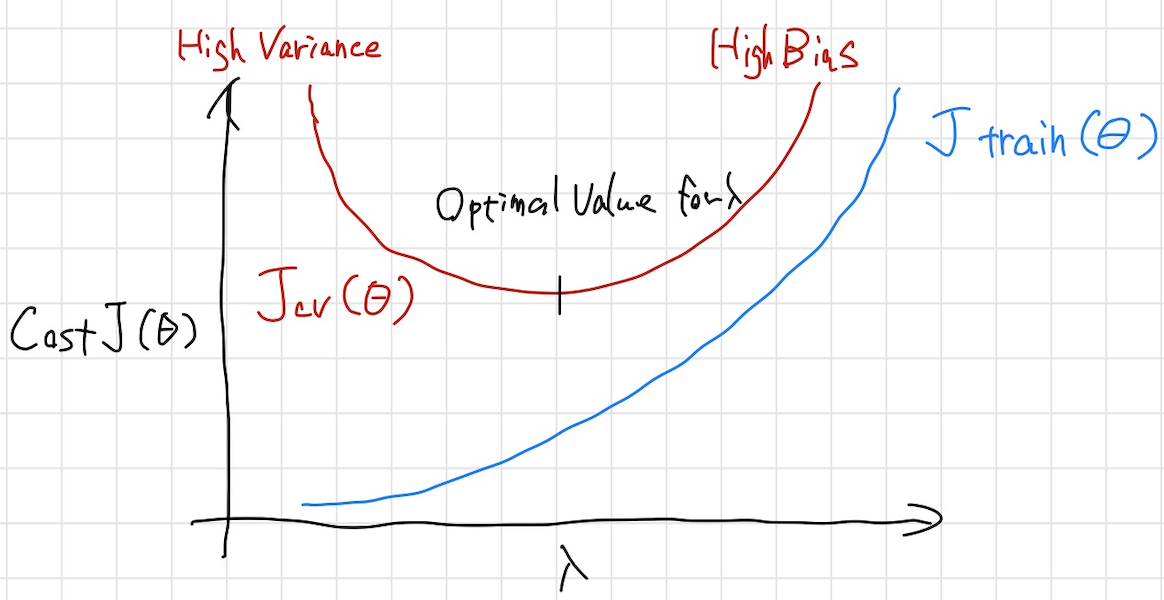
正則化項λ
次に正則化項$\lambda$との関係について考える。
$\lambda$は大きくなればなるほどunderfitし、小さくなればなるほどoverfitする。
$\lambda$と$J(\Theta)$の関係をグラフにすると以下のようになる。
学習曲線 - Learning Curves
ごく少数のデータセットでアルゴリズムをトレーニングすると誤差が0になりやすくなる。なぜなら、例えばデータセットが2つや3つの場合、そのデータセットには二次関数がぴったりフィットするから。一般に、トレーニングセットが大きくなるほど誤差が大きくなる。そして一定まで達すると安定する。
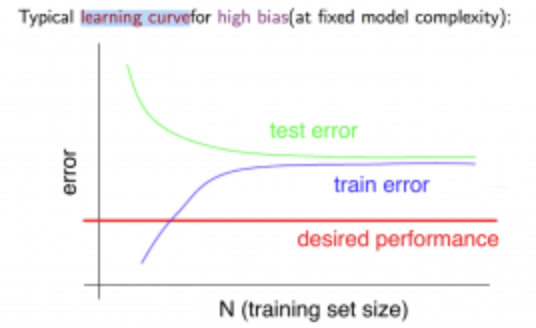
高バイアスの場合、
- トレーニングセットが小さい時: $J_{train}(\Theta)$は低く、$J_{cv}(\Theta)$は高くなる
- トレーニングセットが大きい時: $J_{train}(\Theta)$と$J_{cv}(\Theta)$の両方が高くなり、同じような値になる
グラフにすると以下のようになる。
つまり、高バイアスの場合トレーニングセットを増やすのはあまり効果的ではない。
高バリアンスの場合、
- トレーニングセットが小さい時: $J_{train}(\Theta)$は低く、$J_{cv}(\Theta)$は高くなる
- トレーニングセットが大きい時: $J_{train}(\Theta)$は大きくなり、$J_{cv}(\Theta)$は小さくなり続ける
グラフにすると以下のようになる。
つまり、高バリアンスの場合トレーニングセットを増やすことは効果的である。
適合率と再現率- Precision and Recall
歪んだクラス - Skewed Classes
例えば、腫瘍を良性か悪性か分類する時、実際には悪性である患者が100人中2人いる場合に全ての人を良性に分類する予測を立てたとする。その予測は結果として98%の的中率を持つことになる。さて、これはいい予測と言えるだろうか。
適合率と再現率
予測の精度を図るために用いられる指標が適合率と再現率である。
予測した結果と実際の値を以下のような表にする。
予測されたクラス \ 実際のクラス 1 0 1 True Positive(TP) False Positive(FP) 0 False Negative(TN) True Nagative(TN) 適合率と再現率は以下のように表される。
$Precision(適合率)=\frac{TP}{TP+FP}$
$Recall(再現率)=\frac{TP}{TP+FN}$
0-1の値をとり、高くなるほど精度が高いと言える。
上にあげた全ての腫瘍を良性と予測する場合は再現率が0になる。F値 - F Score
適合率と再現率はトレードオフの関係にある。どちらもいい具合に高くないと良いアルゴリズムとは言えない。それを判断するためにF値を使用する。
$F=2\frac{PR}{P+R}$

- 投稿日:2019-06-25T22:02:18+09:00
ニューラルネットワークのコスト関数とバックプロパゲーション
最近数学をやり直していてふと機械学習がどういう仕組みなのか知りたくなって、Courseraでスタンフォード大学が提供している機械学習講座を受けている。第6週まで終わったので思い出しながら軽くまとめる。講座はこちら Coursera Machine Learning
week1 機械学習とは何か、単線形回帰、仮説関数、コスト関数、最急降下法
week2 重線形回帰、スケーリング、多項式回帰、正規方程式
week3 ロジスティック回帰、共役勾配法・BFGS・L-BFGS、多クラス分類 、過学習と正則化
week4 ニューラルネットワークの基礎
week5 ニューラルネットワークのコスト関数とバックプロパゲーション
week6 機械学習のモデルの評価 - 交差検証、バイアスとバリアンス、学習曲線、適合率と再現率Week 5 ニューラルネットワークのコスト関数とバックプロパゲーション
ニューラルネットワークのパラメータをフィッティングするにはどうするか。いつもと同じようにコスト関数から入る。
コスト関数
ニューラルネットワークはロジスティック回帰が連なったものなので、ロジスティック回帰のコスト関数を思い出すと直感的にイメージしやすい。
- ロジスティック回帰のコスト関数
J(\theta)=−\frac{1}{m}\sum_{i=1}^{m}[y^{(i)}\log(h_\theta(x^{(i)}))+(1−y^{ (i)})\log(1−h_\theta(x^{(i)}))]+\frac{\lambda}{2m}\sum_{j=1}^{n}\theta_j^2
- ニューラルネットワークのコスト関数
- $L=$ レイヤーの合計
- $s_l=$ $l$レイヤーのユニット数
- $K=$ 出力のユニット数
J(\Theta)=−\frac{1}{m}\sum_{i=1}^{m}\sum_{k=1}^{k}[y^{(i)}_k\log((h_\Theta(x^{(i)}))_k)+(1−y^{ (i)}_k)\log((1−h_\Theta(x^{(i)}))_k)]+\frac{\lambda}{2m}\sum_{l=1}^{L-1}\sum_{i=1}^{s_l}\sum_{j=1}^{s_l+1}(\Theta_{j,i}^{(l)})^2バックプロパゲーション - Backpropagation
いつものように$J(\Theta)$を最小化するような$\Theta$を求めたいので、$J(\Theta)$の偏導関数を計算する。
$$
\frac{\partial}{\partial\Theta_{i,j}^{(l)}}J(\Theta)
$$計算するためにバックプロパゲーションというアルゴリズムを使用する。
まず$\{(x^{(1)},y^{(1)})⋯(x^{(m)},y^{(m)})\}$のようなm個のトレーニングセットを考える。
$\Delta_{i,j}^{(l)}:=0$とする。
step 1: $a^{(1)}:=x^{(t)}$
入力層の活性化ユニット$a^{(1)}$に対して$x^{(t)}$をセットする。
step 2: フォワードプロパゲーションを適用して$a^{(l)}$を計算する。レイヤー2,3...と最後のレイヤーまで。
step 3: トレーニングセットの出力$y^{(t)}$を使って、$\delta^{(L)}=a^{(L)}−y^{(t)}$、つまり誤差を計算する。
この時、$L$はレイヤーの合計で、$a^{(L)}$は最後のレイヤーの活性化ユニットの出力のベクトルである。そのため、最後のレイヤーの誤差は、単に最後のレイヤーの仮説が出力した値とトレーニングセット$y$の値の差でしかない。最後のレイヤーよりも前にあるレイヤーの$\delta$を取得するには、右から左に戻る。このことから誤差を右から左に伝播させるという意味でバックプロパゲーションと呼ばれる。
