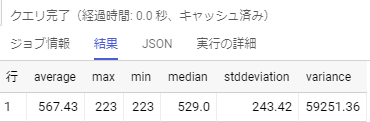
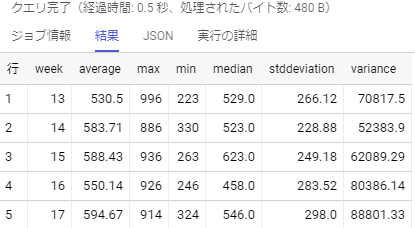
また,今回は全ての分析関数で同じOVER()を用いましたが,例えばWINDOW句で「window_name AS PARTITION BY date」と指定した後にSELECT文で「〇〇() OVER (window_name ORDER BY day)」という様に,WINDOW句で指定した別名とORDER BYやWindow Flame句を組み合わせて使うことも出来るので,OVER()が同じでなかったとしても,やはり使うと楽になる部分が多いかと思います。
User.where(user_type_id: 2).where(['second_prefecture_code LIKE ? or specialized_field LIKE ?',"%#{sanitize_sql_like(searchFirst)}%","%#{sanitize_sql_like(searchSecond)}%"])