- 投稿日:2019-05-22T21:28:07+09:00
RubyでGoogle Natural Language APIを使う
概要
RubyでGoogle Natural Language APIを使うための準備をメモりました。このAPIは普段PythonやPHPで用いられることが多く、Rubyで使おうとするとなかなか参考にできるものが少ないと思ったので。最後にテストで感情分析を行っています。
Google Natural Language APIとは?
Googleが提供する自然言語処理用のAPIです。自然言語処理を行うAPIはいくつか存在しますが、日本語テキストに対応しているのが強みです。基本無料で使用できますが、本人確認のためにクレジットカードが必須です。自然言語処理を行うクラウドサービスを比較している記事があったので、こちらを参考ににどうぞ。
Google Natural Language APIを使う準備
本題です。まずはGoogle Cloud Platform(このAPIを含むプラットホーム)で登録を済ませましょう。
1. 新しいプロジェクトの作成(任意)
ホーム画面の左上に「My First Project」という欄があるはずです。
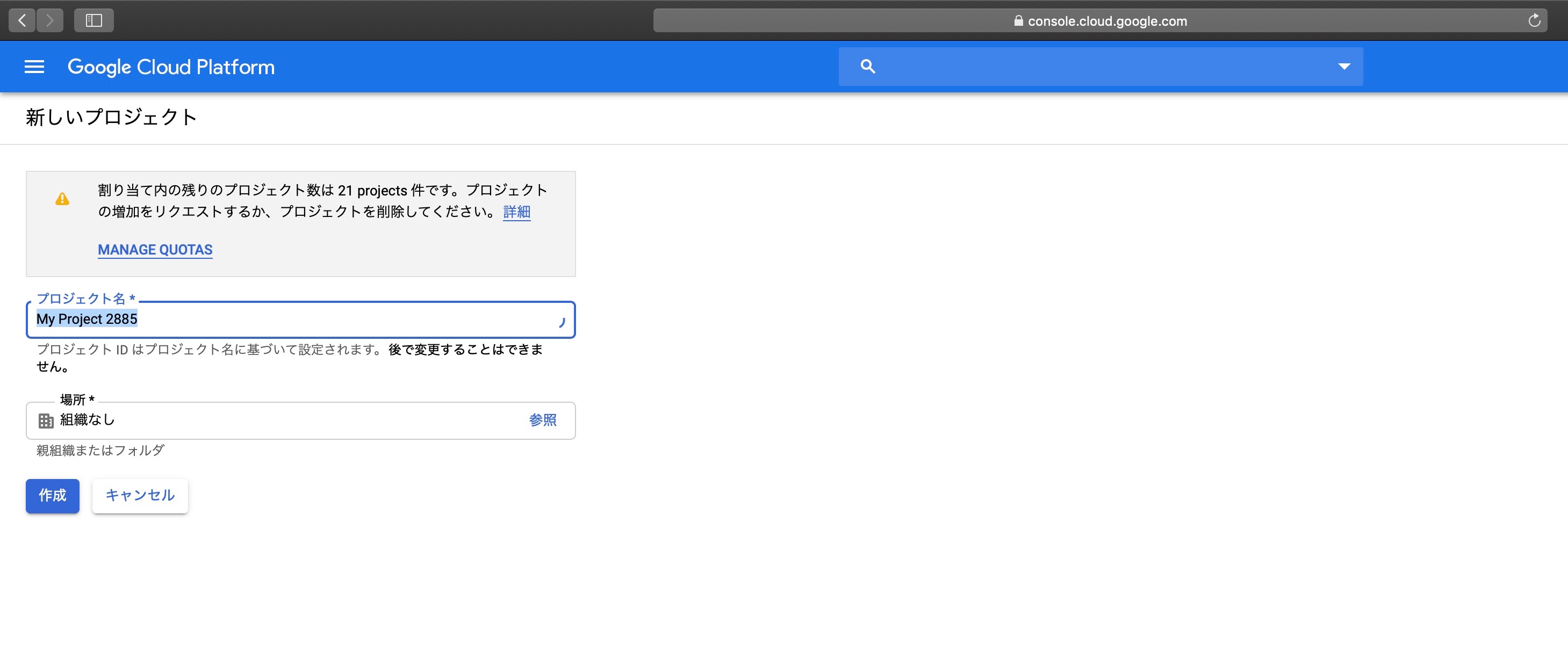
これをクリックし、出てきた画面の右上にある「新しいプロジェクト」を選択、好きなプロジェクト名を付けて「作成」をクリックしてください。
元からあるMy First Projectのままでも作業はできますので、この設定は任意です。何個かプロジェクトを作るつもりの人や、好きな名前でプロジェクトを始めたい人は以上の設定をするといいと思います。
2. gcloudコマンドラインでの設定(多分必須)
Google Cloud Platformには備え付けのコマンドラインがあります。次はそれを使ってRubyでこのAPIを使えるように設定しましょう。
まず、ホーム画面で右上の赤枠のアイコンをクリックし、「Start Cloud Shell」をクリック。
そうすると、画面下にコマンドラインが生成されたと思います。ここで、諸々の設定をしていきます。
まず、作業するプロジェクトが、目的(自分が作ったプロジェクト)のものになっているか確認します。コマンドライン上で、gcloud config listと打ちます。これは、現在作業しているプロジェクトを参照するコマンドです。返ってきた文章の中に
[core] account = [自分のgmailアドレス] project =[現在作業中のプロジェクトのID]とあると思います。このプロジェクトIDが、作業したいプロジェクトのIDと一致しているか確認してください。もし違うようなら、
gcloud config set project [作業したいプロジェクトのID]を実行しましょう。
Updated property [core/project].と返ってくれば、作業するプロジェクトが変更できたことになります。
3. APIを有効にする(必須)
gcloudコマンドラインで次のコマンドを打ちます。
gcloud services enable language.googleapis.comここでエラーが起きる人は、作業2が正常にできていない場合があります。
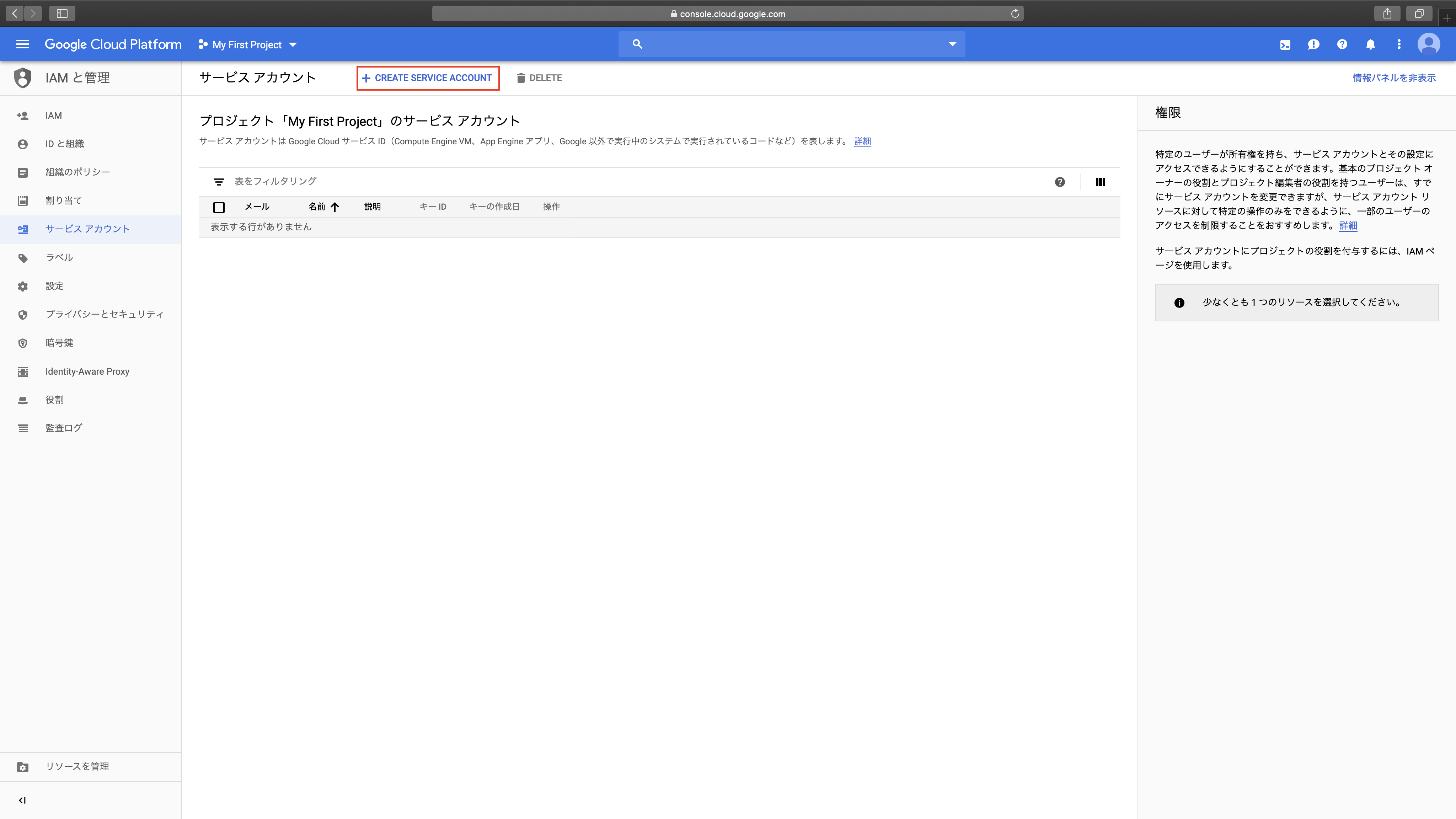
4. サービスアカウントの作成(必須)
APIのリクエストを認証するためには、サービスアカウントというものを作る必要があります。詳しくは以下のリンクをご覧ください。
ここではプラットフォームからサービスアカウントを作成する方法を書きます。
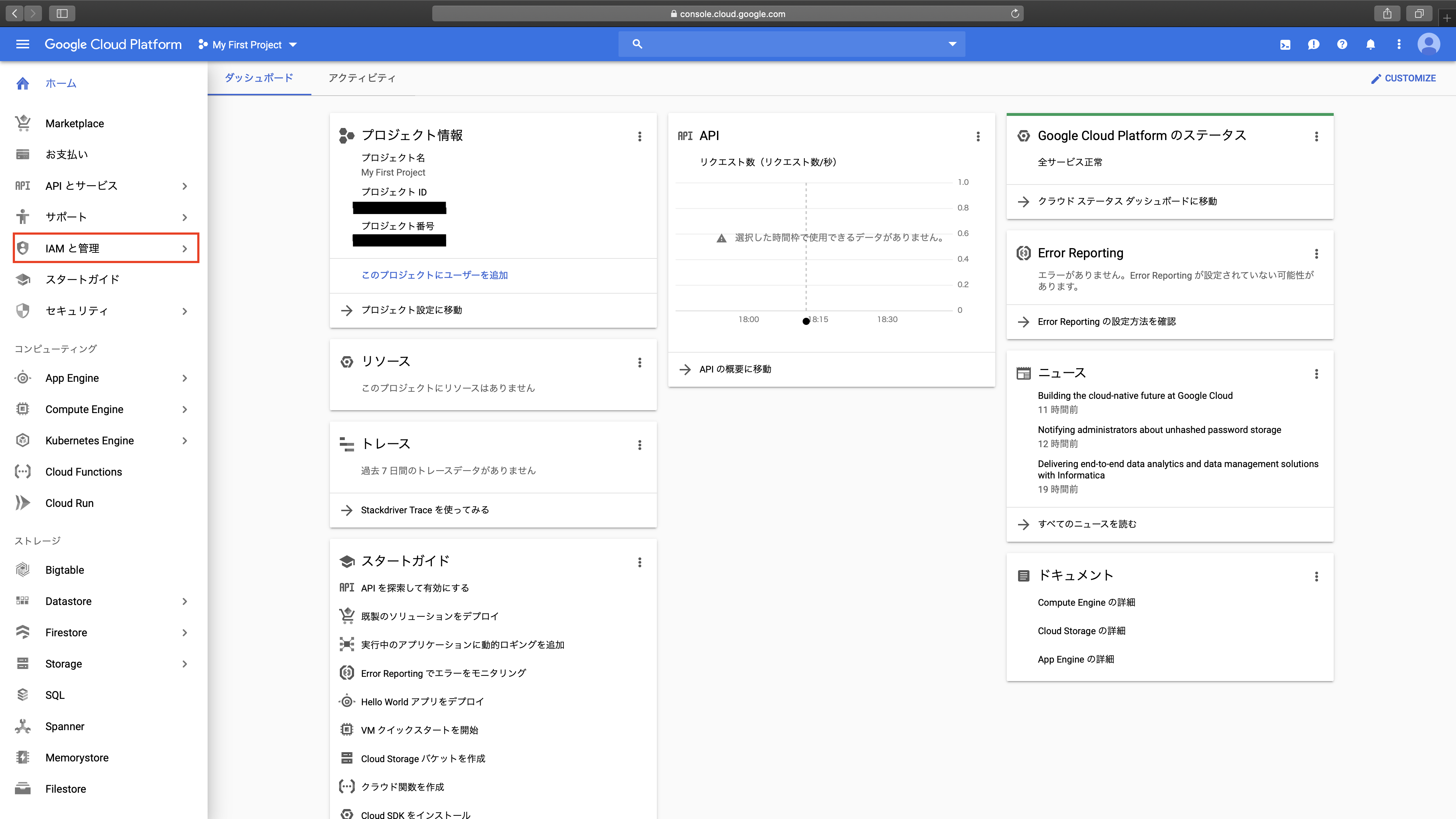
まず、ホーム画面左の「IAMと管理」→「サービスアカウント」→「+ CREATE SERVICE ACCOUNT」をクリックします。
作成画面で、好きなサービスアカウント名を入力します。この後、
- ②このサービスアカウントにプロジェクトへのアクセスを許可する
は省略してOKです。複数人が関わるプロジェクトにおいて、特定の人に何らかの権限を与える必要があるときは記入してください。次に、③ユーザーにこのサービスアカウントへのアクセスを許可 のところで、「キーの作成(オプション)」という欄があります。これは、プログラムを動かす際に必要な秘密鍵を含むファイルをダウンロードするものです。「+ キーを作成」を押し、キーのタイプをJSONにし、作成をクリックしましょう。これで秘密鍵ができました。なお、ページにも書いてある通り、このファイルは復元できないので注意してください。秘密鍵なので扱いも慎重に。
5. 環境変数を設定(必須)
環境変数
GOOGLE_APPLICATION_CREDENTIALSを設定します。OSのコマンドラインで次のようなコマンドを打ちます。
- Mac or Linux
export GOOGLE_APPLICATION_CREDENTIALS="[PATH]" 例) export GOOGLE_APPLICATION_CREDENTIALS="/home/user/Downloads/[FILE_NAME].json"
- Windows(コマンドプロンプト)
set GOOGLE_APPLICATION_CREDENTIALS=[PATH]6. gemをインストール(必須)
OSのコマンドラインで
gem install google-cloud-languageこれでRubyでGoogle Natural Language APIを使う準備ができました。
いざ使ってみるぞ
こんなファイルを用意します。今回はAPIの中の一つの機能である「感情分析」を使ってみました。ソースコードはこんな感じです。
test.rbrequire 'google/cloud/language' #APIを使う language = Google::Cloud::Language.new response = language.analyze_sentiment content: "今日も1日楽しかった。", #ここに分析したい文章 type: :PLAIN_TEXT sentiment = response.document_sentiment score = sentiment.score.to_f.round(1) #float型に変換,少数第2位を四捨五入 magnitude = sentiment.magnitude.to_f.round(1) puts "Score: #{score}" puts "Magnitude: #{magnitude}"出力結果
Score: 0.4 Magnitude: 0.4
- score: -1.0~1.0の中で大きいほど正の感情(ポジティブ)、小さいほど負の感情(ネガティブ)を抱いていることを示す。
- magnitude: 感情の強さ。0~infで、大きいほど感情的であることを示す。scoreが0.0であったとき、magnitudeが大きいなら「感情的であり、ポジティブとネガティブが打ち消しあっている」ことを示し、小さいなら「ニュートラルな文章である」ことを示す。
感想
意外と大変だな〜という印象でした。ただ、どの機能を使うにしてもほぼ同じような作業でできそうなので、一気にいろんなことを覚えなくてもいいのかもしれません。もう少し勉強していきたいなあと思います。
最後に
不明な点やおかしな点などございましたら気軽にコメントしていただけると嬉しいです。(もしかしたら間違っていることもあるかもしれませんが、暖かい目で見てから指摘くださると助かります!)
それでは!
- 投稿日:2019-05-22T21:10:18+09:00
Sinatraを支えるRuby記法 - 処理編
はじめに
ここまで、パスへのリクエストに対する処理の登録、サーバ起動のからくりについて見てきました。最後に実際にリクエストが来たときにどのような処理が行われるのかについて見ていきましょう。
Sinatra::Base.call(クラスメソッド)
前回も少し説明しましたが、Rackハンドラに渡されているのはApplicationクラスオブジェクトです。Rubyはクラスもオブジェクトなので
call(env)というメソッド(クラスなのでクラスメソッド=特異メソッド)さえあればRackハンドラは文句は言いません。
というわけで、読解の起点となるのはこのcallです。sinatra/base.rbより抜粋def call(env) synchronize { prototype.call(env) } endprototypeは前回見たようにインスタンスを作っておくメソッドです。というか名前から作っておいたインスタンスをテンプレに処理を行ってそうです。
synchronizeは想像通りなものなので省略。ちなみにデフォルトは排他制御オフのようです。Sinatra::Base#call(インスタンスメソッド)
prototypeで作られるのはミドルウェアが設定されたアプリケーションオブジェクトをさらにくるんだWrapperオブジェクトですが、起動編で前置きしたようにそこは無視してApplicationオブジェクトのcallインスタンスメソッドに進みます。
sinatra/base.rbより抜粋# Rack call interface. def call(env) dup.call!(env) enddupした上でcall!メソッドが呼ばれています。つまり、テンプレをコピーして個々のリクエストを処理しているようです。
call!に進む。
invoke { dispatch! }が処理本体のようです。