step 4: $\delta^{(l)}=((\Theta^{(l)})^T\delta^{(l+1)})\hspace{2pt}.∗\hspace{2pt}a^{(l)}\hspace{2pt}.∗\hspace{2pt}(1−a^{(l)})$を使って、それぞれの誤差である$\delta^{(L-1)}, \delta^{(L-2)},\dots,\delta^{(2)}$を計算する。$\delta^{(1)}$を計算しないのはレイヤー1は入力層のため誤差が存在しないから。
レイヤー$l$の$\delta$は、次のレイヤーの$\delta$にレイヤー$l$の$\Theta$行列を掛けることによって計算される。次に、$g'$関数を要素ごとに掛ける。これは入力$z^{(l)}$の活性化関数$g$の導関数である。$g'(z^{(l)})=a^{(l)}\hspace{2pt}.∗\hspace{2pt}(1−a^{(l)})$
step 5: $\Delta_{i,j}^{(l)}:=\Delta_{i,j}^{(l)}+a_j^{(l)}\delta_i^{(l+1)}$ もしくはベクトル化した $\Delta^{(l)} := \Delta^{(l)} + \delta^{(l+1)}(a^{(l)})^T$で$\Delta$行列をアップデートする。
\begin{align} D_{i,j}^{(l)}&:=\frac{1}{m}(\Delta_{i,j}^{(l)}+\lambda\Theta^{(l)}_{i,j})\hspace{4pt},if\hspace{4pt}j≠0\\ D_{i,j}^{(l)}&:=\dfrac{1}{m}\Delta_{i,j}^{(l)}\hspace{4pt},if\hspace{4pt}j=0 \end{align}最終的に以下となる。
$$
\frac{\partial}{\partial\Theta_{i,j}^{(l)}}J(\Theta)=D_{i,j}^{(l)}
$$
- 投稿日:2019-06-25T20:57:02+09:00
FCN(Fully Convolutional Network)について
FCNはその名の通り、全てがConvolution層で構成されているネットワーク。
この名前と全結合層とはとくに関係ない。
- 構成が複雑ではなく、計算コストは畳み込みが主なため、end-to-endな学習ができ予測計算にかかる時間も少ない。
- また畳み込みなので、Inputする画像の大きさに縛りがない。
- 投稿日:2019-06-25T14:19:34+09:00
Machine Learning Recommender Pitch 勉強会メモ
概要
Machine Learning Recommender Pitch
Machine Learning Pitchは、機械学習について業務で培った知見や経験や苦労話を共有できる場を提供することを目的としたMeetupグループです。機械学習に取り組み、実社会への適用に日々もがき苦しみ楽しんでいる方々を対象としております。
機械学習を実際の製品やサービスに提供するためには、企画(プランナー)、設計(機械学習エンジニア、データサイエンティスト)、基盤(サーバーサイドエンジニア、インフラエンジニア)、品質保証(QAエンジニア、セキュリティエンジニア)、分析(データアナリスト)など様々な職種の協力が必要です。Machine Learning Pitchでは、定期的に毎回テーマを決めて実務者の方々に発表して頂きます。
発表内容
パーソナライゼーションのためのマルチリービング
マルチリービング
- ABテストと比べ、複数アルゴリズムの検証期間が少なくて済む
- 群のバイアスに左右されない
- 一方、ランキングの間接的な影響を評価しにくい
- 検索で適応されたもので、パーソナライゼーション上での適用事例がない
課題
- パーソナライゼーションにおいて、マルチリービングの負荷が高い
- 定式化の修正により、高速化
- フィードバック関数の設計
オフライン評価
- 安定性を検証
- ランキング長とランキングの種類を変化させる
- 提案手法の方が安定している
オンライン評価
- ABテストとマルチリービングでサンプルサイズとp値をを比較
- 効率的に性能評価できる
Graph Convolutional Networkを使った推薦システム
問題設定
- 記事をユーザごとに出し分け
- 記事へのアクセス数は少ない
- inactiveユーザにもうまくだしたい
- 日本の医師は30万と限られているため、inactiveユーザへのアプローチが重要
- 興味に合わせたものを出したい
- 若手にはキャリア関連
- 医師の専門分野(内科、外科など)
GCNモデル
- ユーザとアイテムの二部グラフ
- 属性データはLatent crossに統合する
- ユーザは、クリックしたアイテムのembeddingの平均で表現する
- アイテムは、クリックしたユーザのembeddingの平均で表現する
- ユーザがアイテムをクリックする確率をembeddingのコサイン類似度で計算する
- 新しいアイテムもクリックがあれば計算できる
評価
- 直近のデータを分割して、テストデータをする
- データがたまっていない直近のデータからレコメンドされるかを確認する
- オフライン検証で、Rankingモデルよりも高いスコア
- ユーザに対して、様々な記事を満遍なく推薦できている
モデルの挙動
- 似ているユーザの埋め込みは近くなる
- ユーザのクリックからアイテムの埋め込みが計算される
- みんなに見られる人気のアイテムは、平均をとるとみんなから遠くなる
その他
- 毎日クリックしているようなユーザは推薦するメリットがないので除いている
クックパッドにおける推薦(と検索)の取り組み
検索と推薦
- 検索 クックパッド内で回遊させたい
- 推薦 気に入ったレシピをいち早く見つけたい
KPIが立てづらい
- ビジネスモデルとしてはプレミアム会員数、施策のゴールとしては遠い
- CGMとしては、人気のレシピだけを推薦すると、多くのユーザの満足度に繋がらない
- ユーザが目当てのレシピに行き着いたかどうかわからない
負の影響
- 検索による回遊率の低下への影響
- 推薦結果が悪い場合のプレミアム会員数低下
- 投稿日:2019-06-25T13:25:55+09:00
【ポケモンバトルAI】超簡易ポケモンバトルをゼロから学習させてみる【強化学習】
タイトル通りです。
深層学習 + 強化学習を用いて、ポケモンバトルをaiに学習させます。今回のポケモンバトルのルール/環境
使えるポケモン及び技は以下の通り
ポケモン名 技1 技2 フシギダネ たいあたり つるのムチ ゼニガメ みずでっぽう ヒトカゲ ひのこ ピカチュウ でんきショック
- シングルバトル
- アイテム無し
