- 投稿日:2019-05-22T23:54:59+09:00
Flaskで簡単アプリケーション構築
はじめに
この記事ではFlaskでアプリケーションを立ち上げ、Flaskマスターに俺はなる!と画面に表示することを最終目標としています。
開発環境(前提条件)
・python3.7.3(筆者のpythonバージョンです)
・pipコマンドが使える
・macもし、python3系をインストールしていない場合は
https://qiita.com/nissynishizawa/items/1b2cfb6c4e4518185276
この方の記事を参考にpyenvというパッケージ管理ツールをインストールしpythonのバージョンを変更してください。フォルダの構成
今回作るアプリのフォルダ構成です!
Flask ├── Pipfile ├── Pipfile.lock ├── flask_box │ ├── __init__.py │ └── views.py └── server.pyPipenvとFlaskのインストール
PipenvはPythonのパッケージングツールで、簡単に仮想環境を用意できるありがたいツールです。
それでは、早速インストールしてみましょう!
以下のコマンドをターミナルで実行してください。pip install pipenvインストール後に
pipenv --versionと実行しバージョンが表示されたら成功です!
では、次に仮想環境の準備をしていきましょう!
まずは、Flaskというフォルダを作成してください。作成できたらFlaskフォルダ内に移動し、以下のコマンドを実行してください。pipenv --threeこのコマンドは仮想環境を用意するためのものです、実行すると「Pipfile」が作成されていると思います。
仮想環境ができたので、早速中に入ってみましょう!
以下のコマンドを実行してください。pipenv shellこのコマンドを実行することで、仮想環境が動きます。ターミナルのuser名の左側に(Flask)と表示されていたら成功です。
ここまで完了したら、Flaskのパッケージをインストールします。
以下のコマンドを実行してください。pipenv install Flaskインストールに成功すると、「Pipfile.lock」が作成されていると思います!
アプリケーションの作成
仮想環境を作成できたので、ここからはviewに文字を表示するためのプログラムを書いていきましょう!
まずは、サーバーを立ち上げるためのファイルを作成します。Flaskフォルダの直下にserver.pyというファイルを作成してください。作成したら以下のように記述してください。
server.pyfrom flask_box import app if __name__ == '__main__': app.run(debug=True)簡単に説明をします。「from flask_box import app」で、flask_boxフォルダ内のappというモジュールをこのファイルで使わせてくれ〜とお願いをして、「app.run」でアプリケーションを立ち上げてーと命令していると思ってください。「debug=True」はデバッグモードを有効にするという意味です。
サーバー起動用のファイルを作成したので、次はviewファイルを作成していきましょう!
Flaskフォルダの直下にflask_boxというフォルダを作成してください。作成したら、flask_box内に移動し、__init__.pyというファイルを作成し、以下のように記述してください。
flask_box/__init__.pyfrom flask import Flask app = Flask(__name__) import flask_box.viewsこれも簡単に説明すると、Flask本体を使えるようにimportして、appという変数にアプリケーションの核を入れ、flask_box内のviewsファイルを読み込めるようにしておいて〜と指示している感じです。
ここまで完了したら、viewファイルの作成に入りましょう!
flask_boxの直下にviews.pyというファイルを作成し、以下のように記述してください。flask_box/views.pyfrom flask_box import app @app.route("/") def index(): return "Flaskマスターに俺はなる!"ここではルーティングの設定をしています。
書いている内容は、アプリケーションを立ち上げたらindexメソッドを実行してviewに表示してーといった感じです!これで準備は整いましたので、最後にサーバーを起動してみましょう。
以下のコマンドを実行してください。
(一つ注意ですが、このコマンドはFlaskフォルダに移動してから実行してください。flask_box内で実行すると「No such file or directory」といったメッセージがでてしまいます。)python server.pyサーバーの起動に成功すると、このようなメッセージが表示されると思います。
Serving Flask app "flask_box" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. * Debug mode: on * Running on http://127.0.0.1:5000/ (Press CTRL+C to quit) * Restarting with stat最初は赤文字でびっくりすると思いますがエラーではないので大丈夫です↓
WARNING: This is a development server. Do not use it in a production deployment.最後に、以下のurlをGoogleに貼り付けてEnterを押してください。
http://127.0.0.1:5000/画面にFlaskマスターに俺はなると表示されていたらアプリの完成です!
おわりに
ここまで読んでいただきありがとうございます。間違い等がありましたらご指摘いただければ幸いです。
- 投稿日:2019-05-22T23:37:27+09:00
UploadしてPlotするだけの簡単なhttp経由の可視化ツールを作った
Just Upload & Plot. Easy visualize tool via http.
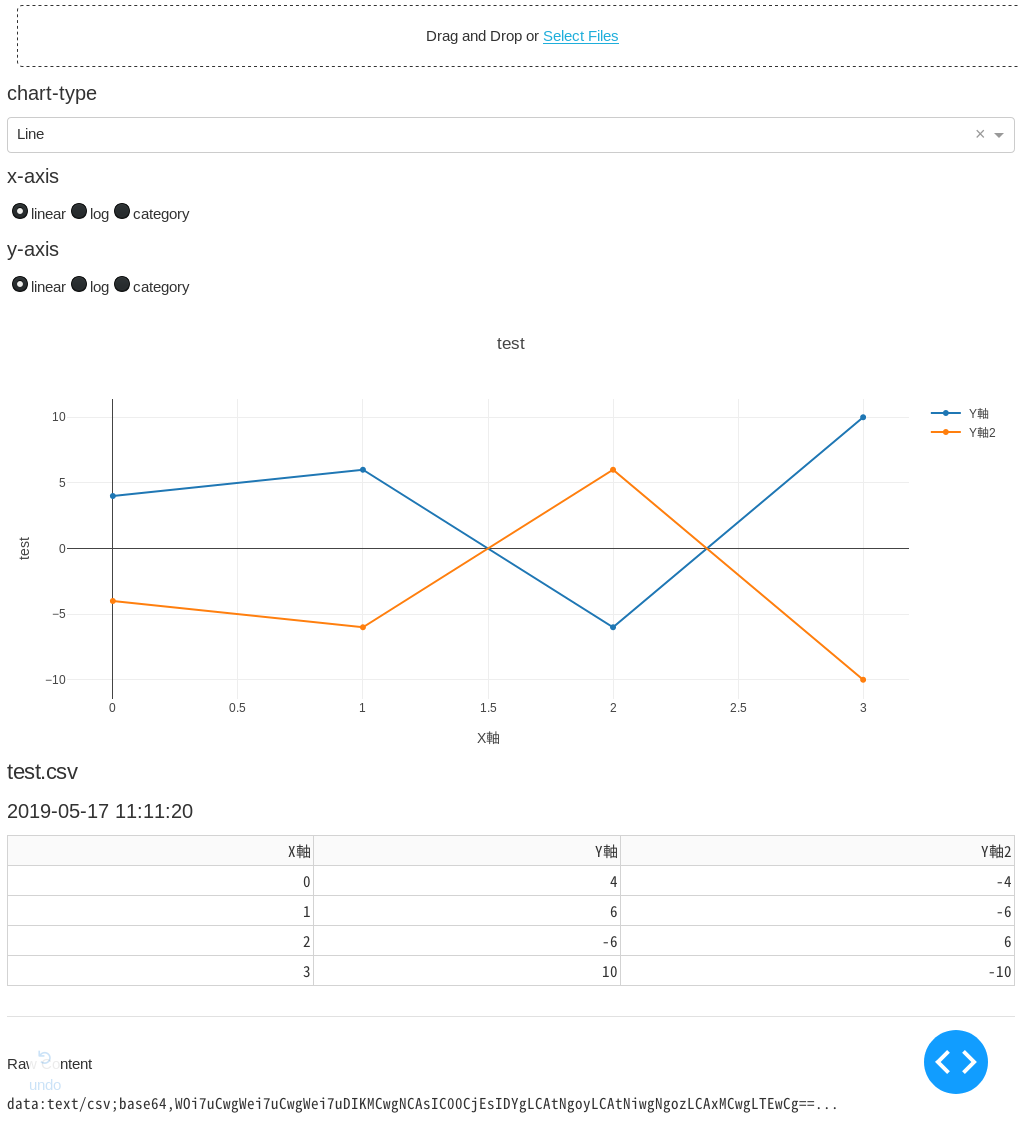
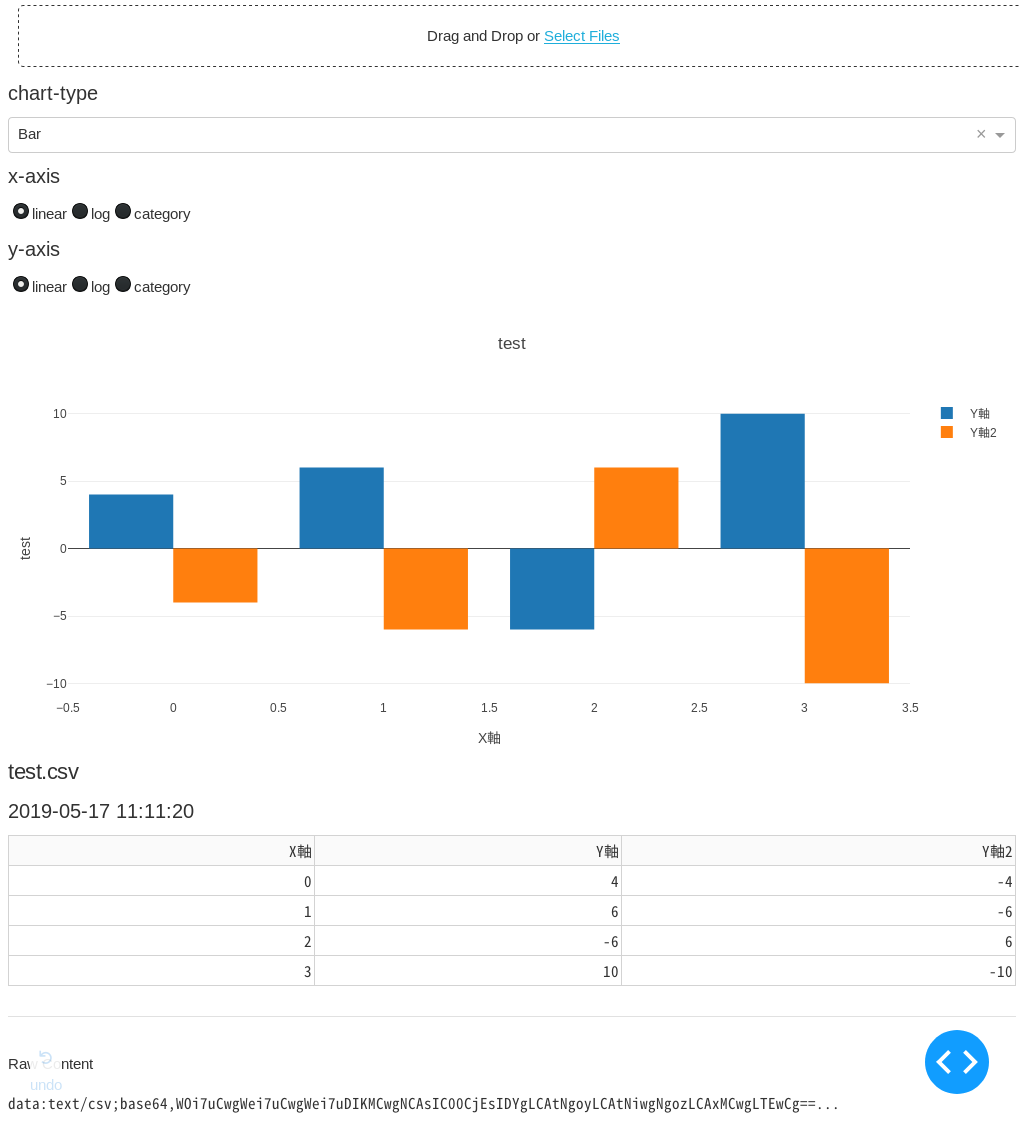
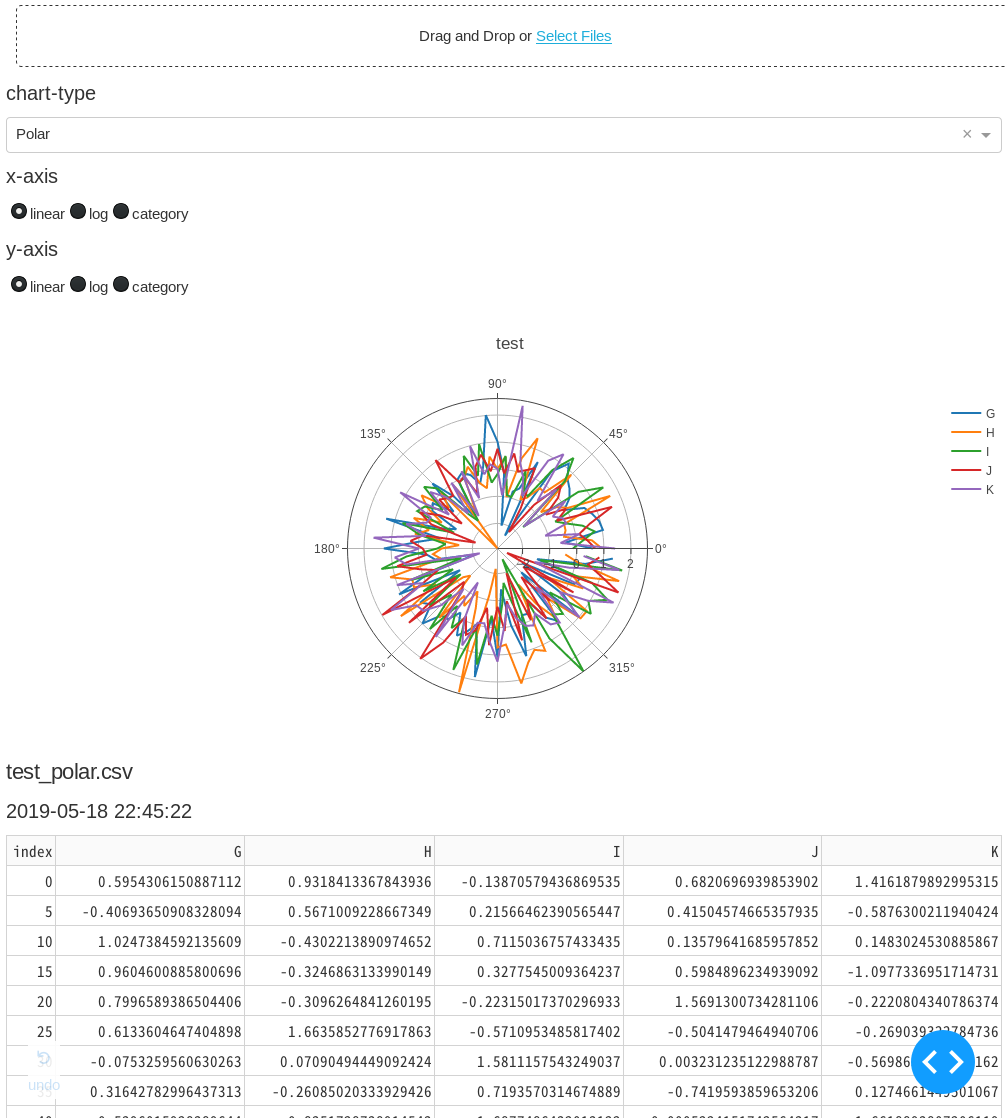
UplodしてPlotするだけの簡単なhttp経由の可視化ツールです。
csvまたはxlsファイルをブラウザ上のUpload欄に上げるだけでさまざまな形式のグラフを描きます。
csv, xlsを作成時の注意
- 1行目の1列目はx軸のタイトルになります。
- 1列目の2行目以降はx軸になります。
- 1行目の2列目以降は凡例になります。
- 2行目以降の2列目以降がデータになります。
- ファイル名はグラフタイトルになります。
- ファイル名に
_が含まれている時、最初の_で区切られて、前半部分がグラフタイトル、後半部分がy軸のタイトルになります。対応しているグラフ形式
- 'Line'
- 'Bar'
- 'Histogram'
- 'Pie'
- 'Polar'
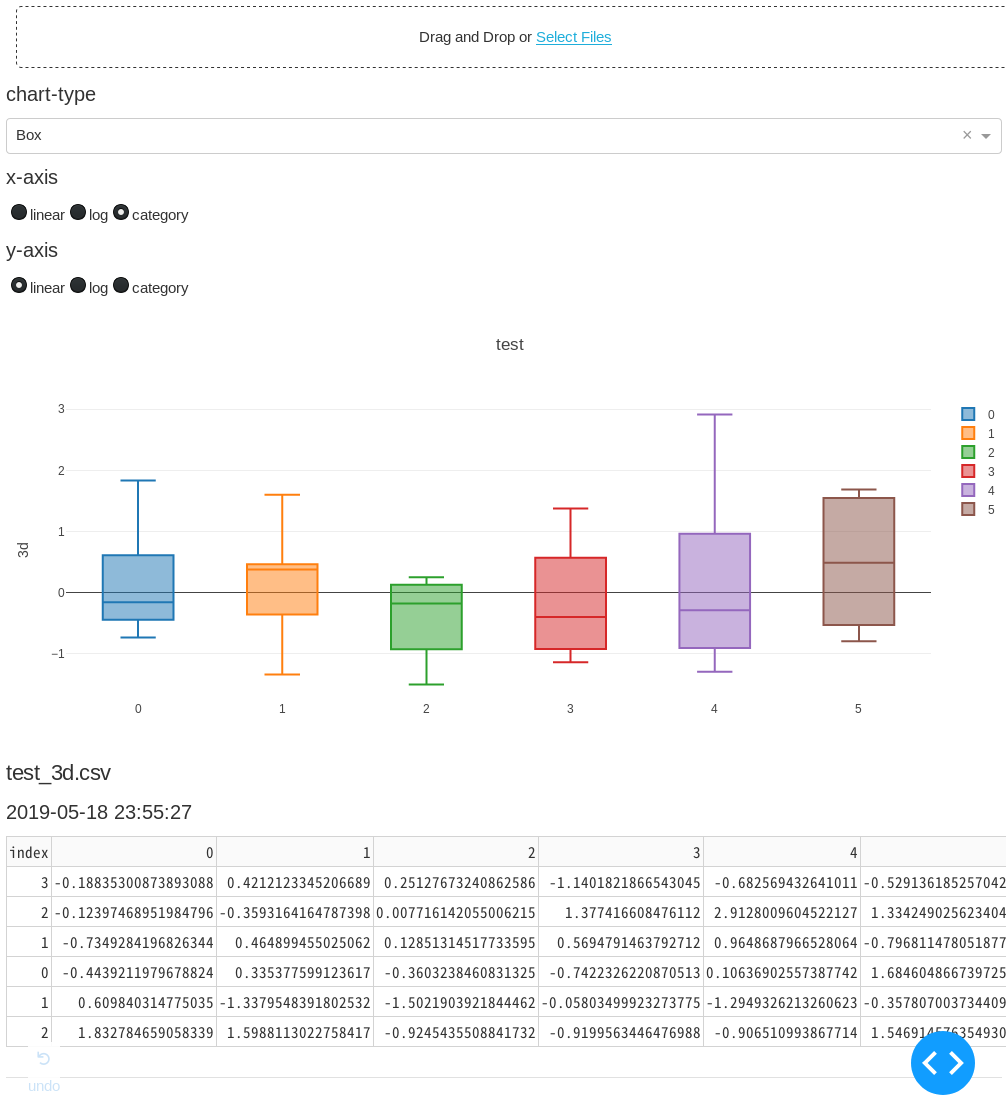
- 'Box'
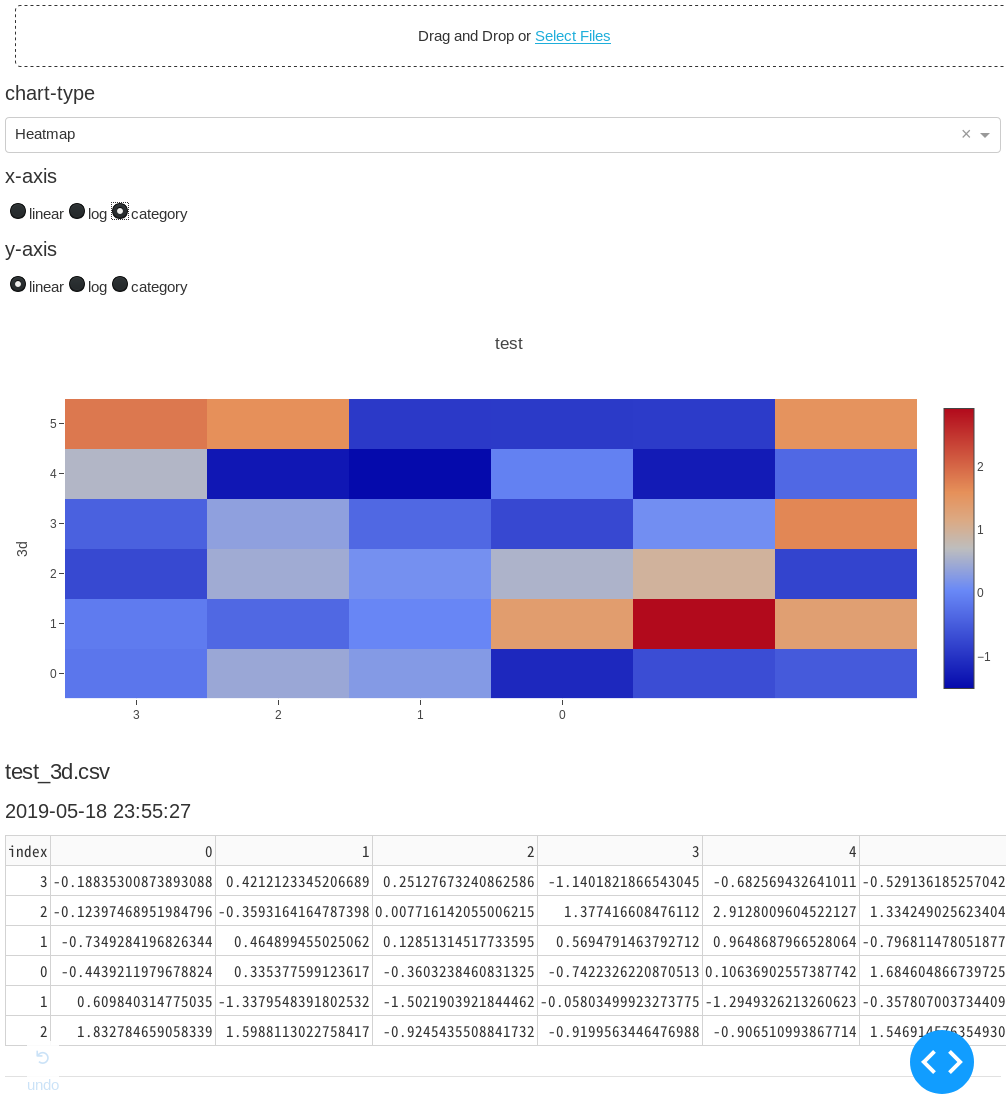
- 'Heatmap'
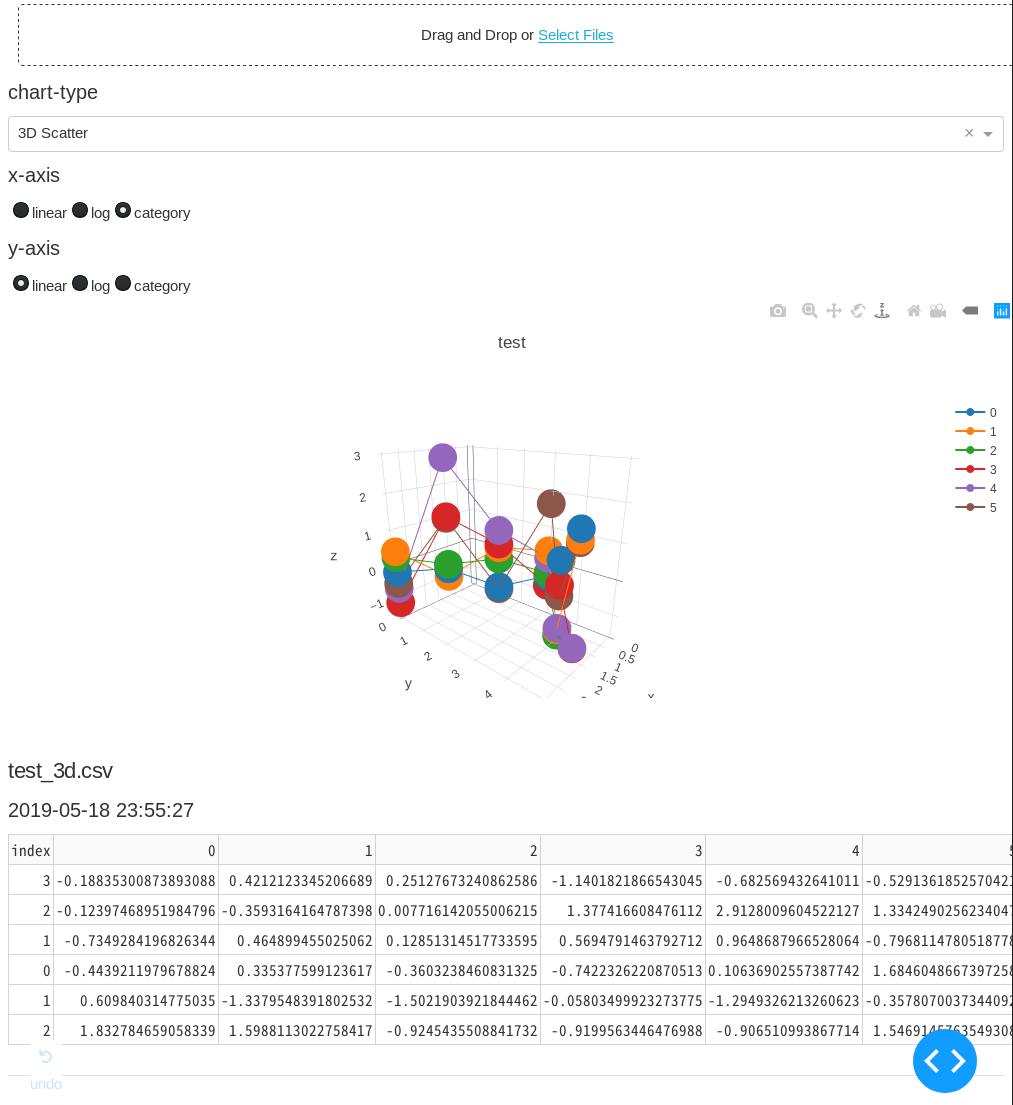
- '3D Scatter'
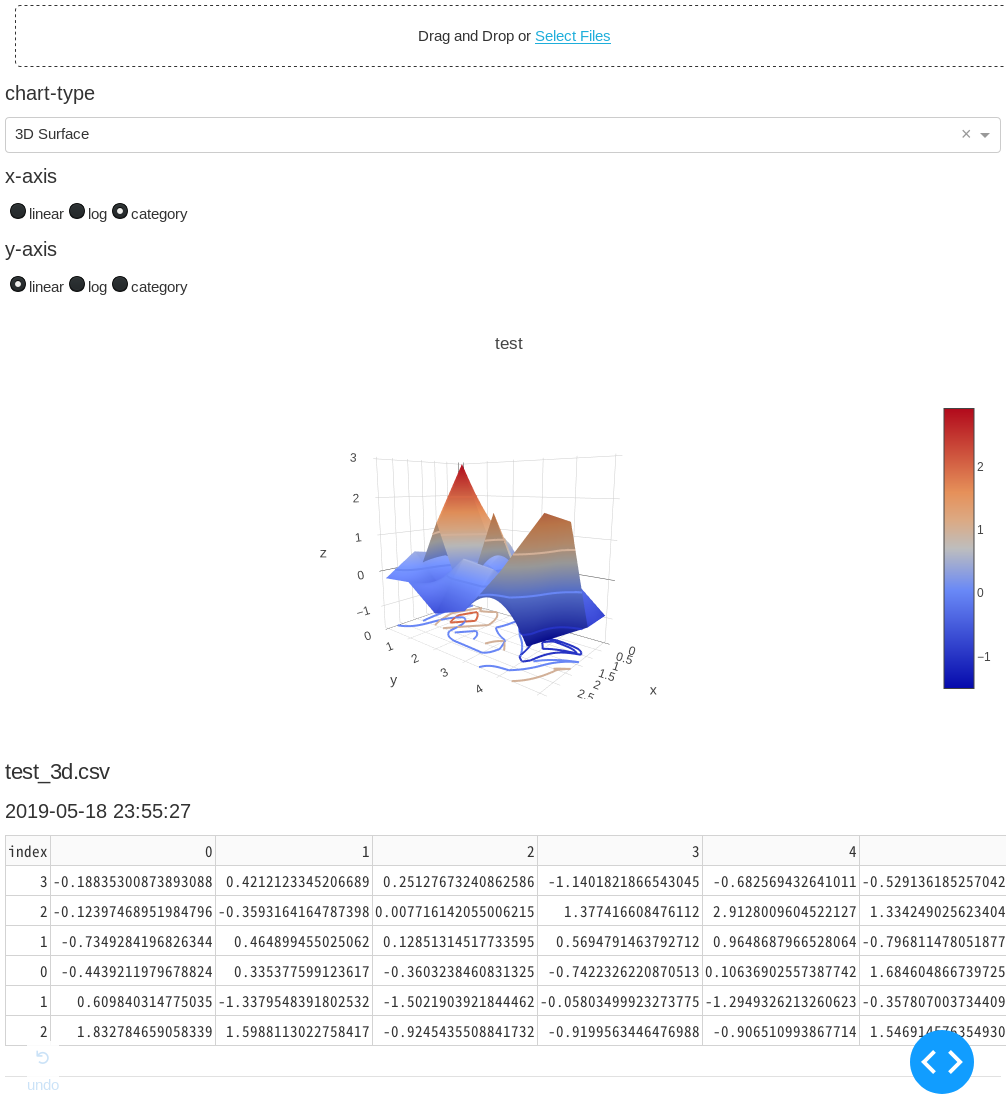
- '3D Surface'
- '2D Histogram'
対応予定のグラフ形式
- 'Contour'
- 'Candlestick'
Install
pip
あとでpypi登録予定
Github
GitHub u1and0/uplot
クローン後、$ python uplot.pyDockerhub
$ sudo docker pull u1and0/uplot $ sudo docker run -d -p 8880:8880 u1and0/uplotUSAGE
- サーバーを立ち上げたらブラウザに
http//:localhost:8880と打ち込みます。- csvかxlsで作成したファイルをドラッグ・アンド・ドロップしてグラフ種類を選択します。
ScreenShots
作り方
python製
dash (= plotly + flask)でHTMLパーツを配置していって、plotlyで可視化。サーバーをflaskで立てる。uplot.py#!/usr/bin/env python3 import base64 import datetime import io import os from collections import defaultdict import dash from dash.dependencies import Input, Output, State import dash_core_components as dcc import dash_html_components as html import dash_table import pandas as pd import plotly.graph_objs as go external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css'] app = dash.Dash(__name__, external_stylesheets=external_stylesheets) CHART_LIST = [ 'Line', 'Bar', 'Histogram', 'Pie', 'Polar', 'Box', 'Heatmap', # 'Contour', # 'Candlestick', '3D Scatter', '3D Surface', '2D Histogram', ] CHART_LIST.sort() app.layout = html.Div( [ # File upload bunner dcc.Upload( id='upload-data', children=html.Div(['Drag and Drop or ', html.A('Select Files')]), style={ 'width': '100%', 'height': '60px', 'lineHeight': '60px', 'borderWidth': '1px', 'borderStyle': 'dashed', 'borderRadius': '5px', 'textAlign': 'center', 'margin': '10px' }, # Allow multiple files to be uploaded multiple=True), html.H6('chart-type'), dcc.Dropdown(id='chart-type', options=[{ 'label': i, 'value': i } for i in CHART_LIST], value='Line'), html.H6('x-axis'), dcc.RadioItems(id='xaxis-type', options=[{ 'label': i, 'value': i } for i in ['linear', 'log', 'category']], value='linear', labelStyle={'display': 'inline-block'}), html.H6('y-axis'), dcc.RadioItems(id='yaxis-type', options=[{ 'label': i, 'value': i } for i in ['linear', 'log', 'category']], value='linear', labelStyle={'display': 'inline-block'}), html.Div(id='the_graph'), html.Div(id='output-data-upload'), ], ) def data_graph( df, filename, chart_type, xaxis_type, yaxis_type, ): """アップロードされたデータのグラフを描画""" basename = os.path.splitext(filename)[0] # ファイル名の1つ目の'_'で区切って、グラフタイトルとY軸名に分ける if '_' in basename: title, yaxis_name = basename.split('_', 1) # ファイル名に'_'がなければグラフタイトル、Y軸名ともにファイル名 else: title, yaxis_name = basename, basename def args(i): """graph_objs helper func""" return {'x': df.index, 'y': df[i], 'name': i} # チャートの種類をディクショナリで分岐 # 内包表記でdfの列の数だけトレース data = { 'Line': [go.Scatter(args(i)) for i in df.columns], 'Bar': [go.Bar(args(i)) for i in df.columns], 'Histogram': [go.Histogram(x=df[i], name=i, opacity=.5) for i in df.columns], 'Pie': [ go.Pie(labels=df.index, values=df[i], name=i, domain={'column': list(df.columns).index(i)}) for i in df.columns ], 'Polar': [ go.Scatterpolar( r=df[i], theta=df.index, name=i, ) for i in df.columns ], 'Heatmap': [go.Heatmap(x=df.index, y=df.columns, z=df.values)], 'Box': [go.Box(y=df[i], name=i) for i in df.columns], # 'Contour': [go.Contour(x=df.index, y=df.columns, z=df.values)] '3D Scatter': [ go.Scatter3d(x=df.index, y=df.columns, z=df[i], name=i) for i in df.columns ], '3D Surface': [ go.Surface(x=df.index, y=df.columns, z=df.values, name=yaxis_name, contours=go.surface.Contours( z=go.surface.contours.Z(show=True, usecolormap=True, highlightcolor="#42f462", project=dict(z=True)))), ], '2D Histogram': [go.Histogram2d(x=df.iloc[:, 0], y=df.iloc[:, 1])] } # チャートの種類でレイアウトを分岐 # 分岐にはdefaultdictを使い、デフォルトはlambda式で返す layout = defaultdict( # default layout lambda: go.Layout(title=go.layout.Title(text=title), xaxis={ 'type': xaxis_type, 'title': df.index.name, 'rangeslider': dict(visible=False), }, yaxis={ 'type': yaxis_type, 'title': yaxis_name, }, margin={ 'l': 60, 'b': 50 }, hovermode='closest'), # other layout { 'Histogram': go.Layout(title=title, xaxis={'title': 'Value'}, yaxis={'title': 'Count'}, barmode='overlay', hovermode='closest'), 'Pie': go.Layout(title=go.layout.Title(text=title), grid={ 'columns': len(df.columns) - 1, 'rows': 1 }, hovermode='closest') }) return dcc.Graph(id='the_graph', figure={ 'data': data[chart_type], 'layout': layout[chart_type] }) def data_table(df): """アップロードされたデータの表を描画""" df.reset_index(inplace=True) # indexもテーブルに含めるため data = df.to_dict('records') columns = [{'name': _i, 'id': _i} for _i in df.columns] return dash_table.DataTable(data=data, columns=columns) def parse_contents(contents, filename, date, chart_type, xaxis_type, yaxis_type): content_type, content_string = contents.split(',') decoded = base64.b64decode(content_string) try: if 'csv' in filename: # Assume that the user uploaded a CSV file df = pd.read_csv(io.StringIO(decoded.decode('utf-8')), index_col=0, parse_dates=True) elif 'xls' in filename: # Assume that the user uploaded an excel file df = pd.read_excel(io.BytesIO(decoded), index_col=0, parse_dates=True) except Exception as e: print(e) return html.Div(['There was an error processing this file.']) return html.Div([ data_graph(df, filename, chart_type, xaxis_type, yaxis_type), html.H5(filename), html.H6(datetime.datetime.fromtimestamp(date)), data_table(df), html.Hr(), # horizontal line # For debugging, display the raw contents provided by the web browser html.Div('Raw Content'), html.Pre(contents[0:200] + '...', style={ 'whiteSpace': 'pre-wrap', 'wordBreak': 'break-all' }) ]) @app.callback(Output( 'output-data-upload', 'children', ), [ Input('upload-data', 'contents'), Input('chart-type', 'value'), Input('xaxis-type', 'value'), Input('yaxis-type', 'value'), ], [State('upload-data', 'filename'), State('upload-data', 'last_modified')]) def update_output(list_of_contents, chart_type, xaxis_type, yaxis_type, list_of_names, list_of_dates): if list_of_contents is not None: children = [ parse_contents(c, n, d, chart_type, xaxis_type, yaxis_type) for c, n, d in zip(list_of_contents, list_of_names, list_of_dates) ] return children if __name__ == '__main__': app.run_server(debug=True, host='0.0.0.0', port=8880)
- 投稿日:2019-05-22T23:36:13+09:00
Google Colabで書いたipynbファイルをpyに変換してそのまま実行する
はじめに
プログラミングは本業ではないですが、最近機械学習を学ぶ機会があり、
これを機会にPythonやらRやらを勉強中。G検定もクリアし、次はE資格かなと思うこの頃。Pythonで機械学習のモデルを学習をさせる際、GPUが非力でも
GoogleColaboratoryを使えば、どんなPC環境でも快適に走らせられるので
最近気に入って使っています。
本気スペックPC+Anacondaよりこっちで十分足りる。というか速い。。。本題
教本を見ながら完成したスクリプトを引数指定して、実行しようと思ったときに
通常ならコマンドプロンプトからpyファイルを実行すれば良いと思うのですが、
これをGoogleCoab上で完結させようと思ったらどうすれば・・・?
と行き詰ったので、調べた結果を備忘録として以下に記載します。自分はGoogleドライブをマウントしてお勉強するので、一連の動きを記載します。
前提として、コードは書き終えていて、Googleドライブ内にipynb形式で保存しているとします。Googleドライブをマウントするfrom google.colab import drive drive.mount('/content/drive')これで認証画面のリンクが表示されるので、認証を済ませてマウントさせる。
カレントディレクトリをGoogleドライブ上の目的フォルダへ移動cd /content/drive/My Drive/Colab Notebooks/'目的フォルダ'実行するipynbファイルを確認!lsプロンプト上ではipynb形式は走らせられないので、pyファイルに変換する!jupyter nbconvert --to python '目的ファイル名'.ipynbこれでGoogleDrive上にpyファイルが作成される。
最後に、pyファイルを実行する。GoogleColab上(セル上)でpyファイル実行!python "目的ファイル名".pyちなみに、numpyのバグなのか走らないことがあるので以下の通りに
numpyをバージョン指定してインストールするのが吉。numpyのバグでコードが走らないことがあるので、バージョン指定してnumpyを入れ直す!pip install numpy==1.16.1あとがき
初Qiita投稿です。今後も調べものの備忘録を記載していく予定です。
- 投稿日:2019-05-22T22:56:58+09:00
[Python]リスト内法表記で複数の返り値を返す方法
リストなどでまとめて返してあげましょう。
OK[[i,i] for i in range(0,10,1)]「リスト内法表記 複数 返り値」で検索しても一瞬で出てこなかったので、検索用として記しておきます。
リストに入れないとエラーが出ます。
NG[i,i for i in range(0,10,1)]
これで大丈夫だったので感覚的に大丈夫かなと思ったらいけませんでした。
関数の返り値が複数の場合はタプルで帰ってくるので当たり前でしたね。OKdef double(x): return x,x [double(i) for i in range(0,10,1)]これと同じですね。
OK[(i,i) for i in range(0,10,1)]
条件式と内法表記でもちゃんと使えます。
[[i,"even"] if i%2 else [i,"odd"] for i in range(0,10,1)]返り値の個数を可変にもできますが、処理がめんどくさくなるので、避けたほうがいいと思います。
[[i,"even"] if i%2 else ["odd"] for i in range(0,10,1)]
リスト内法表記は以下の記事が非常に参考になります。
上記の内容も「二次元リストを作る」に書いてありましたが、実装したい動作イメージと検索ワードが異なっており、見逃しておりました。
リスト内包表記の活用と悪用 - Qiita
- 投稿日:2019-05-22T21:18:09+09:00
Python個人的メモ:入力編
はじめに
初投稿です.
今までなんとなくPythonを触ってきて,分からないことがあったら都度調べる,みたいなことをやってきたのですが
それが煩わしい+やっぱり自分の言葉でまとめたいので個人的なメモを兼ねて書いていきます.#Python でプログラミングをするにあたって,まず知っておかないといけないのは入力を受け取る方法.
大きく分けて二つ種類があると思っています.
1. 標準入力を受け取る
2. ファイルからの入力を受け取るこの二つについてそれぞれ入力を受け取る典型的な方法を示します.
標準入力
だいたいこのケースだとは思います.
inputという関数を使います.基本的にこれをやると一行の入力を取ってこれます.
ただ受け取るだけだとstr型なので,int(input())として数字として扱えるようにします.
- python
- #input は基本的に1行を取る forで回すと複数行取る
- n=int(input())
- string_list=[input() for i in range(n)]一行に複数の入力がスペース区切りで与えられることもよくあります.
その場合はmapをすればよろしくやってくれます.そのままlist()で包むとリストにできます.input- #スペースで区切られていてもこれで取ってこれる - b, c = map(int, input().split()) - #リストにぶちこむことも可能. - listA=list(map(int,input().split()))ファイルを開いてそこから入力を受け取る
あらかじめすべてのテストケースが与えられて,それを適宜保存して,入力として用いて実行して結果を貼り付けろ,という形式もまれによくあります.
その場合はファイルの場所を指定して,openを用います.
readline()で一行ずつ読み込むことが可能です.それ以外は標準入力とほぼ同じように扱えます.input_filepath = 'input.txt' #読み取り専用でオープン file_data = open(path,"r") #一行読み込み line = file_data.readline() #intにしてから変数に格納 a=int(file_data.readline()) #スペース区切りされているときのやり方も同じ b,c = file_data.readline().split()さいごに
入力を扱えないと問題以前の問題です.
こんなところで時間をかけずにさっさと問題を解くためのアルゴリズムを考えていきましょう.追記:fileinputというライブラリがあるそうです.
importして,fileinput.input()とすると実行時に引数としてファイルパスを指定するとファイルから読み込み(複数指定可),しないと標準入力を受け取るという便利なものです.@c-yanさんありがとうございます.