なお登録編でもコメントしましたがSinatraでは「!」をinternal的な意味で使っているように思われます。sinatra/base.rbより抜粋def call!(env) # :nodoc: @env = env @params = IndifferentHash.new @request = Request.new(env) @response = Response.new template_cache.clear if settings.reload_templates @response['Content-Type'] = nil invoke { dispatch! } invoke { error_block!(response.status) } unless @env['sinatra.error'] unless @response['Content-Type'] if Array === body and body[0].respond_to? :content_type content_type body[0].content_type else content_type :html end end @response.finish endinvokeメソッド
invokeメソッドに進む。
sinatra/base.rbより抜粋# Run the block with 'throw :halt' support and apply result to the response. def invoke res = catch(:halt) { yield } res = [res] if Integer === res or String === res if Array === res and Integer === res.first res = res.dup status(res.shift) body(res.pop) headers(*res) elsif res.respond_to? :each body res end nil # avoid double setting the same response tuple twice endここでポイントとなるのは次の二点です。
- Sinatraはthrow-catchの仕組みを使っているようだ。なおJavaとかに慣れてる人には誤解を与えると思いますがRubyのthrow-catchは例外処理ではなく大域脱出を行う仕組みです。
- というわけで大域脱出して返された値をもとにレスポンスを設定している様子。ここで使われているstatusやbodyについては後ほど触れます。
dispatch!メソッド
invokeメソッドでyieldされているものは「invokeメソッドにブロックとして渡されたもの」、つまり、dispatch!メソッド呼び出しです。
sinatra/base.rbより抜粋# Dispatch a request with error handling. def dispatch! @params.merge!(@request.params).each { |key, val| @params[key] = force_encoding(val.dup) } invoke do static! if settings.static? && (request.get? || request.head?) filter! :before route! end rescue ::Exception => boom invoke { handle_exception!(boom) } ensure begin filter! :after unless env['sinatra.static_file'] rescue ::Exception => boom invoke { handle_exception!(boom) } unless @env['sinatra.error'] end endなんとまたinvokeメソッドが呼ばれています。ここがどう動いているのかについては後で詳しく説明するとしてroute!に進みます(static!やfilter!は名前通りのことをやっているので飛ばします)
route!メソッド
登録編で見た「routeクラスメソッド」は登録処理で、「route!インスタンスメソッド」は実際のリクエストの処理というのはなかなか名前付けがいまいちに思うわけですがroute!の定義です。
sinatra/base.rbより抜粋# Run routes defined on the class and all superclasses. def route!(base = settings, pass_block = nil) if routes = base.routes[@request.request_method] routes.each do |pattern, conditions, block| returned_pass_block = process_route(pattern, conditions) do |*args| env['sinatra.route'] = "#{@request.request_method} #{pattern}" route_eval { block[*args] } end # don't wipe out pass_block in superclass pass_block = returned_pass_block if returned_pass_block end end # Run routes defined in superclass. if base.superclass.respond_to?(:routes) return route!(base.superclass, pass_block) end route_eval(&pass_block) if pass_block route_missing end今までに比べると少し複雑ですが、雰囲気で読むと以下のようになっていると思われます。
- baseで示されるオブジェクト(デフォルトはsettings)から登録されてる処理の一覧を取り出して、
- process_routeメソッド呼び出してリクエストパスに対応する処理かチェック、
- 対応する処理ならroute_evalが呼び出される。
一つずつちゃんと確かめていきましょう。
settings
まずはsettingsです。「デフォルト値として設定されているsettingsってなんだ?」と思われるかもしれませんが実はメソッドです。Rubyはデフォルト引数としてメソッド呼び出しが書ける言語となっています。
というわけで「settingsメソッド」を探すと以下のようになっています。要するにApplicationクラスオブジェクトですね。登録編で処理が「Applicationクラスの@routes」に登録されていたのを覚えているでしょうか。そこから取り出してマッチングが行われているわけです。
sinatra/base.rbより抜粋# Access settings defined with Base.set. def settings self.class.settings end # Access settings defined with Base.set. def self.settings self endprocess_route
次はprocess_routeです。
sinatra/base.rbより抜粋# If the current request matches pattern and conditions, fill params # with keys and call the given block. # Revert params afterwards. # # Returns pass block. def process_route(pattern, conditions, block = nil, values = []) route = @request.path_info route = '/' if route.empty? and not settings.empty_path_info? route = route[0..-2] if !settings.strict_paths? && route != '/' && route.end_with?('/') return unless params = pattern.params(route) params.delete("ignore") # TODO: better params handling, maybe turn it into "smart" object or detect changes force_encoding(params) original, @params = @params, @params.merge(params) if params.any? regexp_exists = pattern.is_a?(Mustermann::Regular) || (pattern.respond_to?(:patterns) && pattern.patterns.any? {|subpattern| subpattern.is_a?(Mustermann::Regular)} ) if regexp_exists captures = pattern.match(route).captures.map { |c| URI_INSTANCE.unescape(c) if c } values += captures @params[:captures] = force_encoding(captures) unless captures.nil? || captures.empty? else values += params.values.flatten end catch(:pass) do conditions.each { |c| throw :pass if c.bind(self).call == false } block ? block[self, values] : yield(self, values) end rescue @env['sinatra.error.params'] = @params raise ensure @params = original if original endこれも少し長いですが、http://localhost:4567 にアクセスされたとすると結局実行されるのは以下となります。