- 技を使用してもPPは減らない
- ダメージ乱数は常に100%
- 急所無し
- 特性は発動しない
- 技の追加効果は発動しない
その他は現行のポケモンバトルと同じルールです。
学習させる内容
- パーティ編成~ポケモン選出時~ゲーム終了までの期待勝率(評価値)
- バトル時の技選択/交代などのコマンドの推移確率
ネットワーク構造
- CNNを使わないニューラルネットワーク
- 入力サイズ 12537 (バイナリ表現)
- 1層目 128サイズの積和演算 → batch_normailzation → lrelu → dropout
- 2層目 1層目と同じ
ここから先は評価値の重み付けとバトル時のコマンド推移確率の重み付けを枝分かれさせます。(Alpha Zeroでも使われたDualNetwork構造)
以下 評価値に関連する部分はvalue バトル時の推移確率に関連する部分はpolicyと表現します。
- value3層目 64サイズの積和演算 → batch_normailzation → lrelu → dropout
value出力層 2サイズの積和演算 → softmax出力
policy3層目 value3層目と同じ
policy出力層 6サイズの積和演算 → softmax出力
valueネットワークはtanhやsigmoidが一般的ですが、今回はsoftmaxを使用しています。
0番目の出力を自身の勝率 1番目の出力を相手の勝率として表現します。policyネットワークは以下の行動の価値を示します。
- 技1の使用
- 技2の使用
- 技3の使用
- 技4の使用
- 2番目のポケモンと交代
- 3番目のポケモンと交代
※今回のルールでは、3番目と4番目の行動価値は存在する意味はありません。
特徴入力の詳細
※実装の都合上、今回のルールでは、意味のない特徴量も存在します。
特徴入力は0と1のみで表現します。
入力範囲 特徴 無しを含むかどうか 0~4 ポケモン名1 含む 5~9 ポケモン名2 含む 10~14 ポケモン名3 含む ... ... ... 25~29 ポケモン名6 含む ※無しを含むかどうかというのは、自己対局の欄で説明します。
特徴名の順番は以下のようになっています。
- なし
- フシギダネ
- ヒトカゲ
- ゼニガメ
- ピカチュウ
もし以下のようなパーティの評価をしたいとします。
- フシギダネ
- ピカチュウ
- ゼニガメ
- 無し
- 無し
- 無し
この場合は、1番目・9番目・13番目・15番目・20番目・25番目に1を入力するという感じになります。
後は同じように、
ポケモン1に関する特徴入力をする。
↓
入力範囲をずらしてポケモン2に関する特徴入力する。
↓
入力範囲をずらしてポケモン3に関する特徴入力する。
という風に続いてきます。一つ一つ丁寧に書いていくと長くなるので、ここからはポケモン1~6を省略して記述していきます。
また特徴量の種類数がわかれば、入力範囲もわかるので、入力範囲も省略し、特徴量の種類のみを記述します。
- 名前(なし/フシギダネ/ヒトカゲ/ゼニガメ/ピカチュウ)
- レベル(1~50)
- 特性(しんりょく/ようりょくそ/もうか/サンパワー/げきりゅう/あめうけざら)
- 性格(25種類)
- 性別(♂/♀/不明)
- 持ち物(なし/くろいヘドロ/でんきだま)
- 技1(なし/たいあたり/つるのムチ/ひのこ/みずでっぽう/でんきショック)
- 技2
- 技3
- 技4
- 技1のポイントアップ(0~3)
- 技2のポイントアップ
- 技3のポイントアップ
- 技4のポイントアップ
- HP個体値(0~31)
- 攻撃個体値
- 防御個体値
- 特攻個体値
- 特防個体値
- 素早さ個体値
- HP努力値(0~252)
- 攻撃努力値
- 防御努力値
- 特攻努力値
- 特防努力値
- 素早さ努力値
ここまではパーティ構築に関する特徴量です。
ここから先は主に、互いにパーティを見せあいして、ポケモンを選出するまでに使用する特徴量になります。
- 相手のポケモンの名前
- 相手のポケモンのレベル
- 相手のポケモンの性別
- 相手のアイテム所持の有無(なし/あり)
- 選出する先頭のポケモン(長さ6)
- 選出する控え1のポケモン
- 選出する控え2のポケモン
名前・レベル・性別に関してはパーティ構築と同じ種類数です。アイテム所持に関しては、見せあい段階では、持っているか持っていないかしかわからないので、2種類になります。
選出するポケモンは、自分のパーティの位置を元に特量入力します。
例えば、パーティのポケモン名の特徴量の並びが以下の通りとします。
- ゼニガメ
- ピカチュウ
- フシギダネ
- ヒトカゲ
そして以下の並びで選出した場合の評価値が知りたいとします。
- ピカチュウ
- フシギダネ
- ゼニガメ
この場合、選出する先頭のポケモンの1番目・選出する控え1のポケモンの2番目・選出する控え2のポケモンの0番目に1を入力します。
その為、入力の長さは 6種類 * 3 の計18になります。ここまでが見せあい~選出に関する特徴入力になります。
最後は、バトル開始~バトル終了までの特徴入力です。
- 自分の現在の先頭のポケモン(パーティの位置を元にする)
- 控え1のポケモン
- 控え2のポケモン
- 自分の先頭のポケモンの現在のHP(長さ152)
- 控え1のポケモンの現在のHP
- 控え2のポケモンの現在のHP
- 相手の先頭のポケモン(相手のパーティの位置を元にする(長さ6))
- 相手の控えのポケモン(一度でも場に出た場合のみ入力)(相手のパーティの位置を元にする)
- 相手の現在のHP%(一度でも場に出たポケモンのみ入力)(相手のパーティの位置を元にする)(長さ6 * 100)
自分の先頭のポケモン・控えのポケモンに関しては選出の特徴入力と同じです。
今回のルールではあり得る最大HPが152なので、味方の現HPを表す特徴入力の長さは、152 * 3 の計456になります。相手の控えのポケモンの情報は一度でも場に出た場合のみ入力し、相手のポケモン控え1・相手のポケモン控え2と入力範囲分けずに、同じ範囲に入力します。
何故かという理由は以下の通りです。
- 自分視点から見て、相手の控え1・控え2はどちらであるかがわからない
- わかったとしても、入力をわける意味は薄い(どの順番で控えていようが同じである為)
- 同じポケモンが使えないルールであれば、同じ場所に入力してしまう事がないので、一つの入力範囲にまとめれば、計算量を削れる。
などが挙げられます。
その為、相手の先頭のポケモン + 控えのポケモンの特徴入力の長さは、6 + 6 の計12になります。ちなみに、自分の控えのポケモンの位置はpolicyで行動価値を示す場合に必要となってきます。
自己対局の流れ
※valueにはパーティ構築~バトル終了までの評価を学習させていますが、今回の場合は、バトル時の評価値はただ学習させるだけであってないようなものです。同様にpolicyも学習させるだけで、対局時に使用する事はありません。