- 投稿日:2019-05-22T20:46:45+09:00
Pythonでアクセス元IPのwhois情報を取得する
概要
サーバ側でアクセス元のIPアドレスを取得して、そのIPアドレスのwhois情報を取得する方法。
Flaskフレームワークでの例を紹介します。アクセス元IPアドレスを取得
request.remote_addrでリクエストの送信元IPアドレスを取得できます。from flask import request from flask import jsonify @app.route("/get_ip", methods=["GET"]) def get_ip(): return jsonify({'ip': request.remote_addr}), 200ipwhoisのインストール
pip3 install ipwhois私の環境ではdnspython-1.16.0とipwhois-1.1.0がインストールされました。
アクセス元IPアドレスのwhois情報を取得
from flask import request from flask import jsonify from ipwhois import IPWhois @app.route("/get_whois", methods=["GET"]) def get_whois(): obj = IPWhois(request.remote_addr) whoisInfo = obj.lookup_whois() return jsonify({'whois': whoisInfo}), 200参考文献
・クイックスタート — requests-docs-ja 1.0.4 documentation
・ipwhois · PyPI
・Python Flaskを使って訪問者のIPアドレスを取得する
- 投稿日:2019-05-22T20:20:31+09:00
AWS CodeStarを使って,Django製アプリをデプロイするまで
環境
- AWS CodeStar
- Python: 3.6
- pipenv: 2018.7.1
- pip: 18.0.0
- Django: 1.11.18
執筆したきっかけ
- 研究で開発する実験用システムをデプロイするため
- AWSに(ちゃんと)初挑戦する!
- 開発するシステムをそれなりな環境で動かす必要があるため,herokuじゃ厳しそう
- 毎度手作業でデプロイするのがしんどい
CodeStarとは
AWS CodeStar を使用すると、アプリケーションを迅速に開発および構築して AWS にデプロイできます。
AWS CodeStarとのこと.
つまり,「CI/CDも含めたWEBアプリの開発環境を,お手軽に構築するよ!」というサービスです.
対応する言語やフレームワークがたくさんあり,困ることはなさそうです.
ちなみに,2019-05-22時点では,
- Go
- Node.js
- Python, (FlaskやDjangoを含む)
- Ruby on Rails
- Lalavel
- Java
などがありました.
さらに,AWS CodeStar に対する追加料金はありません。CodeStar プロジェクトでプロビジョニングした AWS リソース (例: Amazon EC2 インスタンス、AWS Lambda の実行、Amazon EBS ボリューム、Amazon S3 バケット) に対してのみ料金を支払います。実際に使用した分に対してのみ料金が発生します。最低料金や前払いの義務はありません。
AWS CodeStar の料金嬉しい限りです.
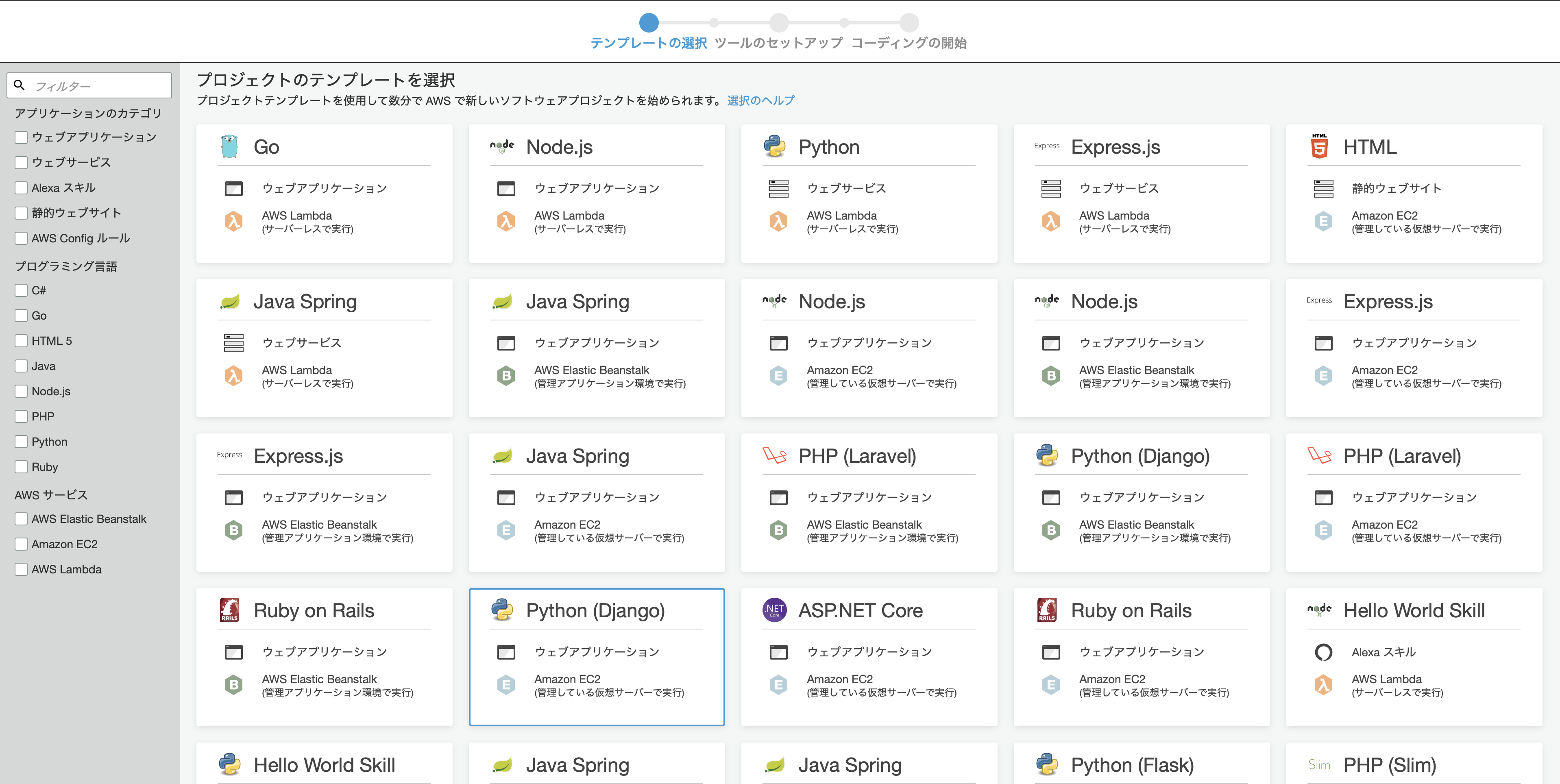
Djangoのテンプレート
テンプレートは2種類ありました.
1. EC2で実行する
2. Elastic Beanstalkを介して実行するつまり,Dockerを使うかどうかが大きく違うところでしょうか(間違っていたらすみません)
私の場合,大規模開発でもないので,1でやってみました.プロジェクトを作成する
AWSのコンソールから,CodeStarを選択します
テンプレートから,Djangoを選択します.
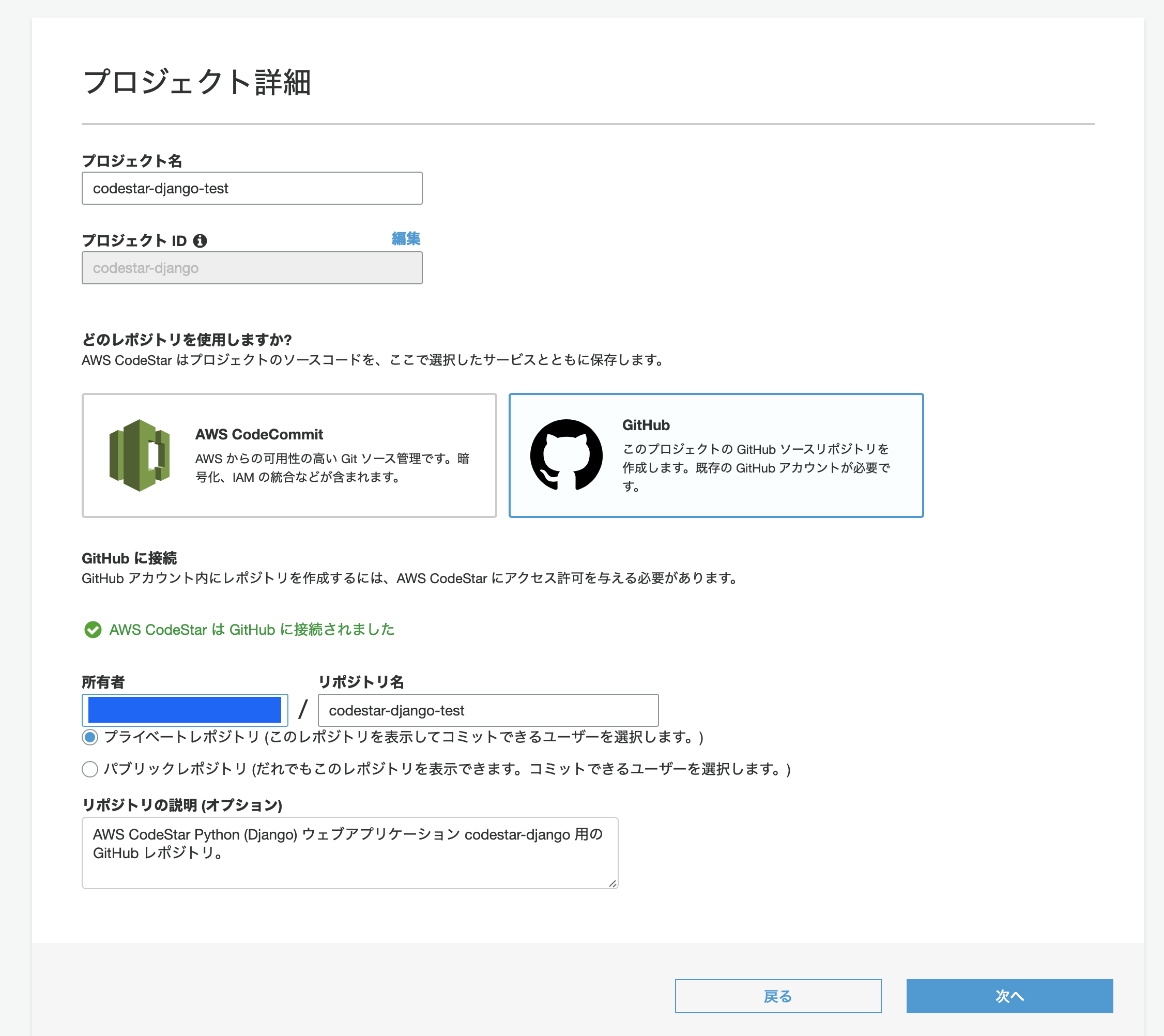
プロジェクト名や,ソースコードのリポジトリを選択します.
私は,GiHubを選択しました.GitHubを選択すると,リポジトリ名やリポジトリをprivateかpublicに選択できます.
続いて,AWSCodeStarに権限を付与することを許可します.その他,
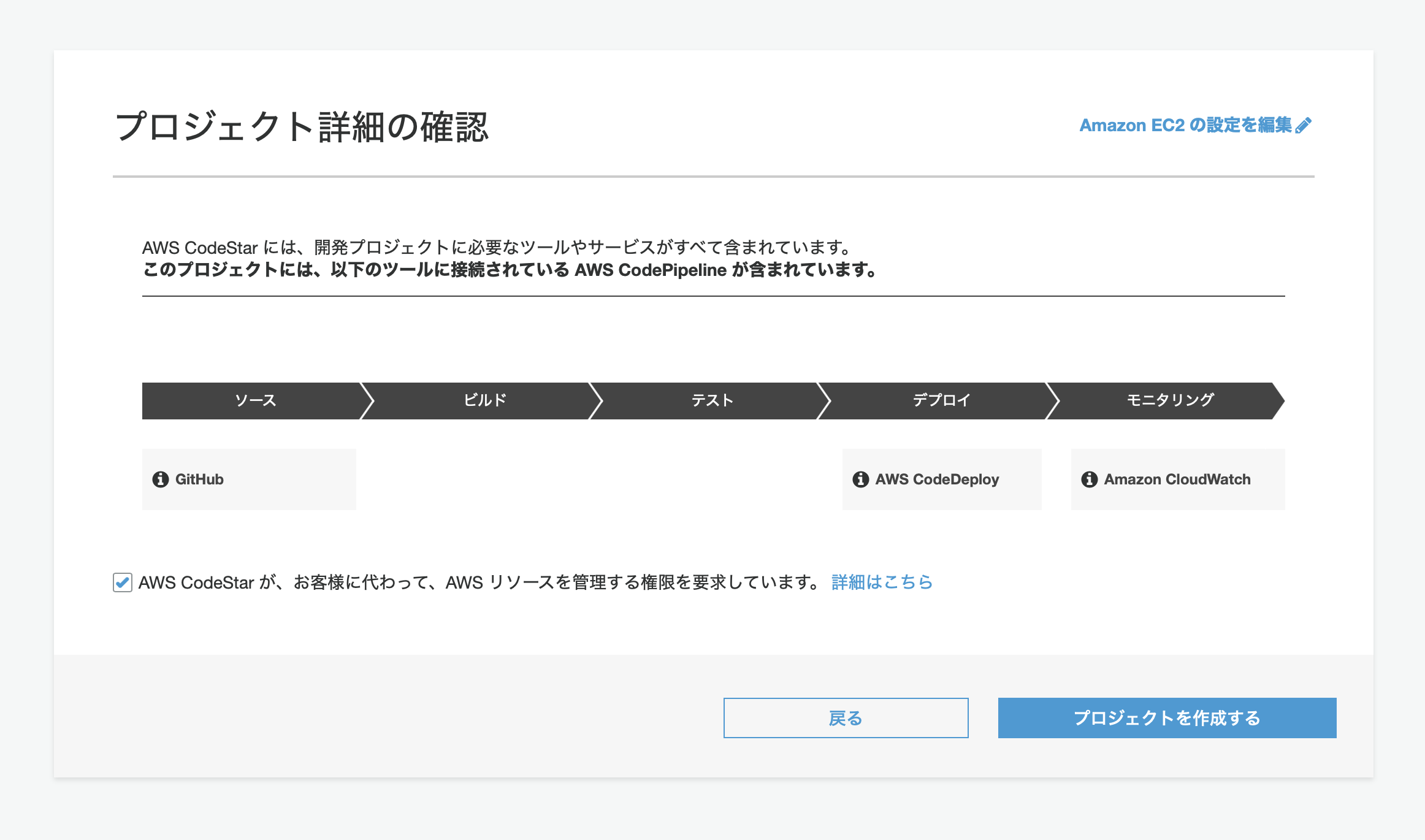
Amazon ECの設定を編集から,使用するEC2,VPC,サブネットを変更することもできます.
ご丁寧に,作成したリポジトリも案内してくれます.
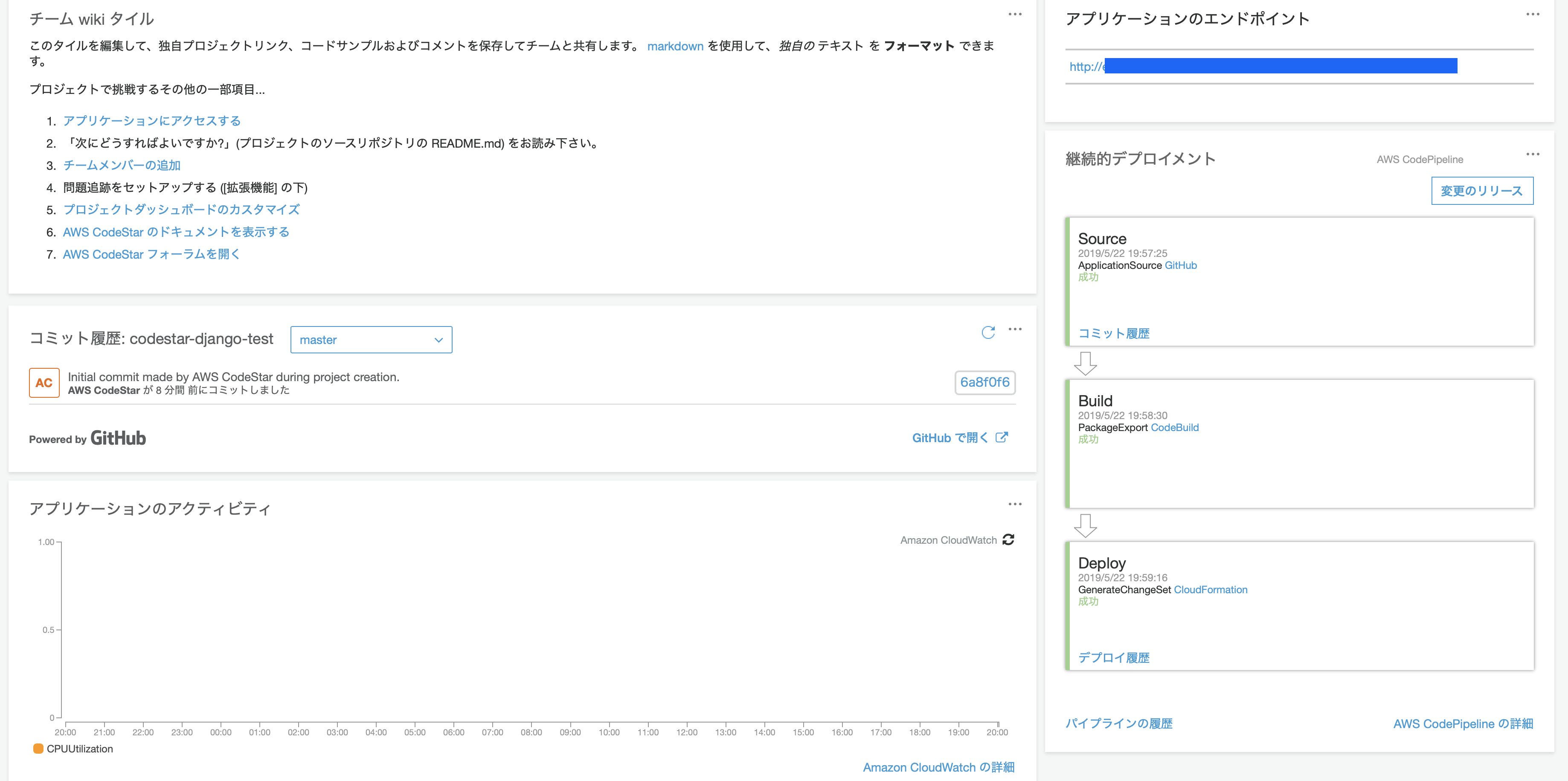
後はデプロイが完了するまで待機です.
これで,デプロイ完了です.
アプリ自体は,
アプリケーションのエンドポイントよりアクセスできます.
今後はGitHub上のmasterへpushすると,CodeStarがそれを検知してデプロイまでやってくれます.感想
すごい...ただし,現状はCIが回っていません.また,DBはSqliteのままです.これから,頑張ります!!
iOS以外の領域にうとい私でもできました.AWS様々です.補足
CodeStarが作成したリポジトリのREADMEを見ると,各ファイルの説明や,ローカル環境下でDjango製のアプリを起動するまで書かれていました.また,READMEにはvirtualenvを使用した方法を紹介していましたが,私はpipenvを使用しました.
参考文献

- 投稿日:2019-05-22T19:59:38+09:00
Django MVC
Django MVC
前回までの記事で、アプリケーション作成まで進みましたが、まだ何の機能も持っていません。
機能を実装していく前に、まずは何を作るのかを考えてみましょう。Web App
Djangoを使うわけでですから、データベースとかも使うようなそれなりのWebアプリケーションを作るんだろうなーって思ってますが、皆さんそれでよいですよね?
個人用のホームページ作りたい!とかいう人がいたら、回れ右しましょうね。笑アプリケーションって一言で言っても、複数の形態があります。
主に、アプリケーションの提供方法によって分類できます。
- デスクトップアプリケーション
- スマートフォンアプリケーション
- クライアントサーバ型アプリケーション
- Webアプリケーション
デスクトップアプリケーションで一番イメージをしてもらいやすいのは、メモ帳です。
デスクトップ上で、スタンドアロンで動きます。
スマートフォンアプリケーションもパソコンがスマートフォン変わっただけで、同じくメモ帳のようなものをイメージする人が多いのではないでしょうか?
これらのように、アプリケーションそのものをインストールしてクライアントマシン上で動くものをネイティブアプリと呼んだりします。
こういうのが作りたいっていう人も、回れ右しましょう。次に、クライアントサーバ型アプリケーションとWebアプリケーションです。
これは、サーバマシン上で動くアプリケーションを、ユーザが使用します。
Webブラウザを介さない場合は特に、クライアントサーバ型アプリケーションと呼ぶことが多いです。
要するに、ひとつのマシンに色んな人がアクセスして使うアプリケーションです。そして、DjangoはWebアプリケーションを作成するのに使います。
Web アプリケーション = ひとつのマシンで動くアプリをブラウザを介してみんなで使うアプリケーションです。MVC
次に、MVCというものの説明をしていきます。
MVCというのは、Webアプリケーションを構成する各種機能を、どう分類するかという考え方のことです。
Webアプリ作りたい!と思ったら結構目にするキーワードではないでしょうか。はじめに
ご自身がWebアプリケーションを使用するケースを思い浮かべてください。
恐らくですが、こんな感じですよね?
- メニューから使いたい機能を選択する
- 以前に登録したデータなどが表示される
- 既存のデータを操作して保存ボタンを押す
MVCっていうのは、これらの機能を役割分担しながら提供しまっせっていう考え方です。
V = View (T = Template)
まずはView(ビュー)の部分からいきましょう。
Viewって名前からも察してもらえるかもしれませんが、ユーザの目に触れる部分です。
厳密には違うのですが、HTMLファイルみたいなもんと思ってください。
そして、これがとても重要なのですが、、、
一般的には V ですが、DjangoではT = Templateという名称になっています。
名称がちょっと違うんですよね..