process_route超抜粋def process_route(pattern, conditions, block = nil, values = []) yield(self, values) endroute!に戻って、process_routeからyieldされるブロックを改めて見てみましょう。
route!の一部routes.each do |pattern, conditions, block| returned_pass_block = process_route(pattern, conditions) do |*args| env['sinatra.route'] = "#{@request.request_method} #{pattern}" route_eval { block[*args] } end*argsとして渡されるのは、selfとvaluesです。これを登録されているblockに渡す・・・、[]で囲んでいるのがこれは、
block([*args])と解釈されるようです。つまり、*argsと受け取った残余引数を展開し、改めて配列として渡す、意味あるのかな。昔はこう書かないと動かなかったとか?さて、このblockが何者かというのは登録編の復習になりますが以下となります。
compile!の一部wrapper = block.arity != 0 ? proc { |a, p| unbound_method.bind(a).call(*p) } : proc { |a, p| unbound_method.bind(a).call }つまり、self(Applicationオブジェクト)がunboundなメソッド(オブジェクトに結び付いてないメソッド。ここでは登録編でインスタンスメソッドとして登録されたパスに対するリクエスト処理のブロック)バインドされ、呼び出されています。
route_eval
上で説明した「リクエストに対する処理」はroute_evalにブロックとして渡されるので、route_evalでyieldされないと実際には実行されません。というわけでroute_evalを見てみましょう。
sinatra/base.rbより抜粋# Run a route block and throw :halt with the result. def route_eval throw :halt, yield end渡されたブロックがyieldされ、その戻り値(リクエストの処理ブロックからの戻り値)を引数にthrowが行われています。
invoke再訪
route_evalではthrowが行われていました。これは対応する(同じシンボルを指定して待っている)catchまで呼び出しを一気に戻るという仕組みになっています。:haltで待っているのはどこかというとinvokeメソッドです。
sinatra/base.rbより抜粋# Run the block with 'throw :halt' support and apply result to the response. def invoke res = catch(:halt) { yield } res = [res] if Integer === res or String === res if Array === res and Integer === res.first res = res.dup status(res.shift) body(res.pop) headers(*res) elsif res.respond_to? :each body res end nil # avoid double setting the same response tuple twice endただし、ここまで見てきた中でinvokeは二回呼び出されていました。call!からroute_evalに至るまでの呼び出しは以下のようになっています。
call! invoke dispatch! invoke route! process_route route_evalこの場合、内側のinvokeまで戻るということになります。その後、dipatch!では(登録されていたら)後処理が実行され、外側のinvokeにはnilが返されるので何もしないというようになっているようです。何故このようなややこしいことしているのかについては「歴史的経緯」な気がしますがともかくthrow-catchの大域脱出を使うことで処理を一気に巻き戻すということが行われています。
Sinatra::Helpers
最後に複線しておいたstatusやbodyについて。Sinatraではステータスコードやボディーを戻り値として返す以外に以下のように書くことも可能です。個人的には宣言的に書けるので好きです。
get '/' do status 200 body 'Hello world!' end大体察しはつくと思いますがこのstatusやbodyはApplicationオブジェクトのインスタンスメソッドです。もっとも「DSLとして」Sinatraを使う人にはインスタンスメソッドであるということは意識せずに書けるようになっています。
これらのメソッドはSinatra::Helpersモジュールに定義されており、Baseクラスがインクルードする、リクエストの処理ブロックは先に見たようにApplicationオブジェクトのインスタンスメソッドのため、インクルードされているメソッドが使える(それらを介してインスタンス変数を操作する)というからくりになっています。sinatra/base.rbより抜粋# Methods available to routes, before/after filters, and views. module Helpers # Set or retrieve the response status code. def status(value = nil) response.status = Rack::Utils.status_code(value) if value response.status end処理編まとめ
以上ここまでリクエストが来たときにどのように処理が行われるのかについて見てきました。登録編、起動編に比べると少し複雑でした。
- クラスはオブジェクトなので、呼び出し側の指定を満たすメソッドが定義していれば特異メソッドでも問題ない(呼ばれる側として渡すことができる)
- リクエストが来るとあらかじめ作成しておいた「アプリケーションオブジェクト」を複製し、リクエストに割り当てる。再利用とかを行っていないのは「そこまでパフォーマンスを追求してないから」と思われる。
- Rubyではデフォルト引数にメソッド呼び出しを書くことができる。
- 大域脱出を行うためにthrow-catchが使われている(例外処理ではない)
おわりに
三回にわたってSinatraの中身がどうなっているかを見てきました。「DSLをどう実現してるんだろ?(あと、マイクロフレームワークと呼ばれる類の実装を見てみたい)」という興味から読んでみましたがとてもRubyを使い倒したコードになっていたように思います。明日書くコードの役には立たなそうですが参考になりました(笑)
- 投稿日:2019-05-22T21:01:58+09:00
Sinatraを支えるRuby記法 - 起動編
はじめに
前回はリクエストに対する処理(getで書いたブロック)がどう登録されるのかを見てきました。今回は起動編、つまり、
ruby myapp.rbとした場合に何が起こっているのかを見ていきます。
あらためてmyapp.rbを見てみましょう。
myapp.rbrequire 'sinatra' get '/' do 'Hello world!' endmyapp.rbにはサーバを起動するコードは書かれていません。が、先の通りにmyapp.rbを実行するとサーバが起動します。今回はこのからくりを探るのが目的です。
Sinatra::Application(sinatra/main.rbの方)
sinatra/main.rbに書かれているコードのうち前回無視した方を見てみます。
sinatra/main.rbより抜粋module Sinatra class Application < Base # we assume that the first file that requires 'sinatra' is the # app_file. all other path related options are calculated based # on this path by default. set :app_file, caller_files.first || $0 set :run, Proc.new { File.expand_path($0) == File.expand_path(app_file) } # オプション処理 end at_exit { Application.run! if $!.nil? && Application.run? } endsetやcaller_files等はSinatra::Baseに書かれていますが大体予想通りのものなので省略します。
上記のコードで注目すべきは下から2行目、at_exitです。リファレンスにあるようにこのメソッドで登録したブロックはインタプリタが終了するときに実行されます。これが「サーバ起動を書いてないのにサーバが起動するからくり」です。Sinatra::Base.run!