初めに、1つのネットワークで2つのパーティを作成します。
その際、1手先の評価値を全て探索し、パーティ構築を進めていきます。例えば、パーティの最初のポケモンを選択する場合は
- 0番目にのみ1を入力した入力値
- 1番目にのみ1を入力した入力値
- 2番目にのみ1を入力した入力値
- 3番目にのみ1を入力した入力値
- 4番目にのみ1を入力した入力値
の計5つの入力値をバッチにまとめてネットワークに流し込み、評価が一番良かった(実際には乱数が含まれている)入力値を採用します。
ここでは1番目に1を入力した入力値(フシギダネ)が最大値だったとします。次に、2番目のポケモンを選択する場合は(同じポケモンは採用出来ない事に注意)
- 1番目と5番目に1を入力した入力値
- 1番目と7番目に1を入力した入力値
- 1番目と8番目に1を入力した入力値
- 1番目と9番目に1を入力した入力値
の計4つ入力値を用意し、同じように、バッチにまとめてネットワークに流し込み評価を見て、また採用するポケモンを決めます。
ポケモン6匹を採用したら、今度はレベルの評価値を見て、レベルを決める...という事を繰り返していきます。
ポケモンのパラメーターを決めていく順番は
- レベル
- 特性
- 性格
- 性別
- 持ち物
- 技1
- 技2
- 技3
- 技4
- 技1のポイントアップ
- 技2のポイントアップ
- 技3のポイントアップ
- 技4のポイントアップ
- HP個体値
- 攻撃個体値
- 防御個体値
- 特攻個体値
- 特防個体値
- 素早さ個体値
- HP努力値
- 攻撃努力値
- 防御努力値
- 特攻努力値
- 特防努力値
- 素早さ努力値
になります。
但し、努力値だけは、HP~素早さをランダムにシャッフルして順番を決めます。何故なら努力値は合計510までと決められているので、上から順番に決めていくと、偏りが出てしまう恐れがあるからです。
また、同じ技を覚えさせてはいけないなどのポケモンのルールに従って行動します。
もしポケモンを採用しない場合(なしを選択した場合)は、その枠のポケモンのパラメーターには何も入力しません。
特徴入力の詳細に記述した、なしを含むかどうかについて意味は、なしが含むものは、選択しないという選択を自らの意志で選んだものであり、何も入力されていない部分に関しては、ポケモンがそもそも選択されなかったから何も選べない、技を1つしか選んでないからポイントアップも1つしか選択出来ないといった具合に、それが自分の意志で選択しなかったのか、ルール的に選択不能だから選択しなかったのかを明確に区別する為のものです。
パーティ構築が完了したら、今度は互いの入力値に互いのパーティの情報を入力します。
次に、選出する先頭のポケモン・選出する控え1のポケモン・選出する控え2のポケモンの入力範囲に全て同時かつ総当たりで入力します。
そしてバッチにまとめて評価値を出力し、選出するポケモンを決めます。バトルが開始したらモンテカルロシュミレーション(uctアルゴリズム)を行い最大訪問回数を選択しながら対戦を進めていきます。
ポケモンは不完全情報公開ゲームである為、実際の対局では、モンテカルロをそのまま使う事は難しいですが、policyに学習させる分には、問題ないだろうという事で、モンテカルロを使用しました。要は、学習時はカンニングした状態の最善手を教えてもらい、実際の対局で、その最善手を予測するのが狙いです。
※モンテカルロuctについては各自で調べていただくか僕の記事(笑)を参照。
モンテカルロの設定は以下の通りです。
試行回数 定数X ノード展開の有無 その局面の合法手 * 128 1 なし モンテカルロ探索は、ノードを展開しながらシュミレーションを進めるのが普通ですが、ポケモンでは互いに同じ手を選んでも別の局面に辿りつく場合があり、実装するのがかなり面倒...という理由で今回はノード展開はなしにしました。
一応、展開無しでも原始モンテカルロよりかは強い事は確認出来ました。
対戦が終了したら、パーティ構築~バトル終局までに現れた局面(入力値)全てを教師データとして学習させます。
valueには、勝った場合は[1, 0] 負けた場合は[0, 1]のone hot labelを与えます。
policyには、勝ち負け関係なく、モンテカルロで訪問した回数に応じた値(訪問回数を温度パラメーター1のボルツマン分布に変換した値)をそのまま正解ラベルとして与えます。
"""とある方からツイッターで頂いたコード""" def boltzmann_distribution(array, temperature_parameter): return array ** (1 / temperature_parameter) / np.sum(array ** (1 / temperature_parameter))最適化手法はAdaBoundOptimizerを使用しました。
この最適化手法はAdamの初期学習の速さ + SGDやMomentumの汎化性能の高さの良いとこどりをしたものらしいです。
この最適化手法の実装は、此方のコードを丸コピーして使わせていただきました。また直近64試合分のデータを記録しておき、64試合毎に
バッチサイズ16、64試合分のデータを1.5回見る割合でミニバッチ学習をさせます。おおまかな流れはこんな感じですが、これに加えて以下のような事も行っています。
その1. パーティ構築は、一定の確率で温度パラメータ0.075のボルツマン分布に従って行動する。
パーティ構築のランダム行動は、ランダムで行動する/しないを一定確率(初期は50%)でランダム選択し、ランダム行動すると選択した場合は、パーティ構築の全ての行動をボルツマン分布でランダム行動します。
その2. 勝利した側は同じパーティは続けて使用する。
勝利した側のパーティを続けて使用する事で、そのパーティが本当に強いパーティであれば、強いパーティであると素早く学習する事が可能です。
もしそのパーティが弱い場合は、すぐに負けるはずなので、弱いパーティを強いパーティとして使い続ける事はありません。また、私の環境下では、パーティを構築させるのに3秒から3.5秒かかってしまうのですが、この時間を省く事が出来ます。学習の結果(2)
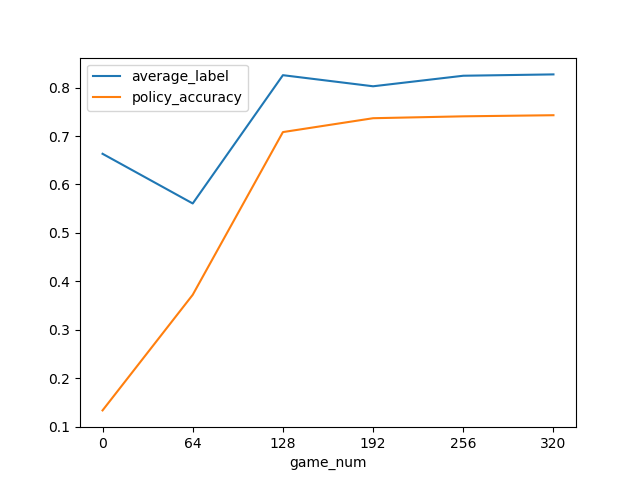
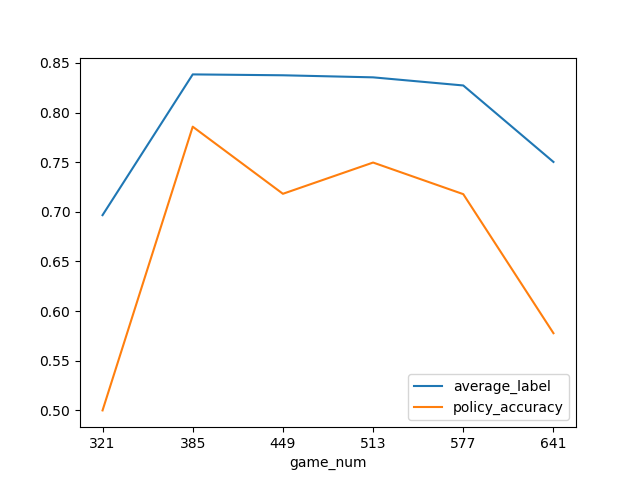
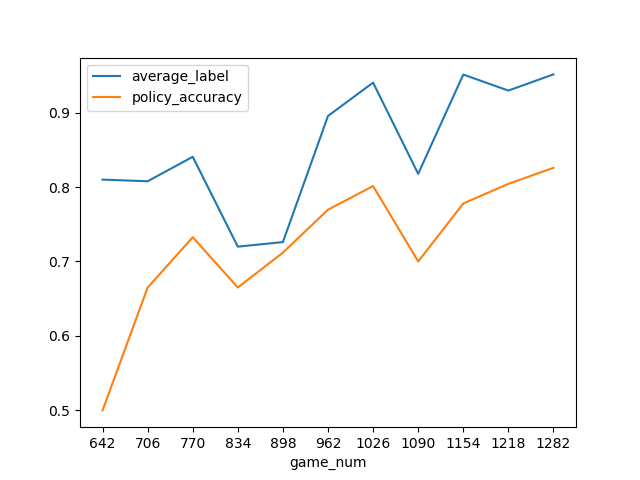
うまく学習出来ているかどうかを確認する指標はいくつかあると思いますが、今回は、勝敗の結果に最も大きく関わるであろう選出したポケモンの平均レベルと、policyがモンテカルロの最大訪問数をどの程度予知出来ているのかをグラフで見ます。
特にレベルは、ゼロから学習させる上では、最初の壁であるように思います。