お気をつけください..M = Model
このModel(モデル)というのは少し難しい部分です。
よくモデリングという言葉がソフトウェア設計で使われるのですが、このモデリングで作るものがModelです。
モデリングとは、荒っぽくいうとユーザのデータや振る舞いなどを、データ構造へと落とし込む行為です。
なので、ここでのModel(モデル)というのは、データ構造の定義と思ってください。C = Controler
最後にControler(コントローラ)ですね。
これはTemplateとModelを関連付ける機能となります。
どういうことかというと、、
ユーザはURLにアクセスして、機能の使用を要求してきます。
Webアプリケーションは、Modelの内容をTemplateに渡して、最終的な画面をクライアントのWebブラウザへと送信します。以上で今回の内容はおわりです。
次回以降は、この内容を念頭に置いたうえで、アプリケーションに機能を実装していきます。お疲れ様でした。
- 投稿日:2019-05-22T18:59:35+09:00
Pythonの特殊な引数 *args **kwargsの意味
はじめに
Pythonのデコレータで、ラッパー関数の引数が
def wrapper(*args, **kwargs):となっているのを見て、*argsや**kwargsはどういう物?と思い、調べてみました。関数の引数として使う
*argsや**kwargs関数の引数で、
*argsや**kwargsを使うと、どんな引数でも受け取れる関数が作れます。
*argsは任意の数の引数を許可し、argsという名前のタプルに割り当てられます。
**kwargsは任意の数のキーワード引数を許可し、kwargsという名前の辞書(dict)に割り当てられます。サンプルコード
pythondef fn(*args, **kwargs): print("*args:", args) print("*kwargs:", kwargs) #(1)任意の数の引数を指定 fn(11, "aa", ["ラーメン", "素麺"]) #-> *args: (11, 'aa', ['ラーメン', '素麺']) #-> *kwargs: {} #(2)任意の数のキーワード引数を指定 fn(key1=22, key2="bb", key3=["パスタ", "スープ"]) #-> *args: () #-> *kwargs: {'key1': 22, 'key2': 'bb', 'key3': ['パスタ', 'スープ']} #(3)混在 fn(11, "aa", key1=22, key2="bb") #-> *args: (11, 'aa') #-> *kwargs: {'key1': 22, 'key2': 'bb'}アンパック引数として使う
*argsや**kwargs別の使い方で、リストや辞書(dict)を引数として渡すとき、先頭に
*や**をつけると、リストや辞書を分解して引数に渡せます。サンプルコード
リストをアンパックして、各要素の値を引数で渡す例
pythondef sample(p1, p2): print("p1=", p1) print("p2=", p2) params = [111, "AAA"] sample(*params) #-> p1= 111 #-> p2= AAA辞書(dict)をアンパックして、各要素の値をキーワード引数で渡す例
pythondef sample(foo, bar): print("foo=", foo) print("bar=", bar) params = { 'foo': 222, 'bar': "BBB" } sample(**params) #-> foo= 222 #-> bar= BBB
- 投稿日:2019-05-22T18:25:26+09:00
Talibで使えるローソク足についての関数まとめ(3)
同時線
CDLDOJI - Doji
Doji(同時線)とは?
ろうそく足の実体が小さいため、始値と終値が同じであればそれは「同時線」と呼ばれます。
始値と終値の要求が全く同じであり、データに厳しい制約が設けられるので、同時線はほとんど見られません。
始値と終値の差が数個のティック(最小価格変動)を超えることがなければ、これは十分以上です。
integer = CDLDOJI(open, high, low, close)同時線(星)
CDLDOJISTAR - Doji Star
【買いのサイン】
最初は長い陰線となり、二本目はトレンド方向のブレイクがある同時線が出る時です。
【売りのサイン】
最初は長い陽線となり、二本目はトレンド方向のブレイクがある同時線が出る時です。
integer = CDLDOJISTAR(open, high, low, close)同時線(とんぼ)
CDLDRAGONFLYDOJI - Dragonfly Doji
上ヒゲのない十字線です。高値圏に現れれば高値を買い上る勢いが衰えてきたこと、また、底値圏に現れれば押し戻す買い勢力を暗示します。
【買いのサイン】
低値圏(0 > x > -100 [x:自然数])
【売りのサイン】
高値圏(0 < x < 100 [x:自然数])
integer = CDLDRAGONFLYDOJI(open, high, low, close)CDLEVENINGDOJISTAR - Evening Doji Star
integer = CDLEVENINGDOJISTAR(open, high, low, close, penetration=0)同時線(塔婆)
CDLGRAVESTONEDOJI - Gravestone Doji
下ヒゲがない十字線。寄り付き後、買い方が買いあがったが、勢いが続かず、大引けには寄り付きの値段まで戻る。高値圏では買い方と上売り方の力が接近し上げ止まりを暗示。それ以外の場面で現れれば、小休止を暗示するローソク足。
integer = CDLGRAVESTONEDOJI(open, high, low, close)長い足の同時線
CDLLONGLEGGEDDOJI - Long Legged Doji
この長い足がある同時線は強い上昇トレンドや強い下落トレンドで最も重要とされています。
理由は足の長い同時線は、需要と供給の力が均衡に近づいており、トレンドの逆転が起こる可能性があることを示唆しています。integer = CDLLONGLEGGEDDOJI(open, high, low, close)CDLEVENINGSTAR - Evening Star
【買いのサイン】
一番目と三番目のセッションは「長い」ろうそく足です。星のヒゲは短く、色は関係ありません。最初のろうそく足の終値から星は離れています。
三番目のろうそく足は一番目より短くその長さの内側に収まっています。
【売りのサイン】
一番目と三番目のセッションは「長い」ローソク足です。星のヒゲは短く、色は関係ありません。最初のろうそく足の終値から星は離れています。
三番目のろうそく足は一番目より短くその範囲に収まっています。
integer = CDLEVENINGSTAR(open, high, low, close,penetration=0)CDLGAPSIDESIDEWHITE - Up/Down-gap side-by-side white lines
【買いのサイン】
市場は上昇トレンドであり、最初のローソク足は陽線であり、2本目のローソク足の始値は最初のローソク足の終値より上にある。(ギャップアップ)
3本目のローソク足は始値と同じくらいもしくは高い2本目のローソク足と同じ大きさの実体
The third candle has a real body with the same length as the second candle with an open that’s at the same level or higher than the real body of the first candle.
integer = CDLGAPSIDESIDEWHITE(open, high, low, close)ハングマン
CDLHANGINGMAN - Hanging Man
実体(四角の部分)が小さくした側に長いひげがあるろうそく足。
上昇傾向に出現した場合をハングマンと呼び、似下降傾向に出現した場合には「ハマー」と呼ばれる。
ハマーの場合には下降傾向が終わる吉兆とされています。
しかし、ハングマンの意味は「絞首刑執行人」。
上昇傾向が終わる可能性を示す凶兆となるのです。
怖いね~
integer = CDLHANGINGMAN(open, high, low, close)
明けの明星
CDLABANDONEDBABY - Abandoned Baby
【買いのサイン】
一日目に陰線が出現した翌日、それより下に十字星、極性が現れます。その後、三本目のロウソク足はヒゲの間に同じ隙間のある「長い」陽線のろうそく足で、一番目より短くなっています。
【売りのサイン】
一日目に陽線が出現した翌日、それより上に十字星、極性が現れます。その後、三本目のロウソク足はヒゲの間に同じ隙間のある「長い」陰線のろうそく足で、一番目より短くなっています。
integer = CDLABANDONEDBABY(open, high, low, close, penetration=0)収束
つつみ線
CDLENGULFING - Engulfing Pattern
【買いのサイン】
様々な陰線の黒色のローソクを飲み込んでいるネオンサインのように陽線の白色のローソクが存在しています。
これは投資家の心が動いている様子がを凄く簡単に分かるようになっています。いくつかの単純な原因が強気な巻き込みパターンをより説得力のあるものにして、前の日のローソクが飲み込まれるほど、新しいトレンドシグナルはより効果的になります。
【売りのサイン】
弱気なつつみ線は、これからの低価格を示唆するテクニカルチャートのパターンです。パターンは、陽線のローソク足と、それに続いて小さい陽線のローソクを隠し、大きな陰線のローソク足で構成されています。これは、売り手が買い手を追い越し、買い手がそれを押し上げるよりも積極的に価格を引き下げている(ろうそくを上げている)ことを示しているので重要です。
integer = CDLENGULFING(open, high, low, close)
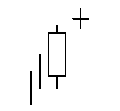

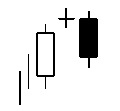

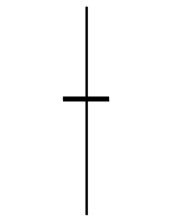
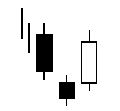
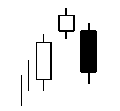

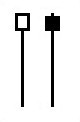
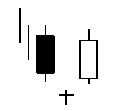
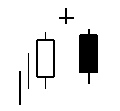
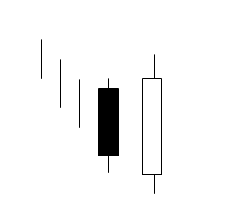
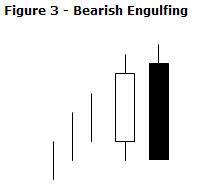
- 投稿日:2019-05-22T16:30:25+09:00
best programming courses and tutorials
When it comes to learning a new skill, e-learning sources are preferred more than any physical institute these days. The basic reason is that they are full of convenience and have greater accessibility. Also, some of them are available for free and provides certifications too, so why should anyone visit and pay a whole lot of fees to these institutes.
Though having a degree or certification in a proper format enhances the credibility of your profile or resume. But again not everyone could sit into long lectures and learn a skill. People need flexibility in accordance with time and accessibility. So a huge number of people love to learn through e-learning websites. As we cannot ignore the fact that the online presence of the world is insanely huge and growing day by day.
So as question is best Programming and design tutorial or courses? so what i suggest that at least once Check out the best Programming and design tutorial or courses recommended by programming community. http://letsfindcourse.com
So as many student want to learn Programming and design and want certification but unable to find best course or tutorial. So Programming and design tutorials???????
help student to find the best Programming and design online tutorial, with detailed information(certification) and it will be easy for student to find course.
http://letsfindcourse.com/python
- 投稿日:2019-05-22T16:16:11+09:00
bow-tie構造解析
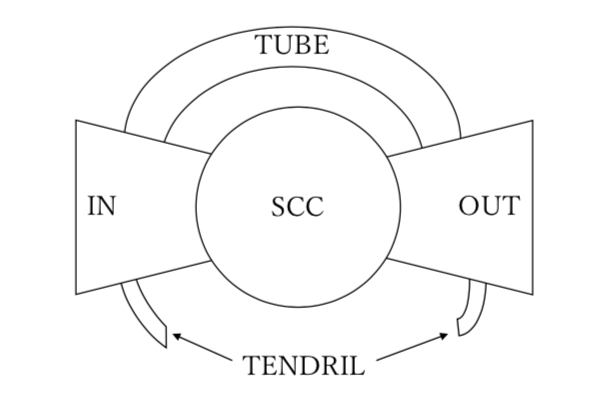
Bow-tie構造とは
有効ネットワークにおいて、Bow-tie構造とは強連結成分(SCC)、SCCに入るIN、SCCから出るOUT、INとOUTを結ぶTUBE、INとOUTから伸びるひげ(TENDRIL)から構成されるネットワークである。
上の画像のような構造をしていて、その見た目からBow-tie構造と呼ばれている。隣接行列(adjacency)と行列積
このネットワークの隣接行列$A$はA = \begin{pmatrix} 0 & 1 & 0 \\ 0 & 0 & 1 \\ 0 & 0 & 0 \end{pmatrix}また、2の頂点の位置ベクトル$x$は
x = \begin{pmatrix} 0 \\ 1 \\ 0 \end{pmatrix}隣接行列$A$と位置ベクトル$x$の行列積$Ax$,$xA$はそれぞれ
x^TA = \begin{pmatrix} 0\\ 0\\ 1 \end{pmatrix}^T Ax = \begin{pmatrix} 1\\ 0\\ 0 \end{pmatrix}このようにある位置ベクトルに隣接行列を右からかけると矢印方向にすすみ、左からかけると矢印方向と逆に辿る形となる。
ここでネットワークに自己ループを持たせ、この行列積を用いるとIN、OUT、TENDRILが一つのベクトルで表すことができるだろう。
Bow-tie構造の分類
Bow-tie構造を分類する。
はじめにimportするライブラリはimport numpy as np import networkx as nx import scipy次に分類するコードは以下である。
bow_tie.pydef bow_tie(G): np.seterr(divide='ignore', invalid='ignore')#0徐算で起こるWarningを表示しない components = max(nx.strongly_connected_components(G), key=len) components = list(components) nodes = list(G.nodes()) length = G.number_of_nodes() adjacency = nx.to_scipy_sparse_matrix(G) adjacency = adjacency + scipy.sparse.eye(length)#自己ループ付きのadjacency scc = np.zeros(length) ones = np.ones(length) intersects = np.isin(nodes, components)#重複する要素True indices = np.where(intersects)#重複する要素のnodesのindex scc[indices] = 1 scc_difference = ones - scc scc_copy = scc loop1 = [1] for i in loop1: scc_in1 = adjacency @ scc_copy#行列積 scc_in2 = adjacency @ scc_in1 if np.count_nonzero(scc_in2) != np.count_nonzero(scc_in1):#全てのINを網羅すると0の数が一致する。 loop1.append(i+1) scc_copy = scc_in1 else: scc_in1 = scc_in1 * scc_difference#要素積を用い、SCCを省く scc_in1 /= scc_in1#0徐算が起こる scc_in1 = np.nan_to_num(scc_in1)#NaN to 0 scc_copy = scc loop2 = [1] for i in loop2: scc_out1 = scc_copy @ adjacency scc_out2 = scc_out1 @ adjacency if np.count_nonzero(scc_out2) != np.count_nonzero(scc_out1): loop2.append(i+1) scc_copy = scc_out1 else: scc_out1 = scc_out1 * scc_difference scc_out1 /= scc_out1 scc_out1 = np.nan_to_num(scc_out1) difference = scc_difference - scc_in1 - scc_out1 in_copy = scc_in1 loop3 = [1] for i in loop3: in_tendril1 = in_copy @ adjacency in_tendril1 = in_tendril1 * difference in_tendril2 = in_tendril1 @ adjacency in_tendril2 = in_tendril2 * difference if np.count_nonzero(in_tendril2) != np.count_nonzero(in_tendril1): loop3.append(i+1) in_copy = in_tendril1 else: in_tendril1 /= in_tendril1 in_tendril1 = np.nan_to_num(in_tendril1) out_copy = scc_out1 loop4 = [1] for i in loop4: out_tendril1 = (adjacency @ out_copy) * difference out_tendril2 = (adjacency @ out_tendril1) * difference if np.count_nonzero(out_tendril2) != np.count_nonzero(out_tendril1): loop4.append(i+1) out_copy = out_tendril1 else: out_tendril1 /= out_tendril1 out_tendril1 = np.nan_to_num(out_tendril1) in_sum = np.sum(scc_in1) out_sum = np.sum(scc_out1) if in_sum == 0 and out_sum == 0:#INとOUTがなかった場合 tube = np.zeros(length) elif in_sum == 0 or out_sum ==0: tube = np.zeros(length) else: tube = in_tendril1 * out_tendril1 in_tendril1 = in_tendril1 - tube out_tendril1 = out_tendril1 - tube return scc, scc_in1, scc_out1, in_tendril1, out_tendril1, tube#, [loop1[-1], loop2[-1], loop3[-1], loop4[-1]]実際に動かす
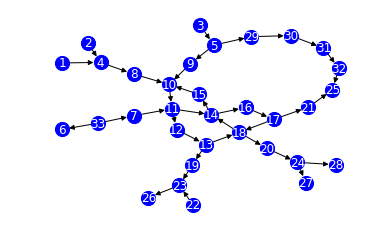
実際に分類できるかどうか動かしてみる。
以下の画像を分類する。
bow_tie(G) #(array([0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, # 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]), # array([1., 1., 1., 1., 0., 1., 0., 1., 0., 1., 1., 1., 0., 0., 0., 0., 0., # 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]), # array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., # 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 1., 1., 1., 1., 1., 1.]), # array([0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., # 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]), # array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., # 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]), # array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 0., # 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]))このように分類できた。
それではこれをもとに頂点を色分けする。color = [] a = bow_tie(G) for i in range(len(a[0])): if a[0][i] == 1:#SCC color.append('b')#青 elif a[1][i] == 1:#IN color.append('y')#黄色 elif a[2][i] == 1:#OUT color.append('g')#緑 elif a[3][i] == 1:#IN_TENDRIL color.append('m')#マゼンタ elif a[4][i] == 1:#OUT_TENDRIL color.append('r')#赤 elif a[5][i] == 1:#TUBE color.append('c')#シアン else: color.append('k')#黒描画ライブラリであるmatplotlibをimportし、
import matplotlib.pyplot as plt以下のコードを実行する。
pos = nx.nx_pydot.pydot_layout(G) nx.draw_networkx(G, pos=pos, node_size=200, node_color=color, font_color='w') plt.axis('off') plt.gca().invert_yaxis() plt.show()出力結果
うまく分類できている。
最後に
まあまあな速さでうまく分類できていると思う
とても大きなノードを持つネットワークで分類できないノードがあった。
どこかに不備や修正箇所があると思うがお手上げ状態である。
ひげのひげまでは分類していないが、それを分類しようとするとキリがないのでここまでにしておく。
間違っている部分や修正箇所のご指摘をお願いします。

- 投稿日:2019-05-22T16:11:11+09:00
pyenv及びpyenv-virtualenvの使い方
pyenv
pyenvとはPythonの複数のバージョンを使い分けるコマンドラインツールです。これを使えば同じ端末にPythonのバージョン毎に環境を作成することが出来ます。
- Githubのリンク:https://github.com/pyenv
- できること:同じ端末に複数バージョンのPython環境を簡単に管理する
- 出来ないこと:同じバージョンで複数の環境を作成や管理する
pyenvのインストール
pyenv-installerでのインストール
Githubにインストール手順を記載しています。
$ curl https://pyenv.run | bash.bashrcに設定を書き込む
pyenvのみを利用する場合に不要と思いますが、後記のpyenv-virtualenvを使いたいので、初期化処理の関連コマンドを追記します。
$ echo 'export PATH="$HOME/.pyenv/bin:$PATH"' >> ~/.bashrc $ echo 'eval "$(pyenv init -)"' >> ~/.bashrc $ echo 'eval "$(pyenv virtualenv-init -)"' >> ~/.bashrc $ source ~/.bashrc $ pyenv -v pyenv 1.0.10-2-geef042a失敗の場合
インストールに失敗する場合は、ここに色々注意点が書いてある。
pyenvのコマンド
よく使うコマンドを下記に記載します。その他はドキュメントを参照してください。
インストール可能なコマンド
pyenv install --listでインストールできるpythonのバージョンを一覧表示する。pythonバージョンのインストール
pyenv install 3.6.1で指定バージョンのPythonをインストールする。バージョンの確認
pyenv versionで現在アクティブなバージョンがどれか教えてくれる。
pyenv versionsで、インストール済み一覧が表示され、現在アクティブなバージョンがどれか教えてくれる。$ pyenv install --list $ apt-get install -y make build-essential libssl-dev zlib1g-dev libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev xz-utils $ pyenv install 3.6.1 $ pyenv install anaconda3-4.3.1 $ pyenv versions * system (set by /root/.pyenv/version) 3.6.1 anaconda3-4.3.1pythonバージョンの切り替え
pyenv shell 3.6.1で現在のShellのみ有効なバージョンを指定するpyenv global 3.6.1で全局有効なバージョンを指定する$ mkdir python_3.6.1 $ cd python_3.6.1 $ pyenv global 3.6.1 $ pyenv version 3.6.1 (set by /root/.pyenv/version) $ cd .. $ pyenv version 3.6.1 (set by /root/.pyenv/version)
pyenv local 3.6.1でフォルダ範囲有効なバージョンを指定する(globalの設定より優先)$ mkdir python_anaconda3-4.3.1 $ cd python_anaconda3-4.3.1 $ pyenv local python_anaconda3-4.3.1 $ pyenv version python_anaconda3-4.3.1 (set by /root/python_anaconda3-4.3.1/.python-version) $ cd .. $ pyenv version 3.6.1 (set by /root/.pyenv/version)pyenv-virtualenv
pyenvの出来ない同じバージョンで複数の環境作成や管理するコマンドラインツールです。
pyenv-virtualenvのインストール
pyenvのインストール時に一緒に設定することが出来ます。
個別インストールの場合に以下のコマンドを参考してください。
brew update brew install pyenv-virtualenv.bash_profileや.zshrcに以下を追加する
export PATH="$HOME/.pyenv/bin:$PATH" eval "$(pyenv init -)" eval "$(pyenv virtualenv-init -)"pyenv-virtualenvを使う
利用方法はpyenv-virtualenvのコマンドで環境を作成する。
その後、Pyenvで作った環境を指定して、環境の指定や、管理などの操作をする。$ pyenv virtualenv 3.6.4 mypyenv $ mkdir mypyenv $ cd mypyenv $ pyenv local mypyenv上記のコマンドは、python3.6.4を指定して、「mypyenv」という名前の仮想環境を作成しました。
その後、pyenv localでフォルダ「mypyenv」に仮想環境「mypyenv」を設定しました。
この状態でパケージをインストールする場合、仮想環境「mypyenv」にしかインストールしていません。その他
Visual Studio Codeで開発する場合に環境を簡単に切り替えれます。
しかし、pyenv localで指定したバージョンとVisual Studio Codeで指定したバージョンの有効範囲は異なりますので、開発時に気を付けてください。参考リンク
https://qiita.com/mogom625/items/b1b673f530a05ec6b423#pyenv%E3%81%A8%E3%81%AF
https://ensekitt.hatenablog.com/entry/2018/03/13/200000
- 投稿日:2019-05-22T15:36:21+09:00
二項ツリーモデルをmatplotlibでアニメーション化する
matplotlibのanimationを用いた記事が意外に少なかったので,自分で作ったものを共有したいと思って書きました.