以上終わり、となるわけはもちろんなく、Application.run!の中に入っていきます。前回も見たようにApplicationにはあまり処理は書かれておらず、run!メソッドはBaseクラスの方に書かれています。
sinatra/base.rbより抜粋# Run the Sinatra app as a self-hosted server using # Thin, Puma, Mongrel, or WEBrick (in that order). If given a block, will call # with the constructed handler once we have taken the stage. def run!(options = {}, &block) return if running? set options handler = detect_rack_handler handler_name = handler.name.gsub(/.*::/, '') server_settings = settings.respond_to?(:server_settings) ? settings.server_settings : {} server_settings.merge!(:Port => port, :Host => bind) begin start_server(handler, server_settings, handler_name, &block) rescue Errno::EADDRINUSE $stderr.puts "== Someone is already performing on port #{port}!" raise ensure quit! end enddetect_rack_handlerと関連コード
detect_rack_handlerはrun!のコメントに書かれているようなことが行われているわけですがRubyに慣れてないとわかりにくいと思うので説明します。
sinatra/base.rbより抜粋def detect_rack_handler servers = Array(server) servers.each do |server_name| begin return Rack::Handler.get(server_name.to_s) rescue LoadError, NameError end end fail "Server handler (#{servers.join(',')}) not found." end「で、serverはどうなってるの?」と探すと以下のようになっています。
sinatra/base.rbより抜粋set :server, %w[HTTP webrick] if ruby_engine == 'macruby' server.unshift 'control_tower' else server.unshift 'reel' server.unshift 'puma' server.unshift 'mongrel' if ruby_engine.nil? server.unshift 'thin' if ruby_engine != 'jruby' server.unshift 'trinidad' if ruby_engine == 'jruby' endrun!のコメントと違ってるようなw
それはともかく、このsetやif文がどこに書かれているかというと、SinatraモジュールのBaseクラス直下です。
Rubyは(Pythonもですが)「クラス定義に普通の実行文が書ける。それらの実行文はクラスが定義される際に実行される(そもそもメソッド定義なども実行文である)」という特徴があります。ここら辺がJavaなどとは大きく異なる点です。start_server
サーバの起動はstart_serverメソッドで行われます。
ここで重要なのはRackハンドラに渡しているのはApplicationクラスオブジェクト1という点です。つまり、リクエストが届いてハンドラから呼び出される場合、Applicationクラスのクラスメソッドのcallが呼び出されることになります。call後の流れについては詳しくは処理編で説明します。sinatra/base.rbより抜粋# Starts the server by running the Rack Handler. def start_server(handler, server_settings, handler_name) # Ensure we initialize middleware before startup, to match standard Rack # behavior, by ensuring an instance exists: prototype # Run the instance we created: handler.run(self, server_settings) do |server| unless suppress_messages? $stderr.puts "== Sinatra (v#{Sinatra::VERSION}) has taken the stage on #{port} for #{environment} with backup from #{handler_name}" end setup_traps set :running_server, server set :handler_name, handler_name server.threaded = settings.threaded if server.respond_to? :threaded= yield server if block_given? end endprototypeメソッド
start_serverでは初めにprototypeというメソッドが呼び出されています。起動編の最後にこのメソッドについて見てみましょう。
sinatra/base.rbより抜粋# The prototype instance used to process requests. def prototype @prototype ||= new endprototypeはクラスメソッドなので、newとはつまり、「Application.new」ということです。
「つまり、ここでApplicationクラスのインスタンスが作られてるんだな」と普通は考えると思いますが、話はもう少し複雑です(複雑でなければ取り上げません)
以下のコードを見てください。sinatra/base.rbより抜粋# Create a new instance without middleware in front of it. alias new! new unless method_defined? :new! # Create a new instance of the class fronted by its middleware # pipeline. The object is guaranteed to respond to #call but may not be # an instance of the class new was called on. def new(*args, &bk) instance = new!(*args, &bk) Wrapper.new(build(instance).to_app, instance) endなんじゃこりゃ( ゚д゚)
そう、なんとRubyはインスタンスを作るnewメソッドを差し替えることができるのです。つまり以下のことが行われています。
- 本来のnew→new!にエイリアスすることで保存
- newを再定義
buildメソッドではコメントにあるようにミドルウェアの初期化が行われ、それがWrapperインスタンスにくるまれます。まあそこら辺については本題ではないので次のリクエスト処理編では無視して読み進めていきます。
ここまでのまとめ
以上ここまでサーバ起動について見てきました。大事なのはat_exitです。他にも「自分で書くことはないかもしれないけどライブラリ読む際には出てくるかもしれない記法」がいくつかありました。
- Sinatraでサーバ起動コードを書かなくてもサーバが起動するのはat_exitにサーバ起動が書かれているから。
- Rubyではクラス定義直下に実行文が書ける。うまく利用すると環境に応じた処理を記述することなどができる。
- クラスメソッド中で単に「new」と書かれている場合、「そのクラスのインスタンスを生成する(self.new。selfはクラスオブジェクト)」という意味である。
- Rubyではnewメソッドを再定義することが可能である(本来のnewはaliasを使うことで保存できる)
処理編に続く。
書かれているのはBaseクラスですが普通にアプリを動かす際にはBaseクラスを継承したApplicationクラスがselfです。 ↩
- 投稿日:2019-05-22T20:57:01+09:00
Sinatraを支えるRuby記法
はじめに
SinatraはWebアプリケーションを記述するためのDSL(を実装するライブラリ)です。
READMEでは以下のようにアプリケーションを記述し、myapp.rbrequire 'sinatra' get '/' do 'Hello world!' endこのrbファイルを実行すればすぐにサーバを立ち上げることができると書かれています(もちろんこれだけじゃ実用的ではないというところは置いといて)
ruby myapp.rbこの記事の目的はSinatraの使い方を説明することではなく、上のように書いたDSLが「どうやって動いているのか(動かされているのか)」を調べることで、明日役に立つ(ことがあるかもしれない)知識を学ぶことにあります。
Sinatraを読んでいくにあたって以下の三段階に分けて説明していきます。
- Sinatraはルーティングをどのように登録しているのか(この記事)
- Sinatraはサーバをどのように起動しているのか
- Sinatraはリクエストをどのように処理しているのか
なお、読解対象とする(記事でリンクを張る)Sinatraのバージョンは2.0.5とします。
sinatra/main.rbとextend
アプリケーションのファイルがrequireしているsinatra.rbは、sinatra/main.rbをrequireしています。さらにsinatra/main.rbはsinatra/base.rbをrequireしており、このsinatra/base.rbが一番核となるファイルなのですがまずはsinatra/main.rbを見てみましょう。以下の記述があります(上の方に書いてある部分は起動編で説明します)
sinatra/main.rbより抜粋# include would include the module in Object # extend only extends the `main` object extend Sinatra::DelegatorSinatra::Delegatorがextendされています。extendは「モジュールに定義されたメソッドをオブジェクトの特異メソッドとして追加する(オブジェクトのクラス全部にではなく特定のオブジェクトのみにメソッドを追加する)」という動作をします。
上記ではextendはオブジェクトを指定することなく書かれています。実はRubyのトップレベル(class内とかじゃない単にputsとか書くところ)はmainというオブジェクトがself(メソッドのレシーバー)になっています。つまり、「extend Sinatra::Delegator」により、Delegatorに定義されているメソッドがトップレベルにメソッドとして定義されます。先に書いておくとこのDelegatorにgetなどのルーティングメソッドが定義されています。
Delegator(移譲者)という名前から想像できるようにDelegatorには単純にメソッドが定義されているわけではありません。というわけで次にsinatra/base.rbに入りSinatra::Delegatorを見てみましょう。Sinatra::Delegator
Sinatra::Deletatorの定義はsinatra/base.rbの最後の方にあります。
sinatra/base.rbより抜粋# Sinatra delegation mixin. Mixing this module into an object causes all # methods to be delegated to the Sinatra::Application class. Used primarily # at the top-level. module Delegator #:nodoc: def self.delegate(*methods) methods.each do |method_name| define_method(method_name) do |*args, &block| return super(*args, &block) if respond_to? method_name Delegator.target.send(method_name, *args, &block) end private method_name end end delegate :get, :patch, :put, :post, :delete, :head, :options, :link, :unlink, :template, :layout, :before, :after, :error, :not_found, :configure, :set, :mime_type, :enable, :disable, :use, :development?, :test?, :production?, :helpers, :settings, :register class << self attr_accessor :target end self.target = Application endDelegatorの動作についてはコメントに書かれている通りです。日本語に訳すと「このモジュールをオブジェクトにミックスする(Ruby的に言うとextendする)とそのメソッド呼び出しはSinatra::Applicationクラスのメソッド呼び出しに移譲される」となります。
Delegatorメソッドで行われている処理は以下のようになります。難解なのは「moduleでselfってどういうこと?」ということだと思います。module~endの間でのselfはモジュールオブジェクトになります。
- target属性の定義と初期値設定
- attr_accessorを使用し、target属性(ゲッターメソッドとセッターメソッド)を定義する。「class << self」とあるがここではクラスとは関係なくメソッドが実行されるコンテキストをself(=Delegatorモジュール)にするという意味。つまり、Delegatorモジュールにクラス変数的1にtarget属性が追加される。このような書き方になっているのはattr_accessorがprivateメソッド(レシーバを指定してのメソッド呼び出しができないメソッド)のため。
- targetの初期値としてApplicationクラス(Sinatra::Application)を設定。
- delegateメソッドの定義と実行
- delegateメソッドを定義する。これは「self.delegate」なのでDelegatorモジュールの特異メソッド(クラスで言うとクラスメソッド)になる。このメソッドはextendしてもオブジェクトにメソッドは追加されない。
- 定義したdelegateメソッドを呼び出す。delegateメソッドではdefine_methodを使い「targetで設定されたクラスのメソッドを呼び出す移譲メソッド」が定義されている。つまり、例えばgetメソッドを呼び出すとSinatra::Applicationクラスのgetクラスメソッドが呼び出されるようになる。なおここで定義されるメソッドはextend時にオブジェクトに追加される。
トップレベル(グローバル)でルーティングを定義するのだから裏側にオブジェクトがいてそいつに登録されるのだろうなとは思ってましたが、予想よりもかなり複雑なことをしているなという印象です。