何故ならいくらバトルコマンドが正確であったとしてもレベル50 * 3匹 vs レベル1 * 3匹 のように極端にレベル差開いてしまうと勝つ事はほぼ不可能であり、逆にレベル差が開いていれば多少雑なプレイをしても勝ててしまいます。
その為、とりあえず高レベルなポケモンを使用するという事を学習出来ないと始まらないように思えます。
グラフを分けている意味は特にありませんが、パーティ構築時のランダム選択は上から順に、50% 50% 20% 20% 5%になっています。
平均レベルは最大50から最大1.0に変換しています。最終モデル+ランダム行動なしのパーティ構築
※今回のルールで意味があるパラメーターのみ記載
ポケモン名 レベル 性格 個体値 努力値 技1 技2 フシギダネ 48 すなお 17, 30, 30, 20, 30, 31 195, 9, 51, 209, 23, 12 たいあたり なし ヒトカゲ 49 きまぐれ 1, 7, 18, 10, 28, 3 182, 12, 60, 64, 127, 9 ひのこ ピカチュウ 50 おくびょう 0, 27, 5, 25, 17, 23 13, 2, 174, 40, 205, 0 でんきショック ゼニガメ 49 おっとり 30, 23, 8, 10, 18, 25 0, 186, 142, 118, 36, 4 みずでっぽう レベルに関してはそこそこ、他はまだまだと言った所ですね...
改善点/将来に向けて
考えられる改善点はいくつかあります。
まずは、モンテカルロを展開ありにする事ですね。
その方が明らかに強くなるので。次にチーム構築時のランダム行動です。
強化学習のランダム行動は、greedyもよく使われますが、学習が進むにつれてランダム行動を減らしていく、というチューニングが面倒であった為、ボルツマン選択であれば、勝手に行動価値に応じてランダム行動してくれる→チューニング不要!やったぜ!とか思っていたんですが、どうやら甘かったようです。今回のグラフがガタガタなのはランダム行動のチューニングがうまくいっていないのが原因だと思います。
パーティ構築時にランダム行動をすると決定した場合は、パーティ構築の全ての行動にランダム要素を入れるという事をしていましたが、これもよろしくなく、N回ランダム要素を取り入れるとかにした方が、細かく調整出来ますし、より最適化しようと思ったらその微調節のようなランダムが必要になってくると思います。次に考えられる点は、入力層の次元削減です。
例えば、今回はポケモン1~6を別々の入力範囲としてましたが、そもそも同じポケモンを選択する事は出来ない為、入力範囲は同じでも被る事はありません。なしを選択する場合は、同じ場所になってしまう為、なしの数を入力する場所は必要になってきますが。同様に同じ技も選択する事が出来ないので、入力範囲を一つにまとめる事が出来そうです。順番は固定になってしまいますが、パーティ構築の際のポケモン・技の並びはどの順番であっても出来る事は変わりません。
パーティ構築のおけるポケモン1~3や技の1はルール上なしを選択する事が出来ないので、この部分も削れそうです。
このあたりは実装のしやすさやわかりやすさを優先しました。バトル時の特徴量にも抜け目があります。
今回は、味方の並び、味方のHP、相手の並び、相手のHPを特徴量としていましたが
、他にも、味方の先頭のポケモンの技1が相手の先頭のポケモンに今までどのくらいダメージを与えたのかとか、逆に相手からどのくらいダメージを受けたのとかの情報も本来であれば必要ですし、もっと言うのであれば、先頭同士の情報だけではなく、過去の局面から洗い出せる情報は全て特徴量にすべきです。(先手後手の結果や相手がどの技を所持していたのかとか、逆に自分は相手に対してどの情報を公開しているのかなどなど)
結局この辺りも実装が面倒でしませんでしたが、本格的に学習させたいのであれば、やはり必要です。今回は、モンテカルロの結果を学習させましたが、元々はポリシー同士の対局で勝ったらの勝ちの報酬を与えて、負けたら負けの報酬を与えるという方法で学習させて強くしていくつもりでした。その方が0からの学習感がしていいので。
しかしうまく学習出来ず、色々考えてもよさげな方法が見つからなかったので、諦めていたんですが、いい感じの方法を思いついたのでそれなりにうまくいったらその事についても書こうと思います。最後にバトル時の探索についてです。
しばらくの間はpolicyの強化でバトルコマンドの精度を上げる事を考えてるのですが、最終的にはバトル時の探索も必要になってくるかもしれません。
前にも書いたように、ポケモンは不完全情報ゲームである為、通常の探索手法は使えません。そこで、私が考えているのは、現局面でわかっている相手の情報を元に、ネットワークに何種類かの有望なパーティを構築させて、その作成したパーティをランダムでサンプリングし、モンテカルロなどのシュミレーションを行うという手法です。この方法であれば、パーティの評価値の精度さえ上がれば、割とうまくいくんじゃないかなと思っています。ただし、これを本格的に試そうと思ったらそれなりの計算資源が必要になりそうです...手元のPCがせいぜいミドルスペックなので、気軽には試せないというのが現状です。というわけでずっとしたい思っていたポケモンバトルの強化学習の始めの一歩を何とか踏み出せました。今の人生の目標は、ポケモンソード・シールドが発売するまでに、基盤を作る事です。もし興味がいる人がいれば一緒に作って、コンピューター将棋みたいに盛り上がったら嬉しいなと思っています。


- 投稿日:2019-06-25T13:25:55+09:00
【ポケモン ai】超簡易ポケモンバトルをゼロから学習させてみる【強化学習】
タイトル通りです。
深層学習 + 強化学習を用いて、ポケモンバトルをaiに学習させます。今回のポケモンバトルのルール/環境
使えるポケモン及び技は以下の通り
ポケモン名 技1 技2 フシギダネ たいあたり つるのムチ ゼニガメ みずでっぽう ヒトカゲ ひのこ ピカチュウ でんきショック
- シングルバトル
- アイテム無し
- 技を使用してもPPは減らない
- ダメージ乱数は常に100%
- 急所無し
- 特性は発動しない
- 技の追加効果は発動しない
その他は現行のポケモンバトルと同じルールです。
学習させる内容
- パーティ編成~ポケモン選出時~ゲーム終了までの期待勝率(評価値)
- バトル時の技選択/交代などのコマンドの推移確率
ネットワーク構造
- CNNを使わないニューラルネットワーク
- 入力サイズ 12537 (バイナリ表現)
- 1層目 128サイズの積和演算 → batch_normailzation → lrelu → dropout
- 2層目 1層目と同じ
ここから先は評価値の重み付けとバトル時のコマンド推移確率の重み付けを枝分かれさせます。(Alpha Zeroでも使われたDualNetwork構造)
以下 評価値に関連する部分はvalue バトル時の推移確率に関連する部分はpolicyと表現します。
- value3層目 64サイズの積和演算 → batch_normailzation → lrelu → dropout