二項ツリー
二項ツリーモデルは上昇確率$p$と下降確率$1-p$の二項分布を用いた不確実性を記述するモデルである.今回は,二項分布から得られた値をモンテカルロ・シミュレーションにより発生させ,そのパスで記述していく.
matplotlibでアニメーション
参考文献: matplotlibでアニメーションを作る
https://qiita.com/yubais/items/c95ba9ff1b23dd33fde2ArtistAnimation
あらかじめグラフの配列を用意することで,intervalごとに1つずつデータを取り出し,アニメーション化してくれる.
FuncAnimation
データを動的に変化させる必要がある.データが大きい場合にはデータを全て保持しないため,メモリ効率が良い.
プログラムコード
インポート
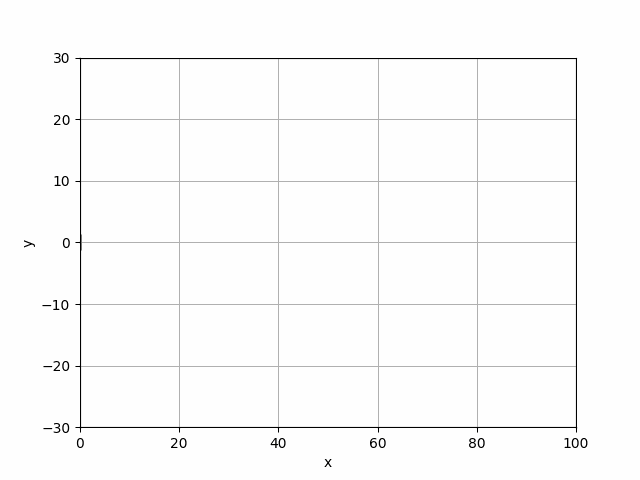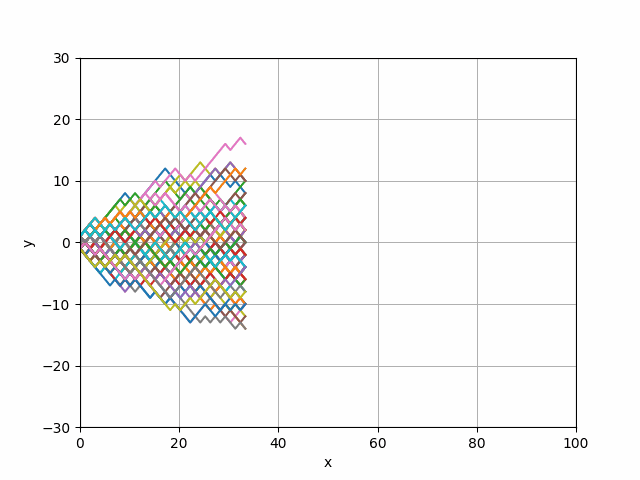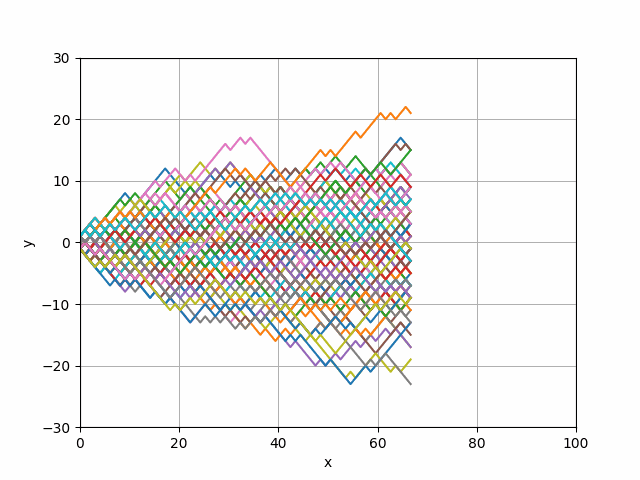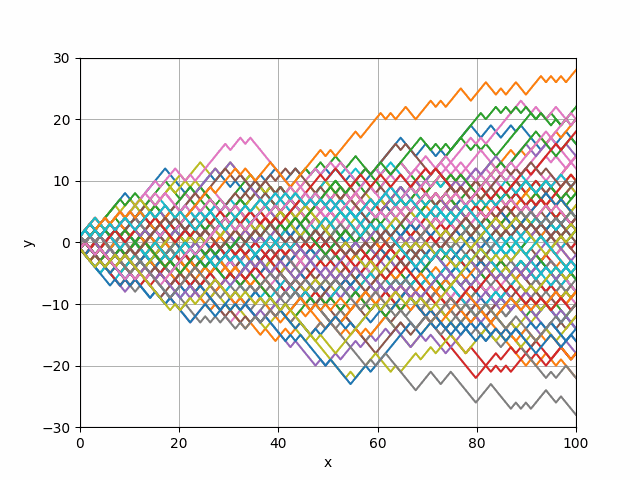
import math from numpy import * import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation import pylab描画の設定
特に%matplotlib nbaggを加えることで,Jupyter上でインタラクティブな画像表示が可能になります.
N = 100 # 描画個数 %matplotlib nbagg fig = plt.figure() ax = fig.add_subplot(111) ax.set_xlim(0, 100) # x軸の範囲 ax.set_ylim(-30, 30) # y軸の範囲 ax.set_xlabel('x') # x軸ラベル ax.set_ylabel('y') # y軸ラベル ax.grid() # gridを描画する描画するリストを準備
line = [] # 描画するグラフを格納する for j in range(N): line.append(ax.plot([], [])[0]) x_list = [] y_list = []データの生成
$x, y$の逐次返す関数を指定します.
FuncAnimationの第3引数に指定します.def gen(): y = [0 for i in range(N)] for x in np.linspace(0, 100, 100): # [start, end, 間隔] for i in range(N): y[i] += np.random.choice([-1,1]) yield x, yコールバック関数
FuncAnimationの第2引数に指定する関数です.
gen関数から受け取ったデータを描画するline配列に格納します.def func(data): # コールバック関数 x, y = data x_list.append(x) for i in range(N): y_list.append(y[i]) line[i].set_data(x_list, [y_list[j] for j in range(i, len(y_list), N)])アニメーション関数を定義
ani = animation.FuncAnimation(fig, func, gen, blit=False, interval=100, repeat=False)最終的なプログラム
import math from numpy import * import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation import pylab N = 30 # 描画工数 %matplotlib nbagg fig = plt.figure() ax = fig.add_subplot(111) ax.set_ylim(-30, 30) ax.set_xlim(0, 100) ax.set_xlabel('x') ax.set_ylabel('y') ax.grid() line = [] # 描画するグラフ for j in range(N): line.append(ax.plot([], [])[0]) x_list = [] y_list = [] def gen(): y = [0 for i in range(N)] for x in np.linspace(0, 100, 100): # [start, end, 間隔] for i in range(N): y[i] += np.random.choice([-1,1]) # -1か1を選択 yield x, y def func(data): # コールバック関数 x, y = data x_list.append(x) for i in range(N): y_list.append(y[i]) line[i].set_data(x_list, [y_list[j] for j in range(i, len(y_list), N)]) ani = animation.FuncAnimation(fig, func, gen, blit=False, interval=100, repeat=False)二項ツリーのシミュレーションをすることができました.
参考文献
matplotlibでアニメーションを作る
https://qiita.com/yubais/items/c95ba9ff1b23dd33fde2
Jupyter上でmatplotlibのアニメーションを再生する
https://qiita.com/Tatejimaru137/items/6083e2e3a4e618da6274
- 投稿日:2019-05-22T14:22:37+09:00
ScrolledTextで最後の行を表示する
Tkライブラリに収録されているScrolledTextでは、テキストをユーザーが入力したときは、入力部分が画面に表示されるよう、必要に応じてスクロールされます。
ただし、プログラムから
ScrolledText#insert()などでテキストを挿入した場合は、スクロールされず、スクロールバーの表示幅だけが更新されてしまいます。これを表示できるようにしたいという話。資料はなかなか見つかりませんが、やることは単純で、テキストを挿入した後
ScrolledText#yview_moveto(1)というメソッドを呼べば良いです。1が何を示しているのかは分かりませんでしたが周辺の文脈からするとおそらくスクロールの位置でしょう(0~1)。今回の思考プロセス
いちおうこれだけではなんなので、今回の思考プロセスをメモしておきます。
- ScrolledTextに文字を書き込んだときに、テキストが見えなくなっていることを確認
- 「Python ScrolledText」で検索したところとりあえず
ほとんどろくに何も書かれていないPythonの公式リファレンスにたどり着く- (初手で情報量のこんなに少ない公式リファレンスが出てきてしまう以上、)これ以上ググっても無駄そうなのでリンクよりソースコードを見る
- ScrolledTextは
ScrollBarとTextの複合コントロールであることが分かったのでScrollBarのソースコードを見る- ScrollBar#set()メソッドあたりが願いを叶えてくれそうなので使ってみるも意味が無かったので諦める
- ScrolledTextのソースコードで気になったyviewという文言を頼りにTextのソースコードを見る
- コード内を
yviewで検索したところなんかそれっぽいメソッドを見つけたので、改めて「Python Scrollbar yview_moveto」でググる- Stackoverflowのそれらしい記事を見つけたので、該当メソッドを使っている回答を探す。その値をそのまま入れて実行
- 動いた!
なにかの機能を探すときの参考になれば幸いです。
というわけで
Tkinterはクラスの記述がどこにあるのか分かりにくいのと、パラメータやプロパティに設定できる値が書かれてなかったりとドキュメントコメントがイマイチ機能していないので嫌ですね(Tkを熟知している前提なのかそうでないのか不明ですが)。
これからPythonでGUIのアプリを書きたいというときは素直にPyWebViewなどを使いましょう。
- 投稿日:2019-05-22T13:47:27+09:00
辞書をpd.DataFrameに変換
異なる長さのリストを含む辞書をpd.DataFrameに変換
dict_to_df.py#!/usr/bin/env python3 import pandas as pd d1={'key1': [1,2,3], 'key2': [4,5,6,7], 'key3': [8,9]} d2={} for k,v in d1.items(): # 一度pd.Seriesに変換 d2[k]=pd.Series(v) df=pd.DataFrame(d2) print(df) key1 key2 key3 0 1.0 4 8.0 1 2.0 5 9.0 2 3.0 6 NaN 3 NaN 7 NaN追記 (より良い方法)
以下のコメントでnkayさんから良い方法を教えていただきました。
とても簡潔にpd.DataFrameに変換できます。d = {'key1': [1,2,3], 'key2': [4,5,6,7], 'key3': [8,9]} df = pd.DataFrame.from_dict(d, orient='index').T # もしくは df = pd.DataFrame(d.values(), index=d.keys()).T print(df) key1 key2 key3 0 1.0 4.0 8.0 1 2.0 5.0 9.0 2 3.0 6.0 NaN 3 NaN 7.0 NaNこれはできない
ValueError: arrays must all be same lengthのエラーが出るd={'key1': [1,2,3], 'key2': [4,5,6,7], 'key3': [8,9]} df=pd.DataFrame(d) # これはできない辞書に含まれるリストの長さが同じ時のみ、可能
d={'key1': [1,2,3], 'key2': [4,5,6], 'key3': [7,8,9]} df=pd.DataFrame(d) # これはできる print(df) key1 key2 key3 0 1 4 7 1 2 5 8 2 3 6 9環境
Ubuntu 18.04
Python 3.7.2
pandas 0.24.1
- 投稿日:2019-05-22T13:46:13+09:00
PyYAMLがyaml.loadでYAMLLoadWarningを出してくるようになった件
今日何気なくPyYAMLを使おうとしたら、
yaml.load(f)のようなコードが軒並みYAMLLoadWarningを吐くようになった件。file.py:***: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.
まあ、内容としては書いてあるとおりなのですが・・・。
PyYAML5.1以降、Loader引数無しで
yaml.load()を呼ぶのは、エクスプロイトを仕込めてしまう危険があるのでダメになったそうな。なので、こうしなきゃいけなくなりました。yaml.load(f, Loader=yaml.SafeLoader)
yaml.safe_load()メソッドあたりを使ってもいいよとのこと。警告に書かれたURLのページに書いてあるとおりですね。
- 投稿日:2019-05-22T11:34:28+09:00
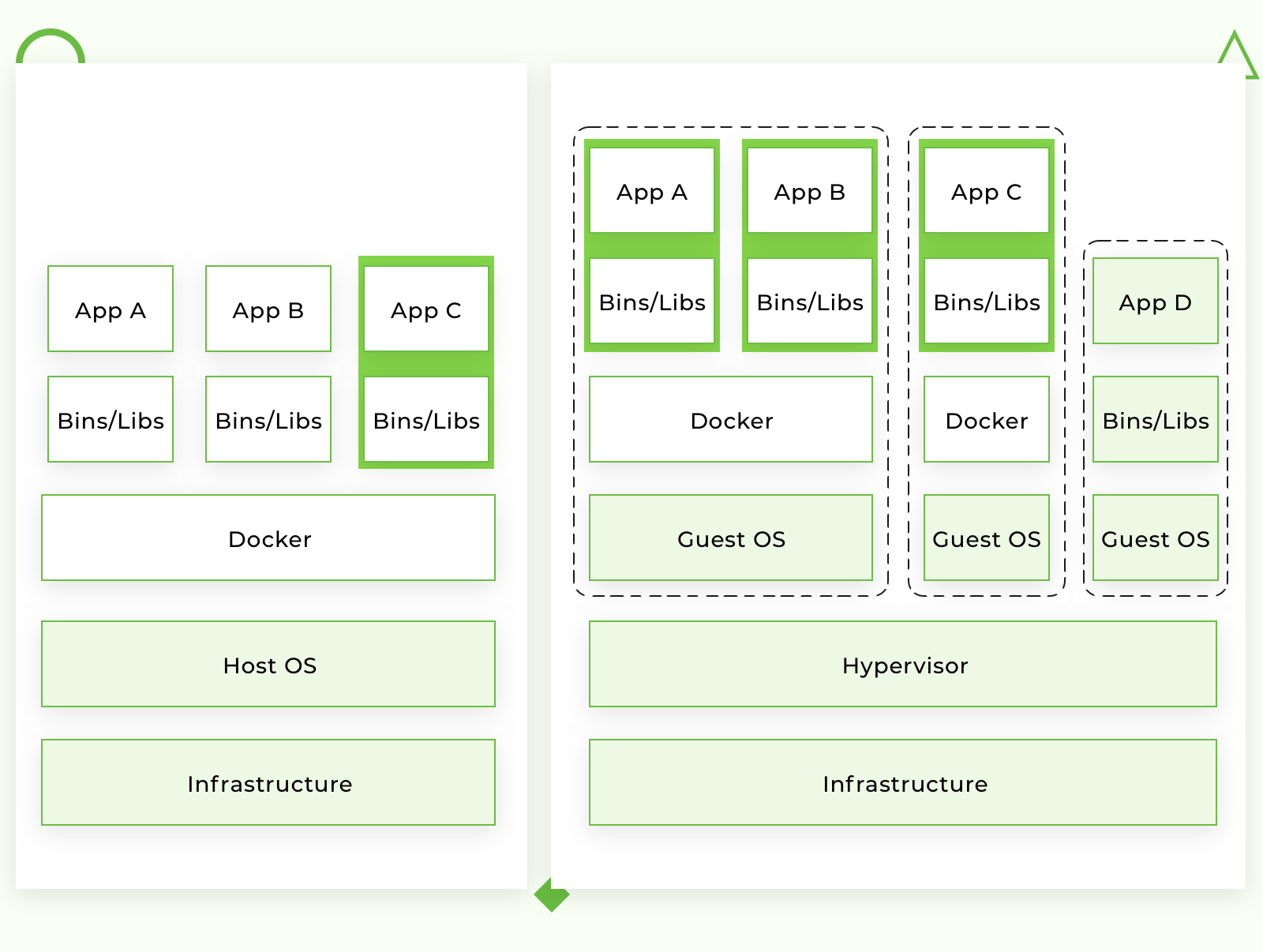
Python・Redis・Nginxを使って始めるDocker Tutorial
Docker Tutorial — Getting Started with Python, Redis, and Nginx.という海外の記事が凄くdocker初学者向けで、人気だったので分かりやすく翻訳してみました。
はじめに
これはDockerコンテナに関する入門チュートリアルです。この記事を読み終わると、ローカルマシン上でDockerを使う方法を知る事が出来ます。
この記事ではPython、Redis、Nginxコンテナを実行します。
今回、この記事の読者は上記の3つの技術の基本概念に精通していると仮定しています。
シェルを使った例を沢山使うので、ターミナルを用意して読み進めて下さい!Dockerとは何か
Dockerとは、ソフトウェアコンテナ内のアプリケーションの開発を自動化する為に作られたオープンソースツールです。
このDockerの概念を理解する一番簡単な方法は、現実世界の運送コンテナと比較することでしょう。
ここでは、あくまで一例として読んでください。昔、運送会社は次のような問題に直面していました。
・どうやって、異なるタイプの品物(食べ物、化学薬品、ガラス製品、レンガなど)を並べて輸送すればいいのか
・同じ車両を使って、どうやって異なるサイズの荷物を運べばいいのかしかし、コンテナを導入した後にこれらの問題を解決する事が出来ました。
レンガはガラスの上に置き、化学製品は食べ物の隣に置き、異なるサイズの荷物はあらかじめ規定されたコンテナに入れ、同じ車両を使って荷物を下ろしたり積んだりする事が出来るようになりました。理解出来たでしょうか?それでは、ソフトウェア開発におけるコンテナに話を戻します。
アプリケーションを開発する際に、ライブラリやWebサーバー、データベースなどの関係を意識してコードを書くと思いますが、実行環境がそれぞれのコンピュータで異なる時にアプリケーションが作動しなくなる経験をした事があるかもしれません。
しかし、この問題はアプリケーションとシステムを分離させることにより解決する事が出来ます。
普通の仮想化とは何が違うのか?
従来は、仮想マシンを使って上記の問題を回避していました。しかし、この仮想マシンの問題は、ホストOS上にある“余分なOS”が数GBの容量を使ってしまう事でした。ほとんどの場合、サーバーはさらに多くのスペースを占有する仮想マシンをホストすることになってしまいます(余談ですが今現在、大半のクラウドサーバーサービスはその余分なスペースの分を請求しています)
また、もう一つの重大な欠点は起動が遅い事です。DockerはホストOSの別々のプロセスとして、OSのカーネルを全てのコンテナをまたいで共有することにより、上記のような問題を全て解決してくれます。
Dockerが唯一のコンテナ化プラットフォームではないですが、現時点では市場で最も大きく、ユーザー数も多いです。
なぜDockerが必要なのか
下記にメリットをまとめておきました。
・開発プロセスの迅速にする事ができる
・アプリケーションを手軽にまとめられる
・local/dev/staging/production環境で同じ動作が可能になる
・簡単で分かりやすい監視が出来る
・拡張が簡単になる開発プロセスの迅速にする事ができる
PostgreSQL, Redis, Elasticsearchのような外部のアプリをシステム上にインストールする必要はありません。コンテナを起動させるだけで実行する事が出来ます!
Dockerを使うことによって、同じアプリの異なるバージョンを同時に実行する事も出来ます。
例えば、PostgreSQLの古いバージョンを新しいバージョンに手動で移行させる必要があるとします。最新の外部のアプリを使った新しいマイクロサービスを作りたい時に、マイクロサービスの設計でこのような状況になることは頻繁にあります。この時、1つのホストOS上で同じアプリの異なるバージョンを同時に実行するのは非常に困難です。しかし、Dockerならこの問題を完璧に解決することが出来ます。Dockerを使えばサービスと外部のアプリをそれぞれ分離した独自の環境を構築出来るからです。
アプリケーションを手軽にまとめられる
Dockerを使えば、アプリケーションを1つのカタマリとして運用することが出来ます。
大半のプログラミング言語、フレームワーク、オペレーションシステムはそれぞれパッケージマネージャを持っています。たとえもしそれぞれのパッケージマネージャでアプリをまとめたとしても、他のシステムでそのアプリを使うのは難しいです。
しかし、Dockerなら異なるホストやクラウドサービスの垣根を越えて、あるフォーマットに統一されたイメージを作ることによって他のシステムでもアプリを使う事が出来ます。
local/dev/staging/production環境で同じ動作が可能になる
どんな技術にもヒューマンファクタがあるため、Dockerはlocal/dev/staging/productionが全て同じ環境であることを保証することは出来ません。
しかし、OSやシステムの依存関係によって起こるエラーの確率をほとんどゼロに減らしてくれます。正しい方法でDocker imageをビルドする事が出来れば、同じOSやシステム上の依存関係を持ったアプリを使う事が出来ます!