さて次はgetメソッドが定義されているSinatra::Applicationですね。と言いたいところですが、Applicationはあまり処理が書かれておらず、Sinatraの本体と言えるのはその親クラスのSinatra::Baseです。Sinatra::Base(登録処理周り)
Sinatra::Baseは長い(ほぼ1000行)のでこの記事ではルーティング登録に関する部分のみを説明します。それ以外の部分については起動編、処理編で説明します。
getメソッドは以下のようになっています。routeメソッドでルーティングが設定されているのだろうなと予測できます。
sinatra/base.rbより抜粋class << self # Defining a `GET` handler also automatically defines # a `HEAD` handler. def get(path, opts = {}, &block) conditions = @conditions.dup route('GET', path, opts, &block) @conditions = conditions route('HEAD', path, opts, &block) endrouteメソッド(念のためですが、これ以降もすべて特異メソッド=クラスメソッドです)。compile!メソッドを呼び出して処理を行ったうえで
@routesに追加しています。@routesにはHTTPメソッド(動詞)ごとに処理が登録されているということがわかります。sinatra/base.rbより抜粋def route(verb, path, options = {}, &block) enable :empty_path_info if path == "" and empty_path_info.nil? signature = compile!(verb, path, block, options) (@routes[verb] ||= []) << signature invoke_hook(:route_added, verb, path, block) signature endcompile!に進む。ちなみにSinatraコードの特徴として、メソッドに「!」を付けているものが多く、Rubyのお決まり的には「オブジェクト状態が変わるメソッドは!を付ける」だと思いますが、読んでる分にinternal的な意味で付けているように思います。
sinatra/base.rbより抜粋def compile!(verb, path, block, **options) # Because of self.options.host host_name(options.delete(:host)) if options.key?(:host) # Pass Mustermann opts to compile() route_mustermann_opts = options.key?(:mustermann_opts) ? options.delete(:mustermann_opts) : {}.freeze options.each_pair { |option, args| send(option, *args) } pattern = compile(path, route_mustermann_opts) method_name = "#{verb} #{path}" unbound_method = generate_method(method_name, &block) conditions, @conditions = @conditions, [] wrapper = block.arity != 0 ? proc { |a, p| unbound_method.bind(a).call(*p) } : proc { |a, p| unbound_method.bind(a).call } [ pattern, conditions, wrapper ] end def compile(path, route_mustermann_opts = {}) Mustermann.new(path, mustermann_opts.merge(route_mustermann_opts)) endcompileメソッドではパターンマッチングに使うMustermannオブジェクトが作成されています。今回の本題ではないのでこちらは置いといて、generate_methodに進みます。
sinatra/base.rbより抜粋def generate_method(method_name, &block) define_method(method_name, &block) method = instance_method method_name remove_method method_name method end書いてあるままですが何をしているかというと、
- 渡されたブロック(getメソッドに渡されるブロック。つまり、パスに対する処理)を「インスタンスメソッドとして」定義する。
- 定義したメソッド(メソッドオブジェクト)を取得する。なおcompile!での受け取り側変数が示すようにここで取得されるのはUnboundMethod(特定のインスタンスに結び付いていないメソッド)
- 定義したメソッドを削除する。なお「クラスのインスタンスメソッド一覧」から削除されるだけで一つ前で「オブジェクト参照」が取得されているのでガーベジコレクトされることはありません。ちなみに削除しているのは「一覧からは消す」ためと思われます。
最後にcompile!の一部を再掲します。ここで作られているprocが実行されるのは実際にパスに対するリクエストが来たときですが、unboundなメソッドにインスタンスを関連付けて実行しているということが推測できます。
compile!の一部wrapper = block.arity != 0 ? proc { |a, p| unbound_method.bind(a).call(*p) } : proc { |a, p| unbound_method.bind(a).call }うーんだいぶややこしい。「ブロックをインスタンスのコンテキストで実行してるのかな」と思ってはいたのですが、それを実現するにはこんな風に書かないといけないのですね・・・
ここまでのまとめ
以上ここまでルーティングの登録処理について見てきました。「普通のオブジェクト」以外のselfについて理解することがここまでを読み解く鍵と言えるでしょう。
- DSLで使うメソッドはSinatra::Delegatorに定義されており2、mainオブジェクトがSinatra::Delegatorをextendすることでトップレベルに定義される。
- module~end内のselfはモジュールオブジェクトになる。このselfを利用し、モジュールオブジェクトにクラス変数的に属性を定義したり、クラスメソッド的にメソッドを定義したりできる。
- 渡されたブロックはSinatra::Baseクラスのインスタンスメソッドとして登録される(ただしメソッド一覧からはすぐに削除される)。リクエスト処理時にインスタンスをバインドして実行すると推測される。
起動編へ続く。
- 投稿日:2019-05-22T20:57:01+09:00
Sinatraを支えるRuby記法 - 登録編
はじめに
SinatraはWebアプリケーションを記述するためのDSL(を実装するライブラリ)です。
READMEでは以下のようにアプリケーションを記述し、myapp.rbrequire 'sinatra' get '/' do 'Hello world!' endこのrbファイルを実行すればすぐにサーバを立ち上げることができると書かれています(もちろんこれだけじゃ実用的ではないというところは置いといて)
ruby myapp.rbこの記事の目的はSinatraの使い方を説明することではなく、上のように書いたDSLが「どうやって動いているのか(動かされているのか)」を調べることで、明日役に立つ(ことがあるかもしれない)知識を学ぶことにあります。
Sinatraを読んでいくにあたって以下の三段階に分けて説明していきます。
- Sinatraはルーティングをどのように登録しているのか(この記事)
- Sinatraはサーバをどのように起動しているのか
- Sinatraはリクエストをどのように処理しているのか
なお、読解対象とする(記事でリンクを張る)Sinatraのバージョンは2.0.5とします。
sinatra/main.rbとextend
アプリケーションのファイルがrequireしているsinatra.rbは、sinatra/main.rbをrequireしています。さらにsinatra/main.rbはsinatra/base.rbをrequireしており、このsinatra/base.rbが一番核となるファイルなのですがまずはsinatra/main.rbを見てみましょう。以下の記述があります(上の方に書いてある部分は起動編で説明します)
sinatra/main.rbより抜粋# include would include the module in Object # extend only extends the `main` object extend Sinatra::DelegatorSinatra::Delegatorがextendされています。extendは「モジュールに定義されたメソッドをオブジェクトの特異メソッドとして追加する(オブジェクトのクラス全部にではなく特定のオブジェクトのみにメソッドを追加する)」という動作をします。
上記ではextendはオブジェクトを指定することなく書かれています。実はRubyのトップレベル(class内とかじゃない単にputsとか書くところ)はmainというオブジェクトがself(メソッドのレシーバー)になっています。つまり、「extend Sinatra::Delegator」により、Delegatorに定義されているメソッドがトップレベルにメソッドとして定義されます。先に書いておくとこのDelegatorにgetなどのルーティングメソッドが定義されています。
Delegator(移譲者)という名前から想像できるようにDelegatorには単純にメソッドが定義されているわけではありません。というわけで次にsinatra/base.rbに入りSinatra::Delegatorを見てみましょう。Sinatra::Delegator
Sinatra::Deletatorの定義はsinatra/base.rbの最後の方にあります。
sinatra/base.rbより抜粋# Sinatra delegation mixin. Mixing this module into an object causes all # methods to be delegated to the Sinatra::Application class. Used primarily # at the top-level. module Delegator #:nodoc: def self.delegate(*methods) methods.each do |method_name| define_method(method_name) do |*args, &block| return super(*args, &block) if respond_to? method_name Delegator.target.send(method_name, *args, &block) end private method_name end end delegate :get, :patch, :put, :post, :delete, :head, :options, :link, :unlink, :template, :layout, :before, :after, :error, :not_found, :configure, :set, :mime_type, :enable, :disable, :use, :development?, :test?, :production?, :helpers, :settings, :register class << self attr_accessor :target end self.target = Application endDelegatorの動作についてはコメントに書かれている通りです。日本語に訳すと「このモジュールをオブジェクトにミックスする(Ruby的に言うとextendする)とそのメソッド呼び出しはSinatra::Applicationクラスのメソッド呼び出しに移譲される」となります。
Delegatorメソッドで行われている処理は以下のようになります。難解なのは「moduleでselfってどういうこと?」ということだと思います。module~endの間でのselfはモジュールオブジェクトになります。
- target属性の定義と初期値設定
- attr_accessorを使用し、target属性(ゲッターメソッドとセッターメソッド)を定義する。「class << self」とあるがここではクラスとは関係なくメソッドが実行されるコンテキストをself(=Delegatorモジュール)にするという意味。つまり、Delegatorモジュールにクラス変数的1にtarget属性が追加される。このような書き方になっているのはattr_accessorがprivateメソッド(レシーバを指定してのメソッド呼び出しができないメソッド)のため。
- targetの初期値としてApplicationクラス(Sinatra::Application)を設定。
- delegateメソッドの定義と実行
- delegateメソッドを定義する。これは「self.delegate」なのでDelegatorモジュールの特異メソッド(クラスで言うとクラスメソッド)になる。このメソッドはextendしてもオブジェクトにメソッドは追加されない。
- 定義したdelegateメソッドを呼び出す。delegateメソッドではdefine_methodを使い「targetで設定されたクラスのメソッドを呼び出す移譲メソッド」が定義されている。つまり、例えばgetメソッドを呼び出すとSinatra::Applicationクラスのgetクラスメソッドが呼び出されるようになる。なおここで定義されるメソッドはextend時にオブジェクトに追加される。
トップレベル(グローバル)でルーティングを定義するのだから裏側にオブジェクトがいてそいつに登録されるのだろうなとは思ってましたが、予想よりもかなり複雑なことをしているなという印象です。
さて次はgetメソッドが定義されているSinatra::Applicationですね。と言いたいところですが、Applicationはあまり処理が書かれておらず、Sinatraの本体と言えるのはその親クラスのSinatra::Baseです。Sinatra::Base(登録処理周り)
Sinatra::Baseは長い(ほぼ1000行)のでこの記事ではルーティング登録に関する部分のみを説明します。それ以外の部分については起動編、処理編で説明します。
getメソッドは以下のようになっています。routeメソッドでルーティングが設定されているのだろうなと予測できます。
sinatra/base.rbより抜粋class << self # Defining a `GET` handler also automatically defines # a `HEAD` handler. def get(path, opts = {}, &block) conditions = @conditions.dup route('GET', path, opts, &block) @conditions = conditions route('HEAD', path, opts, &block) endrouteメソッド(念のためですが、これ以降もすべて特異メソッド=クラスメソッドです)。compile!メソッドを呼び出して処理を行ったうえで