value出力層 2サイズの積和演算 → softmax出力
policy3層目 value3層目と同じ
policy出力層 6サイズの積和演算 → softmax出力
valueネットワークはtanhやsigmoidが一般的ですが、今回はsoftmaxを使用しています。
0番目の出力を自身の勝率 1番目の出力を相手の勝率として表現します。policyネットワークは以下の行動の価値を示します。
- 技1の使用
- 技2の使用
- 技3の使用
- 技4の使用
- 2番目のポケモンと交代
- 3番目のポケモンと交代
※今回のルールでは、3番目と4番目の行動価値は存在する意味はありません。
特徴入力の詳細
※実装の都合上、今回のルールでは、意味のない特徴量も存在します。
特徴入力は0と1のみで表現します。
入力範囲 特徴 無しを含むかどうか 0~4 ポケモン名1 含む 5~9 ポケモン名2 含む 10~14 ポケモン名3 含む ... ... ... 25~29 ポケモン名6 含む ※無しを含むかどうかというのは、自己対局の欄で説明します。
特徴名の順番は以下のようになっています。
- なし
- フシギダネ
- ヒトカゲ
- ゼニガメ
- ピカチュウ
もし以下のようなパーティの評価をしたいとします。
- フシギダネ
- ピカチュウ
- ゼニガメ
- 無し
- 無し
- 無し
この場合は、1番目・9番目・13番目・15番目・20番目・25番目に1を入力するという感じになります。
後は同じように、
ポケモン1に関する特徴入力をする。
↓
入力範囲をずらしてポケモン2に関する特徴入力する。
↓
入力範囲をずらしてポケモン3に関する特徴入力する。
という風に続いてきます。一つ一つ丁寧に書いていくと長くなるので、ここからはポケモン1~6を省略して記述していきます。
また特徴量の種類数がわかれば、入力範囲もわかるので、入力範囲も省略し、特徴量の種類のみを記述します。
- 名前(なし/フシギダネ/ヒトカゲ/ゼニガメ/ピカチュウ)
- レベル(1~50)
- 特性(しんりょく/ようりょくそ/もうか/サンパワー/げきりゅう/あめうけざら)
- 性格(25種類)
- 性別(♂/♀/不明)
- 持ち物(なし/くろいヘドロ/でんきだま)
- 技1(なし/たいあたり/つるのムチ/ひのこ/みずでっぽう/でんきショック)
- 技2
- 技3
- 技4
- 技1のポイントアップ(0~3)
- 技2のポイントアップ
- 技3のポイントアップ
- 技4のポイントアップ
- HP個体値(0~31)
- 攻撃個体値
- 防御個体値
- 特攻個体値
- 特防個体値
- 素早さ個体値
- HP努力値(0~252)
- 攻撃努力値
- 防御努力値
- 特攻努力値
- 特防努力値
- 素早さ努力値
ここまではパーティ構築に関する特徴量です。
ここから先は主に、互いにパーティを見せあいして、ポケモンを選出するまでに使用する特徴量になります。
- 相手のポケモンの名前
- 相手のポケモンのレベル
- 相手のポケモンの性別
- 相手のアイテム所持の有無(なし/あり)
- 選出する先頭のポケモン(長さ6)
- 選出する控え1のポケモン
- 選出する控え2のポケモン
名前・レベル・性別に関してはパーティ構築と同じ種類数です。アイテム所持に関しては、見せあい段階では、持っているか持っていないかしかわからないので、2種類になります。
選出するポケモンは、自分のパーティの位置を元に特量入力します。
例えば、パーティのポケモン名の特徴量の並びが以下の通りとします。
- ゼニガメ
- ピカチュウ
- フシギダネ
- ヒトカゲ
そして以下の並びで選出した場合の評価値が知りたいとします。
- ピカチュウ
- フシギダネ
- ゼニガメ
この場合、選出する先頭のポケモンの1番目・選出する控え1のポケモンの2番目・選出する控え2のポケモンの0番目に1を入力します。
その為、入力の長さは 6種類 * 3 の計18になります。ここまでが見せあい~選出に関する特徴入力になります。
最後は、バトル開始~バトル終了までの特徴入力です。
- 自分の現在の先頭のポケモン(パーティの位置を元にする)
- 控え1のポケモン
- 控え2のポケモン
- 自分の先頭のポケモンの現在のHP(長さ152)
- 控え1のポケモンの現在のHP
- 控え2のポケモンの現在のHP
- 相手の先頭のポケモン(相手のパーティの位置を元にする(長さ6))
- 相手の控えのポケモン(一度でも場に出た場合のみ入力)(相手のパーティの位置を元にする)
- 相手の現在のHP%(一度でも場に出たポケモンのみ入力)(相手のパーティの位置を元にする)(長さ6 * 100)
自分の先頭のポケモン・控えのポケモンに関しては選出の特徴入力と同じです。
今回のルールではあり得る最大HPが152なので、味方の現HPを表す特徴入力の長さは、152 * 3 の計456になります。相手の控えのポケモンの情報は一度でも場に出た場合のみ入力し、相手のポケモン控え1・相手のポケモン控え2と入力範囲分けずに、同じ範囲に入力します。
何故かという理由は以下の通りです。
- 自分視点から見て、相手の控え1・控え2はどちらであるかがわからない
- わかったとしても、入力をわける意味は薄い(どの順番で控えていようが同じである為)
- 同じポケモンが使えないルールであれば、同じ場所に入力してしまう事がないので、一つの入力範囲にまとめれば、計算量を削れる。
などが挙げられます。
その為、相手の先頭のポケモン + 控えのポケモンの特徴入力の長さは、6 + 6 の計12になります。ちなみに、自分の控えのポケモンの位置はpolicyで行動価値を示す場合に必要となってきます。
自己対局の流れ
※valueにはパーティ構築~バトル終了までの評価を学習させていますが、今回の場合は、バトル時の評価値はただ学習させるだけであってないようなものです。同様にpolicyも学習させるだけで、対局時に使用する事はありません。
初めに、1つのネットワークで2つのパーティを作成します。
その際、1手先の評価値を全て探索し、パーティ構築を進めていきます。例えば、パーティの最初のポケモンを選択する場合は
- 0番目にのみ1を入力した入力値
- 1番目にのみ1を入力した入力値
- 2番目にのみ1を入力した入力値
- 3番目にのみ1を入力した入力値
- 4番目にのみ1を入力した入力値
の計5つの入力値をバッチにまとめてネットワークに流し込み、評価が一番良かった(実際には乱数が含まれている)入力値を採用します。
ここでは1番目に1を入力した入力値(フシギダネ)が最大値だったとします。次に、2番目のポケモンを選択する場合は(同じポケモンは採用出来ない事に注意)
- 1番目と5番目に1を入力した入力値
- 1番目と7番目に1を入力した入力値
- 1番目と8番目に1を入力した入力値
- 1番目と9番目に1を入力した入力値
の計4つ入力値を用意し、同じように、バッチにまとめてネットワークに流し込み評価を見て、また採用するポケモンを決めます。