*ヒューマンファクタ・・・人間や組織・機械・設備等で構成されるシステムが、安全かつ経済的に動作・運用できるために考慮しなければならない人間側の要因のこと。一言でいえば「人的要因」である。
簡単で分かりやすい監視が出来る
起動しているコンテナのログファイルを読むための統一された方法がDockerにはあります。
どこにログファイルを保存しておくかも覚える必要はなく、外部のログドライバーとモニターを1つの場所にまとめておく事が出来ます。拡張が簡単になる
設計上Dockerは環境変数の設定、TCP/UDPポートを通した通信などの主要な原則に沿って使う事が出来ます。
正しくアプリを完成させればDockerの中だけではなく、色々な所にスケールを広げる事が簡単に出来ます。対応プラットフォーム
DockerのネイティブプラットフォームはLinuxです。これはLinuxカーネルに基づいてDockerが作られているからです。しかし、macOSやWindows上で使う事が出来ます。
Linuxとの唯一の違いはmacOSとWindows上のDockerは小さな仮想マシンにカプセル化されている事ですが、現在では、macOSとWindows上のDockerは本来のDockerと同じくらい使いやすくなっています。インストール
Dockerのインストール方法はここから確認する事が出来ます。
(もしLinuxでDockerを実行しているなら、以下のすべてのコマンドをrootとして実行するか、ユーザーをdockerグループに追加して再ログインする必要があります。)
sudo usermod -aG docker $(whoami)`用語
・コンテナ
必要なソフトウェアをまとめたインスタンスのことです。コンテナはイメージから作られ、他のコンテナや外部と通信するためにポートとボリュームを公開することが出来ます。また、コンテナは簡単に短時間でキルしたり削除したり再構築したりすることが出来ます。
そして、コンテナは状態を保持しません。・イメージ
コンテナの元となる要素のことです。イメージによって構築する時に時間がかかることがあります。一方、コンテナはイメージからすぐに構築する事が出来ます。・ポート
元々の意味ではTCP / UDPポートという意味です。ですが、もっと分かりやすく理解するために、他のコンテナやホストOSから接続可能な外部のネットワークと通信する時に必要なものと考えてください。・ボリューム
Dockerにおける共有フォルダのことです。コンテナを作ると初期化されます。ボリュームはデータを保持しておくために設計されており、コンテナの動作には影響されません。・レジストリ
イメージを保存しているサーバーのことです。Githubと比較すると分かりやすいかもしれません。
ローカルでイメージを使う時にレジストリからイメージをpullしたり、ローカルで作ったイメージをレジストリにpushする事が出来ます。・DockerHub
Docker Inc.が提供するWebインターフェイスを備えたレジストリのことです。様々なソフトウェアを含むDockerイメージを多数保存しています。
Docker Hubは、Dockerチーム、またはオリジナルのソフトウェア製造者と共同で作成された「公式の」Dockerイメージのソースです。
公式のイメージはそれらの潜在的な脆弱性をリストにまとめてあります。このリストはDockerHubにログインしているすべてのユーザーが閲覧する事が出来ます。
無料と有料の両方のアカウントがあります。
パブリックイメージは無制限に持つことができますが、プライベートイメージは1つのアカウントに1つまでです。
Docker Hubと非常によく似たサービスに、Docker Storeもあります。評価、レビューなどが掲載されています。Example 1: hello world
それでは、最初のコンテナを動かしてみましょう!
docker run ubuntu /bin/echo 'Hello world'コンソールの出力結果Unable to find image 'ubuntu:latest' locally latest: Pulling from library/ubuntu 6b98dfc16071: Pull complete 4001a1209541: Pull complete 6319fc68c576: Pull complete b24603670dc3: Pull complete 97f170c87c6f: Pull complete Digest:sha256:5f4bdc3467537cbbe563e80db2c3ec95d548a9145d64453b06939c4592d67b6d Status: Downloaded newer image for ubuntu:latest Hello world・docker runはコンテナを実行するためのコマンドです。
・ubuntuは今実行しているイメージです。たとえば、UbuntuOSのイメージを使う時に、イメージを指定すると、Dockerは最初にDockerホスト上のイメージを探します。イメージがローカルに存在しない場合、そのイメージはパブリックイメージレジストリ=Docker Hubから取得してきます。
・
/bin/echo 'Hello world'は作ったコンテナの中で実行されるコマンドです。このコンテナは単に「Hello world」と表示して実行を停止します。それでは、Dockerコンテナ内でシェルを作ってみましょう!
docker run -i -t --rm ubuntu /bin/bash・
-tは、作成するコンテナ内に疑似的なターミナルを割り当てる設定をしてます・
-iは、コンテナーの標準入力(STDIN)を取得し、双方向の接続をする設定をしてます。・
-rmは、プロセスが終了する時にコンテナを削除する設定をしてます。デフォルトだと、コンテナは削除されません。このrmの設定によって作られたコンテナは、シェルのセッションを維持する間ずっと残りますが、リモートサーバーとのssh通信などのようにセッションが無くなると削除されます。セッション終了後もコンテナを実行し続けたい場合は、デーモン化する必要があります。
docker run --name daemon -d ubuntu /bin/sh -c "while true; do echo hello world; sleep 1; done"・
--name daemonは「daemon」という名前でコンテナに割り当てる設定をしてます。名前を明示的に指定しない場合、Dockerは自動的に名前を生成し割り当てます。・
-dはバックグラウンドでコンテナを実行させる設定をしてます。(つまり、デーモン化です)それでは今どんなコンテナを持っているのか見てみましょう。
docker ps -aコンソールの出力結果CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1fc8cee64ec2 ubuntu "/bin/sh -c 'while..." 32 seconds ago Up 30 seconds daemon c006f1a02edf ubuntu "/bin/echo 'Hello ..." About a minute ago Exited (0) About a minute ago gifted_nobel・
docker psはコンテナをリスト表示するためのコマンドです。・
-aは全てのコンテナは表示させるためのコマンドです。(docker psだけだと起動中のコンテナしかリスト表示されません)
docker psをしてみると、現在2つのコンテナを持っていることが分かります。*
gifted_nobelは、「Hello,World」と出力させた、最初に作ったコンテナです。 (このコンテナの名前は自動的に生成されます。ご自身のコンピュータによって名前は異なります。)*
daemonは、デーモンとして作った3番目のコンテナです。注:2番目のコンテナ(対話型シェルを持つコンテナ)はありません。何故なら、
-rmオプションを設定しているからです。そのため、2番目のコンテナは実行された時に自動的に削除されています。それでは、ログを見てデーモンコンテナが何をしているのか見てみましょう!
docker logs -f daemonコンソールの出力結果... hello world hello world hello world・
docker logを使うとdockerのログを取得することが出来ます。
・-fを使うとログの出力結果を追跡することが出来ます。では、デーモンコンテナを停止してみましょう!
docker stop daemon停止しているかどうか確かめて見てください。
docker ps -aコンソールの出力結果CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1fc8cee64ec2 ubuntu "/bin/sh -c 'while..." 5 minutes ago Exited (137) 5 seconds ago daemon c006f1a02edf ubuntu "/bin/echo 'Hello ..." 6 minutes ago Exited (0) 6 minutes ago gifted_nobelコンテナが停止していますね。もう一度、起動させてみましょう。
docker start daemon起動しているか確かめてみてください。
docker ps -aコンソールの出力結果CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1fc8cee64ec2 ubuntu "/bin/sh -c 'while..." 5 minutes ago Up 3 seconds daemon c006f1a02edf ubuntu "/bin/echo 'Hello ..." 6 minutes ago Exited (0) 7 minutes ago gifted_nobel起動出来ていますね。では、今度はもう一度停止して、手動で消してみましょう!
docker stop daemon docker rm <your first container name> docker rm daemon全てのコンテナを消したい場合は、次のコマンドを使用します。
docker rm -f $(docker ps -aq)・
docker rmはコンテナを削除するためのコマンドです。
・-f $()は実行中のコンテナを停止させてます(つまり、強制的に消すという事です)。
・-q(ps用) はコンテナIDのみを表示させるためのコマンドです。Example 2: 環境変数とボリューム
この例を始める前に、私のGithubレポジトリ から新たなファイルを追加してください。
私のレポジトリをクローンするか、このリンクをクリックしてファイルをダウンロードしてください。
それでは、ここからはNginxのような、もっと難易度の高いコンテナを作っていきましょう!
examples/nginxにカレントディレクトリを切り替えて下さい!
docker run -d --name "test-nginx" -p 8080:80 -v $(pwd):/usr/share/nginx/html:ro nginx:latest・
-pは、HOST PORT(8080)をCONTAINER PORT(80)としてマッピングしてます。・
-vは、HOST DIRECTORY(pwd)をCONTAINER DIRECTORY(/usr/share/nginx/html:ro)にボリュームをマウントさせてます。注:このコマンドは非常にコンピュータに負荷がかかりますが、環境変数とボリュームを説明するためにあえて分かりやすくしています。実際の開発では、こんな風に手動でDockerコンテナをスタートさせたりせずにオーケストレーションサービスを使うか、カスタムスクリプトを書いてスタートさせます。
コンソールの出力結果Unable to find image 'nginx:latest' locally latest: Pulling from library/nginx 683abbb4ea60: Pull complete a470862432e2: Pull complete 977375e58a31: Pull complete Digest: sha256:a65beb8c90a08b22a9ff6a219c2f363e16c477b6d610da28fe9cba37c2c3a2ac Status: Downloaded newer image for nginx:latest afa095a8b81960241ee92ecb9aa689f78d201cff2469895674cec2c2acdcc61c重要:
runコマンドは絶対パスのみ受け付けます。この例では、カレントディレクトリの絶対パスとして$(pwd)を使ってます。また、
/example/nginx/index.html(コンテナの中に/usr/share/nginx/htmlディレクトリとしてマウントされてるファイル)を変更してページを更新することも出来ます。それでは、test-nginxコンテナに関する情報を入手しましょう。
docker inspect test-nginxこのコマンドはDockerのインストールに関するシステム全体の情報を表示します。
この情報には、カーネルのバージョン、コンテナーとイメージの数、公開ポート、マウント済みボリュームなどが含まれます。Example 3: 初めてのDockerfile
DockerイメージをビルドするためにはDockerfileを作る必要があります。Dockerfileとはコンテナなどの説明や実行させたい命令などを書いておくテキストファイルのことです。
今回の例で使う命令の説明はこんな感じです。
FROM:ベースとなるイメージを設定するRUN:コンテナ内でコマンドを実行ENV:環境変数を設定するWORKDIR:作業ディレクトリを設定するVOLUME:ボリュームのマウントする場所を設定するCMD:コンテナを※実行可能コンテナとして設定する※「実行可能コンテナ」とは、他のコンテナのベースイメージとして利用するのではなく、docker runで直接実行することを目的としたコンテナイメージのこと。
詳細はDockerfile referenceで見ることが出来ます。
では、URLを使ってWebサイトの中身を取得するイメージを作り、テキストファイルに保存してみましょう!
『SITE_URL』という環境変数を経由してWebサイトのURLをパスする必要があります。実行結果のファイルはボリュームとしてマウントされて、ディレクトリの中に配置されます。
Dockerfileという名前のファイルを
examples/curlディレクトリの中に配置して、次のような内容を書いてください。DockerfileFROM ubuntu:latest RUN apt-get update \ && apt-get install --no-install-recommends --no-install-suggests -y curl \ && rm -rf /var/lib/apt/lists/* ENV SITE_URL http://example.com/ WORKDIR /data VOLUME /data CMD sh -c "curl -Lk $SITE_URL > /data/results"Dockerfileの準備が出来ました。それでは、実際にイメージをビルドしてみましょう!
examples/curlディレクトリに移動して、次のコマンドを実行してイメージをビルドしてください。docker build . -t test-curlコンソールの出力結果Sending build context to Docker daemon 3.584kB Step 1/6 : FROM ubuntu:latest ---> 113a43faa138 Step 2/6 : RUN apt-get update && apt-get install --no-install-recommends --no-install-suggests -y curl && rm -rf /var/lib/apt/lists/* ---> Running in ccc047efe3c7 Get:1 http://archive.ubuntu.com/ubuntu bionic InRelease [242 kB] Get:2 http://security.ubuntu.com/ubuntu bionic-security InRelease [83.2 kB] ... Removing intermediate container ccc047efe3c7 ---> 8d10d8dd4e2d Step 3/6 : ENV SITE_URL http://example.com/ ---> Running in 7688364ef33f Removing intermediate container 7688364ef33f ---> c71f04bdf39d Step 4/6 : WORKDIR /data Removing intermediate container 96b1b6817779 ---> 1ee38cca19a5 Step 5/6 : VOLUME /data ---> Running in ce2c3f68dbbb Removing intermediate container ce2c3f68dbbb ---> f499e78756be Step 6/6 : CMD sh -c "curl -Lk $SITE_URL > /data/results" ---> Running in 834589c1ac03 Removing intermediate container 834589c1ac03 ---> 4b79e12b5c1d Successfully built 4b79e12b5c1d Successfully tagged test-curl:latest
docker buildはローカルで新しいイメージをビルドしてます。-tはnameタグをイメージに取り付けてます。これで新しいイメージを持つことが出来ました。ここで、今現在持っているイメージを一覧で見てみましょう。
docker imagesコンソールの出力結果REPOSITORY TAG IMAGE ID CREATED SIZE test-curl latest 5ebb2a65d771 37 minutes ago 180 MB nginx latest 6b914bbcb89e 7 days ago 182 MB ubuntu latest 0ef2e08ed3fa 8 days ago 130 MBイメージからコンテナを作ったり、実行させる事が出来ます。デフォルトのパラメータを使ってやってみましょう。
docker run --rm -v $(pwd)/vol:/data/:rw test-curl実行した結果がファイルに保存されたことを確認するには、次のコマンドを実行します。
cat ./vol/resultsFacebook.comで試してみましょう。
docker run --rm -e SITE_URL=https://facebook.com/ -v $(pwd)/vol:/data/:rw test-curl実行した結果がファイルに保存されたことを確認するには、次のコマンドを実行します。
cat ./vol/results効率よくイメージを作るためのbest practice
必要なコンテキストのみを含める :
.dockerignoreファイルを使用する (gitの.gitignoreのように)不要なパッケージをインストールしない :
余分なディスク容量が消費されます。キャッシュを使用する:
Dockerfileの最後に大きな変更を加えるコンテキスト(プロジェクトのソースコードなど)を追加します。Dockerキャッシュを効果的に利用します。ボリュームに注意する:
ボリューム内のデータが何であるかを覚えておく必要があります。ボリュームは永続的であり、コンテナーと共存しないため、次のコンテナーは前のコンテナーによって作成されたボリュームのデータを使用します。環境変数を使用する(RUN、EXPOSE、VOLUMEなど):
Dockerfileを変更しやすくなります。Alpineイメージについて
多くのDockerイメージ(イメージのバージョン)がAlpine Linux上に作成されています。これは容量を分散化させてDockerイメージの全体サイズを縮小するためです。
Redis, Postgresなどのサードパーティサービスには、Alpineベースのイメージを使うことをオススメします。
Appイメージにはbuildpackベースのイメージを使用してください。コンテナ内でデバッグするのが簡単になりますし、システム全体に必要な要素が事前にインストールされてます。どのベースイメージを使用するかを決めるだけではなく、このように1つの基本イメージを使用することによって最大の効果を得ることができます。これは、キャッシュがより効果的に使用されるからです。
Example 4:コンテナ同士を接続してみよう
Docker composeを使っていきます。
Docker composeとはコンテナ同士を接続するためのCLIです。
pip経由でインストールする事が出来ます。sudo pip install docker-compose今回の例では、PythonコンテナとRedisコンテナを接続してみたいと思います。
version: '3.6' services: app: build: context: ./app depends_on: - redis environment: - REDIS_HOST=redis ports: - "5000:5000" redis: image: redis:3.2-alpine volumes: - redis_data:/data volumes: redis_data:example/composeにカレントディレクトリを移動して、次のコマンドを実行してみてください。
docker-compose upコンソールの結果Building app Step 1/9 : FROM python:3.6.3 3.6.3: Pulling from library/python f49cf87b52c1: Pull complete 7b491c575b06: Pull complete b313b08bab3b: Pull complete 51d6678c3f0e: Pull complete 09f35bd58db2: Pull complete 1bda3d37eead: Pull complete 9f47966d4de2: Pull complete 9fd775bfe531: Pull complete Digest: sha256:cdef88d8625cf50ca705b7abfe99e8eb33b889652a9389b017eb46a6d2f1aaf3 Status: Downloaded newer image for python:3.6.3 ---> a8f7167de312 Step 2/9 : ENV BIND_PORT 5000 ---> Running in 3b6fe5ca226d Removing intermediate container 3b6fe5ca226d ---> 0b84340fa920 Step 3/9 : ENV REDIS_HOST localhost ---> Running in a4f9a1d6f541 Removing intermediate container a4f9a1d6f541 ---> ebe63bf5959e Step 4/9 : ENV REDIS_PORT 6379 ---> Running in fd06aa65fd33 Removing intermediate container fd06aa65fd33 ---> 2a581c31ff4f Step 5/9 : COPY ./requirements.txt /requirements.txt ---> 671093a12829 Step 6/9 : RUN pip install -r /requirements.txt ---> Running in b8ea53bc6ba6 Collecting flask==1.0.2 (from -r /requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/7f/e7/08578774ed4536d3242b14dacb4696386634607af824ea997202cd0edb4b/Flask-1.0.2-py2.py3-none-any.whl (91kB) Collecting redis==2.10.6 (from -r /requirements.txt (line 2)) Downloading https://files.pythonhosted.org/packages/3b/f6/7a76333cf0b9251ecf49efff635015171843d9b977e4ffcf59f9c4428052/redis-2.10.6-py2.py3-none-any.whl (64kB) Collecting click>=5.1 (from flask==1.0.2->-r /requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/34/c1/8806f99713ddb993c5366c362b2f908f18269f8d792aff1abfd700775a77/click-6.7-py2.py3-none-any.whl (71kB) Collecting Jinja2>=2.10 (from flask==1.0.2->-r /requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/7f/ff/ae64bacdfc95f27a016a7bed8e8686763ba4d277a78ca76f32659220a731/Jinja2-2.10-py2.py3-none-any.whl (126kB) Collecting itsdangerous>=0.24 (from flask==1.0.2->-r /requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/dc/b4/a60bcdba945c00f6d608d8975131ab3f25b22f2bcfe1dab221165194b2d4/itsdangerous-0.24.tar.gz (46kB) Collecting Werkzeug>=0.14 (from flask==1.0.2->-r /requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/20/c4/12e3e56473e52375aa29c4764e70d1b8f3efa6682bef8d0aae04fe335243/Werkzeug-0.14.1-py2.py3-none-any.whl (322kB) Collecting MarkupSafe>=0.23 (from Jinja2>=2.10->flask==1.0.2->-r /requirements.txt (line 1)) Downloading https://files.pythonhosted.org/packages/4d/de/32d741db316d8fdb7680822dd37001ef7a448255de9699ab4bfcbdf4172b/MarkupSafe-1.0.tar.gz Building wheels for collected packages: itsdangerous, MarkupSafe Running setup.py bdist_wheel for itsdangerous: started Running setup.py bdist_wheel for itsdangerous: finished with status 'done' Stored in directory: /root/.cache/pip/wheels/2c/4a/61/5599631c1554768c6290b08c02c72d7317910374ca602ff1e5 Running setup.py bdist_wheel for MarkupSafe: started Running setup.py bdist_wheel for MarkupSafe: finished with status 'done' Stored in directory: /root/.cache/pip/wheels/33/56/20/ebe49a5c612fffe1c5a632146b16596f9e64676768661e4e46 Successfully built itsdangerous MarkupSafe Installing collected packages: click, MarkupSafe, Jinja2, itsdangerous, Werkzeug, flask, redis Successfully installed Jinja2-2.10 MarkupSafe-1.0 Werkzeug-0.14.1 click-6.7 flask-1.0.2 itsdangerous-0.24 redis-2.10.6 You are using pip version 9.0.1, however version 10.0.1 is available. You should consider upgrading via the 'pip install --upgrade pip' command. Removing intermediate container b8ea53bc6ba6 ---> 3117d3927951 Step 7/9 : COPY ./app.py /app.py ---> 84a82fa91773 Step 8/9 : EXPOSE $BIND_PORT ---> Running in 8e259617b7b5 Removing intermediate container 8e259617b7b5 ---> 55f447f498dd Step 9/9 : CMD [ "python", "/app.py" ] ---> Running in 2ade293ecb25 Removing intermediate container 2ade293ecb25 ---> b85b4246e9f8 Successfully built b85b4246e9f8 Successfully tagged compose_app:latest WARNING: Image for service app was built because it did not already exist. To rebuild this image you must use `docker-compose build` or `docker-compose up --build`. Creating compose_redis_1 ... done Creating compose_app_1 ... done Attaching to compose_redis_1, compose_app_1 redis_1 | 1:C 08 Jul 18:12:21.851 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf redis_1 | _._ redis_1 | _.-``__ ''-._ redis_1 | _.-`` `. `_. ''-._ Redis 3.2.12 (00000000/0) 64 bit redis_1 | .-`` .-```. ```\/ _.,_ ''-._ redis_1 | ( ' , .-` | `, ) Running in standalone mode redis_1 | |`-._`-...-` __...-.``-._|'` _.-'| Port: 6379 redis_1 | | `-._ `._ / _.-' | PID: 1 redis_1 | `-._ `-._ `-./ _.-' _.-' redis_1 | |`-._`-._ `-.__.-' _.-'_.-'| redis_1 | | `-._`-._ _.-'_.-' | http://redis.io redis_1 | `-._ `-._`-.__.-'_.-' _.-' redis_1 | |`-._`-._ `-.__.-' _.-'_.-'| redis_1 | | `-._`-._ _.-'_.-' | redis_1 | `-._ `-._`-.__.-'_.-' _.-' redis_1 | `-._ `-.__.-' _.-' redis_1 | `-._ _.-' redis_1 | `-.__.-' redis_1 | redis_1 | 1:M 08 Jul 18:12:21.852 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. redis_1 | 1:M 08 Jul 18:12:21.852 # Server started, Redis version 3.2.12 redis_1 | 1:M 08 Jul 18:12:21.852 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect. redis_1 | 1:M 08 Jul 18:12:21.852 # WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled. redis_1 | 1:M 08 Jul 18:12:21.852 * The server is now ready to accept connections on port 6379 app_1 | * Serving Flask app "app" (lazy loading) app_1 | * Environment: production app_1 | WARNING: Do not use the development server in a production environment. app_1 | Use a production WSGI server instead. app_1 | * Debug mode: on app_1 | * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) app_1 | * Restarting with stat app_1 | * Debugger is active! app_1 | * Debugger PIN: 170-528-240このリンクをクリックしてブラウザで確認してみてください。
docker-composeの使い方は今回の趣旨とはズレるので、割愛させて頂きます。
最初はDocker Hubのイメージで試してみるのがいいでしょう。もし、自分のイメージを作りたい時は上記に乗せた「効率よくイメージを作るためのbest practice」を参照してみてください。
docker-composeを使うことに関していうと、docker-compose.ymlを書く時になるべく分かりやすい名前をボリュームにつけてください。
これをやるだけで、将来ボリュームを調べる時に様々な問題に苦しまずに済みます。version: '3.6' services: ... redis: image: redis:3.2-alpine volumes: - redis_data:/data volumes: redis_data:この場合、redis_dataは
docker-compose.ymlファイル内で名付けられた名前となります。
最終的なボリューム名は、プロジェクト名を接頭辞につけたものとなります。ボリュームを見てみましょう。
docker volume lsコンソールの結果DRIVER VOLUME NAME local apptest_redis_dataDocker Way
Dockerにはいくつかの制限や必要条件があり、それらはシステム(コンテンの中に入っているアプリ)の構成によって変化します。もちろん、これらの制限を無視したり、一時的に対処したりする事も出来ますが、Dockerの恩恵を100%受ける事が出来なくなってしまいます。
私は下記の条件に従うことを強くオススメします。
1アプリケーション= 1コンテナ
プロセスをフォアグラウンドで実行する(systemd、upstart、その他の類似のツールは使用しないでください)。
データをコンテナに入れずに、ボリュームを使用してください。
SSHを使用しないでください(コンテナーの中に入る必要がある場合は、docker execコマンドを使用できます)。
コンテナの中で手動で設定しないで下さい
最後に
最後にまとめると、DockerはIDEやGitのように開発者にとって必須なツールとなりました。すぐに使えて、豊富なサービスを備えているサービスと言えます。
Dockerは、プロジェクトの規模や複雑さに関係なく、色々な場面で使用できます。はじめにcomposeとSwarmから始めて、プロジェクトが拡大したらAmazon Container ServicesやKubernetesなどのクラウドサービスに移行する事が出来ます。
貨物輸送で使用される実際のコンテナと同様に、コードをDockerコンテナに入れると、より迅速で効率的なCI / CDプロセスを構築するのに役立ちます。
これは、ギーク達によって促進されている単なる技術トレンドではありません。
DockerはPayPal、Visa、Swisscom、General Electric、Splinkなどの大企業で設計時にすでに使用されています!