@routesに追加しています。@routesにはHTTPメソッド(動詞)ごとに処理が登録されているということがわかります。sinatra/base.rbより抜粋def route(verb, path, options = {}, &block) enable :empty_path_info if path == "" and empty_path_info.nil? signature = compile!(verb, path, block, options) (@routes[verb] ||= []) << signature invoke_hook(:route_added, verb, path, block) signature endcompile!に進む。ちなみにSinatraコードの特徴として、メソッドに「!」を付けているものが多く、Rubyのお決まり的には「オブジェクト状態が変わるメソッドは!を付ける」だと思いますが、読んでる分にinternal的な意味で付けているように思います。
sinatra/base.rbより抜粋def compile!(verb, path, block, **options) # Because of self.options.host host_name(options.delete(:host)) if options.key?(:host) # Pass Mustermann opts to compile() route_mustermann_opts = options.key?(:mustermann_opts) ? options.delete(:mustermann_opts) : {}.freeze options.each_pair { |option, args| send(option, *args) } pattern = compile(path, route_mustermann_opts) method_name = "#{verb} #{path}" unbound_method = generate_method(method_name, &block) conditions, @conditions = @conditions, [] wrapper = block.arity != 0 ? proc { |a, p| unbound_method.bind(a).call(*p) } : proc { |a, p| unbound_method.bind(a).call } [ pattern, conditions, wrapper ] end def compile(path, route_mustermann_opts = {}) Mustermann.new(path, mustermann_opts.merge(route_mustermann_opts)) endcompileメソッドではパターンマッチングに使うMustermannオブジェクトが作成されています。今回の本題ではないのでこちらは置いといて、generate_methodに進みます。
sinatra/base.rbより抜粋def generate_method(method_name, &block) define_method(method_name, &block) method = instance_method method_name remove_method method_name method end書いてあるままですが何をしているかというと、
- 渡されたブロック(getメソッドに渡されるブロック。つまり、パスに対する処理)を「インスタンスメソッドとして」定義する。
- 定義したメソッド(メソッドオブジェクト)を取得する。なおcompile!での受け取り側変数が示すようにここで取得されるのはUnboundMethod(特定のインスタンスに結び付いていないメソッド)
- 定義したメソッドを削除する。なお「クラスのインスタンスメソッド一覧」から削除されるだけで一つ前で「オブジェクト参照」が取得されているのでガーベジコレクトされることはありません。ちなみに削除しているのは「一覧からは消す」ためと思われます。
最後にcompile!の一部を再掲します。ここで作られているprocが実行されるのは実際にパスに対するリクエストが来たときですが、unboundなメソッドにインスタンスを関連付けて実行しているということが推測できます。
compile!の一部wrapper = block.arity != 0 ? proc { |a, p| unbound_method.bind(a).call(*p) } : proc { |a, p| unbound_method.bind(a).call }うーんだいぶややこしい。「ブロックをインスタンスのコンテキストで実行してるのかな」と思ってはいたのですが、それを実現するにはこんな風に書かないといけないのですね・・・
ここまでのまとめ
以上ここまでルーティングの登録処理について見てきました。「普通のオブジェクト」以外のselfについて理解することがここまでを読み解く鍵と言えるでしょう。
- DSLで使うメソッドはSinatra::Delegatorに定義されており2、mainオブジェクトがSinatra::Delegatorをextendすることでトップレベルに定義される。
- module~end内のselfはモジュールオブジェクトになる。このselfを利用し、モジュールオブジェクトにクラス変数的に属性を定義したり、クラスメソッド的にメソッドを定義したりできる。
- 渡されたブロックはSinatra::Baseクラスのインスタンスメソッドとして登録される(ただしメソッド一覧からはすぐに削除される)。リクエスト処理時にインスタンスをバインドして実行すると推測される。
起動編へ続く。
- 投稿日:2019-05-22T19:24:15+09:00
Cloud9 エラー: No space left on device の解決 (実際にスペースがない場合)
No space left on device というエラー。容量がないことを示すエラーだが、容量が余裕なのにこのエラーがでる怪奇現象もある見たい。今回は、ちゃんと容量がない時の対処法を書く。
ファイル容量を確認
$df -hFilesystem Size Used Avail Use% Mounted on
/dev/sda1 15G 15G 0 100% /
none 312M 0 312M 0% /dev/shm100%容量使っています。
解決方法: 容量を増やします。解決の流れ
https://console.aws.amazon.com/
上記AWSコンソールから操作する。1 インスタンス停止
公式 https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/Stop_Start.html
右側のナビゲーターペインで、、インスタンスを選択 → 容量を増やしたいワークスペースのアベイラビリティ(us-east-xx)を確認し、選択して、アクション→状態→停止 をしておく
2 ヴォリュームデタッチ
右側のナビゲーターペインで、、
Volumeを選択 → 容量を増やしたいワークスペースのアベイラビリティ(us-east-xx)を確認し、選択して、アクション→ボリュームのデタッチ
*あとで使うのでボリュームIDをコピーする3 ボリュームのスナップショットをとる
右側のナビゲーターペインで、、
スナップショットを選択 → スナップショットの作成
ボリュームIDをペースト、コメントは任意だけどワークスペース名とか入れると作業しやすい。4 スナップショットを使って新しいボリュームを作る
そのままスナップショットの画面で、スナップショットを選択し、アクションから、ボリュームの作成を選択。
大きさはスナップショットより大きくなるようにする。
アベイラビリティゾーンは、該当ワークスペースのものを選択する。5 スナップショットのアタッチ
公式 https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ebs-restoring-volume.html
右側のナビゲーターペインで、、ボリュームを選択 → 製作したスナップショットを選択し、アクションからボリュームのアタッチをする。このときのインスタンスIDは、アタッチ先のもので。手順1で訪れたインスタンスの画面から確認できる。
注 この時重要なのが、デバイスがデフォルトで
/dev/sdfとなっているが、Cloud9なら、/dev/xvdfとしないと、インスタンスの起動に失敗する。
状態がin-use になったら、ワークスペースにアクセスしてインスタンスを起動できるはず。
参考
https://stackoverflow.com/questions/6151695/ec2-instance-on-amazon-and-i-am-greeted-with-no-space-left-on-the-disk
- 投稿日:2019-05-22T18:50:29+09:00
Rails Tutorial(2週目)-3-
静的なページの作成
動的なページとはデータベースと連携しているページ
静的なページとはHTMLファイルだけで構成されているページコントローラの生成
$rails generate controller コントローラ名(キャメルケース) アクション名1 アクション名2
アクションと同時にそれに対応するビューも生成される。キャメルケース(英: camel case)は、複合語をひと綴りとして、要素語の最初を大文字で書き表すことをいう。キャメルケースとは、大文字が「らくだのこぶ」のように見えることからの命名である。
スネークケースとはコンピューターで、スペース(空白)を入れずに複合語を表記する際、下線記号(アンダースコア)を用いる方式。プログラミング言語やファイル名、ハッシュタグなどに用いられる。名称は、文字列がヘビ(スネーク)のように見えることから。
$ git add -A
$ git commit -m "Add a Static Pages controller"
$ git push -u origin static-pages
以降は、$git pushのみで同じ事ができる失敗した場合にもとに戻す
controllerの場合
$rails generate controller StaticPages home help
$rails destroy controller StaticPages home helpマイグレーションの場合
$ rails db:migrate
一つ前に戻るのは
rails db:rollback
最初の状態に戻したいときは
$ rails db:migrate VERSION=0
マイグレーションにはバージョン番号が付与されるため、バージョンを指定すればその状態まで復元できる。HTTPメソッドについて
GETは最も頻繁に使われるHTTPリクエストで、主にWeb上のデータを読み取る (get) ときに使われます。「ページを取得する (get a page)」という意味のとおり、ブラウザはhttp://www.google.com/やhttp://www.wikipedia.org/などのWebサイトを開くたびにGETリクエストをサイトに送信します。
POSTは、GETの次によく使用されるリクエストで、ページ上のフォームに入力した値を、ブラウザから送信する時に使われます。例えばRailsアプリケーションでは、POSTリクエストは何かを作成するときによく使われます (なお本来のHTTPでは、POSTを更新に使ってもよいとしています)。例えばユーザー登録フォームで新しいユーザーを作成するときは、POSTリクエストを送信します。
他にも、PATCHと DELETEという2つの操作があり、それぞれサーバー上の何かを更新したり削除したりするときに使われます。これら2つの操作は、GETやPOSTほどは使われていません。これは、ブラウザがPATCHとDELETEをネイティブでは送信しないからです。しかし、Ruby on Railsなどの多くのWebフレームワークは、ブラウザがこれらの操作のリクエストを送信しているかのように見せかける技術 (偽装) を駆使して、PATCHとDELETEという操作を実現しています。結果として、Railsはこの4つのHTTPリクエスト (GET・POST・PATCH・DELETE) を全てサポートできるようになりました。
テスト駆動開発について
テスト駆動開発 (TDD) とは、テストの手法の1つで最初に「正しいコードがないと失敗するテスト」を書き、次に本編のコードを書いてそのテストがパスするようにする方法。
TDDのメリット
・テストが揃っていれば、機能停止に陥るような回帰バグ (Regression Bug: 以前のバグが再発したり機能の追加/変更に副作用が生じたりすること) を防止できる
・テストが揃っていれば、コードを安全にリファクタリング (機能を変更せずにコードを改善すること) ができる
・テストコードは、アプリケーションコードから見ればクライアントとして動作するので、アプリケーションの設計やシステムの他の部分とのインターフェイスを決めるときにも役に立つ。
TDDか一括テストかの目安
・アプリケーションのコードよりも明らかにテストコードの方が短くシンプルになる (=簡単に書ける) のであれば、「先に」書く
・動作の仕様がまだ固まりきっていない場合、アプリケーションのコードを先に書き、期待する動作を「後で」書く
・セキュリティが重要な課題またはセキュリティ周りのエラーが発生した場合、テストを「先に」書く
・バグを見つけたら、そのバグを再現するテストを「先に」書き、回帰バグを防ぐ体制を整えてから修正に取りかかる
・すぐにまた変更しそうなコード (HTML構造の細部など) に対するテストは「後で」書く
・リファクタリングするときは「先に」テストを書く。特に、エラーを起こしそうなコードや止まってしまいそうなコードを集中的にテストする埋め込みRuby
app/views/static_pages/home.html.erb<% provide(:title, "Home") %> <!DOCTYPE html> <html> <head> <title><%= yield(:title) %> | Ruby on Rails Tutorial Sample App</title> </head> <body> <h1>Sample App</h1> <p> This is the home page for the <a href="https://railstutorial.jp/">Ruby on Rails Tutorial</a> sample application. </p> </body> </html><% ... %>と書くと、中に書かれたコードを単に実行するだけで何も出力しない。<%= ... %>のように等号を追加すると、中のコードの実行結果がテンプレートのその部分に挿入される
ブロックとyieldについて
ブロックとはメソッドの引数として渡すことができる処理のかたまり
例えば…numbers = [1, 2, 3] sum = 0 numbers.each do |n| sum += n endというコードでは、eachメソッドが配列numbersから要素を一つずつ取り出し、その値をdo以降のブロックに渡している。
yieldはブロックに引数を渡したり、ブロックの戻り値を受け取ったりできる。
def greeting puts 'aa' text = yield 'bb' puts text puts 'cc' end greeting do |nn| nn * 2 end => aa bbbb cc上の処理では,
①puts 'aa'
②bbはブロック引数として、ブロックに渡され、yieldにより、ブロックの処理を行う
③bbがブロック引数nnに代入されブロック内の処理が行われる
④ブロックの戻り値をyieldが受け取り、それが変数textに代入
⑤puts text
⑥puts 'cc'
の流れ個人的な理解としてはyieldはブロックを呼び出し、その戻り値を返す処理。
provideとyieldの関係
以上を整理した上で、先程のprovideとyieldが出てくるコードを見ると
provideヘルパは、:title というラベルと "Home"という文字列を関連付けており、yieldによってそれを呼び出している形。
あまり、ブロック処理のときのyiledとは関係ないのかな?
- 投稿日:2019-05-22T12:50:10+09:00
Rails6 のちょい足しな新機能を試す21(html_safe編)
はじめに
Rails 6 に追加されそうな新機能を試す第21段。 今回のちょい足し機能は、
String#html_safe編です。
Rails 6.0 では、html_safe?がtrueな文字列から[]でインデックスを指定して抜き出した部分文字列もhtml_safe?が true となるようになりました。Ruby 2.6.3, Rails 6.0.0.rc1 で確認しました。Rails 6.0.0.rc1 は
gem install rails --prereleaseでインストールできます。$ rails --version Rails 6.0.0.rc1Rails プロジェクトを作る
$ rails new rails6_0_0rc1 $ cd rails6_0_0rc1Controller と View を作る
controller と View を作ります。
$ bin/rails g controller html_safe index
HtmlSafeController#indexを修正するcontroller で、html_safe な文字列を作成し、そこから一部を抜き出します。
app/controllers/html_safe_controller.rbclass HtmlSafeController < ApplicationController def index str = '<em>This is HTML safe string first part</em><strong>This is HTML safe string second part</strong>'.html_safe i = str.index('<strong>') @html_safe_str1 = str[0...i] @html_safe_str2 = str[i..] end endView を修正する
index.html.erbで controller で抜き出した一部の文字列を表示します。app/views/html_safe/index.html.erb<h1>HtmlSafe</h1> <p> @html_safe_str1 = <%= @html_safe_str1 %> </p> <p> @html_safe_str2 = <%= @html_safe_str2 %> </p>rails server を実行して表示する
bin/rails sを実行してブラウザから http://localhost:3000/html_safe/index にアクセスします。
html safe な文字列として処理されていることがわかります。
Rails 5 では?
Rails 5.2.3 では、抜き出した文字列の
html_safe?がfalseになるため、以下のようにエスケープ処理されてしまいます。
試したソースは以下にあります。
https://github.com/suketa/rails6_0_0rc1/tree/try021_html_safe参考情報


- 投稿日:2019-05-22T12:39:16+09:00
error Command "webpack-dev-server" not found. info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
$ bin/webpack-dev-serverで出るタイトルのエラー
error Command "webpack-dev-server" not found. info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.解決コマンド
yarnのアップグレード
$ brew upgrade yarn
webpackerインストール$ bundle exec rails webpacker:install
webpack-dev-server立ち上げ$ bin/webpack-dev-server
- 投稿日:2019-05-22T11:58:55+09:00
Serverspecで正規表現が使えない場合のor条件テスト
概要
Ansible Playbookの動作確認にServerspecを利用しています。
設定量が多いためServerspecでサーバの状態を可視化しています。Ansibleでディレクトリの作成を行うのですが、roleによって
ディレクトリの権限がuidである状態と、ユーザ名である状態に分かれてしまいます。一つのServerspecのroleで上記の差分を吸収したいのですが、Specinfraの仕様上、ファイル等の権限確認に正規表現が使えません。
specinfra/lib/specinfra/command/base/file.rbdef check_is_owned_by(file, owner) regexp = "^#{owner}$" if owner.is_a?(Numeric) || (owner =~ /\A\d+\z/ ? true : false) "stat -c %u #{escape(file)} | grep -- #{escape(regexp)}" else "stat -c %U #{escape(file)} | grep -- #{escape(regexp)}" end endなので、無理やりSpecinfraを使うことで対応しました。
ほかに方法あったらご教授お願いします。対応策
- パラメータを初期化
spec/spec_helper.rbrequire 'net/ssh' require 'serverspec' require 'specinfra' include Specinfra::Command set :host, ENV['TARGET_HOST'] # :ssh | :exec set :backend, :exec # backendにsshを利用する場合 set :ssh_options, Net::SSH::Config.for(ENV['TARGET_HOST']).update({ :user => 'user' :keys => '/home/user/.ssh/id_ecdsa' }) # sudoユーザの場合 set :sudo_password, 'password' # 複合化処理等は省略 set :require_pty, true
- Specinfraでのコマンド実行結果で条件分岐を行う
spec.rbrequire 'spec_helper' describe file('/tmp/testuser/') do # コマンドを取得 cmd = Command::Base::File.check_is_owned_by('/tmp/testuser/', 'testuser') # 終了ステータスコードを取得 rc = Specinfra::Runner.run_command(cmd).exit_status if rc != 0 it { should be_owned_by 9999 } else it { should be_owned_by 'testuser' } end end実践
- Rakefileを準備
Rakefilerequire 'rake' require 'rspec/core/rake_task' task :defeult => :spec RSpec::Core::RakeTask.new(:spec) do |task| ENV['TARGET_HOST'] = 'example' task.pattern = 'spec.rb' end
- 構成
./Rakefile ./spec/spec_helper.rb ./spec.rb
- ディレクトリを作成、ユーザ権限をuidで設定
mkdir /tmp/testuser && chown 9999 $_
- テスト実行
rake
- uidマッピング
useradd -u 9999 testuser
- テスト実行
rake上記の2通りのテストが通るはずです。
バージョン情報
- chefdk-0.6.2-1
- serverspec-2.18.0
- specinfra-2.35.1
- 投稿日:2019-05-22T11:54:55+09:00
Ruby・Ruby on Railsの環境構築(Mac向け)
はじめに
こんにちは!
今回はRuby・Ruby on Railsを勉強し始めようかな〜と思っている方に向けて、簡単な環境構築の方法をご紹介しようと思います。そもそもRuby・Ruby on Railsとは
Rubyというのはまつもとゆきひろ氏が開発したオブジェクト指向スクリプト言語であり、JavaやC言語と違ってコンパイルする必要がなく、初心者でもすぐにプログラムを実行できるようになっています。
Rubyは「楽しさ」に焦点を当てて作られているようで、まつもと氏もこう語っています。
Ruby には Perl や Python とは決定的に違う点があり、それこそが Ruby の存在価値なのです。それは「楽しさ」です。私の知る限り、Ruby ほど「楽しさ」について焦点を当てている言語は他にありません。Ruby は純粋に楽しみのために設計され、言語を作る人、使う人、学ぶ人すべてが楽しめることを目的としています。しかし、ただ単に楽しいだけではありません。Ruby は実用性も十分です。実用性がなければ楽しめないではありませんか。そして、Ruby on Railsは先ほどご紹介したRubyを用いてWebアプリケーションを開発するためのフレームワークであり、比較的簡単にバリエーション豊富なWebアプリケーションを作ることができます。Ruby on Railsを使って作られたサービスにはCookPadや価格.comなどがあり、どれも有名なものばかりです。Ruby on Railsを使ってWebアプリを開発し起業することも夢じゃないかも??
それでは実際に環境構築をしていきましょう!!
Rubyの環境構築
まず「ターミナル」と「テキストエディタ」を用意しましょう。
テキストエディタはAtomなどいろいろありますが、お好きなものを使っていただいて大丈夫です。
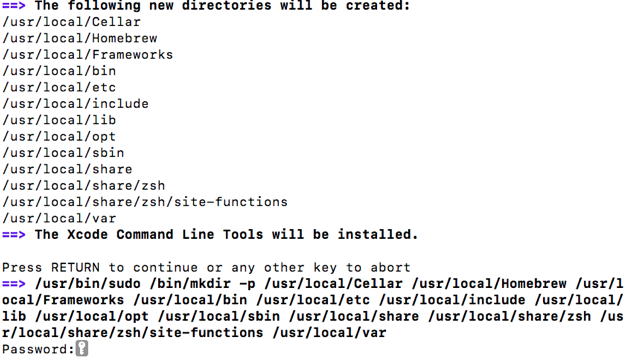
これからRubyをインストールしていくのですが、実際の開発環境では複数のバージョンのRubyを扱うことが多く、それらの管理には「rbenv」というツールが欠かせないものになります。では、実際に手順を踏んでインストールしましょう。①まずHomebrewをインストールします。ターミナルにこのようなコードを打ち込みましょう。
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"これを打ち込むとEnterキーの入力が求められますのでEnterキーを押します。次に端末のパスワードを入力します。
パスワードを入力してもターミナル上には何も表示されませんが、それで正解です。気にせず入力しましょう。
しばらくするとインストールが完了します。brew -vと入力して「Homebrew 1.X.X」のように表示されたら完了です!
②次にrbenvをインストールしていきます。
以下のようにコードを入力しましょう。
brew install rbenv ruby-buildしばらくするとインストールが完了するので
rbenv -vと入力して先ほどのようにバージョンが表示されたらOKです!