ポケモン6匹を採用したら、今度はレベルの評価値を見て、レベルを決める...という事を繰り返していきます。
ポケモンのパラメーターを決めていく順番は
- レベル
- 特性
- 性格
- 性別
- 持ち物
- 技1
- 技2
- 技3
- 技4
- 技1のポイントアップ
- 技2のポイントアップ
- 技3のポイントアップ
- 技4のポイントアップ
- HP個体値
- 攻撃個体値
- 防御個体値
- 特攻個体値
- 特防個体値
- 素早さ個体値
- HP努力値
- 攻撃努力値
- 防御努力値
- 特攻努力値
- 特防努力値
- 素早さ努力値
になります。
但し、努力値だけは、HP~素早さをランダムにシャッフルして順番を決めます。何故なら努力値は合計510までと決められているので、上から順番に決めていくと、偏りが出てしまう恐れがあるからです。
また、同じ技を覚えさせてはいけないなどのポケモンのルールに従って行動します。
もしポケモンを採用しない場合(なしを選択した場合)は、その枠のポケモンのパラメーターには何も入力しません。
特徴入力の詳細に記述した、なしを含むかどうかについて意味は、なしが含むものは、選択しないという選択を自らの意志で選んだものであり、何も入力されていない部分に関しては、ポケモンがそもそも選択されなかったから何も選べない、技を1つしか選んでないからポイントアップも1つしか選択出来ないといった具合に、それが自分の意志で選択しなかったのか、ルール的に選択不能だから選択しなかったのかを明確に区別する為のものです。
パーティ構築が完了したら、今度は互いの入力値に互いのパーティの情報を入力します。
次に、選出する先頭のポケモン・選出する控え1のポケモン・選出する控え2のポケモンの入力範囲に全て同時かつ総当たりで入力します。
そしてバッチにまとめて評価値を出力し、選出するポケモンを決めます。バトルが開始したらモンテカルロシュミレーション(uctアルゴリズム)を行い最大訪問回数を選択しながら対戦を進めていきます。
ポケモンは不完全情報公開ゲームである為、実際の対局では、モンテカルロをそのまま使う事は難しいですが、policyに学習させる分には、問題ないだろうという事で、モンテカルロを使用しました。要は、学習時はカンニングした状態の最善手を教えてもらい、実際の対局で、その最善手を予測するのが狙いです。
※モンテカルロuctについては各自で調べていただくか僕の記事(笑)を参照。
モンテカルロの設定は以下の通りです。
試行回数 定数X ノード展開の有無 その局面の合法手 * 128 1 なし モンテカルロ探索は、ノードを展開しながらシュミレーションを進めるのが普通ですが、ポケモンでは互いに同じ手を選んでも別の局面に辿りつく場合があり、実装するのがかなり面倒...という理由で今回はノード展開はなしにしました。
一応、展開無しでも原始モンテカルロよりかは強い事は確認出来ました。
対戦が終了したら、パーティ構築~バトル終局までに現れた局面(入力値)全てを教師データとして学習させます。
valueには、勝った場合は[1, 0] 負けた場合は[0, 1]のone hot labelを与えます。
policyには、勝ち負け関係なく、モンテカルロで訪問した回数に応じた値(訪問回数を温度パラメーター1のボルツマン分布に変換した値)をそのまま正解ラベルとして与えます。
"""とある方からツイッターで頂いたコード""" def boltzmann_distribution(array, temperature_parameter): return array ** (1 / temperature_parameter) / np.sum(array ** (1 / temperature_parameter))最適化手法はAdaBoundOptimizerを使用しました。
この最適化手法はAdamの初期学習の速さ + SGDやMomentumの汎化性能の高さの良いとこどりをしたものらしいです。
この最適化手法の実装は、此方のコードを丸コピーして使わせていただきました。また直近64試合分のデータを記録しておき、64試合毎に
バッチサイズ16、64試合分のデータを1.5回見る割合でミニバッチ学習をさせます。おおまかな流れはこんな感じですが、これに加えて以下のような事も行っています。
その1. パーティ構築は、一定の確率で温度パラメータ0.075のボルツマン分布に従って行動する。
パーティ構築のランダム行動は、ランダムで行動する/しないを一定確率(初期は50%)でランダム選択し、ランダム行動すると選択した場合は、パーティ構築の全ての行動をボルツマン分布でランダム行動します。
その2. 勝利した側は同じパーティは続けて使用する。
勝利した側のパーティを続けて使用する事で、そのパーティが本当に強いパーティであれば、強いパーティであると素早く学習する事が可能です。
もしそのパーティが弱い場合は、すぐに負けるはずなので、弱いパーティを強いパーティとして使い続ける事はありません。また、私の環境下では、パーティを構築させるのに3秒から3.5秒かかってしまうのですが、この時間を省く事が出来ます。学習の結果(2)
うまく学習出来ているかどうかを確認する指標はいくつかあると思いますが、今回は、勝敗の結果に最も大きく関わるであろう選出したポケモンの平均レベルと、policyがモンテカルロの最大訪問数をどの程度予知出来ているのかをグラフで見ます。
特にレベルは、ゼロから学習させる上では、最初の壁であるように思います。
何故ならいくらバトルコマンドが正確であったとしてもレベル50 * 3匹 vs レベル1 * 3匹 のように極端にレベル差開いてしまうと勝つ事はほぼ不可能であり、逆にレベル差が開いていれば多少雑なプレイをしても勝ててしまいます。
その為、とりあえず高レベルなポケモンを使用するという事を学習出来ないと始まらないように思えます。
グラフを分けている意味は特にありませんが、パーティ構築時のランダム選択は上から順に、50% 50% 20% 20% 5%になっています。
平均レベルは最大50から最大1.0に変換しています。最終モデル+ランダム行動なしのパーティ構築
※今回のルールで意味があるパラメーターのみ記載
ポケモン名 レベル 性格 個体値 努力値 技1 技2 フシギダネ 48 すなお 17, 30, 30, 20, 30, 31 195, 9, 51, 209, 23, 12 たいあたり なし ヒトカゲ 49 きまぐれ 1, 7, 18, 10, 28, 3 182, 12, 60, 64, 127, 9 ひのこ ピカチュウ 50 おくびょう 0, 27, 5, 25, 17, 23 13, 2, 174, 40, 205, 0 でんきショック ゼニガメ 49 おっとり 30, 23, 8, 10, 18, 25 0, 186, 142, 118, 36, 4 みずでっぽう レベルに関してはそこそこ、他はまだまだと言った所ですね...