- 投稿日:2019-05-22T11:34:21+09:00
テキストファイルをいい感じにwekaで使えるarffに変換したい
はじめに
みなさんご存知、機械学習のソフトwekaはarffファイルというweka独自のファイルを使います。
なので、テキストファイルからarffに自動で変換するやつを作りました。arffファイルを作る
import os #実行中のディレクトリの場所 path = os.path.dirname(__file__)+'作りたいarffの名前.arff' #実行中のディレクトリの場所にarffファイルを新規作成 with open(path, 'w') as f1: f1.write('@reration accepted\n\n@attribute 属性の名前1 属性の型\n@attribute 属性の名前2 {属性の要素1,属性の要素2}\n\n@data\n') #テキストファイルを読み込んで fp = open('読みたいテキストファイル', 'r') #for文でテキストファイルを一行ずつ処理 for line in fp.readlines(): #さっき作ったarffに追記 with open(os.path.join(path,filename + '.arff'), 'a') as f1: f1.write('\''+line[:-1]+'\',accepted\n') line = fp.readlines() fp.close()
- 投稿日:2019-05-22T11:10:25+09:00
pythonでcsvの列を別のcsvのリストから検索したい
はじめに
「この列にある文字列を別のファイルの文字列のリストから検索してぇなぁ...」ってときに使うやつです。
Pandasをインストール
いつもどおりインストールしましょう。
pip install pandas
csv読み込み
import pandas as pd df = pd.read_csv('読みたいcsv.csv') df1 = pd.read_csv('読みたいcsv2.csv')変数dfとdf1にcsv入ってるんでdf.関数でcsvいろいろいじれます。
文字列検索
for index, row in df.iterrows(): #dfを1行ごと最後の行までfor文回します for index1, row1 in df1.iterrows(): if row[0]==row1[0]: #dfとdf1の0列の値が同じだったら行う処理 else: #同じじゃなければ。省略可2重for文というかなりアナログな方法使いました。
もっと簡単な関数あるよーって方は教えろください。
ぼくは今回、「ある文字列が一致したらその隣の値を足す」ってのをやりたかったので、
もし、そういうのやりたかったらrow[1]に1列目の値入ってるので使ってください。出力
検索してなんやかんやした結果を出力したいときはwith open()なりprint()などを使ってください。
- 投稿日:2019-05-22T10:46:21+09:00
【Python】オブジェクト指向風にオセロゲームを実装
概要
研修でオセロゲームを作る機会がありコードを書いたので、せっかくなので記事にします。
実装はPythonで行っていますが、頑張ってオブジェクト指向(風)な感じで作りました。
出来上がりはこんな感じです。
コードは、こちらに置いてあります。
コード
プレーヤーを表すクラスと、オセロ盤を表すクラスを作り、メインの関数内でそれらのインスタンスを作成し、ゲームを進めていきます。
Player
プレーヤーは自身の名前、コマを表す記号、自身のコマの総数を持ち、それらのgetterとsetterを用意します。
get_user_move関数で、ユーザの入力を受け付けます。Player.pyclass Player: def __init__(self, symbol, name): """ コンストラクタ """ # コマを表す記号 self.symbol = symbol # プレーヤーの名前 self.name = name # コマの総数 self.total_count = 0 def get_users_move(self): """ 入力を受け付ける """ print("\n%sのターンです (記号:%s)\n" % (self.name, self.symbol)) user_move = input("入力箇所を半角スペース区切りで指定してください(例:1 2) >> ") return user_moveBoard
オセロ盤を表すクラスです。
construct_board_str関数で、ボードの状況を文字列で作成します。
↓こんな感じのやつ0 1 2 3 4 5 6 7 0 • • • • • • • • 1 • • • • • • • • 2 • • • • • • • • 3 • • • o + • • • 4 • • • + o + • • 5 • • • • • o • • 6 • • • • • • • • 7 • • • • • • • •以下がコードです。
Board.pyclass Board: def __init__(self, player1_symbol, player2_symbol): """ コンストラクタ """ self.cells = [] self.blank_symbol = "•" # セルを初期化 for i in range(8): self.cells.append([self.blank_symbol for j in range(8)]) # 最初のコマをセット self.cells[3][4] = player1_symbol self.cells[4][3] = player1_symbol self.cells[3][3] = player2_symbol self.cells[4][4] = player2_symbol def construct_board_str(self): """ ボードの状況を表す文字列を作成 """ result_str = " 0 1 2 3 4 5 6 7\n" count = 0 for y in self.cells: result_str += str(count) for x in y: result_str += " " + x result_str += "\n" count += 1 return result_strGame
ゲーム自体を表すクラスです。
move関数でゲームを進めます。
search_reversible_cells関数で、ひっくり返すことのできるコマの位置のリストを取得します(個数が0である場合、「そのセルにはコマはおけません」とユーザに知らせます)。
is_next_player_movable関数で、次のプレーヤーがコマを置くことができるかチェックします(もし置くことができない場合、次のプレーヤーは自動的にパスをすることとなります)。Game.pyclass Game: def __init__(self,board,player_one,player_two): """ コンストラクタ """ # ゲーム盤クラスのインスタンス self.board = board # プレーヤークラスのインスタンス self.player_one = player_one self.player_two = player_two # ゲームが何ターン目かを保持 self.counter = 1 # このターンにプレーヤーがコマを置けるかどうか self.movable = True def move(self): """ ゲームを1ターン進める """ # どちらのプレーヤーのターンであるかを判断 current_player = self.player_one if self.counter % 2 == 1 else self.player_two if self.movable is False: # プレーヤーがコマを置けない場合 print("\n%sはコマを置けません。パスをします。\n" % current_player.name) self.movable = True return True, self.board.construct_board_str() # ユーザが不正でない値を入力するまで処理を繰り返す input_valid = False while (input_valid is False): users_move = current_player.get_users_move() if users_move == "quit": # 'quit'と入力されたら、ゲームをやめる sys.exit() if self.validate_input(users_move): # 実際にコマを配置する(配置できないことが判明した場合、入力をやり直させる) point_y = int(users_move[0]) point_x = int(users_move[2]) reverse_points = self.search_reverse_cells(point_y,point_x,current_player) if len(reverse_points) > 0: input_valid = True else: print("そのセルにはコマは置けません") # 実際にコマをひっくり返す for cell in reverse_points: self.board.cells[cell["Y"]][cell["X"]] = current_player.symbol self.board.cells[point_y][point_x] = current_player.symbol # ボードの状況を表す文字列を作成 board_str = self.board.construct_board_str() # コマ数のカウント p1_count = 0 p2_count = 0 for y in self.board.cells: for x in y: if x == self.player_one.symbol: p1_count += 1 self.player_one.total_count = p1_count for y in self.board.cells: for x in y: if x == self.player_two.symbol: p2_count += 1 self.player_two.total_count = p2_count # ゲーム終了かどうか if self.player_one.total_count + self.player_two.total_count < 64: # ゲームがまだ続く場合 # 次のターンに相手がコマを置けるかどうか調査 next_player = self.player_one if current_player == self.player_two else self.player_one self.movable = self.is_next_player_movable(next_player) # ターンのカウントを一つ進める self.counter += 1 return True, board_str else: return False, board_str def validate_input(self, user_input): """ ユーザの入力値が不正でないかを確認する """ # 入力値が短すぎる場合 if len(user_input) < 3: print("入力値が短すぎます") return False # 半角スペース区切りでない場合 if user_input[1] != " ": print("半角スペースで区切った数値二つを入力してください") return False # 数値以外のものが入力された場合 try: int(user_input[0]) int(user_input[2]) except ValueError: print("整数を入力してください") return False # 数値が大きすぎ/小さすぎでないかを確認 try: self.board.cells[int(user_input[0])][int(user_input[2])] except IndexError: print("数値が不正です") return False # すでにセルにコマが置いてある場合 if self.board.cells[int(user_input[0])][int(user_input[2])] is not self.board.blank_symbol: print("すでにコマが置いてあります") return False # 入力値は正常だと判断 return True def search_reverse_cells(self, y, x, player): """ ひっくり返すべきコマのリストを返す Args: y(int): コマの配置セルのy座標 x(int): コマの配置セルのx座標 player(Player): 現在ターン中のプレーヤー Returns: Object: ひっくり返すべきコマの位置情報 """ # ひっくり返せるコマがあるか調べる方向を保持 dir_y = [0,1,1,1,0,-1,-1,-1] dir_x = [1,1,0,-1,-1,-1,0,1] # 探索中の座標 cursor_position = {"X":x,"Y":y} # ひっくり返したコマの位置情報(ループごとに初期化) reversed_points = [] # 最終的に、ひっくり返すコマの位置情報 confirmed_reverse_points = [] # 8方向全てを調べる for cursor_y, cursor_x in zip(dir_y,dir_x): # 初期化 reversed_points = [] cursor_position = {"X":x,"Y":y} while (True): # カーソルを進める cursor_position["Y"] += cursor_y cursor_position["X"] += cursor_x # カーソルがボードの枠を超えていれば、調査をやめる if cursor_position["Y"] >= len(self.board.cells) or cursor_position["X"] >= len(self.board.cells[cursor_position["Y"]]): break if self.board.cells[cursor_position["Y"]][cursor_position["X"]] is player.symbol: # カーソルの位置が自身のコマであった場合 # これまでにひっくり返したコマがない場合は、調査をやめる if len(reversed_points) < 1: break else: # ひっくり返す場合 for p in reversed_points: confirmed_reverse_points.append(p) break elif self.board.cells[cursor_position["Y"]][cursor_position["X"]] is self.board.blank_symbol: # カーソルの位置が空欄であった場合 break else: # カーソルの位置が相手のコマであった場合 reversed_points.append({"Y":cursor_position["Y"],"X":cursor_position["X"]}) return confirmed_reverse_points def is_next_player_movable(self,player): """ 次のプレーヤーがコマを置けるかどうかを判断 """ y_count = 0 for y in self.board.cells: x_count = 0 for x in y: if x is self.board.blank_symbol: # 空白セルすべてを、コマが置けるかどうか判断 movable_cells = self.search_reverse_cells(y_count,x_count,player) if len(movable_cells) > 0: # ひっくり返せるコマが一つでもある場合、Trueを返す return True x_count += 1 y_count += 1 # 次のプレーヤーがコマを置けない場合 return Falseメイン部分
上記のクラスのインスタンスを作成し、ゲームを進めていきます。
必要に応じて、いろいろな情報を出力します。
othello.pydef main(): """ メインの関数 Args: None Returns: None """ print("\nオセロゲームのスタート\n") # 各インスタンスの作成 p1 = Player("+", "プレーヤー1") p2 = Player("o", "プレーヤー2") board = Board(p1.symbol,p2.symbol) game = Game(board,p1,p2) print(board.construct_board_str()) # ゲームを続けるべきかどうかを保持 should_continue = True while (should_continue): should_continue, board_situation = game.move() print("\n" + board_situation) print("%sのコマ数:%d" % (p1.name,p1.total_count)) print("%sのコマ数:%d" % (p2.name,p2.total_count)) print("ゲーム終了") winner = p1.name + "の勝ち" if p1.total_count > p2.total_count else p2.name + "の勝ち" if p2.total_count > p1.total_count else "引き分け" print("結果:%s " % winner) if __name__ == "__main__": main()

- 投稿日:2019-05-22T08:16:46+09:00
python scheduleライブラリでimport errorになる時に確認すること
schedule ライブラリでimport errorになる時に確認すること
scheduleはpythonで関数を定期実行する際に活躍する便利なライブラリです。
しかし、下のようなエラーが発生することがあります。
AttributeError: module 'schedule' has no attribute 'every'確認すること
scheduleがインストールできている確認する。
pip freezepythonファイルが
schedule.pyになっていない事を確認する。
python ファイルが
schedule.pyになっているとimoprtエラーが起こるみたい。
参考:https://github.com/dbader/schedule/issues/37

- 投稿日:2019-05-22T06:08:51+09:00
aliyun-python-sdkを利用して、イメージからインスタンスを作成する #Python #Image #サーバ作成
はじめに
作成したサービスを市場に公開するために、クラウドサーバを利用することが当たり前になっています。
個人的には、AWS・GCPと触れて、世界トップ3のIaaSプロバイダーであることから
「AlibabaCloud」
を見ていました。お恥ずかしながら、調査するまでは、結構軽視していましたが、
サーバ・データベース・ドメインなど、展開はされており、
AWSやGCPと遜色なく使えているので、クラウドサーバの選択肢として持っても良いです。そこで、イメージからインスタンスを作成することをAPIから作成してみました。
ちなみに内容みたことあると思った人は、1年前ぐらいに書いたものをQiitaに転機したものになります。
実行環境
- CentOS 6.8
- Python 2.7 → v3あることあとで気づきました
実行準備
$ pip install aliyun-python-sdk-core $ pip install aliyun-python-sdk-ecs →必要なライブラリをインストール $ pip install logging $ pip install retry $ pip install argparse実行
実行内容
事前に
Imageを作成して、インスタンスを作成する。
ミニマムのサーバリソースで同じセキュリティグループで同じサーバ名で作成していきたかったため、利用しました。
もちろん、UIでインスタンス数指定してもちろん複数構築は可能です。
ただ、また増設するときに必要になるので、書きました。
あと、オートスケーリングすれば。。。との話は置いておきます。ソースコード
# -*- coding: utf8 -*- #!/usr/bin/env python import json import argparse from retry import retry from aliyunsdkcore.client import AcsClient from aliyunsdkcore.acs_exception.exceptions import ClientException from aliyunsdkcore.acs_exception.exceptions import ServerException from aliyunsdkecs.request.v20140526 import CreateInstanceRequest def acs_client(api_key, api_access_key): return AcsClient( api_key, api_access_key, region_id ); @retry(tries=4, delay=5, backoff=2) def request_cli(req): status, headers, body = clt.implementation_of_do_action(req) print('[ status: ' + str(status) + ' ] [ headers: ' + str(headers) + ' ] [ body: ' + str(body) + ' ]') if status != 200: raise('[ status: ' + str(status) + ' ] [ headers: ' + str(headers) + ' ] [ body: ' + str(body) + ' ]') json_body = json.loads(body) return status, json_body def create_instance(): req = CreateInstanceRequest.CreateInstanceRequest() req.set_accept_format('json') req.add_query_param('RegionId', region_id) req.add_query_param('ImageId', image_id) req.add_query_param('InstanceType', 'ecs.t5-lc2m1.nano') req.add_query_param('SecurityGroupId', '[security_group_id]') req.add_query_param('InstanceName', '[instance_name]') req.add_query_param('InternetMaxBandwidthIn', '50') req.add_query_param('InternetMaxBandwidthOut', '50') req.add_query_param('VSwitchId', '[vswitch_id]') req.add_query_param('SystemDisk.Size', '20') req.add_query_param('KeyPairName', '[key_pair_name]') status, body = request_cli(req) def main(): init_logger() create_instance() def init_args(): parser = argparse.ArgumentParser( prog='aliyun_sample', usage='python aliyun_sample.py --region [ap-northeast-1] --key [api key] --access [api access key] --image [image id], description='description', epilog='end', add_help=True ) parser.add_argument("-r", "--region", help="please set region id", type=str, default='ap-northeast-1') parser.add_argument("-k", "--key", help="please set api key", type=str, required=True) parser.add_argument("-a", "--access", help="please set api access key", type=str, required=True) parser.add_argument("-i", "--image", help="please set image id", type=str, required=True) return parser.parse_args() if __name__ == '__main__': args = init_args() region_id = args.region image_id = args.image clt = acs_client(args.key, args.access) main()コマンド
$ python aliyun_sample.py --region [ap-northeast-1] --key [api key] --access [api access key] --image [image id]やってみたことまとめ
- OpenAPI Explorerがあり、プログラムは相当簡単にかけます。
- APIへリクエストが叩けない時があるので、リトライ処理入れる方が良い。(お決まり?)
- OpenAPI Explorer に記されている
do_actionでリクエスト送るより、ServerExceptionの処理があるdo_action_with_exceptionをリクエストを送る方が良い。- 自分でStatus拾って実行考えたい場合は、
do_action_with_exceptionではなくget_responseかimplementation_of_do_actionで実行する。採用
- 投稿日:2019-05-22T03:42:17+09:00
速度分布関数についてsympyで計算し可視化するまで
はじめに
大学院の講義で出た課題で計算した結果をグラフにまとめる必要がありました.
せっかくなので手計算ではなくpythonのライブラリであるsympyで計算させ, 続けてmatplotlibで可視化することにしました.やること
陽子の速度分布関数をプロットし, 特徴的な物理量をマークする.
sympy(微分・積分の計算)
- 3次元速度分布関数を変数空間全体で積分し1に規格化する.
- 規格化した速度分布関数に速度を掛けて積分することで平均速度$\bar{v}$をだす.
- 同様のやり方で根二乗平均速度$\sqrt{\bar{v^2}}$をだす.
- 微分して速度分布関数がピークをとるときの速度をだす.
matplotlib(可視化)
- 規格化した速度分布関数をプロットする.
- 平均速度, 根二乗平均速度, ピーク時の速度の部分に印をつける.
背景
3次元速度分布関数$f(v)$は以下のように表されます。
$$
f(v) = 4\pi Cv^2\exp(-mv^2/2k_\mathrm{B}T)
$$
ここで$v$は速さ, $m$は質量, $k_\mathrm{B}$はボルツマン定数, $T$は温度, $C$は規格化定数です.
$C$は注目したい物理量によって規格化し, 速度分布関数から密度の分布を得たい場合は,
$$
\int^\infty_0 f(v)\mathrm{d}v=n
$$
となり, 確率を得たい場合は1に規格化します. (確率密度関数になる)
$$
\int^\infty_0f(v)\mathrm{d}v=1
$$
ここでは1に規格化することとすれば平均速度$\bar{v}$, 根二乗平均速度$\sqrt{\bar{v^2}}$, ピークをとる速度$v_\mathrm{p}$は以下の式を解くことで得ることができます.
$$
\bar{v}=\int^\infty_0vf(v)\mathrm{d}v
$$
$$
\sqrt{\bar{v^2}}=\sqrt{\int^\infty_0v^2f(v)\mathrm{d}v}
$$
$$
\left.\frac{\mathrm{d}f}{\mathrm{d}v}\right|_{v=v_p}=0
$$
そこで, 以上の計算を手計算ではなくsympyを使って計算していきます.やってみる
インポート
matplotlibとnumpyとsympyをインポートします
import numpy as np import matplotlib.pyplot as plt import matplotlib as mp import sympy as sm plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' plt.rcParams['xtick.major.width'] = 1.2 plt.rcParams['ytick.major.width'] = 1.2 plt.rcParams['axes.linewidth'] = 1.2 plt.rcParams['axes.grid']=True plt.rcParams['grid.linestyle']='--' plt.rcParams['grid.linewidth'] = 0.3 plt.rcParams["font.size"] = 14 plt.rc('text', usetex=True)定義
速度分布関数をsympyで扱うため, シンボルを定義します.
k = 1.38064852E-23 # ボルツマン定数 m = 1.67262190E-27 # 陽子の質量(kg) T = 1000000 # 温度(K) a = m/(2*k*T) # 簡単化のための係数 # 変数の定義 v = sm.Symbol('v') f = sm.Function('f') F = sm.Function('F') C = sm.Symbol('C') # 速度分布関数(三次元) f = 4*C*sm.pi*v**2*sm.exp(-v**2*a)この時点で$f$を表示させると以下のようになります.
$$
f(v) = \displaystyle 4 \pi C v^{2} e^{- 6.05737765901491 \cdot 10^{-11} v^{2}}
$$規格化
次にこの速度分布関数を規格化します.
sm.integrate(f, (v, 0, sm.S.Infinity))この結果はこのようになります.
$$
\int^\infty_0f(v)\mathrm{d}v=\displaystyle 5.82306221790302 \cdot 10^{-35} \pi^{\frac{3}{2}} C
$$
1に規格化するため, (右辺)=1すなわち, (右辺)-1=0を$v$について解きます.sm.solve(sm.integrate(f, (v, 0, sm.S.Infinity))-1)[0])結果はタプルで返ってきます.
[8.46646598960099e-17]
この値を$C$に代入し, $f$を規格化します.F = f.subs([(C,sm.solve(sm.integrate(f, (v, 0, sm.S.Infinity))-1)[0])])規格化定数$C$に具体的な数字を代入した$f$は以下のようになります.
$$
F(v)=\displaystyle 3.38658639584039 \cdot 10^{-16} \pi v^{2} e^{- 6.05737765901491 \cdot 10^{-11} v^{2}}
$$
この$F$について色々みていこうと思います.諸物理量
平均速度
$vF$を積分すると平均速度$\bar{v}$を出すことができます.
vmean = sm.integrate(v*F,(v, 0, sm.S.Infinity))$$
\bar{v}=\displaystyle 46149.0601591185 \pi=144981.5483659602
$$
100万度下において、陽子の平均速度はおよそ144 km/sだということがわかります.根二乗平均
$v^2F$を積分し平方根を出すと根二乗平均速度$\sqrt{\bar{v^2}}$を出すことができます.
vsquare = sm.sqrt(sm.integrate(v**2*F,(v, 0, sm.S.Infinity)))$$
\sqrt{\bar{v^2}}=\displaystyle 66686.9568088195 \pi^{\frac{3}{4}}=157363.24542811327
$$ピーク時の速度
$F$を$v$について微分し0となる時の$v$を求めます.
F.diff().doit() # 微分を実行$$
\displaystyle - 4.10276655489749 \cdot 10^{-26} \pi v^{3} e^{- 6.05737765901491 \cdot 10^{-11} v^{2}} + 6.77317279168079 \cdot 10^{-16} \pi v e^{- 6.05737765901491 \cdot 10^{-11} v^{2}}
$$以下のようにすると, $F$が極値をとる時の$v$が得られます.
sm.solve(F.diff().doit()) vpeak = sm.solve(F.diff().doit())[2][-128486.551855745, 0.0, 128486.551855745]
ただし, $v>0$のところしか意味を持たないので, 3番目をピークをとる速度として採用します.可視化
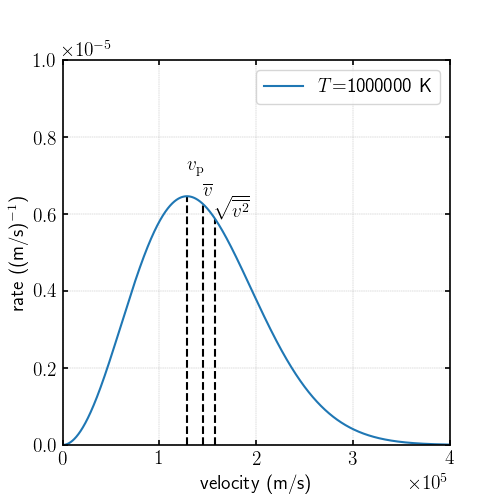
sympyにもプロットする機能(matplotlibをラッパーしているらしい)がありますが扱いにくいので, matplotlibに直接プロットしたいデータを投げたいと思います.
このまま$F$を投げてもプロットできないのでnumpyで扱える形(=ラムダ式)にしてやります.Flam = sm.lambdify(v,F,'numpy')このFlamにはnumpyの配列を入れることができます.
次のようにプロットしますxlim = 400000 ylim = 1E-5 Flam = sm.lambdify(v,F,'numpy') fig = plt.figure(figsize=(5,5)) ax = fig.add_subplot(111) x = np.linspace(0,xlim,10000) ax.plot(x, Flam(x), label='$T$=%d K' % T) ax.legend() ax.set_xlim(0,xlim) ax.set_ylim(0,ylim) ax.set_xlabel('velocity (m/s)') ax.set_ylabel('rate ((m/s)${}^{-1}$)') ax.xaxis.set_ticks_position('both') ax.yaxis.set_ticks_position('both') ax.xaxis.set_major_formatter(mp.ticker.ScalarFormatter(useMathText=False)) ax.yaxis.set_major_formatter(mp.ticker.ScalarFormatter(useMathText=False)) ax.ticklabel_format(style="sci", axis="x", scilimits=(0,0)) ax.ticklabel_format(style="sci", axis="y", scilimits=(0,0)) ax.vlines(vpeak,0, Flam(float(vpeak)), linestyles='dashed') ax.vlines(vmean,0, Flam(float(vmean)), linestyles='dashed') ax.vlines(float(vsquare),0, Flam(float(vsquare)), linestyles='dashed') ax.text(vpeak,1.2*Flam(float(vsquare)),"$v_\mathrm{p}$") ax.text(vmean,1.1*Flam(float(vsquare)),"$\overline{v}$") ax.text(float(vsquare),1*Flam(float(vsquare)),"$\sqrt{\overline{v^2}}$") fig.savefig('hoge.png')可視化するとこのようになります.
全コード
import numpy as np import matplotlib.pyplot as plt import matplotlib as mp import sympy as sm # プロットの全体設定 plt.rcParams['xtick.direction'] = 'in' plt.rcParams['ytick.direction'] = 'in' plt.rcParams['xtick.major.width'] = 1.2 plt.rcParams['ytick.major.width'] = 1.2 plt.rcParams['axes.linewidth'] = 1.2 plt.rcParams['axes.grid']=True plt.rcParams['grid.linestyle']='--' plt.rcParams['grid.linewidth'] = 0.3 plt.rcParams["font.size"] = 14 plt.rc('text', usetex=True) k = 1.38064852E-23 # ボルツマン定数 m = 1.67262190E-27 # 陽子の質量(kg) T = 1000000 # 温度(K) a = m/(2*k*T) # 簡単化のための係数 # 変数の定義 v = sm.Symbol('v') f = sm.Function('f') F = sm.Function('F') C = sm.Symbol('C') # 速度分布関数(三次元) f = 4*C*sm.pi*v**2*sm.exp(-v**2*a) F = f.subs([(C,sm.solve(sm.integrate(f, (v, 0, sm.S.Infinity))-1)[0])]) vmean = float(sm.integrate(v*F,(v, 0, sm.S.Infinity))) vsquare = float(sm.sqrt(sm.integrate(v**2*F,(v, 0, sm.S.Infinity)))) vpeak = sm.solve(F.diff().doit())[2] xlim = 400000 ylim = 1E-5 Flam = sm.lambdify(v,F,'numpy') fig = plt.figure(figsize=(5,5)) ax = fig.add_subplot(111) x = np.linspace(0,xlim,10000) ax.plot(x, Flam(x), label='$T$=%d K' % T) ax.legend() ax.set_xlim(0,xlim) ax.set_ylim(0,ylim) ax.set_xlabel('velocity (m/s)') ax.set_ylabel('rate ((m/s)${}^{-1}$)') ax.xaxis.set_ticks_position('both') ax.yaxis.set_ticks_position('both') ax.xaxis.set_major_formatter(mp.ticker.ScalarFormatter(useMathText=False)) ax.yaxis.set_major_formatter(mp.ticker.ScalarFormatter(useMathText=False)) ax.ticklabel_format(style="sci", axis="x", scilimits=(0,0)) ax.ticklabel_format(style="sci", axis="y", scilimits=(0,0)) ax.vlines(vpeak,0, Flam(float(vpeak)), linestyles='dashed') ax.vlines(vmean,0, Flam(float(vmean)), linestyles='dashed') ax.vlines(float(vsquare),0, Flam(float(vsquare)), linestyles='dashed') ax.text(vpeak,1.2*Flam(float(vsquare)),"$v_\mathrm{p}$") ax.text(vmean,1.1*Flam(float(vsquare)),"$\overline{v}$") ax.text(float(vsquare),1*Flam(float(vsquare)),"$\sqrt{\overline{v^2}}$") fig.savefig('hoge.png')最後に
sympyは文字式を計算できるのでとても便利です!
- 投稿日:2019-05-22T01:31:39+09:00
子音を保ったまま音声の無音区間を削除する
無音区間が邪魔だから削除したい
DNNに音声データを与えるにあたって無音区間は大敵なようです。特に今私が取り組んでいるリアルタイム音声変換では邪魔です。なのでそれを取り除きます。
修正記録
5/22: コードを、median/2以下を削除するものからmaxが定数以下のところを削除する方法に変更。こちらのほうがブレが少なかった。
方法
無音区間の削除自体はpydubだとpydub.silence.split_on_silence、librosaだとlibrosa.effects.splitを使えばできます。
しかしこれらの手法は
- db単位で無音区間を定義するため、子音まで削除されてしまう
- まとめてFTなどするときに誤差部分も考慮されて変換されてしまう
といった問題点があります。どちらもできる限り避けたいです。
なので私は先に離散コサイン変換 -> そのまま無音区間削除といった形をとりました。
コード
sound = np.array(sound.get_array_of_samples()).astype('f') sound = sound[:2 ** 18].reshape((-1, 2 ** 9)) convert = dct(sound, norm='ortho') abs_c = np.abs(convert)[:, :comp//2] where = np.where(np.max(abs_c, axis=1) < 512)[0] convert = np.delete(convert, where, axis=0)
離散コサイン変換したものを絶対値にして足し合わせます。無音は基本的に低周波の方にエネルギーを持たないので省けます。
256までを使っているのは、子音は低周波にエネルギーを持たないからです。32など、もっと低い数値でしてしまうと普通の手法と同様に子音が消えてしまいます。
中央値を2で割っているのはそのままでは消えすぎ感があったからです。もうちょっと工夫の余地があるかも。前の方法だと状況に左右されすぎていたのでもっと単純にmaxで考えることにしました。これだと声が小さいデータの場合ほとんど残らなくなってしまうので、そこそこのボリュームで録音する必要があります。
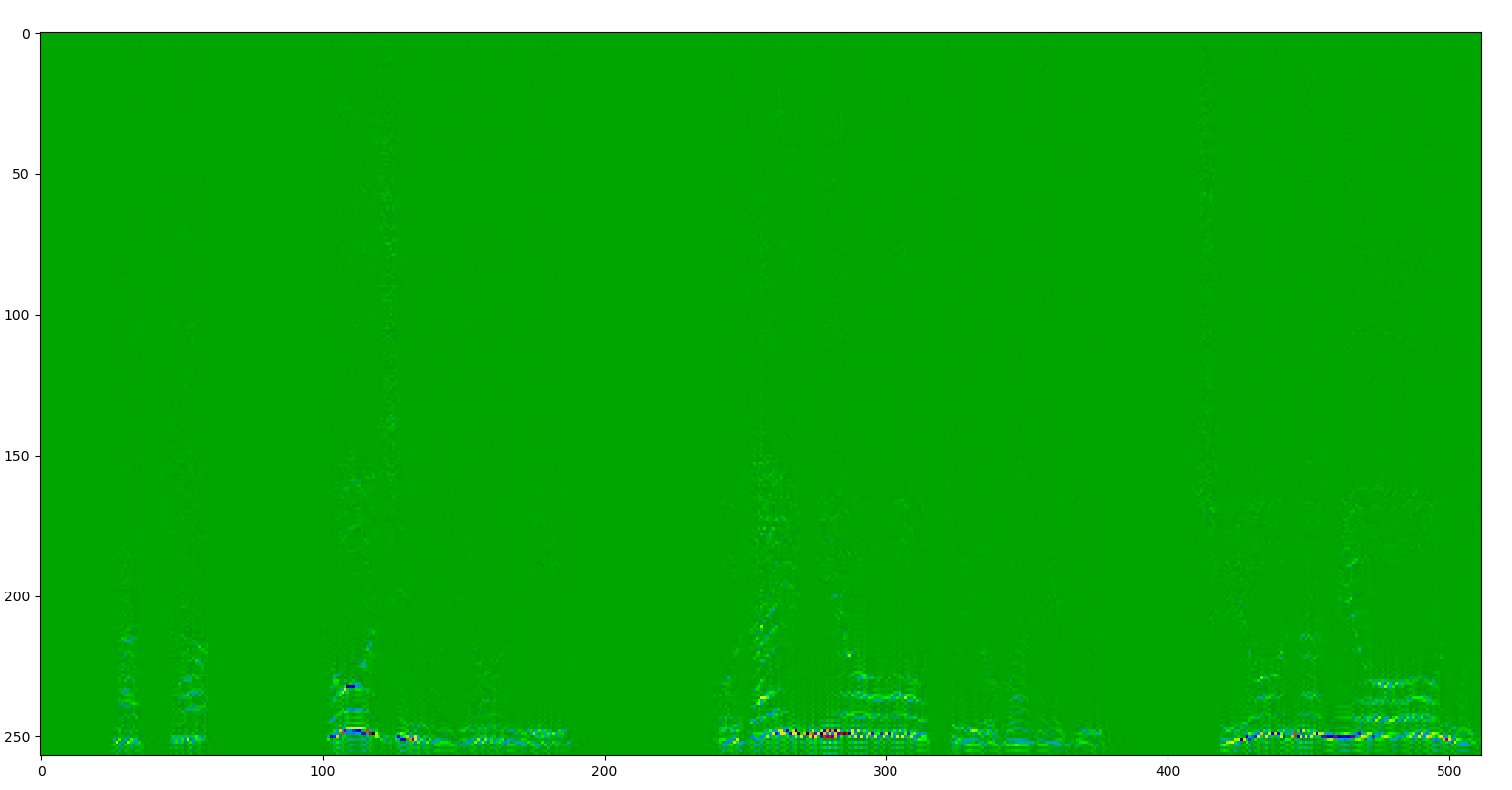
結果
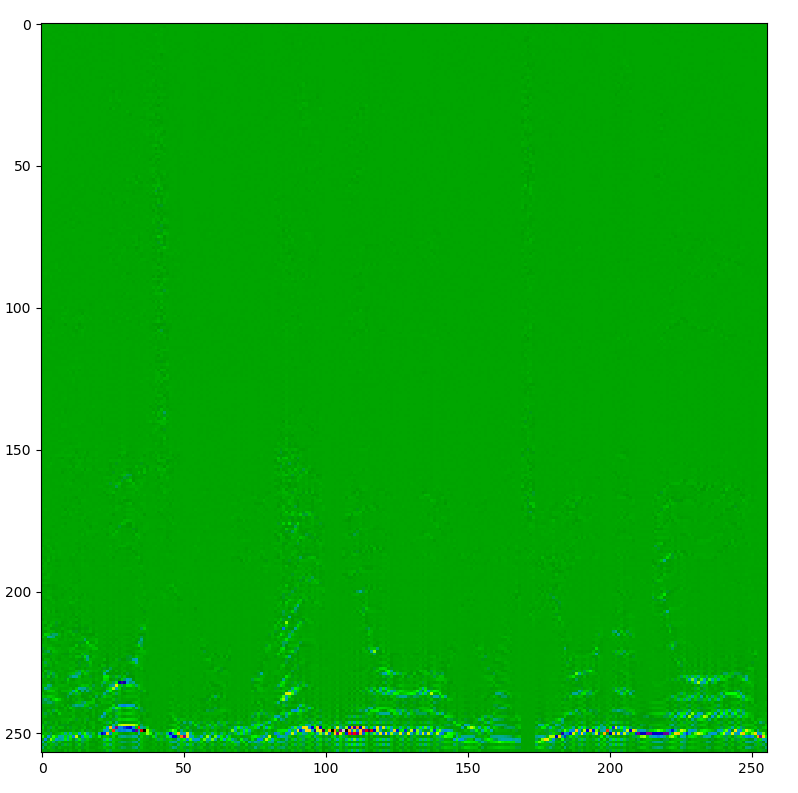
スペクトルを載せときます。
before
after
(高周波帯は出力していません)
しっかり削除されているのがわかります。音をチェックしても消えすぎずちょうどいい具合でした。もっと普遍的な感じのやり方があればいいなあ
- 投稿日:2019-05-22T00:25:41+09:00
HerokuとPython3.6で近場の居酒屋を検索してくれるLineBotを作成した。
背景
社会人になると同期たちがよく飲みに行っていたので2次会の店を決定するために作成しました。
飲み屋に迷ったときなどに使ってもらえると嬉しいです。QRコード
環境
Python3.6
Flask
Heroku食べログAPI
LineBot_SDK※本記事ではLineBotそのものの作り方や、Herokuへのデプロイの仕方は割愛させていただきます。
また、Herokuの無料枠を使用しているのでレスポンスが悪い場合がありますがご了承ください。位置情報から居酒屋を検索する
適宜ぐるナビAPIからアクセスキーを取得します。
その後、緯度と軽度から居酒屋を検索できるようにします。latとlon以外のパラメータで日本国内の居酒屋を検索するようにしています。
また、defaultでは5件までの検索ですがhit_per_pageの値を変更することで変更することができます。また、取得したデータをリストに格納しています。
""" 緯度(latitude),軽度(longitude)を引数に取ります """ def rest_search(lat,lon): URL = "https://api.gnavi.co.jp/RestSearchAPI/v3/" api_params = { "keyid":"ACCESS_KEY", "category_s":"RSFST09004", "latitude":lat, "longitude":lon, "range":3, "hit_per_page":5 } rest = requests.get(URL,params = api_params).json()["rest"] json_datas = [data for data in rest] return json_datasLineBotの設定
基本的にはLineBotSDKのサンプルプログラムを少し弄っただけです。
app.pyimport os import sys from flask import Flask, request, abort import requests from linebot import LineBotApi, WebhookHandler from linebot.exceptions import InvalidSignatureError from linebot.models import * from carousel import create_carousel,rest_search app = Flask(__name__) channel_secret = os.environ['YOUR_CHANNEL_SECRET'] channel_access_token = os.environ['YOUR_CHANNEL_ACCESS_TOKEN'] if channel_secret is None: print('Specify LINE_CHANNEL_SECRET as environment variable.') sys.exit(1) if channel_access_token is None: print('Specify LINE_CHANNEL_ACCESS_TOKEN as environment variable.') sys.exit(1) line_bot_api = LineBotApi(channel_access_token) handler = WebhookHandler(channel_secret) @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): line_bot_api.reply_message( event.reply_token, TextSendMessage(text="住所をおくってね!") ) @handler.add(MessageEvent, message=LocationMessage) def handle_location(event): lat = event.message.latitude lon = event.message.longitude rest_datas = rest_search(lat,lon) template_message = TemplateSendMessage(alt_text='周辺の居酒屋だよ!', template=create_carousel(rest_datas)) line_bot_api.reply_message(event.reply_token, template_message) if __name__ == "__main__": app.run()carousel の中身はこんな感じです。
carousel.pyfrom linebot.models import ( CarouselTemplate, CarouselColumn,URITemplateAction) import requests def create_carousel(rest_colum): carousel_template = CarouselTemplate( columns=[ CarouselColumn( text=rest["name"], actions=[ URITemplateAction( label="開く", uri=rest["url_mobile"] )] ) for rest in rest_colum ]) return carousel_template def rest_search(lat,lon): URL = "https://api.gnavi.co.jp/RestSearchAPI/v3/" api_params = { "keyid":"ACCESS_KEY", "category_s":"RSFST09004", "latitude":lat, "longitude":lon, "range":3, "hit_per_page":5 } rest = requests.get(URL,params = api_params).json()["rest"] json_datas = [data for data in rest] return json_datas結果
作成したLineBotをHerokuにデプロイし実際に使用してみます。
写真が無いので少しリッチ感にかけますがうまく表示することができました!
ぐるナビAPIが返してくるデータの中に写真用のURLがあるのですが登録していないお店のほうが多いのでどうやって写真を添付するか悩み中です。

- 投稿日:2019-05-22T00:00:25+09:00
英数字の判定 python
isalnum()
このメソッドは、文字列中ののすべての文字が英数字(a-z, A-Z, 0-9)かどうかを判定する。
全角文字も判定します
>>> print('ab123'.isalnum()) True >>> print('ab123#'.isalnum()) Falseisalpha()
このメソッドは、文字列中のすべての文字が英字(a-z, A-Z)かどうかを判定する。
全角文字も判定します
>>> print('abcD'.isalpha()) True >>> print('abcd1'.isalpha()) Falseisdigit()
このメソッドは、文字列中のすべての文字が数字(0-9)かどうか判定する。
全角文字も判定します
>>> print('1234'.isdigit()) True >>> print('123edsd'.isdigit()) Falseislower()
このメソッドは、文字列中のすべての文字が小文字の英字(a-z)かどうか判定する。
全角文字も判定します
小文字+大文字小文字の区別の無い文字だけで構成された文字列にも True を返します。>>> print 'abcd123#'.islower() True >>> print 'Abcd123#'.islower() Falseisupper()
このメソッドは、文字列中のすべての文字が大文字の英字(A-Z)かどうか判定する。
全角文字も判定します
小文字+大文字小文字の区別の無い文字だけで構成された文字列にも True を返します。>>> print 'ABCD123#'.isupper() True >>> print 'Abcd123#'.isupper() False