そして、これからRubyのインストールに移っていくのですが、その前にrbenvの設定を済ませます。ターミナルにecho 'eval "$(rbenv init -)"' >> ~/.bash_profileと入力してEnterキーを押します。何も表示されなければ大丈夫です。
次はsource ~/.bash_profileと入力します。これでも何も表示されません。以上で設定完了です!
③最後はいよいよRubyのインストールです。
今回インストールするのはバージョン2.5.0のRubyです。
rbenv install 2.5.0と入力して待ちます。結構長いです。。。
終了したらrbenv versionsと入力しましょう。ちゃんとインストールできていたら2.5.0と表示されます。
今回インストールしたRubyを使えるようにするためにrbenv global 2.5.0と入力します。これで2.5.0のRubyが使えるようになりました!お疲れ様です。
Ruby on Railsの環境構築
Rubyが導入できた興奮冷めやらぬうちにRuby on Railsの導入も済ませてしまいましょう。もっと言うと、サーバーの起動まで済ませます。
①まずは以下のようなコードを入力します。
gem install rails -v 5.0.3これでRails自体のインストールは完了です。
②ではアプリケーションを新規作成しましょう。
今回はひとまずテストということで
rails new test_appと入力します。これでテスト用のアプリケーションは作れました。
テキストエディタで先ほど作ったtest_appを開きましょう。すると、そのフォルダ内に「Gemfile」という名前のファイルがあると思います。これを開きgem 'sqlite3'と書かれている行を
gem 'sqlite3', '~> 1.3.6'に書き換えます。この状態で一旦セーブします。
再びターミナルに戻ってcd test_appでtest_appフォルダに移動し、
bundle updateを実行します。しばらく待って
「Bundle updated!」と表示されたら成功です!③最後にサーバーを起動してみます!
rails sと入力して実行すると文章がダーーーっと表示され、最後に「Use Ctrl + C to stop」と書かれていたらOKです。
起動したサーバーにアクセスしてみます。
ブラウザを開いてurlバーにlocalhost:3000と入力して検索します。
すると、、、
このような画面が表示されると思います。サーバー起動成功です!ちなみにサーバーをストップさせたい時は「control + C」を押します。
終わりに
以上が一連の流れです。
僕も最近Rubyを勉強し始めて環境構築でつまづいたので、同じようにつまづいている方の参考になれば幸いです。これから勉強を進めて何かしらWebサイトを作れたら嬉しいな〜なんて思っています。それではまた次の記事で!

- 投稿日:2019-05-22T11:51:41+09:00
モデルに書いた定数を参照する
environment.rb
config/environments/は環境単位の設定ファイルを格納するディレクトリ(Railsドキュメント参照)
で簡単にまとめると、よく使う定数を置いて置ける場所という認識でも共通でこの定数は使わないよって場合はモデルに書いた方が見やすいのでモデルに定数を書く
モデル
モデルに書くときも書き方は変わらないが、呼び出し方が違う
expert_collection_achieved.rbCOMPLETE_STATUS = { :not_achieved => 0, :achieved => 1 }書き方としてはこんな感じで
environment.rbに書いたものを呼び出すときはCOMPLETE_STATUS[:achieved]で1が表示される
モデルに書いたものだと、モデル名::COMPLETE_STATUS[:achieved]で呼び出すex)
ExpertCollectionAchieved::COMPLETE_STATUS[:achieved]
- 投稿日:2019-05-22T04:31:09+09:00
Rails: 検索フォームでLike演算子を使うときはsanitize_sql_likeを使おう
備忘録
Webアプリを作るとき、必ずどこかで検索フォームを実装するときがあるかと思う。
その際に、ただ何も考えずに今までは、Like演算子を使ってきたがそれだとまずいということが分かったので備忘録として残しておくrailsでは
sanitize_sql_likeを使うことで検索でLIKE演算子のワイルドカードである_や%が使われてもエスケープすることができるじゃあどのように書くのか?
User.where(user_type_id: 2).where(['second_prefecture_code LIKE ? or specialized_field LIKE ?', "%#{sanitize_sql_like(searchFirst)}%", "%#{sanitize_sql_like(searchSecond)}%"])一例だが、上記のように書くことで、ワイルドカードである_や%が使われてもエスケープできるようになるはずである。
- 投稿日:2019-05-22T01:40:44+09:00
一番わかりやすいパンくずの実装(gem 'gretel')
今回はパンくずの実装についての記事を分かり易く説明します。
パンくずとは?
下記の画像のように画面遷移してきて、自分がどの位置にいるのか視覚的に分かり易く表示しているこれらをパンくずと総称しています。
また、リンクも持たせられるので、画面を戻る際にクリックしたら遷移するのでUI的にも優しいです。下記メルカリの参考画像です。
導入手順
使用gemは下記です。
gem 'gretel'
_breadcrumbs.html.haml(パンくずview)の説明
パンくずを表示させるViewを部分テンプレートに分けておく。
(分けないでも良いが、変更や調整の際にメンテナンスを容易にするため)
下記以外の方法もあるが、私の場合は分かり易く呼び出されたコントローラーと、その先のアクション名でパンくずの表示を切り替えれるようにcase文を使い組んでいる。case文については過去の記事を参考にしてください。
┗ case文での条件分岐方法
case params.values_at :controller, :actionの部分は
binding.pryでデバックした際にコントローラー名とアクション名が入っているのを確認できるので、
when ['users', 'show']とすることでusersコントローラーのshowアクションに遷移したい際にこちらが参照される。
breadcrumb :user_showの部分は次々項で説明するconfig/breadcrumbs.rb内のメソッドを呼び出すためのメソッド名(readcrumbs.rb側のメソッド名)。
少し紛らわしいが、先にこちらでメソッド名を命名してしまってreadcrumbs.rb側に当てがった方がスムーズなので私の場合はこのような手順で進めています。末尾にあるに下記のコードは、表示を区切る際に間に入る記号などを指定できる。
見慣れない文字が入っている部分はHTMLの特殊文字になる。
下記のサイトのように様々な記号を当てれる。
https://www.benricho.org/symbol/tokusyu_02_arrow.html= breadcrumbs separator: " 〉 "上記の結果が下記のように変換される。
>の前後に空白を入れている。
= breadcrumbs separator: " 〉 "app/views/shared/_breadcrumbs.html.haml- case params.values_at :controller, :action - when ['users', 'show'] - breadcrumb :user_show - when ['user_chat_rooms', 'index'] - breadcrumb :user_chat_rooms_index = breadcrumbs separator: " 〉 "
上記の部分テンプレートをパンくずを表示させた場所に下記のようにおく。
大体の場合はヘッダーの下に置かれていることがほとんどだと思うので、
ヘッダーの部分テンプレート中に組み込ませた方が効率は良いと思う。=render 'shared/breadcrumbs'
次にconfig下にbreadcrumbs.rbを作成し下記のように記述。
linkの後に続く部分に画面に表示させたいパンくず名を入力する。
後にroot_pathやuser_chat_rooms_path(user_id:current_user.id)とあるが、
こちらはパンくずの表示部がクリックされた際に画面遷移するためのpathなので、クリックして遷移の必要がなければ記述しなくてのよい。
parent :rootの部分は親のメソッド名を記述する。config/breadcrumbs.rbcrumb :root do link 'ホーム', root_path end crumb :user_show do link "#{current_user.name}" parent :root end crumb :user_chat_rooms_index do link "メッセージ一覧",user_chat_rooms_path(user_id:current_user.id) parent :user_show end完成
そして最終的には下記のようになる。
次回は少し複雑なパンくずの表示方を記事にします。
``

- 投稿日:2019-05-22T00:43:44+09:00
[初心者]プログラミングを約250時間学んで感じたこと
はじめに
スクールでプログラミングを学び始めて、約1ヶ月が経ちます。
細かく言えば、今日で25日目になります(笑)
言語としては、
・Ruby ・Rails
・HTML ・CSS
を学んできました。
決め事として、1日最低10時間以上を毎日続けるようにしています!
単純計算で、約250時間です。
ということで今回は、全くの初心者が250時間勉強して感じたことを書いていこうと思います。予想以上のキツさ
多数の言語を短期間に学ぶのは大変ですが、本気でやれば各言語の基礎は学ぶことができました。
ただ、正直かなりキツイです。
スクールは毎日通っていて、25日間1日も欠席はしていません!!!
新しい知識ばかり頭に入ってくる中で、毎日が格闘です(笑)しかしそのおかげで、全くの無知だった私ですが、今ではTwitterの簡易版のようなアプリであれば自力で作成することができるようになりました!
正直初めは、「これ、本当に自分でも理解できるのか・・・?」
と思ってました。(笑)
ですが、絶対サボらず、折れずに毎日頑張っていたらいつの間にかアプリが作れるようになってました!
人生の中で1番頑張ったといっても過言ではないかもしれせん・・・(笑)多くの衝撃事実
プログラミングを少しずつ学んでいく中で、「え!?」と思うことがいくつかありました。
まず1つは、
「プログラミングは暗記ではない」
ということです。私は最初、プログラミングはありったけのコードをたくさん暗記しなきゃいけないと思ってました。(笑)
しかし、学んでいく中で
「わからないことがあったらすぐに調べて、それを適応させる能力」
がとても大事なのだと気付かされました。「プロのエンジニアでもGoogleは必須なんだよ」と言われてから、私の勉強法は8割がアウトプット作業ばかりです。
2つ目は、
エラーの多さ、難しさです。アプリを作成する中で、エラー、エラー、エラー、エラー・・・・・。
どれだけ調べても解決できないものだったり、本当に折れそうになります。(笑)各言語における仕組み等を理解していないとエラーが解決できないため、
エラーが起きるたびに土台の脆さを痛感させられました。ですが、数をこなすうちに段々と理解できて、簡単なエラーなら1人で解決できるようになることができました^^
しかし、実際まだたくさんの種類のエラーがあると思うので、勉強して数をこなしていくしかないですね・・・
おわりに
まだまだ、ほんの一部を学んだだけです。
もっといえば、基礎も全て完璧とはいえず、まだまだ知識不足だといえます。
これからもコツコツ努力して、一人前のプログラマーになれるよう日々精進です・・・明日からは、「Javascript」「jQuery」を学んでいこうと思います!
ありがとうございました^^