改善点/将来に向けて
考えられる改善点はいくつかあります。
まずは、モンテカルロを展開ありにする事ですね。
その方が明らかに強くなるので。次にチーム構築時のランダム行動です。
強化学習のランダム行動は、greedyもよく使われますが、学習が進むにつれてランダム行動を減らしていく、というチューニングが面倒であった為、ボルツマン選択であれば、勝手に行動価値に応じてランダム行動してくれる→チューニング不要!やったぜ!とか思っていたんですが、どうやら甘かったようです。今回のグラフがガタガタなのはランダム行動のチューニングがうまくいっていないのが原因だと思います。
パーティ構築時にランダム行動をすると決定した場合は、パーティ構築の全ての行動にランダム要素を入れるという事をしていましたが、これもよろしくなく、N回ランダム要素を取り入れるとかにした方が、細かく調整出来ますし、より最適化しようと思ったらその微調節のようなランダムが必要になってくると思います。次に考えられる点は、入力層の次元削減です。
例えば、今回はポケモン1~6を別々の入力範囲としてましたが、そもそも同じポケモンを選択する事は出来ない為、入力範囲は同じでも被る事はありません。なしを選択する場合は、同じ場所になってしまう為、なしの数を入力する場所は必要になってきますが。同様に同じ技も選択する事が出来ないので、入力範囲を一つにまとめる事が出来そうです。順番は固定になってしまいますが、パーティ構築の際のポケモン・技の並びはどの順番であっても出来る事は変わりません。
パーティ構築のおけるポケモン1~3や技の1はルール上なしを選択する事が出来ないので、この部分も削れそうです。
このあたりは実装のしやすさやわかりやすさを優先しました。バトル時の特徴量にも抜け目があります。
今回は、味方の並び、味方のHP、相手の並び、相手のHPを特徴量としていましたが
、他にも、味方の先頭のポケモンの技1が相手の先頭のポケモンに今までどのくらいダメージを与えたのかとか、逆に相手からどのくらいダメージを受けたのとかの情報も本来であれば必要ですし、もっと言うのであれば、先頭同士の情報だけではなく、過去の局面から洗い出せる情報は全て特徴量にすべきです。(先手後手の結果や相手がどの技を所持していたのかとか、逆に自分は相手に対してどの情報を公開しているのかなどなど)
結局この辺りも実装が面倒でしませんでしたが、本格的に学習させたいのであれば、やはり必要です。今回は、モンテカルロの結果を学習させましたが、元々はポリシー同士の対局で勝ったらの勝ちの報酬を与えて、負けたら負けの報酬を与えるという方法で学習させて強くしていくつもりでした。その方が0からの学習感がしていいので。
しかしうまく学習出来ず、色々考えてもよさげな方法が見つからなかったので、諦めていたんですが、いい感じの方法を思いついたのでそれなりにうまくいったらその事についても書こうと思います。最後にバトル時の探索についてです。
しばらくの間はpolicyの強化でバトルコマンドの精度を上げる事を考えてるのですが、最終的にはバトル時の探索も必要になってくるかもしれません。
前にも書いたように、ポケモンは不完全情報ゲームである為、通常の探索手法は使えません。そこで、私が考えているのは、現局面でわかっている相手の情報を元に、ネットワークに何種類かの有望なパーティを構築させて、その作成したパーティをランダムでサンプリングし、モンテカルロなどのシュミレーションを行うという手法です。この方法であれば、パーティの評価値の精度さえ上がれば、割とうまくいくんじゃないかなと思っています。ただし、これを本格的に試そうと思ったらそれなりの計算資源が必要になりそうです...手元のPCがせいぜいミドルスペックなので、気軽には試せないというのが現状です。というわけでずっとしたい思っていたポケモンバトルの強化学習の始めの一歩を何とか踏み出せました。今の人生の目標は、ポケモンソード・シールドが発売するまでに、基盤を作る事です。もし興味がいる人がいれば一緒に作って、コンピューター将棋みたいに盛り上がったら嬉しいなと思っています。
- 投稿日:2019-06-25T02:44:04+09:00
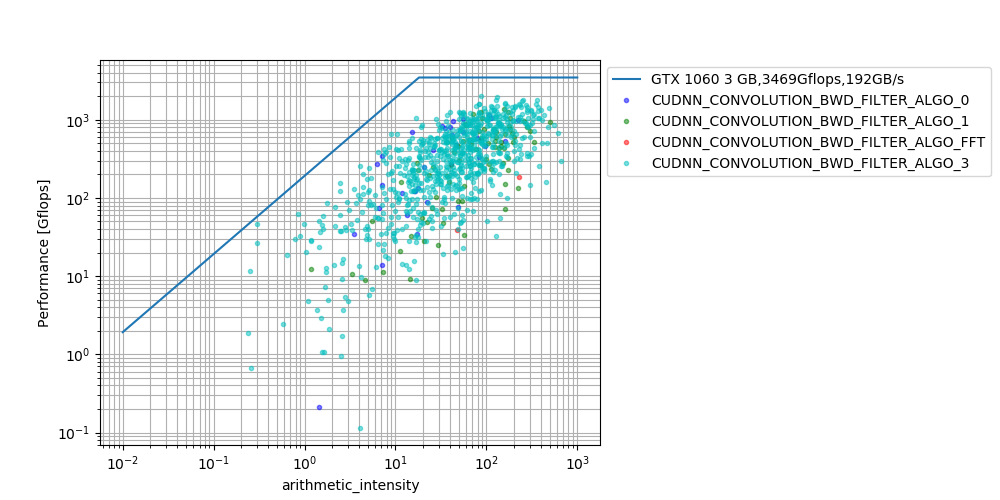
nVIDIA cudnnConvolutionBackwardFilterを調べる, ルーフラインモデル
TL;DR
cudnnConvolutionBackwardFilter()を1000通りのパラメータでプロファイルし、
GTX1060のルーフラインモデルにプロットした。
多くの場合で、100Gflops以上の性能が出る一方で、極端に性能劣化するパラメータが存在することがわかった。
CUDNN_CONVOLUTION_BWD_FILTER_ALGO_FFTも一応使われることがあることがわかった。評価対象
Machine nVIDIA GeForce GTX1060 3G ピーク演算性能 3.469Tflops ピークバンド幅 192GB/sec CUDA v10.0 cuDNN v7.4 評価条件(パラメータ)
1000通りのパラメータをランダムに生成。値域は下表の通り。
パラメータ 値域 バッチサイズn randint(1, 32) 入力チャネルci randint(1, 20) 入力画像サイズHi randint(1, 122) 入力画像サイズWi randint(1, 122) ストライドu(h方向) randint(1, 7) カーネルkernel_h randint(1, 7) カーネルkernel_w randint(1, 7) パディングpad_h randint(0, 8) パディングpad_w randint(0, 8) dilation_h 1固定 dilation_w 1固定 ※ アルゴリズムは、1000通りのパラメータそれぞれに対し最速のアルゴリズムを選択している。
→ cudnnGetConvolutionBackwardFilterAlgorithm(..., CUDNN_CONVOLUTION_BWD_FILTER_PREFER_FASTEST,...)評価式
- Performance [Gflops] = (演算回数) / (実行時間)
- Arithmetic intensity [GB/sec] = (演算回数) / (入出力データサイズ)
- (演算回数): c++でconvolution backward filterを愚直に書いて数え上げた。mulとaddは2operationとしてカウントしている。
- (実行時間):cudaEventElapsedTime()を用いてcudnnConvolutionBackwardFilter()単体の実行時間を測定した。
- (入出力データサイズ) = (n*ci*hi*wi + n*co*ho*wo + co*ci*kernel_h*kernel_w)*4 [Byte]
評価環境
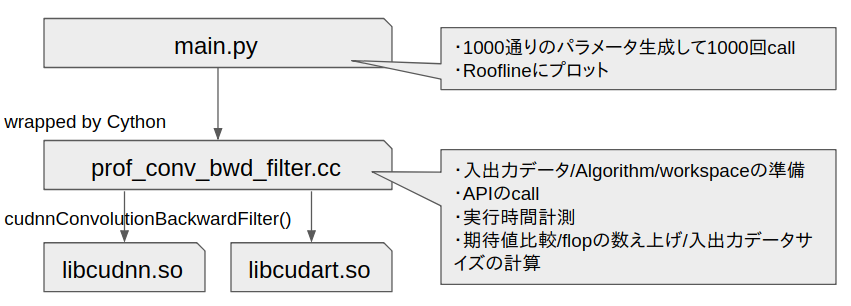
ソースコード一式
※ Cythonのsetpu.pyだけはいろいろハードコーディングしているのでリポジトリに入れていません。すみません。参考文献
- ルーフラインモデルについて:
- Cythonによるc++のWarp方法について:
- CUDA Runtimeによる実行時間測定について: